2024-10-21 08:41:56
 今天聊一下时间的话题。在分布式系统中,“时间” 是一个挺有趣,但是很难处理的东西。我把自己的理解简单整理下来。
今天聊一下时间的话题。在分布式系统中,“时间” 是一个挺有趣,但是很难处理的东西。我把自己的理解简单整理下来。
首先,单一节点的物理时钟是不可靠的。
物理时钟本身就有偏差,可是除此之外,可以引起节点物理时钟不准确的原因太多了,比如 clock jump。考虑到 NTP 协议,它基于 UDP 通信,可以从权威的时钟源获取信息,进行自动的时间同步,这就可能会发生 clock jump,它就是说,时钟始终会不断进行同步,而同步回来的时间,是有可能不等于当前时间的,那么系统就会设置当前时间到这个新同步回来的时间。即便没有这个原因,考虑到数据从网络传输的延迟,处理数据的延迟等等,物理时钟是非常不可靠的。
如果一个分布式系统,多个节点想要仅仅依赖于物理时钟来完成什么操作,那么只能祈祷运气足够好了。在 《从物理时钟到逻辑时钟》这篇文中,我已经介绍了对于物理时钟不可靠的问题,我们有一个解决的办法,就是引入 Lamport 逻辑时钟,或者使用向量时钟,这里就不赘述了。
分布式系统中什么样的执行结果最难处理,成功还是失败?其实都不是,最难处理的结果是超时,因为执行超时了,但是系统却并不知道它:
所谓超时,一个显然的问题是,超过多少时间才算超时?往往没有一个公式,更没有一个标准答案,我觉得《Designing Data-Intensive Applications》这本书里面对这一点总结得很好——对于超时时间的定义,其实就是一个 tradeoff,一个基于 failure detection delay 和 risk of premature timeouts 之间抉择的平衡。如果超时时间设置长了,就会减少超时判定的误杀,但是对于系统失败的识别就会延迟;反之,如果超时时间设置过短,那就会触发更多看起来是超时的 case,但是它们本身其实并没有真正超时。
通常来说,对于超时的处理,其实办法也不多。一种是放弃,一种是重试。就像消息投递,如果要保证 “至多投递一次”,那在投递超时后,就直接放弃;如果要保证 “至少投递一次”,那在投递超时后,就重试。如果要重试,那就需要引入保证幂等性的机制。
分布式事务 SAGA 对于超时的处理,其实也是遵照上面的原则,在系统内单步都成为事务的基础上,把流程视作一个状态机,无论单步操作是成功还是失败,都会根据清晰的预定义逻辑,触发相应的正向流程或者反向流程,可是唯独超时,多数情况下最有意义的事情就是重试,也只能重试,因为谁也不知道它究竟实际是成功了还是失败了。
说完操作超时,再来说一下节点超时。很多分布式系统中都会使用一种 lease(租约)的机制,比如一个集群中的 leader,作为 leader 会扮演不同的角色,但是必须要 renew 这个 lease,否则超过一定的时间,无论它给不给响应,它都会被开除出 leader 的角色,而 follower 会重新选举(或者其他方式)一个 leader。
比较难处理的是,如果这个节点本来是被 hang 住了,导致了超时,它也已经被踢下 leader 的角色,但是之后它 “活” 过来了(比如经过了一个超长时间的 GC),它还以为自己是 leader,继续去干 leader 干的事,变成了一个假 leader。这其实就是出现了脑裂,本质上是一个一致性的问题。这种情况比较难处理,因为即便有 heartbeat 不断检测,在每两个 heartbeat 的间隙,可能这种重要的变动就发生了。
要解决这种问题,需要使用 token fence 的方法,即让每次最关键的状态数据的更改,携带一个单调递增的 token,这种情况下这个假 leader 发起更改的 token,已经小于系统中最新的 token 了,接收这个数据更改的子系统应该拒掉这个请求。上面说的节点超时的情况我在《谈谈分布式锁》里面有详细说明。
有两种时钟是计算机普遍支持的,一种叫做 time-of-day clock,就是我们一般意义上的时钟,代表着相对于 1970 年 1 月 1 日的 epoch 时间,也就是 Java 里面 System.currentTimeMillis() 返回的。网络时间协议 NTP 就是用来同步计算机这个时间的。
不过,其实还有一种时钟,叫做 monotonic clock(单调时钟),在 Java 里面相应的接口是 System.nanoTime()。这个时钟有一个特点,就是它永不回头。对于 time-of-day clock 来说,时间是可能 “回头” 的,对于很多应用来说,时间回头是要命的。不过这个时钟给出的具体时间却是毫无意义,如果在不同的机器上调用 System.nanoTime(),会得到完全随机的结果。API 的名字是纳秒,可是这个时钟并不给出到纳秒的时间精度,它的作用是用来帮助计算间隔时间的:在同一个节点,第二次调用的时间减掉第一次调用的时间,这个结果(时间间隔)是严格递增(不回头)的。从这个意义上说,除去时间这个视角本身,这个时钟更像是一个单调的计数器。既然是单调的计数器,就可以用来帮助产生系统严格自增的 ID。
下面是 System.nanoTime() Javadoc 上面的解释:
Returns the current value of the most precise available system timer, in nanoseconds.
This method can only be used to measure elapsed time and is not related to any other notion of system or wall-clock time. The value returned represents nanoseconds since some fixed but arbitrary time (perhaps in the future, so values may be negative). This method provides nanosecond precision, but not necessarily nanosecond accuracy. No guarantees are made about how frequently values change. Differences in successive calls that span greater than approximately 292 years (263 nanoseconds) will not accurately compute elapsed time due to numerical overflow.
一般来说,我们都知道计算机的时钟有误差,可是这个误差是多少,差 1 毫秒还是 1 分钟,并没有任何严格保证。绝大多数接触到的时间 API 也是如此,可是,Google 数据库 Spanner 的 TrueTime API 却。它使用了 GPS 时钟和原子钟两种完全独立的机制来冗余某一个机制失败导致的时钟问题,增加 reliability。此外,它还有和 System.nanoTime() 一样的严格递增的特点。
它有三个核心 API,很有意思:
有了 TrueTime,这让分布式系统中,本来无法通过物理时钟解决的问题也变得可解决了。比如对于操作冲突的问题,现在的新办法就是等一个 buffer 时间,TrueTime 认为已经前一个操作的结束时间肯定已经过去了,再来启动后一个操作。当然,这个方法的缺点是 throughput,因为整个操作周期因为 buffer 时间的关系变长了。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
2024-10-02 08:46:16
 分布式系统有它特有的设计模式,无论意识到还是没有意识到,我们都会接触很多,网上这方面的材料不少,比如 《Catalog of Patterns of Distributed Systems》,还有 《Cloud Design Patterns》等等。这里简单谈谈几个我接触过的,也觉得比较有意思的模式。
分布式系统有它特有的设计模式,无论意识到还是没有意识到,我们都会接触很多,网上这方面的材料不少,比如 《Catalog of Patterns of Distributed Systems》,还有 《Cloud Design Patterns》等等。这里简单谈谈几个我接触过的,也觉得比较有意思的模式。
对于这个话题,基本上第一个在我脑海里蹦出来的就是 LSM 树(Log Structured Merge Tree)。其实,LSM 树本来只是指一种数据结构,这种数据结构对于大吞吐量的写入做了性能上的优化(比如日志写入),同时对于根据 key 的读取也有不错的性能。换言之,对于读写性能的平衡,大幅优化了写入,而小幅牺牲了读取,现在它也不再被局限于数据结构本身,而是泛化为能够提供这样特性的一种机制。
整个写入过程分为两个部分,为了追求极致的写入速度,写入方式都被设计成追加的:
所以,为了追求写性能,数据写入会直接插入到 C0 中,一旦 C0 达到一定大小,就会建立一个新的 C0’ 来替代旧的,而原有的 C0 会被异步持久化成 C1 中的一个新文件(其实就是做 snapshot);C1 中的文件全都是有序的,它们会不断地被异步 merge,小文件不断被合并成大文件(下图来自维基百科)。极端情况下,同一个 key 可以有若干次更新,并且更新能同时存在于 C0 和 C1 所有的文件中。

对于根据 key 的查询,需要先去 C0 中找,如果找到了最好,没找到的话需要去 C1 中找,最坏的情况下需要找每个文件。如果数据存在于多个地方,数据采用的优先级是,C0> 新的 C1 文件> 旧的 C1 文件。
对于不存在 C0 中的数据查询,为了尽量避免去每一个 C1 的文件中查询,Bigtable 会使用 bloom filter 来做第一步的存在性判断(校验用的数据全量加载在内存中),根据结果,如果这一步判断通过,这意味着数据可能存在于目标文件;如果没通过,这意味着数据肯定不存在于目标文件。
顺着 LSM Tree 的话题,说到 WAL。WAL 适用于解决这样一个问题:一个系统对于写请求有较苛刻的延迟或者吞吐量的要求,同时又要严格保证 durability(数据不丢)。
因此直观上,WAL 包含三步:
基本上思路就是把能延迟的操作全延迟了,如果服务端挂掉了,根据持久性存储+日志就可以完全恢复到挂掉之前的状态,因此数据不会丢。
于此,有一系列相关的 pattern,比如:
Request Batch 太常见不过了,请求可以批量发送,减少 overhead,从而减少资源(网络带宽、序列化开销等等)的消耗。通常的 batch 是根据大小或者数量来划分批次的,但是修饰词 Clock Bound 指的是,这样的分批还要依据时间,就是说,系统可以等待一段时间,这一段时间内的请求都可能打包成一个 batch,但是这样的打包还要有时间限制,到了这个时间,无论当前的 batch 有多小,都必须要发送出去了。
Kafka 客户端就有这样的一个机制,message 可以被 group,但是:
还有一些流处理系统也采用这种方式,比如 Spark 的 micro batching。
Singular Update Queue 非常有用,queue 本身就是用来处理异步的事件,可以有若干个 producer 产生消息到队列里面,有若干个 consumer 来处理它们。这种场景下这个 queue 为核心的机制扮演了至少这样几个角色:
对于写请求,我们需要保证这些事件处理不会有并发的问题,通过采用 Singlar Update Queue,对特定的 topic,我们可以设计一个良好的 sharding 规则,加上对于每一个 sharding(在 Kafka 等系统里面我们叫做 partition),设置为只有一个 consumer 线程,这样的话就保证了不会有并发问题,因为只有一个线程来处理所有这个 sharding 的消息,这种方式可以简化系统,不需要引入第三方锁系统就可以处理同一个 sharding 之间存在并发冲突的消息。
我想起另外一个相关的话题,monolith(单体应用)还是 microservices(微服务),一直是一个争论。早些时候,在微服务概念刚提出的时候,它受到了追捧,但是现在出现了越来越多批评的声音。一个突出的微服务的问题就是各个微服务之间像蜘蛛网一样复杂调用依赖的问题。而这样的问题,其中一个解决办法就是引入这样的 queue 在中间解耦。
有些时候,queue 里面未必存放全部完成 update 所需的数据,而是只放很少的内容,比如只有一个 key,consumer 拿到这个 key 以后去别的 service 获取完成任务需要的信息,因此这个 queue 就起到一个通知的作用。这其实就是 Claim Check 模式了。
Asynchronous Request-Reply 本身是一个简单而且常用的机制,就是请求发起以后,服务端响应说,请求任务正在处理中,并返回给 client 一个 token。后续 client 拿着这个 token 就可以来(可以是另外一个单独的用于状态查询和结果获取的服务)查询请求的处理状态(poll),同时,服务端也可能会通知(push)客户端情况。
不过,既然上面谈到了 Singular Update Queue,它们俩有时是有关联的。
在使用 Singular Update Queue 的时候,如果 consumer 处理一个消息需要花很长的时间,那么它就可能成为整个系统吞吐量的瓶颈。很多时候,这个 consumer 花很长时间来处理往往不是因为有复杂的 CPU 计算,而是等待,比如等待一个远程调用结束,等待一个文件写入结束等等。
对于这样的问题,有两种解决思路:
最后比较一下 Rate Limiting 和 Throttling。我也是不久前才区分清楚,以前我基本是把它们混在一起使用的。它们都是用来限流的,并且有多重不同的方式,可以是基于 fixed window,sliding window 等等。
但是它们的区别,本质上是它们工作的角度不同。Rate Limiting 是从 client 的角度来管理资源的,比如说,规定某一个/每个用户对于资源的访问不能超过一定的限度,因为资源不能让一个客户端全占了,这样其他人才可以有访问资源的权利;而 Throttling 则是从 service 的角度来管理资源的,比如说,规定某个/每一个 API 的访问 throughput 上限是多少,一道超过这个限度,请求就会被拒掉,从而保护服务。
和这两个可以放在一起的,其实还有一个 Circuit Breaker,不过 Circuit Breaker 的功能和这两个有较大区别,不太容易弄混,因此就不赘述了。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
2024-09-27 06:52:08
我有 Mac 和 Windows,这些年折腾软件方面的环境 Linux 用得比较多,最近想安装一个 Kubernetes 的本地环境,本着 “生命不息,折腾不止” 的精神,打算在 Windows 上动手。了解到可以尝试 Minikube,在此简单记录一下。
首先得要安装 Docker,但是在 Windows 下跑 Docker 有两种方式,WSL(Windows Subsystem for Linux)或者 Hyper-V。我首先把这些 Windows 组件都勾上:
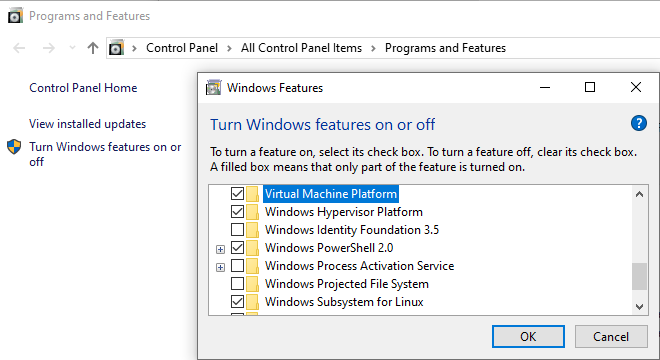
我两条路都去走了一下,为了使用 Hyper-V,我还去 BIOS 里面打开虚拟化支持的选项。不过,后来才知道,因为操作系统版本是 Windows 10 Home,虽说 Windows 上面跑 docker 有两种方式:
但在 Windows 10 Home 版本上只支持第一种。由于 Hyper-V 本质上是额外的虚拟机,而 WSL 更新,是虚拟化的 Linux 环境,是 Windows 操作系统原生支持的,性能要好一些。
其实,在 Docker 的设置里面也有说了:

可以列出所有 WSL(我使用的 WSL 2)目前支持的 Linux Distributions:
wsl --list --online可以选一两个自己熟悉的安装了体验一下:
wsl --install Ubuntu
wsl --install Debian整个 Windows 的文件系统都可以以 Linux 的方式访问。以往我一般在 Windows 上运行 Linux 命令都是使用 Cygwin 的,但是现在我了解到两者很不相同,WSL 是真正的虚拟化 Linux 环境,而 Cygwin 只不过把一些 Linux 命令编译成 Windows 的二进制版本。
安装 Minikube 和相关工具,配置环境变量。这次学到了可以用 Chocolatey,它是 Windows 下的软件安装工具。比如:
choco install kubernetes-cliMinikube 可以以 VM、container,甚至 bare metal(Windows 下不支持)的方式来运行,通过 driver 参数指定。
我们使用 docker,这也是官方认定 preferred 的一种方式。这种方式下,Minikube 应用本身会作为 Docker container 跑在 Docker 里面(driver 的含义),同时,Minikube 也会使用 Docker 来跑其它的应用 container。
minikube config set driver docker
minikube delete
minikube start --driver=docker看一下状态:
Done! kubectl is now configured to use “minikube” cluster and “default” namespace by default
看一下状态:
minikube status
type: Control Plane
host: Running
kubelet: Running
apiserver: Running
kubeconfig: Configured此外,检查一下 WSL 已经安装的 Linux subsystem,能看到:
wsl -l
Windows Subsystem for Linux Distributions:
Ubuntu (Default)
docker-desktop
Debian在 Docker 的 UI 上,也能看到:

跑起来以后,用 kubectl 验证一下:
kubectl cluster-info
Kubernetes control plane is running at https://127.0.0.1:57514查看所有 namespace:
kubectl get pods –all-namespaces
启动 dashboard:
minikube dashboard
接着,创建和部署一个 hello minikube 的 service:
kubectl create deployment hello-minikube --image=kicbase/echo-server:1.0
kubectl expose deployment hello-minikube --type=NodePort --port=8080
kubectl get services hello-minikube
通过访问:
minikube addons list可以列出一堆可以立即安装的 addon,有一些是 K8s 的,有一些是 minikube 的,比如:
minikube addons enable auto-pause这个可以在一段时间没有使用的情况下,暂停 K8s。
还有一个 addon 能让 dashboard 的 metrics 显示更多信息:
minikube addons enable metrics-server后来,一通折腾以后发现,原来 Docker 的 settings 里面已经有了一个 Kubernetes 选项:
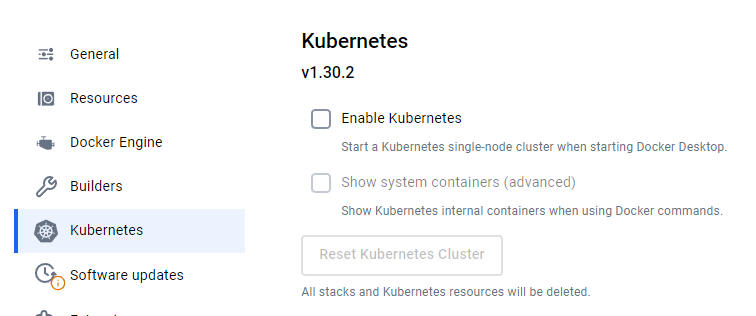
原来新版本的 Docker 里面自带了一套 K8s,它是完全跑在 Docker instance 里面,并且无法配置的,主要用于本地测试。它的运行也是基于 WSL。
现在就试一下,停掉 Minikube:
minikube stopUI 确认确实停了(或者 docker ps):

然后把 Docker 的 Kubernetes tab 上面的两个选项都勾上,apply & restart。
不过等了好久,似乎卡在这一步了,我 reset 并且更新 Docker 以后,问题解决。打开以后我看到 Docker 启动了一堆 container。确认跑起来也没问题:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
docker-desktop Ready control-plane 10m v1.30.2文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
2024-09-19 07:33:44
 就像 Martin Fowler 说的那样,“分布式调用的第一原则就是不要分布式”,谈分布式锁也要先说,不要使用分布式锁。原因很简单,分布式系统是软件系统中复杂的一种形式,而分布式锁是分布式系统中复杂的一种形式,没有必要的复杂性就不要引入。
就像 Martin Fowler 说的那样,“分布式调用的第一原则就是不要分布式”,谈分布式锁也要先说,不要使用分布式锁。原因很简单,分布式系统是软件系统中复杂的一种形式,而分布式锁是分布式系统中复杂的一种形式,没有必要的复杂性就不要引入。
有的逻辑是没有副作用的(纯函数代码),那就可以无锁执行;有的数据经过合理的 sharding 之后,可以使用单线程(单节点)执行,那就单线程执行。
比如一种常见的模式就是使用 queue(比如 Kafka),任务全部放到队列中,然后根据 sharding 的逻辑,不同的 consumer 来处理不同的任务,互相之间不会干扰冲突。
还有一个例子是 Kotlin Coroutine,通过指定一个单线程的 dispatcher,也可以保证它执行的操作之间互相不会有多线程的冲突问题。
有了这样的原则以后,再来谈谈几种分布式锁。
分布式系统中,我觉得我们最常见的锁就是使用一个中心数据库来做的。
一种是悲观锁,就是 “select xxx … for update” 这样的,相应的数据行会被锁上,直到 commit/rollback 操作发生。如果被别人锁了,当前线程没得到锁的话就会等着。
还有一种是乐观锁,就是使用版本号,“update … where … version=A” 这样的。如果 update 成功,表示获取锁成功,并且操作也成功;否则就是 update 失败,需要重新获取状态再来操作一遍。
大多数情况下,后者要更高效一些,因为阻塞的时间通常更短,不过在锁竞争比较激烈的情况下,反而效率会反过来。另外一个,悲观锁代码写起来会容易一些,因为 select 语句执行和 commit/rollback 是两步操作,因此二者之间可以放置任意逻辑;而乐观锁则是需要把数据的写操作和 version 的比较放在一条语句里面。
这两种都很常见,基本上我接触过的一半以上的项目都用过两者。这个数据库不一定非得是关系数据库,但是强一致性必须是保证的。
使用 S3 来创建文件,让创建成功的节点得到锁,文件里面也可以放自定义的内容。我们去年的项目用到这个机制。这种方式是建立在 S3 2020 年 12 月 1 日,上线的 strong consistency 的 feature。
大致上,有这样两种思路:
使用这种方式,对于那些本来就需要使用 S3 文件系统来共享任意信息的情况很方便,但是需要自己处理超时的问题,还有 retention 策略(该不该/什么时候删掉文件)。
Redlock 就是 Redis 的锁机制。Martin Kleppmann(就是那个写《Design Data-Intensive Applications》的作者)几年前写过一篇文章,来吐槽 Redlock 在几种情况下是有问题的:
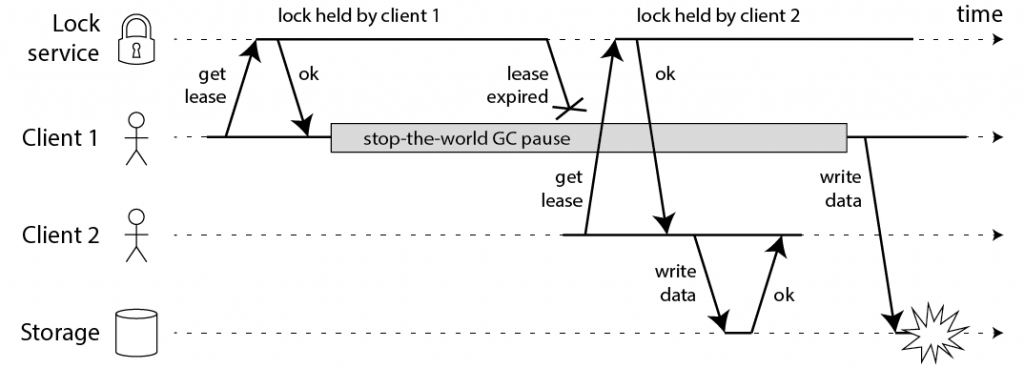
问题可以理解,可是仔细想想这个问题的本质是什么?它的本质其实就是消息延迟+重排序的问题,或者更本质地说,就是分布式系统不同节点保持 consistency 的问题,因为 lock service 和 client 就是不同的节点,lock service 认为之前的锁过期了,并重分配锁给了 client 2,并且 client 2 也是这样认为的,可是 client 1 却不是,它在 GC 之后认为它还持有者锁呢。
如果我们把数据的写操作和锁管理的操作彻底分开,这个问题就很难解决,因为两个节点不可能 “一直” 在通信,在不通信的时间段内,就可能会发生这种理解不一致的情况。但是如果我们把写操作和锁管理以某种方式联系上,那么这个问题还是可以被解决的。简单说,就是物理时钟不可靠,逻辑时钟可以解决这个问题。
之后 Martin Kleppmann 提出了解决方案,他的解决方案也就是按照这个思路进行的。他的方法很简单,就是在获取锁的时候,得到一个永远递增的 token(可以被称作 “fencing token”),在执行写操作的时候,必须带上这个 token。如果 storage 看到了比当前 token 更小的 token,那么那个写操作就要被丢弃掉。
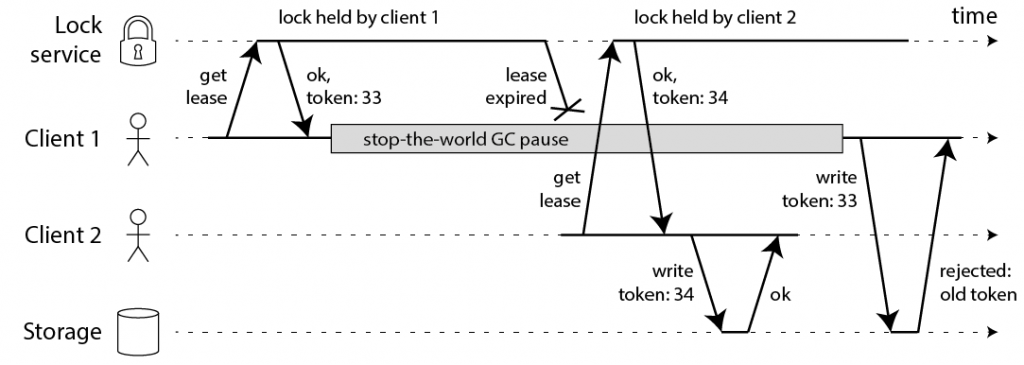
Chubby 是 Google 的分布式锁系统,论文在这里可以找到,还有这个胶片,对于进一步理解论文很有帮助。从时间上看,它是比较早的。
Chubby 被设计成用于粗粒度的(coarse-grained)锁需求,而非细粒度(fine-grained,比如几秒钟以内的)的锁需求。对于这样一个系统,文中开始就提到 consistency 和 availablity 重要性要大过 performance,后面再次提到首要目标包括 reliability,能够应对较多数量的 clients,和易于理解的语义,而吞吐量和存储容量被列在了第二位。
Chubby 暴露一个文件系统接口,每一个文件或者文件夹都可以视作一个读写锁,文件系统和 Unix 的设计思路一致,包括命名、权限等等的设计都是基于它。这是一个很有意思的设计。
对于一致性的达成,它使用 Paxos,客户端寻找 master 和写数据都使用 quorum 的机制,保证写的时候大部分节点成功,而读的时候则是至少成功读取大部分节点(R+W>N,这个思路最早我记得是 Dynamo 的论文里面有写);如果 lock 有了变化,它还提供有通知机制,因为 poll 的成本太高。
内部实现上面,每一个 Chubby 的 cell 都是由作为 replica 的 5 个服务节点组成,它们使用 Paxos 来选举 master 和达成一致,读写都只在 master 上进行(这个看起来还是挺奢侈的,一个干活,四个看戏)。如果 master 挂掉了,在 master lease 过了以后,会重新选举。Client 根据 DNS 的解析,会访问到该 cell 里面的某一个节点,它不一定是 master,但是它会告知谁是 master。
分布式锁里面比较难处理的问题不是失败,而是无响应或者响应慢的超时问题。Chubby 采用一种租约的机制,在租约期内,不会轻易变动当前的 master 节点决定。在响应超时的时期,客户端的策略就是 “不轻举妄动”,耐心等待一段时间等服务端恢复,再不行才宣告失败:
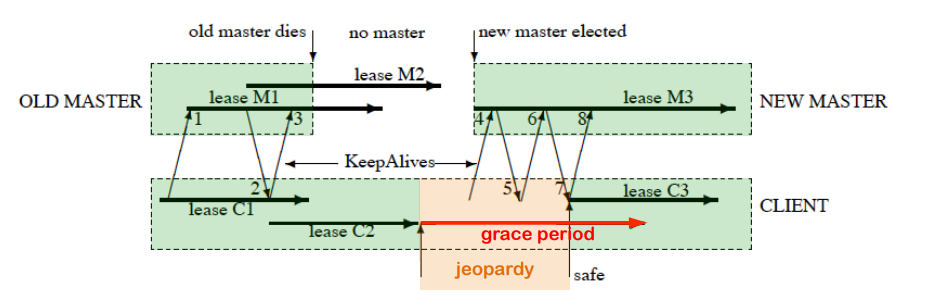
这个图的大致意思是,第一次租约 C1 续订没有问题;第二次租约续订 C2 了之后,原来的 master 挂了,心跳请求无响应,这种情况客户端不清楚服务端的状况,就比较难处理,于是它只能暂时先阻塞所有的操作,等到 C2 过期了之后,有一个 grace period;接着再 grace period 之内,新的 master 被选举出来了,心跳就恢复了,之后租约续订的 C3 顺利进行。
这显然是一个异常情形,但是一旦这种情况发生,系统是被 block 住的,会有非常大的延迟问题。思考一下,这种情况其实就是从原来的 master 到新的 master 转换的选举和交接期间,锁服务是 “暂停” 的。再进一步,这个事情的本质,其实就是在分布式系统中,CAP 原理告诉我们,为了保证 Consistency 和 Partition Tolerance,这里的情形下牺牲掉了 Availability;同时,为了保证 consistency,很难去兼顾 performance(latency 和 throughput)。
此外,有一个有点反直觉的设计是,Chubby 客户端是设计有缓存的。通常来讲,我们设计一个锁机制,第一印象就是使用缓存会带来复杂性,因为缓存会带来一致性的难题。不过它的解决办法是,使用租约。在租约期内,服务端的锁数据不可以被修改,如果要修改,那么就要同步阻塞操作通知所有的客户端,以让缓存全部失效(如果联系不上客户端那就要等过期了)。很多分布式系统都是采用 poll 的方案——一堆 client 去 poll 一个核心服务(资源),但是 Chubby 彻底反过来了,其中一个原因也是低 throughput 的考虑,毕竟只有一个 master 在干活。
对于前面提到的 Martin Kleppmann 谈到的那个问题,Chubby 给了两个解决方法:
回过头思考 Chubby 的实现机制,我觉得有这样几个启发:
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》
2024-09-16 11:10:45
我裸辞了。
工作差不多十六年了,从来没有以离职后休假的方式休息过。今年还是比较特别的,我做了很多新的尝试,想改变一下自己,包括这最近发生的一件事情。事情发生得很快,我辞职了,在作为 engineer 加入 Doordash 一年零十个月后。
记录一下。
我不是在二十岁的年纪,做决定容易缺乏思考,其实,我已经想了这件事情好久了。在这期间,我也和不同的朋友和同事讨论过,他们有的还在 Doordash,而有的也已经离开了。说起来,大致有三个原因:
第一个,是兴趣的不匹配。
 郭德纲说过,如果你每天做的事情是你喜欢做的,那就是老天爷赏饭吃。这样的情况只在少数人身上发生,而我大致就是这样的少数人——不能说每天如此,但是在我职业生涯八成以上的时间,我工作做的事情,恰恰就是我喜欢做的。不过,今年我从一个做平台的 Gateway 组换到了一个做产品的 Order 组,我察觉到情况有了变化,这里面原因有些复杂,但明确的是,impact 是有,但做这个产品工程师并不是我所喜欢的。回头想起来,过往一直都是一个 platform engineer,这算是我第一次做 product engineer,也许这个角色并不适合我。
郭德纲说过,如果你每天做的事情是你喜欢做的,那就是老天爷赏饭吃。这样的情况只在少数人身上发生,而我大致就是这样的少数人——不能说每天如此,但是在我职业生涯八成以上的时间,我工作做的事情,恰恰就是我喜欢做的。不过,今年我从一个做平台的 Gateway 组换到了一个做产品的 Order 组,我察觉到情况有了变化,这里面原因有些复杂,但明确的是,impact 是有,但做这个产品工程师并不是我所喜欢的。回头想起来,过往一直都是一个 platform engineer,这算是我第一次做 product engineer,也许这个角色并不适合我。
兴趣,其实是一个复杂的事情。但是匹配还是不匹配,却是可以直接感受到的。有兴趣的时候,我会感觉充满热情,也不太容易感觉疲倦,做事情都很有动力,工作就是一件快乐的事情;没有兴趣的时候,依然会努力做好工作,但这些特点都不在了。
第二个,是对于职业生涯有了进一步的思考。
我想停下来,休息一下,整理一下,总结自己的经验、技能,想一想之后应该做些什么。一方面是作为 individual contributor,我觉得在进一步发展上,我遇到了瓶颈;另一方面,则是看到当前的工作内容和和团队文化,对我进一步在职业生涯的道路上进一步前进不利。
今年有点特殊,我换了一个 team,最近几个月,我在做一个也许工作两三年的 engineer 也可以做的事情,重要程度很高,可是我自己擅长的技能和经验,却没有足够的施展空间。我注意到,这个团队需要解决很多知识迷局的问题,这些问题涵盖了大量的复杂逻辑和业务流程,这些都不是困难的技术问题,而是说,每个新来人都需要较长时间的 onboarding,我倒是不排斥这个,但这种情况下,我的背景就没有太大优势了。我和我的老板也聊过,没有任何责怪的意思,但是我能看得到的是,和报酬无关,和 impact 无关,但和自我价值的实现相关。
最后一个,则是大多数人离开的时候,说的 work life balance。
我不是一个能把生活和工作分得很开的人,我看到自己的生活被工作侵蚀得太严重,尤其是当我看到团队中的 role model,每天长时间在线,被迫忽视所谓的下班时间,一直响应各种问题,你可以说这就是 “卷”,但无论如何,我觉得这对我来说不是一个可持续发展的方向。
事实上,这是一个团队整体的情况,而不是个人的情况。我注意到,无论是讨论、询问,还是争辩,在这里大家都似乎太忙了,无论是谁抛出一个问题,因为太忙了,大家都更倾向于专注于自己的事情,而不是热心地解答。对于 incident handling,经常要面对长时间的加班和压抑的氛围。一张一弛,文武之道,可以忙一阵、闲一阵。如果一直非常忙,这就一定是有问题的。
而忙碌给我带来的影响并不是只有时间上的。其实,每天晚上我也能挤出时间来做一些自己列表上的事情,但问题在于,白天高强度的工作把我的精力消耗光了,不但是咖啡当水喝,有时候甚至连午饭也没有机会吃。这种情况下,到了下班以后,大脑就不想运转了,只想做一些简单的劳动,比如刷短视频,看短新闻,根本不想做其它消耗脑力的事情,比如看书。这些与我的来说,是非常不健康的。
这些事情,更和公司的文化相关。我在离开前,也评估了换一个组而非离职的可能性。但是对于这一点,其实并不能很好地解决。于是我想,既然这个方向与我而言是有明确问题的,那为什么不换一个公司,人生那么短暂,职业生涯那么短暂,没有必要在这个地方吊着。
于是,上周五是我的最后一天。
那接下去的计划呢?
第一步,我打算休息几周,把某些身体健康问题处理一下,做一做体检,解决幽门螺旋杆菌感染的问题,解决牙齿的问题等等;看几本书,基本都是之前找借口没时间看的书;多陪陪家人,和孩子多玩一玩,也找机会出去溜达溜达;放松一下,和心理医生多聊聊,采取措施去努力纠正心理的健康问题;规划适合自己的生活方式,目标能够平衡生活、运动、休息、学习和工作;再把职业生涯的下一步想清楚,而现在,对此我只有个模糊的概念。
第二步,接着几周,则是回顾和总结我所具备的软硬技能。每个人都会积累经验,不过一定时间以后需要总结一下,否则很多经验只是茶壶里的饺子倒不出来,有个朦胧的回忆,但无法在实际中快速落地变成好的想法和观点。近期,我也会多写一些 blog,弥补之前错过太多的遗憾,以技术文章为主。
第三步,才是 job hunting。现在我有公司、团队和职位类型等等大致的目标,但是快到那时,可能会有不一样的想法,但我一定还是 IC。通常来说,到年底工作机会往往不太多,所以我做了心理建设,预期这有可能会花费较长时间。
所以现阶段,我根本不想考虑任何和过往工作有关的事情。
没有遗憾么?
我总体来说确实是个患得患失的人,但我一直想改变自己,并且今年也做出了不少改变,至少我觉得现在更能拿得起放得下。遗憾也许会有,但是这不会影响我当前做决定。我在短期内会失去还挺不错的收入,而离开的 Doordash 其实依然是一家我看好的高速成长的企业,我会继续拿着少量它的股票,并且,现在的就业市场也说不上好。
尤其是就业市场这一条,我想,软件工程师这个职业,因为加息、AI 等等原因,应该比较难回到疫情初期 2020 年那种状态了,那个企业时候借贷成本低,大幅扩招,市场有些疯狂,小红书上一堆其它专业 “转码上岸” 的程序员。市场经济就是如此,但是,长期来看这依然是个朝阳行业。据我了解,现在的就业市场比去年有所改善,但可以说依然不太好,不过,事实就是没有什么是完美的,追求完美也容易走入难以行动的误区,反而做出更糟的选择。
做出决定前思考足够深入吗?
这是一个很难回答的问题,一方面很难评估是不是已经做了足够的思考;另一方面,敢于做决定也是我努力在提高的一件事情,尤其要避免对于完美的追求,不要惧怕失败,追求完美只会让自己失去机会。
不过,可以确认的是,这件事情我思考很久了,今年大概三、四月份就萌发了这样的念头,所以,这不是一个仓促的决定。我和朋友同事聊过不少,包括那些在今年离开的,他们都有很有意思的近况,有找到新的、更理想的工作,有依然在旅行和休息的,还有已经启动创业项目了的。我得到了很多好的点子,这让我对于下一份工作之前,有了更多的憧憬。
关于 Doordash 这家公司,我还是长期保持正面观点的。外卖平台和配送的行业,虽说在我看来肯定谈不上是一个好生意,因为它的门槛低,护城河不硬核,可回想在美的十年间,多少外卖平台零零散散地萌芽、成长、衰落,连巨头亚马逊都尝试过,但是最终也是止损放弃,但是从未有一家公司做这样的生意,能像 Doordash 一样能够做到这样出色的营收和市占率。有的公司是做好生意,但是管理层离谱;有的则是生意难做,但是管理层的决策总是很靠谱,Doordash 就是后者。
在离职前两周,我请了一周的假和家人去了趟夏威夷,接着就是离职前一周比较轻的工作,再到上周五正式离开之后,到今天,已经在那之后休息了接近一周。这段时间我直观的感受是反差鲜明的,我觉得自己放松、从容多了,这更加佐证了一件事情,那就是,无论自己曾经怎么认为,以往工作就是带来了较大的压力,足以明显影响生活的压力。
对于就业市场,虽然我还远没有开始找工作,但是根据被 recruitor“骚扰” 的频率来看,尤其是从小公司雇主来看,现在比 2022 年中下旬我上一次换工作要好了很多,在如今宏观经济的这个阶段,利率高企,消费减弱,没有办法去期望和最疯狂的疫情初期相比,但是已经要比前两年好不少。
前面已经谈到,今年我在努力改变自己,在离职以后,虽然只有一周,但是已经开始看到一些不错的迹象,比如每天的精力比以前好多了,白天时间充满了能量,不再需要那么多咖啡。还有一些事情,在我的列表上,一件一件去做,继续观察能不能让自己变得更好。
我喜欢一个说法,大致是说,有两种人生追求,第一种是 “简历美德”,第二种是 “悼词美德”。第一种是可以写在简历上的,自己的事业成就等等便是如此;而第二种,是在追悼会上说的,都是人的品行和为人等等。我觉得人的一生,就是一个把重心从对追求简历美德逐步过渡到悼词美德的过程。在我当前这个阶段,我觉得工作依然是生活的重心之一,但是未来它的比例应该下降,需要考虑多一点为人处世等其它方面,双修自己的美德。
就记录这么多吧。
文章未经特殊标明皆为本人原创,未经许可不得用于任何商业用途,转载请保持完整性并注明来源链接 《四火的唠叨》