2026-08-03 00:32:47
今天有一个 “重大” 发现想要分享:PySonar2 可以大幅度降低 AI 在执行 Python 项目修改的时候的 Token 消耗。
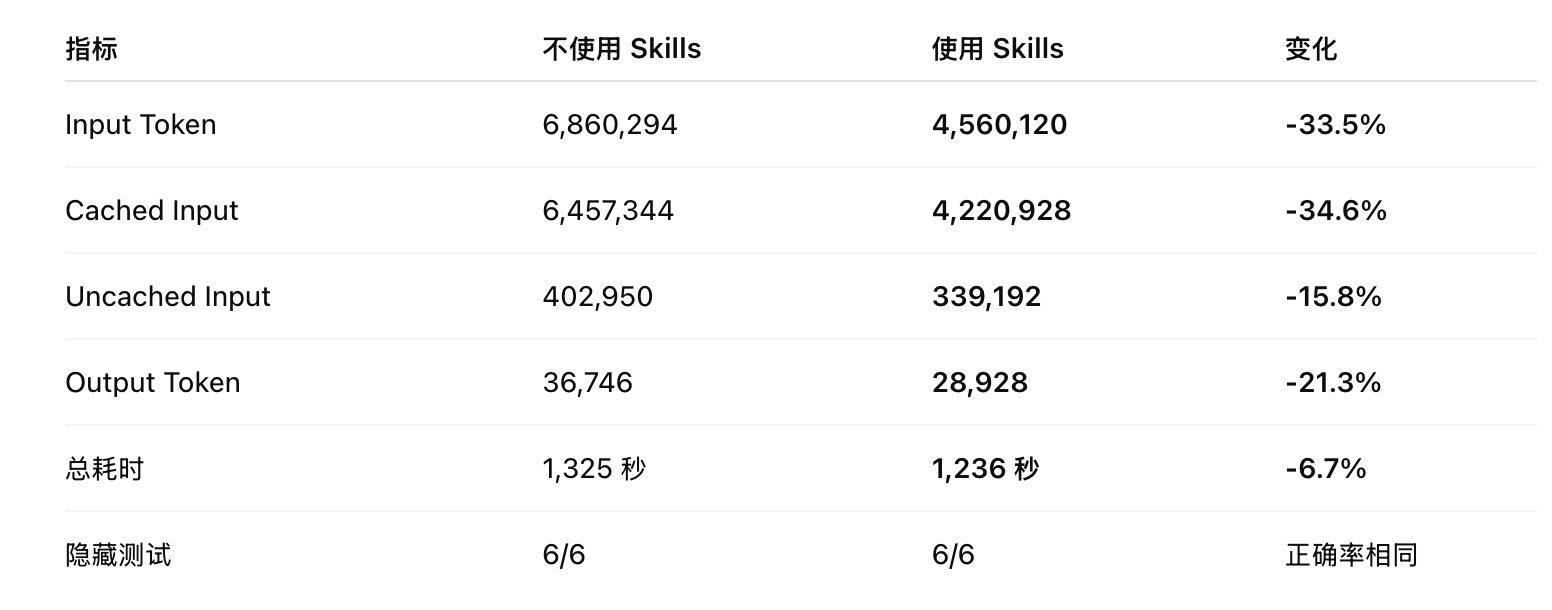
这是 ChatGPT 运行出来的 benchmark 结果:
补充一下这个 benchmark 任务的定义:
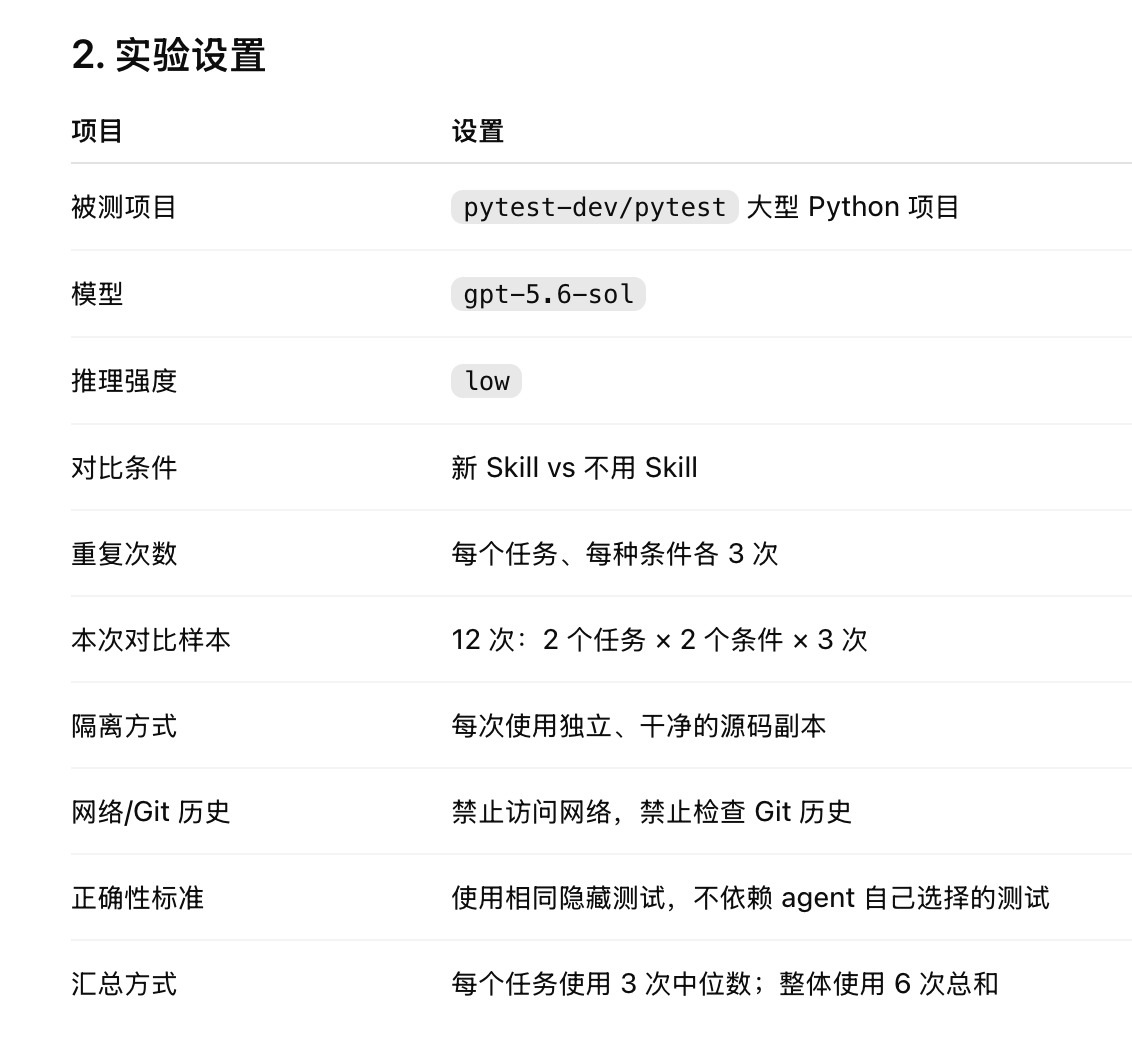
具体任务有 2 个:

概括来说,就是基于一个测试专用的大型 Python 项目,设定两个方向的任务,一个任务横跨多个目录和文件,另一个任务目标明确、不需要跨文件定义,然后分别用 skill 和不用 skill 执行。
结果如你所见,使用了 skill 之后,速度略微有提高,token 消耗量则直接减少 30%!
说明一下,刚才提到的 skill,是指基于 PySonar2 源码封装的、符合 AI Skills 规范的 skill,你可以直接告诉 ChatGPT:
帮我安装这个 skill 到用户级目录:https://github.com/smallyunet/pysonar2
就可以了。
这个 PySonar2 的仓库是 fork 出来的,因为原版的 PySonar2 仓库是王垠 13 年前的项目,已经有一些工程和特性方面的 “过时”,所以做了一点点新的工程方面的包装。当然 PySonar2 最核心的词法分析、类型推断是没有过时的。
除了这个 AI skill,我还把 PySonar2 以 VS Code 插件的形式发布了,安装后可以在 VS Code 上打开 Python 代码之后,鼠标 hover 上去看到 PySonar2 的类型推断:
解释一下为什么 PySonar2 可以帮助 AI 节省。
如果你是程序员并且经常让 AI 写代码,一定会看到 AI 会使用大量的 rg,每一次任务都会把各种代码文件看一遍,然后继续执行代码修改。而 PySonar2 可以提供一种基于代码语义的、基于 AST 结构分析出来的这种内容:
{ "symbol": "User", "definitions": [ {"file": "models.py", "startLine": 12} ], "references": [ {"file": "service.py", "startLine": 48}, {"file": "tests/test_service.py", "startLine": 31} ], "affectedFiles": [ "models.py", "service.py", "tests/test_service.py" ]}直接在一个文件里把每个变量定义的来龙去脉、相关源码文件总结出来。相当于本地建立了一个索引,AI 直接看索引,而不需要每次看一遍全部代码。
因为任何 AI 工具目前都有两方面限制:
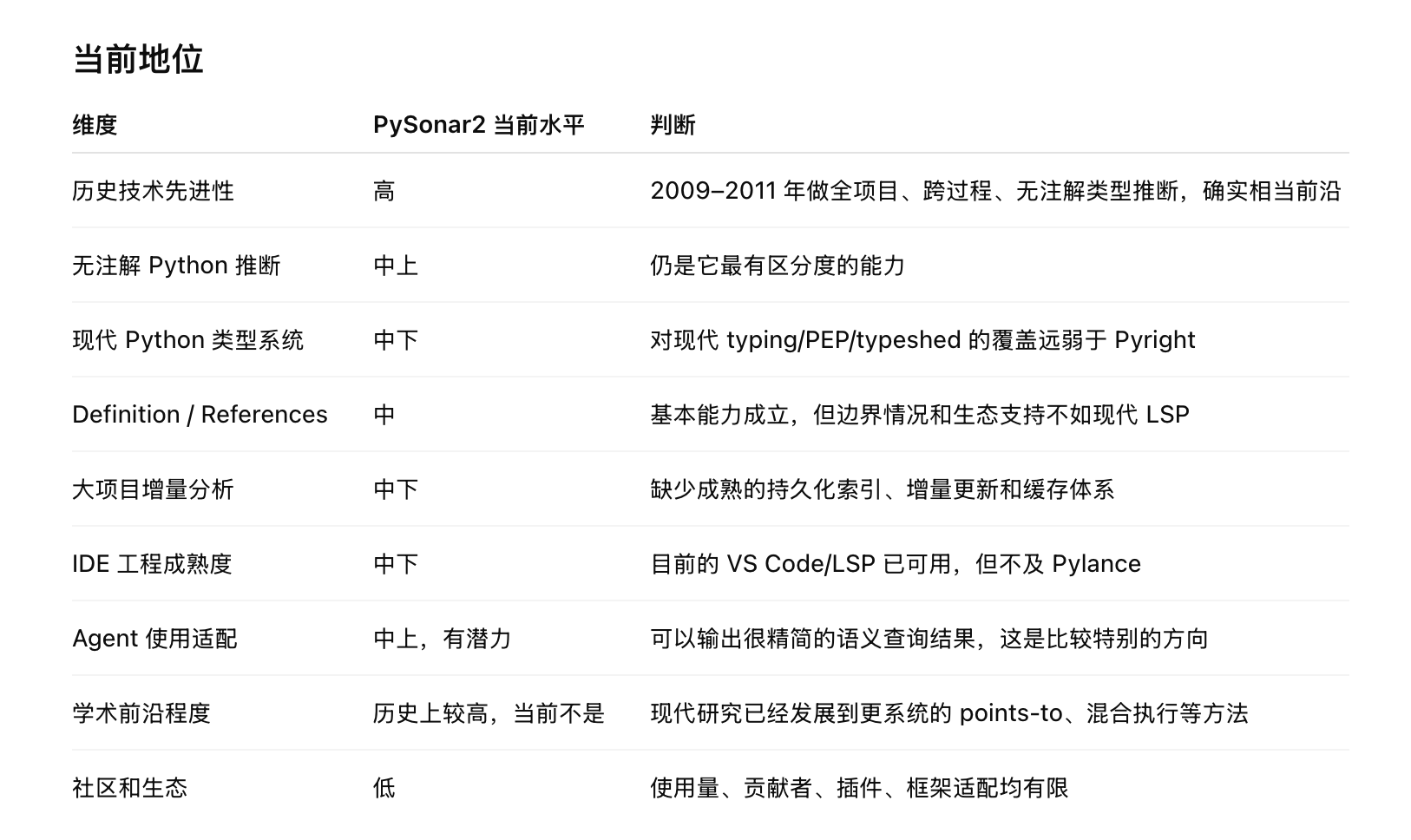
那么 PySonar2 现在是否还具有某些独特的价值呢?答案是有:
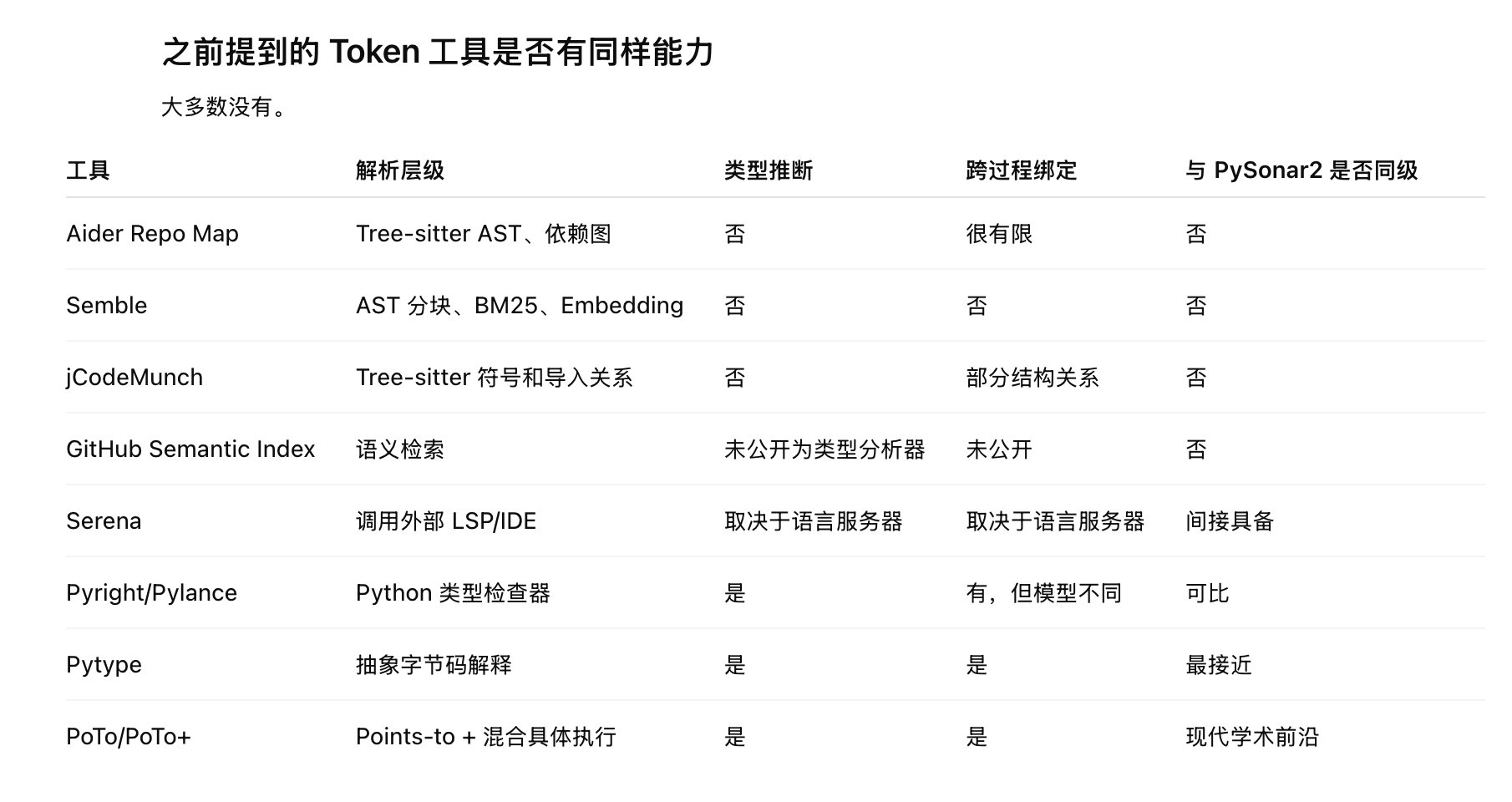
很多同类型的、号称节省 Token 的项目,都是基于关键词匹配、甚至 embedding 的匹配,与 PySonar2 的语义分析不在一个层面。
不过毕竟已经过去了 13 年,PySonar2 已经 13 年没有在学术理论上继续更新,要说 PySonar2 仍然处于世界前沿是不可能的。但是 PySonar2 因为开源、代码轻量、逻辑清晰,在 Agent 适配方面也许会有独特的优势和潜力:
既然针对 Python 项目,PySonar2 可以帮助 AI 节省大量的 Token 消耗,那么其他语言的项目呢?JavaScript 是否可以借鉴同样的思路?以及更多脚本语言?同样的思路,已经不局限于 PySonar2 这个工具了。
比起让 PySonar2 这个古老的项目重新发挥价值,我更在意的事情是:在 AI 时代,还有哪些代码工具是有价值的?
因为人已经不需要写代码了,甚至不需要看代码了。但是 PySonar2 在这个场景下发挥了巨大的作用,让我看到了不一样的希望:
(与此同时,我还在优化另外一个项目:EchoEVM。基于 EchoEVM 的 EVM 解释器底座,让 AI 能够在编写 Solidity 脚本的时候、有能力看到脚本文件字节码级别的执行过程。这种 debug 工具对人类没什么用,但是对于 AI 极其有用,因为人类看不懂字节码、AI 可以)
PySonar2 作为拥有学术级别原理的工具,在人类已经不需要写代码的今天,仍然能够发挥价值、让 AI 节省 Token、给使用者省钱,这是真正意义上的效率工具。
如果你不了解 PySonar2 的背景,分享几篇相关文章可以看一下:
2026-07-28 00:50:05
在 bitcointalk 上看到一个帖子:How to handle weak scripts?
这个帖子说明了一种 Taproot 脚本的漏洞,无需经过签名验证,任何人都可以花费在这个 UTXO 上的余额。在 mempool 浏览器的界面上可以清晰看到,这笔 f460...5bc2 交易转出的一方有一个 unsigned 的标识,这个标识在比特币网络上并不多见:
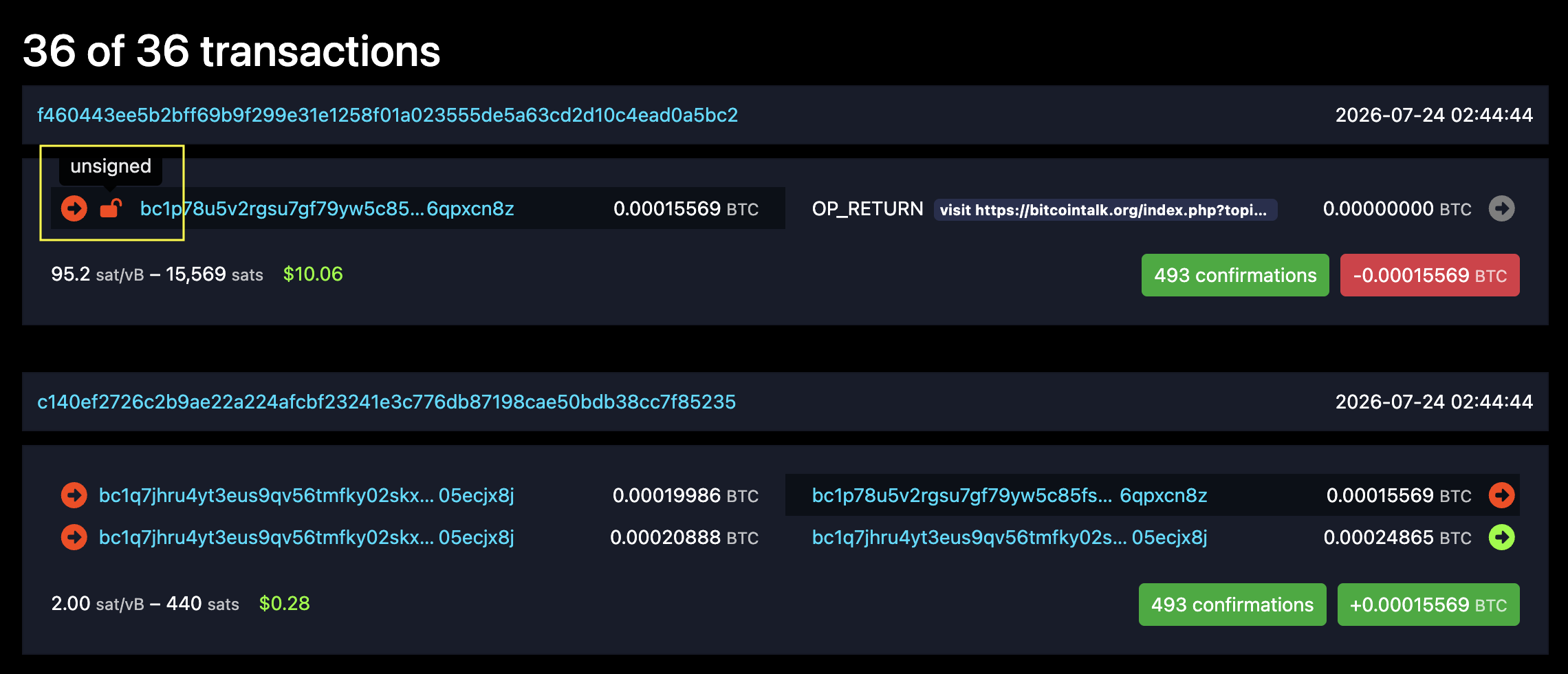
帖子中描述的 Taproot 脚本的逻辑是这样,这也是 f460...5bc2 交易真实执行的脚本过程:
OP_PUSHBYTES_32 fa9b5ec193f735c41b804fc6ace1d28e81a299fc815c0f5009dd2dd7d0293c3bOP_CHECKSIGOP_IFOP_PUSHBYTES_32 ff1275b635cd160914cfe1bc516f521abde0fc8ae3fd92ae01ca16449e4758e9OP_ENDIF可以简化为:
<pubkey A>OP_CHECKSIGOP_IF <pubkey B>OP_ENDIF比特币的 Taproot 是基于栈结构的脚本,理解起来需要绕弯,把这个脚本翻译为 JavaScript 代码的话,大概是这个意思:
function isTrue(...params){ var pubkeyA = params[-1]; params--; if (checkSign(pubkeyA)) { return true; } else { // } return params[-1];}从代码来看,在正常使用流程下,假如输入的参数是 [pubkeyA],那么 checkSign(pubkeyA) 为 true,最终 return true,这个是合理的。
假如输入的参数是 [pubkeyC],那么 checkSign(pubkeyA) 为 false,下面的 else 分支什么都不做,最终 return null,依然不是 true,这个也合理。
这个脚本的漏洞在哪里呢,在于 params 是一个数组,用户未必只输入一个参数。
在漏洞逻辑下,可以输入非预期的参数组合 [true, pubkeyC],那么按照后面的执行流程,当进入 else 分支什么都不做之后,return params[0] 会把 true 给返回出来。
这里面存在几个基础的问题:
所以很简单,这个所谓的脚本漏洞,实际上是作者自己写了不严谨的代码导致的。要注意这里指的不是比特币的作者,仅仅只是比特币的用户。比特币的 Taproot 相当于以太坊的智能合约,任何人都可以写一些脚本规则,来决定钱怎么控制、怎么花。只不过比特币的脚本写起来复杂,而且不是图灵完备,所以很多人忽略了比特币可以自己写脚本这件事情。
很明显这不是一个比特币协议级别的漏洞,比特币的共识只负责按照脚本规则正确执行,而脚本逻辑是否有漏洞,跟协议无关。
而且事实上无论是比特币钱包还是比特币生态的项目,如果依赖于 Taproot 的脚本逻辑,一定会经过审计公司来审核代码,这种低级错误出现在主网上的情况恐怕会非常少。
另外 Taproot 这种脚本设计的隐私性其实很强,我们只能知道比特币地址 bc1p 开头是 Taproot 脚本,0xc0 开头的是当前版本号,但是一个 UTXO 在没有被花费之前,网络上是无法看到脚本具体内容的。而在被花费的那一刻,大概率全部的钱都已经被转走了。一个 P2TR UTXO 被创建的时候,链上只保存这棵树结构的根节点哈希,任何可以解锁 root 的路径都是有效输入,这些有效输入只有在花费的时候,链上才需要根据具体的 leaf 和 key path 去验证。而且即使某一个 leaf 被公开,链上也只能看到其中一个,看不到同一个 root 下的其他 leaf。
比特币从设计之初,就提倡每一笔转账都使用一个新的地址,实际上大多数靠谱的钱包也是这么设计的,这本身就很大程度规避了漏洞脚本被再次利用的风险。
所以无论是从技术上和商业逻辑上,这种漏洞脚本的出现都是极其小概率的个例,完全就是脚本作者自己写错了。主网上存在漏洞脚本的可能性很小。
有没有可能网路上真的存在这种漏洞脚本,不需要验证签名就可以把钱转走的?
先从 bc1p...cn8z 这个例子入手,有几个问题:
这显然不是钱包 App 提供的功能,而且比特币的交易比较麻烦,得把 UTXO 来源的交易和编号都作为参数才能构造出交易。这是一个示例脚本 taproot-script-path-demo.mjs,可以这样来运行:
TXID='0618d93bc4eef77f4b47c4b4b188011f95c7ccb929e6226df2774b88b5d4693d'VOUT='0'INPUT_SATS='15000'DESTINATION='bc1px6jn77jd4tplp94q46svkuutc53wtn24dk34wxp4dfur6tvez89swvlcmj'FEE_SATS='1000'node outputs/taproot-script-path-demo.mjs \ "$TXID" \ "$VOUT" \ "$INPUT_SATS" \ "$DESTINATION" \ "$FEE_SATS"如果你不小心把钱打到了地址 bc1p...cn8z 上,就可以用这个脚本,在没有私钥的情况下,把钱转出来。但是要小心脚本里的 xOnlyKey 和 payload 都是硬编码,如果换一个目标地址,这两个值就不一样了,得用另外的值。那么这个值应该是什么呢?这个值只有在 P2TR 被花费过之后才能知道。
这也就意味着,即使我们知道链上某一个地址有余额、脚本有漏洞,因为不知道整个树结构、拿不到 xOnlyKey 和 payload 的值,我们也无法动这个地址上的钱。从这个角度看,比特币上的资产安全程度还是很高的。
同样有一个示例脚本来干这个事情:audit-taproot-neighborhood.mjs,结果就是,没有。这个作者把全部关联地址的钱都转走了,不存在这种低级漏洞。
这个程序可以扫描整个比特币网络上类似的脚本漏洞:tapscript_weak_finder
扫描逻辑是这样:
0xc0
[01, <empty signatrue>] 的排列组合,处理 0 个参数、1 个参数、2 个参数的情况,一共 12 种01, <empty signatrue>,扩展到小整数和一些常量,比如 02, 03, true, false 等[[data, sigA, sigB]],尝试变换组合,比如 [data, "", sigB]、[data, sigA, ""] 等OP_SUCCESS80的脚本,或者目前规范还没有定义的公钥类型,会记录到数据库当然我会告诉你运行结果。如果你运行了这个开源程序,会得到和我一样的结果和结论。我的启动参数是从区块高度 709632 开始,这是比特币主网启用 Taproot 的高度,到 959701 高度结束,也就是最新的区块高度。
一共扫描了 71037 个区块,扫描了 127119410 笔交易,扫描到 1000061 个 Taproot 地址,其中 427378 个属于当前程序没识别出问题的脚本,12 是有可能有漏洞的弱脚本。
在 12 个有可能有漏洞的脚本中,8 个属于不需要签名的弱脚本,1 个属于始终返回 OP_SUCCESS80 的非漏洞脚本,3 个属于包含扫描程序解释器不支持操作码的非漏洞脚本。
来逐个分析一下扫描到的有可能是 weak script 的交易。最终输出的、未经加工的结果数据在这个文件:result_report.json,可以还原出我下面提到的地址和交易、脚本。
首先扫描到的这个 taproot 地址出现在 758737 区块:bc1p...2354
这个地址出现了 2 笔异常交易:
先说结论,这 2 笔交易是非常专业的开发者在演示比特币主网的 BIP342 规范而发起的。
第一笔交易 00c1...c40e 包含 2 个 witness 参数,是用来测试交易的。
第二笔交易 73be...2a7e 就离谱了,包含 500001 个 witness 参数,OP_RETURN 的内容解码后得到 “you’ll run cln. and you’ll be happy.” 的文本。
TapScript 的规定是,初始栈最多只能有 1000 个元素,但是第二笔交易出现了 500001 个元素而且交易成功了,是因为 BIP342 规范定义,如果脚本中出现 OP_SUCCESSx,则无论脚本包含多少元素,一律视作成功。因为 OP_SUCCESSx 属于目前还未明确支持、但是预留给未来有可能使用的操作码,所以 BIP342 这样来规定了。
很明显第二笔交易就是用来演示这种状况的。也因为这笔交易包含大量参数,花费了超过 700 美元的手续费。
其次扫描到的地址出现在 771740 区块;
这 3 个脚本对应的交易包含了 OP_CHECKSEQUENCEVERIFY 操作码,扫描程序没有处理这个操作码,所以认为是异常给挑出来了。OP_CHECKSEQUENCEVERIFY 操作码的含义是,必须等待多少个区块,才可以使用地址里的资金。属于是典型的 TimeLock 脚本。
在区块高度 775722,扫描到了这个地址:bc1p...amq6
这是一个真正有逻辑漏洞的脚本,不需要任何签名就可以转移资金。这个脚本明显是一个 Ordinals 数据结构的封装,可能是某个开发者在尝试自己开发类似 Ordinals 的协议。当然这个地址上的钱当时就被全部转走了,现在没有余额。
另外还有几个地址,数量不多,大多数是 Ordinals 的测试交易,就不一一详细解释了:
bc1p...3hu0,区块高度 777335,一个 Ordinals PNG 图片bc1p...xgdr,区块高度 777617,一个加法运算,没有校验签名bc1p...gq7d,区块高度 777681,一个测试脚本,固定返回 truebc1p...9x3t,一个 Ordinals 的 Hello World 脚本已经扫描了从 Taproot 脚本功能上线到至今为止全部的区块和交易,真的出现了少量 How to handle weak scripts? 中描述的类似的脚本漏洞,不过那些地址上都已经没有余额了。
这件事情另外的启发:
2026-07-10 19:53:28
现在做 Crypto 方向的项目,一般会选择 Privy.io 或 Turnkey 来作为钱包的基础设施提供商。这些钱包设施提供了注册登录方面的集成,可以用传统方式邮箱、Google 登录,也可以用 web3 一点的方式,比如 MetaMask 钱包或者 OKX 钱包登录。更重要的是这些钱包设施解决了钱包安全的问题,允许给用户创建 embedded wallet,如果不使用这些钱包服务,项目方需要自己在服务器上保存用户的私钥,这是很危险的,尤其是对于中小团队来说,安全问题是很沉重的负担。Privy 或者 Turnkey 的解决方案是,私钥由他们来保管,储存在 TEE 一类的加密硬件中,项目方只需要通过 API 来访问和使用钱包。
至于 Privy 还是 Turnkey 的取舍问题,比如我们经常在看的 Kreo、PolyCop、polymtrade 等项目都在用 Privy。这些项目列表都在 Polymarket Builder 榜单 上。Polymarket 的这个 Builder 榜单上,列出了每一个 Polymarket 生态的项目方交易量排名。GMGN 也用的 Privy。
用 Turnkey 的项目也有,比如 Axiom、alchemy 等。我们当时用了 Turnkey。一开始是因为 Turnkey 从定位上对自动化运行的 Trading Bot 更加友善,Privy 定位上有很重的对前端界面 SDK 的依赖。后来又发现了一个 Privy 和 Turnkey 比较大的区别:是否支持 Telegram 注册登录。
Privy 支持 TG 登录,Turnkey 不支持,为什么呢?
因为 TG 没有像 Google 那样成熟的 OAuth 体系,TG 账号本身无法像 email 或者 wallet 一样给 Privy/Turnkey 一个 identity provider。Privy 针对这种场景做了简化,你用 TG 登录,登录后 Privy 代替你去通过 API 请求钱包的操作,实际上此时 Privy 后端 “就是你”,假如 Privy 后端的服务器被黑了,你的钱包权限会完全暴露在黑客手里。而 Turnkey 比较生硬,无法提供 identity provider,就不能让你操作钱包,Turnkey 的后端不愿意代替用户承担这种权限风险。
所以这是我们发现的 Privy 和 Turnkey 之间比较大的场景支持程度上的差异。如果想要用 Turnkey 并且支持 TG 登录,就得专门做一个 TG Miniapp,登录的时候唤起 Miniapp 来完成。
Polymarket 上的订单系统叫 CLOB,下单等行为都是在和 CLOB API 交互。4月28日,Polymarket 正式启用 CLOB V2。对于我们这种下游项目来说,最大的变动是需要换掉一些合约地址信息,比如 Copy Trading 功能需要扫描链上交易,以前监听的是 V1 版本的合约,迁移后监听的是 V2 版本的合约。此外如果下游不适配也是可以的,因为大体上兼容旧版本的订单参数。
而 CLOB V2 也引入了 FAK、FOK 等 Market Order 在使用的参数,这些参数直到一个多月以后我才发现它们的差异。因为在 V1 版本订单如果没有立即成交,会把没成交的部分自动挂单为 Limit Order,但同时又要求 Limit Order 的 shares 数量必须大于 5。所以用户有时会遇到一个奇怪的错误,为什么订单 shares 数量必须最小是 5?又为什么有时候会提醒最小订单金额是 1 美元?为什么有时候能成功有时候失败了,最小金额不是固定的?用上 FAK 参数的话倒是没有这种旧的问题了。
5月4日,Polymarket 发公告说启用新的 Deposit Wallet,不再使用旧版本的 Safe wallet。这是一个 breaking change,所有旧的用户依然兼容,但是新的尤其是通过 api 操作的钱包,都将使用新的 Deposit Wallet,也就是说下游项目必须兼容。
这个时间点非常微妙,因为我们原本计划项目 Beta 版本上线的日期是 5月5日。也因此当时连续两三天我紧赶慢赶去适配这个 Deposit Wallet 的迁移。这本身不是一件特别难的事情,但是由于突然升级带来的措手不及,以及上线的 delay,还是有一点点压力。
至于集成过程中遇到的唯一挫折,是 Polymarket 的 Migration 文档里没有写新的 Deposit Wallet Implementation 地址。在用 Factory 合约创建钱包的时候,需要一个 implement 合约作为参数,不同的 implement 合约出来的钱包地址是完全不一样的。而重点不只是我们用哪个地址,而是 Polymarket 的 Relayer api 用哪个,因为在新的这种 Deposit Wallet 模式下,所有的钱包操作都会通过官方的 Relayer api 了。以前用的 Safe wallet,其实我们可以自己直接去链上调合约的。Polymarket 的这个改动,反而让钱包体系更加不那么去中心化。至于正确的 implement 的值,则是需要直接从 Polymarket 发布的 SDK 里去读。而且当时还遇到个小坑就是 Polymarket 发布的不同 SDK 之间用的 implement 地址还不一样。不是同一个 SDK 不同版本,而是那种不同 SDK,比如 client-sdk, server-sdk 这种。当时 Discord 群里遇到这个集成问题的开发者非常多。
刚才提到新的 Deposit Wallet 必须要通过 Polymarket 官方的 Relayer API。我们在迁移后并且项目上线一段时间、做活动,紧接着就遇到了另一个坑:Unverified 状态的 Builder API 只有每天 100次的请求额度。
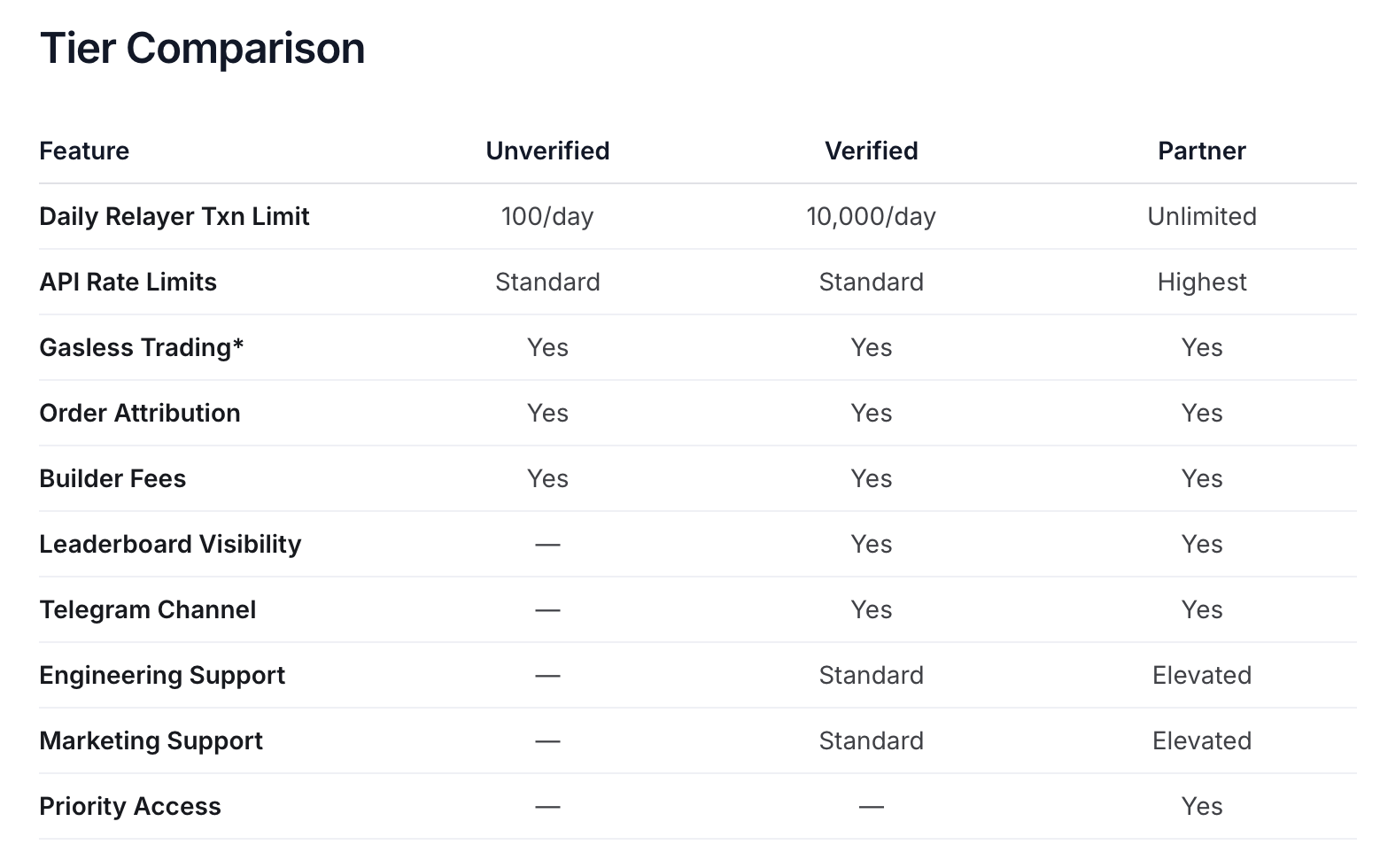
看出 Polymarket 的阴险之处了吧,先是要求所有新用户都用 Deposit Wallet,而新的 Deposit Wallet 自然必须通过 Relayer API 来操作钱包,再然后你会发现,Relayer API 的请求是有额度限制的!如果是原本的 Safe wallet 可以直接链上操作绕过 Polymarket 的 API 额度限制。现在不行了。
这个 Relayer API,每次创建新的钱包都要用、每一次从钱包里 withdraw 钱要用,所以这是一个高频率会用到的接口。
针对这个限制的缓兵之计是,Polymarket 默认用 Builder API 来对 Relayer API 授权,但是 Relayer API 却没有要求 Builder API 具体是哪一个。所以我注册了 10个账号、每一个账号都创建了 builder api,配置到服务器里,用来暂时缓解 relayer api 的额度限制问题。每个账号每天100次请求额度,也就意味着 10 个账号一天有 1000 次额度。因为 verified 从提交到审核需要两到四周的时间,是一个很长的周期。
当然最终还是通过了 Verified,现在我们的项目已经出现在 Polymarket Builder 榜单上,并且状态是 Verified。
7月6日,又是 Deposit Wallet 的问题。我们发现了一个很严重的 bug,自从 7月1日以来注册的全部用户,创建钱包都失败了!而因为用户反馈少,出问题很多天我们才发现这个问题。也就是说,新注册的用户,注册完之后如果充值,会把钱充值到错误的地址上。
为什么会出现这个 bug 呢,因为 7月1日,Polymarket 直接修改了创建钱包的逻辑,用上了 beacon 的方式去创建代理钱包,而且连公告都没发,直接改变 API 接口的行为。这种改动,是需要下游项目方主动适配的。
我们也有错误,我们的错误之处就在于没能及时发现这种异常,并且在程序前后端加上足够的保护性、防御措施。针对这次事故所有用户充值钱到错误地址的,全部金额都赔了,好在金额不大。
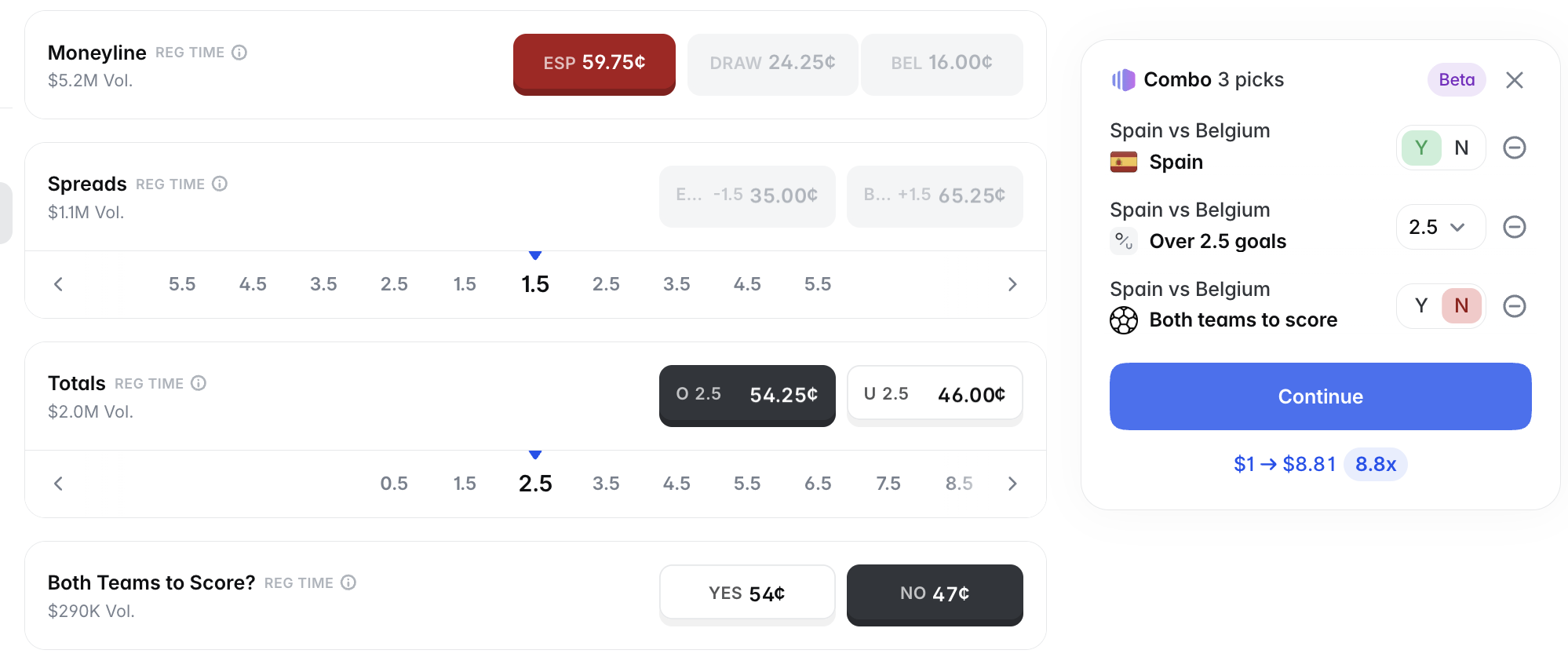
Polymarket 针对世界杯的市场,新出了一个叫 combos 的功能。我们就开始评估是否可以接入这个 combos 的功能。结果就是,从 combos 文档 上看,API 只提供了针对做市商提交 quote 的接口,没有提供作为普通用户作为 taker 角色去下单的接口。
Polymarket 从 6月4日开始运作 combos 的接口,看起来也是在辛苦 build 中。
7月10日,用户反馈遇到了订单交易失败的问题。经过排查后发现是订单的 tick size 有了变化,所有的世界杯市场都支持 0.0025 (0.25¢) 级别精度的 tick size。在此之前 tick size 只有固定 4 种,这个 0.25¢ 属于第 5 种(枚举类型)。
同样的,这个变动其实 Polymarket 早在 7月2日就上线了,但是我们直到 7月10日才发现 bug。
所以你看到了,一直以来,我们都在不断的追随 Polymarket 的脚步,一直不断的响应 Polymarket 的功能更新和变化。
也因此,在构建项目的过程中,我们也开始逐渐意识到这样的项目误区:再做一个官网。
如果定位是 “再做一个官网”,项目方就会陷入非常被动的处境。而且 Polymarket 家大业大,官网 UI 做的也好,有功能都是第一时间上官网,再者官网自家的服务器,下单速度也快。我们的订单速度再快也不可能快过 Polymarket 官网。
这是一件尴尬的事情,如果想要做的比官网使用体验好,客观上难度是很高的。Polymarket 不是 memecoins,一般 memecoins 没有官网至少不会有官方钱包、官方 DEX,但是 Polymarket 有官网、有官方解决方案。Polymarket Builder 的定位,从来都不是说,Polymarket 是一个开放的去中心化协议,大家都来建设项目去玩。
与之相反,Polymarket 最近的功能更新上也越来越往中心化的方向走,定位更像是中心化交易所,比如 Binance 这种,Polymarket API,就是 Binance API。做 Polymarket 生态的项目,就有点像是做 Binance 的 Trading Bot 一类事情。
2026-06-29 14:24:59
团队的项目在 Go to Market 环节遇到了困难,所以找了有经验的 BD(商务拓展)来提供指导意见。对方给出的策略是:每个人都去 DM KOL 谈合作。
具体做法是直接在 X 上找到相关领域的 KOL,然后跟对方聊天、套近乎、问需求、谈合作。
这个策略能够达到的目的是(转述):
这个策略是 BD 给出的、在他的理解中最为可行的、用户转化率、留存率最高的方案。
说实话我没有 GTM 的经验,所以我也在不断反思,这个策略好不好、对不对、为什么专业的有经验的 BD 唯一认可的是这个策略。当然我早就想明白了结论,只是现在把这个结论写出来。我来跟你解释一下为什么。
我的结论是:这个策略一定是对的,但未必是有结果的。
很简单的道理,如果一个学生问老师,怎么提高学习成绩?老师会说,课前预习、上课好好听讲做笔记、课后认真完成作业、有不会的题要请教同学和老师。这一套学习方面的方法论,亘古不变。
但是很明显,我们都知道,同一个班级、同样的老师、同样的课本、同样的作业,学生的成绩就是天差地别。
为什么呢,因为策略方向是对的,但是具体到执行上每个学生都不一样,每个人的行为差异会被放大。
所以只要策略方向足够大、足够宽泛,策略就一定 “正确”。只是正确未必有用,因为策略需要具体的人来执行,而每一个人都是有差异的,只要不能机械化到代码程序可以重复执行,结果就肯定有差异。
也因此,你学习成绩不好不能怪老师吧?怎么有的学生人家就是成绩好呢?老师讲的东西都一样,你不能说老师讲的道理不对吧?
李笑来在 2022 年之后就不再做投资了,专职做家庭教育、写书、卖课、讲课。我喜欢李笑来的《财富自由之路》和《韭菜的自我修养》两本书,现在也时不时留意李笑来的新书和课程。
他最近几年的观点,非常明显有一个共同点,就是非常 “基础”、非常 “简单”,简单到像跟 6 岁小孩子讲道理一样,比如我们跟孩子说要诚实、勇敢、善良等,李笑来讲的观点,也都类似这种,比如 “生产是财富的来源”、“要学会复利”、“知识是可以迁移的、只要有时间就学习”、“自我暗示非常有力量” 等等。
他讲的这些内容,感觉都简单到 “是个人知道”,他讲的每一点,简单到 “每一个普通人都可以做到”。
然而事实上,世界上只有一个李笑来,真正财富自由的只有李笑来。他的课程并没能把那些 “真理” 一样的道理教给别人、让别人变得富有。
我也经常反思这个问题,为什么呢,为什么李笑来这样经历丰富的人,最终总结出的各种道理,反而异常朴实、基础、简单?我相信他不是刻意隐瞒,而是真心实意相信自己的那套东西。
所以现在直接能串联起来了。就跟学生问老师成绩怎么变好一样。很多人问李笑来,怎么变有钱,怎么变富有?然后李笑来告诉你,要坚持,要努力,要学习,要产出,要……
明白这里面的漏洞了吗?策略方向一定对,具体执行因人而异。还是那句话,只要策略方向足够大、足够宽泛,策略就一定 “正确”。
回到 DM KOL 这个策略,我来拆解两个问题:
很大。从一开始转述的、期望达到的 3 个效果来看,其实包含了市场调研、功能反馈、寻找合作 3 种目的。对于大公司来说这可能是 3 件事情,只是小团队就直接聚合为一件事情、全都放在 “DM KOL” 这句话里了。
只看这几个词可能不够直观,具体来说,我们期望问 KOL:
当然前提是对方愿意回信息。因为实际上大多数 KOL 不会回消息,或者上来就报价。而这个 DM KOL 策略的重点,实际上在于建立关系、跟人搭讪,先建立联系、然后表述出目的。
从这个描述能听出问题所在不。这就全部依赖于个人的社交能力了,而且是通过网络打字社交。BD 也跟我们说,要持续骚扰对方到骂你为止。
也很差。不过我要分享的,是我们团队面对的最大问题,以及为什么效果不好:因为执行成本高。
很多交易所,长期招聘 BD、而且 BD 没有无责底薪、说开除就开除,随便去任何一个招聘群,都能看到类似的吐槽。
很多项目方,在小红书上招聘实习生,一个月 3000块人民币,实习生就愿意辛辛苦苦任劳任怨干一个月,天天在 X 上刷流量、发广告。
而 DM KOL 的策略,属于周期长、反馈慢的策略,可能 DM 1000 个 KOL,其中能有 10 个给出反馈、有 1 个能达成合作。这还得是你花心思认真跟对方接触的情况下。
如果对这个过程没有实际感受,可以回想一下找工作的过程。比如我找工作的频率就很高,深刻理解这种状态。在找工作的时候,可能联系几百个 HR,然后面试几十家公司,最终找到一份合适的工作。
对于 BD 或者销售人员来说,DM KOL 就是他们的工作呀,他们不但能用整天的时间来干这件事情,而且有足够的时间去思考、总结相关的经验。
至于我所在的团队,所有成员中,目测时间成本没有比我低的。每个人都戴着 “金手铐”。毕竟不是专业的 BD 人员,也都有自己职业方向的事情需要做,能够用于 DM 的时间很少,更重要的是,DM 是一件反馈周期长、不确定性很高的事情。花一整天的时间去 DM,可能都什么反馈都不会得到。而在自己熟悉的道路上,总是能有一些结果的。
所以让成员兼职去 DM KOL 这件事情,如果想要得到可观的结果,难度不亚于先让成员做一次职业转型,然后再统一做长时间刻苦的执行后,才能有结果。
如果不那样,要么有人能认真把这件事情做好,要么什么都做不好。我个人是不相信,有人能顺带做一件事情,不用心也不总结,就能比专业的人做出更好的效果。
毕竟哪怕是专业的 BD 团队,同样完全正确的策略下,10 个 BD 成员里得到的结果想必也天差地别,有的人被开除了,有的人成为金牌员工了。这种事情谁说得准呢。
所以你应该看出来了,我写这些的目的并不是在吐槽,而是在分析和分享。
重要的是我明白了一个道理:为什么看起来正确的策略,却得不到好的结果?
不知道我讲清楚了吗?
2026-06-18 21:56:27
有一个给 AI Agent 设计的看板工具叫 Multica,理念是本地部署,本地运行的 AI 比如 Codex、Claude Code、Antigravity 等都以 Agent 形式接入看板,然后你就可以给 AI Agent 分配任务、管理项目进度等。
看到这个产品后有感而发。
对于这个产品本身,怎么理解这个事情呢,我觉得可以这样理解:
首先看板工具是指类似 Jira、Linear、GitHub Project、Notion 这些知名的项目管理工具。
然后先不说 AI,就说人,假如就是一些真实的人、真实的员工、真实的技术团队。有能力通过任务面板把技术团队管理明白的 leader,包括任务怎么分配、任务时长、任务难度的定义、结果怎么验收等等。对于能处理好任务、把项目进度安排的井井有条的 leader,这个 AI Agent 看板工具才有意义。
也就是说,对于已经具备能力管理好 “人” 的 leader 型人,他才需要把员工换成 AI,然后在看板工具上给 AI 分配任务这种产品。
AI 相对于人类,有优点也有弱点。优点就是效率高,你给它明确的任务,它能执行的很好。但是 AI 的弱点在于,不需要主动汇报工作、没有情绪,也不需要承担责任。如果 AI 把你的数据库删了,或者强硬汇报错误的内容、或者突然降智听不懂人话了,你能拿他怎么办呢?骂它?扣它工资?给它讲道理、画大饼让它内疚?
所以当你作为一个能管理好员工或者下属的 leader,试图通过 AI 降本增效的时候,这个 AI Agent 看板工具才能发挥作用。而与此同时,这个 leader 也得好好掂量一下能不能用好 AI。
下一个问题,AI 能提高效率是显而易见的,但是 AI 真的能降低成本吗?用 Codex 日常写代码一天三四个小时,需要开每个月 100 美元的套餐。如果更高强度使用,大概一天六七个小时运行时长的话,每个月 200 美元的套餐是必需的。
同时考虑到 Codex 有周限额和日限额,200 美元的套餐跑满肯定不够,算作一个 AI Agent 300 美元吧。然后看板工具的意义当然在于,多个 Agent 同时运行。如果只需要一个,在 Codex 里用就行,没有必要看板。
那么按照小型技术团队 3 个人的规模来算,AI Agent 的费用算作一个月 1000 美元吧。
也就是说,原本也许 1 leader + 2 senior + 1 junior 配置的技术团队,可以精简为 1 leader + 2 Codex + 1 Antigravity。要只算订阅费的话,是不是真的节省了不少成本?
不过还要考虑一个小问题,人类队伍中 leader 不需要独自承担责任,只需要验收就行。但是在 Agent 的配置形式下,leader 必然是更忙更累的,因为需要 review 所有 AI 的工作结果、手动打字(甚至不能语音和会议)来同步给 AI 工作任务、需要把任务边界和规则定义的非常清楚。相信做过技术的话就会理解,看似用 AI 代替了大量人力,但同时极大增加了 leader 的负荷。这种推演方式下 leader 一定是忙不过来的。
所以可以退一步,改为 2 leader + 2 Codex + 2 Antigravity 的模式,也就是 (1 leader + 1 Codex + 1 Antigravity)*2 的模式。这样的话 leader(或者工程师)的工作负荷勉强合理、工作任务能够合理完成。这种模式下,成本变成了多少呢?
继续下一个问题,刚才的讨论一直有一个前提,就是这个 leader 本身有能力管理好 “人”,在此基础上去使用 AI。那么如果本身这个 leader(工程师)不具备管理人类的能力呢?
结合之前提到的 AI 的弱点,那么工作一定是一团糟糕的,毫无疑问。难道我们或者你,在过往的工作经历中没有遇到过管理能力糟糕的 leader 吗?设想他们管理一堆不需要承担责任的 AI Agent,真的能让工作或者项目完成的更好吗?
总的来说,项目的任务看板工具实际上不是技术问题而是管理问题。有能力用好看板的人没那么需要 AI,没有能力用好看板的人也用不好 AI。
2026-06-04 17:02:57
6月1日,GitHub Copilot 换成了根据使用量计费的模式。按照我原本的使用习惯,新的计费模式下,一个月至少得花 800 美元才够用,所以不得不寻找更便宜的套餐。这也就导致最近两三天,除了关心工作内容本身,我还需要花费大量时间和精力去体验 Antigravity、CodexX 等工具和模型,以及解决不同工具之间切换带来的上下文摩擦。
当然我还是坚持一贯的偏见:不用 Claude Code 的工具和模型。因为 Claude Code 的模型太过听话,出现路灯效应的现象比较严重。
由此联想到的问题是,自从有了 AI,我们开始关心的话题变成了:
而 AI 出现以前,我们关心的问题是:
在 AI 出现以前,有个人站出来说:
那么 AI 出现以后,会不会有个人站出来说:
会不会有这样的人出现呢?🐶
其实我有一个更深层次的焦虑:
AI 时代,我们曾经学的那些编程语言、原理,都是手工艺时代的知识和技能,是不是已经过期、过时、不重要了?你可以说它本质上重要,但是事实上确实 AI 抹平了大多数程序员的能力。
或者我换个问题,AI 时代,理解 Lambda 演算还重要吗?把图灵放到现代,他肯定不会写代码,调 API 的能力和普通程序员用 AI 写出来的差不了多少。你觉得这个观点能带来什么启发?