2024-09-29 10:24:37
本篇文章只用于技术分享,用dnfm作为例子来展示应用,不提供完整源码。大家只讨论技术就好了,dnf检测还是很强的,我被封了好几次了。。。
我们先来看看效果怎样,大家可以二倍速观看,我视频里没有快进:
去年的时候写过两篇文章,如何学习强化学习,以及如果用AI玩 FlappyBird:
最近后开始玩DNFM,但是经过了几个月的搬砖实在是有点乏了,那么我们怎么用AI来代替我们在DNFM里面搬砖呢?
我们知道AI在游戏领域其实有很多的应用了,比如 MaaAssistantArknights:明日方舟游戏助手。因为它的最主要的功能都是静态的,并且位置固定,不存在需要移动的场景,那么基于静态的图像识别技术 OpenCV,就实现一键完成明日方舟游戏的全部日常任务。
那么 DNFM 的搬砖 AI 应该要用什么算法来做呢?首先要分析一下在 DNFM 手游中搬砖这个任务包含了哪些行为:
从上面的分析,我们知道,要完成这个任务其实远比我们想象中要复杂,并且上面即使实现了,也只是半自动,还有多角色自动切换,角色自动移动到指定地图等等。
那么通过上面的“需求”,我们应该大体知道,对于静态图标文字之类的,我们可以使用 OpenCV 来解决,因为这些东西的相对位置不会变动,比如识别是否应该进入下一张图,我们直接识别这张图片即可:

其他动态信息都需要用到深度学习来实现,识别什么是怪物,什么是角色,什么是物品等等。这类的算法有很多,在 《动手学深度学习》 中第七章和第八章里面就讲到了如何用卷积神经网络 CNN 来进行图像识别。我们这次也是要使用大名鼎鼎的 YOLO 算法来实现我们的动态的图像识别。
那么除了图像识别以外,接下来需要解决如何玩游戏的问题了,那么就需要对手机进行控制,这类的解决方式有很多,但是对于DNFM来说,游戏里面是有反作弊系统的,所以要在不修改数据包,不root手机的情况下完成这个任务。我的解决方案是用 ADB 连接电脑,然后通过软件映射的方式来在电脑上控制手机玩游戏,几乎不需要任何权限,只需要一台安卓机即可。
好了,分析完之后来总结一下,我们的技术实现方案:
下面我们进行挨个的技术爆破。
YOLO算法是one-stage目标检测算法最典型的代表,其基于深度神经网络进行对象的识别和定位,运行速度很快,可以用于实时系统。one-stage 直接从图像中生成类别和边界框位置预测,即网络一次性完成目标位置预测和分类任务,这个特性正是符合我们实时的游戏操作。
相对来说 two-stage 它是分成两步的,需要把任务细化为目标定位与目标识别两个任务,简单来说,找到图片中存在某个对象的区域,然后识别出该区域的具体对象是什么。这种算法的缺点是识别比较慢,但是小物体检测好,精度高,这类的代表算法有 RCNN 系列。
我们可以简单对比一下 RCNN 和 YOLO 的区别,YOLO的mAP要低于Fast-rcnn,但是FPS却远高于Fast-rcnn:
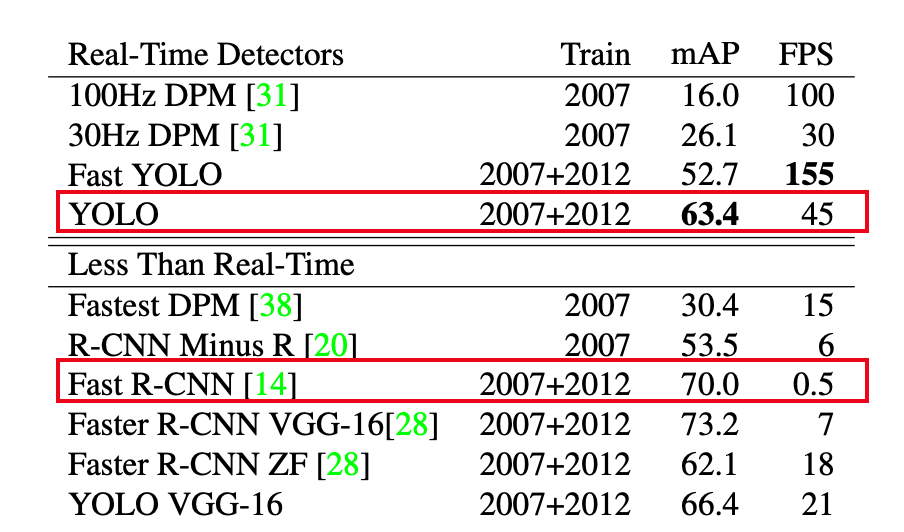
而我们只是用来玩一个游戏, 不需要这么高的精度,实时性更重要,这也是为什么选用YOLO算法。
说点题外话,由于YOLO算法的实时性和准确性,所以YOLO也被用于一些军事领域上,YOLO算法的原作者Joseph Redmon于2020年宣布退出计算机视觉领域,他在社交媒体上表示,他不想看到自己的工作被用于可能造成伤害的用途,因此选择退出这一研究领域。
现在 YOLO 已经出到了 V9 版本,前3个版本是Joseph Redmon开发的,先来看看 V1 版的论文。
YOLO将输入图像划分为 S×S 网格,如果物体的中心落入网格单元,则该网格单元负责检测该物体。我们以下面 7×7 的格子为例:
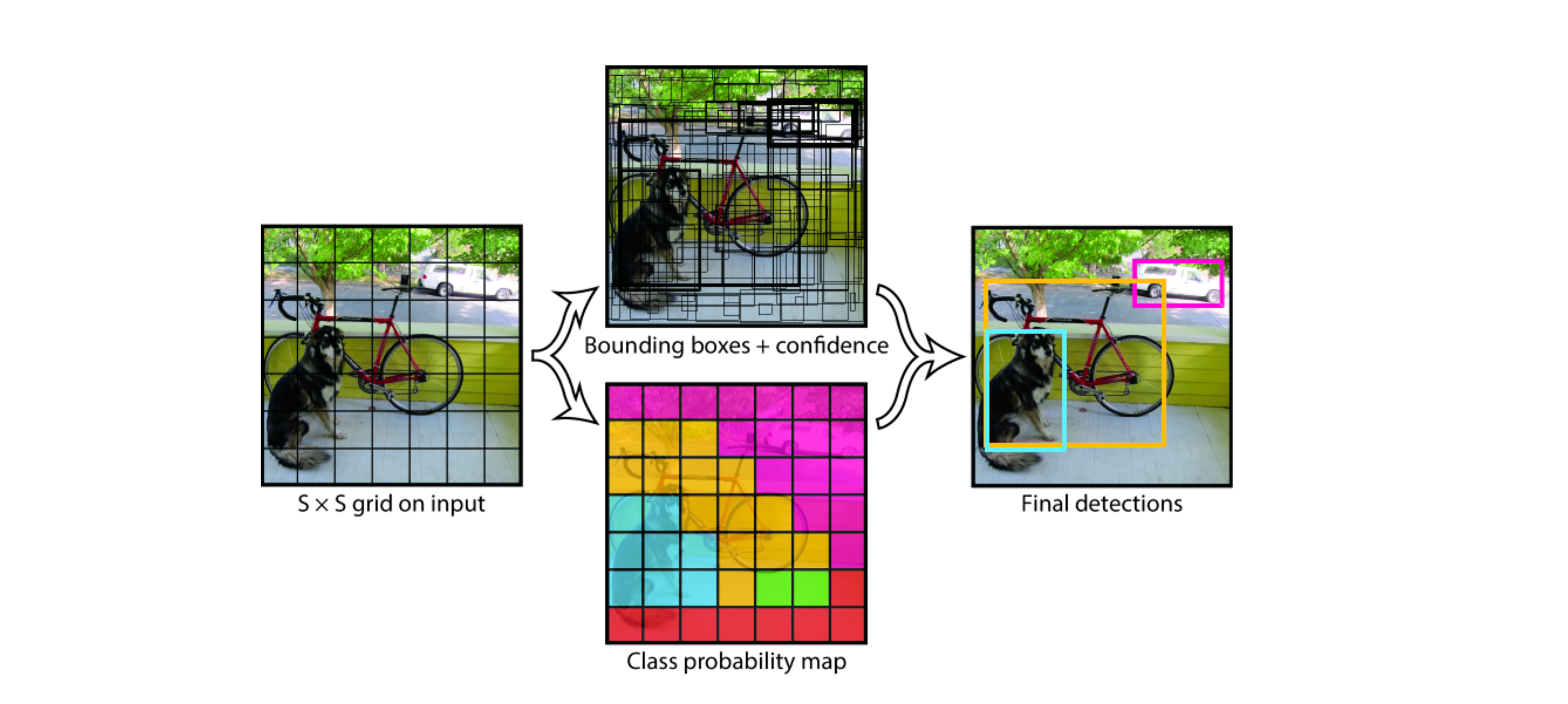
具体实现过程如下:
因为每个网格单元只会预测两个boxes,然后从中选出最高的IOU的box作为结果,也就是最终一个网格只能预测一个物体,那么这种空间约束限制了YOLO模型可以预测的附近对象的数量。如果要预测的多个物体小于网格的大小,那么将识别不出来,比如远处的鸟群。
还有就是由于输出层为全连接层,因此在检测时,YOLO 训练模型只支持与训练图像相同的输入分辨率,yolo-v1的输入是448×448×3的彩色图片。其它分辨率需要缩放成此固定分辨率;
这里我选用Ultralytics的 YOLOv5 版本 https://github.com/ultralytics/yolov5 来完成本次任务,一来因为是需要快速响应的场景,并且游戏场景里面也没有很小的物体或密集的场景需要识别。并且提供多个模型尺寸(如s、m、l、x),适应不同的应用场景。活跃的社区和易用性,也适合初学者和快速开发。
对于一个YOLOv5 这样的监督学习框架,要使用总共要经历以下这么几步:
安装
pip install label-studio启动
label-studio start然后就可以在浏览器访问 http://localhost:8080 打开打标签的界面了。然后我们需要打开游戏,玩一局并录像,然后对视频进行抽帧生成游戏内的图片,代码如下:
def main(source: str, s: int = 60) -> None:
"""
:param source: 视频文件
:param s: 抽帧间隔, 默认每隔60帧保存一帧
:return:
"""
video = cv2.VideoCapture(source)
frame_num = 0
success, frame = video.read()
while success:
if frame_num % s == 0:
cv2.imwrite(f"./images/{frame_num // s}.png", frame)
success, frame = video.read()
frame_num += 1
video.release()
cv2.destroyAllWindows()setting 设置 box 检测任务:
设置label:
我们这里主要标记这么几个物体:
'Gate' # 门, 'Hero' # 玩家人物, 'Item' # 掉落物品, 'Mark' # 箭头标记, 'Monster' # 怪物, 'Monster_Fake' # 怪物尸体 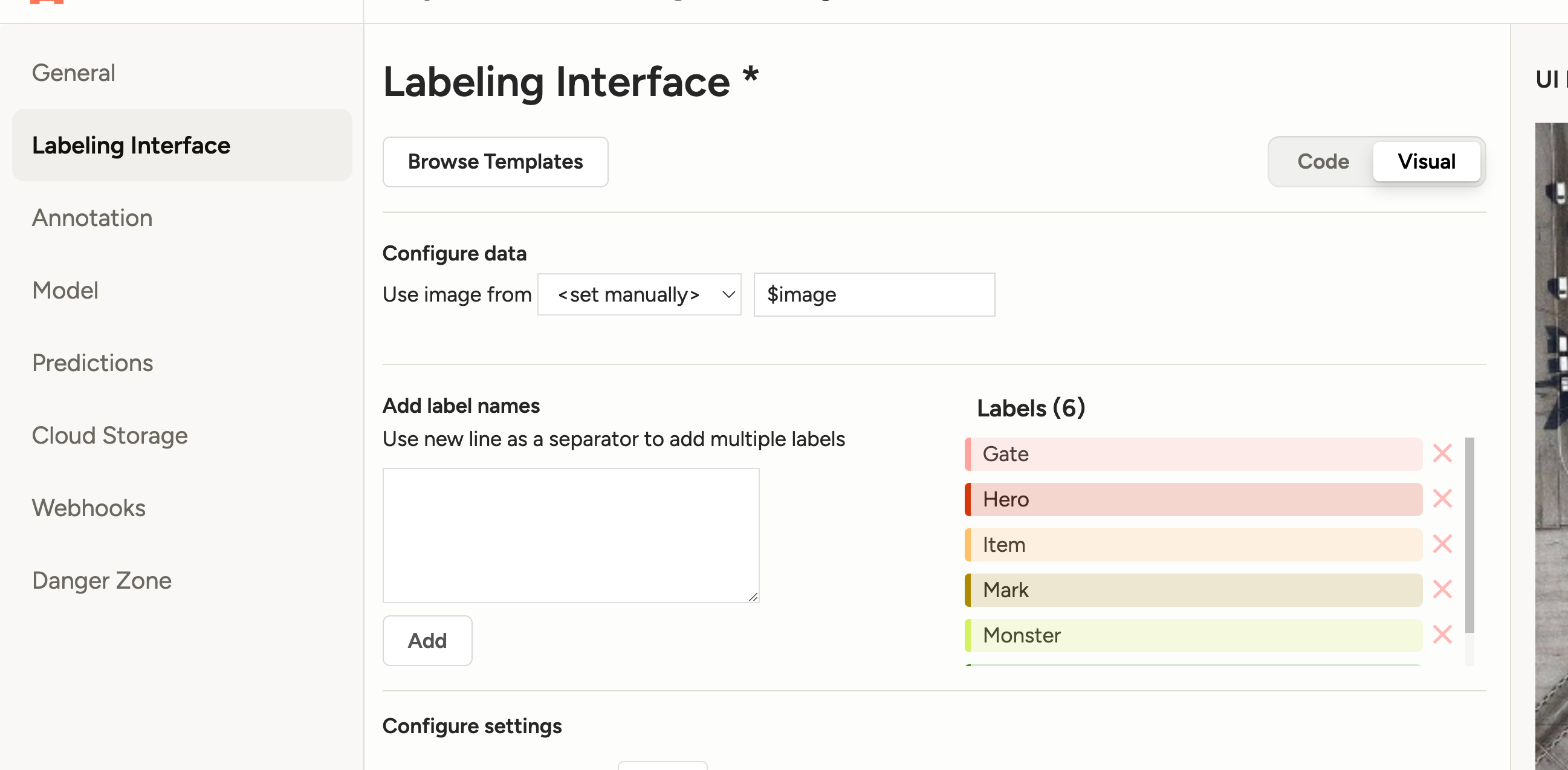
然后将我们抽好帧的图片 import 进入到工程里面。
然后就一张张的图片进行手动的标记:
这里你有可能要问了,如果我的角色换了一套衣服,那我的模型是不是就不认识了呀。确实是这样,会不认识,并且不同角色要多次标记,每个角色差不多标记个50张图片就好了(这个过程真累啊)。
导出为YOLO:
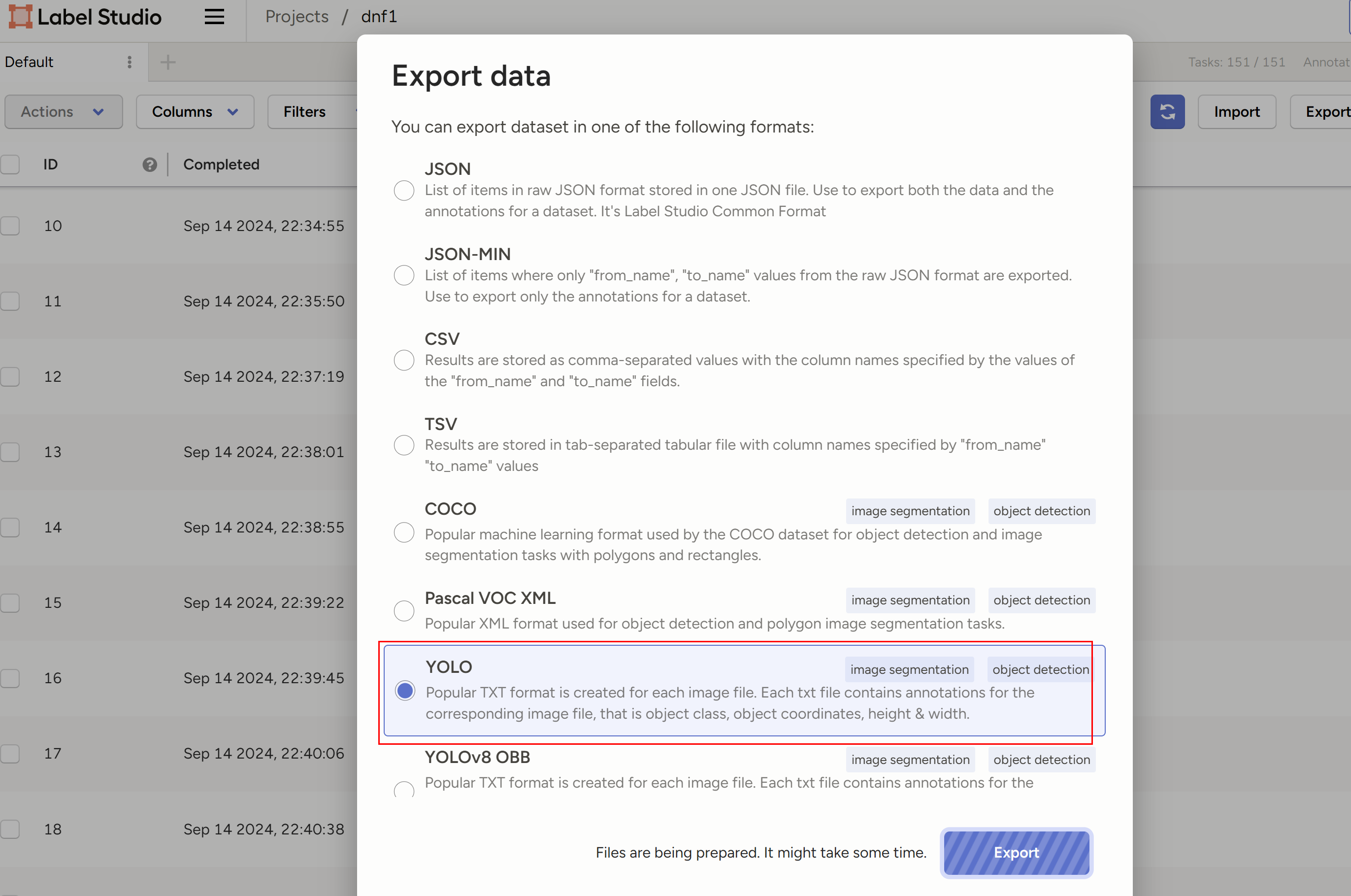
到这里之后,我们进入到YOLOv5 https://github.com/ultralytics/yolov5 工程里面,我们先在 data 目录下面创建 mydata.yaml,配置好要训练的数据集:
# 训练和验证的数据集
train: ../train_data/project-1-at-2024-09-17-00-48-5c375b91/images
val: ../train_data/project-1-at-2024-09-17-00-48-5c375b91/images
# number of classes 表示有多少分类,等于 names 数量就行了
nc: 6
# class names 分类的名字
names: ['Gate', 'Hero','Item','Mark','Monster','Monster_Fake']然后打开 models 里面的 yolov5s.yaml 文件,只需要把 nc 改成 6就好了。
然后直接执行训练:
python train.py --epochs 100 --batch 8 --data data/mydata.yaml --cfg yolov5s.yaml --weights yolov5s.pt --device 0 epochs 和 batch 会影响最后的收敛效果以及速度,根据自己的显卡来调试就好了,我的4090 100张图片大概训练了10分钟左右。
训练完之后可以用我们刚刚录好的视频做验证:
python detect.py --source D:\document\dnfm-auto\video\Record_2024-09-14-21-29-31.mp4 --weights best.pt我这里把我跑完的视频上传了,可以看到即使是 YOLOv5s 效果也足够好了:
然后我们把 pt 模型导出成 onnx模型:
python export.py --weights best.pt --img 640 --batch 1 --device 0 --include onnx主要因为使用ONNX(Open Neural Network Exchange)来部署模型相比于直接使用PyTorch(.pt格式)有几个显著的优点:
对于 ONNX 的部署我们使用 ONNXRuntime 来进行,它几乎可以在不修改的源码的基础上进行部署它的整个架构就像Java的JVM机制一样。具体可以参考onnxruntime.ai的具体介绍。
Python部署yolov5模型几乎就是参照了源码的流程,主要分为以下几步:
具体,我们可以参考这个项目 https://github.com/iwanggp/yolov5_onnxruntime_deploy 把推理的 demo 给写出来,然后尝试导入图片看是不是能生成这样的 anchor 图片:
对于上面的的图片检测算法最后可以为每个anchor是可以生成:[centerX,centerY,width,height,label,BoxConfidence ],分别表示中心点坐标,宽和高,标签索引,置信度,我们只需要前5个数据即可。
这个项目做的过程并不是这么轻松,本来想要让它代替我肝游戏的,但是目前来看只完成了第一版就懒得再动了,当然能够自动打完全图还是激动的,我也曾想向 MaaAssistantArknights 这个明日方舟工具一样开源,让大家一起来共建,但是感觉避免不了会有黑产影响dnfm项目组业绩,还是作罢。
勇士在怎样热爱这个游戏终究不是年轻时的勇士,没时间继续迭代更新这个工程,也没时间继续每天花1小时自己肝,让我觉得我是时候该放下了。
https://blog.csdn.net/Deaohst/article/details/127835507
https://github.com/iwanggp/yolov5_onnxruntime_deploy
https://github.com/luanshiyinyang/YOLO
https://arxiv.org/abs/1506.02640
https://www.datacamp.com/blog/yolo-object-detection-explained
2024-06-29 18:03:28
最近沉迷于暗黑4第四赛季,所以就在倒腾,怎样才能随时随地玩到暗黑4,掌机steam deck 我试过了,太重并且性能很差,已经被我卖了,于是折腾起了云游戏。
先来看看我的折腾成果:https://www.bilibili.com/video/BV1Z93TeuEQ4/
其实效果我没想到有这么好,在远程串流的情况,可以 1080p 60hz 几乎无卡顿的玩暗黑4,延迟只有20ms左右,配上我的手柄简直就是一个强大的掌机。
有了上面的需求之后,我就去试了以下几个平台:GeForce Now、Xbox Game Cloud、Start云游戏、网易云游戏。
但是遗憾的是,几乎每个平台都有自己的问题。首先上面列举到的所有平台,IOS 都只有网页版,因为苹果不让上架。
Start云游戏:我检查了一下,只有少数的几个单机游戏,大多是网游手游,并没有暗黑4;
网易云游戏:无论是快速启动还是普通启动,都非常的慢,估计要3分钟左右才能启动。并且我充值了一下玩了一下,网络倒是很流畅,延迟只有15ms左右,但是非常的卡,并且经常进入游戏界面死机,估计是机器性能不行,说实话我有点心疼我充值的10块钱了。
所谓的高配,其实性能很低:
Xbox Game Cloud:微软自家的平台,好处是有了XGPU之后可以畅玩所有云游戏,最大的问题是服务器不在国内,所以连接延迟其实很高,并且常有波动,如果要玩Xbox Game Cloud 那么还需要充值XGPU才行;
Xbox Game Cloud 强大的游戏阵容:
GeForce Now:这个云游戏平台可以说只能用无敌两个字来形容,每次登录都可以免费半个小时,即使服务器在海外,但是开了加速器也可以很稳定,画面有720P,在手机上玩还可以,主机性能也很好,经常分配到2080以上的机器。但是唯一不爽得是,免费用户每次都要排队挺长时间的,并且如果要付费,其实挺贵的,基本要100元每个月了。
GeForce Now价格表:

所以尝试了这么的云游戏发现都不好用之后,为什么不可以自己弄个呢?其实所谓的云游戏,无非是用客户端连接到主机端而已。那么我们实际上也可以把自己家里运行的PC或者主机,变成了由云游戏服务商提供的云上服务,这种行为就叫做串流游戏。
所以我们要做的是怎样把我们的私有网络的PC或者主机做成云服务提供给外网访问,让我们可以随时随地,只要有网就可以使用。
那么我的要求主要有这么几点:
正好自己有台闲置的 4090 的机器,那我就可以用它来作为主机端,我的安卓机作为客户端进行串流云游戏。
目前服务端主要有以下几个实现方案:
客户端主要有:Moonlight
如果你使用N卡,并且是GTX960以上可以通过GeForce Experience进行串流。只需要打开GeForce Experience在设置里找到SHELD这个串流配置,并添加游戏或者应用程序即可。
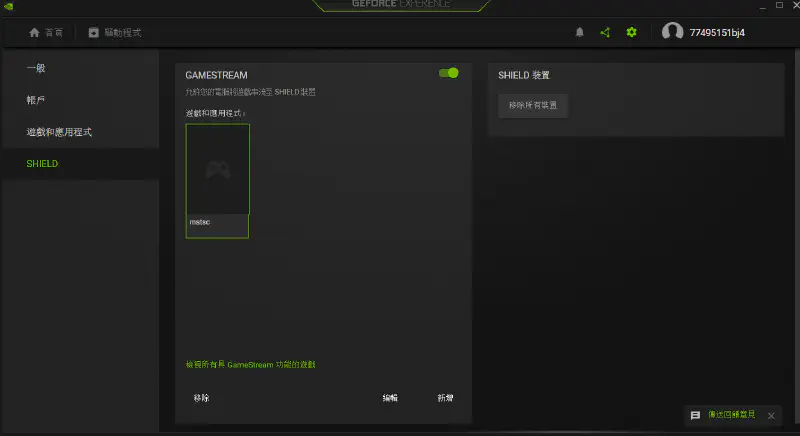
但是我现在不是很推荐这个方案,因为NV说过他们要把这个功能去掉,只是现在没有去掉而已。
它是一个开源推流方案 https://github.com/LizardByte/Sunshine , 属于通用串流方案,支持Nvidia、AMD、Intel。尤其适合核显串流(如果你用的是P106这类显卡没有视频编码器,只能使用Sunshine串流方案)。
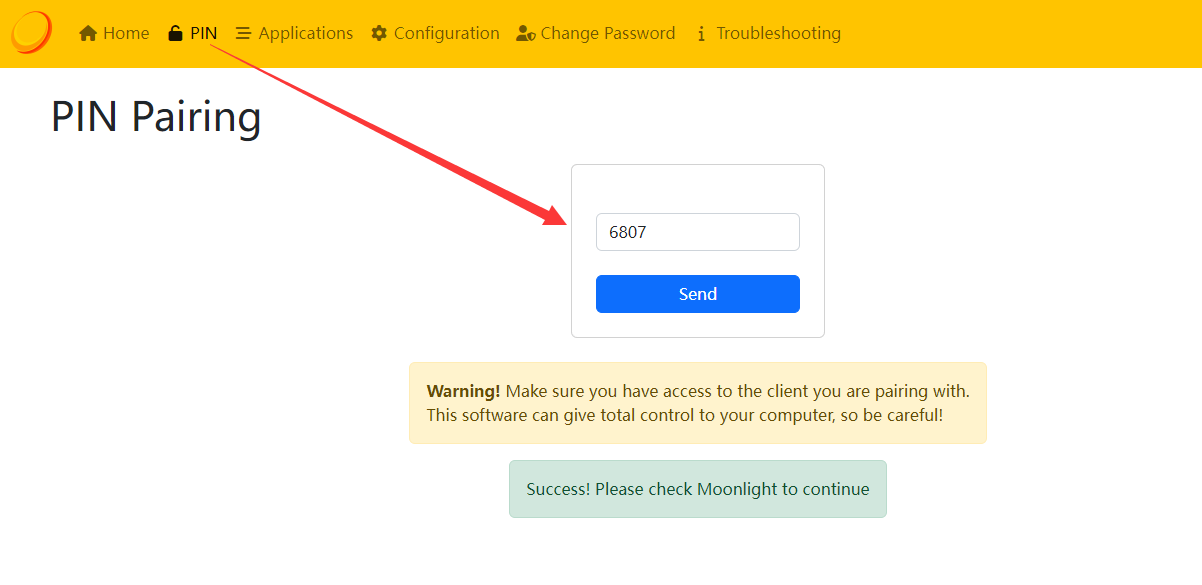
下载Sunshine后首先需要运行服务端安装脚本install-service.bat,然后再运行sunshie。sunshine没有UI界面,设置需要通过网页端。运行sunshine后访问https://127.0.0.1:47990进行设置。设置里最重要的是进行PIN码配对,设备之间PIN匹配之后就可以进行串流了。
Moonlight 以方便的将Windows电脑画面传输到各主流操作系统的客户端软件上,甚至可以直接传输至谷歌浏览器。画面方面,移动端最高支持4K120帧,且支持HDR(需要显卡支持),而桌面端甚至可以直接自定义分辨率和帧数;交互方面支持键鼠/手柄/触摸屏/触控板/触控笔,就像用自己的电脑一样使用远程电脑。该方案无广告,完全免费。
手机端可以在各大商店下载,也可以去 Moonlight官网地址:https://moonlight-stream.org 下载。如果使用iphone作为客户端,直接在App store下载Moonlight即可。
保持主机和客户端在同一局域网内,打开客户端软件,应该能够看到主机的计算机名。点击会弹出4位PIN码,需要在Sunshine配置网页 https://localhost:47990/pin 中输入PIN码。建立连接后,点击桌面(DESKTOP)将启动桌面串流。
网络配置好之后,在局域网内串流延迟通常相当的底,我经常躺床上用 pad 串流我书房的 pc 玩游戏,延迟只有几毫秒。
由于Geforce Experience和Sunshine默认只在本地网络监听端口,客户端和主机位于同一局域网内才能连接成功,如果要真正实现远程连接,最简单稳定的方法是公网直连。
独一无二的IP地址使得主机能够在互联网中被识别,但是由于IPv4地址匮乏,大多数家庭网络并不具备公网IPv4地址。
所以我这里采用内网穿透的方式来构建我们的云服务:
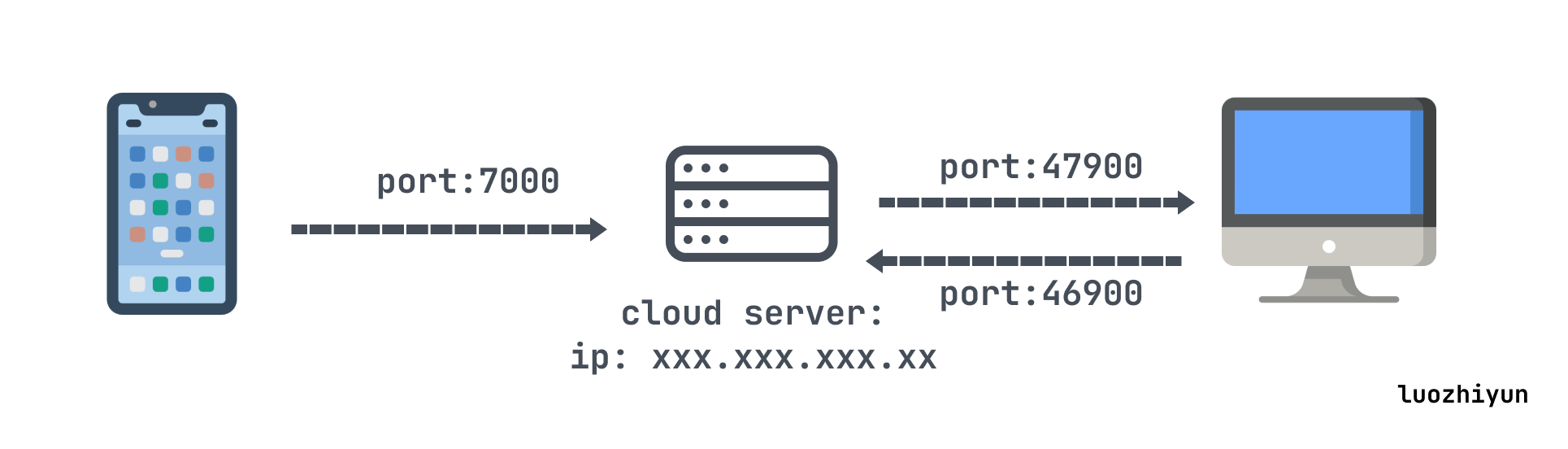
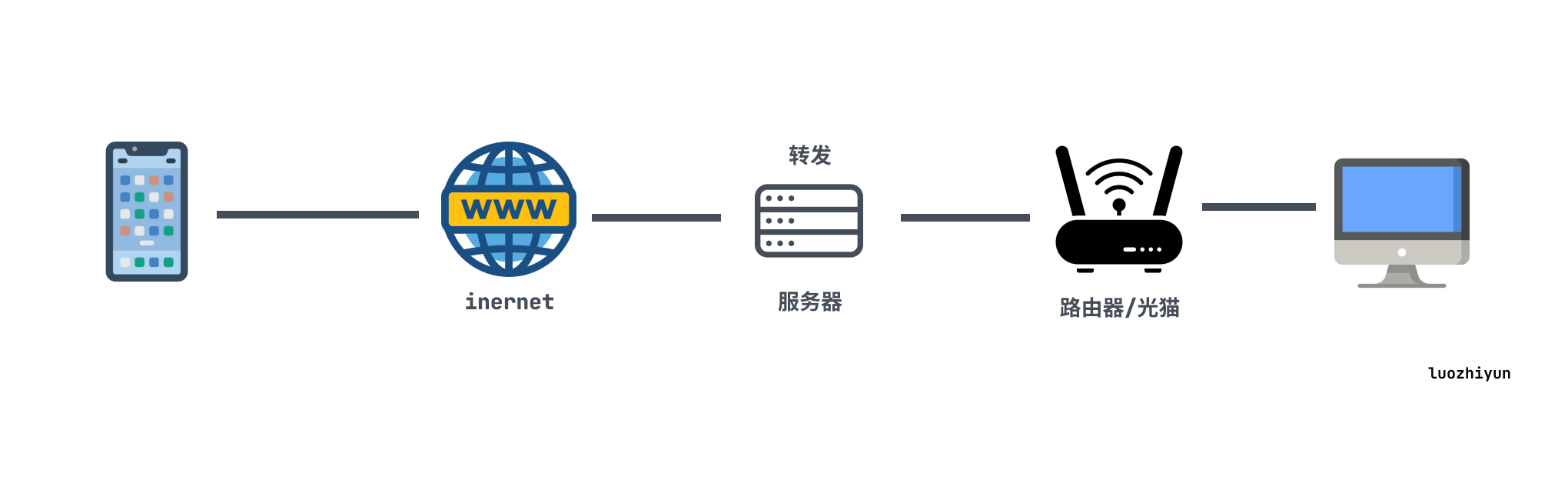
内网穿透的核心思想就是“映射”和“转发”,把私有网络的设备的端口映射到公网设备的端口上,来进行流量转发。思想其实很简单,由于内网设备没有ip,那么我们通过一台有公网ip的机器来代替把流量做一层转发。比如上图,
我们在外网设置的用手机访问云服务器的 7000 端口,实际上云服务器会接收到之后通过47900进行转发到我们私有网络的pc机器,然后pc机器处理完之后再通过46900 端口转发给云服务器,上面所提到的端口都是可以自定义的。
那么对于做内网穿透一般现在流行两种做法:
其实在互联网的世界中,如果每个用户都有真实的IP情况下,那么我们可以通过源IP+源端口+目标IP+目标端口+协议类型很容易的找到对方,是根本不需要P2P的,因为本来任何对象都可以作为Server或者Client来提供服务,彼此之间是可以互联。
但是IP和端口,是有限的,最初设计者也是没想到发展如此迅速,整个IPv4的地址范围,完全不够互联网设备来分配,那为了解决地址不够用的问题,就引入了NAT。
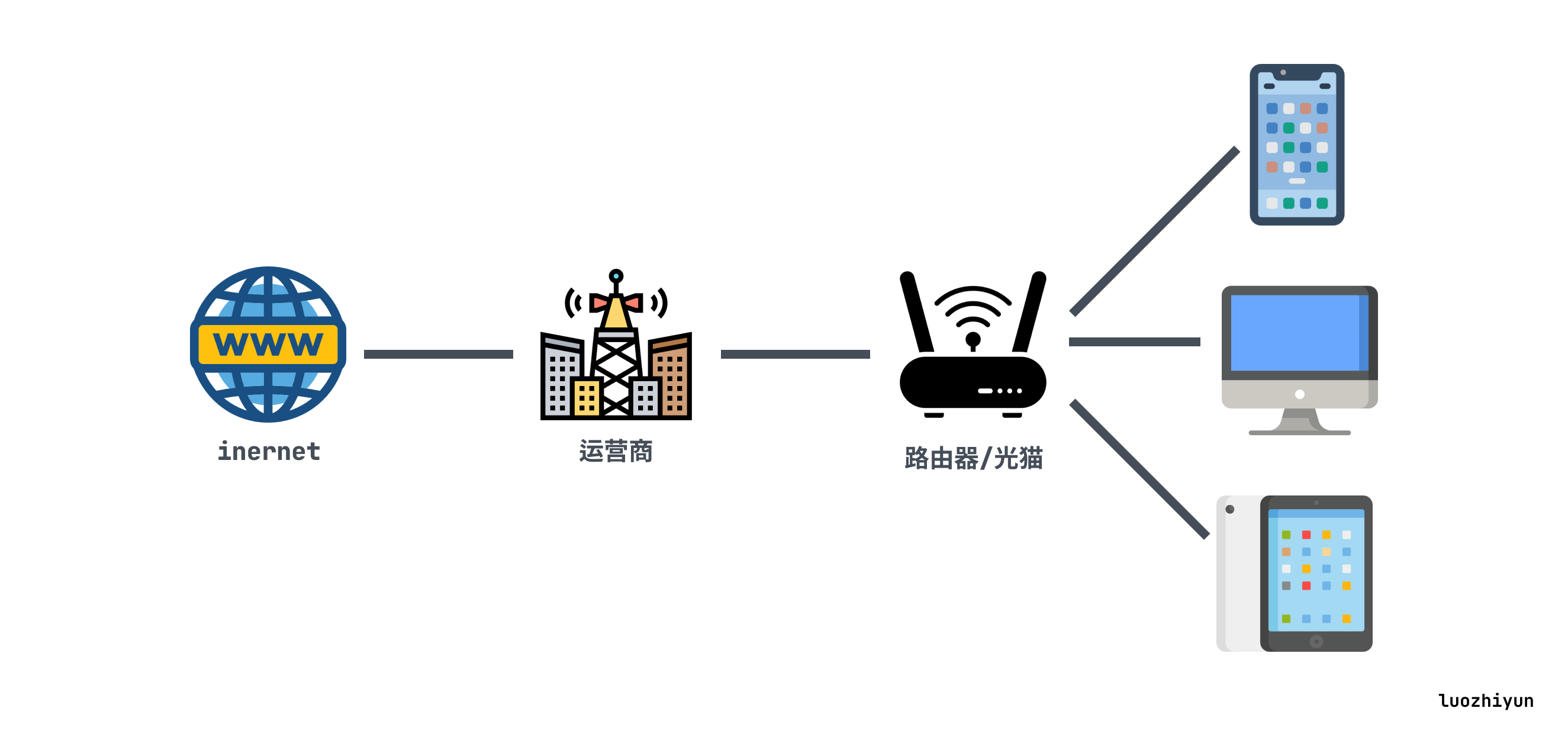
NAT(Net Address Translate,网络地址转换)是一种IP复用的一种技术,将有限的IP扩展成无限,由于IPv4地址资源有限,而NAT将网络划分成了公有网络和私有网络,允许多个设备使用一个公共IP地址访问互联网。路由器会将内部网络中的私有IP地址转换为公共IP地址,从而节省了IPv4地址资源。
所以我们在用 WIFI 的时候可以看到我们手机或PC上的IP地址通常是:192.168.x.xxx,这其实就是由路由器分配的地址,并不是真的地址。
另外,在 IPv4 地址资源越来越紧张的今天,很多电信运营商,已经不再为用户分配公网 IP;而是直接在运营商自己的路由器上运营 NAT,所以会出现甚至一整个小区共用一个 IP 出口的情况。
通过NAT技术的公私网络隔离,可以实现IP复用,解决了IPv4不够用的问题,但是也同时带来了新问题,那就是直接导致通信困难,由于NAT导致IP成为虚拟IP,外网无法针对内网某台主机进行直连通信,因为没有真实地址可用。
所以为了将NAT设备内外通信打通,就有了内网穿透技术。
zerotier 是一个开源的内网穿透软件 https://github.com/zerotier/ZeroTierOne ,有社区版本和商业版本,唯一的区别是社区版本有 25台连接数量的限制,但对普通用户足够了,用它可以虚拟出一组网络,让节点之间的连接就像是在局域网内连接一样。
zerotier 底层是通过一个加密的p2p网络来实现连接。由于节点之间通常存在NAT隔离,无法直接通信,所以 zerotier 存在一个根服务器来帮助通路建设,所谓通路建设俗称打洞(hole punching),也就是穿透NAT隔离实现两个节点的连接。打洞也是区分 UDP 和 TCP 的,由于 zerotier 用的是 UDP,所以这里以 UDP 讲解打洞原理。
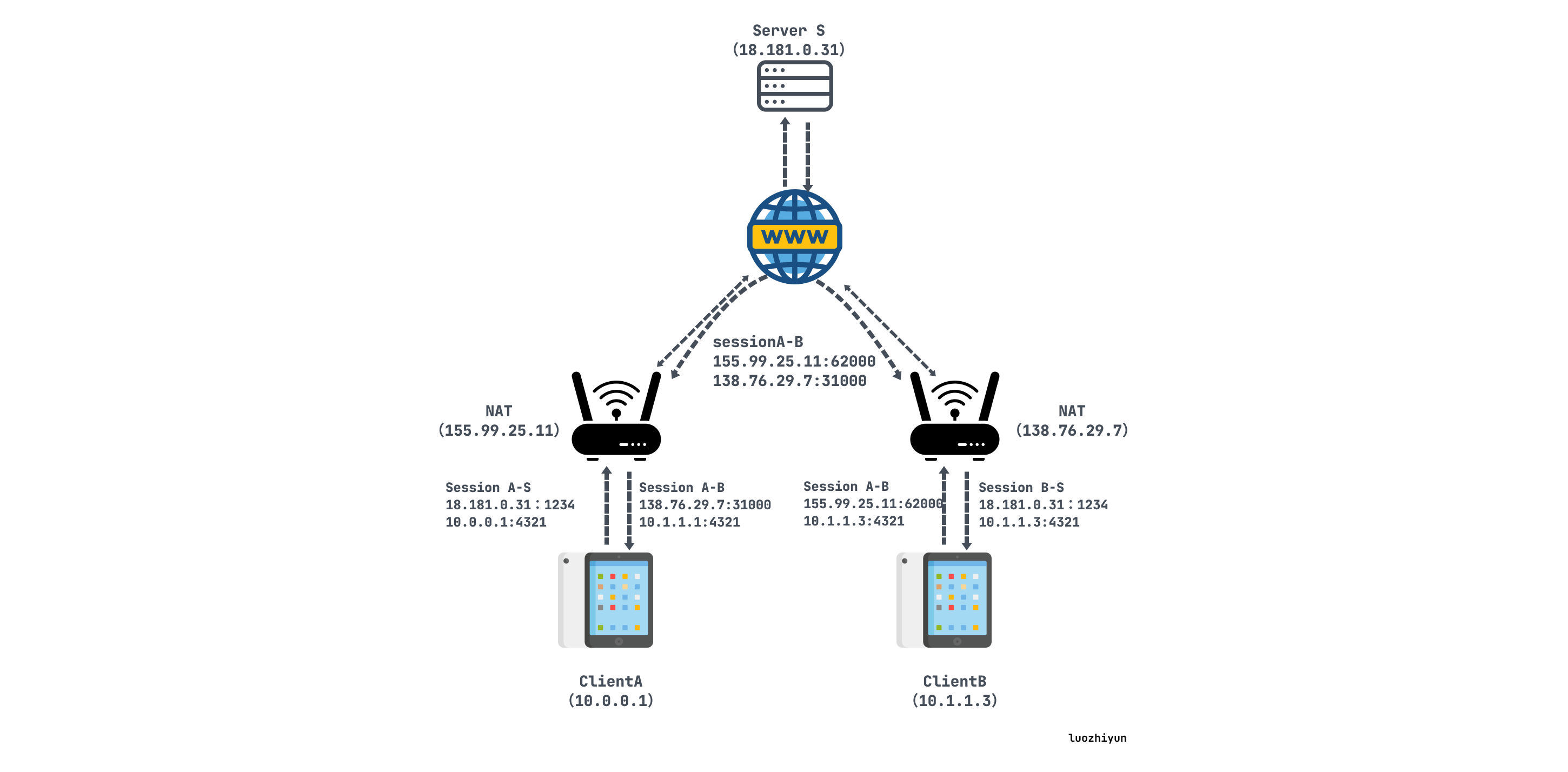
假设clientA 想要直接与clientB 建立UDP会话,用S表示根服务器:
A最初不知道如何到达B,因此A请求S帮助与B建立UDP会话,S会记录下他们各自的内外网IP端口:
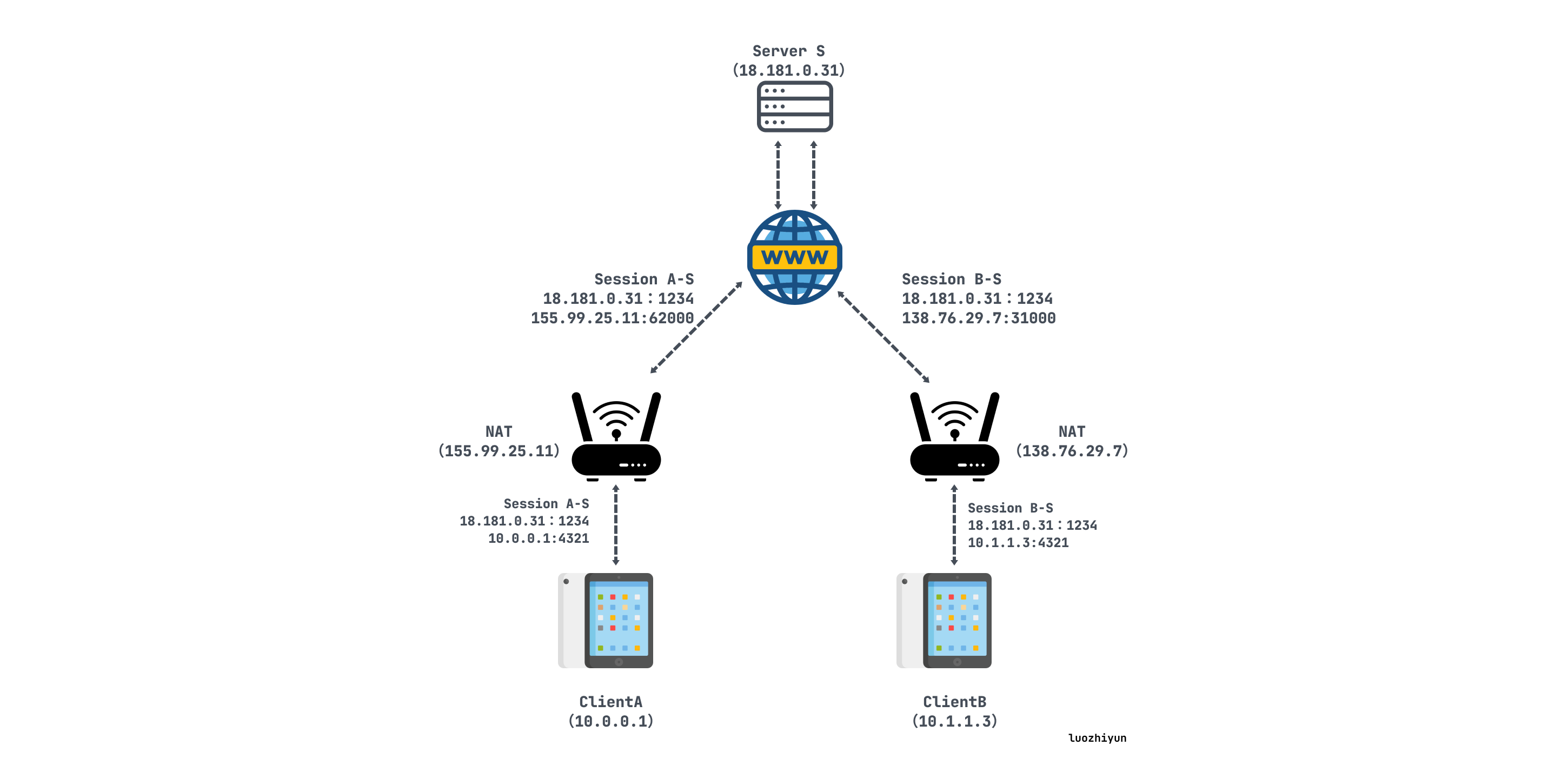
打洞中:
S用包含B的内外网IP端口的消息回复A。同时,S使用其与B的UDP会话发送B包含A的内外网IP端口的连接请求消息。一旦收到这些消息,A和B就知道彼此的内外网IP端口;
当A从S接收到B内外网IP端口信息后,A始向这两个端点发送UDP数据包,并且A会自动锁定第一个给出响应的B的IP和端口;
B开始向A的内外网地址二元组发送UDP数据包,并且B会自动锁定第一个给出相应的A的IP和端口;
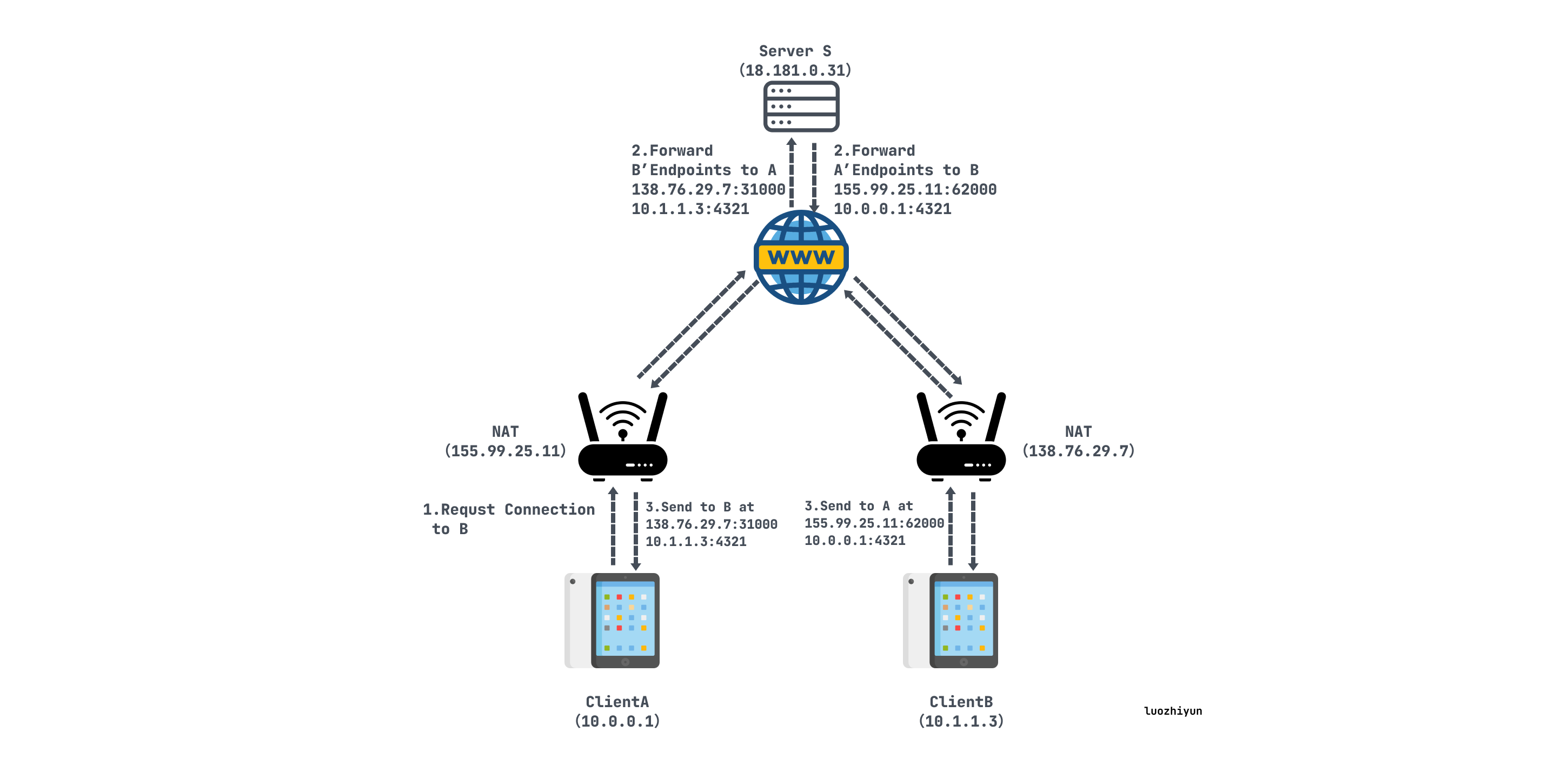
打洞后:
A和B直接利用内网地址通信
zerotier 的根服务实际上是部署在海外的,如果我们直接使用,很可能连不上,并且延迟基本在200ms以上,我们可以通过 zerotier-cli listpeers 查看根服务器:
# ./zerotier-cli listpeers
200 listpeers <ztaddr> <path> <latency> <version> <role>
200 listpeers 62f865ae71 50.7.252.138/9993;24574;69283 341 - PLANET
200 listpeers 778cde7190 103.195.103.66/9993;24574;69408 213 - PLANET
200 listpeers cafe9efeb9 104.194.8.134/9993;4552;69462 159 - PLANET上面的 PLANET 节点就是是ZeroTier网络中的根服务器。它们负责在对等点之间中继初始流量,帮助对等点建立对等连接,并充当身份和相关公钥的缓存。
我们随便 ping一下它的延迟:
# ping 50.7.252.138
PING 50.7.252.138 (50.7.252.138) 56(84) bytes of data.
64 bytes from 50.7.252.138: icmp_seq=1 ttl=46 time=347 ms
64 bytes from 50.7.252.138: icmp_seq=2 ttl=46 time=347 ms
64 bytes from 50.7.252.138: icmp_seq=3 ttl=46 time=354 ms这样的游戏明显是玩不了云游戏的,zerotier 也考虑到这种延迟的情况,所以可以让有需要的用户自建 MOON 服务器。
ZeroTier中的MOON节点是用户定义的根服务器,可以添加到ZeroTier网络中。它的行为类似于ZeroTier的默认根服务器(称为PLANET节点),但由用户控制,我们可以把 MOON 服务器部署在离自己更近的地方,比如我就部署在广州,可这样以通过提供更近或更快的根服务器来提高网络性能。
怎样部署我这里就不贴教程了,可以自己去search一下,很简单。 但是现实场景中的网络要复杂的多,远远不是部署一个 MOON 节点就可以解决延迟的问题。通常我们的网络会涉及到防火墙限制、运营商级NAT、路由器兼容问题,还有就是 ZeroTier 走的是 UDP, 在国内的网络环境下一些运营商会对UDP流量实施QoS(服务质量)策略,,丢包可能会比较严重。
所以总之ZeroTier这条路并不是这么好走,看起来 p2p 直连貌似可以很美好,理论上可以不受根服务器的影响,两端直连跑满所有带宽,但实际上当不能打洞成功的时候那么就会退化成根服务器转发,那么实际的速率就取决于你自建的 MOON 节点的转发带宽了。
并且还有一个问题是,ZeroTier 是需要客户端的,到目前为止移动端的 app 是不支持添加自建 MOON 节点信息的,也就是说只能在电脑上进行串流,这实用性还是下降了不少。
所以总结一下优缺点:
优点:
缺点:
frp 也是一个开源软件 https://github.com/fatedier/frp ,实际上它没有这么多花哨的功能,就是帮我们做了一个流量的转发。它的客户端连接不需要app,所以用来串流的话直接用moonlight直接连接frp远程转发服务器即可,可以说很方便了。
它的架构如下:
在安装frp远程转发服务的时候,我这里给一下配置,因为现在网上找的教程都是老的 ini 配置,现在新版本用的是 toml配置。
服务端的配置:
#frps服务监听的本机端口
bindPort = 9200
bindAddr = "0.0.0.0"
# frpc客户端连接鉴权token,默认为token模式
auth.token="xxxx"
#日志打印配置
log.to = "./log"
log.level = "debug"
log.maxDays = 7
allowPorts = [
// 远程连接需要用的端口
{ start = 47000, end = 48010 }
]sunshine主要连接的端口是这几个:
TCP 47984, 47989, 48010
UDP 47998, 47999, 48000, 48002, 48010所以我们需要给这几个端口都加上防火墙,服务器和pc都要开放相应的端口,在测试的时候可以先全打开,测试完了再挨个加上,免得莫名其妙的问题。
pc端的配置:
#token需要与服务端的token一致
auth.token = "xxxxx"
# 服务端的公网ip
serverAddr = "1xx.xxx.xx.xx"
# 服务端的监听端口
serverPort = xxx
[[proxies]]
name = "47984"
type = "tcp"
localIP = "127.0.0.1"
localPort = 47984
remotePort = 47984
[[proxies]]
name = "47989"
type = "tcp"
localIP = "127.0.0.1"
localPort = 47989
remotePort = 47989
[[proxies]]
name = "47990"
type = "tcp"
localIP = "127.0.0.1"
localPort = 47990
remotePort = 47990
[[proxies]]
name = "48010"
type = "tcp"
localIP = "127.0.0.1"
localPort = 48010
remotePort = 48010
[[proxies]]
name = "47998"
type = "udp"
localIP = "127.0.0.1"
localPort = 47998
remotePort = 47998
[[proxies]]
name = "47999"
type = "udp"
localIP = "127.0.0.1"
localPort = 47999
remotePort = 47999
[[proxies]]
name = "48000"
type = "udp"
localIP = "127.0.0.1"
localPort = 48000
remotePort = 48000
[[proxies]]
name = "48002"
type = "udp"
localIP = "127.0.0.1"
localPort = 48002
remotePort = 48002
[[proxies]]
name = "48010"
type = "udp"
localIP = "127.0.0.1"
localPort = 48010
remotePort = 48010
windows系统开机自启比较麻烦,不像linux简单,所以为了保证windows后台运行 frpc,创建脚本 frpc.vbs,将以下内容粘贴进去:
set ws=WScript.CreateObject(“WScript.Shell”)
ws.Run “[frpc执行文件] -c [frpc配置]”,0注意可能需要修改路径(默认路径是放C盘目录下)
将 frpc.vbs 放入 C:\ProgramData\Microsoft\Windows\Start Menu\Programs\StartUp 目录内,即可实现开机自启动。
家里的电脑如果经常开机的话很费电,所以按需开机是最佳办法,那么就需要远程登陆开机。远程唤醒需要主板的支持,现在的主板基本都支持。
首先我们要进入到主板的 BIOS 设置选项里面把 WOL 功能打开,具体方法视厂商而定,可以参考的关键词包括:
然后在我们被唤醒的电脑里面找到网卡设置:
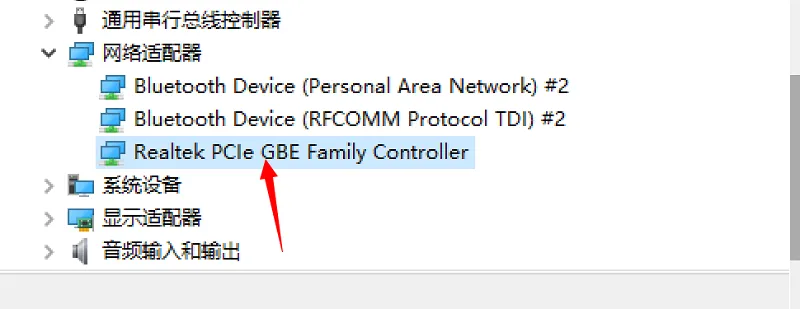
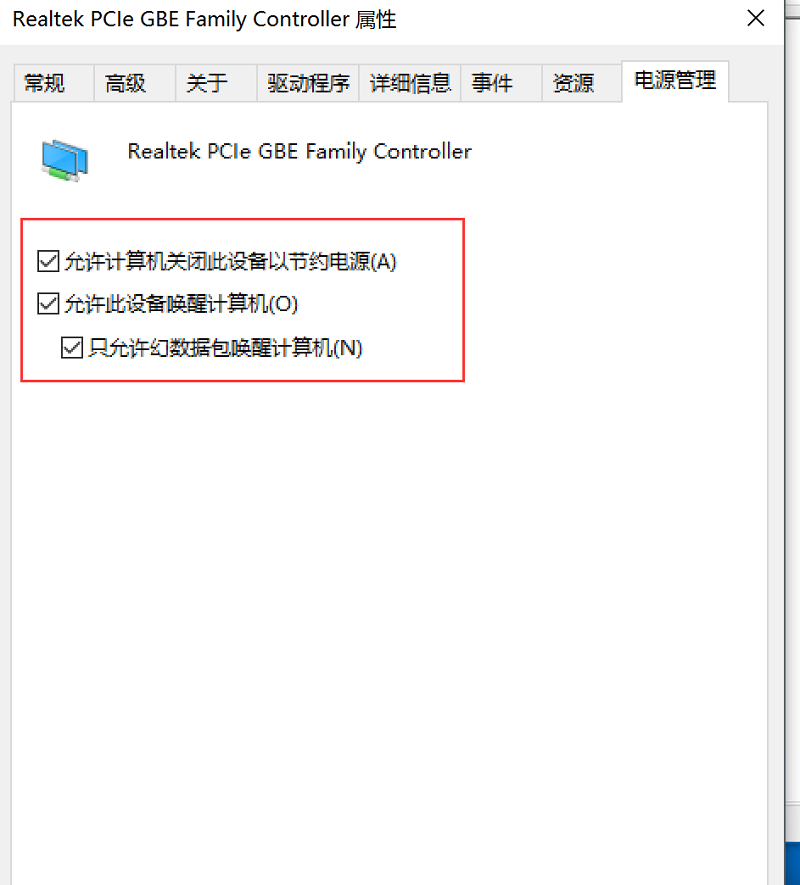
然后我们可以在内网尝试一下,是否可以唤醒成功,在应用市场随便找个WOL软件,填上内网被唤醒机器的IP地址和MAC地址即可:
外网唤醒,我们需要一个中间设备来中转我们的流量,因为我们需要被唤醒的机器已经被休眠了,是无法接收到请求的,所以我这里内网用我的软路由进行转发:
首先我们要做的就是 DHCP固定住自己内网PC的内网IP,要不然无法转发唤醒,通常可以在路由器里面设置:

然后我是通过 OpenWrt 来和我远端服务器建立好 frp通信,监听转发端口,到时候外面的请求会先到 OpenWrt ,然后由它再转发给我的内网PC:

最后如果觉得麻烦,其实可以用远程物理按键解决,一劳永逸:

在用 sunlight 串流的时候由于显示的是桌面的,,因为串流软件会捕捉屏幕上的内容并编码成视频流。如果关闭屏幕,编码器将无法获取到需要的画面信息,导致串流中断。
那么如果我们想要关闭屏幕串流,那么可以用这个工具 https://github.com/VergilGao/vddswitcher ,通过 vdd 创建一个虚拟屏幕可以实现即使主屏关闭也能串流。
游戏串流最后不仅满足了我在外网想要随时随地玩游戏的想法,并且还拯救了我的腰椎,在家里玩游戏现在基本是用平板串流到我的电脑上面,然后买个支架夹着我的平板,然后躺着玩,但愿各位游戏佬都能找到属于自己的游戏环境。

https://github.com/VergilGao/vddswitcher
https://github.com/LizardByte/Sunshine
https://github.com/moonlight-stream/moonlight-qt
https://keenjin.github.io/2021/04/p2p/
https://bford.info/pub/net/p2pnat/

2024-06-01 18:03:14
本文从 RocksDB 基本架构入手介绍它是怎么运作的,以及从它的操作方式解释为什么这么快,然后探讨RocksDB 所遇到的性能挑战,各种放大问题是如何解决的,最后讨论一些新的 LSM 树优化方法,希望能对大家有所启发。
RocksDB 是一个高性能的 KV 数据库,它是由 Facebook 基于 Google 的 LevelDB 1.5构建的。RocksDB 被设计为特别适用于在闪存驱动(如 SSD)和 RAM 上运行,主要用于处理海量数据检索,以及需要高速存取的场景。 Facebook在 Messenger 上使用RocksDB,用户可以在其中体验快速消息发送和接收功能,同时确保其消息数据的持久性。
RocksDB 是一款内嵌式数据库使用 C++ 编写而成,因此除了支持 C 和 C++ 之外,还能通过 С binding 的形式嵌入到使用其他语言编写的应用中,如 https://github.com/linxGnu/grocksdb 。由于它是内嵌的数据库,所以它是没有独立进程的,它需要被集成进应用,和应用共享内存等资源,也没有跨进程通信的开销,也无法网络通信,也不是分布式的。
RocksDB 的设计目标是主要有以下几点:
基于以上这几点,如今很多分布式存储用它来做内部存储组建之一,如Apache Flink流处理框架中用作状态存储,它为维护流应用程序的状态提供快速高效的存储;TiDB 用它来构建存储引擎 TiKV,来支持大量的数据读写。
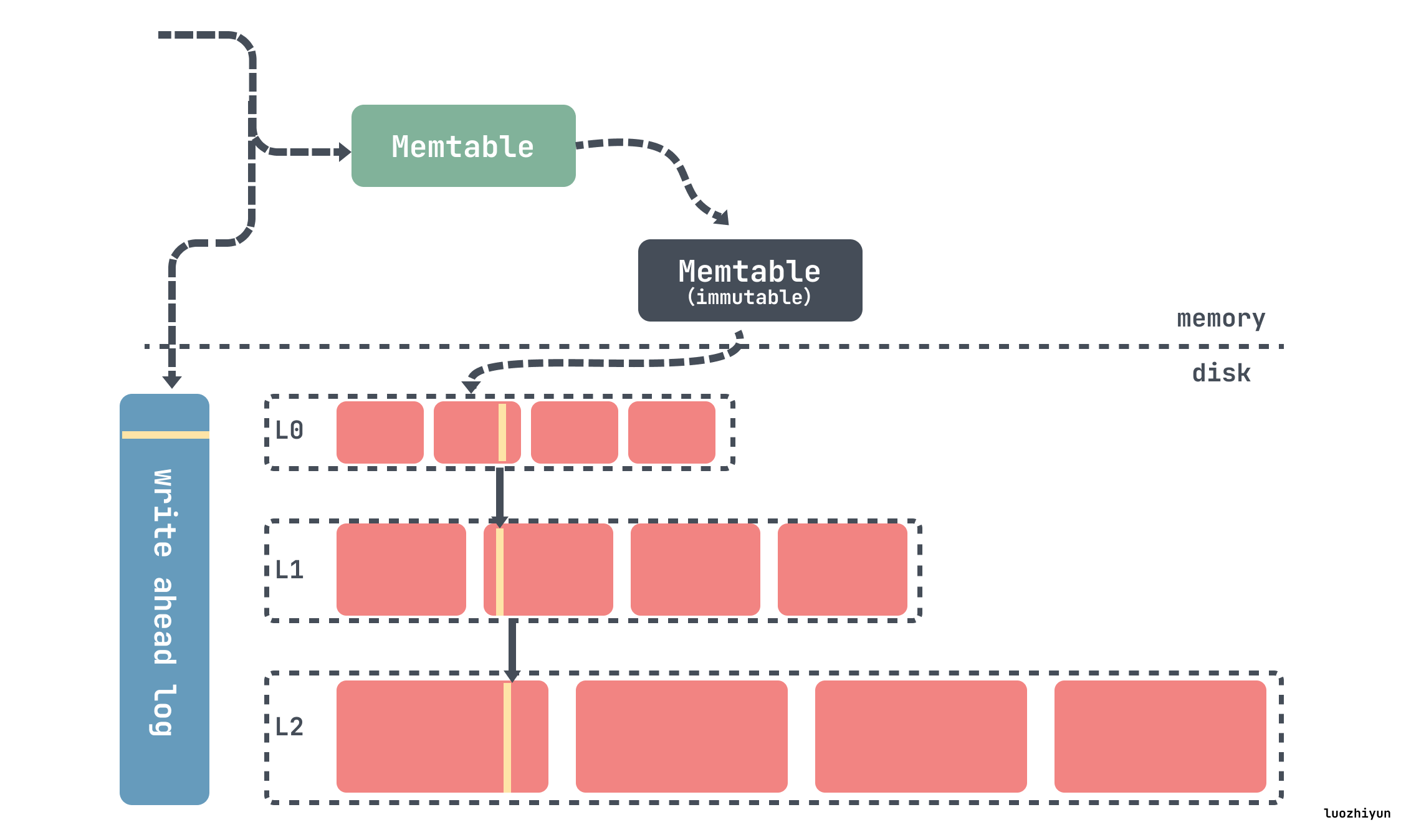
RocksDB 基础的组件是MemTable、SSTable和 预写日志(WAL)日志。每当数据被写入RocksDB时,它会被添加到一个内存中的写缓冲区称为MemTable,同时也支持配置是否同步记录在磁盘上的预写日志(WAL)中,WAL主要用来做数据持久性和系统故障时的崩溃恢复使用,MemTable 默认是用跳表实现的,因此能保持数据有序,插入和搜索开销为 O(log n)。
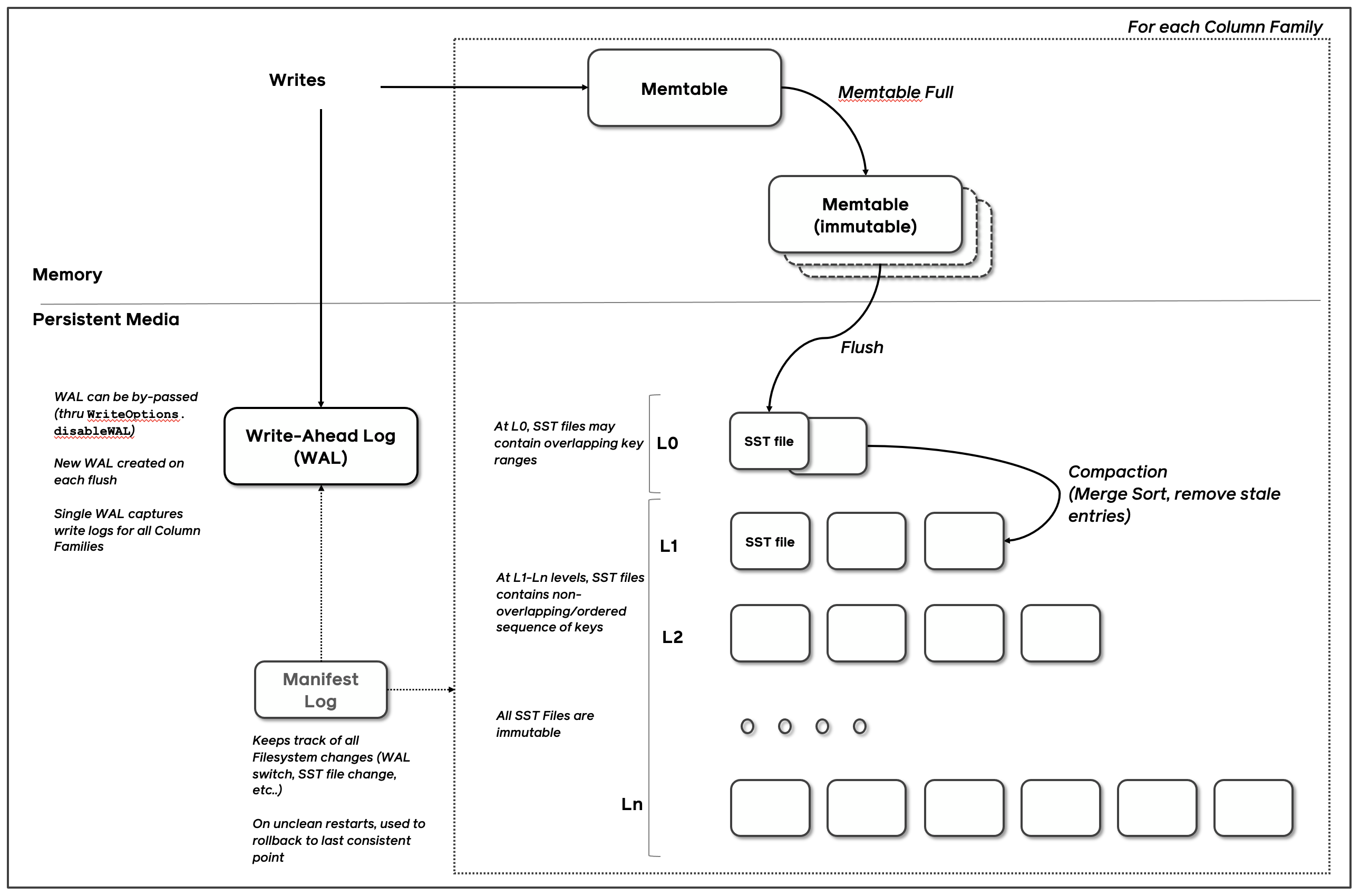
MemTable 会根据配置的大小和数量来决定什么时候 flush 到磁盘上。一旦 MemTable 达到配置的大小,旧的 MemTable 和 WAL 都会变成不可变的状态,称为 immutable MemTable,在任何时间点,都只有一个活跃的 MemTable 和零个或多个 immutable MemTable。然后会重新分配新的 MemTable 和 WAL 用来写入数据,旧的 MemTable 会被 flush 到SSTable文件中称为L0层的数据。
被 flush 到磁盘上的 SSTable 会按照层级一层层存放,如上图从 L0 到 Ln,在每层中(级别0除外),数据被范围分区为多个 SSTable 文件。
这些 SSTables 都是是不可变的和有序的,每一层SSTable被组织成固定大小的块存放,每个SSTable都包含一个数据段和一个索引,可以通过二分查找快速查找数据,并且还可以通过布隆过滤器过滤无效数据,这种不变性、有序和索引结构的组合有助于RocksDB的整体性能和可靠性。
RocksDB是通过 LSM Tress 的方式通过将所有的数据添加修改操作转换为追加写方式,对于 insert 直接写入新的kv,对于 update 则写入修改后的kv,对于 delete 则写入一条 tombstone 标记删除的记录。
所以数据的查找会从 MemTable 内存数据开始,如果不存在,然后再从L0层级的 SSTable 开始找起,直到找到或者遍历完所有的 SSTable。SSTable 查找的时候会根据二分法加上布隆过滤器进行查找,过滤掉 key 不存在的 SSTable 文件,提升查询效率。
所以通过上面的简介可以知道对于 RocksDB 来说内部主要有以下几个结构:
上面我们概述了一下 RocksDB 写入修改的过程是怎样的,数据首先会写入到 MemTable 中,当 MemTable 满了之后就会 flush 到磁盘中,称为 L0 级的 SSTable,L0 级的 SSTable 满了之后就会被 Compaction 到下一层级,也就是 L1 级中,以此类推。
如果没有 Compaction 行不行?直接把 L0 级的文件放入到 L1 中,这样不就省去了磁盘 IO 的开销,不需要重写数据,但是答案当然是不行。
因为 LSM Tree 通过将所有的数据修改操作转换为追加写方式,insert会写入一条新的数据,update会写入一条修改过的数据,delete会写入一条tombstone标记的数据,因此读取数据时如果内存中没有的话,需要从L0层开始进行查找 SSTable 文件,如果数据重复的很多的话,就会造成读放大。因此通过 Compaction 操作将数据下层进行合并、清理已标记删除的数据降低放大因子(Amplification factors)的影响。
一般我们说放大因子包括一下几种:
空间放大(Space amplification) :指的是需要使用的空间和实际数据量的大小的比值,如果您将10MB放入数据库,而它在磁盘上使用100MB,则空间放大为10。
读放大(Read amplification) :指的是每个查询的磁盘读取次数。如果每次查询需要读取5页来查询,则读取放大为5。
写入放大(Write amplification):指的是写入磁盘的数据与写入数据库的字节数的比值。比如正在向数据库写入10 MB/s,但是观察到30 MB/s的磁盘写入速率,您的写入放大率为3。如果写入放大率很高,高工作负载可能会在磁盘吞吐量上遇到瓶颈。如果写入放大为50,最大磁盘吞吐量为500 MB/s,那么只能维持 10 MB/s 的写入速度。
虽然 Compaction 可以降低放大因子的影响,但是不同的 Compaction 策略是对不同放大因子有侧重点,需要在三者之间权衡,后面我们会聊到。
RocksDB的 Compaction 包含两方面:一是MemTable写满后flush到磁盘;二是从L0 层开始往下层合并数据。
最顶层的 L0 层级的 SSTable 是通过 MemTable 生成的,RocksDB的所有写入都首先插入到一个名为 MemTable 的内存数据结构中,一旦 MemTable 达到配置的大小,旧的 MemTable 和 WAL 都会变成不可变的状态,称为 immutable MemTable,然后会重新分配新的 MemTable 和 WAL 用来写入数据,旧的 MemTable 会被写入到SSTable文件中。
在任何时间点,都只有一个活跃的 MemTable 和零个或多个 immutable MemTable。 因为 MemTable 是有序的,所以 SSTable 文件也是有序的,所以 SSTable 都有自己的索引文件,通过二分查找来索引数据。
除L0层级的 SSTable 都是后台进程Compaction操作产生的。所以 Compaction 实际上就是一个归并排序的过程,将Ln层写入Ln+1层,过滤掉已经delete的数据,实现数据物理删除。
所以 Compaction 之后可以降低低放大因子的影响,使数据更紧凑,查找速度更快,但是因为会有一个 merge 过程,所以会造成写放大。
现在主要的compaction策略就两种:Size-Tiered Compaction 和 Leveled Compaction,Leveled Compaction 是 RocksDB 中的默认 Compaction 策略。
Size-Tiered Compaction 策略的做法相当简单。当新的数据写入系统时,首先被写入到内存中的一个结构 MemTable 中,一旦 MemTable 达到一定大小,MemTable会定期刷新到新的SSTable。
系统会监视 SSTable 的大小并将大小相似的 SSTables 分组。当一组中 SSTable 的数量达到预设的阈值(如 Cassandra 默认是 4),系统就会将这些 SSTable 合并成一个更大的 SSTable。在合并过程中,相同键的数据行会被合并,最新的更新会覆盖旧的数据。
如下4个小SSTable会合并成一个中等的SSTable,当我们收集到足够多的中等SSTable文件时,再将它们压缩成一个大SSTable文件,以此类推,压缩后的SSTable 越来越大。
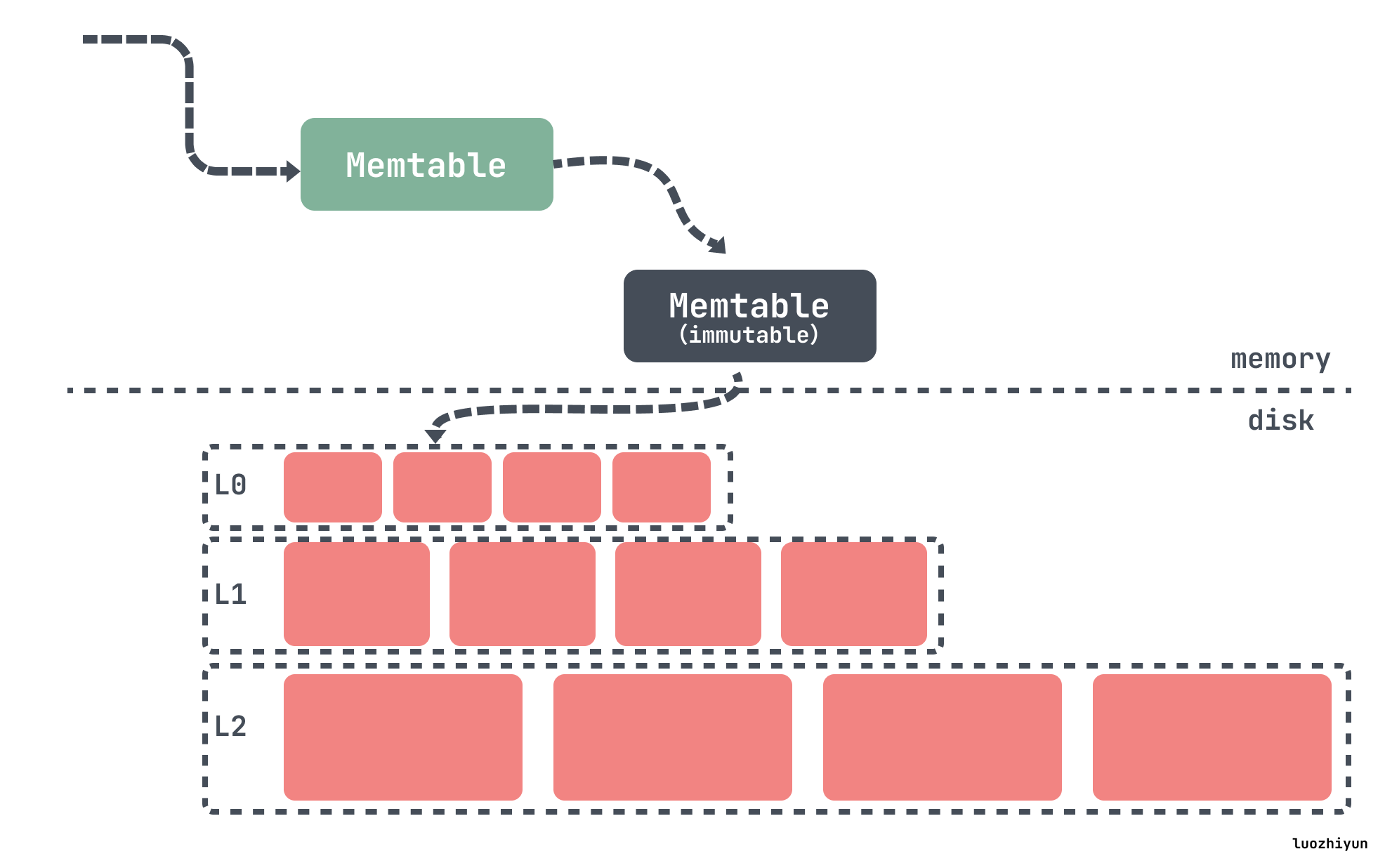
Size-Tiered Compaction 的优点是简单且易于实现,并且SST数目少,定位到文件的速度快。缺点是空间放大比较严重。
空间放大指的是需要使用的空间和实际数据量的大小的比值,Size-Tiered Compaction造成空间放大主要有这几个原因:
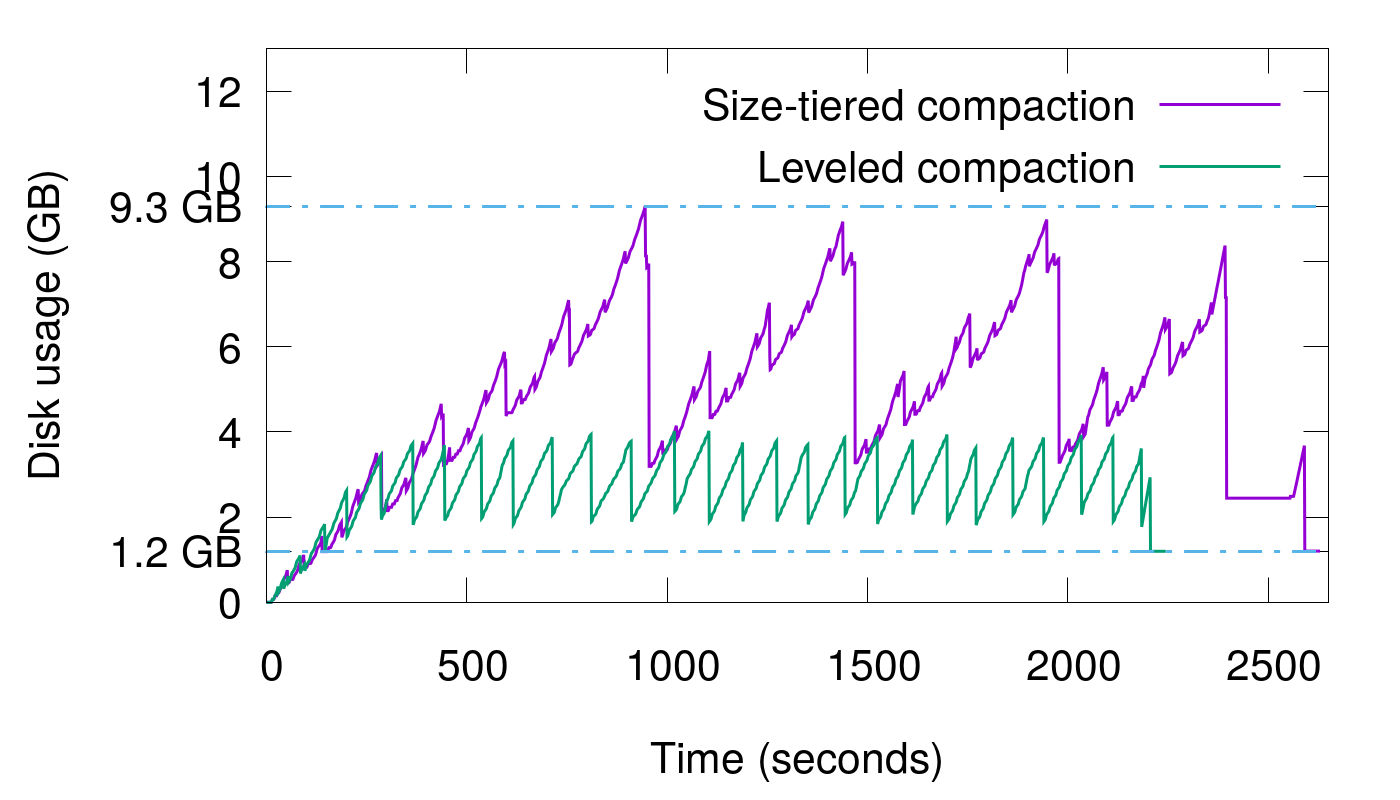
可以使用 cassandra 的极端的例子,在这个例子中,400万数据连续写入15次,写完之后将所有数据Compaction到一个文件中,显示磁盘使用与时间的图表现在如下所示:
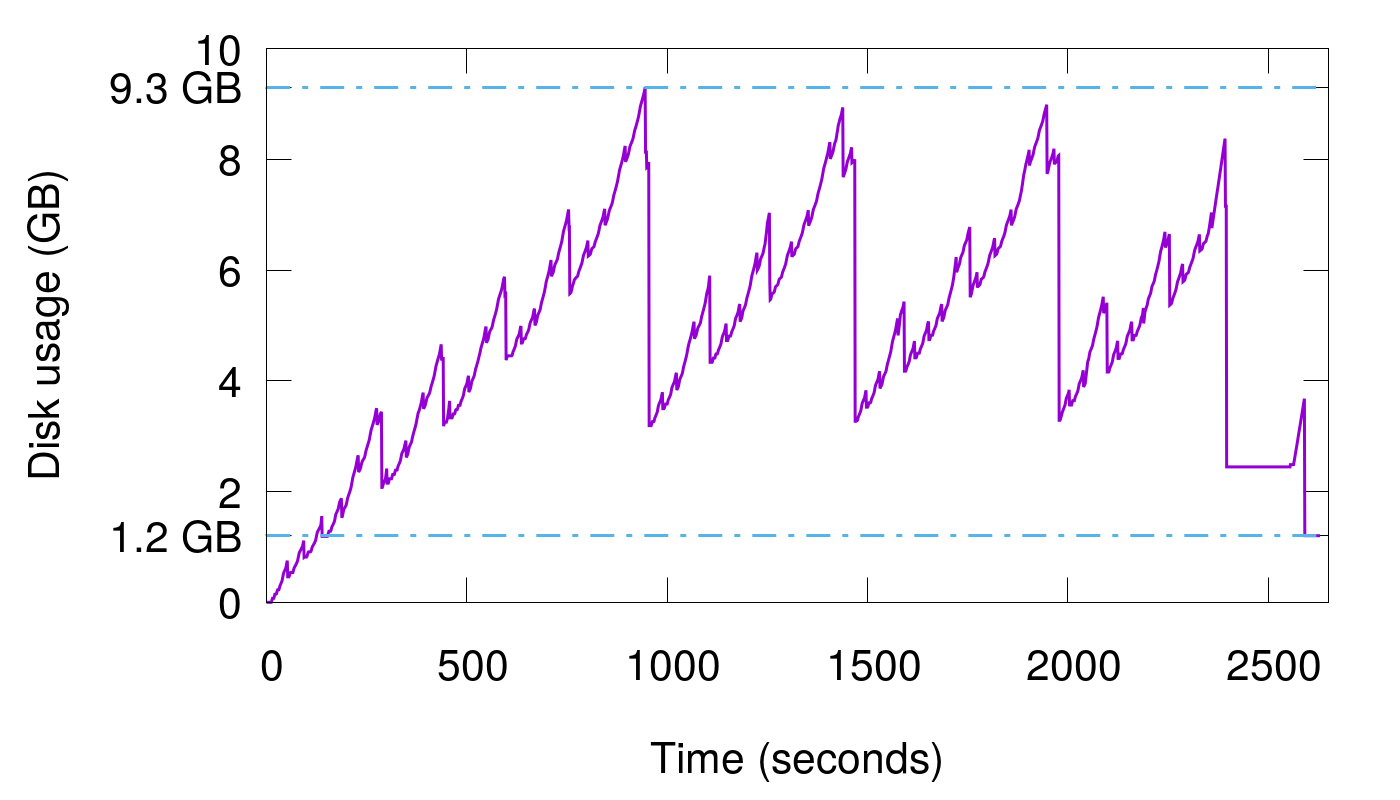
由于最后进行了Compaction操作,所以在这张图中,我们可以看到我们数据库中真正拥有的数据量是1.2 GB。但是磁盘使用量的峰值是9.3 GB,并且在运行的大部分时间里,空间放大都高于3倍。
Leveled Compaction 的思路是将原本 Size-Tiered Compaction 中原本的大 SSTable 文件拆开,成为多个key互不相交的小SSTable的序列。L0层是从 MemTable flush过来的新 SSTable,该层各个 SSTable 的key是可以相交的,并且其数量由配置控制,除L0外都是不相交的 SSTable。
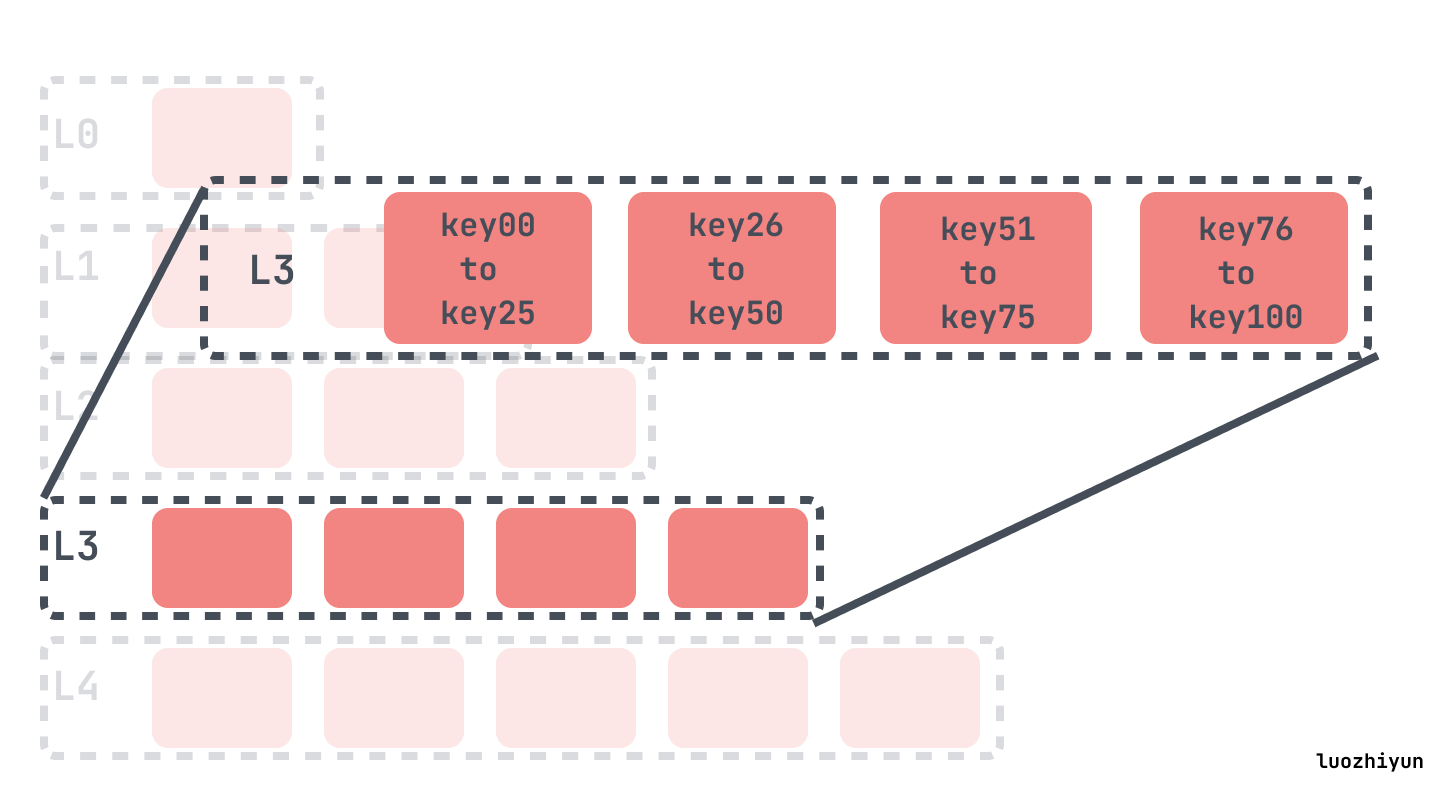
其他层级中的每一个,L1、L2、L3等,每一层都有最大的大小,超过了层级的限制的最大大小会倍compaction 到下一层中,每一层的最大的大小通常呈指数增长。
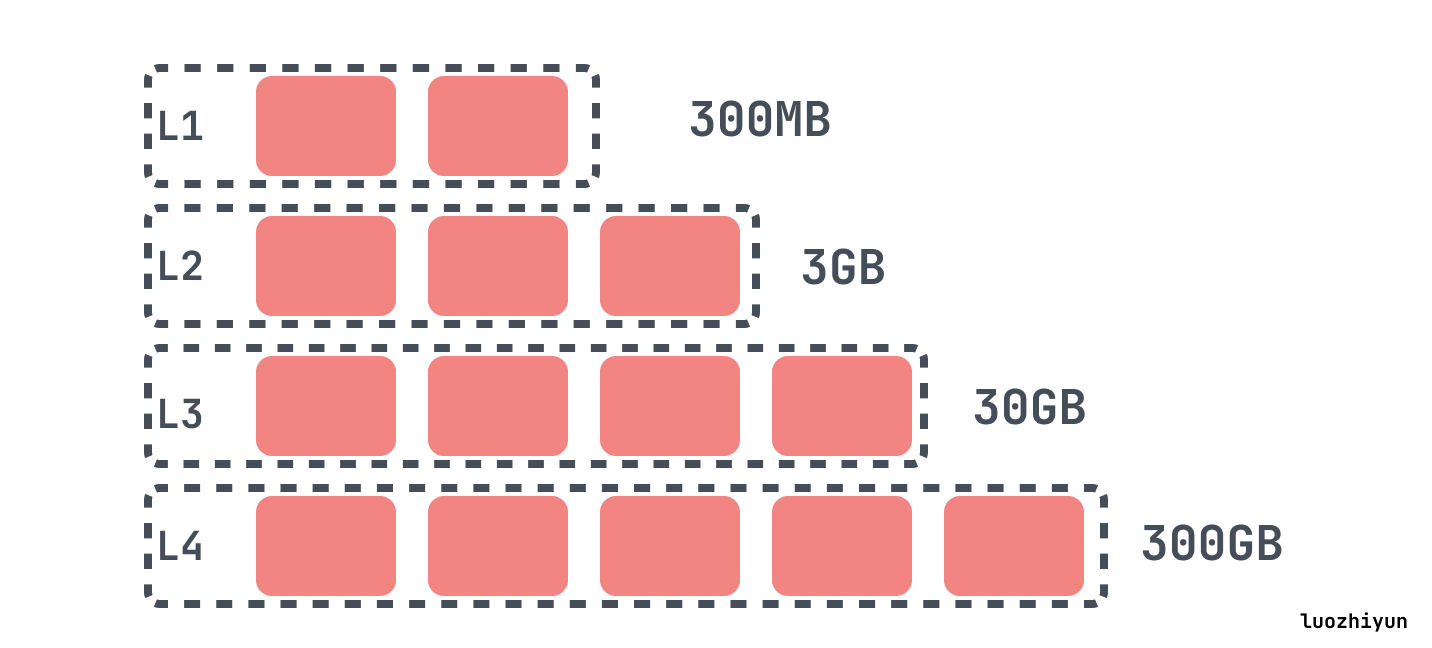
在 RocksDB 中,当L0文件数达到 level0_file_num_compaction_trigger 时触发 compaction,会将所有 L0 的文件合并入 L1 中。
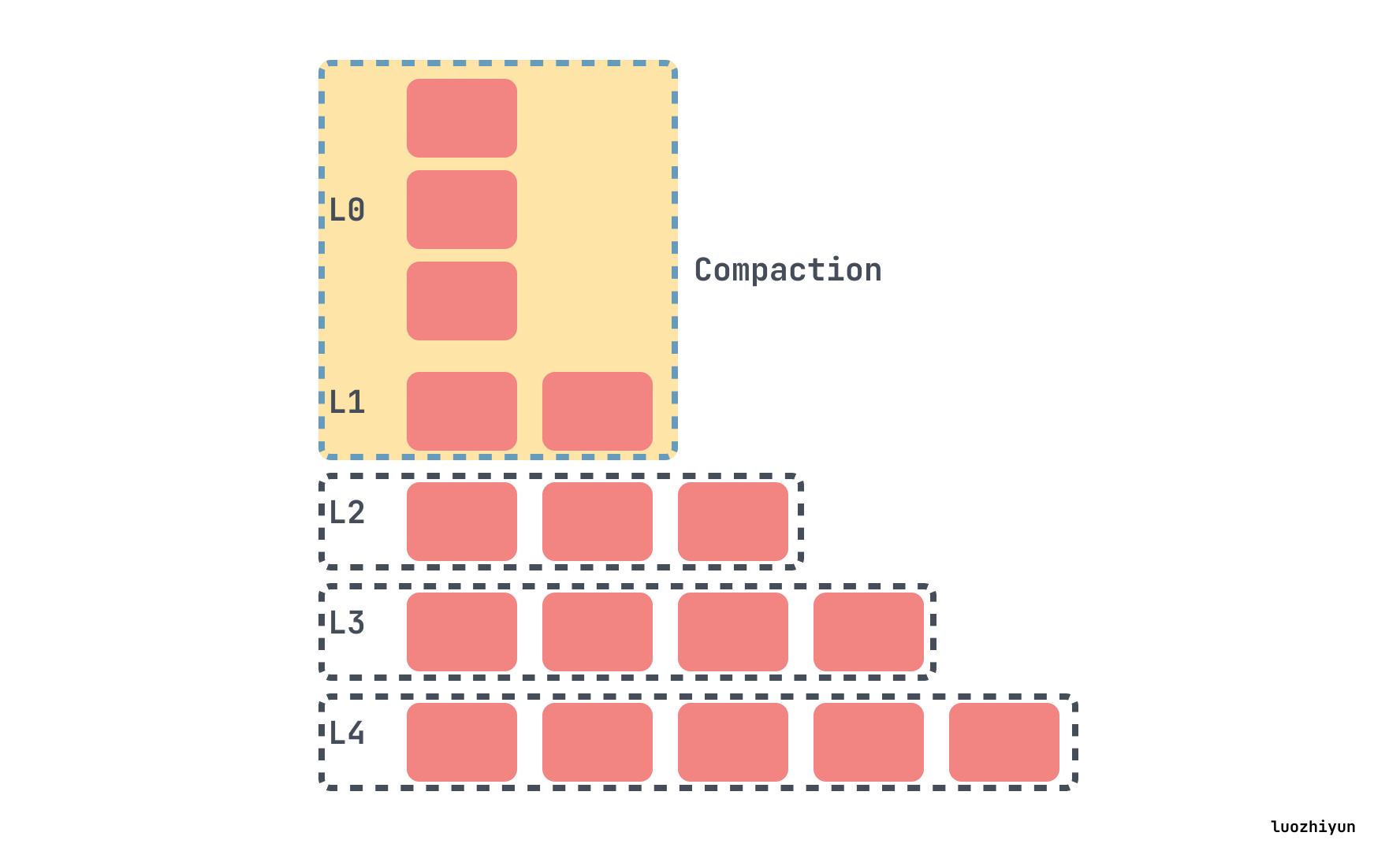
在L0 compaction 之后,可能会使 L1 超过其规定的大小,在这种情况下,我们将从L1中选择至少一个文件并将其与L2的重叠范围合并。结果文件将放置在L2中:
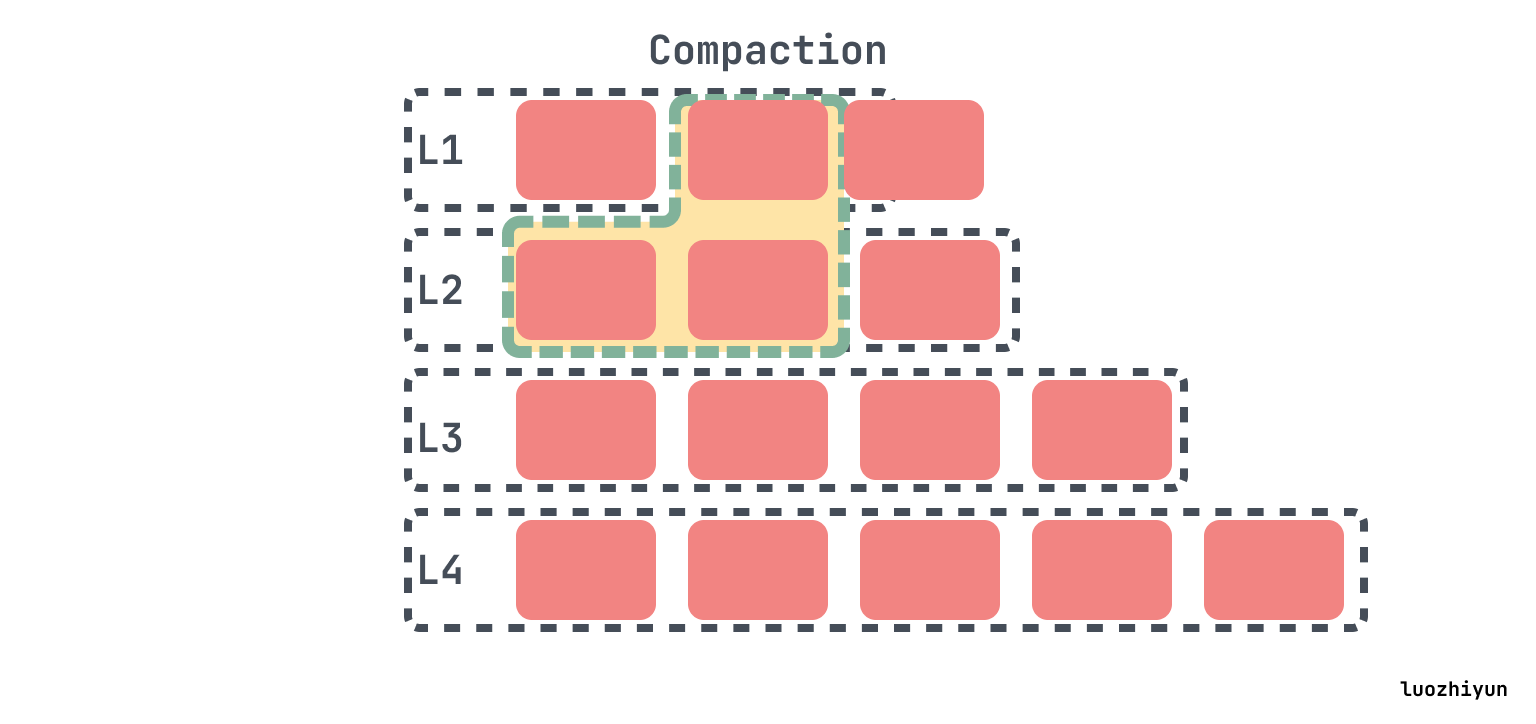
如果下一级的大小继续超过目标,那么会像以前一样执行操作,挑选一个文件进行合并。
所以由 Leveled Compaction 的 compaction 规则可以看出,它通过两种方式来解决空间放大的问题:
同样1.2 GB数据集被一遍又一遍地写入15次。通过上图我们可以看到Leveled Compaction需要的空间要小的多,空间放大实际上达到了预期的1.1-2。
Leveled Compaction 虽然没有空间放大问题,但是随之而来的是写入放大的问题
写入放大指的是写入磁盘的数据与写入数据库的字节数的比值。在写入数据的时候 RocksDB 会有多次写磁盘的操作,如下图所示显示的是 Size-Tiered Compaction 策略写入放大情况,每个字节的数据都必须写入4次,有多少层就会写入多少次,还会写入一次 WAL log,至少4的写入放大。
但是 Leveled Compaction 是需要挑选上一层的一个 SSTable 然后找到下一层的重叠的SSTable进行合并写入,Ln层SST在合并到Ln+1层时是一对多的,如果下一层是上一层的十倍,那么在选择一个大小为X的sstable进行压缩的时候,它在下一个更高级别中会找到与此sstable重叠的大约10个sstable,并将它们与一个输入sstable进行压缩,它将大小约为11*X的结果写入下一个级别。所以在最坏的情况下, Leveled Compaction 可能比Size-Tiered Compaction 多写11倍。
写入放大最大最大值我们也可以很简单计算出来。首先假设每一层的级别乘数为10,L1 大小为 512MB,数据大小为 500GB,那么L2大小为5GB,L3为51GB,L4为512GB,因为数据大小为 500GB,所以更高级别将为空。
那么我们可以简单的算出空间放大为(512 MB + 512 MB + 5GB + 51GB + 512GB) / (500GB) = 1.14。
计算写放大的时候可以从顶层开始写入。每个字节写到L0,然后将其压缩到L1,由于L1大小与L0相同,因此L0->L1压缩的写放大为2。然而,当来自L1的字节被压缩到L2时,它将被压缩为来自L2的10个字节(因为2级大10倍)。L2->L3和L3->L4压缩也是如此。因此,总写入放大大约为 1 + 2 + 10 + 10 + 10 = 33 。
写放大会带来两个风险:一是更多的磁盘带宽耗费在了无意义的写操作上,会影响读操作的效率;二是对于闪存存储(SSD),会造成存储介质的寿命更快消耗,因为闪存颗粒的擦写次数是有限制的。
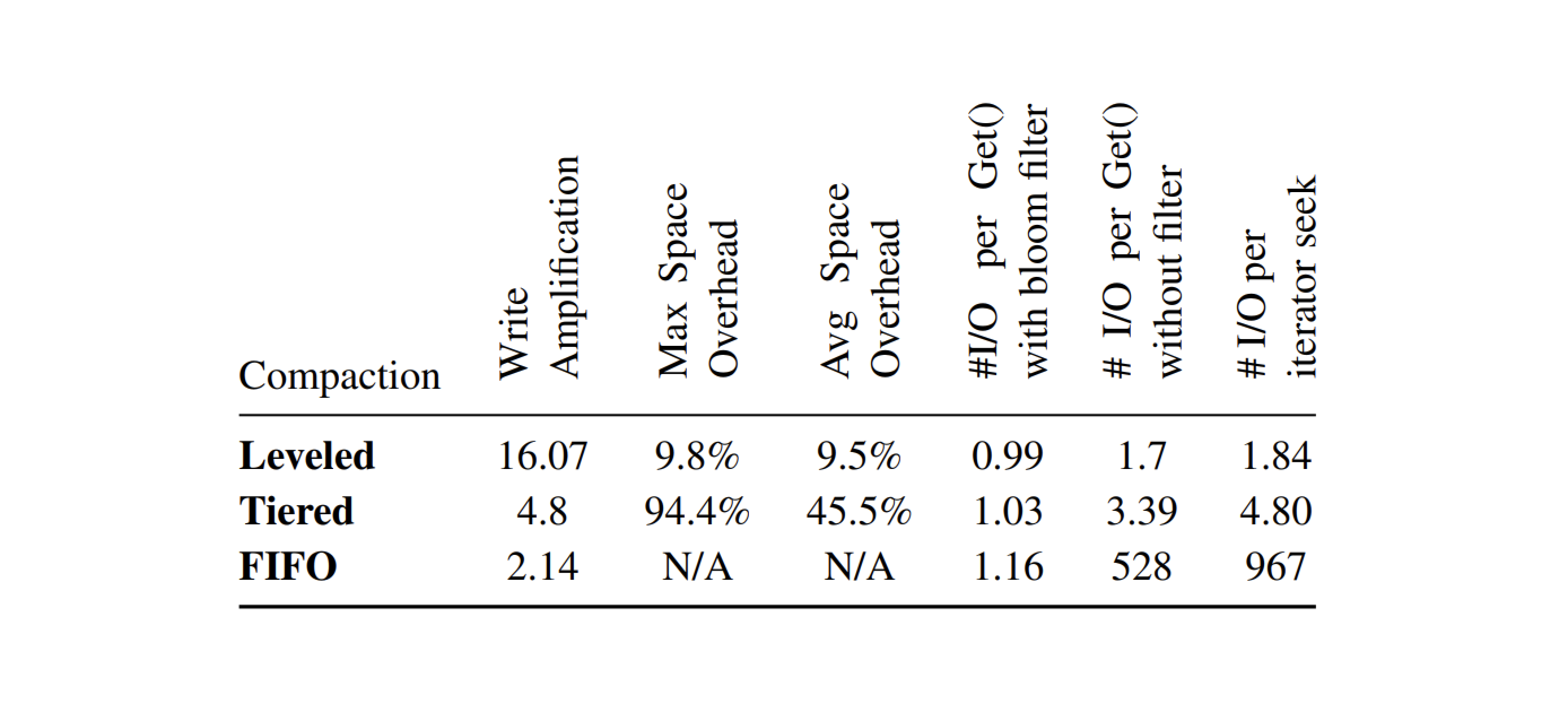
RocksDB 的优化目标最初是减少写放大,之后过渡到减少空间放大。在 RocksDB 上 Leveled Compaction 压缩方式的写放大通常在 10~ 30之间,在许多情况下,与 MySQL 中使用的 InnoDB 引擎相比,RocksDB 的写数量仅为其的 5% 左右。但是这个量级的写放大在频繁写的应用场景下面还是太大了,所以 RocksDB 引入了 Tiered Compaction 压缩方式,它的写放大只有 4–10 。
在经过若干年开发后,RocksDB 的开发者们观察到对于绝大多数应用来说,空间使用率比写放大要重要得多,此时 SSD 的寿命和写入开销都不是系统的瓶颈所在。实际上由于 SSD 的性能越来越好,基本没有应用能用满本地 SSD,因此 RocksDB 开发者们将其优化重心迁移到了提高磁盘空间使用率上。
RocksDB 开发者们引入了 Dynamic Leveled Compaction 策略,此策略下,每一层的大小是根据最后一层的大小来动态调整的。
我们来看个例子,如果不是动态调整,我们假设我们设置了 RocksDB 有4个层级,它们的大小是1GB、10GB、100GB、1000GB,如果数据都放满的话,那么空间放大将会是 (1000GB+100GB+10GB+1GB)/1000GB=1.111 ,可以看到空间放大非常小。但是实际中,是很难恰好让最后一级的实际大小是1000GB,如果在生产中,数据只有200GB,那么空间放大将是(200GB+100GB+10GB+1GB)/200GB=1.555。
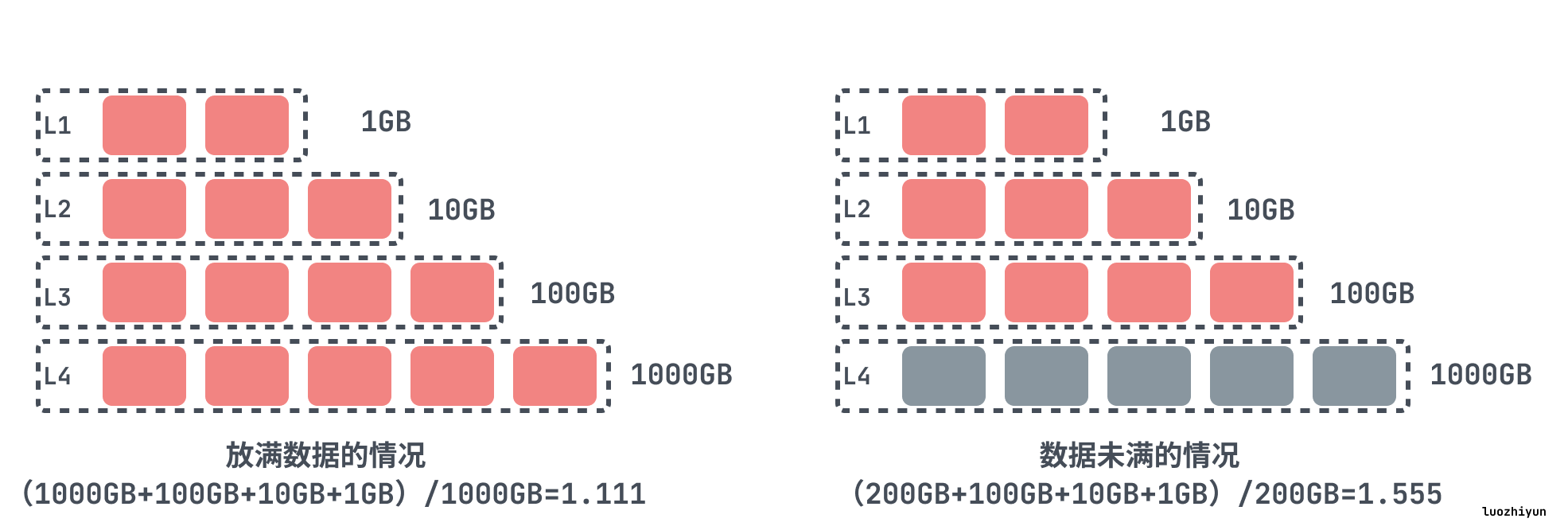
所以动态级别大小目标是根据最后一级的大小动态改变的。假设级别大小乘数为10,DB大小为200GB。最后一级的目标大小自动设置为级别的实际大小,即200GB,倒数第二个级别的大小目标将自动设置为size_last_level/10=20GB,倒数第三个级别的size_last_level/100=2GB,倒数第四个级别是 200MB。这样,我们就可以实现1.111的空间放大,而不需要对级别大小目标进行微调。
此策略的效果如下所示,Dynamic Leveled Compaction 策略将空间开销限制在13%,而Leveled Compaction策略在空间开销上可以超过 25%,在Facebook实际应用中,使用RocksDB替换InnoDB作为UDB数据库的引擎,可以使空间占用减少50%。
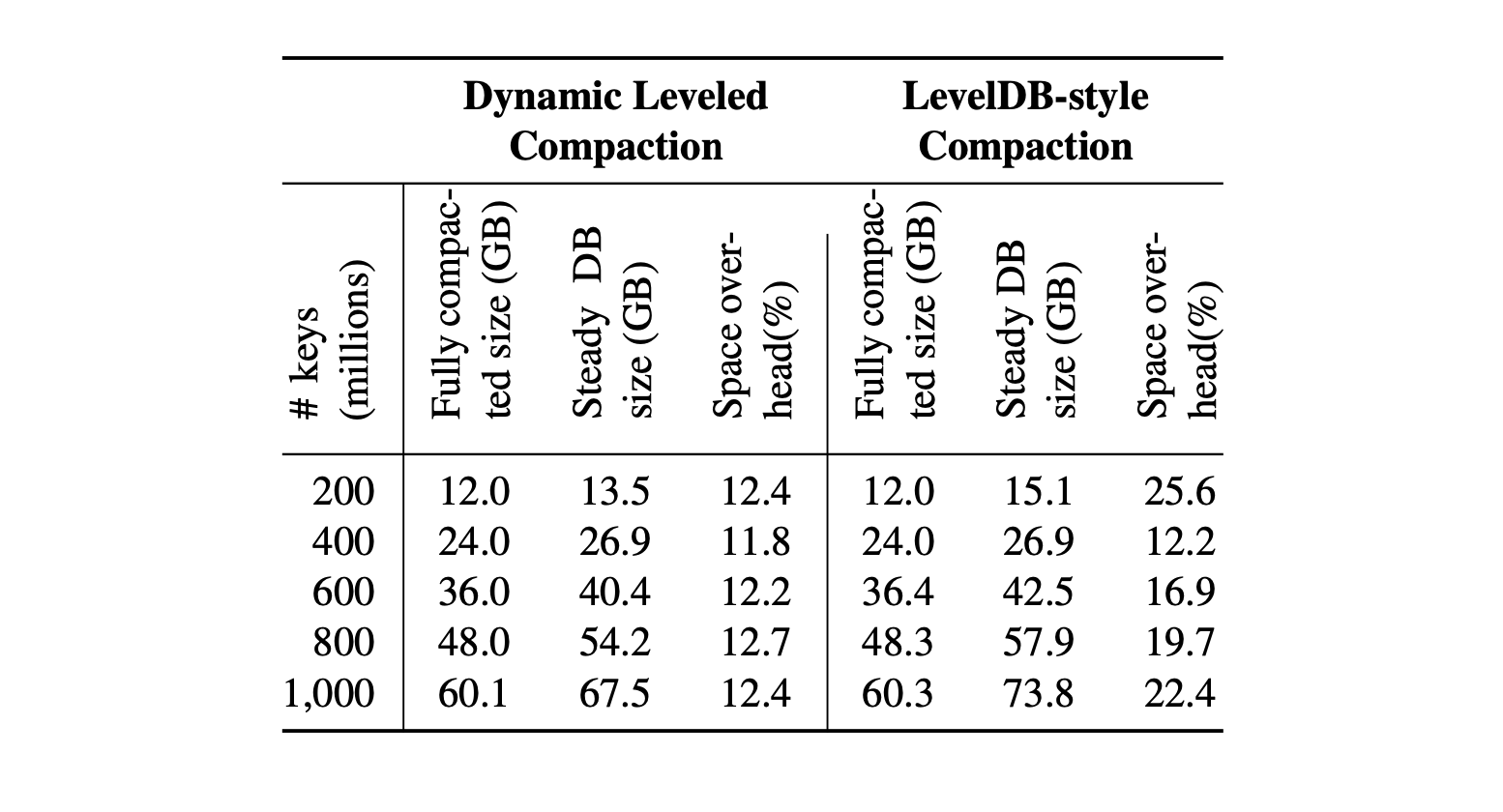
所以 RocksDB 应用程序的所有者应该选择合适的 compation 方式,来实现压缩率、写入放大、读取性能之间的平衡。
通过上面的分析,我们知道在 RocksDB 中的 compation 策略总有一定的问题,Size-Tiered Compaction 会增加空间放大,因为 SSD 成本比较高,后面 RocksDB 转向减少空间放大使用 Leveled Compaction 以及后面推出的微调版本 Dynamic Leveled Compaction 。
但是貌似写入放大的问题并 RocksDB 没有解决,因为我们知道 SSD 的擦写次数是有限制的,如果频繁的擦写也会减少 SSD 的寿命,增加 SSD 的使用。那么在业界,是如何解决 LSM 树写入放大问题的呢?主要有两种方式:
下面我们就WiscKey和PebblesDB仔细聊聊他们是怎么做的。
FAST16,WiscKey: Separating Keys from Values in SSD-Conscious Storage
WiscKey 主要思想就是将key 和 value 剥离,在LSM树中只保留key值,用一个指针指向 value 的位置。因为一般情况下,Key比 Value小的多,所以这样做可以缩小 LSM 树的大小,降低写入放大。举个例子,假设现在 key 大小 1B,Value 大小 1KB,在LSM 树中按照10倍的写入放大来说,那么根据公式,实际的写入放大应该是:
写入放大 = 写入数据的大小/数据实际的大小 = (10*16+1024)/(16+1024) = 1.14不过这样做的弊端是查找的时候比传统LSM树查找多一次IO,找到 key 之后需要再取 value。但是相对来说更小的LSM树也会有更好的查找性能,在LSM树中,查找可能会搜索更少层级的SSTables文件,并且由于LSM树很小,所以它的大部分内容可以很容易地缓存在内存中,所以在缓存住 key 的情况下,只有一次随机IO查找 value 的开销,大多数情况还是比 LevelDB要快的。
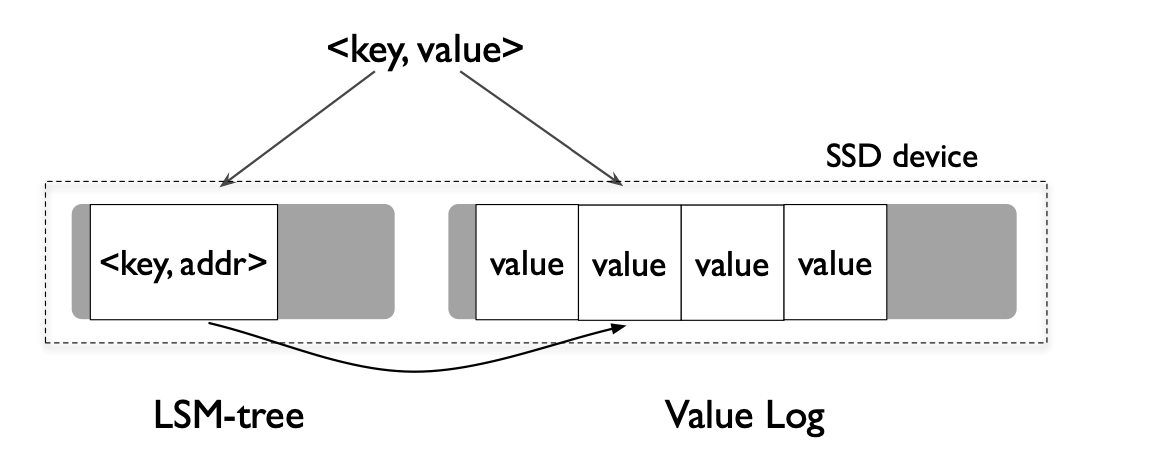
WiscKey 的架构其实很简单,像上面的图一样,把 key 和 value 分开存储,value 这部分的文件叫做 value-log file 简称 vLog。
在插入数据的时候会将 value 数据 append 到 vLog 里面,然后写入一条key数据到 LSM 树里面,key 数据里面还包含了 value 的偏移和大小,类似这样 (<vLog-offset, value-size>)。在删除的时候还是只和LevelDB一样,写入一条标记了删除的记录到 LSM 树,vLog 里面的 value 数据随后会由一个单独的线程进行垃圾收集。
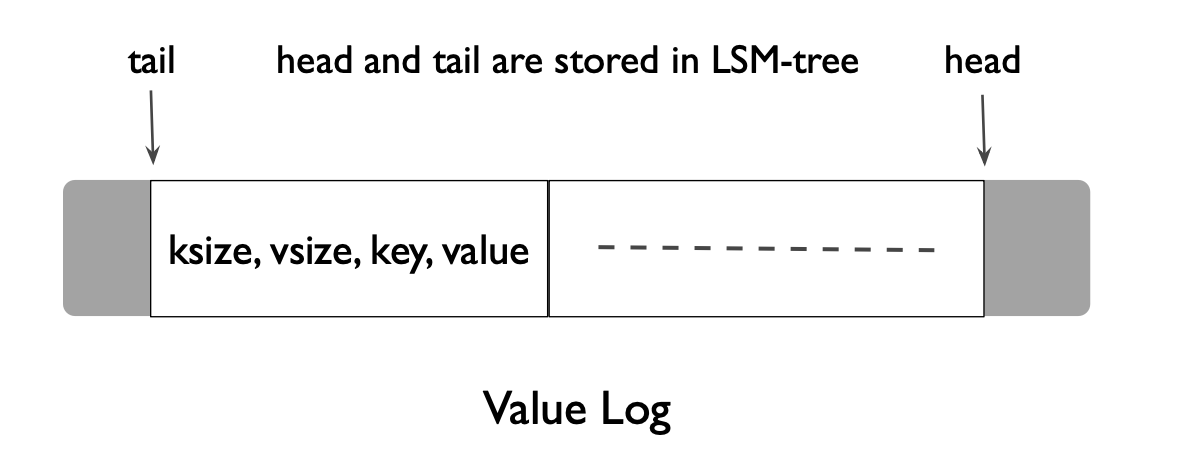
为了能够实现更轻量化的 vLog 垃圾收集,vLog 不单只保存了 value 还保存了 key 值,保存的格式如上图为 (key size, value size, key, value)。在 vLog 中还用了 tail 和 head 表示头和尾,新的数据都从 head append 进入到文件里面。
在垃圾回收的时候会直接从 tail 读取一批数据,然后通过查询 LSM 树找出其中哪些值是有效的,将有效的数据 append 进 vLog 的 head,然后垃圾收集器会将这些被重新 append 的数据新的地址值 append 进入 LSM树,并更新 tail 位置的地址。
SOSP17,PebblesDB: Building Key-Value Stores using Fragmented Log-Structured Merge Trees
PebblesDB 主要使用了一种新的数据结构 Fragmented Log-Structured Merge Trees (FLSM),它借鉴了 skiplist + lsm 的结构。通过这种结构,PebblesDB 在论文中提到了,它的写的的吞吐量是 RocksDB的 6.7倍,读的吞吐量比 RocksDB 高 27%,写入IO比RocksDB减少了2.4-3倍。
在 skiplist 中,其实是通过类似下面这样建立多层级的索引,上面的层级索引的节点实际上代表的一个范围内的数据,并且每一层的索引都是有序的列表,我们可以通过下图简明的看一下怎么查找 u 节点。
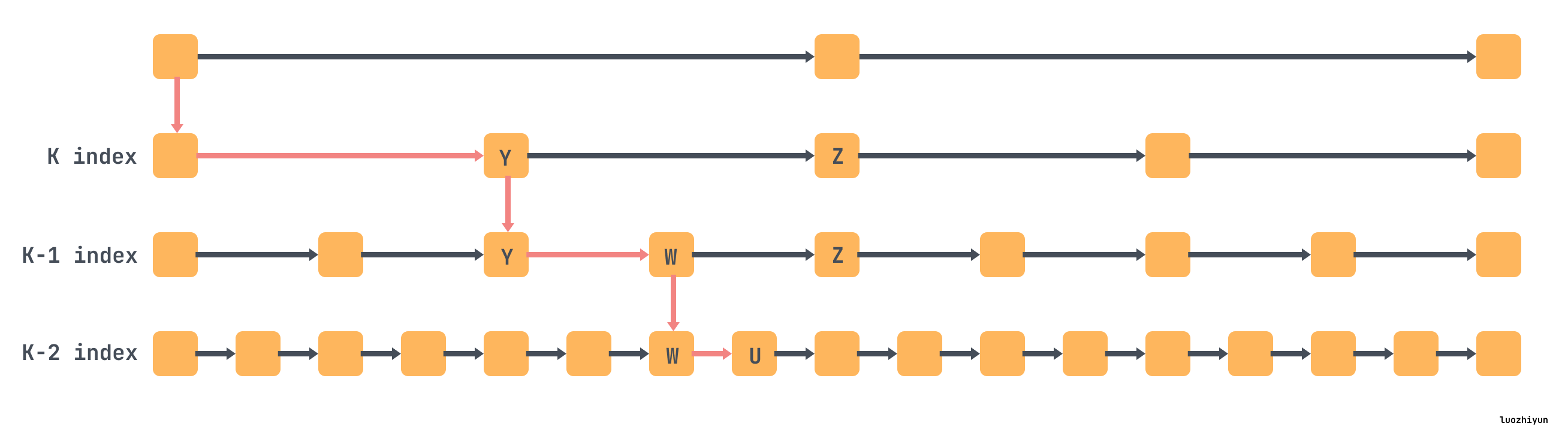
FLSM 就借用了上面索引的概念,定义了 Guards 结构来组织数据。Guards 就是 skiplist 里面的索引的概念,它会在插入数据的时候随机选择插入的key作为 Guard,L0 没有 Guard。
Guards 数量会随着层级的增加而增加,并且上层被的 Guard 也会带入到下一层,如下图 L1 中 5 被作为 Guard,那么 L2 和 L3 中它依然是 Guard。Guards 里面由一个个 SSTable组成,在同一层之间 Guards 是有序排列的,没有重叠,但是在单个 Guard 里面的 SSTable 是有可能重叠的。
Guard 和 skiplist 索引里面的作用一样,用来限定数据范围,如下图L1中,SSTable key 值超过 5 的都被放入到 Guard5 中,小于 5 的 SSTable 被放入到 Sentinel 中存放。L2 中 key 超过 375 的值都被放入到 Guard375 中,依次类推。所以 L1 Guard5 代表的其实是 [5,∞), L2 Guard5 代表 [5,375),Guard375代表 [375,∞)。这是一个左开右闭的合集。
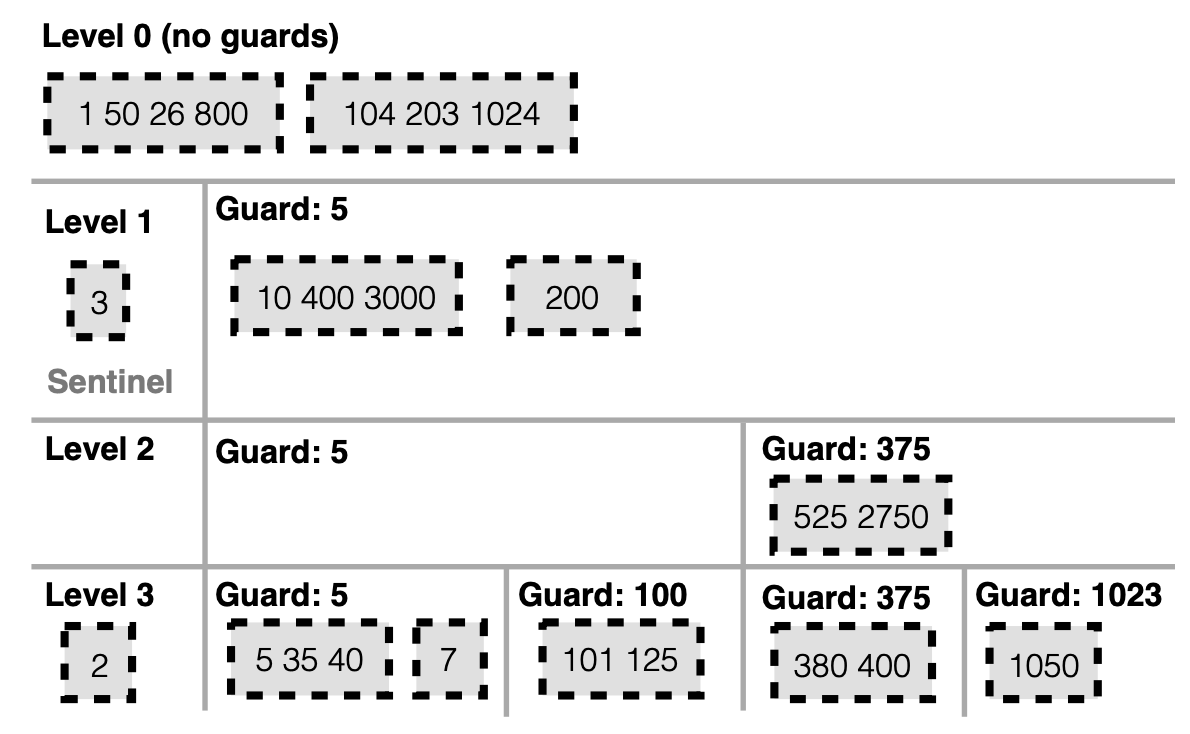
在大多数情况下,FLSM 的 compaction 不会重写 SSTables。在 PebblesDB 中,数据是通过 Guards 来组织的,这些 Guards 用于指示给定键范围在某一层级上的位置。每个 Guard 可以包含多个重叠的 SSTables。当一个层级上的 Guards 数量达到一个预设的阈值时,这些 Guards 和相应的键会被移动到下一个层级,这一过程通常不需要重写 SSTables,这是 FLSM 减少写入放大的主要方法。
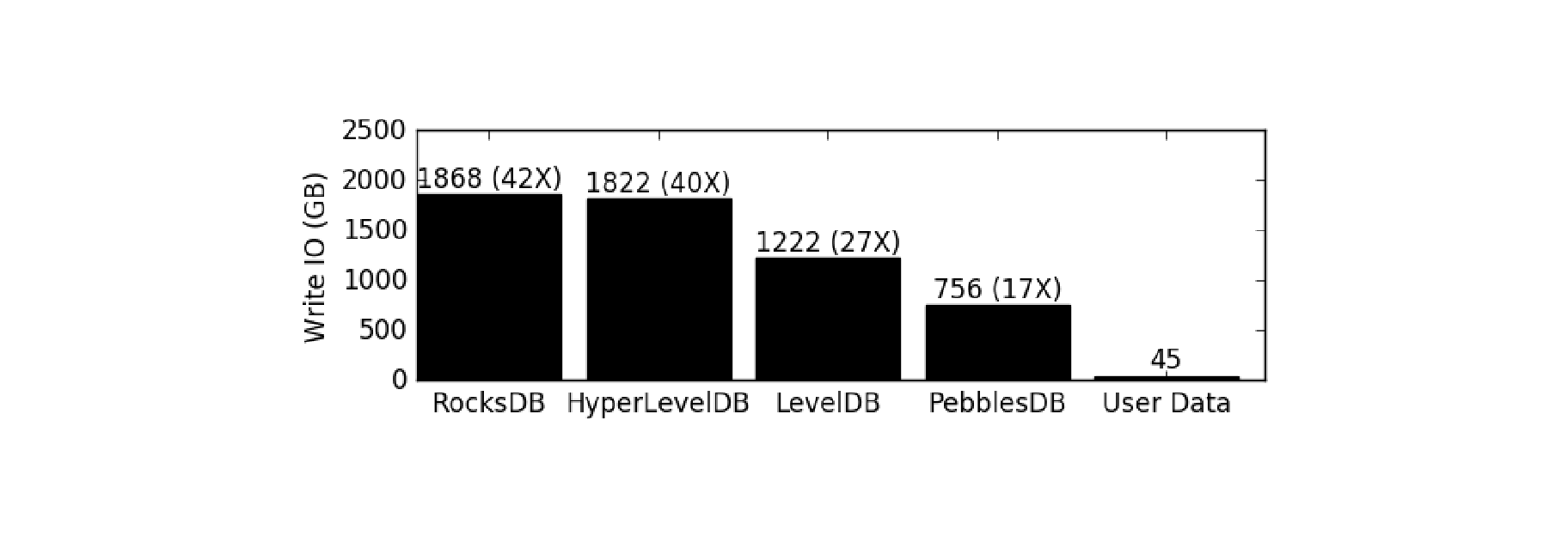
PebblesDB 相比其他几个引擎,写放大是有显著的优势。下图显示了在插入或更新5亿个键值对(总计45 GB)时,不同键值存储引擎的总写入IO量(以GB为单位)。
我们从 RocksDB 的 LSM Tree结构入手解释了 RocksDB 通过将所有的数据修改操作转化为追加写方式从而提高了数据操作的性能,解释了为什么这种结构支持高效的数据读写操作,然后说明了这种结构所引发写放大、读放大和空间放大等问题,以及对于 RocksDB 是如何通过 Compaction 策略去解决相应的放大问题。
此外,文章还探讨了如 WiscKey 和 PebblesDB 等新的 LSM 树优化方法,这些方法通过结构和操作的改进,旨在降低写放大,从而提高数据库的整体效率和性能。
《Evolution of Development Priorities in Key-value Stores Serving Large-scale Applications: The RocksDB Experience》
《PebblesDB: Building Key-Value Stores using Fragmented Log-Structured Merge Trees》
《WiscKey: Separating Keys from Values in SSD-Conscious Storage》
https://artem.krylysov.com/blog/2023/04/19/how-rocksdb-works/
https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide
https://github.com/facebook/rocksdb/wiki/Leveled-Compaction
https://github.com/facebook/rocksdb/wiki/Compaction
https://tidb.net/blog/eedf77ff#2%20%E4%B8%BA%E4%BB%80%E4%B9%88%E9%9C%80%E8%A6%81%20compaction%20?
https://github.com/facebook/rocksdb/wiki/RocksDB-Overview
https://www.scylladb.com/2018/01/17/compaction-series-space-amplification/
https://www.scylladb.com/2018/01/31/compaction-series-leveled-compaction/
https://rocksdb.org/blog/2015/07/23/dynamic-level.html
https://zhuanlan.zhihu.com/p/490963897
2024-04-05 14:47:26
我们平时见到的最多的就是行式存储数据库,如:MySQL、PostgreSQL等,它们通常是将属于同一行的值存储在一起,它的布局非常的像我们 Excel 表格的布局,比如下面面向行的数据库存储用户数据:
|ID|Name |Birth Date|Phone Number|
|10|John |1-Aug-82 |1111 222 333|
|20|Sam |14-Sep-88 |5553 888 999|
|30|Keith|7-Jan-84 |3333 444 555|在需要按行访问数据的情况下,面向行的存储最有用,将整行存储在一起可以提高空间局部性。因为对磁盘来说不管是 HDD 还是 SSD 通常都是按块访问的,所以单个块可能将包含某行中所有列的数据。这对于我们希望访问整个用户记录的情况非常有用,但这样存储布局会使访问多个用户记录某个字段的查询开销更大,因为其他字段的数据在这个过程中也会被读入。
比如上面这个用户表的数据,我这样查询:
select Name from user;我只需要 Name 这个字段,但是每次都会都会逐行扫描、并获取每行数据的全部字段,然后返回 Name 字段。这是由行式存储的存储方式决定一定需要这样做。
而对于列式存储数据库同一列的值被连续的存储在磁盘上,例如我们想要存储股票市场的历史价格,那么股票这一列的数据便会被存储在一起。将同一列的值存储在一起可以便于按列查询,不需要对整行进行读取后再丢弃掉不需要的列。列式存储数据库非常适合计算聚合的分析型需求,如查找趋势、计算平均值等。
所以列式存储数据库的存储布局由于需要按列存储,所以很容易你可以想到,最简单的列存储引擎数据可能长这样:
Name: 10:John;20:Sam;30:Keith
Birth Date: 10:1-Aug-82;20:14-Sep-88;30:7-Jan-84
Phone Number: 10:1111 222 333;20:5553 888 999;30:3333 444 555那么我们如果只查询 Name 这个字段,列式存储数据库就可以直接扫描 Name 这列数据的文件并返回,从而避免了多余的数据扫描。
ClickHouse 是一个开源的列式数据库管理系统(DBMS),专门设计用于在线分析处理查询(OLAP)。由俄罗斯的Yandex公司开发,首次发布于2016年,它的主要目标是快速进行数据分析。也就是说 ClickHouse 主要用于在大数据的场景下做一些实时的数据分析。
得益于列式存储的特性,以及 ClickHouse 做的诸多优化,使得它在批量查询分析上面非常的具有优势。 对一张拥有 133 个字段的数据表分别在 1000 万、1 亿和 10 亿三种数据体量下执行基准测试,基准测试的范围涵盖 43 项SQL查询。在 1 亿数据级体量的情况下,ClickHouse 的平均响应速度是 Vertica 的2.63倍、InfiniDB 的 17 倍、MonetDB 的 27 倍、Hive 的 126 倍、MySQL 的 429 倍以及 Greenplum 的 10 倍。
具体的Benchmark可以看这里:https://benchmark.clickhouse.com/,这里随便放一下对比差异:

基于 ClickHouse 这么快的查询和分析速度,所以一般可以用来:
Clickhouse是一个支持多种数据存储引擎的数据库。它可以将几乎任何数据源导入Clickhouse数据库,并支持快速灵活的下钻分析。例如,微信目前使用Clickhouse来存储日志数据,因为日志通常包含大量重复项。使用Clickhouse可以实现高压缩比,减少日志占用的存储空间。Cloudflare、Mux、Plausible、GraphCDN和PanelBear等公司使用Clickhouse来存储流量数据,并在其仪表板中向用户呈现相关报告。Percona也在使用Clickhouse来存储和分析数据库性能指标。
但是 Clickhouse 不能替代关系数据,ClickHouse 不支持事务,并且希望数据保持不变,尽管从技术上讲可以从ClickHouse数据库中删除大块数据,但速度并不快。ClickHouse根本不是为数据修改而设计的。由于稀疏索引,按键查找和检索单行的效率也很低。
ClickHouse 的数据全都在 /var/lib/clickhouse/data 这个目录下面,比如我按照官网教程 https://clickhouse.com/docs/en/getting-started/example-datasets/ontime#creating-a-table 创建一个这样的表:
CREATE TABLE hits_UserID_URL
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (UserID, URL)
ORDER BY (UserID, URL, EventTime)
SETTINGS index_granularity = 8192, index_granularity_bytes = 0; 在这个表里面我们指定了一个复合主键(UserID, URL),排序键(UserID, URL, EventTime)。如果只指定排序键,那么主键会被隐式设置为排序键。如果同时指定了主键和排序键,则主键必须是排序键的前缀。
执行成功后会在文件系统 /var/lib/clickhouse/data/default/hits_UserID_URL 中创建如下的目录结构:
.
├── all_1_1_0
...
│ ├── primary.cidx
│ ├── URL.bin
│ ├── URL.cmrk
│ ├── UserID.bin
│ └── UserID.cmrk
├── all_1_7_1
...
│ ├── primary.cidx
│ ├── serialization.json
│ ├── URL.bin
│ ├── URL.cmrk
│ ├── UserID.bin
│ └── UserID.cmrk
├── detached
└── format_version.txt/var/lib/clickhouse/data 目录里面的一层 default 表示 database 名称,没有指定默认就是default,然后再往里面就是 hits_UserID_URL 表示表名,all_1_1_0 表示分区目录。
然后就是列字段相关的文件了,每列都会有两个字段:
{column}.bin:列数据的存储文件,以列名+bin为文件名,默认设置采用 lz4 压缩格式;
{column}.cmrk:列数据的标记信息,记录了数据块在 bin 文件中的偏移量;
primary.cidx:这个是主键索引相关的文件的,用于存放稀疏索引的数据。通过查询条件与稀疏索引能够快速的过滤无用的数据,减少需要加载的数据量。
因为我们设定了主键和排序键,所以数据在写入的时候会按照 UserID、URL、EventTime 顺序写入到bin 文件里面:

因为主键的顺序和文件的写入是相关的,所以一张表也只能有一个主键。
出于数据处理的目的,表的列值在逻辑上被划分为 granule。granule 是为进行数据处理而流式传输到ClickHouse中的最小的不可分数据集。这意味着ClickHouse不是读取单个行,而是始终读取(以流式传输方式并行读取)整个组(granule)行数据。
比如我们上面在创建表的时候指定了 index_granularity 为 8192,即数据将会以 8192 行为一个组,表里面我们插入了 886w 条数据,那么就分为了 1083 个组:
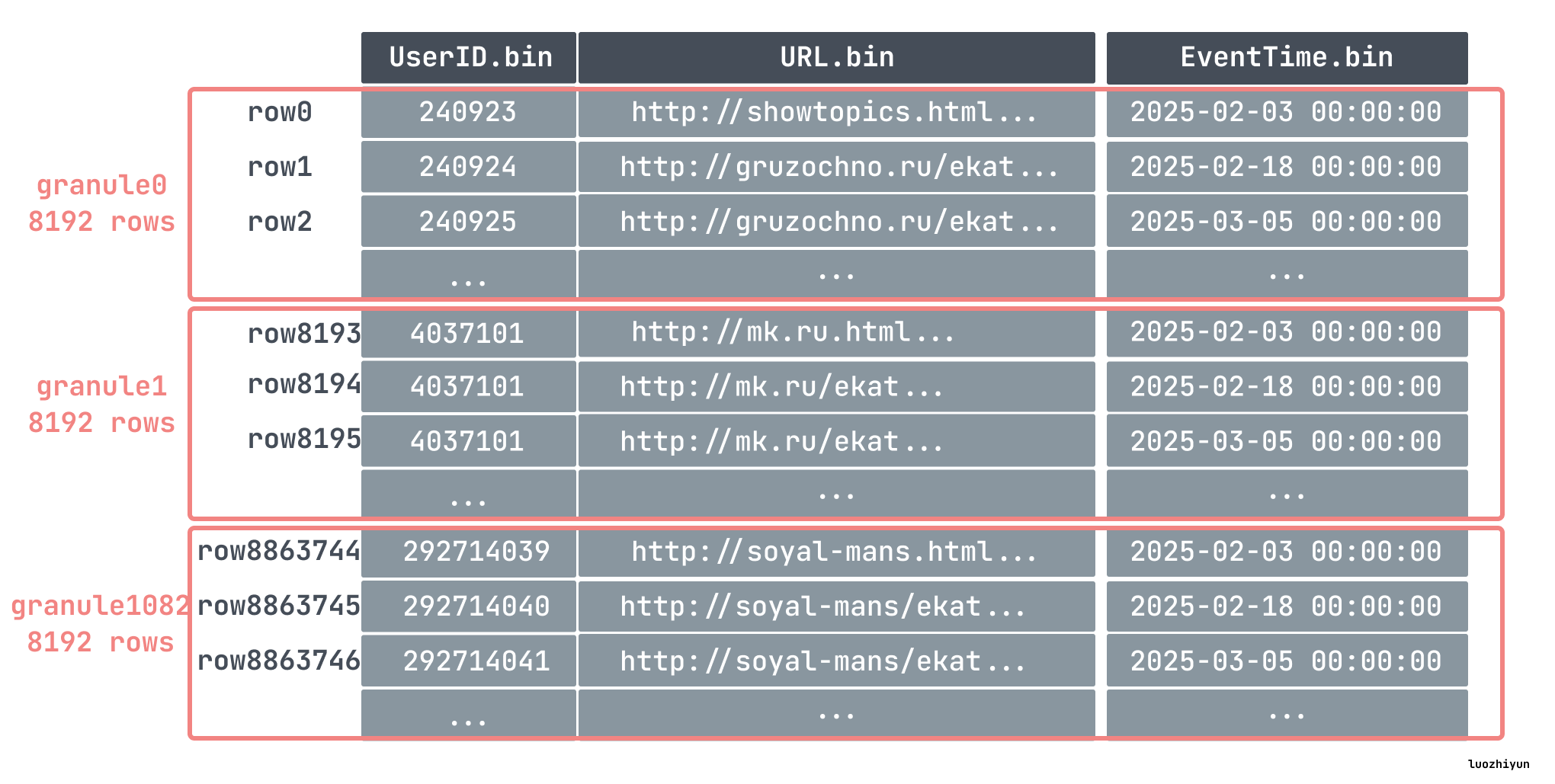
每个 granule 分组的第一条数据会被写入到 primary.cidx 当作索引处理。
ClickHouse 是通过稀疏索引的方式来构建主键索引的,所以它只记录 granule 的开始位置,一条索引记录就能标记大量的数据。所以像我们上面的例子中,886w 条数据,只有 1083 个 granule ,那么索引数量也只有 1083 条,索引少占用的空间就小,所以对 ClickHouse 而言,primary.cidx 中的数据是可以常驻内存。
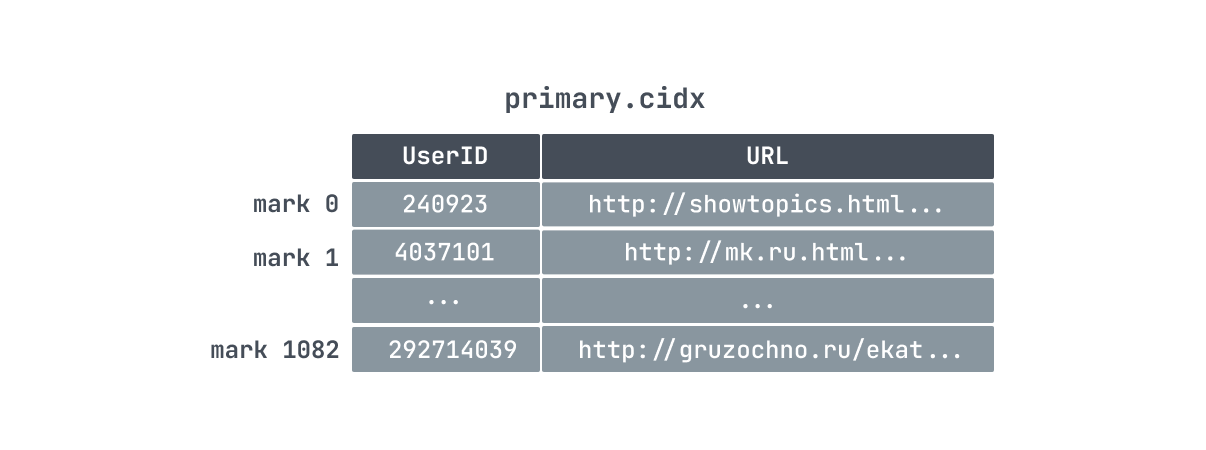
再加上数据存储的时候就是顺序存储,所以 ClickHouse 在利用索引过滤查找数据的时候可以用二分查找快速的定位到索引数据位置。
但是由于 granule 是个逻辑数据块,我们并不直接知道它在数据文件(.bin)中的存储位置。因此,我们还需要一个文件用来定位 granule,这就是标记(.mrk)文件。
这里需要说明一下,根据 ClickHouse 版本、数据情况、压缩格式,标记文件会有不同的结尾,如:cmrk 、cmrk2、mrk2、mrk3 等等,由于它们的作用都是用来做文件映射,找到数据的物理地址用的,所以这里都叫它们 mrk 标记文件好了。
对于 mrk 标记文件每一行包含了两部分的信息,block offset 以及 granule offset,在 bin 文件中,为了减少数据文件大小,数据需要进行压缩存储。如果直接将整个文件压缩,则查询时必须读取整个文件进行解压,显然如果需要查询的数据集比较小,这样做的开销就会显得特别大。因此,数据是以块(Block) 为单位进行压缩,一个压缩数据块可以包含若干个 granule 的数据,如下:

比如上面我们通过 primary.cidx 找到了对应数据所在 mark176,然后就可以对应的去 mrk 里面找对应的 block offset 和 granule offset。然后通过 block offset 找到该数据文件包含的压缩数据。一旦所定位的文件块被解压缩到主内存中,就可以使用标记文件的 granule offset 在未压缩的数据中定位对应的数据。
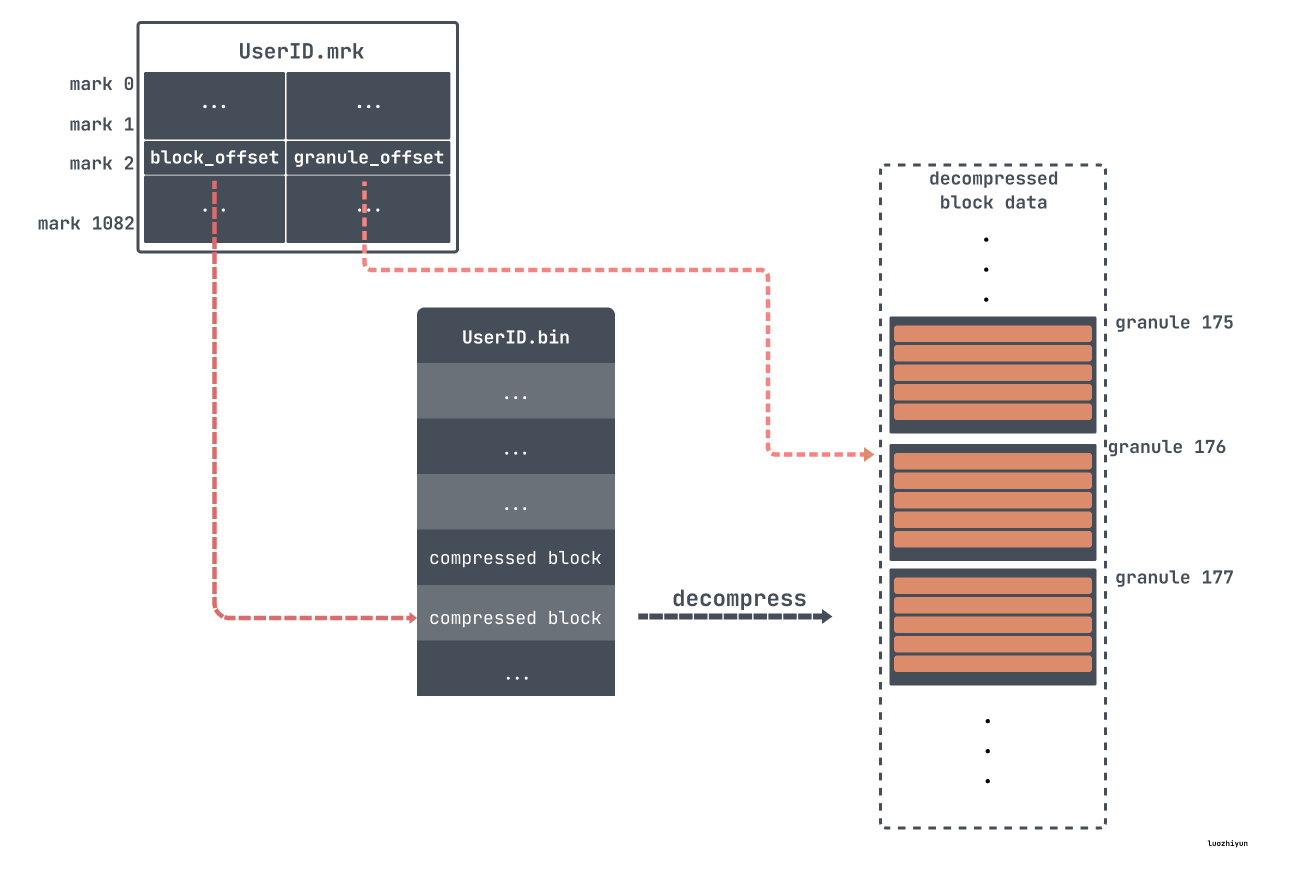
像我们上面的例子中,key 设定的是 UserID, URL 两个字段,这种 key 被称为联合主键。机遇我们上面给出的 ClickHouse 主键索引构造的方式可以很容易想到,如果 where 条件里面包含了联合主键的第一个键列,那么ClickHouse可以使用二分查找法进行快速的索引。
但是,当查询过滤的列是联合主键的一部分,但不是第一个键列时会发生什么?比如我们 where 条件里面只写了 URL='xxx',那么ClickHouse会执行全表扫描,因为数据是首先按 UserID 排列,当 UserID 相同时,才会按照 URL 排列,那么URL可能分布在各个地方。
前面我们也说了,ClickHouse 主键或排序键都是按照顺序存储,然后按 block 进行压缩存储,那么如果删除又是怎样做的呢?
Clickhouse是个分析型数据库。这种场景下,数据一般是不变的,因此Clickhouse对update、delete的支持是比较弱的。标准SQL的更新、删除操作是同步的,即客户端要等服务端反回执行结果,而Clickhouse的update、delete是通过异步方式实现的。
对于删除操作来说有两种方式 DELETE FROM和ALTER…DELETE。
对于 DELETE FROM 操作操作来说,只是对已经删除的数据做了个标记,表示已经删了,并将自动从所有后续查询中过滤出来。但是,在下一次数据合并整理期间会清理数据。因此,在可能存在一定的时间段内,数据可能不会从存储中实际删除,而只是标记为已删除。这种删除属于轻量级删除,这种方式的缺点是数据并没有立即从磁盘种被清理。
执行删除时,ClickHouse为每一行保存一个掩码,指示它是否在 _row_exists 列中被删除。后续查询反过来会排除那些已删除的行。
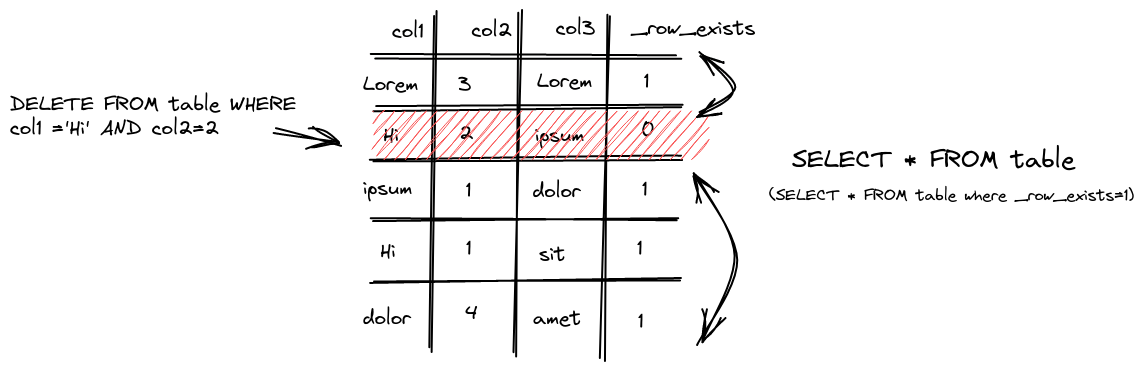
对于立即需要从磁盘中清理需求,可以通过使用ALTER…DELETE操作:
alter table hits_UserID_URL delete where UserID = 240923ALTER…DELETE操作默认情况是异步执行的,我们可以通过 system.mutations 表执行监控:
SELECT
command,
is_done
FROM system.mutations
WHERE `table` = 'hits_UserID_URL'
Query id: 78c3169a-abbc-415a-bcb2-0377d29fa547
┌─command──────────────────────┬─is_done─┐
│ DELETE WHERE UserID = 240923 │ 1 │
└──────────────────────────────┴─────────┘如果 is_done 的值为 0 ,表示它仍在执行中, is_done 的值为 1表示执行完毕。
对于 update 来说,主键的列或者排序键的值就不能被更改了,这是因为更改键列的值可能会需要重写大量的数据和索引,这对于一个以高性能读操作为设计目标的列式数据库来说,是非常低效的。所以只能修改非主键的列或者排序键的值。更新ClickHouse表中数据的最简单方法是使用ALTER… UPDATE语句。
ALTER TABLE hits_UserID_URL
UPDATE col1 = 'Hi' WHERE UserID = 240923 ALTER… UPDATE操作和ALTER…DELETE一样都同属于 mutation 操作,都是异步的。那么对于异步的方式来更新删除数据,就会涉及到一致性的问题。
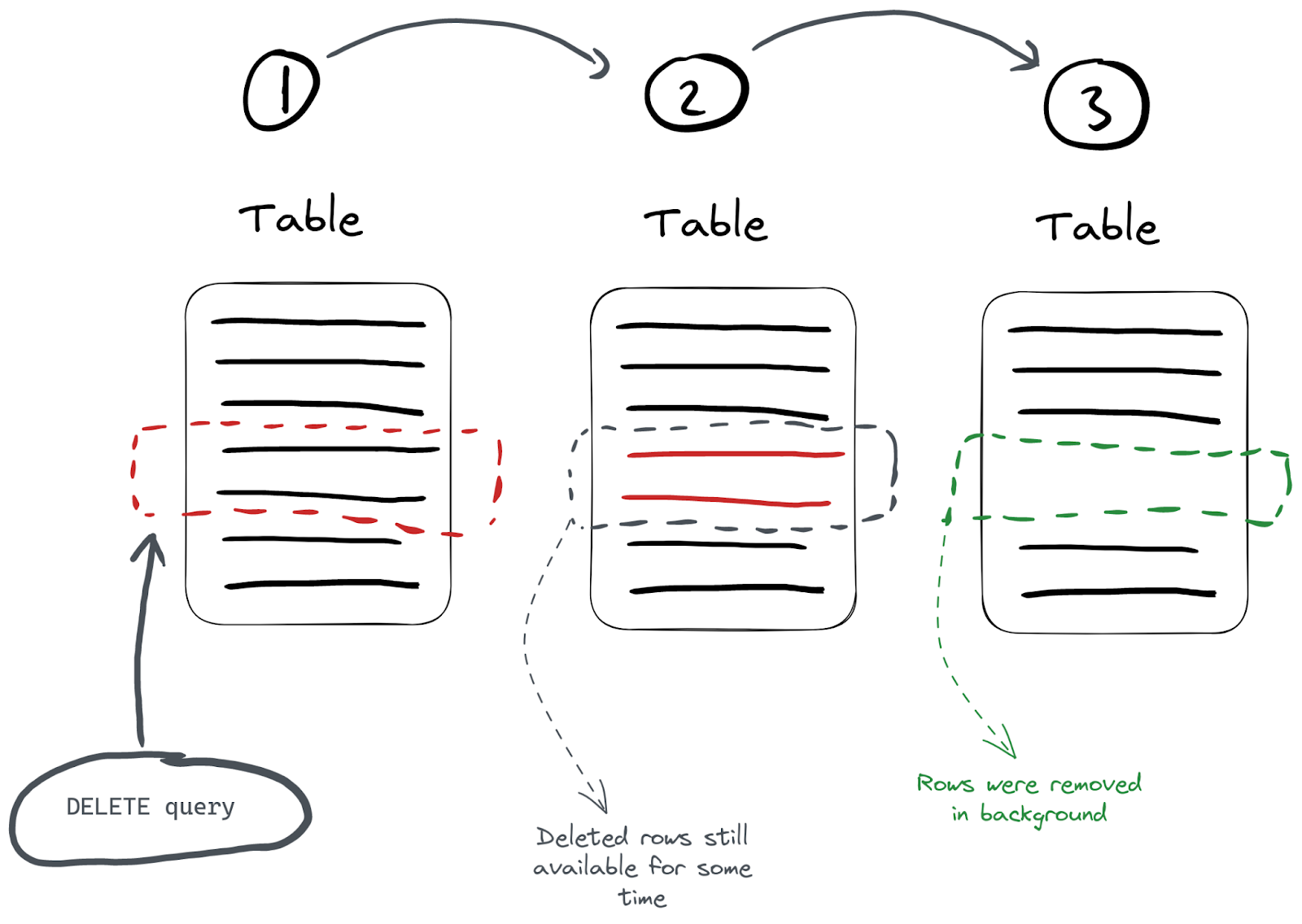
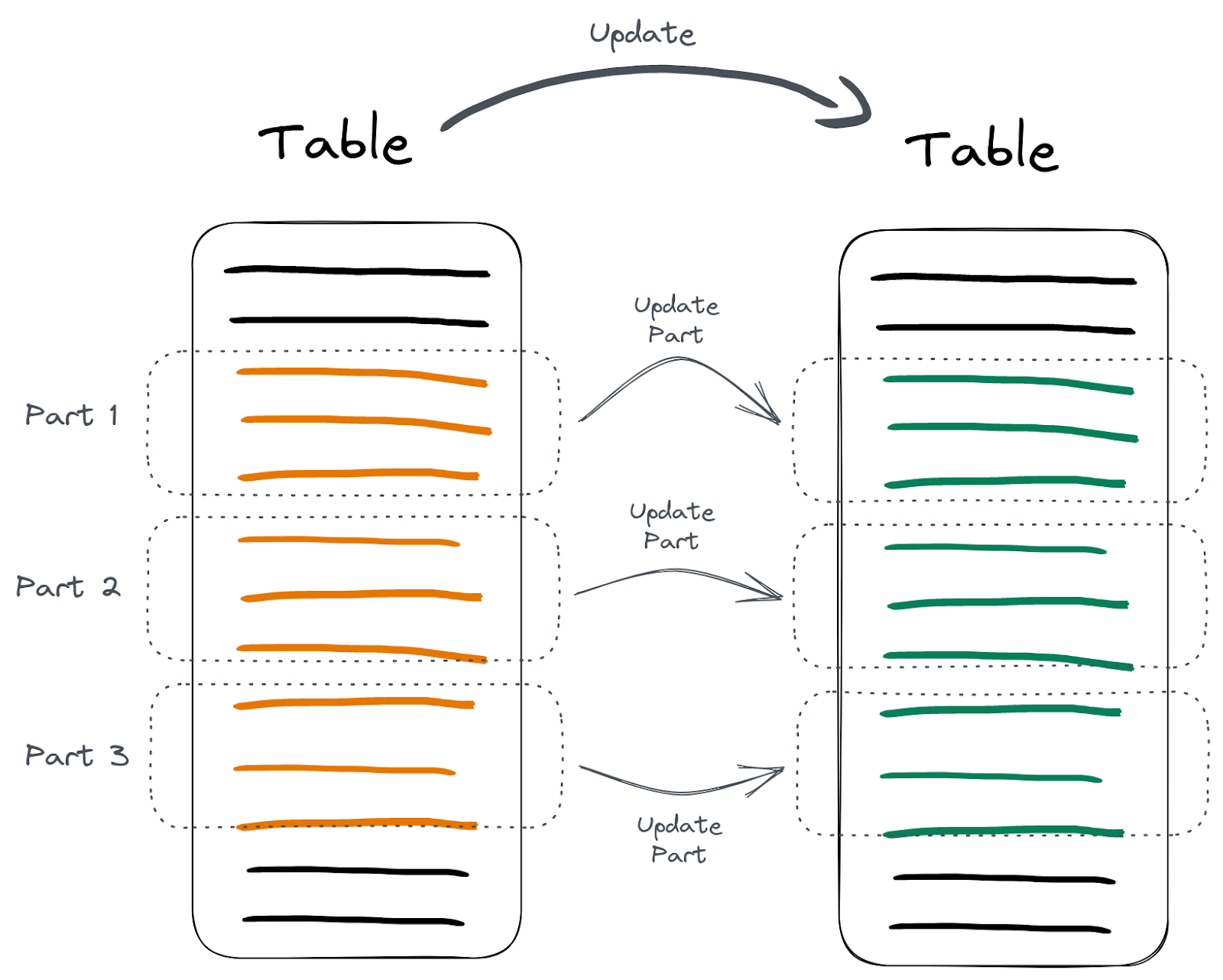
像上图所示,mutation 操作具体过程实际上分为这么几步:
数据的重建替换不是全部同时执行的,而是分批执行的。
如果在重建替换的过程中,用户去查询数据,如果查询跨越了部分已经被更新的数据段和部分尚未被更新的数据段,用户可能会同时看到旧数据和新数据,也就是说ClickHouse是不做原子性保证的。
按照官方的说明,update/delete 的使用场景是一次更新大量数据,也就是where条件筛选的结果应该是一大片数据。
通过上面ClickHouse的分析我们大概知道了列式数据库有啥优缺点,优点是可以忽略不需要的字段查询非常快,数据可以压缩,索引使用稀疏索引的方式不需要占用很多空间,可以支持超大量的数据分析;缺点是没有事务,对于单行数据的查询效率并不高,删除修改效率很低。所以在选型上面可以根据自己的业务需求,如果是有大量数据分析的需求,不妨试一下 ClickHouse。
《Database Internals A Deep-Dive into How Distributed Data Systems Work》
https://clickhouse.com/docs/en/optimize/sparse-primary-indexes
https://www.cnblogs.com/traditional/p/15218565.html
https://xie.infoq.cn/article/9f325fb7ddc5d12362f4c88a8
https://zhuanlan.zhihu.com/p/646518360
https://chistadata.com/why-clickhouse-is-so-fast/
https://clickhouse.com/docs/zh/guides/improving-query-performance/skipping-indexes
https://clickhouse.com/blog/handling-updates-and-deletes-in-clickhouse
https://altinitydb.medium.com/updates-and-deletes-in-clickhouse-d5df6f336ce9
2024-02-25 20:42:28
这篇文章主要来探讨一下SSD相关的问题,以及我们在写代码的时候如何更高效的利用好 SSD 的特性。
其实现在 SSD 已经很普及了,SSD 被称之为固态硬盘是相对于普通的机械硬盘 HDD 而言,因为它没有机械结构。普通的机械硬盘 HDD 一般都需要将执行器臂将读写头定位在驱动器的正确区域上以读取或写入信息。
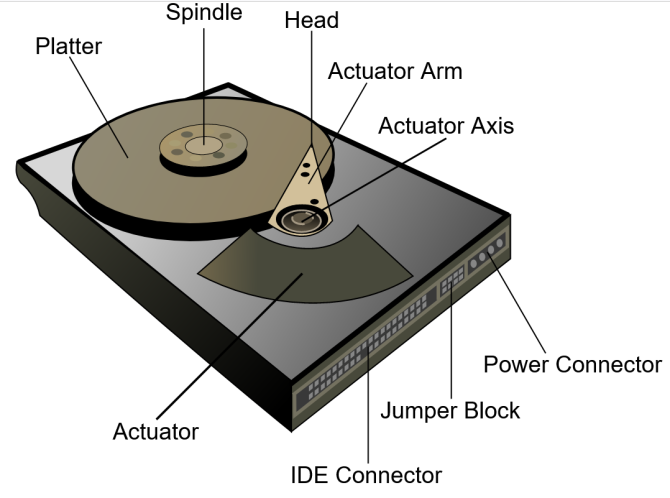
因为驱动器磁头必须在磁盘的某个区域对齐才能读取或写入数据,并且磁盘不断旋转,所以在访问数据之前会有延迟。HDD 的延迟通常以毫秒为单位,硬盘驱动器通常需要10-15ms才能在驱动器上找到数据并开始读取,即使是现在 15000 转的 HDD 延迟最低也要 4ms,IOPS(每秒的输入输出量) 在 200 左右,顺序读写速度在300MB/s 左右 。
反观我们看现在 SSD,以三星的 990 PRO为例,读写速度最高达到了 7000+ MB/s ,IOPS 高达 1,400K,延迟在 41us 左右,这么一对比,大家可以知道其实 SSD 比 HDD 快了好几个数量级。
SSD 的内部结构一般是由三部分构成:1. Controller 控制器 ;2.DRAM缓存;3.NAND闪存;

控制器是用来控制 SSD 的所有操作的,从实际读取和写入数据到执行垃圾回收和耗损均衡算法等,以保证SSD 的速度及整洁度;
DRAM缓存不是所有的硬盘都有,对于我们上面提到的 990 PRO 来说会有 2GB 左右的缓存,主要是用来存放的是逻辑物理映射表,控制器会通过缓存的映射表来查找数据使用。还承载了一部分待写入的数据,等够一页的时候一次性写入到NAND颗粒里面,用来缓解写入放大;
顺带提一下无缓的固态硬盘也不用过于担心性能问题,一般来说会使用 HMB 技术通过PCIe通道找内存借用一部分内存空间来存储映射表,在每次开机的时候往内存写入部分常用的FTL表,这个空间大小通常是64MB。像我们国产的致钛TiPlus7100就是采用的无缓+HMB机制,其速度也不差。
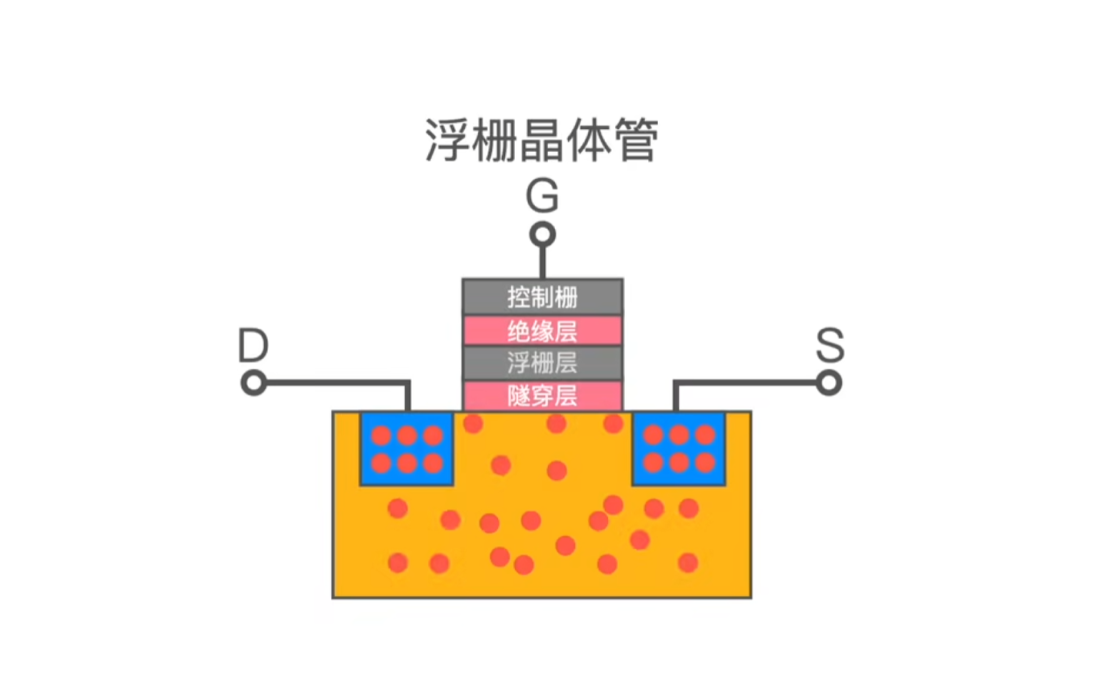
NAND 闪存是最终用来存放数据的地方,它不仅决定了SSD的使用寿命,而且对SSD的性能影响也非常大。比如大家所熟知的 SLC, MLC, TLC 闪存。NAND本身由所谓的浮栅晶体管组成,它是一种非易失性存储器,即使不通电也能保持状态,NAND 由一个个浮栅晶体管堆叠而成。根据每个浮栅晶体管可以保存1bit, 2bit, 3bit数据量可以分为SLC, MLC, TLC。
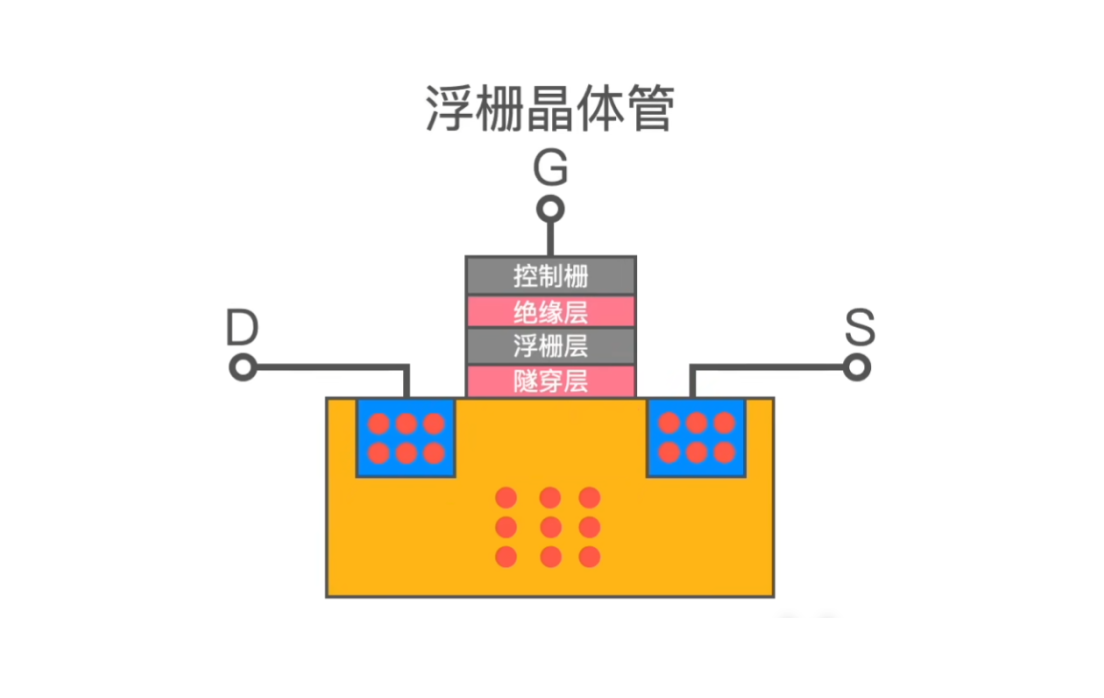
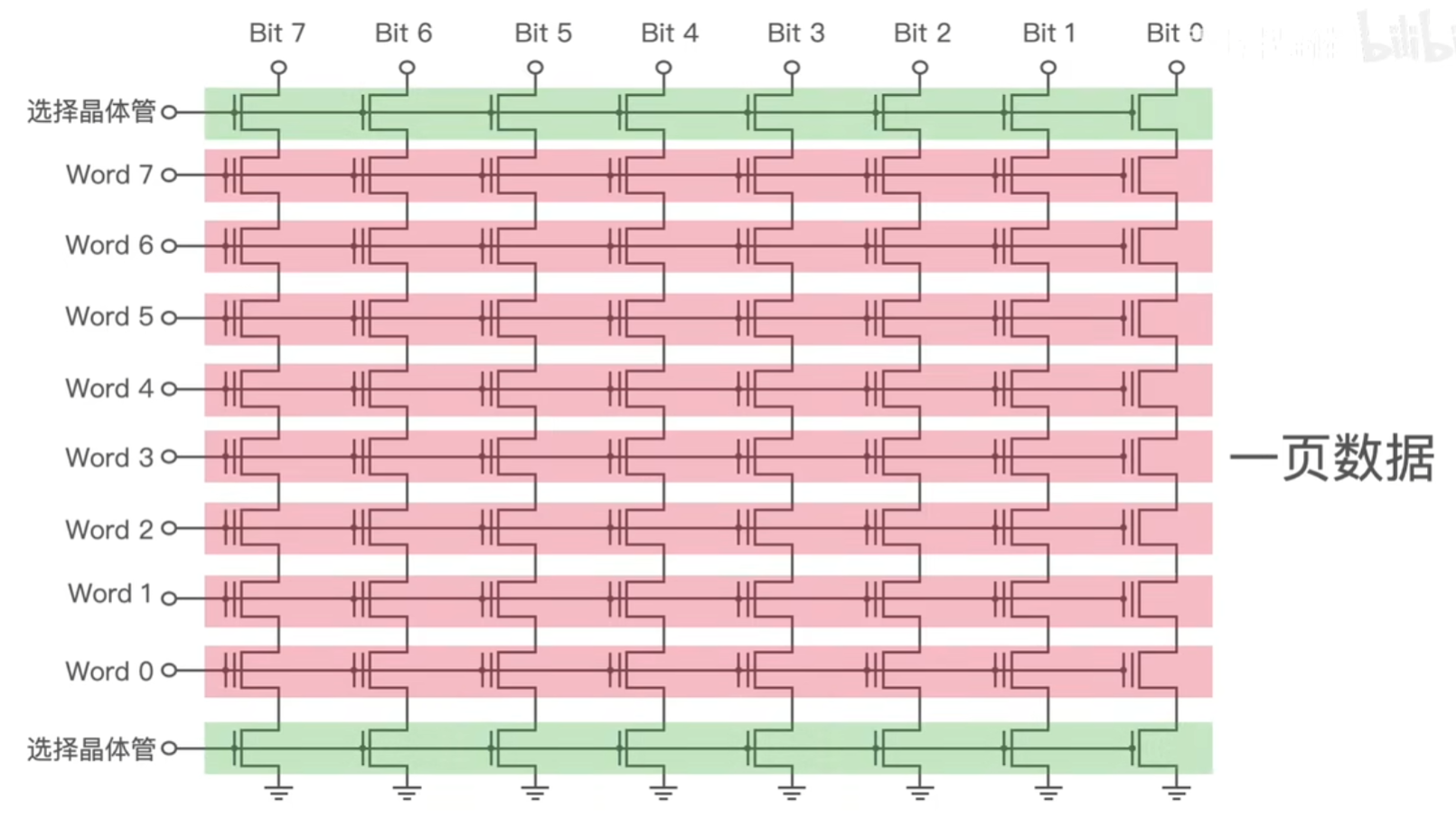
1个Page 一般是4KB 或者 8 KB ,上面我们提到的 990 PRO 是 16KB, 不同 SSD 大小也不同。因为浮栅晶体管被分组并以非常特定的属性访问,所以我们只能按页来进行数据的读写,如下简化图中红色的每一行都代表一个 Page ,写数据的时候会给行列两端加上不同的电压,加电压只能加到行和列上,所以没法控制到单个浮栅晶体管;
Block 是擦除的基本单位,每个 Block 会包含 128 到 256 个上面这样的 Page。如下图由于一块 Block 上面的所有浮栅晶体管其实是共用一个衬底,只要给这个衬底施加高压,浮栅晶体管里面存储的数据就会被清空,所以 Block 是擦除数据的基本单位。

其实这取决于浮栅晶体管的结构,它的结构下图所示,我不打算概述它的原理,但是我们可以知道在浮栅晶体管中电子是存储在浮栅层的,读写数据的时候电子需要穿过隧穿层,由隧穿层来锁住电子,隧穿层穿越次数是有限制的,进出次数多了,就锁不住电子了,那么该 Block 就没法擦写数据了。
所以如果一直在同一个 Block 擦写数据,这个 Block 的寿命很快就会消耗完,为了有效的延迟 SSD 的使用寿命就很考验 Block 的管理技术了,后面我们可以看看现在的 SSD 有哪些管理抓手。
当首次向SSD写入数据时,因为数据都处于已擦除的状态,所以数据可以直接写入,至少一次性写入一个 Page。因为在写入的时候会按照 Page 为单位进行写入,所以如果要写入的数据小于一个 Page,那么其余写入超过必要的数据称为写入放大。
只有空闲的Page才能被写入,并且是不能覆盖的,所以在修改数据的时候数据会被写入到一个空闲页面中,一旦被持久化到页面上,原来的旧页面会被标记成 stale 状态,表示它可以被擦除。
所以一个 Page 变成 stale 状态之后唯一能让它们再次使用的方式就是擦除它们,但是擦除的维度我们上面也讲过了,是以 Block 为维度进行擦除的,并且擦除命令不由用户控制,擦除命令是由SSD控制器中的垃圾回收机制进程在需要回收陈旧页面以腾出空闲空间时自动触发的。
除了上面提到的写入放大以外,如果在写入数据的时候不是以 Page 为单位进行写入,会导致Page 被修改并写回驱动器之前被读入缓存,这种操作被称为读-修改-写,比直接操作页面要慢。
所以我们写入数据的时候应该要对齐写入,也就是按 Page 整倍大小写入。并且为了最大限度地提高吞吐量,尽可能将小写入保留到 RAM 中的缓冲区中,当缓冲区已满时,执行一次大写入以批处理所有小写入。
数据以 Page 为单位写入到存储中。然而,存储器只能以较大的单位 Block 擦除。如果不再需要一个Block 中某些Page内的数据,仅会读取该块中含有有效数据的Page,并重新写入到另一个先前擦除的空 Block 中,然后将原来的 Block 进行擦除,擦除之后的 Block 又可以重新使用,这个过程叫做垃圾回收。
所有的SSD都包含不同程度的垃圾回收机制,但在执行的频率和速度上有所不同,垃圾回收占了SSD上写入放大的很大一部分。

比如上面这个例子中,在 Block 1000 中写入 x,y,z 三个数据,然后想要修改 PPN 为 0 的这块数据时由于不能覆盖,所以只能在 PPN 为 3 的 Page 上面写入 x` 。当后台的垃圾回收进程启动的时候会将有效的数据拷入到另一个空闲的 BLock 中,然后将原来的 Block 1000 中的数据擦除。
SSD 擦除写入的次数也叫做 P/E 周期( program/erase cycle),由于 P/E 周期是有限的,所以假设SSD其中数据总是从同一个精确的块中读取和写入,那么这块 Block 很快就达到了使用寿命的上限,SSD控制器会将其标记为不可用。然后磁盘的整体容量会下降。
所以实现磨损均衡(wear leveling)是控制器的主要目标之一,即在块之间尽可能均匀地分配P/E周期,理想情况下,所有块都将达到其P/E周期限制并同时磨损。
我这里用长江存储致钛的图来解释一下,上面三张是没有磨损均衡的,那么反复写就会出现坏页,下面三张是有磨损均衡,那么控制器会根据不同的算法挑选出擦写次数较低的 Page 进行写入。
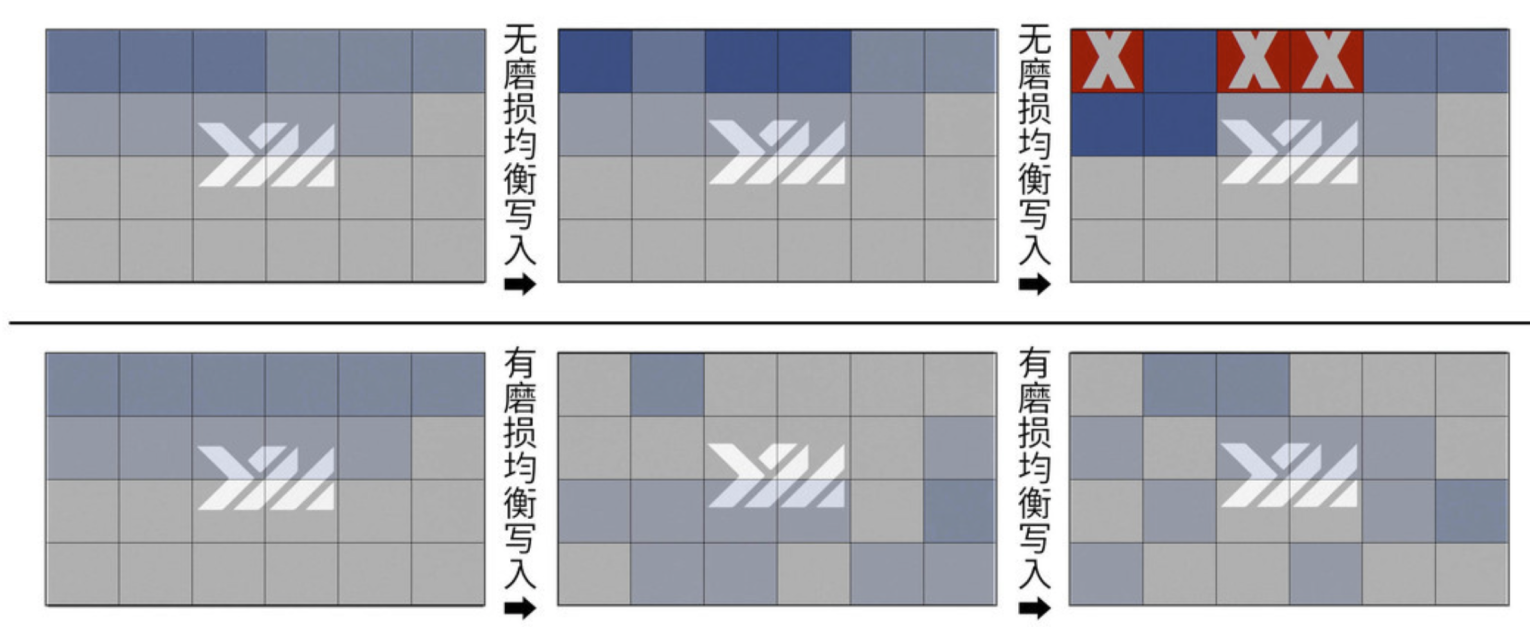
当然我们也知道,理论和现实总是有区别的,具体实现起来还是很难的。因为想要磨损均衡,那必须要写入的时候将一些Block的数据进行移动,这一过程本身会导致写入放大的增加。因此,块管理是最大化磨损均衡和最小化写入放大之间的权衡,也就是它是一个 trade-off 的艺术。

磨损均衡分为静态磨损均衡与动态磨损均衡。动态磨损平衡是指当需要更改某个Page中的数据时,将新的数据写入擦除次数较少的物理页上,同时将原页标为无效页,动态磨损平衡算法的缺点在于,如果刚刚写入的数据很快又被更新,那么,刚刚更新过的数据块很快又变成无效页,如果频繁更新,无疑会让保存冷数据的Block极少得到擦除,对闪存整体寿命产生不利影响。早期的SSD主控多用动态磨损平衡算法。
静态磨损均衡是在每次写入时从空白Page中挑选擦写次数最少的进行写入,并且为了防止冷数据的Block极少得到擦除,静态磨损均衡会在条件具备的情况下搬走长期占用Block的不变数据,将其释放出来用于新数据写入,从而避免过度消耗其他闪存单元的寿命。
预留空间 Over-provisioning,也叫OP,指的是 SSD 一般会保留一部分的空间对用户不可见,大多数的厂商都会预留7%到25%左右的空间,额外的预留空间有助于降低控制器写入闪存时的写入放大。用户可以通过将磁盘分区为低于其最大物理容量的逻辑容量来创建更多的过度配置。例如,可以在100 GB驱动器中创建一个90 GB分区,并将剩余的10 GB预留不使用。
比如下面的这种图中, 是我找到金士顿官网的预留空间图:
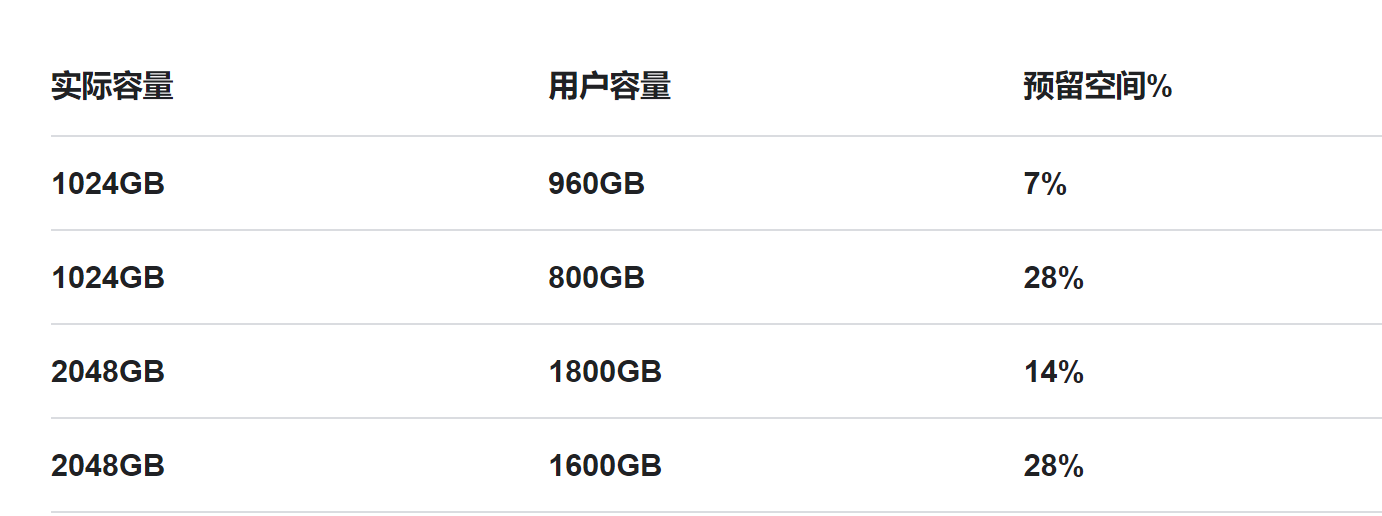
预留空间主要是给 SSD 控制器使用,一方面是用来做是用来做磨损平衡,替换可见空间中被磨损的 Block,另一方面是用来提升性能使用;
因为上面也提到了,SSD 的写入是无法覆盖的,只能在空白页面上写入,所以在这个过程中预留空间足够大则从空白的页中进行写入,可以减少擦除次数也能够减少有效数据的再次写入,降低 Block 的磨损,从而提升硬盘的耐用性。
预留空间在读写工作负载很重的时候可以充当NAND闪存块的缓冲区,帮助垃圾回收机制处理吸收写入高峰。因为垃圾回收擦除数据比写入要花费更多的时间,垃圾回收一般在空闲的时候做,如果在负载很重的时候垃圾回收来不及擦除,那么可能会和写入操作同时进行,而预留空间可以作为缓冲区给垃圾回收机制留出足够的时间来赶上并再次擦除块。
另一方面预留空间也可以减少垃圾回收次数,空白页面多了自然就不用频繁的做垃圾回收了,这同时也减少了写入放大。
简单来说,TRIM主要是优化固态硬盘,解决SSD使用后的降速与寿命的问题。
原本在机械硬盘上,写入数据时,Windows会通知硬盘先将以前的擦除,再将新的数据写入到磁盘中。而在删除数据时,Windows只会在此处做个标记,说明这里应该是没有东西了,等到真正要写入数据时再来真正删除,由于这个标记只是在操作系统层面,SSD 并不知道哪些数据被删了,所以我们日常的文件删除,都只是一个操作系统层面的逻辑删除。这也是为什么,很多时候我们不小心删除了对应的文件,我们可以通过各种恢复软件,把数据找回来。
SSD 只有当操作系统在同一个被删了的 Block 里面写入数据的时候才知道这个数据已经被删了,那么才会把它标记成废弃,等待垃圾回收。。这就导致,我们为了磨损均衡,很多时候在都在搬运很多已经删除了的数据。这就会产生很多不必要的数据读写和擦除,既消耗了 SSD 的性能,也缩短了 SSD 的使用寿命。
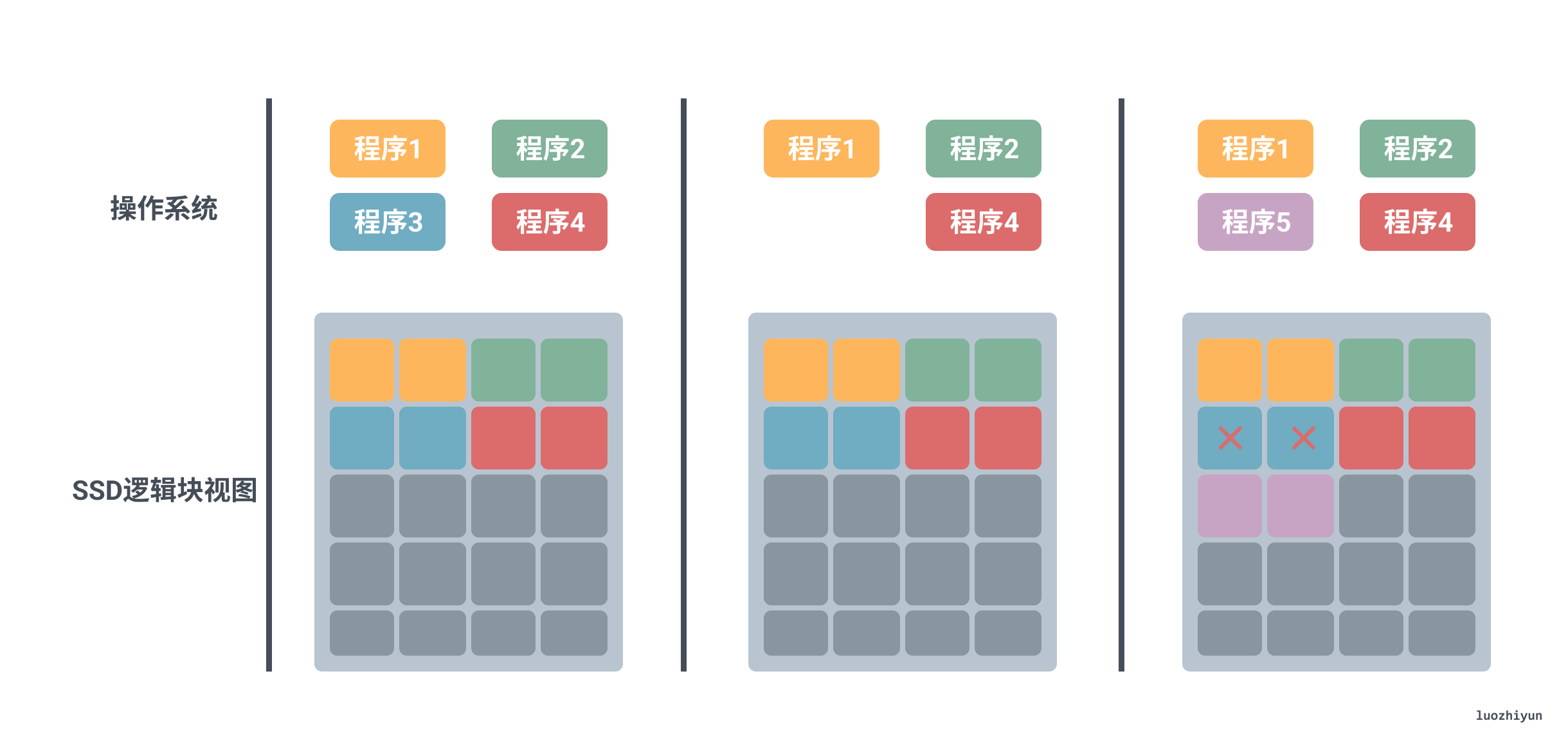
比如上面这个图中,我们在系统层面删除了程序3,但是在SSD 的逻辑块层面,其实并不知道这个事情。这个时候,如果我们需要对 SSD 进行垃圾回收操作,程序3占用的物理页仍然要在这个过程中,被搬运到其他的 Block 里面去。只有当操作系统在里面重新写入数据的时候SSD才会把它标记成废弃掉。
TRIM指令让操作系统可以告诉固态驱动器哪些数据块是不会再使用的;否则SSD控制器不知道可以回收这些闲置数据块。TRIM的简约性将极大减少写入负担,同时允许SSD更好地在后台预删除闲置的数据块,以便让这些数据块可以更快地预备新的写入。
TRIM命令只有在SSD控制器、操作系统和文件系统支持它的情况下才有效。
来看并发性之前,先来看看 SSD 具体的层级结构,SSD 使用层级的方式管理NAND Flash。Controller会使用多Channel的方式与NAND Flash Chip连接。每个Channel可以被视为一条数据传输路线,多个通道可以让控制器同时读写更多的数据,提高数据传输的速度和效率。每个NAND Flash Chip内部封装(Packaging)了多个Die,每个Die上排列了多个Plane,每个Plane中包含多个Block,每个Block中有多个Page。
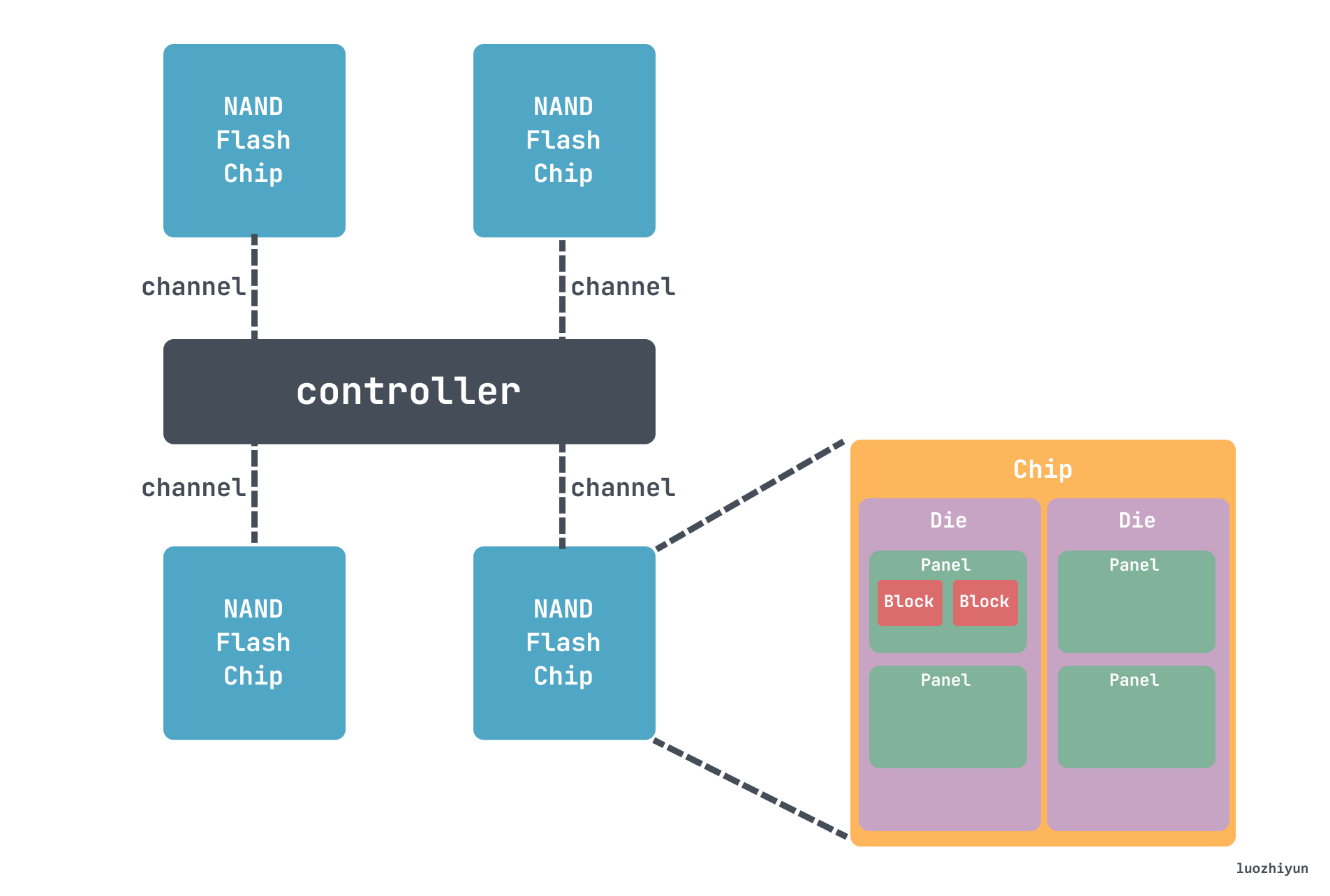
像我们上面提到的 990 Pro 这款 SSD,有 8条 Channel,每条Channel可以传输2,000 MT/s,MT/s代表每秒百万次传输(MegaTransfers per second)。每个 Chip 里面有 16 个 Die,每个 Die 有 4 个 Plane。
所以通过上面信息可以知道,SSD 是可以并行写入多个 Block 的,所以利用 SSD 多级并行机制,可以被并行访问的最大数量的 Block 集合称为一组 Cluster Blocks,它的可以从几十MB到几百MB,具体取决于控制器策略、SSD 容量、NAND 闪存类型等,不过我查过了,一般厂商没有给出这个具体的大小。
利用Cluster Blocks的并行性能,SSD可以把一次大块写打散到多个Cluster Blocks上并行执行,有效降低时延,提高吞吐量。
如果写操作每次写入的数据量小于 Cluster Blocks 大小时则顺序写的吞吐量显著高于随机写,所以如果随机写入既是Cluster Blocks 的倍数,那么它们的性能与顺序写入一样好。两者的区别主要体现在以下两个方面:
最后,关于并发,其实用一个线程写入一大块数据和用许多并发线程写入许多较小块数据一样快。事实上,一个大写入保证了SSD的所有内部并行性都被使用。因此,尝试并行执行多个写入不会提高吞吐量。然而,与单线程访问相比,许多并行写入会导致延迟增加。所以一次大写入比多次小并发写入要好。
再来就是当写入很小并且无法合并的时候,多线程是有益的,许多并发的小写请求将提供比单个小写请求更好的吞吐量。所以如果I/O很小并且无法批处理,最好使用多个线程。
总结就是这样:
| 大块写 | 小块写 | |
|---|---|---|
| 单线程 | 最快 | 最慢 |
| 多线程并发 | 无助于吞吐量,提高时延 | 有助于提高多级并发机制的利用,提高吞吐量 |
同样的为了提高读取性能,最好将相关数据一起写入。因为读取性能是写入模式的结果。当一次写入一大块数据时,它会分布在单独的NAND闪存芯片上。因此,您应该在同一页、块或集群块中写入相关数据,这样以后就可以利用内部并行性,通过单个I/O请求更快地读取这些数据。
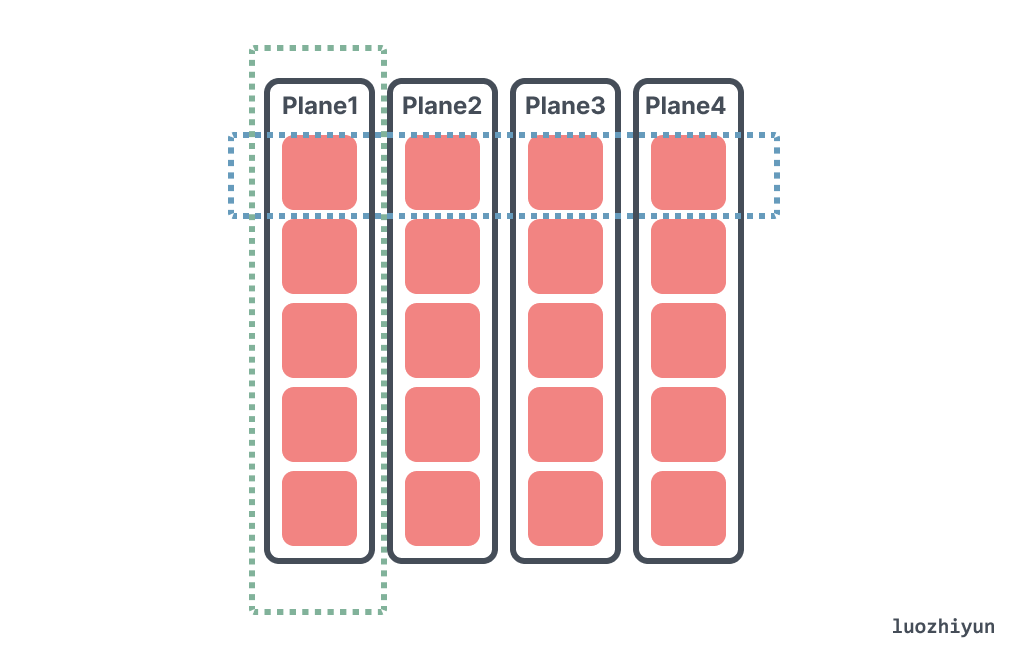
因为写入的时候SSD会尽量的把所写的Page打散到多个Clustered Block上进行并行,那么读操作如果同时读取这些Page将会获得最多的并行。相反如果读操作总是读取不同写操作写入的Page,那么这些Page很可能处于相同的Plane上,必须串行读取。如上图所示。
对于多线程并发小块数据读取来说,性能是不如单线程大块数据读取的,因为这不能用到预读机制,这种机制通过预先读取可能接下来会被请求的数据到缓存中,减少了数据访问的等待时间,从而提升了读取性能。
更好的利用SSD可以获得一些免费的好处,如:提升应用程序性能、延长SSD的寿命、提高SSD的 IO 效率等等。
假设我们将冷热数据混合排布在同一个区块,对于 SSD 来说,如果要修改其中的一小块内容(小于 1 页),SSD 仍然会读取整页的数据,这样会导致写入放大。所以对于一些改动非常频繁的热数据应该尽可能的 cache 住在内存里,然后批量的进行更新,这样不仅更快,而且还能提升SSD寿命。
这其实也和 SSD 的结构相关,更紧凑的数据结构可以尽量让数据都聚拢在同一个 Block 中,减少 SSD 的读取操作,同时也能更好的利用缓存。同样的,由于SSD 写入方式的特殊性,紧凑数据结构将关联数据放置到相邻区域,减少可能的垃圾回收的同时,还能够降低写入放大带来的问题。
避免写入小于NAND闪存页面大小的数据块,以最大限度地减少写入放大并防止读取-修改-写入操作。目前页面的最大大小为16 KB,因此默认情况下应使用该值,此大小取决于SSD型号。
当数据不足一页时为了最大限度地提高吞吐量,尽可能将小写入保留到RAM中的缓冲区中,当缓冲区已满时,执行一次大写入以批处理所有小写入。
读取性能是写入模式的结果。当一次写入一大块数据时,它会分布在单独的NAND闪存芯片上。因此,您应该在同一 Page、Block或 clustered block 中写入相关数据,这样以后就可以利用内部并行性,通过单个I/O请求更快地读取这些数据。
由小交错读写混合组成的工作负载将阻止内部缓存和预读机制正常工作,并将导致吞吐量下降。最好避免同时读取和写入,并在大块中一个接一个地执行它们,最好是clustered block的大小。例如,如果必须更新1000个文件,您可以迭代文件,对文件进行读写,然后移动到下一个文件,但那会很慢。最好一次读取所有1000个文件,然后一次写回这1000个文件。
如果写入很小(即低于clustered block的大小),则随机写入比顺序写入慢。如果写入既是clustered block的倍数,又与clustered block的大小对齐,随机写入将使用所有可用的内部并行级别,并且执行与顺序写入一样好。对于大多数驱动器,集群块的大小为16 MB或32 MB,因此使用32 MB是安全的。
上面我们也提到了,并发随机读取不能充分利用预读机制。此外,多个逻辑块地址可能最终在同一芯片上,没有利用或内部并行性。大型读取操作将访问顺序地址,因此能够使用预读缓冲区(如果存在)并使用内部并行性。因此,如果用例允许,最好发出大型读取请求。
大型单线程写入请求提供与许多小型并发写入相同的吞吐量,但是就延迟而言,大型单线程写入比并发写入具有更好的响应时间。因此,只要有可能,最好执行单线程大型写入。
许多并发的小写请求将提供比单个小写请求更好的吞吐量。所以如果I/O很小并且无法批处理,最好使用多个线程。
预留空间有助于磨损均衡机制应对NAND闪存单元固有的有限生命周期。对于写入不那么重的工作负载,10%到15%的过度配置就足够了。对于持续随机写入的工作负载,保持高达25%的过度配置将提高性能。过度配置将充当NAND闪存块的缓冲区,帮助垃圾回收机制处理吸收写入高峰。
https://codecapsule.com/2014/02/12/coding-for-ssds-part-1-introduction-and-table-of-contents/
https://www.bilibili.com/video/BV1aF411u7Ct/?vd_source=f482469b15d60c5c26eb4833c6698cd5
https://www.extremetech.com/gaming/210492-extremetech-explains-how-do-ssds-work
https://www.bilibili.com/video/BV1644y157mB/?vd_source=f482469b15d60c5c26eb4833c6698cd5
https://zh.wikipedia.org/wiki/%E5%86%99%E5%85%A5%E6%94%BE%E5%A4%A7
https://time.geekbang.org/column/article/118191
https://www.techpowerup.com/ssd-specs/samsung-990-pro-2-tb.d862