2024-10-26 08:00:00
I mentioned before that getting an interpreter working is a nerd-snipe. Once it works a little, it’s so much fun to keep adding functionality you end up working on it despite yourself. In this spirit, here is a writeup about my latest changes to ts-wolfram.
I initially wrote the interpreter using OOP. There were three AST types (Integer, Symbol, and Form), each one derived from a Node interface. This worked but bothered me, primarily as an aesthetic matter. I prefer to think of programs in terms of pipelines of transformations between data types. You can do this with classes, but stylistically it doesn’t quite fit and tends to leave a feeling of dissatisfaction. So I got rid of classes in favor of an algebraic data type, which to me looks much nicer:
export type Expr = Integer | Symbol | Form | String;
export enum Types {
Form, Integer, Symbol, String,
}
export type Form = {
type: Types.Form,
head: Expr,
parts: Expr[],
}
export type Integer = {
type: Types.Integer,
val: number,
}
// ...Many small changes downstream of dropping OOP also made the code much nicer. For example, I got rid of ugly instanceof calls. But overall, code organization could still use one more pass of deliberate thinking through the file structure, and putting code that belongs together in dedicated files.
Second, I changed the interpreter to support mixing “kernel” and “userspace” code in expression evaluation. Previously a function could either be defined in Typescript, or in Mathematica code, but not both. For example, Times is defined in Typescript, which meant I couldn’t put convenient transformation code into the prelude. Typing -a (-b) in the REPL produced Times[Minus[a], Minus[b]]. It would be convenient to add a rule to transform this into Times[a, b], but the evaluator didn’t support that.
Supporting this ended up being a small change. Once the evaluator supported mixed definitions I added the following line to the prelude:
Times[Minus[x_], Minus[y_]] := Times[x, y];And voilà! Typing -a (-b) now produces Times[a, b] without any changes to Typescript code.
Finally, I wanted to improve printing. Typing something like Hold[a /. a->b] printed the full form Hold[ReplaceAll[a, Rule[a, b]]]. I wanted to print shorthand. My original plan was to add string support and then use the same trick as with Times[Minus[...], Minus[...]] to do pretty printing in userspace. I added strings, ToString and <>/StringJoin, but then realized adding userspace rules to ToString doesn’t quite work. Calling ToString from the interpreter to pretty print caused additional evaluation and printed incorrect results.
Instead of going against the grain and trying to get this to work, I just kept the string commands and implemented pretty printing in Typescript. I added support for basic syntax so expressions like Hold[a /. a->b] print correctly in shorthand. I also added the FullForm command to help with debugging when I do need to see the full form.
However, getting a good printer working is non-trivial. For example, Sin[Cos[x]] Sin[x] currently prints (Sin[Cos[x]]) (Sin[x])– the printer doesn’t know to drop parentheses. I didn’t look into this too closely, but it seems like the naive approach would require lots of special cases to print expressions nicely. To get the printer working well, I need either to add many of the special cases, or find a more general approach (assuming one exists).
2024-10-21 08:00:00
My original plan for ts-wolfram was to quickly write a toy Wolfram Language interpreter in Typescript to better understand Mathematica internals, then abandon it as an exhaust product of learning. But one feature of interpreters is that building them is really fun. Once you get something working you want to keep hacking on it. So, last weekend I decided to allow myself to get nerd-sniped and worked on ts-wolfram some more.
I wanted to find out how much slower ts-wolfram is than Mathematica. To measure this I added two more commands: Do which evaluates an expression a specified number of times, and Timing which does actual measurement. I then measured the performance of a simple (and deliberately very inefficient) fibonacci function on my Apple M1:
fib[1] := 1
fib[2] := 1
fib[n_] := fib[n-2] + fib[n-1]
Timing[Do[fib[15], 1000]]
(* Mathematica: 0.44s *)
(* ts-wolfram: 3.4s *)A mere ~8x slowdown was surprising! I put no effort into efficiency and expected closer to ~100x slowdown. Still, I was curious how much time I could shave off with simple optimizations. I reran the code with node --inspect, connected Chrome’s excellent profile visualizer, and narrowed down the hot spots. I then made the following changes:
Map allocations in the inner loop.All of these changes combined got me down to… 0.98s, an only ~2.2x slowdown!1 I find this incredible. Certainly Mathematica’s term rewrite loop is optimized to death, and I only spent an hour or two making the most basic optimizations. The fact that V8 runs my barely optimized term rewriting code only ~2.2x slower than Mathematica’s hyper-optimized engine is a testament to the incredible work done by V8 performance engineers.
EDIT: Thanks to Aaron O’Mullan’s PR, ts-wolfram now has performance parity with Mathematica on the fib benchmark. I find this absolutely mindblowing.
As I write this I still find myself surprised. I always vaguely knew that V8 is fast. But it never sunk in exactly how fast it is until now.
All the usual benchmarking disclaimers apply. This is meant to be a smoke test of a pet project rather than a serious industry benchmark.↩︎
2024-10-17 08:00:00
Try it on GitHub: https://github.com/coffeemug/ts-wolfram
I’ve been using Mathematica to help with learning math (and using math to help learn Mathematica). Too often my Mathematica code has surprising behavior, which means I don’t really understand the language or how it’s evaluated. So I thought I’d do two things to get better.
First, write a bunch of Mathematica rules to implement a toy symbolic differentiation operator. Second, write a toy Mathematica interpreter in Typescript that’s good enough to correctly run my custom differentiation code.
Writing a toy differentiator turns out to be shockingly easy. It’s a near verbatim transcription of differentiation rules from any calculus textbook:
D[_?NumberQ, x_Symbol] = 0;
D[x_, x_Symbol] = 1;
D[Times[expr1_, expr2_], x_Symbol] =
D[expr1, x] expr2 + D[expr2, x] expr1;
D[Plus[expr1_, expr2_], x_Symbol] = D[expr1, x] + D[expr2, x];
D[Sin[x_], x_Symbol] = Cos[x];
D[Cos[x_], x_Symbol] = -Sin[x];
D[f_Symbol[expr_], x_Symbol] :=
(D[f[x], x] /. x -> expr) * D[expr, x];
D[Power[expr_, p_Integer], x_Symbol] := p expr^(p - 1) * D[expr, x];My first implementation had three more rules (one for each of , and ), which I later realized you don’t need. These are shortcuts for human differentiators, but they’re automagically covered by the multiplication and exponentiation rules above.
Some problems I encountered while writing these rules: infinite recursion, rules not matching, and rules matching but evaluating to a surprising result. The hobby edition of Mathematica has some tools for debugging these problems, but not much. Ultimately I fixed bad rules by staring at the code and thinking really hard. I found Trace impossible to read, and TracePrint (which is supposed to be better) not much better. Also MatchQ is good, but somehow not as useful for debugging as I would have liked.
I first implemented basic parsing of integers, symbols, forms, and arithmetic operators using ts-parsec (which I wrote for this project). In Mathematica a 2 b 3 evaluates to Times[6, a, b] because Times has a Flat attribute. To get this behavior I implemented attributes next– Flat, and also HoldFirst, HoldRest, and HoldAll which I’d eventually need. I also exposed Attributes, SetAttributes, and ClearAttributes. These all accept (and Attributes returns) lists, so I added those too. All this was easy enough.
I wanted to implement assignment next so I could say a = 1. In Mathematica even something this simple is implemented by adding RuleDelayed[HoldPattern[a], 1] to OwnValues.1 So the next step was to build the skeleton of a term rewriting system.2 I first implemented a version of MatchQ that does a deep equal, extended it to handle Blank[], extended it again to handle Blank[...], and extended it again to handle Pattern[foo, Blank[...]]. The version exposed to the interpreter returns True or False, but under the hood it also returns an environment with matched variables. I built on that next to implement term rewriting.
A really simple rewrite rule is f[1] /. f[x_] :> x + 1. In Mathematica this parses to
ReplaceAll[f[1], RuleDelayed[f[Pattern[x, Blank[]]], Plus[x, 1]]]With my MatchQ implementation there was now enough machinery to get this working. I added operators /. and :> to the grammar, implemented Replace, and built ReplaceAll on top. I tested a bunch of rewrite rules and they all worked! From here it was also easy to add -> and //. which I did next.
I had enough machinery to implement assignment. I added Set and SetDelayed, and modified evaluation to apply the rules stored in OwnValues and DownValues. This let me assign values to symbols and define functions! I could now run code like this:
fib[1] := 1
fib[2] := 1
fib[x_] := fib[x-2] + fib[x-1]One caveat is that Mathematica inserts rules into value lists in order of specificity, so specific rules are tried before general rules. I initially added rules in order of definition to get assignment working, but then went back and added a simple specificity ordering function3.
EDIT: I wrote specificity ordering code late at night, and just realized it was completely broken. I removed it; rules are now processed in the order they’re entered. But everything else still works!
Finally, I added support for PatternTest/? and NumberQ. These were all the features needed to do differentiation!
ts-wolfram
I ran D in ts-wolfram on the following examples, and cross-checked with the results in Mathematica:
D[1, x]
D[x, x]
D[x^5, x]
D[3 x^2, x]
D[(x + 1) (x + 2), x]
D[x^2 + x^3, x]
D[Cos[x], x]
D[x^3/(x^2 + 1), x]
D[Cos[Cos[x]], x]
D[Cos[Cos[Cos[x]]], x]
D[Cos[x^2 + 1], x]
D[(x + 1)^2, x]Somewhat miraculously, ts-wolfram got correct results on every test! Since I didn’t add any manipulation to simplify expressions, the results weren’t exactly the same. For example:
D[Cos[Cos[x]], x]
(* ts-wolfram outputs *)
Times[Minus[Sin[Cos[x]]], Minus[Sin[x]]]
(* With `FullForm`, Mathematica outputs *)
Times[Sin[x], Sin[Cos[x]]]This would be easy to fix by adding the rule Times[Minus[x_], Minus[y_]]=x y, but (a) Times is implemented in typescript, and the interpreter doesn’t currently support mixing kernel and userspace rules, and (b) extending the system to simplify algebraic expressions feels like a different undertaking.
Overall, this has been a really fun and instructive project. I built it in four days hacking on it after work, and learned a great deal about Mathematica internals. Of course this is still only scratching the surface, but now I feel a lot less lost when Mathematica doesn’t behave the way I expect. I’m very happy with this outcome!
You can check this by running a = 1; OwnValues[a].↩︎
If you don’t already understand how this works, reverse engineering it is tricky, even with Mathematica’s great docs. For examples why, see Stack Overflow questions here, here, and here.↩︎
The exact details for how Mathematica handles pattern specificity are not so easy to find. I didn’t try too hard to reverse engineer it; I just did what seemed reasonable and moved on.↩︎
2024-10-12 08:00:00
Try it on GitHub: https://github.com/coffeemug/ts-parsec
I write a lot of throwaway interpreters to play with programming language design ideas. For these projects, writing a parser is usually the most frustrating part. Parser libraries are hard to learn, easy to forget, and finicky to use. The other option, hand-coding a custom parser for each interpreter, raises the activation energy to start a project high enough that I abandon too many ideas before I try them.
All of this is unsatisfactory. To solve this problem I wrote a parser combinator library for myself in Typescript. It has these design goals:
Here is a simple example:
const digit = range('0', '9');
const lower = range('a', 'z');
const upper = range('A', 'Z');
const alpha = either(lower, upper);
const alnum = either(alpha, digit);
const ident = seq(alpha, many(alnum)).map(([first, rest]) =>
[first, ...rest].join(""));You can see how these parsers build on top of each other. I added a map method to support transforming the concrete syntax tree into an AST on the spot. Here seq(alpha, many(alnum)) return a tuple with an alphabetic character and an array of alphanumeric characters. But we don’t want to deal with that when handling identifiers– we just want to deal with a string. I can do that with a simple map.
Parsers operate on a special stream type that’s mostly irrelevant to the end user. To parse an identifier you’d do this:
const input = "Hello";
const stream = fromString(input);
ident(stream);Actually, I lied a little. By default the stream automagically skips whitespace. That’s the desired behavior for most higher-order parsers, but when parsing keywords, identifiers, numbers, etc. we want to turn that behavior off. So in practice ident would be defined like this:
// `lex` turns off skipping whitespace for the parser it's wrapping
const ident = lex(seq(alpha, many(alnum))).map(([first, rest]) =>
[first, ...rest].join(""));All the usual suspects like seq, either, maybe, some, many, and sepBy are implemented in the library. This turns out to be enough to write parsers for most grammars I may ever want to parse.1
One limitation of recursive descent parsers is that they fall into an infinite loop on left recursion. You can manually rewrite your parser to avoid left recursion, but it’s a pain. This is relevant for toy interpreters because left recursion is the most natural way to express grammars for basic arithmetic. To avoid having to deal with this problem I added a helper parser binop for parsing binary operators. Using binop a calculator grammar looks like this:
const factor = binop(either(str('*'), str('/')), int,
(op, l, r) => [op, l, r]);
const term = binop(either(str('+'), str('-')), factor,
(op, l, r) => [op, l, r]);
const input = "1 + 2 * 3";
const stream = fromString(input);
// produces `['+', 1, ['*', 2, 3]]`
term(stream);(The version binop is left-associative. There is a right-associative version binopr for binary operators like assignments.)
There are two painful limitations of this library, one fixable (but not yet fixed), the other inherent to its design.
The fixable problem is that the library produces no error messages whatsoever. It’s structurally set up to handle errors, but I haven’t implemented error reporting yet. So if something goes wrong during parsing, there is no useful information at all. I have some ideas for how to make error reporting easy and really good, but haven’t gotten around to working on this.
The more serious problem is that type safe parser combinators seem like an elegant, obviously good idea, but they turn out to kind of suck in practice. Maybe I’m not smart enough, or maybe I’m too lazy to properly understand the ins and outs of the Typescript type system, or maybe I just need to work a little harder to mature the library. But whatever the reason, every time I do semi-advanced type hackery like this, I end up spending more time dealing with weird type errors than actually working on my grammar. It’s all right in this narrow case because it’s fun, I know the ins and outs of the library, and it’s meant for throwaway/toy interpreters. But for a serious project I’d use an ugly, boring, old-school parser generator.
Or, more likely, bite the bullet and code the parser by hand.
There are many grammars this doesn’t parse, but see the design goals. It’s not meant to! Actually, I would argue that if your programming language can’t be parsed with a PEG parser, it’s hard for humans to parse too.↩︎
2024-10-06 08:00:00
The mean value theorem is a surprising Calculus result that states for any function differentiable on 1 there exists such that
Here are three informal intuitions for what this means (all of them say the same thing in different ways):
The proof is remarkably straightforward. You define a function that maps values between and to a height from to the line segment between the endpoints. This function turns out to be differentiable, and hence has a maximum value (and hence there is a point such that ). From there it’s an easy algebraic transformation to demonstrate the mean value theorem is true. See figure 2 for an illustration.
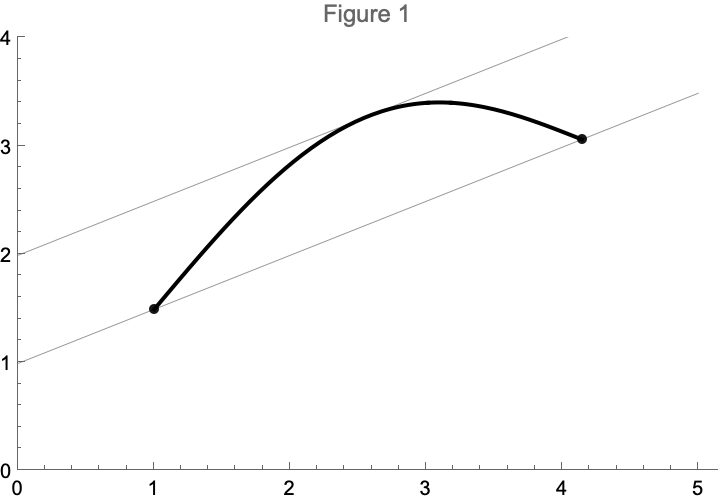
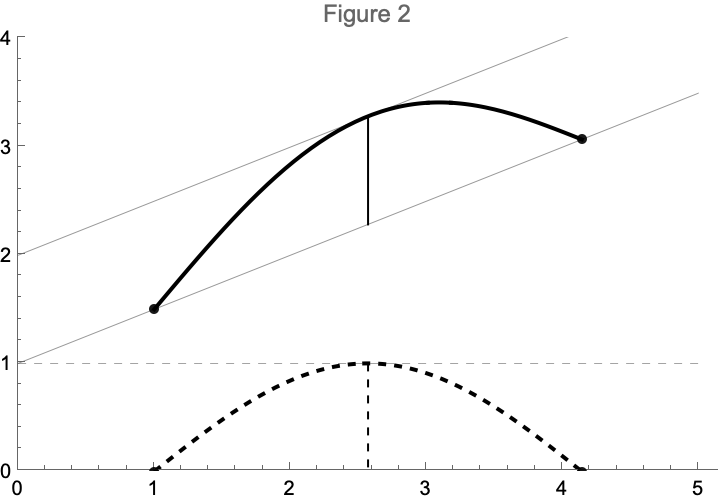
I won’t repeat the proof, but what I wanted to do is play with Mathematica to generate an interactive visualization of how the proof works (I generated above figures in Mathematica, but the final product has an interactive slider to make the proof more clear).
For tasks like this Mathematica is wonderful. Here I define a line at an angle, and another function that adds a sine to it. Because the visualization is interactive will allow the user to change the slope:
interpol[s_, a_, b_] := a + s*(b - a);
g[s_, x_] = interpol[s, 1/2, 0]*x + interpol[s, 1, 0];
f[s_, x_] = Sin[x - 1] + g[s, x];These are symbolic definitions. We can plot them, take derivatives, integrate, and do all kinds of fancy computer algebra system operations. Here is an example. The vertical line in figure 2 comes down from the mean value of – i.e. a point on where the tangent is parallel to the average change. In Mathematica code we can take the derivative of (using Mathematica function D), and then solve (using Solve) for all values where the derivative is equal to mean value:
fD[a_] := D[f[s, x], x] /. x -> a;
avgSlope[s_] = (f[s, Pi + 1] - f[s, 1])/Pi;
meanPoint[s_] =
Solve[fD[x] == avgSlope[s] && x > 1 && x < Pi + 1, x];This is the core of the code. Most of the rest of the code is plotting, which Mathematica does exceptionally well. I exported the plots to figures above using the Export function. Another notable function is Manipulate– this is what makes the graph dynamic as the user drags a slider (by changing the variable s which the equations depend on). Finally I was able to publish the notebook in a few clicks, as well as publish the visualization itself using CloudDeploy. Instantaneous deployment of complex objects is very cool and useful.
There are a few things I don’t like, but it’s too early to say these are Mathematica’s flaws (more likely it’s my lack of familiarity):
Normally I learn very unfamiliar/weird programming languages by writing a toy interpreter of the target language in a language I already know. The Mathematica rules engine is a great candidate. Putting this in my virtual shoebox of future projects. EDIT: this is now done here with follow-ups here and here.
2024-10-01 08:00:00
There are all sorts of things people want. To pay off debt1, to help the environment, to be kind to strangers.
But we don’t want these things now. Right now we want the latest iPhone, our drink to go, to zip through traffic faster. And since anything we ever do we do in the now, paying off debt, helping the environment, and kindness to strangers remain perpetually in the future.
Failed products aren’t necessarily products people don’t want. But they are always products people don’t want now. Confusing “wanting” for “wanting now” is an easy mistake to make. I’ve probably made it more than anyone. People are adamant about the urgency of their wants (or maybe I’m just credulous). But once you know what to look for, you can begin telling the two apart. Wanting is free. Wanting now exacts a price.
Put differently, there is no tradeoff to wanting. It costs nothing to want to pay off debt. You are not confronted with a tradeoff until it’s time to write a check to the credit card company, or to deny yourself an expensive purchase. And when that time comes, you have to want to pay off debt now. Which to your surprise you discover you don’t actually want.
The surprise is important. We don’t know what we want now until the now comes, and we have infinite capacity to lie about it to ourselves and others. So to predict behavior you cannot trust what people say. You can only trust the data as you observe them confront a tradeoff. This is so important it’s worth repeating. To predict behavior you must observe people confront a tradeoff.
Wanting has different texture from wanting now. Because it’s tradeoff-free, wanting tends to be abstract, altruistic, and aspirational. Conversely, wanting now is concrete, selfish, tangible, and opportunistic. Wanting is in far mode, wanting now in near mode. Wanting preferences are often stated but rarely revealed; wanting now preferences are eventually revealed but are rarely stated.
Can you ever give people what they want? Yes, if you bundle it with what they want now. This was the brilliance of Tesla. You got what you want now, a badass car. And in the process you also got what you want– to migrate the world away from fossil fuels. The first part is hard enough. So most products don’t bother with the second part, or at best do it as a marketing exercise. Only magical products credibly give you both.
This is true for technical debt as much as for credit card debt.↩︎