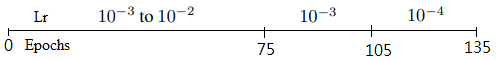2024-08-30 23:05:35
训练是一个不断迭代的过程,每一次迭代,都会计算输出,计算输出的损失(和真实值的差距),收集损失相对参数的导数,然后使用梯度下降优化这些参数。
import torch
from torch import nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import os
# 数据源来自: https://www.kaggle.com/datasets/muniryadi/cat-vs-rabbit
train_path = './cat_or_rabbit/train-cat-rabbit'
test_path = './cat_or_rabbit/test-images'
val_path = './cat_or_rabbit/val-cat-rabbit'
# ToTensor 对输入做归一化处理,将资料范围变成[0,1]之间
# 正规化是机器学习常用的资料前处理,将资料范围变成[-1,1]之间
normalize=transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5])
transform=transforms.Compose([
transforms.RandomCrop(224), # 随即裁剪
transforms.RandomHorizontalFlip(), # 水平翻转
transforms.ToTensor(), # tensor 格式
normalize
])
# 建立資料集
train_dataset = datasets.ImageFolder(train_path, transform = transform)
val_dataset = datasets.ImageFolder(val_path, transform = transform)
test_dataset = datasets.ImageFolder(test_path, transform = transform)
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=64, shuffle=True)
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
print(f"Using {device} device")
class NeuralNetwork(nn.Module):
def __init__(self, img_size):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(img_size, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork(3*224*224).to(device)
print(model)
learning_rate = 1e-3
batch_size = 64
epochs = 10
# 初始化loss function
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
# 將資料讀取到GPU中
X, y = X.to(device), y.to(device)
# 運算出結果並計算loss
pred = model(X)
loss = loss_fn(pred, y)
# 反向傳播
loss.backward()
optimizer.step()
optimizer.zero_grad()
if batch % 100 == 0:
print(batch)
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test_loop(dataloader, model, loss_fn):
model.eval()
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
# 驗證或測試時記得加入 torch.no_grad() 讓神經網路不要更新
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
epochs = 10
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(train_dataloader, model, loss_fn, optimizer)
test_loop(val_dataloader, model, loss_fn)
print("Done!")
# 保存为内部字典
torch.save(model.state_dict(), 'cat_vs_rabbit_cls_v1.pth')
# 重新载入的时候,要先建立和原来一样的模型结构
reload_model = NeuralNetwork(3*224*224)
reload_model.load_state_dict(torch.load('cat_vs_rabbit_cls_v1.pth'))
reload_model.to(device)
reload_model.eval()
# 验证
epochs = 1
for t in range(epochs):
test_loop(val_dataloader, reload_model)
实际工作中,我们很少会从同训练一个模型,这样的工作量太大了,往往会拿一个已经训练好的模型,在其基础上进行微调。预训练模型已经有了比较强的泛化能力,我们只需要在我们感兴趣的数据集上进行微调,就可以得到比较好的效果。
1.对ConvNet进行微调(Finetuning):与随机初始化不同,我们使用预训练的网络来初始化网络,例如那些在Imagenet 数据集上训练过的网络。其馀的训练过程与平常步骤一样。
2.ConvNet作为固定特徵提取器:在这裡,我们会冻结网络的所有权重,除了最后的全连接层之外。这个最后的全连接层会被一个新的、带有随机权重的层所取代,并且只训练这一层。
import torchvision.models as models
import torchvision
# torchvision.models下面有很多已经训练好的模型,我们可以直接加载
mobilenet_v3_model = models.mobilenet_v3_small(pretrained=True)
print(mobilenet_v3_model)
# 针对新模型参数做优化
optimizer = torch.optim.SGD(mobilenet_v3_model.parameters(), lr=learning_rate)
# 修改一下输出参数,因为我们的输出类别是2个
num_classes = 2
mobilenet_v3_model.classifier = nn.Sequential(
nn.Linear(576, 1024),
nn.ReLU(),
nn.Linear(1024, num_classes)
)
mobilenet_v3_model.to(device)
2024-08-28 23:51:17
整个网络的搭建基于pytorch的框架,其中 torch.nn 的命名空间包含了所有构建神经网络需要的基础组件。
nn.Flatten 层 把二位图像打平成一维数组,tensor第一位置代表的是通道数,并不参与打平的运算
input_image = torch.rand(3,224,224)
print(input_image.size())
# torch.Size([3, 224, 224])
flatten = nn.Flatten()
flat_image = flatten(input_image)
print(flat_image.size())
# torch.Size([3, 50176])
nn.Linear 层
通过权重w和偏差b对输入数据进行线性变化,输出结果。这个最基本的神经网络结构
layer1 = nn.Linear(in_features=224*224, out_features=1024)
hidden1 = layer1(flat_image)
print(hidden1.size()
#torch.Size([3, 1024])
nn.ReLU 层
非线性激活函数,帮助神经网络引入非线性的特性
print(f"Before ReLU: {hidden1}\n\n")
hidden1 = nn.ReLU()(hidden1)
print(f"After ReLU: {hidden1}")
nn.Sequential
一个有序容器,把各个模块顺序连接起来
nn.Softmax层
将(-无穷,+无穷)范围的数值,压缩到(0,1),用于表示模型对每个类别的预测概率
softmax = nn.Softmax(dim=1)
pred_probab = softmax(logits)
# 引入对应的模块
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 选择模型的训练资源
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
print(f"Using {device} device")
# 初始化神经网络实例,并把它迁移到对应的设备上
model = NeuralNetwork(224*224).to(device)
print(model)
# 验证输出
X = torch.rand(1, 224, 224, device=device)
logits = model(X)
pred_probab = nn.Softmax(dim=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")
2024-08-06 21:20:48
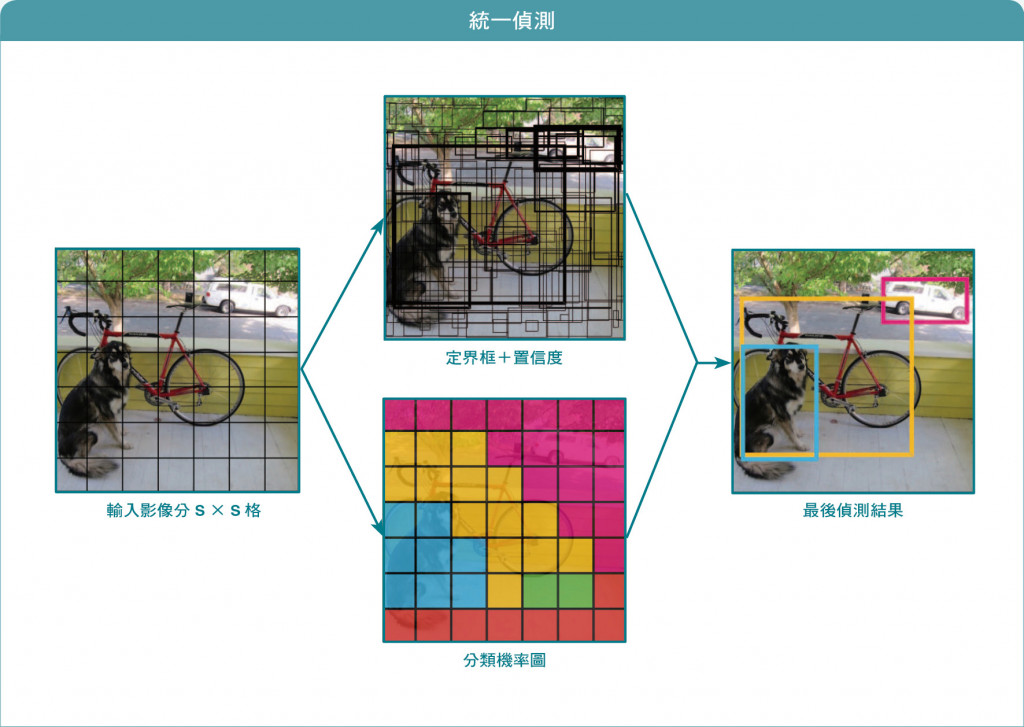
YOLO(You Only Look Once),使用CNN方法,一次性检测物体类别 和 位置的算法。是深度学习算法中的一种。突出的优点是端到端检测,速度快。输入为448448的图片,输出为7730的向量(77源自输入切分的Grid,30源自20个类别和2个x,y,w,h,c的加和)。YOLO将物体检测问题看成是回归问题,直接从图片生成图片框坐标和类别。
这里再顺带说一下CNN(卷积神经网络),它是深度学习的一种网络架构,基本结构为:卷积层+池化层+全连接层。其中,卷积层相当于一个过滤器,过滤出图片的某种特征;池化层相当于一个重点提取器,只留下重要的特征;全连接层把上面的网络结构打平,输出分类结果。
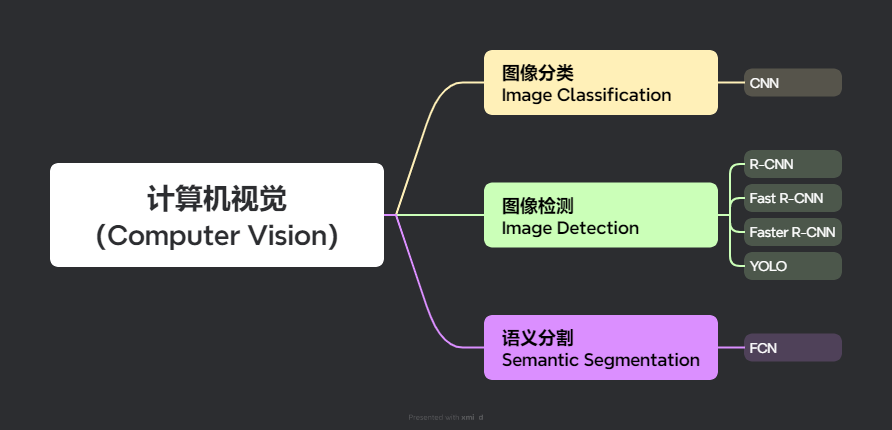
另外,YOLO属于计算机视觉领域的一个分支,所处的位置如下图所示。
1.将图片切分成S*S个Grid,并分别输出Bounding Boxes+confidence以及Class probability map
2.每个Grid会输出B个Bounding Box以及物件信心值(若不存在物件則Pr(Object)为0)。
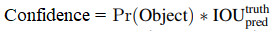
3.Bounding Box预测5个值: x , y , w , h , confidence。
4.每个Grid Cell会预测C类别的可能性(Class Probability map)
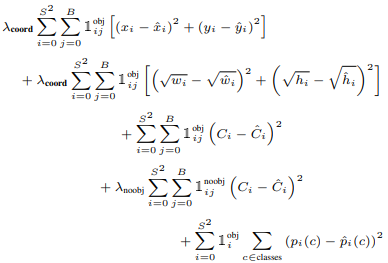
coord是为了加大位置权重的比例,对长、宽求根号是为了提升小物体损失面积的比重,noobj是为了降低其它无效Grid在confidence上面产生的累积效果
S(grid)=7
B=2(每个grid输出出Bounding Boxes数量为2)
C(Class Probability map)=20 (使用PASCAL VOC数据集,该数据集有20个类别)。
Epochs=135
Batch size=64
Momentum and decay: 0.9 & 0.0005
Learning Rate: