住在湾区,爱好:智能家居、星际争霸、摄影。复旦大学软件工程硕士,Ted翻译。
RSS 地址: https://blog.yxwang.me/index.xml
请复制 RSS 到你的阅读器,或快速订阅到 :
2020-06-27 09:36:00
最近因为新冠病毒长期宅在家里,决定开始一个很早就想做的项目:搭一个服务器机架。第一次搭经验不足,买错过几次零件,只能重新下单,前前后后花了不少时间。于是写了这篇博客介绍下用到的设备和配件,给有兴趣自己搭一个的朋友做参考。

我选择的机架是 Raising 的 15U 机架。这个机架优点是够结实,深度可变,价格也比 StarTech 的便宜一点。如果预算足够可以考虑买 StarTech 的机架(12U, 25U)。这里 U 是用来衡量机架中组件高度的单位,1U 约等于 43.66 毫米。机架上每个 U 的高度都会对应的三个孔,如下图所示。

因为我有不少没法直接固定在机架上的设备,得把它们放在隔板上。我一共买了四块隔板:
此外出于美观考虑还可以买挡板,StarTech 的 1U 挡板就挺好。
配线架(Patch Panel)可以让前面板的网线看起来干净清爽。它的背面连接各种设备的背部网线口,正面用短网线连接路由器和其他网线口在正面的设备。网上大多数的配线架都是一面连 CAT 5/6 网线,另一面是打线柱,很少有两面都是网线口的配线架。于是我买了两条 TRENDnet 1U 24 口空白网络配线架,加上 48 个两端都是网线口的 Keystone。这个 Keystone 从用户评论来看,以太网供电(PoE)和网速都不会受到影响。
过长的网线用在前面板也不好看,我先试了 1ft (30cm) 的 Monoprice 网线,装上以后还是觉得网线太长。后来换成了 0.5ft (15cm) 的 网线,看起来干净好多。
设备选择方面,我只是把原有的监控设备和服务器搬了过来,放在了层板上。犹豫过要不要买一个机架式服务器,但是考虑到机架式服务器的耗电量,加上已经有了视频监控机和独立 NAS,最后还是买了个翻新的 HP EliteDesk i7-4785T 用来跑智能家居服务和 Unifi Controller。除了 HP 以外,Dell 和 Lenovo 都有类似的微主机,买一个二手的很适合当智能家居服务器。另外推荐使用 Intel T 系列的 CPU,专门为了省电设计。
机架上的一些其他设备:
具体的智能家居和监控的使用这篇文章就不细谈了,对它们感兴趣的朋友,可以参考我的另外两篇博文:
2019-07-22 11:54:27
家里用的是三星的洗衣机和烘干机,买的时候为了完成时有提醒特地挑了带有「智能监控」功能的机型。然而对应的三星洗衣机的 app 几乎没法用,推送和状态更新都有问题。于是我打算自己实现一个类似的功能。
因为洗衣机和烘干机用电量比较大,通过监控用电量很容易判断出设备当前的运行状态,于是我决定用智能插座来实现这个功能。现在很多智能插座都有电量检测的功能,选择的时候要注意插座支持的最大电量,我用了 TP-Link 的 HS110,支持最多 1500 瓦的设备,对于一般的洗衣机和烘干机来说绰绰有余。和智能插座对接的系统依然是 Home Assistant,它对 HS110 的支持很好,可以方便地读出设备当前用电量。
接下来是 Home Assistant 的配置部分,主要分状态定义和自动化脚本。
为了简化我只用两种状态(空闲和运转)描述洗衣机和烘干机的状态(代码只给出了洗衣机部分,烘干机部分几乎一样):
input_select:
washer_status:
name: Washer Status
options:
- Idle
- Running
initial: Idle
为什么要定义状态而不是直接通过用电量判断呢?因为这些机器运转过程里会有几次几乎不用电的阶段,如果只通过用电量很容易产生错误信号,用电量配合状态持续时间才能做出更精准的判断。
接下来定义虚拟的洗衣机传感器,我们会通过自动化脚本更新这个传感器的值:
sensor:
- platform: template
sensors:
washer_status:
value_template: '{{ states.input_select.washer_status.state}}'
friendly_name: 'Washer Status'
自动化脚本分两块,一块是检测到电量后的更新洗衣机状态为运转。这里我用了 10 瓦作为运转开始的阈值。
automation:
- alias: Set washer active when power detected
trigger:
- platform: numeric_state
entity_id: switch.hs110_washer
value_template: '{{ state.attributes.current_power_w }}'
above: 10
condition:
condition: or
conditions:
- condition: state
entity_id: sensor.washer_status
state: Idle
action:
- service: input_select.select_option
data:
entity_id: input_select.washer_status
option: Running
另一块是设备停止运转的检测,根据不同的设备可能要进行微调。我这里设置了洗衣机用电低于 3 瓦且超过 1 分钟以上后,把状态切换成空置并通过 Twilio 发送短信通知。
automation:
- alias: Set washer inactive
trigger:
- platform: numeric_state
entity_id: switch.hs110_washer
value_template: '{{ state.attributes.current_power_w }}'
below: 3
for:
minutes: 1
condition:
condition: or
conditions:
- condition: state
entity_id: sensor.washer_status
state: Running
action:
- service: input_select.select_option
data:
entity_id: input_select.washer_status
option: Idle
- service: notify.twilio_sms
data:
message: Washer finished at {{ now() }}
target:
- 15555555555
这个脚本用了一个多月没出现误报,虽然一开始折腾一点,最后还是省了我们不少时间。
关于智能家居和 Home Assistant 的更多信息,可以参考我写的其他文章。
2019-03-30 07:03:45
随着无人驾驶的兴起,激光雷达数据的目标检测成为了这几年的研究热点之一。常见的 3D 检测模型可以分成两类,一类是用 3D 小方格代表所有的激光点数据,每个小方格包含了这个方格内的特征,例如 VoxelNet 和 Vote3deep 。另一类则是先把三维信息投射到一个二维平面,通常是鸟瞰图 (BEV, Bird Eye View) 或是正视图 (Range View),生成二维特征图后再用传统的二维目标模型检测图中的物体,例如 MV3D 和 FaF。
无人驾驶场景中的大多数的目标物体都处在同一地面上,非常适合 BEV。相比正视图,BEV 中的目标在不同位置大小固定,我们可以用已知的常见物体大小优化检测效果。对于 BEV 模型来说,主要的问题在于如何选择最终图像的特征,如何生成的图像中做出精确的检测。此文旨在介绍 BEV 检测相关的模型 Pixor 和 HDNet。
Pixor 是 Uber ATG 的 Bin Yang 等人在 CVPR 18 上提出的 BEV 检测模型。在特征生成方面,Pixor 把整个点云切成了 L x W x H 个小方格,每个小方格用 0 或 1 表示这个方格内是否有激光点存在,接着沿高度方向把三维特征压缩到一个二维平面,每个压缩后的二维方格就有了 H 个特征表示这个方格上的不同高度是否有点存在。此外 Pixor 还计算了落在每个方格中激光点的平均强度作为额外的特征,最终拿到了一个分辨率为 L x W、包含 H + 1 个特征通道的图像。
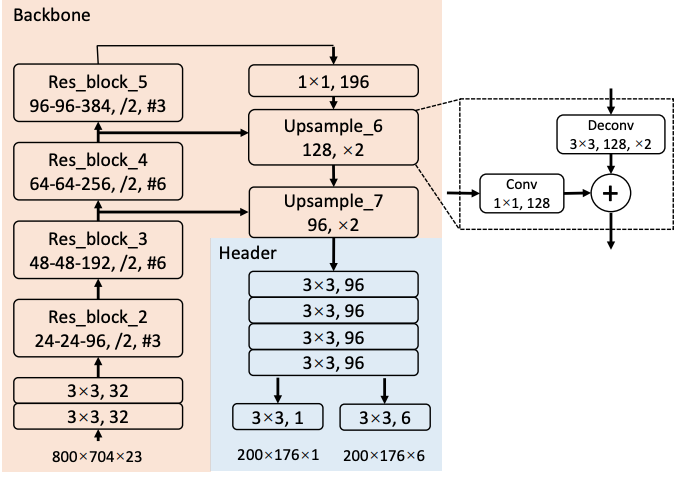
检测方面,Pixor 采用了基于 RetinaNet 的 one-stage 的结构,如上图所示(这里用了海报上的截图,和论文中的有一些细小的差别)。网络里面用了 ResNet 和类似 FPN 的结构。FPN 结构输出的特征图经过一个头部网络后,直接生成对每个像素点的分类和 bounding box 的回归结果。
优化目标方面,分类目标用了 RetinaNet 中的 focal loss,回归目标用了 smoooth L1。论文中回归目标有笔误,按照海报和 FAQ 的说法应该是 \(\{ \cos 2\theta, \sin 2\theta, dx, dy, \log W, \log L \}\)。这里巧妙的用了 \(2 \theta\) 的三角函数作为车头朝向的回归目标,因为车辆是往前还是往后开这个问题会在 tracker 中处理,在检测的时候只要知道车身线的偏离角度就行了,至于这个角度是 5° 还是 185° 影响不大。
整个网络的运行速度非常快,在 Titan XP 上可以在 35 毫秒内完成。除此之外论文还测试了不同 backbone 网络和头部网络特征层共享的不同选择,做了模型简化测试 (ablation study),感兴趣的朋友可以细读。
Pixor 沿高度方向把整个点云切成不同的高度区间,例如 Kitti 数据集上 -2.5 到 1 米之间的点会被分成 35 片,这个区间之外的点会被忽略。当地面坡度较大时,远处的点很容易被排除在外。为了解决这个问题,Bin Yang 等人提出了把高精地图作为额外特征的方案,发表在 CoRL 18 上。

如图所示,HDNet 的核心思路在于引入了高精地图信息,从而可以把地面「摊平」(图 b),并提供道路语义信息帮助检测(图 d)。网络结构和 Pixor 非常相似,采用了 FPN,并把 Pixor 中的反卷积层换成了更高效的双线性插值层。
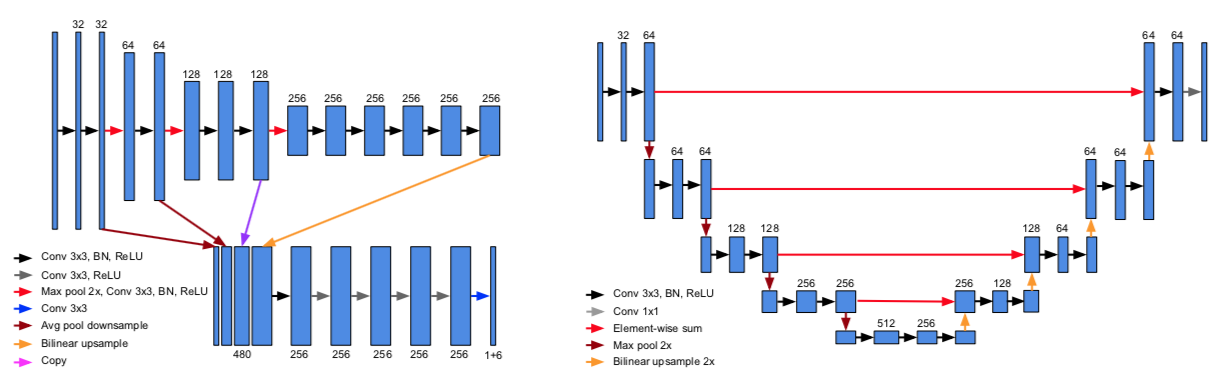
为了提高模型的稳定性,确保在缺失地图信息或者地图不准确的情况下仍然有较好的检测结果,作者会在训练模型时随机去除地图信息,并提出了通过 Lidar 扫描结果在线生成地图的方案。
本文介绍了两篇近期的基于纯激光雷达数据的 BEV 检测论文。基于纯激光雷达的模型非常适合车辆的检测,但对于行人检测的精度并不理想,往往需要借助图像提供额外的信息。在接下来的博客中我会和大家一起分享更多的相关研究,同时也欢迎各位提出不同的意见。
最后做一个小广告,我目前在 Ike 做无人卡车视觉的相关工作。我们公司在旧金山,最近拿到了 5200 万 A 轮融资,正在招人中。如果你对无人卡车感兴趣,欢迎联系我。
2018-10-31 12:35:07
来美国五年后绿卡终于批了,没有太大曲折,不过也干等了好久,中间还找了议员催绿。总结下流程,希望给后来的朋友有帮助。
整个过程中 EB-3 的 I-140 拖了好久,因为律师说加急需要 9089 原件,而我的原件已经在第一份 I-140 申请中提交了,没法再次加急。另外比较后悔的一件事就是绿卡面试前没有再去准备一份体检卡。面试通知上写着体检要求「valid within last year」,我以为只要是前一年办过体检就行,律师也建议面试完了再看要不要补办。等重新做体检提交,第二个月正好排期倒退了。
另外一个经验就是即使绿卡面试完了,也得催律师重新申请 EAD / AP。我的律师觉得绿卡马上拿到了就没急着帮我重新申 AP,导致我在绿卡迟迟没下来加上 Visa 过期的情况下,年底出游计划受限不少,如果有一张 AP 就可以放心安排出国计划了。
催绿方面,我们研究过参议员和众议员两个方案。两者效果应该差不多,都是通过官方问一下进度,以免你的 case 堆积在某个角落没人管。我们只联系了众议员,具体的流程如下:
整个过程没等多久,而且工作人员态度很好,之后发邮件问都是一刻钟内会有回复。
拿到绿卡后似乎还要去更新下 SSN,去掉上面的工作限制。另外就是可以办 Global Entry 啦。
祝愿等绿卡的各位早日顺利拿到绿卡。
2018-08-07 15:56:13
最后一周讲定位 (localization),也就是 SLAM 里面的 L。主要包括粒子滤波和迭代最近点。
里程计定位法直接从设备里读取信息,更新当前的位置状态。例如要跟踪车子的位置状态,可以在车轮上安装计数器记录车轮转动的次数,从而了解车子前进了多少。对于转弯的情况,可以从内外轮子的计数差得到转弯的角度。假设内轮转了 \(e_i\) 圈,外轮转了 \(e_o\) 圈,内轮半径 \(r_i\),外轮半径 \(r_o\),则有 \[ e_i = \theta r_i \\ e_o = \theta r_o \] 这里 \(\theta\) 就是车子转动的角度,上面的方程可以解得 \[ \theta = \frac{e_o - e_i}{r_o - r_i} \] 然后就能根据转动角度更新车辆当前的位置了。
这种方法用车辆本身的坐标系统记录位置,虽然实现起来简单但是测量精度非常局限于测量误差。例如上例中轮子打滑或事漂移都会导致结果不准确。更成熟的方案需要结合地图信息。
可以用下面三张图来来介绍地图定位问题,左图是当前的区域地图,中间是激光测距传感器得到的结果,地图定位的目的就是根据传感器返回的结果判断机器人当前坐标和朝向,右图就是一个理想的结果。
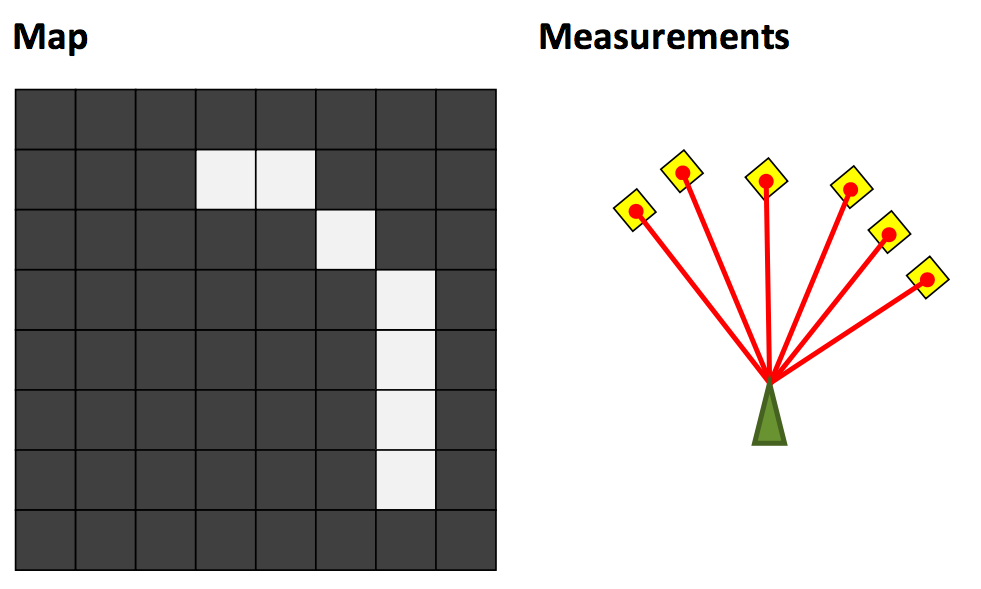
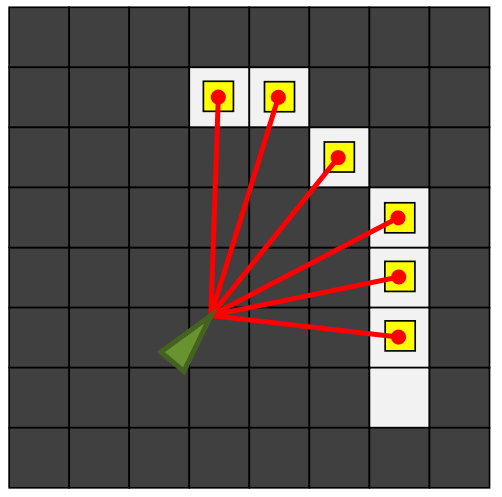
配合第三周讲的占据栅格地图障碍物的概率 \(m(x, y)\),我们可以定义最佳定位结果应该满足 \[ \max_p \sum_r \delta(p_x + r\cos(p_{\theta} + r_{\theta}), p_y + r\sin(p_{\theta} + r_{\theta})) \cdot{m(x,y)} \] 接下来介绍两种解决地图定位的方法。
粒子滤波(有没有觉得这个术语的中文翻译很科幻)又称为序列蒙特卡洛 (Sequential Monte Carlo),是一种非参数 (non-parametric) 模型。它用一系列样本(粒子)表示可能性分布。每一个粒子都是方差接近于 0 的高斯分布,这种分布又被称为狄拉克δ函数 (Dirac Delta),采用这个分布好处之一是可以把连续数学中的工具应用到离散的结果中。
在地图定位问题中,粒子的状态代表位置和朝向,同时每个粒子分别有自己的权重。初始状态的粒子滤波分布由一开始的假设决定,可能是均匀分布,也可能是以某个点为中心的高斯分布。初始化完成后,重复以下步骤更新粒子的分布:
粒子滤波的缺点之一在于高维度中,需要大量的粒子才能保证理想的分布。ICP 算法可以更好的适应高维度的场景。
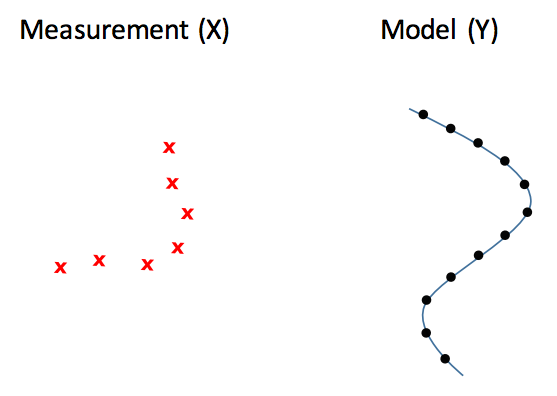
如图所示,ICP 的目的在于已知测量结果和地图,要求出左侧测量结果如何旋转移动后,可以和右侧的地图局部吻合。这里主要有两个问题,一是旋转和移动矩阵,二是测量点和地图点的对应关系。具体的 ICP 算法可以参考这篇论文,它的大致思路和第一周提到的解高斯混合模型的 EM 算法很接近:
这次的作业是实现一个粒子滤波,应该是整个课程最麻烦的一次了。问题本身不算难,尤其简化了动力学模型之后。但是调参比较麻烦,尤其是最后提交的那个地图,容易卡在某个转角跑不出来。
动力学模型方面,我一开始假设机器人位置和朝向的变化量和前一次接近,移动一次粒子之后再添加噪音。这个方法在机器人变向的时候容易位置偏离过多导致粒子失效,后来注意到作业的 Tips 里面建议假设机器人不动,利用高斯噪音移动粒子,这样的话相当于就不需要针对动力学模型做任何操作了。
计算每个例子的得分时,一种做法是用上一周的作业中用到的 bresenham 函数计算发出点到障碍物中间所经历的空白格,然后对每个空白格计算加权,但是这个做法实在太慢了,我最后计算得分时只用了障碍物所在格的状态。
关于粒子的数量,我看到网上有一种做法是设置一个得分的阈值(例如 70% 的障碍物要正好打到墙上),如果所有的粒子都没法超过这个阈值,就重新再跑一次。这么做容易在测量不准时卡死,而且和书中的实现有出入,在现实中会导致粒子滤波每次估计位置时使用的时间不稳定。比较好的做法还是把粒子的数量和高斯分布的参数放在一起调,跑偏了可以看看是因为粒子不够还是分布参数有问题。
作业里其实有两个地图,样例地图比较容易过(可能是参数变化不大)。提交用的地图调参要不少时间,我看了自己的输出以后,发现有几个点的运动变化很大,有可能是这几个点的测量本身也不精确。另外两个地图用来标记墙和空白方格的数值也是不一样的。
至此 Robotics Estimation and Learning 这门课就上完了。课程设置不错,但是讲解不够详细,尤其是第二周和第四周,这小哥讲得太简单了,slides 上还有不少错误。推荐《Probabilistic Robotics》这本书,在上课的时候参考了里面一部分章节,写得很详细,作者 Thrun 也是机器人领域的大神。
2018-08-01 15:07:22
这一周的内容和地图有关,最后的作业就是通过传感器的数据创建一个地图。
常见的题目类型有三种:
在现实中绘制地图有几个难点,一是测量误差会导致坐标不精确,二是设备本身需要不断地移动才能绘制,三是地图本身是对现实世界的反应,会不断的变化。
栅格地图用二维栅格表示整个环境,每个栅格都有一个概率值表示这个栅格是否有物体存在。绘制栅格地图常用的设备之一是测距传感器,通过发出激光并测量接受反射所用的时间,传感器可以了解前方障碍物的大致距离。
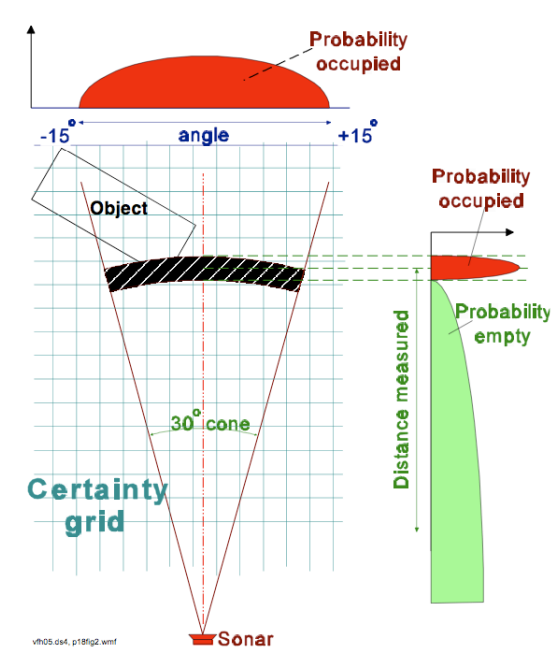
如图所示,传感器本身测量存在误差,我们只能认为在传感器正前方给定距离处有一定几率存在障碍物。对于这种测量有误差的环境,我们再次引入贝叶斯模型描述。记 \(p(m_{x, y})\) 为 (x, y) 格中存在障碍物的概率的先验知识,根据测量的设备模型我们可以得到条件概率 \(p(z | m_{x,y})\)。\(p(z=1|m_{x,y}=1)\) 就代表栅格中有障碍物,且检测成功的概率,而 \(p(z=1|m_{x,y}=0)\) 则代表栅格中不存在障碍物,但是却检测到障碍的概率(假阳性)。
根据贝叶斯公式,我们可以得到测量之后的后验概率 \[ p(m_{x,y}|z) = \frac{p(z | m_{x,y}) p(m_{x,y})}{p(z)} \] 为了简化计算,引入 \(Odd(X) = \frac{p(X)}{p(\neg{X})}\) ,则有 \[ Odd(m_{x,y} = 1 | z) = \frac{p(m_{x,y} = 1 | z)}{p(m_{x,y} = 0 | z)} = \frac{p(z | m_{x,y} = 1) p(m_{x,y} = 1)}{p(z | m_{x,y} = 0) p(m_{x,y} = 0)} \] 其中最后一步可以代入贝叶斯公式得到。对 \(Odd\) 求对数,则有 \[ \begin{align} \log \frac{p(m_{x,y} = 1 | z)}{p(m_{x,y} = 0 | z)} &= \log \frac{p(z | m_{x,y} = 1) p(m_{x,y} = 1)}{p(z | m_{x,y} = 0) p(m_{x,y} = 0)} \\ &= \log \frac{p(z | m_{x,y} = 1)}{p(z | m_{x,y} = 0)} + \log \frac{p(m_{x,y} = 1)}{p(m_{x,y} = 0)} \end{align} \] 令 \(\log{odd\ meas}\) 表示 \(\log \frac{p(z | m_{x,y} = 1)}{p(z | m_{x,y} = 0)}\) ,上式可以简化为 \[ \log odd(m_{x,y} = 1 | z) = \log{odd\ meas} + \log odd(m_{x,y} = 1) \] 如果用 \(\log{odd}\) 表示栅格的状态,这一状态可以简单的通过加减来维护。当检测到障碍物时,该栅格的 \(\log{odd}\) 增加 \(\frac{p(z=1 | m_{x,y} = 1)}{p(z=1 | m_{x,y} = 0)}\),没有检测到障碍物时,该栅格的 \(\log{odd}\) 减少 \(\frac{p(z=0 | m_{x,y} = 0)}{p(z=0 | m_{x,y} = 1)}\)。初始状态为 0,即 \(odd = 1\)。
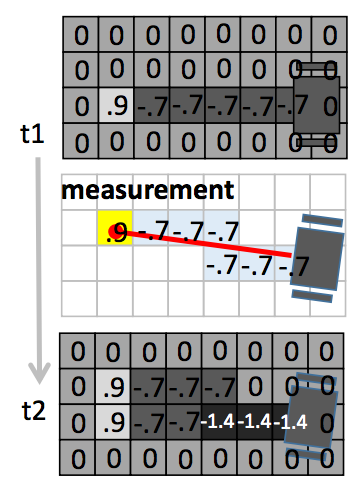
下图为一个具体的例子,第一个栅格地图为 t1 时刻的状态,做了一次探测后,经过的空闲栅格的 \(\log{odd}\) 减少 0.7(这个值由传感器决定),而最后的障碍物所在格的 \(\log{odd}\) 增加了 0.9。第三个栅格地图为 t2 时刻更新后的状态。
常见的三维传感器:
地图的数据格式也有多个方案:
这次的作业是根据一组 Lidar 测量结果绘制一个二维地图。输入包含四个参数(这里 K 为扫描总次数,N 为 Lidar 光线数):
我实现的方法没有用向量并行,用了两层循环依次处理每次测试的各条光线。在 i7 6700K 上大概 25 秒可以跑完最终测试,测试程序里会提到整个过程可能要五分钟,性能差一点的机器这个时间里面应该也能跑完了。
最后跑地图的时候,注意 example_test.m 里传给 occGridMapping 的参数只取了前 1000 次测量结果,所以要制作完整地图要把这个限制去掉。另外文档里面坐标转换时用了 ceil,我在本地测试时只能拿到 27/30 分,换成 round 就能到满分了。

2018-07-25 15:57:26
这一周主要讲卡尔曼滤波 (Kalman Filter),视频讲得比较简略,slides 做得里也有不少错误。最后看了一些其他网站的文章和视频才有了比较深刻的理解。参考资料推荐在本文结尾。
卡尔曼滤波可以从一系列包含噪音的观测数据中,估计出每个时间点系统的状态。KF 有几个基本假设:
基于高斯分布的假设,我们可以用贝叶斯模型描述状态 \[ p(x_{t+1}|x_t) = Ap(x_t) \\ p(z_t|x_t) = Cp(x_t) \]
加入运动和观测误差导致的不确定性 \(v_m\) 和 \(v_0\) \[ p(x_{t+1}|x_t) = Ap(x_t)+v_m \\ p(z_t|x_t) = Cp(x_t)+v_0 \]
假设误差基于高斯分布 \[ p(x_{t+1}|x_t) = A\mathcal{N}(x_t, P_t) + \mathcal{N}(0, \Sigma_m) \\ p(z_t|x_t) = C\mathcal{N}(x_t, P_t) + \mathcal{N}(0, \Sigma_0) \]
把线性变换 A 和 C 代入正态分布 \[ p(x_{t+1}|x_t) = \mathcal{N}(Ax_t, A P_t A^T) + \mathcal{N}(0, \Sigma_m) \\ p(z_t|x_t) = \mathcal{N}(Cx_t, C P_t C^T) + \mathcal{N}(0, \Sigma_0) \]
线性加和 \[ p(x_{t+1}|x_t) = \mathcal{N}(Ax_t, A P_t A^T+ \Sigma_m) \\ p(z_t|x_t) = \mathcal{N}(Cx_t, C P_t C^T + \Sigma_0) \]
接下来讲如何估计这两个高斯分布的参数。
最大后验概率估计的目的在于最大化后验概率 \(p(x_t | z_t)\),即在对 \(x_t\) 有一个预测(先验),同时获得了观测结果 \(z_t\) 之后修正 \(x_t\) 的值,用符号表示有 \(\hat{x_t} = \argmax_{x_t} p(x_t | z_t)\)
由贝叶斯公式 \[ p(x_t | z_t) = \frac{p(z_t | x_t) p(x_t)}{P (z_t)} \] 代入正态分布得 \[ \hat{x_t} = \argmax_{x_t} \mathcal{N}(Cx_t, \Sigma_0) \mathcal{N}(Ax_t, A P_t A^T+ \Sigma_m) \] 令 \[ \begin{align} P &= A P_{t-1} A^T + \Sigma_m \\ R &= \Sigma_0 \end{align} \] 代入多元高斯分布(参考第一周笔记)把两个分布合并后求导,或者利用边界条件概率公式,可解得 \[ \begin{align} \hat{x_t} &= (P^{-1} + C^T R^{-1}C)^{-1} (C^T R^{-1} Z_t + P^{-1} A x_{t-1}) \\ \hat{P_t} &= (P^{-1} + C^T R^{-1}C)^{-1} \end{align} \]
接下来根据 Woodbury 矩阵求逆式 (Woodbury Matrix Identity),可以得到 \[ \hat{P_t} = P - P C^T (R^{-1} + C P C^T)^{-1} C P \] 令 \(K = P C^T (R + C P C^T)^{-1}\),有 \(\hat{P_t} = P - KCP\),\(\hat{x_t}\) 简化过程如下 \[ \begin{align} \hat{x_t} &= (P^{-1} + C^T R^{-1}C)^{-1} (C^T R^{-1} z_t + P^{-1} A x_{t-1}) \\ &= (P - KCP) (C^T R^{-1} z_t + P^{-1} A x_{t-1}) \\ &= A x_{t-1} + P C^T R^{-1} z_t - K C A x_{t-1} - KCP C^T R^{-1} z_t \\ &= A x_{t-1} - K C A x_{t-1} + (P C^T R^{-1} - KCP C^T R^{-1}) z_t \\ &= A x_{t-1} - K C A x_{t-1} + K z_t \end{align} \]
这里 K 就是卡尔曼增益 (Kalman gain)。
KF 的局限之一在于假设了线性模型,EKF 去掉了线性模型的限制,可以处理更一般的状态变化函数 \[ \begin{align} x_{t+1} = A x_t + B u_t &=> x_{t+1} = f(x_t, u_k) \\ z_t = C x_t &=> z_t = h(x_t) \end{align} \]
于是协方差的预测变成了 \[ p(x_{t+1}|x_t) = \mathcal{N}(f(x_t), \frac{\partial{f}}{\partial{x}} P_t \frac{\partial{f^T}}{\partial{x}} + \Sigma_m) \] 卡尔曼增益为 \[ K = P \frac{\partial{h^T}}{\partial{x}} (\frac{\partial{h}}{\partial{x}} P_t \frac{\partial{h^T}}{\partial{x}})^{-1} \] 更新方程为 \[ \begin{align} \hat{x_t} &= f(x_{t-1}) + K(z_t - h(f(x_t))) \\ \hat{P_t} &= P - K \frac{\partial{h}}{\partial{x}} P \end{align} \]
EKF 的局限之一在于只是对非线性的变换做了近似,用泰勒级数展开后取一阶项,容易产生导致较大的误差。UKF 采用了确定性的取样方法来近似高斯分布,这个取样方法又被称为无迹变换 (Unscented Transformation)。
UT 可以用来计算非线形变换后随机变量的分布情况。考虑 L 维随机变量 x 和非线性的函数 \(\pmb{y} = f(\pmb{x})\),假设 x 的均值为 \(\bar{\pmb{x}}\),协方差矩阵 \(P_x\)。为了计算 \(\pmb{y}\) 的分布情况,我们根据下面三个式子创造一个维数为 2L + 1 的 sigma 矩阵 \(\pmb{\mathcal{X}}\): \[ \begin{align} \mathcal{X}_0 &= \bar{\pmb{x}} \\ \mathcal{X}_i &= \bar{\pmb{x}} + (\sqrt{(L + \lambda)\pmb{P}_x})_i && i = 1, \dots, L \\ \mathcal{X}_i &= \bar{\pmb{x}} + (\sqrt{(L + \lambda)\pmb{P}_x})_{i - L} && i = L + 1, \dots, 2L \end{align} \] 这里 \(\lambda = \alpha^2(L + \kappa) - L\) 为调节参数,\(\alpha\) 决定采样点围绕均值的扩散程度等参数。下标 i 表示矩阵的第 i 列。这里的 \(\mathcal{X}_i\) 也被称为 sigma 向量,通过非线性函数后转变到同一个矩阵中: \[ \mathcal{Y}_i = f(\mathcal{X}_i) \]
\(\pmb{y}\) 的均值和协方差就可以通过对 \(\mathcal{Y}\) 矩阵列的加权求和获得了 \[ \begin{align} \pmb{y} &\approx \sum_{i=0}^{2L} W_i^{(m)} \mathcal{Y}_i \\ \pmb{P}_y &\approx \sum_{i=0}^{2L} W_i^{(c)} \{\mathcal{Y}_i - \bar{\pmb{y}}\}\{\mathcal{Y}_i - \bar{\pmb{y}}\}^T \end{align} \] 其中权值 \(W_i\) 的定义为 \[ \begin{align} W_0^{(m)} &= \lambda / (L + \lambda) \\ W_0^{(c)} &= \lambda / (L + \lambda) + (1 - \alpha^2 + \beta) \\ W_0^{(c)} &= W_0^{(m)} = 1 / \{ 2(L + \lambda) \} & i = 1, \dots, 2L. \end{align} \] 下图很好地解释了上述几个式子的变换过程
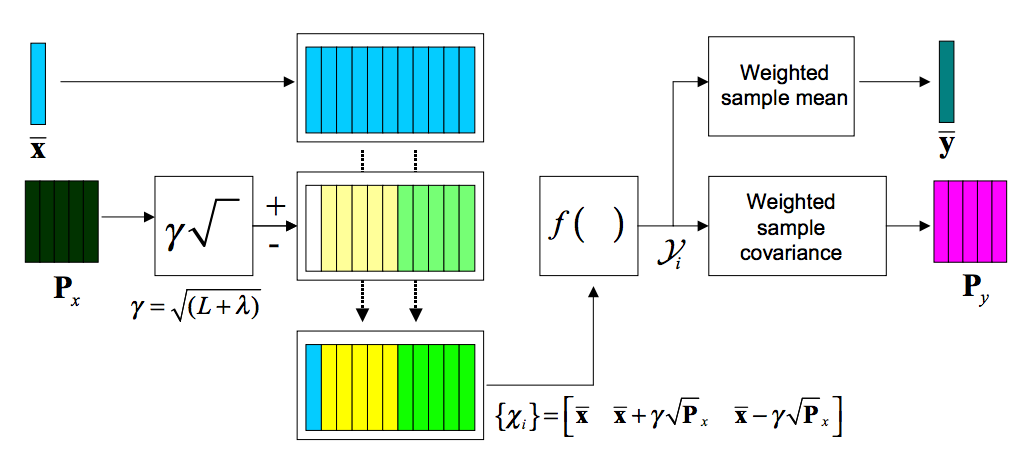
接下来回到 UKF。介绍了 UT 之后 UKF 就容易多了。首先构造一个包含初始状态和噪音的矩阵 \(\pmb{x}_k^{\alpha} = [\pmb{x}_k^T \pmb{v}_k^T \pmb{n}_k^T ]^T\),这里三个向量分别为状态向量、控制向量和噪音向量。接下来对这个矩阵应用无迹变换获得 sigma 矩阵 \(\mathcal{X}_k^{\alpha}\),之后就回到了普通 KF 过程。具体的状态转移公式可以参考本文结尾参考资料《Kalman Filtering and Neural Networks》一书中的章节。
这周的作业是用卡尔曼滤波预测一个小球运动 10 帧之后的位置。理解了卡尔曼滤波后做起来不难,定义好动力学矩阵 A 和测量矩阵 C,接着根据上面的公式计算卡尔曼增益 K、新状态的均值和协方差矩阵,再通过新状态的位置和速度计算 10 帧之后的位置就好。
调参方面有一些小技巧,一开始测试的时候可以先给 \(\Sigma_m\) 设一个很大的值,同时给 \(\Sigma_0\) 设一个很小的值,这样每次算出来的位置都应该是测量出来的位置,否则代码里可能有 bug。接下来就可以根据生成的预测图来调整 \(\Sigma_m\),肉眼估一下坐标的误差范围(注意到 y 的变化速度比 x 的慢很多),然后根据坐标误差算一下速度误差。测量误差根据文档可以给一个 0.01 - 0.1 的参数。
2018-07-23 08:18:32
最近宾大在 Coursera 上开了一个机器人系列课程,包含了视觉、运动规划、机械设计等课题。我对 SLAM 很感兴趣,于是就选了 Robotics Estimation and Learning 这门课,课程主页是https://www.coursera.org/learn/robotics-learning/。第一周的内容是高斯分布。
给定数据集 \(\{x_i\}\),可以通过最大似然 (Maximum Likelihood Estimate) 来估计均值 \(\mu\) 和标准差 \(\sigma\) \[ \hat{\mu}, \hat{\sigma}=\argmax_{\mu, \sigma}{p(\{x_i\}|\mu, \sigma)} \]
假设所有观测数据独立分布,则有
\[ p(\{x_i\}|\mu, \sigma) = \prod_{i=1}^N p(x_i|\mu, \sigma) \]
解这个优化函数:
\[ \begin{align} \hat{\mu}, \hat{\sigma} &= \argmax_{\mu, \sigma} \prod_{i=1}^N p(x_i|\mu, \sigma) \\ &= \argmax_{\mu, \sigma} \prod_{i=1}^N \ln p(x_i|\mu, \sigma) \\ &= \argmax_{\mu, \sigma} \prod_{i=1}^N \ln (\frac{1}{\sqrt{2\pi}\sigma} \exp(-\frac{(x_i-\mu)^2}{2\sigma^2})) \end{align} \]
设损失函数 \(J(\mu, \sigma) =\sum_{i=1}^N (\frac{(x_i-\mu)^2}{2\sigma^2} + \ln{\sigma})\),则有 \(\hat{\mu}, \hat{\sigma} = \argmin_{\mu, \sigma} J(\mu, \sigma)\)
\[ \begin{align} \frac{\partial{J}}{\partial{\mu}} &=\frac{\partial{}}{\partial{\mu}}\sum_{i=1}^N (\frac{(x_i-\mu)^2}{2\sigma^2} + \ln{\sigma}) =\sum_{i=1}^N (\frac{\partial{}}{\partial{\mu}}\frac{(x_i-\mu)^2}{2\sigma^2}) \\ \frac{\partial{J}}{\partial{\sigma}} &=\frac{\partial{}}{\partial{\sigma}}\sum_{i=1}^N (\frac{(x_i-\mu)^2}{2\sigma^2} + \ln{\sigma}) =(\frac{\partial}{\partial{\sigma}} \frac{1}{2\sigma^2}) (\sum_{i=1}^N (x_i-\mu)^2) + \frac{N}{\sigma}) \end{align} \]
求极值令两式都为 0,可以解得 \[ \begin{align} \hat{\mu} &= \frac{1}{N} \sum_{i=1}^{N} x_i \\ \hat{\sigma}^2 &= \frac{1}{N} \sum_{i=1}^N (x_i - \hat{\mu})^2 \end{align} \]
\[ p(x) = \frac{1}{(2\pi)^{\frac{D}{2}} |\Sigma|^{\frac{1}{2}}} \exp(-\frac{1}{2}(\pmb{x} - \pmb{\mu})^T \Sigma^{-1} (\pmb{x} - \pmb{\mu})) \]
用最大似然估计多元高斯分布:
\[ \hat{\pmb{\mu}}, \hat{\Sigma}=\argmax_{\pmb{\mu}, \Sigma}{p(\{\pmb{x}_i\}|\pmb{\mu}, \Sigma)} \] 类似于一元高斯分布,假设所有观测独立,则有 \[ \begin{align} \hat{\pmb{\mu}}, \hat{\Sigma} &= \argmax_{\pmb{\mu}, \Sigma} \prod{p(\pmb{x}_i|\pmb{\mu}, \Sigma)} \\ &= \argmax_{\pmb{\mu}, \sigma} \prod_{i=1}^N \ln p(x_i|\pmb{\mu}, \sigma) \\ &= \argmax_{\pmb{\mu}, \sigma} \sum_{i=1}^N (-\frac{1}{2}(\pmb{x}_i - \pmb{\mu})^T \Sigma^{-1} (\pmb{x}_i - \pmb{\mu}) - \frac{1}{2}\ln |\Sigma| + C) \\ &= \argmin_{\pmb{\mu}, \sigma} \sum_{i=1}^N (\frac{1}{2}(\pmb{x}_i - \pmb{\mu})^T \Sigma^{-1} (\pmb{x}_i + \pmb{\mu}) + \frac{1}{2}\ln |\Sigma|) \end{align} \]
设损失函数 \(J(\pmb{\mu, \Sigma}) = \sum_{i=1}^N (\frac{1}{2}(\pmb{x}_i - \pmb{\mu})^T \Sigma^{-1} (\pmb{x}_i + \pmb{\mu}) + \frac{1}{2}\ln |\Sigma|))\),用类似估计一元高斯分布的方法,令 \(\frac{\partial{J}}{\partial{\pmb{\mu}}}\) 和 \(\frac{\partial{J}}{\partial{\Sigma}}\) 为 0,可以解得 \[ \begin{align} \hat{\pmb{\mu}} &= \frac{1}{N} \sum_{i=1}^{N} \pmb{x}_i \\ \hat{\Sigma} &= \frac{1}{N} \sum_{i=1}^N (\pmb{x}_i - \hat{\pmb{\mu}})(\pmb{x}_i - \hat{\pmb{\mu}})^T \end{align} \]
GMM 就是多个高斯模型的加权和:
\[ p(x) = \sum_{k=1}^K w_k g_k (\pmb{x}|\pmb{u}_k, \Sigma_k) \]
解 GMM 的方法之一就是 EM (Expectation-Maximization)。
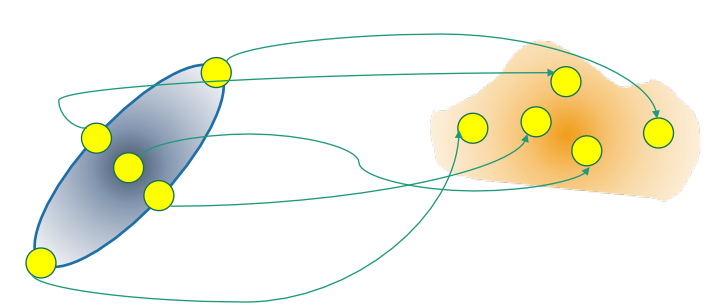
引入隐含变量 \[ z_k^i = \frac{g_k(\pmb{x}_i) | \pmb{u}_k, \Sigma_k}{\sum_{k=1}^K g_k(\pmb{x}_i) | \pmb{u}_k, \Sigma_k} \]
\(z_k^i\) 的表示第 i 个观测数据中,第 k 个高斯函数占全体的比重,直观表示如下图
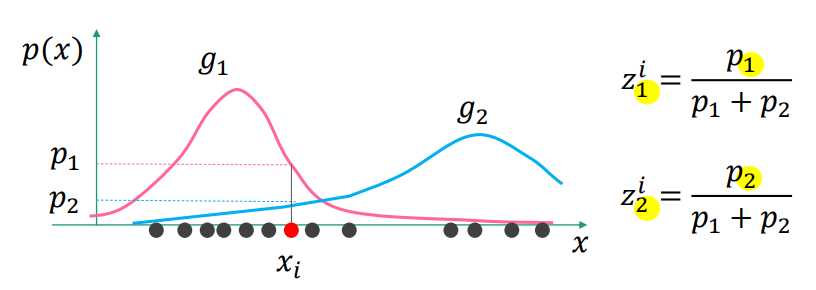
均值向量和协方差矩阵可以通过 \(z_k\) 估计 \[ \begin{align} \hat{\pmb{\mu}}_k &= \frac{1}{z_k} \sum_{i=1}{N} z_k^i \pmb{x}_i \\ \hat{\Sigma}_k &= \frac{1}{z_k} \sum_{i=1}{N} z_k^i (\pmb{x}_i - \hat{\pmb{\mu_k}})(\pmb{x}_i - \hat{\pmb{\mu_k}})^T \\ z_k &= \sum_{i=1}^N z_k^i \end{align} \]
2018-07-22 06:14:53
Prime Day 的时候入了一套 Sous Vide (真空低温烹饪,读作 soo veed)装备,周末在家尝试了龙虾,味道很不错。
先上最后的效果图:

烹饪过程并不麻烦,只是中间低温煮的时间比较长,具体步骤如下:







这里用到的工具有
其他可以考虑入手的工具
2018-07-14 08:00:00
最近抽空把线性代数重新过了一遍,整理了一份概念笔记,希望对别人也有用。主要参考了同济大学的《线性代数》和 《Deep Learning》 的第二章。
其中 \(A_{ij}\) 为代数余子式
2017-10-15 08:09:39
装修了半年多,两个月前正式入住,可以开始好好折腾智能家居了。现在用的一些方案和之前写的智能家居之计划篇差了不少,于是有了这篇博客聊聊现在的设计。这里直入主题,之前的计划篇里有更多的背景介绍。
我用了一台几年前的联想笔记本做服务器,装了个 Debian。这篇文章提到的大多数应用其实在树莓派上都能跑,Home Assistant 还专门给树莓派优化做了一个集成包叫 Hass.io 。下面主要讲软件部分。
一开始用的是 SmartThings,尝试了 Home Assistant 之后就决定改用它了。HA 相对于 ST 有不少优势,首先 ST 的大部分需要联网才能工作,增加了额外的不稳定因素和延迟;同时 HA 是开源的 Python 项目,可定制性比 ST 高很多,例如可以把所有状态变化记录到第三方数据库,支持 FloorPlan 等强大的插件。
HA 本身只是个软件,并不直接支持 Z-Wave 和 Zigbee 等协议。我选了 Aeotec Z-Stick Gen5 用来接收 Z-Wave 的信号,家里 Zigbee 的设备不多,需要的时候也可以用 ST 通过 MQTT 传给 HA。
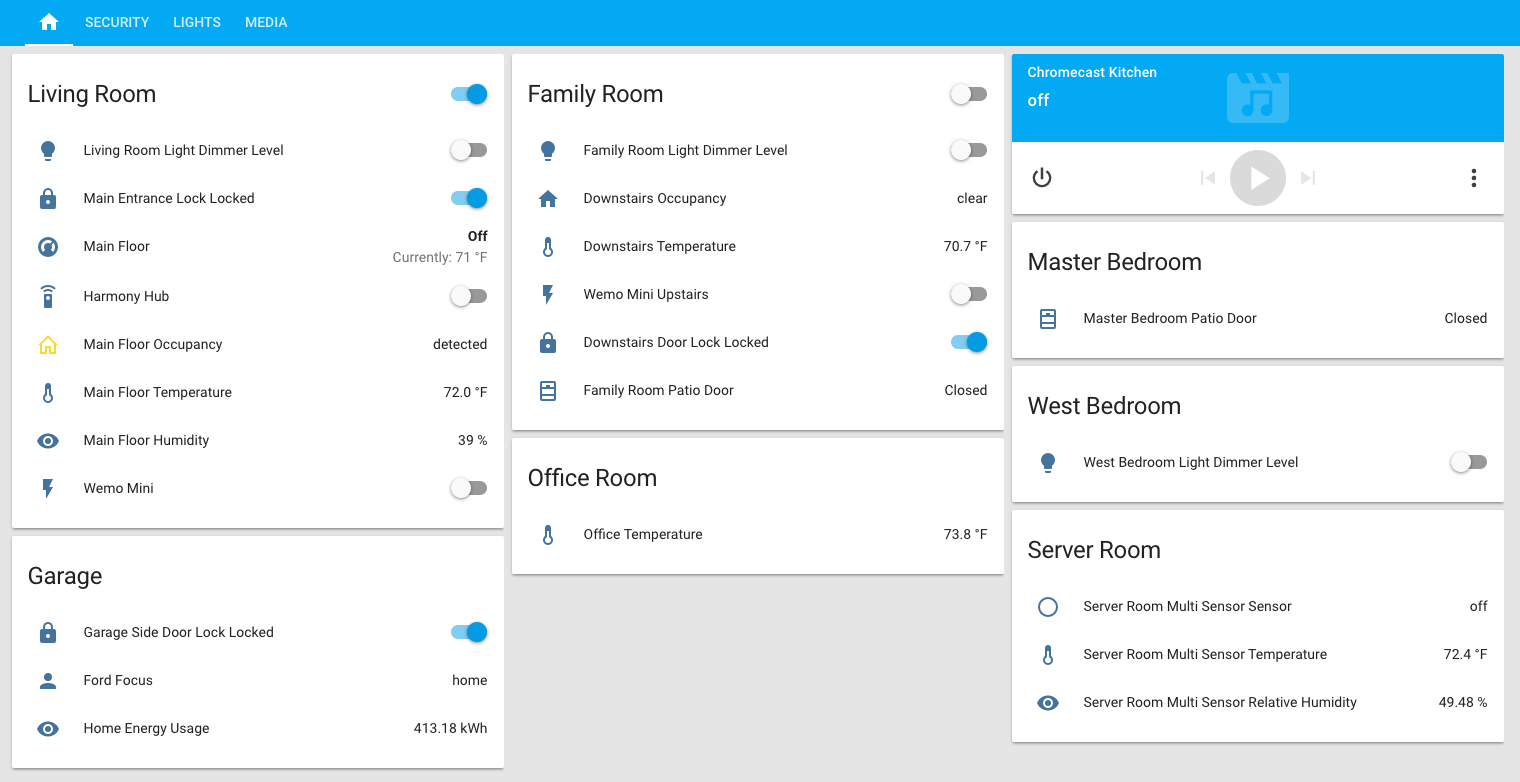
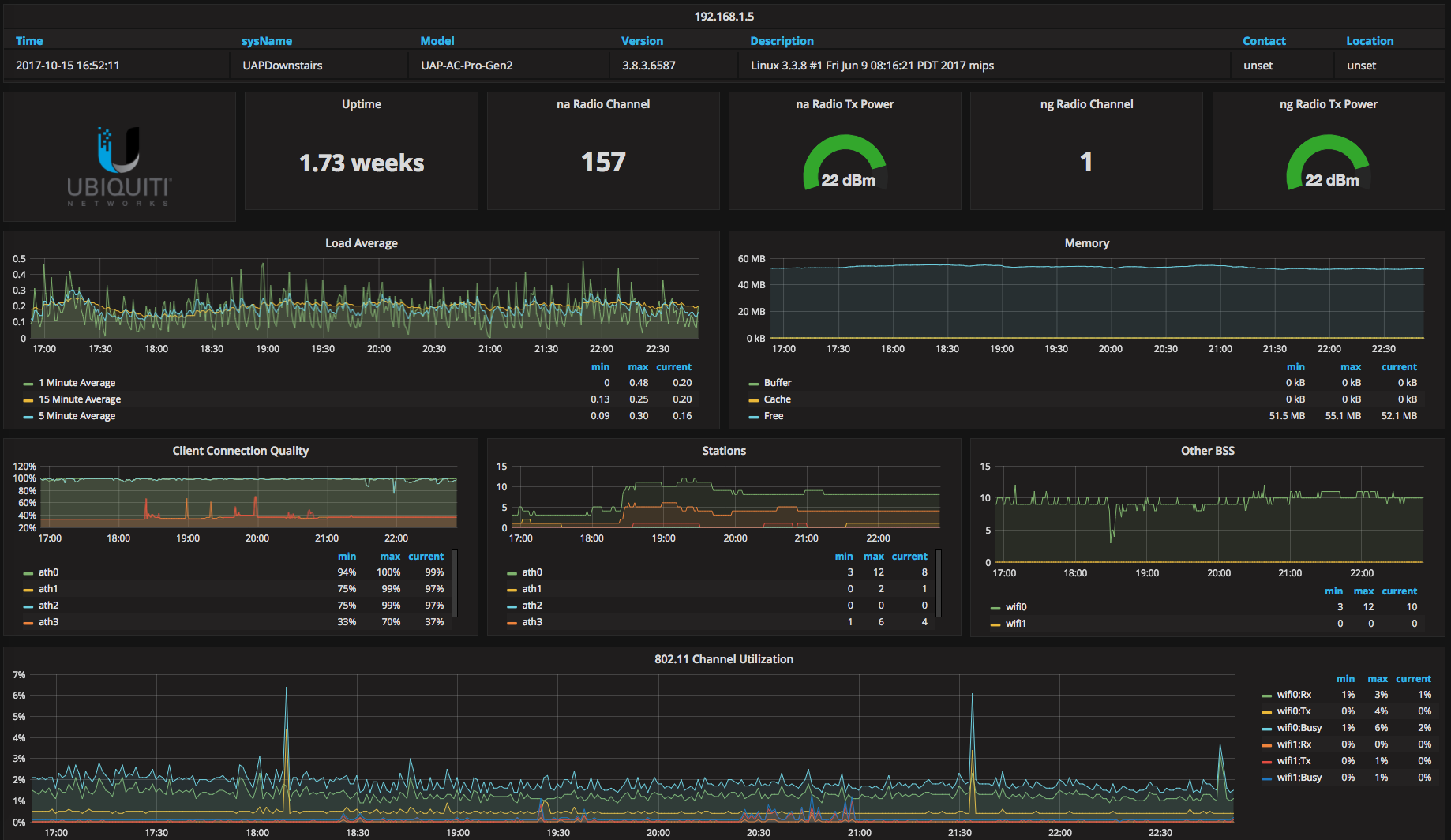
下图就是 Home Assistant 的面板截图,可以设置多个场景方便控制。比如我在睡觉前会看一眼 Security 确保门都锁好,以及其他监控正常。
Home Assistant 默认会把所有的事件信息保存在 SQLite 数据库里,并不适合长时间保存,而且没法简单的导出给其他应用。我把所有的事件信息都保存到了 InfluxDB 里,在前端搭了一个 Grafana 做监控面板。
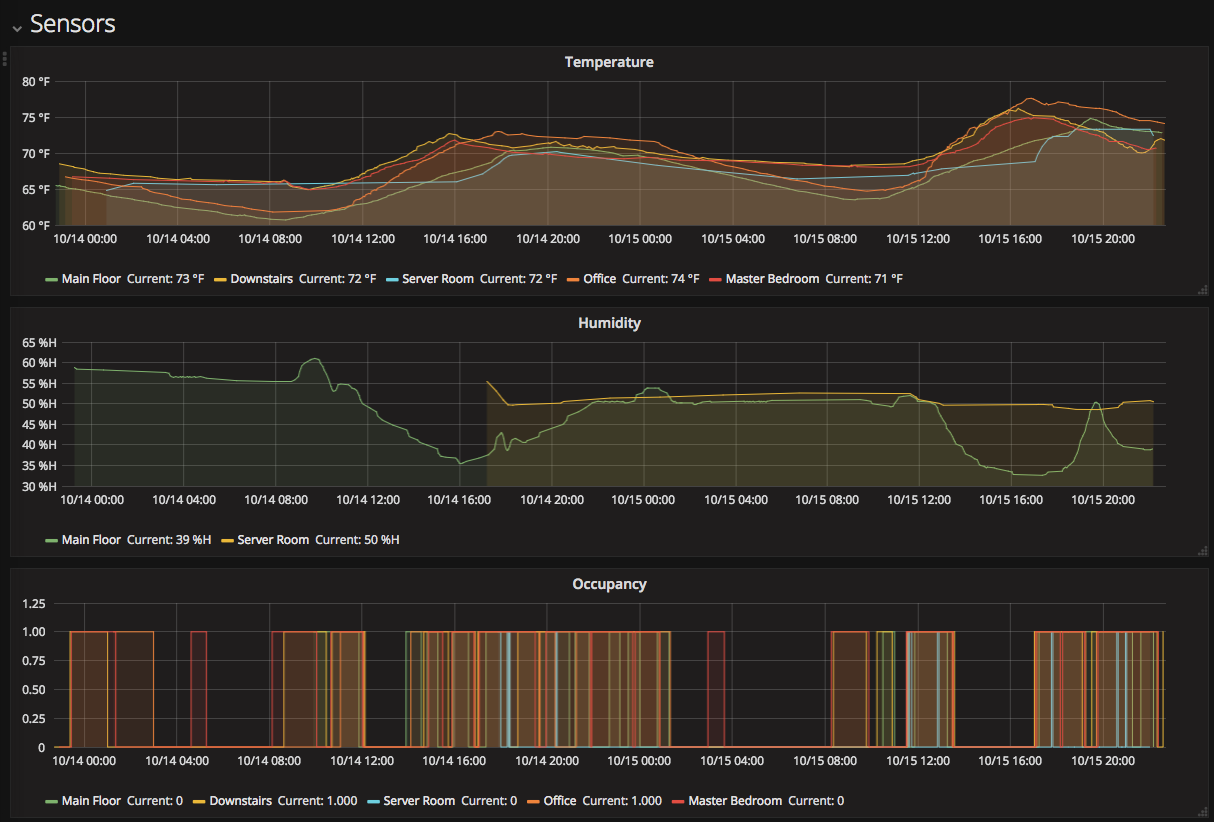
HA 对 InfluxDB 的支持很好,参考官方文档就能搞定,设置好以后所有的传感器更新、开关变化等信号都会保存到 InfluxDB 里。下图就是温度、湿度和占空传感器的一个 Grafana 页面。
以及 Unifi AP 的信号监控页面,借用了网上的一个 Grafana 模版
传感器可以用来监控房间的温度、湿度,是否有人,以及门窗是否关好等。接下来介绍一下我研究过的几款传感器。
因为家里是用 Ecobee 控制暖气的,所以多买几个 Room Sensor 可以很方便的集成到网络里。Ecobee 会根据有人的房间的温度控制暖气,同时 Ecobee API 也会输出这些 Sensor 的数据(温度、是否有人)。购买链接
性价比挺高的门窗传感器,外观也比较低调。基于 Z-Wave Plus 协议,会报告剩余电量。购买链接
可以报告温度、湿度、是否有人和自身电量。默认的报告频率有点低(差 2 度才会发送更新),需要发个指令调节。购买链接
需要先买一个 Tag Manager,可以接入多达 40 个传感器,而且有效范围在 400ft (120m)。这个方案看起来很不错,不过我用 Ecobee sensor 再加几个 Monoprice 的 multi sensor 已经够用了。
小米的温湿度传感器和门窗传感器都只要 ¥49,性价比非常高,而且外观也不错。不过最后我还是没买小米的设备,主要原因是小米用的是私有的 Zigbee 协议,不支持 Smart Things,得买小米自己的中控。然而小米中控的有效范围在 10m 左右,用电池的传感器也不支持信号中继,得在楼上楼下放好几个小米中控才能保证足够的覆盖范围。
Monoprice 的门窗感应器,我在两扇院子门上各装了一个,方便查看院子门有没有关上。购买链接
一开始我用的是 Arlo Pro,然而用了一阵子后觉得 Arlo 还是有不少问题,比如有录像延迟,检测到物体时经常会错过一开始的几秒,而且不付月租费话不支持 24 小时录像,即使插电源也不可以。
最后决定还是用传统 IP 摄像头 + NVR。视频录制在 NVR 的本地硬盘,出于安全考虑 NVR 不直接暴露给外网,而是通过中控服务器上的 ZoneMinder 间接访问。ZoneMinder 是一个开源的录像监控方案,其实它的功能已经相当强大了,但是同时监控几个摄像头会长时间占用中控的 CPU,所以我还是用了 NVR 专门负责监控录像。
研究了几个带亮度控制的开关,主要推荐两款,都是 Z-Wave Plus 协议的:
另外我还试过 Leviton DZMX1-1LZ,不推荐这款,要求有零线,价格不便宜而且还不支持 Z-Wave Plus。Leviton 应该有新款的开关,不过我没研究过。
这一块没怎么研究,Hue 用过一段时间,还算方便,但就像之前那篇文章里提到的,智能灯泡的问题在于很难和普通开关一起用,得用配套的遥控开关才行,会导致墙上多不少开关。
另外 IKEA 今年出了不少智能灯泡,用了 Zigbee 协议,看评测感觉很有前途。
一开始我在 Eero 和 Orbi 之间纠结,结果有位研究无线网络 4 年的同事给我推荐 Unifi 的无限路由,试了下的确好用。
UniFi Pro AP (UAP‑PRO) 可以通过 PoE 供电。不过 Unifi 设备的 PoE 比较特殊,这款 UAC-PRO 是同时支持 802.3af 和 802.3at 协议的,然而 UAP-AC-LITE 只支持 802.3at。如果你打算用 Unifi 官方的 PoE 网关,不需要担心这个问题。但如果你像我一样用的是其他的(我用了 NETGEAR JGS516PE),买之前得研究下这个供电问题。
Unifi Pro AP 的信号覆盖很好,我家楼上楼下各有 1400 sqft(130 平方米),院子不大。我在楼下入口和楼上靠近院子的房间各放了一个 AP,基本上就做到整个房子包括院子无死角覆盖了。这样算下来成本其实和用 Eero / Orbi 也差不多,但是性能会好很多,因此推荐给房间里布置了网线口的朋友。
Unifi 也出了类似 Eero 的 mesh network 的解决方案,没有研究过所以不做评价。
客厅用了原来的 Harmony 遥控,配合 Amazon Echo 开关电视很方便。
装修的时候在其他房间布置了天花板音响,但是没有现成的价格又不是太贵的多个房间的音响解决方案。研究了一通之后采用了 Echo Dot + T-Amp 的方案,每个房间配一个 Echo Dot 和一个小型功放,用手机控制各个房间的音乐。功放我用的是 Topping TP30,不算音响成本大概在 $130 左右,比起其他动辄两千的解决方案划算多了。
天花板音箱用的是 Polk MC60,天花板音响效果的期望本来就不高,这个 6” 的音箱的音质已经够好了。另外它还防潮,所以厕所也能用。
网上有一个开源的 Homebridge 插件,可以让 Homebridge 支持 Home Assistant,这样在 HomeKit 里面控制 HA 上的设备了。不过我很少用 HomeKit,没有花时间把一个个设备整理好。
门锁用的是 Schlage Camelot Touchscreen Deadbolt,Z-Wave 协议,很稳定,用到现在没出什么问题。用电量很小,三个月下来我的几个门锁还有 99% 的电(当然也有可能是 Z-Wave 电量报告不准确)。
Automatic 是一个车载装置,它可以记录你的车辆行驶状态、当前位置等信息,HA 官方支持 Automatic,可以把车辆信息作为条件放到 HA 的自动化脚本里,比如车在车库里熄火以后关闭内部摄像头。
试了下 Aeotec 的电量检测工具,需要安装在电箱附近。这套工具价格不贵($15 左右),但是很不好用,有实时更新的问题。Home Assistant 的论坛上有个帖子讨论怎么搞定它的自动更新。
家里车库门的动力引擎用了 LiftMaster,所以我就买了他家的 Chamberlain MYQ-G0201 MyQ-Garage。这个设备不支持 Z-Wave 协议,但是 Home Assistant 有个插件可以以用户名密码的方式登陆后台控制。
如果想要支持 Z-Wave 协议的车库门开关,可以考虑 GoControl GD00Z-4。
看下来 Bali 的方案还不错,Home Depot 可以试,不过最后因为各种原因还是没装。
发短信的平台,配合 HA 的自动脚本很好用。比如我的设置里有一条规则是外门超过 5 分钟以上没锁就发短信提醒自己。正常的推送量用 Twilio 很便宜,价格大概是 $0.0075 一条,所以我都没有设置 HA 的推送平台。
最近在折腾的一个叫 Floorplan 的 HA 插件,顾名思义就是让所有的智能设备显示在一个平面图上方便控制。
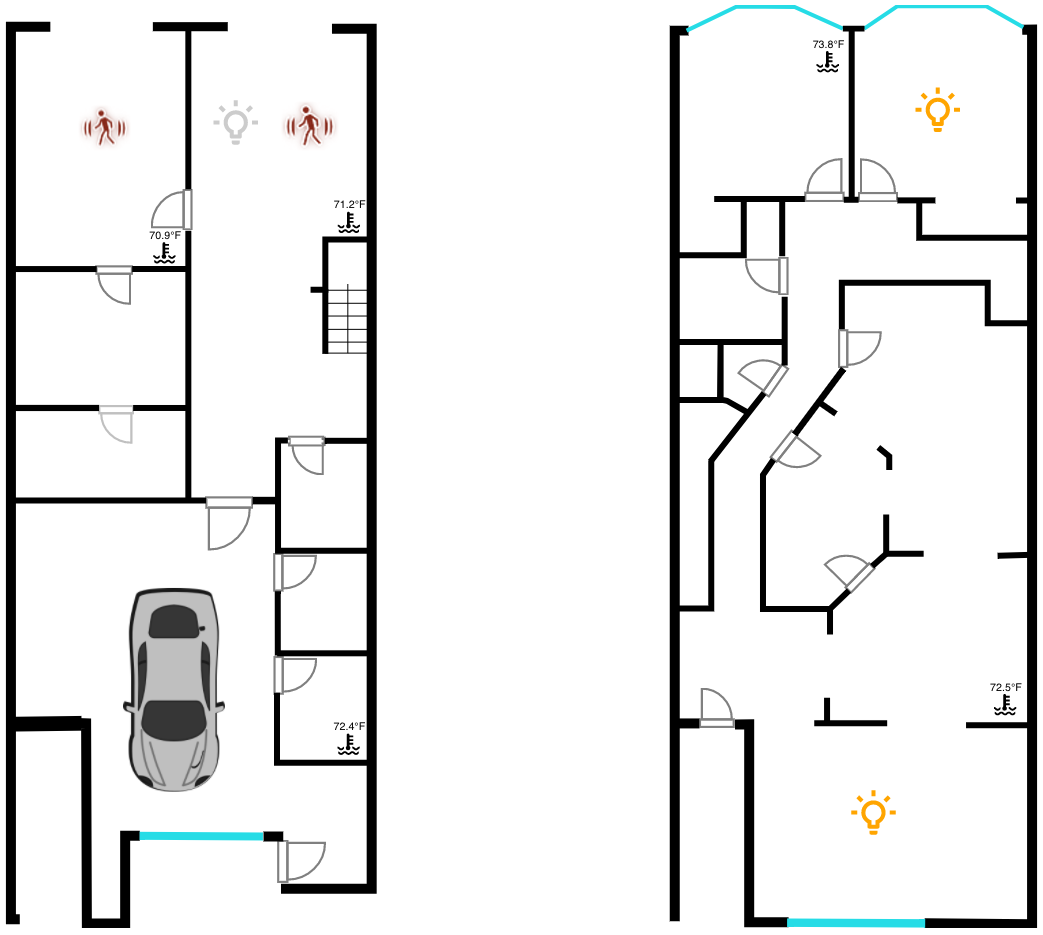
这是我目前的效果图,现在只加入了灯光、占空和温度信息,点击对应的房间可以控制这个房间的灯光。接下来打算在左侧放一排全局控制的按键,把弄一个平板挂到墙上,就可以在进家和出门的时候方便的控制全屋设备了。类似下图的效果(图片来源)。

2017-03-21 08:00:00
二月中旬开始装修房子,做了不少智能家居的研究,分享一下。坐标湾区,项目目前还在计划和购买阶段,欢迎拍砖,欢迎种草。
中控协议是要先决定的一项,因为选定以后就优先考虑支持这个协议的设备了。 现在比较热门的有 Z-Wave、Zigbee 和 Insteon。Zigbee 和 Z-Wave 走的是网状 (mesh) 网络,每一个设备都可以作为中继节点传播信号,所以家里支持这一协议的设备买得越多,信号覆盖就越好。Insteon 除了和 Z-Wave 类似的无线信号外,还可以从电力线直接发送信号,理论上会更稳定些。Insteon 的灯光控制开关做得比较好,不少人因为这个在灯光开关上选择了 Insteon。Zigbee 相比 Z-Wave 是一个更开放的协议,用的频段和 Z-Wave 互不冲突。Z-Wave 的最大优点在于支持的设备类型非常多,窗帘、门锁、灯光都有不少支持的设备。所以最后我还是决定用 Z-Wave 为主的无线控制。
选好协议后就是决定控制中心了,没有花太多时间研究,选了支持 Z-Wave 的 Smart Things,主要是因为它的用户社区很活跃,产品迭代也比较快。
语音控制我选了 Alexa (Echo),出来早,支持的产品多,和 Smart Things 的对接做得也很好。Echo 目前有三个产品,语音功能上都一样,主要是携带性以及音响效果的差别。买几个 Dot 在常去的房间里保证语音控制覆盖就好。
另外可以考虑买一块平板挂在墙上当全屋的控制器,有个叫 SmartTiles 的应用,本质上是一个网页,可以用来控制 Smart Things 的各种功能。
照明灯的远程控制主要有两种方案,一种基于智能开关,一种基于智能灯泡。
基于智能灯泡的方案的最大问题在于设备事实上一直都处于带电状态,对于多路开关控制电灯的场景,需要在每个开关位置边上放一个不走电的无线开关,同时还要避免和物理开关混用,导致设备电源被切断的情况。除非从一开始决定就只用假开关,不在墙上布置多路电开关,否则墙上开关的数量就会多不少,在使用时也容易按错。
而基于智能开关的方案则解决了这个问题,因为把无线开关做进了电开关,所以使用的时候就可以像用普通多路开关一样。智能开关的另一个好处在于成本相对便宜,一个无线调光开关的价格大概在 $50 左右,而一个智能灯泡价格在 $15 左右,对于装 6 个顶灯的大厅来说无线开关的方案会便宜点。
基于智能灯泡的方案的好处在于一些灯泡可以调色温,甚至不同颜色,此外每个灯泡还可以单独控制。对于卧室这种不需要多路开关,而且关灯可以只用手机或者语音的房间,我还是选择了黄白双色的 Hue,这样可以白天用白灯,晚上切换成昏黄的灯光。
具体选购方面,智能开关以前一般推荐 GE 的无线调光开关,不过最近 Homeseer 出了一款新的无线调光开关,相比 GE 的优势在于支持实时状态更新。多路无线开关要买配套的开关。此外不同的灯泡对无线调灯开关的支持不一样,Homeseer 官网上有一份兼容性列表可以参考。
Hue 还有个灯带产品,也挺好玩,可以考虑放在厨房橱柜的顶端做照明。
我在大厅、饭厅、厨房和厕所的天花板都装了无线音响,厨房和厕所的音响需要注意买防潮的。
走线方面,楼上的音响线都绕到一个储物柜里,楼下的音响线都绕到储物间(有网关)。音响线记得要买 CL2 或者 CL3(出于防火考虑),同时如果音响线超过 50 尺,得换用 14 AWG 的厚度。
音源方面,我的计划是买几个 Sonos CONNECT:AMP 分别控制这几个房间的音乐。由于 Sonos 的功放太贵了,打算先把音响和走线搞定了,到时候再一个个买。另外可以考虑把相邻两个房间(比如饭厅和客厅)的音响连到一个 Sonos 功放,不过得确保音响的阻抗是 8 欧姆的。
另外 Sonos 现在有个问题是还不支持 Alexa,不过公司已经明确表明要好好做这个功能了。
Crutchfield 上有几片文章讲得很详细,分别关于音响和排线,可以参考。
每天醒来能吼一声让 Alexa 拉开窗帘的感觉应该不错,所以我们很想装个可以远程控制的电动窗帘。做电动窗帘的小公司不少,但是大多数都是用传统的红外控制,这就意味着如果要把它接入到家里的控制网络,还得单独买一个 Z-Wave 到红外的发射器。
最后看下来 Lutron Serena 和 Somfy 两套系统比较靠谱。不过 Serena 不支持 Z-Wave,只好放弃。Somfy 似乎不直接卖窗帘杆,而是和一个专门卖窗帘的品牌 Bali 合作,在卖窗帘的同时提供电动控制的选项。
Bali 电动窗帘可以在两种供电模式里面选择,一是用 8 节 AA 电池,可以用12 到 18 个月;或者插座供电。虽然可以在窗帘杆边上加个新的插口,不过还是觉得接电线的方案太丑了,也没有理性的隐藏方案,所以决定还是用更折腾的电池方案。
研究了三种解决方案:传统的无线扩展器,Eero 和 Orbi。传统的扩展器方案似乎稳定性不咋的,而且还要花时间设置。Eero 和 Orbi 的主要区别在于 Orbi 的主从设备之间用了独有的信道传输,所以理论上不会影响 WiFi 信道的性能;Eero 支持所有设备连接有限网络从而增强信号。因为是重新装修,每个房间本来就会提供网线接口,Eero 的这个特性就很有用。
没研究别的方案,家里本来就有个 Logitech Harmony,而且对 Smart Things 的支持也很好,所以就继续用了。Harmony 现在最大的好处就是看完电视不用再找遥控器了,用语音就能关掉。
另外推荐一个联想的迷你键鼠 N5902,很适合用来当 HTPC 的遥控,不过好像已经停产了。
视频监控方面选了 Arlo Pro,优点在于可以户外使用,有 7 天免费云存储,也可以备份视频到本地。Arlo Pro 有个延迟的问题,为了省电它会在红外感应到有人进入检测区域后才开始录像,所以可能会有几秒的延迟。网上也有很多人因为这个原因最后放弃了 Arlo。不过我在目前的租房里面试了下,放好相机的位置可以把延迟缩短到 1 秒左右。
门锁还没仔细研究,不过应该会用 Schlage 的电子锁。话说这套 193x 年的老房子,外面铁门的锁从来没换过,居然也是 Schlage 的。
车库门应该也有无线的选项,不过也还没仔细研究。
暖气控制应该会买 Ecobee3,因为家里的供暖系统是统一的,没法按房间分别控制。Ecobee3 可以在不同房间安装感应器保证有人在的房间的温度稳定。
2014-02-13 08:00:00
最近一直用 iA Writer 做笔记,用不同的文件保存不同的主题,由于 iA Writer 并没有很好的管理和浏览功能,于是就想做个 Web 工具方便浏览和管理。
markdown-wiki 是我用 Sinatra 做的一个简单的预览工具,它可以把某个目录下的 Markdown 文件以 Wiki 的形式呈现出来。界面上借用了 Ghost 的 CSS,可以在 http://markdown-wiki-demo.herokuapp.com/ 预览(因为是非本地的内容,上方的 Edit 按钮没有作用)。
Markdown 语法方面,由于用了 redcarpet 所以有不少语法扩展,包括代码块、删除线、下划线、上标等,另外包含了 Wiki 内部链接支持。
bundle install安装后在项目目录下运行 rackup(如果要限制只能本地访问可以运行 rackup -o localhost),并访问 http://localhost:9292 即可。
在网页上打开本地编辑器的功能是通过 URL Scheme 实现的,mac/webeditor opener.app 会将 wikieditor:// 注册给一个 AppleScript,后者负责运行 iA Writer 并打开相应的文件。mac/ 下已经包含了预先打包好的 app 文件,如果你需要修改 AppleScript,可以打开 mac/webeditor opener.scpt,编辑完成后点击 File -> Export,在 File Format 中选择 Application,并将 mac/Info.plist 放到新生成的应用包中。
如果在打开 iA Writer 时提示权限问题,请先在 iA Writer 中手动打开一次需要编辑的文件,之后就能顺利编辑这个目录下的所有文件了。
目前功能比较简单,有几个接下来考虑加入的功能:
源代码在 GitHub 上,欢迎提供建议和 Pull Request。
2013-08-21 08:00:00
写了个 Alfred 插件,用于外接 PC 键盘控制 Mac 的系统音量。
快捷键为 Alt + F10/F11/F12,分别和 MacBook Pro 键盘的 F10/F11/F12 功能对应:
音量调整后会播放 /System/Library/Sounds/Frog.aiff,这个声音和默认的调整提示音比较像。(有谁知道默认的音量调整提示音用的是哪个文件吗?)
另外如果在 Alfred 里把中间的 Run NSAppleScript 和右边的 Push Notification 一一连起来,就能在修改音量后看到当前音量的提示,不过我觉得没啥用所以默认取消了。
2013-07-14 08:00:00

我们选岛时参考的分类主要是一家淘宝店和马尔代夫DIY的选岛页面,最后也是找了后者帮忙订机票和酒店。
因为老婆想要住好点的酒店,我又想浮潜,综合考虑这两个因素后我们选择了 Dusit Thani(都喜天阙岛),四晚豪水 + 水飞 + 早晚餐一共每人 23000 元。
关于住宿,我看到不少代理都给出了两沙两水的配置,这样其实很折腾,中间还要搬一次家。另外 Dusit 岛上的水屋也分普水(Water Villa)和豪水(Ocean Villa),前者在退潮的时候就会变成沙屋,建议大家还是选择四晚豪水,毕竟相比总价两者差不了多少钱。
另外四晚住下来我们都觉得时间有点短,应该选择住五晚或者六晚。


出发前几天在网上搜美佳航空的评价,发现这个航空很不靠谱,在微博上搜索「美佳航空」的结果除了广告几乎都是抱怨。北京机场出发的美佳航班在7月1号和7月8号都有过七八个小时的延误。所以建议大家如果去马代的话尽量不要选择这个航空公司。
不过我们在美佳航空的体验还不错,往返航班都是准点的。通过旅行社顺利申请到了蜜月蛋糕,去程航班上空姐还会给每人发一个可爱多。


岛上潜水中心可以免费租浮潜装备,但是得先上它们的浮潜课,浮潜课每人 55 美元。另外潜水中心还可以租借水下相机(Sony TX10),一小时 25 美元。浮潜的时候还可以请教练帮忙照相,他会潜入水中近距离拍摄。
岛上的浮潜面罩都是平光镜,高度近视的朋友还是去淘宝上买一副近视面罩吧。另外如果觉得租借的呼吸管不太卫生,也可以自带。脚蹼就没必要自带了。

2013-06-24 08:00:00
知乎日报每天都会更新有意思的问答。我比较习惯用 Kindle 看这样的文章,就写了一个 calibre 的插件抓取每天的内容。


另外 calibre 还有定时抓取和推送的功能。前者可以在抓取的对话框中设置,后者在 Preference -> Change calibre behavior -> Sharing books by email 中设置。结合这两个功能就可以在抓取完成后自动把最新的内容推送到 Kindle 了。
2013-02-14 08:00:00
如果要查看 ActiveRecord 的 update_attribute 函数的源代码,一个比较常见的方法是直接在 Rails 源码中搜索 def update_attribute。博客 The Pragmatic Studio 介绍了一个更方便的技巧,在 Ruby 命令行中就能启动编辑器直接访问。
通过 Object#method 方法可以获得 update_attribute 方法的对象,而 Method#source_location 则返回这个方法定义的文件和位置。有了这个信息后,就能启动编辑器查看源代码了:
> method = User.first.method(:update_attribute)
User Load (0.5ms) SELECT `users`.* FROM `users` LIMIT 1
=> #<Method: User(ActiveRecord::Persistence)#update_attribute>
> location = method.source_location
=> ["/Users/wyx/.rvm/gems/ruby-1.9.2-p180/gems/activerecord-3.2.11/lib/active_record/persistence.rb",
177]
> `subl #{location[0]}:#{location[1]}`
=> ""
把这段代码封装成函数,加到 .pryrc 或者 .irbrc 中:
def source_for(object, method)
location = object.method(method).source_location
`subl #{location[0]}:#{location[1]}` if location && location[0] != '(eval)'
location
end
如果要查看 User 的实例方法 update_attribute,可以直接在 pry / irb 中调用
source_for(User.first, :update_attribute)
如果要使用其他编辑器,得把 subl #{location[0]}:#{location[1]} 换成这个编辑器对应的命令行:
# TextMate
mate #{location[0]} -l #{location[1]}
# MacVim
mvim #{location[0]} +#{location[1]}
# Emacs
emacs {location[0]} +#{location[1]}
原文链接:http://pragmaticstudio.com/blog/2013/2/13/view-source-ruby-methods
2013-01-24 08:00:00
我用的 zsh 提示符是 oh-my-zsh 自带的 steeef。最近发现用这个主题时,有些 Rails 项目即使把所有改动都提交后,还是会有红色标记表示存在未追踪文件:
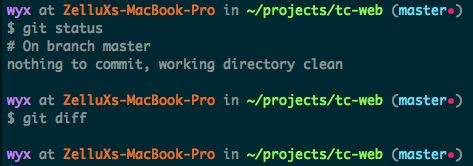
使用 git status 和 git diff,都看不到任何未提交的改动。一开始我以为是 zsh 或者 git 的 bug,把它们的版本都更新到最新版后还是有这个问题。于是看 steeef 主题的源码,发现了红色标记的判断依据:
# check for untracked files or updated submodules, since vcs_info doesn't
if git ls-files --other --exclude-standard --directory 2> /dev/null | grep -q "."; then
PR_GIT_UPDATE=1
FMT_BRANCH="(%{$turquoise%}%b%u%c%{$hotpink%}●${PR_RST})"
else
FMT_BRANCH="(%{$turquoise%}%b%u%c${PR_RST})"
fi
因为 vcs_info 没有提供未追踪文件或模块的方法,作者在这里用了 git ls-files --other --exclude-standard --directory 检测当前项目是否包含未追踪的文件,而在我的项目根目录下运行这个命令后,可以看到有三个目录未被追踪:
$ git ls-files --others --exclude-standard --directory
log/
public/system/
tmp/
这几个目录在 .gitignore 中都有声明,当时项目刚创建时借用了 gitignore 中的模版,相关的声明是:
/log/*
/tmp/*
/public/system/*
看来问题就出在这里用了通配符 *,把目录下的所有文件而不是目录本身忽略了。因为 git 不允许把空目录加到项目中,git status 和 git ignore 都不会显示这些目录,而作者检测时用的 git ls-files --directory 又会包含未追踪的空目录,就出现了这个提示有改动却找不到的情况。知道问题后解决方案很简单,把 .gitignore 文件中的 xxx/* 都改成 xxx/,或者把 --directory 参数去掉就好了。
2013-01-09 08:00:00
Emacs 的 xcscope 插件默认不会扫描 Java 文件,另外 Android 源码里有不少 .aidl 的文件,默认也不包含在 xcscope 的扫描范围里。解决这个问题的一个方法是在项目根目录下手动创建 cscope 索引:
$ find . -name "*.java" -or -name "*.aidl" -or -name "*.cpp" > cscope.files
$ cscope -b
这样做的缺点很明显,索引功能没有做到 Emacs 里,需要单独起一个 shell,比较麻烦。我发现这个问题的本质在于 xcscope 创建索引用的是 cscope-indexer 这个脚本,而 cscope-indexer 默认只会扫描 C/C++ 的源码文件。所以其实只要修改 cscope-indexer,把第 140 行从原来的
egrep -i '\.([chly](xx|pp)*|cc|hh)$' | \
改成
egrep -i '\.([chly](xx|pp)*|cc|hh|java|aidl)$' | \
之后就能用 C-c s I 在 Emacs 中创建 Android 项目的索引了。
2013-01-04 08:00:00
以前没注意过 Rails controller 中 respond_to 的格式顺序,后来碰到了一个诡异的 bug,才发现这里的顺序对程序行为是有影响的。bug 的现象是用某个应用商店桌面端浏览网站时,会出现返回 JSON 而不是网页的情况。由于当时报告错误的用户给出的 bug 描述是「点击链接后出现乱码」,导致 debug 一开始没找对方向,废了不少功夫才解决这个问题。
问题就出在不同格式的声明先后上,有问题的代码是:
respond_to do |format|
format.json { render json: @items }
format.html
end
有些浏览器或者内嵌了 WebKit 控件的程序,发送的 HTTP 请求头中,Content-Type 的值是 */*。这就导致 JSON 的 MIME (application/json) 匹配成功后返回给了浏览器。自然用户看到的是 JSON 而不是一个完整的网页。所以从这个角度来说,把 format.html 放在第一位比较合适(不知道有什么例外情况吗?)。
当然这个 bug 也可以说是程序或者控件的行为引起的,因为浏览器需要的 HTML 而不是 JSON,不应该发送格式为 */* 的请求。
2012-12-31 08:00:00
博客最早用的是 wordpress,首页上提供的 Atom 源是 /feed/。迁移到 Octopress 后,Atom 源地址变成了 /atom.xml。在 Google Reader 里看到订阅 /feed/ 的读者还是有不少的,用默认的地址这些读者就收不到博客更新了。
一个方法是改服务器的配置文件,以我之前使用的 nginx 为例,在相应站点的配置中增加一项 /feed/,把所有对它的访问重定向到 /atom.xml 即可:
location = /feed/ {
rewrite ^(.*)$ http://blog.yxwang.me/atom.xml;
}
如果服务器支持 .htaccess 也可以用类似的 rewrite 方法重定向。
后来服务器转移到了一个静态空间,不支持 .htaccess,我也没有访问 nginx 配置的权限,只能想办法自己改 Octopress,让它生成两份 Atom 文件。我想到的比较简单的方法是在 Rakefile 的 generate 任务结束后,把生成 atom.xml 复制一份为 /feed/index.html,这样访问 /feed/ 也就能访问到最新的 atom.xml 了:
desc "Generate jekyll site"
task :generate do
raise "### You haven't set anything up yet. First run `rake install` to set up an Octopress theme." unless File.directory?(source_dir)
puts "## Generating Site with Jekyll"
system "compass compile --css-dir #{source_dir}/stylesheets"
Rake::Task['minify_and_combine'].execute
system "jekyll"
system "mkdir -p #{public_dir}/feed"
system "cp #{public_dir}/atom.xml #{public_dir}/feed/index.html"
end
2012-12-26 08:00:00
Hulu 是这几个公司里唯一一个我没有找人内推而拿到面试机会的,也是面试体验最好的一个公司。Hulu 和 Twitter、Zynga、Foursquare 等公司一样,用了 jobvite 接受和追踪职位申请。因为是申请的第一家公司,我在申请 Hulu 时的 cover letter 写得很详细,针对职位需求上的每一条都写了我的相关工作经验,这也许是最后能拿到面试机会的原因吧。其他公司的 cover letter 都写得很简单,短短两段就结束了。
Hulu 的第一轮电面和其他公司的有些不同。45 分钟里要做四个题。面试官提前十分钟发了一封邮件给我,上面有两段代码。第一段代码是一个检查两个字符串是否是 anagram 的程序,写得很绕而且性能很差。面试官先问我这段代码的用途,然后问有什么方法优化,并要求我把代码写在 titanpad 上。接着他问了我第二段代码是做什么的。第二段代码也写得有点复杂,不过可以看出是一个检查有向图里面是否存在环的程序。
然后是设计题,要求设计一个 LRU Cache,只要说出接口、用到的数据结构和大致的算法就可以了,我想了个用一个 LinkedList 和一个 HashMap 的方案。
第四题还是代码题,写一个合并两个有序链表的程序。
面完后还有点时间,我们就聊了聊。面试官是在 Hulu 做支付的,主要用的语言是 Scala(Hulu 里面各个团队用的技术都很自由,可以选择自己喜欢的语言开发,Python Ruby C# Java 都有)。我当时正好在字节社做 iOS 上的应用内购验证,就问了他有没有处理黑卡坏账方面的经验。可惜 Hulu 在 iOS 上只有订阅方式的支付途径,没有 non-consumable product 的相关经验。
面完后 HR 给我安排了第二轮电面。面试官来自法国人,是 FFmpeg 的维护者之一。面试官看我简历上有星际比赛的奖项,还当过校队的队长,就和我聊起了星际2的平衡性。接着说到最近的虫群之心 beta,他觉得改动没有当年母巢之战的有意思,因为前期的改动不大。
聊了二十分钟的星际2后才切入正题,coding 题很简单,就是在一个数组里找出两个数,使得他们和为给定的数。写完这个最基本的版本后还有些别的变化,比如如果所有的数都是一定范围内的正整数,这时可以用一个数组统计每个数字的出现频率。
二面结束后等了三星期还没有消息,不知道是默拒了还是 HR 忘了。三星期后我又写了封信询问我的二面结果,HR 回信说欢迎我去他们公司 onsite 面,之前校招忙把我忘了。
Hulu 的总部在洛杉矶,Santa Monica 附近,离海滩只有几公里的路程。一进面试的会议室就看到白板上写着「Welcome Yuanxuan to Hulu」,一下子对这个公司充满了好感。
Hulu 的 onsite 面试题是面过的几家公司里最难的,一共有四轮。前三轮由来自内容团队、API 团队和架构团队的工程师面试,最后一轮的面试是 CTO 亲自面的。题目也是涵盖了算法、设计和实际的编码,有一轮的问题从设计一个分布式系统开始,讨论了这个系统的身份验证、数据分片、原子性、容错等问题的设计,考察了很多细节的地方,最后还让我写了 SQL,以及如何优化这些查询指令。不过我对 SQL 很不熟悉,每次用都要查手册,当时用了 ActiveRecord 的查询接口代替。
CTO 面完后 HR 进来问了我有没有其他公司的 offer,接着带我逛了一圈 Hulu 的工作场所。Hulu 总部只有 40 位左右的工程师,大家相互之间都很熟,气氛非常好,也比较自由。逛完后 CTO 带我出去买了杯咖啡,在回来的路上给我发了 offer。Hulu 的 package 和 Facebook 的在数额上差不多,但是因为公司性质的问题没法发股票给我,只能用相近的奖金代替。
回到公司后,CTO 问我对哪个团队比较有兴趣,我说如果我最后签了 Hulu 的话应该会想去做后端。HR 就安排了这个团队的工程师和我一起出去吃晚饭,还给了我两张 voucher 用于支付回去的出租车。当时因为觉得去 Hulu 可能性不大,觉得对方这么热情实在不好意思,可是还是推脱不掉,只得跟着他们去了附近一家餐厅。因为 Hulu 主要内容是美剧和电影的,饭桌上讨论的主题也是各种电视剧,还提到接下来 Hulu 可能会搬到附近另一个办公楼。
最后还是没有接受 Hulu 的 offer,虽然对他家印象非常好。一方面我更希望在湾区工作,另一方面小公司吸引人的一个点在于初期的股票,由于 Hulu 没法发股票所以这个优势也就没了。
Twitter 用的也是 jobvite 的招聘系统,我麻烦了一位在里面工作的学姐帮忙内推。据说 Twitter 相比其他互联网公司 work-life balance 是比较好的,工作会相对轻松。而在给我安排面试时 HR 给出的可以约的最晚的时间点,也是几个公司里最早的,于是我只能很早起床等待面试官的电话。
第一面是一位负责移动端网页前端开发的工程师面的。他说我的简历上工作经历很丰富,就不让我做 coding 题了,让我谈谈做过的这些项目。谈完项目后又进入了聊天时间,我提到喜欢 Twitter 的一个原因在于他有很多好用的开源项目。比如我平时写一些小型的 web 应用都会用 bootstrap,省时省力;而我之前实习的时候做的一个分布式的内容下载系统,也参考了 murder 的实现。另外因为当时我在实现字节社 iPhone 和 iPad 的 web 界面时碰到了之前修复的 bug 后来再次出现,忘了测试的情况,就问了他 Twitter 是怎么做移动端 web 界面的测试的。结果面试官说他们也基本上是买一堆设备然后人工测的,倒是桌面端可以用 Selenium。
愉快的结束第一面后,就开始了略有点无语的二面。我的二面前三次都没面成,第一次被放鸽子了;第二次面试官是 iOS 团队的,听我介绍完自己想做后端时,说他面我不合适,会让 HR 再帮我重新安排一轮;第三次再次被放鸽子,面试官那天很忙,抽不出身。每次面试失败后都要再等一星期才能收到 HR 的消息,所以光二面就拖了一个月。
第四次二面终于面成了。我听面试官介绍应该是来自平台相关的团队,不过面试官接着问我是喜欢写代码还是喜欢倒腾环境的时候,我说喜欢写代码,结果面试官说他的团队主要是做运维的,开发的工作量很小。估计是考虑到之前已经放过一次鸽子了,这次面试官还是继续面下去了。
虽然运维团队本身不是我喜欢的,但是面试官的问题相当对我胃口。一上来就是一连串的几个关于僵尸进程的问题:什么是僵尸进程?如何列出所有的僵尸进程?如何获得这些僵尸进程的 PID?如何把它们终止?我用 ps grep awk xargs 配合管道把这几个问题用一行命令行解决了,他很满意。
第二问是统计一个 httpd 的访问日志中,访问量最大的前五个 IP。我用 Ruby 写了一个,六行代码就能搞定。
接着面试官了解 DNS 吗,如果浏览器没法上网一般怎么诊断?我的回答是先 dig 看 DNS 解析是否正确,然后用 ping 判断 IP 是否可以访问,再用 curl 看是不是浏览器设置的问题。最后还可以用类似 www.websitedown.info 的服务检查。
第四个问题是怎么把一个文件复制到多个机器上?我说可以先用 ssh-copy-id 把公钥拷过去,然后再用 scp 拷文件。面试官说这样机器多就麻烦了。我解释到可以用 expect 写脚本自动输入密码,还加了句当然也可以用 Twitter 的开源工具 murder 分布式部署。
第五问是文件系统中 soft link 和 hard link 的区别。我的解释是 soft link 是一种特殊的文件,它的内容是被指向的文件的路径,而 hard link 是直接指向 inode 的。所以 soft link 可以用于目录,但是 hard link 不可以。
文件系统中 inode 和 path 的区别。我回答是 inode 是文件系统的一个数据结构,指向某个磁盘上的文件;而 path 是由多个 struct dentry 组成的,每个 dentry 描述了 inode 的父子关系。
最后一问是如何修改 DNS 服务器?我说可以修改 /etc/resolve.conf。
感觉 Twitter 的电面题会包含不少概念题,当然也有可能是运维团队的特点。几天后我收到 HR 的邮件,告诉我两位二面面试官都表示我对他们的团队不怎么感兴趣,而除了这两个团队外目前还没有其他团队可以给我安排面试。估计从此就进入等待列表了,没能去总部 onsite 面试,我在签掉 Facebook 后就联系 HR 把招聘进程终止了。
最后签了 Facebook,等着下一步关于工作签证手续的通知。mm 也表示愿意和我一起去美国,她应该会先在那里读个硕士再找工作。
希望接下来的签证手续等事情都一切顺利了。
2012-12-25 08:00:00
Google 面试也是托学长推荐了。HR 说我的简历看起来很不错,先给我安排了两轮电面。
电面都和 coding 有关,面试官会给你一个 Google Docs 链接,在电话里描述题目后要求你在 Google Docs 上写程序。题目的难度不高,两轮一共四题,都是对基本数据结构的操作,例如给在一个未排序的数组中去掉重复的数字,还有把一个有序数组转成一个平衡二叉搜索树,在一个已排序但有重复数字的数组中查找元素等。
第一轮电面聊天的时候还发现第一轮的面试官是在 ITA Software 做的。正好前几天用他们的产品 Matrix Airfare Search 订到了低价的去土耳其的机票,过了一星期神奇的在面试的时候碰到了这个团队的工程师。当时一下子就兴奋起来,聊了不少和 Matrix 的有关的话题。这位面试官听说中国的机票也能用他们的平台查询,还挺吃惊的。他还提到他们原本想把计算任务放到 Google 内部的计算框架上,但是由于和合作方的合同的限制,没法把一些商业数据放到 Google 的平台里,只能继续用原有的计算引擎。
第二轮电面的面试官是位印度人,虽然我很难听懂他的口音,但是他很耐心,会和我重复描述问题,所以题目做下来也没啥困难。在和他的聊天中得知他除了正业(Youtube)外还在闲余时间研究机器人。
电面结束后第二天收到了 HR 的邮件,邀请我去总部面试。由于当时已经是九月底了,而我十月初打算去土耳其玩两星期,于是只能从土耳其回来后开始准备签证了。Google 的 HR 非常热情,每次回邮件都很及时,经常能在加州时间晚上十一点左右收到她的邮件。她帮我弄来了 Google 的面试邀请信,顺利的过了签证面试。之后另一位 HR 还帮我订好了从上海往返 San Jose 机场的机票,以及三晚的住宿(因为考虑到我需要倒时差,多了一晚住宿,这一点也很体贴)。
Google 给我安排的住宿是 Wild Palms Hotel,在 Sunnyvale。不愧是硅谷的旅馆,每天早上起来吃旅馆的早饭,都能听到有人讨论 Java。在 Sunnyvale 的第二天我坐公共汽车到处逛了逛,考虑到接下来要在加州玩一圈,就办了张 T-mobile 的一个月电话卡(60 美元,包括不限量的短信、通话和 3G 流量,但是这家的信号非常差)。这家旅馆和苹果总部也很近,出门有公交车直达,作为半个果粉自然不会浪费这个机会。
第三天在 Google 工作的学长开车带我去了公司。Google 的园区里有不少免费自行车,没有锁,直接就可以骑。我在 Google 商店买了点礼品,在园区骑车转了一会儿后就开始面试了。
面试一共有四轮,每轮 45-55 分钟,中间有 5 分钟的休息时间。中午会有 Google 工程师带你吃饭。带我吃饭的 Google 工程师也是中国人,了解到这点后我们就知道用中文聊天了。吃饭时间里了解了不少在 Google 工作的优缺点,也一定程度影响了我之后做的决定。
由于签了 NDA,没法在这里透露具体的面试题目。面试主要都是算法题,比电面难一点。除了算法题外我还被问到一个分布式系统的设计题,以及一个多线程相关的 coding 题,后者用信号量很容易解决。其实如果能和面试官好好交流,这些题目做出来应该是没啥问题的。
面完第二周 HR 通知我拿到 offer 了,打电话告之了 offer 的具体细节。Google offer 的邮件附件还包括一份各项福利的介绍,着实吸引人。我还记得 HR 打电话来的时候我正好在三藩 Exploratorium 边上的小湖旁,在湖边美景中听到这样的好消息自然分外兴奋。HR 还告诉我没有限制我的签约时间,可以在任意长的时间后再做出决定,也算是 Google 非常体贴的地方。另外具体的职位会在入职前一段时间决定,HR 的说法是可以根据自己的喜好在一些项目之中选择。
我在今年三月份投过一次 Facebook 的暑期实习,被告之已经招满了,接下来校招时会再联系我。七月份的时候我又在网站上投了一次开发职位,还麻烦一位在里面实习的学长帮我内推了。八月一位 HR 联系我安排第一轮面试,电面安排在了九月。
Facebook 的 HR 也很负责,她在电面前几天打电话和我聊天,介绍 Facebook 的基本情况,以及面试流程。第一轮电面结束后的情况分三种,如果面试表现很不错,那就直接获得了 onsite 的机会;如果面试表现一般,面试官不确定要不要,就会再加面一轮;如果面试表现不好,就可能直接被刷了。除此之外 Facebook 的 HR 比较体贴的一点在于给中国人安排的第一轮面试官很有可能也是个中国人,降低了语言上出现问题的可能。
HR 的电话里还提到 Facebook 入职后有六星期的 bootcamp,可以熟悉各个项目和团队,具体的项目是 bootcamp 结束后自己选的。问了一下在那工作的朋友,做出的选择一般都会被满足,因为 bootcamper 的选择分布还算比较平均的。
Facebook 电面和 Google 差不多,是在 collabedit 上进行的。也是面试官在电话中口述题目,我在网站上写代码。老实说这个网站的体验不怎么样,面试过程中出现过几次我这边写的代码没在面试官那里出现的情况。好在面试官比较有经验,一发现有问题就会提醒我刷新页面。
第一轮电面我做了三个 coding 题,题目都不难,但是要求 bug free。电面的面试官抓 bug 的能力着实厉害,找出了两个我一开始没发现的 bug。好在他提示说有 bug 但没指出的情况下,我把它们都修正了。面试题目难度和 Google 的电面难度差不多,都是对数组、二叉树和字符串的基本操作。第一题是把一个字符串中的 %20 都转成空格,第二题是按层打印一棵二叉树,第三题是找出两个有序数组里不同的数字(类似求集合的异或)。程序正确后面试官还会问一些优化方面的问题,例如在不同的情形下应该使用哪一种算法。
面完后第二天收到 recruiter 的消息说我拿到 onsite 的资格了,具体的时间会在十一月通知我。
Facebook 给我安排的酒店是 Palo Alto 的 Sheraton。酒店门口停着不少出租车,面试那天的出租车司机还是用 Square 收的钱。我的面试正好赶上了他们的 University Day。这一天的安排是上午三轮面试,中午吃饭,下午逛一圈公司以及三场讲座。我的第三轮面试还出了点茬子,面试官一直没出现,HR 只能先带我去吃中饭。中饭结束后 HR 带着别人边逛公司边介绍,我只能继续我的第三轮面试了。
Facebook 校招时本科生和硕士生是统一级别的,面试只包括算法题,不会有设计题;而博士生则高一级,面试的时候还会有设计题。三轮 onsite 面试包括一轮 jedi 和两轮 ninja。jedi 面主要是让面试者介绍自己的项目经历,了解面试者的技术专长和偏好,不过面试官也让我做了一个简单的 coding 题。ninja 面各有两个 coding 题,题目难度都不大,和电面差不多。但是与电面不同的是,面试官会深入问一些细节的问题,例如代码里生成了多少个新的对象,有没有办法优化等,有一个问题还要求我用一种算法实现后,再用另一种完全不同的思路实现一次。(onsite 面试是签了 NDA 的,这里就不方便透露具体的题目了)
面试完之后有三个讲座,第一个讲座介绍了 Facebook 总体的工作环境。第二个分产品和后台两个讲座,同时进行所以只能选一个。我一开始选择了后台开发,不过当时突然对产品有了兴趣,就去听了产品的讲座。一位负责 Events 开发的工程师结合这个产品介绍了下 Facebook 内部产品开发的流程,例如新特性是怎么出来的,如何测试等。最后一个环节是几位刚从 bootcamp 毕业的员工和我们分享他们在 Facebook 中工作的感受。
University Day 结束后,参加活动的每位学生还收到一个包装精致的礼物。拆开来后是一块两面分别刻着「Move fast and break things」和「Proceed and be bold」的玻璃砖。我还是很喜欢这个礼物的,这也一定程度上影响了我最后的选择。
面试完第二天 HR 从我这里要了三位 reference,包括他们的职称和联系方式,接下来 HR 会联系他们询问我的情况。Facebook 的动作也很快,第二周就给我发了 offer。有意思的是,offer 邮件的 welcome package 最后一页建议面试者在入职前熟悉一下 Unix,还推荐了几篇文章和两本书。
Google 和 Facebook 的 onsite 是在同一星期面的,前后只隔了一天,收到 offer 的时间也只差了一天。package 方面, Facebook 比 Google 的要好不少,但是 Google 的 HR 说可以 match Facebook 的 offer。去之前我想过如果两个 offer 都拿到,那就去 Google。但是到了这两个公司,和几位面试官以及在里面工作的朋友深入聊天后,最终还是选择了 Facebook,因为它规模更小,应该能有更多的锻炼机会。
另外我了解到的 Google 和 Facebook 的面试流程都是先由各位面试官给你打分,例如分 strong hire / hire / weak no hire / strong no hire 四档(不一定完全一致,比如可能会多一档 neutral)。同时要写下关于你的面试情况的报告。再接着由 hiring committee 讨论要不要给你 offer,以及 package 如何。有亮点(某位面试官的 strong hire)很重要,一个 strong hire 和几个 weak no hire 会比平庸的清一色的 weak hire 好。
2012-12-24 08:00:00
最近签掉了 offer,找工作的事情算是告一段落。在这里写一点面试体验和心得,希望对有兴趣去北美工作的朋友有所帮助。
先简单介绍下自己,国内硕士在读,明年毕业,没有牛 paper,也没参加过 ACM-ICPC 竞赛。在实验室做过内核、虚拟机和 Android 底层相关的研究工作,接过一些网页和移动开发的外包,2011 年开始在字节社兼职负责后台开发。另外也经常上 Stackoverflow 和 GitHub。
这次决定直接申请美国的职位后,由于心里没底,不知道国外公司招聘的难度,所以一开始投了很多公司。几个大公司都找人内推或者直接投了,小公司也投了不少,比如 Foursquare、Path、Pinterest 和 Square 等都试了。当时甚至在手机上找了一圈应用,把可能涉及后端开发的应用都投了一遍。不过大多数公司都没给我安排面试,最后 Microsoft、Google、Facebook、Twitter 和 Hulu 这五家公司愿意给我面试机会。
一般来说,国内毕业后直接投国外公司,会比出国留学毕业后找工作的难度大一些。除了语言因素之外,我了解到的主要原因在于工作签证,出国留学毕业后可以通过 OPT 签证入职,之后再过渡到 H-1B 签证。而国内毕业的学生只能通过 H-1B,这意味着要等到第二年的十月份才能入职。好在 Google、Facebook 等公司不太介意这个问题,还是会欢迎国内的应届生申请。
校招的 HR 一般会有各自的职责。比如 technical sourcer 负责发现有希望进入自己公司的应届生;recruiter coordinator 会帮助 recruiter 安排面试者的面试时间、面试官,以及 onsite 面试时帮助面试者订机票和酒店;staffing consultant 则负责发 offer 以及介绍公司的具体福利制度,并解释面试者相关的问题。不同公司的 HR 职责的分法自然也不一样,我在 Facebook 的面试过程中只和两位 HR 联系过,而在微软的面试过程中则联系过五六位 HR。
在面试流程方面,相比我了解到的国内公司的面试,国外公司的面试安排上会更人性化一些。例如安排面试时间时,HR 一般会先让你给出几个空闲的时间点,然后他们再从这些时间中给你安排面试。此外在为你安排 onsite 的住宿时,也会询问你有没有相关的要求。
关于面试题目,大多数公司都比较侧重面试者对基本的数据结构和算法的掌握程度,以及把这些内容实现为实际代码的能力(一般会要求你选一个语言实现,而不允许用伪代码)。越是规模大的公司越注重这些基本功,而小公司除此之外还会考察你的开发经验,例如对某个框架的了解和性能优化方面的技巧。关于这一点区别我的理解是大公司里面会有自己的框架和开发工具,面试者的基本功好就能比较快的上手;而小公司一般用社区现有的工具,所以已有的开发经验可以直接用在将来的工作中。
下面是这几个公司的面试细节,有些公司因为在 onsite 面试的时候签了 NDA,所以没法透露具体的面试题,还请见谅。
微软是我最早投的公司之一,托了在微软总部工作的一位学长帮忙内推。面试包括一轮 HR 面和四轮 onsite 面。
申请了一个多月后一直都没有反应,直到微软国内招聘的前一天,北京的 HR 打电话问我是不是投过微软的职位,要我参加第二天上海站的笔试。
笔试过后,又过了一个多月,收到了微软一位招聘人员的邮件,问我是不是对微软北美的职位有兴趣,要我填一份基本情况的问卷,里面有问到其他公司的面试进度。我当时已经收到了 Google 和 Facebook 的面试邀请,就如实填写了。回复第二天后就收到了邮件通知,告诉我会有 HR 进一步跟进。第三天有一位 HR 联系我和我约电面的时间。微软约电面的方式和其他公司不大一样,HR 会给出很多个选项,让你在里面选择几个空闲的时间。另外值得一提的是这些时间都转成北京时间了,这也是微软在安排面试时比较人性化的一个地方。
第一轮面试是 HR 面。HR 先问了一些技术无关的问题,比如喜欢做什么,工作地点的偏好,什么时候开始学的编程,为什么投了微软等等。接着是一些智力题,比如 9 个小球,8 个质量相等,另一个比其他的重,如何用天平称两次把它找出来;公司开发了一种新键盘,有哪些测试它的方法;在会议室内怎么估计室外的温度。都是些更像是考验英语水平而不是技术能力的问题。
面完第二天收到了 onsite 的通知。虽然是北美的职位,onsite 面试地点却是在上海。我参加的是周日的面试,和我一起参加面试的还有一位学生,他之前在微软实习,了解到这次有去北美工作的机会后也想尝试下。面试官是从总部飞过来的工程师,一共有四位,其中三位都已经是 principal 级的了。HR 提到一般技术面试要五轮,因为我们之前参加过一轮笔试,所以只需要面四轮。
onsite 面每一轮的过程都差不多,都是面试官自我介绍,接着我介绍自己和做过的一些项目,然后开始技术问题,最后是我提问的环节。微软的面试问题会考察面试者编码、设计和测试三方面的能力。
coding 环节要求直接在白板上写代码,我被问到两个 coding 问题。一是如何检查一棵二叉搜索树是否正确,二是写一个解数独的程序。第一个问题写起来很快,第二个问题因为时间有限,我先写了一个没啥剪枝的暴力搜索的版本,写完后和面试官分析了可以在此之上做的优化。
设计方面的问题有两个。第一个问题是设计一个分布式的数据管理系统。使用场景可以是一个连锁店信息的记录系统,每个分店都有可能更新自己的信息,并把这些改动传播到整个系统中。在设计这一系统的同时要考虑性能、容错、一致性等要求。我一开始想了一个基于 push 的机制,在面试官指点下逐步优化,最后还是有不少问题。于是干脆重新设计了一个基于 poll 的系统,优化改进之后面试官满意了。
另一个设计问题和类的设计有关,要求设计一个包含图形界面的棋盘游戏。因为之前做过不少相关的开发,所以这一部分我还挺擅长的。按照 Single Responsibility 的原则设计了几个分工明确的类,另外把网络对战和 AI 接口都考虑进去了。设计完成后面试官要求我从用户鼠标单击这一事件开始介绍整个控制流程,在某些类中还会问及这么设计的原因,以及和其他设计方案相比的优缺点。
测试部分的问题也有两个。第一个问题是如何测试一个随机函数。第二个问题和分布式系统有关,面试官先向我介绍了一个分布式系统,包括它的使用场景和基本的架构,然后问我其中某一个部件应该如何测试。提到正确性、可伸缩性、一致性和容错性后再给出相应的测试方法应该差不多了。
onsite 面试后的第二天后就收到了 HR 的邮件,祝贺我拿到了 offer,并和我约时间谈具体的 offer 细节。虽然微软一开始拖了两个多月才开始安排面试,但是一旦开始面试后他家的效率非常高,是这次面试的几家公司里效率最高的了。
2012-12-09 08:00:00
虽然这一年还没结束,还是想为这一年写点什么。
一月到四月还是一如既往的波澜不惊的生活着。因为在一个创业公司兼职,做的事情比一年前有意思一些,但基本上还是实验室寝室两点一线,周末和 tt 出去逛逛。四月初去了一次杭州。
过年的时候和 tt 商量一起去台湾玩,但那时候去台湾还只是个完全没有谱的事情。三月底 tt 看到一个台湾自由行的优惠活动,四天内截止,两个人就这样一冲动报了去台湾的团购。四月准备好了各种手续,准备五月中旬出发。但是老实说,甚至在出发前的那一天,我都没觉得这件事情是彻底定下来了,或者说,总觉得去台湾玩这样一件事还是离自己遥远了点。也许是宅生活惯了,一下子这样进行一个离开大陆的持续 10 天的旅游让自己觉得太遥远了。去台湾我还是第一次坐飞机。
但是当下了飞机,双脚踏在松山机场的时候,我才意识到这一次台湾之旅真的成行了。
台湾这次旅游其实对我心理上的积极意义很大,不知道怎么描述,大致就是一件事原以为离自己很远的事情从慢慢部署准备到突然意识到已经成功了的感觉。
接着是暑期实习。在此之前我一直在 D 和 M 之间犹豫,最后去 M 实习的前一段时间还后悔当初没去 D,因为不大习惯 M 的企业文化。但是现在发现就实习而言的确应该选择 M,虽然 D 里面做的事情应该会更有挑战也更有意思,但是在 M 里 soft skill 得到了很大的锻炼。回复邮件时的措辞是一方面,对一个大公司的一些基本了解是另一方面。更重要的是,mentor 是位英国人,实习的三个月里约了他两次一共进行了三次面对面的聊天,这对英语口语的提升非常明显。
关于这一点,岔开来说口语提升的帮助不仅仅在这三次锻炼直接得到的提高上,而是养成了注意美剧、电影中常用语积累的习惯。比如聊天的时候我不知道我回答完问题后应该怎么表示已经说完了,「That’s all 」听起来正式了一点。后来看了《Before Sunset》后发现可以用「Did I answer your question?」。如果之前没有经历这样的聊天,恐怕看电影的时候听到这些用语我是不会注意的吧。
十月的土耳其之旅。是在八月中旬决定的,订了机票。即使已经有过去台湾的经历,到达伊斯坦布尔的那一刻我还是有一种很强的「居然真到这里了」的感觉。算是加强了这种实现原本觉得遥远的事情的信心吧。
当然这一年最重要的,还是最近的找工作的经历了。一开始只是打算试试一两家硅谷的公司,后来某一晚听了学长的建议打算多投几个试试。去 LinkedIn 翻了一圈一度二度人脉,发现真要投还有不少公司可以内推。一下子动了心开始认真准备起来。
这一段时间准备工作时的状态可以说是有史以来最积极的,一方面憧憬着美好的各种可能性,另一方面电面之后一个接一个的好消息又不断激励着自己,让我充满动力的准备面试。
而现在还真拿到了 FG 的 onsite 资格,可以飞去加州面试了。不贪心的话已经是可以满意的结果了吧。
还有一个半月,结果就差不多都出来了。不管最后结果如何,这一年,最大的收获就是体验了好几次这种以为离自己很远,但却逐渐变得可能直到最后变成现实的感觉。这种感觉的正面动力太强大了,会让人真的相信「Impossible is nothing」。
2012-10-21 08:00:00
顺带把几个月前写的台湾旅游 tips 也放到这个博客来。
我们在台湾住的都是民宿:
2012-10-17 08:00:00
刚从土耳其呆了两星期回来,我们的行程是 Istanbul(一天一晚),过夜大巴到 Göreme(三天两晚),过夜大巴到 Fethiye(三天两晚),过夜大巴到 Bursa(一天一晚),下午的轮船回 Istanbul(四天三晚)。趁着记忆还新鲜,写一点土耳其旅游相关的 tips。




2012-08-10 01:37:12
这是一篇两年前 Twitter 开发团队写的文章,今天挖出来研究了一下。原文地址 http://engineering.twitter.com/2010/06/announcing-snowflake.html
Twitter 早期用 MySQL 存储数据,随着用户的增长,单一的 MySQL 实例没法承受海量的数据,开发团队就开始用 Cassandra 和 sharded MySQL 替代原有的系统。然而和 MySQL 不同的是,Cassandra 没有内置为每一条数据生成唯一 ID 的功能,因为在一个分布式环境下,很难有完美的 ID 生成方案。
对于 Twitter 而言,这样的 ID 生成方案要满足两个基本的要求,一是每秒能生成几十万条 ID 用于标识不同的 tweet;二是这些 ID 应该可以有个大致的顺序,也就是说发布时间相近的两条 tweet,它们的 ID 也应当相近,这样才能方便各种客户端对 tweet 进行排序。
第一个要求意味着 ID 生成要以一种非协作的(uncoordinated)的方式进行,例如不能有一个全局的原子变量。
第二个要求使得 tweet 按 ID 排序后满足 k-sorted 条件。如果序列 A 要满足 k-sorted,当且仅当对于任意的 p, q,如果 1 <= p <= q - k (1 <= p <= q <= n),则有 A[p] <= A[q]。换句话说,如果元素 p 排在 q 前面,且相差至少 k 个位置,那么 p 必然小于或等于 q。如果 tweet 序列满足这个条件,要获取第 r 条 tweet 之后的消息,只要从第 r - k 条开始查找即可。
Twitter 解决这两个问题的方案非常简单高效:每一个 ID 都是 64 位数字,由时间戳、节点号和序列编号组成。其中序列编号是每个节点本地生成的序号,而节点号则由 ZooKeeper 维护。
具体的参数可以在这个 IdWorker.scala 中看到。序列编号有 12 位,意味着每个节点在每毫秒可以产生 4096 个 ID。节点号在源码中被分成两部分,数据中心的 ID 和节点 ID,各自占 5 位。时间戳则是记录了从 1288834974657 (Thu, 04 Nov 2010 01:42:54 GMT) 这一时刻到当前时间所经过的毫秒数,占 41 位(还有一位是符号位,永远为 0)。
2012-08-02 08:00:00
Things Cloud for iOS 的同步功能出来后一直不能正常使用,必须得先翻墙才行。用代理截了下请求后发现 Things Cloud 用的同步服务器是 multithreaded.thingscloud.appspot.com,难怪一直没法访问。
好在 Things Cloud 同步走的是 HTTPS 协议,所以恢复方法也很简单,换用一个没有被污染的 DNS 服务器就好。对于越狱了的机器,也可以直接修改 iOS 上的 /etc/hosts 文件,在里面添加下面两行地址。
203.208.46.161 multithreaded.thingscloud.appspot.com
203.208.46.161 thingscloud.appspot.com
2012-07-21 08:00:00
最近实验室做的一个东西会向 Android 应用快速注入一系列触屏事件,模拟用户的点击。但是我们发现当按下和弹起的 MotionEvent 之间时间间隔过小(例如小于 100ms)时,会导致该事件被忽略。看了代码后发现 Android 中按下和弹起之间时间间隔要在 115ms 以上才会被认为是一个点击事件。这里结合 Android 的源码分析一下点击事件的产生过程。
当用户触摸屏幕后,底层驱动会将这一事件包装成一个 MotionEvent 对象,传递给 WindowsManagerService。后者维护了一个事件队列,会将事件分发给正获得焦点的控件,其中,dispatchPointer 方法负责将触屏事件发送给当前活动窗口(Window)。每一个 Window 都有一个 ViewRoot 实例接收来自 WindowManagerService 的消息。活动窗口的 ViewRoot 在 handleMessage 方法中接收了这一触屏事件后,就会调用最上层的 View 对象的 dispatchTouchEvent 方法。和大多数图形系统一样,Android 中的 view 也是以树状结构组织的,事件会从最上层依次向下层传递,直到某一结点能处理这一事件为止。
View 对象的 onTouchEvent 负责处理触屏事件,这里也是点击事件产生的地方,下面这段代码创建了一个点击事件,并把它添加到事件链中,在触屏事件处理完成后再执行。
// Only perform take click actions if we were in the pressed state
if (!focusTaken) {
// Use a Runnable and post this rather than calling
// performClick directly. This lets other visual state
// of the view update before click actions start.
if (mPerformClick == null) {
mPerformClick = new PerformClick();
}
if (!post(mPerformClick)) {
performClick();
}
}
而在前面的判断条件可以看到,这一点击事件创建的前提是 mPrivateFlags 的 PRESSED 位和 PREPRESSED 位同时被置上 (View.java):
boolean prepressed = (mPrivateFlags & PREPRESSED) != 0;
if ((mPrivateFlags & PRESSED) != 0 || prepressed) {
...
}
接着看触屏按下事件的处理 (View.java):
case MotionEvent.ACTION_DOWN:
if (mPendingCheckForTap == null) {
mPendingCheckForTap = new CheckForTap();
}
mPrivateFlags |= PREPRESSED;
mHasPerformedLongPress = false;
postDelayed(mPendingCheckForTap, ViewConfiguration.getTapTimeout());
break;
mPrivateFlags 的 PREPRESSED 位会被立即置上,另外 postDelayed 方法会在经过 ViewConfiguration.getTapTimeout() 时间后,执行一个 CheckForTap 的实例,看来这就是我们要找的东西了。CheckForTap 是一个很简单的 Runnable 对象,它所做的就是把 mPrivateFlags 中除了 PREPRESSED 的位都清零,再把 PRESSED 位置上,并注册一个长按事件的检测对象。而 ViewConfiguration.getTapTimeout() 的默认值便是 115ms。注释中还说明了这个延时的用意在于区分滑动操作和点击操作,如果触屏区域在这一时间内没有移动,这个操作才会被识别成点击。
2012-06-30 08:00:00
先来看一个 Java 中的例子,Java 中的数组是协变的。也就是说,一个 String 数组(String[])是可以被当成 Object 数组(Object[])处理的:
String[] a1 = { "abc" };
Object[] a2 = a1;
这种协变虽然在读取数组内容时不会有问题(a1 数组中的 String 元素可以被当成 Object 使用),但是修改数组内容时就会出现无法在编译期检测出来的错误了:
a2[0] = new Integer(17)
String s = a1[0] // java.lang.ArrayStoreException
之所以要采用这种设计,Java 的发明者 James Gosling 曾解释说,这样做就能用一种简单通用的方式处理 Java 数组了。例如 java.util.Arrays 提供了sort 方法用于所有数组类型的排序,它的函数声明是 sort(Object[] a, Comparator c),如果 Java 数组不支持协变,那么就很难简单的写出这样通用的排序方法了。
wikipedia 上关于[协变和逆变的解释](http://en.wikipedia.org/wiki/Covariance_and_contravariance_(computer_science)是:
Within the type system of a programming language, covariance and contravariance refers to the ordering of types from narrower to wider and their interchangeability or equivalence in certain situations (such as parameters, generics, and return types).
简单来说,它们指定了不同类型相互之间的可转换性。协变类型可以从较普通的类(动物)转换到更精细的类(猫),而逆变则允许从较精细的类(三角形)转换到较普通的类(几何图形)。
Scala 中默认的参数类型是不变(invariant)的,也就是说,下面代码中 Invariant[Object] 类和 Invariant[String] 类的实例,均无法转化成另外一种类型。
scala> class Invariant[T]
defined class Invariant
scala> var x: Invariant[Object] = new Invariant[Object]
x: Invariant[java.lang.Object] = Invariant@8e43b44
scala> var x: Invariant[Object] = new Invariant[String]
<console>:8: error: type mismatch;
found : Invariant[String]
required: Invariant[java.lang.Object]
scala> var x: Invariant[String] = new Invariant[Object]
<console>:8: error: type mismatch;
found : Invariant[java.lang.Object]
required: Invariant[String]
在 Scala 中,如果要把某一参数类型 T 声明为协变,只需要在它的前面加上 + 号即可:
scala> class Covariant[+T]
defined class Covariant
scala> var x: Covariant[Object] = new Covariant[String]
x: Covariant[java.lang.Object] = Covariant@36527386
类似的,声明 T 为逆变的方式是在它前面加上 - 号。
判断一个类型是逆变、协变还是不变的方法,被称为里氏替换原则(Liskov Substitution Principle)。LSP 指出,如果所有类型 U 出现的地方都能用类型 T 替换,那么 T 就可以被认为是 U 的一个子类型。
协变和逆变有时候可以同时作用在一个类型上,比较经典的一个例子就是 Scala 中的 Function1。当出现类似 A => B 的 lambda 函数时,编译器会自动将它转成一个 Function1[A, B] 的定义。标准库中 Function1 的定义如下:
{% codeblock lang:scala %} trait Function1[-S, +T] { def apply(x: S): T } {% endcodeblock %}
这里 S 是函数参数,T 是函数的返回类型。不难理解,当一个函数 f 能替换另一个函数 g 时,f 接受的参数必须是 g 的父类,而 f 的返回结果必须是 g 的返回结果的子类。因此这里 S 是逆变的,而 T 则是协变的。
参考:
2012-06-11 08:00:00
Revisiting Storage for Smartphones 是今年 FAST 会议上的最佳论文,这篇论文提出了一个违背直觉的观点,很有意思。这里简单介绍一下这篇论文的内容,有兴趣的朋友可以直接访问前面的链接下载原文或是观看现场录像。
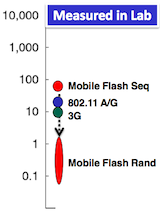
传统的观点认为,移动应用性能的主要瓶颈在网络和 CPU,而闪存的读写速率明显高于网络传输速度,不会成为性能的瓶颈。然而,根据上图作者给出的关于移动存储性能的图例(纵坐标单位为 Mbps,本文图片均来自演讲 slides 和原论文),我们可以看到,虽然移动存储顺序读写的性能明显高于 wifi 和 3G,但是随机写的性能却比它们差很多,因此移动存储成为应用性能瓶颈是完全有可能的。
为了证明移动存储的确会给应用带来不小的性能影响,作者在 Nexus One 上尝试了多个应用,并测试它们在使用不同配置时的性能表现。
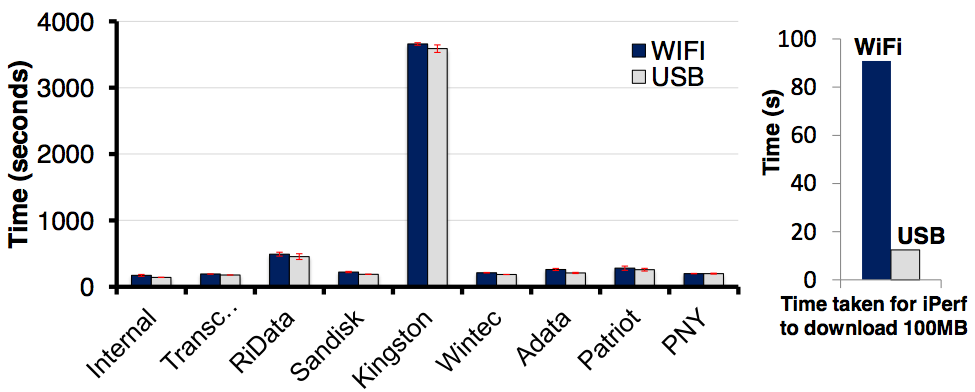
下图为一个浏览器应用的测试结果(基于 WebKit,测试了 50 个网站)。左侧柱状图展示了使用不同价位的存储卡时,该测试的性能表现。可以看到,不同存储卡的带来的性能影响非常大,Kingston 甚至产生了 20 倍左右的性能差别。另外值得注意的是,图中蓝色柱子表示的是在 wifi 条件下的性能,灰色柱子表示的是通过 USB 连接电脑网络时的性能。右侧柱状图中可以看到,USB 连接网络的性能比 wifi 连接快 10 倍左右,即使如此,左图中蓝色柱和灰色柱的差别不大,从而可以看出网络提升 10 倍后对总的性能影响还是不大(不过我觉得这里 wifi 连接的速度已经很快了,可能加一个 3G 的测试会更公平一点)。
作者还测试了 Facebook、地图、邮件、安装程序等应用在不同配置下的表现,均得出了好的闪存卡能明显提升应用速度的结论。

既然存储卡的性能影响这么大,有没有优化的空间呢?上图是作者关于浏览器优化的一些测试。浏览器保存在磁盘上的数据主要有两种,一种是缓存,以 write-back 的方式写到磁盘;另一种是缓存索引等数据,以同步的方式写到磁盘的 SQLite 数据库文件中。上图中可以看到,把浏览器的缓存放在内存中对性能提升并不大(A),把数据库文件放到内存中则能明显提升应用的性能(B),而如果把数据库文件的写操作改成异步的方式,也能提升应用的性能(D)。由此可见,SQLite 数据库操作是影响应用性能的主要原因。应用使用 SQLite 数据库有时只是为了方便,而不需要它保证一定的可靠性。同时可以看出 SQLite 的写操作是相当随机的。
最后作者还给出了一些可能的优化的方案,例如使用 RAID,采用日志式文件系统,或是由应用指定异步/同步操作等。不过这些都不是这篇论文的重点了。可以预见的是,这篇论文挖了一个好坑,将来肯定会有更多的论文研究如何提高闪存上移动应用存储的性能。
2012-03-28 08:00:00
以前部署新机器时都要把一堆配置文件 scp 过去,今天折腾了下用 Git 统一管理这些配置文件。
做起来很简单,创建一个 dotfiles 目录,把所有要同步的配置文件都放到这个目录下,并重命名去掉文件名开头的点,以免被 Git 忽略。写了一个脚本链接这些配置文件到 HOME 目录:
#!/usr/bin/env ruby
safe_mode = ARGV.include? '--safe'
files = %w(zshrc tmux.conf gitconfig vimrc emacs gitignore_global LS_COLORS)
files.each do |file|
unless safe_mode and File.exists?("#{ENV['HOME']}/.#{file}")
%x(ln -s -i -v $PWD/#{file} ~/.#{file})
puts ".#{file} linked" if safe_mode
end
end
为了方便同步脚本到 GitHub,我在 .zshrc 中定义了两个命令用来上传、下载最近的脚本配置:
alias pull-dotfiles='pushd $HOME/dotfiles && git pull origin master && ./link-files.rb --safe; popd'
alias push-dotfiles='pushd $HOME/dotfiles && git add -A && git commit -m "Update" && git push origin master; popd'
pull-dotfiles 可以获取最新的配置,push-dotfiles 则是提交最近的改动到 Git 服务器。我的配置文件在 https://github.com/zellux/dotfiles,希望对大家有用。
2012-02-18 08:00:00
ETag 是 HTTP 协议的一部分,可以用来检测客户端的缓存是否仍然有效。不少网站都实现了对 ETag 的支持,在 HTTP 响应头中加入当前传送内容的 ETag。以 heroku.com 为例:
$ curl -I www.heroku.com
HTTP/1.1 200 OK
Server: nginx
Date: Fri, 17 Feb 2012 17:36:44 GMT
Content-Type: text/html; charset=utf-8
Connection: keep-alive
Etag: "f74bb78aa48d36e6a0b2072a131b20b9"
Cache-Control: public, max-age=300
Content-Length: 15481
可以看到响应头中给出了请求内容的 ETag 为 f74…b9。接下来我们再次向服务器发起请求,并通过 If-None-Match 字段告之服务器我们已经获得过一份 ETag 为 f74…b9 的内容。服务器收到请求并生成页面后,如果发现页面的 ETag 不变,就会返回 304,声明缓存有效:
$ curl -I -H 'If-None-Match: "f74bb78aa48d36e6a0b2072a131b20b9"' www.heroku.com
HTTP/1.1 304 Not Modified
Server: nginx
Date: Fri, 17 Feb 2012 17:37:03 GMT
Connection: keep-alive
Last-Modified: Fri, 17 Feb 2012 17:34:00 GMT
Cache-Control: public, max-age=300
ETag: "f74bb78aa48d36e6a0b2072a131b20b9"
浏览器在访问网页时,记录下上一次服务器返回的 ETag,在下一次访问该网页时发送这个 ETag,这样就能有效的利用本地缓存,减少不必要的网络传输了。
Nginx 和 Apache 都很好的支持了 ETag 功能,它们会为静态资源计算 Hash,并将它作为 ETag 返回给客户端。 而对于 CPU 负载较高的应用,还有一个可以优化的空间。Web 服务器在处理客户端请求时,通常的过程是从数据库读取所需数据,交给模版引擎生成 HTML,计算该页面的 ETag,再回复客户端。事实上所需的数据读取完成后,就足以判断缓存是否有效了。
Rails 早在版本 2.2 就加入了 stale? 方法方便开放人员自定义 ETag。以一个博客文章页面为例,页面内容由文章和评论内容生成,如果这两份内容都没有变化,就可以认为客户端缓存依然有效了:
def show
@article = Article.find(params[:id])
@comments = @article.comments.all
if stale?(:etag => [@article, @comments])
respond_to do |format|
# ...
end
end
end
除此之外,还可以通过 Last Modified 字段控制缓存有效性,Rails 也同样提供了很方便的支持。但是ETag 方法控制缓存更为精确,而且在服务器时间变化时用 Last Modified 容易出错,因此 ETag 往往是更被推荐的方案。
2012-01-02 08:00:00
Windows 7 及 Visio 2010 下验证可行:
这样输出的 EPS 文件的边框是整个 A4 页面,需要用 epstool 把它们周围的白边框去掉:
epstool --copy --bbox figure.eps figure-fixed.eps
epstool 在常见的几个软件源中应该都能找到。
2011-12-05 08:00:00
一直在国服大师组混,最让我头疼,同时研究的也最多得对战就是 ZvT 了。这里写一点自己关于 ZvT 的心得,欢迎探讨。
探路农民不能少,我一般在 14d 的时候拉个农民出去探路。探到对方位置后农民别急着走,要在对方路口停留一会儿,注意对手的第一个枪兵有没有跑出来,以便做好防 rush 的准备。同时这也避免了对方农民在你基地旁造一个欺骗性的地堡时,拉过多的农民下来防守。
分矿处女王造出来后第一件事是铺菌毯而不是补虫卵。第三个女王也一定要出,保证菌毯铺开的速度。
防火车的话,我现在还是倾向于用蟑螂。用蟑螂的另一个好处在于配合小狗应付对手第一波坦克+枪兵的压制比较有效,第一波出来的时候自爆速度往往还没有好,在没有菌毯的地方很难起效果。
T 开局还有几个变种,如果看到对方出了火车,数量不多,而且其他地面部队也不多的话,还是老老实实补个 bv 造防空吧。
还是关于侦查。对方二矿开始运作后,小狗要时不时的看看对方家门口。一要注意对手兵力组合,二要注意攻防。如果枪兵不多也没升攻防,对手就有可能用机械化部队了。
如果对手是标准的枪兵+坦克的组合,我倾向于防下对手第一波部队或者自己飞龙出来后再开三矿。不要因为对手开矿早,就以为自己也能随意补农民发展经济了。现在 T 第一波的 timing 都抓得蛮准,三矿农民补早了很有可能第一波就被推掉了。
相反,打机械化组合就要利用对方部队成形前的真空期尽早开矿,这也是前面强调小狗侦查的原因。
开三矿后记得在主矿分矿上都码上几个地堡,这点可以好好像雀茶学学。T 空投你的目的不单单是骚扰经济,而是让自己的主力部队能舒舒服服的推到合适的位置。防下对手一船空投后发现对手已经在咽喉位置架好坦克,摆好枪兵阵形了,这时候就很难打下来。
对方坦克阵慢慢推进的时候切记一定要耐心,对手总能出现疏漏的。同时飞龙记得吃掉落单的补给部队。
小狗+自爆和对方枪兵+坦克打正面的时候,能包最好包,不能包也要记得拉一队小狗拦住枪兵,干扰走位。
怎么打机械化。发现得早的话我一般就做好龙狗换家的准备了,成功率也不低。但是发现晚的话,只能硬着头皮打正面了。现在 GSL 上比较常见是在对手刚出家门,坦克还没架起的时候,用蟑螂吸引火力,同时大量的自爆上去换雷神。我试了几次效果不是很好,可能是时机没选择好的缘故吧。
飞龙一定要保存好。攒多了威慑力非常大,能很有效的牵制对手的部队。
天梯上有时还能看到另一个比较奇葩的战术:爆维京。听起来很不靠谱的战术,但是实战中经常能把人打懵(Z 人口补不上,对方维京成型后地面骚扰能力也很强)。当然这种战术应对起来也不难,多预留点人口,每个分矿都码几个堡,准备一两队小狗,接着出飞龙就好了。类似的战术还有火车女妖流,都是能打得你很不舒服,但是一旦放下来就没啥威力的战术。
我觉得 ZvT 后期的关键在于防空投,因为自爆+狗+感染+母巢王虫的组合基本不怎么怕 T 打正面。但是三攻三防的枪兵拆分矿的能力很强,对应方法,也就只有放好领主侦查,同时在分矿补更多的堡了。
出母巢王虫后记得拉上所有的女王,加血效果会让对手很无语。
一个女王加虫卵的技巧。星际2里有一个切换主基地的快捷键,默认是Backspace,我把它设置成了Tab上边那个键。把所有女王编队后,按住Shift,点切换键,按v后再点一个基地,再按切换键,再v一个基地,这样一轮循环下来可以给所有基地注上虫卵。
不过这么做有一个问题就是女王数量比基地数少的时候,会出现女王到处跑的现象。我现在用的方法是不按Shift,点切换键快速切到基地视角,如果这个基地旁有女王就控制它注卵。这样操作上麻烦了一点,而且注卵时间上有个判断的延迟,但是灵活性高了不少。
2011-11-29 08:00:00
jekyll 是一个静态博客生成工具,可配置性很强。但是它的配置对于初学者不是很友好,没有现成的模版,需要自己从头搭一个。octopress 大大简化了这一配置过程,在 jekyll 的基础上提供了一个默认主题,以及一些常用的插件。
在 github 上捣鼓了一阵子 octopress 后,决定把原来的 wordpress 博客的数据转移到这个 octopress 博客上了。相对于 wordpress,octopress 的优点在于:
支持 Markdown 语法。Markdown 是 github、stackoverflow 上的默认标记语言,写笔记我也一直用这个。Mac 平台上有不少好用的 Markdown 编辑器,例如收费的 Byword,免费的 Mou,这些工具都增加了写日志时的愉悦感。
静态。对主页空间没有要求,甚至放到 github pages 上都可以。静态页面如果要加评论,可以考虑 disqus 等第三方 JS 工具。
对内嵌代码支持很好。内置了 pygments ,这里有一份支持语言的列表。值得一提的是 octopress 还支持内嵌 Gist。
日志文件都在本地,而且是纯文本,管理很方便(可以用 git),也不用担心租用的服务器数据丢失等问题。
rake new_post; rake gen_deploy 这样写博客很过瘾 :)
关于 wordpress 到 octopress 的数据转移,本文结尾的两篇参考文章已经说得很详细了,这里再补充几点:
编码:jekyll 的 wordpressdotcom.rb 用了 yaml 库生成博客文章的 meta 信息,碰到中文标题会出现乱码,换用 ya2yaml 后问题解决。
博客图片:把原来的 wp-content 目录复制过来,再统一改下路径即可。
文章格式:wordpress 导出的文章内容格式比较特殊,不是标准的 HTML,因为它的换行都是有意义的,考虑到这点我就把文章保存成 .markdown 后缀了,效果也不错。Vito 的博客上还介绍了 downmark_it 这个把 HTML 转成 Markdown 的工具。
评论:用了 disqus,它还支持导入 wordpress 上过去的评论。
代码高亮:之前博客用的是一个基于 JS 的 SyntexHighlighter,octopress 自带了 pygments 作为语法高亮工具,两者高亮标记不一样,需要用 nokogiri 转换下。
RSS:虽然 octopress 自带了生成 Atom 的插件,但是只能生成一个,而之前博客的 /feed/ 和 /rss.xml 都有人订阅,所以得在 nginx 配置里加了几条重写规则保证这些 URL 都有效。
主题:octopress 支持用 SCSS 自定义主题。现在这个用的主题还是默认的,改天再考虑要不要把原来的主题也移植过来。
写作:建议在 Rakefile 的 new_post 方法结尾启动 Markdown 编辑器打开新生成的文件,这样就免去手动查找的麻烦了。
这个是修改后的 wordpressdotcom.rb,根据我的博客的情况加了一些特殊情况的处理,有同样需求的朋友可以参考下。
参考:
2011-11-24 08:00:00
ActiveRecord 对象在数据库中的属性并不是以实体变量的方式保存的,如果要为一个属性设置默认值的话,
class Item < ActiveRecord::Base
def category
@category || 'n/a'
end
end
这样的实现是不可行的。读取和修改这些属性时应该使用 read_attribute 和 write_attribute:
class Item < ActiveRecord::Base
def category
read_attribute(:category) || 'n/a'
end
end
ActiveRecord 的 hash 值是根据主键的值计算出来的,这就意味着未保存对象的 hash 值是不可靠的。同样两个 model 对象的相等比较(即==操作符)也是基于主键的,所以两个 model 对象即使它们的其他属性不一样,仍有可能被当作相等。
find_by_attribute 方法后面加个 ! 号,即使用 find_by_attribute!,就能在找不到对象的时候触发一个 RecordNotFound 异常,而不是返回 nil。
find_or_initialize_by 和 find_or_create_by 也是两个好用的方法,它们在找不到对象时分别使用 new 和 create 新建一个,并用查找的属性初始化新建的对象。
不得不手写 SQL 同时又要防止注入攻击的一个比较简洁的写法是
Order.where("name = :name and pay_type = :pay_type", params[:order])
出于性能考虑,after_find 和 after_initialize 只能通过函数声明的方式定义,即不能用类似 before_validation :normalize_fields 这样的形式。
参考
2011-11-20 08:00:00
:content_type 设置返回内容的 MIME 类型
render :file => filename, :content_type => 'application/rss'
:layout 指定 layout
:status 指定返回的 HTTP 代码
:location 指定 HTTP 头中的 Location 字段
Rails 生成的 controller 代码中,create.json 方法在生成对象后会将 Location 设置为新生成对象的 json 地址:
respond_to do |format|
if @item.save
format.html { redirect_to @item, notice: 'Item was successfully created.' }
format.json { render json: @item, status: :created, location: @item }
else
format.html { render action: "new" }
format.json { render json: @item.errors, status: :unprocessable_entity }
end
end
参考:http://guides.rubyonrails.org/layouts_and_rendering.html#using-render
2011-11-20 08:00:00
HEAD 方法和 GET 方法比较像,但是它不返回对象的实际表示,只返回一个 HTTP 头。HEAD 可以用来查看对象修改时间、大小等信息,Amazon S3 的客户端就用它来读取文件元信息。
用 PUT 和 POST 创建对象时的一个区别在于,使用前者时客户端知道被创建对象的 URL(例如 /items/3),而后者则不需要客户端了解(例如 /items/new)。
OPTIONS 用来查看客户端对某个资源有那些可用的操作。
正确的设计应当保证:
这两点保证了在一个不可靠的网络中,客户端仍能进行有效的操作。
2011-11-20 08:00:00
有些测试比较耗时间,而且很少被修改,如果能在测试的时候跳过它们就能让 spec 快不少。
跳过测试的方法很简单,spec 的 describe 方法可以给对应的测试加上标签,例如
describe SalesController, :slow => true do
# specs
end
接下来只要在 spec/spec_helper.rb 中声明跳过这个标签即可:
RSpec.configure do |config|
config.filter_run_excluding :slow => true
end
与 filter_run_excluding 相反的是 filter_run,指定会被运行的标签,不包含在这个列表中的测试将被忽略。
2011-09-17 08:00:00
最近要给某个类写一个 hash 方法,这个类包括一些整型和字符串属性,需要把它们都放到 hash 中。担心自己想出来的 hash 算法会造成比较严重的冲突,网上搜了一下,发现 Effective Java 中已经介绍过一种简单有效的算法了:
2011-07-28 08:00:00
前几天给我的 MacBook Pro 装上了 Lion,不过原来的 Emacs 并不支持在 Lion 下全屏运行。github 上搜了下发现已经有让 Emacs 支持全屏模式的补丁了,Homebrew 中这个补丁也已经被吸收。
直接用 brew install emacs –cocoa –srgb 似乎会碰到编译错误:
Finding pointers to doc strings...
Finding pointers to doc strings...done
Dumping under the name emacs
unexec: cannot write section __data
--- List of All Regions ---
address size prot maxp
--- List of Regions to be Dumped ---
address size prot maxp
--- Header Information ---
Magic = 0xfeedfacf
CPUType = 16777223
CPUSubType = -2147483645
FileType = 0x2
NCmds = 20
SizeOfCmds = 3464
Flags = 0x00200085
Highest address of load commands in input file: 0x5dd000
Lowest offset of all sections in __TEXT segment: 0x22f0
--- List of Load Commands in Input File ---
github issues 上已经有人报告这个问题了,解决方法也很简单,运行 brew edit emacs 打开 emacs 的安装脚本,在 def install 的后面加上两行:
def install
ENV['CFLAGS']='-fno-pie -O2'
ENV['LDFLAGS']='-fno-pie'
args = ["--prefix=#{prefix}",
"--without-dbus",
"--enable-locallisppath=#{HOMEBREW_PREFIX}/share/emacs/site-lisp",
"--infodir=#{info}/emacs"]
# ...
再运行一次 brew install emacs,就能在 /usr/local/Cellar/emacs/23.3 下找到支持全屏模式的 Emacs.app 了。M-x ns-toggle-fullscreen 可以在全屏/非全屏模式之间切换。
2011-03-02 08:00:00
我平时用的系统是 Windows 7 和 Mac OS X,实验室项目一般都是 ssh 远登到 Ubuntu 和 Linux 上开发的。有时碰到内核和虚拟机等项目编译比较耗时,编译开始后要时不时的看一下编译任务是否完成,或者有没有中途出错,这时候如果有个通知系统就比较方便了。
Google 了一把找到了 netgrowl 这个好东东,它是一个开源的 Python 模块,实现了 Growl 协议,可以向 Mac 或 Windows 上的 Growl 服务发送通知。使用也非常方便,先用 GrowlRegistrationPacket 函数注册一个应用,接着就可以用 GrowlNotificationPacket 发送通知了:
notify.py
#!/usr/bin/python
from netgrowl import *
import sys
title = "Notification from Ubuntu"
desc = ""
if len(sys.argv) > 2:
title = sys.argv[1]
desc = sys.argv[2]
addr = ("10.131.251.101", GROWL_UDP_PORT)
s = socket(AF_INET,SOCK_DGRAM)
p = GrowlRegistrationPacket(application="Ubuntu", password="i")
p.addNotification("Ubuntu Notifications", enabled=True)
s.sendto(p.payload(), addr)
p = GrowlNotificationPacket(application="Ubuntu",
notification="Ubuntu Notifications", title=title,
description=desc, priority=1,
sticky=True, password="i")
s.sendto(p.payload(),addr)
s.close()
这里的 addr 是接收方的地址,GrowlRegistrationPacket 和 GrowlNotificationPacket 中需要指定 Growl 远程服务的密码。
然后是一个简化 notify.py 调用的 shell 脚本:
growl.sh
#!/bin/bash
cmd=$@
$cmd
python ~/bin/notify.py Done "$cmd under $PWD is finished"
把 growl.sh 加入到 PATH 中,之后只要运行 growl.sh make all 就能运行 make all 命令 ,并且在执行完成后向 Growl 客户端发送消息了。如果安装了 BoxCar,还能把这条消息转发到 iPhone / iPad 上。
P.S. Growl for Windows 可以在这里找到。
2011-01-16 08:00:00
在上一篇文章中我们介绍了 return-oriented 这种攻击手段,它的强大之处在于攻击者不需要插入恶意代码,通过构造特殊的函数返回栈利用程序中原有的代码即可达到攻击者的目地。
北卡州立大学的学者们提出了一种防止 return-oriented 攻击的思路,思路很简单,一句话概括,就是去掉代码里所有的 ret 指令!
思路很简单,真正做起来还是很复杂的。x86 中的 ret 指令只有一个字节,即 0xc3。要去掉所有的 0xc3,不仅要修改原来代码中的 ret 指令,还要移除其他指令片段中的 0xc3(例如 movl $0xc3, %rax)。接下来我们来看看 EuroSys 10 上的这篇文章是怎么解决这些问题的。
首先是原来就作为 ret 指令用的 0xc3 代码。注意 return-oriented 之所以成功一大原因就是 ret 指令在返回时不会检查栈上的返回地址是否正确。要保证这一点,需要引入一个间接跳转层。传统的调用过程是调用者把返回地址压入栈上,然后被调用函数返回时从栈上得到返回地址并返回。现在我们加入一个新的跳转表,这张表里记录了所有的返回地址,而且它不在栈上,因此不能被攻击者修改。当调用者调用函数时,把返回地址在表中的序号压入栈上;函数返回时,从栈上读出地址序号,再查表得到实际地址,然后返回。通过引入这样一层额外的地址转换机制,攻击者就不能通过修改栈上返回地址让函数返回到任意地址了。
接下来我们要解决其他指令引入的 0xc3,这里面也分几类情况。首先是由于寄存器分配引起的。例如 movl %rax, %rbx 对应的机器码是 48 89 c3,这边就有个 0xc3。对于这一类代码,只需要在编译器做寄存器分配时把有可能产生 0xc3 的情况排除掉即可。
另一类是代码中直接使用了 0xc3 作为直接数。这种情况需要对代码进行适当的修补,以 cmp $0xc3, %ecx 为例,0xc3 这个直接数可以通过 0xc4 - 1 得到,于是这条指令可以被修改为:
mov $0xc4, %reg
dec %reg
cmp %reg, %ecx
到这里所有包含 0xc3 的代码都已经被修改成具有同等功能的不包含 0xc3 的版本了,也就彻底杜绝了 ret 指令被用来做 return-oriented 攻击的可能。对具体实现细节有兴趣的同学可以读一下这篇论文,作者借助 LLVM 生成了一个没有 0xc3 的 FreeBSD 内核。
如果一个程序没有 0xc3,是不是意味着 return-oriented 攻击也从根本上被阻止了呢?
2010-11-19 08:00:00
众多的安全漏洞中,栈溢出(stack-based buffer overflows)算是非常常见的了。一方面因为程序员的疏忽,使用了 strcpy、sprintf 等不安全的函数,增加了栈溢出漏洞的可能。另一方面,因为栈上保存了函数的返回地址等信息,因此如果攻击者能任意覆盖栈上的数据,通常情况下就意味着他能修改程序的执行流程,从而造成更大的破坏。
对于栈溢出漏洞,传统的攻击方式是嵌入攻击代码,然后修改栈上的返回地址,使它指向攻击代码段,从而执行攻击者指定的代码。本科时候上过一门计算机系统基础,其中的某一个lab就要求学生做这么一件事。
现在的安全技术已经能比较好的防范传统的栈溢出攻击了。常见的技术有这么几种:
随机空间,前面提到攻击者需要修改栈上返回地址,使它指向注入的代码起始地址。但如果用户栈的起始地址是随机分布的,甚至每次新建一个栈帧时的地址都有一定程度的随机波动,要获得准确的返回地址就很困难了。这个技术大大增加了代码嵌入攻击的难度,但是却没用从理论上杜绝成功的可能性。攻击者可以使用大量的空指令(nop),并在可以修改的区域重复添加攻击代码,以此增加攻击成功的几率。
W ^ X,把所有的可读可写页标记为不可执行,也就是说攻击者无法添加或修改可执行代码,这样包含了嵌入代码的页面就无法被攻击者调用执行了。Windows 的 DEP、 Linux 的 PaX 都利用了这一项技术。
此外还有一些诸如 StackGuard 等栈保护手段,不过由于它们对性能影响很大,实际中使用并不广泛。
这些手段使得在受保护的进程中利用栈溢出嵌入恶意代码并执行变得几乎不可能,然而这并不意味着栈溢出漏洞没有利用的价值了。聪明的黑客们想到了另外一种自定义程序行为的途径:利用程序或者动态库中原有的代码。这些代码虽然本身是良性的,但适当利用的话,同样可以产生恶意的效果。
最简单的手段就是著名的 return-to-libc 攻击。libc 中有一些函数可以用于执行其他的进程,例如 execve 和 system。这些函数很容易被攻击者利用,只要找到一个栈溢出漏洞,并适当的构造函数调用参数,并使栈上返回地址指向这些函数的起始地址,攻击者就能以这个程序的权限执行任意其他程序了!注意这里所有执行的代码都是合法的,所以前面提到的W^X技术对此就无能为力了。
return-to-libc 这种攻击方式也有一个局限,就是需要代码库中有 system 这样符合要求的函数,如果对于内核代码,或是检查调用来源的库,return-to-libc 就不那么给力了。于是另一种理论上更强大、也更难构造的攻击方式浮出水面,也就是标题的 return-oriented 攻击。
关于 return-oriented 攻击,我之前的一篇博文已经介绍过这个概念了,这里再解释一下。
一般程序中都包含着大量的返回指令(ret),它们通常位于一个函数的结尾,或是中途返回的地方。而这些返回指令之前的一两条指令,成为了 return-oriented 攻击指令的来源。攻击者要做的就是把这些零零碎碎的指令拼接起来,拼成一段恶意的代码。这里的难点有两个地方,一是怎么找到符合要求的代码片段,二是找到之后怎么拼接。
先来看第一个问题,可用的代码片段虽然多,但是都是固定的。这就意味着原来的一条指令现在可能需要多条指令执行后得到相同的效果了。举例来说,要把一个寄存器赋值为 4 的话,可能没有现成的直接赋值的代码片段,需要一条赋值为 1 的指令,和三条寄存器加 1 的指令拼凑而成。这样通过拼凑,受限的指令可以完成一些基本的操作,再由这些基本的操作,组成一段有实际意义的攻击代码。这里涉及到不少编译相关的知识,具体细节就不赘述了。
关于第二个问题,因为前面找到的代码片段都是以 ret 指令结尾的,所以只要把栈上的返回地址改成片段1的起始地址,代码片段1执行之后就会通过 ret 指令返回,此时读取的返回地址还是在被攻击的栈上,所以攻击者只要把对应位置的值改成代码片段2的起始地址,就能紧接着执行代码片段2了,如此循环,只要栈够大,就可以把攻击片段跑完。
对于 Linux 内核、glibc 这些庞大的程序来说,ret 指令前面一两条指令组成的代码库非常巨大,基本上可以达到图灵完备的要求了,也就是说,只要栈够大,任何程序都能由这些代码片段表达出来。另外这里为什么强调“一两条指令”呢?当然四五条甚至十几条指令的复用也是可以的,只是这样会大大增加搜索空间,要通过这些可能的代码片段生成一个程序需要太多的时间了。
那么如何防范 return-oriented 攻击呢?之后的博文里,我会介绍一些和它相关的国外研究。
2010-10-19 08:00:00
我经常使用的几台电脑中的Caps Lock 键都被我改成了 Ctrl 键,这样修改以后用起 Emacs 来就顺手多了。
最近在 Windows 上用 VMware Remote Control 远登虚拟机调试内核的时候,问题就出来了:可能是这个浏览器插件的 bug,有时键盘的 Caps Lock 会被莫名打开。然后我的这个键盘键位又比较少,不想再让 Caps Lock 键替换另一个用得更少的按键了,于是想到了软件关闭的方法。
搜了下 Stackoverflow 找到个很好用的 Python 库SendKeys,只要两行代码就能在 Windows 下模拟 Caps Lock 按键了:
import SendKeys
SendKeys.SendKeys("{CAPSLOCK}")
另外在 Linux 要模拟按键,可以直接访问 /dev/console:
import fcntl
import os
KDSETLED = 0x4B32
console_fd = os.open('/dev/console', os.O_NOCTTY)
# Turn on caps lock
fcntl.ioctl(console_fd, KDSETLED, 0x04)
# Turn off caps lock
fcntl.ioctl(console_fd, KDSETLED, 0)
原问题地址
2010-08-25 08:00:00
这几天看KVM代码的时候看到里面有个内联汇编的语法很陌生(下面的代码截取了部分内联汇编片段):
asm (
"mov %c[rax](%3), %%rax \n\t"
"mov %c[rbx](%3), %%rbx \n\t"
"mov %c[rdx](%3), %%rdx \n\t"
"mov %c[rsi](%3), %%rsi \n\t"
"mov %c[rdi](%3), %%rdi \n\t"
: "=q" (fail)
: "r"(vcpu->launched), "d"((unsigned long)HOST_RSP),
"c"(vcpu),
[rax]"i"(offsetof(struct kvm_vcpu, regs[VCPU_REGS_RAX])),
[rbx]"i"(offsetof(struct kvm_vcpu, regs[VCPU_REGS_RBX])),
[rcx]"i"(offsetof(struct kvm_vcpu, regs[VCPU_REGS_RCX]))
: "cc", "memory" );
stackoverflow上问了下才知道这是gcc的operand substitution语法,%c后面跟上常量名,就能在内联汇编中使用这个常量了。
以这段代码为例,vcpu是struct kvm_vcpu类型,[rax]“i”(offsetof(struct kvm_vcpu, regs[VCPU_REGS_RAX])这句话把vcpu->regs[VCPU_REGS_RAX]相对于vcpu的偏移赋值给了rax这一常量。接下来回到第一行mov %crax, %%eax,%c[rax]等于前面得到的偏移量,加上vcpu并取值后就是vcpu->regs[VCPU_REGS_RAX]中保存的值了,这个指令会把这个值保存在%rax寄存器中,从而完成了vcpu的rax寄存器恢复工作。
2010-05-14 08:00:00
网上找了不少设置方法,终于翻出来一个可行的,和大家分享下。
ArchLinux 和 Ubuntu 的源里就有,也可以从 http://www.agroman.net/corkscrew/ 下载源码编译一个。
Host gitproxy
User git
Hostname ssh.github.com
Port 443
ProxyCommand corkscrew proxy.example.com 3128 %h %p
IdentityFile /home/username/.ssh/id_rsa
修改其中的 proxy.example.com 和 3128 为代理 IP 和端口,如果代理需要帐号密码,就在 ProxyCommand 这一行的最后加上密码文件,内容为用户名:密码。
参数 IdentitiFile 指定相应帐号的私钥文件地址。
另外 @cyfdecyf 同学指出只要把这里的 Host 改成 github.com,就可以直接用 [email protected]:user/repository 访问 GitHub 了。
例如要把 foo/bar.git 拖下来,执行 git clone git@gitproxy:foo/bar.git 即可。
原文地址:http://www.wetware.co.nz/blog/2010/03/cant-access-github-behind-proxy-or-firewall/
更新: 由于 GitHub 现在支持 HTTPS 协议了,所以更简单的方法是使用 GitHub 提供的 HTTPS 地址,然后用 git config --add http.proxy 指定 HTTPs 代理。
2010-03-03 08:00:00
Blueprint: Robust prevention of cross-site scripting attacks for existing browsers
这篇论文提出了一种防范是跨站脚本攻击(XSS)的新的方法,发在IEEE S&P 2009上,作者是UIUC的Mike Ter Louw。
所谓跨站脚本攻击,简单地说就是在网页中注入非法的脚本代码,从而达到攻击的效果。比较著名的例子有当年在MySpace上泛滥的Samy蠕虫,通过特殊的脚本注入手段,每一位访问Samy主页的用户,他们的主页都会被修改加上一段Samy is my hero文字,并且他们的主页也会被植入攻击代码,从而把这段脚本扩散给更多的用户。
通常防范跨站脚本攻击的方式有两种。一种做在服务器端,为每一段用户上传的内容做检查,并剔除恶意代码。但这种方式很难保证能过滤掉所有的恶意字符串,一方面攻击方法防不甚防,有兴趣的朋友可以参考下XSS Cheat Sheet,上面给出了很多一般人很难想到的攻击代码的组合方式。另一方面由于现在大多数论坛和博客都支持一些基本的文本修饰标签,所以简单的标签剔除或者重新编码都不可行。
另一种方法是做在浏览器端,但是由于浏览器无法区分某一段脚本到底是来源于不可信的用户还是可信的站点,所以这种方法实现起来也有很大的困难。
这里实现防范措施的一个难点在于,Web应用把生成HTML的返回给浏览器后,就不参与浏览器的HTML解析工作了。这样浏览器就不知道哪部分出现脚本是安全的,哪部分出现是不安全的。
BluePrint就着眼于这个点,提出了一种让Web应用“参与”HTML解析工作的设计。下面通过论文里面的一个例子,简单介绍下它的防范机制。
假如一位恶意的用户在一个博客上上传了这样一段含有恶意代码的留言:
<p>
Here is a page you might find
<b """><script>doEvil(. . .)</script>">very</b>
interesting:
<a href="  javasc
ript:doEvil(. . .);">
Link</a>
</p><p style="nop:expres/*xss*/sion(doEvil(. . .))">
Respectfully,
Eve
</p>
可以看到,这段代码里包含了很多可能引发脚本执行的代码,而要在服务器端把这些所有隐藏的攻击可能找出来是一件比较困难的事。那么BluePrint是怎么在不知道这段代码是否含有恶意代码的前提下处理的呢?
首先,这种由用户上传的不可信的字符串会先在服务器端被解析成一棵树,就像HTML在浏览器中被解析一样,这棵HTML解析树可以用一些简单的DOM API来生成,例如appendChild, createElement等。这些描述如何生成HTML解析树的方法会和数据值(URL、标签属性等)一起,通过特殊的编码(Base64)传递给浏览器。例如上面这段代码,最后在浏览器接收到的HTML中,会变成这样:
<code style="display:none;" id="__bp1">
=Enk/sCkhlcmUgaXMgYSBwYWdlIHlvdSBta...
=SkKICAgICI+dmVyeQ===C/k/QIGhlbHBmd...
=ECg===C/Enk/gCiAgUmVzcGVjdGZ1bGx5L...
</code><script id="__bp1s">
__bp__.cxPCData("__bp1", "__bp1s");
</script>
在浏览器端,这段特殊的代码会被JS库解析成自定义的命令和数据格式,并由前面提到的DOM API动态生成这些HTML结点,从而达到和传统的方式一样的显示效果。当然可信的HTML代码,例如文章正文,还是按传统的方式传输的。
通过这种方式,BluePrint绕过了浏览器对不可信代码的解析,从而防止了不可信代码里内嵌的脚本的执行。
此外还有一些细节的问题,例如为什么使用Base64编码来描述自定义的命令和数据,而不是常用的例如UTF-8呢?这是因为使用UTF-8的话攻击者就有可能通过构造一段特殊的字符串,而这段字符串对应的编码恰好能起到攻击作用。而使用Base64编码就不会有这个问题。
攻击例子中的第5行和第7行还分别包括了通过恶意URL和CSS风格实现的代码,前面提到的措施还不足以防范这两种类型的攻击。论文里面也提到了相应的解决方案,这里不再赘述,有兴趣的朋友可以搜索论文阅读相关部分。
把BluePrint整合到现有的应用程序里也不难,只要把包含不可信内容显示部分的代码重新加一层包装就行了,像这样:
// Code for trusted blog content
// appears untransformed aboveˆˆ.
<?php foreach ($comments as $comment): ?>
<li>
<?php
$model = Blueprint::cxPCData($comment);
echo($model);
?>
</li>
<?php endforeach; ?>
在BluePrint的开销方面,包含25个用户评论的wordpress页面产生速度慢了55%,不过作者提到wordpress本身还有HTML解析和恶意代码检查过滤的功能,用了BluePrint后就不需要这些冗余的检查了,所以把这部分代码去掉会快不少。另外由于不可信内容都需要动态的被解码并创建相应的HTML结点,浏览器端的显示速度慢了很多,作者也解释到这种解析开销其实并不重要,因为通常看一篇博文的时候都是先看内容,由于文章内容本身是可信的,所以会以传统的方式传输并显示,若干秒后再显示评论也未必会对用户体验造成太大的影响。
这篇论文给我的感觉是思路很清晰,抓住了主要的难点后用了对应的方法绕过了浏览器的HTML解析。不过应用面上还有一些局限,只能防止不可信代码中脚本的执行,对于需要执行脚本的情形(例如Blogger上的Gadget)就不适用了。MIT去年发在EuroSys ‘09上的BFlow就是针对这样一种情形,通过类似于Flume的标签系统,使得不可信的脚本读取了隐私数据后就无法将它们传输给不可信的网站。
用beamer做了slides,在这里可以下载到: http://zellux-notes.googlecode.com/hg/slides/blueprint/
2010-03-01 08:00:00
GNU screen中执行的历史命令保存在内存中,默认情况下并不会像在bash中直接执行的命令一样保存在.bash_history中,这在某些场合下带来了一定的不便。
在superuser上看到一个解决方法,指定历史文件的读写方式为追加,并在每次命令行提示符显示的时候,自动更新bash的历史命令记录。要实现这个方法很简单,只要在.bashrc中加入下面两行代码即可
shopt -s histappend
export PROMPT_COMMAND="history -a; history -n"
另外如果之前设置过PROMPT_COMMAND的话,只要在history -a前加入$PROMPT_COMMAND; 就行了。
2010-02-24 08:00:00
SICP第二章里提到了一种用来画图的Lisp方言,用来演示数据抽象和闭包的表达能力(见http://mitpress.mit.edu/sicp/full-text/book/book-Z-H-15.html#%_sec_2.2.4)。
最近尝试了下,发现soegaard同学已经在PLT Scheme中实现了一个类似的库,可以很方便的在DrScheme上使用。
sicp.plt包使用很简单,在Language->Choose Language中选择Module,然后在需要用到这个包的时候用
(require (planet soegaard/sicp:2:1/sicp))
声明即可。第一次运行时DrScheme会自动下载这个包并安装,如果网络有限制可以先从http://planet.plt-scheme.org/display.ss?package=sicp.plt&owner=soegaard下载然后在DrScheme中选择本地包安装。
另外SICP上使用的两个painter(wave和rogers)没有在这个包里提供,取而代之是diagonal-shading和einstein。
下面这个程序显示了一个简单的分形图像:
#lang scheme
(require (planet "sicp.ss" ("soegaard" "sicp.plt" 2 1)))
(define (right-split painter n)
(if (= n 0)
painter
(let ((smaller (right-split painter (- n 1))))
(beside painter (below smaller smaller)))))
(define (up-split painter n)
(if (= n 0)
painter
(let ((smaller (up-split painter (- n 1))))
(below painter (beside smaller smaller)))))
(define (corner-split painter n)
(if (= n 0)
painter
(let ((up (up-split painter (- n 1)))
(right (right-split painter (- n 1))))
(let ((top-left (beside up up))
(bottom-right (below right right))
(corner (corner-split painter (- n 1))))
(beside (below painter top-left)
(below bottom-right corner))))))
(paint (corner-split diagonal-shading 4))
程序输出:
2010-02-14 08:00:00
gitk是用Tcl/Tk写的工具,默认使用Tk 8.4,不支持抗锯齿,因此字体显示很难看。好在Tk 8.5支持了部分抗锯齿字体,修改gitk使用Tk 8.5后显示效果会好一点。
以Ubuntu为例,安装tk8.5包后,编辑/usr/bin/gitk文件,把开头调用wish的那行
exec /usr/bin/wish "$0" -- "$@"
改成
exec /usr/bin/wish8.5 "$0" -- "$@"
这样就能在gitk中开启抗锯齿了,虽然效果还不是很好。另外qgit也是一个不错的选择。
2010-02-09 08:00:00
Linear page table 又叫 virtual page table,是一种方便虚拟机监控器 (VMM) / 操作系统 (OS) / 应用程序访问页表的技巧。Xen、64 位 Linux 内核、JOS 操作系统中都用到了这个设计。这里以 x86_32 系统为例,简单介绍一下它的实现和使用,如有错误敬请指出。
一般情况下,如果 OS 需要访问某个页表,需要将它映射到自己的虚拟空间中,然后再访问。这样带来两个问题,一是访问比较繁琐,需要临时的页映射;二是对于 exo-kernel 这种 fork 等行为都是在用户态程序实现的系统,可能会增加一下安全上的问题。因为用户程序在 fork 的时候需要访问自己的页表,而这时候除非操作系统提供另一些权限控制更精确的系统调用,否则就很难让不可信的应用程序访问自己的页表且不做有害的改动。
Linear page table 很好的解决了这两个问题。它的实现很简单,只需要在页目录中增加一项 VPT (virtual page table entry),和一般的页目录项不同的是,这个 VPT 指向的是页目录本身。
这样带来了什么好处呢?借用一下 MIT 6.828 课件上的图片来更好的说明这个问题:
增加了 VPT 后,通常的物理地址 -> 虚拟地址的转换还是没变。和之前唯一的不同在于虚拟地址的页目录索引号 (PDX) 为之前设置的 VPT 的时候。
举个例子来说,假如现在要访问的虚拟地址是 (VPT << 22) | (VPT << 12),即这里的 PDX 和 PTX 都等于 VPT 的时候,整个转换过程是怎么样的呢(假设 TLB miss 的情况)?首先根据 CR3 中的物理地址,硬件开始查找页目录中的第 VPT 项,然后根据这一项中的物理地址,找到了下一级「页表」。注意这时候硬件以为自己得到的页表地址,实际上访问的还是页目录本身。同样,在这个「页表」中找到第 VPT 项指出去的最终页,得到了最终页的物理地址。因为 PTX 还是等于 VPT,所以最后得到的物理地址还是页目录的。
也就是说,通常的页表访问的顺序是 CR3->页目录->页表->最终页,现在访问这个特殊地址的过程则成了 CR3->页目录->页目录->页目录,通过 VPT 这一项在页目录上绕了两圈后返回。
接下来,再来看看如何通过这个机制来访问某个页表,假如现在要访问第 i 个页目录项指向的页表上的第 j 项,那么我们应该构造这样一个特殊地址:
(VPT << 22) | (i << 12) | (j * 4)
即 PDX = VPT, PTX = i, offset = j * 4。通过这个地址就能得到需要的页表项了,另外由于 (i << 12) | (j * 4) = (i * 1024 + j) * 4,定义 vpn 为虚拟页的编号,vpn = i * 1024 + j,则这个地址可以转换为
(VPT << 22) + vpn * 4
在 JOS 中,就是把 VPT 定义为一个 uint32_t 的数组,然后 vpt[vpn] 就是第 vpn 个虚拟页的页表项了。前面提到的另一个问题,如果要让用户以只读权限访问页表,又应该怎么做呢?很简单,在页目录中为用户设置另一个只读项,指向页目录自己就行了。
2010-02-08 08:00:00
今天碰到一个gcc优化相关的问题,为了让一个页变成脏页(页表中dirty位被置上),需要执行下面这段代码:
uint32_t *page;
// ...
page[0] = page[0];
最后一行代码很有可能被gcc优化掉,因为这段代码看起来没有任何实际的作用。那么如何防止gcc对这段代码做优化呢?
设置gcc编译时优化级别为-O0肯定是不合适的,这样对程序性能影响会比较大。stackoverflow上的Dietrich Epp给出了一个强制类型转换的方案:
((unsigned char volatile *)page)[0] = page[0];
通过volatile关键字禁止gcc的优化,和我之前采用的方法类似。
Plow同学给出了另一个利用gcc 4.4特性的方法:
#pragma GCC push_options
#pragma GCC optimize ("O0")
your code
#pragma GCC pop_options
这里用到了gcc 4.4的特性Function Specific Option Pragmas,在特定代码前保存当前的编译选项,然后对特定的代码使用O0优化级别,最后再恢复之前保存的编译选项。
俺觉得这个特性有些场合下挺好用的,在这里分享下,虽然因为编译器版本问题最后我还是用了前面一种方法。
2010-02-07 08:00:00
前几天试用了下ECB,非常喜欢它的定义列表和文件浏览历史的功能。但是却发现了另外一个问题:使用ECB之前我把整个窗口分成左右两块,左边是代码,右边是cscope的查找结果,现在开启ECB之后就不能再切一块窗口给cscope用了。
感谢stackoverflow上的sanitynic,给出了自定义ECB窗口的参考。现在俺终于能把cscope窗口绑定到屏幕左下角啦。
自定义ECB layout其实也挺方便的,上图对应的配置为
(ecb-layout-define "my-cscope-layout" left nil
(ecb-set-methods-buffer)
(ecb-split-ver 0.5 t)
(other-window 1)
(ecb-set-history-buffer)
(ecb-split-ver 0.25 t)
(other-window 1)
(ecb-set-cscope-buffer))
(defecb-window-dedicator ecb-set-cscope-buffer " *ECB cscope-buf*"
(switch-to-buffer "*cscope*"))
(setq ecb-layout-name "my-cscope-layout")
;; Disable buckets so that history buffer can display more entries
(setq ecb-history-make-buckets 'never)
my-cscope-layout这个layout左边窗口分为三部分,最上面的函数列表占一半高度,中间为历史文件列表,下面为cscope的查找结果,它们各占四分之一的高度。
另外再简单提下cscope插件的安装和配置,使用前需确认当前系统已经安装了cscope,另外要有cscope-indexer这个脚本。在cscope/contrib目录下找到一个xcscope.el,复制到Emacs的插件目录中,并在Emacs初始化文件中加入
(require 'xcscope)
即可。某些发行版的包里面似乎没有cscope-indexer和xcscope.el,直接从网上下一个好了。
几个常用的快捷键:
C-c s I 建立cscope索引C-c s a 设置搜索目录C-c s d 查找定义C-c s s 查找字符串C-c s c 查找调用者C-c s n 下一个查找结果C-c s p 上一个查找结果更多的快捷键可以在 C-h b 跳转的帮助页面的 cscope-minor-mode 区找到。
2010-02-04 08:00:00
简单来说就是给定一个未初始化的巨大的数组,然后通过它实现一个字典。所谓未初始化是指一开始里面元素的值都是随机的,巨大是指可以假设数组长度范围很大,对这个数组做初始化工作(例如清零)的代价自然也是很大。现在的问题是,利用这个数组设计出来的字典,要求初始化、查找、插入、删除操作都能在O(1)时间内完成。
Intructor’s Manual 上的解答设计了一个很巧妙的验证策略。假设T为那个巨大的数组,S为辅助栈,那么对于一个键k,如果k存在于这个字典中,则T[k]保存的是 k在S中的位置j,而S[j]则保存了k值。即1 ≤ T[k] ≤ top[S], S[ T[k] ] = k, T [ S[j] ] = j,我们称这个条件为“验证环”。这个设计的关键在于T和S能够互相验证,从而排除了未初始化位置上随机值的干扰。
还有一个问题就是,键k对应的值v应该怎么保存呢?其实只要维护另外一个和T或者S平行的数组就行了,既然S的元素个数远小于T,选择和S平行即可。
根据这个验证策略,我们就能设计出词典的基本操作了: 初始化:建立一个大小为0的栈 查找:给定键k,检查 1 ≤ T [k] ≤ top[S] && S[ T[k] ] = k,如果满足则返回对应值,否则返回NULL 插入:如果键已经存在则直接替换;否则将新的键值入栈,并且维护T[k] ← top[S] 删除:要确保两件事,一是验证环要被破坏,二是栈S的空洞要被填补。通过把栈顶的元素移动到要删除的元素位置,我们能同时确保这两点:
S[ T[k] ] ← S[ top[S] ]
S[ T[k] ] ← S [ top[S] ]
T[ S[ T[k] ] ] ← T [k]
T[k] ← 0
top[S] ← top[S] − 1
所有操作都能在O(1)时间内完成
原题:We wish to implement a dictionary by using direct addressing on a huge array. At the start, the array entries may contain garbage, and initializing the entire array is impractical because of its size. Describe a scheme for implementing a direct-address dictionary on a huge array. Each stored object should use O(1) space; the operations SEARCH, INSERT, and DELETE should take O(1) time each; and the initialization of the data structure should take O(1) time. (Hint: Use an additional stack, whose size is the number of keys actually stored in the dictionary, to help determine whether a given entry in the huge array is valid or not.)
2010-02-03 08:00:00
semantic是cedet的组件之一,它可以对程序做语义分析,结合company等其他插件,可以实现自动补全菜单等功能。
之前用semantic+company写MIT 6.828的lab时几乎不需要什么特殊的设置就能直接用,这次拿来改Xen的代码的时候却出现了semantic无法找到符号定义的问题,究其原因在于MIT 6.828的目录结构相对简单,头文件都在inc/目录下,而Xen的头文件在多个目录下,而且做预处理时还要加上Makefile里定义的一些预定义宏。今天参考了Alex Ott的这篇文章终于成功地让semantic支持Xen的代码分析了:
这里分享一下和项目相关的一些设置,semantic安装等问题请参考网上的其他文章。也可以参考我的配置文件http://code.google.com/p/zellux-emacs-conf/source/browse/my-cc-mode.el,cscope ecb semantic和company等配置都在这个文件里了,不过有点混乱。
;; Danimoth-specified configurations
(add-to-list 'semanticdb-project-roots "~/danimoth/xen")
(setq semanticdb-project-roots
(list
(expand-file-name "/")))
(setq danimoth-base-dir "/home/wyx/danimoth")
(add-to-list 'auto-mode-alist (cons danimoth-base-dir 'c++-mode))
(add-to-list 'auto-mode-alist (cons danimoth-base-dir 'c-mode))
(add-to-list 'semantic-lex-c-preprocessor-symbol-file (concat danimoth-base-dir "/xen/include/config.h"))
(add-to-list 'semantic-lex-c-preprocessor-symbol-file (concat danimoth-base-dir "/xen/include/asm-x86/config.h"))
(ede-cpp-root-project "Danimoth"
:name "Danimoth"
;; Any file at root directory of the project
:file "~/danimoth/xen/Makefile"
;; Relative to the project's root directory
:include-path '("/"
"/include/asm-x86"
"/include/xen"
"/include/public"
"/include/acpi"
"/arch/x86/cpu/"
)
;; Pre-definds macro for preprocessing
:spp-table '(("__XEN__" . "")
))
其中,/home/wyx/danimoth/xen是项目的主目录,xen/include/config.h和xen/include/asm-x86/config.h里定义了一些基本的宏。
接下来,ede-cpp-root-project指定了这个项目的其他信息: :file 指向项目主目录下任一一个存在的文件 :include-path 指定头文件的所在目录 :spp-table 给出了预处理时的使用的宏,通常是在Makefile里使用-DXXX定义的宏,例如这里的__XEN__。
配置好semantic后,可以用M-x semantic-ia-complete-symbol测试。如果Emacs能正确显示补全列表,这就说明semantic已经配置成功了。配合这个简单的company设置,就能用Shift-Tab显示类似图片中的自动补全菜单了。
2010-02-02 08:00:00
终端下的效果图(Windows 7下使用pietty远登)
下载
http://ecb.sourceforge.net/downloads.html CVS或者压缩包都可以,当然也可以通过各发行版的包管理器安装。
安装
在.emacs中加入
;; ECB configurations
(add-to-list 'load-path "~/emacs/ecb-2.40")
(add-to-list 'load-path "~/emacs/cedet-1.0pre6/eieio")
(add-to-list 'load-path "~/emacs/cedet-1.0pre6/semantic")
(add-to-list 'load-path "~/emacs/cedet-1.0pre6/speedbar")
(setq semantic-load-turn-everything-on t)
(require 'semantic-load)
(require 'ecb-autoloads)
运行Emacs后执行ecb-byte-compile,并重启Emacs(我这里不重启的话执行ecb-active后会报错)。
使用
第一次使用时先要设置项目目录,M-x customize-variable ecb-source-path ,在这里加上你的项目根目录。
接下来使用M-x ecb-active就能激活ECB了,成功激活后Emacs窗口会被切成左右两半。左边的几个窗口依次显示:目录,当前目录下的文件,当前文件中的函数/全局变量等定义,文件浏览历史。如果打开了一个源文件后函数定义窗口里面是空的,有可能是因为这个项目过大cedet尚未完成对它的分析,闲置一段时间后就能看到文件里的定义。
ECB提供了方便在这些窗口间切换的快捷键:
切换到目录窗口 Ctrl-c . g d 切换到函数/方法窗口 Ctrl-c . g m 切换到文件窗口 Ctrl-c . g s 切换到历史窗口 Ctrl-c . g h 切换到上一个编辑窗口 Ctrl-c . g l
最基本的使用就是这样,Ctrl-C . h可以看到更详细的帮助信息。
2010-01-28 08:00:00
reddit programming版面最近的热帖,下面这个程序输出的结果是一个近似的圆周率(3.156)。
#define _ F-->00 || F-OO--;
long F=00,OO=00;
main(){F_OO();printf("%1.3f\n", 4.*-F/OO/OO);}F_OO()
{
_-_-_-_
_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_-_-_-_
_-_-_-_-_-_-_-_-_
_-_-_-_
}
乍看下这个程序有点莫名其妙,分析一下宏后就知道它的方法了。两个全局变量F和OO分别记录 圆的面积和直径 的相反数,根据4*面积/直径/直径就能得到近似的圆周率了。
至于面积和直径的计算,F在会在每一个_展开的地方减一,这样就得到了圆的面积。直径的计算要展开几行代码才能看得更清楚:
F-->00 || F-OO--;
-F-->00 || F-OO--;
-F-->00 || F-OO--;
-F-->00 || F-OO--;
F-->00 || F-OO--;
-F-->00 || F-OO--;
-F-->00 || F-OO--;
-F-->00 || F-OO--;
-F-->00 || F-OO--;
-F-->00 || F-OO--;
-F-->00 || F-OO--;
-F-->00 || F-OO--;
-F-->00 || F-OO--;
这是用cpp展开圆形前两行代码的结果,因为或运算的特殊性,F- OO- -只会在每一段的第一行执行,所以OO- -执行的次数就等于圆的直径了。
2010-01-26 08:00:00
因为大多数情况下程序都是通过libc间接地发出系统调用的,所以只要编译一个只使用int 0x80的glibc库,然后在执行程序的时候用LD_LIBRARY_PATH或其他方法指定使用新编译的glibc库即可。
以glibc-2.9, Linux i386为例,在sysdeps/unix/sysv/linux/i386/syscall.S中可以看到
ENTRY (syscall)
PUSHARGS_6 /* Save register contents. */
_DOARGS_6(44) /* Load arguments. */
movl 20(%esp), %eax /* Load syscall number into %eax. */
ENTER_KERNEL /* Do the system call. */
POPARGS_6 /* Restore register contents. */
cmpl $-4095, %eax /* Check %eax for error. */
jae SYSCALL_ERROR_LABEL /* Jump to error handler if error. */
这里使用了ENTER_KERNEL这个宏做系统调用,接下来在sysdeps/unix/sysv/linux/i386/sysdep.h里可以找到这个宏的定义
/* The original calling convention for system calls on Linux/i386 is
to use int $0x80. */
#ifdef I386_USE_SYSENTER
# ifdef SHARED
# define ENTER_KERNEL call *%gs:SYSINFO_OFFSET
# else
# define ENTER_KERNEL call *_dl_sysinfo
# endif
#else
# define ENTER_KERNEL int $0x80
#endif
而I386_USE_SYSENTER这个宏也是在同一个头文件中定义的
#if defined USE_DL_SYSINFO \
&& (!defined NOT_IN_libc || defined IS_IN_libpthread)
# define I386_USE_SYSENTER 1
#else
# undef I386_USE_SYSENTER
#endif
把这个条件宏改成
#undef I386_USE_SYSENTER
就能强制glibc使用int 0x80了。
这个方法只能过滤通过glibc做的系统调用。对于程序里写死使用sysenter的情况就要使用反汇编或者其他手段了。
2010-01-25 08:00:00
在Pro Git上看到的技巧,git的源代码包里的contrib/completion目录下有个git-completion.bash,把这个文件保存到~/.git-completion.bash,然后在.bashrc中加入一行
source ~/.git-completion.bash
这样就能在bash下用tab自动补全git命令、branch等内容了。另外Debian/Ubuntu里有个包就叫git-completion,这个包安装完成后会自动把这个补全脚本放到/etc/bash_completion.d/下,由bash-compleletion载入执行。
2010-01-21 08:00:00
使用grep在ps aux的输出结果中查找进程的时候经常会把grep进程本身也找出来,比如查找emacs进程:
$ ps aux | grep emacs
wyx 7090 0.0 0.0 3336 796 pts/2 S+ 04:49 0:00 grep emacs
wyx 10128 0.1 4.9 66904 50388 pts/3 S+ Jan21 2:21 emacs
一个常见的防止grep进程出现的方法就是在后面再加一个grep -v grep:
$ ps aux | grep emacs | grep -v grep
wyx 10128 0.1 4.9 66904 50388 pts/3 S+ Jan21 2:21 emacs
今天在Santosa的博客上看到了另一个巧妙的做法,使用grep [e]macs来搜索emacs这个进程:
$ ps aux | grep [e]macs
wyx 10128 0.1 4.9 66904 50388 pts/3 S+ Jan21 2:21 emacs
为什么会有这样的效果,知道grep正则中[]的作用后想一想就能明白啦。很有意思的trick,虽然说它比| grep -v grep也未必方便多少,因为后者能通过alias简化输入。
2009-12-17 08:00:00
在Ubuntu下编译Linux-xen时碰到arch/i386/kernel/head-xen.o无法找到的问题,而该目录下有head-xen.S这个文件,说明make之前的的工作并没有把这个.S文件编译成.o。而同样的代码,在ArchLinux和Fedora上svn checkout后编译没有任何问题。
最后发现问题在于Ubuntu默认会把/bin/sh指向/bin/dash,在scripts/Makefile.build里面加上一行SHELL=/bin/bash指定$(shell)使用bash即可。后来还搜了一下为什么Ubuntu使用dash而不是bash,其理由是dash的执行效率更高,但不可否认的是这个改动也导致了一些项目无法成功编译,虽然无法成功编译的原因可能是Makefile里使用了一些bash的特性而非POSIX shell所提供的那些。
另外在debug过程中在网上找到了一些debug Makefile的技巧:
make -n 可以仅仅打印出将要被执行的命令,而不去实际执行
make -np 可以打印出更多的信息(使用的规则和变量),并执行每一条命令
remake也是个不错的选择:“remake is a patched and modernized version of GNU make utility that adds improved error reporting, the ability to trace execution in a comprehensible way, and a debugger.”
在检查shell命令的时候,可以使用set -x使得所有shell命令在执行前都能被输出。
2009-12-13 08:00:00
把一堆石子排成n行m列,两人轮流从里面取出石子,条件是取出一个石子后所有在它右边和上面的石子也要被取走。谁取走最后一个石子就算输。以3*5的棋盘举例来说,先手取了(2,5),因此(3,5)也要被取走;后手取了(3,3),同时也要取走(3,4)。现在棋盘的状态如下(O代表这个位子的石子还没被取走,x代表已经被取走):
3 O O x x x
2 O O O O x
1 O O O O O
1 2 3 4 5
接下来先手又取了(2,1),于是第二排和第三排就一颗石子都不剩了
3 x x x x x
2 x x x x x
1 O O O O O
1 2 3 4 5
后手取(1,2)
3 x x x x x
2 x x x x x
1 O x x x x
1 2 3 4 5
接下来先手就只能取最后一个石子了,后手胜。
这个游戏像是 Nim Game 的二维版本。于是问题也来了,能不能保证先手或者后手有必胜策略呢?
答案是除了 1 * 1 的棋盘,对于其他大小的棋盘,先手总能赢。有一个很巧妙的证明可以保证先手存在必胜策略,可惜这个证明不是构造性的,也就是说没有给出先手怎么下才能赢。证明如下:
如果后手能赢,也就是说后手有必胜策略,使得无论先手第一次取哪个石子,后手都能获得最后的胜利。那么现在假设先手取最右上角的石子(n,m),接下来后手通过某种取法使得自己进入必胜的局面。但事实上,先手在第一次取的时候就可以和后手这次取的一样,进入必胜局面了,与假设矛盾。
另外这个证明是基于 Zermelo’s theory,这个理论保证在这样一种游戏中(两人博弈,信息完全公开,不存在偶然事件且能在有限步里面决出胜负),先手或后手肯定存在一种必胜策略。
相关链接:
2009-12-01 08:00:00
我的Emacs配置里C语言默认的缩进风格是用4个空格,最近要修改Chromium的代码,而Google的C/C++风格统一为2个空格缩进,所以改代码的时候要把c-basic-offset设置为2。这样在不同项目间切换的时候很不方便。
在stackoverflow上发帖求助后发现了Emacs 23.1一个很好用的新功能,Per-Directory Local Variables,只需要在项目主目录下放一个.dir-locals.el文件,里面设置该项目特有的变量值,就能应用到整个项目了。
以我的Chromium为例,Google已经提供了一份C/C++风格的配置,只需要在~/chromius/src/.dir-locals.el里把google-c-style常量粘贴进去即可。另外我不知道为啥加上c-offsets-alist那段后Emacs缩进会变得很奇怪,所以我把它删了。附修改后的.dir-locals.el
((c++-mode . ((c-recognize-knr-p . nil)
(c-enable-xemacs-performance-kludge-p . t) ; speed up indentation in XEmacs
(c-basic-offset . 2)
(indent-tabs-mode . nil)
(c-comment-only-line-offset . 0)
(c-hanging-braces-alist . ((defun-open after)
(defun-close before after)
(class-open after)
(class-close before after)
(namespace-open after)
(inline-open after)
(inline-close before after)
(block-open after)
(block-close . c-snug-do-while)
(extern-lang-open after)
(extern-lang-close after)
(statement-case-open after)
(substatement-open after)))
(c-hanging-colons-alist . ((case-label)
(label after)
(access-label after)
(member-init-intro before)
(inher-intro)))
(c-hanging-semi&comma-criteria
. (c-semi&comma-no-newlines-for-oneline-inliners
c-semi&comma-inside-parenlist
c-semi&comma-no-newlines-before-nonblanks))
(c-indent-comments-syntactically-p . nil)
(comment-column . 40)
(c-cleanup-list . (brace-else-brace
brace-elseif-brace
brace-catch-brace
empty-defun-braces
defun-close-semi
list-close-comma
scope-operator)))))
2009-11-30 08:00:00
最近写了篇survey,分享下用NoteExpress一些经验
工具->样式->选择当前输出样式,选择BibTex,然后就能在题录的字段中找到bibtex 关键字一项了
导出bibtex时选择ANSI编码,如果设置为UTF-8貌似编译latex时会给出类似You’re missing an entry type—line 1 of file xxx.bib的提示。
导出引用的网页:我的解决方法是在BibTex样式->题录->模版里新增一个网页模版,然后右键编辑区选择从模版通用复制,并在里面增加一条***Howpublished = {\url{链接}}, 这样就能使用howpublished字段导出网页链接了。不过好像这样网页地址不会换行,于是我最后还是用手动断行改了下.bib。
另外提下,把png/jpg转成eps,我用的是sam2p,aur上就有。
2009-11-10 08:00:00
其实这个问题我以前在 Stackoverflow 上回答过别人(链接),不过现在自己反而忘了,还是贴在这下次查起来方便点
先用 git rebase bbc643cd^ --interactive 退回到要修改的commit的前一个点,这里 bbc643cd 就是要修改的 commit,执行后 git 会调用默认的编辑器显示该次 commit 到最新 commit 的所有记录,在这里我们把要修改的那一项的行首的 pick 改成 edit。
接下来运行 git commit --amend,使用默认编辑器修改这次 commit。
最后执行 git rebase --continue 就能提交修改后的 commit 并且返回到原来的 commit 了。
2009-10-23 08:00:00
这周买了块西数的1T硬盘,用来放各种美剧/高清电影。装好进入Win7后提示检测到新硬盘,然后进入磁盘管理一看发现磁盘大小只有31兆,重启进入BIOS看到的磁盘容量是0MB。换了一台电脑问题依然存在。
于是求助superuser,发现了这篇文章http://www.pcstats.com/articleview.cfm?articleid=1139&page=12,貌似是LBA(Logical Block Addressing)相关的问题,下载了个HDD Capacity Restore Tool修复后问题解决。
附该软件下载地址:http://hdd-tools.com/products/cr/download/crsetup.exe
2009-09-28 08:00:00
Quine是指一类能生成自己的程序,例如下面这个C程序运行后就能把自己的源码完整的打印出来:
char*f="char*f=%c%s%c;main()
{printf(f,34,f,34,10);}%c";
main(){printf(f,34,f,34,10);}
这类程序的构造方法计算理论导引或者其他相关的书籍中都有涉及,这里不再赘述。这个月看到几个Quine的变种,都挺有趣的。
首先是sigfpe构造出来的三阶Quine,这是一个只有两行的Haskell程序:
q a b c=putStrLn $ b ++ [toEnum 10,'q','('] ++ show b ++ [','] ++ show c ++ [','] ++ show a ++ [')']
main=q "q a b c=putStrLn $ b ++ [toEnum 10,'q','('] ++ show b ++ [','] ++ show c ++ [','] ++ show a ++ [')']" "def q(a,b,c):print b+chr(10)+'q('+repr(b)+','+repr(c)+','+repr(a)+')'" "def e(x) return 34.chr+x+34.chr end;def q(a,b,c) print b+10.chr+'main=q '+e(b)+' '+e(c)+' '+e(a)+' '+10.chr end"
这段程序牛逼在哪里呢?运行后这个程序首先会输出一个Python程序,然后再运行这个Python程序会输出一段Ruby代码,最后这个Ruby代码的运行结果是原来的程序。或者说
$ runhaskell quine.hs | python | ruby
的运行结果就是这段程序本身。
另外两个Quine变种都和zip有关。一个是解压得到自己的gzip文件;另一个看起来更强大一点(不过是真的“更强大”吗?),解压自己能得到一个图片和自己本身,基于lz77算法。
两个zip quine的下载地址分别是http://upload-001.yo2cdn.com/wp-content/uploads/74/7487/2009/09/selfgz.rar和http://steike.com/code/useless/zip-file-quine/droste.zip。
2009-09-26 08:00:00
Dreamhost提供的php有不少限制,昨天折腾了一个晚上终于成功地在自己的虚拟主机上编译了php5。
Why
用下来,发现使用自己编译的php5有这么几个好处:
可以自定义内存分配上限,默认只有32M,通过wordpress安装插件的时候经常出现内存不够的问题。
上传文件大小限制也能改,默认只有2M,基本没法通过wordpress传音乐之类的比较大的文件。
使用自己的php后解释执行的进程uid也是自己了,这样就避免了很多nobody用户访问/修改/增加文件所带来的问题。
How to compile
编译和安装的大部分步骤可以参考http://wiki.dreamhost.com/index.php/Installing_PHP5,这里补充一点我碰到的问题和解决方法。
因为我这台dreamhost虚拟主机用的是x86_64,而通过下载的php5的configure文件默认查找的是/usr/lib/下面的共享库,通过–with-libdir=lib64设置查找路径后却无法找到openssl库了,于是我用了个很山寨的方法,把configure脚本里查找libmysqlclient时的路径临时改成了/usr/lib64,然后再改回/usr/lib。
安装脚本开头定义的几个包的名字可能也要修改下,如果下载出现错误的话去上级目录看下最新的包的名字是什么就行了。另外脚本中解压.Z和.tar.gz文件用的是uncompress命令,似乎在我的这个主机上没有安装,改成tar zxf就行了。
How to use
最后说下编译成功后怎么使用,具体方法那个网页上也讲过了,只要把编译后的php.cgi放到/cgi-bin/下然后改下.htaccess即可。
对于子域名,比如我这个techblog.iamzellux.com,参照网页上的说明把整个cgi-bin用符号链接的方式link到子域名的根目录下是最方便的方案,当然别忘了修改.htaccess。
2009-08-12 08:00:00
这篇题目为Return-Oriented Rootkits: Bypassing Kernel Code Integrity Protection Mechanisms的论文发在了今年的Usenix Security上,现在在Usenix网站上还不能下到这篇paper的pdf,可以去作者的主页上下。
现在有不少用来防止栈溢出攻击的技术,比如操作系统保证任何一个页不能同时为可写且可读(WinXP SP2、Win 2003、Exec Shield for Linux等都采用了这个策略),这个方法实现起来比较简单,但只能防范部分形式的攻击,如果攻击者事先准备一张含有恶意代码的用户态的只读页,然后跳转到这个页,就能绕开这种保护措施了;另外也有人提出在操作系统的下面再加一层虚拟层,让它来保证上层系统没有因为各种buffer overflow而执行恶意代码(NICKLE)。
而这里提到的return-oriented的攻击方法不同于传统的攻击机制,它所采用的攻击代码都是内核自身的代码,因此能绕过前面提到的各种保护手段。
所谓return-oriented programming,简单的说就是把原来已经存在的代码块拼接起来,拼接的方式是通过一个预先准备好的特殊的返回栈,里面包含了各条指令结束后下一条指令的地址。
例如现在函数A里面有这么一段指令 instruction A ret
函数B里面有另外一段: instruction B ret
它们在正常的运行情况下没有任何关系,但是我发现如果把A和B拼起来就能达到我想要的结果,于是我构造了一个包含有A和B的地址的栈,先通过ret指令返回到instruction A处,之后再执行ret指令时,由于栈是精心构造的,因此接下来会执行到instruction B,这样就得到我想要的结果了。只要这个ret前的指令库足够大,就能实现几乎所有的程序。
这种攻击方式并非这篇paper的首创,最早是由Shacham提出的(http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.140.9210,http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.78.7135)
这篇paper的一大贡献在于实现了一个自动从libc和驱动、内核等代码中找到可用的指令,并拼接成所需程序的系统,这里面包括一个扫描可利用代码、并把它们结合起来的Constructor,一套专用的语言,以及把这套语言编译成对应代码片段之和的编译器,最后还有一个计算实际代码地址的Loader。
这套攻击机制在WinXP SP2/Sp3, Vista SP1等系统上都获得了成功,尽管查找代码并生成这个过程的overhead很大,但对于一次成功的rootkit攻击来说影响并不大。
2009-07-07 08:00:00
前几天给测试Xen用的虚拟机挂了,只能用VMware的snapshot返回到之前的镜像,然后似乎因为时间问题启动Xen的时候总是会定时打印出类似
571 Timer ISR/0: Time went backwards: delta=-11072481 delta_cpu=298927519 shadow=196807680595 off=288495093 processed=197107247546 cpu_processed=196797247546
572 0: 196797247546
573 1: 197107247546
的信息,google了下发现是时间同步的问题,用ntp协议同步时间即可解决这个问题。另外这里再给出一个最暴力的解决方法:在linux-xen源码的arch/i386/kernel/time-xen.c文件中找到Time went backwards,把这行打印语句以及后面的循环打印删除,然后重新编译内核。x86_64体系结构也是修改这个文件。方法很暴力,也没真正解决问题,但是至少不影响我看/var/log/messages的输出了。
2009-07-01 08:00:00
记得以前用Firefox 3.0.x时把Tools -> Options -> Tabs -> Always show the tab bar勾上就行了,升级到3.5以后就没用了,搜了下Knowledge Base,最后在
看到只要将about:config页中的browser.tabs.closeWindowWithLastTab项设为false即可
2009-06-16 08:00:00
主要功能:开发人员执行svn commit后自动将开发人id、修订版本号和日志内容通过短信的方式通知所有人。
首先修改svn服务器对应项目目录hook/post-commit文件
#!/bin/bash
export LANG=en_US.utf8
REPOS="$1"
REV="$2"
cd /home/svn/repositories/sebank/hooks
./sms.py commit $REPOS $REV
注意别忘了这里的export LANG,我一开始测试的时候发现中文一直有乱码,后来才意识到shell的环境变量里缺这个。 hook/sms.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys, urllib, os
from subprocess import *
user = 'your mobile number'
pword = 'fetion password'
phone = [
'13764444444',
'13813333333',
]
repo = sys.argv[2]
rev = sys.argv[3]
cmdlog = 'svnlook log -r %s %s'%(rev, repo)
cmdauthor = 'svnlook author -r %s %s'%(rev, repo)
log = Popen(cmdlog, stdout=PIPE, shell=True).stdout.read().strip()
author = Popen(cmdauthor, stdout=PIPE, shell=True).stdout.read().strip()
msg = 'sebank #%s %s: %s' % (rev, author, log)
for number in phone:
url = 'http://sms.api.bz/fetion.php?username=%s&password=%s&sendto=%s&message=%s' % (user, pword, number, urllib.quote_plus(msg))
cmd = 'curl "%s"' % url
send = Popen(cmd, shell=True, stdout=PIPE, stderr=PIPE)
send.wait()
这里user是发送者的手机号,且该用户的飞信好友需包含其他用户,pword为飞信密码,phone为用户手机号码列表。 最后设置下这两个文件的权限,保证http/svn用户能执行即可。另外由于sms.py中飞信密码是明文保存的,注意控制它的读权限。
2009-06-09 08:00:00
某门课程的Open Topic,我的话题是关于云计算的,读了一篇技术报告 Above the Clouds: A Berkeley View of Cloud Computing。
这是 UCB 的 RAD(Reliable Adaptive Distributed) 实验室花了六个月时间 brainstorm 总结出来的 paper,介绍了云计算的概念、现状及未来展望。以下内容主要来自于我上交的文档,做了一些修改,欢迎大家指正。
虽然现在对云计算这个概念的炒作大于实际研究,以至于很多人听到云计算这个名词就想到忽悠,但这里面还是很多东西需要好好考虑和设计的。云计算和以前的 cluster computing 等概念虽有相同之处,区别也有不少,它涉及了经济学、虚拟化技术、安全等诸多领域的内容。
云计算包含两方面内容,一是在网络上提供的为计算服务的应用,例如以前被称为 SaaS(Software as a Service) 的那一类应用;二是提供这些服务的在数据中心的硬件和系统软件,这部分也就是我们通常所称呼为「云」的东西。
云计算带来了三个新颖的观点:
提供了看起来没有上限的可用计算资源,用户不需要提前考虑设备的需求量;
免去了云计算用户的前期投入,使得公司可以从一个规模较小的硬件资源起家,并根据自己的需要增加资源;
细粒度的计费手段,例如按每小时使用处理器数或者每天使用的存储空间计算,并在暂时不需要机器和存储空间时即时减免费用。
云计算资源拥有很好的弹性,以 Amazon EC2 为例,用户可以在几分钟内完成硬件资源的添加或者减少操作,这在传统的应用程序部署中是很难做到的。文中提到了 Facebook 上的一个应用 Animoto,这个应用的资源需求在三天内从 50 台服务器上升到了 3500 台服务器。在传统的部署情景中,这样的需求是很难通过预先准备好硬件来满足的。另外还有一个问题,当资源需求下降时,传统方式部署的服务器资源就被闲置了,而通过云计算部署的资源则灵活很多,例如一个网站到了深夜访问量下降,此时就可以通过减少占用的计算资源从而降低支出。
现在的云计算平台提供了不同粒度的 API。Amazon EC2 是一个底层的极端,它提供了类似物理硬件的接口,用户可以几乎控制从内核开始的整个软件栈。通过虚拟技术提供的 CPU、块设备、IP 级别的连通技术使得开发人员几乎可以做任何事情。高度的灵活性带来的是可控性的损失,在自动伸缩性 (automatic scalability) 和容错转移 (failover) 方面,服务商就力不从心了。而 Google AppEngine 则提供了比较高层的 API,主要面向传统的 web 应用,在牺牲灵活性之后能很好的实现自动伸缩和转移,并对用户完全透明。而微软的 Azure 则介于这两者之间,提供了接近 CLR 字节码的接口,用户可以通过 .Net 的一系列语言和类库实现自己的应用程序。
不同的平台有不同的适用范围,不可能有一方压倒性的胜过另一方,这个问题就像 Ruby 和 C 语言孰优孰劣一样。
即如何保证服务总是可以访问,考虑到服务提供商可能倒闭等情况
文中提出的方法是不同的公司能提供独立的软件栈,以保证某一个服务无法使用后能及时切换到另一个。但这个实现似乎会有不少阻力,至少现在的云计算服务平台各自的 API 都还大相径庭,要在不同的平台间转移应用不怎么可行。
服务有效性的另一个问题是 DDoS 攻击,云计算的弹性机制可以很好的化解这个问题。作者算了一笔账,从黑市租借 50 万个攻击机器人攻击一个 EC2 的实例会使得受害者遭受额外的每小时 460 美刀的支出,但由于租借这些机器人需要 1.5 万美刀的资金,要使得受害者的损失大于攻击者的支出,这样的攻击需要持续 32 小时,对于攻击者来说得不偿失。
数据被锁在服务提供商的数据平台中,客户无法很简单的把数据从一个站点转移到另一个。这也是 Stallman 反对云计算的一个重要原因,客户可能因为数据锁在云计算平台中而不得不接收服务提供商的价格提升等要求。
文中提到的一个解决方案就是统一平台的 API,使得数据能在不同的服务提供商之间转移。我觉得这个方案也不现实,就像有了 GAppEngine 后,应该不会有另一家服务商提供类似的 Python 或者 Java 的 API 支持了吧?
不过也许可以有一个第三方的库把不同的服务商的 API 再做一层抽象,让应用程序来使用这些平台无关的 API,就像是 OpenCL/Streamware 之于 GPU。
这个问题我想不算难点,可信计算已经是研究的热门之一了,而用户自己也可以将机密数据加密后再保存到云中。而虚拟机监控器层也能提供相应的保障,例如CHAOS 和 VMware 的 OverShadow 可以保护在不可信的操作系统中应用程序运行的安全性,这样即使攻击者能利用操作系统层的漏洞,也无法对操作系统上面的受保护的应用程序进行攻击。
用户的数据要传输到云里面,消耗的时间和带宽都很高,怎么办呢?
一个简单和实用的方案就是直接通过快递公司邮递硬盘,几 TB 的数据不到一天就能传到数据中心了。
另一个手段是尽可能地把数据保留在云中。我觉得广义的来说这也是一种 locality 的优化吧,但是这样就又要考虑到前面提到的数据锁定的问题了。
此外,降低网络传输的费用也是一个研究方向,据估计三分之二的网络带宽费用都是用在高端的路由器上,而另外的三分之一才是用在传输介质中。如何减少路由器的耗费是一个需要深入研究的问题,另外如何更有效的设计云里面的网络的拓扑结构也值得探讨。
我觉得相对其他问题,这个问题应该算是很难解决的了。由于客户使用的虚拟机往往和其他虚拟机共享了云中的硬件资源,在共用 I/O 设备的时候表现性能会有较大的起伏。
提高性能稳定性的最直接的途径自然是提高体系结构和操作系统虚拟中断及 I/O 通道时的效率了。另外文中还考虑了使用闪存来降低 I/O 干扰的可能,不过我认为闪存随机写的性能很差,代替硬盘后的性能未必会好,尤其在多个虚拟机同时访问的情况下,稳定性就很难说了。
另外,在调度虚拟机的时候,还要采用 Gang Schedule,即对于一些必须几个线程同时运行的程序,要保证这些虚拟机能被同时调度运行。
包括存储设备的可伸缩性,如何快速伸缩、大规模分布式系统中的bug问题,这可以通过开发相应的可伸缩存储系统、算法以及分布式调试器解决。另外还有声誉共享(一个客户的恶意行为被其他网站记录,可能影响到同一台物理机上的另一个无辜的客户),软件协议等问题。这些应该都不是难点,而软件协议方面,微软也已经推出 Windows Server 和 Windows SQL Server 的到期支付 (pay as you go)的协议。
2009-06-02 08:00:00
Company的全写是complete everything,它只是一个补全的前端,会自动调用semantic等后端插件。
新版的Company可以从它的官方主页(http://nschum.de/src/emacs/company-mode/)下载到,也可以从ELPA下载安装这个插件。
使用这个插件时只要在.emacs中加入
(add-to-list 'load-path "/path/to/company")
(autoload 'company-mode "company" nil t)
然后Emacs中使用M-x company-mode启动company模式即可。
具体的按键可以在company.el中看到
(defvar company-active-map
(let ((keymap (make-sparse-keymap)))
(define-key keymap "\e\e\e" 'company-abort)
(define-key keymap "\C-g" 'company-abort)
(define-key keymap (kbd "M-n") 'company-select-next)
(define-key keymap (kbd "M-p") 'company-select-previous)
(define-key keymap (kbd "") 'company-select-next)
(define-key keymap (kbd "") 'company-select-previous)
(define-key keymap [down-mouse-1] 'ignore)
(define-key keymap [down-mouse-3] 'ignore)
(define-key keymap [mouse-1] 'company-complete-mouse)
(define-key keymap [mouse-3] 'company-select-mouse)
(define-key keymap [up-mouse-1] 'ignore)
(define-key keymap [up-mouse-3] 'ignore)
(define-key keymap "\C-m" 'company-complete-selection)
(define-key keymap "\t" 'company-complete-common)
(define-key keymap (kbd "") 'company-show-doc-buffer)
(define-key keymap "\C-w" 'company-show-location)
(define-key keymap "\C-s" 'company-search-candidates)
(define-key keymap "\C-\M-s" 'company-filter-candidates)
(dotimes (i 10)
(define-key keymap (vector (+ (aref (kbd "M-0") 0) i))
`(lambda () (interactive) (company-complete-number ,i))))
keymap)
"Keymap that is enabled during an active completion.")
这里默认的补全按键是Tab,由于已经把它绑定到了yasnippet,我用了Shift-Tab替代(Ctrl-Tab似乎在terminal下没法用,不知道哪位能解决这个问题)
(define-key company-mode-map "\t" nil)
(define-key company-mode-map [(backtab)] 'company-complete-common)
如果按了Shift-Tab没有任何反应,请确认你的后端插件已经配置正确,可以参考这篇博文。
另外这里还有个视频,不喜欢看文字的话看一下这个就知道company怎么用了。http://nschum.de/src/emacs/company-mode/screencast/
2009-06-01 08:00:00
http://stackoverflow.com/questions/731832/interview-question-ffn-n http://stackoverflow.com/questions/732485/interview-question-ffx-1-x
问题描述很简单,第一个问题是实现一个函数f,参数为一个带符号的32位整型,使得f(f(x)) = -x,即调用两次后返回的结果为原来的相反数;另一个问题也是实现一个函数g,参数为一个32位浮点,最后使得g(g(x)) = 1/x。如果不能满足所有的情况,就满足尽可能多的情形。
第二个问题比第一个问题简单一点,目前支持数最高的两个答案如下:
问题1的解无法满足n = 2^31 - 1的情况
def f(n):
if n == 0: return 0
if n >= 0:
if n % 2 == 1:
return n + 1
else:
return -1 * (n - 1)
else:
if n % 2 == 1:
return n - 1
else:
return -1 * (n + 1)
问题2的解的想法也很巧妙
float f(float x)
{
return x >= 0 ? -1.0/x : -x;
}
2009-05-27 08:00:00
VMware支持虚拟串口设备,对于调试内核或者虚拟机的帮助很大,具体设置如下(VMware Server 2, Xen 3.3):
VMware中为虚拟机增加串口设备 Add Hardware->Serial Port,然后在设置中将Connection模式设为File,指定相应的文件路径(如[standard] debian-xen/serial-port.log)
修改虚拟机的grub启动参数,以我的/boot/menu/lst为例
title Xen 3.3.0 / Debian GNU/Linux, kernel 2.6.18.8-xen
root (hd0,0)
kernel /boot/xen-3.3.0.gz com1=115200,8n1 loglvl=all guest_loglvl=all console_to_ring console=com1,vga sync_console
module /boot/vmlinuz-2.6.18.8-xen root=/dev/sda1 ro console=tty0
savedefault
2009-05-26 08:00:00
参考文章:
[1] http://hokietux.net/blog/?p=58 [2] http://scie.nti.st/2007/11/14/hosting-git-repositories-the-easy-and-secure-way [3] http://www.nkuttler.de/2009/04/06/git-clone-ssh-could-not-resolve-hostname/
很简单,直接用pacman安装即可 sudo pacman -S git
gitosis是一个方便管理git仓库的工具,安装方法:
从yaourt或者aur下载安装gitosis-git包 http://aur.archlinux.org/packages.php?ID=23419
新建git用户 sudo useradd –system –shell /bin/sh –comment ‘git version control’–user-group –home-dir /home/git/ git
将开发用户的rsa公钥导入gitosis,(没有公钥的话请先运行ssh-keygen -t rsa生成) sudo -H -u git gitosis-init < ~/.ssh/id_rsa.pub
如果以上步骤没有问题,那么运行 git clone ssh://git@hostname/gitosis-admin.git 后应该就能看到gitosis-admin.git这个目录了
新建项目、添加用户等操作参见[2],这里不再赘述
事实上ArchLinux中安装的git包自带了gitweb,可以用which gitweb搜到,一般默认在/usr/share/gitweb。下面假设我的http根目录为/home/httpd
将/usr/share/gitweb下的文件复制到/home/httpd/cgi-bin(其实似乎只要gitweb.cgi就够了) sudo cp -R /usr/share/gitweb /home/httpd/cgi-bin/
/usr/share/gitweb下的.css和.png复制到/home/httpd/html/git/
修改或创建/etc/gitweb.conf,具体配置如下
# git命令的地址
$GIT = "/usr/bin/git";
# 项目仓库地址
$projectroot = "/home/git/repositories";
# 网页显示相关的文件,我把它们都放在了/home/httpd/html/git/下
$stylesheet = "/git/gitweb.css";
$logo = "/git/git-logo.png";
$favicon = "/git/git-favicon.png";
# 首页显示的站点名
$site_name = "ZelluX's Git Trees";
# 项目信息中显示的地址,
@git_base_url_list = ("ssh://git\@hostname");
# 网页中项目说明的显示长度
$projects_list_description_width = 50;
# 发布的项目的标记。例如/home/git/repositories/hello/git-daemon-export-ok存在,
# 那么hello这个项目就会显示在项目列表上。
# 但是似乎每次pull或者push操作都会导致git把这个它认为多余的文件删掉,不知道有没有其他的解决方案。
# 把这行注释掉就允许所有的项目显示在网页上。
$export_ok = "git-daemon-export-ok";
$feature{'pathinfo'}{'default'} = [1];
$feature{'blame'}{'default'} = [1];
$feature{'blame'}{'override'} = [1];
$feature{'pickaxe'}{'default'} = [1];
$feature{'pickaxe'}{'override'} = [1];
$feature{'snapshot'}{'default'} = [1];
$feature{'snapshot'}{'override'} = [1];
$feature{'search'}{'default'} = [1];
$feature{'grep'}{'default'} = [1];
$feature{'grep'}{'override'} = [1];
RewriteEngine on
RewriteRule ^/gitweb/(.*) /cgi-bin/gitweb.cgi/$1 [L,PT]
2009-05-12 08:00:00
Multi-Execution: Multicore Caching for Data-Similar Executions
这篇paper针对以multi-execution这种模式运行的程序提出了一种新的cache手段。
所谓multi-execution,指的是同时运行同一个程序的多个进程,而它们的输入数据又互不相同。这种模式在machine-learning领域比较常见,一些相对独立的learner可以以并行的方式被训练,而它们的结果可以通过一种叫做boosting的方式合并起来。给我的感觉似乎有点像mapreduce?
然后呢,作者们发现以这种方式运行的程序进程的数据有很大一部分是相同的,在合并cache数据上可以做一下文章,节省cache的使用。
于是这篇paper提出了一种叫做mergeable cache的架构,用于代替传统的L2 cache,L1 cache还是传统的cache架构。首先假设相同的数据的虚拟地址往往也是相同的(应该去掉了address space randomization的影响),以类似Page Coloring的策略进行物理页的分配,使得不同进程同一虚拟地址所对应的物理页都是相邻的。然后把虚拟地址的头9位作为cache tag,再为每个cache line记录一个bit vector用以表示某个processor的数据是否保存在这条cache line中。于是L2 cache hit当且仅当:
另外为了简化cache策略,L1和L2的数据内容是互斥的,或者说一段被cache的数据要么在L1,要么在L2,不可能同时存在于两者中。这样一来L2就只有从L1淘汰出来的数据了,而L2中的数据修改分三步完成:
这就是这篇paper提出的cache架构的主要内容,后面的evaluation部分做的也很不错。从数据中可以看出合并的cache里面dirty cache占了比较大的比例,从而说明简单的copy-on-write策略的效果不会很好,因为copy-on-write只能合并clean cache。最后平均的speedup提升在2.5x左右,很不错。但是对于数据无关的并行程序运行,会产生一定的overhead,此时可以选择传统的L2 cache机制。
2009-05-11 08:00:00
读 Multi-Execution (ISCA ’09) 的时候看到的名词,中文叫做高速缓冲器页着色,有点拗口,还是用英文术语好了。
早期的处理器缓存都是映射虚拟内存的,这样带来两个问题,一是进程切换等场合下需要清空缓存,二是由于多个虚拟地址可能指向同一个物理地址,因此会出现缓存中数据别名的问题(data aliasing)。
于是现代的处理器更多的通过物理地址进行数据缓存,这也引入了另一个问题,虚拟内存中看到的相邻的两块数据在缓存中很有可能是不相邻的,如果操作系统分配物理页时不考虑这点就会影响性能。
举例来说,假设CPU能缓存4个物理页,缓存策略是 CS:APP 中提到的最简单的方式,即第n号缓存只用于物理页号除4余数为n的物理页(n=0,1,2,3),比如第2号缓存对应于2,6,10,..号页面。现在用户为页面号为0的虚拟页申请空间,操作系统把第16号物理页分配给它;接下来用户又为页面号为1的虚拟页申请空间,而17-19号物理页已经用掉,此时操作系统就不应该分配20号物理页给它,因为20号物理页和16号物理页占用同一个缓存地区,假设用户程序的局部性(locality)很好的话这样的分配方式会产生比较严重的抖动(thrashing),影响系统缓存的性能。所以操作系统应该分配21号物理页给它,而保证这种分配策略的方式就是为每个页标记不同的颜色,并使得同一时间使用的页面颜色尽可能的不同。
2009-05-06 08:00:00
吴总讲的一篇paper,题目是Orchestra: Intrusion Detection Using Parallel Execution and Monitoring of Program Variants in User-Space,发在EuroSys ‘09上,UCI的。
这篇paper提出了一种检测栈上buffer overflow攻击的方法。想法很有意思,它运行两个孪生进程,这两个进程的唯一的区别就是一个进程的栈往上长而另一个进程的栈往下长,这样在大多数情况下如果没有出现buffer overflow的问题的话那么两者的行为应该是一致的。
栈的增长行为是由编译器控制的,作者修改了gcc的代码使之生成的代码的栈增长方向相反,关于这个编译器他们之间发过一篇paper在一个叫CATARS的workshop上,题目是Reverse stack execution in a multi-variant execution environment。
“行为一致”的精确定义是两者的system call的调用方式、参数都一样,也就是说这里system call成了两个进程运行的synchronization point。如果某个点上两个进程调用的syscall不同或者调用参数不同就认为它已经被buffer overflow攻击了。
整个monitor都是跑在user态的,主要利用了ptrace,使两者的行为尽可能的一致。这里要做的事情很多,比如要保证进程调用getpid()的得到返回值一样才能使得后面的其他系统调用的参数相同,又比如一个进程调用write写入文件时不能影响到另一个进程,此外还要保证两个进程获得的file descriptor、随机数、时间、信号等信息都相同,甚至在进程创建子进行的时候也要保证所有子线程关系的同构。
用ptrace能够解决上面的大多数问题,但还有一些open problem以及false positive。如这篇paper无法解决进程用MAP_SHARED方式打开一个文件并修改的情况,尽管作者说这种mmap的用例很少见;此外由于两个进程的同步并不是原子性的,中间可能被第三方的程序干扰(比如进程A读入某个文件开头后,该文件被其他进程修改,进程B再读取就和进程A读到的不一样了),这就造成了false positive;另外由于无法截取rdtsc指令的使用,也就无法保证它们的返回值一样,也可能引起另一种false positive。
感觉这个东东想法不错,但是没什么实用性,工程量也很大。
2009-05-05 08:00:00
在kernel 2.6.29上编译vmware modules时报错了
/usr/src/linux-2.6.29/arch/x86/include/asm/apicdef.h:132:1: warning: this is the location of the previous definition
/tmp/vmware-config0/vmmon-only/linux/driver.c: In function ‘LinuxDriverSyncCallOnEachCPU’:
/tmp/vmware-config0/vmmon-only/linux/driver.c:1423: error: too many arguments to function ‘smp_call_function’
/tmp/vmware-config0/vmmon-only/linux/driver.c: In function ‘LinuxDriver_Ioctl’:
/tmp/vmware-config0/vmmon-only/linux/driver.c:1987: error: ‘struct task_struct’ has no member named ‘euid’
/tmp/vmware-config0/vmmon-only/linux/driver.c:1987: error: ‘struct task_struct’ has no member named ‘uid’
/tmp/vmware-config0/vmmon-only/linux/driver.c:1988: error: ‘struct task_struct’ has no member named ‘fsuid’
/tmp/vmware-config0/vmmon-only/linux/driver.c:1988: error: ‘struct task_struct’ has no member named ‘uid’
/tmp/vmware-config0/vmmon-only/linux/driver.c:1989: error: ‘struct task_struct’ has no member named ‘egid’
/tmp/vmware-config0/vmmon-only/linux/driver.c:1989: error: ‘struct task_struct’ has no member named ‘gid’
/tmp/vmware-config0/vmmon-only/linux/driver.c:1990: error: ‘struct task_struct’ has no member named ‘fsgid’
/tmp/vmware-config0/vmmon-only/linux/driver.c:1990: error: ‘struct task_struct’ has no member named ‘gid’
/tmp/vmware-config0/vmmon-only/linux/driver.c:2007: error: too many arguments to function ‘smp_call_function’
貌似是2.6.29的task_struct有了改动导致的,网上搜到一堆vmware workstation在kernel 2.6.29上的补丁,都不好用,最后在http://www.saarlinux.de/blog/?p=5 翻到一个已经打了补丁的vmware modules包,解压到/usr/lib/vmware/modules/source覆盖原来的几个.tar文件再运行vmware-config.pl就可以了
2009-05-04 08:00:00
长时间使用Emacs经常会觉得小指疼痛,一个月前我把自己用的三台电脑(两台winxp,一台archlinux)的Caps Lock键的功能都改成了和左Ctrl一样,这样小指按起来就舒服多了,另外由于平时不需要用到Caps Lock键所以也不需要找个组合键来代替它了。
Windows下有个很方便的改键工具 remapkey,xp安装盘自带。
Mac OS X系统中改键也很方便,10.4以上版本的OSX中可以直接在Keyboard Preference里找到修改键位映射的选项。
Linux下的改键我知道两种方法,一种是修改xorg.conf文件,把里面的键盘设备设置改成
Section "InputDevice"
Identifier "Generic Keyboard"
Driver "kbd"
Option "CoreKeyboard"
Option "XkbRules" "xorg"
Option "XkbModel" "pc104"
Option "XkbLayout" "us"
Option "XkbOptions" "ctrl:swapcaps"
EndSection
另一种是使用xmodmap这个工具,具体可以参见这篇文章 Changing your caps lock into Ctrl in X,这里简单介绍下
修改前记得先备份当前的键位映射,xmodmap -pke > xmodmap.backup
接下来运行
xmodmap -e 'keycode 66 = Control_L'
xmodmap -e 'clear Lock'
xmodmap -e 'add Control = Control_L'
这样就修改了Caps Lock的键位映射而不需要重启x,如果要在每次启动时自动修改Caps Lock键的映射,可以新建/修改一个.Xmodmap或者.xmodmap的文件,在里面加入
keycode 66 = Control_L
clear Lock
add Control = Control_L
2009-04-29 08:00:00
http://linux.about.com/od/emacs_doc/a/emacsdoc567.htm
M-x xterm-mouse-mode 开启鼠标支持,操作的时候按住shift能恢复到之前的xterm鼠标模式
M-x mouse-wheel-mode 开启滚轮支持
一些相关的参数: mouse-drag-copy-region 选中后自动复制 mouse-wheel-scroll-amount 每次滚动的行数 mouse-wheel-follow-mouse 滚动位置 mouse-wheel-progressive-speed 滚动速度
2009-04-20 08:00:00
FastForward for Efficient Pipeline Parallelism http://systems.cs.colorado.edu/~moseleyt/publications/giacomoni-2008-ppopp-ff.pdf
这篇paper介绍了一种针对多核访问优化的队列, 主要的特点:
经典的Lamport的lock-free的队列实现可以用下面的伪代码来表述(同样只适用于单一生产者/单一消费者的情形):
enqueue_nonblock(data) {
if (NEXT(head) == tail) {
return EWOULDBLOCK;
}
buffer[head] = data;
head = NEXT(head);
return 0;
}
dequeue_nonblock(data) {
(head == tail) {
return EWOULDBLOCK;
}
data = buffer[tail];
tail = NEXT(tail);
return 0;
}
这种实现尽管做到了lock-free,但是存在几个问题,首先是它只适用于sequential consistency内存模型,在relaxed consistency的内存模型里可能会出现类似于Double-Checked Lock(http://techblog.zellux.czm.cn/?p=30)的问题,当然这个问题可以通过插fence指令来解决;第二个问题是这篇paper着重解决的,就是enqueue和dequeue这两个操作都用到了tail和head这两个全局变量,导致多核在读取/修改这两个变量时的为了保证cache coherency会频繁的进行cache的更新,从而导致cache line threading,降低了效率。
接下来看FastForward的实现:
enqueue_nonblock(data) {
if (NULL != buffer[head]) {
return EWOULDBLOCK;
}
buffer[head] = data;
head = NEXT(head);
return 0;
}
dequeue_nonblock(data) {
data = buffer[tail];
if (NULL == data) {
return EWOULDBLOCK;
}
buffer[tail] = NULL;
tail = NEXT(tail);
return 0;
}
这个版本的队列实现粗看和Lamport的那个区别很小,而实际上这里解决了一个重要的问题:解除了head和tail的共享问题。dequeue操作只需要关心tail,enqueue操作只关心head,这样两个变量就变成CPU本地的资源了,不需要做任何同步。当然这个实现同样局限于sequential consistency,不过加fence保证顺序的overhead不大。最后测试中这个版本的单次操作比Lamport的快3.7倍左右,可见这样一个小小的改动对性能的提升起了举足轻重的作用。
paper后面还严格的证明了这种队列实现的正确性,即保证了消费者读出的数据的顺序和它们在生产者写入时的顺序一致,此处略去。
2009-04-10 08:00:00
水木上有个帖子讨论tuple这个词该怎么读,于是有人翻出来这个三年前的新闻组邮件
http://coding.derkeiler.com/Archive/Python/comp.lang.python/2006-02/msg01915.html
Then we went to hear Guido speak about Python 2.2 at a ZPUG meeting in Washington, DC. When he said toople I almost fell out of my chair laughing, particularly because the people who taught me to say it the “right” way were with me. When I looked over, they just hung their head in shame.
I work with Guido now and I’m conflicted. I’m still conditioned to say tuhple. Whenever he says toople, I just get a smile on my face. I think most of the PythonLabs guys pronounce it toople. 有意思,嘿嘿
我一直习惯把这个词读成/tʌpəl/,估计是受tunnel这个词的影响,然后查了下http://en.wiktionary.org/wiki/tuple#Pronunciation_2 发现/tuːpəl/和/tʌpəl/都可以
2009-04-09 08:00:00
Double-Checked Lock是一个常见的由于程序员把内存模型默认为sequential momery consistency导致的问题,具体见我去年写的一篇博文http://techblog.iamzellux.com/2008/07/singleton-pattern-and-double-checked-lock/
虽然Java 5解决了这个问题,但是C++等语言中这个问题依然存在,依然有很多因为程序员假设sequential consistency而编译器做了错误的指令调度后导致的bug,见http://www.newsmth.net/bbscon.php?bid=335&id=250203
CGO 09的这篇paper Detecting and Eliminating Potential Violations of Sequential Consistency for Concurrent C/C++ Programs针对这个问题进行了深入研究,通过加fence指令的方法解决了因编译器的指令调度造成的违背程序员原义的问题,可以在http://ppi.fudan.edu.cn/yuelu_duan下载到。没有认真读过,俺在这里就不误人子弟了 O.O
2009-04-08 08:00:00
趁还在编译内核的时候把以前写过的东西都转过来,今年寒假读的 (SOSP ‘97)
很早的一篇paper,发表的第二年Rosenblum就创办了VMWare。这篇paper介绍了一个跑在 FLASH机器上的虚拟机Disco,FLASH的架构是实验性质的cache coherent non-uniform memory architechure(ccNUMA)。
传统的VMM在实现上主要有三个问题
Disco虚拟CPU时是把指令放到物理CPU上直接执行的。当调度到某个虚拟CPU时,Disco就把物理机的寄存器设置为虚拟机的寄存器并跳转到相应的PC。
直接执行的好处在于大多数操作能获得和在真机上跑一样的效率,而难点在于处理不能直接放到真机上运行的指令,如修改tlb,访问物理内存等。
Disco为每个虚拟CPU记录了一个类似于传统操作系统中process table entry的数据结构。为了模拟特权指令,Disco还在这个数据结构中维持了虚拟CPU的特权寄存器和tlb的内容。
在MIPS处理器上,Disco运行在kernel mode掌握着对硬件的完全控制;控制器交给虚拟机的操作系统时,Disco把CPU置为supervisor mode;当进入user mode时取消。Supervisor模式允许操作系统访问受保护的内存区域(supervisor segment),但仍不能执行特权指令,也不能访问物理内存。诸如page fault的trap发生时,vmm会捕获到这个异常,修改相应的特权寄存器并跳转到虚拟机的trap vector。
Disco增加了一层物理地址到机器地址的转换。虚拟机使用从0开始的物理地址,大小和为虚拟机的内存相等,Disco把这些物理地址映射到了 FLASH的40位机器地址上。这种映射的实现借助于MIPS处理器的software-reloaded TLB,当操作系统尝试在TLB中插入一个virtual-to-physical的映射时,Disco会把这里的physical address改成对应的machine address,这样之后通过这条TLB记录的地址访问就不需要再经过VMM的处理了,没有额外的overhead。
为了方便计算TLB地址,Disco为每个虚拟机记录了一个pmap数据结构,每个pmap结构对应着虚拟机的一个物理页。pmap包含了一个指向 机器内存的引用,以及指向虚拟地址的映射(虚拟地址可能有多个,原文中用了复数形式),这主要用于页面被VMM回收时TLB的重置。另外MIPS处理器为 每个TLB记录标记了一个地址空间标识符(ASID, address space identifier),用来防止context switch时不必要的TLB刷新。Disco为了简单化处理,就在物理CPU被调度为另一个虚拟CPU时刷新TLB,这样ASID就能直接使用虚拟机提 供的了。
这样的处理带来了性能问题,由于TLB在虚拟CPU切换时会被刷新,带来了额外的TLB miss,而TLB miss由于需要被模拟,它的代价很大。为了减少这种性能影响,Disco维持了一个virtual-to-machine的二级软TLB,TLB miss发生的时候首先查看软TLB有没有相关的记录,如果找不到再交给虚拟机上的操作系统去处理。这种处理的影响就是虚拟机所看到的TLB会比实际 CPU的TLB大很多。
不怎么熟悉NUMA,这部分先粗读了,大致思想是通过动态的页面转移和复制维持locality,从而避免remote cache miss。
增加特殊的设备驱动是最清晰的实现方法,每个Disco设备都定义了一个monitor call,供设备驱动传参调用。对于支持DMA操作的设备,Disco也需要截获这些DMA请求并转换为相应的machine address。对于仅有一个虚拟机访问的设备,Disco只要保证访问的排外性并翻译DMA请求即可,而不需要虚拟IO资源。截获所有DMA操作的一个 好处是Disco可以在虚拟机间共享磁盘和内存资源。
DMA请求被截获时,如果请求的磁盘块已经在内存里了,就不需要再访问磁盘。如果请求的大小正好是虚拟机页面大小的整数倍,直接把对应的物理页映射 到虚拟机里就行,另外考虑到以后可能会修改这部分内存,需要将那些页面设为read-only,从而实现copy-on-write,同时这些处理对虚拟 机完全透明的。
磁盘被写入时,分两种情况处理:对于持久性的磁盘,如包含用户文件的,同一时间Disco只允许一个虚拟机挂载这个磁盘,其他虚拟机可以通过NFS 等分布式文件系统协议访问它;而对于非持久的磁盘,如根磁盘,使用copy-on-write的策略,即在写操作发生时记录下被修改的扇区,而copy- on-write的磁盘自身不会被修改。
虚拟机间通过NFS共享文件时,不做特殊处理的话,客户端和服务器端会各有一份buffer cache保存共享的数据。因此copy-on-write的策略同样被用在了网络实现上,虚拟机间的信息传送是通过在发送方和接收方上映射同一个只读页来完成的。
SPLASHOS是一个特制的跑在Disco上的library os,包括了线程创建、同步操作、libc函数和一个用于文件IO的NFS客户端栈,应用程序和这个library os链接后就能直接跑在Disco上,配合跑多个这样的操作系统的话就能利用起整个机器的资源。另外这种操作系统也不需要自己处理page fault等异常了,直接交给虚拟机就行。
整个测试是跑在SimOS这个模拟器上的,模拟的配置是一个特点类似于FLASH的large-scale multiprocessor。测试的workload是四个比较具有代表性的,并行编译(pmake),verilog模拟,raytrace和 sybase关系数据库。 测试的结果,跑单个workload的时间比不用Disco慢3%到16%
2009-04-08 08:00:00
同样是今年寒假读的
容错和动态资源管理在某种程度上相互矛盾的。因此在分配资源的时候,要尽可能的减少一个虚拟机使用的cell数。这里的cell是指相对独立的容错 单元,后面还提到一个node的概念,Origin 2000上每个node含两个CPU。CD还提供了两种快速的进程间通讯的primitive,RPC和message。
关于容错,有这么个问题,Disco在操作系统和硬件之间多弄了这么一层虚拟层,某个虚拟的操作系统出问题时可以不影响到其他操作系统,可是操作系 统不也是保证了进程间的互相独立,当一个进程异常时不影响另一个进程吗?多设立一层Disco对容错有什么帮助吗?这个问题的答案在于,VMM的代码量很 小,可以看作是一个可信的系统软件层(trusted system software layer),因为当VMM的代码行数少于五万行时,它的复杂度就和其他可信的层(如cache coherence protocol)差不多了,这个复杂度比现代操作系统的复杂度差不多要低两个等级。
传统操作系统通常使用一个全局的run queue来管理和分配进程在多个CPU上的运行,这种实现不适合CD的容错要求,也带来了更多的contention。所以CD为每个VCPU维护了一 个run queue,同时引入了VCPU migration的机制来平衡VCPU的负载,按颗粒度分三级,intra-node intra-cell inter-cell。内存管理方面,CD实现了memory borrowing机制,使得一个cell可以暂时的从其他cell里获得内存,如果这种借用受限于容错性,就只能使用原来的paging机制了。
测试比较了两个测试环境,跑在真机上的IRIX 6.4(增加了多核支持),和跑在CD上的IRIX 6.2。最后的结果显示大部分情况下(单核、8核、32核)后者和前者的差距在10%以内,最差情况下也只有20%的overhead。接下来的容错机制 的overhead同样很小,不高于2%。
2009-04-07 08:00:00
Paper标题是DFTL: A Flash Translation Layer Employing Demand-based Selective Caching of Page-level Address Mappings,PSU发表在ASPLOS 09上。这篇paper对我来说更像是篇flash存储的科普文。
flash存储单元分block和page,每个block有32/64个page,一个page有512/2048K大小。flash的一个缺点在于改写数据时只能先把要改写的block清空,然后再写,由于block的颗粒度比较大,这就带来了比较严重的性能问题。所以现在的flash都在驱动层维护了一张对文件系统透明的logical-to-physical address的映射表(Flash Translation Layer),这样改写时只要先写在预先清空的page上,再把映射表的对应项的物理地址改成新的page的地址,然后把原来要改的页置为invalid,等gc去清空即可。
如果为每个page都在内存中维护一份映射关系,会占用比较大的内存空间。以往的ftl的实现试图在page-level和block-level的映射中找平衡,但效果都不甚理想,尤其在随机写比较频繁时会产生比较严重的gc负荷,从而影响写操作的反应速度(因为预先清空的页面不足时需要先做gc)。这篇paper提出的DFTL可以比较好的减少gc的负荷,同时近需要很小的内存空间,前提是程序访问flash的locality很好。
感觉DFTL的大致思想仿照了二级页表和TLB:flash上的一些page保存了page-level的映射,分散在整个flash中,在内存里面有一个block-level的映射表,记录了每个page-level映射表在flash中的地址。内存中的映射表相当于二级页表中的page directory,指向了flash上的page-level映射表(page table),另外内存中还有一个全局的page-level的映射表用于记录最近访问到的page的logical-to-physical映射,类似于TLB。这样如果程序locality很好的情况下大多数情况下只要查询这张表就行了。
2009-04-07 08:00:00
写完代码测试时重复的最多的步骤就是
于是写了个自动执行3 4 5的脚步,主要用到了熊熊推荐的pexpect,这东东很赞啊
为了提高用户体验,读取domainU的启动信息时我采用的方法是读一行输出一行,读到结尾登陆字符时通过超时设置退出循环,这样可能效率比较低,不过测试脚本也不care这个了
实际使用时碰到了另一个问题,domainU执行完自动命令后命令行会出现很严重的对齐问题,最后发现登陆后运行一次reset就可以了。
脚本如下
#!/usr/bin/python
# Automatic test script for Xen DomainU
# Author: zellux
import pexpect, os
conf = {
'login_name' : 'm2-vm2',
'domainU_name' : 'R900-DomU0',
'domainU_conf' : '/home/wyx/domU1',
'domainU_id' : '2',
'domainU_user' : 'wyx',
'domainU_passwd' : 'wyx',
}
# Command to be executed after domainU starts
cmd = """
cd m2
cd reg_test
./base_test -t affinity
"""
# Create domainU
print '[M2 Test] Starting domainU ...',
pexpect.run('xm create %(domainU_conf)s' % conf)
print 'done'
# Get domainU id
print '[M2 Test] SGetting domainU id ...',
ret = pexpect.run('xm list')
for line in ret.split('\n')[1:]:
part = line.split()
if part[0] == conf['domainU_name']:
conf['domainU_id'] = part[1]
break
print 'done'
# Run domainU commands
child = pexpect.spawn('xm console %(domainU_id)s' % conf)
print '[M2 Test] SReading from domainU console...'
try:
while True:
child.expect('\n', timeout=1, )
print child.before.split['\n'][-1]
except:
pass
child.expect('%(login_name)s login:' % conf)
child.sendline(conf['domainU_user'])
child.sendline(conf['domainU_passwd'])
for line in cmd.split('\n'):
child.sendline(line)
try:
child.expect(pexpect.EOF, timeout=1)
except:
pass
print child.before
child.interact()
2009-04-06 08:00:00
MIT出品,发在1984年的TOCS上,很值得细细品味的一篇paper,可惜做presentation时由于是第一次在组会上讲,效果很差。
这篇paper的核心思想就是,在设计一个系统各个层次的功能时,如果把某个功能放到某一层时无法保证功能的完全可靠,那就干脆不要做,除非是为了性能等其他因素考虑。
这里举了一个文件传输的例子,假设要把电脑A的资料通过网络传输给电脑B,而其中文件系统、传输程序、网络等各个子系统都有可能出现问题,那么如果保证传输的可靠,即B能完整不出错的得到A的数据并保存呢?
如果把验证做在子系统,比如网络数据包校验,文件系统里也为每个文件加checksum,读出来的时候验证下,从而避免磁盘出错的可能。但是这些常见的措施只能保证部分环节的正确性,降低出错的可能,并不能从根本上保证数据传输的可靠性。举个例子来说,这里如果文件传输程序出了bug,网络和文件系统里面的检查即使通过了,最后的结果还是错误的。
针对这个问题的End-to-End的解决方案很简单,就是在电脑A上保留一份该文件的checksum,电脑B接收并保存后再算一次checksum,相等就说明传输成功了(当然这里要钻牛角尖的话也可以说还是有可能出问题的,但是这个概率已经小到可以完全忽视的地步了,在这里我们假设checksum符合就说明这个环节没有问题)。而这种保障措施不需要任何子系统的参与,也就是End-to-End的。
那么当一个子系统对要做的事情并不完全了解的时候(比如这里的网络传输层只能保证对方接受到的数据包的正确性,却不知道文件有没有损坏),是不是就没必要在子系统实现这个功能了呢?从正确性是来说是,但是考虑到其他方面,在子系统作检查还有另外两个好处:
一是大大的降低了出错的概率,准确的说是出错的概率呈指数级降低,这在并不需要一种完美的保障措施的场合下还是很有用的;
二是提高了性能,如果只用End-to-End的检验的话,有可能传输中丢了个包要等整个文件传输完毕做checksum的时候才会发现;而如果中间在网络传输层加个丢包检验的话就可以及早的发现错误并恢复了。这个问题在网络不可靠,或者文件很大的情况下尤为突出,仅仅是End-to-End的保证会使传输时间的期望值随着文件大小的增加呈指数级上升。
上网络课的时候有一次老师的问题就是既然OSI七层协议的上层(如transport层)已经做了校验措施,为什么下层(如data-link层)还会有“多余”的error detection呢?当时我想到的一个答案就是为了性能考虑,因为那会儿正好在读这篇paper ;-)
但是并不是说把功能放到子系统里就一定能提高性能了。如果子系统里面塞满了各种并不是上层都必需的检验机制,整个系统的性能势必会受到影响。所以这个trade-off值得深思熟虑。Exokernel的论文就提出了传统的操作系统中存在的这样一个问题,底层内核过于冗余,影响了应用程序性能,也隐藏了一些对部分应用程序比较重要的信息(比如给数据库提供磁盘原生数据访问的API可以获得更优的性能,另外应用程序也应当能控制自己发生缺页错误时候的行为)。
这里的“End”在不同的环境下会对应不同的模块。比如在网上聊天这个通信过程中,没有必要在底层做很多校验来保证数据包的完整性,这时候及时性更重要,当数据包丢失或者数据出错时,会有一个更常用的End-to-End的解决方案:没听清的那一方通过语音要求重述就行了,“我听不清,能再说一遍刚才的话吗?”,而此时的End自然是谈话双方。如果换一种情形,在语音留言系统中,就需要保证传输的正确性了,因为这时候数据的及时性变得很次要,而留言系统的特点要求用End-to-End的验证加上底层的措施来保证一方的语音信息尽可能忠实的保存到另一方的留言系统中。
修改于 2010.2.16
2009-04-04 08:00:00
http://emacsbugs.donarmstrong.com/cgi-bin/bugreport.cgi?bug=2800
Emacs在窗口过窄时使用minibuffer的auto-complete功能会挂掉,就把这bug报告上去了。负责人貌似是MIT的物理系毕业的博士?敬仰下。
从后面回复来看,似乎这个bug emacs22里也有,应该还是蛮常见的呀,为啥之前没人report呢@@
不管怎么说,总算也给Emacs出了份力,嘿嘿。
2009-04-03 08:00:00
在默认的基础上,把这几个都改成built-in (*),通过Xen启动时就不需要额外加载initrd了
2010.1.19更新:支持网络
Device Drivers
SCSI device support --->
<*> SCSI disk support
<*> SCSI generic support
SCSI low-level drivers --->
[*] LSI Logic New Generation RAID Device Drivers
<*> Serial ATA (SATA) support
<*> Intel PIIX/ICH SATA support
Fusion MPT device support --->
<*> Fusion MPT ScsiHost drivers for SPI
<*> Fusion MPT ScsiHost drivers for FC
<*> Fusion MPT ScsiHost drivers for SAS
(128) Maximum number of scatter gather entries (16 - 128)
<*> Fusion MPT misc device (ioctl) driver
<*> Fusion MPT LAN driver
Network device support --->
Ethernet (10 or 100Mbit) --->
[*] EISA, VLB, PCI and on board controllers
<*> AMD PCnet32 PCI support
2009-03-18 08:00:00
最近有点忙,今天总算在某个课题deadline前把论文憋出来交上去了。跑这儿来推荐两篇上个月看到的比较有意思的paper,都比较偏理论,也很老。
今天写介绍下第一篇,剑桥大学的A Logic of Authentication,中了SOSP ‘89,整理后发在1990年的ACM Transactions on Computer Systems上。 http://www.csie.fju.edu.tw/~yeh/research/papers/os-reading-list/burrows-tocs90-logic.pdf
(另一篇是Safe Kernel Extensions Without Run-Time Checking,改天再写点介绍)
这篇paper的主要工作是通过构造一种多种类的模态逻辑(many-sorted model logic),来检查网络中验证协议的安全性。
基础的逻辑分三部分: 原语,如验证双方A和B,以及服务器S,下文用P Q R泛指 密钥,如K_ab代表a和b之间的通讯密钥,K_a代表a的公钥,{K_a}^{-1}代表对应的私钥,下文用K泛指 公式(或者陈述),用N_a, N_b等表示,下文用X Y泛指
接下来定义以下约定(constructs) P 信任 X: 原语P完全信任X P 看到 X: 有人发送了一条包含X的信息给P,P可以阅读它或者重复它(当然通常是在做了解密操作后) P 说了 X: 原语P发送过一条包含X的信息,同时也可以确定P是相信X的正确性的 P 控制 X: P可以判定X的正确与否。例如生成密钥的服务器通常被默认为拥有对密钥质量的审核权。 X 是新鲜的: 在此之前X没有被发送过。这个事实可以通过绑定一个时间戳或者其他只会使用一次的标记来证明。 P <-K-> Q: P和Q可以通过共享密钥K进行通讯,且这个K是好的,即不会被P Q不信任的原语知道。 K-> P: P拥有K这么一个公钥,且它对应的解密密钥K^{-1}不会被其他不被P信任的原语知道。 P <=X=> Q: X是一个只被P和Q或者P和Q共同信任的原语知道的陈述,只有P和Q可以通过X来相互证明它们各自的身份,X的一个例子就是密码。 {X}_K: X是一个被K加密了的陈述 _Y: 陈述X被Y所绑定,Y可以用来证明发送X的人的身份
好了,总算把这些约定列完了,然后来看看通过这些约定能推出一些什么东东: 如果 P 相信 (P <-K-> Q), 且 P 看到 {X}_K,那么 P 相信 Q 说了 X。 这个例子很简单,既然P Q有安全的密钥K,那么P看到通过K加密后的X肯定认为就是Q发出的。
又比如, 如果 P 相信 Q 控制 X,P 相信 (Q 相信 X),那么 P 相信 X 也很容易理解,既然 P 相信 Q 的判断,那么 Q 相信什么 P 自然也就相信了。
再举一个例子 如果 P 相信 Y 是新鲜的,那么 P 相信 (X, Y) 也是新鲜的。 这里(X, Y)表示 X 和 Y 的简单拼接,也很容易理解,既然 Y 之前没出现过,那么 X 和 Y 的组合自然也没出现过。
一个协议要被定义为安全,最起码要满足 A 相信 A <-K->B,B 相信 A <-K->B 即双方要互相信任密钥是安全的
再健壮一点的协议,还要满足 A 相信 (B 相信 (A 相信 A <-K->B)),反之一样 即A B不仅相信密钥,也相信对方相信自己对密钥的信任。
有 了这些简单却强大的工具后,接下来这篇paper开始着手分析一些协议,包括Kerberos协议,Andrew Secure RPC 握手协议等,还指出了其中的一些问题和改进措施,例如CCITT X.509 协议中可以通过重复发送一条老的信息来模仿成加密双方中的一员。
具体的分析不贴上来了,一方面对于我这个不熟悉TeX的人来说码公式实在麻烦,另一方面我实在困死了 =_=
建议有兴趣的朋友好好看看这篇经典paper
2009-02-19 08:00:00
今天下午真是惊悚,我想把机房的winxp分区删了,ftp上好放点美剧,结果winxp的那个分区是扩展分区,删掉后导致linux的几个分区都消失了。赶紧把硬盘拆下来装到实验室用Disk Genius修复了下,数据基本没什么损坏,分区表还是有点问题。差一点俺就见不到这个博客了 =_=
然后把昨天折腾了一晚上没搞定的debian 4安装搞定了,关键在于netinst.iso的版本号要和hd-media的完全一致,4.0r7。
另外 initrd文件的生成需要安装initrd-tools包
kernel中memory barrier的实现很简单,barrier宏展开后就是 asm volatile(”” : : : “memory”) 这样就保证了在barrier()执行后,cpu不会直接读取寄存器中cache的内存值。
生成initrd mkinitramfs -o /boot/initrd-2.6.18.8-xen.img 2.6.18.8-xen
syscall和m2_fastcall的性能测试 测的是getpid()函数,当然为了保证m2_fastcall不在运行逻辑上吃亏,它的对应功能仅仅是返回current->pid,第一次测出来的结果是syscall明显由于m2_fastcall。宋大牛指出很有可能是glibc做了缓存,果然,自己用汇编发软中断后的数据就正常了。
2009-02-11 08:00:00
Fishing reading Xen 内存管理综述 and have a superficial look on Xen source code.
在Debian x86-64上编译并安装了Xen 3.3.0,安装需要的几个包zlib1g-dev python-dev libncurses-dev libssl-dev libx11-dev bridge-utils iproute gawk gettext
3.interrupt gate的注册
[arch/x86/traps.c]
set_swint_gate(TRAP_int3,&int3); /* usable from all privileges */
set_swint_gate(TRAP_overflow,&overflow); /* usable from all privileges */
set_intr_gate(TRAP_bounds,&bounds);
set_intr_gate(TRAP_invalid_op,&invalid_op);
set_intr_gate(TRAP_no_device,&device_not_available);
set_intr_gate(TRAP_copro_seg,&coprocessor_segment_overrun);
set_intr_gate(TRAP_invalid_tss,&invalid_TSS);
以page_fault为例
SAVE_ALL负责把rsp以外的15个寄存器的值保存入栈,然后从exception table中读出对应的函数地址,并调用(do_page_fault)。
Dijkstra的The structure of the “the”-multiprogramming system,第一次提出了操作系统的分层结构,从而可以运行多个任务,另外里面还提出了semaphore等用来解决concurrent问题的方案,以及类似virtual address的想法,如果这两个概念也是在这个paper第一次提出的话,我只能说Dijkstra是个神了 @.@
第二篇是Peter Denning的The working set model for program behavior,里面用了大量的数学公式(主要是概率统计方面)推导得出了\tau和traverse time T的关系,这里的\tau是一个参数,某个页面在经过\tau时间没有被访问后即被认为是可以替换的,这样就不需要用LRU之类的算法花时间来寻找一个victim page了。paper后面还给出了调度和资源分配的算法。
2009-02-11 08:00:00
[include/asm-x86/config.h]
/*
* Memory layout:
* 0x0000000000000000 - 0x00007fffffffffff [128TB, 2^47 bytes, PML4:0-255]
* Guest-defined use (see below for compatibility mode guests).
* 0x0000800000000000 - 0xffff7fffffffffff [16EB]
* Inaccessible: current arch only supports 48-bit sign-extended VAs.
* 0xffff800000000000 - 0xffff803fffffffff [256GB, 2^38 bytes, PML4:256]
* Read-only machine-to-phys translation table (GUEST ACCESSIBLE).
* 0xffff804000000000 - 0xffff807fffffffff [256GB, 2^38 bytes, PML4:256]
* Reserved for future shared info with the guest OS (GUEST ACCESSIBLE).
* 0xffff808000000000 - 0xffff80ffffffffff [512GB, 2^39 bytes, PML4:257]
* Reserved for future use.
* 0xffff810000000000 - 0xffff817fffffffff [512GB, 2^39 bytes, PML4:258]
* Guest linear page table.
* 0xffff818000000000 - 0xffff81ffffffffff [512GB, 2^39 bytes, PML4:259]
* Shadow linear page table.
* 0xffff820000000000 - 0xffff827fffffffff [512GB, 2^39 bytes, PML4:260]
* Per-domain mappings (e.g., GDT, LDT).
* 0xffff828000000000 - 0xffff8283ffffffff [16GB, 2^34 bytes, PML4:261]
* Machine-to-phys translation table.
* 0xffff828400000000 - 0xffff8287ffffffff [16GB, 2^34 bytes, PML4:261]
* Page-frame information array.
* 0xffff828800000000 - 0xffff828bffffffff [16GB, 2^34 bytes, PML4:261]
* ioremap()/fixmap area.
* 0xffff828c00000000 - 0xffff828c3fffffff [1GB, 2^30 bytes, PML4:261]
* Compatibility machine-to-phys translation table.
* 0xffff828c40000000 - 0xffff828c7fffffff [1GB, 2^30 bytes, PML4:261]
* High read-only compatibility machine-to-phys translation table.
* 0xffff828c80000000 - 0xffff828cbfffffff [1GB, 2^30 bytes, PML4:261]
* Xen text, static data, bss.
* 0xffff828cc0000000 - 0xffff82ffffffffff [461GB, PML4:261]
* Reserved for future use.
* 0xffff830000000000 - 0xffff83ffffffffff [1TB, 2^40 bytes, PML4:262-263]
* 1:1 direct mapping of all physical memory.
* 0xffff840000000000 - 0xffff87ffffffffff [4TB, 2^42 bytes, PML4:264-271]
* Reserved for future use.
* 0xffff880000000000 - 0xffffffffffffffff [120TB, PML4:272-511]
* Guest-defined use.
*/
2.shadow page table主要用在两个地方,一是full-virtualization下的页表维护,overhead很大,不过有了VT-x或者AMD-V的硬件支持后会在一定程度上减少这个代价;二是在guest os被live-migrate的时候,需要一个shadow page table来跟踪转移后被修改的页面。
今天还搞清楚了以前我一直模糊的一个概念。以前翻过一点那本The Definitive Guide to Xen Hypervisor,里面提到一个writable page table,然后我就把这个东西和后来看的那篇paper的shadow page table搞混了,其实是两个完全不一样的东西。shadow page table如前文所说,仅用于full-virtualization的情况,硬件访问到的是Xen维护的shadow page table而不是guest page table;而writable page table则是用在para-virtualization的场合,
当满足以下几个条件时,xen调用ptwr_do_page_fault()处理guest os更新页表的情况: (1) 不在irq中断过程中 且 中断未被禁用(eflags的if被置上) (2) 出错地址不属于hypervisor的保留地址 (3) guest os处于kernel mode (4) error code的write位被置上,而reserved位未被置上
接下来看这个关键性的ptwr_do_page_fault(),通过guest_get_eff_l1e获得被访问的virtual address对应的PTE,然后获得这个PTE对应的page,接下来确定当前的情况是guest os正在尝试修改一个PTE,要满足下面几个条件: (1) present位被置上,rw位没有被置上 (2) mfn(machine frame number)正确,即小于最大值,检查的代码是!mfn_valid(l1e_get_pfn(pte)),这是由于是在pv模式下,mfn=pfn。 (3) page的类型PGT_l1_page_table,即最下层的page table (4) page的引用计数不为0 (5) page的owner为当前domain
这些检查都通过后,调用x86_emulate()函数执行ptwr_emulate_ops代码。
另外Xen 3.3.1这里似乎利用了reserved bit位,根据Intel手册的说法,When the PSE and PAE flags in control register CR4 are set, the processor generates a page fault if reserved bits are not set to 0. 以及The RSVD flag indicates that the processor detected 1s in reserved bits of the page directory, when the PSE or PAE flags in control register CR4 are set to 1。于是就可以在第一次guest os试图修改pte被xen截获后把这个reserved bit给置上,下次访问前还是会因为这个reserved bit而出page table,此时检查下guest os改的machine address是否正确,然后再把reserved bit给清零即可。
2009-02-09 08:00:00
很好用的东东,可以方便的打开需要root权限或是远程服务器上的文件。
统一的url格式是 /method:usr@machine:port/path/to.file,这种方式需要在载入tramp前设置tramp-syntax
(setq tramp-syntax 'url)
(require 'tramp)
也可以用(setq tramp-default-method “scp”) 指定默认的访问方法,这样就不需要/method://了
以我现在的org日程管理为例,个人日程文件保存在机房的73号机上,实验室电脑和寝室电脑上的电脑只要通过tramp远程访问这个org文件即可:
(setq org-agenda-files (list "/scp:[email protected]:/home/wyx/notes/lab.org"))
2009-01-08 08:00:00
以前碰到这个问题都得先重启PieTTY然后用screen -x恢复到原来的工作界面,今天不知怎么的emacs里C-x C-s按了就挂起,只能google。
传说中,早期的终端会遇到显示字符的速度慢于接收字符的速度,为了解决这个问题,C-s用于先挂起当前终端,在数据传输之后用C-q恢复显示。所以最简单的解决方法就是在挂起后按C-q。
不过我的WinXP中C-q已经和快速启动工具(寝室里是Turbo Launcher,实验室的是Launchy)绑定了,也懒得为了这么个问题改操作习惯,于是再次google,终于找到一个一劳永逸的方法,以bash为例,在~/.bashrc中加入一行
stty -ixoff -ixon
即可。另外这样设置后似乎恢复了C-s在bash中正向增量查找的功能。恩。
2008-11-30 08:00:00
Finding and Reproducing Heisenbugs in Concurrent Programs
OSDI ‘08上微软研究院发的paper,针对并发编程中难以发现的bug问题。
paper的内容主要分两大块。
一是如何在发现bug的时候记录下线程的运行先后(thread interleaving),途径是在线程API和用户程序多写一层wrapper functions,这里还有一些其他的问题,比如只记录下了thread interleaving的话出现data race怎么解决等。
另外一块内容是如何遍历出给定程序运行后所能产生的结果的集合,加入这个能实现的话那就能把所有隐藏的bug都找出来了。但是这个搜索空间很大,是指数级的,的一个结论就是:给定一个程序有n个的线程,所有线程共完成k条指令,那么c次占先调度后线程的排列情况数的复杂度是$$k^{c}$$的,所以在实现遍历代码的时候必须有效的降低k和c的值。
2008-11-17 08:00:00
模块动态加载机制
IMPORT_NAME把sys模块导入并保存到栈上,STORE_NAME把这个指针当作普通对象保存在sys这个变量中。
2. IMPORT_NAME指令行为分析 将参数打包并用PyEval_CallObject()这个统一调用接口运行__import__方法,bltinmodule.c中的builtin__import__函数包装了这个功能。help(import)显示的__import__方法的参数列表 import(…) import(name, globals={}, locals={}, fromlist=[], level=-1) -> module
对应于builtin__import__中调用的另一层函数封装
PyObject *
PyImport_ImportModuleLevel(char *name, PyObject *globals, PyObject *locals,
PyObject *fromlist, int level)
这个函数调用了真正干活的函数,import.c中的
static PyObject *
import_module_level(char *name, PyObject *globals, PyObject *locals,
PyObject *fromlist, int level)
3. import_module_level函数 首先调用get_parent()得到import发生时的package对象,接下来多次调用load_next依次得到各级的包名,跟踪了下import xml.dom.minidom的行为,发现name的值依次是"dom.minidom”, “minidom”。最后根据import的形式是from … import …还是import …返回不同的处理结果。
4. import_submodule函数 load_next函数中调用这个函数进行模块的查找和载入。主要分三步:find_module, load_module, add_submodule。
5. from … import … ensure_fromlist处理了这个情况。另外对于from … import *的情况,会从module文件中读入一个__all__对象,从中知道module公开的符号信息。
几个以后可能用到的函数:
[import.c]
/* Parse a source file and return the corresponding code object */
static PyCodeObject * parse_source_module(const char *pathname, FILE *fp);
/* Execute a code object in a module and return the module object
* WITH INCREMENTED REFERENCE COUNT. If an error occurs, name is
* removed from sys.modules, to avoid leaving damaged module objects
* in sys.modules. The caller may wish to restore the original
* module object (if any) in this case; PyImport_ReloadModule is an
* example.
*/
PyObject * PyImport_ExecCodeModule(char *name, PyObject *co);
2008-11-11 08:00:00
2008-11-10 08:00:00
哥德尔定理 用比较通俗的英文来说,就是 All consistent axiomatic formulations of number theory include undicidable propositions.
图形和衬底也许会不带有完全相同的信息 There exist formal systems whose negative space (set of non-theorems) is not the positive space (set of theorems) of any formal system. 用更technical的说法 There exist recursively enumerable sets which are not recursive. 这里recursively enumerable指能按照typographical规则生成,而recursive则对应域指衬底也是个图形的图形。 由此得出一个结论 There exist formal systems for which there is no typographical decision procedure. 证明很简单,用反证法。如果所有的形式系统都能有typographical的判定方法,那么逐个测试所有的符号串,从而能生成一个非定理集合,与前面的定理矛盾。
关于那个数列谜题 {Ai} = 1, 3, 7, 12, 18, 26, 35, 45, 56, 69, … 既然讲到了衬底自然要考虑这个,负空间数列为 {Bi} = 2, 4, 5, 6, 8, 9, 10, 11, 13, 14, … An = An-1 + Bn-1
2008-11-08 08:00:00
第三届复旦电竞赛,不过这次星际项目报名的高手很少。
小组赛居然输了一场,不过最后在半决赛把这个对手3:0,复仇成功了,恩。
貌似今天打了1把zvz,11把zvp,恩
决赛zvz,不过估计没多少时间准备了。。
2008-10-27 08:00:00
Bruce Eckel的一篇日志建议把self从方法的参数列表中移除,并把它作为一个关键字使用。 http://www.artima.com/weblogs/viewpost.jsp?thread=239003
Guido的这篇日志说明了self作为参数是必不可少的。 http://neopythonic.blogspot.com/2008/10/why-explicit-self-has-to-stay.html
第一个原因是保证foo.meth(arg)和C.meth(foo, arg)这两种方法调用的等价(foo是C的一个实例),关于后者可以参见Python Reference Manual 3.4.2.3。这个原因理论上的意义比较大。
第二个原因在于通过self参数我们可以动态修改一个类的行为:
# Define an empty class:
class C:
pass
# Define a global function:
def meth(myself, arg):
myself.val = arg
return myself.val
# Poke the method into the class:
C.meth = meth
这样类C就新增了一个meth方法,并且所有C的实例都可以通过c.meth(newval)调用这个方法。
前面两个原因或许都可以通过一些workaround使得不使用self参数时实现同样的效果,但是在存在decorator的代码中Bruce的方法存在致命的缺陷。(关于decorator的介绍可以参见http://www.python.org/dev/peps/pep-0318/)
根据修饰对象,decorator分两种,类方法和静态方法。两者在语法上没有什么区别,但前者需要self参数,后者不需要。而Python在实现上也没有对这两种方法加以区分。Bruce日志评论中有一些试图解决decorator问题的方法,但这些方法都需要修改大量底层的实现。
最后提到了另一种语法糖实现,新增一个名为classmethod的decorator,为每个方法加上一个self参数,当然这种实现也没必要把self作为关键字使用了。不过我觉得这么做还不如每次写类方法时手工加个self =_=
2008-10-24 08:00:00
定义一个简单的Python函数
dir(f)可以看到函数的几个主要属性 ‘func_closure’, ‘func_code’, ‘func_defaults’, ‘func_dict’, ‘func_doc’, ‘func_globals’, ‘func_name’。在funcobject.c中对PyFunction_Type的定义中可以看到这些属性的来源:
static PyMemberDef func_memberlist[] = {
{"func_closure", T_OBJECT, OFF(func_closure), RESTRICTED|READONLY},
{"func_doc", T_OBJECT, OFF(func_doc), WRITE_RESTRICTED},
{"__doc__", T_OBJECT, OFF(func_doc), WRITE_RESTRICTED},
{"func_globals", T_OBJECT, OFF(func_globals), RESTRICTED|READONLY},
{"__module__", T_OBJECT, OFF(func_module), WRITE_RESTRICTED},
{NULL} /* Sentinel */
};
static PyGetSetDef func_getsetlist[] = {
{"func_code", (getter)func_get_code, (setter)func_set_code},
{"func_defaults", (getter)func_get_defaults, (setter)func_set_defaults},
{"func_dict", (getter)func_get_dict, (setter)func_set_dict},
{"__dict__", (getter)func_get_dict, (setter)func_set_dict},
{"func_name", (getter)func_get_name, (setter)func_set_name},
{"__name__", (getter)func_get_name, (setter)func_set_name},
{NULL} /* Sentinel */
};
f.func_defaults记录函数的默认值,这个例子中就是一个tuple(10,16)
f.func_code是一个code对象,对应于源码中的PyCodeObject。除了《Python源码剖析》中提到的几个属性外,有三个tuple记录了不同类型的变量,co_varnames, co_freevars和co_cellvars,分别对应local variables, free variables和cell variables。
free variables指enclosing scope中的变量,cell variables则是指会被多个scope访问的变量。
def foo():
a = 5
def bar():
return a
print "cellvars:", bar.func_code.co_cellvars
print "freevars:", bar.func_code.co_freevars
return bar
g = foo()
print foo.func_code.co_freevars
print foo.func_code.co_cellvars
最后的结果显示bar的cellvars为空,freevars为(‘a’, 0);foo的cellvars为(‘a’, 0),freevars为空。
2008-10-17 08:00:00
BBS上的一个帖子,问题是
def a():
def b():
x += 1
x = 1
print "a: ", x
b()
print "b: ", x
def c():
def d():
x[0] = [4]
x = [3]
print "c: ", x[0]
d()
print "d: ", x[0]
运行a()会报UnboundLocalError: local variable ‘x’ referenced before assignment 但是运行c()会正确地显示3和4。
原因在于原因在于CPython实现closure的方式和常见的functional language不同,采用了flat closures实现。
“If a name is bound anywhere within a code block, all uses of the name within the block are treated as references to the current block.”
在第一个例子中,b函数x += 1对x进行赋值,rebind了这个对象,于是Python查找x的时候只会在local environment中搜索,于是就有了UnboundLocalError。
换句话说,如果没有修改这个值,比如b中仅仅简单的输出了x,程序是可以正常运行的,因为此时搜索的范围是nearest enclosing function region。
而d方法并没有rebind x变量,只是修改了x指向的对象的值而已。如果把赋值语句改成x = [4],那么结果就和原来不一样了,因为此时发生了x的rebind。
所以Python中的closure可以理解为是只读的。
另外第二个例子也是这篇文章中提到的一种workaround:把要通过inner function修改的变量包装到数组里,然后在inner function中访问这个数组。
至于为什么Python中enclosed function不能修改enclosing function的binding,文中提到了主要原因还是在于Guido反对这么做。因为这样会导致本应该作为类的实例保存的对象被声明了本地变量。
2008-10-17 08:00:00
两者配合,更完美的知识管理方案
http://hi.baidu.com/qq303520912/blog/item/de5cba082db83e36e924889e.html
Endnote是目前国内科研人员使用最多的文献管理软件,功能最完备,各数据库或大学图书馆等和它的兼容也是最好。它的Filter和style也最为丰富,而且可以自己创建修改。看看周围的人,大部分都是Endnote的用户。 Zotero作为一个新的文件管理系统,与Endnote相比还是稚嫩了些,特别对于国内数据库的支持不佳,更是限制了它的应用。
不过,Zotero作为Firefox浏览器的插件,还是有一些特别之处。
第一,便携。Firefox是有Portable版本的,当然Zotero也就是Portable了,也就是说可以把火狐和Zotero放到U盘里,在任何一台电脑上都可以 使用。而Endnote就没有这么方便了。
第二,便利。使用电脑时,我们使用浏览器的时间要大大多于Endnote的时间,遇到有用的文献、网页或者需要做笔记,直接使用Zotero更加省时省力。而且它自动收集网页中文献信息的功能也大大方便了操作。
第三, 分享。EndnoteX以后可以把一个library发送成一个档案文件(.enlx),使得文献交换更为方便。不过有时我们只需要几条文献时,这样操作 就大动干戈了。当然Endnote也支持所选部分文献的导出,但这样有不能够导出附件,包括图片、PDF等(此处为个人经验,是否Endnote也能导出 附件来还望您不吝赐教)。而Zotero就可以实现某条文献所有内容(题录、笔记、附件)的全部导出,而且可以为另一Zotero用户所完整接受。
第四,跟踪文献的收集。很多数据都支持检索式或者引文的提醒,会随时把新的内容发送到邮箱或者以RSS的形式发布。一般来说,查看这些都需要浏览器。有了Zotero,我们可以在查看的同时收集下有用的文献信息。
Zotero更适合于在日常工作、学习甚至娱乐时使用,而Endnote更适合在有明确目的时使用。有人说Zotero更像“知识管理软件”, 而 Endnote就是为文献服务的。两者可以实现互补,在日常工作中使用Zotero收集零散的资料,积累一定量之后将文献信息导入到Endnote中,使 用Endnote管理、引用文献信息。至于PDF、图片等附件的管理,我还是建议使用Zotero,方便且可以完整导出。
下面谈一下Zotero和Endnote中文献的互相导入。
Zotero导入Endnote: 1 选定文献,右键点选”export selected items”;如果是导入整个Library或者cellection可在相应图标上右键点选; 2 在弹出的对话框中选择导出的格式为”Refer/BibIX”, 选择文件目录,保存文件,格式为.txt; 3 在Endnote中打开一个library,执行“files-import”; 4 在对话框中选择刚才的.txt文件, Impott Option选Refer/BibIX,Text Translation选Unicode(UTF-8)。点确定后即可导入。
Endnote导入Zotero: 1 选择文献后,执行“files-export”; 2 选择Output Style为Endnote Export,命名后导入,得到.txt文件。 3 在Zotero中执行“actions-import” ,选择得到的文件,点确定即可导入。 上述导入方式仅能实现文献题录的导入。
2008-10-16 08:00:00
http://bc.tech.coop/blog/070713.html
Joe Armstrong的原话 Live code upgrading is one of the things Erlang was designed for.
一个最简单的例子
loop(Fun, State)
receive
{From, {rpc, Tag, Q}} ->
{Reply, State1} = Fun(Q, State),
From ! {Tag, Reply},
loop(Fun, State1);
{code_upgrade, Fun1} ->
loop(Fun1, State)
end.
使用时只要发送一个{code_update, Fun1}消息即可 在实际的项目中,live code update需要在一个进程的稳定状态中进行。好在有Erlang天生的分布式特性,结点i进行更新时其他结点可以接管这个结点的任务,直到结点i更新成功,再进行下一个结点的更新。这个形式和结点的crash处理有点类似。于是Erlang中live updating的实际难点在于
另外http://www.erlang.org/doc/man/code.html#12介绍了Erlang中的Code Server模块。
2008-10-13 08:00:00
acm queue 9月的杂志的主题是The Concurrency Problem,力推了Erlang这个语言,其中有篇文章简单的介绍了下这个message-oriented语言。
查了下这个名字的读法,正确的读法应该是air-lang,这里元音a的发音和bang中的a一样。
文章中的第一个程序就有点令人费解,主要原因在于Erlang的语法和一般的imperative language差别很大,和functional language比较类似,但是本质上也有很大的不同。
以Java的一个计数程序为例
// A shared counter.
public class Sequence {
private int nextVal = 0;
// Retrieve counter and increment.
public synchronized int getNext() {
return nextVal++;
}
// Re-initialize counter to zero.
public synchronized void reset() {
nextVal = 0;
}
}
这个程序的功能不用多说了,一个同步的计数程序。它的Erlang翻译版的代码为
-module(sequence1).
-export([make_sequence/0, get_next/1, reset/1]).
% Create a new shared counter.
make_sequence() ->
spawn(fun() -> sequence_loop(0) end).
sequence_loop(N) ->
receive
{From, get_next} ->
From ! {self(), N},
sequence_loop(N + 1);
reset ->
sequence_loop(0)
end.
% Retrieve counter and increment.
get_next(Sequence) ->
Sequence ! {self(), get_next},
receive
{Sequence, N} -> N
end.
% Re-initialize counter to zero.
reset(Sequence) ->
Sequence ! reset.
初看这个程序自然是一头雾水,不过程序的函数式风格味还是很浓的。
前面提到,Erlang是基于message的,或者说message sending机制是包含在语言系统内部的,语法就是 pid ! message
接下来再来分析这个简单的程序。开头两行是模块和函数声明,略去。make_sequence开始这个进程,spawn/1内置函数创建一个新的进程,并返回pid到调用者。
初始时运行的函数是sequence_loop(0),这个函数接收两种信息,用receive表达式声明:如果收到形式是{From, get_next}的信息,就返回当前的N并调用sequence_loop(N+1),这样下一次收到同样的信息时就能返回N+1了;reset则等价于Java版本中的n=0语句。
get_next/1则是发送给pid为Sequence的进程 {self(), get_next} 这样一个信息,上面解释的sequence_loop/1函数收到这个信息后会返回一个 {self(), N} 的tuple给get_next/1,收到这个信息后get_next/1就能返回N这个值了。
最后reset/1函数则是发送给Sequence一个reset信息。
这个简单的程序里能大致窥见一些Erlang的特点,尤其是它基于信息发送的本质。
2008-09-25 08:00:00
The Definitive Guide to Xen Hypervisor 第二章的 Exercise,通过调用 hypercall page 中的 console_io 项输出Hello World。
void start_kernel(start_info_t * start_info)
{
HYPERVISOR_console_io(CONSOLEIO_write,12,"Hello Worldn");
while(1);
}
但是默认选项编译和启动的Xen是不会保留DomainU中输出的信息。参考 drivers/char/console.c,可以看到主要有两个选项控制了 DomainU 的 do_console_io 输出:
#ifndef VERBOSE
/* Only domain 0 may access the emergency console. */
if ( current->domain->domain_id != 0 )
return -EPERM;
#endif
if ( opt_console_to_ring )
{
for ( kptr = kbuf; *kptr != ''; kptr++ )
putchar_console_ring(*kptr);
send_guest_global_virq(dom0, VIRQ_CON_RING);
}
在编译 Xen 的时候开启 debug 选项即可置上 VERBOSE,而 opt_console_to_ring 则是一个启动选项,在 grub 的启动选项中增加 loglvl=all guest_loglvl=all console_to_ring 即可。
重启 Xen 后就能通过 xm dmesg 看到 Hello World 了。
2008-09-18 08:00:00
The Definitive Guide to Xen Hypervisor 中第二章的例子,make 成功后运行 xen create domain_config,报错
Error: (2, 'Invalid kernel', 'xc_dom_compat_check: guest type xen-3.0-x86_32 not supported by xen kernel, sorryn')
Google 之后发现是虚拟机类型设置的问题,运行 xm info 可以看到
xen_caps : xen-3.0-x86_32p
末尾的 p 表示 Xen 内核开启了 PAE 模式,所以载入的 kernel 也必须开启 PAE,在bootstrap.x86_32.S 中加入 PAE=yes 选项即可。
2008-09-08 08:00:00
很经典的问题了,求环的长度可以用两个步长分别为1和2的指针遍历链表,直到两者相遇。相遇后把其中指针重新设定为起始点,让两个指针以步长1再走一遍链表,相遇点就是环的起始点。
证明也很简单,注意第一次相遇时
慢指针走过的路程S1 = 非环部分长度 + 弧A长
快指针走过的路程S2 = 非环部分长度 + n * 环长 + 弧A长
S1 * 2 = S2,可得非环部分长度 = n * 环长 - 弧A长
指针A回到起始点后,走过一个非环部分长度,指针B走过了相等的长度,也就是n * 环长 - 弧A长,正好回到环的开头。
2008-09-01 08:00:00
在开始分析Support Code之前,先配置下我们的Source Insight,使它能够支持.s文件的搜索。
在Options->Document Options->Document Types中选择x86 Asm Source File,在File fileter中增加一个*.s,变成*.asm;*.inc;*.s 然后在Project->Add and Remove Project Files中重新将整个oslab的目录加入,这样以后进行文本搜索时.s文件也不会漏掉了。
接下来简单分析下内核启动的过程,在浏览代码的过程中可以迅速的掌握Source Insight的使用技巧。
lib/multiboot /multiboot.s完成了初始化工作,可以看到其中一句call EXT(multiboot_main)调用了C函数multiboot_main,使用ctrl+/搜索包含multiboot_main的所有文件,最终base_multiboot_main.c中找到了它的定义。依次进行cpu、内存的初 始化,然后开启中断,跳转到kernel_main函数,也是Lab1中所要改写的函数之一。另外 在这里可以通过ctrl+单击或者ctrl+=跳转到相应的函数定义处,很方便。
来看下Lab 1的重点之一,irq的处理。跟踪multiboot_main->base_cpu_setup->base_cp u_init->base_irq_init,可以看到这行代码
gate_init(base_idt, base_irq_inittab, KERNEL_CS);
继续使用ctrl+/找到base_irq_inittab的藏身之处:base_irq_inittab.s
这个汇编文件做了不少重复性工作,方便我们在c语言级别实现各种handler。
GATE_INITTAB_BEGIN(base_irq_inittab) /* irq处理函数表的起始,还记得jump
table 吗? */
MASTER(0, 0) /* irq0 对应的函数 */
来看看这个MASTER(0, 0)宏展开后是什么样子:
#define MASTER(irq, num)
GATE_ENTRY(BASE_IRQ_MASTER_BASE + (num), 0f, ACC_PL_K|ACC_INTR_GATE) ;
P2ALIGN(TEXT_ALIGN) ;
0: ;
pushl $(irq) /* error code = irq vector */ ;
pushl $BASE_IRQ_MASTER_BASE + (num) /* trap number */ ;
pusha /* save general registers */ ;
movl $(irq),%ecx /* irq vector number */ ;
movb $1 << num,%dl /* pic mask for this irq */ ;
jmp master_ints
依次push irq号,trap号(0x20+irq号),通用寄存器(eax ecx等)入栈,把irq号保 存到ecx寄存器,然后跳转到master_ints,master_ints是所有master interrupts公用 的代码。
跳过master_ints的前几行,从第七行开始
/* Acknowledge the interrupt */
movb $0x20,%al
outb %al,$0x20
/* Save the rest of the standard trap frame (oskit/x86/base_trap.h). */
pushl %ds
pushl %es
pushl %fs
pushl %gs
/* Load the kernel's segment registers. */
movw %ss,%dx
movw %dx,%ds
movw %dx,%es
/* Increment the hardware interrupt nesting counter */
incb EXT(base_irq_nest)
/* Load the handler vector */
movl EXT(base_irq_handlers)(,%ecx,4),%esi
注释写得很详细,首先发送0x20到0x20端口,也就是Lab1文档上所说的发送INT_CTL_DON E到INT_CTL_REG,看来这一步support code已经替我们完成了。接下来保存四个段寄存 器ds es fs gs,并读入kernel态的段寄存器信息。
最后一句很关键,把base_irq_handlers + %ecx * 4这个值保存到了esi寄存器中,%ecx 中保存了irq号,而*4则是一个函数指针的大小,那么base_irq_handlers是什么呢?继 续用ctrl+/搜索,可以在base_irq.c中找到这个数组的定义 unsigned int (*base_irq_handlers[BASE_IRQ_COUNT])(struct trap_state *ts) 且初始时这个数组的每一项都是base_irq_default_handler
看来这句汇编代码的功能是把处理irq对应的函数地址保存到了esi寄存器中。 为了证实这一点,继续看base_irq_inittab.s的代码:
#else
/* Call the interrupt handler with the trap frame as a parameter */
pushl %esp
call *%esi
popl %edx
#endif
果然,在保存了esp值后,紧接着就调用了esi指向的那个函数。而从那个函数返回后, 之前在栈上保存的相关信息都被恢复了:
/* blah blah blah */
/* Return from the interrupt */
popl %gs
popl %fs
popl %es
popl %ds
popa
addl $4*2,%esp /* Pop trap number and error code */
iret
这样就恢复到了进入这个irq处理单元前的状态,文档中所要求的保存通用寄存器这一步 其实在这里也已经完成了,不需要我们自己写代码。
好了,这样一分析后,我们要做的事情就很简单,就是把base_irq_handlers数组中的对 应项改成相应的handler函数就行了。 注意index是相应的idt_entry号减去BASE_IRQ_SLAVE_BASE,或者直接使用IRQ号。
另外这个数组的初始值都是base_irq_default_handler,用ctrl+左键跳到这个函数的定 义,可以看到这个函数只有一句简单的输出语句: printf(“Unexpected interrupt %dn”, ts->err); 而这就是没有注册handler前我们所看到的那句Unexpected interrupt 0的来源了。
所有的handler函数的参数都是一个struct trap_state *ts,这个参数是哪来的呢? 注意call *%esi的前一行
/* Call the interrupt handler with the trap frame as a parameter */
pushl %esp
这里把当前的esp当作指向ts的指针传给了handler,列一下从esp指向的地址开始的内容 ,也就是在此之前push入栈的内容:
pushl $(irq) /* error code = irq vector */ ;
pushl $BASE_IRQ_MASTER_BASE + (num) /* trap number */ ;
pusha /* save general registers */ ;
pushl %ds
pushl %es
pushl %fs
pushl %gs
再看一下trap_state的定义,你会发现正好和push的顺序相反:
/* Saved segment registers */
unsigned int gs;
unsigned int fs;
unsigned int es;
unsigned int ds;
/* PUSHA register state frame */
unsigned int edi;
unsigned int esi;
unsigned int ebp;
unsigned int cr2; /* we save cr2 over esp for page faults */
unsigned int ebx;
unsigned int edx;
unsigned int ecx;
unsigned int eax;
/* Processor trap number, 0-31. */
unsigned int trapno;
/* Error code pushed by the processor, 0 if none. */
unsigned int err;
而这个定义后面的
/* Processor state frame */
unsigned int eip;
unsigned int cs;
unsigned int eflags;
unsigned int esp;
unsigned int ss;
则是发生interrupt时硬件自动push的五个数据(参见Understand the Linux Kernel)
也就是说,ts指针指向的是调用当前handler前的寄存器状态,也是当前handler结束后 用来恢复的寄存器状态,了解这一点对以后的几个lab帮助很大。
p.s. 另外提一句和这个lab无关的话,非vm86模式下栈上是不会有v86_es等四个寄存器 信息的,所以以后根据task_struct指针计算*ts的地址时使用的偏移量不应该是sizeof( struct trap_state)
这样差不多就把support code中处理interrupt的方法过了一遍(另外还有base_trap_in ittab.s,不过和irq的处理很相似)
了解这些后Lab1就比较简单了,不需要任何内嵌汇编代码即可完成。
2008-08-31 08:00:00
还算顺利,不过这个lab蛮无聊的,等有空了把syscall改成类似linux的做法,单一中断号+寄存器选择syscall。
最花时间的一个bug是ls返回值没有改成应用程序数,结果一开始一直以为是brk系统调用没写好,最后才发现问题出在这么小的地方。
brk的逻辑还不是很清楚,尽管通过了简单的测试,但是debug输出的信息显示brk增长的很快,经常是一个页一个页涨的,看来还得查下brk的具体行为。
写了个比MAGIC_BREAK好用一点的宏,因为用户态的程序都是按二进制读入的,Simics无法得到函数信息(函数名、当前行数等),利用C99的宏写了个新的INFO_BREAK
#define INFO_BREAK \
do { \
lprintf_kern("break in %s:%d", __FUNCTION__, __LINE__); \
MAGIC_BREAK; \
} while (0) \
2008-08-24 08:00:00
s前缀的malloc函数(包括smalloc、smemalign等)不记录分配块的大小,比较节省空间,但是要求用户在用sfree释放内存的时候指定被释放的内存块大小。
malloc则和libc中的同名函数很相似。
整个分配信息(包括哪些块已被使用)都记录在malloc_lmm这个全局变量中,内存被分为若干个region,每个region中有若干个nodes,这些信息可以通过lmm_dump查看(需要include <lmm.public.h>)。
smemalign很适合分配需要页对齐的内存块,因为如果使用memalign分配的话,每个页面就需要多用8字节的空间来记录当前块的大小了(保存在每个内存块的前面),会产生大量内存碎片。
2008-08-22 08:00:00
用Simics跟踪一条条汇编分析页表映射、寄存器值还真是体力活啊。。
实现 Copy On Write 时,如果某一个用户态页面有多个进程共享,其中一个进程修改该页面时需要创建一个新的页面。一开始偶忘了把原来页面的内容复制到新的页面了 =_= 另外由于新的页面要代替老的页面,或者说它们的物理地址不同,但虚拟地址相同,我的方法是在内核态开辟一个大小为一个页面的空间作为中转。
do_fork函数中,子进程复制父进程的页表的同时会把父进程页表项置为不可写,注意最后要flush tlb。因为一开始没有flush tlb,导致最后用户态fork返回以后读取的信息来自于tlb,直接改写了共享页面中fork的返回地址,导致切换到子进程时fork的返回地址丢失。这个bug让我郁闷了两三个小时。。
使用两次fork时,第二次fork返回的pid会被改掉。查了下发现为用户空间分配物理页面的代码里居然在分配好以后没有把对应的struct置为已使用,结果导致第二个子进程COW创建新页面时得到了原来的父进程页面,改写了父进程页面内容。
2008-08-20 08:00:00
写fork函数的时候发现实际传给trap handler的ts地址和用(struct trap_state *) (KSTACK_TOP(old))) - 1
计算出来的结果不一样,后者比前者小0x10。另外ts的实际地址加上ts的大小(92个字节)后就超出了内核栈的范围。
/*
* This structure corresponds to the state of user registers
* as saved upon kernel trap/interrupt entry.
* As always, it is only a default implementation;
* a well-optimized kernel will probably want to override it
* with something that allows better optimization.
*/
struct trap_state
{
/* Saved segment registers */
unsigned int gs;
unsigned int fs;
unsigned int es;
unsigned int ds;
/* PUSHA register state frame */
unsigned int edi;
unsigned int esi;
unsigned int ebp;
unsigned int cr2; /* we save cr2 over esp for page faults */
unsigned int ebx;
unsigned int edx;
unsigned int ecx;
unsigned int eax;
/* Processor trap number, 0-31. */
unsigned int trapno;
/* Error code pushed by the processor, 0 if none. */
unsigned int err;
/* Processor state frame */
unsigned int eip;
unsigned int cs;
unsigned int eflags;
unsigned int esp;
unsigned int ss;
/* Virtual 8086 segment registers */
unsigned int v86_es;
unsigned int v86_ds;
unsigned int v86_fs;
unsigned int v86_gs;
};
可以看到在trap发生时硬件自动push的eip cs eflags esp ss后还有四个v86的数据,而通常的trap过程中这些数据是不会被push到内核栈的,而这四个数据的长度正好是0x10,也就解释了为什么计算出来的地址和实际的地址有偏差。
2008-08-20 08:00:00
Linux 2.4.18的linux/linkage.h文件定义了若干相关的宏
#define SYMBOL_NAME(X) X
#ifdef __STDC__
#define SYMBOL_NAME_LABEL(X) X##:
#else
#define SYMBOL_NAME_LABEL(X) X/**/:
#endif
#define __ALIGN .align 16,0x90
#define __ALIGN_STR ".align 16,0x90"
#define ALIGN __ALIGN
#define ALIGN_STR __ALIGN_STR
#define ENTRY(name)
.globl SYMBOL_NAME(name);
ALIGN;
SYMBOL_NAME_LABEL(name)
用ENTRY(name)就能定义函数了。后来发现Flux OSKit中本来就提供了类似功能的宏,定义在inc/asm.h中。
使用的时候需要再写一个c语言的wrapper function(至少2.4.18里面是这么做的)
asmlinkage void ret_from_fork(void) __asm__("ret_from_fork");
2008-07-19 08:00:00
Paper: LeakSurvivor: Towards Safely Tolerating Memory Leaks for Garbage-Collected Languages
http://www.usenix.org/events/usenix08/tech/tang.html
Yan Tang, Qi Gao, and Feng Qin, The Ohio State University
三位作者好像都是中国人
这篇paper针对支持垃圾收集的语言中内存泄露问题,提出了一种比较保守的“换出”策略,即把可疑的内存泄露的对象(这些对象通常都是长时间没有被访问的)从内存移动到硬盘上暂时保存,减小内存的压力;如果这些对象后来被再次访问(这种可能性很小),就把它们从硬盘上移回内存。
2008-07-04 08:00:00
看 OOP 教材时,书里提到了一个双检测锁定(Double-Checked Lock, DCL)的问题,但是没有更多介绍,只是说这是一个和底层内存机制有关的漏洞。查阅了下相关资料,对这个问题大致有了点了解。
从头开始说吧。
在多线程的情况下Singleton模式会遇到不少问题,一个简单的例子
class Singleton {
private static Singleton instance = null;
public static Singleton instance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
假设这样一个场景,有两个线程调用 Singleton.instance(),首先线程一判断 instance 是否等于 null,判断完后一瞬间虚拟机把线程二调度为运行线程,线程二再次判断 instance 是否为 null,然后创建一个Singleton 实例,线程二的时间片用完后,线程一被唤醒,接下来它依然会创建一个新的 Singleton 实例,导致两次调用范围的对象不同。
最简单的方法自然是在类被载入时就初始化这个对象:
private static Singleton instance = new Singleton();
JLS (Java Language Specification) 中规定了一个类只会被初始化一次,所以这样做肯定是没问题的。
但是如果要实现延迟初始化(Lazy initialization),比如这个实例初始化时的参数要在运行期才能确定,应该怎么做呢?
依然有最简单的方法:使用 synchronized 关键字修饰初始化方法:
public synchronized static Singleton instance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
然而引入 synchronized 关键字后,产生了一个性能问题:多个线程同时访问这个方法时,会因为同步原语而导致每次只有一个线程执行这段代码,影响程序性能。而事实上初始化完毕后只需要简单的返回 instance 的引用就行了。
于是有人提出了 DCL 解决这个问题,这是一个看似有效的解决方法:
class Singleton {
private static Singleton instance = null ;
public static Singleton instance() {
if (instance == null ) {
synchronized (this) {
if (instance == null)
instance = new Singleton();
}
}
return instance;
}
}
用一篇 JavaWorld 上的文章的标题来评论这种做法就是 smart, but broken。来看原因:
Java 编译器为了提高程序性能会进行指令调度,CPU 在执行指令时同样出于性能会乱序执行(至少现在用的大多数通用处理器都是 out-of-order 的),另外 cache 的存在也会改变数据回写内存时的顺序[2]。而 JMM (Java Memory Model, 见[1]) 则指出所有的这些优化都是允许的,只要运行结果和严格按顺序执行所得的结果一样即可。
Java 假设每个线程都跑在自己的处理器上,享有自己的内存,和共享的主存交互。注意即使在单核上这种模型也是有意义的,考虑到 cache 和寄存器会保存部分临时变量。理论上每个线程修改自己的内存后,必须立即更新对应的主存内容。但是 Java 设计师们认为这种约束会影响程序性能,他们试着创造了一套让程序跑得更快、但又保证线程之间的交互与预期一致的内存模型。
synchronized 关键字便是其中一把利器。事实上,synchronized 块的实现和 Linux 中的信号量(semaphore)还是有区别的,前者过程中锁的获得和释放都会都会引发一次 Memory Barrier 来强制线程本地内存和主存之间的同步。通过这个机制,Java 中的同步机制保证了 synchronized 块中指令的原子性。
好了,回过头来看 DCL 问题。看起来访问一个未同步的 instance 字段不会产生什么问题,我们再次来假设一个场景:
线程一进入同步块,执行 instance = new Singleton(); 线程二刚开始执行 getResource();
按照顺序的话,接下来应该执行的步骤是
前面说过,编译器或处理器都为了提高性能都有可能进行指令的乱序执行,线程一的真正执行步骤可能是
如果线程二在 2 完成后 3 执行前被唤醒,它看到了一个不为 null 的 instance,就把这个引用返回,而这个引用指向的对象其实可能还没有完成初始化过程。
错误发生的一种情形就是这样,关于更详细的编译器指令调度导致的问题,可以参看这个网页 [4]。
[3] 中提供了一个编译器指令调度的证据:instance = new Singleton(); 这条命令在 Symantec JIT 中被编译成
0206106A mov eax,0F97E78h
0206106F call 01F6B210 ; 分配空间
02061074 mov dword ptr [ebp],eax ; EBP中保存了instance的地址
02061077 mov ecx,dword ptr [eax] ; 解引用,获得新的指针地址
02061079 mov dword ptr [ecx],100h ; 接下来四行是inline后的构造器
0206107F mov dword ptr [ecx+4],200h
02061086 mov dword ptr [ecx+8],400h
0206108D mov dword ptr [ecx+0Ch],0F84030h
可以看到,赋值完成在初始化之前,而这是 JLS 允许的。
另一种情形是,假设线程一安稳地完成 Singleton 对象的初始化,退出了同步块,并同步了和本地内存和主存。线程二来了,看到一个非空的引用,拿走。注意线程二没有执行一个 Read Barrier,因为它根本就没进后面的同步块。所以很有可能此时它看到的数据是陈旧的。
还有很多人根据已知的几种提出了一个又一个fix的方法,但最终还是出现了更多的问题。可以参阅 [3] 中的介绍。
[5] 中还说明了即使把 instance 字段声明为 volatile 还是无法避免错误的原因。
好在 JDK 5 中以及修复了这个问题,将变量申明为 volatile 就可以避免编译器或 CPU 做乱序调度。而在 JDK 1.4 及更早的版本,安全的 Singleton 的构造一般只有两种方法,一是在类载入时就创建该实例,二是使用性能较差的 synchronized 方法。
参考资料:
2008-06-23 08:00:00
折腾了一下午加晚上,看了一堆包后总算把HTTPS协议搞定了,趁热写点心得。
这个Lab很强大,把11 12 13三章的内容全串起来了。
HTTP部分很简单,读个请求头把主机分析出来(有现成的函数),然后把客户端的所有请求传给Web服务器,再把服务器的所有反馈信息传给客户端就行了。另外注意传信息的时候不要使用Rio_readlineb之类的函数,而要用Rio_readnb,否则传图像时会碰到问题。
另外把版本统一成HTTP 1.0能明显的提高代理服务器的速度,具体原因还不清楚,明天再问问。
如果要把这个代理服务器写得健壮一点,要注意各种异常的处理,比如通常浏览器都能发送正确的报头,但是如果有人通过telnet发送了错误的报头也要能够正确的释放内存再结束线程。
然后是线程,这个问题也不大,使用信号量实现互斥锁,另外在即时free资源就好。
最后就是HTTPS协议的处理了,由于没正确理解文档的意思,在这上面花了很多时间,不过倒也接触了不少新东西。
首先是用gdb调试多线程程序,使用info threads查看当前所有线程,然后thread #切换到该线程就能查看那个线程的相关信息了。
然后来说下HTTPS协议的处理。一开始我有个错误的概念,就是代理服务器的责任是把所有客户端的信息转发到服务器端,把所有服务器端的信息转发到客户端,或者说在浏览器的眼中代理服务器和普通的Web服务器没有区别。其实并非如此,在我用OmniPeek截包看了半天后才意识到自己错了 =_=
浏览器不通过代理进行HTTPS连接时,只发送加密后的数据;而通过代理服务器时,先告诉代理服务器相关信息,然后再发送密文。另外,HTTPS的明码报头一般不会像文档中那样只有一行,代理服务器要记得所有的明文都读进来(但不转发给Web服务器),然后回复HTTP/1.0 200 Connection established,最后再负责密文的转发。
HTTPS的数据转发也和HTTP不一样,它需要客户端和服务器端多次的双向数据传输。而默认的read方法在没有信息读取和其他中断发生的时候是会block的。对于这个问题我的解决方法是结合I/O Multiplexing和Non-blocking I/O(搜资料的时候看到过这样处理的效率也比较高,见http://www.kegel.com/c10k.html)。用fcntl设置两个file descriptor的模式为O_NONBLOCK,然后再用select/poll实现multiplexing即可。不知道还有没有更好的方法。
另外测试HTTPS时建议使用https://mail.google.com,文档中的两个网页貌似firefox都打不开的。
2008-06-16 08:00:00
这个Lab是要自己实现一个malloc函数,要求内存利用率和速度尽可能高。 用红黑树的版本最后得分是97/100,没有针对测试数据作任何优化,据说可以改到100/100,不过95分以上就满分了我也懒得再改了。
这个Lab的重点在可用内存的管理上。关于数据的组织,似乎有两种比较常见的形式(我不知道的就不算进来了,下同 =_=)。一是slab/buddy系统,就是书上讲的segregated list;还有一种用二叉树实现,这个lab我用了二叉树。
第一种方法对提高性能很有帮助,但是利用率方面就比较有限了。而这个lab似乎提高性能比较容易,难点在于利用率的提高。
二叉树方面,也有两种:平衡二叉搜索树(AVL树、红黑树等),字典树(Trie, 似乎也叫Radix tree)
这些数据结构都比较经典,很多书上都有现成的代码,网上也有一堆,拿来改一下就行了(注意算法导论上的红黑树的left-rotate是有bug的,见勘误表)。
另外还有个优化,树的结点要保存很多数据,比如父结点、左右结点、前后结点(考虑到同一大小的块的存在),红黑树中还需要保存一个颜色值(当然这个值可以保存在header中)。如果所有的空结点都以这种形式保存的话,势必对利用率影响很大。
所以建议另外维护一个block size相对较小的(比如小于128字节)的list,把小于这个值的空闲块都放到那个list里。
差不多就这样了,思路还是蛮简单的,就是实现起来很恶心。
另外做的时候还可以考虑考虑多线程的情况下这个malloc的表现会如何。
感觉下学期的几个lab,Lab 4 5 7都和优化程序性能有关,颗粒度不断提高,从最底层的汇编指令,到语言级别的unrolling、splitting,直到现在和具体语言无关的算法层次,对写高效代码的帮助蛮大的。
2008-05-28 08:00:00
Application-Level Isolation and Recovery with Solitude
Shvetank Jain, Fareha Shafique, Vladan Djeric, Ashvin Goel
Department of Electrical and Computer Engineering, University of Toronto
http://portal.acm.org/citation.cfm?id=1357010.1352603
引入一个新的文件系统层(Isolation File System)将安全可信的基础文件系统和不可信的环境(如网上下载的文件等)隔离开来,并对不可信的环境中做出的改动加以记录,一旦发现问题就能即使恢复。
2008-05-27 08:00:00
重定向:
主要用到open, close, read和write这几个函数,关于它们的使用方法可以使用 man 2 <函数名> 查看。
这里简单介绍下: Linux内核为每个进程维护了一张已打开的文件的表格,用File Descriptor(整型,以下简写成fd)可以访问到这些文件。所以很容易理解tsh.c中的函数listjobs为什么需要一个output_fd的整型参数,注意它的后面有这么一行: if (writer(output_fd, buf, strlen(buf)) < 0) …
这一行就把前面构造好的buf字符串(包括当前进程的信息)输出到这个output_fd对应的文件中了。
每个进程的值为0, 1, 2的fd都指向相同的文件,0对应标准输入(通常是键盘输入),1对应标准输出(通常为屏幕),2对应标准错误输出。
可以看到在main方法的开头,有这么一句 dup2(1, 2);
dup2的作用是把参数二指向的文件改成和参数一一样(如果之前打开了文件,则先关闭),这句话的作用就是把原来要输出到标准错误端(stderr)的内容 输出到标准输出端(stdout),便于调试。
理解了fd和dup2的作用后,重定向也就很容易实现了,一种最简单的方法就是先用open函数打开输出文件并得到对应的fd,然后用dup2把标准输出/输入端的指向改成文件的fd。
另外注意用open创建输出重定向的文件的时候要加上S_IRUSR和S_IWUSR选项,否则创建后的文件没有读写权限。(不过好像这个lab的测试数据比较厚道,会事先touch一下,不加这两个选项应该也能通过测试)
一些文档中未定义的行为: argv 假如我输入的命令是/bin/ls -l > ls.txt,对应的argv应该包括哪些内容呢? 一般的情况argv的内容应该是['/bin/ls’, ‘-l’],后面的重定向符是不包括的不过在这个lab中似乎没有这个限制,不去掉重定向和管道部分应该还是能通过测试的。
Job ID的分配 如果现在1, 2, 4号子任务在后台运行,再新增一个进程的话应该给它分配多少呢? 这个问题不需要处理,只要所有的jobs队列操作统一使用tsh.c中给出的几个函数就行。
其他: 关于信号的转发、后台前台的转换等内容,文档和书上都说得很清楚了,这里不再赘述。
P.S. 多进程程序的调试大家之前应该接触的比较少,其实这个lab大致的代码不难写,难点在于细节上的debug比较困难,调试过程对第八章的理解很有帮助。
2008-05-05 08:00:00
Proceedings of the 2006 IEEE Symposium on Security and Privacy
作者来自密西根大学和微软研究部门
一个利用虚拟机进行攻击的rootkit。
1. Introduction 传统的攻击程序通常和安全工具(杀毒软件等)在同一个级别上(kernel mode),两者间没有绝对优势可言,因此有很大的限制,比如强大的功能和良好的隐蔽性不能兼得。而虚拟机的出现则可以解决这个问题,通过把恶意程序放在虚拟机上,可以做到对目标机(guest os)的完全监控,同时目标机完全不会知情。这种程序称为VMBR(virtual-machine based rootkit)。
2. Virtual machines VMM(virtual-machine monitor)这里就不多介绍了。VMM上跑着一些其他服务进程,主要用于操作系统的debug,运行中的虚拟机的迁移等功能。这些服务的主要面临的一个问题是理解对应的guest os状态和事件。因为在VMM和虚拟机处在不同的抽象级别,前者只能看到磁盘块(disk blocks),网络包(network packets),以及内存;而后者则把这些东西抽象为例如文件、TCP连接、变量等概念,这种差异称为语义差异(semantic gap)。
于是有了Virutal-machine introspection(VMI),它包含了一系列让VMM上的服务了解并修改guest os的技术。
3. Virtual-machine based rootkit design and implementation 3.1 Installation VMBR的安装和一般病毒程序类似,通过欺骗有管理员权限的用户执行安装程序实现。
当目标机是WinXP时,VMBR被安装在第一个活动分区的开始部分;目标机是Linux时,安装程序会禁止swap分区,把VMBR放在swap分区上(够狠的。。。)
修改系统引导信息的时候还有一个细节,直接修改容易被安全检查程序发现。WinXP上的一种解决方案就是尽可能的在所有程序退出之后再修改(通过注册一个LastChanceShutdownNotification事件处理器),并且使用底层的磁盘驱动进行VMBR启动代码的复制,这样可以绕过文件系统层,而大多数反病毒软件都跑在文件系统层上。Linux上,通过修改关机脚本来保证安装程序在其他程序退出后执行。
安装完成后,目标系统的内容就被保存到了一个虚拟磁盘上。重启后就由VMM控制最底层,它把目标机的对虚拟磁盘的访问转换为对应的物理磁盘的访问。
3.2 Malicious services VMBR使用一个独立的系统执行各种攻击程序,这样目标机就无法察觉到了。对目标系统的攻击主要分三种:
一种是不需要和目标系统进行交互的恶意服务,例如垃圾电子邮件的发送(spam relays),DDoS攻击,网络钓鱼(phishing web servers)。
第二种恶意服务需要监视目标系统的数据和事件。通过修改VMM的设备模拟软件就能记录下所有硬件级的数据(比如按键信息、网络包等),而这个过程不需要修改guest os,所以目标系统完全不知情。
VMBR还可以用VMI帮助理解目标系统软件级的抽象信息,VMI可以中断目标系统的任意指令,并重新组织数据。例如一个目标应用程序将要使用一个加密的socket发送信息,攻击者可以截获所有的SSL write函数调用并且在明文被加密前得到它。同样这个过程对目标系统完全透明,因为攻击程序跑在它的外层,或者说是“上帝”层 ;-)
第三种攻击是恶意修改目标系统的执行。例如篡改网络通讯,删除email,改变目标应用程序的行为。
最简单的,开了个thttpd web服务器进行网络钓鱼,任何发送到8080端口的TCP请求都会被这个服务器截获。
然后是一个按键记录程序,号称只用了60行代码就搞定了这个模块,然后写了一个254行的带图形界面的程序来分析日志并显示。
一个扫描目标机文件系统的程序,这是一个24小时运行的perl脚本,会把诸如/etc/shadow, user_home/.ssh/id_dsa之类的机密信息保存下来。
最后是防止VMM被目标机侦测到的一个服务。paper中提到了一种叫做redpill的虚拟机侦测手段,通过使用sidt指令。这个指令会读出处理器的中断列表(interrupt descritor table),在VMM上跑的系统和普通的操作系统读出来的结果不一样,当这个指令在内核态被执行时,VMM会模拟这个指令的执行;但是用户态却不会被截获(考虑到性能因素)。所以redpill通过用户态执行sidt来判断当前系统是否运行在虚拟机上。这篇paper提到的针对redpill的解决方案是在每个可执行文件的sidt指令前设置一个断点,截获这个指令后就模拟这个指令,以此绕过redpill检测。但是这种方法不适合于在程序运行期动态生成二进制的sidt指令的程序(想到我的lab4了,呵呵)。道高一丈魔高一尺(原文是Continuing the arms race,军备战争),通过二进制转换(binary translation),动态生成的sidt同样可以被截获,但是这种方法的overhead会很大。
3.4 Maintaining Control 这块主要讲了对系统重启、关闭的处理。
系统要求重启时,VMBR总是尽可能的通过重启guest os来完成,这样就能最大化的掌握控制权。
另外通过ACPI模拟系统关闭也可以欺骗使用者。这种模式下硬盘、风扇停止,RAM仍然上电,下一次开机后可以恢复到上一次关机的状态,于是VMBR继续在第一时间掌握控制权。
4. Evaluation 测试下来开机、重启的速度都慢了不少。不过很正常,因为用的是Virtual PC和VMWare。
不过随着虚拟技术的发展,对系统性能的影响肯定越来越小的(比如Xen),这篇paper关键在于占了个坑,至少现在看来实用性还很差。
5. Defending against virtual-machine based rootkits 5.1 Security software below the VMBR 比VMBR更低的层次就很容易检测到VMBR了。比如硬件级别的安全支持(Intel LaGrande),或者CDROM启动(注意这里首先要冷重启,否则说不准虚拟机给你模拟CDROM启动了),还可以先装个安全的VMM,即使收到VMBR攻击,VMBR也只能在安全的VMM和操作系统之间那层运行。
5.2 Security software above the VMBR 在VMBR上层要检测就有一定技术难度了。
一种基本的方法是利用CPU时间、内存上限、硬盘上限、网络带快来测定。
VMBR的存在必定会影响到CPU的表观性能,通过这种时间上的差异就能发现问题。不过VMBR可以通过放慢系统时钟返回的时间来欺骗目标机,对于这种欺骗,测试人员可以使用其他的不可控的计时工具(比如手表 -_-b)
另外硬盘、内存上限都会因为VMBR的存在而变小。后者很难侦查到,因为有一层虚拟内存。而针对前者的检测,VMBR可以截获对它占用的地址的访问,然后返回一些随机的信息,让guest os以为那是坏扇区从而躲过检查。所以这招不怎么好用。
另外由于性能考虑,并不是所有的硬件都是被迷你的,通常只有需要保护的设备(比如启动盘)和需要攻击的设备(比如网卡)被虚拟化,其他的硬件都是guest os直连的,这样就只需要在这些未被虚拟化的硬件上做一个DMA,把物理内存中的部分信息读过来就能分析了(通过这个貌似可以对同一个物理机上的其他虚拟机进行攻击啊)
另外一种方法就是前面的提到的通过sidt指令了。
6. Trends toward virtualization 略 7. Related work 略
2008-04-23 08:00:00
算法导论第27章,在并行处理的条件下效率很高的排序算法。
介绍 如下面左图所示,每条横线(wire)代表一个待 比较的数值,竖线(comparator)表示连接的两条横线要做一次比较,并将较小的值放在输出横线的上方,较大的放在下面。排序过程就是从左往右依次 调用各个comparator(在同一位置上的comparator可以同时做) 有图表示了四个数字3, 2, 4, 1在经过这个Sorting Network时的行为。(由于背景为深色,建议点击图片查看)
下图是一个冒泡排序的Sorting Network表示
可以看到所有的比较都没有并行,效率很低。接下来先介绍一个0-1原理,然后利用它来构造一些比较高效的网络。
性质 首先是引理27.1: 对 于输入数据A = <a_1, a_2, .., a_n>,如果某个比较网络(comparison network)的输出是B = <b_1, b_2, …, b_n>,那么对于任一单调递增的函数f,这个网络能把输入数据f(A) = <f(a_1), f(a_2), …, f(a_n)>变为f(B) = <f(b_1), f(b_2), …f(b_3)>
这个引理的证明很简单,关键在于min(f(x), f(y)) = f(min(x,y))
接下来就是0-1原理: 一个有n个输入数据的比较网络,如果它能将仅由0和1组成的序列正确的排序(这种输入共有2^n种可能),那么它也能正确的将任意数字组成的序列排序。 证明也不难,利用前面的引理反正即可得到这个定理。
双调排序 接 下来先考虑双调序列(bitonic sequence)这种特殊情况,所谓双调序列就是先单调递增,后单调递减,或者可以通过环形旋转变化出上述特性的序列,比如<1, 4, 6, 8, 3, 2>和<6, 9, 4, 2, 3, 5>都满足条件(对于后面一种序列,只要把最后的3, 5移到序列开头就行了)。 双调排序(bitonic sorter)有若干步骤,其中有一步叫做half-cleaner,每一次half-cleaner讲数据放到一个深度为1的排序网络中,第i行和第i+n/2行比较(i=1,2,..,n/2)
引理27.3: 做完上述的half-cleaner后,输出的上半部分和下半部分都保持双调的特点,而且上半部分的每个元素都不大于下半部分的任一元素。 分四种情况讨论即可。
通过递归调用half-cleaner即可完成双调队列的排序。要对n个元素进行双调排序Bitonic-Sorter(n),首先调用Half-Cleaner(n),将元素分成上下两部分,接着依次对这两部分执行Bitonic-Sorter(n/2)即可。 调用的深度D(n) = lgn
归并网络 书上只给出了对0-1序列排序的算法,任意数字的排序算法留作了习题。 合并网络基于这样一个事实:对于两个已经排序了的序列X = 00000111,Y = 00001111,将Y倒过来后和X拼接的结果是一个双调序列。对这个双调序列再做一次Bitonic-Sorter就能有序。 通 过修改Bitonic-Sorter方法的第一步就能实现Merger,关键在于隐式的反转输入的下半部分。Half-Cleaner方法中比较了第i和 第i+n/2两个元素,如果下半部分反转的话就相当于比较第i和第n-i+1个元素。直接继续执行Bitonic-Sorter方法即可,如下图所示。
排序网络 我们已经有了构造一个排序网络所需的工具,接下来介绍一种利用归并网络进行排序的并行版本。 大致方法和传统的归并排序类似,从最小的颗粒开始二分增长,直到整个序列有序。 这样,一共需要lg(n)次Merger,每次归并中需要做lg(i)次Sorter,排序的总深度 D(n) = 0 (n = 1) D(n/2) + lg(n) (n = 2^k且 k>=1) 由Master Method可推出D(n) = big-omega(lg^2(n)) 也就是说理想的并行环境中,n个数可以在O(lg^2(n))时间内完成排序。
Bitonic Sorter http://www.iti.fh-flensburg.de/lang/algorithmen/sortieren/bitonic/bitonicen.htm
图片来自于Wikipedia以及算法导论附图
2008-04-16 08:00:00
Streamware: Programming General-Purpose Multicore Processors Using Streams
Jayanth Gummaraju, Joel Coburn, Yoshio Turner, Mendel Rosenblum
ASPLOS 08上的文章 http://portal.acm.org/citation.cfm?id=1353534.1346319
提出了一个通用的多核平台,支持Cell CUDA Brook等多种体系结构,用户只需使用这个平台统一提供的API。
另外还加入了cache hierarchy的管理,能很好的安排各级cache保存的内容,以至于某个测试结果中单核的情况下用了Streamware的程序比不用的程序跑得还快。
2008-04-15 08:00:00
问题很简单,给定一个 8 位整型,要求写程序计算这个数的二进制表示中 1 的个数,要求算法的执行效率尽可能的高。
先来看看样章上给出的几个算法:
解法一,每次除二,看是否为奇数,是的话就累计加一,最后这个结果就是二进制表示中1的个数。
解法二,同样用到一个循环,只是里面的操作用位移操作简化了。
int Count(int v)
{
int num = 0;
while (v) {
num += v & 0x01;
v >>= 1;
}
return num;
}
解法三,用到一个巧妙的与操作,v & (v - 1) 每次能消去二进制表示中最后一位 1,利用这个技巧可以减少一定的循环次数。
解法四,查表法,因为 8 位整型的范围是 0 - 255,可以直接把结果保存在一张表中,然后查表就行。书上强调这个算法的复杂度为 O(1)。
int countTable[256] = { 0, 1, 1, 2, 1, ..., 7, 7, 8 };
int Count(int v) {
return countTable[v];
}
好了,这就是样章上给出的四种方案,下面谈谈我的看法。
首先是对算法的衡量上,复杂度真的是唯一的标准吗?尤其对于这种数据规模给定,而且很小的情况下,复杂度其实是个比较次要的因素。
查表法的复杂度为 O(1),用解法一,循环次数不会超过 8 次,所以时间复杂度也是 O(1)。至于数据规模变大,例如变成 32 位整型,那查表法自然也不合适了。
其次,既然是一个执行时间很短的操作,衡量的尺度也必然要小,CPU 时钟周期可以作为参考单位。
解法一里有若干次整数加法,若干次整数除法(一般的编译器都能把它优化成位移),还有几个循环分支判断,几个奇偶性判断(这个比较耗时间,根据 CSAPP 上的数据,一般一个 branch penalty 得耗掉 14 个左右的 cycle),加起来大概几十个 cycle 吧。
再看解法四,查表法看似一次地址计算就能解决,但实际上它用到了查表访存操作,而访存的时候很有可能那个数组不在 cache 里,需要从内存重新读取。这样一个 cache miss 导致的后果可能就是耗去几十甚至上百个 cycle(因为要访问内存)。所以实际情况中这个算法的性能是很差的。
这里我再推荐几个解决这个问题的算法,以 32 位无符号整型为例。
int Count(unsigned x) {
x = x - ((x >> 1) & 0x55555555);
x = (x & 0x33333333) + ((x >> 2) & 0x33333333);
x = (x + (x >> 4)) & 0x0F0F0F0F;
x = x + (x >> 8);
x = x + (x >> 16);
return x & 0x0000003F;
}
这里用的是二分法,两两一组相加,之后四个四个一组相加,接着八个八个,最后就得到各位之和了。
还有一个更巧妙的 HAKMEM 算法
int Count(unsigned x) {
unsigned n;
n = (x >> 1) & 033333333333;
x = x - n;
n = (n >> 1) & 033333333333;
x = x - n;
x = (x + (x >> 3)) & 030707070707;
x = x % 63;
return x;
}
用了二分法,先将二进制表示分组,每三位一组,并求出每组中 1 的个数。然后相邻两组归并,分组变成了每六位一组。最后除 63 取余得到结果。因为 26 = 64,也就是说 x0 + x1 * 64 + x2 * 64 * 64 = x0 + x1 + x2 (mod 63) (这里的等号表示同余)。
这个程序只需要十条左右指令,虽然有除法指令,但是由于不访存,速度还是会比较快。
综上,衡量一个算法实际效果不单要看复杂度,还要结合其他情况具体分析。关于书后的两道扩展问题,问题一是问 32 位整型如何处理,这个上面已经讲了。问题二是给定两个整数 A 和 B,问 A 和 B 有多少位是不同的。这个问题可以规约到数 1 问题——只要先算出 A 和 B 的异或结果,然后求这个值中 1 的个数就行了。
2008-03-23 08:00:00
几个基本的优化:
Unrolling相关:
Jump Table
由Duff’s Device引申出来的想法,代替了我原来那个32-16-8-4-1程序。 很好用的一个技巧,配合unrolling就不需要不断比较i和len的大小了。 比如len=15的时候,只要跳转到倒数第15个复制段落,就可以挨个做下来,而不需要多余的判断。 具体的实现可以想想x86里的情况,假设几个复制段落的标签为Loop1, Loop2, …
jump: .long Loop1 .long Loop2 …
之后就只要取出jump + (len - 1) * 4处的值,然后跳到这个位置就行了。 跳的时候还有个技巧,最简单的是把这个值push到栈,然后再ret。这样的话bubble很多。
考虑到这个模拟器里代码段是不受保护的,也就是说运行的时候可以动态修改内存中的代码,于是在跳转的地方写个jmp 0,然后运行的时候动态把这个0改掉就行。
另外要注意用这个方法的时候得手动写几个nop,或者在改内存的语句和jmp语句之间加几个其他命令,因为y86模拟器是默认程序不会修改自己的代码的(p328 灰色背景部分)。
用这个方法的时候还有一些细节可以优化,就不列举了。另外不知道利用自我修改这个特点能不能做出更神奇的效果呢?
比如我还想到另一种类似的方法,让程序从头到尾运行,不跳转,而是在程序运行时动态的插入ret语句直接把程序运行流掐断。我还没试过,有兴趣的同学可以试一试。
不知道还有没有其他的优化方法,欢迎讨论~
2008-03-16 08:00:00
不安装图形界面: 修改sim/Makefile,把前三行非注释部分用#注释掉,变成
# GUIMODE ...
# TKLIB ...
# TKINC ...
保存后运行 make
Redhat 9:
可以在Redhat菜单->System Settings->Add/Remove Applications中添加X Software Development,根据提示载入相关镜像文件。
然后在 sim 目录下运行 make
Arch Linux:
有包管理机制的发行版直接用相关软件安装(比如 Arch 中 pacman -S tcl tk),注意安装好以后生成的动态链接库可能带有版本号(比如 libtcl8.5.so libtk8.5.so)
具体版本号通过 pacman -Ql tcl tk | grep '.so' 查得
接着只要修改Makefile中的TKLIBS参数,或者用ln建个链接即可
Ubuntu
由于ubuntu默认没有lex词法分析工具,在编译时需要先安装flex:sudo apt-get install flex
图形界面和Arch类似
sudo apt-get install tcl8.5-dev tk8.5-dev tcl8.5 tk8.5
然后修改 Makefile
ltcl->ltcl8.5
ltk->ltk8.5
/usr/local/lib/.. -> /usr/lib/..
/usr/local/include/ -> /usr/lib/tcl8.5/include/
用y86写三个小程序,基本上仿照seq/asum.ys写就行了。装了图形界面的模拟器的话调试起来也很方便。
相关命令(假设在seq目录下):
make asum.yo../misc/yis asum.yo./ssim -g asum.yo同样不需要花多少力气,把Homework 16的答案写成HCL语言就行,可以参照opl, irmovl, popl这三个指令的写法。
通过ICS主页上的Lab4.pdf中的几个测试命令即可。
通过修改HCL和y86代码优化程序,最麻烦的一块。
在pipe目录下运行./benchmark.pl -f ncopy.ys,这个脚本就会自动运行一系列测试程序并计时,最后一行显示了平均所需的时间。
优化方法很多,系版的精华区的讨论帖里就有不少。
另外可以看看pipe/README这个文件,里面也说了几种方法。
最简单的就是实现iaddl指令,用它替换部分语句缩短时间;还有一个比较重要的就是loop unrolling,所谓loop unrolling就是把一个循环中的语句合并,减少循环次数。 用C语言简单的举一个例子。
for (int i = 0; i < 10; i++)
dst[i] = src[i];
把相邻两个循环合并起来,变成
for (int i = 0; i < 10; i += 2) {
dst[i] = src[i];
dst[i + 1] = src[i + 1];
}
这样增加i的值的语句就从原来的10个减少到了现在的5个。
另外这里还有一个潜在的好处,dst[i] = src[i] 在执行的时候有个Load/Use Data Hazards,会产生一个bubble,如果先读出src[i],再读出src[i+1],然后依次写入dst[i],dst[i+1],这样就可以消去这个bubble,从而为每个元素节约一个左右的时钟数。
测试方法:
先保证pipe-full.hcl中的iaddl语句的正确,make以后在ptest目录下运行
make SIM=../pipe/psim TFLAGS=-i TFLAGS=-i
之后在pipe目录下运行./correctness.pl -f ncopy.ys测试样例程序,通过以后再运行./benchmark.pl -f ncopy.ys就能看到这个程序的性能了。
correctness.pl这个脚本测试时报的错误可能会和实际不一致,比如Bad count和Incorrect copying貌似会混淆。
unrolling的时候建议写个专门生成相关代码片段的脚本,否则改起来太麻烦了。
2007-12-15 08:00:00
这个 Lab 应该比上一个 Lab 简单不少, Lab 的说明文档也差不多把基本的过关要点都提到了,所以这里主要介绍一下几个相关工具的使用,帮助大家进一步熟悉 Linux 命令行 ;-)
首先从主页上下载一个压缩包,最简单的方法是直接在命令行使用 wget 工具
wget http://10.132.143.100/lab2007/buflab-handout.tar
顺便提一下 wget 的功能很强大,除了可以在后台运行,它还支持 ftp https http 等协议,提供整个网站下载的功能(类似于 Windows 下的 WebZIP )
接着使用 tar 命令解压这个文件
tar xvf buflab-handout.tar
其中, x 参数表示解压工作, v 表示显示解压所得的文件列表, f 及其后面跟着的文件 名指定了待解压文件
这样在当前目录下就多出了三个文件: bufbomb, makecookie, sendstring
接下来使用 makecookie 得到自己学号对应的 cookie 号,用法是
./makecookie 学号
这个 cookie 号在后面的几个关卡中都有可能会用到,同时 http://10.132.143.234/bufbombstatus.html 中可以通过自己的 cookie 号随时获得自己现在的过关情况。
和上一个 Lab 一样,这里介绍一下怎么过 Level 0 。
这个热身关和两个函数有关, test() 和 smoke() ,正常情况下 smoke 不会被任何函数调用,我们要做的就是输入一串特定的字符,使得 smoke 被调用。另外这个关卡简单之处在于 smoke 被调用后就直接退出程序,我们在破坏了栈的数据后不需要恢复原样。
注意到 test 中调用了 getbuf 函数,联系到 CS:APP Section 3.13 ,看来只要把 getbuf 的返回地址改成 smoke 的地址就行了。
召唤 gdb 监视 bufbomb 的运行,设置断点在 getbuf ,使用 run -t 学号 运行,程序停在 getbuf 的第三行,使用 disas 查看当前函数 (getbuf) 的汇编代码
0x08048ab3 : lea 0xffffffe8(%ebp),%eax
0x08048ab6 : sub $0x24,%esp
0x08048ab9 : push %eax
0x08048aba : call 0x8048bbc
0x08048abf : mov $0x1,%eax
看来这里的 %eax 保存了字符串的首字节地址,从第一句可以算出,它与 %ebp 指向的地址相差了 24 。
也就是说我们输入 24 个字符后,接下来输入的 4 个字符会覆盖掉原来的帧指针,再之后的 4 个字符就会覆盖函数的返回地址。把这个地址覆盖成 smoke 的就行,用 disas smoke 得到 smoke 的地址为 0x08048964 。
知道了这些后,我们就来构造这条特殊的字符串,新建一个文本文件(当然也可以在 sendstring 中键盘输入,不过调试起来比较麻烦),输入
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 64 89 04 08
最后四个字节就是 smoke 的地址,注意是 little endian 约定。假设保存文件为 ans.txt
但这只是文本格式的指令,需要把它转换为二进制值, sendstring 工具可以帮助我们生成二进制串:cat ans.txt | ./sendstring > raw.txt
这行命令用到了 shell 的管道和重定向功能,它的作用是把 ans.txt 的内容放到 sendstring 中,把 sendstring 生成的内容放到 raw.txt 中。这样在 raw.txt 中包含了最后的二进制代码。
回到 gdb ,使用 run -t 学号 < raw.txt 运行程序,程序停在 getbuf 中的断点后,使用几个 ni 命令往下运行,等调用完 Gets 函数后(一般是在 0x08048abf ),查看当前的帧指针附近的信息:
(gdb) p/x *(int*) ebp@2
$ 1 = {0x0, 0x8048964}
看来我们已经成功得把返回地址改掉了,使用 c(ontinue) 继续运行,就可以看到成功信息了。
后面几关(除了最后一个)和这个热身关差不多,只是返回地址需要指向 buf 数组,运行嵌在其中的代码再返回原来的地址,要获得嵌入的二进制代码,可以先写一个包含汇编指令的 .s 文件,使用 gcc -c 把这个文件编译成 relocatable object ,再用 objdump -d 得到这段二进制代码。大致思路 pdf 上已经写得很详细了,这里不再赘述。
关于最后一关, CS:APP 书上有一个类似的题目 (3.38, P236) ,我记得我当时做的时候栈帧地址也是会跳动的,只是没有 Level 4 那个那么明显,有兴趣的同学可以试一下。
程序的下载地址: http://10.132.141.124/study/ics/bufbomb.c
输入的文本格式的二进制代码计算字节数比较麻烦,可以每 10 个字节一行,写完后使用 vim 的 shift+j 快捷键把这几行都拼起来。
本地过关后记得查看网站确定一下。
gdb 的 run 命令会自动根据上一次的参数运行程序,所以第一次输入 run -t 学号 < raw.txt 后,以后只要简单的使用 r 就可以了。
建议开两个 PieTTY 窗口,一个 gdb 调试,一个修改、生成二进制文本,很方便。
2007-11-20 08:00:00
这个lab主要考察gdb的使用和对汇编代码的理解。后者在平时的作业中涉及得较多,这里不再赘述,主要介绍一下gdb。其实偶对这个也不是很熟,有错误请指正。
简单的说,gdb是一款强大的调试工具,尽管它只有文本界面(需要图形界面可以使用ddd,不过区别不大),但是功能却比eclipse等调试环境强很多。
接下来看看怎样让它为lab2拆炸弹服务,在命令行下运行gdb bomb就能开始调试这个炸弹程序,提高警惕,恩。
首先最重要的,就是如何阻止炸弹的引爆,gdb自然提供了一般调试工具都包括的断点功能——break命令。
在gdb中输入help break能够看到相关的信息。
可以看到 break 允许我们使用行号、函数名或地址设置断点。
按ctrl+z暂时挂起当前的gdb进程,运行 objdump –d bomb | more 查看反编译后的炸弹文件,可以看到里面有这么一行(开始的那个地址每个人都不同):
08049719 <explode_bomb>:
这个就是万恶的引爆炸弹的函数了,运行 fg 返回 gdb 环境,在这个函数设置断点:break explode_bomb (可以使用tab键自动补齐)
显示
Breakpoint 1 at 0x8049707
接下来你可以喘口气,一般情况下炸弹是不会引爆的了
下面我们来拆第一个炸弹,首先同样是设置断点,bomb.c中给出了各个关卡的函数名,第一关就是phase_1,使用break phase_1在第一关设置断点
接下来就开始运行吧,输入run
我们已经设置了炸弹断点,这些恐吓可以直接无视。
输入ABC继续(输入这个是为了方便在后面的测试中找到自己的输入串地址)
提示Breakpoint 2, 0x08048c2e in phase_1 (),说明现在程序已经停在第一个关了
接下来就是分析汇编代码,使用disassemble phase_1显示这个函数的汇编代码
注意其中关键的几行:
这个lab很厚道的一点就是函数名很明确地说明了函数的功能 ^_^
估计这三行代码的意思就是比较两个字符串相等,不相等的话应该就会让炸弹爆炸了
因为字符串很大,所以传递给这个比较函数的肯定是他们的地址,分别为0x80499b4和0x8(%ebp)
我们先来看后者,使用p/x *(int*)($ebp + 8)查看字符串所在的地址
$1 = 0x804a720
````
继续使用`p/x *0x804a720`查看内存中这个地址的内容
$2 = 0x434241
连续的三个数,是不是想起什么了?把这三个数分别转换为十进制,就是67 66 65,分别为 CBA 的 ASCII 码,看来这里保存了我们输入的串。
接下来 0x80499b4 里肯定保存着过关的密码 `p/x *0x80499b4`
$3 = 0x62726556
c中的字符串是以0结尾的,看来这个字符串还不止这个长度,继续使用
`p/x *0x80499b4@10` 查看这个地址及其后面36个字节的内容,终于在第二行中出现了终结符”0x0”(不一定是四个字节)
$4 = {0x62726556, 0x7469736f, 0x656c2079, 0x20736461, 0x75206f74, 0x656c636e, 0x202c7261, 0x72616e69, 0x75636974, 0x6574616c, 0x69687420, 0x2e73676e, 0x0, 0x21776f57, 0x756f5920, 0x20657627, 0x75666564, 0x20646573, 0x20656874, 0x72636573}
把开头到0x0的所有信息字节下来,通过手算或者自己写程序得出最后的密码串(注意little endian中字符的排列方式!)
输入run重新运行,输入刚才得出的密码串,如果前面的计算正确的话,就会提示
Phase 1 defused. How about the next one?
关于这个lab的一些其他心得:
1. VMware中开发很不舒服,屏幕小、字体丑@@、需要Ctrl+Alt切换回windows,不怎么方便,推荐在windows下使用pietty登录虚拟机中的linux系统(RedHat 9默认安装了sshd),个人觉得这样比较方便。
2. ASCII查询可以在linux终端中运行man ascii。
3. 退出gdb后,再次进入时一定要注意使用break给explode_bomb上断点,不可大意 ~.~
4. 后面的几关涉及递归等内容,也有和前面几次作业很相似的东东。
5. gdb中还有一个很好用的jump指令,可以在运行时任意跳转。
6. 看汇编代码时,使用`objdump -d bomb > bomb.asm`把汇编代码保存到bomb.asm中,然后使用sftp工具把这个文件下载到windows或者直接在vim中查看,这样比在gdb中看方便一些。
7. 个人认为lab2和期中考试不冲突,这个lab2可以帮你理清很多汇编语言的概念
其他补充:
sfox:
可以通过GDB中的<u>x /s addr</u>输出以\0结尾的字符串
ICSLab:
为了防止每次拆的时候都不停的输入之前的stage的key,可以把key存入文本文件,一行一个key,不要有多余字符
然后GDB run 的时候用`gdb bomb`
(gdb) b … … (gdb) r password.txt
这样bomb就会自动从password.txt中读入之前的密码直到到达最后一个空行处,如Lab2的说明文档中所述。