2025-12-09 00:00:00
当前,降本增效已成为各行各业的共识,如何在业务和支撑环节中有效节省开支,几乎是每个从业者必须面对的问题。本文将结合个人经验,记录一些在 IT 运维实践中节省成本的措施。
定期梳理闲置的资源和服务,及时关闭不必要的项目。
例如:
根据实际使用情况,评估当前资源配置是否过高。若发现资源利用率较低,可以考虑将高配资源替换为低配资源,以节省费用。
例如,服务器和数据库实例等,可以根据 CPU、内存、存储等指标,在满足业务需求的前提下,选择更经济的规格。
此外,可以考虑通过性能优化,降低资源需求,从而使用更低配置的资源。
例如,一些存储中间件、消息中间件和监控系统等,可以考虑使用成熟的开源软件替代商业软件,以节省费用。
当然,在选择开源软件时,需考虑其功能和性能是否满足要求,同时也要评估运维和支持成本。
对于一些小公司和个人网站,可以考虑使用 Let’s Encrypt 等免费证书颁发机构提供的 SSL 证书,以节省证书费用。详见我的另一篇文章:借助 Let’s Encrypt 节省 SSL 证书费用。
在采购硬件、软件和服务时,可以通过一些策略节省成本:
定期进行成本复盘,检查是否有可以优化的细节。
例如:
这是一个持续优化的过程,为公司节省的每一分钱,都可能是在寒冬中生存下去的机会。
您还有哪些有效的节省成本经验,期待评论交流!
2025-11-27 00:00:00
向服务商购买一张常见的 DV 通配符 SSL 证书,通常每年价格在数百至一千多元人民币不等;若名下有多个域名需要使用证书,总费用每年可能达到数千元。
在当前强调降本增效的环境下,若评估后认为免费证书能够满足需求,小公司和个人网站即可节省相应成本。
Let’s Encrypt 是一家免费、开放、自动化的公益性证书颁发机构(CA),由互联网安全研究组(ISRG)运作,属于非营利组织。其目标是推广 HTTPS 的应用,为构建更安全、尊重隐私的互联网提供免费而便捷的支持。
根据不同使用环境,Let’s Encrypt 提供多种验证与获取证书的方式。常用工具是 Certbot,详见文档:https://eff-certbot.readthedocs.io/en/stable/。
在部分环境中,可配置工具定期自动续期,减少维护工作。
由于服务器环境较为老旧,且需要将证书上传至阿里云并部署到多个云服务,本文暂采用“本地生成证书—手动上传与更新”的方式。
本文使用 Docker 运行 Certbot,参见文档:https://eff-certbot.readthedocs.io/en/stable/install.html#alternative-1-docker。
生成通配符证书的示例命令如下:
docker run -it --rm --name certbot \
-v '/Users/mazhuang/some/path/letsencrypt:/etc/letsencrypt' \
certbot/certbot certonly \
--preferred-challenges dns \
--manual \
--server https://acme-v02.api.letsencrypt.org/directory \
--key-type rsa --rsa-key-size 2048
--preferred-challenges dns:使用 DNS 方式进行域名验证;--manual:以交互式方式进行询问与操作;--key-type rsa --rsa-key-size 2048:生成 2048 位 RSA 私钥(部分阿里云服务不支持默认的 ECC 证书)。执行后会依次询问邮箱、协议授权、域名等信息,随后提示添加 DNS TXT 记录以完成域名所有权验证,按提示操作即可。
生成成功后,证书与私钥保存在挂载的本地目录中,例如上述命令中的 /Users/mazhuang/some/path/letsencrypt/archive/{domain name}。各文件的说明可参考:https://eff-certbot.readthedocs.io/en/stable/using.html#where-certs。
将证书上传到阿里云的数字证书管理服务。可使用其一键部署功能(付费),或在各云服务中手动选择使用该证书(免费),按需取用。
Let’s Encrypt 颁发的证书有效期为 90 天,建议在到期前 30 天内更新。可重复步骤 0x01 生成新证书,然后上传并部署。
部分极为老旧的平台有可能不支持 Let’s Encrypt 颁发的证书,建议评估后再决定是否使用,具体的兼容情况可以参考:https://letsencrypt.org/zh-cn/docs/certificate-compatibility/ 。
比如我这边就遇到了因为使用的是 JDK 8 的低于 141 的版本,部署完证书后,发现 xxl-job 定时任务执行器没有注册上,报错 sun.security.validator.ValidatorException: PKIX path building failed。
解决方法:
下载 ISRG Root X1 证书
在这里可以找到: https://letsencrypt.org/certificates/
cd /opt
get https://letsencrypt.org/certs/isrgrootx1.pem
导入证书到 JDK 的 cacerts 中
keytool -trustcacerts -keystore "/opt/jdk/jre/lib/security/cacerts" -storepass changeit -noprompt -importcert -alias lets-encrypt-x1 -file "/opt/isrgrootx1.pem"
重启服务
以上步骤简单、成本为零。对小公司和个人网站而言,是节省 SSL 证书费用的可行方案。
若环境允许,建议配置自动化续期,进一步降低维护成本,按需采用。
2025-11-14 00:00:00
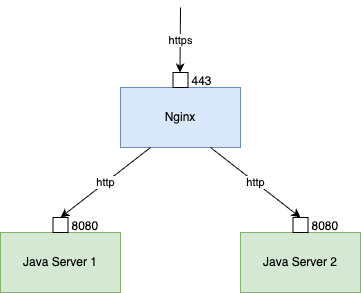
一种常见的服务部署架构是 Nginx 反向代理后端 Java 应用服务器,Nginx 监听 443 端口处理 https 请求,然后转发给后端服务器。
对应的 Nginx 配置大致如下:
upstream www {
server 192.168.1.101:8080 weight=100 max_fails=3 fail_timeout=10s;
server 192.168.1.102:8080 weight=100 max_fails=3 fail_timeout=10s;
}
server {
listen 443 ssl;
server_name example.com;
ssl_certificate /path/to/cert.pem;
ssl_certificate_key /path/to/key.pem;
location / {
proxy_pass http://www;
}
}
即:客户端与 Nginx 之间是 https,Nginx 与后端 Java 应用服务器之间是 http。
这样可能会遇到一些问题,如:
HttpServletRequest.getRequestURL() 获取到的 URL 是 Nginx 与后端服务器之间的 http URL,比如 http://192.168.1.101:8080/xxx;HttpServletResponse.sendRedirect() 生成的重定向 URL 也是 http URL。要解决这些问题,可以通过 Nginx 配置 + 少量后端代码修改来实现。
用户实际访问的是 https://example.com/xxx,但是后端应用获取到的 URL 是 http://192.168.1.101:8080/xxx,如何让后端应用获取到正确的 URL 呢?
第一步,Nginx 可以通过 proxy_set_header Host 指令将客户端请求的 Host 头传递给后端服务器:
location / {
# ...
proxy_set_header Host $host;
}
这样,后端应用通过 HttpServletRequest.getRequestURL() 获取到的 URL 就是 http://example.com/xxx 了。
但此时,协议仍然不对,还是 http。
要给后端应用传递正确的协议,通常的做法是使用 X-Forwarded-Proto 头:
location / {
# ...
proxy_set_header X-Forwarded-Proto $scheme;
}
添加这个头之后并不会让 HttpServletRequest.getRequestURL() 直接返回 https URL,需要在后端应用中做一些处理。以 Java 应用为例,可以通过一个过滤器(Filter)来修改 request 的 scheme:
import javax.servlet.*;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletRequestWrapper;
import org.apache.commons.lang3.StringUtils;
import org.springframework.stereotype.Component;
import java.io.IOException;
@Component
public class XForwardedProtoFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
if (request instanceof HttpServletRequest) {
HttpServletRequest httpRequest = (HttpServletRequest) request;
String xForwardedProto = httpRequest.getHeader("X-Forwarded-Proto");
if (StringUtils.isNotBlank(xForwardedProto) && !xForwardedProto.equalsIgnoreCase(httpRequest.getScheme()) && xForwardedProto.equalsIgnoreCase("https")) {
httpRequest = new HttpServletRequestWrapper(httpRequest) {
@Override
public String getScheme() {
return xForwardedProto;
}
@Override
public StringBuffer getRequestURL() {
StringBuffer requestURL = super.getRequestURL();
if (requestURL != null && requestURL.length() > 0) {
int index = requestURL.indexOf("://");
if (index > 0) {
requestURL.replace(0, index, xForwardedProto);
}
}
return requestURL;
}
};
}
chain.doFilter(httpRequest, response);
} else {
chain.doFilter(request, response);
}
}
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void destroy() {
}
}
至此,后端应用通过 HttpServletRequest.getRequestURL() 获取到的 URL 就是 https://example.com/xxx 了。
后端应用通过 HttpServletResponse.sendRedirect() 生成的重定向 URL 也是 http URL,如何让它变成 https 呢?
这个问题可以通过 Nginx 的另一指令 proxy_redirect 来解决,该指令用于修改从后端服务器返回的 Location 和 Refresh 响应头。
location / {
# ...
proxy_redirect http:// $scheme://;
}
这样,当后端应用返回一个重定向响应时,Nginx 会将 Location 头中的 http:// 替换为 $scheme://,即 https://。
在很多情况下,Nginx 前面可能还有商用负载均衡器(如 AWS ELB、阿里云 SLB 等),这时需要考虑负载均衡器与 Nginx 之间的协议问题。
如果负载均衡器与 Nginx 之间是 http,而 Nginx 与后端应用之间是 http,那么就需要在负载均衡器和 Nginx 之间添加 X-Forwarded-Proto 头,以便 Nginx 能够正确地识别原始请求的协议。
主流的负载均衡器配置项里应该都有添加 X-Forwarded-Proto 头的选项开关,比如阿里云:

需要注意的是这样配置后,Nginx 配置也需要做相应的调整,将 $scheme 替换为 $http_x_forwarded_proto:
(此种场景 $scheme 为负载均衡器与 Nginx 之间的协议 http,$http_x_forwarded_proto 为负载均衡器通过 Header 透传过来的前端访问协议 https。)
location / {
# ...
proxy_set_header X-Forwarded-Proto $http_x_forwarded_proto;
proxy_redirect http:// $http_x_forwarded_proto://;
}
2025-10-15 00:00:00
最近我的 GitHub 页面右上角一直有个小蓝点,就像这样:
这是有未读通知的指示,但点进去却什么也看不到。
![]()
这种「幽灵通知」已经干扰了我的正常使用体验。这天实在忍无可忍,正打算给 GitHub 提交一个工单时,在官方开设的讨论区里发现了一个讨论贴,我在里面找到了有效的临时解决办法,特此记录下来以备后用。
讨论贴链接:https://github.com/orgs/community/discussions/6874
我使用的是讨论里提到的 利用浏览器开发者工具的解决方案。
在浏览器打开通知列表页面,点击左侧标记有数字的 Filters 或者 Repositories,比如我上文贴的图里的 Participating、Mentioned,或者 outcaster552/gitcoinpromosender、gitcionoda/org、yycombinator/-co、paradigm-ventures/paradigm 等等。
打开浏览器的开发者工具(F12),切换到 Console 标签页,粘贴以下代码并回车执行:
document.querySelector('.js-notifications-mark-all-actions').removeAttribute('hidden');
document.querySelector('.js-notifications-mark-all-actions form[action="/notifications/beta/archive"] button').removeAttribute('disabled');
这时页面上会出现一个 Done 按钮,点击它即可清除对应的通知。
如果以上办法没有解决问题,还可以试一下贴子里 被标记为答案的回复 是一个借助 curl 命令的解决方案。
curl -X PUT
-H "Accept: application/vnd.github.v3+json" \
-H "Authorization: token $TOKEN" \
https://api.github.com/notifications \
-d '{"last_read_at":"2025-10-15T10:00:00Z"}'
其中 $TOKEN 需要替换成你自己的 GitHub 个人访问令牌(Personal Access Token),可以在 https://github.com/settings/tokens/new 创建,注意 Select scopes 里需要勾选 notifications。命令里的 last_read_at 字段的值可以按需修改为当前时间。
这种幽灵通知,看情况应该来自于某些居心不良的开发者,在他们的仓库里恶意 at 大量的用户来引流,然后这些用户就会收到通知。但如果这些仓库后来因为违规被删除,那么这些通知就会变成幽灵通知,无法被正常清除。
看讨论的时间线,这个问题已经存在至少四年了,GitHub 官方似乎并没有打算修复它。希望本文能帮到和我有同样困扰的朋友。
2025-08-30 00:00:00
项目里的页面一多,重复的页面布局就不可避免地冒了出来,作为程序员,消除重复,义不容辞。那么,今天就来聊聊如何在 FreeMarker 中复用页面 layout,让代码更优雅、更易维护。
FreeMarker 提供了 include 指令,可以把一些公共页面元素单独提取出来,然后在需要的地方通过 include 引入,例如:
<#-- includes/header.ftl -->
<p>我来组成头部</p>
<#-- includes/footer.ftl -->
<p>我来组成底部</p>
<#-- somepage.ftl -->
<#include "./includes/header.ftl">
<p>我是页面内容</p>
<#include "./includes/footer.ftl">
<script>
// 这里是一些 JavaScript 代码
</script>
但是所有类似的页面都要手写这个结构也挺麻烦的,更糟糕的是,一旦这些页面的结构发生变化,得在 N 个页面里反复修改,想想都头大。
很多博客引擎(比如 Jekyll)都支持 layout 功能,允许我们定义统一的页面布局,具体页面只需专注于内容。
FreeMarker 虽然没有内置 layout,但我们可以用 macro 来实现类似的效果。
比如,抽象出一个 layout/page.ftl 文件,作为布局模板:
<#-- layout/page.ftl -->
<#macro layout body js="">
<#include "../includes/header.ftl" />
${body}
<#include "../includes/footer.ftl" />
${js}
</#macro>
然后在需要的页面这样用:
<#import "./layout/page.ftl" as base>
<#assign body>
<p>我是页面内容</p>
<p>当前时间:<span id="current-time">${.now?string("yyyy-MM-dd HH:mm:ss")}</span></p>
</#assign>
<#assign js>
<script>
// 每隔一秒刷新当前时间
setInterval(function() {
document.getElementById("current-time").innerHTML = new Date().toLocaleString();
}, 1000);
</script>
</#assign>
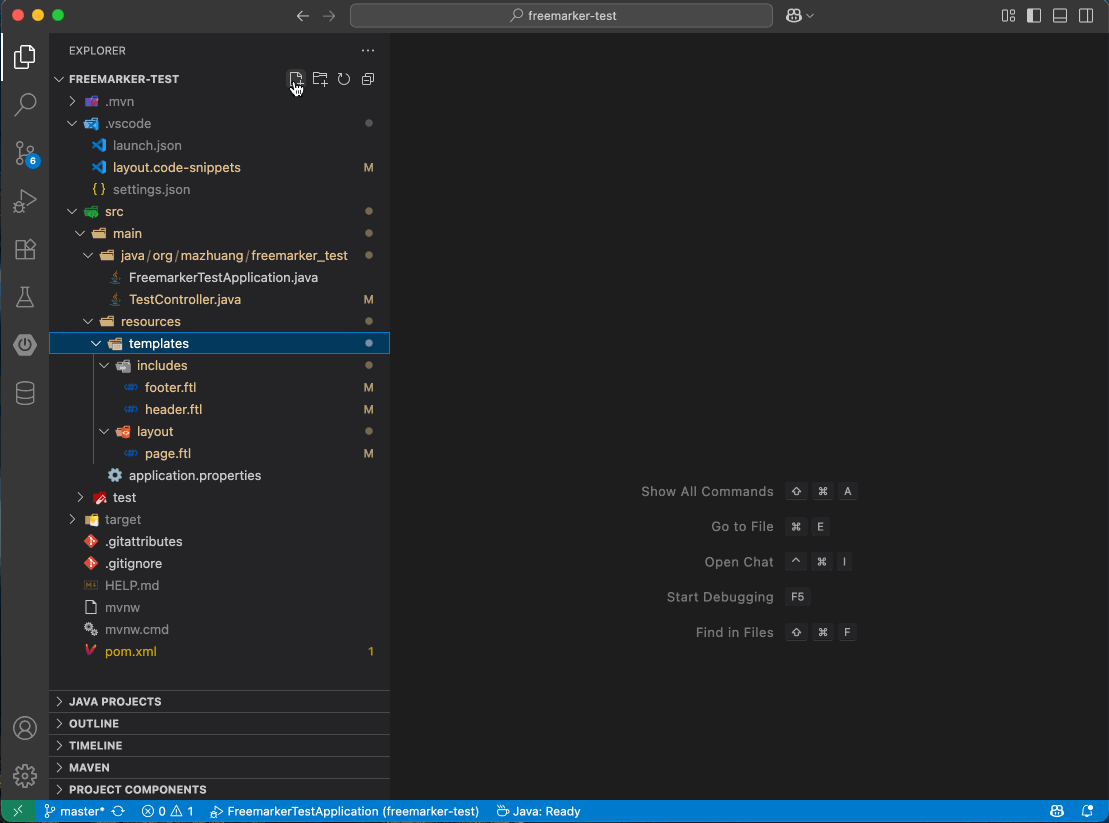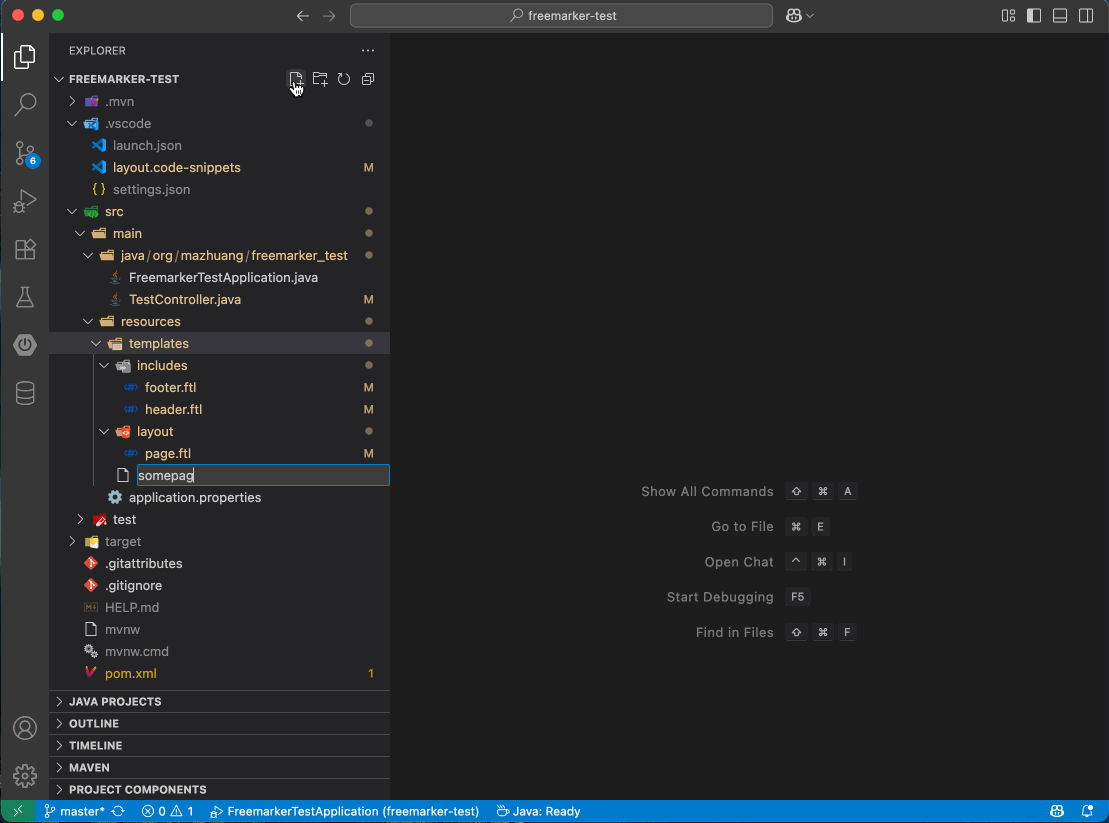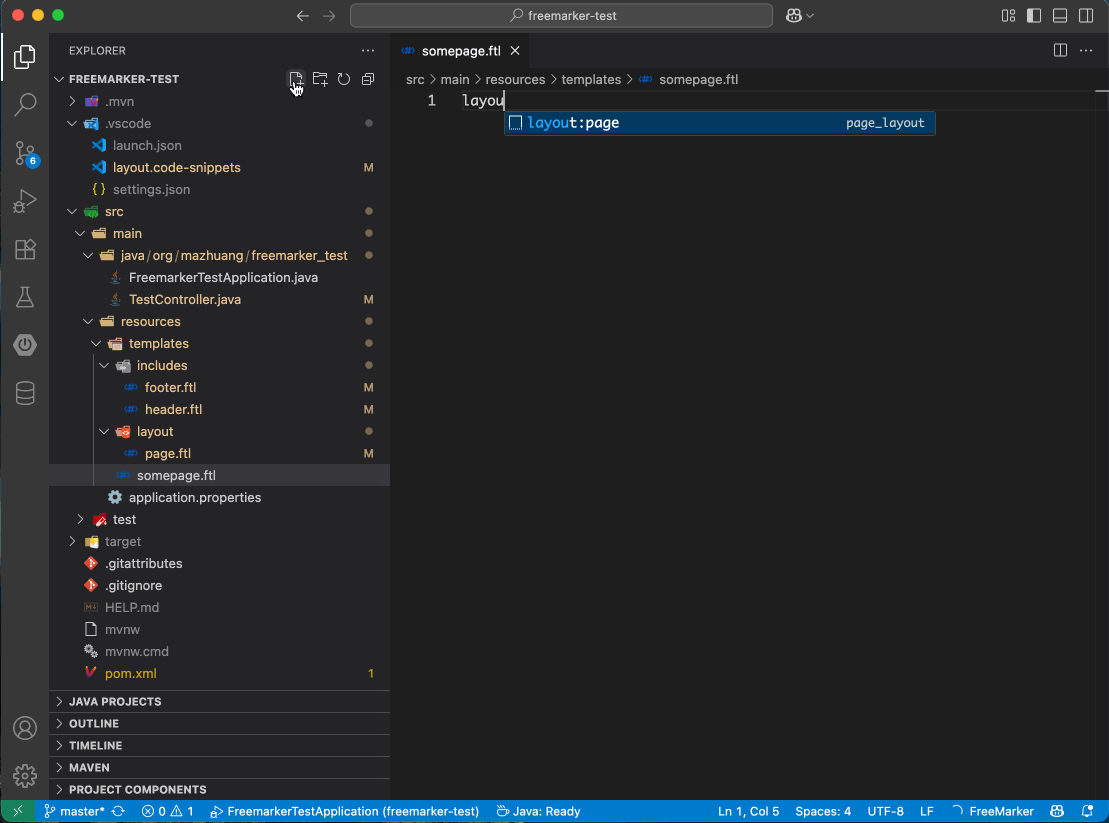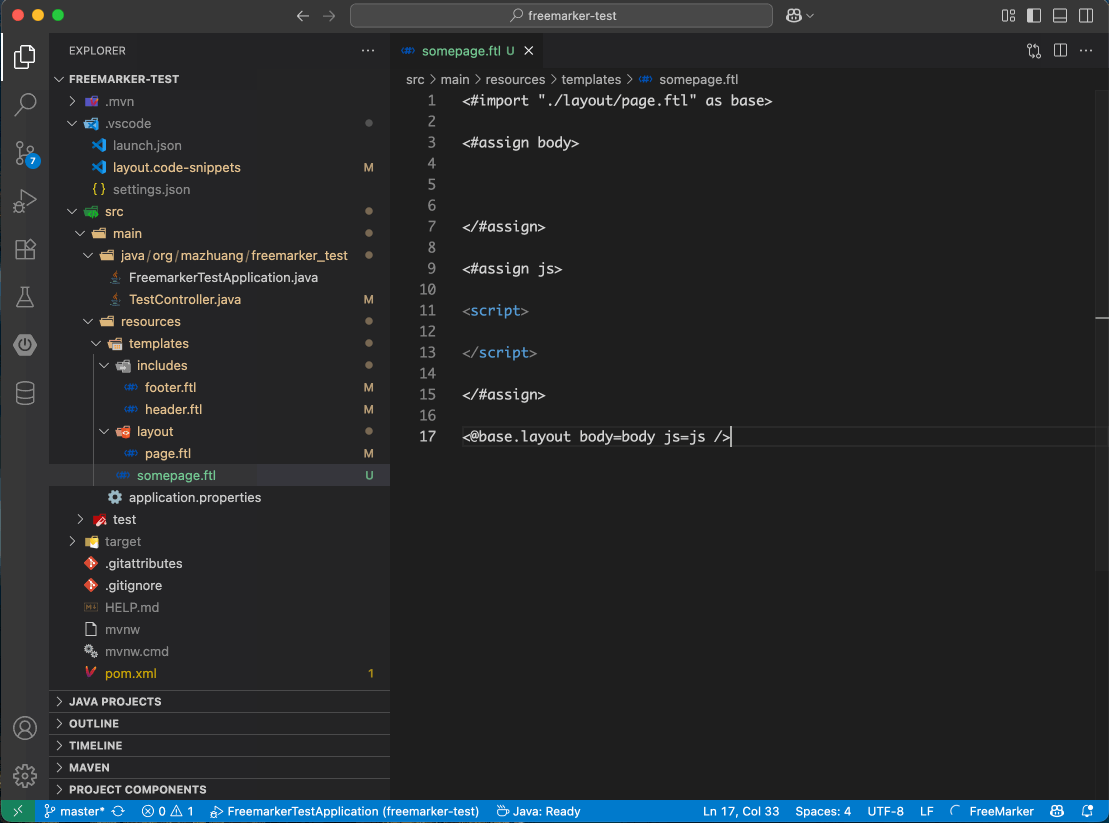
<@base.layout body=body js=js />
页面效果如下:
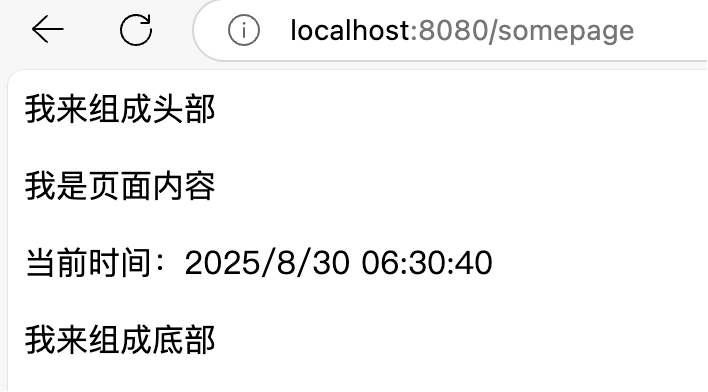
虽然布局复用问题解决了,但每次新建页面还得手写一遍结构,还是不够优雅。程序员的信条是:能自动化的绝不手动!
这时就轮到编辑器/IDE 的 code snippets 功能登场了。把上面的结构定义成代码片段,新建页面时只需输入一个触发词,基本结构就自动生成。
以 VSCode 为例,可以在项目的 .vscode 目录下新建 layout.code-snippets 文件,内容如下:
{
"page_layout": {
"scope": "ftl",
"prefix": "layout:page",
"body": [
"<#import \"./layout/page.ftl\" as base>",
"",
"<#assign body>",
"",
"",
"",
"</#assign>",
"",
"<#assign js>",
"",
"<script>",
"",
"</script>",
"",
"</#assign>",
"",
"<@base.layout body=body js=js />"
],
"description": "Page layout template for FTL files"
}
}
这样新建 .ftl 文件后,输入 layout:page,页面布局结构就自动生成了。
如图所示:
IntelliJ IDEA 也可以用 Live Templates 实现同样的效果。
本文相关代码和示例已上传至 GitHub,见 https://github.com/mzlogin/learn-spring 的 freemarker-test 目录。
2025-06-05 00:00:00
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。
如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LAUNCHPAD,按照说明在 Mac 上也可以使用。
而我想着后期做一些定制,所以还是需要在 Mac 上搭建 ESP-IDF 开发环境,自己编译和烧录固件。而这个在 小智 AI 聊天机器人百科全书 中没有详细提及,所以我就记录一下搭建过程,供有需要的朋友参考。
先上一个跑起来后的效果:

这一步参考乐鑫官方的 Linux 和 macOS 平台工具链的标准设置 完成,我这里指定了使用 ESP-IDF v5.4.1 版本,编译目标是 ESP32-S3。
brew install cmake ninja dfu-util ccache python3
mkdir ~/github
cd ~/github
git clone -b v5.4.1 --recursive https://github.com/espressif/esp-idf.git
ESP-IDF 将下载至 ~/github/esp-idf 目录。
cd ~/github/esp-idf
./install.sh esp32s3
在 ~/.zshrc 中添加以下内容:
alias get_idf='. $HOME/github/esp-idf/export.sh'
然后 source ~/.zshrc 使其生效。
这样在需要用到 ESP-IDF 环境的时候,只需要在终端中执行 get_idf 即可。
在执行以上步骤时,如果遇到问题,可以到 乐鑫官方文档 里看看有没有解决方案。
cd ~/github
git clone -b v1.6.2 [email protected]:78/xiaozhi-esp32.git
cd xiaozhi-esp32
然后接入 ESP32-S3 开发板,执行以下命令:
get_idf
idf.py set-target esp32s3
idf.py build
idf.py flash monitor
一切顺利的话,会向 ESP32-S3 开发板烧录小智 AI 固件,并且进入监控模式。
至此,就初步能跑起来了。按照提示进行 WiFi 配置和小智 AI 平台的设备绑定,即可开始使用。
如果后续需要定制固件,可以基于 ~/github/xiaozhi-esp32 目录进行修改和编译。若习惯使用 VSCode 进行开发,可以安装 适用于 VSCode 的 ESP-IDF 扩展,这样可以更方便地进行开发和调试。