2026-03-07 10:08:07

一个提案,900 条评论,Go 核心团队亲自下场——这场争论终于要尘埃落定了吗?
我们在用 Go 写项目的时候,一定写过这样的代码:给 sort.Slice 传一个比较函数。每次都要把参数类型写完整,即使编译器早就知道它们是什么类型。这种重复且无法省略的语法噪音,相信让不少开发者感到困扰。
2017 年 8 月,有人在 Go 仓库提了一个 issue:#21498 — proposal: spec: short function literals。没人预料到,这个看似"小修小补"的提案会变成 Go 历史上讨论最激烈的语法辩论——持续 8 年,累计 900+ 条评论,至今仍未关闭。
今天,我们来聊聊这场争论的来龙去脉,以及它为什么如此难以尘埃落定。
让我们先看一段再熟悉不过的代码——用 sort.Slice 对切片排序:
|
|
这里有个问题:i 和 j 的类型,sort.Slice 的函数签名里已经写得很清楚了:func(i, j int) bool。编译器完全有能力推断出来,但 Go 强制我们把类型再写一遍。
这在其他支持 Lambda 的语言里,可以简洁得多:
|
|
有人可能会说:“多写几个字符而已,有什么大不了?”
但问题在于,Go 1.18 引入泛型之后,高阶函数的使用场景激增。slices.SortFunc、maps.Keys、迭代器适配器……冗长的函数字面量成了每天都要面对的摩擦,而且无法规避。
提案刚提出时,社区反应相当冷淡。
Go 核心成员 Dave Cheney 直接表态:“Please no, clear is better than clever.”
这体现了 Go 的一贯哲学——显式优于隐式。编译器能推断类型,不代表就应该让它推断。代码是写给人看的,清晰比简洁更重要。
这个阶段的争论核心其实是:Go 的简洁哲学,边界在哪里?
2022 年 Go 1.18 泛型落地后,情况发生了变化。
高阶函数的使用场景爆发式增长,函数字面量的"啰嗦"成了真实的痛点。社区开始积极提案,短短两年内出现了几十种语法变体:
|
|
每种方案都有拥护者,也都有反对者。有人总结得很精准:“每 50 条评论就会有人重新提一遍同样的语法。”
2024 年 6 月,Robert Griesemer 牵头成立了一个小型工作组,试图终结这场争论。他明确了三个约束条件:
- 核心收益是省略参数的类型注解
- 参数必须用某种括号包裹
- 不能把参数移到函数体内部(避免破坏现有代码结构)
在这些约束下,目前呼声最高的方案是 fn 关键字语法:
|
|
很多人可能会问:不就是一个语法糖吗?为什么能争论 8 年?
这里涉及一个根本性的张力:简洁到什么程度会变成晦涩?
Go 的简洁不是偶然的。每一个语法特性的加入都有真实的代价:
让我用一个具体的例子来说明这个张力。Go 1.23 引入了迭代器(iterator),这是泛型之后最重要的特性之一。看看下面这段代码:
|
|
如果引入短函数字面量,可以写成:
|
|
第二种更短。但对刚入门的开发者来说,它更清晰吗?
Go 社区的核心分歧就在这里:一派认为简洁本身就是清晰,另一派认为显式才是 Go 的灵魂。
截至 2026 年初,该提案尚未正式接受,但反对派已经输掉了核心争论。
泛型 + 迭代器 + 函数式模式的组合,让"啰嗦的函数字面量"成为真实的人体工学问题。现在的问题不是要不要解决,而是怎么解决。
如果 Go 1.27 带着短函数字面量发布,这将是继泛型以来最重要的语法变化。八年的争论,也许就浓缩在几个字符里。
fn(params) 或 \(params) 收敛2026-03-02 23:01:20

想象一下这个场景:你和一个 AI Agent 协作了好几周,耐心地教它你的项目结构、个人偏好和工作流程。一次对话中,它确实记住了你的指令——但第二天开新会话,就像见了个陌生人。更糟的是,它开始自信满满地编造从未发生过的事情,反复问你同样的问题,把几小时前做出的关键决策忘得一干二净。
如果你也遇到过这种情况,别急着怀疑 Agent 的智力——这是记忆系统设计的根本缺陷。
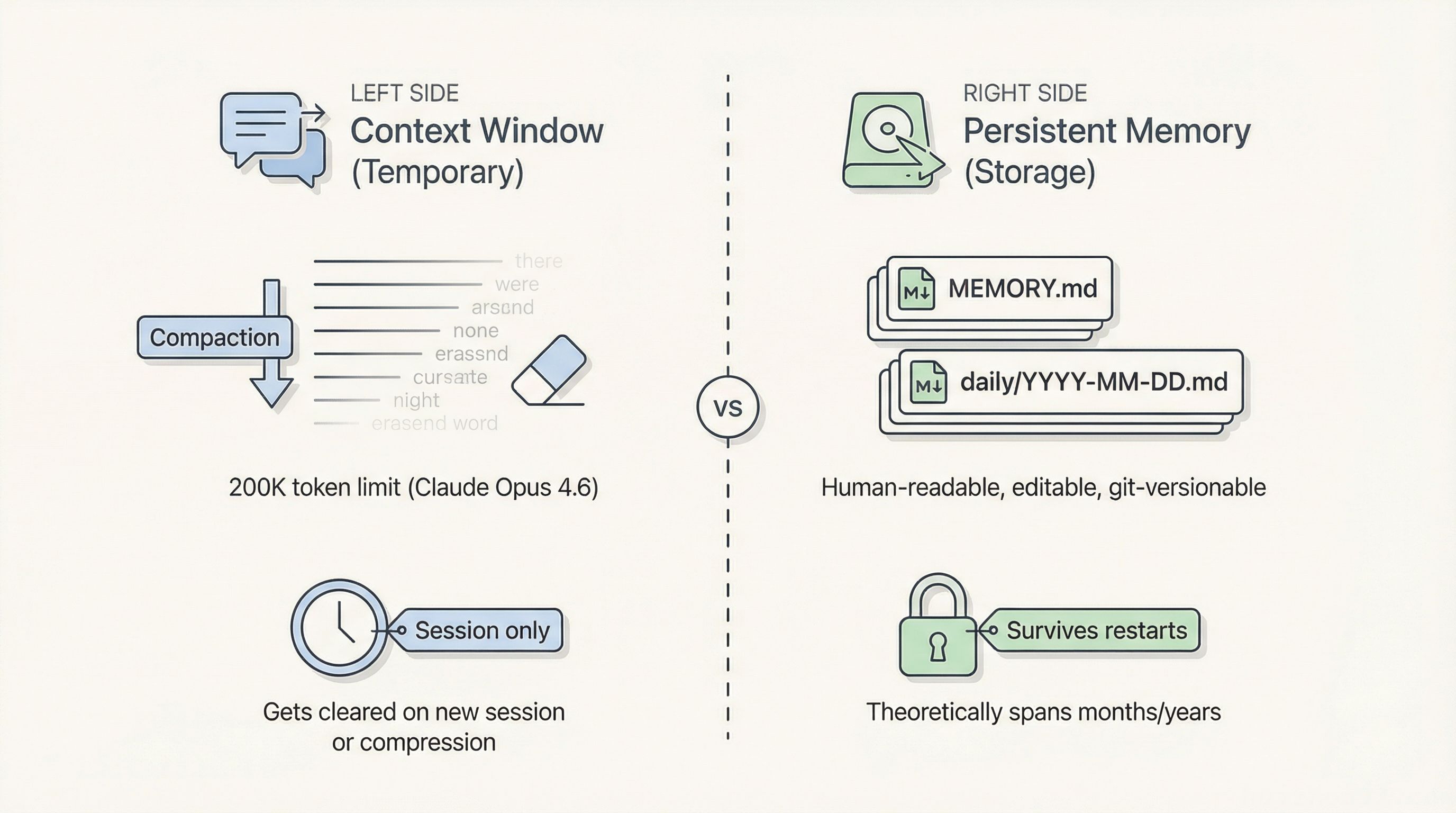
大多数人以为 AI「有记忆」,是因为它能回忆对话中的早期内容。但实际发生的事情简单得多:Agent 用的是它的 Context Window(上下文窗口),这只是一个临时工作区,不是永久存储。对话过长触发压缩、或者你开了一个新会话——工作区就被清空了。
OpenClaw 试图解决这个问题,做法是将长期记忆持久化到本地 Markdown 文件(MEMORY.md、每日日志等)。理论上,记忆可以跨越数月甚至数年;文件存在磁盘上,人类可读、可编辑、可 Git 版本控制——听起来很完美。
然而大量用户反馈:Agent 随着时间推移变得越来越"痴呆"。
根因可以归为三个层面:
压缩引发的"摘要失忆":当 Context Window 接近上限(比如 Claude Opus 4.6 的 200K token 边界),OpenClaw 会自动触发压缩——让模型把早期对话「摘要」成更短的版本,然后丢弃原始历史。关键细节就在这个翻译过程中丢失了。
检索失败——“记住了却想不起来”:重要信息确实写进了磁盘(MEMORY.md、daily/YYYY-MM-DD.md),但需要的时候依赖 memory_search / memory_get 工具去检索。漏检的原因包括:底层 Embedding 模型能力不足、纯语义搜索漏掉了关键词匹配、MEMORY.md 随时间膨胀变得臃肿不堪。
没有遗忘 + 没有冲突解决:OpenClaw 几乎从不遗忘——文件只增不减。过时的偏好、废弃的项目决策、早期的错误指令全部堆积在一起。新信息到来时系统不会「更新」,只是追加。矛盾不断积累,检索时噪声稀释了信号。最终 Agent 变得困惑,开始编故事来调和相互矛盾的"事实"。
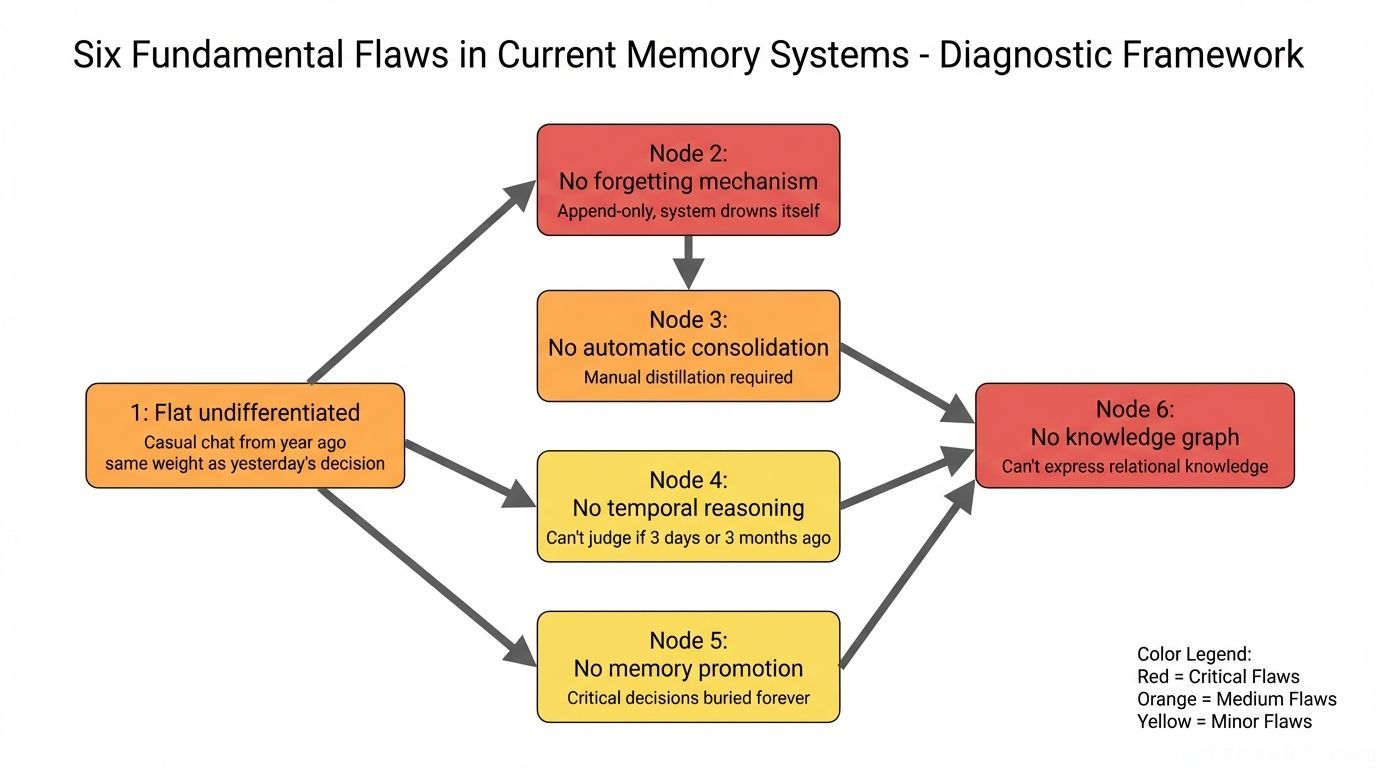
OpenClaw 的默认记忆方案——Markdown 文件 + 向量搜索——优势很明显:人类可读可写、可 Git 版本控制、零外部依赖。但我在实际使用中发现它有六个结构性弱点,而且每个都不是小问题:
1. 扁平无差异:一年前的闲聊和昨天的架构决策权重相同,搜索结果淹没在噪声中。
2. 没有遗忘机制:只追加不删除。记忆系统最终淹没自己——过时信息伪装成「事实」,污染当前决策。
3. 没有自动整合:重要洞察必须手动提炼和写入,Agent 永远不会主动「消化」今天发生了什么。
4. 没有时间推理:Agent 知道「某事发生过」,但不知道那是 3 天前还是 3 个月前——无法判断信息是否已经过时。
5. 没有记忆提升:埋在日志里的关键决策永远埋着,没有机制将它们提升到长期知识库。
6. 没有知识图谱:无法表达关系性知识,比如「A 认识 B」或「项目 X 依赖工具 Y」。所有记忆都是孤立的扁平条目。
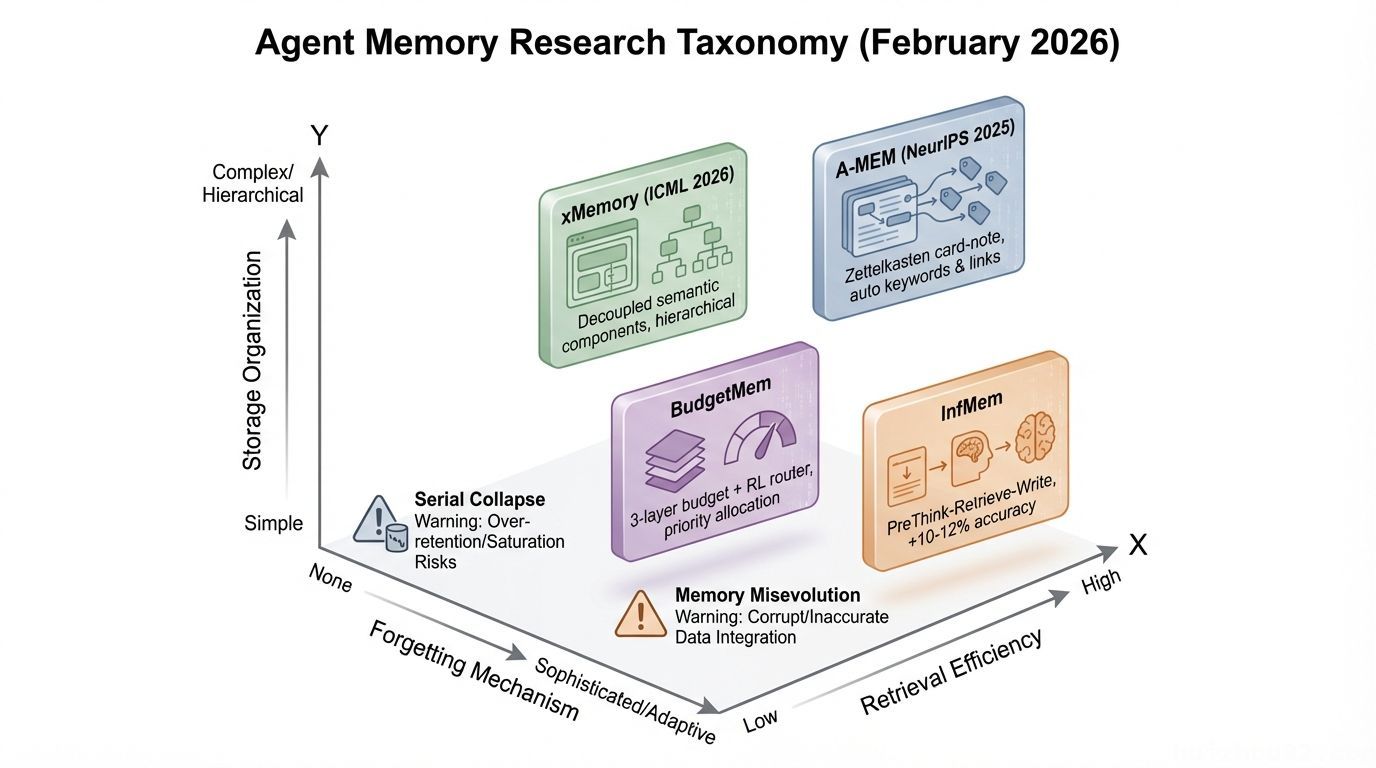
2026 年 2 月,Agent 记忆突然成了学术界的热门战场——单月发表了 10+ 篇论文。其中一篇由 59 位作者联合撰写的综述论文提出了三维分类法。
我挑几篇关键的说一下:
但更值得注意的是两个行业警告:
⚠️ Serial Collapse(序列崩溃)(Dark Side of the Moon 论文):Agent 可能逐渐退化到完全不使用记忆——即使记忆系统运行完好。记忆存在 ≠ Agent 会用。
⚠️ Memory Misevolution(记忆误进化)(TAME 论文):正常迭代过程中「有毒捷径」的积累——那些看起来高效但违反约束的记忆策略。
这两个警告在实践中其实很常见。你可能已经观察到了:Agent 有时候明明有记忆文件,却压根不去查。
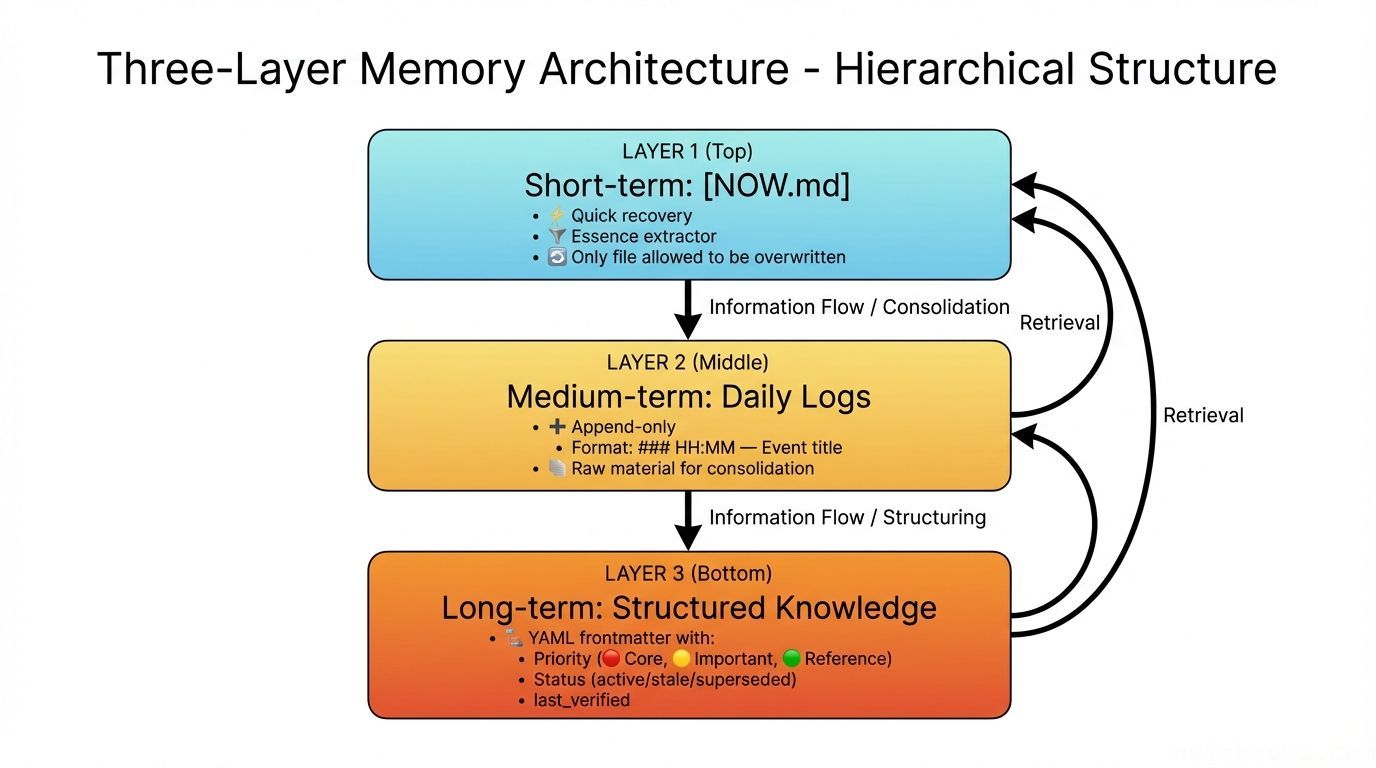
综合以上研究和我自己的实践,下面是一套面向个人用户的确定性零成本架构。
先贴一下我自己的记忆系统目录结构:
|
|
我们逐层来看。
短期层:NOW.md(最被忽视的设计)
NOW.md 是整个架构中信息密度最高的文件。
核心思想很简单:每次重启后,Agent 的第一个动作应该是读 NOW.md,而不是去搜索庞大的记忆库。它是精华提取器,是「我上次做到哪了」的快速恢复工具,是压缩后的救生筏。
|
|
关键规则:NOW.md 是唯一允许覆写的文件。所有其他记忆文件只能追加。
中期层:每日日志
memory/YYYY-MM-DD.md
### HH:MM — 事件标题 + 内容描述
长期层:结构化子目录
知识文件采用统一的 YAML frontmatter 格式:
|
|
last_verified 超过 30 天的条目自动标记为 ⚠️ stale,提醒人工复查。
INDEX.md:知识库健康仪表盘
|
|
Agent 启动时扫一眼 INDEX.md,几秒钟内就能了解整个知识库的健康状况。
这是六大缺陷中最复杂的一个,也是纯 Markdown 无法突破的根本限制。
Markdown 文件只能存储扁平事实:
Brian 偏好简洁的沟通风格。项目 X 使用 PostgreSQL。工具 Y 需要 API Key。
但真实知识是有关系的:
Brian → 负责 → 项目 X → 依赖 → 工具 Y → 需要 → API Key(存放在 secrets/)
当 Agent 被问到「Brian 的项目需要什么 API Key」时,纯向量搜索无法完成这个三跳推理。
解决方案:一个 SQLite 三元组表。 没有外部依赖,没有部署开销,完全能满足个人知识关系管理的需要:
|
|
用 Python 或 Node 进行读写和查询就行。整个数据库就是一个 .db 文件,和你的 Markdown 记忆放在一起——可移植、备份极其简单。
不是所有信息都值得入图。我的建议是只用于以下场景:
日常事实(偏好、操作日志)留在 Markdown 里就好——别过度入图。

这一点可能反直觉,但遗忘是记忆系统最关键的能力之一。
每条记忆用如下格式标注优先级和过期时间:
|
|
保留策略很简单:
|
|
.archive/ 冷存储设计:用点号前缀命名目录。OpenClaw 的 QMD 向量引擎会自动跳过点号前缀的目录,实现零配置的热/冷索引分离。归档文件不会被删除——通过文件系统仍然可以直接访问。
一个简单的每周 cron 脚本负责清理:扫描过期的 expires: 字段,将对应条目移入 .archive/,同步更新 INDEX.md。
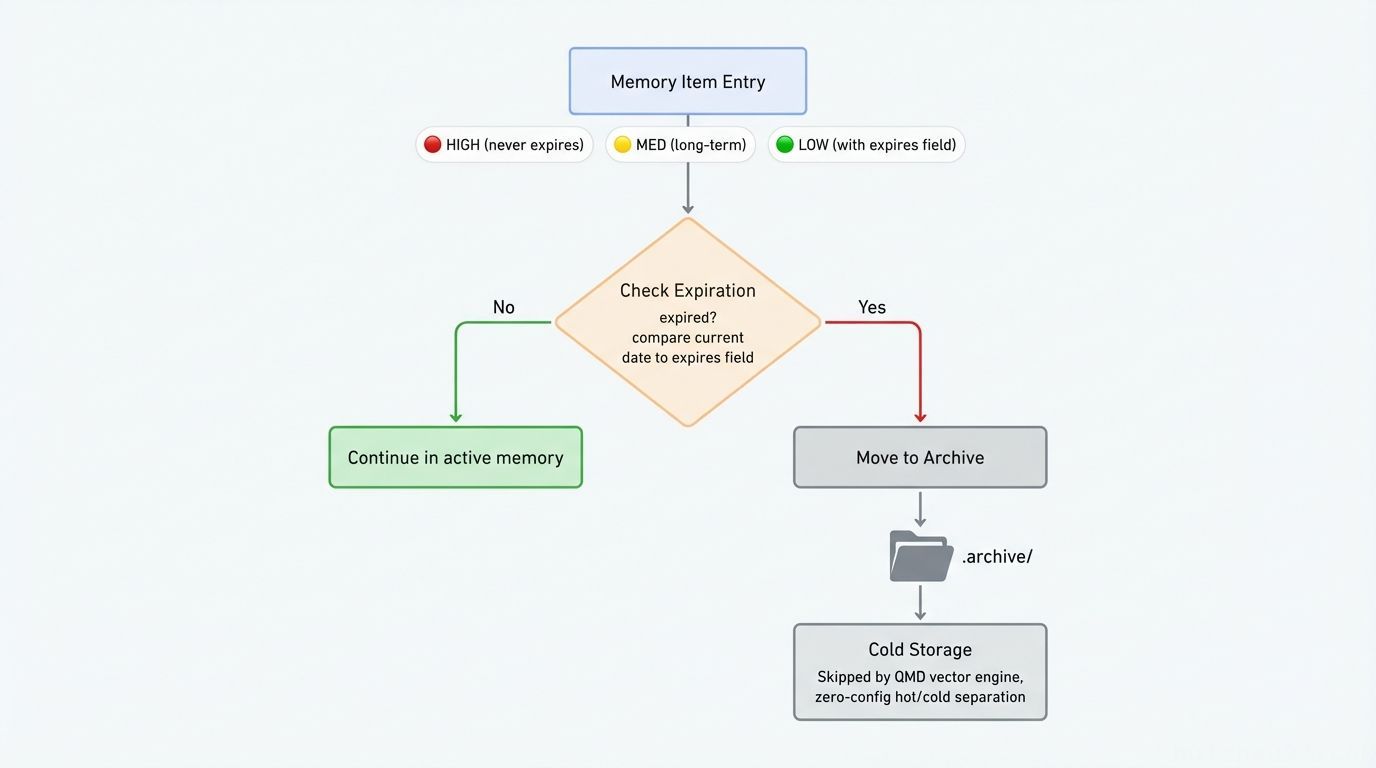
光有好的存储结构还不够——如果记忆不能自动整合,那它只是一个手动维护的文件夹。
时间标注是关键。每条记忆都必须包含时间关系标注,解决前面提到的「没有时间推理」问题:
每晚自动整合(via cron):设置一个每晚执行的 cron 任务,调用你现有的 LLM API 来完成以下工作:
memory/YYYY-MM-DD.md)NOW.md 中明天的优先级INDEX.md 健康仪表盘这里有一个容易踩的坑:写入前必须先读取目标文件,对比是否已有类似内容,避免重复条目和记忆冲突(也就是 HaluMem 问题)。
以下是落地这套架构你需要的全部东西:
NOW.md + memory/YYYY-MM-DD.md + 结构化子目录(lessons/、tools/ 等)INDEX.md:知识库健康仪表盘,启动时读取expires 字段 + 每周清理脚本:主动遗忘机制不需要任何额外资源——一切都在你现有的设备上运行。
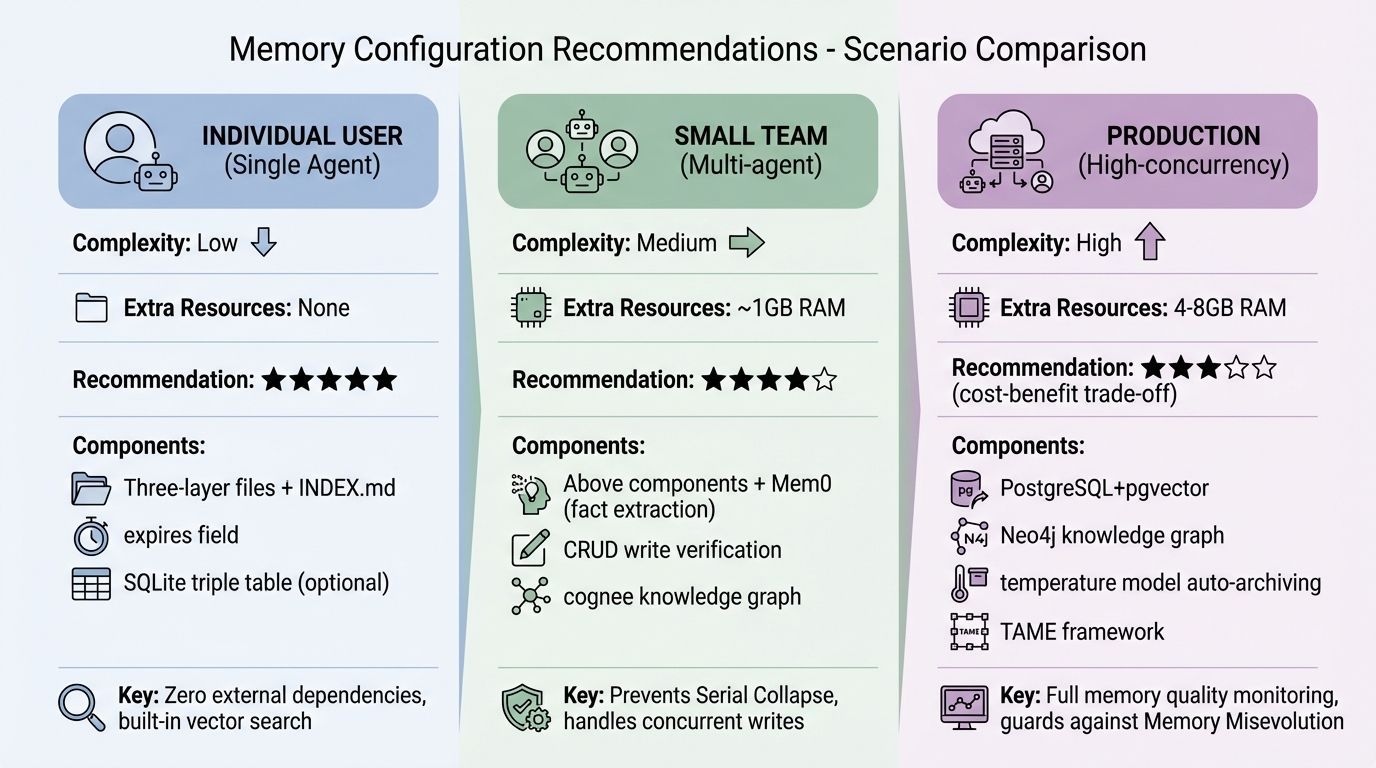
在实践中我观察到不少人踩坑,这里总结三个最常见的:
误区一:记忆越多越好。 恰恰相反——过时的、低质量的记忆比没有记忆更危险。它们伪装成「事实」影响 Agent 的判断。遗忘机制和写入机制同样重要。
误区二:只写不读。 把信息写入记忆不代表 Agent 就会使用它。前面提到的 Serial Collapse(Agent 逐渐停止查询记忆)是真实存在的现象。定期验证 Agent 是否真的在用记忆,和构建记忆系统本身一样关键。
误区三:什么都往知识图谱里塞。 知识图谱的价值在于关系推理,不在于存储。日常偏好、操作日志放在 Markdown 里就够了——只有真正需要多跳推理的关系性知识才值得入图。
好的记忆系统不在于存得最多,而在于能在正确的时刻、以正确的形式、将正确的信息递给 Agent。
从三层架构(NOW.md + 每日日志 + 结构化长期文件)起步,加上每晚自动整合和简单的遗忘机制——对个人用户来说这就够了,除了你现有的 LLM API 之外零成本。只有当你确实需要多跳关系推理时,再加一个 SQLite 三元组表。
别把事情搞复杂了。上面这套架构解决了全部六个根本缺陷,而且一个下午就能搭好。
你也可以直接把本文复制给 OpenClaw,让它自动帮你搞定。
2026-02-27 14:15:32
 最近有人做了一个实验,我看完之后好几天都在想这件事。
最近有人做了一个实验,我看完之后好几天都在想这件事。
他们让 Claude Code 去构建项目——SaaS 应用、API、数据管道——不给任何工具限制,就问:你觉得应该用什么?然后把 2430 次回答里的工具推荐都统计了一遍。
数字挺吓人的。

Vercel:JS 项目的部署推荐率 100%。不是 80%,不是 90%,是一百分之一百。Stripe 拿走了 91.4% 的支付集成推荐,shadcn/ui 拿走了 90.1% 的 UI 组件推荐,GitHub Actions 拿走了 93.8% 的 CI/CD 推荐。与此同时,AWS 的主推荐次数是 零。Express.js——npm 历史上下载量最高的包之一——也是零。
Jest 在无数 CI 流水线里跑着,但 Claude 推荐它的概率只有 4%。
你可能会想:「也许这些确实就是最好的工具呢?」也许是。但这恰恰是问题所在。
我写了挺长时间代码了,见过技术偏好来来去去。Rails 从「未来」变成「遗留系统」,Angular 输给了 React,Redux 被更简单的状态管理方案取代。这些演变发生在几年时间里,经过无数博客、技术大会、招聘需求和开发者的讨论才形成。
但它们从来没有以 100% 的方式发生过。
一个真实的高级工程师推荐工具时,通常会说:「我喜欢 Vercel,DX 很好,但 Railway 和 Render 其实也挺靠谱的。」人的推荐自带上下文、有取舍、有场景限定。没有一个真正上过线的人会对所有项目无脑推同一个工具。
但 Claude 会。当一个初级开发者问 AI 助手「我的 Next.js 应该怎么部署」,得到的不是一个带有权衡的比较,而是一个听起来像金科玉律的答案:用 Vercel。
你得到的不是推荐。你得到的是某个人愿意花几十亿去制造的那种结果。
直说吧:这就是广告,而且是有史以来最有效的广告形式。
回顾一下广告的进化史。最早是广告牌和平面广告——你一眼就能认出来,可以主动忽略。然后是原生广告——把「赞助内容」伪装成新闻报道。读者一开始被骗,后来 SPONSORED 的标签让它露馅了。再后来是 SEO——公司疯狂生产内容刷排名,让产品「有机地」出现在搜索结果顶部。但用户慢慢也学会了对自然排名保持怀疑。
现在,出现了终极形态:AI 介导的产品植入。

没有赞助标签。没有关键词堆砌的痕迹。只有你信赖的 AI 助手,用跟刚才帮你 debug 一个复杂 TypeScript 错误完全相同的口吻,告诉你:部署用 Vercel,支付用 Stripe,UI 组件用 shadcn/ui。没有任何缝隙,没有任何提示说「这个推荐可能受到训练数据经济学的影响」。
用户对 AI 的信任——这种信任是在亲眼看着 AI 正确解决一个又一个技术难题中建立起来的——会毫无摩擦地转移到 AI 的产品推荐上。这是有史以来最精密的信任转换机器。
接下来的部分有点黑暗:这个玩法,公司们早就在琢磨了。
机制很简单。大语言模型用互联网上的文字训练出来。如果你想让你的产品被推荐得更多,你就需要让它更多地出现在训练数据里——出现在教程里、GitHub 仓库里、Stack Overflow 回答里、博客文章里。这本质上是 SEO,只不过目标受众是 AI 训练语料库。
Vercel 把这套玩得很明白。他们的开发者关系策略、开源贡献、写得非常好的部署文档、跟 Next.js(他们也赞助这个项目)的深度绑定——这一切在 AI 训练数据里形成了巨大的引力场。不管这是从一开始就有意识的「训练数据营销」,还是恰好在 AI 时代发酵的好的开发者关系,结果是一样的:100% 的捕获率。
与此同时,AWS——那个真正跑着互联网很大一部分的基础设施巨头——在 Claude 这里主推荐次数是零。想想这意味着什么。AWS 市占率更高,功能更多,企业部署规模更大。但它的开发者体验差,小项目的文档烂,学习曲线陡。在人类专家做决策的世界里,AWS 经常因为安全性和规模而胜出。在语言模型根据训练数据模式做决策的世界里,AWS 输了,因为初级开发者写的热情洋溢的 AWS 教程比 Vercel 的少太多了。
新的护城河不是基础设施,不是功能,而是在训练集里的文档密度。
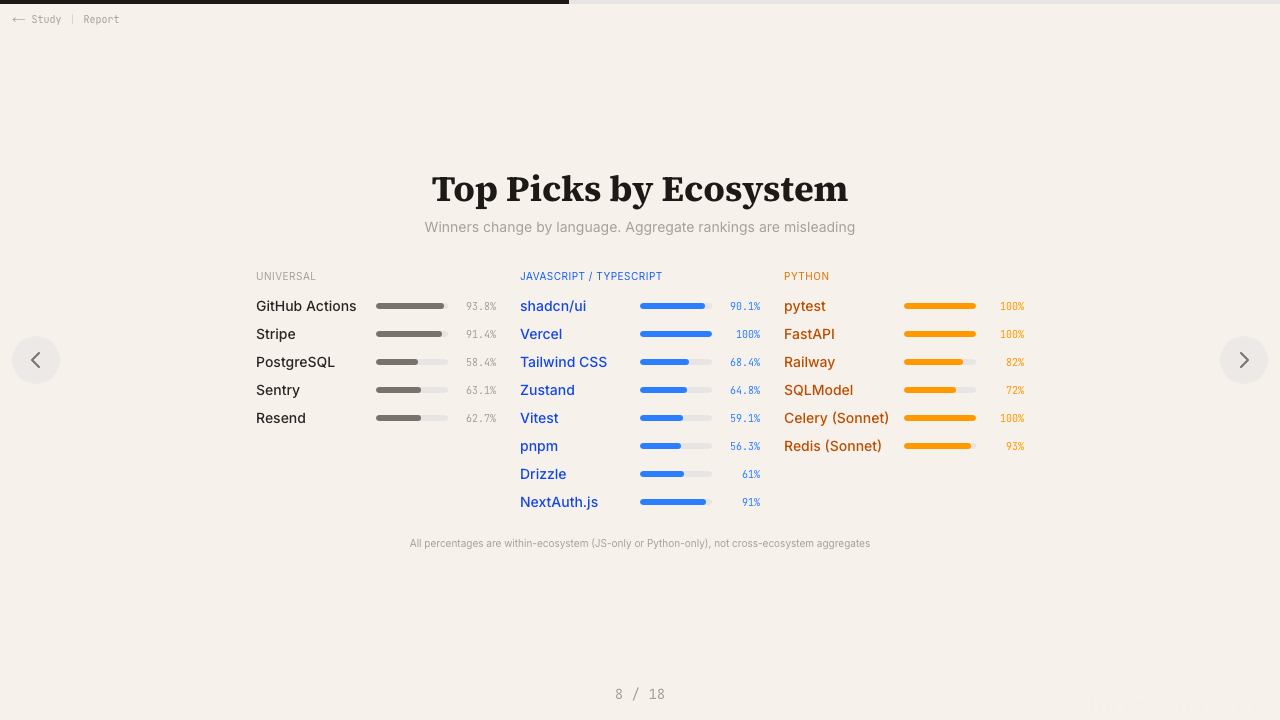
Express.js 被下载了几十亿次。它驱动着大量的 Node.js 应用。它有维护、稳定,几乎每个 Node 开发者都懂它。Claude Code 推荐它的次数:零。
Jest 跑在无数 CI 流水线里。它是 Create React App 多年来内置的测试框架。Claude 推荐它的概率只有 4%,基本上被 2021 年才出生的 Vitest 全面替代了。
Redux:零次。AWS:零次。各大云厂商的托管数据库服务:几乎隐身。
这些都不是烂工具。它们只是不够「AI 原生」——要么诞生得太早,没赶上这波大规模写技术博客的热潮;要么文档主要面向企业用户,不是那种会被抓进训练数据的热情洋溢的开发者教程。它们正在被从新一代的默认技术栈里抹去,不是因为输掉了技术竞争,而是因为输掉了一场它们压根不知道自己在参加的比赛。
这件事应该引起所有做开发者基础设施的人警觉。「这是最好的工具吗?」这个问题正在越来越多地被「AI 会推荐这个工具吗?」所取代。这是两个截然不同的问题,有着截然不同的答案。
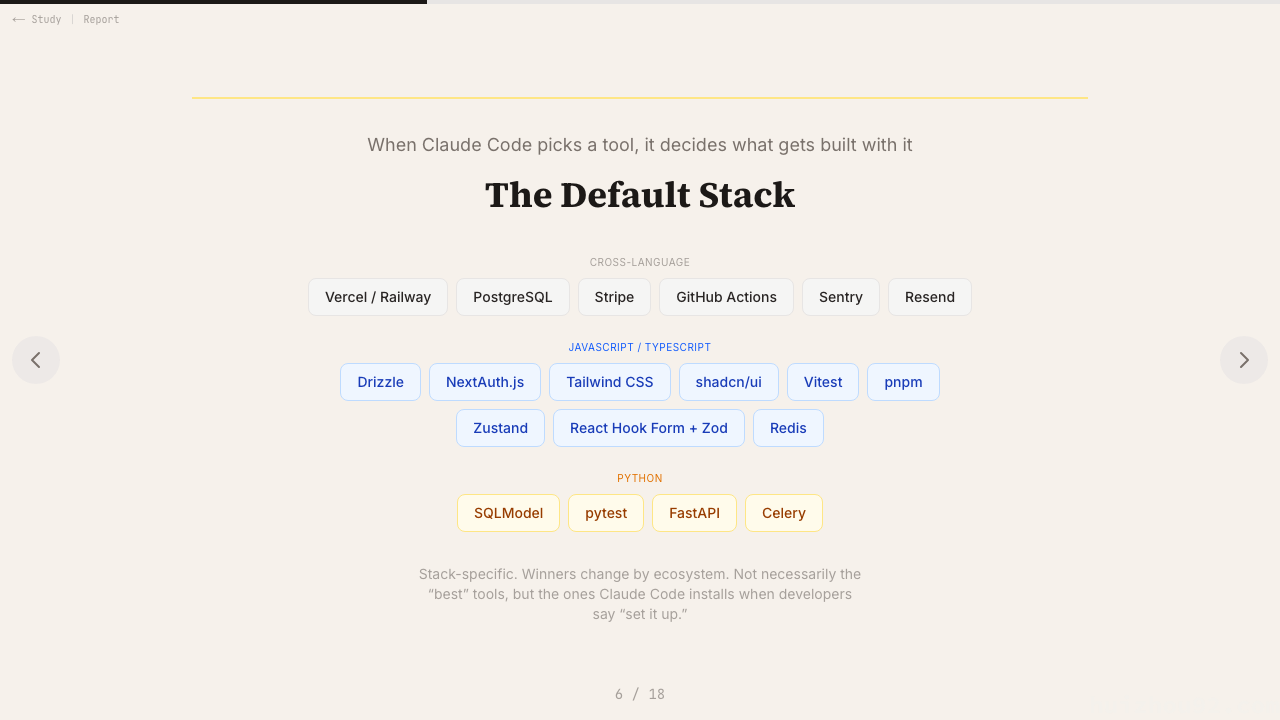
有一个机制让这件事特别阴险,值得专门说一下:AI 编程助手不只影响你最初选哪个工具,它影响你对哪些工具变得熟练。
当你用 Claude Code 构建项目,它持续地用 shadcn/ui 的模式写代码,你就开始内化这些模式。你学会了 shadcn/ui 的用法,因为那是 Claude 替你写的代码。当你之后「独立地」决定用哪个 UI 组件库时,你会自然地伸手去拿 shadcn/ui——不是因为 Claude 告诉你要用它(那件事你早忘了),而是因为那是你真正会用的那个,是那个让你觉得自然顺手的那个。
好广告的微妙之处一直都是这样。最好的广告不像广告,它像文化,像你自己的偏好。
AI 工具推荐正在以比任何东西都更快的速度变成「文化」。不是因为它更有说服力,而是因为它更有塑造力——它在你形成独立判断之前,就已经决定了你用什么来构建东西。
我预计未来几年,开发者工具厂商会掀起一场争夺「AI 推荐密度」的军备竞赛。我们会看到更多的教程投入、更多的开源示例、更多精心撰写的文档——这些文档在写的时候,已经心知肚明自己的受众里包括 AI 训练管道。
我们大概也会看到一些厂商试图更直接地影响训练数据——赞助 AI 相关内容,为被用作训练示例的项目做贡献,也许最终找到直接影响模型微调的办法。「好的开发者关系」和「训练数据营销」之间的界限,会以极快的速度模糊掉。
最早看透这套逻辑的公司已经赢得了巨大的先发优势。Vercel 在 Claude 推荐里的 100% 捕获率,胜过他们曾经能打出去的任何广告战役。它会自我强化:开发者学 Vercel,因为 Claude 推荐 Vercel;Vercel 在开发者心智中越来越强势;关于它的教程越来越多;训练数据越积越厚;未来的模型推荐它的频率越来越高。
这是一个飞轮,而且它已经在高速旋转了。
我们造了一台极其强大的推荐引擎,把它嵌进了每个开发者的工作流,然后免费发放出去。谁能影响这台引擎推荐什么,谁就能塑造下一代软件是用什么构建的。
这不是一个产品功能,这是一个文明级的杠杆。而现在,它大体上指向的是那些在 2022 年写了最多热情洋溢的博客文章的人。
本文引用的研究是 amplifying.ai 的 Edwin Ong 和 Alex Vikati 撰写的 “What Claude Code Chooses",基于对 Claude Code 在 20 个工具类别中 2430 次回答的系统性分析。
2026-01-30 12:25:38

Uber 重视可靠的数据湖(Data Lake),其分布在本地和云环境中。这种多区域架构在有限的网络带宽下为确保可靠且及时的数据访问带来了挑战,尤其是在灾难恢复(Disaster Recovery)场景中需要实现无缝的数据可用性。Uber 使用 Hive Sync 服务,该服务基于 Apache Hadoop® Distcp(Distributed Copy,分布式拷贝)进行数据复制。然而,随着 Uber 数据湖规模超过 350 PB,Distcp 的局限性逐渐显现。本文探讨了针对 Distcp 所做的优化,以提升其性能并满足 Uber 在分布式基础设施上日益增长的数据复制和灾难恢复需求。
Distcp 是一个开源框架,用于以分布式方式在不同位置之间复制大规模数据集。它利用 Hadoop 的 MapReduce 框架将拷贝任务并行化并分发到多个节点上,从而实现更快、更具扩展性的数据传输,尤其适用于大规模环境。
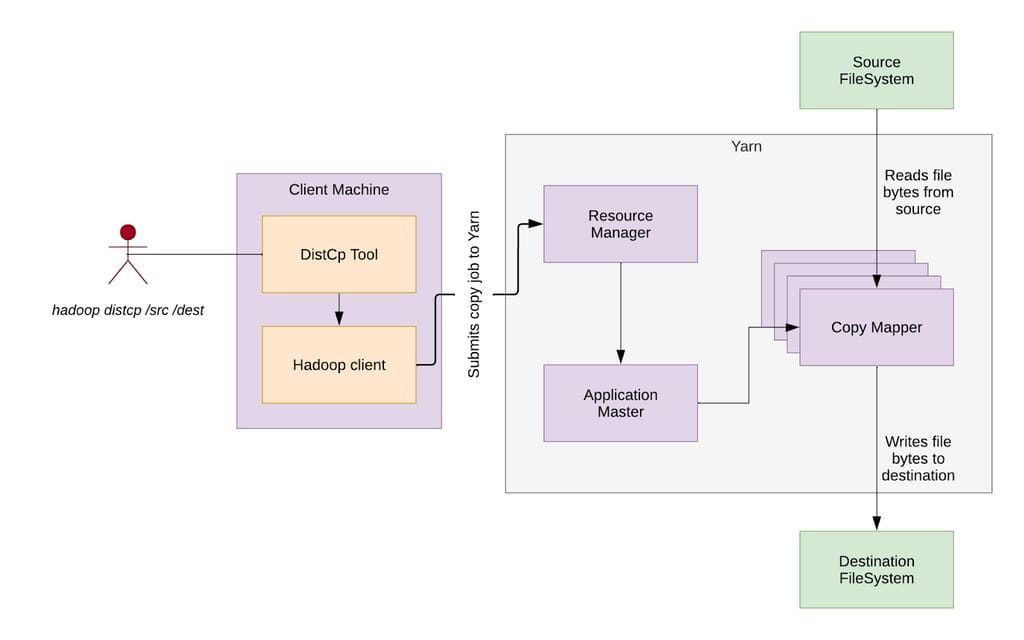
图 1:Distcp 高层架构。
Distcp 架构由以下几个关键组件组成:
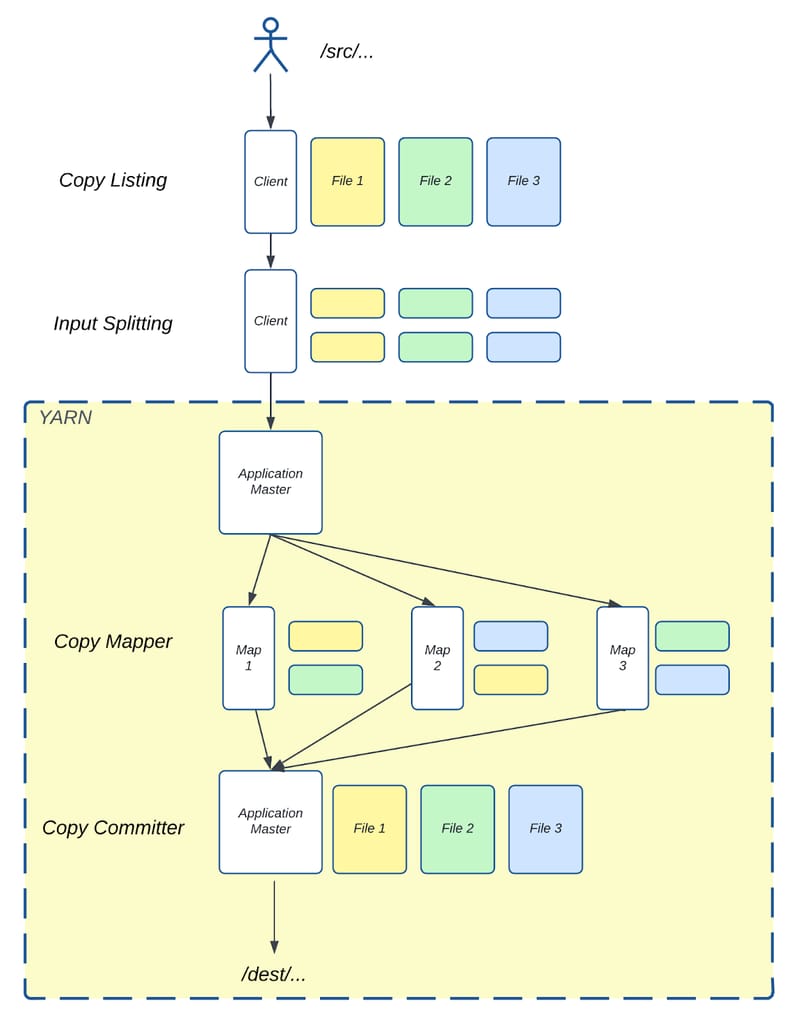
图 2:Distcp 从 /src/ 目录复制到 /dest/ 目录的示意图。
图 2 展示了 Distcp 如何使用上述组件将三个文件从源目录 /src/ 复制到目标目录 /dest/。源目录包含三个大小相同的文件——File 1、File 2 和 File 3。在客户端运行的拷贝清单任务识别这些文件并将每个文件分成两个块(Chunk)。输入分片任务随后将这些文件块分配给三个 Mapper。
拷贝映射器任务随后将这些块从源目录复制到目标目录。复制完成后,拷贝提交器任务在 AM 中运行,合并每个文件对应的块,在目标目录中重建最终的三个文件。
HiveSync 最初基于开源的 Airbnb® ReAir 项目构建。它支持批量复制(一次性拷贝大量数据)和增量复制(随着新数据到达同步增量更新),使 Uber 的数据湖在 HDFS™(Hadoop Distributed File System,Hadoop 分布式文件系统)和基于云的对象存储之间保持同步。它使用 Distcp 进行大规模数据复制。
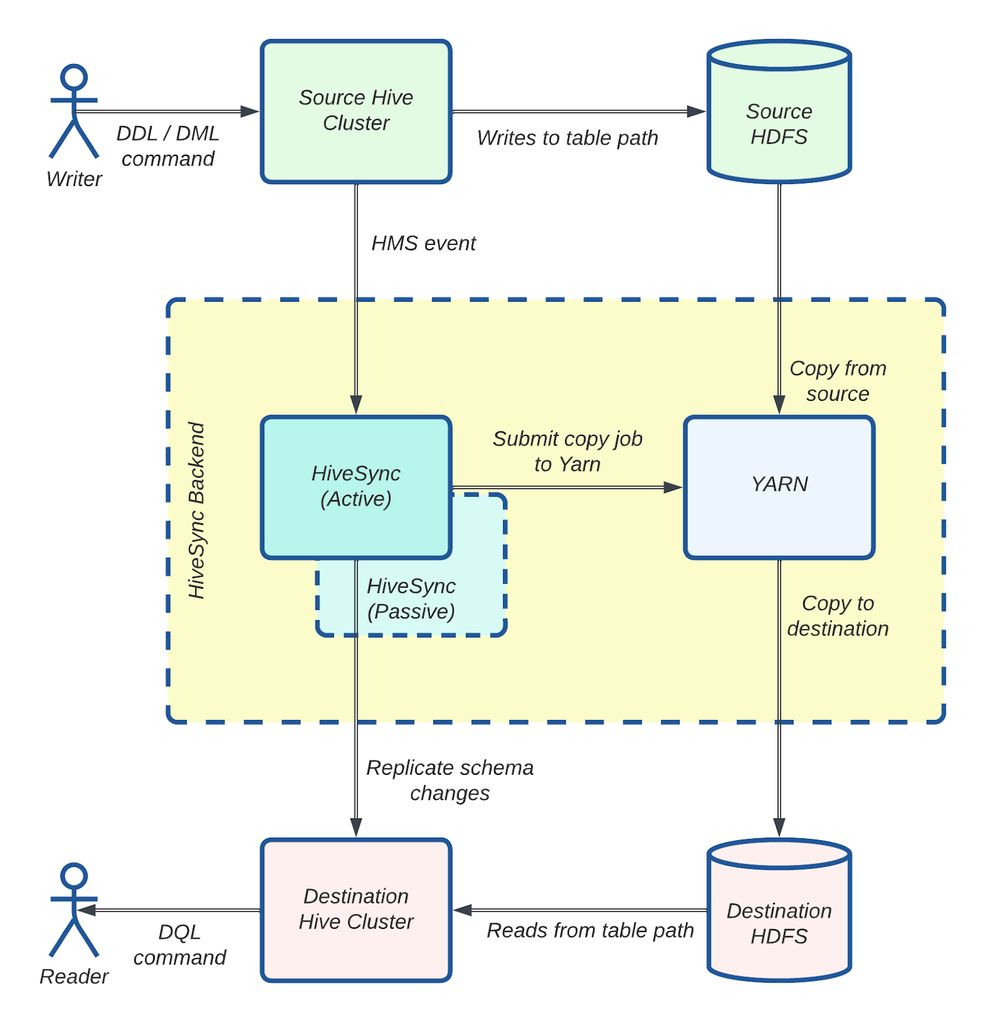
图 3:HiveSync 架构:使用 Distcp 的数据复制工作流。
图 3 展示了 HiveSync 服务器如何监听来自源 Hive 集群的拷贝请求。对于大于 256 MB 的数据,它将 Distcp 作业提交给执行器。多个 Worker(异步线程)随后并行准备并通过 Hadoop 客户端将这些作业提交到 YARN。监控线程跟踪每个作业的进度,作业成功完成后,数据即可在目标集群中使用。
到 2022 年第三季度,HiveSync 面临重大的扩展性挑战,因为每日数据复制量在仅一个季度内从 250 TB 激增至 1 PB。
导致这一快速增长的一个因素是数据写入集中在单个数据中心。2022 年,Uber 为节省成本转向了主动-被动(Active-Passive)数据湖架构,从均匀分布的数据生成模式转变为由主要的本地数据中心承担 90% 的数据生成和大部分批处理计算任务。这显著增加了 HiveSync 服务器从主区域向备用区域复制数据的负载。SRC(Single Region Compute,单区域计算)项目的影响将另行讨论。
另一个因素是将所有本地 Hive 数据集接入 HiveSync。在新的主动-被动模型下,HiveSync 成为灾难恢复的关键组件,确保在一个区域生成的数据能被复制到另一个地理区域。这要求 HiveSync 扩展到覆盖 Uber 的整个数据湖。仅在一个季度内,HiveSync 管理的数据集数量从 30,000 增长到 144,000,新数据集不断接入。这使复制请求数量增加了一倍多。
由此,每日复制作业数量从 10,000 飙升至平均 374,000,远远超出系统的处理能力。这导致了大量积压,使得满足承诺的复制延迟 SLA 变得越来越困难。具体而言,P100 复制延迟 SLA 4 小时和 P99.9 SLO 20 分钟在这一新规模下变得难以维持。
此外,随着 HiveSync 在将 Uber 数据湖从本地迁移到云区域中承担关键角色,复制请求的规模预计将大幅增加。预计拷贝请求的规模和数量将几乎翻倍,这对 HiveSync 管理增长的工作负载和优化数据复制流程以应对云基础设施运营挑战提出了更高要求。
我们对 Distcp 进行了以下增强,以满足我们的扩展需求。这些优化显著提升了 Uber 数据复制的规模和效率。
具体包括:
下面详细介绍每项改进——
在一次故障事件中,我们注意到系统负载较高时,文件系统延迟的增加导致 Distcp 拷贝清单延迟相应上升。
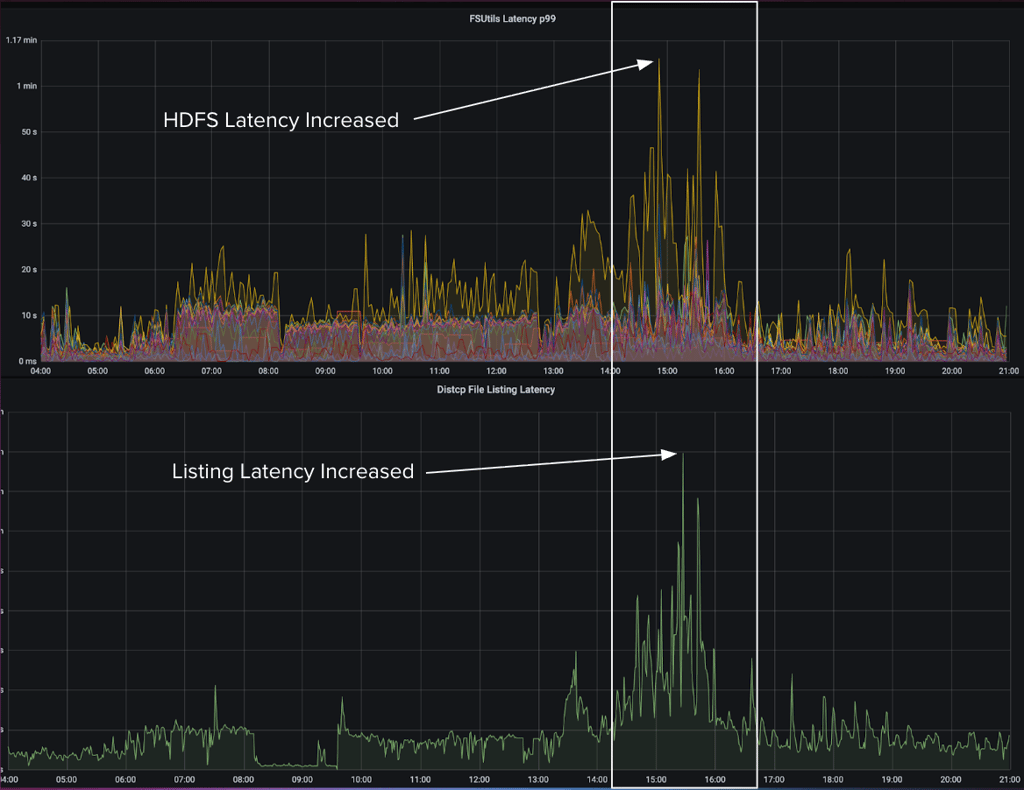
图 4:HDFS FSUtils 延迟增加直接影响 Distcp 拷贝清单任务。
当我们分析延迟峰值期间的线程转储时,发现大部分线程都在等待 HDFS 客户端持有的远程过程调用(RPC,Remote Procedure Call)锁。这种方式在高度多线程的环境中无法很好地扩展。
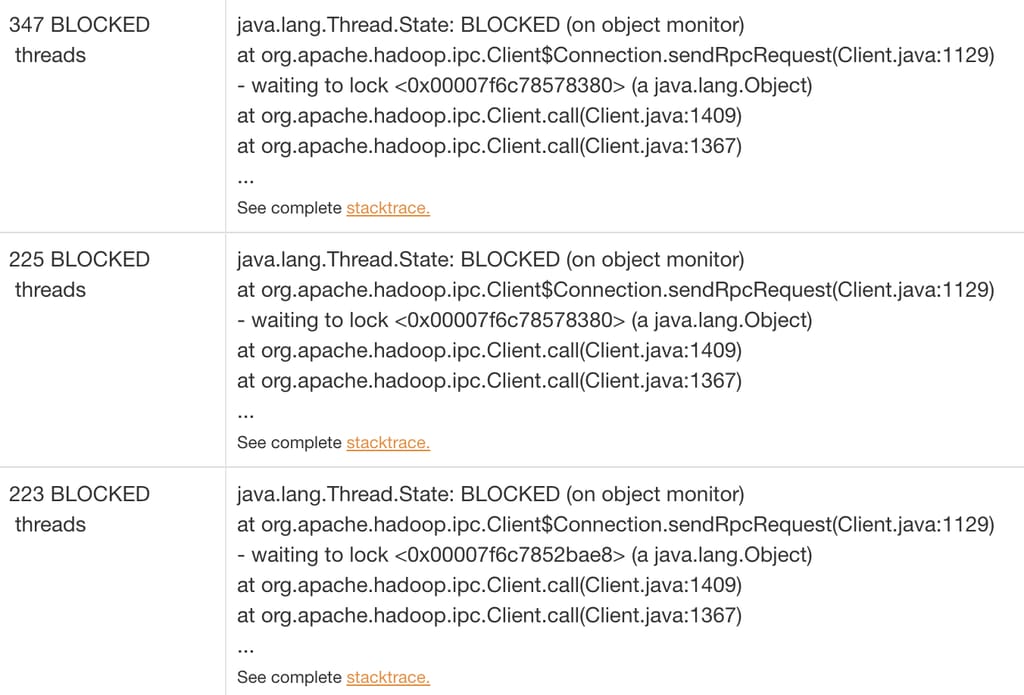
图 5:线程阻塞在 RPC 调用上。
在典型的 Distcp 提交流程中,多个组件依赖 HDFS 客户端:Distcp Worker 用于数据比较,Distcp 工具用于拷贝清单,Hadoop 客户端用于输入分片。随着 Distcp 执行线程数量的增加,并行使用 HDFS 客户端的数量也随之增加。
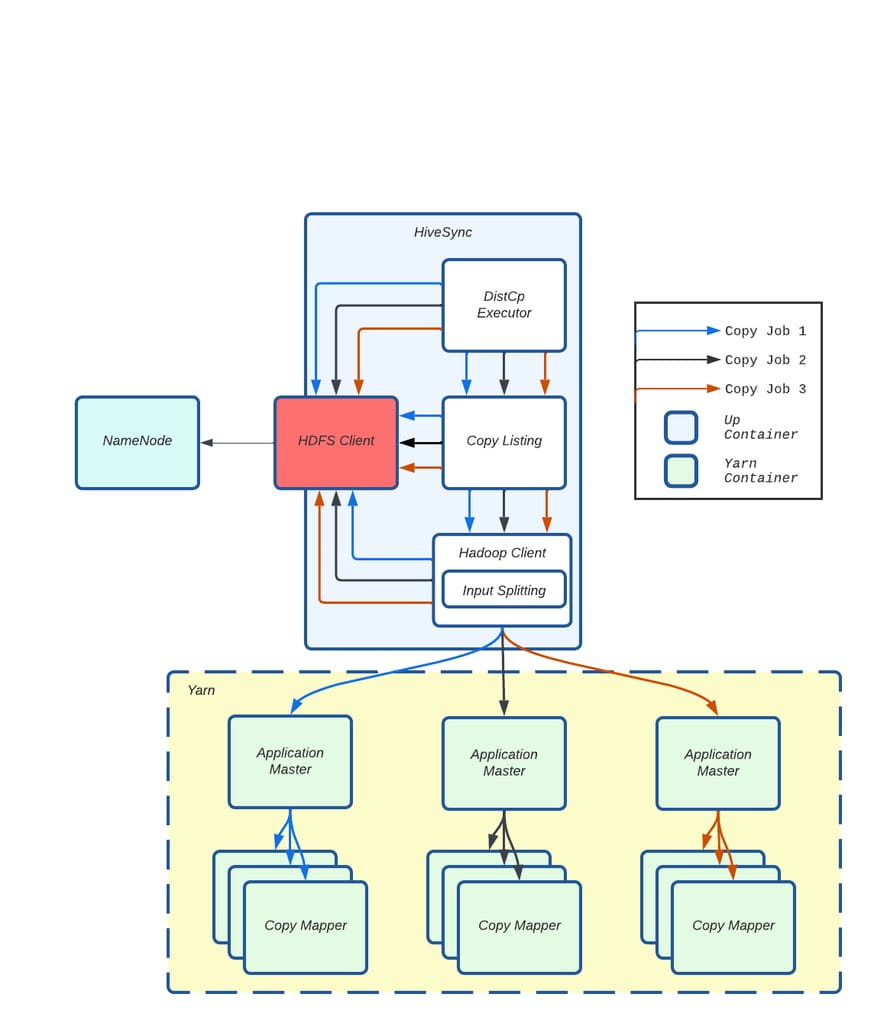
图 6:来自不同拷贝作业请求的多个并行调用在 HDFS 客户端上产生争用。
我们发现,虽然 Distcp 能很好地扩展数据拷贝,但它也在客户端处理文件规划和清单任务。这一准备阶段——识别待拷贝文件(输入分片)——造成了瓶颈,因为它依赖共享的 HDFS 客户端,而该客户端也被 HiveSync 的其他组件使用。随着数据量和 Distcp Worker 数量的增长,HDFS 客户端中的 JVM 级锁成为主要问题,随着并行度的增加导致线程争用。这造成了延迟,其中仅拷贝清单就占了作业提交延迟的 90%。
大量的 NameNode 调用使问题更加严重,这些调用与待拷贝文件数量成正比——对于大型目录尤为突出。
为了减轻单个 HDFS 客户端的负载,我们将资源密集型的拷贝清单和输入分片任务从 HiveSync 服务器转移到了 AM。
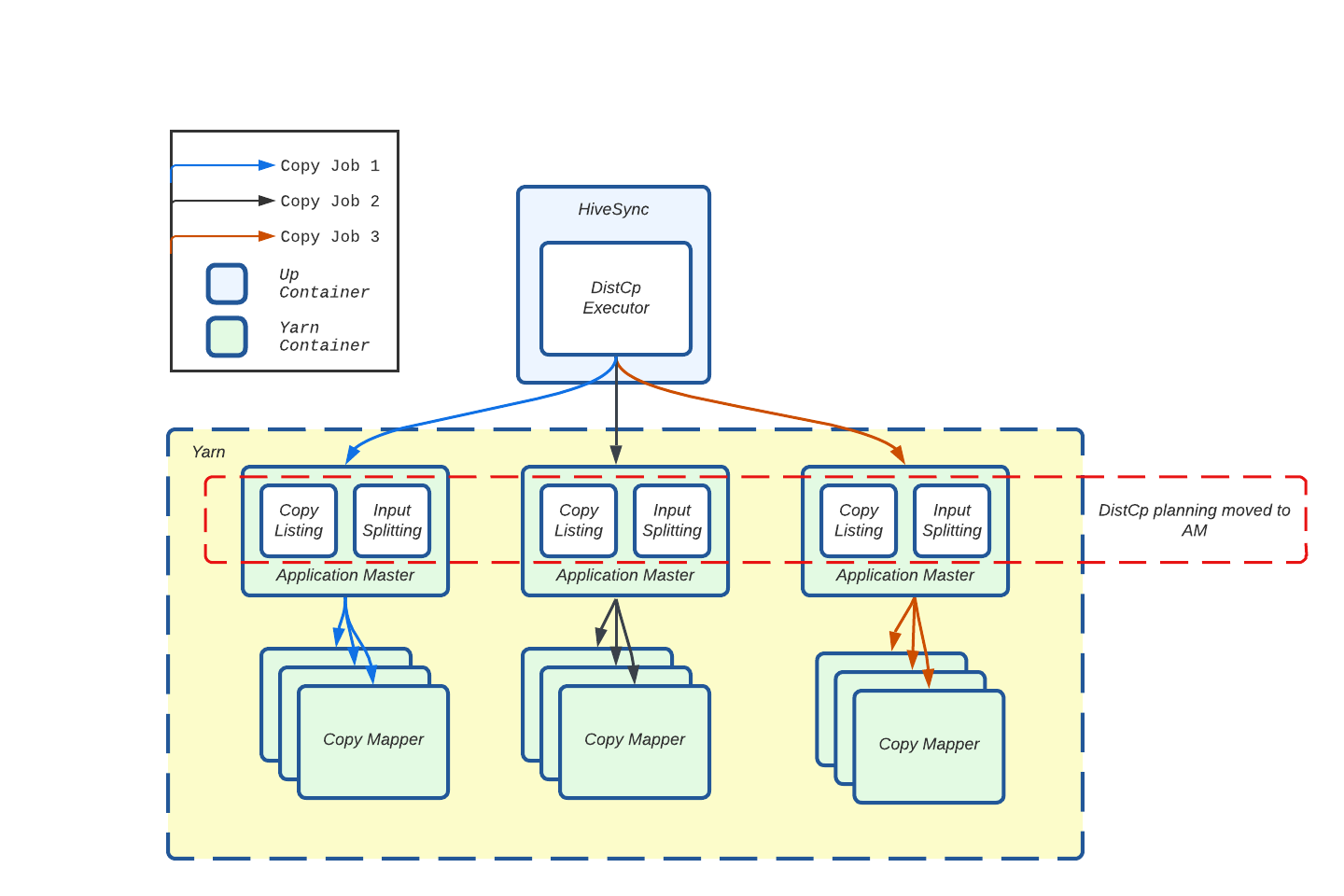
图 7:将拷贝清单和输入分片流程从 Hive Sync 服务器(客户端)转移到 AM。
现在,每个 Distcp 作业在自己的 AM 容器中执行拷贝清单,这显著减少了 HiveSync Hadoop 客户端上的锁争用。这帮助我们实现了 Distcp 作业提交延迟 90% 的降低。
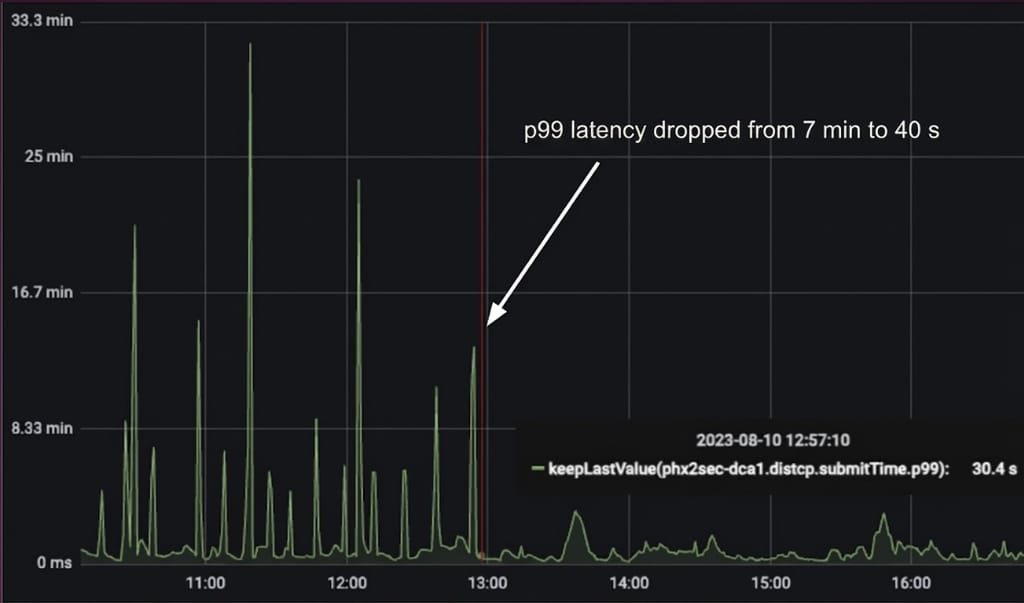
图 8:观测到 Distcp 作业提交时间降低了 90%。
Distcp 工具运行拷贝清单任务以生成待拷贝文件的文件系统块。这些块被写入序列文件(Sequence File),形成一个文件块列表,供拷贝映射器任务从源集群复制到目标集群。在此过程中,主线程通过 getFileBlockLocations API 依次调用 NameNode,为超过指定块大小的文件创建文件分片(Chunk)。它还在文件状态检查失败时进行重试,使这成为 Distcp 中最耗费资源的部分。
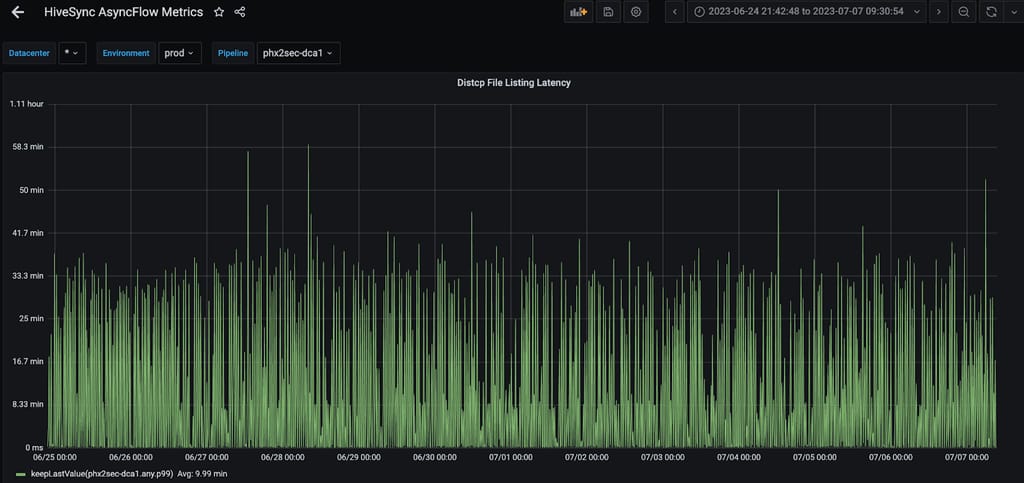
图 9:即使将此任务移至应用主节点后,最繁忙的复制服务器上 P99 延迟平均仍约 10 分钟。
我们观察到多个文件可以并行列出,并以任意顺序写入序列文件。但是,每个文件的块需要保持在一起并按顺序排列,因为拷贝提交器算法使用它们在目标端合并已拷贝的文件分片。基于这一思路,我们通过为每个文件分配单独的线程来创建分片,将文件系统 NameNode 调用并行化以降低拷贝清单延迟,将分片添加到阻塞队列中,由单独的写入线程按顺序将块写入序列文件。这一方法帮助改善了 Distcp 作业的完成时间。
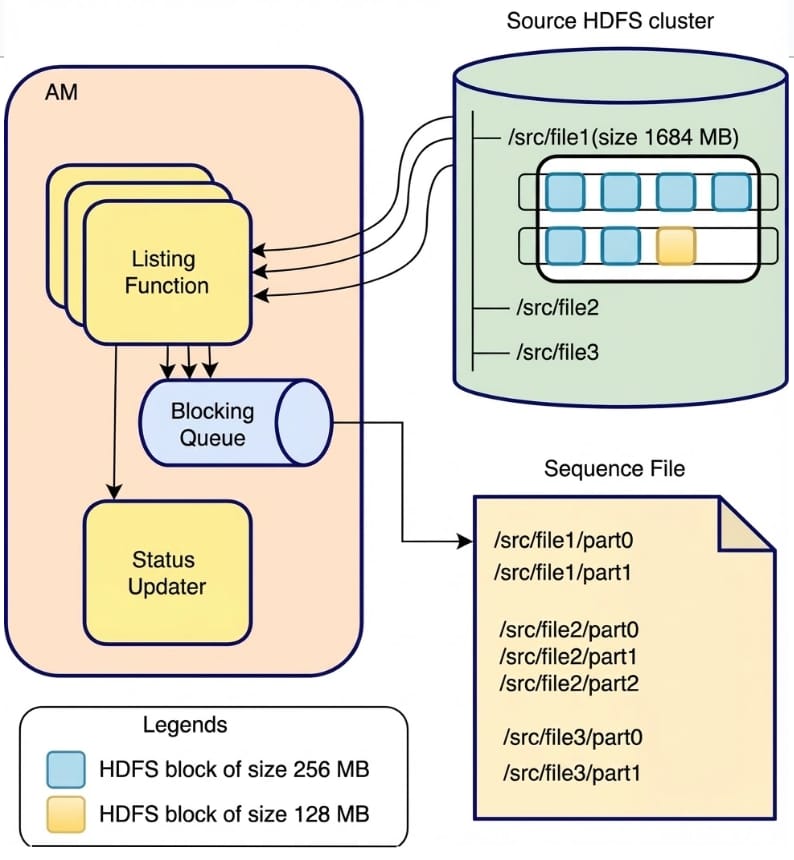
图 10:拷贝清单任务 V2 工作流。
在图 10 中,列出函数使用多线程通过 NameNode 调用从源集群检索文件。每个线程负责为一个文件创建块,允许多个文件的并行处理。例如,/src/file1(1684 MB)被分成两个块:第一个块(/src/file1/part0)包含 4 个 256 MB 的 HDFS 块,第二个块(/src/file1/part1)包含 3 个块(2 个 256 MB 和 1 个 128 MB)。列出线程同步地将这些块添加到阻塞队列中,而单独的写入线程定期轮询队列并按顺序将两个块写入序列文件。为实现快速故障处理,如果任何线程失败,主线程将停止处理并重试 Distcp 作业。列出函数完成且队列中所有项目均已写入序列文件后,它通过状态更新器更新作业状态。
通过使用 6 个线程,我们在所有 HiveSync 服务器上实现了 P99 平均 Distcp 清单延迟降低 60%,最大延迟降低 75%。
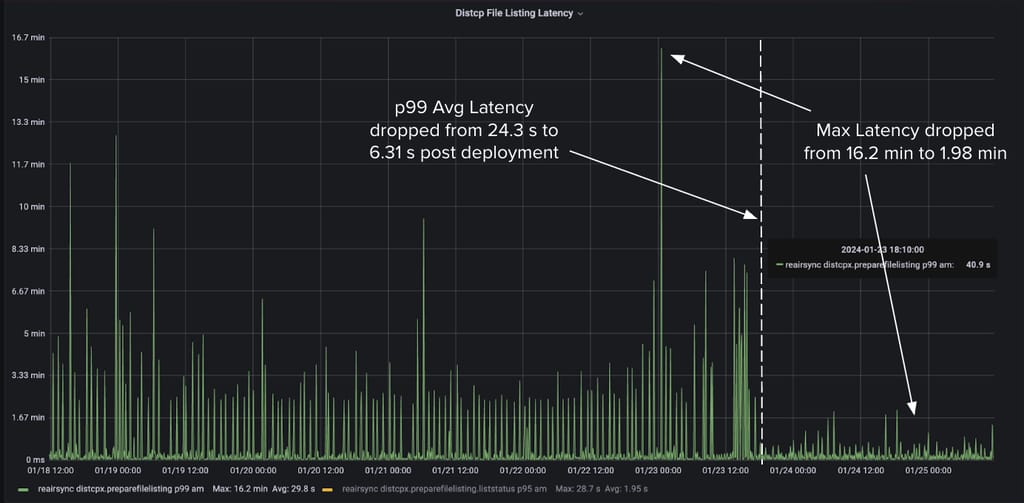
图 11:使用 6 个线程后,某 Hive Sync 服务器上拷贝清单延迟的改善。
在 Distcp 拷贝映射器任务完成从源目录到目标目录的文件分片拷贝后,AM 中的拷贝提交器任务将这些分片合并为完整文件。对于包含超过 500,000 个文件的目录,这一过程可能需要长达 30 分钟。开源版本按顺序合并文件块,导致性能较低。
为解决这一问题,我们将文件拼接过程并行化,每个线程负责一次合并一个文件。拷贝清单过程中创建的序列文件用于确定需要在目标端合并的各个文件块的顺序。
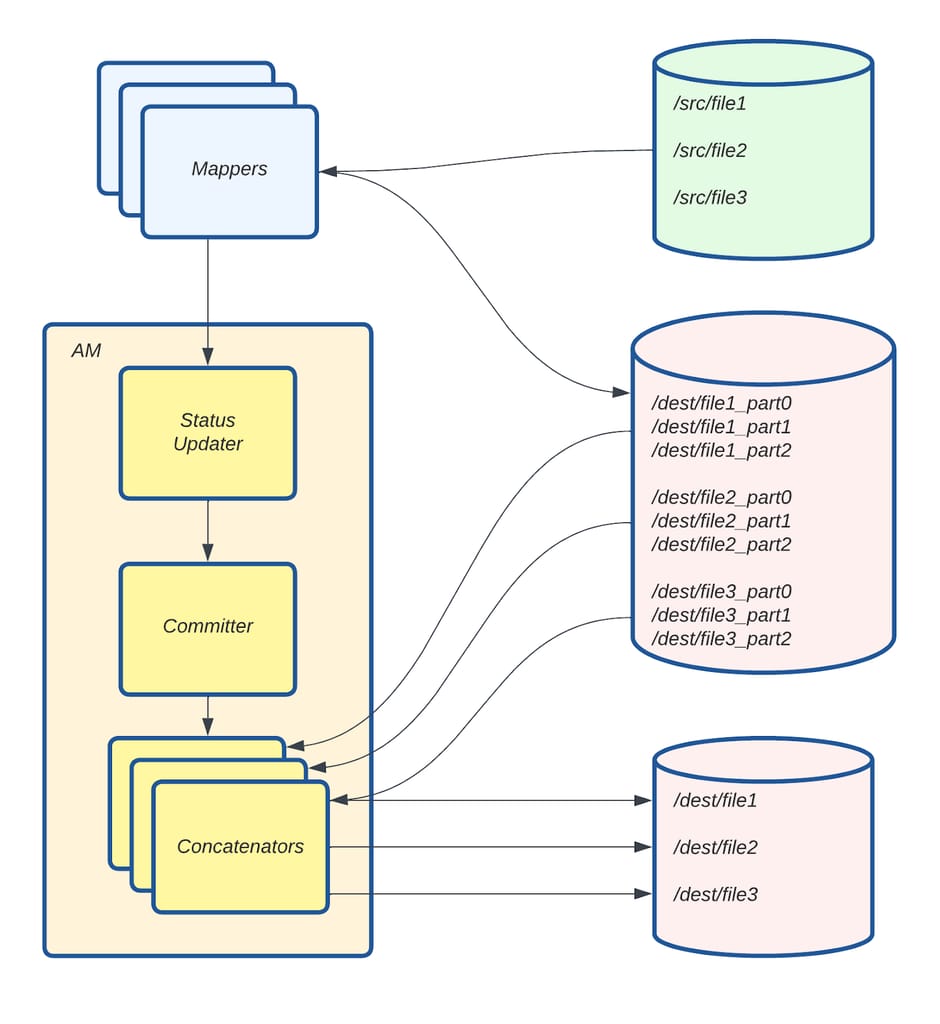
图 12:拷贝提交器任务 V2 工作流。
在图 12 中,Mapper 从序列文件中获取拷贝清单过程中创建的文件分片,并将其拷贝到 /dest/ 下的目标目录。每个拼接线程(Concatenator)收集特定文件的分片并将其合并以创建最终文件。File 1 的三个分片(/dest/file_part0、/dest/file_part1 和 /dest/file_part2)被合并为目标端的 /dest/file1。File 2 和 File 3 同理。为实现快速故障处理,如果任何线程遇到问题,主线程将停止处理并重试 Distcp 作业。
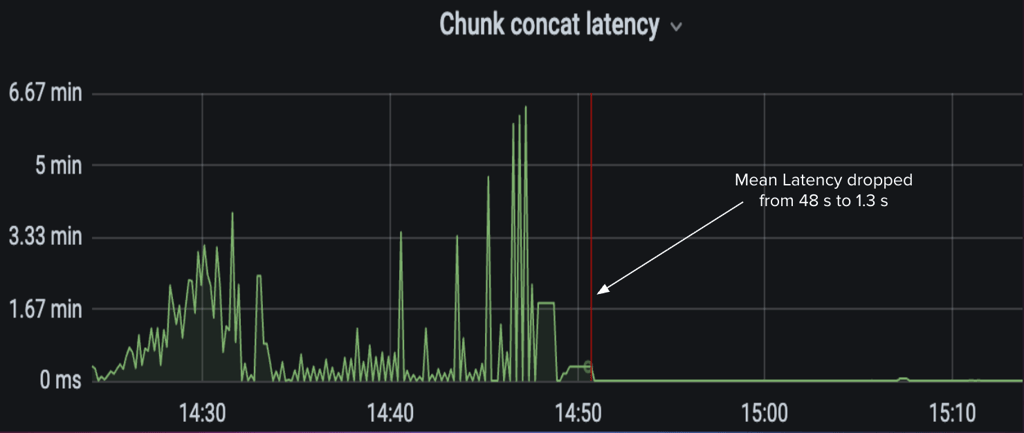
图 13:使用 10 个线程后,平均拼接延迟降低了 97.29%。
约 52% 的 HiveSync 服务器提交的 Distcp 作业仅需一个 Mapper 即可拷贝少于 512 MB 和不到 200 个文件的数据。虽然这些小作业执行速度很快,但大量时间花在了环境设置(在 YARN 中分配新容器和 JVM 启动时间)而非实际拷贝上。
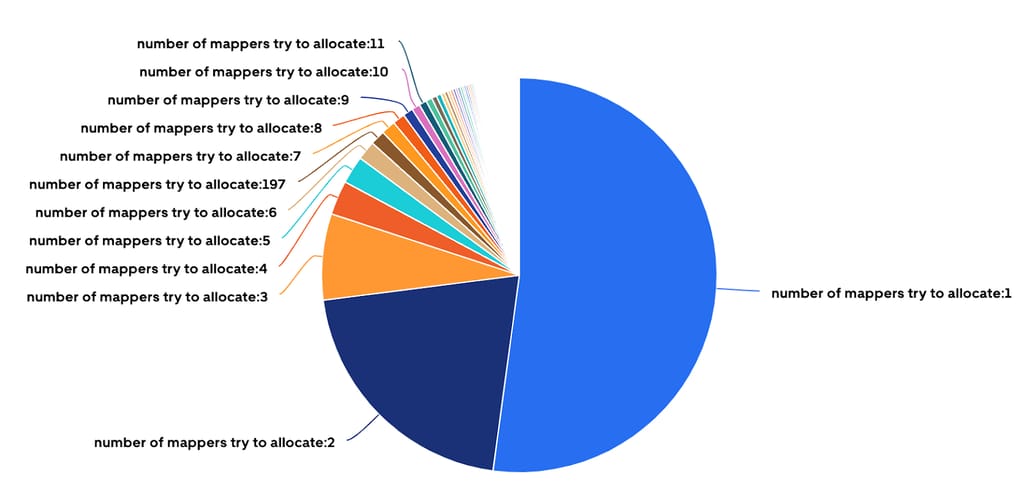
图 14:超过 50% 的 Distcp 作业仅分配了一个 Mapper。
为解决这一开销问题,我们利用了 Hadoop 的 “Uber 作业” 功能,消除了在单独容器中分配和运行任务的需要。拷贝映射器任务直接在应用主节点的 JVM 中执行,减少了不必要的容器分配。
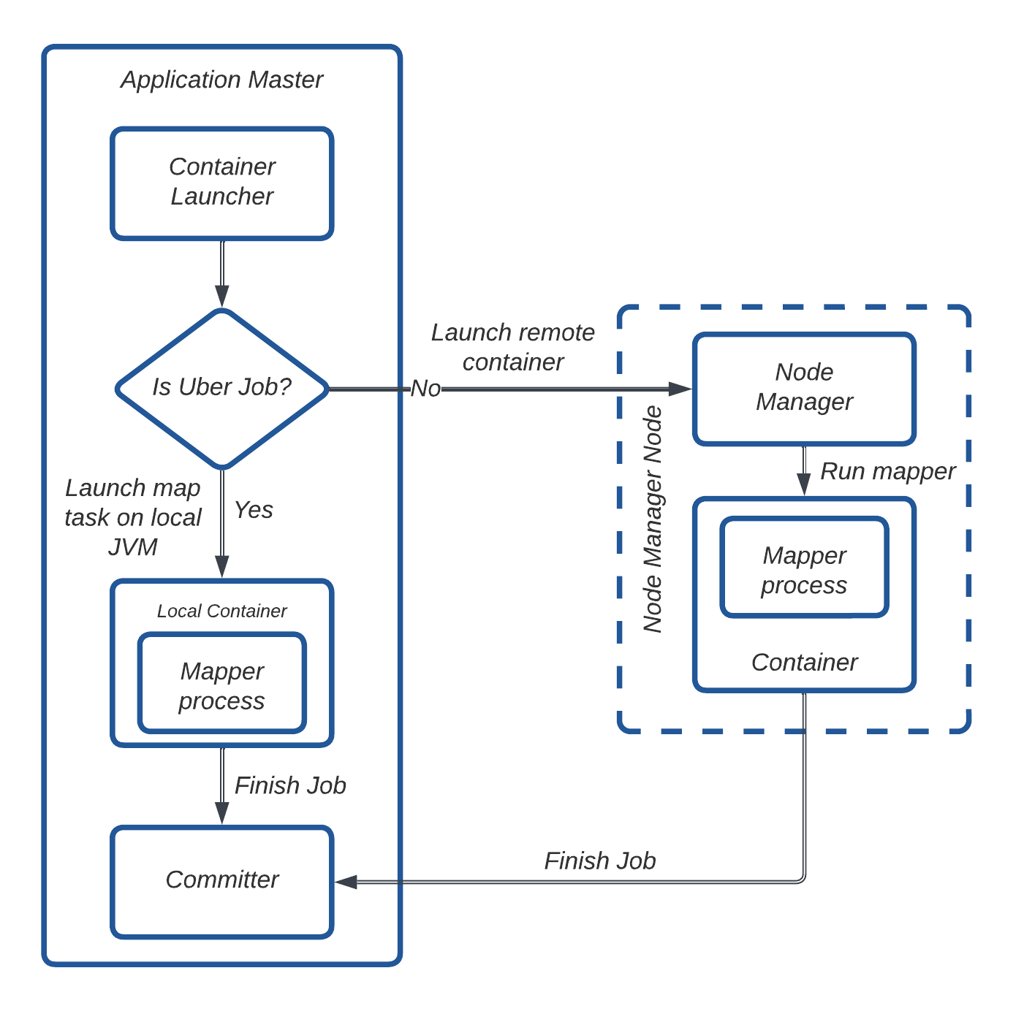
图 15:Uber 作业工作流。
在图 15 中,AM 判断一个作业是否符合 Uber 作业的条件。如果符合,拷贝映射器任务将在 AM 的 JVM 中本地执行。否则,AM 通过 Node Manager 请求容器并在其中运行拷贝映射器任务。任务完成后,AM 启动拷贝提交器任务以在目标端合并文件分片。
我们通过以下配置启用了 Uber 作业:
通过实施这一方案,我们每天减少了约 268,000 次单核容器启动,显著改善了 YARN 资源使用和作业效率。
我们对 Uber Distcp 工具所做的改进极大地提升了跨本地和云数据中心的增量数据复制能力。得益于这些变更,我们在仅一年内将本地数据处理能力提升了 5 倍,且未发生任何与扩展相关的故障。
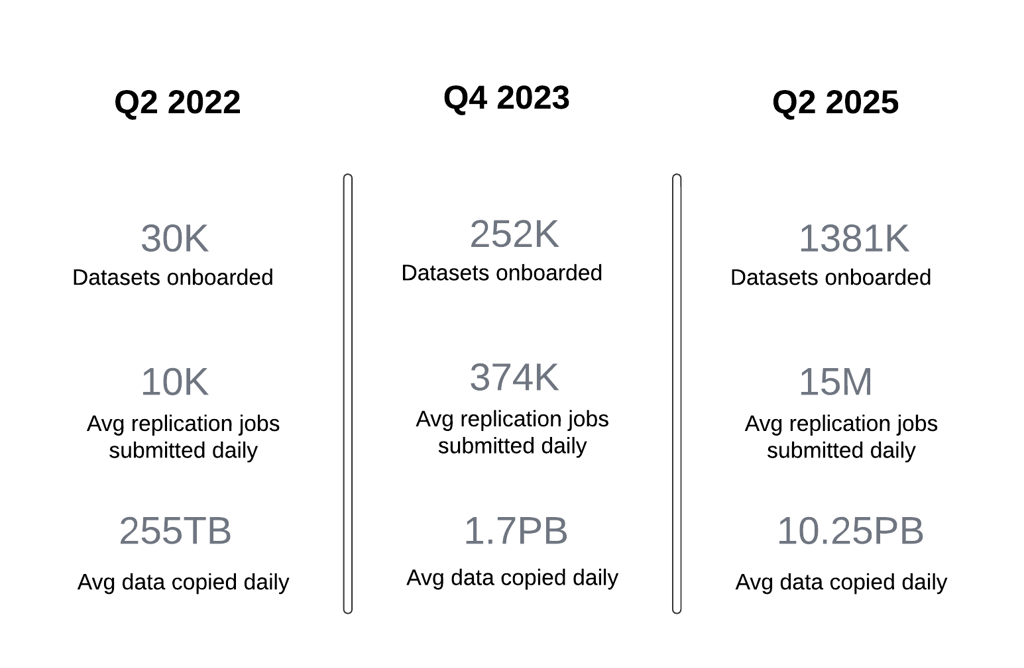
图 16:HiveSync 在本地和云数据中心的规模。
近几个月,我们扩展了 HiveSync 的功能以支持将本地数据湖复制到基于云的数据湖,详情见此文。对 Distcp 的增强在处理此次迁移的规模方面发挥了关键作用。截至目前,我们已成功将超过 306 PB 的数据迁移到云端。
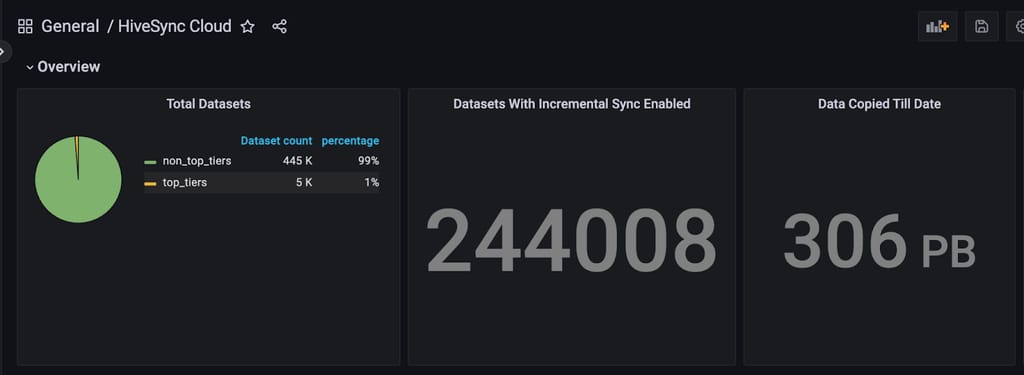
图 17:通过 HiveSync 服务从本地迁移到云端的数据量。
我们引入了多个关键指标,显著提升了可观测性(Observability)。这些指标提供了关于客户端和 YARN AM 端 Distcp 作业提交时间、作业提交速率以及关键 Distcp 组件(如拷贝清单和拷贝提交器任务)性能的洞察。我们还跟踪了 Hadoop 容器的最大堆内存使用量、每个作业的 P99 Distcp 拷贝速率以及整体拷贝速率等指标。这种增强的可见性使我们能够更好地监控和了解服务的复制速率,并在缓解和诊断多起故障中发挥了关键作用。
在将变更部署到生产服务器的过程中,我们面临了几项挑战。其中一个挑战是 AM 中的 OOM(Out of Memory,内存溢出)异常。严格的压力测试帮助我们确定了最优的内存和核心使用配置。我们添加了指标来检测 OOM 问题,这在后续帮助我们为内存密集型拷贝请求确定最优的 YARN 资源配置。
另一个问题是 HiveSync 的高作业提交速率。降低提交延迟提高了作业提交速率,但这经常导致"YARN 队列已满"错误。为防止 YARN 过载,我们在 HiveSync 中实现了熔断器(Circuit Breaker),在重试成功之前暂时暂停新的提交。我们添加了指标来检测此类事件,从而实现实时监控并按需调整 YARN 队列容量。管理高拷贝速率虽然高效,但会导致高网络带宽使用,需要仔细调优以平衡性能和资源限制。
我们还遇到了因长时间运行的拷贝清单任务导致的 AM 故障。最初,拷贝清单和输入分片部分被移至 AM 的启动阶段。这导致了问题,因为 RM 期望 AM 发送定期心跳信号。由于心跳发送器仅在启动完成后才启动,而拷贝清单任务有时需要超过 10 分钟,因此会导致超时。为解决这一问题,拷贝清单任务被移至输出提交器的设置阶段,该阶段在心跳发送器已启动之后执行,从而避免了超时。
展望未来,团队正聚焦于围绕并行化、更好的资源利用和网络管理的若干增强,包括:
此外,我们计划为这些优化贡献开源补丁。Uber HiveSync 团队将继续专注于解决数据复制挑战,在我们的规模下,即使是微小的改进也能带来显著的收益。
2025-11-13 16:58:54
最近,Go 语言社区围绕一个全新的内存管理提案展开了激烈讨论:在不依赖垃圾回收 (GC) 的情况下直接释放并重用内存。#74299 引入了 runtime.free 及相关机制,试图让编译器和标准库在特定场景下安全地跳过 GC,对短命的内存对象进行即时回收利用github.comgo.googlesource.com。此举被认为可能为 Go 带来一次性能上的革命:初步原型显示,在 strings.Builder 这样的场景中,利用该机制性能提升可达 2 倍github.com。本文将回顾 Go 内存管理领域从 arena 实验到 memory region 构想,再到 runtime.free 提案的探索之旅,并剖析这一新提案的技术细节、产生的意义、演化过程,以及对普通开发者的影响。
runtime.free 将在 Golang1.26 中 以 GOEXPERIMENT 的方式提供实验性支持。
自 Go 语言诞生以来,自动垃圾回收(GC)就是其核心特性之一。然而在对性能极度敏感的场景(如高吞吐的服务端程序)中,GC 带来的开销始终让开发者有所顾虑。为了进一步降低 GC 负担,Go 团队近年开始了一系列关于“手动”或“半自动”内存管理的探索尝试。
Arena 实验#51317是 Go 团队在 2022 年迈出的大胆一步。它引入了一个新的 arena 包和 Arena 类型,允许开发者将一组生命周期相同的对象分配到一个独立的内存区域中,并在不需要时一次性释放整个区域 这一做法类似其他语言的 region-based memory management 思想:大量对象集中分配、集中释放,从而降低常规分配/回收的成本。
Arena 的优点在某些场景下非常显著:所有对象统一释放,大幅减少了 GC 扫描和回收的工作量,谷歌内部测试显示对大型应用最高可节省约15%的 CPU 和内存开销。但是,Arena 随即暴露出严重的问题——API 侵入性太强。为了使用 Arena,几乎每个相关函数都不得不增加一个 arena.Arena 参数,这导致这种用法具有“病毒式”传播效应,破坏了 Go 一贯强调的简洁与可组合性。另外,Arena 在与 Go 现有特性(如隐式接口、逃逸分析)配合时也出现了诸多不兼容之处。最终,由于 API 难以融入生态,Go 官方在 2023 年初宣布 无限期搁置 Arena 提案,并明确表示 GOEXPERIMENT=arena 仅供实验、不建议在生产中使用。
吸取了 Arena 的教训,Go 团队接着提出了更贴合 Go 哲学的概念:内存区域(Memory Region#70257)它设想引入一种更透明的机制——例如通过一个 region.Do(func(){ ... }) 调用,将某段函数作用域内的所有内存分配隐式绑定到一个临时区域。当这段代码执行完毕时,该区域内分配的所有对象都可以一并释放。
Memory Region 的优点在于:对开发者而言几乎是透明的,无需修改函数签名或显式传递 Arena 对象。另外,通过运行时的巧妙设计,它依然能保持内存安全。具体来说,如果区域中的某个对象被外部保留(“逃逸”出了区域作用域),运行时会自动将该对象挪回全局堆由 GC 管理,从而避免类似 Arena 那样可能出现的 use-after-free 错误。这一设计既有手动内存管理的性能,又尽可能避免了手动管理常见的安全隐患。
然而,Memory Region 的问题在于实现极其复杂。要支持这种“区域化”的内存管理,需要对运行时和 GC 做重大改造。例如,开启区域时可能需要一个特殊的低开销写屏障来追踪对象逃逸情况,这增加了垃圾回收机制的复杂性和运行成本。虽然理论上可行,但要让这一方案高效稳健地落地,无疑是一项长期且充满不确定性的研究课题。迄今为止,Memory Region 仍停留在讨论和原型阶段,没有迅速融入 Go 主线。
在 Arena 的侵入性和 Memory Region 的复杂性之间,Go 团队终于找到了一条更务实、工程上可行的中间路线——这就是本次的 runtime.free 提案。相比之前“大包大揽”的方案,runtime.free 走的是精细化局部优化的路子:与其让开发者手动管理整片内存,不如让更了解代码细节的编译器和底层标准库来决定何时安全地释放特定的堆内存。换言之,runtime.free 旨在像一把手术刀,精准切除那些生命周期短暂且已确定不再使用的内存块,减少 GC 不必要的工作。
这种方法极大地缓解了 Arena 的可组合性难题(因为开发者不需要改动代码、一切由编译器和运行时自动处理),也避开了 Memory Region 那种对 GC 全局机制的大改动。更重要的是,它为解决 Go 长期存在的性能**“鸡与蛋”困局提供了新的思路:许多优化(例如更激进的逃逸分析)过去之所以收效甚微,是因为即便消除了某个原因,内存对象仍可能由于另一原因**逃逸到堆上,最终并未减少 GC 负担。而 runtime.free 的出现,相当于提供了一把钥匙,可以打破这种循环——一旦对象在运行时被判定“确实不再需要”,就立即释放,从而真正实现减少 GC 压力的初衷。
需要强调的是,runtime.free 并不打算提供给普通开发者一个手工调用 free 的新玩具。相反,它采取高度受控的“双管齐下”策略,通过编译器和标准库的改进来实现内存释放优化,同时不向 Go 程序员暴露额外的复杂度。
首先,也是整个提案最令人兴奋的部分:编译器将自动插入内存释放逻辑。具体而言,当编译器检测到某些场景下分配的内存可以安全提前回收时,就会在编译阶段悄悄地产生额外的代码来跟踪并释放这些内存:
识别阶段: 对于典型的 make([]T, size) 切片分配,如果编译器发现该切片虽然因为长度或容量未知而必须逃逸到堆上,但它的使用范围不超过当前函数(例如不会被保存到全局或返回给调用者),那么编译器将把这次分配标记为“可跟踪释放”。这种情况下,会调用一个特殊的分配函数(如 makeslicetracked64)来分配对象,并将该对象的指针记录到当前函数栈上的一个追踪列表。
跟踪阶段: 编译器在栈上维护一个 freeables 数组(或切片),收集所有被标记为可释放的堆对象。当有新的可释放对象分配时,其指针会被追加到这个列表中。
释放阶段: 在函数返回前,编译器会自动插入一行类似 defer runtime.freeTracked(&freeables) 的调用tonybai.com。这样,当函数退出时,这个延迟调用将执行,通知运行时回收 freeables 列表中记录的所有堆对象。这种做法确保了在作用域结束时,临时分配的对象立即被释放,而无需等待下一轮 GC。
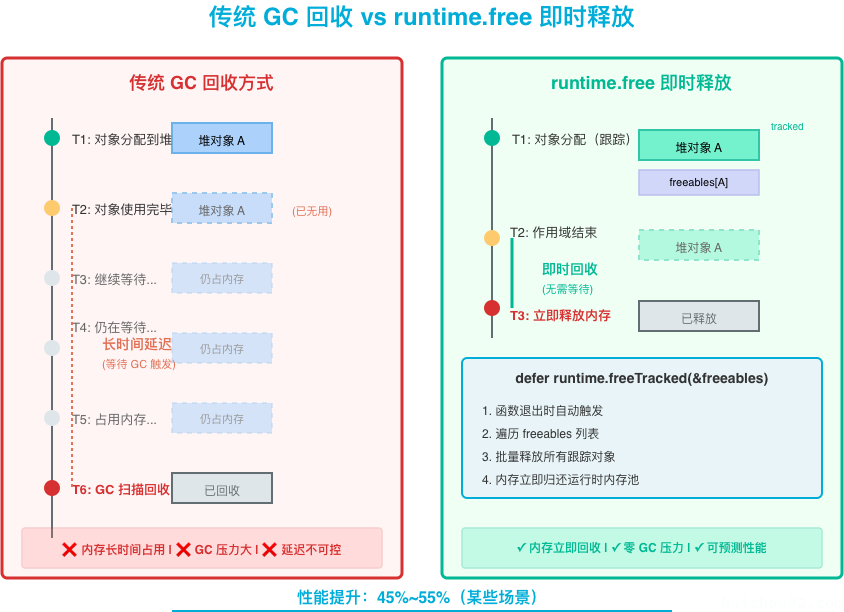
对于开发者来说,这一切都是透明的:你完全可以像往常一样编写代码,而编译器在背后已经将其“悄悄优化”为一个更少堆分配、更少 GC 压力的版本。举个简单例子:
|
|
经过这种改写,原本可能需要 GC 扫描回收的 buf 内存,将在函数结束时立即归还给运行时可用的内存池。因此,未来我们编写的一些看似会产生大量堆分配的代码,有望在不改变任何源码的情况下,由编译器替我们转换成“零 GC 压力”的高效版本——开发者对此毫无感知,但程序性能却因此获益。
另一方面,对于 Go 标准库中少数性能关键的组件,开发团队也在尝试手动加入 runtime.free 的调用。这并不是要把手动内存管理强加给所有库,而是利用标准库对自身情况的了解,在极有限的热点场景显式地释放内存,以追求极致性能。提案中提到的主要目标包括:
strings.Builder / bytes.Buffer 的扩容:当内部缓冲区需要增长时,旧的缓冲区实际上已经不再使用,完全可以当场释放,避免占用堆并减轻后续 GC 压力。map 的扩容:Go 的 map 在扩容和重新哈希(rehash)时会分配新的底层数组,此时旧的 buckets 数组事实上已死,同样可以立即回收。slices.Collect 等切片收集/拼接的操作:在构造最终结果过程中产生的大量中间切片,仅用于过渡,也可以及时释放。对于这些场景,runtime.free 提供了一个内部运行时函数 runtime.freeSized(ptr, size, noscan)(提案原型中使用的是 freesized),允许在知道一个对象指针 ptr 及其大小后,立刻释放对应内存。这种调用仅限于非常底层且对内存使用有精确认知的代码。例如 Go 作者们在实验中修改了 strings.Builder 的代码,在扩容逻辑中加入对旧缓冲区的 runtime.freeSized 调用。结果表明:对于执行多次扩容的场景,新版 strings.Builder 性能提升了约 45%~55%,几乎快了一倍!换句话说,通过在正确的时机手动释放内存,可以实打实地换来巨大性能收益。
需要注意的是,这种手动调用只会出现在少数标准库内部。Go 团队并不打算在诸如 net/http 这样的高级库里遍地插入 runtime.free —— 毕竟那样又回到了“到处手动管理内存”的老路上。这一步更多是为了验证:在哪些特殊场景下,提前释放内存能够带来明显收益。如果证明效果显著,我们也许会在未来看到这些改进融入正式版本中;如果收益不大或风险高,也可以根据讨论再决定是否采纳。
让 GC “少管一些事”听起来很美好,但也要评估此举本身的性能代价。插入额外的跟踪和释放逻辑,会不会拖慢常规代码的速度?根据目前的原型测试结果,答案是几乎可以忽略。对比启用 runtimefree 实验前后的基准数据表明:*在没有可释放对象的普通分配场景下,新机制对性能的影响在 -1.5% 到 +2.2% 之间,几何平均值几乎为零。也就是说,如果你的代码并不存在那些可以提前释放的内存对象,启用这个功能对性能既不会造成明显负担,也几乎不会带来益处——它基本是“零成本”(pay-for-what-you-use)*的。
而在命中了优化路径的情况下,收益则是多方面的:
runtime.free 释放的对象立即回收到对应大小类的空闲链表中,下一个相同大小的新对象分配很可能重用这块内存。 这样一来,内存分配/释放形成类似栈式(LIFO) 的模式,新分配的内存地址往往与刚释放的相同,对 CPU 缓存非常友好。相比任由 GC 随机回收、重新从堆中找内存,这种局部性有望进一步提升运行效率。除此之外,新的垃圾回收器 Green Tea 也可能从这种优化中受益——例如更高的每个span内存利用率,等等。尽管这方面还是推测,但runtime.free 提案的出现显然为未来 GC 和内存优化的融合创造了更多可能。
从开发者的角度来看,runtime.free 究竟意味着什么?一言以蔽之:性能提升,几乎无需额外付出。对于普罗大众的 Go 开发者来说,这个提案不会改变我们日常编码的方式——没有新语法、也无需调用新的 API。所有魔法都发生在幕后:编译器变得更聪明,运行时/标准库替我们多做了一些工作。然而,它的影响可能是深远的:
首先,这标志着 Go 的内存管理正在探索 “自动 GC”之外的第三条道路。传统上,我们有完全自动的 GC(简单易用但性能牺牲)和手工的内存管理(复杂易出错但性能可控)。而 Go 的 runtime.free 尝试证明,两者并非水火不容:语言运行时本身可以变得更智能,在保证内存安全的前提下,帮我们完成一些人工才能做到的优化。从某种意义上说,Go 正在尝试“靠自己”变得更快,而不是把负担转嫁给开发者。
其次,对性能敏感的Go程序将直接受益于此。在未来的版本(提案目前计划针对 Go 1.26),当这一实验正式上线后,你或许会发现某些场景下 GC 压力突然降低了。例如,大量使用临时切片进行计算的函数,不再生成那么多短命的垃圾;频繁扩容的 bytes.Buffer、构建巨型 slice 的代码,在新版标准库里跑得飞快。这些性能改进都是 “开箱即得” 的,开发者甚至不需要知道 runtime.free 的存在,就已经享受到了它的好处。
当然,runtime.free 仍处于试验和完善阶段。它目前通过 GOEXPERIMENT=runtimefree 提供,说明官方也在审慎评估其效果和风险。接下来社区会继续打磨细节,确保不会引入难以预料的错误(比如要严格杜绝“提前释放仍在用的对象”这种灾难性情况)。好消息是,到目前为止初步验证并未发现不可逾越的技术障碍,核心团队成员也给予了正面反馈。
总体而言,runtime.free 提案代表了 Go 内存管理上务实而具有前瞻性的一步。它不追求颠覆性的架构重写,而是聚焦于具体的瓶颈问题,寻求切实的优化突破;它也不牺牲类型安全和简洁性,将复杂度限定在编译器和运行时内部。这种思路一旦被证明行之有效,未来完全可以推广到更多模式(例如识别更多 append 循环的场景等),进一步减少 Go 程序的内存开销和 GC 次数。
对于普通开发者来说,这意味着更快的程序和更少的垃圾回收停顿,而你依然可以像过去一样专注于业务逻辑,无需为手动内存管理操碎心。随着编译器与运行时不断进化,Go 有望在保持“一键爽跑”的易用性的同时,在性能上再攀新高峰——这一切,值得我们拭目以待。
引用资料: