1970-01-01 08:00:00
今天是个特殊的日子,十年前的这个时候我根本无法想像我可以在一家公司呆十年,坚持做一样工作十年之久。于是我就想要写点儿东西来回顾一下这十年的发生在我身上的事情。工作、学习、编程、生活。
我接触电脑的时间比较早,大约在小学五、六年级的时候就有了微机课。似乎是邓小平爷爷的一句「计算机要从娃娃抓起」的原因,学校采购了一批微机。每周都有一节课,大家都很期待。课堂上老师会教我们打字,在漆黑的屏幕上敲击 DOS 命令。
那个时候只感觉电脑很神奇,似乎就是电视机和游戏机的合体。
直到后来上了初中,有了互联网,有了网上聊天,有了局域网对战游戏。似乎电脑的用处又多了很多。
我人生中的第一台电脑是上高中时我三伯从深圳带回来的。上面装的是 Windows 98,后来有了 XP。但是我发现那台电脑太旧了硬件根本不支持安装 XP。这让我很失望,因为当时的 XP 看起来非常赏心悦目,比起 98 那种棱角分明的黑白灰风格漂亮多了。
直到现在我还记得,当时我专门进了一趟城,买了两张 3.5 英寸软盘。打算去网吧下载几首歌曲用软盘复制回家里的电脑上面。因为那时候家里面的电脑还没联网。因为3.5寸软盘容量只有 1.44MB,一首 mp3 格式的歌至少 3M 起,完全放不下。后来专门下载了另外一种音乐文件格式叫 wma,比 mp3 有更高的压缩率。一张软盘可以复制差不多两首歌曲。虽然那时候已经有能放 mp3 的随身听了但是折腾这个还挺有意思的。
接着就是玩 QQ 空间,那时候比较流行空间装扮。网上有很多看不懂的代码,复制到 QQ 空间的自定义模块里面去就会有很多神奇的效果。Flash 动画,一首动听的音乐,一张漂亮的图片。每当我去看别人的空间时总感觉:人家的空间怎么装扮的这么漂亮。
高中毕业后我就从城里买了一本年度版本的《电脑报》,用来排解那段无聊的夏日。当然我看完后,其实真正懂的只有一半不到,很多专业的用词,根本不知道是什么意思。当时就觉得会安装操作系统就已经非常利害了。
也就是由于这本电脑报的启蒙,让我在放假期间报志愿时选择了计算机软件这个领域。我几乎是很轻易的就做出了这个选择,选什么专业这个问题上家人们并没有强行给我建议。我当时只知道一点:世界首富比尔盖茨是干这个的,所以我觉得我要是做这个应该也不会太差。
上了大学就开始学软件专业相关的知识,实际上真正学起来的时候也是很枯燥,理论上的东西对于我来说总是让我感到望而生畏。但是好在我因为我是这个专业的,所以还保持了这个专业的一些基本操守。比如:我喜欢写博客、搭网站、倒腾服务器什么的。写博客是因为当时也流行这个,当年韩寒和徐静蕾博客就很出名。我觉得自己也可以写写,但是毕竟咱是搞计算机的,怎么着也得弄个专业一点的,完全是自己设计的网站那种。而不是用新浪博客这种托管的博客站点。最重要的一点是:托管的博客站点他们提供的控制博客主题样式的功能限制太大,而且也没法自定义域名。这就让我觉得没意思,因为我就想做一点和别人不一样的事情。
然后专业课上也学习了网页制作相关的技术。用 Dreamweaver 拖图片到表格布局中去,拼成一个网页,这是当时书上教的。但是我上网上查过之后发现这种模式已经过时了,当时流行一个网站重构的概念,使用 CSS 来进行页面设计,会让你的页面更加炫酷。
当时我就知道有一个网站叫做 CSS Zen Garden,它的主题思想就是提供一套 HTML 代码,然后只允许你使用 CSS 对页面的元素进行布局、设计。上面有很多非常棒的设计作品,只是你很难想像这是基于同一个 HTML 设计出来的。这也是 CSS 的魅力所在,限制你的并不是技术,而是你的创意和想法。
我大概就是这样进入到前端这个领域的。
大学还没毕业,就赶上了当时互联网的一股浪潮 —— 电子商务,其实就是网上卖东西。那些年几乎每年都有一样新的互联网概念出世:论坛、聊天室、博客、微博、团购、电商。似乎是中国互联网百花齐放的时代。哦,对了。那时候社交网络是 MySpace,Twitter 还没流行起来。不一样的是当时这些网站都可以访问。
通过写博客、逛论坛。我被一些创业的老板盯上了,还没毕业就联系我想让我去北京上班。我当时想的是先毕业再说。只是当时其它同学好像都很着急找工作了,但是我一点都不急,最后一个学期了我还常常自己玩自己的游戏,自己学自己的东西。好像在我的意识里从来就没有找不到工作这种设定。后来我才知道当时一些同学早早的去找工作,在西安一个月七八百块钱就不错了,还不管吃住的那种。
后来毕业后我就来到了北京,这个让人充满向往的城市。先后呆了两家公司后,来到了现在的公司。基本上我换工作的原因只有一个,就是我做的事情限制了我的成长。我感觉学不到什么新东西了我就会离职。
刚开始都是只写 HTML/CSS,小公司一般会这个就够了。但是稍大一点的公司,就需要我会写 JavaScript,那时候才感觉至少水平到了 JS 这一层才有了编程的概念。会 JS 就能去大公司、正规公司,也能学到很多未知的技术。
后来在公司一直做了大概有4年的前端工程师,那段时间里是我写代码频率最高的一段时间,因为业务需求多,前端要做的事情也很多。那时候流行模块化、组件化、工具自动化这些概念。慢慢的 Node.JS 也出现了,前端有了要开始要跨越和后端之间的那条界线的趋势。整个行业中前端工程师的整体素质也有了很大的提升。再后来你会发现很多做后端的同学转做前端,反而做的更好了。因为大家认识到了前端的重要性,前端不再是一些表层的东西。前端变成了一种和用户沟通的形式。
此时我也发现了自身的一些瓶颈,很多东西无法深入下去。有的概念几乎全是空白,于是我就去看一些更专业领域的书箱资料。学习了 Python, 了解了 Ruby,补上了操作系统相关知识点。后端可以说也入门了,此时我只需要一个实践的机会。
也是机缘巧合,由于公司变动调整,我转做了一年的 Java 工程师。这让我对于无论是编程语言层面,还是系统框架层面都有了新的认知,把我之前学习的零散的东西都建立成了一种体系。并且当我维护过十万行级别的代码的时候,我才对技术有了更加深刻的认识,对技术才产生了敬畏之心。
我在考虑问题的时候不再只看到我自己的那一面。而是技术上从系统层面看,功能上从产品层面看,管理上从项目的层面多角度的去理解一个软件产品生命周期。因此,我似乎具有了一种跨跃式的思维模式,从技术层面看清产品的本质,从产品层面理清楚技术的突破点。
直到现在,虽然我冠有前端工程的虚名。但事实上这并没有限制我做的事情。因为我从来不给我自己打标签。相对于这些名义上的东西来讲我更关心我正在做的具体的事情,是我做的这些事情定义了我是一个怎么样的人,而不是那些标签。
现在回看这十年间的我。北漂、地下室、租房、买房、成家、养育,这些关键词都成为了我经历中的一部分。我从来都没有想像过我能在北京这座城市实现这一切。
从感情上讲我是很讨厌北京这个城市的,因为他没有生活,只有拼搏。但是从理性上讲,我现在拥有的几乎所有世俗意义上的成就都是北京这个城市给我的。因为她公平,所以我才有机会。
我在公司这十年里面,几乎每年都会晋升。我和公司的关系已经不是简单的雇佣和被雇佣关系。而是相互成就、相互欣赏。
虽然不知道未来的路还能走多长,但是有句话说得好:
但行好事,莫问前程。
许多人都会因为自己工作或者职位的原因而给自己画个圈圈。我是一个程序员,程序员就是怎样、怎样的。
我在刚开始的时候,出于一种自恋式的骄傲我自己也这么认为。我觉得程序员是不善言辞的、有思想的、专注的一个群体。当我尝试用一些美好的词语去描绘他们的时候,我发现这并不完整,之于我自己更是如此。
但事实上程序员也是普通人。
他们有细腻、感性的一面
他们也有果敢、理性的一面
他们有或专业或普通的能力
他们有或高雅或低俗的需求
他们豪放、他们矜持
他们独一无二
…
不为别的,只因为他们是芸芸众生中所有普通人中的某一个完整的人而已。
如果说非要我总结几句身为程序员的行事格律,那我觉得应该是以下几句话:

1970-01-01 08:00:00
昨夜雨疏风骤,浓睡不消残酒。试问卷帘人,却道海棠依旧。知否,知否?应是绿肥红瘦。
—— 李清照〔宋〕
开头两句「昨夜雨疏风骤,浓睡不消残酒」是交代场景。昨天晚上下着稀疏小雨,伴着大风。睡了一觉醉意仍然没有消退。浓睡不消残酒,此处用「浓」字形容沉睡,浓本来是形容液体的,「浓睡」,「残酒」等字眼这就已经奠定了一大早她本身内心还未化解开的某种忧怨。她这才意识到院子里面的海棠花经历了风雨交加的夜晚,不知道情况如何了。
于是有了对话「试问卷帘人,却道海棠依旧」。这两句中的「试」、「却」被认为是最为精妙的内心情景描写。
「试」是因为李清照还不确定海棠花全部凋谢了,她内心还暂存了一点希望,哪怕只是一点点,就是这一点点支撑着她一大早醒来就急切地想知道院子里的情况。
「却」是因为「海棠依旧」肯定是不可能的,李清照读了很多书,经历了多少春夏秋冬,她不可能不知道春去夏来之时,下雨会带走海棠花。
虽然李清照不情愿承认海棠花凋零的事实,但是理智让她发出了对卷帘人的嗔叹:
「知否,知否?应是绿肥红瘦」。知道吗,知道吗?这个时节,现在的院子里应该是绿叶茂盛,红花凋零的时候。「绿肥红瘦」是全词最为绝妙的四个字,绿代表着夏天、树叶,红代表着春天、花开。「绿肥红瘦」则表达的是春去夏来海棠花凋零,青春、时光即逝的伤感。
通常多数人认为在这首词中,卷帘人只是不走心的说了一句「海棠依旧」。但是恰恰相反,我觉得在这首词里面「卷帘人」才是点睛之笔。
卷帘人的回答「海棠依旧」充满了智慧,卷帘人有着极高的情商,或许只有她懂李清照。
我们从「试问卷帘人」这句开始分析,此刻李清照很想知道风雨过后院子里面的情况。
卷帘人回答「海棠依旧」有两种可能:
其一,李清照当时问的就是「院子里面的海棠花怎么样了?」,卷帘人说:「海棠依旧」 其二,李清照的院子里面几乎全是海棠花,她问院子里的情况,卷帘人自然知道她问的是海棠花,于是说:「海棠依旧」
这两种可能,无论是哪种都至少说明了李清照非常关心海棠花如何了,她关心海棠花是因为她不想看见海棠花凋零而因此伤感,但是理智又告诉他时间(海棠花凋零的)到了,再美的东西都熬不过时间。只是她心里面还有那么一点点念想,或许还有那么几支还未凋零呢?
可以想象,此时如果卷帘人告诉他院子里的真实情景,那该有多残酷。难道卷帘人要告诉她:你那些心爱的海棠花都被昨天夜里的大雨打的凋零不堪、破败不堪、全部死掉了。那李清照岂不要哭死?
所以说卷帘人很懂李清照为何尽兴、为何伤感。卷帘人天天和李清照在一起,她的一个表情、一个神态、一颦一笑一忧愁都在卷帘人的眼里...
如果我是那个卷帘人,我是段不忍心告诉李清照真实情况的,那将是无比残忍、无比无情的人才说的出来的。
试问没有卷帘人「知否」何在?
试问没有卷帘人「绿肥红瘦」又将何在?
事实上如果没有卷帘人的存在,这首词似乎也能讲得通。我们理解的「试」和「却」两个字之间存在一种矛盾感。「试」表示不确定,心存的期许。「却」表示确定的转折对比,事实的无奈。
此语境更像是一位说梦的痴人被「海棠依旧」点醒了一般,又好像是一种痴人说梦般的暗自言语。
这首词音律是那么的完美,没有一个多余的字。节奏时急时缓、时快时慢、时抑时扬、时而押韵、时而叙述,如绵绵细流一般任意思绪流淌。如此只可能是一个人的自言自语,才能一气呵成。
所以其实根本没有卷帘人,只是李清照自言自语罢了。因为孤独的人都喜欢旁若有人般的暗自言语~
那么「海棠依旧」究竟意味着什么?
你难道不觉得「海棠依旧」这四个字充满了智慧吗?智慧到根本不像是由卷帘人口中说出来的。要么是李清照自己杜撰的,要么就是上面分析的那种可能——卷帘人有着超人的智慧。
或许李清照只想到了当下的绿肥红瘦,伤感于青春、时光的即逝。还在伤感困惑的她被卷帘人口中的「海棠依旧」所点化。
卷帘人淡淡地说道:「明年海棠花依旧会开,你又何必如此的感伤。春去春会回来,又有谁人绕过了时光?」
「海棠依旧」的真正意思不就是所谓的天之道吗?客观规律,不以人的意志为转移的道。
不管你信不信,海棠花每年都会开,不会因为你的怜惜海棠花就晚几日凋谢,也不会因为你的期许海棠花就提前开放。
此时,「海棠依旧」到底是出自谁口已经不重要了。
因为明天太阳照常升起,因为明年海棠依旧。
悟
悟道休言天命,
修行勿取真经。
一悲一喜一枯荣,
哪个前生注定?
袈裟本无清净,
红尘不染性空。
幽幽古刹千年钟,
都是痴人说梦。
1970-01-01 08:00:00
是的,我今天就想批判一下那些披着「设计(系统/语言)」外衣的研发工程师。
设计系统(Design system)这个概念应该是从国外最先有的。它的定义是:
A Design System is a set of interconnected patterns and shared practices coherently organized
设计系统是被统一组织起来的一系列紧密关联的模式和可重用的实践。
国内的组件库只有 Antd 在推出的时候声称自己是 一个 UI 设计语言,虽然当时我还不知道什么叫做设计语言,什么是设计系统。但是从工程师的角度我知道它就是 一套组件库。
一直到近两年,越来越多的前端团队以设计系统为排面推出自己的组件库的时候,我就觉得有些不对劲儿了。
哪里不对劲儿了?我在想我们实际上做的事情不就是设计了一套组件库吗,为什么要把设计放在前面。这似乎传达给我们一种信号:
我们应该是设计先行?我们应该优先做设计角度取舍。
相反的,工程层面实现那就应该向设计方向妥协?
我想并不是这样的,或者说不应该是这样的。
设计 永远是最上层的,它们关注的用户的外在、外观感受,它是感性的、多变的,没有唯一标准的。你很难想象用一套设计系统满足所有人的需求对吧?因为我喜欢蓝色,你喜欢红色这是不需要解释的。
工程 永远是最底层的,它关注事物内在的东西、自身属性,它是理性的、不变的,有迹可循的。所以工程层面追求的是一致、复用和效率。没人喜欢一个相同的组件在不同的实现上有不一样的 API。
在「前端工程师」这个职位名字中,「前端」是个形容词,「工程师」才是名词。
我们得先是工程师再是前端对吧。当我们不由自主地和设计靠拢时,思维模式也受到了影响,似乎只有设计思维才会关注到那些形容词。
当我们在设计一套组件库的时候会遇到很多不一致的情况,在我的经验里面:
来自与设计和实现的不一致要多于纯粹实现层面的不一致。
当我们设计的组件库需要考虑到跨端情况的时候,我们的组件库应该有一套一致的 API、一致的命名规则。但是从设计角度去决策的时候这件事情变得非常困难。
比如说:日期选择 这个组件,移动端通常叫做 DatePicker,这个词强调的是用户的动作(pick),在 PC 端通常叫做 Calendar,这个词强调的是组件本身的特征。
但是我们在工程实现层面真他妈不需要这种差别,它就是一个日期选择组件而已。
还有:按钮 组件的类型属性,有的是表形的:default/info/warning/error,有的是表义的:primary/secondary/danger
再一次,我们在工程实现层面真他妈不需要这种差别。它就是一个简单的按钮而已。
造组件库的人没有想清楚这件事情,用组件库的人却得承受这种不一致。那什么组件库的设计者们没想清楚这件事情?
因为他们的思维也被设计系统带偏了。一味的追求设计上的形式化的一致,却忽略了工程上逻辑的一致。
当这股邪风吹来,没人会在意组件库的工程化设计,没人在意它好不好用,每个人都想复制粘贴快速实现一套组件库,然后再披上设计系统的外衣,为自己的似锦前程添砖加瓦...
1970-01-01 08:00:00
我们先来看看官方的定义:
Fabric.js is a framework that makes it easy to work with HTML5 canvas element. It is an interactive object model on top of canvas element. It is also an SVG-to-canvas parser.
Fabric.js 是一个可以让 HTML5 Canvas 开发变得简单的框架 。 它是一种基于 Canvas 元素的 可交互 对象模型,也是一个 SVG 到 Canvas 的解 析器(让SVG 渲染到 Canvas 上)。
Fabric.js 的代码不算多,源代码(不包括内置的三方依赖)大概 1.7 万行。最初是 在 2010 年开发的, 从源代码就可以看出来,都是很老的代码写法。没有构建工具,没有 依赖,甚至没使用 ES 6,代码中模块都是 用 IIFE 的方式包装的。
但是这个并不影响我们学习它,相反正因为它没引入太多的概念,使用起来相当方便。不需 要构建工具,直接在 一个 HTML 文件中引入库文件就可以开发了。甚至官方都提供了一个 HTML 模板代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<script src="https://rawgit.com/fabricjs/fabric.js/master/dist/fabric.js"></script>
</head>
<body>
<canvas id="c" width="300" height="300" style="border:1px solid #ccc"></canvas>
<script>
(function() {
var canvas = new fabric.Canvas('c');
})();
</script>
</body>
</html>
这就够了不是吗?
从它的官方定义可以看出来,它是一个用 Canvas 实现的对象模型。如果你需要用 HTML Canvas 来绘制一些东西,并且这些东西可以响应用户的交互,比如:拖动、变形、旋转等 操作。 那用 fabric.js 是非常合适的,因为它内部不仅实现了 Canvas 对象模型,还将一 些常用的交互操作封装好了,可以说是开箱即用。
内部集成的主要功能如下:
如果你之前没有过 Canvas 的相关开发经验(只有 JavaScript 网页开发经验),刚开始 入 门会觉得不好懂,不理解 Canvas 开发的逻辑。这个很正常,因为这表示你正在从传统 的 JavaScript 开发转到图形图像 GUI 图形图像、动画开发。 虽然语言都是 JavaScript 但是开发理念和用到的编程范式完全不同。
这两种开发方式各有各的优势,比如:
Canvas 开发的本质其实很简单,想像下面这种少儿画板:

Canvas 的渲染过程就是不断的在画板(Canvas)上面擦了画,画了擦。
动画就更简单了,只要渲染 帧率 超过人眼能识别的帧率(60fps)即可:
<canvas id="canvas" width="500" height="500" style="border:1px solid black"></canvas>
<script>
var canvas = document.getElementById("canvas")
var ctx = canvas.getContext('2d');
var left = 0
setInterval(function() {
ctx.clearRect(0, 0, 500, 500);
ctx.fillRect(left++, 100, 100, 100);
}, 1000 / 60)
</script>
当然你也可以用 requestAnimationFrame,不过这不是我想说明的重点。
fabric.js 的模块我大概画了个图,方便理解。
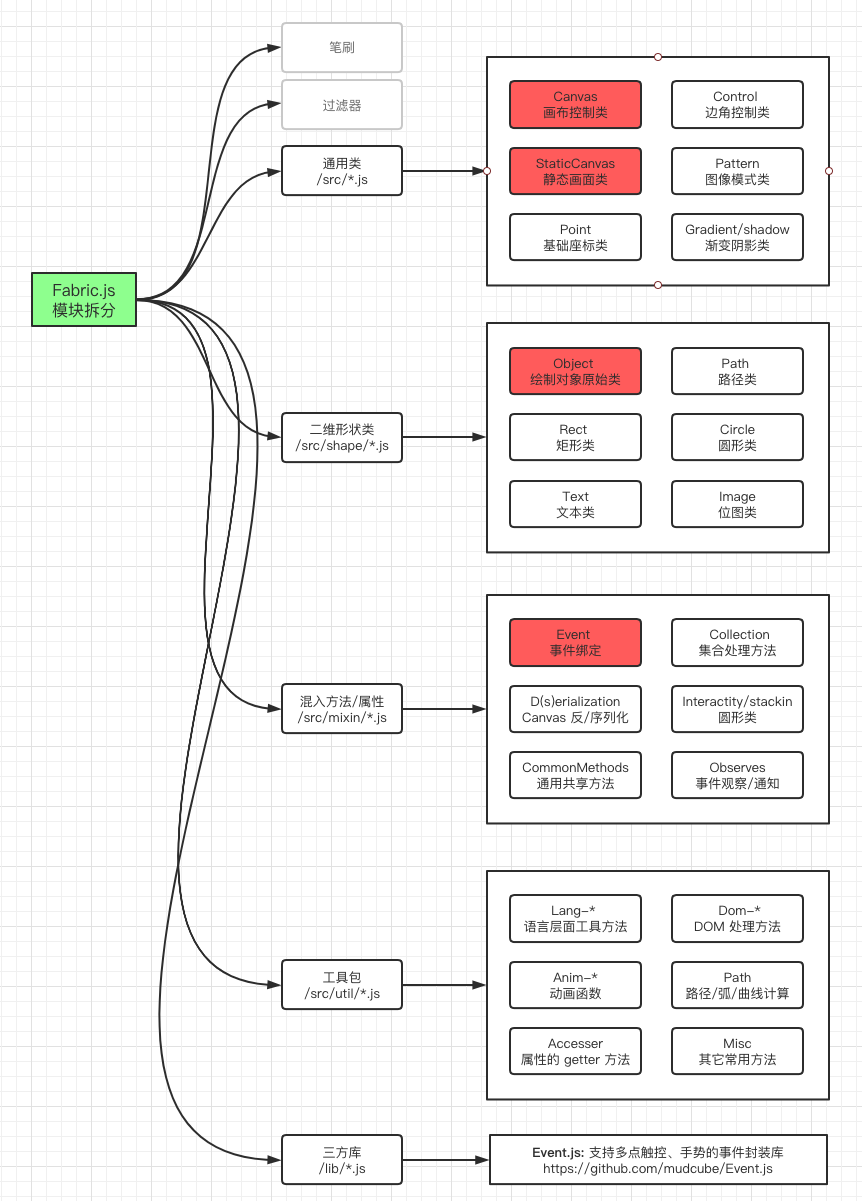
fabric.js 在初始化的时候会将你指定的 Canvas 元素(叫做 lowerCanvas)外面包裹上一 层 div 元素, 然后内部会插入另外一个上层的 Canvas 元素(叫做 upperCanvas),这两 个 Canvas 有如下区别
| 内部叫法 | 文件路径 | 作用 |
|---|---|---|
| upperCanvas | src/canvas.class.js | 上层画布,只处理 分组选择,事件绑定 |
| lowerCanvas | src/static_canvas.class.js | 真正 绘制 元素对象(Object)的画布 |
上图中,灰色的模块对于理解 fabric.js 核心工作原理没多大作用,可以不看。其它核心 模块我按自己的理解来解释一下。
所有模块都被挂载到一个 fabric 的命名空间上面,都可以用 fabric.XXX 的形式访问。
fabric.util 工具包工具包中一个最重要的方法是 createClass ,它可以用来创建一个类。 我们来看看这
个方法:
function createClass() {
var parent = null,
properties = slice.call(arguments, 0);
if (typeof properties[0] === 'function') {
parent = properties.shift();
}
function klass() {
this.initialize.apply(this, arguments);
}
// 关联父子类之间的关系
klass.superclass = parent;
klass.subclasses = [];
if (parent) {
Subclass.prototype = parent.prototype;
klass.prototype = new Subclass();
parent.subclasses.push(klass);
}
// ...
}
为什么不用 ES 6 的类写法呢?主要是因为这个库写的时候 ES 6 还没出来。作者沿用了
老 式的基 于 JavaScript prototype 实现的类继承的写法, 这个方法封装了类的继承、
构造方法、 父子类之前的 关系等功能。注意 klass.superclass 和
klass.subclasses 这两行, 后面会讲到。
添加这两个引用关系后,我们就可以在 JS 运行时动态获取类之间的关系,方便后续序列化 及反序列化操 作,这种做法类似于其它编程语言中的反射机制,可以让你在代码运行的时 候动态的构建、操作对象
initialize() 方法(构造函数)会在类被 new 出来的时候自动调用:
function klass() {
this.initialize.apply(this, arguments);
}
fabric.Canvas 类上层画布类,如上面表格所述,它并不渲染对象。它只来处理与用户交互的逻辑。 比如: 全局事件绑定、快捷键、鼠标样式、处理多(分组)选择逻辑。
我们来看看这个类初始化时具体干了些什么。
fabric.Canvas = fabric.util.createClass(fabric.StaticCanvas, {
initialize: function (el, options) {
options || (options = {});
this.renderAndResetBound = this.renderAndReset.bind(this);
this.requestRenderAllBound = this.requestRenderAll.bind(this);
this._initStatic(el, options);
this._initInteractive();
this._createCacheCanvas();
},
// ...
})
注意:由于 createClass 中第一个参数是 StaticCanvas,所以我们可以知道 Canvas
的父类 是 StaticCanvas。
从构造方法 initialize 中我们可以看出:
只有 _initInteractive 和 _createCacheCanvas 是 Canvas 类自己的方法,
renderAndResetBound,requestRenderAllBound,_initStatic 都继承自父类
StaticCanvas
这个类的使用也很简单,做为 fabric.js 程序的入口,我们只需要 new 出来即可:
// c 就是 HTML 中的 canvas 元素 id
const canvas = new fabric.Canvas("c", { /* 属性 */ })
fabric.StaticCanvas 类fabric 的核心类,控制着 Canvas 的渲染操作,所有的画布对象都必须在它上面绘制出来 。我们从构造函数中开始看
fabric.StaticCanvas = fabric.util.createClass(fabric.CommonMethods, {
initialize: function (el, options) {
options || (options = {});
this.renderAndResetBound = this.renderAndReset.bind(this);
this.requestRenderAllBound = this.requestRenderAll.bind(this);
this._initStatic(el, options);
},
})
注意:StaticCanvas 不仅继承了 fabric.CommonMethods 中的所有方法,还继承了
fabric.Observable 和 fabric.Collection,而且它的实现方式很 JavaScript,在
StaticCanvas.js 最下面一段:
extend(fabric.StaticCanvas.prototype, fabric.Observable);
extend(fabric.StaticCanvas.prototype, fabric.Collection);
requestRenderAll() 方法从下面的代码可以看出来,这个方法的主要任务就是不断调用 renderAndResetBound 方
法 renderAndReset 方法会最终调用 renderCanvas 来实现绘制。
requestRenderAll: function () {
if (!this.isRendering) {
this.isRendering = fabric.util.requestAnimFrame(this.renderAndResetBound);
}
return this;
}
renderCanvas() 方法renderCanvas 方法中代码比较多:
renderCanvas: function(ctx, objects) {
var v = this.viewportTransform, path = this.clipPath;
this.cancelRequestedRender();
this.calcViewportBoundaries();
this.clearContext(ctx);
fabric.util.setImageSmoothing(ctx, this.imageSmoothingEnabled);
this.fire('before:render', {ctx: ctx,});
this._renderBackground(ctx);
ctx.save();
//apply viewport transform once for all rendering process
ctx.transform(v[0], v[1], v[2], v[3], v[4], v[5]);
this._renderObjects(ctx, objects);
ctx.restore();
if (!this.controlsAboveOverlay && this.interactive) {
this.drawControls(ctx);
}
if (path) {
path.canvas = this;
// needed to setup a couple of variables
path.shouldCache();
path._transformDone = true;
path.renderCache({forClipping: true});
this.drawClipPathOnCanvas(ctx);
}
this._renderOverlay(ctx);
if (this.controlsAboveOverlay && this.interactive) {
this.drawControls(ctx);
}
this.fire('after:render', {ctx: ctx,});
}
我们删掉一些不重要的,精简一下,其实最主要的代码就两行:
renderCanvas: function(ctx, objects) {
this.clearContext(ctx);
this._renderObjects(ctx, objects);
}
clearContext 里面会调用 canvas 上下文的 clearRect 方法来清空画布:
ctx.clearRect(0, 0, this.width, this.height)
_renderObjects 就是遍历所有的 objects 调用它们的 render() 方法,把自己绘制
到画布上去:
for (i = 0, len = objects.length; i < len; ++i) {
objects[i] && objects[i].render(ctx);
}
现在你是不是明白了文章最开始那段 setInterval 实现的 Canvas 动画原理了?
fabric.Object 对象根类型虽然我们已经明白了 canvas 的绘制原理,但是一个对象(2d元素)到底是怎么绘制到
canvas 上去的,它们的移动怎么实现的?具体细节我们还不是很清楚。 这就要从
fabric.Object 根类型看起了。
由于 fabric 中的 2d 元素都是以面向对象的形式实现的,所以我画了一张内部类之间的继 承关系,可以清楚的看出它们之间的层次结构
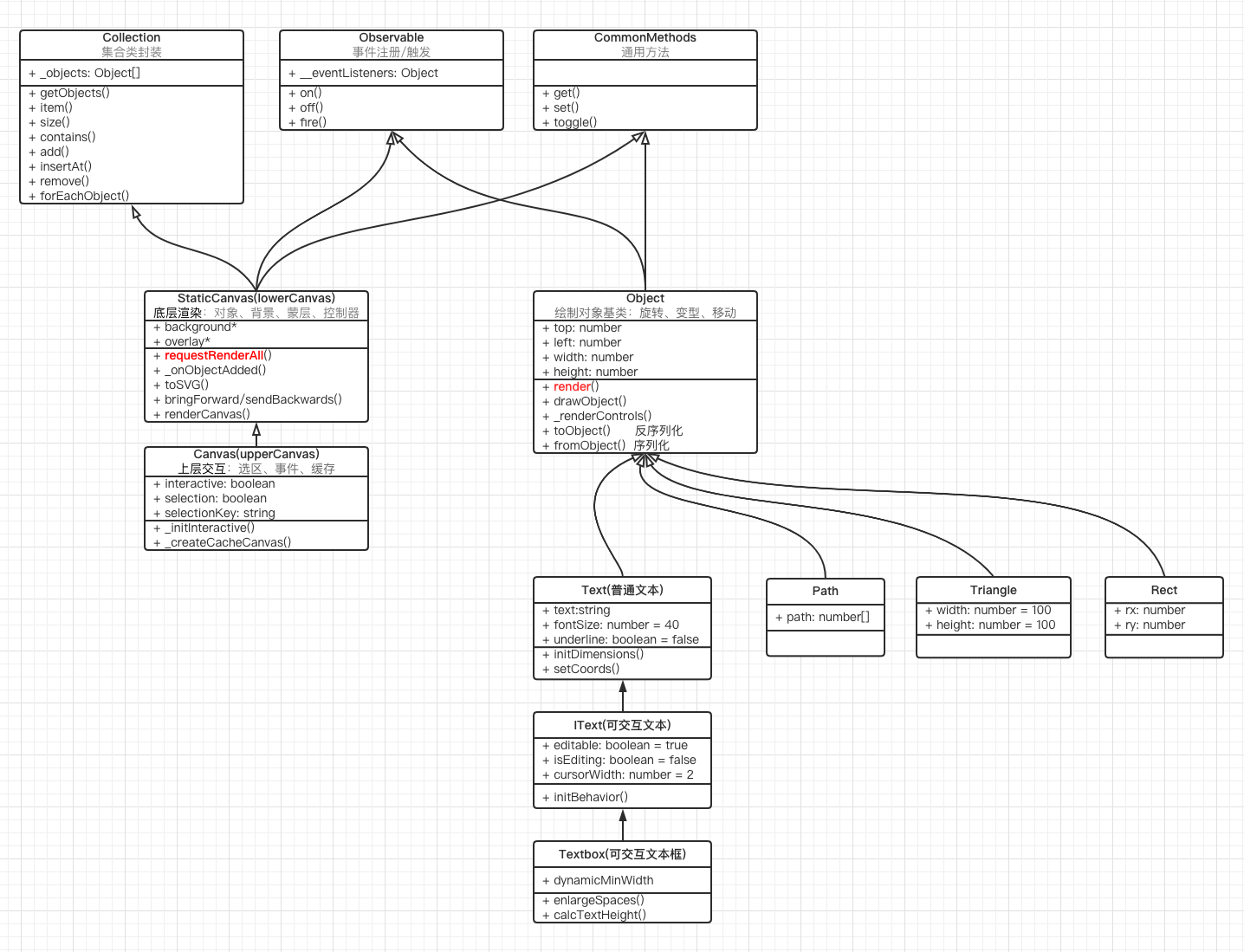
不像传统的 UML 类图那样,这个图看起来还稍有点乱,因为 fabric.js 内部实现的是多重 继承,或者说类似于 mixin 的一种混入模式实现的继承。
从图中我们可以得出以下几点:
底层 StaticCanvas 继承了 Collection 对象和 Observable 对象,这就意味着
StaticCanvas 有两种能力:
所有的 2d 形状(如:矩形、圆、线条、文本)都继承了 Object 类。Object 有的属
性、方法,所有的 2d 形状都会有
所有的 2d 形状都具有自定义事件发布/订阅的能力
下面的注释中,边角控制器 是 fabric.js 内部集成的用户与对象交互的一个手柄,当 某个对象处于激活状态的时候,手柄会展示出来。如下图所示:
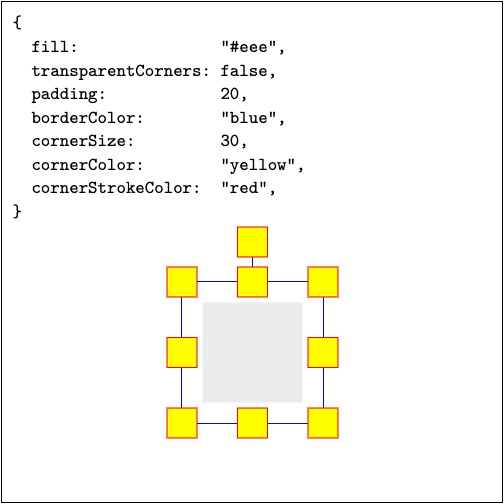
常用属性解释:
// 对象的类型(矩形,圆,路径等),此属性被设计为只读,不能被修改。修改后 fabric 的一些部分将不能正常使用。
type: 'object',
// 对象变形的水平中心点的位置(左,右,中间)
// 查看 http://jsfiddle.net/1ow02gea/244/ originX/originY 在分组中的使用案例
originX: 'left',
// 对象变形的垂直中心点的位置(上,下,中间)
// 查看 http://jsfiddle.net/1ow02gea/244/ originX/originY 在分组中的使用案例
originY: 'top',
// 对象的顶部位置,默认**相对于**对象的上边沿,你可以通过设置 originY={top/center/bottom} 改变它的参数参考位置
top: 0,
// 对象的左侧位置,默认**相对于**对象的左边沿,你可以通过设置 originX={top/center/bottom} 改变它的参数参考位置
left: 0,
// 对象的宽度
width: 0,
// 对象的高度
height: 0,
// 对象水平缩放比例(倍数:1.5)
scaleX: 1,
// 对象水平缩放比例(倍数:1.5)
scaleY: 1,
// 是否水平翻转渲染
flipX: false,
// 是否垂直翻转渲染
flipY: false,
// 透明度
opacity: 1,
// 对象旋转角度(度数)
angle: 0,
// 对象水平倾斜角度(度数)
skewX: 0,
// 对象垂直倾斜角度(度数)
skewY: 0,
// 对象的边角控制器大小(像素)
cornerSize: 13,
// 当检测到 touch 交互时对象的边角控制器大小
touchCornerSize: 24,
// 对象边角控制器是否透明(不填充颜色),默认只保留边框、线条
transparentCorners: true,
// 鼠标 hover 到对象上时鼠标形状
hoverCursor: null,
// 鼠标拖动对象时鼠标形状
moveCursor: null,
// 对象本身与边角控制器之间的间距(像素)
padding: 0,
// 对象处于活动状态下边角控制器**包裹对象的边框**颜色
borderColor: 'rgb(178,204,255)',
// 指定边角控制器**包裹对象的边框**虚线边框的模式元组(hasBorder 必须为 true)
// 第一个元素为实线,第二个为空白
borderDashArray: null,
// 对象处于活动状态下边角控制器颜色
cornerColor: 'rgb(178,204,255)',
// 对象处于活动状态且 transparentCorners 为 false 时边角控制器本身的边框颜色
cornerStrokeColor: null,
// 边角控制器的样式,正方形或圆形
cornerStyle: 'rect',
// 指定边角控制器本身的虚线边框的模式元组(hasBorder 必须为 true)
// 第一个元素为实线,第二个为空白
cornerDashArray: null,
// 如果为真,通过边角控制器来对对象进行缩放会以对象本身的中心点为准
centeredScaling: false,
// 如果为真,通过边角控制器来对对象进行旋转会以对象本身的中心点为准
centeredRotation: true,
// 对象的填充颜色
fill: 'rgb(0,0,0)',
// 填充颜色的规则:nonzero 或者 evenodd
// @see https://developer.mozilla.org/zh-CN/docs/Web/SVG/Attribute/fill-rule
fillRule: 'nonzero',
// 对象的背景颜色
backgroundColor: '',
// 可选择区域被选择时(对象边角控制器区域),层级低于对象背景颜色
selectionBackgroundColor: '',
// 设置后,对象将以笔触的方式绘制,此属性值即为笔触的颜色
stroke: null,
// 笔触的大小
strokeWidth: 1,
// 指定笔触虚线的模式元组(hasBorder 必须为 true)
// 第一个元素为实线,第二个为空白
strokeDashArray: null,
drawObject() 对象的绘制方法drawObject() 方法内部会调用 _render() 方法,但是在 fabric.Object 基类中它
是 个空方法。 这意味着对象具体的绘制方法需要子类去 实现。即子类需要 重写
父 类的空 _render() 方法。
_onObjectAdded() 对象被添加到 Canvas 事件这个方法非常重要,只要当一个对象被添加到 Canvas 中的时候,对象才可以具有 Canvas
的引用上下文, 对象的一些常用方法才能起作用。比如:Object.center() 方法,调用
它可以让一个对象居中到画布中央。 下面这段代码可以实现这个功能:
const canvas = new fabric.Canvas("canvas", {
width: 500, height: 500,
})
const box = new fabric.Rect({
left: 10, top: 10,
width: 100, height: 100,
})
console.log(box.top, box.left) // => 10, 10
box.center()
console.log(box.top, box.left) // => 10, 10
canvas.add(box)
但是你会发现 box 并没有被居中,这就是因为:当一个对象(box)还没被添加到 Canvas
中的时候,对象上面 还不具有 Canvas 的上下文,所以调用的对象并不知道应该在哪个
Canvas 上绘制。我们可以看下 center() 方法的源代码:
center: function () {
this.canvas && this.canvas.centerObject(this);
return this;
},
正如上面所说,没有 canvas 的时候是不会调用到 canvas.centerObject() 方法,也就
实现不了居中。
所以解决方法也很简单,调换下 center() 和 add() 方法的先后顺序就好了:
const canvas = new fabric.Canvas("canvas", {
width: 500, height: 500,
})
const box = new fabric.Rect({
left: 10, top: 10,
width: 100, height: 100,
})
canvas.add(box)
console.log(box.top, box.left) // => 10, 10
box.center()
console.log(box.top, box.left) // => 199.5, 199.5
「为什么不是 200,而是 199.5」—— 好问题,但是我不准备讲这个。有兴趣可以自己研究 下。
toObject() 对象的序列化正向的把对象序列化是很简单的,只需要把你关注的对象上的属性拼成一个 JSON 返回即可 :
toObject: function(propertiesToInclude) {
var NUM_FRACTION_DIGITS = fabric.Object.NUM_FRACTION_DIGITS,
object = {
type: this.type,
version: fabric.version,
originX: this.originX,
originY: this.originY,
left: toFixed(this.left, NUM_FRACTION_DIGITS),
top: toFixed(this.top, NUM_FRACTION_DIGITS),
width: toFixed(this.width, NUM_FRACTION_DIGITS),
height: toFixed(this.height, NUM_FRACTION_DIGITS),
// 省略其它属性
};
return object;
},
当调用对象的 toJSON() 方法时会使用 JSON.stringify(toObject()) 来将对象的属性
转换成 JSON 字符串
fromObject() 对象的反序列化fromObject() 是 Object 的子类需要实现的反序列化方法,通常会调用 Object 类的默
认方法 _fromObject()
fabric.Object._fromObject = function(className, object, callback, extraParam) {
var klass = fabric[className];
object = clone(object, true);
fabric.util.enlivenPatterns([object.fill, object.stroke], function(patterns) {
if (typeof patterns[0] !== 'undefined') {
object.fill = patterns[0];
}
if (typeof patterns[1] !== 'undefined') {
object.stroke = patterns[1];
}
fabric.util.enlivenObjects([object.clipPath], function(enlivedProps) {
object.clipPath = enlivedProps[0];
var instance = extraParam ? new klass(object[extraParam], object) : new klass(object);
callback && callback(instance);
});
});
};
这段代码做了下面一些事情:
Object 的子类 fromObject 中指定)找到挂载在
fabric 命名空间上的对象的所属类噫,好像不对劲?反序列化入参不得是个 JSON 字符串吗。是的,不过 fabric.js 中并没 有在 Object 类中提供这个方法, 这个自己实现也很简单,将目标 JSON 字符串 parse 成 普通的 JSON 对象传入即可。
Canvas 类上面到是有一个画布整体反序列化的方法:loadFromJSON(),它做的事情就是
把一段静态的 JSON 字符串转成普通对象 后传给每个具体的对象,调用对象上面的
fromObject() 方法,让对象具有真正的渲染方法,再回绘到 Canvas 上面。
序列化主要用于
持久存储,反序列化则主要用于将持久存储的静态内容转换为 Canvas 中可操作的 2d 元素,从而可以实现将某 个时刻画布上的状态还原的目的如果你的存储够用的话,甚至可以将整个在 Canvas 上的绘制过程进行录制/回放
一些绘制过程中常见的功能也是通过序列化/反序列化来实现的,比如:撤销/重做
混入类(mixin)通常用来给对象添加额外的方法,通常这些方法和画布关系不大,比如:
一些无参方法,事件绑定等。 通常混入类会通过调用 fabric.util.object.extend() 方
法来给对象的 prototype 上添加额外的方法。
混入类里面有一个很重要的文件:canvas_event.mixin.js,它的作用有以下几种:
__onMouseMove() 可以说是一个核心事件,对象的变换基本上都要靠它来计算距离才能实
现,我们来看看它是如何实现的
__onMouseMove: function (e) {
this._handleEvent(e, 'move:before');
this._cacheTransformEventData(e);
var target, pointer;
if (this.isDrawingMode) {
this._onMouseMoveInDrawingMode(e);
return;
}
if (!this._isMainEvent(e)) {
return;
}
var groupSelector = this._groupSelector;
// We initially clicked in an empty area, so we draw a box for multiple selection
if (groupSelector) {
pointer = this._pointer;
groupSelector.left = pointer.x - groupSelector.ex;
groupSelector.top = pointer.y - groupSelector.ey;
this.renderTop();
}
else if (!this._currentTransform) {
target = this.findTarget(e) || null;
this._setCursorFromEvent(e, target);
this._fireOverOutEvents(target, e);
}
else {
this._transformObject(e);
}
this._handleEvent(e, 'move');
this._resetTransformEventData();
},
注意看源码的时候要把握到重点,一点不重要的就先忽略,比如:缓存处理、状态标识。我
们只看最核心 的部分,上面这段代码里面显然 _transformObject() 才是一个核心方法
。我们深入学习下。
/**
* 对对象进行转换(变形、旋转、拖动)动作,e 为当前鼠标的 mousemove 事件,
* **transform** 表示要进行转换的对象(mousedown 时确定的)在 `_setupCurrentTransform()` 中封装过,
* 可以理解为对象 **之前** 的状态,再调用 transform 对象中对应的 actionHandler
* 来操作画布中的对象,`_performTransformAction()` 可以对 action 进行检测,如果对象真正发生了变化
* 才会触发最终的渲染方法 requestRenderAll()
* @private
* @param {Event} e 鼠标的 mousemove 事件
*/
_transformObject: function(e) {
var pointer = this.getPointer(e),
transform = this._currentTransform;
transform.reset = false;
transform.shiftKey = e.shiftKey;
transform.altKey = e[this.centeredKey];
this._performTransformAction(e, transform, pointer);
transform.actionPerformed && this.requestRenderAll();
},
我已经把注释添加上了,主要的代码实现其实是在 _performTransformAction() 中实现
的。
_performTransformAction: function(e, transform, pointer) {
var x = pointer.x,
y = pointer.y,
action = transform.action,
actionPerformed = false,
actionHandler = transform.actionHandler;
// actionHandle 是被封装在 controls.action.js 中的处理器
if (actionHandler) {
actionPerformed = actionHandler(e, transform, x, y);
}
if (action === 'drag' && actionPerformed) {
transform.target.isMoving = true;
this.setCursor(transform.target.moveCursor || this.moveCursor);
}
transform.actionPerformed = transform.actionPerformed || actionPerformed;
},
这里的 transform 对象是设计得比较精妙的地方,它封装了对象操作的几种不同的类 型,每种类型 对应的有不同的动作处理器(actionHandler),transform 对象就充当了一 种对于2d元素进行操作 的 上下文,这样设计可以得得事件绑定和处理逻辑分离,代码 具有更高的内聚性。
我们再看看上面注释中提到的 _setupCurrentTransform() 方法,一次 transform 开始
与结束 正好对应着鼠标的按下(onMouseDown)与松开(onMouseUp)两个事件。
我们可以从 onMouseDown() 事件中顺藤摸瓜,找到构造 transform 对象的地方:
_setupCurrentTransform: function (e, target, alreadySelected) {
var pointer = this.getPointer(e), corner = target.__corner,
control = target.controls[corner],
actionHandler = (alreadySelected && corner)
? control.getActionHandler(e, target, control)
: fabric.controlsUtils.dragHandler,
transform = {
target: target,
action: action,
actionHandler: actionHandler,
corner: corner,
scaleX: target.scaleX,
scaleY: target.scaleY,
skewX: target.skewX,
skewY: target.skewY,
};
// transform 上下文对象被构造的地方
this._currentTransform = transform;
this._beforeTransform(e);
},
control.getActionHandler 是动态从 default_controls.js 中按边角的类型获取的:
| 边角类型 | 控制位置 | 动作处理器(actionHandler) | 作用 |
|---|---|---|---|
| ml | 左中 | scalingXOrSkewingY | 横向缩放或者纵向扭曲 |
| mr | 右中 | scalingXOrSkewingY | 横向缩放或者纵向扭曲 |
| mb | 下中 | scalingYOrSkewingX | 纵向缩放或者横向扭曲 |
| mt | 上中 | scalingYOrSkewingX | 纵向缩放或者横向扭曲 |
| tl | 左上 | scalingEqually | 等比缩放 |
| tr | 右上 | scalingEqually | 等比缩放 |
| bl | 左下 | scalingEqually | 等比缩放 |
| br | 右下 | scalingEqually | 等比缩放 |
| mtr | 中上变形 | controlsUtils.rotationWithSnapping | 旋转 |
对照上面的边角控制器图片更好理解。
这里我想多说一点,一般来讲,像这种上层的交互功能,做为一个 Canvas 库通常是不会封 装好的。 但是 fabric.js 却帮我们做好了,这也验证了它自己定义里面的一个关键词:** 可交互的**,正 是因 为它通过边角控制器封装了见的对象操作,才使得 Canvas 对象可以 与用户进行交互。我们普通开发者不需要关心细节,配置一些通用参数就能实现功能。
fabric.js 中内置了很多自定义事件,这些事件都是我们常用的,非原子事件。对于日常开 发来说非常方便。
明白了上面这几个核心模块的工作原理,再使用 fabric.js 来进行 Canvas 开发就能很快 入门, 实际上 Canvas 开发并不难,难的是编程思想和方式的转变。
1970-01-01 08:00:00
此篇文章实际上就是《前端开发的瓶颈与未来》的番外篇。主要想从实用的角度给大家介绍下 Deno 在我们项目中的应用案例,现阶段我们只关注应用层面的问题,不涉及过于底层的知识。

我们从它的官方介绍里面可以看出来加粗的几个单词:secure, JavaScript, TypeScript。简单译过来就是:
一个 JavaScript 和 TypeScript 的安全运行时
那么问题来了,啥叫运行时(runtime)?可以简单的理解成可以执行代码的一个东西。那么 Deno 就是一个可以执行 JavaScript 和 TypeScript 的东西,浏览器就是一个只能执行 JavaScript 的运行时。
Mac/Linux 下命令行执行:
curl -fsSL https://deno.land/x/install/install.sh | sh
也可以去 Deno 的官方代码仓库下载对应平台的源(可执行)文件,然后将它放到你的环境变量里面直接执行。如果安装成功,在命令行里面输入:deno --help 会有如下输出:
➜ ~ deno --help
deno 1.3.0
A secure JavaScript and TypeScript runtime
Docs: https://deno.land/manual
Modules: https://deno.land/std/ https://deno.land/x/
Bugs: https://github.com/denoland/deno/issues
...
以后如果想升级可以使用内置命令 deno upgrade 来自动升级 Deno 版本,相当方便了。
Deno 内置了丰富的命令,用来满足我们日常的需求。我们简单介绍几个:
直接执行 JS/TS 代码。代码可以是本地的,也可以是网络上任意的可访问地址(返回JS或者TS)。我们使用官方的示例来看看效果如何:
deno run https://deno.land/std/examples/welcome.ts
如果执行成功就会返回下面的信息:
➜ ~ deno run https://deno.land/std/examples/welcome.ts
Download https://deno.land/std/examples/welcome.ts
Warning Implicitly using latest version (0.65.0) for https://deno.land/std/examples/welcome.ts
Download https://deno.land/[email protected]/examples/welcome.ts
Check https://deno.land/[email protected]/examples/welcome.ts
Welcome to Deno 🦕
可以看到这段命令做了两个事情:1. 下载远程文件 2. 执行里面的代码。我们可以通过命令查看这个远程文件里面内容到底是啥:
➜ ~ curl https://deno.land/[email protected]/examples/welcome.ts
console.log("Welcome to Deno 🦕");
不过需要注意的是上面的远程文件里面没有 显示的 指定版本号,实际下载 std 中的依赖的时候会默认使用最新版,即:[email protected] ,我们可以使用 curl 命令查看到源文件是 302 重定向到带版本号的地址的:
➜ ~ curl -i https://deno.land/std/examples/welcome.ts
HTTP/2 302
date: Fri, 14 Aug 2020 01:53:06 GMT
content-length: 0
set-cookie: __cfduid=d3e9dfbd32731defde31eba271f19933b1597369985; expires=Sun, 13-Sep-20 01:53:05 GMT; path=/; domain=.deno.land; HttpOnly; SameSite=Lax; Secure
location: /[email protected]/examples/welcome.ts
x-deno-warning: Implicitly using latest version (0.65.0) for https://deno.land/std/examples/welcome.ts
cf-request-id: 048c44c2dc000019dd710cc200000001
expect-ct: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
server: cloudflare
cf-ray: 5c270a4afd5719dd-SIN
header 头中的 location 就是实际文件的下载地址:
location: /[email protected]/examples/welcome.ts
这就涉及到一个问题:实际使用的时候到底应不应该手动添加版本号?一般来说如果是生产环境的项目引用一定要是带版本号的,像这种示例代码里面就不需要了。
上面说到 Deno 也可以执行本地的,那我们也试一试,写个本地文件,然后 运行它:
➜ ~ echo 'console.log("Welcome to Deno <from local>");' > welecome_local.ts
➜ ~ ls welecome_local.ts
welecome_local.ts
➜ ~ deno run welecome_local.ts
Check file:///Users/zhouqili/welecome_local.ts
Welcome to Deno <from local>
可以看到输出了我们想要的结果。
这个例子太简单了,再来个复杂点的吧,用 Deno 实现一个 Http 服务器。我们使用官方示例中的代码:
import { serve } from "https://deno.land/[email protected]/http/server.ts";
const s = serve({ port: 8000 });
console.log("http://localhost:8000/");
for await (const req of s) {
req.respond({ body: "Hello World\n" });
}
保存为 test_serve.ts,然后使用 deno run 运行它,你会发现有报错信息:
➜ ~ deno run test_serve.ts
Download https://deno.land/[email protected]/http/server.ts
Download https://deno.land/[email protected]/encoding/utf8.ts
Download https://deno.land/[email protected]/io/bufio.ts
Download https://deno.land/[email protected]/_util/assert.ts
Download https://deno.land/[email protected]/async/mod.ts
Download https://deno.land/[email protected]/http/_io.ts
Download https://deno.land/[email protected]/async/deferred.ts
Download https://deno.land/[email protected]/async/delay.ts
Download https://deno.land/[email protected]/async/mux_async_iterator.ts
Download https://deno.land/[email protected]/async/pool.ts
Download https://deno.land/[email protected]/textproto/mod.ts
Download https://deno.land/[email protected]/http/http_status.ts
Download https://deno.land/[email protected]/bytes/mod.ts
Check file:///Users/zhouqili/test_serve.ts
error: Uncaught PermissionDenied: network access to "0.0.0.0:8000", run again with the --allow-net flag
at unwrapResponse (rt/10_dispatch_json.js:24:13)
at sendSync (rt/10_dispatch_json.js:51:12)
at opListen (rt/30_net.js:33:12)
at Object.listen (rt/30_net.js:204:17)
at serve (server.ts:287:25)
at test_serve.ts:2:11
PermissionDenied 意思是你没有网络访问的权限,可以使用 --allow-net 的标识来允许网络访问。这就是文章开头特性里面提到的默认安全。
默认安全就是说被 Deno 执行的代码会默认被放进一个沙箱中执行,代码使用到的 API 接口都受制于 Deno 的宿主环境,Deno 当然是有网络访问、文件系统等能力的。但是这些系统级别的访问需要 deno 命令的 执行者 授权。
这个权限控制很多人觉得没必要,因为当我们运行代码时提示了受限,我们肯定手动添加上允许然后再执行嘛。但是区别是 Deno 把这个授权交给了执行者,好处就是如果执行的代码是第三方的,那么执行者就可以主动拒绝一些危险性很高的操作。
比如我们安装一些命令行工具,而一般命令行工具都是不需要网络的,我们就可以不给它网络访问的权限。从而避免了程序偷偷地上传/下载文件。
执行一段 JS/TS 字符串代码。这个和 JavaScript 中的 eval 函数有点类似。
➜ ~ deno eval "console.log('hello from eval')"
hello from eval
安装一个 deno 脚本,通常用来安装一个命令行工具。举个例子,在之前的 Deno 版本中有一个命令特别好用:deno xeval 可以按行执行 eval 命令,类似于 Linux 中的 xargs 命令。后来这个内置命令被移除了,但是 deno 的开发人员编写了一个 deno 脚本,我们可以通过 install 命令安装它。
➜ ~ deno install -n xeval https://deno.land/[email protected]/examples/xeval.ts
Download https://deno.land/[email protected]/examples/xeval.ts
Download https://deno.land/[email protected]/flags/mod.ts
Download https://deno.land/[email protected]/io/bufio.ts
Download https://deno.land/[email protected]/bytes/mod.ts
Download https://deno.land/[email protected]/_util/assert.ts
Check https://deno.land/[email protected]/examples/xeval.ts
✅ Successfully installed xeval
/Users/zhouqili/.deno/bin/xeval
➜ ~ xeval
xeval
Run a script for each new-line or otherwise delimited chunk of standard input.
Print all the usernames in /etc/passwd:
cat /etc/passwd | deno run -A https://deno.land/std/examples/xeval.ts "a = $.split(':'); if (a) console.log(a[0])"
A complicated way to print the current git branch:
git branch | deno run -A https://deno.land/std/examples/xeval.ts -I 'line' "if (line.startsWith('*')) console.log(line.slice(2))"
Demonstrates breaking the input up by space delimiter instead of by lines:
cat LICENSE | deno run -A https://deno.land/std/examples/xeval.ts -d " " "if ($ === 'MIT') console.log('MIT licensed')",
USAGE:
deno run -A https://deno.land/std/examples/xeval.ts [OPTIONS] <code>
OPTIONS:
-d, --delim <delim> Set delimiter, defaults to newline
-I, --replvar <replvar> Set variable name to be used in eval, defaults to $
ARGS:
<code>
[]
-n xeval 表示全局安装的命令行名称,安装完以后你就可以使用 xeval 了。
举个例子,我们使用 xeval 过滤日志文件,仅仅展示 WARN 类型的行:
➜ ~ cat catalina.out | xeval "if ($.includes('WARN')) console.log($.substring(0, 40)+'...')"
2020-08-12 13:37:39.020 WARN 202 --- [I...
2020-08-12 13:37:39.020 WARN 202 --- [I...
2020-08-12 13:37:39.019 WARN 202 --- [I...
2020-08-12 13:34:42.822 WARN 202 --- [o...
2020-08-12 13:34:42.822 WARN 202 --- [o...
2020-08-12 13:34:42.814 WARN 202 --- [o...
2020-08-12 13:34:42.805 WARN 202 --- [o...
$ 美元符表示当前行,程序会自动按行读取让执行 xeval 命令后面的 JS 代码。
catalina.out 是我本地的一个文本日志文件。你可能会觉得这样挺麻烦的,直接 | grep WARN 不香嘛?但是 xeval 的可编程性就高很多了。
deno 内置了一个简易的测试框架,可以满足我们日常的单元测试需求。我们写一个简单的测试用例试试,新建一个文件 test_case.ts,保存下面的内容:
import { assertEquals } from "https://deno.land/std/testing/asserts.ts";
Deno.test("1 + 1 在任何情况下都不等于 3", () => {
assertEquals(1 + 1 == 3, false)
assertEquals("1" + "1" == "3", false)
})
使用 test 命令跑这个测试用例:
➜ deno test test_case.ts
Check file:///Users/zhouqili/.deno.test.ts
running 1 tests
test 1 + 1 在任何情况下都不等于 3 ... ok (3ms)
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out (3ms)
可以看到测试通过了。
还有其它很多好用的命令,但是在我并没用太多的实际使用经验,就不多介绍了。
上面说了这么多基础知识,终于可以讲点实际应用场景了。我们在自己的一个 SDK 项目中使用了 Deno 来做自动化单元测试的任务。整个流程走下来还是挺流畅的。代码就不放出来了,我只简单的说明下这个 SDK 需要做哪些事情,理想的开发流程是什么样的。
如果你的场景和上面的吻合,那么就可以使用 Deno 来开发。本质上讲我们开发的时候写的还是 TypeScript,只是需要我们在发布 NPM 包的时候稍微的进行一下处理即可。
我们以实现一个 fetch 请求的封装方法为例来走通整个流程。
➜ ~ mkdir mysdk
➜ ~ cd mysdk
➜ mysdk npm init -y
建立好文件夹目录,及主要文件:
➜ mysdk mkdir src tests
➜ mysdk touch src/index.ts
➜ mysdk touch src/request.ts
➜ mysdk touch tests/request.test.ts
如果你使用的是 vscode 编辑器,可以安装好 deno 插件(denoland.vscode-deno),并且设置 deno.enable 为 true。你的目录结构应该是这样的:
├── package.json
├── src
│ ├── index.ts
│ └── request.ts
└── tests
└── request.test.ts
index.ts 为对外提供的导出 API。
使用 tsp --init 来初始化项目的 typescript 配置:
tsc --init
更新 tsconfig.json 为下面的配置:
{
"compilerOptions": {
"target": "ES5",
"lib": ["es6", "dom", "es2017"],
"declaration": true,
"outDir": "./build",
"strict": true,
"allowUmdGlobalAccess": true,
"forceConsistentCasingInFileNames": true
},
"include": [
"src/**/*.ts"
]
}
注意指定 outDir 为 build 方便我们将编译完的 JS 统一管理。
为了演示,这里就简单写下。request.ts 代码实现如下:
export async function request(url: string, options?: Partial<RequestInit>) {
const response = await fetch(url, options)
return await response.json()
}
调用端封闭好 GET/POST 请求的快捷方法,并且从 index.ts 文件导出:
import {request} from "./request.ts";
export async function get(url: string, options?: Partial<RequestInit>) {
return await request(url, {
...options,
method: "GET"
})
}
export async function post(url: string, data?: object) {
return await request(url, {
body: JSON.stringify(data),
method: "POST"
})
}
在 tests/request.test.ts 目录写上单元测试用例:
import { assertEquals } from "https://deno.land/std/testing/asserts.ts";
import {get, post} from "../src/index.ts";
Deno.test("request 正常返回 GET 请求", async () => {
const data = await get("http://httpbin.org/get?foo=bar");
assertEquals(data.args.foo, "bar")
})
Deno.test("request 正常返回 POST 请求", async () => {
const data = await post("http://httpbin.org/post", {foo: "bar"});
assertEquals(data.json.foo, "bar")
})
最后在命令行使用 deno test 命令跑测试用例。注意添加 --allow-net 参数来允许代码访问网络:
➜ mysdk deno test --allow-net tests/request.test.ts
Check file:///Users/zhouqili/mysdk/.deno.test.ts
running 2 tests
test request 正常返回 GET 请求 ... ok (632ms)
test request 正常返回 POST 请求 ... ok (342ms)
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out (974ms)
我们可以看到测试都通过了,下面就可以安心的发布 NPM 包了。
需要注意一点 Deno 写 TypeScript 的时候严格要求导入的 文件路径 必须添加 .ts 后缀。但是 TS 语言并不需要显式的添加这个后缀,TS 认为引入(import)的是一个 模块 而不是文件。这一点 TS 做的比较极端,tsc 要求你必须删除掉 .ts 后缀才能编译通过,这个我个人认为是非常不合理的。但是 Deno 有它的考虑,因为没有严格的文件名后缀引起程序 BUG 我自己也遇到过。
上面的几步都相对流畅,唯独到发布 NPM 包这一步就比较麻烦。因为本质上讲 Deno 只是 TypeScript/JavaScript 的运行时,并不兼容 NPM 这种包管理工具。而且 NPM 是为 Node.JS 设计的,它也没有办法直接发布 TypeScript 的包,我们只能把 TypeScript 编译成 JavaScript 再进行发布。
发布这里我们的需求有两点:
window.MySDK 访问到第二个简单,我们直接使用 tsc 的命令就可以完成:
tsc -m esnext -t ES5 --outDir build/esm
这时你会发现我上面提到的问题,tsc 报错了:
➜ mysdk tsc -m esnext -t ES5 --outDir build/esm
src/index.ts:1:23 - error TS2691: An import path cannot end with a '.ts' extension. Consider importing './request' instead.
1 import {request} from "./request.ts";
~~~~~~~~~~~~~~
说我不能使用 .ts!
这就尴尬了,deno 要求我必须添加,TS 又要求我不能添加。你到底想让人家怎么样嘛?
而且还有一个问题,我们现在实现的功能还很简单,引入的文件很少,可以手动修改下。但是以后功能多了怎么办?文件很多手动修改肯定不是办法啊。实在不行还是算了,不用 Deno 了?
其实嘛,解决方法还是有的,上面我们不是介绍过 Deno 安装脚本功能了吗。我们自己写个脚本放在 NPM Script 里面,每次编译发布前这个脚本自动把 .ts 去掉,发布完再自动改回来不就好了。
于是乎我自己写了一个 Deno 脚本,专门用来给项目的文件批量添加或者删除引用路径上面的 .ts 后缀:
源代码我就不全部贴出来了,简单讲就是用正则匹配出每个 ts 文件中的头部的 import 语句,按命令传入的参数去处理后缀就可以了。代码我放到了 gist 上,有兴趣的可以研究下:
https://gist.github.com/keelii/d95492873f35f96d95f3a169bee934c6
你可以使用下面的命令来安装并使用它:
deno install --allow-read --allow-write -f -n deno_ext https://gist.githubusercontent.com/keelii/d95492873f35f96d95f3a169bee934c6/raw/9736099cb47ef706e6c184e83c78fdfc822810dd/deno_ext.ts
使用 deno_ext 命令即可:
~ deno_ext
✘ error with command.
Remove or restore [.ts] suffix from your import stmt in deno project.
Usage:
deno_ext remove <files>...
deno_ext restore <files>...
Examples:
deno_ext remove **/*.ts
deno_ext restore src/*.ts
工具告诉你如何使用它,remove/restore 两个子命令+目标文件即可。
我们配合 tsc 可以实现发布时自动更新后缀,发布完还原回去,参考下面的 NPM script:
{
"scripts": {
"proc:rm_ext": "deno_ext remove src/*.ts",
"proc:rs_ext": "deno_ext restore src/*.ts",
"tsc": "tsc -m esnext -t ES5 --outDir build/esm",
"build": "npm run proc:rm_ext && npm run tsc && npm run proc:rs_ext"
}
}
我们使用 npm run build 命令就可以完成打包 ESModule 的功能:
➜ mysdk npm run build
> [email protected] build /Users/zhouqili/mysdk
> npm run proc:rm_ext && npm run tsc && npm run proc:rs_ext
> [email protected] proc:rm_ext /Users/zhouqili/mysdk
> deno_ext remove src/*.ts
Processing remove [/Users/zhouqili/mysdk/src/index.ts]
Processing remove [/Users/zhouqili/mysdk/src/request.ts]
> [email protected] tsc /Users/zhouqili/mysdk
> tsc -m esnext -t ES5 --outDir build/esm
> [email protected] proc:rs_ext /Users/zhouqili/mysdk
> deno_ext restore src/*.ts
Processing restore [/Users/zhouqili/mysdk/src/index.ts]
Processing restore [/Users/zhouqili/mysdk/src/request.ts]
最终打包出来的文件都在 build 目录里面:
build
└── esm
├── index.d.ts
├── index.js
├── request.d.ts
└── request.js
接下来我们还需要将源代码打包成单独的一个 UMD 模块,并展出到全局变量 window.MySDK 上面。虽然 TypeScript 是支持编译到 UMD 格式模块的,但是它并不支持将源代码 bundle 到一个文件里面,也不能添加全局变量引用。因为本质上讲 TypeScript 是一个编译器,只负责把模块编译到支持的模块规范,本身没有 bundle 的能力。
但是实际上当你选择 --module=amd 时,TypeScript 其实是可以把文件打包 concat 到一个文件里面的。但是这个 concat 只是简单地把每个 AMD 模块拼装起来,并没有 rollup 这类的专门用来 bundle 模块的高级功能,比如 tree-shaking 什么的。
所以想达到我们目标还得引入模块 bundler 的工具,这里我们使用 rollup 来实现。什么?你问我为啥不用 webpack?别问,问就是「人生苦短,学不动了」。
rollup 我们也就不搞什么配置文件了,越简单越好,直接安装 devDependencies 依赖:
npm i rollup -D
然后在 package.json 中使用 rollup 把 tsc 编译出来的 esm 模块再次 bundle 成 UMD 模块:
"scripts": {
"rollup:umd": "./node_modules/.bin/rollup build/esm/index.js --file build/umd/index.bundle.js --format umd --name 'MySDK'"
}
然后可以通过执行 npm run rollup:umd 来实现打包成 UMD 并将 API 绑定到全局变量 MySDK 上面。我们可以直接将 build/umd/index.bundle.js 的代码复制进浏览器控制台执行,然后 看看 window 上有没有这个 MySDK 变量,不出意外的话,就会看到了。

我们在 index.ts 文件中 export 了两个 function:get/post 都有了。来试试看能不能运行起来
注意:有的浏览器可能还不支持 async/await,所以我们使用了 Promise 来发送请求
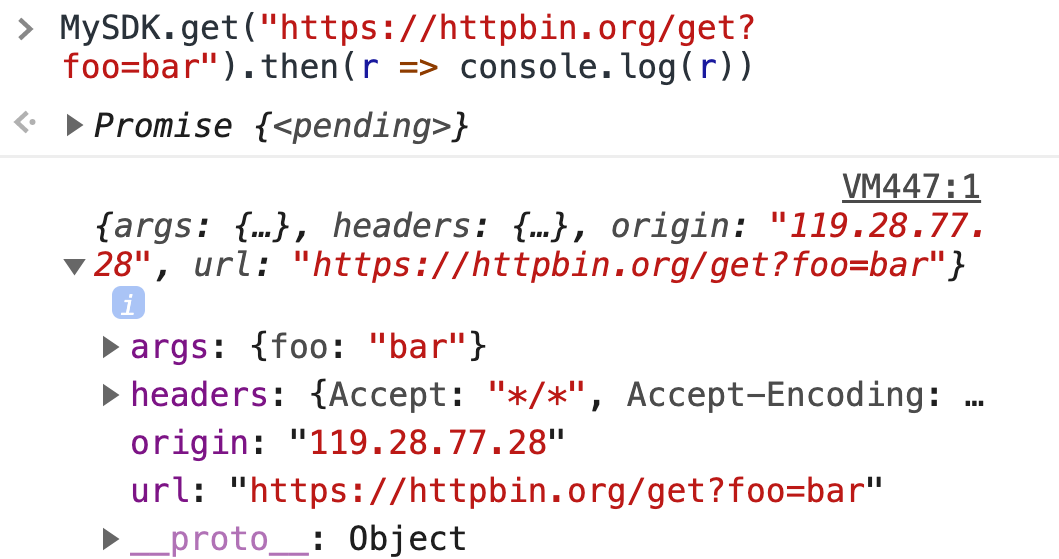
到此,我们所有的需求都满足了,至少对于开发一个 SDK 级别的应用应该是没问题了。相关代码可以参考这里:https://github.com/keelii/mysdk
需要注意的几个问题:
.ts 的后缀这个操作是比较有风险的,如果你的项目比较大,就不建议直接这么处理了,这个脚本目前也只在我们一个项目里面实际用到过。正则匹配换后缀这种做法总不是 100% 安全的1970-01-01 08:00:00
前端开发的瓶颈到底在哪里,前端技术是否已经走到一个十字路口,全栈化的系统架构是否能改变目前的窘境?本文将根据作者自身的开发经历谈谈当下前端开发中遇到的一些问题和想法。
近两年我一直在思考的一个问题:
如果前端不用考虑性能问题、不用考虑终端兼容性、不用考虑历史遗留问题,甚至不用考虑具体技术实现...
如果我们假设自己有丰富的技术储备,同时不用考虑上面的问题,那么前端究竟 能 做出什么样有价值的东西?
我们把时间拉到 5 年前...
如果你「那时」还是前端开发的话。上面的问题肯定是你不得不面临的典型问题。甚至是当时前端开发的意义所在。
但是随着时间的推移,前端技术的更新迭代,以及互联网的发展。你会发现这些曾经的问题似乎已经不再是问题,或者说在能预见的未来 可能 不再是问题。
页面加载性能可能不再是问题,技术上有了 HTTP2,基建上有了 5G,硬盘也越来越快。
兼容性问题慢慢淡出大家的视角,Chrome 一家独大,微软也不得不向它靠拢。
很多前端开发已经具备了后端(或者说多端)的技术能力,技术储备也可能不是问题,当然前提是你能招到人。
到底什么是前端开发,前端与后端的界限在哪里?我在三年前对它的定义是:
前端为 界面、交互展示负责; 后端为 数据、业务逻辑负责;
不过现在看来似乎已经过时了,我越来越觉得不应该有这样一个清晰的界限把前后端分割开来,尤其是技术层面(除了职能层面的界限有利于协作以外)。这就好比说:如果你不能打破规则,那就必将被规则束缚。
我一直认为程序员应该对新的技术、工具、理念有比平常人更快的适应能力。举个简单的例子,我以前写代码通常使用 tab 缩进,后来大家都建议使用空格,刚开始尝试换成空格肯定是拒绝的,因为让人改变习惯是一件很难的事情。但是当你真正为了改变做出实践的时候,往往就会发现一条新大路。同样还有加不加分号的问题。
现在回过头来再看,前端在整个系统层面担任的角色至少应该是整个视图 View 层面的。视图层面的技术更接近软件系统的上层,更感性。感性的东西就是说一个颜色,我觉得好看,他觉得不好看,完全属于个人情感诉求。所以前端更注重与UI、交互 以及整个产品层面需要解决的问题。优秀的前端必然要具备敏锐的产品洞察能力。
当然这还只是前端最基础的职责所在。同时前端做为最接近产品的技术角色,技术才是前端真正的硬实力。
大约在去年一年的时间,我的岗位从前端转向了后端 Java 程序员的角色。虽然只做了一年的 Java 程序员,但是对我自身的技术提升而言是最多的一年。大家可能普遍的认为后端转前端比较容易,前端转后端会有门槛,实际上根据我自己的体验来讲并非如此。
Java 这门语言是商业化、成熟度特别高的语言。无论是语言本身,还是周边框架、工具都有一套非常成熟且层次分明的系统化抽象。如果你有两、三年的编程经验,突然让你上转写 Java 是非常容易的一件事情,尤其是写 Java web。Spring 框架已经为程序员屏蔽了很多复杂问题,而且已经事实上成为了各大互联网公司的主流框架选型。
我特意按我自己的学习线路绘制了一张 Java 版的程序员学习线路,仅供参考:
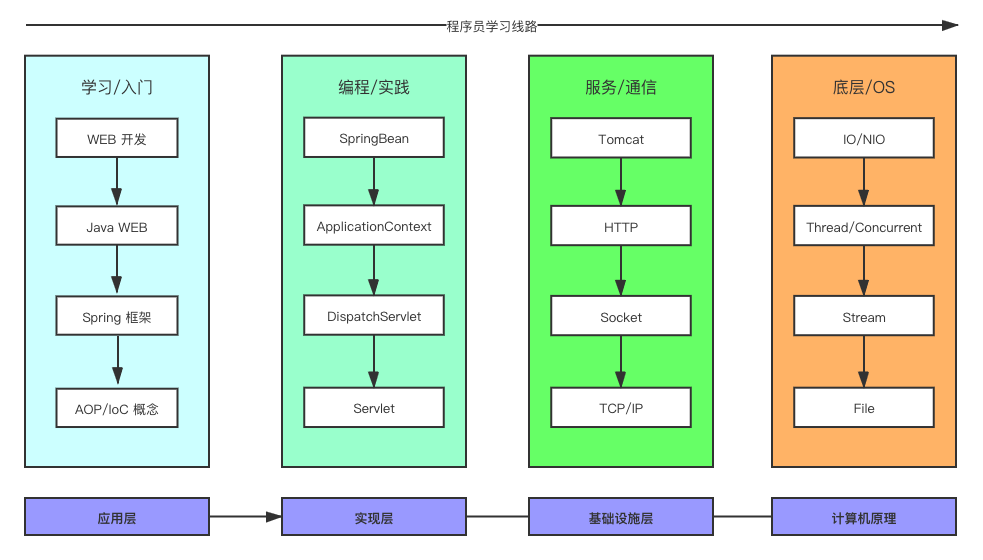
我们可以清楚的看出来 Java 构建的整个体系最大的特点:它是渐进式的,一步一步地给开发者建立正向的引导。
当我处在在应用层阶段的时候,我需要关心的只是一些概念,方法,具备基础了以后就可以借助 Spring 框架入门,入门后就可以研究源码,你会发现 Spring 的本质核心类 DispatchServlet,从此 Servlet 就出现在了你的视野。我以前上学时理解不了 java 中 Servlet 的概念,后来参加了工作又学些了 Python,再次看到 Java 中的 Servlet 的时候瞬间就明白了它就是 Python 中的 uwsgi,就是一种接口,将编程语言和服务器网关链接起来的一种规范。
然后你就可以顺利进入下一环节,服务器/通信。这里你会发现整个网络编程的核心 Socket,同样以前上学的时候没理解 Socket 的概念,继续学习后你就会明白 Socket 其实就是操作系统提供给编程语言的一种能力,有了它就可以建立服务器与客户端之间的通信。在这一环节中你会学习到网络层 TCP/IP 协议,明白了 TCP/UDP 的区别,while (true) { socket.listen() } 建立 Socket 监听会有性能问题,此时你便进入下一个抽象层次,操作系统和计算机原理。
为了解决「while true」监听连接的性能问题,你会去学习多线程技术,了解并发的概念。你可能总会听到别人讨论并发和并行的区别。继续学习后,慢慢的你就会明白:并发多用来解决网络IO(硬盘)的效率问题,而并行则是为了更好的利用多/核处理器(CPU)的问题。这时你会发现这个阶段涉及到了很多的计算机硬件知识。内存分配、CPU计算、IO 复用等等。
像 Spring 这种框架才能真正意义上被称做 框架,因为它不仅仅解决了软件开发的问题,更重要的是 AOP/IoC 这类概念可以完全改变编程的一些理念。使用 Spring 开发 web 应用,联合 Java 构建出来的生态,整个开发流程就像呼吸一样自然。
Java 构建出来的软件开发体系就像是把程序员放进了一个一个的层次分明的小柜子里面,进去了以后你根本不需要关注外界是怎么样的,做好自己那部分工作就可以了。如果你对外界有兴趣可以一点点的顺藤摸瓜,跳出你原来的小柜子。即保证精力专注的同时又建立起一套有秩序的提升曲线。这一点是别的语言体系没有的。
实际上我在转 Java 之前对 Java 有着不小的误解,甚至转 Java 本身也不是我自己的想法。但当你真正转型成 Java 程序员后。看懂了数以百万行记的代码仓库、维护过每秒好几十万的 QPS 项目、见识过百行的 SQL 的时候,你才会对 Java 和软件开发产生一种敬畏之心,才会对技术才有了更深层次的理解。
这时候再回过头来看前端,看 JavaScript,才会发现它们之间的区别与特点。很多之前争论的东西也就有了结论。
我相信从事前端工作稍微长一点(5年以上)的人近两年都会有一种感觉:前端似乎没什么东西可以玩出花样了。这是因为很多东西都已经成为了前端事实上的主流,以前前端没有的基建慢慢的被完善。语言、框架、可视化、跨端、游戏、工具/自动化/工程化 这些领域都在发展。
语言方面 TypeScript 必然是主流,无论你愿意与否,你都将不得不使用它来写前端。框架方面 React 已经是事实上的主流了,没必要再做选择题。打包工具 Webpack 也是一家独大,虽然被很多人诟病,但是社区生态起来了,想改变就很难。跨端应用 Electron 也不用想了,VSCode 能做好你做不好那就不是选型的问题了。2D 游戏/绘图方面 PixiJS 6 已经在设计中了,3D 我个人认为就先别玩了。
这些看似成熟的体系实际上还是有很多可以挖掘的东西。如果你不深入研究,或许会认为过两年这些技术就稳定了前端就可以做到大一统的状态。这个想法可能就过于天真了,我举例解释下它们各自的瓶颈:
React(并不特指 React)虽然现在看起来是主流,但是它本身有很多问题是没解决的,甚至可以说是无解的。React 的本质只是一个 UI Library,并不是框架 Framework。框架要解决的问题是系统层面的不是某个抽象层面的。用 React 写过几个项目以后你就会认识到用 React 去写大型项目是非常麻烦的事情,React 本身并不解决 SPA 应用中数据流的问题,甚至没解决状态管理的问题(或者说状态管理本来就是个伪命题?)。一个很简单的父子组件之间状态共享的问题一直没有成熟的解决方案,hooks 这种方案更像是拆了东墙补西墙。
而且现在 React 社区弥漫着一种崇尚函数式编程的邪气,hooks 更像是一块遮羞布。多数人用 hooks 的原因仅仅是不想使用 Class,因为 Class 很臃肿,function 更简单。当然这个逻辑是没问题的。函数确实简单,但是如果你把一个函数里面写上几百行的代码,各种 hooks 用到飞起的时候,你才会回过头来反思如何组织代码。如果 Class 能以一种更好/更易于理解的方式去抽象那为什么不用呢?
前端框架如此,基于 Node.JS 的后端框架也好不到哪儿去,难道你真的想用 Express/Koa.js 去写大型的后端应用?这种量级的框架连 web 开发最简单的三层模型( 模型、视图、控制器)支持都不完整。当然你可能会说小型框架本来就只关注某一方面嘛,视图和模型层的东西可以用其它三方库解决。是的,确实可以这样,不过你不觉得 Node.JS 的第三方库有点太多了吗。正如 NestJS 在文档中提到的一个问题一样「很多 JavaScript 类库都没有高效地解决一个问题 架构。」React/Vue/Express/Koa 这些都是相对独立的点,没有一个东西能把他们连接起来形成一个面,形成一种框架级别的体系。这就是架构的问题。
这里多说一点,结合上面 Java 构建出来的生态,对比 Node.JS 的话。我借用自己打过的比喻:如果你低头看到的是 Node.JS,那么你抬头未必能看见 Java。假如你从事前端开发 2,3 年遇到瓶颈,想转学 Node.JS,你会学习 Exporess/Koa 这类框架,但是很快你就会发现一个严重的问题:没办法深入下去了。因为当你用 Express 写完一个页面后就面临着各种技术上的盲点,会让你无所适从。
我也尝试绘制一张我对 JavaScript/Node.JS 或者说大前端体系理解的一张图:
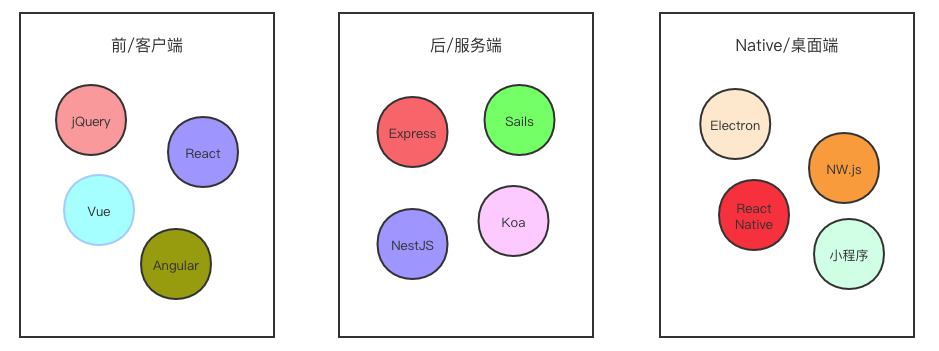
JavaScript 体系看似前后端通吃,客户端、 服务端甚至桌面端皆有。但是最大的问题在于:没有一个东西能给他们建立起关系并发展成为一种体系。
插播一条娱乐看点,前两天写 Ruby on rails 框架的作者 DHH 发推并配图:
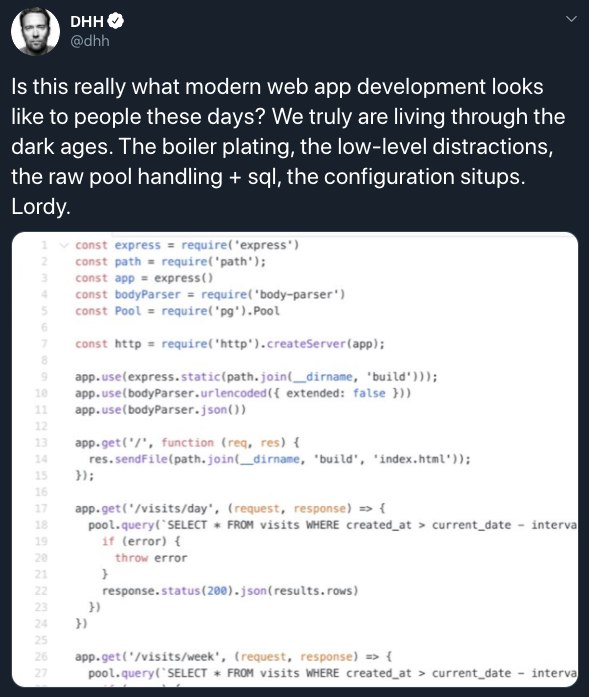
大意如下:
现在的年轻人在 web 开发的时候是这样的嘛?底层逻辑、纯手写连接池 + 纯手工 SQL、配置文件都放在了一起。天哪!(截图中使用的式TJ大神写的 Express 框架)
然后 TJ 大神也回复了:
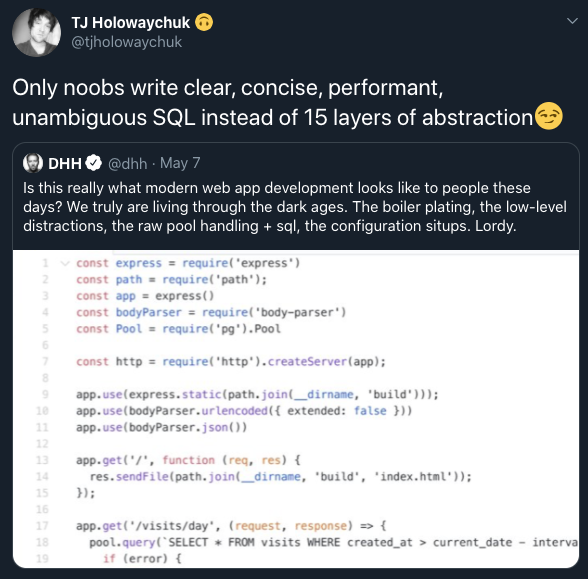
大意如下:
只有菜鸟玩家才能写出干净、简洁、高性能(黑 Ruby 性能)、见名知意的 SQL,而不是去写一个有15层的抽象。
两者的推特对话挺有意思,大家娱乐一下。
TypeScript 也主流,但是持续关注 TS 到现在,我发现 TS 也遇到了瓶颈,这个瓶颈不仅来自于 TS 的设计目标与理念,更多的还是社区及 TC39。TS 的设计初衷是 JavaScript 的超集,由于本身要编译成 JS,这一点本质上限制了 TypeScript 的方向,设计者对于添加一个新特性会非常谨慎,一者怕与 TC39 ES proposal 冲突,二者要考编译到不同版本 JavaScript 的兼容性问题。以至于现在 TS 新的语言特性只会跟进 TC 39 发布的最新 ES proposal。但是我个人对于 TC 39 的效率及未来持怀疑态度,decorator 的提案一直还处于 Stage 2 的阶段,像这种其它语言都成为标配好几年的事情,现在 JavaScript 社区还在草案(stage-2)阶段。
普及下 ECMA 的标准的流程:
- stage-1:前期设想
- stage-2:正式提案(装饰器所在的阶段)
- stage-3:实现候选
- Stage-4:完成测试
- 各个浏览器 JS 引擎实现;TypeScript 实现
在这个问题上我认为其实也很好解决,开个脑洞:如果微软想借助编程语言一统浏览器和客户端是没有什么不可能的。并入 TC39 组织,开发真正属于 TypeScript 的原生引擎,奉天子以令不臣的方式也未尝不可。
近几年 Microsoft 对于开源的投入是肉眼可见的,微软要发力我相信很多东西都会有翻天覆地的变化。
Webpack/Babel 就更不用说了,主流中的主流。但是也是问题最严重的一个。Webpack/Babel 的流行恰恰从反面证明了前端的基础设施有多么的烂。现在国外网友老天天叫喊着 Webpack/Babel is eval 也是挺值得深思的。我们引入了一个新工具来解决问题,却又在不经意之间产生了新问题。
前端构建工具问题的本质还是在于 Node.JS 的包管理工具的设计。这一点在 Node.JS 的作者 Ryan Dahl 关于 Deno 演讲《10 Things I Regret About Node.js》中也有过「官方」的承认。我相信任何一个实现过构建工具的人都被 Node gyp 打败过。node-sass, fsevent 的痛不必细说。更不用说万年被黑的 node_modules 了,你根本不知道一个简单的 npm install 命令会导致安装成千上万个 npm 包被安装到你的机器上。

当然每种编程语言对应的包管理工具都要解决依赖问题,而且这是一个普遍的问题,脚本/解释型编程语言尤为突出,Python/Ruby/PHP 都有这些类似的问题。或许 Go/Rust 这种把源代码编译打包成单个可执行文件的方式才是好的解决方式。
从前人们总是抱怨 JavaScript 这门语言,黑它、讽刺它。但是我看到的是它在一点点变好。不仅是语言层面逐步完善,工具链生态日趋成熟,使用它的也人越来越多。大家对它的关注程度也在提高,整个 JavaScript 开发者的水平也在向更高更强的方向发展。生存环境只会淘汰那些老旧不再进化的事物,能适应变化的才会永存。
JavaScript 这门语言有两个其它 任何 编程语言都不具备的优点:
当下的前端开发状况不由得让我我想起苏东坡《晁错论》中的一段话:
天下之患,最不可为者,名为治平无事,而其实有不测之忧...
最大的问题在于,有些事物,从表面上看着平淡无奇,但实际上底层暗流涌动,似乎每一时刻都有着巨变的可能性。这也是前端开发最有趣也最有潜力的地方。
作为一名新时代的前端开发者,就是要在这看似风平浪静的表面之下,找到一些真正的突破点,兴许只是一个简单的想法,顺应时势然后造就出不斐的成就也说不定呢。
无论是前端还是后端、国内还是国外,技术才是真正的核心竞争力,只有技术革新才能提高生产力,而对于我们程序员来讲,编程则是唯一能提升硬实力的方法。只要你心中充满了热情,坚持下去总会走出一条自己的路子。
分享一段小经历
我在 2018 年有幸参加了 TypeScirpt 的推广大会,TypeScript 的作者 Anders Hejlsberg 亲自主讲。一位将近 60 岁的程序员在讲台上滔滔不绝的讲技术方案,TS 的设计理念。你真的很难想像这样一位处于「知天命」阶段的老头子(实际上很年轻)讲的东西。

QA 环节有个年轻小伙问到 Anders「在中国做程序员很累、很难应该怎么坚持下去(类似这样的描述,细节记不清楚了)」的问题。
Anders 几乎毫不犹豫的说出了「Passion」这个单词。我瞬间就被打动了。因为在此之前我对于「激情」这个词的认识还停留在成功人士的演讲说辞层面,当 Anders 亲口说出 Passion 一词的时候,让人感觉真的是一字千金。
直到现在 Anders 还做为 TypeScript 的核心贡献者为它提交代码,到处奔走为 TypeScript 宣传。
我们再回到前端,那么未来的前端到底会发展成什么样?长期而言充满了未知数,谁也没法预测,但是短期来讲我比较关注几个东西:
如果你仔细研究一番,上面的这些新鲜东西,都是起源于前端,但又不把视野局限在前端。或许这就是前端未来的发展方向吧。
这几项技术我们会在后期的更新中会有专门的干货文章,敬请期待~
1970-01-01 08:00:00
注:此文翻译自 Java Concurrency and Multithreading Tutorial,本文只是首篇翻译
Java 中的并发是一个术语,涉及 Java 平台中的多线程、并发、并行等概念。包括 Java 并发工具,问题和解决方案。这个教程涵盖了多线程的核心概念、并发组成结构、并发的问题、成本与收益以及与 Java 多线程相关的问题。
多线程的意思是在同一个应用中有多个执行线程。线程就好比是你应用中的一个独立的 CPU。因此多线程的应用就好比一个拥有多个 CPU 的应用程序,这些 CPU 可以在同一时间执行不同的代码。
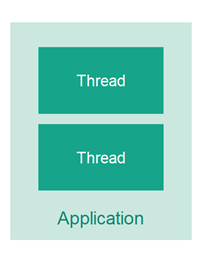
尽管一个线程并不等同于一个 CPU,但是通常一个 CPU 将会共享执行时间给多个线程,CPU 会在不同的线程之间来回切换,每个线程上执行一点。当然让应用中的线程执行在不同的 CPU 上也是可以的。
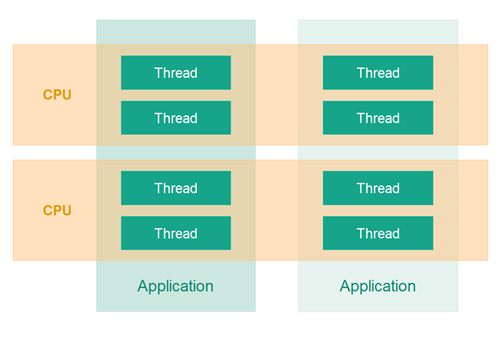
大家需使用多线程的原因有很多,最重要的有以下几点:
更好的利用单个 CPU
更好的利用多个(核)CPU
更好的用户响应体验
更好的用户公允体验
下面的章节中我将一一解释这几个原因的细节。
最常见的原因之一是能够更好地利用计算机中的资源,比如说,一个线程正在等待一个网络请求响应的同时,另一个线程可以利用 CPU 做别的事情。另外,如果计算机有多个 CPU 或者 CPU 有多个执行内核,那么多线程同样可以帮你更好的利用这些 CPU 内核。
如果计算机有多个 CPU 或者 CPU 有多个执行内核,那么你需要在应用中使用多线程来更好的利用到所有的 CPU 和多核 CPU。单个线程最多只能利用一个 CPU,就像我上面提到的,有时甚至不能完全地利用好一个 CPU。
另外一个使用多线程的原因是提供良好的用户体验。比如说,当你点击了一个 GUI 界面上的按钮,这个动作会触发一个网络请求,接着哪个线程来处理这个请求就非常关键了。如果你同时又使用这个处理请求的线程来更新 GUI 界面,然后当 GUI 线程等待请求响应时用户就会体验到 GUI 挂起的状态。作为替代方案,这个处理请求的线程可以单独创建成后台线程,这样的话 GUI 线程就可以用来同时响应其它请求。
第四个原因是在用户之间更公平的共享资源,想象一个例子,服务器接收客户端的请求,但是只有一个线程来处理这些请求。如果有一个客户端发送了一个请求并且处理了很久,然后其它客户端请求不得不等待那个请求结束。让每个请求都有一个属于自己的处理线程去执行,这样的话就不会有任何一个任务可以完全地霸占 CPU。
以前的计算机只有一个 CPU,并且在同一时间只能执行一个程序。许多的小型计算机并没有强大到能在同一时间执行多个程序,也没有尝试过这么设计。坦白地说,许多主机系统可以在同一时间执行多任务这比个人电脑已经提前好多年了。
后来多任务出现了,这意味着计算机可以同时执行多个程序(或者说任务、进程),这才真正意义上叫做同时执行。CPU 在多个程序之间被共享。操作系统在运行的程序中来回切换,每次执行一小会儿。
随着多任务处理给软件开发人员带来了新的挑战,程序不再假设 CPU 一直可用,其它如内存这样的计算机资源也一样。好的程序员会在不使用资源的时候释放它们,这样别的程序才可以使用到这些资源。
后来又出现了多线程。这意味着在程序内部你可以有多个执行线程。执行线程可以想象成 CPU 执行程序。当你有多个线程执行同一个程序时,就好比多个 CPU 在同一个程序中执行。
对于某些程序而言,多线程是一个非常好的提升性能的办法。然而多线程的使用相对于多任务来说具有更高的挑战。多个线程在同一个程序中执行,因此可以同时读取和写入相同的内存。这可能会导致一些单线程应用中不存在的问题。这些问题在单 CPU 的机器上可能不会被发现,因为两个线程永远不可能真正地同时执行。尽管如此,现代计算机可以拥有多核CPU,或者多个 CPU。这意味着不同的线程可以在不同核心的 CPU 上被同时执行。
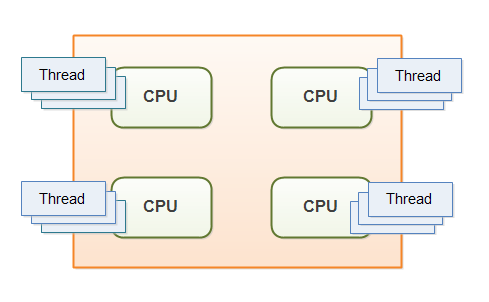
如果没有合适的预防措施,这些问题就很可能会出现。程序行为甚至不能被预测。结果可能频繁地改变。因此对于程序员来说做好预防措施就变得非常重要—意味着需要去学习线程是如何访问到共享资源(内存、文件、数据库)的,这也是一个本教程要讲到的主题。
Java 是首个把多线程处理特性提供给开发者的编程语言之一。Java 在最开始的时候就提供了多线程处理的能力。因此 Java 程序员经常面临上面我们提到的问题。这也是我写这篇文章的初衷,做为我自己的学习记录的同时也希望其它 Java 程序员能从中受益。
本教程将主要关注 Java 中的多线程处理。但是有的多线程问题与分布式系统中多任务处理面临的问题很相似。所以教程中也会出现多任务与分布式系统的相关引用,因此教程使用「并发」而不是「多线程」这个关键字。
第一种并发模型假定多个线程在同一个程序中执行并可以同享对象。这种并发模型被称做「共享状态的并发模型」,有很多并发语言的组件构成都支持这种并发模型。
然而,自从第一本 Java 并发书被写出以来并发构架设计已经发生了很多变化,甚至是从 Java 5并发工具包发布以来,并发构架设计也经历了很多的变化。
共享状态的并发模型会引发很多难以解决的并发问题,因此,另外一种被叫做「无共享/状态分离」的并发模型流行了起来。在状态分离的并发模型中线程之间不共享任何对象或数据。这样就可以避免很多在共享并发模型中的并发访问类题。
最新的如 Netty, Vert.x 和 Play,Akka, Qbit 等异步「状态分离」平台套件慢慢崭露头角。新的非阻塞并发算法也已经发布,新的非阻塞工具像 LMax Disrupter 也被加进了套件中。Java 7 中的 Fork 和 Join 框架也引入了新的函数式编程并行特性。
随着技术的不断发展,也是时候更新下这篇教程了。因此这篇教程再一次进入了重写状态。新的教程会在合适的时间发布。
如果你对 Java 并发还不是很了解,我建议你按下面的学习计划。你可以在左侧的菜单中找到所有主题的链接。
通用的并发与多线程理论:
Java 并发基础:
Java 并发中的经典问题:
Java 中用来解决上面问题并发体系:
更多主题:
1970-01-01 08:00:00
谈到哲学,多数人都会直觉性的认为它是很高深的一门学问。实际上大多数情况并非如此,哲学研究的往往是非常简单的一些命题,而这些命题在常人看来可能并没有现实意义。
比如说:到底是先有鸡还是先有蛋的问题;比如说:一个号称只给不能给自己理发的人理发的理发师到底能不能给自己理发的问题。当然本文的目的并不在于讨论这两个问题,我们来聊聊几个稍微简单一些的概念:
理性是超越的,本质在于追求无限
超越 的意思是说理性本身不依赖任何现实或者经验社会中的任何对象,无限 实际上就是说理性本身需要达到的某种理想状态。
比方说:「100%的金」 就是一种无限状态。我们不使用任何经验就可以判断出 100% 的金是必然有的,概念上没人能否定这一点。
但是运用在经验社会中的知识来判断,这个命题就是不正确的,或者说不具有普遍的正确性。因为我们知道无论人类的技术如何高超也无法制造出来 100% 的金。即使到 99.99% 逻辑上也没到达 100%。
这个时候人们对于类似的事情就会产生了不同的反应。有的人会因为理想状态达不到而反向地认为原来的命题是错误的;有的人内心则有一种说不清道不明的东西指引着他,不会因为到达不到无限状态而肯定整个命题。
这个问题也一直困扰了我很久,因为在现实生活中在你看来很多明显正确的事情忽出现了一个反例,结果就会有一堆人来告诉你你错了。
德国哲学家康德在《纯粹理性批判》这本书中给出了一种解释:
理性的调节性是引导经验去追求无限,追求绝对,但是永远也达不到。达不到也有作用 — 它使得经验科学不断的前进,并且有了明确的目的和方向…
类似的哲学观点好就好在一但明白了其中的本质和它阐述的真理以后,它就可以在某种层次上解释经验世界的各种现象。这或许就是大家说的哲学是任何其它学科的奠基,是第一学科的原因。
对应的在编程领域也有一些无限的概念,对于多数前端工程师来讲「实现一个无限级的下拉菜单」似乎也在表达着一种无限状态。当然用户在使用的时候根本不可能用到无限级的菜单,无限级的菜单在交互方面也也是极其反人类的,一步可以做到的事情没人愿意多增加一步。但是为什么程序员们热衷于实现这种类似的无限状态。实际上这就是理性的力量,总有一种说不清楚的力量在引导着你,你也没法解释。
理解了这一点你就会有一个很简单的评判程序好坏的论点,即:程序或者代码是否表现了某种无限状态?如果你的程序函数里面只是几个简单的 if else,那你有没有考虑过如果当输入不断的增加或者变化时,原来的代码是否还可以正常返回。或者说在不考虑硬件等客观条件的前提下,你的程序是否存在极限状态。
我们经常在知乎或者其它论坛上争论一些问题,本质上讲大家都没有区分清楚自己对于一个论点的逻辑认知和情感认知。太多人喜欢用自己的感情认知去否定逻辑事实,以至于争来争去谁也没能说服谁,试图用唯心观点去解释唯物的现象或者相反,这是极其不正确的。
一个典型的问题是我不久之前在知乎上回答的一个问题:谁能大致说下vue和react的最大区别之处?我的回答简单总结就两句话:Vue 有一种设计层面追求的简洁感性之美,React 则是一种数学层面的逻辑一致之美。本质上讲没有什么好坏之分。但是诸如些类的一些前端框架问题正在变成一种帮派化的「站队」风气。
注意这里讲的 low/hight level 并不是计算机术语中特定的某种形式。
有个笑话是这么讲的:
一个程序员去相亲,程序员自己介绍说「我是做嵌入式C语言底层开发的」,妹子反问「那啥时候做到高层开发呢」?
程序员们内心都有一个做底层开发的梦,因为这才是一个真正的程序员的追求与理想。
但是现实往往相反,大多数程序员每天都在写业务代码(重复的 CRUD)。所以很多程序员得出来一个结论就是:越底层的东西越重要,越高层的东西越肤浅。通常这也会行成一条鄙视链,他们会不由自主地忽略高层的东西。
注意这里有两个问题:
1. 业务代码有没有价值?
当然有了,业务部分的代码是系统的最终结果。从结果导向上讲底层代码如何优雅、实现如何科学我们根本不关心,我们更关心整个系统层面的稳定与健壮。这是一种领导的高层次视角。
2. 底层的东西就一定重要?
并不一定,这里说的不一定不是要完全否定底层的重要性。恰恰相反,软件领域一些特别优秀或者说伟大的软件底层并不是那么的如人意。比方说微软开发的 VSCode 代码编辑器。要是从底层去讨论它的构架合理性那确实挺像一个笑话的。因为本质上讲 VSCode 基于 electron,它把编辑器放在了一个 webview 中去运行,但是 webview 是用来浏览网页的,而且 electron 居然把 NodeJS 运行时也整合进去,以至于最小的一个应用解压完也有上百兆。
这感觉就像是上学的时候你很期待一个数学教授教你数学课,但是实际上你的数学课却是一个体育老师带的,这不是可不可以的问题对吧。
然而 VSCode 这样做的结果是:它还真的成功了,而且编辑器的性能比很多原生软件做的都要好,以至于周围所有人都在使用它,VSCode 在 Github 上名列前茅,也改变了很多程序员对于微软的刻板印象。
如果我们再回过头从哲学的角度去思考这个问题,实际上计算机中的底层与高层正好对应着哲学中的理性与感性。
底层更注重逻辑严谨,因为这是构建高层建筑的基础,它面向的是理论
高层更注重表现形式,因为高层的部分呈现出来的是一个完整的系统,它面向的对象是人。是人,那需求就是多样化的,因为人的想法总是特别的感性
理性的认知是有对错可以批判的,但是感性的直观是没有对错的,因为即使是同一种声音、颜色对不同人观感都是不一样的。
比如说你在火车上看书,对面的人说话声音太大吵到了你。你说:你们说话小声点可以吗?对方会说:车上这么多人说话为啥就我们吵到你了?你说:因为就你们声音最大。对方说:我咋没觉得?
现实生活中我们经常会遇到一些对于论点的评价:主观还是客观。但是很多人没搞清楚这两个词的关系。多数人都觉得客观的观点就是好的,主观的就是臆断的。
主观和客观的关系就像是主人与客人的关系一样,有的人会认为应该主随客便,有的人则认为应该是客随主便。
如果一个人表达的观点全是主观的,那我们会认为这些观点是不可以讨论与评判的,不经过讨论批判的观点是站不住脚的。
如果一个人表达的观点全是客观的,那似乎也不对,因为这些观点全是别人的,你可能忽略了自己的意识,最终只能游走在别人的规则中。
任何语言中都有那么一些词语是成对儿出现的,像因果、主客、高低,这些词在被造出来的时候就是成对出现的,缺一不可。没有前者,后者将不会单独存在。它们之间没有绝对性的对于错。如果有,那对方就没有了存在的意义,反过来自己也将不存在。
当有人抛出一个观点的时候我的经验是一定要听清楚对方说的是「我觉得」还是「我认为」。「我觉得」那必然就是人家的主观感受,这种观点我们就没必要讨论了。你应该回复:「嗯,没错,确实是这样的。」。如果对方说「我认为」那你要是有不同的观点就完全可以和他讨论,因为说「我认为」的观点必然是有一些客观事实做为依据的,有事实有逻辑,那就可以有对错。
哲学中的知识并不能完全解释现实中的事物,因为哲学研究的终点是一些没有结论的东西:上帝、自由、灵魂不朽。这些东西并非常人能理解的,但是人们对于无限真理的追求驱使着大家去研究它,很多人会觉得既然研究不出来结果那是不是就没意义了,当然不是。事实恰恰相反,如果我们把所有的事物本质都研究清楚了,那我们的存在也将失去意义。
1970-01-01 08:00:00
本文翻译自:I want my AOP
关注点表示人们的一种特殊的意愿、理念或是某个感兴趣的领域。从技术角度来讲:软件系统包括若干核心的、系统级别的关注点。比方说:信用卡处理系统的核心关注点是处理交易,同时系统级别的关注点或许应该是处理日志、事务、一致性、授权、安全、性能等。许多这种关注点被叫做横切关注点 — 往往会影响许多模块的实现。
使用目前的编程方法,跨越多个模块横切关注点会导致系统更难设计、理解、实现和迭代。
阅读完全的「我想要 AOP」系列文章:
第一部分
第二部分
第三部分
面向切面的编程相比之前的方法更简单的分享了关注点,从而提供横切关注点的模块化。
在本系列文章中,第一篇涉及 AOP 的概念,我首先解释了在一般复杂的软件系统中由横切关注点引起的问题。然后,我引入了 AOP 核心概念,并展示了 AOP 是如何通过横切关注点解决问题的。
这个系列的第二篇文章将介绍 AspectJ,Xerox PARC 基于 Java 实现的 AOP 框架。最后一篇文章将以几个示例的方式向你展示 AOP 的概念,并基于建立更易懂、易实现、易迭代的软件系统。
早些年的计算机科学领域,开发者直接使用机器码进行编程。不幸的是,程序员花了更多时间去考虑特定机器的指令集而不是手头的问题。慢慢地,我们迁移到高级编程语言,高级编程语言允许对底层机器码进行一些抽象。然后结构化的语言出现了;我们现在可以根据任务的执行过程来分解我们的问题。然而,随着复杂度的增长,我们需要更好的技术。面向对象的编程让我们可以把系统看成一系列的合作对象。类可以让我们隐藏接口背后的实现细节。多态提供了通用行的为和接口,并允许更特殊的组件更改指定定行为,而无需接触基本概念的实现。
编程方法和语言定义了我们与机器交流的方式。每一种新方法都提供某种分解问题的方式:机器码、独立于机器的代码、过程、类等等。每种方法都在建立某种系统需求与程序结构之间的对应关系。这些编程方法的演进让我们可以创建越来越复杂的系统。反过来复杂的系统使得我们又必须使用更先进的技术去解决这些复杂度。
目前来讲,放多新的软件项目开发都使用面向对象的编程模式。的确,面向对象的编程模式能模拟常见行为方面表现出了强大的能力。然而,我们很快将会看见,或许你已经有所体验了,面向对象的编程模式没能充分地解决许多跨区的行为的问题 — 那种通常不相关的模块。相比而言,面向切面的编程方法填补了这个空白。AOP 很可能代表了编程方法演进的下一个重要方向。
我们可以将复杂系统看做是多个关注点的联合实现。典型的系统可能包含多种关注点,包括业务逻辑、性能、数据持久化 、日志,以及调试、授权、安全、线程安全 、错误检查等等。而且你还会遇到开发流程中的关注点,比如说:可理解、可维护,可追溯、更易迭代。图1描绘出了一个系统中不同模块关注点的实现。
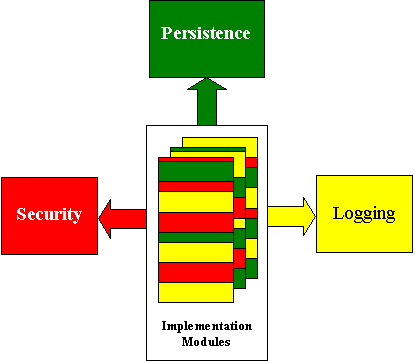 图1
图1
图2展示了一系列的需求(一个光束)通过关注点识别器(棱镜)分离各种关注点成为独立模块。这个过程就对应着我们开发过程的关注点。
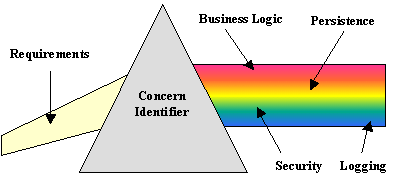 图2
图2
开发者建立一个系统并且负责实现多个需求。我们可以把这些需求大体上从核心模块级别需求与系统级别需求两个维度进行分类。许多系统级别的需求相互之间(或与模块级别的需求)是正交的(相互依赖)。系统级别的需求倾向于横切许多核心模块,比如,一个个典型的企业应用包含的横切关注点有:身份验证,日志记录,资源池,管理,性能和存储管理。每个都被横切成多个子系统。比如,存储管理会影响每个业务对象。
让我们举个简单的例子,比如有一个单例实现封装了一些业务逻辑:
public class SomeBusinessClass extends OtherBusinessClass {
// 核心数据成员
// 其它数据成员:比如日志,数据一致性标识
// 重写基类中的方法
public void performSomeOperation(OperationInformation info) {
// 保证授权正常
// 保证条件正常满足
// 锁定对象保证数据一致性
// 线程进入threads access it
// 保证缓存正常
// 打印操作启动日志
// ==== 进行具体的操作 ====
// 打印操作完成日志
// 解锁对象
}
// 与上面类似的其它操作
public void save(PersitanceStorage ps) {
}
public void load(PersitanceStorage ps) {
}
}
上面的代码中我们必须考虑至少三个问题,首先,其它数据成员不属于这个类所关心的内容。其次,performSomeOperation 的实现似乎比核心操作执行了更多的逻辑;它处理了日志、授权、线程安全以及其它外部关注点。重要的是,似乎这些许多外围关注点其它类也会用到。最后,save() 和 load() 方法操作存储层,这两个方法放在这个类中比较合适还是放在其它类中比较合适,这个问题并不是很清楚。
虽然会跨模块横切关注点,但是现在的技术实现倾向于使用一维的方式实现,把问题聚焦在需求与实现的单一维度。这个单一维度的实现将变成核心模块级别的实现。其余的需求围绕着这个主导维度被分类。换句话说,需求空间是多维的,然而实现空间是单维的。这种不匹配会导致需求与实现之间的映射难以做到。
使用目前的方法实现横切关注点会出现一些问题/症状,大体上分两类:
代码纠缠:系统中的模块可能会同时地与多个需求交互。比如,开发者经常同时考虑业务逻辑、性能、同步、日志和安全等问题。大量的并行需求导致需要许多关注点的实现同时存在,最终导致代码纠缠。
代码分散:由于横切关注点,按定义,很多模块都需要分离,甚至是相关的实现都需要分离。比如,一个使用数据库的系统,性能问题可能会影响所有访问数据库的模块
代码纠缠与代码分散对软件设计和开发有以下影响:
不可追溯:同时分离多个关注点会掩盖关注点与实现之间的对应关系,导致关系不清楚
低效的:同时实现多个关注点会打乱开发者的注意力,将注意力分散到外围问题上,这将导致低效
代码复用性低:由于模块实现了多个需求,其它系统将无法很容易地复用这个模块,进一步导致低效
代码质量低:代码纠缠会产生一些不易查觉的问题。此外,一次关注太多问题,某些关注点可能没有被真正关注到
难于迭代:有限的视界和受限的资源通常会产生仅解决当前关注点的设计。解决未来问题通常需要重新实现。由于这个实现并不是模块化的,这表示触摸许多模块。为了实现新需求需要修改每个子系统可能会引起不一致的问题。它还需要大量的测试工作来保证实现做出的变更没有引入新问题。
由于大多数系统都可以横切关注点,因此出现模块化实现的一些技术就不足为奇了。这些技术包括混入(mix-in)类,设计模式和领域特定的解决方案。
使用混入类可以让你延迟分离关注点到最终的实现。主类包含混入类实例,并允许系统的其他部分设置该实例。例如,上面的信用卡处理例子,将一个实现了业务逻辑的类组合成混入类,系统的其它模块可以通过配置来获取适合自身的日志器。例如,日志器可以设置成使用文件系统或者消息中间件。发送日志的被延后了,但是各个消息发送点(调用的地方)还是需要加入相关的代码。
基于行为的设计模式,比如说访问者、模板方法,可以让你延迟实现。但是就像混入类一样,控制操作—调用访问逻辑或者模板方法—仍然在主类中。
领域特定的解决方案,比如说框架和应用服务,让开发者可以用模块化的方式实现横切关注点。比如 EJB 架构,在安全、管理、性能和持久容器管理方面实现横切关注点。Bean 的开发者专注于业务逻辑,部署工程师专注于部署相关问题,比如 bean-data 与数据库的对应关系。对于 Bean 开发者来讲其余需要关注的就只有存储的问题了。在这个例子中你可以使用基于 XML 的映射描述符来实现横切关注点。
领域特定的解决方案提供了一种特殊的办法来解决指定的问题。它的缺点是,开发者必须为它学习新的技术。然后由于这些解决方案都是领域特定的,它并不能直接有效地横切关注点。
好的系统架构会考眼前与未来的一些需求,从而避免打补丁式的实现。但是这有一个问题,预测未来是一件非常困难的事情。如果你没有搞清楚未来的需求,那就需要改变、或者将系统的很多地方重新实现。另外一方面,将精力聚焦在低可能性的一些需求会导致过度的设计、混乱和臃肿的系统。因此系统构架的一个困境是:应该设计到什么程度?我应该保守式的设计还是盈余式的设计。
比方说,构架中是否应该追念一个初始化时并不需要的日志系统?如果是,日志打点的地方应该在哪里,什么样的信息应该被记录?这个是一个类似的出现在优化相关需求过程中的困境—我们很少提前知道瓶颈,常归的做法是构建一个系统,对其进行分析,并通过优化进行改进以提高性能。这种方法会潜在引导我们根据分析结果去修改系统很多部分。过不了多久,一个新的瓶颈又会出现,而这个瓶颈很可能就是上一步的改进引起的。设计可复用库架构的任务会变得非常困难,因为找到库的所有的使用场景并非易事。
总之,架构师很少知道系统所有可能需要解决的问题。即使提前了解了需求,一个实现的具体细节可能并没有被考虑到。因此,架构师面临着究竟应该保守设计还是盈余设计的困境。
到这里我们主要讨论了模块化的横切关注点会有很大益处。研究人员已经研究了在「关注点分离」这一更为泛化的主题下完成该任务的各种方法。 AOP 就是这样的一种方法。AOP 力争将关注点彻底分离,以克服上述问题。
AOP 的核心在于,以松散耦合的方式让你实现一个独立的关注点,然后结合这些实现成为一个最终的系统。确实,AOP 使用松散耦合、模块化的分离关注点的方式来创建系统。相反,OOP,则使用松散耦合、模块化的实现共同关注点方式来创建系统。AOP 中模块化的单位叫做横切面(aspect),好比 OOP 中共同的关注点是类(class)。
AOP涉及三个不同的开发步骤:
切面分解:将需求分解并识别出横切关注点与共同关注点。你可以将系统级别的关注点与模块级别关注点分离。比如说,上面提到的信用卡模块,你需要识别三种关注点:信用卡核心流程,日志和授权。
关注点实现:分离的实现各个关注点。像上面的例子一样,你可以单独实现核心流程、日志和授权三个单元。
切面重组:在这个步骤中,切面集成器通过创建模块化单元来指定重组规则 — 切面。重组过程(也称为编织或集成)使用此信息来组合成最终系统。比如上面的信用卡例子,你得使用一种 AOP 实现的语言具体/规范化操作中哪一步需要打日志。还得指定每个操作在被前都需要清除授权。
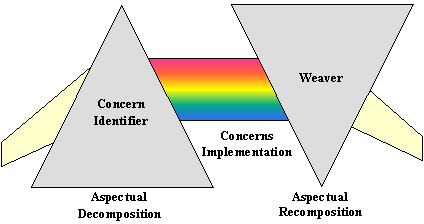
AOP 实现横切关注点的方法与 OOP 不一样。对于 AOP 来讲,每个关注点的实现并不会意识到其它关注点下在横切它。比如上面的信用卡例子,信用止处理模块并不知道其它的关注点是日志、授权操作。这对于 OOP 来讲意味着很大的范式转换。
注意:一个 AOP 的实现可以采用其它编程方法作为它的基本方法。因此可以保证基础系统非常完善。比如说,一个 AOP 的实现可以选择 OOP 做为基础系统,这样就可以获得 OOP 共同关注点的优势。每个独立的关注点可以采用 OOP 技术识别关注点。这类似于过程式的语言可以做为许多 OOP 语言的基础语言。
编织器是一个将独立的关注点纺织起来的过程。换句话说,编织器根据提供给它的某些标准将不同的执行逻辑片段编织起来。
为了能够演示编织过程,让我们回到之前的信用卡处理系统的例子。为了看起来更简单,我们只考虑两个操作:信用卡和借记卡。并且已经有一个合适的日志器了。
考虑下面的信用卡处理模块:
public class CreditCardProcessor {
public void debit(CreditCard card, Currency amount)
throws InvalidCardException, NotEnoughAmountException,
CardExpiredException {
// Debiting logic
}
public void credit(CreditCard card, Currency amount)
throws InvalidCardException {
// Crediting logic
}
}
同样还有一个日志接口:
public interface Logger {
public void log(String message);
}
我们想要的组合需要以下编织规则,这些规则以自然语言表示(稍后将提供这些编织规则的编程语言版本):
打印每个公共操作的开始
打印每个公共操作完成
打印每个公共操作的异常
编织器随后将使用这些规则,并关注每个实现以产生等价于以下代码的效果。
public class CreditCardProcessorWithLogging {
Logger _logger;
public void debit(CreditCard card, Money amount)
throws InvalidCardException, NotEnoughAmountException,
CardExpiredException {
_logger.log("Starting CreditCardProcessor.credit(CreditCard,
Money) "
+ "Card: " + card + " Amount: " + amount);
// Debiting logic
_logger.log("Completing CreditCardProcessor.credit(CreditCard,
Money) "
+ "Card: " + card + " Amount: " + amount);
}
public void credit(CreditCard card, Money amount)
throws InvalidCardException {
System.out.println("Debiting");
_logger.log("Starting CreditCardProcessor.debit(CreditCard,
Money) "
+ "Card: " + card + " Amount: " + amount);
// Crediting logic
_logger.log("Completing CreditCardProcessor.credit(CreditCard,
Money) "
+ "Card: " + card + " Amount: " + amount);
}
}
就像其它编程语言方法的实现,AOP 实现包括两个部分:一种语言规范和一种实现。语言规范描述语言的构成与语法。实现则根据语言规范去论证代码的正确性,然后转换成机器码然后执行。在这小节中,我将解释 AOP 语言的不同组成部分。
在一个高层次上,AOP 语言有两种组件:
关注点的实现:创建一个独立的需求与代码之间的对应关系,这样编译器才能翻译成可执行代码。由于关注点的实现需要通过具体的过程,你可以使用传统的语言,比如 C,C++ 或者 Java
编织规则的规范:如何将独立的关注点实现结合成最终的系统。为了达到这个目标,实现需要使用或者创建一种语言来具体说明结合的规则。具体化编织规则的语言可以是实现语言的一种扩展,或者其它完全不同的东西。
AOP 语言编译器有以下两个逻辑步骤:
结合独立的关注点
转换最终结果成可执行代码
AOP 语言实现编织器的方法有很多,包括源码到源码的翻译。你可以预处理独立切面的源码,然后将它加工成编织过的源码。然后 AOP 编译器将这些源码转交给基本语言编译器用来生成最终可执行代码,最后让 Java 编译器把代码编译成子节码。同样的,编织过程可以是子节码级别的;毕竟,子节码也是一种源代码。引外底层系统—VM虚拟机,是可以感知到切面的。使用这种基于 Java 的 AOP 实现,比如,VM虚拟机将首先加载编织规则,然后将这些规则应用到随后加载的类中。换句话说,它表现得像是 JIT 化的切面编织。
AOP 有助于克服由代码纠缠和代码分散引起的上述问题。以下是 AOP 提供的其他优势:
模块化地横切关注点:AOP 使得每个独立的关注点有最小化的耦合,最终产出模块化的实现。这样的一种实现会产生很少的重复代码。由于每个关注点的实现是分离的,也将减少无用代码,更重要的模块化的实现让最终系统更易于理解与维护。
更便于系统迭代:由于切面模块对于横切关注点是无感知的,添加新功能、新切面将变得简单。而且当你在系统中添加新模块时,现有的切面将横切它们,这有助于你构建一系列连贯的迭代演进。
延迟设计目标的绑定:回顾下架构师的困境,有了 AOP,架构师对于将来的需求就可以推迟做出设计上的决定,因为他可以用分离的切面来实现。
更高的代码复用性:由于 AOP 分离的实现每个切面,每个独立模块之间的耦合更加的松散。比如说,你可以使用不同的日志器来记录你模块与数据库的操作。通常来讲,松散耦合的实现是代码高复用性的关键点。 AOP 的实现比 OOP 的实现更加松散耦合。
略
1970-01-01 08:00:00
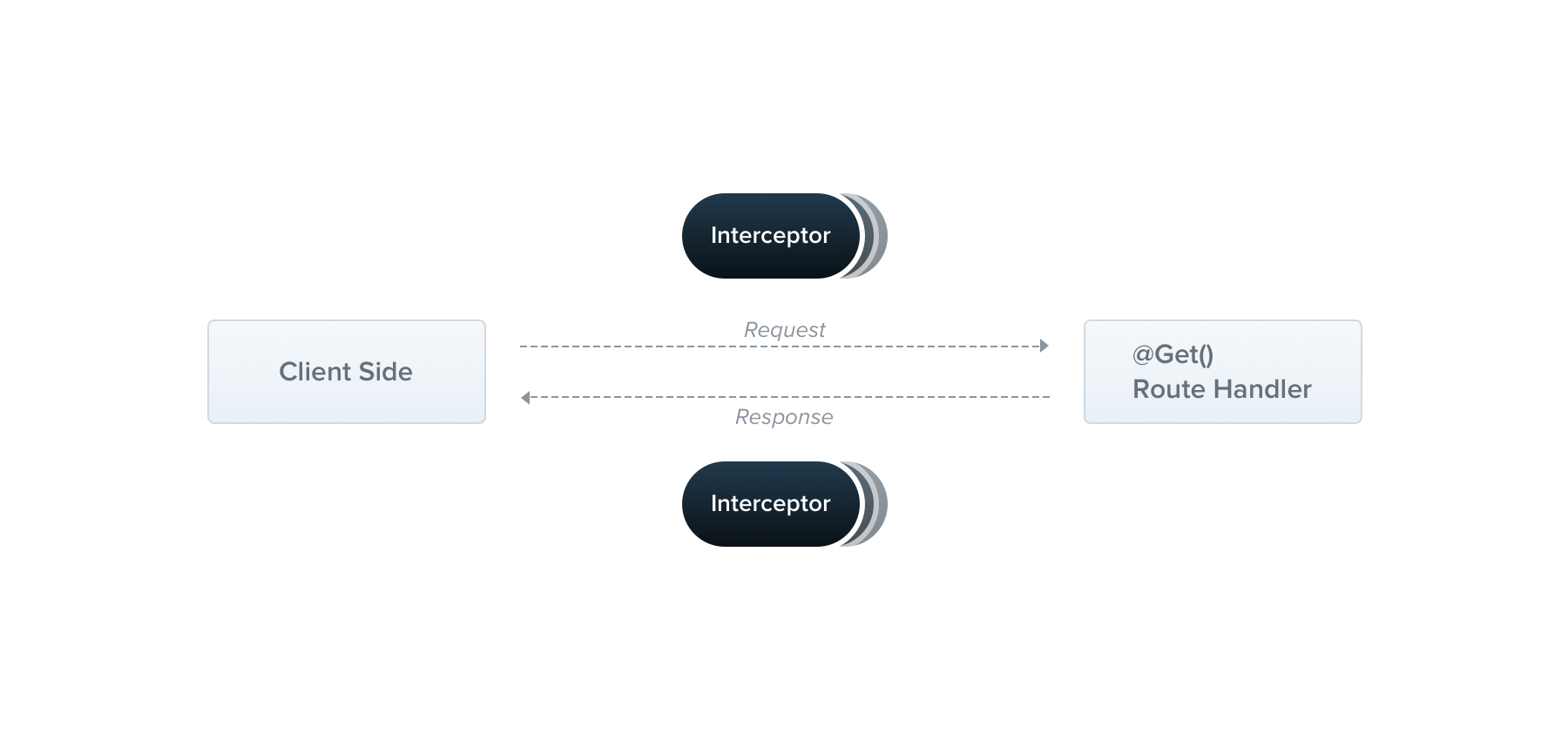
拦截器(Interceptors)是一个使用 @Injectable() 装饰的类,它必须实现 NestInterceptor 接口。
拦截器有一系列的功能,这些功能的设计灵感都来自于面向切面的编程(AOP)技术。这使得下面这些功能成为可能:
在函数执行前/后绑定额外的逻辑
转换一个函数的返回值
转换函数抛出的异常
扩展基础函数的行为
根据特定的条件完全的重写一个函数(比如:缓存)
每个拦截器都要实现 intercept() 方法,此方法有两个参数。第一个是 ExecutionContext 实例(这和守卫中的对象一样)。ExecutionContext 继承自 ArgumentsHost。上一节中我们见过,它是一个包装了传递向原始处理器而且根据应用的不同包含不同的参数数组的类
ExecutionContext 通过继承 ArgumentsHost,提供了更多的执行过种中的更多细节,它看起来长这样:
export interface ExecutionContext extends ArgumentsHost {
getClass<T = any>(): Type<T>;
getHandler(): Function;
}
getHandler() 方法返回一个将会被调用的路由处理器的引用。getClass() 方法返回控制器类的类型。例如,如果当前进行着一个 POST 请求,假定它会由 CatsController 的 create() 方法处理,那么 getHandler() 方法将返回 create() 方法的引用,而 getClass() 则会返回 CatsController 的类型(非实例)
第二个参数是一个 CallHandler。CallHandler 接口实现了 handle() 方法,这个方法就是你可以在你拦截器的某个地方调用的路由处理器。如果你的 intercept() 方法中没调用 handle() 方法,那么路由处理器将不会被执行。
不像守卫与过滤器,拦截器对于一次请求响应有完全的控制权与责任。这样的方式意味着 intercept() 方法可以高效地包装请求/响应流。因此,你可以在最终的路由处理器执行前/后实现自己的逻辑。显然,你已经可以通过在 intercept() 方法中的 handle() 调用之前写自己的代码,但是后续的逻辑应该如何处理?因为 handle() 方法返回的是一个 Observable,我们可以使用 RxJS 做到修改后来的响应。使用 AOP 技术,路由处理器的调用被称做一个 切点(Pointcut),这表示一个我们的自定义的逻辑插入的地方。
假如有一个 POST /cats 的请求,这个请求将被 CatsController 中的 create() 方法处理。如果一个没调用 handle() 方法的拦截器在某处被调用,create() 方法将不会被执行。一但 handle() 方法被调用(它的 Observable 已返回),create() 处理器将被触发。一但响应流通过 Observable 接收到,附加的操作可以在注上被执行,最后的结果将返回给调用方。
我们将要研究的第一个例子就是用户登录的交互。下面展示了一个简单的日志拦截器:
@Injectable()
export class LoggingInterceptor implements NestInterceptor {
intercept(context: ExecutionContext, next: CallHandler): Observable<any> {
console.log('Before...');
const now = Date.now();
return next
.handle()
.pipe(
tap(() => console.log(`After... ${Date.now() - now}ms`)),
);
}
}
由于 handle() 方法返回了一个 RxJS 的 Observable 对象,对于修改流我们将有更多的选择。上面的示例中我们使用了 tap() 操作符。它在 Observable 流的正常或异常终止时调用我们的匿名日志记录函数,但不会干扰到响应周期。
我们可以使用 @UseInterceptors() 装饰器来绑定一个拦截器,和管道、守卫一样,它即可以是控制器作用域的,也可以是方法作用域的,或者是全局的。
@UseInterceptors(LoggingInterceptor)
export class CatsController {}
上面的实现,在请求进入 CatsController 后,你将看到下面的日志输出。
Before...
After... 1ms
我们已经知道了 handle() 方法返回一个 Observable。流包含路由处理器返回的值,因此,我们可以很容易的使用 RxJS 的 map() 操作符改变它。
注意:响应映射功能并不适用于库级别的响应策略(不可以使用 @Res 装饰器)
让我们新建一个 TransformInterceptor,它可以修改每个响应。它将使用 map() 操作符来给响应对象符加 data 属性,并且将这个新的响应返回给客户端。
import { Injectable, NestInterceptor, ExecutionContext, CallHandler } from '@nestjs/common';
import { Observable } from 'rxjs';
import { map } from 'rxjs/operators';
export interface Response<T> {
data: T;
}
@Injectable()
export class TransformInterceptor<T> implements NestInterceptor<T, Response<T>> {
intercept(context: ExecutionContext, next: CallHandler): Observable<Response<T>> {
return next.handle().pipe(map(data => ({ data })));
}
}
当有请求进入时,响应看起来将会是下面这样:
{
"data": []
}
拦截器对于创建整个应用层面的可复用方案有非常大的意义。比如说,我们需要将所有响应中出现的 null 值改成空字符串 ""。我们可以使用拦截器功能仅用下面一行代码就可以实现
import { Injectable, NestInterceptor, ExecutionContext, CallHandler } from '@nestjs/common';
import { Observable } from 'rxjs';
import { map } from 'rxjs/operators';
@Injectable()
export class ExcludeNullInterceptor implements NestInterceptor {
intercept(context: ExecutionContext, next: CallHandler): Observable<any> {
return next
.handle()
.pipe(map(value => value === null ? '' : value ));
}
}
另外一个有趣的用例是使用 RxJS 的 catchError() 操作符来重写异常捕获:
import {
Injectable,
NestInterceptor,
ExecutionContext,
BadGatewayException,
CallHandler,
} from '@nestjs/common';
import { Observable, throwError } from 'rxjs';
import { catchError } from 'rxjs/operators';
@Injectable()
export class ErrorsInterceptor implements NestInterceptor {
intercept(context: ExecutionContext, next: CallHandler): Observable<any> {
return next
.handle()
.pipe(
catchError(err => throwError(new BadGatewayException())),
);
}
}
有一些情况下我们希望完全阻止处理器的调用并返回一个不同的值。比如缓存的实现。让我们来试试使用缓存拦截器来实现它。当然真正的缓存实现还包含 TTL,缓存验证,缓存大小等问题,我们这个例子只是一个简单的示意。
import { Injectable, NestInterceptor, ExecutionContext, CallHandler } from '@nestjs/common';
import { Observable, of } from 'rxjs';
@Injectable()
export class CacheInterceptor implements NestInterceptor {
intercept(context: ExecutionContext, next: CallHandler): Observable<any> {
const isCached = true;
if (isCached) {
return of([]);
}
return next.handle();
}
}
上面的代码中我们硬编码了 isCached 变量,以及返回的缓存数据 []。关键点在于我们返回了一个新的流,使用了 RxJS 的 of() 操作符。因此路由处理器永远不会被调用。为了实现一个更完整的解决方案,你可以通过使用 Reflector 创建一个自定义的装饰器来实现缓存功能。
RxJS 的操作符有很多种能力,我们可以考虑下面这种用例。你需要处理路由请求的超时问题。当你的响应很久都没正常返回时,你会想把它关闭并返回一个错误的响应。
import { Injectable, NestInterceptor, ExecutionContext, CallHandler } from '@nestjs/common';
import { Observable } from 'rxjs';
import { timeout } from 'rxjs/operators';
@Injectable()
export class TimeoutInterceptor implements NestInterceptor {
intercept(context: ExecutionContext, next: CallHandler): Observable<any> {
return next.handle().pipe(timeout(5000))
}
}
5 秒后,请求处理将会被取消。
1970-01-01 08:00:00
守卫(Guards)是一个使用 @Injectable() 装饰的类,它必须实现 CanActivate 接口。
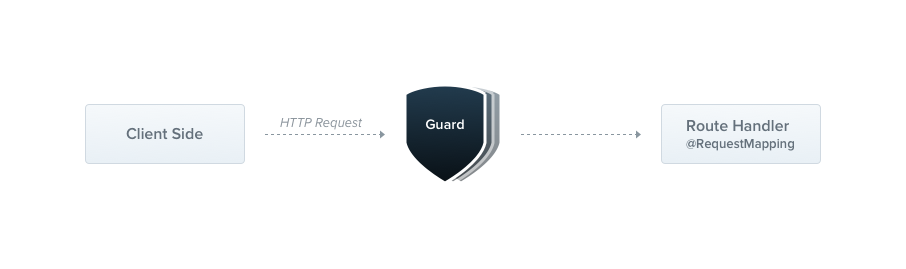
守卫只有一个职责,就是决定请求是否需要被控制器处理。一般用在权限、角色的场景中。
守卫和中间件的区别在于:中间件很简单,next 方法调用后中间的任务就完成了。但是守卫需要关心上下游,它需要鉴别请求与控制器之间的关系。
守卫会在中间件逻辑之==后==、拦截器/管道之==前==执行。
import { Injectable, CanActivate, ExecutionContext } from '@nestjs/common';
import { Observable } from 'rxjs';
@Injectable()
export class AuthGuard implements CanActivate {
canActivate(
context: ExecutionContext,
): boolean | Promise<boolean> | Observable<boolean> {
const request = context.switchToHttp().getRequest();
return validateRequest(request);
}
}
canActivate 返回 true,控制器正常执行,false 请求会被 deny
ExecutionContext 不但继承了 ArgumentsHost,还有两个额外方法:
export interface ExecutionContext extends ArgumentsHost {
getClass<T = any>(): Type<T>;
getHandler(): Function;
}
getHandler() 方法会返回一个将被调用的方法处理器,getClass() 返回处理器对应的控制器类。
我们来实现一个小型的基于角色的认证系统。
创建一个守卫,先让它返回 true,后面再改:
import { Injectable, CanActivate, ExecutionContext } from '@nestjs/common';
import { Observable } from 'rxjs';
@Injectable()
export class RolesGuard implements CanActivate {
canActivate(
context: ExecutionContext,
): boolean | Promise<boolean> | Observable<boolean> {
return true;
}
}
就像过滤器一样,守卫可以是控制器作用域的,也可以是方法作用域或者全局作用域。我们使用 @UseGuards 来引用一个控制器作用域的守卫。
@Controller('cats')
@UseGuards(RolesGuard)
export class CatsController {}
如果想引用到全局作用域可以调用 useGlobalGuards 方法。
const app = await NestFactory.create(ApplicationModule);
app.useGlobalGuards(new RolesGuard());
由于我们在根模块外层引用了全局守卫,这时守卫无法注入依赖。所以我们还需要在要模块上引入。
import { Module } from '@nestjs/common';
import { APP_GUARD } from '@nestjs/core';
@Module({
providers: [
{
provide: APP_GUARD,
useClass: RolesGuard,
},
],
})
export class ApplicationModule {}
虽然现在已经有了守卫,但是它还没有执行上下文。CatsController 应该有一些需要访问到的权限类型。比如:管理员(admin)角色可以访问、其它角色不可以。
这时我们需要对控制器(或方法)添加一些元数据,用来标记这个控制器的权限类型。在 Nest 中我们通常使用 @SetMetadata() 装饰器来完成这个工作。
@Post()
@SetMetadata('roles', ['admin'])
async create(@Body() createCatDto: CreateCatDto) {
this.catsService.create(createCatDto);
}
上面的代码表示给 create 方法设置角色的元数据,用来标识 create 方法只能是 roles 关联的一些角色(admin…)才能访问到的。
如果你觉得 SetMetadata 这个装饰器看着不是那么见名知意,也可以实现一个自定义的装饰器。
import { SetMetadata } from '@nestjs/common';
export const Roles = (...roles: string[]) => SetMetadata('roles', roles);
这样就可以用更简洁的方式来声明角色权限关系了:
@Post()
@Roles('admin')
async create(@Body() createCatDto: CreateCatDto) {
this.catsService.create(createCatDto);
}
我们将使用反射机制来获取控制器上的元数据。
import { Injectable, CanActivate, ExecutionContext } from '@nestjs/common';
import { Observable } from 'rxjs';
import { Reflector } from '@nestjs/core';
@Injectable()
export class RolesGuard implements CanActivate {
constructor(private readonly reflector: Reflector) {}
canActivate(context: ExecutionContext): boolean {
const roles = this.reflector.get<string[]>('roles', context.getHandler());
if (!roles) {
return true;
}
const request = context.switchToHttp().getRequest();
const user = request.user;
const hasRole = () => user.roles.some((role) => roles.includes(role));
return user && user.roles && hasRole();
}
}
当 canActivate 方法返回 false 时,Nest 将会抛出一个 ForbiddenException 异常。你也可以手动抛出别的异常:
throw new UnauthorizedException();
1970-01-01 08:00:00
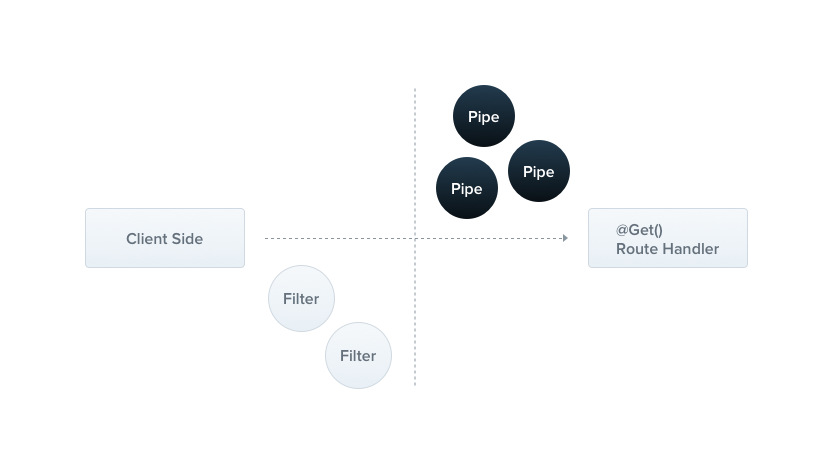
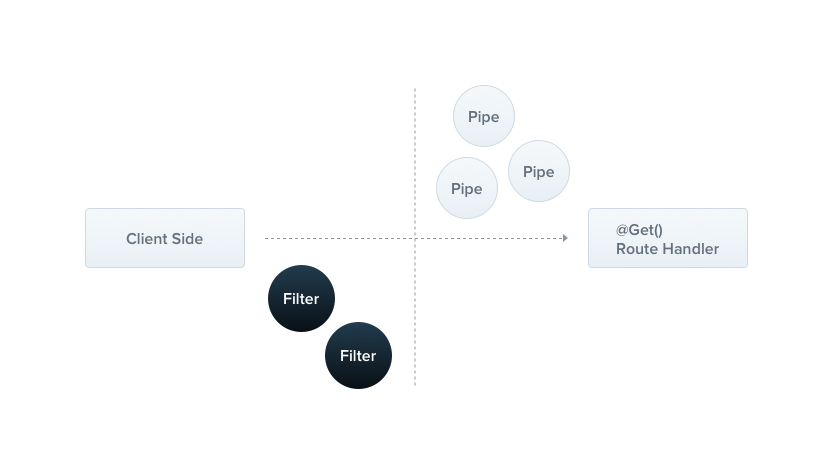
管道(Pipes)是一个用 @Injectable() 装饰过的类,它必须实现 PipeTransform 接口。
从官方的示意图中我们可以看出来管道 pipe 和过滤器 filter 之间的关系:管道偏向于服务端控制器逻辑,过滤器则更适合用客户端逻辑。
过滤器在客户端发送请求**==后==处理,管道则在控制器接收请求==前==**处理。
管道通常有两种作用:
转换/变形:转换输入数据为目标格式
验证:对输入数据时行验证,如果合法让数据通过管道,否则抛出异常。
管道会处理控制器路由的参数,Nest 会在方法调用前插入管道,管道接收发往该方法的参数,此时就会触发上面两种情况。然后路由处理器会接收转换过的参数数据并处理后续逻辑。
++小提示++:管道会在异常范围内执行,这表示异常处理层可以处理管道异常。如果管道发生了异常,控制器的执行将会停止
Nest 内置了两种管道:ValidationPipe 和 ParseIntPipe。
import { PipeTransform, Injectable, ArgumentMetadata } from '@nestjs/common';
@Injectable()
export class ValidationPipe implements PipeTransform {
transform(value: any, metadata: ArgumentMetadata) {
return value;
}
}
注意这里可能不太好理解,因为我们前面已经在控制器参数上使用了 @body 装饰器,并且使用 TypeScript 的类型声明它为 CreateCatDto,如下:
async create(@Body() createCatDto: CreateCatDto) {
this.catsService.create(createCatDto);
}
但是 TypeScript 类型是静态的、编译时类型,当编译成 JavaScript 后在运行时并没有任何类型校验。这时我们就需要自己去验证,或者借助第三方工具、库来验证。
Nest 官方文档在这一节中使用了 joi 这个验证库。这个验证库的使用需要传入一个 schema,实际上对应着我们的在 Nest 中写的 dto 类型,所以我们只需要给 joi 传入一个 CreateCatDto 类的实例即可。
首页在 ValidationPipe 管道中添加 joi 的验证功能。验证通过就返回,不通过直接抛出异常:
@Injectable()
export class JoiValidationPipe implements PipeTransform {
constructor(private readonly schema: Object) {}
transform(value: any, metadata: ArgumentMetadata) {
const { error } = Joi.validate(value, this.schema);
if (error) {
throw new BadRequestException(SON.stringify(error.details));
}
return value;
}
}
管道有了,我们还需要在控制器方法上绑定它。
@Post()
@UsePipes(new JoiValidationPipe(createCatSchema))
async create(@Body() createCatDto: CreateCatDto) {
this.catsService.create(createCatDto);
}
使用 @UsePipes 修饰器即可,传入管道的实例,并构造 schema。此时我们的应用就可以在运行时通过 schema 去校验参数对象的开头了。createCatSchema 的写法可以参考相关文档。
const createCatSchema = {
name: Joi.string().required(),
age: Joi.number().required(),
breed: Joi.string().required(),
}
例如上面的 schema,如果客户端发送的 POST 请求中如果缺少任意参数 Nest 都会捕获到这个异常并返回信息:
{
"statusCode": 400,
"error": "Bad Request",
"message": "[{\"message\":\"\\\"name\\\" is required\",\"path\":[\"name\"],\"type\":\"any.required\",\"context\":{\"key\":\"name\",\"label\":\"name\"}}]"
}
注意 message 就是我们在管道中传到异常类 BadRequestException 中的参数。
当然上面这种方法看起来没那么优雅,因为毕竟 CreateCatDto 和 createCatSchema 太重复了。Nest 还支持类型验证器,虽然也需要借助于三方库,但是看起来会优雅很多。
首先,要使用类验证器,你需要先安装 class-validator 库。
npm i --save class-validator class-transformer
class-validator 可以让你使用给类变量加装饰器的写法给类添加额外的验证功能。这样以来我们就可以直接在原始的 CreateCatDto 类上添加验证装饰器了,这样看起来就整洁多了,而且还没有重复代码:
import { IsString, IsInt } from 'class-validator';
export class CreateCatDto {
@IsString()
readonly name: string;
@IsInt()
readonly age: number;
@IsString()
readonly breed: string;
}
不过管道验证器中的代码也需要适配一下:
import { validate } from 'class-validator';
import { plainToClass } from 'class-transformer';
@Injectable()
export class ValidationPipe implements PipeTransform<any> {
async transform(value: any, { metatype }: ArgumentMetadata) {
if (!metatype || !this.toValidate(metatype)) {
return value;
}
const object = plainToClass(metatype, value);
const errors = await validate(object);
if (errors.length > 0) {
throw new BadRequestException('Validation failed');
}
return value;
}
private toValidate(metatype: Function): boolean {
const types: Function[] = [String, Boolean, Number, Array, Object];
return !types.includes(metatype);
}
}
注意这次的 transform 是 async 异步的,因为内部需要用到异步验证方法。Nest 是支持你这么做的,因为管道可以是异步的。
然后我们可以插入这个管道,位置可以是方法级别的,也可以是参数级别的。
++参数作用域++
@Post()
async create(
@Body(new ValidationPipe()) createCatDto: CreateCatDto,
) {
this.catsService.create(createCatDto);
}
++方法作用域++
@Post()
@UsePipes(new ValidationPipe())
async create(@Body() createCatDto: CreateCatDto) {
this.catsService.create(createCatDto);
}
管道修饰器入参可以是类而不必是管道实例:
@Post()
@UsePipes(ValidationPipe)
async create(@Body() createCatDto: CreateCatDto) {
this.catsService.create(createCatDto);
}
这样以来将实例化过程留给框架去做并肝启用依赖注入。
由于 ValidationPipe 被尽可能的泛化,所以它可以直接使用在全局作用域上。
async function bootstrap() {
const app = await NestFactory.create(ApplicationModule);
app.useGlobalPipes(new ValidationPipe());
await app.listen(3000);
}
bootstrap();
我们还可以用管道来进行数据转换,比如说上面的例子中 age 虽然声明的是 int 类型,但是我们知道 HTTP 请求传递的都是纯字符流,所以通常我们还要把期望传进行类型转换。
import { PipeTransform, Injectable, ArgumentMetadata, BadRequestException } from '@nestjs/common';
@Injectable()
export class ParseIntPipe implements PipeTransform<string, number> {
transform(value: string, metadata: ArgumentMetadata): number {
const val = parseInt(value, 10);
if (isNaN(val)) {
throw new BadRequestException('Validation failed');
}
return val;
}
}
上面这个管道的功能就是强制转换成 Int 类型,如果转换不成功就抛出异常。我们可以针对性的对传入控制器的某个参数插入这个管道:
@Get(':id')
async findOne(@Param('id', new ParseIntPipe()) id) {
return await this.catsService.findOne(id);
}
比较贴心的是 Nest 已经内置了如上面的例子类似的一些通用验证器,你可以以参数的方式去实例化 ValidationPipe。
@Post()
@UsePipes(new ValidationPipe({ transform: true }))
async create(@Body() createCatDto: CreateCatDto) {
this.catsService.create(createCatDto);
}
ValidationPipe 接收一个 ValidationPipeOptions 类型的参数,并且这个参数继承自 ValidatorOptions
export interface ValidationPipeOptions extends ValidatorOptions {
transform?: boolean;
disableErrorMessages?: boolean;
exceptionFactory?: (errors: ValidationError[]) => any;
}
ValidatorOptions 又继承了如下所有 class-validator 的参数:
| Option | Type | Description |
|---|---|---|
skipMissingProperties |
boolean |
If set to true, validator will skip validation of all properties that are missing in the validating object. |
whitelist |
boolean |
If set to true, validator will strip validated (returned) object of any properties that do not use any validation decorators. |
forbidNonWhitelisted |
boolean |
If set to true, instead of stripping non-whitelisted properties validator will throw an exception. |
forbidUnknownValues |
boolean |
If set to true, attempts to validate unknown objects fail immediately. |
disableErrorMessages |
boolean |
If set to true, validation errors will not be returned to the client. |
exceptionFactory |
Function |
Takes an array of the validation errors and returns an exception object to be thrown. |
groups |
string[] |
Groups to be used during validation of the object. |
dismissDefaultMessages |
boolean |
If set to true, the validation will not use default messages. Error message always will be undefined if its not explicitly set. |
validationError.target |
boolean |
Indicates if target should be exposed in ValidationError |
validationError.value |
boolean |
Indicates if validated value should be exposed in ValidationError. |
1970-01-01 08:00:00
Nest 框架内部实现了一个异常处理层,专门用来负责应用程序中未处理的异常。
默认情况未处理的异常会被全局过滤异常器 HttpException 或者它的子类处理。如果一个未识别的异常(非 HttpException 或未继承自 HttpException)被抛出,下面的信息将被返回给客户端:
{
"statusCode": 500,
"message": "Internal server error"
}
我们可以从控制器的方法中手动抛出一个异常:
@Get()
async findAll() {
throw new HttpException('Forbidden', HttpStatus.FORBIDDEN);
}
客户端将收到如下信息:
{
"statusCode": 403,
"message": "Forbidden"
}
当然你也可以自定义返回状态值和错误信息:
@Get()
async findAll() {
throw new HttpException({
status: HttpStatus.FORBIDDEN,
error: 'This is a custom message',
}, 403);
}
比较好的做法是实现你自己想要的异常类。
export class ForbiddenException extends HttpException {
constructor() {
super('Forbidden', HttpStatus.FORBIDDEN);
}
}
然后你就可以手动在需要的地方抛出它。
@Get()
async findAll() {
throw new ForbiddenException();
}
Nest 内置了以下集成自 HttpException 的异常类:
BadRequestException
UnauthorizedException
NotFoundException
ForbiddenException
NotAcceptableException
RequestTimeoutException
ConflictException
GoneException
PayloadTooLargeException
UnsupportedMediaTypeException
UnprocessableEntityException
InternalServerErrorException
NotImplementedException
BadGatewayException
ServiceUnavailableException
GatewayTimeoutException
如果你想给异常返回值加一些动态的参数,可以使用异常过滤器来实现。例如下面的异常过滤器将会给 HttpException 添加额外的时间缀和路径参数:
import { ExceptionFilter, Catch, ArgumentsHost, HttpException } from '@nestjs/common';
import { Request, Response } from 'express';
@Catch(HttpException)
export class HttpExceptionFilter implements ExceptionFilter {
catch(exception: HttpException, host: ArgumentsHost) {
const ctx = host.switchToHttp();
const response = ctx.getResponse<Response>();
const request = ctx.getRequest<Request>();
const status = exception.getStatus();
response
.status(status)
.json({
statusCode: status,
timestamp: new Date().toISOString(),
path: request.url,
});
}
}
注意:所有的异常过滤器都必须实现泛型接口 ExceptionFilter
上面代码中的 host 参数是一个类型为 ArgumentsHost 的原生请求处理器包装对象。根据应用程序的不同它具有不同的接口。
export interface ArgumentsHost {
getArgs<T extends Array<any> = any[]>(): T;
getArgByIndex<T = any>(index: number): T;
switchToRpc(): RpcArgumentsHost;
switchToHttp(): HttpArgumentsHost;
switchToWs(): WsArgumentsHost;
}
可以使用 @UseFilters 装饰器让一个控制器方法具有过滤器处理逻辑。
@Post()
@UseFilters(HttpExceptionFilter)
async create(@Body() createCatDto: CreateCatDto) {
throw new ForbiddenException();
}
当然过滤器可以被使用在不同的作用域上:方法作用域、控制器作用域、全局作用域。比如应用一个控制器作用域的过滤器,可以这么写:
@UseFilters(new HttpExceptionFilter())
export class CatsController {}
全局过滤器可以通过如下代码实现:
async function bootstrap() {
const app = await NestFactory.create(ApplicationModule);
app.useGlobalFilters(new HttpExceptionFilter());
await app.listen(3000);
}
bootstrap();
不过这样注册的全局过滤器无法进入依赖注入,因为它在模块作用域之外。为了解决这个问题,你可以在根模块上面注册一个全局作用域的过滤器。
import { Module } from '@nestjs/common';
import { APP_FILTER } from '@nestjs/core';
@Module({
providers: [
{
provide: APP_FILTER,
useClass: HttpExceptionFilter,
},
],
})
export class ApplicationModule {}
@Catch() 装饰器不传入参数就默认捕获所有的异常:
import { ExceptionFilter, Catch, ArgumentsHost, HttpException, HttpStatus } from '@nestjs/common';
@Catch()
export class AllExceptionsFilter implements ExceptionFilter {
catch(exception: unknown, host: ArgumentsHost) {
const ctx = host.switchToHttp();
const response = ctx.getResponse();
const request = ctx.getRequest();
const status = exception instanceof HttpException
? exception.getStatus()
: HttpStatus.INTERNAL_SERVER_ERROR;
response.status(status).json({
statusCode: status,
timestamp: new Date().toISOString(),
path: request.url,
});
}
}
通常你可能并不需要自己实现完全定制化的异常过滤器,可以继承自 BaseExceptionFilter 即可复用内置的过滤器逻辑。
import { Catch, ArgumentsHost } from '@nestjs/common';
import { BaseExceptionFilter } from '@nestjs/core';
@Catch()
export class AllExceptionsFilter extends BaseExceptionFilter {
catch(exception: unknown, host: ArgumentsHost) {
super.catch(exception, host);
}
}
1970-01-01 08:00:00
中间件就是一个函数,在路由处理器之前调用。这就表示中间件函数可以访问到请求和响应对象以及应用的请求响应周期中的 next() 中间间函数。
Nest 中间件实际上和 Express 的中间件是一样的,Express 文档中对中间件的描述如下:
中间件函数主要做以下的事情:
执行任意的代码
对请求/响应做操作
终结请求-响应周期
调用下一个栈中的中间件函数
如果当前的中间间函数没有终结请求响应周期,那么它必须调用 next() 方法将控制权传递给下一个中间件函数。否则请求将被挂起
Nest 允许你使用函数或者类来实现自己的中间件。如果用类实现,则需要使用 @Injectable() 装饰,并且实现 NestMiddleware 接口。
import { Injectable, NestMiddleware } from '@nestjs/common';
import { Request, Response } from 'express';
@Injectable()
export class LoggerMiddleware implements NestMiddleware {
use(req: Request, res: Response, next: Function) {
console.log('Request...');
next();
}
}
中间件也是支持依赖注入的,就像其它支持方式一样,你可以使用构造函数注入依赖。
@Module() 装饰器中并不能指定中间件参数,我们可以在模块类的构 configure() 方法中应用中间件,下面的代码会应用一个 ApplicationModule级别的日志中间件 LoggerMiddleware
@Module({
imports: [CatsModule],
})
export class ApplicationModule implements NestModule {
configure(consumer: MiddlewareConsumer) {
consumer
.apply(LoggerMiddleware)
.forRoutes('cats');
}
}
上面的代码 forRoutes 方法表示只将中间件应用在 cats 路由上,还可以是指定的 HTTP 方法,甚至是路由通配符:
.forRoutes({ path: 'cats', method: RequestMethod.GET });
.forRoutes({ path: 'ab*cd', method: RequestMethod.ALL });
当然,你也可以指定不包括某些路由规则:
consumer
.apply(LoggerMiddleware)
.exclude(
{ path: 'cats', method: RequestMethod.GET },
{ path: 'cats', method: RequestMethod.POST }
)
.forRoutes(CatsController);
不过请注意 exclude 方法不能运用在函数式的中间件上,而且这里指定的 path 也不支持通配符,这只是个快捷方法,如果你真的需要某种路由级别的控制,那完全可以把逻辑写在一个单独的中间件中。
函数式的中间件可以用一个简单无依赖函数来实现:
export function logger(req, res, next) {
console.log(`Request...`);
next();
};
apply 方法传入多个中间件参数即可:
consumer.apply(cors(), helmet(), logger)
.forRoutes(CatsController);
在实现了 INestApplication 接口的实例上调用 use() 方法即可:
const app = await NestFactory.create(ApplicationModule);
app.use(logger);
await app.listen(3000);
1970-01-01 08:00:00
模块(Module)是一个使用了 @Module() 装饰的类。@Module() 装饰器提供了一些 Nest 需要使用的元数据,用来组织应用程序的结构。
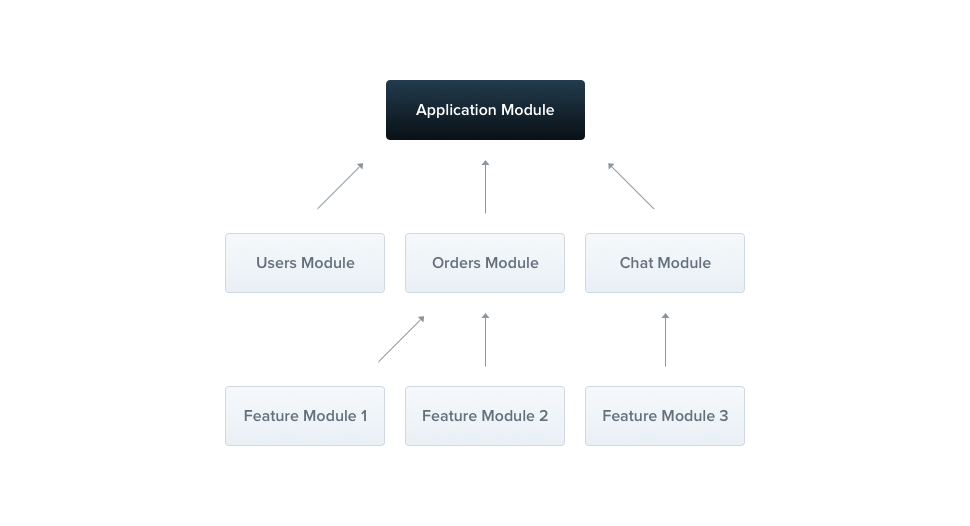
每个应用都至少有一个根模块,根模块就是 Nest 应用的入口。Nest 会从这里查找出整个应用的依赖/调用图。
@Module() 装饰器接收一个参数对象,有以下取值:
| providers | 可以被 Nest 的注入器初始化的 providers,至少会在此模块中共享 |
| controllers | 这个模块需要用到的控制器集合 |
| imports | 引入的其它模块集合 |
| exports | 此模块提供的 providers 的子集,其它模块引入此模块时可用 |
模块默认会封装 providers,如果要在不同模块之间共享 provider 可以在 exports 参数中指定。
使用下面的代码可以将相关的控制器和 Service 包装成一个模块:
import { Module } from '@nestjs/common';
import { CatsController } from './cats.controller';
import { CatsService } from './cats.service';
@Module({
controllers: [CatsController],
providers: [CatsService],
})
export class CatsModule {}
++小提示++:也可以使用 CLI 来自动生成模块:$ nest g module cats
这样我们就完成了一个模块的封装。
在 Nest 中模块默认是单例的,因此你可在不同的模块之间共享任意 Provider 实例。
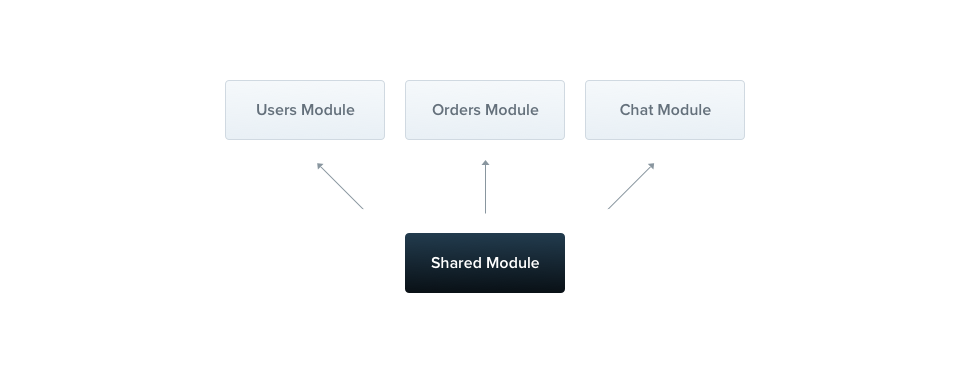
模块都是共享的,我们可以通过导出当前模块的指定 Service 来实现其它模块对 Service 的复用。
import { Module } from '@nestjs/common';
import { CatsController } from './cats.controller';
import { CatsService } from './cats.service';
@Module({
controllers: [CatsController],
providers: [CatsService],
exports: [CatsService] // 导出
})
export class CatsModule {}
给模块包装一层即可实现:
@Module({
imports: [CommonModule],
exports: [CommonModule],
})
export class CoreModule {}
模块的构造函数中也可以注入指定的 providers,通常用在一些配置参数场景。
@Module({
controllers: [CatsController],
providers: [CatsService],
})
export class CatsModule {
constructor(private readonly catsService: CatsService) {}
}
但是模块类本身并不可以装饰成 provider,因为这会造成循环依赖
当一些模块在你的应用频繁使用时,可以使用全局模块来避免每次都要调用的问题。Angular 会把 provider 注册到全局作用域上,然而 Nest 会默认将 provider 注册到模块作用域上。如果你没有显示的导出模块的 provider,那么其它地方就无法使用它。
如果你想让一个模块随处可见,那就使用 @Global() 装饰器来装饰这个模块。
@Global()
@Module({
controllers: [CatsController],
providers: [CatsService],
exports: [CatsService],
})
export class CatsModule {}
@Global() 装饰器可以让模块获得全局作用域
Nest 模块系统支持动态模块的功能,这将让自定义模块的开发变得容易。
import { Module, DynamicModule } from '@nestjs/common';
import { createDatabaseProviders } from './database.providers';
import { Connection } from './connection.provider';
@Module({
providers: [Connection],
})
export class DatabaseModule {
static forRoot(entities = [], options?): DynamicModule {
const providers = createDatabaseProviders(options, entities);
return {
module: DatabaseModule,
providers: providers,
exports: providers,
};
}
}
模块的静态方法 forRoot 返回一个动态模块,可以是同步或者异步模块。
1970-01-01 08:00:00
Provider 主要的设计理念来自于控制反转(Inversion of Control,简称 IOC[1] )模式中的依赖注入(Dependency Injection)特性。使用 @Injectable() 装饰的类就是一个 Provider,装饰器方法会优先于类被解析执行。
到这里我们应该要了解整个 Nest 框架的三层结构,Nest 和传统的 MVC 框架的区别在于它更注重于后端部分(控制器、服务与数据)的架构,视图层相对比较独立,完全可以由用户自定义配置。
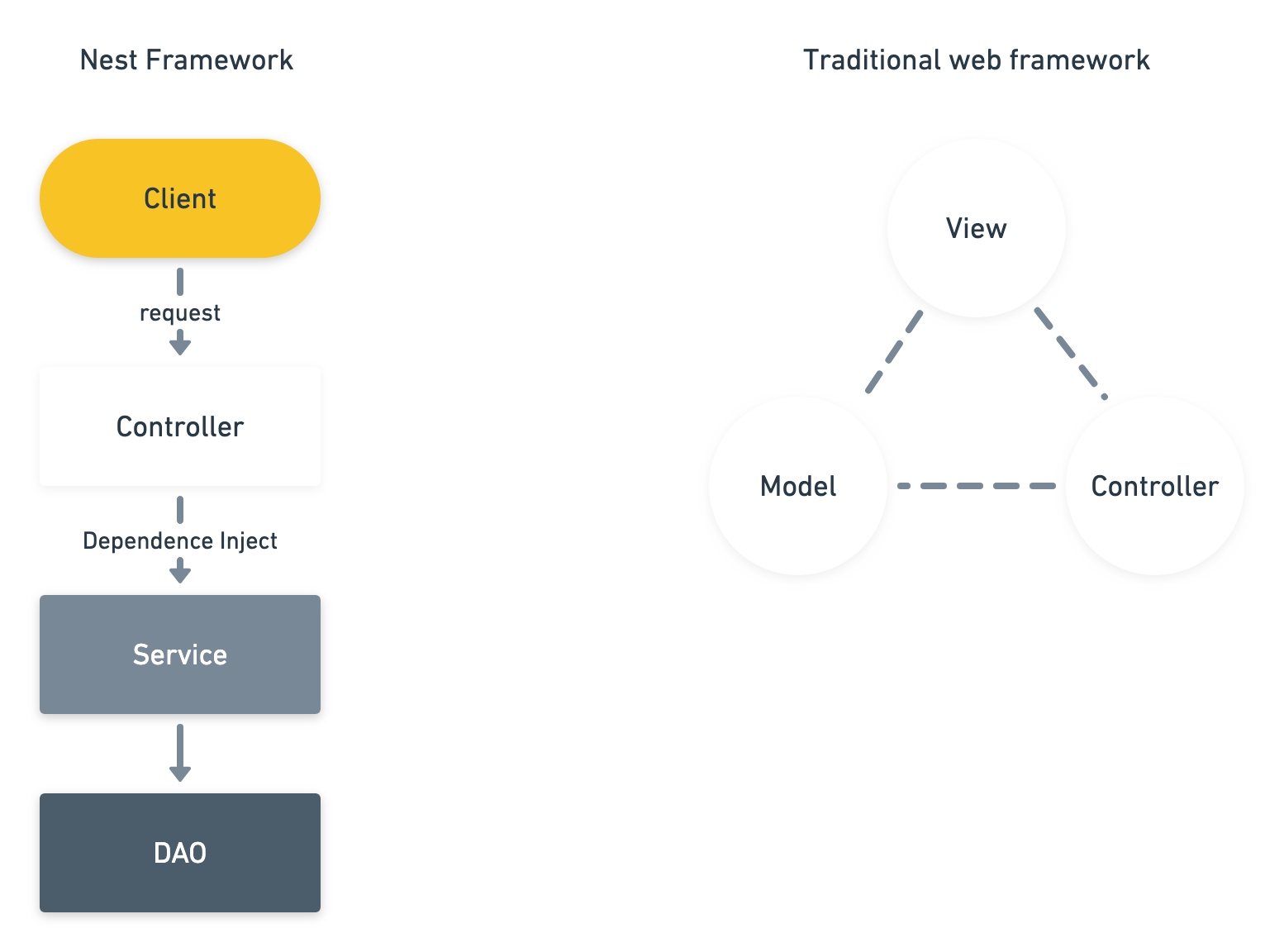
Nest 的分层借鉴自 Spring,更细化。随着代码库的增长 MVC 模式中 Modal 和 Controller 会变得含糊不清,导致难于维护。
我们可以自己实现一个名叫 CatsService 的 Service
export interface Cat {
name: string;
age: number;
breed: string;
}
import { Injectable } from '@nestjs/common';
import { Cat } from './interfaces/cat.interface';
@Injectable()
export class CatsService {
private readonly cats: Cat[] = [];
create(cat: Cat) {
this.cats.push(cat);
}
findAll(): Cat[] {
return this.cats;
}
}
++小提示++:也可以使用 CLI 工具自动生成一个 Service $ nest g service cats
有了 Service 我们就可以在控制器中注入并引用到它了
@Controller('cats')
export class CatsController {
constructor(private readonly catsService: CatsService) {}
// 等同于
private readonly catsService: CatsService
constructor(catsService: CatsService) {
this.catsService = catsService
}
@Post()
async create(@Body() createCatDto: CreateCatDto) {
this.catsService.create(createCatDto);
}
@Get()
async findAll(): Promise<Cat[]> {
return this.catsService.findAll();
}
}
依赖注入的很多种方法,Nest 使用了构建函数注入的方式,看起来非常直观。这个时候我们就可以发现 Nest 的优点了,至少你能发现 Controller 和 Service 处于完全解耦的状态:Controller 做的事情仅仅是接收请求,并在合适的时候调用到 Service,至于 Service 内部怎么实现的 Controller 完全不在乎。
这样以来有两个好处:其一,Controller 和 Service 的职责边界很清晰,不存在灰色地带;其二,各自只关注自身职责涉及的功能,比方说 Service 通常来写业务逻辑,但它也仅仅只与业务相关。当然你可能会觉得这很理想,时间长了增加了诸如缓存、验证等逻辑后,代码最终会变得无比庞大而难于维护。事实上这也是一个框架应该考虑和抽象出来的,后续 Nest 会有一系列的解决方法,但目前为至我们只需要了解到 Controller 和 Service 的设计原理即可。
constructor(private readonly catsService: CatsService) {}
得益于 TypeScript 类型,Nest 可以通过 CatsService 类型查找到 catsService,依赖被查找并传入到控制器的构造函数中。
通常我们在没有依赖注入的时候如果 A 依赖于 B,那么在 A 初始化或者执行中的某个过程需要先创建 B,这时我们就认为 A 对 B 的依赖是正向的。但是这样解决依赖的办法会得得 A 与 B 的逻辑耦合在一起,依赖越来越多代码就会变的越来越糟糕。如下图所示,齿轮之间是相互依赖的,一损俱损。
控制反转(IOC)模式就是要解决这个问题,它会多引入一个容器(Container)的概念,让一个 IOC 容器去管理 A、B 的依赖并初始化。
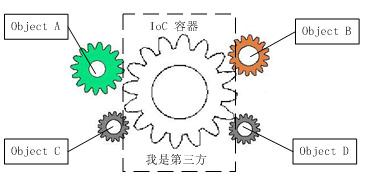
当我们去掉容器时,剩下的齿轮成了一个个独立的功能模块。
Providers 有一个和应用程序一样的生命周期。当应用启动,每个依赖都必须被获取到。将会有单独的一章来讲解注入作用域
Nest 有一个内置的 IOC 容器,用来解析 Providers 之间的关系。这个功能相对于 DI 来讲更底层,但是功能却异常强大,@Injectable() 只是冰山一角。事实上,你可以使用值,类和同步或者异步的工厂。
有时候,你可以会需要一个依赖,但是这个依赖并不需要一定被容器解析出来。比如我们通常会传入一个配置对象,但是如果不传会使用一个默认值代替。可以使用 @Optional() 来装饰一个非必选的参数。
@Injectable()
export class HttpService<T> {
constructor(
@Optional()
@Inject('HTTP_OPTIONS')
private readonly httpClient: T
) {}
}
前面我们提过了 Nest 实现注入是基于类的构造函数的,但是在一些特殊情况下,基于属性的注入会特别有用。
比如一个顶层的类依赖一个或多个 Providers 时,通过在子类的构造函数中调用 super() 方法并不是很优雅,为了避免这种情况我们可以在属性上使用 @Inject() 装饰器。
@Injectable()
export class HttpService<T> {
@Inject('HTTP_OPTIONS')
private readonly httpClient: T;
}
++警告++:如果你的类并没有继承其它 Provider,那么一定要使用基于构造函数注入方式
一般来讲控制器就是 Service 的消费(使用)者,我们需要将这些 Service 注册到 Nest 上,这样就可以让 Nest 帮你完成注入操作。通常我们会使用 @Module 装饰器来完成注册的过程。
import { Module } from '@nestjs/common';
import { CatsController } from './cats/cats.controller';
import { CatsService } from './cats/cats.service';
@Module({
controllers: [CatsController],
providers: [CatsService],
})
export class ApplicationModule {}
控制反转 ↩︎
1970-01-01 08:00:00
控制器(Controller)负责处理客户端请求并发送响应内容,在传统的 MVC 架构中控制器就是负责处理指定请求与应用程序的对应关系,路由则决定具体处理哪个请求。
得益于 TypeScript,在 Nest 中我们可以使用类来实现控制器的功能,使用装饰器来实现路由功能。它们分别需要配合 @Controller 和 @Get 饰器来使用,前者是控制器类的装饰,后者是具体方法的装饰器。
比如下面的代码:
import { Controller, Get } from '@nestjs/common';
@Controller('cats')
export class CatsController {
@Get()
findAll(): string {
return 'This action returns all cats';
}
}
上面的代码声明了一个猫咪控制器类,实现了 findAll 方法,当你在浏览器中发送请求到 /cates 时程序就返回给你 This action returns all cats
++小提示++:可以使用 Nest-cli 工具来自动生成上面的代码:$ nest g controller cats
@Get() 表示 HTTP 请求装饰器。控制器类的装饰器和 HTTP 方法的装饰器共同决定了一个路由规则。findAll 将返回一个状态码为 200 的响应,当然你有两种方法来指定返回的状态码:
| 标准模式(建议的) | 使用内置方法时,如果返回一个 JavaScript 对象或者数据,将自动序列化成 JSON,如果是字符串将默认不会序列化,响应的返回状态码默认总是 200,除非是 POST 请求会默认设置成 201。可以使用 @HttpCode() 装饰器来改变它 |
| 指定框架 | 也可以使用指定框架的请求处理方法,比如 Express 的响应对象。可以使用 @Res() 装饰器来装饰响应对象使用,这样以来你就可以使用类 Express API 的方式处理响应了:response.status(200).send() |
++警告++:你可以同时使用上面两种方法,但是 Nest 会检测到,同时标准模式会在这个路由上被禁用
处理器一般需要访问到请求对象。一般配合 @Req() 装饰器来使用,请求对象包含查询字符串、参数、HTTP 头,请求体等。但是大多数情况只用到其中某个,我们可以单独使用指定的装饰器来装饰请求。
| @Request() | req |
| @Response() | res |
| @Next() | next |
| @Session() | req.session |
| @Param(key?: string) | req.params / req.params[key] |
| @Body(key?: string) | req.body / req.body[key] |
| @Query(key?: string) | req.query / req.query[key] |
| @Headers(name?: string) | req.headers / req.headers[name] |
举个例子:比如我们只需要处理请求的查询字符串(query string),就可以使用 @Query 来装饰入参,这样取到的值就自然是一个 query string 的字典了。
@Get()
getHello(@Query() q: String): string {
console.log(q)
return this.appService.getHello();
}
如果我们的请求是:http://localhost:3000/?test=a
那么控制台将打印一个 { test: 'a' } 字典
++小提示++:建议安装 @types/express 包来获取 Request 的相关类型提示
除了使用 @Get 装饰器,我们还可以使用其它 HTTP 方法装饰器。比如:@Put(), @Delete(), @Patch(), @Options(), @Head(), and @All(),注意 All 并不是 HTTP 的方法,而是 Nest 提供的一个快捷方式,表示接收任何类型的 HTTP 请求。
Nest 支持基于模式的路由规则匹配,比如:星号(*)表示匹配任意的字母组合。
@Get('ab*cd')
The 'ab*cd' 路由将匹配 abcd, ab_cd, abecd 等规则。同时:?, +, *, and () 通配符(wildcard)都可以使用
| 通配符 | 说明 | 示例 | 匹配 | 不匹配 |
|---|---|---|---|---|
* |
匹配任意数量的任意字符 | Law* |
Law, Laws, or Lawyer |
GrokLaw, La, or aw |
*Law* |
Law, GrokLaw, or Lawyer. |
La, or aw |
||
? |
匹配任意单个字符 | ?at |
Cat, cat, Bat or bat |
at |
[abc] |
匹配方括号中的任意一个字符 | [CB]at |
Cat or Bat |
cat or bat |
[a-z] |
匹配字母、数字区间 | Letter[0-9] |
Letter0, Letter1, Letter2 up to Letter9 |
Letters, Letter or Letter10 |
响应的默认状态码是 200,POST 则是 201,我们可以使用装饰器 @HttpCode(204) 来指定处理器级别的 默认 HttpCode 为 204
@Post()
@HttpCode(204)
create() {
return 'This action adds a new cat';
}
如果想动态指定状态码,就要使用 @Res() 装饰器来注入响应对象,同时调用响应的状态码设置方法。
同样的我们可以使用 @Header() 来设置自定义的请求头,也可以使用 response.header() 设置
@Post()
@Header('Cache-Control', 'none')
create() {
return 'This action adds a new cat';
}
通常我们需要设置一些动态的路由来接收一些客户端的查询参数,通过指定路由参数可以很方便的捕获到 URL 上的动态参数到控制器中。
@Get(':id')
findOne(@Param() params): string {
console.log(params.id);
return `This action returns a #${params.id} cat`;
}
通过使用 @Param() 装饰器可以在方法中直接访问到路由装饰器 @Get() 中的的参数字典,:id 就表示匹配到所有的字符串,可以通过引用 params.id 在方法中访问到。
当然,就像前面学到的参数装饰器也可以指定到具体的某个参数值:
@Get(':id')
findOne(@Param('id') id): string {
return `This action returns a #${id} cat`;
}
路由的注册顺序与控制器类中的方法顺序相关,如果你先装饰了一个 cats/:id 的路由,后面又装饰了一个 cats 路由,那么当用户访问到 GET /cats 时,后面的路由将不会被捕获,因为参数才都是非必选的。
1970-01-01 08:00:00
这篇教程起,你将会学习到 Nest 的几个核心点。为了更好的了解 Nest 应用中的模块,我们将开发一个有基本 CRUD[1] 功能的入门级应用。
Nest 是 TypeScript 写的,所以天生就很好的并且渐进地支持 JavaScript。
保证你的操作系统上安装的 Node.js 版本大于 8.9.0 即可。
就像上节讲到的直接用 nest new project-name 就可以了。我们来回顾下目录结构:
src
├── app.controller.spec.ts
├── app.controller.ts
├── app.module.ts
├── app.service.ts
└── util.ts
分别对应的功能如下表:
| app.controller.ts | 只有一个路由的控制器(controller)示例 |
| app.module.ts | 应用程序的根模块(root module) |
| util.ts | 应用程序的入口文件,使用 NestFactory 方法创建应用实例 |
在 util.ts 中我们可以看到,默认使用了 NestFactory 的 create() 静态方法返回创建的应用对象,此对应会实现 INestApplication 接口。
Nest 的目标是一个平台无关的框架。这个意思就是说 Nest 本身并不造某个细分领域的轮子,他只构建一套构架体系,然后把一些好用的库或者平台融合进来。所以 Nest 可以衔接任何 HTTP 框架,默认支持 express 和 fastify 两个 web 框架。
| platform-express | Express 是一个 Node web 框架,有很多社区成熟的资源。@nestjs/platform-express 默认会被引入,大家都很熟悉了,用起来会容易上手 |
| platform-fastify | Fastify 是一个高能低耗的框架,致力于最大化效率与速度 |
无论使用哪个平台,都要暴露自己的应用接口。上面两个平台暴露了对应的两个变量 NestExpressApplication and NestFastifyApplication。
如下的代码会创建一个 app 对象,并且指定了使用 NestExpressApplication 平台:
const app = await NestFactory.create<NestExpressApplication>(ApplicationModule);
不过一般情况下不需要指定这个类型。
Create, Read, Update, Delete 通常对应于数据的增删改查功能 ↩︎
1970-01-01 08:00:00

请注意:本教程结合官方文档内容并添加了许多我自己学习过种中的理解,存在许多个人观点
Nest 是一个用于构建高效、可扩展的 Node.js 服务端应用框架,基于 TypeScript 编写并且结合了 OOP[1]、FP[2]、FRP[3] 的相关理念。并且设计上很多灵感来自于 Angular[4]。
Angular 的很多模式又来自于 Java 中的 Spring 框架,依赖注入、面向切面编程等,所以你可以认为: Nest 是 Node.js 版的 Spring 框架。
或许很多前端工程师看到这里就自动劝退了,事实上我以前也挺讨厌 Java 的(现在也不怎么喜欢),后来由于工作原因学习到了一些 Java 相关的知识后才发现自己的认识很片面。现在 WEB 后端主流的技术栈都基于 Spring 框架,框架必然是解决了很多实际问题,能学习到它的思想比它自己的出身、派系更重要。同时建议那些没有学习或者接触过 Java 的前端可以了解一些相关概念,不要拒绝,因为这可能会为你打开另一扇门。
可能在很多伪 FP 爱好者来看 OOP 是臃肿无用的东西。但是从使用角度讲:FP 小而美,OOP 大而全,如果不关注场景去讨论好坏没有任何意义。而且事实上这两者完全是不冲突的,可以结合得非常完美。不要被那些所谓的纯函数、纯面向对象的概念误导,能写出真正的好代码才是重要的。
如果你以前在使用 Node.js 开发后端应用时常常不知道如何规划代码关系,搞不清楚控制器、服务、模型和数据的关系,或者是你打算使用 Node.js 构建大型应用,那就建议你了解一下 Nest。
在开始体验前,有必要简单介绍下 Nest 框架的的设计理念,我结合我自己的理解大概梳理下。
近几年由于 Node.js 的出现,JavaScript 成为了前端和后端的「lingua franca[5]」,前端方面出现了 Angular, React, Vue 等众多的 UI 框架,后端方面也有像 Express, Koa 这样优秀的框架出现,但这些框架都没有高效地解决一个核心问题 — 架构
官方的这段介绍和我看到的非常一致,注意作者说是高效地解决,我的理解是现在 Node.js 或者说 JavaScript 框架都是各做各的,都是些点,可能确实有做的很不错的,但是整体而言并没有一个把各种好东西串链起来做成一种通用模式的框架,或者说是架构。
这个问题主要有三方面原因:其一,现在大多前端工程师的工作范围还是局限于前端 UI 层,或者说视图层,后端一般都由更加成熟的一技术栈来实现;其二,Node.js 诞生于 2009 年,相比于 2002 就发第一版的 Spring 差的很远;其三,Node.js 实际上就是 JavaScript,这门语言本身也有很多缺陷,以至于无法胜任大型应用的架构场景。
虽然有这些问题但是我始终认为 Nest 是个很好的开端,或者说对于所谓的「全栈」工程师来讲是个好事。因为我认为在大型项目中构架层面的复用比代码层面的复用更重要。
安装 Nest 最方便的方法就是使用它额外提供的一个 CLI 工具(需要安装 Node.js > 8.9 版本),使用下面的命令它可以帮你自己生成项目的目录结构和预定义的最小模块:
npm i -g @nestjs/cli
nest new project-name
执行后命令行可以看见它自动生成的文件:
➜ github.com nest new project-name
⚡ We will scaffold your app in a few seconds..
CREATE /project-name/.prettierrc (51 bytes)
CREATE /project-name/README.md (3370 bytes)
CREATE /project-name/nest-cli.json (84 bytes)
CREATE /project-name/nodemon-debug.json (163 bytes)
CREATE /project-name/nodemon.json (67 bytes)
CREATE /project-name/package.json (1808 bytes)
CREATE /project-name/tsconfig.build.json (97 bytes)
CREATE /project-name/tsconfig.json (325 bytes)
CREATE /project-name/tslint.json (426 bytes)
CREATE /project-name/src/app.controller.spec.ts (617 bytes)
CREATE /project-name/src/app.controller.ts (274 bytes)
CREATE /project-name/src/app.module.ts (249 bytes)
CREATE /project-name/src/app.service.ts (142 bytes)
CREATE /project-name/src/util.ts (208 bytes)
CREATE /project-name/test/app.e2e-spec.ts (561 bytes)
CREATE /project-name/test/jest-e2e.json (183 bytes)
? Which package manager would you ❤️ to use? yarn
▹▸▹▹▹ Installation in progress... ☕
🚀 Successfully created project project-name
👉 Get started with the following commands:
$ cd project-name
$ yarn run start
这时可以按提示,进入到 project-name 运行项目。如果看到下面的输出就表示成功了:
➜ github.com cd project-name
➜ project-name git:(master) ✗ yarn run start
yarn run v1.10.1
$ ts-node -r tsconfig-paths/register src/util.ts
[Nest] 26470 - 2019/06/30 下午8:58 [NestFactory] Starting Nest application...
[Nest] 26470 - 2019/06/30 下午8:58 [InstanceLoader] AppModule dependencies initialized +11ms
[Nest] 26470 - 2019/06/30 下午8:58 [RoutesResolver] AppController {/}: +5ms
[Nest] 26470 - 2019/06/30 下午8:58 [RouterExplorer] Mapped {/, GET} route +3ms
[Nest] 26470 - 2019/06/30 下午8:58 [NestApplication] Nest application successfully started +3ms
然后我们访问 http://localhost:3000 就可以看到 Hello World! 了。用编辑器打开目录结构如下图所示
自动生成的配置文件还是挺多的,我们现在暂不用关注这些,只需要知道大概是做什么的就行了。
从上面的命令行中可以看出来整个项目是用 ts-node 跑起来的,这样的目的就是在开发环境节去了编译 .ts 的过程(实际上是 ts-node 在背后做了这个事情)。我们只需要关注 src/util.ts 这个入口文件即可。
整个 util.ts 文件就 8 行代码,使用 Nest 的工厂函数创建了一个应用实例,并且监听 3000 端口。注意,Nest 默认会使用 ES 的 async/await 语法,所以你再也不用怕嵌套回调函数了,以同步的编码方式获取异步的效率。
1970-01-01 08:00:00
相信复联4的热度也应该过了,今天我来聊天复联4的观影感受以及我对漫威系列电影的一些看法。
当然我并不是一名合格的漫威迷,对漫威系列电影的一些细节也不是很了解,更没看过漫画。我只想说说做为一名普通的观电影者的感受。
我看的第一部温威电影就是《钢铁侠》,记得还是在上大学的时候。那种感觉就像是小时候看的变形金刚变成真人了。人与机器居然能结合的那么天衣无缝,简直酷毙了。这全要归功于托尼这个角色的设计。
托尼·史塔克是一名企业家、天才发明家兼极度自恋的花花公子 — 单是这描述就能让大多数人惊叹不已了。但是他身上却有着更重要的一样东西,反复看过几遍钢铁侠后你会发现托尼身上有一种人类理性的闪光点。
回顾每次托尼面临困境时,他似乎总是能像计算机一样进行精确计算从而得出问题的最佳解决方法。即:
用最少的代价,获取最大的收益
所有的逻辑分支他都会考虑进去。为了达到最终目标,他可以忍气吞声,放下牵挂。而且他还有很强大的意志力,这种能力可能就来自于「with great power comes great responsibility」。因为他自视甚高,他相信自己是天才,自己是被选中的。
当然他也是普通人,有爱、有恨也有罪过。你很难想像这样一个有有血有肉的常人同时结合了机器的优点。有了飞行、攻击、防御这些特殊技能后,托尼就可以完全放飞自己,因为他想到的东西立马就可以做到,随着顶尖科学技术的进化与探究,时间/空间这些以前限制人类的东西都有可能都会被打破。
从托尼身上你能看到人类思想的一种无限状态,在不受物理限制情况下人类的思维创意能达到什么样的高度?
在钢铁侠系列影片中我最喜欢的一个片部分就是钢铁侠盘旋冲上天空的那个片段,这远比看着航天飞机升空的感觉更加震撼。

这仿佛就是冲破规则的束缚自由超越的一种象征


同时他也是个正常人类,有感情,有爱恨

复联3是继钢铁侠系列之后我最喜欢的一部漫威电影。实际上我在评价一部电影的时候并不会太在意之前几部的质量。
因为我认为衡量一部好电影的标准应该是:
给任何一个人看完之后都有所受益就是一部好电影。这个受益可能是娱乐八卦,可能是爱恨情仇,也可能是角色创意或者影片本身要表达的某种哲理思想
并且我认为最重要的一点就是影片要表达的某种思想或者哲理,因为这是最能引发人反思的东西。
毫无疑问,复联3中灭霸这个角色是有史以来众多反派角色中最出色的一个。灭霸被设计成了一个外在与内在都很强大的角色。
外形上灭霸有着比普通从大的多的尺寸用以艺术上的对比效果。他的手可以轻松抓住一个人的头部(开头抓雷神的头),小物件放在他手里有很强的视觉冲击:

这让我想起了《三国志》中对典韦的一段描写:「形貌魁梧,旅力过人,有志节任侠。一手执定旗杆,立于风中,巍然不动…」
同时灭霸的声音也非常有特色,沉稳,冷酷中透着死一般的坚定。虽然女性观众可能更喜欢雷神或者洛基的声音。
内在方面主要由感情和信念理想两条主线:
这一段是全剧中我最喜欢的一段,几乎没有任何瑕疵。这个不到5分钟的片段,好就好在无论你有没有看过前几部甚至是单看这一段,每个人都会理解到「中心思想」,当然这个中心思想因人而异。下面我就简单解析下我对这段剧情理解。
Red Skull(红骷髅)
What you seek lies front of you — 你想要的东西就在前面
as does what you fear — 就像你恐惧的一样

为什么说「你想要的东西就在前面,就像你恐惧的一样」,我的理解是当一个人想要一样东西的欲望到极致的时候,就会有一种矛盾恐惧 — 怕得不到,同时也怕得到。得不到意味着自己的所有努力和牺牲就白费了,同时越不容易得到的东西总会给人一种越容易丢失错觉。
美好的东西都在一瞬间,不容易得到的东西一旦拥有失去也会很快。当你经历过这个轮回才会发现没有什么东西是美好的,美好的背后可能是你看不见的丑陋的牺牲,没有这些丑陋的牺牲美好也失去了意义。这一切都在于你是否准备好了拿等价的牺牲去交换…
Gamora(卡魔拉)
What’s this — 这是什么
Red Skull(红骷髅)
The price — 代价
Soul holds a special place among the infinity stones, you might say it has a certain wisdom — 灵魂宝石在众多无限宝石中有特殊的地位,或者说有一种特殊的智慧
Thanos(灭霸)这里灭霸还没意识到代价是什么
Tall me what it needs — 告诉我它需要什么
Red Skull(红骷髅)
to ensure that whoever possesses it understands its power… 为了保证持拥有它的人明白它的威力
the stone demands a sacrifice — 宝石需要一样「牺牲」
Thanos(灭霸)
of what — 什么
Red Skull(红骷髅)
in order to take the stone, you must lose that which you love — 为了得到宝石,你必须牺牲一件你的至爱
a soul for a soul — 一个灵魂换一个灵魂
注意此时灭霸和卡魔拉的心理状态的不同:
灭霸陷入了沉思,他可能在思考什么才算得上是自己的至爱,他一生做的事情太多,但回想起来似乎连自己都找不到哪件事情能表现出他的爱

此时卡魔拉内心窃喜,因为在她看来灭霸没有半点人性,更谈不上爱

于是他说了下面这段现在看来很残忍的话:
Gamora(卡魔拉)
all my life, i dreamed of a day… a moment… — 我一生都梦想有一天,此刻…
when you got what you deserved. and i always so disappointed. — 每当你如尝所愿,我就对你恨之入骨
But now… — 但是现在…
you kill and torture… and you call it mercy. — 你暴虐滥杀无辜… 你自许仁慈.
The universe has judged you. — 现在老天终于要惩罚你.
You asked it for a prize, and it told you no. — 你想用一个条件换宝石,但是你不会特呈的.
You failed. — 而且你已经输了.
And do you wanna know why? — 想知道为什么吗?
Because you love nothing, no one — 因为你从来没有爱过,一次都没有

这段话字字珠玑,开始或许灭霸还没有意思到自己至爱到底是什么,但是没过多久他就开始意识到自己的至爱就是卡魔拉,此时眼角已经有泪痕。
此时剧情已到了关键的转折点,灭霸的背影则暗喻着一位父亲的高大形象

Thanos(灭霸)
No. — 不.
注意此刻的灭霸说 No 的语气,绝对不是想去否定些什么,而像是一种安慰。充满爱意的「No」,如果他是其它角色相信后面的台词都出自动出现在我们脑子里「No, my litter gril, i love you more than i can say…」

灭霸实际上是非常的孤独,所有他的想法都不被周围的人认可,虽然他强大的内心可以完全不在意外人的评判,但是他还做不到不在乎自己的女儿对他的评价。所以反射性的去否定卡魔拉,他非常坚定的相信自己是爱自己女儿的,同时也表露出了即将要失去女儿的真挚情感。
Gamora(卡魔拉)此时的卡魔拉还没有反应过来,她认为灭霸是因为自己的计划无法得逞而为自己流泪。
Really, tears? — 真的吗,你也会为自己流泪?
她还没有发现自己在恨父亲的同时实际上对灭霸也是有感情的,正所谓爱之深、恨之切…
Red Skull(红骷髅)
They’are not for him. — 他并不是为自己

还没来得及反应,红骷髅的话惊醒了她,同时她似乎也感受到了她与灭霸之间的那份父女之情(脸色表情也开始变化,赞演技),真正的爱恰恰是只能通过感觉而来,不用任何语言来表达的。
内心已经感觉到了自己与灭霸之间的亲情,这是无法否定的,此时她也陷入了无助

虽然是这样理智还是让她不肯相信这个事实,于是卡魔拉也开始否定。
No, this isn’t love — 不,这不是爱
Thanos(灭霸)很难想像灭霸在这一小段时间内,内心情绪有多么的复杂。他终其一生想要完成的事业却要让他失去至爱。他是一个无比理想化的存在,为了自己的理想可以放弃任何东西,而且他已经错过一次命运,所以这次他选择了完成自己的宿命。
I ignored my destiny once, i can't do that again, Even for you — 我已经错过一次命运了,不能再错一次,即使以失去你为代价

此时灭霸的脸上完成没有了恶霸的冷酷表情,而是一种对于将要失去至爱的无助与失落…

接着他亲手将自己的女儿仍下悬崖,但此刻灭霸的表情似乎呆住了,可能他自己也不能相信他自己的所做所为


一个从不说谎的人只有一种可能,就是及其的理想主义,在他们的认知里面只有真理、对错以及自己的信念。从灭霸和卡魔拉的对话就能看出。
You are strong — me
You're generous — me
But i never taought you to lie
当然外在的的强大只是陪衬,他身上最能感染人的是那种不惜一切代价追求自己理想的一种信仰
从这个层面来讲,钢铁侠和灭霸的信仰是平等的。在这个层面他们之间没有矛盾,没有正义/邪恶 之分。理由很简单:你认为拯救更多的人类是你的正确信仰,那我认为通过随机消灭一半生命可以让宇宙达到一种平衡也是我的正确信仰。
托尼和灭霸想要维护的东西不在一个层面上,所以无法判断对方是否正确。我觉得复联3留给观众的一个最大的问题就是
托尼拯救地球的理想是理想,那灭霸要维护宇宙的平衡的理想算不算是理想?
人类看待这个问题会受限于自身的环境,理性上受制于时间空间,感性上受制于感情。所以在这个问题上多数人连判断的资格都没有
第3部在我看来是这一个巨大的切入点,并期待第4部能有所解释
仅过了一年,我带着期待去看了复联4,但并没有达到我的预期。因为大家都了把复联当成了一部电视剧在看。电影本身也几乎没有了电影的元素,除了各种超级英雄的梗外我实在没看出来有什么亮点。
这可能也符合了事物发展的规律,当有太多人喜欢一样东西、追求一样东西的时候事情就变味儿了,毕竟电影公司做为商业机构是要维护自己的品牌,要照顾多数人的情感。就好比电视剧演久了观众就会有了心理预期,很难创新一样。
但是复联4做为 MCU 电影的标致性阶段,也算是一个好的结尾,毕竟要照顾到多数的人喜好,同时要融合各种英雄人物的离场,还要演的不那么生硬确实太难了。
总的来说,复联3杂而不乱,主线支线明显,影片整体有层次感,剧情紧凑连续演员的演技也非常棒。复联4则是让所有普通的每一个人(类)都享受到了一种胜利的喜悦。
1970-01-01 08:00:00
我经常会使用 markdown 来写一些东西。比如:博客文章、技术文档什么的。但是时间长了总是会觉得编辑 Markdown 源码的写作方式太容易让人分心了。
Markdown 确实是一个非常好的通用排版格式,因为它很简单,学习使用起来没有门槛。但是随着人们越来越多的使用 Markdown 创作,Markdown 本身的一些问题也显露出来。比如:当你需要一些高级排版格式的时候 Markdown 是无能为力的,更不用说表格编辑这类重排版的工作在 Markdown 中的编辑体验了。
当然开源社区会有一些开源项目来扩展 Markdown 的功能,甚至是用 Markdown 来画流程图。这且没有什么问题,问题是当你使用了一些扩展的高级功能时又想把他扩展到其它系统(比如博客),这时你又不得不改造博客来适配这些功能,Markdown 也就丧失了它的便携性。所以说使用 Markdown 的关键问题在于:
如何能更简单方便的使用 Markdown,同时又不失一些好用的功能
编辑排版最佳的体验毫无疑问是「所见即所得」的模式。因为人们总是喜欢改完东西立即看见效果。目前常用的 Markdown 编辑器通常分左右两列:++源码++ | ++预览++。实际上我认为这种模式并不好,甚至是错的。因为整个编辑过程会非常痛苦,你不得不既关注源码里面的格式,如:空格、Markdown 符号,还得关注预览出来的效果是不是满意然后再调整。
相比之下 Typora 给出了稍好一些的体验方案 — 富文本的编辑模式 + Markdown 源码格式。这应该也是目前 Markdown 最好的编辑方式了,但是在我看来还是不够好。
我自己在书写 Markdown 文件的时候会格外注意格式排版,比如:标点符号,中英文空格,分行留白等,Typora 的编辑模式并不能让我免于这样的困扰(本质就在于 Typora还是要让用户自己去编辑源码),我还是不得不关注 Markdown 的那些符号,这些符号就像听音乐时的耳机里面的「杂音」一样。当你专注于写作,一口气写下上千字的时候,很容易就会被这种杂音打断,灵感转瞬即逝…
这个问题我认为不应该给 Markdown 扩展功能,因为扩展 Markdown 只能通过添加更多符号的形式实现。而这会增加它的复杂度,不同平台都要适配才行,最终让 Markdown 格式变的不可交换。
各种编辑方式按功能强大的排序应该是:Makrdown < 富文本 < Word。复杂的功能应该由后面两种工具来胜任,Markdown 应该做为一种格式上的约定。重功能不需要它来实现,比如编辑表格的体验在 Markdown 里简直就是灾难,但是在富文本或者 Word 中却异常简单。这就像是 Markdown 应该做为++接口++来定义一些规范,而不应该让它去关心具体++实现++。
既然如此那有没有更好的解决方案呢(广告预警)。我正在开发一款基于网页的 WYSIWYG[1] 富文本编辑器应用,并试着解决上面的这些问题,解决 Markdown 问题的同时又能获得富文本编辑的优质体验,主要面向有写作和编辑文章/笔记需求的用户。如果你也刚好有这个需求,不妨试试:
wtdf.io — 基于网页的所见即所得 Markdown 写作应用
What You See Is What You Get — 中译「所见所得」 ↩︎
1970-01-01 08:00:00
前几天无意在微博上看见了《流浪汉沈巍自述》一文,此文来自一个上海的流浪汉语录。
不同的是他并不是为了生计而流浪捡破烂,沈巍从小喜欢捡破烂,捡完破烂换了钱买书看。家庭环境不理解更不支持,到了社会上,他本来可以按大多数人眼中的 正常 人一样工作,一辈子当公务员。
但是他还是改不了自己捡破烂的习惯,这样以来单位也容不下他。想法完全不与主流融合,只能被流浪。可以即便是这样,在看它的文字里,你仍然能感受到字里行间都散发着对生活的无限向往,对信念的追求,以及对残酷现实的一丝温柔。
有人说故事分两种:一种开始就讲给你最美好的东西,最完美无缺的事物,人性最善良的部分。后来慢慢的什么都变了,以前那些看似美好的东西都有了瑕疵,人性也没能经得住时间的考验,所有的认识都支离破碎;还有一种一开始就告诉你最丑恶的东西,最让人恶心、难受的事物,人性最黑暗的一面。后来慢慢的也似乎变了,不经意的发现好像还有那么一丝光明的东西,一点点能让人感动的事情。
前一种更像是从教科书到现实的一种过程,可能很多人慢慢的都受不了这种落差,逐渐没有了精神支柱,厌恶了生活。后一种则看似悲观、反面,实则能激发出人们本能善良的一面。
这让我想起了一句话:
人不是活一辈子,不是活几年几月几天,而是活那么几个瞬间。
对于沈巍来说,社会和家庭给他的都是排斥、否认和异样的眼光。但是可能他就只能从书中找到了那么一丝光明,一些让自己感动的瞬间吧。
我们可以反思下我们的现实生活。现实中我们总是说「自己没有选择,我不得不这样、没有退路…」。但事实上真的是这样吗?或许正是因为我们拥有的太多才让自己没法选择。
人是很奇怪的,当你某天没有加班,工作完成后早早回家后突然发现居然还有很多时间可以安排。这时候你会想做很多事情:玩手机、睡觉、好好做顿饭、看部电影…
但当你真正的面临很多种选择时,自己会去权衡。可能自己精神上很需要放松一下,需要娱乐一下。但是理智又告诉你应该做一些「有意义」的事情。最终可能一件事都没做好。
这时候其实你需要用 肉体操纵精神,不要想,先去做。因为实际上当你持续专注的做一件事情的时候,精神上会特别放松,你不需要再考虑那么多的选择,只需要 像机器 一样去做好一件事情。
人总是可以通过做事情来让自己的 内心变的安稳。我曾经无意中听到两人女生聊天,其中一个女生说
我特别喜欢洗衣服,因为当我特别专注的把衣服洗干净的时候,那种感觉特别安静,虽然需要你耗费一些体力,但是洗完后你的内心会有一种解脱,一种如释重负的感觉…
我听到这段聊天的时候是特别惊讶的,原话特别有感染力。后来我发现了这种感觉就像是我平常写代码一样,一写起代码,就很专注,似乎能忘记时间。当你解决了一个问题,完成了一个功能模块的时候长呼一口吸、伸个懒腰,瞬间感觉特别满足。即使回到现实中你还得面临很多复杂的事情,但在这一时刻你是自由的。
后来我也理解了那句 Nick 经典广告语「Just do it」的深刻涵义,当然这和我选择做 IT 行业是两码事。
图:https://www.pexels.com/photo/abstract-bright-color-dark-397998/
1970-01-01 08:00:00
原文: PART 1・ PART 2・ PART 3・ PART 4
关注 @chriscaleb
这个系列的教程已经更新到了 PixiJS v4 版本。
欢迎再次来到这个系列教程的第三部分,这一节将会涉及到如何使用 pixi.js 制作视差滚动游戏的地图。整个教程到目前为止已经涵盖了很多内容。在第一个教程中,我们学习了一些 pixi.js 基础知识,并将视差滚动应用于几个层上。在第二部分,通过代码重构将一些面向对象的概念应用到实践中。这一节我们将把重点放在第三个更复杂的视差层上,它将代表玩家角色在游戏时将会穿越的地图。
我们将继续从上一个教程结束的地方开始。你可以使用前两个教程编写的代码,也可以从 GitHub 下载第二个教程的源代码。也可以在 GitHub上 找到第三节完整教程的 源代码,即使你遇到了问题,我也鼓励你完成本教程,有疑问可以请仅参考源代码。
这个系列的教程非常受到 Canabalt 和 Monster Dash 游戏的启发,当玩家的英雄在平台之间奔跑和跳跃时,这些游戏都能很好地利用视差滚动来提供花哨的视觉效果。
在接下来的两节教程中,我们将构建一个非常类似于 Monster Dash 中的滚动游戏地图。 Monster Dash 的游戏地图是由一系列不同宽度和高度的砖块儿构建而成。游戏的目的是通过在砖块儿之间跳跃来尽可能长地生存。游戏地图的滚动速度随着时间的推移而增加。

上面就是你这一节将要完成的示例。单击图片即可查看包含砖块儿和间隙的滚动地图。
如果你还没有看过第一节和第一节教程,我建议你应该先看完这两节。
在本节教程中,我们将使用一些新的图片素材。可以直接从 这里 下载,并将其内容解压缩到项目的 resource 文件夹中。
下面就是你的 resource 文件夹的样子(Windows):
macOS 下则是这样:
此外,如果你还没有建立一个本地的 web 服务器,请参考第一节的内容。
值得注意的是,本教程比前两篇长。你可能需要大约两个小时才能完成所有工作。
正如上面的演示中展示的那样,我们的游戏地图有很多种展示形式。如砖块儿的宽度和高度各不相同。每个跨度还包括一系列窗户和墙壁装饰元素。墙壁装饰本身由管道和通风口组成。
那么墙跨度是如何构建的?每个跨度都是由一系列拼接在一起的垂直切片构成的。每个切片的大小为 64 x 256 像素。下图显示了示例砖块儿。

通过垂直移动每个切片的位置来处理砖块儿的高度。下面的示意图中我们可以看到,第二个面墙的切片部分位于视口的可见区域下方(译者:超出视口),使其看起来低于第一面墙。
大多数情况,一而墙内的每个切片将会是水平对齐的。但有一个例外。 Monster Dash 有一个阶梯式的跨度,让玩家可以直接跌落到下一个水平线上。以下是它的构造方式:
如果你仔细观察上面的示意图,你应该注意到这里真正的是墙面有两个(第一个跨度高于第二个),它们通过中间的一个切片(台阶)连接起来。
你可能会惊讶地发现我们的整个游戏地图只由八种不同类型的垂直切片构成:
这些切片的顺序很重要。我们再来谈谈这个问题。
一面砖块墙包括三个主要部分:
前/后边缘都只由一个垂直切片表示。然而,中间部分可以由一个或多个切片制成。切片越多,墙跨度就越长。我们将制作一面有 30 个切片的砖块墙。下图可以解释砖块墙的三大部分。
墙的中间部分只有下面两种切片:
因此整个墙的中间部分长度为 6,结构如下:
window, decoration, window, decoration, window, decoration
然而,通常情况下,砖块墙的中间部分是非偶数个切片才能保证出现的容器即有亮灯的也有灭的。所以我们使用 7 个切片来制作中间部分
window, decoration, window, decoration, window, decoration, window
为了保证砖块墙尽可能看起来有趣,窗户可以点亮或不点亮,我们可以随机选择三种装饰切片。因此,墙的中间部分将由五种不同类型的切片构成。
为了增加更多的切片种类,我们从砖块墙的边缘素材中(两个)选择两个切片做为前后边缘(译者:边缘素材有两个,可以随机选一个做前边缘,然后翻转它做成后边缘,但是不能一个做前一个做后,示意图中的 front & back 和图片没有对应关系),后边缘也可以使用同样的前边缘,因为我们只需要把它(前边缘)水平翻转然后正确地拼接到后边缘即可。台阶切片很少会出现,所以我们只需要用一个切片。
打开上面的素材,单独放在一个浏览器 tab 里面,可以方便制作时查看它。
不要将切片 类型 与用于构建指定砖块墙的切片数混淆。例如,一面砖块墙可以有 30 个垂直切片,但实际上只由 8 类切片构建。
现在你已经了解了砖块墙是如何构建的,我们可以开始实现它了。
如上所述,我们的砖块墙由八种不同类型的砖块构成。表示这些切片的最简单方法是为每个切片提供单独的 PNG文件。虽然这是一种办法,但我们实际上会将所有切片添加到一个称为 精灵表 的大型 PNG 文件中。
精灵表通常也称为 纹理图集(texture atlas) 。我们将在本教程中使用 精灵表 这个术语。
我在本教程的 resources.zip 文件中提供了精灵表。这是一个名为 wall.png 的文件,如下所示。所有八个切片都已打包到一个位图上。

资源文件夹中还有一个与精灵表对应的 wall.json 文件。可以直接用文本编辑器打开。此文件使用 JSON 数据格式来定义精灵表中单独位图切片的名称和位置。使用精灵表时,表中的每个单独的位图称为 帧。
我们的整个精灵表将作为纹理加载到代码中(中间层和远景图层也这么加载过)。因此,有时会将框架视为子纹理。
并不需要完全理解 JSON 文件,因为 Pixi 将处理它。但是,我们可以探索一下正在使用的这个文件。下面这段是来自 JSON 数据中的一段,表示第一个墙边切片的框架。我已经为高亮了一些代码行:
"edge_01": // 高亮
{
"frame": {"x":128,"y":0,"w":64,"h":256},// 高亮
"rotated": false,
"trimmed": false,
"spriteSourceSize": {"x":0,"y":0,"w":64,"h":256},
"sourceSize": {"w":64,"h":256}
},
第一行包含与框架关联的 唯一名称(edge_01):
"edge_01":
每当我们想要从精灵表中直接获取这个墙切片的图像时,我们将使用此名称。
如果你不熟悉 JSON 数据格式,则可以在此 Wikipedia 条目 中找到更多信息。
下一个高亮行代码定义了框架的矩形区域:
"frame": {"x":128,"y":0,"w":64,"h":256},
本质上,它用于在精灵表中定位帧的位图。
JSON 文件中还有其他七种类型的切片。每个切片将由唯一的帧名称表示。使用精灵表时,你只需要知道 唯一名称 即可。下面我还提供了一张标有每个切片类型的图片。也可以单独打开这个图片,方便回顾。
wall.json 的后面,有一些元数据:
"meta": {
"app": "http://www.codeandweb.com/texturepacker ",
"version": "1.0",
"image": "wall.png",
"format": "RGBA8888",
"size": {"w":256,"h":512},
"scale": "1",
"smartupdate": "$TexturePacker:SmartUpdate:fc102f6475bdd4d372c..."
}
在该数据表示精灵表的实际文件的相对路径。 Pixi 将使用该数据加载正确的 PNG 文件。
我使用了一个工具来生成本教程的精灵表和 JSON 文件。它的名字叫 TexturePacker,可用于Windows,Mac OS X 和 Linux。它可以导出许多精灵表格式,包括 pixi.js 使用的JSON(哈希)格式。我不会在本教程中介绍如何使用 TexturePacker,但它非常容易掌握。付费版本也物超所值,还有一个免费版本,适合那些想先学习基础知识的人。
既然我们对精灵表有一点了解了,就让我们继续把它加载进程序。我们首先将一些代码添加到项目的 Main 类中。用文本编辑器中打开 Main.js。
在文件的末尾,添加以下方法来加载精灵表:
Main.prototype.loadSpriteSheet = function() {
var loader = PIXI.loader;
loader.add("wall", "resources/wall.json");
loader.once("complete", this.spriteSheetLoaded.bind(this));
loader.load();
};
我们使用了 PIXI.loaders.Loader 类,它可用于加载图像,精灵表和位图字体文件。我们直接从 PIXI.loader 属性获取加载器的预定义的实例来使用加载器,所有资源都可以人这里加载。所以,只需把 wall.json 文件也添加进去。我们传递一个与文件关联的唯一 ID 作为第一个参数,并将资源的实际相对路径作为第二个参数传递。
加载精灵表后,PIXI.loaders.Loader 类会触发一个 complete 事件。为了响应该事件,我们只需要绑定 complete 方法到自定义函数 spriteSheetLoaded() 中,这个函数我们稍后实现。
最后,调用我们的 PIXI.loaders.Loader 实例的 load() 方法来真正加载我们的精灵表。加载完后,Pixi 将提取所有帧并将其存储在内部的纹理缓存中以便后续使用。
目前,远景层和中间层图像在其构造函数中加载。但是,我们实际上可以预先加载这些图像,并避免在实例化远景层和中间类时出现短暂的延迟。将它们添加到我们的 Loader 实例中:
loader.add("wall", "resources/wall.json");
loader.add("bg-mid", "resources/bg-mid.png"); // 添加
loader.add("bg-far", "resources/bg-far.png"); // 添加
无需对 Far 或 Mid 类进行任何更改,因为在尝试从文件系统加载纹理之前,对
PIXI.Texture.fromImage()的调用将优先查询内部纹理缓存。
现在让我们编写 spriteSheetLoaded() 方法。在文件末尾添加以下内容:
Main.prototype.spriteSheetLoaded = function() {
};
我们需要编写这个空方法。之前我们创建了一个 Scroller 类的实例,并在 Main 类的构造函数中启动了我们的主循环。但是,我们现在要等到精灵表加载完成后再进行所有操作。让我们将该代码移动到我们的 spriteSheetLoaded() 方法中。
向上滚动到构造函数并删除以下两行:
function Main() {
this.stage = new PIXI.Container();
this.renderer = PIXI.autoDetectRenderer(
512,
384,
{view:document.getElementById("game-canvas")}
);
this.scroller = new Scroller(this.stage); // 删除
requestAnimationFrame(this.update.bind(this)); // 删除
}
再回到你的 spriteSheetLoaded() 方法并在那里添加删除的两行:
Main.prototype.spriteSheetLoaded = function() {
this.scroller = new Scroller(this.stage);
requestAnimationFrame(this.update.bind(this));
};
最后,返回构造函数并调用 loadSpriteSheet() 方法:
function Main() {
this.stage = new PIXI.Container();
this.renderer = PIXI.autoDetectRenderer(
512,
384,
{view:document.getElementById("game-canvas")}
);
this.loadSpriteSheet(); // 添加
}
现在保存代码并刷新浏览器。在 Chrome 的 JavaScript 控制台中查看没有错误。
虽然我们已经成功加载了精灵表,但我们并不知道帧(我们的八个垂直壁切片类型)是否已真正地存储在 Pixi 的纹理缓存中。所以让我们继续创建一些使用其中一些精灵来使用这使用帧。
我们将在 spriteSheetLoaded() 方法中执行我们的测试。将以下代码添加到其中:
Main.prototype.spriteSheetLoaded = function() {
this.scroller = new Scroller(this.stage);
requestAnimationFrame(this.update.bind(this));
var slice1 = PIXI.Sprite.fromFrame("edge_01"); // 高亮
slice1.position.x = 32; // 高亮
slice1.position.y = 64; // 高亮
this.stage.addChild(slice1); // 高亮
};
在上面的代码中,我们利用了 PIXI.Sprite 类的 fromFrame() 静态方法。它使用纹理缓存中与指定帧 ID 匹配的纹理创建一个新的精灵。我们指定 edge_01 帧用来表示砖块墙前边缘的切片。
保存代码并刷新浏览器以查看切片。不用担心它展示的位置,位置现在还不重要。
让我们添加第二个垂直切片。这次我们将使用砖块墙中间的切片类型。为了更精确,我们将使用精灵表中名为decoration_03 的帧:
Main.prototype.spriteSheetLoaded = function() {
this.scroller = new Scroller(this.stage);
requestAnimationFrame(this.update.bind(this));
var slice1 = PIXI.Sprite.fromFrame("edge_01");
slice1.position.x = 32;
slice1.position.y = 64;
this.stage.addChild(slice1);
var slice2 = PIXI.Sprite.fromFrame("decoration_03"); // 添加
slice2.position.x = 128; // 添加
slice2.position.y = 64; // 添加
this.stage.addChild(slice2); // 添加
};
再次保存并测试。现在应该看到两个垂直墙切片位于舞台上,类似于下面的这个屏幕截图。

希望你现在对精灵表的框架已成功加载并缓存产生了一些成就感。从 spriteSheetLoaded() 方法中删除测试代码。方法应再次如下所示:
Main.prototype.spriteSheetLoaded = function() {
this.scroller = new Scroller(this.stage);
requestAnimationFrame(this.update.bind(this));
};
保存你的修改
我还没有解释为什么我们选择将切片打包成一个精灵表而不是单独加载八个 PNG 到内存中。原因和性能相关。 Pixi 的 WebGL 渲染器利用计算机的图形处理单元(GPU)来加速图形性能。但是为了保证最佳性能,我们必须至少了解一点 GPU 的工作原理。
GPU 更擅长一次处理大数据量的场景。 Pixi 会迎合 GPU 的这个特点,把数据对象批量发送给 GPU。但是,它只能批量处理具有相似状态的展示对象。当遇到具有不同状态的显示对象时,表示已经发生状态改变并且 GPU 会停止以绘制当前批次。程序中发生的状态更改越少,GPU 需要执行的绘制操作就越少,以便呈现展示列表。 GPU 执行的绘制操作越少,渲染性能就越快。
刚刚提到的 绘制(draw) 操作和我们平常绘画意思差不多。
不幸的是,每当遇到具有不同纹理的展示对象时,状态就会发生改变。精灵表可以帮助避免状态更改,因为所有图像都存储在单个纹理中。 GPU 可以非常愉快地从精灵表中绘制每个帧(或子纹理),而无需单独的调用绘制。
但是,可以存储在 GPU 上的纹理存在大小限制。大多数现代 GPU 可以存储大小为 2048×2048 像素的纹理。因此,如果你要使用精灵表,请确保其尺寸不超过 GPU 纹理的限制。值得庆幸的是,我们的精灵表很小。
因此,与将每个墙切片的图像存储在单独的纹理上相比,我们的精灵表可以帮助显着提高滚动器的性能。
所以我们已经成功加载了精灵表并且还设法显示了一些帧,但是我们如何真正地构建一个包含砖块墙的大地图?
我想最简单的方法是创建一个精灵数组,其中每个精灵代表我们地图中的垂直墙切片。然而,考虑到每个切片的宽度比较短,我们的整个地图将很容易由数千个精灵组成。这是很多精灵都将存储在内存中。另外,如果我们只是将所有这些精灵转储到我们的展示列表上,那么它会给渲染器带来很大的压力,可能会影响游戏的帧速率。
另一种方法是实例化并仅显示将在视口中可见的精灵。当地图滚动时,最左边的精灵最终将离开屏幕。当发生这种情况时,我们可以从显示列表中删除该精灵,并在视口最右边的外部添加一个新的精灵。通过这种方法,我们可以向用户提供滚动整个地图的错觉,而实际上只需要处理视口中当前可见的地图部分。
虽然第二种方法肯定比第一种方法更好,但它需要为我们的精灵进行不断的内存分配和释放:为进入的每个新精灵分配内存,为离开的精灵释放内存。为什么这么做比较糟糕呢?因为分配内存需要宝贵的 CPU 周期,这可能会影响游戏的性能。如果你必须不断地分配内存,那将避免不了这个问题。
释放之前对象使用的内存也是潜在的 CPU 性能损耗。 JavaScript 运行时利用垃圾收集器释放以前被不再需要的对象使用的内存。但是,你无法直接控制何时进行垃圾收集,假如需要释放大量内存,该过程可能需要几毫秒。因此,不断实例化精灵再从展示列表中删除精灵将导致频繁的垃圾收集,这会影响游戏的性能。
第三种方法可以避免前两种问题。它被称为 对象池,它能在不触发 JavaScript 的垃圾收集器的情况下更加智能地使用内存。
想理解对象池,请考虑一个简单的游戏场景。在射击游戏中,玩家的船可能会在游戏过程中发射数十万枚射弹,但由于船的射速,任何时候都只能有 20 枚射弹进入屏幕。因此,仅在游戏代码中创建 20 个射弹实例并在游戏过程中重新使用这些射弹是更好的。
20 个射弹可以存放在一个阵列中。每次玩家开火时,我们从阵列中移除一个射弹并将其添加到屏幕上。当射弹离开屏幕(或击中敌人)时,我们将其添加回阵列以便稍后再次使用。重要的是我们永远不需要创建新的射弹实例。相反,我们只使用预先创建的 20 个实例池。在我们的示例中,数组将是我们的对象池。这样合理吗?
如果你想了解有关对象池的更多信息,请查看此 Wikipedia条目。
我们可以将对象池应用到游戏地图中,并具有以下内容:一个窗口(window)切片池;一幢墙面装饰(decoration)切片;一层前边缘;一层后边缘;还有一个台阶。
因此,虽然我们的游戏地图最终可能包含数百个窗口,但实际上我们只需要创建足够的窗口精灵来覆盖视口的宽度。当一个窗口即将在我们的视口中显示时,我们只需从 windows 对象池中检索一个窗口精灵。当该窗口滚出视图时,我们将其从显示列表中删除并将其返回到对象池。我们将这个原则应用于边缘,装饰和台阶。
知道这就足够了。让我们开始构建一个对象池类来保存我们的切片精灵。
由于我们的游戏地图代表了一系列砖块墙,我们将创建一个名为 WallSpritesPool 的类,作为我们各种墙壁部件的池子。
更通用的类名可能是
MapSpritesPool,也可以是ObjectPool。但是,就本教程而言,WallSpritesPool是比较合适的。
在文本编辑器中创建一个新文件并添加以下构造函数:
function WallSpritesPool() {
this.windows = [];
}
保存文件并将其命名为 WallSpritesPool.js。
在构造函数中,我们定义了一个名为 windows 的空数组。此数组将充当我们地图中所有的窗口精灵的对象池。
我们的数组需要预先填充一些窗口精灵。请记住,我们的砖块墙可以支持两种类型的窗户 — 一个开灯的窗户和一个没有开灯的窗户 - 所以我们需要确保我们添加两种类型足够多。通过将以下代码添加到构造函数来填充数组:
function WallSpritesPool() {
this.windows = [];
this.windows.push(PIXI.Sprite.fromFrame("window_01"));
this.windows.push(PIXI.Sprite.fromFrame("window_01"));
this.windows.push(PIXI.Sprite.fromFrame("window_01"));
this.windows.push(PIXI.Sprite.fromFrame("window_01"));
this.windows.push(PIXI.Sprite.fromFrame("window_01"));
this.windows.push(PIXI.Sprite.fromFrame("window_01"));
this.windows.push(PIXI.Sprite.fromFrame("window_02"));
this.windows.push(PIXI.Sprite.fromFrame("window_02"));
this.windows.push(PIXI.Sprite.fromFrame("window_02"));
this.windows.push(PIXI.Sprite.fromFrame("window_02"));
this.windows.push(PIXI.Sprite.fromFrame("window_02"));
this.windows.push(PIXI.Sprite.fromFrame("window_02"));
}
上面的代码为对象池添加了 12 个窗口精灵。前 6 个精灵代表我们亮灯的窗口(window_01),而余他 6 个精灵代表未亮灯的窗口(window_02)。
从对象池中检索精灵时,它们将从数组的前面获取。根据我们在填充时将精灵添加到数组中的顺序,对窗口精灵的前 6 个请求将始终返回一个亮灯的窗口,而接下来的 6 个请求将始终返回一个未亮灯的窗口。我们从池中获得的窗口切片类型需要 随机 出现。这可以通过在填充数组后数组元素进行打乱来实现。
以下方法将把传递给它的数组打乱。添加方法:
WallSpritesPool.prototype.shuffle = function(array) {
var len = array.length;
var shuffles = len * 3;
for (var i = 0; i < shuffles; i++)
{
var wallSlice = array.pop();
var pos = Math.floor(Math.random() * (len-1));
array.splice(pos, 0, wallSlice);
}
};
现在从构造函数调用 shuffle() 方法:
function WallSpritesPool() {
this.windows = [];
this.windows.push(PIXI.Sprite.fromFrame("window_01"));
this.windows.push(PIXI.Sprite.fromFrame("window_01"));
this.windows.push(PIXI.Sprite.fromFrame("window_01"));
this.windows.push(PIXI.Sprite.fromFrame("window_01"));
this.windows.push(PIXI.Sprite.fromFrame("window_01"));
this.windows.push(PIXI.Sprite.fromFrame("window_01"));
this.windows.push(PIXI.Sprite.fromFrame("window_02"));
this.windows.push(PIXI.Sprite.fromFrame("window_02"));
this.windows.push(PIXI.Sprite.fromFrame("window_02"));
this.windows.push(PIXI.Sprite.fromFrame("window_02"));
this.windows.push(PIXI.Sprite.fromFrame("window_02"));
this.windows.push(PIXI.Sprite.fromFrame("window_02"));
this.shuffle(this.windows); // 调用
}
现在让我们做一些重构,因为有一个更简洁的方法来填充我们的数组。由于我们实际上是在数组中添加两组精灵(亮灯和不亮灯的窗口),我们可以替换以下代码行:
function WallSpritesPool() {
this.windows = [];
this.windows.push(PIXI.Sprite.fromFrame("window_01")); // 删除
this.windows.push(PIXI.Sprite.fromFrame("window_01")); // 删除
this.windows.push(PIXI.Sprite.fromFrame("window_01")); // 删除
this.windows.push(PIXI.Sprite.fromFrame("window_01")); // 删除
this.windows.push(PIXI.Sprite.fromFrame("window_01")); // 删除
this.windows.push(PIXI.Sprite.fromFrame("window_01")); // 删除
this.windows.push(PIXI.Sprite.fromFrame("window_02")); // 删除
this.windows.push(PIXI.Sprite.fromFrame("window_02")); // 删除
this.windows.push(PIXI.Sprite.fromFrame("window_02")); // 删除
this.windows.push(PIXI.Sprite.fromFrame("window_02")); // 删除
this.windows.push(PIXI.Sprite.fromFrame("window_02")); // 删除
this.windows.push(PIXI.Sprite.fromFrame("window_02")); // 删除
this.shuffle(this.windows);
}
用下面的代替:
function WallSpritesPool() {
this.windows = [];
this.addWindowSprites(6, "window_01"); // 添加
this.addWindowSprites(6, "window_02"); // 添加
this.shuffle(this.windows);
}
// 添加
WallSpritesPool.prototype.addWindowSprites = function(amount, frameId) {
for (var i = 0; i < amount; i++)
{
var sprite = PIXI.Sprite.fromFrame(frameId);
this.windows.push(sprite);
}
};
WallSpritesPool.prototype.shuffle = function(array) {
var len = array.length;
var shuffles = len * 3;
for (var i = 0; i < shuffles; i++)
{
var wallSlice = array.pop();
var pos = Math.floor(Math.random() * (len-1));
array.splice(pos, 0, wallSlice);
}
};
保存更改。
addWindowSprites() 方法允许我们向 windows 数组中添加一些在精灵表中指定的精灵帧。因此,它可以很容易地为我们的池子添加一组 6 个亮灯精灵和一组 6 个未亮灯精灵。
在继续之前,我们应该再做一次重构。将构造函数中的代码移动到单独的方法中。删除以下行:
function WallSpritesPool() {
this.windows = []; // 删除
this.addWindowSprites(6, "window_01"); // 删除
this.addWindowSprites(6, "window_02"); // 删除
this.shuffle(this.windows); // 删除
}
使用一个新方法替换:
WallSpritesPool.prototype.createWindows = function() {
this.windows = [];
this.addWindowSprites(6, "window_01");
this.addWindowSprites(6, "window_02");
this.shuffle(this.windows);
};
最后,从构造函数中调用 createWindows() 方法:
function WallSpritesPool() {
this.createWindows();
}
好的,我们目前用代码创建了窗口精灵,将它们添加到一个数组,并打乱该数组。继续之前保存文件。
从技术上讲,我们可以在池中使用少于 12 个窗口精灵。毕竟,我们只需要足够的精灵来覆盖视口的宽度。我选择十二个的原因是为了让砖块墙的亮灯和不亮灯窗户具有一些随机性。然而值得注意的是,我可以在合理范围内使用任意数量的精灵,只要它为我提供足够的窗口精灵以在视口内生成砖块墙。
我们的对象池有一组窗口精灵,但是我们还没有提供从池中获取精灵或返回池的公共方法。
所有方法和属性都可以在 JavaScript 中公开访问。这可能使你难以识别属于你的类 API 的方法和属性以及处理实现细节的方法和属性。当我把某些东西称为“公开”时,我的意思是说我打算在类的外部使用它。
我们将提供以下两种方法:
borrowWindow()returnWindow()borrowWindow() 方法将从 windows 池中删除一个窗口精灵,并返回对它的引用供你使用。完成后,可以通过调用 returnWindow() 将精灵作为参数传递回游戏池。
好的,我们在类的构造函数之后添加 borrowWindow() 方法:
function WallSpritesPool() {
this.createWindows();
}
// 添加
WallSpritesPool.prototype.borrowWindow = function() {
return this.windows.shift();
};
正如你所看到的,这是一个相当简单的方法,它只是从 windows 数组的前面删除第一个精灵并返回它。
borrowWindow()方法不会检查池中是否还有精灵。我们在这一系列教程中都不会太在意这种异常情况,但在尝试从中返回内容之前,检查一下精灵池是否为空是一个好习惯。有多种策略可用于处理空池子。一个常见的方法是在干燥(没有元素)时动态增加池的大小。
现在直接在其下面添加 returnWindow() 方法:
WallSpritesPool.prototype.borrowWindow = function() {
return this.windows.shift();
};
// 添加
WallSpritesPool.prototype.returnWindow = function(sprite) {
this.windows.push(sprite);
};
就像 borrowWindow() 一样,returnWindow() 方法很简单。它将精灵作为参数并将该精灵压入到 windows 数组的末尾。
我们现在有一种从对象池中借用窗口精灵的方法,一旦我们完成它就将精灵返回给(归还)对象池的方法。
保存更改。
查看一下 WallSpritesPool 类。并没有很多代码,但重要的是你要了解在添加之前发生了什么。以下是类的当前版本:
function WallSpritesPool() {
this.createWindows();
}
WallSpritesPool.prototype.borrowWindow = function() {
return this.windows.shift();
};
WallSpritesPool.prototype.returnWindow = function(sprite) {
this.windows.push(sprite);
};
WallSpritesPool.prototype.createWindows = function() {
this.windows = [];
this.addWindowSprites(6, "window_01");
this.addWindowSprites(6, "window_02");
this.shuffle(this.windows);
};
WallSpritesPool.prototype.addWindowSprites = function(amount, frameId) {
for (var i = 0; i < amount; i++)
{
var sprite = PIXI.Sprite.fromFrame(frameId);
this.windows.push(sprite);
}
};
WallSpritesPool.prototype.shuffle = function(array) {
var len = array.length;
var shuffles = len * 3;
for (var i = 0; i < shuffles; i++)
{
var wallSlice = array.pop();
var pos = Math.floor(Math.random() * (len-1));
array.splice(pos, 0, wallSlice);
}
};
该类只创建一个包含 6 个亮灯窗口精灵和 6个未亮灯窗口精灵数组。该数组充当窗口的精灵池,并且被打乱以确保随机混合两种状态。提供了两个公共方法 — borrowWindow() 和 returnWindow() - 它们允许从精灵池中借用一个窗口精灵,然后归还到池中。
这就是它要做的所有事情了。当然,我们仍然需要考虑其他切片类型(前边缘,后边缘,墙面装饰和墙壁台阶),但我们很快就会将它们添加到我们的 WallSpritesPool 类中。首先让我们把将精灵池的代码引用到页面,保证正常运行。
转到你的 index.html 文件并引用 WallSpritesPool 类的源文件:
<script src="https://cdnjs.cloudflare.com/ajax/libs/pixi.js/4.0.0/pixi.min.js"></script>
<script src="Far.js"></script>
<script src="Mid.js"></script>
<script src="Scroller.js"></script>
<script src="WallSpritesPool.js"></script> <!-- 添加 -->
<script src="Main.js"></script>
保存代码。
现在打开 Main.js。我们将对 Main 类进行一些临时更改,以便测试对象池。
我们首先在 spriteSheetLoaded() 方法中创建我们的对象池的实例,创建将用于保存从池中获取的切片精灵数组:
Main.prototype.spriteSheetLoaded = function() {
this.scroller = new Scroller(this.stage);
requestAnimationFrame(this.update.bind(this));
this.pool = new WallSpritesPool(); // 添加
this.wallSlices = []; // 添加
};
在上面的代码中,我们将对象池实例存储在名为 pool 的成员变量中,而我们的数组的成员变量名为 wallSlices。
现在让我们编写一些代码来从池中获取指定数量的窗口并将它们连续地添加到舞台上。添加以下测试方法:
Main.prototype.borrowWallSprites = function(num) {
for (var i = 0; i < num; i++)
{
var sprite = this.pool.borrowWindow();
sprite.position.x = -32 + (i * 64);
sprite.position.y = 128;
this.wallSlices.push(sprite);
this.stage.addChild(sprite);
}
};
除了将窗口精灵添加到舞台,上面的 borrowWallSprites() 方法还将每个精灵添加到我们的 wallSlices 成员变量中。这样做的原因是我们需要能够从第二个测试方法中访问(删除、移除、归还)这些窗口精灵,我们现在将编写它们。添加以下内容:
Main.prototype.returnWallSprites = function() {
for (var i = 0; i < this.wallSlices.length; i++)
{
var sprite = this.wallSlices[i];
this.stage.removeChild(sprite);
this.pool.returnWindow(sprite);
}
this.wallSlices = [];
};
这个 returnWallSprites() 方法删除添加到舞台的所有窗口切片,并将这些精灵归还到对象池。
通过这两种方法,我们可以验证我们是否可以从对象池中借用窗口精灵,并将这些精灵归还给池子。我们将使用Chrome 的 JavaScript 控制台窗口:
刷新浏览器并打开JavaScript控制台。手动执行如下代码:
main.borrowWallSprites(9);
请记住,我们的 Main 类可以通过主全局变量 main 访问,我们可以使用它来调用
borrowWallSprites()方法。
就像下面的截图一样,你应该看到舞台上有九个窗口精灵。都是从你的对象池中 借 来的,然后被添加到舞台上。还要注意,亮灯和亮灯的窗口序列可能是随机出现的。这是因为池中的窗口数组在创建后被打乱了。

现在让我们验证是否可以将这些精灵归还给对象池。在控制台中输入以下内容:
main.returnWallSprites();
精灵墙应该从舞台上消失,并将返回到对象池。
这还不能满足我们的实际需示。最简单的方法是从池中请求更多窗口并检查它们是否也出现在屏幕上。让我们从游泳池中再借用九个窗口:
main.borrowWallSprites(9);
然后再归还:
main.returnWallSprites();
我们现在从对象池中获得了总共18个精灵。请记住,池中只包含 12 个窗口精灵(6个开灯的,6 个不开灯的)。因此,精灵正在从池中借用并在我们完成后成功返回。如果没有被返还,那么当对象池的内部数组变空时,会报运行时错误。
JavaScript 中的所有内容都可以公开访问,我们可以在任何时候轻松检查对象池的内部数组。尝试从控制台检查数组的大小:
main.pool.windows.length
这么做应该返回长度 12。现在使用以下方法从池中借用四个窗口精灵:
main.borrowWallSprites(4);
再次查看池子中的精灵个数:
main.pool.windows.length
它现在应该只包含 8 个精灵。最后通过调用 returnWallSprites() 将精灵集返回池中。再次检查对象池的大小,并确认其长度为 12。
我对咱们的对象池能正常运行感到满意。让我们继续,但保留你添加到 Main 类的测试代码,因为我们很快就会再次使用它。
目前我们的对象池仅提供窗口精灵,但我们还需要添加对前边缘,后边缘,墙面装饰切片和台阶的支支持。让我们从三个墙面装饰切片开始。
如果你还记得,我们的一些墙上装饰着管道和通风口。这些切片安插在在每个窗口之间。让我们更新我们的 WallSpritesPool 类以包含墙面装饰切片。代码与口的对象池非常相似,所以它们看起来都应该很熟悉。
打开 WallSpritesPool.js 并在构造函数中进行以下调用:
function WallSpritesPool() {
this.createWindows();
this.createDecorations(); // 添加
}
现在真正来实现 createDecorations() 方法:
WallSpritesPool.prototype.createWindows = function() {
this.windows = [];
this.addWindowSprites(6, "window_01");
this.addWindowSprites(6, "window_02");
this.shuffle(this.windows);
};
// 实现
WallSpritesPool.prototype.createDecorations = function() {
this.decorations = [];
this.addDecorationSprites(6, "decoration_01");
this.addDecorationSprites(6, "decoration_02");
this.addDecorationSprites(6, "decoration_03");
this.shuffle(this.decorations);
};
上面的代码通过调用 addDecorationSprites() 方法将 18 个装饰精灵添加到对象池中(稍后我们将实现这个方法)。前六个精灵使用我们的精灵表中的 decoration_01 帧。接下来的六个使用 decoration_02,最后六个使用 decoration_03。然后调用 shuffle() 确保精灵随机放置在我们的装饰数组中,我们已将其声明为此类的成员变量,并用于存储墙面装饰精灵。
现在让我们来编写 addDecorationSprites() 方法。在 addWindowSprites() 方法之后直接添加以下内容:
WallSpritesPool.prototype.addWindowSprites = function(amount, frameId) {
for (var i = 0; i < amount; i++)
{
var sprite = new PIXI.Sprite(PIXI.Texture.fromFrame(frameId));
this.windows.push(sprite);
}
};
// 实现
WallSpritesPool.prototype.addDecorationSprites = function(amount, frameId) {
for (var i = 0; i < amount; i++)
{
var sprite = new PIXI.Sprite(PIXI.Texture.fromFrame(frameId));
this.decorations.push(sprite);
}
};
现在剩下要做的就是添加两个新方法,允许从对象池借用装饰精灵并返还。方法名称将遵循用于窗口精灵的命名约定。添加 borrowDecoration() 和 returnDecoration() 方法:
WallSpritesPool.prototype.borrowWindow = function() {
return this.windows.shift();
};
WallSpritesPool.prototype.returnWindow = function(sprite) {
this.windows.push(sprite);
};
// 实现
WallSpritesPool.prototype.borrowDecoration = function() {
return this.decorations.shift();
};
WallSpritesPool.prototype.returnDecoration = function(sprite) {
this.decorations.push(sprite);
};
保存代码。
我们的对象池现在支持窗口和装饰两种切片类型。让我们回到之前添加到 Main类中的测试方法,并测试一切是否正常。
前面我们建造了一面粗糙墙,完全由我们的对象池中的窗口组成。让我们稍微改变我们的测试代码,在每个窗口之间放置装饰切片。这将可以测试到是否真的可以从对象池中借用到窗口切片和装饰切片。
打开 Main.js 并从 borrowWallSprites() 方法中删除以下行:
Main.prototype.borrowWallSprites = function(num) {
for (var i = 0; i < num; i++)
{
var sprite = this.pool.borrowWindow(); // 删除
sprite.position.x = -32 + (i * 64);
sprite.position.y = 128;
this.wallSlices.push(sprite);
this.stage.addChild(sprite);
}
};
用下面几行代替:
Main.prototype.borrowWallSprites = function(num) {
for (var i = 0; i < num; i++)
{
if (i % 2 == 0) { // 添加
var sprite = this.pool.borrowWindow(); // 添加
} else { // 添加
var sprite = this.pool.borrowDecoration(); // 添加
} // 添加
sprite.position.x = -32 + (i * 64);
sprite.position.y = 192;
this.wallSlices.push(sprite);
this.stage.addChild(sprite);
}
};
上面的代码使用模运算符(%)来确保我们在循环的奇数次迭代借用一个窗口精灵,偶数次迭代时借用一个装饰精灵。这个简单的更改允许我们现在生成具有以下模式的测试砖块墙:
window, decoration, window, decoration, window, decoration, window
现在转到 returnWallSprites() 方法并删除以下行:
Main.prototype.returnWallSprites = function() {
for (var i = 0; i < this.wallSlices.length; i++)
{
var sprite = this.wallSlices[i]; // 删除
this.stage.removeChild(sprite);
this.pool.returnWindow(sprite);
}
this.wallSlices = [];
};
用下面几行代替:
Main.prototype.returnWallSprites = function() {
for (var i = 0; i < this.wallSlices.length; i++)
{
var sprite = this.wallSlices[i];
this.stage.removeChild(sprite);
if (i % 2 == 0) { // 添加
this.pool.returnWindow(sprite); // 添加
} else { // 添加
this.pool.returnDecoration(sprite); // 添加
} // 添加
}
this.wallSlices = [];
};
我们再次使用了模运算符,这次确保我们将正确的精灵(窗口或装饰)返回给对象池。
保存代码。
刷新浏览器,然后使用 Chrome 的 JavaScript 控制台测试我们的对象池。通过在控制台窗口中输入以下内容来生成测试墙:
main.borrowWallSprites(9);
如果不出意外,那么你应该看到一个由窗户构成的测试墙,其间插有各种墙壁装饰,如管道和通风口。实际上,你的砖块墙应该类似于下面的图片,它是从我的开发机上截取的。

虽然我们目前只编写了一些简单的测试,但我们所做的并不是为了生成整个游戏地图。
使用以下调用将精灵返还到对象池:
main.returnWallSprites();
通过对 borrowWallSprites() 和 returnWallSprites() 进行一些手动调用来验证对象池是否完全正常工作(译者:建议多调用几次验证程序是否正常)。此外,使用控制台检查对象池的窗口和装饰数组的长度是否正常。
我们正一步步走向成功。精灵池目前使得我们可以创建一个原始的砖块墙,但它还没有墙的前后边缘。让我们继续添加这些切片类型。
在文本编辑器中打开 WallSpritesPool.js 并将以下两行添加到其构造函数中:
function WallSpritesPool() {
this.createWindows();
this.createDecorations();
this.createFrontEdges(); // 添加
this.createBackEdges(); // 添加
}
现在添加一个 createFrontEdges() 和一个 createBackEdges() 方法:
WallSpritesPool.prototype.createDecorations = function() {
this.decorations = [];
this.addDecorations(6, "decoration_01");
this.addDecorations(6, "decoration_02");
this.addDecorations(6, "decoration_03");
this.shuffle(this.decorations);
};
// 添加
WallSpritesPool.prototype.createFrontEdges = function() {
this.frontEdges = [];
this.addFrontEdgeSprites(2, "edge_01");
this.addFrontEdgeSprites(2, "edge_02");
this.shuffle(this.frontEdges);
};
// 添加
WallSpritesPool.prototype.createBackEdges = function() {
this.backEdges = [];
this.addBackEdgeSprites(2, "edge_01");
this.addBackEdgeSprites(2, "edge_02");
this.shuffle(this.backEdges);
};
你应该能够轻松地看出来两种方法在干什么。第一个方法创建四个前边缘切片,其中两个使用精灵表的 edge_01 帧,另外两个使用 edge_02。第二个方法创建四个后边缘切片,并使用精灵表中与前边缘完全相同的帧。
四个前壁边缘可能看起来相当少,但它会绰绰有余,因为即使砖块墙长度很短也至少会占视口一半宽度。换句话说,我们在任何时候都不会使用超过四个前壁边缘。后墙边缘也是如此。
现在继续添加 addFrontEdgeSprites() 和 addBackEdgeSprites() 方法:
WallSpritesPool.prototype.addDecorationSprites = function(amount, frameId) {
for (var i = 0; i < amount; i++)
{
var sprite = new PIXI.Sprite(PIXI.Texture.fromFrame(frameId));
this.decorations.push(sprite);
}
};
// 添加
WallSpritesPool.prototype.addFrontEdgeSprites = function(amount, frameId) {
for (var i = 0; i < amount; i++)
{
var sprite = new PIXI.Sprite(PIXI.Texture.fromFrame(frameId));
this.frontEdges.push(sprite);
}
};
// 添加
WallSpritesPool.prototype.addBackEdgeSprites = function(amount, frameId) {
for (var i = 0; i < amount; i++)
{
var sprite = new PIXI.Sprite(PIXI.Texture.fromFrame(frameId));
sprite.anchor.x = 1;
sprite.scale.x = -1;
this.backEdges.push(sprite);
}
};
上面的代码没什么特殊的地方,但 addBackEdgeSprites() 方法中有几行值得注意:
var sprite = new PIXI.Sprite(PIXI.Texture.fromFrame(frameId));
sprite.anchor.x = 1; // 高亮行
sprite.scale.x = -1;// 高亮行
this.backEdges.push(sprite);
由于我们使用的是前边缘所使用的相同的精灵帧,我们需要水平翻转后边缘精灵,以便它们适当地贴合在砖块墙的的末端。下图能说明我的意思。它在翻转之前显示后边缘。它与墙跨没有正确连接,看起来不对。
然而,在翻转后的后边缘精灵,会紧贴着砖块墙的末端。如下图。
翻转精灵很容易。我们只需使用 PIXI.Sprite 类的 scale 属性即可。 scale 属性具有 x 和 y 值,可以调整该值以更改 sprite 的大小。但是,将 scale.x 值设置为 -1,我们可以强制精灵水平翻转而不是缩放。
Pixi 的 PIXI.Sprite 类还提供了一个 anchor 属性,用于定义 sprite 的锚点(轴心点)。默认情况下,精灵的锚点在左上角。你可以设置锚点的 x 和 y 位置以调整精灵的锚。anchor.set() 方法设置用于 x 和 y 位置的 比率值,0,0 表示精灵的左上角,1,1 表示其右下角。
在我们的教程中只使用默认值,这意味着所有定位都在精灵的左上角。然而,通过水平翻转边缘精灵,我们也翻转了它们的锚点的位置。换句话说,在水平翻转精灵之后,它的原点会改变到它的右上角,这不是我们想要的。为了解决这个问题,我们在将它们水平翻转之前将精灵的原点设置为右上角。这样,翻转后,它将被正确设置到左上角。
好的,现在让我们来编写可以借用边缘并返还给对象池的方法。
WallSpritesPool.prototype.returnDecoration = function(sprite) {
this.decorations.push(sprite);
};
// 添加
WallSpritesPool.prototype.borrowFrontEdge = function() {
return this.frontEdges.shift();
};
WallSpritesPool.prototype.returnFrontEdge = function(sprite) {
this.frontEdges.push(sprite);
};
WallSpritesPool.prototype.borrowBackEdge = function() {
return this.backEdges.shift();
};
WallSpritesPool.prototype.returnBackEdge = function(sprite) {
this.backEdges.push(sprite);
};
保存你的代码。
我们的精灵池现在支持足够多的垂切片类型,可以用来构建完整的砖块墙了。记住,一块完整的砖块墙包括 前边缘,中间部分 和 后边缘。中间部分至少应包括 窗户 和墙壁 装饰。一些砖块墙也可能包括一个 台阶。
让我们回到 Main 类,并编写一些测试代码,在我们的视口中绘制一个完整的砖块墙。
首先,删除以前的测试方法。打开 Main.js 并删除 borrowWallSprites() 和 returnWallSprites()。
我们将实现一个名为 generateTestWallSpan() 的新方法,用它来生成七个切片宽度的砖块墙。我们将把所有切片存放在一张表里面。首先添加以下内容:
Main.prototype.generateTestWallSpan = function() {
var lookupTable = [
this.pool.borrowFrontEdge, // 第一个切片
this.pool.borrowWindow, // 第二个切片
this.pool.borrowDecoration, // 第三个切片
this.pool.borrowWindow, // 第四个切片
this.pool.borrowDecoration, // 第五个切片
this.pool.borrowWindow, // 第六个切片
this.pool.borrowBackEdge // 第七个切片
];
}
这张表是一个存放函数引用的数组。数组中的每个索引代表七个切片中的一个。第一个索引表示墙的前边缘,最后一个表示后边缘。中间的指数代表代表墙壁中段的五个切片。
每个索引都包含对构建砖块墙所需的对象池中对应的引用。例如,第一个索引包含对池的 borrowFrontEdge() 方法的引用。第二个索引包含对 borrowWindow() 的引用,第三个索引包含对 borrowDecoration() 的引用。
Main.prototype.generateTestWallSpan = function() {
var lookupTable = [
this.pool.borrowFrontEdge, // 1st slice
this.pool.borrowWindow, // 2nd slice
this.pool.borrowDecoration, // 3rd slice
this.pool.borrowWindow, // 4th slice
this.pool.borrowDecoration, // 5th slice
this.pool.borrowWindow, // 6th slice
this.pool.borrowBackEdge // 7th slice
];
// 添加
for (var i = 0; i < lookupTable.length; i++)
{
var func = lookupTable[i];
var sprite = func.call(this.pool);
sprite.position.x = 32 + (i * 64);
sprite.position.y = 128;
this.wallSlices.push(sprite);
this.stage.addChild(sprite);
}
};
在循环内部,我们的代码获取对应切片的借用方法的引用,并将其存储在名为 func 的局部变量中:
var func = lookupTable[i];
一旦我们有了这个正确的引用,就使用以下方法调用它:
var sprite = func.call(this.pool);
call() 是一种原生的 JavaScript 方法,可用来从函数引用调用函数。例如,在循环的第一次迭代中,func 变量将指向精灵池的 borrowFrontEdge() 方法。因此,调用 func 的 call() 方法与下面的代码等价:
this.pool.borrowFrontEdge()
有了生成测试墙的方法,我们也需要编写另一个名为 clearTestWallSpan() 的清除墙的方法。此方法将从舞台移除砖块墙并将切片返还到对象池中。
在你的文件中加入下面的代码:
Main.prototype.clearTestWallSpan = function() {
var lookupTable = [
this.pool.returnFrontEdge, // 1st slice
this.pool.returnWindow, // 2nd slice
this.pool.returnDecoration, // 3rd slice
this.pool.returnWindow, // 4th slice
this.pool.returnDecoration, // 5th slice
this.pool.returnWindow, // 6th slice
this.pool.returnBackEdge // 7th slice
];
for (var i = 0; i < lookupTable.length; i++)
{
var func = lookupTable[i];
var sprite = this.wallSlices[i];
this.stage.removeChild(sprite);
func.call(this.pool, sprite);
}
this.wallSlices = [];
};
我们再一次使用了一张表。但是这次我们存储的是对应的切片返还方法的引用。例如,我们知道砖块墙的第一个切片是墙的前边缘。因此,存储在表中的第一个方法是 returnFrontEdge()。
另外,请注意,这次使用原生 JavaScript call() 方法时,我们将第二个参数传递给它。第二个参数是我们想要返还给池子的精灵。
保存更改并刷新浏览器。让我们看看完整的砖块墙是什么样的。
打开 Chrome 的 JavaScript 控制台并执行生成砖块墙的代码:
main.generateTestWallSpan();
你应该会看到七个切片宽的砖块墙。还有前后边缘。你的浏览器窗口应类似于下面的屏幕截图。

七个切片都是从我们的对象池中借来的。让我们通过在控制台中输入以下内容来返还它们:
main.clearTestWallSpan();
切片精灵应该会被从舞台上移除并返回到你的对象池中。
再次生成砖块墙:
main.generateTestWallSpan();
你会再次看到砖块墙,但这次你看到墙壁上的装饰与上次不同,窗口类型也可能会有所不同,甚至前后边缘的外观也会发生变化。

这些差异是由于我们这次借用了不同的墙片造成的。我们之前的切片返回到了每个对象池的数组 最后面,而借用的精灵总是来自我们数组的 前面。这样效果会比较好,因为玩家很难准确预测从池中获取每个切片类型的样子。它会让我们游戏地图的墙块随机出现,这正是我们想要的。
希望你能从上面的实现代码中得到成就感。我们能够使用对象池构建完整的砖块墙。现在剩下要做的就是为对象池添加台阶的支持。让我们继续吧。
返回文本编辑器并确保 WallSpritesPool.js 已打开。
添加下面一行到构造函数中。
function WallSpritesPool() {
this.createWindows();
this.createDecorations();
this.createFrontEdges();
this.createBackEdges();
this.createSteps(); // 添加
}
现在来实现 createSteps() 方法:
WallSpritesPool.prototype.createSteps = function() {
this.steps = [];
this.addStepSprites(2, "step_01");
};
并且添加一个 addStepSprites() 方法:
WallSpritesPool.prototype.addStepSprites = function(amount, frameId) {
for (var i = 0; i < amount; i++)
{
var sprite = new PIXI.Sprite(PIXI.Texture.fromFrame(frameId));
sprite.anchor.y = 0.25;
this.steps.push(sprite);
}
};
台阶很少会出现,虽然我们将在精灵池中只使用两个。但说实话,但已经足够了。
此外,就像后边缘切片类型一样,我们使用了 anchor 属性来改变精灵的锚点。这次我们通过向下移动 64 像素来改变锚点的垂直位置。请记住,使用锚属性的值是比率。每个切片的高度为 256 像素,将锚点的 y 位置向下移动 64 个像素对应的比率为 0.25。
那么为什么要改变锚属性呢?好吧,当我们最终实际生成游戏地图时,一定范围的所有切片将使用相同的 y 位置以确保正确对齐。但是,台阶切片位图的设计使其成为特例 — 它将无法与砖块墙的其他切片正确对齐。你可以在下图中发现这种情况,其中所有切片(包括台阶)具有相同的 y 位置并且其锚点设置在左上角。

如你所见,台阶的垂直位置显然是不正确的。但是,通过将其锚点向下移动 64 像素,我们可以强制它在砖块墙内正确展示。下图中就是设置过的,其中每个切片(包括台阶)仍然 共享 相同的 y 位置,但由于其锚点已被移动,步骤切片现在正确地位于砖块墙内。
现在我们需要做的就是提供允许我们从对象池借用并返回一个步骤的方法。添加以下 borrowStep() 和 returnStep() 方法:
WallSpritesPool.prototype.borrowStep = function() {
return this.steps.shift();
};
WallSpritesPool.prototype.returnStep = function(sprite) {
this.steps.push(sprite);
};
将更改保存到文件。对象池类现已完成了。
这一节的教程即将完成。让我们通过生成包含台阶的测试砖块墙来结束它。
打开 Main.js 并删除 generateTestWallSpan() 方法中的代码。将其替换为以下内容:
Main.prototype.generateTestWallSpan = function() {
var lookupTable = [
this.pool.borrowFrontEdge, // 1st slice
this.pool.borrowWindow, // 2nd slice
this.pool.borrowDecoration, // 3rd slice
this.pool.borrowStep, // 4th slice
this.pool.borrowWindow, // 5th slice
this.pool.borrowBackEdge // 6th slice
];
var yPos = [
128, // 1st slice
128, // 2nd slice
128, // 3rd slice
192, // 4th slice
192, // 5th slice
192 // 6th slice
];
for (var i = 0; i < lookupTable.length; i++)
{
var func = lookupTable[i];
var sprite = func.call(this.pool);
sprite.position.x = 64 + (i * 64);
sprite.position.y = yPos[i];
this.wallSlices.push(sprite);
this.stage.addChild(sprite);
}
};
generateTestWallSpan() 几乎与前一版相同。这次墙只有六个切片宽,我们还添加了第二个名为 yPos 的数组。
如果查看这张表,你将发现第 4 个索引表示台阶切片。请记住,该步骤可让玩家直接跌落到正下方的墙面上。如果你回想一下教程的开头,你应该记住,当我们处理一个步骤时,我们实际处理的是两个连接在一起的独立砖块墙。第一个砖块墙将高于第二个,台阶切片本身将属于第二个砖块墙。
两个砖块墙之间的高度差异由我们的 yPos 数组处理。它对于我们的每个切片都有一个 y 位置。前三个切片 y 都是 128 个像素,而剩余的切片是 192个像素。
让我们转到我们的 clearTestWallSpan() 方法。从现有版本的方法中删除代码,并将其替换为以下内容:
Main.prototype.clearTestWallSpan = function() {
var lookupTable = [
this.pool.returnFrontEdge, // 1st slice
this.pool.returnWindow, // 2nd slice
this.pool.returnDecoration, // 3rd slice
this.pool.returnStep, // 4th slice
this.pool.returnWindow, // 5th slice
this.pool.returnBackEdge // 6th slice
];
for (var i = 0; i < lookupTable.length; i++)
{
var func = lookupTable[i];
var sprite = this.wallSlices[i];
this.stage.removeChild(sprite);
func.call(this.pool, sprite);
}
this.wallSlices = [];
};
如你所见,表中包含对将每个切片返还到对象池所需的所有方法的引用,包括台阶。
保存更改并刷新浏览器。
在 JavaScript 控制台中输入以下内容:
main.generateTestWallSpan();
你应该会在屏幕上看到一个带有台阶的墙。它应该看起来像这样:

再返还整个砖块墙给对象池:
main.clearTestWallSpan();
多试几次生成砖块墙然后返还到对象池,确保一切都正常。
我们不断地测试对象池,现在它已经成型。为了准备本系列的最后一个教程,我们现在从 Main 类中删除测试代码:
Main.prototype.spriteSheetLoaded = function() {
this.scroller = new Scroller(this.stage);
requestAnimationFrame(this.update.bind(this));
this.pool = new WallSpritesPool();
this.wallSlices = [];
};
还要完全删除 generateTestWallSpan() 和 clearTestWallSpan() 方法。
现在保存你的更改。
感谢你能坚持到这里。本教程已经涉及到了大量的内容。我们已经讨论了滚动游戏地图的各种技术点,并了解了为什么选择使用对象池。
虽然本教程很长,但对象池的概念实际上相当简单。不过有人可能会很容易陷入到一些实现细节中,但记住最重要的一点对象池只一个非常简单的 API:有一组从池中借用精灵,另一组返还这些精灵。
我们还学到了更多关于 pixi.js 的知识,包括精灵表和 PIXI.Sprite 类的其它功能。此外,我们也介绍了 GPU 加速的好处,以及为什么使用精灵表可以带来巨大的性能提升。
虽然我们还没有真正地开始构建滚动游戏地图,但我们已经编写了一些代码来生成一些测试砖块墙。这应该有助于你了解如何使用对象池,也可以帮助你熟悉砖块墙的结构和游戏地图。
下一节中我们将真正的添加流动游戏中的第三层。和前两层不一样,第三层将组成整个游戏地图所需要的砖块墙。这些切片都将从我们的对象池中借取。
与往常一样,GitHub上提供了本系列和之前教程的 源代码。
很快你将开始教程的的 第四部分,也是最后一部分。
1970-01-01 08:00:00
原文: PART 1・ PART 2・ PART 3・ PART 4
关注 @chriscaleb
这个系列的教程已经更新到了 PixiJS v4 版本。
在这个系列教程中我们将探索如何构建一个类似 Canabalt 和 Monster Dash 的视差滚动地图游戏界面。第一篇介绍了 pixi.js 的渲染引擎并且涉及到了视差滚动的基础知识。现在我们将在上一篇的基础之上添加 视口 的概念。
你将以第一篇教程中的代码为基础,或者直接下载上篇教程中的 源代码,另外整个教程的完全源代码也在 github 上可以找到。
作为提示,点击上面的图片,将会加载当前版本的视差滚动,目前来说只有两个层,我们将添加每三个更复杂的层。与此同时,我们将通过添加视口的概念来添加第三层。我们还会执行一些重要代码重构,以便将滚动器封装在类中。
虽然本教程非常针对那些对面向对象有基础概念的初学者级别,如这些概念让你感到不舒服,也不用担心,因为我仍然会为那些不熟悉这些枞的的人提供足够的指导。
如果你还没有看过第一篇教程,我建议你应该从那篇开始。
还有一点值得提醒的是,为了能够测试你的代码,你需要开启一个本地的 web 服务器。如果你还没有做这一步,那么可能参考上一篇教程中的章节建立好自己的 web 服务器。
正如我们之前发现的,pixi.js 提供了几种可使用的 展示对象 类型。如果你还记得的话,我们在使用 PIXI.extras.TilingSprite 来满足我们的需求之前,先简单地使用了 PIXI.Sprite。
这两个类共享许多公用的功能。例如,它们都为你提供位置(position),宽度(width),高度(height)和 alpha 属性。此外,两者都可以通过 addChild() 方法添加到容器中。事实上,PIXI.Container 类本身就是一个 展示对象,它还提供了许多 Sprite 和 TilingSprite 类都能使用的属性。
所有这些公用的功能都来自于 继承(inheritance) 的魔力。它使得类可以继承和扩展功能到其它类上。为了让你能理解它,可以参考下面的示意图,它将为你展示 pixi.js 中提供的大多数展示对象
从上面的示意图中,我们可以看出最基础的类型是 PIXI.DisplayObject 类,所有其它类都从它继承而来。这个类是将对象呈现到屏幕所必须需的元素。
当我说 展示对象 时,并非指
PIXI.DisplayObject这个类。而当使用PIXI.DisplayObject这个说法时,却表示所有继承自它的对象。本质上讲,当我使用 展示对象 这一术语时,我指的是可以通过 pixi.js 呈现给屏幕的 任何对象。
下一层是 PIXI.Container,它允许对象充当其他展示对象的 容器。我们在第一个教程中使用的 addChild() 方法是 PIXI.Container 这个类提供的实例方法,也可以通过 PIXI.Sprite 和 PIXI.TilingSpite 继承获得。
本质上讲,继承树中的每个类都是它继承的(父)类的 更特殊 版本(译者:面向对象的 具体化 与 泛化 概念)。好的一点是我们可以使用继承来创建我们自己的自定义的展示对象。换而言之,我们可以为每个视差滚动器中的元素编写专用的类,并让 pixi.js 处理它们就像是处理其它展示对象一样。这给使我们封装代码更简单,代码也更多漂亮、整洁。
让我们开始制作远景层吧。
打开index.html文件,在 init() 函数中查找创建和设置图层的代码。这是你要找的东西:
var farTexture = PIXI.Texture.fromImage("resources/bg-far.png");
far = new PIXI.extras.TilingSprite(farTexture, 512, 256);
far.position.x = 0;
far.position.y = 0;
far.tilePosition.x = 0;
far.tilePosition.y = 0;
stage.addChild(far);
理想的情况是,我们可以创建一个代表远景层的类,并把大部分实现细节隐藏在类中。因此,我们希望找到以下代码,而不是上面的代码:
far = new Far();
stage.addChild(far);
代码量大幅减少了吧?另外,我认为它比我们原来的尝试更具可读性。
我们通过创建一个代表我们的滚动条远景层的名为 Far 的类来实现这一目标。在项目的根文件夹中创建一个新文件,并将其命名为 Far.js。
现在定义一个名为 Far 的函数,它将表示我们类的构造函数:
(译者:原作者使用了 ES 5 和 prototype 来实现 JavaScript 中的继承,看起来可能没那么直观,可以参考我自己实现的 ES 6 版的代码)
function Far(texture, width, height) {
PIXI.extras.TilingSprite.call(this, texture, width, height);
}
在构造函数下面添加以下行,然后保存文件:
Far.prototype = Object.create(PIXI.extras.TilingSprite.prototype);
上面的代码继承了 PIXI.extras.TilingSprite 类的功能。
构造函数是一种特殊类型的函数,用于创建类实例。在 JavaScript 中,构造函数的名称也用于指定类的名称(译者:ES 6 中的类有专门的 construct 方法)。
那么为什么 Far 类继承自 PIXI.TilingSprite 呢?好吧,如果你还记得第一个教程,我们使用 TilingSprite 实例来表示每个视差层。因此,在更具体化的类中使用这些功能是有必要的。本质上讲,我们所说的是:Far 类是 PIXI.extras.TilingSprite 的一个更特殊的版本。
因为 Far 类继承自 PIXI.extras.TilingSprite,所以我们要记得去初始化TilingSprite 类的功能。这是通过从构造函数中调用 TilingSprite 的构造函数来完成的。我高亮显示了以下代码行:
function Far(texture, width, height) {
PIXI.extras.TilingSprite.call(this, texture, width, height); // 这一行
}
Far.prototype = Object.create(PIXI.extras.TilingSprite.prototype);
这样做是因为我们希望 Far 类继承 TilingSprite 的所有功能。由于 TilingSprite 需要将三个参数传递给它的构造函数,我们需要确保我们自己的类也接受这些参数并使用它们初始化瓦片精灵。以下是高亮显示参数的类:
// 注意 texture, width, height 三个参数
function Far(texture, width, height) {
PIXI.extras.TilingSprite.call(this, texture, width, height);
}
Far.prototype = Object.create(PIXI.extras.TilingSprite.prototype);
我们还有一些额外的功能可以添加 Far 类中,但实际上已经可以开始将它集成到 index.html 页面中了。
返回你的 index.html 页面。
要使用 Far 类,你需要引用它的源文件。在页面正文顶部附近添加以下行:
<body onload="init();">
<div align="center">
<canvas id="game-canvas" width="512" height="384"></canvas>
</div>
<script src="https://cdnjs.cloudflare.com/ajax/libs/pixi.js/4.0.0/pixi.min.js"></script>
<script src="Far.js"></script><!--这里-->
现在向下滚动并删除以下行:
var farTexture = PIXI.Texture.fromImage("resources/bg-far.png");
far = new PIXI.extras.TilingSprite(farTexture, 512, 256); // 删除此行
far.position.x = 0;
far.position.y = 0;
far.tilePosition.x = 0;
far.tilePosition.y = 0;
stage.addChild(far);
替换成这样:
var farTexture = PIXI.Texture.fromImage("resources/bg-far.png");
far = new Far(farTexture, 512, 256); // 新行
far.position.x = 0;
far.position.y = 0;
far.tilePosition.x = 0;
far.tilePosition.y = 0;
stage.addChild(far);
好吧,我承认。目前这似乎并没有太大的改进,但我们现在可以开始在 Far 类中直接隐藏更多代码,让我们继续吧。
在 index.html 中,我们当前设置了 far 层的 position 和 tilePosition 属性。让我们删除它,并将其封装在我们的 Far 类中。
var farTexture = PIXI.Texture.fromImage("resources/bg-far.png");
far = new Far(farTexture, 512, 256);
far.position.x = 0; // 删除
far.position.y = 0; // 删除
far.tilePosition.x = 0; // 删除
far.tilePosition.y = 0; // 删除
stage.addChild(far);
保存更改并打开 Far.js 文件。现在直接在类的构造函数中设置图层的位置和tilePosition 属性:
function Far(texture, width, height) {
PIXI.extras.TilingSprite.call(this, texture, width, height);
this.position.x = 0;
this.position.y = 0;
this.tilePosition.x = 0;
this.tilePosition.y = 0;
}
如果你不熟悉面向对象的 JavaScript 或面向对象编程,那么你可能会好奇 this 关键字在上面的代码中的用途是什么。基本上可以这么理解,它可以让你引用类的已创建实例。通过 this,我们可以引用该实例的所有 属性 和 方法。
因为 Far 类继承自 PIXI.extras.TilingSprite,它还具有 TilingSprite 的所有 属性 和 方法,包括 position 和 tilePosition。要访问这些属性,我们只需使用this 关键字。这是再次设置图层 x 位置的代码:
this.position.x = 0;
还应注意,this 关键字还用于引用新添加到类中的属性或方法。
现在保存更改并在浏览器中测试代码。一切都应按预期运行。另外,请查看 Chrome 的 JavaScript 控制台,确保没有错误。
好的,我们应该从哪里开始呢。如果你回顾一下 index.html 页面,你应该看到代码好像开始变得更加简洁了:
var farTexture = PIXI.Texture.fromImage("resources/bg-far.png");
far = new Far(farTexture, 512, 256);
stage.addChild(far);
但仍有改进的余地。毕竟,如果我们可以直接在 Far 类中隐藏我们的定位代码,那么为什么我们不能把纹理的逻辑也放在 Far 类中呢?
切换到 Far.js 文件并在构造函数的开头添加一行以创建图层的纹理:
function Far(texture, width, height) {
var texture = PIXI.Texture.fromImage("resources/bg-far.png"); // 添加
PIXI.extras.TilingSprite.call(this, texture, width, height);
现在显式地将纹理的宽度和高度传递给 TilingSprite 的构造函数:
function Far(texture, width, height) {
var texture = PIXI.Texture.fromImage("resources/bg-far.png");
PIXI.extras.TilingSprite.call(this, texture, 512, 256); // 512, 256
由于我们现在直接在类中处理纹理,因此实际上不需要将纹理,宽度和高度参数传递给构造函数。删除所有三个参数并保存你的代码:
function Far(texture, width, height) { // 删除 texture, width, height
你的构造函数现在应该是这样:
function Far() {
var texture = PIXI.Texture.fromImage("resources/bg-far.png");
PIXI.extras.TilingSprite.call(this, texture, 512, 256);
this.position.x = 0;
this.position.y = 0;
this.tilePosition.x = 0;
this.tilePosition.y = 0;
}
剩下要做的就是返回到你的 index.html 文件并删除我们之前创建的纹理并传递给 far的构造函数:
var farTexture = PIXI.Texture.fromImage("resources/bg-far.png");
far = new Far(farTexture, 512, 256);
stage.addChild(far);
改成这样:
far = new Far();
stage.addChild(far);
比以前简洁了,对吧?我们所有层的丑陋实现细节现在都安全地隐藏在 Far 类中。
保存 index.html 和 Far.js ,然后在 Chrome 中测试最新版本的代码。
我花了一些时间引导你完成创建 Far类所需的步骤。该类继承自PIXI.extras.TilingSprite,其行为与任何其他 pixi.js 展示对象相同。虽然我们尚未完成,但我们将暂时停止一下并应用我们学到的知识来创建一个代表视差滚动器中的中间层(Mid)的类。
创建一个名为 Mid.js 的新文件,并开始向其添加以下代码:
function Mid() {
}
Mid.prototype = Object.create(PIXI.extras.TilingSprite.prototype);
同样在构造函数中,创建中间层的纹理并设置其定位属性:
function Mid() {
var texture = PIXI.Texture.fromImage("resources/bg-mid.png");
PIXI.extras.TilingSprite.call(this, texture, 512, 256);
this.position.x = 0;
this.position.y = 128;
this.tilePosition.x = 0;
this.tilePosition.y = 0;
}
Mid.prototype = Object.create(PIXI.extras.TilingSprite.prototype);
保存 Mid.js 文件,然后转到 index.html 并引用 Mid 类的源文件:
<script src="https://cdnjs.cloudflare.com/ajax/libs/pixi.js/4.0.0/pixi.min.js"></script>
<script src="Far.js"></script>
<script src="Mid.js"></script> <!--添加-->
完成后,向下滚动到 init() 函数并删除以下行:
far = new Far();
stage.addChild(far);
var midTexture = PIXI.Texture.fromImage("resources/bg-mid.png"); // 删除
mid = new PIXI.extras.TilingSprite(midTexture, 512, 256);// 删除
mid.position.x = 0;// 删除
mid.position.y = 128;// 删除
mid.tilePosition.x = 0;// 删除
mid.tilePosition.y = 0;// 删除
stage.addChild(mid);
用这一行代码替换它们:
far = new Far();
stage.addChild(far);
mid = new Mid(); // 此行
stage.addChild(mid);
保存 Mid.js 文件并在浏览器中测试最新版本。像往常一样,在运行时检查是否有 JavaScript 错误,并确保滚动器仍然按预期执行。
我们已经对代码库进行了大量的重构,但仍然有一些事情可以做。返回 index.html 文件,查看动画主更新逻辑。它应该如下所示:
function update() {
far.tilePosition.x -= 0.128;
mid.tilePosition.x -= 0.64;
renderer.render(stage);
requestAnimationFrame(update);
}
update 方法中的前两行通过更新其 tilePosition 属性来滚动我们的图层。但是,我们的代码目前存在一些问题:通过直接更改 tilePosition 属性,我们将暴露 Mid 和 Far 类的内部 实现(译者:类的外部不应该知道类的具体实现细节,只需要控制类的行为)。这违背了面向对象的封装原则。
理想情况下,我们希望在类中隐藏具体细节。如果两个类只有一个实际为我们执行滚动的 update() 方法,那么我们的代码会更易读。换句话说,对于我们的主循环来说,这样似乎更合适:
function update() {
far.update();
mid.update();
renderer.render(stage);
requestAnimFrame(update);
}
值得庆幸的是,这样的改变是微不足道的。我们将向 Far 类和 Mid 类添加一个 update() 方法,每个类都会一点点的滚动。
从 Far 类开始,打开 Far.js 并向其添加以下方法:
Far.prototype = Object.create(PIXI.extras.TilingSprite.prototype);
Far.prototype.update = function() {
this.tilePosition.x -= 0.128;
};
该方法(update)的主体应该看起来很熟悉。它只是将纹理的平铺位置移动 0.128 像素,这正是我们在 index.html 的主循环中所做的。
好的,保存更改并向Mid.js添加类似的方法:
Mid.prototype = Object.create(PIXI.extras.TilingSprite.prototype);
Mid.prototype.update = function() {
this.tilePosition.x -= 0.64;
};
两个方法的唯一区别是 Mid 类中的 update() 方法的滚动量更多。
保存更改并返回 index.html。现在我们需要做的就是从主循环中调用每个层的 update() 方法。删除以下两行代码:
function update() {
far.tilePosition.x -= 0.128; // 删除
mid.tilePosition.x -= 0.64; // 删除
renderer.render(stage);
requestAnimFrame(update);
}
替换成:
function update() {
far.update();
mid.update();
renderer.render(stage);
requestAnimFrame(update);
}
保存更改并测试,保证 Chrome 中按预期正常运行。
虽然视差滚动器和以前一样表现正常,但我们实际上已对代码的整体架构进行了一些重大的更改。我们采用了更加面向对象的设计,利用继承创建了两个代表视差层的特殊展示对象。
能够编写特殊的展示对象是一个强大的概念,在许多情况下都能派上用场。我们的 Far 类和 Mid 类都像 pixi.js 支持的任何其他展示对象一样。下图说明了我们的两个特殊类位于 Pixi 展示对象类的继承结构中的位置。
在继续之前,看看你的代码文件并确保我们迄今为止所做的一切都有意义。实际上并没有很多代码,但如果你是面向对象编程的新手,那么完全消化代码所表示的知识可能需要一些时间。
本教程开头概述的目标之一是将我们的视差滚动器包装到一个类中。现在我们已经编写了 Far 类和 Mid 类,现在我们写一个滚动器类。
这样的话我们就能够从 index.html 中删除 Mid 和 Far 实例,将它们封装在一个单独的对象中,以满足我们所有的滚动类需要实现的需求。
让我们写一个能够实现我们想法的类。创建一个名为 Scroller.js 的新 JavaScript 文件,并通过向其添加以下代码来定义名为 Scroller 的类:
function Scroller(stage) {
}
关于这个类,有两点值得注意。首先,它的构造函数需要引用我们的舞台(Pixi.Container)。其次,它不会继承任何东西。
与 Far 和 Mid 类不同,我们的 Scroller 类不是特殊的展示对象。相反,它将使用构造函数的 stage 参数添加我们的 远景层和中间层实例。(译者:Scroller 类只起到封装和控制作用,并不用继承任何 Pixi 中的类)
让我们先在类中添加远景层的实例:
function Scroller(stage) {
this.far = new Far();
stage.addChild(this.far);
}
第一行代码创建了 Far 类的实例。请注意,我们将实例存储在名为 far 的 成员变量 中。
成员变量 是通过 this 关键字直接向类添加 属性 来创建的。成员变量具有在类实例的整个生命周期中持久化可见的优点,这意味着类的任何其他方法也可以访问它。
第二行将远景层实例添加到舞台。
现在让我们为中间层做同样的事情。将以下两行添加到构造函数中:
function Scroller(stage) {
this.far = new Far();
stage.addChild(this.far);
this.mid = new Mid();
stage.addChild(this.mid);
}
现在 Scroller 类中有两个成员变量:far 和 mid。这是很有用,因为它允许我们从类中的任何其他方法中访问我们的视差层。这也很方便,因为我们确实需要添加一个额外的方法。它将用于更新两个层的位置。我们现在继续添加此方法(update):
function Scroller(stage) {
this.far = new Far();
stage.addChild(this.far);
this.mid = new Mid();
stage.addChild(this.mid);
}
Scroller.prototype.update = function() {
this.far.update();
this.mid.update();
};
还记得我们为 Mid 和 Far 类编写了 update() 方法吗?在我们的 Scroller 类自己的 update() 方法需要做的就是调用这些更新方法。
现在 Scroller 类可以表示我们的视差滚动器了,我们可以回到 index.html 页面并将其插入。
打开 index.html 并引用 Scroller.js:
<script src="https://cdnjs.cloudflare.com/ajax/libs/pixi.js/4.0.0/pixi.min.js"></script>
<script src="Far.js"></script>
<script src="Mid.js"></script>
<script src="Scroller.js"></script>
现在向下移动到 init() 函数并删除以下代码行:
function init() {
stage = new PIXI.Stage(0x66FF99);
renderer = PIXI.autoDetectRenderer(
512,
384,
{view:document.getElementById("game-canvas")}
);
far = new Far(); // 删除
stage.addChild(far); // 删除
mid = new Mid(); // 删除
stage.addChild(mid); // 删除
requestAnimationFrame(update);
}
请记住,远景层和中间层现在都由 Scroller 类处理。因此,我们需要创建一个Scroller 实例来替换我们刚删除的行:
function init() {
stage = new PIXI.Stage(0x66FF99);
renderer = PIXI.autoDetectRenderer(
512,
384,
{view:document.getElementById("game-canvas")}
);
scroller = new Scroller(stage); // 实例化 Scroller
requestAnimationFrame(update);
}
另请注意,我们将 stage 引用传递给 Scroller 类的构造函数。这样做非常重要,因为 Scroller 类需要这个引用才能将 远景层和中间层添加到 展示列表 中。
现在需要做的就是在主循环中调用 scroller 的 update() 方法。首先,从主循环中删除以下两行:
function update() {
far.update(); // 删除
mid.update(); // 删除
renderer.render(stage);
requestAnimationFrame(update);
}
现在添加以下行来更新滚动器:
function update() {
scroller.update(); // 添加
renderer.render(stage);
requestAnimationFrame(update);
}
保存更改并使用 Chrome 测试所有内容。一如既往地在 JavaScript 控制台中查找是否有错误,如果有,请仔细检查你的代码。
我们已经成功地重新构建了视差滚动,以便所有内容都包含在一个类中。如果你查看 index.html,你会发现我们已经隐藏了我们上次在第一篇教程中写的所有实现代码。
我们已经取得了巨大的进步,但还有一件事我们做。为了使我们的滚动条完整,需要添加 视口 的概念。将视口视为一个查看游戏地图的窗口。
你可能会问「我们不是已经有一个视口了吗?」是的,毕竟,当你在浏览器中运行代码时,我们只能看到在舞台边界内可以看到的内容。这是似乎就是一个视口了,但是我们还没有办法知道我们在游戏世界中 滚动了多远(译者:需要实现视口是因为后续会涉及到地图的概念,地图中游戏场景是有长度、距离的概念的,这就方便我们实现一些特殊场景,比如落箱子,障碍物等。因为不引用视口的概念游戏将是无限循环滚动的。这会导致计算距离变得很复杂,而且无法将地图设计成一种具体的抽象)。另外,如果我们可以简单地跳到某个位置并确切地看到我们的图层应该如何看起来,那不是很好吗?一旦我们添加了视口的概念并提供了设置其当前位置的方法,那么一切都将成为可能。
目前我们有一个 update() 方法,我们用它来连续滚动我们的视差层。可以使用一个名为 setViewportX() 的新方法替换它,我们可以用它来设置视口的水平位置。调用此方法将让我们随意定位我们的游戏地图。
让我们从 Scroller 类开始。
打开 Scroller.js 并删除现有的 update() 方法:
function Scroller(stage) {
this.far = new Far();
stage.addChild(this.far);
this.mid = new Mid();
stage.addChild(this.mid);
}
Scroller.prototype.update = function() { // 删除
this.far.update();// 删除
this.mid.update();// 删除
};// 删除
我们的 setViewportX() 方法非常简单。它期望将一个数字作为方法的 viewportX 参数传递,然后将该值传递给我们的每个层。显然,我们的图层都需要实现自己的 setViewportX() 方法。让我们继续吧,现在就去做吧。
我们首先删除类中的现有 update() 方法。打开 Far.js 并删除以下行:
function Far() {
var texture = PIXI.Texture.fromImage("resources/bg-far.png");
PIXI.extras.TilingSprite.call(this, texture, 512, 256);
this.position.x = 0;
this.position.y = 0;
this.tilePosition.x = 0;
this.tilePosition.y = 0;
}
Far.prototype = Object.create(PIXI.extras.TilingSprite.prototype);
Far.prototype.update = function() { // 删除
this.tilePosition.x -= 0.128; // 删除
}; // 删除
我们需要能够跟踪视口的水平位置。为此,我们在类的构造函数中定义新的成员变量:
function Far() {
var texture = PIXI.Texture.fromImage("resources/bg-far.png");
PIXI.extras.TilingSprite.call(this, texture, 512, 256);
this.position.x = 0;
this.position.y = 0;
this.tilePosition.x = 0;
this.tilePosition.y = 0;
this.viewportX = 0; // 新的成员变量
}
再添加一个类的 静态常量(DELTA_X):
Far.prototype = Object.create(PIXI.extras.TilingSprite.prototype);
Far.DELTA_X = 0.128;
DELTA_X 常量的值看起来应该很熟悉。它是我们之前在每次调用 update() 时移动图层的 tilePosition 的像素数。显然,使用常量会使我们的代码更具可读性和可维护性,这就是我们选择使用常量的原因。基本上,每当我们的视口移动一个单元时,我们将使用常量将远景层移动 0.128 像素。所以现在让我们编写一个 setViewportX() 方法,添加以下内容:
Far.prototype = Object.create(PIXI.extras.TilingSprite.prototype);
Far.DELTA_X = 0.128;
Far.prototype.setViewportX = function(newViewportX) {
var distanceTravelled = newViewportX - this.viewportX;
this.viewportX = newViewportX;
this.tilePosition.x -= (distanceTravelled * Far.DELTA_X);
};
上面的代码并不难理解。首先,我们计算自从上次调用 setViewportX() 以来的滚动的距离。然后视口的新水平位置存储在我们的 viewportX 成员变量中。最后,我们乘以 DELTA_X 常数,以确定将图层的瓦片移动了多远。
应该注意,我们的 x 位置代表视口窗口的左侧。在其他实现中,x 位置代表视口的中心也很常见。
保存最新版本的 Far.js。
现在我们需要对 Mid 类进行相同的更改。
Mid 类的代码几乎与 Far 类相同,所以我们能快速写出来。
打开 Mid.js 并删除其 update() 方法、并添加 setViewportX 方法:
function Mid() {
var texture = PIXI.Texture.fromImage("resources/bg-mid.png");
PIXI.extras.TilingSprite.call(this, texture, 512, 256);
this.position.x = 0;
this.position.y = 128;
this.tilePosition.x = 0;
this.tilePosition.y = 0;
this.viewportX = 0;
}
Mid.prototype = Object.create(PIXI.extras.TilingSprite.prototype);
Mid.DELTA_X = 0.64;
Mid.prototype.setViewportX = function(newViewportX) {
var distanceTravelled = newViewportX - this.viewportX;
this.viewportX = newViewportX;
this.tilePosition.x -= (distanceTravelled * Mid.DELTA_X);
};
这两个类之间的唯一区别是 Mid 类的 DELTA_X 常量值为 0.64,这是为了确保图层的滚动速度比 far 层快。保存更改。
我们应该测试视口并确保设置其位置反映在我们的视差层中。首先,我们需要打开 index.html 并删除 scrolller 的 update() 方法:
function update() {
scroller.update(); // 删除
renderer.render(stage);
requestAnimationFrame(update);
}
保存 index.html 文件并在浏览器中测试更改。你应该注意到你只能看见视差层,但都没有滚动。那是因为我们没有添加任何代码来真正更改视口的水平位置。目前它固定在默认的 x 位置 0。
在我们添加代码之前,我们可以在 Chrome 的 JavaScript 控制台中测试一下我们的滚动条的 setViewportX() 实际上是有效的。
scroller.setViewportX(50); /// 控制台中调用
JavaScript 控制台可以访问程序中的任何全局变量。因此,我们可以通过全局
scroller变量访问滚动条并调用其setViewportX()方法。
你应该看到视差图层向左移动,这表示我们已成功重新定位了视口。
尝试将视口移动到 x = 7000 的位置 :
scroller.setViewportX(7000);
很明显,我们可以通过不断更新滚动器的视口位置来模拟游戏世界中的移动。我们可以在主循环中执行此操作,但是我们得够获取视口的当前水平位置。让我们继续为 Scroller 类添加一个新方法。
目前来讲我们的 Scroller 类并没存储当前视口位置,我们需要一个成员变量来实现它。
打开 Scroller.js 并在构造函数中定义以下成员变量:
function Scroller(stage) {
this.far = new Far();
stage.addChild(this.far);
this.mid = new Mid();
stage.addChild(this.mid);
this.viewportX = 0; // 水平滚动量
}
并在 setViewportX() 方法中更新 viewportX 成员变量的值:
Scroller.prototype.setViewportX = function(viewportX) {
this.viewportX = viewportX; // 更新
this.far.setViewportX(viewportX);
this.mid.setViewportX(viewportX);
};
完成后,我们可以编写一个 getViewportX() 方法,该方法将返回视口的当前位置:
Scroller.prototype.setViewportX = function(viewportX) {
this.viewportX = viewportX;
this.far.setViewportX(viewportX);
this.mid.setViewportX(viewportX);
};
// 新方法
Scroller.prototype.getViewportX = function() {
return this.viewportX;
};
保存你的代码。
现在要做的就是不断更新滚动器的视口位置。我们将在主循环中执行此操作。
打开 index.html,只需添加以下两行代码:
function update() {
var newViewportX = scroller.getViewportX() + 5; // 添加
scroller.setViewportX(newViewportX); // 添加
renderer.render(stage);
requestAnimationFrame(update);
}
第一行获取视口的 x 位置并将其增加 5 个单位。第二行采用新值并更新视口的当前 x 位置。从本质上讲,它会强制视口在每次调用主循环时滚动 5 个单位。
保存代码并在 Chrome 中运行它。你应该会再一次看到视差层向外滚动。试试不同的滚动速度看。例如,将视口增加 15 个单位而不是 5 个单位。
让我们在 Scroller 类中再添加一个方法 moveViewportXBy,可以将视口从其当前位置移动指定的距离。这将让主循环看起来更加简洁。
在保存更改之前,打开 Scroller.js 并添加以下方法:
Scroller.prototype.getViewportX = function() {
return this.viewportX;
};
// 添加新方法
Scroller.prototype.moveViewportXBy = function(units) {
var newViewportX = this.viewportX + units;
this.setViewportX(newViewportX);
};
就像我们之前做过的一样,这个新方法不难理解。它只是计算出视口的新位置然后调用类的 setViewportX() 方法来实际设置视口位置。
移回 index.html 并删除以下行:
function update() {
var newViewportX = scroller.getViewportX() + 5; // 删除
scroller.setViewportX(newViewportX); // 删除
renderer.render(stage);
requestAnimationFrame(update);
}
用 moveViewportXBy() 方法的单行替换它们:
function update() {
scroller.moveViewportXBy(5); // 调用新的方法
renderer.render(stage);
requestAnimationFrame(update);
}
保存更改并在 Web 浏览器中测试更改。
本系列教程的第二部分即将结束。在我们完成之前,让我们回顾下 index.html 并做最后一个重构。
虽然我们已经完成了减少对全局变量的依赖的这样一项令人敬重的工作,但我们的 index.html 文件仍然有一些零散的全局变量。实际上,在大型应用程序中,将尽可能多的 JavaScript 与 HTML 页面分开也是一种很好的做法。虽然我们的 HTML 页面中没有多少 JavaScript,但我们可以做得更好。让我们把代码单独封装在一个与自己类名相同的文件中。这样,我们当前所依赖的全局变量将封装到类的成员变量中。
创建一个新文件并将其命名为 Main.js。
为类创建构造函数,并将HTML页面的 init() 函数中的代码放入其中:
function Main() {
this.stage = new PIXI.Container();
this.renderer = PIXI.autoDetectRenderer(
512,
384,
{view:document.getElementById("game-canvas")}
);
this.scroller = new Scroller(this.stage);
requestAnimationFrame(this.update.bind(this));
}
注意上面使用 this 关键字。我们使用它来定义 stage,renderer 和 scroller 作为成员变量。
this 关键字也用于调用 JavaScript 函数 requestAnimationFrame()。代码大概是这样:
requestAnimationFrame(this.update.bind(this));
这里使用它来指定我们的类名为 update() 的方法(我们仍然要写这个方法)将在下一次重绘时调用。另外,还调用另一个你可能不熟悉的名为 bind() 的JavaScript 函数。它用来保证在调用 update() 时它正确地访问到 Main 类的实例。如果不用 bind(),update() 方法将无法访问和使用任何 Main 类的成员变量。
好吧,让我们实际编写我们的类的 update() 方法。它将只包含我们原来 HTML 页面的 update() 函数中的代码:
Main.prototype.update = function() {
this.scroller.moveViewportXBy(Main.SCROLL_SPEED);
this.renderer.render(this.stage);
requestAnimationFrame(this.update.bind(this));
};
我们再次使用了 this 关键字,而且利用了JavaScript 的 bind() 函数来确保我们的更新循环始终在正确的作用域下。
另外,请注意上面的代码在调用 scrolller 的 moveViewportXBy() 方法时使用了一个名为 SCROLL_SPEED 的常量。以前我们刚刚传递了一个硬编码值。我们实际可以将该常量添加到 Main 类中做为静态常量。在构造函数后面直接添加以下行:
requestAnimationFrame(this.update.bind(this));
}
Main.SCROLL_SPEED = 5; // 添加
Main.prototype.update = function() {
好的,保存你的代码。
现在让我们打开 index.html 并删除以前的老代码。
删除以下行:
<!-- 全部删除 -->
<script>
function init() {
stage = new PIXI.Container();
renderer = PIXI.autoDetectRenderer(
512,
384,
{view:document.getElementById("game-canvas")}
);
scroller = new Scroller(stage);
requestAnimationFrame(update);
}
function update() {
scroller.moveViewportXBy(5);
renderer.render(stage);
requestAnimationFrame(update);
}
</script>
用一个简单的实例化 Main 类的新 init() 函数代替:
<script>
function init() {
main = new Main();
}
</script>
最后,通过添加以下行来引用到类 :
<script src="https://cdnjs.cloudflare.com/ajax/libs/pixi.js/4.0.0/pixi.min.js"></script>
<script src="Far.js"></script>
<script src="Mid.js"></script>
<script src="Scroller.js"></script>
<script src="Main.js"></script> <!-- 添加 -->
保存你的工作并测试仍在 Google Chrome 中运行的所有内容。
我们已经成功地将所有内容都移到了一个主应用程序类中,而 index.html中只剩下几行 JavaScript 来解决所有问题。
哇哦!我们这一节涉及到了很多内容。虽然最终结果是相同的(我们仍然只有两个滚动视差层),但我希望你能看到重构代码的好处。现在一切都比干净了很多,我们有一个用于管理视差层的 Scroller 类。虽然这次我们的重点不是 pixi.js,但你至少应该体会到扩展 Pixi 展示对象类的好处。
所有这些变化都处于理想的位置,可以在此基础上开发第三个更复杂的视差层了。这个图层将作为游戏世界的 地图,并将由一系列 精灵 构建,而不是简单的重复纹理。我们将把目标放在 pixi.js 上,将涉及各种各样的好东西,包括精灵表(Spritesheet),纹理帧(texture frames)和对象池(object pooling)。
记得 GitHub 上提供了本系列和本系列教程的源代码哦。
第三部分 见。
1970-01-01 08:00:00
原文: PART 1・ PART 2・ PART 3・ PART 4
关注 @chriscaleb
这个系列的教程已经更新到了 PixiJS v4 版本。
曾经玩过 Canabalt 和 Monster Dash,好奇他们是如何构建一个滚动游戏地图的?在这个教程中我们将向「构建一个视差滚动器」迈出第一步,我们将使用 JavaScript 和 pixi.js 这个 2D 渲染引擎。
JavaScript 无处不在,由于浏览器的不断改善和大量的 JavaScript 库,我们真的开始看到 HTML5 游戏领域开发蓬勃发展。但是当有很多库可用的时候,选择合适的并非易事。
这个系列的教程将向你介绍 JavaScript 游戏开发的基础,我们会聚焦到 pixijs。它是一个支持 WebGL 和 HTML5 Canvas 的渲染框架。教程最后你将完成如下的一个视差滚动地图程序:
点击上面的链接启动最终版的程序,这就是你将要完成的。注意它包含了三个视差层:一个远景(far)层,一个中间(mid)层,一个前景(foreground)层。在第一篇教程中我们将集中精力构建远景层和中间层。当然为了做到这一点教程必须涉及 pixi.js 的基础,当然如果你还是个 JavaScript 新手,这会是个很好的开始学习 HTML5 游戏编程的地方。
开始之前,点击上面的链接预览下这篇教程中将做成的效果。你也可以从 github 上下载这个程序的 源代码。
为了完成编码,你需要一个代码编辑器,我将使用一个体验版的 sublime text,可以在 这里 下载到。
还需要一个浏览器来测试你的程序。任何现代浏览器都可以,我将用 Google Chrome,开发过程中将会涉及到一些开始者工具的使用。如果你还没有安装 Chrome,可以去 这里 下载。
为了测试你的程序,你还需要在你的开发机上安装一个 web 服务器。如果你用的是 Window,可以 安装 IIS,macOS 用户可以配置下系统默认的 Apache,如果你的系统是 OS X Mountain Lion 配置 web 服务器可以会比较麻烦,可以参考这个 教程。
如果你有自己托管的 web 服务器,就可以直接上传所以文件来测试,或者如果你有一个 Dropbox 账号,你可以通过 DropPages 服务来托管你的文件。
web 服务器建好后,创建一个目录 parallax-scroller 如果你使用 Windows。你的 web 服务器根目录应该类似 C:\inetpub\parallax-scroller 。如果你使用 OS X 则应该是 /Users/your_user_name/Sites,your_user_name 就是你电脑的用户名。
最后,在教程中我们将使用几个图片素材,不用你自己去找,我已经为你打包好了一个 zip 文件,下载并解压好你的 parallax-scroller 目录。
下面就是你的 parallax-scroller 文件夹的样子(Windows):
如果你用的是 Mac OS X 则应该如下图:
现在我们已经准备好开始写代码了,启动 Sublime Text 2 或者你最喜欢的编辑器。
所有的 pixijs 项目都以一个 HTML 文件开始。在这里我们将创建一个 canvas 元素以及引入 pixi.js 库。canvas 元素表示HTML页面上将呈现滚动条的区域。
在你的项目根目录 parallax-scroller 下使用编辑器新建一个文件,命名为 index.html,并写入下面的代码:
<html>
<head>
<meta charset="UTF-8">
<title>Parallax Scrolling Demo</title>
</head>
<body>
</body>
</html>
现在看起来还非常奇怪,我们的 HTML 页面只有一个 <head> 和 <body> 元素。
现在让我们在页面上添加 HTML5 Canvas 元素,在 body 元素中添加如下的代码:
<body>
<div align="center">
<canvas id="game-canvas" width="512" height="384"></canvas>
</div>
</body>
我们指定了 canvas 宽度 512 像素,高度 384 像素。这就是 pixi.js 为库渲染游戏的地方。注意我们给 canvas 了一个 id 属性,值为 game-canvas 这将使我们易于控制它,当 pixi.js 启动时也需要它
现在启动你的 web 服务器,在 浏览器中打开类似 http://localhost/parallax-scroller/index.html 或者 http://localhost/~your_user_name/parallax-scroller/index.html 的链接
你会发现并没有什么东西,我们来给 canvas 加点样式(style 标签):
<html>
<head>
<meta charset="UTF-8">
<title>Endless Runner Game Demo</title>
<style>
body { background-color: #000000; }
canvas { background-color: #222222; }
</style>
</head>
<body>
</body>
</html>
保存并刷新,你将会看见一个水平居中的灰色区域出现在页面上。
在
<script src="https://cdnjs.cloudflare.com/ajax/libs/pixi.js/4.0.0/pixi.min.js"></script>
</body>
Pixi.js 库文件托管在 CDN 上,URL 上的 4.0.0 表示库的版本号,你可以替换成其它的发行版。
给 body 元素添加 onload="init(); 表示页面加载完成时调用 init 方法。我们在 script 标签中添加一个 init 方法
<body onload="init();">
<div align="center">
<canvas id="game-canvas" width="512" height="384"></canvas>
</div>
<script src="pixi.js-master/bin/pixi.dev.js"></script>
<script>
function init() {
console.log("init() successfully called.");
}
</script>
</body>
打开 Chrome Console,Windows 下按 F12,macOS 下按 Cmd + Opt + i。正常的话控制台就会有下面的输出:
> init() successfully called.
现在这个 init 方法做的事情还很少,最终它将做为入口负责你程序的调用。
我们在 init 方法中需要做下面两件事情:
我们先来创建一个舞台对象,如果你是个 Flash 开发者,你可能会对舞台的概念比较熟悉了。基本上舞台就是你游戏的图形内容呈现的地方。另一方面,渲染器控制舞台并且把游戏绘制到你的 HTML 页面中的 canvas 元素上,这样你的做的东西才最终呈现给了用户。
我们来创建一个舞台对象并将它关联到一个名字叫做 stage 的全局变量上。并且删除之前的 log 语句:
function init() {
console.log("init() successfully called.");
stage = new PIXI.Container();
}
pixi.js 的 API 包含了一些类和函数,并且被保存在 PIXI 模块命名空间下面。PIXI.Container 类用来表示一些 展示对象(display object) 的集合,同样也可以表示舞台这个根展示对象。
现在我们已经创建好了一个舞台,我们还需要一个渲染器。Pixi.js 支持两种渲染器:WebGL 和 HTML5 Canvas。你可以通过 PIXI.WebGLRenderer 或者 PIXI.CanvasRenderer 来分别创建它们各自的实例。然而,更好的做法是让 Pixi 为你判断浏览器自动检测并使用正确的渲染器。Pixi 默认会尝试使用 WebGL,如果不支持则回滚到 canvas。我们调用用 Pixi 的 PIXI.autoDetectRenderer() 函数来自动帮我们选择合适的渲染器。
function init() {
stage = new PIXI.Container();
renderer = PIXI.autoDetectRenderer(
512,
384,
{view:document.getElementById("game-canvas")}
);
}
autoDetectRenderer() 函数需要传入渲染舞台上 cavnas 的宽度和高度,以及 cavnas 元素的引用,它返回 PIXI.WebGLRenderer 或 PIXI.CanvasRenderer 的实例,我们将其保存在名为 renderer 的全局变量中。
在上面的代码中,我们通过一个包含 view 属性的 JavaScript 对象来传递给 autoDetectRenderer 方法,表示 canvas 元素的引用。我们传递这个对象做为函数的第三个参数而不是直接传 canvas 对象的引用。
我们使用了硬编码的方式指定了宽,高,实际上可以直接通过 canvas 元素取得这两个值:
var width = document.getElementById("game-canvas").width;
为了能看到舞台上的内容,你得指导你的渲染器把舞台上的内容真正的绘制到 canvas 上。可以通过调用 renderer 的 render 方法,并传入舞台对象的引用来做到:
function init() {
stage = new PIXI.Container();
renderer = PIXI.autoDetectRenderer(
512,
384,
{view:document.getElementById("game-canvas")}
);
renderer.render(stage);
}
这将成功的把舞台渲染到浏览器中。当然我们还没有给舞台上添加任何东西,所以你还看不出来
现在你的舞台已经建成,让我们继续往上面添加一些实际的东西。毕竟我们不想一直只到一个黑色的窗口。
舞台上的东西被添加到一个 树型结构 的展示列表中。你的舞台扮演着这些展示列表的根元素的角色,同时展示列表也会有栈顺序的问题,这意味着有的对象展示在别的对象上面,这由他们被设计的索引深度决定。
有很多种类的 展示对象(display object) 可以被添加到 展示列表 中,最常见的是 PIXI.Sprite,它可以添加图片素材。
由于这个教程是关于创建视差滚动背景的,让我们来添加一个表示远景层的图片。 我们将以添加一行代码来加载 bg-far.png 文件,这个文件在 resources 目录中:
function init() {
stage = new PIXI.Container();
renderer = PIXI.autoDetectRenderer(
512,
384,
{view:document.getElementById("game-canvas")}
);
var farTexture = PIXI.Texture.fromImage("resources/bg-far.png");
renderer.render(stage);
}
图片素材被加载并保存为纹理(textures),这个纹理可以随后被符加到一个或者多个精灵上面。在上面的代码中我们调用了静态 PIXI.Texture.fromImage() 方法来创建一个PIXI.Texture 实例并将 bg-far.png 文件加载到其中。为了方便使用,我们将纹理引用赋值给名为 farTexture 的局部变量。
现在让我们创建一个精灵并将纹理附加到它上面。并将精灵定位在舞台的左上角:
function init() {
stage = new PIXI.Container();
renderer = PIXI.autoDetectRenderer(
512,
384,
{view:document.getElementById("game-canvas")}
);
var farTexture = PIXI.Texture.fromImage("resources/bg-far.png");
far = new PIXI.Sprite(farTexture);
far.position.x = 0;
far.position.y = 0;
renderer.render(stage);
}
PIXI.Sprite 类用于创建精灵。它的构造函数将接收一个纹理的引用参数。我们使用了一个名为 far 的全局变量,并将新创建的 sprite 实例存储在其中。
聪明的你可能已经发现我们是如何使用 position 属性将精灵的 x 和 y 坐标设置到舞台的左上角的。舞台的坐标从左到右,从上到下,这意味着舞台的左上角位置为(0,0),右下角为(512,384)。
精灵有一个轴心点(pivot),它们可以来回旋转。轴心点也可以用来定位精灵。精灵的默认轴心点设置为左上角(0,0)。这就是为什么当我们的精灵定位在舞台的左上角时,我们将其位置设置为(0,0)。(译者:如果你将轴心点设置到正中央,那位置是(0,0)的精灵就会展示不全)
最后一步是将精灵添加到舞台上。这是使用 PIXI.Stage 类的(实例方法) addChild() 方法完成的。来看看怎么做吧:
var farTexture = PIXI.Texture.fromImage("resources/bg-far.png");
far = new PIXI.Sprite(farTexture);
far.position.x = 0;
far.position.y = 0;
stage.addChild(far);
renderer.render(stage);
}
好的,保存你的代码并刷新浏览器。你可能已经满坏期望能看到背景图,但实际上可能看不到。为什么呢?在素材纹理被加载完成之前就渲染它可能并不能有任何效果。因为纹理加载是需要一小段时间的。
我们可以通过简单地等一段时间,然后再次调用 render 方法来解决这个问题。通过 Chrome 的控制台执行下面的代码即可:
renderer.render(stage);
由于我们之前声明的
renderer是全局变量,所以你能在 console 中直接使用它。console 中可以使用任何 JavaScript 中声明的全局变量。
恭喜你!现在应该看到紧贴在屏幕顶部的背景图层了。
现在让我们继续添舞台上的中间层:
var farTexture = PIXI.Texture.fromImage("resources/bg-far.png");
far = new PIXI.Sprite(farTexture);
far.position.x = 0;
far.position.y = 0;
stage.addChild(far);
var midTexture = PIXI.Texture.fromImage("resources/bg-mid.png");
mid = new PIXI.Sprite(midTexture);
mid.position.x = 0;
mid.position.y = 128;
stage.addChild(mid);
renderer.render(stage);
保存代码并刷新浏览器。你需要再次手动在 Chrome 控制台中调用渲染方法才能看到两个层:
renderer.render(stage);
因为中间层是在远景层 之后 加入的,所以它离我们更进,或者说有更高的层深度。也就是说每次调用 addChild() 方法添加的展示对象都会在上一次添加的对象之上。
我们在这一节的教程中将只会聚焦到远景层和中间层的展示,后面的几节中,我们会实现更复杂的前景层
现在我们有两个背景图层,我想我们可以尝试实现一些视差滚动,并且还可以找到一种渲染内容的方法,而不用从 JavaScript 控制台中手动执行。
为了避免疑惑,让我们快速解释下究竟是什么视差滚动。这是一种用于视频游戏的滚动技术,其中背景层在屏幕上移动的速度比前景层慢。这样做会在2D游戏中产生一种幻觉,并让玩家更有沉浸感(更真实)。
根据上面这些信息,我们可以将它应用于我们的两个精灵层,来生成一个水平视差滚动器,我们将背景层移动到屏幕上的速度比中间层慢一点。为了能让每个层都滚动,我们将创建一个主循环,我们可以不断改变每个层的位置。为了实现这一点,我们将使用 requestAnimationFrame() 的帮助,这是一个 JavaScript 函数,它能决定浏览器的最佳帧速率,然后在下一次重绘 canvas/stage 时调用指定的函数。我们还将使用这个主循环来 不断地 呈现我们的内容。
var midTexture = PIXI.Texture.fromImage("resources/bg-mid.png");
mid = new PIXI.Sprite(midTexture);
mid.position.x = 0;
mid.position.y = 128;
stage.addChild(mid);
renderer.render(stage);
requestAnimationFrame(update);
上面的代码,我们指定了一个 update 函数,如果你想连续调用 requestAnimationFrame() ,这将使得你的 update 方法每秒调用 60 次。或者通常称为每秒 60 帧(FPS)。
我们还没有 update 函数,但是在实现它之前,先删除渲染方法的调用,因为主循环中会处理这个逻辑。
var midTexture = PIXI.Texture.fromImage("resources/bg-mid.png");
mid = new PIXI.Sprite(midTexture);
mid.position.x = 0;
mid.position.y = 128;
stage.addChild(mid);
renderer.render(stage); // 删除它
requestAnimationFrame(update);
好吧,让我们来编写主循环并让它稍微改变两个层的位置,然后渲染舞台的内容,这样我们就可以看到每个帧重绘的差异。在 init() 函数之后直接添加 update() 函数:
function update() {
far.position.x -= 0.128;
mid.position.x -= 0.64;
renderer.render(stage);
requestAnimationFrame(update);
}
前两行代码更新了远景层和中间层精灵的水平位置。请注意,我们将远层向左移动0.128 像素,而我们将中间层向左移动 0.64 像素。要向左移动某些东西,我们得使用负值,而正值则会将其移动到右侧。另外请注意,我们将精灵移动了 小数 像素。 Pixi 的渲染器可以存储它们并使用子像素来处理它们位置。当你想要非常缓慢地在屏幕上轻推东西时,这是理想的选择。
在循环结束时,我们再次调用 requestAnimationFrame() 函数,以确保在下次再次绘制画布时自动再次调用 update()。正是它确保了我们的主循环被连续调用,从而能确保我们的视差层在屏幕上稳定移动。

保存代码并刷新浏览器看看它长什么样子。你应该看到两个图层自动呈现在屏幕上。此外,当两个图层都在移动时,中间层实际上比远景层更快地移动,从而为场景提供深度感。但是你也应该发现有一个明显问题:当每个精灵移出屏幕的左侧时,它会向右边留下一个间隙。换句话说,两个图层的图形都没有循环,以给出连续滚动的错觉。还好,有一个解决方案。
到目前为止,我们已经学会使用 PIXI.Sprite 类来表示展示列表中的对象。然而,pixi.js 还提供了几个其他 展示对象 以满足不同的需求。
如果你细心的观察一下 bg-far.png 和 bg-mid.png 的话,你应该注意到这两个图像都设计成可以水平平铺的(译:平铺就好比瓦片)。检查每个图像的左右边缘。你可以发现,最右边的边缘完美地匹配连接到最左边的边缘。换句话说,两个图像都被设计成无缝循环的。
因此,如果有一种方法可以简单地移动每个精灵的纹理以给出他们正在移动的错觉,而不是物理地移动我们的远景层和中间层精灵的位置,这不是很好吗?值得庆幸的是 pixi.js 提供了 PIXI.extras.TilingSprite 类,它就是用来做这个的。
所以,让我们对代码进行一些调整,来使用瓦片精灵。我们首先关注远景层。继续从建立函数中删除以下行:
var farTexture = PIXI.Texture.fromImage("resources/bg-far.png");
far = new PIXI.Sprite(farTexture); // 删除它
far.position.x = 0;
far.position.y = 0;
stage.addChild(far);
替换成这样:
far = new PIXI.extras.TilingSprite(farTexture, 512, 256);
然后设置他们的位置:
far.tilePosition.x = 0;
far.tilePosition.y = 0;
在继续之前,让我们讨论 TilingSprite 类的构造函数及它的 tilePosition 属性。
和 Sprite 类的单个参数比较,您会注意到 TilingSprite 类的构造函数需要 3 个参数:
far = new PIXI.extras.TilingSprite(farTexture, 512, 256);
它的第一个参数与之前相同:纹理的引用。第二个和第三个参数分别表示瓦片精灵的宽度和高度。通常,将这两个参数设置为 纹理 的宽度和高度,比如 bg-far.png 为 512 x 256 像素。
我们又一次的硬编码的传入了两个宽高参数,可以通过下面的方法改善:
far = new PIXI.extras.TilingSprite(
farTexture,
farTexture.baseTexture.width,
farTexture.baseTexture.height
);
我们还利用了平铺精灵的 tilePosition 属性,该属性用于偏移精灵纹理的位置。换句话说,通过调整偏移量,就可以水平或垂直地移动纹理,并使纹理环绕。本质上,你可以模拟滚动而无需实际更改精灵的位置。
我们将精灵的 tilePosition 属性默认设置为(0,0),这意味着远景层的外观在初始化的状态下没有变化:
far.tilePosition.x = 0;
far.tilePosition.y = 0;
剩下要做的就是通过不断更新精灵的 tilePosition 属性的水平偏移来模拟滚动。为此,我们将对 update() 函数进行更改。首先删除以下行:
function update() {
far.position.x -= 0.128; // 删除它
mid.position.x -= 0.64;
renderer.render(stage);
requestAnimationFrame(update);
}
替换成下面这样:
function update() {
far.tilePosition.x -= 0.128;
mid.position.x -= 0.64;
renderer.render(stage);
requestAnimationFrame(update);
}
现在保存 index.html 并再次刷新浏览器。你将看到远景层无缝滚动并一直重复着,这和我们的预期结果的一样。
好的,让我们继续为中间层做出相同的修改。以下是进行更改后 init() 函数:
function init() {
stage = new PIXI.Container();
renderer = PIXI.autoDetectRenderer(
512,
384,
{view:document.getElementById("game-canvas")}
);
var farTexture = PIXI.Texture.fromImage("resources/bg-far.png");
far = new PIXI.extras.TilingSprite(farTexture, 512, 256);
far.position.x = 0;
far.position.y = 0;
far.tilePosition.x = 0;
far.tilePosition.y = 0;
stage.addChild(far);
var midTexture = PIXI.Texture.fromImage("resources/bg-mid.png");
mid = new PIXI.extras.TilingSprite(midTexture, 512, 256);
mid.position.x = 0;
mid.position.y = 128;
mid.tilePosition.x = 0;
mid.tilePosition.y = 0;
stage.addChild(mid);
requestAnimationFrame(update);
}
现在继续对 update() 函数进行以下重构:
function update() {
far.tilePosition.x -= 0.128;
mid.tilePosition.x -= 0.64;
renderer.render(stage);
requestAnimationFrame(update);
}
保存并测试你的代码。这次你应该看到两个图层完全地滚动,同时环绕屏幕的左右边界。
我们已经介绍了pixi.js 的一些基础知识,并了解了 PIXI.extras.TilingSprite 如何用于创建无限滚动图层的。我们还看到了如何使用 addChild() 将瓦片精灵堆叠在一起以产生真实的视差滚动。
我建议你继续尝试使用 Pixi 并查看它的文档和代码示例。两者都可以在 PixiJS 官方网站 上找到。
虽然我们有一个水平视差滚动器并且能运行起来,但它仍然有点简单。下次我们将介绍 视口 和 世界 位置的概念,如果你想最终将你的卷轴添加到游戏中,这两个都很重要。它还将使我们处于添加前景层的良好位置,这将代表一个简单的平台游戏地图。
我们将花很多时间来重构现有的代码库。我们将采用更加面向对象的架构,摆脱目前对全局变量的依赖。在下一个教程结束时,所有滚动功能都将整齐地包含在一个类中。
我希望这个教程能帮助到你,也希望下次能在 第二部分 中见到你。
1970-01-01 08:00:00
本文将会讲述一个完整的跨端桌面应用 代码画板 的构建,会涉及到整个软件开发流程,从开始的设计、编码、到最后产品成型、包装等。
本文不仅仅是一篇技术方面的专业文章,更会有很多产品方面的设计思想和将技术转换成生产力的思考,我将结合我自己的使用场景完全的讲解整个开发流程,当然涉及到设计方面的不一定具有普遍实用性,多数情况下都是我自己的一些喜好,我只关心自己的需求。
同时本文只从整体上讲思路,也会有个别的技术细节和常规套路,有兴趣的也可以直接去 github 上看 源码,文章会比较长,如果你只想知道一些拿来即用的「干货」,或许这篇文章并不是一个好的选择
事情的起因是这样的,因为我们内部会有一些培训会议。会经常现场演示一些代码片段。比如说我们讲到 React 的时候会现场写一些组件,让大家能直观的感受到 React 的一些功能。
但是通常由于条件所所限,会议总会遇到一些意外。比如断网、投影分辨率低看不清文字等
起初我们用的是在线版的 codepen,但是感觉并不是那么好用。比如不能方便的修改字体大小,必须要在连网的情况下才能使用。另外它的 UI 设计不是很紧凑,通常我们展示代码的时候都投影是寸土寸金的,应该有一个简洁又不失功能的 UI 界面,能全屏展示…
于是我解决自己实现一个这样的轮子,那么大概的需求目标是有了:
代码画板解决的是 临时性 的一些 演示代码 的需求,所以它的本质属性是一个拿来即用的工具,它不应该有更复杂的功能,比如用户登录、代码片段的管理等。这些需求不是它要解决的。代码画板会提供一个简单的导出成 HTML 文件的功能,可以方便用户存储整个 HTML 文件。
既然是用来演示代码的,那么它的界面上应该只有两个东西,一个是 代码,一个就是 预览。像代码/控制台切换的功能都做成 tab 的形式,正常情况不需要让他们展示出来。像 codepen 那样把所有的代码编辑器功能都展示出来我认为是不对的。
codepen 的界面给人感觉非常复杂,有很多功能点。当然我并不是在批评它,codepen 做为一个需要商业化运营的软件,势必会做的非常复杂,这样才能满足更多用户的需求。然而程序员写软件则可以完全按照自己的想法来,哪怕这个应用只给自己一个人用呢。
桌面应用的设计和 web 界面的设计还是有些细微区别的,同样的基于 electron 的应用,有的应用会让人感觉很「原生」,有的则一眼就能看出来是用 CSS 画的。我在设计代码画板的时候也尽量向原生靠近,避免产生落差感。比如禁用鼠标手型图标、在按钮或者非可选元素上禁止用户选择:
cursor: default;
user-select: none
因为实际上用户在使用一款应用的时候感性的因素影响占很大一部分,比如说有人不喜欢 electron 可能就是因为看到过 electron 里面嵌一个完整的 web 页面的操作,这就让人很反感。但是这不是 electron 的问题,而是应用设计者的问题。
说实话应用 logo 设计我也是业余水平,但是聊胜于无。既然水平不行,那就尽量设计的不难看就行了。可以参考一些好的设计。我用 sketch 画出 logo 的外形,sketch 有很多 macOS 的模块可以从网上下载下来,直接基于模板修改就可以了。
代码画板主要的界面是分割开的两个面板,左边是代码,右边是预览。所以我就大概画了一个形状

这个 logo 有个问题就是线条过多,小尺寸的时候看不清楚。这个问题我暂时先忽略了,毕竟我还不是专业的,后续有好的创意可以再改
代码画板也 不会有 设置界面,因为常用的设置都预定义好了,你不需要配置。顶多改变下代码字体的大小。使用编辑器的通用快捷键 command++/- 就解决了,或者插入三方库,直接使用编辑器的通用命令快捷键 command+p 调出。我们的思路就是把复杂的东西帮用户隐藏在后台,观众只需要关注演员台上的一分钟,而不必了解其它细节。
由于代码画板的界面非常简单,在一些细小的必要功能就得添加一些快捷键。比如:切换 HTML/CSS/JS/Console 代码编辑器,我在每个 tab 上加了数字标号,暗示它是有顺序有快捷键的,而且这个切换方式和 Chrome tab 切换的逻辑一致,使用 command+数字 就可以实现,万一还是有人不会用的话,可以去看帮助文档。里面有所有的快捷键。

界面中间的分割条可以自定义拖动,双击重置平分界面
刚开始的时候我把每个 tab 页签都分割成单独的面板,因为我觉得这个能拖动自定义面板大小的交互实在是太爽了,忍不住想去拖动它。但是后来想想,其实并没有必要,我们写代码时应该更专注于代码本身,如果只有两个面板,那么这个界面无论是认知还是使用起来就没有任何困难。
因为我们并不需要把一堆的功能的界面摔给用户,让他们自己去选择。
通过使用流行的几款在线代码运行工具,我发现他们有一个共同的问题:控制台很难用。无法像 Chrome Console 那样展示任意类型的 JS 值。比如我想 log 一段嵌套的 JS 对象:
console.log({ a: { b: 1, c: { d: [1, 2, 3] } }})
大多数都展示成这样的:
[object Object] {
a: [object Object] {
b: 1
}
}
Chrome 是这样的:

显然 Chrome 控制台中更直观。所以我们需要在前面的基础上加一个需求,即:实现一个基于 DOM 的日志展示界面(无限级联选择)
日志界面应该有下面这些功能:
现代化的前端写页面肯定不是 HTML/CSS/JS 一把梭了,至少应该有 Sass/Babel 的支持吧。
Sass 嵌套能让你少写很多选择器,当然 Less 也可以,但是在我们的这个应用里面区别不大,一般来说临时性的写一些代码很少会用到它们的细节功能。有 变量 和 选择器 嵌套就够了
Babel 主要是解决了写 React 的问题,不用再安装一大堆的构建工具了,直接使用 UMD 的 React/ReactDOM 就可以了,而且 electron 内嵌的 chromium 也支持了 es6 的 class 写法,实际上 Babel 主要的目的还是用来转译 JSX
注意这里是有一个我认为是 刚性 的需求,比如临时忽然有个想法,或者想验证一段代码的话,正常情况是使用你的编辑器,新建 demo.html/demo.css/demo.js 等这些操作。但是这些动作太浪费时间了。有了代码画板以后,直接打应用就可以开始 coding 了,真正能做到开箱即用。
我们在写 demo 页面时通常是要引用很多第三方类库的,比如:Bootstrp/jQuery 等。我希望有一种方法可以方便的引用到这些库,直接把库文件的 link/script 标签插入到代码画板的 HTML 中,但是前端框架真的是太多了,又不能一个个去扣来写死到页面,就算是写死了随着框架版本的升级,可能就无法满足我们的需求。
以前写页面时经常会用到 bootcdn,无意中发现它提供了相关 API,可以直接拿来使用。接下来就得想办法让用户通过界面选择即可。
这个 API 有三层数据结构:库 - 版本 - 资源链接。这个功能要用界面来实现肯定会非常臃肿,界面上可能会放很多按钮。这就违背了「更简洁」的需求目标。
这时就得参考下我们经常使用的一些软件是如何解决 简洁性 和 功能性 需求之间的矛盾问题的,我比较喜欢 Sublime Text 的一些界面设计,Command Palette 是我经常使用的,所以我决定再模拟一个 Command Palette 来实现插入第三方库的需求。而且重要的是这个 Command Palette 并不一定只用来实现这一个功能,或者后期会有一些别的功能需要添加,那这个 Command Palette 也是个很好的入口。
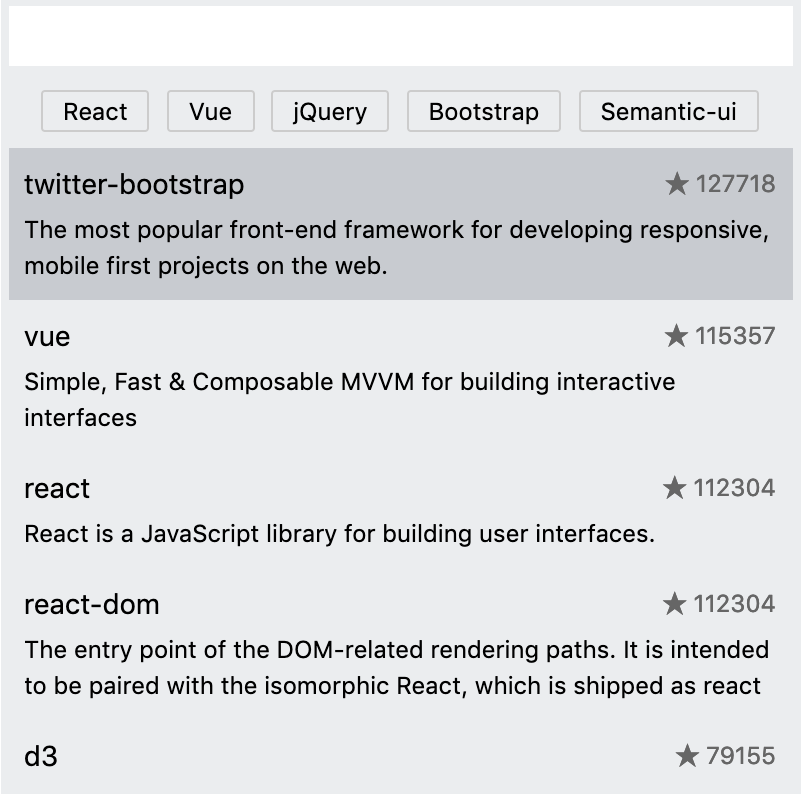
实现离线可用很多方法,比如使用 PWA 技术。但是 PWA 并不能给我带来一种原生应用的那种可靠感,相反 electron 刚好可以解决我的顾虑。同时它可以把你的应用打包成各个平台(macOS/Window/Linux)的原生应用。唯一的缺点就是安装包确实很大,一般来讲一个 electron 应用 安装完 至少要 100 多兆,不过我觉得还能接受,毕竟硬盘存储现在已经很廉价了。
有人可能对 electron 有抗拒,觉得 electron 应用太庞大、占系统资源什么的,不过我们做的这个应用并不需要常驻系统,临时性的使用一下,用完就关闭,正常写生产环境的代码肯定还是要换回 编辑器/IDE 的。同时因为 electron 降低了写桌面应用的门槛,确实有很多人把一个完整的在线的网页直接嵌进去,这也是有问题的。
electron 还有一个好处,因为它完全基于 HTML/CSS/JS 来实现 UI(可以使用 Chrome only 的一些新功能),那我们理论上可以在做桌面应用时顺手把 web 应用也做了。这就可以同时支持各个系统下的原生应用,并且有 web 在线版本。如果你不愿意使用原生应用,直接登录 web.code-sketch.com 使用在线版也没是一种选择。这样就使得我们的应用具有真正的 跨端 能力。
由于我们团队都使用了 macbook,所以我优先支持 macOS 的开发,另外 macOS Mojave 的系统级别的暗色主题我也比较喜欢,刚好实现支持 mojave 暗色主题这个需求也做上。
大方向确定了,像框架选择这个就简单了,基于 electron 的应用,需要你区分开 render/main process 来选择。
渲染进程 就是 electron 中界面的实现部分 ,一般来说就是一个 webview,选自己喜欢的框架即可。我使用 React 来实现界面。样式方面就不再使用框架了,因为我们的界面原则上没有复杂的元素,直接手写 CSS,300 行内基本上就可以解决问题。可能有人会觉得这不可能,实际情况是当你写样式只跑在 Chrome 里面的时候那感觉完全爽到飞起,CSS variable/flex/grid/calc/vh/rem 什么的都可以拿来用,实现一个功能的成本就降低了很多。
我使用 Codemirror 来做为主界面的代码编辑器,Monaco 也是一个好选择,但是它有点过于庞大了,而且如果想要自定义功能得自己写很多实现
主界面上的分割组件,使用了 React-split。
主进程 就是 electron 应用程序的进程,主要的区别在于主进程中可以调用一些与原生操作系统交互的 API,比如对话框、系统风格主题等。并且有 node 的运行时,可以引用 NPM 包。当然渲染进程也可以有 node 支持,但是我建议渲染进程中就只放一些纯前端的逻辑,这样的话方便后期把应用分离成 web 版
因为我们要集成 Sass 编译功能,如果你也经历过 node-sass 的各种问题,那就应该果断选择 dart-sass — 使用 dart 实现,编译成了原生的 JS,没有依赖问题。dart-sass 我放在了 main process 中,因为我试过放在 render process 中会有各种报错。如果 web 端要实现这个功能就需要其它的解决办法了,比如做成一个 http 服务,让 web 调 http 服务。
Babel 的话我是放在了 渲染进程 中以 script 标签的方式调用,这样即使在 web 端 Babel 编译也是可用的。
总之如果你使用 electron 构建应用并且引入的第三方 NPM 包可以 支持 运行在客户端(浏览器)上,那就尽量把包放在渲染进程里面。
我使用 Parcel 来构建 React 而不是 Create React App。后者用来写个小应用还可以,稍微大一点的,需要定制化一些东西你就得 eject 出来一大堆 webpack 配置文件,即便是我已经用 webpack 开发过几个项目了,但是说实话我还是没用会 webpack。写 webpack 配置的时间足够我自己写 npm script 来满足自己的需求了。
使用 electron-builder 来打包到平台原生应用,并且如果你有 Apple 开发者账号的话应用还可以提交到 AppStore 上去。
我目前的打包参数是这么配置的:
{
"build": {
"productName": "Code Sketch",
"extends": null,
"directories": { "output": "release" },
"files": [
"icon.icns",
"main.js",
"src/*.js",
"所有需要的文件",
"package.json",
"node_modules/@babel",
"node_modules/sass"
],
"mac": {
"icon": "icon.icns",
"category": "public.app-category.productivity",
"target": [ "dmg" ]
}
}
}
在你的 package.json 中添加 build 字段,productName, directories 这些按自己需要更改即可
代码画板项目开过过程中涉及两个关键环境
import 这样的语句的,但是渲染进程由于你使用了 Parcel 编译,则无需考虑这里温馨提示下:想要做到 electron 中的 渲染进程与主进程之间共享 JS 代码是非常困难的。就算是有办法也会特别的别扭,我的建议是尽量分离这两个进程中的代码,主进程主要做一些系统级别的 API 调用、事件分发等,业务逻辑尽量放在渲染进程中去做
如果非要共享,那建议单独做成一个 NPM 包分别做为主进程运行时依赖,和渲染进程的 Parcel 编译依赖,唯一的缺点就是实际上共享的代码会有两份。
渲染进程中调用 node API 可能会和 Parcel 打包工具冲突,一般在调用比如文件模块时,可以加上 window.require(‘fs’) 这样就可以兼容两个环境:
get ipc() {
if (window.require) {
return window.require('electron').ipcRenderer
} else {
return { on() {}, send() {}, sendToHost() {} }
}
}
this.ipc.send('event', data)
这样的话你在浏览器端调试也不会产生报错。一般情况下,建议当你用渲染进程中的 JS 引用(require)包的时候都加上 window. 前缀就可以了。因为渲染进程中 window 是全局变量,调用 require 和调用 window.require 是等价的
通常在测试的时候应用会调用一些 electron 内置的系统级别 API,这部分调用通常需要启动 electron,但是有时候只有渲染进程中 UI 界面上的改动,就不用再启动 electron 了,直接在浏览器里面测试即可。使用 Parcel 运行一个本地的服务,这样就可以在浏览器里面调试页面。整个开发过程需要两个命令(NPM Script):
启动 Parcel 编译服务器
"scripts": {
"start": "./node_modules/.bin/parcel index.html -p 2044"
}
调试 electron 原生功能,注意设置 ELECTRON_START_URL
{
"scripts": {
"dev": "ELECTRON_START_URL=http://localhost:2044 yarn electron",
}
}
整个应用只有两个功能是需要我们自己写代码实现的:日志控制台,Sublime 命令行。我们分别来分析下这两个模块的难点。
日志控制台 的难点在于,我们需要打印任意类型的 JS 值。如果你对 JS 了解比较多的话自然会想到在 JS 中所有的东西都是 对象,即 Object,那么实际上当你想打印一个变量的时候,其实你只要把整个 Object 递归的遍历出来,然后做成一个无限级的下拉菜单就可以了。看起来大概想下面这样:
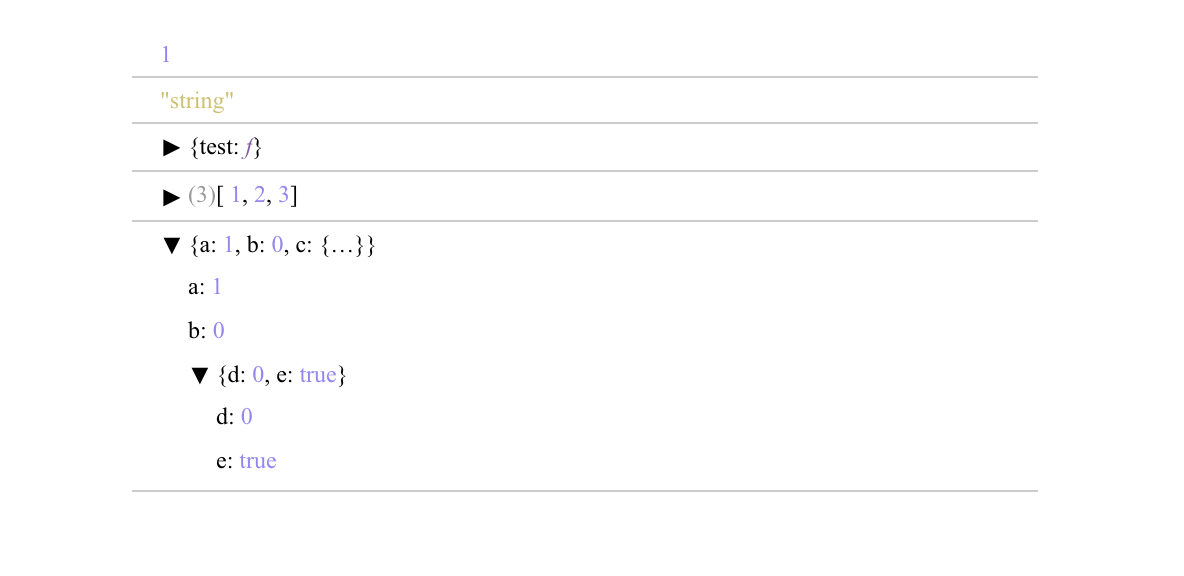
Sublime 命令行 实际上开发起来还是比较简单的,使用 React 很简单就实现了功能,比较麻烦的是调用 bootcdn 的接口,过程中我发现接口返回数据量还是挺大的,有必要做上一层 localStorage 缓存,加快二次打开速度。
然而在使用的过程中你会发现当我想插入一个前端库需要很多操作,因为有 三级选择:库-版本-CDN 链接。虽然这个流程解决了 所有用户 的使用问题,但是却损害了 大部分 用户的体验。这个时候插入一个常用库的成本就很高了,所以我们就要加上一些快捷入口,来实现一键插入流行框架。
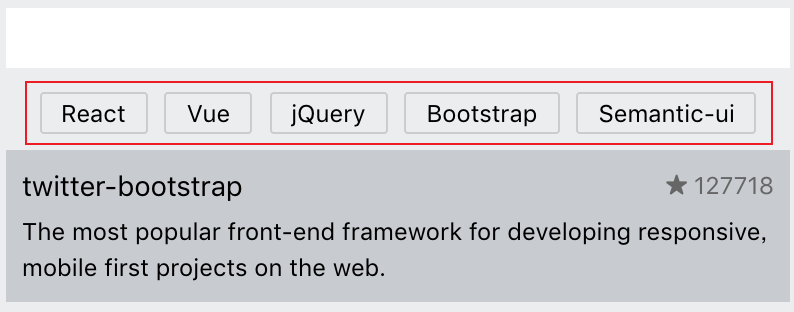
我们写代码的思路是满足所有用户的使用需求,但是一个好产品的思路是先满足大多数用户(80%)的常规需求,再让其余的用户(20%)可以有选择
还有一个问题比较典型就是 React 这类框架在渲染大列表并且进行过滤(关键字查询)时性能的问题。注意这个性能问题 并不是 引入框架产生的,真正的原因是当你渲染的 HTML 节点数以千计的时候,批量操作 DOM 会使得 DOM Render 特别慢。
所以说当我们遇到性能问题的时候应该去查找问题的根源,而不是停留在框架使用上,实际上在 DOM 操作这个层面来讲 jQuery 提供了更多的性能优化,比如自身的缓存系统,以致于当你在使用的时候很难发现有性能问题。但是在类 React 框架中它们框架本身的重点并不在于解决你应用的性能问题。
类似我们上面讲到的,实际上 jQuery 帮助你屏蔽了很多舞台背后的东西,以致于你可以不用操心技术细节,你甚至可以把 jQuery 当做一个 产品 来使用,而类 React 框架你却要亲力亲为的用他来设计你的代码。
话题再转回性能问题。这时候需要我们去实现一个类似于 react-window 的功能,让列表元素根据滚动按需加载。这可能是一种通用的解决大列表加载的方案,但是我的解决方法更粗暴,因为我们的下拉过滤功能使用时用户只关注 最佳的匹配项 即可,后面匹配程度不高的项可以直接限制数量裁剪就行了嘛。很少有用户会一直滚动到下面去查找某个选项,如果有,那就说明我们这个匹配做的有问题。
slice() {
const idx = (this.props.itemsPerPage || 50) * (this.state.activeFrame + 1)
return this.props.items.slice(0, idx)
}
整个匹配筛选的状态大概是这样的:
this.state = {
// 当前第N步选择
step: 0,
// 当前步骤数据
items: [],
// 是否显示
active: false,
// 当前选中项
current: {},
// 过滤关键字
keyword: ''
}
这个 items 是当前步骤的所有数据,实际上我们这个组件是支持无限级的扩展的,那么我们通过组件的 props 传入所有层级的数据,然后持久存储在内存中。这个 所有层级的数据 是数据结构层面的,实际上它可能是通过异步接口获取的。
再来看看我们组件提供的所有 props:
static defaultProps = {
step: 0,
active: false,
data: [[]], // 无限层级数据 [[], [], [], ...]
// 数据的主键,用于钩子函数返回用户选择的结果集
pk: 'id',
autoFocus: true,
activeCls: 'active',
delay: 300,
defaultSelected: 0,
placeholder: '',
async: false,
alias: [],
done: () => {}
}
这些数据都可以通过组件的 props 传入,这就意味着我们的这个组件才是真正的组件,别人也可以使用这样的功能,而他们并不用在意里面的细节,使用者只需要做好类似调用自己接口的这种业务逻辑。
组件的调用大概是这样的:
<CommandPalette step={0}
key="CommandPalette"
async={injectData}
done={this.done.bind(this)}
alias={alias}
aliasClick={this.aliasClick.bind(this)}
data={[ [], [], [] ]}
/>
async 这个 props 实际上是一个异步调用的钩子方法,它会回传给你组件上当前操作的相关数据状态,通过这些数据使用者就可以按自己的需求在不同的步骤上调用不同的方法
export const injectData = (step, item, results, cb) => {
const API = 'https://api.bootcdn.cn/libraries'
if (step === 0) {
fetchData(`${API}.min.json`)
.then(processLibraryData)
.then(cb)
} else if (step === 1) {
// ...
} else if (step === 2) {
// ...
}
}
另外关于 React 这里安利下自己翻译过的一个教程:React 模式,里面讲到 18 种短小精悍的 React 模式案例,非常简单易懂。
还有一个小窍门,我们在适配暗色主题时,传统的方法是直接写两套主题 CSS 代码,实际上我们要使用 CSS Variable 的话完全没必要生成两套了,背景色,字体都做成 CSS 变量,切换的时候只需要动态往页面插入更新过的 CSS 变量值即可
系统的一些参数想直接传给渲染进程也是比较麻烦的,我的做法是直接从主进程中的 loadUrl 方法上以 queryString 的方式传到渲染页面的 URL 上
const query = {
theme: osTheme,
app_path: app.getAppPath(),
home_dir: app.getPath('home')
}
mainWindow.loadURL(process.env.ELECTRON_START_URL ? url.format({
slashes: true,
protocol: 'http:',
hostname: 'localhost',
port: 2044,
query
}) : url.format({
slashes: true,
protocol: 'file:',
pathname: path.resolve(app.getAppPath(), './dist/index.html'),
query
}))
像程序运行时的一些参数(比如程序的根目录)也可以这么动态传过去,而且还有一个好处就是你甚至可以在渲染进程中测试与这些参数相关的功能。
我会把最终所有功能的使用方法录制成一个视频,万一有人不不想下载你的软件,只是要了解一下,这就是个很好的方法。我同时上传到了 Youtube 和 bilibili 这两个平台,其它的都有广告就没必要了
使用 Quicktime Player 即可,录制完使用 iMovie 转码成两倍速率的 mp4。如果你有兴趣还可以加上一段音乐什么的,让视频看起来更灵动
域名是一个能让用户记住你产品的方法,如果你做的是一个成型的产品,那就一定要申请个域名。
我总是有这样的体验,有的时候看到一个非常不错的产品但由于当时没需求就忽略了,想起来或者突然有需求的时候缺记不起来名字叫什么了。
事实上代码画板最开始我给他起的名字是 code playground,这个更直观,但是名字太长,而且想用到的一些域名呀、Github 名、NPM 包都被注册了。
想来想去就换成了 code sketch,这和符合我们的设计初衷,即:一边是代码,一边是效果/草图
域名申请我一般会上 Godaddy,不用备案,.com 域名一年 ¥65.00,然后 DNS 服务器转到了 cloudflare,后续域名也会直接转到 cloudflare。因为据说以后在 cloudflare 上续费域名最便宜
宣传网站直接放在 github pages 上,做个自定义域即可,实在是太方便了。而且还有 SSL 支持,Github 真的是业界良心
web 版的代码画板,由于我们把渲染进程中的代码分离开发,所以直接把 parcel 打包出来的静态文件也做成 github pages 就可以了,爽歪歪,网站就等于一分钱不花了。后续做一些 web 版的增强功能时,可以做成前后端分离的 http 服务,这就是后话了
GA 可以让你了解网站的用户分布情况,清楚的知道网站访问的波动。比如说你把自己的链接放到某个网站上分享了,GA 里面就能看出来所有的推荐来源和波动,对于运营来说是非常有必要的
这个我还真想了好长时间,基于我对于代码画板的定义,我觉得它应该是一个我们有一个想法的时候需要快速去实现一个 demo 的地方,想来想去就定了一段看起来文邹邹的话,虽然听名字根本不知道它是干啥用的,但是没关系,程序员写东西就是要有个性,因为我的受众只有自己。
First place where the code was written... 一个你最初写代码的地方...
麻雀虽小,五脏俱全。我们来看下代码画板总共用到了多少东西:
实事上我自己的开发这个应用的时候并没有严格按照这篇文章的顺序执行,而是想到一些实现一些,可能一个功能实现了后来觉得不好又干掉了,是不断的取舍、提炼的结果。
开发中我也不断的问自己这个功能是否有必要,如果可有可无那是不是可以去掉,这样才能使得用户更加关注于代码本身。
整个开发过程中自己实现的功能模块并不多,只有控制台、命令行窗口是自己实现的,其它的功能基本上都是靠社区现有的工具库来完成的,从这一点来说前端技术的生态还是挺好的。这使得当我从整体上构思一个产品时我不必在意那些细节,虽然过程中还是能感觉到前端工具/库的割裂感,但是整体而言还是向好的,毕竟工具对于开发者只是一种选择的。
八、引用
1970-01-01 08:00:00
最初写代码的地方...
Command+eCommand++/-Command+sCommand+shift+sCommand+oCommand+p浅色主题
深色主题
错误日志
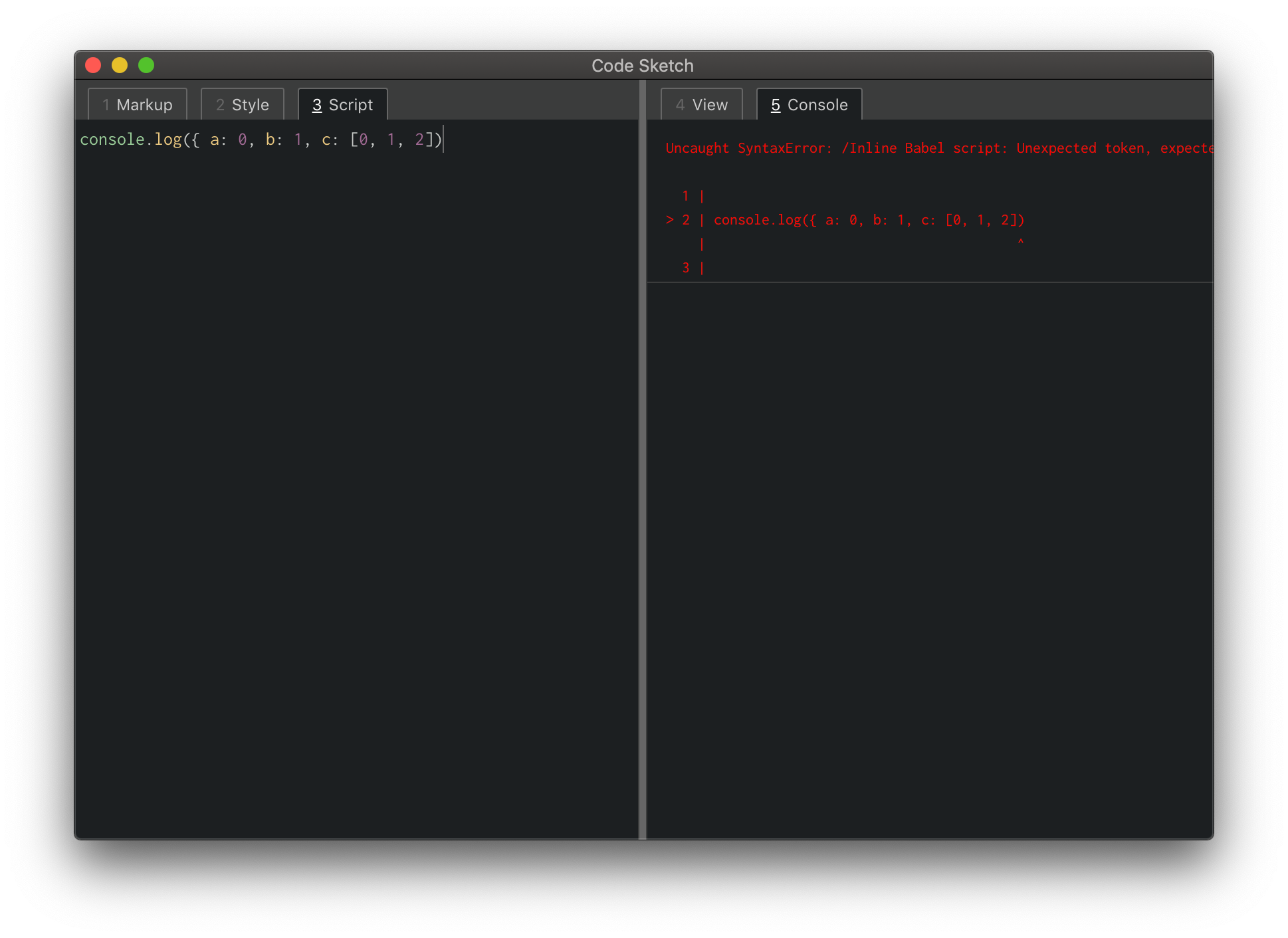
控制台日志
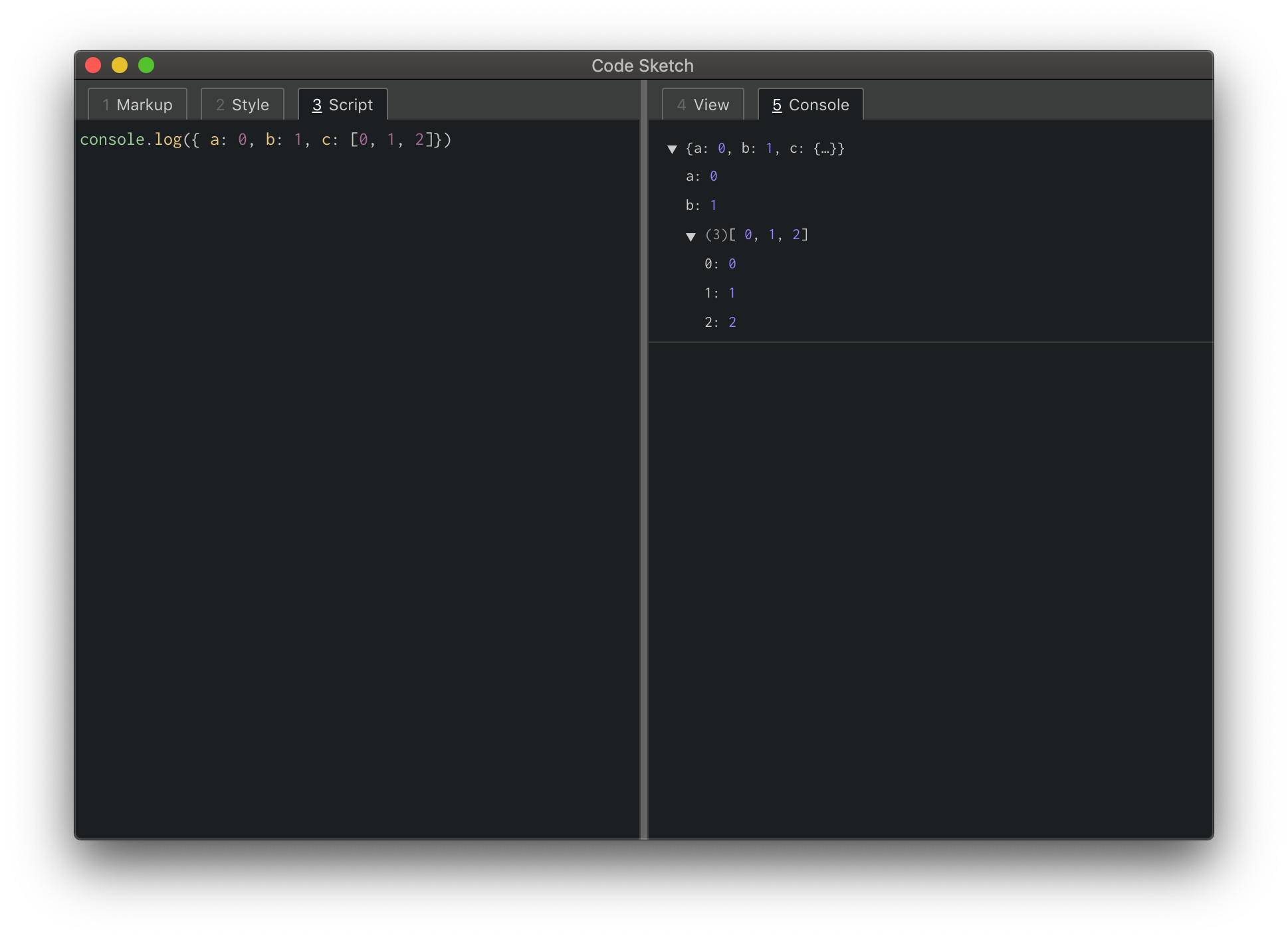
yarn or npm
yarn install
yarn start
yarn dev
# build release for mac
yarn release
...
1970-01-01 08:00:00
很早以前就想聊聊这个话题,但是一直没机会。昨天看完电影《无名之辈》后让我心里突然有了一点感想。这便记录下来
这部片子的剧情围绕着几小人物之间展开。一心想做协警的保安、一辈子想出人头地的劫匪、一个遭遇了车祸身体瘫痪的女孩、一心只想赚钱娶媳妇过日子普通男人…
这些角色在我们现实生活中实在是太普通了,而且都处在社会底层。每个人对背负着生活压力,每人个都过着悬崖勒马日子。为了生存和仅有的那点「并不远大的」理想坚持前行
中间那段胡广生痛骂电视台恶搞他们抢劫的桥段,让我感触很深。电视上那些转微博、发视频娱乐的网友不就是我们自己么,我们经常在网站上看到一些匪夷所思的新闻:一个没有智商的劫匪,拿上一杆枪,跑到手机店里面去抢手机。抢完了才发现是手机模型。这个事情在普通人看来真的是荒诞极了,简直是搞笑,大家都来消费这种新闻。却没有人真的去思考劫匪为什么会做这么愚蠢的事情
谁知道这个愚蠢的劫匪是一个没见过大世面的农村小伙,不识字,也没什么文化;一心想进城干大事,胸中充满了对生活的渴望。可是谁又知道他进城后遭受了些什么、被多少人排斥、鄙视。现实中处处碰壁,梦想被别人看的一文不值。这种落差感长久积存在心里,有一天终于爆发了,他开始报复社会,打架、抢劫
胡广生在电视上看见网友的恶搞时情绪完全崩溃,他撕心裂肺的哭着骂到:「老子要是犯法、你抓老子啊,关老子,你枪毙老子,老子认帐啊,为啥要恶搞老子、侮辱老子」
他是多么强大,强大到不怕犯法被枪毙;他又多么可怜,可怜没人尊重他,没人理解他
我们总是在网络上看到很多人在讲平等。各种阶层,各种角色
员工与老板的平等、父母和子女的平等、老师与学生的平等、女人和男人的平等、穷人与富人的平等。归结起来只有一种:强势者和弱势者的平等
但是实际上强势者强的本质是与生俱来的:老板有权利的优势、父母/老师有地位的优势、男人有生理的优势、富人有家族的优势
在这些角色之间要求平等是一件很「无理」的事情。举个简单的例子,人都是动物,都有动物的本性,一个高个子的人站在矮个子的人旁边,根本不用讲话,高个子的人会有一种原始的身体上的气势压迫感,矮个子的人会有原始的一种害怕与自我防卫的反应。当然人类是高级动物,人类可以通过语言、眼神的沟通来降低这种差异感。但是本质上讲这两种人的「不平等」是改变不了的,尤其是高个子的人,即使你有很好的修养、很高的受教育程度,这种与生俱来的东西也是没办法完全抹去的。事实上这两个人是没法平等的,你总不能要求别人和你长得一样高吧
为什么现在很多人要求所谓平等。是因为「平等」这个词可以「量化」。你有的东西我也必须有,你能做的事情我也可以做。这种感觉就像是我们开发了一个复杂的系统,我们需要有一个能实时检测到异常的监控系统,因为监控系统可以量化一个系统的好坏,可以给出一个简单的评价标准。但是监控并不能解决系统本身的好坏问题。与其花费大量精力在监控上面,不如多花时间来了解系统的核心逻辑,各个个部件之间的关系。这样的话即使系统出了问题也是在可预测范围内,监控也只是锦上添花的一个部件
回到主题上,那么为什么理解或者说同理心更重要呢。
这要从人的情感说起,其实人类是一种非常奇怪的生物,个体之间的差异让你很难理解对方的一些情绪变化。很多人都觉得很了解自己(我也是),实际上并不是的。我就有个非常困扰自己的问题,每当我唱歌非常投入的时候,唱到那么两句伤感的歌词时七窍都会有反应,我自己有的时候也在想,实际上我唱的歌词可能和我境遇半毛钱关系都没有,怎么会有这种反应呢。后来慢慢的我就理解了,因为人和人是不一样的,我们彼此有不同的年龄、性别、生活经历,同时在情感方面人又非常的奇怪,可能有的人会因为一句诗词而哭泣,可能有人会因为一段音乐而哭泣,有的人会因为一张泛黄的照片而哭泣,不同的人有不同的感受周围世界的能力,你通过视觉,别人通过听觉嗅觉。同时这些东西被记忆在大脑内的时候是立体的,全方位的。可能就是某个动作触发到了深藏在大脑中的一幅画面,瞬间你就会想起当时的天气,人物、气氛等,然后立马产生了真情的流露。从这一点来看人的大脑比起计算机简直高得不知道到哪里去了
以前我老看见电视上很多追星族,在演唱会上痛哭流涕,激动不已。我就很难理解,怎么会有这种人呢,真的是歌手唱的好听吗?可是一首歌又能有多好听呢。然后上大学时听了很多的摇滚乐,当时的状态就是:我觉得年轻时不喜欢摇滚乐是有病吧。到现在为止我也没去听过场摇滚演唱会,但是我可以想像到如果我去了,绝对也是和大部分人一样的那种摇头晃脑,疯狂呐喊,兴奋不已的状态。
所以说,看到一些匪夷所思的事情的时候不要急于去评价,或者下结论。试着去理解一下对方的境遇,万一自已经说错话了那也不要紧,承认自己的错误其实并没有那么困难,可能在你看来很简单的一句话就会让对方感受到整个世界的温柔

图:https://www.pexels.com/photo/photography-of-body-of-water-and-mountains-1544880/
1970-01-01 08:00:00
名正言顺这个成语大家都知道,尤其在一些政治典故中经常被提及。今天就来聊聊这个话题
名正言顺的梗概出自于《论语·子路》中孔子和子路的一段对话:
子路曰:“卫君待子而为政,子将奚先?”
子曰:“必也正名乎!”
子路曰:“有是哉,子之迂也!奚其正?”
子曰:“野哉由也!君子于其所不知,盖阙如也。名不正,则言不顺;言不顺,则事不成;事不成,则礼乐不兴;礼乐不兴,则刑罚不中;刑罚不中,则民无所措手足。故君子名之必可言也,言之必可行也。君子于其言,无所苟而已矣。”
大概意思是说:
子路问孔子:“如果让你去卫国执政,你首先会做什么?”
孔子说:“一定要先找对名份!”
子路说:“是这样的吗?,你也太迂腐了吧,名份有什么用?”
孔子说:“你太粗野了!君子对于不懂的事情,一般都采取保留意见。名分不正当,说话就不合理;说话不合理,事情就办不成。事情办不成,法律就不能深入人心;法律不能深入人心,刑罚就不会公正;刑罚不公正,老百姓就会手足无措…”
正名的「名」就是名份的「名」。是古代官场政治制度下的一种阶级角色感,也是儒家思想核心部分 礼 的角色感。如:君臣、父子、兄弟,各个角色应该做什么事情才是正确的,被提倡的
比如说《八佾》中开篇第一段:
孔子谓季氏:“八佾舞于庭,是可忍也,孰不可忍也?”
意思是说这个季氏用天子的舞蹈阵容在自己家里开 Party。「佾yì」就是舞蹈队伍中的列,天子八列、诸侯六列、大夫四列、士二列,每佾八人。孔子要从政得先正名,正名就要先把礼放在第一位,没有礼的话就会成为君不君、臣不臣、父不父、子不子的状态,这种「八佾舞于庭」的行为在孔子看来就是大逆不道,绝不能忍的事情
再如:
定公问:“君使臣,臣事君,如之何?”孔子对曰:“君使臣以礼,臣事君以忠。”
意思是 定公问孔子:“上级怎样对待下级?下级怎样对待上级?”孔子答:“上级尊重下级,下级忠于上级。”
其实古文是非常精炼的,有的句子我们根本不需要全部搞懂是什么意思,只看几个字眼儿就明白了,比如上面的:君 使 shǐ 臣,臣 事 shì 君。使 就是驱使、使唤;事 就是为人做事、服侍的意思。我觉得这句话问之前就有了定位,根本不需要再回答
封建社会,人们对于名份的认同感处处可见。春秋时期的尊王攘夷,三国时期曹操奉天子以令不臣,刘备打江山也要号称汉景帝阁下玄孙,这些都是政治场上的所谓的正名
当这种思想蔓延到整个现代社会甚至是家庭里面的时候就更值得思考了
儒家思想中关于礼的部分我更倾向于认同它的角色感,这一点是古今通用的。现实生活中我们经常会有一种感觉:同样是一句话从某些人口中说出来就很合情合理,从另外一些人口中说出来则让人很难理解甚至气愤。就是因为中国人讲话是非常讲究角色和场合的
比如说:我(男的)看见一对男女聊天儿,谈到关于生活、工作的话题时,如果这个女的说:男人的一生很不容易,因为他们的一生都注定了要竞争,为钱、为权为了家人过得更好,他们们身上背负着很重的担子。
当我做为一个男的听到这段话的时候会觉得这话说的很好听,让人很舒服,同时也非常佩服女的身上的那种同理心。但如果这段话是从这个男的口中说出来的我只会觉得这男的矫情娘娘腔,甚至我会找很多理由来推翻他的观点
在男权社会下女人本来就是弱视的,社会能给予她们的不论是精神上的还是物质上的回报都没有男性多,相反男性天生就获得了更多的优待和资源,所以男性理应肩负更多的责任。事实上女性的一生更不容易,大部分的女性的一生会受到社会舆论家庭伦理方面的影响,以至于她们很少有自己的事业,健立家庭以后通常还有更多身体和精神上的付出,这使得她们几乎没机会做自己想做的事情
所以说这个角色非常重要,但问题是当你定义了自己是什么样的角色时,再去看问题,其实本来就是不客观的。最终可能会形成一种非黑即白的观点偏见
当我们今天再去回顾名正言顺的典故时,会发现即就是当下社会,大家还是有很多古时候遗留下来的碎片化的认识,这种认识会让人只相信权威的或者大众的观点,这种所谓名份上正确的角色传达出来的观点
社会上的名流、功成名就的人说出来的话就是可信的,匹夫布衣甚至都没有说话的权利。所以说名正言顺真的就是正确的吗?难道只有先正其名然后才能有话语权?就算是个小人物,他也有自己的人生境遇,也有喜怒哀乐。只要人家说话有理有据,那就理当受到尊重
名正言顺事实上讲的是一种政治上的正确,在国外也有很多这方面的讨论,比如说:Code of conduct,它就给出了一系列的准则,诸如人与人之间基本尊重、宗教、人种、道义方面的一些准则。这些准则在大多数人眼里是正确的,但是应不应该强加到其它不认同这个准则的人身上呢,或者说人们可不可以对里面的一些准则进行反驳
《鸦片战争》大家都知道,船坚炮利的英帝国都打到天津港口了,道光皇帝还是那种处理边疆叛乱,攘除蛮夷的态度,整个大众的的意识形态还停留在天下都是天子的,天朝之外全是名份不正确的蛮族夷地,皇帝发诏告还是「奉天承运皇帝诏曰」的口气。真正枪炮打到脸上的时候才意识到疼
1970-01-01 08:00:00
这个指南介绍了很多编辑器的设计理念,以及他们之间的关系。想完整的了解整个系统,建议按顺序阅读,或者至少阅读视图组件部分
ProseMirror 提供了一组工具和设计概念用来构建富文本编辑器,UI 的使用源于 WYSIWYG 的一些灵感,ProseMirror 试着屏蔽一些排版中的痛点
ProseMirror 的主要原则是:你的代码对于文档及其事件变更有完整的控制权。这个 文档 并不是原生的 HTML 文档,而是一个自定义的数据结构,这个数据结构包含了通过你明确允许应该被包含的元素,它们的关系也由你指定。所有的更新都会在一个你可以查看并做出响应的地方进行
核心的代码库并不是一个容易拿来就用的组合 — 我们会优先考虑 模块化 和 可自定义 化胜过简单化,希望将来有用户会基于 ProseMirror 分发一个拿来就用的版本。因此,ProseMirror 更像是乐高积木而不是火柴盒拼的成的玩具车
总共有四个核心模块,任何编辑行为都需要用到它们,还有很多核心团队维护的扩展模块,类似于三方模块 — 它们提供有用的功能,但是你可以删除或者替换成其它实现了相同功能的模块
核心模块分别是:
prosemirror-model 定义了编辑器的文档模型,数据结构用来描述编辑器的内容prosemirror-state 提供了整个编辑器状态的数据结构,包括选区和维护状态变化的事务系统prosemirror-view 实现一个用户界面组件,用来在浏览器中把编辑器的状态展示成可编辑元素,并且与其进行交互prosemirror-transform 包含了一种可以记录/重放文档修改历史的功能组件,这是 state 模块中事务的基础,而且这还使得编辑器的恢复历史和协作编辑功能成为可能此外,还有一些诸如 基础的编辑命令、快捷键绑定、恢复历史、输入宏、协作编辑,简单的文档骨架 的模块。Github prosemirror 组织 代码库中还有更多
事实上 ProseMirror 并没有分发一个独立的浏览器可以加载的脚本,这表示你可能需要一些模块 bunder 来配合使用它。模块 Bunder 就是一个工具,用来自动化查找你的脚本依赖,然后合并到一个单独文件中,使你能很容易的在 web 面页中使用。你可以阅读更多关于 bundling 的东西,比如:这里
就像拼乐高积木一样,下面的代码可以创建一个最小化的编辑器:
import {schema} from "prosemirror-schema-basic"
import {EditorState} from "prosemirror-state"
import {EditorView} from "prosemirror-view"
let state = EditorState.create({schema})
let view = new EditorView(document.body, {state})
ProseMirror 需要你为文档指定一个自己觉得合适的骨架(schema),所以上面的代码第一件事情就是引入一个基础骨架模块
接着这个骨架被用来创建一个状态,它将按骨架的定义生成一个空的文档,光标会在文档最开始的地方。最后创建了一个与状态关联的视图,并且插入到 document.body。这将会把状态的文档渲染成一个可编辑的 DOM 节点,并且一旦用户输入内容就会生成一个状态事务(transactions)
现在这个编辑器还没什么用处。比如说当你按下回车键时没有任何反应,因为核心库并不关心回车键应该用来做什么。我们马上就会谈到这一点
当用户输入或者与视图交互时,将会生成「状态事务」。这意味着它不仅仅是只修改文档并以这种方式隐式更新其状态。相反,每次更改都会触发一个事务的创建,该事务描述对状态所做的更改,而且它可以被应用于创建一个新状态,随后用这个新状态来更新视图
这些过程都会默认地在后台处理,但是你可以写一个插件来挂载进去,或者通过配置视图的参数。例如,下面的代码添加了一个 dispatchTransaction 属性(props),每当创建一个事务时都会调用它
// (省略了导入代码库)
let state = EditorState.create({schema})
let view = new EditorView(document.body, {
state,
dispatchTransaction(transaction) {
console.log("Document size went from", transaction.before.content.size,
"to", transaction.doc.content.size)
let newState = view.state.apply(transaction)
view.updateState(newState)
}
})
每次状态变化都会经过 updateState,而且每个普通的编辑更新都将通过调度一个事务来触发
插件用于以各种方式扩展编辑器和编辑器状态的状态,有的会非常简单,比如 快捷键 插件 — 为键盘输入绑定具体动作;有的会比较复杂,比如 编辑历史 插件 — 通过观察事务并逆序存储来实现撤销历史记录,以防用户想要撤消它们
让我们为编辑器添加这两个插件来获取撤消(undo)/重做(redo)的功能:
// (Omitted repeated imports)
import {undo, redo, history} from "prosemirror-history"
import {keymap} from "prosemirror-keymap"
let state = EditorState.create({
schema,
plugins: [
history(),
keymap({"Mod-z": undo, "Mod-y": redo})
]
})
let view = new EditorView(document.body, {state})
当创建一个状态的时候插件就会被注册(因为插件需要访问状态事务),当这个开启了编辑历史状态的视图被创建时,你将可以通过按 Ctrl-Z 或者 Cmd-Z 来撤消最近的一次变更
上面示例代码中的 undo 和 redo 变量值是绑定到指定键位的一种叫做 命令 的特殊值。大多数编辑动作都是作为可绑定到键的命令编写的,它可以用来挂载到菜单栏,或者直接暴露给用户
prosemirror-commands 包提供了许多基本的编辑命令,其中一些是你可以需要用到的基本的快捷键,比如 回车,删除编辑器中指定的内容
// (Omitted repeated imports)
import {baseKeymap} from "prosemirror-commands"
let state = EditorState.create({
schema,
plugins: [
history(),
keymap({"Mod-z": undo, "Mod-y": redo}),
keymap(baseKeymap)
]
})
let view = new EditorView(document.body, {state})
现在,你已经有了一个算得上可以使用的编辑器了
添加菜单,额外的为特定骨架指定的快捷键绑定 等功能,可以通过查看 prosemirror-example-setup 包了解更多。这个模块提供给你一组插件用来创建一个基础的编辑器,但是就像它的名字一样,只是个例子,并不是生产环境级别的代码库。真正的开发中,你可能会需要替换成自定义的代码来精确实现你想要的功能
一个状态的文档被挂在它的 doc 属性上。这是一个只读的数据结构,用各种级别的节点来表示文档,就像是浏览器的 DOM。一个简单的文档可能会由一个包含了两个「段落」节点,每个「段落」节点又包含一个「文本」节点的「文档」节点构成
当初始化一个状态时,你可以给它一个初始文档。这种情况下,schema 就变成非必传项了,因为 schame 可以从文档中获取
下面我们通过传入一个 DOM 元素 (ID 为 content)做为 DOM parser 的参数初始化一个状态,它将利用 schema 中的信息来解析出对应的节点:
import {DOMParser} from "prosemirror-model"
import {EditorState} from "prosemirror-state"
import {schema} from "prosemirror-schema-basic"
let content = document.getElementById("content")
let state = EditorState.create({
doc: DOMParser.fromSchema(schema).parse(content)
})
ProseMirror 定义了他自己的一种用来表示文档内容的数据结构。由于文档是构建所有编辑器的核心元素,了解它们的工作原理会对我们很有帮助
一个 ProseMirror 文档就是一个节点,它包含一个片段,其中可以有一个或者多个子节点
这个和浏览器 DOM 非常相似,浏览器 DOM 是一个递归的树型结构。但是 ProseMirror 的不同点在于它存储内联元素的方式
在 HTML 中,一个段落的标记表示为一个树,就像这个:
<p>This is <strong>strong text with <em>emphasis</em></strong></p>

而在 ProseMirror 中,内联内容被建模为 扁平 的序列,标记作为元数据附加到节点
这更符合我们思考和使用此类文本的方式,这允许我们使用字符来表示位置而不是树的路径,这使得一些操作如分割、更改内容样式变得比维护树简单
这也意味着每个文档都只有一种合法的表现层。具有相同标记集的相邻文本节点总是组合在一起,并且不允许有空文本节点,标记出现的顺序由骨架指定
所以说一个 ProseMirror 文档就是一颗块级节点树,其中大多数叶子节点都是文本块,块级节点可以包含这些文本块儿。你也可以有一些空的叶子节点,比如水平分隔线或者视频元素
节点对象有很多属性,它们代表所处文档中的角色:
isBlock 和 isInline 告诉你给定的节点是一个块级节点还是内联节点inlineContent 表示一个节点希望它的内容是是内联元素isTextblock 表示一个块级节点包含内联内容isLeaf 告诉你节点不允许有任何内容典型的「段落」节点是一个文本节点,而「引用块」可能是一个包含其它块级元素的元素。文本、硬换行(
)以及内联图片都是内联叶子节点,水平分隔线节点则是一种块级叶子节点
骨架允许你更准确地指定什么东西应该出现在什么位置,例如。即使一个节点允许块级内容,这并不表示他会允许所有的节点做为它的内容
另外一个 DOM 树和 ProseMirror 文档不同的地方是,对象表示节点的行为。在 DOM 中,节点是具有标识的可变的对象,这表示一个节点只能出现在一个父节点中,当节点更新的时候对象也会被修改
另外一方面,在 ProseMirror 中,节点仅仅是一些 值,和你想表示数字 3 一样,3 可以同时出现在很多数据结构中,它自己所处的部分与父元素没有连系,如果你给它加 1,你会得到一个新值 4,并且不用改变和原来 3 相关的任何东西
所以它是 ProseMirror 文档的一部分,它们不会更改,但是可以用作计算修改后的文档的起始值。它们也不知道自己处在什么数据结构当中,但可以是多个结构的一部分,甚至多次出现在一个结构中。它们是值,不是状态化的对象
这表示每当你更新文档,你将会获得一个新的文档值。文档值将共享所有子节点,并且不会修改原来的文档值,这使得它创建起来相对廉价
这有很多优点。它可以使两次更新之间的过程无效(严格控制更新的内容和过程),因为具有新文档的新状态可以瞬间转换。它还使得文档以某种数学方式推理变得更容易,相反的如果你的值不断的在后台发生变化这将会很难做到。这也使得协作编辑成为可能,并允许 ProseMirror 通过将最后一个绘制到屏幕的文档与当前文档进行比较来运行非常高效的 DOM 更新算法
由于此类节点使用了常规的 JavaScript 对象来表示,如果并且明确地冻结(freezing)其属性可能会影响到性能,实际上属性是 可以 改变的,但是并不建议你这么做,这将会导致程序中断,因为它们几乎总是在多个数据结构之间共享。所以要小心!请注意,这也适用于作为节点对象一部分的数组和普通对象,例如用于存储节点属性的对象或片段中子节点的数组(译注:意思是你最好不要更改类似的内部对象,给对象添加或者删除属性)
一个文档的对象看起来像这样:
每个节点都是一个 Node 类的实例。都有一个 type 做为标签,通过 type 可以知道节点的名字,节点的属性字段也是有效的等等。节点的类型(和标识类型)每骨架会创建一次,他们知道自己属于骨架的哪个部分
节点的内容存储在 Fragment 的一个实例中,它掌握着节点序列。即使节点没有或者不允许有内容,这个字段也会有值(共享的空 fragment)
一些节点类型允许添加属性,它些值被存储到每个节点上。比如,图片节点一般会使用属性来存储 alt 文本和图片的 URL
此外,内联节点包含一组活动标记 — 例如强调(emphasis)或链接(link)— 活动标记就是一组 Mark 实例
整个文档就是一个节点。文档内容表现为一个顶级节点的子节点。通常,它将包含一系列块节点,其中一些块节点可能是包含内联内容的文本块。但顶级节点本身也可以是文本块,这样的话文档就只包含内联内容
什么样的节点可以被允许,是由文档的骨架决定的。用代码的方式创建节点(而不是直接用基础骨架库),你必须通过骨架来实现,比如使用 node 和 text 方法
import {schema} from "prosemirror-schema-basic"
// 如果需要的话可以把 null 参数替换成你想给节点添加的属性
let doc = schema.node("doc", null, [
schema.node("paragraph", null, [schema.text("One.")]),
schema.node("horizontal_rule"),
schema.node("paragraph", null, [schema.text("Two!")])
])
ProseMirror 节点支持两种索引 — 它们可以看做是树,使用单个节点的偏移量,或者它们可以被视为一个扁平的标识(tokens)序列
第一种 允许你执行类似于对 DOM 与单个节点进行操作的交互,使用 child 方法和 childCount 直接访问子节点,编写扫描文档的递归函数(如果你只想查看所有节点,请使用 descendants 或 nodesBetween)
第二种 当访问一个文档中指定的位置时更好用。它允许把文档任意位置表示为一个整数 — 即标记序列中的索引。这些标识并不做为对象在内存中 — 它们仅仅是用来计数的惯例 — 但是文档的树形状以及每个节点都知道它的大小,这使得按位置访问变的廉价(译注:类似于用下标访问扁平数组,而不是递归遍历嵌套结构的树)
因此,如果你有一个文档,当表示为 HTML 时,将如下所示:
<p>One</p>
<blockquote><p>Two<img src="..."></p></blockquote>
标识序列以及位置下标,将会是这样:
0 1 2 3 4 5
<p> O n e </p>
5 6 7 8 9 10 11 12 13
<blockquote> <p> T w o <img> </p> </blockquote>
每个节点都有一个 nodeSize 属性,可以为告诉你整个节点的大小,你可以访问 .content.size 来获取节点 内容 的大小。注意,对于外部文档节点,打开和关闭标记不被视为文档的一部分(因为你无法将光标放在文档外面),因此文档的大小为 doc.content.size,而不是 doc.nodeSize
手动解释这样的位置会涉及相当多的计数操作。你可以调用 Node.resolve 来获取关于节点位置的更具有描述性的数据结构。这个数据结构将告诉你该位置的父节点是什么,它与父节点的偏移量是什么,父节点的祖先是什么,以及其他一些东西
注意区分子索引(每个 childCount),文档范围的位置和 node-local 偏移(有时在递归函数中用于表示当前正在处理的节点中的位置)
为了处理一些诸如复制/粘贴和拖拽之类的操作,通过切片与文档进行通信是非常必要的,比如,两个位置之间的内容。这样的切片不同于整个节点或者片段,一些节点可能位于切片开始或者结束(译注:切片的开始位置可能在某个节点的中间)
例如,从一个段落的中间选择到下一个段落的中间,你所选择的切片中会有两个段落,那么切片的开始位置在第一个段落打开的地方,结束位置就在第二个段落打开的地方。然而如果你 node-select 一个段落,你就选择了一整个有关闭的节点。可能的情况是,如果将此类开放节点中的内容视为节点的完整内容,则会违反骨架约束(标签可能没关闭),因为某些所需节点落在切片之外
Slice 数据结构用于表示这样的切片。它存储一个 fragment 以及两侧的 节点打开深度(open depth)。你可以在节点上使用切片方法从文档外剪切切片
/*
0 1 2 3 4
<p> a b </p>
4 5 6 7 8
<p> a b </p>
*/
// doc holds two paragraphs, containing text "a" and "b"
let slice1 = doc.slice(0, 3) // The first paragraph
/*
0| 1 2 3 |4
<p> a b </p>
*/
console.log(slice1.openStart, slice1.openEnd) // → 0 0
let slice2 = doc.slice(1, 5) // From start of first paragraph
// to end of second
/*
0 1| 2 3 4
<p> a b </p>
4 5|6 7 8
<p> a b </p>
*/
console.log(slice2.openStart, slice2.openEnd) // → 1 1
由于节点和片段是持久存储的,因此 永远 不要修改它们。如果你有文档(或节点或片段)的句柄,那这个句柄引用的对象将保持不变(译注:这意味着并不能通过拿到的引用直接修改节点,因为这个节点的引用是不可变的值,当你想改变的时候节点可能已经成为历史)
大多数情况下,你将使用转换(transformations)来更新文档,而不必直接接触节点。这些也会留下更改记录,当文档是编辑器状态的一部分时,这是必要的
如果你确实想要「手动」派发更新的文档,那么 Node 和 Fragment 类型上有一些辅助方法可用。要创建整个文档的更新版本,通常需要使用Node.replace,它用一个新的内容切片替换文档的给定范围。要少量地更新节点,可以使用 copy 方法,该方法使用新内容创建类似的节点。Fragments 还有各种更新方法,例如 replaceChild 或 append
每个 ProseMirror 文档都有一个与之关联的骨架,骨架描述了文档中可能出现的节点类型以及它们嵌套的方式。例如,它可能会指定顶级节点可以包含一个或多个块,并且段落节点可以包含任意数量的内联节点,内联节点可以使用任何标记
有一个包含基础骨架的包,但 ProseMirror 的优点在于它允许你定义自己的骨架
文档中的每个节点都有一个类型,表示其语义和属性,正如其在编辑器中呈现的方式
定义骨架时,可以枚举其中可能出现的节点类型,并使用 spec 对象描述:
const trivialSchema = new Schema({
nodes: {
doc: {content: "paragraph+"},
paragraph: {content: "text*"},
text: {inline: true},
/* ... and so on */
}
})
这段代码定义了一个骨架,其中文档可能包含一个或多个段落,每个段落可以包含任意数量的文本
每个骨架必须至少定义顶级节点类型(默认为名称「doc」,但你可以设置),以及文本内容的(text)类型
注意内联的节点必须使用 inline 属性声明(但对于文本类型,根据定义是内联的,可以省略它)
上面示例模式中的内容字段(paragraph+, text*)中的字符串称为内容表达式。它们控制子节点的哪些序列对此节点类型有效
例如 paragraph 表示「一个段落」, paragraph+ 表示「一个或者多个段落」。相似地,paragraph* 表示「零个或者更多个段落」, caption? 表示「零个或者一个说明文字」。你可以使用类正则的范围区间,比如 {2} 表示精确的两次,{1, 5} 表示 1~5 次,{2,} 表示 2~更多多次
可以组合这些表达式来创建序列,比如 heading paragraph+ 表示「首先是标题,然后是一个或多个段落」。你也可以使用管道运算符 | 表示两个表达式之间的选择,如 (paragraph|blockquote)+
某些元素类型组将在你的模式中出现多种类型 — 例如,你可能有一个「块」节点的概念,它可能出现在顶层但也嵌套在块引用内。你可以通过为节点规范提供 group 属性来创建节点组,然后在表达式中按名称引用该组
const groupSchema = new Schema({
nodes: {
doc: {content: "block+"},
paragraph: {group: "block", content: "text*"},
blockquote: {group: "block", content: "block+"},
text: {}
}
})
这里的 block+ 相当于 (paragraph | blockquote)+
建议在具有块内容的节点中始终需要至少一个子节点(例如上面示例中的 doc 和 blockquote),因为当节点为空时,浏览器将完全折叠节点,不方便编辑
节点在 or-表达式中的显示顺序非常重要。为非可选节点创建默认实例时,例如,为了确保在替换步骤后文档仍符合模式,将使用表达式中的第一个类型。如果这是一个组,则使用组中的第一个类型(由组成员在节点映射中显示的顺序确定)。如果我在示例骨架中切换 paragraph 和 blockquote 的位置,编辑器尝试创建一个块节点时,你会得到堆栈溢出 - 它会创建一个 blockquote 节点,其内容至少需要一个块,因此它会尝试创建另一个 blockquote 作为内容, 等等
库中的节点操作函数并非每个都会检查它是否正在处理有效的内容 - 高层次的概念,例如 转换(transforms)会,但原始节点创建方法通常不会,而是负责为其调用者提供合理的输入。完全可以使用例如 NodeType.create 来创建具有无效内容的节点。对于在切片边缘 打开 的节点,这甚至是合理的事情。有一个单独的 createChecked 方法,以及一个事后 check 方法,可用于断言给定节点的内容是有效的。
标记用于向内联内容添加额外样式或其他信息。骨架必须声明允许的所有标记类型。标记类型 是与 节点类型 非常相似的对象,用于标记标记对象并提供其他信息
默认情况下,具有内联内容的节点允许将骨架中定义的所有标记应用于其子项。你可以使用节点规范上的 marks 属性对其进行配置
这有一个简单的骨架,支持段落中文本的 strong 和 emphasis 标记,但不支持标题:
const markSchema = new Schema({
nodes: {
doc: {content: "block+"},
paragraph: {group: "block", content: "text*", marks: "_"},
heading: {group: "block", content: "text*", marks: ""},
text: {inline: true}
},
marks: {
strong: {},
em: {}
}
})
标记集被解释为以空格分隔的标记名称或标记组字符串 — _ 充当通配符,空字符串对应于空集
文档骨架还定义了每个节点或标记具有的属性。如果你的节点类型需要存储额外的信息,例如标题节点的级别,那就最好使用属性
属性集可以认为就是普通对象,具有预定义(每个节点或标记)属性集,包含任何 JSON 可序列化值。要指定它允许的属性,请使用节点中的可选 attrs 字段或标记规范
heading: {
content: "text*",
attrs: {level: {default: 1}}
}
在上面的骨架中,标题节点的每个实例都将具有 level 属性。如果不指定,则默认为 1
如果不指定属性默认值,在尝试创建此类节点又不传属性时将引发错误。在满足模式约束条件下进行转换或调用 createAndFill 时,也无法使用库生成此类节点并填充
为了能够在浏览器中编辑它们,必须能够在浏览器 DOM 中表示文档节点。最简单的方法是使用 node spec 中的 toDOM 字段包含有关骨架中每个节点的 DOM 表示的信息
该字段应包含一个函数,当以节点作为参数调用时,该函数返回该节点的DOM 结构的描述。这可以是直接 DOM 节点或描述它的数组,例如:
const schema = new Schema({
nodes: {
doc: {content: "paragraph+"},
paragraph: {
content: "text*",
toDOM(node) { return ["p", 0] }
},
text: {}
}
})
表达式 [“p”, 0] 声明了一个段落会被渲染成 HTML <p> 标签。零是一个「孔」用来表示内容被渲染的地方,你还可以在标记名称后面包含具有 HTML 属性的对象,例如:["div", {class: "c"}, 0]。叶节点在其 DOM 表示中不需要「洞」,因为它们没有内容
Mark specs 允许类似于 toDOM 方法,但它们需要渲染成直接包装内容的单个标记,因此内容始终直接在返回的节点中,并且不需要指定「孔」
你可能经常需要从 DOM 数据中 解析 文档,例如,当用户将某些内容粘贴或拖动到编辑器中时。模型(Model) 模块具有相应的功能,建议你使用 parseDOM 属性直接在骨架中包含解析信息
这可以列出一个解析规则数组,它描述映射到给定节点或标记的 DOM 结构。例如,基础骨架具有以下表示 emphasis 标记:
parseDOM: [
{tag: "em"}, // Match <em> nodes
{tag: "i"}, // and <i> nodes
{style: "font-style=italic"} // and inline 'font-style: italic'
]
解析规则中标记的值可以是 CSS 选择器,因此你也可以使用 div.myclass 之类的操作。同样,style 属性匹配内联 CSS 样式
当骨架包含 parseDOM 注解时,你可以使用 DOMParser.fromSchema 为其创建DOMParser 对象。这是由编辑器完成的,用于创建默认剪贴板解析器,但你也可以覆写它
文档还带有内置的 JSON 序列化格式。你可以在文档上调用 toJSON 以获取可以安全地传递给 JSON.stringify 的对象,并且骨架对象具有将此表示形式解析回文档的 nodeFromJSON 方法
传递给 Schema 构造函数的 nodes 和 marks 选项采用了 OrderedMap 对象以及纯 JavaScript 对象。骨架的 spec.nodes 和 spec.marks 属性始终是一组 OrderedMap,可以用作其它骨架的基础
此类映射支持许多方法以方便地创建更新版本。例如,你可以调用 schema.markSpec.remove(“blockquote”) 来派生一组没有 blockquote 节点的节点,然后可以将其作为新骨架的节点字段传入
schema-list 模块导出一个便捷方法,将这些模块导出的节点添加到节点集中
转换是 ProseMirror 工作方式的核心。它们构成了事务的基础,转换使得历史追踪和协作编辑成为可能
为什么我们不能直接改变文档?或者至少创建一个新版本的文档,然后将其放入编辑器中?
有几个原因。一个是代码清晰度。不可变数据结构确实使得代码更简单。但是,转换系统的主要工作是留下更新的痕迹,以值的形式表示旧版本的文档到新版本所采取的各个步骤
撤消历史记录可以保存这些步骤并反转应用它们以便及时返回(ProseMirror 实现选择性撤消,这比仅回滚到先前状态更复杂)
协作编辑系统将这些步骤发送给其他编辑器,并在必要时重新排序,以便每个人最终都使用相同的文档
更一般地说,编辑器插件能够检查每个更改并对其进行响应是非常有用的,为了保持其自身状态与编辑器的其余状态保持一致
对文档的更新会分解为步骤(step)来描述一次更新。通常不需要你直接使用这些,但了解它们的工作方式很有用
例如使用 ReplaceStep 来替换一份文档,或者使用 AddMarkStep 来给指定的范围(Range)添加标记
可以将步骤应用于文档来成新文档
console.log(myDoc.toString()) // → p("hello")
// A step that deletes the content between positions 3 and 5
let step = new ReplaceStep(3, 5, Slice.empty)
let result = step.apply(myDoc)
console.log(result.doc.toString()) // → p("heo")
应用一个步骤是一件相对奇怪的过程 — 它没有做任何巧妙的事情,比如插入节点以保留骨架的约束,或者转换切片以使其适应约束。这意味着应用步骤可能会失败,例如,如果你尝试仅删除节点的打开标记,这会使标记失衡,这对你来说是毫无意义的。这就是为什么 apply 返回一个 result 对象的原因,result 对象包含一个新文档或者一个错误消息
你通常会使用工具函数来生成步骤,这样就不必担心细节
一个编辑动作可以产生一个或多个步骤(step)。处理一系列步骤最方便的方法是创建一个 Transform 对象(或者,如果你正在使用整个编辑器状态,则可以使用 Transaction,它是 Transform 的子类)
let tr = new Transform(myDoc)
tr.delete(5, 7) // Delete between position 5 and 7
tr.split(5) // Split the parent node at position 5
console.log(tr.doc.toString()) // The modified document
console.log(tr.steps.length) // → 2
大多数转换方法都返回转换本身,方便链式调用 tr.delete(5,7).split(5)
会有很多关于转换的方法可以使用,删除、替换、添加、删除标记,以及维护树型结构的方法如 分割、合并、包裹等
当你对文档进行更改时,指向该文档的指针可能会变成无效或并不是你想要的样子了。例如,如果插入一个字符,那么该字符后面的所有位置都会指向一个旧位置之前的标记。同样,如果删除文档中的所有内容,则指向该内容的所有位置现在都会失效
我们经常需要保留文档更改的位置,例如选区边界。为了解决这个问题,步骤可以为你提供一个字典映射,可以在应用该步骤之前和之后进行转换并且应用应该步骤
let step = new ReplaceStep(4, 6, Slice.empty) // Delete 4-5
let map = step.getMap()
console.log(map.map(8)) // → 6
console.log(map.map(2)) // → 2 (nothing changes before the change)
转换对象会自动对其中的步骤(step)累加一系列的字典,使用一种叫做 映射 的抽象,它收集了一系列的步骤字典来帮助你一次性映射它们
let tr = new Transaction(myDoc)
tr.split(10) // split a node, +2 tokens at 10
tr.delete(2, 5) // -3 tokens at 2
console.log(tr.mapping.map(15)) // → 14
console.log(tr.mapping.map(6)) // → 3
console.log(tr.mapping.map(10)) // → 9
在某些情况下,并不是完全清楚应该将给定位置映射到什么位置。考虑上面示例的最后一行代码。位置 10 恰好指向我们分割节点的地方,插入两个标识。它应该被映射到插入内容后面还是前面?例子中明显是映射到插入内容后面
但是有时候你需要一些其它的行为,这是为什么 map 方法有第二个参数 bias 的原因,你可以设置成 -1 当内容被插入到前面时保持你的位置
console.log(tr.mapping.map(10, -1)) // → 7
当使用步骤和位置映射时,比如实现一个变更追踪的功能,或者给协作编辑符加一些功能,你可能就会遇到使用 rebase 步骤的场景
…(本小节译者并没有完全理解,暂不翻译,有兴趣可以参考原文)
编辑的状态由什么构成?当然,你有自己的文档。还有当前的选区。例如当你需要禁用或启用一个标记但还没在该标记上输入内容时,需要有一种方法来存储当前标记集已更改的情况
一个 ProseMirror 的状态由三个主要的组件构成:doc, selection 和 storedMarks
import {schema} from "prosemirror-schema-basic"
import {EditorState} from "prosemirror-state"
let state = EditorState.create({schema})
console.log(state.doc.toString()) // An empty paragraph
console.log(state.selection.from) // 1, the start of the paragraph
但是插件可能也有存储状态的需求 — 例如,撤消历史记录必须保留其变更记录。这就是为什么所有激活的插件也被存放在状态中的原因,并且这些插件可以用于存储自身状态的槽(slots)
ProseMirror 支持几种选区类型(并允许三方代码定义新的选区类型)。选区就是 Selection 类的一个实例。就像文档和其它状态相关的值一样,它们是不可变的 — 想改变选区,就得创建一个新的选区对象让新的状态关联它
选区至少包含一个开始(.from)和一个结束(.to)做为当前文档的位置指针。许多选区还区分选区的 anchor(不可移动的)和 head(可移动的),因此这两个属性在每个选区对象上都存在
最常见的选区类型是文本选区(text selection),它用于常规的光标(当 anchor 和 head 一样时)或者选择的文本。文本选区两端必须是内联位置,比如 指向内联内容的节点
核心库同样也支持节点选区(node selections),当一个文档节点被选择,你就能得到它,比如,当你按下 ctrl 或者 cmd 键的同时再用鼠标点击一个节点。这样就会产生一个节点开始到结束的选区
在正常的编辑过程中,新状态将从它们之前的状态派生而来。但是某些情况例外,例如 你想要创建一个全新的状态来初化化一个新文档
通过将一个事务应用于现有状态,来生成新状然后进行状态更新。从概念上讲,它们只发生一次:给定旧状态和事务,为状态中的每个组件计算一个新值,并将它们放在一个新的状态值中
let tr = state.tr
console.log(tr.doc.content.size) // 25
tr.insertText("hello") // Replaces selection with 'hello'
let newState = state.apply(tr)
console.log(tr.doc.content.size) // 30
Transaction 是 Transform 的子类,它继承了构建一个文档的方法,即 应用步骤到初始文档中。另外一点,事务会追踪选区和其它状态相关的组件,它提供了一些和选区相关的便捷方法,例如 replaceSelection
创建事务的最简单方法是使用编辑器状态对象上的 tr getter。这将基于当前状态创建一个空事务,然后你可以向其添加步骤和其他更新
默认情况下,旧选区通过每个步骤映射以生成新选区,但可以使用 setSelection 显式设置新选区
let tr = state.tr
console.log(tr.selection.from) // → 10
tr.delete(6, 8)
console.log(tr.selection.from) // → 8 (moved back)
tr.setSelection(TextSelection.create(tr.doc, 3))
console.log(tr.selection.from) // → 3
同样地,在文档或选区更改后会自动清除激活的标记集,并可使用 setStoredMarks 或 ensureMarks 方法设置
最后,scrollIntoView 方法可用于确保在下次绘制状态时,选区内容将滚动到视图中。大多情况下都需要执行此操作
与 Transform 方法一样,许多 Transaction 方法都会返回事务本身,以方便链式调用
当创建一个新状态时,你可以指定一个插件数组挂载到上面。这些插件将被应用在这个新状态以及它的派生状态上,这会影响到事务的应用以及基于这个状态的编辑器行为
插件是 Plugin 类的实例,可以用来实现很多功能,最简单的一个例子就是给编辑器视图添加一些属性,例如 处理某些事件。复杂一点的就如添加一个新的状态到编辑器并基于事务更新它
创建一个插件,你可以传入一个对象来指定它的行为:
let myPlugin = new Plugin({
props: {
handleKeyDown(view, event) {
console.log("A key was pressed!")
return false // We did not handle this
}
}
})
let state = EditorState.create({schema, plugins: [myPlugin]})
当一个插件需要他自己的状态槽时,可以定义一个 state 属性:
let transactionCounter = new Plugin({
state: {
init() { return 0 },
apply(tr, value) { return value + 1 }
}
})
function getTransactionCount(state) {
return transactionCounter.getState(state)
}
示例中的插件定义了一个非常简单的状态,它只计算已经应用于某个状态的事务数。辅助函数使用插件的 getState 方法,该方法可用于从编辑器的状态对象中(插件作用域外)获取插件状态
因为编辑器状态是持久化(不可变)的对象,并且插件状态是该对象的一部分,所以插件状态值必须是不可变的。即需要更改,他们的 apply 方法必须返回一个新值,而不是更改旧值,并且其他代码是不可以更改它们的
可对于插件而言向事务添加一些额外信息是非常有用的。例如,撤销历史记录在执行实际撤消时会标记生成的事务,以便在插件可以识别到,而不仅仅是生成一个新事务,将它们添加到撤消堆栈,我们需要单独处理它,从撤消(undo)堆栈中删除顶部项,然后同时将此事务添加到重做(redo)堆栈
为此,事务允许附加元数据(metadata)。我们可以更新我们的事务计数器插件,过滤那些被标记过的事务,如下所示:
let transactionCounter = new Plugin({
state: {
init() { return 0 },
apply(tr, value) {
if (tr.getMeta(transactionCounter)) return value
else return value + 1
}
}
})
function markAsUncounted(tr) {
tr.setMeta(transactionCounter, true)
}
metadata 的属性键可以是字符串,但是要避免命名冲突,建议使用插件对象。有一些属性名库中已经定义过了,比如:addToHistory 可以设置成 false 表示事务不可以被撤消,当处理一个粘贴动作时,编辑器将在事务上设置 paste 属性为 true
ProseMirror 编辑器视图是一个 UI 组件,它向用户显示编辑器状态,并允许它们进
核心视图组件使用的 编辑操作 的定义相当狭义 — 它用来直接处理与编辑器界面的交互,比如 输入、点击、复制、粘贴、拖拽,除此之外就没了。这表示核心视图组件并不支持一些高级一点的功能,像 菜单、快捷键绑定 等。想实现这类功能必须使用插件
浏览器允许我们指定 DOM 的某些部分是可编辑的,这具有允许我们可以在上面聚焦或者创建选区,并且可以输入内容。视图创建其文档的 DOM 展示(默认情况下使用模式的 toDOM 方法),并使其可编辑。当聚焦到可编辑的元素时,ProseMirror 确保 DOM 选区对应于编辑器状态中的选区
它还会注册很多我DOM在事件处理程序,并将事件转换为适当的事务。例如,粘贴时,粘贴的内容将被解析为 ProseMirror 文档切片,然后插入到文档中
很多事件也会按原生方式触发,然后才会由 ProseMirror 的数据模型重新解释。浏览器很擅长处理光标和选区等问题(当需要两向操作时则变得困难无比),所以大多数与光标相关的键和鼠标操作都由浏览器处理,之后 ProseMirror 会检查当前 DOM 选区对应着什么样的文本选区类型。如果该选区与当前选区不同,则通过调度一次事务来更新选区
甚至像输入这种动作通常都留给浏览器处理,因为干扰它往往会破坏诸如 拼写检查,某些手机上单词自动首字母大写,以及其它一些设配原生的功能。当浏览器更新 DOM 时,编辑器会注意到,并重新解析文档的更改的部分,并将差异转换为一次事务
编辑器视图展示给定的编辑器状态,当发生某些事件时,它会创建一个事务并广播它。然后,这个事务通常用于创建新状态,该状态调用它的 updateState 方法将状态返回给视图
这样就创建了一个简单的循环数据流,在 JavaScript 的世界,通常会立即处理事件处理器(可以理解成命令式的触发事件后直接操作 DOM),后者往往会创建更复杂的数据流网络(数据流可能是双向的,不容易理解与维护)
由于事务是通过 dispatchTransaction 属性来调度的,所以拦载事务是可以的做到的,为了将这个循环数据流连接到一个更大的周期 — 如果你的整个应用程序使用这样的数据流模型,就像类似 Redux 的体系结构一样,你可以使 ProseMirror 的事务与主动作调度(main action-dispatching)周期集成起来,将 ProseMirror 的状态保留在你应用程序的 store 中
// The app's state
let appState = {
editor: EditorState.create({schema}),
score: 0
}
let view = new EditorView(document.body, {
state: appState.editor,
dispatchTransaction(transaction) {
update({type: "EDITOR_TRANSACTION", transaction})
}
})
// A crude app state update function, which takes an update object,
// updates the `appState`, and then refreshes the UI.
function update(event) {
if (event.type == "EDITOR_TRANSACTION")
appState.editor = appState.editor.apply(event.transaction)
else if (event.type == "SCORE_POINT")
appState.score++
draw()
}
// An even cruder drawing function
function draw() {
document.querySelector("#score").textContent = appState.score
view.updateState(appState.editor)
}
一种简单的实现 updateState 的方法是在每次调用文档时重绘文档。但对于大型文档而言,这会变得很慢
由于在更新期间,视图可以访问到旧文档和新文档,可以用它们来做对比,单独保留没发生变化的节点对应的 DOM 部分。 ProseMirror 就是这么做的,这将使得常规的更新动作只需要做很少的工作
在某些情况下,例如 通过浏览器的编辑操作添加到 DOM 的更新文本。确保DOM 和状态一致,根本不需要任何 DOM 更改(当以一个事务被取消,修改时,视图将撤消 DOM 更改以确保 DOM 和状态保持同步)
类似地,DOM 选区仅在实际与状态中的选区不同步时才会更新,这是为了避免破坏浏览器在选区中的各种「隐藏 hidden」状态(例如,当你使用向下或向上箭头空过短行时,你的水平位置会回到你进入下一条长行的位置)
大体上讲 Props 很有用,这是从 React 学过来的。属性就像是 UI 组件中的参数。理想情况下,组件的属性完全定义其行为
let view = new EditorView({
state: myState,
editable() { return false }, // Enables read-only behavior
handleDoubleClick() { console.log("Double click!") }
})
因此,当前的状态就是一个属性。即使一段代码控制了组件并更新某属性,它也不是真正意义上的状态,因为组件 自己 并没有改变它们,updateState 方法也只是更新状态中某个属性的一种简写
插件可以声明除了 state 和 dispatchTransaction 以外的任意属性,它们可以直接传给视图
function maxSizePlugin(max) {
return new Plugin({
props: {
editable(state) { return state.doc.content.size < max }
}
})
}
当一个给定的属性被多次声明时,它的处理方式取决于属性类型。直接传入的的属性优先,然后每个插件按顺序执行。对于一些属性而言,比如 domParser,只会使用第一次声明的值。如果是事件处理函数,可以返回一个布尔值来告诉底层事件系统是否要执行自己的逻辑(比如 事件处理函数反回 false,这表示底层事件上绑定的相同事件处理函数将不会被处理),有的属性,像 attributes 则会做合并然后使用
装饰使你可以控制视图绘制文档的方式。它们是通过从 装饰器 属性返回值创建的,有三种类型
为了能够有效地绘制和比较装饰器,它们需要作为装饰数组提供(这是一种模仿实际文档的树形数据结构)。你可以使用静态 create 方法创建,提供文档和装饰对象数组
let purplePlugin = new Plugin({
props: {
decorations(state) {
return DecorationSet.create(state.doc, [
Decoration.inline(0, state.doc.content.size, {style: "color: purple"})
])
}
}
})
如果你有很多装饰器,那么每次重新绘制时都要重新创建这些装置成本会很高。这种情况下,维护装饰器的推荐方法是将数组放在插件的状态中,通过更改将其映射到之前的状态,并且只在需要时进行更改
let specklePlugin = new Plugin({
state: {
init(_, {doc}) {
let speckles = []
for (let pos = 1; pos < doc.content.size; pos += 4)
speckles.push(Decoration.inline(pos - 1, pos, {style: "background: yellow"}))
return DecorationSet.create(doc, speckles)
},
apply(tr, set) { return set.map(tr.mapping, tr.doc) }
},
props: {
decorations(state) { return specklePlugin.getState(state) }
}
})
上面的插件将其状态初始化为装饰器数组,该装饰器数组将会执行每 4 个位置添加黄色背景。这个例子可能并不是非常有用,但有点类似于突出显示搜索匹配或注释区域的场景
当事务应用于状态时,插件状态的 apply 方法将装饰器数组向前映射,使装饰器保持原位并「适应」新文档形状。通过利用装饰器数组的树形结构使得映射方法(典型的局部变化)变得高效 - 树形结构中只有变化的部分才会被处理或者重建
在插件的实际使用过程中,apply 方法也可以根据你基于新事件添加或删除装饰的位置而定,或者是通过检测事务中的更新,或基于特定的附加到事务的插件元数据
最后,装饰属性只是返回插件状态,这就导致装饰器会展示在视图中
还有一种方法可以影响编辑器视图绘制文档的方式。节点视图可以为文档中的各个节点定义一种微型的 UI 组件。它们允许你展示 DOM,定义更新方式,并编写自定义代码以及响应事件
let view = new EditorView({
state,
nodeViews: {
image(node) { return new ImageView(node) }
}
})
class ImageView {
constructor(node) {
// The editor will use this as the node's DOM representation
this.dom = document.createElement("img")
this.dom.src = node.attrs.src
this.dom.addEventListener("click", e => {
console.log("You clicked me!")
e.preventDefault()
})
}
stopEvent() { return true }
}
上面的示例为图片节点定义了视图对象,为图像创建了自定义的 DOM 节点,添加了事件处理程序,并使用 stopEvent 方法声明 ProseMirror 应忽略来自该DOM 节点的事件
通常你可能会有与节点交互以影响文档中的实际节点的需求。但是要创建更改节点的事务,首先需要知道该节点的位置。为此,节点视图将传递一个 getter 函数,该函数可用于查询文档中当前节点的位置。让我们修改示例,实现单击节点查询你输入图像的 alt 文本:
let view = new EditorView({
state,
nodeViews: {
image(node, view, getPos) { return new ImageView(node, view, getPos) }
}
})
class ImageView {
constructor(node, view, getPos) {
this.dom = document.createElement("img")
this.dom.src = node.attrs.src
this.dom.alt = node.attrs.alt
this.dom.addEventListener("click", e => {
e.preventDefault()
let alt = prompt("New alt text:", "")
if (alt) view.dispatch(view.state.tr.setNodeMarkup(getPos(), null, {
src: node.attrs.src,
alt
}))
})
}
stopEvent() { return true }
}
setNodeMarkup 是一个方法,可用于更改给定位置的节点的类型或属性集。在示例中,我们使用 getPos 查找图像的当前位置,并使用新的 alt 文本为其提供新的属性对象
节点更新后,默认行为是保持节点外部 DOM 结构不变,并将其子项与新的子元素集进行比较,根据需要更新或替换它们。节点视图可以使用自定义行为覆盖它,这允许我们执行类似于根据内容更改段落类(css class)属性的操作
let view = new EditorView({
state,
nodeViews: {
paragraph(node) { return new ParagraphView(node) }
}
})
class ParagraphView {
constructor(node) {
this.dom = this.contentDOM = document.createElement("p")
if (node.content.size == 0) this.dom.classList.add("empty")
}
update(node) {
if (node.type.name != "paragraph") return false
if (node.content.size > 0) this.dom.classList.remove("empty")
else this.dom.classList.add("empty")
return true
}
}
图片标签不会有子内容,所以在我们之前的例子里,我们并不需要关心它是如何渲染的,但是段落有子内容。Node view 支持两种处理内容的方式:要么你让 ProseMirror 库来管理它,要么完全由你自己来管理。如果你提供一个 contentDOM 属性,ProseMirror 将把节点渲染到这里并处理内容更新。如果你不提供这个属性,内容对于编辑器将变成一个黑盒,内容如何展示如何交互都将取决于你
在这种情况下,我们希望段落内容的行为类似于常规可编辑文本,因此contentDOM 属性被定义为与 dom 属性相同,因为内容需要直接渲染到外部节点中
魔术发生在 update 方法中。首先,该方法负责决定是否可以更新节点视图以显示新节点。此新节点可能是编辑器更新算法尝试绘制的任何内容,因此你必须验证此节点有对应的节点视图来处理它
示例中的 update 方法首先检查新节点是否为段落,如果不是,就退出。然后它确保 empty 类存在或不存在,具体取决于新节点的内容,返回true,则表示更新成功(此时节点的内容将被更新)
在 ProseMirror 的术语中,命令是实现编辑操作的功能,用户可以通过按某些组合键或与菜单交互来执行命令
出于实际原因考虑,命令的接口稍微有点复杂。一个接收 state 和 dispatch 参数的函数,该函数返回一个布尔值。下面是一个非常简单的例子:
function deleteSelection(state, dispatch) {
if (state.selection.empty) return false
dispatch(state.tr.deleteSelection())
return true
}
当一个命令非正常执行时应该返回 false,表示什么都不会发生。相反如果返正常执行,则应该调度一个事务并且返回 true。确实是这样的,当一个命令被绑定到一个健位并执行时,keymap 插件中对应于这个健位的事件将会被阻止
为了能够查询一个命令对于一个状态下是否具有可执行性(可执行但又不通过执行来验证),dispatch 参数是可选的 — 当命令被调用并且没传入 dispatch 参数时,如果命令具有可执行性,那就应该什么也不做并返回 true
function deleteSelection(state, dispatch) {
if (state.selection.empty) return false
if (dispatch) dispatch(state.tr.deleteSelection())
return true
}
为了能够知道一个选区否可以被删除,你可以调用 deleteSelection(view.state, null),然而如果你想真正执行这个命令就应该这样调 deleteSelection(view.state, view.dispatch)。菜单栏就是用这个来决定菜单按钮的可用性的
这种行式下,命令并不需要访问实际的编辑器视图 — 大多数命令都不需要,这样的话命令就可以在设置中应用和测试而不必关心视图是否可用。但是有的命令则偏偏需要与 DOM 交互 — 可能需要查询指定的位置是否在文本块儿后面,或者打开一个相对于视图定位的对话框。为了解决这种需求,命令还提供了第三个(整个编辑器视图)参数
function blinkView(_state, dispatch, view) {
if (dispatch) {
view.dom.style.background = "yellow"
setTimeout(() => view.dom.style.background = "", 1000)
}
return true
}
上面的例子可能并不是合适,因为命令并没有调度一次事务 — 调用他们可能会产生副作用,所以 通常 需要调度一次事务,但是也可能不需要,比如弹出一个层(因为这个层不在编辑器视图里面,并不属于编辑器的状态,所以调度事务就显得多余了)
prosemirror-commands 模块提供了很多编辑器命令,从简单如 deleteSelection 命令到复杂如 joinBackward 命令,后者实现了块级节点的拼合,当你在文本块开始的地方触发 backspace 键的时候就会发生。它也会附加一些基本的快捷键绑定
chainCommands 函数可以合并一系列的命令并执行直到某个命令返回 true
举个例子,基础的快捷键绑定模块中,backspace 会被绑定到一个命令链上:1. deleteSelection 当选区不为空时删除选区;2. joinBackward 当光标在文本块开始的地方时;3. selectNodeBackward 选择选区前的节点,以防骨架中不允许有常规的拼合操作。当这些都不适用时,允许浏览器运行自己的 backspace 行为,这对于清除文本块内容是合理的
命令模块还导出许多命令构造器,例如 toggleMark,它采用标记类型和可选的一组属性,并返回一个命令函数,用于切换当前选区上的标记
其他一些模块也会导出命令函数 — 例如,从 history 模块中 undo 和 redo。要自定义编辑器,或允许用户与自定义文档节点进行交互,你可能还需要编写自定义命令
实时协作编辑允许多人同时编辑同一文档。它们所做的更改会立即应用到本地文档,然后发送给对等(pears)方,这些对等方会自动合并这些更改(无需手动解决冲突),以便编辑动作可以不间断地进行,文档也会不断地被合并
这一节将介绍如何给 ProseMirror 嫁接上协作编辑的功能
ProseMirror 的协作编辑使用了一种中央集权式的系统,它会决定哪个变更会被应用。如果两个编辑器同时发生变更,他们两都将带着自己的变更进入系统,系统会接受其中之一,并且广播到其它编辑器中,另外一方的变更将不会被应用,当这个编辑器接收到新的变更时,它将被基于其它编辑器之上执行本地变更的 rebase 操作,然后再次提交更新
集权式的系统的角色其实是相对简单的,它只须做到以下几点…
让我们实现一个简单的集权式的系统,它在与编辑器相同的 JavaScript 环境中运行
class Authority {
constructor(doc) {
this.doc = doc
this.steps = []
this.stepClientIDs = []
this.onNewSteps = []
}
receiveSteps(version, steps, clientID) {
if (version != this.steps.length) return
// Apply and accumulate new steps
steps.forEach(step => {
this.doc = step.apply(this.doc).doc
this.steps.push(step)
this.stepClientIDs.push(clientID)
})
// Signal listeners
this.onNewSteps.forEach(function(f) { f() })
}
stepsSince(version) {
return {
steps: this.steps.slice(version),
clientIDs: this.stepClientIDs.slice(version)
}
}
}
当编辑器试着提交他们的变更到系统时,可以调用 receiveSteps 方法,传递他们接收到的最新版本号,同时携带着新的变更及他们自己的 client ID(用来识别变更来自哪里)
当这步骤被接收,客户端就会知道被接收了。因为系统会通知他们新的可用步骤,然后发送给他们自己的步骤。真正的实现中,做为优化项,你也可以调用 receiveSteps 返回一个状态码,然后立即确认发送的步骤,但是这里用到的东西必须要在不可靠的网络环境下保证同步
这种权限的实现保持了一系列不断增长的步骤,其长度表示当前版本
collab Modulecollab 模块导出一个 collab 函数,该函数返回一个插件,负责跟踪本地变更,接收远程变更,并对于何时必须将某些内容发送到中央机构做出指示
import {EditorState} from "prosemirror-state"
import {EditorView} from "prosemirror-view"
import {schema} from "prosemirror-schema-basic"
import collab from "prosemirror-collab"
function collabEditor(authority, place) {
let view = new EditorView(place, {
state: EditorState.create({schema, plugins: [collab.collab()]}),
dispatchTransaction(transaction) {
let newState = view.state.apply(transaction)
view.updateState(newState)
let sendable = collab.sendableSteps(newState)
if (sendable)
authority.receiveSteps(sendable.version, sendable.steps,
sendable.clientID)
}
})
authority.onNewSteps.push(function() {
let newData = authority.stepsSince(collab.getVersion(view.state))
view.dispatch(
collab.receiveTransaction(view.state, newData.steps, newData.clientIDs))
})
return view
}
collabEditor 函数创建一个加载了collab 插件的编辑器视图。每当状态更新时,它都会检查是否有任何内容要发送给系统。如果有,就发送
它还注册了一个当新的步骤可用时系统应该调用的函数,并创建一个事务来更新我们的本地编辑器反映这些步骤的状态
当一组步骤被系统拒绝时,它们将一直保持未确认状态,这个时间段应该会比较短,持续到我们从系统收到新的步骤之后。接着,因为 onNewSteps 回调调用 dispatch,dispatch 再调用我们的 dispatchTransaction 函数,代码才会将尝试再次提交其更改
这基本上就是的所有协作模块的功能了。当然,对于异步数据通道(例如上面的演示代码中的长轮询或 Web套接字),你需要更复杂的通信和同步代码,而且你也可能需要集权系统在某些情况下开始抛出步骤,而不至于内存被消耗完。但是这个小例子大概也描述清楚了实现过程
1970-01-01 08:00:00
在很久之前我就说过同样的话,表达过我觉得做为前端工程师而言设计素养的重要性,今天我想聊天为什么我有这种观点
实际上生活中设计是中无处不在的,大到建筑工程、工业设计,小到网页设计、产品设计。我认为设计的本质就是 理解你(或者你的用户)内心想法的一个过程,在完成了一个物件的物理功能后,你需要考虑它的适用场景及多数用户的实用需求
我在北京呆了很多年,你要问我对北京的印象是什么颜色,我会毫不犹豫的告诉你「蓝色」。有的人会认为是雾霾的灰色、有的人会认为是天安门的红色。为什么我的印象是蓝色呢,因为在北京无论你去哪儿都会选择公共交通,所有的交通标识牌都是蓝背景加白前景色,环路上的路标、地铁标、普通道路的路标,到处都会有蓝色的标识牌。使用蓝色的好处在于 标识性强,尤其对我这种视觉异常的人特别友好。但是却缺乏美感,因为要照顾大多数人的体验
我也常去西安,你要问我对西安的印象是什么颜色,我也会告诉你是「暗红」。西安的地铁标识牌就是这种暗红,我也不太确定这种颜色准确的叫法,赤红或者朱红?总之这种颜色和西安这个城市的调性很搭。无论是古城门上的各种架梁、门柱、瓦石的着色,还是现代的地铁标识颜色,到处都有暗红色的设计。西安地铁标的设计虽然说是和整个城市的气质具有一致性,但是 识别性很差,尤其城市里面绿化比较好,树木多的时候绿色和这种红色标识交错在一起是很难分辨的
从这个例子中我们可以了解到,其实设计并不是那种只存在于理论或者艺术世界里面的东西,大多数的设计都源于生活。都表达了人们对于生活的思考与理解
狭义点讲前端工程师(程序员)们的日常是程序设计或者软件设计。有一个关于用户体验的真相是:大多数用户当他们不喜欢你的产品时,他们会 直接离开并放弃。用户的选择是正向的,他会因为你的软件好用选择,但 并不一定 会因为你的软件不好而批评反馈。所以我一直认为很多所谓的为了提高用户体验的调查问卷并没有什么作用。相反的很多反馈都是没有经过深思熟虑,或者是很个人的需求,这反倒会影我们的判断
所以说代码设计的的好不好,交互是否流畅,体验是否极致。这个门槛的最后一步就在前端
当然后端也很重要,后端的重要性是我们在这聊设计聊体验的前提。「仓廪实而知礼节」,很多前端在知乎提问类似「Node.JS 和 Java 相比…」的话题的时候却从来没想过这个问题,不过这个话题就不细聊了
前端需要关注设计,原因有二:
一、离用户更近。这个毫无疑问,前端在整个软件的系统栈里面是最顶部一个元素,他们写出来的代码第一用户是自己,一个功能好不好用前端会有第一知觉。同时这个也依赖于工程师对于设计体验的素养。很多东西是没法区分 逻辑上的好坏,同时有些东西应该是 不言而喻 的:
页面的链接到底应该在当前面页打开还是新页签
这就是一个典型的没法从逻辑上区分好坏的问题。当然所有页面都新窗口打开肯定是不对的。我认为 <base target="_blank"/> 在任何时时候都不应该被使用。看看自己每天使用的浏览器 tab 页的个数就明白了。实际使用的时候要根据用户的场景、喜好、链接去向内容、技术实现等各方面因素综合考虑,一刀切 的做法绝对是错误的
弹出层、hover 提示 应该是尽量少的使用
这就是不言而喻的,因为在 PC 端用户的鼠标是最常用的输入设备。鼠标的 mouseover 事件会产生很多误操作,浮层的显示这会骚扰用户的视觉。当然技术上我们可以通给 mouseover 事件添加延迟的方式来避免误操作的机率,但是我认为这是一种 打补丁 的解决方法,因为当一个提示信息足够重要的时候,任何延迟都是错误的,更何况打补丁还有副作用
最近刚好发现一个笔记类应用「www.notion.so」,初次使用的时候感觉真的非常棒。设计精美、交互流畅、动画细腻,好的产品不就应该是这样的么

但是当你深入使用的时候你会发现这个页面上充满了各个的 hover 效果,提示信息、状态切换等。它几乎在所有的图标上都加了 功能提示或快捷键的 hover 提示,这个在我看来就非常的骚扰用户。就比如左侧菜单的收起按钮使用了左箭头的图标「<」,这种图标就是不言而喻的,不需要再用 tooltip 来提示
二、审美需求。这一点其实上是所有人都需要关注的,很多程序员在使用 macOS 一段时间后就再也没法忍受 windows 的界面了。单从审美诉求这一项讲,macOS 体现出来的简洁、专注是 windows 系统没有的。结合上面的问题可以思考下:*为什么 macOS 系统的鼠标 hover 的交互很少?*我觉得应该是操作系统给用户带来的那种稳定、可靠的感觉。当你专注的做一件事情的时候最好不要有任何形式的打扰,像系统通知、气泡提醒什么的应该完全被禁止
很多人会认为程序员不需要审美,因为他们实现功能就行了。事实上甚至很多程序员也可能是这么想的。但是他们并没有意识到一点,即使是那种特别不关心审美的人也有基本审美的需求,或者说一个长像其丑无比的人也有基本审美的需求,爱美之心人皆有之。只是程序员这类群体写代码太久就会进入特别专注的状态,只在乎代码,忘了其它一些同样有价值的东西
我想表达的意思并不是说这样不好,而是我认为在专注技术的前提下了解一些设计方面的东西会让我们理解别人(用户)的想法,这其实也是一种与外界的沟通形式,也能弥补程序员天生的弱点
很多对设计一知半解的人会说一句别人经过实践总结出来的真理:
Rules are meant to be broken — 规则就是用来被打破的
在《写给大家看的设计书》中就讲过这个问题,我是比较同意作者的观点,即:打破规则的前提应该是你足够了解规则是什么,意味着什么
同时书中开篇分享了另外一个观点,我也很赞同:
当你能叫出一个东西的名字后,这个东西就无处不在了
这个估计很多人都会有这种体验,某一天某个人说了一个你以前从来没听过的词儿,然后你觉得这个词很新鲜,接着在后来一段时间内这个词就会不段的出现在你的周围
作者的意思是,其实就是设计在很多人眼中遙不可及并不是因为它很高深,而是你没听过、没见过一些设计规则
后面的东西就不聊了,读者有兴趣可以读下原著,书中提到的几个原则至今都在我的脑海里:亲密、对齐、重复、对比
封面图:https://www.pexels.com/photo/black-pencils-and-design-word-6444/
1970-01-01 08:00:00
单看这篇文章的标题可能会有点言重,但是我更愿意记录下来给自己当做警钟。同时这也不是一篇聊历史的文章
为什么会谈到这个话题,是因为最近新闻实在太多,无论是「金马奖台独」、「俞敏洪关于堕落的演讲」还是「D&G辱华」。每一次舆论的风口浪尖上总是会有一些公众号 站出来表达立场 ,我并不打算聊这三件事情中的任何一件,我想聊聊我对于公众号的一些反醒及看法
事实上最开始公众号流行的时候,我也会跟风转发一些高赞文章。比如当年咪蒙写的《致贱人:我凭什么要帮你》。当我看完这篇文章时第一感觉就是:太解气、太过瘾了,浑身上下产生了一种从心理到生理上的一种爽快感
现在想起来当时的感觉应该和吸鸦片没有什么两样,但当我回过头来再看这件事情的时候我会觉得这文章无论对于我自己还是观众来说都没有半点益处。就像文章里面提到的那种伸手党,你帮了他他还觉得理所应当的人,这种人在现实生活中总会存在,不会因为转了这篇文章而消失、更不会因为你骂他两句他就幡然醒悟。所以我觉得与其痛述现实与之争长短,不如静下心来,多看书学习,用提高自己的方式拉开与它们的距离
然后我也想分析下这类的文章为什么能受到很多人的追捧(下面的分析并不针对指定公众号)
虽然公众号名曰「公众」,但是我认为 个人公众号 是挺私人的东西。大多数人发的内容都是和自身经历相关的,不具有事实客观性,大家都在聊自己的观点
比较会写文章的那类公众号发展一段时间,会有很多粉丝,他们写的一些东西因为本质上就是私人的一些想法,写的多了总会不自觉的迎合上某些观众的心理。再加上互联网肆虐的传播途径从而行成蝴蝶效应。再后来他们会成立所谓的「xx 公司」来专门运营公众号,但是本质上并没有提高内容的质量。慢慢的公众号成了一种娱乐、八卦的媒体
很多观众也不具备独立思考的能力,大家对于文章好块的判断通常是感性的,通常是某些字眼、句子触动了内心深处的某个地方。由此产生的点赞或是转发完全属于一种 生理反射
大家都会说当你被一只狗咬一口的时候你不应该咬回去,因为你是人,你会思考… — 但事实是任何人被狗咬的第一反应就是回踹他两脚或者更甚
这就解释了我们很多时候平心静气讲道理的时候都很懂,都能说得头头是道。但真正自己处于指定条件下的时候也不免产生非理智行为,尤其是被情绪控制的时候
其实再深入点,对于专业的写手来讲,他们很懂得利用大众的心态与喜好,很容易就能写出来一些据有煽动性言论。举例个不太恰当的例子,如果让我写一篇关于「D&G辱华」事件的文章,在尽可能获取更高点赞的前提下我完全可以把这篇文章写得非常有煽动性,让多数人看了捶胸顿足、拍案叫绝。但是我不会,因为相对于做好事来讲,做坏事简直太简单了,没什么技术含量
所以我认为一些公众号及其观众大多数都是在宣泄私人的情绪,没有什么正常的逻辑推理,更没有什么值得思考的东西
接着上面的蝴蝶效应讲。其实上面的现象并不是最可怕,最让人无解的是当蝴蝶效应延伸到大多数人的脑子里面时,整个事情就完全变味儿了。人们会上升到政治正确、非主流、异教徒的观念
中国人喜欢大一统,因为大一统的观点才是权威的、名正言顺的。所谓的「一家之言」反而会遭到质疑,或者说 政治不正确,甚至被认为是 freak,然后接着拿的两样观点做对比。结果就是「我的观点永远是伟大、光荣、正确的,你的观点就是错的、可耻的、应该被消灭的」
我们去看诸葛亮的《后出师表》,开头第一句就是「先帝深虑汉、贼不两立,王业不偏安」。我就特别奇怪,为什么非要分 汉、贼 呢?可能在对方看来你才是贼,「不两立」在现在看来 就更可笑了,怎么就不能两立了,各安一方水土、各抚一方百姓 不好吗?王业不偏安,那么你的王是王,别人的王就不是王了?
当然我上面讲的是在现在看来,在古代群雄逐鹿的时代不是你死就是我亡。可那是当时的实世。现如今都 21 世纪了,全世界都在讲求同存异、自由平等,为什么很多人就是接受不了新的观点与想法,接受不了异已呢
人类是感情动物,不是机器。有情绪就需要表达与宣泄。就我自己职业而言,属于程序员这种被认为没有感情需求的一类人。但事实是即使是程序员这类不懂沟通交流的人群,在实际生活中也需要表达,也需要沟通与被肯定。就好比大家觉得男人本质上就是动物,没有情绪一样。这是一个极其错误的观点,只是他们更喜欢把自己的感情深藏在内心罢了
情绪宣泄并不是某类人的特殊需求,言论自由同样是每个人天生的权利。无论是家庭、工作还是社会中,人们总会积累到一些负面情绪,同时总会在某一角色中表现出来
我认为下面三种文章是我比较认同的:
一、没有结论,只有论点和客观事实。结论交给观众,每个人自然有属于自己的判断
二、有论点、有结论,并且结论根据客观事实逻辑出来。这类文章即使结论有感情色彩,对观众来讲也会产生好的引导、或者说观众也能自我判断
三、看完后能让人反省思考。我认为单纯的读书、学习只能提高自己的知识水平,并不能综合性的提升自我意识与自我修养(学而不思则罔,思而不学则殆),只有不断的反省思考才能让人健全
最后分享一段讨论传统文化是否阻碍科技发展的视频:
关注微信公众号「肆零玖陆」查看视频
我们的文化传统是不提倡怀疑、不提倡批判、不提倡分析、不提倡实证,哪来的科学,哪儿来的科学精神
封面图:https://www.pexels.com/photo/blur-capsule-close-close-up-209495/
1970-01-01 08:00:00
最近由于工作内容需要特地了解了一下国外在线购物网站的一些特点,过程中发现一些比较有意思的地方,记录下来同时聊聊我的感受
我很少上国外购物网站买东西。毕竟做为个人来讲跨境消费是非常不方便的。但是我会通过信用卡购买一些服务类的产品,像虚拟服务器、域名、正版软件等。大概算是有一点国外网站的消费经历
我研究了美国 TOP 10 的线上购物网站,类型上大概分三种:
像 Amazon, Ebay 这种属于综合类的线上购物网站,大部分的人会上这样的网站购物,因为商品种类齐全,覆盖面广。而且这类网站通常都是电商的先驱,用户早就行成了消费习惯。所以它们能占市场的很大份额
一般是某个特定商品分类领域,或者比较小众的网站。例如:Newegg - 消费电子、Esty - 手工艺、Sears - 工具/器具、ModCloth - 非主流女装、Rockler - 木工五金。这类网站的特点就是目标用户比较小众,网站的设计风格也非常个性化。newegg 是数码极客风,Esty 是小清新路线,Sears 是实用主义,ModCloth 是潮流与时尚,Rockler 是匠人。每个网站都有它特定的气质。Rockler 比较有代表性,在国内很难想像有买五金制品的网站,在 Rockler 甚至可以买到木头原材料,估计是因为国外人工成本高,很多家庭常用的东西都是自己做,所以才存在这种小众类目购物网站
这个分类可能国人没啥概念,渠道就表示线上、线下百货零售等。Walmart(沃尔玛)、Best Buy(百思买)、Target(塔吉特)。这其中数沃尔玛最典型,沃尔玛是一家美国的跨国零售企业,一个典型的家族企业。已经连续 N年在「财富世界500强」排名第一。可以说是美国零售企业的鼻祖了。这类网站的特点就是它们的线下零售渠道非常成熟,沃尔玛全球员工就超过两百万,线上对于它们来说只是多了一种销售途径。线上的销售完全可以靠自己的品牌影响力来推广
在实际体验过这些网站后,我汇总出了如下几个和国内网站有鲜明区别的地方:
国外购物网站上一个最主要的特点:图片特别大,而且图片中除了商品以外没有别的干扰元素。比如下面这个母婴类目首页的导航图

看一眼大概就能知道分别是:贴身寝具/尿不湿、儿童服饰、婴儿用的安全器具。这是一个引导页,图片上不会有具体商品信息
他们的的频道页(首页、类目展示页)很少有具体的商品展示,频道页只做一个大概的分类引导,页面很短,一般就是几张简单的图片,一眼就知道这个分类卖些什么东西。如果有感兴趣的内容就点到下一个具体类目进行筛选
对比国内的频道页都是以楼层的概念陈列商品列表:
天猫:

京东:
可能国内用户都习惯了杂货铺的体验,大家喜欢在一堆东西里面挑选购物的感觉吧。
大部分人上购物网站的目的就是要购买某样商品,我们现在很多人网上购物本来想买 A,结果国内网站一顿干扰+瞎推荐引导买了 B 或者什么都没买,这难道不是倒行逆施么
以买衣服为例,我们看看国外网站的列表页是怎么展示商品的:
Target 的女士毛衣列表
Modcloth 的女士连衣裙列表
亚马逊的女士连衣裙列表
总体上给人的感觉是列表页非常清楚、简单。一眼扫过去就能知道衣服穿上的效果。而且图片中的人物也比较素雅普通,尤其 Modcloth 网站上,不同肤色、不同形体、不同风格会让你感觉到这就是平常人穿搭效果
另外我发现亚马逊比较特殊,很多模特都不会露脸。猜测可能是为了排除人物形象对商品的干扰?
再看看国内网站是怎么做的:
天猫的连衣裙列表
天猫的这个列表就明显过于突出模特的妆容和身材,根本感觉不到这件衣服的材质、面料、风格以及实际穿在身上的效果,而且一张图片里面的元素太多了,品牌 logo、背景、配饰都干扰了用户的视觉
京东的女装当季热卖
图 3 和图 5 到底买的是衣服还是包包让人无比的困惑,图 1 更离谱,到底卖是手上的配饰还是裤子还是衣服根本说不清楚
大多国内网站的服装列表基本上都会在左/右上角标出来 品牌 这个是真正的中国用户习惯,大家买东西就看品牌,衣服好不好不重要么?品牌意识在国内真的是根深蒂固。以我们上面的例子为例,我列出的是天猫和京东网站上卖的东西,很多人买完商品觉得不好的时候会觉得是天猫或者京东不好。这是一个值得思考的问题
总结起来国内的衣服卖的是 模特 和 品牌,国外衣服更注重 穿搭效果
国外网站上推荐相关的内容比较少,顶多会有一个 you may like 的推荐商品模块,推荐的东西比较少而且通常在不显眼的地方。其实本来就应该如此,所谓的推荐、个性化应该是建立在尊重用户原始的购买目的之上的点睛之笔。比如我买了个 iPhone 电池,网站推荐给我一个螺丝刀我就会觉得很贴心,反之就不行
再比如有人攒钱买个苹果笔记本,那在一段时间内就别再给人家推荐笔记本类的商品了嘛。大多数情况这种推荐是毫无意义的。大家整天在吹人工智能、大数据推荐什么的。但是这个简单的逻辑都做不到那人工智能就变成了人工智障了吗
国外网站一般就提供两种支付方式:信用卡、PayPal。像 Apple Pay, Android Pay 什么的都是非主流。除非有对中国的业务才有可能提供支付宝这种支付方式。国内的移动端支付方式可以说是碾压性的优势,大家会觉得国外的支付方式简直就是停留在原始社会
国外的购物网站促销都比较单一,不像国内有各种的玩法。一般来说有三种:
优惠码 (Gift code):通常用在一些特殊的日子,类似国内的店庆一样。优惠码在一段时间内所有用户通用,比如使用 happy2018 就能获得 80% off 的优惠
礼品卡 (Gift card) :类似于购物网站的虚拟货币。这个就有点意思了,很多外国人会直接送亲戚朋友礼品卡而不是实物。他们会认为大家的需求不一样,我给你买的东西你不一定喜欢,还不如直接送张购物卡,你爱买啥买啥,你高兴我也不发愁送啥
黑五大促 (Black friday):黑五的促销一般都是实打实的打折甚至半价,不玩虚的,用国内的标语就是:在黑五那天你买不到吃亏,买不了上当,明码标价,老外诚不欺我。这不快到 2018 的黑五了,Google Pixel 3 促销第二台半价 (Buy a Pixel 3/3 XL, get another up to 50% off)
1970-01-01 08:00:00
马上要到双十一大促了,无论你喜不喜欢,各种广告、短信都扑面而来。当大部分广告都在高呼打折、特价买买买的时候,大家似乎都忘记了自己想要买什么了。
提到广告首先让我印象深刻的是 youtube 视频网站的广告。youtube 的广告一般大概两分钟,每次看到新广告总能让人感觉特别惊喜,同样的视频网站,国内的优酷、腾迅视频却很少让人记住。
于是我做了个简单的分析,总结出来我认为 youtube 广告更棒的几个原因:
观看 youtube 需要视频需要科学上网,没法观看的可以关注公众号 肆零玖陆 对应有文章更新
这个是毋庸置疑的,无论大众的审美如何,人们天生喜欢看到美的东西,能传递思想形成共鸣东西。即使广告也不例外,好广告最基础的一点就是要让用户看完之后知道你传达的信息是什么,似有似无、估做深沉的广告毫无意义。
如果你是个程序员并且经常上 youtube 的话,你一定会看过 Wix 这个广告。它是一个网站,使用它可以让你快速的制作属于自己的网页、博客等。我们来欣赏一下 Wix 的广告:
这个广告无论从内容传达、产品特点、动感音效还是品牌效应都一应俱全,看完之后不仅印象深刻,而且即使你不怎么懂英文也知道 wix 是用来做什么的。
广告一开始就开门见山告诉你:
「With Wix you can create professional website that looks stunning, Just go to wix.com…」
不到 4 秒的时间就把整个广告的主功能告诉你了(猜想可能是因为 youtube 广告 5 秒之后可以跳过),接着音乐节奏一变,开始演示一些常用功能,如果你是第一次看这个广告那这部分还是挺有效的「入门指引」,如果你看到过很多次这个广告,那现在你跳过去也不会错过什么,因为第一句话已经达到了效果,对于跳过的用户后面的部分自然是没有意义的。
所谓的品牌效应就是看过很多次以后你脑子里面的那几个字,如果你还看过这个广告的其它版本,你就会发现有几个频繁出现的关键字「professional, stunning, website」,这就是广告想告诉用户的最重要的信息了
还有类似 Grammarly 这样的广告,简洁清新的设计风格,让你一看就懂:
推荐关联性强,这一点不得不说,youtube 上的广告真的是覆盖面非常广泛,如果你经常在 youtube 上看一些编程方面的视频,它就会推荐给你很多技术相关的广告,前两天突然给我推送了一个 React Native 组件的广告,我们来欣赏下:
这个广告相比而言更小众了,估计不是做前端的根本看不懂是个啥意儿了。其实就是他们做了一些 React Native 的商业化组件,种类多,你可以付钱直接购买使用,不用自己开发。
可能是因为我经常看一些人文历史方面的视频,youtube 还推送过一些公益性质的文化传播类的广告比如这个「中文化遗产保护的合作关系」:
这让我无比惊讶。一方面在于这种细分领域而且还是我特别了解的东西居然也有商业化的广告,另一方面也感叹 youtube 的推荐确实非常准确。而且我时常感觉以前在 google 搜索上搜索关键词后,再上 youtube 居然能推给我新的相关广告。当然这种推荐有可能会影响到你的隐私,不过由于 GDPR 的原因,国外的网站现在基本上都有了不记录用户操作历史的一些选择。这个对于多数人来讲都是有好处的,因为对于用户来讲他们 始终 是有选择的。推荐这个话题很大,有时间单独写写
这一条对于国内用户来讲尤其重要,要知道腾迅视频不开会员每次打开都是有 40~90 秒不能跳过的广告哦,爱奇艺,稍好点的是一定时间内再看新视频就不会播广告了。而且我发现国内的视频网站广告都 出奇的统一,要么是名牌汽车、婴儿牛奶,要么是可口可乐、肯德基汉堡。都是大家挺熟悉的东西。完全没有新鲜感。
再看 youtube 的广告,说起来其实我也没搞懂 youtube 广告的展示逻辑,有的时候点进去完全没广告,有时候每次点进去都会有。但是值得一提的是 youtube 的广告不仅和你的喜好有关,而且和广告所在的视频内容也相关。比如你看一个手机的开箱视频,那广告很可能就是和手机相关的,比如摄影照像相关。如果你不喜欢 5 秒后跳过,一段时间内就不会再有广告了。虽然 youtube red 可以让你付费免去所有广告,但是对于我这种视频观看量级还是用不到的,能用到的前提也得是没有科学上网的成本。
最后再附送一条之前真正让我产生转换率的广告,也是 youtube 推荐的,起初我并不知道这是个什么东西,看完之后莫名的被吸引,然后去搜索相关资料,了解了这个品牌的一些设计理念,刚好赶上七夕,所以就顺利成章的形成了一次「冲动」购买
1970-01-01 08:00:00
很多从事 IT 互联网公司工作的人(尤其是程序员)会常常提到「技术驱动与技术重视」的问题,大部分人在面临职业选择的时候也优先选择那些所谓的「技术驱动」型的公司。因为在这种公司里面技术氛围好,对自己的职业发展有帮助。
这种想法肯定是无可厚非的。本文试着从大环境与自我两方面聊一下这个话题
首先。在大家聊到这个话题时往往都 出奇一致 的认为国内没有技术驱动型公司。因为大众对技术的认识很少,很多人对于程序员的第一印象是「修电脑」。
当然你可能会觉得「不会呀,我周围都是一些非常专业的同事,我也在一家很重视技术的公司工作,我的工作内容大家都认可」,这么认为当然也是对的,但是我想说是的大众的意识问题。
为什么大家会有这种「偏见」,在我看来根本原因就是一种 普世的价值观对于偏才的误解。因为大众喜欢看到一个十全十美的东西。儒家的思想提倡自我的实现,君子应该如何如何…,君子应该是上知天闻下知地理,既洞明学问,又练达人情。但事实上并非如此。诸葛亮就是一个很好的例子,大众认可的是他小说中的角色,一个样样精通的人,政治、军事、管理各个领域都很精通,但事实上诸葛亮除了人长得帅气,有政治才能以外并没有别的什么长处
大家喜欢全才而不是偏才,这也是《论语》中讲「君子不器」的道理。就是说君子不能像固定的器具/东西一样只有一个功能。上学的时候老师会告诉你不能偏科,学校会要求你德智体美劳全面发展。这是一种美好的愿望,但是真的有几个人会成为大家眼里的完人呢。我始终认为每个人都是不一样的,与其要求成为大众一致认为的完美,不如让自己成就真实的自我。
再回到现在,为什么人们开始崇尚「工匠精神」,科技发展飞速的今天,大家才意识到技术的重要性,才意识到「科学技术是第一生产力」,只有掌握了核心技术才有能力去创造更多的价值,然而任何一样好的技术,一定是经过了几代人的努力长时间的积累实践才最终产业化。我们现在社会缺乏的恰恰是这种持之以恒的精神。
在我看来工匠精神就是那种对做事要求特别专业、极致,实现自我价值的同时影响别人的一类人,这类人(比如说程序员)他们在用大量的时间去学习了专业知识,但是却疏于交际、不善言谈、或者说除了专业知识其他能力很弱。如果周围的环境能给予足够的理解于支持,比如说刚刚过去的程序员节就是个很好的例子,我觉得那个时候才会出现真正的技术驱动
其次。上面讲的都是大环境,事实上通常是无法改变的,那么程序员是不是应该自己反思下如何提升自己来获得外界的支持于尊重。很多时候大家在要一样东西时会觉得「本来就是这样」,程序员就应该被放在一个被尊重的地方,一个认可技术的公司。但是这种尊重与认可怎么可能凭空而来呢,所谓的尊重应该是通过自己的专业能力换来的。别人眼中的你也是自己塑造出来的才对。要想大家重视技术,首先自己得重视技术,能用技术做到别人做不到的事情,这才是技术的价值。如果你自己写代码不追求极致,得过且过那就必然会成为被淘汰的对象
可能会有很多人认为写代码对于自己来说只是为了赚钱生活,并不追求极致。这当然也是非常合理且正常的,因为并不是每个人的工作都是自己选择的、喜欢的。但是我比较认同的是一种做事情的态度。环顾你周围的那些优秀的人,你会发现他们无论做什么事都会做的像模像样,即使他们做一些非擅长领域的事情,也可以做的非常优秀甚至出彩。
所以说编程对于大家来说 for fun 还是 for 饭并不重要,重要的是大家的态度
1970-01-01 08:00:00
前几天听说《生活大爆炸》将于 2019 年 5 月完成终结季(12季),一时间让我想起上大学那会刚开始看这部美剧的。起初是因为大学生活确实过的没意思,也是无意中在腾讯视频上点进去的。刚开始我是从第二季开始看的,后来大学毕业参加工作后就很少看了,一方面工作后确实时间少,一方面看大爆炸时间长了也会有一些审美疲劳,感觉里面的内容不再那么有意思。
说到有意思这又让我忽然想起来另外一部同样题材的情景喜剧(英剧)《The IT crowed》,这是一部给我留下深刻印象的英国喜剧。讲的是一个公司里的 IT 部门两个技术极客和一个女经理之间发生的一些有趣的事情
如果你同时看过这两部剧的话你会发现他们之间有很大的差别,美式幽默和英式的幽默完全不是一个风格。英式幽默特别夸张、无理头,甚至讽刺、搞怪。他会用一些你很难想象的非常夸张的表现手法,比如在第一季中的「火焰屏保」

一本正经的胡说八道,却让人笑到抽
还有 灭火器着火。我从来没见过甚至听过有比灭火器着火更离谱且搞笑的事情了吧

这还不算,镜头一转

「Made in Britain - 英国制造」,这算是把自己国家完整的黑了一把
其实了解英国文化的人应该会懂,英国人特别喜欢讽刺,即使自己国家的东西也可以拿来嘲讽娱乐。剧中这种讽刺还有很多,比如 0118 999 881 999 119 725 这居然是一个电话号码!没错,而且还是 紧急服务 电话**,**有没有搞错,紧急服务哎。这个电话号码在剧中被演绎包装成了一个政府应急服务的广告,其实就是在讽刺政府的工作效率低下。你很难想象一个老年人从楼梯上摔下去快不行的时候打这个电话的场景
英式的幽默也很注重反转与对比,比如 Moss 和 Ray 翘班的那集。前脚说「我们是同事,我不会丢下你不管的…」后脚撒腿就跑的场景,诸如此类的场景剧中随处可见。以至于我有时候会隐约觉得这种英式幽默和东北人骨子里的那种搞笑爽快的性格非常相似
在我看来这部剧中的很多元素都来自于英国文化中的 摇滚精神
前面说过大学时间很无聊,当年我也实在是没事儿干,去图书馆看过一些摇滚乐方面的东西,所以我在看这剧的时候很有感触
摇滚乐发源于上世纪 60 年代至 90 年代末期,大家对早期摇滚印象深刻的可能就几个人:美国的猫王(埃尔维斯·普雷斯利),英国的甲壳虫(披头士),再到后来的朋克风平克·弗洛伊德,再到我们这一代人熟悉的迈克杰·克逊、邦·乔维等。你会发现摇滚发展了这么多年,但是摇滚的核心并没变,在我看来摇滚精神就是那种追求自由的孤独感。事实上尤其在国内,大部分人对于摇滚的印象就是吵闹、杂乱、满嘴飙脏话的阶段。大家并没有意识到实际上每个人心中都有摇滚精神体现的。对于生活追求、自由的渴望、世道不公的控诉 — 这些都是。其实摇滚乐是很简单的,有节奏的东西就是摇滚的,而且摇滚的本质就是激发人们听觉(对声音)的原始动力,这是一种特别原生、特别真实的表现方式
引用一句谢天笑的《命运还是巧合》中的一句歌词:
「命运给了我一双眼睛,放在我的心里,从此为勇敢者哭泣,为不平的世界叹息…」
话题再转到这部剧上,我在这部剧中看到很多摇滚的元素,无论是剧情的设计和演员演技(哥特男)、服饰(珍的狂暴发型)都充满了摇滚风
同时这又是一部 IT 技术方面的喜剧,这个题材能设计出完美的搞 IT 的程序员的角色是非常不容易的。导演虽然是拍喜剧的,但是他对演员角色的理解相当深刻,并且深谙程序员的套路,就如 Roy 经常提起电话时的一句反馈「Have you tried turning it off and on again-重启试试」,看这句话懂的人自然就懂了,正所谓「运维有三宝 注销、重启、装系统」。还有就是细心的人会发现这部剧里面的片头曲非常有意思,只有两种音调,以不同的音阶搭配,听起来非常有节奏感觉,是不是就象征着程序员世界中的二进制 0 和 1 呢
其实最令我印象深刻的是 2013 特别篇中的「The Internet」,这一节中可以说完美的体现了导演对于程序员心理理解,再加上旁观者傻白甜的举动行成了鲜明的对比。当 Moss 对珍说「This, Jan is The Internet - 珍,这就是 Internet」的时候程序员估计会笑喷了吧

这一集是真正意义上的完完全全从程序员的视角拍摄的一集,看过之后你会有一种这集就是为自己拍的的感觉。这种感觉是在其它剧或者电影里面没有的。一开始看似无理头的搞怪,最后逐渐发酵 Jen 居然拿到公司去给一大帮人讲这个盒子上的东西就是整个 Internet,荒唐的是居然大家都信了!再到最后的 Internet 被摔整个「闹剧」结束。整集看下来过瘾的同时也无比的感叹导演对剧本的精准设计和演员出色的演技。反观国内大多数人对程序员的认知还在「牛仔裤、格子衬衫」的阶段吧
要看完全懂这部剧得有一点关于英国文化关于摇滚的一点认识。英国有很多著名的摇滚乐队,像前面讲到的披头士、弗洛伊德以及滚石、性手枪等一系列的优秀摇滚乐队。这些已经成为了英国人的历史文化基因,摇滚到疯狂的程序被写到了英国人的骨子里。你很难想象 2012 伦敦奥运会开幕式上居然出现一个中年男子抱着一部电吉他在那搞演唱会。你会发现这个国家对于文化的传承有多么的重视,同时对于大众的批判性讽刺性思维有多高的认同与「容忍」程度
事实上,我觉得程序员这种对技术追求到 nerd 的程度的人群有着非常强烈的摇滚精神,像摇滚一样不顾一切疯狂的追求真理,讨厌任何规矩与束缚。很多时候尤其在一个不重视技术的国家里面(预告下次话题),虽然周围的人对程序员有很深刻的偏见,但是骨子里的那种摇滚精神才使他们真正与众不同
1970-01-01 08:00:00
事实上在讲清楚这个问题之前,必须知道一个所有人都无法拒绝的常识,即:对大多数人来说 iOS 绝对比 Android 好用。本文试着从使用者的角度出发谈谈自己对两个手机端操作系统的理解与认识
决定一个操作系统好用与否的原因有很多,系统的功能健全、用户体验、稳定性、应用程序及其周边生态等。iOS 操作系统从本质上讲是一个闭源、高度统一且集中式的操作系统,这个集中可以理解为中心化的。回顾 iOS 发展历你会感觉这种高度集中的程度甚至达到了「集权」的程度,苹果对自己的操作系统有着几乎所有的控制权,这就使得 iOS 系统无论是 UI 交互、设计风格还是应用生态都天然的具备了近乎完美的一致性。当你手里拿着最新款的 iPhone 的时候你会觉得她简直就是一件艺术品。深层次上这就使得苹果的产品在审美上可以 主动的 影响用户,而不是被动的接受用户的反馈
大家都知道 iOS 的生态好,但是到底好在哪里?我认为好在两方面
其一 应用生态,一个应用从前期的设计、中期的开发、后期的运营苹果都提供了很多解决方案。设计时有 HIG,开发时有 Xcode 集成开发环境,运营商业化的时候有应用内购买、Apple Pay、Searchads 等一系列的解决方案,所以我们看到很多独立开发者做的应用都非常优秀甚至超过了某些商业公司。细心的话你会发现上面提到的这些似乎在 Android 平台也有一些影子。但实际上差别还是很大的,这就好比程序员写的代码示例和生产环境跑的应用程序对比起来完全不是一个量级的概念
其二 系统生态,这一点可能很多人并没在意,但是却非常重要。操作系统做为所有上层应用的基础其重要性不言而喻,据说 iOS 12 安装率已达到了 50%,iOS 11 使用了一个月的时间才达到的水平 iOS 用了 20 天内就完成了。由此可见其高效的更新迭代周期。在软件开发的过程中有重要的一个概念就是软件的生命周期。其实软件和人是一样的,人有生老病死,软件有增删查改。好的软件应该保持这种平衡。老旧的部分该删除的就应该删除,欠缺的部分该添加添加应该升级升级。可是大多时候人们都只喜欢添加加功能。程序员应该非常清楚这一点,维护或者兼容老系统是非常痛苦的,但是在苹果却能把 iOS 系统维护的相当完备。当然这不仅仅在于 iOS 的集中性,也在于苹果对自己产品的营销手段及用户心理的预期控制
Android 令人印象深刻的当属国内的 应用市场,国外的应用市场并没有国内这么泛滥,国外的应用市场要么是第三方的那种综合类下载站要么就是有能力做手机的厂商。手机厂商都想建立属于自己的闭环系统,但是实际上只有 Google 才能从根本上做到闭环,手机厂商本质上只是一层 ROM 或者 UI,就是上面提到的应用生态。事实上很多公司连自己的应用生态都做不好。
Android 系统本质上讲是一个开源、自由的操作系统。这是它的基因,但是开源与自由有的时候会被人滥用,甚至利用。自由的基因决定了 Android 会提供给用户几乎所有的选择和路径。你喜欢的不喜欢的、想要的不想要的它统统都有,你不得不自己做出选择。但是当手机做为一种工具的时候,很多用户并不需要一个瑞士军刀,它们只想要一个简单好用的螺丝刀就够了。对于那些挑剔的特殊用户 Android 再适合不过了,你可以把 Android 看成一个微型计算机,你可以像玩树莓派一样去定制它,Web 服务器、智能家居、私有云等等,但这些都要建立在你有能力的基础上
Android 零乱的原因还有一点就是用户的需求总是多样的,而 Andoird 本身的使命就是满足他们。比如就会有人看到 iPhone 的刘海觉得很别致,自己可能换不了 iPhone,然后就会理所当然的认为 Android 也应该有,因为这是 潮流
既然提到了 iPhone,那也应该聊下 Google 的 Pixel。Pixel 最近刚出 3 系列,刘海居然是默认的设置,大家已经有很多吐槽了。自然不必多讲。事实上 Pixel 系列手机让我看到了很多的闪光点,Google 现在似乎也慢慢明白了自己做手机的方向,在 Pixel 3 的发布会上多次提到了 End-to-End 的摄像头的概念,它可以从一张照片里面分析出里面的建筑、人物,进而知道和人物相关的东西,比如它的年龄、性别、穿着。有了这些信息后他就可以做一些真正有用的推荐。如果你是 Google 的重度用户的话你会发现近两年 Google 的一些新的技术/软件正在成体系的发展,这是在苹果系统上看不到的。举个例子,iOS 的 Siri 和 Google 的 Assistant。一方面 Google Assistant 的智能程度好过 Siri 几条街,一方面你会觉得 Google Assistant 真的可以做到一些有用的事情而不只是一个玩具。比如 接到来电识别出来是骚扰电话,assistant 就可以帮你「礼貌」回绝了
Google 做 Android 手机可以很好的解决 Android 的一些问题,但是由于 Google 本身是一家技术基因的公司,它所有的软件都会以功能为主。设计和用户体验不会是它的强项,这就使得 Google 做的手机用起来总是有一种不爽的感觉。比如就滚动这个操作,iOS 的交互处理的非常好,不仅仅界面操作流畅,而且响应快,该停的时候立即停下来。反观 Android,虽然流畅度上可能很多用户已经体会不出来与 iOS 之间的差异了,但是使用 Android 总让你感觉该顺滑的时候顺滑,不该顺滑的时候也很「顺滑」。还有 Pixel 3 上展示的和 iPhone 对比夜间成像的问题,Pixel 可以做到把夜晚照得和白天一样,大多数情况下是有好处的,但是假如用户就想拍张夜晚的照片那就比较尴尬了吧
事实上很多时候大家讨论 iOS 与 Android 好坏只是在说其中某一点,因为这些点能打动用户。但是很诡异的是人们总是喜欢以贬低对方的不足来突出自己的优势,因为没有人甘于承认自己花钱买来的东西不如别人的
1970-01-01 08:00:00
本书翻译自 realpython 网站上的文章教程 Socket Programming in Python (Guide),由于原文很长,所以整理成了 Gitbook 方便阅读。你可以去 首页 下载 PDF/Mobi/ePub 格式文件或者 在线阅读
Nathan Jennings 是 Real Python 教程团队的一员,他在很早之前就使用 C 语言开始了自己的编程生涯,但是最终发现了 Python,从 Web 应用和网络数据收集到网络安全,他喜欢任何 Pythonic 的东西 —— realpython
译者 是一名前端工程师,平常会写很多的 JavaScript。但是当我使用 JavaScript 很长一段时间后,会对一些 语言无关 的编程概念感兴趣,比如:网络/socket 编程、异步/并发、线/进程通信等。然而恰好这些内容在 JavasScript 领域很少见
因为一直从事 Web 开发,所以我认为理解了网络通信及其 socket 编程就理解了 Web 开发的某些本质。过程中我发现 Python 社区有很多我喜欢的内容,并且很多都是高质量的公开发布且开源的。
最近我发现了这篇文章,系统地从底层网络通信讲到了应用层协议及其 C/S 架构的应用程序,由浅入深。虽然代码、API 使用了 Python,但是底层原理相通。非常值得一读,推荐给大家
另外,由于本人水平所限,翻译的内容难免出现偏差,如果你在阅读的过程中发现问题,请毫不犹豫的提醒我或者开新 PR。或者有什么不理解的地方也可以开 issue 讨论,当然 star 也是欢迎的
本文(翻译版)通过了 realpython 官方授权,原文版权归其所有,任何转载请联系他们。翻译版遵循本站 许可证协议
网络中的 Socket 和 Socket API 是用来跨网络的消息传送的,它提供了 进程间通信(IPC) 的一种形式。网络可以是逻辑的、本地的电脑网络,或者是可以物理连接到外网的网络,并且可以连接到其它网络。英特网就是一个明显的例子,就是那个你通过 ISP 连接到的网络
本篇教程有三个不同的迭代阶段,来展示如何使用 Python 构建一个 Socket 服务器和客户端
教程结束后,你将学会如何使用 Python 中的 socket 模块 来写一个自己的客户端/服务器应用。以及向你展示如何在你的应用中使用自定义类在不同的端之间发送消息和数据
所有的例子程序都使用 Python 3.6 编写,你可以在 Github 上找到 源代码
网络和 Socket 是个很大的话题。网上已经有了关于它们的字面解释,如果你还不是很了解 Socket 和网络。当你你读到那些解释的时候会感到不知所措,这是非常正常的。因为我也是这样过来的
尽管如此也不要气馁。 我已经为你写了这个教程。 就像学习 Python 一样,我们可以一次学习一点。用你的浏览器保存本页面到书签,以便你学习下一部分时能找到
让我们开始吧!
Socket 有一段很长的历史,最初是在 1971 年被用于 ARPANET,随后就成了 1983 年发布的 Berkeley Software Distribution (BSD) 操作系统的 API,并且被命名为 Berkeleysocket
当互联网在 20 世纪 90 年代随万维网兴起时,网络编程也火了起来。Web 服务和浏览器并不是唯一使用新的连接网络和 Socket 的应用程序。各种类型不同规模的客户端/服务器应用都广泛地使用着它们
时至今日,尽管 Socket API 使用的底层协议已经进化了很多年,也出现了许多新的协议,但是底层的 API 仍然保持不变
Socket 应用最常见的类型就是 客户端/服务器 应用,服务器用来等待客户端的链接。我们教程中涉及到的就是这类应用。更明确地说,我们将看到用于 InternetSocket 的 Socket API,有时称为 Berkeley 或 BSD Socket。当然也有 Unix domain sockets —— 一种用于 同一主机 进程间的通信
Python 的 socket 模块提供了使用 Berkeley sockets API 的接口。这将会在我们这个教程里使用和讨论到
主要的用到的 Socket API 函数和方法有下面这些:
socket()bind()listen()accept()connect()connect_ex()send()recv()close()Python 提供了和 C 语言一致且方便的 API。我们将在下面一节中用到它们
作为标准库的一部分,Python 也有一些类可以让我们方便的调用这些底层 Socket 函数。尽管这个教程中并没有涉及这部分内容,你也可以通过socketserver 模块 中找到文档。当然还有很多实现了高层网络协议(比如:HTTP, SMTP)的的模块,可以在下面的链接中查到 Internet Protocols and Support
就如你马上要看到的,我们将使用 socket.socket() 创建一个类型为 socket.SOCK_STREAM 的 socket 对象,默认将使用 Transmission Control Protocol(TCP) 协议,这基本上就是你想使用的默认值
为什么应该使用 TCP 协议?
相反,使用 socket.SOCK_DGRAM 创建的 用户数据报协议(UDP) Socket 是 不可靠 的,而且数据的读取写发送可以是 无序的
为什么这个很重要?网络总是会尽最大的努力去传输完整数据(往往不尽人意)。没法保证你的数据一定被送到目的地或者一定能接收到别人发送给你的数据
网络设备(比如:路由器、交换机)都有带宽限制,或者系统本身的极限。它们也有 CPU、内存、总线和接口包缓冲区,就像我们的客户端和服务器。TCP 消除了你对于丢包、乱序以及其它网络通信中通常出现的问题的顾虑
下面的示意图中,我们将看到 Socket API 的调用顺序和 TCP 的数据流:
左边表示服务器,右边则是客户端
左上方开始,注意服务器创建「监听」Socket 的 API 调用:
socket()bind()listen()accept()「监听」Socket 做的事情就像它的名字一样。它会监听客户端的连接,当一个客户端连接进来的时候,服务器将调用 accept() 来「接受」或者「完成」此连接
客户端调用 connect() 方法来建立与服务器的链接,并开始三次握手。握手很重要是因为它保证了网络的通信的双方可以到达,也就是说客户端可以正常连接到服务器,反之亦然
上图中间部分往返部分表示客户端和服务器的数据交换过程,调用了 send() 和 recv()方法
下面部分,客户端和服务器调用 close() 方法来关闭各自的 socket
你现在已经了解了基本的 socket API 以及客户端和服务器是如何通信的,让我们来创建一个客户端和服务器。我们将会以一个简单的实现开始。服务器将打印客户端发送回来的内容
下面就是服务器代码,echo-server.py:
#!/usr/bin/env python3
import socket
HOST = '127.0.0.1' # 标准的回环地址 (localhost)
PORT = 65432 # 监听的端口 (非系统级的端口: 大于 1023)
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.bind((HOST, PORT))
s.listen()
conn, addr = s.accept()
with conn:
print('Connected by', addr)
while True:
data = conn.recv(1024)
if not data:
break
conn.sendall(data)
注意:上面的代码你可能还没法完全理解,但是不用担心。这几行代码做了很多事情,这 只是一个起点,帮你看见这个简单的服务器是如何运行的 教程后面有引用部分,里面有很多额外的引用资源链接,这个教程中我将把链接放在那儿
让我们一起来看一下 API 调用以及发生了什么
socket.socket() 创建了一个 socket 对象,并且支持 context manager type,你可以使用 with 语句,这样你就不用再手动调用 s.close() 来关闭 socket 了
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
pass # Use the socket object without calling s.close().
调用 socket() 时传入的 socket 地址族参数 socket.AF_INET 表示因特网 IPv4 地址族,SOCK_STREAM 表示使用 TCP 的 socket 类型,协议将被用来在网络中传输消息
bind() 用来关联 socket 到指定的网络接口(IP 地址)和端口号:
HOST = '127.0.0.1'
PORT = 65432
# ...
s.bind((HOST, PORT))
bind() 方法的入参取决于 socket 的地址族,在这个例子中我们使用了 socket.AF_INET (IPv4),它将返回两个元素的元组:(host, port)
host 可以是主机名称、IP 地址、空字符串,如果使用 IP 地址,host 就应该是 IPv4 格式的字符串,127.0.0.1 是标准的 IPv4 回环地址,只有主机上的进程可以连接到服务器,如果你传了空字符串,服务器将接受本机所有可用的 IPv4 地址
端口号应该是 1-65535 之间的整数(0是保留的),这个整数就是用来接受客户端链接的 TCP 端口号,如果端口号小于 1024,有的操作系统会要求管理员权限
使用 bind() 传参为主机名称的时候需要注意:
如果你在 host 部分 主机名称 作为 IPv4/v6 socket 的地址,程序可能会产生非确 定性的行为,因为 Python 会使用 DNS 解析后的 第一个 地址,根据 DNS 解析的结 果或者 host 配置 socket 地址将会以不同方式解析为实际的 IPv4/v6 地址。如果想得 到确定的结果传入的 host 参数建议使用数字格式的地址 引用
我稍后将在 使用主机名 部分讨论这个问题,但是现在也值得一提。目前来说你只需要知道当使用主机名时,你将会因为 DNS 解析的原因得到不同的结果
可能是任何地址。比如第一次运行程序时是 10.1.2.3,第二次是 192.168.0.1,第三次是 172.16.7.8 等等
继续看上面的服务器代码示例,listen() 方法调用使服务器可以接受连接请求,这使它成为一个「监听中」的 socket
s.listen()
conn, addr = s.accept()
listen() 方法有一个 backlog 参数。它指定在拒绝新的连接之前系统将允许使用的 未接受的连接 数量。从 Python 3.5 开始,这是可选参数。如果不指定,Python 将取一个默认值
如果你的服务器需要同时接收很多连接请求,增加 backlog 参数的值可以加大等待链接请求队列的长度,最大长度取决于操作系统。比如在 Linux 下,参考 /proc/sys/net/core/somaxconn
accept() 方法阻塞并等待传入连接。当一个客户端连接时,它将返回一个新的 socket 对象,对象中有表示当前连接的 conn 和一个由主机、端口号组成的 IPv4/v6 连接的元组,更多关于元组值的内容可以查看 socket地址族 一节中的详情
这里必须要明白我们通过调用 accept() 方法拥有了一个新的 socket 对象。这非常重要,因为你将用这个 socket 对象和客户端进行通信。和监听一个 socket 不同的是后者只用来授受新的连接请求
conn, addr = s.accept()
with conn:
print('Connected by', addr)
while True:
data = conn.recv(1024)
if not data:
break
conn.sendall(data)
从 accept() 获取客户端 socket 连接对象 conn 后,使用一个无限 while 循环来阻塞调用 conn.recv(),无论客户端传过来什么数据都会使用 conn.sendall() 打印出来
如果 conn.recv() 方法返回一个空 byte 对象(b''),然后客户端关闭连接,循环结束,with 语句和 conn 一起使用时,通信结束的时候会自动关闭 socket 链接
现在我们来看下客户端的程序, echo-client.py:
#!/usr/bin/env python3
import socket
HOST = '127.0.0.1' # 服务器的主机名或者 IP 地址
PORT = 65432 # 服务器使用的端口
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.connect((HOST, PORT))
s.sendall(b'Hello, world')
data = s.recv(1024)
print('Received', repr(data))
与服务器程序相比,客户端程序简单很多。它创建了一个 socket 对象,连接到服务器并且调用 s.sendall() 方法发送消息,然后再调用 s.recv() 方法读取服务器返回的内容并打印出来
让我们运行打印程序的客户端和服务端,观察他们的表现,看看发生了什么事情
如果你在运行示例代码时遇到了问题,可以阅读 如何使用 Python 开发命令行命令,如果 你使用的是 windows 操作系统,请查看 Python Windows FAQ
打开命令行程序,进入你的代码所在的目录,运行打印程序的服务端:
$ ./echo-server.py
你的命令行将被挂起,因为程序有一个阻塞调用
conn, addr = s.accept()
它将等待客户端的连接,现在再打开一个命令行窗口运行打印程序的客户端:
$ ./echo-client.py
Received b'Hello, world'
在服务端的窗口你将看见:
$ ./echo-server.py
Connected by ('127.0.0.1', 64623)
上面的输出中,服务端打印出了 s.accept() 返回的 addr 元组,这就是客户端的 IP 地址和 TCP 端口号。示例中的端口号是 64623 这很可能是和你机器上运行的结果不同
想查找你主机上 socket 的当前状态,可以使用 netstat 命令。这个命令在 macOS, Window, Linux 系统上默认可用
下面这个就是启动服务后 netstat 命令的输出结果:
$ netstat -an
Active Internet connections (including servers)
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 0 0 127.0.0.1.65432 *.* LISTEN
注意本地地址是 127.0.0.1.65432,如果 echo-server.py 文件中 HOST 设置成空字符串 '' 的话,netstat 命令将显示如下:
$ netstat -an
Active Internet connections (including servers)
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 0 0 *.65432 *.* LISTEN
本地地址是 *.65432,这表示所有主机支持的 IP 地址族都可以接受传入连接,在我们的例子里面调用 socket() 时传入的参数 socket.AF_INET 表示使用了 IPv4 的 TCP socket,你可以在输出结果中的 Proto 列中看到(tcp4)
上面的输出是我截取的只显示了咱们的打印程序服务端进程,你可能会看到更多输出,具体取决于你运行的系统。需要注意的是 Proto, Local Address 和 state 列。分别表示 TCP socket 类型、本地地址端口、当前状态
另外一个查看这些信息的方法是使用 lsof 命令,这个命令在 macOS 上是默认安装的,Linux 上需要你手动安装
$ lsof -i -n
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
Python 67982 nathan 3u IPv4 0xecf272 0t0 TCP *:65432 (LISTEN)
isof 命令使用 -i 参数可以查看打开的 socket 连接的 COMMAND, PID(process id) 和 USER(user id),上面的输出就是打印程序服务端
netstat 和 isof 命令有许多可用的参数,这取决于你使用的操作系统。可以使用 man page 来查看他们的使用文档,这些文档绝对值得花一点时间去了解,你将受益匪浅,macOS 和 Linux 中使用命令 man netstat 或者 man lsof 命令,windows 下使用 netstat /? 来查看帮助文档
一个通常会犯的错误是在没有监听 socket 端口的情况下尝试连接:
$ ./echo-client.py
Traceback (most recent call last):
File "./echo-client.py", line 9, in <module>
s.connect((HOST, PORT))
ConnectionRefusedError: [Errno 61] Connection refused
也可能是端口号出错、服务端没启动或者有防火墙阻止了连接,这些原因可能很难记住,或许你也会碰到 Connection timed out 的错误,记得给你的防火墙添加允许我们使用的端口规则
引用部分有一些常见的 错误
让我们再仔细的观察下客户端是如何与服务端进行通信的:
当使用回环地址时,数据将不会接触到外部网络,上图中,回环地址包含在了 host 里面。这就是回环地址的本质,连接数据传输是从本地到主机,这就是为什么你会听到有回环地址或者 127.0.0.1、::1 的 IP 地址和表示本地主机
应用程序使用回环地址来与主机上的其它进程通信,这使得它与外部网络安全隔离。由于它是内部的,只能从主机内访问,所以它不会被暴露出去
如果你的应用程序服务器使用自己的专用数据库(非公用的),则可以配置服务器仅监听回环地址,这样的话网络上的其它主机就无法连接到你的数据库
如果你的应用程序中使用的 IP 地址不是 127.0.0.1 或者 ::1,那就可能会绑定到连接到外部网络的以太网上。这就是你通往 localhost 王国之外的其他主机的大门
这里需要小心,并且可能让你感到难受甚至怀疑全世界。在你探索 localhost 的安全限制之前,确认读过 使用主机名 一节。 一个安全注意事项是 不要使用主机名,要使用 IP 地址
打印程序的服务端肯定有它自己的一些局限。这个程序只能服务于一个客户端然后结束。打印程序的客户端也有它自己的局限,但是还有一个问题,如果客户端调用了下面的方法s.recv() 方法将返回 b'Hello, world' 中的一个字节 b'H'
data = s.recv(1024)
1024 是缓冲区数据大小限制最大值参数 bufsize,并不是说 recv() 方法只返回 1024个字节的内容
send() 方法也是这个原理,它返回发送内容的字节数,结果可能小于传入的发送内容,你得处理这处情况,按需多次调用 send() 方法来发送完整的数据
应用程序负责检查是否已发送所有数据;如果仅传输了一些数据,则应用程序需要尝试传 递剩余数据 引用
我们可以使用 sendall() 方法来回避这个过程
和 send() 方法不一样的是,
sendall()方法会一直发送字节,只到所有的数据传输完成 或者中途出现错误。成功的话会返回 None 引用
到目前为止,我们有两个问题:
send() 或者 recv() 直到所有数据传输完成应该怎么做呢,有很多方式可以实现并发。最近,有一个非常流程的库叫做 Asynchronous I/O 可以实现,asyncio 库在 Python 3.4 后默认添加到了标准库里面。传统的方法是使用线程
并发的问题是很难做到正确,有许多细微之处需要考虑和防范。可能其中一个细节的问题都会导致整个程序崩溃
我说这些并不是想吓跑你或者让你远离学习和使用并发编程。如果你想让程序支持大规模使用,使用多处理器、多核是很有必要的。然而在这个教程中我们将使用比线程更传统的方法使得逻辑更容易推理。我们将使用一个非常古老的系统调用:select()
select() 允许你检查多个 socket 的 I/O 完成情况,所以你可以使用它来检测哪个 socket I/O 是就绪状态从而执行读取或写入操作,但是这是 Python,总会有更多其它的选择,我们将使用标准库中的selectors 模块,所以我们使用了最有效的实现,不用在意你使用的操作系统:
这个模块提供了高层且高效的 I/O 多路复用,基于原始的
select模块构建,推荐用 户使用这个模块,除非他们需要精确到操作系统层面的使用控制 引用
尽管如此,使用 select() 也无法并发执行。这取决于您的工作负载,这种实现仍然会很快。这也取决于你的应用程序对连接所做的具体事情或者它需要支持的客户端数量
asyncio 使用单线程来处理多任务,使用事件循环来管理任务。通过使用 select(),我们可以创建自己的事件循环,更简单且同步化。当使用多线程时,即使要处理并发的情况,我们也不得不面临使用 CPython 或者 PyPy 中的「全局解析器锁 GIL」,这有效地限制了我们可以并行完成的工作量
说这些是为了解析为什么使用 select() 可能是个更好的选择,不要觉得你必须使用 asyncio、线程或最新的异步库。通常,在网络应用程序中,你的应用程序就是 I/O 绑定:它可以在本地网络上,网络另一端的端,磁盘上等待
如果你从客户端收到启动 CPU 绑定工作的请求,查看 concurrent.futures模块,它包含一个 ProcessPoolExecutor 类,用来异步执行进程池中的调用
如果你使用多进程,你的 Python 代码将被操作系统并行地在不同处理器或者核心上调度运行,并且没有全局解析器锁。你可以通过 Python 大会上的演讲 John Reese - Thinking Outside the GIL with AsyncIO and Multiprocessing - PyCon 2018 来了解更多的想法
在下一节中,我们将介绍解决这些问题的服务器和客户端的示例。他们使用 select() 来同时处理多连接请求,按需多次调用 send() 和 recv()
下面两节中,我们将使用 selectors 模块中的 selector 对象来创建一个可以同时处理多个请求的客户端和服务端
首页,我们来看眼多连接服务端程序的代码,multiconn-server.py。这是开始建立监听 socket 部分
import selectors
sel = selectors.DefaultSelector()
# ...
lsock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
lsock.bind((host, port))
lsock.listen()
print('listening on', (host, port))
lsock.setblocking(False)
sel.register(lsock, selectors.EVENT_READ, data=None)
这个程序和之前打印程序服务端最大的不同是使用了 lsock.setblocking(False) 配置 socket 为非阻塞模式,这个 socket 的调用将不在是阻塞的。当它和 sel.select() 一起使用的时候(下面会提到),我们就可以等待 socket 就绪事件,然后执行读写操作
sel.register() 使用 sel.select() 为你感兴趣的事件注册 socket 监控,对于监听 socket,我们希望使用 selectors.EVENT_READ 读取到事件
data 用来存储任何你 socket 中想存的数据,当 select() 返回的时候它也会返回。我们将使用 data 来跟踪 socket 上发送或者接收的东西
下面就是事件循环:
import selectors
sel = selectors.DefaultSelector()
# ...
while True:
events = sel.select(timeout=None)
for key, mask in events:
if key.data is None:
accept_wrapper(key.fileobj)
else:
service_connection(key, mask)
sel.select(timeout=None) 调用会阻塞直到 socket I/O 就绪。它返回一个(key, events) 元组,每个 socket 一个。key 就是一个包含 fileobj 属性的具名元组。key.fileobj 是一个 socket 对象,mask 表示一个操作就绪的事件掩码
如果 key.data 为空,我们就可以知道它来自于监听 socket,我们需要调用 accept() 方法来授受连接请求。我们将使用一个 accept() 包装函数来获取新的 socket 对象并注册到 selector 上,我们马上就会看到
如果 key.data 不为空,我们就可以知道它是一个被接受的客户端 socket,我们需要为它服务,接着 service_connection() 会传入 key 和 mask 参数并调用,这包含了所有我们需要在 socket 上操作的东西
让我们一起来看看 accept_wrapper() 方法做了什么:
def accept_wrapper(sock):
conn, addr = sock.accept() # Should be ready to read
print('accepted connection from', addr)
conn.setblocking(False)
data = types.SimpleNamespace(addr=addr, inb=b'', outb=b'')
events = selectors.EVENT_READ | selectors.EVENT_WRITE
sel.register(conn, events, data=data)
由于监听 socket 被注册到了 selectors.EVENT_READ 上,它现在就能被读取,我们调用 sock.accept() 后立即再立即调 conn.setblocking(False) 来让 socket 进入非阻塞模式
请记住,这是这个版本服务器程序的主要目标,因为我们不希望它被阻塞。如果被阻塞,那么整个服务器在返回前都处于挂起状态。这意味着其它 socket 处于等待状态,这是一种 非常严重的 谁都不想见到的服务被挂起的状态
接着我们使用了 types.SimpleNamespace 类创建了一个对象用来保存我们想要的 socket 和数据,由于我们得知道客户端连接什么时候可以写入或者读取,下面两个事件都会被用到:
events = selectors.EVENT_READ | selectors.EVENT_WRITE
事件掩码、socket 和数据对象都会被传入 sel.register()
现在让我们来看下,当客户端 socket 就绪的时候连接请求是如何使用 service_connection() 来处理的
def service_connection(key, mask):
sock = key.fileobj
data = key.data
if mask & selectors.EVENT_READ:
recv_data = sock.recv(1024) # Should be ready to read
if recv_data:
data.outb += recv_data
else:
print('closing connection to', data.addr)
sel.unregister(sock)
sock.close()
if mask & selectors.EVENT_WRITE:
if data.outb:
print('echoing', repr(data.outb), 'to', data.addr)
sent = sock.send(data.outb) # Should be ready to write
data.outb = data.outb[sent:]
这就是多连接服务端的核心部分,key 就是从调用 select() 方法返回的一个具名元组,它包含了 socket 对象「fileobj」和数据对象。mask 包含了就绪的事件
如果 socket 就绪而且可以被读取, mask & selectors.EVENT_READ 就为真,sock.recv() 会被调用。所有读取到的数据都会被追加到 data.outb 里面。随后被发送出去
注意 else: 语句,如果没有收到任何数据:
if recv_data:
data.outb += recv_data
else:
print('closing connection to', data.addr)
sel.unregister(sock)
sock.close()
这表示客户端关闭了它的 socket 连接,这时服务端也应该关闭自己的连接。不过别忘了先调用 sel.unregister() 来撤销 select() 的监控
当 socket 就绪而且可以被读取的时候,对于正常的 socket 应该一直是这种状态,任何接收并被 data.outb 存储的数据都将使用 sock.send() 方法打印出来。发送出去的字节随后就会被从缓冲中删除
data.outb = data.outb[sent:]
现在让我们一起来看看多连接的客户端程序,multiconn-client.py,它和服务端很相似,不一样的是它没有监听连接请求,它以调用 start_connections() 开始初始化连接:
messages = [b'Message 1 from client.', b'Message 2 from client.']
def start_connections(host, port, num_conns):
server_addr = (host, port)
for i in range(0, num_conns):
connid = i + 1
print('starting connection', connid, 'to', server_addr)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setblocking(False)
sock.connect_ex(server_addr)
events = selectors.EVENT_READ | selectors.EVENT_WRITE
data = types.SimpleNamespace(connid=connid,
msg_total=sum(len(m) for m in messages),
recv_total=0,
messages=list(messages),
outb=b'')
sel.register(sock, events, data=data)
num_conns 参数是从命令行读取的,表示为服务器建立多少个链接。就像服务端程序一样,每个 socket 都设置成了非阻塞模式
由于 connect() 方法会立即触发一个 BlockingIOError 异常,所以我们使用 connect_ex() 方法取代它。connect_ex() 会返回一个错误指示 errno.EINPROGRESS,不像 connect() 方法直接在进程中返回异常。一旦连接结束,socket 就可以进行读写并且通过 select() 方法返回
socket 建立完成后,我们将使用 types.SimpleNamespace 类创建想会传送的数据。由于每个连接请求都会调用 socket.send(),发送到服务端的消息得使用 list(messages) 方法转换成列表结构。所有你想了解的东西,包括客户端将要发送的、已发送的、已接收的消息以及消息的总字节数都存储在 data 对象中
让我们再来看看 service_connection()。基本上和服务端一样:
def service_connection(key, mask):
sock = key.fileobj
data = key.data
if mask & selectors.EVENT_READ:
recv_data = sock.recv(1024) # Should be ready to read
if recv_data:
print('received', repr(recv_data), 'from connection', data.connid)
data.recv_total += len(recv_data)
if not recv_data or data.recv_total == data.msg_total:
print('closing connection', data.connid)
sel.unregister(sock)
sock.close()
if mask & selectors.EVENT_WRITE:
if not data.outb and data.messages:
data.outb = data.messages.pop(0)
if data.outb:
print('sending', repr(data.outb), 'to connection', data.connid)
sent = sock.send(data.outb) # Should be ready to write
data.outb = data.outb[sent:]
有一个不同的地方,客户端会跟踪从服务器接收的字节数,根据结果来决定是否关闭 socket 连接,服务端检测到客户端关闭则会同样的关闭服务端的连接
现在让我们把 multiconn-server.py 和 multiconn-client.py 两个程序跑起来。他们都使用了命令行参数,如果不指定参数可以看到参数调用的方法:
服务端程序,传入主机和端口号
$ ./multiconn-server.py
usage: ./multiconn-server.py <host> <port>
客户端程序,传入启动服务端程序时同样的主机和端口号以及连接数量
$ ./multiconn-client.py
usage: ./multiconn-client.py <host> <port> <num_connections>
下面就是服务端程序运行起来在 65432 端口上监听回环地址的输出:
$ ./multiconn-server.py 127.0.0.1 65432
listening on ('127.0.0.1', 65432)
accepted connection from ('127.0.0.1', 61354)
accepted connection from ('127.0.0.1', 61355)
echoing b'Message 1 from client.Message 2 from client.' to ('127.0.0.1', 61354)
echoing b'Message 1 from client.Message 2 from client.' to ('127.0.0.1', 61355)
closing connection to ('127.0.0.1', 61354)
closing connection to ('127.0.0.1', 61355)
下面是客户端,它创建了两个连接请求到上面的服务端:
$ ./multiconn-client.py 127.0.0.1 65432 2
starting connection 1 to ('127.0.0.1', 65432)
starting connection 2 to ('127.0.0.1', 65432)
sending b'Message 1 from client.' to connection 1
sending b'Message 2 from client.' to connection 1
sending b'Message 1 from client.' to connection 2
sending b'Message 2 from client.' to connection 2
received b'Message 1 from client.Message 2 from client.' from connection 1
closing connection 1
received b'Message 1 from client.Message 2 from client.' from connection 2
closing connection 2
多连接的客户端和服务端程序版本与最早的原始版本相比肯定有了很大的改善,但是让我们再进一步地解决上面「多连接」版本中的不足,然后完成最终版的实现:客户端/服务器应用程序
我们希望有个客户端和服务端在不影响其它连接的情况下做好错误处理,显然,如果没有发生异常,我们的客户端和服务端不能崩溃的一团糟。这也是到现在为止我们还没讨论的东西,我故意没有引入错误处理机制因为这样可以使之前的程序容易理解
现在你对基本的 API,非阻塞 socket、select() 等概念已经有所了解了。我们可以继续添加一些错误处理同时讨论下「房间里面的大象」的问题,我把一些东西隐藏在了幕后。你应该还记得,我在介绍中讨论到的自定义类
首先,让我们先解决错误:
所有的错误都会触发异常,像无效参数类型和内存不足的常见异常可以被抛出;从 Python 3.3 开始,与 socket 或地址语义相关的错误会引发 OSError 或其子类之一的异常 引用
我们需要捕获 OSError 异常。另外一个我没提及的的问题是延迟,你将在文档的很多地方看见关于延迟的讨论,延迟会发生而且属于「正常」错误。主机或者路由器重启、交换机端口出错、电缆出问题或者被拔出,你应该在你的代码中处理好各种各样的错误
刚才说的「房间里面的大象」问题是怎么回事呢。就像 socket.SOCK_STREAM 这个参数的字面意思一样,当使用 TCP 连接时,你会从一个连续的字节流读取的数据,好比从磁盘上读取数据,不同的是你是从网络读取字节流
然而,和使用 f.seek() 读文件不同,换句话说,没法定位 socket 的数据流的位置,如果可以像文件一样定位数据流的位置(使用下标),那你就可以随意的读取你想要的数据
当字节流入你的 socket 时,会需要有不同的网络缓冲区,如果想读取他们就必须先保存到其它地方,使用 recv() 方法持续的从 socket 上读取可用的字节流
相当于你从 socket 中读取的是一块一块的数据,你必须使用 recv() 方法不断的从缓冲区中读取数据,直到你的应用确定读取到了足够的数据
什么时候算「足够」这取决于你的定义,就 TCP socket 而言,它只通过网络发送或接收原始字节。它并不了解这些原始字节的含义
这可以让我们定义一个应用层协议,什么是应用层协议?简单来说,你的应用会发送或者接收消息,这些消息其实就是你的应用程序的协议
换句话说,这些消息的长度、格式可以定义应用程序的语义和行为,这和我们之前说的从socket 中读取字节部分内容相关,当你使用 recv() 来读取字节的时候,你需要知道读的字节数,并且决定什么时候算读取完成
这些都是怎么完成的呢?一个方法是只读取固定长度的消息,如果它们的长度总是一样的话,这样做很容易。当你收到固定长度字节消息的时候,就能确定它是个完整的消息
然而,如果你使用定长模式来发送比较短的消息会比较低效,因为你还得处理填充剩余的部分,此外,你还得处理数据不适合放在一个定长消息里面的情况
在这个教程里面,我们将使用一个通用的方案,很多协议都会用到它,包括 HTTP。我们将在每条消息前面追加一个头信息,头信息中包括消息的长度和其它我们需要的字段。这样做的话我们只需要追踪头信息,当我们读到头信息时,就可以查到消息的长度并且读出所有字节然后消费它
我们将通过使用一个自定义类来实现接收文本/二进制数据。你可以在此基础上做出改进或者通过继承这个类来扩展你的应用程序。重要的是你将看到一个例子实现它的过程
我将会提到一些关于 socket 和字节相关的东西,就像之前讨论过的。当你通过 socket 来发送或者接收数据时,其实你发送或者接收到的是原始字节
如果你收到数据并且想让它在一个多字节解释的上下文中使用,比如说 4-byte 的整形,你需要考虑它可能是一种不是你机器 CPU 本机的格式。客户端或者服务器的另外一头可能是另外一种使用了不同的字节序列的 CPU,这样的话,你就得把它们转换成你主机的本地字节序列来使用
上面所说的字节顺序就是 CPU 的 字节序,在引用部分的字节序 一节可以查看更多。我们将会利用 Unicode 字符集的优点来规避这个问题,并使用UTF-8 的方式编码,由于 UTF-8 使用了 8字节 编码方式,所以就不会有字节序列的问题
你可以查看 Python 关于编码与 Unicode 的 文档,注意我们只会编码消息的头部。我们将使用严格的类型,发送的消息编码格式会在头信息中定义。这将让我们可以传输我们觉得有用的任意类型/格式数据
你可以通过调用 sys.byteorder 来决定你的机器的字节序列,比如在我的英特尔笔记本上,运行下面的代码就可以:
$ python3 -c 'import sys; print(repr(sys.byteorder))'
'little'
如果我把这段代码跑在可以模拟大字节序 CPU「PowerPC」的虚拟机上的话,应该是下面的结果:
$ python3 -c 'import sys; print(repr(sys.byteorder))'
'big'
在我们的例子程序中,应用层的协议定义了使用 UTF-8 方式编码的 Unicode 字符。对于真正传输消息来说,如果需要的话你还是得手动交换字节序列
这取决于你的应用,是否需要它来处理不同终端间的多字节二进制数据,你可以通过添加额外的头信息来让你的客户端或者服务端支持二进制,像 HTTP 一样,把头信息做为参数传进去
不用担心自己还没搞懂上面的东西,下面一节我们看到是如果实现的
让我们来定义一个完整的协议头:
其中必须具有的头应该有以下几个:
| 名称 | 描述 |
|---|---|
| byteorder | 机器的字节序列(uses sys.byteorder),应用程序可能用不上 |
| content-length | 内容的字节长度 |
| content-type | 内容的类型,比如 text/json 或者 binary/my-binary-type |
| content-encoding | 内容的编码类型,比如 utf-8 编码的 Unicode 文本,二进制数据 |
这些头信息告诉接收者消息数据,这样的话你就可以通过提供给接收者足够的信息让他接收到数据的时候正确的解码的方式向它发送任何数据,由于头信息是字典格式,你可以随意向头信息中添加键值对
不过还有一个问题,由于我们使用了变长的头信息,虽然方便扩展但是当你使用 recv() 方法读取消息的时候怎么知道头信息的长度呢
我们前面讲到过使用 recv() 接收数据和如何确定是否接收完成,我说过定长的头可能会很低效,的确如此。但是我们将使用一个比较小的 2 字节定长的头信息前缀来表示头信息的长度
你可以认为这是一种混合的发送消息的实现方法,我们通过发送头信息长度来引导接收者,方便他们解析消息体
为了给你更好地解释消息格式,让我们来看看消息的全貌:
消息以 2字节的固定长度的头开始,这两个字节是整型的网络字节序列,表示下面的变长 JSON 头信息的长度,当我们从 recv() 方法读取到 2 个字节时就知道它表示的是头信息长度的整形数字,然后在解码 JSON 头之前读取这么多的字节
JSON 头包含了头信息的字典。其中一个就是 content-length,这表示消息内容的数量(不是JSON头),当我们使用 recv() 方法读取到了 content-length 个字节的数据时,就表示接收完成并且读取到了完整的消息
最后让我们来看下成果,我们使用了一个消息类。来看看它是如何在 socket 发生读写事件时与 select() 配合使用的
对于这个示例应用程序而言,我必须想出客户端和服务器将使用什么类型的消息,从这一点来讲这远远超过了最早时候我们写的那个玩具一样的打印程序
为了保证程序简单而且仍然能够演示出它是如何在一个真正的程序中工作的,我创建了一个应用程序协议用来实现基本的搜索功能。客户端发送一个搜索请求,服务器做一次匹配的查找,如果客户端的请求没法被识别成搜索请求,服务器就会假定这个是二进制请求,对应的返回二进制响应
跟着下面一节,运行示例、用代码做实验后你将会知道他是如何工作的,然后你就可以以这个消息类为起点把他修改成适合自己使用的
就像我们之前讨论的,你将在下面看到,处理 socket 时需要保存状态。通过使用类,我们可以将所有的状态、数据和代码打包到一个地方。当连接开始或者接受的时候消息类就会为每个 socket 创建一个实例
类中的很多包装方法、工具方法在客户端和服务端上都是差不多的。它们以下划线开头,就像 Message._json_encode() 一样,这些方法通过类使用起来很简单。这使得它们在其它方法中调用时更短,而且符合 DRY 原则
消息类的服务端程序本质上和客户端一样。不同的是客户端初始化连接并发送请求消息,随后要处理服务端返回的内容。而服务端则是等待连接请求,处理客户端的请求消息,随后发送响应消息
看起来就像这样:
| 步骤 | 端 | 动作/消息内容 |
|---|---|---|
| 1 | 客户端 | 发送带有请求内容的消息 |
| 2 | 服务端 | 接收并处理请求消息 |
| 3 | 服务端 | 发送有响应内容的消息 |
| 4 | 客户端 | 接收并处理响应消息 |
下面是代码的结构:
| 应用程序 | 文件 | 代码 |
|---|---|---|
| 服务端 | app-server.py | 服务端主程序 |
| 服务端 | libserver.py | 服务端消息类 |
| 客户端 | app-client.py | 客户端主程序 |
| 客户端 | libclient.py | 客户端消息类 |
我想通过首先提到它的设计方面来讨论 Message 类的工作方式,不过这对我来说并不是立马就能解释清楚的,只有在重构它至少五次之后我才能达到它目前的状态。为什么呢?因为要管理状态
当消息对象创建的时候,它就被一个使用 selector.register() 事件监控起来的 socket 关联起来了
message = libserver.Message(sel, conn, addr)
sel.register(conn, selectors.EVENT_READ, data=message)
注意,这一节中的一些代码来自服务端主程序与消息类,但是这部分内容的讨论在客户端 也是一样的,我将在他们之间存在不同点的时候来解释客户端的版本
当 socket 上的事件就绪的时候,它就会被 selector.select() 方法返回。对过 key 对象的 data 属性获取到 message 的引用,然后在消息用调用一个方法:
while True:
events = sel.select(timeout=None)
for key, mask in events:
# ...
message = key.data
message.process_events(mask)
观察上面的事件循环,可以看见 sel.select() 位于「司机位置」,它是阻塞的,在循环的上面等待。当 socket 上的读写事件就绪时,它就会为其服务。这表示间接的它也要负责调用 process_events() 方法。这就是我说 process_events() 方法是入口的原因
让我们来看下 process_events() 方法做了什么
def process_events(self, mask):
if mask & selectors.EVENT_READ:
self.read()
if mask & selectors.EVENT_WRITE:
self.write()
这样做很好,因为 process_events() 方法很简洁,它只可以做两件事情:调用 read() 和 write() 方法
这又把我们带回了状态管理的问题。在几次重构后,我决定如果别的方法依赖于状态变量里面的某个确定值,那么它们就只应该从 read() 和 write() 方法中调用,这将使处理socket 事件的逻辑尽量的简单
可能说起来很简单,但是经历了前面几次类的迭代:混合了一些方法,检查当前状态、依赖于其它值、在 read() 或者 write() 方法外面调用处理数据的方法,最后这证明了这样管理起来很复杂
当然,你肯定需要把类按你自己的需求修改使它能够符合你的预期,但是我建议你尽可能把状态检查、依赖状态的调用的逻辑放在 read() 和 write() 方法里面
让我们来看看 read() 方法,这是服务端版本,但是客户端也是一样的。不同之处在于方法名称,一个(客户端)是 process_response() 另一个(服务端)是 process_request()
def read(self):
self._read()
if self._jsonheader_len is None:
self.process_protoheader()
if self._jsonheader_len is not None:
if self.jsonheader is None:
self.process_jsonheader()
if self.jsonheader:
if self.request is None:
self.process_request()
_read() 方法首页被调用,然后调用 socket.recv() 从 socket 读取数据并存入到接收缓冲区
记住,当调用 socket.recv() 方法时,组成消息的所有数据并没有一次性全部到达。socket.recv() 方法可能需要调用很多次,这就是为什么在调用相关方法处理数据前每次都要检查状态
当一个方法开始处理消息时,首页要检查的就是接受缓冲区保存了足够的多读取的数据,如果确定,它们将继续处理各自的数据,然后把数据存到其它流程可能会用到的变量上,并且清空自己的缓冲区。由于一个消息有三个组件,所以会有三个状态检查和处理方法的调用:
| Message Component | Method | Output |
|---|---|---|
| Fixed-length header | process_protoheader() | self._jsonheader_len |
| JSON header | process_jsonheader() | self.jsonheader |
| Content | process_request() | self.request |
接下来,让我们一起看看 write() 方法,这是服务端的版本:
def write(self):
if self.request:
if not self.response_created:
self.create_response()
self._write()
write() 方法会首先检测是否有请求,如果有而且响应还没被创建的话 create_response() 方法就会被调用,它会设置状态变量 response_created,然后为发送缓冲区写入响应
如果发送缓冲区有数据,write() 方法会调用 socket.send() 方法
记住,当 socket.send() 被调用时,所有发送缓冲区的数据可能还没进入到发送队列,socket 的网络缓冲区可能满了,socket.send() 可能需要重新调用,这就是为什么需要检查状态的原因,create_response() 应该只被调用一次,但是 _write() 方法需要调用多次
客户端的 write() 版大体与服务端一致:
def write(self):
if not self._request_queued:
self.queue_request()
self._write()
if self._request_queued:
if not self._send_buffer:
# Set selector to listen for read events, we're done writing.
self._set_selector_events_mask('r')
因为客户端首页初始化了一个连接请求到服务端,状态变量_request_queued被检查。如果请求还没加入到队列,就调用 queue_request() 方法创建一个请求写入到发送缓冲区中,同时也会使用变量 _request_queued 记录状态值防止多次调用
就像服务端一样,如果发送缓冲区有数据 _write() 方法会调用 socket.send() 方法
需要注意客户端版本的 write() 方法与服务端不同之处在于最后的请求是否加入到队列中的检查,这个我们将在客户端主程序中详细解释,原因是要告诉 selector.select()停止监控 socket 的写入事件而且我们只对读取事件感兴趣,没有办法通知套接字是可写的
我将在这一节中留下一个悬念,这一节的主要目的是解释 selector.select() 方法是如何通过 process_events() 方法调用消息类以及它是如何工作的
这一点很重要,因为 process_events() 方法在连接的生命周期中将被调用很多次,因此,要确保那些只能被调用一次的方法正常工作,这些方法中要么需要检查自己的状态变量,要么需要检查调用者的方法中的状态变量
在服务端主程序 app-server.py 中,主机、端口参数是通过命令行传递给程序的:
$ ./app-server.py
usage: ./app-server.py <host> <port>
例如需求监听本地回环地址上面的 65432 端口,需要执行:
$ ./app-server.py 127.0.0.1 65432
listening on ('127.0.0.1', 65432)
<host> 参数为空的话就可以监听主机上的所有 IP 地址
创建完 socket 后,一个传入参数 socket.SO_REUSEADDR 的方法 to socket.setsockopt() 将被调用
# Avoid bind() exception: OSError: [Errno 48] Address already in use
lsock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
设置这个参数是为了避免 端口被占用 的错误发生,如果当前程序使用的端口和之前的程序使用的一样,你就会发现连接处于 TIME_WAIT 状态
比如说,如果服务器主动关闭连接,服务器会保持为大概两分钟的 TIME_WAIT 状态,具体时长取决于你的操作系统。如果你想在两分钟内再开启一个服务,你将得到一个OSError 表示 端口被战胜,这样做是为了确保一些在途的数据包正确的被处理
事件循环会捕捉所有错误,以保证服务器正常运行:
while True:
events = sel.select(timeout=None)
for key, mask in events:
if key.data is None:
accept_wrapper(key.fileobj)
else:
message = key.data
try:
message.process_events(mask)
except Exception:
print('main: error: exception for',
f'{message.addr}:\n{traceback.format_exc()}')
message.close()
当服务器接受到一个客户端连接时,消息对象就会被创建:
def accept_wrapper(sock):
conn, addr = sock.accept() # Should be ready to read
print('accepted connection from', addr)
conn.setblocking(False)
message = libserver.Message(sel, conn, addr)
sel.register(conn, selectors.EVENT_READ, data=message)
消息对象会通过 sel.register() 方法关联到 socket 上,而且它初始化就被设置成了只监控读事件。当请求被读取时,我们将通过监听到的写事件修改它
在服务器端采用这种方法的一个优点是,大多数情况下,当 socket 正常并且没有网络问题时,它始终是可写的
如果我们告诉 sel.register() 方法监控 EVENT_WRITE 写入事件,事件循环将会立即唤醒并通知我们这种情况,然而此时 socket 并不用唤醒调用 send() 方法。由于请求还没被处理,所以不需要发回响应。这将消耗并浪费宝贵的 CPU 周期
在消息切入点一节中,当通过 process_events() 知道 socket 事件就绪时我们可以看到消息对象是如何发出动作的。现在让我们来看看当数据在 socket 上被读取是会发生些什么,以及为服务器就绪的消息的组件片段发生了什么
libserver.py 文件中的服务端消息类,可以在 Github 上找到 源代码
这些方法按照消息处理顺序出现在类中
当服务器读取到至少两个字节时,定长头的逻辑就可以开始了
def process_protoheader(self):
hdrlen = 2
if len(self._recv_buffer) >= hdrlen:
self._jsonheader_len = struct.unpack('>H',
self._recv_buffer[:hdrlen])[0]
self._recv_buffer = self._recv_buffer[hdrlen:]
网络字节序列中的定长整型两字节包含了 JSON 头的长度,struct.unpack() 方法用来读取并解码,然后保存在 self._jsonheader_len 中,当这部分消息被处理完成后,就要调用 process_protoheader() 方法来删除接收缓冲区中处理过的消息
就像上面的定长头的逻辑一样,当接收缓冲区有足够的 JSON 头数据时,它也需要被处理:
def process_jsonheader(self):
hdrlen = self._jsonheader_len
if len(self._recv_buffer) >= hdrlen:
self.jsonheader = self._json_decode(self._recv_buffer[:hdrlen],
'utf-8')
self._recv_buffer = self._recv_buffer[hdrlen:]
for reqhdr in ('byteorder', 'content-length', 'content-type',
'content-encoding'):
if reqhdr not in self.jsonheader:
raise ValueError(f'Missing required header "{reqhdr}".')
self._json_decode() 方法用来解码并反序列化 JSON 头成一个字典。由于我们定义的 JSON 头是 utf-8 格式的,所以解码方法调用时我们写死了这个参数,结果将被存放在 self.jsonheader 中,process_jsonheader 方法做完他应该做的事情后,同样需要删除接收缓冲区中处理过的消息
接下来就是真正的消息内容,当接收缓冲区有 JSON 头中定义的 content-length 值的数量个字节时,请求就应该被处理了:
def process_request(self):
content_len = self.jsonheader['content-length']
if not len(self._recv_buffer) >= content_len:
return
data = self._recv_buffer[:content_len]
self._recv_buffer = self._recv_buffer[content_len:]
if self.jsonheader['content-type'] == 'text/json':
encoding = self.jsonheader['content-encoding']
self.request = self._json_decode(data, encoding)
print('received request', repr(self.request), 'from', self.addr)
else:
# Binary or unknown content-type
self.request = data
print(f'received {self.jsonheader["content-type"]} request from',
self.addr)
# Set selector to listen for write events, we're done reading.
self._set_selector_events_mask('w')
把消息保存到 data 变量中后,process_request() 又会删除接收缓冲区中处理过的数据。接着,如果 content type 是 JSON 的话,它将解码并反序列化数据。否则(在我们的例子中)数据将被视 做二进制数据并打印出来
最后 process_request() 方法会修改 selector 为只监控写入事件。在服务端的程序 app-server.py 中,socket 初始化被设置成仅监控读事件。现在请求已经被全部处理完了,我们对读取事件就不感兴趣了
现在就可以创建一个响应写入到 socket 中。当 socket 可写时 create_response() 将被从 write() 方法中调用:
def create_response(self):
if self.jsonheader['content-type'] == 'text/json':
response = self._create_response_json_content()
else:
# Binary or unknown content-type
response = self._create_response_binary_content()
message = self._create_message(**response)
self.response_created = True
self._send_buffer += message
响应会根据不同的 content type 的不同而调用不同的方法创建。在这个例子中,当 action == 'search' 的时候会执行一个简单的字典查找。你可以在这个地方添加你自己的处理方法并调用
一个不好处理的问题是响应写入完成时如何关闭连接,我会在 _write() 方法中调用 close()
def _write(self):
if self._send_buffer:
print('sending', repr(self._send_buffer), 'to', self.addr)
try:
# Should be ready to write
sent = self.sock.send(self._send_buffer)
except BlockingIOError:
# Resource temporarily unavailable (errno EWOULDBLOCK)
pass
else:
self._send_buffer = self._send_buffer[sent:]
# Close when the buffer is drained. The response has been sent.
if sent and not self._send_buffer:
self.close()
虽然close() 方法的调用有点隐蔽,但是我认为这是一种权衡。因为消息类一个连接只处理一条消息。写入响应后,服务器无需执行任何操作。它的任务就完成了
客户端主程序 app-client.py 中,参数从命令行中读取,用来创建请求并连接到服务端
$ ./app-client.py
usage: ./app-client.py <host> <port> <action> <value>
来个示例演示一下:
$ ./app-client.py 127.0.0.1 65432 search needle
当从命令行参数创建完一个字典来表示请求后,主机、端口、请求字典一起被传给 start_connection()
def start_connection(host, port, request):
addr = (host, port)
print('starting connection to', addr)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setblocking(False)
sock.connect_ex(addr)
events = selectors.EVENT_READ | selectors.EVENT_WRITE
message = libclient.Message(sel, sock, addr, request)
sel.register(sock, events, data=message)
对服务器的 socket 连接被创建,消息对象被传入请求字典并创建
和服务端一样,消息对象在 sel.register() 方法中被关联到 socket 上。然而,客户端不同的是,socket 初始化的时候会监控读写事件,一旦请求被写入,我们将会修改为只监控读取事件
这种实现和服务端一样有好处:不浪费 CPU 生命周期。请求发送完成后,我们就不关注写入事件了,所以不用保持状态等待处理
在 消息入口点 一节中,我们看到过,当 socket 使用准备就绪时,消息对象是如何调用具体动作的。现在让我们来看看 socket 上的数据是如何被读写的,以及消息准备好被加工的时候发生了什么
客户端消息类在 libclient.py 文件中,可以在 Github 上找到 源代码
这些方法按照消息处理顺序出现在类中
客户端的第一个任务就是让请求入队列:
def queue_request(self):
content = self.request['content']
content_type = self.request['type']
content_encoding = self.request['encoding']
if content_type == 'text/json':
req = {
'content_bytes': self._json_encode(content, content_encoding),
'content_type': content_type,
'content_encoding': content_encoding
}
else:
req = {
'content_bytes': content,
'content_type': content_type,
'content_encoding': content_encoding
}
message = self._create_message(**req)
self._send_buffer += message
self._request_queued = True
用来创建请求的字典,取决于客户端程序 app-client.py 中传入的命令行参数,当消息对象创建的时候,请求字典被当做参数传入
请求消息被创建并追加到发送缓冲区中,消息将被 _write() 方法发送,状态参数 self._request_queued 被设置,这使 queue_request() 方法不会被重复调用
请求发送完成后,客户端就等待服务器的响应
客户端读取和处理消息的方法和服务端一致,由于响应数据是从 socket 上读取的,所以处理 header 的方法会被调用:process_protoheader() 和 process_jsonheader()
最终处理方法名字的不同在于处理一个响应,而不是创建:process_response(),_process_response_json_content() 和 _process_response_binary_content()
最后,但肯定不是最不重要的 —— 最终的 process_response() 调用:
def process_response(self):
# ...
# Close when response has been processed
self.close()
我将通过提及一些方法的重要注意点来结束消息类的讨论
主程序中任意的类触发异常都由 except 字句来处理:
try:
message.process_events(mask)
except Exception:
print('main: error: exception for',
f'{message.addr}:\n{traceback.format_exc()}')
message.close()
注意最后一行的方法 message.close()
这一行很重要的原因有很多,不仅仅是保证 socket 被关闭,而且通过调用 message.close() 方法删除使用 select() 监控的 socket,这是类中的一段非常简洁的代码,它能减小复杂度。如果一个异常发生或者我们自己主动抛出,我们很清楚 close() 方法将处理善后
Message._read() 和 Message._write() 方法都包含一些有趣的东西:
def _read(self):
try:
# Should be ready to read
data = self.sock.recv(4096)
except BlockingIOError:
# Resource temporarily unavailable (errno EWOULDBLOCK)
pass
else:
if data:
self._recv_buffer += data
else:
raise RuntimeError('Peer closed.')
注意 except 行:except BlockingIOError:
_write() 方法也有,这几行很重要是因为它们捕获临时错误并通过使用 pass 跳过。临时错误是 socket 阻塞的时候发生的,比如等待网络响应或者连接的其它端
通过使用 pass 跳过异常,select() 方法将再次调用,我们将有机会重新读写数据
经过所有这些艰苦的工作后,让我们把程序运行起来并找到一些乐趣!
在这个救命中,我们将传一个空的字符串做为 host 参数的值,用来监听服务器端的所有IP 地址。这样的话我就可以从其它网络上的虚拟机运行客户端程序,我将模拟一个 PowerPC 的机器
首页,把服务端程序运行进来:
$ ./app-server.py '' 65432
listening on ('', 65432)
现在让我们运行客户端,传入搜索内容,看看是否能看他(墨菲斯-黑客帝国中的角色):
$ ./app-client.py 10.0.1.1 65432 search morpheus
starting connection to ('10.0.1.1', 65432)
sending b'\x00d{"byteorder": "big", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 41}{"action": "search", "value": "morpheus"}' to ('10.0.1.1', 65432)
received response {'result': 'Follow the white rabbit. 🐰'} from ('10.0.1.1', 65432)
got result: Follow the white rabbit. 🐰
closing connection to ('10.0.1.1', 65432)
我的命令行 shell 使用了 utf-8 编码,所以上面的输出可以是 emojis
再试试看能不能搜索到小狗:
$ ./app-client.py 10.0.1.1 65432 search 🐶
starting connection to ('10.0.1.1', 65432)
sending b'\x00d{"byteorder": "big", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 37}{"action": "search", "value": "\xf0\x9f\x90\xb6"}' to ('10.0.1.1', 65432)
received response {'result': '🐾 Playing ball! 🏐'} from ('10.0.1.1', 65432)
got result: 🐾 Playing ball! 🏐
closing connection to ('10.0.1.1', 65432)
注意请求发送行的 byte string,很容易看出来你发送的小狗 emoji 表情被打印成了十六进制的字符串 \xf0\x9f\x90\xb6,我可以使用 emoji 表情来搜索是因为我的命令行支持utf-8 格式的编码
这个示例中我们发送给网络原始的 bytes,这些 bytes 需要被接受者正确的解释。这就是为什么之前需要给消息附加头信息并且包含编码类型字段的原因
下面这个是服务器对应上面两个客户端连接的输出:
accepted connection from ('10.0.2.2', 55340)
received request {'action': 'search', 'value': 'morpheus'} from ('10.0.2.2', 55340)
sending b'\x00g{"byteorder": "little", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 43}{"result": "Follow the white rabbit. \xf0\x9f\x90\xb0"}' to ('10.0.2.2', 55340)
closing connection to ('10.0.2.2', 55340)
accepted connection from ('10.0.2.2', 55338)
received request {'action': 'search', 'value': '🐶'} from ('10.0.2.2', 55338)
sending b'\x00g{"byteorder": "little", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 37}{"result": "\xf0\x9f\x90\xbe Playing ball! \xf0\x9f\x8f\x90"}' to ('10.0.2.2', 55338)
closing connection to ('10.0.2.2', 55338)
注意发送行中写到客户端的 bytes,这就是服务端的响应消息
如果 action 参数不是搜索,你也可以试试给服务器发送二进制请求
$ ./app-client.py 10.0.1.1 65432 binary 😃
starting connection to ('10.0.1.1', 65432)
sending b'\x00|{"byteorder": "big", "content-type": "binary/custom-client-binary-type", "content-encoding": "binary", "content-length": 10}binary\xf0\x9f\x98\x83' to ('10.0.1.1', 65432)
received binary/custom-server-binary-type response from ('10.0.1.1', 65432)
got response: b'First 10 bytes of request: binary\xf0\x9f\x98\x83'
closing connection to ('10.0.1.1', 65432)
由于请求的 content-type 不是 text/json,服务器会把内容当成二进制类型并且不会解码 JSON,它只会打印 content-type 和返回的前 10 个 bytes 给客户端
$ ./app-server.py '' 65432
listening on ('', 65432)
accepted connection from ('10.0.2.2', 55320)
received binary/custom-client-binary-type request from ('10.0.2.2', 55320)
sending b'\x00\x7f{"byteorder": "little", "content-type": "binary/custom-server-binary-type", "content-encoding": "binary", "content-length": 37}First 10 bytes of request: binary\xf0\x9f\x98\x83' to ('10.0.2.2', 55320)
closing connection to ('10.0.2.2', 55320)
某些东西运行不了是很常见的,你可能不知道应该怎么做,不用担心,所有人都会遇到这种问题,希望你借助本教程、调试器和万能的搜索引擎解决问题并且继续下去
如果还是解决不了,你的第一站应该是 python 的 socket 模块文档,确保你读过文档中每个我们使用到的方法、函数。同样的可以从引用一节中找到一些办法,尤其是错误一节中的内容
有的时候问题并不是由你的源代码引起的,源代码可能是正确的。有可能是不同的主机、客户端和服务器。也可能是网络原因,比如路由器、防火墙或者是其它网络设备扮演了中间人的角色
对于这些类型的问题,额外的一些工具是必要的。下面这些工具或者集可能会帮到你或者至少提供一些线索
ping 命令通过发送一个 ICMP 报文来检测主机是否连接到了网络,它直接与操作系统上的 TCP/IP 协议栈通信,所以它在主机上是独立于任何应用程序运行的
下面是一段在 macOS 上执行 ping 命令的结果
$ ping -c 3 127.0.0.1
PING 127.0.0.1 (127.0.0.1): 56 data bytes
64 bytes from 127.0.0.1: icmp_seq=0 ttl=64 time=0.058 ms
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.165 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.164 ms
--- 127.0.0.1 ping statistics ---
3 packets transmitted, 3 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 0.058/0.129/0.165/0.050 ms
注意后面的统计输出,这对你排查间歇性的连接问题很有帮助。比如说,是否有数据包丢失?网络延迟怎么样(查看消息的往返时间)
如果你与主机之间有防火墙的话,ping 发送的请求可能会被阻止。防火墙管理员定义了一些规则强制阻止一些请求,主要的原因就是他们不想自己的主机是可以被发现的。如果你的机器也出现这种情况的话,请确保在规则中添加了允许 ICMP 包的发送
ICMP 是 ping 命令使用的协议,但它也是 TCP 和其他底层用于传递错误消息的协议,如果你遇到奇怪的行为或缓慢的连接,可能就是这个原因
ICMP 消息通过类型和代号来定义。下面有一些重要的信息可以参考:
| ICMP 类型 | ICMP 代码 | 说明 |
|---|---|---|
| 8 | 0 | 打印请求 |
| 0 | 0 | 打印回复 |
| 3 | 0 | 目标网络不可达 |
| 3 | 1 | 目标主机不可达 |
| 3 | 2 | 目标协议不可达 |
| 3 | 3 | 目标端口不可达 |
| 3 | 4 | 需要分片,但是 DF(Don't fragmentation) 标识已被设置 |
| 11 | 0 | 网络存在环路 |
查看 Path MTU Discovery 更多关于分片和 ICMP 消息的内容,里面遇到的问题就是我前面提及的一些奇怪行为
在 查看socket状态 一节中我们已经知道如何使用 netstat 来查看 socket 及其状态的信息。这个命令在 macOS, Linux, Windows 上都可以使用
在之前的示例中我并没有提及 Recv-Q 和 Send-Q 列。这些列表示发送或者接收队列中网络缓冲区数据的字节数,但是由于某些原因这些字节还没被远程或者本地应用读写
换句话说,这些网络中的字节还在操作系统的队列中。一个原因可能是应用程序受 CPU 限制或者无法调用 socket.recv()、socket.send() 方法处理,或者因为其它一些网络原因导致的,比如说网络的拥堵、失败、硬件及电缆的问题
为了复现这个问题,看看到底在错误发生前我应该发送多少数据。我写了一个测试客户端可以连接到测试服务器,并且重复的调用 socket.send() 方法。测试服务端永远不调用 socket.recv() 或者 socket.send() 方法来处理客户端发送的数据,它只接受连接请求。这会导致服务器上的网络缓冲区被填满,最终会在客户端上报错
首先运行服务端:
$ ./app-server-test.py 127.0.0.1 65432 listening on ('127.0.0.1', 65432)
然后运行客户端,看看发生了什么:
$ ./app-client-test.py 127.0.0.1 65432 binary test
error: socket.send() blocking io exception for ('127.0.0.1', 65432):
BlockingIOError(35, 'Resource temporarily unavailable')
下面是用 netstat 命令在错误发生时执行的结果:
$ netstat -an | grep 65432
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 408300 0 127.0.0.1.65432 127.0.0.1.53225 ESTABLISHED
tcp4 0 269868 127.0.0.1.53225 127.0.0.1.65432 ESTABLISHED
tcp4 0 0 127.0.0.1.65432 *.* LISTEN
第一行就表示服务端(本地端口是 65432)
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 408300 0 127.0.0.1.65432 127.0.0.1.53225 ESTABLISHED
注意 Recv-Q: 408300
第二行表示客户端(远程端口是 65432)
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 0 269868 127.0.0.1.53225 127.0.0.1.65432 ESTABLISHED
注意 Send-Q: 269868
显然,客户端试着写入字节,但是服务端并没有读取他们。这导致服务端网络缓冲队列中应该保存的数据被积压在接收端,客户端的网络缓冲队列积压到发送端
如果你使用的是 windows 电脑,有一个工具套件绝对值得安装 Windows Sysinternals
里面有个工具叫 TCPView.exe,它是 windows 下的一个可视化的 netstat 工具。除了地址、端口号和 socket 状态之外,它还会显示发送和接收的数据包以及字节数。就像 Unix 工具集 lsof 命令一样,你也可以看见进程名和 ID,可以在菜单中查看更多选项
有时候你可能想查看网络底层发生了什么,忽略应用程序的输出或者外部库调用,想看看网络层面到底收发了什么内容,就像调试器一样,当你需要看清这些的时候,没有别的办法
Wireshark 是一款可以运行在 macOS, Linux, Windows 以及其它系统上的网络协议分析、流量捕获工具,GUI 版本的程序叫做
wireshark,命令 行的程序叫做 tshark
流量捕获是一个非常好用的方法,它可以让你看到网络上应用程序的行为,收集到关于收发消息多少、频率等信息,你也可以看到客户端或者服务端如何关闭/取消连接,或者停止响应,当你需要排除故障的时候这些信息非常的有用
网上还有很多关于 wireshark 和 TShark 的基础使用教程
这有一个使用 wireshark 捕获本地网络数据的例子:
还有一个和上面一样的使用 tshark 命令输出的结果:
$ tshark -i lo0 'tcp port 65432'
Capturing on 'Loopback'
1 0.000000 127.0.0.1 → 127.0.0.1 TCP 68 53942 → 65432 [SYN] Seq=0 Win=65535 Len=0 MSS=16344 WS=32 TSval=940533635 TSecr=0 SACK_PERM=1
2 0.000057 127.0.0.1 → 127.0.0.1 TCP 68 65432 → 53942 [SYN, ACK] Seq=0 Ack=1 Win=65535 Len=0 MSS=16344 WS=32 TSval=940533635 TSecr=940533635 SACK_PERM=1
3 0.000068 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=1 Ack=1 Win=408288 Len=0 TSval=940533635 TSecr=940533635
4 0.000075 127.0.0.1 → 127.0.0.1 TCP 56 [TCP Window Update] 65432 → 53942 [ACK] Seq=1 Ack=1 Win=408288 Len=0 TSval=940533635 TSecr=940533635
5 0.000216 127.0.0.1 → 127.0.0.1 TCP 202 53942 → 65432 [PSH, ACK] Seq=1 Ack=1 Win=408288 Len=146 TSval=940533635 TSecr=940533635
6 0.000234 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [ACK] Seq=1 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635
7 0.000627 127.0.0.1 → 127.0.0.1 TCP 204 65432 → 53942 [PSH, ACK] Seq=1 Ack=147 Win=408128 Len=148 TSval=940533635 TSecr=940533635
8 0.000649 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=147 Ack=149 Win=408128 Len=0 TSval=940533635 TSecr=940533635
9 0.000668 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [FIN, ACK] Seq=149 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635
10 0.000682 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=147 Ack=150 Win=408128 Len=0 TSval=940533635 TSecr=940533635
11 0.000687 127.0.0.1 → 127.0.0.1 TCP 56 [TCP Dup ACK 6#1] 65432 → 53942 [ACK] Seq=150 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635
12 0.000848 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [FIN, ACK] Seq=147 Ack=150 Win=408128 Len=0 TSval=940533635 TSecr=940533635
13 0.001004 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [ACK] Seq=150 Ack=148 Win=408128 Len=0 TSval=940533635 TSecr=940533635
^C13 packets captured
这一节主要用来引用一些额外的信息和外部资源链接
下面这段话来自 python 的 socket 模块文档:
所有的错误都会触发异常,像无效参数类型和内存不足的常见异常可以被抛出;从 Python 3.3 开始,与 socket 或地址语义相关的错误会引发 OSError 或其子类之一的异 常 引用
异常 | errno 常量 | 说明
BlockingIOError | EWOULDBLOCK | 资源暂不可用,比如在非阻塞模式下调用 send() 方法,对方太繁忙面没有读取,发送队列满了,或者网络有问题
OSError | EADDRINUSE | 端口被战用,确保没有其它的进程与当前的程序运行在同一地址/端口上,你的服务器设置了 SO_REUSEADDR 参数
ConnectionResetError | ECONNRESET | 连接被重置,远端的进程崩溃,或者 socket 意外关闭,或是有防火墙或链路上的设配有问题
TimeoutError | ETIMEDOUT | 操作超时,对方没有响应
ConnectionRefusedError | ECONNREFUSED | 连接被拒绝,没有程序监听指定的端口
socket.AF_INET 和 socket.AF_INET6 是 socket.socket() 方法调用的第一个参数
,表示地址协议族,API 使用了一个期望传入指定格式参数的地址,这取决于是
AF_INET 还是 AF_INET6
| 地址族 | 协议 | 地址元组 | 说明 |
|---|---|---|---|
| socket.AF_INET | IPv4 | (host, port) | host 参数是个如 www.example.com 的主机名称,或者如 10.1.2.3 的 IPv4 地址 |
| socket.AF_INET6 | IPv6 | (host, port, flowinfo, scopeid) | 主机名同上,IPv6 地址 如:fe80::6203:7ab:fe88:9c23,flowinfo 和 scopeid 分别表示 C 语言结构体 sockaddr_in6 中的 sin6_flowinfo 和 sin6_scope_id 成员 |
注意下面这段 python socket 模块中关于 host 值和地址元组文档
对于 IPv4 地址,使用主机地址的方式有两种:
''空字符串表示INADDR_ANY,字符'<broadcast>'表示INADDR_BROADCAST,这个行为和 IPv6 不兼容,因此如果你的 程序中使用的是 IPv6 就应该避免这种做法。源文档
我在本教程中使用了 IPv4 地址,但是如果你的机器支持,也可以试试 IPv6 地址。socket.getaddrinfo() 方法会返回五个元组的序列,这包括所有创建 socket 连接的必要参数,socket.getaddrinfo() 方法理解并处理传入的 IPv6 地址和主机名
下面的例子中程序将返回一个通过 TCP 连接到 example.org 80 端口上的地址信息:
>>> socket.getaddrinfo("example.org", 80, proto=socket.IPPROTO_TCP)
[(<AddressFamily.AF_INET6: 10>, <SocketType.SOCK_STREAM: 1>,
6, '', ('2606:2800:220:1:248:1893:25c8:1946', 80, 0, 0)),
(<AddressFamily.AF_INET: 2>, <SocketType.SOCK_STREAM: 1>,
6, '', ('93.184.216.34', 80))]
如果 IPv6 可用的话结果可能有所不同,上面返回的值可以被用于 socket.socket() 和
socket.connect() 方法调用的参数,在 python socket 模块文档中的 示例
一节中有客户端和服务端
程序
这一节主要适用于使用 bind() 和 connect() 或 connect_ex() 方法时如何使用主机名,然而当你使用回环地址做为主机名时,它总是会解析到你期望的地址。这刚好与客户端使用主机名的场景相反,它需要 DNS 解析的过程,比如 www.example.com
下面一段来自 python socket 模块文档
如果你主机名称做为 IPv4/v6 socket 地址的 host 部分,程序可能会出现非预期的结果 ,由于 python 使用了 DNS 查找过程中的第一个结果,socket 地址会被解析成与真正的 IPv4/v6 地址不同的其它地址,这取决于 DNS 解析和你的 host 文件配置。如果想得到 确定的结果,请使用数字格式的地址做为 host 参数的值 源文档
通常回环地址 localhost 会被解析到 127.0.0.1 或 ::1 上,你的系统可能就是这么设置的,也可能不是。这取决于你系统配置,与所有 IT 相关的事情一样,总会有例外的情况,没办法完全保证 localhost 被解析到了回环地址上
比如在 Linux 上,查看 man nsswitch.conf 的结果,域名切换配置文件,还有另外一个 macOS 和 Linux 通用的配置文件地址是:/etc/hosts,在 windows 上则是C:\Windows\System32\drivers\etc\hosts,hosts 文件包含了一个文本格式的静态域名地址映射表,总之 DNS 也是一个难题
有趣的是,在撰写这篇文章的时候(2018 年 6 月),有一个关于 让 localhost 成为真正的 localhost的 RFC 草案,讨论就是围绕着 localhost 使用的情况开展的
最重要的一点是你要理解当你在应用程序中使用主机名时,返回的地址可能是任何东西,如果你有一个安全性敏感的应用程序,不要使用主机名。取决于你的应用程序和环境,这可能会困扰到你
注意: 安全方面的考虑和最佳实践总是好的,即使你的程序不是安全敏感型的应用。如果你的应用程序访问了网络,那它就应该是安全的稳定的。这表示至少要做到以下几点:
无论是否使用主机名称,你的应用程序都需要支持安全连接(加密授权),你可能会用到 TLS,这是一个超越了本教程的范围的话题。可以从 python 的 SSL 模块文档了解如何开始使用它,这个协议和你的浏览器使用的安全协议是一样的
考虑到接口、IP 地址、域名解析这些「变量」,你应该怎么应对?如果你还没有网络应用程序审查流程,可以使用以下建议:
| 应用程序 | 使用 | 建议 |
|---|---|---|
| 服务端 | 回环地址 | 使用 IP 地址 127.0.0.1 或 ::1 |
| 服务端 | 以太网地址 | 使用 IP 地址,比如:10.1.2.3,使用空字符串表示本机所有 IP 地址 |
| 客户端 | 回环地址 | 使用 IP 地址 127.0.0.1 或 ::1 |
| 客户端 | 以太网地址 | 使用统一的不依赖域名解析的 IP 地址,特殊情况下才会使用主机地址,查看上面的安全提示 |
对于客户端或者服务端来说,如果你需要授权连接到主机,请查看如何使用 TLS
如果一个 socket 函数或者方法使你的程序挂起,那么这个就是个阻塞调用,比如 accept(), connect(), send(), 和 recv() 都是 阻塞 的,它们不会立即返回,阻塞调用在返回前必须等待系统调用 (I/O) 完成。所以调用者 —— 你,会被阻止直到系统调用结束或者超过延迟时间或者有错误发生
阻塞的 socket 调用可以设置成非阻塞的模式,这样他们就可以立即返回。如果你想做到这一点,就得重构并重新设计你的应用程序
由于调用直接返回了,但是数据确没就绪,被调用者处于等待网络响应的状态,没法完成它的工作,这种情况下,当前 socket 的状态码 errno 应该是 socket.EWOULDBLOCK。setblocking() 方法是支持非阻塞模式的
默认情况下,socket 会以阻塞模式创建,查看 socket 延迟的注意事项 中三种模式的解释
有趣的是 TCP 连接一端打开,另一端关闭的状态是完全合法的,这被称做 TCP「半连接」,是否需要这种保持状态是由应用程序决定的,通常来说不需要。这种状态下,关闭方将不能发送任何数据,它只能接收数据
我不是在提倡你采用这种方法,但是作为一个例子,HTTP 使用了一个名为「Connection」的头来标准化规定应用程序是否关闭或者保持连接状态,更多内容请查看 RFC 7230 中 6.3 节, HTTP 协议 (HTTP/1.1): 消息语法与路由
当你在设计应用程序及其应用层协议的时候,最好先了解一下如何关闭连接,有时这很简单而且很明显,或者采取一些可以实现的原型,这取决于你的应用程序以及消息循环如何被处理成期望的数据,只要确保 socket 在完成工作后总是能正确关闭
查看维基百科 字节序 中关于不同的 CPU 是如何在内存中存储字节序列的,处理单个字节时没有任何问题,但是当把多个字节处理成单个值(四字节整型)时,如果和你通信的另一端使用了不同的字节序时字节顺序需要被反转
字节顺序对于字符文本来说也很重要,字符文本通过表示为多字节的序列,就像 Unicode 一样。除非你只使用 true 和 ASCII 字符来控制客户端和服务端的实现,否则使用 utf-8 格式或者支持字节序标识(BOM) 的 Unicode 字符集会比较合适
在应用层协议中明确的规定使用编码格式是很重要的,你可以规定所有的文本都使用 utf-8 或者用「content-encoding」头指定编码格式,这将使你的程序不需要检测编码方式,当然也应该尽量避免这么做
当数据被调用存储到了文件或者数据库中而且又没有数据的元信息的时候,问题就很麻烦了,当数据被传到其它端,它将试着检测数据的编码方式。有关讨论,请参阅 Wikipedia 的 Unicode 文章,它引用了 RFC 3629:UTF-8, a transformation format of ISO 10646
然而 UTF-8 的标准 RFC 3629 中推荐禁止在 UTF-8 协议中使用标记字节序 (BOM),但是 讨 论了无法实现的情况,最大的问题在于如何使用一种模式在不依赖 BOM 的情况下区分 UTF-8 和其它编码方式
避开这些问题的方法就是总是存储数据使用的编码方式,换句话说,如果不只用 utf-8 格式的编码或者其它的带有 BOM 的编码就要尝试以某种方式将编码方式存储为元数据,然后你就可以在数据上附加编码的头信息,告诉接收者编码方式
TCP/IP 使用的字节顺序是 big-endian,被称做网络序。网络序被用来表示底层协议栈中的整型数字,好比 IP 地址和端口号,python 的 socket 模块有几个函数可以把这种整型数字从网络字节序转换成主机字节序
| 函数 | 说明 |
|---|---|
| socket.ntohl(x) | 把 32 位的正整型数字从网络字节序转换成主机字节序,在网络字节序和主机字节序相同的机器上这是个空操作,否则将是一个 4 字节的交换操作 |
| socket.ntohs(x) | 把 16 位的正整型数字从网络字节序转换成主机字节序,在网络字节序和主机字节序相同的机器上这是个空操作,否则将是一个 2 字节的交换操作 |
| socket.htonl(x) | 把 32 位的正整型数字从主机字节序转换成网络字节序,在网络字节序和主机字节序相同的机器上这是个空操作,否则将是一个 4 字节的交换操作 |
| socket.htons(x) | 把 16 位的正整型数字从主机字节序转换成网络字节序,在网络字节序和主机字节序相同的机器上这是个空操作,否则将是一个 2 字节的交换操作 |
你也可以使用 struct 模块打包或者解包二进制数据(使用格式化字符串):
import struct
network_byteorder_int = struct.pack('>H', 256)
python_int = struct.unpack('>H', network_byteorder_int)[0]
我们在本教程中介绍了很多内容,网络和 socket 是很大的一个主题,如果你对它们都比较陌生,不要被这些规则和大写字母术语吓到
为了理解所有的东西如何工作的,有很多部分需要了解。但是,就像 python 一样,当你花时间去了解每个独立的部分时它才开始变得有意义
我们看过了 python socket 模块中底层的一些 API,并了解了如何使用它们创建客户端服务器应用程序。我们也创建了一个自定义类来做为应用层的协议,并用它在不同的端点之间交换数据,你可以使用这个类并在些基础上快速且简单地构建出一个你自己的 socket 应用程序
你可以在 Github 上找到 源代码
恭喜你坚持到最后!你现在就可以在程序中很好地使用 socket 了
我希望这个教程能为你开始 socket 编程旅途中提供一些信息、示例、或者灵感
1970-01-01 08:00:00
HTTPie 是一个命令行 HTTP 客户端。目标是让 CLI 与 Web services 的交互尽可能的更友
好。它提供了一个简单的 http 命令,可以让我们用简单自然的表述发送任意 HTTP 请求
,并且可以输出带代码高亮的结果。HTTPie 可以使用在测试、调试以及通用的与 HTTP 交
互场景
wget 的下载模式在 macOS 系统中推荐使用 Homebrew 来安装:
brew install httpie
当然 MacPorts 也是可以的:
port install httpie
大多数的 Linux 构建版都提供了包管理组件,可以使用他们来安装:
# 基于 Debian Linux 的构建版,比如 Ubuntu
apt-get install httpie
# 基于 RPM Linux 的构建版
yum install httpie
# Arch Linux 系统
pacman -S httpie
使用 pip 是一种通用的(可以使用在 Windows, MacOS, Linux ...)并且提供最新版本安装包的安装方法
# 确保使用了最新版本的 pip 和 setuptools:
pip install --upgrade pip setuptools
pip install --upgrade httpie
最新的开发版本可以直接通过 github 安装
# Homebrew
brew install httpie --HEAD
# pip
pip install --upgrade https://github.com/jkbrzt/httpie/archive/master.tar.gz
虽然兼容 Python 2.6, 2.7 版本的,但是如果可以的话还是建议使用最新版的 Python 3.x
来安装 HTTPie。这将保证一些比较新的功能(比如:SNI )可以开箱即用。Python 3 在 Homebrew 0.9.4 版本以上
已经成为了默认的 Python 版本。可以使用 http --debug 来查看 HTTPie 使用的
python 版本
最简单的使用:
http httpie.org
使用语法:
http [flags] [METHOD] URL [ITEM [ITEM]]
也可以使用 http --help 来查看更多使用方法:
自定义 HTTP 方法,HTTP 头和 JSON 数据:
http PUT example.org X-API-Token:123 name=John
表单提交:
http -f POST example.org hello=World
使用一个输出参数 -v 来查看请求信息(默认不显示请求信息):
http -v example.org
使用 Github API 向 issue 发送一条评论(需要授权验证参数):
http -a USERNAME POST https://api.github.com/repos/jkbrzt/httpie/issues/83/comments body='HTTPie is awesome! :heart:'
通过命令行的输入重定向上传文件:
http example.org < file.json
使用 wget 风格下载文件:
http --download example.org/file
使用命令会话对同一 host 进行请求之间的持久通信:
http --session=logged-in -a username:password httpbin.org/get API-Key:123
http --session=logged-in httpbin.org/headers
自定义请求 host 头:
http localhost:8000 Host:example.com
HTTP 方法的名称在 URL 参数之前:
http DELETE example.org/todos/7
这看起来就像是原生的 HTTP 请求发送的文本一样:
DELETE /todos/7 HTTP/1.1
HTTPie 唯一必传的一个参数是请求 URL,默认的方案不出意料的是 http://,可以在请
求的时候缺省 - http example.org 是没问题的
如果需要在命令行手动构建 URLs,你可能会觉得使用 param==value 添加参数的方式是
比较方便的,这样你就不需要担心命令行中转义链接字符串 & 的问题,当然参数中的特
殊字符也将被自动转义(除非已经转义过)。用下面的命令搜索 HTTPie logo 可以在
google 图片上结果:
http www.google.com search=='HTTPie logo' tbm==isch
GET /?search=HTTPie+logo&tbm=isch HTTP/1.1
另外,类似 curl 的 localhost 缩写也是支持的。这表示你可以使用 :3000 来代替
http://localhost:3000, 如果不传入端口号,80 将会默认被使用
http :/foo
GET /foo HTTP/1.1
Host: localhost
http :3000/bar
GET /bar HTTP/1.1
Host: localhost:3000
http :
GET / HTTP/1.1
Host: localhost
你可以使用 --default-scheme <URL_SCHEME> 参数来指定非 HTTP 的其它协义
alias https='http --default-scheme=https'
不同的请求项类型提供一种便捷的方法来指定 HTTP 头、简单的 JSON 、表单数据、文件、URL 参数
URL 参数后面紧随的是 键/值 对参数都会被拼装成请求发送。不同类型的 键/值 对分
割符号分别是::, =, :=, @, =@, :=@。用 @ 分割的参数表示文件路径
| 项类型(item type) | 描述(Description) |
|---|---|
HTTP 头参数Name:Value |
任意的 HTTP 头,比如:X-API-Token:123 |
URL 参数name==value |
通过分割符 == 表示一个查询字符串的 键/值 对 |
数据域field=value,[email protected] |
请求一个默认会被序列化成 JSON 的数据域,或者表单类型 form-encoded(--form, -f) |
纯 JSON 域field:=json,field:[email protected] |
当需要指定一个或者多数域参数类型 boolean, number .. 时非常有用, 比如:meals:='["ham","spam"]' or pies:=[1,2,3] (注意引号). |
| Form 表单文件域 | 仅当传入参数 --form, -f 时有效,比如 screenshot@~/Pictures/img.png 文件内容将会被序列化成 multipart/form-data 发送 |
数据域不是唯一的指定请求数据的方式,重定向输入也可以
可以使用 \ 来转义不应该被用于分割符的情况。比如 foo\==bar 会被转义成一个数据
键值对(foo= 和 bar)而不是 URL 参数
通常情况需要使用引号包围值,比如 foo='bar baz'
如果有一个域的名字或者 header 以减号开头,你需要把这些参数放在一个特殊符号 --
后面 ,这样做是为了和 --arguments 区分开
http httpbin.org/post -- -name-starting-with-dash=foo -Unusual-Header:bar
POST /post HTTP/1.1
-Unusual-Header: bar
Content-Type: application/json
{
"-name-starting-with-dash": "value"
}
JSON 是现代 web services 通用规范,HTTPie 也默认遵循了它的 不严格的数据类型
http PUT example.org name=John email=[email protected]
PUT / HTTP/1.1
Accept: application/json, */*
Accept-Encoding: gzip, deflate
Content-Type: application/json
Host: example.org
{
"name": "John",
"email": "[email protected]"
}
如果你的命令包含了一些请求项数据,它们将默认被序列化成 JSON 对象。HTTPie 会默认 自动添加下面两个 header 头,当然这两个头也可以重新传入
| Content-Type | application/json |
|---|---|
| Accept | application/json, */* |
你可以使用命令行参数 --json, -j 明确地设置 Accept 为 application/json 而无
需在意发送的数据是什么(这是个快捷方式,也可以使用普通的 header 注解:http url Accept:'application/json, */*'),另外,HTTPie 会试着检测 JSON 响应,即使
Content-Type 是不正常的 text/plain 或者未知类型
非字符串类型的 JSON 域使用 := 分割,这可以允许你嵌入原生纯 JSON 到结果对象,文
本和原生的纯 JSNO 文件也可以使用 =@ 和 :=G 嵌入
http PUT api.example.com/person/1 \
name=John \
age:=29 married:=false hobbies:='["http", "pies"]' \ # Raw JSON
description=@about-john.txt \ # Embed text file
bookmarks:=@bookmarks.json # Embed JSON file
PUT /person/1 HTTP/1.1
Accept: application/json, */*
Content-Type: application/json
Host: api.example.com
{
"age": 29,
"hobbies": [
"http",
"pies"
],
"description": "John is a nice guy who likes pies.",
"married": false,
"name": "John",
"bookmarks": {
"HTTPie": "http://httpie.org",
}
}
不过请注意,当发送复杂数据的时候,这个例子使用的语法会显得很笨重。在这种情况下重定向输入 将会更合适:
http POST api.example.com/person/1 < person.json
提交表单和发送 JSON 请求很相似,通常情况下唯一的不同是添加额外的 --form, -f 参
数,这将确保数据域和 Content-Type 被设置成 application/x-www-form-urlencoded; charset=utf-8
http --form POST api.example.org/person/1 name='John Smith'
POST /person/1 HTTP/1.1
Content-Type: application/x-www-form-urlencoded; charset=utf-8
name=John+Smith
如果有一个文件域,序列化方式和 content type 会是 multipart/form-data:
http -f POST example.com/jobs name='John Smith' cv@~/Documents/cv.pdf
上面的请求和下面的 HTML 表单发送请求是一样的:
<form enctype="multipart/form-data" method="post" action="http://example.com/jobs">
<input type="text" name="name" />
<input type="file" name="cv" />
</form>
注意 @ 用来模拟文件上传域,而 =@
是把文件内容以文本的方式嵌入到数据域的值里面
可以使用 Header:Value 注解的形式来添加自定义头信息
http example.org User-Agent:Bacon/1.0 'Cookie:valued-visitor=yes;foo=bar' \
X-Foo:Bar Referer:http://httpie.org/
GET / HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate
Cookie: valued-visitor=yes;foo=bar
Host: example.org
Referer: http://httpie.org/
User-Agent: Bacon/1.0
X-Foo: Bar
有几个默认的请求头是 HTTPie 设置的
GET / HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate
User-Agent: HTTPie/<version>
Host: <taken-from-URL>
可以使用 Header: 来取消上面的几个默认头信息
http httpbin.org/headers Accept: User-Agent:
请求中的 Accept 和 User-Agent 头都会被移除
使用 Header; 表示添加一个为空的头信息,注意须使用引号
http -v httpbin.org/headers 'Host;'
GET /headers HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate
Connection: keep-alive
Host:
User-Agent: HTTPie/0.9.9
...
目前支持的验证方案有基础和摘要两种(查看更多 授权插件),有两种标识 来控制验证:
| 参数 | 说明 |
|---|---|
--auth, -a |
把 用户名:密码 做为键值对参数传入,如果只指定用户名可以使用 -a 用户名,密码在接下来的提示符中输入,空密码使用 username:,username:password@hostname 格式的 URL 语法也是支持的,证书通过 -a 参数传入且具有更高的优先级 |
--auth-type, -A |
指定指定身份验证机制。basic(默认) 和 digest 两种 |
http -a username:password example.org
http -A digest -a username:password example.org
http -a username example.org<Paste>
从你的 ~/.netrc 文件授权也可以
cat ~/.netrc
machine httpbin.org
login httpie
password test
http httpbin.org/basic-auth/httpie/test
HTTP/1.1 200 OK
[...]
授权机制可以使用安装插件的方式来实现,可以在 Python Package 上面找到更多相关插件
HTTP 重定向默认不会自动跳转,请求发出后命令行只会显示 第一次 收到的响应
http httpbin.org/redirect/3
指定 --follow, -F 参数让 HTTPie 自动跟随 30x 响应头中的 location
字段值进行跳转,并且显示最终的响应内容
http --follow httpbin.org/redirect/3
如果你也想看到更多的跳转信息,可以指定 --all 参数
http --follow --all httpbin.org/redirect/3
改变默认最大 30 次重定向值可以使用 --max-redirects=<limit> 参数
http --follow --all --max-redirects=5 httpbin.org/redirect/3
你可以通过添加参数 --proxy 来指定各自协义(为了防止跨协义的重定向,协义被包含
在了参数值中)的代理服务器
http --proxy=http:http://10.10.1.10:3128 --proxy=https:https://10.10.1.10:1080 example.org
添加 basic 授权
http --proxy=http:http://user:[email protected]:3128 example.org
也可以通过设置 HTTP_PROXY 和 HTTPS_PROXY 环境变量来配置代理,底层的 request
库也将使用这些代理配置,如果你想指定某些 host 不使用代理,可以通过添加
NO_PROXY 参数来实现
在你的 ~/.bash_profile 文件中(zsh 则在 ~/.zshrc 中)
export HTTP_PROXY=http://10.10.1.10:3128
export HTTPS_PROXY=https://10.10.1.10:1080
export NO_PROXY=localhost,example.com
要启用 socks 代理支持请使用 pip 安装 requests[socks] 库
pip install -U requests[socks]
用法与其它类型的代理相同:
http --proxy=http:socks5://user:pass@host:port --proxy=https:socks5://user:pass@host:port example.org
使用参数 --verify=no 可以跳过主机 SSL 验证(默认:yes)
http --verify=no https://example.org
使用 --verify=<CA_BUNDLE_PATH> 指定 CA 认证包路径
http --cert=client.pem https://example.org
使用客户端 SSL 证书进行 SSL 通信,可以用 --cert 参数指定证书文件路径
http --cert=client.pem https://example.org
如果证书中不包含私钥,可以通过 --cert-key 参数指定密钥文件路径
http --cert=client.crt --cert-key=client.key https://example.org
参数 --ssl=<PROTOCOL> 用来指定你想使用的 SSL 协义版本,默认是 SSL v2.3。这将
会协商服务端和你安装的 OpenSSL 支持的最高 SSL 协议版本。可用的版本有: ssl2.3,
ssl3 , tls1 , tls1.1 , tls1.2 (实际上可用的协义可能有很多种,这由你安装
的 OpenSSL 决定)
# 指定容易受到攻击的 SSL v3 协义与老服务器进行通信
http --ssl=ssl3 https://vulnerable.example.org
如果你的 HTTPie 版本(可以使用 http --debug 查看版本)小于 2.7.9,又需要使用
SNI 与服务器会话。那么你需要安装额外的依赖
pip install --upgrade requests[security]
使用下面的命令测试 SNI 支持
http https://sni.velox.ch
HTTPie 默认只输出最终响应信息并且打印(header, body同样),你可以通过下面一些参 数控制打印内容:
| 命令行参数 | 描述 |
|---|---|
| --headers, -h | 仅打印响应头 |
| --body, -b | 仅打印响应体 |
| --verbose, -v | 打印所有的 HTTP 请求来回内容,这将默认开启 --all 参数 |
使用 --verbose 参数来调试请求或生成文档时是非常有用的
http --verbose PUT httpbin.org/put hello=world
PUT /put HTTP/1.1
Accept: application/json, */*
Accept-Encoding: gzip, deflate
Content-Type: application/json
Host: httpbin.org
User-Agent: HTTPie/0.2.7dev
{
"hello": "world"
}
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 477
Content-Type: application/json
Date: Sun, 05 Aug 2012 00:25:23 GMT
Server: gunicorn/0.13.4
{
[…]
}
所有的 HTTP 输出选项都属于更强大的 --print, -p 参数的快捷方式。--print, -p
接受一个字符串,字符串的每个字母都表示下面的 HTTP 某一部分
| 字符 | 代表 |
|---|---|
H |
请求头 |
B |
请求体 |
h |
响应头 |
b |
响应体 |
打印请求头和响应头:
http --print=Hh PUT httpbin.org/put hello=world
使用 --all 参数可以查看 HTTP 通信中的所有信息,中间的 HTTP 通信包括跟随重定向
(使用参数--follow)和使用 HTTP 摘要授权时第一次未授权的请求(使用参数
--auth=diggest)
# 包括最终响应之前的所有响应信息
http --all --follow httpbin.org/redirect/3
中间请求/响应默认会使用 --print, -p 参数指定的值格式化,可以使用
--history-print, -P 指定, 参数和 --print, -p 是一样的。但是这只实用于 中
间请求
# 中间请求/响应信息使用 H 格式化,最终请求/响应信息使用 Hh 格式化:
http -A digest -a foo:bar --all -p Hh -P H httpbin.org/digest-auth/auth/foo/bar
做为一个优化项,响应体在仅作为输出一部分时才会被下载,这和 HEAD 类型的请求类似
(除了 HEAD 可以使用在任何 HTTP 请求中)
比如有一个 API 更新后会返回整个资源,但是你只对更新后响应头中的状态码感兴趣:
http --headers PATCH example.org/Really-Huge-Resource name='New Name'
由于我们在上面设置了只打印头信息,当响应头接收完成的时候服务器连接就会被关闭, 带宽和时间不会浪费在下载响应体,你可以不必在意。响应头总是会被下载的无论它是不是 输出部分
直接从 stdin (标准输入)管道传入请求数据是大部分人认为比较好的方法。 这些数据
被缓冲而且不需要更多的操作就可以做为请求体被使用,使用管道有下面几个好用的方法:
从一个文件重新定向
http PUT example.com/person/1 X-API-Token:123 < person.json
或者从其它程序的输出
grep '401 Unauthorized' /var/log/httpd/error_log | http POST example.org/intruders
当然也可以使用 echo 命令来传简单数据
echo '{"name": "John"}' | http PATCH example.com/person/1 X-API-Token:123
甚至可以使用 web services
http GET https://api.github.com/repos/jkbrzt/httpie | http POST httpbin.org/post
也可以使用 cat 命令来输入多行文本
cat | http POST example.com
<paste>
^D
cat | http POST example.com/todos Content-Type:text/plain
- buy milk
- call parents
^D
在 macOS 中可以使用 pbpaste 命令把剪贴板中的内容做为数据发送
pbpaste | http PUT example.com
通过 stdin 传递数据的方式 不能 和指定数据域的方式混合使用
echo 'data' | http POST example.org more=data # 不可以
指定文件路径(@/path/to/file)方式可以替代上面使用 stdin 的方式
这个方法有个优点,Content-Type 可以根据提供的文件扩展名自动设置成对应的。比如
下面的请求会被设置头 Content-Type: application/xml
http PUT httpbin.org/put @/data/file.xml
HTTPie 默认会做一些事情,目的是为了让命令行输出内容有更高的可读性
语法高亮会应用在 HTTP 请求的 headers 和 body 里面。如果你不喜欢默认的配色方案,
可以使用 --style 参数自定义(使用http --help命令查看更多选项)
还有下面几个格式化规则会被使用:
下面这些参数可以用在处理输出结果中:
| 命令行参数 | 描述 |
|---|---|
| --pretty=all | 应用颜色和格式化,默认 |
| --pretty=colors | 仅应用颜色 |
| --pretty=format | 仅应用格式化 |
| --pretty=none | 不使用颜色和格式化,重定向时默认使用 |
二进制数据在命令行中会被禁止,这会使处理响应返回的二进制数据变得更安全,重定向时 也禁止二进制数据,但是会被装饰输出。一旦当我们知道响应体是二进制数据时,连接会关 闭
http example.org/Movie.mov
你几乎可以立即看见下面的提示:
HTTP/1.1 200 OK
Accept-Ranges: bytes
Content-Encoding: gzip
Content-Type: video/quicktime
Transfer-Encoding: chunked
+-----------------------------------------+
| NOTE: binary data not shown in terminal |
+-----------------------------------------+
与命令行输出相比,重定向输出使用了不同的默认值,不同之处在于:
--pretty被指定)原因是为了把 HTTPie 的结果直接 piping 到其它程序,并且使下载文件不需要额外的参数 标识。多数情况下输出重定向时只有响应体有意义
下载一个文件:
http example.org/Movie.mov > Movie.mov
下载 Octocat 图片,使用 ImageMagick 修改大小,上传到其它地方:
http octodex.github.com/images/original.jpg | convert - -resize 25% - | http example.org/Octocats
强制使用格式化与颜色,在 less 的分页中显示请求和响应
http --pretty=all --verbose example.org | less -R
-R 标识告诉 less 命令解析 HTTPie 输出中的颜色序列
你可以使用下面的 bash 函数代码建立一个调用 HTTPie 分页格式化且高亮输出的快捷方式:
function httpless {
# `httpless example.org'
http --pretty=all --print=hb "$@" | less -R;
}
HTTPie 具有下载模式,这和 wget 命令类似
使用 --download, -d 标识启用,响应头会打印到命令行,下载响应体的进度条也会显示
http --download https://github.com/jkbrzt/httpie/archive/master.tar.gz
HTTP/1.1 200 OK
Content-Disposition: attachment; filename=httpie-master.tar.gz
Content-Length: 257336
Content-Type: application/x-gzip
Downloading 251.30 kB to "httpie-master.tar.gz"
Done. 251.30 kB in 2.73862s (91.76 kB/s)
如果没有指定参数 --output, -o,文件名将由 Content-Disposition 决定,或者通过
URL 及其 Content-Type,如果名字已占用,HTTPie 会添加唯一后缀
即使响应头和进度状态显示在命令行中,你仍然可以将响应重定向到其它的程序
http -d https://github.com/jkbrzt/httpie/archive/master.tar.gz | tar zxf -
如果指定 --output, -o,你可以 --continue, -c
恢复部分下载。不过仅当服务器支持 Range 请求而且响应返回 206 Partial Content
才可以,如果服务器不支持这个功能,那就只会下载整个文件
http -dco file.zip example.org/file
--download 仅更改响应正文的处理方式--verbose, -v 等--download 意味着启用 --follow1 并退出Accept-Encoding 不能和 --download 一起使用响应体会被以块的形式下载和打印,这使程序在不使用大量内存情况下进行流式传输和下载 ,然而如果使用颜色和格式化参数,整个 响应体会被缓冲,然后立即处理
可以使用 --stream, -S 进行下面的操作:
tail -f 命令
一样修饰过的流响应
http --stream -f -a YOUR-TWITTER-NAME https://stream.twitter.com/1/statuses/filter.json track='Justin Bieber'
像 tail -f 一样小块的流输出
http --stream -f -a YOUR-TWITTER-NAME https://stream.twitter.com/1/statuses/filter.json track=Apple \
| while read tweet; do echo "$tweet" | http POST example.org/tweets ; done
默认情况下,同一个 host 每个 HTTPie 发出的请求完全独立
然而,HTTPie 支持使用 --session=SESSION_NAME_OR_PATH 参数进行持久会话。在同一
个 host 的会话中,自定义 header(除了以Content- 和 If- 开头)、authorization、
cookies(手动指定或者服务器发送) 会持续保存
# 创建一个新会话
http --session=/tmp/session.json example.org API-Token:123
# 复制用已存在的会话 API-Token 会自动设置
http --session=/tmp/session.json example.org
所有的会话数据都会被存储成纯文本,这表示会话文件可以使用编辑器手动添加或者修改—— 其实就是 JSON 数据
每个 host 都可以建一个或者多个会话,比如:下面的命令将为 host 是 example.org
的请求建一个名为 name1 的会话:
http --session=user1 -a user1:password example.org X-Foo:Bar
从现在起,你就通过名字来选择会话,当你选择使用一个会话时,之前用过的授权、HTTP 头都会被自动添加:
http --session=user1 example.org
创建或者重用不同的会话,只需要指定不同的名字即可:
http --session=user2 -a user2:password example.org X-Bar:Foo
具名会话将被以 JSON 的数据格式存储在 ~/.httpie/sessions/<host>/<name>.json
下面(windows下则是 %APPDATA%\httpie\sessions\<host>\<name>.json)
不同与具名会话,你也可以直接使用一个文件路径来指定会话文件的存储地址,这也可以在 不同的 host 间复用会话:
http --session=/tmp/session.json example.org
http --session=/tmp/session.json admin.example.org
http --session=~/.httpie/sessions/another.example.org/test.json example.org
http --session-read-only=/tmp/session.json example.org
如果复用一个会话又不想更新会话信息,可以通过指定
--session-read-only=SESSION_NAME_OR_PATH 来实现
HTTPie 使用了一个简单的 JSON 配置文件
默认的配置文件路径在 ~/.httpie/config.json (window 在
%APPDATA%\httpie\config.json),配置文件的路径也可以通过修改环境变量
HTTPIE_CONFIG_DIR 来更改,可以使用 http --debug 命令查看当前配置文件路径
JSON 配置文件包含以下的键:
default_options
参数默认值数组(默认为空),数组里面的参数会被应用于每次 HTTPie 的调用
比如说,你可以使用这个选项改变默认的样式和输出参数:"default_options": ["--style=fruity", "--body"] ,另外一个常用的默认参数是 "--session=default",
这会让 HTTPie 总是使用会话(名称为default)。也可以使用 --form 改变默认 不严
格的 JSON 类型为 form 类型
**meta**
HTTPie 自动存储了一些它自己的元数据,不要动它
配置文件中的参数和其它任何指定参数的方法,都可以使用 --no-OPTION 参数来取消,
比如:--no-style 或者 --no-session
当你在 shell 脚本中使用 HTTPie 的时候,--check-status 标识会比较好用。这个标识
将告知 HTTPie 如果响应状态码是 3xx, 4xx, 5xx 时程序将退出并显示对应的错误
码 3(除非 --follow 参数被指定), 4, 5
#!/bin/bash
if http --check-status --ignore-stdin --timeout=2.5 HEAD example.org/health &> /dev/null; then
echo 'OK!'
else
case $? in
2) echo 'Request timed out!' ;;
3) echo 'Unexpected HTTP 3xx Redirection!' ;;
4) echo 'HTTP 4xx Client Error!' ;;
5) echo 'HTTP 5xx Server Error!' ;;
6) echo 'Exceeded --max-redirects=<n> redirects!' ;;
*) echo 'Other Error!' ;;
esac
fi
在非交互式调用的情况下通常不希望使用 stdin 的默认行为,可以使用
--ignore-stdin 参数来禁止它
如果没有这个选项,HTTPie 可能会挂起,这是一个常见的问题。发生的场景可能是——例如
从定时任务中调用HTTPie时,stdin 未连接到终端。因此,重定向输入的规则适用,即
HTTPie 开始读取它,希望请求体将被传递。由于没有数据也没有 EOF,它会被卡住。因此
,除非你将一些数据传递给 HTTPie,否则应在脚本中使用此标志
当然使用 --timeout 参数手动设置(默认 30 秒)延迟时间是个比较好的做法
命令行参数的设计与通过网络发送 HTTP 请求的过程密切相关。这使得 HTTPie 的命令更容 易记忆和阅读。有时你甚至可以把原生的 HTTP 请求串连到一行就很自然的形成了 HTTPie 的命令行参数。例如 对比下面这个原生 HTTP 请求:
POST /collection HTTP/1.1
X-API-Key: 123
User-Agent: Bacon/1.0
Content-Type: application/x-www-form-urlencoded
name=value&name2=value2
和使用 HTTPie 命令发送同样的参数:
http -f POST example.org/collection \
X-API-Key:123 \
User-Agent:Bacon/1.0 \
name=value \
name2=value2
注意他们两者的顺序和参数都非常相似,并且只有一小部分命令用于控制 HTTPie(-f 表
示让 HTTPie 发送一个 from 请求),并且不直接对应于请求的任何部分
两种模式:--pretty=all(命令行中默认)、--pretty=none(重定向输出时默认),
对交互式使用和脚本调用都比较友好,HTTPie 在这过程中作为通用的 HTTP 客户端
由于 HTTPie 还在频繁的开发中,现有的一些命令行参数在最终版 1.0 发布之前可能会
有一些微小的调整。这些调整都会在变更日志 里面记录
你可以通过下面的一些途径找到帮助支持
HTTPie 底层使用了两个特别棒的库:
Requests — Python HTTP 库 Pygments — Python 代码高亮
HTTPie 可以和下面两个好友愉快地玩耍:
BSD-3-Clause: LICENSE
Jakub Roztocil (@jkbrzt) 创造了 HTTPie,还有一些 优秀的人 也贡献力量
1970-01-01 08:00:00
Ultisnips 插件安装分两部分,一个是 ultisnips 插件本身,另外一个是代码片段仓库。一般来说把默认的代码片段仓库下载下来按需修改后上传到自己的 github 即可。如果你和我一样也使用 vim-plug 来管理插件的话,添加下面的代码到你的 vimrc 中保存刷新即可
Plug 'SirVer/ultisnips'
# 你自己的代码仓库 git 地址
Plug 'keelii/vim-snippets'
上面的示例中所有的代码片段都存放在插件安装目录下面的 vim-snippets/UltiSnips 中,文件命名格式为 ft.snippets, ft 就是 vim 中的 filetype,其中有个 all.snippets 是唯一一个所有文件都适用的代码片段
快捷键设置,我一般使用 tab 来触发代码片段补全,且不使用 YCM (官方文档表示使用YCM的话就不能使用tab补全)
let g:UltiSnipsExpandTrigger="<tab>"
" 使用 tab 切换下一个触发点,shit+tab 上一个触发点
let g:UltiSnipsJumpForwardTrigger="<tab>"
let g:UltiSnipsJumpBackwardTrigger="<S-tab>"
" 使用 UltiSnipsEdit 命令时垂直分割屏幕
let g:UltiSnipsEditSplit="vertical"
ultisnips 插件需要你的 vim 支持 python,可以在 vim 命令模式下使用下面的检测你的 vim 版本是否支持 python
# 1 表示支持
:echo has("python")
:echo has("python3")
snippet 触发字符 ["代码片段说明" [参数]]
代码片段内容
endsnippet
snippet if "if (condition) { ... }"
if (${1:true}) {
$0
}
endsnippet
这时当你在 vim 中输入 if 敲 tab 就会展开一条 if 语句,第一个触发点是 if 条件表达式,最后一个是 if 语句体
${1:true} 表示这是第一个触发点,占位符为 true,如果占位符没有默认值可直接使用 $1, $2, $3...
snippet if "if (...)"
if (${1:true}) {
${VISUAL}
}
endsnippet
${VISUAL} 表示在 vim 中使用可视模式下选择的文本,这个在重构代码的时候非常有用(后面会有高级用法),上个图感受一下
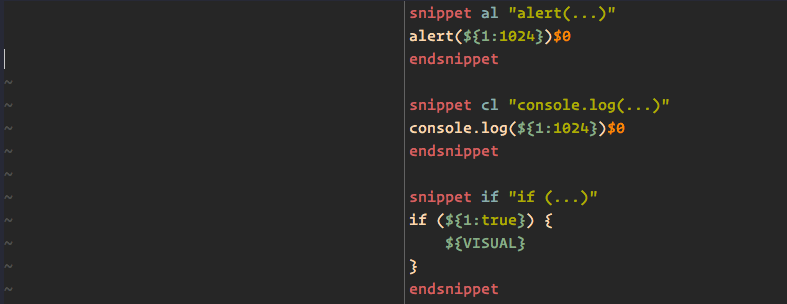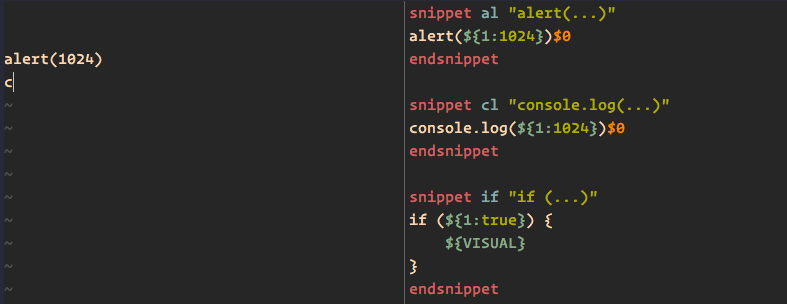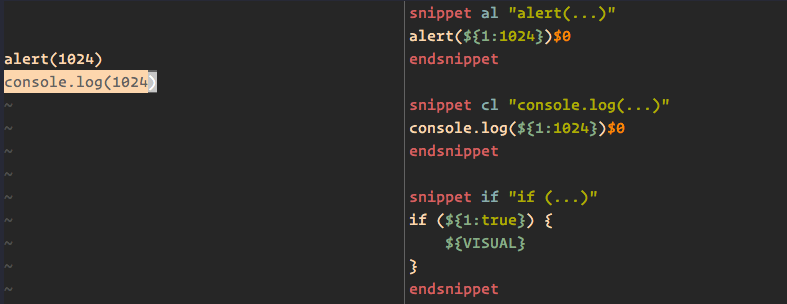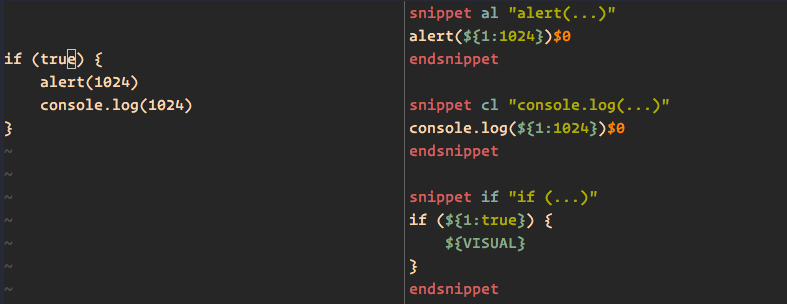
b 表示触发字符应该在一行的开始i 表示触发字符可以在单词内(连续展示会使用这个选项)w 表示触发字符的前后必须是一个字母分界点r 表示触发字符可以是一个正则表达式t 表示展开的代码片段中如果有制表符,原样输出,即使你的 vimrc 里面设置了 expandtabm 表示删除代码片段右边的所有空白字符e 表示自定义上下文A 表示自动触发,不需要按 tab,类似于 VIM 中的 abbrUltisnips 定义的代码片段中支持三种不同的语言注入:shell, vimscript, python,在代码片段中用反引号表示
就是在你的命令行 shell 能执行的代码片段,比如输出当前时间
➜ date
2018年 8月27日 星期一 18时19分38秒 CST
在代码片段中用反引号「`」引用即可
snippet today
Today is the `date`.
endsnippet
输入 today 按 tab 展开后(格式和上面shell中的不一样,估计是因为 vim 语言设置的问题):
Today is the Mon Aug 27 18:24:51 CST 2018.
使用 indent 来输出当前缩进值,使用前缀 !v 表示是 vimscript
snippet indent
Indent is: `!v indent(".")`.
endsnippet

在代码片段中解释执行 python 代码是 ultisnips 最强大的功能,以前缀 !p 开始。系统会向 python 中注入一些变量,可以使用 python 代码直接对其进行操作
fn - 表示当前文件名path - 当前文件名的路径t - 占位符的字典,可以使用 t[1], t[2], t.v 来取占位符内容snip - UltiSnips.TextObjects.SnippetUtil 对象的一个实例match - 正则代码片段时返回的匹配元素(非常强大)其中最常用的 snip 对象提供了下面一些变量:
snip.rv 表示 return value,python 代码执行后处理过的字符串赋给 rv 即可snip.fn 表示当前文件名snip.ft 表示当前文件类型snip.v 表示 VISUAL 模式变量,其中 snip.v.mode 表示模式类型,snip.v.text 表示 VISUAL 模式中选择的字符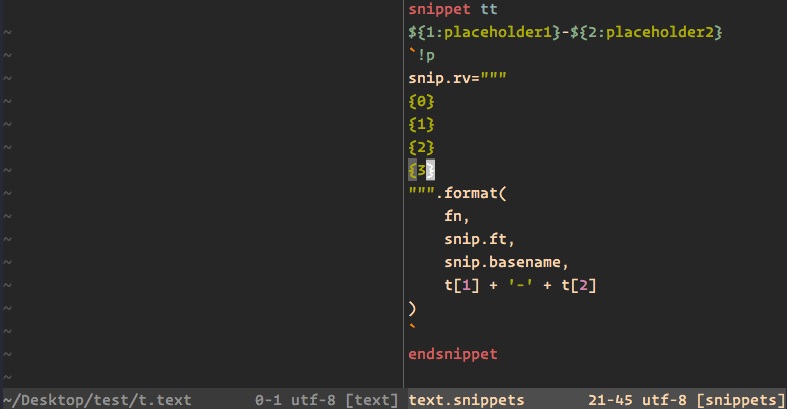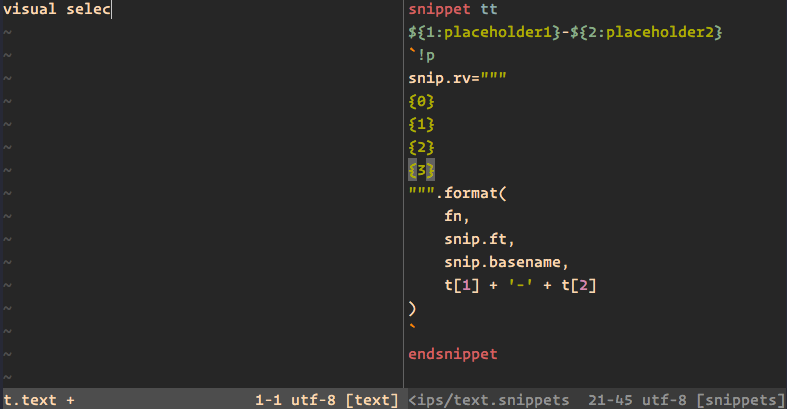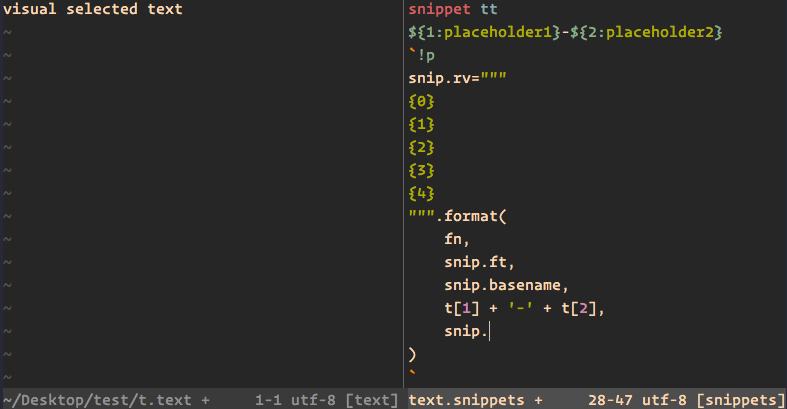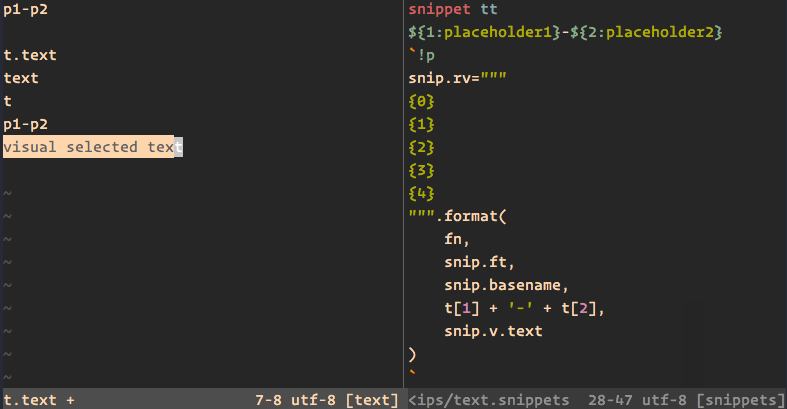
UltiSnips 支持使用快捷键切换占位符,我使用 <tab> 和 <shift-tab> 来切换 下一个 和 上一个 占位符,占位符切换的作用域为当前代码片段内部(即使占位符已被修改过),当光标移动出去以后就不起作用了
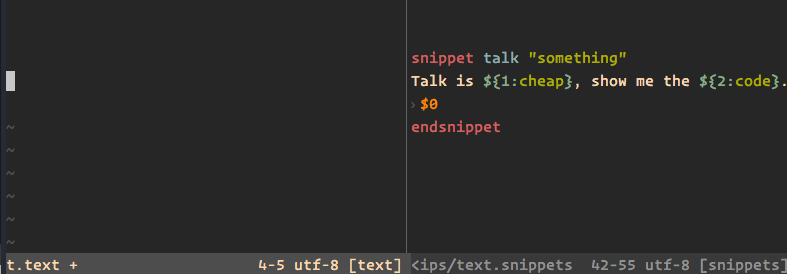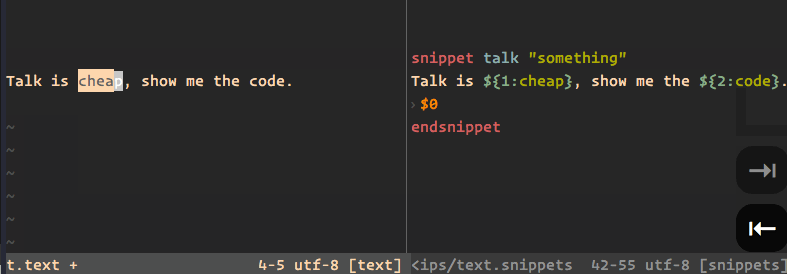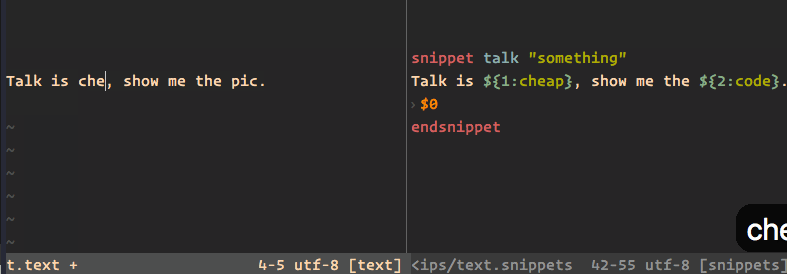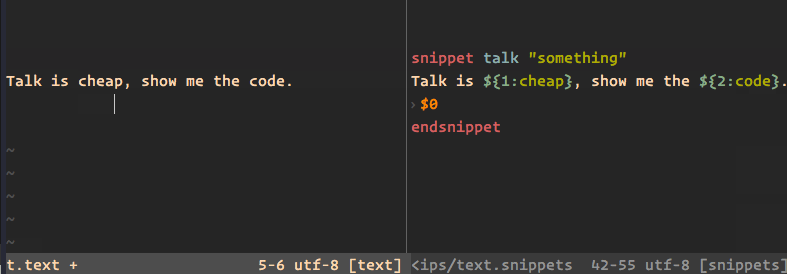
自定义上下文可以通过正则匹配来决定代码片断是否可用,比如判断在指定的 if 语句里面才起作用的代码片断,定义格式如下:
snippet 触发字符 "描述" "表达式" 参数
比如我们定义一个 只有 在上一行以 if (DEVELOPMENT) { 开头才可以展开的代码片段
snippet dbg "if (DEVELOPMENT) dbg" "re.match('^if \(DEVELOPMENT\) \{', snip.buffer[snip.line-1])" be
debugger;
endsnippet
这个常见于需要连续展开代码片段的情况,比如,有两个片段,一个打印变量,一个处理 JSON 序列化。这时需要使用参数选项 in-word
通常写代码的时候需要使用 log, print 等来打印上下文中的变量。使用普通片段按 cl 展示 console.log() 然后把变量字符复制进括号,这样操作会比较复杂。使用正则来动态匹配前面的字符可以很好的解决这个问题
# 展开 console.log
snippet "([^\s]\w+)\.log" "console.log(postfix)" r
console.log(`!p snip.rv = match.group(1)`)$0
endsnippet
# 当前行转换成大写
snippet "([^\s].*)\.upper" "Uppercase(postfix)" r
`!p snip.rv = match.group(1).upper()`$0
endsnippet
# 上一个单词转换成小写
snippet "([^\s]\w+)\.lower" "Lowercase(postfix)" r
`!p snip.rv = match.group(1).lower()`$0
endsnippet
动图演示
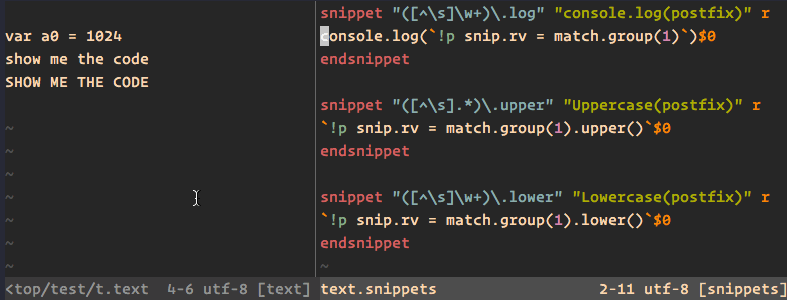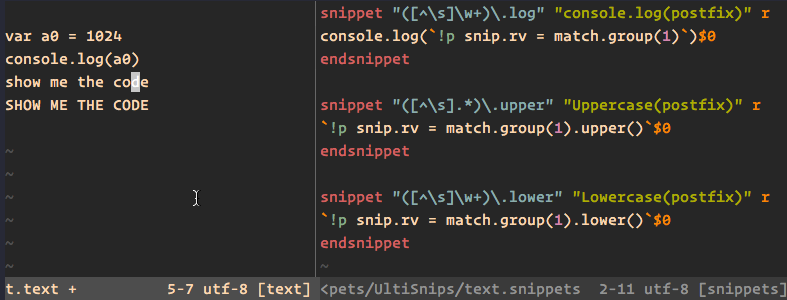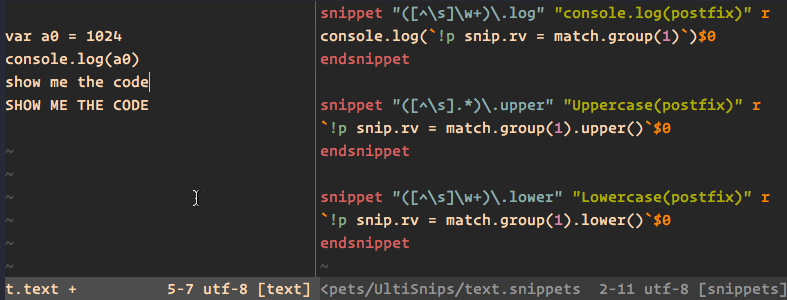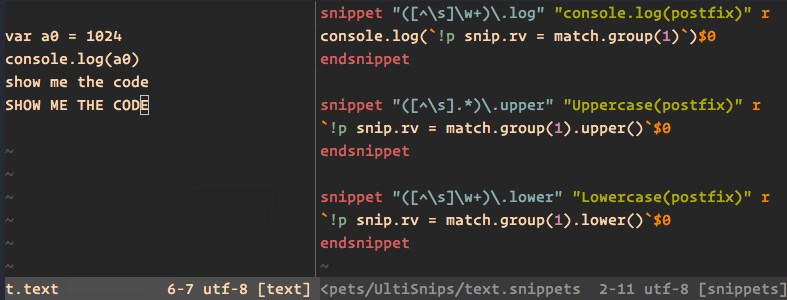
注意:正则代码片段只适用于单行文本处理,如果是多行转换还是得用到下面的 python + VISUAL 代码片段来处理
通常我们需要使用一大堆插件来实现各种代码的注释功能。不过 Ultisnips 提供了 VISUAL 模式可以提取 vim 可视模式中选择的内容到代码片段里面,于是我们就可以结合起来制作一个具有注释功能的代码片段
流程大概是这样的:
由于实现的 python 代码相对复杂一些,主要分成两个方法。单行注释和多行注释,注意 Ultisnips 中可以直接写 python 但是大段的方法建议放在插件目录下面的 pythonx 目录下面,使用的时候在对应的代码片段中的全局 python 代码 global !p 引入即可
单行注释(pythonx/javascript_snippets.py):
def comment(snip, START="", END=""):
lines = snip.v.text.split('\n')[:-1]
first_line = lines[0]
spaces = ''
initial_indent = snip._initial_indent
# Get the first non-empty line
for idx, l in enumerate(lines):
if l.strip() != '':
first_line = lines[idx]
sp = re.findall(r'^\s+', first_line)
if len(sp):
spaces = sp[0]
break
# Uncomment
if first_line.strip().startswith(START):
result = [line.replace(START, "", 1).replace(END, "", 1) if line.strip() else line for line in lines]
else:
result = [f'{spaces}{START}{line[len(spaces):]}{END}' if line.strip() else line for line in lines ]
# Remove initial indent
if result[0] and initial_indent:
result[0] = result[0].replace(initial_indent, '', 1)
if result:
return '\n'.join(result)
else:
return ''
多行注释:
def comment_inline(snip, START="/* ", END=" */"):
text = snip.v.text
lines = text.split('\n')[:-1]
first_line = lines[0]
initial_indent = snip._initial_indent
spaces = ''
# Get the first non-empty line
for idx, l in enumerate(lines):
if l.strip() != '':
first_line = lines[idx]
sp = re.findall(r'^\s+', first_line)
if len(sp):
spaces = sp[0]
break
if text.strip().startswith(START):
result = text.replace(START, '', 1).replace(END, '', 1)
else:
result = text.replace(spaces, spaces + START, 1).rstrip('\n') + END + '\n'
if initial_indent:
result = result.replace(initial_indent, '', 1)
return result
代码片段定义:
global !p
from javascript_snippets import (
comment, comment_inline
)
endglobal
# ...
snippet c "Toggle comment every single line"
`!p
snip.rv = comment(snip, START='// ', END='')
`$0
endsnippet
snippet ci "Toggle comment inline."
`!p
snip.rv = comment_inline(snip, START="/* ", END=" */")
`$0
endsnippet
动图演示
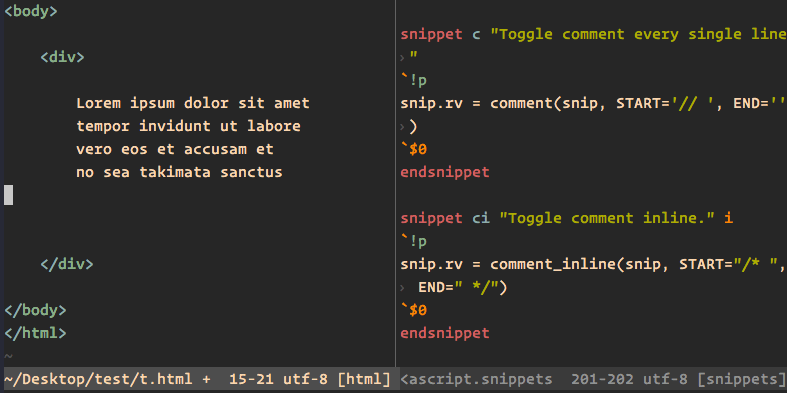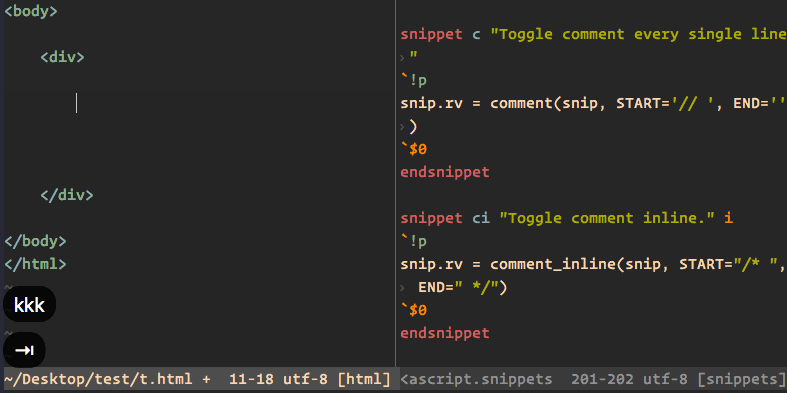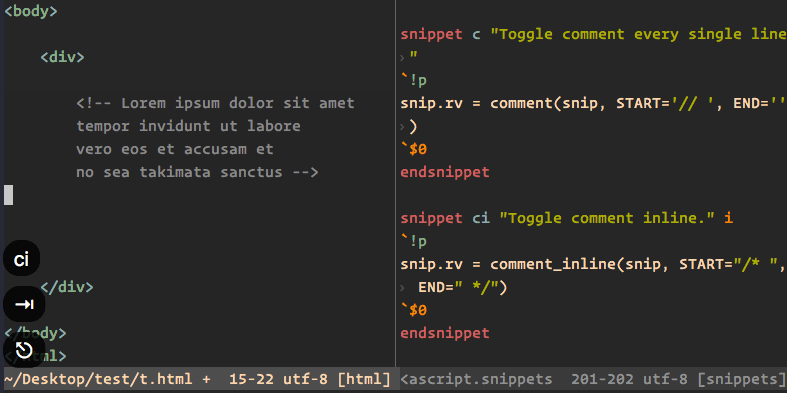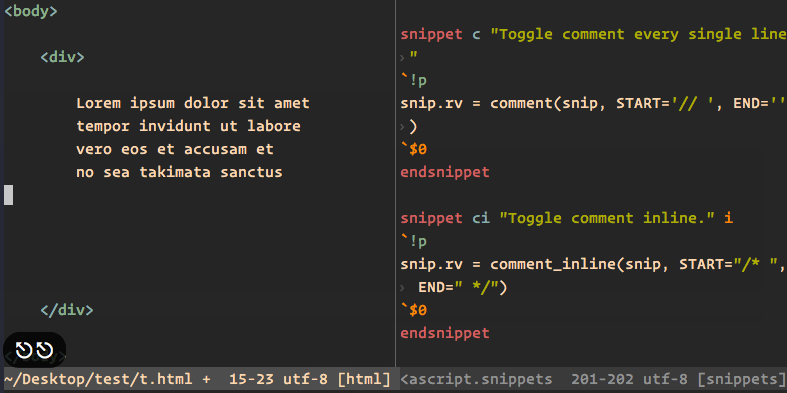
不同的语言可以在对应的片段文件中定义并传入注释符号参数即可,有了这个功能就可以愉快的删除其它的 vim 注释插件了 😀
1970-01-01 08:00:00
Fuzzy finder 是一款使用 GO 语言编写的交互式的 Unix 命令行工具。可以用来查找任何 列表 内容,文件、Git 分支、进程等。所有的命令行工具可以生成列表输出的都可以再通过管道 pipe 到 fzf 上进行搜索和查找
以 macOS 为例子,直接使用 homebrew 安装即可
brew install fzf
# 如果要使用内置的快捷键绑定和命令行自动完成功能的话可以按需安装
$(brew --prefix)/opt/fzf/install
命令行下执行 fzf 即可展示当前目录下所有文件列表,可以用键盘上下键或者鼠标点出来选择
或许你会觉得这个查找提示看起来挺漂亮的,但是并没有什么卵用,因为查找出来就没有然后了。其实这也是 Fuzzy finder 最核心的地方,他只是一个通用的下拉查找功能,自己本身并不关心你用它来做什么,通常我们需要组合使用才会有很好的效果
比如我们用 vim 组合 fzf 来查找并打开目录下的文件:
vim $(fzf)
再比如进入到某个文件夹下面,使用 fzf 的过滤选择真是太方便了
cd $(find * -type d | fzf)
这是个组合 (cd+find+fzf) 命令,完成切换到任意子目录的功能。可以看出来当 fzf 和其它命令组合使用时就能使得一些操作更方便:
git checkout $(git branch -r | fzf)
不过这样组合使用命令的实在太长了,如果你不使用自动补全的话巧起来很累的。建议把常用的 alias 放在 .zshrc 中管理嘛
fzf 默认使用 ** 来补全 shell 命令,比起默认的 tab 补全,fzf 补全不知道高到哪里去了。cd, vim, kill, ssh, export... 统统都能补全,好用哭了 🤣
fzf 提供了两个 环境变量 配置参数,来分别设置默认的调用命令和 fzf 默认配置参数
对于使用 fzf 来查找文件的情况,fzf 其实底层是调用的 Unix 系统 find 命令,如果你觉得 find 不好用也可以使用其它查找文件的命令行工具「我使用 fd」。注意:对原始命令添加一些参数应该在这个环境变量里面添加
比如说我们一般都会查找文件 -type f,通常会忽略一些文件夹/目录 --exclude=...,下面是我的变量值:
export FZF_DEFAULT_COMMAND="fd --exclude={.git,.idea,.vscode,.sass-cache,node_modules,build} --type f"
界面展示这些参数在 fzf --help 中都有,按需配置即可
export FZF_DEFAULT_OPTS="--height 40% --layout=reverse --preview '(highlight -O ansi {} || cat {}) 2> /dev/null | head -500'"
界面配置参数加上后就漂亮多了
--preview 表示在右侧显示文件的预览界面,语法高亮的设置使用了 highlight 如果 highlight 失败则使用最常见的 cat 命令来查看文件内容
highlight 安装可能会有个小插曲。highlight 需要手动编译安装,默认安装目录在 /usr/bin, /usr/share 下面。然而在 macOS 中由于 SIP 保护,用户安装的程序不能在这几个目录下面「即使有 sudo 权限也不行」。我们可以手动更改下 highlight 源代码中 makefile 中的参数即可
# PREFIX = /usr
PREFIX = /usr/local
将 PREFIX = /usr 改成 PREFIX = /usr/local,然后 make,sudo make install 就可以了
默认是 **,一般不用修改
如果你使用 vim,那么官方提供的插件会让你的 vim 使用更加流畅
如果你本地安装过 fzf 命令行工具了,只需要在 .vimrc 里面添加下面两个插件配置即可
Plug '/usr/local/opt/fzf'
Plug 'junegunn/fzf.vim'
注意:使用了 vim-plug 插件管理
插件主要对 fzf 集成绑定了一些和 vim 相关的功能,比如:查找当前 Buffer、Tag、Marks。甚至切换 window 更换 vim 主题配色等
命令模式下敲 Files 即可选择当前目录下所有文件,Buffers 可以过滤当前所有 vim buffer 内容
再配置几个常用快捷键就可以直接取代 CtrlP 插件了 🤔
nmap <C-p> :Files<CR>
nmap <C-e> :Buffers<CR>
let g:fzf_action = { 'ctrl-e': 'edit' }
当然 fzf 还可以在很多其它场景下用来。如果你想使用可视化的列表选择而不是咣咣敲命令,那就自己搭配一些组合来使用吧
1970-01-01 08:00:00
使用 jQuery ajax 方法调用异步接口时 data 参数默认会被添加转码 encodeURIComponent,如下:
$.ajax({
url: 'http://your.domain.com/action',
dataType: 'jsonp',
data: {
spaces: 'a b',
other: '&'
}
})
上面的代码会向 http://your.domain.com/action?spaces=a+b&other=%26 发送 get 请求,奇怪的是参数中的 & 被正确转码成 %26,但是 被转成了 + 而不是 %20
看看正确的转码结果长啥样
encodeURIComponent('&') // => "%26"
encodeURIComponent(' ') // => "%20"
既然 data 参数里面的 key,value 都要被 encodeURIComponent,那么出现这种情况只能去查 jQuery 源代码了。jQuery 会调用 $.param 方法来编码 data 参数,大概在 jQuery-1.7.2 的 (7736) 行:
param: function( a, traditional ) {
// ...
} else {
// If traditional, encode the "old" way (the way 1.3.2 or older
// did it), otherwise encode params recursively.
for ( var prefix in a ) {
buildParams( prefix, a[ prefix ], traditional, add );
}
}
// Return the resulting serialization
return s.join( "&" ).replace( r20, "+" );
}
param 方法内部会再调用 buildParams 来把 data 对象键值对添加编码,一切都很正常
然饿最后一行 replace( r20, "+" ) 是什么鬼!r20 变量是内部的一个空白转义符的正则 /%20/g
这就有点意思了,为啥把正确的空格编码再转回 + 呢?
外事不决问 Google,搜索 why jquery ajax convert %20 to + 结果发现有一条 jQuery 官方的 github issue: Only change %20 to + for application/x-www-form-urlencoded
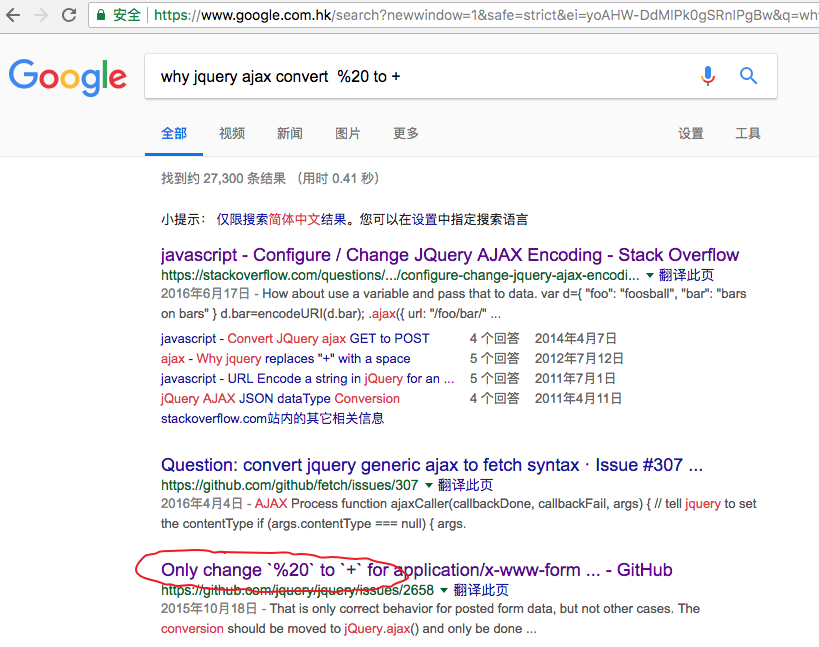
根据 issue 的描述大意是说 convert %20 to + 这个逻辑只应该在 POST 请求的时候做转换,而不是所有请求。我们的示例中的 jsonp 刚好是 get 请求
继续往下看找到了一个 commit(60453ce) 修复了这个问题
注意一点,我们并不能简单的在 data 对象传入的时候手动添加 encodeURIComponent:
$.ajax({
url: 'http://your.domain.com/action',
dataType: 'jsonp',
data: {
// 错误的做法
spaces: encodeURIComponent('a b'),
other: '&'
}
})
如果 spaces 参数有别的应该被正常编码的字符串,这样会导致正常的被编码的字符被 两次 encodeURIComponent。所以要正确解决这个问题需要修改 jQuery 源代码,这个可以参考上面的那个 fix commit
1970-01-01 08:00:00
切 host 对于平常开发来说再正常不过了,可是「切 host 难」的问题一直没解决,因为手动修改 host 文件会有很多(系统dns、浏览器)缓存问题。经常听到xx说「我这是好的呀,你 host 有问题吧...」
在 windows 下我一直使用 fiddler 来切换 host,很多人可能不知道这个功能。他的实现本质就是实用代理映射来实现 host 切换。这样的欢最大的优点就是 无延迟,秒切 host 这个体验就非常赞,而且是系统级别的,也就是说别的浏览器里面也适用(前提是浏览器代理设置为系统)
然后由于最近切换到 mac 开发环境,发现 mac 下面的解决方案都不是很完美,或者说不适合我的要求。无外乎以下几种:
像 iHosts, Switchhosts 这类,但据我所知这种方法都有延迟
比如 mac 下的 Wireshark、Charles,这些工具据说很强大,可是我自己用不惯,而且我是需求也很小,杀鸡焉用牛刀。fiddler for mac 虽然也能跑起来,但是体验太差了,界面卡的要死
像 Chrome 下的 Chrome-host-switch、 Switch host plus 等,试用了下效果很理想。美中不足的是体验不好,只有标签没有分组,把标签当分组切的人很蛋疼
简单看了下 switch host plus 的实现方式,再加上自己之前也写过 chrome 插件就决定自己造个轮子。Chrome 插件基于html、css、javascript 自然很适合前端来做
由于最近在看 react 相关的东西,刚好拿来练练手。技术选型基本上都是现成的框架拿来用就行了

和 host 文件规则一致
192.168.100.1 your.domain.com your-anther.domain.com
新建分组加入以下规则(按自己实际情况修改)
SOCKS5 127.0.0.1:1080
SOCKS 127.0.0.1:1080
Github(MIT)
1970-01-01 08:00:00
使用 seajs 的过程中偶尔会发现 require 进来的模块甚至都没有加载。查看源代码之后发现 seajs 是通过正则表达式匹配出了模块 factory 中的 require 路径
正常情况下,下面这个模块里面 require 的外部模块会解析出依赖 GLOBAL_ROOT/base/cookie 和 GLOBAL_ROOT/base/utils
define('moduleName', function() {
var a = require('GLOBAL_ROOT/base/cookie')
var b = require('GLOBAL_ROOT/base/utils')
// 正常情况 a 应该是个对象,
console.log(a)
})
但是如果 cookie 模块加载失败,a 就会返回 null 这时候再调 a 上面的方法就会报错。当 seajs 内部解析依赖时发生了错误时就会出现这种情况,由于我们使用的是比较老的 seajs 版本(2.2.0),去查看源代码发现 parseDependencies 方法使用了一个正则表达式
var REQUIRE_RE = /"(?:\\"|[^"])*"|'(?:\\'|[^'])*'|\/\*[\S\s]*?\*\/|\/(?:\\\/|[^\/\r\n])+\/(?=[^\/])|\/\/.*|\.\s*require|(?:^|[^$])\brequire\s*\(\s*(["'])(.+?)\1\s*\)/g
var SLASH_RE = /\\\\/g
function parseDependencies(code) {
var ret = []
code.replace(SLASH_RE, "")
.replace(REQUIRE_RE, function(m, m1, m2) {
if (m2) {
ret.push(m2)
}
})
return ret
}
我们在控制台里面跑一下看看结果,上面的模块解析正确:
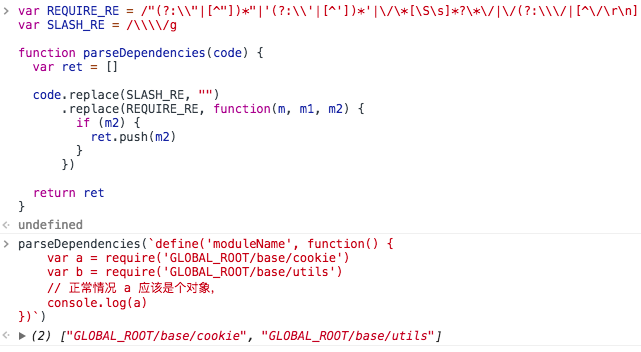
但是我自己的场景并没有这么简单,我贴上自己的代码时就异常了,由于源码比较多我就放到 jsbin 上了
有意思的地方就在于 压缩成一行 的代码中是异常的,但是当我把代码格式化后就正常了?!
解决方法
seajs 3.x 版本以后 util-deps.js 引入了一个依赖解析器方法,直接用这个替代原来的即可。至于为什么那个正则对于压缩后的代码没起作用我暂还没详细研究,不过感觉像获取模块依赖关系这种静态分析任务还是用解析器靠谱点,正则有太多的不确定性,虽然它能节省很多代码
1970-01-01 08:00:00
本文来自于我自己配置两台 macOS 开发环境的过程,主要记录一些常用的配置技巧
macOS 默认的计算机名称「xx的xx」,我一般会把这个名字改成英文,在命令行中看起来会漂亮一点。修改 系统设置-共享-电脑名称 即可
桌面搜索当前文件夹
系统偏好设置-键盘-输入法-自动切换到文稿输入法 应用切换的时候会保持原来的输入法不变桌面空白处右键-排序方式-贴紧网格 右键整理图标的时候就会按网格排列方便后续编译安装其它应用
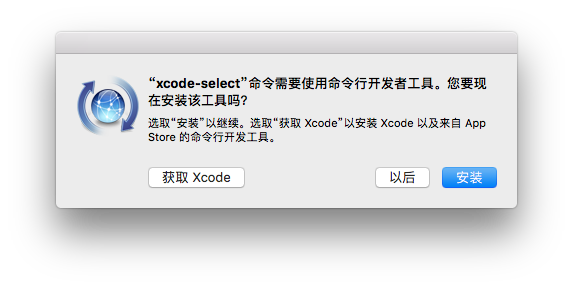
xcode-select --install
一般命令行的工具,或者开发环境包都用 brew 来安装。GUI 的应用直接去网站下载安装包即可,App Store 我一般用来购买安装一些收费软件
打开命令行执行下面的命令来安装 brew
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
使用下面的命令替换 brew 源为中科大镜像
# 替换brew.git:
cd "$(brew --repo)"
git remote set-url origin https://mirrors.ustc.edu.cn/brew.git
# 替换homebrew-core.git:
cd "$(brew --repo)/Library/Taps/homebrew/homebrew-core"
git remote set-url origin https://mirrors.ustc.edu.cn/homebrew-core.git
由于 brew 安装下载源码包有时是用 curl 的,所以可以配置下 curl 来走 番习习墙 代理,我一般在配置文件中设置 vim ~/.curlrc
socks5 = "127.0.0.1:1080"
Zsh 是一种 shell,功能和 bash, csh 一样,用来和操作系统交互
# 安装 zsh
brew install zsh
# 安装 oh-my-zsh 插件
# 更换默认 shell 为 zsh
chsh -s /bin/zsh
sh -c "$(curl -fsSL https://raw.github.com/robbyrussell/oh-my-zsh/master/tools/install.sh)"
安装成功的话会有下面的提示
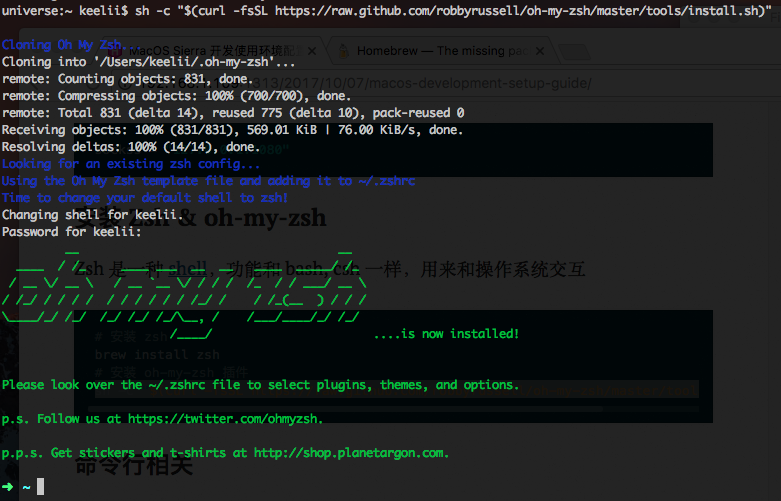
安装自动补全提示插件 zsh-autosuggestions
git clone git://github.com/zsh-users/zsh-autosuggestions ~/.zsh/zsh-autosuggestions
source ~/.zsh/zsh-autosuggestions/zsh-autosuggestions.zsh
下载 并安装,打开 Preferences 偏好设置
General 关闭 Native full screen windows 我不使用系统的全屏(因为有过渡动画),是为了使用全局快捷键 立即 调出命令行Profiles-Window-Transparency 设置透明度 10%~20% 即可,太高会和桌面背景冲突。如果需要临时禁用透明度可以使用快捷键 ⌘+uKeys-Hotkey 设置全局显示隐藏快捷键 系统级别的快捷键设置为 ⌘+\最佳实践,启动 iTerm2 后按
⌘+enter全屏,然后⌘+\隐藏它,这时候就可以做别的事情去了。任何时间想再用 iTerm2 只需要按⌘+\即可
下面这些都是用 brew 安装的,即 brew install xxx
用来查看当前运行的程序,top 命令的升级版
显示文件为树形菜单
➜ keelii.github.io tree . -L 2
.
├── config.toml
├── content
│ ├── about
│ └── archives
├── deploy.sh
├── public
│ ├── 2016
...
│ └── tags
└── themes
└── octo-enhance
17 directories, 8 files
使用比 curl 简单多了,而且还有一些代码高亮的效果
安装 vim 添加一些默认的模块和编程语言支持 cscope, lua, python 并且覆盖系统默认的 vim
brew install vim --HEAD --with-cscope --with-lua --with-override-system-vim --with-luajit --with-python
安装 vim-plug
curl -fLo ~/.vim/autoload/plug.vim --create-dirs https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim
方便在命令行中快速跳转目录,安装后程序会读取你 cd 过的目录并存起来,方便后面用快捷方式调用,支持模糊匹配。注意: autojump 只会记录安装后使用 cd 命令进入过的目录
npm 的替代品,Production Ready。如果系统中安装过 node,就使用 yarn --without-node 命令只安装 yarn 工具
下载 get-pip.py 在命令行中使用 python 运行这个文件
sudo python get-pip.py
gem sources --add https://mirrors.tuna.tsinghua.edu.cn/rubygems/ --remove https://rubygems.org/
gem sources -l
cat ~/.gemrc
---
:backtrace: false
:bulk_threshold: 1000
:sources:
- https://mirrors.tuna.tsinghua.edu.cn/rubygems/
:update_sources: true
:verbose: true
cat ~/.yarnrc
registry "https://registry.npm.taobao.org"
disturl "https://npm.taobao.org/dist"
electron_mirror "http://cdn.npm.taobao.org/dist/electron/"
node_inspector_cdnurl "https://npm.taobao.org/mirrors/node-inspector"
sass_binary_site "http://cdn.npm.taobao.org/dist/node-sass"
可以参照我的 dotfiles 配置文件
1970-01-01 08:00:00
由于最近全面切换工作环境到 Mac 上,快捷键基本上成了适应期的最大问题
传统意义上像 Ctrl, Alt, Shift, Win, Option, Command 都属于 修饰键,只能和其它键配合使用才可以(Ctrl+c,Ctrl+v),单独敲击并没有效果
但是 Win 键在 Windows 中被赋予了更多的功能,下面这几个系统级别的快捷键用起来是非常方便的:
Win + E ⇒ 打开资源管理器Win + D ⇒ 显示桌面Win + L ⇒ 锁定计算机之前使用过 Windows 和 Ubuntu gnome,特别方便的一点就是 super(Win) 键 不仅 可以做为修饰键和其它键组合使用,而且还可以响应 单独的 点击事件,Windows 中点击 Win 键会全局呼出 开始菜单 方便我们 查找/打开 应用。这样的话单独点击相当于可以少按一个按键,切找应用什么的非常快
Mac 中我通常使用 Spotlight 来快速切换程序。用惯了 Mac 的人会觉得 command 键位非常舒服好按(键位原因),这时候我希望尽可能把常用的键组织到 command 上又 不影响 原来的组合键,比如我有下面两个最常使用的快捷键:
⌘ ⇒ 呼出 Spotlight⌘ + Space ⇒ 切换输入法然而 Mac 系统中并不允许我们这么做 🤔,于是我使用了一个改键器 Karabiner 😎
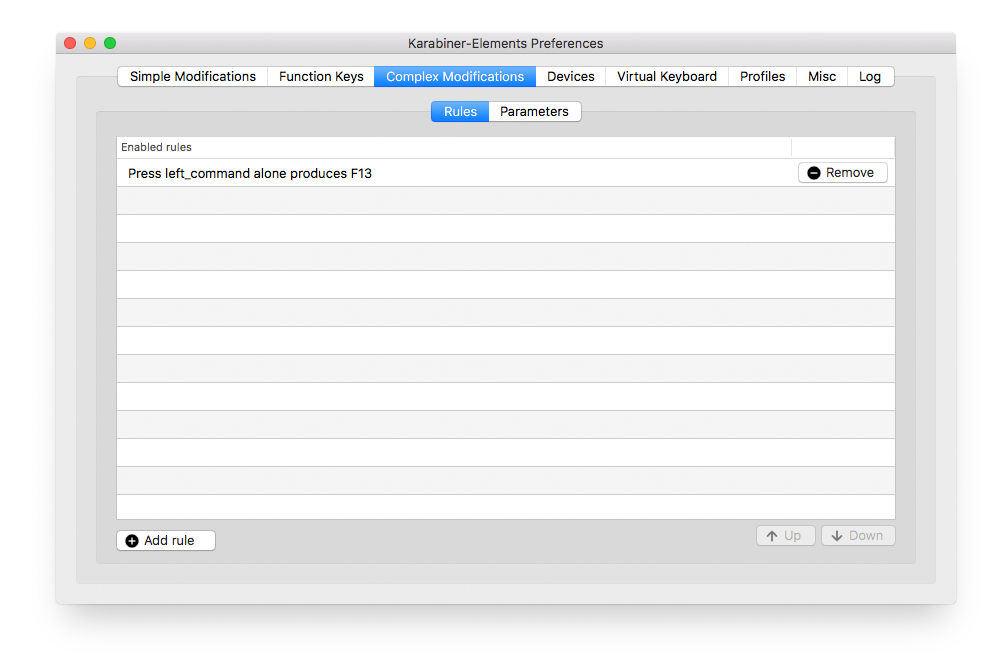
我的配置方法是使用 Complex Modifications 因为它允许我把修饰键改成其它按钮功能。在这里我将其改为一个没用的键位(f13 - PrtSc),因为 Spotlight 不接受单独的修饰键,所以只能这样区线救国了
然后在系统偏好设置 - 键盘 - 快捷键 中将 Spotlight 设置成 F13
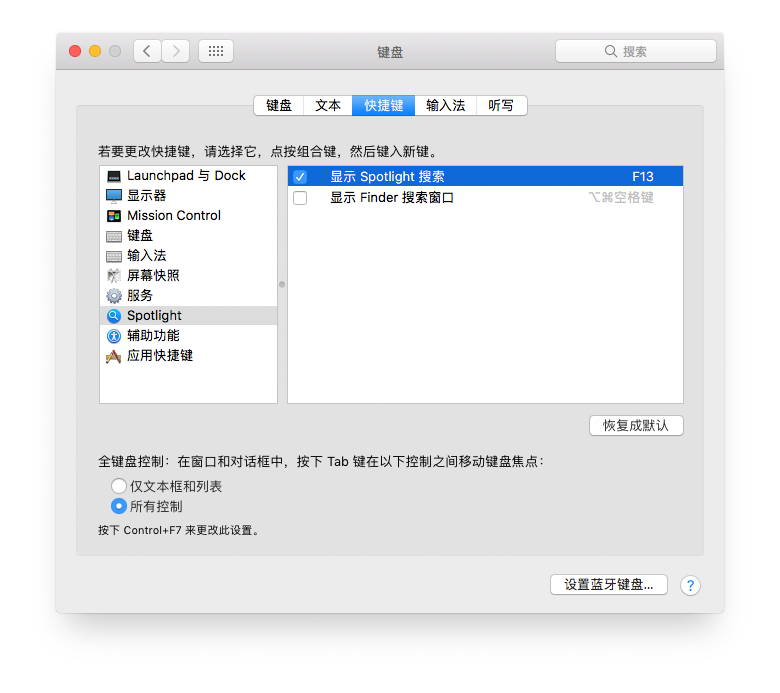
注意:默认的 Complex Modifications 里面是空的,需要你手动导入一个叫 Tapping modifier-keys produces a f-key.。然后我们 enable 这条:Press left_command alone produces F14,噫~我们是要 map 成 F13 这里默认的是 F14,怎么改下呢。改配置文件吧,打开下面这个文件:
vim ~/.config/karabiner/karabiner.json
将里面的 F14 改成 F13 即可:
// ...
"complex_modifications": {
"parameters": {
"basic.to_if_alone_timeout_milliseconds": 600
},
"rules": [
{
"description": "Press left_command alone produces F14",
"manipulators": [
{
"from": {
"key_code": "left_command",
"modifiers": { "optional": [ "any" ] }
},
"to": [ { "key_code": "left_command" } ],
"to_if_alone": [ { "key_code": "f14" } ],
"type": "basic"
}
]
}
]
}
这样基本上的完成我的需求了,打开应用只需要按一次 ⌘ 即可呼出 Spotlight,像打开 Google Chrome 只需要两个键即可 ⌘ g、Webstorm ⌘ w、Firefox ⌘ f ...
备注:我用的机器是 Mac mini 主机 + filco 87 键盘
1970-01-01 08:00:00
通常我们在用 JavaScript 操作 DOM 元素的时候会往 DOM 上临时添加一些参数,用来记住一些状态,或者从后端取参数值等
一般通过在 HTML 标签上添加自定义属性来实现,但是这样会不可避免的访问 DOM,性能上并不好。如果你使用 jQuery 的话建议使用 $el.data() 方法来取元素上 data-* 的值,比如:
<div id="demo" data-key="value"></div>
<script>
$('#demo').attr('data-key')
$('#demo').data('key') // 第一次访问 DOM,以后从缓存取
</script>
这两个方法的区别在于 attr 每次都会直接访问 DOM 元素,而 data 方法会缓存第一次的查找,后续调用不需要访问 DOM
很明显建议使用后者,但是在 低版本的 jQuery 中默认会对 data 方法取到的值进行粗暴的强制数据类型转换「parseFloat」。看下面代码
<div id="demo0" data-key="abc">字符串</div>
<div id="demo1" data-key="123">数字</div>
<div id="demo2" data-key="123e456">科学计数法</div>
<div id="demo3" data-key="0000123">八进制数字</div>
<script src="jquery-1.6.4"></script>
<script>
$('#demo0').data('key') // "abc"
$('#demo1').data('key') // 123
$('#demo2').data('key') // Infinity
$('#demo3').data('key') // 83
</script>
后面两种显然出错了,就是因为 jQuery 对属性值进行了强制 parseFloat 操作。这种转换是方便了使用者,如果是数字的话我们取到这个值进行计算什么的就不用再转数据类型了,但是一不小心就会出 bug
发现这个 bug 的时候第一感觉是 jQuery 不应该没考虑到这一点呀。后来果断去查了下最新版的 jQuery 源代码,发现已经修复了。核心代码在 data.js 35 行,如下
function getData( data ) {
if ( data === "true" ) {
return true;
}
if ( data === "false" ) {
return false;
}
if ( data === "null" ) {
return null;
}
// Only convert to a number if it doesn't change the string
// 重点就在这里 →_→
if ( data === +data + "" ) {
return +data;
}
if ( rbrace.test( data ) ) {
return JSON.parse( data );
}
return data;
}
getData 方法就返回了节点属性的值,只不过加了一些特殊处理使得我们取到了没有 bug 的值,关键地方就在这里: data === +data + "" 。这行代码做了些什么神奇的事情
将节点的属性值强制转换成数字「+data」后再转成字符串「+ ""」,如果转换后的值与原来相等就取转换后的值
可以简单的这么理解:jQuery 会尝试转换数据类型,如果转换后和转换前的 长得一样 那么 jQuery 就认为它是需要被转换成数字的。这样就可以完美规避上面例子中的两种问题,我们来测试一下
var data = 'abc'
console.log(data === +data + "") // false 不转换,直接返回字符串原值
var data = '123'
console.log(data === +data + "") // true 转换,使用转换后的数字类型值
var data = '123e456'
console.log(data === +data + "") // false 不转换,直接返回字符串原值
var data = '0000123'
console.log(data === +data + "") // false 不转换,直接返回字符串原值
1970-01-01 08:00:00
到你的项目根目录生成一个 package.json 文件,如果没有使用 yarn init -y 来自动生成
ESLint 默认的 parser 是 esprima,如果你需要检查 Babel 转义的 JSX 等文件那可以选择安装 babel-eslint
yarn init -y
yarn global add eslint
使用 sublime text 3 配置 eslint 来做代码检查
SublimeLinter 是一个代码检查框架插件,功能非常强大,支持各种语言的检查。但是它本身并没有代码检查的功能,需要借助 ESLint 这样的特定语言检查支持。我们只需要使用对应的 SublimeLinter-contrib-eslint 插件即可
在 Sublime text 中 Ctrl + Shift + p > Package Control:Install Package 里面搜索关键词 linter,注意别选成了 SummitLinter。然后再搜索 eslint 找到 SublimeLinter-contrib-eslint 安装(不得不吐槽下 Sublime package 搜索匹配让人无法理解)
到项目根目录下面使用 eslint 命令交互式的生成配置文件。这里 ESLint 会让你确认项目的配置项目,包括代码风格、目标文件等。我一般选择 Answer questions about your style,即通过选择性的回答命令行中的问题让 ESLint 生成适合我项目的配置文件
生成的配置文件我一般选择 JavaScript 因为这样比较方便写注释。我的配置项大概如下:
How would you like to configure ESLint?
Answer questions about your style
Are you using ECMAScript 6 features? No
Where will your code run? Browser
Do you use CommonJS? No
Do you use JSX? No
What style of indentation do you use? Spaces
What quotes do you use for strings? Single
What line endings do you use? Unix
Do you require semicolons? No
What format do you want your config file to be in? JavaScript
生成的配置文件竟然是这样的:
module.exports = {
"env": {
"browser": true
},
"extends": "eslint:recommended",
"rules": {
"indent": [
"error",
4
],
"linebreak-style": [
"error",
"unix"
],
"quotes": [
"error",
"single"
],
"semi": [
"error",
"never"
]
}
}; // Do you require semicolons? No !!!
上面的 extends 设置成 eslint:recommended 表示在 ESLint 规则页面 中标记成 「✔」 的项都开启检测
打开项目中任意一个 JavaScript 文件,右键 SublimeLint > Lint this view 来试试检查当前文件,如果有错误,编辑器会展示对应 Gutter 错误行和信息。可以使用 SublimeLint > Show all errors 来查看所有的错误
上个图吧
1970-01-01 08:00:00
由于博客主题使用了 Google fonts PT Serif 字体,国内只能通过中科大的代理来使用 Google fonts 字体。然而最近发现其速度不稳定,响应时间有时候甚至超过 600ms。刚好因为自己有 vultr 的 VPS(带小尾巴) 就自己动手搭了个来用
VPS 环境如下:
如果之前编译安装没开启相关模块的话需要重新编译,大概参数如下:
./configure --prefix=/usr/local/nginx --with-http_ssl_module --with-openssl=/usr/local/ssl --with-http_v2_module --with-http_sub_module
编译完没有出错的话就 make && make install 就 OK 了
upstream google {
server fonts.googleapis.com:80;
}
upstream gstatic {
server fonts.gstatic.com:80;
}
proxy_temp_path /your/path/tmp 1 2;
proxy_cache_path /your/path/cache levels=1:2 keys_zone=cache1:100m inactive=30d max_size=1g;
server {
listen 80;
server_name your.proxy.domain;
root /your/path/;
location /css {
sub_filter 'fonts.gstatic.com' 'your.proxy.domain';
sub_filter_once off;
sub_filter_types text/css;
proxy_pass_header Server;
proxy_set_header Host fonts.googleapis.com;
proxy_set_header Accept-Encoding '';
proxy_redirect off;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Scheme $scheme;
proxy_pass http://google;
proxy_cache cache1;
proxy_cache_key $host$uri$is_args$args;
proxy_cache_valid 200 304 10m;
expires 365d;
}
location / {
proxy_pass_header Server;
proxy_set_header Host fonts.gstatic.com;
proxy_redirect off;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Scheme $scheme;
proxy_pass http://gstatic;
proxy_cache cache1;
proxy_cache_key $host$uri$is_args$args;
proxy_cache_valid 200 304 10m;
expires 365d;
}
}
首先你得有个免费的 HTTPS 证书,这个可以参考我之前的文章:免费 Https 证书(Let'S Encrypt)申请与配置
注意设置 sub_filter 字段的时候 你的域名要加上 https://,要不然会出现代理的 CSS 文件中的字体文件引用是 HTTP 而请求报 blocked/mixed-content 错
server {
listen 443 ssl http2;
ssl on;
ssl_certificate /etc/letsencrypt/live/your.proxy.domain/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/your.proxy.domain/privkey.pem;
ssl_dhparam /etc/ssl/certs/dhparams.pem;
ssl_protocols SSLv3 TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers HIGH:!aNULL:!MD5;
server_name your.proxy.domain;
root /var/sites/fonts/;
location /css {
sub_filter 'http://fonts.gstatic.com' 'https://your.proxy.domain';
sub_filter_once off;
sub_filter_types text/css;
proxy_pass_header Server;
proxy_set_header Host fonts.googleapis.com;
proxy_set_header Accept-Encoding '';
proxy_redirect off;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Scheme $scheme;
proxy_pass http://google;
proxy_cache cache1;
proxy_cache_key $host$uri$is_args$args;
proxy_cache_valid 200 304 10m;
expires 365d;
}
location / {
proxy_pass_header Server;
proxy_set_header Host fonts.gstatic.com;
proxy_redirect off;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Scheme $scheme;
proxy_pass http://gstatic;
proxy_cache cache1;
proxy_cache_key $host$uri$is_args$args;
proxy_cache_valid 200 304 10m;
expires 365d;
}
}
如果不共享给其它人用的话还需要在配置中加入 referer 白名单判断,不符合条件的将返回 403
valid_referers server_name *.your.domain.com *.other.domain.com;
if ($invalid_referer) {
return 403;
}
1970-01-01 08:00:00
集合运算符
| 运算符 | 含义 | 英文 |
|---|---|---|
| $∪$ | 并 | Union |
| $−$ | 差 | Difference |
| $∩$ | 交 | Intersection |
| $×$ | 笛卡尔积 | Cartesian Product |
比较运算符
| 运算符 | 含义 |
|---|---|
| $>$ | 大于 |
| $≥$ | 大于等于 |
| $<$ | 小于 |
| $≤$ | 小于等于 |
| $=$ | 等于 |
| $≠$ | 不等于 |
专门的关系运算符
| 运算符 | 含义 | 英文 |
|---|---|---|
| $σ$ | 选择 | Selection |
| $π$ | 投影 | Projection |
| $⋈$ | 链接 | Join |
| $÷$ | 除 | Division |
逻辑运算符
| 运算符 | 含义 |
|---|---|
| $∧$ | 与 |
| $∨$ | 或 |
| $¬$ | 非 |
关系 R 与 S 具有相同的关系模式,即 R 与 S 的元数相同(结构相同),R 与 S 的并是属于 R 或 属于 S 的元组构成的集合,记作 R ∪ S,定义如下:
关系 R 与 S 具有相同的关系模式,关系 R 与 S 的差是属于 R 且 不属于 S 的元组构成的集合,记作 R − S,定义如下:
两个无数分别为 n 目和 m 目的关系 R 和 S 的 笛卡尔积是一个 (n+m) 列的元组的集合。组的前 n 列是关系 R 的一个元组,后 m 列是关系 S 的一个元组,记作 R × S,定义如下:
$(t^n,t^m)$ 表示元素 $t^n$ 和 $t^m$ 拼接成的一个元组
投影运算是从关系的垂直方向进行运算,在关系 R 中选出若干属性列 A 组成新的关系,记作 $π_A(R)$,其形式如下:
选择运算是从关系的水平方向进行运算,是从关系 R 中选择满足给定条件的元组,记作 $σ_F(R)$,其形式如下:
设有关系 R、S 如图所示,求 $R∪S$、 $R−S$、 $R×S$、 $π_{A,C}(R)$、 $σ_{A>B}(R)$ 和 $σ_{3<4}(R×S)$
进行并、差运算后结果如下:
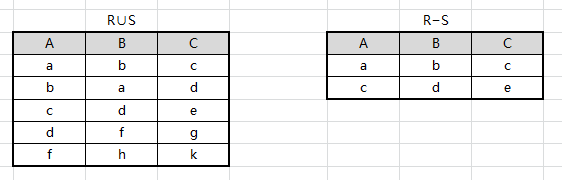
进行笛卡尔、 投影、 选择运算后结果如下:
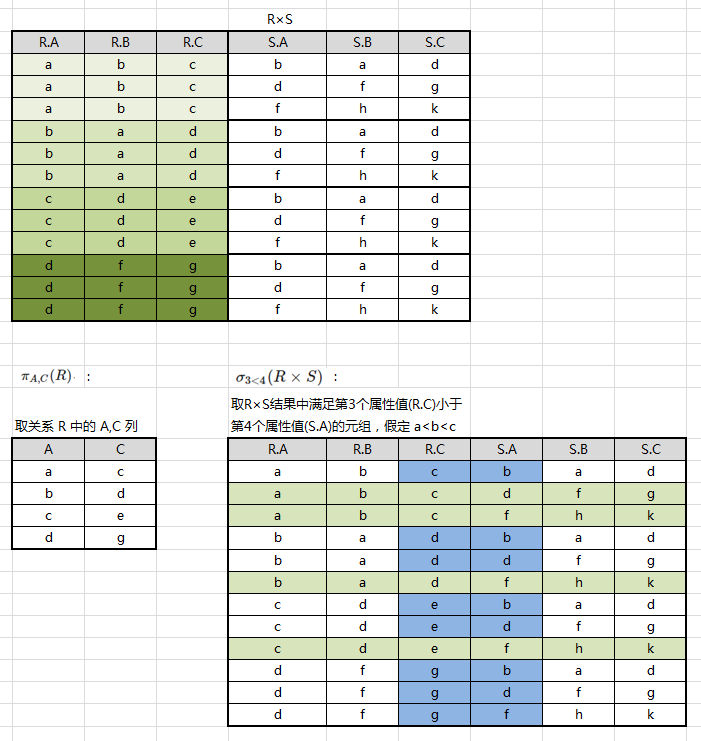
关系 R 和 S 具有相同的关系模式,交是由属于 R 同时双属于 S 的元组构成的集合,记作 R∩S,形式如下:
注:下面的 θ 链接应该记作:
从 R 与 S的笛卡尔积中选取属性间满足一定条件的元组,可由基本的关系运算笛卡尔积和选取运算导出,表示为:
XθY 为链接的条件,θ 是比较运算符,X 和 Y 分别为 R 和 S 上度数相等且可比的属性组
例如:求 $R \Join_{R.A<S.B} S$,如果为:
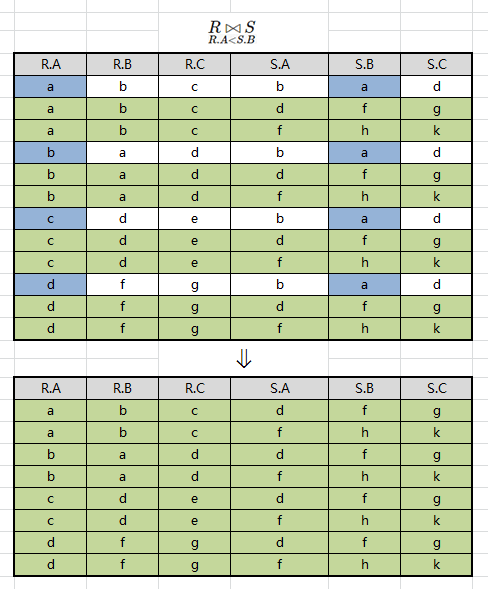
当 θ 为「=」时,称之为等值链接,记为: $R\Join_{X=Y}S$
自然链接是一种特殊的等值链接,它要求两个关系中进行比较的分量必须是 相同的属性组,并且在结果集中将 重复的属性列 去掉
例如:设有关系 R、S 如图所示,求 $R \Join S$
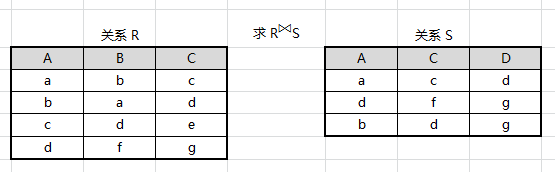
先求出笛卡尔积 $R×S$,找出比较分量(有相同属性组),即: R.A/S.A 与 R.C/S.C
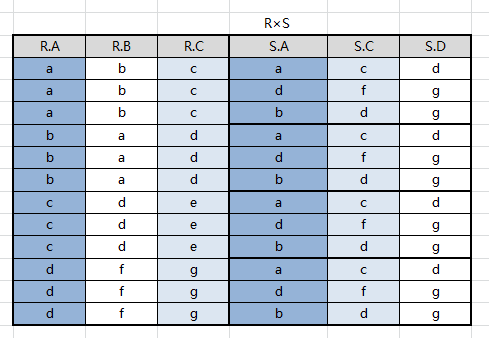
取等值链接 $R.A = S.A$ 且 $R.C = S.C$
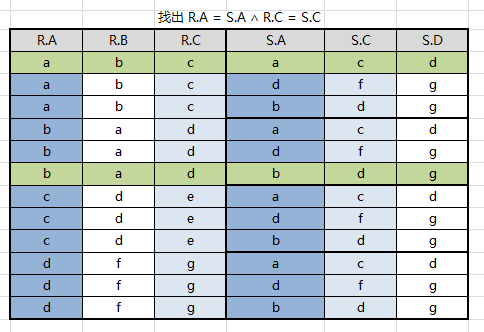
结果集中去掉重复属性列,注意无论去掉 R.A 或者 S.A 效果都一样,因为他们的值相等,结果集中只会有属性 A、B、C、D
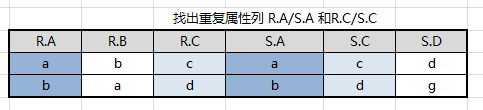
最终得出结果
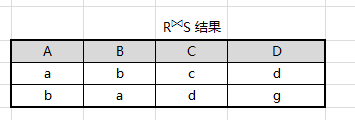
设有以下如图关系,求 $R÷S$
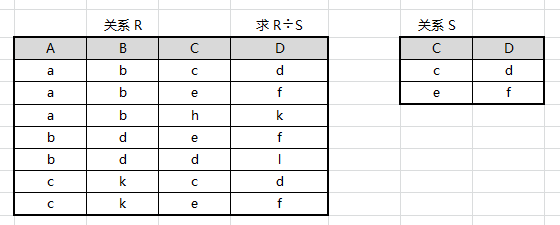
取关系 R 中有的但 S 中没有的属性组,即:A、B

取唯一 A、B 属性组值的象集
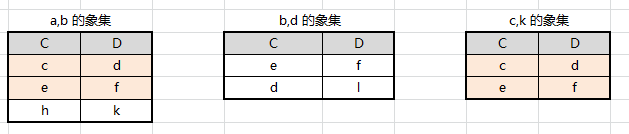
可知关系S存在于 a,b/c,k 象集 中。即 $R÷S$ 得
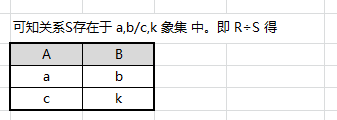
1970-01-01 08:00:00
这个问题来源于选择商品属性的场景。比如我们买衣服、鞋子这类物件,一般都需要我们选择合适的颜色、尺码等属性
先了解一下 sku 的学术概念吧
最小库存管理单元(Stock Keeping Unit, SKU)是一个会计学名词,定义为库存管理中的最小可用单元,例如纺织品中一个SKU通常表示规格、颜色、款式,而在连锁零售门店中有时称单品为一个SKU。最小库存管理单元可以区分不同商品销售的最小单元,是科学管理商品的采购、销售、物流和财务管理以及POS和MIS系统的数据统计的需求,通常对应一个管理信息系统的编码。 —— form wikipedia 最小存货单位
简单的结合上面的实例来说: sku 就是你上购物网站买到的最终商品,对应的上图中已选择的属性是:颜色 黑色 - 尺码 37
我先看看后端数据结构一般是这样的,一个线性数组,每个元素是一个描述当前 sku 的 map,比如:
[
{ "颜色": "红", "尺码": "大", "型号": "A", "skuId": "3158054" },
{ "颜色": "白", "尺码": "中", "型号": "B", "skuId": "3133859" },
{ "颜色": "蓝", "尺码": "小", "型号": "C", "skuId": "3516833" }
]
前端展示的时候显然需要 group 一下,按不同的属性分组,目的就是让用户按属性的维度去选择,group 后的数据大概是这样的:
{
"颜色": ["红", "白", "蓝"],
"尺码": ["大", "中", "小"],
"型号": ["A", "B", "C"]
}
对应的在网页上大概是这样的 UI

这个时候,就会有一个问题,这些元子属性能组成的集合(用户的选择路径) 远远大于 真正可以组成的集合,比如上面的属性集合可以组合成一个 笛卡尔积,即。可以组合成以下序列:
[
["红", "大", "A"], // ✔
["红", "大", "B"],
["红", "大", "C"],
["红", "中", "A"],
["红", "中", "B"],
["红", "中", "C"],
["红", "小", "A"],
["红", "小", "B"],
["红", "小", "C"],
["白", "大", "A"],
["白", "大", "B"],
["白", "大", "C"],
["白", "中", "A"],
["白", "中", "B"], // ✔
["白", "中", "C"],
["白", "小", "A"],
["白", "小", "B"],
["白", "小", "C"],
["蓝", "大", "A"],
["蓝", "大", "B"],
["蓝", "大", "C"],
["蓝", "中", "A"],
["蓝", "中", "B"],
["蓝", "中", "C"],
["蓝", "小", "A"],
["蓝", "小", "B"],
["蓝", "小", "C"] // ✔
]
根据公式可以知道,一个由 3 个元素,每个元素是有 3 个元素的子集构成的集合,能组成的笛卡尔积一共有 3 的 3 次幂,也就是 27 种,然而源数据只可以形成 3 种组合
这种情况下最好能提前判断出来不可选的路径并置灰,告诉用户,否则会造成误解
看下图,如果我们定义红色为当前选中的商品的属性,即当前选中商品为 红-大-A,这个时候如何确认其它非已选属性是否可以组成可选路径?

规则是这样的: 假设当前用户想选 白-大-A,刚好这个选择路径是不存在的,那么我们就把 白 置灰

以此类推,如果要确认 蓝 属性是否可用,需要查找 蓝-大-A 路径是否存在
...
根据上面的逻辑代码实现思路就有了:
"白", "蓝", "中", "小", "B", "C"
"颜色", "尺码", "型号"
看来问题似乎已经解决了,然而 ...
我们忽略了一个非常重要的问题:上例中虽然 白 元素置灰,但是实际上 白 是可以被点击的!因为用户可以选择 白-中-B 路径
如果用户点击了 白 情况就变得复杂了很多,我们假设用户 只选择了一个元素 白,此时如何判断其它未选元素是否可选?

即:如何确定 "大", "中", "小", "A", "B", "C" 需要置灰? 注意我们并不需要确认 "红","蓝" 是否可选,因为属性里面的元素都是 单选,当前的属性里任何元素都可选的
我们先 缩小问题范围:当前情况下(只有一个 白 已选)如何确定尺码 "大" 需要置灰? 你可能会想到根据我们之间的逻辑,需要分别查找:
他们都不存在的时候把尺码 大 置灰,问题似乎也可以解决。其实这样是不对的,因为 型号没有被选择过,所以只需要知道 白-大是否可选即可
同时还有一个问题,如果已选的个数不确定而且维度可以增加到不确定呢?
这种情况下如果还按之前的算法,即使实现也非常复杂。这时候就要考虑换一种思维方式
之前我们都是反向思考,找出不可选应该置灰的元素。我们现在正向的考虑,如何确定属性是否可选。而且多维的情况下用户可以跳着选。比如:用户选了两个元素 白,B
 图1
图1
我们再回过头来看下 原始存在的数据
[
{ "颜色": "红", "尺码": "大", "型号": "A", "skuId": "3158054" },
{ "颜色": "白", "尺码": "中", "型号": "B", "skuId": "3133859" },
{ "颜色": "蓝", "尺码": "小", "型号": "C", "skuId": "3516833" }
]
// 即
[
[ "红", "大", "A" ], // 存在
[ "白", "中", "B" ], // 存在
[ "蓝", "小", "C" ] // 存在
]
显然:如果第一条数据 "红", "大", "A" 存在,那么下面这些子组合 肯定都存在:
同理:如果第二条数据 "白", "中", "B" 存在,那么下面这些子组合 肯定都存在:
...
我们提前把 所有存在的路径中的子组合 算出来,算法上叫取集合所有子集,数学上叫 幂集, 形成一个所有存在的路径表,算法如下:
/**
* 取得集合的所有子集「幂集」
arr = [1,2,3]
i = 0, ps = [[]]:
j = 0; j < ps.length => j < 1:
i=0, j=0 ps.push(ps[0].concat(arr[0])) => ps.push([].concat(1)) => [1]
ps = [[], [1]]
i = 1, ps = [[], [1]] :
j = 0; j < ps.length => j < 2
i=1, j=0 ps.push(ps[0].concat(arr[1])) => ps.push([].concat(2)) => [2]
i=1, j=1 ps.push(ps[1].concat(arr[1])) => ps.push([1].concat(2)) => [1,2]
ps = [[], [1], [2], [1,2]]
i = 2, ps = [[], [1], [2], [1,2]]
j = 0; j < ps.length => j < 4
i=2, j=0 ps.push(ps[0].concat(arr[2])) => ps.push([3]) => [3]
i=2, j=1 ps.push(ps[1].concat(arr[2])) => ps.push([1, 3]) => [1, 3]
i=2, j=2 ps.push(ps[2].concat(arr[2])) => ps.push([2, 3]) => [2, 3]
i=2, j=3 ps.push(ps[3].concat(arr[2])) => ps.push([2, 3]) => [1, 2, 3]
ps = [[], [1], [2], [1,2], [3], [1, 3], [2, 3], [1, 2, 3]]
*/
function powerset(arr) {
var ps = [[]];
for (var i=0; i < arr.length; i++) {
for (var j = 0, len = ps.length; j < len; j++) {
ps.push(ps[j].concat(arr[i]));
}
}
return ps;
}
有了这个存在的子集集合,再回头看 图1 举例:
图1
红 可选? 只需要确定 红-B 可选中 可选? 需要确定 白-中-B 可选2G 可选? 需要确定 白-B-2G 可选算法描述如下:
以最开始的后端数据为例,生成的所有可选路径表如下: 注意路径用分割符号「-」分开是为了查找路径时方便,不用遍历
{
"": {
"skus": ["3158054", "3133859", "3516833"]
},
"红": {
"skus": ["3158054"]
},
"大": {
"skus": ["3158054"]
},
"红-大": {
"skus": ["3158054"]
},
"A": {
"skus": ["3158054"]
},
"红-A": {
"skus": ["3158054"]
},
"大-A": {
"skus": ["3158054"]
},
"红-大-A": {
"skus": ["3158054"]
},
"白": {
"skus": ["3133859"]
},
"中": {
"skus": ["3133859"]
},
"白-中": {
"skus": ["3133859"]
},
"B": {
"skus": ["3133859"]
},
"白-B": {
"skus": ["3133859"]
},
"中-B": {
"skus": ["3133859"]
},
"白-中-B": {
"skus": ["3133859"]
},
"蓝": {
"skus": ["3516833"]
},
"小": {
"skus": ["3516833"]
},
"蓝-小": {
"skus": ["3516833"]
},
"C": {
"skus": ["3516833"]
},
"蓝-C": {
"skus": ["3516833"]
},
"小-C": {
"skus": ["3516833"]
},
"蓝-小-C": {
"skus": ["3516833"]
}
}
为了更清楚的说明这个算法,再上一张图来解释下吧:
所以根据上面的逻辑得出,计算状态后的界面应该是这样的:
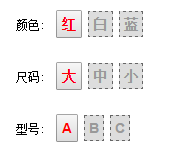
现在这种情况下如果用户点击 尺码 中 应该怎么交互呢?
因为当前情况下路径 红-中-A 并不存在,如果点击 中,那么除了尺码 中 之外其它的属性中 至少有一个 属性和 中 的路径搭配是不存在的
交互方面需求是:如果不存在就高亮当前属性行,使用户必须选择到可以和 中 组合存在的属性。而且用户之间选择过的属性要做一次缓存
所以当点击不存在的属性时交互流程是这样的:
这个过程的流程图大概是这样的,点进不存在的属性就会进入「单选流程」
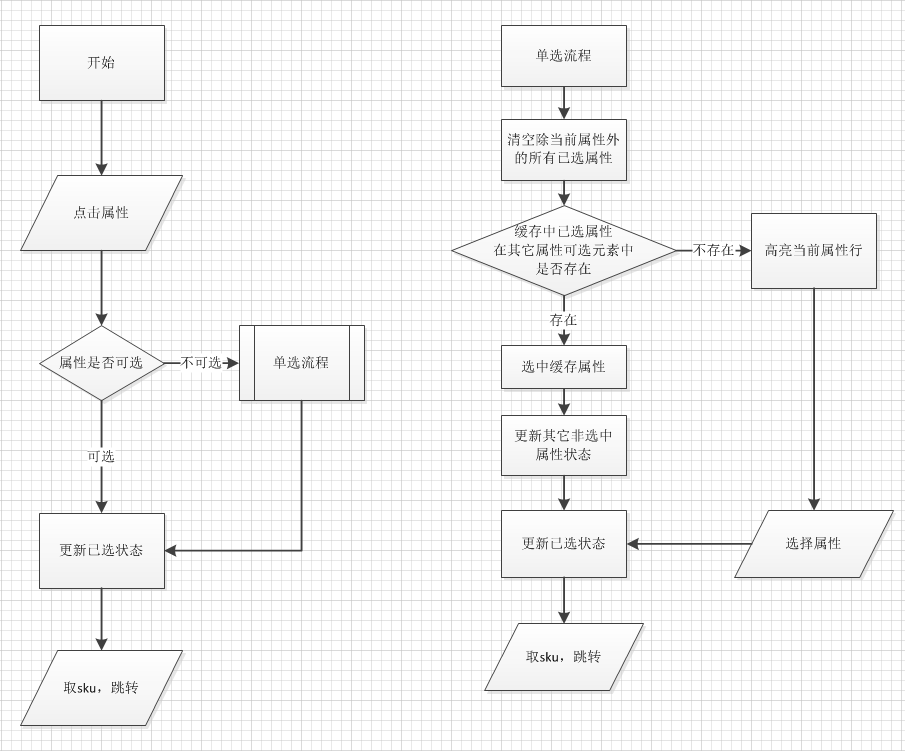
假设后端数据是这样的:
[
{ "颜色": "红", "尺码": "大", "型号": "A", "skuId": "3158054" },
{ "颜色": "白", "尺码": "大", "型号": "A", "skuId": "3158054" }, // 多加了一条
{ "颜色": "白", "尺码": "中", "型号": "B", "skuId": "3133859" },
{ "颜色": "蓝", "尺码": "小", "型号": "C", "skuId": "3516833" }
]
当前选中状态是:白-大-A
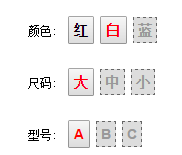
如果用户点击 中。这个时候 白-中 是存在的,但是 中-A 并不存在,所以保留颜色 白,高亮型号属性行:

由此可见和 白-中 能搭配存在型号只有 B,而缓存的作用就是为了少让用户选一次颜色 白
到这里,基本上主要的功能就实现了。比如库存逻辑处理方式也和不存属性一样,就不再赘述。唯一需要注意的地方是求幂集的复杂度问题
幂集算法的时间复杂度是 O(2^n),也就是说每条数据上面的属性(维度)越多,复杂度越高。sku 数据的多少并不重要,因为是常数级的线性增长,而维度是指数级的增长
{1} 2^1 = 2
=> {},{1}
{1,2} 2^2 = 4
=> {},{1},{2},{1,2}
{1,2,3} 2^3 = 8
=> {},{1},{2},{3},{1,2},{1,3},{2,3},{1,2,3}
...
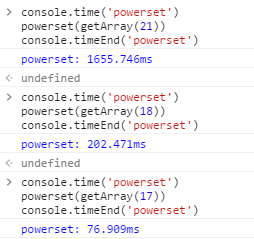
在 chrome 里面简单跑了几个用例,可见这个算法非常低效,如果要使用这个算法,必须控制维度在合理范围内,而且不仅仅算法时间复杂度很高,生成最后的路径表也会非常大,相应的占用内存也很高。
举个例子:如果有一个 10 维的 sku,那么最终生成的路径表会有 2^10 个(1024) key/value
最终 demo 可以查看这个: sku 多维属性状态判断
相关资料: sku组合查询算法探索
1970-01-01 08:00:00
TrimPath 是一款轻量级的前端 JavaScript 模板引擎,语法类似 FreeMarker, Velocity,主要用于方便地渲染 json 数据
表达式和修饰符(其它模板语言中叫做过滤器 filter)中间用 | 分割且 不能有空格
${expr}
${expr|modifier}
${expr|modifier1:arg1,arg2|modifier2:arg1,arg2|...|modifierN:arg1,arg2}
{if testExpr}
{elseif testExpr}
{else}
{/if}
{for varName in listExpr}
{/for}
{for varName in listExpr}
...循环主体...
{forelse}
...当 listExpr 是 null 或者 length 为 0 ...
{/for}
变量声明语句用花括号 {} 括起来,不需要关闭。类似 JavaScript 中的赋值语句
{var varName}
{var varName = varInitExpr}
{macro macroName(arg1, arg2, ...argN)}
...macro 主体...
{/macro}
CDATA 部分用来告诉模板引擎不用做任何解析渲染,直接输出。比如展示一个模板字符串本身
{cdata}
${customer.firstName} ${customer.lastName}
{/cdata}
eval blocks 用来执行 JavaScript 代码片段
{eval}
...模板渲染的时候执行的 JavaScript 代码...
{/eval
minify blocks 用来压缩内容中的换行符,比如压缩 HTML 属性
<div id="commentPanel" style="{minify}
display:none;
margin: 1em;
border: 1px solid #333;
background: #eee;
padding: 1em;
{/minify}">
...
</div>
修饰符用来处理上一个表达式的结果,并输出内容。类似于 Linux shell 中的管道操作符,使用「|」分割不同修饰符,可以串联使用
${name|capitalize}
${name|default:"noname"|capitalize}
自定义修饰符可以挂载到 contextObject 上的 _MODIFIERS 属性上
var Modifiers = {
toFixed: function(value, num) {
return value.toFixed(num)
}
}
var out = '${num|toFixed:2}'.process({
_MODIFIERS: Modifiers,
num: 1024
})
// => "1024.00"
macro 一般用来封装可复用 HTML 模板,类似函数的功能。对于每个模板来说 macro 是私用的。如果想公用 macro,可以保存 macro 引用到 contextObject 上(下次调用 process() 方法的时候再手动挂载上!? )。需要在调用 process() 方法之前给 contextObject 设置一个空的 exported 属性:contextObject['exported'] = {}
这个公用的 macro 设计的有点奇葩,可以参考这个 示例
{macro link(href, name)}
<a href="${href}">${name}</a>
{/macro}
${link('http://google.com', 'google')} => <a href="http://google.com">google</a>
${link('http://facebook.com', 'facebook')} => <a href="http://facebook.com">facebook</a>
var data = {
name: 'iPhone 6 Plus',
weight: 480,
ram: '16gb',
networks: [
'移动(TD-LTE)',
'联通(TD-LTE)',
'电信(FDD-LTE)'
]
}
data._MODIFIERS = {
toFixed: function(n, num) {
return n.toFixed(num)
}
}
var template = '\
名称: ${name}<br>\
重量:${weight|toFixed:2}<br>\
内存:${ram|capitalize}<br>\
网络:\
{for item in networks}\
{if item_index!=0}|{/if}\
${item}\
{/for}';
template.process(data)
上面的代码输出:
名称: iPhone 6 Plus<br>
重量:480.00<br>
内存:16GB<br>
网络:
移动(TD-LTE)
| 联通(TD-LTE)
| 电信(FDD-LTE)
1970-01-01 08:00:00
本文首发于 infoQ 及「前端之巅」微信公众号(微信群直播记录),感谢 infoQ 前端之巅尾尾同学对文章的整理和校对、微信群直播的组织策划。「前端之巅」是个非常棒的前端知识分享平台,想了解最前沿的前端知识资讯果断关注吧
通常在一个大型的 Web 项目中有很多监控,比如后端的服务 API 监控,接口存活、调用、延迟等监控,这些一般都用来监控后台接口数据层面的信息。而且对于大型网站系统来说,从后端服务到前台展示会有很多层:内网 VIP、CDN 等。但是这些监控并不能准确地反应用户看到的前端页面状态,比如:页面第三方系统数据调用失败,模块加载异常,数据不正确,空白开天窗等。这时候就需要从前端 DOM 展示的角度去分析和收集用户真正看到的东西,从而检测出页面是否出现异常问题
页面通常出现以下问题时需要使用邮件、短信通知相关人员修复问题
触发报警时要有现场快照,以便复现问题
监控的意义和回归测试的在本质上是一致的,都是对已上线功能进行回归测试,但不同的是监控需要做长期的可持续可循环的回归测试,而测试仅仅需要在上线之后做一次回归
既然监控和测试的本质一致,那我们完全可以采用测试的方式来做监控系统。在自动化测试技术遍地开花的时代,不乏很多好用的自动化工具,我们只需要把这些自动化工具进行整合为我们所用即可
NodeJS 是一个 JavaScript 运行环境,非阻塞 I/O 和异步、事件驱动,这几点对于我们构建基于 DOM 元素的监控是非常重要的
PhantomJS 是一个基于 webkit 的浏览器引擎,可以使用 JavaScript API 来模拟浏览器的操作。它使用 QtWebKit 作为它的浏览器核心,使用 webkit 来编译解释执行 JavaScript 代码。也就是说任何你可以在 webkit 浏览器里做的事情,它都能做到
它不仅是个隐形的浏览器,提供了诸如 CSS 选择器、支持 Web 标准、DOM 操作、JSON、HTML5、Canvas、SVG 等,同时也提供了处理文件 I/O 的操作等。PhantomJS 的用处可谓非常广泛,诸如网络监测、网页截屏、无浏览器的 Web 测试、页面访问自动化等
为什么不是 Selenium
做自动化测试的同学肯定都知道 Selenium。可以使用 Selenium 将测试用例在浏览器中执行,而且 Selenium 对各种平台和常见浏览器支持比较好,但是 Selenium 上手难度系数略高,而且使用Selenium 需要在服务器端安装浏览器
考虑到监控主要任务在监控不在测试。系统并不需要太多考虑兼容性,而且监控功能相对单一,主要对页面进行功能上的回归测试,所以选择了 PhantomJS

对于 DOM 监控服务,在应用层面上进行了垂直划分:
在应用层面上进行的垂直划分可以对应用做分布式部署,提高处理能力。后期也方便做性能优化、系统改造扩展等
这是一个独立的 Web 系统,系统主要用来收集用户录入的页面信息、页面对应的规则、展示错误信息。通过调用后端页面抓取服务来完成页面检测的任务,系统可以创建三种类型的检测页面:常规监控、高级监控、可用性监控
录入一个页面地址,和若干检测规则。注意这里的检测规则,我们把常用的一些检测点抽象成了一条类似测试用例的语句。每条规则用来匹配页面上的一个 DOM 元素,用 DOM 元素的属性来和预期做匹配,如果匹配失败系统就会产生一条错误信息,后续交由报警系统处理
匹配类型 一般有这么几种:长度、文本、HTML、属性
处理器 类似编程语言中的操作符:大于、大于等于、小于、小于等于、等于、正则
这样做的处就是,录入规则的人只要了解一点 DOM 选择器的知识就可以上手操作了,在我们内部通常是交由测试工程师统一完成规则的录入

主要用来提供高级页面测试的功能,一般由有经验的工程师来撰写测试用例。这个测试用例写起来会有一些学习成本,但是可以模拟 Web 页面操作,如:点击、鼠标移动等事件从而做到精确捕捉页面信息

可用性监控侧重于对页面的可访问性、内容正确性等比较 严重的问题 做即时监控。通常这类页面我们只需要在程序里面启一个 Worker 不断的去获取页面 HTML 就可以对结果进行检测匹配了,所以我们选择了 NodeJS 来做异步的页面抓取队列,高效快速的完成这种网络密集型任务

页面引入一段监控脚本来收集页面产成 error 事件返回的错误信息,自动上报给后端服务,在系统里面可以汇总所有报错信息,以及对应的客户端浏览器版本、操作系统、IP 地址等
这个功能需要对应的前端工程师在代码中调用错误上报 API,来主动提交错误信息。主要使用的场景有,页面异步服务延时无响应、模块降级兜底主动通知等。监控脚本提供几个简单的 API 来完成这项任务
// error 方法调用后立即上报错误信息并发出邮件、短信通知
errorTracker.error('错误描述')
// info 方法调用后立即上报信息,并在单位时间内仅产生一条邮件、短信通知
errorTracker.info('信息描述')
// log 方法调用后由报错检测是否达到设置阀值,最终确认是否报错
errorTracker.log('日志信息')
由于京东很多页面内容是异步加载的,像首页、单品等系统有许多第三方异步接口调用,使用后端程序抓取到的页面数据是同步的,并不能取到动态的 JavaScript 渲染的内容,所以就必须使用像 PhantomJS 这种能模拟浏览器的工具
常规监控我们使用 PhantomJS 模拟浏览器打开页面进行抓取,然后将监控规则解析成 JavaScript 代码片段执行并收集结果
高级监控我们使用 PhantomJS 打开页面后向页面注入像 jasmine, mocha 等类似的前端 JavaScript 测试框架,然后在页面执行对应的录入测试用例并返回结果
规则队列生成器会将采集的规则转化类成消息队列,然后交由长时持续处理器一次处理
为什么采用类消息队列的处理方式?
这和 PhantomJS 的性能是密不可分的,由多次实践发现,PhantomJS 并不能很好地进行并发处理,当并发过多,会导致 CPU 过载,从而导致机器宕机
在本机环境下的虚拟机中进行并发测试,数据并不理想,极限基本在 ab -n 100 -c 50 左右。 所以为了防止并发导致的问题,就选择了使用类消息队列来避免因为并发过高导致的服务不可用
我们这里通过调用内部的分布式缓存系统生成类消息队列,队列的生成其实可以参考数据结构--队列。最基本的模型就是在缓存中创建一个 KEY ,然后根据队列数据结构的模式进行数据的插入和读取
当然,类消息队列的中间介质可根据你实际的条件来选择,你也可以使用本机内存实现。这可能会导致应用和类消息队列竞争内存
长时持续处理器是要功能就是消费规则队列生成器生成的类消息队列
在长时持续处理器的具体实现中,我们利用了 JavaScript 的 setInterval 方法来持续获取累消息队列的内容下发给规则转化器,然后转发给负载均衡调度器。之后再对返回的结果进行统一处理,比如邮件或者短信报警
PhantomJS 服务可以做为公共 API 提供给客户端进行测试需求的处理, API 通过 HTTP 方式调用。在 API 的处理上需要提供 HTTP 数据到规则和 PhantomJS 的转换。从而又演化出了 HTTP 数据到规则转换器
PhantomJS 服务是指将 PhantomJS 结合 HTTP 服务和子进程进行服务化的处理
首先、启动 HTTP 服务,然后将长时处理器下发的规则进行进一步转化,转化后启动子进程,HTTP 服务会监听子进程的处理结果,并在处理完毕之后返回
报警系统我们目前使用的是京东内部自己的统一监控平台 UMP,通过调用平台提供的一些 API 来实现报警邮件与短信通知
用户通过监控管理系统录入规则后,监控系统会根据 UMP 规则针对用户录入的页面生成 UMP 使用的 key。当长时持续处理器发现 PhantomJS 服务返回的结果标示为异常后,就会使用 key 来进行日志记录
报警主要分为了短信和邮件报警。邮件报警是在每条异常之后就会发给指定系统用户。短信则是根据异常次数来进行处理的,当异常次数过大,就会下发短信通知
对于系统部署可以分为两大块进行。因为机器资源数量有限,没有将所有部分都单独部署
规则管理系统以及规则队列生成器和持续处理器整合部署在一台机器上,PhantomJS 服务部署在了其他的机器上。进程管理使用了著名的 NPM 模块 —— PM2
PM2 是一个带有负载均衡功能的 NodeJS 应用的进程管理器。可充分利用 CPU,并保证进程稳定存活
PM2 特性:
不过在目前部署任务中,并没有使用内建负载均衡的特性,没用通过集群的方式部署代理。仅使用了后台运行和无缝重启的特性
其实我们现在开发的这套监控系统并不复杂,只是合理的运用了一些现有的技术框架。抽象出来我们自己需要的一些功能。但却有效的达到了我们的预期功能,并且节省了很多之前需要人肉测试的时间成本。系统本身还有很多问题在待解决状态,比如报警系统的规则处理与阀值设定,JavaScript 报错的准确过滤机制等,这些问题我们都会逐个解决,并且未来的前端监控系统会成为一个平台,核心服务在后端爬取页面服务,应用端可以有多种形式,比如监控、测试工具等
一些可以持续优化点:
1970-01-01 08:00:00
自从新博客建立以来一直用 Octopress 这个博客框架来搭建静态文章页面。漂亮的默认主题、方便的发布到 github page 等功能吸引了我
但就在最近因为家里的用 Macbook,刚好升级到了新版的 Sierria,杯具的是之前安装的 Octopress bundle 都失效了。调试了很久还没把环境搭建好,再加上之前发现 Octopress 的 Markdown 解析器老报错,于是就决定要更换一个配置安装简单点的博客生成器了
在参考了这个网站上的各种生成器后 staticgen,果断选择了 Hugo。没有什么特殊原因,下载安装试用一下就明白了。Hugo 由于是 Go 语言写的,所以你只需要下载好官方给的二进制可执行文件就可以了,再也不用安装各种依赖,然后各种换源什么的乱折腾了。这一点就足以让我转入 Hugo
由于自己还是比较喜欢 Octopress 默认的这套主题,所以在读过 Hugo 开发文档后,在严格尊重原主题的原则下修改了部分增强样式,制做了一个适配 Hugo 的 Octopress 主题。虽然 Hugo 官方有一个适配 Octopress 的主题 hugo-octopress 但是对原主题改动太多,我并不喜欢
Octopress 使用的文章描述头是 yaml 格式的,需要转换成 Hugo 的 toml,自己手动写了个 NodeJS 脚本 来完成这个工作,基本上很轻松就完成了。注意:建议放在 content/archives 目录下面,这样的话原来的文件目录和新的就是一致的了
再吐槽下 md 文件名,Octopress 默认是生成时间为前缀的,如:2016-06-13-name.markdown。 如果转移到 Hugo 永久链接还要保持原来文件名格式的话就得把这个前缀干掉(name.md),这样的话排序就乱了。在各种编辑器、文件夹中不按创建顺序排序,看起来很别扭也不方便
考虑到之间已经写过很多文章了,搜索引擎都已收录,所以要保持原来的文章链接格式不变。在 Hugo 配置文件里面加上这段,使用文件名做文章永久链接:
[permalinks]
archives = "/:year/:month/:day/:filename/"
Octopress 默认的存档地址是 archives,这个我们可以直接在 Hugo 博客目录 content 里面新建一个目录名为 archives 就可以了,以后新建文章都以这个 Section 为准:hugo new archives/your-post-name.md
Octopress 默认的是 atom.xml,然而 Hugo 中默认的是 index.xml。不过我们可以在 Hugo 中做个配置,和之间保持一致:
RSSUri = "atom.xml"
然而实际测试的时候在模板里面调用 {{ .RSSlink }} 始终都返回 index.xml。手动把模板里面的 RSS 链接改成 {{ .Site.BaseURL }}atom.xml 居然能生效?!这估计是 Hugo 的一个 bug。好在被发现了,要不然新老订阅 RSS 地址不一样事情就比较麻烦了
Octopress 默认的格式是 posts/2,Hugo 中是 posts/2 同样需要加个配置:
paginatePath = "posts"
这几个概念主要在修改主题的时候能用到
类似 markdown 文件的配置描述,用来配置文章的标题、时间、链接、分类等元信息,提供给模板调用
+++
title = "post title"
description = "description."
date = "2012-04-06"
tags = [ ".vimrc", "plugins", "spf13-vim", "vim" ]
categories = [
"cat1",
"cat2"
]
+++
在 content 下面的一级目录,通常有分类的概念,但只是文件夹维度的物理隔离
如果没有为文章指定 type 配置,文章默认就属于当前属的 Section,type 可以在 Front Matter 中指定,而 Section 不可以
新建文章时候的默认模板,会带有指定的 Front Matter 头
分类、标签、系列这种描述文章属性的都属于 Taxonomy Terms
Hugo 确实是一个不错的博客框架,配置简单、功能强大,很多东西都以「惯例」默认提供了,比如内置 TableOfContents,用来写博客足亦
不过由于是 Go 语言写的,很多人并不知道有这么好用的一个东西,所以社区并不是很好。这可能就是所谓的编程的帮派论吧
1970-01-01 08:00:00
Macbook 电源用的时候久了,接口里面的几个针脚弹性变差,有时候接通电源然而灯不能亮
在网上搜索了下发现一个好方法:接电源那头是突出金属的,稍微打磨下去一点就可以了,亲测有效
PS: 如果没有打磨工具可以直接找个空地面磨,有条件的话磨完再用砂纸抛光下就可以了
来两张图片看看
 
1970-01-01 08:00:00
JavaScript 程序采用了异步事件驱动编程(Event-driven programming)模型,维基百科对它的解释是:
事件驱动程序设计(英语:Event-driven programming)是一种电脑程序设计模型。这种模型的程序运行流程是由用户的动作(如鼠标的按键,键盘的按键动作)或者是由其他程序的消息来决定的。相对于批处理程序设计(batch programming)而言,程序运行的流程是由程序员来决定。批量的程序设计在初级程序设计教学课程上是一种方式。然而,事件驱动程序设计这种设计模型是在交互程序(Interactive program)的情况下孕育而生的
简页言之,在 web 前端编程里面 JavaScript 通过浏览器提供的事件模型 API 和用户交互,接收用户的输入
由于用户的行为是不确定的,也就是说不知道用户什么时候发生点击、滚动这些动作。这种场景是传统的同步编程模型没法解决的,因为你不可能等用户操作完了才执行后面的代码
比如我们在 Python 里面调用接收用户输入的方法 raw_input() 后终端就会一直等待用户的输入,直到输入完成才会执行后面的代码逻辑。但是在下面这段 NodeJS 代码中,接收用户输入的方法 process.stdin.read 是在一个事件中调用的。后面的代码不会被阻塞(blocked)
'use strict';
process.stdin.on('readable', () => {
var chunk = process.stdin.read();
if (chunk !== null) {
process.stdout.write(`Async output data: ${chunk}`);
}
});
process.stdin.on('end', () => {
process.stdout.write('end');
});
console.log('Will not be blocked');
事件驱动程序模型基本的实现原理基本上都是使用 事件循环(Event Loop),这部分内容涉及浏览器事件模型、回调原理,有兴趣的去看链接里面的视频学习下
需要说明的是在客户端 JavaScript 中像 setTimeout, XMLHTTPRequest 这类 API 并不是 JavaScript 语言本身就有的。而是 JavaScript 的宿主环境(在客户端 JavaScript 中就是浏览器),同样像 DOM、BOM、Event API 都是浏览器提供的
直接在 DOM 元素上通过设置 on + eventType 来绑定事件处理程序
<a href="#none" onclick="alert('clicked.')">点击我</a>
这种绑定方法是最原始的,有两个缺点:
1 事件处理程序和 HTML 结构混杂在一起
早期在结构、样式、表现分离的时代很忌讳这一点。现在看来在很多 MVX 框架中将事件绑定和 DOM 结构放在一起处理,这样似乎更方便维护(不用来回切换 HTML,JavaScript 文件),而且也符合可预见(predictable)性的规则
2 命名空间冲突
因为 onclick 中的 JavaScript 代码片段执行环境是全局作用域。然而在 JavaScript 语言中并没有相关的命名空间特性。所以就很容易造成命名空间的冲突,非要用这种方法绑定事件的话只能用对象来做一些封装
使用 DOM Element 上面的 on + eventType 属性 API
<a href="#none" id="button">click me</a>
<script>
var el = getElementById('button');
el.onclick = function() { alert('button clicked.') };
el.onclick = function() { alert('button clicked (Rewrite event handler before).') };
</script>
这种方法也有一个缺点,因为属性赋值会覆盖原值的。所以无法绑定 多个 事件处理函数,如果我们要注册多个 onload 事件处理程序的话就得自己封装一个方法来防止这种事情发生,下面这个例子可以解决这个问题
function addLoadEvent(fn) {
var oldonLoad = window.onload;
if (typeof oldonLoad !== 'function') {
window.onload = fn;
} else {
window.onload = function() {
oldonLoad();
fn();
}
}
}
addLoadEvent(function() { alert('onload 1') });
addLoadEvent(function() { alert('onload 2') });
注意这只是个示例,生产环境很少会用到。一般用 DOM Ready 就可以了,因为 JavaScript 的执行通常不用等到页面资源全部加载完,DOM 加载完就可以了
标准的绑定方法有两种,addEventListener 和 attachEvent 前者是标准浏览器支持的 API,后者是 IE 8 以下浏览器支持的 API。通常需要我们做个兼容封装
function addEvent(target, type, handler) {
if (target.addEventListener) {
target.addEventListener(type, handler, false);
} else {
target.attachEvent('on' + type, handler)
}
}
addEvent(document, 'click', function() { alert(this === document) });
addEvent(document, 'click', function() { alert(this === document) });
上面的例子在 IE 8 以下和标准浏览器的效果是不一样的,问题就在于 addEventListener 中的事件回调函数中的 this 指向元素(target)本身,而 attachEvent 则指向 window 为了修复这个问题上面的 attachEvent 可以做一点小调整让其保持和 addEventListener 的效果一样,不过这样的话注册的 handler 就是个匿名函数,无法移除!
function addEvent(target, type, handler) {
if (target.addEventListener) {
target.addEventListener(type, handler, false);
} else {
target.attachEvent('on' + type, function() {
return handler.call(target)
});
}
}
addEvent(document, 'click', function() { alert(this === document) });
当上面这几种情况同时出现的时候就比较有意思了,可以试试下面这段代码的你输出
<a href="javascript:alert(1)" onclick="alert(2)" id="link">click me</a>
<script>
var link = document.getElementById('link');
link.onclick = function() { alert(3); }
$('#link').bind('click', function() { alert(4); });
$('#link').bind('click', function() { alert(5); });
</script>
正确的结果应该是 3,4,5,1,根据结果我们可以得出以下结论:
大部分事件会沿着事件触发的目标元素往上传播。比如:body>div>p>span 如果他们都注册了点击事件,那么在 span 元素上触发点击事件后 p,div,body 各自的点击事件也会按顺序触发
事件冒泡是可以被停止的,下面这个函数封闭了停止事件冒泡的方法:
function stopPropagation(event) {
event = event || window.event;
if (event.stopPropagation) {
event.stopPropagation()
} else {// IE
event.cancelBubble = true
}
}
addEvent('ele', 'click', function(e) {
// click handler
stopPropagation(e);
});
标准浏览器中在事件处理程序被调用时 事件对象 会通过参数传递给处理程序,IE 8 及以下浏览器中事件对象可以通过全局的 window.event 来访问。比如我们要获取当前点击的 DOM Element
addEvent(document, 'click', function(event) {
// IE 8 以下 => undefined
console.log(event);
});
addEvent(document, 'click', function(event) {
event = event || window.event;
// 标准浏览器 => [object HTMLHtmlElement]
// IE 8 以下 => undefined
console.log(event.target);
var target = event.target || event.srcElement;
console.log(target.tagName);
});
有时候我们需要给 不存在的(可能将来会有)的一段 DOM 元素绑定事件,比如给一段 Ajax 请求完成后渲染的 DOM 节点绑定事件。一般绑定的逻辑会在渲染前执行,绑定的时候找不到元素所以并不能成功,当然你也可以把绑定事件的代码放在 Ajax 请求之后。这样做在一些事件逻辑简单的应用里面没问题,但是会加重数据渲染逻辑和事件处理的逻辑耦合。一但事件处理程序特别多的时候,我们通常建议把事件的逻辑和其它代码逻辑分离,这样方便维护。
为了解决这个问题,我们通常使用事件代理/委托(Event Delegation )。而且通常来说使用 事件代理的性能会比单独绑定事件高 很多,我们来看个例子
<ul id="list">
<li id="item-1">item1</li>
<li id="item-2">item2</li>
<li id="item-3">item3</li>
<li id="item-4">item4</li>
<li id="item-5">item5</li>
</ul>
假如 ul 中的 HTML 是 Ajax 异步插入的,通常我们的做法是 插入完成后遍历每个 li 绑定事件处理程序
<ul id="list"></ul>
<script>
function bindEvent(el, n) {
addEvent(lis[i], 'click', function() { console.log(i); });
}
// 用 setTimeout 模拟 Ajax 伪代码
setTimeout(function() {
var ajaxData = '<li id="item-1">item1</li> <li id="item-2">item2</li> <li id="item-3">item3</li> <li id="item-4">item4</li> <li id="item-5">item5</li>';
var ul = document.getElementById('list')
ul.innerHTML(ajaxData);
var lis = ul.getElementsByTagName('li');
for (var i = 0; i < lis.length; i++) {
bindEvent(lis[i], i);
}
}, 1000);
</script>
我们再使用事件代理把事件绑定到 ul 元素上,我们知道很多事件可以冒并沿着 DOM 树传播到所有的父元素上,我们只需要判断目标元素是不是我们想绑定的真正元素即可
<ul id="list"></ul>
<script>
function delegateEvent(el, eventType, fn) {
addEvent(el, eventType, function(event) {
event = event || window.event;
var target = event.target || event.srcElement;
fn(target);
});
}
var el = document.getElementById('list');
// 用 setTimeout 模拟 Ajax 伪代码
setTimeout(function() {
var ajaxData = '<li id="item-1">item1</li> <li id="item-2">item2</li> <li id="item-3">item3</li> <li id="item-4">item4</li> <li id="item-5">item5</li>';
el.innerHTML(ajaxData)
}, 1000);
delegateEvent(el, 'click', function(target) {
console.log(target.id);
});
</script>
显然使用了事件代理之后,代码变少了。逻辑也很清晰,关键是以前需要 N 次的绑定操作现在只需要一次
以 jQuery1.6.4 为例,jQuery 提供了很多事件绑定的 API。例如: delegate(), bind(), click(), hover(), one(), live(),这些方法其实都是一些别名,核心是调用了 jQuery 底层事件的 jQuery.event.add 方法。其实现也是上文提到的 addEventListener 和 attachEvent 两个 API
这些 API 主要是为了方便绑定事件的各种场景,并且内部处理好了兼容性问题。还有一个比较好用的地方就是 事件命名空间。比如:两个弹出层都向 document 绑定了点击关闭事件,但是如果只想解绑其中一个。这时候使用命名空间再合适不过了。可以试试这个小例子 Event Binding
$(document).bind('click.handler1', function() { console.log(1);})
$(document).bind('click.handler2', function() { console.log(2);})
$(document).unbind('click.handler2'); // 解除指定的
$(document).unbind('click'); // 解除所有点击事件
$(document).unbind() // 解除所有事件
自定义事件是设计模式中的 发布/订阅者 的一种实现。发布者与订阅者松散地耦合,而且不需要关心对方的存在。这里有 NC 大师的一种实现。实际使用过程中,主要被运用在异步操作比较多的场景和不同系统之间消息通信,之前的文章中有过一些实例
1970-01-01 08:00:00
每个 Window 对象有一个 document 属性引用了 Document 对象。Document 对象表示窗口的内容,它是一个巨大的 API 中的核心对象,叫做文档对象模型(Document Obejct Model, DOM),用来展示和操作文档内容
HTML 或 XML 文档的嵌套元素在 DOM 中以「树」的形式展示。HTML 文档的树装结构包含表示 HTML 标签或元素(如 body, p)和表示文本字符串的节点,也可能包含表示 HTML 注释的节点
<html>
<head>
<title>Simple Document</title>
</head>
<body>
<h1>Heading</h1>
<p>This is a <i>paragraph</i></p>
</body>
</html>
置换成 DOM 树表示
+------------+
| Document |
+-----+------+
|
+-----+------+
| <html> |
+-----+------+
|
+--------------------+--------------------+
| |
+----+------+ +----+-----+
| <head> | | <body> |
+----+------+ +----+-----+
| |
+----+------+ +------------+------------+
| <title> | | |
+-----------+ +----+---+ +---------+
| <h1> | | <p> |
+------------------+ +--------+ +---------+
| "Simple Document"| |
+------------------+ +-----------+-----------+
| |
+------+--------+ +----+-----+
| "This is a" | | <i> |
+---------------+ +----+-----+
|
+----+------+
|"paragraph"|
+-----------+
上图中每个方框是文档的一个节点(node),它表示一个 Node 对象。注意树形的根部是 Document 节点,它代表整个文档。代表 HTML 元素的节点是 Element 节点。代表文本的节点是 Text 节点。Document、Element 和 Text 是 Node 的子类
HTML 元素可以有一个 id 属性,在文档中该值必须 唯一,可以使用 getElementById() 方法选取一个基于唯一 ID 的元素
var section1 = document.getElementById('selection1');
在低于 IE 8 版本的浏览器中,getElementById() 对匹配元素的 ID 不区分大小写,而且也返回匹配 name 属性的元素
var radiobuttons = document.getElementsByName('favorite_color');
getElementsByName() 定义在 HTMLDocument 类中,而不在 Document 类中,所以它 只针对 HTML 文档可用,XML 中不可用。它返回一个 NodeList 对象,后者的行为类似一个包含若干 Element 对象的只读数组。在 IE 中,也会返回 id 属性匹配指定的元素
// 返回所有的 span 标签元素
var spans = document.getElementsByTagName('span');
// 返回所有元素
var allTags = document.getElementsByTagName('*');
// 选取第一个 span 里面的所有 a 标签
// Element 类也定义 getElementsByTagName() 方法,
// 它只取调用该方法的元素(spans)的后代元素
var links = spans[0].getElementsByTagName('a');
HTMLDocument 对象还定义了两个属性,它们指代特殊的单个元素而不是集合:document.body 是一个 HTML 文档的
document.head 是 元素。这些属性总是会定义的。即使文档中没有 head 或 body 元素,浏览器也将隐式地创建他们
getElementsByName() 和 getElementsByTagName() 都返回 NodeList 对象,而类似 document.images 和 document.forms 的属性为 HTMLCollection 对象。 这些对象都是只读类数组对象。有 length 属性,也可以被索引到,也可以进行循环迭代
HTML 元素的 class 属性值是一个以空格隔开的列表,可以为空或者包含多个标识符
// 查找 class 属性追念 warning 的所有元素
var warnings = document.getElementsByClassName('warning')
注意除了 IE8 及以下低版本浏览器,getElementsByClassName() 在所有的浏览器中都实现了
CSS 样式表有一种非常强大的语法,那就是选择器,用来描述文档中的若干元素
#nav // id="nav" 的元素
div // 所有 <div> 元素
.warning // 所有 class 属性值包含 "warning" 的元素
p[lang="fr"] // 所有属性 lang 为 fr 的 <p> 元素
*[lang="fr"] // 所有属性 lang 为 fr 的元素
Document 对象、它的 Element 对象和文档中表示文本的 Text 对象都是 Node 对象。Node 对象有以下属性:
// 注意删除了空格和换行
// <html><head><title>Test</title></head><body>Hello World!</body></html>
document.childNodes[0].childNodes[1] // => body 节点
document.firstChild.firstChild.nextSibling // => null title 节点的下个兄弟节点为 null
HTML 元素由一个标签和一组称为属性(attribute)的名/值对组成
var image = document.getElementById('myimage');
var imgurl = image.src;
var f = document.forms[0];
f.action = 'http://www.example.com/submit.php';
f.method = 'POST';
HTML 属性名不区分大小写,但是 JavaScript 则区分。用 JavaScript 取元素属性名的时候一般用小写,如果属性名是多个单词用驼峰式的规则,例如:defaultChecked、tabIndex。如果属性是 JavaScript 中的保留字,一般用 html 前缀,比如 for 属性,使用 htmlFor 来访问。class 则不同,使用 className 来访问
var image = document.images[0];
// getAttribute 始终返回字符串
var width = parseInt(image.getAttribute('width'))
image.setAttribute('class', 'thumbnail)
有时候在 HTML 元素上绑定一些额外的信息会很有帮助(通常给 JavaScript 来读取),一般可以把信息存储在 HTML 属性上
HTML 5 提供了一个解决文案。在 HTML 5 文档中,任意以「data-」为前缀的小写的属性名称都是合法的。这些「数据集属性」将不会对元素表示产生影响
HTML 5 还在 Element 对象上定义了 dataset 属性。该属性指代一个对象,它的各个属性对应于去掉前缀的 data- 属性。因此 dataset.x 应该保存 data-x 属性的值。带连字符的属性对应于驼峰命名法属性名:data-jquery-test 属性就变成 dataset.jqueryTest 属性
读取 Element 的 innerHTML 属性作为字符串标记返回那个元素的内容。设置元素的 innerHTML 属性则调用 Web 浏览器的解析器,用新的字符串内容解析替换当前内容
通常来说设置 innerHTML 效率很高,但是对 innerHTML 属性使用「+=」操作符时效率比较低下,因为它既要序列化又要解析
HTML 5 还标准化了 outerHTML 属性,表示返回包含标签本身的 HTML 内容
另外 IE 引入了一个 insertAdjacentHTML() 方法,它将任意的 HTML 标记字符串插入到指定的元素「相邻」的位置。标记是该方法的第二个参数。并且「相邻」的精确含义依赖于第一个参数的值。第一个参数为具有以下值之一的字符串:「beforebegin」、「afterbegin」、「beforeend」、「afterend」
|<div id="target">|This is the element content|</div>|
| | | |
beforebegin afterbegin beforeend afterend
查询线文本形式的元素内容, 标准的方法是 Node 的 textContent 属性
var para = document.getElementsByTagName('p')[0]
var text = para.textContent;
para.textContent = 'Hello World!';
textContent 属性除 IE 其它浏览器都支持,不支持的可以用 innerText 属性来代替。textContent 属性就是将指定元素所有的后代 Text 节点简单地串联在一起。但是和 textContent 不同。innerText 不返回 script 元素的内容,它会忽略多余空白,并试图保留表格格式。同时 innerText 针对某些表格元素(如 table、tbody、tr)是只读的属性
function textContente(e) {
var child, type, s = '';
for (child = e.firstChild; child != null; child = child.nextSibling ) {
type = child.nodeType;
if ( type === 3 || type === 4 )
s += child.nodeValue;
else if ( type === 1 )
s += textContent(child);
}
return s;
}
一个简单的动态插入脚本的方法
function loadasyn(url) {
var head = document.getElementsByTagName('head')[0];
var s = document.createElement('script');
s.src = url;
head.appendChild(s);
}
document.createElement('script')
document.createTextNode('text node content')
还有一种创建新文档节点的方法是复制已存在的节点。第个节点有一个 cloneNode() 方法来返回该节点的一个全新副本。给方法传递参数 true 也能够递归地复制所有后代节点,或传递参数 false 只执行一个浅复制
下面代码展示了 insertBefore() 和 appendChild() 方法使用场景
function insertAt(parent, child, n) {
if ( n < 0 || n > parent.childNodes.length ) throw new Error('invalid index');
else if ( n == parent.childNodes.length ) parent.appendChild(child);
else parent.insertBefore(child, parent.childNodes[n]);
}
removeChild() 方法删除一个子节点并用一个新的节点取而代之
n.parentNode.removeChild(n);
n.parentNode.replaceChild(document.createTextNode('[ REDACTED ]'), n)
DocumentFragment 是一种特殊的 Node,它作为其他节点的一个临时窗口。像这样创建一个 DocumentFragment:
var frag = document.createDocumentFragment();
像 Document 节点一样,DocumentFragment 是独立的,而不是任何其他文档的一部分。它的 parentNode 总是 null。但类似 Element,它可以有任意多的子节点,可以用 appendChild()、insertBefore() 等方法来操作它们
元素的位置是以像素来表示的,向右代表 X 坐标增加,向下代表 Y 坐标增加。但是,有两个不同的点作为坐标系原点:元素的 X 和 Y 坐标可以相对于文档的左上角或者相对于在其中显示文档的视口左上角。在顶级窗口和标签页中,「视口」只是实际显示文档内容的浏览器的一部分:它 不包括 浏览器「外壳」(如菜单、工具条和标签页)。针对框架页中显示的文档,视口是定义了框架页的 iframe 元素。无论在何种情况下,当讨论元素的位置时,必须弄清楚所使用的坐标是文档坐标还是视口(窗口)坐标
如果文档比视口要小,或者说它还未出现滚动,则文档的左上角就是视口的左上角,文档和视口坐标系统是同一个。但是,一般来说,要在两种坐标系之间互相转换,必须加上或者减去滚动的偏移量(scroll offset)
为了在坐标系之间互相转换,我们需要判定浏览器窗口的流动条的位置。Window 对象的 pageXOffset 和 pageYOffset 属性在所有浏览器中提供这些值。除了 IE 8 以及更早的版本以外。也可以使用 scrollLeft 和 scrollTop 属性来获得滚动条的位置。令人迷惑的是,正常情况下通过查询文档的根节点(document.documentElement)来获取这些属性值,但在怪异模式下,必须在文档的 body 元素上查询它们,下面这个是一种兼容方法
function getScrollOffsets(w) {
w = w || window;
if ( w.pageXOffset != null ) return { x: w.pageXOffset, y: pageYOffset };
var d = w.document;
if ( document.compatMode == 'CSS1Compat' )
return { x: d.documentElement.scrollLeft, y: d.documentElement.scrollTop };
return { x: d.body.scrollLeft, y: d.body.scrollTop };
}
判定一个元素的尺寸和位置最简单的方法是调用它的 getBoundingClientRect() 方法。该方法是在 IE 5 中引入的,而珔当前的所有浏览器都实现了(然而并非如此)。它不需要参数,返回一个有 left, right, top 和 bottom 属性的对象
window 对象的 scrollTop() 方法接受一个点的 X 和 Y 坐标,并作为滚动条的偏移量设置它们。也就是窗口滚动到指定的点出现在视口的左上角
getBoundingClientRect() 方法在所有当前的浏览器上都有定义,但如果需要支持老式浏览器就不行了。元素的尺寸比较简单:任何 HTML 元素的只读属性 offsetWidth 和 offsetHeight 以 CSS 像素返回它的屏幕尺寸。返回尺寸 包含 元素的边框和内边距,除去了外边距
所有 HTML 元素拥有 offsetLeft 和 offsetTop 属性来返回元素的 X 和 Y 坐标。对于很多元素,这些值是文档坐标,并直接指定元素的位置。但对于已定位的元素的后代元素和一些其他元素(如表格),这些属性返回的坐标是相对于祖先元素的而非文档。 offsetParent 属性指定这些属性所相对的父元素。如果 offsetParent 为 null,这些属性都是文档坐标,因此,一般来说用 offsetLeft 和 offsetTop 来计算元素 e 的位置需要一个循环:
function getElementPosition(e) {
var x = 0, y = 0;
while (e != null) {
x += e.offsetLeft;
y += e.offsetTop;
e = e.offsetParent;
}
return { x: x, y: y };
}
除了这些名字以 offset 开头的属性外,所有的文档元素定义了其它的两组属性,基名称一组以 client 开头,另一组以 scroll 开头。即,每个 HTML 元素都有以下这些属性:
offsetWidth clientWidth scrollWidth
offsetHeight clientHeight scrollHeight
offsetLeft clientLeft scrollLeft
offsetTop clientTop scrollTop
offsetParent
clientWidth 和 clientHeight 类似 offsetWidth 和 offsetHeight,不同的是它们 不包含边框大小,只包含内容和它的内边距。同时,如果浏览器在内边距和边框之间添加了滚动条,clientWidth 和 clientHeight 在其返回值中也不包含滚动条。内联元素,clientWidth 和 clientHeight 总是返回 0
表 15-1 HTML 表单元素
| HTML 元素 | 类型属性 | 事件处理程序 | 描述和事件 |
|---|---|---|---|
| <input type="button"> or <button type="button"> |
“button” | onclick | 按钮 |
| <input type="checkbox"> | “checkbox” | onchange | 复选按钮 |
| <input type="file"> | “file” | onchange | 文件域,value 属性只读 |
| <input type="hidden"> | “hidden” | none | 数据由表单提交,但对用户不可见 |
| <option> | none | none | Select 对象的单个选项,事件对象 在 Select 对象上,而不是 option |
| <input type="password"> | “password” | onchange | 密码输出框,输入的字符不可见 |
| <input type="radio"> | “radio” | onchange | 单选按钮 |
| <input type="reset"> or <button type="reset"> |
“reset” | onclick | 重置表单按钮 |
| <select> | “select-one” | onchange | 单选下拉框 |
| <select multiple> | “select-multiple” | onchange | 多选列表 |
| <input type="submit"> or <button type="submit"> |
“submit” | onclick | 表单提交按钮 |
| <input type="text"> | “text” | onchange | 单行文本输出域;type 默认 text |
| <textarea> | “textarea” | onchange | 多行文本输入域 |
Select 元素表示用户可以做出选择的一组选项(用 Option 元素表示)。浏览器通常将其渲染为下拉菜单的形式,但当指定其 size 属性值大于 1 时,它将显示为列表中的选项(可能有滚动条)。Select 元素的 multiple 属性决定了 Select 是不是可以多选
当用户选取或取消一个选项时, Select 元素触发 onchange 事件。针对「select-one」属性的 Select 元素,它的可读/写属性 selectedIndex 指定了哪个选项当前被选中。针对「select-multiple」元素,单个 selectedIndex 属性不足以表示被选中的一组选项。这种情况下需要遍历 options[] 数组的元素,检测每个 Option 对象的 selected 属性。注意 Option 并没有相关事件处理程序,一般只能给 Select 元素绑定事件
document.write() 会将其字符串参数连接起来,然后将结果字符串插入到文档中调用它的脚本元素的位置。当脚本执行结束,浏览器解析生成输出并显示它。例如,下面代码把信息输出到一个静态的 HTML 文档中:
<script>
document.write('Document title: ' + document.title);
document.write('URL: ' + document.URL);
document.write('Referred by: ' + document.referrer);
</script>
只有在解析文档时才能使用 write() 方法输出 HTML 到当前文档中。也就是说能够在 script 元素的顶层代码中调用 document.write(),就是因为这些脚本的执行是文档解析流程的一部分。如果将 docuemnt.write() 放在一个函数的定义中,而该函数的调用是从一个事件处理程序中发起的,产生的结果未必是你想要的——事实上,它会擦除当前文档和它包含的脚本。同理,在设置了 defer 或 async 属性的脚本中不要使用 document.write()
1970-01-01 08:00:00
详情页也叫做单品页,域名以「item.jd.com/skuid.html」为格式的页面。是负责展示京东商品 SKU 的落地页。主要任务是展示和商品相关的信息,如:价格、促销、库存、推荐,从而引导用户进入购买流程。同时单品页有很多版本。一般分为两类。一类我们通常看到的「通用类目详情页」—— 所有类目都可以使用,一类是不经常看到的「垂直属性详情页」—— 一些有特殊属性的商品集合
首先。由于详情页大量(sku上亿)、高并发(日 pv 约 5000 万)等特性,在很长的一段时间里,单品页面都是后端程序生成静态页面使用 CDN 来解决大量、高并发的问题
其次。单品页涉及的「三方」系统特别多,比如:促销、库存、合约、秒杀、预售、推荐、IM、店铺、评价社区。而单品页的主要任务就是展示这些系统的信息,并且适当的处理他们之间的冲突关系,而这些系统的接口一般都使用 异步 Ajax 来完成,因为 其一 CDN 无法做到页面的动态化,其二 一些系统的信息对实时性要求特别高(价格、秒杀),即使使用后端动态渲染也很难做到无缓存 0 延迟
基于上面两个原因,注定了单品页是一种重多系统业务逻辑展示型页面。重前端页面。我大概汇总了一下页面上异步接口,总共约有 30 个,页首屏的接口特别重要,接口之间几乎都有耦合关系
混沌时期的单品页并没有前端开发的概念。核心的功能脚本只有三个:促销价格(promotion.js)、库存地区(iplocation.js)、其它逻辑(pshow.js)。这三个脚本分别是三个不同团队的同事负责维护,当时我刚进入京东的时候在 UED 部门,负责页面脚本整体的维护工作和 pshow的开发。那时候我自己维护的 pshow.js 脚本压缩后只有 80 kb,所有的代码都是过程式的,没有任何使用模式和代码技巧,JS 最多也只被用来做个判断渲染 DOM。那时候的前端工作内容只在 UI 层面,写样式和一些交互脚本
这个阶段给我最深刻的感觉是单品页后端模板很少维护(后端架构是最老的 aspx 版本)。大多数的改动都要用 JavaScript 去动态渲染。因为后端页面是一个生成器生成的。如果页面后端模板有改动那么就需要全量的生成一次,过程可能需要几个小时
当我接手这个项目时刚好有一次大改版,就在这时候老大说页面上的脚本都要放在我们手里维护。然后就是一大波的重构、重写。基本上 pshow 被重写了大概 80% 其它的因为业务逻辑的问题并没有完全重写,只是做了些代码层面的优化
有一个模板引擎叫 trimPath,知道这个的估计都算老前端的了。最早的客户端 JavaScript MVC 模式代表作品,只到现在还是使用。这个阶段像评价这种完全异步加载的模块特别适合使用模板引擎来减少维护的工作量。这个时候虽然页面上的代码并不都是我们写的,但基本上前端对页面的 JavaScript 有了控制权,接下来的事情就是寻找机会逐个优化
这段时间是最痛苦的时候,维护的工作统一到前端。然后后端几乎没有变化,只是在一段时间将后台的架构从 aspx 过渡到了 java。本质上并没有什么改变。前端却做了比以前更多的事情,也是在这个时候我接手了大量的维护工作(包含全站公共库的维护)使得我意识到了一些自动化、工程化方面的重要性,后文会主要讲解,顺便说下,那时候前端自动化工具 Grunt 刚面世,但是我自己却用的是 apache ant,不过不久就切换到了 Grunt 来构建项目
单品页不仅重系统逻辑,也重维护
在这段时间里一方面有正常的维护类需求要做,一方面自己也不断的学习新知识为以后的改版做铺垫。不过就在这时单品页有历史意义的一次技改出现了 —— 单品页动态化技改。关于后端部分的改造细节可以去 开涛的文章 了解
总的来说这次的改版后很多数据直接从后端读取,不再从前端异步获取而且我们也做过一些异步加载的优化,多接口 combo 从统一服务吐出给前端使用。这时前端就不用再为异步接口的加载时苦脑了,只需要专注系统接口的逻辑
随着这次技改,前端的代码也迎来了模块化的时代。我们把所有的前端代码都进行了模块化然后基于 SeaJS 重写,配合 Nginx concat 功能实现了本地模块化开发,线上服务端合并
上图可以看出,基本上最核心的模块都在首屏。每个模块都有单独的一/多个脚本。代码行数(LOC)由 230+ ~ 1200+ 不等。通常来说代码行数越多代码复杂性就越高,逻辑越复杂。很难想象「购买方式」这种只有一行属性选择功能的代码行数却 高达 1200 多行。其主要原因就在于购买方式所在的系统和其它首屏核心系统(库存、促销、地址选择、白条)都有逻辑上的耦合
看着不错,然而在一个前端工程师眼里至少应该是这样的(我只取了一些典型的模块,并不是全部):
这就可以解释为什么有的时候只是加一个很小的东西我们都为考虑再三然后通过 AB 测试提取相关数据,最后后再进行决策。单品页的首屏可以说是寸土寸金
起初我按模块的属性划分,比如:核心、公共脚本、模块脚本。但用了一段时候以后发现这样划分在单品这种大型系统中并不科学,因为这样划分出来的代码只有划分的人知道是什么规则,其它人接手代码很难快速掌握代码架构,而且尤其在模块比较多的时候不方便维护
后来我尝试完全以功能模块在页面上出现的位置维度划分。这样以来维护起来方便多了,需要修改某个模块代码只需要对照着图里面标识的模块信息就能轻易找到代码
我们按页面上的模块结构首屏划分出来这几个核心模块:
项目的整体树形结构是这样的:

比如下面这个大图预览的功能,我全部放在一个文件夹里面维护,但是逻辑上的 JavaScript 模块是分离的,只是说文件夹(preview)就代表页面上的某一部分功能集合
注意文件夹的命名有一定的规则:
我们再来看下自动生成生成的 __sprite.scss 是什么内容:
/* __sprite.scss 自动生成 */
@mixin sprite-arrow-next {
width: 22px;
height: 32px;
background-image: url(i/__sprite.png);
background-position: -0px -30px;
}
/* preview.scss 手动添加 */
@import "./__sprite";
.sprite-arrow-next {
@include sprite-arrow-next;
}
注意引用的 mixin 名称和我们需要手动添加的样式类名一致。当然也可以直接生成一个类名对应的样式,但是灵活性不好。比如 hover 的时候是另外一张图片就没法自动生成了
与重业务逻辑的页面不同,重展示的页面一般具有很高的 DOM 节点数。比如京东首页,正常情况加载完页面一共有 3500 多个 DOM 节点,基本上全部用于展示商品信息、广告图和内容布局,页面上的三方异步服务也比较少。尤其像频道页基本上没有什么业务上的逻辑,全部是静态页面。这种页面的特点是更新换代频率高,一年两三次改版很正常,CMS 做模块化后两天换个皮肤都是没问题的。但是这种思路并不适合单品页。单品页更重业务逻辑,同时展示层 UI 逻辑也有很多关系
我自己的经验是:页面上的 DOM 节点数绝对不能超过 5000 个,否则页面滚动的时候就会出现卡顿的情况,尤其是移动端
理论情况下最好做法是后端同步动态渲染页面,但是由于 Web 应用中很多功能都是用户行为驱动的。同步加载不可避免的消耗了后端服务资源。比如:非首屏模块(公共头尾、评价)、点击事件触发的 DOM 内容(异步 tab)
所以我的经验是:能放到后端做判断渲染的 DOM 就尽量放在后端(尤其是首屏)。这样做的好处有四点好处
对于异步渲染的模块来说,后端通常需要判断 「页面有什么元素」,以及元素之间的依赖对应关系;而前端需要专注于 「元素应该怎么展示」,UI 层面的交互以及模块与模块之前的逻辑关系
其实更多的时候 异步是一种没有办法的办法,也就是说异步是其它方案都解决不了的情况下才考虑的
尽量使用外链 CSS 和 JavaScript 资源,一方面便于缓存,减少服务同步输出的资源浪费。IE 6 里面会有一些可怪的 bug,比如有内联样式 style 标签的页面 A 如果在另外一个页面 B 中的 link 标签中引用,那么这段 style 会在 B 页面也起作用
使用 // 来代替http: 和 https: 浏览器会自动适应两种协议的资源访问,兼容性较好。注意 IE 8 下使用脚本更新 src 为双协议时会出现 bug,建议使用 location.protocol 来判断然后做兼容处理
比如 script 标签默认的 type 就是 text/javascript,如果 script 里面的内容是 JavaScript 时可以不用写 type。另外如果要在页面里面插入一段不需要浏览器解析的 HTML 片段时可以将 type 写成 text/x-template(任意不存在的 type) 用于放置模板文件,通常用来在脚本中获取其 innerHTML 而无任何负作用
在脚本中取页面元素使用 J- 前缀类名,与普通样式类分离。这样做会生成很多冗余的类名,但却很好的降低了样式和脚本的耦合,并且在重构和脚本职位分开团队里会是一条最佳实践
所有页面只共享一个 sass Mixin,里面包含了基础的 sass 语法糖、常用类(清浮动、页面整体颜色字体等)
模块级的样式分为两类:
关于雪碧图 我经验是:永远不要想把所有的图标拼合在一起。按模块而不是按页面去拼 sprite 更合理,更方便维护,然后配合构建工具自动接合生成样式文件才是最好的解决方案。当然如果你的页面比较简单,那这条规则并不适用。说到这个问题我就得把珍藏多年的图片拿出来 show 一把,用事实来说明为什么把所有图片都拼在一张图上就一定是对的
早期由于年轻笃信将所有的 icon 拼在一张图上才是完美的(图 1)
后来维护起来实在不方便,就把按钮全部单独接合起来。注意,当时的按钮都是图片,设计方面要求的很严格。加入购物车按钮做的也非常漂亮(图 2)

然后这些都不是最典型的,下面这个 promise icon 才是 (图 3)

从图里面可以看到,这个功能在第一个版本的时候只有 7 个 icon,后来不断增加,最多的时候达到 77 个。以至于当时每周都会添加两个的频率
同时这个 icon 当时接合的时候技术上也有问题:不应该把文字也切到图片里面,主要原因是早期 icon 比较少加上外边框样式对齐的问题综合选择了直接使用图片
后来我就觉得这样是不对的。然后通过和产品的沟通,说明我的考虑以及新的解决方案后得到了认同。结果就是对图片不进行拼合,后台上传经过审核的不带文字 icon,文字由接口输出,然后在产品上做了约定:icon 最多不能超过 4 个,代码里也做了相应限制。这样就能保证页面上的请求数不会太多同时方便系统维护,问题得到了解决
这个在一些小图片场景方面特别适合,比如 1*1 的占位图、loading 图等,不过 IE 6 并不支持这种写法,需要的时候可以加上一些兼容写法:
.ELazy-loading {
background: url(data:image/gif;base64,R0lGODlhKwAeAJEAAP///93d3Xq9VAAAACH/C05FVFNDQVBFMi4wAwEAAAAh+QQFFAAAACwDAA0AJQADAAACEpSPAhDtHxacqcr5Lm416f1hBQAh+QQJFAAAACwDAA0AJQADAAACFIyPAcLtDKKcMtn1Mt3RJpw53FYAACH5BAkUAAAALAMADQAlAAMAAAIUjI8BkL0CoxQtrYrenPjcrgDbVAAAOw==) center center no-repeat;
*background-image: url(//misc.360buyimg.com/lib/skin/e/i/loading-jd.gif);
}
兼容性可以说是前端工程师在平常开发中花费很大量无意义工作的地方。关于兼容性我想说的是 如果你不愿意去说服周围的人放弃或者让他们意识到兼容性是个不可能完全解决的问题,那么你就得为那些低级浏览器给你带来的痛苦埋单
其实更好的办法是你和设计、产品沟通然后给出一种分级支持的方案。把每种浏览器定义一个级别。然后在开发功能的时候以「渐进增强」的方式。通常来讲我们的解决方案是在低级浏览器里面保证流程正常进行、模块可以使用,但忽略一些无关紧要的错位、不透明等问题,在高级浏览器里面需要对设计稿进行精确还原,适当的加上一些井上添花在细节。比如微小的动画、逻辑细节上的处理等
举个例子吧,下面这个进度条表示预约的人数,它是接口异步加载完才展示的。如果加载完就立即设置进度条宽度会显得生硬无趣,但是如果加上一点动画效果的话就好多了。然而问题又来了,如果加上动画那么逻辑上这个进度条应该是一点点的增加,对应的人数也应该是逐个增加。于是我就做了个优化,让人数在这段时间内均匀的增加。这个细节并不是很容易被人发现,但是这种设计会让用户感觉很用心而且有意思
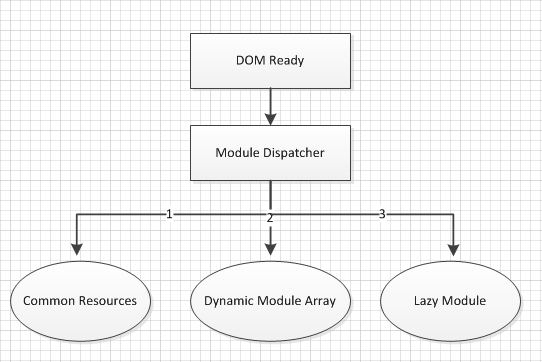
单品页的脚本加载/执行顺序:
require.async 方法异步调用大致代码如下
/**
* 模块入口(1. 公共脚本 2. 首屏模块资源 3. 非首屏「后加载模块」)
*/
var entries = [];
// 页面公共脚本样式
entries.push('common');
// 页面使用到的首屏模块(后端开发根据页面不同配置需要调用的模块)
entries = entries.concat(config.modules);
// 非首屏「后加载模块」
entries.push('lazyinit');
for (var i = 0; i < entries.length; i++) {
entries[i] = 'MOD_ROOT/' + entries[i] + '/' + entries[i];
}
if (/debug=show_modules/.test(location.href)) console.log(entries);
require.async(entries, function() {
var modules = Array.prototype.slice.call(arguments);
var len = modules.length;
for (var i = 0; i < len; i++) {
var module = modules[i];
if (module && typeof module.init === 'function') {
module.init(config);
} else {
console.warn('Module[%s] must be exports a init function.', entries[i]);
}
}
});
注意模块路径中的 MOD_ROOT 是提前在页面定义好的一个 seajs path。目的是为了把前端版本号更新的控制权释放给后端,从而解决了前后端依赖上线不同步造成的缓存延迟问题,配置脚本中只有几个定义好的路径:
seajs.config({
paths: {
'MISC' : '//misc.360buyimg.com',
'MOD_ROOT' : '//static.360buyimg.com/item/default/1.0.12/components',
'PLG_ROOT' : '//static.360buyimg.com/item/default/1.0.12/components/common/plugins',
'JDF_UI' : '//misc.360buyimg.com/jdf/1.0.0/ui',
'JDF_UNIT' : '//misc.360buyimg.com/jdf/1.0.0/unit'
}
});
还有一点,在测试环境的页面中版本号(上面代码中的 1.0.12 是一个全量的版本号)是后端从 URL 上动态读取的(使用参数访问就可以命中对应版本 item.jd.com/sku.html?version=1.0.12)。这样以来测试环境上就可以并行测试不同版本的需求,而且互不影响。当然如果不同版本的后端代码也有修改的话这样是不行的,因为后端代码也需要有个对应的版本号
不过我们已经解决了这个问题。后端会在测试环境里 动态加载后端模板 并且可以做到版本号与前端一致。这样以来配合 git 方便的分支策略就可以同时并行开发测试多个需求,不用单独配多个测试环境。什么?你还在使用 SVN!哦。那当我没说过
客户端的 JavaScript 代码基本上都是事件驱动的,代码的加载解析依赖于浏览器提供的 DOM 事件。比如 onload, mouseover, scroll 等
事件驱动的的模型特别适用于异步编程,而 JavaScript 天生就是异步,所有的异步操作行为都最终会在一个回调函数(callback)中触发
比如单品页中价格接口,加载完成后需要更新 DOM 元素来展示实时价格;地区选择接口加载完成后会更新配送信息、库存/商品状态等,伪代码如下:
/* onPriceReady 和 onAreaChange 可以认为都是一个 Ajax 异步函数调用
* code 1 和 code 2 执行到的时间是不确定先后顺序的
*/
/* prom.js */
onPriceReady(function(price) {
// code 1
$('#price').html(price);
});
/* address.js */
onAreaChange(function(area) {
// code 2
$('#stock').html(area.stockInfo);
});
上面的两段代码分别在两个脚本中维护,因为他们的逻辑相对独立。早期并没有关联关系。后来需求有变,他们之间需要共享一些对方的数据(切换地区后需要重新获取价格数据并展示)。但是物理上又不能放在一起通过使用全局变量的方式共享,而且它们都是异步加载接口后才取到数据的,并不好确定谁先谁后(非要做到那就只能用全局变量双向判断)。所以这样并不能很好的解决问题,而且代码的耦合度会成倍增加
这时候我们引入了一种设计模式来解决这种问题 —— 发布者/订阅者,我们把这种模式抽象成了自定义事件代码来解决这一问题。这段代码是由 YUI 核心开发者 Nicholas C. Zakas 实现的。代码很简单,事件对象主要有两个方法 addListener(type, listener) 和 fire(event)
于是我们重构了上面的伪代码:
/* prom.js */
// 在代码中注册一个地区变化事件,获取变化后的地区 id
// 然后重新请求价格接口并展示
Event.addListener('onAreaChange', function(data) {
getAreaPrice(data.areaIds)
});
onPriceReady(function(price) {
$('#price').html(price);
Event.fire({
type: 'onPriceReady',
data: 'Any data you want'
})
});
/* address.js */
onAreaChange(function(area) {
$('#stock').html(area.stockInfo);
// 在地区变化后除了做自己该做的事情以外
// 触发一个名为 onAreaChange 的事件,用来
// 通知其它订阅者事件完成,并传递地区相关参数
// 这个时候在 onAreaChange Ajax 回调函数
// 中就只需要关心自己的逻辑,其它模块的耦合关系
// 交给它们自己通过订阅事件来处理
Event.fire({
type: 'onAreaChange',
data: area.ids
})
});
需要注意的一点是,必须确保事件先注册后触发执行,也就是说先 addListener, 再 fire
基本上客户端的 JavaScript 性能问题都来自于 DOM 查找和遍历,在用于的时候一定要小心,可能不经意的一个操作就会损失很多性能,尤其在低端浏览器中。顺便多说一点,现代的 JavaScript 解释器本身是很快的,语言层面的性能问题很少遇到。DOM 查找慢是因为 浏览器给 JavaScript 访问页面提供的一套 DOM API 本身慢
find('li').find('a') 而是 find('li a')show()/hide() 方法,而不是 css('display', 'block/none') 前者有缓存,后者会强制触发 reflowdata-xx 属性在存放一些数据,通过使用 jQuery 的 data('xx') 方法取更高效,减少 DOM 属性访问前端工程化其实并不是最近两年才有的概念。大约在 2013 年的时候 Grunt 问世的时候就已经有所涉及。这类打包工具主要的目的是自动化一些开发流程,我最早使用 Grunt 来构建代码的时候只解决了三个问题:
当时我还在组内做过一个分享,有兴趣的可以去围观一下 Best Workflow With Grunt
其实这些工具出现的原因是:当时前端领域的各种基础设施很缺乏,而前端的工作内容又相对零散。工作时需要开很多的软件。再加上 JavaScript 语言本身也很弱,就连包管理这种基础的东西也没有内置,以至于模块化要通过一些第三方类库来实现,比如:RequireJS, SeaJS
工具的重要性可以在我之前的一个分享中找到 前端开发工具系列
如今前端工程的生态环境由于 NodeJS 的出现已经变得很好了。你可以根据自己的需求选一个合适的直接用到项目里面。像 Grunt, Gulp, browserify, webpack 等。不过要明白这些工具的出现从另一方面证明了前端开发天生存在很多的问题:
这些问题几乎都是历史性的原因和兼容性因素造成的。作为一名好的前端工程师要看清楚现状,然后按自己项目的需求去定制一些前端工程化的方案,而不是随波逐流。
其实现在自己开发一套前端工程化/自动化流程的成本已经很低了,你只需要学习一些 NodeJS 的知识,配合 NPM 包管理机制,随手就搞出一个构建工具出来。因为并不需要你去实现什么东西,所有的东西都有现成的包。脚本压缩有 UglifyJS,CSS 优化有 CSS-min,图片压缩优化有 PNG-quant 等等。你只需要想清楚自己要达到什么目的,解决什么问题就可以抄家伙自己写一套工作流出来
我自己的经历也从 Grunt, GulpJS 到现在自造轮子。自己根据需求开发出来一套集成的打包工具,有兴趣的可以去围观一下 Wooo
当然你也可以不用任何打包工具,自己写一些 NPM Script 来完全定制化项目开发/测试/打包流程。我猜这也是为什么现在类似 Grunt 不再那么火,Gulp 迟迟没有发布 4.0 版本的原因。写一个构建工具的成本太低了,而且这种集成的工具很难满足差异的开发需求。君不知已有人意识到了这一点么why-i-left-gulp-and-grunt-for-npm-scripts
我始终认为程序、设计是为了产品服务的。好的产品是要重视设计的,好的(前端)工程师是要有一些审美素养
其实很多时候技术解决方案都是要根据产品的定位来设计的,了解产品需求以后才能定制出真正合适的高效的解决方案。好比前面讲到的那个 sprite 案例,如果一开始就和产品讨论好方案后来也不可能有那种失控的情况发生。在产品形成/上线前期能发现问题比上线后发现问题更容易解决
这部分内容和代码无关,就不多说了。然而早年我还有一次分享关于前端、改变
关于单品页的前端开发本篇文章只是冰山一角,还有很多没有提及,每个小东西都可以单独写一篇文章来分享。随后希望可以有更多的总结和分享
1970-01-01 08:00:00
本章介绍 Window 对象的属性和方法
setTimeout() 和 setInterval() 可以用来注册指定时间之后调用的函数,不同的是 setInterval 会在指定毫秒数的间隔里重复调用。它们都返回一个值,这个值可以传递给 clearInterval/clearTimeout,用于取消后续函数的调用
由于历史原因(通常不建议这么做),setTimeout 和 setInterval 的第一个参数可以作为字符串传入。如果是字符串,当到达指定时间时相当于执行 eval 字符串内容
// 4 秒后显示 log
var t1 = setTimeout(function () {
console.log('show after 4s');
}, 4000);
function fn() { console.log('show every 1s'); }
setTimeout('fn()', 1000);
Window 对象的 location 属性引用的是 Location 对象,它表示窗口中当前显示的文档 URL。并且定义了方法来使窗口载入新的文档
Document 对象上的 location 属性也引用到 Location 对象:
window.location = document.location
Document 对象也有一个 URL 属性,是文档首次载入后保存的该文档的 URL 静态字符串。如果定位到文档中的片段标识符(如#table-of-content,其实就是锚点),Location 对象会做相应的更新,而 document.URL 属性不会
Location 对象的 href 属性是一个字符串,后者包含 URL 的完整文本。Location 对象的 toString() 方法返回 href 属性的值,因此会隐式调用 toString() 的情况下,可以使用 location 代替 location.href
这个对象的其它属性——protocol, host, hostname, port, pathname 和 search 分别表示 URL 的各个部分。它们称为「URL 分解」属性,同时被 link 对象(通过 HTML 文档中的 a 和 area 元素创建)支持

Location 对象的 assign() 方法可以使用窗口载入并显示你指定的 URL 中的文档。replace() 方法也类似,但它在 载入新文档之前会从浏览器历史中把当前文档删除,assign 会产生一个新的历史记录,也就是说可以使用浏览器的返回按钮到上一页,replace 则不行
Window 对象的 history 属性用来把窗口的浏览历史用文档和文档状态列表的形式表示。history 对象的 length 属性表示浏览历史列表中的元素数量,但是脚本并不能访问已保存的 URL
history 对象的 bace() 和 forward() 方法与浏览器的「后退」和「前端」按钮一样。go() 方法接收一个整数参数,可以在历史列表中向前(正数)或向后(负数)跳过任意多个页
history.go(-2); // 后退两个历史记录
如果窗口包含多个子窗口(比如 iframe 元素),子窗口的浏览历史也会被记录,这音中着在主窗口调用 history.back() 可能会使子窗口跳转而主窗口不变
Window 对象的 navigator 属性引用的是包含浏览器厂商和版本信息的 navigator 对象。navigator 有四个属性用于提供关于运行中的浏览器版本信息,并且可以用来做浏览器嗅探
appName
Web 浏览器的全称。在 IE 中,就是「Microsoft Internet Explorer」,在 Firefox 中就是「Netscape」
appVersion
此属性通常以数字开始,并跟着包含浏览器厂商和版本信息的详细字符串。字符串前面的数字通常是 4.5 或 5.0,表示它是第 4 或 5 代兼容的浏览器
userAgent
浏览器在它的 USER-AGENT HTTP 头部中发送的字符串。这个属性通常包含 appVersion 中的所有信息,以及其它细节
platform
在其上运行浏览器的操作系统字符串
screen 对象提供有关窗口显示的大小和可用的颜色数量信息,属性 width 和 height 指定的是以像素为单位的窗口大小。属性 avilWidth 和 avilHeight 指定的是实际可用的显示大小,它们排除了像浏览器任务栏这样的特性所占用的屏幕空间
Window 对象提供了 3 个方法来向用户显示简单的对话框。
alert() 向用户显示一条消息并等待用户关闭 confirm() 也显示一条消息并要求用户单击「确定」或「取消」,并返回一个布尔值 prompt() 也显示一条消息并等待用户输入字符串,并返回那个字符串
do {
var name = prompt('What is your name?');
var correct = confirm('You entered: ' + name + '\n\
Click OK to processed or Cancel to re-enter')
} while(!correct)
这三个方法都会产生阻塞,也就是说,在用户关掉它们所显示的对话框之前,它们不会返回,这就意味着在弹出一个对话框前,代码就会停止运行。如果当前正在载入文档,也会停止载入。直到用户用要求的输入进行响应为止
Window 对象的 onerror 属性是一个事件处理程序,当未捕获的异常传播到调用栈上的时候就会触发它,并把错误消息输出到浏览器的 JavaScript 控制台上,onerror 事件处理函数调用通过三个字符串参数,而不是事件对象。分别是错误信息、产生错误的页面地址、错误源代码的行号,onerror 的返回值也很重要,如果 onerror 处理程序返回 false,表示它通知浏览器事件处理程序已经处理错误了,不需要其它操作。Firefox 则刚好相反
如果 HTML 文档中用 id 属性来为元素命名,并且如果 Window 对象没有此名字的属性(并且这个id是个合法的标识符),Window 对象会赋予一个属性,它的名字就是 id 属性的值,而它的值指向表示文档元素的 HTMLElement 对象
元素 ID 作为全局变量的隐式应用是 Web 浏览器进化过程中遗留的问题,主要是出于兼容性的考虑。但并不推荐使用这种做法
Web 浏览器的窗口中每一个标签页都是独立的「浏览上下文」(browsing context),每一个上下文都有独立的 Window 对象,而且相互之间不干扰,也不知道其他标签页的存在
但是窗口并不总是和其它窗口完全没关系,因为可以通过脚本打开新的窗口或标签页。如果这么做就可以通过脚本跨窗口进行操作(参照之前的 同源策略)
使用 Window 对象的 open() 方法可以打开一个新的浏览器窗口
var windowObjectReference = window.open(url, name, [features]);
第一个参数 url 是要在新窗口中显示文档的 URL,如果参数省略,默认会使用空页面的 URL about:blank
第二个参数 name 表示打开窗口的名字,如果指定的是一个已经存在的窗口名字(并且脚本允许跳转到那个窗口),会直接用已存在的窗口。否则,会打开新的窗口,并将这个指定的名字赋值给它。如果省略此参数,会使用指定的名字「_blank」打开一个新的未命名窗口
第三个参数 features(非标准)是一个以逗号分隔的列表,包含表示打开窗口的大小和各种属性
open() 也可以有第四个参数,且只在第二个参数命名的是一个存在的窗口时才有用。它是一个布尔值,𡔬了由第一个参数指定的 URL 是应用替换掉窗口浏览器历史的当前条目(true),还是应该在窗口浏览历史中创建一个新的条目(false),后者是默认设置
open() 的返回值是代表命名或新创建的窗口的 Window 对象。可以在自己的 JavaScript 代码中使用这个 windows 对象来引用新创建的窗口,就像用隐式的 Window 对象 window 来引用运行代码的窗口一样:
var w = window.open();
w.alert('About to visit http://jd.com');
w.location = 'http://jd.com';
由 window.open() 方法创建的窗口中,opener 属性引用的是打开它的脚本的 Window 对象,在其它窗口中,opener 为 null
w.opener !== null; // => true
w.open().opener === w // => true
关闭窗口
像 open() 方法一样,close() 用来关闭一个(脚本打开的)窗口,注意,大多数浏览器只允许自己关闭自己的 JavaScript 代码创建的窗口,要关闭其它窗口,可以用一个对话框提示用户,要求他关闭窗口的请求进行确认。在表示窗体而不是顶级窗口或者标签页上的 Window 对象上执行 close() 方法不会有任何效果,它不能关闭一个窗体
即使一个窗口关闭了,代表它的 Window 对象 仍然存在。已关闭的窗口会有一个值为 true 的 closed 属性,它的 document 会是 null, 它的方法通常也不会再工作
任何窗口中的 JavaScript 代码都可以将自己的窗口引用为 window 或 self。窗体可以用 parent 属性引用包含它的窗口的 Window 对象。如果一个窗口是顶级窗口或标签,那么其 parent 属性引用的就是这个窗口本身:
parent.history.back();
parent == self; // 只有顶级窗口才会返回 true
如果一个窗体包含在另一个窗体中,而后者又包含在顶级窗口中,那么该窗体就可以使用 parent.parent 来引用顶级窗口。top 属性是一个通用的快捷方式,无论一个窗体被嵌套几层,它的 top 属性引用的都是指向包含它的顶级窗口。如果一个 Window 对象代表的是一个顶级窗口,那么它的 top 属性就是窗口本身。对于那些顶级窗口的直接子窗体,top 属性就等价于 parent 属性
parent 和 top 属性允许脚本引用它的窗体的祖先。有不止一种方法可以引用窗口的子孙窗体。窗口是通过 iframe 元素创建的,可以获取其他元素的方法来获取一个表示 iframe 的元素对象,iframe 元素有 contentWindow 属性,引用该窗体的 Window 对象。也可以反向操作,使用 Window 对象的 frameElement 属性来引用被包含的 iframe 元素,对于顶级窗口来说 Window 对象的 frameElement 属性为 null
// 假设页面有一个 id="f1" 的 iframe 元素
var iframeElement = document.getElementById('f1');
var iframeWindowObject = iframeElement.contentWindow;
// 对于 iframe 来说永远是 true
iframeWindowObject.frameElement === iframeElement
// 对于顶级窗口来说 frameElement 永远是 null
window.frameElement === null;
每个 window 上都会有一个 frames 属性,表示当前窗口里面引用的窗口。frames 是个类数组对象,并可以通过数字或者窗体名称(如 iframe name 属性)进行索引。注意 frames 元素引用的是窗口的 Window 对象,而不是 iframe 元素
每个窗口都是它自身的 JavaScript 执行上下文,以 window 做为全局对象
设想一个 Web 页面里面有两个 iframe 元素,分别叫「A」和「B」,并假设这些窗体所包含的文档来自于相同的一个服务器,并且包含交互脚本。我们在窗体 A 里的脚本定义了一个变量 i:
var i = 3;
这个变量只是全局对象的一个属性,也是 Window 对象的一个属性。窗体 A 中的代码可以用标识符 i 来引用变量,或者用 Window 对象显示地引用这个变量:
i // => 3
window.i // => 3
由于窗体 B 中的脚本可以引用窗体 A 的 Window 对象,因此它也可以引用那个 Window 对象的属性:
parent.A.i = 4; // 修改窗体 A 中的变量
parent.A.fun(); // 调用 A 窗体中的全局函数
var s = new parent.Set(); // 甚至可以构造父窗口中的对象
和用户定义的类不同,内置类(比如 String, Date 和 RegExp)都会在所有的窗口中自动预定义。但是要注意,每个窗口都有构造函数的一个独立副本和构造函数对应的原型对象的一个独立副本。例如,每个窗口都有自己的 String() 构造函数和 String.prototype 对象副本。因此,如果编写一个操作 JavaScript 字符串的新方法,并且通过把它赋值给当前窗口中的 String.prototype 对象而使它成为 String 类的一个方法,那么该窗口中的所有字符串就可以使用这个新方法。但是,别的窗口中定义的字符串不能使用这个新方法
1970-01-01 08:00:00
Window 对象是所有客户端 JavaScript 特性和 API 的主要接入点。它表示 Web 浏览器的一个窗口或者窗体,并且可以用标识符 window 来引用它。Window 对象定义了一些属性,比如:
// 页面跳转
window.location = 'http://www.oreilly.com/';
// 页面圣诞框
alert('Hello World')
setTimeout(function () { alert('Hello later World') }, 1000)
window 对象也是全局对象。可以省略「window.」来调用上面的方法。这意味着 windows 对象牌作用域链的顶部,它的属性和方法实际上是全局变量和全局函数。window 对象有一个引用自己的属性,叫做 window。如果需要引用窗口对象本身可以用这个属性,但是如果只想要引用全局窗口对象的属性,通常并不需要用 window
windows 对象还定义了很多其他重要的属性、方法和构造函数。其中最重要的一个属性是 document,它引用 Document 对象,后者表示显示在窗口中的文档。document 对象有一些重要方法,比如 getElementById() 获取一个 DOM 元素,它返回一个 Element 对象也有其他重要属性和方法,比如,给元素绑定点击事件 onclick
在 HTML 里嵌入 客户端 JavaScript 有 4 种方法:
<!--html 中的事件处理程序-->
<input type="checkbox" onchange="any_javascript_statement" />
<!--url 中的javascript-->
<a href="javascript: new Date().toLocaleTimeString();">What time is it?</a>
使用外链 src 文件方式有一些优点:
script 标签默认的类型「type」是「text/javascript」,如果要使用不标准的脚本语言,如 Microsoft 的 VBScript(只有 IE 支持),就必须用 type 属性指定脚本的 MIME 类型:
<script type="text/vbscript">
// 这里是 VBScript 代码
</script>
另外很多老的浏览器还支持 language 属性,作用和 type 一样,不过已经废弃了,不应该再使用了
当 Web 浏览器遇到 <script> 元素,并且这个元素包含其值不之前能点浏览器识别的 type 属性时,它会解析这个元素但不会尝试显示或执行它的内容。这意味着可以使用 <script> 来嵌入任意的文件数据到文档里,比如 handlebars 模板引擎,通常把模板放在自定义 type 的 script 标签中:
<script id="entry-template" type="text/x-handlebars-template">
<div class="entry">
<h1>{{title}}</h1>
<div class="body">
{{body}}
</div>
</div>
</script>
JavaScript 第一次添加到 Web 浏览器时,还没有 API 可以用来遍历和操作文档的结构和内容。当文档还在载入时,JavaScript 影响文档内容的唯一方法是使用 document.write() 方法
<h1>Table of Factorials</h1>
<script>
function factorial(n) {
if ( n <= 1 ) return n;
else return n * factorial(n - 1);
}
document.write('<table>');
document.write('<tr><th>n</th><th>n!</th></tr>');
for (var i = 1; i <= 10; i++) {
document.write('<tr><td>'+ i +'</td><td>'+ factorial(i) +'</td></tr>')
}
document.write('</table>');
document.write('Generated ad ' + new Date());
</script>
当脚本把文本传递给 document.write() 时,这个文本被添加到文档输入流中,HTML 解析器会在当前位置创建一个文本节点,将文本插入这个文本节点后面。我们并不推荐使用 document.write(),但在某些场景下它有很重要的用途。当 HTML 解析器遇到 script 元素时,它默认 必须先执行脚本,然后恢复文档的解析和渲染。这对于内联脚本没什么问题,但如果脚本源代码是一个由 src 属性指定的外部文件,这意味着脚本后面的文档部分在下载和执行脚本之间,都不会出现在浏览器中
脚本的执行只在默认情况下是同步和阻塞的。script 标签可以有 defer 和 async 属性,这可以改变脚本的执行方式。HTML 5 说这些属性只在和 src 属性联合使用时才有效,但有些浏览器还支持延迟的内联脚本
<script src="a.js" defer></script>
<script src="b.js" async></script>
defer 和 async 属性都在告诉浏览器链接进来的脚本不会使用 document.write(),也不会生成文档内容,因此不蜂鸣器可以在下载脚本时继续解析和渲染文档,defer 属性使得浏览器延迟脚本的执行,直到文档的载入和解析完成,并可以操作。async 属性使得浏览器可以尽快地挂靠脚本,而不用在下载脚本时阻塞文档解析。如果 script 标签同时有两个属性,同时支持两者的浏览器会 遵从 async 属性并忽略 defer 属性
注意,延迟的脚本会按它们在文档里的 出现顺序执行。而异步脚本在它们载入后执行,这意味着它们可能会 无序执行
上面的打印斐波那契数列程序在页面载入时开始挂靠,生成一些输出,这种程序今天已经不沉凶了。通常我们使用注册事件处理程序函数来写程序。之后在注册的事件发生时 异步 调用这些函数。
事件都有名字,比如 click, change, load, mouseover, keypress, readystatechange 等,如果想要程序响应一个事件,就需要注册一个事件处理函数
事件处理程序的属性名字一般都以「on」开始,后面跟着事件的名字。大部分浏览器中的事件会把一个对象传递给事件处理程序作为参数,那个对象的属性提供了事件的详细信息。比如,传递给点击事件的对象,会有一个属性说明鼠标的哪个按钮被点击了。(在 IE 里,这些事件信息被存储在全局 event 对象里,而不是传给处理程序的函数)
有些事件的目标是文档元素,它们会经常往上传递事件给文档树。这个过程叫做「冒泡」
关于事件传播顺序可以参考 ppk 的 这篇文章
JavaScript 语言核心并不包含任何线程机制,并且客户端 JavaScript 传统上也没有定义任何线程机制。HTML 5 定义了一种作为后台线程的「WebWorker」,但是客户端 JavaScript 还像严格的单线程一样工作。甚至当可能并发执行的时候,客户端 JavaScript 也不会知道是否真的的有并行逻辑执行
单线程执行是𧫂让编程更加简单。编写代码时可以确保两个事件处理程序不会同一时刻运行,操作文档的内容时也不必操心会有其它线程试图同时修改应该没配,并且永远不需要在写 JavaScript 代码的时候操心锁、死锁和竟态条件(race condition)
单线程执行意味着浏览器 必须在脚本和事件处理程序运行的时候停止响应用户输入。这为 JavaScript 程序员带来了负担,它意味着 JavaScript 脚本和事件处理程序不能运行太长时间。如果一个脚本执行 计算密集 的任务,它将会使文档载入带来延迟,用户无法在脚本执行完成前看到内容。浏览器可能变得无法响应甚至崩溃
JavaScript 程序执行的时间线
这是一条理想的时间线,但是所有浏览器都没支持它的全部细节,所有浏览器普遍都支持 load 事件,都会触发它,它是决定文档完全载入并可以操作最通用的技术,除了 IE 之外,document.readyState 属性已被大部分浏览器实现,但是属性的值在浏览器之间有细微的差别
客户端 JavaScript 兼容性和互用性的问题可以归纳为以下三类:
演化
Web 平台一直在演变和发展当中。一个标准规范会倡导一个新的特性或 API。如果特性看起来有用,浏览器开发商实现它。如果足够多的开发商实现,开发者开始试用这个特性。有时新浏览器支持一些特性老的却不支持
未实现
比如,IE 8 不支持 convas 元素,虽然其它浏览器已经实现了它。IE 也没有对 DOM Level 2 Event 规范实现,即使这个规范在十年前就是标准化了
bug
每个浏览器都有 bug,并且没有按照规范准确地实现所有客户端 JavaScript API。有时候编写能兼容各个浏览器的 JavaScript 程序是个很麻烦的工作,必须要研究各种浏览器的兼容性问题
比如有的浏览器客户端不支持 canvas 元素,可以使用开源的「explorer canvas」项目,引用 excanvas.js 即可模拟 canvas 元素的功能
分级浏览器支持(graded browser support)是由 Yahoo! 率先提出的一种测试技术。从某种维度对浏览器厂商/版本/操作系统进行分级。根据分级来确定哪些特性在哪些浏览器需要支持的程度
功能测试(capability testing)是解决不兼容性问题的一种技术。比如添加事件 API,在标准浏览器里面是 addEventListener 而低版浏览器里面是 attachEvent,我们就可以通过特性检测来给一个添加事件的公共方法
<script>
if (element.addEventListener) {
element.addEventListener("keydown", handler, false);
} else if (element.attachEvent) {
element.attachEvent("keydown", handler);
} else {
element.onkeydown = handler
}
</script>
doctype 可以触发浏览器的渲染模式,IE 浏览器有怪异模式,可以通过 document.compatMode 属性判断是否是标准模式。如果返回值为「CSS1Compat」则说明浏览器工作在标准模式;如果值是「BackCompat」或者 「undefined」则说明工作在怪异模式
通常我们用功能测试来处理兼容性问题,但有时候可能需要在某种浏览器中解决个别的 bug,同时又没有可用的特性 API,这里只能通过判断浏览器来做兼容性处理,通常可以使用浏览器 UA(user agent)来解析浏览器版本、类型等
IE 浏览器中可以通过在 HTML 中添加特殊的注释来告诉浏览器代码在哪个浏览器中作用
<!--[if IE 6]>
这里面的内容只会显示在 IE 6 浏览器中
<![endif]-->
IE 的 JavaScript 解释器也支持条件注释,以文本 /*@cc_on 开头,以文本 @*/结束。下面的条件注释包含了只在 IE 中执行的代码
<script><!--忽略 script 标签系统解析有问题-->
/*@cc_on
@if (@_jscript)
alert("in IE")
@end
@*/
</script>
Web 浏览器针对恶意代码的第一条防线就是它们不支持某些功能。例如,客户端的 JavaScript 没有权限来写入或删除计算机上的文件/目录,这意味着 JavaScript 不能删除数据或者植入病毒
类似地,客户端 JavaScript 没有任何通用的网络能力。HTML 5 有一个附属标准叫 WebSockets 定义了一个类套接字的 API,用于和指定的服务器通信。但是这些 API 都不允许对于范围更广的网络进行直接访问
浏览器针对恶意代码的第二条防线是在自己支持的某些功能上施加限制。比如:
同源策略是对 JavaScript 代码能够操作哪些 Web 内容的一条完整的安全限制。当 Web 页面使用多个 iframe 元素或者打开其它浏览器窗口的时候,这一策略通常就会发挥作用。在这情况下,同源策略负责管理窗口或窗体中的 JavaScript 代码以及和其它窗口或帧的交互
文档的来源包含协议、主机、以及载入文档的 URL 商品。从不同 Web 服务器载入的文档具有不同的来源。通过同一主机不同商品载入的文档具有不同来源。使用 http: 协议载入的文档和使用 https: 协议载入的文档具有不同的来源,即使它们来自同一个服务器
脚本本身的来源和同源策略并不相关,相关的是脚本所嵌入文档的来源。例如,来自主机 A 的脚本被包含到宿主 B 的一个 Web 页面中。这个脚本的 来源(origin) 是主机 B,并且可以完整地访问包含它的文档的内容。如果脚本打开一个新的窗口并载入来自主机 B 的另一个文档,脚本对这个文档的内容也具有完全的访问权限。但是如果脚本打开第三个窗口并载入一个来自主机 C 的文档(或者来自主机 A),同源策略就会发挥作用,阻止脚本访问这个文档
A 页面包含一个 B 脚本,B 脚本对 A 页面有完全的访问权限,如果 B 脚本控制打开一个 A 服务器上另外一个页面 C,那么脚本也可以访问这个 C 页面,如果 B 脚本控制打开了一个 D 页面,这时就会触发同源策略,即 B 脚本不可以访问 D 页面,因为 A 和 C 同源,A 和 D 不同源
不严格的同源策略
在某些情况下,同源策略就显得太过严格了,常常表现在多个子域名站点的场景中。比如:来自 A.yourdomain.com 的文档里脚本无法直接读取 B.yourdomain.com 页面的文档,不过可以通过设置 document.domain 为同一个主域来获取访问权限,即给两个域名下的页面都设置 document.domain="yourdomain.com",这样以来两个文档就有了同源性可以相互访问
还有一项已经标准化的技术:跨域资源共享(Cross-Origin Resource Sharing)这个标准草案用新的「Origin:」请求头和新的 Access-Control-Allow-Origin 响应头来扩展 HTTP,它允许服务器用头信息显式地列出源,或使用能本符来匹配所有的源并允许由任何地址请求文件,这样就可以实现跨域的 HTTP 请求, XMLHttpRequest 也不会被同源策略所限制了
还有一种新技术,叫做跨文档消息(cross-document messaging),允许来自一个文档的脚本可以传递文本消息到另一个文档的脚本,而不管脚本的来源是否不同。调用 window 对象上的 postMessage() 方法,可以异步传递消息事件
跨站脚本(Cross-site scripting),或者叫 XXS,这个术语表示一类安全问题。攻击者向目标 Web 站点注入 HTML 标签或者脚本
如果 Web 页面动态地产生文档内容,并且这些文档内容是用户提交的,如果没有过滤用户提交内容的话,这个页面很容易遭到跨站脚本攻击,比如:
<script>
var name = decodeURIComponent(window.location.search.substring(1) || "");
document.write("hello " + name)
</script>
当页面的 url 被手动拼成恶意参数提交时就会产生 XXS 攻击,比如:
http://example.com/greet.html?%3Cscript%3Ealert(%22XXS%20attack%22)%3C%2Fscript%3E
打开这个 url 就会弹出「XXS attack」,解决办法通过是对接收参数进行标签屏蔽
<script>
name = name.replace(/</g, "<").replace(/>/g, ">");
</script>
从某种意义上讲类库也是框架,它们对 Web 浏览器提供的标准和专用 API 进行封闭,向上提供更高级别的 API,用以更高效地进行客户端编程开发。一但使用就要用框架定义的 API 来写代码,后面有专门的章节讲 jQuery,除了这个常用的类库还有一些其它广泛使用的:
1970-01-01 08:00:00
Node 是基于 C++ 的调整 JavaScript 解释器,绑定了用于进程、文件和网络套接字等底层 Unix API,还绑定了 HTTP 客户端和服务器 API。除了一些专门命名的同步方法外,Node 的绑定是异步的,且 Node 程序默认绝不阻塞,这意味着它们通过具备强大的可伸缩能力并能有效地处理高负荷。由于 API 是异步的,因此 Node 依赖事件处理程序,其通常使用嵌套函数和闭包来实现
Node 在其全局对象中实现了所有标准的 ECMAScript 5 构造函数、属性和函数。除此之外,它也支持客户端講器函数集 setTimeout(), setInterval()
Node 在 process 名字空间中定义了其它重要的 全局 属性:
process.version // Node 的版本字符串信息
process.argv // 'node' 命令行数组参数,argv[0] 是 "node"
process.pid // 进程 id
process.getuid() // 返回用户 id
process.cwd() // 返回当前的工作目录
process.chdir() // 改变当目录
process.exit() // 退出
在有的情况下,可以使用 Node 的事件机制。Node 对象产生事件(称为事件触发器(event emitter)),定义 on() 方法来注册处理程序。当传入参数时,将事件类型(一个字符串)作为第一参数,处理程序函数作为第二参数。不同的事件类型传递给处理程序函数的参数不同:
emitter.on(name, f)
emitter.addListener(name, f)
emitter.once(name, f)
emitter.removeListener(name, f)
emitter.removeListeners(name)
上面的 process 全局对象也是一个事件触发器,它继承了 EventEmitter 类
process.on('exit', function () { console.log('Goodbye'); });
process.on('uncaughException', function (e) { console.log(Exception, e); });
Node 的文件和文件系统 API 位于「fs」模块中,这个模块提供了大部分方法的「同步版本」。任何名字以「Sync」结尾的方法都是一个 阻塞方法,它返回一个值或抛出一个异常,不以「Sync」结尾的文件系统方法都是非阻塞的,它们会把结果或者错误传给指定的回调函数
// 同步读取文件,指定编码获取文本而不是字节
var text = fs.readFileSync('config.json', 'utf8');
// 异步读取二进制文件,通过传递函数获得数据
fs.readFile('image.png', function (err, buffer) {
if (err) throw err;
process(buffer);
})
类似地,存在用来写文件的 writeFile() 和 writeFileSync() 函数:
fs.writeFile('config.json', JSON.stringify(json))
「net」模块是用于基于 TCP 网络的 API,下面是 Node 中一个非常简单的 TCP 服务器
var net = require('net');
var server = net.createServer();
server.listen(2000, function() { console.log('Listening on port 2000'); });
server.on('connection', function (stream) {
console.log('Accepting connection from', stream.remoteAddress);
stream.on('data', function (data) {
stream.write(data)
});
stream.on('end', function(data) {
console.log('Connection closed');
});
});
var http = require('http');
var hostname = '127.0.0.1';
var port = 3000;
var server = http.createServer(function(req, res) {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Hello World\n');
});
server.listen(port, hostname, function() {
console.log('Server running at http://$s:%s/', hostname, port);
});
1970-01-01 08:00:00
正则表达式(regular expression)是一个描述字符模式的对象。在 JavaScript 中 String 和 RegExp 都定义了相关方法对文本进行模式匹配、检索和替换
JavaScript 中的正则表达式用 RegExp 对象表示,可以使用 RegExp() 构造函数来创建 RegExp 对象,不过也可以通过两个双斜杠「/reg/」以正则直接量的形式创建
var pattern = /s$/; // 通过直接量创建
var pattern = new RegExp('s$'); // 通过构造函数创建
JavaScript 正则表达式语法也支持非字母的字符匹配,这些字符需要通过反斜线(\)作为前缀进行转义
表10-1
| 字符 | 匹配 |
|---|---|
| 字母和数字 | 自身 |
| \0 | NUL 字符(\u0000) |
| \t | 制表符(\u0009) |
| \n | 换行符(\u000A) |
| \v | 垂直制表符(\u000B) |
| \f | 换页符(\u000C) |
| \r | 回车符(\u000D) |
| \xnn | 由十六进制数 nn 指定的拉丁字符 |
| \uxxxx | 由十六进制数 xxxx 指定的 unicode 字符 |
| \cX | 控制字符 ^x |
正则表达式中,许多标点符号也具有特殊含义,它们是:
^ $ . * + ? = ! : | \ / ( ) { }
将直接量字符单独放进方括号内组成了字符类(charactor class)
表10-2
| 字符 | 匹配 |
|---|---|
| [...] | 方括号内的任意字符 |
| [^...] | 不在方括号内的任意字符 |
| . | 除换行符和其它 Unicode 行终止符之外的任意字符 |
| \w | 任何 ASCII 字符组成的单词,等价于 [a-zA-Z0-9] |
| \W | 任何不是 ASCII 字符组成的单词,等价于 [^a-zA-Z0-9] |
| \s | 任何 Unicode 空白符 |
| \S | 任何非 Unicode 空白符 |
| \d | 任何 ASCII 数字,等价于 [0-9] |
| \D | 任何非 ASCII 数字,等价于 [^0-9] |
| [\b] | 退格直接量 |
表10-3
| 字符 | 含义 |
|---|---|
| {n, m} | 匹配前一项至少 n 次,但不能超过 m 次 |
| {n,} | 匹配前一项 n 次或者更多次 |
| {n} | 匹配前一项 n 次 |
| ? | 匹配前一项 0 次或者 1 次,也就是说前一项是可选的,等价于 {0,1} |
| + | 匹配前一项 1 次或者多次,等价于 {1,} |
| * | 匹配前一项 0 次或者多次,等价于{0,} |
举例说明:
/\d{2,4}/ // 匹配 2 ~ 4 个数字
/\w{3}\d?/ // 匹配三个单词和一个可选的数字
/\s+java\s+/ // 匹配前后带有一个或者多个空白字符串 "java"
/[^(]*/ // 匹配一个或多个非左括号字符
表10-3 中列出一匹配重复字符是尽可能多地匹配,而且允许后续的正则表达式继续匹配。因此,我们称之为「贪婪的」匹配。我们同样可以使用正则表达式进行非贪婪匹配。只需在特匹配的字符后跟随一个问题即可:「??」、「+?」、「*?」或「{1,5}?」
表10-4
| 字符 | 含义 |
|---|---|
| | | 选择,匹配的是该符号左边的子表达式或者右边的子表达式 |
| (...) | 组合,将几个项组合为一个单元,这个单元可通过「*」、「+」、「?」和「|」等符号 加以修饰,而且可以记住和这个组合相匹配的字符串 以供此后的引用使用 |
| (?:...) | 只组合,把项组合到一个单元,但不记忆与该组想匹配的字符 |
| \n | 和第 n 个分级第一次匹配的字符相匹配,组是圆括号中的子表达式 (也有可能是嵌套的),组索引是从左到右的左括号数, 「(?:」形式的分组不编码 |
表10-5
| 字符 | 含义 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的结尾 |
| \b | 匹配一个单词的边界 |
| \B | 匹配非单词边界的位置 |
| (?=p) | 零宽正向先行断言,要求接下来的字符都与 p 匹配,但不能包括匹配 p 的那些字符 |
| (?!p) | 零宽负向先行断言,要求接下来的字符都不与 p 匹配 |
/reg/flag
标识是放在斜扛右边的,通常有 i, g, m 三种
String 支持 4 种使用正则表达式的方法
search() 方法返回第一个与之匹配的子串起始位置,如果找不到匹配的子串,它将返回 -1
"JavaScript".search(/script/i); // => 4
如果 search() 参数不是正则表达式,则首先会 通过 RegExp 构造函数将它转换成正则表达式,search() 方法不支持全局检索,因为它 忽略 正则表达式参数中的标识 g
str.replace(regexp|substr, newSubStr|function)
replace() 方法用以执行检索与替换操作,正则表达式如果带标识 g,则会替换所有匹配子串
// 将所有不区分大小写的 javascript 都替换成 JavaScript
text.replace(/javascript/gi);
// 用中文引号替换英文应该引号,同时要保持引号之间的内容(存储在 $1 中)没有被修改
var quote = /"([^"]*)"/g;
text.replace(quote, '“$1”')
match() 方法返回一个由匹配结果组成的数组,如果没有标识全局搜索,match() 只检索第一个匹配
"1 plus 2 equals 3".match(/\d+/g); // => ["1", "2", "3"]
RegExp(pattern [, flags])
RegExp 构造函数一般用在动态创建正则表达式的时候,这种情况往往没办法通过写死在代码中的正则直接量来实现,比如检索字符串是用户输出的
每个 RegExp 对象都包含 5 个属性:
exec() 对一个指定的字符串执行一个正则表达式,如果没有找到任何匹配,它就返回 null,但如果它找到一个匹配,将返回一个数组
var pattern = /Java/g;
var text = "JavaScript is more fun than Java!";
var result;
while((result = pattern.exec(text)) != null) {
console.log("Matched '%s' at position '%s'; next search begins at %s",
result[0],
result.index,
pattern.lastIndex);
}
// Matched 'Java' at position '0'; next search begins at 4
// Matched 'Java' at position '28'; next search begins at 32
test() 对方法转入字符串进行检测,匹配到结果返回 true,否则返回 false
var pattern = /java/i;
pattern.test('JavaScript'); // => true
1970-01-01 08:00:00
最近在看 MIT 公开课-计算机程序的构造和解释,即使你像我一样根本没学过 lisp 也能看懂下面这段代码,这段代码展示了怎么实现加法运算,这种我们几乎从来不会去想为什么的问题,这几行简单的代码告诉我们如何计算出 3 + 4 的值
由 皮亚诺 算术定义的求 x 和 y 之和的过程
; Define a [+] processor
(define (+ x y)
(if (= x 0)
y
(+ (-1+x) (1+y))))
; x = 3, y = 4
(+ 3 4)
(if (= 3 0) 4 (+ (-1+3) (1+4)))
(+ (-1+3) (1+4))
(+ 2 5)
(if (= 2 0) 5 (+ (-1+2) (1+5)))
(+ (-1+2) (1+5))
(+ 1 6)
(if (= 1 0) 6 (+ (-1+1) (1+6)))
(+ (-1+1) (1+6))
(+ 0 7)
(if (= 0 0) 7 (-1+0) (1+7))
7
1970-01-01 08:00:00
每个 JavaScript 对象都是一个属性集合,相互之间没有任何联系。在 JavaScript 中也可以定义对象的类,让每个对象都共享某些属性,这种「共享」的特性是非常有用的。类的成员或实例都包含一些属性,用以存放或者定义它们的状态,其中有些属性定义了它们的行为(通常称为方法)。这些行为通常是由类定义的,而且为所有实例所共享。例如,假设有一个 Complex 的类用来表示复数, 同时还定义了一些复数运算,一个 Complex 实例应当包含实数的实部和虚部(状态),同样 Complex 类还会定义复数的加法和乘法操作(行为)
JavaScript 中类的一个重要特性是「动态可继承」(dynamically extendable),我们可以将类看做是类型,本章会介绍一种编程哲学 —— 「鸭子类型」(duck-typing),它弱化了对象的类型,强化了对象的功能
在 JavaScript 中,类的所有实例对象都从同一个原型对象上继承属性。因此,原型对象是类的核心。在之前的 章节 里定义了 inherit() 函数,这个函数返回一个新创建的对象,后者继承自某个原型对象。如果定义一个原型对象,然后通过 inherit() 函数创建一个继承自它的对象,这样就定义了一个 JavaScript 类。通常,类的实例还需要进一步的初始化,通常是通过定义一个函数来创建并初始化这个新对象
// 一个简单的实现表示值的范围的类
function range(from, to) {
var r = inherit(range.methods);
r.from = from;
r.to = to;
return r;
}
range.methods = {
includes: function(x) {
return this.from <= x && x <= this.to;
},
foreach: function (f) {
for (var x = Math.ceil(this.from); x <= this.to; x++) f(x);
}
toString: function() {
return "(" + this.from + "..." + this.to + ")";
}
}
var r = range(1, 3);
r.includes(2) // => true
r.foreach(console.log)
// => 1
// => 2
// => 3
console.log(r); // => (1...3)
这段代码定义了一个工厂方法 range(),用来创建新的范围对象。range.methods 属性用来快捷地存放定义类的原型对象。range() 函数给每个范围对象都定义了 from 和 to 属性,用以定义范围的起始和结束位置,这两个属性是 非共享 的,当然也是不可继承的。
上节中展示了定义类的一种方法,但是这种方法并不常用,它没定义构造函数。构造函数是用来初始化新创建的对象的。调用构造函数的一个重要特征是,构造函数的 prototype 属性被用做新对象的原型。这意味着 通过同一个构造函数创建的所有对象都继承自一个相同的对象,因此它们都是同一个类的成员
例9-2
function Range(from, to) {
this.from = from;
this.to = to;
}
Range.prototype = {
includes: function(x) {
return this.from <= x && x <= this.to;
},
foreach: function (f) {
for (var x = Math.ceil(this.from); x <= this.to; x++) f(x);
}
toString: function() {
return "(" + this.from + "..." + this.to + ")";
}
};
var r = new Range(1, 3)
r.includes(2) // => true
r.foreach(console.log)
// => 1
// => 2
// => 3
console.log(r); // => "(1...3)"
从某种意义上讲,定义构造函数既是定义类,并且 类名首字母要大写,而普通普通的函数和方法都是首字母小写,Range() 构造函数是通过 new 关键字调用的,而在上一节的工厂函数则不必使用 new。通过 new 调用不必再用 inherit 来创建对象,构造函数会自动创建对象,然后将构造函数作为这个对象的方法来调用一次,最后返回这个对象
上文提到,原型对象是类的唯一标识:当且仅当两个对象继承自同一个原型对象时,它们才是属于同一个类的实例。而初始化对象的状态的构造函数则不能作为类的标识,两个构造函数的 prototype 属性可能指责同一个原型对象。那么这两个构造函数创建的实例是属于同一个类的
构造函数的名字通常用做类名,比如我们说 Range() 构造函数创建 Range 对象。然而,更根本地讲,当使用 instancdof 运算符来检测对象是否属于某个类时会用到构造函数。假设有一个对象 r,我们想知道它是否是 Range 对象,可以这样判断
r instanceof Range // 如果 r 继承自 Range.prototype,则返回 true
实际上 instanceof 运算符并不会检查 r 是否是由 Range() 构造函数初始化而来,而是 检查 r 是否继承自 Range.prototype
每个 JavaScript 函数(bind除外)都自动拥有一个 prototype 属性。这个属性的值是一个对象,这个对象包含唯一一个不可枚举属性 constructor。constructor 属性的值是一个函数对象
var F = function() {};
var p = F.prototype;
var c = p.constructor;
c === F // => true
图 9-1 展示了构造函数和原型对象之间的关系,包括原型到构造函数的反向引用以及构造函数创建的实例
图9-1
构 造 函 数 原 型 实 例
+------------------+ +------------------+ +---------------+
| | | | inherits | |
| Range() <---------- contructor <----------+ new Range(2) |
| | | | | |
| | | | +---------------+
| | | includes |
| prototype ------------> |
| | | foreach | +---------------+
| | | | inherits | |
| | | toString <----------+ new Range(3,4)|
| | | | | |
| | | | +---------------+
+------------------+ +------------------+
例9-2中定义的 Range 类使用它自身的一个新对象重写预定义的 Range.prototype 对象。这个新定义的原型对象不含有 constructor 属性。因此 Range 类的实例也不含有 constructor 属性。我匀可以通过补救措施来修正这个问题,显式给原型添加一个构造函数:
Range.prototype = {
constructor: Range,
incluces: function() {/*code*/}
};
// 当然也可以使用给 prototype 指定方法赋值的方式,避免重写整个 prototype
Range.prototype.includes = function() {/*code*/}
在 Java 或者其它类似强类型面向对象语言中,类成员可能是这样的:
实例字段 它们是基于实例的属性或变量,用以保存独立对象的状态
实例方法 它们是类的所有实例共享方法,由每个独立的实例调用
类字段 这些属性或变量是属于类的,而不属于类的某个实例
类方法 这些方法是属于类的,而不属于类的某个实例
JavaScript 和 Java 的一个不同之处在于,JavaScript 中的函数都是以值的形式出现的,方法和字段之间并没有太大的区别。如果属性是函数,那么这个属性就定义一个方法,否则,它只是一个普通的属性或「字段」
之前我们已经了解过 instanceof 运算符。左操作数是待检测其类的对象,右操作数是定义类的构造函数。如果 o 继承自 c.prototype,则表达式 o instanceof c 值返回 true。这里的继承可以不是直接继承,如果 o 所继承的对象继承自另一个对象,后一个对象继承自 c.prototype,这个表达式的运算结果也是 true
构造函数是类的公共标识,但原型是唯一的标识。尽管 instanceof 运算符的右操作数是构造函数,但计算过程实际上是检测了对象的继承关系,而不是检测创建对象的构造函数
另一种识别对象是否属于某个类的方法是使用 constructor 属性,因为构造函数是类的公共标识,所以最直接的方法就是使用 constructor 属性,比如:
function typeAndValue(x) {
if (x == null) return "";
switch(x.constructor) {
case: Number:
return "Number: " + x;
case: String:
return "String: " + x;
case: Date:
return "Date: " + x;
case: RegExp:
return "RegExp: " + x;
case: Complex:
return "Complex: " + x;
}
}
使用 constructor 属性检测对象属于某个类的技术不足之处和 instanceof 一样。在 多个执行上下文 场景中它是无法正常工作的(比如在浏览器窗口的多个框架子页面中)。在这种情况下每个框架页面各自拥有独立的构造函数集合。比如一个框架页面中的 Array 构造函数和另一个构架页面的 Array 构造函数不是同一个
上面描述的检测对象的类的各种技术多少都会有些问题,至少在客户端 JavaScript 中是如此。解决办法就是规避掉这些问题:不要关注「对象是什么」,而是关注「对象能做什么」。这种思考问题的方式在 Python 和 Ruby 中右学普遍,称为「鸭子类型」
像鸭子一样走路、游泳并且嘎嘎叫的鸟就是鸭子
这又让我想起了《蝙蝠侠》里面的那句话:
It’s not who you are underneath, it’s what you do that defines you
集合(set)是一种数据结构,用来表示非重复值的无序集合。集合有添加值、检测值是否存在等方法,下面的例子实现了一个更加通用的 Set 类
function Set() {
this.values = {};
this.n = 0;
this.add.apply(this, arguments)
}
Set.prototype.add = function () {
for (var i = 0; i < arguments.length; i++) {
var val = arguments[i];
var str = Set._v2s(val);
if (!this.values.hasOwnProperty(str)) {
this.values[str] = val;
this.n++;
}
}
return this;
}
Set.prototype.remove = function () {
for (var i = 0; i < arguments.length; i++) {
var str = Set._v2s(arguments[i]);
if (this.values.hasOwnProperty(str)) {
delete this.values[str];
this.n--;
}
}
}
Set.prototype.contains = function (value) {
return this.values.hasOwnProperty(Set._v2s(value))
}
Set.prototype.size = function () {
return this.n;
}
Set.prototype.foreach = function(f, context) {
for (var s in this.values) {
if (this.values.hasOwnProperty(s)) {
f.call(context, this.values[s]);
}
}
}
Set._v2s = function (val) {
switch (val) {
case undefined: return 'u';
case null: return 'n';
case true: return 't';
case false: return 'f';
default:
switch (typeof val) {
case 'number': return '#' + val;
case 'string': return '"' + val;
default: return '@' + objectId(val)
}
}
function objectId(o) {
var prop = "|**objectid**|";
if (!o.hasOwnProperty(prop)) {
o[prop] = Set._v2s.nex++;
}
return o[prop];
}
}
Set._v2s.next = 100;
var s = new Set(1,2,3);
s.values; // => Object {#1: 1, #2: 2, #3: 3}
var s1 = new Set(1,2,3,3,2,1, null, undefined)
s1.values; // => Object {#1: 1, #2: 2, #3: 3, n: null, u: undefined}
s1.remove(null, undefined);
s1.values; // => Object {#1: 1, #2: 2, #3: 3}
有时候,我们希望对象的初始化有多种方式,比如 Set 对象,我们想专入一个数组或者类数组,而不是多个参数来初始化它,我们可以加一些判断来实现重载(overload)
// 重载
function Set() {
this.values = {};
this.n = 0;
if (arguments.length == 1 && isArrayLike(arguments[0])) {
this.add.apply(this, arguments[0])
} else {
this.add.apply(this, arguments)
}
}
// 工厂方法: 可以从数组创建一个集合对象
Set.fromArray = function(a) {
var s = new Set();
s.add.apply(s, a)
return s;
}
// Set 类的一个辅助构造函数
function SetFromArray(a) {
Set.apply(this, a);
}
SetFromArray.prototype = Set.prototype;
var s = new SetFromArray([1,2,3]);
s instanceof Set // => true
在面向对象编程中,类 B 可以继承自另外一个类 A。我们将 A 称为父类(superclass),将 B 称为子类(subclass)。B 的实例从 A继承了所有的实例方法。类 B 可以定义自己的实例类方法,有些方法可以重载类 A 中的同名方法,如果 B 的方法重载了 A 中的方法,B 中的重载方法可能会调用 A 中的重载类 A 方法,这种做法称为「方法链」(method chaining)。同样子类的构造函数 B() 有时需要调用父类的构造函数 A(),这种做法称为「构造函数链」(constructor chaining)。子类还可以有子类,当涉及类的层次结构时,往往需要定义抽象类(abstract class)。抽象类中定义的方法没有实现。抽象类中的抽象方法是在抽象类的具体子类中实现的
JavaScript 的对象可以从类的原型对象中继承属性。如果 O 是类 B 的实例,B 是 A 的子类,那么 O 也一定从 A 中继承了属性。为此,首先要确保 B 的原型对象继承自 A 的原型对象,通过 inherit() 函数可以实现
B.prototype = inherit(A.prototype);
B.prototype.constructor = B;
我们定义一个 Set 的子类 NonNullSet,它不允许 null 和 undefined 作为集合成员,这就需要在子类的 add() 方法中对 null 和 undefined 值做检测。它需要完全重新实现一个 add() 方法
function NonNullSet() {
Set.apply(this, arguments);
}
NonNullSet.prototype = inherit(Set.prototype);
NonNullSet.prototype.constructor = NonNullSet;
NonNullSet.prototype.add = function() {
for (var i = 0; i < arguments.length; i++) {
if (arguments[i] == null) {
throw new Error("Cant't add null or undefined to a NonNullSet");
}
}
return Set.prototype.add.apply(this, arguments);
};
上节中定义的集合可以根据特定的标准对集合成员做限制,而且使用了子类的技术来实现这种功能
然后还有一种更好的方法来完成这种需求,既面向对象编程中一条广为人知的设计原则:「组合优于继承」。这样,可以利用组合的原理定义一个新的集合实现,它「包装」了另外一个集合对象,在将受限制的成员过滤掉之后会用到这个集合对象
1970-01-01 08:00:00
函数是一段 JavaScript 代码,定义一次,可以被执行多次。JavaScript 函数是参数化的:函数定义会包括一个形参(parameter)的标识符列表,这些参数在函数体中像 局部变量 一样工作,函数被调用的时候会为形参提供实参(argument)的值。使用实参的值计算返回值,成为该函数的 **调用表达式**值,调用上下文(invocation context)可以用 this 引用,嵌套函数可以构成闭包(closure)
使用 function 关键字来定义一个函数,可以用在函数定义表达式或者函数声明语句里
// 打印对象名称和值
function printprops(o) {
for(var p in o)
console.log(p + ": " + o[p] + "\n");
}
// 递归调用计算阶乘
function factorial(x) {
if (x <= 1) return 1;
return x * factorial(x - 1);
}
// 函数定义表大式,函数名称可以省略
var square = function(x) { return x * x; }
return 语句导致函数停止执行,并返回它的表达式给调用都。如果 return 语句没有一个与之相关的表达式,则它返回 undefined 值,没有 return 语句也会默认返回 undefined 值给调用者
嵌套函数
function hypotenuse(a, b) {
function square(x) { return x*x; }
return Math.sqrt(square(a) + square(b));
}
嵌套函数的作用域规则:它们可以访问嵌套它们的函数的参数和变量。上面的代码里,内部函数 square() 可以读写外部函数 hypotenuse() 定义的参数 a 和 b
有 4 种方式来调用 JavaScript 函数:
function_name(param1, param2);
object.method(param1, param2);
// 对象直接量
var calculator = {
operand1: 1,
operand2: 1,
add: function() {
this.result = this.operand1 + this.operand2;
},
add1: function(a) {
this.operand1 + a;
return this;
},
add2: function(b) {
this.operand2 + a;
return this;
}
};
calculator.add();
calculator.result // => 2
// 使用对象属性访问表达式调用方法
calculator['result'] // => 2
// 链式调用
calculator.add1(1).add2(2)
calculator.operand1 // => 2
calculator.operand2 // => 3
new Object(param1, param2);
如果没有参数可以省略括号 new Object
function_name.call()
JavaScript 中的 函数也是对象,和其它 JavaScript 对象没什么区别,函数对象也可以包含方法。其中两个 call() 和 apply() 可以用来间接地调用函数。两个方法都允许显式地指定调用所需的 this 值
JavaScript 的函数定义不用指定形参的类型,调用传入的实参也可以是任意类型,JavaScript 甚至 不检查传入实参的个数
如果调用函数的时候传入的实参比指定的形参少,剩下的形参都将设置为 undefined 值,通常使用逻辑与运算符给形参指定默认值
function getName(name) {
// 如果 name 传入值则使用传入值,否则使用默认值 "no name"
// 通常建议可选参数放在参数列表最后
name = name || "no name";
// code
return name;
}
当调用函数的时候传入实参人个数超过形参个数时(和上面相反),没有办法直接获得未命名值的引用。参数对象解决了这个问题,在函数体内,标识符 arguments 是指向实参对象的引用,参数对象是一个 类数组对象,这样可以通过索引来访问实参了
function fn(x, y, z) {
console.log(arguments);
}
fn(1,2,3) // => [1,2,3]
fn(1,2,3,4,5) // => [1,2,3,4,5]
实参对象的重要用处就是让函数可以操作任意数量的实参,比如我们自己实现一个数组的 push 方法
function push(arr /* optional items [, item ... [, item]] */) {
var items = Array.prototype.slice.call(arguments, 1)
for (var i = 0; i < items.length; i++) {
arr[arr.length] = items[i];
}
}
var arr1 = [1,2,3];
push(arr1, 4,5,6);
arr1 // => [1, 2, 3, 4, 5, 6]
在非严格模式下,修改 arguments 元素的值,实参的值也会变。不过在 ECMAScript 5 中这个特性被移除了。在非严格模式中,函数里的 arguments 仅仅是个标识符。在严格模式中,它变成了一个保留字,严格模式中函数无法使用 arguments 作为 形参名 或者 局部变量名,也不能给它(arguments)赋值
function f(x) {
console.log(x); // => 实参的初始值
arguments[0] = null;
console.log(x); // => 非严格返回 null, 非严格返回 1
}
f(1)
除了数组元素,实参对象还定义了 callee 和 caller 属性。严格模式中对这两个属性读写操作会产生一个类型错误,非严格模式下,ECMAScript 标准规范规定 callee 属性指代当前正在执行的函数。caller 是非标准的,但大多数浏览器都实现了这个属性,它指代调用当前正在执行的函数的函数。通过 caller 属性可以访问调用栈,callee 属性在某些时候非常有用,比如在匿名函数中通过 callee 来递归调用自身
var factorial = function(x) {
if (x <= 1) return 1;
return x * arguments.callee(x-1);
}
当一个函数包含超过三个形参时,很难记住参数顺序。这时我们可以用名/值对的形式来传入参数,这样参数的顺序就无关紧要了(然后名/值对里面的键名还是得记住)
function arraycopy(from, from_start, to, to_start, length) {
}
function easycopycopy(args) {
arraycopy(args.from,
args.from_start || 0,
args.to,
args.to_start || 0,
args.length);
}
var a = [1,2,3,4], b = [];
easycopy({ from: a, to: b, length:4 })
JavaScript 函数中形参并未声明类型,在形参数传入之前也未做任何类型检查,JavaScript 会在必要的时候进行类型转换,因此如果函数期望接收一个出神入化串实参,而调用函数时传入其它类型的值,所传入的值会在函数体内将其转换为字符串
函数的定义和调用是 JavaScript 的词法特性,其它语言也一样。然而在 JavaScript 中,函数不仅仅是一种语法,也可以是值,也就是说,可以将函数赋值给变量,存储在对象的属性或数组元素中,作为参数传入另外一个函数等
function square(x) { return x*x; }
var s = square;
square(4) == s(4) // => true
var a = [ function square(x) { return x*x; }, 20 ];
a[0](a[1]); // => 400
// 将函数用做值
function add(x, y) { return x + y; }
function subtract(x, y) { return x - y; }
function multiply(x, y) { return x * y; }
function divide(x, y) { return x / y; }
function operate(operator, operand1, operand2) {
return operator(operand1, operand2)
}
// => 25 (2 + 3) + (4 * 5)
var i = operate(add, operate(add, 2, 3), operate(multiply, 4, 5))
JavaScript 中函数并不是原始值,而是一种特殊的对象,也就是说,函数可以拥有 属性。当函数需要一个 静态变量 来在调用时保持某个值不变,最方便的方式就是给函数定义属性,而不是定义全局变量
// 注意静态变量不必在函数后面声明
uniqueInteger.counter = 0;
function uniqueInteger() {
// 注意 ++counter 和 count++ 不一样
return ++uniqueInteger.counter;
}
下面这个函数 factirial() 使用了自身的属性(将自身当做数组来对待)来缓存上一次的计算结果:
// 计算阶乘
function factorial(n) {
if (isFinite(n) && n > 0 && n == Math.round(n)) {
if (!(n in factorial)) {
factorial[n] = n * factorial(n-1)
}
return factorial[n]
} else {
return NaN;
}
}
// 初始化缓存以保存这种基本情况
factorial[1] = 1;
(function(/*paramater*/) {
// 模块代码
// 这个模块使用的所有变量(通过 var 声明)都是局部变量
// 不会污染全局命名空间
})(/*arguments*/);
(function(win, doc) {
var obj = {
privateMethod: function() {},
publicMethod: function() {}
};
win.yourPublicAPIMethodName = obj.publicMethod
})(window, document);
使用 立即执行函数表达式(IIFE) 可以隔离代码块的命名空间,在匿名函数中声明的变量只在内部有效,不会对全局产生影响,同时可以有选择地向全局输出变量用来给外部代码访问
词法作用域(lexical scoping)的执行依赖于变量作用域,这个作用域是在函数 定义时 决定的,而不是函数调用时,为了实现这种词法作用域,JavaScript 函数对象的内部状态不仅包含函数的代码逻辑,还必须引用当前的作用域链。函数对象可以通过作用域链相互关联起来,函数体内部的变量都可以保存在函数作用域内,这种特性在计算机科学文献中称为「闭包」
从技术角度讲,所有的 JavaScript 函数都是闭包:它们都是对象,它们都关联到作用域链。当调用函数时闭包所指向的作用域链和定义函数时的作用域链不是同一个作用域链时,事情就变得非常我刚好和。当一个函数嵌套了另外一个函数,外部函数将嵌套的函数对象 作为返回值返回 的时候,这种事情就发生了
先看一下嵌套函数的词法作用域规则:
// 例 1
var scope = "global scope";
function checkscope() {
var scope = "local scope";
function f() { return scope;}
return f();
}
checkscope(); // => "local scope"
// 例 2
var scope = "global scope";
function checkscope() {
var scope = "local scope";
function f() { return scope;}
return f;
}
checkscope()() // => "local scope"
在例 2 中我们将 checkscope 返回值 f 调用的括号移动到了 checkscope 调用后面。复习一下作用域的基本规则:JavaScript 函数的执行用到了作用域链,这个作用域链是函数 定义的时候 创建的,嵌套的函数 f() 定义在这个作用域链里,其中的变量 scope 一定是局部变量,不管在何时执行函数当 f(),这种绑定在执行 f() 时依然有效。因此最后一行代码返回「local scope」而不是「global scope」。简而言之,闭包的这个特性强大到让人吃惊:它们可以捕捉到局部变量(和参数),并一直保存下来
很多程序员觉得闭包非常难理解,他们觉得在外部函数中定义的局部变量在函数返回后就不存在了,那么嵌套的函数如何能调用不存在的作用域链呢?如果你想搞清楚这个问题,还得更深入地了解类似 C 语言这种更底层的编程语言,并了解基于栈的 CPU 架构 如果一个函数的尾部变量定义在 CPU 的栈中,那么当函数返回时它们的确就不存在了
上节中的 uniqueInteger() 函数,这个函数有一个问题,函数本身是全局可访问的,这个 counter 很可能被外部修改。如果使用闭包就没有这个问题
var uniqueInteger = (function() {
var counter = 0;
return function() {
return ++counter;
}
})();
上面的代码将匿名立即执行函数赋值给 uniqueInteger 变量,所以函数的返回值赋值给变量 uniqueInteger,内部变量 counter 只在函数体内部可以访问,外部无法操作
私有变量也可以被多个闭包访问到,比如:
function counter() {
var n = 0;
return {
count: function() { return n++ },
reset: function() { n = 0 }
}
}
// 创建两个计数器
var c = counter(), d = counter();
c.count() // => 0 互
c.count() // => 1 不
d.count() // => 0 干
d.count() // => 1 扰
c.reset() // => 0 重置 c
d.count() // => 2 不影响 d
在同一个作用域链中定义两个闭包,这两个闭包共享同样的私有变量或变量。这是一种非常重要的技术,但是要特别小心那些不希望共享的变量往往不经意间共享给了其它的闭包,了解这一点也很重要
function constfunc(v) { return function() { return v; } }
var funcs = [];
for(var i = 0; i < 10; i++) {
funcs[i] = constfunc(i);
}
如果这样写就完全不一样了
function constfuncs() {
var funcs = [];
for (var i = 0; i < 10; i++) {
funcs[i] = function() {
return i;
};
}
return funcs;
}
var funcs = constfuncs();
funcs[5]() // => 10 !!!
上面这段代码循环创建了 10 个闭包,并将它们存储到一个数组中。这些闭包都是在同一个函数调用中定义的,因此它们可以共享变量 i。当 constfuncs() 返回时,变量的 i 值是 10,所有的闭包都共享这一个值,因此,数组中的函数的返回值是同一个值,因此,数组中的函数的返回值都是同一个值,这不是我们想要的结果。关联到闭包的作用域链都是「活动的(live)」,记住这一点非常重要。嵌套的当函数不会将作用域内的私有成员复制一份,也不会对所绑定的变量生成静态快照(static snapshot)
书写闭包的时候还需注意一件事情,this 是 JavaScript 的关键字,不是变量。正如之前讨论的,每个函数调用都包含一个 this 值,如果闭包在外部函数里是无法访问 this 的,除非外部函数将 this 默契为一个变量
function outerFn() {
var self = this;
function innerFn() {
// self.xxxx
}
}
在 JavaScript 中,函数是值,对函数执行 typeof 运算会返回字符串 "function",但是函数是 JavaScript 中特殊的对象。因为函数也是对象,它们也可以拥有属性和方法,像普通对象一样。甚至可以用 Function() 构造函数来创建新的函数对象
每一个当函数都包含一个 prototype 属性,这个属性是指向一个对象的引用,这个对象称做「原型对象」(prototype object)。每一个函数都包含不同的原型对象。当将函数胜仗构造函数的时候,新创建的对象会从原型对象上继承属性
fun.call(thisArg[, arg1[, arg2[, ...]]])
fun.apply(thisArg[, argsArray])
我们可以将 call 和 apply 看做是某个对象的方法,通过调用方法的形式来间接调用函数
// 将对象 o 中名为 m 的方法替换为另外一个方法
function trace(o, m) {
var original = o[m];
o[m] = function() {
console.log(new Date, "Entering: ", m);
var result = original.apply(this, arguments)
console.log(new Date, "Exiting: ", m);
}
}
trace() 函数接收两个参数,一个对象和一个方法名,它将指定的方法替换为一个新方法,这个新方法就是「包裹」原始方法的另一个泛函数。这种动态修改已有方法的做法有时称做「猴子补丁 monkey-patching」
fun.bind(thisArg[, arg1[, arg2[, ...]]])
bind 方法是 ECMAScript 5 中新增的方法,但在 ECMAScript 3 中可以模拟出来。主要用于将函数绑定到某个对象。当在函数 f 上调用 bind 方法并传入一个对象 o 做参数,这个方法将返回一个新的函数。调用新的函数将会把原始的函数 f 当做 o 的方法来调用。传入新函数的任何实参都将传入原始函数
function f(y) { return this.x + y; }
var o = { x: 1};
var g = f.bind(o);
g(2) // => 3
可以通过下面代码实现 bind 方法
function bind(f, o) {
if (f.bind) {
return f.bind(o);
} else {
return f.apply(ok arguments)
}
}
bind 方法还有一些其他应用:除了第一个实参之外,传入 bind 的实参也会绑定至 this,这个附带的应用是一种常见的函数式编程技术,有时也被称为「柯里化」(currying)
var sum = function(x, y) { return x + y }
var succ = sum.bind(null, 1)
succ(2) // => 3
function f(y, z) { return this.x + y + z }
var g = f.bind({x:1}, 2)
g(3) // => 6
注意 bind 方法有些特性是模拟不出来的
和所有的 JavaScript 对象一样,函数也有 toString 方法,ECMAScript 规范规定这个方法返回一个字符串,这个字符串和函数声明语句的语法相关。实际上,大多数的 toString 方法的实现都返回函数的完成源码。内置函数往往返回一个类似 "[native code]" 的字符串作为函数体
new Function ([arg1[, arg2[, ...argN]],] functionBody)
关于 Function() 构造函数有几点需要特别注意:
var scope = "global";
function constructFunction() {
var scope = "local";
return new Function("return scope");
}
constructFunction()(); // => "global"
「类数组对象」类似数组但并不是真正的数组,「可调用对象(callable object)」类似于函数但并不是真正的函数。可调用对象在两个 JavaScript 实现中不能算作函数。首先,IE Web 浏览器(IE 6 及之前的版本)实现了客户端方法(如 Window.alert() 和 Document.getElementById()),使用了可调用的宿主对象,而不是内置函数对象,IE 中的这些方法在其它浏览器中都存在,但它们本质上不是 Function 对象。IE 9 将它们实现为真正的函数,因此这类可调用的对象将越来越罕见
另外一个常见的可调用对象是 RegExp 对象,对 RegExp 执行 typeof 运算的结果并不统一,有些返回 "function" 有些返回 "object"。可以使用下面的方法判断是不是真正的函数对象
function isFunction(o) {
return Object.prototype.toString.call(x) === "[object Function]"
}
JavaScript 并不是一种像 List 或 Haskell 的函数式编程语言,但在 JavaScript 中可以像操控对象一样操控函数,也就是说可以在 JavaScript 中应用函数式编程技术
假设有一个数组,元素都是数字,我们想要计算这些元素的平均值和标准差。若使用非函数式编程风格的话代码一般会是这样:
var data = [1,1,3,5,5]
var total = 0;
for (var i = 0; i < data.length; i++) {
total += data[i];
}
var mean = total / data.length; // => 3
total = 0;
for (var i = 0; i < data.length; i++) {
var deviation = data[i] - mean;
total += deviation * deviation;
}
var stddev = Math.sqrt(total/(data.length-1)) // => 2
可以使用数组方法 map() 和 reduce() 来实现同样的计算,这种实现极其乘法:
var sum = function(x, y) { return x + y; }
var square = function(x) { return x*x; }
var data = [1,1,3,5,5]
var mean = data.reduce(sum)/data.length;
var deviations = data.map(function(x) { return x-mean; })
var stddev = Math.sqrt(deviations.map(square).reduce(sum)/(data.length-1))
当然 ECMAScript 3 并没有 map, reduce 这两个方法,不过我们也可以自己实现一个 Polyfill,可以参考链接里面的内容
所谓高阶函数(higher-order function)就是操作函数的函数,它接收一个或多个函数作为参数,并返回一个新函数
function not(f) {
return function() {
var result = f.apply(this, arguments);
return !result;
}
}
var even = function(x) {
return x % 2 == 0;
}
var odd = not(even);
[1,1,3,5,5].every(odd) // => true
mapper() 函数也是一个高阶函数,它接收一个函数作为参数,并返回一个新函数,这个新函数将一个数组映射到另一个使用这个函数的数组上,这个函数使用了之前定义的 map() 函数
function mapper(f) {
return function(a) { return map(a, f); }
}
var increment = function(x) { return x + 1; }
var incrementer = mapper(increment);
incrementer([1,2,3]) // => [2,3,4]
还有一个更常见的例子,它接收两个函数 f() 和 g(),并返回一个新的函数用以计算 f(g())
function compose(f, g) {
return function() {
return f.call(this, g.apply(this, arguments))
}
}
var square = function(x) { return x * x; }
var sum = function(x, y) { return x + y; }
var squareofsum = compose(square, sum)
squareofsum(2, 3) // => 25
/* - 伪代码执行过程大致如下 -
arguments: 2, 3
return square.call(this, sum.apply(this, arguments))
return square.call(this, sum(2, 3))
return square.call(this, 5)
arguments: 5
return square(5)
return 25
*/
函数 f() 的 bind() 方法返回一个新函数,给新函数传入特定的上下文和一组指定的参数,然后调用函数 f()。我们说它把函数「绑定至」对象并传入一部分参数。bind() 方法只是将实参放在左侧,也就是说传入 bind() 的实参都是放在传入原始函数的实参列表开始的位置,但有时我们期望将传入 bind() 的实参放在右侧
// 将类数组对象转换为真正的数组
function array(arr, n) { return Array.prototype.slice.call(arr, n || 0); }
// 这个函数的实参传递到左侧
function partialLeft(f) {
var args = arguments;
return function() {
var a = array(args, 1);
a = a.concat(array(arguments))
return f.apply(this, a)
}
}
function partialRight(f) {
var args = arguments;
return function() {
var a = array(arguments)
a = a.concat(array(args, 1))
return f.apply(this, a)
}
}
function partial(f) {
var args = arguments;
return function() {
var a = array(args, 1)
var i = 0, j = 0;
for (; i < a.length; i++) {
if ( a[i] === undefined ) a[i] = arguments[j++];
}
a = a.concat(array(arguments, j))
return f.apply(this, a);
}
}
var f = function(x, y, z) { return x * (y - z) }
partialLeft(f, 2)(3, 4) // => -2 2 * (3-4)
partialRight(f, 2)(3, 4) // => 6 3 * (4-2)
partial(f, undefined, 2)(3, 4) // => -6 3 * (2-4)
上面的 章节 中定义了一个阶乘函数,它可以将上次的计算结果缓存起来。在函数式程序当中,这种缓存技巧叫做「记忆」(memorization)。下面的代码展示了一个高阶函数,memorize() 接收一个函数作为实参,并返回带有记忆能力的函数
function memorize(f) {
var cache = {};
return function() {
// 将实参转换为字符串形式,并胜仗缓存的键名
var key = arguments.length + Array.prototype.join.call(arguments, ",")
if ( key in cache ) {
return cache[key];
} else {
return cache[key] = f.apply(this, arguments)
}
}
}
function factorial (num) {
console.log('Actually invoked.');
if (num < 0) {
return -1;
} else if (num === 0 || num === 1) {
return 1;
} else {
return (num * factorial(num - 1));
}
}
var cached_factorial = memorize(factorial);
cached_factorial(3)
// => 'Actually invoked.'
// => 'Actually invoked.'
// => 'Actually invoked.'
// => 6
cached_factorial(3)
// => 6
/**
* 注意下面的调用方式将不会缓存
* 因为新建了多个闭包,闭包在每
* 调用一次 memorize 就返回一
* 份新的 cache 变量
*/
memorize(factorial)(3)
// => 'Actually invoked.'
// => 'Actually invoked.'
// => 'Actually invoked.'
// => 6
memorize(factorial)(3)
// => 'Actually invoked.'
// => 'Actually invoked.'
// => 'Actually invoked.'
// => 6
1970-01-01 08:00:00
表达式在 JavaScript 中是短语(phrases),那么语句(statements)就是 JavaScript 整句或命令,语句以分号结束。表达式计算出一个值,语句用来执行以使某件事情发生
赋值语句、递增/减运算、delete 运算符删除对象属性、函数调用都是表达式语句
gretting = "Hello " + name;
i *= 3;
count++;
delete o.x;
alert(greeting)
window.close();
Math.cos(x)
cs = Math.cos(x);
逗号运算符将几个表达式连接在一起形成一个表达式,同样,JavaScript 中还可以将多条语句联合在一起,形成一条复合语句(compound statement)。只须用花括号括起来即可,下面几行代码就可以当成一条单独语句
{
x = Math.PI;
cx = Math.cos(x);
console.log("cos(x) = " cx);
}
需要注意的两点:
空语句(empty statement)允许包含 0 条语句,空语句在初化一个数组时偶尔会用到
var a = Array(50);
a // => [undefined,,,,undefined]
for (i = 0; i < a.length; a[i++] = 0) ; // 初始化一个数组,注意末尾的分号不能少
a // => [0,,,0]
这个循环中,所有操作都在表达式 a[i++]=0 中完成,这里并不需要任何循环体。然而 JavaScript 需要循环体中 至少包含一条语句,因此,这里只使用了一个单独的分号来表示一条空语句
var 和 function 都是声明语句,声明语句本身什么也不做,只用来更好地组织代码的语义
var 语句用来声明一个或者多个变量,用法如下:
var name_1 [= value_1] [,..., name_n [= value_n]]
如果 var 语句出现在函数体内,那么它定义的是一个 局部变量,其作用域就是这个函数,如果在顶层代码中使用 var 语句,它声明的是 全局变量,整个程序中都是可用的
全局变量是全局对象的属性。然而通过 var 声明的全局变量 无法 通过 delete 删除
如果 var 语句中的变量没有指定初始化表达式,那么这个变量的值初始为 undefined
函数声明的语句的语法如下:
function fun_name([arg1 [, arg2 [..., argn]]]) {
statements
}
var f = function(x) { return x+1; }; // 通过 var 声明函数
function f(x) { return x+1; }
if (expression) {
statement
}
这种形式中,需要计算 expression 的值,如果结果是真值,那么就执行 statement
为了避免歧义,建议 总是 给 if 语句添加花括号
if (expression) {
statement
} else if (expression) {
statement
}
switch(expression) {
statement
}
var count = 0;
while (count < 10) {
console.log(count);
count++
}
function printArray(a) {
var len = a.length, i = 0;
if (len == 0) {
console.log('Empty Array);
} else {
do {
console.log(a[i]);
} while(++i < len);
}
}
for 循环的 执行顺序 是:
for (initialize; test; increment) {
statement
}
多数情况下与之等价的 while 循环写法:
initialize;
while(test) {
statement
increment;
}
for (variable in object) {
statement
}
variable 通常是一个变量名(也可以是个表达式),也可以是一个可以产生左值的表达式或者一个通过 var 语句声明的变量,总之必须是一个适用于赋值表达式左侧的值。object 是一个 表达式,这个表达式计算结果是一个对象
在执行 for/in 语句的过程中,JavaScript 解释器首先计算 object 表达式。如果表达式为 null 或者 undefined,解释器将会跳过循环并执行后续代码(ECMAScript 3 可能会抛出一个类型错误异常)。如果表达式等于一个原始值,这个原始值将会转换为与之对应的 包装对象(wrapper object)否则,expression 本身已经是对象了。JavaScript 会依次遍历 可枚举 的对象属性来执行循环体语句
for/in 循环并不会遍历对象的所有属性,只有「可枚举」(emumerable)的属性才会遍历到。JavaScript 语言核心所定义的内置方法就 不是「可枚举的」,比如,所有对象都有方法 toString(),但 for/in 循环并不枚举 toString 这个属性,还有很多内置属性也是不可枚举的(nonenumerable)。而代码中定义的所有属性和方法都是可枚举的
属性枚举的顺序
ECMAScript 规范并没有指定 for/in 循环按照何种顺序来枚举对象属性。但实际上,主流浏览器厂商的 JavaScript 实现是按照 属性定义的先后顺序 来枚举简单对象的属性
JavaScript 中另一类语句是跳转语句(jump statement)。通常有 break, continue, return, throw
语句是可以添加标签的,标签由语句前的标识符和冒号组成:
indetifier: statement
标识符必须是一个合法的 JavaScript 标识符
mainloop: while(token != null) {
// statement
continue mainloop;
}
单独使用 break 语句的作用是立即退出最内层的 循环 或者 switch 语句,break 关键字后面也可以跟一个语句标签,当 break 和标签一块使用时,程序将跳转到这个标签所标识的语句块的结束
不管 break 语句带不带标签,它的控制权都无法超过函数的边界
类似于 break,但是它不退出循环,而是转而执行下一次循环。continue 语句只能在循环体内使用,其它地方使用会报错
在不同类型的循环中,continue 的行为也是有所区别:
需要注意的是 continue 语句在 while 和 for 循环中的区别,while 循环直接进入一下轮的循环条件判断,但 for 循环首先计算其 increment 表达式,然后判断循环条件,所以 for 循环并不能完全等价模拟出 while 循环
// while 语句中的写法会造成死循环,for 语句则不会
// for 语句中的 increment 表达式总是会执行到
var i = 0;
while (i < 10) {
if (i < 5 ) {
continue;
}
console.log(i);
i++;
}
for (var k = 1; k < 10; k++) {
if (k < 5) {
continue;
}
console.log(k);
}
return expression;
return 语句 只能 出现在函数体内,如果不是的话会报语法错误。当执行到 return 语句的时候,函数终止执行,并返回 expression 的值给调用程序,例如:
function square(x) { return x*x; }
square(2) // => 4
return 可以单独使用而不必带有 expression,这样的话函数会向调用程序返回 undefined
所谓异常(exception)是当发生了落地生根异常情况或错误时产生的一个信号。抛出异常(throw exception),就是用信号通知发生错误或者异常头部。捕获(catch)异常是指处理这个信号,即采取必要的手段从异常中恢复
throw expression;
expression 的值可以是任意类型的。当 JavaScript 解释器抛出异常的时候通常采用 Error 类型和其子类型
function factorial(x) {
// 如果输出参数是非法的,则抛出一个异常
if (x < 0) throw new Error('x 不能是负数');
for (var f = 1; x > 1; f*= x, x--) ;
return f;
}
当异常招聘时,JavaScript 解释器会 立即停止 当前正在执行的逻辑,并跳转到 就近的 异常处理程序。异常钼是程序是用 try/catch/finally 语句的 catch 从句编写的,JavaScript 会沿着方法的词法结构和调用栈向上传播
try 从句定义了需要处理的异常所有代码块。catch 从句跟在其后,当 try 块内某处发生了异常时,调用 catch 内的代码逻辑。catch 从句后跟随 finally 块,后者中放置清理代码,不管 try 块中是否产生异常,finally 块内的逻辑总是会执行。尽管 catch 和 finally 都是可先的,但 try 从句需要至少二者之一(catch/finally)与之组成完整的语句。
try, catch 和 finally 语句块都 必须 使用花括号括起来,即使只有一条语句
try {
// 通常来讲,这里的代码会从头执行到尾而不会产生任何问题,
// 但有时会招聘一个异常,要么是由 throw 语句直接抛出,要
// 么是通过调用一个方法间接抛出异常
} catch (e) {
// 当且仅当 try 语句块抛出了异常,才会执行这里的代码
// 这里可以通过局部变量 e 来警告对 Error 对象或者抛出的其他值的引用
// 还可以通过 throw 语句重新抛出异常
} finally {
// 不管 try 语句是否抛出了异常,这里的逻辑总是会执行,终止 try 语句块的方式有:
// 1. 正常终止,执行完语句块的最后一条语句
// 2. 通过 break, continue 或 return 语句终止
// 3. 抛出一个异常,异常被 catch 从句捕获
// 4. 抛出一个异常,异常未被捕获,继续向上传播
}
一般来说 JavaScript 使用 try/catch 语句的时候很少使用 finally。通常在一些后端语言 IO 操作中使用 finally 的比较多,比如打开一个文件,出现异常或者正常执行完 try 从句都需要关闭文件句柄
with, debugger 和 use strict
with 语句用于临时扩展作用域链,语法如下:
with (object) {
statement
}
这条语句将 object 添加到 作用域链的头部,然后执行 statement,最后把作用域链恢复到原始状态
严格模式中是禁止使用 with 语句的,并且在非严格模式里也是 不推荐 使用 with 语句的。使用 with 语句的 JavaScript 代码非常难于优化,并且和没有使用 width 语句的代码相比,运行更慢
在对象嵌套层次很深的时候通常会使用 with 语句来简化代码编写。比如:
document.forms[0].address.value = 'a'
document.forms[0].name.value = 'b'
document.forms[0].job.value = 'c'
// 等价于
with (document.forms[0]) {
address.value = 'a'
name.value = 'b'
job.value = 'c'
}
// 使用 with 语句减少了对象访问前缀,但是仍然可以不使用 with 解决这个问题
// 使用变量 f 缓存对象引用
var f = document.forms[0];
f.address.value = 'a'
f.name.value = 'b'
f.job.value = 'c'
只有在查找标识符的时候才会用到作用域链,创建新的变量的时候不使用
var d = 0;
var o = { a: 1, b: 2, c: 3};
with(o) {
a = 2;
d = 1
}
d // => 1
o // => {a: 2, b: 2, c: 3}
debugger 语句通常什么也不做。当调试程序可用并运行的时候,JavaScript 解释器将会(非必需)以调试模式运行。这条语句用来产生一个断点(breakpoint),JavaScript 代码的挂靠会停止在断点的位置,这时可以使用调试器转出当前的变量、调用栈等
ECMAScript 5 中,debugger 语句正式加入到了语言规范里,在此之前注流浏览器厂商基本都已经实惠过了
'use strict' 是 ECMAScript 5 引入的一条指定。非常类似语句但不是,区别在于:
使用 'use strict' 指令的目的是说明(脚本或函数中)后续的代码将会解析为严格代码
严格代码以 严格模式 执行,严格模式悠了语言的重要缺陷,并提供健壮的查氏功能和增强的安全机制,和非严格模式的区别如下:
var hasStrictMode = (function() { "use strict"; return this === undefined }())1970-01-01 08:00:00
对象是 JavaScript 的基本数据类型。是一种复合值:将很多值聚合在一起。对象可以看做是无序集合,每个属性都是一个名/值对。这种基本数据结构还有很多叫法,比如「散列」(hash)、「散列表」(hashtable)、「字典」(dictionary)、「关联数组」(associative array)。JavaScript 还可以从一个称为 原型 的对象继承属性
JavaScript 对象是动态的 —— 可以新增属性也可以删除属性,除了字符串、数字、布尔值、null 和 undefined 之外,JavaScript 中的值都是对象
对象是可变的,通过引用操作对象原对象也会受到影响
属性包括名字和值。名字是可以包含空字符串在内的 任意字符串,值可以是任意 JavaScript 值,或者(在 ECMAScript 5中)可以是一个 getter 或者 setter (或都有),每个属性还有一些与之相关的值称为「属性特性」(property attribute):
ECMAScript 5 之前,通过代码给对象创建的所有属性都是可写、可枚举和可配置的
除了包含属性之外,每个对象还拥有三个相关的对象特性(object attribute):
下面这些术语用来区分三类 JavaScript 对象和两类属性:
var empty = {}
var point = { x:0, y:0 }
var point2 = { x:point.x, y:point.y + 1 }
var book = {
"main title": "JavaScript",
"for": "all audiences",
author: {
firstname: "David",
surname: "Flanagan"
}
}
在 ECMAScript 5 中,保留字可以用做不带引号的属性名。然后对于 ECMAScript 3 来说,使用保留字作为属性名必须使用引号引起来。ECMAScript 5 中属性最后一个逗号会被忽略,但在 IE 中则报错
new 运算符创建并初始化一个新对象。new 后跟随一个函数调用。这里的函数称做构造函数(constructor),用来初始化一个新创建的对象。JavaScript 语言核心的原始类型都包含内置构造函数(另一方面也证实了 JavaScript 中一切皆对象)
var o = new Object();
var a = new Array();
var d = new Date();
var r = new RegExp('js');
每一个 JavaScript 对象(null 除外)都和另一个对象相关联,这个对象就是「原型」,每一个对象都从原型继承属性
通过 new 创建的对象原型就是构造函数的 prototype 属性值,通过 new Object() 创建的对象也继承自 Obejct.property
没有原型对象的为数不多,Obejct.prototype 就是其中之一。它不继承任何属性,普通对象都具有原型。所有的内置构造函数都具有一个继承自 Object.prototype 的原型。例如,Date.prototype 的属性继承自 Object.prototype,因此由 new Date() 创建的 Date 对象的属性现时继承自 Date.prototype 和 Object.prototype,这一系列链接的原型对象就是所谓的「原型链」(prototype chain)
ECMAScript 5 定义了一个名为 Obejct.create() 的方法,用来创建一个新对象,其中第一个参数是这个对象的原型,第二个可选参数用来对对象的属性进行进一步描述,Object.create() 是一个 静态函数,不是提供给对象调用的方法
var o1 = Object.create({ x:1, y:2 }); // o1 继承了属性 x 和 y
var o2 = Obejct.create(null); // o2 不继承任何属性和方法
在 ECMAScript 3 中可以用类似代码来模拟原型继承:
function inherit(p) {
if (p == null) throw TypeError();
if (Object.create) return Object.create(p);
var t = typeof p;
if (t !== "object" && t !== "undefined") throw TypeError();
function f() {}
f.prototype = p;
return new f();
}
var o = { x: "test o" }
var c = inherit(o);
c.x = "test c";
console.log(c.x); // => "test c"
console.log(o.x); // => "test o"
var author = book.author; // 取得 book 的 author 属性
var title = book["main title"]; // 使用 [] 访问属性时 [] 内必须是一个计算结果为字符串的表达式
book.edition = 6; // 给 book 创建一个名为 edition 的属性,「.」号运算符后的标识符不能是保留字
当通过 [] 来访问对象属性时,属性名通过字符串来表示。字符串是 JavaScript 的数据类型,在程序运行时可以修改创建它们。因此,可以在 JavaScript 中使用下面这种代码来动态添加/查找属性:
var addr = "";
for (i = 0; i < 4; i++) {
addr += customer["address" + i] + '\n';
}
假设要查询对象 o 的属性 x,如果 o 中不存在 x,那么将会继续在 o 的原型对象中查询属性 x。如果原型对象中也没有 x,但这个原型对象还有原型,那么继续在这个原型对象的原型上执行查找,直到找到 x 或者找到一个原型是 null 的对象为止。可以看出来,原型的属性构成了一个「链接」,通过这个「链」可以实现属性的继承
var o = {}
o.x = 1;
var p = inherit(o);
p.y = 2;
var q = inherit(p);
q.z = 3;
var s = q.toString(); // => "[object Object]"
q.x + q.y // => 3
属性访问并不总是返回或设置一个值,下页场景给对象 o 设置 属性 p 会失败:
使用 delete 运算符可以删除对象的属性,delete 运算符只能删除 自有属性,不能删除继承属性(要删除继承属性必须从定义这个属性的原型对象上删除它,而且这会影响到所有继承自这个原型的对象)
如果删除成功或者删除了一个没有影响的值(不存在的属性),delete 表达式返回 true。当 delete 运算符的操作数不是一个对象的属性的时候也返回 true
var o = { x: 1 }
delete o.x; // => true
delete o.x; // => true x 并不存在
delete o.toString; // => true toString 是继承属性
delete 1 // => true 不是对象属性
this.b = 1;
delete b; // => true 删除全局对象上的变量 b
delete Object.property // => false
var x = 1;
delete this.x; // => false 不能删除这个属性,因为是通过 var 声明的
function f() {}
delete f // => false 不能删除全局函数
可以通过 in 运算符、hasOwnProperty() 方法和 propertyIsEnumerable() 方法来检测对象是否存在某属性,propertyIsEnumerable 只有检测到是自有属性且这个属性的可枚举性为 true 时它才返回 true
var o = { x: 1 };
"x" in o; // => true
"y" in o; // => false
"toString" in o // => true
o.hasOwnProperty("x") // => true
o.hasOwnProperty("y") // => false
o.hasOwnProperty("toString") // => false
var o = inherit({ y: 2});
o.x = 1;
o.propertyIsEnumerable("x") // => true
o.propertyIsEnumerable("y") // => false
o.propertyIsEnumerable("toString") // => false
还可以通过判断属性是否是 undefined 来模拟 in 运算符
o.x !== undefined; // => true
o.y !== undefined; // => false
o.toString !== undefined; // => true
然而有一种场景只能使用 in 运算符而不能通过只判断 undefined 的方式。in 可以区分不存在的属性和存在但值为 undefined 的属性
var o = { x: undefined }
o.x !== undefined // => false 存在 x,只是值为 undefined
o.y !== undefined // => false
"x" in o // => true
"y" in o // => false
delete o.x // => true
"x" in o // => false delete 后 o 完全不存在了
许多工具库给 Object.prototype 添加了新的方法或者属性(通常不建议这么做),这些方法和属性可以被所有对象继承并使用。然而在 ECMAScript 5 标签之前,这些添加的方法是 不能定义为不可枚举的,因此它们都可以在 for/in 循环枚举出来。为了避免这和践情况,需要过滤 for/in 循环返回的属性,下面两种方法是最常见的:
Object.prototype.test = 1;
var o = { a: 1, b:2, c: function() {} };
for (p in o) {
if (!o.hasOwnProperty(p)) continue;
console.log(p);
}
for (p in o) {
if (typeof o[p] === "function") continue;
}
除了 for/in 循环之外,ECMAScript 5 定义了两个用以枚举属性名称的函数。第一个是 Object.keys(),它返回一个数组,由对象中的 可枚举的自有属性名称 组成,第二个是 Object.getOwnPropertyNames(),它和上面的方法类似,只是它返回对象的 所有自有属性名称,不仅仅是可枚举的属性
在 ECMAScript 5 中,属性的值可以用一个或两个方法替代,这两个方法就是 getter 和 setter。由它们定义的属性称做「存取器属性」(accessor property),不同于「数据属性」(data property),数据属性只有一个简单的值
当程序查询存取器属性的值时,JavaScript 调用 getter 方法(无参数)。这个方法返回属性的存取表达式值。当程序设置一个存取器属性的值时,调用 setter 方法,将赋值表达式右侧的值当做参数传入 setter。从某种意义上讲,这个方法负责「设置」属性值。可以忽略 setter 方法的返回值
使用存取器属性写入的属性不具有可写性(writable)。如果属性同时具有 getter 和 setter 方法,那么它是一个读/写属性。哪果它只有 getter 方法,那么它是一个只读属性。如果只有 setter 方法,那么它是一个只写属性,读取只写属性总是返回 undefined
var p = {
x: 1.0,
y: 1.0,
get r() {
return Math.sqrt(this.x*this.x + this.y*this.y);
},
set r(newValue) {
var oldValue = Math.sqrt(this.x*this.x + this.y*this.y);
var ratio = newValue/oldValue;
this.x *= ratio;
this.y *= ratio;
},
get theta() {
return Math.atan2(this.y, this.x)
}
};
p.r // => 1.4142135623730951
除了包含名字和值之外,属性还包含一些标识它们可写、可枚举和可配置的特性。ECMAScript 3 程序创建的属性都是可写、可枚举、可配置的,且无法对这些特性做出修改。ECMAScript 5 中却提供了查询和设置这些属性鹅的 API,这些 API 对于库的开发者来说非常重要,因为:
数据属性 的 4 个属性分别是它的值(value)、可写性(writable)、可枚举性(enumerable)和可配置性(configurable)
存取器属性 不具有值(value)特性和可写性,它们的可写性是由 setter 方法存在与否决定,因此存取器属性的 4 个特性是读取(get)、写入(set)、可枚举性和可配置性
为了实现属性特性的查询和设置操作,ECMAScript 5 中定义了一个名为「属性描述符」(property descriptor)的对象,这个对象代表那 4 个特性。描述符对象的属性和它们所描述的属性特性是同名的。因此,数据属性的描述符对象的属性有 value, writable, enumerable 和 configurable。存取器属性描述符对象则用 get, set 属性代替 value, writable。其中 writable、enumerable 和 configurable 都是布尔值,get、set 都是函数值
通过调用 Object.getOwnPropertyDescriptor() 可以获得某个对象特定属性的属性描述符
// => {value: 1, writable: true, enumerable: true, configurable: true}
Object.getOwnPropertyDescriptor({ x: 1}, "x")
var random = {
get octet() {
return Math.floor(Math.random() * 256)
},
get uint16() {
return Math.floor(Math.random() * 65536)
},
get int16() {
return Math.floor(Math.random() * 65536 - 32768)
}
}
// => {set: undefined, get: function, enumerable: true, configurable: true}
Object.getOwnPropertyDescriptor(random, "octet")
// => undefined
Object.getOwnPropertyDescriptor({}, "x")
从函数名字就可以看出来 Object.getOwnPropertyDescriptor() 只能得到自有属性的描述符。继承属性的特性需要遍历原型链
要想设置属性的特性,或者让新建属性具有某种特性,则需要调用 Object.defineProperty(),传入要修改的对象、要创建或者修改的属性的名称以前属性描述符对象:
var o = {};
Object.defineProperty(o, "x", {
value: 1,
writable: true,
enumerable: false,
configurable: true
});
// x 属性存在但不可枚举
Object.keys() // => []
Object.defineProperty(o, "x", { writable: false })
o.x = 2 // 试图更改这个属性的值,会操作失败不报错,严格模式中则抛出类型错误异常
o.x // => 1
// 将 x 从数据属性修改为存取器属性
Object.defineProperty(o, "x", { value: 2 })
Object.defineProperty(o, "x", { get: function() { return 0} }
o.x // => 0
传入 Object.defineProperty() 的属性描述符对象 不必 包含所有 4 个特性。对于创建属性来说,默认的特性值是 false 或 undefined。对于修改的已有属性来说,默认的特性值没有做任何修改。注意,这个方法要么修改已有属性要么新建自胡属性,但 不能修改继承属性,想要同时修改或者创建多个属性则需要使用 Object.defineProperties(),使用方法可以参考 MDN 相关 api
对于那些不允许创建或者修改的属性来说,如果用 Object.defineProperty() 对其操作就会抛出类型错误异常,比如给一个不可扩展的对象新增属性就会抛出类型错误异常。可写性控制着对特定值特性的修改,可配置性控制着对其它特性的修改,使用的时候以下情况会抛出类型错误异常:
// 给 Object.prototype 添加一个不可枚举的 extend() 方法
// 这个方法继承自调用它的对象,将作为参数什入的对象属性都复制
Object.defineProperty(Object.prototype, "extend", {
writable: true,
enumerable: false,
configurable: true,
value: function(o) {
var names = Object.getOwnPropertyNames(0);
for (var i = 0, l = names.length; i < l; i++) {
if (names[i] in this) continue;
var desc = Object.getOwnPropertyDescriptor(o, name[i]);
Object.defineProperty(this, names[i], desc)
}
}
});
getter 和 setter 的老式 API
在ECMAScript 5标准被采纳之前,大多数 JavaScript 的实现(IE 除外)已经可以支持对象直接量语法中的 get 和 set 写法。这些实现提供了非标准的老式 API 用来查询和设置 getter 和 setter。这些 API 由 4 个方法组成,所有对象都拥有这些方法。 **lookupGetter**() 和 **lookupSetter**() 用以返回一个命名属性的 getter 和 setter 方法, **defineSetter**() 和 **defineGetter**() 用以定义 getter 和 setter
每个对象都胡与之相关的 原型(prototype)、类(class)和 可扩展性(extensible attribute)
原型属性是在实例对象创建之初就设置好的,ECMAScript 5 中,对象作为参数传入 Object.getPrototypeOf() 可以查看它的原型,在 ECMAScript 3 中,则没有与之等价的函数,但经常使用表达式 o.constructor.prototype 来检测一个对象的原型。通过 new 表达式创建的对象,通常继承一个 constructor 属性,这个属性指代创建这个对象的构造函数
要想检测一个对象是否是另一个对象的原型(或者处于原型链中),请使用 isPrototypeOf() 方法,这个方法和 instanceof 运算符非常类似,例如:
var p = { x:1 };
var o = Object.create(p);
p.isPrototypeOf(o) // => true
Object.prototype.isPrototypeOf(o) // => true
对象的类属性是一个字符串,用以表示对象的类型信息。ECMAScript 3/5 都未提供设置这个属性的方法,并只有一种间接的方法可以查询它。默认的 toString() 方法(继承自 Object.prototype),返回了如下这种格式的字符串:
[object class]
所以可以通过 toString() 方法返回的字符串截取处理取到 class 名,不过很多对象继承的 toString() 方法被重写了,为了能调用正确的 toString() 版本,必须间接地调用 Function.call() 方法
function classof(o) {
if (o === null) return "Null";
if (o === undefined) return "Undefined";
return Object.prototype.toString.call(o).slice(8, -2);
}
classof(null) // => "Null"
classof(1) // => "Number"
classof("") // => "String"
classof(true) // => "Boolean"
classof({}) // => "Object"
classof([]) // => "Array"
classof(/./) // => "Regexp"
classof(new Date) // => "Date"
function f() {}
classof(new f()) // => "Object"
可扩展性用以表示是否可以给对象是添加新属性。所有内置对象和自定义对象都是显式可扩展的,宿主对象的可扩展属性是由 JavaScript 引擎定义的,ECMAScript 5 中,所有的内置对象和自定义对象都是可扩展的,除非将它们转换为不可扩展的,宿主对象的可扩展性也是由实现 ECMAScript 5 的 JavaScript 引擎定义的
ECMAScript 5 定义了用来查询和设置对象可扩展性的函数:Object.isExtensible(),如果将对象转换为不可扩展的,需要调用 Object.preventExtensions(),不过一量旦将对象转换为不可扩展的,就无法再转换回去了。
Object.seal() 和 Object.preventExtensions() 类似,除了能将对象设置为不可扩展的,还可以将对象的所有自有属性都设置为不可配置的,也就是说不能给对象添加新的属性,已有的属性也不能删除或配置,已封闭(sealed)的对象是不能解封的,可以使用 Object.isSealed() 来检测对象是否封闭
Object.freeze() 将更严格地锁定对象 —— 「冻结」,它还可以将它自有的所有数据属性设置为只读,可以使用 Object.isFrozen() 来检测对象是否冻结
对象序列化(serialization)是指将对象的状态转换为字符串,也可将字符串还原为对象。ECMAScript 5 提供了内置函数 JSON.stringify 和 JSON.parse() 用来序列化和还原 JavaScript 对象。这些方法都使用 JSON 作为数据交换格式,JSON的全称是「JavaScript Object Notation」—— JavaScript 对象表示法,正如其名,它的语法和 JavaScript 对象与数组直接量的语法非常相近
ECMAScript 3 环境中可以引用 json2 类库来支持这两个序列化函数
JSON 语法是 JavaScript 语法的子集,它并不能表示 JavaScript 里的所有值,函数、RegExp、Error 对象和 undefined 值不能序列化和不愿。JSON.stringify() 只能序列化对象可枚举的自有属性,关于 JSON 对象更多 API 可以参考 JSON.stringify
toString() 方法没有参数,在需要将对象转换为字符串的时候,JavaScript 都调用这个方法
var s = { x: 1, y: 1 }
s.toString(); // => "[object Ojbect]"
返回一个对象的本地化字符串。Object 中默认的 toLocaleString() 方法并不做任何本地化自身操作,它仅调用 toString() 方法并返回值。Date 和 Number 类对 toString() 方法做了定制,可以用它对数字、日期和时间做本地化的转换
Object.prototype 实际上不有定义 toJSON() 方法,但对于需要执行序列化的对象来说,JSON.stringify() 方法会调用 toJSON() 方法,如果存在则调用它,返回值即是序列化的结果,而不是原始对象,参见 Date.toJSON
valueOf() 和 toString() 方法非常类似,但往往当 JavaScript 需要 将对象转换为某种原始值而非字符串 的时候才会用到它,尤其是转换为数字的时候。如果在需要使用原始值的上下文中使用了对象,JavaScript 就会自动调用这个方法,同样有些内置类自定义了 valueOf() 方法,比如 Date.valueOf
1970-01-01 08:00:00
数组是值的 有序集合。每个值(任意 JavaScript 数据类型)叫做一个元素,元素在数组中的位置叫索引。JavaScript 数组是无/弱类型的(untyped),数组元素可以是任意类型
JavaScript 数组是 动态的,根据需要它们会增长或缩减,创建的时候不须要声明一个固定的大小
JavaScript 数组可能是 稀疏的,数组元素索引不一定要连续
JavaScript 数组是 JavaScript 对象的特殊形式。数组的实现是经过优化的,用数字索引来访问数组元素一般来说比访问常规的对象属性要 快很多
var empty = []; // 使用数组直接量创建一个空数组
var primes = [2, 3, 5, 7, 11];
var base = 1024;
var misc = [1.2, true, "a", base + 1, [1,2,3], { a: 1}] // 元素可以是任意值,甚至表达式
var count = [1, ,3]; // 数组有三个元素中间那个值为 undefined
var a = new Array(); // 调用构造函数 Array() 也可以创建数组
var a = new Array(10);
a.length; // => 10 创建一个长度为 10 的数组
var a = new Array(1, 2, 3);
a; // => [1, 2, 3]
使用方括号 [] 操作符来访问数组中的一个元素,方括号左边是数组的引用,右边是一个返回 非负整数值 的任意表达式
var a = ["world"];
a[0] // => "world"
a[1] = 3.14 // => 写入第 1 个元素 3.14
a // => ["world", 3.14]
i = 2;
a[i] = 3; // => 写入第 2 个元素
a[i+1] = "hello"; // => 写入第 2 个元素
可以使用负数或者非整数来索引数组。这种情况下,数值转换为字符串,字符串作为属性名来用。既然名字不是非负整数,它就只能当做常规的对象属性,而非数组的索引。同样如果如果凑巧使用了非负整数的字符串,它就当做数组索引,而非对象属性
a[-1.23] = true // 给数组 a 创建一个名为 "-1.23" 的属性
a["1000"] = 0 // 这是数组的第 1001 个元素
a[1.000] // 和 a[1] 相等
事实上数组索引仅仅是对象属性名的一种特殊类型,这意味着 JavaScript 数组 没有越界 错误的概念。当试图查询任何对象中不存在的属性时,不会报错,只会得到 undefined 值,这一点类似于对象
通常,数组的 length 属性代表数组中的元素个数。如果是稀疏数组,length 属性值大于元素个数。当在数组直接量中省略值是不会创建稀疏数组。省略的元素是存在的只是值为 undefined。使用 Array() 构造函数或者手动指定 length 大于当前的数组可以创建稀疏数组
a = new Array(5); // 数组没元素,但 a.length 是 5
a = [];
a[1000] = 0; // 赋值添加一个元素,但设置 length 为 1001
var a1 = [,,,]; // 数组是 [undefined, undefined, undefined]
var a2 = new Array(3);
var a3 = [1,,3];
0 in a1 // => true 非稀疏数组
0 in a2 // => false 稀疏数组
1 in a3 // => false 稀疏数组
在一些旧版的实现中,[1,,3] 和 [1, undefined, 3] 却是一模一样的
每个数组都有一个 length 属性,就是这个属性使其区别于常规的 JavaScript 对象。针对稠密数组,length 属性值代表数组中元素的个数,其值比数组中最大的索引大 1
数组有两个 特殊行为:
a = [1,2,3,4,5];
a.length = 3;
a // => [1,2,3]
a.length = 0;
a.length = 5; // 长度为 5,类似 new Array(5)
数组也继承了对象的一些方法,比如 Object.defineProperty(), 可以使用这个方法让数组的 length 属性变成只读
a = [1,2,3]
Object.defineProperty(a, "length", {
writable: false
});
a.length = 0
a // => [1,2,3] 不会改变
可以给新的索引赋值来添加元素,也可以调用 Array 对象的内置方法 push() 来在数组 末尾 增加一个或者多个元素,或者用 unshift() 给数组头部插入一个元素,并且将其它元素依次移动到更高的索引处
a = []
a[0] = "zero"
a[1] = "one"
a // => ["zero", "one"]
a = []
a.push("zero")
a.push("one", "two")
a // => ["zero", "one", "two"]
a.unshift(0)
a // => [0, "zero", "one", "two"]
可以使用 delete 运算符来删除数组元素,效果和对数组元素赋值 undefined 类似,使用 delete 删除数组后数组的长度是不变的
使用 for 循环是遍历数组元素最常见的方法,for/in 也可以但并不推荐
var keys = Object.keys(o);
var values = [];
for (var i = 0; i < keys.length; i++) {
var key = keys[i];
values[i] = o[key]
}
for (var i = 0; i < keys.length; i++) {
if (!a[i]) continue; // 跳过 null, undefined 和不存在的元素
}
for (var i = 0; i < keys.length; i++) {
if (!(i in a)) continue; // 只跳过不存在的元素
}
for (var i in a) {
if (!a.hasOwnProperty(i)) continue; // 跳过继承属性
}
ECMAScript 5 定义了一些遍历数组元素的新方法,比如 forEach()
[1,2,3,4,5].forEach(function(x) {
console.log(x);
});
JavaScript 并不支持真正的多维数组,但可以模拟出来
var table = new Array(10);
for (var i = 0; i < table.length; i++) {
table[i] = new Array(10);
}
for (var row = 0; row < table.length; row++) {
for (var col = 0; col < table[row].length; col++) {
table[row][col] = row * col;
}
}
table[5][7]; // => 35
将所有元素都转化为字符串并通过分隔符链接起来,分隔符默认是逗号「,」
与之相反的 split 方法则是把字符串按分割符分割开来并返回数组,并且分割符可以是正则表达式
var a = [1,2,3];
a.join(); // => "1,2,3"
a.join(" ") // => "1 2 3"
a.join("") // => "123"
new Array(10).join('-') // => "----------"
var str = "Hello world";
str.split(' ') // => ["Hello", "world"]
var str = "0a1b2c3d";
str.split(/\d/g); // => ["", "a", "b", "c", "d"]
反转数组元素
var a = [1,2,3];
a.reverse(); // => [3,2,1]
将数组中的元素排序并返回排序后的数组。不带参数调用 sort() 时,数组元素以字母表顺序排序,如果数组包含 undefined 元素,它们会被排到数组的尾部
var a = ["banana", "cherry", "apple"]
a.sort(); // => ["apple", "banana", "cherry"]
sort 方法可以接收一个函数参数,该函数决定了它的两个参数在排好序的数组中的先后顺序。假设第一个参数应该在前,比较函数应该返回一个小于 0 的数值
var a = [3,4,1,2]
a.sort() // [1,2,3,4]
a.sort(function(a, b) {
return b - a
}) // [4,3,2,1]
Array.concat(value1, value2, ..., valueN)
创建并返回一个新数组,它的元素包括调用 concat 的原始数组元素和 concat 的每个参数
var a = [1,2,3]
a.concat(4,5) // => [1,2,3,4,5]
a.concat([4,5]) // => [1,2,3,4,5]
a.concat([4,5], [6,7]) // => [1,2,3,4,5,6,7]
a.concat(4, [5, [6,7]]) // => [1,2,3,4,5,[6,7]]
Array.slice([begin[, end]])
返回指定数组的一个片段或子数组,它的两个参数分别指定了片段的开始和结束的 位置,如果只指定一个参数(开始位置),返回的数组将包含从开始位置到数组结尾的所有元素,如果参数中出现了负数,它表示相对于数组中最后一个元素的位置,slice 不会修改原数组
var a = [1,2,3,4,5]
a.slice(0, 3) // => [1,2,3]
a.slice(3) // => [4,5]
a.slice() // => [1,2,3,4,5]
a.slice(1, -1) // => [2,3,4]
a.slice(-3, -2) // => [3]
Array.splice(start, deleteCount[, item1[, item2[, ...]]])
splice 方法是在数组中插入或删除元素的通用方法,会 修改 调用的数组
splice 能够从数组中删除元素、插入元素到数组中或者 同时完成 这两种操作。在插入或删除点之后的数组元素会根据需要增加或减小它们的索引值,因此数组的其它部分仍然保持连续。splice 第一个参数指定了插入和(或)删除的起始位置。第二个参数指定了应该从数组中删除的元素个数。如果省略第二个参数,从起始点开始到数组结尾的所有元素都将被删除。splice 返回一个由删除元素组成的数组
var a = [1,2,3,4,5,6,7,8]
a.splice(4) // => [5,6,7,8]
a // => [1,2,3,4]
a.splice(1,2) // => [2,3]
a // => [1,4]
a.splice(1,1) // => [4]
a // => [1]
splice 前两个参数指定了需要删除的数组元素。其后任意个数参数指定了需要插入到数组中的元素
var a = [1,2,3,4,5]
a.splice(2, 0, "a", "b") // => 0
a // => [1,2,"a","b",3,4,5]
a.splice(2, 2, [1,2], 3) // => ["a", "b"]
a // => [1,2,[1,2],3,3,4,5]
push 和 pop 方法谲诈将数组当做 栈 来使用,push 方法在数组尾部添加一个或者多个元素,并返回新的数组长度。pop 删除数组的最后一个元素,减小数组长度并返回它删除的值
var stack = [];
stack.push(1,2) // => 2 stack: [1,2]
stack.pop(1,2) // => 1 stack: [2]
stack.push(3) // => 2 stack: [1,3]
unshift 在数组的头部添加一个或者多个元素,shift 删除数组的第一个元素并将其返回
需要注意的是,当使用多个参数调用 unshift() 的时候,参数是一次性插入的,而非一次一个插入。这会影响插入到数组中元素的位置
var a = [4,5,6];
a.unshift(3)
a // => [3,4,5,6]
a.unshift(1,2)
a // => [1,2,3,4,5,6]如果一次一个插入的话结果应该是 [2,1,3,4,5]
forEach() 从头至尾遍历数组,为每个元素调用指定的函数。传递函数作为 forEach() 的第一个参数,然后 forEach() 使用三个参数调用该当函数:数组元素、元素的索引和数组本身。forEach() 无法在所有元素都传递给调用的函数之前终止遍历,除非 forEach() 方法放在一个 try 块中,并抛出一个异常
[1,2,3,4,5].forEach(function(value, index, arr) { arr[i] = v + 1 });
// => [2,3,4,5,6]
map() 方法将调用数组的每个元素传递给指定的函数,并返回一个数组。如果是稀疏数组,返回的也是相同方式的稀疏数组
a = [1,2,3]
b = a.map(function(x) { return x*x })
b // [1, 4, 9]
filter() 方法返回数组元素是调用数组的一个 子集。传递的函数是用来逻辑判定的(true 或 false),如果返回 true 或者能转化为 true 的值,那么传递给判定函数的元素就是这个子集的成员,它将被添加到一个作为返回值的数组中,filter() 会跳过稀疏数组中缺少的元素,总是返回稠密的
a = [5,4,3,2,1]
smallvalues = a.filter(function(x) { return x < 3 }) // [2, 1]
数组的逻辑判定,它们对数组元素应用指定的函数进行判定,返回 true 或 false
a = [1,2,3,4,5]
a.every(function(x) { return x < 10 }) // => true 数组元素都少于 10
a.some(function(x) { return x%2 === 0 }) // => true 数组中有一些值是偶数
注意,一旦 every() 和 some() 确认应该返回什么值时它们就会停止遍历数组元素(可以认为是惰性判断)。即:
Array.reduce(callback, [initialValue])
reduct() 和 reduceRight() 方法使用指定的函数将数组元素进行组合,生成单个值,这在 函数式编程(functional programming) 中是很常见的操作,也可以称为「注入」和「折叠」,他们只是执行化简操作的顺序不一样,一个从左到右,一个从右到左
var a = [1,2,3,4,5]
var sum = a.reduce(function(x, y) { return x + y }, 0) // 数组求和
/**
+---------------------------------+
| |
| x + y return |
| |
| init: 0 a[0]: 1 1 |
| |
| 1 a[1]: 2 3 |
| |
| 3 a[2]: 3 6 |
| |
| 6 a[3]: 4 10 |
| |
| 10 a[4]: 5 15 |
| |
+---------------------------------+
*/
var product = a.reduce(function(x, y) { return x * y }, 1) // 数组求积
reduce 需要两个参数。第一个是执行化简操作的函数,它的任意就是用某种方法把两个值组合或化简为一个值,并返回化简后的值,第二个参数是传递给函数的初始值,如果没有指定初始值,它将使用数组的第一个元素作为其初始值。这意味着第一次调用化简函数就使用了第一个和第二个数组元素作为 x,y
Array.indexOf(searchElement[, fromIndex = 0])
搜索整个数组中指定值的索引,没找到就返回 -1。indexOf() 从头至尾搜索,而 lastIndexOf() 则反向搜索。它们都接收第二个参数,指定数组中的一个索引,从这个索引处开始搜索
a = [0,1,2,1,0]
a.indexOf(1) // => 1
a.lastIndexOf(1) // => 3
a.indexOf(3) // => -1
// 在数组中查找所有出现的 x,并返回一个包含匹配索引的数组
function findall(a, x) {
var results = [];
var len = a.length;
var pos = 0;
while(pos < len) {
pos = a.indexOf(x, pos);
if (pos === -1) break;
results.push(pos)
pos = pos + 1;
}
return results;
}
findall([1,2,3,1,3,2], 1) // => [0, 3]
ECMAScript 5 中可以使用 Array.isArray() 函数来判断是否为数组,在 ECMAScript 5 之前判断却没这么简单,因为 typeof 运算符操作数组返回的是「对象」,一般用下面的方法下判断是否是数组
var isArray = Array.isArray || function(o) {
return typeof o === "object" &&
Object.prototype.toString.call(0) === '[object Array]';
};
JavaScript 数组的一些特性是其他对象没有的:
以下代码为一个常规对象增加了一些属性使其变成类数组对象,然后遍历生成的伪数组的「元素」
var a = {}
var i = 0;
while (i < 10) {
a[i] = i * i;
i++;
}
a.length = i;
a // => { 0: 0, 1: 1, 2: 4, 3: 9 ..., length: 10 }
// 现在就可以当成真正的数组遍历它
var total = 0;
for (var j = 0; j < a.length; j++) {
total+=a[j]
}
Arguments 对象就是一个类数组对象,DOM 方法 document.getElementsByTagName() 也返回类数组对象,它们都有数组的一些特性,比如索引访问、length 属性,但它们并不是真正的数组
function isArrayLike(o) {
if ( o &&
typeof o === "object" &&
isFinite(o.length) &&
o.length >= 0 &&
o.length === Math.floor(o.length) &&
o.length < 4294967296 ) { // 数组长度的最大值 2^32
return true;
} else {
return false;
}
}
JavaScript 数组方法是 特意定义为通用的,它们不仅可以应用在数组而且可以应用在类数组对象上,一般使用 Array.prototype.method.call 来使用
var a = {"0": "a", "1": "b", "2": "c", length: 3};
Array.prototype.join.call(a, "+") // => "a+b+c"
在 ECMAScript 5 中,字符串的行为类似于 只读 的数组。除子用 charAt() 方法来访问单个字符以外,还可以使用方括号:
var s = "test";
s.charAt(0) // => "t"
s.[1] // => "e"
字符串的行为类似于数组的事实使得通用的数组方法可以应用到字符串上。不过请记住,字符串是 不可变值,当把它们作为数组看待时,它们是只读的。所以诸如:push(), sort(), reverse 等 会修改数组 的方法 如果被使用在字符串上是无效的,而且会导致错误并且没有相关提示
s = "JavaScript"
Array.prototype.join.call(s, " ") // => "J a v a S c r i p t"
1970-01-01 08:00:00
表达式(expression)是 JavaScript 中的一个短语(phrases),JavaScript 解释器会将其计算(evaluate)出一个结果。程序中的常量、变量名、数组访问等都是表达式
简单表达式组合成复杂表达式最常用的方法就是使用运算符(operator)
是最简单的表达式是「原始表达式」(primary expression)。是表达式的 最小单位 ———— 不再包含其他表达式。常量、直接量、关键字、变量都是原始表达式
1.23
"hello"
/pattern/
true
false
null
this
i
sum
undefined
对象和数组的始化表达式实际上是一个新创建的对象和数组,这些表达式有时也称做「对象直接量」和「数组直接量」
[]
[1+2, 3+4]
var sparseArray = [1,,,,,5] // 数组分割逗号之前的元素可以省略,空位默认填充 undefined
var matrix = [[1,2,3], [4,5,6], [7,8,9]]
var p = { x: 2.3, y: -1.2}
var q = {}
q.x = 2.3; q.y = -1.3
JavaScript 对数组始化表达式进行求值的时候,数组初始化表达式中的元素表达式也都会各自计算一次。也就是说,数组初始化表达式每次计算的值有可能是不同的
var square = function(x) { return x*x }
// expression.identifier
// expression[expression]
var o = { x:1, y:{z:3} };
var a = [0, 4, [5, 6]];
o.x // => 1 表达式 o 的 x 属性
o.y.z // => 3 表达式 o.y 的属性 z
o["x"] // => 1 对象 o 的 x 属性
a[1] // => 4 表达式 a 中索引为 1 的元素
a[2]["1"] // => 6 表达式 a[2] 中索引为 1 的元素
a[0].x // => 1 表达式 a[0] 的 x 属性
不管使用哪种形式的属性访问表达式,在「.」和「[」 之前的表达式总是会首先计算。如果计算结果是 null 或者 undefined,表达式会抛出一个类型错误异常,因为这两个值都不能包含任意属性。如果运算结果不是对象(或者数组),JavaScript 会将其转换为对象。如果对象表达式后跟随一对方括号,则会计算方括号内的表达式的值并将它转换为字符串, 不论哪种情况,如果命名的属性不存在,那么整个属性访问表达式的值就是 undefined
JavaScript 中的调用表达式(invocation expression)是一种调用(或者执行)函数或者方法的语法表示。它以一个函数表达式开始,后面跟随一对圆括号,括号内是一个以逗号隔开的参数列表
f(0)
Math.max(x, y, z)
a.sort()
new Object()
new Point(2, 3)
// 如果不需要传入参数给构造函数,圆括号可以省略
new Object
new Date
JavaScript 中的运算符用于自述表达式、比较表达式、逻辑表达式、赋值表达式等。大多数运算符都是由标点符号表示的,比如:「+」和「= 」,另外的一些运算符则是由关键字表示的,比如:delete 和 instanceof。
表4-1
| 运算符 | 操作 | A | N | 类型 |
|---|---|---|---|---|
| ++ | 前/后增量 | R | 1 | lval→num |
| -- | 前/后增量 | R | 1 | lval→num |
| - | 求反 | R | 1 | num→num |
| + | 转换为数字 | R | 1 | num→num |
| ~ | 按位求反 | R | 1 | int→int |
| ! | 逻辑非 | R | 1 | bool→bo |
| delete | 删除属性 | R | 1 | lval→bool |
| typeof | 检测操作数类型 | R | 1 | any→str |
| void | 返回 undefined 值 | R | 1 | any→undef |
| *, /, % | 乘、除、求余 | L | 2 | num,num→num |
| +, - | 加减 | L | 2 | num,num→num |
| + | 字符串链接 | L | 2 | str,str→str |
| << | 左移位 | L | 2 | int,int→int |
| >> | 有符号右移 | L | 2 | int,int→int |
| >>> | 无符号右移 | L | 2 | int,int→int |
| <, <=,>, >= | 比较顺序 | L | 2 | num,num→bool |
| <, <=,>, >= | 比较在字母表中的顺序 | L | 2 | str,str→bool |
| instanceof | 测试对象类 | L | 2 | obj,func→bool |
| in | 测试属性是否存在 | L | 2 | str,obj→bool |
| == | 判断相等 | L | 2 | any,any→bool |
| != | 判断不等 | L | 2 | any,any→bool |
| === | 判断恒等 | L | 2 | any,any→bool |
| !== | 判断非恒等 | L | 2 | any,any→bool |
| & | 按位与 | L | 2 | int,int→int |
| ^ | 按位异或 | L | 2 | int,int→int |
| | | 按位或 | L | 2 | int,int→int |
| && | 按位与 | L | 2 | any,any→any |
| || | 逻辑或 | L | 2 | any,any→any |
| ?: | 条件运算符 | R | 3 | bool,any,any→any |
| = | 变量赋值或对象属性赋值 | R | 2 | lval,any→any |
| *=, /=, %=, += -=, &=, ^=, | = <<=, >>=, >>>= |
运算且赋值 | R | 2 | lval,any→any |
运算符可以根据操作数的个数进行分类,JavaScript 中的大多数运算符(比如「*」乘法运算符)是一个二元运算符(binary operator),将两个表达式合并成一个稍复杂的表达式。JavaScript 同样支持一元运算符(unary operator),表达式 -x 中的「-」运算符就是一个一元运算符,是将操作数 x 求负值。JavaScript 支持一个三元运算符(ternary operator),条件判断运算符「?:」,它将三个表达式合并成一个表达式
JavaScript 运算符通常会根据需要对操作数进行类型转换。乘法运算符「*」希望操作数为籽安,但是表达式 "3" * "5" 却是合法的,因为 JavaScript 会将操作数转换为数字。结果是数字类型的 15
一些运算符对操作数类型有着不同程度的依赖。比如加法运算符「+」可以对数字进行加法,也可以做字符串连接。同样「<」比较运算符可以进行数值大小比较,也可以比较字符在字母表中的次序先后
左传是一个古老的术语,它指「表达式只能出现在赋值运算符的左侧」。在 JavaScript 中,变量、对象属性、数组元素均是左值,ECMAScript 规范中允许内置函数返回一个左值,但自定义函数则不能
计算一个简单的表达式(比如 2*3)不会对程序的运行状态造成任何影响,程序后续执行的计算也不会受到该计算的影响。而有一些表达式则具有很多副作用,赋值运算符是最明显的一个例子:如果给一个变量或者属性赋值,那么那些使用这个变量或者属性的表达式的值都会发生改变。「++」和「--」与些类似,因为它们包含 隐式的 赋值。delete 运算符同样有副作用删除一个属性就像(但不完全一样)给这个属性赋值 undefined
如果你不确定你所使用的运算符的优先级,最简单的方法就是使用圆括号来强行指定运算次序
表 4-1 标题为 A 的列说明了运算符的结合性。L 指从左至右结合,R 指从右至左结合。结合性指定了在多个具有同样优先级的运算符表达式中的运算顺序。
w = x - y - z; // 减法运算符具有从左至右的结合性
x = ~-y // 等价于 ~(-y)
w = x = y = z // 等价于 w = (x = (y = z))
q = a?b:c?d:e?f:g // 等价于 q = a?b:(c?d:(e?f:g))
运算符优先级和结合性规定了它们在复杂的表达式中的运算顺序,但并没有规定子表达式的计算过程中的运算顺序。JavaScript 总是严格按照从左至右的顺序来计算表达式。例如,在表达式 w = x + y * z 中,将首先计算子表达式 w, 然后计算 x, y 和 z,然后,y,z 相乘,再加上 x 的值,最后赋值给表达式 w 所指代的变量或者属性
假设存在 a = 1,那么「b = (a++) + a」将如何计算呢?
按照「++」的定义,第 [2] 步中 a++ 的结果依然是 1,即 c 为 1,随后 a 立即增 1, 因此在执行第 [3] 步时,a 的值已经是 2。所以 b 的结果为 3
所有那些无法转换数字的操作数都转换为 NaN 值,如果操作数(或者转换结果)是 NaN 值,算术运算的结果也是 NaN。
加号的转换规则 优先 考虑字符串链接,如果其中一个操作数是字符串或者转换为字符串的对象,另外一个操作数将会转换为字符串,加法将进行字符串的连接操作
加法操作符的行为表现为:
如果其中一个操作数是对象,则对象会遵循对象到原始值的转换规则转换成原始类值:日期对象通过 toString() 方法执行转换,其它对象则通过 valueOf() 方法执行转换(如果 valueOf 谅坂加一个原始值的话)。由于多数对象都不具备可用的 valueOf() 方法,因为它们会通过 toString() 方法来执行转换
1 + 2 // => 3
"1" + "2" // => "12"
"1" + 2 // => "12"
1 + {} // => "1[object Object]"
true + true // => 2
2 + null // => 2
2 + undefined // => NaN
1 + 2 + " blind mice" // => "3 blind mice"
1 + (2 + " blind mice") // => "12 blind mice"
一元运算符作用于一个单独的操作数,并产生一个新值。在 JavaScript 中一元运算符有很高的优先级,而且都是 右结合(right-associative),「+」和「-」是一元运算符,也是二元运算符
一元加运算符把操作数转换为数字(或者 NaN),并返回这个转换后的数字。如果操作数本身就是数字,则直接返回这个数字
当「-」胜仗和一元运算时,它会根据需要把操作数转换为数字,然后改变运算结果的符号
递增「++」运算符对其操作数进行增量(加一)操作,操作数是一个左传(lvalue)(变量、数组元素或对象属性)。运算符将操作数转换为数字,然后给数字加 1,并将加 1 后的数值重新赋值给变量、数组或者对象属性
递增「++」运算符的返回值 依赖于 它相对于操作数的位置。当运算符在操作数之前,称为「前增量」(pre-increment)运算符,它对操作数进行增量计算,并返回计算后的值。当运算符在操作数之后,称为「后增量」(post-increment)运算符,它对操作数进行增量计算,但返回未做增量计算的(unincremented)值
var i = 1, j = ++i; // i,j 都是 2
var i = 1, j = i++; // i 是 2, j 是 1
同递增
位运算符可以对由数字表壳的二进制数据进行更低层级的按位运算
位运算要求它的操作数是整数,这些整数表示为 32 位整数而不是 64 位。必要时运算符先将操作数转换为数字,并将数字强制表示为 32 位整型,这时会魅力原格式中的小数部分和任何超过 32 位的二进制位。移位运算符要求右操作数在 0 ~ 31 之前。在将其操作数转换为无符号的 32 位整数后,它们将作序第 5 位之后的二进制位,以便生成一个位数正确的数字。需要注意的是,位运算符会将 NaN, Infinity, -Infinity 都转换为 0
「==」和「===」运算符用于比较两个值是否相等,两个运算符 允许任意类型 的操作数,如果操作数相等返回 true,否则返回 false。「===」也称为严格相等(strict equality)运算符,有时也称做恒等运算符(identity operator)
严格相等运算符「===」首先计算期操作数的值,然后比较这两个值,比较过程 没有任何类型转换:
相等运算符「==」和恒等类似,但是如果操作数不是同一类型,相等运算符会尝试进行一些类型转换,然后比较:
比较运算符用来检测两个操作数的大小关系(数值大小或者字母表顺序),例如:<, >, <=, >=
比较运算符的操作数可能是任意类型。然而 只有数字和字符串才能真正执行比较操作,因此那些不是数字和字符串的操作都将进行类型转换,规则如下:
需要注意的是,JavaScript 字符串是一个由 16 位整数值组成的序列,字符串的比较也只是两个字符的数值比较。字符串的比较是区分大小写的,所有的大写 ASCII 字母都「小于」小写的 ASCII 字母。比如比较「Zoo」和「aardvark」,结果为 true
1 + 2 // => 3
"1" + 2 // => "12"
"11" < "3" // => true 字符串的比较
"11" < 3 // => false 转换后数字的比较
"one" < 3 // => false 数字的比较,"one"转换成 NaN
注意比较运算符(<=, >=)并没有严格「大、小」于的说法
in 运算符希望它的左操作数是一个字符串或者可以转换为字符串,希望它的右操作数是一个对象。如果右侧的对象拥有一个名为右操作数值的属性名,那么表达式返回 true,例如:
var point = { x:1, y:1 }
"x" in point
"z" in point
"toString" in point
var data = [7,8,9]
"0" in data // => true data["0"]
1 in data // => true data[1]
3 in data // => false data[3]
instanceof 运算符希望左侧操作数是一个对象,右操作数标识对象的类。如果左侧的对象是右侧类的实例,则表达式返回 true,否则返回 false。
var d = new Date();
d instanceof Date; // => true
d instanceof Object; // => true
d instanceof Number; // => false
var a = [1,2,3];
a instanceof Array // => true
a instanceof Object // => true
a instanceof RegExp // => false
需要注意的是,所有的对象都是 Ojbect 的实例。当通过 instanceof 判断一个对象是否是一个类的实例的时候, 这个判断也会包含对「父类」(superclass)的检测。如果左操作数不是对象的话,instanceof 返回 false。如果右操作数不是函数,则抛出一个类型错误异常
如果逻辑与运算符的左操作数转换成逻辑值为假的时候 && 操作符不会去计算右操作数,比如:
var o = { x: 1 }
var p = null;
o && o.x // => 1
p && p.x // => null p 是伟假值,因此将其返回,并不计算 p.x
「&&」的行为有时候称做「短路」(short circuiting),我们经常看到很多代码利用这一我来有条件的执行代码,例如下面两条代码完全等价:
if (a == b) stop();
(a == b) && stop;
|| 会首先计算第一个操作数的值,也就是说会首先计算左侧的表达式。如果计算结果为真值,就返回这个真值。否则,再计算第二个操作数的值,即右侧的表达式,并返回计算结果
通常我们用「||」来从一组备选表达式中选出第一个真值:
var max = max_width || preferences.max_width || 500
function copy(o, p) {
p = p || {} // 用来给函数参数添加默认值
}
// 对于 p 和 q 取任意值,这两个等式都永远成立
!(p && q) === !p || !q
!(p || q) === !p && !q
i = 0
o.x = 1
(a = b) == 0 // b 的值赋给 a 再进行相等判断
i = j = k = 0; // 把三个变量寝化为 0
total += sales_tax // 带操作的赋值运算
total = total + sales_tax // 和上面等价
表4-2
| 运算符 | 示例 | 等价于 |
|---|---|---|
| += | a += b | a = a + b |
| -= | a -= b | a = a - b |
| *= | a *= b | a = a * b |
| /= | a /= b | a = a / b |
| %= | a %= b | a = a % b |
| <<= | a <<= b | a = a << b |
| >>= | a >>= b | a = a >> b |
| >>>= | a >>>= b | a = a >>> b |
| &= | a &= b | a = a & b |
| |= | a |= b | a = a | b |
| ^= | a ^= b | a = a ^ b |
eval() 是一个函数,但是它通常被当成运算符。如果一个池娄调用了 eval(),那么解释器将无法对这个函数做进一步的优化。而将 eval() 定义为函数的另一个问题是,它可以被赋予其他的名字:
var f = eval;
var g = f;
eval() 只有一个参数。如果传入的参数不是字符串,它直接返回这个参数。如果参数是字符串,它会把字符串当成 JavaScript 代码进行编译(parse),如果编译失败则抛出一个语法错误(SyntaxError)异常。如果编译成功,则开始执行这段代码,并返回字符串中的最后一个表达式或者语句的值,如果最后一个表达式或者语句没有值,则最终返回 undefined
eval() 使用了调用它的变量作用域 环境。也就是说,它查找变量的值和定义新变量和函数的操作和局部作用域中的代码完全一样
eval() 具有更改局部变量的能力。ECMAScript 3 标准规定了任何解释器都不允许对 eval() 赋予别名,通过别名调用会抛出一个 EvalError 异常
实际上,大多数的实现并不是这么做的。当通过别名调用时,eval() 会将其字符串当成顶层的全局代码来执行
ECMAScript 5 是返回使用 EvalError 的,并且规范了 eval() 的行为
var geval = eval;
var x = "global", y = "global";
function f() {
var x = "local";
eval("x += 'changed'");
return x
}
function g(){
var y = 'local';
geval("y += 'changed'");
return y
}
console.log(f(), x);
"changed global"
console.log(g(), y);
"globalchanged"
ECMAScript 5 严格模式函数的行为施加了更多的限制,甚至对标识符 eval 的使用也施加了限制。当在严格模式下调用 eval() 时,或者 eval() 执行的代码段以「use strict」指令开始,这里的 eval() 是私有上下文环境中的局部 eval。也就是说,在严格模式下,eval 挂靠的代码段可以查询或者更改局部变量。但不能在局部作用域中定义新的变量或者函数,此外严格模式将「eval」列为保留字,这让 eval() 更像一个运算符。不能用一人上别名覆盖 eval() 函数。并且变量名、函数名、函数参数或者异常捕获的参数都不能取名为「eval」
条件运算符是 JavaScript 中唯一的个三元运算符(三个操作数)。
条件运算符的操作数可以是任意类型。第一个操作数当成布尔值,如果它是真值,那么将计算第二个操作数,并返回其计算结果。否则,如果第一个操作数是假值,那么将计算第三个操作数,并返回期计算结果。第二、三个操作数总是会计算其中一个,不可能同时执行
gretting = "hello " + (username ? username : "there");
// 等价于下面的条件语句
gretting = "hello ";
if (username)
gretting += username;
else
gretting += "there";
typeof 是一元运算符,放在其单个操作数前面,操作数可以是任意类型。返回值为表示操作数类型的一个字符串
表4-3
| 值 | typeof运算结果 |
|---|---|
| undefined | "undefined" |
| null | "object" |
| true/false | "boolean" |
| 任意数字或者NaN | "number" |
| 任意字符串 | "string" |
| 任意函数 | "function" |
| 任意内置对象(非函数) | "object" |
| 任意宿主对象 | 由编译器各自实现的字符串,但不是 "undefined", "boolean", "number", "string" |
delete 是一元运算符,它用来删除对象属性或者数组元素。就像赋值、递增/减运算符一样,delete 也是有副作用的
var o = { x: 1, y: 2 }
delete o.x // => true 删除成功
"x" in o // => false 没有 "x" 元素
var a = [1,2,3]
delete a[2] // => true 删除最后一个元素成功
2 in a // => false 不存在 2 这个元素
a.length // => 3
需要注意的是,删除属性或者数组元素不难舍难分是设置了一个 undefined 值。当删除一个属性时,这个属性将不再存在。庋了一个不存在的属性将返回 undefined,但是可以通过 in 运算符来检测这个属性是否在对象中存在
delete 希望他的操作数是一个左传,如果它不是左传,那么 delete 将 不进行任何操作同时返回 true。否则,delete 将试图删除这个指定的左传。如果删除不成功,delete 将返回 true。然后并不是所有的属性都可删除,一些内置核心和客户端属性是不能删除的,用户通过 var 语句声明的变量、function语句声明的函数 也不能删除
ECMAScript 5 严格模式中,如果 delete 的操作数是非法的,比如变量、函数或者函数参数,delete 操作将抛出一个语法错误(SyntaxError)异常,只有操作数是一个属性访问表达式的时候它才会正常工作。在严格模式下,delete 删除不可配置的属性时会抛出一个错误异常,非严格模式下,不会报错,只是简单地返回了 false
var o = { x:1, y: 2 }
delete o.x // => true
typeof o.x // => "undefined"
delete o.x // => true 删除一个不存在的属性
delete o // => false 不能删除通过 var 声明的变量
delete 1 // => true 参数不是一个左值
this.x = 1 // => 给全局对象一个属性 x,没使用 var
delete x // => 试图删除它,在非严格模式下返回 true,严格模式下会抛出异常,这时只能使用 delete this.x
void 是一元运算符,它出现在操作数之前,操作数可以是任意类型。这个运算符不经常使用:操作数会照常计算,但忽略计算结果并返回 undefined。由于 void 会忽略操作数的值,因为在操作数具有副作用的时候使用 void 来让程序更具语义
这个运算符最学用丰客户端的 URL —— javascript: URL 中,在 URL 中写带有副作用的表达式,而 void 则让浏览器不必显示这个表达式的计算结果
<a href="javascript: void window.open();">打开一个窗口</a>
逗号运算符是二元运算符,它的操作数是任意类型。它首先计算左操作数,然后计算右操作数,最后返回右操作数的值,看下面的示例代码
i = 0, j = 1, k = 2;
// 和下面的代码基本上是等价的
i = 0; j = 1; k = 2;
总会计算左侧的表达式,但计算结果魅力掉,也就是说只有左侧表达式具有副作用,最常用的场景是 for 循环
for (var i = 0, j = 10; i < j; i++,j--)
console.log(i+j);
1970-01-01 08:00:00
第一章 主要介绍 JavaScript 的大概情况、基本语法。之前没有 JavaScript 基础的看不懂也没关系,后续章节会有进一步的详细说明,我会通读一遍 《JavaScript 权威指南》,然后根据个人的理解整理出来我认为重要的核心概念,同时我也会参考原版英文版 JavaScript The Definitive Guide,取一些关键性、重要的单词做补充,以及对原版和译版做的一些勘误
中文排版指南遵守 中文文案排版指北,欢迎批评批正
JavaScript 是面向 web 的编程语言,是一门 高阶的(high-level)、 动态的(dynamic)、 弱类型的(untyped) 解释型(interpreted)编程语言,适合面向对象(oop)和函数式的(functional)编程风格。JavaScript 语法源自 Java 和 C,一等函数(first-class function)来自于 Scheme,它的基于原型继承来自于 Self
JavaScript 语言规范由 ECMA 国际发布,版本号一般叫做 ECMAScript x,如:ECMAScript 3, ECMAScript 5, ECMAScript 6,简称 ES x
Mozilla 发布的 JavaScript 版本一般叫做 JavaScript x.x,如:JavaScript 1.3, JavaScript 1.5
Micorsoft 发布的 JavaScript 版本一般叫做 JScript
可以这么说 「Mozilla 和 Micorsoft 开发的浏览器中 JavaScript内核一般都实现了某个 ECMAScript 版本的规范」
JavaScript 语言核心有很多 API,比如:针对字符串、数组、正则、日期。但这些通常不包括输入输出 API(类似网络、存储、图形相关的特性),输入输出 API 一般是由 JavaScript 的宿主环境(host environment)提供的,通常是浏览器
快速预览下 JavaScript 变量的用法
// 双斜线之后内容是单行注释
/* 这是多行注释 */
// 变更是表示值的一个符号名字,通过 var 关键字声明
var x; // 声明一个变量 x
// 值可以通过等号赋值给变量
x = 0 // 现在变量 x 的值为 0
x // => 0 通过变量获取其值
// JavaScript 支持多种数据类型
x = 1; // 数字
x = 0.01; // 整数和实数都是数字(number)类型
x = "hello world" // 字符串
x = 'JavaScript'; // ...
x = true; // 布尔值
x = false; // ...
x = null; // 是一个特殊的值,意思是「空」
x = undefined; // 和 null 非常累似
JavaScript 中两个非常重要的数据类型是对象和数组
// 对象是名/值对的集合,或字符串到值映射的集合
var book = { // 对象由花括号括起来
topic: 'JavaScript', // book 对象的属性 topic 的值是 "JavaScript"
fat: true
};
// 通过「.」或「[]」来访问对象属性
book.topic // => "JavaScript"
book.['fat'] // => true
book.author = 'Flanagan' // 通过赋值给 book 对象创建一个新属性 author
// JavaScript 数组
var primes = [2, 3, 5, 7];
primes[0] // => 2 通过数组下标访问第一个元素
primes.length // => 4 数组中元素的个数
primes[4] = 9 // => 9 添加新元素
primes[6] = 11 // => 11 此时数组变成 [2, 3, 5, 7, 9, undefined, 11], 长度也变为 7
// 对象数组
var points = [
{ x: 0, y: 0 },
{ x: 1, y: 1 }
];
// 数组对象
var data = {
listA: [1, 3, 5],
listB: [2, 4, 6]
};
通过方括号定义数组元素和通过花括号定义对象属性名和值的语法称为 初始化表达式(initializer expression),表达式是 JavaScript 中的一个短语,这个短语可以通过运算得出一个值。通过「.」和「[]」来引用对象属性或数组元素的值就构成一个表达式。上面的代码中注释中箭头(=>)后的值就是表达式的运算结果
JavaScript 中最常见的表达式写法就是像下面代码一样使用运算符(operator),运算符作用于操作数,生成一个新的值
// 最常见的是算术运算符
3 + 2 // => 5 加法
3 - 2 // => 1 减法
3 * 2 // => 6 乘法
3 / 2 // => 1.5 除法
points[1].x - points[0].x // => 1 复杂的操作数运算
'3' + '2' // => '32' 字符串连接
// 运算符简写形式
var count = 0;
count++; // 自增1
count--; // 自减1
count += 2; // 自加2, 相当于 count = count + 2
count *= 3; // ...
count // => 6 变量名本身也是表达式
var x = 2, y = 3
x == y // => false
x != y // => true
x < y // => true
x <= y // => true
x == y // => false
'two' == 'three' // => false
'two' > 'three' // => true 'tw' 在字母表中的索引大于 'th'
false == (x > y) // => true
// 逻辑运算符
(x == 2) && (y == 3) // true
(x > 2) && (y < 3) // false
!(x == y) // true
如果 JavaScript 中的「短语」是表达式,那么整个句子就称做 语句(statement),以分号结束的行都是一条语句。语句和表达式有很多共同之处
粗略了讲,表达式仅仅计算出一个值并不进行其它操作,不会改变程序的运行状态,而语句并不包含一个值(或者说它包含的值我们并不关心),但它们改变了程序运行状态
函数是带有名称(named)和参数的 JavaScript 代码片段,可以一次定义多次调用
function plus1(x) { // 定义了一个名为 plus1 的函数,带有参数 x
return x + 1; // 返回一个比传入参数大 1 的数值
} // 函数代码块是由花括号包裹起来的部分
plus1(3) // => 4 函数调用结果为 3+1
var square = function(x) { // 函数是一种值,可以赋值给变量
return x * x;
};
square(plus1(3)) // => 16 在一个表达式中调用两个函数
当函数和对象合写在一起时,当函数就变成了「方法」(method):
// 当函数赋值给对象的属性,我们称为「方法」,所有 JavaScript 对象都含有方法
var a = []; // 创建一个空数组
a.push(1, 2, 3); // 调用数组的添加元素方法
a.reverse(); // 调用数组的次序反转方法
// 自定义方法
points.dist = function() {
var p1 = this[0];
var p2 = this[1];
var a = p2.x - p1.x;
var b = p2.y - p1.y;
return Math.sqrt(a*a + b*b) // 勾股定理,用 Math.sqrt 来计算平方根
}
points.dist(); // => 求得两个点之间的距离
JavaScript 中的面向对象特性和传统语言的很大的区别,下面展示一个类用来表示 2D 平面中的几何点,这个类实例化后的对象有一个名为 r() 的方法,可以计算该点到原点的距离:
function Point(x, y) {
this.x = x;
this.y = y;
}
// 通过给构造函数的 prototype 对象赋值,来给 Point 对象定义方法
Point.prototype.r = function() {
return Math.sqrt(this.x * this.x + this.y * this.y)
};
// 使用 new 关键字和构造函数来创建一个实例 p
var p = new Point(1, 1);
// Point 的实例对象 p(以及所有 Point 的实例对象)继承了方法 r()
p.r() // => 1.414...
JavaScript 代码可以通过 <script> 标签来嵌入到 HTML 文件中
<html>
<head>
<script src="外链脚本文件.js"></script>
</head>
<body>
<p>正常 HTML 段落</p>
<script>
// 这里可以写 JavaScript 代码
// 通过弹出一个圣诞框来询问用户一个问题
function moveon() {
var answer = confirm('准备好了吗?');
// 单击「确认」按钮,浏览器会跳转到 jd.com
if (answer) window.location = 'jd.com';
}
setTimeout(moveon, 6000);
</script>
</body>
</html>
JavaScript 可以通过浏览器提供的 DOM API 来操作 HTML 元素
// 调用 debug 传入字符串,JavaScript 会动态创建一个 HTML 节点并字符串内容显示其中
function debug(msg) {
var log = document.getElementById('debuglog');
if (!log) {
log = document.createElement('div');
log.id = 'debuglog';
log.innerHTML = '<h1> Debug Log </h1>';
document.body.appendChild(log);
}
var pre = document.createElement('pre');
var text = document.createTextNode(msg);
pre.appendChild(text);
log.appendChild(pre);
}
debug('this is debug message');
JavaScript 可以通过浏览器提供的 DOM API 来操作 HTML 元素,从而影响 CSS 样式
// 设置元素的 CSS 属性 display/visiblity
function hide(el, reflow) {
if (reflow) {
el.style.display = 'none'; // 隐藏元素
} else {
el.style.visibility = 'hide'; // 隐藏元素,但元素仍然占空间
}
}
// 设置 HTML 元素的 class 属性,class 属性可以是多个(空格分割),如:<div class="c1 c2 c3">
function highlight(e) {
if (!e.className) {
e.className = 'hilite';
} else {
e.className += ' hilite';
}
}
JavaScript 通过注册事件函数来定义文档/用户的行为,比如:点击,鼠标 hover 等
给 HTML 元素添加事件处理程序的一种方法是直接给 HTML 元素添加行内的 on[event name],比如给按钮绑定点击事件
<script src="debug.js"></script>
<script src="hide.js"></script>
Hello
<button onclick="hide(this, true);debug('hide button1')">Hide1</button>
<button onclick="hide(this);debug('hide button2')">Hide2</button>
World
另外一种方法是调用元素的 添加事件处理函数,通常是 addEventListener 或 attachEvent(IE专用)
// 注册 onload 事件,效果和在 HTML 上写 onload 是一样的
// 不过只有部分 HTML 元素支持,比如: img 标签的 onload
window.onload = function() {
var images = document.getElementsByTagName('img');
for (var i = 0, l = images.length; i < l; i++) {
var image = images[i];
if ( image.addEventListener )
image.addEventListener('click', hide, false);
else
image.attachEvent('onclick', hide);
}
function hide(event) { event.target.style.visibility = 'hidden'; }
}
使用 jQuery 类库会使 DOM 操作、事件绑定等操作非常方便,而且不用担心浏览器兼容问题(JavaScript api 层面的兼容)
function debug(msg) {
var $log = $('#debuglog');
if (!$log.length) {
log = $('<div id="debuglog"><h1>Debug Log</h1></div>');
log.appendTo(document.body)
}
log.append($('<pre />').text(msg))
}
1970-01-01 08:00:00
词法结构(Lexical Structure)是程序语言的一套基础性规则,用来描述如何使用这门语言来编写程序
JavasSript 程序是用 Unicode 字符集 编写的,Unicode 是 ASCII 和 Latin-1 的超集,支持几乎所有在用的语言。ECMAScript 3 要求 JavaScript 的实现必须支持 Unicode 2.1 及后续版本,ECMAScript 5 则要求支持 Unicode 3 及其以后的版本
JavaScript 是区分大小写的。关键字、变量、函数名和所有的标识符(identifier)都必须采取一致的大小写形式
需要注意的是 HTML, HTML 5(标签、属性名)并不区分大小写,XHTML 是区分大小写的,但是现代浏览器通常有容错能力,即使标签名、属性名大小写乱用也会正常解析。特别注意 HTML 标签的 属性值 是区分大小写的,比如
<!-- select 和 Select 是两个不同的 CSS 选择器 -->
<div class="selector Selector"></div>
JavaScript 会忽略程序中标识(token)之间的空格。多数情况下,JavaScript 会忽略换行符。
JavaScript 会识别下面的空白字符
JavaScript 会识别下面的字符识别为行结束符
回车符加换行符在一起被解析为一个单行结束符
在有的计算机硬件和软件里面无法显示 Unicode 字符全集,JavaScript 定义了一种特殊序列,使用 6 个 ASCII 字符来代表任意 16 位 Unicode 内码。这些内码均以 \u 为前缀,其后跟随 4 个十六进制数。这种 Unicode 转义写法可以用在 JavaScript 字符串直接量、正则表达式直接量和标识符(除关键字)中。例如:
"\u4F60\u597D\uFF0C\u4E16\u754C" === "你好,世界" // => true
// 注意由于 \u 后面的 4 个16进制数并不区分大小写,所以 unicode 码并不区分大小写
"\u4f60\u597d\uff0c\u4e16\u754c" === "你好,世界" // => true
注意中的 Unicode 码是不会被 JavaScript 转义的
注释类似 Java 和 C,多行注释 不能嵌套
// 这是单行注释
/* 这是多行注释 */
/**
* 这也是多行注释
*/
直接量(literal)就是程序中直接使用的数据值
12 // 数字
1.2 // 小数数字
'hello' // 字符串
true // 布尔真
false // 布尔假
/javascript/gi // 正则表达式直接量
标识符 (indetifiers)就是一个名字,用来对变量和函数命名,JavaScript 标识符必须以字母、下划线(_)或美元符($)开头
也可以使用 Unicode 字符全集,比如:
var 你好 = '你';
var π = 3.14;
你好 // => "你"
π // => 3.14
保留字(Reserved Words)是 JavaScript 用做自己关键字的标识符,写程序的时候要避免使用这些标识符来命名
break delete function return typeof case do if switch var catch else in this void continue false instanceof throw while debugger finally new true with default for null try
ECMAScript 5 中多保留了这些关键字,未来可能会用到
class const enum export extends import super
下面这些关键字在普通 JavaScript 代码中是合法的,但是在严格模式下是保留字:
implements let private public yield interface package protected static
JavaScript 中定义了很多全局变量和当函数,要 避免 使用这些名字做变量名或函数名,比如:arguments encodeURI JSON Math 等
通常来说 JavaScript 语句通常用分号(;)分隔,但是多数情况下 JavaScript 解析器会自动添加分号,所以有的程序员不喜欢加分号,如果代码有正确的书写这样也是可行的
这样两个分号可以省略
var a = 3;
var b = 4;
如果写在一行就不能省略
var a = 3; var b = 4;
下面的代码
var a
a
=
3
console.log(a)
JavaScript 将其解析为:
var a; a = 3; console.log(a);
一般情况下如果一条语句以「(」、「[」、「/」,「+」或「-」开始,那么它极有可能和前一条语句合在一起解析
1970-01-01 08:00:00
JavaScript 中的数据类型分为两类:原始类型(primitive type)和对象类型(object type)。原始类型包括数字、字符串和布尔值
JavaScript 中有两个特殊的原始值:null(空)和 undefined(未定义),它们不是数字、字符串或布尔值。它们通常代表了各自特殊类型的唯一的成员
除此之外的就是对象了。对象是属性(property)的集合,每个属性都由「名/值对」(值可以是原始值或者对象)构成。JavaScript 对象很多时候也是 JSON/map/hash/dict,只是在不同语言中叫法不一样
普通对象是「命名值」的 无序 集合。数组则是一种有序集合对象
JavaScript 还定义了另一种特殊对象 —— 函数。如果用来初始化(使用 new 运算符)一个新建的对象,我们把这个函数称作 构造函数(constructor)。每个构造函数定义了一类(class)对象 —— 由构造函数初始化的对象组成的集合,常用的 JavaScript 核心类有 Array, Function, Date, RegExp, Error 等
JavaScript 解释器(interpreter)有自己的内存管理机制,可以自动对内存进行垃圾回收 GC(garbage collection)。当 不再有任何引用指向一个对象,解释器就会自动释放它占用的内存资源
JavaScript 是一种面向对象的语言,几乎一切皆对象。数据类型本身可以定义方法(method)来使用
从技术上讲,只有 JavaScript 对象才能拥有方法。然而数字、字符串和布尔值也可以拥有自己的方法。但是 null 和 undefined 是无法拥有方法的值
JavaScript 数据类型还可以分为:可以拥有方法和不可以拥有方法类型、 可变(nutable)类型和 不可变(imutable)类型
JavaScript 程序可以更改对象属性值和数组元素的值。数字、布尔值、null 和 undefined 属于不可变类型 —— 比如,修改一个数值的内容本身就说不通。字符串可以看成由字符组成的数组,你可能会认为它是可变的。然而在 JavaScript 中,字符串是不可变的。可以访问字符串任意位置的文本,但不能修改其内容
JavaScript 可以自由地进行数据类型转换。比如程序期望使用字符串的地方使用了数字, JavaScript 会自动将数字转换为字符串。期望使用布尔值的地方使用了非布尔值也会自动进行相应转换
JavaScript 变量是无/弱类型的(untyped),变量可以被赋予任何类型的值,也可以动态改变不同类型的值。JavaScript 采用 词法作用域(lexical scoping)。不在任何函数内声明的变量称做全局变量(global variable),函数内声明的变量具有函数作用域(function scope),且只在函数内可见
JavaScript 不区分 整数和浮点数。所有的数字均用浮点数值表示。JavaScript 采用 IEEE 754 标准定义的 64 位浮点格式表示数字
当一个数字直接出现在 JavaScript 程序中,我们称为数字直接量(numberic literal)。JavaScript 支持多种格式的籽安直接量。注意,在任何数字直接量前添加负号(-)可以得到它们的负值。但负号是 一元 求反 运算符,并不是数字直接量语法组成部分
十进制整数,例如:
0
3
1000000
十六进制值,指直接量以「」或为前缀,其后跟随十六进制数串的直接量。十六进制值是 0 ~ 9 之间的数字和 a(A) ~ f(F) 之前的字母构成,a ~ f 的字母对应的表示数字 10 ~ 15
0x2Af5 // 8192 + 2560 + 240 + 5 = 10996(十进制)
/*
+-------------------------------------------------+
| |
| 2 A F 5 |
| |
| 3 2 1 0 |
| |
| 2*16^3 A*16^2 F*16^1 5*16^0 |
| |
| 2*4096 10*256 15*16 5*1 |
| |
| 8192 + 2560 + 240 + 5 |
| |
| 十六进制 2AF5 转换成十进制为10996 |
| |
+-------------------------------------------------+
*/
ECMAScript 标准 不支持 八进制直接量,ECMAScript 6 严格模式下不能使用八进制
浮点型直接量可以含有小数点,采用传统实数的写法。此外,还可以使用指数记数法表示浮点型直接量,即在实数后跟字母 e 或 E,后面再跟正负号,其后再加一个整形指数。这种记数方法表示的数值,是由前面的实数乘以 10 的指数次幂,例如:
3.14
2134.789
.33 // 0.33
6.02e23 // 6.02 乘以 10 的 23 次方
1.47e-32 // 1.47 乘以 10 的负 32 次方
JavaScript 中的算术运算在 溢出(overflow)、 下溢(underflow)或被零整除时不会报错,当数字运算结果超过了 JavaScript 所能表示的数字上限(溢出),结果为一个特殊的无穷大(infinity)值,相应的也有负无穷大(-infinity)值
下溢是当运算结果无限接近于零并比 JavaScript 能表示的最小值还小的时候发生的一种情况。这种情况下,JavaScript 将会返回 0。当一个负数发生下溢时,JavaScript 返回一个特殊的值「负零」,这个值几乎和正常的零完全一样
实零带除在 JavaScript 中并不报错:它会返回正或者负无穷大。但有一个例外,零除以零是没有意义的,这种整除运算结果也是一个非数字(not-a-number)值,用 NaN 表示
1/0 // => Infinity
-1/0 // => -Infinity
Number.NEGATIVE_INFINITY // => -Infinity
Number.MAX_VALUE // => 1.7976931348623157e+308
Number.MAX_VALUE + 1 // => Infinity (经测试在 Chrome 里面并不是)
0/0 // => NaN
Number.MIN_VALUE / 2 // => 0 发生下溢
-Number.MIN_VALUE / 2 // => -0 负零
-1/Infinity // => -0
NaN == NaN // => false
isNaN('hello') // => false
isFinite(123) // => true 参数不是 NaN, Infinity 或 -Infinity 时返回 true
isFinite(-1/0) // => false
JavaScript 中的非数字值(NaN)和任何值都不相等,包括 NaN,NaN == NaN 返回 false 但是可以使用 isNaN 判断一个值是不是 NaN
IEEE-754 浮点表示法是一种二进制表示法,但是并不能精确表示十进制分数,在任何使用二进制浮点数的编程语言中都会有这个问题
下面的代码中 x 和 y 的值非常 接近 彼此和最终正确值。这种计算结果可以用途大多数的计算任务, 这个问题也只有在比较两个值是否相等的时候才会出现
0.3 - 0.2 // => 0.09999999999999998
0.2 - 0.1 // => 0.1
var x = 0.3 - 0.2;
var y = 0.2 - 0.1;
x == y // => false
JavaScript 语言核心包括 Date() 构造函数,用来创建表示日期和时间对象,大致使用方法如下:
var then = new Date(2011, 0, 1); // 2011 年 1 月 1 日
var later = new Date(2011, 0, 1, 17, 10, 30) // 下午 5 点 10 分 30 秒
var elapsed = now - then; // 日期减法:计算时间间隔的毫秒数
later.getFullYear(); // => 2011
later.getMonth(); // => 0 月份从 0 开始
...
字符串(string)是一组 16 位值组成的不可变的有序序列,每个字符通常来自于 Unicode 字符集。字符串的长度(length)是其所含 16 位值的个数。字符串索引从零开始
"" // 空字符串
'testing'
"3.14"
"Wouldn't you prefer O'Reilly's book?"
"This string\nhas Two lines" // 显示为两行
"one\
long\
line" // 显示为单行,但是可以分行书写
JavaScript 中转文字符用反斜线(\)加一个字符表示,比如 \n 就是一个转义字符,表示一个换行符
| 转义字符 | 含义 | Unicode |
|---|---|---|
| \o | NUL 字符 | \u0000 |
| \b | 退格符 | \u0008 |
| \t | 水平制表符 | \u0009 |
| \n | 换行符 | \u0009 |
| \v | 垂直制表符 | \u0009 |
| \f | 换页符 | \u0009 |
| \r | 回车符 | \u0009 |
| " | 双引号 | \u0009 |
| ' | 单引号 | \u0009 |
| \ | 反斜线 | \u0009 |
| \xXX | 2位十六进制数XX指定的 Latin-1 字符 | |
| \uXXXX | 4位十六进制数XX指定的 Unicode 字符 |
加号(+)运算符作用于字符串表示链接,字符串通过访问 length 属性得到长度
var s = "hello world"
s.charAt(0) // => "h" 下标为 0 的字符
s.substring(1, 4) // => "ell" 下标从 1 ~ 4 的字符
s.slice(1, 4) // => "ell" 同上
s.slice(-3) // => "rld" 最后三个字符
s.indexOf("l") // => 2 字符 l 首次出现的下标
s.lastIndexOf("l") // => 10 字符 l 最后一次出现的下标
s.split(", ") // => ["hello", "world"] 分割字符串
s.replace("h", "H") // => "Hello, world" 全文字替换
s.toUpperCase() // => "HELLO, WORLD"
一定要记住,在 JavaScript 中字符串是固定不变的,类似 replace() 和 toUpperCase() 的方法都 返回新字符串,原字符串本身并没有发生改变。在 ECMAScript 5 中字符串可以当做只读数组,可以通过下标访问单位字符
JavaScript 定义了 RegExp() 构造函数,用来创建表示文本匹配模式的对象。这些模式称为「正则表达式」(regular expression), JavaScript 采用 Perl 中的正则表达式语法。String 和 RegExp 对象均定义了正则模式匹配、查找和替换的函数
/^HTML/ // 匹配以 HTML 开始的字符串
/[1-9][0-9]*/ // 匹配一个非零数字,后面是任意个数字
/\bjavascript/i // 匹配单词「javascript」,忽略大小写
var text = "testing: 1, 2, 3"
var pattern = /\d+/g // 匹配所有包含一个或者多个数字的实例
pattern.test(text) // => true 匹配成功
text.search(pattern) // => 9 首次匹配成功的位置
text.match(pattern) // => ["1", "2", "3"] 所有匹配组成的数组
text.replace(pattern, "#") // => "testing: #, #, #"
text.split(/\D+/) // => ["", "1", "2", "3"] 用非数字字符截取字符串
JavaScript 中比较语句的结果通常都是布尔值,布尔值通常用于控制结构中。任意 JavaScript 的值都可以转换成布尔值。所有对象(数组)都会转换成 true, 面这些则都是 false
undefined
null
0
-0
NaN
"" // 空字符串
null 是 JavaScript 语言的关键字,执行 typeof 运算返回 「object」,也就是说,可以将 null 认为是一个特殊的对象值,含义是「非对象」。但实际上,通常认为 null 是它自有类型的唯一一个成员,它可以表示数字、字符串或对象是「无值」的
undefined 是一种取值,表明变量没有初始化,如果要查询对象属性或者数组元素的值时返回 undefined 则说明这个属性或者元素不存在。如果函数没有返回任何值,则返回 undefined引用没有提供实参的函数形参的值也只会得到 undefined。
undefined 不是关键字,是 JavaScript 预定义的全局变量,它的值就是「未定义」。ECMAScript 3 中,undefined 是 可读/写的变量,可以给它赋任意值。这个错误在 ECMAScript 5 中做了修正,变成了只读的。如果执行 typeof 运算得到 undefined 类型,则返回 "undefied"
null 和 undefined 都 不包含任何属性和方法
全局对象的属性是全局定义的符号,JavaScript 程序可以直接使用。当解释器启动时,它将创建一个新的全局对象,并给它一组初始属性:
全局属性,比如 undefined, Infinity 和 NaN 全局函数,比如 isNaN(), parseInt(), eval() 构造函数,比如 Date(), RegExp(), String(), Object() 和 Array() 全局对象,比如 Math 和 JSON
全局对象的 初始属性 并不是保留字(可以被污染/重写),但它们应该当做保留字来对待。对于客户端的 JavaScript 来讲,Window 对象定义了一些额外的全局属性
var s = "test", n = 1, b = true;
var S = new String(s);
var N = new Number(N);
var B = new Boolean(b);
s == S // => true
s === S // => false
typeof s // => "string"
typeof S // => "object"
可以通过 Number() 或 Boolean() 构造函数来显式创建包装对象,JavaScript 会在必要的时候将包装对象转换成原始值。上段代码中的对象 S, N 和 B 常常但不总是表现的和值 s, n 和 b 一样。「==」运算符将原始值和其包装对象视为相等,但「===」全等运算符将它们视为不等,通过 typeof 运算符可以看到原始值和其包装对象的不同
JavaScript 中原始值(undefined, null, 布尔值,数字和字符串)和对象(包括数组和函数)有着根本的区别, 原始值是不可更改的,比如字符串的所有方法都是新返回一个值
var s = "hello";
s.toUpperCase(); // => "HELLO"
s // => "hello"
对象和原始值不同,首先,它他是 可变的 —— 值可以修改
var o = { x: 1};
o.x = 2;
oxy = 3;
var a = [1,2,3]
a[0] = 0;
a[3] = 4;
对象的比较并非值的比较,即使两个对象包含同样的属性及相同的值
var o = {x:1}, p = {x:1};
o === p // => false
var a = [], b = [];
a === b // => false
通常将对象𤠕引用类型(reference type),以此来和 JavaScript 基本类型区分开。按术语的叫法,对象值都是引用(reference),对象的比较均是引用的比较: 当且仅当它们引用同一个基本对象时,它们才相等
var a = [];
var b = a;
b[0] = 1;
a[0] // => 1 变量 a 也会修改
a === b // => true a 和 b 引用一个相同的数组,所以它们相等
JavaScript 中的取值类型非常灵活,从布尔值可以看到这一点:当 JavaScript 期望使用一个布尔值的时候,你可以提供任意类型值, JavaScript 将根据需要自行转换类型。这在其它类型转换中同样适用
10 + " objects" // => "10 objects" 数字 10 转换成字符串
"7" * "4" // => 28 两个字符串均转换为数字
var n = 1 - "x" // => NaN 字符串 "x" 无法转换为数字
n + " objects" // => "NaN objects" NaN 转换为字符串 "NaN"
常用值转换成对应的类型结果
表3-1
| 值 | 字符串 | 数字 | 布尔值 | 对象 |
|---|---|---|---|---|
| undefined | "undefined" | NaN | false | throws TypeError |
| null | "null" | 0 | false | throws TypeError |
| true | "true" | 1 | new Boolean(true) | |
| false | "false" | 0 | new Boolean(false) | |
| "" (空字符串) | 0 | false | new String("") | |
| "1.2" (非空数字) | 1.2 | true | new String("1.2") | |
| "one" (非空,非数字) | NaN | true | new String("one") | |
| 0 | "0" | false | new Number(0) | |
| -0 | "0" | false | new Number(-0) | |
| NaN | "NaN" | false | new Number(NaN) | |
| Infinity | "Infinity" | true | new Number(Infinity) | |
| -Infinity | "-Infinity" | true | new Number(-Infinity) | |
| 1 (无穷大,非零) | "1" | true | new Number(1) | |
| {} (任意对象) | 参考 §3.8.3 | 参考 §3.8.3 | true | |
| [] (任意数组) | "" | 0 | true | |
| [9] (1 个数字元素) | "9" | 9 | true | |
| ['a'] (其它数组) | use join() method | NaN | true | |
| function(){} (任意函数) | 参考 §3.8.3 | NaN | true |
以下结果均为 true
null == undefined
"0" == 0
0 == false
"0" == false
显式类型转换最简单的方法就是使用 Boolean(), Number(), String() 或 Object() 函数。
Number("3") // => 3
String(false) // => "false"
Boolean([]) // => true
Object(3) // => new Number(3)
除了 null 和 undefined 之外 任何值 都具有 toString() 方法
JavaScript 中的某些运算符会做隐式的类型转换。如果「+」运算符的一个操作数是字符串,它将会把另外一个操作数转换为字符串。一元「!」运算符将其操作数转换为布尔值并取反
x + "" // 等价于 String(x)
+x // 等价于 Number(x)
!!x // 等价于 Boolean(x)
Number 类型定义的 toString() 方法可以接收表示转换基数的可选参数,默认是基于十进制的,toFixed(), toExponential(), toPrecision() 三个方法都会适当地进行四舍五入或填充 0
var n = 17
binary_sting = n.toString(2) // 转换为 "10001"
octal_string = "0" + n.toString(8) // 转换为 "021"
hex_string = "0x" + n.toString(16) // 转换为 "0x11"
通过 Number() 转换函数传入一个字符串,它会试图将其转换为一个整数或浮点数直接量,这个方法只能基于十进制数进行转换,并且不能出现 非法的尾随字符。parseInt() 和 parseFloat() 函数(全局函数,不属于任何类的方法)更加灵活。如果字符前缀是「0x」或「0X」,parseInt() 将其解释为十六进制数,parseInt() 和 parseFloat() 都会跳过任意数量的前导空格,尽可能解析更多数值字符,并忽略 后面的内容
parseInt("3 blind mice") // => 3
parseFloat(" 3.14 meters") // => 3.14
parseInt(0xFF) // => 255
parseInt("0.1") // => 0
parseInt(".1") // => NaN
parseFloat("$72.47") // => NaN
所有对象继承了两个转换方法 toString(), valueOf()
toString() 的作用是返回一个反映这个对象的字符串
({x:1, y:2}).toString() // => "[object Object]"
[1,2,3].toString() // ==> "1,2,3"
(function(x) { f(x); }).toString() // => "function(x) {\n f(x);\n }"
/\d+/g.toString() // => "/\\d+/g"
new Date(2010,0,1).toString() // => "Fri Jan 01 2010 00:00:00 GMT+0800 (中国标准时间)"
valueOf() 这个方法的作答并未详细定义:如果存在任意原始值,它就默认将对象转换为表示它的原始值。复合值默认返回对象本身
JavaScript 中对象到字符串的转换经过了如下这些步骤:
var now = new Date();
typeof (now +1) // => "string" 「+」将日期转换为字符串
typeof (now -1) // => "number" 「-」使用对象到数字的转换
now == now.toString() // => true
now > (now - 1) // => true
var i;
var sum;
var i, sum; // 单 var 声明多个变量
如果未在 var 声明语句中给变量指定初始值,那么虽然声明了这个变量,但在给它存入一个值之前,它的初始值就是 undefined
JavaScript 是弱类型语言,变量可以是任意数据类型,下面的写法是合法的:
var i = 10;
i = "ten";
变量作用域(scope)是程序源代码中定义它的区域。在函数体内,局部变量的优先级高于 同名 的全局变量,并且函数内部可以修改外部变量
var scope = "global";
function checkScope() {
var scope = 'local';
return scope
}
在声明全局变量时可以不使用 var 前缀,但在声明局部变量时 一定 要使用 var
scope = "global"; // 定义一个全局变量
function checkScope2() {
scope = 'local';
myscope = 'local';
return [scope, myscope]
}
checkScope2() // => ['local', 'local']
scope // => "local"
myscope // => "local"
像一些类 C 的编程语言中,花括号({})内的每一段代码都具有各自的作用域,变量在声明它们的代码段之外是不可见的,我们称为 块级作用域(block scope),而 JavaScript 中没有块级作用域。JavaScript 中使用了 函数作用域(function scope):
变量在声明它们的函数体以及这个函数体嵌套的任意函数体内都是可以被访问到的
下面的代码中,在不同位置定义了变量 i,j 和 k,它们都在同一个作用域内。当调用 test() if 语句并没有执行,但是变量 j 已经定义却没被始化
function test(o) {
var i = 0;
if ( typeof o === 'object' ) {
var j = 0;
for (var k = 0; k < 10; k++) {
console.log(k);
}
console.log(k);
}
console.log(j);
}
JavaScript 的函数作用域是指在函数内声明的所有变量在函数体内始终是可见的。这就意味着变量在声明之前甚至已经可用。JavaScript 的这个被非正式地称为声明提前(hoisting),即 JavaScript 函数里声明的所有变量(不包括赋值)都被「提前」到函数体的顶部 参考
var scope = "global";
function f() {
console.log(scope); // => undefined
var scope = "local";
console.log(scope); // => "local"
}
f();
function b() {
console.log(scope); // => "global"
}
b();
上面的代码中函数 f 的局部变量 scope 由于 声明提前,代码刚执行进入 f 内部的时候 scope 就被赋值 undefined,这时局部变量优先级高于同名全局变量,所以就返回了 undefined,只有代码执行到 var 的时候 scope 才真正被赋值。所以函数 f 等价于:
function f() {
var scope;
console.log(scope); // => undefined
scope = "local";
console.log(scope); // => "local"
}
这也是为什么建议函数体内的变量尽量放在上面,避免造成混乱或者误解
当声明一个 JavaScript 全局变量时,实际上是定义了全局对象的一个属性。当使用 var 声明一个变量时,这个变量是无法通过 delete 运算符删除的。不使用 var 声明的全局变量却是可以被 delete 的
var truevar = 1;
fakevar = 2; // 不用 var 创建一个全局变量
this.fakevar2 = 3;
delete truevar // => false 不可删除
delete fakevar // => true
delete this.fakevar2 // => true
JavaScript 是基于 词法作用域(lexically scoped)的语言:通过阅读包含变量定义在内的源代码就能知道变量的作用域
每一段 JavaScript 代码(全局代码或函数)都有一个与之关联的作用域链。这个作用域链是一个对象列表或者链表,这组对象定义了这段代码「作用域中」的变量。当 JavaScript 需要查找变量 x 值的时候(这个过程称做「变量解析」(valable resolution)),它会从链中的第一个对象开始查找,如果有则直接使用,如果没有 JavaScript 就会继续查找链上的下一个对象,以此类推。如果作用域名链上没有任何一个对象含有属性 x,那么就认为这段代码的作用域链接上不存在 x,并最终抛出一个引用错误(ReferenceError)异常
a();
function a() {
alert('1');
}
a();
function a() {
alert('2');
}
a();
var a = function() {
alert('3');
};
a();
1970-01-01 08:00:00
vim 一些插件需要其它编程语言支持,比如 neocomplete 自动补全插件需要 lua 官方下载的 vim 版本是不带这种第三方语言支持的,得自己手动编译一个支持的版本。但是 Windows 下编译源代码需要选择一个 GUN 工具集,比较流行的有 Cygwin, MinGW。主要是为了使用一些编译源码的工具,比如 gcc, make等
需要下载的链接都在这里了:
我自己的电脑环境配置是:Windows 7 SP1 64bit 企业版
官方的 MinGW 安装了需要自己手动选择工具再安装到系统,有个简单的办法,直接使用上页的链接下载打好包的 Distro 版本,下载完就解压到任意目录即可,我放在了 C:\MinGW
下载上面链接中 Windows 64bit 中的编译好的二进制文件 和 库文件,放在一个目录,比如我放在 C:\lua, 如图:

去 vim 官方 github 仓库下载最新源代码,解压到任意目录。进入源码 src 目录,打开 os_mswin.c 注释掉下面的代码,这样 vim 就可以支持非等宽字体了
#ifndef FEAT_PROPORTIONAL_FONTS
/* Ignore non-monospace fonts without further ado */
/*
* hzmangel: I need non-monospace fonts!
if ((ntm->tmPitchAndFamily & 1) != 0)
return 1;
*/
#endif
打开 MinGW 命令窗口 (C:\MinGW\open_distro_window.bat),cd 到 vim 源代码的 src 目录,执行以下命令:
make -f Make_ming.mak GUI=yes FEATURES=HUGE MBYTE=yes IME=yes GIME=yes DYNAMIC_IME=yes OLE=yes PYTHON="C:\Python27" DYNAMIC_PYTHON=yes PYTHON_VER=27 CSCOPE=yes DEBUG=no LUA="C:\Lua" DYNAMIC_LUA=yes LUA_VER=52 USERNAME=keelii USERDOMAIN=[email protected] ARCH=x86-64 gvim.exe
注意:我系统之前安装过 python27 到 C 盘,你可以根据自己的情况选择。关于 lua 的两个参数要写对:lua 安装目录 LUA="C:\Lua" 和 lua 版本 LUA_VER=52,其它编译语言也大同小异
如果编译成功的话不会有错误提示,并在当前目录生成 gvim.exe, 这个 exe 就是我们需要的带有 lua 支持的 vim 可执行文件,把这个文件和 C:\lua\lua.dll 复制到你的 vim runtime文件夹,这时候就可以把 runtime 重命名一个放到其它你想要的目录,点击 gvim.exe 就可以了
第一次执行 vim 需要先注册一下,出现弹窗口点确定就行了。
进入命令模式,输出 echo has('lua') 来验证下是否已开启 lua 支持,如果显示 1 就说明 OK 了


发现编译完直接使用会有 「找不到 VIMRUN.EXE」提示,解决方法:从官方安装版的 vim 根目录把 vimrun.exe 复制到你的 runtime 文件夹下即可
知友 @fantiq 反馈某些情况下会报下面的错误,原因可能是 MinGW 下的 mkdir 命令有问题,无法创建目录,手动执行mkdir gobjx86-64 就可以解决了
mkdir -p gobjx86-64
process_begin: CreateProcess(NULL, mkdir -p gobjx86-64, ...) failed.
make (e=2): 系统找不到指定的文件。
make: *** [Make_cyg_ming.mak:860: gobjx86-64] Error 2
1970-01-01 08:00:00
一直以来被称为编辑器之神的 vim 在 Windows 下很难发挥其强大的功能,本文从实用的角度阐述如何调校出一个比较好用的 vim
不过仍然要说明下,在众多 vim 构建版本中 Mac OS 平台的 MacVim 是我认为最好用的一个版本。由于自己公司主力用 Windows,又因笔者是一枚对编辑器颜值体验有要求的前端工程师, 所以才有了下文 ^!^
先说明下开发环境:
本文旨在配置和使用 vim,并不适合太初级的 vim 用户,本文作者也不是 vim 死忠粉,经常混用 Webstrom 和 vim
开始之前我们先看一眼 Windows 上安装 Gvim 的默认界面,我们将从这里开始一步步的学习和配置

由于 vimrc 里面会有很多的配置项,为了避免混乱,我大概按自己的使用习惯分成了几个小组:
" Startup {{{
filetype indent plugin on
" vim 文件折叠方式为 marker
augroup ft_vim
au!
au FileType vim setlocal foldmethod=marker
augroup END
" }}}
设置 vim 相关文件打开后默认折叠方式为 marker,约定俗成的用三个花括号注释包裹起来,这样在你打开配置文件的时候 vim 就会帮你折叠起来,配置文件看起来就简洁多了,如图:

" General {{{
set nocompatible
set nobackup
set noswapfile
set history=1024
set autochdir
set whichwrap=b,s,<,>,[,]
set nobomb
set backspace=indent,eol,start whichwrap+=<,>,[,]
" Vim 的默认寄存器和系统剪贴板共享
set clipboard+=unnamed
" 设置 alt 键不映射到菜单栏
set winaltkeys=no
" }}}
基本上一眼就能看出来这是些啥玩意,不过后面两项目我个人感觉比较好用:
clipboard+=unnamed 比如你在其它地方 copy 了一段文字回到 vim 里面可以粘贴进来
winaltkeys=no 一般 windows 下应用程序的 alt 是用来定位菜单栏目的快捷键,我们需要禁用它,因为我们后面很多设置都需要使用 alt,需要使用 alt 来定位菜单的情况很少
" Lang & Encoding {{{
set fileencodings=utf-8,gbk2312,gbk,gb18030,cp936
set encoding=utf-8
set langmenu=zh_CN
let $LANG = 'en_US.UTF-8'
"language messages zh_CN.UTF-8
" }}}
vim 里面设置编码的地方很多,上面这些配置可以保证不会出现乱码,像文件菜单、vim默认语言建议设置成 en_US
" GUI {{{
colorscheme Tomorrow-Night
source $VIMRUNTIME/delmenu.vim
source $VIMRUNTIME/menu.vim
set cursorline
set hlsearch
set number
" 窗口大小
set lines=35 columns=140
" 分割出来的窗口位于当前窗口下边/右边
set splitbelow
set splitright
"不显示工具/菜单栏
set guioptions-=T
set guioptions-=m
set guioptions-=L
set guioptions-=r
set guioptions-=b
" 使用内置 tab 样式而不是 gui
set guioptions-=e
set nolist
" set listchars=tab:▶\ ,eol:¬,trail:·,extends:>,precedes:<
set guifont=Inconsolata:h12:cANSI
" }}}
编辑器配色建议使用 Tomorrow-Night,下载文件 copy 到 colors 目录即可
从上面的设置可以看出来,为了得到一个简洁漂亮的界面,我们去掉了菜单栏、各种滚动条、使用 vim 内置 tab 而不是 gvim 系统的 tab 样式,注意很多开发者喜欢显示不可见字符,比如:tab 制表符、换行符号、尾空格等。
我自己并不喜欢这样,因为这样只会使界面看起来更零乱,尤其是某插件纵向标尺
字体方面个人推荐 Inconsolata 这个在我看来是 Windows 平台最漂亮的等宽字体了
此时你的编辑器应该好看了很多:

" Format {{{
set autoindent
set smartindent
set tabstop=4
set expandtab
set softtabstop=4
set foldmethod=indent
syntax on
" }}}
这个设置容易引起争议,我自己是这么个设置,大家按个人喜好就行了,反正我是不建议使用 tab 的,对代码格式有强迫症的人一般都会设置 foldmethod=indent
可以说快捷键是每个编辑器必备的功能,科学的设置快捷键能很大程度的提高效率。快捷键的设置要遵循一个规则:尽量不要修改系统默认配置的快捷键,非要设置的话选择好相应的模式
" Keymap {{{
let mapleader=","
nmap <leader>s :source $VIM/_vimrc<cr>
nmap <leader>e :e $VIM/_vimrc<cr>
map <leader>tn :tabnew<cr>
map <leader>tc :tabclose<cr>
map <leader>th :tabp<cr>
map <leader>tl :tabn<cr>
" 移动分割窗口
nmap <C-j> <C-W>j
nmap <C-k> <C-W>k
nmap <C-h> <C-W>h
nmap <C-l> <C-W>l
" 正常模式下 alt+j,k,h,l 调整分割窗口大小
nnoremap <M-j> :resize +5<cr>
nnoremap <M-k> :resize -5<cr>
nnoremap <M-h> :vertical resize -5<cr>
nnoremap <M-l> :vertical resize +5<cr>
" 插入模式移动光标 alt + 方向键
inoremap <M-j> <Down>
inoremap <M-k> <Up>
inoremap <M-h> <left>
inoremap <M-l> <Right>
" IDE like delete
inoremap <C-BS> <Esc>bdei
nnoremap vv ^vg_
" 转换当前行为大写
inoremap <C-u> <esc>mzgUiw`za
" 命令模式下的行首尾
cnoremap <C-a> <home>
cnoremap <C-e> <end>
nnoremap <F2> :setlocal number!<cr>
nnoremap <leader>w :set wrap!<cr>
imap <C-v> "+gP
vmap <C-c> "+y
vnoremap <BS> d
vnoremap <C-C> "+y
vnoremap <C-Insert> "+y
imap <C-V> "+gP
map <S-Insert> "+gP
cmap <C-V> <C-R>+
cmap <S-Insert> <C-R>+
exe 'inoremap <script> <C-V>' paste#paste_cmd['i']
exe 'vnoremap <script> <C-V>' paste#paste_cmd['v']
" 打开当前目录 windows
map <leader>ex :!start explorer %:p:h<CR>
" 打开当前目录CMD
map <leader>cmd :!start<cr>
" 打印当前时间
map <F3> a<C-R>=strftime("%Y-%m-%d %a %I:%M %p")<CR><Esc>
" 复制当前文件/路径到剪贴板
nmap ,fn :let @*=substitute(expand("%"), "/", "\\", "g")<CR>
nmap ,fp :let @*=substitute(expand("%:p"), "/", "\\", "g")<CR>
" 设置切换Buffer快捷键"
nnoremap <C-left> :bn<CR>
nnoremap <C-right> :bp<CR>
" }}}
首页我们设置了 leaderkey 为逗号「,」,不要问为什么约定的就是它。别设置成空格就行了
注意「,e」和「,s」分别用编辑配置文件,刷新配置文件,后面的路径要按你自己的情况去写,我默认使用了 vim 安装目录里面的 vimrc
分屏编辑操作的时候经常要在不同的屏之间跳来跳去 「Ctrl + vim方向」设置跳转方便顺滑的切换,顺便说下我个人的习惯是在当前tab下编辑一个项目的文件,如果要临时维护其它项目就新开tab,每个tab单独编辑一个项目文件
后面还设置了一些和 Windows 默认编辑操作兼容的快捷键,比如:复制,粘贴
注意有个细节,因为 vim 里面多行操作快捷键是 Ctrl + v 和 windows 粘贴冲突了,一个机智的做法是仅仅在 vim 插件模式设置 Ctrl 为粘贴,正常模式 Ctril + v 进入多选模式,两全其美
插入模式下要移动光标 还得 ESC 一下进入插入模式,这样太麻烦了,使用 「alt + vim方向」就简单多了
插件方面根据我自己的工作内容和个人喜好,选择了以下几个,全部使用 vundle 来管理:
具体配置我就不帖代码了,可以上git上参观,下面大概解释下每个插件的用途
文件目录树管理,我一般设置成打开 vim 就启动
if exists('g:NERDTreeWinPos')
autocmd vimenter * NERDTree D:\repo
endif
类似 sublime 多选,进入 visual 模式选择文本 Ctrl+shif+n 即可一直选择下一个匹配文本

对齐插件,文章末尾 gif 图里面有展示,visual 模式下选择要对齐的多行文本,进入命令模式 :Tabularize /对齐符号<cr>
状态栏美化插件,准备弃用了
类似IDE里面的最近打开的文件,用于快速定位文件/Buffer
注释插件,默认是快捷键是 <leader> c <SPACE>
用来快速写 HTML

代码片段管理, 这个插件很早之前的那个版本不维护了,现在最新版的非常强大,不过有另外两个依赖,默认是没有任何内置的 snippet 的,如果需要样版,可以安装 这个插件 需要自定义的话手动更改 snippets 目录下的文件即可(其实就是个git仓库,你可以换成自己的)

Git 命令增强工具,在 vim 使用 git,状态栏的分类名称就是调用的这个插件的方法 fugitive#head()
自动补全插件,这个代码实例插件是需要 lua 支持的,可能你需要手动编译一个带 lua 支持版本的 gvim,下篇文章 我将记录下自己在 Windows 上编译安装的过程
什么?你说为啥不装 YouCompleteMe,官方作者都不支持的插件就别折腾了吧,Neocomplete 这个实例插件对于我的情况来说已经够用了
常用方法这里我只有一个,移除尾空格
" Function {{{
" Remove trailing whitespace when writing a buffer, but not for diff files.
" From: Vigil
" @see http://blog.bs2.to/post/EdwardLee/17961
function! RemoveTrailingWhitespace()
if &ft != "diff"
let b:curcol = col(".")
let b:curline = line(".")
silent! %s/\s\+$//
silent! %s/\(\s*\n\)\+\%$//
call cursor(b:curline, b:curcol)
endif
endfunction
autocmd BufWritePre * call RemoveTrailingWhitespace()
" }}}
No picture U say a ... ?

这个是动图,不动戳大

还有一点没说明,vimrc 里面的一些 windows 独有的设置我并没有加一些判断来兼容其它平台,这个是个人喜好而已,我会单独分开维护不同平台的配置文件,而不是全部放在一起各种逻辑判断
1970-01-01 08:00:00
之前要申请免费的 https 证书操作步骤相当麻烦,今天看到有人在讨论,就搜索了一下。发现现在申请步骤简单多了。
git clone https://github.com/certbot/certbot
cd certbot
./certbot-auto --help
解压打开执行就会有相关提示
./certbot-auto certonly --webroot --agree-tos -v -t --email 邮箱地址 -w 网站根目录 -d 网站域名
./certbot-auto certonly --webroot --agree-tos -v -t --email [email protected] -w /path/to/your/web/root -d note.crazy4code.com
注意 这里 默认会自动生成到 / 网站根目录/.well-known/acme-challenge 文件夹,然后 shell 脚本会对应的访问 网站域名/.well-known/acme-challenge 是否存在来确定你对网站的所属权
比如:我的域名是 note.crazy4code.com 那我就得保证域名下面的 .well-known/acme-challenge/ 目录是可访问的
如果返回正常就确认了你对这个网站的所有权,就能顺利生成,完成后这个目录会被清空
如果上面的步骤正常 shell 脚本会展示如下信息:
- Congratulations! Your certificate and chain have been saved at
/etc/letsencrypt/live/网站域名/fullchain.pem
...
使用 openssl 工具生成 dhparams
openssl dhparam -out /etc/ssl/certs/dhparams.pem 2048
打开 nginx server 配置文件加入如下设置:
listen 443
ssl on;
ssl_certificate /etc/letsencrypt/live/网站域名/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/网站域名/privkey.pem;
ssl_dhparam /etc/ssl/certs/dhparams.pem;
ssl_protocols SSLv3 TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers HIGH:!aNULL:!MD5;
然后重启 nginx 服务就可以了
https 默认是监听 443 端口的,没开启 https 访问的话一般默认是 80 端口。如果你确定网站 80 端口上的站点都支持 https 的话加入下面的配件可以自动重定向到 https
server {
listen 80;
server_name your.domain.com;
return 301 https://$server_name$request_uri;
}
免费证书只有 90 天的有效期,到时需要手动更新 renew。刚好 Let's encrypt 旗下还有一个 Let's monitor 免费服务,注册账号添加需要监控的域名,系统会在证书马上到期时发出提醒邮件,非常方便。收到邮件后去后台执行 renew 即可,如果提示成功就表示 renew 成功
./certbot-auto renew
1970-01-01 08:00:00
在浏览器 DOM 事件里面,有一些事件会随着用户的操作不间断触发。比如:重新调整浏览器窗口大小(resize),浏览器页面滚动(scroll),鼠标移动(mousemove)。也就是说用户在触发这些浏览器操作的时候,如果脚本里面绑定了对应的事件处理方法,这个方法就不停的触发。
这并不是我们想要的,因为有的时候如果事件处理方法比较庞大,DOM 操作比如复杂,还不断的触发此类事件就会造成性能上的损失,导致用户体验下降(UI 反映慢、浏览器卡死等)。所以通常来讲我们会给相应事件添加延迟执行的逻辑。
通常来说我们用下面的代码来实现这个功能:
var COUNT = 0;
function testFn() { console.log(COUNT++); }
// 浏览器resize的时候
// 1. 清除之前的计时器
// 2. 添加一个计时器让真正的函数testFn延后100毫秒触发
window.onresize = function () {
var timer = null;
clearTimeout(timer);
timer = setTimeout(function() {
testFn();
}, 100);
};
细心的同学会发现上面的代码其实是错误的,这是新手会犯的一个问题:setTimeout 函数返回值应该保存在一个相对全局变量里面,否则每次 resize 的时候都会产生一个新的计时器,这样就达不到我们发的效果了
于是我们修改了代码:
var timer = null;
window.onresize = function () {
clearTimeout(timer);
timer = setTimeout(function() {
testFn();
}, 100);
};
这时候代码就正常了,但是又多了一个新问题 —— 产生了一个全局变量 timer。这是我们不想见到的,如果这个页面还有别的功能也叫 timer 不同的代码之前就是产生冲突。为了解决这个问题我们要用 JavaScript 的一个语言特性:闭包 closures 。相关知识读者可以去 MDN 中了解,改造后的代码如下:
/**
* 函数节流方法
* @param Function fn 延时调用函数
* @param Number delay 延迟多长时间
* @return Function 延迟执行的方法
*/
var throttle = function (fn, delay) {
var timer = null;
return function () {
clearTimeout(timer);
timer = setTimeout(function() {
fn();
}, delay);
}
};
window.onresize = throttle(testFn, 200, 1000);
我们用一个闭包函数(throttle节流)把 timer 放在内部并且返回延时处理函数,这样以来 timer 变量对外是不可见的,但是内部延时函数触发时还可以访问到 timer 变量。
当然这种写法对于新手来说不好理解,我们可以变换一种写法来理解一下:
var throttle = function (fn, delay) {
var timer = null;
return function () {
clearTimeout(timer);
timer = setTimeout(function() {
fn();
}, delay);
}
};
var f = throttle(testFn, 200);
window.onresize = function () {
f();
};
这里主要了解一点:throttle 被调用后返回的 function 才是真正的 onresize 触发时需要调用的函数
现在看起来这个方法已经接近完美了,然而实际使用中并非如此。举个例子:
如果用户 不断的 resize 浏览器窗口大小,这时延迟处理函数一次都不会执行
于是我们又要添加一个功能:当用户触发 resize 的时候应该 在某段时间 内至少触发一次,既然是在某段时间内,那么这个判断条件就可以取当前的时间毫秒数,每次函数调用把当前的时间和上一次调用时间相减,然后判断差值如果大于 某段时间 就直接触发,否则还是走 timeout 的延迟逻辑。
下面的代码里面需要指出的是:
/**
* 函数节流方法
* @param Function fn 延时调用函数
* @param Number delay 延迟多长时间
* @param Number atleast 至少多长时间触发一次
* @return Function 延迟执行的方法
*/
var throttle = function (fn, delay, atleast) {
var timer = null;
var previous = null;
return function () {
var now = +new Date();
if ( !previous ) previous = now;
if ( now - previous > atleast ) {
fn();
// 重置上一次开始时间为本次结束时间
previous = now;
} else {
clearTimeout(timer);
timer = setTimeout(function() {
fn();
}, delay);
}
}
};
实践:
我们模拟一个窗口 scroll 时节流的场景,也就是说当用户滚动页面向下的时候我们需要节流执行一些方法,比如:计算 DOM 位置等需要连续操作 DOM 元素的动作
完整代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>throttle</title>
</head>
<body>
<div style="height:5000px">
<div id="demo" style="position:fixed;"></div>
</div>
<script>
var COUNT = 0, demo = document.getElementById('demo');
function testFn() {demo.innerHTML += 'testFN 被调用了 ' + ++COUNT + '次<br>';}
var throttle = function (fn, delay, atleast) {
var timer = null;
var previous = null;
return function () {
var now = +new Date();
if ( !previous ) previous = now;
if ( atleast && now - previous > atleast ) {
fn();
// 重置上一次开始时间为本次结束时间
previous = now;
clearTimeout(timer);
} else {
clearTimeout(timer);
timer = setTimeout(function() {
fn();
previous = null;
}, delay);
}
}
};
window.onscroll = throttle(testFn, 200);
// window.onscroll = throttle(testFn, 500, 1000);
</script>
</body>
</html>
我们用两个 case 来测试效果,分别是添加至少触发 atleast 参数和不添加:
// case 1
window.onscroll = throttle(testFn, 200);
// case 2
window.onscroll = throttle(testFn, 200, 500);
case 1 的表现为:在页面滚动的过程(不能停止)中 testFN 不会被调用,直到停止的时候会调用一次,也就是说执行的是 throttle 里面 最后 一个 setTimeout ,效果如图(查看原 gif 图):

case 2 的表现为:在页面滚动的过程(不能停止)中 testFN 第一次会延迟 500ms 执行(来自至少延迟逻辑),后来至少每隔 500ms 执行一次,效果如图

至此为止,我们想要实现的效果已经基本完成。后续的一些辅助性优化读者可以自己琢磨,如:函数 this 指向,返回值保存等。
1970-01-01 08:00:00
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmodtempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam,quis nostrudexercitation ullamco laboris nisi ut aliquip ex ea commodoconsequat. Duis aute irure dolor in reprehenderit in voluptate velit essecillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat nonproident, sunt in culpa qui officia deserunt mollit anim id est laborum.
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodoconsequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
天下之患,最不可为者,名为治平无事,而其实有不测之忧,坐观其变,而不为之所,则恐至于不可救,起而强为之则天下狃于治平之安,而不吾信 ——《苏东坡 晁错论》
大汉开国元勋淮阴侯韩信死于长乐钟室,年仅三十五岁。随后,韩信三族被诛,数千无辜,血染长安,哭号之声,传荡千古,当是时,寒风凛冽,长空飘雪,长安满城人尽嗟叹,无不悲怆,皆言淮阴侯一饭千金,不忘漂母;解衣推食,宁负汉皇?萧何一言便强入贺,欲谋逆者怎会坦率如斯?是侯不负汉,而汉忍于负侯,侯之死,冤乎哉! 不日,蒯通被带到,高祖亲自审问。「当日汝与韩信之言,究竟为何?」 蒯通道「吾相韩信,言其面不过封侯,背则贵不可言。因说之背汉自立,则可三分天下也。」 高祖又问:「然信有何言?」 蒯通长叹一声道:
「韩信言『汉王遇我甚厚,载我以其车,衣我以其衣,食我以其食。吾闻之,乘人之车者载人之患,衣人之衣者怀人之忧,食人之食者死人之事,吾岂可以见利而忘义乎?』」
高祖顿时愣住,良久没有说话,眼泪却在眶中打转了。蒯通又叹道「汉之所以得天下者,大抵淮阴侯之功也。」
大江东去,浪淘尽,千古风流人物。故垒西边,人道是,三国周郎赤壁。乱石穿空,惊涛拍岸,卷起千堆雪。江山如画,一时多少豪杰。 遥想公瑾当年,小乔初嫁了,雄姿英发。羽扇纶巾,谈笑间,樯橹灰飞烟灭。故国神游,多情应笑我,早生华发。人生如梦,一樽还酹江月。[1]
var MD5 = function(str) {
var hasher = cry.createHash('md5');
hasher.update(str);
return hasher.digest('hex');
};
[1] 《念奴娇·赤壁怀古》 苏轼
1970-01-01 08:00:00
部门分享 ⎡前端,改变⎦,一些个人对前端的见解和想法
前端是一种介于程序和设计之间的契合,拥有程序严谨逻辑的同时也存在设计的感性,前端是设计师的代码实现更是一门艺术。
{kind=link}