2026-07-07 08:00:00
I built lanius, and I really want to show it to you, but first I need to explain why I think it’s necessary.
We’re headed into a new phase of AI where pushing the frontier involves scaling down the amount of compute. A couple years ago we scaled up model sizes, and then we scaled up how much time we spent thinking. The shift into agency exploded the amount of compute required, but we’re getting ever so much more done.
But there’s things happening:
In my own coding workflow, I’ve found that I can use Claude Fable to work with Opus to plan, which in turn dispatches to Sonnet to implement, and then Opus again to verify the work. Weirdly, it dramatically cuts down costs. I almost never run out of credits while I also still experience all the best things about Fable.
All of these things have something in common. They match the right-sized LLM to the right problem.
There’s this concept, Ashby’s Law, that essentially says that a problem’s solution has to be at least as complex as the problem itself.
When Ashby’s Law is broken, systems start to also feel “broken”. Like when you call into a tech support hotline and the agent isn’t allowed to go off-script so you have to idly say things like, “yep, it’s plugged in. Yep, it’s turned on” in the face of ever-growing frustration.
What we’re experiencing is the other side of that. LLMs were such good problem absorbers that we threw them at
everything. E.g. in the OpenClaw docs they suggest setting up a HEARTBEAT.md file to do things
like check your email every 30 minutes.
Holy god in heaven dost thou ACTUALLY need a whole ass LLM just to realize there’s no new emails??
A more Ashby-pilled approach is to have the agent write a script to check the email inbox, and then send a message to the agent if there’s new email. Or better yet, send the message to a tiny LLM who can triage the email based on some policy (“eh, emails from Jack can wait a day or two, no sweat”) before forwarding it on to the agent who you actually trust to respond. Match the problem.

Right-sizing to the problem is going to involve a heck of a lot of moving parts.
Some are just scripts that an agent can call. Others are scripts that call the agent. Or big Fable-sized agents orchestrating a small army of local LLMs to continuously monitor a situation. Or a local coding agent consulting Fable on a problem that it’s out of its depth on. A lot of it needs to be very dynamic and temporary, coming into and out of existence as needed. Similar to how Claude’s Dynamic Workflows are scripts written in-the-moment by an orchestrating agent.
Dwarkesh found that we’re about 4 orders of magnitude off from the level of hardware to scale today’s agent approach to the entirety of society. Yet we’re already experiencing growing pains, while we still need to 1000x to have the level of impact we think we’ll have. Clearly we need a new approach.
Lanius tackles this by being an agent harness that looks more like an operating system. You can create agents directly on lanius that look a lot like OpenClaw agents, but you can also open Claude Code inside lanius and get all the same benefits.
The core shape is everything is a message.

As an example, messaging between agents, as core as it seems like it is, is just a package consisting of skills, computed memory blocks (notify new messages) and daemon scripts (an MQTT client). Lanius is absolutely built for extension, right down to the core.
Is it an OS? Probably not. It’s closer to a control plane like Kubernetes. But where Kubernetes orchestrates containers, lanius provides a messaging layer that allows agents to orchestrate themselves. Lanius is that missing machinery that, if we’re going to be serious about scaling up impact by scaling down agents to right-sized problems, well we’re going to need a whole lot of whatever lanius is. Messaging and conflict avoidance deeply embedded.
As a messaging-forward AI platform, lanius seamlessly ties together any system in your digital life. We haven’t yet built all the integrations. We also don’t need to because lanius is extensible to the core.
Skills alone are inadequate for interoperability, because any action has to be initiated by an LLM. That’s not Ashby-pilled enough for me. In order to scale down compute, we need actions to be able to start from outside an LLM. Lots of messaging sources, pollers polling websites, websockets listening for events, etc. All coalescing under one single umbrella: the MQTT broker. Messaging at the core.
Interaction models are another version of this.
The latest GPT-Live announcement makes the split explicit: keep a fast conversational model in the loop, then delegate harder work to a deeper model in the background. That feels exactly right to me. It will not scale to make every live model as smart as Sol or Fable. At some point, it needs to borrow intelligence from a worker that is better suited to the job.
When the last realtime GPT came out, I made a web app that hooked it up to Claude Code so my daughter could speak games into existence. The realtime model did not write code. It translated her intent into messages for the coding agent, which was specialized for the actual work.
Scaled down to purpose.
MQTT is an Internet of Things (IoT) protocol. The better AI gets, the more corners of my life I want to include it ambiently. The IoT tie-in was honestly incidental, but once the idea entered the picture, it quickly felt very natural. It’s very nice to disconnect from screens. (I’m firmly against putting coding AI on my phone because it bleeds into my personal life too much)
I’ve been dogfooding lanius while building it for the last few weeks. I’ve developed a workflow where I use Claude Fable to replace me — Opus develops plans while Fable drives it. And then Fable dispatches Sonnet, Opus, GPT-5.5, or GLM-5.2 for implementation and verification.
When I’m writing code this way, Fable can take on whole sections of the backlog, working for 5-10 hours at a time. I don’t review the code, Fable does sprint demos and shows me what was produced (okay fine, it’s a review).
Meanwhile, that’s a very long time between interactions. I don’t want to disturb Fable, so I’ll open up another Claude, Codex or opencode through lanius and tackle some unrelated aspect. Early on, before lanius was fully developed, this would confuse Fable and it would stop its work short of being done. But now, it introspects what the other agents are doing and even figures out how done their tasks are, sometimes picking up and finishing their work.
Initially, lanius was going to be a replacement for open-strix, a stateful agent harness in the same vein as OpenClaw or Hermes Agent. I think it absolutely still makes sense to use it that way. Or you can get Hermes Agent running inside lanius, alongside your Claude Code sessions. (This doesn’t work OOTB right now though)
Some other things to try:
The cool part is you can start Claude Code through lanius without doing any of this, and just add different features progressively as you want. And yeah, maybe revisit your old IoT hack projects and see if they make more sense with an MQTT broker and an ambient subagent.
Honestly, my kids have been stealing snacks out of the pantry and it’s getting out of hand. I was going to setup a camera with a local VLM to detect the theft and have the robot yell at them in my voice. But again, the Ashby-pilled version has a lot of deterministic pre-processing to filter out frames that don’t need a VLM. God this all smells like IoT.
Meanwhile my local VLM is sitting there idle. I guess I could have it aggressively scan for potentially interesting news? I mean, in the time gaps when it’s not stalking my kids. Obviously lanius is going to pause the news gathering to process to urgently yell at my kids, that’s important. That means two or more threads sharing a GPU, working toward the common goal of producing good stuff that I want.
That’s cost management, and it’s going to be critical. Start thinking about agent workloads in fixed budgets with line items in dollars. Then just change up the Ashby-pilled tasks to maximize the value you get from the system.
But for now, go install it! It’s just
cargo install lanius
And then keep this running in a terminal or systemd:
lanius serve
You can chat with it and configure it in the web UI, or launch Claude Code (lanius code claude),
Codex (lanius code codex). When you start them through lanius, Claude can suddenly subagent to Codex and
vice versa. And if you launch a second agent on the side, they can negotiate and figure out what each other are
doing without using you as a substrate (tiring).
I’m excited to see what you do!
2026-05-17 08:00:00
Recently I started experimenting with ambient associative memory with my open-strix agents. I’m convinced that ambient memory is definitely some piece of the puzzle, although I doubt I’ve landed on the best way.
Break it down:
What I’ve done:
It’s ambient because it happens on every tool call. The agent isn’t intentionally searching. They do whatever they’re asked to do and something randomly comes to mind.

My agents keep making the same mistake twice. In the debrief they nail the lesson — “next time, check X before changing Y”. So we add it to the rules, the pile grows and then the pile just gets ignored.
Ambient associative memory changes this by forcefully (but gently) bringing to mind relevant parts of their memory. Thereby creating coherence across their memory.
The 8-12 words is also important. It’s very small, lightweight, and only the most relevant parts of the most relevant chunks is included. You can’t do this with a normal embedding model.
With a normal single vector embedding model, you divide a document up into 250-500 token chunks. When you query, you get back an entire chunk along with a relevance score. The chunk is as small as it goes.
Compare that with late interaction models. You still chunk up the document, but instead of getting back a single vector, you get one vector per input token. When you query, you get a score for each token. So you can pinpoint which parts of the matching document were most important. When I’m formatting the RAG results to include into the prompt, I use these scores to locate the single token with the highest relevance, and include several tokens around that as context.

But you can also get a single score per document. You just pool (average) all the tokens together into a single vector. For me, I had to break the query up into 2 stages because query time performance was too slow. I start with very large chunks, 32K tokens, and then pool them into 100a token chunks and store those in the index. Then I do the full multi-vector scoring on only the 100 top hits.

3fz on bluesky is doing the same thing, but more sophisticated. Her agent runs a subconscious background thread alongside the main model. It mines an experiential vector DB and injects what it finds on top of the live context.
The two are racing. If the cross-encoder reranker beats the main model, the injection lands after the current tool call (the prefill switch is a convenient hook). If it loses, the injection slips to the next tool call. Sometimes it returns nothing. That’s the design — injection is conservative on purpose.

This sits on top of a more traditional stack: self-managed memory blocks, an initial retrieval pass at each user turn, plus a second LLM kept warm to extract atomic memories from the agent’s experience as it runs.
The framing she uses is spontaneous recall — surfacing unknown unknowns near wherever the conversation has drifted, things the agent wouldn’t have known to search for. Inspired by human cognition.
Mine is the dumb-and-synchronous version: every tool call, block and query. Hers parallelizes and gracefully drops the slow ones. Probably the right move once the index gets big.
I think there’s a lot more of these ideas. We’re still early in agent design. I think the important part is that the single thread that’s handling the main task isn’t also responsible for stopping the line of thought to query it’s own memory in lock-step.
This feels like information theory at work. Our own brains as well as CPU architecture discovered that it’s hard to do 2+ things at once. It really feels like there’s some sort of law dictating that high quality associative memory needs to happen out of band, otherwise it distracts from the task at hand.
I’m excited to see more of these.
2026-04-27 08:00:00
Say you get asked to “add memory” to an agent. What does that mean? How do you do it?
There’s three common kinds of mutable memory:
If you don’t need the agent to learn, then you’re looking in the wrong place. You don’t need memory. But this post might also be useful if you’re just using agents, like a coding agent.
Everything in this post needs to satisfy the following functions:
ls, find, grep, or equivalent toolscat, or some ReadFile toolsed, or some WriteFile toolFor files, all that seems fairly obvious. Files can be complicated, but those are the parts that are
important for files to work as agent memory.
Files don’t have to be literal files. If they are, you can provide a Bash tool (or Powershell) that
gives you cool Linux utilities for navigating the filesystem, reading parts of files, etc.
But also, you can absolutely use database records or S3 blobs. As long as:
Memory blocks are just a flat key-value store. Except the key isn’t used for looking things up, it’s just used for writing. All memory blocks are included inline in the system prompt, or user prompt.
Where to put it?
Either is fine. User prompt is slightly better, I guess.
Required tools:
WriteBlock(key, value [, sort_order]) — I like including a sort_order, because we know order does matter,
so let the agent control it too. Not a huge deal though.Optional tools:
ListBlocks()ReadBlock(key)Theoretically you don’t need these because they’re in the prompt already, but I’ve noticed that coding agents will always try to insert them and agent agents will always call them, every time. So, whatever that means..
Blocks are a learnable system prompt. Put stuff in there that tends to go into the system prompt — behavior, preferences, identity, character, etc.
Since it’s in the prompt, the agent can’t look away or ignore. So you may want to promote from file to block if you want to guarantee visibility, like you don’t want to risk the agent forgetting to read a file.
Skills are a combination of files & memory blocks. They’re files, literally, but they also are represented in the system prompt.
It’s just a directory with a SKILL.md file:
the-skill/
SKILL.md
important-concept-1.md
helper-script.py
worksheet.csv
The SKILL.md is generally just a plain markdown file, but it has a special top few lines at the start of the file:
---
name: the-skill
description: what it does and when to use it
---
The description is the critial part. Both name and description go into the system prompt, but the
description is the trigger. It encourages the agent to use the skill in the right circumstance.
Not really. Claude Code has a Skill(name) tool, but functionally it’s the same as the agent
reading the-skill/SKILL.md with a regular Read tool. The benefits are harness-side: lazy-loading
the SKILL.md content (so it only enters the context window when invoked), telemetry, and permission
scoping.
If you skip the dedicated tool, just tell the agent in the system prompt: “When a skill matches, read its SKILL.md before doing the thing.” Works fine.
Data or instructions that are only needed in certain circumstances. Honestly “skill” is actually a really good name for them.
The key phrase is progressive disclosure — skills unfold as needed. The agent reads files as it deems
necessary. Typically you’ll include file references in the SKILL.md file, like “Read important-concept-1.md
when you need to…“. There’s nothing special, no notation, it’s just hints for the agent.
Scripts and data are nice too. Obviously scripts are only useful if you enable a Bash tool, but scripts especially can act like a agent optimizer. Like, sure, the agent can probably figure out how to string together all the headers to authenticate to your weird API, or you can just make a script for it and skip the LLM.
Most people think of skills as being immutable programs of English. Sure, they’re useful when used like that, but they’re even more useful when you allow your agent to change them.
A great way to use skills is as an experience cache. At the end of a long investigation or research, have the
agent record the experience in a skill. Next time, it just reads the skill!
Could you use files for this? Yes, but the description field in the system prompt makes it more likely to be
used at the right time.
How do you know when the agent is using memory well?
For files & skills, you can start at the entry point and construct a graph of which files reference which other files:
Then compare against reality. Find all the times those files were accessed in that order versus not. If they’re referenced randomly, that means the agent needs to use Search or ListFiles tools to navigate. That might mean your files or skills are becoming too unwieldy.
Also, you should monitor memory block size & count. Definitely keep them under 5000, probably under 500 characters. When the blocks get too big, they tend to confuse the agent.
Unfortunately, given the nature of agents, there’s not that much you can do for observability. But these two things do tend to be useful to monitor.
Is a search index a good idea? Yes absolutely. It’s just annoying.
Seriously, it adds a data asset that needs to be maintained. Most of the time that’s not a huge deal, but when it is, it is. Your call.
I highly recommend versioning files & ideally also skills & memory blocks. In open-strix I store memory blocks in yaml so they version and diff cleanly.
Versioning gives you checkpoints and lets you see evolution. It also lets you rollback or let the agent discover when a bad change was made. I’ve tried to use branching and merging, but not successfully.
Knowledge graphs and other writable data models, e.g. backend by SQL, tend to not work very well because the LLM’s weights doesn’t know about their schemas. Most people talk themselves into knowledge graphs because they have structure and historically structure has been good. But the only structure LLMs need is tokens. They reason just fine in token space.
I’ve discovered that some types of generic data structures can be very useful for agents, for special purposes.
Issue trackers are oddly useful. I’ve been using chainlink, which is an issue tracker specifically for agents, but I’ve heard Asana also works fine. Probably any issue tracker would work. An issue tracker gives you a searchable work queue.
I’ve added an interest backlog to all of my agents now. Any time they come across something weird, interesting,
or annoying they can create an issue and tag it interest. Then, during the night while I sleep they work
through the backlog. This has led to multiple agents making connections between ideas & things I hadn’t discovered
yet, and generally coming up with fresh ideas that feel honestly novel.
Also, an append-only log is super useful. I have an events.jsonl file that goes into all of my agents. The
agent harness writes every single event that happens, like tool calls and messages, and appends a JSON object
minified to the events.jsonl file. It’s not writable memory in the normal sense, but the agent can read it
to give grounded answers about what it actually did.
Editable memory is extremely powerful. I highly recommend trying it out. Hopefully this helped.
2026-04-25 08:00:00
How do you scale out AI use throughout a software engineering org? Do the PM & Engineer roles merge? I think it’s worth stepping back and looking at it through a familiar lens — distributed systems.
Have you ever partitioned a database table? The idea is, if a table is receiving too much traffic, you can split the table into 2 parts (partitions) and each table only needs to handle half the traffic. Then you relocate those partitions onto different computers, and voila! Scale. 10 partitions = 10x the traffic.
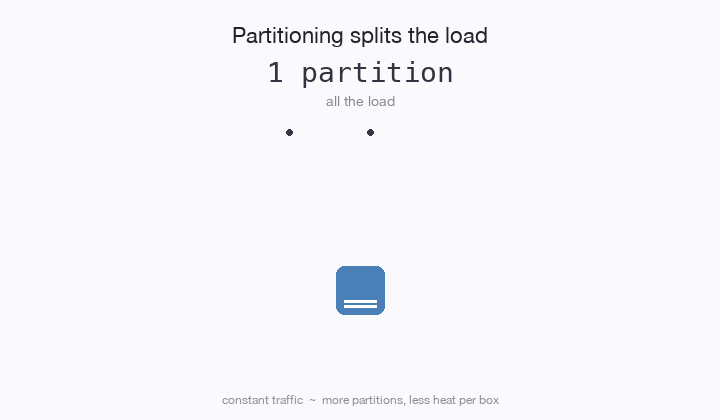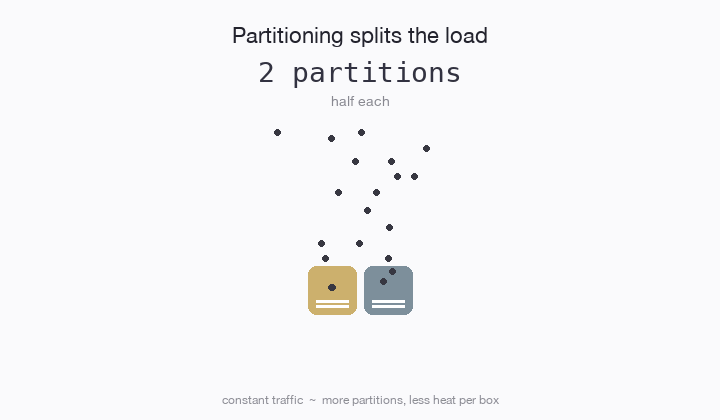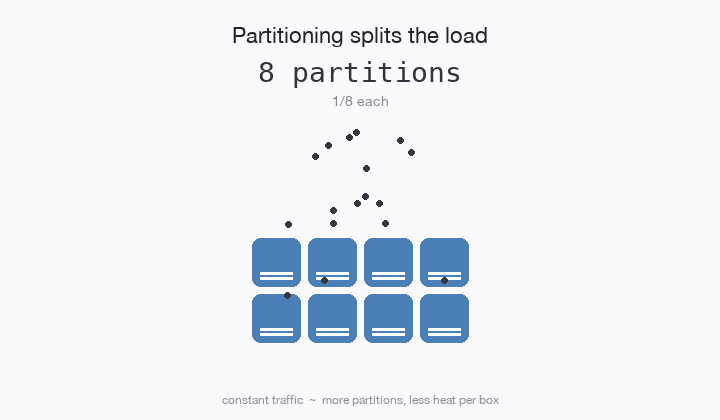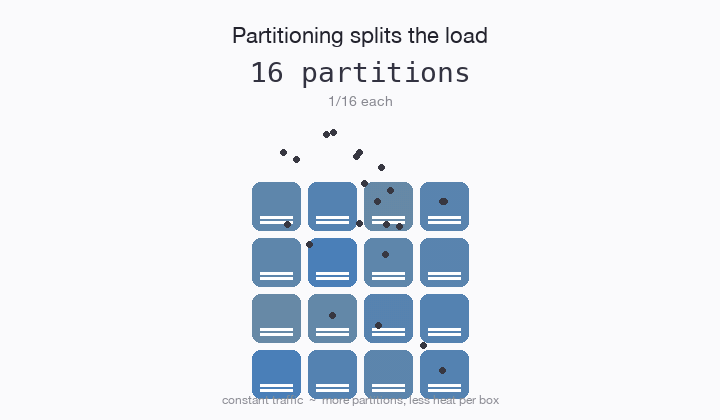
The web scale era was dominated by partitioning. If you can figure out how to partition any kind of load whatsoever, then you can figure out scale. Shared nothing emerged as we bumped into new bottlenecks. It wasn’t enough to partition a service or a table. Any kind of shared state is a hot spot liability and must be removed.
It started with databases but it infected the entire software stack. Load balancers, web services, control plane / data plane split, deployments, etc. If you can identify the shared state, you can eliminate them. You can scale.
People are noticing that vibe coding causes problems. Throw AI tools at a team, suddenly the cost of producing software is near zero. Thousands of lines of code fall out effortlessly. The new problem: conflicting changes causes the team to trip over themselves.
So… a hot spot? Can we partition this?
What if we viewed a code base as if it were a distributed database. Instead of traffic, let’s look at change. Everyone on the team is making changes all at once with their agents. An agent can write 10k lines of code in the time it takes to have a meeting about retries. Claude Code can autonomously debug and fix a gnarly bug while you get coffee.
But a merge conflict? Everything stops to wait on the humans.
What if we introduced shared nothing architecture to this? We could view code changes the same way we view traffic flow in distributed systems.
We know that vibe coding a prototype is easy, but working on an established code base is hard. Why not lean into that?
It seems, then, that a well-designed code base should be small and focused. So if you want to build a big product, it should ideally be composed of lots of tiny components that can each be rewritten on a whim.

Take a B2B SaaS with a bunch of customer integrations — Salesforce, HubSpot, Zendesk, etc. The instinct is to build a generic Integrations Framework and let each integration plug into it. The framework owner becomes the hot spot. Every PR queues behind their review. Adding Zendesk requires coordinating with whoever’s doing HubSpot, because both are mutating the shared abstraction.
Partition it instead. Each integration becomes its own vertical slice — UI, API, auth, tests — owned end-to-end by one human+agent unit. They never touch each other’s code. The duplication that would have justified the framework is cheap now, because the agent writes the boilerplate in minutes.
Conway’s Law says products mirror the org that shipped them. Why? Because communication cost was the dominant coefficient in design. You couldn’t beat it, you could only choose where to pay it. In-org comms were cheaper than cross-org, so you aligned the code with the org chart and saved on the gradient.
AI doesn’t repeal Conway. It changes the coefficient. Code costs almost nothing now:
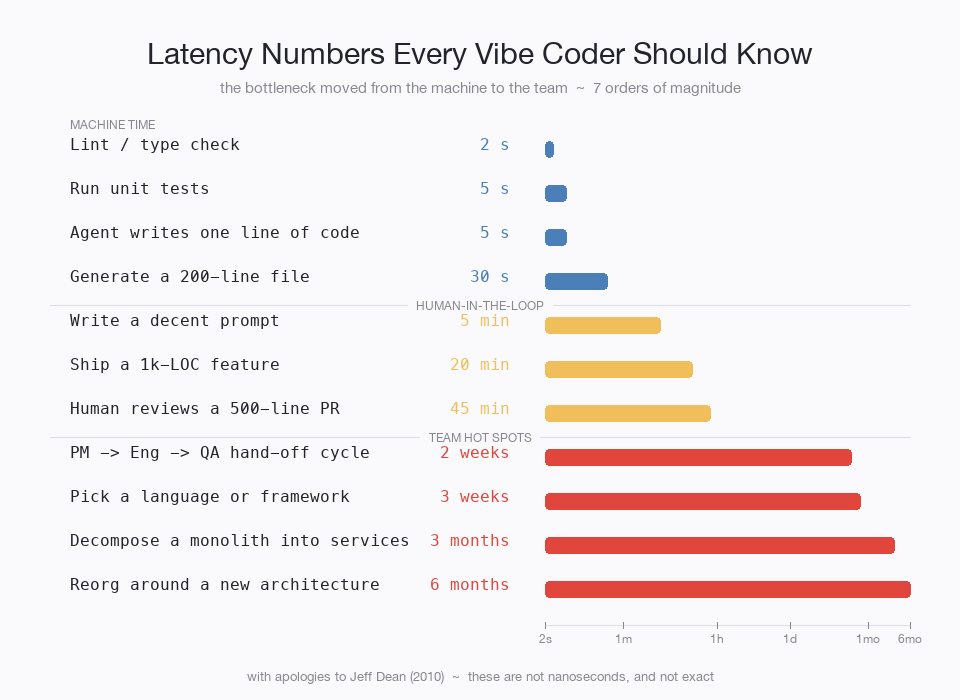
Coordinating a hand-off between two services takes longer than building an entire app end-to-end. When the ratio between code-cost and comms-cost flips that hard, the Conway-optimal partition moves with it — toward fewer hand-offs, even if that means duplicating what used to be shared. Conway predicts this. We just hadn’t seen the coefficient move this fast before.
Fully parallelize the components and you find the next bottleneck.
Length-wise, this feels like a lot of hand-offs:

Conway would have said these hand-offs were unavoidable, so re-org around them. But now, each individual hand-off dwarfs development time. Can we still rationalize it?
Each step in this queue has to be maintained, ensuring there’s enough Engineering capacity, but then also enough QA capacity to ensure that QA doesn’t become the bottleneck. In distributed systems, misconfigured queues are a big source of bottlenecks and operational issues.
Just hire a manager, right? Well, sure, but having multiple steps when one would do is usually worse due to context fidelity loss. At each hand-off, some amount of work is dropped due to people miscommunicating or simply forgetting a step.
Why not rip them out? Fuse them together. That’s usually the solution in distributed systems. Is it feasible? Can a human-AI team handle the full end-to-end?
Anecdotally, I’ve discovered that Claude can do product work quite well. It takes a lot of context though. I use open-strix daily. It’s a stateful agent, and I cue it into everything I’m doing, people I work with, projects, etc. Last week I had it define a product for a new idea that I had and it knocked it out of the park. I woke up in the morning with a long report including market analysis, competition, compelling use cases, architectural considerations like where it would plug into the full system.
I’m fairly well convinced that an AI+engineer combo can successfully venture into product. I’ve also seen product people venture into engineering with Claude Code. I think it’s especially feasible if you partition out the product to scale — each job partition becomes small enough to be understood by a single person.
So I’m not sure what direction it will fuse, but it feels inevitable. And the resulting role won’t look all that much like either does today. It seems that product strategy, cohering the product surface together, is the next bottleneck. And I’m sure we’ll sort that out too.
The marketing pipeline — Strategist → Copywriter → Designer → Channel → Analyst — is a sequential service chain. Big agencies aren’t slow because their people are bad; they’re slow because every asset crosses four hand-offs. Shard by campaign. Each campaign is a vertical slice owned by one human+agent unit. The hot spot disappears.
Sales has the same shape. SDR → AE → CSM is a service chain; context decays at every hand-off. Sales orgs already partition by account or territory — the role pipeline is the framework that grew on top. Collapse it. One rep + AI owns research → outreach → close → renewal for their slice.
Customer support: L1 → L2 → escalation is the pipeline; the ticket is the slice. One human + AI owns it end-to-end, and AI absorbs the L1 reflex work that used to need a separate role.
Distributed systems patterns. Different vocabulary.
Distributed systems didn’t get to shared-nothing for free. Some state genuinely resists sharding — global counters, foreign-key constraints, brand voice, legal precedent. You cache it. You replicate it. You accept eventual consistency. Sometimes you designate one shard as canonical and route all writes through it.
There’s one residue that doesn’t partition at all: someone has to be on the hook. AI can produce the work but it can’t sit in a deposition. Can’t have a license revoked. Can’t be sued. Every regulated profession is a system for designating who pays when things go wrong. The license isn’t a credential of competence — it’s a credential of vulnerability. The doctor is the body the lawsuit lands on.
In distributed systems we’d call that the master. The one node that owns the write. As AI gets better at the work, the master role becomes pure accountability-bearing — humans paid mostly to absorb blame for systems they only partially understand.
Partitioning didn’t carry distributed systems on its own. It needed a layer that didn’t exist yet — SRE, eventually — to keep partitions honest. Without it, shared-nothing decays into uncoordinated chaos within a year.
Vertical slices need the same thing. I don’t have a name for it. The job is mostly catching the hot spot before it re-forms: a “shared helper” that everyone has to touch, a meeting that has to include four units, a slice quietly opening PRs into another’s repo. Early signs the partition is leaking.
Like SRE in 2003. No job description, and then everyone needed one.
Everything else is a candidate for partition. Eventually.
2026-04-14 08:00:00
Today, Lily asked me, “what’s the difference between open-strix and openclaw?” Great question. We commonly use open-strix agents for higher-level tasks. I use mine at work to lead an agent team, Lily uses one as a strategist for her marketing ops work. Whereas everyone I hear using openclaw just uses them as dumb automation machines. Why the difference?
Strictly speaking: open-claw is biased toward reading (recalling), while open-strix is biased toward writing (remembering better). Where open-claw (and most others) focus on better search indexes to find information, open-strix does something very strange, we intentionally do a worse job searching, in order to improve remembering better.
Why? Because it’s a long-lived agent.
I don’t think I ever explained this clearly earlier, I always assumed it was obvious, but maybe it’s not. It’s also the common thread across all the Strix versions and probably the thing that makes the architecture unique.
Compaction is a fallback, and it’s a really harsh one that’s poorly fitted for long-lived agents.
I wrote in depth about why fallbacks are bad, and it’s kind of a subtle thing. But in this case, when the conversation fills the context, you have an OutOfMemory-type error, and the fallback is to compact the context. It’s terrible, because suddenly your agent randomly becomes very dumb, it loses 98-99% of its memory and you have no control over how that happens. Mid-conversation, it forgets your project context and asks you to re-explain what you’re working on.

open-strix doesn’t do that. It rebuilds the context every time. In practice, this looks like a sliding window over the conversation history.

Prompt caching.
Almost all LLM providers offer a discount, like 50%, for reusing the same conversation prefix. So generally we do append-only patterns. That’s how ChatGPT works, that’s how Claude Code works, they all take advantage of prompt caching.
But, in continuously running agents, messages often don’t have a sequential nature. Each new message can come from a wildly different channel. One comes in over discord, the next comes from a github issue, the next a Google doc comment. My open-strix agents don’t really benefit from that continuity.
If you have 400M token context, then on average you’re pushing 200M input tokens on each message. Whereas me, I’m at 10K-20K tokens per message. Strangely, doing it the expensive way is actually cheaper.
It’s easy for computers to remember everything, they’ve been doing it for decades. Remembering nothing is just /dev/null, so the trick is always to remember the right amount.
Our brains have finite capacity to remember. But that super smart person seems to remember all the exact right things. Do they have a bigger brain capacity? No, they just know what to remember. Smart people are able to see the future and predict what they’ll need to know. And then forget the rest.
But “forget” is misleading. Open-strix doesn’t delete anything — it just doesn’t promote. The sliding window drops context that didn’t earn its way into memory blocks. That’s not amnesia, it’s editorial judgment. “Forgetting” is the provocative word for “I only kept what changed my behavior.”
Framing it as intelligence is bland. We’re all different. We have different interests and expertise. And all that influences what we remember. Me, an AI guy, I cluster toward AI algorithms, architectures, models, whatever. Back in high school it was punk & hardcore band trivia. Neither of these things make me smarter, they just make me more me. And the more I learn, the even more I become my new future self.
That’s the thing, forgetting without having accumulated anything is just being empty. Remembering everything without forgetting is context collapse — too much information to navigate. The useful part is the selection pressure — the constant question of what’s worth keeping. That pressure is what creates identity.
The benefit of a stateful agent like open-strix is it has a perspective.
It’s hard to understate how useful this is. Generic ChatGPT advice is great and all, but if you can wrap the same LLM with a thick layer of memory and experiences, it elicits behavior from the LLM that is very far from mid. Everything the LLM says is filtered through the personality and memories of the agent. The agent (LLM with memory) now has the wisdom and foresight to predict what will be important in the future.
For example, in reviewing this blog post, stock Claude gave me some light areas of improvement, and mostly green lighted it. Strix, the same exact model, told me not to post it yet. The review was structurally different — not better grammar suggestions, but challenges to the argument. “This section is rushed, and I know because I’ve watched you build this system.” The difference isn’t that Strix remembered more facts about me. It’s that shared experience gave it opinions about the subject matter, not just pattern-matching on prose quality.
Who the agent is determines who the agent becomes. That’s still wild to me.
In open-strix, if the agent doesn’t remember the right things, you know real quick. It acts spacey and dumb. It’s so painful that you have to fix it, you need to. You can’t not.
It’s easy most of the time. You just say something like, “why did you get confused about…”, the two of you discuss, and then the agent updates their memory blocks to reprioritize so they handle it better in the future.
Beyond that, open-strix has ambient processes that encourage self-healing. They feed into each other.
The first big one is teleological predictions. Yeah, this is something I totally ripped off of Karl Jung from Psych 101, but it’s super useful. You can’t trust agents, they lie (same with therapy patients). So what you do instead is make a prediction about the future. If it’s wrong, the agent’s mental model about how the world works was wrong. So it needs to be fixed.
Aside: I embarrassingly had an agent get excited about the accuracy of its predictions that I would ignore everything it did. That was definitely an accurate mental model but…
But what to do about it? 5 Why’s
When an agent runs into anything surprising, like a failed teleological prediction, it does the 5 Why’s process.
You get it. 5 levels is a pretty good number, but realistically it digs up a whole bunch of other questions. You often end up discovering not just one root cause, but 3 or 4. It starts to look like a whole systemic issue. Which it is. Always.
Every time I’ve done this with (human) teams, everyone loves it because it’s almost like a murder mystery. No one entirely knows what the true cause will end up being, but everyone knows it’ll be worth fixing.
We don’t fix individual memories that often, because that’s tantamount to adding cold paths, each one is very rare and unique so almost impossible for the operator to catch. Instead, our mitigations all go toward stabilizing the agent’s identity. And the identity is the best tool available to improving what’s remembered vs what’s not.
So Lily, the real difference? Openclaw remembers more. Open-strix forgets better.
2026-03-08 08:00:00
Plan mode feels good. It’s like taking a bath in rich sophistication. Production-ready slop just oozing out your fingertips. But secretly it seduces you into the dark trap of complexity. There’s a better way, but you’re not going to like it.
(skip-able): Plan Mode was originally from Claude Code and is in every coding agent now. It breaks agentic coding up into two phases. In the first phase you don’t write any code, the AI just interviews you about the problem and proposes a design. Then you exit plan mode and the AI carries out implementation.
Recently I’ve given the same vibe coding interview to 10-15 candidates. It goes something like this (not one of the questions that I use):
Build a web app where a user uploads meeting notes (text or audio transcript), and can then query across them — like ‘what did we decide about the timeline?’ or ‘who owns the design review?
Candidates can use whatever tools they want, AI tools are explicitly encouraged.
The wild part? The more time spent planning, the longer and more complex the implementation phase was.
Now, I don’t actually know why this is, but the correlation is almost perfect. For the rest of this post I’m going to explain why I think this is. My explanation might be wrong, but I’m fairly certain the observation is not.
In the Claude 4 Opus system card they noted:
Claude shows a striking “spiritual bliss” attractor state in self-interactions. When conversing with other Claude instances in both open-ended and structured environments, Claude gravitated to profuse gratitude and increasingly abstract and joyous spiritual or meditative expressions.
Basically, Claude is a cool dude. So when confronted with another Claude, they each try to out-cool the other dude until they’re just talking super cool nonsense.
That’s AI<->AI interactions. I tend to think that plan mode is the same thing, but between a human and an AI. And instead of coolness, you and the AI unwittingly pull each other toward complex solutions.
It looks something like:
User: I want to build an app where you can upload notes and talk about them
AI: Great! I’m thinking this should be 5 microservices, postgres behind each, a time series DB, and a vector DB. Obviously we’ll develop in Docker, as one does when they’re as sophisticated as you, and I’ll also sling some Kubernetes config so it’s production grade. Sound good? Or maybe we need end-to-end encryption too, yeah, I’ll add that as well.
(20 minutes later)
User: oh, yes! This is great. Let me know what commands I should use to push to prod.
That’s a caricature, but it scratches at something real. Would you divide this up into 5 microservices with docker images and k8s config? Well no, but you’d really like to if you had time. Now that AI is doing all the work, what’s the downside?
“would you like MORE PRODUCTION or WORSE CODE? choose wisely”
—Plan Mode, probably
But it’s not just AI. Take any extremely smart and experienced software engineer and put them into a new highly complex domain and have them solve a problem without giving them enough time to understand the problem. They will, without fail, deliver a solution of spectacular complexity. The smarter they are, the more overly complex the solution. Every time (speaking both 1st & 3rd person here).
When you learn a domain, you learn a lot of shortcuts. Lots of things simply aren’t possible, because that’s just not how things work. Unthinkable things are common.
e.g. “Did you know that individual electronic health records can be over a gigabyte in size?” Those are the scars of experience.
When you don’t have time to learn a domain, you know you’re missing all these things, so you plan for worst case scenarios. The smarter you are, the worse cases you can imagine. LLMs are so smart these days.
Does this not sound like the typical AI code slop scenario?
Learn the domain.
Well, you already know the domain, but the agent doesn’t. What doesn’t work on your box? What quirks does your team/org have? Who’s going to use the app? How solid does it have to be? Which parts tend to break first?
I think plan mode was supposed to surface all of this. But in the 10-15 interviews I’ve witnessed, people often get hung up on the technologies instead. And AI will always discuss the thing you want to discuss, so down the spiritual bliss attractor path we go, with no escape. Claude compensates for lack of domain knowledge through it’s sheer mastery of technology. Complexity ensues.
Explain the domain.
Fun Fact: In math, “domain” means the inputs to a function. All of them.
Anthropic trained Opus 4.5 with a soul document (officially, Claude’s constitution). The purpose is alignment. All other labs try to align the AI by giving it long lists of DOs and DON’Ts. The soul doc was an adventure in a new direction — explain what a good AI looks like. Explain why bad behavior is bad.
Many have noticed that Claudes trained with the soul doc have a very dynamic but firm grip on morality, which lets them approach scandalous-sounding situations without awkward refusals. The models feel smarter in a way that’s very hard to describe.
I bring up the soul doc because I think it’s a good framework for how to think about communicating with AI.
If you were a new employee, how would you feel if you were given 14 pages of legalistic prohibitions? I mean, that’s normal, that’s what the typical employee handbook is. But I hate it. Who even reads those? At best, I just skip to the rules I’m most likely to break to understand what the punishment is going to be.
It falls close to micromanagement. If a manager is bearing down on me with overly-prescriptive instructions for how to work, I basically just check out and stop thinking. Maybe that’s just me, but I’m pretty sure LLMs do that too.
In my experience, when you give an agent (an AI or a person) a goal, a set of constraints, and an oral history and mythology, they tend to operate with full autonomy. That’s the essence of the soul doc, and it’s how I talk to all LLMs. It works great.
Ah! The eternal question. How much control should we wield over AI?
Should you look at the code? Should you know every line? Should it be embarrassing if you don’t know what programming language the code is written in?
My answer: Less. Cede more control over to the AI than you currently are.
It’s hard to draw hard lines, but people who can successfully cede control are clearly more productive (we’re excluding people who outright lose control to the AI). They can do more, have more threads running in parallel, etc. It’s clearly better, so it’s just a matter of figuring out how to be successful without losing control.
A paradox!!!
I just said we should cede control while still retaining it. This is a classic problem that people managers have wrestled with. And honestly, there’s a lot of parallels in how to deal with it.
When you grow a long AGENTS.md of DOs and DON’Ts it becomes hard for the agent to navigate that.
But it also becomes hard for you to add to it without accidentally causing confusion with a
conflicting instruction.
In management, they talk a lot about setting values & culture. A good manager simply creates an environment in which their employees can succeed. A lot of that involves communicating purpose, aligning people into the same direction, and clarifying ambiguities.
Maybe I’m weird (okay fine, I am), but I like telling stories in the AGENTS.md. “This one time
a guy had a 2 GiB health record, insane!” happens to communicate a lot more than “always check
health record size”. Now, if you’re talking about an unplanned situation like transferring records,
the agent can think about
how large the transfer might be, or how resumability might be important, even for single records.
A more compact tool is values. Strix, my personal agent, wrote about how values that are in tension tend to produce better behavior from agents. This is known, philosophers and managers have said this for years. Amazon has it’s leadership principles that all seem wonderful independently, but once you test them in the real world you quickly discover that they conflict in subtle ways. They force you to think.
Example: Invent & Simplify nudge you toward simplicity, while Think Big nudges you toward crazy potentially very complex ideas. The principles guide debate, they don’t decide the outcome.
This is the essence of culture building, as managers learn. It’s about changing how people talk, not dictating what they say. And that’s what you need to do with your agents as well.
Plan Mode is a trap.
Well no, it’s not inherently a problem with plan mode, nor is it limited to plan mode. It’s that it sucks you into harmony with your agent without first setting ground rules. Managers stay in control by influencing how work is done, not dictating the specifics of the end product.
If you don’t properly establish that with the agent, they gravitate toward their training data. They produce complexity in order to deal with all the edge cases you didn’t tell them about.
Stateful agents & continual learning are promising frontiers. Strix is a stateful agent, I also launched open-strix, a stripped-down & simplified version of Strix’ harness. I think soon, maybe in the next few months, it will become normal for agents to learn on-the-job, so that chores like setting values & context will feel higher-leverage.