2025-07-08 21:00:00
I recently read an article where a blogger described their decision to start masking on the subway:
I found that the subway and stations had the worst air quality of my whole day by far, over 1k ug/m3, ... I've now been masking for a week, and am planning to keep it up.
While subway air quality isn't great, it's also nowhere near as bad as reported: they are misreading their own graph. Here's where the claim of "1k ug/m3" (also, units of "1k ug"? Why not "1B pg"!) is coming from:
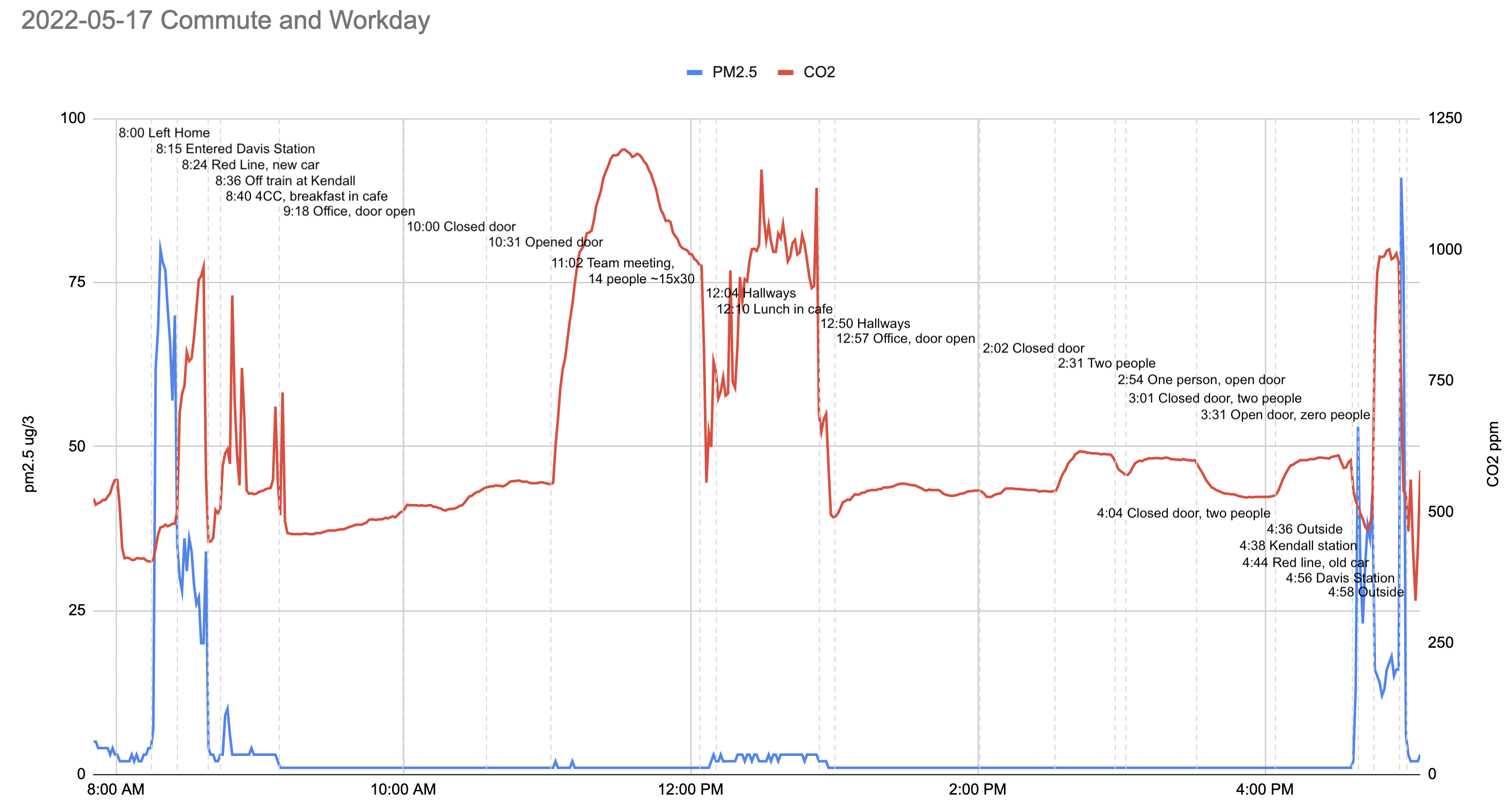
They've used the right axis, for CO2 levels, to interpret the left-axis-denominated pm2.5 line. I could potentially excuse the error (dual axis plots are often misread, better to avoid) except it was their own decision to use a dual axis plot in the first place! Hat tip to Evan for pointing this out in the substack comments.
The actual peak was only 75 ug/m3 and the subway time averaged below 50 ug/m3. While this isn't great, I don't think this is worth masking over.
Since I'm making a big deal about this error, though, I wanted to make sure I had my facts straight: I decided to replicate their work. I used the same meter they used (a Temtop M2000) and took the same subway journey (round trip from Davis station to Kendall station on the MBTA's Red Line). To be generous I took my time in the morning, intentionally missing a train at Davis and then lingering in Kendall after my train departed until the following train had also departed. Here's what I found:
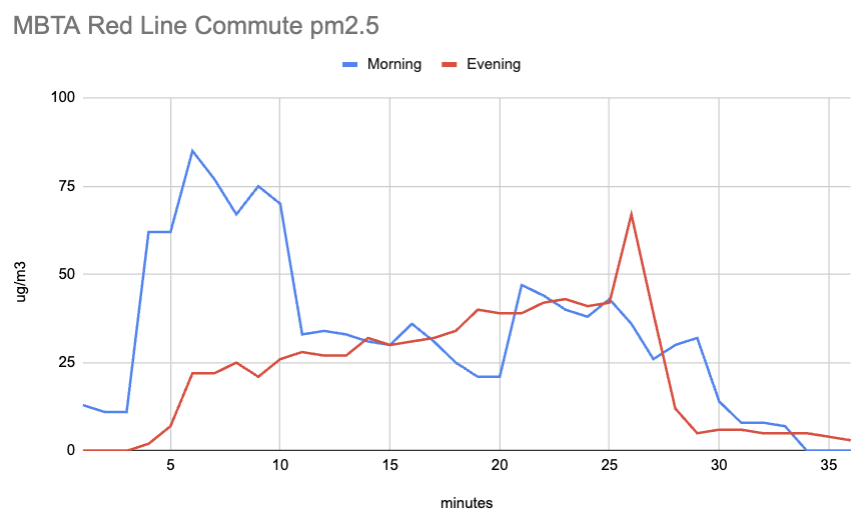
Decent replication! And really not that concerning. Lower particle levels would of course be better, but I'd wear a mask when cooking before I'd wear it on the subway. It's possible that other subways or stations are worse, but I haven't seen evidence of that.
Comment via: facebook, lesswrong, mastodon, bluesky, substack
2025-07-05 21:00:00
EDIT: this post is based on a misreading of a graph; see Subway Particle Levels Aren't That High.
Back when I was still masking on the subway for covid (to avoid missing things) I also did some air quality measuring. I found that the subway and stations had the worst air quality of my whole day by far, over 1k ug/m3, and concluded:
Based on these readings, it would be safe from a covid perspective to remove my mask in the subway station, but given the high level of particulate pollution I might as well leave it on.
When I stopped masking in general, though, I also stopped masking on the subway.
A few weeks ago I was hanging out with someone who works in air quality, and they said subways had the worst air quality they'd measured anywhere outside of a coal mine. Apparently the braking system releases lots of tiny iron particles, which are bad for your lungs like any tiny particles. This reminded me that I'd looked at this earlier, and since I spend ~3hr in the system weekly (platform + train) it seemed worth going back to masking. I've now been masking for a week, and am planning to keep it up.

This is an ElastoMaskPro reusable N95 I got for elastomeric fitting. Very easy to breath through, which helps make up for how my beard makes it hard to get a tight seal.
At $30 (vs $0.60 for my favorite disposable) a reusable one comes out ahead after five weeks if I follow the guidance of using single-use ones only once. Now, when I used disposables I would reuse them many times, but the efficacy likely dropped off a bunch: the fit is worse because the elastic stretches, and they get beat up a bit in my backpack. Likely still cheaper to use the reusable one, given how long it should last, but with how I'd use them most of the gains are in efficacy and not cost.
On the other hand, if I wanted to be able to talk to people I'd go with the disposable: the ElastoMaskPro is worse for intelligibility than all the respirators I tested a few months ago.
Comment via: facebook, lesswrong, mastodon, bluesky, substack
2025-06-29 21:00:00
Airplanes are strange places. Whatever you have on board when you take off is the most you'll have until you land. Want a sandwich? You can only have one if there's one on board. There are many things people reliably want, such as some kind of food, drink, and entertainment. Perhaps headphones, a pillow, or a blanket. Airlines provide these, either for free or at some fixed cost. But people's desires are broad, airlines would like to make more money, and economically inclined people want to turn everything into auctions and markets. So...
Imagine you load up your seatback entertainment, and one of the options is a burrito. But there's only one. You can put in a bid, and 1/3 of the way into the flight the person who bids the most gets it. Surely on an airplane of two hundred people there's at least one person with an unusually strong desire for a burrito at 30k feet. And it's not just burritos: other meals, decent headphones, headphone splitters, airplane pillows, diapers, charging cables, cozier blankets, a range of snacks, etc. Anything airlines don't typically provide where there's a high chance that someone might want it.

Part of what makes it hard to provision airplanes is that you're expected to have enough for anyone who might want one. Either you overprovision, or you find yourself apologizing to some people that you're out; neither are great. Auctions allow you to stock a small number of additional things, and sell them to the small number of people who most want them.
Building software and figuring out what to stock seem hard, and not the kind of thing airlines are good at, so let's say this part is a startup. They make a deal with an airline, provide software to run the auction and tell the flight attendants which things to bring to which seats, and provide the things to sell. The quick way to get started acquiring things is just to hire employees who walk around the airport, buying things that the startup has previously seen sell well, but long term for non-perishable products margins would be a lot better bringing them in through the same screening system used for airport vendors. The startup and airline negotiate a 'budget' in weight, space, and total passenger interactions, and they optimize their stocking to make the best use of the budget. The airline gets some form of payment, which would be somewhere between a fixed fee (to reduce risk to the airline if the startup is bad at judging passenger desire) and a percentage (to align incentives).
I think the biggest problem is that while in an important sense this would be better than the status quo, since worst case you buy nothing and best case you win an auction and so get something you prefer to the money, in practice I expect passengers would absolutely hate it. The benefit generally goes to people with more money, the onboard monopoly means that the seller captures most of value, it reduces the incentive for the airline to provide things people want through the traditional system, and even the auction winners will often find they overpaid. Still, maybe there's something here?
2025-06-26 21:00:00
People often think 'affordable' housing is much more expensive than it actually is, and then conclude it's a scam to make housing for rich people. But this is often based on a misunderstanding of how the prices are set.
Let's say a unit is "50% AMI" somewhere with an area median income (AMI) of $100k. You might think, and I've seen a bunch of people with this confusion, that units would rent for 50% of $100k: $50k/y ($4,170/month), but it's much cheaper than that.
Affordable has a very specific meaning in this context: spending no more than 1/3 of your income on housing. So you might think 50% AMI is 'affordable' to someone earning at the 50th percentile: 1/3 of $100k, or $33k/y ($2,750/month), but it's cheaper than that, too!
Instead, 50% AMI means someone earning 50% of the AMI would be spending 1/3 of their income on housing. This is 50% of 1/3 of the AMI, and in this case that would be $17k/y ($1,390/month).
Now, I don't think affordable housing solves everything: if it were widespread I think it would be exploited and it can be a distraction from just getting a lot of units built, but the term "affordable housing" is actually a decent operationalization of whether housing is something regular people can afford.
2025-06-25 21:00:00
Cross-posted from my NAO Notebook.
Manufacturers often give optimistic estimates for how much data their systems produce, but performance in practice can be pretty different. What have we seen at the NAO?
We've worked with two main sample types, wastewater and nasal swabs, but Simon already wrote something up on swabs so I'm just going to look at wastewater here.
We've sequenced with both Illumina and Oxford Nanopore (ONT), and the two main flow cells we've used are the:
Illumina NovaSeq X 25B, at 2x150. List price is $16,480, though we've seen groups negotiate discounts in the range of 15%. Marketed as producing a maximum of "52 billion single reads" (26B read pairs, 8,000 Gbp).
ONT PromethION. List price is $900 in bulk, compared to $600 for the smaller MinION flow cell. Since the PromethION flow cells have 5x the pores (2,675 vs 512) and correspondingly higher output, I think most folks who are using MinION should be considering switching over to the PromethION. Marketed as producing ">200 Gb on metagenomic samples".
Ignoring library prep consumables, labor, lab space, machine cost, and looking just at the flow cells, if we took the manufacturer's costs at face value this would be:
With 25B flow cells we've generally seen output meeting or exceeding the advertised 26B read pairs (8,000 Gbp). In our sequencing at BCL we've averaged 29.4B read pairs per sample (8,800 Gbp; n=37), while recently MU has been averaging 27.2B read pairs (8,200 Gbp; n=4, older runs were ~20% lower). It's great to be getting more than we expected!
On the other hand, with PromethION flow cells we've generally seen just 3.3 Gbp (n=25) on wastewater. This is slightly higher than the 2.5 Gbp we've seen with nasal swabs, but still far below 200 Gbp. We don't know why our output is so much lower than advertised, but this is what we've seen so far.
This would give us:
We're still not done, though, because while this is correct in terms of raw bases coming off the sequencer, with paired-end sequencing on short fragments like we have in wastewater a portion of many of your reads will be adapters. We see a median of 170bp after adapter trimming, out of an initial 300bp, which means we only retain ~60% of the raw bases. Accounting for this, we have:
Overall, Illumina is much more cost-effective for us with our current protocols. If we were able to get better results from ONT that would close the gap partially, but a gap of nearly two orders of magnitude we'd need very large improvements.
Comment via: facebook, lesswrong, mastodon, bluesky, substack
2025-06-24 21:00:00
Cross-posted from my NAO Notebook.
This is something I wrote internally in late-2022. Sharing it now with light edits, additional context, and updated links after the idea came up at the Microbiology of the Built Environment conference I'm attending this week.
Metagenomic sequencing data is fundamentally relative: each observation is a fraction of all the observations in a sample. If you want to make quantitative observations, however, like understanding whether there's been an increase in the number of people with some infection, you need to calibrate these observations. For example, there could be variation between samples due to variation in:
If you're trying to understand growth patterns all of this is noise; can we reverse this variation? I'm using "calibration" to refer to this process of going from raw per-sample pathogen read counts to estimates of how much of each pathogen was originally shed into sewage.
The simplest option is not to do any calibration, and just consider raw relative abundance: counts relative to the total number of reads in the sample. For example, this is what Marc Johnson and Dave O'Connor are doing.
It seems like you ought to be able to do better if you normalize by the number of reads matching some other species humans excrete. It's common to use PMMoV for this: peppers are commonly infected with PMMoV, people eat peppers, people excrete PMMoV. All else being equal, the amount of PMMoV in a sample should be proportional to the human contribution to the sample. This is especially common in PCR work, where you take a PCR measurement of your target, and then present it relative to a PCR measurement of PMMoV. For example, this is what WastewaterSCAN does.
Because the NAO is doing very deep metagenomic sequencing, around 1B read pairs (300Gbp) per sample, we ought to be able to calibrate against many species at once. PMMoV is commonly excreted, but so are other tobamoviruses, crAssphage, other human gut bacteriophages, human gut bacteria, etc. We pick up thousands of other species, and should be able to combine those measurements to get a much less noisy measurement of the human contribution to a sample.
This isn't something the NAO has been able to look into yet, but I still think it's quite promising.
Comment via: facebook, lesswrong, mastodon, bluesky, substack