2024-11-05 13:29:00
Amazon CloudFront 是一项快速内容分发网络 (CDN) 服务,可以安全地以低延迟和高传输速度向全球客户分发数据、视频、应用程序和 API,全部都在开发人员友好的环境中完成。
首先我们需要一个亚马逊云科技账号,访问亚马逊云科技按照提示注册账号登录,在控制台进入CloudFront即可看见CDN面板,在创建加速前,我们需要先为站点申请一个Amazon Certificate Manager证书,以便为站点开启SSL。
在证书管理页面,可以选择导入我们已有的SSL证书或者申请一张新的证书。

这里我们以申请新的证书举例,填入域名后点击下一步,页面会给出我们要验证的DNS信息,按照给出的记录去域名解析处添加即可。


解析添加后只需要等待几分钟,刷新页面,当页面上显示“状态:已颁发”,则表示证书已经申请成功,现在回到CloudFront,继续添加加速站点。
在CloudFront页面,点击右上角创建分配,输入需要加速的网站信息:

输入域名之后其它默认即可,在最下面选择开启SSL,选择刚刚申请的证书,点击下一步即可创建站点加速,此时页面上会给出一个CNAME地址,我们需要去域名DNS解析处添加这个CNAME解析。

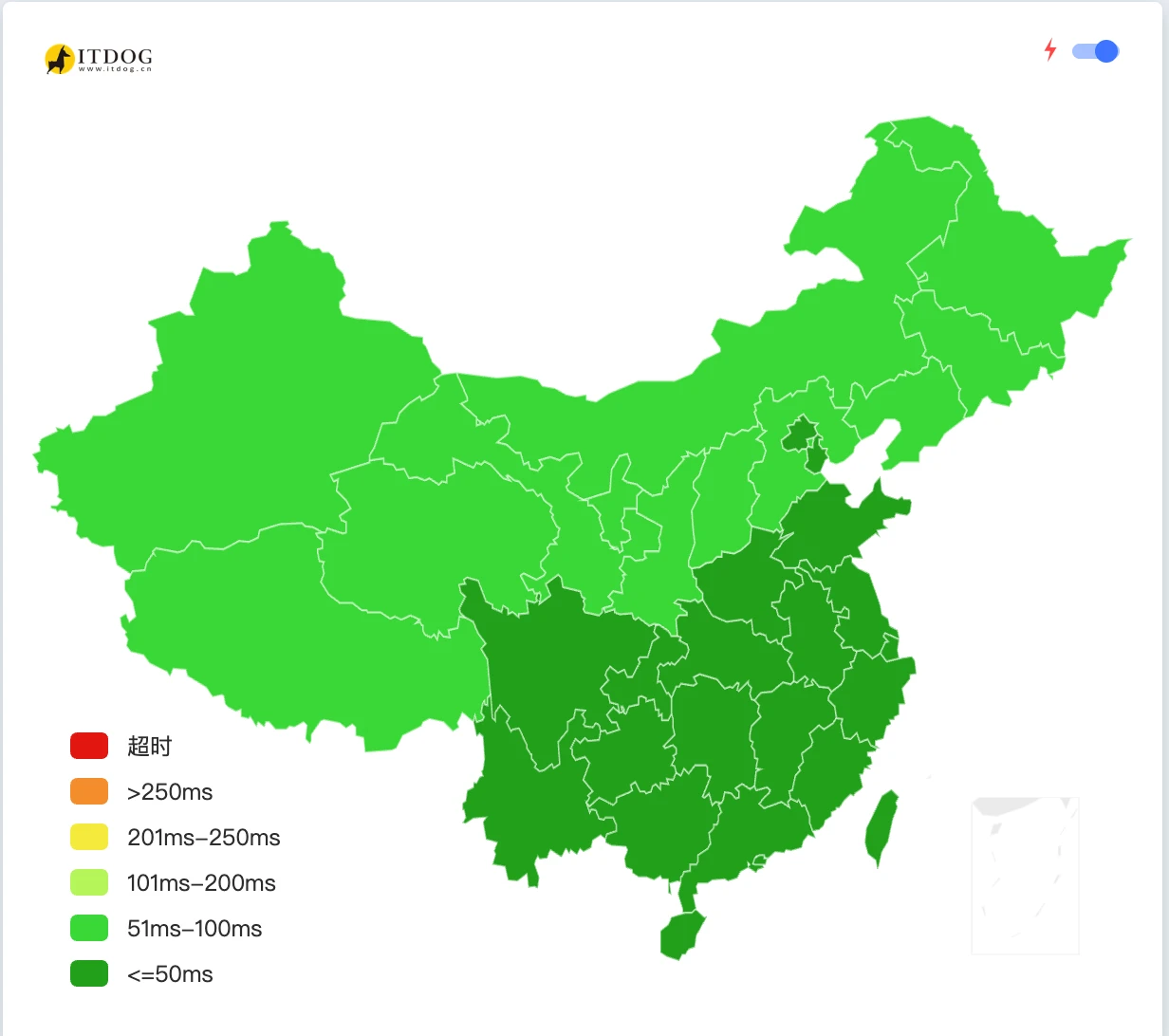
我们先PING一下这个CNAME地址看看大陆访问情况如何:

能看见移动和联通的默认线路还是很不错的,而电信线路延迟略高,但也有部分速度快的节点,如果你的DNS支持分线路解析,我们可以选择给移动和联通以及海外线路解析到 CloudFront 给出的CNAME地址,如果你动手能力强的话,还可以手动选择一些低延迟优质节点,直接A解析节点IP,这样在大陆访问也可以做到秒开体验。

解析添加完毕后可以进行PING你的域名查看解析情况,如有出现“解析失败”之类,可能是DNS解析在部分地区还未生效,需要等待最多72小时生效时间。
至此,利用Amazon CloudFront为网站提供加速服务就添加完成了,如果有防护需要,还可以在创建站点设置里面,点击安全性,开启WAF防护,但这个功能是付费的,开启页面中有便捷的价格计算器,请根据自身需求选择是否开启。

除此之外,还可以自定义缓存配置,一般情况默认即可,也可根据你网站需求进行自定义修改。
亚马逊云科技还提供众多免费云产品,可以访问:亚马逊云科技查看适合你的产品。
2024-10-23 22:54:00
十月二十三《毒液3》上映,兴冲冲找特价票平台买了两张准备和小Y一起看,买完才发现买成了2D票,因为是特价票的缘故,不支持退换。
实在太久没看3D电影了,忍不住重新买了IMAX3D,幸运的是那两张2D票券放闲鱼上亏了13块钱卖掉了,不幸的是IMAX3D没看成。
到了影院取完票,临入场时才说IMAX厅设备出了问题,不能看了,影院给的方案是可以随意观看一场其它电影,明天可以拿这场的电影票再来看IMAX的,最近好像也没别的电影吸引我,烂片《749局》?还是《小丑2》?来都来了,还是将就一下普通3D看《毒液3》吧,体验不好明天再来补IMAX。
果然,普通厅的屏幕和音响效果都不如意,特别是位置有些靠后了,字幕太小,我全程没看清一句字幕。

电影谈不上多好,可能是抱的期望太大了,没看到想看的画面有些失望。比如在《毒液2》末尾彩蛋里毒液和艾迪被传送到了漫威宇宙,而在《蜘蛛侠:英雄无归》末尾彩蛋里毒液说想吃荷兰弟蜘蛛侠的脑袋。
我以为在这部毒液最终篇里会有蜘蛛侠和毒液的同框碰撞,结果是 没有。电影一开场就是毒液和艾迪被传送回了自己的宇宙,但是在漫威宇宙留下了一滴共生体,这段在几年前的彩蛋中就已经出现过。
整部电影出现的最大反派——共生体之神 纳尔,一直被囚禁在宇宙一把椅子上没离开过,只是派了一些像章鱼类似的怪物到地球抓毒液,电影结局就是这些小喽啰被解决了,电影突然结束。
挺。。。让人感觉看了一个寂寞,我看了个啥?特别是在看不见字幕的情况下我更懵逼了。
设定也挺离谱,纳尔派的小怪找毒液,就是因为毒液身上有法典,而法典可以让纳尔统领宇宙大概是这个意思,看不起字幕我不知道法典怎么诞生的,总之就是那么多共生体就毒液有,而且小怪来地球是找不到毒液的,只有在毒液变身包裹着艾迪的时候小怪才能感应到,哪怕是毒液脱离艾迪,或者是他俩一半一半,小怪都感应不到,这明明就很安全啊?而他们偏偏要合体变身,就为了...莫名其妙的跳舞。
然后就是被小怪追杀了,最后是在51区这个地方,军方关押着很多共生体,明明一直在被关起来研究,小怪杀来找毒液的时候,这些共生体就莫名其妙的出来保护毒液撤离...然后全部被杀,前面两部共生体都在杀毒液啊喂,怎么突然帮忙了?
真的挺没有逻辑的,甚至没看到毒液和小怪大战,全程被追着跑,在51区也是其它共生体出来和小怪打了半天,然后毒液出来吸引着那堆小怪拉一起在硫酸自杀,就尼玛结束了???
这个实力怎么大战共生体之神纳尔,不过这应该是毒液最后一部电影了,后续毒液估计是以漫威宇宙留下的那滴共生体出场,毕竟漫画中蜘蛛侠也是共生体之一,到了漫威宇宙找上蜘蛛侠也说不准,而且在抖音刷到别人截图的彩蛋有句字幕旁白是说 纳尔将在蜘蛛侠电影中登场,我是没看见,因为我看不见字幕。。。
是否适合电影院观看?我的建议是 等资源吧。
2024-10-09 13:02:00
以前找moe.one要了一个TG新帖推送插件,我上TG上的少没细心关注,这几天才发现这个推送机器人抽风很厉害,不能做到实时推送,中间会间隔一堆才推一次,看不懂代码逻辑,于是自己在网上找了RSS订阅BOT部署,试了两个用的人多的项目,都是docker部署,我想改改消息格式都不知道怎么下手,实在对docker不懂...默认的消息格式让我强迫症实在难受,于是让AI配合写了如下Python脚本,此文记录一下搭建步骤,避免以后有需要时又要去找AI掰扯。
打开服务器终端,安装Python和所需库
安装 pip
更新包列表:
apt update安装 python3-pip:
apt install python3-pip安装完成后,确认 pip 是否正确安装:
pip3 --version正常会返回 pip 的版本信息。
安装所需库
pip3 install feedparser requests python-telegram-bot下一步,我们需要去Telegram创建Bot,在TG里搜索@BotFather,进入对话框,输入/newbot以创建新机器人,然后回复一个机器人名字,再回复一个机器人的用户名,需要带bot,可以参考截图设置:

@BotFather会回复你一个机器人的HTTP API,保存它,后面会用到。
进入刚刚创建的机器人对话框,将他拉进一个你需要推送的群,或者直接给你自己推送也行,拉群记得给它管理员和消息权限。
TG搜索@get_id_bot,进入对话框点击右上角,将他拉到刚刚的群里,在群聊对话框输入:/my_id@get_id_bot发送,会得到一个-开头的群聊ID,记录它,包括-符号。

信息获取完成,接下来就是创建脚本了,回到服务器终端
mkdir dalaorss
cd dalaorssnano rss_bot.pyimport feedparser
import logging
import asyncio
import json
import os
from telegram import Bot
from telegram.error import TelegramError
# Telegram Bot Token 和目标聊天 ID
TELEGRAM_TOKEN = 'Bot Token'
CHAT_ID = '群ID'
# 存储已发送的帖子 ID 的文件
POSTS_FILE = 'sent_posts.json'
# 读取已发送的帖子 ID
def load_sent_posts():
if os.path.exists(POSTS_FILE):
with open(POSTS_FILE, 'r') as f:
return json.load(f)
return []
# 保存已发送的帖子 ID
def save_sent_posts(post_ids):
with open(POSTS_FILE, 'w') as f:
json.dump(post_ids, f)
# 从 RSS 源获取更新
def fetch_updates():
feed_url = "订阅地址"
try:
return feedparser.parse(feed_url)
except Exception as e:
logging.error(f"获取 RSS 更新时出错: {e}")
return None
# 转义 Markdown 特殊字符
def escape_markdown(text):
special_chars = r"_*~`>#+-.!"
for char in special_chars:
text = text.replace(char, f"\{char}")
return text
# 发送消息到 Telegram
async def send_message(bot, title, link):
# 转义 Markdown 特殊字符
escaped_title = escape_markdown(title) # 转义 Markdown 特殊字符
escaped_link = escape_markdown(link) # 转义 Markdown 特殊字符
# 使用 Markdown 格式,将标题包裹在反引号中以避免超链接,链接直接显示
message = f"`{escaped_title}`\n{escaped_link}"
try:
await bot.send_message(chat_id=CHAT_ID, text=message, parse_mode='MarkdownV2')
logging.info(f"消息发送成功: {escaped_title}")
except TelegramError as e:
logging.error(f"发送消息时出错: {e}")
# 主函数
async def check_for_updates(sent_post_ids):
updates = fetch_updates()
if updates is None:
return # 如果获取更新出错,则返回
new_post_ids = [] # 用于存储新帖子 ID
for entry in updates.entries:
# 从 guid 中提取帖子 ID
post_id = entry.guid.split('-')[-1].split('.')[0] # 提取 ID
# 检查是否为新帖子
if post_id not in sent_post_ids:
new_post_ids.append((post_id, entry.title, entry.link)) # 存储 ID, 标题和链接
# 如果有新帖子,按 ID 升序排序并发送最新帖子
if new_post_ids:
new_post_ids.sort(key=lambda x: int(x[0])) # 升序排序
latest_post_id, title, link = new_post_ids[0] # 获取最新的帖子
async with Bot(token=TELEGRAM_TOKEN) as bot:
await send_message(bot, title, link)
# 更新已发送的帖子 ID
sent_post_ids.append(latest_post_id)
save_sent_posts(sent_post_ids) # 保存到文件
# 主循环
async def main():
logging.basicConfig(level=logging.INFO)
# 加载已发送的帖子 ID
sent_post_ids = load_sent_posts()
while True:
try:
await check_for_updates(sent_post_ids)
except Exception as e:
logging.error(f"检查更新时出错: {e}")
await asyncio.sleep(60) # 每 60 秒检查一次
if __name__ == "__main__":
asyncio.run(main())
nohup python3 rss_bot.py &现在就可以去更新rss看看推送状态了,这里的脚本内容以我自己论坛为例,如果你也是xiuno论坛那么照抄就行,如果是博客或者其它程序,可能还需要做一些修改。
推送效果:

个人比较喜欢这种格式,如果你喜欢别的模式比如消息内预览,可以使用docker版本的,网上搜一下就有。
脚本运行后,怎么查看或关闭:
检查当前运行的进程
ps aux | grep python会得到正在运行的进程,查看到rss_bot那条,最前面有一个ID,命令行输入
kill ID即可停止。
2024-10-05 12:15:00
国庆的时候,智联IDC联系我说:给你赞助服务器,需要啥开口就行。
于是,我要了一台韩国物理机。

大陆优化,我还是保持套用CDN,昨晚已经将论坛迁移上去了,可能是心理作祟,明显觉得响应速度比之前快了。
第一件事还是搞定时备份,数据库好说,压缩下来也就40多MB,搞了个每两小时备份一次到又拍,但是网站压缩包有5GB大,每次自动备份上传都会因为文件过大失败,所以昨晚研究了一下增量备份。
我的操作很简单,这个备份方式也适用所有人,非常方便,以下教程以宝塔为例,把网站数据从主服务器(网站所在)备份到副服务器(专门备份)
首先,安装 rsync:
确保在两台服务器上都安装了 rsync,可以使用以下命令安装,打开终端输入对应命令:
sudo apt-get install rsync # Debian/Ubuntu
sudo yum install rsync # CentOS/RHEL然后,在主服务器SSH里连接副服务器:
ssh-keygen
ssh-copy-id 副服务器SSH用户名@副服务器IP回车根据提示输入密码即可,弹出Enter passphrase (empty for no passphrase):是让你设置密码短语,直接回车不要设置。
然后,在主服务器根目录下的/root/目录里,创建一个文件:backup.sh,内容写:
#!/bin/bash
# 设置变量
SOURCE_DIR="/www/wwwroot/网站目录" # 主服务器上的网站目录
DEST_DIR="副服务器SSH用户名@副服务器IP:/www/wwwroot/网站目录" # 副服务器上的备份目录
LOG_FILE="/root/backup.log" # 日志文件路径
# 输出脚本开始执行的消息
echo "脚本开始执行" | tee -a "$LOG_FILE"
# 使用 rsync 进行增量备份,排除 .user.ini 系统文件
rsync -avz --delete --exclude='.user.ini' "$SOURCE_DIR/" "$DEST_DIR" >> "$LOG_FILE" 2>&1
# 输出备份完成的消息
echo "备份完成" | tee -a "$LOG_FILE"
因为在上面脚本中我们加入了日志,所以还需要在/root目录下手动创建一个backup.log文件,以便备份日志记录。
再次打开终端,执行
chmod +x ~/backup.sh赋予它执行权限,现在可以运行脚本。执行以下命令:
~/backup.sh看到提示信息就说明备份成功了,接下来创建一个脚本来定时执行这个任务。
要定时执行 ~/backup.sh 脚本,在终端中运行以下命令,以打开 crontab 编辑器:
crontab -ecrontab 的格式如下:
第一个 * 表示分钟(0 - 59)
第二个 * 表示小时(0 - 23)
第三个 * 表示日期(1 - 31)
第四个 * 表示月份(1 - 12)
第五个 * 表示星期几(0 - 7,0和7都表示星期日)
比如我每小时执行,就是:
0 * * * * ~/backup.sh按 Ctrl + O 保存,按 Ctrl + X 退出。
查看当前的定时任务是否创建成功:
crontab -l或者
直接在宝塔定时任务那里添加shell脚本任务,以root身份执行,脚本内容:
sh ~/backup.sh增量备份机制:
在备份过程中,会比较源目录和备份目录中的文件,它通过检查文件的大小和修改时间来判断文件是否被修改过,如果源目录中的文件被修改,只传输这些变化的文件,而不是重新传输整个目录,这种机制大大减少了需要传输的数据量,提高了备份速度和效率。
假设在主服务器的 /www/wwwroot/www.dalao.net 目录中有以下文件:
file1.txt(未修改)
file2.txt(已修改)
file3.txt(已删除)
当执行命令后:
file1.txt 会保持不变(未修改)。
file2.txt 会被传输到备份服务器,因为它已经被修改。
file3.txt 会从备份服务器中删除,因为它在源目录中被删除了。
以上是网站文件的增量备份,数据库也大同小异,但我没有去做,因为文件不大,直接备份到七牛了,这样增量似乎也可以实现多源站方案。
2024-10-01 15:27:00