2024-11-07 20:03:24
CKB 相关技术文章第三篇。
CKB 的每一个交易在提交到交易池之前都会经过一个 script verification 的过程,本质上就是通过 CKB-VM 把交易里的 script 跑一遍,如果失败了则直接 reject,如果通过了才会继续后面的流程。

这里的 script 就是一种可以在链上执行的二进制可执行文件,也可以称之为 CKB 上的合约。它是图灵完备的,我们通常可以通过 C、Rust 来实现这些 script,比如 nervosnetwork/ckb-system-scripts 就是 CKB 上的一些常用的系统合约。用户在发起交易的时候就设置好相关的 script,比如 lock script 是用来作为资产才所有权的鉴定,而 type script 通常用来定义 cell 转换的条件,比如发行一个 User Define Token 就需要指定好 UDT 所对应的 type script。script 是通过 RISC-V 指令集的虚拟机上运行的,更多内容可以参考 Intro to Script | Nervos CKB。
通常一个简单的 script 在 CKB-VM 里面执行是非常快的,VM 上跑完之后会返回一个 cycle 数目,这个 cycle 数量很重要,我们用来衡量 script 校验所耗费的计算量。一个合约的 cycle 数多少,理论上来说依赖于 VM 跑的使用用了多少个指令,这由 VM 在跑的时候去计算 VM Cycle Limits。
随着业务的复杂,逐渐出现了一些大 cycles 的交易,跑这些交易可能会耗费更多的时间,但我们总不可能让 VM 一直占着 CPU,比如在处理新 block 的时候,CPU 应该在让渡出来。但之前 CKB-VM 对这块的支持不够,为了达到变相的暂停,处理大 cycles 的时候我们可以设置一个 step cycles,假设我们设置为 100 cycles,每次启动的时候就把 max_cycles 设置为 100,这样 VM 在跑完 100 cycle 的时候会退出,返回的结果是 cycle limitation exceed,然后我们就知道这个 script 其实是没跑完的,先把状态保存为 suspend,然后切换到其他业务上做完处理之后再继续来跑。回来后如何才能恢复到之前的执行状态呢,这就需要保存 VM 的 snapshot,相当于给 VM 当前状态打了一个快照:
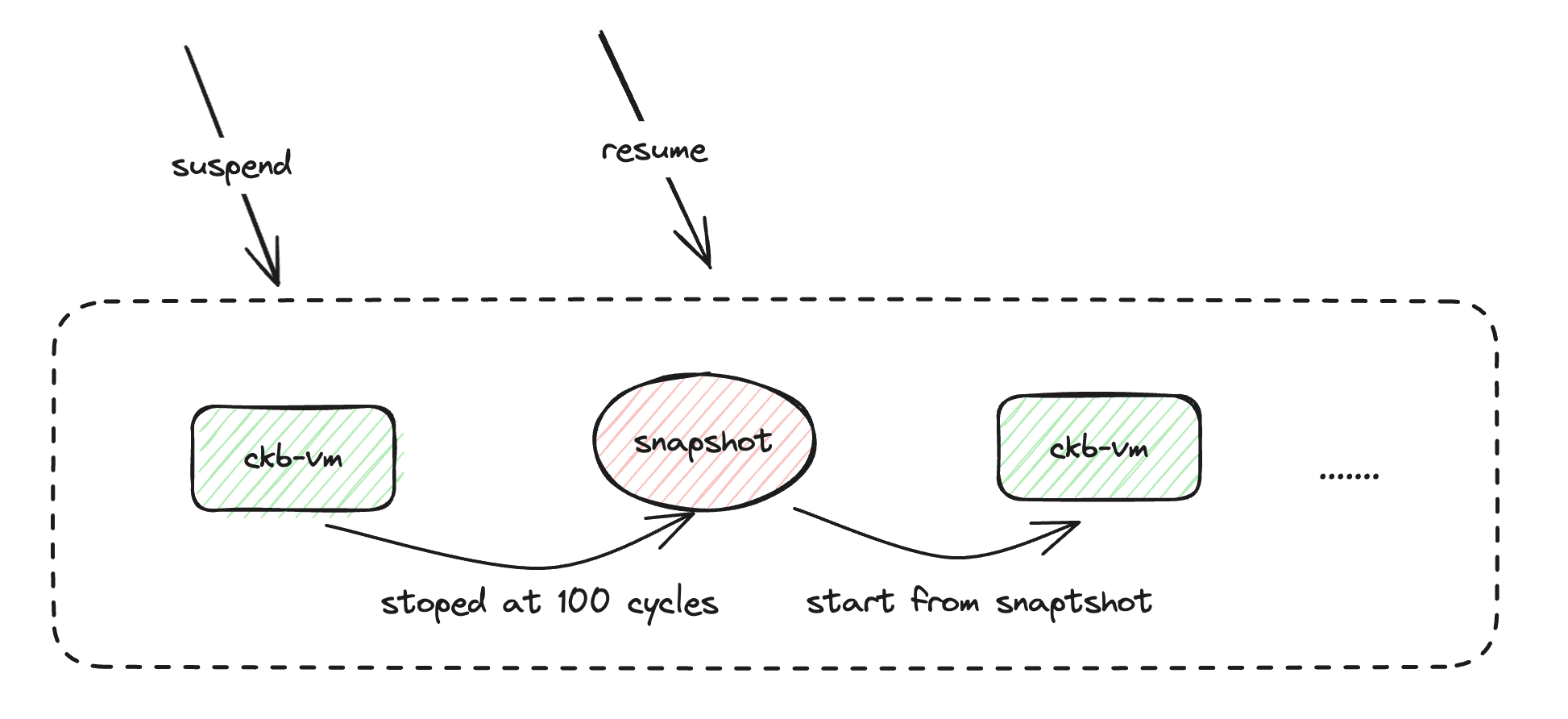
根据这个机制,我们老的 script 校验大交易的整个流程是通过一个 FIFO 的队列保存大交易,然后通过一个后台任务不断地从这个队列中取交易跑 VM,每次都跑 1000w cycle 左右,在这个过程中就可能切换出去,没跑完的交易继续放入队列等待下一次执行:

对应到代码就是 ChunkProcess 这个单独服务来处理的。由于 ChunkProcess 是一个单独的服务,它的处理流程和其他交易的处理流程是不一样的,这样会导致代码的复杂度增加,比如:
chunk_process 里的 process_inner 和 _resumeble_process_tx。这些问题的根本是 VM 只能通过 cycle step 的方式来暂停,有没有一种方式是我们任何时候想暂停就暂停,就是 event based 的方式。所以后来 CKB-VM 团队做了一些改进:
这个方法的本质是通过 VM 的 set_pause 接口,把一个 Arc<AtomicU8> 的 pause 共享变量设置给 VM。然后在 VM 外通过更新这个 pause 的变量让 VM 进入暂停状态或者继续执行,这样我们就不需要 dump snapshot 等操作,因为 VM 整个就还是在内存中等着:

基于这些改进我们可以重新设计和实现 CKB verify 这部分的代码,主要是为了简化这部分代码,并且提高大交易处理的效率。这是一个典型的 queue based multiple worker 方案:
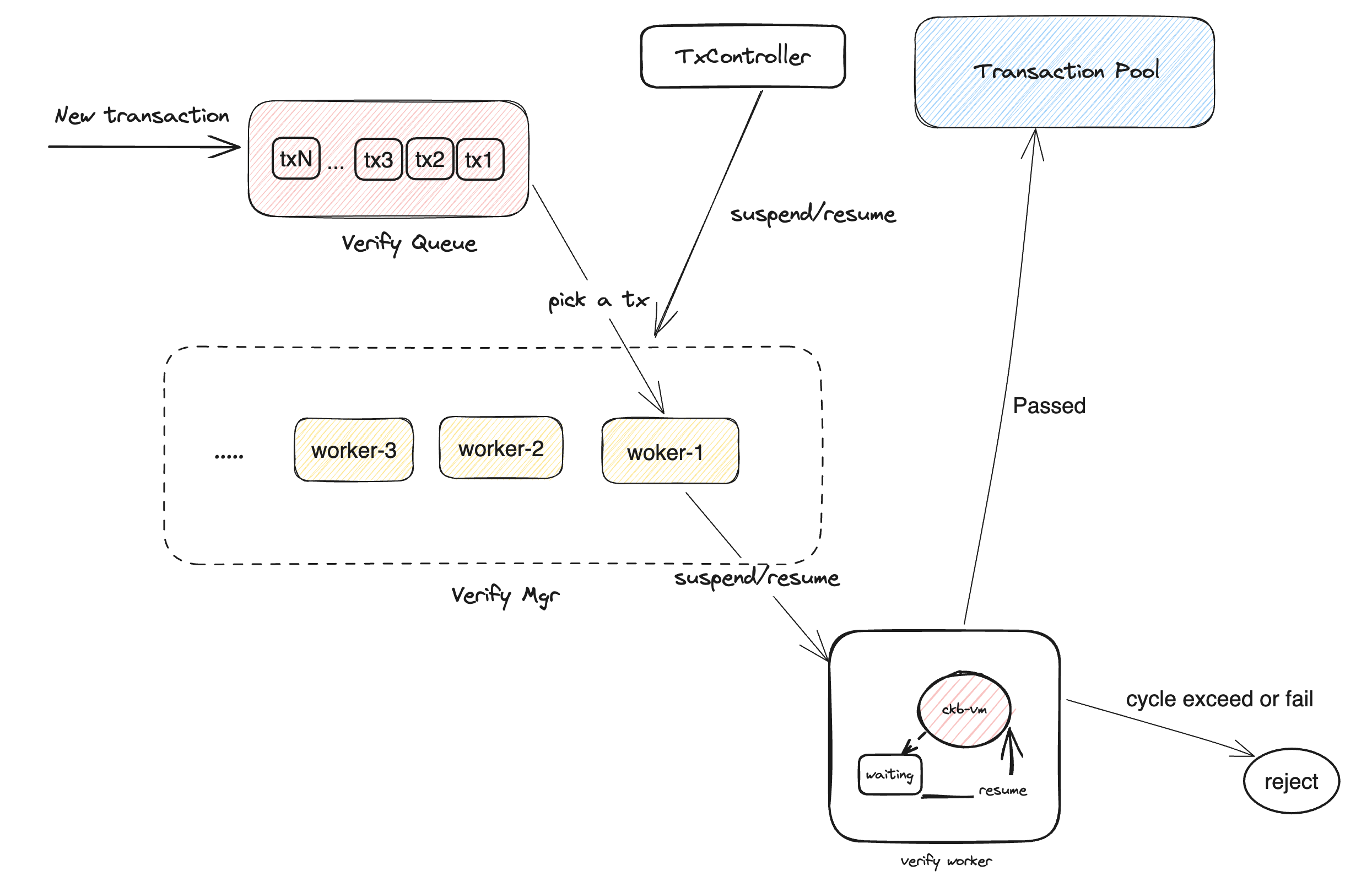
主要的核心是就是这段异步执行 VM 的逻辑:chunk_run_with_signal。做的过程中发现一些其他问题:
SubmitLocalTx 和 SubmitRemoteTx 如果 verify 失败目前会立即返回 Reject,如果改成加入队列的方式,这个结果无法实时给到,所以做了如下改动:Child VM 是执行 syscall 的时候执行 machine.run ,如果不改这块执行 child vm 的时候不可暂停Pause 传递给子,然后暂停的时候给父的 Pause 设置暂停,这样所有的子 machine 同样返回 VMError::Pause ,同时把当前的 machine 栈重新入栈,恢复的时候继续执行,这里逻辑比较重,相关代码实现:run_vms_child。整个 PR 在这里:New script verify with ckb-vm pause
2024-11-06 19:55:13
CKB 相关技术文章第二篇。
如果一个交易成功发送到交易池,但可能出现因为费用较低而一直得不到处理。之前 CKB 没有其他措施来处理这种情况。
例如 Dotbit 4 位域名注册拥堵 这个事故发生过程中,CKB 的应用方无法使用任何方式来尽快让自己的交易被打包,这就是引入 Replace-by-fee(RBF) 的原因,我们需要一个机制来提高已经在交易池里交易的费用,替换掉旧的交易,让新的交易尽快被打包。
在新的 multi_index_map 重构后,交易在 pending 阶段也会按照交易的 score 来优先处理 (通常费用高的交易 score 也会高),这会避免高费用的交易被阻塞住,所以理论上述需要手动提高费用的情况会减少,但我们还是需要 RBF 来手动提高交易的费用,应对意外的情况。
另外,RBF 可能将多个老的交易替换出去,因此也是将两个或多个支付合并为一的方法,例如下图所示,如果满足条件 tx-a, tx-b, tx-c, tx-d 都会被 tx-e 这个交易替换掉:

中本聪最初的 Bitcoin 版本中就有引入一个 nSequence 的字段,如果相同交易的 nSequence 更高,就可以替换之前老的交易,这个实现的问题是没有支付额外的 fee,miner 没用动力去替换交易,另外因为没有 rate-limiting 从而导致可能被滥用,所以 Bitcoin 在 0.3.12 版本中禁止了这个功能。后来 Bitcoin 重新引入了新的 RBF 改进,主要包括需要支付额外的费用来替换老交易,另外为 RBF 指定了更多的限制条件。
在 CKB 上我们之前做过两次 RBF 的相关调研,因为之前 Pending 是一个 FIFO 的数据结构,所以处理替换不是很方便,在 RBF in CKB(draft 2023.01.05) 尝试引入一个 high priority queue 来实现 inject-replace。交易池改造之后,整个交易池可当作一个优先队列,所以应对 RBF 会简单很多。
RBF 的流程
pre-check 为 entry 加入到 tx-pool 之前必须要做的检查,之前只是做双花的检查,新增 RBF 后如果双花检查失败(这里意味着冲突),继续做 RBF 的相关检查,如果 RBF 检查成功则也返回成功,否则直接返回错误。这里默认直接做 resolve_tx 的检查,如果成功则走正常流程,目的是不给正常流程增加额外成本。所以这就是pre-check 修改后的主要逻辑 。RBF 的检查规则参考 Bitcoin 的六条,check_rbf 初步实现
实现细节:(Bitcoin Core 0.12.0)~~1. 交易需要声明为可替换交易~~ 2. 新替换交易没有包含新的、未确认的 inputs3. 新替换交易的交易费用比待替换交易费用高4. 新替换交易费用必须比节点的 min relay fee 高5. 待替换交易的子交易数量不可超过 100 条(即使用了该交易的任意 outputs,该交易替换后它们将被从内存池中移出)6. 因为 ckb 是做了两步提交,我们新增规则:被替换的交易只能是 Pending 或者 Gap 阶段的。我们不给交易加新的字段表示是否可以被替换,而是通过节点是否配置了 min_rbf_rate 来决定是否能做替换,因此 规则 1 不做对应考虑。
修改 tx-pool 的 submit_entry 函数,传入 conflicts,在新增 entry 之前把所有冲突的交易删除 放入 rejected 记录,另外确保所有检查完成了之后才做删除和写操作:submit_entry 逻辑。
最终实现在这个 PR 里Tx pool Replace-by-fee。
在最初的实现版本中,隐藏了一个并发的 bug 后来在测试发现了。RBF 的检查如果放在 pre-check 中,如果多个线程中的多个交易发生了冲突,input resolve 可能会出问题。Fix concurrency issue for RBF 这个 PR 修复了这个问题,把 RBF 的冲突检查移动了 submit entry 之前,因为在这个函数里面会持有 write 锁。
后来我们在做闪电网络的时候又发现 RBF 可能会引入 cycling attack 的风险,这个攻击通过构造巧妙的新交易,让支付路径上的中间节点的 commitment tx 不能按时上链,Lightning Replacement Cycling Attack Explained这篇文章有更详细的描述。
所以我们后来又做了这么一个改进:Recover possible transaction in conflicted cache when RBF 来规避这个问题。
2024-11-06 19:39:21
在 11.9 号清迈的 CKCON 会议上我会做一个关于 CKB 交易池的演讲,这是我准备的 slides Key Upgrades of the CKB Core 。所以这段时间在整理之前做项目的时候写的一些文档,顺便分享到自己的博客上。既然我们整个项目的源码都是公开的,所以这些文档其实也是可以分享的。
第一次听说 CKB 的读者可以参考这个文档以了解什么是 CKB 以及如何工作的:How CKB Works | Nervos CKB。
我加入 Cryptape 之后一年内做的主要工作,涉及到交易池重构、Replace-by-fee 功能、以及 new-verify。这是第一篇关于交易池重构的文章。
在 bitcoin 中交易池叫作 mempool,比如 mempool - Bitcoin Explorer 这个网站就很好地展示了其当前的状态。
交易池是 bitcoin 中的一个重要的组件,但感觉专门关于这块的资料很少,只能通过 PR 和邮件列表上的讨论看到一些文档。但交易池非常重要,因为一个交易要上链必须会通过交易池,而其中的交易打包算法涉及到如何选择合适的交易,这里面有很多因素需要考虑,所以在实现上也是比较复杂的。
当一个交易被提交到一个节点时,或者一个节点从网络中同步到交易时,这个交易首先需要被加入到交易池中,交易池里会根据一定的算法去选择下一个需要被打包的交易,另外交易池作为一个缓存,我们需要为其设置一个最大的 size。所以交易池里面最重要的两个操作就是 packaging 和 evicting。
交易池里面的交易存在父子关系,打包的时候需要从交易链的纬度去考虑,后面的 Replace by fee 这些功能也需要关注整个交易的所有子交易。
![]()
根据 RFC consensus-protocol 的设计,CKB 里的 tx-pool 采用了两段提交的方式:
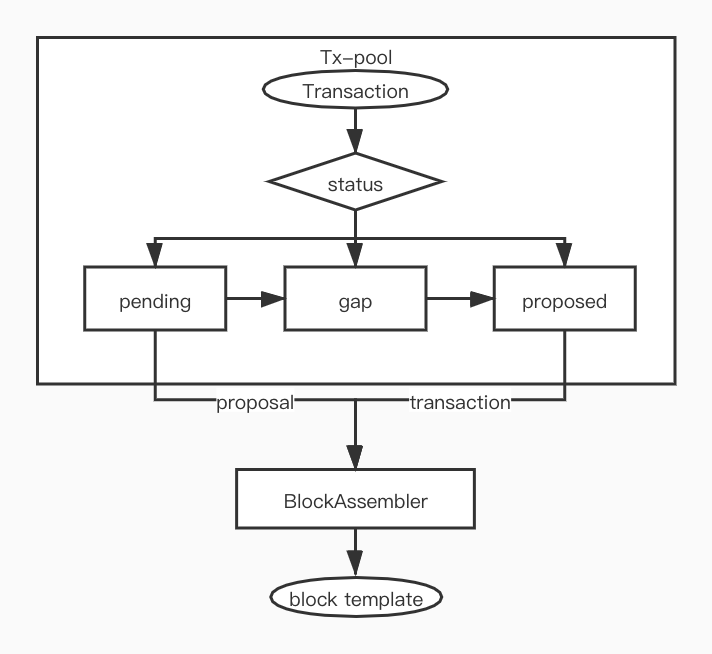
相应地在交易池最初实现的时候, ckb 的代码实现中 tx-pool 同样采用了三个独立的队列,具体定义如下:
pending 交易刚加入到交易池时候的状态,我们每次只能处理不多于 MAX_BLOCK_PROPOSALS_LIMIT 个交易,交易需要先进入 gap 备选,具体代码逻辑在 update_proposals 。gap 已经被 proposed 了,但是还不能被打包,需要等一个块后才能被打包,所以这只是内部中间过渡状态。proposed 交易可以加入到 block_template.transactions , 最终打包到 block 里,具体代码逻辑在 block_assembler。实现中 pending 和 gap 同样都是使用了 PendingQueue(LinkedHashMap),而 proposed 采用了 SortedTxMap(HashMap + BTreeSet) :
pub struct TxPool { pub(crate) config: TxPoolConfig, /// The short id that has not been proposed pub(crate) pending: PendingQueue, /// The proposal gap pub(crate) gap: PendingQueue, /// Tx pool that finely for commit pub(crate) proposed: ProposedPool, .... pub(crate) expiry: u64,}这样的实现存在以下问题:
我们不容易对所有在交易池中的 entry 做统一排序,这样会存在以下问题:
pending, gap 和 proposed 除了所采用的数据结构不同外,有很多逻辑雷同的代码,比如 entry 的新增和删除等操作,同样都维护了 deps 和 header_deps,resolve_conflict, resolve_conflict_header_dep, resolve_tx 等函数的逻辑也是类似的,但实现上有些细微差异,这导致长期来说代码不容易维护。
tx-pool 上对 entry 做迭代和查询时,需要依次针对 pending, gap, proposed 做相同的逻辑,比如 resolve_conflict_header_dep 这样的函数在 pool 中有几个类似的,甚至 get_tx_with_cycles 这样的函数,需要依次判断各个队列。基于以上解决现有问题、应对未来的潜在需求、保持代码可维护性的角度,同时参考 Bitcoin txmempool 的实现,我们提出引入 Multi_index_map 对 tx-pool 进行重构。
总体方向是把所有的 entry 放入统一的数据结构中进行管理,加入一个新的字段 status 标识目前 entry 所处的阶段,然后通过 index_map 的方式根据不同的属性进行排序和迭代:
pub enum Status { Pending, Gap, Proposed,}#[derive(MultiIndexMap, Clone)]pub struct PoolEntry { #[multi_index(hashed_unique)] pub id: ProposalShortId, #[multi_index(ordered_non_unique)] pub score: AncestorsScoreSortKey, #[multi_index(ordered_non_unique)] pub status: Status, #[multi_index(ordered_non_unique)] pub evict_key: EvictKey, // other sort key pub inner: TxEntry,}其中根据 Rust 社区的 multi_index_map 内部实现采用的数据结构看,性能上应该没有什么大问题:
具体实现时我们是否把 inner 也放在 Slab 里面以后可以通过 benchmark 来选择,从实现的简洁性角度考虑统一放在一个数据结构里面更容易。
目前的实现版本:Tx pool rewrite with multi_index_map #3993
我们首先只是做模块内的重构 (保持对外逻辑和以前一样),当然考虑引入了新的数据结构,不管是从性能上还是内存占用上都会有一些影响。
为了做统一排序这件额外的事,本质上我们引入了额外的 Map(FxHashMap 或 BTreeMap) 来存储,所以比以前需要更多内存。另外,我们有时候需要调用 get_by_status 来筛选某个状态的 entries,这在新的实现里面需要先从 index 里面找出 slab 的 id,然后再找到对应的 entry,所以必然也会比以前慢。
从最终的性能对比结果上,除了内存会稍微有增加,性能上没有大的变化。另外我们在实现的过程中对所用到的 Rust 包 multi-index-map 做了一些贡献:Non-unique index support, capacity operations, performance improvement & more by wyjin。
这是我入职后做的第一个主要工作,因为我们的各种测试比较齐全,所以做大的重写信心也比较足。Rust 的生态就有这种问题,如果一个 crate 不是被广泛使用的,必然还是会存在各种坑需要填。总体来说,第一个项目很顺利。做完这个重构之后对于后面的 Replace by fee 等功能也准备好了。
2024-04-05 02:04:33
写写最近一周的大瓜 xz-backdoor,该事件可能成为开源供应链安全的一个分水岭,从技术角度看,这里面的社工和混淆也是精彩。
简单介绍一下背景,xz 是一个开源的无损压缩工具,在出事之前可能很少有人注意到这个压缩库使用如此之广,几乎任何一个 Unix-Like 的操作系统里面都有 xz-utils。在两年多的时间里,一个名为 Jia Tan 的程序员勤奋而高效地给 xz 项目做贡献,最终获得了该项目的直接提交权和维护权。之后他在 libzma 中加入了一个非常隐蔽的后门,该后门可以让攻击者在 SSH 会话开始时发送隐藏命令,使攻击者能够跳过鉴权远程执行命令。
Timeline of the xz open source attack 总结了该事件的主要时间点,这里我挑一些关键节点:
ifunc,这也是为了避免 fuzz 可能发现后门。.,使得代码会编译失败从而让 Landlock 不会被激活。从主要攻击者的名称看似乎是中国人,但 Git 昵称和时区这种东西很容易伪造,有人分析过开发者的代码提交时间,分析得出实际可能是欧洲人/以色列人冒充。
但不可否认,肯定会有不少国外的开发者会默认这就是中国人所为,我也看到了一些开发者开始带节奏,开始找各种和 Jia Tan 有过互动的中国程序员。
我倾向于相信这不是中国攻击者,感觉其 commit 信息里面的英文中没找到中式表达。比较确定的是,从这些马甲之间的密切配合来看,这像是一个有密谋的组织团体。
开源意味着透明,但并不意味着安全。
10 多年前我们经历了 OpenSSL 的心脏滴血,如今类似的事情再次发生。甚至这次事件的性质更严重,心脏滴血漏洞本身是因为代码的逻辑问题导致被恶意利用,而这次是攻击者通过供应链恶意植入后门。
有一种观点是开源软件被更多人 review,所以理论上来说安全漏洞更容易被发现。但实际上看来,被巧妙设计过的代码改动,很不容易被发现问题,比如这次事件中这个提交,我相信绝大部分开发者无法发现被恶意添加的 .:
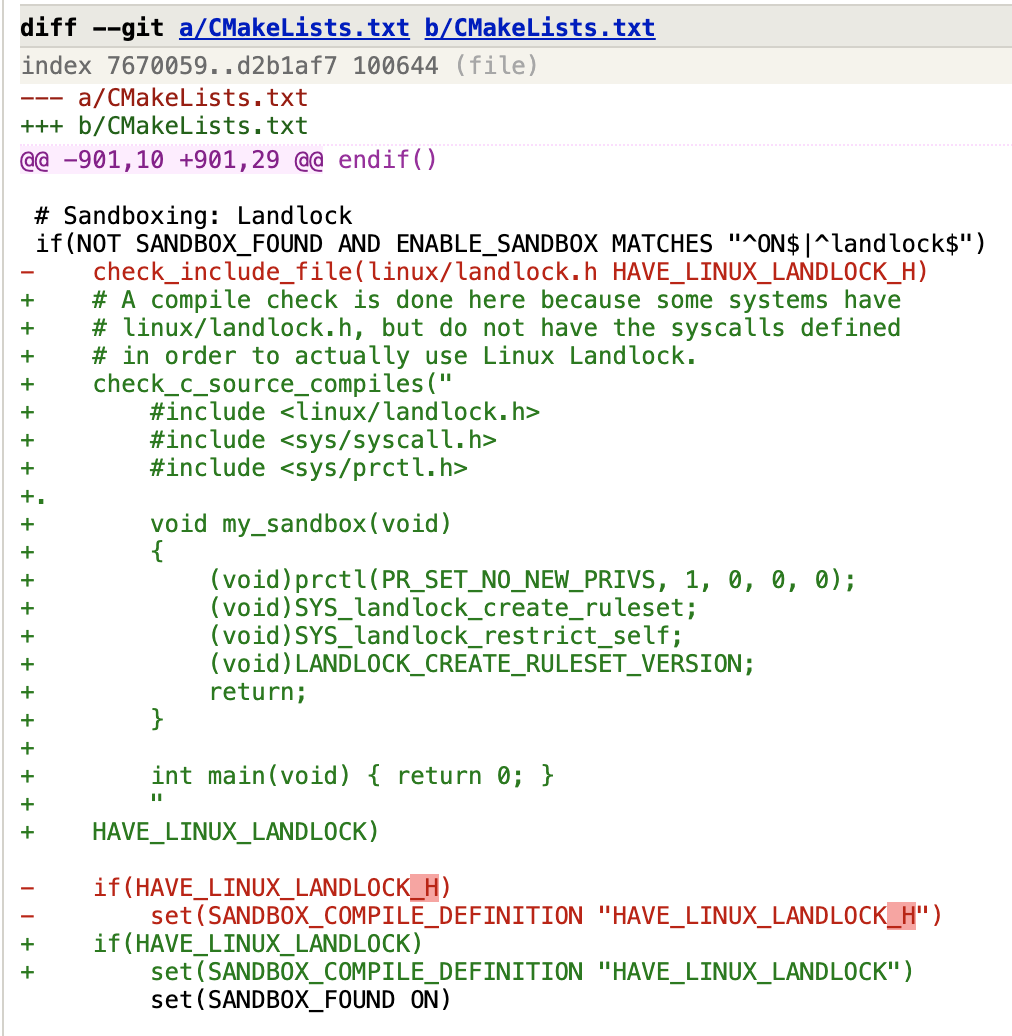
这次后门被发现有很大的运气成分,多亏了 Andres Freund 的细心和刨根问底的精神,这也算是有足够多的眼睛盯着所以发现了问题吧。
如果有一个开源贡献者的身份识别机制,就可能预防类似的事情。我看到有人举例 Linux Kernel 提交必须使用 Git 的 Sign-off,但这个 Sign-off 更多的是在解决法律上的问题,Sign-off 本来就是因为法律诉讼而引入的。而且,在最坏情况下,一个开发者可能被社工或者入侵而导致身份被冒用,所以 Sign-off 并不意味着身份识别。
有的人提到通过支付来进行 KYC(Know Your Customer),这必然是不可能的,因为开源本来就是一个黑客文化的产物,大量的开发者会刻意选择使用匿名身份提交代码。
我们来看看 Bitcoin,如果论项目值钱程度,比特币的代码应该能排得上号。但比特币是支持 Permissionless and Pseudonymous development 的,甚至这是保证比特币去中心化的两个很重要的手段,中本聪的身份仍然是一个迷。中本聪选择匿名对比特币本身来说也至关重要,No one controls Bitcoin 是其价值根本。
那比特币如何保证不会被植入后门,比如这种供应链攻击?
另外比特币的安全在于 PoW,其设计本来就假设了少部分节点可能是恶意节点,除非黑客控制住了大部分节点才能造成破坏,而要达成这点在的概率可以认为就是零
从这个安全事件我们可以继续探讨开源的可持续性这个问题。这个事件中 xz 的维护者 Lesse Collin 看起来已经是处于疲于应付的地步。从贡献者统计可以看到这么多年几乎就是他一个人在给项目提交代码,Jia Tan 通过两年的潜伏就成为了贡献者第二的开发者:
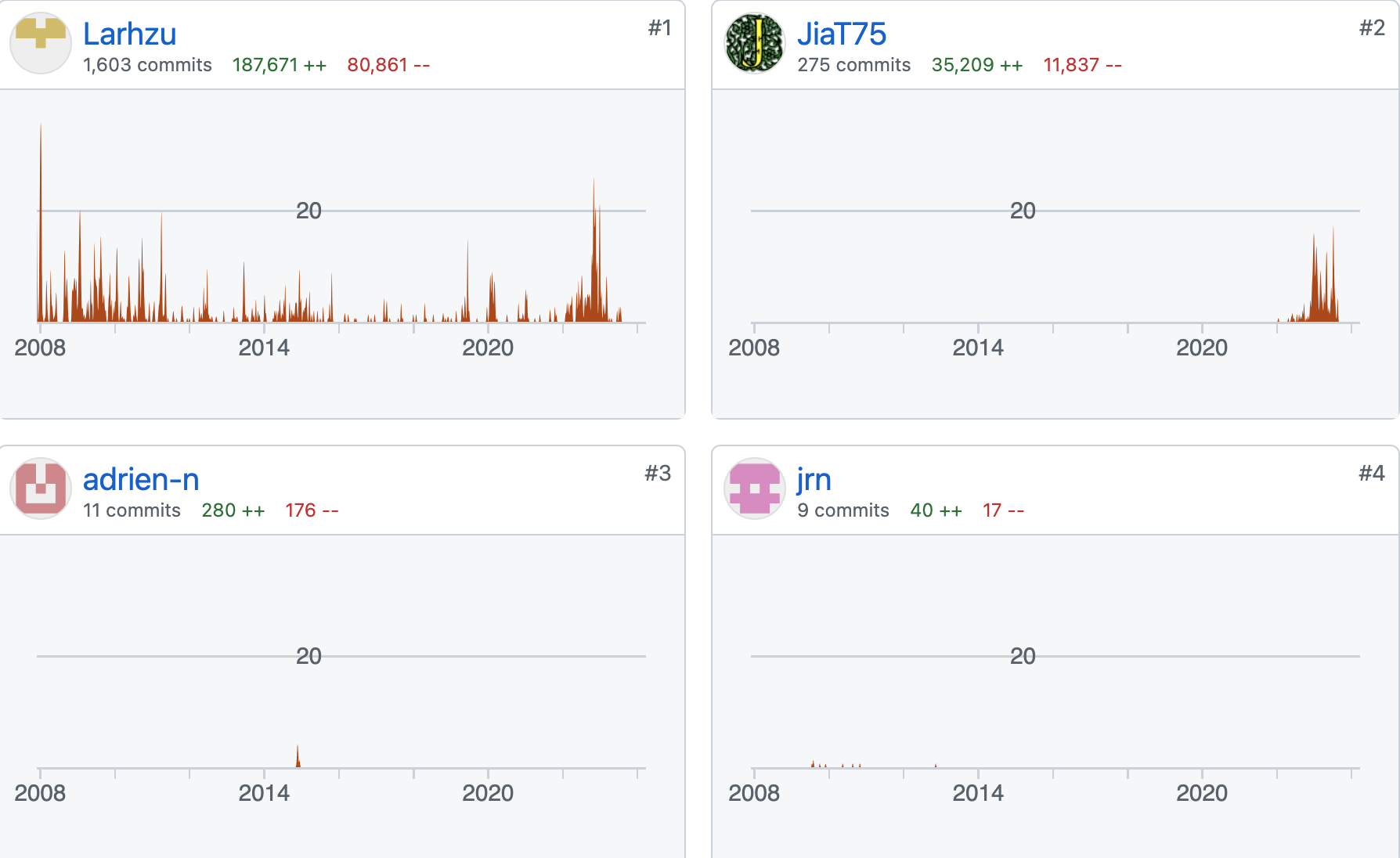
长时间维护一个被大量使用的开源项目是个巨大的负担,对维护者而言不仅仅是时间的投入,有时候也是精神上的折磨,即使开发者当初的有多好的愿景,但谁也无法保证常年的持续投入。关于这点可以阅读这篇文章,The Dark Side of Open Source。
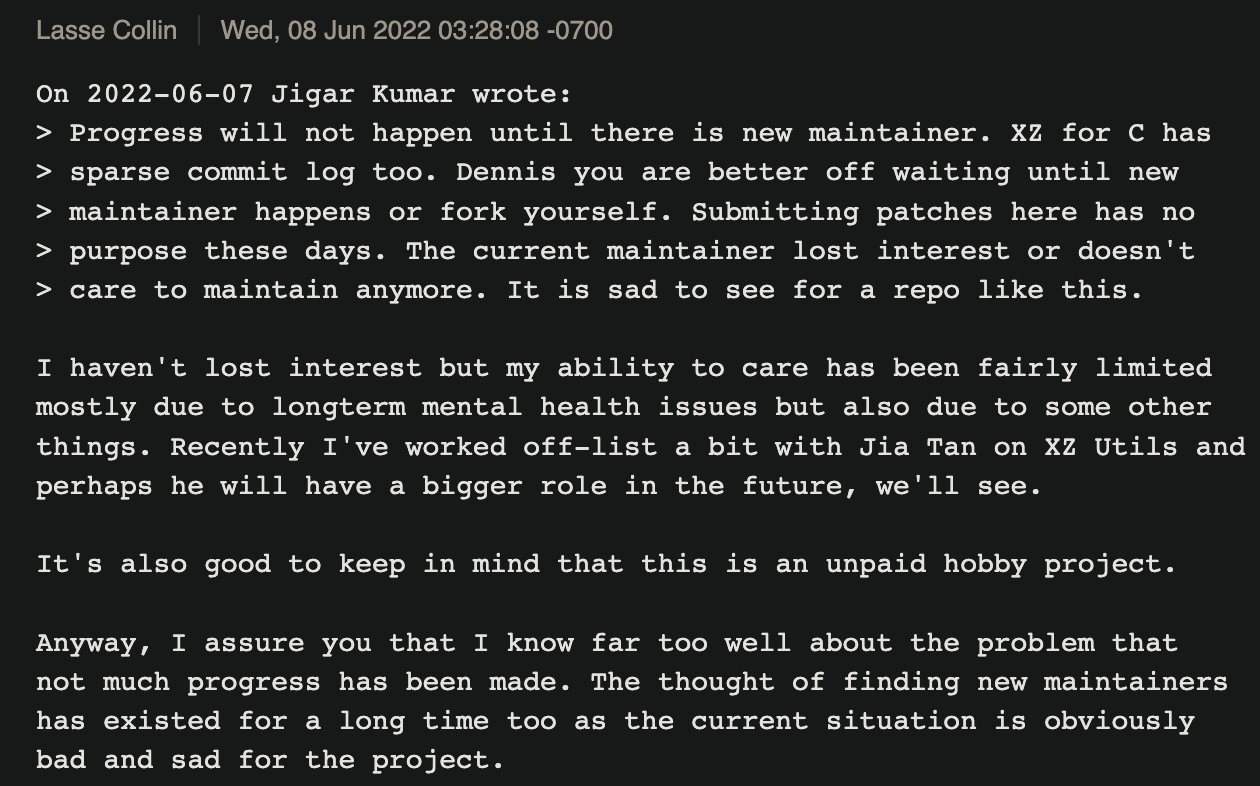
Lesse Collin 在这次事件中被利用了这个弱点,他在这封邮件里解释到自己作为项目主导者的困境:
写到这里我想起自己也曾经催过一个库的作者,是不是考虑让更多人来维护项目 Maintenance status · Issue 😅。
也许未来可能有一套机制,能够让基础开源软件的维护者得到经济激励,但这条路如何演化出来我还没看出来,如果真的出来或许与加密货币有一定关联。
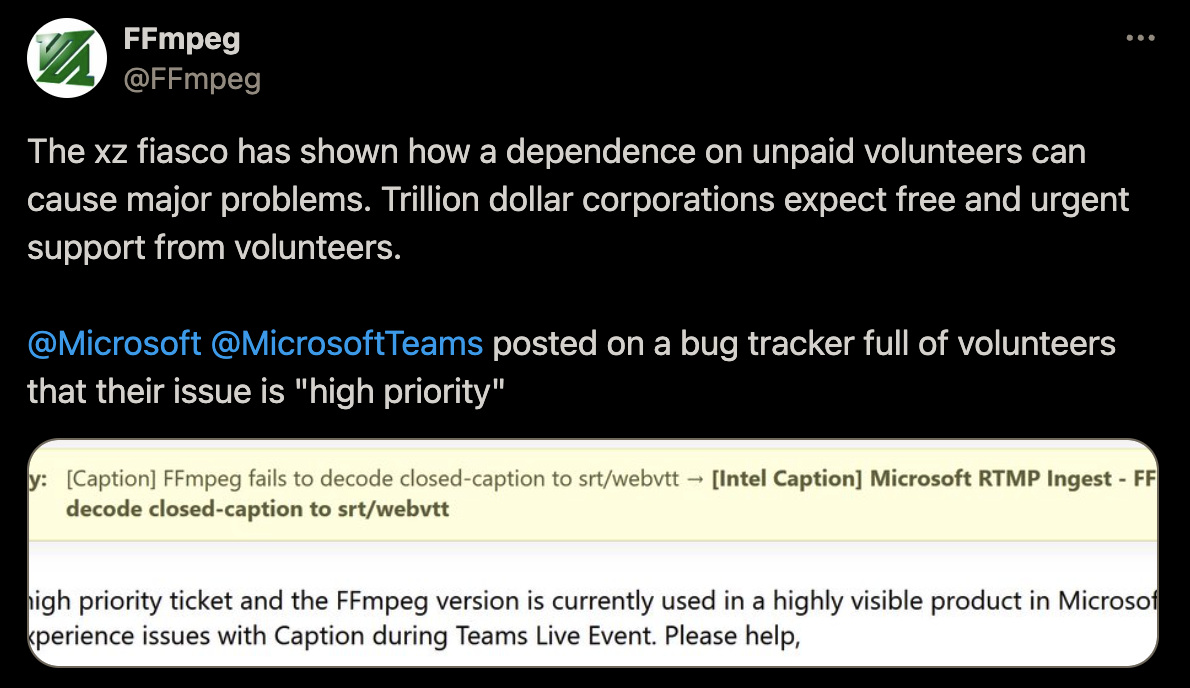
可怕的是,现在还有很多人没有意识到开源贡献者困境,那些价值几千上万亿的公司也是在期望开源的开发者能够像雇员似的响应他们的 High Priority:
这个世界上还是有无数的默默耕耘的开源代码维护者,比如 SQLite,全球大概有上万亿的 SQLite 数据实例跑在服务器上、手机上、浏览器里,但这个软件其实只由 3 个程序员维护了 20 多年;几乎所有工程师都使用的工具 curl,由 Daniel Stenberg 从 1998 维护到至今;vim 的作者 Bram Moolenaar 从 1991 年维护项目到自己去世,总共整整 32 年。
实际上没有人知道,多少被广泛使用的基础组件和代码是由各种默默无闻、分毫未取的开发者在用自己的业余时间维护着。

从这个角度看,人类数字基础设施这艘巨轮其实建立在非常脆弱的基础上,说不定哪天一个地方就裂开了。我现在养成了一个习惯,升级从来不追新,任何安装到自己电脑上的二进制都小心翼翼。
这个世界上有无数的恶魔,也会有一些英雄和吹哨人,致敬 Andres Freund。
2024-03-19 00:28:13
3 月是怀念海子的月份:
从明天起,做一个 Rust 程序员,喂马、劈柴,周游世界。
10 年前我开始写第一行 Rust 程序,到如今全职远程做 Rust 开源项目,也许我真能去过喂马劈柴周游世界了😆。但回想自己的学习旅程,其中有各种曲折有几度放弃的时候,如果你也想学习或者提高 Rust 方面的技能,我这篇文章里有一条更容易的路。
Rust 1.0 发布已经快 10 年,所以并不是一门新编程语言了,从发展的角度来看 Rust 已经度过了生存期,并进入了迅速发展的阶段。从目前可见的业界方向来说,Rust 主要在以下几个方面取得了成功:
如果你对 Rust 的发展情况感兴趣,可以参考 2023 Annual Rust Survey Results。在内卷的 IT 市场,作为程序员选择一门小众的编程语言是避免过度竞争的方式,我之前介绍过其他人的类似经验,我们称之为 The Niche Programmer。Rust 还未成为主流编程语言,但潜力和发展空间很大,而门槛相对其他语言比较高,所以我认为从求职的角度来考虑是值得一试的。
之前提到 Google 投入更多的资金在 Rust 上面,钱进来后相关的职位就出来了 C++/Rust Interop Initiative Software Engineer Lead。
我 2014 年时践行每年学习一门新的编程语言,Rust 作为一门新的编程语言进入了我的视野。我开始使用 Rust 写些简单的个人学习项目,然后我继续做了 Rust exercises 。
后续几年我偶尔看看 Rust 相关的新闻和项目,时不时动手写点代码都会有点磕磕碰碰。直到四年前开始在 Github 上给一些 Rust 开源项目贡献,两年前开始给 Rust 编译器做贡献,一年前开始全职从事 Rust 区块链相关的工作。
从技术角度来说,Rust 非常有趣,这里面包含了近些年程序设计方面的一些良好实践。全职写 Rust 程序这一年多是我开发体验最好的阶段,当然有时候我们需要和编译器斗智斗勇、做类型体操,但很多问题在开发阶段给规避掉了。
Rust 的最大问题还是在于学习门槛相对较高,因为在 Rust 中程序员接触最多的 = 语义都变了。从我个人体验来说,在学会了 Rust 语法后会陷入一个瓶颈,如果日常工作中不使用 Rust,就没有多少机会去实践,另外不知道做一些什么项目。
我相信很多人同样如此,看了官方 tutorial 之后不知道如何下手,我想如果有一个经验丰富的老师带,会少走很多弯路,这就是我要介绍的极客时间训练营要解决的问题。
说起来我与这个训练营还有些渊源。
当极客时间在筹划这个 Rust 训练营的时候,策划人员找到过我问我是否有意愿当这个课程的讲师。我还稍微犹豫了一下,因为我之前也想过如何在 Rust 领域做更多的分享,我很羡慕优秀的技术分享者比如 Jon Gjengset能够非常自如地通过视频分享 Rust 方面的技术。当老师当然是个机会能从沟通和表达方面提高这方面的能力。
后来考虑到自己时间方面安排不过来,我有全职工作、有业余的 Rust 社区工作、还有三个小孩,所以我应该真没时间去录制课程了,而且他们已经找到了我认为最合适的讲师:
我看了这个项目的大纲,陈天老师希望可以教大家怎么用 Rust 比较简单的语法和技巧,来完成 80% 的日常工作,主要是通过各种实践项目来学习,这也是我最推崇的 Learn by doing 的方式。
有很多主题我都没怎么接触过,比如构建一个 ChatGPT 的应用、比如跨平台 GUI 之类的,所以我对这个课程很感兴趣,然后我和策划说能不能做这个项目的助教,后来沟通下来发现当助教也需要不少时间的,所以就没机会参与到具体的教学里面了。
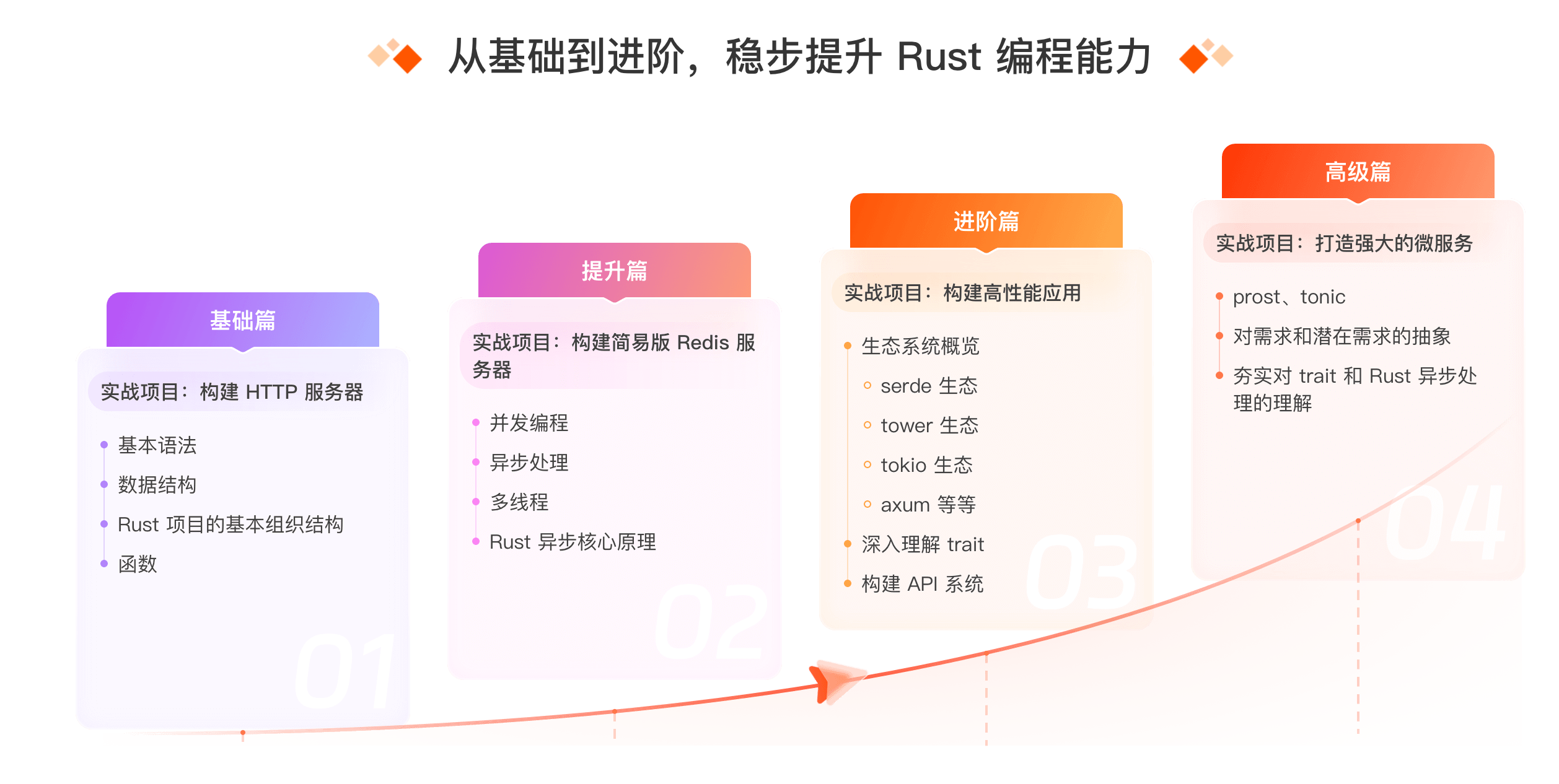
总之,这个项目对于想学习 Rust 或者已经有一定 Rust 经验,但想获得更多实践经历的人是非常合适的。在和极客时间的相关人员沟通的过程中,我发现他们做事情很用心,这个训练营的课程质量我认为是有保证的。
这个训练营一共是 15 周的课程安排,其中每周都会有明确的项目安排,课后还有助教答疑。关于训练营的更多信息请参考:极客时间训练营-Rust 训练营

我最早知道陈天是他写的公众号《程序人生》,他是那种技术和文笔都非常棒的程序员,非常难得。我还看过他的 B 站上的技术讲解视频,他的演讲和分享都很流畅。陈天是极客时间《陈天 · Rust 编程第一课》专栏作者,已有 2.3w 人学过,广受好评。技术能力、演讲表达、对技术的热情这些都是讲师最重要的素质要求,所以陈天是这个训练营最好的讲师人选。
再分享一个小故事,我一年多前跳槽的时候还有些犹豫,因为自己的职业规划方面有些困惑,所以想找些人聊聊。当时我突然想到陈天之前从事过区块链方面的创业,后来从里面退出来了,所以我就想向他咨询一下。我没有他的联系方式,但灵机一动我想到了从 Git 的提交记录里面找 Email,然后抱着试一试的想法给他发了个邮件说明了自己的情况和困惑。没想到他很快给我回复了,并很详细地告诉我他对于区块链的想法,还有如何判断自己是否适合一个公司,通过各种途径了解公司的相关产品来作为决策的依据等等。
我作为一个陌生人,陈天老师都会乐于给与指导和帮助,可见为人真的很好。还没能有幸和陈天老师现实中有所交流,我本来想用当助教的机会和陈天老师多学习,但时间方面安排不过来了。希望大家能在老师的的训练营学到知识、经验、还有探索技术的乐趣!