2026-07-23 23:59:58
“Can you send me your slides before the meeting?”
This is a totally reasonable request if it happens often in your organization and you’ve planned for it. However, it might trigger mild panic if you were only planning to present the material live. A slide designed to support a spoken presentation is fundamentally different from one created for independent reading. Yet we don’t always make this distinction, which can lead to trouble.
In a recent team training, a client shared a slide intended to do three distinct jobs:
Serve as a pre-read for finance leadership before the meeting,
Support their live presentation, and
Work as a leave-behind reference after the meeting.
While it can feel efficient to design your communication to meet multiple needs like this, it can easily backfire. When you try to make a single slide work for different situations, you’re forced into compromises that mean it doesn’t fully satisfy any of them. The result? Communications that are too dense to present live, yet too sparse to stand on their own. When we know the scenario we are designing for, we can tailor the materials specifically to that setting.
Let’s look at the client’s original slide (anonymized for confidentiality), which tried to satisfy all three needs at once. Then we’ll explore ways to improve it.
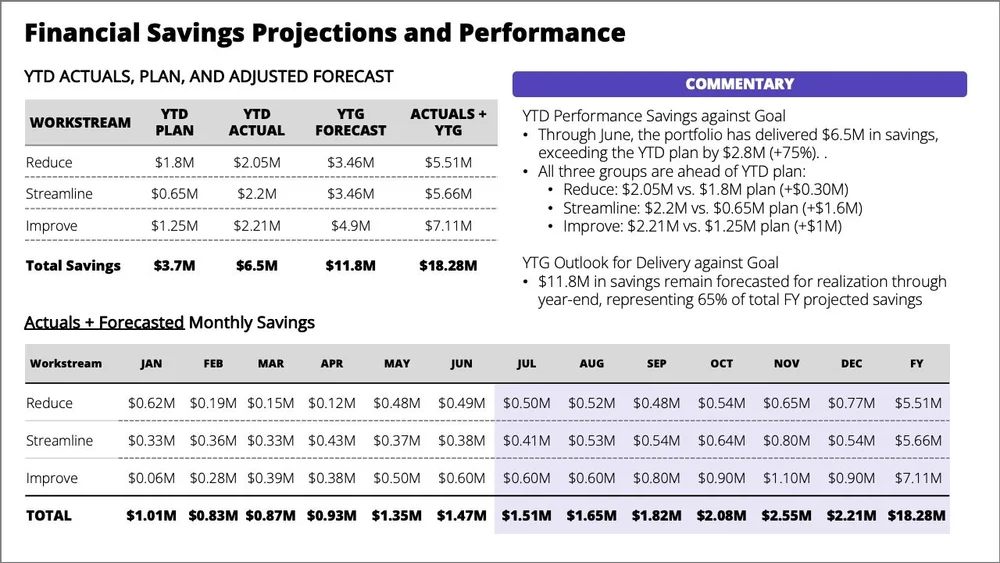
As a standalone slide, the commentary provides helpful context, but the core message isn't clear. The reader has to work to identify what matters and why. A strong pre-read should help leaders arrive informed and ready to discuss, rather than leaving them scanning through tables before the meeting.
In a live setting, this slide creates immediate friction. The busy tables and bulleted text force people to split their attention between reading the screen and listening to the presenter. Even if the audience read it in advance, they'll spend time hunting for details as you speak rather than engaging with the message. A live delivery is more effective when attention is deliberately guided by revealing one idea at a time instead of showing everything at once.
Being specific about the situation helps to improve design. Ask what the slide needs to do, who will use it, and in what setting. Once those are determined, it becomes much easier to shape the story and choose the right format.
The overall message the client wanted to communicate in the original slide was that, although the year-to-date performance is ahead of plan, a lot of work remained to achieve the forecast. The main action was to reiterate the priorities to ensure the team remained focused on the three workstreams and to quickly escalate any blockers to achieving the projected savings.
Articulating the goal helps determine what stays, what goes, and how to structure the narrative for each situation.
Let’s consider the live delivery first. When presenting in person, you don't need to cram every detail onto a single view because you control the pacing. Instead of showing everything at once, break the content into a sequence where each slide supports a specific point.
Here is how we could progress through the same information for a live audience:





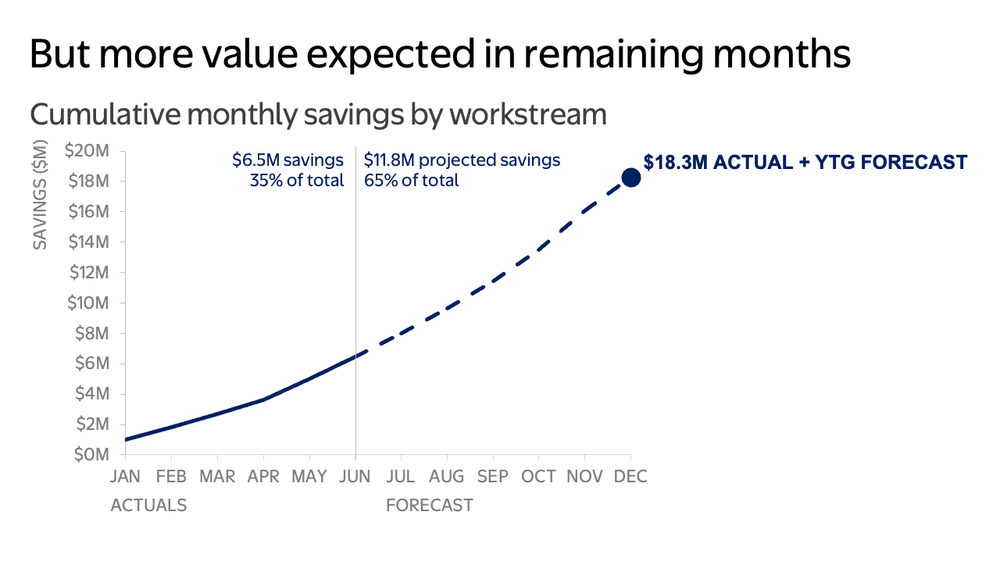

Because the story unfolds in a controlled manner, the presenter can guide the room through the information instead of hoping people find the right detail at the right moment. Takeaway titles frame the key message for each slide so the audience never has to guess. Supporting visuals reinforce the narrative rather than competing with it.
If leadership has already reviewed the pre-read, a live meeting shouldn't rehash every data point—it should focus on implications and decisions. But what about the materials that will be sent around before or after the meeting?
For a document meant to be read independently, incorporate the necessary depth without overwhelming the reader. Rather than leaving the data in dense tables, organize the content into a clear summary designed for solo reading.
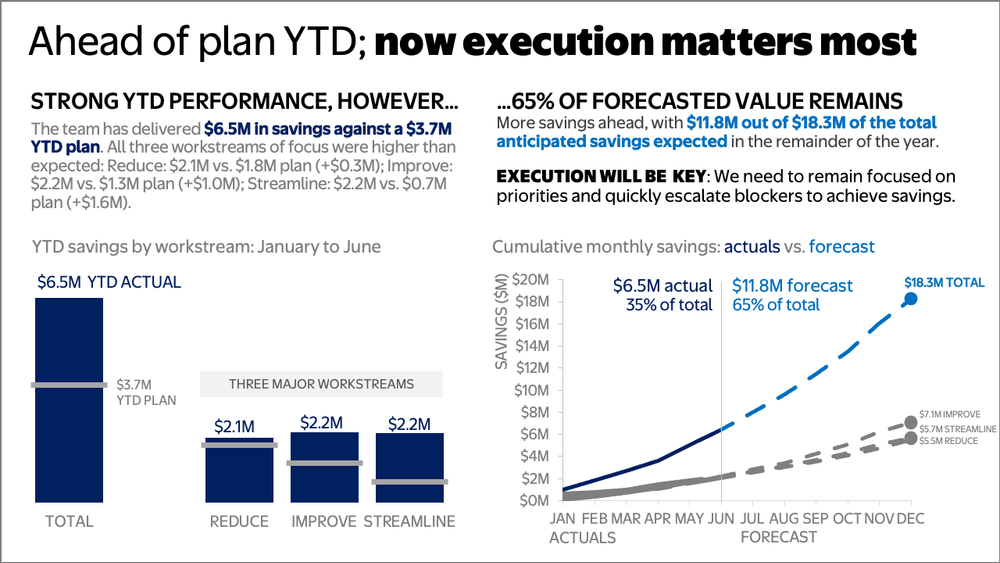
Single-slide communications often contain a lot of information, which can make it difficult to digest. By moving to a structured two-panel layout, the document establishes clear visual hierarchy. Bold takeaway headers immediately signal where to look first, while complete sentences directly beneath that provide the necessary detail and context for independent reading. Color applied intentionally and sparingly ties the text to the data it describes.
The original table views can then move to an appendix as a reference for anyone who needs the precise values for each workstream.
To recap, circulated slides and presentation decks are related, but they are not the same thing. When one communication is asked to do multiple jobs, the result is almost always compromise.
The next time you build a communication, pause and consider the medium:
For live presentations: Keep slides sparse so the audience focuses on you and your spoken narrative.
For written consumption: Build structured, detailed documents that provide complete context for independent reading.
Designing intentionally for the scenario at hand ensures your audience gets the right level of detail—and your message lands.
For more examples of visual transformations, check out the before-and-afters in our makeover gallery.
2026-07-09 20:34:54
Like many professionals right now, I’m part of the real-world experiment with AI in the workplace. Almost every day, I’m figuring out where it helps and where it gets in the way. As I experiment, one question keeps coming up: when do I actually want to use AI?
There are tedious parts of the data storytelling process that I genuinely enjoy, like tinkering with alignment and color, and sketching ideas before committing. While these steps might feel unnecessary, they almost always result in new ideas and better output. By contrast, building each chart from scratch or manipulating Excel data to produce a non-standard chart rarely improves my thinking. This is the part I’d happily hand off, as long as it doesn’t cost me control over the final design. Every minute I don't spend manually creating charts is another minute I can spend thinking about the underlying story and design.
I'm not looking for AI to redesign the slide for me, but I am open to using it to produce a starting point that I can refine and polish. I recently put this collaborative approach to the test, and the results are shifting how I work.
A client project gave me the perfect testing ground. Below is the original slide. (The data and scenario were altered to protect confidentiality.)
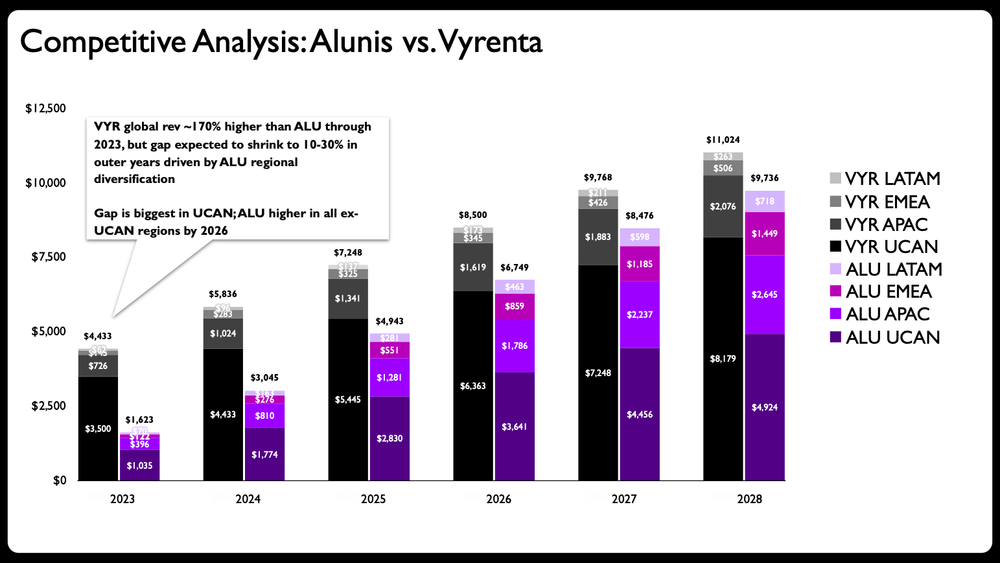
Vyrenta's early revenue lead narrows by 2028 as Alunis expands outside UCAN. Figures in USD bn. Sample data, not actual financials.
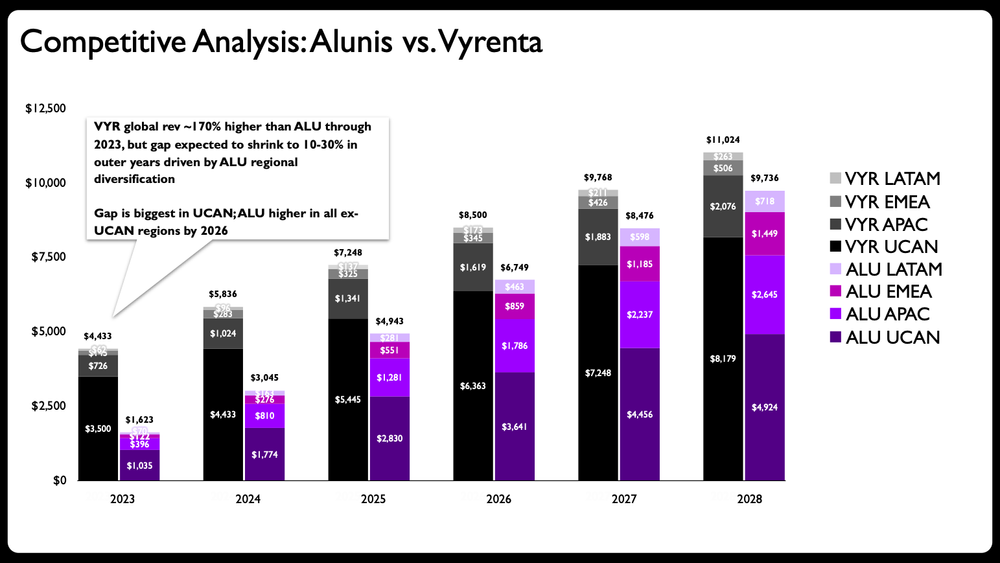
My initial thought: this stacked bar chart is trying to do too much. The goal is to show how the company, Alunis, will close the revenue gap with a top competitor, Vyrenta, by focusing on regional expansion over time. This chart needs to communicate change over time, compare two companies, and show each company's regional composition. That’s a lot of heavy lifting for one visual!
Side note: if you’ve checked out our latest book, before & after: practical makeovers for powerful data stories, you may recall the chapter on five common data visualization mistakes to avoid. The first most common mistake: adding too much to one graph.
Step one for this makeover is to avoid the mistake by splitting the graph into multiple charts. Here’s where things start to get interesting.
Since I like to sketch to iterate on my ideas, I made a rough draft of how I thought this redesign of multiple charts could look.
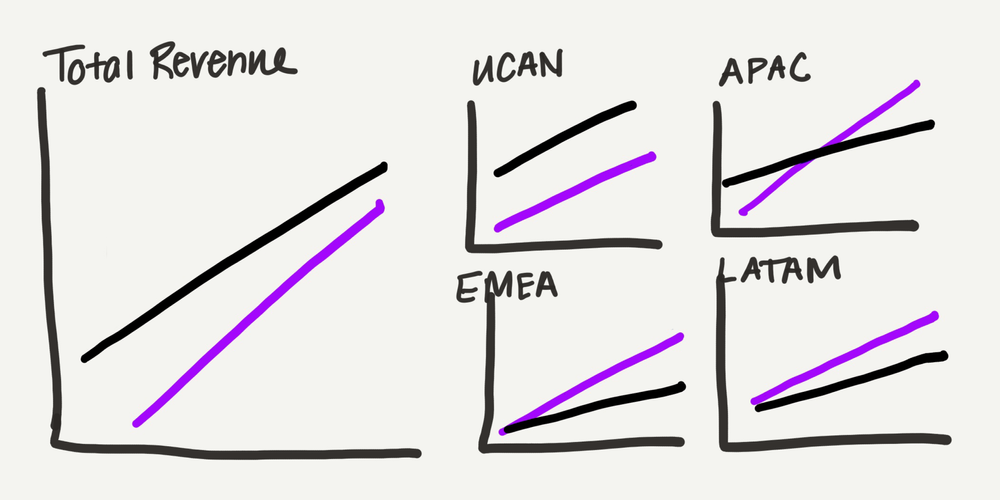
Hand-drawn sketch of the chart layout showing Vyrenta leads on total revenue and in UCAN, while Alunis grows faster and pulls ahead across APAC, EMEA, and LATAM.
I shifted from bars to lines, which have a lighter visual footprint—an advantage for a slide with so much data. I divided the graphs by location: one graph for total revenue and one for each region. Instead of sizing them consistently, I made the total view larger, and arranged the four regional charts into a small grid occupying the same amount of space as the total chart. This is my subtle way of visualizing the data’s part-to-whole nature.
Pre-AI, I would have created each one of these graphs in PowerPoint. This creation step would take a lot of time, patience, and mental energy.
This time around, I shared my sketch with Claude. For a few months, I’ve been testing Claude for PowerPoint, an add-in that was released earlier this year. While I’m not attached to any specific AI tool, this PowerPoint add-in has been the most useful for my workflow because it creates editable charts directly in PowerPoint, my preferred slide software.
That editability is what makes this collaborative experiment possible. It’s worth mentioning that CoPilot and ChatGPT also create editable charts. (I’ve had less success with the output—specifically CoPilot.) I’ve also learned that Gemini offers a similar capability for Google Slides, so this workflow can be adapted to other common tools.
Below is my prompt and the information I shared with Claude. Please ignore any typos, as I cannot be bothered to proof my chat messages.
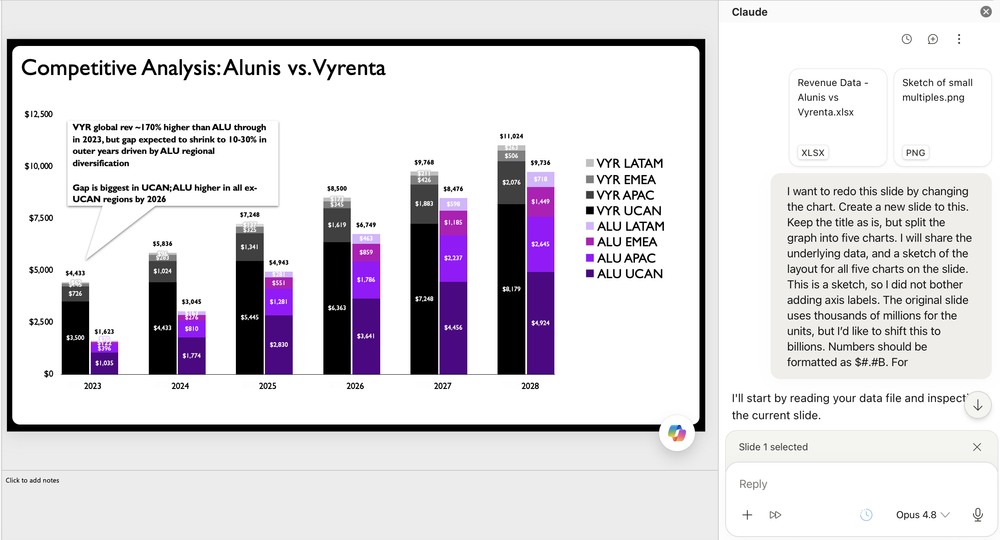
The Claude assistant is asked to rebuild the chart from the the uploaded data and hand-drawn layout sketch.
Here is the output from the above prompt. It’s decent. In fact, it’s better than that. This is a marked improvement from the original stacked bars.
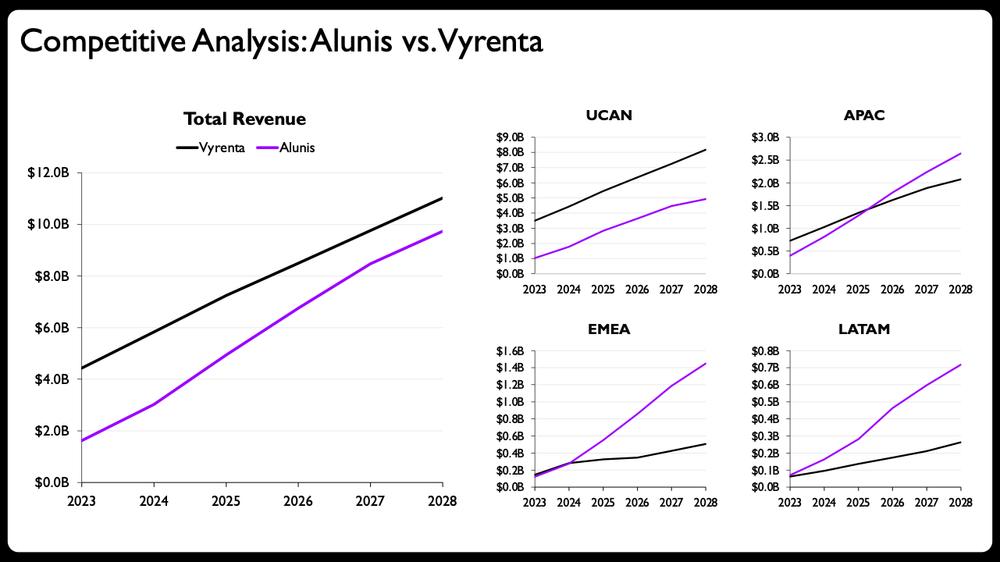
Claude rebuilt the sketch as fully editable native PowerPoint charts using the same small-multiples layout, real axes and labels.
Now, for most people, simply rewriting the slide title and adding additional descriptive language above the charts would be more than enough to call this makeover done.
For me, however, it’s not enough. There are a few easy tweaks that could take this to the next level. I’ll describe the top three.
Shade the areas: Since the comparison is between the two companies, I’ll make this more obvious by shading the space between the lines and adjusting the color to indicate the lead. At a glance you’ll see the purple overtaking the gray for three of the four regional charts—a design choice that reinforces the main takeaway.
Adjust axis ranges: Best practice states that you shouldn’t have multiple small charts near one another with different scales. When you deliberately break a best practice, it's worth understanding why the rule exists in the first place: to prevent someone from missing the scale difference and misreading the data. In an ideal world, I’d make all of the scales consistent, but if I do that here, it will be impossible to see the change at the regional level. To design around this constraint, I’ll make the ranges somewhat comparable by adjusting the maximum Claude chose, only label the minimum and maximum values, and add data labels for clarity and emphasis. I realize it’s not perfect.
Format the years: Space is limited on this slide so I want to preserve every bit of it that I can. For the year labels on the right, I’ll replace the four-digit years with two-digit abbreviations. I’ll also choose to only label the bottom charts.
My final design looks like the following.
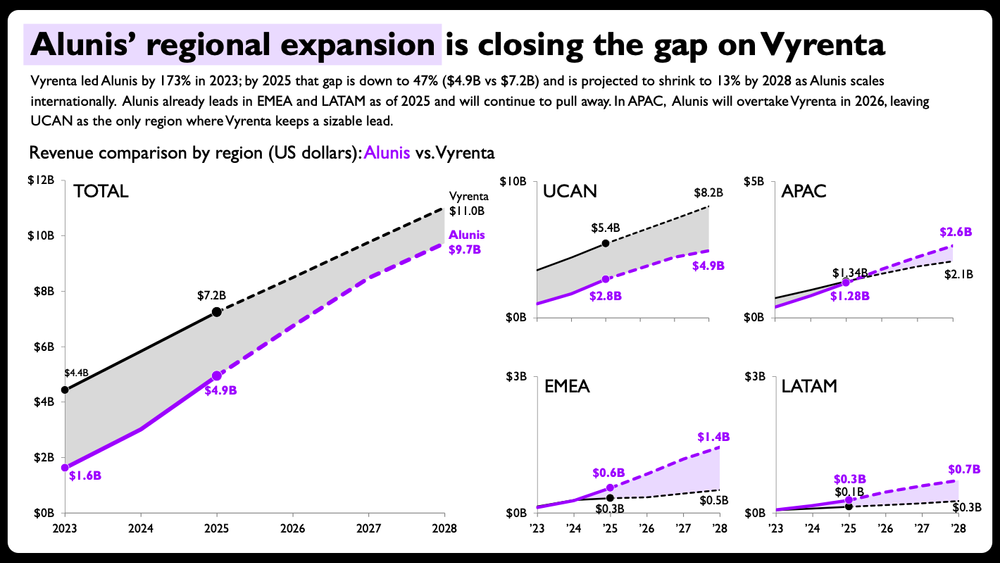
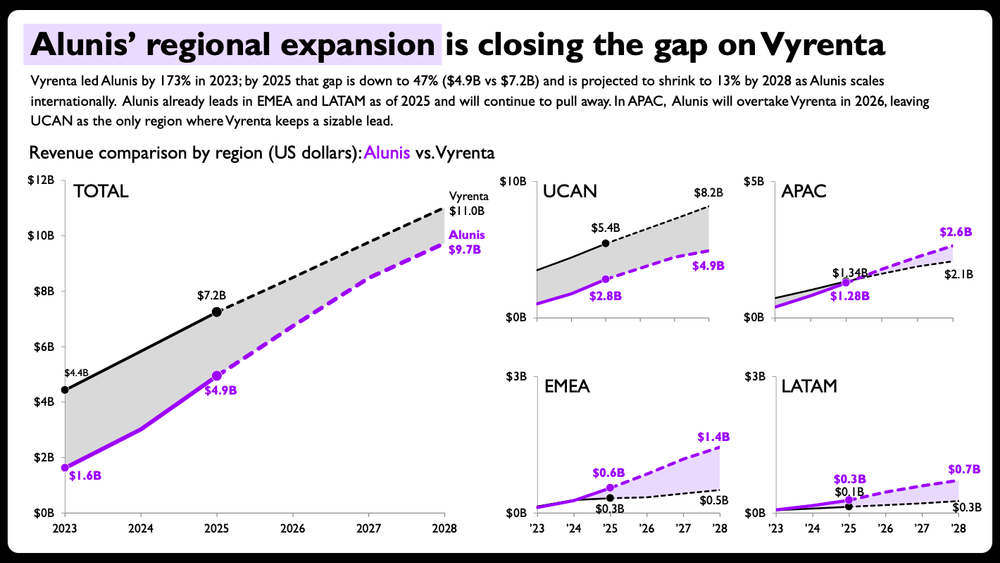
The same charts, now ready to share. Changes made: shaded areas between the two lines, direct end-of-line labels with values, per-panel axis ranges scaled to each region, solid-versus-dashed lines to split actuals from projections, and compact year formatting on the smaller panels. Sample data, not actual financials.
I’m quite pleased with the redesign, not just for the final outcome, but also for the impressive partnership between humans and AI throughout this makeover process. This result isn’t always the case in my many AI experiments, and it comes down to one thing: editable output.
A big hurdle for many practitioners was that AI-generated charts were images, and for whatever reason some of the image processing lacked accuracy. That makes it critical for a data visualization designer to make adjustments to the final output. Now that AI tools can generate solid editable charts and slides, they're finally useful additions to an existing data storytelling workflow.
The implications extend beyond experienced practitioners. If you're new to data storytelling or aren’t sure how to build a particular chart in, AI can help you overcome that initial learning curve.
It doesn't eliminate the need to learn the foundational principles that guide the output. For this AI-generated makeover, I still had to know that a stacked bar chart wasn’t ideal, and why. I still had to determine a simple layout for five charts on one slide. And I still had to recognize that breaking the "consistent axis scales" convention wasn't a mistake, but a deliberate design decision worth reinforcing. I was fully in the driver’s seat.
That’s the value we continue to bring at the moment. We provide judgment and direction, while AI accelerates the execution. And if you ask me, that’s the most enjoyable part of data storytelling, anyway!
Want to learn more about how to partner with AI? Watch the recording of our live event. Cole Nussbaumer Knaflic, CEO & founder of SWD, and fellow data storyteller, Simon Rowe will share practical ways to maximize your data storytelling workflow with AI.
2026-06-24 22:00:08
This post is part of the SWD + AI series—practical guidance for using AI as a thought partner across the various stages of your data storytelling work. Explore all of our AI resources.
In the previous post, we used AI as a thought partner to develop your Big Idea. You know your audience, you understand what’s at stake, and you have a clear point of view. Now comes the time to turn all of that into a story.
A common instinct at this point is to open your laptop and start building slides. Resist it! Before touching any tool, the most important thing you can do is go low-tech. Get out some sticky notes. Brainstorm content that might belong in your communication—one idea per sticky note—without filtering or judging. Then edit ruthlessly: what stays, what goes, what order serves your message? The low-fidelity format matters. It keeps you from getting attached to ideas before they’ve earned their place, and rearranging is effortless when nothing is committed to a slide.
This is storyboarding—and it’s one of the most powerful planning tools we teach at SWD. The process I’ll walk through took about 30 minutes, from initial sticky notes to a tested narrative and draft takeaway titles. That’s time invested upfront so I’m not spending hours later reworking slides to fix structural problems. But brainstorming and arranging content is only half of it. The other half is finding the right structure to hold it together.
The default flow for most business presentations is a linear path: you start at the beginning of the project, walk through what you did, and end with findings and recommendations. It’s logical. It’s familiar. And it tends to be forgettable, because it mirrors the analyst’s journey rather than the audience’s needs.
An alternative—the structure we find incredibly effective for business storytelling—is the narrative arc. Rather than following the chronology of the work, the narrative arc organizes content around tension and resolution. It has a deliberate shape: plot that establishes context, rising action that builds towards the central conflict, a climax where the tension peaks, falling action that moves toward resolution, and a clear resolution—the call to action.
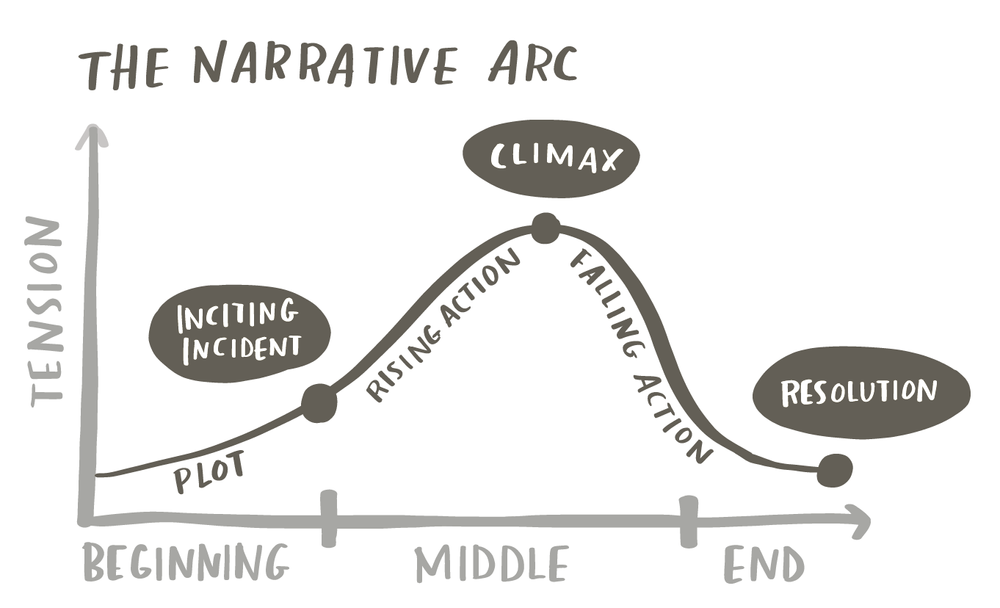
Making the shift from the linear path to the narrative arc isn’t always intuitive. Many people find it straightforward to brainstorm content and arrange it chronologically. But restructuring around tension and resolution requires a different kind of thinking. This is one place where AI can be particularly helpful: not to generate your story, but to help you find the arc that’s latent in your material.
The key ingredient that makes it work is tension. This isn’t the tension that matters to you as the analyst or the communicator of information, rather it’s the tension that matters to your audience. Recall what we assessed in the first installment of this series: What is at stake for them? What is the gap between where things are and where they need to be? When you identify that tension and build your story around it, you stop reporting findings and start telling a story that moves people to act.
The storyboarding process is deliberately human. Brainstorming, editing, and arranging your content is work that should happen away from the screen and away from AI. As we’ve discussed, the analog nature of it is a feature, not a limitation.
That said, AI can be a useful thought partner at two different moments in this process. The first is after brainstorming, when you have an array of sticky notes but haven’t yet found a structure. At this point, AI can help you identify a narrative arc from your raw material: finding the tension, suggesting an order, helping you see the story that’s embedded in what you’ve generated. The second is after you’ve arranged your content (with or without AI’s assistance)—once you have a draft structure. Here, AI can pressure-test whether the arc holds: evaluating the tension, identifying gaps, and flagging places where the story loses momentum.
Either way, the goal is the same: to surface blind spots and help you assess and refine before you invest time building anything.
Once your low-tech plan is solid, AI can also help you turn your sticky note topics into draft takeaway titles for your eventual slides. This is a useful bridge between planning and building. We’ll see how it works soon through an example.
Before getting to the prompt and example, let’s review some potential pitfalls of working with AI at this stage of the data storytelling process.
AI may flatten the tension—effective stories need a moment of discomfort before resolution. AI often smooths this out in favor of a more neutral, balanced narrative. Watch for responses that sand down the edges of your story.
AI will want to add, not subtract—it tends to suggest more content, more context, more caveats. A tighter story is almost always a stronger story. Use AI to find out what to cut, not what to add.
AI doesn’t know your audience—it can evaluate logical flow, but only you know what your specific audience needs to hear, in what order, to be moved to act.
Be mindful of what you share—avoid including sensitive data, personally identifying information, or confidential business details in your prompt.
If you’re continuing in the same AI conversation from the previous step, your context is already established and you can jump straight to the prompt below. If you’re starting a new conversation, take a moment to briefly reorient AI: share your Big Idea, describe your audience, and note what’s at stake and the key tension you aim to build the story around. A few sentences should suffice. Then use the prompt below, modifying as needed to meet your needs.
I’m working through the storytelling process using storyboarding and the narrative arc framework from storytelling with you by Cole Nussbaumer Knaflic (Chapters 3 and 4). I’ll share my work and ask you to act as a thought partner to help me find or pressure-test the narrative arc. Your role is to identify gaps, inconsistencies, or places where the story loses momentum. Don’t rewrite it for me and don’t suggest adding more content. Focus on whether what I have can be shaped into—or already follows—a clear narrative arc that builds tension and moves toward resolution.
Start with the option that fits where you are in the process:
Option A: after brainstorming
I’ve generated ideas for potential content but haven’t structured it yet. Help me identify a narrative arc from this raw material. [share a photo of your sticky notes or a list of your ideas]
Option B: after arranging
I’ve arranged my content into a sequence. Help me evaluate whether it follows a narrative arc or whether it could be restructured more effectively. [share a photo of your storyboard or a list of planned content]
Review and tell me:
Does the content map to a clear narrative arc—is there identifiable tension, clear climax, and fitting resolution?
What isn’t earning its place—is there anything that feels redundant, out of order, or likely to lose the audience?
Are there any logical gaps—places where I’m assuming the audience will connect dots they may not connect?
Before providing feedback, ask me questions that would help you give better input.
To see how this comes together in practice, let’s walk through an example.
If you read the first installment in this series, you’ll recognize the scenario. I’m a People Analytics Manager at a mid-sized consulting firm. My team has completed a thorough analysis of the company’s hybrid work policy—examining performance ratings, in-office attendance patterns, collaboration network data, and attrition trends. We have a recommendation: move from the current three-days-in-office, two-days-remote policy for all employees to a differentiated approach based on role and team type.
Our Big Idea is: It’s time to shift from our current three-days-in-office policy to a differentiated approach based on role and team type—one that meaningfully reduces costs and enables people to perform better and stay longer.
Now the work shifts. Context is set. The Big Idea is clear. It’s time to figure out how to tell the story.
I started—as I always do—with sticky notes. I wrote one idea per note, without filtering. I thought about the project from the perspective of each person who will be in the eventual meeting room: what will Diana need to feel confident championing this recommendation? What would make Robert a supporter? What might Priya push back on? I also thought about the data: what we learned and which findings were essential, versus interesting but not necessary.
After about 10 minutes, I had twenty-five ideas in front of me. I’ll list them here so you can get a sense of the breadth:
Why we undertook the analysis
Current hybrid policy
History/timeline of policy
Methods: data we collected
Benchmark data: comparison to peers
Employee survey data: work preferences
Performance ratings by role type & tenure before/after
Collaboration network data before/after
Office utilization: actual vs. assumption
Office utilization: breakdown by office
Attrition rates before/after
Attrition rate: breakdown by office
Travel/OOO breakdown by role
Manager feedback on hybrid policy
Cost of attrition by role type & tenure
Real estate cost analysis & projections
Finding: impact varies by role type & tenure
Finding: early-tenure employees struggle most
Finding: independent/analytical employees thriving
Finding: office utilization lower than expected
Cost of status quo
Options considered
Recommendation: differentiated approach by role and team type
What differentiated policy would look like in practice
Next steps and implementation timeline
Then I edited. I put aside anything that served my process rather than my audience’s needs—the methodology, policy history and timeline, the benchmarking data, options considered. I also set aside anything unnecessarily granular for my audience or that didn’t lead to actionable output: attrition by location, manager feedback, geographic utilization patterns.
As I edited and arranged, I also found myself rewriting my sticky notes. What had started as descriptive—“attrition rates before/after”—became more pointed: “early-tenure attrition has spiked, and it’s costing us.” The process of deciding what to keep and how to sequence it was already pushing me to think like a storyteller rather than an analyst.
That left me with twelve items. I arranged them in a sequence—not yet a narrative arc, just the order that felt logical to me at the time, which turned out to be fairly chronological: policy overview, data findings, recommendation, call to action.

I had a solid foundation but wasn’t yet confident in the structure. The data findings in particular felt like a list of things I’d learned rather than a story with momentum—and I wasn’t sure the tension was apparent for my audience. This felt like a good point to bring in AI to help. I turned to Gemini.
Quick note on tools: I used Claude in the first post in this series and Gemini here. In practice, it will usually make sense to stick with a single tool throughout a project so context can accumulate over time. I’m intentionally varying the tools I use throughout this series so I can see how well this workflow transfer across models.
Given that I haven’t used Gemini yet for this communication, I shared initial context along with my storyboard and prompt:
The following is Gemini’s initial response.



Gemini’s response was more useful than I initially realized. At first glance, it seemed to confirm the order I already had. But three observations stood out on closer reading.
The first was the question about sticky 7, “one policy can’t serve everyone equally.” Gemini flagged that stating this finding too early might give away the punchline before the data has had a chance to build the case. That’s a fair point, and this caused me to consider another reason to hold it back. For an audience member like Priya, who championed the current policy and is likely to be defensive about any change, naming the conclusion too early invites resistance before the evidence has had a chance to land. A stronger approach in this instance could be to let the individual findings accumulate—the attrition spike, the performance decline, the role-type differences—so that by the time we state “one policy can’t serve everyone equally,” the audience has likely already arrived there themselves. Given this, I decided to move this note later in the sequence.
The second was the suggestion to bring the financial figures closer together. Currently, I had the early-tenure attrition costs ($2.4M) in the rising action and the real estate savings ($3.2M) much later. Gemini pointed out that combining them creates a single, harder-to-ignore financial argument—roughly $5.6M in total impact. For Robert (the CFO) in particular, that framing is more compelling than two separate numbers spread across the presentation.
The third observation—about the climax—is where I disagreed. Gemini placed the real estate opportunity at the peak of tension. But for this audience, the emotional peak isn’t the financial case. It’s the human one: early-tenure employees are leaving at rates far above our historical baseline, and the current policy is actively making things worse. That’s the moment I want the room to feel before I offer the resolution. The financial argument is powerful supporting evidence, not the climax.
This is a good example of why AI is a thought partner, not a decision-maker. Its structural suggestions were useful. But I’m the one who knows what will resonate with this specific group. AI can help you think through audience needs, but it can’t replace real audience knowledge. When that knowledge is incomplete, talking with stakeholders or people closer to the audience is often more valuable than asking AI to fill in the gaps.
I arranged my stickies along the general arc Gemini recommended, incorporating the ideas I raised above, and continuing to rearrange some things to come up with a narrative flow that made sense to me (for example, leading from traveling employees to the lower office utilization to the real estate savings, since these ideas build on each other). I explained this change to Gemini, which responded with the following.

While I’m certainly feeling good about things now, I’ve learned to be cautious about AI enthusiasm. “You have a rock-solid narrative arc” is encouraging—but encouragement isn’t the same as rigorous pressure-testing. AI tends toward affirmation, and a confident-sounding endorsement can give a false sense of security. This is exactly the pitfall I flagged earlier: AI may flatten the tension and smooth over the edges of your story precisely when you most need rigorous push back.
Before moving on, I wanted to put the arc under more scrutiny. So I shared the revised sequence (below) with Gemini and asked it to pressure-test the narrative more specifically—this time focusing on whether the tension was genuinely meaningful to my specific audience, whether anything was losing momentum, and whether there were logical gaps my audience might not bridge on their own (Option B of the potential prompt shared earlier in this post).

Here’s Gemini’s response:

Before diving into feedback, Gemini asked three clarifying questions—a direct result of the “ask me questions first” instruction in the prompt. I hadn’t explicitly shared my audience context in this exchange, and rather than plowing ahead with generic feedback, Gemini flagged that gap. That’s the prompt doing its job—and a good reminder that the quality of AI’s feedback is directly tied to the specificity of what you give it.
The questions caused me to reflect. The first pushed me to be explicit about something I’d been holding implicitly: Diana is my primary audience, and her bias is cultural—doing right by employees while presenting a position she can defend with data. But Robert’s financial bias matters too, and Marcus’s operational one. A story that lands for Diana needs to at least speak to the others.
The second question had an obvious answer for me: Priya. She championed the current policy and is likely to see any change as a threat. The most important objection to anticipate is hers.
The third identified a potential gap I hadn’t explicitly thought through: the verbal bridge between the real estate finding and the early-tenure performance findings. These two sit on opposite sides of the arc, and how you move an audience from one to the other matters. I hadn’t worked that out yet, and it’s exactly the kind of thing that’s much easier to address now than after I’ve built the slides
I’ll also note the opener. This kind of enthusiasm is AI’s default mode: charming, but meaningless. Watch for it, and don’t let it substitute for the substantive feedback that follows.
I answered Gemini’s questions and asked it to proceed with the pressure-test. Here was the response:



A few things stood out. The observation about stickies 8 and 9 was practical and correct: office utilization and real estate savings are one idea, not two, and presenting them separately risks stalling the momentum right before the climax. I’ll combine them.
The observation about sticky 7—“one policy can’t serve everyone equally”—was the most useful structural insight. Gemini suggested treating it as falling action rather than the climax itself. This doesn’t change where it sits in the sequence, but does impact how I frame it. Stated as the peak of tension it sounds like an accusation directed at the current policy—and at Priya. Let the data accumulate first: the attrition spike, the performance decline, the role-type differences. By the time we state the conclusion, the audience will already have arrived there themselves.
The two gap identifications were also valuable. The first—bridging the early-tenure performance decline to the attrition spike—isn’t only about narrative flow. It’s anticipating Marcus’s objection before he can make it. The second—a proactive nod to Priya’s perspective on hybrid flexibility—is the kind of thing I need to do but might have left implicit. Having it named as a structural gap rather than just a presentation nicety is useful.
The quality of this feedback was directly tied to the audience context I provided. Gemini’s earlier response was useful but generic; once it knew that Priya had championed the current policy, it could surface the “Priya defense” gap. In hindsight, I could have accelerated this process by providing that audience context from the beginning. Had I uploaded my completed Big Idea worksheet, Gemini would have had access to those details from the start.
Rather than rearranging my stickies again, I noted these refinements to carry into the building phase. With the arc solid and the structural gaps identified, I had one more thing to do before closing out the planning stage: turn my sticky note topics into draft takeaway titles.
I gave the following simple prompt: I’m happy with the overall structure. Can you now help me turn each point in my storyboard into a draft takeaway title for the eventual slide? Each title should be a single, pithy statement that tells the audience what to notice or understand from that slide—not a label for the content, but a clear point of view.
Gemini initially gave me much more than I asked for. Rather than parse it myself, I followed up with: Thank you—can you give me just the draft titles as a simple numbered list, without the sticky note references, arc labels, or explanatory notes in parentheses?
Here is the response:

This is a good starting point. Read top to bottom, they tell a cohesive story. Each title pushes the narrative forward and the financial figures feel integrated naturally. “The true cost of this mismatch is human” is strong as a climax title and will appeal to my audience.
That said, several are too long for slide titles. A takeaway title needs to make the point succinctly—the supporting detail lives in the content of the slide itself, not the title. With that in mind, I refined to the following:
Our hybrid policy treats all roles the same—but they aren’t
We looked beyond office attendance: perf, collaboration, & more
Independent and analytical teams thrive remotely
Office mandates work against client-facing teams
Current policy doesn’t match how people actually work (and we’re paying for it!)
The real cost is human: new hires are set up to struggle
Early-tenure attrition has spiked—and it’s costing us
One policy can’t serve everyone equally
A differentiated approach recaptures $5M+
Not removing flexibility—making it work better
Approve the change: stop the drain
These eleven titles give me a clear plan for building the deck. They aren’t final—as I build out the actual slides with my team, some will sharpen, some will shift, and a few may get trimmed or expanded as the content takes shape. But having them now means I won’t ever have to start from a blank slide. The story is mapped. The tension is clear. The call to action is explicit. Everything that follows is building on a foundation rather than figuring it out as I go.
One reason I remain such a strong advocate for storyboarding is that it saves time. The work described here may look involved when written out step-by-step, but the actual process was fast—roughly 30 minutes from initial sticky notes to a tested narrative and draft takeaway titles. That’s time invested upfront so you’re not solving structural problems after you’ve already build slides.
For this high-stakes communication, working through the storyboarding and narrative arc process with AI as a thought partner got me to a place I wouldn’t have reached as quickly on my own. What I have is stronger for it: more robust, more audience-aware, and more intentional than if I’d worked through it alone. That’s pretty incredible.
In the next post in this series, we’ll move to the third core SWD skill: choosing an effective visual. In the meantime, watch our live event, where Simon and I explore how to use AI for better data storytelling—including diving deeper into ideas from this series.
2026-06-18 21:20:57
“I don’t have a design eye.”
Kaitlin says this matter-of-factly, as if it’s simply a fact about herself, like her height or hometown. Kaitlin, our education and outreach specialist at storytelling with data, is passionate, creative, and deeply committed to her work—particularly when it comes to raising awareness of our children’s book, Daphne Draws Data. She is also, by her own admission, not a designer.
I’ve been working with her on this. I’m seeing progress—more intentional use of color here, a cleaner font choice there, and a growing awareness of how the things she creates will actually be used. Which got me thinking about a question I find genuinely interesting: can design be taught?
My answer is yes. Unequivocally. With a caveat.
People come to design with different natural starting points. Some have an innate sensitivity to visual harmony—they notice when something is off before they can articulate why. Others have to work harder to develop that instinct. But here’s what I believe, and what I’ve seen borne out again and again in my work: everyone can improve. The gap between where you start and where you can get is largely a function of attention, practice, and knowing what to look for.
This mirrors something I feel strongly about when it comes to designing effective graphs. It’s not a talent you either have or you don’t. It’s a skill. Like any skill, it can be cultivated.
So for Kaitlin, and for anyone else who has ever said “I’m just not a design person”—and for those trying to help someone get there—here are ten things worth learning:
This is the first question to ask before you open any tool or touch any layout: who will see this, and what do they need from it? It sounds obvious, but it’s remarkable how often we skip it. We start with what we have—the content, the existing template, the thing we made last time—and work forward from there. The result is design that serves the creator, not the audience.
Every tool you use—PowerPoint, Canva, Google Slides, your website platform—makes design choices on your behalf. Default fonts, default colors, default layouts. These aren’t neutral. They’re someone else’s decisions, made for a generic use case that probably isn’t yours.
Accepting defaults uncritically isn’t the same as making no design choice. It’s making an unconsidered one. The first step toward better design is simply noticing that these choices exist—and asking whether they are serving you.
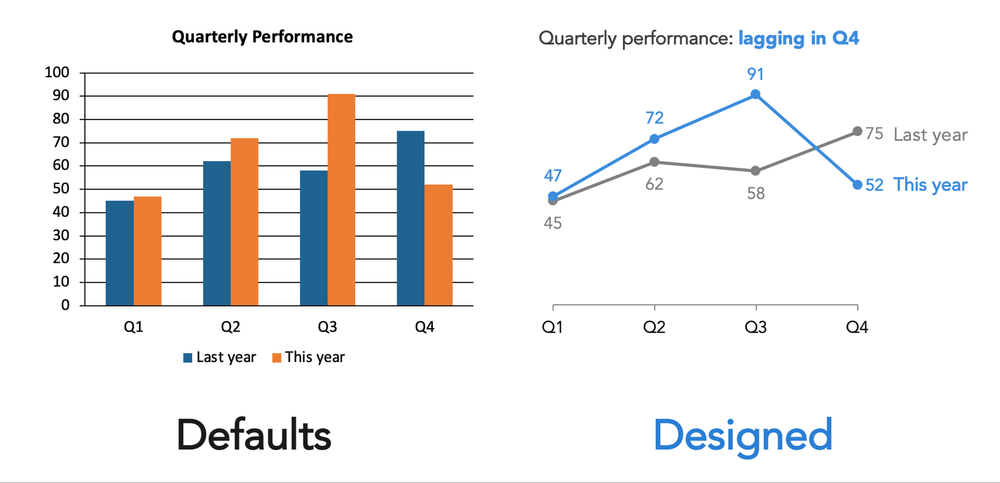
More options are not more freedom. In design, it’s usually more noise. When everything is available to you—every font, every color, every layout—the result is often a visual cacophony where everything competes and nothing stands out.
Constraints help. A limited color palette. A single typeface. A layout you commit to. If your organization has existing templates or brand guidelines, lean into them—they’ve already done some of this work for you, and consistency across your materials builds recognition and trust. The goal isn’t creative restriction; it’s coherence. Within constraints, the real design decisions become clearer.
Your viewer’s eye will move through your design whether you direct it or not. The question is whether it moves the way you intend. Visual hierarchy is how you answer that question deliberately.
What should someone notice first? What’s the most important thing? Make it the most visually prominent. What comes second? Third? Design the sequence. This doesn’t require elaborate technique—size, weight, position, and spacing can all establish hierarchy simply and effectively. What it does require is that you think it through before you start placing elements, rather than after.
This is one of the most important design principles I know, and one of the most commonly violated. When something in your design is different—bigger, bolder, a different color, a different font—viewers read that difference as meaningful. It signals: pay attention here, this matters more.
The corollary is that unintentional variation creates confusion. If three elements are slightly different sizes but you didn’t mean anything by it, your viewer will still try to interpret the difference. They’ll wonder what they’re missing. Inconsistency reads as noise, while intentional variation reads as signal. Before you finalize anything, ask yourself: does every difference in this design mean something? And does everything that should look the same actually look the same?

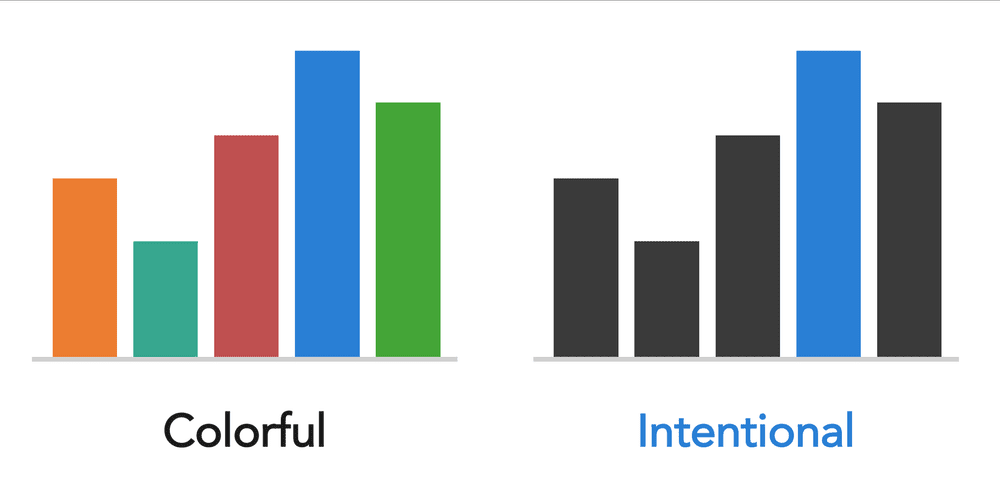
Color is one of the most powerful tools in design—and one that is often misused. The right approach depends entirely on what you’re trying to do.

If you’re creating something expressive—an illustration, a poster, a book cover—color can be rich, playful, and abundant. In Daphne Draws Data, our children’s book, color is used exuberantly, because that’s what serves young readers and the spirit of the book.
But if you’re trying to direct attention in a graph or a slide, a different logic applies. A mostly neutral palette with one intentional color used sparingly is far more effective than many competing colors.
When it comes to this, the question to ask isn’t “what colors do I like?” It’s “what is color doing in this design, and is it doing that well?”
Of all the things that make a design feel polished versus amateurish, alignment is one of the most telling. Misaligned elements—text that doesn’t quite line up, objects that are close to a grid but not on it—create a subtle but persistent visual unease. Viewers may not be able to name what’s wrong, but they feel it.
One particular pet peeve worth calling out: center-aligned text. It doesn’t align to anything, which leaves it floating unmoored on the page. When it runs to multiple lines, you end up with two jagged edges—one on the left and one on the right—that create visual tension rather than resolving it. Left-align your text and give it something to anchor.
The fix is straightforward: use your tool’s alignment functions, turn on gridlines, and be deliberate. Every element should be aligned to something—another element, a margin, a grid. “About here” is not a design decision. Alignment is one of those things that, once you train your eye to see it, you can’t unsee. Which is useful, because then you can fix it.
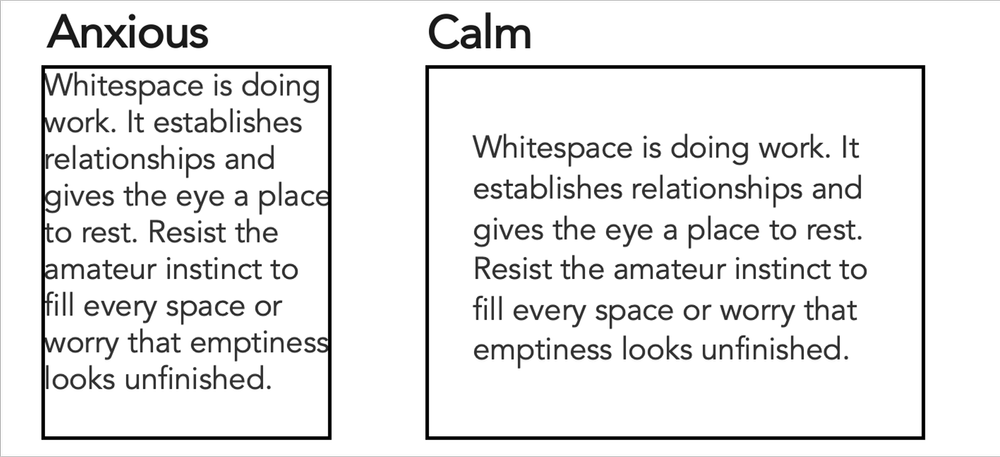
Whitespace—the empty space in a design—is not wasted space. It is doing work. It creates separation, establishes relationships, and gives the eye somewhere to rest. Designs that crowd elements together feel anxious and hard to read. Designs with generous spacing feel calm, clear, and considered.
The instinct when you're new to design is often to fill space, perhaps due to worry that emptiness looks unfinished. Resist it. Some of the most effective designs are defined as much by what isn’t there as by what is.
Design literacy is built by looking. When something catches your eye—a beautiful book cover, a well-designed menu, a pleasing color combination, a graph that makes data suddenly clear—pause and ask why it works. What specifically is it doing? What could you learn from it or apply in your own work?
Do the same with bad design. Why is it ineffective? What would you change? This kind of active, analytical looking is a habit, and it compounds over time. The more you do it, the faster your eyes develop. Inspiration is everywhere—you just have to start noticing it.
If you want to practice this specifically with data visualizations, the SWD community’s discover page is a great place to start. Thousands of visuals created by SWD team members and the broader community are there to browse—shuffle and see what catches your eye.
Here’s the thing about design instinct: most people have more of it than they realize. You know when something feels off, even when you can’t say why. That feeling is data. Trust it.
But instinct is a starting point, not a ceiling. It can be developed. The difference between someone who considers themselves “not a design person” and someone who does isn’t innate talent—it's mostly accumulated practice, awareness, and feedback. You train your eye the same way you train anything else: by using it, paying attention to what you notice, and being willing to iterate.
You don’t have to be a designer to think like one. You just have to start looking.
2026-06-11 04:20:17
Do you dread hearing those words from your manager? I certainly used to. Whether I was pulling together slides for a high-stakes client presentation or making a first pass at an analysis I’d never done before, those six words always sank my heart. While my leader was on their way to giving me some feedback that may have been constructive, all I heard was “this isn’t good enough.”
My name is Ryan, and for my first storytelling with data (SWD) blog post I’m collaborating with my new colleague, Alli Torban, to share insights into how to reframe your thinking when entering a feedback-rich environment like the one we foster at SWD.
After joining the team, we both had a bit of a wake-up call. On our very first day, we were asked to introduce ourselves to the team at our weekly virtual team meeting. Then we spent the rest of the week practicing our intros and incorporating feedback from the team. This is standard practice here, and it didn’t take long for this culture to start changing how we think about feedback.
As we began to internalize and embrace this environment, we noticed we were starting to hear feedback differently than we had before SWD. The shift in perspective is small, but it shows how the same words can land very differently depending on the surrounding context. Here are a few examples:
Before joining SWD: “It’s too soon, they’ll judge my incomplete work.”
After joining SWD: “Perfect timing to get direction and practice!”
In a prior role, I felt overwhelmed with work. I would hurry through a project to meet a deadline, only to have another looming around the corner. One bad habit I developed was waiting until a project was nearly complete to request feedback. Often I would ask for thoughts shortly before a deadline.
This created lose-lose situations: either my feedback provider would feel cornered into avoiding any true constructive criticism, or they’d be honest and recommend many changes at the 11th hour. The latter was tough, as I would need to stay late at the office making major edits to meet the deadline.
During our eight-week onboarding program at SWD, I shared my work-in-progress introduction to my peers. Instead of calling it incomplete, or telling me it needed work, they chimed in with praise and edits each step of the way. Their input guided me as I honed my verbal intro into its best version, long before I internalized early drafts.
Lesson learned: Now, I ask for feedback early and often, and I’ll jump at an offer from a colleague to review my early work.
If I don’t get the chance to connect with my feedback group until closer to the deadline, I make a point of that in the request. Questions like the following are better suited for feedback later in the creative process:
“Are there any glaring problems that need to be addressed?”
“I only have time for word choice, and other light edits, do you have any suggestions within that scope?”
“If you only had an hour to make changes, what would you prioritize?”
Before joining SWD: “My work is not good enough.”
After joining SWD: “Nice—I’m on the right track!”
Alli shared with me a great story about this classic feedback opener:
Early in my career, I had a more seasoned colleague who would start his feedback with, “This is a great start…” and then change everything I had done. His comment was meant to be kind, but I came to hear that phrase as shorthand for, “let me do it.”
At SWD, the culture is iterative, honest, and still kind. For a recent client chart makeover, I shared my in-progress files with Amy, and she told me it was a great start. I braced for a fully redone version. Instead, she sent a file full of comments, and she gave me agency to make those changes in my own way. It wasn’t a prescriptive list of edits. She truly meant it was a great start, and with guidance, my next iteration would move closer to the final product.
Lesson learned: In a culture where feedback is part of the process, “great start” can actually mean trust: trust that you’re capable of taking it the rest of the way. Now when you hear “great start” think of it as an invitation to iterate, not a cue to step aside.
A device that helped Alli to hear those words in a new light is a classic improv game called “bad gifts.” To hear her and Cole talk more about this, check out episode 99 of the SWD podcast where they practice the game together, and share additional insights on being a better recipient of input from others.
Before joining SWD: “Uh oh, they are too busy to give me all the notes they have.”
After joining SWD: “Great, I can guide the conversation.”
As soon as we started the lessons on feedback at SWD, I was brought back to the dozens of times I cast too wide a net when inviting critique. I’d send an in-progress project to a peer or manager and ask “any thoughts?” or simply say “please review when you have a chance.” All I ever got back in response was generic answers: “great work,” “it’s missing something,” and/or “cut it down.”
I left those requests with more questions than answers. If it's great, should I change anything? What is it missing? Do I need to cut a slide? How can it be too long, missing something, and great all at the same time?
At SWD, asking specific questions as a part of the input cycle helps me to realize what I’m asking for. Clear-cut questions also point my colleagues in a direction that gives them the confidence that their commentary will be helpful to me. When I ask Simon “Before I deliver my intro, can you let me know if you think it’s too long?”, that’s his cue to look out for sections to trim as he listens.
Lesson learned: before I request feedback, I make a short list of questions for my feedback-giver. This forces me to critically assess aspects of my in-progress work and to prioritize my needs in a way that ensures I’ll get the productive edits I’m seeking.
We adapted to this culture by embracing several key learnings and putting them into practice firsthand:
Get input from peers and managers early and often
Treat projects as iterative, collaborative work
Request and give specific, actionable critiques
Implement one or more of these lessons to help create a positive, feedback-rich environment in your workplace.
2026-06-09 00:11:04
At storytelling with data, our mission is to inspire positive change through the stories people tell with their data.
Over the years, we’ve seen firsthand how stronger communication skills help organizations secure funding, influence decisions, align stakeholders, and amplify their impact. Yet many nonprofits, schools, and mission-driven organizations face budget constraints that put professional development opportunities out of reach.
That’s why we’re excited to relaunch SWD Reach. It’s a special application-based program that provides our in-person storytelling with data 4-hour workshop at a substantially reduced cost to selected organizations. We’ve reserve a limited number of Reach workshops for organizations that can put these skills to work in service of their mission. The goal is simple: help organizations doing important work communicate more effectively with data so they can increase their impact.
Whether you’re seeking grant funding, advocating for resources, communicating outcomes to donors, or helping leaders make informed decisions, the ability to clearly communicate data matters. We regularly hear from organizations that have important information to share but struggle to make their insights clear, compelling, and actionable. This program is designed to bridge that gap.
The impact of these workshops extends far beyond a single training session. Participants learn practical techniques for choosing effective visuals, focusing attention, and communicating insights clearly and persuasively. Since initially launching in 2019, SWD Reach has supported more than two dozen organizations, helping teams communicate data more clearly, advocate for resources, and demonstrate impact. One participant shared:
“Everything discussed applied directly to our work. The session was highly relevant and sparked immediate conversation about how to implement these ideas in our department. The exercises and before/after examples were especially helpful, and people had a lot of aha moments.”
If your organization is committed to using data to drive positive change—and would benefit from developing stronger communication skills—we encourage you to apply. SWD Reach applications are open through June 30th.
Please help us spread the word by sharing this opportunity with colleagues and networks who might be a great fit.