在后台手动修正之前,先通过界面进入后台手动将用户原先绑定的 RDN 修改为 LDAP 服务中正确的 RDN。
2025-09-05 10:30:00
在之前的《LDAP 集成之 Gitlab 篇》 和 《基于 LDAP 的统一认证服务 Keycloak》 中,分别探索了 LDAP 与 Gitlab、Keycloak 的集成。实际上,Gitlab 天然支持三者合一的认证方式,即 “LDAP 为 Gitlab 提供最底层的用户认证“和”Keycloak 提供统一的用户认证入口“。这样一来,
services:
...
gitlab:
...
environment:
...
- LDAP_ENABLED=true
- LDAP_PREVENT_LDAP_SIGN_IN=true
...
- OAUTH_AUTO_LINK_LDAP_USER=true
- OAUTH_AUTO_LINK_USER=IDP
- OAUTH_OIDC_LABEL=IDP
- OAUTH_OIDC_ISSUE=https://<Keycloak domain>/realms/master
- OAUTH_ODIC_CLIENT_ID=<id>
- OAUTH_ODIC_CLIENT_SECRET=<secret>
这里比较关键的配置就是要启用自动链接 LDAP 用户(OAUTH_AUTO_LINK_LDAP_USER)和指定自动链接的第三方认证方式(OAUTH_AUTO_LINK_USER)。为了规避用户直接使用 LDAP 认证登录,可以通过设置 LDAP_PREVENT_LDAP_SIGN_IN 来隐藏 LDAP 登录界面。
通过以上设置就可以让用户使用 Keycloak 作为统一入口登录 Gitlab,但是因为 Gitlab 会自动处理 LDAP 后台用户和自动链接,当后台 LDAP 发生变化时(比如修改 RDN 但保持邮件不变), Gitlab 会自动将用户的状态修改为 禁用 LDAP。由于 Gitlab 界面上不提供对于这种特殊情况的解禁操作,所以必须通过后台手动修正。
在后台手动修正之前,先通过界面进入后台手动将用户原先绑定的 RDN 修改为 LDAP 服务中正确的 RDN。
# 进入 Gitlab 容器
docker exec -ti gitlab-gitlab-1 bash
# 进入 Gitlab 控制台,可能需要等待 1 分钟
root@gitlab:/home/git/gitlab# RAILS_ENV=production bundle exec rails console
--------------------------------------------------------------------------------
Ruby: ruby 3.2.9 (2025-07-24 revision 8f611e0c46) [x86_64-linux]
GitLab: 18.3.1 (bccd1993b5d) FOSS
GitLab Shell: 14.44.0
PostgreSQL: 16.9
------------------------------------------------------------[ booted in 41.09s ]
Loading production environment (Rails 7.1.5.1)
irb(main):001>
# 查看被禁用 LDAP 的用户
irb(main):002> User.where(state: 'ldap_blocked')
# 解禁单个用户
irb(main):003> u = User.find_by_username('username')
irb(main):004> u.activate!
irb(main):005> u.save!
# 退出控制台
irb(main):006> exit
如果想要批量解禁 LDAP 用户可以在控制台执行以下命令:
# 批量解禁
User.where(state: 'ldap_blocked').find_each do |u|
u.activate!
u.save!
puts "✅ Activated #{u.username}"
end
由于 Gitlab 默认使用 Gravatar 为用户提供头像,且 Gravatar 访问一直不稳定,推荐使用自定义的 Gravatar 地址,如下设置:
services:
...
gitlab:
...
environment:
...
- GITLAB_GRAVATAR_ENABLED=true
- GITLAB_GRAVATAR_HTTP_URL=https://weavatar.com/avatar/%{hash}?s=%{size}&d=identicon
- GITLAB_GRAVATAR_HTTPS_URL=https://weavatar.com/avatar/%{hash}?s=%{size}&d=identicon
2025-06-16 12:42:00
之前在《JupyterLab 的搭建与运维》一文中,尝试了在单机上搭建部署 JupyterHub。不得不说,的确方便了团队内部共同使用同一台 GPU 服务器。但也有比较大的限制:
其实,JupyterHub 官方很早就意识到了这些,并通过拥抱 Kubernetes (以下简称“K8S”)来解决以上限制。可以说 K8S 天然是为 JupyterHub 多机资源管理调度而生,可以:
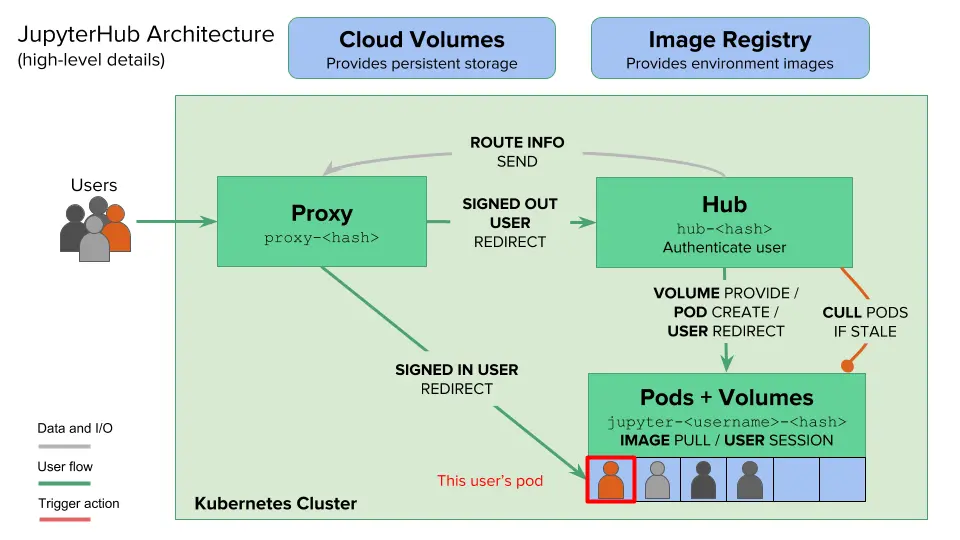
这里我们以一个简单的 CPU/GPU 科学计算集群为例:
以下为集群节点对应的 IP 地址信息:
| 节点主机名 | IP 地址 | 备注 |
|---|---|---|
| l0 | 192.168.120.100 | 登录节点,K8S 控制节点 |
| l1 | 192.168.120.101 | CPU/GPU 节点,K8S 工作节点 |
| l2 | 192.168.120.102 | CPU/GPU 节点,K8S 工作节点 |
| nas | 192.168.120.99 | 存储节点,NFS 服务 |
K8S 集群节点子网为 192.168.120.0/24。另外Pod 子网设置为 192.168.144.0/20、Service 子网设置为 192.168.244.0/20。
集群搭建过程请见《Kubernetes 不完全入门》一文,需配置好节点识别 NVIDIA 显卡和 NFS CSI 存储。
类似于操作系统的 APT 等包管理器,Helm 是 Kubernetes 的包管理器,一般定义了部署在 K8S 集群中的应用所需的所有配置文件。
Helm 可以通过系统包管理工具安装或者直接下载二进制文件使用。Ubuntu 系统如下操作:
curl https://baltocdn.com/helm/signing.asc | gpg --dearmor | sudo tee /usr/share/keyrings/helm.gpg > /dev/null
sudo apt-get install apt-transport-https --yes
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/helm.gpg] https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helm -y
二进制文件请自行前往 https://github.com/helm/helm/releases 下载。
Chart 是 Helm 使用的包格式,可以被认为是“软件源中的软件名”(实际是多种软件的集合)。这主要是因为如果要编写部署一整套应用所需的配置文件实在太复杂、耗时了,使用 Chart 只需要写一个自定义配置文件来覆盖想要修改的默认配置即可。
helm repo add jupyterhub https://hub.jupyter.org/helm-chart/
helm repo update
自定义配置文件可以是任意文件名,但必须是 yaml 格式,比如 config.yaml。对于以下配置我们可能需要进行自定义:
proxy.service.nodePorts.http 配置为 34567 端口。另外,我们可以将 proxy.chp.networkPolicy.enabled 置为 false 来取消 K8S 网络限制。为了安全,在 1.0.0 版本之前也许手动设置 proxy.secretToken 字段(使用 openssl rand -hex 32 命令生成)。hub.networkPolicy.enabled 为 false 取消网络限制;(2)(可选)使用 hub.extraVolumes 字段来添加指定的持久化卷名;(3)(可选,推荐)配置 hub.config 来启用 Oauth2 认证登录,目前官方支持 Github、Gitlab 在内的多款认证方式,详细请见 The OAuthenticator。这里我们使用自建 Gitlab 来测试。prePuller.hook.enabled 为 false 来禁用节点预拉取运行实例镜像。启用的情况下,当有新节点加入可用集群时可以自动拉取,以避免第一次在新节点部署实例时用户需要等待一段时间。(2)(可选)限制实例最长可运行时间 cull.maxAge和最长闲置时间cull.timeout,通过自动销毁来提升集群的可用率。cull.enabled字段也需要置为 true 从而生效。cull.every 字段可以设置每分钟检查是否超出限制。singleuser.extraPodConfig.securityContext 中的 fsGroup (值为 100) 和 fsGroupChangePolicy (值为 OnRootMismatch) 来实现启动实例跳过每次修改文件夹权限,仅当文件夹父目录不为 root 用户 (id 为 100) 拥有时才会修改文件夹权限。(2)基本配置,包括网络策略、环境变量、启动超时最长限制(即最长等待启动时间)。(3)动态存储卷配置,设置 singleuser.storage.dynamic.storageClass 为 nfs-csi 来启用自动动态存储卷,可以用 singleuser.storage.capacity 来设置默认卷大小限制。由于实例中默认的缓冲区较小,在內存有限的情况下某些任务可能用缓冲区,因此可以挂载较大的本地临时卷来充当 /dev/shm 和 /dev/fuse。(4)可用资源配置方案,相比单机部署的单一选择,K8S 部署方案可以提供多样化的资源配置方案,不仅包括 CPU、内存资源的集合,还有 GPU 资源。甚至于还可以通过 K8S 的节点标签来由用户手动选择哪个节点(当然仅在资源满足的情况下会成功创建)。以下为一个样例:
proxy:
chp:
networkPolicy:
enabled: false
service:
nodePorts:
http: 34567
secretToken: "<GENERATE SECRET TOKEN BY YOURSELF>"
hub:
networkPolicy:
enabled: false
extraVolumes:
- name: hub-db-dir
persistentVolumeClaim:
claimName: hub-db-dir
config:
JupyterHub:
authenticator_class: oauthenticator.gitlab.GitLabOAuthenticator
GitLabOAuthenticator:
client_id: "<COPY IT FROM YOUR OAUTH2 SERVER>"
client_secret: "<COPY IT FROM YOUR OAUTH2 SERVER>"
oauth_callback_url: "https://jupyter.lisz.me/hub/oauth_callback"
gitlab_url: "https://git.lisz.me"
login_service: "Gitlab"
scope:
- read_user
- read_api
- api
- openid
- profile
- email
admin_users:
- <adminer_username>
allowed_gitlab_groups:
- <group_name>
prePuller:
hook:
enabled: false
cull:
enabled: true
maxAge: 172800
timeout: 600
every: 60
singleuser:
extraPodConfig:
securityContext:
fsGroup: 100
fsGroupChangePolicy: "OnRootMismatch"
networkPolicy:
enabled: false
extraEnv:
EDITOR: "vim"
SHELL: "/bin/zsh"
PYTHONUNBUFFERED: "1"
startTimeout: 300
storage:
capacity: 100Gi
dynamic:
storageClass: nfs-csi
extraVolumes:
- name: shm-volume
emptyDir:
medium: Memory
sizeLimit: "20Gi"
- name: fuse-device
hostPath:
path: /dev/fuse
type: CharDevice
extraVolumeMounts:
- name: shm-volume
mountPath: /dev/shm
- name: fuse-device
mountPath: /dev/fuse
image:
name: quay.io/zhonger/base-notebook
tag: v3
pullPolicy: Always
profileList:
- display_name: "CPU 分区"
description: '包含 Conda、Python 环境(8核16G)'
default: true
kubespawner_override:
cpu_gurantee: 1
memo_gurantee: "1G"
cpu_limit: 8
mem_limit: "16G"
profile_options:
image:
display_name: "主机"
choices:
lab6:
display_name: "l1"
kubespawner_override:
node_selector: {'kubernetes.io/hostname': 'l1'}
lab9:
display_name: "l2"
kubespawner_override:
node_selector: {'kubernetes.io/hostname': 'l2'}
- display_name: "GPU 分区"
description: "包含 Conda、Python、CUDA 环境(8核16G)"
kubespawner_override:
image: quay.io/zhonger/gpu-notebook:v3
image_pull_policy: Always
cpu_gurantee: 1
mem_gurantee: "1G"
cpu_limit: 8
mem_limit: "16G"
profile_options:
image:
display_name: "资源配置"
choices:
A100x1:
display_name: "A100 (Python 3.11, CUDA 12) GPU x1"
kubespawner_override:
node_selector: {'gputype': 'A100'}
extra_resource_limits:
nvidia.com/gpu: "1"
P100x1:
display_name: "P100 (Python 3.11, CUDA 12) GPU x1"
kubespawner_override:
node_selector: {'gputype': 'P100'}
extra_resource_limits:
nvidia.com/gpu: "1"
如果用标签来选择节点的话,需要通过类似 kubectl label node l1 gputype=A100 命令预先配置好标签。
准备好以上配置文件后,可以使用以下命令启动。
helm upgrade --cleanup-on-fail \
--install <helm-release-name> jupyterhub/jupyterhub \
--namespace <k8s-namespace> \
--create-namespace \
--version=<chart-version> \
--values config.yaml
建议先下载好 JupyterHub 所需的镜像,可以通过 helm show values jupyterhub 来查看所有的镜像列表。或者可以用 helm pull jupyterhub/jupyterhub --version 4.2.0 来下载原始 Chart 文件,解压后查看 values.yaml 文件即可。如果想要使用国内镜像的话,就修改 values.yaml 文件里的镜像名再启动 JupyterHub。这里可以用本地的文件夹名称或压缩包名称来替代 jupyterhub/jupyterhub 。
当 JupyterHub 启动后,默认用户还是无法从本地访问服务器上部署的 JupyterHub 的,还需要使用 Nginx 代理一下。以下是 Nginx 虚拟主机配置样例。这样一来,就可以在用户端通过域名来直接访问部署好的 JupyterHub 了。
server {
listen 443 ssl;
server_name jupyter.lisz.me;
ssl_certificate /home/ubuntu/ssl/jupyter.lisz.me.cert.pem;
ssl_certificate_key /home/ubuntu/ssl/jupyter.lisz.me.key.pem;
# SSL settings (optional but recommended)
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
client_max_body_size 10G;
# Logging
access_log /var/log/nginx/jupyter_access.log;
error_log /var/log/nginx/jupyter_error.log;
location / {
proxy_pass http://localhost:30000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# WebSocket support
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
# Redirect HTTP to HTTPS
server {
listen 80;
server_name jupyter.lisz.me;
return 301 https://$host$request_uri;
}
JupyterHub 的 proxy 本身也可以提供对外访问的 HTTPS,详见 JupyterHub for Kubernetes – Administrator Guide/Security/HTTPS。其他反向代理软件也都适用。
由于 proxy 配置使用了 nodePorts 来创建端口映射,默认是可以在其他节点访问到指定的端口的。如果想要仅允许 Nginx 代理所在主机访问,可以通过 ingress 来支持更精细的访问控制,详见 JupyterHub for Kubernetes – Resources/ingress。
部署完成后,我们需要通过 K8S 的 kubectl 命令来查看、管理 JupyterHub 应用。以下为一些常见的命令:
## 假设为 JupyterHub 创建的 namespace 为 jhub
# 查看 JupyterHub 所有 Pod 状态
╰─$ kubectl get pod -n jhub
NAME READY STATUS RESTARTS AGE
continuous-image-puller-76bkq 1/1 Running 0 5d1h
continuous-image-puller-hntww 1/1 Running 0 5d1h
hub-6867b9b6c7-slg9c 1/1 Running 0 5d1h
proxy-cc45cd6f6-g2t24 1/1 Running 0 5d1h
user-scheduler-7b465896b-bq4l6 1/1 Running 0 5d1h
user-scheduler-7b465896b-rvqgx 1/1 Running 0 5d1h
# 查看节点资源使用情况
╰─$ kubectl describe node l1
# 查看用户实例状态或启动问题
╰─$ kubectl descirbe -n jhub pod jupyter-zhonger
# 查看用户动态存储卷情况
╰─$ kubectl get -n jhub pvc
由于使用动态存储卷,卷配置显得尤为重要。(毕竟 NFS 存储在远端,独立于 K8S 集群。)可以通过以下命令备份和恢复存储卷。
# 备份所有 PV 和 PVC
kubectl get pv -o yaml > all_pvs.yaml
kubectl get pvc --all-namespaces -o yaml > all_pvc_by_namespace.yaml
# 从备份文件中恢复所有 PV 和 PVC
kubectl apply -f all_pvs.yaml
kubectl apply -f all_pvc_by_namespace.yaml
从查阅的资料来看,NFS 存储是无法动态更新存储卷大小的。换句话说,重新定义存储卷就可以手动更改存储大小。举个例子,现在想要为用户 zhonger 从默认的存储卷大小 100G 更改到 1T。那么我们先要获得用户 zhonger 的存储卷配置文件 pvc 和 pv。
# 保存 PVC 配置到 YAML 文件
kubectl get pvc claim-zhonger -n jhub -o yaml > claim-zhonger-pvc.yaml
# 从 claim-zhonger-pvc.yaml 获知 PV_NAME
kubectl get pv <PV_NAM> -o yaml > claim-zhonger-pv.yaml
# 确保实例已经被销毁后,删除 PVC 和 PV
kubectl delete -f claim-zhonger-pvc.yaml
kubectl delete -f claim-zhonger-pv.yaml
# 修改存储卷大小
sed -i "s/100Gi/1Ti/" claim-zhonger-*.yaml
# 重新定义存储卷
kubectl apply -f claim-zhonger-pv.yaml
kubectl apply -f claim-zhonger-pvc.yaml
这里需要注意的是,PV 和 PVC 之间的依赖关系。PV 是先定义的,不属于任何命名空间。PVC 是依托于 PV 定义的,必须属于某个命名空间。所以删除的时候要先 PVC 再 PV,定义的时候要先 PV 再 PVC。
对于资源配置方案,我们可以根据镜像、CPU 核数、内存大小、GPU 块数的不同来创建出多样化方案。可以参考 Amazon 提供的丰富示例 jupyterhub-values-dummy.yaml 了解更多。
目前可以使用 Grafana + Prometheus 的方式来对 K8S 集群中所有的资源利用情况进行监控,也可以自行设计一个 Grafana 面板来展示当前 JupyterHub 应用中启动的用户实例情况。但对于更加进一步详细、细致的监控与统计还有待设计(类似于“单个用户的利用报告”、“全平台的利用报告”等)。
JupyterHub 在 K8S 平台上散发出越来越强大的魅力,使得研究团队搭建自己的科学计算平台越来越容易。当然目前依然还是有一些挑战,比如“多节点 GPU 的调用”。类似于“机器学习模型训练任务”通常需要调试后再放在大规模的 GPU 集群上训练,而 JupyterHub 长于调试代码,是否可以调试完成后直接提交给更大规模的 GPU 集群后台计算呢?
2025-05-19 15:16:00
判断下列算子是否可交换?
\[[1]\ [\hat{x},\hat{p}_x] \quad [2]\ [\hat{l}_x, \hat{l_y}] \quad [3]\ [\hat{\boldsymbol{l}}^2, \hat{l}_z]\]解决本题首先要了解可交换的定义,对于任意两个算子有:
\[\hat{f}\hat{g}\psi(\boldsymbol{r})=\hat{g}\hat{f}\psi(\boldsymbol{r})\ 或\ (\hat{f}\hat{g}-\hat{g}\hat{f})\psi(\boldsymbol{r})=0\]那么这两个算子可交换,否则不可交换。其中下列式子称为交换子:
\[[\hat{f}, \hat{g}] \equiv \hat{f}\hat{g}-\hat{g}\hat{f}\]除此之外,还需要了解以下观测量在古典力学中的变量和量子力学中的算子对应:
| 观测量 | 变量 | 算子 |
|---|---|---|
| 位置 | \(x\ (\boldsymbol{r})\) | \(\hat{x}\ (\hat{\boldsymbol{x}})\) |
| 动量 | \(p_x\ (\boldsymbol{p})\) | \(\hat{p}_x=-\mathrm{i}\hbar{d \over dx}\ (\hat{\boldsymbol{p}})\) |
| 角动量 | \(\boldsymbol{l}^2=l_x^2+l_y^2+l_z^2\) | \(\hat{\boldsymbol{l}}^2=\hat{l}_x^2+\hat{l}_y^2+\hat{l}_z^2\) |
| \(\hat{l}_x=-\mathrm{i}\hbar\left(y\frac{\partial}{\partial z}-z\frac{\partial}{\partial y}\right)\) | ||
| \(\hat{l}_y=-\mathrm{i}\hbar\left(z\frac{\partial}{\partial x}-x\frac{\partial}{\partial z}\right)\) | ||
| \(\hat{l}_z=-\mathrm{i}\hbar\left(x\frac{\partial}{\partial y}-y\frac{\partial}{\partial x}\right)\) |
将 \(\hat{p}_x=-\mathrm{i}\hbar{d \over dx}\) 代入可得
\[\begin{align} [\hat{x}, \hat{p}_x]\psi(x)&=(\hat{x}\hat{p}_x-\hat{p}_x\hat{x})\psi(x) \\\\ &= -\mathrm{i}\hbar x \frac{d}{dx}\psi(x)-(-\mathrm{i}\hbar)\frac{d}{dx}[x\psi(x)] \end{align}\]这里需要注意算子 \(\frac{d}{dx}\) 是求导算子,根据链式法则应该对 \([x\psi(x)]\) 分别对 \(x\) 求导,于是:
\[\begin{align} 原式&=-\mathrm{i}\hbar x \frac{d}{dx}\psi(x) + \mathrm{i}\hbar\left[x\frac{d}{dx}\psi(x)+\psi(x)\right] \\\\ &= \mathrm{i}\hbar\psi(x) ≠ 0 \end{align}\]因此,这两个算子不可交换。
将 \(\hat{l}_x\) 和 \(\hat{l}_y\) 代入可得 (注意 \(\mathrm{(-i)}^2=-1\))
\[\begin{align} \hat{l}_x\hat{l}_y&=(-\mathrm{i}\hbar)^2\left(y\frac{\partial}{\partial z}-z\frac{\partial}{\partial y}\right)\left(z\frac{\partial}{\partial x}-x\frac{\partial}{\partial z}\right) \\\\ &=-\hbar^2\left(y\frac{\partial}{\partial z}z\frac{\partial}{\partial x}-z\frac{\partial}{\partial y}z\frac{\partial}{\partial x}-y\frac{\partial}{\partial z}x\frac{\partial}{\partial z}+z\frac{\partial}{\partial y}x\frac{\partial}{\partial z}\right) \end{align}\]这里需要注意“求偏导的函数中是否包含了偏导的对象”,如果不包含则可以直接将变量左移,如果包含则需要根据链式法则分别求导。
接着有
\[\begin{align} \hat{l}_x\hat{l}_y&=-\hbar^2\left[y\left(z\frac{\partial^2}{\partial z \partial x}+\frac{\partial}{\partial x}\right)-z^2\frac{\partial^2}{\partial y \partial x}-xy\frac{\partial^2}{\partial z^2}+xz\frac{\partial^2}{\partial y \partial z}\right] \\\\ &=-\hbar^2\left[yz\frac{\partial^2}{\partial z \partial x}+y\frac{\partial}{\partial x}-z^2\frac{\partial^2}{\partial y \partial x}-xy\frac{\partial^2}{\partial z^2}+xz\frac{\partial^2}{\partial y \partial z}\right] \end{align}\]同理
\[\begin{align} \hat{l}_y\hat{l}_x&=(-\mathrm{i}\hbar)^2\left(z\frac{\partial}{\partial x}-x\frac{\partial}{\partial z}\right)\left(y\frac{\partial}{\partial z}-z\frac{\partial}{\partial y}\right) \\\\ &=-\hbar^2\left(z\frac{\partial}{\partial x}y\frac{\partial}{\partial z}-x\frac{\partial}{\partial z}y\frac{\partial}{\partial z}-z\frac{\partial}{\partial x}z\frac{\partial}{\partial y}+x\frac{\partial}{\partial z}z\frac{\partial}{\partial y}\right) \\\\ &=-\hbar^2\left[yz\frac{\partial^2}{\partial x \partial z}-xy\frac{\partial^2}{\partial z^2}-z^2\frac{\partial^2}{\partial x \partial y}+x\left(\frac{\partial}{\partial y}+z\frac{\partial^2}{\partial z \partial y}\right)\right] \\\\ &=-\hbar^2\left(yz\frac{\partial^2}{\partial x \partial z}-xy\frac{\partial^2}{\partial z^2}-z^2\frac{\partial^2}{\partial x \partial y}+x\frac{\partial}{\partial y}+xz\frac{\partial^2}{\partial z \partial y}\right) \end{align}\]因此交换子为(减法抵消相同项)
\[\begin{align} [\hat{l}_x, \hat{l}_y]&=\hat{l}_x\hat{l}_y-\hat{l}_y\hat{l}_x \\\\ &=-\hbar^2\left(y\frac{\partial}{\partial x}-x\frac{\partial}{\partial y}\right) \\\\ &=\mathrm{i}^2\hbar^2\left(y\frac{\partial}{\partial x}-x\frac{\partial}{\partial y}\right) \\\\ &=\mathrm{i}\hbar\left[-\mathrm{i}\hbar\left(x\frac{\partial}{\partial y}-y\frac{\partial}{\partial x}\right)\right] \\\\ &=\mathrm{i}\hbar\hat{l}_z≠0 \end{align}\]因此,这两个算子不可交换。
通过算子组二可以类似推理得到:
\[[\hat{l}_y, \hat{l}_z]=\mathrm{i}\hbar\hat{l}_x\] \[[\hat{l}_z, \hat{l}_x]=\mathrm{i}\hbar\hat{l}_y\]将其代入可得:
\[\begin{align} [\hat{\boldsymbol{l}}^2, \hat{l}_z]&=\hat{\boldsymbol{l}}^2\hat{l}_z-\hat{\boldsymbol{l}}^2\hat{l}_z \\\\ &=(\hat{l}_x^2+\hat{l}_y^2+\hat{l}_z^2)\hat{l}_z-\hat{l}_z(\hat{l}_x^2+\hat{l}_y^2+\hat{l}_z^2) \\\\ &=\hat{l}_x\hat{l}_x\hat{l}_z+\hat{l}_y\hat{l}_y\hat{l}_z+\hat{l}_z\hat{l}_z\hat{l}_z-\hat{l}_z\hat{l}_x\hat{l}_x-\hat{l}_z\hat{l}_y\hat{l}_y-\hat{l}_z\hat{l}_z\hat{l}_z \\\\ &=\hat{l}_x\hat{l}_x\hat{l}_z+\hat{l}_y\hat{l}_y\hat{l}_z+\bcancel{\hat{l}_z\hat{l}_z\hat{l}_z}-\hat{l}_z\hat{l}_x\hat{l}_x-\hat{l}_z\hat{l}_y\hat{l}_y-\bcancel{\hat{l}_z\hat{l}_z\hat{l}_z} \\\\ &=\hat{l}_x\hat{l}_x\hat{l}_z+\color{red}{\hat{l}_x\hat{l}_z\hat{l}_x-\hat{l}_x\hat{l}_z\hat{l}_x}\color{black}{-\hat{l}_z\hat{l}_x\hat{l}_x}+\hat{l}_y\hat{l}_y\hat{l}_z+\color{red}{\hat{l}_y\hat{l}_z\hat{l}_y-\hat{l}_y\hat{l}_z\hat{l}_y}\color{black}{-\hat{l}_z\hat{l}_y\hat{l}_y} \\\\ &=\hat{l}_x(\hat{l}_x\hat{l}_z-\hat{l}_z\hat{l}_x)+(\hat{l}_x\hat{l}_z-\hat{l}_z\hat{l}_x)\hat{l}_x+\hat{l}_y(\hat{l}_y\hat{l}_z-\hat{l}_z\hat{l}_y)+(\hat{l}_y\hat{l}_z-\hat{l}_z\hat{l}_y)\hat{l}_y \\\\ &=\hat{l}_x(-[\hat{l}_z, \hat{l}_x])+(-[\hat{l}_z, \hat{l}_x])\hat{l}_x+\hat{l}_y[\hat{l}_y, \hat{l}_z]+[\hat{l}_y, \hat{l}_z]\hat{l}_y \\\\ &=-\mathrm{i}\hbar\hat{l}_x\hat{l}_y-\mathrm{i}\hbar\hat{l}_y\hat{l}_x+\mathrm{i}\hbar\hat{l}_y\hat{l}_x+\mathrm{i}\hbar\hat{l}_x\hat{l}_y = 0 \end{align}\]因此,这两个算子可交换。
2025-05-14 15:52:00
判断下面的算子是否厄米(Hermitian)或为厄米算子(Hermite Operator)。
\[[1]\ {d \over dx} \quad [2]\ {\mathrm{i}{d \over dx}} \quad [3]\ {d^2 \over dx^2}\]解答本题首先要理解厄米的判断条件:
\[\int\psi_{i}^*(\boldsymbol{r}) \hat{f}\psi_{j}(\boldsymbol{r})d\boldsymbol{r}=\int\psi_{j}(\boldsymbol{r}) \hat{f}^*\psi_{i}^*(\boldsymbol{r})d\boldsymbol{r}\]其中 \(\hat{f}^*\) 是 \(\hat{f}\) 的复共轭或伴随算子, \(\psi_{i}(\boldsymbol{r})\) 和 \(\psi_{j}(\boldsymbol{r})\) 为基底函数,其对应的复共轭函数为 \(\psi_{i}^*(\boldsymbol{r})\) 和 \(\psi_{j}^*(\boldsymbol{r})\)。
基底函数符合正交归一化条件,即“任意两个不同基底函数正交”和“任意一个基底函数在全空间上的积分为 1”。形式化可以表示为 \(\int\psi_{i}^*(\boldsymbol{r})\psi_{j}(\boldsymbol{r})d\boldsymbol{r}=0\) 和 \(\int|\psi(\boldsymbol{r})|^2 d\boldsymbol{r}=1\)。
求导数时的链式法则:\((uv)'=u'v+uv'\)。转换为积分形式: \(uv=\int{u'v}d\boldsymbol{r}+\int{uv'}d\boldsymbol{r}\),将右边的第一项移到左边于是有 \(\int{uv'}d\boldsymbol{r}=uv-\int{u'v}d\boldsymbol{r}\)。
现在开始考虑第一个算子 \(\hat{f}={d \over dx}\),显然这个算子就是求导算子(这里是对后面的函数微分求导),于是
\[\begin{align} 左边&= \int\psi_{i}^*(x)\left({d \over dx}\psi_{j}(x)\right)dx \\\\ &=[\psi_{i}^*(x)\psi_{j}(x)]_{-\infty}^{+\infty}-\int\left({d \over dx}\psi_{i}^*(x)\right)\psi_{j}(x)dx \end{align}\]由于 \(\displaystyle \lim_{x \to \pm\infty} \psi_{i}^*(x)=0\) 和 \(\displaystyle \lim_{x \to \pm\infty }\psi_{j}(x)=0\)(有限,作为波函数的基底函数在无穷处必须快速衰减),所以有
\[[\psi_{i}^*(x)\psi_{j}(x)]_{-\infty}^{+\infty}=0\]即
\[\begin{align} 左边&=-\int\left({d \over dx}\psi_{i}^*(x)\right)\psi_{j}(x)dx \\\\ &=-\int\psi_{j}(x){d \over dx}\psi_{i}^*(x)dx \\\\ &≠右边 \end{align}\]因此第一个算子不是厄米算子。
类似第一个算子,对于第二个算子 \(\hat{f}=\mathrm{i}{d \over dx}\) 有
\[\begin{align} 左边&=\int\psi_{i}^*(x)\left(\mathrm{i}{d \over dx}\psi_{j}(x)\right)dx \\\\ &=\mathrm{i}[\psi_{i}^*(x)\psi_{j}(x)]_{-\infty}^{+\infty}-\int\left(\mathrm{i}{d \over dx}\psi_{i}^*(x)\right)\psi_{j}(x)dx \end{align}\]应用基底函数的有限条件和上述的伴随算子可得
\[\begin{align} 左边&=0-\int\left(-\left(\mathrm{i}{d \over dx}\right)^*\psi_{i}^*(x)\right)\psi_{j}(x)dx \\\\ &=\int\left(\left(\mathrm{i}{d \over dx}\right)^*\psi_{i}^*(x)\right)\psi_{j}(x)dx=右边 \end{align}\]因此第二个算子是厄米算子。
二阶导的伴随算子还是它本身,于是有
\[\left( {d^2 \over dx^2} \right)^*={d^2 \over dx^2}\]根据链式法则,求一阶导有: \((uv')'=u'v'+uv''\) 和 \((u'v)'=u'v'+u''v\)。 对应的积分形式:\(\int{uv''}=uv'-\int{u'v'}\) 和 \(\int{u'v'}=u'v-\int{u''v}\)。
第三个算子是二阶导数,有
\[\begin{align} 左边 &=\int\psi_{i}^*(x){d^2 \over dx^2}\psi_{j}(x)dx \\\\ &=[\psi_{i}^*(x){d \over dx}\psi_{j}(x)]_{-\infty}^{+\infty}-\int\left({d \over dx}\psi_{i}^*(x)\right)\left({d \over dx}\psi_{j}(x)\right)dx \\\\ &=-\int\left({d \over dx}\psi_{i}^*(x)\right)\left({d \over dx}\psi_{j}(x)\right)dx \\\\ &=-\left(\left[\left({d \over dx}\psi_{i}^*(x)\right)\psi_{j}(x)\right]_{-\infty}^{+\infty}-\int\left({d^2 \over dx^2}\psi_{i}^*(x)\right)\psi_{j}(x)dx\right) \\\\ &=0+\int\left({d^2 \over dx^2}\psi_{i}^*(x)\right)\psi_{j}(x)dx \\\\ &=\int\left(\left({d^2 \over dx^2}\right)^*\psi_{i}^*(x)\right)\psi_{j}(x)dx=右边 \end{align}\]因此,第三个算子是厄米算子。
2024-10-08 15:50:00
Web 应用的生产环境部署随着技术的发展不断地发生改变,如下图所示,从最早期的单机环境到多机环境,再发展到复杂环境:
自从代码版本跟踪软件 Git 横空出世以来,逐步形成了以 Git 为中心的持续开发、持续集成和持续部署的现代应用开发方式。这与复杂环境的部署方式完全契合,由云服务提供商来提供和维护各类运行环境、数据库服务和文件存储,开发团队只需要专注于对代码存储库的管理。
举个例子,当某个开发成员完成了某个模块的开发并推送到某个分支,该分支创建后会自动触发持续集成进行自动 Review。自动 Review 通过后,开发团队负责人可以对该分支的代码更改进行审核,通过后允许将该分支与其他某个指定分支进行合并(合并操作也是通过持续集成自动进行)。当所有代码开发完毕后,由总负责人审核汇入最终部署的分支。审核通过后持续集成会自动合并代码并通过持续部署将完整的代码部署到真实的运行环境中。如今的 GitHub、GitLab 均能完成持续开发、持续集成和持续部署的全过程。当然,也有一些软件(比如 Jenkins 等)可以完成持续集成和持续部署两步,而持续开发则可以依托任意的 Git 托管服务。
以上叙述非专业解释,仅为个人看法,不喜勿喷。Kubernetes 官方将部署方式分为传统部署、虚拟化部署和容器部署三类。
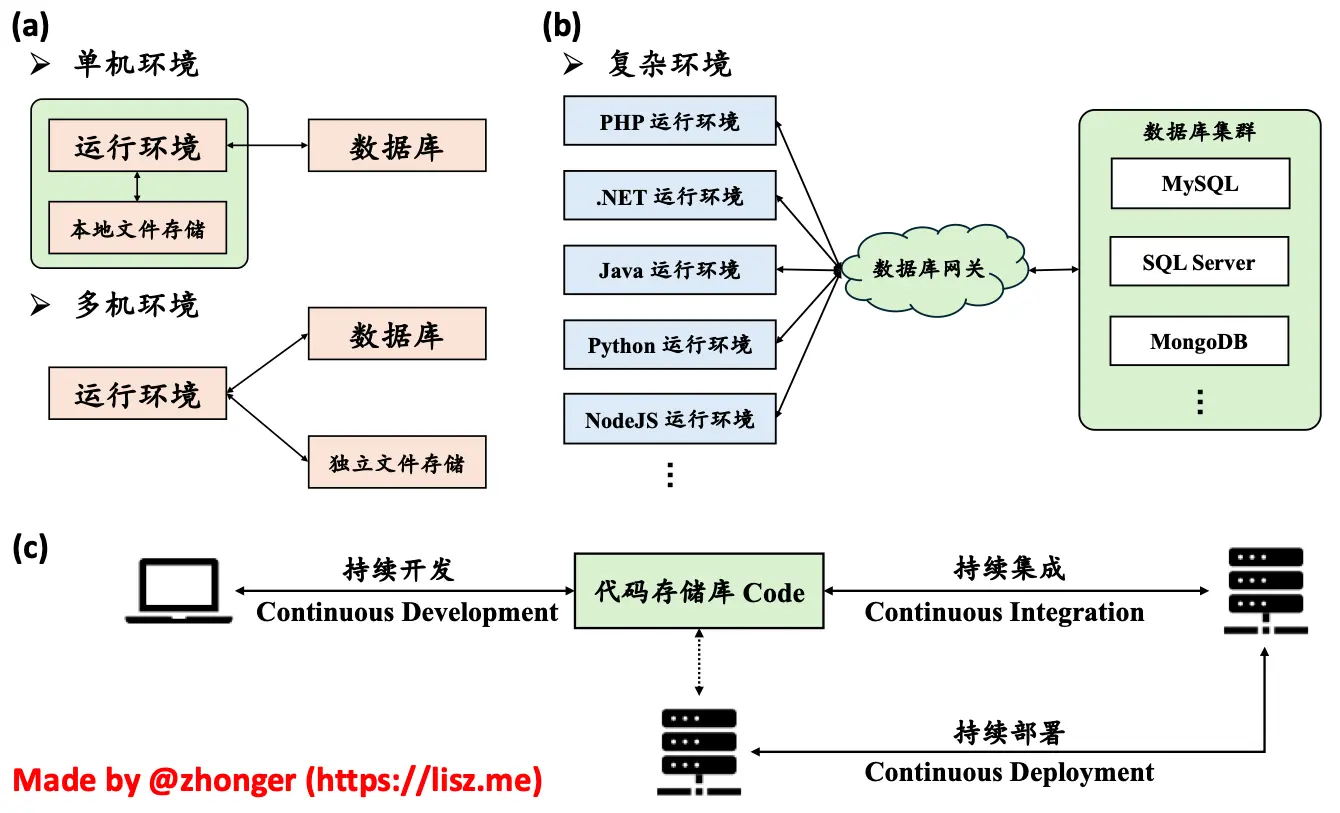
假设一个 Web 应用同时需要使用:
在单机环境中,按照以前我们碰见这种要求可能就要头大了,毕竟同时配置这么多环境难免会有不可预知的问题。不过现在,容器化技术(比如 Docker)可以帮助我们将所有的需求都拆分成独立的 container 实例。不但可以让它们之间在内部网络中互通,还可以对外只暴露必要的应用入口所需的 80 和 443 端口。这样一来,既将各项服务进行了合理拆分,又能保证应用服务的安全性。即使是需要对某个运行环境或者数据库服务进行版本升级,也可以很容易做到。
在多机环境中,我们如果还想用容器化技术,那就必须用容器化集群。很久以前,Docker 官方就提供了一种 Swarm 模式来组成容器化集群。这种方式的好处是非常简单配置、轻量易用,对于熟悉使用 Docker 的开发者来说只需要花很少的时间就能搞明白。缺点也很明显,Docker Swarm 依赖于 Docker API。也就是说,Docker 本身不支持的东西还是不支持,比如更加高效安全的网络、花式多样的存储等。为了能够更好跨主机集群地自动部署、扩展以及运行应用程序容器,我们选择使用 Kubernetes(缩写为 K8S)。
在 2014 年 Google 开源了 Kubenetes 项目,后来又贡献给了云原生计算基金会 CNCF。很多公司以 Kubernetes 为基础开发了自家的容器化集群平台,比如 RedHat 的 OpenShift,AWS 的 Elastic Kubenetes Services, EKS,Azure 的 Azure Kubernetes Services, AKS,阿里云的 Aliyun Container Service for Kubernetes, ACK,腾讯云的 Tencent Kubernetes Engine, TKE 等。
虽然 Kubernetes 官方文档已经将架构图以及相关概念介绍得非常清楚,但还是想说说自己的理解。类似于一般集群平台,K8S 也需要有至少一个控制节点(官方称之为“控制平面”)和一个工作节点。默认来说,K8S 不推荐控制节点同时作为工作节点,因为这会影响集群调度的可靠性和可用性。从下面的重绘架构图可以看出,K8S 集群会对外提供 API 以供用户从集群外进行调度。在集群内部,工作节点通过 kubelet 服务与控制节点直接连接,控制节点也通过 kubelet 服务向工作节点下达调度指令来管理工作节点上的 pod。
Pod 可以理解为 K8S 中应用的最小单位,一个 Pod 中可能会包括一个或多个 container (容器),这些容器间可以互通,但对外只有 Pod 有资格拥有 IP。这有点类似于进程与线程之间的关系,进程是拥有资源的最小单位,线程依赖于进程而存在,同一进程间的线程间可以无障碍通信,而不同进程间的通信则需要通过端口或 socket 来进行。
同一个工作节点上的 Pod 的 IP 属于同一个子网,不同工作节点的子网又属于同一个大子网 (podSubnet,一般需要在初始化集群时定义)。这样的设计在很大程度上减少了 IP 管理的难度,并且能够最大程度上减少容器暴露的风险。
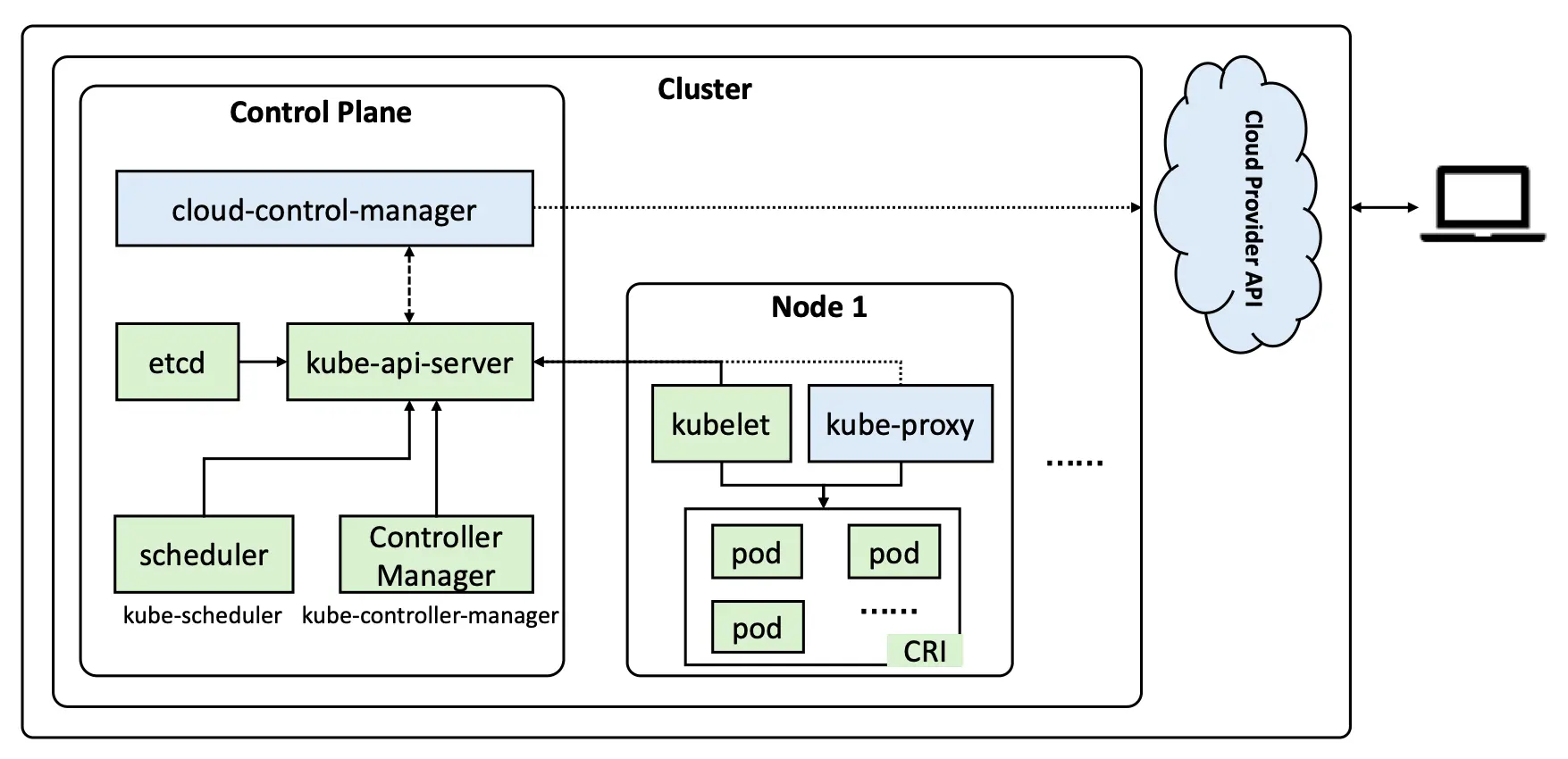
CRI,全名为 Container Runtime Interface(容器运行时接口),是 K8S 架构中 kubelet和容器运行时通信的主要协议。我们所熟知的 Docker 就是一种容器运行时,但是自从 K8S 1.20 版本弃用 Docker 自带的容器运行时接口 Dockershim 以来,我们只能使用额外的 CRI – cri-dockerd 来调用 Docker。因此推荐使用包含 CRI 的容器运行时 containerd 或者 cri-o 来替代 Docker。
由于 K8S 是一款平台无关的容器集群方案,所以官方提供的方案只是一个整体,我们需要自行选择以下各项组件:
在学习环境中,我们可以使用 kind、minikube 或者 kubeadm 在本地快速部署 K8S 集群;在生产环境中,我们可以使用 kops、Kubespray 或者 kubeadm 在多节点上快速部署 K8S 集群。所以这里我们采用了通用的 kubeadm 来搭建 K8S 集群。
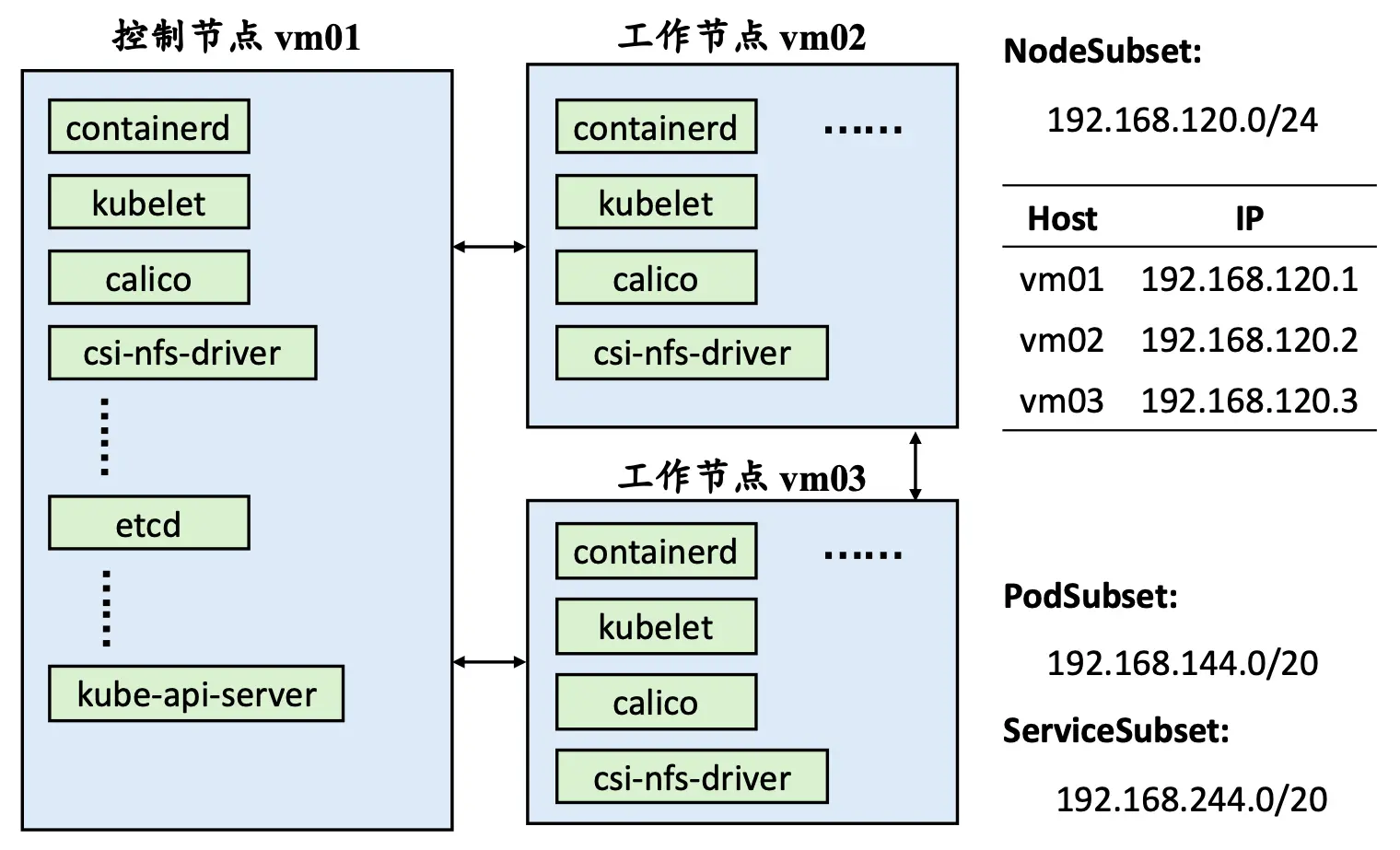
在正式部署之前需要规划实际架构、做一些基本准确以及安装必要的软件和工具 – kubelet,kubectl 和 kubeadm。下图为本实践规划的 NodeSubset、PodSubset 和 ServiceSubset。
K8S 为了性能考虑默认必须关闭 SWAP 交换分区,而通常实体服务器安装后会有 SWAP 交换分区,云服务器或 VPS 没有。通过 sudo swapoff -a 命令可以临时关闭 SWAP 分区,或者通过注释 /etc/fstab 文件中的 swap.img 这一行并重启服务器永久关闭 SWAP 交换分区。
由于 K8S 集群中同一个 Service 的 Pod 可能被分配到不同节点,那么不同节点间的 Pod 通信是非常必要的,即不同 PodSubnet 之间的通信需要通过 Node IP 来进行 IPv4 转发。执行以下命令添加允许 IPv4 转发到 /etc/sysctl.d/k8s.conf 文件里,并且立即生效:
# 添加配置
sudo tee -a /etc/sysctl.d/k8s.conf << EOF
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
EOF
# 立即生效
sudo sysctl --system
K8S 集群初始化时会自动搜索主机名的 DNS 解析,目前测试的主机名没有完整的 FQDN 或 PTR 解析,因此有必要设置好主机名和 IP 对应信息到本地静态 DNS 解析文件 /etc/hosts 中。
# 分别在不同节点根据规划设置好主机名
sudo hostnamectl set-hostname vm01
sudo hostnamectl set-hostname vm02
sudo hostnamectl set-hostname vm03
# 修改所有节点的 /etc/hosts
sudo tee -a /etc/hosts << EOF
192.168.120.1 vm01
192.168.120.2 vm02
192.168.120.3 vm03
EOF
K8S 集群的运行必须保证节点的时间是完全同步的,否则容易造成某些未知的 Bug。比如证书的过期时间将会被某些时间不同步的节点错误判断。推荐使用同一时区和同一 NTP 服务器,如下即可完成设置。
# 设置相同时区并查看
sudo timedatectl set-timezone Asia/Shanghai
timedatectl
timedatectl status
# 修改 NTP 服务器
sudo timedatectl set-ntp false
sudo sed -i 's/#NTP=/NTP=ntp.lisz.top/' /etc/systemd/timesyncd.conf
sudo sed -i 's/#FallbackNTP=ntp.ubuntu.com/FallbackNTP=ntp.aliyun.com/' /etc/systemd/timesyncd.conf
sudo timedatectl set-ntp true
# 重启服务使配置生效、同步时间并查看信息
sudo systemctl restart systemd-timesyncd
timedatectl show-timesync --all
date
containerd 虽然是由 containerd 开发团队负责发布,但是 APT 或 YUM 镜像源仍然是由 Docker 官方负责,所以当我们添加 docker-ce 的镜像源后可以直接下载 containerd.io 来安装 containerd。当然, 我们可以从 containerd/containerd 直接下载二进制可执行文件。
# 添加镜像源
curl -fsSL https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/docker.gpg
sudo tee -a /etc/apt/sources.list.d/docker.list << EOF
deb [arch=amd64 signed-by=/etc/apt/trusted.gpg.d/docker.gpg] https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu/ $(lsb_release -c --short) stable
EOF
# 更新软件列表缓存并安装 containerd
sudo apt update && sudo apt upgrade -y && sudo apt install -y containerd.io
个人推荐使用 APT 或 YUM 方式安装 containerd。原因有二:一是国内有 docker-ce 镜像安装比较快,二是想要更新时非常容易。
containerd 安装后默认没有配置文件也不会自动启动后台程序,所以需要准备配置文件并复制到 /etc/containerd/config.toml 再启动。由于 K8S 集群默认使用 registry.k8s.io 和 registry-1.docker.io 源下载容器镜像,为了提升速度建议切换到阿里云和 DaoCloud 的加速器。
containerd config default > containerd_config.toml
sed -i "s#registry.k8s.io#registry.cn-hangzhou.aliyuncs.com/google_containers#g" containerd_config.toml
sed -i "/containerd.runtimes.runc.options/a\ \ \ \ \ \ \ \ \ \ \ \ SystemdCgroup = true" containerd_config.toml
sed -i "s#https://registry-1.docker.io#https://docker.m.daocloud.io#g" containerd_config.toml
sudo mkdir -p /etc/containerd
cp containerd_config.toml /etc/containerd/config.toml
sudo systemctl daemon-reload
sudo systemctl enable containerd
sudo systemctl restart containerd
sudo systemctl status containerd.service && sudo ctr --version
由于 ctr 命令连接的 containerd 的 socket 文件只有 root 用户组有权限访问,所以目前只能使用 sudo ctr。如果想要直接使用 ctr 命令,可以使用 sudo usermod -aG root ubuntu 来将当前用户添加到 root 用户组。赋权之后需退出登录后再次登录才能生效。
国内清华大学 TUNA 镜像源、阿里云镜像源等都提供了 kubeadm 等三件套工具的 APT 或 YUM 源,通过以下命令可以很容易完全安装。
由于 kubernetes 不同版本可能会存在较大差异,并且为了避免节点 kubernetes 版本在不自觉的时候升级造成兼容性问题,这里推荐固定 kubeadm 等三件套版本号,即不启用 apt upgrade 自动升级。管理员关闭 K8S 集群手动升级版本时不受影响。
# 添加镜像源
curl -fsSL https://mirrors.tuna.tsinghua.edu.cn/kubernetes/core:/stable:/v1.30/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
sudo tee -a /etc/apt/sources.list.d/kubernetes.list << EOF
deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.tuna.tsinghua.edu.cn/kubernetes/core:/stable:/v1.30/deb/ /
# deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.tuna.tsinghua.edu.cn/kubernetes/addons:/cri-o:/stable:/v1.30/deb/ /
EOF
# 更新软件列表缓存并安装 kubeadm 三件套
sudo apt update && sudo apt install -y kubeadm kubelet kubectl
# 固定 kubeadm 等三件套版本
sudo apt-mark hold kubeadm
sudo apt-mark hold kubelet
sudo apt-mark hold kubectl
在所有节点上使用以下命令提前下载好 K8S 集群所需的基本镜像,避免初始化时一直在等待各个节点下载镜像。
kubeadm config images list | sed -e 's/^/sudo ctr image pull /g' -e 's#registry.k8s.io#registry.cn-hangzhou.aliyuncs.com/google_containers#g' | sh -x
下载完所需的容器镜像后,在控制节点上使用 sudo kubeadm init --config=kubeadm_config.yaml 命令初始化控制节点。kubeadm_config.yaml 的内容如下所示:(建议将配置文件放置在 ~/k8s 目录下,cd ~/k8s 目录后执行初始化命令。)
apiVersion: kubeadm.k8s.io/v1beta3
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.120.1
bindPort: 6443
nodeRegistration:
criSocket: "unix:///run/containerd/containerd.sock"
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
kubernetesVersion: stable
imageRepository: "registry.cn-hangzhou.aliyuncs.com/google_containers"
networking:
podSubnet: 192.168.144.0/20
serviceSubnet: 192.168.244.0/24
如果没有配置主机名对应的话,这里初始化会一直卡在 API Health 检测的步骤,实际上是因为没有主机名和 IP 对应而无法启动 API Server。
kubeadm 初始化成功后需要复制验证文件才能在控制节点管理 K8S 集群,如下所示:
# 复制验证文件
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 查询节点状态
kubectl get nodes -o wide
刚才初始化集群后会出现工作节点加入集群的命令,形如:
kubeadm join 192.168.120.1:6443 --token z9sdsdi.tdeu74psxqi8rhdt \
--discovery-token-ca-cert-hash sha256:87c4f8dd9dabaf2e5e793c0404c74dd8f9f56153000dad3c1a3238a3e8b0beff
注意这里需要加上 sudo 之后再在工作节点上执行加入集群操作。加入完成后可以在控制节点上使用 kubectl get nodes -o wide 查看是否有了刚加入的工作节点的信息。由于目前还没有配置网络组件,除了控制节点外,其他工作节点应该均为 NotReady 状态。如果使用 kubectl get pods --all-namespaces 命令查看所有启动的 Pod,应该看到除两个 CordDNS 的 Pod (比如 0/1) 以外的所有 Pod 的状态都是完成启动 (比如 1/1)。
工作节点加入后可以配置不同的标签,比如如下是配置为工作节点和添加 gputype 字段标签:
kubectl label node vm02 node-role.kubernetes.io/worker=
kubectl label node vm03 node-role.kubernetes.io/worker=
kubectl label node vm02 gputype=P100
kubectl label node vm03 gputype=A100
Calico 支持一套灵活的网络选项,可以根据情况选择最有效的选项,包括非覆盖和覆盖网络,带或不带 BGP。Calico 使用相同的引擎为主机、Pod 和应用程序在服务网格层执行网络策略。如下所示可以很简单地为 K8S 集群启用 Calico 网络:
quay.io/tigera/operator:v1.34.5,可提前下载),仅在控制节点创建 Pod;registry 字段来使用 DaoCloud 加速器。mkdir -p ~/k8s/calico & cd ~/k8s/calico
wget -c https://raw.githubusercontent.com/projectcalico/calico/v3.28.1/manifests/tigera-operator.yaml
wget -c https://raw.githubusercontent.com/projectcalico/calico/v3.28.1/manifests/custom-resources.yaml
kubectl create -f tigera-operator.yaml
kubectl create -f custom-resources.yaml
# This section includes base Calico installation configuration.
# For more information, see: https://docs.tigera.io/calico/latest/reference/installation/api#operator.tigera.io/v1.Installation
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
# Configures Calico networking.
calicoNetwork:
ipPools:
- name: default-ipv4-ippool
blockSize: 26
cidr: 192.168.144.0/20
encapsulation: VXLANCrossSubnet
natOutgoing: Enabled
nodeSelector: all()
registry: m.daocloud.io
---
# This section configures the Calico API server.
# For more information, see: https://docs.tigera.io/calico/latest/reference/installation/api#operator.tigera.io/v1.APIServer
apiVersion: operator.tigera.io/v1
kind: APIServer
metadata:
name: default
spec: {}
如果通过 kubectl get pod --all-namespaces 发现哪个相关 Pod 卡在了拉取镜像的步骤,可以手动镜像。一般来说,使用修改的 DaoCloud 加速器下载应该没什么太大问题。创建 Calico 网络完成后会多出来 3 个命名空间: tigera-operator、 calico-system 和 calico-apiserver。新增的 Pod 应该如下所示:
| 节点主机名 | 新增 Pod | 备注 |
|---|---|---|
| vm01 | tigera-operator | Calico 网络所需的描述子 |
| vm01 | calico-kube-controller | Calico 网络控制器 |
| vm01 | calico-apiserver | Calico 网络 API,一般有两个 Pod |
| vm01 | calico-typha | 优化和减少 Calico 对 K8S API 服务器的负载 |
| vm01 | calico-node | Calico 网络节点客户端 |
| vm01 | csi-node-driver | CSI 驱动 |
| vm02 | calico-typha | 优化和减少 Calico 对 K8S API 服务器的负载 |
| vm02 | calico-node | Calico 网络节点客户端 |
| vm02 | csi-node-driver | CSI 驱动 |
| vm03 | calico-node | Calico 网络节点客户端 |
| vm03 | csi-node-driver | CSI 驱动 |
NFS CSI 驱动由 kubernetes-csi/csi-driver-nfs 项目提供支持。不过在正式安装驱动之前需要先安装 NFS 客户端,否则 NFS CSI 驱动也无法正常启用。为了加速下载容器镜像,这里推荐将配置中的 registry.k8s.io 源切换到 k8s.m.daocloud.io 加速器。
# 在所有节点安装 NFS 客户端支持
sudo apt install -y nfs-common
# 下载 NFS CSI Driver 配置文件
mkdir -p ~/k8s/csi && cd ~/k8s/csi
git clone https://github.com/kubernetes-csi/csi-driver-nfs.git
# 修改容器镜像为 DaoCloud 加速器
cd csi-driver-nfs/deploy/v4.9.0
sed -i "s/registry.k8s.io/k8s.m.daocloud.io/" ./*
# 返回上上层目录,并安装 NFS CSI 驱动
cd ../../
./deploy/install-driver.sh v4.9.0 local
安装 NFS CSI 驱动后会在 kube-system 命名空间中多出四个 Pod,其中一个 Pod 为 csi-nfs-controller,其他每个节点一个 csi-nfs-node 的 Pod。然后需要使用 kubectl apply -f nfs.yaml 命令创建一个 NFS 的存储类用于提供给应用程序,配置文件 nfs.yaml 内容如下所示:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-csi
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: nfs.csi.k8s.io
parameters:
server: nfs_server_ip
share: /home/data
reclaimPolicy: Retain
volumeBindingMode: Immediate
allowVolumeExpansion: true
mountOptions:
- async
- rsize=32768
- wsize=32768
- nconnect=8
- nfsvers=4.1
- hard
# 查看新增的存储类
╰─$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-csi (default) nfs.csi.k8s.io Retain Immediate true 4d1h
K8S 的 GPU 支持是由 NVIDIA 提供的,需要工作节点先安装 NVIDIA 驱动和容器驱动,再在控制节点上部署 nvidia-device 插件支持。
# 查看可安装 NVIDIA 驱动
╰─$ ubuntu-drivers devices
modalias : pci:v000010DEd000026BAsv000010DEsd00001957bc03sc02i00
vendor : NVIDIA Corporation
driver : nvidia-driver-550-open - distro non-free
driver : nvidia-driver-550 - distro non-free recommended
driver : nvidia-driver-535-server - distro non-free
driver : nvidia-driver-535-server-open - distro non-free
driver : nvidia-driver-535-open - distro non-free
driver : nvidia-driver-535 - distro non-free
driver : xserver-xorg-video-nouveau - distro free builtin
# 安装 NVIDIA 驱动,并重启生效
sudo apt install -y nvidia-driver-535
sudo apt-mark hold nvidia-driver-535
# 添加 NVIDIA Container Toolkit 源
curl -fsSL https://mirrors.ustc.edu.cn/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://mirrors.ustc.edu.cn/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 更新软件列表缓存,安装 nvidia-container-toolkit
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
# 为 containerd 容器运行时增加 NVIDIA 选项
sudo nvidia-ctk runtime configure --runtime=containerd
# 修改 /etc/containerd/config.toml 配置文件中默认运行时为 NVIDIA
# 原来的默认运行时是 runc
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "nvidia"
# 重新加载 containerd 配置文件并重启服务生效
sudo systemctl daemon-reload
sudo systemctl restart containerd
# 在控制节点为 K8S 集群创建 NVIDIA device 插件支持
cd ~/k8s
wget -c https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.16.2/deployments/static/nvidia-device-plugin.yml
sed -i "s/nvcr.io/nvcr.m.daocloud.io/" nvidia-device-plugin.yml
kubectl create -f nvidia-device-plugin.yml
# 验证 GPU 是否被 K8S 识别
kubectl describe node vm02 | grep nvidia.com/gpu:
NVIDIA GPU 驱动和容器驱动只需在有 NVIDIA GPU 的工作节点上配置,并且一定要修改默认运行时为 NVIDIA,否则无法被 K8S 识别。NVIDIA device 插件支持在控制节点上提交安装请求但会在每一个工作节点上安装,即使没有 NVIDIA GPU 存在。
这种情况下需要为 kubelet 和 containerd 的 service 设置代理。kubelet 的配置文件为 /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf,containerd 的配置文件为 /usr/lib/systemd/system/containerd.service。配置内容如下所示。配置完后需要使用 sudo systemctl daemon-reload 来应用配置更改,并且使用 sudo systemctl restart kubelet 和 sudo systemctl restart containerd 重启服务。
# sudo vim /usr/lib/systemd/system/containerd.service
# sudo vim /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
[Service]
...
Environment="HTTP_PROXY=http://proxy.ip:3128"
Environment="HTTPS_PROXY=http://proxy.ip:3128"
Environment="NO_PROXY=localhost,127.0.0.1"
K8S 集群的搭建并非一件十分复杂的事情,比较复杂的是根据实际的需求和自己对于 K8S 的理解来搭建出更合适的 K8S 集群。虽然 K8S 集群已经逐步开始取代一般的 Docker 单机应用服务部署方案,但是就个人实际的应用规模或者应用本身而言,K8S 集群本身的维护和调整的代价要远高于 Docker 单机应用服务部署。如果是有高可用性、高可靠性等的需求,那么 K8S 可能是目前最好的需求。
正如在前言中所述,有了 K8S 持续开发、持续集成和持续部署成为了现实,开发者可以把更多的注意力都放在应用代码开发。同时,类似于 JupyterHub 这类会有动态扩展和分配资源需求的应用,最佳的部署方式可能就是 K8S 了。当然,听说现在的大模型 ChatGPT 等也都是在 K8S 上训练出来的。
K8S 的确是大有可为!
2024-07-02 14:15:00
谈到生活中经常坐的公交车,比较常见的算法问题可能是寻找“耗时最少公交路线”、“最少换乘公交路线”、“最便宜公交路线”、“综合最优公交路线”等。这些算法由于在地图软件中经常被使用,已经被大家研究得非常透彻,比如 Dijkstra 算法就可以用来计算“最短距离公交路线”。如想了解更多,可以阅读参考资料 2 给出的中文文献。
相比这些常见的算法问题,不如让我们来一起看看不大被人提及的“公交计费问题”。笔者经常在下雨的时候乘坐公交车,每次上车前会先取一张票,然后下车前可以看屏幕显示来知道票价。于是笔者就有了一个小问题:票价是如何正确显示的,是否可以对其建模并写个小程序模拟一下。
如图 1 所示为公交计费问题描述。
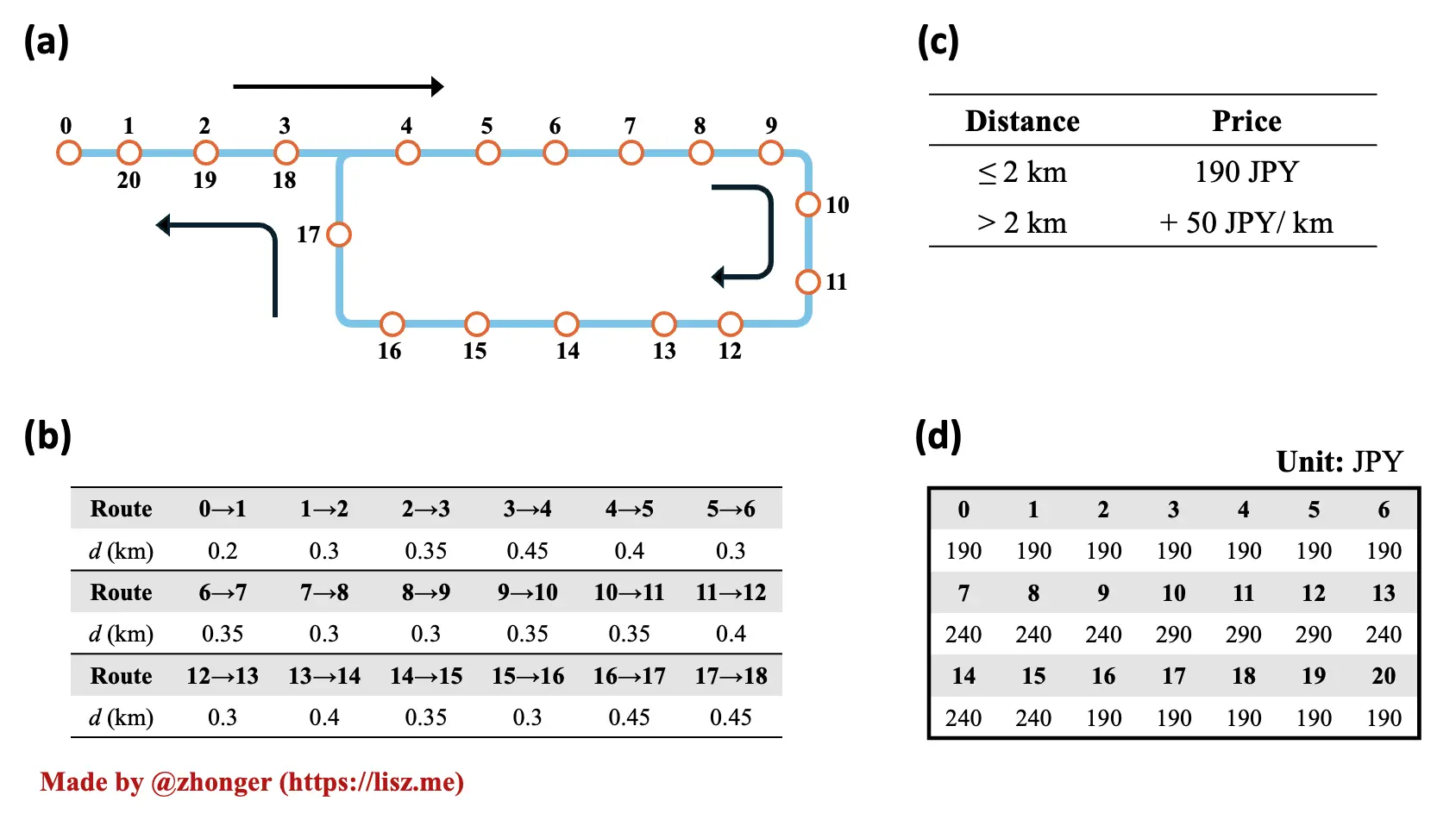
解决公交计费问题,首先要将图 1 中给出的信息进行集成,可得如下图 2。其中,站点间的橙色数字为相邻站点间距离,红色数字为几个关键(0~2 km,2~3 km 和 3~4 km 的阈值站点)站点与出发站点 0 之间的有效距离。
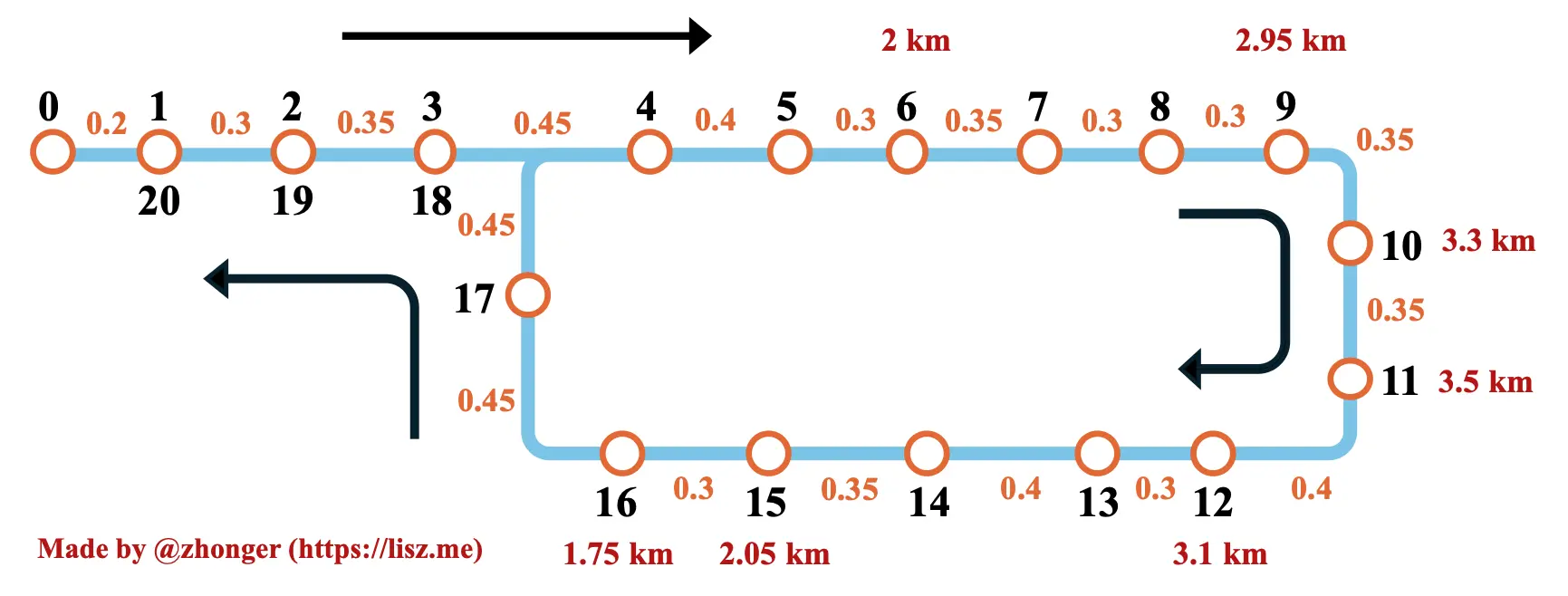
其实整个问题的核心就在于对有效距离的理解。从题干可知,有效距离并非是实际行进距离。这主要是因为给出的公交路线是环线而非直线,即出发站点与结束站点为同一站点。除此之外,刚开始的 1~3 与最后的 20~18 三个站点是重合的。根据给出的例子解释,我们可以将这里的“有效距离”粗略定义为“上车站点与下车站点在公交路线上正反距离的最小值”。我们不妨从以下示例中进一步加深对于“有效距离”的理解:(~ 表示“大约”)
得出总结:
题干中给出信息“公交从站点 0 出发最终回到站点 0 并停止运行”,鉴于任何跨过出发站点 0 计算的距离实际上只可能由两辆公交车完成,不可能出现在一辆公交的票价计算方式中,当只在循环圈上的站点上下车时应该不考虑直线上的站点(0~3、18~20)。
说句题外话,如例 3~5 所示,可能直接走过去还更快更方便,而非坐这趟公交。
| 变量名 | 变量类型 | 描述 |
|---|---|---|
| distances | list | 站点列表,[0, 0.2, 0.3, …] |
| currentStop | int | 当前站点编号,0 |
| lineStops | list | 直线站点,[1, 2, 3, 18, 19, 20] |
| circleStops | list | 循环圈站点,[4, 5, …, 17] |
| ticketBase | float | 基础票价,190.00 |
| ticketStep | float | 票价梯度,50.00 |
| ticketUnit | str | 票价单位,JPY |
| baseDistance | float | 基础距离,2.00 |
| stepDistance | float | 基础距离,1.00 |
| distanceUnit | str | 距离单位,km |
| validDistances | list | 有效距离,长度为 21,默认值为 None |
| prices | list | 票价,长度为 21,默认值为 None |
| validStops | list | 有效站点,经过站点时将编号添加到列表里,默认为 [0] |
程序整体步骤:
计算任意两个上下车站点间的有效距离的步骤:
根据以上思路,笔者采用 Python 实现了解决方案。源代码请见 Github Gist。以下为程序模拟运行效果:
虽然现有的公交线路大部分还是很规则的,不同时存在循环圈和直线的情况,计费也较为简单,但是思考特殊公交线路的计费方式也不失为一件有趣的事情。上面给出的分析和算法描述,也可以用其他编程语言实现,比如用前端编程语言就可以直接可视化整个公交计费过程。