2025-04-28 22:00:00
When building a project, it's very likely that we will install third-party packages from npm to offload some tasks. On that topic, we know there are two major types of dependencies: dependencies (prod) and devDependencies (dev). In our package.json, it might look something like this:
{
"name": "my-cool-vue-components",
"dependencies": {
"vue": "^3.5.15"
},
"devDependencies": {
"eslint": "^9.15.0"
}
}
The main difference is that devDependencies are only needed during the build or development phase, while dependencies are required for the project to run. For example, eslint in the case above only lints our source code; it's no longer needed when we publish the project or deploy it to production.
The concept of dependencies and devDependencies was originally introduced for authoring Node.js libraries (those published to npm). When you install a package like vite, npm automatically installs its dependencies but not its devDependencies. This is because you are consuming vite as a dependency and don't need its development tools. So, even if vite uses prettier during its development, you won't be forced to install prettier when you only need vite in your project.
As the ecosystem has evolved, we can now build much more complex projects than ever before. We have meta-frameworks for building full-stack websites, bundlers for transpiling and bundling code and dependencies, and so on. Node.js became a lot more than just running JavaScript code and packages on the server side.
I'd roughly categorize projects into three types:
package.json primarily keeps track of dependency information, and the app itself is never published to npm.Fundamentally, the distinction between dependencies and devDependencies only truly makes sense for libraries intended for publication on npm. However, due to different scenarios and usage patterns, their meaning has extended far beyond the original purpose.
Tools often overload the meaning of dependencies and devDependencies to fit various scenarios, aiming for sensible defaults and better Developer Experience.
For example, Vite treats dependencies as "client-side packages" and automatically runs pre-optimization on them. Build tools like tsup, unbuild, and tsdown treat dependencies as packages to be externalized during bundling, automatically inlining (bundling) anything not listed in dependencies.
While these conventions certainly simplify things in most cases, they also force dependencies and devDependencies to wear multiple hats, making it harder to grasp the purpose of each package.
If we see vue listed in devDependencies, it could mean several things:
Simply classifying packages as dependencies or devDependencies doesn't provide the full picture of that package's purpose without external documentation (also note that package.json doesn't support comments).
Let's forget about dependencies and devDependencies for a moment, how might we categorize our dependencies? Here are some rough ideas I could come up with:
test: Packages used for testing (e.g., vitest, playwright, msw).lint: Packages for linting/formatting (e.g., eslint, knip).build: Packages used for building the project (e.g., vite, rolldown).script: Packages used for scripting tasks (e.g., tsx, tinyglobby, cpx).frontend: Packages for frontend development (e.g., vue, pinia).backend: Packages for the backend server.types: Packages for type checking and definitions.inlined: Packages that are included directly in the final bundle.prod: Runtime production dependencies.Categorization might differ between projects. But that point is that dependencies and devDependencies lack the flexibility to capture this level of detail.
This thing had been bothering me for a while, though it didn't feel like a critical problem needing immediate resolution. Only until pnpm introduced catalogs, opening up possibilities for dependency categorization we never had before.
PNPM Catalogs is a feature allowing monorepo workspaces to share dependency versions across different packages via a centralized management location.
Basically, you add catalog or catalogs fields to your pnpm-workspace.yaml file and reference them using catalog:<name> in your package.json.
# pnpm-workspace.yaml
catalog:
vue: ^3.5.15
pinia: ^2.2.6
cac: ^6.7.14
// package.json
{
"dependencies": {
"vue": "catalog:",
"pinia": "catalog:",
"cac": "catalog:"
}
}
Or with named catalogs:
# pnpm-workspace.yaml
catalogs:
frontend:
vue: ^3.5.15
# We locked the version for some reason, etc.
pinia: 2.2.6
prod:
cac: ^6.7.14
// package.json
{
"dependencies": {
"vue": "catalog:frontend",
"pinia": "catalog:frontend",
"cac": "catalog:prod"
}
}
During installation and publishing, pnpm automatically resolves dependencies to the versions specified in the catalogs. While it's originally designed for managing version consistency across monorepos, I found Named Catalogs are also a great way to also categorize dependencies. As shown above, we can categorize vue and cac into different catalogs even though they both presented in dependencies. This information makes version upgrade easier and would help on reviewing dependency changes.
A nice bonus: you can use comments in
pnpm-workspace.yamlto share additional context with your team.
Given that catalogs are still quite new, this shift requires better tooling support. A significant pain point for me on this was losing the ability to see a dependency's version at a glance in package.json when using catalog:<name>.
To address this, I created a VS Code extension, PNPM Catalog Lens, which displays the resolved version inline within package.json.
It also adds distinct colors to each named category for easier identification. This gives us the categorization and centralized version control without significantly impacting DX.
Since versions move to pnpm-workspace.yaml, CLI tools would need to make some integrations to support this. So far, we've adapted the following tools:
taze: Checks and bumps dependency versions, now supporting reading and updating versions from catalogs.eslint-plugin-pnpm: Enforces using catalogs for all dependencies in package.json, with auto-fixes.
@antfu/eslint-config, enable this by setting pnpm: true.pnpm-workspace-yaml: A utility library for reading and writing pnpm-workspace.yaml while preserving comments and formatting.node-modules-inspector: Visualizes your node_modules, now labeling dependencies with their catalog name for a better overview of their origin.nip: Interactive CLI to install packages to catalogsCurrently, I see the value of categorize dependencies is mainly for better communication and easier version upgrade reviews. However, as this convention gains wider adoption and tooling support improves, we could integrate this information more deeply with our tools.
For example, in Vite, we could gain more explicit control over dependency optimization, decoupling it from the dependencies and devDependencies fields:
// vite.config.ts
import { readWorkspaceYaml } from 'pnpm-workspace-yaml'
import { defineConfig } from 'vite'
const yaml = await readWorkspaceYaml('pnpm-workspace.yaml') // pseudo-API
export default defineConfig({
optimizeDeps: {
include: Object.keys(yaml.catalogs.frontend)
}
})
Similarly, for unbuild, we could explicitly control externalization and inlining without manually maintaining lists in multiple places:
// build.config.ts
import { readWorkspaceYaml } from 'pnpm-workspace-yaml'
import { defineBuildConfig } from 'unbuild'
const yaml = await readWorkspaceYaml('pnpm-workspace.yaml')
export default defineBuildConfig({
externals: Object.keys(yaml.catalogs.prod),
rollup: {
inlineDependencies: Object.keys(yaml.catalogs.inlined)
}
})
For linting or bundling, we could enforce rules based on catalogs, such as throwing errors when attempting to import backend packages into frontend code, preventing accidental bundling mistakes.
This categorization could also provide valuable context for vulnerability reports. Vulnerabilities in build tools might be less severe than those in dependencies shipped to production.
...and so on.
I've already started migrating many of my projects to use named catalogs(node-modules-inspector for example). Even outside monorepos, the ability to categorize dependencies is a compelling reason to adopt to pnpm catalogs. I consider this an exploratory phase where we're still discovering best practices and improving tooling support.
So, that's why I'm writing this post: to invite you to consider this approach and try it out. We'd love to hear your thoughts and how you would utilize it. I look forward to seeing more patterns like this emerge, helping us build more maintainable projects with a better DX. Thanks for reading!
2025-04-08 08:00:00
Seven years ago, my first visit to Japan - a trip to 大阪, 京都, and 北海道 - planted the seed of wanting to live in Japan one day. It was an unforgettable experience that changed the way I see the world. The meticulous attention to detail, the dedication to craftsmanship, and the seamless blend of tradition and modernity continue to inspire me.
Here are some photos I took back in 2018 on that trip:
The language also intrigued me. Japanese has a unique rhythm and musicality that I find fascinating. As an anime enthusiast, I've been passively learning Japanese through watching countless shows, but I've never had the opportunity to study it formally to have it useful enough.
Living in Japan has been one of my life goals, but life took some unexpected turns along the way. My work in programming suddenly gained recognition at the last year of my university, igniting my passion and leading me into the exciting world of Open Source, which has been filled with incredible opportunities and experiences.
After graduating from university, I was incredibly fortunate to join {@NuxtLabs}, where I got to collaborate with amazing people and work in Open Source. This opportunity led me to move to Paris two years ago. Paris is a magnificent city, and life in Europe opened my eyes to so many new experiences - attending conferences and meetups, and meeting wonderful friends along the way. Although Europe wasn't part of my initial plan, I'm deeply grateful for the chance to live there, as it has completely transformed my life.
It would never be enough for me to explore and discover the profound history and culture of Europe. However, down to the heart, there is also a part of me that wanted to experience more different lifestyles and see more of the world while I am still young. Thanksfully, the flexibility of my work allows me to work remotely and be in different timezones. In addition, the conferences held all over the world also made it easier for me to travel and go back to catch up with friends.
After careful consideration, I decided to take the leap and give Japan a try - checking off another item on my life's bucket list.
So here I am.
Right on the second day I arrived, 東京 gave me an amazing welcoming surprise - a rare heavy snowfall in March!
Shortly after, the sakura season began. One of the things I love most about Tokyo is how cherry blossoms can be found almost everywhere, painting the spring with so much of romantic vibes.
It's now my third week here, and the time has been incredibly fulfilling. Beyond setting up my apartment and getting settled, I got to see many old friends and meet quite some new ones. I attended the v-tokyo and PHP x Tokyo meetups in person, and enjoyed several 飲み会 with many nice and welcoming friends. While I've visited Japan for travel several times before, living here is a completely different experience with its own unique challenges.
About the language, while I am still struggling on it, the people here are so friendly and patient, surprisingly, I managed to get over many communication barriers (and knowing 漢字 from my Chinese background definitely helps a lot). I am taking a language school starting from this week, it's interesting to back as a part-time student after so many years.
It was indeed quite overwhelming at the beginning to deal with so many things at the same time. I'm grateful for the tremendous help from many friends who made it possible for me to settle in quickly and establish a routine in this new environment.
I am incredibly grateful to {@Atinux} and {@NuxtLabs} for their unwavering support during my move, making this transition possible. Thanks to {@kazupon} {@ubugeeei} {@nozomuikuta} {@448jp} and the entire {@vuejs-jp} community for their warm welcome (I might keep bothering for a while). Big thanks to {@privatenumber} for assisting with the logistics, {@sxzz} for traveling all the way from Hangzhou to help me settle in, and れいさん for helping me found this perfect apartment and managing the entire process.
Lastly, a special thanks to {@hannoeru}, who supported me in almost every aspect of preparing for and during this move. Without the help from him, I might still be wandering the streets right now 🤣.
I'll usually be in between 新宿 and 秋葉原 during weekdays. If you live in Tokyo or come by to visit, please don't hesitate to reach out! I'd love to meet and chat! I'm eager to learn more about Japan and the people here (or if you're visiting, I'd be happy to show you around!).
You can message me on SNS, or send me an email at [email protected], looking forward to that! 🌸
Thanks for reading!
2025-03-12 20:00:00
As you might have noticed, I added a photos page on this site recently. It's something I wanted to do for a very long time but always procrastinated on.
During certain periods of my life, photography was my greatest passion, just as much as I do today with Open Source and programming. Instagram was once a delightful, minimalist platform for photo sharing that I frequently used - until Meta's acquisition changed everything. While I could even tolerate the algorithms, ads, and short videos, the recent change of profile photo grids' aspect ratio from square to 4:5 was the final straw - an arrogant decision that impacts every user's content without providing proper solutions.
I am not sure if anger or disappointment are the right words to describe my feelings. But I'm certainly lucky to be a frontend developer - so I can leverage my skills to build my own website and host my photos here.
I requested to download all my data from Instagram (it took roughly a day to process in my case), and imported them to the website. Thankfully, the downloaded data was relatively easy to process, with photos dating back to 2015. I use sharp to process the images and compress them with this script. This automation helps me manage the photos without worrying about image sizes for hosting.
Looking through these old photos brings back so many memories. While some may not meet my current standards - and I admittedly feel a bit embarrassed sharing them - they hold too many precious memories to leave behind. So I decided to keep most of them - hope you won't look too closely at them :P
Here are some of my recent photos:
It's a shame that the image quality from Instagram isn't great, since they compress photos heavily upon posting. I might replace some of them with higher quality originals in the future, but for now, I think it's a good start.
That said, I hope to get back into regularly sharing photos (as I keep saying 😅), especially now that I have my own platform for it.
Thanks for reading! And I hope you find my photos interesting. Cheese 🧀!
2025-03-03 08:00:00
In modern programming, the function coloring problem isn't new. Based on how functions execute: synchronous (blocking) and asynchronous (non-blocking), we often classify them into two "colors" for better distinction. The problem arises because you generally cannot mix and match these colors freely.
For instance, in JavaScript:
This restriction forces developers to propagate the "color" throughout their codebase. If a function deep in your logic needs to become async, it forces every caller up the chain to also become async, leading to a cascading effect (or "async inflection"). This makes refactoring harder, increases complexity, and sometimes leads to awkward workarounds like blocking async calls with await inside sync contexts, or vice versa.
We often discuss the async inflection problem, where a common solution is to make everything async since async functions can call both sync and async functions, while the reverse is not true. However, the coloring problem actually goes both ways, which seems to be less frequently discussed:
While an async function requires all the callers to be async, a sync function also requires all the dependencies to be sync.
At its core, it's the same problem with different perspectives. It depends on which part of the code you're focusing on and how difficult it is to change its "color." If the function you're working on must be async, the burden shifts to the callers. Conversely, if it must be sync, you'll need all your dependencies to be sync or provide a synchronous entry point.
For example, the widely used library find-up provides two main APIs, findUp and findUpSync, to avoid dependents being trapped by the coloring problem. If you look into the code, you'll find that the package essentially duplicates the logic twice to provide the two APIs. Going down, you see its dependency locate-path also duplicates the locatePath and locatePathSync logic.
Say you want to build another library that uses findUp, like readNearestPkg, you would also have to write the logic twice, using findUp and findUpSync separately, to support both async and sync usage.
In these cases, even if our main logic does not come with its own "colors," the whole dependency pipeline is forced to branch into two colors due to an optional async operation down the road (e.g., fs.promises.stat and fs.statSync).
Another case demonstrating the coloring problem is a plugin system with async hooks. For example, imagine we are building a Markdown-to-HTML compiler with plugin support. Say the parser and compiler logic are synchronous; we could expose a sync API like:
export function markdownToHtml(markdown) {
const ast = parse(markdown)
// ...
return render(ast)
}
To make our library extensible, we might allow plugins to register hooks at multiple stages thoughout the process, for example:
export interface Plugin {
preprocess: (markdown: string) => string
transform: (ast: AST) => AST
postprocess: (html: string) => string
}
export function markdownToHtml(markdown, plugins) {
for (const plugin of plugins) {
markdown = plugin.preprocess(markdown) // [!code hl]
}
let ast = parse(markdown)
for (const plugin of plugins) {
ast = plugin.transform(ast) // [!code hl]
}
let html = render(ast)
for (const plugin of plugins) {
html = plugin.postprocess(html) // [!code hl]
}
return html
}
Great, now we have a plugin system. However, having markdownToHtml as a synchronous function essentially limits all plugin hooks to be synchronous as well. This limitation can be quite restrictive. For instance, consider a plugin for syntax highlighting. In many cases, the best results for syntax highlighting might require asynchronous operations, such as fetching additional resources or performing complex computations that are better suited for non-blocking execution.
To accommodate such scenarios, we need to allow async hooks in our plugin system. This means that our main function, markdownToHtml, as the caller of the plugin hooks must also be async. We could implement it like this:
// [!code word:Promise]
// [!code word:async]
// [!code word:await]
export interface Plugin {
preprocess: (markdown: string) => string | Promise<string>
transform: (ast: AST) => AST | Promise<AST>
postprocess: (html: string) => string | Promise<string>
}
export async function markdownToHtml(markdown, plugins) { // [!code hl]
for (const plugin of plugins) {
markdown = await plugin.preprocess(markdown) // [!code hl]
}
let ast = parse(markdown)
for (const plugin of plugins) {
ast = await plugin.transform(ast) // [!code hl]
}
let html = render(ast)
for (const plugin of plugins) {
html = await plugin.postprocess(html) // [!code hl]
}
return html
}
While this maximized the flexibility of the plugin system, this approach also forces all users to handle the process asynchronously, even in the cases where all plugins are synchronous. This is the cost of accommodating the possibility that some operations "might be asynchronous". To manage this, we often end up duplicating the logic to offer both sync and async APIs, and restrict async plugins to the async version only.
Such duplications lead to increased maintenance efforts, potential inconsistencies, and larger bundle sizes, which are not ideal for maintainers or users.
Is there a better way to handle this?
What if we could make our logic decoupled from the coloring problem and let the caller decide the color?
Trying to make the situation a bit better, {@sxzz} and I took inspiration from gensync by {@loganfsmyth} and made a package called quansync. Taking it even further, we are dreaming of leveraging this to create a paradigm shift in the way we write libraries in the JavaScript ecosystem.
The name Quansync is borrowed from Quantum Mechanics, where particles can exist in multiple states simultaneously, known as superposition, and only settle into a single state when observed (try hovering over the atom below).
You can think of quansync as a new type of function that can be used as both sync and async depending on the context. In many cases, our logic can escape the async inflection problem, especially when designing shared logic with optional async hooks.
Quansync provides a single API with two overloads.
Wrapper allows you to create a quansync function by providing a sync and an async implementation. For example:
import fs from 'find-up'
import { quansync } from 'quansync'
export const readFile = quansync({
sync: filepath => fs.readFileSync(filepath),
async: filepath => fs.promises.readFile(filepath),
})
const content1 = readFile.sync('package.json')
const content2 = await readFile.async('package.json')
// The quansync function itself can behave like a normal async function
const content3 = await readFile('package.json')
Generator is where the magic happens. It allows you to create a quansync function by using other quansync functions. For example:
import { quansync } from 'quansync'
export const readFile = quansync({
sync: filepath => fs.readFileSync(filepath),
async: filepath => fs.promises.readFile(filepath),
})
// Create a quansync with `function*` and `yield*`
// [!code word:function*:1]
export const readJSON = quansync(function* (filepath) {
// Call the quansync function directly
// and use `yield*` to get the result.
// Upon usage, it will auto select the implementation
// [!code word:yield*:1]
const content = yield* readFile(filepath)
return JSON.parse(content)
})
// fs.readFileSync will be used under the hood
const pkg1 = readJSON.sync('package.json')
// fs.promises.readFile will be used under the hood
const pkg2 = await readJSON.async('package.json')
If the function* and yield* syntax scares you a bit, {@sxzz} also made a build-time macro unplugin-quansync allowing you to write normal async/await syntax, and it will be transformed to the corresponding yield* syntax at build time.
// [!code word:quansync/macro]
import { quansync } from 'quansync/macro'
// Use async/await syntax
// They will be transformed to `function*` and `yield*` at build time
export const readJSON = quansync(async (filepath) => {
const content = await readFile(filepath)
return JSON.parse(content)
})
// Expose the classical sync API
export const readJSONSync = readJSON.sync
Thanks to unplugin, it can work in almost any build tool, like compiling with unbuild or testing with vitest. Please refer to the docs for more detailed setup.
Generators in JavaScript are a powerful yet often underutilized feature. To define a generator function, you use the function* syntax (note that arrow functions do not support generators). Inside a generator function, you can use the yield keyword to pause execution and return a value. This effectively splits your logic into multiple "chunks," allowing the caller to control when to execute the next chunk.
By leveraging this behavior, we can pause execution at each yield point. In an asynchronous context, we can wait for the async operation to complete before resuming execution. In a synchronous context, the next chunk runs immediately. This approach offloads the coloring problem to the caller, allowing them to decide whether the function should run synchronously or asynchronously.
In fact, during the early days of JavaScript, before the async and await keywords were widely adopted, Babel used generators and yield to polyfill async behavior. While this technique isn't new, we believe it has significant potential to improve how we handle the coloring problem, especially in library design.
Frankly, I wish most of time you don't even need to think about it. High-level tools should support async entry points for most cases, where choice sync and async is not a problem. However, there are still many cases where in the context, it's required to be colored. In such cases, quansync could be a good fit for progressive and gradual adoption.
Promise in JavaScript naturally a microtask that delays a tick. yield also introduce certain overhead (around ~120ns on M1 Max). In performance-sensitive scenarios, you might also want to avoid using either asyncor quansync.
While quansync doesn't completely solve the coloring problem, it provides a new perspective that simplifies managing synchronous and asynchronous code. Quansync introduces a new "purple" color, blending the red and blue. Quansync functions still face the coloring problem, as wrapping a function to support both sync and async requires it to be a quansync function (or generator). However, the key advantage is that a quansync function can be "collapsed" to either sync or async as needed. This allows your "colorless" logic to avoid the red and blue color inflection caused by some operations that might have a color.
This is a new approach to tackling the coloring problem we are still exploring. We will slowly roll out quansync in our libraries and see how it improves our experience and the ecosystem. We are also
looking for feedback and contributions, so feel free to join us in the Discord or GitHub Discussions to share your thoughts.
2025-02-05 08:00:00
[[toc]]
Three years ago, I wrote a post about shipping ESM & CJS in a single package, advocating for dual CJS/ESM formats to ease user migration and trying to make the best of both worlds. Back then, I didn't fully agree with aggressively shipping ESM-only, as I considered the ecosystem wasn't ready, especially since the push was mostly from low-level libraries. Over time, as tools and the ecosystem have evolved, my perspective has gradually shifted towards more and more on adopting ESM-only.
As of 2025, a decade has passed since ESM was first introduced in 2015. Modern tools and libraries have increasingly adopted ESM as the primary module format. According to {@wooorm}'s script, the packages that ships ESM on npm in 2021 was 7.8%, and by the end of 2024, it had reached 25.8%. Although a significant portion of packages still use CJS, the trend clearly shows a good shift towards ESM.

npm-esm-vs-cjs script. Last updated at 2024-11-27Here in this post, I'd like to share my thoughts on the current state of the ecosystem and why I believe it's time to move on to ESM-only.
With the rise of Vite as a popular modern frontend build tool, many meta-frameworks like Nuxt, SvelteKit, Astro, SolidStart, Remix, Storybook, Redwood, and many others are all built on top of Vite nowadays, that treating ESM as a first-class citizen.
As a complement, we have also testing library Vitest, which was designed for ESM from the day one with powerful module mocking capability and efficient fine-grain caching support.
CLI tools like tsx and jiti offer a seamless experience for running TypeScript and ESM code without requiring additional configuration. This simplifies the development process and reduces the overhead associated with setting up a project to use ESM.
Other tools, for example, ESLint, in the recent v9.0, introduced a new flat config system that enables native ESM support with eslint.config.mjs, even in CJS projects.
Back in 2021, when {@sindresorhus} first started migrating all his packages to ESM-only, for example, find-up and execa, it was a bold move. I consider this move as a bottom-up approach, as the packages that rather low-level and many their dependents are not ready for ESM yet. I was worried that this would force those dependents to stay on the old version of the packages, which might result in the ecosystem being fragmented. (As of today, I actually appreciate that move bringing us quite a lot of high-quality ESM packages, regardless that the process wasn't super smooth).
It's way easier for an ESM or Dual formats package to depend on CJS packages, but not the other way around. In terms of smooth adoption, I believe the top-down approach is more effective in pushing the ecosystem forward. With the support of high-level frameworks and tools from top-down, it's no longer a significant obstacle to use ESM-only packages. The remaining challenges in terms of ESM adoption primarily lie with package authors needing to migrate and ship their code in ESM format.
The capability to require() ESM modules in Node.js, initiated by {@joyeecheung}, marks an incredible milestone. This feature allows packages to be published as ESM-only while still being consumable by CJS codebases with minimal modifications. It helps avoid the async infection (also known as Red Functions) introduced by dynamic import() ESM, which can be pretty hard, if not impossible in some cases, to migrate and adapt.
This feature was recently unflagged and backported to Node.js v22 (and soon v20), which means it should be available to many developers already. Consider the top-down or bottom-up metaphor, this feature actually makes it possible to start ESM migration also from middle-out, as it allows import chains like ESM → CJS → ESM → CJS to work seamlessly.
To solve the interop issue between CJS and ESM in this case, Node.js also introduced a new export { Foo as 'module.exports' } syntax in ESM to export CJS-compatible exports (by this PR). This allows package authors to publish ESM-only packages while still supporting CJS consumers, without even introducing breaking changes (expcet for changing the required Node.js version).
For more details on the progress and discussions around this feature, keep track on this issue.
While dual CJS/ESM packages have been a quite helpful transition mechanism, they come with their own set of challenges. Maintaining two separate formats can be cumbersome and error-prone, especially when dealing with complex codebases. Here are some of the issues that arise when maintaining dual formats:
Fundamentally, CJS and ESM are different module systems with distinct design philosophies. Although Node.js has made it possible to import CJS modules in ESM, dynamically import ESM in CJS, and even require() ESM modules, there are still many tricky cases that can lead to interop issues.
One key difference is that CJS typically uses a single module.exports object, while ESM supports both default and named exports. When authoring code in ESM and transpiling to CJS, handling exports can be particularly challenging, especially when the exported value is a non-object, such as a function or a class. Additionally, to make the types correct, we also need to introduce further complications with .d.mts and .d.cts declaration files. And so on...
As I am trying to explain this problem deeper, I found that I actually wish you didn't even need to be bothered with this problem at all. It's frankly too complicated and frustrating. If you are just a user of packages, let alone the package authors to worry about that. This is one of the reasons I advocate for the entire ecosystem to transition to ESM, to leave these problems behind and spare everyone from this unnecessary hassle.
When a package has both CJS and ESM formats, the resolution of dependencies can become convoluted. For example, if a package depends on another package that only ships ESM, the consumer must ensure that the ESM version is used. This can lead to version conflicts and dependency resolution issues, especially when dealing with transitive dependencies.
Also for packages that are designed to used with singleton pattern, this might introduce multiple copies of the same package and cause unexpected behaviors.
Shipping dual formats essentially doubles the package size, as both CJS and ESM bundles need to be included. While a few extra kilobytes might not seem significant for a single package, the overhead can quickly add up in projects with hundreds of dependencies, leading to the infamous node_modules bloat. Therefore, package authors should keep an eye on their package size. Moving to ESM-only is a way to optimize it, especially if the package doesn't have strong requirements on CJS.
This post does not intend to diminish the value of dual-format publishing. Instead, I want to encourage evaluating the current state of the ecosystem and the potential benefits of transitioning to ESM-only.
There are several factors to consider when deciding whether to move to ESM-only:
I strongly recommend that all new packages be released as ESM-only, as there are no legacy dependencies to consider. New adopters are likely already using a modern, ESM-ready stack, there being ESM-only should not affect the adoption. Additionally, maintaining a single module system simplifies development, reduces maintenance overhead, and ensures that your package benefits from future ecosystem advancements.
If a package is primarily targeted for the browser, it makes total sense to ship ESM-only. In most cases, browser packages go through a bundler, where ESM provides significant advantages in static analysis and tree-shaking. This leads to smaller and more optimized bundles, which would also improve loading performance and reduce bandwidth consumption for end users.
For a standalone CLI tool, it's no difference to end users whether it's ESM or CJS. However, using ESM would enable your dependencies to also be ESM, facilitating the ecosystem's transition to ESM from a top-down approach.
If a package is targeting the evergreen Node.js versions, it's a good time to consider ESM-only, especially with the recent require(ESM) support.
If a package already has certain users, it's essential to understand the dependents' status and requirements. For example, for an ESLint plugin/utils that requires ESLint v9, while ESLint v9's new config system supports ESM natively even in CJS projects, there is no blocker for it to be ESM-only.
Definitely, there are different factors to consider for different projects. But in general, I believe the ecosystem is ready for more packages to move to ESM-only, and it's a good time to evaluate the benefits and potential challenges of transitioning.
The transition to ESM is a gradual process that requires collaboration and effort from the entire ecosystem. Which I believe we are on a good track moving forward.
To improve the transparency and visibility of the ESM adoption, I recently built a visualized tool called Node Modules Inspector for analyzing your packages's dependencies. It provides insights into the ESM adoption status of your dependencies and helps identify potential issues when migrating to ESM.
Here are some screenshots of the tool to give you a quick impression:
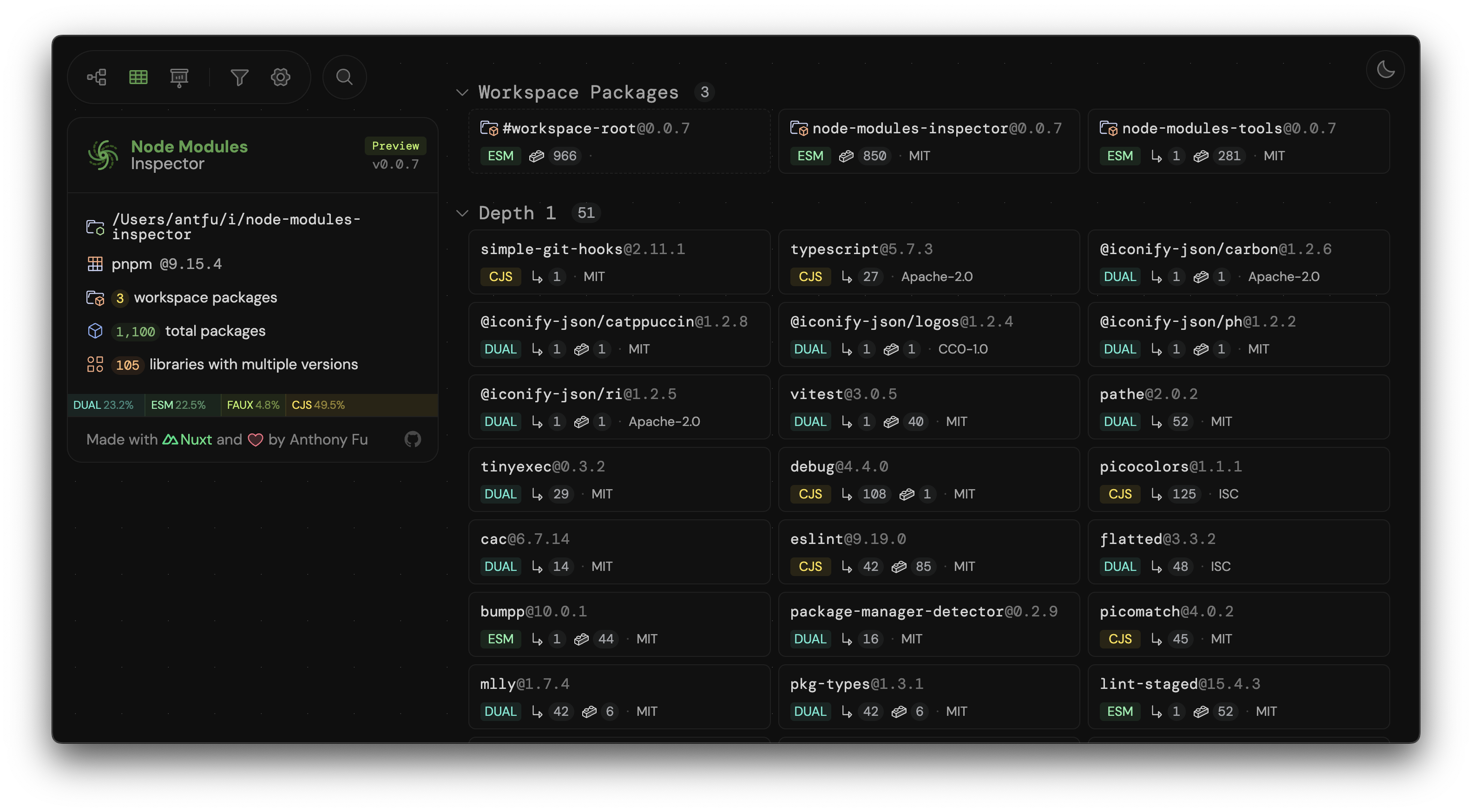
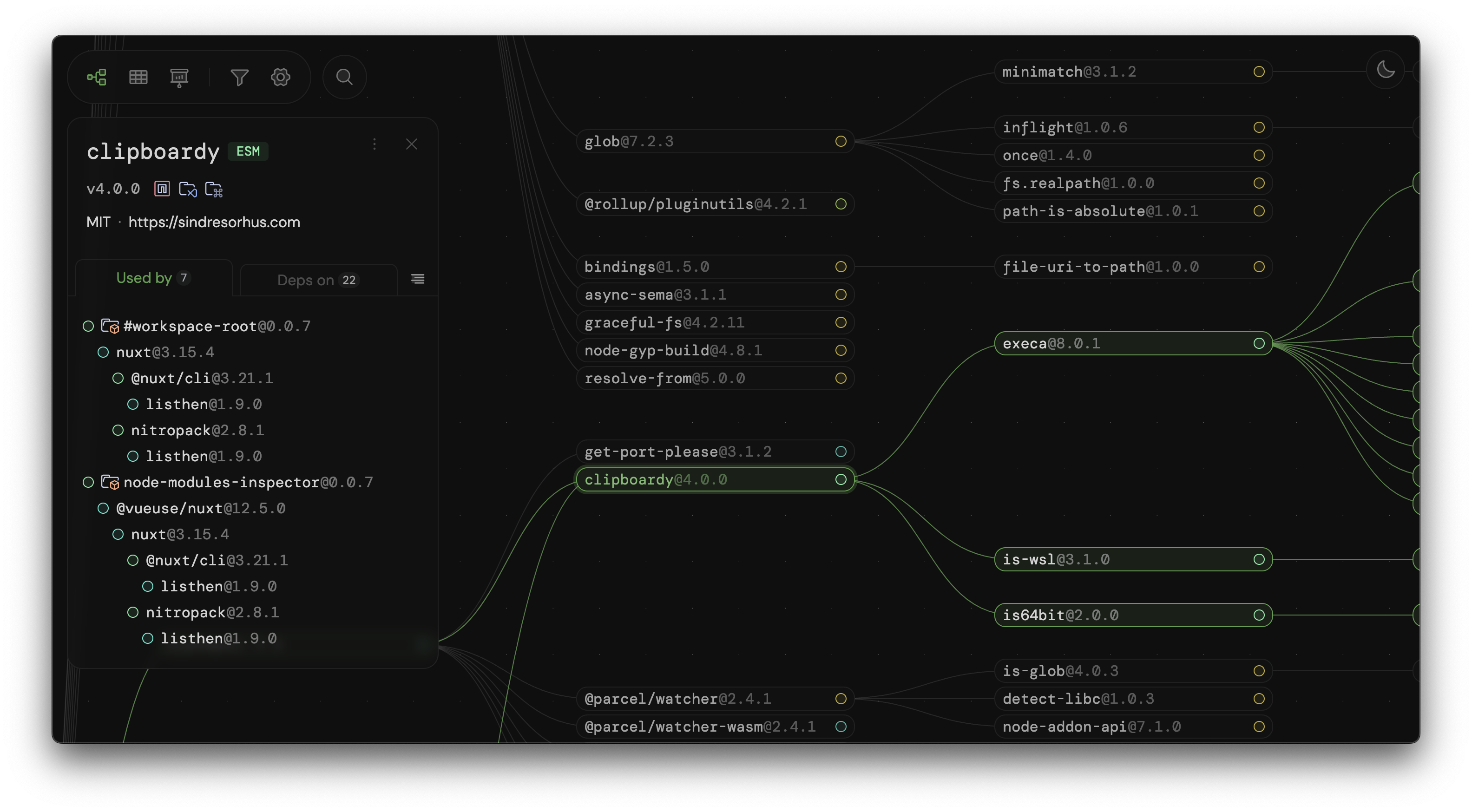
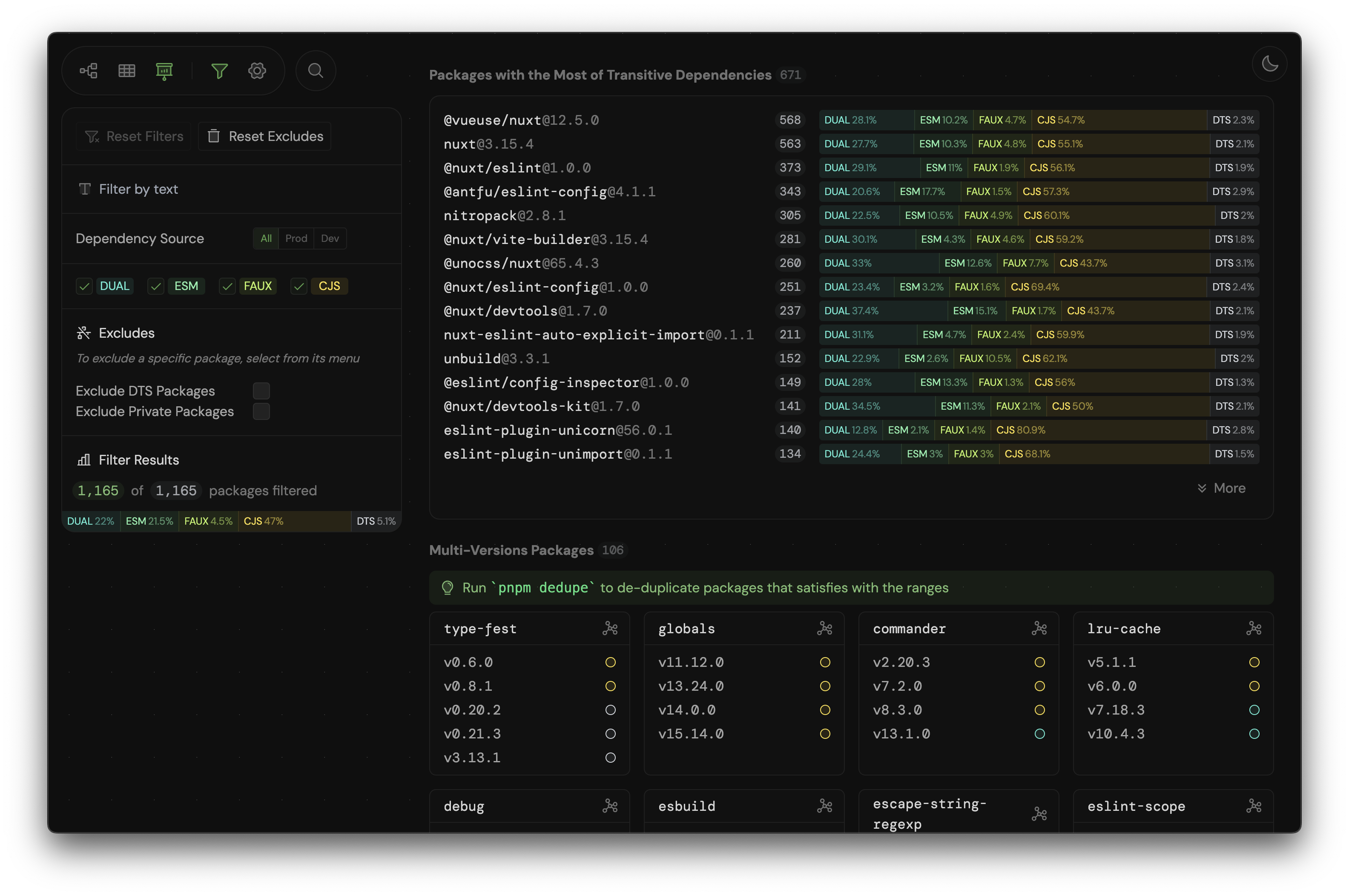
This tool is still in its early stages, but I hope it will be a valuable resource for package authors and maintainers to track the ESM adoption progress of their dependencies and make informed decisions about transitioning to ESM-only.
To learn more about how to use it and inspect your projects, check the repository
I am planning to gradually transition the packages I maintain to ESM-only and take a closer look at the dependencies we rely on. We also have plenty of exciting ideas for the Node Modules Inspector, aiming to provide more useful insights and help find the best path forward.
I look forward to a more portable, resilient, and optimized JavaScript/TypeScript ecosystem.
I hope this post has shed some light on the benefits of moving to ESM-only and the current state of the ecosystem. If you have any thoughts or questions, feel free to reach out using the links below. Thank you for reading!
2025-01-07 20:00:00
If you've been following my work in open source, you might have noticed that I have a tendency to stick with zero-major versioning, like v0.x.x. For instance, as of writing this post, the latest version of UnoCSS is v0.65.3, Slidev is v0.50.0, and unplugin-vue-components is v0.28.0. Other projects, such as React Native is on v0.76.5, and sharp is on v0.33.5, also follow this pattern.
People often assume that a zero-major version indicates that the software is not ready for production. However, all of the projects mentioned here are quite stable and production-ready, used by millions of projects.
Why? - I bet that's your question reading this.
Version numbers act as snapshots of our codebase, helping us communicate changes effectively. For instance, we can say "it works in v1.3.2, but not in v1.3.3, there might be a regression." This makes it easier for maintainers to locate bugs by comparing the differences between these versions. A version is essentially a marker, a seal of the codebase at a specific point in time.
However, code is complex, and every change involves trade-offs. Describing how a change affects the code can be tricky even with natural language. A version number alone can't capture all the nuances of a release. That's why we have changelogs, release notes, and commit messages to provide more context.
I see versioning as a way to communicate changes to users — a contract between the library maintainers and the users to ensure compatibility and stability during upgrades. As a user, you can't always tell what's changed between v2.3.4 and v2.3.5 without checking the changelog. But by looking at the numbers, you can infer that it's a patch release meant to fix bugs, which should be safe to upgrade. This ability to understand changes just by looking at the version number is possible because both the library maintainer and the users agree on the versioning scheme.
Since versioning is only a contract, and could be interpreted differently to each specific project, you shouldn't blindly trust it. It serves as an indication to help you decide when to take a closer look at the changelog and be cautious about upgrading. But it's not a guarantee that everything will work as expected, as every change might introduce behavior changes, whether it's intended or not.
In the JavaScript ecosystem, especially for packages published on npm, we follow a convention known as Semantic Versioning, or SemVer for short. A SemVer version number consists of three parts: MAJOR.MINOR.PATCH. The rules are straightforward:
Package managers we use, like npm, pnpm, and yarn, all operate under the assumption that every package on npm adheres to SemVer. When you or a package specifies a dependency with a version range, such as ^1.2.3, it indicates that you are comfortable with upgrading to any version that shares the same major version (1.x.x). In these scenarios, package managers will automatically determine the best version to install based on what is most suitable for your specific project.
This convention works well technically. If a package releases a new major version v2.0.0, your package manager won't install it if your specified range is ^1.2.3. This prevents unexpected breaking changes from affecting your project until you manually update the version range.
However, humans perceive numbers on a logarithmic scale. We tend to see v2.0 to v3.0 as a huge, groundbreaking change, while v125.0 to v126.0 seems a lot more trivial, even though both indicate incompatible API changes in SemVer. This perception can make maintainers hesitant to bump the major version for minor breaking changes, leading to the accumulation of many breaking changes in a single major release, making upgrades harder for users. Conversely, with something like v125.0, it becomes difficult to convey the significance of a major change, as the jump to v126.0 appears minor.
{@TkDodo|Dominik Dorfmeister} had a great talk about API Design, which mentions an interesting inequality that descripting this: "Breaking Changes !== Marketing Event"
I am a strong believer in the principle of progressiveness. Rather than making a giant leap to a significantly higher stage all at once, progressiveness allows users to adopt changes gradually at their own pace. It provides opportunities to pause and assess, making it easier to understand the impact of each change.
I believe we should apply the same principle to versioning. Instead of treating a major version as a massive overhaul, we can break it down into smaller, more manageable updates. For example, rather than releasing v2.0.0 with 10 breaking changes from v1.x, we could distribute these changes across several smaller major releases. This way, we might release v2.0 with 2 breaking changes, followed by v3.0 with 1 breaking change, and so on. This approach makes it easier for users to adopt changes gradually and reduces the risk of overwhelming them with too many changes at once.

The reason I've stuck with v0.x.x is my own unconventional approach to versioning. I prefer to introduce necessary and minor breaking changes early on, making upgrades easier, without causing alarm that typically comes with major version jumps like v2 to v3. Some changes might be "technically" breaking but don't impact 99.9% of users in practice. (Breaking changes are relative. Even a bug fix can be breaking for those relying on the previous behavior, but that's another topic for discussion :P).
There's a special rule in SemVer that states when the leading major version is 0, every minor version bump is considered breaking. I am kind of abusing that rule to workaround the limitation of SemVer. With zero-major versioning, we are effectively abandoning the first number, and merge MINOR and PATCH into a single number (thanks to David Blass for pointing this out):
ZERO.MAJOR.{MINOR + PATCH}
Of course, zero-major versioning is not the only solution to be progressive. We can see that tools like Node.js, Vite, Vitest are rolling out major versions in consistent intervals, with a minimal set of breaking changes in each release that are easy to adopt. It would require a lot of effort and extra attentions. Kudos to them!
I have to admit that sticking to zero-major versioning isn't the best practice. While I aimed for more granular versioning to improve communication, using zero-major versioning has actually limited the ability to convey changes effectively. In reality, I've been wasting a valuable part of the versioning scheme due to my peculiar insistence.
Thus, here, I am proposing to change.
In an ideal world, I would wish SemVer to have 4 numbers: EPOCH.MAJOR.MINOR.PATCH. The EPOCH version is for those big announcements, while MAJOR is for technical incompatible API changes that might not be significant. This way, we can have a more granular way to communicate changes. Similarly, we also have Romantic Versioning that propose HUMAN.MAJOR.MINOR. The creator of SemVer, Tom Preston-Werner also mentioned similar concerns and solutions in this blog post. (thanks to Sébastien Lorber for pointing this out).
But, of course, it's too late for the entire ecosystem to adopt a new versioning scheme.
If we can't change SemVer, maybe we can at least extend it. I am proposing a new versioning scheme called 🗿 Epoch Semantic Versioning, or Epoch SemVer for short. It's built on top of the structure of MAJOR.MINOR.PATCH, extend the first number to be the combination of EPOCH and MAJOR. To put a difference between them, we use a fourth digit to represent EPOCH, which gives MAJOR a range from 0 to 999. This way, it follows the exact same rules as SemVer without requiring any existing tools to change, but provides more granular information to users.
The name "Epoch" is inspired by Debian's versioning scheme.
The format is as follows:
{EPOCH * 1000 + MAJOR}.MINOR.PATCH
I previously proposed to have the EPOCH multiplier to be
100, but according to the community feedback, it seems that1000is a more popular choices as it give more room for theMAJORversion and a bit more distinguision between the numbers. The multiplier is not a strict rule, feel free to adjust it based on your needs.
For example, UnoCSS would transition from v0.65.3 to v65.3.0 (in the case EPOCH is 0). Following SemVer, a patch release would become v65.3.1, and a feature release would be v65.4.0. If we introduced some minor incompatible changes affecting an edge case, we could bump it to v66.0.0 to alert users of potential impacts. In the event of a significant overhaul to the core, we could jump directly to v1000.0.0 to signal a new era and make a big announcement. I'd suggest assigning a code name to each non-zero EPOCH to make it more memorable and easier to refer to. This approach provides maintainers with more flexibility to communicate the scale of changes to users effectively.
[!TIP]
We shouldn't need to bumpEPOCHoften. It's mostly useful for high-level, end-user-facing libraries or frameworks. For low-level libraries, they might never need to bumpEPOCHat all (ZERO-EPOCHis essentially the same as SemVer).
Of course, I'm not suggesting that everyone should adopt this approach. It's simply an idea to work around the existing system, and only for those packages with this need. It will be interesting to see how it performs in practice.
I plan to adopt Epoch Semantic Versioning in my projects, including UnoCSS, Slidev, and all the plugins I maintain, and ultimately abandon zero-major versioning for stable packages. I hope this new versioning approach will help communicate changes more effectively and provide users with better context when upgrading.
I'd love to hear your thoughts and feedback on this idea. Feel free to share your comments using the links below!