2026-05-24 08:00:00
This post is part of a series on Theseus, my win32/x86 emulator.
Theseus now can produce WebAssembly output, allowing it to translate a .exe
file into something that runs on the web.
Try it out here, but note it is full of bugs
(e.g. Minesweeper crashes if you win).
This was pretty straightforward to get working, with the exception of one major detail that this post will go into.
The x86 emulation part of this is just recompiling the existing Theseus output
with a different CPU target. This is one of the main benefits of this binary
translation approach. The translated code is almost (with the exception of how
main gets invoked) wholly agnostic to the environment it eventually runs in.
In principle I now get optimized wasm compiler output for relatively free. The
main challenge was figuring out the code layout to get Cargo to cooperate with
my weird requirements.
The win32 part was changing things to abstract over a "Host" API that is able to do things like fetch mouse events and render pixels. That is now implemented once for SDL and once for the web. This was also relatively straight forward, at least in my first pass.
So what was hard? It comes to a part of the design space I hadn't previously explored well: whether the emulator is allowed to block.
In retrowin32, the emulator was designed to be able to step through some instructions and then return control to the caller. This is critical for the web version in particular, where you cannot block the main thread. In my earlier post "threading in two ways" I went into some detail on the various tradeoffs on how I could emulate threads in a browser, ultimately choosing a single thread.
This has its advantages, but is unsatisfying in a few important ways:
MoveWindow will
synchronously send Windows messages related to moving to the window, so it is
also async with respect to the message handling.In the spirit of exploring the design space, when I got to revisit this choice in Theseus I instead made everything synchronous and implemented threads using real OS threads. In particular because Theseus maps the original program's code to function calls, it makes the debugging experience pretty pleasant: if I set a breakpoint or if something crashes, I get a stack trace that goes through both the source program and emulator code.
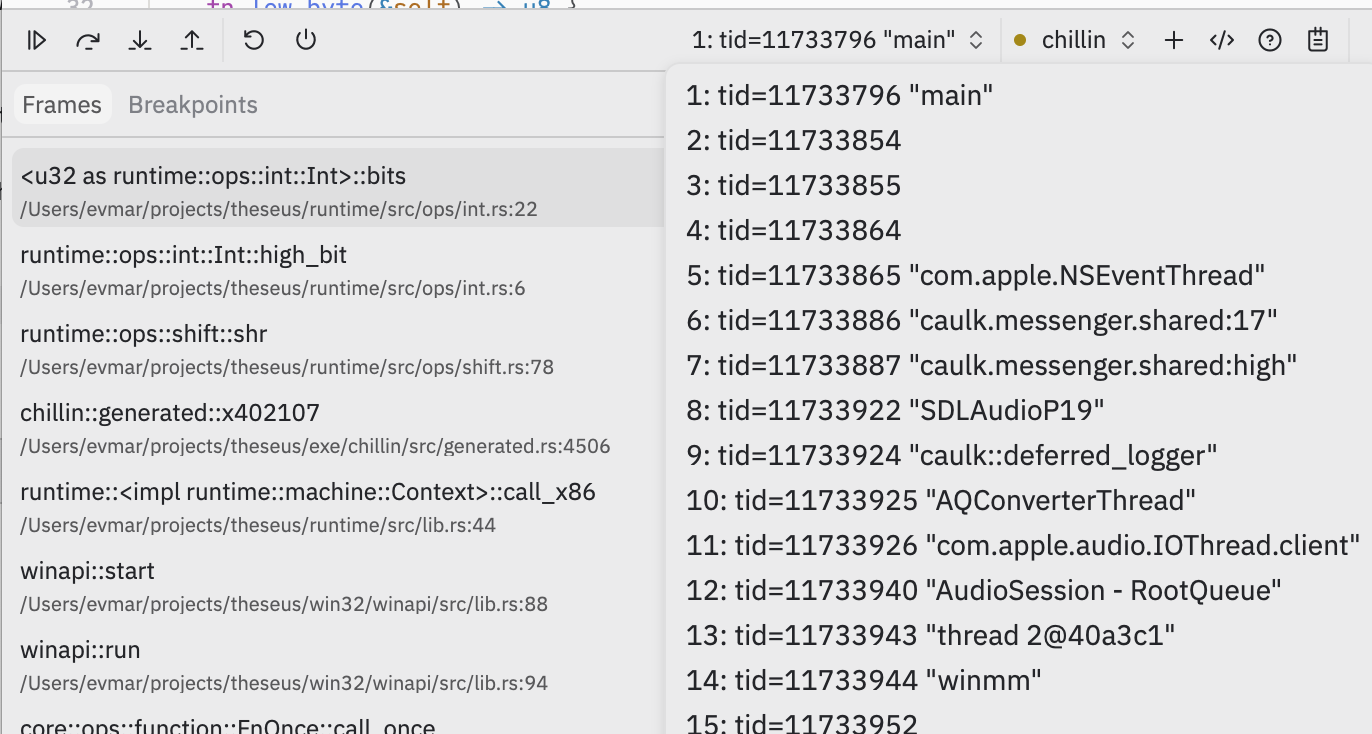
Picture: a Theseus program in a native debugger, with a stack trace including a generated x86 address on the left, and with a thread picker showing the Windows "winmm" multimedia thread on the right.
I mostly care about the developer experience here, but one additional reason this approach is nice is performance. Computers are really good at quickly running simple code made of nested function calls that store things on the stack. My asynchronous approach meant there was a lot of control overhead, even in tight loops.
In all, blocking is great. But on the web, you cannot block the main thread.
Even in a single-threaded program a call to a Windows API like GetMessage is
supposed to block until a message is available, but browser events will only
come in via the browser event loop once you've returned control. It would seem
you're stuck.
What it really means is that fundamentally, if you want to block, you must use a
thread — even in the case where the program you're emulating is itself
single-threaded — because worker threads are allowed to block. So here's the
approach: I run the emulator's threads in web workers. When the emulator needs
something from the browser, it can send a message via the postMessage API that
comes in on the main thread's event loop. And here I can make the worker block
until the message is handled.
This where the atomics API comes in. (Uh oh, synchronization code! The chances that I got this wrong are extremely high; I welcome your feedback on this, and I post it in part to provoke some reader who knows more than me to correct me.)
If you share memory between the main thread and worker, you can make the worker block on an atomic until the main thread is done. To do this, the worker sends the address of a local when it posts its message:
fn blocking_call() {
let mut buf = 0i32;
let msg = create_message(
/* ... some JavaScript data indicating what function to call ... */,
// ... and include the *address* of the above 'buf' variable
&mut buf as *mut _ as u32
);
post_message(msg);
unsafe {
// wait while buf==0 until we get an Atomic notify on it
wasm32::memory_atomic_wait32(&mut buf, 0, -1 /* forever */);
}
}
The main thread receives these, and wakes the worker up when it's done by prodding the shared memory:
window.onmessage = (e) => {
const msg = e.data;
// ... handle message ...
// interpret msg.buf as a pointer within the shared memory:
const ints = new Int32Array(sharedMemory.buffer, msg.buf, /* length */ 1);
ints[0] = 1; // set `buf` from above to mark it successfully handled
// wake up the waiting thread:
Atomics.notify(ints, /* index */ 0, /* how many to wake up */ 1);
}
Note that because the worker is blocked until its message is processed, we know that the address of the local stack variable remains live until the main thread is done with it. This means we can effectively pass the address of any local variable from the worker and the main thread can safely modify it as it chooses.
From this sketch I hope you can see how I extended this to pass buffers in both ways. When the worker generates pixels, it sends a message just with a pointer to the pixels that the main thread can read directly from its memory (no copies!). And when the worker blocks to wait for an event, it can supply a buffer that the main thread can fill in.
The main limitation of this approach is that the main thread cannot transfer any
browser objects to the worker thread, because the only communication back is via
the shared memory buffer. Objects can only be transferred by attaching them to
postMessage, and those arrive via the browserevent loop.
You might have noticed the above code switches into TypeScript to show the main thread handler. At first I intended to write all of this as a single wasm blob that contained the code for both the main thread and the worker threads. I eventually turned back to TypeScript for a few reasons.
Because the main thread cannot block, this means it cannot practically share its memory with the workers if any synchronization might be involved. That would veto even using a malloc implementation. I think the best way to make this work is by running the main thread wasm with its own private memory, and handing it a reference to the workers' shared memory. I think because that shared memory object is opaque, you would need to call out to browser APIs to interact with it, rather than the native wasm memory APIs.
Unlike the main thread, the workers can safely malloc despite sharing memory because they can use locks like an ordinary program would. ...except that for reasons I don't fully understand, the Rust standard library under wasm isn't compiled with support for atomics turned on. Thankfully, there's a relatively supported but still nightly Rust path to rebuild the standard library itself as part of the worker build process. (It does however highlight that using shared memory web workers at all with Rust is still not exactly a supported path.)
The other main reason I turned back to TypeScript is that the worker threads cannot access the DOM, and while that can be cumbersome it also provides a nice wall between the Rust worker code and browser hosting code. The Rust/wasm support for interacting with the DOM is better than it could be, but it's still pretty clunky, where e.g. any DOM function you call gets wrapped in a JS helper that is imported by the wasm module. Instead I can write my Rust code without any knowledge of browser API, and do all of the DOM munging on the TypeScript side.
In general, it's hard to beat the experience of using TypeScript for web development. Tools like debugging and interactively inspecting objects are far superior to wasm debugging. (Also the recent TypeScript compiler rewrite in Go works well, it's so fast!)
The main downside so far is serialization. I still haven't yet figured out a mechanism I'm happy with for transporting more complex objects across the host/worker boundary. I saw a tech talk recently where someone used Rust's rkyv library for this purpose and it looked pretty neat.
Ultimately the purpose of any of these projects is just to learn about the things I was curious about.
From this excursion I conclude that writing apps in wasm is impressive but still not quite there yet — I am glad I have my native build to fall back on when I want to deploy fancier tools. This is definitely a pattern I learned at Figma (where they also had a native build of their wasm-based app) and one that I would recommend to you.
Similarly, I conclude that Rust with shared memory workers is still pretty early. I think for an app where you really cared it works pretty well, but "use a nightly compiler so you can recompile the standard library" is not a great sign.
For Theseus itself, I have a few ideas of where to go next, but those will have to wait for another post!
2026-04-24 08:00:00
This post is part of a series on Theseus, my win32/x86 emulator.
Theseus, my new Windows binary translator, must see all the code it might run ahead of time to translate it. In that post I highlighted how this means it doesn't support programs that have a JIT. Someone emailed to ask about the packed executables found in the demoscene, which also unpack code at runtime. This absolutely nerd sniped me.
I wrote before about packed executables, so if you're not familiar with the term this is useful background context.
At a high level unpacking is simple. You run the packed program up to the point
where it finishes decompressing and is about to jump to the original main()
function, at which point you grab all the decompressed state and write it out to
a new unpacked program.
I could use Theseus to do the same, just as two passes: run Theseus once to translate the packed program, amend it to make it write an executable file to disk when ran, run it, and now you have a normal executable to run Theseus a second time on. When I implemented unpacking in retrowin32 I added some flags to support that "write out an executable" mode. I could do the same here.
But the big picture idea I have with Theseus is this framing that the translated program is this mutable thing you can reach into and monkey with. Here's a kind of tidier approach to unpacking that uses that.
First, I run Theseus on the packed program, and in its output it prints:
WARN tc/src/traverse.rs:40 omitting 004085dd: block appears zero-filled
This is saying "I saw a jump to this address, but on the other side there is no
code". This immediately reveals the address of the original main() function:
once unpacked, that's where the real program starts.
Next, I manually implement that function
within the Theseus output
to call my own do_unpack function. When control reaches there, I know the
program has now unpacked itself into memory, and I can invoke Theseus itself on
that memory to have it generate a program from the unpacked code.
In other words, I don't need to write out an intermediate .exe file and invoke
Theseus again — I can modify the generated unpacker program to directly link
and call back to Theseus itself! This is weird because Theseus-generated
programs don't generally need to link the Theseus translator itself. But there's
no reason it can't, the code is right there.
The total implementation ends up extremely simple, because I don't need to go through generating a proper PE file, I just gather the data Theseus needs. (Generic unpackers are thousands of lines of code; UPX's own functionality for unpacking is significantly more code than this; even retrowin32's implementation is twice as long.) And Theseus doesn't grow an unpacker mode, and rather just supports programs with manual modifications in general.
Unfortunately, I was so consumed by the nerd snipe here that I forgot the other reason you typically have to unpack a packed executable: to load it into a debugger. For that I would need to generate an exe, oh well. It's still neat.
2026-04-19 08:00:00
This post is likely the end of my series on retrowin32.
I bring you: Theseus, a new Windows/x86 emulator that translates programs statically, solving a bunch of emulation problems while surely introducing new ones.
Here are some other posts (written after this one) about Theseus:
I haven't been working on retrowin32, my win32 emulator, in part due to life stuff and in part because I haven't been sure where I wanted to go with it. And then someone who had contributed to it in the past posted retrotick, their own web-based Windows emulator that looks better than my years of work, and commented on HN that it took them an hour with Claude.
This is not a post about AI, both because there are too many of those already and because I'm not yet sure of my own feelings on it. But one small thing I have been thinking about is that (1) AI has been slowly but surely climbing the junior to senior engineer ladder; and (2) one of the main pieces of being a senior engineer is better understanding what you ought to be building, as distinct from how to build it.
(Is that just the Innovator's Dilemma's concept of "retreating upmarket", applied to my own utility as a human? Not even sure. I am grateful I do this work for the journey, to satisfy my own curiosity, because that means I am not existentially threatened like a business would be in this situation. As Benny Feldman says: "I cheat at the casino by secretly not having an attachment to material wealth!")
So, Mr. Senior Engineer, what ought we build? What problem are we even solving with emulators, and how do our approaches meet that? I came to a kind of unorthodox solution that I'd like to tell you about!
The simplest CPU emulator is very similar to an interpreter. An input program, after parsing, becomes x86 instructions like:
mov eax, 3
add eax, 4
call ... ; some Windows system API
An interpreting emulator is a big loop that steps through the instructions. It looks like:
loop {
let instr = next_instruction();
match instr {
// e.g. `mov eax, 3`
Mov => { set(argument_1(), argument_2()); }
// e.g. `add eax, 4`
Add => { set(argument_1(), argument_1() + argument_2()); }
...
}
}
Like an interpreter, this approach is slow.
At a high level interpreters are slow because they are doing a bunch of dynamic
work for each instruction. Imagine emulating a program that runs the same add
instruction in a loop; the above emulator loop has all these function calls to
repeatedly ask "what instruction am I running now?" and inspect the arguments,
only to eventually do the same add on each iteration. x86 memory references
are extra painful because they are
very flexible.
Further, on x86 the add instruction not only adds the numbers but also
computes six derived values, including things like the parity flag: whether the
result contains an even number of 1 bits(!). A correct emulator needs to either
compute all of these as well, or perform some sort of side analysis of the code
to decide how to run it efficiently.
There are various fun techniques to improve emulators. But if you want to go fast what you really need is some combination of analyzing the code and generating native machine code from it — a JIT. JITs are famously hard to write! They are effectively optimizing compilers, which means all the complexity of optimization and generating machine code, but also where the runtime of the compilation itself is in the critical performance path. I liked this post's discussion of why JITs are hard which mentions there have been more than 15 attempts at a Python JIT.
So suppose you want to generate efficient machine code, but you don't want to write a JIT. You know what's really good at analyzing code and generating efficient machine code from it? A compiler!
So here's the main idea. Given code like the above input x86 snippet, we can process it into source code that looks like:
regs.eax = 3;
regs.eax = add(regs.eax, 4);
windows_api(); // some native implementation of the API that was called
We then feed this code back in to an optimizing compiler to get a program native to your current architecture, x86 no longer needed.
In other words, instead of handing an .exe file directly to an emulator that
might JIT code out, we instead have a sort of compiler that statically
translates the .exe (via a second compiler in the middle) directly into a
"native" executable.
(I write native in scare quotes because while the resulting executable is a
native binary, it is a binary that is carrying around a sort of inner virtual
machine representing the x86 state, like the regs struct in the above code.
More on this in a bit.)
I think I came up with this basic idea on my own just by thinking hard about what I was trying to achieve, but it turns out this approach is known as static binary translation and is well studied. It has some nice properties, and also some big problems.
I'll go into those, but first, a minor detour about how I ended up here.
Have you heard of decompilation? These madmen (madpeople?) are manually recreating the source code to old video games, one function at a time. They take the game binary, extract the machine code of one function, then use a fancy UI (click one of the entries under "Recent activity") to iteratively tinker on reproducing the higher-level code that generates the exact same machine code. It's kind of amazing.
(To do this, they need to even run the same original compiler that was used to compile the target game. Those compilers are often Windows programs, which means implementing the above fancy UI involves running old Windows binaries on their Linux servers. This is how I first learned about them — they need a Windows emulator!)
Decompilation is not only just a weird and fascinating (and likely tedious?) human endeavor. It also highlighted something important for me: I don't so much care about having an emulator that can run any random program, I care about running a few very specific programs and I'm willing to go to even some manual lengths to help out.
In practice, if you look at a person building a Windows emulator, they end up as surgeons needing to kind of manually reach in and pump the heart of the target program themselves anyway, including debugging the target program and working around its individual bugs. It's common for emulators to even manually curate a list of programs that are known to work or fail.
Statically translating machine code is not a new idea. Why isn't it more popular? My impression in trying to read about it is that it is often dismissed because it can't work, but at least so far it's worked well. Maybe I haven't yet encountered some impossible problem that I've so far overlooked?
(When trying to look up related work for this blog post, I saw this attempt at statically translating NES that concluded it can't be done, but then also these people seem to be succeeding at it so it's hard to say.)
I think there are two main problems, a technical one and a more cultural one.
The technical part is that the simple idea has complex details. To start with, any program that generates code at runtime (e.g. itself containing a JIT) won't work, but it's easy for me to just dismiss those programs as out of scope. There are also challenges around things like how control flow works, but those are small and interesting and I might go into them in future posts.
A common topic of research is that it's in the limit impossible to statically find all of the code that might be executed even in a program that doesn't generate code at runtime, because of dynamic control flow from vtables or jump tables. In particular, while there are techniques to find most of the code, no approach is guaranteed to work perfectly. This is where decompilation changed my view: if I'm willing to manually help out a bit on a specific program, then this problem might be fine?
The main cultural reason I think binary translation isn't more common is that it's not as convenient as a generic emulator that handles most programs already. Users aren't likely to want to run a compiler toolchain, though I have seen projects embed the compiler (e.g. LLVM) directly to avoid this.
The other cultural problem is there are legal ramifications if you intend to distribute translated programs. Every video game emulator relies on the legal fiction of "first, copy the game data from the physical copy you already own and pass that in as an input", so they get to plausibly remain non-derivative works.
But I'm not solving for users, I'm solving for my own interest. These cultural problems don't matter to me.
Again consider the snippet above, which is adding 3 and 4. In a static translator world we parse the instruction stream ahead of time, so the compiler gets to see that we want to put a 3 in eax and not (as an interpreter would) spend runtime considering what values we are reading and writing where.
A compiler will not only generate the correct machine code for the target architecture, it even will optimize code like the above to just store the resulting value 7. And a compiler is capable of eliminating unneeded code like parity computations if you frame things right. Because the Theseus code generation happens "offline", separately from the execution of the program, I can worry less than a JIT might to about spending runtime analyzing the code to try to help.
When I started this I had thought that performance would be the whole benefit of this approach, but it turns out to be easier to develop as well because it brings in all of the other developer tools:
In retrowin32 I ended up building a whole debugger UI to help track down problems, but in Theseus I've just used my system debugger so far and it's been fine.
In retrowin32 I also spent a lot of time fiddling with the bridge between the emulator and native code. This boundary still exists in Theseus but it is so much smaller, because the translated code can directly call my native win32 system API implementation (with a bit of glue code to move data in and out of the inner machine's representation).
On MacOS retrowin32 could run under Rosetta but it meant the entire executable needed to be an x86-64 binary, which meant it required a cross-compiled SDL. A Theseus binary is native code that just calls the native SDL.
All told it is just much simpler. From the start of this idea to getting the test program I've tinkered with all this while running its first scene, including DirectX, FPU, and MMX, only took me a couple weeks.
You can think of the different approaches of interpreter to JIT to static binary as a spectrum of how much work you do ahead of time versus at runtime. Theseus take the dynamic question of "what kind of mov is this" and move it to the ahead of time compilation step, partially evaluating the generic instruction handler into a specific instruction with nailed-down arguments. (I'll link again to the excellent blog about meta-tracing C code. Read about Futamura projections for this idea taken to its extreme conclusion!)
For another example, a typical Windows emulator must parse and load the PE executable on startup, but Theseus does that at compile time and writes out just the data structures needed to execute it. The PE-parsing code isn't needed in the output.
Similarly, executable startup involves linking and loading any referenced DLLs
including those from the system, but Theseus must see all the code it will run,
so it does this linking ahead of time. Here's some output near a call to a
Windows API, where at compile time it resolved an IAT reference (the ds:[...]
address) directly to the Rust implementation I wrote:
// 004012a0 push 4070A4h
push(ctx, 0x4070a4u32);
// 004012a5 push 8
push(ctx, 0x8u32);
// 004012a7 call dword ptr ds:[4060E8h]
call(ctx, 0x4012ad, Cont(user32::CreateWindowExA_stdcall))
In some sense it's as if Theseus at compile time is partially running the system binary loader and the output source code is a snapshot of the ready state. It reminds me a bit of the problem of unpacking executables.
Theseus should easily extend to running on the web under WebAssembly; most of it is just compiling the generated program with wasm as the target architecture. (I initially had this working then decided I don't need the additional complexity for now, so it isn't implemented.)
Separately, the output program from Theseus is inspired by how WebAssembly is executed. In both there is an outer host program that carries within it a "machine" with its own idea of code and memory. The code within that machine can only read/write to its own memory and must call provided hooks to bridge out to the host. Like WebAssembly, the Theseus output executable code is isolated from the data, with the nice property that no amount of unintentional/malicious memory writes can create new code.
A wasm Theseus would be a turducken of machines:
In thinking about it, it's tempting to try to blend some layers of machines here, and make the WebAssembly program's memory 1:1 with the input Windows program's idea of memory. That is, if the input program writes to some address $x, you could translate that to exactly writing to WebAssembly memory address $x. (You'd need to adjust the middle layer to hide its data structures in places the x86 program doesn't use.) I had to do something like this to make retrowin32 work under an x86 emulator. WebAssembly even would let me lay out the memory directly from the binary. I don't think this really buys you much, it would just be kind of cute.
On the topic of WebAssembly and static binary translation, check out wastrel which is static binary translation applied to the problem of executing WebAssembly. Reading about it surely gave me the seeds of this idea.
I named this project Theseus, as in the ship.
Consider again the x86 assembly at the top of the post. What does it do? Depending on how you look at it, one correct answer is "adds three and four" or even just "computes 7". Or you could say it puts 3 in the eax register, adds 4 to the eax register, consumes some CPU clocks, and sets various CPU flags.
If I or my compiler replaces one of these interpretations with another, is it still the same program? Depending on which context you care about — my impression is that emulating systems like the NES requires getting the clocks exactly right — these details either matter or don't. In the case of Theseus I am explicitly throwing away the input program because I have replaced all its parts, one by one.
I have one farther off idea, again along the lines of the ship of Theseus.
Implementing the Windows API is an endless stream of working around four decades
of Hyrum's Law. Consider
that random bug workaround again:
if you were documenting the API of DirectPlayEnumerateA would you write that
it calls the callback, or would it be more correct to say that it calls the
callback and also restores a preserved stack pointer? If you look at the code of
a Windows emulator like Wine today it is full of things like this.
One idea I've been thinking about is that for problems like these, rather than making the emulator more complicated, you could take a page from the decompilation playbook and provide an easy way to manage replacing parts of the program itself.
Once you're willing to replace pieces of a program there are more interesting possibilities. If a program has some bit of code that doesn't perform well, instead of making a JIT fancier, you could just manually replace the code with your own implementation. (It's plausible you wouldn't even need to change algorithms, it might be enough to just write the same algorithm in native code and let your modern compiler apply its autovectorization logic to it.) With enough machinery, you could even replace parts to add features, as one contributor to retrowin32 investigated here and even implemented for some GameBoy games.