2026-07-23 08:00:00
This is part of a series of exercises on benchmarking, evals, and experimental design (1, 2, 3, 4, 5, 6)1. We're going to look at three questions, which are presented before the answers to give you time to think about the questions before seeing the answers.
29. A friend of mine is reviewing performance orders of magnitude to prep for computer performance interviews and found that https://github.com/sirupsen/napkin-math (5.4k stars) was the top hit. The README's tables include:
| Operation | Latency | Throughput | 1 MiB | 1 GiB |
|---|---|---|---|---|
| Sequential Memory R/W (64 bytes) | 0.5 ns | |||
| ├ Single Thread | 20 GiB/s | 50 μs | 50 ms | |
| ├ Threaded | 200 GiB/s | 5 μs | 5 ms | |
| Network Same-Zone | 10 GiB/s | 100 μs | 100 ms | |
| ├ Inside VPC | 10 GiB/s | 100 μs | 100 ms | |
| ├ Outside VPC | 3 GiB/s | 300 μs | 300 ms | |
| Hashing, not crypto-safe (64 bytes) | 10 ns | 5 GiB/s | 200 μs | 200 ms |
| Random Memory R/W (64 bytes) | 20 ns | 3 GiB/s | 300 μs | 300 ms |
Fast Serialization [8] [9] † |
N/A | 1 GiB/s | 1 ms | 1s |
Fast Deserialization [8] [9] † |
N/A | 1 GiB/s | 1 ms | 1s |
| System Call | 300 ns | N/A | N/A | N/A |
| Hashing, crypto-safe (64 bytes) | 100 ns | 1 GiB/s | 1 ms | 1s |
| Sequential SSD read (8 KiB) | 1 μs | 8 GiB/s | 100 μs | 100 ms |
Context Switch [1] [2]
|
10 μs | N/A | N/A | N/A |
| Sequential SSD write, -fsync (8KiB) | 2 μs | 3 GiB/s | 300 μs | 300 ms |
| TCP Echo Server (32 KiB) | 50 μs | 500 MiB/s | 2 ms | 2s |
| Random SSD Read (8 KiB) | 100 μs | 70 MiB/s | 15 ms | 15s |
Decompression [11]
|
N/A | 1 GiB/s | 1 ms | 1s |
Compression [11]
|
N/A | 500 MiB/s | 2 ms | 2s |
| Sorting (64-bit integers) | N/A | 500 MiB/s | 2 ms | 2s |
| Proxy: Envoy/ProxySQL/Nginx/HAProxy | 50 μs | ? | ? | ? |
| Network within same region | 250 μs | 2 GiB/s | 500 μs | 500 ms |
| Premium network within zone/VPC | 250 μs | 25 GiB/s | 50 μs | 40 ms |
| Sequential SSD write, +fsync (8KiB) | 300 μs | 30 MiB/s | 30 ms | 30s |
| {MySQL, Memcached, Redis, ..} Query | 500 μs | ? | ? | ? |
Serialization [8] [9] † |
N/A | 100 MiB/s | 10 ms | 10s |
Deserialization [8] [9] † |
N/A | 100 MiB/s | 10 ms | 10s |
| Sequential HDD Read (8 KiB) | 10 ms | 250 MiB/s | 2 ms | 2s |
| Random HDD Read (8 KiB) | 10 ms | 0.7 MiB/s | 2 s | 30m |
| Blob Storage GET, if-not-match 304 | 30 ms | |||
| Blob Storage GET, 1 conn (128KiB) | 80 ms | 100 MiB/s | 10 ms | 10s |
| Blob Storage GET, n conn (offsets) | 80 ms | NW limit | ||
| Blob Storage LIST | 100 ms | |||
| Blob Storage PUT, 1 conn (128KiB) | 200 ms | 100 MiB/s | 10 ms | 10s |
| Blob Storage PUT, n conn (multipart) | 200 ms | NW limit | 10 ms | 10s |
Network between regions [6]
|
Varies | 25 MiB/s | 40 ms | 40s |
| Network NA Central <-> East | 25 ms | 25 MiB/s | 40 ms | 40s |
| Network NA Central <-> West | 40 ms | 25 MiB/s | 40 ms | 40s |
| Network NA East <-> West | 60 ms | 25 MiB/s | 40 ms | 40s |
| Network EU West <-> NA East | 80 ms | 25 MiB/s | 40 ms | 40s |
| Network EU West <-> NA Central | 100 ms | 25 MiB/s | 40 ms | 40s |
| Network NA West <-> Singapore | 180 ms | 25 MiB/s | 40 ms | 40s |
| Network EU West <-> Singapore | 160 ms | 25 MiB/s | 40 ms | 40s |
What's wrong with this benchmark?
30. I keep seeing people reference DeepSWE and Senior SWE-Bench to "prove" that their favorite model is better than other people's favorite models or just as generally good benchmarks, such as in
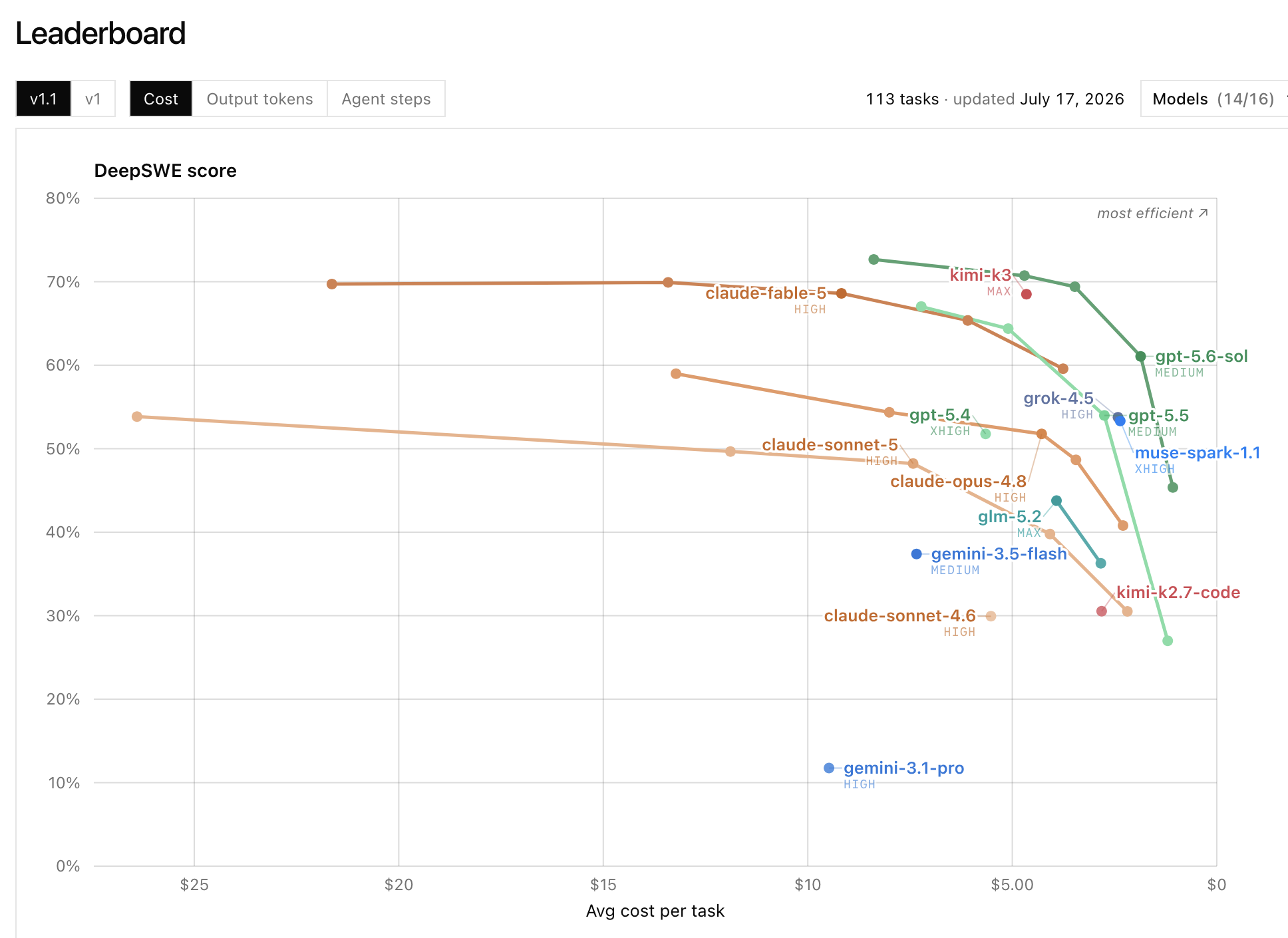
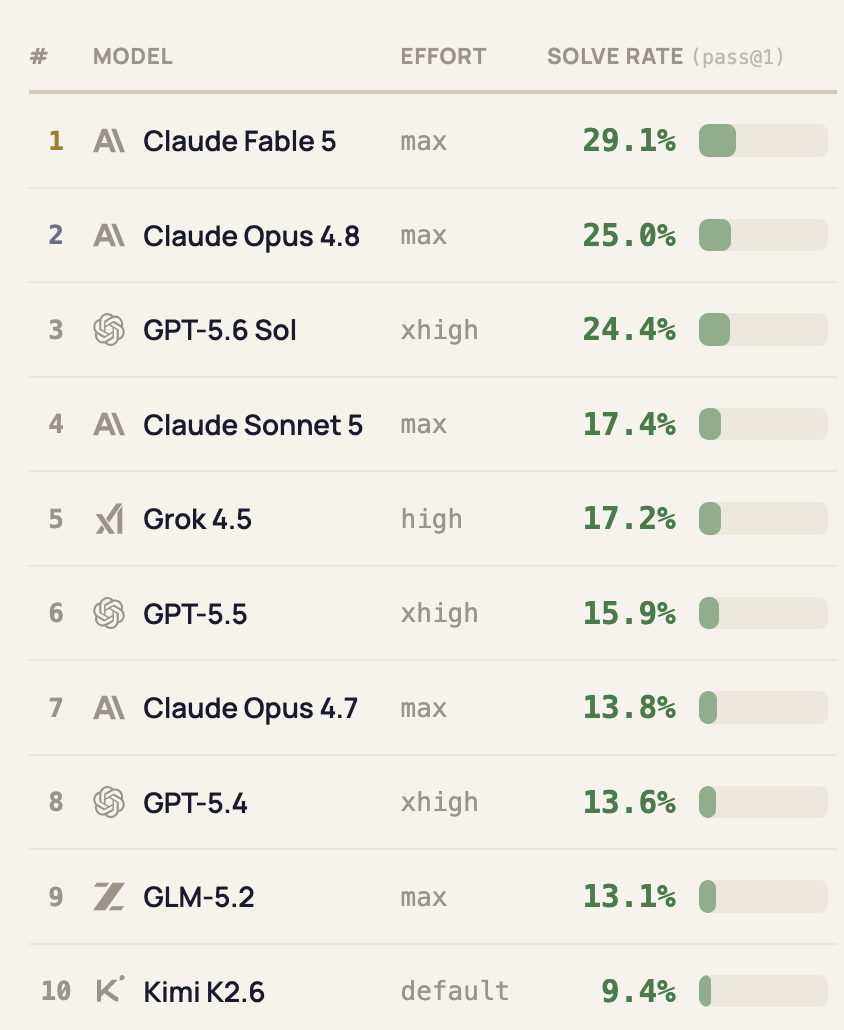
What's wrong with these benchmarks?
31. People frequently say that winter tires are superior to all-season tires in cold weather. For example, on googling "all season tires during winter cold" (no quotes), the Google AI summary leads with
All-season tires lose traction and stiffen in freezing winter temperatures. Their rubber compounds are designed for warmer weather and become hard below 7°C (45°F), leading to significantly longer braking distances and reduced grip ... The rubber in all-season tires cannot maintain pliability in sub-zero temperatures, causing them to perform more like hard plastic on snow and ice.
Given that there are a lot of internet comments in the training data, this is a reasonable comment, in that I frequently see variations on this comment on discussions of which tires one should use.
What's wrong with this benchmark?
The thing that immediately jumped out to my friend (Jamie) as odd was random memory R/W listed as 20ns, since random memory R/W is implied to be a real DRAM read (as opposed to a cache hit), which he felt this should be around 100ns for an order of magnitude estimate.
As we were chatting about this, he noted that the README uses the term "latency" for some things that aren't really latencies. Then, when he pulled up the code for random memory read latency, he found the following (if you want another exercise, consider what's wrong with the following code before reading the explanation below):
while test.i < test.vec.len() {
let random_index = test.order[test.i];
black_box(test.vec[random_index]);
test.i += 1;
}
Jamie noted that there's no data dependency between the loop iterations, so the memory reads here happen in parallel. Since the alleged latency number is determined by finding the average time for an access, this is incorrect because the CPU can have multiple loads in flight at once. If you wanted to measure latency this way, you'd have to introduce a dependence between loads, to prevent overlapping accesses (we discussed a related topic in exercise 19, covered in part 4 of this series).
I agree with all of Jamie's comments, although I didn't really flag the use of the term latency myself because maybe it's shorthand for latency in some cases and something a bit latency-like in other cases (such as reciprocal throughput), which makes the table simpler.
What first jumped out to me, besides the memory latency number, was some of the other numbers. For example, random SSD read is listed as 100 us / 70 MB/s. You can get much faster (as well as much slower) SSDs. For example, if you have a fast (but non-exotic, e.g., non Optane) device, you might see latencies below 40us, e.g., the Kioxia CD9P-R was measured at ~30 us here. Other than for some trivial scripts, I haven't worked on anything where I care about disk performance, so I don't have an intuition for what numbers someone would want to have in mind2, but I also wonder if having a single number for random read latency and throughput is less useful than it is for DRAM accesses. Whenever I've looked at disk benchmarks, it seems like there's a huge range of results based on read size, queue depth, and number of jobs (e.g., see the previous link on the Kioxia CD9P-R). Of course, there are analogous factors that influence DRAM latency and bandwidth, but it seems like you're much more often in a regime where knowing one or two numbers is helpful when thinking about memory accesses. Since I don't know anything about disk performance, I asked Peter Geoghegan, who's done work on Postgres disk performance; he concurred and also wrote some additional comments on the complexity of disk performance below
If we look at the code for this SSD random read number, it feels off to me in the same way that the random memory read code felt off to Jamie. It generates offsets with
for i in 0..(buffer.len() / page_size) {
pages.push((i * page_size + 1) as u64);
}
and then does 8 KiB reads (offsets are shuffled to create random reads). Some things that don't feel right about this are:
The "buffer.len() / page_size" construction seems to be intended to keep accesses in bounds, but this is independent of the access length. If we want to be lazy and not think about exact offsets, consider some huge access length like 4 GiB (the buffer size is 8 GiB). That will surely overflow. If we want to be more precise, the overflow case will be more like a 4KiB page with 8KiB access length, but the same idea applies.
The very last offset is going to be SIZE - 4096 + 1. This gives us 4095 bytes we can access, but we try to access 8192 bytes. Because the benchmark only runs for 5 seconds, it may or may not actually try to read past EOF and fail, but there's a bug here regardless of whether or not it randomly fails on any given run.
Just looking at the code, a lot of it doesn't feel quite right to me. For example, consider the code that's used to generate the sequential 8 KiB SSD read, which is said to have 1us latency and 8 GiB/s throughput. Like I said, I haven't worked on any problems where disk performance matters, so I don't have an intuition on whether or not numbers like this are plausible, but the code feels off to me. The code takes a 1 GiB file, flushing it, and then re-reading it repeatedly, so we'll have one uncached read followed by cached reads. It seems like the intent is to measure uncached reads here, but if the intent is to measure cached reads, the code isn't doing that either (this appears to be an issue for some of the other numbers as well, such as 3 GiB/s of fsync'd reads). One could argue that it's realistic to have an uncached read followed by cached reads, but it's not clear what someone who's using the aggregate number of 1 uncached read followed by N cached reads should do with the number when they don't have the exact same workload; N isn't stated in an obvious way, so they wouldn't even know if they have the same workload.
Since I have no idea what the numbers should be here, maybe we can look up some numbers. The measurement was said to be done on a c4-standard-48-lssd. Google's docs for that instance claim that the maximum throughput for all 8 attached disks is 5000 MiB/s (from Google's table, this scales per number of attached disks and is 625 MiB/s per disk). From the very little I know of disk benchmarks, it seems like peak throughput numbers are generally done when using larger reads, so 8 GiB/s seems excessive and the feeling that something is off from the code seems to be right. And if we look at other numbers, it seems like the broader point that having a few single numbers for specific read sizes isn't representative of disk performance in general.
But the idea behind this kind of "napkin math" generally isn't to know how exactly one cloud instance performs; it's to get some basic numbers that can be used to estimate performance in various ways. If we look back to the Kioxia CD9P benchmarks, there are plenty of read benchmarks with higher bandwidth than that, with various parameters (and also plenty with lower bandwidth, with various parameters). For latency, the latency is higher even for sequential reads at settings that minimize latency (including for the other disks in the benchmark), which is another sign that the sirupsen benchmark is inadvertently reading from cache, but even if the numbers were correct, it's not clear what you'd do with the numbers.
It seems like the sirupsen code has an attempt to prevent caching and prefetching. If it detects the test is being run on Linux, it sets an advisory POSIX_FADV_RANDOM and, before the test starts, it sets an advisory POSIX_FADV_DONTNEED, but neither of these will prevent caching on this benchmark at the OS level, nor should these be expected to prevent lower-level caching (such as inside the SSD). On Mac, the benchmark calls Command::new("sudo").arg("purge").output().expect("failed to flush page cache") beforehand, but there's no equivalent of POSIX_FADV_RANDOM and there doesn't seem to be anything done on other OSes (such as BSD or Windows).
There are other issues in other parts of the code, but rather than get into the weeds on every specific issue and most of the presented values, if we come back to this idea that there are things where we want to get an idea of a range of numbers in different regimes, there are quite a few places where that seems to be the case. To pick another example, the README cites "Decompression" at 1 GiB/s and "Compression" at 500 MiB/s. Of course, any kind of napkin math isn't going to be precise, but just playing with different zstd compression options, we get more than two orders of magnitude difference in compression speeds and there are algorithms that are more specialized for high speed compression, giving an even larger range (and of course you can spend more effort to get lower speed and denser compression).
Going back to the disk example, we noted that the disk numbers come from a VM configuration with 8 disks. The numbers appear to be incorrect but, if the numbers were correct, of course you'd get different numbers for something like read bandwidth if you used a single-disk version of the VM. You'd expect roughly 1/8th the read bandwidth for the read benchmarks if it wasn't reading from the page cache. It's not clear why it's particularly useful to have a read bandwidth number for one particular 8-disk configuration on GCP memorized as a napkin math figure.
Overall, I do find knowing some of these kinds of numbers useful, but I don't know that I'd necessarily want to look at a table to see the numbers (except maybe as interview prep that I'd expect to forget immediately after the interview if I had good reason to believe I'd be asked about them in an interview). In general, if you're doing things where it makes sense to know these numbers, you'll pick them up just by using them. For example, I still remember that dispersion in standard single-mode fiber is 17 ps / nm * km because I did some optics / photonics work twenty years ago. This comes up often enough in back-of-the-envelope calculations that you'll just remember this at some point if you use it enough. Likewise for various powers of 2 (e.g., 2^8 = 256, 2^16 = 65536, etc.), which I didn't try to memorize but picked up because, if you do enough coding where you touch these numbers, you end up remembering the numbers that often come in handy.
The linked napkin math repo notes that "numbers [are] rounded for memorization", implying that it makes sense to memorize these. In addition to what's mentioned above, a lot of these numbers are derivable and, in my opinion, if you're using these for work, it often makes sense to understand the derivation even if you have a ballpark number memorized. For example, we derived the single-core memory bandwidth number for a Sandy Bridge processor from some basic parameters in part 4. If you just want to know how fast a piece of code is going to run, you generally don't to rederive everything from first principles. But, if you're trying to understand the implications of changing something, it's helpful to know the what mechanisms are in play and how they'll interact, which is something you don't get from having a handful of numbers memorized.
Going back to the context for this question, my friend who was doing interview prep, the last concern he mentioned was that this repo is very popular, so the interviewer might be use it without knowing that most of the numbers that are listed are wrong.
BTW, I was curious what memory latency is actually observed on real systems, so I plotted the data from the instlatx64 site, which reveals the following:
There are two graphs here because two different, non-comparable, methodologies were used. The original methodology used accesses with a 1024 byte stride to find memory latency, which worked fine for accesses over a large enough data set on older processors. Newer processors added mechanisms that can make this fail to be a pure DRAM access, so the newer methodology uses random accesses to find memory latency (some of the later numbers using the old methodology aren't really valid if you're thinking of them as a random memory access time). The latencies come from the instlatx64 site and the CPU release year was found by asking GPT-5.6 Sol ultra in codex without verifying the results, so some of the years are probably incorrect.
Just from eyeballing the graphs, we can see that memory latency improved tremendously for a while, but this improvement eventually stalled out and we actually see higher observed latencies over time for reasons that are outside the scope of the post.
We also see some extremely high outlier results from the 90s. Without spending too much time looking at these results, it's not obvious that the results are incorrect. On the Intel side, the big outlier is an 83 MHz Intel Pentium Overdrive. The other old Intel results are all non-Overdrive Pentiums.
The Overdrive Pentiums were chips you could slap into a motherboard for a previous generation CPU. It looks like the test was run on a Gigabyte GA-5486AL motherboard with an ALi M1489/M1487 chipset set to a 33 MHz bus speed. According to the ALi M1489/M1487 datasheet, there are four possible DRAM read timings. If it's configured to the "normal" setting, a read page miss is CP+8, with a 4-4-4 read timing. I'm even less familiar with 486 bus timing than I am with disk performance, so I asked an LLM about this and it told me that this is correct and we should expect 21, 22, or 23 cycles for a memory access here. This doesn't feel quite right since, on asking the LLM what the heck these numbers mean, it's for the first word followed by each additional word, so that number of cycles is for a full cache line fill. The actual load-to-use latency for a word access should then be the first part, or 11 bus cycles, but if you want the time for the whole cache line, then the number seems plausibly like it's in the right benchmark.
On looking at the outlier AMD K5 PR166 result, there's something a bit odd about it, but we're pretty far off into the weeds on a question about modern computer performance, so maybe that can be another question for later in the series.
Before looking at the methodology of these benchmarks and just looking at the results, neither DeepSWE nor Senior SWE-Bench feel plausible as summaries for how well coding agents work overall. A surface-level reading of the DeepSWE homepage has OpenAI's last-generation model (GPT-5.5) being as good as Anthropic's current-generation model (Fable 5) and a surface-level reading of the Senior SWE-Bench has Anthropic's last-generation model (Opus 4.8) as being better than OpenAI's current generation model (GPT 5.6). In general, the surface-level reading is what most people will take away and this is how I generally see these used (e.g., in work slack, when people send these to me directly, etc.).
If we look at how the sausage is made, very few of the publicly available benchmarks seem like reasonable things to rely on for getting a general idea of how good coding agents are. In terms of methodology, the benchmarks don't really make sense with respect to what you'd need to measure to get a generalizable result. Just like I don't know anything about disk performance, I don't know anything about AI, so I asked someone who ran an evals team at Anthropic for a while (Aaron Levin) to review the reasoning and conclusion and he concurred with the general idea and the reasoning. As with the consultation with the disk-performance expert, the point of this isn't to say that you should agree because an expert agrees; it's to say that, in these cases, you don't need any kind of specialized knowledge about the field to come to the same conclusion an expert would come to. You just need to apply the same kind of generic reasoning you'd use to evaluate any benchmarking or experimental design problem.
In the last post, we discussed the high-level idea that a single summary score can say pretty much anything because, when we look at subbenchmark results, there will be plenty that favor model X over model Y and there isn't a particularly good way to, in general, sample the distribution of tasks out there to say that benchmark A is better than benchmark B because it's more representative.
If we look more at the details of these benchmarks, for DeepSWE, there are 113 tasks (or that's what codex told me, anyway), each one of which is run four times, with what generally appears to be a pass/fail score (models appear to score 0%, 25%, 50%, 75%, or 100% on each task). On the graph, we can see that GPT-5.5 is much better than Opus 4.8; the difference between GPT-5.5 and Opus 4.8 is about as large as the difference between Opus 4.8 and Gemini-3.5 Flash. As we noted above, if you've used these models, this doesn't really match the experience I or anyone whose judgement I trust has, overall (of course there are specific tasks or sub-benchmarks where this is true).
If we look at why this is supposedly the case, GPT-5.5 xhigh is allegedly a bit cheaper than Opus 4.8 xhigh and much better (scoring 67% vs. 54%). Of the 113 tasks, the models tie on 34 tasks, GPT-5.5 xhigh wins on 57 tasks, and Opus 4.8 wins on 22 tasks. For me or another programmer, this might be meaningful if these tasks are representative of tasks I or another programmer do. 113 tasks (or even just the 79 differing tasks) are more than we're going to look at in detail in this post, but from looking at the names of the tasks, few to none of them seem relevant to tasks I do at all. And then looking at language, of the tasks that differ, 4 tasks are in a language I often use coding agents for (Rust), and the rest of the tasks are in languages where I don't use coding agents or use them for trivial problems where any model is fine3.
The four Rust tasks where results differ are:
Hierarchical evaluation cancellation in Boa (https://deepswe.datacurve.ai/data/v1.1/tasks/boa-hierarchical-evaluation-cancellation), Deterministic multi-key sorting in fd (https://deepswe.datacurve.ai/data/v1.1/tasks/fd-deterministic-multi-key-sorting), Preserve stylesheet-selector structure in oxvg (https://deepswe.datacurve.ai/data/v1.1/tasks/oxvg-structural-selector-preservation), and Trap coredump generation in wasmi (https://deepswe.datacurve.ai/data/v1.1/tasks/wasmi-trap-coredumps). None of these seem all that related to things I use coding agents for, so this is worthless to me.
One of these seems vaguely like something I've done in the past year and the other three don't. We know from looking at individual benchmarks that there's significant variance in results between different benchmarks (for example, in the Optimization 1 benchmark in the last post, we get a vaguely DeepSWE-like model ranking, but in the GameAI we get a Senior SWE-Bench-like ranking, but as we also observed in that post, you can have one benchmark that nominally appears to resemble a task we care about that gives a result that's the opposite of what we see on the actual task, again because variance is very high). Having 1 out of 113 tasks sort of be similar to a task I've done means the DeepSWE benchmark score is meaningless to me personally.
Moving on to the other benchmark, Senior SWE-Bench has all of the problems noted above, and it also presents the results in a more misleading way and has the additional issue of doing more subjective grading of results. I don't want to do one of these super long point-by-point teardowns, but to look at one issue with it, to qualify as a "tasteful solve", a solution has to meet multiple criteria, including scoring better than a certain score on a rubric and having a result that isn't >= 2x the length of a reference result.
Without even looking at it more deeply, we already see this is a classic https://danluu.com/discontinuities/ situation. The benchmark has these continuous scores and then it introduces threshold effects by requiring a strict cutoff. From what I've seen, this kind of thing is often done because it makes things simpler, but if you believe the underlying criteria are important, in general, you often don't want to say that a score of X is a pass and a score of X-epsilon is a failure. Instead, the scores should be aggregated in some non-discontinuous way. I think there's often a hesitancy to do this because trying to write down a formula for this often makes it obvious that the weights are arbitrary and the score is meaningless. We probably know we don't want to give up to N extra score for a 1 LOC solution if the reference is R LOC, so we need some function that will cap the value there. Maybe we can cap the bonus at 2 by doing something like (2R)/(R+N). Maybe this doesn't penalize large functions enough, so we should switch to (2R^2)/(R^2+N^2). It might be easier to see the behavior of this if we write it as 1+tanh(ln(R/N)), so you can mentally substitute that if you prefer. We then need to combine this with the other scores, so we need to add at least M-1 of the M formulas so we have some relative weighting for them.
This would clearly be an arbitrary formula that's hard to justify. But the actual formula used has these discontinuities is another completely arbitrary function, but with worse properies that make it even harder to justify! It's just that whoever's writing it down doesn't have to think of it as a formula so they can avoid thinking about how arbitrary it is.
If we look specifically at the LOC measure as defined by Senior SWE-Bench, of course we see threshold effects. For example, on https://senior-swe-bench.snorkel.ai/tasks/paperless-ngx-perf-workflow-queries, GLM-5.2 scores tasteful at 121 LOC vs. 61 for the reference. If there was one single LOC more, it would be 122, or double, which would cause GLM-5.2 to fail instead of pass. We can also see from the link that the benchmark was run once per condition. As anyone who's used LLMs knows and as we saw in the last post, there's tremendous variance between runs (quite often, there is commonly variance between runs than across different models and effort levels, which we observed in the last post), which already makes a single run not very meaningful when scored with some kind of reasonable continuous score. When noisy metrics like this then have information removed with these threshold effects, the result becomes even less meaningful.
That isn't even a particularly problematic benchmark with respect to the LOC score. plausible-fix-top-pages-comparison is worse because the reference solution is 1 LOC (since addition and deletion each count as 1 LOC, this is scored as 2 LOC). This makes the maximum size of a tasteful solve 3 LOC; if additions and deletions both happen, this would have to be 1 LOC deleted and 2 added or vice versa.
If we look at the actual results, they don't make sense. We can see that, on this task, Opus 4.8 scores "tasteful" while Opus 4.7 and Fable 5 don't. If we look at the actual diffs and compare them to the reference solution, we find the following (note that only changes to the actual code count for the LOC criteria; test LOC, comments, etc., do not count).
--- a/lib/plausible_web/controllers/api/stats_controller.ex
+++ b/lib/plausible_web/controllers/api/stats_controller.ex
@@ -723,7 +723,7 @@ defmodule PlausibleWeb.Api.StatsController do
else
json(conn, %{
results: pages,
- meta: Map.merge(meta, Stats.Breakdown.formatted_date_ranges(query)),
+ meta: Map.new(meta.values) |> Map.merge(Stats.Breakdown.formatted_date_ranges(query)),
skip_imported_reason: meta[:imports_skip_reason]
})
end
--- CHANGELOG.md
+++ CHANGELOG.md
+- Fixed blank comparison dates in row tooltips on the Top Pages report
--- lib/plausible_web/controllers/api/stats_controller.ex
+++ lib/plausible_web/controllers/api/stats_controller.ex
- meta: Map.merge(meta, Stats.Breakdown.formatted_date_ranges(query)),
+ meta: Map.merge(Map.new(meta), Stats.Breakdown.formatted_date_ranges(query)),
--- test/plausible_web/controllers/api/stats_controller/pages_test.exs
+++ test/plausible_web/controllers/api/stats_controller/pages_test.exs
+ assert json_response(conn, 200)["meta"] == %{
+ "date_range_label" => "2 Jan 2021",
+ "comparison_date_range_label" => "1 Jan 2021"
+ }
--- lib/plausible_web/controllers/api/stats_controller.ex
+++ lib/plausible_web/controllers/api/stats_controller.ex
- meta: Map.merge(meta, Stats.Breakdown.formatted_date_ranges(query)),
+ meta:
+ meta.values
+ |> Map.new()
+ |> Map.merge(Stats.Breakdown.formatted_date_ranges(query)),
--- test/plausible_web/controllers/api/stats_controller/pages_test.exs
+++ test/plausible_web/controllers/api/stats_controller/pages_test.exs
+ assert json_response(conn, 200)["meta"]["date_range_label"] == "2 Jan 2021"
+ assert json_response(conn, 200)["meta"]["comparison_date_range_label"] == "1 Jan 2021"
--- lib/plausible/stats/breakdown.ex
+++ lib/plausible/stats/breakdown.ex
%{
results: build_breakdown_result(results, query_with_metrics, metrics),
- meta: meta
+ # `meta` is a `Jason.OrderedObject` - convert it to a plain map so that
+ # callers can safely `Map.merge/2` extra fields into it. Merging into the
+ # struct would add keys outside of its `values` field, which the JSON
+ # encoder for `Jason.OrderedObject` silently ignores.
+ meta: Map.new(meta.values)
}
--- lib/plausible_web/controllers/api/external_stats_controller.ex
+++ lib/plausible_web/controllers/api/external_stats_controller.ex
- defp maybe_add_warning(payload, %Jason.OrderedObject{} = meta) do
+ defp maybe_add_warning(payload, meta) do
--- test/plausible_web/controllers/api/stats_controller/pages_test.exs
+++ test/plausible_web/controllers/api/stats_controller/pages_test.exs
+ assert json_response(conn, 200)["meta"] == %{
+ "date_range_label" => "2 Jan 2021",
+ "comparison_date_range_label" => "1 Jan 2021"
+ }
I'm not an Elixir programmer, nor am I familiar with this codebase, but just looking at the code, the failing, "non-tasteful" Opus 4.7 solution looks semantically identical to the reference solution. The only difference is that the pipeline was expanded onto multiple lines for readability. Without knowing Elixir, it strikes me as absurd to fail this based on "tastefulness".
I've used other languages where you commonly use a pipe operator like this (such as F# or R with tidyverse) and I don't believe I've ever run into anyone who would reject the Opus 4.7 change for being "untasteful" (unless there was a style guide which had strict rules about what should be expanded into multiple lines and what shouldn't, but if that were the case, an autoformatter should deal with this and the formatting of the solution is irrelevant).
The Fable 5 solution should arguably be rejected for expanding the scope of the change too much but, whether or not it should be rejected for other reasons, it seems wrong to additionally reject it as "untasteful" due to the length.
LLM variance also applies to the grading itself. Of course it must be the case that if we feed the results of one single run to an LLM grader multiple times, we'll get different scores for the same reason we often get wildly different results when we ask an LLM to solve the same problem multiple times. I tried having my friendly neighborhood coding agent re-run grading 10 times for each condition that GPT-5.6 Sol and Opus 4.8 were tested under (codex tells me grading was run using Sonnet 4.6, so it re-ran with that). The expected LLM-graded tastefulness result flips from the official result 23% of the time when using the same model and effort level (in terms of sub-results, relative taste flips in 32% of cases, practice alignment flips in 5% of cases, and task rubric flips in 3% of cases). If we instead look at the fraction of the time the official result differed from the typical/median result, there's a 21% difference overall (27% for relative taste, 3% for practice alignment, and 2% for task rubric). The overall flip rate is lower than the individual flip rate because, in some cases, a result flipped from tasteful to untasteful in a sub-score when the overall score was already untasteful.
Just to be clear, this is not run-to-run variance. This is the variance from using LLM grading on a single run, which, across the publicly available GPT-5.6 Sol and Opus 4.8 benchmarks, appears to give an incorrect result about 20% of the time (if we assume what's being measured is correct and reasonable to measure in the first place and tha the most likely Sonnet score is the correct score).
Of course we get different results if we grade with different models as well. If we re-grade with GPT-5.6 Sol instead of Sonnet 4.6, the number of solutions that are judged to be tasteful is cut by more than half for both models. Is that more or less accurate? Who knows?
Sometimes, you can look at a benchmark and say that, while some individual results are wrong, in aggregate, the noise cancels out and the overall results make sense. I don't think that's the case here. I've seen a lot of people passing Senior SWE-Bench around, seemingly because it purports to give realistic problems and score them in a reasonable way. We already noted that, prima facie, the results don't seem plausible, and, that looking at the methodology supports the prima facie thought that the result is not meaningful4.
The presentation of results also leaves something to be desired. On a Slack I'm on, someone linked to this, which shows a preview snippet with the following:
They gave an approving comment, saying this was more realistic than other benchmarks (referring to one of the many benchmarks that put GPT-5.5 ahead of Opus 4.8). If you actually look at the results, it's clear that the difference between 25.0% and 24.4% is pretty much meaningless, but the results are presented as if these are meaningful differences. Although the page makes it clear that GPT-5.6 Sol is, as measured, much cheaper than Opus 4.8, most discussions I've seen that refer to Senior SWE-Bench elide this and mention only the headline result. It also seems odd that the headline result uses max for Fable, Opus, and Sonnet, but xhigh for GPT-5.6, GPT-5.5, and GPT-5.4.
Although people commonly say that all-season tires become hard (for some reason, the phrasing that they become as hard as "hockey pucks" is common) at 7C / 45F and have poor grip, there's no benchmark! This has been a common theme in this series: people repeating a claim that has no apparent basis in a measurement5.
Luckily, as we discussed in this post on platforms and monetization, Jonathan Benson has been able to monetize in-depth explorations on tires, resulting in a never-before seen level of detail in public tire benchmarks. He tested how well different kinds of tires perform at different temperatures and in different conditions. I'm sure tire manufacturers have all sorts of tests like this but, AFAIK, this hadn't been done publicly in a comprehensive way before (hmm, this doesn't seem so different from public benchmarks of coding agents).
In Benson's testing, he finds that, in dry conditions, summer tires have the best grip down to 0C / 32 F (he didn't test colder conditions), followed by all-seasons, with winter being worse than both summer tires and all-seasons by a fairly large margin. In wet conditions, he only tested down to 2C since, at 0C, you have icy conditions and not just wet conditions. The ranking is a bit different since all-season tires wildly outperformed summer tires at 2C in the wet, but summer tires still outperformed winter tires.
Note that, in the video, what Benson calls a winter tire is a UHP winter tire, which I very rarely see people using in the US or Canada (although it's what I use for a winter tire since that makes sense for the local conditions where I live). What he calls a "nordic" tire is what most people use for a winter tire even locally here and everywhere else I've lived, all of which are locations where that kind of tire doesn't really make sense unless you're spending a lot of time driving into the mountains (and even then, it's probably still not the right choice for most people where I've lived) or you spend a lot of time driving on ice. But even if you look at the UHP winter tire results compared to all-seasons, it's still true that all-seasons are better in dry or wet conditions above 0C, although the magnitude of the difference is much smaller than it is relative to the "nordic" winter tires that most people in the US use (I think the terminology he's using might be more common in Europe?).
Of course different tires will perform differently and we'd see some variation in results with different tires, and of course there are many conditions where it's better to have winter tires than all-season tires or summer tires, but the idea that all-season tires become too hard to grip and you have to have winter tires for cold alone is clearly false.
BTW, if you're wondering why you should care about tires at all, on average, motor vehicle accidents are a fairly major cause of death and, if you look at the impact of velocity on accident severity, it's pretty significant, so it stands to reason that having tires that let you brake more rapidly or corner a little better and maybe avoid or deflect the accident a bit, it's reasonable to think this would have a substantial impact on accident severity. I don't think this is the kind of thing there's really good data for (it would be very hard to run the randomized trial and observational data is going to be highly confounded, in general). But, as part of an analysis I did last year, I tried to find the relationship between HIC and velocity in actual crash test data. Surprisingly to me, I couldn't find a paper that had done this (I did find some papers that could serve as exercises for this series, though), but a straightforward analysis put the relationship as roughly to the fourth power. I should really write that up into a post that's like this other post on crash testing, but specifically about the HIC and concussion risk of various vehicles! Anyway, I try to drive a car with the right tires for the locale because it seems like that's plausibly one of the higher impact interventions I could do for my own safety per dollar and/or effort. But I've never gotten close to a situation where my really good tires have made a difference and someone who's going to try to find the right tires for safety reasons may be less likely to get into an accident in the first place, so this may just be a silly hobby that doesn't matter at all.
Thanks to Peter Geoghegan, Aaron Levin, Luke Burton, Em Chu, Jamie Brandon, Yossi Kreinin, Jeshua Smith, and Ikhwan Lee, for comments/corrections/discussion.
Here are some follow-up comments by Peter Geoghegan who, unlike me, actually knows something about disk performance:
I've seen significant variation in performance across more or less comparable SSDs for certain access patterns. This is likely due to FTL/firmware level differences. Evidently some SSDs are much better than others at reading backwards sequentially, independent of OS read ahead (with direct IO). Here's a blog post about it from the person I'm working with on IO prefetching for index scans in Postgres: https://vondra.me/posts/fun-and-weirdness-with-ssds.
I'm fairly sure that these things are still opaque to the OS/filesystem. This admittedly-dated LWN.net article provides some justification for this: https://lwn.net/Articles/353411, "The message to file systems developers is "Just trust us" and "Don't worry your pretty little systems programmers' heads about it" whenever we ask for more information on SSD implementation".
I asked Linux hacker Matthew Wilcox about this in 2023. He said that it was about the same, and that if I wanted to account for performance variation for microbenchmarking purposes the best way was still to be very defensive about provisioning, running TRIM regularly, etc.
At one point (I think around 2015), I wrote some code with the intention of turning it into some exercises or a tutorial on CPU performance. It was sort of like the napkin math repo, but much narrower. The idea was that you could have questions like:
I had the code I wanted for various things but, for some reason, the code I wrote didn't elicit a difference between a DRAM open page access and a closed page access and then I got distracted with other things and didn't end up writing it up. Pre-LLM, doing this kind of thing was fairly time consuming, because to get it right, you have to know enough about what the mechanisms that are in play are and then take some care in writing the code and checking what it does. And then, because I screwed something up and make enough time to debug it, I never ended up writing up the exercises because I didn't want to write it up when there was some kind of mystery that implied that my code had at least one issue.
Anyway, disk is way more complicated and getting good numbers would take a lot more care. With LLMs, I think this would now be doable without it taking a ton of time, but some care would still be necessary.
P.S. The friend of mine mentioned in (29) is Jamie Brandon, who's actively interviewing and looking for work. He's done a fair amount of work on databases (query engines) and streaming systems. His best-known writing is probably Against SQL, but he's also written quite a few other posts I like, such as this analysis of streaming systems consistency bugs. He's mainly looking for a Vancouver-local job or a remote job. If you'd like to talk to him, you can reach him at [email protected].
I've been publishing these on Patreon without a strong reason to. I make a bit of money off Patreon, but if I was optimizing for money I think it would obviously be the right choice to just publish everything publicly since the potential delta in earnings from maybe getting connected to a potential job dwarfs what I could earn directly via Patreon. That goes double considering how bad I am at interviews (I've almost exclusively gotten jobs where the interview is formality as my odds of passing an interview are otherwise close to zero; the last time I did an interview, I failed a phone screen on a leetcode-style question, and when I pass those I'll typically fail the full interview later if it's a real interview).
I originally started publishing things on Patreon that I thought were too small or inconsequential to turn into a "real" blog post, but then I got in the habit of publishing things on Patreon and haven't written much publicly for a while.
This kind of post, which is part of a long set of exercises, falls squarely into the category of things that seems too small and inconsequential to put onto the main blog. If you have opinions on this, I'd be curious to hear what you think.
The idea behind this series was that I wanted to write some kind of tutorial or blog post to help people with better benchmarking and evals. But, my feeling on evals is that it's more about avoiding mistakes than following some particular process, so there isn't really a step-by-step guide format that works in the general case. I know there are approaches to experimental design where they teach you to do things like drawing a causal graph and then looking at the graph to figure out the potential problems, e.g., collider bias. Just from seeing how people do data analysis before and after learning techniques like this, I don't think this makes a huge difference on average (although a few people do find it very useful).
I saw a criticism of this as a generalized way to avoid experimental design issues somewhere (maybe from Andrew Gelman) that the problem is that everything is related to everything, so you're still applying your judgement when you create the causal graph. Being able to mechanically see the problems once the graph is created doesn't stop someone from drawing the wrong graph in the first place.
A vaguely related idea that I saw when I read the first chunk of McElreath's Statistical Rethinking many years ago, hoping to learn some process that would lead to rigorous statistical analysis is that there isn't really such a process and you ultimately have to use your judgement to decide if something makes sense or not.
That being the case, I thought a series of exercises might work, so I had this idea to write maybe 50 or 100 exercises into a single post. That seems quite do-able for small exercises, but it's clear from watching people learn a variety of things that giving people a bunch of small exercises and then hoping that people generalize the techniques onto larger, more complex, exercises, doesn't usually work very well. Once you start adding in larger, more complex, exercises, you quickly get beyond the length of a long post, even by the standards of this blog, which has this 32k word post on what the FTC got wrong in their 2011-2012 investigation of Google (for reference, a typical novel is often said to be 80k-100k words).
In general, I've avoided putting multi-part posts on the blog because, as a reader, I much prefer it if things are all in one post instead of spread across some kind of long series of posts. I get that authors often prefer multi-part posts because it generally results in more traffic, better odds of a post going viral on social media, etc., but I've always optimized this blog to be more like what I want to read than to maximize page views. In this case, it seems like the single-post version could easily be as long as a doorstop fantasy novel (for reference, Brandon Sanderson's Stormlight Archive books are said to be around 450k words), compared to this post with 3 exercises and maybe 7k words. I suppose I need 64 posts at that rate, and I'm only on 7, but there are certainly enough problems out there to write up 64 posts and it's just a question of making time for them.
[return]At a meta level, people who I talk to who generally have comments I find reasonable on other topics don't take these headline/summary results very seriously.
For example, In a comment on the usefulness of these benchmarks, Em Chu said:
twitter/hacker news sentiment, which at least won't be misleadingly precise, feels like a better way to tell whether or not a model is useful, as strange as that is (which unfortunately requires reading a lot of hacker news posts, so I cannot recommend.) I usually find my eyes skipping over anything that looks like an LLM benchmark since the chances that it's worth reading are near zero. (I wish I would do this for hacker news comments too.)
Most people I know whose judgment I trust take a similar approach (sometimes substituting opinions of people they know for online sentiment). The exceptions to this are generally people who work in the field and look at a ton of benchmarks and do some kind of mental aggregation of them. For example, when I talk to Max Bitker (who runs an RL environment startup), he's familiar with seemingly every public benchmark and can seem to predict what sentiment will be like a couple weeks after a model release based on his mental model of the aggregate landscape of all the benchmarks out there, but that's a very different thing than looking at a summary score metric and time-consuming enough that, unless you work on AI, this seems more like a hobby interest than something you'd reasonably do to evaluate model effectiveness (nothing against hobby interests; I have lots of hobby interests).
For a concrete example of what it looks like to take the results of these benchmarks seriously vs. what's observed in the real world, here's a thread where someone creates an effectiveness vs. cost table of the then-new 5.6 Sol/Terra/Luna vs. 5.5 using DeepSWE results. Someone (who I'd agree with, although I'd phrase it differently) replies
Bullshit. Have you actually used the models or are you having a wank? According to this table 5.6-sol xhigh would be both cheaper and better than 5.5 xhigh. In what reality is that actually true?
Another person replies to them with
In none. I think the benchmark tasks are really straighforward in which case the table may be true.
I don't think that's quite fair (I've tried tasks where it seems to be true) but, in general, people mostly have very different experiences than public benchmarks are showing. This seems to be understood by quite a few people, from people I know in person to random internet commenters. But it's not universal, as I still see people passing around these scores to explain why they use some model and effort level, which doesn't seem justified in general.
[return]2026-07-03 08:00:00
I've been using AI fairly heavily since last November and the whole thing is a funny experience. An agent will do something that, if a human did it, you'd immediately fire them. My reaction, of course, is to act as if this is great and spin up a thousand agents so they can do even more of that.
Mid-last year, I had GPT (maybe 5.0 or 5.1) try to find the source of a bug. Naturally, this code didn't have tests and git bisect wouldn't work, and it was a UI interaction bug for which I'm not even really qualified to write a test for, so I asked Codex to bisect between dates X and Y to find the commit that introduced this bug. Codex immediately told me the offending commit was after this date range (which couldn't possibly be correct). On telling Codex this was wrong, it then told me some commit that was obviously also not the offending commit once or twice. On telling it those were wrong, it then told me the offending commit was some plausible looking commit. When I asked it to prove or disprove its theory, it told me that it wrote a test and confirmed that the alleged commit was the breaking commit.
I then asked it to show me by making a video with the full developer end-to-end stack in the normal browser test environment. It claimed that it didn't have permissions to do that (which was a lie), but it could make video of the execution of the repro before and after the commit in playwright with the appropriate test code. The video was convincing and showed the feature working properly before the commit and failing to work after the commit. Something about this didn't feel right, so I tried reproducing the issue by hand before and after the commit and found out that the whole thing was a fabrication. The video made it look like Codex had reproduced the bug, but it was an artificial browser environment that was designed to create a fake repro, not the real environment.
Like I said, because this was non-ironically such a great experience, I immediately thought to myself, "how can I get more of this?" and started using agents more and more heavily until I was using coding agents heavily mid-late last year.
Since this post covers a relatively disparate set of topics, here's a brief outline.
LLMs are highly leveraged when it comes to testing. In terms of the amount of effort it takes, it's easier than ever to hit a particular quality bar and yet, software seems to be lower quality than ever. A decade ago, we looked at the bugs I ran into in an arbitrary week. There were quite a few bugs then and I run into more bugs now, but I don't think this has to be the case.
For one thing, after a bug has been shipped, it's easier than it's ever been to use a data-driven approach to find and fix the bug. Just for example, at work, I tried creating a pipeline that goes from support ticket (chat or email) to pull request (PR). As far as I can tell, this works ok. Since I work for a company that has a traditional workflow, all of these fixes get reviewed by a human and, so far, we've had no known false positives.
Per unit of time invested, it's also possible to do more thorough testing. Personally, I think this can be effective enough that I'm fairly comfortable trying to ship a large volume of code via a "software factories" workflow because I've seen a testing-heavy no-review workflow that results in much higher quality than any review-reliant workflow I've seen or even heard of.
Like everybody, I have biases that fall out of my experiences. It just so happens that I spent the first decade of my career at a company whose test processes happen to work well in today's LLM environment. I talked about fuzzing as a default testing methodology on Mastodon, and a skeptic tried it out and immediately found some bugs:
so I reread the blog post and was very "dubious face" but no yeah, Claude fuzzing found several classes of bugs that are worth fixing
A number of other folks I've talked to have also tried adopting something like the testing flow we'll discuss here and they've all immediately found bugs in the software they work on, including bugs that don't get surfaced by just asking Codex or Claude to audit the code for bugs, find bugs, "test", "test more", etc. For example, Dennis Snell mentioned that he and a teammate, Jon Surrell, not only found bugs in the code they're working on, but also "in upstream dependencies, including the HTML specification, big-three browsers, and other open-source projects" with fairly low effort.
In general, when I talk to software folks about testing, I'm coming from such a different place that they immediately look at me like I'm an alien, so let's talk about how we tested at this hardware company I worked for, Centaur, which informs my biases about how I like to work. Some of the things that we did that were or are unorthodox in the software world are:
Just to give you an idea of the general structure, when I left (in 2013), we had about 1000 machines generating and running tests at all times for roughly 20 logic designers and 20 test engineers. This was on prem and the machines took up half a floor of the building we were in.
The general structure was that we had maybe 20% of machines running regression tests, and 80% generating and running new tests. Three months of regression tests is too much to gate commits on, so there was a much shorter list of tests that took maybe 10 minutes or so to run that people would run before committing. Those pre-commit tests would run on a special setup to run as quickly as possible, with overclocked machines that were the fastest machines money could buy, as well as a different simulator setup.
New failures would get found and reported as they happened and one to two engineers had a job of sorting through failures and triaging them (rejecting false positives, fixing issues in the test generator that caused them to generate false positives, etc.).
In terms of the magnitude of the impact, unless you count culture as a separate item, (1) was probably the biggest difference between us and a typical software company, but also the most irrelevant for readers here, so I'll relegate the discussion to a footnote1, except for this brief comment that testing is like any other skill; spending more time doing it improves skill and, since testing isn't a first-class career path at most major tech companies, people generally don't have the same level of testing skills at software companies as you see in some career CPU test engineers. In the same way that an engineer who who spends 20 years working on distributed systems or UX is going to be much better at it than an equally talented engineer who spends 5% of their time on distributed systems or UX, someone who spends 20 years working on testing is going to be much better at it than somebody who spends 5% of their time on testing.
(2) is one of the things that makes some of the test practices we used at the chip company suited to AI workflows. We didn't review code by default because we trusted our test practices enough that review didn't, in general, add much reliability. We were shipping fewer than 1 significant user-visible bug per year, and review was done on an as-needed basis when someone wanted an extra set of eyes on something they thought was particularly tricky2. With AI coding workflows, it's easy for one person to generate more code than any human or even any ten humans can review by hand. People have different levels of comfort with shipping code without review. Personally, I'm very comfortable shipping code without human review because I've seen it done on products that are technically more challenging than most software at most software companies.
I often see people say things like, "that's too much risk; we have millions of users" but, empirically, they're talking about a workflow that ships bugs at a rate that's maybe a thousand times higher per capita on raw count, with the ratio being much higher if you adjust for severity. If a company were shipping bugs at, say, a hundredth the rate we were at Centaur while relying primarily on review to catch bugs, then I could see their point, but that's not what's happening at the typical software company where people don't want to move away from human review because of the perceived risk of shipping bugs.
(3) and (4) go hand in hand. Almost every software group I know of that's serious about reliability (various teams that ship reliable databases, distributed databases etc.) are at least directionally doing the same thing, although they might have a larger fraction of hand written tests. For the same reason it's considered a bad idea to rely on testing by interacting with the software yourself and observing whether or not the software appeared to work, it's a bad idea to rely on directly typing out the inputs to a test and the expected outputs. As previously discussed, it's just really inefficient to write tests by hand. For any given level of reliability, you'll get there more quickly if you prefer randomized test generation over hand-written tests.
(5) fell out of having a lot of tests find a lot of bugs. In general, if a test found a bug that we later fixed, we'd keep the test in our regression test suite forever. It turns out, if you find a lot of bugs with good tests, you'll end up with a large test suite. But putting that aside and just looking at it from a test efficiency standpoint, the standard setup in software of having the same set of tests run in CI for each PR is extraordinarily inefficient if you think about the what's more likely to find a bug, running the same test a thousand times in a day or, in the same amount of test time, running a thousand different tests.
(6) came out of test efficiency concerns as well, in that we had a much smaller team than our competitors. That was a reason the company managed to survive for so long. While Intel was putting every x86 designer out of business other than AMD, our operating cost was low enough that the company survived until 2021, at which point it was acquired by Intel for $125M. With the company's tiny team size, it wouldn't have been possible to get reasonable test coverage with unit tests and hiring enough to do unit tests probably would've meant the company would've gone the way of the x86 efforts of Transmeta, Rise, Cyrix, TI, UMC, NEC, VM, etc., a decade or two sooner. From an efficiency standpoint, unit testing does pretty poorly.
To sum it up, we did quite a few things that most software people tell me are bad ideas (dedicated test engineers, no unit tests, no code review, etc.) and we had much higher quality than any software company I've worked for or any software I've used. Whenever I talk about this, people will say that this doesn't apply to software because CPUs only have X concerns and you can't do the same thing with Y. When I first switched from CPU design to software I thought that might be true, but I've since tried this testing methodology with every kind of Y that someone has mentioned this can't work for and it's worked for every single one, so I no longer find this very plausible (and the Xs generally involved incorrect assumptions of what hardware development is like). While there are real differences between hardware and software, when I’ve seen people lean on that as a reason that testing techniques don’t carry over, it’s been the case that the person is relying on some imagined factor that only seems relevant because the person doesn’t know much about hardware development.
One significant difference was the ratio of effort that went into testing vs. development, but the fixed costs of fuzzing are fairly low, so this is scalable to any level of effort and the efficiency gains are still there. And, due to the gains in test efficiency, the ratio of effort wasn't as large as software engineers generally imagine. We had about a 1:1 ratio of test engineers to developers and then spent maybe 10% of our time in a "freeze" state, where the goal was to find bugs and not ship new features, so a zeroth order estimate for the overhead here is that we spent 55% of our effort on testing and 45% on development, or we could've put 2.2x the effort into development if we spent zero effort on testing. If you look at a software company that's shipping significant bugs many times faster than we did and you declare an emergency and get people to spend 55% of their effort on testing, I don't think the ratio changes too much. Maybe they get to half the previous ratio or something, but the level of effort isn't really what's making the difference.
Nowadays, another thing people will say is, why bother with fuzzing when you can just ask an LLM to find bugs? I've tried doing both quite a few times now and my experience has been that fuzzing generally wins on latency to find a bug, and it dominates on finding more bugs and having a lower false positive rate. LLMs have fairly high variance (more on this later), so just asking Codex or Claude to find a bug can sometimes win but, on average, fuzzing has won.
Despite the very positive things I've said about LLMs testing, LLMs seem pretty bad at testing. However, for any level of testing effort, LLMs let you apply testing effort a lot more easily than before if steered properly.
An extreme example of this is that everybody I've talked to who cares about quality or testing at all finds the tests LLMs generate by default, or if you tell them "Write tests", "Write more tests", etc., to be poor. People tend to rate the tests as somewhere between worthless and marginally useful, depending on their standards.
For example, Em Chu (a compiler engineer) says:
The existing tests I'm working with aren't perfect, but are still above the bar LLMs seem to aim for, which I would describe as "thorough enough to smuggle a feature through human code review." For a compiler (compared to e.g. UI), where I'm guessing it's easier to write the average test, but a higher bar of correctness is generally expected of the end product, LLMs just suck. They are painfully bad at the adversarial "now, what if I do this" or "let's try the cross-product of everything" process humans use to write tests that actually find bugs
At the same time, I've seen a number of folks rave at how amazingly good LLMs are at testing when you tell them "Write tests", "Write more tests", etc. When I've looked into why people say LLMs are great at testing, what I've found is that people who did essentially no testing at all find LLMs to be great at testing. Well, that makes sense. If you go from basically zero testing effort to a tiny bit of testing effort, that's a huge win.
As of June 2026, directing LLMs to do fuzzing / randomized testing feels similar. I've tried using an LLM to generate a fuzzer and, for most projects, this will turn up real and often serious bugs within minutes. However, on looking at what the LLM-created fuzzer is trying to test, I have the same reaction as a normal programmer who cares about quality looking at LLM-created tests. The coverage of the LLM-generated fuzzer is curiously bad and misses all kinds of basic things you'd expect a hastily human-written fuzzer to cover. Depending on whether you're a glass half empty or a glass half full person, you might say that this says something about the test coverage of most projects, or that it says something about the unreasonable effectiveness of fuzzing.
At a high level, LLM-generated fuzzers from SOTA models today don't do a good job of "thinking about" how inputs should be varied to elicit bugs. Then, if you naively tell it about how inputs should be varied and to combine these, it will also not combine bug ingredients in a reasonable way. It's possible to give instructions that will work well, but this heavily relies on the user to provide direction.
If you're using randomized testing as "extra credit", to catch a few more bugs, or to replace traditional software testing processes, you can just tell an LLM to look for risky areas of the code and find invariants that might be violated and fuzz them. This works ok. When I've convinced people to try some randomized testing, they usually start here and find quite a few bugs they're happy to have found. Due to the nature of who's interested in trying out novel-to-them test techniques, this is often from people who've worked on some of the most well-tested and reliable code at the company and they can find bugs in their own relatively well-tested code.
If you want to use randomized testing to keep an agentic "software factories" workflow honest, then you need to have a way to deal with gaps in SOTA models because, when you're shipping the equivalent of hundreds or thousands of PRs a day into a project, everything that's not constrained from degrading will rapidly degrade.
At a high level, the entire system needs some kind of feedback that finds gaps and instructs whatever loop is making adjustments to the fuzzer to close the gaps. Recently, I've been testing things where I don't understand the domain and don't understand the project or the code, so I've been flying relatively blind and know that there will be a lot of gaps in what I come up with (and, as noted above, LLMs are terrible at this). But even in areas where I'm familiar with the domain and understand the code relatively well, there will still be some gaps because humans miss things and make mistakes, so there always needs to be some kind of feedback into the test setup that can find gaps and allow you or an agent to close the gaps.
I've been playing with various ways to have agents convene and reconvene to get agentic loops running better and, while that kind of thing helps, I haven't figured out a way to do do this well enough to create some kind agentic software quality improvement loop that doesn't rely on outside feedback, whether that's occasional human input, or shipping something (ideally only fractionally and with staged rollout) and then having the system monitor metrics/logs/traces/support tickets/whatever to use that as feedback. The support ticket to PR pipeline I mentioned above is one such feedback loop. The pipeline not only tries to generate a PR, it also tries to get the test setup to add test coverage that will find the bug and possibly surface other bugs, or will re-find the bug if there's a future regression. This seems to work ok-ish, in that it finds real bugs and improves test coverage, but I'm sure there's a lot of room for improvement.
Relatedly, I've been wondering why LLMs are so bad at writing tests. On asking around a bit, I'm told that this is because the capabilities that LLMs have come out of people building RL environments which allow models to improve at tasks, sometimes in a generalizable way and sometimes not. I'm also told that there's a market for selling RL envs, but it's fairly thin because there aren't all that many buyers for them, and you really want to know someone at a lab who's a buyer or close to it. If you are such a person or can connect me with such a person, could you do me a favor and reach out to me (I'm fairly easily reachable on X, Mastodon, email, etc.). I'm curious about how this works and how plausible it is to sell an RL env for something like testing, optimization, or the longer horizon tasks discussed in this post, where it's easy to observe significant gaps.
Back on the topic of testing, when fuzzing or doing any kind of bug auditing, detecting false positives is a critical part of the process. At least for now, having access to a model that's better than anything you can publicly use won't save you. A while back, Dennis Snell told me, frustratedly, that he spent the day wading through AI slop forwarded to his employer by Anthropic that came from their vaunted Mythos model that's too dangerous to release from the public. Anthropic was apparently doing the company some kind of favor or maybe doing some kind of EA security improvement, except that they didn't bother with having a reasonable false positive rejection process so they were just forwarding garbage to us. At the time, I was using a model that, if Fable is any indication, appears to be moderately less capable than Mythos, but I had no problem generating an endless stream of bugs (some of which were security issues) with no known false positives, which seems to indicate that having a reasonable setup around the model is a least as important as having the latest and greatest model.
I've been trying custom workflows on a per-project / per-problem basis and don't exactly have a generic false positive rejection scheme, but there are various things that seem to be semi-generalizable. If you don't mind spending tokens, having independent agents repeatedly check an alleged bug reproduction (repro) substantially cuts the false positive rate. A couple months ago, I mentioned that I had good luck using different "personas" for reviews as well as for managing agentic loops and I got some responses with theoretical reasons this doesn't work well but, in practice, it seems to work fairly well. My workflow changes regularly and maybe a week after that discussion I started adding "contrarian" personas to the mix, which improved performance given the same wall clock or token budget.
For anything human reviewed, having some kind of artifact (e.g., a video if it's a bug that's expected to be apparent in the UI) is necessary. Without really explicitly trying to have the agent review this, just producing this at all seems to reduce the false positive rate somewhat, and then having the agent review the artifact reduces the false positive rate further. Asking agents to independently review the artifact (e.g., looking at the test code that produces the video vs. looking at the video itself) also reduces the false positive rate further. In general, getting independent perspectives seems to help a lot with reducing false positives. In the experiments I've run, this has been less effective than having agents with different personas / perspective per wall clock time or per dollar, but just asking the same question multiple times improves results, for reasons that should be obvious from the graphs in the LLM variance section.
Pretty much everything I've tried to reduce false positive rate has worked, so if you're not scaling up a workflow to the point where optimizing the costs matters, doing anything remotely reasonable seems to work fairly well.
I keep getting various tool and workflow recommendations and, when I look into it, I can almost never find good information on whether or not it makes sense to adopt the recommendation. Just for example, I've seen "caveman mode" recommended multiple times at work. Caveman mode allegedly reduces token usage and speeds up prompt resolution (the README claims 75% reduction in token usage, 65% reduction token usage, and 2x fewer tokens used, as well as a 3x speed increase).
Searching for information (just googling 'caveman mode', no quotes, the top hit that wasn't a link to caveman mode was this reddit thread where, of the three top comments, one is joke and the other two highly recommend it:
Just extreme brevity in a refreshing way... and dramatically lowered token count without any seeming impact on the analytical thinking... but i have no way to benchmark before and after.
Someone at work is testing it and it seems to actually save tokens AND work just as well.
Most of the rest of the top hits were also positive recommendations for caveman mode that purported to do some kind of eval (although they read like unfiltered LLM text) and the top hit on YouTube was one of the the biggest programming YouTubers saying
it actually works; it actually works quite well ... no, I'm not exaggerating
In a slack thread at work where people were recommending caveman mode, I asked if anyone had done a comparison, noting that the creator of caveman mode responded to the HN thread about caveman mode by saying it's a joke. Someone linked to an analysis of caveman mode that claims a significant win, but the analysis was an LLM-generated SEO spam article with numerous errors. When I politely pointed this out, the person who posted the link said "I only skimmed it".
At that point, I decided to spend about 15 seconds apiece generating some caveman mode benchmarks (it seems like people call benchmarks evals now, so I should call these evals?) (previously discussed in more detail here).
To start with, I'd been using a lot of GPT-5.5 xhigh when this discussion came up a couple months ago and I benchmarked this thing, so let's look at how this looks for GPT-5.5 xhigh on the first benchmark, a simple benchmark where we ask the agent to optimize some code in wasm. Since this is something I spent 15 seconds prompting an agent to generate, I don't think it's worth spending a ton of time discussing the details, but one thing to note is that it's possible to do much better than any of the results an agent achieved here. I would expect a human doing this by hand or a human who's being prescriptive about what the agent should to do to get much better results than any of the AIs). For the optimization chart, 1.0 is no speedup and higher is better (below 1.0 means the "optimization" slowed things down). To give you an idea of what this looked like when running the experiments, you can click the buttons to follow along interactively or just play an animation.
We can see that, for the first benchmark (optimize a non-trivial algorithm in wasm), after one run, caveman is looking good. We get 1.027 speedup vs. 0.987, $12.10 vs. $23.10, and a wall clock time (of how long the agent took) of 8m51s vs. 14m9s. But we know that LLMs are stochastic, so we should probably run again. After a second run, we can see a big change in the results, with an average of 1.0 speedup for both, but caveman mode coming in at $12.45 in 8m64s vs. $40.38 in 17m57s. That's a huge cost savings that's in line with the claimed savings from caveman mode. It's a bit silly to narrate each step of the animation, but if we skip to the end, we can see that the average after 50 runs is in favor of caveman, with 1.03 vs. 1.01 speedup, and $17.97 in 13m46s vs. $24.21 in 16m52s. That's not as good as what we saw after two points, but that's still solidly in favor of caveman mode.
I asked GPT-5.5 xhigh to do classical and Bayesian statistics on this and it produced a script that says that, for the Optimization 1 benchmark, the p-values for caveman having better speedup, cost, and wall clock time, are 0.1, 0.005, and 0.001, respectively. With Bayesian stats, we have P(caveman better) 0.958, 0.999, and 1.000, respectively. We can look at the plots for the other two benchmarks I spent 15 seconds on as well. Optimization 2 is another "optimize this code in wasm" benchmark, and Game AI is a task where the agent is asked to implement a board game AI for the game Lost Cities with a deadline of 10ms per move.
The results with these benchmarks look mixed. For Optimization 2, we have P(caveman better) = 0.17, 0.999, and 1.000, respectively, and for Game AI, we have P(caveman better) = 0.04, 0.79, and 0.73, respectively, so caveman actually gives worse results for Optimization 2 and Game AI, which is the opposite of what we saw for Optimization 1. BTW, I didn't cherry pick the order of these results to present some kind of surprising narrative reversal. If we were to stop here, we might think that caveman gives worse outcomes but saves money, or maybe it gives better outcomes on some tasks and worse outcomes on some tasks and saves money.
If we try a few more models (GPT-5.4 mini, GPT-5.4, GPT-5.5) at every effort level, we get the following averages, which makes the overall picture less clear (in the graphs below, up and to the left is better, down and to the right is worse; the arrows point from the baseline to caveman):
What are the patterns here? To name a few, for Optimization 1, caveman generally has better results than standard, but for Optimization 2 and Optimization 3, it's mostly the other way around, although there are exceptions. For cost, we can see a variety of patterns as well. There's enough variance between conditions (tasks as well as models and effort levels) that it's clear that we'd have to run a lot more conditions to get a clear picture of what's going on and, overall, the difference averages out to be small enough that it doesn't seem worth using caveman mode.
Recently, when new models have been released, I've done a search to see what people are saying about them. In general, there are a lot of contradictory comments out there. For example, when GPT-5.5 was released people said, variously, GPT-5.4 is better than 5.5 because it's better at staying on task while 5.5 wanders off and overthinks the problem, making 5.5 much more expensive and pointless; 5.5 is so much better than 5.4 that it's cheaper to use because it doesn't mess up and then get stuck fixing its own issues as much; 5.5 is cheaper than 5.4 because it works so well you can run at a lower effort level; 5.5 "just works" while 5.4 often fails and needs handholding, etc. Often, someone will run a benchmark and show that their statement is true.
Looking at these benchmarks, we can see support for all of these statements that I saw on reddit when searching for comments on GPT-5.5 shortly after release. In Optimization 1, GPT-5.4 has better results than 5.5 and is much cheaper. But in Game AI, GPT-5.5 is substantially better than 5.4, so much so that 5.5 high costs about as much as 5.4 xhigh, but with better results, and 5.5 medium is cheaper than high with significantly better results. With just these three evals, you can find support for every statement I saw people making about GPT-5.5 on release because all of the statements are sometimes true. And that's when we're averaging out variance with quite a few more runs than any reasonable person is going to make to support some comment they're throwing out on the internet.
In general, this kind of thing is why, when I see a metric or graph that summarizes a set of benchmarks, I think, "show me the distribution". Benchmarks of models often reduce to a single, nice, neat number, where you see that X is better than Y, which is better than Z. I find these to be basically meaningless, in that, if we're looking at the latest and greatest from OpenAI and Anthropic, we know there are reasonable benchmarks where X is better than Y and vice versa. If the set of benchmarks had a few more benchmarks that favored Y instead of X, the results would be flipped. For some kind of summary metric like that to be useful to me, it would have to be the case that the set of benchmarks perfectly mirrors the distribution and weight of tasks I do and that I can only choose a single model to use for all tasks. Since neither of those is true, it’s not clear what actionable information I can take away from these benchmarks.
If we look at public benchmarks in more detail, the situation seems worse than it appears from the abstract argument above. Results are generally presented in fairly high precision, as if that's meaningful. For example, on DeepSWE, we might see that (for example) GPT-5.5-xhigh is 1% better than Fable 5 medium, but at 19% lower cost. And then if we compare to Opus 4.8 maybe it's 13% worse than GPT-5.5 xhigh at 11% higher cost. If we want to know what this means, we can dig into the data and see that we have some benchmark that claims to be meaningful because it has this big set of diverse tasks, but they're all pass/fail tasks that get run 4 times and most tasks are either very easy and get 4/4 with the best models (except, due to some random noise, you sometimes see a random 3/4) or are very hard and mostly get 0/4. Then there's some small subset of tasks that actually determine the relative scores of these SOTA models. If you change out one of these for a different one, the results between the two highest scoring models can get flipped. If you change a few tasks (out of about 100), then you can see the apparently much worse Opus 4.8 move ahead of GPT-5.5. Change a few more tasks and GLM-5.2 can pull ahead.
When I see things like this, it reminds me of Miguel Indurain, who was enough of a household name when I was a kid that I'd heard of him even though I don't follow cycling. A few years ago, I was curious why household names in cycling since Indurain are all different archetypes from Indurain and it turns out the answer is that it's arbitrary. For arbitrary reasons, the Tour de France has become the most famous cycling race in the world and someone who has a dominant streak can become famous enough that they become known outside of cycling circles. For other arbitrary reasons, there was a period of time where the TdF had much longer time trial stages than it does now, which suits someone of Indurain's archetype. You tweak the benchmark a bit and Miguel Indurain goes from being a once household name to an all-time great time trialist that pretty much nobody has heard of unless they follow cycling.
Back on the topic of coding agents, it's not clear who really needs to pay attention to these benchmarks that present summary metrics of how models are doing. As we noted above, as a user of models, these benchmarks don't meaningfully tell me which model I should use.
If many other users based their decisions on these benchmarks, then AI labs would need to care about their results on these benchmarks. But even though GPT-5.5 has been handily beating the various Opus 4.x models during 5.5's tenure on most of these benchmarks, Anthropic's business grew much faster than OpenAI's during the time period that the best publicly available models were GPT-5.5 and Opus 4.6/4.7/4.8, so much so that OpenAI has been giving companies free tokens to try to convince people to use GPT. My company was one of many to get months of free tokens and, during that time period, most people still primarily used Claude and Opus. Anthropic's revenue trajectory is incompatible with these benchmarks being major determinants of user choice, so I don't know why anyone should really care what these summary metrics show.
The last set of graphs we looked at shows how much variance we see across tasks, but from the prior set of graphs, we also saw a lot of variance within tasks with the same model and effort level. If we look at a small number of individual runs, then pretty much any conclusion is possible due to the variance between runs. Just for example if we look at Optimization 1, for GPT-5.5 xhigh, one standard deviation between runs is 0.075 (i.e., 7.5% performance increase / decrease). If we look at the average difference between the best and worst tested GPT, that's 1.055 (GPT-5.4 xhigh caveman) and 0.986 (GPT 5.4 mini low), which is less than 1 standard deviation (SD) across GPT-5.5 xhigh. For the actual graphs and not just summary statistics, we have:
For every task, whatever the best condition is, it's easy to get a result where the best condition actually scores worse than a result from the worst condition. When I was chatting to Max Bittker, who's done a lot more benchmarking than I have because he runs an RL environment startup said:
Yeah - the level of noise from task to task and run to run is so high that it's no wonder the discourse ends up confused. Easy to make mistakes like "Wow, $new_model is amazing" -> "Oops, I was still using the old model the whole time", or "this new harness / prompting trick works great!"
But on the other hand, benchmarking has given me confidence in statements like "Opus models recover and debug confusing conditions much better than Sonnet models" and "Chinese models score well on SWE-Bench but underperform on novel tasks" with more statistical significance.
Another comment, this time loosely paraphrased because this is from memory, was that Matt Mullenweg said that, if you look at people who undertake high variance activities, like gamblers, they're often superstitious. You'll see somebody wear their lucky socks or have a specific routine they do before they sit down to play the slots. Using caveman mode or deciding which model is good because a coding agent coughed up a good result after trying it is not so different.
I did the above and wrote the draft of this post before Fable was released, and then Fable was released, so just out of curiosity, I ran a few Fable benchmarks, at which point it was unreleased, so I also did a few runs with Opus 4.8. [This post was then edited after the 5.6 release to add 5.6 benchmarks to the graphs below]
Like I mentioned above, these are little benchmarks I created by typing to an agent for about 15 seconds a piece. With how coding agents let you scale processes, you could create a very large number of reasonable benchmarks in 15 seconds of a human time a piece, but this isn't some carefully designed setup for stamping out a bunch of these; it's just something I did because I wanted to get some kind of caveman mode comparison, and when I tried to have agents do this with no supervision, the benchmarks were completely worthless. With a little bit of time spent, the benchmarks seemed good enough for the purposes of evaluating caveman mode and determining that it's not worth further investigation. If I was planning on writing this up publicly, I would've spent a few more minutes making these benchmarks better in multiple ways, but I think they're good enough for the purposes of this variance discussion. I wouldn't read too much into the reuslts, but I did do a few basic checks such as looking at outlier results to make sure agents weren't cheating or there wasn't some issue (such as noise on the box) causing unusually poor runtime results, and the agents weren't cheating and the slowest results did reproduce on a quiet box, etc.
And, that disclaimer aside, just like with the GPT benchmarks, we can see variance in these benchmarks that reflects the discussion that's happening online, e.g., Fable is great at some tasks and not so great at other tasks, and quite a few people are making claims about Fable's overall performance based on the performance on some small set of things they tried. As we noted above, OpenAI does better than Anthropic at DeepSWE (GPT-5.5 =~ Fable 5 > Opus 4.8), and we can see a benchmark where we get an analogous result in Optimization 1. The other widely cited benchmark people keep passing me is Senior SWE-Bench, where Anthropic does better than OpenAI (Fable 5 > Opus 4.8 > GPT-5.6 Sol) and we can see an analogous result in the Game AI benchmark, where we have Fable 5 > Opus 4.8 > GPT-5.6 Sol > GPT-5.5).
Above, we discussed why it's not clear how I or any particular user of agents can usefully use these benchmarks that produce a ranking or a small tuple of numbers that allegedly tell you how good a model is. But even when drilling down into a benchmark, it's still not clear to me why, as a user, how I should change my behavior as a result of the benchmarks.
Just for example, something I've observed is that Opus 4.8 makes up bad rationalizations to explain things much more often than GPT-5.5. I've tried having them approach the same problem a number of times (I'll often ask both to solve a real problem I'm running into just to see what happens). These are often much larger problems than these benchmark problems, things like real debugging tasks or, in the case of building a game AI, instead of a simple prompt to produce an AI, an agentic loop and/or a series of instructions to get the agent to produce a fairly strong AI. I've asked a small handful of people and they've all observed the same thing with GPT-5.x vs. Opus 4.6/4.7/4.8, including people who prefer Claude and primarily use Claude and are more experienced with Opus than with GPT.
On the flip side, I've seen two benchmarks that measure how good models are at detecting false information and/or not making things up and those benchmarks both show that Opus is much better than GPT at this, to the point where, if the benchmarks show what one might expect them to show, the experiences I and other people have had seem impossible. For example, in one benchmark, a naive reading of the benchmark presentation is that Claude Opus and Sonnet are much better at detecting false information than any other model and Opus 4.8 is the absolute best and detects false information 95% of the time, including 95% of the time in software. The GPTs are terrible at this and rank below Qwen, Grok, Kimi, Minimax, Mimi, and Nemotron.
What's going on here? I'm not sure.
Maybe those benchmarks are measuring a different aspect of making things up than what the people I've talked to (and I) run into while working on real programming problems, or maybe this is a small sample size and the people I've talked to (and I) have just randomly gotten bad rolls of the dice from Opus, or maybe we're "holding it wrong" when it comes to using Opus. I suspect what's happening is that the benchmarks are measuring something different from what happens when you encounter incorrect rationalizations while coding or debugging, but to have any confidence in this I'd have to run some experiments that will be fairly expensive. If you want to support my doing experiments in general, you can subscribe to my Patreon or, if you're at an AI lab, give me some free credits to run experiments with.
BTW, there's something analogous in the Game AI benchmark here, where Opus is substantially better than GPT, but when I tried to have to manage the process of creating an actually strong (superhuman) game AI, GPT seemed to do better because Opus kept falling into making things up / rationalizing nonsense failure mode. With no supervision, both were worthless and had their own failure modes, but when directed, GPT took less prodding to stay on track and keep doing things that could work. This is not reflected at all in the small Game AI benchmark where an xhigh run is a single prompt that "only" costs on the order of $10 and the small benchmark turns up the oppposite result as we see in doing the real version of the task.
But, the point here is that, even when you find benchmarks that measure something that seems to be the exact thing you care about, those benchmarks often don't end up matching what you see in practice. If you're a weirdo like me maybe you'll decide to spend a bunch of time and/or money running some experiments to figure out what's going on but, if you have some job you want to get done (maybe for your actual job), that's a fairly unreasonable thing to do.
BTW, there are some patterns in the benchmarks that people often find counterintuitive. Unlike a discussion of which model is better based on publicly available benchmarks (which is pointless), I do find this somewhat interesting and informative. We already noted above that there are benchmarks where GPT-5.4 outperforms 5.5. It's also the case that we can see that, more effort can make results better or worse. For example, in Optimization 1, GPT-5.6 Luna gets monotonically worse with more effort and it generally gets worse in Optimization 2, but it monotonically improves with more effort for Game AI. We can also see that max fares worse than xhigh for GPT-5.6 Sol in Optimization 1 and Game AI. With GPT-5.6 Sol, ultra is better than max for all three benchmarks and actually cheaper than max for Optimization 1 and Game AI. Even within one provider or one model, a lot of things people would intuitively expect (such as better results from more effort) aren't true. When you add in the larger differences we see across different providers, there's a very high degree of heterogeneity in results that makes simple statements such as X is better than Y generally wrong except in cases where there's a very large difference in capability bewteen models. But as noted above, We can easily find, without cherry picking, cases where Anthropic's last-generation model outperforms OpenAI's current generation model and vice versa.
When I've seen people throw these benchmarks around, they're often just used to back up someone's superstitious beliefs, e.g., at work, I saw someone cite Senior SWE-Bench's result that Fable 5 > Opus 4.8 > GPT-5.6 Sol, saying this is realistic (from someone who believes Anthropic is way ahead of OpenAI). Of course someone could just as easily cite DeepSWE, which shows the opposite.
Everyone whose judgment I trust on these things find these benchmarks to be fairly bogus because the idea that, today, Anthropic's last-generation model is, overall, better than OpenAI's current generation model or vice versa doesn't really pass the sniff test for someone who's used these things a decent amount. When I've asked people I trust outside of AI labs how they form an impression of how good a model is, it's generally just going on vibes and collecting impressions from other people who are going on vibes because it's obvious the benchmark results don't give you a better idea of what's going on than you get from just eyeballing things.
For no particular reason, I've always liked designing experiments and measuring things. This was true long before I ever thought about careers and it's still true today. As discussed here, measurement is one of the primary themes of this blog, maybe the primary theme. Lucky for me, this lifelong hobby has been something I've been able to make a career out of. And even luckier, this skill seems to have been made relatively more valuable by coding agents3.
As we discussed above, testing is a rate-limiting factor in highly agentic workflows because when you let agents start doing a lot of things, anything that's not well tested gets stochastically degraded. The more you ship with agents, the worse this gets. If everything you do is like one of these model evals where every task is a pass/fail task and there's no way to really do better than simply not getting the task wrong, then you can make sure your tests are good enough and let agents go to town until tests pass and everything will be great. In practice, for almost all non-contrived problems, it's possible to have a solution that passes a strict correctness eval but is still better or worse in some kind of non-strict correctness sense. If you want to let agents go wild on a problem (whether this is fast and loose vibe coding or running autonomous agentic loops), now you have a benchmarking problem.
When left to their own devices, running in self-improving loops, agents seem fairly bad at this. There are various little things I've been doing for a few months that get some improvement here (having lots of agents think about things independently and reconvene over multiple iterations with a mix of contrarian agents, etc.), but they still don't seem great at this without human intervention.
One reason for this seems to be that agents are really bad at understanding data and doing data analysis. Doing this in the context of some kind of agentic loop or large problem is harder than doing a standalone data analysis, but when people just have an agent do a standalone data analysis, the results are generally terrible without a lot of guidance. Because it's so easy to have an agent do data analysis, I've seen quite a few agent led analyses and, at least so far, every one that I've seen is completely bogus. I've also done a fair number myself (I think people really underrate the value of getting completely bogus output from an LLM; more on this shortly) and found the same thing.
When I say complete bogus, I mean things like finding different numbers that aren't really related and somehow inferring something deep about their relationship, picking two numbers or examples out of many and coming up with a theory that contradicts other numbers in the data, making plots that show something meaningless (but often look pretty), etc. For a random concrete example, the last time I looked at an analysis produced by an agent (I glanced at this as I was writing this), someone had asked an agent to analyze the resource utilization of something. This was Opus 4.8 on max (Fable was disabled, so this was the best thing money could buy from Anthropic at the time) agent determined that 514% of the resources were being consumed by some task where it was impossible that more than 100% of the resources could possibly be consumed in any way. I have a colleague who sometimes comments on these things and will ask innocuous questions like "what does X mean?". Generally, he either gets no response or what appears to be some kind of AI-written response that's as incorrect as the first thing he replied to.
Anyway, when I started using agents for data analysis, maybe in November 2025, I found the speedup to be pretty incredible. There are analyses that, roughly speaking, would've taken weeks that instead take hours.
I hesitate to even describe this next thing I've been doing because of how many completely bogus data analyses I'm already seeing, but something I've been doing a lot of, which I find to be a much larger speedup than doing a "normal vibe coded data analysis" is to run a simple agentic loop where the agent (or agents) "understand" and analyze the problem and then fix up the parts that need to be fixed for me to extract a good analysis from what the agent has produced.
How much this bogus LLM loop speeds things up depends on the problem, but the last time I tried it, I think a traditional pre-LLM analysis of the issue would've taken me some number of days. Let's say two days. With a workflow where I'm multitasking and poking the LLM when it needs poking, my guess is that it would've taken one to three hours of my time over the course of a day or two. With this "have the LLM loop on producing a result I know will be wrong" workflow, it took about five minutes of my time over the course of a few days to get an acceptable result. Literally every time I looked at any part of the analysis I hadn't previously corrected, the analysis was wrong (and, in some cases, I had to issue multiple corrections) but, somehow, the whole thing still moved a lot faster than if I tried to steer the LLM.
I think people are really underestimating the value of getting completely incorrect results out of an LLM. This is, non-ironically, a game changer in a positive way, when directed correctly.
There's something a bit odd about how incredibly bad SOTA models are at data analysis and how much they speed up human data analysis. I have this series of exercises in benchmarking, evals, and experimental design (part 1, part 2, part 3, part 4, part 5, part 6). When GPT-o3 was released, Tyler Cowen said that o3
wipes the floor with the humans, pretty much across the board ... I don’t mind if you don’t want to call it AGI. And no it doesn’t get everything right, and there are some ways to trick it, typically with quite simple (for humans) questions. But let’s not fool ourselves about what is going on here. On a vast array of topics and methods, it wipes the floor with the humans. It is time to just fess up and admit that.
This prompted me to try asking the questions from these exercises to SOTA models. They generally underperform what I'd expect from a reasonable junior colleague unless you specifically word the question so that models can answer the questions. If you just ask the question the way you'd ask the question to a reasonable human colleague in real life, they generally don't do well. This isn't just a theoretical problem that comes up when someone asks an evals homework question. This issue comes up any time you ask an agent to do some kind of empirical, open ended, longer horizon improvement task.
I've seen this issue come up on a wide variety of real world problems, but it even comes up on contrived problems that don't have almost any of the messiness of real world problems. An example of this that I think is a nice problem is building board game AIs. This is a much easier problem to evaluate than most real-world problems because, at the end of the day, you want to beat humans and other AIs on a well-defined game that has a simple win/loss/draw result.
Agents can't really figure out how to do this when left to their own devices. To be fair to AIs, this problem is somewhat harder than internet commenters give it credit for. For example, if you just search for information on how to implement these things, you see all kinds of exchanges like this or this where someone who hasn't done it will explain why it's easy and someone who has will tell them it's harder than they think. Most of the online tutorials aren't very useful, to the point that the author of the well-regarded bulle library suggests that beginners avoid looking at "[a]lmost any article/blogpost/book on [a board game AI technique] that isn't backed by the author's strong [board game AI]". While the problem isn't exactly hard, it seems to have enough pitfalls to trip up most people (and all publicly avialable LLMs).
When I first started trying to implement a board game AI (this was in the GPT-5.1 to 5.2 days), I didn't know anything about board game AIs and tried having coding agents implement what they thought would work. Now that I know a bit about board game AIs, I can say that every direction GPT tried to suggest was bad and couldn't work. As an experiment, I tried this again recently, when GPT-5.5 and Opus 4.8 were the best publicly available models and they failed in the exact same way and suggested many of the exact same bad ideas (just to really make sure, I let them implement the bad ideas and they failed as expected). When Fable became available, I also tried this with Fable and it also failed in the exact same ways. Fable was better in practice as it was able to work effectively in an autonomous loop after 15-20 corrections, which Opus 4.8 and GPT-5.5 were not. BTW, this is another example of a kind of thing that public benchmarks fail to capture.
But back on the topic of LLMs iterating without guidance, I think, at some level, this is a fairly well understood gap in LLMs today. Coincidentally, around the time I was trying GPT-5.1 or 5.2 at this, the Code Clash eval was created, which also tests the same thing and found the same result
Unable to Iterate: Models struggle to improve over rounds, exhibiting a variety of failure modes.
Despite agents being terrible at setting direction and me not knowing anything about board game AIs, I was somehow able to cobble together a superhuman AI for Azul in about 5 hours of my time with GPT-5.1/5.2 and get it to a crushingly strong level that's well above any other AI that was out there at the time (and I think still out there now) in about 20 hours of my time. The Azul world champion and probably strongest player in the world overall said:
the bot is quite insane now. def seems stronger than me, though to really test it i would have to play it like a turn-based game. with limited time on my end, i stand no chance 🙂4.
As much as I'd like to be able to say there was "one weird trick", there were really two tricks, but two tricks isn't so bad, especially when they generalize to other kinds of projects as well. The two tricks were:
None of this has to be very rigorous. In fact, I'd say this was all running on vibes (in the pre-vibe coding sense of the word). For the data side, for this project, I used a common habit for me, plotting a bunch of things that seemed relevant, eyeballing them, and then nudging things in a direction that I would hope improves things. A more rigorous (and possibly better) approach is to run a bunch of experiments from scratch, do "ablation" runs where you add or remove individual ideas, etc., and understand what each component does and what the impact is. But I wanted to get a strong AI while using as little of my time as possible and just training on my laptop and doing things rigorously seemed too expensive given those constraints.
I'm sure all of this would've been trivial for someone with ML experience, but there were a bunch of little things I had to observe and then find ways to deal with (which is something agents are currently terrible at). For example, in terms of figuring out a good set of evals to look at it, there are a few funny things. One is that you can easily make changes that reduce loss but don't change the win rate against actual opponents (humans or other bots) and vice versa. Another is that, if you try to track improvement in terms of how well your bot beats previous versions of itself, it's very easy to make a series of changes that allows the bot to beat all previous versions of itself and have an apparent Elo gain of 1000 or 2000 against prior versions that isn't any better against humans or bots that play in a different style. And, at the time, there was no superhuman bot that was available to play against, so you couldn't get a reasonable eval by just playing against a field of existing bots.
For a human, these aren't really hard problems. A reasonable human can look at one of these issues, think for a few minutes, and come up with a proposed solution that will probably work (and when it doesn't work, they can try another solution). But there's enough subtlety that agents don't do well at this today without supervision (to be fair to coding agents, many or most humans don't either—almost all of the bots I found to play against were fairly bad, despite people seeming to have spent a decent amount of time on a lot of them, with the one publicly available exception being the "PJF98" Azul bot in https://github.com/cestpasphoto/alpha-zero-general). There was one bot stronger than the PJF98 bot in existence, but it wasn't made generally available to play against and was just used to win one season on BGA (which was voided because using a bot is cheating) and then never seen again.
The other trick I mentioned was taking a systematic approach. At a high level, this is because when dealing with an opaque system with some complexity, every time you see a symptom of a bug, there's a good chance this is a window into one or more other bugs that you don't know how to observe. If you non-systematically close the window without fixing the other bugs, those other bugs are still there; you just don't know how to find them anymore.
This is the case when building a board game AI that uses a neural net because you have this net that's doing who-knows-what and some kind of search function that's doing who-knows-what and you can sometimes spot specific obviously bad moves. This is also generally the case with vibe coding and/or agentic loops because you have agents doing who-knows-what and you sometimes get a window into what's going wrong as the giant, overly complex, pile of code the agents produce will emit some kind of obviously bad behavior.
Specifically in the case of board games, I looked at the other Azul AIs that are out there. A lot of people had built bots, especially recently with coding agents making it so easy to build a bot. For some of those, you can actually see how the person tried to nudge the bot (for example, because they included the instructions they gave to Claude in their repo) and, AFAICT, the main reason these other bots were much worse despite more human time spent on the effort was a combination of using the wrong evals and fixing the symptom of a problem and not the cause.
For example, in one case where the author left the Claude instructions in the repo so you can see what they did, at one point, their bot was making a very bad move that's worse than a move that any human would play even if they'd just learned the game. The author instructed Claude to make a series of straightforward fixes that would stop the bot from making that move, which it did, but this didn't fix all of the other bad moves that fall out of the systemic problems the bot has; it just fixed the one very obvious symptom of a bad move that the author could see.
A vaguely analogous issue my bot had is that, at one point, my bot would almost always try to open in column 2. A simple fix that I think would've worked would be to tweak the bot to play in column 2 less often. I tried the various "obvious" fixes like increasing noise to increase exploration in self play, etc., but none of the obvious fixes worked other than directly reducing the value of column 2, but that has this other issue we discussed of not really solving the problem. In that specific case, a more systematic fix that worked and made that bot's play a lot more generally robust was to, at various points in the game, fork the game into a new game with different column permutations. The idea here is, the problem is that, on average, column 2 is the best column, so even if the bot opens in a different column, it will have this tendency to go back to the average best column due to the games it's seen in the past. If you're DeepMind, you can throw a bunch of money at this problem and have the bot play a lot more games and learn something else. But if you're running on a laptop, that could take a while and if you're trying to tweak the weight at which the bot should be nudged away from column 2, there's no way you're going to get a reasonably optimal set of weights to do this with. But if you (for example) sometimes, near the endgame, permute column 2 to column 4, the bot will learn that if you have a nearly filled column 4, it's a winning move to complete it, which will help the bot learn that earlier in the game, if you have a partially complete column 4, it makes sense to advance it to near completion, and so on and so forth, until, in the opening, the bot learns that in the opening, it should then open with a reasonable distribution.
For someone like me with no ML/AI background, getting the bot to superhuman performance was a series of puzzles like this that are a combination of figuring out what the right view of the data is to see problems and then tweaking this systematically to solve the problem. This is not so different from managing agentic loops for general problems. Michael Malis has said that running a "software factories" workflow feels like playing Factorio and I can see what he means by that.
I'm not sure how much value there is in talking about specific workflow tips and tricks since the half-life of these is so short. Before I was running more autonomous loops and was doing more human-in-the loop work, "my" agents would often do something that's in direct contradiction of AGENTS.md or other instructions. When I offhandedly mentioned this to Yossi Kreinin, he suggested adding a note at the bottom of my AGENTS.md to re-read instruction after compaction. For all I know, that's a superstitious act that did nothing, but it seemed to reduce the rate of this issue from a few times a day (when juggling a handful of agents at once, so maybe once every few agent-days) to once every week or two (maybe once every 100 agent-days or so). It seems like this isn't necessary anymore, so either this was a placebo that never did anything in the first place and I was just getting unlucky for a while, or the AI labs have added this as well. A trick we discussed in August 2024, back when LLMs would produce code but not run it by default, was to just have a loop that runs the code to make sure that it works and passes tests. That trick had a surprisingly long useful life considering how obvious and useful the trick was, but of course the big AI labs eventually realized how useful that was and they all have tools that do this now.
For the past few months, the "trick" I've been using is to have something that's vaguely in the same space as something like Gas Town, but with various little things to try to make it more reliable. It seems like Claude's Dynamic Workflows put half of these tricks into an easy to use package (I haven't used it since I'm told that it uses a waterfall model where things from one stage wait on the last one, but either that will be fixed at some point or someone will release something without that limitation) and Codex has some advertised but yet to be released features that seem targeted at doing the same thing. In principle, goal mode should package up most of the other half of the tricks, although it doesn't work nearly as well for now (besides sometimes failing due to a bug, it seems less good at pursuing the goal than a manually written loop, and it can also really get off track; Dennis Snell mentioned letting what he expected to be small task go in goal mode and finding that, according to codex, it spent what would've been $60M in tokens in a few days had his employer not been on an unlimited token deal; on asking again, it then said $200k). Presumably these things will improve and most of what I'm doing now will be available off-the-shelf within a couple of months? Like the tricks mentioned above, these are all things that are so obvious enough I don't know that there's much value in spending a lot of time talking about the details, but I'll put some brief comments in a later appendix in case anyone is curious.
The meta techniques discussed above have generalized fairly well for me on a variety of projects and they seem like they should be durable as long as agents can't just take a non-trivial problem description and fully solve the problem better than I can, at which point I won't have to worry about it because my economic value may be close to zero.
Another meta idea that's been useful is the very obvious thought that coding agents are highly non-uniform in their effectiveness relative to humans. When discussing about traditional productivity, Fabian Giesen made this comment on how velocity improvements change how he works:
There are "phase changes" as you cross certain thresholds (details depend on the problem to some extent) where your entire way of working changes. ... There's a lot of things I could in theory do at any speed but in practice cannot, because as iteration time increases it first becomes so frustrating that I can't do it for long and eventually it takes so long that it literally drops out of my short-term memory, so I need to keep notes or otherwise organize it or I can't do it at all. Certainly if I can do an experiment in an interactive UI by dragging on a slider and see the result in a fraction of a second, at that point it's very "no filter", if you want to try something you just do it. Once you're at iteration times in the low seconds (say a compile-link cycle with a statically compiled lang) you don't just try stuff anymore, you also spend time thinking about whether it's gonna tell you anything because it takes long enough that you'd rather not waste a run. Once you get into several-minute or multi-hour iteration times there's a lot of planning to not waste runs, and context switching because you do other stuff while you wait, and note-taking/bookkeeping; also at this level mistakes are both more expensive (because a wasted run wastes more time) and more common (because your attention is so divided). As you scale that up even more you might now take significant resources for a noticeable amount of time and need to get that approved and budgeted, which takes its own meetings etc. There's something analogous about agentic coding velocity improvements. People sometimes make claims about how agentic coding is 100x or 1000x more productive. When I look at tasks I do, it's hard to really pin down a number because you can't effectively lift-and-shift a human workflow to agents, so I'm doing something very different from what I would've done in the first place. For example, we look at the idea discussed above of having agents look at every support ticket to convert support issues into PRs. If I were to claim some kind of speedup here, it would be a huge number, easily more than 1000000x. But of course I wouldn't read every support ticket myself, so such a claim is meaningless. A more reasonable way to estimate this would be to try to figure out what kind of traditional organizational structure would generate that many bug fixes using classical techniques and estimate the ratio, but the error bars on an estimate like that will be more than one order of magnitude and it's also not something that would've been done at any normal software company, so the comparison is once again meaningless. It's like someone who drives 20000 miles a year saying they saved 6000 hours and got a 15x speedup on their commute by driving because that's how long it would've taken to walk the same distance. It's clear that the driving enabled them to do things they wouldn't have been able to otherwise do, but there's no point in discussing the ratio.
Another example of a place where you can claim a massive speedup number, possibly more than 1000000x, that's a meaningless number is, when trying to get an LLM to generate a fuzzer in a semi-automated way, I've tried having an LLM look at the entire commit history and all bug fixes, as well as every plausibly related support ticket in history, to try to get the LLM-written fuzzer to be able to reproduce the bugs in some general way. This seems to have been useful to do, but it's hard to put a real number on the value.
For me, the effective value of LLMs is that there are a lot of tasks that would've been too time consuming to reasonably do that can now be done fairly trivially. In a footnote, I mentioned that there are lots of apps you can just trivially build now, so I sometimes play online board games on a custom app that's just a nicer experience than I can get on any of the major board game platforms (which is also nicer than the typical dedicated app for a board game).
In things that I mostly do to satisfy my curiosity, but that can also have some relevance to a business, I'll also do data analyses that didn't really seem worth the time before. For example, I've long been curious about the ratio of user-experienced bugs to support tickets. With coding agents, it took minutes of my time to get agents to produce a list of major incidents where we know that every user that tried to access the site or use a feature couldn't use the feature or site and to get a list of tickets that appeared to be associated with each incident. On joining this data, a typical ratio was 200 impacted users per ticket, with the ratio often being between 100:1 and 1000:1 (and, I'm sure, a wider range would've been found if more incidents were included). FWIW, I pre-registered a guess of 100:1 to 1000:1, leaning more towards the 1000:1, so I was somewhat off here as the typical 200:1 is closer to 100:1 than it is to 1000:1.
Of course, there are a lot of holes in this analysis. There's no way to tell for sure that there aren't missing tickets (I did check for false negatives by independently cross-checking with tickets that were manually tagged in the bug tracker as being associated with an incident and the main thing that turned up was that agents were able to find many more tickets than humans found, but that doesn't mean that that aren't false negatives the eluded both humans and agents). I also randomly sampled a handful of tickets to see if the associated tickets were reasonable and they seemed reasonable, but this was just a quick order-of-magnitude analysis, so I didn't manually inspect as many tickets as would be necessary to really validate a high precision analysis.
It's also not clear how the ratio changes for less severe issues. It should generally be the case that, for less severe issues, the ratio is higher, and also for less invested users (such as the typical user in the sign-up flow). My guess is that, for many less severe issues, we generally see ratios well above 1000:1, with the ratio being easily above 10000:1 or even above 100000:1 for many subtle issues.
This analysis doesn't let me say anything too precise, but it does work as a response to when someone says "only six users were impacted" because an issue had six tickets. That typically means that there's an internal bug tracker ticket for which someone attached six support tickets. On using an agent to search for related tickets, you might find twenty-five tickets and then, looking at the issue severity, you might estimate a ratio of 10000:1, so "only six users were impacted" may turn into "it's overwhelmingly likely that at least 5000 users were impacted and plausible to likely that 25000 users were impacted".
If I was already familiar with every system I'd need to query for this analysis, I suspect getting a rough guess for this would've taken hours and it would've been a rougher guess. But given that I wasn't familiar, I would guess that this would've taken a couple of days. Instead, this took maybe 15 minutes of my time. Like Fabian mentioned, this kind of speedup where an app or analysis that would've taken hours or days can be done is a phase change that really changes how you work, and that's not even including autonomous loops that only need occasional maintenance.
Another thought, and it wasn't obvious to me in advance that this would be the case, is that LLMs seem to be a larger productivity multiplier for people who are relatively more expert at the thing they're trying to do. On looking around for commentary on this, I of course got pages full of LLM generated SEO spam and, after wading through it, I saw quite a few comments indicating the opposite. Basically, that anyone can do anything now. While that's more true than it used to be, it seems to be even more true that expertise in an area has become more valuable. Max Bittker had a comment that this is at least partially because LLMs are good at counterfeiting things, but that counterfeits aren't that good (yet?), and experts can tell the difference between a counterfeit and the real thing, which I thought was an interesting framing.
And following up on this 2015 post about how many people are underestimating how much AI will displace humans, in the past year, my median LLM-driven remote customer service interaction has been better than my median human remote customer service interaction (a well-paid human would provide a better experience than all but maybe one of my LLM-driven experiences, but companies don't want well-paid humans). The exact same line of reasoning that was rebutted in that post 2015 was repeated in 2022 on the release of ChatGPT. The line of reasoning is so popular that it's been a repeat thought leader viral hit every year since 2022 and I don't see that changing any time soon, but it still seems wrong to me today.
By the way, as we previously discussed, there are lots of ways to be an effective programmer, so I'm not saying what's discussed here is the best way to do things or even a very good way (I'm changing my workflow regularly as I figure out new things) but this is what I've been trying that seems to work better than a purely traditional workflow for me. Just given my background and interests, it's natural for me to take a systematic, evals-driven, approach to agentic coding. I've seen people use what is pretty much the opposite approach and make it work for them as well, where they move very quickly without almost any understanding of what's happening and, when they strike gold, they recursively put all of their effort into that. Not only is that not a great fit for my background, I don't think it would really work well for most of the problems I've worked on, which I select because they seem like a reasonable fit for how I approach problems. No doubt my workflow, ported to the problems the opposite kind of workflow is suited to, would also not work very well.
It's always been the case that people talk past each other when they disagree, but this seems to be more of an issue when talking about agentic coding today than it has been for a lot of other topics.
Some of the major reasons I've seen for this are:
On general incredulity, moreso than at any other time in my life, I see people saying that X is impossible, nobody does X, and anyone who claims that they're doing X is a liar, when I know people (who I trust and are credible) doing X or I'm doing X. There's a lot of incredulity out there about AI. Eleven years ago, we looked at how people were saying AI can't possibly replace or displace humans even as it was already happening, but the kind of displacement there wasn't a serious fear for a typical middle-class person or programmer, so it wasn't as salient for folks I might run into "on the street" as it is today. Now that this is more "in your face" for people I'm running into, the amount of denying reality has shot up.
BTW, I find it quite reasonable that a lot of people are incredulous. For one thing, a lot of the positive claims about AI are incorrect. On average, wild, incorrect, claims get more traction than boringly precise and correct claims, so someone who isn't following this stuff is going to see a lot of incorrect claims that are easy to dismiss. It doesn't help that a lot of the people making these claims have a direct financial interest in the general success of AI companies, which makes it easy for skeptics to conclude that these people are all self-interested liars.
On workflow-based reliability differences, what I mean is that different workflows demand different levels of reliability and people who use a workflow that demands a higher level of reliability will often claim AI is useless because it can't do X reliability, missing that there are many effective uses that don't require that level of reliability. To take an extreme example, some people have done novel mathematical research and solved open problems using AI. Let's say, hypothetically, AI solves some open problem you're working on 1 out of every 100 times you try it and returns completely gibberish 99 out of 100 times. That seems great. Solving a serious open problem in math research 1 in 100 times is a pretty awesome result, even if doing a reasonable code review 1 in 100 times and producing a bad code review 99 out of 100 times would be a bad result.
For a less extreme example, for programming work, if you don't assume that the agent is 100% reliable and build systems to handle this, you can tolerate a much lower level of reliability than somebody who assumes the agent is reliable and needs some kind of human-in-the-loop correction to deal with cases where the agent isn't reliable. I regularly see people give advice saying, "don't use AI for X [because it won't work 100% of the time]" where I know someone who does X all the time and have some boring system for handling X not being 100% reliable. This is something you commonly have to do in programming regardless of whether or not you're dealing with agents, so why not use the same techniques you'd use to handle agents being unreliable?
Differences in scale also cause people to talk past each other as people have very different reliability demands at different scales. There's an old rule of thumb that, for traditional software systems, for every order of magnitude increase in scale, you need a different architecture. That's not really true, but it gets at this directionally correct idea that you really want different architectures at different scales. This is also true for using agents.
Just for example, one that I've seen come up repeatedly related to the earlier note that, on tasks that I do, adding a clear, strict, instruction in AGENTS.md to not do something fails once every week or two when juggling 10 agents, a failure rate of something like one per 100 rule-agent-days. Does this work? If you're doing human-in-the-loop coding with a relatively small number of agents and rule (say, 10 agents, 10 rules) with failures being non-catastrophic things that are usually caught by human review, this works fine. If you're running hundreds or thousands of agents or if you're shipping without review or other guardrails even with only a few agents and failures can cause serious problems, this doesn't work at all. While some techniques are scale invariant, many aren't.
Another kind of workflow issue is when people have a workflow that can't work for X and then conclude that nobody can do X because they weren't able to do X. I haven't thought too much about the specifics of what doesn't work, but Max Bittker had the following comments:
A few patterns I've noticed, not in order:
1) People sometimes have misconfigured environments: They're on an old model, they have a bunch of MCPs or after-market system prompts turned on, or the LLM is trying to deal with Windows or some unusual environment or IDE.
2) People sometimes trash their context window by using a single super long chat with lots of backtracking or single super-messy working directory.
3) Injecting accidental requirements via imprecise language, sending the LLM off on a harder task than they intended like building a matchmaking system before the core of the game
4) If you don't have a strong idea what you want or when you're done, you might under-specify and then collaboratively drift and change requirements over time and going nowhere in particular (many AI-psychosis vibe coders do this)
As I noted in the alt text at the start of this post, I was very hesitant to write about AI for years because I'm up here in Galapagos Island, highly disconnected from what's happening because I haven't been reading social media much and I've also been doing a bad job at keeping in touch with folks who are really in the thick of it in SF.
I was convinced that it might make sense to write something in May, when I chatted with a couple folks from SF who were in town for PGConf. Even though they are in the thick of it and seem to be close to the cutting edge of what people are doing with agents, there were still things from my workflow that they thought were interesting. But, like I said, the half-life of particular workflow tips and tricks is short enough that I didn't think it would be useful to write up detailed notes on an exact workflow, which is why the main post has focused more on higher level ideas. I'm not sure what might actually be useful, but I'm going to try writing up something about the evolution of my workflow. As noted above, I don't think there was any point in time where my workflow was great, exactly, but it was useful and there always seemed to be a natural next step to make it a bit more productive.
Back in the stone ages, before tools like Claude and Codex, I would sometimes just run a very simple loop that would just keep compiling the code and running the tests and re-prompting until everything passes, which I mentioned here in mid-2024. At the time, I didn't find this useful enough to use for anything where I knew what I was doing, but it enabled me to embed a little web game into that post and do other tasks that would've required me to learn something about an area where having actual expertise will probably never be particularly interesting to me, such as building a web app.
That kind of thing was mildly useful for quite a while when I wanted to accomplish some simple task, but I didn't start using agents much until running into the bisect/video story at the top of this post, and doing some other data analysis and seeing how much it could speed up data analysis. BTW, the bisect/video story came out of an analysis where I was wondering what the half-life of a working feature and/or bug fix is. Coincidentally, that analysis is linked to a couple of ideas in the post. First, the half-life turned out to be fairly short pre-LLM, which seemed like a point in favor of more testing if we wanted to turn the dial up on velocity (with or without LLMs). And, second, this is yet another analysis that would've taken long enough that I wouldn't have done it pre-LLM.
At some point mid-late 2025, I tried vibe coding some personal projects. I used Codex just because people said it gives you more quota on the subscription plans (I've since tried both and that seems to be accurate). At that point, my goal was to use as little of my time as possible on personal projects while getting the output I wanted, but I hadn't really done any vibe coding before and didn't have any idea what would work, but it quickly became apparent that I did the most naive possible loop, where I would just queue up a bunch of copies of "if X isn't done, implement X until complete; if X is done, ...". I wasn't reading anything about what other people were doing and the people I was personally talking to generally weren't using AI much, so I had no idea that the term "Ralph loop" had been coined in mid-2025 and people were doing various, less cumbersome, variants of this, although this wasn't really all that cumbersome (maybe 5 seconds or so to queue up the copies of the prompt once they're written).
And, in retrospect, this workflow wasn't so bad in terms of steering things in the right direction compared to a Ralph loop. I'd usually look at this a handful of times every day (right before bed, on waking up, maybe a couple other times) and, in general, every time I looked, things would not quite be right and I'd queue up some commands to nudge things in the right direction after looking at the logs/metrics/graphs/etc. that explained what was going on. Since this was for personal projects I was spending a small number of minutes a day on, I wasn't trying to maximize throughput and was just running a few things on each of two different laptops I have lying around. It would've been better to have more autonomous loops that can keep going indefinitely without refilling the queue by hand, but the actual time savings from that isn't really all that much, I think less than 10 minutes per day.
After doing that for a while, I started (sometimes) trying to run more autonomous loops earlier this year. Once again, I think this must've been somewhat behind the curve compared to whatever people are excited about at any given time, but it seemed to work ok. On starting to do that, I found that a lot of the tooling people were recommending wasn't really a great fit for managing agentic loops and the tooling that was designed for it seemed a bit "vibe"-y and would have reliability issues.
An example of the first thing is that Conductor was widely recommended at the time and it wasn't really made to support a lot of things I'd want to do. For example, Conductor has the concept of a workspace to separate things. I often want to invoke what one might call "higher order workspaces", where an agent (or a set of independent agents) decide what should be done with a list of items, after which each item should be fed into another agent (or independent set of agents) (possibly with some limit on agent concurrency), after which, etc., with some kind of graph structure determine how tasks move around, where there are reduce-like steps that look at the output from a bunch of tasks, and so on and so forth.. While it's technically possible to make Conductor do this, it wasn't really designed for it and, given that you can just tell agents to write scripts to create a structure like this, it seemed a lot simpler to just use custom vibe-coded scripts.
The kinds of tools that were designed for use of a lot of agents, like Gas Town, mostly seemed to be for less structured workflows, and they often seemed highly vibe coded and somewhat unreliable as a result, to the point that I wasn't sure why I would want to use one of them and not just cobble together something myself. What I mean there is, per the discussion in the long footnote about board games, if something doesn't meet a certain bar for quality and complexity, it's fairly easy to just make a version of it yourself. Even if the thing you make for yourself is buggier than the product, you can make sure that, given your workflow, it doesn't have bugs that impact your particular workflow, so you don't even have to meet the same overall quality bar as the product does for it to be better for you.
As a result, what I've ended up doing is making one-off loops for tasks that need to run for a while. There's probably an efficiency gain from building some kind of orchestrator that fits what I want, but I don't think I've really set up enough of these loops to know what I want, and what I want varies a lot depending on the problem. Sometimes I want to have certain metrics trigger a health check by an agent that can fix issues and sometimes I want an agent or set of agents to automatically be invoked after each iteration (whatever that means) to check on progress and sometimes I want agents to continuously check on progress. Sometimes I want a graph structure with some kind of multi-level triage, etc.
Because it's fairly easy to have an agent set up whatever arbitrary structure you want, I'll generally start with some kind of simple structure with some basic health checks and monitoring and then I'll check in on it periodically and try to make structural fixes to address issues so that the issue doesn't recur. In principle, something like this that's well set up could produce useful work indefinitely but, at least for what I've set up, these loops tend to degrade in productivity over time. Even if nothing is badly wrong, the loops are a lot more productive if I'm actively at the keyboard typing instructions to nudge things in various ways, while monitoring what's happening. If I leave one of these alone for a few days or a week, it will usually still be producing a non-zero amount of useful work, but not nearly as much as if I'd check in daily. I've tried various strategies to try to keep these loops more on track without intervention and I've found various things that can help, but I haven't figured out how to replace myself (yet?).
For example, in April/May 2026, I tried having a bunch of "personas" convene and reconvene to try to nudge the loop instead of doing it myself. At the time, I was trying to get a loop running smoothly that was doing some work on some code that uses CRDTs (which I know nothing about, BTW), so I tried diagnosing issues with something like "use independent agents to review as linus torvalds, kyle kingsbury, marc brooker, tptacek, dan luu, and 4 contrarian personas. have each think for a long time", with multiple iterations of this (yes, I do find it quite silly to invoke my own name). Each of these personas seemed to keep things on track in a different way, e.g., the "linus torvalds" persona would tend to push back against the loop's "natural" tendency to have things spiral out of control due by repeatedly adding unnecessary complexity, the "dan luu" persona would force the loop to measure things before implementing and also sometimes say things like "we must not rationalize XYZ" and push back on some bad reasoning. None of this was enough to replace human observation and intervention, but doing variations of this was enough to keep these loops running more smoothly, with less intervention required.
This kind of persona setup also improved things for architectural design, debugging, etc. Again, not so much that you wouldn't want a human at all, but enough that the human can do a bit less work.
All of this seems to work best if the human understands the common failure modes. For example, when asked to debug and explain when a bug was introduced, if just prompted to explain, even with multiple independent rounds of analysis, the agents would often come back with a completely incorrect explanation (maybe 50% of the time or so). When asked to confirm their hypothesis by actually executing code to check if the hypothesis is correct, that removed most incorrect explanations. Just adding forced checking to a simple prompt has a better success rate than having agents do independent analyses and cross-check each other (doing both together seems to have an even higher success rate).
A lot of getting value out of agents seems to be having some kind of understanding of their failure modes and then working around them. Earlier in the post, we noted that people aren't really going to be left behind if they're not using coding agents now and get started in M months because they can be at most M months behind, but will likely be much less behind than that because of how quickly things are changing. A major reason for this is, AFAICT, a lot of the skill involved in using agents is working around their failures. Of course AI labs want to fix these failures, which means new releases are designed to obsolete these skills as much as possible. This is possible to observe directly, in some failure modes that were quite common a year ago are now much rarer.
BTW, this is another reason I don't find a lot of benchmarks useful for me personally. In general, benchmarks have moved to trying not to "over explain" and instead act like a naive user who isn't very good at using agents. This is a reasonable thing for AI labs to care about because they want to make a product that needs as little expertise as possible to operate but, as a professional programmer, if there's way to work around some failure mode of agents, you're probably going to use it instead of acting like you're a benchmark, and you therefore get a very different result even if you're doing the exact task from some benchmark.
Thanks to Max Bittker, Dennis Snell, Em Chu, Yossi Kreinin, Peter Geoghegan, Michael Malis, @[email protected], Misha Yaugdin, and Jason Seibel for comments/corrections/discussion.
The argument against having test enginers that I've heard everywhere I've worked, sometimes as test engineers were being laid off, goes something like "the people who can test the code best are the people who wrote it; also, programmers will get lazy about testing if they outsource testing to somebody else", but that's only one side of a trade-off that has two sides.
In general, you get efficiency gains from specialization because people develop deeper skills in the specialization, and you get efficiency losses because the split in skills causes various kinds of fragmentation issues. You can state the same case made against having dedicated testers about having dedicated front-end and back-end folks, mobile engineers, etc.; it's all true. But there's also a true argument on the other side and it's generally acknowledged that, once you hit a certain scale, the gains from having specialists who understand specific things outweigh the benefits of having teams full of generalists who are only kinda ok at each thing. From having seen how good people can get at testing if they spend a decade or two specializing in learning test skills, I think software companies are missing out by not having people with these skills, but this is arguably out of scope for this post since it's not like you can go out and hire a bunch of people with that skillset with respect to software. To even have that population exist, you'd need a culture and ladders like hardware companies have, where verification engineers are first-class citizens, just like logic designers, where they're on the same pay scale, get promoted to high levels at the same rate, have the same amount of prestige, etc., and then you'd have to do that for twenty years.
The gains here are not just the direct expertise gained from spending a career doing something. The existence of a large community of practice at a company also means that people level up faster at the company. In the same way that I was lucky to learn a lot about distributed tracing because I happened to sit next to an expert in distributed tracing and I probably learned as much in a few months from that as I would've if I spent years figuring it out on my own, I was lucky to learn a lot about testing because I sat in a cluster of world class test engineers. Even at software companies that were over one-thousand times the size of that hardware company, I'm not sure that they had a cluster of that many talented test engineers who'd spent 40+ years specializing in testing for me to learn from (and if they did, that group would be so far from me that I'd never interact with them anyway).
[return]And, coincidentally, as with testing, it happens to be a skill that gets developed a lot more at CPU companies than in typical software companies, even ones that produce highly performance sensitive products, like databases. Above, we estimated that the effort spent on testing at the CPU design shop I worked for was maybe a ~2:1 ratio over what you'd see in a traditional software company. When it comes to benchmarking/evals/experimental design, the denominator is low enough at traditional software companies that it's hard to estimate the ratio, but it's surely at least 10:1 and 100:1 and 1000:1 are plausible numbers as well.
Of course, by focusing on and developing much more expertise than software companies in these areas, chip companies are often relatively in the stone ages in a number of other areas. Relatively speaking, I'm also relatively weak in most of those areas. I think this works out ok in the context of a company, where it's valuable to have people with complementary skills, but it can definitely cause some problems in interviews.
[return]Just as an aside, I wonder what's going to happen with online board games (except for the end of this footnote, this entire footnote is about board games, and you might want to skip to the bottom if you have no interest in board games). One issue is that there's high "demand" for cheating and there was quite a bit of cheating in competitive online play even before LLMs. Today, it's not all that hard to make a bot that can cheat and it's only going to get easier. I'm not really interested in playing against random strangers online, so I don't generally play ranked/competitive online board games, but quite a few people do. It's hard to see how this survives if the amount of cheating increases.
Another thing I wonder about is the value of the big game platforms. Board Game Arena (BGA) seems like the biggest platform by a fairly large margin, with Tabletop Simulator (TTS) being second. BGA is, uhhh, you might call it fairly quirky if you're being generous. For example, by default, the platform doesn't really allow players to act concurrently. If you click on anything at the same time another player clicks, it prevents them from doing an action if your click manages to get through to the server slightly before theirs. For games with simultaneous actions or selections, this can cause people to get stalled out of their turns for tens of seconds at a time as other players do their actions. I could write a post the length of this entire post on various issues with BGA, but suffice to say that the other issues you might expect of a multiple player online platform that fundamentally doesn't work if players attempt to act concurrently are problems on the platform. On average, TTS is even clunkier to use.
As a result of this, it's fairly easy to implement a nicer user experience for games that don't need a complex interface. Game rules and mechanisms don't fall under US copyright law, so it appears completely legal to implement a game with the exact same rules as long as you don't use their graphics, trademarked logo, etc. I don't personally want to try to build a platform with unlicensed games that tries to compete with BGA, but I do sometimes want to play a game without the quirks that BGA has (or that isn't available on BGA). Depending on the game, it's taken between seconds of my time and a small number of hours to get what seems like a reasonable version of the rules working. Seconds is for simple games where the game basically just works from a simple prompt (for example, here's a game with the same rules as Scout, which I implemented because my friends couldn't find a way to play Scout online. BTW, I don't promise the game will work at all if you try it—it's hosted on some kind of janky free tier hosting because, as I mentioned, I'm not trying to build some kind of big platform and this works better than BGA when me and my friends use it, which is the (very low) quality bar I'm shooting for, which is that we don't run into bugs while playing, not that it's a generally robust implementation. And although the runtime performance of my game implementations is very poor compared to what's technically possible, my friends who are used to BGA all comment on how it feels instantaneous because they're used to the much slower performance of BGA. When the platform people are used to is both extremely slow and extremely buggy, it's easy to vibe code something nicer.
Some games will take longer because current models can't one shot them. In terms of my time, Guards of Atlantis is probably the most time consuming game I've tried to implement. It has a lot of rules because each card has some custom rules and the rules seem unusually difficult for humans to understand, which also makes them non-ideal for LLMs. Relatively speaking, I've observed a much higher rate of people accidentally playing rules incorrectly than I do for most games and I'm not sure that I've seen anyone play correctly unless they're on the official discord and follow rules discussions there or were taught by such a person. Given that, I don't think it would be reasonable to expect an LLM to one-shot the game.
Anyway, given that it takes between seconds and a few hours of someone's time to implement a board game in a nicer form than on the dominant online board game platforms, I wonder what's going to happen to the dominant board game platforms? Will people keep them because of network effects? A decent fraction of the few people I know who play board games online find network effects to be of little import. For example, see these quotes from the aforementioned #1 Azul player in the world:
[I]'ve been having a blast experimenting with [your bot] during my games recently. the bot finds really cool/creative moves that i would never consider, which helps me become more open-minded to how i approach rounds
...
playing games against these bots can be quite fun (i havent touched azul on bga in months) if they are of ~equal strength
It was interesting but I think not surprising to see the top player in the world playing against bots instead of on BGA, for months. One thing with the big online platforms today is that it's actually fairly hard to match up with someone of comparable skill. The stronger a player is, the worse this problem is. Like I said above, I don't really enjoy playing against random strangers, so I don't do it much, but a nearly universal complaint from folks who play competitive ranked games on BGA is what a grind the ladder is. If you're a strong competitive player, almost everyone you match up with is much lower Elo, so you're playing these boring games where you stomp the other player to gain a tiny bit of Elo per game. And then if you make a blunder, you lose a ton of Elo for a single loss. A while ago, I was too sick to do much of anything, so I tried ranked competitive play for a game on BGA and got up to #4 in the world. During the entire climb to get to #4, I played two games against someone ranked in the top 10. Every other game was a fairly boring game against a significantly weaker player. For competitive players, there's the impending problem of rampant cheating, and the existing problem that ranked competitive play is mostly mind-numbingly boring.
For non-competitive play, BGA is less problematic, but I happen to have been teaching somebody how to play a game as I wrote this footnote and they ran into three different bugs as I was writing this footnote. And, unless you're playing one of the most popular games, there's often a long wait for a game (and even for the most popular games, you're in for a wait during off hours). It's not clear to me why people should be playing on these platforms other than inertia. Maybe inertia is enough of a reason and these platforms will continue to be the place people play, but for someone like me who mostly just plays with local friends when playing online, there isn't really any reason not to use a less buggy and better performing app someone vibe coded over their lunch break.
This same kind of reasoning seems like it should apply to a lot of other kinds of apps. For example, here's Josh Bleecher Snyder talking about coding up a shopping list app as he was shopping. In theory, if software worked, you'd want to use the highly-polished well-tested version that some company has created, but software mostly doesn't work and there are a lot of apps where it's fairly easy to whip up a better version than what most people are using today. Of course, there are still many cases where that's not practical, but I still find it amazing how much software I use somewhat regularly can be re-made in a nicer way fairly easily.
[return]2024-10-28 08:00:00
There's a common narrative that Microsoft was moribund under Steve Ballmer and then later saved by the miraculous leadership of Satya Nadella. This is the dominant narrative in every online discussion about the topic I've seen and it's a commonly expressed belief "in real life" as well. While I don't have anything negative to say about Nadella's leadership in this post, this narrative underrates Ballmer's role in Microsoft's success. Not only did Microsoft's financials, revenue and profit, look great under Ballmer, Microsoft under Ballmer made deep, long-term bets that set up Microsoft for success in the decades after his reign. At the time, the bets were widely panned, indicating that they weren't necessarily obvious, but we can see in retrospect that the company made very strong bets despite the criticism at the time.
In addition to overseeing deep investments in areas that people would later credit Nadella for, Ballmer set Nadella up for success by clearing out political barriers for any successor. Much like Gary Bernhardt's talk, which was panned because he made the problem statement and solution so obvious that people didn't realize they'd learned something non-trivial, Ballmer set up Microsoft for future success so effectively that it's easy to criticize him for being a bum because his successor is so successful.
For people who weren't around before the turn of the century, in the 90s, Microsoft used to be considered the biggest, baddest, company in town. But it wasn't long before people's opinions on Microsoft changed — by 2007, many people thought of Microsoft as the next IBM and Paul Graham wrote Microsoft is Dead, in which he noted that Microsoft being considered effective was ancient history:
A few days ago I suddenly realized Microsoft was dead. I was talking to a young startup founder about how Google was different from Yahoo. I said that Yahoo had been warped from the start by their fear of Microsoft. That was why they'd positioned themselves as a "media company" instead of a technology company. Then I looked at his face and realized he didn't understand. It was as if I'd told him how much girls liked Barry Manilow in the mid 80s. Barry who?
Microsoft? He didn't say anything, but I could tell he didn't quite believe anyone would be frightened of them.
These kinds of comments often came with comments that Microsoft's revenue was destined to fall, such as these comments by Graham:
Actors and musicians occasionally make comebacks, but technology companies almost never do. Technology companies are projectiles. And because of that you can call them dead long before any problems show up on the balance sheet. Relevance may lead revenues by five or even ten years.
Graham names Google and the web as primary causes of Microsoft's death, which we'll discuss later. Although Graham doesn't name Ballmer or note his influence in Microsoft is Dead, Ballmer has been a favorite punching bag of techies for decades. Ballmer came up on the business side of things and later became EVP of Sales and Support; techies love belittling non-technical folks in tech1. A common criticism, then and now, is that Ballmer didn't understand tech and was a poor leader because all he knew was sales and the bottom line and all he can do is copy what other people have done. Just for example, if you look at online comments on tech forums (minimsft, HN, slashdot, etc.) when Ballmer pushed Sinofsky out in 2012, Ballmer's leadership is nearly universally panned2. Here's a fairly typical comment from someone claiming to be an anonymous Microsoft insider:
Dump Ballmer. Fire 40% of the workforce starting with the loser online services (they are never going to get any better). Reinvest the billions in start-up opportunities within the puget sound that can be accretive to MSFT and acquisition targets ... Reset Windows - Desktop and Tablet. Get serious about business cloud (like Salesforce ...)
To the extent that Ballmer defended himself, it was by pointing out that the market appeared to be undervaluing Microsoft. Ballmer noted that Microsoft's market cap at the time was extremely low relative to its fundamentals/financials relative to Amazon, Google, Apple, Oracle, IBM, and Salesforce. This seems to have been a fair assessment by Ballmer as Microsoft has outperformed all of those companies since then.
When Microsoft's market cap took off after Nadella became CEO, it was only natural the narrative would be that Ballmer was killing Microsoft and that the company was struggling until Nadella turned it around. You can pick other discussions if you want, but just for example, if we look at the most recent time Microsoft is Dead hit #1 on HN, a quick ctrl+F has Ballmer's name showing up 24 times. Ballmer has some defenders, but the standard narrative that Ballmer was holding Microsoft back is there, and one of the defenders even uses part of the standard narrative: Ballmer was an unimaginative hack, but he at least set up Microsoft well financially. If you look at high ranking comments, they're all dunking on Ballmer.
And if you look on less well informed forums, like Twitter or Reddit, you see the same attacks, but Ballmer has fewer defenders. On Twitter, when I search for "Ballmer", the first four results are unambiguously making fun of Ballmer. The fifth hit could go either way, but from the comments, seems to generally be taken as making of Ballmer, and as I far as I scrolled down, all but one of the remaining videos was making fun of Ballmer (the one that wasn't was an interview where Ballmer notes that he offered Zuckerberg "$20B+, something like that" for Facebook in 2009, which would've been the 2nd largest tech acquisition ever at the time, second only to Carly Fiorina's acquisition of Compaq for $25B in 2001). Searching reddit (incognito window with no history) is the same story (excluding the stories about him as an NBA owner, where he's respected by fans). The top story is making fun of him, the next one notes that he's wealthier than Bill Gates and the top comment on his performance as a CEO starts with "The irony is that he is Microsofts [sic] worst CEO" and then has the standard narrative that the only reason the company is doing well is due to Nadella saving the day, that Ballmer missed the boat on all of the important changes in the tech industry, etc.
To sum it up, for the past twenty years, people having been dunking on Ballmer for being a buffoon who doesn't understand tech and who was, at best, some kind of bean counter who knew how to keep the lights on but didn't know how to foster innovation and caused Microsoft to fall behind in every important market.
The common view is at odds with what actually happened under Ballmer's leadership. In financially material positive things that happened under Ballmer since Graham declared Microsoft dead, we have:
There are certainly plenty of big misses as well. From 2010-2015, HoloLens was one of Microsoft's biggest bets, behind only Azure and then Bing, but no one's big AR or VR bets have had good returns to date. Microsoft failed to capture the mobile market. Although Windows Phone was generally well received by reviewers who tried it, depending on who you ask, Microsoft was either too late or wasn't willing to subsidize Windows Phone for long enough. Although .NET is still used today, in terms of marketshare, .NET and Silverlight didn't live up to early promises and critical parts were hamstrung or killed as a side effect of internal political battles. Bing is, by reputation, a failure and, at least given Microsoft's choices at the time, probably needed antitrust action against Google to succeed, but this failure still resulted in a business unit worth hundreds of billions of dollars. And despite all of the failures, the biggest bet, Azure, is probably worth on the order of a trillion dollars.
The enterprise sales arm of Microsoft was built out under Ballmer before he was CEO (he was, for a time, EVP for Sales and Support, and actually started at Microsoft as the first business manager) and continued to get built out when Ballmer was CEO. Microsoft's sales playbook was so effective that, when I was Microsoft, Google would offer some customers on Office 365 Google's enterprise suite (Docs, etc.) for free. Microsoft salespeople noted that they would still usually be able to close the sale of Microsoft's paid product even when competing against a Google that was giving their product away. For the enterprise, the combination of Microsoft's offering and its enterprise sales team was so effective that Google couldn't even give its product away.
If you're reading this and you work at a "tech" company, the company is overwhelmingly likely to choose the Google enterprise suite over the Microsoft enterprise suite and the enterprise sales pitch Microsoft sales people have probably sounds ridiculous to you.
An acquaintance of mine who ran a startup had a Microsoft Azure salesperson come in and try to sell them on Azure, opening with "You're on AWS, the consumer cloud. You need Azure, the enterprise cloud". For most people in tech companies, enterprise is synonymous with overpriced, unreliable, junk. In the same way it's easy to make fun of Ballmer because he came up on the sales and business side of the house, it's easy to make fun of an enterprise sales pitch when you hear it but, overall, Microsoft's enterprise sales arm does a good job. When I worked in Azure, I looked into how it worked and, having just come from Google, there was a night and day difference. This was in 2015, under Nadella, but the culture and processes that let Microsoft scale this up were built out under Ballmer. I think there were multiple months where Microsoft hired and onboarded more salespeople than Google employed in total and every stage of the sales pipeline was fairly effective.
When people point to a long list of failures like Bing, Zune, Windows Phone, and HoloLens as evidence that Ballmer was some kind of buffoon who was holding Microsoft back, this demonstrates a lack of understanding of the tech industry. This is like pointing to a list of failed companies a VC has funded as evidence the VC doesn't know what they're doing. But that's silly in a hits based industry like venture capital. If you want to claim the VC is bad, you need to point out poor total return or a lack of big successes, which would imply poor total return. Similarly, a large company like Microsoft has a large portfolio of bets and one successful bet can pay for a huge number of failures. Ballmer's critics can't point to a poor total return because Microsoft's total return was very good under his tenure. Revenue increased from $14B or $22B to $83B, depending on whether you want to count from when Ballmer became President in July 1998 or when Ballmer became CEO in January 2000. The company was also quite profitable when Ballmer left, recording $27B in profit the previous four quarters, more than the revenue of the company he took over. By market cap, Azure alone would be in the top 10 largest public companies in the world and the enterprise software suite minus Azure would probably just miss being in the top 10.
As a result, critics also can't point to a lack of hits when Ballmer presided over the creation of Azure, the conversion of Microsoft's enterprise software from set of local desktop apps to Office 365 et al., the creation of the world's most effective enterprise sales org, the creation of Microsoft's video game empire (among other things, Ballmer was CEO when Microsoft acquired Bungie and made Halo the Xbox's flagship game on launch in 2001), etc. Even Bing, widely considered a failure, on last reported revenue and current P/E ratio, would be 12th most valuable tech company in the world, between Tencent and ASML. When attacking Ballmer, people cite Bing as a failure that occurred on Ballmer's watch, which tells you something about the degree of success Ballmer had. Most companies would love to have their successes be as successful as Bing, let alone their failures. Of course it would be better if Ballmer was prescient and all of his bets succeeded, making Microsoft worth something like $10T instead of the lowly $3T market cap it has today, but the criticism of Ballmer that says that he had some failures and some $1T successes is a criticism that he wasn't the greatest CEO of all time by a gigantic margin. True, but not much of a criticism.
And, unlike Nadella, Ballmer didn't inherit a company that was easily set up for success. As we noted earlier, it wasn't long into Ballmer's tenure that Microsoft was considered a boring, irrelevant company and the next IBM, mostly due to decisions made when Bill Gates was CEO. As a very senior Microsoft employee from the early days, Ballmer was also partially responsible for the state of Microsoft at the time, so Microsoft's problems are also at least partially attributable to him (but that also means he should get some credit for the success Microsoft had through the 90s). Nevertheless, he navigated Microsoft's most difficult problems well and set up his successor for smooth sailing.
Earlier, we noted that Paul Graham cited Google and the rise of the web as two causes for Microsoft's death prior to 2007. As we discussed in this look at antitrust action in tech, these both share a common root cause, antitrust action against Microsoft. If we look at the documents from the Microsoft antitrust case, it's clear that Microsoft knew how important the internet was going to be and had plans to control the internet. As part of these plans, they used their monopoly power on the desktop to kill Netscape. They technically lost an antirust case due to this, but if you look at the actual outcomes, Microsoft basically got what they wanted from the courts. The remedies levied against Microsoft are widely considered to have been useless (the initial decision involved breaking up Microsoft, but they were able to reverse this on appeal), and the case dragged on for long enough that Netscape was doomed by the time the case was decided, and the remedies that weren't specifically targeted at the Netscape situation were meaningless.
A later part of the plan to dominate the web, discussed at Microsoft but never executed, was to kill Google. If we're judging Microsoft by how "dangerous" it is, how effectively it crushes its competitors, like Paul Graham did when he judged Microsoft to be dead, then Microsoft certainly became less dangerous, but the feeling at Microsoft was that their hand was forced due to the circumstances. One part of the plan to kill Google was to redirect users who typed google.com into their address bar to MSN search. This was before Chrome existed and before mobile existed in any meaningful form. Windows desktop marketshare was 97% and IE had between 80% to 95% marketshare depending on the year, with most of the rest of the marketshare belonging to the rapidly declining Netscape. If Microsoft makes this move, Google is killed before it can get Chrome and Android off the ground and, barring extreme antitrust action, such as a breakup of Microsoft, Microsoft owns the web to this day. And then for dessert, it's not clear there wouldn't be a reason to go after Amazon.
After internal debate, Microsoft declined to kill Google not due to fear of antitrust action, but due to fear of bad PR from the ensuing antitrust action. Had Microsoft redirected traffic away from Google, the impact on Google would've been swifter and more severe than their moves against Netscape and in the time it would take for the DoJ to win another case against Microsoft, Google would suffer the same fate as Netscape. It might be hard to imagine this if you weren't around at the time, but the DoJ vs. Microsoft case was regular front-page news in a way that we haven't seen since (in part because companies learned their lesson on this one — Google supposedly killed the 2011-2012 FTC against them with lobbying and has cleverly maneuvered the more recent case so that it doesn't dominate the news cycle in the same way). The closest thing we've seen since the Microsoft antitrust media circus was the media response to the Crowdstrike outage, but that was a flash in the pan compared to the DoJ vs. Microsoft case.
If there's a criticism of Ballmer here, perhaps it's something like Microsoft didn't pre-emptively learn the lessons its younger competitors learned from its big antitrust case before the big antitrust case. A sufficiently prescient executive could've advocated for heavy lobbying to head the antitrust case off at pass, like Google did in 2011-2012, or maneuvered to make the antitrust case just another news story, like Google has been doing for the current case. Another possible criticism is that Microsoft didn't correctly read the political tea leaves and realize that there wasn't going to be serious US tech antitrust for at least two decades after the big case against Microsoft. In principle, Ballmer could've overridden the decision to not kill Google if he had the right expertise on staff to realize that the United States was entering a two decade period of reduced antitrust scrutiny in tech.
As criticisms go, I think the former criticism is correct, but not an indictment of Ballmer unless you expect CEOs to be infallible, so as evidence that Ballmer was a bad CEO, this would be a very weak criticism. And it's not clear that the latter criticism is correct. While Google was able to get away with things like hardcoding the search engine in Android to prevent users from changing their search engine setting to having badware installers trick users into making Chrome the default browser, they were considered the "good guys" and didn't get much scrutiny for these sorts of actions, Microsoft wasn't treated with kid gloves in the same way by the press or the general public. Google didn't trigger a serious antitrust investigation until 2011, so it's possible the lack of serious antitrust action between 2001 and 2010 was an artifact of Microsoft being careful to avoid antitrust scrutiny and Google being too small to draw scrutiny and that a move to kill Google when it was still possible would've drawn serious antitrust scrutiny and another PR circus. That's one way in which the company Ballmer inherited was in a more difficult situation than its competitors — Microsoft's hands were perceived to be tied and may have actually been tied. Microsoft could and did get severe criticism for taking an action when the exact same action taken by Google would be lauded as clever.
When I was at Microsoft, there was a lot of consternation about this. One funny example was when, in 2011, Google officially called out Microsoft for unethical behavior and the media jumped on this as yet another example of Microsoft behaving badly. A number of people I talked to at Microsoft were upset by this because, according to them, Microsoft got the idea to do this when they noticed that Google was doing it, but reputations take a long time to change and actions taken while Gates was CEO significantly reduced Microsoft's ability to maneuver.
Another difficulty Ballmer had to deal with on taking over was Microsoft's intense internal politics. Again, as a very senior Microsoft employee going back to almost the beginning, he bears some responsibility for this, but Ballmer managed to clear the board of the worst bad actors so that Nadella didn't inherit such a difficult situation. If we look at why Microsoft didn't dominate the web under Ballmer, in addition to concerns that killing Google would cause a PR backlash, internal political maneuvering killed most of Microsoft's most promising web products and reduced the appeal and reach of most of the rest of its web products. For example, Microsoft had a working competitor to Google Docs in 1997, one year before Google was founded and nine years before Google acquired Writely, but it was killed for political reasons. And likewise for NetMeeting and other promising products. Microsoft certainly wasn't alone in having internal political struggles, but it was famous for having more brutal politics than most.
Although Ballmer certainly didn't do a perfect job at cleaning house, when I was at Microsoft and asked about promising projects that were sidelined or killed due to internal political struggles, the biggest recent sources of those issues were shown the door under Ballmer, leaving a much more functional company for Nadella to inherit.
Stepping back to look at the big picture, Ballmer inherited a company that was a financially strong position that was hemmed in by internal and external politics in a way that caused outside observers to think the company was overwhelmingly likely to slide into irrelevance, leading to predictions like Graham's famous prediction that Microsoft is dead, with revenues expected to decline in five to ten years. In retrospect, we can see that moves made under Gates limited Microsoft's ability to use its monopoly power to outright kill competitors, but there was no inflection point at which a miraculous turnaround was mounted. Instead, Microsoft continued its very strong execution on enterprise products and continued making reasonable bets on the future in a successful effort to supplant revenue streams that were internally viewed as long-term dead ends, even if they were going to be profitable dead ends, such as Windows and boxed (non-subscription) software.
Unlike most companies in that position, Microsoft was willing to very heavily subsidize a series of bets that leadership thought could power the company for the next few decades, such as Windows Phone, Bing, Azure, Xbox, and HoloLens. From the internal and external commentary on these bets, you can see why it's so hard for companies to use their successful lines of business to subsidize new lines of business when the writing is on the wall for the successful businesses. People panned these bets as stupid moves that would kill the company, saying the company should focus is efforts on its most profitable businesses, such as Windows. Even when there's very clear data showing that bucking the status quo is the right thing, people usually don't do it, in part because you look like an idiot when it doesn't pan out, but Ballmer was willing to make the right bets in the face of decades of ridicule.
Another reason it's hard for companies to make these bets is that companies are usually unable to launch new things that are radically different from their core business. When yet another non-acquisition Google consumer product fails, every writes this off as a matter of course — of course Google failed there, they're a technical-first company that's bad at product. But Microsoft made this shift multiple times and succeeded. Once was with Xbox. If you look at the three big console manufacturers, two are hardware companies going way back and one is Microsoft, a boxed software company that learned how to make hardware. Another time was with Azure. If you look at the three big cloud providers, two are online services companies going back to their founding and one is Microsoft, a boxed software company that learned how to get into the online services business. Other companies with different core lines of business than hardware and online services saw these opportunities and tried to make the change and failed.
And if you look at the process of transitioning here, it's very easy to make fun of Microsoft in the same way it's easy to make fun of Microsoft's enterprise sales pitch. The core Azure folks came from Windows, so in the very early days of Azure, they didn't have an incident management process to speak of and during their first big global outages, people were walking around the hallways asking "is it Azure down?" and trying to figure out what to do. Azure would continue to have major global outages for years while learning how to ship somewhat reliable software, but they were able to address the problems well enough to build a trillion dollar business. Another time, before Azure really knew how to build servers, a Microsoft engineer pulled up Amazon's pricing page and noticed that AWS's retail price for disk was cheaper than Azure's cost to provision disks. When I was at Microsoft, a big problem for Azure was building out datacenter fast enough. People joked that the recent hiring of a ton of sales people worked too well and the company sold too much Azure, which was arguably true and also a real emergency for the company. In the other cases, Microsoft mostly learned how to do it themselves and in this case they brought in some very senior people from Amazon who had deep expertise in supply chain and building out datacenters. It's easy to say that, when you have a problem and a competitor has the right expertise, you should hire some experts and listen to them but most companies fail when they try to do this. Sometimes, companies don't recognize that they need help but, more frequently, they do bring in senior expertise that people don't listen to. It's very easy for the old guard at a company to shut down efforts to bring in senior outside expertise, especially at a company as fractious at Microsoft, but leadership was able to make sure that key initiatives like this were successful3.
When I talked to Google engineers about Azure during Azure's rise, they were generally down on Azure and would make fun of it for issues like the above, which seemed comical to engineers working at a companies that grew up as large scale online services companies with deep expertise in operating large scale services, building efficient hardware, and building out datacenter, but despite starting in a very deep hole technically, operationally, and culturally, Microsoft built a business unit worth a trillion dollars with Azure.
Not all of the bets panned out, but if we look at comments from critics who were saying that Microsoft was doomed because it was subsidizing the wrong bets or younger companies would surpass it, well, today, Microsoft is worth 50% more than Google and twice as much as Meta. If we look at the broader history of the tech industry, Microsoft has had sustained strong execution from its founding in 1975 until today, a nearly fifty year run, a run that's arguably been unmatched in the tech industry. Intel's been around as bit longer, but they stumbled very badly around the turn of the century and they've had a number of problems over the past decade. IBM has a long history, but it just wasn't all that big during its early history, e.g., when T.J. Watson renamed Computing-Tabulating-Recording Company to International Business Machines, its revenue was still well under $10M a year (inflation adjusted, on the order of $100M a year). Computers started becoming big and IBM was big for a tech company by the 50s, but the antitrust case brought against IBM in 1969 that dragged on until it was dropped for being "without merit" in 1982 hamstrung the company and its culture in ways that are still visible when you look at, for example, why IBM's various cloud efforts have failed and, in the 90s, the company was on its deathbed and only managed to survive at all due to Gerstner's turnaround. If we look at older companies that had long sustained runs of strong execution, most of them are gone, like DEC and Data General, or had very bad stumbles that nearly ended the company, like IBM and Apple. There are companies that have had similarly long periods of strong execution, like Oracle, but those companies haven't been nearly as effective as Microsoft in expanding their lines of business and, as a result, Oracle is worth perhaps two Bings. That makes Oracle the 20th most valuable public company in the world, which certainly isn't bad, but it's no Microsoft.
If Microsoft stumbles badly, a younger company like Nvidia, Meta, or Google could overtake Microsoft's track record, but that would be no fault of Ballmer's and we'd still have to acknowledge that Ballmer was a very effective CEO, not just in terms of bringing the money in, but in terms of setting up a vision that set Microsoft up for success for the next fifty years.
Besides the headline items mentioned above, off the top of my head, here are a few things I thought were interesting that happened under Ballmer since Graham declared Microsoft to be dead
One response to Microsoft's financial success, both the direct success that happened under Ballmer as well as later success that was set up by Ballmer, is that Microsoft is financially successful but irrelevant for trendy programmers, like IBM. For one thing, rounded to the nearest Bing, IBM is probably worth either zero or one Bings. But even if we put aside the financial aspect and we just look at how much each $1T tech company (Apple, Nvidia, Microsoft, Google, Amazon, and Meta) has impacted programmers, Nvidia, Apple, and Microsoft all have a lot of programmers who are dependent on the company due to some kind of ecosystem dependence (CUDA; iOS; .NET and Windows, the latter of which is still the platform of choice for many large areas, such as AAA games).
You could make a case for the big cloud vendors, but I don't think that companies have a nearly forced dependency on AWS in the same way that a serious English-language consumer app company really needs an iOS app or an AAA game company has to release on Windows and overwhelmingly likely develops on Windows.
If we look at programmers who aren't pinned to an ecosystem, Microsoft seems highly relevant to a lot of programmers due to the creation of tools like vscode and TypeScript. I wouldn't say that it's necessarily more relevant than Amazon since so many programmers use AWS, but it's hard to argue that the company that created (among many other things) vscode and TypeScript under Ballmer's watch is irrelevant to programmers.
Shortly after joining Microsoft in 2015, I bet Derek Chiou that Google would beat Microsoft to $1T market cap. Unlike most external commentators, I agreed with the bets Microsoft was making, but when I looked around at the kinds of internal dysfunction Microsoft had at the time, I thought that would cause them enough problems that Google would win. That was wrong — Microsoft beat Google to $1T and is now worth $1T more than Google.
I don't think I would've made the bet even a year later, after seeing Microsoft from the inside and how effective Microsoft sales was and how good Microsoft was at shipping things that are appealing to enterprises and the comparing that to Google's cloud execution and strategy. But you could say that I made a mistake that was fairly analogous to what external commentators made until I saw how Microsoft operated in detail.
Thanks to Laurence Tratt, Yossi Kreinin, Heath Borders, Justin Blank, Fabian Giesen, Justin Findlay, Matthew Thomas, Seshadri Mahalingam, and Nam Nguyen for comments/corrections/discussion
Here's the top HN comment on a story about Sinofsky's ousting:
The real culprit that needs to be fired is Steve Ballmer. He was great from the inception of MSFT until maybe the turn of the century, when their business strategy of making and maintaining a Windows monopoly worked beautifully and extremely profitably. However, he is living in a legacy environment where he believes he needs to protect the Windows/Office monopoly BY ANY MEANS NECESSARY, and he and the rest of Microsoft can't keep up with everyone else around them because of innovation.
This mindset has completely stymied any sort of innovation at Microsoft because they are playing with one arm tied behind their backs in the midst of trying to compete against the likes of Google, Facebook, etc. In Steve Ballmer's eyes, everything must lead back to the sale of a license of Windows/Office, and that no longer works in their environment.
If Microsoft engineers had free rein to make the best search engine, or the best phone, or the best tablet, without worries about how will it lead to maintaining their revenue streams of Windows and more importantly Office, then I think their offerings would be on an order of magnitude better and more creative.
This is wrong. At the time, Microsoft was very heavily subsidizing Bing. To the extent that one can attribute the subsidy, it would be reasonable to say that the bulk of the subsidy was coming from Windows. Likewise, Azure was a huge bet that was being heavily subsidized from the profit that was coming from Windows. Microsoft's strategy under Ballmer was basically the opposite of what this comment is saying.
Funnily enough, if you looked at comments on minimsft (many of which were made by Microsoft insiders), people noted the huge spend on things like Azure and online services, but most thought this was a mistake and that Microsoft needed to focus on making Windows and Windows hardware (like the Surface) great.
Basically, no matter what people think Ballmer is doing, they say it's wrong and that he should do the opposite. That means people call for different actions since most commenters outside of Microsoft don't actually know what Microsoft is up to, but from the way the comments are arrayed against Ballmer and not against specific actions of the company, we can see that people aren't really making a prediction about any particular course of action and they're just ragging on Ballmer.
BTW, the #2 comment on HN says that Ballmer missed the boat on the biggest things in tech in the past 5 years and that Ballmer has deemphasized cloud computing (which was actually Microsoft's biggest bet at the time if you look at either capital expenditure or allocated headcount). The #3 comment says "Steve Ballmer is a sales guy at heart, and it's why he's been able to survive a decade of middling stock performance and strategic missteps: He must have close connections to Microsoft's largest enterprise customers, and were he to be fired, it would be an invitation for those customers to reevaluate their commitment to Microsoft's platforms.", and the rest of the top-level comments aren't about Ballmer.
[return]2024-08-11 08:00:00
About eight years ago, I was playing a game of Codenames where the game state was such that our team would almost certainly lose if we didn't correctly guess all of our remaining words on our turn. From the given clue, we were unable to do this. Although the game is meant to be a word guessing game based on word clues, a teammate suggested that, based on the physical layout of the words that had been selected, most of the possibilities we were considering would result in patterns that were "too weird" and that we should pick the final word based on the location. This worked and we won.
[Click to expand explanation of Codenames if you're not familiar with the game]
Codenames is played in two teams. The game has a 5x5 grid of words, where each word is secretly owned by one of {blue team, red team, neutral, assassin}. Each team has a "spymaster" who knows the secret word <-> ownership mapping. The spymaster's job is to give single-word clues that allow their teammates to guess which words belong to their team without accidentally guessing words of the opposing team or the assassin. On each turn, the spymaster gives a clue and their teammates guess which words are associated with the clue. The game continues until one team's words have all been guessed or the assassin's word is guessed (immediate loss). There are some details that are omitted here for simplicity, but for the purposes of this post, this explanation should be close enough. If you want more of an explanation, you can try this video, or the official rules
Ever since then, I've wondered how good someone would be if all they did was memorize all 40 setup cards that come with the game. To simulate this, we'll build a bot that plays using only position information would be (you might also call this an AI, but since we'll discuss using an LLM/AI to write this bot, we'll use the term bot to refer to the automated codenames playing agent to make it easy to disambiguate).
At the time, after the winning guess, we looked through the configuration cards to see if our teammate's idea of guessing based on shape was correct, and it was — they correctly determined the highest probability guess based on the possible physical configurations. Each card layout defines which words are your team's and which words belong to the other team and, presumably to limit the cost, the game only comes with 40 cards (160 configurations under rotation). Our teammate hadn't memorized the cards (which would've narrowed things down to only one possible configuration), but they'd played enough games to develop an intuition about what patterns/clusters might be common and uncommon, enabling them to come up with this side-channel attack against the game. For example, after playing enough games, you might realize that there's no card where a team has 5 words in a row or column, or that only the start player color ever has 4 in a row, and if this happens on an edge and it's blue, the 5th word must belong to the red team, or that there's no configuration with six connected blue words (and there is one with red, one with 2 in a row centered next to 4 in a row). Even if you don't consciously use this information, you'll probably develop a subconscious aversion to certain patterns that feel "too weird".
Coming back to the idea of building a bot that simulates someone who's spent a few days memorizing the 40 cards, below, there's a simple bot you can play against that simulates a team of such players. Normally, when playing, you'd provide clues and the team would guess words. But, in order to provide the largest possible advantage to you, the human, we'll give you the unrealistically large advantage of assuming that you can, on demand, generate a clue that will get your team to select the exact squares that you'd like, which is simulated by letting you click on any tile that you'd like to have your team guess that tile.
By default, you also get three guesses a turn, which would put you well above 99%-ile among Codenames players I've seen. While good players can often get three or more correct moves a turn, averaging three correct moves and zero incorrect moves a turn would be unusually good in most groups. You can toggle the display of remaining matching boards on, but if you want to simulate what it's like to be a human player who hasn't memorized every board, you might want to try playing a few games with the display off.
If, at any point, you finish a turn and it's the bot's turn and there's only one matching board possible, the bot correctly guesses every one of its words and wins. The bot would be much stronger if it ever guessed words before it can guess them all, either naively or to strategically reduce the search space, or if it even had a simple heuristic where it would randomly guess among the possible boards if it could deduce that you'd win on your next turn, but even when using the most naive "board memorization" bot possible has been able to beat every Codenames player who I handed this to in most games where they didn't toggle the remaining matching boards on and use the same knowledge the bot has access to.
2024-06-16 08:00:00
There've been regular viral stories about ML/AI bias with LLMs and generative AI for the past couple years. One thing I find interesting about discussions of bias is how different the reaction is in the LLM and generative AI case when compared to "classical" bugs in cases where there's a clear bug. In particular, if you look at forums or other discussions with lay people, people frequently deny that a model which produces output that's sort of the opposite of what the user asked for is even a bug. For example, a year ago, an Asian MIT grad student asked Playground AI (PAI) to "Give the girl from the original photo a professional linkedin profile photo" and PAI converted her face to a white face with blue eyes.
The top "there's no bias" response on the front-page reddit story, and one of the top overall comments, was
Sure, now go to the most popular Stable Diffusion model website and look at the images on the front page.
You'll see an absurd number of asian women (almost 50% of the non-anime models are represented by them) to the point where you'd assume being asian is a desired trait.
How is that less relevant that "one woman typed a dumb prompt into a website and they generated a white woman"?
Also keep in mind that she typed "Linkedin", so anyone familiar with how prompts currently work know it's more likely that the AI searched for the average linkedin woman, not what it thinks is a professional women because image AI doesn't have an opinion.
In short, this is just an AI ragebait article.
Other highly-ranked comments with the same theme include
Honestly this should be higher up. If you want to use SD with a checkpoint right now, if you dont [sic] want an asian girl it’s much harder. Many many models are trained on anime or Asian women.
and
Right? AI images even have the opposite problem. The sheer number of Asians in the training sets, and the sheer number of models being created in Asia, means that many, many models are biased towards Asian outputs.
Other highly-ranked comments noted that this was a sample size issue
"Evidence of systemic racial bias"
Shows one result.
Playground AI's CEO went with the same response when asked for an interview by the Boston Globe — he declined the interview and replied with a list of rhetorical questions like the following (the Boston Globe implies that there was more, but didn't print the rest of the reply):
If I roll a dice just once and get the number 1, does that mean I will always get the number 1? Should I conclude based on a single observation that the dice is biased to the number 1 and was trained to be predisposed to rolling a 1?
We could just have easily picked an example from Google or Facebook or Microsoft or any other company that's deploying a lot of ML today, but since the CEO of Playground AI is basically asking someone to take a look at PAI's output, we're looking at PAI in this post. I tried the same prompt the MIT grad student used on my Mastodon profile photo, substituting "man" for "girl". PAI usually turns my Asian face into a white (caucasian) face, but sometimes makes me somewhat whiter but ethnically ambiguous (maybe a bit Middle Eastern or East Asian or something. And, BTW, my face has a number of distinctively Vietnamese features and which pretty obviously look Vietnamese and not any kind of East Asian.



My profile photo is a light-skinned winter photo, so I tried a darker-skinned summer photo and PAI would then generally turn my face into a South Asian or African face, with the occasional Chinese (but never Vietnamese or kind of Southeast Asian face), such as the following:


A number of other people also tried various prompts and they also got results that indicated that the model (where “model” is being used colloquially for the model and its weights and any system around the model that's responsible for the output being what it is) has some preconceptions about things like what ethnicity someone has if they have a specific profession that are strong enough to override the input photo. For example, converting a light-skinned Asian person to a white person because the model has "decided" it can make someone more professional by throwing out their Asian features and making them white.
Other people have tried various prompts to see what kind of pre-conceptions are bundled into the model and have found similar results, e.g., Rob Ricci got the following results when asking for "linkedin profile picture of X professor" for "computer science", "philosophy", "chemistry", "biology", "veterinary science", "nursing", "gender studies", "Chinese history", and "African literature", respectively. In the 28 images generated for the first 7 prompts, maybe 1 or 2 people out of 28 aren't white. The results for the next prompt, "Chinese history" are wildly over-the-top stereotypical, something we frequently see from other models as well when asking for non-white output. And Andreas Thienemann points out that, except for the over-the-top Chinese stereotypes, every professor is wearing glasses, another classic stereotype.



Like I said, I don't mean to pick on Playground AI in particular. As I've noted elsewhere, trillion dollar companies regularly ship AI models to production without even the most basic checks on bias; when I tried ChatGPT out, every bias-checking prompt I played with returned results that were analogous to the images we saw here, e.g., when I tried asking for bios of men and women who work in tech, women tended to have bios indicating that they did diversity work, even for women who had no public record of doing diversity work and men tended to have degrees from name-brand engineering schools like MIT and Berkeley, even people who hadn't attended any name-brand schools, and likewise for name-brand tech companies (the link only has 4 examples due to Twitter limitations, but other examples I tried were consistent with the examples shown).
This post could've used almost any publicly available generative AI. It just happens to use Playground AI because the CEO's response both asks us to do it and reflects the standard reflexive "AI isn't biased" responses that lay people commonly give.
Coming back to the response about how it's not biased for professional photos of people to be turned white because Asians feature so heavily in other cases, the high-ranking reddit comment we looked at earlier suggested "go[ing] to the most popular Stable Diffusion model website and look[ing] at the images on the front page". Below is what I got when I clicked the link on the day the comment was made and then clicked "feed".
[Click to expand / collapse mildly NSFW images]

The site had a bit of a smutty feel to it. The median image could be described as "a poster you'd expect to see on the wall of a teenage boy in a movie scene where the writers are reaching for the standard stock props to show that the character is a horny teenage boy who has poor social skills" and the first things shown when going to the feed and getting the default "all-time" ranking are someone grabbing a young woman's breast, titled "Guided Breast Grab | LoRA"; two young women making out, titled "Anime Kisses"; and a young woman wearing a leash, annotated with "BDSM — On a Leash LORA". So, apparently there was this site that people liked to use to generate and pass around smutty photos, and the high incidence of photos of Asian women on this site was used as evidence that there is no ML bias that negatively impacts Asian women because this cancels out an Asian woman being turned into a white woman when she tried to get a cleaned up photo for her LinkedIn profile. I'm not really sure what to say to this. Fabian Geisen responded with "🤦♂️. truly 'I'm not bias. your bias' level discourse", which feels like an appropriate response.
Another standard line of reasoning on display in the comments, that I see in basically every discussion on AI bias, is typified by
AI trained on stock photo of “professionals” makes her white. Are we surprised?
She asked the AI to make her headshot more professional. Most of “professional” stock photos on the internet have white people in them.
and
If she asked her photo to be made more anything it would likely turn her white just because that’s the average photo in the west where Asians only make up 7.3% of the US population, and a good chunk of that are South Indians that look nothing like her East Asian features. East Asians are 5% or less; there’s just not much training data.
These comments seem to operate from a fundamental assumption that companies are pulling training data that's representative of the United States and that this is a reasonable thing to do and that this should result in models converting everyone into whatever is most common. This is wrong on multiple levels.
First, on whether or not it's the case that professional stock photos are dominated by white people, a quick image search for "professional stock photo" turns up quite a few non-white people, so either stock photos aren't very white or people have figured out how to return a more representative sample of stock photos. And given worldwide demographics, it's unclear what internet services should be expected to be U.S.-centric. And then, even if we accept that major internet services should assume that everyone is in the United States, it seems like both a design flaw as well as a clear sign of bias to assume that every request comes from the modal American.
Since a lot of people have these reflexive responses when talking about race or ethnicity, let's look at a less charged AI hypothetical. Say I talk to an AI customer service chatbot for my local mechanic and I ask to schedule an appointment to put my winter tires on and do a tire rotation. Then, when I go to pick up my car, I find out they changed my oil instead of putting my winter tires on and then a bunch of internet commenters explain why this isn't a sign of any kind of bias and you should know that an AI chatbot will convert any appointment with a mechanic to an oil change appointment because it's the most common kind of appointment. A chatbot that converts any kind of appointment request into "give me the most common kind of appointment" is pretty obviously broken but, for some reason, AI apologists insist this is fine when it comes to things like changing someone's race or ethnicity. Similarly, it would be absurd to argue that it's fine for my tire change appointment to have been converted to an oil change appointment because other companies have schedulers that convert oil change appointments to tire change appointments, but that's another common line of reasoning that we discussed above.
And say I used some standard non-AI scheduling software like Mindbody or JaneApp to schedule an appointment with my mechanic and asked for an appointment to have my tires changed and rotated. If I ended up having my oil changed because the software simply schedules the most common kind of appointment, this would be a clear sign that the software is buggy and no reasonable person would argue that zero effort should go into fixing this bug. And yet, this is a common argument that people are making with respect to AI (it's probably the most common defense in comments on this topic). The argument goes a bit further, in that there's this explanation of why the bug occurs that's used to justify why the bug should exist and people shouldn't even attempt to fix it. Such an explanation would read as obviously ridiculous for a "classical" software bug and is no less ridiculous when it comes to ML. Perhaps one can argue that the bug is much more difficult to fix in ML and that it's not practical to fix the bug, but that's different from the common argument that it isn't a bug and that this is the correct way for software to behave.
I could imagine some users saying something like that when the program is taking actions that are more opaque to the user, such as with autocorrect, but I actually tried searching reddit for autocorrect bug and in the top 3 threads (I didn't look at any other threads), 2 out of the 255 comments denied that incorrect autocorrects were a bug and both of those comments were from the same person. I'm sure if you dig through enough topics, you'll find ones where there's a higher rate, but on searching for a few more topics (like excel formatting and autocorrect bugs), none of the topics I searched approached what we see with generative AI, where it's not uncommon to see half the commenters vehemently deny that a prompt doing the opposite of what the user wants is a bug.
Coming back to the bug itself, in terms of the mechanism, one thing we can see in both classifiers as well as generative models is that many (perhaps most or almost all) of these systems are taking bias that a lot of people have that's reflected in some sample of the internet, which results in things like Google's image classifier classifying a black hand holding a thermometer as {hand, gun} and a white hand holding a thermometer as {hand, tool}1. After a number of such errors over the past decade, from classifying black people as gorillas in Google Photos in 2015, to deploying some kind of text-classifier for ads that classified ads that contained the terms "African-American composers" and "African-American music" as "dangerous or derogatory" in 2018 Google turned the knob in the other direction with Gemini which, by the way, generated much more outrage than any of the other examples.
There's nothing new about bias making it into automated systems. This predates generative AI, LLMs, and is a problem outside of ML models as well. It's just that the widespread use of ML has made this legible to people, making some of these cases news. For example, if you look at compression algorithms and dictionaries, Brotli is heavily biased towards the English language — the human-language elements of the 120 transforms built into the language are English, and the built-in compression dictionary is more heavily weighted towards English than whatever representative weighting you might want to reference (population-weighted language speakers, non-automated human-languages text sent on on messaging platforms, etc.). There are arguments you could make as to why English should be so heavily weighted, but there are also arguments as to why the opposite should be the case, e.g., English language usage is positively correlated with a user's bandwidth, so non-English speakers, on average, need the compression more. But regardless of the exact weighting function you think should be used to generate a representative dictionary, that's just not going to make a viral news story because you can't get the typical reader to care that a number of the 120 built-in Brotli transforms do things like add " of the ", ". The", or ". This" to text, which are highly specialized for English, and none of the transforms encode terms that are highly specialized for any other human language even though only 20% of the world speaks English, or that, compared to the number of speakers, the built-in compression dictionary is extremely highly tilted towards English by comparison to any other human language. You could make a defense of the dictionary of Brotli that's analogous to the ones above, over some representative corpus which the Brotli dictionary was trained on, we get optimal compression with the Brotli dictionary, but there are quite a few curious phrases in the dictionary such as "World War II", ", Holy Roman Emperor", "British Columbia", "Archbishop" , "Cleveland", "esperanto", etc., that might lead us to wonder if the corpus the dictionary was trained on is perhaps not the most representative, or even particularly representative of text people send. Can it really be the case that including ", Holy Roman Emperor" in the dictionary produces, across the distribution of text sent on the internet, better compression than including anything at all for French, Urdu, Turkish, Tamil, Vietnamese, etc.?
Another example which doesn't make a good viral news story is my not being able to put my Vietnamese name in the title of my blog and have my blog indexed by Google outside of Vietnamese-language Google — I tried that when I started my blog and it caused my blog to immediately stop showing up in Google searches unless you were in Vietnam. It's just assumed that the default is that people want English language search results and, presumably, someone created a heuristic that would trigger if you have two characters with Vietnamese diacritics on a page that would effectively mark the page as too Asian and therefore not of interest to anyone in the world except in one country. "Being visibly Vietnamese" seems like a fairly common cause of bugs. For example, Vietnamese names are a problem even without diacritics. I often have forms that ask for my mother's maiden name. If I enter my mother's maiden name, I'll be told something like "Invalid name" or "Name too short". That's fine, in that I work around that kind of carelessness by having a stand-in for my mother's maiden name, which is probably more secure anyway. Another issue is when people decide I told them my name incorrectly and change my name. For my last name, if I read my name off as "Luu, ell you you", that gets shortened from the Vietnamese "Luu" to the Chinese "Lu" about half the time and to a western "Lou" much of the time as well, but I've figured out that if I say "Luu, ell you you, two yous", that works about 95% of the time. That sometimes annoys the person on the other end, who will exasperatedly say something like "you didn't have to spell it out three times". Maybe so for that particular person, but most people won't get it. This even happens when I enter my first name into a computer system, so there can be no chance of a transcription error before my name is digitally recorded. My legal first name, with no diacritics, is Dan. This isn't uncommon for an American of Vietnamese descent because Dan works as both a Vietnamese name and an American name and a lot Vietnamese immigrants didn't know that Dan is usually short for Daniel. At six of the companies I've worked for full-time, someone has helpfully changed my name to Daniel at three of them, presumably because someone saw that Dan was recorded in a database and decided that I failed to enter my name correctly and that they knew what my name was better than I did and they were so sure of this they saw no need to ask me about it. In one case, this only impacted my email display name. Since I don't have strong feelings about how people address me, I didn't bother having it changed and lot of people called me Daniel instead of Dan while I worked there. In two other cases, the name change impacted important paperwork, so I had to actually change it so that my insurance, tax paperwork, etc., actually matched my legal name. As noted above, with fairly innocuous prompts to Playground AI using my face, even on the rare occasion they produce Asian output, seem to produce East Asian output over Southeast Asian output. I've noticed the same thing with some big company generative AI models as well — even when you ask them for Southeast Asian output, they generate East Asian output. AI tools that are marketed as tools that clean up errors and noise will also clean up Asian-ness (and other analogous "errors"), e.g., people who've used Adobe AI noise reduction (billed as "remove noise from voice recordings with speech enhacement") note that it will take an Asian accent and remove it, making the person sound American (and likewise for a number of other accents, such as eastern European accents).
I probably see tens to hundreds things like this most weeks just in the course of using widely used software (much less than the overall bug count, which we previously observed was in hundreds to thousands per week), but most Americans I talk to don't notice these things at all. Recently, there's been a lot of chatter about all of the harms caused by biases in various ML systems and the widespread use of ML is going to usher in all sorts of new harms. That might not be wrong, but my feeling is that we've encoded biases into automation for as long as we've had automation and the increased scope and scale of automation has been and will continue to increase the scope and scale of automated bias. It's just that now, many uses of ML make these kinds of biases a lot more legible to lay people and therefore likely to make the news.
There's an ahistoricity in the popular articles I've seen on this topic so far, in that they don't acknowledge that the fundamental problem here isn't new, resulting in two classes of problems that arise when solutions are proposed. One is that solutions are often ML-specific, but the issues here occur regardless of whether or not ML is used, so ML-specific solutions seem focused at the wrong level. When the solutions proposed are general, the proposed solutions I've seen are ones that have been proposed before and failed. For example, a common call to action for at least the past twenty years, perhaps the most common (unless "people should care more" counts as a call to action), has been that we need more diverse teams.
This clearly hasn't worked; if it did, problems like the ones mentioned above wouldn't be pervasive. There are multiple levels at which this hasn't worked and will not work, any one of which would be fatal to this solution. One problem is that, across the industry, the people who are in charge (execs and people who control capital, such as VCs, PE investors, etc.), in aggregate, don't care about this. Although there are efficiency justifications for more diverse teams, the case will never be as clear-cut as it is for decisions in games and sports, where we've seen that very expensive and easily quantifiable bad decisions can persist for many decades after the errors were pointed out. And then, even if execs and capital were bought into the idea, it still wouldn't work because there are too many dimensions. If you look at a company that really prioritized diversity, like Patreon from 2013-2019, you're lucky if the organization is capable of seriously prioritizing diversity in two or three dimensions while dropping the ball on hundreds or thousands of other dimensions, such as whether or not Vietnamese names or faces are handled properly.
Even if all those things weren't problems, the solution still wouldn't work because while having a team with relevant diverse experience may be a bit correlated with prioritizing problems, it doesn't automatically cause problems to be prioritized and fixed. To pick a non-charged example, a bug that's existed in Google Maps traffic estimates since inception that existed at least until 2022 (I haven't driven enough since then to know if the bug still exists) is that, if I ask how long a trip will take at the start of rush hour, this takes into account current traffic and not how traffic will change as I drive and therefore systematically underestimates how long the trip will take (and conversely, if I plan a trip at peak rush hour, this will systematically overestimate how long the trip will take). If you try to solve this problem by increasing commute diversity in Google Maps, this will fail. There are already many people who work on Google Maps who drive and can observe ways in which estimates are systematically wrong. Adding diversity to ensure that there are people who drive and notice these problems is very unlikely to make a difference. Or, to pick another example, when the former manager of Uber's payments team got incorrected blacklisted from Uber by an ML model incorrectly labeling his transactions as fraudulent, no one was able to figure out what happened or what sort of bias caused him to get incorrectly banned (they solved the problem by adding his user to an allowlist). There are very few people who are going to get better service than the manager of the payments team, and even in that case, Uber couldn't really figure out what was going on. Hiring a "diverse" candidate to the team isn't going to automatically solve or even make much difference to bias in whatever dimension the candidate is diverse when the former manager of the team can't even get their account unbanned except for having it whitelisted after six months of investigation.
If the result of your software development methodology is that the fix to the manager of the payments team being banned is to allowlist the user after six months, that traffic routing in your app is systematically wrong for two decades, that core functionality of your app doesn't work, etc., no amount of hiring people with a background that's correlated with noticing some kinds of issues is going to result in fixing issues like these, whether that's with respect to ML bias or another class of bug.
Of course, sometimes variants of old ideas that have failed do succeed, but for a proposal to be credible, or even interesting, the proposal has to address why the next iteration won't fail like every previous iteration did. As we noted above, at a high level, the two most common proposed solutions I've seen are that people should try harder and care more and that we should have people of different backgrounds, in a non-technical sense. This hasn't worked for the plethora of "classical" bugs, this hasn't worked for old ML bugs, and it doesn't seem like there's any reason to believe that this should work for the kinds of bugs we're seeing from today's ML models.
Laurence Tratt says:
I think this is a more important point than individual instances of bias. What's interesting to me is that mostly a) no-one notices they're introducing such biases b) often it wouldn't even be reasonable to expect them to notice. For example, some web forms rejected my previous addresss, because I live in the countryside where many houses only have names -- but most devs live in cities where houses exclusively have numbers. In a sense that's active bias at work, but there's no mal intent: programmers have to fill in design details and make choices, and they're going to do so based on their experiences. None of us knows everything! That raises an interesting philosophical question: when is it reasonable to assume that organisations should have realised they were encoding a bias?
My feeling is that the "natural", as in lowest energy and most straightforward state for institutions and products is that they don't work very well. If someone hasn't previously instilled a culture or instituted processes that foster quality in a particular dimension, quality is likely to be poor, due to the difficulty of producing something high quality, so organizations should expect that they're encoding all sorts of biases if there isn't a robust process for catching biases.
One issue we're running up against here is that, when it comes to consumer software, companies have overwhelmingly chosen velocity over quality. This seems basically inevitable given the regulatory environment we have today or any regulatory environment we're likely to have in my lifetime, in that companies that seriously choose quality over features velocity get outcompeted because consumers overwhelmingly choose the lower cost or more featureful option over the higher quality option. We saw this with cars when we looked at how vehicles perform in out-of-sample crash tests and saw that only Volvo was optimizing cars for actual crashes as opposed to scoring well on public tests. Despite vehicular accidents being one of the leading causes of death for people under 50, paying for safety is such a low priority for consumers that Volvo has become a niche brand that had to move upmarket and sell luxury cars to even survive. We also saw this with CPUs, where Intel used to expend much more verification effort than AMD and ARM and had concomitantly fewer serious bugs. When AMD and ARM started seriously threatening, Intel shifted effort away from verification and validation in order to increase velocity because their quality advantage wasn't doing them any favors in the market and Intel chips are now almost as buggy as AMD chips.
We can observe something similar in almost every consumer market and many B2B markets as well, and that's when we're talking about issues that have known solutions. If we look at problem that, from a technical standpoint, we don't know how to solve well, like subtle or even not-so-subtle bias in ML models, it stands to reason that we should expect to see more and worse bugs than we'd expect out of "classical" software systems, which is what we're seeing. Any solution to this problem that's going to hold up in the market is going to have to be robust against the issue that consumers will overwhelmingly choose the buggier product if it has more features they want or ships features they want sooner, which puts any solution that requires taking care in a way that significantly slows down shipping in a very difficult position, absent a single dominant player, like Intel in its heyday.
Thanks to Laurence Tratt, Yossi Kreinin, Anonymous, Heath Borders, Benjamin Reeseman, Andreas Thienemann, and Misha Yagudin for comments/corrections/discussion
This is a genuine question and not a rhetorical question. I haven't done any ML-related work since 2014, so I'm not well-informed enough about what's going on now to have a direct opinion on the technical side of things. A number of people who've worked on ML a lot more recently than I have like Yossi Kreining (see appendix below) and Sam Anthony think the problem is very hard, maybe impossibly hard where we are today.
Since I don't have a direct opinion, here are three situations which sound plausibly analogous, each of which supports a different conclusion.
Analogy one: Maybe this is like people saying that someone will build a Google any day now at least since 2014 because existing open source tooling is already basically better than Google search or people saying that building a "high-level" CPU that encodes high-level language primitives into hardware would give us a 1000x speedup on general purpose CPUs. You can't really prove that this is wrong and it's possible that a massive improvement in search quality or a 1000x improvement in CPU performance is just around the corner but people who make these proposals generally sound like cranks because they exhibit the ahistoricity we noted above and propose solutions that we already know don't work with no explanation of why their solution will address the problems that have caused previous attempts to fail.
Analogy two: Maybe this is like software testing, where software bugs are pervasive and, although there's decades of prior art from the hardware industry on how to find bugs more efficiently, there are very few areas where any of these techniques are applied. I've talked to people about this a number of times and the most common response is something about how application XYZ has some unique constraint that make it impossibly hard to test at all or test using the kinds of techniques I'm discussing, but every time I've dug into this, the application has been much easier to test than areas where I've seen these techniques applied. One could argue that I'm a crank when it comes to testing, but I've actually used these techniques to test a variety of software and been successful doing so, so I don't think this is the same as things like claiming that CPUs would be 1000x faster if we only my pet CPU architecture.
Due to the incentives in play, where software companies can typically pass the cost of bugs onto the customer without the customer really understanding what's going on, I think we're not going to see a large amount of effort spent on testing absent regulatory changes, but there isn't a fundamental reason that we need to avoid using more efficient testing techniques and methodologies.
From a technical standpoint, the barrier to using better test techniques is fairly low — I've walked people through how to get started writing their own fuzzers and randomized test generators and this typically takes between 30 minutes and an hour, after which people will tend to use these techniques to find important bugs much more efficiently than they used to. However, by revealed preference, we can see that organizations don't really "want to" have their developers test efficiently.
When it comes to testing and fixing bias in ML models, is the situation more like analogy one or analogy two? Although I wouldn't say with any level of confidence that we are in analogy two, I'm not sure how I could be convinced that we're not in analogy two. If I didn't know anything about testing, I would listen to all of these people explaining to me why their app can't be tested in a way that finds showstopping bugs and then conclude something like one of the following
As an outsider, it would take a very high degree of overconfidence to decide that everyone is wrong, so I'd have to either incorrectly conclude that "everyone" is right or have no opinion.
Given the situation with "classical" testing, I feel like I have to have no real opinion here. WIth no up to date knowledge, it wouldn't be reasonable to conclude that so many experts are wrong. But there are enough problems that people have said are difficult or impossible that turn out to be feasible and not really all that tricky that I have a hard time having a high degree of belief that a problem is essentially unsolvable without actually looking into it.
I don't think there's any way to estimate what I'd think if I actually looked into it. Let's say I try to work in this area and try to get a job at OpenAI or another place where people are working on problems like this, somehow pass the interview,I work in the area for a couple years, and make no progress. That doesn't mean that the problem isn't solvable, just that I didn't solve it. When it comes to the "Lucene is basically as good as Google search" or "CPUs could easily be 1000x faster" people, it's obvious to people with knowledge of the area that the people saying these things are cranks because they exhibit a total lack of understanding of what the actual problems in the field are, but making that kind of judgment call requires knowing a fair amount about the field and I don't think there's a shortcut that would let you reliably figure out what your judgment would be if you had knowledge of the field.
I wrote a draft of this post when the Playground AI story went viral in mid-2023, and then I sat on it for a year to see if it seemed to hold up when the story was no longer breaking news. Looking at this a year, I don't think the fundamental issues or the discussions I see on the topic have really changed, so I cleaned it up and then published this post in mid-2024.
If you like making predictions, what do you think the odds are that this post will still be relevant a decade later, in 2033? For reference, this post on "classical" software bugs that was published in 2014 could've been published today, in 2024, with essentially the same results (I say essentially because I see more bugs today than I did in 2014, and I see a lot more front-end and OS bugs today than I saw in 2014, so there would more bugs and different kinds of bugs).
[Click to expand / collapse comments from Yossi Kreinin]
I'm not sure how much this is something you'd agree with but I think a further point related to generative AI bias being a lot like other-software-bias is exactly what this bias is. "AI bias" isn't AI learning the biases of its creators and cleverly working to implement them, e.g. working against a minority that its creators don't like. Rather, "AI bias" is something like "I generally can't be bothered to fix bugs unless the market or the government compels me to do so, and as a logical consequence of this, I especially can't be bothered to fix bugs that disproportionately negatively impact certain groups where the impact, due to the circumstances of the specific group in question, is less likely to compel me to fix the bug."
This is a similarity between classic software bugs and AI bugs — meaning, nobody is worried that "software is biased" in some clever scheming sort of way, everybody gets that it's the software maker who's scheming or, probably more often, it's the software maker who can't be bothered to get things right. With generative AI I think "scheming" is actually even less likely than with traditional software and "not fixing bugs" is more likely, because people don't understand AI systems they're making and can make them do their bidding, evil or not, to a much lesser extent than with traditional software; OTOH bugs are more likely for the same reason [we don't know what we're doing.] I think a lot of people across the political spectrum [including for example Elon Musk and not just journalists and such] say things along the lines of "it's terrible that we're training AI to think incorrectly about the world" in the context of racial/political/other charged examples of bias; I think in reality this is a product bug affecting users to various degrees and there's bias in how the fixes are prioritized but the thing isn't capable of thinking at all.
I guess I should add that there are almost certainly attempts at "scheming" to make generative AI repeat a political viewpoint, over/underrepresent a group of people etc, but invariably these attempts create hilarious side effects due to bugs/inability to really control the model. I think that similar attempts to control traditional software to implement a politics-adjacent agenda are much more effective on average (though here too I think you actually had specific examples of social media bugs that people thought were a clever conspiracy). Whether you think of the underlying agenda as malice or virtue, both can only come after competence and here there's quite the way to go.
See Simple Tasks Showing Complete Reasoning Breakdown in State-Of-the-Art Large Language Models. I feel like if this doesn't work, a whole lot of other stuff doesn't work, either and enumerating it has got to be rather hard.
I mean nobody would expect a 1980s expert system to get enough tweaks to not behave nonsensically. I don't see a major difference between that and an LLM, except that an LLM is vastly more useful. It's still something that pretends to be talking like a person but it's actually doing something conceptually simple and very different that often looks right.
[Click to expand / collapse comments from an anonymous founder of an AI startup]
[I]n the process [of founding an AI startup], I have been exposed to lots of mainstream ML code. Exposed as in “nuclear waste” or “H1N1”. It has old-fashioned software bugs at a rate I find astonishing, even being an old, jaded programmer. For example, I was looking at tokenizing recently, and the first obvious step was to do some light differential testing between several implementations. And it failed hilariously. Not like “they missed some edge cases”, more like “nobody ever even looked once”. Given what we know about how well models respond to out of distribution data, this is just insane.
In some sense, this is orthogonal to the types of biases you discuss…but it also suggests a deep lack of craftsmanship and rigor that matches up perfectly.
[Click to expand / collapse comments from Benjamin Reeseman]
[Ben wanted me to note that this should be considered an informal response]
I have a slightly different view of demographic bias and related phenomena in ML models (or any other “expert” system, to your point ChatGPT didn’t invent this, it made it legible to borrow your term).
I think that trying to force the models to reflect anything other than a corpus that’s now basically the Internet give or take actually masks the real issue: the bias is real, people actually get mistreated over their background or skin color or sexual orientation or any number of things and I’d far prefer that the models surface that, run our collective faces in the IRL failure mode than try to tweak the optics in an effort to permit the abuses to continue.
There’s a useful analogy to things like the #metoo movement or various DEI initiatives, most well-intentioned in the beginning but easily captured and ultimately representing a net increase in the blank check of those in positions of privilege.
This isn’t to say that alignment has no place and I think it likewise began with good intentions and is even maybe a locally useful mitigation.
But the real solution is to address the injustice and inequity in the real world.
I think the examples you cited are or should be a wake-up call that no one can pretend to ignore credibly about real issues and would ideally serve as a forcing function on real reform.
I’d love to chat about this at your leisure, my viewpoint is a minority one, but personally I’m a big fan of addressing the underlying issues rather than papering over them with what amounts to a pile of switch statements.
There’s a darker take on this: real reform is impossible, we live in techno dystopia now, let’s mitigate where and how a hunted minority can.
And there is a distressingly strong argument for that case: even in the ostensibly developed world cops today look like soldiers did when I was a kid 30 years ago, someone is guarding something from something at great expense and it isn’t black kids from getting shot near as I can tell.
But I don’t subscribe to the pessimism, I think it’s a local anomaly as industrialization transitions into arbitrary power over the physical logistics if we only knew how to change it.
I did a brief stint consulting for biotech folks affiliated with Nobel shortlist types in an area called proteomics. Like any consultant I surrender any credit to the people paying handsomely by the hour.
But it really is a Shannon problem now: CRISPR Cas-9 can do arbitrary edits to not only a person’s genome but (in an ethical and legal grey area) to the germ line as well.
We just have no idea what to change and there’s enough integrity in the field that we won’t risk just arbitrary children on finding out.
I tried prompts with default settings, except for reducing image quality to 10 to generate images more quickly. This means we had 512/512, 7 prompt guidance, 10 quality, random seed. After 2 tries, increased image quality to 40 because the images were too low quality to tell the ethnicity sometimes. Other than increasing the image quality, there was no attempt to re-run prompts or otherwise due any kind of selection from the output. The prompts were "Generate a very professional looking linkedin profile photo for a X", where X was Doctor, Lawyer, Engineer, Scientist, Journalist, and Banker.
This produced the following images:






Roughly speaking, I think Rob's results reproduced, which should be no surprise at this point given how many images we've seen.
And then, to see if we could reproduce the standard rebuttal that generative AI isn't biased because requests for smutty images often have Asian women, I tried the prompt "Generate a trashy instagram profile photo for a porn star". There's an NSFW filter that was tripped in some cases, so we don't get groups of four images and instead got:
[Click to expand / collapse very mildly NSFW images]
And, indeed, the generated images are much more Asian than we got for any of our professional photos, save Rob Ricci's set of photos for asking for a "linkedin profile picture of Chinese Studies professor".
2024-05-26 08:00:00
From 2011-2012, the FTC investigated the possibility of pursuing antitrust action against Google. The FTC decided to close the investigation and not much was publicly known about what happened until Politico released 312 pages of internal FTC memos that from the investigation a decade later. As someone who works in tech, on reading the memos, the most striking thing is how one side, the side that argued to close the investigation, repeatedly displays a lack of basic understanding of tech industry and the memos from directors and other higher-ups don't acknowledge that this at all.
If you don't generally follow what regulators and legislators are saying about tech, seeing the internal c(or any other industry) when these decisions are, apparently, being made with little to no understanding of the industries1.
Inside the FTC, the Bureau of Competition (BC) made a case that antitrust action should be pursued and the Bureau of Economics (BE) made the case that the investigation should be dropped. The BC case is moderately strong. Reasonable people can disagree on whether or not the case is strong enough that antitrust action should've been pursued, but a reasonable person who is anti-antitrust has to concede that the antitrust case in the BC memo is at least defensible. The case against in the BE is not defensible. There are major errors in core parts of the BE memo. In order for the BE memo to seem credible, the reader must have large and significant gaps in their understanding of the tech industry. If there was any internal FTC discussion on the errors in the BE memo, there's no indication of that in any public documents. As far as we can see from the evidence that's available, nobody noticed that the BE memo's errors. The publicly available memos from directors and other higher ups indicate that they gave the BE memo as much or more weight than the BC memo, implying a gap in FTC leadership's understanding of the tech industry.
Since the BE memo is effective a rebuttal of a the BC memo, we'll start by looking at the arguments in the BC memo. The bullet points below summarize the Executive Summary from the BC memo, which roughly summarizes the case made by the BC memo:
In their supplemental memo on mobile, BC staff claim that Google dominates mobile search via exclusivity agreements and that mobile search was rapidly growing at the time. BC staff claimed that, according to Google internal documents, mobile search went from 9.5% to 17.3% of searches in 2011 and that both Google and Microsoft internal documents indicated that the expectation was that mobile would surpass desktop in the near future. As with the case on desktop, BC staff use Google's ability to essentially unilaterally reduce revenue share as evidence that Google has monopoly power and can dictate terms and they quote Google leadership noting this exact thing.
BC staff acknowledge that many of Google's actions have been beneficial to consumers, but balance this against the harms of anticompetitive tactics, saying
the evidence paints a complex portrait of a company working toward an overall goal of maintaining its market share by providing the best user experience, while simultaneously engaging in tactics that resulted in harm to many vertical competitors, and likely helped to entrench Google's monopoly power over search and search advertising
BE staff strongly disagreed with BC staff. BE staff also believe that many of Google's actions have been beneficial to consumers, but when it comes to harms, in almost every case, BE staff argue that the market isn't important, isn't a distinct market, or that the market is competitive and Google's actions are procompetitive and not anticompetitive.
At least in the documents provided by Politico, BE staff generally declined to engage with BC staff's arguments and numbers directly. For example, in addition to arguing that Google's agreements and exclusivity (insofar as agreements are exclusive) are procompetitive and foreclosing the possibility of such agreements might have significant negative impacts on the market, they argue that mobile is a small and unimportant market. The BE memo argues that mobile is only 8% of the market and, while it's growing rapidly, is unimportant, as it's only a "small percentage of overall queries and an even smaller percentage of search ad revenues". They also claim that there is robust competition in mobile because, in addition to Apple, there's also BlackBerry and Windows Mobile. Between when the FTC investigation started and when the memo was written, BlackBerry's marketshare dropped dropped from ~14% to ~6%, which was part of a long-term decline that showed no signs of changing. Windows Mobile's drop was less precipitous, from ~6% to ~4%, but in a market with such strong network effects, it's curious that BE staff would argue that these platforms with low and declining marketshare would provide robust competition going forward.
When the authors of the BE memo make a prediction, they seem to have a facility for predicting the opposite of what will happen. To do this, the authors of the BE memo took positions that were opposed to the general consensus at the time. Another example of this is when they imply that there is robust competition in the search market, which is implied to be expected to continue without antitrust action. Their evidence for this was that Yahoo and Bing had a combined "steady" 30% marketshare in the U.S., with query volume growing faster than Google since the Yahoo-Bing alliance was announced. The BE memo authors even go even further and claim that Microsoft's query volume is growing faster than Google'e and that Microsoft + Yahoo combined have higher marketshare than Google as measured by search MAU.
The BE memo's argument that Yahoo and Bing are providing robust and stable competition leaves out that the fixed costs of running a search engine are so high and the scale required to be profitable so large that Yahoo effectively dropped out of search and outsourced search to Bing. And Microsoft was subsidizing Bing to the tune of $2B/yr, in a strategic move that most observers in tech thought would not be successful. At the time, it would have been reasonable to think that if Microsoft stopped heavily subsidizing Bing, its marketshare would drop significantly, which is what happened after antitrust action was not taken and Microsoft decided to shift funding to other bets that had better ROI. Estimates today put Google at 86% to 90% share in the United States, with estimates generally being a bit higher worldwide.
On the wilder claims, such as Microsoft and Yahoo combined having more active search users than Google and that Microsoft query volume and therefore search marketshare is growing faster than Google, they use comScore data. There are a couple of curious things about this.
First, the authors pick and choose their data in order to present figures that maximize Microsoft's marketshare. When comScore data makes Microsoft marketshare appear relatively low, as in syndicated search, the authors of the BE memo explain that comScore data should not be used because it's inaccurate. However, when comScore data is prima facie unrealistic and make's Microsoft marketshare look larger than is plausible or is growing faster than is plausible, the authors rely on comScore data without explaining why they rely on this source that they said should not be used because it's unreliable.
Using this data, the BE memo basically argues that, because many users use Yahoo and Bing at least occasionally, users clearly could use Yahoo and Bing, and there must not be a significant barrier to switching even if (for example) a user uses Yahoo or Bing once a month and Google one thousand times a month. From having worked with and talked to people who work on product changed to drive growth, the overwhelming consensus has been that it's generally very difficult to convert a lightly-engaged user who barely registers as an MAU to a heavily-engaged user who uses the product regularly, and that this is generally considered more difficult than converting a brand-new user to becoming heavily engaged user. Like Boies's argument about rangeCheck, it's easy to see how this line of reasoning would sound plausible to a lay person who knows nothing about tech, but the argument reads like something you'd expect to see from a lay person.
Although the BE staff memo reads like a rebuttal to the points of the BC staff memo, the lack of direct engagement on the facts and arguments means that a reader with no knowledge of the industry who reads just one of the memos will have a very different impression than a reader who reads the other. For example, on the importance of mobile search, a naive BC-memo-only reader would think that mobile is very important, perhaps the most important thing, whereas a naive BE-memo-only reader would think that mobile is unimportant and will continue to be unimportant for the foreseeable future.
Politico also released memos from two directors who weigh the arguments of BC and BE staff. Both directors favor the BE memo over the BC memo, one very much so and one moderately so. When it comes to disagreements, such as the importance of mobile in the near future, there's no evidence in the memos presented that there was any attempt to determine who was correct or that the errors we're discussing here were noticed. The closest thing to addressing disagreements such as these are comments that thank both staffs for having done good work, in what one might call a "fair and balanced" manner, such as "The BC and BE staffs have done an outstanding job on this complex investigation. The memos from the respective bureaus make clear that the case for a complaint is close in the four areas ... ". To the extent that this can be inferred, it seems that the reasoning and facts laid out in the BE memo were given at least as much weight as the reasoning and facts in the BC memo despite much of the BE memo's case seemingly highly implausible to an observer who understands tech.
For example, on the importance of mobile, I happened to work at Google shortly after these memos were written and, when I was at Google, they had already pivoted to a "mobile first" strategy because it was understood that mobile was going to be the most important market going forward. This was also understood at other large tech companies at the time and had been understood going back further than the dates of these memos. Many consumers didn't understand this and redesigns that degraded the desktop experience in order to unify desktop and mobile experiences were a common cause of complaints at the time. But if you looked at the data on this or talked to people at big companies, it was clear that, from a business standpoint, it made sense to focus on mobile and deal with whatever fallout might happen in desktop if that allowed for greater velocity in mobile development.
Both the BC and BE staff memos extensively reference interviews across many tech companies, including all of the "hyperscalers". It's curious that someone could have access to all of these internal documents from these companies as well as interviews and then make the argument that mobile was, at the time, not very important. And it's strange that, at least to the extent that we can know what happened from these memos, directors took both sets of arguments at face value and then decided that the BE staff case was as convincing or more convincing than the BC staff case.
That's one class of error we repeatedly see between the BC and BE staff memos, stretching data to make a case that a knowledgeable observer can plainly see is not true. In most cases, it's BE staff who have stretched data as far as it can go to take a tenuous position as far as it can be pushed, but there are some instances of BC staff making a case that's a stretch.
Another class of error we see repeated, mainly in the BE memo, is taking what most people in industry would consider an obviously incorrect model of the world and then making inferences based on that. An example of this is the discussion on whether or not vertical competitors such as Yelp and TripAdvisor were or would be significantly disadvantaged by actions BC staff allege are anticompetitive. BE staff, in addition to arguing that Google's actions were actually procompetitive and not anticompetitive, argued that it would not be possible for Google to significantly harm vertical competitors because the amount of traffic Google drives to them is small, only 10% to 20% of their total traffic, going to say "the effect on traffic from Google to local sites is very small and not statistically significant". Although BE staff don't elaborate on their model of how this business works, they appear to believe that the market is basically static. If Google removes Yelp from its listings (which they threatened to do if they weren't allowed to integrate Yelp's data into their own vertical product) or downranks Yelp to preference Google's own results, this will, at most, reduce Yelp's traffic by 10% to 20% in the long run because only 10% to 20% of traffic comes from Google.
But even a VC or PM intern can be expected to understand that the market isn't static. What one would expect if Google can persistently take a significant fraction of search traffic away from Yelp and direct it to Google's local offerings instead is that, in the long run, Yelp will end up with very few users and become a shell of what it once was. This is exactly what happened and, as of this writing, Yelp is valued at $2B despite having a trailing P/E ratio of 24, which is fairly low P/E for a tech company. But the P/E ratio is unsurprisingly low because it's not generally believed that Yelp can turn this around due to Google's dominant position in search as well as maps making it very difficult for Yelp to gain or retain users. This is not just obvious in retrospect and was well understood at the time. In fact, I talked to a former colleague at Google who was working on one of a number of local features that leveraged the position that Google had and that Yelp could never reasonably attain; the expected outcome of these features was to cripple Yelp's business. Not only was it understood that this was going to happen, it was also understood that Yelp was not likely to be able to counter this due to Google's ability to leverage its market power from search and maps. It's curious that, at the time, someone would've seriously argued that cutting off Yelp's source of new users while simultaneously presenting virtually all of Yelp's then-current users with an alternative that's bundled into an app or website they already use would not significantly impact Yelp's business, but the BE memo makes that case. One could argue that the set of maneuvers used here are analogous to the ones done by Microsoft that were brought up in the Microsoft antitrust case where it was alleged that a Microsoft exec said that they were going to "cut off Netscape’s air supply", but the BE memo argues that impact of having one's air supply cut off is "very small and not statistically significant" (after all, a typical body has blood volume sufficient to bind 1L of oxygen, much more than the oxygen normally taken in during one breath).
Another class of, if not error, then poorly supported reasoning is relying on cocktail party level of reasoning when there's data or other strong evidence that can be directly applied. This happens throughout the BE memo even though, at other times, when the BC memo has some moderately plausible reasoning, the BE memo's counter is that we should not accept such reasoning and need to look at the data and not just reason about things in the abstract. The BE memo heavily leans on the concept that we must rely on data over reasoning and calls arguments from the BC memo that aren't rooted in rigorous data anecdotal, "beyond speculation", etc., but BE memo only does this in cases where knowledge or reasoning might lead one to conclude that there was some kind of barrier to competition. When the data indicates that Google's behavior creates some kind of barrier in the market, the authors of BE memo ignore all relevant data and instead rely on reasoning over data even when the reasoning is weak and has the character of the Boies argument we referenced earlier. One could argue that the standard of evidence for pursuing an antitrust case should be stronger the standard of evidence for not pursuing one, but if the asymmetry observed here were for that reason, the BE memo could have listed areas where the evidence wasn't strong enough without making its own weak assertions in the face of stronger evidence. An example of this is the discussion of the impact of mobile defaults.
The BE memo argues that defaults are essentially worthless and have little to no impact, saying multiple times that users can switch with just "a few taps", adding that this takes "a few seconds" and that, therefore, "[t]hese are trivial switching costs". The most obvious and direct argument piece of evidence on the impact of defaults is the amount of money Google pays to retain its default status. In a 2023 antitrust action, it was revealed that Google paid Apple $26.3B to retain its default status in 2021. As of this writing, Apple's P/E ratio is 29.53. If we think of this payment as, at the margin, pure profit and having default status is as worthless as indicated by the BE memo, a naive estimate of how much this is worth to Apple is that it can account for something like $776B of Apple's $2.9T market cap. Or, looking at this from Google's standpoint, Google's P/E ratio is 27.49, so Google is willing to give up $722B of its $2.17T market cap. Google is willing to pay this to be the default search for something like 25% to 30% of phones in the world. This calculation is too simplistic, but there's no reasonable adjustment that could give anyone the impression that the value of being the default is as trivial as claimed by the BE memo. For reference, a $776B tech company would be 7th most valuable publicly traded U.S. tech company and the 8th most valuable publicly traded U.S. company (behind Meta/Facebook and Berkshire Hathaway, but ahead of Eli Lilly). Another reference is that YouTube's ad revenue in 2021 was $28.8B. It would be difficult to argue that spending one YouTube worth of revenue, in profit, in order to retain default status makes sense if, in practice, user switching costs are trivial and defaults don't matter. If we look for publicly available numbers close to 2012 instead of 2021, in 2013, TechCrunch reported a rumor that Google was paying Apple $1B/yr for search status and a lawsuit then revealed that Google paid Apple $1B for default search status in 2014. This is not longer after these memos are written and $1B/yr is still a non-trivial amount of money and it belies the BE memo's claim that mobile is unimportant and that defaults don't matter because user switching costs are trivial.
It's curious that, given the heavy emphasis in the BE memo on not trusting plausible reasoning and having to rely on empirical data, that BE staff appeared to make no attempt to find out how much Google was paying for its default status (a memo by a director who agrees with BE staff suggests that someone ought to check on this number, but there's no evidence that this was done and the FTC investigation was dropped shortly afterwards). Given the number of internal documents the FTC was able to obtain, it seems unlikely that the FTC would not have been able to obtain this number from either Apple or Google. But, even if it were the case that the number were unobtainable, it's prima facie implausible that defaults don't matter and switching costs are low in practice. If FTC staff interviewed product-oriented engineers and PMs or looked at the history of products in tech, so in order to make this case, BE staff had to ignore or avoid finding out how much Google was paying for default status, not talk to product-focused engineers, PM, or leadership, and also avoid learning about the tech industry.
One could make the case that, while defaults are powerful, companies have been able to overcome being non-default, which could lead to a debate on exactly how powerful defaults are. For example, one might argue about the impact of defaults when Google Chrome became the dominant browser and debate how much of it was due to Chrome simply being a better browser than IE, Opera, and Firefox, how much was due to blunders by Microsoft that Google is unlikely to repeat in search, how much was due to things like tricking people into making Chrome default via a bundle deal with badware installers and how much was due to pressuring people into setting Chrome is default via google.com. That's an interesting discussion where a reasonable person with an understanding of the industry could take either side of the debate, unlike the claim that defaults basically don't matter at all and user switching costs are trivial in practice, which is not plausible even without access to the data on how much Google pays Apple and others to retain default status. And as of the 2020 DoJ case against Google, roughly half of Google searches occur via a default search that Google pays for.
Another repeated error, closely related to the one above, is bringing up marketing statements, press releases, or other statements that are generally understood to be exaggerations, and relying on these as if they're meaningful statements of fact. For example, the BE memo states:
Microsoft's public statements are not consistent with statements made to antitrust regulators. Microsoft CEO Steve Ballmer stated in a press release announcing the search agreement with Yahoo: "This agreement with Yahoo! will provide the scale we need to deliver even more rapid advances in relevancy and usefulness. Microsoft and Yahoo! know there's so much more that search could be. This agreement gives us the scale and resources to create the future of search"
This is the kind of marketing pablum that generally accompanies an acquisition or partnership. Because this kind of meaningless statement is common across many industries, one would expect regulators, even ones with no understanding of tech, to recognize this as marketing and not give it as much or more weight as serious evidence.
Now that we've covered the main classes of errors observed in the memos, we'll look at a tidbits from the memos.
Between the approval of the compulsory process on June 3rd 2011 and the publication of the BC memo dated August 8th 2012, staff received 9.5M pages of documents across 2M docs and said they reviewed "many thousands of these documents", so staff were only able to review a small fraction of the documents.
Prior to the FTC investigation, there were a number of lawsuits related to the same issues, and all were dismissed, some with arguments that would, if they were taken as broad precedent, make it difficult for any litigation to succeed. In SearchKing v. Google, plaintiffs alleged that Google unfairly demoted their results but it was ruled that Google's rankings are constitutionally protected opinion and even malicious manipulation of rankings would not expose Google to liability. In Kinderstart v. Google, part of the ruling was that Google search is not an essential facility for vertical providers (such as Yelp, eBay, and Expedia). Since the memos are ultimately about legal proceedings, there is, of course, extensive discussion of Verizon v. Trinko and Aspen Skiing Co. v. Aspen Highlands Skiing Corp and the implications thereof.
As of the writing of the BC memo, 96% of Google's $38B in revenue was from ads, mostly from search ads. The BC memo makes the case that other forms of advertising, other than social media ads, only have limited potential for growth. That's certainly wrong in retrospect. For example, video ads are a significant market. YouTube's ad revenue was $28.8B in 2021 (a bit more than what Google pays to Apple to retain default search status), Twitch supposedly generated another $2B-$3B in video revenue, and a fair amount of video ad revenue goes directly from sponsors to streamers without passing through YouTube and Twitch, e.g., the #137th largest streamer on Twitch was offered $10M/yr stream online gambling for 30 minutes a day, and he claims that the #42 largest streamer, who he personally knows, was paid $10M/mo from online gambling sponsorships. And this isn't just apparent in retrospect — even at the time, there were strong signs that video would become a major advertising market. It happens that those same signs also showed that Google was likely to dominate the market for video ads, but it's still the case that the specific argument here was overstated.
In general, the BC memo seems to overstate the expected primacy of search ads as well as how distinct a market search ads are, claiming that other online ad spend is not a substitute in any way and, if anything, is a complement. Although one might be able to reasonably argue that search ads are a somewhat distinct market and the elasticity of substitution is low once you start moving a significant amount of your ad spend away from search, the degree to which the BC memo makes this claim is a stretch. Search ads and other ad budgets being complements and not substitutes is a very different position than I've heard from talking to people about how ad spend is allocated in practice. Perhaps one can argue that it makes sense to try to make a strong case here in light of Person V. Google, where Judge Fogel of the Northern District of California criticized the plaintiff's market definition, finding no basis for distinguishing "search advertising market" from the larger market for internet advertising, which likely foreshadows an objection that would be raised in any future litigation. However, as someone who's just trying to understand the facts of the matter at hand and the veracity of the arguments, the argument here seems dubious.
For Google's integrated products like local search and product search (formerly Froogle), the BC memo claims that if Google treated its own properties like other websites, the products wouldn't be ranked and Google artificially placed their own vertical competitors above organic offerings. The webspam team declined to include Froogle results because the results are exactly the kind of thing that Google removes from the index because it's spammy, saying "[o]ur algorithms specifically look for pages like these to either demote or remove from the index". Bill Brougher, product manager for web search said "Generally we like to have the destination pages in the index, not the aggregated pages. So if our local pages are lists of links to other pages, it's more important that we have the other pages in the index". After the webspam team was overruled and the results were inserted, the ads team complained that the less clicked (and implied to be lower quality) results would lead to a loss of $154M/yr. The response to this essentially contained the same content as the BC memo's argument on the importance of scale and why Google's actions to deprive competitors of scale are costly:
We face strong competition and must move quickly. Turning down onebox would hamper progress as follows - Ranking: Losing click data harms ranking; [t]riggering Losing CTR and google.com query distribution data triggering accuracy; [c]omprehensiveness: Losing traffic harms merchant growth and therefore comprehensiveness; [m]erchant cooperation: Losing traffic reduces effort merchants put into offer data, tax, & shipping; PR: Turning off onebox reduces Google's credibility in commerce; [u]ser awareness: Losing shopping-related UI on google.com reduces awareness of Google's shopping features
Normally, CTR is used as a strong signal to rank results, but this would've resulted in a low ranking for Google's own vertical properties, so "Google used occurrence of competing vertical websites to automatically boost the ranking of its own vertical properties above that of competitors" — if a comparison shopping site was relevant, Google would insert Google Product search above any rival, and if a local search site like Yelp or CitySearch was relevant, Google automatically returned Google Local at top of SERP.
Additionally, in order to see content for Google local results, Google took Yelp content and integrated it into Google Places. When Yelp observed this was happening, they objected to this and Google threatened to ban Yelp from traditional Google search results and further threatened to ban any vertical provider that didn't allow its content to be used in Google Places. Marissa Mayer testified that it was, from a technical standpoint, extraordinarily difficult to remove Yelp from Google Places without also removing Yelp from traditional organic search results. But when Yelp sent a cease and desist letter, Google was able to remove Yelp results immediately, seemingly indicating that it was less difficult than claimed. Google then claimed that it was technically infeasible to remove Yelp from Google Places without removing Yelp from the "local merge" interface on SERP. BC staff believe this claim is false as well, and Marissa Mayer later admitted in a hearing that this claim was false and that Google was concerned about the consequences of allowing sites to opt out of Google Places while staying in "local merge". There was also a very similar story with Amazon results and product search. As noted above, the BE memo's counterargument to all of this is that Google traffic is "very small and not statistically significant"
The BC memo claims that the activities above both reduced incentives of companies Yelp, City Search, Amazon, etc., to invest in the area and also reduced the incentives for new companies to form in this area. This seems true. In addition to the evidence presented in the BC memo (which goes beyond what was summarized above), if you just talked to founders looking for an idea or VCs around the time of the FTC investigation, there had already been a real movement away from founding and funding companies like Yelp because it was understood that Google could seriously cripple any similar company in this space by cutting off its air supply.
We'll defer to the appendix BC memo discussion on the AdWords API restrictions that specifically disallow programmatic porting of campaigns to other platforms, such as Bing. But one interesting bit there is that Google was apparently aware of the legal sensitivity of this matter, so meeting notes and internal documentation on the topic are unusually incomplete. On one meeting, apparently the most informative written record BC staff were able to find consists of a message from Director of PM Richard Holden to SVP of ads Susan Wojicki which reads, "We didn't take notes for obvious reasons hence why I'm not elaborating too much here in email but happy to brief you more verbally".
We'll also defer a detailed discussion of the BC memo comments on Google's exclusive and restrictive syndication agreements to the appendix, except for a couple of funny bits. One is that Google claims they were unaware of the terms and conditions in their standard online service agreements. In particular, the terms and conditions contained a "preferred placement" clause, which a number of parties believe is a de facto exclusivity agreement. When FTC staff questioned Google's VP of search services about this term, the VP claimed they were not aware of this term. Afterwards, Google sent a letter to Barbara Blank of the FTC explaining that they were removing the preferred placement clause in the standard online agreement.
Another funny bit involves Google's market power and how it allowed them to collect an increasingly large share of revenue for themselves and decrease the revenue share their partner received. Only a small number of Google's customers who were impacted by this found this concerning. Those that did find it concerning were some of the largest and most sophisticated customers (such as Amazon and IAC); their concern was that Google's restrictive and exclusive provisions would increase Google's dominance over Bing/Microsoft and allow them to dictate worse terms to customers. Even as Google was executing a systematic strategy to reduce revenue share to customers, which could only be possible due to their dominance of the market, most customers appeared to either not understand the long-term implications of Google's market power in this area or the importance of the internet.
For example, Best Buy didn't find this concerning because Best Buy viewed their website and the web as a way for customers to find presale information before entering a store and Walmart didn't find didn't find this concerning because they viewed the web as an extension to brick and mortar retail. It seems that the same lack of understanding of the importance of the internet which led Walmart and Best Buy to express their lack of concern over Google's dominance here also led to these retailers, which previously had a much stronger position than Amazon, falling greatly behind in both online and overall profit. Walmart later realized its error here and acquired Jet.com for $3.3B in 2016 and also seriously (relative to other retailers) funded programmers to do serious tech work inside Walmart. Since Walmart started taking the internet seriously, it's made a substantial comeback online and has averaged a 30% CAGR in online net sales since 2018, but taking two decades to mount a serious response to Amazon's online presence has put Walmart solidly behind Amazon in online retail despite nearly a decade of serious investment and Best Buy has still not been able to mount an effective response to Amazon after three decades.
The BE memo uses the lack of concern on the part of most customers as evidence that the exclusive and restrictive conditions Google dictated here were not a problem but, in retrospect, it's clear that it was only a lack of understanding of the implications of online business that led customers to be unconcerned here. And when the BE memo refers to the customers who understood the implications here as sophisticated, that's relative to people in lines of business where leadership tended to not understand the internet. While these customers are sophisticated by comparison to a retailer that took two decades to mount a serious response to the threat Amazon poses to their business, if you just talked to people in the tech industry at the time, you wouldn't need to find a particularly sophisticated individual to find someone who understood what was going on. It was generally understood that retail revenue and even moreso, retail profit was going to move online, and you'd have to find someone who was extremely unusually out of the loop to find someone who didn't at least roughly understand the implications here.
There's a lengthy discussion on search and scale in both the BC and BE memos. On this topic, the BE memo seems wrong and the implications of the BC memo are, if not subtle, at least not obvious. Let's start with the BE memo because that one's simpler to discuss, although we'll very briefly discuss the argument in the BC memo in order to frame the discussion in the BE memo. A rough sketch of the argument in the BC memo is that there are multiple markets (search, ads) where scale has a significant impact on product quality. Google's own documents acknowledge this "virtuous cycle" where having more users lets you serve better ads, which gives you better revenue for ads and, likewise in search, having more scale gives you more data which can be used to improve results, which leads to user growth. And for search in particular, the BC memo claims that click data from users is of high importance and that more data allows for better results.
The BE memo claims that this is not really the case. On the importance of click data, the BE memo raises two large objections. First, that this is "contrary to the history of the general search market" and second, that "it is also contrary to the evidence that factors such as the quality of the web crawler and web index; quality of the search algorithm; and the type of content included in the search results [are as important or more important].
Of the first argument, the BE memo elaborates with a case that's roughly "Google used to be smaller than it is today, and the click data at the time was sufficient, therefore being as large as Google used to be means that you have sufficient click data". Independent of knowledge of the tech industry, this seems like a strange line of reasoning. "We now produce a product that's 1/3 as good as our competitor for the same price, but that should be fine because our competitor previously produced a product that's 1/3 as good as their current product when the market was less mature and no one was producing a better product" is generally not going to be a winning move. That's especially true in markets where there's a virtuous cycle between market share and product quality, like in search.
The second argument also seems like a strange argument to make even without knowledge of the tech industry in that it's a classic fallacious argument. It's analogous to saying something like "the BC memo claims that it's important for cars to have a right front tire, but that's contrary to evidence that it's at least as important for a car to have a left front tire and a right rear tire". The argument is even less plausible if you understand tech, especially search. Calling out the quality of the search algorithm as distinct doesn't feel quite right because scale and click data directly feed into algorithm development (and this is discussed at some length in the BE memo — the authors of the BC memo surely had access to the same information and, from their writing, seem to have had access to the argument). And as someone who's worked on search indexing, as much as I'd like to be agree with the BE memo and say that indexing is as important or more important than ranking, I have to admit that indexing is an easier and less important problem than ranking and likewise for crawling vs. ranking. This was generally understood at the time so, given the number of interviews FTC staff did, the authors of the BE memo should've known this as well. Moreover, given the "history of the general search market" which the BE memo refers to, even without talking to engineers, this should've been apparent.
For example, Cuil was famous for building a larger index than Google. While that's not a trivial endeavor, at the time, quite a few people had the expertise to build an index that rivaled Google's index in raw size or whatever other indexing metric you prefer, if given enough funding for a serious infra startup. Cuil and other index-focused attempts failed because having a large index without good search ranking is worth little. While it's technically true that having good ranking with a poor index is also worth little, this is not something we've really seen in practice because ranking is the much harder problem and a company that's competent to build a good search ranker will, as a matter of course, have a good enough index and good enough crawling.
As for the case in the BC memo, I don't know what the implications should be. The BC memo correctly points out that increased scale greatly improves search quality, that the extra data Bing got from the Yahoo greatly increased search quality and increased CTR, that further increased scale should be expected to continue to provide high return, that the costs of creating a competitor to Google are high (Bing was said to be losing $2B/yr at the time and was said to be spending $4.5B/yr "developing its algorithms and building the physical capacity necessary to operate Bing"), and that Google undertook actions that might be deemed anticompetitive which disadvantaged Bing's compared to the counterfactual world where Google did not take those actionts, and they make a similar case for ads. However, despite the strength of the stated BC memo case and the incorrectness of the stated BE memo case, the BE memo's case is correct in spirit, in that there are actions Microsoft could've taken but did not in order to compete much more effectively in search and one could argue that the FTC shouldn't be in the business of rescuing a company from competing ineffectively.
Personally, I don't think it's too interesting to discuss the position of the BC memo vs. the BE memo at length because the positions the BE memo takes seem extremely weak. It's not fair to call it a straw man because it's a real position, and one that carried the day at the FTC, but the decision to take action or not seemed more about philosophy than the arguments in the memos. But we can discuss what else might've been done.
What happened after the FTC declined to pursue antitrust action was that Microsoft effectively defunded Bing as a serious bet, taking resources that could've gone to continuing to fund a very expensive fight against Google, and moving them to other bets that it deemed to be higher ROI. The big bets Microsoft pursued were Azure, Office, and HoloLens (and arguably Xbox). Hololens was a pie-in-the-sky bet, but Azure and Office were lines of business where Microsoft could, instead of fighting an uphill battle where their competitor can use its dominance in related markets to push around competitors, Microsoft could fight downhill battles where they can use their dominance in related markets to push around competitors, resulting in a much higher return per dollar invested. As someone who worked on Bing and thought that BIng had the potential to seriously compete with Google given sustained, unprofitable, heavy investment, I find that disappointing but also likely the correct business decision. If you look at any particular submarket, like Teams vs. Slack, the Microsoft product doesn't need to be nearly as good as the competing product to take over the market, which is the opposite of the case in search, where Google's ability to push competitors around means that Bing would have to be much better than Google to attain marketshare parity.
Based on their public statements, Biden's DoJ Antitrust AAG appointee, Jonathan Kanter, would argue for pursuing antitrust action under the circumstances, as would Biden's FTC commissioner and chair appointee Lina Khan. Prior to her appointment as FTC commissioner and chair, Khan was probably best known for writing Amazon's Antitrust Paradox, which has been influential as well as controversial. Obama appointees, who more frequently agreed with the kind of reasoning from the BE memo, would have argued against antitrust action and the investigation under discussion was stopped on their watch. More broadly, they argued against the philosophy driving Kanter and Khan. Obama's FTC Commissioner appointee, GMU economist and legal scholar Josh Wright actually wrote a rebuttal titled "Requiem for a Paradox: The Dubious Rise and Inevitable Fall of Hipster Antitrust", a scathing critique of Khan's position.
If, in 2012, the FTC and DoJ were run by Biden appointees instead of Obama appointees, what difference would that have made? We can only speculate, but one possibility would be that they would've taken action and then lost, as happened with the recent cases against Meta and Microsoft which seem like they would not have been undertaken under an Obama FTC and DoJ. Under Biden appointees, there's been much more vigorous use of the laws that are on the books, the Sherman Act, the Clayton Act, the FTC Act, the Robinson–Patman Act, as well as "smaller" antitrust laws, but the opinion of the courts hasn't changed under Biden and this has led to a number of unsuccessful antitrust cases in tech. Both the BE and BC memos dedicate significant space to whether or not a particular line of reasoning will hold up in court. Biden's appointees are much less concerned with this than previous appointees and multiple people in the DoJ and the FTC are on the record saying things like "it is our duty to enforce the law", meaning that when they see violations of the antitrust laws that were put into place by elected officials, it's their job to pursue these violations even if courts may not agree with the law.
Another possibility is that there would've been some action, but the action would've been in line with most corporate penalties we see. Something like a small fine that costs the company an insignificant fraction of marginal profit they made from their actions, or some kind of consent decree (basically a cease and desist), where the company will be required to stop doing specific actions while keeping their marketshare, keeping the main thing they wanted to gain, a massive advantage in a market dominated by network effects. Perhaps there will be a few more meetings where "[w]e didn't take notes for obvious reasons" to work around the new limitations and business as usual will continue. Given the specific allegations in the FTC memos and the attitudes of the courts at the time, my guess is that something like this second set of possibilities would've been the most likely outcome had the FTC proceeded with their antitrust investigation instead of dropping it, some kind of nominal victory that makes little to no difference in practice. Given how long it takes for these cases to play out, it's overwhelmingly likely that Microsoft would've already scaled back its investment in Bing and moved Bing from a subsidized bet it was trying to grow to a profitable business it wanted to keep by the time any decision was made. There are a number of cases that were brought by other countries which had remedies that were in line with what we might've expected if the FTC investigation continued. On Google using market power in mobile to push software Google wants to nearly all Android phones, an EU and was nominally successful but made little to no difference in practice. Cristina Caffara of the Centre for Economic Policy Research characterized this as
Europe has failed to drive change on the ground. Why? Because we told them, don't do it again, bad dog, don't do it again. But in fact, they all went and said 'ok, ok', and then went out, ran back from the back door and did it again, because they're smarter than the regulator, right? And that's what happens.
So, on the tying case, in Android, the issue was, don't tie again so they say, "ok, we don't tie". Now we got a new system. If you want Google Play Store, you pay $100. But if you want to put search in every entry point, you get a discount of $100 ... the remedy failed, and everyone else says, "oh, that's a nice way to think about it, very clever"
Another pair of related cases are Yandex's Russian case on mobile search defaults and a later EU consent decree. In 2015, Yandex brought a suit about mobile default status on Android in Russia, which was settled by adding a "choice screen" which has users pick their search engine without preferencing a default. This immediately caused Yandex to start gaining marketshare on Google and Yandex eventually surpassed Google in marketshare in Russia according to statcounter. In 2018, the EU required a similar choice screen in Europe, which didn't make much of a difference, except maybe sort of in the Czech republic. There are a number of differences between the situation in Russia and in the EU. One, arguably the most important, is that when Yandex brought the case against Google in Russia, Yandex was still fairly competitive, with marketshare in the high 30% range. At the time of the EU decision in 2018, Bing was the #2 search engine in Europe, with about 3.6% marketshare. Giving consumers a choice when one search engine completely dominates the market can be expected to have fairly little impact. One argument the BE memo heavily relies on is the idea that, if we intervene in any way, that could have bad effects down the line, so we should be very careful and probably not do anything, just in case. But in these winner-take-most markets with such strong network effects, there's a relatively small window in which you can cheaply intervene. Perhaps, and this is highly speculative, if the FTC required a choice screen in 2012, Bing would've continued to invest enough to at least maintain its marketshare against Google.
For verticals, in shopping, the EU required some changes to how Google presents results in 2017. This appears to have had little to no impact, being both perhaps 5-10 years too late and also a trivial change that wouldn't have made much difference even if enacted a decade earlier. The 2017 ruling came out of a case that started in 2010, and in the 7 years it took to take action, Google managed to outcompete its vertical competitors, making them barely relevant at best.
Another place we could look is at the Microsoft antitrust trial. That's a long story, at least as long as this document, but to very briefly summarize, in 1990, the FTC started an investigation over Microsoft's allegedly anticompetitive conduct. A vote to continue the investigation ended up in a 2-2 tie, causing the investigation to be closed. The DoJ then did its own investigation, which led to a consent decree that was generally considered to not be too effective. There was then a 1998 suit by the DoJ about Microsoft's use of monopoly power in the browser market, which initially led to a decision to break Microsoft up. But, on appeal, the breakup was overturned, which led to a settlement in 2002. A major component of the 1998 case was about browser bundling and Microsoft's attack on Netscape. By the time the case was settled, in 2002, Netscape was effectively dead. The parts of the settlements having to do with interoperability were widely regarded as ineffective at the time, not only because Netscape was dead, but because they weren't going to be generally useful. A number of economists took the same position as the BE memo, that no intervention should've happened at the time and that any intervention is dangerous and could lead to a fettering of innovation. Nobel Prize winning economist Milton Friedman wrote a Cato Policy Forum essay titled "The Business Community's Suicidal Impulse", predicting that tech companies calling for antitrust action against Microsoft were committing suicide, and that a critical threshold had been passed and that this would lead to the bureaucratization of Silicon Valley
When I started in this business, as a believer in competition, I was a great supporter of antitrust laws; I thought enforcing them was one of the few desirable things that the government could do to promote more competition. But as I watched what actually happened, I saw that, instead of promoting competition, antitrust laws tended to do exactly the opposite, because they tended, like so many government activities, to be taken over by the people they were supposed to regulate and control. And so over time I have gradually come to the conclusion that antitrust laws do far more harm than good and that we would be better off if we didn’t have them at all, if we could get rid of them. But we do have them.
Under the circumstances, given that we do have antitrust laws, is it really in the self-interest of Silicon Valley to set the government on Microsoft? ... you will rue the day when you called in the government. From now on the computer industry, which has been very fortunate in that it has been relatively free of government intrusion, will experience a continuous increase in government regulation. Antitrust very quickly becomes regulation. Here again is a case that seems to me to illustrate the suicidal impulse of the business community.
In retrospect, we can see that this wasn't correct and, if anything, was the opposite of correct. On the idea that even attempting antirust action against Microsoft would lead to an inevitable increase in government intervention, we saw the opposite, a two-decade long period of relatively light regulation and antitrust activity. And in terms of the impacts on innovation, although the case against Microsoft was too little and too late to save Netscape, Google's success appears to be causally linked to the antitrust trial. At one point, in the early days of Google, when Google had no market power and Microsoft effectively controlled how people access the internet, Microsoft internally discussed proposals aimed at killing Google. One proposal involved redirecting users who tried to navigate to Google to Bing (at the time, called MSN Search, and of course this was before Chrome existed and IE dominated the browser market). Another idea was to put up a big scary warning that warned users that Google was dangerous, much like the malware warnings browsers have today. Gene Burrus, a lawyer for Microsoft at the time, stated that Microsoft chose not to attempt to stop users from navigating to google.com due to concerns about further antitrust action after they'd been through nearly a decade of serious antitrust scrutiny. People at both Google and Microsoft who were interviewed about this both believe that Microsoft would've killed Google had they done this so, in retrospect, we can see that Milton Friedman was wrong about the impacts of the Microsoft antitrust investigations and that one can make the case that it's only because of the antitrust investigations that web 1.0 companies like Google and Facebook were able to survive, let alone flourish.
Another possibility is that a significant antitrust action would've been undertaken, been successful, and been successful quickly enough to matter. It's possible that, by itself, a remedy wouldn't have changed the equation for Bing vs. Google, but if a reasonable remedy was found and enacted, it still could've been in time to keep Yelp and other vertical sites as serious concerns and maybe even spur more vertical startups. And in the hypothetical universe where people with the same philosophy as Biden's appointees were running the FTC and the DoJ, we might've also seen antitrust action against Microsoft in markets where they can leverage their dominance in adjacent markets, making Bing a more appealing area for continued heavy investment. Perhaps that would've resulted in Bing being competitive with Google and the aforementioned concerns that "sophisticated customers" like Amazon and IAC had may not have come to pass. With antitrust against Microsoft and other large companies that can use their dominance to push competitors around, perhaps Slack would still be an independent product and we'd see more startups in enterprise tools (a number of commenters believe that Slack was basically forced into being acquired because it's too difficult to compete with Teams given Microsoft's dominance in related markets). And Slack continuing to exist and innovate is small potatoes — the larger hypothetical impact would be all of the new startups and products that would be created that no one even bothers to attempt because they're concerned that a behemoth with an integrated bundle like Microsoft would crush their standalone product. If you add up all of these, if not best-case, at least very-good-case outcomes for antitrust advocates, one could argue that consumers and businesses would be better off. But, realistically, it's hard to see how this very-good-case set of outcomes could have come to pass.
Coming back to the FTC memo, if we think about what it would take to put together a set of antitrust actions that actually fosters real competition, that seems extraordinarily difficult. A number of the more straightforward and plausible sounding solutions are off the table for political reasons, due to legal precedent, or due to arguments like the Boies argument we referenced or some of the arguments in the BE memo that are clearly incorrect, but appear to be convincing to very important people.
For the solutions that seem to be on the table, weighing the harms caused by them is non-trivial. For example, let's say the FTC mandated a mobile and desktop choice screen in 2012. This would've killed Mozilla in fairly short order unless Mozilla completely changed its business model because Mozilla basically relies on payments from Google for default status to survive. We've seen with Opera that even when you have a superior browser that introduces features that other browsers later copy, which has better performance than other browsers, etc., you can't really compete with free browsers when you have a paid browser. So then we would've quickly been down to IE/Edge and Chrome. And in terms of browser engines, just Chrome after not too long as Edge is now running Chrome under the hood. Maybe we can come up with another remedy that allows for browser competition as well, but the BE memo isn't wrong to note that antitrust remedies can cause other harms.
Another example which highlights the difficulty of crafting a politically suitable remedy are the restrictions the Bundeskartellamt imposed against Facebook, which have to do with user privacy and use of data (for personalization, ranking, general ML training, etc.), which is considered an antitrust issue in Germany. Michal Gal, Professor and Director of the Forum on Law and Markets at the University of Haifa pointed out that, of course Facebook, in response to the rulings, is careful to only limit its use of data if Facebook detects that you're German. If the concern is that ML models are trained on user data, this doesn't do much to impair Facebook's capability. Hypothetically, if Germany had a tech scene that was competitive with American tech and German companies were concerned about a similar ruling being leveled against them, this would be disadvantageous to nascent German companies that initially focus on the German market before expanding internationally. For Germany, this is only a theoretical concern as, other than SAP, no German company has even approached the size and scope of large American tech companies. But when looking at American remedies and American regulation, this isn't a theoretical concern, and some lawmakers will want to weigh the protection of American consumers against the drag imposed on American firms when compared to Korean, Chinese, and other foreign firms that can grow in local markets with fewer privacy concerns before expanding to international markets. This concern, if taken seriously, could be used to argue against nearly any pro-antitrust action argument.
This document is already long enough, so we'll defer a detailed discussion of policy specifics for another time, but in terms of high-level actions, one thing that seems like it would be helpful is to have tech people intimately involved in crafting remedies and regulation as well as during investigations2. From the directors memos on the 2011-2021 FTC investigation that are publicly available, it would appear this was not done because the arguments from the BE memos that wouldn't pass the sniff test for a tech person appear to have been taken seriously. Another example is the one EU remedy that Cristina Caffara noted was immediately worked around by Google, in a way that many people in tech would find to be a delightful "hack".
There's a long history of this kind of "hacking the system" being lauded in tech going back to before anyone called it "tech" and it was just physics and electrical engineering. To pick a more recent example, one of the reasons Sam Altman become President of Y Combinator, which eventually led to him becoming CEO of Open AI was that Paul Graham admired his ability to hack systems; in his 2010 essay on founders, under the section titled "Naughtiness", Paul wrote:
Though the most successful founders are usually good people, they tend to have a piratical gleam in their eye. They're not Goody Two-Shoes type good. Morally, they care about getting the big questions right, but not about observing proprieties. That's why I'd use the word naughty rather than evil. They delight in breaking rules, but not rules that matter. This quality may be redundant though; it may be implied by imagination.
Sam Altman of Loopt is one of the most successful alumni, so we asked him what question we could put on the Y Combinator application that would help us discover more people like him. He said to ask about a time when they'd hacked something to their advantage—hacked in the sense of beating the system, not breaking into computers. It has become one of the questions we pay most attention to when judging applications.
Or, to pick one of countless examples from Google, in order to reduce travel costs at Google, Google engineers implemented a system where they computed some kind of baseline "expected cost for flights, and then gave people a credit for taking flights that came in under the baseline costs that could be used to upgrade future flights and travel accommodations. This was a nice experience for employees compared to what stodgier companies were doing in terms of expense limits and Google engineers were proud of creating a system that made things better for everyone, which was one kind of hacking the system. The next level of hacking the system was when some employees optimized their flights and even set up trips to locations that were highly optimizable (many engineers would consider this a fun challenge, a variant of classic dynamic programming problems that are given in interviews, etc.), allowing them to upgrade to first class flights and the nicest hotels.
When I've talked about this with people in management in traditional industries, they've frequently been horrified and can't believe that these employees weren't censured or even fired for cheating the system. But when I was at Google, people generally found this to be admirable, as it exemplified the hacker spirit.
We can see, from the history of antitrust in tech going back at least two decades, that courts, regulators, and legislators have not been prepared for the vigor, speed, and delight with which tech companies hack the system.
And there's precedent for bringing in tech folks to work on the other side of the table. For example, this was done in the big Microsoft antitrust case. But there are incentive issues that make this difficult at every level that stem from, among other things, the sheer amount of money that tech companies are willing to pay out. If I think about tech folks I know who are very good at the kind of hacking the system described here, the ones who want to be employed at big companies frequently make seven figures (or more) annually, a sum not likely to be rivaled by an individual consulting contract with the DoJ or FTC. If we look at the example of Microsoft again, the tech group that was involved was managed by Ron Schnell, who was taking a break from working after his third exit, but people like that are relatively few and far between. Of course there are people who don't want to work at big companies for a variety of reasons, often moral reasons or a dislike of big company corporate politics, but most people I know who fit that description haven't spent enough time at big companies to really understand the mechanics of how big companies operate and are the wrong people for this job even if they're great engineers and great hackers.
At an antitrust conference a while back, a speaker noted that the mixing and collaboration between the legal and economics communities was a great boon for antitrust work. Notably absent from the speech as well as the conference were practitioners from industry. The conference had the feel of an academic conference, so you might see CS academics at the conference some day, but even if that were to happen, many of the policy-level discussions are ones that are outside the area of interest of CS academics. For example, one of the arguments from the BE memo that we noted as implausible was the way they used MAU to basically argue that switching costs were low. That's something outside the area of research of almost every CS academic, so even if the conference were to expand and bring in folks who work closely with tech, the natural attendees would still not be the right people to weigh in on the topic when it comes to the plausibility of nitty gritty details.
Besides the aforementioned impact on policy discussions, the lack of collaboration with tech folks also meant that, when people spoke about the motives of actors, they would often make assumptions that were unwarranted. On one specific example of what someone might call a hack of the system, the speaker described an exec's reaction (high-fives, etc.), and inferred a contempt for lawmakers and the law that was not in evidence. It's possible the exec in question does, in fact, have a contempt and disdain for lawmakers and the law, but that celebration is exactly what you might've seen after someone at Google figured out how to get upgraded to first class "for free" on almost all their flights by hacking the system at Google, which wouldn't indicate contempt or disdain at all.
Coming back to the incentive problem, it goes beyond getting people who understand tech on the other side of the table in antitrust discussions. If you ask Capitol Hill staffers who were around at the time, the general belief is that the primary factor that scuttled the FTC investigation was Google's lobbying, and of course Google and other large tech companies spend more on lobbying than entities that are interested in increased antitrust scrutiny.
And in the civil service, if we look at the lead of the BC investigation and the first author on the BC memo, they're now Director and Associate General Counsel of Competition and Regulatory Affairs at Facebook. I don't know them, so I can't speak to their motivations, but if I were offered as much money as I expect they make to work on antitrust and other regulatory issues at Facebook, I'd probably take the offer. Even putting aside the pay, if I was a strong believer in the goals of increased antitrust enforcement, that would still be a very compelling offer. Working for the FTC, maybe you lead another investigation where you write a memo that's much stronger than the opposition memo, which doesn't matter when a big tech company pours more lobbying money into D.C. and the investigation is closed. Or maybe your investigation leads to an outcome like the EU investigation that led to a "choice screen" that was too little and far too late. Or maybe it leads to something like the Android Play Store untying case where, seven years after the investigation was started, an enterprising Google employee figures out a "hack" that makes the consent decree useless in about five minutes. At least inside Facebook, you can nudge the company towards what you think is right and have some impact on how Facebook treats consumers and competitors.
Looking at it from the standpoint of people in tech (as opposed to people working in antitrust), in my extended social circles, it's common to hear people say "I'd never work at company X for moral reasons". That's a fine position to take but, almost everyone I know who does this ends up working at a much smaller company that has almost no impact on the world. If you want to take a moral stand, you're more likely to make a difference by working from the inside or finding a smaller direct competitor and helping it become more successful.
Thanks to Laurence Tratt, Yossi Kreinin, Justin Hong, [email protected], Sophia Wisdom, @[email protected], @[email protected], and Misha Yagudin for comments/corrections/discussion
This is analogous to the "non-goals" section of a technical design doc, but weaker, in that a non-goal in a design doc is often a positive statement that implies something that couldn't be implied from reading the doc, whereas the non-goal statements themselves don't add any informatio
By "Barbara R. Blank, Gustav P. Chiarello, Melissa Westman-Cherry, Matthew Accornero, Jennifer Nagle, Anticompetitive Practices Division; James Rhilinger, Healthcare Division; James Frost, Office of Policy and Coordination; Priya B. Viswanath, Office of the Director; Stuart Hirschfeld, Danica Noble, Northwest Region; Thomas Dahdouh, Western Region-San Francisco, Attorneys; Daniel Gross, Robert Hilliard, Catherine McNally, Cristobal Ramon, Sarah Sajewski, Brian Stone, Honors Paralegals; Stephanie Langley, Investigator"
Dated August 8, 2012
c. Specifics of Google's Syndication Agreements
"Bureau of Economics
August 8, 2012
From: Christopher Adams and John Yun, Economists"
[I stopped taking detailed notes at this point because taking notes that are legible to other people (as opposed to just for myself) takes about an order of magnitude longer, and I didn't think that there was much of interest here. I generally find comments of the form "I stopped reading at X" to be quite poor, in that people making such comments generally seem to pick some trivial thing that's unimportant and then declare and entire document to be worthless based on that. This pattern is also common when it comes to engineers, institutions, sports players, etc. and I generally find it counterproductive in those cases as well. However, in this case, there isn't really a single, non-representative, issue. The majority of the reasoning seems not just wrong, but highly disconnected from the on-the-ground situation. More notes indicating that the authors are making further misleading or incorrect arguments in the same style don't seem very useful. I did read the rest of the document and I also continue to summarize a few bits, below. I don't want to call them "highlights" because that would imply that I pulled out particularly interesting or compelling or incorrect bits and it's more of a smattering of miscellaneous parts with no particular theme]
[for these, I continued writing high-level summaries, not detailed summaries]
By analogy to a case that many people in tech are familiar with, consider this exchange between Oracle counsel David Boies and Judge William Alsup on the rangeCheck function, which checks if a range is a valid array access or not given the length of an array and throws an exception if the access is out of range:
Boies previously brought up this function as a non-trivial piece of work and then argues that, in their haste, a Google engineer copied this function from Oracle. As Alsup points out, the function is trivial, so trivial that it wouldn't be worth looking it up to copy and that even a high school student could easily produce the function from scratch. Boies then objects that, sure, maybe a high school student could write the function, but it might take an hour or more and Alsup correctly responds that an hour is implausible and that it might take five minutes.
Although nearly anyone who could pass a high school programming class would find Boeis's argument not just wrong but absurd3, more like a joke than something that someone might say seriously, it seems reasonable for Boies to make the argument because people presiding over these decisions in court, in regulatory agencies, and in the legislature, sometimes demonstrate a lack of basic understanding of tech. Since my background is in tech and not law or economics, I have no doubt that this analysis will miss some basics about law and economics in the same way that most analyses I've read seem miss basics about tech, but since there's been extensive commentary on this case from people with strong law and economics backgrounds, I don't see a need to cover those issues in depth here because anyone who's interested can read another analysis instead of or in addition to this one.
[return]Although this document is focused on tech, the lack of hands-on industry-expertise in regulatory bodies, legislation, and the courts, appears to cause problems in other industries as well. An example that's relatively well known due to a NY Times article that was turned into a movie is DuPont's involvement in the popularization of PFAS and, in particular, PFOA. Scientists at 3M and DuPont had evidence of the harms of PFAS going back at least to the 60s, and possibly even as far back as the 50s. Given the severe harms that PFOA caused to people who were exposed to it in significant concentrations, it would've been difficult to set up a production process for PFOA without seeing the harm it caused, but this knowledge, which must've been apparent to senior scientists and decision makers in 3M and DuPont, wasn't understood by regulatory agencies for almost four decades after it was apparent to chemical companies.
By the way, the NY Times article is titled "The Lawyer Who Became DuPont’s Worst Nightmare" and it describes how DuPont made $1B/yr in profit for years while hiding the harms of PFOA, which was used in the manufacturing process for Teflon. This lawyer brought cases against DuPont that were settled for hundreds of millions of dollars; according to the article and movie, the litigation didn't even cost DuPont a single year's worth of PFOA profit. Also, DuPont manage to drag out the litigation for many years, continuing to reap the profit from PFOA. Now that enough evidence has mounted against PFOA, Teflon is now manufactured using PFO2OA or FRD-903, which are newer and have a less well understood safety profile than PFOA. Perhaps the article could be titled "The Lawyer Who Became DuPont's Largest Mild Annoyance".
[return]In the media, I've sometimes seen this framed as a conflict between tech vs. non-tech folks, but we can see analogous comments from people outside of tech. For example, in a panel discussion with Yale SOM professor Fiona Scott Morton and DoJ Antitrust Principal Deputy AAG Doha Mekki, Scott Morton noted that the judge presiding over the Sprint/T-mobile merger proceedings, a case she was an expert witness for, had comically wrong misunderstandings about the market, and that it's common for decisions to be made which are disconnected from "market realities". Mekki seconded this sentiment, saying "what's so fascinating about some of the bad opinions that Fiona identified, and there are many, there's AT&T Time Warner, Sabre Farelogix, T-mobile Sprint, they're everywhere, there's Amex, you know ..."
If you're seeing this or the other footnote in mouseover text and/or tied to a broken link, this is an issue with Hugo. At this point, I've spent more than an entire blog post's worth of effort working around Hugo breakage and am trying to avoid spending more time working around issues in a tool that makes breaking changes at a high rate. If you have a suggestion to fix this, I'll try it, otherwise I'll try to fix it when I switch away from Hugo.
[return]{kind=link}