2026-07-27 14:55:03
The recently published RFC 9421 describes how to do HTTP Message Signatures, and starting just now, curl experimentally supports them.
The specification describes this as a mechanism for creating, encoding, and verifying digital signatures or message authentication codes over components of an HTTP message. It is a way to verify that selected parts of the HTTP request arrives unmodified and exactly the same as when the request was created by the client.
These days, it is very common that there are layers of proxies, load balancers, front-ends, CDNs, web firewalls and what not in between the client and the ultimate application. With HTTP Message Signatures, there can be assurances that the headers are components of the request end are unaltered.
This functionality comes with four new command line options to allow users to use its full power:
--httpsig-algo allows the user to specify which algorithm to use, with ed25519 being used by default. The only other algorithm supported right now is hmac-sha256.
--httpsig-key specifies the key to use when signing the request.
--httpsig-keyid is the key identifier, a string that is passed on in the headers.
--httpsig-headers details exactly which parts of the request and which headers that should be signed. If not set, it defaults to signing the method, authority, path and query.
With these four new flags added to the list, curl supports 278 different command line options.
The corresponding options of course also exist as options for curl_easy_setopt:
CURLOPT_HTTPSIG_ALGORITHM: signing algorithm (“ed25519” or “hmac-sha256”)CURLOPT_HTTPSIG_KEY: the key to use for the signingCURLOPT_HTTPSIG_KEYID: key identifier for Signature-InputCURLOPT_HTTPSIG_HEADERS: a space-separated list of components to signThis feature is marked experimental. This means that it need to be explicitly enabled in the build to appear, and that we strongly discourage use of it in production as we reserve the rights to change it before it gets supported for real. We use the experimental phases as a time for people to test it, to tweak it and to learn what we should fix so that we then can support this to the end of time. We do not guarantee any backward compatibility for experimental features.
Please test this feature and tell us how you experienced it! The more tests and more feedback we get, the faster we can get moved out of the experimental phase to have it present for real for everyone.
This feature is already merged into git and will be part of the pending curl 8.22.0 release. As experimentally supported.
This feature was graciously brought to us by Sameeh Jubran.
Top image by Antonios Ntoumas from Pixabay
2026-07-25 22:29:28
It takes a village to make curl. A rather big village.
I have not been a solo maintainer of curl for a long time and I don’t even do half of the commits anymore
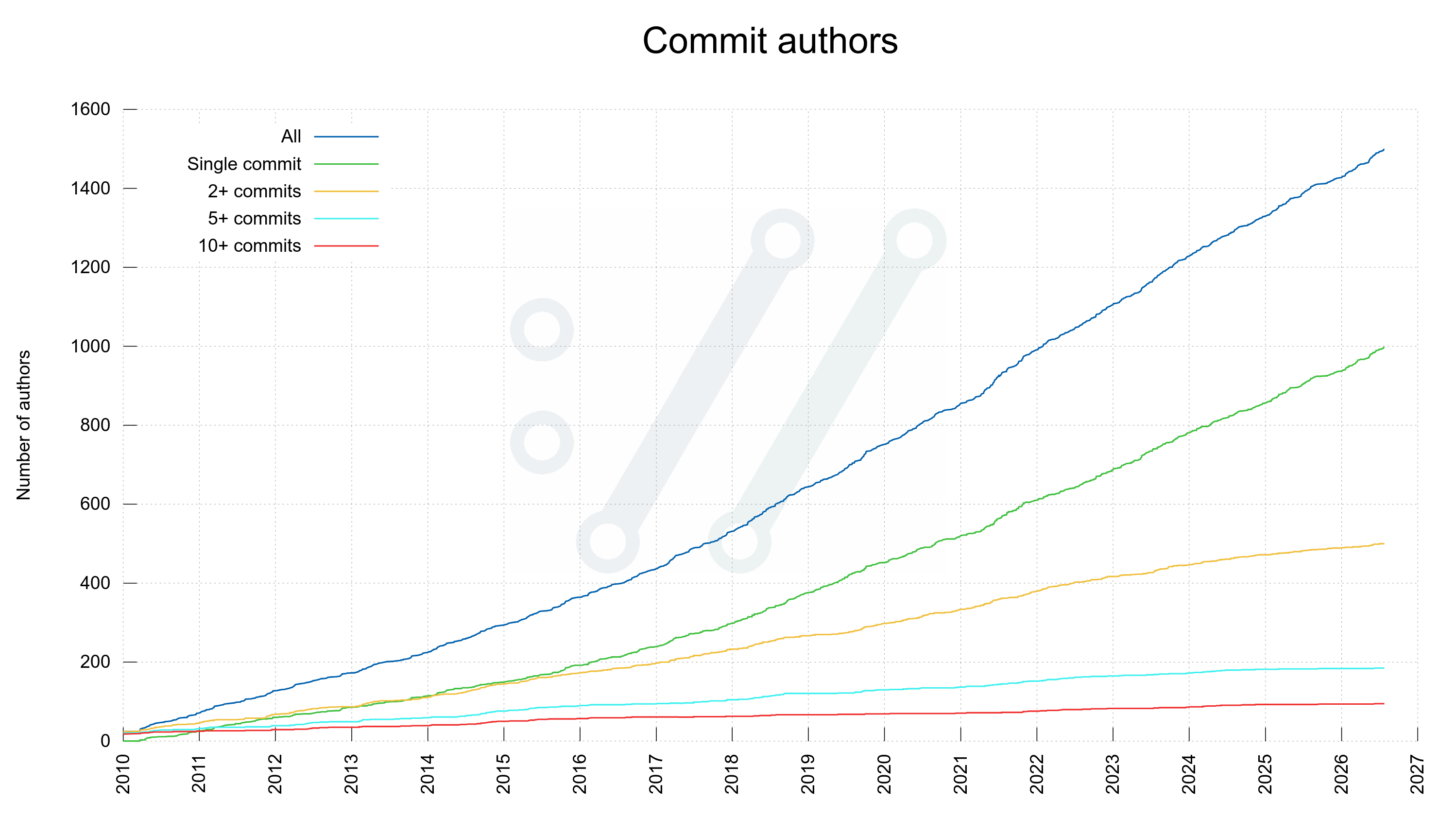
Since today, the curl git repository holds the accumulated efforts from 1,500 separate and named individuals. Only 4.5 years since we passed 1,000. Yay for us!
Author 1,500 turned out to be Sameeh Jubran who authored this.
2026-07-17 04:01:14
There is only one thing that is better than two days of HTTP workshop, and that is of course three days of HTTP workshop. The final day of this edition of the series started out with us again shuffling around where we parked ourselves around the big table. Except Mr captain of course who once again got to herd us forward through another day from the same seat.
MOQ (Media over QUIC transport) is not HTTP, but it uses QUIC so it is at least tangentially interesting and it involves a lot of the same people so this status update still felt welcome and suitable. Compared to existing HTTP based solutions, MOQ is supposed to offer less complexity and lower latency. The moon landing was broadcasted with less latency than current live-streamed TV and maybe MOQ can make us come close to those numbers again. In MOQ clients subscribe to a track that then contains a lot of objects that are delivered. It’s not the request + response approach of HTTP. The fact that this is not HTTP of course brings a lot of questions and well, doubts, and we lingered on various aspects of this topic for quite a while.
My prize for the best slides of the HTTP workshop 2026 goes to [redacted] for the excellent use of potato images in their presentation.
PTTH is HTTP spelled backwards, commonly pronounced as PoTaToH. A client sets up the connection but the actual HTTP request is sent from the server to the client. One of the intended use cases for this, is to allow an origin server to connect to the CDN proxy and then be able to deliver traffic to the world, rather than to have the CDN connect to the origin the way they usually do. Apparently most CDNs already have custom and proprietary solutions for exactly this kind of feature, so maybe doing it in a standard way instead makes sense?
The draft explains the new proposed way to continue a previously interrupted upload over HTTP. The upload request gets a Location: header back for the resource being uploaded, and if it gets stopped prematurely, a client can then HEAD that resource, figure out the size and then do a second upload (using the PATCH method) request that tells the server that this transfer should start at offset X.
Exactly how this should be supported in browser’ upload forms seemed a little bit uncertain. For my own sake I can see a challenge to implement this nicely for curl in particular when the upload is using formpost upload (curl’s -F flag) which after all still is a very common way to do uploads on the current web. I’ll return to this topic at a later time when I written an implementation to test…
io_uring is a Linux asynchronous I/O framework that avoids the overhead of traditional system calls. It uses two shared ring buffers between user space and the kernel, allowing applications to batch I/O operations with zero-copy efficiency.
The feature is disabled by Google in ChromeOS, Android and in production Google servers which certainly holds back some use of it.
io_uring can be helpful to speed up things, but might be complicated to use in existing software architectures and the presentation went into some details on why this is so.
A walk-through of some of the recent developments and improvements in Firefox’s UDP networking stack. Going from single datagrams to the modern ways to ship large chunks of data offloaded to the kernel to speed things up. Upload throughput in Firefox is up 60-90% over the last 11 releases. Lots of fun graphs and metrics were shown. This work is based on the quinn-udp stack.
Happy Eyeballs v3 is coming and Firefox is implementing it. It now takes into account many more data sources than before, including alt-svc and HTTPS-RR and races connections against each other to use the one that connects first. There are some recommended timers in the specification and parts of the discussion was around how maybe the timers could instead be tightened a bit, and maybe the delay between the subsequent attempts could then use an exponential backoff instead sticking to a fixed interval?
(I know I’ll discuss some of these details with my curl hacker friends and see what we should adjust… curl already supports most of the Happy Eyeballs v3 specification.)
As we approached the end of the day a few shorter topics were ventilated to give us a little more to consider before going home:
With this, the seventh HTTP workshop had ended. Again a very fine event. This time graciously sponsored and arranged by Adobe. Thank you everyone!
The general idea is to continue with these events roughly every second year and I support this. The HTTP workshops are definitely one of my favorite events.
The top image on this post was used in the final presentation and the author told me he is aware of the AI errors in there, “of which there are at least two”.
2026-07-16 04:07:14
If you missed it. I already described day one.
Caffeinated and ready, we all gathered in the same spacious room as yesterday, but seated in new places as “suggested” by our captain. Some of us even remembered to move over the name tags we wrote yesterday to our new seats.
No time was wasted on introductions today. We dove straight in at the deep end.
Is the future of software that we check-in the AI prompts in the git repository and trust it to generate the correct code? Are specifications the new level o
f abstraction for source code? These questions triggered long discussions with a huge mix of opinions and experiences getting shared about how AI is used, should be used and could be used now and in the future.
The Common Crawl spidering upgraded to using HTTP/2 for their scan and as an end result, I believe 61% of the responses used HTTP/2 and the entire round ended a few percent faster than before, which when you traverse a few billion URLs really makes a difference. They apparently use a locally patched version of Apache Nutch for this.
The HTTP probe project runs a lot of tests on HTTP/1 servers and compares how they behave in a lot of different aspects and then generates these awesome tables. Looks like something for every server implementer team to have a look at and decide what of these red boxes that should rather be converted into green alternatives.
HTTP Zoll is a new test suite for intermediaries that tests intermediaries (what we often call proxies) for a large amount of request and response smuggling issues. Some real world problems found were discussed and as this project aims at going Open Source words were expressed on what kind of precautions and checks that maybe should be done first. I hope we get to hear more about this project soon.
The HTTP Arena is another project that does performance and measurements. They test HTTP server frameworks and present the results in various ways on their site.
In this presentation, we were presented with different HTTP/3 deployment numbers from different sources and the associated reasoning around why they differ but then more importantly. what can and should be done to increase HTTP/3 usage.
Anti-virus interceptions, enterprise blocks and server-side performance not yet on par with TCP were mentioned as reasons for holding back the numbers.
Reasons for using HTTP/3 include use cases that encourage QUIC adoption: WebTransport, Media over QUIC and MASQUE (HTTP/3 proxies and HTTP/3 proxies over older HTTP proxies).
Using HTTPS-RR for upgrade was promoted, as every alt-svc response that is returned with an ALPN using h3 should perhaps also offer h3 over DNS. Why doesn’t your server announce its h3 support over HTTPS-RR?
QUIC v2 is deployed on an amazing 0.003% of all QUIC v1 domains and there was a discussion why this is so and the common sentiment in the room seemed to be that very few saw a reason for deploying v2 and several expressed a concern that doing so might in fact introduce issues. Someone (you can probably guess who) in the room increased that number a lot by quietly mentioning that haxproxy.org certainly supports it.
QUIC multiplexing over bi-directional streams is a proposal on how to do QUIC-style multiplexing over TLS (or anything else really). It has been adopted by the IETF QUIC working group and there was a somewhat extended discussion about what the HTTPbis group should or should not do with it. The biggest interest might be for data center use, but is that then something IETF should bother about? This is not the first time I blog about this, and even if there did not seem to be a strong demand or need for this, it also did not seem to be completely dead. I bet we will hear more about this later.
Doing a TLS terminating MITM proxy has its challenges and we were given some insights and experiences on the challenges of doing HTTP/2 and HTTP/3 to the server.
The browsers refuse to do HTTP/3 when they detect custom CA certs installed, which apparently is mostly because of lots of past bad experiences with anti-virus software that in particular seems to break QUIC and for users it is not obvious where the blame should go. This then makes browsers not do HTTP/3 over any MITM proxy.
Some time was spent on how allowing different clients to the proxy uses a shared h2 connection to the target server is complicated and not used, even though in theory it should be possible. An argument was made that it could even lead to worse performance than when using HTTP/1 but I could not quite follow that reasoning. I’m sure I missed some subtle detail in that explanation.
When the afternoon is running late and we have been promised beer and snacks after the final talk, what is better than a hard core technical presentation with lots of graphs and numbers showing how QUIC performance can be improved by tweaking the congestion control algorithm and send more data in the startup phase of a new QUIC connections? This new approach is called Rapid Start and it looks like a promising and yet simple improvement. According to experiments done on real world traffic, the time to last byte was reduced by 14.7% on average. Not bad at all.
Our meeting sponsor Adobe graciously sponsored drinks and food so we got to linger around for a few extra hours and talk even more HTTP and networking until the personal firmly insistent they needed us to leave the room and we instead continued solving world problems elsewhere. Topics around the table included the famous HTTP/2 spec coin flip, the QUIC spin bit, the SCONE situation for QUIC, the timeline behind the QUERY method and many more great stories.
Thanks for the beer!
Now we can’t wait for day three.
2026-07-15 04:25:28
On this hot summer’s day in Basel, Switzerland, the seventh HTTP workshop started. These events tend to work roughly the same way and the people in the room are also to large extent familiar and known since previous editions. Forty people in a meeting room, where we take turns in doing short talks on HTTP and networking topics, with the following question and discussion session. The rules for the meetings are explicitly Chatham rules, which means that everything I write about the meeting will be sufficiently fuzzy and without many company or personal names. This is not the kind of meeting that can be easily summed up in a short blog post anyway. You really should be here.
Present in the room were representatives from all the world’s most prominent and used HTTP deployments: clients, browsers, CDNs, proxies and servers. I’m happy to say that there were also several first-timers. We like fresh blood.
(If you think I’m being overly brief or vague about specifics in this post; that is partially on purpose but primarily because I’m a lousy note-taker and mostly write this up after a busy day that also may have involved beer.)
After a round of introductions, we started.
REST is a set of constraints, and in this presentation it was argued that it can or maybe even should be extended to do more. A number of recent applications like Mastodon/ActivityPub, Bluesky/AT, Matrix, Nostr, IndieWeb, all currently use HTTP to do state synchronization but they all do it differently in their own unique ways. Can REST and maybe HTTP be adjusted to help this for improved interoperability?
Looking at the Common Crawl data and comparing data over time, it was observed that responses use the Last-Modified header field more now than they did in the past, and there were great follow-up speculations on why this is so. Data also shows that a large share of these headers present dates that are almost identical to the time the requests were issued.
With the cc-lint tool, data was gathered on how HTTP is actually used today, proving that there is work to be done: deprecated headers are used, some headers are done wrong, and many are overly big. This indicates that there are well used both servers and clients out there that would benefit from cleanup. It probably also shows that doing HTTP correctly and all the correct headers is far from an easy task.
Another presentation showed data, this time from a well-known CDN, on the impact the existing AI scraper bots have on the Internet from their point of view. It showed that roughly half of the requests and half of the bandwidth are spent by scraper bots. A long discussion followed where the numbers were questioned as maybe the numbers look like this because a sufficiently large number of the “bad AI scrapers” appear as regular users to the classifiers. Speculations of different kinds were made.
As a follow-up from a presentation from a previous HTTP workshop we got to learn how the journey on developing their new HTTP stack has progressed and several fun adventures and lessons from that were shared with the audience.
A look into new HTTP API development at Apple. Some discussions and lessons learned from creating new APIs for both servers and clients.
We got an excellent walk-through of some details and internals of the Android networking stack. Emphasis was perhaps especially put on ECH and QUIC connection migration, and the final “don’t tell us when your connection closed” led to a long new discussion on how we really should fix the problem: when connection has been left idle for a long time and it is closed by the server, the client (mobile phones) don’t want to be told. This, because getting that RST and more, just wakes up the radio and more on the phone only to tell it to go back to sleep. It was theorized that if we could get rid of this unnecessary battery waste, the accumulated gain across billions of devices would make a serious dent.
Several additional HTTP related problems were of course also subsequently solved as we then wandered into the city for dinner and maybe a beer. Of course yours truly returned back to his hotel room in good time to be able to write up this blog post.
The best part of these workshops might be the (no pun intended) networking and discussions had completely outside of the agenda.
End of day one. Two more to come,
2026-06-29 15:47:43
Over the years, we have received, read and handled way over one thousand vulnerability reports filed against curl. We have seen most kinds.
It is time for me to try to help future reporters by providing a short guide on how to submit a truly excellent vulnerability report to an Open Source project.
We tend to call everyone who reports a security problem a security researcher, because by the act of the submission itself they fulfill the definition. There are however many different kinds of people who submit reports; from the most rookie youngster with limited experience, to the multi-decade experienced senior in the field.
Most reports submitted to a project like curl come from reporters who never submitted anything to the project before and are completely previously unknown. Many reporters use hacker handles or pseudonyms, so there is not a lot to learn about the person behind the report either. We don’t know the reporters’ age, experience level, employer, sex or on which continent they live. But also: none of those things matter.
When you submit a vulnerability report, consider telling the project how you want to get credited, should they consider your report real.
There is a potentially almost unlimited amount of security researchers that can find problems in a project. The project receiving your report only has a limited small number of overloaded maintainers that take care of the reports. Consider this imbalance. Make your report as easy as possible for the team to manage.
To us maintainers who receive a steady stream of vulnerability reports, it rarely matters exactly how the problem was detected. Whether you fell over it by accident, you found it by reading every single line of source code or if an AI pointed it out to you, it has little relevance to the security team. The team primarily cares about if the problem is real and if it is, how serious the impact is.
If the problem is documented, then it likely isn’t a vulnerability. This is a common theme in curl: people report that they can find something strange or peculiar to happen when they do something, only to have one of us point out that the action is either documented to have that side-effect, or the action was done in spite of clear warnings in the documentation.
To make a good vulnerability report, you should make sure you understand what the software is supposed to do – and what the documentation says its limitations and conditions are. A good Open Source project has those things documented.
Figure out where and how to submit your report. If you found several problems, it is considered polite to ask the team how they want to receive the rest. As separate individual submissions or maybe as a curated list. Perhaps paced at a slow rate to avoid overflow.
Never circumvent the submission method suggested by the project. That is impolite.
Consider the initial submitting of the issue to be the first step in a multi-step communication process with the project that will continue for as long as at least one of your reported issues has not been resolved or dismissed. This can be days, weeks or in some cases even months.
Expect responses and follow-up questions. Be prepared to clarify, expand and maybe provide more code and reasoning. Remember that you submit vulnerability reports in order to help and improve the project.
These days people like to create enormously long and detailed reports that have all the details, often explained three times and with several embedded lists using bullet points describing impact and providing more or less good analysis attempts.
Your first paragraph of the report should be a human-written, brief explainer of what the problem is and what badness it leads to. You should be able to explain that in just a few sentences. It is a reality-check, because if you can’t do this, if you don’t understand the flaw enough yourself to write such a paragraph, then you have homework to do. Figure it out, then come back and write the intro paragraph.
Having a quality intro saves a lot of time for the security team receiving your report.
Be aware that the Open Source project you contact may be overloaded, on vacation or seeing your report as yet another duplicate they already saw reported seven times.
Be helpful and respect that you add a load to a small team that probably consists of volunteers working on this in their spare time.
Even if you have used a lot of or just a little AI when finding the issue and writing up the report, you must make sure that you communicate as a human. With your human communication skills.
Your report should contain a reproducer. Ideally a fully contained and stand-alone script or source code that the security team can build and run to see the vulnerability trigger.
A reproducer helps prove to the team that the problem is real or maybe already an accepted risk or behavior. It is also convenient for the developers to first understand and reproduce the issue, and then they can convert the reproducer into a project test case for the pending fix.
Without providing a reproducer in your report, you instead push that work to the receiving end. We still need the reproducer. We still need a test case.
Provide a patch for the problem.
If you can figure out a way to fix the code to make your finding no longer trigger, that is great information for the security team and such a patch usually helps them understand the issue better and get a speedier result. It reduces the load.
Sure, such a patch is often perhaps not perfect and it can usually be improved and expanded as the developers have a different view and a more nuanced understanding of the problem and the software architecture involved. It still helps. Getting 80% towards the target is still valuable.
Usually you should look for vulnerabilities in the latest version of the software, often even using an up-to-date git repository. Whatever version you used to find it, you need to specify that in your report.
If the problem turns out to be real, which your report claims and you should never report anything if you don’t think so, it is then also immediately interesting to know when this problem first appeared. Which is the earliest version of the software that you can trigger this problem with?
The project will want to know this to write up a proper advisory for the issue. You can help figuring this out by bisecting etc.
Remain available after your initial submission.
In the curl project at least, we want to work with the reporter to make sure we get every angle and detail right. First, when trying to understand and assess the initial report and agreeing on a severity for it.
Then, we jointly produce and agree to a remedy (patch) for the problem, which ideally means taking the reporter’s version and massaging it into perfection.
If the problem is serious enough, there could be reasons to discuss a rushed patch release at an earlier date than the pending release would otherwise happen on. To reduce the time users in the wild remain vulnerable.
Finally, we collaborate on the description and explainer for the problem that goes into the security advisory.
For every CVE that is registered and assigned to a particular vulnerability, there needs to be a detailed security advisory written. It should ideally describe the issue, how it triggers, what it means, the impact, the affected version ranges and more. Everything related to the vulnerability that we can think might help users.
Your job as a security researcher is to make sure the description in the advisory matches your finding, your understanding of the problem and that the description is understandable.
For every confirmed security report, the receiving project will try to learn from it and fix code and practices to avoid making the same mistake again.
As a reporter, your job is to learn from the submission experience and try to improve your reporting procedure and approach for the next time.
Then submit your next report!