2022-09-08 11:00:17
在日常的需求变更和技术变更中,测试用例覆盖率很难达到100%,再加上变更过程中的各种原因,可能会导致生产环境出现故障。
针对生产故障处理,每位开发同学可能都会有不同的处理方式,如果处理方式得当,故障能够快速止血顺利恢复,反之可能会错上加错!!!
基于以往经验,在这里推荐一套通用的生产故障处理SOP,他可能无法帮你快速定位问题,但是可以尽可能缩短恢复时间,降低故障影响!
| 步骤 | 内容 | 说明 | 故障发现时间 | 注意点 |
|---|---|---|---|---|
| 步骤1 | 拉故障处理群、拉电话会议 | 先拉自己的直属Leader、运维人员 | 1min内 | 【第一时间执行!】,避免信息差! |
| 步骤2 | 识别故障类型、影响范围 | 执行预案、快速恢复(兜底、降级、灾备等等) | 5min内 | 【无法快速定位时】,直接进行步骤3 |
| 步骤3 | 梳理相关变更项(自身+上游) | 执行变更回滚、故障止血恢复 | 10min内 | 【无法恢复故障时】,直接进行步骤4 |
| 步骤4 | 联系业务、运营进行业务恢复 | 通过产品侧、运营侧的业务手段止血 | 15min内 |
| 步骤 | 内容 | 说明 | 故障发现时间 | 注意点 |
|---|---|---|---|---|
| 步骤5 | 定位问题,根因排查 | 切勿在【阶段一】埋头查原因 |
||
| 步骤6 | 修复验证,故障恢复 | 做好验证再执行 |
| 步骤 | 内容 | 说明 | 故障发现时间 | 注意点 |
|---|---|---|---|---|
| 步骤7 | 梳理时间线、原因和处理方案等 | |||
| 步骤8 | 故障复盘,总结经验教训 |
以上是基于 快速恢复快速止血 为宗旨的故障处理SOP,不同的业务和团队可参考其中的处理流程,但需要注意以下几点:
信息同步:第一时间拉群同步信息,避免信息差快速止血:率先考虑应急预案、降级、开关逻辑等止血操作,切记勿要闷头排查!!!故障复盘:故障无法100%避免,所以一定要做好故障复盘,避免同类问题二次踩坑!最后提一嘴,生产故障无法预知,无法避免,所以作为开发同学一定要 敬畏生产敬畏生产敬畏生产!!!
2022-08-01 21:00:17
本文转载自 架构精进之路 的博客:《系统稳定性建设实践总结》
2020年,注定是个不平凡的一年。疫情的蔓延打乱了大家既定的原有的计划,同时也催生了一些在线业务办理能力的应用诉求,作为技术同学,需要在短时间内快速支持建设系统能力并保障其运行系统稳定性。恰逢年终月份,正好梳理总结下自己的系统稳定性建设经验和思考。
在开始介绍服务稳定性之前,我们先聊一下SLA。SLA(service-level agreement,即 服务级别协议)也称服务等级协议,经常被用来衡量服务稳定性指标。通常被称作“几个9”,9越多代表服务全年可用时间越长服务也就越可靠,即停机时间越短。通常作为服务提供商与受服务用户之间具体达成承诺的服务指标——质量、可用性,责任。
3个9,即99.9%,全年可停服务时间:365 * 24 * 60 *(1-99.9%)= 525.6min
4个9,即99.99%,全年可停服务时间:365 * 24 * 60 *(1-99.99%)= 52.56min
5个9,即99.999%,全年可停服务时间:365 * 24 * 60 *(1-99.999%)= 5.256min
在严苛的服务级别协议背后,其实是一些列规范要求来进行保障。
关于系统稳定性是指什么这一问题,相信好多开发同学都会有自己的理解和认知,但可能会存在是否理解片面或者是否标准的疑惑,那到底有什么判定标准和划分边界呢?
我们不妨看下来自于维基百科的解释:
稳定性是数学或工程上的用语,判别一系统在有界的输入是否也产生有界的输出。
若是,称系统为稳定;若否,则称系统为不稳定。
简单理解,系统稳定性****本质上是系统的确定性应答****。
从另一个角度解释,服务稳定性建设就是如何保障系统能够满足SLA所要求的服务等级协议。
可以确定的一点,服务稳定性建设是非常必要的,不管是满足日常系统正常运行还是重大节庆活动的稳定有序运营。
我们来看几个由于服务稳定性故障造成影响的案例:
1)2020年国庆前一天,受“2020年最难打车日”的需求影响,滴滴平台和嘀嗒平台相继出现宕机故障;
2)2018年亚马逊prime day:亚马逊会员日故障(顾客无法将商品添加到购物车结账),导致公司损失高达9900万美元。
3)2015年由于中国工商银行部分地区因计算机系统升级,造成柜面和电子渠道业务办理缓慢,甚至不能受理业务;
4)2012年12306铁路订票网站因机房空调系统故障,导致暂停互联网售票、退票、改签业务。
服务稳定性对于企业来说非常重要,不仅仅会对企业带来直接的经济损失,甚至会对行业、人们的生活造成非常严重的影响。所以说服务稳定性建设的意义非常重大。
关于稳定性以及如何提升稳定性指标,我们可以想到很多的优化项:
1 |
eg. 加服务器、扩容、超时重试、服务降级、资源隔离&备份、代码逻辑优化、异步事件化... |
那系统稳定性建设的主要难点是什么呢?
尤其对于一个新改革上线的新业务而言,系统稳定性建设主要是流量洪峰的是个未知数,由于没有经验可以参考,我不确定是百万级别还是千万级别,还是更高级别?
往往这种系统稳定性建设需要考虑需求主要是短时间内支持XX能力的上线,这其中往往涉及系统层面从下到上的多处变更,包括底层数据结构调整、业务逻辑改造以及用户交互方式的优化等等。时间短,改动大,质量难以保证。
软件工程往往被用来描述“研究用工程化方法构建和维护有效的、实用的和高质量的软件”。其包括软件建设的方方面面,凡事事无巨细,任何细微的疏忽都可能造成全盘故障问题,不确定性问题尤其严重。
多环节分工精细复杂,不容一点疏忽。
从系统构成来看,可以区分为单服务系统稳定性和多服务集群稳定性。
主要包括:功能配置可控、缓存加速(利器) 、服务隔离(第三方)、场景异常兜底方案、服务监控与及时响应等等
主要包括:合理的系统架构、优秀的集群部署、科学的熔断限流、压测机制、精细的监控体系等等
在提出系统稳定性建设解决方案之前,我们需要明确一下前提条件:
业务熟悉 需要对业务全貌流程熟悉,具备较强的掌控力;
架构明确 需要对系统技术架构熟知并具有一定的实操经验。
只有这样,对业务、架构都具备掌控能力之后,才谈得上去做稳定性建设的拆解和优化,才有基本的保障。
一般情况下,我们提到系统稳定性建设,更像将系统稳定性作为一个专项Topic来搞,从其运行流程来看,主要存在以下几个方面:
前提 目标明确(基准)
事前 请求链路优化、服务性能优化&压测、应急预案制定、故障演练
事中 故障监控、定位问题、故障止损、问题修复
事后 故障复盘、整改优化、经验总结沉淀
服务稳定性建设其实是一个系统性的大工程,包括了方方面面。
从上一Part工作拆解来看,稳定性建设囊括的点比较多,而且杂。更多情况下,我们会做服务稳定性专项,针对某些特定场景下的特定问题而梳理出对应的方案。
那我们可以以小见大,从单服务系统本身出发,提炼看看存在哪些稳定性建设的关键点。其实只有每个单服务环节都稳定可靠,那集群系统乃至整个工程系统的稳定性才有保障。
假如系统面对突增的请求流量情况下,如何做好服务稳定性建设呢?
稳定性建设关键动作拆分如下几类:
例如,经典的秒杀场景,春节的火车票抢购、电商平台的双11秒杀等等,都是短时间上亿的用户涌入,瞬间流量巨大(高并发)。
不管前期对服务器资源做了如何的扩容,都会存在一个处理上限,所以一定要进行必要的削峰限流策略,类似于城市早晚高峰错峰限行的解决方案。同样,秒杀场景也需要类似的解决方案。
那具体如何来实现呢?
消息队列来削峰消息队列来缓冲瞬时流量,把同步的直接调用转换成异步的间接推送,中间通过一个队列在一端承接瞬时的流量洪峰,在另一端平滑地将消息推送出去。
消息队列就像“水库”一样,拦蓄上游的洪水,削减进入下游河道的洪峰流量,从而达到减免洪水灾害的目的。
流量挡板过滤,主要是建立一种验证机制过滤掉无效请求,保障核心服务避免受更多外界无效请求的影响。比较常用的方案就是“布隆过滤器”。
产品策略调整是一种特别有效的手段,效果甚至会优于技术层面的改进优化。
例如:利用排队策略,有效打散高并发请求;调整活动宣传时间分散点,避免同一时刻出现高并发请求…
缓存是解决并发的利器,可以有效的提高系统的吞吐量。按照业务以及技术的纬度必要时可以增加多级缓存来保证其命中率。
主要应用思路:在数据库与服务端之间利用 Redis 做缓存服务,减少请求直接冲击到数据库。
与异步对应的就是同步,即所有事情排队一件件的有序进行,等上件事情完成后才会去做下一件事情。有点像一根签子串起来的糖葫芦。需要实时处理并响应,一旦超过时间会结束会话,在该过程中调用方一直在等待响应方处理完成并返回。
异步处理不用阻塞当前线程来等待处理完成,而是允许后续操作,直至其它线程将处理完成,并回调通知此线程。
需要强调一点:异步是一种设计理念,异步操作不等于多线程,常见的消息中间件、发布订阅的广播模式等,都可以实现异步处理的方式。
提前做好系统压测,做到心中有数,防患于未然,压力预估要切合实际,不要盲目过大。对于性能瓶颈点,尽量提前做好改进优化或者重点关注布防
应急预案一定要有,研发人员往往比较自信,这是好事也是坏事,我们需要做最坏的打算。因为经验再丰富的工程师,也无法穷举未来可能发生的意外事件,而故障往往出现在预案之外的地方(墨菲定律)。
建立完善的监控、告警机制,尽量让我们第一时间发现问题点,保障报错及时感知。在监控点的设置上,主要原则是:所有的依赖都是不可信的!
类似于在行驶的飞机上换引擎,过程中无论发生什么样的故障,立即要动用一切力量“快速”止损。服务要有等级划分,保障抓大放小,保护核心服务原则,如确实存在不能快速定位问题时,可逐层降级。主要目标:防止问题扩大,故障止损,快速恢复。
削峰限流 面对资源上限,做技术、业务层面的处理,达到流量削峰保障服务稳定性;
缓存加速 利用缓存解决并发,有效提升系统的吞吐量,同时需注意避免热Key、大Key问题;
异步化处理(同步->异步),有效提升响应效率,保障数据的最终一致性。
技术还是要解决实际问题来落地。应用场景很关键,所有的优化工作不要单纯为了技术而技术,技术归根结底还是为应用场景和产业落地服务。
可以尝试将业务视角目标做为最终目标,通过一切技术手段来保障目标的达成,从而实现技术价值最大化。
稳定性方案需要视场景而灵活调整应用,切忌生搬硬套。在具体实现过程中,关键要把控主要行动路径,多条路径情况下选取投入产出比最高的那一条。推进一个行动路径:问题驱动(问题感知->问题分析->问题控制->问题解决)。
2022-01-11 16:34:27
太久没维护博客了,最近发现Valine评论都展示不出来,看了下console发现是leancloud访问出了问题
查了下前因后果,大概就是LeanCloud对部分域名不再进行维护了,如果继续使用老的域名去拉取评论数据必然失败。
这里和大家同步下我的环境
调整方案如下
替换https://你的appid前8位.api.lncldglobal.com获得新域名
不同的主题可能涉及到的代码位置不同,但是调整思路类似,这里我贴下我的主题配置和涉及到调整的代码片段
主题配置文件config.yml
1 |
|
valine对应的js源码
1 |
//更新av-min.js |
本地构建启动之后可能会因为不在leancloud白名单内,返回403,不过不要紧说明已经生效
直接hexo d发布就能生效了
2022-01-02 15:47:12
感觉像被按下了快进键一样,2021年无论身边的人或事都转瞬即逝…
不知不觉又过了一年,老了一岁,自己也逐渐从一个刚毕业的懵懂少年,变成了现在职场上的老油条~
时间真的是个奇妙的东西,时间是毒药也是解药、时间是让人猝不及防的,2021年的时间现在回想就是像是突然给丢了一样,一起丢的还有很多老朋友、很多自己以前的想法…
记忆中的2021就好像只有前半年,后半年基本上都是一个基调。话虽如此但这一年还是学到了很多新的东西,遇到了很多值得的人。
可能我写的像是流水账
牛年是第一次在外过年,那时候疫情紧张,杭州提倡就地过年,很多同事都响应政府号召,当然我也不例外。因为就地过年政府给发红包呀!
欢欢喜喜过大年的同时当然也在面试看机会,种种原因吧,拿到了叮咚的offer之后便决定过去了,于是开始了2021年的第一次搬家
杭州是个很不错的城市,在杭州呆了三年,突然要离开,追求新生活新工作的我当时其实并没有什么感觉,于是开始了浩浩荡荡的跨省搬家操作。
有时候也挺佩服自己,在杭州有一起拼搏(摸鱼)三载的小伙伴们,而上海…那也没关系,谁还没年轻过,没必要和钱过意不去吧,舒适圈呆久了,就想去经历经历互联网的毒、打体验体验奋斗B的生活。也可能从那开始我就自动离队了吧。
每个人都会经历这个阶段,看见一座山,就想知道山后面是什么。我很想告诉他,可能翻过去山后面,你会发觉没有什么特别,回头看会觉得这边更好。但是他不会相信,以他的性格,自己不试试是不会甘心
其实现在对这句话略有体会,当然人都是有好奇心的,也只有经历过这个阶段才会有不一样的体验
之前听到过一句话说的是进了大厂基本上就是失踪人口了,新公司对比我上一家公司可以算是大厂了,当然不能和BAT对比。但是失踪人口是我本人了。
新工作带给我更多的是心态的变化,从一开始的斗志昂扬,伴随着高强度的工作整个人已经疲惫不堪、工作和生活的节奏也彻底混乱,说实话那段时间天天都在离职的边缘徘徊,工作和生活无法平衡让我不得已要在二者之间做出选择。得失得失,有失才有得,你想要拿高薪总得拿点东西来换。
强行被投喂了大量工作的同时疯狂吸收了大量的新知识,也在那段时间遇到了让自己受益良多的职场贵人。
记得刚入职时,每个月基本都会听到有某某同学某某团队出现了P级故障,作为新人那时候还没什么感觉。但是故障的频发本身就不正常。
在当时,团队服务的稳定性预案基本聊聊无几,可以说稍有不慎就喜提大礼包。
在BOSS的牵头下,开始着手稳定性建设,当然我也是新兵上阵,头一次干这个,但起码没吃过猪肉见过猪跑。基于团队服务的特殊性,截止目前下游依赖至少40+,主要从几个方面入手
目前基本可以做到弱依赖故障无需人工干预,降级预案覆盖90%场景,截止12.31号,没有喜提P级故障,当然这也是一直抓稳定性的一部分成果
大公司就是如此,不像小公司一个人就可以接触到整个流程,你可以有精力去钻研你感兴趣的内容。大公司好比一个精密机械,它可以被拆分到很小的模块,而每一个人在里面都只是不知疲倦的一颗齿轮。
这一年技术能力上基本上原地踏步,更多的是软技能的提升。
所在团队的特殊性,向上与用户直接对接,向下需要统筹所有依赖方。需要强沟通能力。所以日常的工作基本上就是沟通、会议、方案、业务…真正落地开发其实很少,更多的是系统稳定性方案和保障上。
小半年下来若说提升可能就在四方面
现在一想技术提升基本为0,当然整年投入精力最多的就是在稳定性上
失踪人口今年博客的产出为0,这个羞耻的成绩实在是难以启齿
希望疫情早日结束,希望自己能够不忘初心,希望远方的朋友都能心想事成,希望梦想成真~加油!
2021-03-13 20:52:59
近半年博客都没怎么更新和维护,一方面确实是忙,另一方面就是一直在为找工作奔波。
终于工作也尘埃落定,马上也要入职,最近在处理工作交接的事情,就写一篇文章来记录下人生中第一次换工作的经历吧。
首先这次工作是从杭州换到了上海,新工作解决了一些个人问题,薪资也达到了预期,新的开始祝自己一切顺利!
我是从大三校招就进了老东家开始程序生涯、毕业就直接拿到了提前转正,说实话,老东家确实挺好的,无论是工作氛围、领导、同事都是无可挑剔的,我在这里生活了三年,和大家都很熟,这里就好像是我的舒适区,拿着够花的工资,过着朝九晚五的生活,周末和同事朋友约饭、游山玩水。在杭州这样的城市真的可以说是美滋滋,当然了前提是你没有外部压力(诸如房子、车子、等等)。
跳槽、换工作在互联网公司实在是太普遍了,三年间送走了一批又一批,我所在的小组从我入职到现在,除了我之前的人已经全换了一批。以前都是我受邀参加同事的散伙饭,终于今天也到老同事们被我邀请,轮到他们送我,一伙人坐到桌前,仿佛有种不真实的感觉,一起聊着这几年的事,就仿佛都还是昨天…
我差不多是从去年12月份开始陆陆续续投起了简历,然后截止到年前2月初陆陆续续面了大小共6家公司
其中有运气也有自己的因素,拿到了5份offer,最终在年后开工后确定了入职公司。
这也算是参加工作后的第一次换工作,一路上磕磕绊绊总算有了定论。
扯了这么多,还是和大家分享下找工作需要的注意事项
选择一个适合的时间段来执行你的计划是非常重要,都说金三银四、金九银十是跳槽的最佳时间,还是有一定道理的,每年三月份左右企业都过完新年刚开工,年前制定的招聘计划正是开展的时候,我就是在年底这个尴尬的时间点开始的,春招吧有点早,秋招吧有点晚,但是如果你准备好了,其实什么时候找工作都可以,如果刚好赶上金三银四、金九银十岗位的选择机会会更多一些。毕竟开发面试还是得看技术。
既然要找工作了,渠道很重要,如何从岗位海洋里找到和你契合度高的岗位,并且如何高效的送达简历,其实都是至关重要。
简历投出去了,就预示着你随时会收到面试邀请,可万万不能等收到面试再准备复习,到那个时候只能是临时抱佛脚,很可能被佛踢一脚!!
基本上现在的互联网面试方式就三种:电话面试、视频面试、现场面试
论效率的话现场面试效率最高,电话、视频面一般都只是一面、二面简单了解下。我因为是异地面试的原因,通常都会和对方商量,一共几面,可否当天全部安排。一站式的面试很考验人的精神状态。
其实面试就像是平时的技术分享一样,把你掌握的一些骚操作、知识点分享给面试官,在我个人的体会下,一场成功的面试就是两个技术人的经验交流,面试者发挥出了自己的所学也看到了自己的短板,面试官测出了对方的深度也发现了对方的闪光点。
第一场面试结束后,大概率你的心态已经发生了一丝变化,要么信心满满要么就是可能被虐了一顿,但是不论如何,面试后的复盘是尤为重要,技术面试中被问到的问题,哪些是你非常熟悉的,哪些是你印象模糊含含糊糊的,哪些又是你从来没接触过的。这些都需要进行复盘总结。
通过面试后的复盘,来查漏补缺,花时间补一补自己的薄弱点,用每一场面试来磨砺自己,直到你可以在面试中游刃有余,那说明你已经来感觉了。这也代表着你面试大概率要通过了。
无论你的预期是什么,当你在有可以选择的情况下一定要多方面多角度考虑和抉择
最后关于薪资多说两嘴:
时薪时薪时薪!!!!重要的事情说三遍!
有的朋友觉得加班无所谓只要钱管够、有的朋友觉得绝对不加班,加班的我就不去
但是无论加班还是不加班,我都建议你先计算一下时薪,福报型企业加班多自然到手的也多一些,正常型企业不加班但是薪资可能稍微低一点
但是并不是薪资低就不考虑,这个时候建议你算一下时薪,如果不加班的工作可以拿到和加班工作相近的时薪,那还真的需要你好好斟酌,毕竟双休、朝九晚五的生活也是很美的。
唠唠叨叨扯了这么多,也是经历这次换工作后,把自己遇到的一些坑点和经验分享给大家。还是那句话,换工作可以,但是不要盲目的换。
你为什么换工作?你的新工作是否解决了你的困惑,达到了你的预期?
最后,还是祝自己也祝大家工作顺利~
2021-01-15 09:39:34
本文讨论目前市面上基于WIFI智能设备的配网方案,结合自身开发案例,对不同的配网方案进行对比介绍。
阅读本文你可以了解到如下几种配网方案:
提到设备配网这一流程,通俗的理解就是让设备连上网,本文主要就WIFI智能设备的配网展开讨论,目前市面上常见的配网方案都绕不开以下几个步骤:
下面我们针对不同的配网方案来注意分析器配网流程
如果你近几年购买过一些智能灯具、智能插座等等WIFI设备,那么大概率他的配网方式就是一键配网
因为一键配网方案,用户操作简单,只需要录入wifi的ssid和password,即可等待设备完成配网。
正如此一键配网几乎是智能设备的通用标准,但是它最大的痛点就是成功率低,特别低!!!
下面一起来看下一键配网的实现原理:
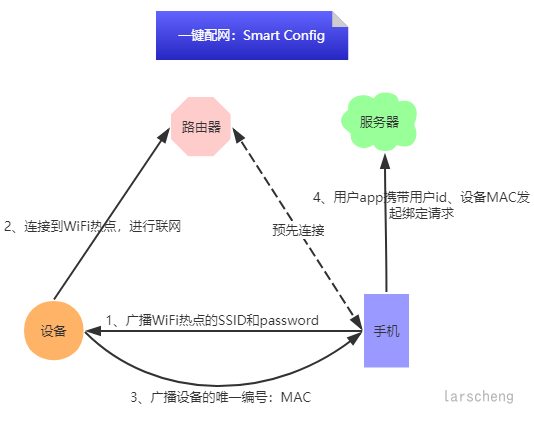
从步骤上来看,没有任何毛病,但是在实际的用户配网过程中会出现各种各样的问题,导致用户体验极差,配网成功率极低
看似用户操作方便,并且使用率极高的配网方式,实际操作中有很苛刻的配网条件,这也是一键配网让人又爱又恨的地方
如果有新的WIFI智能设备项目,不建议选用一键配网方案!
既然一键配网成功率这么低,那有没有成功率高的方案呢,当然是有的:设备热点配网
由于它出众的配网成功率,很快成为wifi设备配网的新宠,像米家的摄像头就采用的这种配网方式
一起来看看他的实现原理:
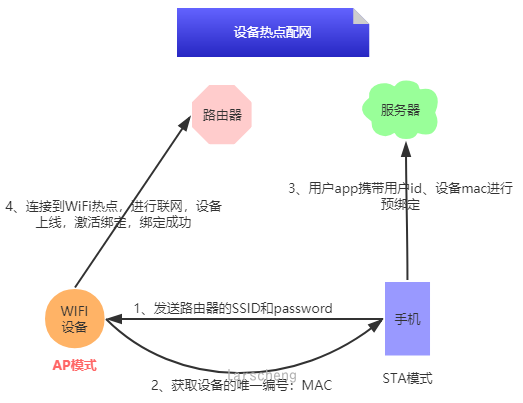
设备热点配网时首先由设备AP模式,手机STA模式,去连接到设备热点上,进行数据传输
整个过程不需要通过路由器广播数据,所以不存在路由器兼容性,也不存在信号频段问题
唯一的风险点就是用户通过APP输入SSID和密码错误,导致设备无法联网。
针对这一风险点,在绑定流程上设计了预绑定和激活绑定:
app携带用户id和设备mac发起预绑定,如果设备正常联网上线,那么绑定生效,设备激活;如果设备拿到了错误的ssid信息一定时间内没有上线,那么清除预绑定记录。
设备热点配网相对于一键配网几乎没有任何额外的成本增加,在尽量不增加用户操作复杂度的前提下,极大的提高了配网成功率,这也是当下新的WIFI设备配网首选方案。
零配,我最早在天猫精灵系列设备的配网方案中遇到过,这是一种特定场景的配网方案,大致思路是通过已经配网成功的设备(智能音箱)给新的设备进行配网,实现真正意义上的零配置配网。
现在大部分的智能音箱联动场景中都支持零配方案。
先看一下的的实现步骤:
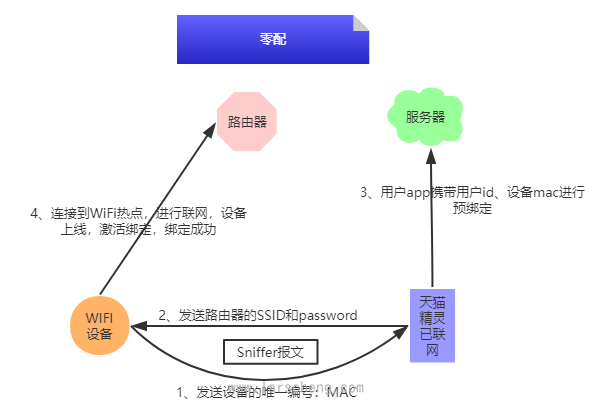
前提:通过其他方式已经完成配网的智能设备(天猫精灵),与服务器连接正常,并存有路由器SSID信息
该方案需要有一台已经联网的智能设备,并且该设备保存了用户信息和路由器SSID信息,优化掉了用户手动输入SSID和密码的步骤,进一步简化了用户配网操作。
在实际使用中,用户开启WIFI设备后,只需要对天猫精灵说一句“找队友”即可完成配网,可以说用户的配网体验感很好。
这种方案和设备热点配网方案比较相似,从名字能看出来,这种方案的热点是由手机提供。同样都是为了解决路由器兼容性而提出的解决方案。
这种方案在阿里IoT中被作为一键配网失败后的补救措施。当一键配网失败后,用户可以通过手机设置特定的wifi热点,设备连接到手机热点上后进行信息交互。
原理图如下:
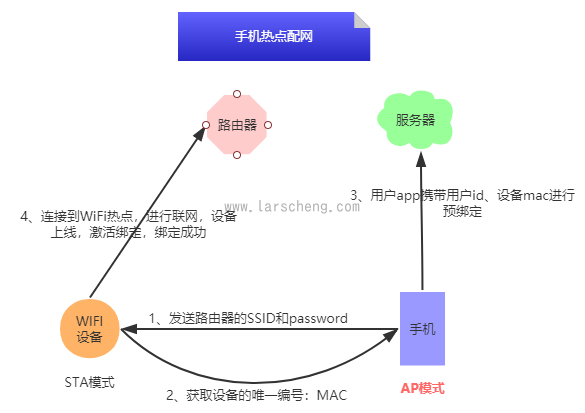
流程基本上和设备热点方案类似,区别就是提供热点的是手机端
不过在实际应用中,使用率不是很高,一方面用户操作复杂度过高,可能用户完全不知道如何开启手机热点。另一方面能想到手机热点配网方案,肯定会采用设备热点配网方案了。
所以总的来说,该方案成功率相对较高,但是用户操作复杂度也随之增大,可以作为其他方案失败后的备选方案,但并不推荐使用,毕竟用户体验是第一位
总结一下上面提到的四种方案的特点:
| 方案 | 使用率 | 成功率 | 用户体验 | 路由器兼容性 | 频段兼容性 | 手机兼容性 | 使用场景 |
|---|---|---|---|---|---|---|---|
| 一键配网 | 高 | 低 | 优 | 差(不支持广播) | 差(2.4G/5G) | 差 | 不推荐使用 |
| 设备热点配网 | 高 | 高 | 优 | 优 | 优 | 优 | WIFI配网首选方案 |
| 零配 | 中 | 高 | 优(免输入SSID信息) | 优 | 优 | 优 | 音箱联动场景推荐 |
| 手机热点配网 | 低 | 高 | 差(手动开启热点) | 优 | 优 | 良 | 不推荐使用 |
以上四种配网方案也是我目前工作中接触到的一些常用方案,为了方便理解,简化了各种方案的细节,实际通讯和交互流程会更为复杂。
当然除了这些,也有一些其他方案比如路由器热点配网方案、WEB配网方案等等,这些方案都因为需要特定场景和复杂流程等因素逐渐不被经常使用。