2024-10-12 21:26:06
承蒙 Michael Wong 赠送激活码,我也终于用上 Follow.is。
This message is used to verify that this feed (feedId:55450866978608128) belongs to me (userId:42181569844995072). Join me in enjoying the next generation information browser https://follow.is.
2024-09-07 00:00:00
新华社专访 [[黑神话:悟空]] 创作人冯骥时,他说了一句“踏上取经路,比抵达灵山更重要”。之前看[[产品沉思录]]时,少楠也说过一句类似的话 “使唐僧成为唐僧的,不是经书,而是取经的那条路”。在上次随想集中说,说要多写写随想集,大概这就是我取经的路吧。
这两周晚上下班之后,大部分时间都是在看这本书,当然是利用 thinking 10 中提到过的 [[Concept-Descriptor Framework]] 方法边阅读边做卡片,目前 Anki 卡片数量超过 1500+。自己之前看过李宏毅的强化学习,这次看书时经常有感觉之前学过,但是忘记,还是需要通过 Anki 这类工具不断复习。
这本书网上应该能找到 PDF 和 epub 版本,优先推荐 PDF 版本,制作比较精美。唯一的问题是 PDF 版本是作者的初稿,可能有一些错误。或者有实力的读者,干脆直接支持一本纸质书。
[[@李沐讲座:大语言模型的实践经验和未来预测]] 链接:bilibili
几年前经常在知乎上看李沐写的总结以及在 B 站看李沐带你读论文,去年开始他已经去 LLM 领域创业。难得今年又出来分享一些经验。这个讲座主要有两个部分,大模型经验以及他自己的个人成长。
对于我这种不做大模型的人来说,这部分内容只能当成听他吹吹牛。
李沐个人经历非常丰富,最早主要到他是发现他从百度离职去美国读博士,当时看到人生的另一种可能。不过了解到他是上交 ACM 班的,就又觉得合理了。这部分内容,给我留下最深印象的是,李沐分享了打工人、博士生和创业三个不同角色的精力,还进行了对比。选择不同的角色,需要考虑你自己的动机能不能匹配上这些角色的特点。最后,李沐分享一个持续提升自我的方法,总结。用你导师、上级的角度时常总结。每周、每季度、每年、每五年进行总结。
这两周还是在打这个游戏,大概玩了 13 个小时,目前进度到第二章虎先锋。前一段时间在b站看到,篮球解说徐静雨大概打了虎先锋 100 多次才通过,感觉自己要尝试的次数也差不多。只能说这游戏卖给我们这些动作游戏新手 268 真是超值。
2024-08-25 00:00:00
最近经常看 polebug23 每周程序员的下班学习记录 vlog,每个视频会列出一些 topic,写上 up主的理解,然后搭配日常学习相关的画面。挺喜欢这种形式,所以又开始重新写随想集。
这几年自己断断续续用过几次 Anki,觉得做卡比较麻烦以及卡片都是孤立的,所以也没有坚持下来。前几周看 [[RemNote]] 的文档时,了解到他们提倡地做闪卡的思路 [[Concept-Descriptor Framework]],简单来说是:
自己的主力笔记软件是 Logseq,所以尝试[[在 logseq 中实践 CDF]],需要记忆的内容按 Concept 和 Descriptor 的形式写下来,然后借助 [[logseq-anki-sync]] 插件将闪卡同步过到 Anki 中学习。目前实现的效果是:

当然这种复刻还是存在一些问题:
话说回来,最理想的方式增强 logseq 中的闪卡功能(可以直接复刻 remnote 的逻辑),但是感觉 logseq 开发者中没有狂热的间隔重复爱好者,可能这只是我最美好的幻想。
本周热度最高的游戏非[[黑神话:悟空]]莫属,自己前几个月就在 PS 上预购普通版的游戏(淘宝上购买港服点卡,最终花费 260 左右)。截止到今天,差不多玩了 10 个小时,由于是 arpg 游戏新手,进度惨不忍睹。昨天下午 50 条命通关幽魂,今天下午挑战白衣秀士差不多 60 次,还是看不到通关的希望。
2024-08-11 00:00:00
链接:Tana Tutorial | How to use Semantic Functions in Tana (youtube.com)。为了更好了解 logseq db 版本新的 tag 找的这个视频,不过感觉这个 youtuber 还是卖课为主,关于 Supertags 介绍有一些简单。有一说一,logseq db 的 ui 和 tana 还有较大的差距,只能说未来可期。
[[Supertags]] define what a node is
Fields define relationships
如何使用
Fields
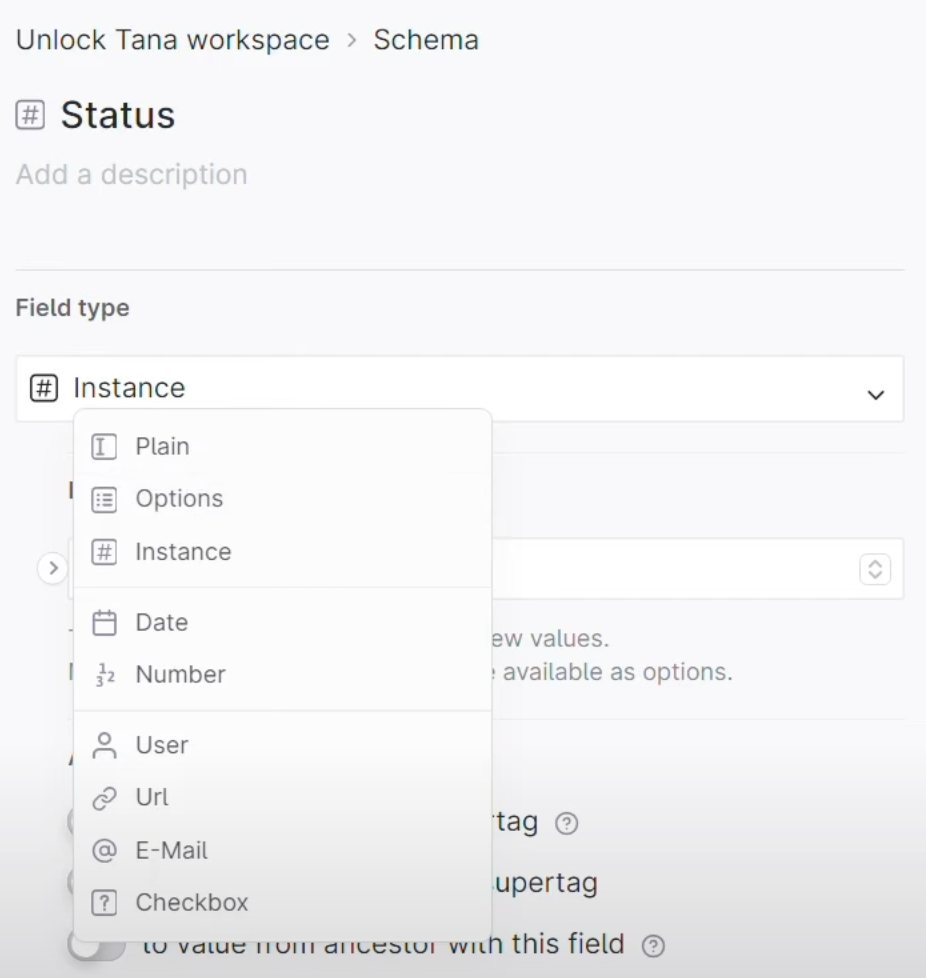
实现层次化关系
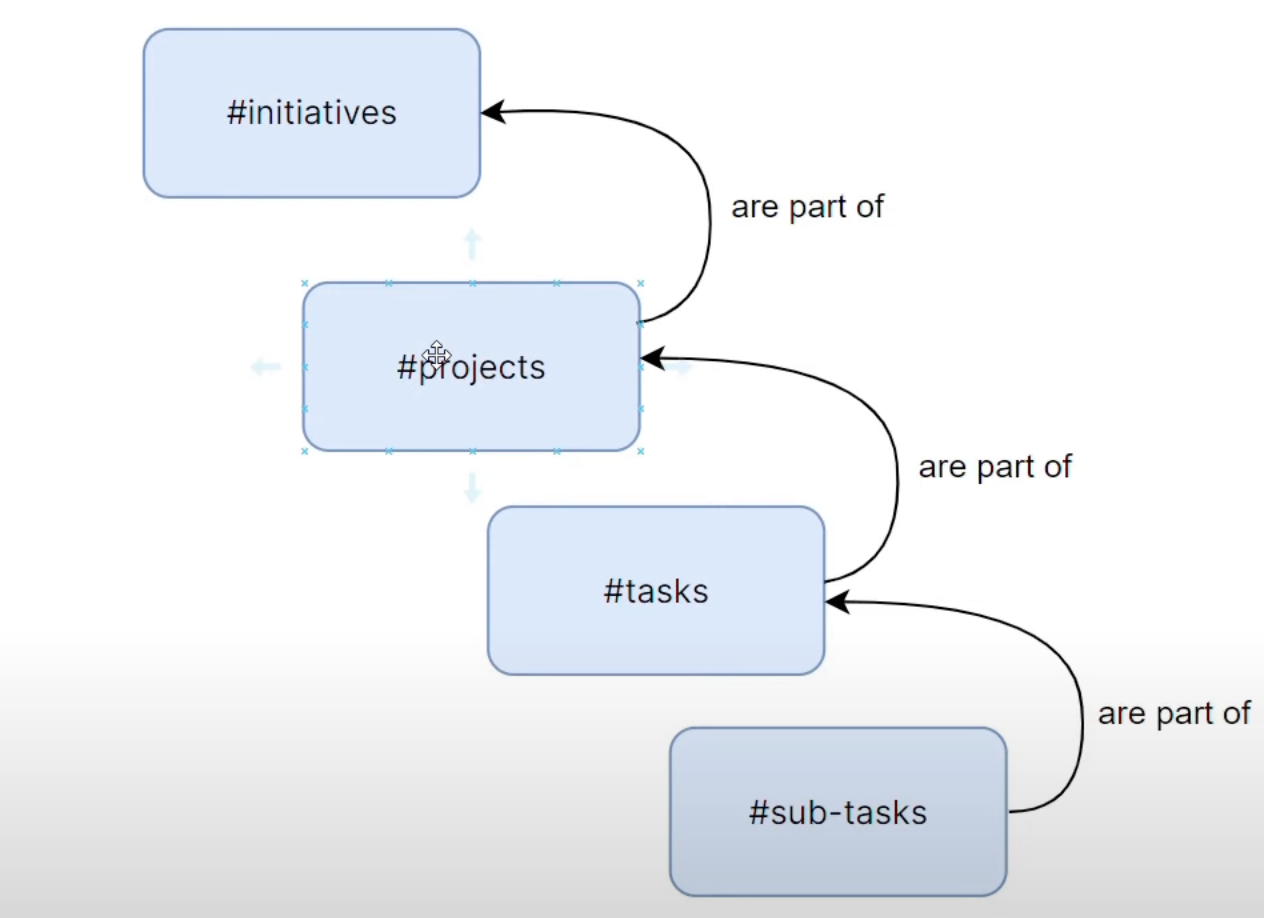
2024-07-30 00:00:00
moc
[[什么是强化学习?]]
[[强化学习问题的基本概念]]
[[强化学习与 Markov Decision Process]]
[[强化学习的 Bellman Equation]]
[[Monte-Carlo 和 Temporal-difference]]
[[On-Policy & Off-Policy]]
[[强化学习中不同的方法]]
[[Q-Learning]] :<-> TD,value-base 方法,利用 critic 网络评价 actor 。
id:: 66659fef-459f-4f58-9bb5-a1efe7e00d0b
[[Policy Gradient]]
思考怎么定义采取动作后的 reward 和最大 reward 的差异以及用什么方法更新参数。