2024-01-08 23:38:59

时间已做了选择,太多感受,绝非三言两语能形容

这是第 35 个年头,我熟悉地扮演着多个角色,父亲、丈夫、儿子,每一刻都在陪伴和成长中交织。 生活的步伐似乎匆匆,但我努力让自己拥有一颗年轻的心,渴望保持对世界的好奇和激情。
时光大多被生活所占据,只有地铁上和饭桌上我能成为时间主宰。 好在我并未感到疲惫或沉闷,反而逐渐适应了这个身份的变化。 或许,正是在这些琐碎的日常中,我找到了一种生活的节奏,一种平和而温馨的状态。
今年我们走过了北京、汉中、西安、淳安、长沙、张家界、台州。 新年即将到来,准备给孩子办理一下护照,走出去看看。

在陪伴孩子的过程中,参与各种自然知识课程,参观各种展览,我发现在陪伴的同时,我们也在不知不觉中共同成长。 生活中的另一个领域,我从母亲那里薅了两只相机,终于决心好好学习摄像, 我把 Canon 6D 出售,保留了 SONY a6500 这支轻便的 APS-C 相机。 期望摄影成为我表达内心、记录生活的一种方式,每一张照片都是时光的凝固,是岁月的见证。

游戏的世界中,我似乎进入了一段电子阳痿期。购买的游戏几乎只能玩上一个小时就变得索然无味, 也许现实生活才是最引人入胜的游戏吧。
或许,人生就是一场不断变化的冒险。在时间的舞台上,我们扮演着各色角色, 演绎着属于自己的故事。

工作上一直压力和张力巨大,我开始进一步成为探索者。 这两年,我在工作中不断推动项目的上线,部门推出的新产品中的一半是我负责的,我很喜欢这个领域,也确实想把事情做好。
但有时候,我感觉自己有点像是公司招进来的清理工,身处于一个「散多垂」的状态, 面对复杂的环境,解决问题绝非易事。在整理垃圾的过程中还在自动产生垃圾,而清理的工作永远不会终结。 现实往往是,大家注意力持续被新事物(比如 AIGC)吸引走,对现存的问题更容易选择性忽视。
企业的大环境在不断变化,一些老朋友选择离开,大部门也经历了一些变革。 从面向风险的团队 re-org 到面向算力的基础设施团队。我认为这是一个好的信号, AI Infra将继续裹挟着整个 Infra 领域前进,算力管理将成为一个新的命题。
在 Github 数据的细碎图形中,映射出一年的自娱自乐,可惜的是,未给开源社区更多的贡献。
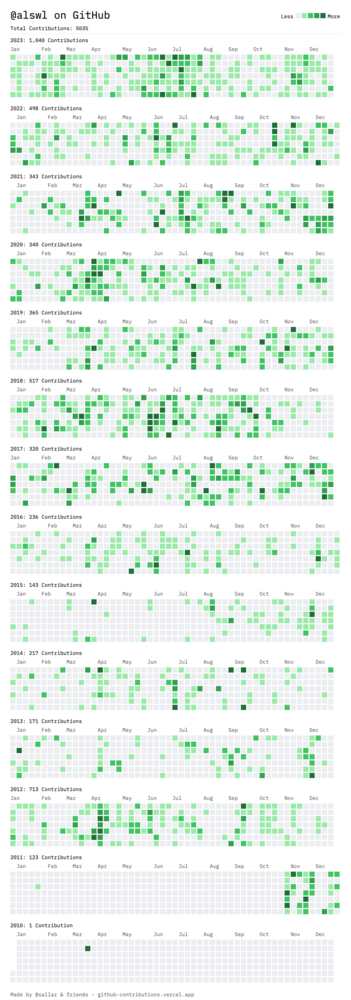
今年,我在开源领域主要的贡献是 alswl/excalidraw-collaboration。 这个 self-host 的 Excalidraw 版本集协作和中文化字体于一身。这个项目以及相关项目吸引了近300个 star,成为我个人最有影响力的开源项目之一,尽管它是一个前端产品。
在暑假期间,趁着家中小神兽不在,我开发了一个关于起名的小程序。虽然这款产品目前有点烂尾, 亏损严重,但我依然希望花更多时间进行开发和改进。一个美好的名字可以给家庭带来无限愉悦, 希望这个项目可以养活服务器资源~
另外,今年我重新活跃在 Twitter 上,分享一些技巧和心得。我的 Follower 从几百人增长到近 4000 人, 虽然离有影响力的推友还有差距,但与许多有趣的朋友交流本身就是一种有趣的事情。
今年一年最受欢迎的内容是:
今年最具价值的文章是介绍「许世伟的架构课」X,赚了几个月 Twitter 的订阅费。
今年我还重新开始听播客,聆听了一大半「内核恐慌」的存档,虽然未能赶上他们活跃的时期。 幸运的是,在外滩大会上我有机会参与了他们的聚会,与 Rio 和吴涛面对面交流。搞笑的是,虽然现场还有一位同事, 但我们却没有互相认出来,令人感叹在庞大的公司中,有时即便共事也未必能够相识(我们一起担任 Go 语言评委)。

除了内核恐慌,我还一直在听「硬地骇客」,一集都没拉,最近还开始听「有知有行」的播客。
在博客输出方面,我分享了两篇关于工程实践心得的文章,希望能够对读者有所帮助。
我最想分享的是 Obsidian Tasks 插件,详细信息可以在我的博客文章中找到, 从 Toodledo 到 Obsidian Tasks - 我的 GTD 最佳实践。我也很高兴成为 Obsidian Tasks 的 Sponser。
回顾一年的时间,我意识到自己在业余时光中的每周时间仅有10小时左右,非常宝贵。 期许着未来能够实现财务自由,以获得更多的自由时间,投入更多的兴趣爱好。

读书仍然大部分都是非虚构类书籍。
士可杀亦可辱;过去带来惆怅,现在带来迷惘,未来带来希望。
讲述做人做事的道理,古人的智慧。常读常新,尤其烦躁时候可以翻出来静一下。
就是为了看 中文的常态与变态。
老男爵举家迁新球,贵公子初入沙漠星。 老皇帝密授哈克南,雷托族全体遭判断。 小保罗掌权弗雷曼,杰西卡诞下遗腹子。 穆阿迪布反攻沙丘,娶伊勒朗再封帝位。
国、企、民、央、地。 悲观。
好希望自己能在 20 岁时候读到这本书。(现在的我已经不需要啦)。教读者如何和自己、周边、世界相处,如何和自己对话以及改变自己。和遇见未知的自己属于同一个路数。
治乱循环在反复。群体的无意识;民主和精英政治是否是解药?评估稳定性一个指标是贫富差距。极权下也孕育变革风险。
管理入门快速操作手册
这本书我给不出星级,超出了我的评价范围。 它可能是一个新学科(因果推断)理论,也可能是统计学中的一个星火闪烁。 作者 Pearl 是统计学大拿,也是人工智能领域权威专家,他确在晚年提出了反对自己过去一系列方法路线。 今天为我们所熟知的大部分机器学习技术,都是基于概率上相关性,从啤酒和尿布,到今天 GPT 大杀四方,AIGC 智能涌现。Peral 认为真正有意义的是提出「为什么」,即解释因果关系。因果关系的论述需要智能能够想象不存在的事物,而这正是当前人工智能无法理解的(Maybe?) 本书成于 2019 年,作者今年已经 87 高龄,不知道他对当前 AIGC 风起云涌是怎么看待的。
作者说的正确但是不全面。
高质量陪伴家人,放下手机,走向户外
执行了周三、周五家庭日给小朋友陪伴;每天早上送小朋友上学;周末一定有一天陪出行。
陪伴小孩这块我做的不如我老婆好,感谢老婆对家庭的贡献。
每月输出文章,特别是 Kubernetes / 研发设计领域可以写一些心得
今年输出 6 篇文章,达标率 50%。其中两篇 实用 Web API 规范 和 架构设计 the Easy Way 我都是很满意的。
经历了新冠,今年计划安排个私教教我健身房运动
没有完成。
投资收益率能做到 10%,今年新手阶段投资以股票型基金为主,投资收益 3.9%,跑赢了大盘和余额宝
今年投资收益率 -1.35%,刚出新手村就被暴击,我还是缺乏对市场和商业的理解。
新的一年 Flag:
每段经历,每次重逢,每本书籍,都是独特的命运线。新的一年已经来临, 期待着与家人、朋友一同继续探寻生活的真谛,去体验伟大与渺小。
往年总结:
2023-11-25 17:23:35
博客自 2012 年从 WordPress 迁移到静态站点后,就选择了 Disqus 作为评论系统。 但最近 Disqus 硬广告过于频繁,迫切寻找新的评论系统。
Disqus 官方 明确说明,要去掉广告就付费。
What if I want to remove Ads? If you’d like to remove Disqus Ads from your integration, you may purchase and ads-free subscription from your Subscription and Billing page. More information on Disqus ads-free subscriptions may be found here.
OK,那再见吧 Disqus,我会找到可靠、免费、易用的评论系统。 最后既然是寻找新的评论系统,现在 2023 年了, 我希望这个新系统充分使用云服务的便利,要做到 免费、可靠、易运维。
在进入探索之前,我先梳理一下自己的原则和选型要求:
从功能上面分析需要的能力:
非功能需求:
通过明晰这些原则和要求,可以更有针对性地选择合适的评论系统,确保满足核心功能和非功能需求。接下来,将根据这些原则,继续探讨如何选择和搭建评论系统。
现在我们初步试验一些方案并进行一些探索,以方便我们熟悉一下当前常见系统的特性和水准。

我同时还看了一些外部的一些方案评测报告:
根据初步方案探索,我可以明确部署形态基本如下:
这是一个横向对比表格,列举我一些关心的特性以及候选者在这些特性方面的表现。除了上述提到几款常见软件, 我还额外调研了海外常用的评论 SaaS 服务:
| Name | self-host | Official SaaS | SaaS Free | Star | Import Disqus | export data | Comments |
|---|---|---|---|---|---|---|---|
| Utterances | x | v | v | 7.8k | v | Github account required | |
| Cusdis | v | v | v? | 2.3k | v | v? | import from Disqus failed |
| Cactus Comments | v | v | 100 | Matrix Protocol, blocked | |||
| Commento | x | v | $10/month | v | v | ||
| Graph Comment | v | Free to $7 | |||||
| Hyvor Talk | x | v | $12/month | ||||
| IntenseDebate | v | ? | x | too old | |||
| Isso | v | x | 4.8k | v | sqlite storage | ||
| Mutt | v | $16/month | |||||
| Remark42 | v | x | 4.3k | v | v | full featured, one file storage | |
| ReplyBox | v | $5/month | |||||
| Staticman | v | 2.3k | v | using github as storage | |||
| Talkyard | v | €4.5/ month | |||||
| Waline | v | 1.5k | v | v | Multi Storage / Service Provider supported | ||
| Twikoo | v | x | 1.1k | v | v | FaaS / MongoDB |
根据横向对比我们可以得出几个结论:
小结
符合我需求的几款产品是:Utterances、Cusdis、Waline。
我最后选择了 utterances 和 Waline 进行 PoC, 其中我的英文博客使用了 utterances, 中文博客使用了 Waline。
为什么不选择 Cusdis 和 Twikoo?因为 Cusdis 使用 PostgreSQL, 而 Twikoo 存储使用腾讯云函数(免费额度有限)或者 MongoDB, 存储上 Waline 选择更多。 另外,作为同类型方案,Waline 是三者贡献者数量最多的,Commit 数量也最多, 社区更有保障。
一个搞笑的点,如果这里使用 h3 标题叫做「Waline」,会直接在这里插入一个当前博客的评论框
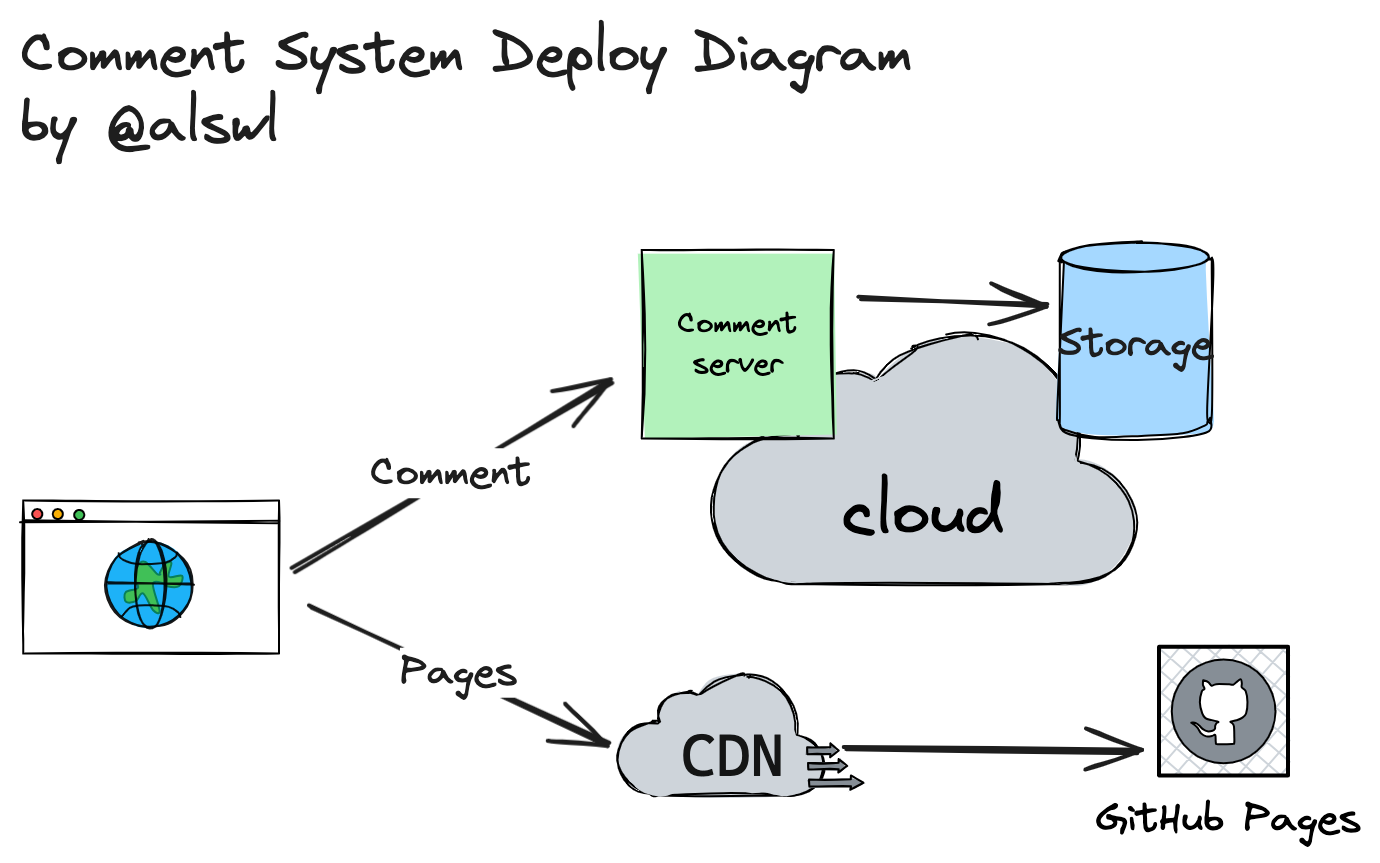
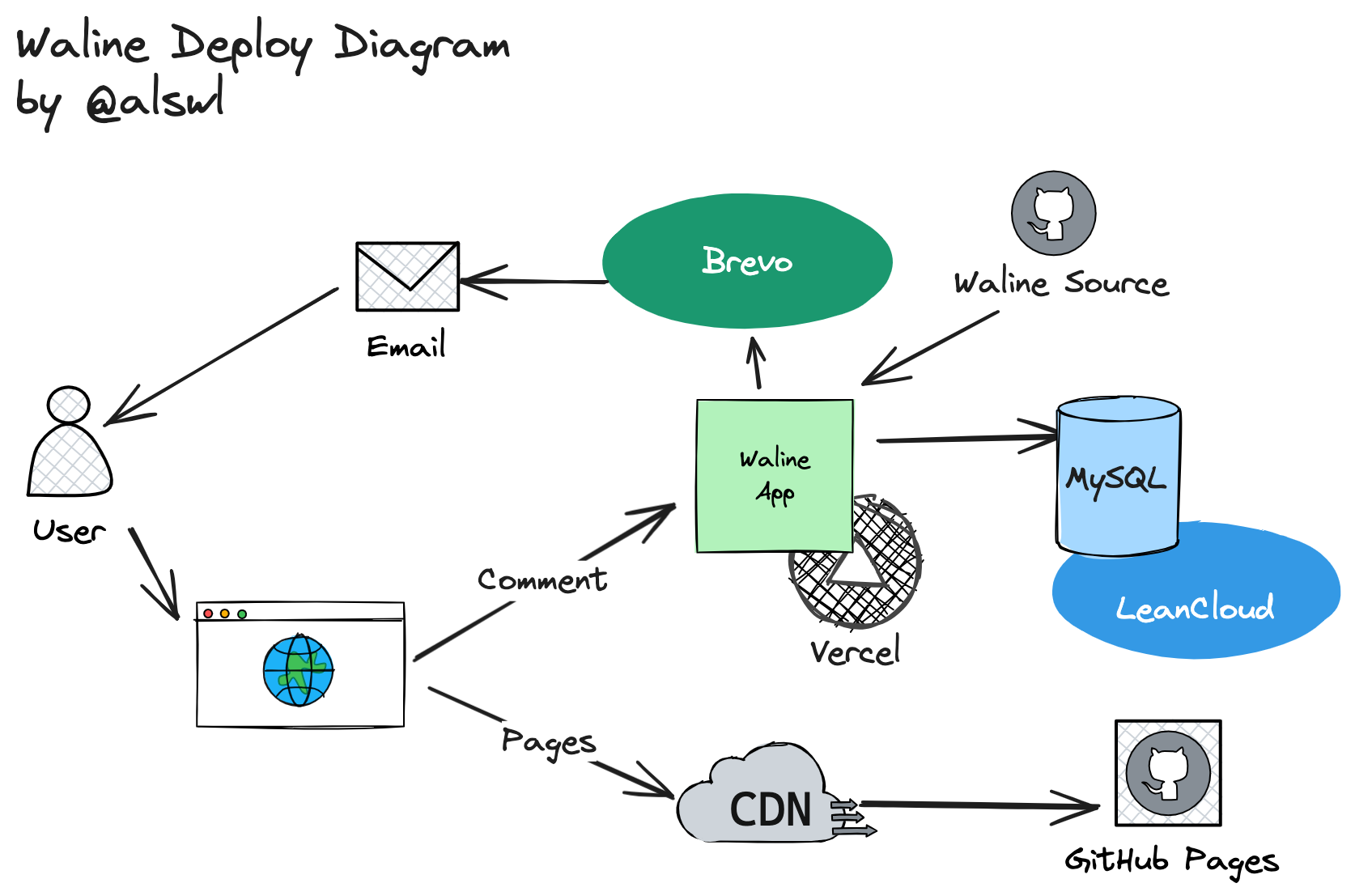
部署图:
具体操作,跟随官方文档即可:
AUTHOR_EMAIL
SENDER_NAME
SENDER_EMAIL
实施 PR(仅包含前端,因为后端代码包含了密钥,不便于分享): feat: comments on waline · alswl/blog.alswl.com@e34e348
utterances 的部署则更为简单,一个 PR 就可以启用。 feat: comment using utteranc · alswl/en.blog.alswl.com@29028f6 (github.com)
也没有什么特色,主打简单省事,考虑我英文博客访问量极低,就简单方案。
最后我选择了 Waline / utterances 作为我的评论系统,两者的部署成本都是 0。
妥协牺牲了一些访问速度、安全性,但进一步增强了数据可控性,完成了 self-host。 从稳定性上面来看,尽管这个系统链路变复杂了,单机上也存在可用性风险, 但依托 Vercel / LeanCloud / Brevo 三家 SaaS 服务商,整体风险可控。
毕竟只是一个小小评论系统,0 成本 + 正常工作就行了。
欢迎在下面评测测试一下哦~
2023-09-23 18:22:27

image via shipvehicles
使用 GitOps 管理交付内容是一个常见的 DevOps 使用模式。 我们会使用 Git 进行版本管理, 并通过 Git Tag 来跟踪部署软件的版本。 虽然这看上去可以工作,但在云原生技术的推动下,版本的概念远非如此简单。
在引入 GitOps 到 DevOps 流程后,我们可以借助 GitOps 的能力进行持续集成和持续交付。 GitOps 解决了三个核心问题:内容、版本 和 协作。然而,我们经常将注意力集中在内容上,却经常忽略了版本管理问题。
在 GitOps 过程中,有哪些版本管理问题需要解决呢?
一套完整的 GitOps 解决方案包括内容描述(Manifest)、构建方案(Builder)和生效方案(Applier)。其中,内容描述衍生出多种描述语言,从最传统的 Ansible / Chef,到云计算和云原生流行起来的 Terraform、Helm、Kustomize 等。引入了这么多内容描述方式之后,当我们想要明确一个应用的版本时,变得非常复杂。
当提到版本时,我们是指应用源代码的版本?还是指镜像的版本?或者是指某个基础设施即代码(IaC)仓库的版本?进一步地,如果我们要发布一组相互关联的应用,例如前端和后端,或者由多个后端应用组成的系统,如何清晰地描述它们之间的版本依赖关系?
一旦版本描述不准确,就会引入一系列问题,例如错误的上线版本、混乱的应用依赖关系、无法回滚等。
大多数团队对于这个问题的解决方案比较模糊:发布最新的版本,先发布后端再发布前端。然而,在一个复杂的业务团队或需要同时保留多个稳定版本的团队中,这种粗暴的方案是无法接受的。
版本管理不仅解决了版本定位的问题,还可以用于管理应用之间的依赖关系。因此,GitOps 版本管理需要解决以下问题:
在所有的交付产品中,版本管理都是一个重要问题。我们将逐步拆分版本管理这个命题,并从原始问题过渡到 GitOps 的版本管理最佳实践。
在开始正文之前,我将简要介绍 GitOps,以避免对关键概念的理解出现分歧。
GitOps 最核心的技术是基础设施即代码(IaC),即使用声明式描述来取代命令式描述。 通常,IaC 的内容基于某种范式,用于描述特定目标的期望状态。这个范式可以是 Terraform、Kubernetes YAML、Pulumi,甚至是 Ansible。而特定目标可以是云服务、Kubernetes,甚至是物理机。 直观的说,通过使用 YAML 取代过去的 Bash 命令,我们可以大大提高变更的准确性和可控性。
对于 GitOps 来说,是否使用 Git 并不是最重要的,我们也可以使用 SVN 来实现 GitOps。只是 Git 具有更广泛的适用范围,并可以充分发挥 Git 仓库在团队协作和持续集成/持续部署中的能力。
引入 Git 仓库后,我们还同时拥有了基于 Git Revision / Tag / Branch 的版本管理能力,这体现在业务上就是版本记录、多版本并行管理等方面。
简单地基于 Git Revision 进行描述还不足以满足我们的实际需求。
在探索版本的源头时,我们会发现最原始的版本是代码的版本。
代码的版本是什么?是代码仓库的版本还是代码编译出来应用的版本。 这个版本并不是代码所在的版本管理系统(如 Git / Mercurial / SVN 等)的版本。尽管这两者经常相关,但事实上,一份代码本身只是一组代码文件,只要构建成功,就会有一个版本。如果没有定义,版本就是未知的,此时与仓库管理没有关联。
注意:下文我们不再区分 Git / Mercurial / SVN 多种版本管理方案,统一使用 Git 进行描述
还需要注意的是,中文中有两个概念(库 Libray 和仓库 Repository)。 无论是哪种定义,都没有表示一个库一定是一个版本化(Git / SVN)仓库, 这意味着我们并没有假设代码库一定是被版本化管理的。当我们将代码文件打包成一个 zip 文件时(GitHub 的 zip 下载就是这种形式),即使这个 zip 文件失去了所有的 Git 历史,它仍然是一个代码库。
代码的版本实质上是应用的版本,这是作者的意图表达。这个版本往往是 vx.y.z 这种形式,而不是 Git commit hash,
最常见的管理方案是基于语义化版本。
我推荐的版本存储方式是使用一个 VERSION 文件将版本存储在代码目录中。例如,Git 的 Version 文件可以清楚地看到当前 Git 的版本是:
GVF=GIT-VERSION-FILE
DEF_VER=v2.42.GIT
其中的 .GIT 也明确说明了这个代码是一个开发模式下的版本。如果我们切换到一个发布版本的代码,例如 v2.39.3 版本,我们可以看到 DEF_VER=v2.39.3,这是一个遵循标准的制品(Artifacts)格式。这里还有两个最佳实践:
dev 模式,只有在进行标记封版之后才会成为正式版本号。源代码的最终产物不仅包括二进制文件、可执行文件和动态库(.dll / .so / .dylib),还包括相应的启动配置文件。这些启动配置文件通常与对应的版本一起进行管理。例如,Nginx 的启动文件 nginx.conf 和 Redis 的启动文件 redis.conf,这些启动配置文件也应该纳入版本管理。
从源代码仓库构建出来的内容就是制品(Artifacts)。制品已经具有两个版本:
VERSION 文件中定义的版本。引入制品版本管理后,问题变得更加复杂,因为制品带来了更多的问题:
制品的概念非常重要,其中最核心的一个理念是:制品可以通过打包器形成新的制品。
由于制品具有版本,而新的制品将形成新的版本,我们将进入多层嵌套。为了避免最原始的版本信息丢失,我们将 Version 的概念扩展为 Upstream Version,这是软件作者人为指定的版本,是所有版本的源头。
为什么制品可以形成新的制品呢?我举一个 Kubernetes 容器环境下的例子。 容器是一种交付形式,它将可执行文件和启动配置文件写入镜像文件中,并可以在容器环境中运行。形成的镜像文件存在于镜像仓库中,本身也是一种制品。
另外,Helm / Kustomize 也是一种交付形式(打包工具链)。 每个构建层解决其特定问题,并且可以在特定环境(例如容器、Kubernetes、云基础设施)中运行。
每个制品都需要构建,过程中会有自己的额外描述信息(Packaging Info),这些额外的描述信息本身也会发生变化,因此会增加一个版本。在实践中,我们希望制品的版本与其上游版本绑定。每种打包机制可能会包含自己的一些定义配置,但仍然遵循上游的版本。例如,Kubernetes 的 Workload 包含一个镜像,Workload 的描述是附加信息,而镜像仍然受到上游控制。
Artifact + Packaging Info = New Artifact,制品经过打包可以形成新的制品。直到最后的 Installer 放置到相应的环境中生效。
如果这些制品可以通过文件(IaC)进行描述,就形成了各种 IaC 仓库,这些仓库成为了 GitOps 的核心对象。
让我们来理清一下这些略有晦涩的概念:
| 中文 | 英文 | 解释 |
|---|---|---|
| 源代码 | Source Code | 程序、应用的源文件集合 |
| 代码仓库 | Source Code Repo | 源代码放到版本管理系统中的管理单元 |
| 版本 | Version | 源代码对应的应用版本,人为定义,语义化,有些场景会说 Upstream Version |
| 可执行文件 | Executable File | 源代码构建出来的结果,一般是 ELF 可执行文件,也可以是 Lib 文件 |
| 启动配置文件 | Configuration File | 配套 ELF / Lib 的启动配置文件,区别于广泛意义上的配置文件(比如 Kubernetes YAML) |
| 制品 | Artifact | 包含可执行文件和启动配置文件的集合,可以运行在运行时下面,一般是文件形态。制品可以嵌套制品。 |
| 安装器 | Installer | 将制品安装到运行时的工具 |
| 运行时 | Runtime | 制品的运行环境,比如特定操作系统,Kubernetes,Docker Engine。 |
| 打包器 | Packer | 将制品打包成特定格式(新的制品)的工具 |
| 打包附属信息 | Packaging Info | 制品打包时候需要的额外信息,比如容器的操作系统,进程的运行容量,默认环境变量等 |
这些概念共同构成了制品版本管理的核心要素,帮助我们管理和跟踪制品的不同版本,以及它们之间的关联和依赖关系。
打包器是一种工具,通过打包操作(Packaging)将制品组织成特定的格式,形成全新的制品。 打包的过程涉及编译、链接、合并和存档等常见概念。
它通常以上游(Upstream)作为输入,上游可以是源码,也可以是其他系统生成的制品(Artifacts)。
例如,在打包 Docker Compose 时,输入是镜像(Image),而对于 Helm,输入则包括镜像、启动配置文件和 Helm 模板,而输出则是 YAML 文件。
制品是一种数据集合,可以在特定环境中运行。 它由可执行文件和启动配置文件等组成,通常以文件形式存在,并且可以在运行时环境下运行。制品具有嵌套的能力,可以包含其他制品。
最常见的形态是二进制文件(ELF),也可以是适用于特定环境的运行物,如容器镜像。
制品通常以文件形式进行传输。
安装器是一种工具,用于将制品安装到运行时环境中。 它负责将制品部署到目标环境并确保其正常运行。 例如,dpkg、Pacman 是常见的安装器工具,而在 Windows 平台上,我们常见自引导的安装器。
对于特定的环境如 Kubernetes,我们可以使用 kubectl 命令进行安装,而 Helm 则使用helm命令来进行安装。
当我们理解了这些概念后,我们或许会惊讶地发现,这些概念与 Linux 社区多年来的实践是如此相似。抛开云原生等新概念,Linux 社区早就拥有了完整的解决方案。
每一层制品都会引入新的配置(Config)/ 扩展(Extension)/ 值(Values)/ 环境变量(Env)等等,无论如何称呼, 我们统一称之为配置。 这些新加入的 Packaging Info 的描述在大规模集群管理下也带来了新的问题。
自豪地使用 ArchLinux。
Arch Linux 使用 Pacman 作为包安装器,并且拥有一套完整的构建方案。
在 Arch Linux 中,PKGBUILD link用于描述包的构建方式,它本身是 Bash 的子集,是描述包的核心文件。
版本管理方面,Arch Linux 提供了清晰明确的方案,并且设计了完整的制品嵌套解决方案。
在 PKGBUILD 中,pkgver 表示上游版本,并经过适当的修正,使用 _ 替代 -,并调整了时间戳的格式。而 pkgrel 则表示发布号,而不是构建号,每次发布都会增加该号码,用于管理 Arch Linux 的发布动作。当大部分 PKGBUILD 发生变化时,发布号都会发生变化。
此外,epoch 是一个强制构建版本的机制,默认为 0 并且隐藏起来。使用 epoch 是一种兜底的解决方案,通过破坏版本对比来强制进行新版本的升级。
另外,在 PKGBUILD 中,使用了版本依赖的方式来优雅地解决模块的问题。
例如,base-devel 包是对 26 个基础软件的依赖,而该包本身并没有具体的内容。这种方案非常优雅,避免了引入一个新的模型(比如叫做 Group / 产品)。
最后让我们回归到 GitOps 版本管理本身,让我们重新面对文中的几个问题,通过以上的分析和调研,是否已经解决了这些问题呢?
VERSION 文件来确定软件版本,也就是上游版本(Upstream Version)v1.2.3-afe12c 的形式来追踪 Git 仓库中的版本,使用 v1.2.3-afe12c-b1 来追踪镜像构建物的版本。版本管理的智慧,其实已经体现在当年的 RPM / DEB / PKGBUILD 中。 我们通过明确版本定义权交给应用作者,提出制品嵌套的概念,允许版本的概念进行多层嵌套。
我们希望,最后运行的制品版本仍然是原始应用版本(Upstream Version)的衍生。毕竟, 让每个运行的程序都知道自己来自何处、自己是谁,在大规模集群管理下已经变得相当重要。
2023-07-29 14:54:27

image via Pixabay
前几日,我在团队内部举行了一场技术分享,我介绍了关于架构设计的最佳实践。将这些实践凝练成了 20 字口诀:
我将顺口溜转到了 Twitter,不少朋友对这些顺口溜产生了浓厚兴趣,希望深入了解。因此,我将我分享中的观点扩展成了这篇文章。
让我们首先澄清 什么是架构设计和系统分析(简称系分)。有些朋友对前者很熟悉,对后者却不太了解。 不过没关系,以下是维基百科上的介绍:
架构,软件架构是有关软件整体结构与组件的抽象描述,用于指导大型软件系统各个方面的设计。
系统分析,旨在研究特定系统结构中各部分(各子系统)的相互作用,系统的对外接口与界面,以及该系统整体的行为、 功能和局限,从而为系统未来的变迁与有关决策提供参考和依据。
来看一下英文定义可能会更清晰:
我们有时候提到的设计文档,可能涵盖整个设计过程,包括架构设计、系统分析以及其他设计活动(交流、PoC)。
软件架构(设计)= Software Architecture
系统分析 = System Analysis
最后,我来解释一下我对这两者边界的理解。实际上,我认为架构设计和系统分析并没有明显的界限。 一个系统或模块不管如何都会进行系统分析,而当出现以下几个特征时,就开始考虑架构设计问题:
在这里,我们讨论的是技术架构,不会涉及业务架构或产品架构等方面。 技术方面的讨论重点是如何更高效地利用技术能力和方法来解决特定类型的问题。
进一步地,技术架构可以分为两种:一种是从顶层向下看,包括业务、战略和框架划分; 另一种是关注工程实现(编码)层面需要解决的架构问题。
那些经验丰富的人常常有较宏观的视角,使用的常见名词有:全局、宏观、领域、战略、平衡、规划。我将这些词汇整理成了一个词云如下:

generted by https://tendcode.com/tool/word-cloud/
以上这些概念在架构设计和系统分析中都非常重要,因为它们帮助我们在整体上考虑问题,甚至超越技术层面, 从业务价值、商业策略和业务战略的角度思考问题。
另一种架构偏重于工程设计和实现。常见的关键词有:领域建模、UML、GoF23,SOLID,高内聚低耦合等等。对应的词云如下:

generted by https://tendcode.com/tool/word-cloud/
架构的话题非常广泛,本文选择从一个切入点出发:通过实践和方法论,使架构意识在日常工作中发挥作用,以满足 80%的工程设计开发场景。 我称之为「架构设计 the easy way」。
理解架构的第一步,也是最重要的一步,就是关注「问题」。也就是说,你遇到了什么问题,你将如何去解决它?
通常情况下,如果我们的业务和系统都稳定运行,没有遇到任何问题,我们就不太需要进行架构设计。但是,只要涉及到架构设计, 必定是因为我们遇到了问题。这些问题可能源自新的需求,也可能是外部环境的变化, 亦或是系统自身随着时间的发展而出现的。无论问题的来源如何,我们都遇到了问题。
遇到问题之后,我们该如何解决?就像将大象装进冰箱一样,需要分成几个步骤。

image via unkown
因此,解决问题也有三个步骤:第一步是将问题描述清楚,第二步是进行协商和决策达成一致,第三步则是着手解决问题。

我还想问一个听上去很愚蠢的问题:为什么不能直接解决问题?
因为问题是复杂的,有许多解决路径,不同的解决方案各有优劣和成本。在架构设计中,我们需要完成这些决策。
那为什么不直接进行决策,甚至直接开始动手?
首先可能涉及到职权问题,架构师未必有最终决策权,需要有决策权的人来做最后的决定。 第二个原因是架构师未必是方方面面的专家,设计一个复杂系统时候需要协调多个部分和领域专家来一起评估决策。
我举 Prometheus 的架构设计来作为例子。
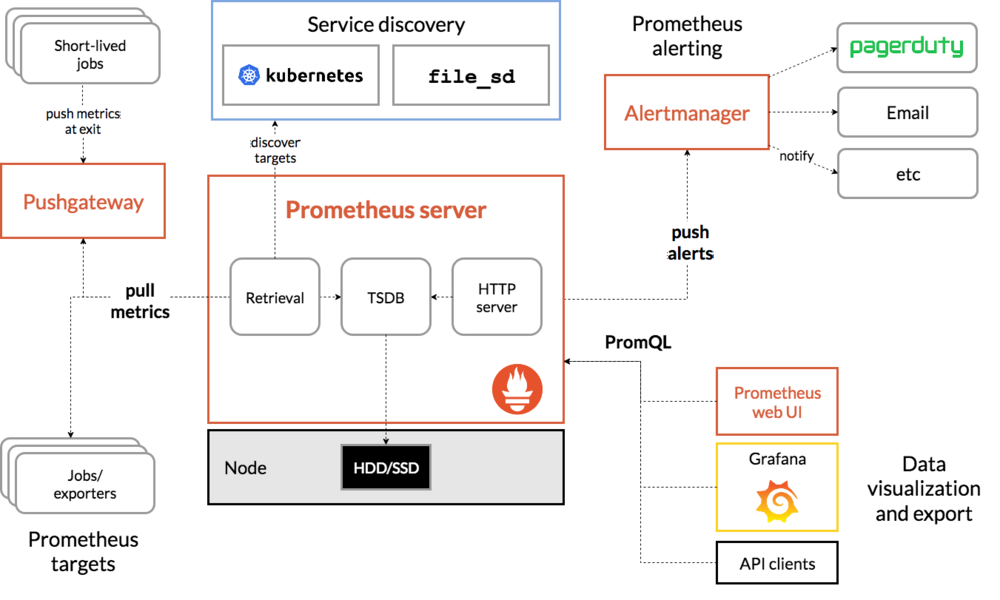
image via Prometheus
这个架构图回答了很多问题,我举几个例子:
问题驱动架构变化,架构方案应对问题,架构评审统一解决方案。
关于决策拍板问题。我强烈推崇架构师根据自己具备的领域知识、对行业的判断以及对现状的了解, 做出自己的思考和独立判断。这些思考过程应该有因果关系的支持,一个优秀的架构师必定拥有自己的观点。
最后,我补充一个小问题:为什么这里没有提到架构分层、模块分层?
不是因为分层和框架不重要,而是在因为大家都很专业。分层和模块化已经是基本常识和技能,因此反而往往不会成为争论和决策的焦点。 如果分层和框架无法快速形成一致,有可能团队构成上存在问题,也可能问题过于复杂已经不是 80% case。
在本阶段,产出的成果包括架构图以及对问题、价值、成本、风险和分工达成一致的认识。
需求是对问题的解答。我个人喜欢用思维导图或白纸来画图,将需求讲清楚。 画什么内容呢?理清角色,并列出各种动作和行为。
那有什么技巧可以将事项都整理出来呢?我经常使用主谓宾状从的方法。 也就是说,明确哪些人,在什么场景(可选),以什么状态(可选)做着什么事情。

image via unkown
通过用例将需求清晰地拆解,并在这个过程中不断与需求提供方进行交流和沟通。
Demo 稿是产品经理的武器,而需求用例则是工程师的武器。
有些初入职场的研发人员会不自然地变成需求的执行者。我比较果断地判断,不了解业务的工程师和外包没什么区别。而需求分析环节是最重要的, 是对业务输入进行理解、梳理、重新设计的机会。通过用例的整理,我们可以将一些不切实际、不可靠的需求反馈给需求方。
这是少数可以推动(反馈)需求方的阶段,一定要珍惜。
这里有一个产品用例的范例:

image via 网易云音乐产品分析报告
实际上,这个用例是敌对势力那边总结的 😄,但仍然能够体现用例的重要性。
除了使用主谓宾的方式来进行设计,还有一些其他技巧:
本阶段的产出物包括:Demo 稿、用例图。
在我看来,设计的核心在于模型:模型确定了数据的载体和边界。而数据确定了组成部分,边界则确定了归属和职责。 在 UML 中,大量的 Entity 和 Object 用于确定模型的边界。 随着业务系统复杂程度的增加,建模也会面临更加复杂的挑战。
我总结了一下我建模的几个要点:
很多人对中英文术语表不屑一顾,但我却很在意这点。有一个效应叫做「外语陌生感」(Foreign Language Effect), 就像博物学使用拉丁语 / 希腊语来描述物种一样。我们非英语母语的工程师,使用英文描述术语可以快速地聚焦问题。
始终牢记 80/20 原则的存在,特别是在设计阶段,一定要关注核心对象,将其放大而非过度关注细节。 一般来说,关注最核心的 20%模型就可以满足大部分场景。
在模型的提炼和抽象过程中要反复斟酌,并且可以将这个过程联动到前期的用例定义和后期的时序设计, 这需要大量领域知识的支持。我个人喜欢在这个阶段参考外部的代码和设计。
模型之间的关联关系主要是 1:1 / 1:N / M:N 关系,需要使用箭头清楚地标记主从关系。主从关系意味着从属关系, 这会影响后续一系列细节设计(如 URL、数据库、生命周期管理等)。 我个人推荐避免使用 M:N 关系,这种形式通常表明中间会有一个凭证(Credential)或关系(Relationship / Binding)。
除了关注静态的数据,还要关注模型的行为(极少量模型才有)。这个阶段可以进一步做一些识别,方便下一步的细节设计。
完成业务模型设计之后,同时要考虑数据模型。对于普通业务系统,这个转换会非常直观简单。业务系统通常是无状态系统, 完全依赖数据库进行存储。如果面临 DIA(Data Intensive Application)系统,就要考虑运行时数据的管理, 以及一系列复杂的生命周期管理和可用性管理(我估计有这个需求的朋友,不会看到这里了)。
我举例一个 Kubernetes 的 RBAC(Role-Based Access Control)系统,这是常见的 AuthZ 授权鉴权系统(注意,不是 AuthN 认证系统)。
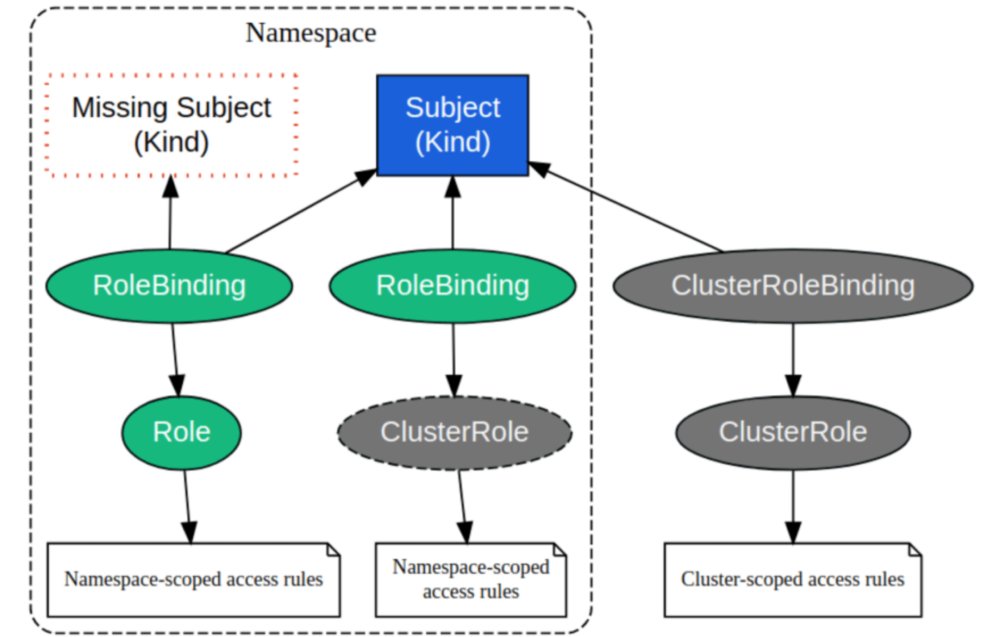
image via Kubernetes RBAC - DEV Community
这里我抛几个问题:
这些答案都需要建模来回答的。
在我们的讨论中,更多关注的是业务模型,即用户能感知并产品能理解的模型,通常需要存储在数据库中。
但在基础设施领域,也是有模型的,有时候称之为"概念"(Concept)。基础设施领域的模型通常会简单得多, 而业务模型可能会非常复杂,因为世界本身就很复杂,而基础设施则专注于解决非常垂直领域的问题,因此相对简单。
此外,基础设施领域的特殊性会导致有很多抽象的建模,例如最简单到我们常常忽略的(Manager / Service)类别。 一些带有数据和状态的模型,比如 Executor,是常见的概念,而 Registry / Queue 也是常见的概念。
这是 Kubernetes的 Concepts,十几个子类,上百个概念更显这个系统的复杂性。
模型不仅仅是数据,还涉及边界,边界决定了其归属和职责。
模型的设计需要动静结合来看,静态方面关注其持有的内容,动态方面则关注其提供的功能。
在基础设施领域,模型的产出可能包括 UML Model 图、ER 图、数据库 DML、类文件、OpenAPI Swagger(部分)等。
程序设计 = 数据结构 + 算法 + 流程控制
在将设计转换为模型之前,最后一个重要的步骤是控制细节。对于需求方和决策者来说,这一步可能并不重要, 但对于实施方(开发团队)来说,这个步骤直接影响交付结果的质量和时间。
我认为细节应该在时序图上进行呈现。
通常我们有两种常用的图形来展示细节:流程图和时序图。两者实际上有很多相似之处, 但我个人更喜欢时序图,因为它不仅包含顺序的概念,还清晰地展示了流程和系统之间的交互边界。
我的技巧是,一般每个用例都会对应一个时序图。
这里以 AWS 一个官方博客作为范例:
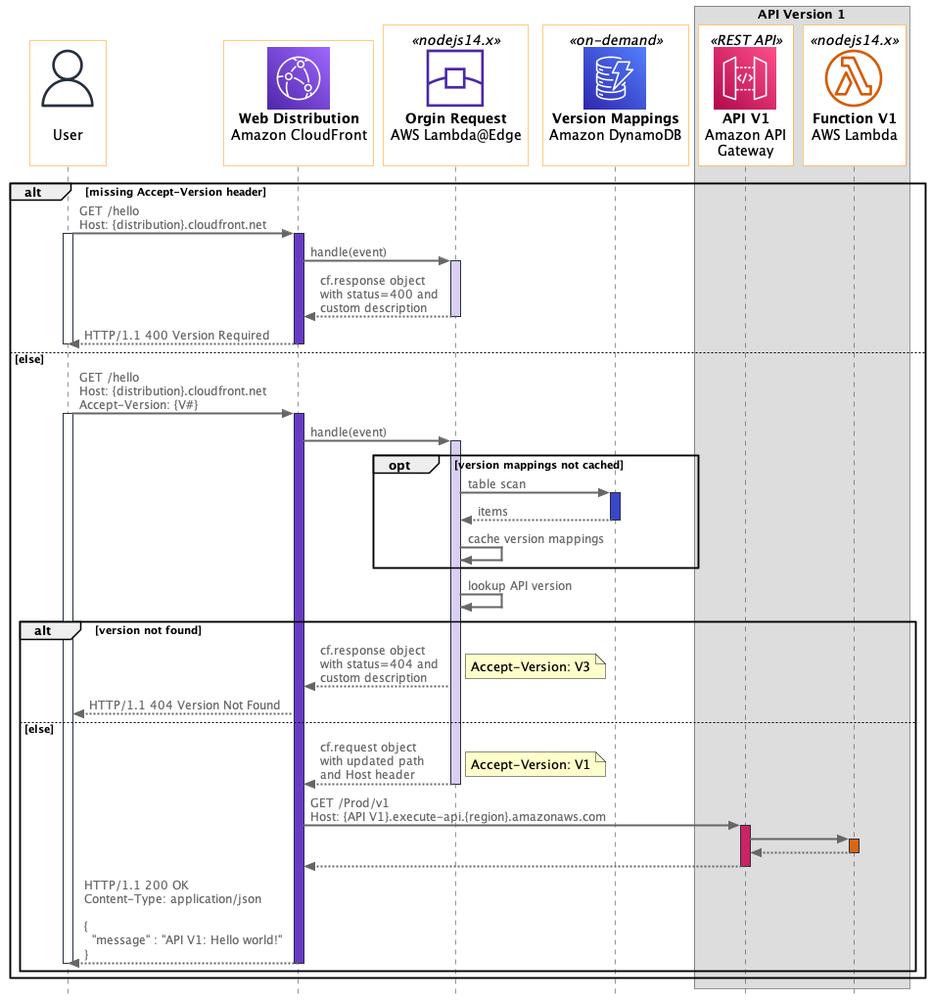
在上图中,展示了 AWS 中使用 CloudFront 的一个时序图,从时序图中可以清晰地看到多个系统之间请求的流转以及多种异常状态的处理。
这里我总结一下时序图的小技巧:
一般来说,时序图画好了,就可以放心地交给项目团队开始实施,不会有大的错误。如果没有时序图,依赖的就完全是彼此之间的合作经验和信任度了。
产出:时序图、API 文档(Open API Swagger)、前端 service 生成(如果有)。
在这个阶段,尽管我们还没有开始编写代码,但已经清楚了需要做什么,以及实现的样子。 我们也有了类结构、API 定义、前端服务生成等产出。多个团队可以同时开始协作,没有明显的瓶颈。
如果未来需要汇报,汇报材料已经有了 1/3 的内容。如果需要撰写技术分享文档,也已经具备了 1/2 的内容。
如果这个项目是一个简单的 CRUD 应用系统,那么基本不会有什么难点。
如果是一个 DIA 系统(Data Intensive Application),则需要开始设计和实施数据存储部分,并考虑数据一致性和并发相关的问题。对于一个复杂的系统, 还需要继续实施多个系统连接处是否存在不确定性。如果在工程上面临同步方面的挑战,例如应用框架改造、通讯系统改造等, 也要提前进行风险排除。(我认为同时进行技术升级和业务开发并不明智)。
我有一套自己的画图工具套件,涵盖了系统架构图、流程图等绘制。 PS:我甚至还给自己的产品设计 Logo,或许这与我内心渴望成为一名设计师有关吧~
作为一名工程师,必须积累自己的画图 UI Kit,熟练掌握其技巧,构建一套属于自己的工具包, 从而能够将脑海中的构思快速还原到文档中。
我的画图工具组合相当丰富。用于绘制架构图的工具包括:
用来做工程设计(UML)的工具如下:
这里我再软广一下我维护的 Excalidraw(Fork),支持中文手写字体,保持风格的统一。
回到本次分享的出发点,给大家一份简单可行的架构设计方案。 但是对于你这样好学的人来说,肯定不会满足于如此简单的流程, 毕竟还有那 20% 的复杂场景无法完全涵盖。 我给你一个关键词列表和一些建议的书单,帮助你进一步加深学习:
以下是一些书单,可以帮助你深入学习:
2023-04-03 11:34:18
当开始创建一个新系统,或参与一个新团队或项目时,都会面临一个简单却深刻的问题:这个系统(Web Server)的 API 是否有设计规范?

image by stable difussion, prompt by alswl
这个问题困扰了我很长时间,始于我求学时期,每一次都需要与团队成员进行交流和讨论。
从最初的自由风格到后来的 REST,我经常向项目组引用 Github v3 和
Foursqure API(已经无法访问,暴露年龄) 文档。
然而,在实践过程中,仍然会有一些与实际工作或公司通用规范不匹配的情况,
这时候我需要做一些补充工作。最终,我会撰写一个简要的 DEVELOPMENT.md 文档,以描述设计方案。
但我对该文档一直有更多的想法,它还不够完善。因此,我想整理出一份简单(Simple)而实用(Pragmatic)的 Web API 最佳实践,也就是本文。
这个问题似乎很明显,但是深入剖析涉及团队协作效率和工程设计哲学。
API(Application Programming Interface,应用程序编程接口)是不同软件系统之间交互的桥梁。在不同软件系统之间进行通信时, API 可以通过标准化的方式进行数据传输和处理,从而实现各种应用程序的集成。
当我们开始撰写 API 文档时,就会出现一个范式(Design Pattern),这是显式还是隐式的, 是每个人一套还是公用同一套。这就像我们使用统一的 USB 接口一样,统一降低了成本,避免了可能存在的错误。具体来说,这有以下几个原因:
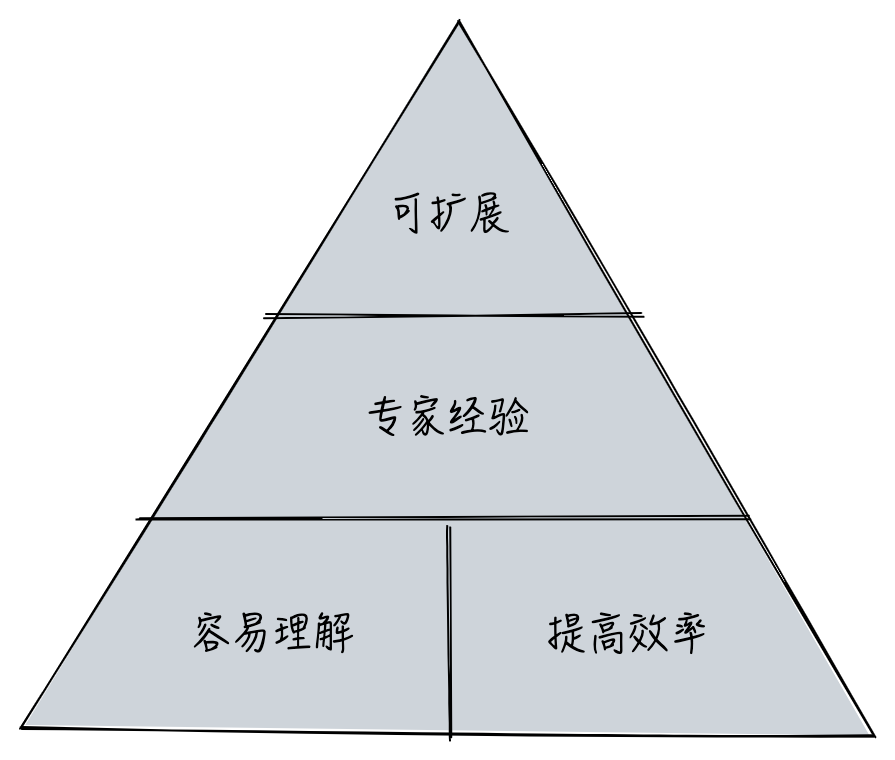
image by alswl
虽然使用统一规范确实有一些成本,需要框架性的了解和推广,但我相信在大部分场景下, 统一规范所带来的收益远远高于这些成本。
然而,并非所有的情况下都需要考虑 API 规范。对于一些短生命周期的项目、影响面非常小的内部项目和产品, 可能并不需要过多关注规范。 此外,在一些特殊的业务场景下, 协议底层可能会发生变化,这时候既有的规范可能不再适用。但即使如此,我仍然建议重新起草新的规范,而不是放弃规范不顾。
在制定 API 规范时,我们应该遵循一些基本原则,以应对技术上的分歧,我总结了三个获得广泛认可的原则:
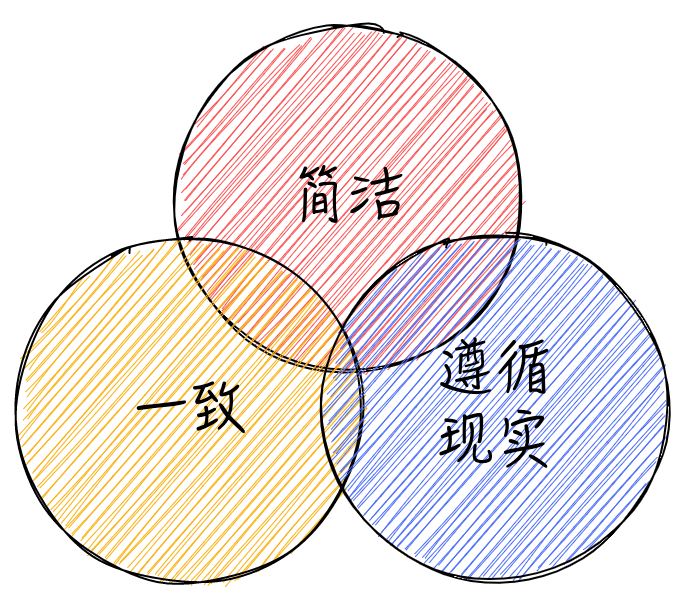
image by alswl
在 Web API 领域,RESTful API 已经成为广受欢迎的协议。 其广泛适用性和受众范围之广源于其与 HTTP 协议的绑定,这使得 RESTful API 能够轻松地与现有的 Web 技术进行交互。如果您对 REST 不熟悉, 可以查看 阮一峰的 RESTful API 设计指南 以及 RESTful API 设计最佳实践。
REST 是一种成熟度较高的协议,Leonard Richardson 将其描述为四种成熟度级别:
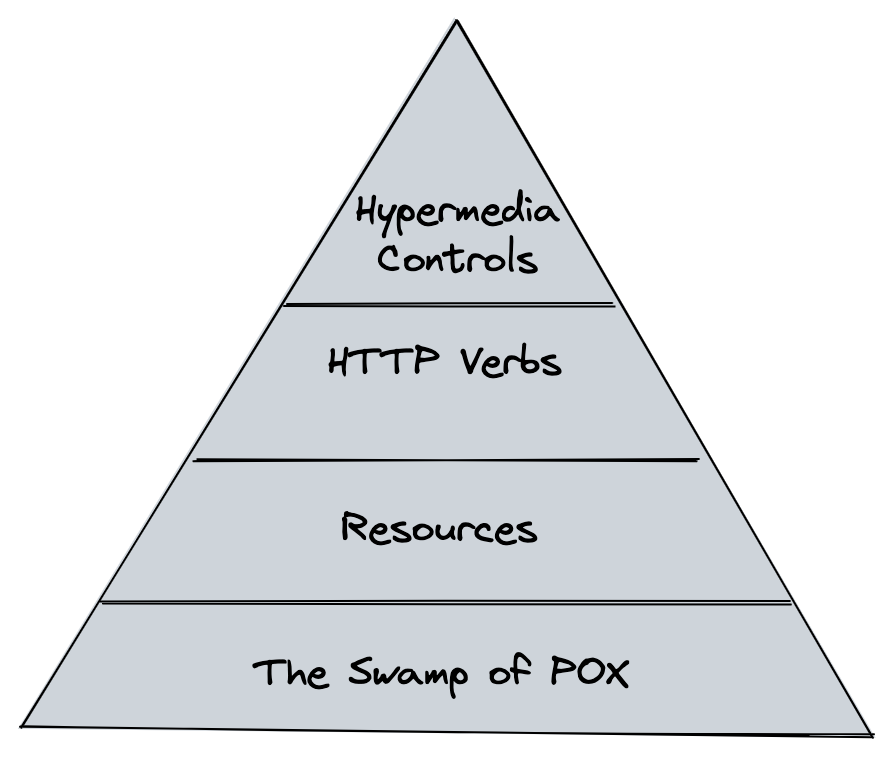
image by alswl
rel 链接进行 API 资源整合,JSON:API 是登峰造极的表现REST 的核心优势在于:
然而,REST 并非一种具体的协议或规范,而是一种风格理念。尽管 REST 定义了一些规则和原则,如资源的标识、统一接口、无状态通信等, 但它并没有规定一种具体的实现方式。因此,在实际开发中,不同的团队可能会有不同的理解和实践, 从而导致 API 的不一致性和可维护性降低。
此外,REST 也有一些局限性和缺陷:
/login)操作,转换成 session 就非常绕口;
同样的问题在转账这种业务也会出现。HTTP 有限的动词无法支撑所有业务场景。因此,虽然 REST 风格是一个不错的指导思想,但在具体实现时需要结合具体业务需求和技术特点,有所取舍,才能实现良好的 API 设计。 最后,我们是否需要 Web API 设计规范,遵循 REST 风格呢?我认为 REST 能够解决 90% 的问题,但还有 10% 需要明确规定细节。
因为我们的协议基于 HTTP 和 REST 设计,我们将以 HTTP 请求的四个核心部分为基础展 开讨论,这些部分分别是:URL、Header、Request 和 Response。
我的 URL 设计启蒙来自于 Ruby on Rails。 在此之前,我总是本能地将模型信息放到 URL 之上,但实际上良好的 URL 设计应该是针对系统信息结构的规划。 因此,URL 设计不仅仅要考虑 API,还要考虑面向用户的 Web URL。
为了达到良好的 URL 设计,我总结了以下几个规则:
通常情况下,URL 的模型如下所示:
/$(prefix)/$(module)/$(model)/$(sub-model)/$(verb)?$(query)#${fragment}
其中,Prefix 可能是 API 的版本,也可能是特殊限定,如有些公司会靠此进行接入层分流; Module 是业务模块,也可以省略;Model 是模型;SubModel 是子模型,可以省略; Verb 是动词,也可以省略;Query 是请求参数;Fragment 是 HTTP 原语 Fragment。
需要注意的是,并非所有的组成部分都是必须出现的。例如,SubModel 和 Verb 等字段可 以在不同的 URL 风格中被允许隐藏。
设计风格选择
注:请注意,方案 A / B / C 之间没有关联,每行上下也没有关联
| 问题 | 解释(见下方单列分析) | 方案 A | 方案 B | 方案 C |
|---|---|---|---|---|
| API Path 里面 Prefix | /apis |
/api |
二级域名 | |
| Path 里面是否包含 API 版本 | 版本在 URL 的优势 | ✅ | 🚫 | |
| Path 是否包含 Group | ✅ | 🚫 | ||
| Path 是否包含动作 | HTTP Verb 不够用的情况 | ✅ | 🚫 (纯 REST) | 看情况(如果 HTTP Verb CRUD 无法满足就包含) |
| 模型 ID 形式 | Readable Stable Identity 解释 | 自增 ID | GUID | Readable Stable ID |
| URL 中模型单数还是复数 | 单数 | 复数 | 列表复数,单向单数 | |
| 资源是一级(平铺)还是多级(嵌套) | 一级和多级的解释 | 一级(平铺) | 多级(嵌套) | |
搜索如何实现,独立接口(/models/search)还是基于列表/models/ 接口 |
独立 | 合并 | ||
| 是否有 Alias URL | Alias URL 解释 | ✅ | 🚫 | |
| URL 中模型是否允许缩写(或精简) | 模型缩写解释 | ✅ | 🚫 | |
| URL 中模型多个词语拼接的连字符 | - |
_ |
Camel | |
| 是否要区分 Web API 以及 Open API(面向非浏览器) | ✅ | 🚫 |
版本在 URL 的优势
我们在设计 URL 时遵循一致性的原则,无论是哪种身份或状态,都会使用相同的 URL 来访问同一个资源。 这也是 Uniform Resource Location 的基本原则。虽然我们可以接受不同的内容格式(例如 JSON / YAML / HTML / PDF / etc), 但是我们希望资源的位置是唯一的。
然而,问题是,对于同一资源在不同版本之间的呈现,是否应该在 URL 中体现呢?这取决于设计者是否认为版本化属于位置信息的范畴。
根据 RFC 的设计,除了 URL 还有 URN(Uniform Resource Name), 后者是用来标识资源的,而 URL 则指向资源地址。实际上,URN 没有得到广泛的使用,以至于 URI 几乎等同于 URL。
HTTP Verb 不够用的情况
在 REST 设计中,我们需要使用 HTTP 的 GET / POST / PUT / DELETE / PATCH / HEAD 等动词对资源进行操作。
比如使用 API GET /apis/books 查看书籍列别,这个自然且合理。
但是,当需要执行类似「借一本书」这样的动作时,
我们没有合适的动词(BORROW)来表示。针对这种情况,有两种可行的选择:
POST /apis/books/borrow,表示借书这一动作;POST /apis/books/borrow-log/;这个问题在复杂的场景中会经常出现,例如用户登录(POST /api/auth/login vs POST /api/session)和帐户转账(vs 转账记录创建)等等。
API 抽象还是具体,始终离不开业务的解释。我们不能简单地将所有业务都笼统概括到 CRUD 上面,
而是需要合理划分业务,以便更清晰地实现和让用户理解。
在进行设计时,我们可以考虑是否需要为每个 API 创建一个对应的按钮来方便用户的操作。
如果系统中只有一个名为 /api/do 的 API 并将所有业务都绑定在其中,虽然技术上可行,
但这种设计不符合业务需求,每一层的抽象都是为了标准化解决特定问题的解法,TCP L7 设计就是这种理念的体现。
Readable Stable Identity 解释
在标记一个资源时,我们通常有几种选择:
我个人有一个设计小技巧:使用 ${type}/${type-id} 形式的 slug 来描述标识符。Slug 是一种人类可读的唯一标识符,
例如 hostname/abc.sqa 或 ip/172.133.2.1。
这种设计方式可以在可读性和唯一性之间实现很好的平衡。
A slug is a human-readable, unique identifier, used to identify a resource instead of a less human-readable identifier like an id .
from What’s a slug. and why would I use one? | by Dave Sag
PS:文章最末我还会介绍一套 Apple Music 方案,这个方案兼顾了 ID / Readable / Stable 的特性。
一级和多级的解释
URL 的层级设计可以根据建模来进行,也可以采用直接单层结构的设计。具体问题的解决方式,
例如在设计用户拥有的书籍时,可以选择多级结构的 /api/users/foo/books 或一级结构的 /api/books?owner=foo。
技术上这两种方案都可以,前者尊重模型的归属关系,后者则是注重 URL 结构的简单。
多级结构更直观,但也需要解决可能存在的多种组织方式的问题,例如图书馆中书籍按照作者或类别进行组织?
这种情况下,可以考虑在多级结构中明确模型的归属关系,
例如 /api/author/foo/books(基于作者)或 /api/category/computer/books(基于类别)。
Alias URL 解释
对于一些频繁使用的 URL,虽然可以按照 URL 规则进行设计,但我们仍然可以设计出一个更为简洁的 URL, 以方便用户的展示和使用。这种设计在 Web URL 中尤其常见。比如一个图书馆最热门书籍的 API:
# 原始 URL
https://test.com/apis/v3/books?sort=hot&limit=10
# Alias URL
https://test.com/apis/v3/books/hot
模型缩写解释
通常,在对资源进行建模时,会使用较长的名称来命名,例如书籍索引可能被命名为 BookIndex ,而不是 Index。
在 URL 中呈现时,由于 /book/book-index 的 URL 前缀包含了 Book,我们可以减少一层描述,
使 URL 更为简洁,例如使用 /book/index。这种技巧在 Web URL 设计中非常常见。
此外,还有一种模型缩写的策略,即提供一套完整的别名注册方案。别名是全局唯一的,
例如在 Kubernetes 中, Deployment
是一种常见的命名,而 apps/v1/Deployment 是通过添加 Group 限定来表示完整的名称,
同时还有一个简写为 deploy。这个机制依赖于 Kubernetes 的 API Schema 系统进行注册和工作。
我们常常会忽略 Header 的重要性。实际上,HTTP 动词的选择、HTTP 状态码以及各种身 份验证逻辑(例如 Cookie / Basic Auth / Berear Token)都依赖于 Header 的设计。
设计风格选择
| 问题 | 解释(见下方单列分析) | 方案 A | 方案 B | 方案 C |
|---|---|---|---|---|
| 是否所有 Verb 都使用 POST | 关于全盘 POST | ✅ | 🚫 | |
| 修改(Modify)动作是 POST 还是 PATCH? | POST | PATCH | ||
| HTTP Status 返回值 | 2XX 家族 | 充分利用 HTTP Status | 只用核心状态(200 404 302 等) | 只用 200 |
| 是否使用考虑限流系统 | ✅ 429 | 🚫 | ||
| 是否使用缓存系统 | ✅ ETag / Last Modify | 🚫 | ||
| 是否校验 UserAgent | ✅ | 🚫 | ||
| 是否校验 Referrral | ✅ | 🚫 |
关于全盘 POST
有些新手(或者自认为有经验的人)可能得出一个错误的结论,即除了 GET 请求以外, 所有的 HTTP 请求都应该使用 POST 方法。甚至有些人要求 所有行为(即使是只读的请求)也应该使用 POST 方法。 这种观点通常会以“简单一致”、“避免缓存”或者“运营商的要求”为由来支持。
然而,我们必须明白 HTTP 方法的设计初衷:它是用来描述资源操作类型的,从而派生出了包括缓存、安全、幂等性等一系列问题。 在相对简单的场景下,省略掉这一层抽象的确不会带来太大的问题,但一旦进入到复杂的领域中, 使用 HTTP 方法这一层抽象就显得非常重要了。这是否遵循标准将决定你是否能够获得标准化带来的好处, 类比一下就像一个新的手机厂商可以选择不使用 USB TypeC 接口。 技术上来说是可行的,但同时也失去了很多标准化支持和大家心智上的约定俗成。
我特别喜欢一位 知乎网友 的 评论:「路由没有消失,只是转移了」。
2XX 家族
HTTP 状态码的用途在于表明客户端与服务器间通信的结果。2XX 状态码系列代表服务器已经成功接收、 理解并处理了客户端请求,回应的内容是成功的。以下是 2XX 系列中常见的状态码及其含义:
2XX 系列的状态码表示请求已被成功处理,这些状态码可以让客户端明确知晓请求已被正确处理,从而进行下一步操作。
是否需要全面使用 2XX 系列的状态码,取决于是否需要向客户端明确/显示的信息, 告知它下一步动作。如果已经通过其他方式(包括文档、口头协议)描述清楚, 那么确实可以通盘使用 200 状态码进行返回。但基于行为传递含义, 或是基于文档(甚至口头协议)传递含义,哪种更优秀呢?是更为复杂还是更为简洁?
设计风格选择
| 问题 | 解释(见下方单列分析) | 方案 A | 方案 B | 方案 C |
|---|---|---|---|---|
| 复杂的参数是放到 Form Fields 还是单独一个 JSON Body | Form Fields | Body | ||
| 子资源是一次性查询还是独立查询 | 嵌套 | 独立查询 | ||
| 分页参数存放 | Header | URL Query | ||
| 分页方式 | 分页方式解释 | Page based | Offset based | Continuation token |
| 分页控制者 | 分页控制者解释 | 客户端 | 服务端 |
分页方式解释
我们最为常见的两种分页方式是 Page-based 和 Offset-based,可以通过公式进行映射。
此外,还存在一种称为 Continuation Token 的方式,其技术类似于 Oracle 的
rownum 分页方案,使用参数 start-from=? 进行描述。
虽然 Continuation Token 的优缺点都十分突出,使用此种方式可以将顺序性用于替代随机性。
分页控制者解释
在某些情况下,我们需要区分客户端分页(Client Pagination)和服务器分页(Server Pagniation)。
客户端分页是指下一页的参数由客户端计算而来,而服务器分页则是由服务器返回 rel 或 JSON.API 等协议。
使用服务器分页可以避免一些问题,例如批量屏蔽了一些内容,如果使用客户端分页,可能会导致缺页或者白屏。
设计风格选择
| 问题 | 解释(见下方单列分析) | 方案 A | 方案 B | 方案 C |
|---|---|---|---|---|
| 模型呈现种类 | 模型的几种形式 | 单一模型 | 多种模型 | |
| 大模型如何包含子模型模型 | 模型的连接、侧载和嵌入 | 嵌入 | 核心模型 + 多次关联资源查询 | 链接 |
| 字段返回是按需还是归并还是统一 | 统一 | 使用 fields 字段按需 |
||
| 字段表现格式 | Snake | Camel | ||
| 错误码 | 无自定,使用 Message | 自定义 | ||
| 错误格式 | 全局统一 | 按需 | ||
| 时区 | UTC | Local | Local + TZ | |
| HATEOAS | ✅ | 🚫 |
模型的几种形式
在 API 设计中,对于模型的表现形式有多种定义。虽然这并不是 API 规范必须讨论的话题,但它对于 API 设计来说是非常重要的。
我将模型常说的模型呈现方式分为一下几类,这并非是专业的界定,借用了 Java 语境下面的一些定义。 这些名称在不同公司甚至不同团队会有不一样的叫法:
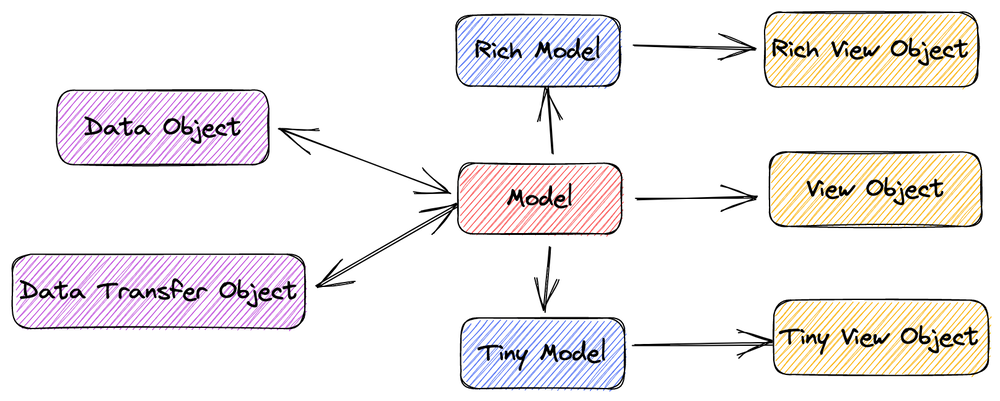
image by alswl
除此之外,还经常使用两类:Rich Model 和 Tiny Model(请忽略命名,不同团队叫法差异比较大):
模型的连接、侧载和嵌入
在 API 设计中,我们经常需要处理一个模型中包含多个子模型的情况,例如 Book 包含 Comments。 对于这种情况,通常有三种表现形式可供选择:链接(Link)、侧载(Side)和嵌入(Embed)。
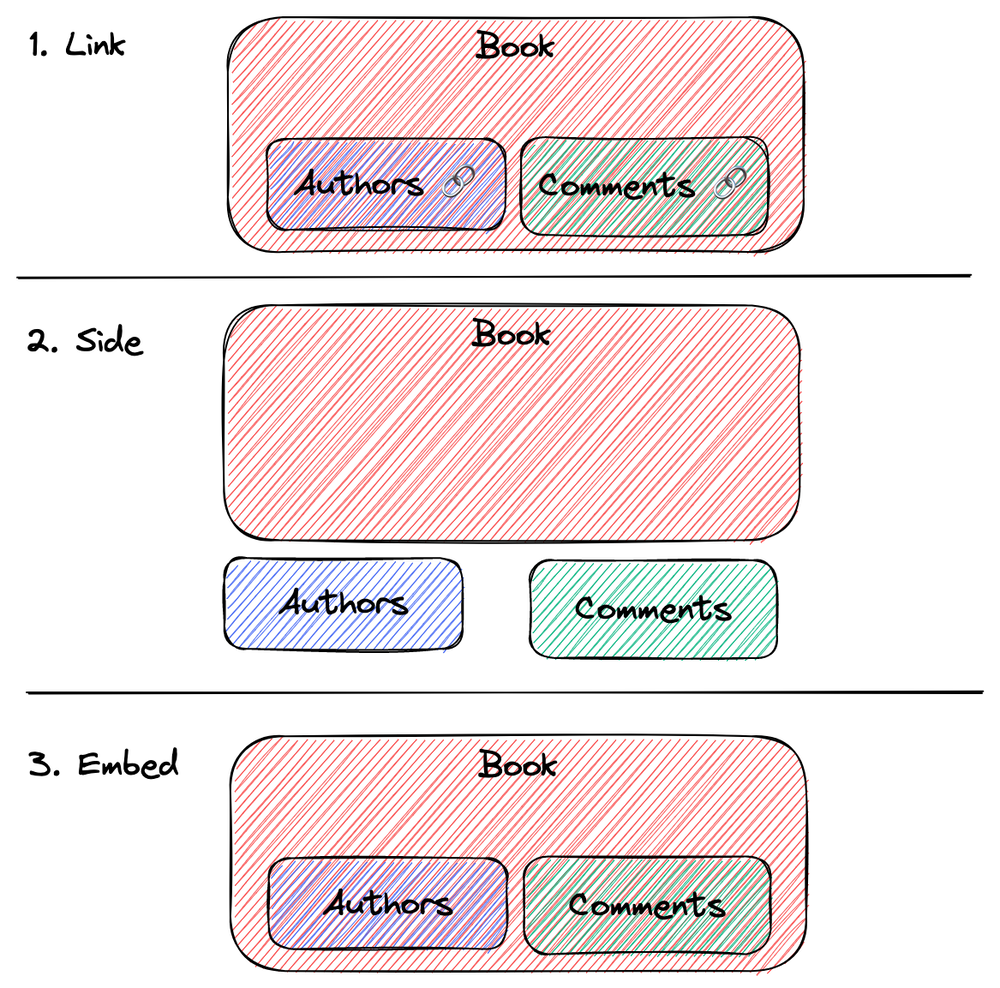
image by alswl
链接(有时候这个 URL 也会隐藏,基于客户端和服务端的隐式协议进行请求):
{
"data": {
"id": 42,
"name": "朝花夕拾",
"relationships": {
"comments": "http://www.domain.com/book/42/comments",
"author": ["http://www.domain.com/author/鲁迅"]
}
}
}
侧载:
{
"data": {
"id": 42,
"name": "朝花夕拾",
"relationships": {
"comments": "http://www.domain.com/book/42/comments",
"authors": ["http://www.domain.com/author/鲁迅"]
}
},
"includes": {
"comments": [
{
"id": 91,
"author": "匿名",
"content": "非常棒"
}
],
"authors": [
{
"name": "鲁迅",
"description": "鲁迅原名周树人"
}
]
}
}
嵌入:
{
"data": {
"id": 42,
"name": "朝花夕拾",
"comments": [
{
"id": 91,
"author": "匿名",
"content": "非常棒"
}
],
"authors": [
{
"name": "鲁迅",
"description": "鲁迅原名周树人"
}
]
}
}
还有一些问题没有收敛在四要素里面,但是我们在工程实践中也经常遇到,我将其捋出来:
我不是 HTTP 协议,怎么办?
Web API 中较少遇到非 HTTP 协议,新建一套协议的成本太高了。在某些特定领域会引入一些协议, 比如 IoT 领域的 MQTT。
此外,RPC 是一个涉及广泛领域的概念,其内容远远不止于协议层面。 通常我们会将 HTTP 和 RPC 的传输协议以及序列化协议进行对比。 我认为,本文中的许多讨论也对 RPC 领域具有重要意义。
有些团队或个人计划使用自己创建的协议,但我的观点是应尽量避免自建协议,因为真正需要创建协议的情况非常罕见。 如果确实存在强烈的需要,那么我会问两个问题:是否通读过 HTTP RFC 文档和 HTTP/2 RFC 文档?
我不是远程服务(RPC / HTTP 等),而是 SDK 怎么办?
本文主要讨论的是 Web API(HTTP)的设计规范,并且其中一些规则可以借鉴到 RPC 系统中。 然而,讨论的基础都是建立在远程服务(Remote Service)的基础之上的。 如果你是 SDK 开发人员,你会有两个角色,可能会作为客户端和远程服务器进行通信, 同时还会作为 SDK 提供面向开发人员的接口。对于后者,以下几个规范可以作为参考:
后者可以参考一下这么几个规范:
认证鉴权方案
一般而言,Web API 设计中会明确描述所采用的认证和鉴权系统。 需要注意区分「认证」和「鉴权」两个概念。关于「认证」这一话题,可以在单独的章节中进行讨论,因此本文不会展开这一方面的内容。
在 Web API 设计中,常见的认证方式包括:HTTP Basic Auth、OAuth2 和账号密码登录等。 常用的状态管理方式则有 Bearer Token 和 Cookie。此外,在防篡改等方面,还会采用基于 HMac 算法的防重放和篡改方案。
忽略掉的话题
在本次讨论中,我未涉及以下话题:异步协议(Web Socket / Long Pulling / 轮训)、CORS、以及安全问题。 虽然这些话题重要,但是在本文中不予展开。
什么时候打破规则
有些开发者认为规则就是为了打破而存在的。现实往往非常复杂,我们难以讨论清楚各个细节。 如果开发者觉得规则不符合实际需求,有两种处理方式:修改规则或打破规则。 然而,我更倾向于讨论和更新规则,明确规范不足之处,确定是否存在特殊情况。 如果确实需要创建特例,一定要在文档中详细描述,告知接任者和消费者这是一个特例,说明特例产生的原因以及特例是如何应对的。
Github 的 API 是我常常参考的对象。它对其业务领域建模非常清晰,提供了详尽的文档,使得沟通成本大大降低。 我主要参考以下两个链接: API 定义 GitHub REST API documentation 和 面向应用程序提供的 API 列表 Endpoints available for GitHub Apps ,该列表几乎包含了 Github 的全部 API。
| 问题 | 选择 | 备注 |
|---|---|---|
| URL | ||
| API Path 里面 Prefix | 二级域名 | https://api.github.com |
| Path 里面是否包含 API 版本 | 🚫 | Header X-GitHub-Api-Version API Versions
|
| Path 是否包含 Group | 🚫 | |
| Path 是否包含动作 | 看情况(如果 HTTP Verb CRUD 无法满足就包含) | 比如 PUT /repos/{owner}/{repo}/pulls/{pull_number}/merge POST /repos/{owner}/{repo}/releases/generate-notes
|
| 模型 ID 形式 | Readable Stable Identity | |
| URL 中模型单数还是复数 | 复数 | |
| 资源是一级(平铺)还是多级(嵌套) | 多级 | |
搜索如何实现,独立接口(/models/search)还是基于列表/models/ 接口 |
独立 | |
| 是否有 Alias URL | ? | |
| URL 中模型是否允许缩写(或精简) | 🚫 | 没有看到明显信息,基于多级模型也不需要,但是存在 GET /orgs/{org}/actions/required_workflows
|
| URL 中模型多个词语拼接的连字符 |
- 和 _
|
GET /repos/{owner}/{repo}/git/matching-refs/{ref} vs GET /orgs/{org}/actions/required_workflows
|
| 是否要区分 Web API 以及 Open API(面向非浏览器) | 🚫 | |
| Header | ||
| 是否所有 Verb 都使用 POST | 🚫 | |
| 修改(Modify)动作是 POST 还是 PATCH? | PATCH | |
| HTTP Status 返回值 | 充分利用 HTTP Status | 常用,包括限流洗损 |
| 是否使用考虑限流系统 | ✅ 429 | |
| 是否使用缓存系统 | ✅ ETag / Last Modify | Resources in the REST API#client-errors |
| 是否校验 UserAgent | ✅ | |
| 是否校验 Referrral | 🚫 | |
| Request | ||
| 复杂的参数是放到 Form Fields 还是单独一个 JSON Body | Body | 参考 Pulls#create-a-pull-request |
| 子资源是一次性查询还是独立查询 | 嵌套 | 从 Pulls 进行判断 |
| 分页参数存放 | URL Query | |
| 分页方式 | Page | Using pagination in the REST API |
| 分页控制者 | 服务端 | 同上 |
| Response | ||
| 模型呈现种类 | 多种模型 | 比如 Commits 里面的 明细和 Parent Commits |
| 大模型如何包含子模型模型 | 核心模型 + 多次关联资源查询? | 没有明确说明,根据几个核心 API 反推 |
| 字段返回是按需还是归并还是统一 | 统一 | |
| 字段表现格式 | Snake | |
| 错误码 | 无 | Resources in the REST API#client-errors |
| 错误格式 | 全局统一 | Resources in the REST API#client-errors |
| 时区 | 复合方案(ISO 8601 > Time-Zone Header > User Last > UTC) | Resources in the REST API#Timezones |
| HATEOAS | 🚫 |
Azure 的 API 设计遵循 api-guidelines/Guidelines.md at master · microsoft/api-guidelines, 这篇文章偏原理性,另外还有一份实用指导手册在 Best practices in cloud applications 和 Web API design best practices。
需要注意的是,Azure 的产品线远比 Github 丰富,一些 API 也没有遵循 Azure 自己的规范。 在找实例时候,我主要参考 REST API Browser , Azure Storage REST API Reference 。 如果具体实现和 Guidelines.md 冲突,我会采用 Guidelines.md 结论。
| 问题 | 选择 | 备注 |
|---|---|---|
| URL | ||
| API Path 里面 Prefix | 二级域名 | |
| Path 里面是否包含 API 版本 | 🚫 | x-ms-version |
| Path 是否包含 Group | ✅ | |
| Path 是否包含动作 | 🚫? | 没有明确说明,但是有倾向使用 comp 参数来进行动作,保持 URL 的 RESTful 参考 Lease Container (REST API) - Azure Storage
|
| 模型 ID 形式 | Readable Stable Identity | Guidelines.md#73-canonical-identifier |
| URL 中模型单数还是复数 | 复数 | Guidelines.md#93-collection-url-patterns |
| 资源是一级(平铺)还是多级(嵌套) | 多级 / 一级 |
api-design#define-api-operations-in-terms-of-http-methods,注 MS 有 comp=? 这种参数,用来处理特别的命令 |
搜索如何实现,独立接口(/models/search)还是基于列表/models/ 接口 |
? | 倾向于基于列表,因为大量使用 comp= 这个 URL Param 来进行子命令,比如 Incremental Copy Blob (REST API) - Azure Storage
|
| 是否有 Alias URL | ? | |
| URL 中模型是否允许缩写(或精简) | ? | |
| URL 中模型多个词语拼接的连字符 | Camel | Job Runs - List - REST API (Azure Storage Mover) |
| 是否要区分 Web API 以及 Open API(面向非浏览器) | 🚫 | |
| Header | ||
| 是否所有 Verb 都使用 POST | 🚫 | |
| 修改(Modify)动作是 POST 还是 PATCH? | PATCH | Agents - Update - REST API (Azure Storage Mover) |
| HTTP Status 返回值 | 充分利用 HTTP Status | Guidelines.md#711-http-status-codes |
| 是否使用考虑限流系统 | ? | |
| 是否使用缓存系统 | ✅ | Guidelines.md#75-standard-request-headers |
| 是否校验 UserAgent | 🚫 | |
| 是否校验 Referrral | 🚫 | |
| Request | ||
| 复杂的参数是放到 Form Fields 还是单独一个 JSON Body | Body | 参考 Agents - Create Or Update - REST API (Azure Storage Mover) |
| 子资源是一次性查询还是独立查询 | ? | |
| 分页参数存放 | ? | 没有结论 |
| 分页方式 | Page based | |
| 分页控制者 | 服务端 | Agents - List - REST API (Azure Storage Mover) |
| Response | ||
| 模型呈现种类 | 单一模型 | 推测 |
| 大模型如何包含子模型模型 | ? | 场景过于复杂,没有单一结论 |
| 字段返回是按需还是归并还是统一 | ? | |
| 字段表现格式 | Camel | |
| 错误码 | 使用自定错误码清单 | 至少在各自产品内 |
| 错误格式 | 自定义 | |
| 时区 | ? | |
| HATEOAS | ? | api-design#use-hateoas-to-enable-navigation-to-related-resources |
Azure 的整体设计风格要比 Github API 更复杂,同一个产品的也有多个版本的差异,看 上去统一性要更差一些。这种复杂场景想用单一的规范约束所有团队的确也是更困难的。 我们可以看到 Azaure 团队在 Guidelines 上面努力,他们最近正在推出 vNext 规范。
我个人风格基本继承自 Github API 风格,做了一些微调,更适合中小型产品开发。 我的改动原因都在备注中解释,改动出发点是:简化 / 减少歧义 / 考虑实际成本。如果备注里面标记了「注」,则是遵循 Github 方案并添加一些观点。
| 问题 | 选择 | 备注 |
|---|---|---|
| URL | ||
| API Path 里面 Prefix | /apis |
我们往往只有一个系统,一个域名要承载 API 和 Web Page |
| Path 里面是否包含 API 版本 | ✅ | |
| Path 是否包含 Group | ✅ | 做一层业务模块拆分,隔离一定合作边界 |
| Path 是否包含动作 | 看情况(如果 HTTP Verb CRUD 无法满足就包含) | |
| 模型 ID 形式 | Readable Stable Identity | |
| URL 中模型单数还是复数 | 复数 | |
| 资源是一级(平铺)还是多级(嵌套) | 多级 + 一级 | 注:80% 情况都是遵循模型的归属,少量情况(常见在搜索)使用一级 |
搜索如何实现,独立接口(/models/search)还是基于列表/models/ 接口 |
统一 > 独立 | 低成本实现一些(早期 Github Issue 也是没有 /search 接口 |
| 是否有 Alias URL | 🚫 | 简单点 |
| URL 中模型是否允许缩写(或精简) | ✅ | 一旦做了精简,需要在术语表标记出来 |
| URL 中模型多个词语拼接的连字符 | - |
|
| 是否要区分 Web API 以及 Open API(面向非浏览器) | 🚫 | |
| Header | ||
| 是否所有 Verb 都使用 POST | 🚫 | |
| 修改(Modify)动作是 POST 还是 PATCH? | PATCH | |
| HTTP Status 返回值 | 充分利用 HTTP Status | |
| 是否使用考虑限流系统 | ✅ 429 | |
| 是否使用缓存系统 | 🚫 | 简单一些,使用动态数据,去除缓存能力 |
| 是否校验 UserAgent | ✅ | |
| 是否校验 Referrral | 🚫 | |
| Request | ||
| 复杂的参数是放到 Form Fields 还是单独一个 JSON Body | Body | |
| 子资源是一次性查询还是独立查询 | 嵌套 | |
| 分页参数存放 | URL Query | |
| 分页方式 | Page | |
| 分页控制者 | 客户端 | 降低服务端成本,容忍极端情况空白 |
| Response | ||
| 模型呈现种类 | 多种模型 | 使用的 BO / VO / Tiny / Rich |
| 大模型如何包含子模型模型 | 核心模型 + 多次关联资源查询 | |
| 字段返回是按需还是归并还是统一 | 统一 | Tiny Model(可选) / Model(默认) / Rich Model(可选) |
| 字段表现格式 | Snake | |
| 错误码 | 无 | 注:很多场景只要 message |
| 错误格式 | 全局统一 | |
| 时区 | ISO 8601 | 只使用一种格式,不再支持多种方案 |
| HATEOAS | 🚫 |
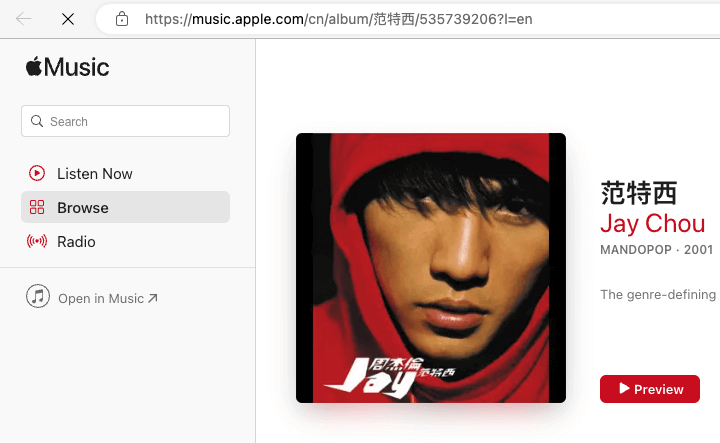
image from Apple Music
我最近在使用 Apple Music 时注意到了其 Web 页面的 URL 结构:
/cn/album/we-sing-we-dance-we-steal-things/277635758?l=en
仔细看这个 URL 结构,可以发现其中 Path 包含了人类可读的 slug,分为三个部分:alumn/$(name)/$(id) (其中包含了 ID)。
我立即想到了一个问题:中间的可读名称是否无机器意义,纯粹面向自然人?
于是我测试了一个捏造的地址:/cn/album/foobar/277635758?l=en。
在您尝试访问之前,您能猜出结果是否可以访问吗?
这种设计范式比我现在常用的 URL 设计规范要复杂一些。我的规范要求将资源定位使用两层 slug 组织,即 $(type)/$(id)。
而苹果使用了 $(type)/(type-id)/$(id),同时照顾了可读性和准确性。
GraphQL 是一种通过使用自定义查询语言来请求 API 的方式,它的优点在于可以提供更灵活的数据获取方式。 相比于 RESTful API 需要一次请求获取所有需要的数据,GraphQL 允许客户端明确指定需要的数据,从而减少不必要的数据传输和处理。
然而,GraphQL 的过于灵活也是它的缺点之一。由于它没有像 REST API 那样有一些业务场景建模的规范, 开发人员需要自己考虑数据的处理方式。 这可能导致一些不合理的查询请求,对后端数据库造成过度的压力。此外,GraphQL 的实现和文档相对较少,也需要更多的学习成本。
因此,虽然 GraphQL 可以在一些特定的场景下提供更好的效果,但它并不适合所有的 API 设计需求。 实际上,一些公司甚至选择放弃支持 GraphQL,例如 Github 的 一些项目。
Complexity is incremental (复杂度是递增的)
- John Ousterhout (via)
风格没有最好,只有最适合,但是拥有风格是很重要的。
建立一个优秀的规则不仅需要对现有机制有深刻的理解,还需要对业务领域有全面的掌握,并在团队内进行有效的协作与沟通, 推广并实施规则。 不过,一旦规则建立起来,就能够有效降低系统的复杂度,避免随着时间和业务的推进而不断增加的复杂性, 并减少研发方面的沟通成本。
这是一项长期的投资,但能够获得持久的回报。希望有长远眼光的人能够注意到这篇文章。
主要参考文档: