2026-02-11 05:59:11
My thoughts/arguments are based on the following three premises:
Looking back in history or current state of the human world, the underlying reason that we did anything can boil down to statement 1, that we live in a world where energies/resources are limited.
So we trade, we create, we make money to buy stuff, we fight each other, we start a war, we exploit, we try to be smart or out win others in a competition, we want to win others’ appreciation. In modern society, in current economic world, people usually get what they want by taking from others' production (regardless “fairly” or not, "legally" or not). That is the nature of a human society. We very much rely on others or the whole society to live. Then the statement 2 applies in a limited world, makes sense of we do everything in this society.
AI helps boost people's productivity. But what AI really help to produce is the question to ask. AI also helps for some people to get more resources or in a special case, make more money from others' boosted productivity and from AI itself.
But as said in premise 3, I doubt the AI will help produce more resources, on the contrary, it consumes more energy. We see AI makes some people richer, at the same time, making others poorer because resources are limited. We are just distributing or carving them up while consuming them in a much faster speed.
I am not against AI, in fact I am learning and use AI in my daily life and work. But this is a worthy question to think about. Is AI making world a better place?
2025-09-24 06:17:51
Note: this article focuses on reading/logging workflow and will be constantly updated.
When I try some new apps or services, the first thing I check is the ability to have the data locally, espeically for memos, bookmarks, read it later, tasks, journals/worklogs/notes.
I would always choose apps/service that fall within the following categories:
For self-hosted apps, data is stored locally on the machine where you deployed the service, all you need to care is to have a regular backup and have the ability to read your database.
For apps with a local database (e.g. Things 3, Day One), the best practice is also backing up the local machine and maybe writing a script to read the local database to plain text, just in case. If the app data is cloud based, (e.g. Notion, Ticktick that I once used), I will be cautious before digging down too much into the rabbit hole. For those apps, at least I should be able to read and export ALL the data on the server, whether via API or built in export functionality.
If an app is cloud only and does not have a export functionality, I will not use it - The data is tightly bound to the specific app/service and is never mine.
This could be beneficial if I want to sync the data elsewhere, I can simply subscribe the RSS in karakeep or using API.
Obsidian is one of the best in this category, a similar app is Logseq. For todo app, there is also taskpaper.
This is mainly for quick retriving your data when you need it.
I use freshrss to consume content online, wallabag for read-it-later, Karakeep for bookmarks, Things for todo, Day One for journaling and worklogs, Obsidian for md notes.
All of my data will be synced/exported locally and periodically via scripts or RSS. For example, if I star an article in freshrss or added one to wallabag, post a Mastodon toot or upvoted a Reddit post, they will be synced to Karakeep via RSS. If I added a task in Things or a worklog entry in Day One, they will be synced to Obsidian via plugin or exported to markdown by scripts that periodically read the local database file. All local plain-text files will be in a private .git repo that keep track the changes over time.
Anybox - bookmark app, local data synced via icloud (platform lock), but no full text search.
Raindrop.io - bookmark app, data is on the server, permnent copy under pay wall (but still on their server afaik)
DEVONthink - A really powerfull app (RSS, read-it-later, bookmark, file-management with full text search and local file storage), the only downside is the file system (databases) is not integrated very well with the Finder system, which means you can only backup and restore the whole database but not individual files.
Readwise reader - A cloud based RSS and read-it-later apps, great for its TTS. But data is only on its server, TTS for Chinese is still buggy.
Pocket, Omnivore - End of life.
I tried to fit these apps into my workflow once, but ending up not using them.
2025-09-12 06:40:16
tldr, 首先尝试去 App Store -> 头像 -> Apps -> My Apps 从已购买列表重新下载,如果购买列表内也找不到,则需要从保留该应用的旧设备导出 IPA 文件用 iMazing 安装;如果你在意应用可能被下架,最好关闭 "Offload Unused Apps" 功能(设置 -> App Store),防止本地应用被删除导致无法备份。
不管是 iPhone 换新机或是去 Apple Store 维修,需要从 iCloud 恢复旧手机数据,又或者是打开了 iOS 17 后推出的 Offload Unused Apps (本意是为了节约手机宝贵的存储空间),你一定会发现在手机某些 App 上出现了小小的下载图标。

(A screenshot of iOS showing offloaded apps, source: r/ios)
iOS 备份并不像时间机器一样全盘备份,而是保存了应用的 iTunes 链接,在恢复备份时重新从 App Store 下载下来。大多数情况,点击 offloaded app 图标后会将其重新下载下来,但是偶尔也会出现以下这种情况,提示你无法下载,应用已经从 App Store 下架。
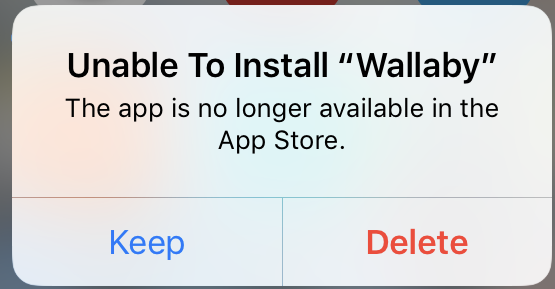
(source: https://talk.macpowerusers.com/t/offloaded-app-removed-from-app-store/17436/3)
如果出现这个提示而你仍想要这个应用,那么最简单的方式可以去 App Store -> 右上角头像 -> Apps -> My Apps 找到所有已经购买的 App (包括已经下载的应用),这种情况通常发生在开发主动将应用退出 App Store (Popclip) 或者老版本被全新的应用替代 (Reeder 4)。这些应用仍能够通过已购买列表重新下载。
当然如果你运气不好,会发现部分 App 在已购买的 App 列表中也无法找到(即使这些 App 是非常合规的、非钓鱼、非低质量),reddit 上有很多这样的案例,我自己也发现了一两个这样的例子 - 个别从 App Store 下架的应用会因为各种原因从购买列表中也完全移除,彻底被苹果封锁从服务器下载的方式。
此时如果你仍有旧设备或者其他同 Apple ID 的设备上仍然保留有这个应用,那么就可以从旧设备中中导出IPA,并以 Imazing 将其安装在新设备上。具体步骤可以见这个帖子。如果你没有保存本地应用,那只能和这些应用说拜拜了,虽然大概率这个 App 也会是你不再需要的。
但是以防万一,如果对你来说重要的 App 可能甚至已经从 App Store 下架,那么最保险的方式便是进入设置关闭 Offload Unused Apps (Settings -> Apps -> App Store -> Offload Unused Apps),并且尽可能在换机前保留旧手机上的应用、或者使用 iMazing 等应用做个全局备份。这样即使发现恢复后的新手机上应用被双下架时,也可以通过 IPA 安装。
如果你比较随缘,并不在意本地应用被删除 Offload,那么打开这个功能也无妨,当换机来临时,被下架的应用自然会被 Offload。
最后岔开个话题,在我闲来无事翻看 2012 年在 iPod Touch 上下载的旧应用,发现这些应用即使下架了这么久,Appraven 仍然可以看到当年的 App Store 截图和信息,比如以下这个。
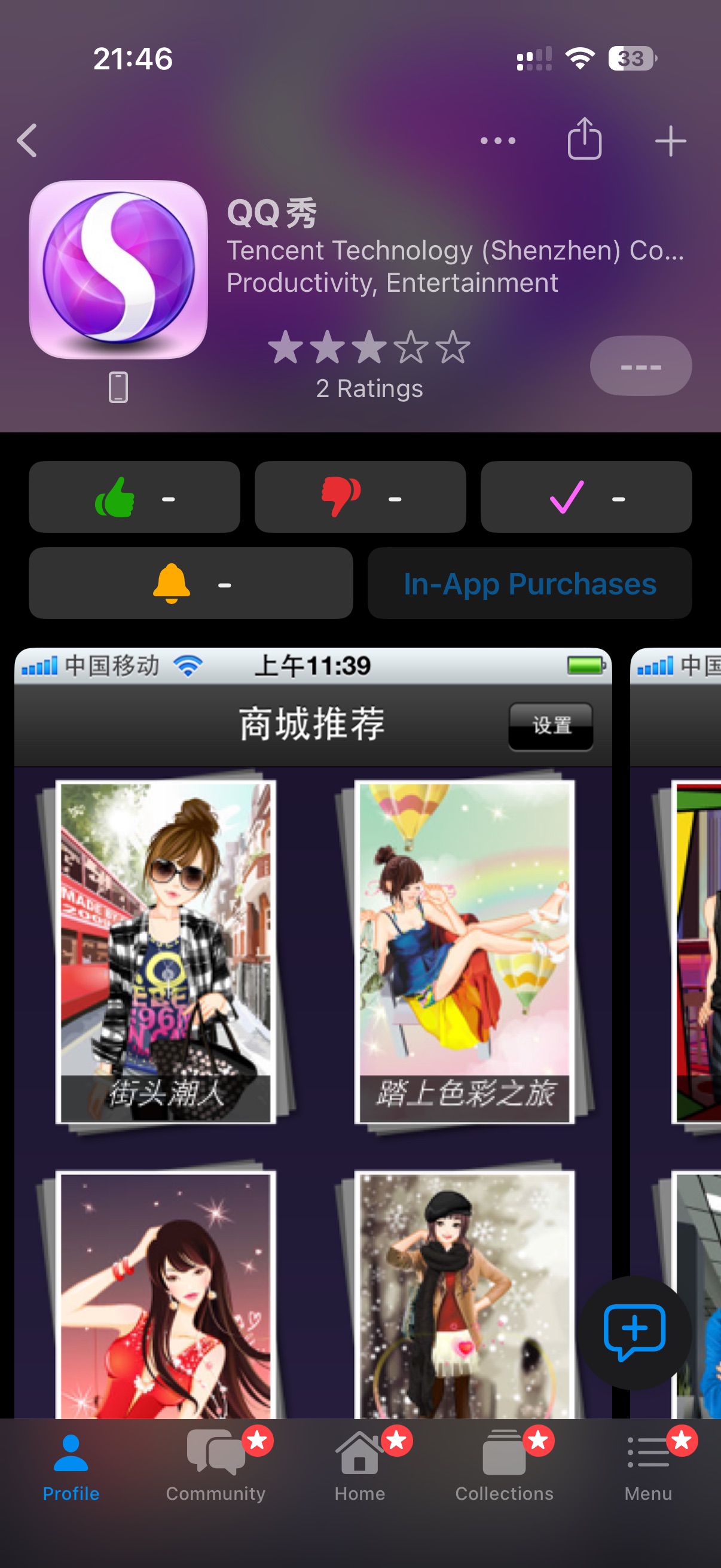
2025-09-05 04:53:26
我总是容易一时兴起,再加上囤积症 + fomo,会花很多时间关注一些感兴趣的内容,最后时间过去,或是兴趣的转移,或是源头已变味,又不得不花大量的时间去整理 - 取关和清除。兜兜转转,花了两倍的精力。
一些曾经关注的 B 站 up 主,不知是卖号了或是其他原因,开始制作一些营销内容。比如说我关注的 r/macapps,自从 AI 浪潮以来,充斥着粗制滥造的 AI app,捞一笔用户而跑路。以前的我可能会把感兴趣的 app 试过,写下自己的使用感受和对比评测,现在我大概能和自己和解了 - 不值得!文字内容也如此,大量 AI 产生的垃圾每时每刻不停产生,蚕食真正有意义的内容。短视频就更不用说了。
更加令人唏嘘的是,互联网的内容正在被各大平台自建高墙,还在其内塞满了糖衣和广告,圈养着创作者和消费者 - 创作者绞尽脑汁迎合平台算法的推荐,企图能获取一点点的流量、推广,而产生的语料被用来训练大语言模型,来继续生产垃圾。另一方面短平快的内容和 for you 不断刺激和消费读者的注意力,最后通过广告营销内容从中获益。一个“完美”的闭环。
当然 AI generated content 并不应全盘否定,但应保留作为人的批判思考和创造力。 互联网也并不是一味的垃圾,但找到好东西有如大海捞针。
写这篇的背景是在整理订阅源的时候发现,很多曾关注的有意思的博客主已经停更了,只有 Freshrss 中的文章存档还能留下 Ta 的一点足迹,当然这或许是一件好事,背后可能意味着博主更加关注现世生活和身边的人。
希望有一天我能真正做到 Minimalism,在网上和在生活中。 杜绝垃圾。
一点胡言乱语的垃圾。只为自己和解。NOT BY AI。
相关:
2025-08-26 01:46:18
前几天升级了 macOS Tahoe 之后,开始逐步从 Chrome 转移到 Safari。这里推荐几个扩展,会持续更新。由于扩展必须上架 App Store,开发者必须交 99刀的年费,所以很多扩展即使是开源的也不一定是免费的。很多插件在手机上的体验也很好。
pplx, gpt, a 等自定义关键词快捷搜索 perplexity,chatgpt,amazon 等。在手机上使用的意义更大些,可以不用下很多 web 套壳 app,电脑上用 Alfred/Raycast 的 websearch/quicklinks 可能就够了。另外 Alfred 有很多 Safari 相关的插件,比如说搜索 tab 历史记录,切换 Profile,这里就不多做介绍了。
https://alfred.app/search/?q=safari
欢迎大家留言推荐更多好用的 Safari 扩展。下回考虑写个在用的油猴脚本。