2026-05-26 10:40:32
一转眼,SwitchHosts 已经存在了 15 年了,距离上一个大版本更新也过去 5 年了。最近抽空把 SwitchHosts 升级到了 5.0,最大的变化是将底层从 Electron 换成了 Tauri,安装包的体积小了很多。
这个过程的大部分工作都是用 AI 完成的,在这儿记录一下。
这次升级的主要动机是想解决 SwitchHosts 体积过大的问题。
之前的版本是基于 Electron 实现的,打包后安装文件有大几十兆,且随着 Electron 版本的提升,这个体积还在不断变大,因为它内部依赖的 Chromium 等在不断变大。
Electron 是一个很好的框架,我还有一些其他项目也是基于 Electron 实现的,我很喜欢它。但 SwitchHosts 只是一个小工具,功能也很简单,几十兆的安装包对它来说有点重了,在 GitHub 的 issues 中也经常有人诟病这一点。
在这个版本之前我已经有很长一段时间没有对 SwitchHosts 做实质性的更新,原因之一就是考虑到后续可能要换架构,因此不太想再在原来的代码上做太多改动。
还有一个升级的动机则有点神奇:去年年底,SwitchHosts 收到了一笔来自 Warp 的赞助。虽然金额不多,却也是一个意外之喜了。
既然还有人在关注和使用 SwitchHosts,我想我也应该继续完善它,于是,就有了 v5 这个版本。
SwitchHosts 需要支持 Windows、macOS、Linux 三个平台,我没有足够的精力同时维护三套代码,因此首选还是跨平台技术或者框架。
考虑到要尽可能复用之前的 UI,技术方案上还是需要选择 WebView 界面或类似的方案,因此最终可用的选项并不是太多,其中最为成熟的就是 Tauri 了。
我也考察过一些其他方案,其中 Wails 看起来不错,也有一些成功案例,不过它的生态似乎还是小了一些,同时它的 v3 还处在 Alpha 阶段,用在正式产品中有一定风险,如果我先用 v2 开发,可能不久之后又要再做一次迁移升级到 v3。
新出现的 Electrobun 也很有吸引力,它最大的优点是类似 Electron 可以使用 JS/TS 来写后台代码,不像 Tauri/Wails 那样需要使用 Rust/Go。不过它才发布没多久,看评价可能还有不少奇怪的 bug 或适配问题。
Tauri 当然也不完美,对前端来说最大的难点是一旦深入或者要做什么定制就要和 Rust 打交道,它打包体积小的代价是不同平台上可能会有不同的表现,推特上就有不少使用 Tauri 遇到大坑然后不得不放弃的经历分享。
不过,考虑到 SwitchHosts 只是一个功能比较简单的小工具,不会涉及太多复杂的平台相关的操作,在考察一圈之后,我最终还是选择了 Tauri。
这次升级,大致上有两个阶段,分别是界面升级和架构升级。
界面升级
在投入 Tauri 之前,我先发了一个 v4.3.0 版,这个版本仍然是 Electron 架构,唯一的目标是先把 UI 框架从 Chakra 升级到 Mantine,主要原因是我在其他项目中大量使用 Mantine,对它更熟悉,也更喜欢它的设计风格。
架构升级
第二阶段则是重头戏,从 Electron 迁移到 Tauri。
迁移的工作基本都是由 AI (Claude Opus 4.6/4.7 + GPT-5.5)完成的,在动手之前我和 AI 聊了很久,先让它理解这个项目,然后评估迁移到 Tauri 的可行性,以及可能会遇到什么问题。
大体上的方案就是界面部分基本不动,但原本 Electron 的 main 进程的逻辑迁移到 Rust 实现。虽然理论上大部分工作可以放到渲染进程中用 JS/TS 完成,后台只负责基础的数据读写等工作以尽量避免写 Rust,但有 AI 的帮助,我还是选择了把所有后台逻辑(原 main 进程的逻辑)转为了 Rust。
当把所有能想到的问题都考虑到,确认迁移能顺利完成之后,我再让 AI 根据结论,制定一个详细的迁移计划,包括分成几个步骤,每步骤要做什么,验收标准是什么,然后将这些步骤保存为多个 Markdown 文档。
接着,我人工检查了这些计划文档,继续向 AI 提问、修改,直到我自己看不出明显问题,然后交给 AI,让 AI 自己反复审核这些计划文档,寻找可能的风险点以及没有考虑周全的地方,直到 Claude Opus 基本没有发现问题,又让 GPT 再检查了几遍,确保没有明显的疏漏。
计划确定后,就是执行的步骤了。这个过程很简单,让 AI 读取计划文档,一步一步地执行,每完成一个步骤,就将进展写入一个专门的 progress.md 文件,这样一方面方便自己随时检查,另一方面也是为了在 AI 流程中断或者新开对话的时候能快速继续工作。
大概是前期计划比较充分,加上现在 AI 确实已经足够智能,迁移工作大体上很顺利,断断续续地搞了几天,核心迁移就基本完成,新的 Tauri 版能跑起来了。
再接下来,就是一些琐碎的工作,各种细节的处理,新版本 UI 的改造,一些小功能的调整,以及反复检查是否存在 bug 或潜在问题。相对于迁移来说这部分的难度小了很多,但耗时却更长一些。
最终,Tauri 版打包后的安装文件只有数兆,其中最小的 Windows 版只有 2.7M,较大的 macOS 通用版也不过 7.6M,体积是 Electron 版的几十分之一。
不过,在运行的时候,Tauri 版仍然会占用一百至数百兆的内存,比 Electron 版略少一些,但不像安装包那样有数量级的变化。这些内存基本上是由 WebView 进程使用的,因为 Tauri 的界面本质上是 Web 页面,除非彻底换成原生方案,不然大概没有特别好的办法来进一步降低内存占用。
现在从体积上来说 SwitchHosts 是一个小工具了。后续我会在保持轻量的前提下,继续完善它。
最近几年 AI 的发展可谓日新月异,即使是在一两年之前,我也无法想象仅靠 Vibe Coding 的方式就能完成如此复杂的工作。
这个迁移很复杂,工作量也很大,且我对 Rust 并不熟悉,如果没有 AI 的帮助,我不会有勇气采用这么激进的迁移方案,即使采用,耗时可能也会是现在的数倍甚至十倍。AI 已经深刻改变了程序员的工作方式。
使用 AI 进行复杂工作是可能的,但要注意先制定好详细的计划,并将这些计划按阶段写成文档,然后让 AI 一步一步地执行。因为 AI 的上下文窗口大小有限,如果不将计划写下来就直接开始,AI 很可能执行到后面就忘了前面。
最后,喜欢各位新老用户喜欢 SwitchHosts 的新版本。❤️
2026-05-12 11:24:59
自从 2010 年注册了域名 oldj.net 并架设了这个博客,一转眼已经 16 年了,这么长的时间足够发生很多事,比如杨过和小龙女都已经再次重逢了,本站也经历过了 N 次重构甚至推倒重来。最近,在 AI 的帮助之下,我重写了站点的后台,并决定将这个博客系统开源。
这个博客最早的版本是使用 Django 写的,后台使用了 Django 自带的 admin,前台则使用 Django 的模板输出 HTML。
一段时间之后,我有点懒得继续改进,便迁移到了 WordPress。不得不说,WordPress 的功能非常完善,插件也很多,使用起来非常方便。
再后来,我担心自己维护的 WordPress 有安全问题,便一度将站点迁移到了 WordPress.com 官方服务。
不过,又一段时间后,我发现官方服务有不少限制,比如想在文章中插入数学公式需要升级高级会员,成本实在有点高,加上官方服务位于海外,访问总是有一点慢,于是又迁回了自已部署的 WordPress。
但很快,我发现使用 WordPress 时,如果启用了某些功能或者某些插件,站点仍然需要从海外下载文件,整个博客的访问速度也因此被拖慢,于是又起了自建的心思,花了一些时间,用 egg.js 重写了博客系统。
不过 egg.js 本质上来说仍是上一代框架,或者说是基于后端视角开发的框架,它很适合写后台服务或者传统网站,但对 React 生态的支持则几乎没有。此时,React 等前端框架的边界不断拓展,除了写前端代码,还出现了 Next.js 这样的框架,让它能在服务端渲染 React 组件,解决了之前 React 站点对搜索引擎不友好的问题。
于是,我又开始折腾,用 Next.js 重写了这个博客站点。但这次我只用 Next.js 写了博客的前台页面,后台则改为继续使用 Django,Next.js 通过 API 向 Django 读取数据并渲染。
随着时间的流逝,我又逐渐厌倦了在 Django Admin 中写博客的体验,一直计划着再次改进这个博客,只是一直没抽出时间。
转眼到了 2026 年,AI 的发展如火如荼,Codex、Claude 等模型在写代码方面的表现已经非常出色,也深刻地改变了我日常写代码的方式。我决定花一些时间,在 AI 的帮助下完成这个博客系统后台的改造。
于是,就有了现在这个博客系统,我叫它 Publa(读音:/ˈpʌb.la/,帕布啦)。

Publa 不是一个大而全的博客系统,它的目标用户是个人或小团队。在设计和开发过程中,我一直秉承着以下设计理念:
轻量
不要做得太重太复杂,要让部署尽可能简单,比如可以直接在 Vercel 上部署,或者只需要一个 Docker 文件就能部署。
动态
现在有很多静态博客系统,它们使用 Markdown 编写内容,最后生成静态文件并发布上线。
这些博客系统都很不错,且因为是纯静态,运行和维护的成本极低。但缺点也在于纯静态,比如作为静态站点,它们天然不支持评论,如果要让访客发布评论,通常还需要使用第三方工具,无论是体验还是数据,都比较割裂。
如果说评论还能用第三方工具搞定,另外一些比如定时发布、历史记录、站内搜索等等功能,静态博客系统就基本没有办法了。
我希望这个新的博客系统自身就能支持评论、留言、定时发布、站内搜索等功能,因此做成动态便是更好的选择。
易于自定义
Publa 内置了浅色和深色两个主题,同时支持自建主题,或者添加自定义 CSS。
同时,在后台设置中,还开放了自定义 HTML 片断的功能,支持在 <head>末尾、 <body> 开头或末尾等位置插入自定义 HTML。
因此,理论上来说,你可以根据偏好,自定义 Publa 博客前台页面的所有外观样式。
易于迁移
Publa 博客的数据可以一键导出为 JSON 文件,你也可以根据这个格式规范,将其他博客的内容转为 JSON 并导入 Publa。
这个导出功能,也可以用作站点的数据备份。
所见即所得编辑器
Markdown 是一项伟大的技术,我也用 Markdown 写了多年的博客和各类文档。不过,当我开始编写 Publa 后台时,我还是添加了一个基于 TipTap 的所见即所得编辑器。我已经用这个编辑器写了几篇文章,目前感觉良好,尤其是在要插入图片等场景,所见即所得编辑器会更加直观易用。
当然,如果你偏好手写 Markdown,或者想发布已经用 Markdown 格式写好的内容,Publa 后台也支持直接输入 Markdown。
顺便,Publa 的编辑器支持内容自动保存,写作的时候,每隔 5 秒会将编辑器中的内容保存到 localStorage,每隔 30 秒会自动将内容保存到云端草稿,如果连续三次自动保存失败(比如网络中断)会在顶部显示通知;同时,后台还会定期为变化的内容保存历史版本,后续如有需要可随时查看或恢复到之前的版本。基本上,你可以放心地在 Publa 后台撰写文章,而不用担心内容丢失。
支持添加自定义页面
除了博客文章,有时我们还需要添加一些自定义页面,比如「关于」页面。
在 Publa 中,你可以任意添加自定义页面,并指定访问路径,只要这个路径与已有页面不重复即可。自定义页面支持复用当前页面框架(页头、页脚),可用于快速添加一些常见的功能页面,也支持不使用任何模板,由你直接输入整个页面的 HTML,添加完全自定义的页面。
除了以上设计理念外,Publa 还有一些值得提一下的特色功能。
支持附件上传
写博客少不了配图,有时可能还要向用户提供一些文件以供下载。Publa 内置支持 AWS S3、Cloudflare R2、阿里云 OSS、腾讯云 COS,如果你有这些平台的账号,可在 Publa 后台添加配置,之后便可以直接在附件管理页面上传和查看附件了。也可以直接在编辑器中粘贴图片,Publa 会自动将图片上传到你配置的平台。
Publa 会管理通过它上传的文件,如果你在 Publa 后台删除了文件,对应的存储平台上的文件也会同时删除。
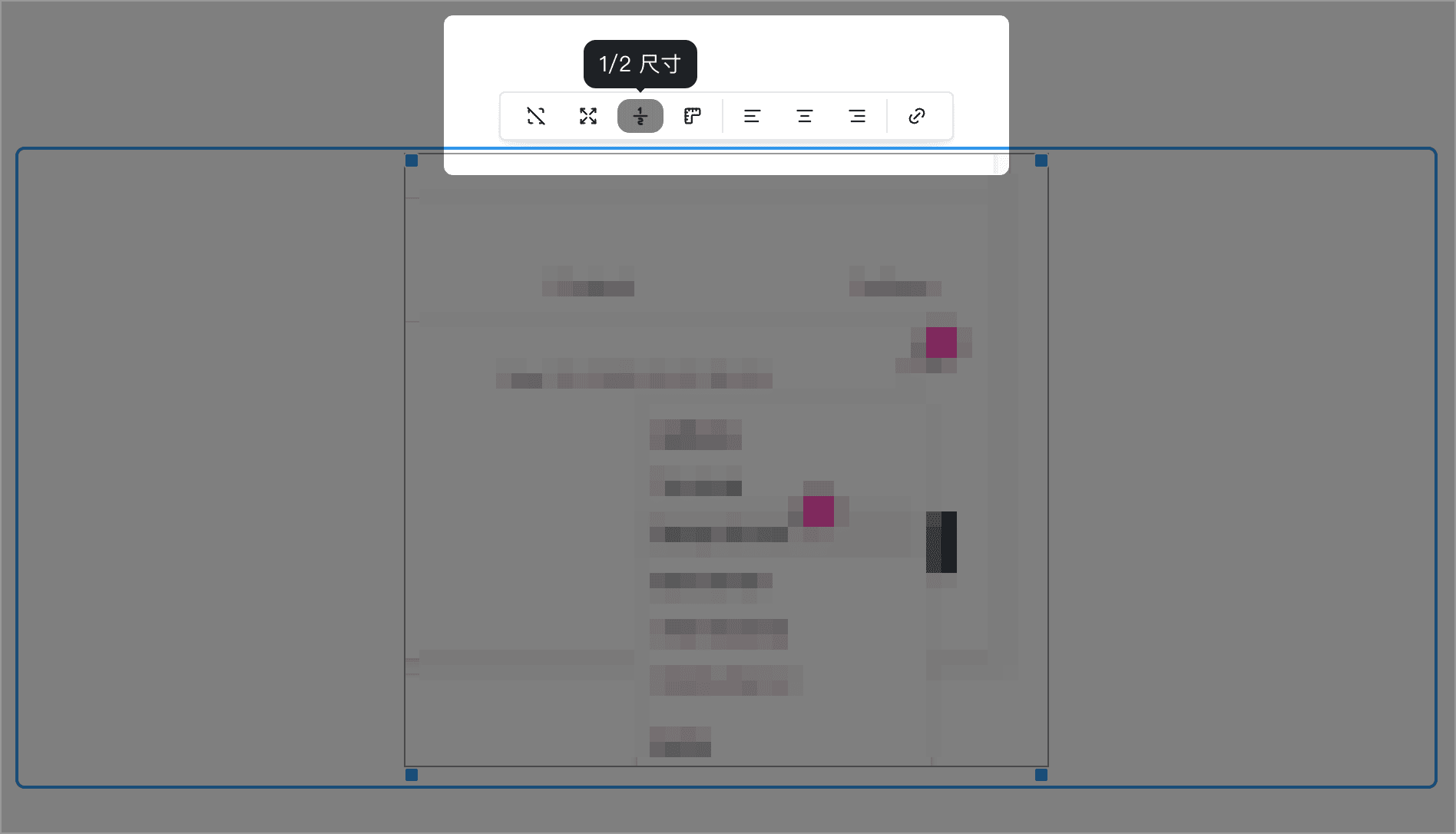
一键将图片设为 1/2 尺寸
这是我之前写博客时的一个痛点。
随着高分屏的普及,我们给屏幕截图时,得到的图片尺寸通常是截图区域的两倍大小,插入到博客中时,我们希望它能以实际尺寸的 1/2 大小进行显示。
在大多数富文本编辑器中,作者只能拖拽调整图片尺寸,然后凭感觉调一个差不多的尺寸。或者在 Markdown 编辑器中,先查看一下原图的尺寸,再人工计算一下,输入一个 1/2 的宽度。
在 Publa 的编辑器中,我专门优化了这个流程,插入图片后,点击选中图片,图片上方便会浮现一个快捷工具栏,其中便有一个将图片一键设为 1/2 尺寸的按钮。如果你使用高分屏并经常要在文章中插入屏幕截图,那么这个功能对你应该会很有用。
支持添加自定义跳转
在 Publa 中,你可以添加自定义跳转规则,将任意访问路径跳转到指定的路径。
如果你之前在使用其他博客系统,它的文章的路径结构和 Publa 不同,那么你可能会需要这个功能,用于将文章的老路径跳转到新路径,以便用户访问老路径时能正确跳到新的页面。
比如老博客系统中文章路径是 /article/{slug} 这样的形式,但 Publa 中文章路径是 /posts/{slug} ,那么便可以设置一条类似下图的跳转规则,以便平滑迁移。

支持 SQLite 和 PostgreSQL
既然是动态博客,后台数据库自然少不了。Publa 同时支持 SQLite 和 PostgreSQL 两种数据库,你可以根据需要选择。
由于支持 SQLite,如果你想开发调试 Publa 非常简单,只需从 GitHub 上下载源码,安装依赖,然后使用 npm run dev 即可启动测试服务器,在没有指定数据库的情况下,Publa 会自动创建并使用本地 SQLite 以便尽快开始开发调试工作。
值得一提的是,Publa 不仅支持本地 SQLite,还支持 Turso 提供的在线 SQLite 服务。Turso 有足够小项目使用的免费额度,因此,对大多数个人博客或小团队博客来说,可以将 Publa 部署在 Vercel 上并使用 Turso 提供的数据库,完全零成本运行。
以上便是对博客系统 Publa 的介绍。
你现在看到的这个博客就是基于 Publa 的,我已经使用这个系统一段时间了,将持续使用并不断改进完善它,如果你也想架设一个动态博客,不妨试一试 Publa。
Publa 基于 MIT 协议开源,任何人都可以免费下载和使用它。
当然,Publa 还很年轻,且之前只有我一位用户,因此可能有一些一直没被发现的 bug,如果你发现了问题,欢迎在 GitHub 上给我提 issue!
最后,希望 Publa 能帮你更好地完成博客写作!❤️
2026-05-02 13:30:55
老牌写作软件 Scrivener 的论坛上有一篇关于是否要支持 AI 的帖子,我花了一些时间仔细地把这篇帖子以及所有回复读了一遍。读完之后,我发现这不是一个简单的“要不要 AI”的技术讨论,更是一场关于写作工具本质、创作者身份认同、以及技术边界的长期争论,也是 AI 为我们这个时代带来的冲击的一个剪影,值得写一篇博客记录一下。
从 2023 年 3 月开始,Scrivener 的官方论坛上发生了一场马拉松式的辩论,主题很直白:要不要给 Scrivener 加上 AI 功能?
这条讨论一直延续到 2025 年底,公开可见的帖子超过 300 条,参与者里有职业作家、程序员、学术研究者,当然还有 Literature & Latte 公司的官方代表。
三年时间里,AI 从一个新鲜话题变成了行业标配,但 Scrivener 的立场却始终清晰而克制。
官方代表的回复让我印象深刻,他们没有用那种“我们永远不会”的绝对化措辞,也没有跟风喊“AI 是未来”,而是用一种近乎工程师式的冷静,把问题拆解成了几个层面。
2023 年 3 月,官方代表 kewms 说得很直接:“We are not interested in any form of subscription model.”(我们对任何形式的订阅模式都不感兴趣)这句话几乎提前封死了“把大模型月费捆绑进 Scrivener”的可能性。
2024 年 5 月,另一位官方代表 AmberV 把理由说得更清楚:他们不愿意把用户的草稿发送到第三方服务器,而消费级硬件上的本地模型“还不够有用”。这不是对新技术的忽视或恐惧,而是对隐私伦理和产品质量的双重坚持。
他们把 AI 工具类比为参考文献软件,Scrivener 可以提供接口,让你用自己选的工具,但不会替你选择、绑死、然后为它的价格变动和服务质量背书。
到 2025 年 11 月,官方给出了一句几乎可以当作政策结论的话:“是否使用 AI 工具,以及使用哪一种,最好留给用户自己决定。”
简单来说,官方温和而坚定地拒绝了在软件中集成 AI 服务。
然而,讨论并不只是一场“挺 AI”对“反 AI”的二元对立。
支持者里,最有代表性的诉求不是“让 AI 替我写小说”,而是一些听起来很实际的需求:
能不能帮我检查一下,这把枪在第一卷里到底有没有上膛?(长篇小说/系列小说的连贯性检查)
能不能把所有角色的对话按风格分类统计一下?
能不能快速识别出世界观设定里的前后矛盾?
能不能帮我起草一个复杂的正则表达式?
这些需求的共同点是:它们不是要 AI “代写”,而是要 AI “帮忙分析或整理”。
反对者的担忧也不是单纯的技术恐惧,他们在意的是:
隐私:未完成的草稿被送去训练,等于创意还没成型就被“偷走”了。
署名:如果 AI 参与了创作,读者怎么知道哪些是你写的?出版合同里写的“100% 我的作品”还算数吗?
产品定位:Scrivener 的价值就在于它是“少数仍然让人自己写”的空间,一旦加入 AI,这个定位就模糊了。
成本转嫁:如果 AI 功能需要订阅,那 Scrivener 还是那个“买断制、属于你”的工具吗?
自然地,也有一些中间派,他们不反对 AI,但坚持认为更好的做法是:让操作系统或第三方工具来提供 AI 能力,Scrivener 只需要保持开放接口,而不是自己深度绑定某个模型。
读完整个讨论,我发现帖子中似乎存在一个隐含的共识:几乎没有人真正支持“让 AI 直接替作者写正文”。
即便是最积极的支持者,也只是把需求限定在头脑风暴、查询、校对、梳理、节奏分析这些辅助性工作上。反对者也基本承认,拼写检查、语法建议这类功能迟早会渗透到操作系统层面。
换句话说,真正被广泛排斥的不是“AI 辅助”,而是“把去作者化的生成机制塞进写作工具的核心”。
如果要做一个类比,大概是这样:人们可以接受用计算器做算术题,甚至能接受带计算器进入考场,但不接受用 AI 直接回答试卷。
梳理下来,核心分歧其实有三条:
第一,隐私的边界在哪里?
支持者认为,只要透明告知、可以关闭,把数据发到云端就是可接受的;官方和反对者则认为,“别人(别的软件)也这么干”不代表这就是对的,尤其是当这些数据是还没发表的创作草稿时。
第二,外接工具够不够用?
官方认为,Alt+Tab 切换到另一个 AI 工具,或者用 Grammarly、ProWritingAid 这类第三方服务,已经是可行甚至更干净的方案;支持者则觉得这会打断沉浸感,制造重复的拷贝粘贴。
第三,AI 到底是“不可逆的大势”还是“被过度营销的泡沫”?
有人说“AI 会变得无处不在,不适应就会落后”;也有人说“我不认为 AI 行业能撑过五年,成本、能耗、法律风险都没算清楚”。
这三条分歧显然短时间内不会有结论,帖子中直到最后也还没有真正收敛。
Scrivener 很克制,这种克制在这个时代显得格外珍贵。
不是因为 AI 不好,而是因为在一个“人人都在加 AI”的环境里,却有一个工具明确说“我们不替你做价值判断,你自己决定”,这本身就是一种立场。
这也符合 Scrivener 一直以来的产品哲学,它不会猜你想写什么,但会给你足够的空间和结构,让你把想写的东西组织好。它的价值不在于“替你做决定”,而在于“让你的决定更容易实现”。它不是一个“智能”工具,而是一个“强大”工具。
从这个角度看,官方的立场就很好理解了:AI 可以存在,但它应该在 Scrivener 的边界之外,由用户自己选择、自己控制、自己承担风险。Scrivener 只需要保持开放,而不是成为某个 AI 服务的前端。
当然,故事还没结束。
Windows 侧会不会出现类似 Mac 上 Apple Intelligence 的“官方允许但不深度绑定”的路径?一些用户想要的“非生成式、但高度语义化”的功能,能否在不依赖大模型的前提下实现?版权、训练集伦理、输出的可版权性,这些法律和行业规范层面的问题,什么时候能有定论?
这些问题,到目前为止的讨论里仍然悬而未决。
但至少有一点是清楚的:Scrivener 不会因为“别人都在加 AI”就跟风,也不会因为“市场需要”就放弃自己的产品哲学。
在一个充满焦虑和跟风的时代,这种克制是一种稀缺的品质。
2026-04-10 12:34:41
之前写过一篇使用 acme.sh 申请 SSL 证书的帖子,最近把这个流程放到了 GitHub Action 上自动化完成,在这儿记录一下要点。
GitHub Action 是托管在 GitHub 上的自动化服务,免费账户的私有仓库每月有 2000 分钟的运行额度,可以用来做很多运维、CI 相关的工作。
要使用 GitHub Action,只需在项目的根目录下的 .github/workflows 中创建一个 .yml 文件即可,比如新建一个 .github/workflows/renew-ssl.yml 。
这个 action 的基本结构类似下面这样:
name: Renew SSL Certificate
on:
schedule:
- cron: '0 20 * * 0' # 每周一 UTC 20:00(北京时间 04:00)
workflow_dispatch: # 支持手动触发
permissions:
contents: read
jobs:
renew-cert:
runs-on: ubuntu-latest
steps:
- name: Task name
run: |
YOUR SCRIPT代码很直白,这儿就不多解释了,下面继续看最主要的任务步骤(steps)。
我们要使用 acme.sh 来申请 SSL 证书,因此第一步需要安装 acme.sh。在以上 YML 文件的 steps 部分,添加以下代码:
- name: Install acme.sh
run: |
curl https://get.acme.sh | sh -s email=${{ secrets.ACME_EMAIL }}接下来,则是使用 acme.sh 申请域名证书。这儿我们申请了一个泛域名证书:
- name: Issue or Renew Certificate
id: issue-cert
env:
Ali_Key: ${{ secrets.ALI_KEY }}
Ali_Secret: ${{ secrets.ALI_SECRET }}
run: |
~/.acme.sh/acme.sh --issue \
-d oldj.net \
-d '*.oldj.net' \
--dns dns_ali \
--keylength ec-256你需要将上面代码中的 oldj.net 替换为你自己的域名。申请泛域名证书时,需要同时传入 your-domain.com 和 *.your-domain.com。
我的域名是在阿里云上,因此 --dns 参数设置的是 dns_ali 。如果你的域名在其他注册商那里,需要把这个参数改为对应的值,具体可查看 acme.sh 的文档。
注意,这儿用到了环境变量 secrets.ALI_KEY 和 secrets.ALI_SECRET ,这两个值需要你去阿里云后台生成,然后在 GitHub 项目仓库的后台添加。
阿里云后台具体位置是 AccessKey 管理页面,建议创建一个子账号,只授予 AliyunDNSFullAccess 权限即可。
GitHub 添加 Secrets 的位置是:仓库页面 → Settings → Secrets and variables → Actions → New repository secret。
证书需要上传到服务器才能发挥作用,在这儿我们使用 SSH 的方式连接服务器。为了能顺利连接服务器,需要你准备一对 SSH 密钥,将公钥上传到服务器的 ~./ssh/authorized_keys 下,同时像上面那样将密钥添加到 GitHub Secrets 中,名称是 SSH_PRIVATE_KEY 。
接下来,再在 renew-ssl.yml 中继续添加以下代码:
- name: Setup SSH
run: |
mkdir -p ~/.ssh
echo "${{ secrets.SSH_PRIVATE_KEY }}" > ~/.ssh/id_rsa
chmod 600 ~/.ssh/id_rsa
echo "StrictHostKeyChecking no" > ~/.ssh/config再接下来是正式的上传步骤:
- name: Deploy to Server-001
if: steps.issue-cert.outcome == 'success'
continue-on-error: true
run: |
scp ~/.acme.sh/oldj.net_ecc/fullchain.cer \
~/.acme.sh/oldj.net_ecc/oldj.net.key \
${{ secrets.SERVER_USER_GATEWAY }}@${{ secrets.SERVER_HOST_GATEWAY }}:${{ secrets.CERT_REMOTE_DIR }}/
ssh ${{ secrets.SERVER_USER_GATEWAY }}@${{ secrets.SERVER_HOST_GATEWAY }} "sudo nginx -s reload"注意 SERVER_USER_GATEWAY 和 SERVER_HOST_GATEWAY 分别是你的服务器的用户名和地址(IP 或域名),CERT_REMOTE_DIR 是你准备把证书上传到的服务器文件夹,需要先创建对应的文件夹。这三个变量也像上面一样添加到 GitHub Secrets 中。
步骤的第一行 if: steps.issue-cert.outcome == 'success' 是要确保前面申请证书成功才会执行后续的操作。
最后一行的 sudo nginx -s reload 作用是让服务器上的 Nginx 重新加载配置以及证书,没有这一句,即使证书文件已经上传了,Nginx 仍会继续使用老证书,直到下一次重载或重启。
到这儿,证书的申请 → 上传 → 应用流程就基本完整了,如果你有多台服务器在使用这个证书,可以继续添加上传任务。
我在使用腾讯云 CDN,所以也研究了一下如何自动更新腾讯云的上传证书。其他云服务商应该也有类似的接口。
另外,腾讯云的 EdgeOne 已经可以自动申请和更新免费证书了,无需再自己上传,不过传统的 CDN 服务目前似乎还需要自己管理免费证书。
相关代码如下:
- name: Upload to Tencent Cloud
if: steps.issue-cert.outcome == 'success'
continue-on-error: true
run: |
pip install tccli
# 配置腾讯云 CLI
tccli configure set secretId ${{ secrets.TENCENT_SECRET_ID }}
tccli configure set secretKey ${{ secrets.TENCENT_SECRET_KEY }}
tccli configure set region ap-guangzhou
CERT=$(cat ~/.acme.sh/oldj.net_ecc/fullchain.cer | base64 -w 0)
KEY=$(cat ~/.acme.sh/oldj.net_ecc/oldj.net.key | base64 -w 0)
# 上传新证书
RESULT=$(tccli ssl UploadCertificate \
--CertificatePublicKey "$(cat ~/.acme.sh/oldj.net_ecc/fullchain.cer)" \
--CertificatePrivateKey "$(cat ~/.acme.sh/oldj.net_ecc/oldj.net.key)" \
--Alias "oldj.net-wildcard-$(date +%Y%m%d)")
NEW_CERT_ID=$(echo "$RESULT" | jq -r '.CertificateId')
echo "New certificate ID: $NEW_CERT_ID"
# 如果有旧证书 ID,自动替换关联资源
if [ -n "${{ secrets.TENCENT_OLD_CERT_ID }}" ]; then
tccli ssl UpdateCertificateInstance \
--OldCertificateId ${{ secrets.TENCENT_OLD_CERT_ID }} \
--ResourceTypes '["cdn"]' \
--CertificateId "$NEW_CERT_ID"
echo "Associated resources updated from ${{ secrets.TENCENT_OLD_CERT_ID }} to $NEW_CERT_ID"
fi
# 自动更新 Secret 中的证书 ID,供下次续期使用
echo "$NEW_CERT_ID" | gh secret set TENCENT_OLD_CERT_ID
echo "TENCENT_OLD_CERT_ID updated to: $NEW_CERT_ID"
env:
GH_TOKEN: ${{ secrets.GH_PAT }}
GH_REPO: ${{ github.repository }}请注意将代码中的证书路径(本例中是 oldj.net_ecc)替换为你的实际路径。
这段代码中使用了腾讯云的 tccli 来实现证书上传和更新工作,和上面类似,你需要先设置一些 Secrets:
TENCENT_SECRET_ID 腾讯云 API SecretId
TENCENT_SECRET_KEY 腾讯云 API SecretKey
TENCENT_OLD_CERT_ID 当前正在使用的证书 ID(如果仅上传,不需要自动替换老证书,可不填此项)
其中 TENCENT_SECRET_*可以前往腾讯云 API 密钥管理页面生成,建议创建子账号,授予 QcloudSSLFullAccess 权限,以及你需要更新的资源的权限,比如 QcloudCDNFullAccess 。
上面的 --ResourceTypes 用于指定要更新的资源,这儿我只写了 CDN,你可以根据需要调整。
首次运行前,需要你先设置一下要更新的证书 ID。由于每次自动更新证书之后,证书 ID 都会变化,为了实现完全自动化,这儿添加了一个 GH_PAT 参数,用于记录你的 GitHub Personal Access Token 。
这个 GitHub Personal Access Token 的创建方式如下:
进入 GitHub Settings → Developer settings → Personal access tokens → Fine-grained tokens
选择对应的组织以及仓库,权限勾选 Secrets → Read and Write
生成后,将 Token 存入仓库 Secret 中,名称是 GH_PAT
这样自动更新腾讯云上的证书的流程便也自动化了。
2026-03-25 19:20:00
想象一下,你有两个工作台:
A 工作台上摆着你最重要的那个大项目——可能是一个复杂的架构设计,可能是一本书的核心章节,或者是一个需要深度思考的研究课题。这个工作需要你全神贯注,不被打扰。
B 工作台上则堆着其他各种各样的事情——紧急但不复杂的需求、日常维护工作、突发的小任务、需要回复的邮件等等。这些事情重要但不需要长时间的深度投入。
AB 工作法的核心思路是:将各项工作放合适的工作台上,然后你的注意力在这两个工作台之间定期切换。比如上午在 A 工作台专注做深度工作,下午切换到 B 工作台处理各种杂事,或者今天做 A,明天做 B,关键是有节奏地轮换,而不是随机跳跃。
这个方法特别适合那些每天要处理大量不同类型事务的人,——你需要推进重要的长期项目,同时又不能让其他事情堆积成山。如果你的工作是流水线式的,按先来后到依次处理就好,可能用不上这个方法。
我们先来看一个常见的困境。
假设你是一位程序员,你的待处理工作列表很长,每项工作的重要性、紧急程度、耗时都不同。你决定按串行方式处理,每次挑一项最重要的处理,完成之后再挑选下一项。这个策略通常运行良好,但偶尔也会遇到麻烦:某项工作特别耗时,你在上面花了一两周,其他耗时短的小任务就都卡住了,有些原本不紧急的需求因此变得紧急起来。
这背后是两个相互冲突的需求:
一方面,我们需要专注。频繁切换任务的成本很高,因为大脑需要时间重新加载上下文,频繁切换不仅降低效率,还会消耗大量精力,导致精神疲劳。
另一方面,我们又不能长时间陷入一件事。如果完全沉浸在一个大项目中,其他重要但耗时短的任务会被无限期推迟,最终可能演变成紧急问题,甚至引发更大的麻烦。
AB 工作法试图在这两者之间找到平衡。
回到“两个工作台”的比喻。AB 工作法的运作方式是:
建立两个工作台
你需要把所有工作分类放到两个工作台上:
A 工作台:存放那些需要深度工作的任务——最重要、最复杂、预计耗时较长的工作。这些任务摆在 A 工作台上,等待你在专注时段处理。
B 工作台:存放其他所有事务——重要但不太复杂的任务、紧急但耗时短的需求、日常维护工作、突发事项等等。这些任务堆在 B 工作台上,可以在较短时间内逐个处理。
定期轮换
你需要设定一个固定的轮换周期。在 A 时段,你只在 A 工作台工作,专注处理深度任务;在 B 时段,你切换到 B 工作台,灵活处理各种事务。这种有节奏的切换,既保证了主要任务的持续推进,又确保了其他事务不会被长期搁置。
保持纪律
关键是严格遵守“在哪个工作台就做哪个工作台的事”。在 A 工作台时,即使 B 工作台上有看起来很紧急的事,也要记下来留到 B 时段处理。在 B 工作台时,即使突然对 A 任务有了灵感,也要克制住冲动,留到 A 时段再说。
拿出你的工作列表,开始分类:
哪些任务该放到 A 工作台?
答案是那些“如果不专注投入就很难推进”的工作。对程序员来说,可能是复杂的架构重构;对作家来说,可能是书的核心章节;对研究者来说,可能是关键实验的设计与实施。判断标准是:这个任务需要长时间的连续思考吗?需要进入“心流”状态才能做好吗?如果答案是肯定的,就放到 A 工作台。
哪些任务该放到 B 工作台?
答案是其他所有工作——包括那些重要但不太复杂的任务、紧急但耗时短的需求、日常维护工作、突发事项等等。不用担心 B 工作台上堆得太满太杂,这个工作台本来就是为处理多样化任务设计的。
根据你的工作性质和个人习惯,选择一个合适的轮换周期:
每半天轮换:上午在 A 工作台,下午在 B 工作台,或者上午在 B 工作台,下午在 A 工作台。这是最常见的节奏,适合工作环境相对安静、任务复杂度高的情况。
每天轮换:今天在 A 工作台,明天在 B 工作台。如果你的深度任务需要更长的连续时间来建立思考状态,这种方式可能更合适。
每个时段轮换:每个工作时段(2-4 小时)切换一次工作台。适合工作环境多变、突发事件较多的情况。
每 2 小时轮换:节奏更快,但不建议更短——太频繁的切换会让上下文切换成本抵消掉收益。
根据效率曲线设置:选择你每天最高效的时间段使用 A 工作台,其他时段使用 B 工作台。比如,如果你在上午 10 点到下午 3 点精力最充沛、思维最清晰,就把这个时段固定为 A 时段,其余时间处理 B 任务。这种方式能最大化利用你的黄金工作时段。
关于时间分配比例
A、B 的时间分配不一定是 1:1。如果你的日常事务相对较少,而深度任务需要大量投入,时间分配可以是 2:1、3:1,甚至可以一周的五个工作日,四天都在 A 工作台,剩下一天在 B 工作台。关键是根据实际工作量来设定合理的比例。
但有一点很重要:一旦定好节奏,就不要轻易改动。频繁调整计划本身就是一种低效的行为,会削弱这个方法的效果。
这是 AB 工作法成败的关键。
在 A 工作台时:坚决拒绝处理 B 工作台上的事项,即使它们看起来很紧急。你可以把它们记在便签上,但要留到 B 时段再处理。这不是不负责任,而是在保护你的深度工作状态。
在 B 工作台时:不要被 A 工作台上的任务吸引回去,即使你突然有了灵感。把灵感记下来,留到 A 时段再展开。这同样是在保护你的工作模式——B 时段的价值在于灵活机动,如果被大任务拖住,就失去了意义。
这种纪律看似僵化,实际上是在保护两种工作模式的完整性。你可以把自己想象成两个不同的人:A 工作台上的你是专注的深度思考者,B 工作台上的你是灵活的问题解决者。
真正的紧急情况例外
当然,如果遇到真正重要且紧急的突发事件——比如生产系统崩溃、客户的关键问题、或者团队成员急需你的帮助——无论你当前在哪个工作台,都可以立刻停下来去处理。
但需要记住:这种打断应该是罕见的例外,而不是常态。如果你发现自己经常因为“紧急情况”打断工作,可能需要重新审视:这些事情真的都是既重要又紧急吗?还是因为缺乏边界,让所有事情都变成了紧急?
一个简单的判断标准是:如果这件事推迟 2 小时(或推迟到下一个工作台时段)会造成严重后果,那就是真正的紧急情况。如果只是“看起来紧急”但推迟几小时也无妨,那就记下来,留到合适的时段处理。
AB 工作法不是一成不变的,需要根据实际情况动态调整:
当 A 工作台清空时:可以从 B 工作台选出最重要、最复杂的任务,把它移到 A 工作台。这样确保你始终有深度任务在推进。
当 B 任务需要升级时:在执行过程中,如果发现某个 B 任务的重要性和复杂度超出了最初的预期,可以把它从 B 工作台移到 A 工作台,作为深度任务来处理。
当 A 任务需要降级时:有时候你可能会发现某个 A 任务其实没那么复杂,或者可以拆分成小块处理,这时也可以把它或者它拆分后的一部分移到 B 工作台。
关键是保持两个工作台的动态平衡,确保 A 工作台上始终有需要深度工作的任务,B 工作台上有足够的机动任务。
这是一个有意思的问题。如果到了 B 时段,却发现 B 工作台上的事情都处理完了,你有两个合理的选择:
选择一:转到 A 工作台
既然没有其他事务需要处理,将这段时间用于推进 A 工作台上的任务是很自然的想法,这样可以加快深度任务的进度。
不过需要注意的是,如果你经常这样做,要警惕 AB 工作法是否正在退化成单线程工作模式。偶尔为之没问题,但如果成为常态,可能需要重新审视你的时间分配比例。
选择二:做“元工作”或休息
“元工作”是指那些不属于具体任务,但对工作系统本身有益的活动:整理工作笔记、回顾近期进展、学习新技能、优化工作流程、清理工作环境、或者进行一些前瞻性思考。这些活动往往在忙碌时被忽视,但长期来看对提升工作质量和效率很有帮助。
如果找不到合适的“元工作”,那就干脆休息一下,——散散步、冥想、或者做一些轻松的事情,为下一个 A 时段储备精力。
最重要的是,不要因为 B 工作台暂时清空就感到焦虑或内疚。这恰恰说明你的工作节奏是健康的,——你既在推进重要的长期项目,又及时处理了其他事务。这正是 AB 工作法追求的理想状态。
AB 工作法的有效性来自于它对人类认知特性的尊重和对工作现实的妥协:
它承认专注的价值
通过为深度任务分配专门的时间块,我们能够进入心流状态。在 A 工作台上,你不需要担心其他事情,可以全身心投入到复杂的思考中。这种不被打扰的专注,是完成复杂工作的必要条件。
它承认灵活的必要
通过 B 工作台的存在,我们不会因为过度专注而忽视其他重要事项。那些看似琐碎但不可或缺的工作——回复邮件、处理临时需求、日常维护——也能得到及时处理,不会堆积成山。
它提供了心理缓冲
知道“我只需要在这个时段专注于 A 工作台,其他事情稍后会有专门时间处理”,这种确定性能够显著降低焦虑。你不会因为“还有很多其他事没做”而分心,也不会因为“一直在做杂事”而焦虑。
它创造了自然的休息点
工作台切换本身就是一种认知上的休息。从深度思考切换到处理多个小任务,或者反过来,都能让大脑的不同区域得到交替使用和恢复。这比连续 8 小时做同类工作要健康得多。
AB 工作法特别适合以下人群:
需要同时推进长期项目和处理日常事务的知识工作者
工作内容多样、优先级复杂的管理者、创业者或独立开发者
需要在创造性工作和事务性工作之间切换的专业人士
容易陷入“只做紧急事,忽视重要事”或“只做重要事,忽视紧急事”两个极端的人
当然,AB 工作法也有它的局限性:
如果你的工作本质上是单线程的(比如流水线工人、客服人员),这个方法可能过于复杂。如果你的工作环境完全不可控、频繁被打断,可能需要先改善工作环境,再尝试这个方法。如果你正处于某个项目的冲刺期,需要全力以赴,暂时放弃 AB 结构、全力投入也是合理的选择。
从简单的节奏开始
如果你是第一次尝试 AB 工作法,建议从每天轮换开始,而不是每小时。今天在 A 工作台,明天在 B 工作台。这样更容易建立习惯,也更容易感受到效果。等习惯养成后,再尝试更短的轮换周期。
用工具标记当前工作台
可以使用日历、番茄钟或专门的时间管理工具来标记你当前在哪个工作台。视觉提示能够帮助你更好地保持纪律。有些人会在桌面上放两个不同颜色的便签纸,A 时段翻开绿色,B 时段翻开黄色,这种物理提示也很有效。
每周回顾与调整
每周花 15 分钟回顾一下:A 工作台上的任务推进得如何?B 工作台是否有积压?两个工作台的任务划分是否合理?轮换节奏是否合适?根据实际情况调整策略。这种定期回顾能帮你不断优化自己的工作节奏。
让同事知道你的节奏
如果你在团队中工作,让同事知道你的工作方式。比如在日历上标注“深度工作时段(A 工作台)”,让他们知道这段时间最好不要打扰你。大多数同事会理解并尊重这种安排,因为他们自己可能也有类似的需求。
保持弹性
AB 工作法是一个框架,不是枷锁。真正的紧急情况出现时,当然可以打破规则。关键是这种打破应该是例外,而不是常态。如果你发现自己经常打破规则,可能需要重新审视你的时间分配或任务分类。
AB 工作法的核心是“两个工作台”,但这不是唯一的可能。如果你的工作情况更复杂,完全可以扩展为三个、四个甚至更多工作台。
什么时候需要更多工作台?
如果你的工作内容跨越多个几乎不相关的领域,每个领域都有自己的深度任务和日常事务,那么多个工作台可能更合适。
比如,假设你同时负责产品开发和市场推广两个领域,你可以采用 ABC 工作法:
A 工作台:产品开发方面的深度工作——架构设计、核心功能开发、技术难题攻关
B 工作台:市场推广方面的深度工作——营销策略规划、重要内容创作、关键活动策划
C 工作台:所有其他日常事务——邮件回复、会议、临时需求、日常维护
然后制定一个轮换策略,比如:周一周二在 A 工作台,周三周四在 B 工作台,周五在 C 工作台。或者每天上午在 A 工作台,下午在 B 工作台,晚上处理 C 工作台的事情。
需要注意的是
工作台越多,轮换的复杂度就越高,上下文切换的成本也会增加。大多数情况下,两个工作台就足够了。只有当你确实需要在多个完全不同的领域之间切换,并且每个领域都有足够的工作量时,才考虑增加工作台数量。
一个简单的判断标准:如果你发现自己在某个“深度工作台”上经常没事可做,或者某两个工作台上的任务其实可以合并处理,那就说明工作台分得太细了,不如简化回两个工作台的结构。
AB 工作法的本质,是在专注与灵活、深度与广度、长期与短期之间寻找平衡。它不是什么神奇的生产力秘诀,而是一种务实的工作组织方式。
想象你面前真的有两个工作台。A 工作台干净整洁,只摆着少量需要全神贯注的大项目;B 工作台上堆着各种各样的事情,等待你灵活处理。你在这两个工作台之间有节奏地切换,既不会因为过度专注而忽视其他事务,也不会因为琐事缠身而无法推进重要项目。
在这个信息过载、任务繁杂的时代,我们既需要能够深入思考的专注时光,也需要能够快速响应的灵活机制。AB 工作法提供了一个简单但有效的框架,让这两种看似矛盾的需求能够在同一个人的工作节奏中和谐共存。
如果你也面临着“重要的大项目总是被琐事打断”或“专注于大项目时其他事情都荒废了”的困扰,不妨试试 AB 工作法。给自己两周时间实验,你可能会发现一种全新的工作节奏。