2026-07-12 05:00:00
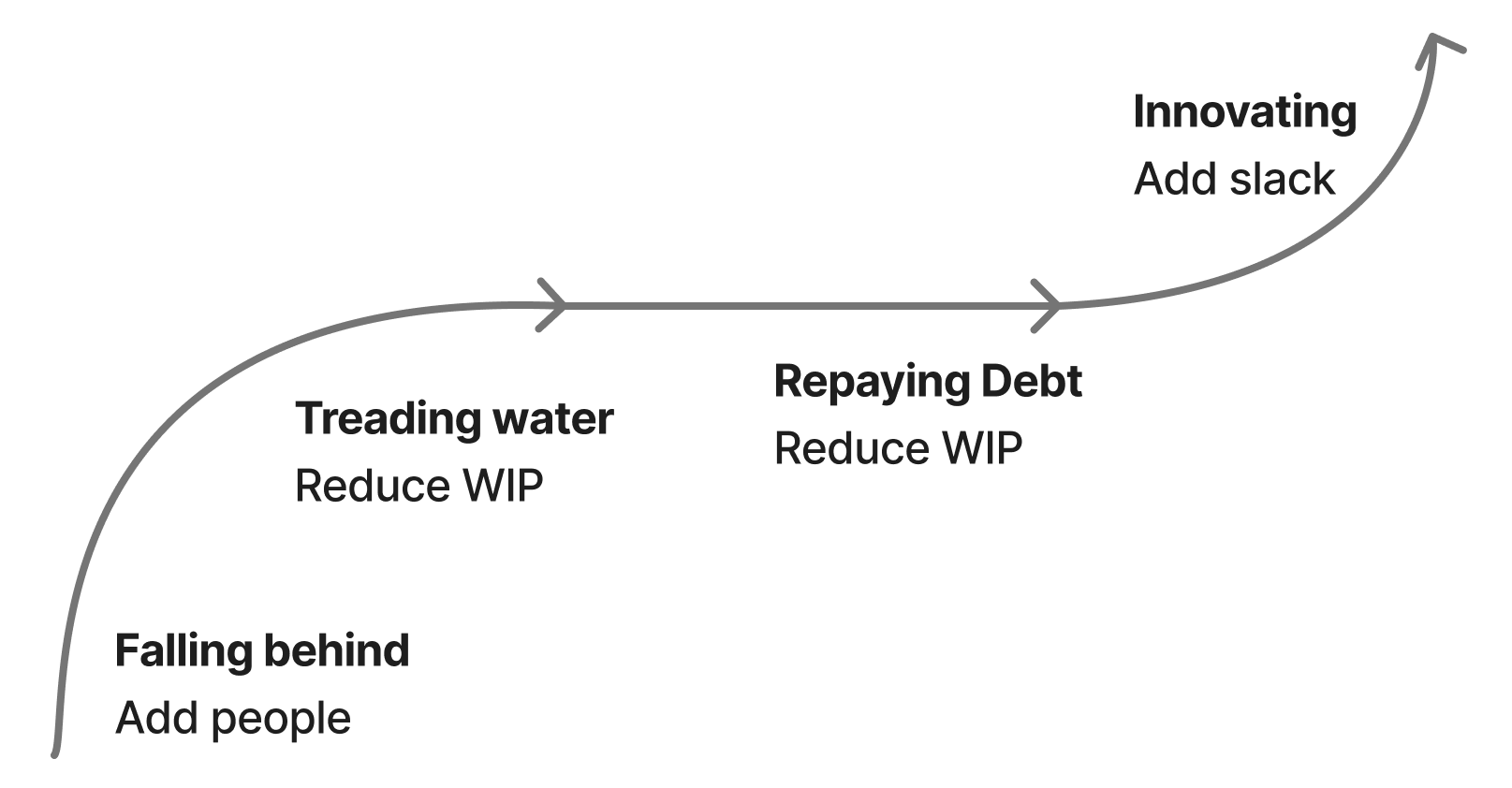
Eight years ago, I wrote about my theory of restoring struggling teams, which came down to four steps:
Even now, I find this mental model extremely valuable, but I do think it is missing one interesting nuance that I’ve seen many teams run into in high-growth environments: suppressed and generated demand. Suppressed demand is the idea of incoming work that isn’t incoming, because teams stop asking you for help. Generated demand is when an increasingly effective team’s progress is noticed, and the previously suppressed demand is converted into actual demand.
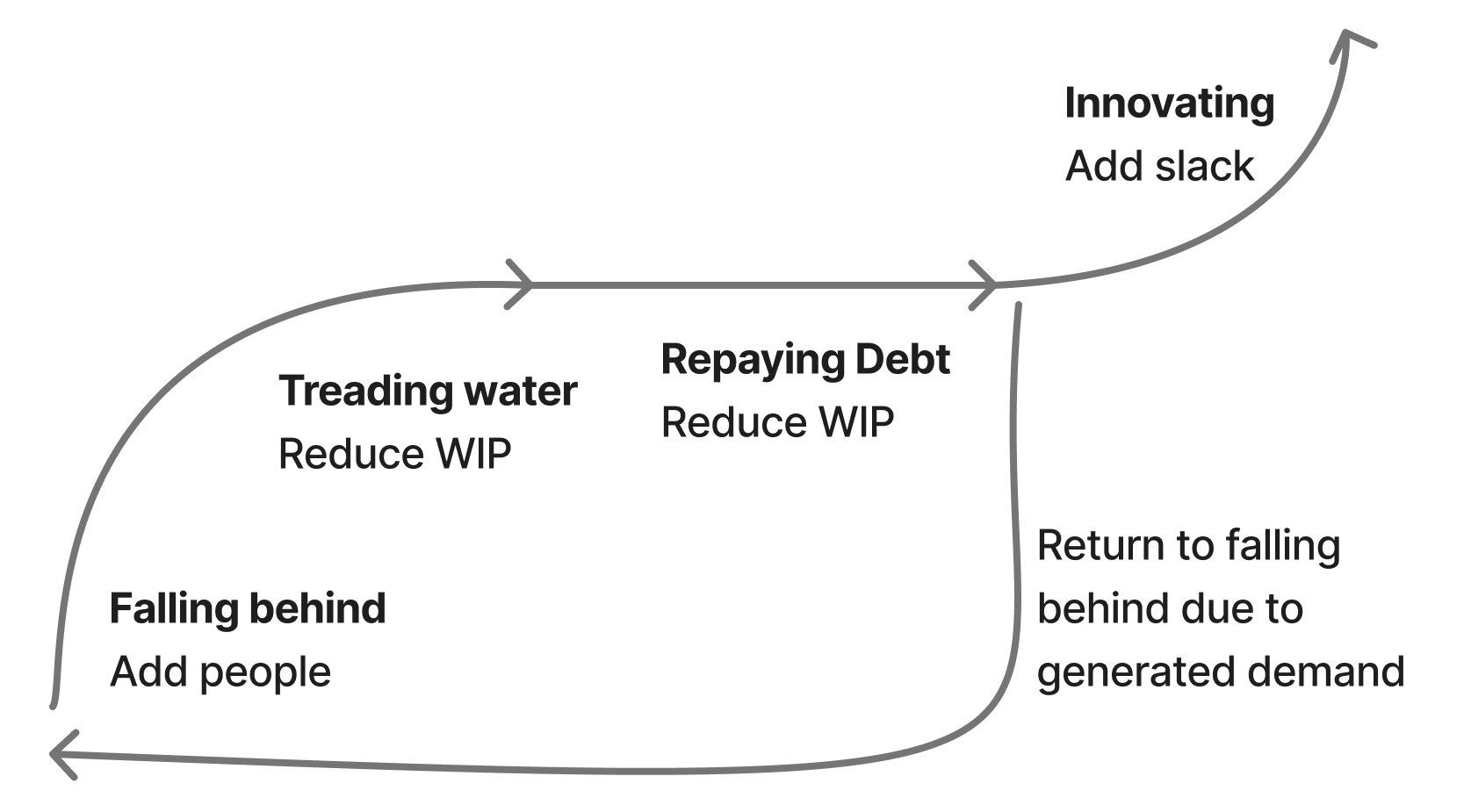
The consequence of generated demand is that a team that was struggling can successfully recover, work through much of its backlog, and then shortly thereafter be just as far underwater as they were at their worst. This is a very disorienting experience, and even a demoralizing one. The team has done everything right, shipped a bunch of genuinely valuable work, and are nonetheless just as far underwater as they were before.
To give a concrete example, our Customer Operations Engineering team didn’t exist a year ago, and instead we invested in customer operations engineering tasks by prioritizing them into a larger team’s tasks. This often meant we had very valuable projects that didn’t get staffed. We then split it out into its own team, launching a number of projects like reworking our internal customer operations tooling and integrating Sierra for our IVR, both of which worked out quite well. As a result of working out well, there are far more requests for work. Despite accomplishing so much, the team is even further behind on the incoming requests than they were a year ago, when they had shipped relatively little and had relatively little capacity to ship more.
Unfortunately, the solution here is not particularly novel: you have to run through the cycle again. And potentially a third time. And potentially a fourth time. You just have to keep running through it until you’ve surfaced the entire backlog of suppressed demand. This is very similar to the problem of latent incidents which cause effective reliability programs to look like they’re failing as they drain the stock of previously created latent incidents. Sometimes you’re doing the right thing, and it just takes a while to work. Your challenge in that moment is building conviction that you are indeed doing the right thing, and convincing your team and leadership of that as well.
Finally, it’s interesting to attempt to predict which teams are, and which aren’t, sitting on top of a backlog of suppressed demand. Some teams run through the recovery cycle, and find that there simply isn’t much else to do. These tend to be teams with very narrow interfaces, for example a team whose job is providing internal queues probably won’t have much generated demand after clearing the initial backlog. Teams with broad interfaces, like customer operations or developer experience, are generally sitting on an incredibly large, albeit currently invisible, backlog of suppressed work.
2026-07-11 21:00:00
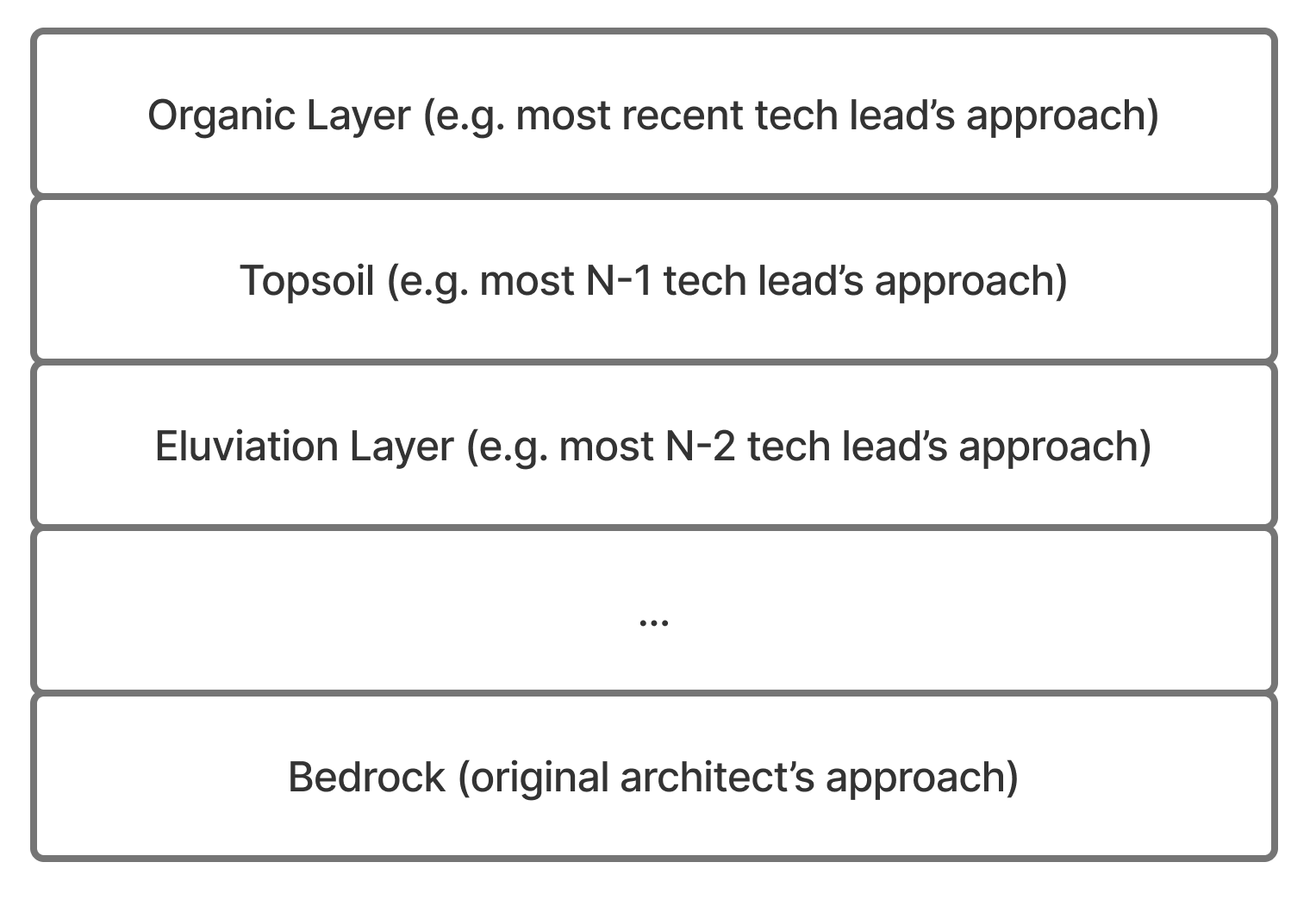
I’ve recently been thinking a lot about the concept of “soil horizons”, which is the idea that there are many distinct layers of soil, from topsoil all the way down to bedrock, which all combine into a soil horizon. Translating this idea into software, the ideal codebase would have a single uniform “code layer”, but a surprisingly large percentage of production software has numerous, distinct code layers as the leading architect shifted over time. I’ve found this particularly true for software in problem-spaces with high essential complexity and low scale complexity, where the purifying challenges of scaling never create enough pressure to compact disjoint layers into a unified layer.
Codebases with the most code layers tend to be created by small teams working on complex domains over a long period of time. In many companies this might be an identity, permissions or payments team: stuff that’s permanently valuable, but usually not the central concern at any given time. On such teams, there is often only one architect who understands the nuances of the domain well enough to make tradeoffs. When that architect leaves, they are replaced by someone who aspires to operate in the same code layer, but simply cannot because they lack enough context to do so. As a result, that new replacement creates a new code layer, despite not intending to. If the team runs through a handful of folks as the new team leads struggle, it’s easy to end up with a complex code horizon very quickly.
The problem of messy code horizons is not a new one, and the general approach to addressing them is the same one I wrote about seven years ago in Reclaim unreasonable software, but with the proliferation of coding and non-coding harnesses, lately I’m running into the problem of messy code horizons more frequently. Even more concerning, I’m seeing this problem expand from impacting code horizons into impacting how organizations make decisions outside of software, e.g. the company’s general reasoning horizons. When individuals or teams rely on LLMs to reason to conclusions, rather than using LLMs to explore or draft options, it’s possible for even the most important decisions to be built on top of flawed reasoning layers underneath.
In the next section, I’ll develop the problem statement a bit about what I’m running into, and then in the final section I’ll lay out the approaches that I am finding (moderately) effective to navigate that problem.
If you give three enthusiastic engineers a problem, a new codebase, a coding harness, and self-approval rights, it’s very easy to end up with three new soil horizons as their harnesses gleefully commit code. However, in engineering we have a number of techniques to derisk this problem. First, we have manual and automated code review, and second we increasingly have the ability for the harnesses to operate off sufficiently clear instructions that they write new code consistently with the existing code, even if the operator is unaware of what good looks like. This is also true for code review, where coding harnesses can drive consistency across pull requests even if the person (or harness) creating the pull requests is not operating off the same shared context as the wider team.
Many codebases are not well-configured for this new reality, and those codebases are getting worse at an accelerating rate as more harness and agent contributions get added. Legacy codebases that reach a certain size before introducing these better practices are easier to fix than before, but still require a lot of work to fix.
That said, I’m confident that coding harnesses are going to substantially improve the quality of code horizons over the next year or two as the way we configure harnesses improves. That’s not the problem I’m worried about. What I’m worried about is the application of harnesses to problems outside of writing software, where there’s no static typing, linting, or unit tests to validate the output.
Let me provide a very recent example from my own work that highlights this problem: I wanted to understand how our incidents were trending over time. So I pulled data via an MCP, and the analysis was unintuitive to me, in particular I thought we were having more Data related incidents than the results reflected. I had to look at the incidents in Slack, then the results in our incident tool, and understand why the two conflicted. After a bit, I recognized the results in our incident tool were only showing incidents that properly tagged a team when the alert was triggered, so it was omitting about half the relevant incidents. After having the agent manually tag the incidents without team assignments, the data made a lot more sense. After recognizing the issue, it was trivial to fix. However, if I had simply accepted the initial analysis, I would have made the perfectly wrong conclusion about what was happening. On top of that wrong conclusion, I could have easily pushed the team to take on a project to solve an illusionary problem.
What’s so pernicious about messy reasoning horizons, is once any reasoning layer is poisoned, it’s impossible to reason effectively on top of it. If you take the incident analysis example, it’s easy to imagine prioritizing the perfectly wrong set of remediations, which have the artifacts of solid strategic reasoning, but are nonetheless just wrong. It’s easy to imagine a team wasting a quarter of time building a solution to this sort of problem that never existed.
It’s true that poor reasoning has always existed, long before harnesses, but my experience is that poor reasoning wearing well-formatted clothing is proliferating more widely than I’ve previously seen, and it is increasingly difficult to combat because certain social norms are – at least temporarily – collapsing around folks actually thinking. That collapse is largely driven by unprincipled adoption of AI techniques without paying attention to whether they work. Widespread adoption is, in my opinion, the fundamental risk for most companies at the moment, and something companies need to be doing, but many approaches inadvertently mix play (experimenting with something new in ways that are likely to fail!) with production (creating load-bearing work product!) in ways that erode social norms for quality.
The norms are not uniformly collapsing by any means, they are generally intact, but even a small increase in the proliferation of low quality reasoning layers has a devastating effect on your ability to reason successfully. Especially true the further up the poor reasoning occurs (sloppy reasoning from senior leaders) or when senior leaders rely on layers of reasoning without inspection (leaders who aren’t sufficiently “in the details” to spot likely reasoning errors in reasoning layers).
As a result, we now live in a world where accepting any part of the reasoning context before inspecting it might lead to making a catastrophic mistake. This is an exhausting way to live.
Accepting that this is the world we live in, I wanted to lay out the techniques that I am finding useful to deal with it. Some of these are novel, but many of them are the same techniques I was using before the LLM-advent:
Make no assumptions. When new hires join my team or my company, the first thing I tell them is that it’s essential that they “make no assumptions.” This is difficult to do, and it goes against every instinct because it forces you to inspect each aspect of how the company works and thinks, but I do think it’s the necessary approach. It’s a bit like learning “internet-skepticism” at some point in your life, where you realize that everything on the internet is self-motivated in some way, and you have to maintain a strict filter on what ideas you accept.
This is a hard change to make, but I genuinely believe this is the correct mindset for accepting new information in the current era. The combination of fewer management layers and more flawed reasoning layers means that the core job of leadership is inspecting the details.
The author must be the first human in the loop for their output. The biggest cultural failure with harnesses is when you can tell that you–the recipient of a piece of work–are the first human in the loop reviewing it. You must set a cultural norm that the creator of a piece of content is always the first human in the loop before asking another human to review it. If you fail to set that cultural expectation, then you will quickly crush the remaining team with a high standard for quality reasoning, which will lead to a full destruction of your reasoning horizon.
Prioritize reasonable software. Run the Reclaim unreasonable software playbook, recognizing that migrations are cheap in 2026, so it’s much faster to remediate gaps. The core idea here is that relying on convention doesn’t work, and instead you have to rely on deterministic decisioning for each approach. For humans this can feel overly prescriptive, but harnesses don’t care.
Learn faster by separating play and production. Many folks trying to learn how to use harnesses and LLMs leap directly into using them in their most critical work. This is a slow way to learn, and can lead to substantial errors in your most critical work. It’s much faster to work by buffering small pockets of time to learn.
For example, our head of data has spent time building an iOS app fully “hands off the keyboard” to get a better feel for the tools. This sort of experiment goes much faster and gives you more repetitions in less time. The very practical version of this is setting aside a day or two periodically for folks to experiment.
Structure how you think with LLMs. In Crafting Engineering Strategy, I lay out a structured approach to reasoning through creating a strategy document, which aims to prevent the reasoning errors that folks make in their thinking. This applies equally in how we use LLMs, and I think you can substantially reduce the chance of introducing flawed reasoning layers by focusing LLM work on exploration (gathering information on internet and via various MCPs), refinement (presenting gathered information effectively), and a final formatting pass. That takes much of the work out of strategy creation while constraining the areas you have to avoid making any assumptions about its output.
I’m certain there are more things! What are you trying?
2026-06-15 21:00:00
From early 2014 through late 2020, I was working in hypergrowth environments, which are challenging, but also educational. The most valuable feature of hypergrowth is that your mistakes reveal themselves next month rather than next year, because things go wrong very loudly when you’re moving fast. I’ve been thinking a lot about hypergrowth recently, because Imprint’s business is growing quickly and we did a large batch of hiring last year, but also because the AI-tooling shift has changed the pace at which it’s possible to work.
This post documents the new rules I’ve revised my approach to engineering leadership around, and then talks through the specific projects I’ve worked on over the past year that caused me to believe in these rules.
Migrations can be done by an individual rather than a team. Even complex, large changes can be 95% owned by the driving individual or team, and done in 10% of the time. As the initial cost of migrations goes down, the reward/penalty of each migration’s quality goes up: even small sharp edges will break your colleagues’ mental models about the software you co-maintain. The impact of individual judgment on your company has never been higher.
While 1st-pass code is nearly free, the cost of working code depends on your development harness, and is not free. We’re in an era when many companies say that everyone should be writing code, however our experience is that writing code that works well, while avoiding messy edgecases, remains difficult. Just how difficult remains a factor of your development harness, e.g. your tests, CI/CD, validation environments, preview-ability of changes, and so on. While I personally don’t imagine it’s valuable for most folks at a company to be contributing code, I suspect that most disagreement about that topic is actually a miscommunication: even at a company where “everyone codes”, the marketing team isn’t reducing allocations in your servers, instead it’s about whether there is a safe boundary where they can participate. (Much like a SaaS product that allows customization by writing software.)
The good news is that this means the things that were most valuable to speed up engineering two years ago are still the things that are most valuable to speed them up today.
Optimize the base-case of process for agents. Most steps of most processes can be fully automated in most cases. With the right harnesses, the right controls, domain context, and good judgment in their designers, you can fully automate the base-case of most processes in modern technology companies. For example, the base case of code review from a human is slower and less effective than a good harness’ code review. Of course, the harness will miss things, but so will human reviewers, and most areas are relatively safe to make changes. Of course, there are some higher risk areas, where this doesn’t hold true. By effectively capturing these distinctions properly, we can go much faster without introducing risk. By failing to capture these distinctions, we’ll create innumerable problems for ourselves.
As a corollary, I think most planning processes like weekly or bi-weekly sprints are operating at too low an altitude. Humans planning together still matters, but should be operating at a higher level.
Durable, high-ownership teams with domain-context are even more important. One of my biggest lessons at Uber was that persistent, durable teams work magic by accumulating domain-context, building a sense of camaraderie, and feeling an increasingly strong sense of ownership over an area as they continue to work in it. Even in an era where specifically doing something is much cheaper, you still have to do the right thing, which has gotten a bit easier but not much easier, and structural improvements help address this. (As a recent example of that, we had an issue in production where the necessary data to optimize it simply wasn’t being captured at all, so the harness’ ideas to solve it were reasonable but wrong, since the only real path forward was instrumenting the missing information.)
As a specific disagreement, there’s a prevailing idea that AI-first companies will be run by a small number of genius engineers who create perfect versions of things one by one, doing such a good job that there’s nothing to maintain. This is a very compelling vision, but I don’t see it happening. High judgment individuals can wander across a company doing remarkable things, but at some point they do get hemmed in by lack of domain context, which is why durable teams are the fundamental building block, even in this era.
Quick, good, and durable decision-making is a prerequisite to meaningfully benefit from AI. Being able to replace a legal review with automation only works if Legal can commit to that change, which depends on designing the automation thoughtfully, and also the teams’ willingness to collaborate. Implementing a new feature is only valuable if you can decide to launch that feature.
Your team and company can only benefit from this increased pace of execution if you can make durable decisions quickly, and those decisions are good. This is the primary reason, in my opinion, why the average CTO role has necessarily become substantially more technical and less bureaucratic than a year ago. In many cases, I am the only person who can make binding decisions when teams disagree on the path forward, and that means I am making decisions constantly in this new world in order to maintain the pace. (That’s not an argument that executives are better decision makers, just that binding executive decisions are uniquely powerful to the extent that the executives themselves are aligned enough to honor those decisions.)
So, I genuinely believe the above rules based on my experiences over the past year, and let me try to connect them to specific projects we’ve worked on that have convinced me of them:
npm for package hosting, which was a source of ongoing friction.npm to pnpm for better security defaults and faster deploys.
This took one engineer a few hours a day for a few days.These are just representative examples, we’ve done a lot more than these. The aperture of what’s possible has continued to expand every month this year, but the things holding us back haven’t changed all that much: organizational misalignment, lack of clarity, and poor technical architecture. It’s a wild time to be working in technology.
2026-04-27 21:00:00
Last week, a colleague asked why I’d hired an additional new leader onto an important area rather than expanding an existing leader’s scope to incorporate that area as well. The existing leader was a known quantity and doing well, so why not keep expanding them? It’s a good question, and depending on the circumstances I might have done either, but explaining why I specifically brought in a new leader this time depends a bit on a distinction I think of as early versus late-stage hypergrowth.
In Cross the Chasm’s world, early-stage is when you’ve proven product market fit, have won the early adopters, and are just starting to win the early majority. In this phase, there are specific problems, and the most important problem is to solve those specific problems. For example, you might be having scalability issues, and solving that is the company’s almost sole focus for a few weeks. After scalability is fixed, next you’ll need to work on onboarding flows to convert for less technical users, and so on. Not only the executives, but much of the company, serially hunts down solutions to their biggest problem.
When you reach late-stage hypergrowth, you are starting to encounter the late majority and laggards cohorts. This reorients the company and executive teams away from only creating an exceptional product, to also having to solve the numerous concerns and checkboxes that a skeptical audience introduces. Sure, your product might save hours a day for our team, but how does your compliance paperwork look? How stable are you? What contractual commitment will you make regarding customer support resolution? At this point, you’ll still be in an extremely competitive environment to retain the innovators and early majority, while also having to solve the long list of skeptic-driven requirements. Instead of hunting down solutions, the company–and the executive team–now has to solve everything, everywhere, all at once.
Going back to my colleague’s question, in early-stage hypergrowth, it would have absolutely been preferable to expand the existing leader’s scope. In late-stage hypergrowth, expanding their scope would have moved the problem, while reintroducing a previous problem, and that’s a losing strategy in that stage.
It’s been a while since the industry has talked a lot about hypergrowth, but a lot of the lessons of hypergrowth are relevant again as we see the productive chaos of the current AI-era, and this is absolutely one of them. In particular, it’s extremely clear that you can speedrun the early hypergrowth phase with a small, AI-empowered team, but it’s far from clear you can speedrun the late hypergrowth phase with the same approach. Personally, I suspect we will figure that out as an industry, but many of the challenges popping up recently in e.g. Anthropic’s messaging to Claude Code power users, feel to me like they’re rooted in the challenges of making this transition.
Even in the unlikely case that we never solve late-stage hypergrowth using the same AI-staffed mechanisms that support the early-stage case, it’s still an economic miracle, since it’ll allow a smaller amount of capital to culminate into relatively large and derisked companies, which should underpin substantial productivity for the economy.
2026-04-13 01:00:00
One of my gifts/curses is an endless fixation with how processes can be optimized. For a brief moment early in my career, that was focused on improving how humans collaborate, but that quickly switched to figuring out how we can minimize human involvement, and eliminate human-to-human handoffs as much as possible. Lately, every time I perform a recurring task–or see someone else perform one–I think about how we might eliminate the human’s involvement entirely by introducing agents. This both has worked well, but also worked poorly, and I wanted to highlight the pattern I’ve found useful.
For a concrete example, a problem that all software companies have is patching security vulnerabilities. We have that problem too, and I check our security dashboards periodically to ensure nothing has gone awry. Sometimes when I check that dashboard, I’ll notice a finding that’s precariously close to our resolution SLAs, and either fix it myself or track down the appropriate team to fix it. However, this feels like a process that shouldn’t require me checking on it.
Five to six months ago, I added Github Dependabot webhooks as an input into our internal agent framework. Then I set up an agent to handle those webhooks, including filtering incoming messages down to the highest priority issues. About a month ago, when I upgraded from GPT 4.1 to GPT 5.4 with high reasoning, I noticed that it got quite good at using the Github MCP to determine the appropriate owners for a given issue, using the same variety of techniques that a human would use: looking at Codeowners files where available, looking at recent commits on the repository, and so on. The alerts and owners were already getting piped into a Slack channel.
So, this worked! However, it didn’t actually work that well, because despite repeated iteration on the prompt,
including numerous CRITICAL: you must... statements, it simply could not reliably restrict itself to critical
severity alerts. It would also include some high severity alerts, and even the occasional medium severity alert.
This is a recurring issue with using agents as drop-in software replacement: they simply are not perfect, and interrupting
your colleagues requires a level of near-perfection.
If I’d hired someone on our Security team to notify teams about critical alerts, and they occasionally flagged non-critical alerts, eventually someone would pop into my DMs to ask me what was going wrong. That didn’t happen here, because the knowledge that those DMs would show up prevented me from rolling the notifications out more aggressively. Coding agents address this sort of issue by running tests, typechecking, or linting, but less structured tasks are either harder or more expensive to verify. For example, I could have added an eval verifying messages didn’t mention medium or high severity tasks before allowing it to send to Slack, but I found that somewhat unsatisfying despite knowing that it would work.
Instead, after some procrastination on other tasks, I finally prompted Claude to update this agent to rely on a code-driven workflow where flow-control is managed by software by default, and only cedes control to an agent where ideal. That workflow looks like:
This works 100% of the time, while still allowing us to rely on our internal ownership skill to determine the most likely teams or individuals to notify for a given problem. It’s now something I can rollout more aggressively.
The immediate fast follow was a weekly follow-up ping for open critical issues, relying on the same split of deterministic and agentic behaviors. The next improvement will be automating the generation of the vulnerability fixes, such that the human involvement is just reviewing the change before it automatically deploys. (We already do this for Dependabot generated PRs, but in my experience Dependabot can solve a reasonable subset of identified issues, but far from all of them.)
That is the pattern that I’ve found effective:
This has worked well for pretty much every problem I’ve encountered. The end-result is faster, cheaper, and more maintainable. It’s also a cheap transition, generally I can take logs of some recent runs, the agent’s prompt, and some brief instructions, throw them into Codex/Claude, and get a working replacement in a few minutes.
2026-03-29 22:30:00
At some point, you will have learned about the passive voice, where the actor in a sentence is unclear. For example, my software didn’t compile. That’s a good example of the passive voice. However, you might not know the full set of rules, because here are some sentences in the passive voice that you might not recognize:
You might think those are active sentences, but those are in fact examples of the agentic passive voice. The rule here is: whenever the actor in a sentence is a model, then it’s a passive sentence. I’m sorry if your grammar instructor never taught you this rule, but this is just the way it works now.
This is an important grammatical distinction to make, because I’m increasingly seeing folks say that Claude made a mistake, without recognizing that they’re writing unclear, nearly ungrammatical sentences that their grade-school teacher would reject. So please, aspire higher. Write in the active voice, avoiding all passive variants.