2024-11-18 15:17:05
如果你了解过*arr stack或者MoviePilot就应该知道有很多人喜欢玩“自动化追剧”,尤其是在PT这个圈子里面。。
“自动化追剧”其实简单点说就是把想看的片子订阅下来,如果出种了就自动调用下载工具下载,再由媒体服务器自动刮削进行整理。这一整套流程全部都是自动的,无需人工干预。一个不太恰当的比喻就像是:你订阅了一个博客的RSS,当博客有新文章发布的时候你能第一时间看到。而在“自动化追剧”中就是把文章换成了各类影视资源。
有很多软件和工具在“自动化追剧”中都扮演非常重要的角色,但这些软件普遍都只支持订阅一般的电影、电视剧、动漫、音乐等,涉及到成人内容的少之又少,在*arr stack中有一个叫Whisparr的软件支持,但该软件维护不积极,并且对JAV的支持不好。
我前段时间通过一个偶然的方式得知AutoLady这个软件,这个软件可以说是专为JAV设计,我当时部署试了一下,觉得功能算完善的了,基本可以实现我想要的需求:通过搜索番号来找片,找到了就订阅下来,片子出种后第一时间自动调用下载器下载。
我用了一段时间后发现有点问题,AutoLady的搜索结果是调用Javbus和JavLibrary的,然而这两个站数据更新太慢,很多新片都发售很久了却还没有收录,试想一下,如果一部新片发售了但是搜不到,那还订阅个毛线,既然要订阅肯定是想在第一时间下载到新片啊。。
然后我就给作者提了个建议,想让作者增加对www.avbase.net的支持,把搜索的数据源改为AVbase,因为这个站的数据是最全的,并且更新也快,基本可以和片商保持在同一天内更新。AVbase除了数据全、更新快以外还有非常重要的一点:AVbase可以识别出每部片的真实女优姓名,尤其是像SIRO、300MIUM、200GANA这种小片商的片子,片商都用假的AV女优姓名,你不知道真名的情况下,订阅个假的名字也没意义。
没想到啊没想到,我也只是建议,AutoLady作者真的给力,没过几天直接发了个新版本,采纳我的建议把搜索功能改成用avbase了,在这里必须给作者点个赞,哈哈哈,太给力了!!下面记录下AutoLady的部署和使用方法。在开始之前有一些注意事项:
1、AutoLady目前只支持有限的PT站点,目前支持的有:M-Team(馒头)、FSM(飞天拉面)、PTT,如果没有这几个站的账号,就没有必要折腾了。
2、下载工具只支持qBittorrent和Transmission,这里我选择用qBittorrent,有关qBittorrent安装方法可参考这篇文章。
3、媒体服务器支持Jellyfin、EMBY、Plex,这里我使用的是Jellyfin,但我不使用AutoLady内置的相关功能,因为我的Jellyfin已经配置好MetaTube了,MetaTube会帮我刮削。有关MetaTube的配置可参考这篇文章。
安装Docker:
apt -y update apt -y install curl curl -fsSL https://get.docker.com -o get-docker.sh sh get-docker.sh
新建compose文件:
mkdir -p /opt/autolady && cd /opt/autolady && nano docker-compose.yml
写入如下内容:
services:
auto-lady:
image: orekiiiiiiiiiiiii/auto-lady:latest
container_name: auto-lady
restart: unless-stopped
ports:
- "127.0.0.1:8043:80"
volumes:
- ./auto-lady-data:/data
启动:
docker compose up -d
首次启动需在日志中查看默认的管理员账号、密码:
docker compose logs
[可选]配置NGINX反向代理,安装NGINX:
apt -y update apt -y install nginx python3-certbot-nginx
新建NGINX站点配置文件:
nano /etc/nginx/sites-available/autolady
写入如下内容:
server {
listen 80;
listen [::]:80;
server_name autolady.example.com;
client_max_body_size 0;
location / {
proxy_pass http://127.0.0.1:8043;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Protocol $scheme;
}
}
启用站点:
ln -s /etc/nginx/sites-available/autolady /etc/nginx/sites-enabled/autolady
签发TLS证书:
certbot --nginx --email [email protected] --agree-tos --no-eff-email
使用管理员账号登录到auto-lady后台,点设置,首先要配置站点,M-team需要一个令牌,FSM需要APITOKEN和PASSKEY:

M-team的令牌在“实验室”-“存取令牌”界面可以生成:

FSM的APITOKEN生成:
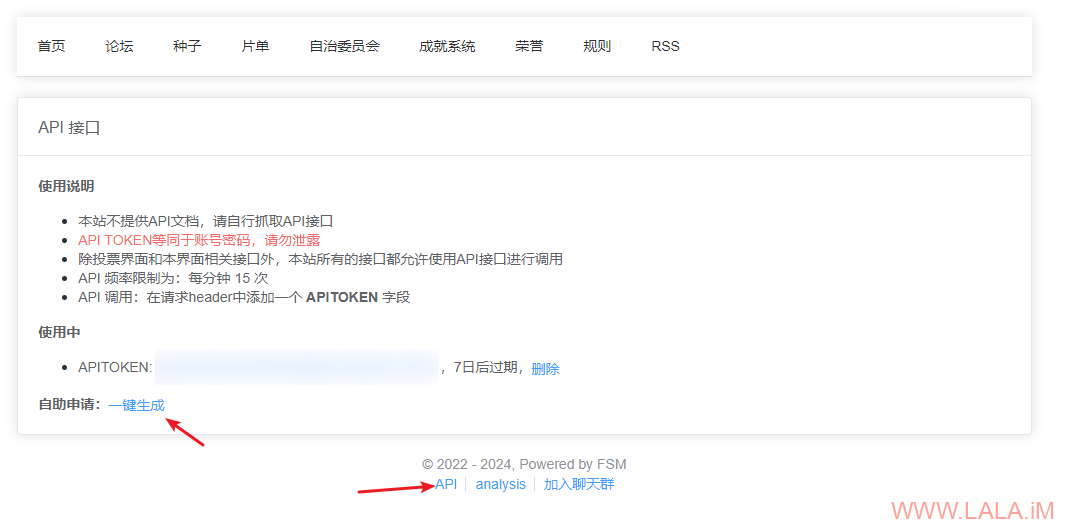
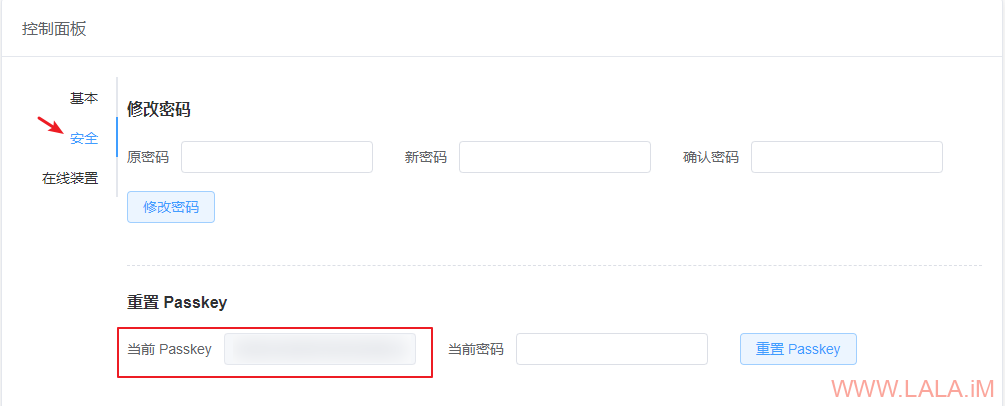
FSM的PASSKEY:
auto-lady下载器的配置:
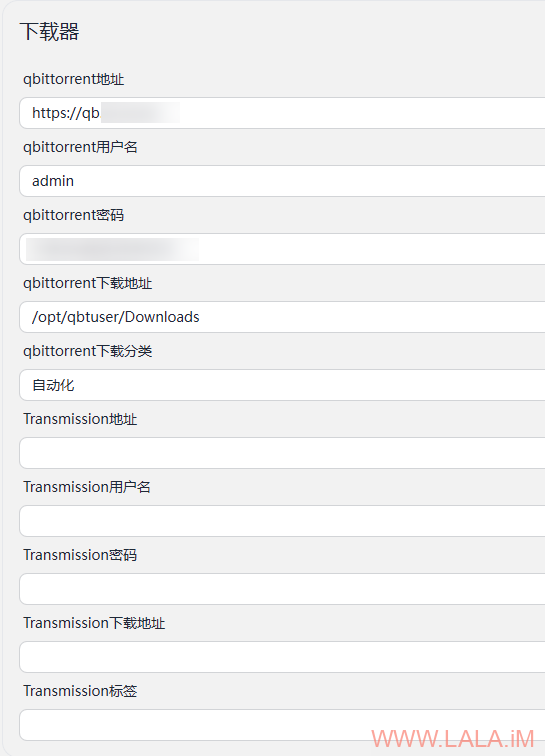
从上图可以看到我把qBittorrent的下载目录设置成:/opt/qbtuser/Downloads。
那么Jellyfin直接挂载这个目录即可:
services:
jellyfin:
image: jellyfin/jellyfin
container_name: jellyfin
restart: 'unless-stopped'
ports:
- "127.0.0.1:8096:8096"
- "127.0.0.1:7359:7359"
volumes:
- ./config:/config
- ./cache:/cache
- /opt/qbtuser/Downloads:/media:ro
有关Jellyfin的安装与刮削配置,可以参考我的这篇文章:https://lala.im/9288.html
剩下的一些设置可选,比如微信、Telegram推送这些,可以根据自身需要来配置,我不需要这些功能就不配置了。
2024-11-13 16:06:02
我前段时间买了两台OVH独立服务器,其中这台KS-LE-E各种问题不断,刚拿到手的时候就发现少了16GB内存,连IPMI上去发现确实是有一根内存条有问题:

当时就只想着解决这个内存的问题去了,发了个工单让他们给我把内存换了一根就好了。其他的硬件,比如硬盘的信息就简单看了下没发现什么大问题就没管它了,直接装了个PVE就拿来用了。这两天看邮箱的垃圾箱突然发现PVE给我发了很多封SMART错误的邮件:
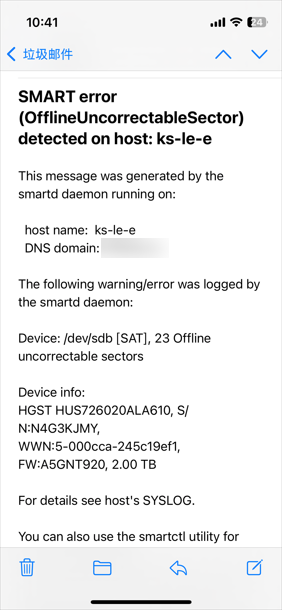
登录服务器一看还真是,这块/dev/sdb的盘确实是有点问题了:

虽然这块盘现在还是能用的,但出于谨慎的态度我还是发了个工单问了下,OVH那边也不墨迹,二话不说直接就把这块盘给换了。在换之前我也没有在服务器上特别设置什么,就是简单看了下硬盘的分区以及当时的ZFS池状态:
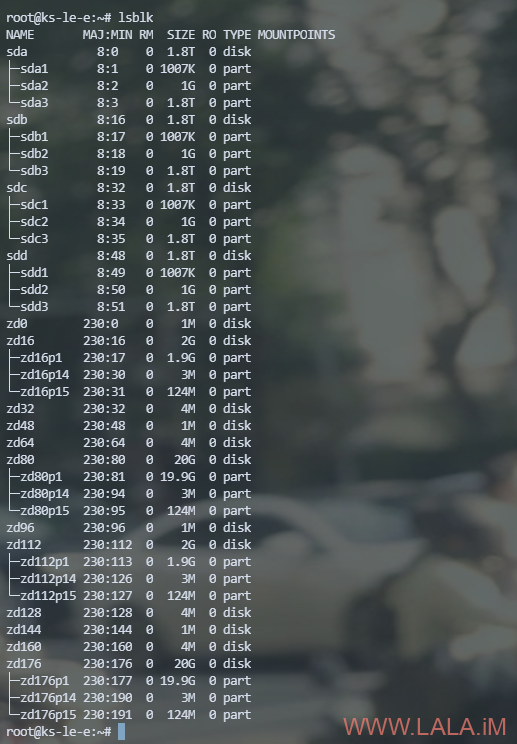
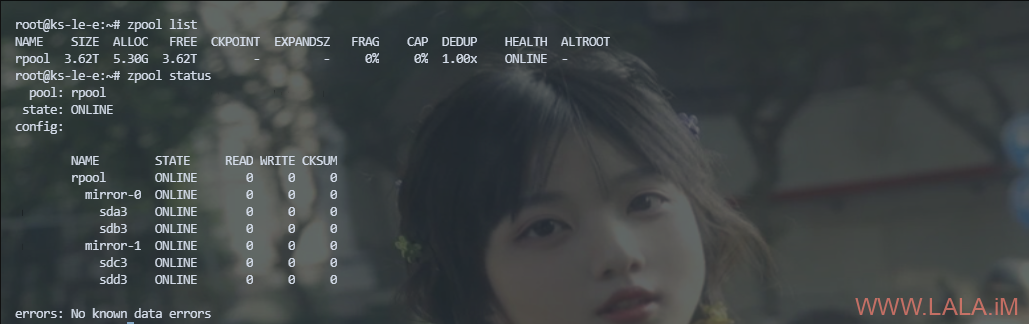
OVH那边换完之后,我再次登录服务器查看,可以看到/dev/sdb这块盘是新换的了,没有了之前的分区表:

查看ZFS池状态,变成降级状态了,因为我这个是RAID10阵列,挂了一块盘也能正常运行:

关于在ZFS中更换硬盘,主要分为两种情况:系统盘(bootable device)、非系统盘。
如果是更换系统盘,则需要复制硬盘的分区表、生成GUID、以及重建EFI分区。而非系统盘的话不需要这些操作,直接更换就好了。
我现在的情况是属于更换系统盘,所以现在我需要把一块健康硬盘的分区表复制到这块新的/dev/sdb。现在我的服务器上除了sdb外还有sda、sdc、sdd三块盘,这些硬盘都是健康的,随便选一个复制就行:
sgdisk /dev/sda -R /dev/sdb
生成随机的GUID:
sgdisk -G /dev/sdb
然后更换ZFS池中的硬盘:
zpool replace -f rpool /dev/sdb3 /dev/sdb3
这个命令可能具有迷惑性,为什么新旧硬盘的分区都是/dev/sdb3?因为新盘的分区表是按照原来的分区表原封不动复制过来的,又因为新换的硬盘设备名正好还是sdb,所以完全相同。如果不是很明白,看看这个命令就懂了:
zpool replace -f [pool] [old zfs partition] [new zfs partition]
再次查看ZFS池状态可以看到在重建了,因为问题发现的早,我也没存多少数据,重建是非常快的:

重建完成后再次查看,全部都在线了:

现在还需要重建EFI分区:
proxmox-boot-tool format /dev/sdb2 proxmox-boot-tool init /dev/sdb2
更新配置:
proxmox-boot-tool refresh
重新生成/etc/kernel/proxmox-boot-uuids:
proxmox-boot-tool clean
查看状态:
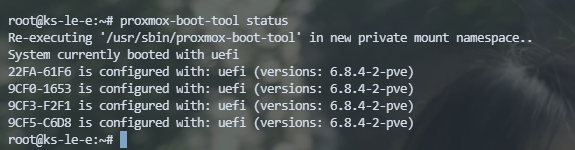
proxmox-boot-tool status
如有下回显说明一切正常:
至此就全部完成了,可以重启一下测试服务器是否能够正常引导:
systemctl reboot
这个方法是通用的,不限于RAID10阵列,无论是RAIDZ-1、RAIDZ-2,或者RAID1,都可以用这个办法在ZFS中更换硬盘。
参考资料:
https://pve.proxmox.com/pve-docs/chapter-sysadmin.html#sysadmin_zfs_change_failed_dev
https://forum.proxmox.com/threads/how-to-regenerate-etc-kernel-proxmox-boot-uuids.99333/
https://pve.proxmox.com/pve-docs/chapter-sysadmin.html#sysboot_proxmox_boot_tool
2024-11-12 21:35:29
记录下在OVH的独立服务器上为Proxmox VE虚拟机配置IPv4、IPv6的过程。如果你使用我这篇文章内的配置,为确保环境一致性,请先按照这篇文章安装好Proxmox VE。
实际上我之前也写过类似的几篇文章,但由于OVH的基础设施(网络)有很多变化,之前的配置可能过时了,遂写一篇文章记录下目前可用的配置方案。
配置IPv4,我们需要在OVH管理界面购买附加IPv4(OVH以前称之为故障转移IP),可以选择购买单个或者整段,这里我为了演示就购买了单个IPv4:


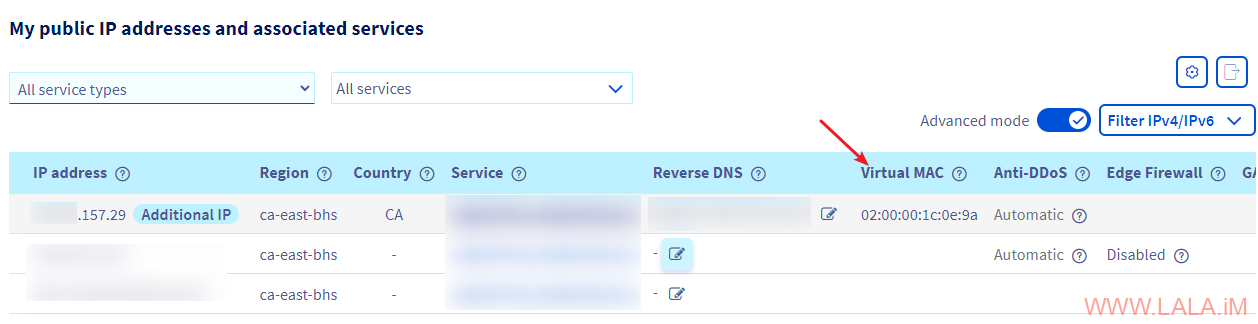
[重要]为刚购买的附加IPv4生成虚拟MAC地址:https://ca.ovh.com/manager/#/dedicated/ip,我这个账号是CA区的,不同区域可能网址不一样。这个需要等待几分钟才能生成好:
在OVH管理界面找到这台服务器的IPv4网关地址,所有的附加IPv4地址都使用这一个网关地址:

做好上述所说的准备工作后,接下来我详细说一下后续配置可能会遇到的坑以及解决办法。
由于OVH的IPv4网关地址与附加IPv4地址不在同一子网,在这种情况下某些基于Debian的Linux发行版需要使用onlink标志才能添加默认路由。
又因为旧版本的cloud-init在这方面存在一些问题,它不为后端的网络管理程序提供onlink标志,这就导致很多Linux系统无法添加默认路由,比如我最常用的Debian12就是如此。
一个典型的例子:假设虚拟机系统是Debian12,当你在PVE的管理界面使用cloud-init配置虚拟机网络时,填写好IPv4和网关地址后,虚拟机启动后没有默认路由。
好在这个问题已经在最近的版本中修复了,更多详细信息见:
https://github.com/canonical/cloud-init/pull/4996
https://github.com/canonical/cloud-init/pull/5654
https://github.com/canonical/cloud-init/issues/5523
但Debian12 cloud image里面的cloud-init还是旧版本,并没有应用上述的更新,我想到几个解决办法,但我只实践了其中两个。
1、使用PVE qm工具的cicustom功能自定义cloud-init的网络配置。
2、使用libguestfs这类工具在Debian12 cloud image里面安装新版本cloud-init。(未实践)
3、这个解决办法最简单,直接用Debian13,13现在是testing,里面的cloud-init是最新版,不存在上述问题。
4、自己从头开始制作Debian image(未实践,个人觉得太麻烦)
下面把第一种和第三种解决办法详细说明一下。首先我们分别创建Debian12、Debian13的系统模板。
下载Debian12 cloud image:
mkdir /root/template && cd /root/template wget https://cloud.debian.org/images/cloud/bookworm/latest/debian-12-generic-amd64.qcow2
创建虚拟机:
qm create 50000 \ --name debian12-template-source \ --cpu host \ --cores 1 \ --memory 1024 \ --machine q35 \ --bios ovmf \ --efidisk0 local-zfs:0,format=raw,efitype=4m,pre-enrolled-keys=1,size=528K \ --net0 virtio,bridge=vmbr0 \ --scsihw virtio-scsi-single \ --agent enabled=1,freeze-fs-on-backup=1,fstrim_cloned_disks=1 \ --serial0 socket
导入Debian12 cloud image:
qm set 50000 --scsi0 local-zfs:0,import-from=/root/template/debian-12-generic-amd64.qcow2,cache=writeback,iothread=1,discard=on,format=raw
配置虚拟机:
qm set 50000 --ide0 local-zfs:cloudinit // 创建cloudinit设备 qm set 50000 --ciuser=root --cipassword="rootpassword" // 设置系统root密码 qm set 50000 --boot order=scsi0 // 修改系统引导顺序
转换成模板:
qm template 50000
下载Debian13 cloud image:
cd /root/template https://cdimage.debian.org/images/cloud/trixie/daily/latest/debian-13-generic-amd64-daily.qcow2
创建虚拟机:
qm create 60000 \ --name debian13-template-source \ --cpu host \ --cores 1 \ --memory 1024 \ --machine q35 \ --bios ovmf \ --efidisk0 local-zfs:0,format=raw,efitype=4m,pre-enrolled-keys=1,size=528K \ --net0 virtio,bridge=vmbr0 \ --scsihw virtio-scsi-single \ --agent enabled=1,freeze-fs-on-backup=1,fstrim_cloned_disks=1 \ --serial0 socket
导入Debian13 cloud image:
qm set 60000 --scsi0 local-zfs:0,import-from=/root/template/debian-13-generic-amd64-daily.qcow2,cache=writeback,iothread=1,discard=on,format=raw
配置虚拟机:
qm set 60000 --ide0 local-zfs:cloudinit // 创建cloudinit设备 qm set 60000 --ciuser=root --cipassword="rootpassword" // 设置系统root密码 qm set 60000 --boot order=scsi0 // 修改系统引导顺序
转换成模板:
qm template 60000
在PVE管理界面克隆一台Debian12系统的虚拟机,假设克隆的这台虚拟机的ID是100:
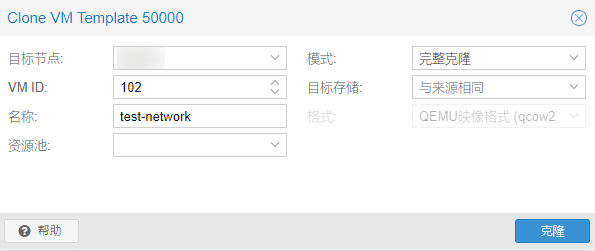
等待克隆完成后,你可以根据自身需求在这里调整虚拟机的CPU、内存、硬盘大小:

对于Debian12而言,虽然后续自定义的cloud-init网络配置会覆盖掉PVE管理界面的设置,但还是需要先在PVE管理界面为虚拟机的网络设备指定OVH的虚拟MAC地址:
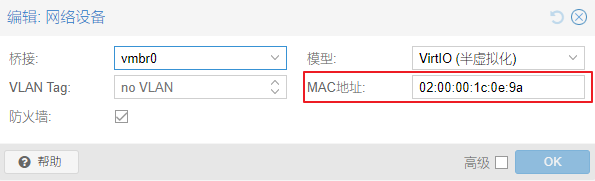
现在就可以来自定义cloud-init的网络配置了。在PVE管理界面找到“数据中心”->“存储”-“local”点击编辑:
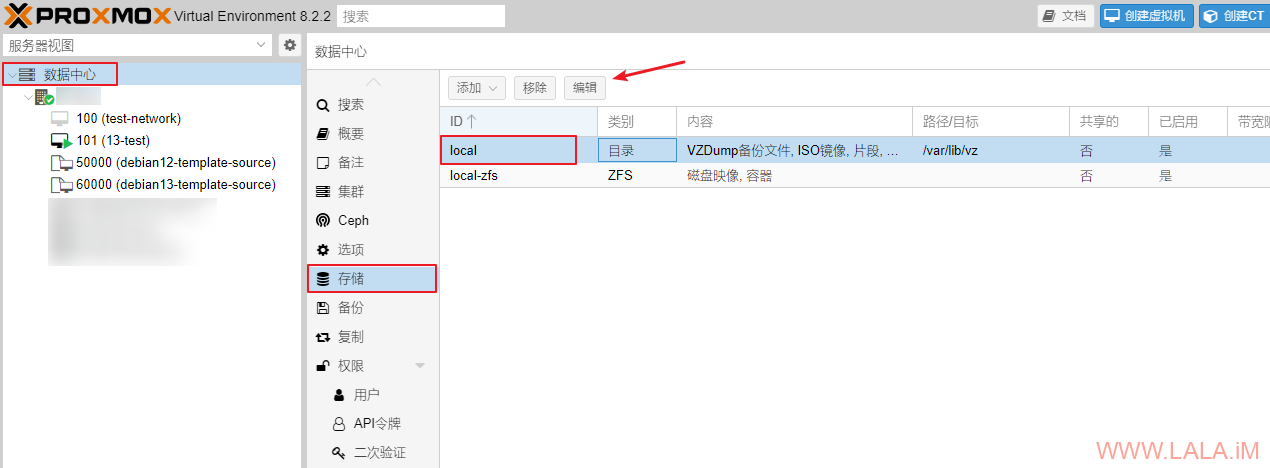
内容选中“片段”:
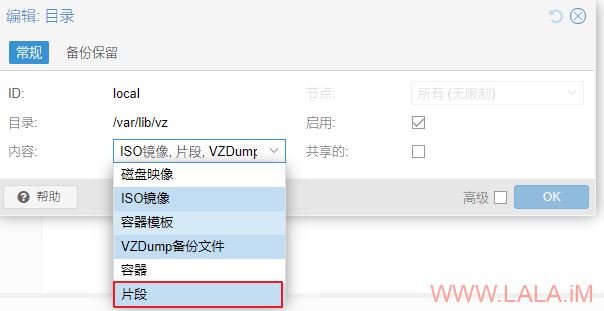
接着在PVE主机的如下目录新建一个yaml配置文件:
nano /var/lib/vz/snippets/vm100-network.yaml
写入如下配置:
network:
version: 2
ethernets:
eth0:
addresses:
- "142.xx.157.29/32" // OVH附加IPv4地址
match:
macaddress: 02:00:00:1c:0e:9a // OVH附加IPv4地址的虚拟MAC地址
routes:
- to: default
via: 158.xx.55.254 // OVH网关IPv4地址
on-link: true
nameservers:
addresses:
- 8.8.8.8
- 1.1.1.1
set-name: eth0
设置ID为100的虚拟机使用刚才创建的自定义网络配置:
qm set 100 --cicustom "network=local:snippets/vm100-network.yaml"
启动虚拟机进行测试:

对于Debian13而言就非常简单了,还是和之前一样克隆一台虚拟机,与Debian12的配置基本相同:

填写之前在OVH管理界面生成的虚拟MAC地址:
然后直接在PVE管理界面配置虚拟机的IPv4地址与网关地址:
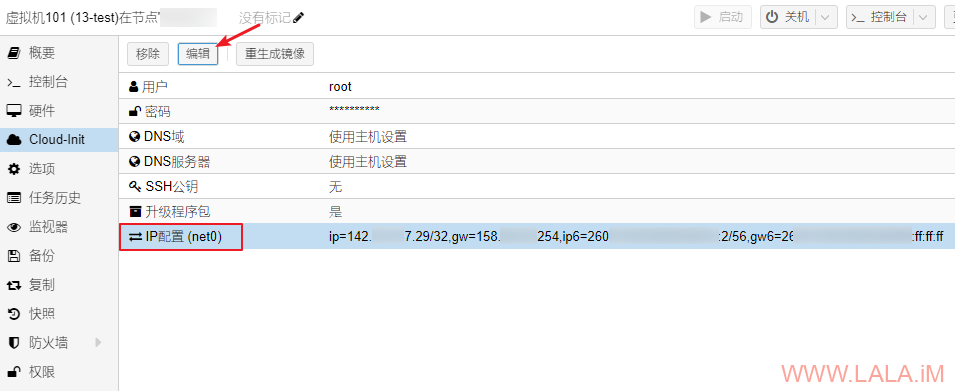
不需要关心IPv4网关地址与附加IPv4地址在不在同一子网,直接往上填就行了:
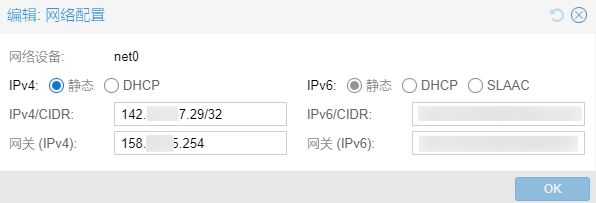
启动虚拟机进行测试:

至此有关IPv4的配置就全部完成了。接下来配置IPv6。
我发现OVH现在的独立服务器应该都给了/56,并且不再需要使用NDPPD。配置起来也是方便了不少。
对于PVE主机而言,直接使用OVH管理面板上提供的IPv6地址与IPv6网关地址即可:
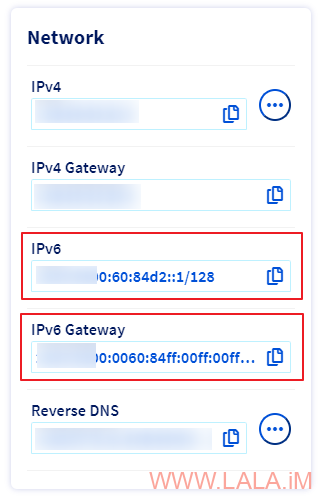
编辑PVE主机的网络配置文件:
nano /etc/network/interfaces
示例配置:
auto lo
iface lo inet loopback
iface eth0 inet manual
auto vmbr0
iface vmbr0 inet static
address 158.xx.xx.210/24
gateway 158.xx.xx.254
bridge-ports eth0
bridge-stp off
bridge-fd 0
iface vmbr0 inet6 static
address xx:xx:60:84d2::1/128 // OVH管理面板上提供的IPv6地址
gateway xx:xx:0060:84ff:00ff:00ff:00ff:00ff // OVH管理面板上提供的IPv6网关地址
source /etc/network/interfaces.d/*
使用如下命令实时重载网络配置,立即生效,不需要重启PVE主机:
ifreload -a
接下来给虚拟机分配IPv6,在开始分配前,可以使用这个网站先计算一下可用的IPv6地址范围,或者拆分IPv6。将OVH管理面板上提供的IPv6地址输上去,Prefix length选择/56即可。
对于Debian12系统的虚拟机,自定义cloud-init网络配置文件,示例配置:
network:
version: 2
ethernets:
eth0:
addresses:
- "142.xx.157.29/32"
- "260x:5x00:00x0:8400::1/56"
match:
macaddress: 02:00:00:1c:0e:9a
routes:
- to: default
via: 158.xx.55.254
on-link: true
- to: default
via: 260x:5x00:00x0:84ff:ff:ff:ff:ff
nameservers:
addresses:
- 8.8.8.8
- 1.1.1.1
- 2001:4860:4860::8888
- 2606:4700:4700::1111
set-name: eth0
还有一种写法,可以为每台虚拟机配置一个/64而不是/56,如果你选择CIDR为/64则需要添加onlink标志,示例配置:
network:
version: 2
ethernets:
eth0:
addresses:
- "142.xx.157.29/32"
- "260x:5x00:00x0:8400::1/64"
match:
macaddress: 02:00:00:1c:0e:9a
routes:
- to: default
via: 158.xx.55.254
on-link: true
- to: default
via: 260x:5x00:00x0:84ff:ff:ff:ff:ff
on-link: true
nameservers:
addresses:
- 8.8.8.8
- 1.1.1.1
- 2001:4860:4860::8888
- 2606:4700:4700::1111
set-name: eth0
测试:
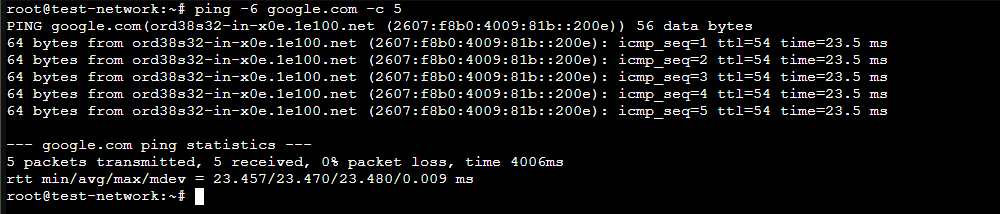
对于Debian13系统的虚拟机,直接在PVE管理界面配置IPv6,按你自己的喜好CIDR配置成/56、/64均可:
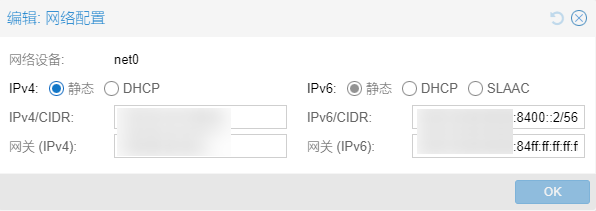
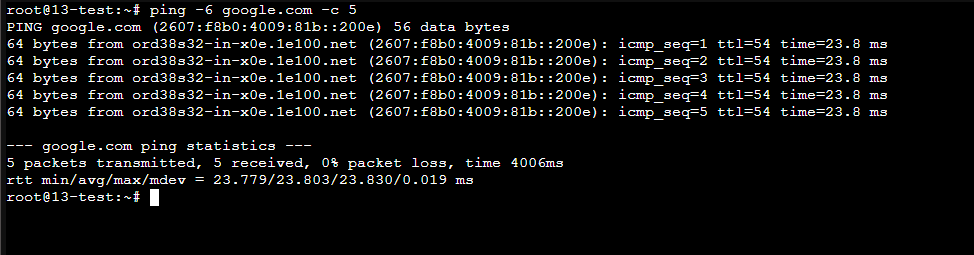
测试:
参考资料:
https://pve.proxmox.com/pve-docs/pve-admin-guide.html#_custom_cloud_init_configuration
https://forum.proxmox.com/threads/bug-no-routing-in-vm-with-cloud-init-ubuntu-18-x-19-4.56966/
https://forum.proxmox.com/threads/cloud-init-network-configuration-with-ubuntu-cicustom-option.115746/
https://pve.proxmox.com/wiki/Network_Configuration
https://help.ovhcloud.com/csm/en-dedicated-servers-network-bridging?id=kb_article_view&sysparm_article=KB0043731
2024-11-12 21:33:53
前段时间OVH出了个活动,上架了几款性价比非常高的独立服务器,我也买了两台,然后根据自己之前写的文章内的步骤来安装Proxmox VE发现有很多问题,我其实写过很多篇这类文章了(以Kimsufi为主),遂决定重新写一篇文章来记录下目前遇到的问题与解决办法。
第一个问题是以前Kimsufi的救援系统是Debian9,现在OVH的救援系统是Debian10,这导致qemu-system-x86_64有很多选项都变了,以前记录的命令不好使了。
第二个问题是我现在这台服务器有4块硬盘,KVM最多只能给Guest提供4个IDE驱动器,超过的话会报错:
machine type does not support if=ide,bus=2,unit=0
根据这篇文章内的说明,可以把IDE改成用Virtio就没有这个限制了。
我改成用Virtio后,把PVE的ISO都启动了,又突然发现PVE文档:ZFS_on_Linux里面有这样一句话:
If you are experimenting with an installation of Proxmox VE inside a VM (Nested Virtualization), don’t use virtio for disks of that VM, as they are not supported by ZFS. Use IDE or SCSI instead (also works with the virtio SCSI controller type).
我就是准备用ZFS的,所以现在我只能改用Virtio SCSI了。。。
第三个问题是关于系统引导方面的,根据PVE文档:Host_Bootloader说明,目前PVE有2种不同的引导加载程序,分别是GRUB、systemd-boot,大多数情况都是使用GRUB,但有一个例外:如果把ZFS作为根文件系统,并且主板BOOT设置使用UEFI,那么将使用systemd-boot。我手上这台服务器的主板BOOT设置就是使用的UEFI,我通过IPMI确认了:
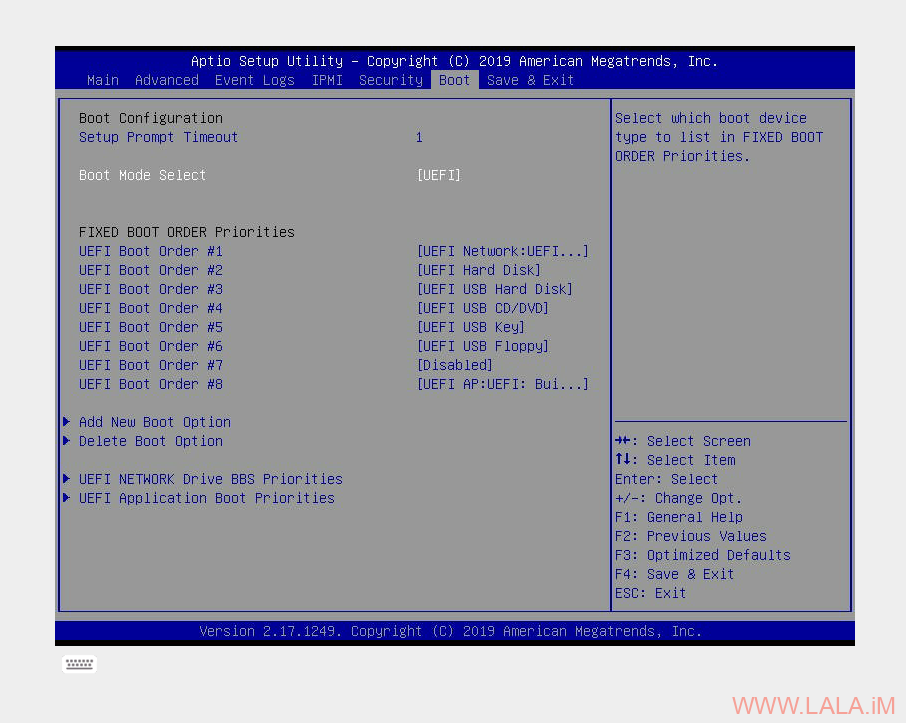
如果服务器没有IPMI,也可以在服务器系统内安装efibootmgr来确认,如果回显有记录说明是UEFI,没有就是BIOS(Legacy)。不过我猜测现在新开通的OVH服务器应该都是UEFI了。
当Proxmox VE使用systemd-boot作为引导加载程序的时候,如果我们要配置内核参数,配置的方法与GRUB引导加载程序是不同的。systemd-boot使用/etc/kernel/cmdline,且需要使用proxmox-boot-tool工具来更新配置。
还有一些细节问题这里就不详细说明了,下面我会把不同环境的可用安装方法都写出来。
首先登录OVH管理面板,启动OVH救援系统:

需要点一下重启才会引导到救援系统,救援系统的登录信息会发送到你指定的邮箱:

登录到救援系统安装qemu-kvm:
apt -y update apt -y install qemu qemu-kvm
如果主板BOOT设置使用UEFI,则还需要安装OVMF:
apt -y install ovmf
下载PVE的ISO:
wget https://enterprise.proxmox.com/iso/proxmox-ve_8.2-2.iso
使用lsblk命令查看当前硬盘、分区、RAID信息:

停止RAID:
mdadm --stop /dev/md2 mdadm --stop /dev/md3
清空分区表信息:
wipefs -a /dev/sda1 wipefs -a /dev/sda2 wipefs -a /dev/sda3 wipefs -a /dev/sda4 wipefs -a /dev/sda5 wipefs -a /dev/sda wipefs -a /dev/sdb1 wipefs -a /dev/sdb2 wipefs -a /dev/sdb3 wipefs -a /dev/sdb4 wipefs -a /dev/sdb wipefs -a /dev/sdc1 wipefs -a /dev/sdc2 wipefs -a /dev/sdc3 wipefs -a /dev/sdc4 wipefs -a /dev/sdc wipefs -a /dev/sdd1 wipefs -a /dev/sdd2 wipefs -a /dev/sdd3 wipefs -a /dev/sdd4 wipefs -a /dev/sdd
准备工作做好后,接下来根据自身情况来启动虚拟机。主要是以下3点:
1、服务器主板使用的引导方式:BIOS(Legacy)、UEFI。
2、如果服务器硬盘大于等于4块,则必须使用Virtio驱动,或者Virtio-SCSI驱动。
3、如果服务器使用ZFS文件系统,则必须使用Virtio-SCSI驱动。
下面是几个示例:
1、BIOS(Legacy)引导方式,不使用ZFS文件系统,使用如下命令启动虚拟机:
qemu-system-x86_64 \ -enable-kvm \ -nodefaults \ -cdrom /root/proxmox-ve_8.2-2.iso \ -drive file=/dev/sda,format=raw,media=disk,index=0,if=virtio \ -drive file=/dev/sdb,format=raw,media=disk,index=1,if=virtio \ -drive file=/dev/sdc,format=raw,media=disk,index=2,if=virtio \ -drive file=/dev/sdd,format=raw,media=disk,index=3,if=virtio \ -cpu host \ -smp 4 \ -m 8G \ -net nic \ -net user \ -vga std \ -vnc :1,password=on -monitor stdio \ -k en-us
2、BIOS(Legacy)引导方式,使用ZFS文件系统,使用如下命令启动虚拟机:
qemu-system-x86_64 \ -enable-kvm \ -nodefaults \ -cdrom /root/proxmox-ve_8.2-2.iso \ -device virtio-scsi-pci,id=scsi0 \ -device scsi-hd,drive=hd0 \ -drive file=/dev/sda,format=raw,media=disk,if=none,id=hd0 \ -device scsi-hd,drive=hd1 \ -drive file=/dev/sdb,format=raw,media=disk,if=none,id=hd1 \ -device scsi-hd,drive=hd2 \ -drive file=/dev/sdc,format=raw,media=disk,if=none,id=hd2 \ -device scsi-hd,drive=hd3 \ -drive file=/dev/sdd,format=raw,media=disk,if=none,id=hd3 \ -cpu host \ -smp 4 \ -m 8G \ -net nic \ -net user \ -vga std \ -vnc :1,password=on -monitor stdio \ -k en-us
3、UEFI引导方式,无论是否使用ZFS文件系统,均可以使用如下命令启动虚拟机:
qemu-system-x86_64 \ -bios OVMF.fd \ -enable-kvm \ -nodefaults \ -cdrom /root/proxmox-ve_8.2-2.iso \ -device virtio-scsi-pci,id=scsi0 \ -device scsi-hd,drive=hd0 \ -drive file=/dev/sda,format=raw,media=disk,if=none,id=hd0 \ -device scsi-hd,drive=hd1 \ -drive file=/dev/sdb,format=raw,media=disk,if=none,id=hd1 \ -device scsi-hd,drive=hd2 \ -drive file=/dev/sdc,format=raw,media=disk,if=none,id=hd2 \ -device scsi-hd,drive=hd3 \ -drive file=/dev/sdd,format=raw,media=disk,if=none,id=hd3 \ -cpu host \ -smp 4 \ -m 8G \ -net nic \ -net user \ -vga std \ -vnc :1,password=on -monitor stdio \ -k en-us
虚拟机启动之后,需执行如下命令修改VNC连接密码:
change vnc password
之后使用任意VNC客户端连接服务器公网IP:5901端口访问,如果正常将可以看到PVE的安装界面:

选择ZFS RAID级别这块,我本来是打算用RAIDZ-2的,但最后还是选择RAID10了:

对于4块盘而言,虽然可用容量都是减半,但是RAID10的性能要稍微好一点,要用RAIDZ-2的话,那估计就是单盘的性能了。当然RAIDZ-2的安全性比RAID10要高一些,但权衡下来我还是用了RAID10。如果你使用RAIDZ类型的话,这里有一个RAIDZ类型的可用容量计算方式可供参考:
N个磁盘的RAIDZ类型vdev的可用空间为N-P,其中P是RAIDZ级别。RAIDZ级别指在不丢失数据的情况下,有多少个任意磁盘可以出现故障。例如3块硬盘的RAIDZ也就是RAIDZ-1,最多允许1块硬盘故障。可用容量为2块盘的容量。
网络这块的配置,把你在OVH管理面板看到的IPv4、IPv4网关地址记下来:

照着填上去就行了,注意CIDR,OVH一般都是24,有关IPv6的配置这里暂且先放一边,PVE的这个界面也不支持配置IPv6,我会单独写一篇文章来介绍如何配置OVH的IPv6:

后面的操作就很简单了,没什么好说的了这里就省略掉了,等待安装完成后,系统会自动重启,还是在这个VNC里面登录到PVE主机,我们需要修改一些配置。
编辑网络配置文件:
nano /etc/network/interfaces
根据服务器的情况需要更改接口名,我这台服务器接口名是ens3,需要改成eth0:
auto lo
iface lo inet loopback
iface eth0 inet manual
auto vmbr0
iface vmbr0 inet static
address xx.xx.xx.210/24
gateway xx.xx.xx.254
bridge-ports eth0
bridge-stp off
bridge-fd 0
然后根据使用的引导加载程序来修改内核参数,我使用的是systemd-boot,需要修改如下配置文件:
nano /etc/kernel/cmdline
注意这个配置文件只能有1行,所有的参数都要在1行内,在原有的基础上增加net.ifnames=0:
root=ZFS=rpool/ROOT/pve-1 boot=zfs net.ifnames=0
更新配置:
proxmox-boot-tool refresh
如果你使用的是GRUB,则需要修改如下配置文件:
nano /etc/default/grub
在GRUB_CMDLINE_LINUX_DEFAULT原有的基础上增加net.ifnames=0:
GRUB_CMDLINE_LINUX_DEFAULT="quiet net.ifnames=0"
更新配置:
update-grub
将虚拟机关机:
systemctl poweroff
回到OVH管理面板,将系统改为从硬盘启动:
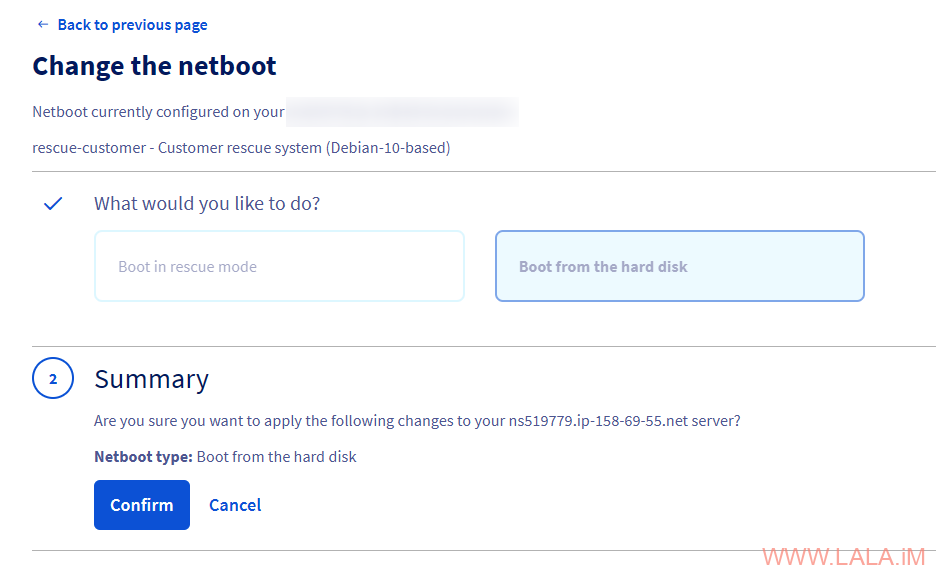
在OVH管理面板点一下重启,等待片刻。
如果一切正常的话,就可以使用https://publicip:8006访问到PVE的管理界面了。
参考资料:
https://wiki.gentoo.org/wiki/QEMU/Options#Hard_drive
https://wiki.netbsd.org/tutorials/how_to_setup_virtio_scsi_with_qemu/
https://blog.onodera.asia/2021/12/qemunetbsdamd64-current-virtio-scsi.html
2024-10-25 06:05:23
qbittorrent-nox-static项目是一个bash脚本,这个脚本可以编译出完全静态的qbittorent-nox二进制文件,这就意味着可以在任意的Linux操作系统上使用qbittorent-nox。
同时项目作者会定期发布编译好的qbittorent-nox二进制文件,不需要我们自己去用脚本编译,要使用的话,基本操作就相当于是下载给个执行权限运行就可以了。
我喜欢用这种方式安装qbittorrent-nox的原因是更新简单,有新版本了下载新的二进制文件替换掉旧的就行,并且可以自由选择libtorrent的版本,作者每次发布新的qbittorrent-nox都会提供依赖于libtorrent1.2或libtorrent2.0的两个版本。有人说1.2好,有人说2.0好,反正切换来去自由= =
创建一个普通用户来运行qbittorent-nox:
useradd -m -d /opt/qbtuser -s /usr/sbin/nologin qbtuser adduser qbtuser sudo
下载qbittorent-nox二进制文件、给执行权限:
curl -L https://github.com/userdocs/qbittorrent-nox-static/releases/latest/download/x86_64-qbittorrent-nox -o /usr/local/bin/qbittorrent-nox chmod +x /usr/local/bin/qbittorrent-nox
手动运行一次,按个回车同意软件使用条款,之后按Ctrl+C退出:
sudo -u qbtuser qbittorrent-nox --webui-port=10000
注意事项:
1、由于我的服务器8080端口被占用了,这里我把端口修改成10000了,请注意这个修改是永久生效的,qbittorent会把这个端口信息写到配置文件里面,所以下次启动的时候就不需要指定–webui-port了。
2、较新版本的qbittorrent将Web UI的管理员密码改为随机生成了,并且是直到你在Web UI手动设置好管理员密码后才停止随机生成,也就意味着如果你不在Web UI里面设置管理员密码,那么qbittorrent每次启动的时候都会使用随机生成的管理员密码,所以这次启动生成的随机密码在你按Ctrl+C停止运行后就失效了,不需要去特意记住,后续用systemd放到后台运行的时候会再生成。
新建systemd配置文件:
nano /usr/lib/systemd/system/[email protected]
写入如下配置:
[Unit] Description=qBittorrent-nox service for user %I Documentation=man:qbittorrent-nox(1) Wants=network-online.target After=local-fs.target network-online.target nss-lookup.target [Service] Type=simple PrivateTmp=false User=%i ExecStart=/usr/local/bin/qbittorrent-nox TimeoutStopSec=1800 [Install] WantedBy=multi-user.target
启动:
systemctl start qbittorrent-nox@qbtuser
设置开机自启:
systemctl enable qbittorrent-nox@qbtuser
查看随机生成的管理员密码:
journalctl -u qbittorrent-nox@qbtuser
[可选]用NGINX反向代理qbittorrent Web UI,安装需要的软件包:
apt -y update apt -y install nginx python3-certbot-nginx
新建NGINX站点配置文件:
nano /etc/nginx/sites-available/qbittorrent
写入如下内容:
server {
listen 80;
server_name qb.example.com;
client_max_body_size 0;
location / {
proxy_pass http://127.0.0.1:10000/;
proxy_http_version 1.1;
http2_push_preload on;
proxy_set_header Host $proxy_host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Host $http_host;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Real-IP $remote_addr;
}
}
启用站点:
ln -s /etc/nginx/sites-available/qbittorrent /etc/nginx/sites-enabled/qbittorrent
签发TLS证书:
certbot --nginx --email [email protected] --agree-tos --no-eff-email
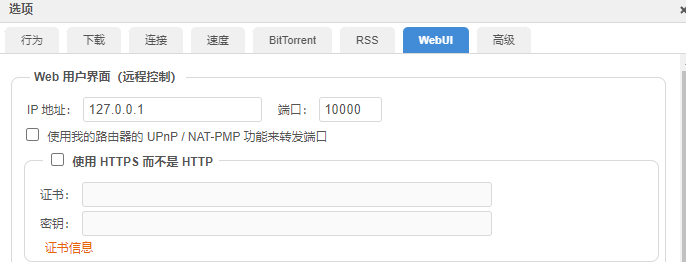
登录Web UI将监听地址修改为127.0.0.1:
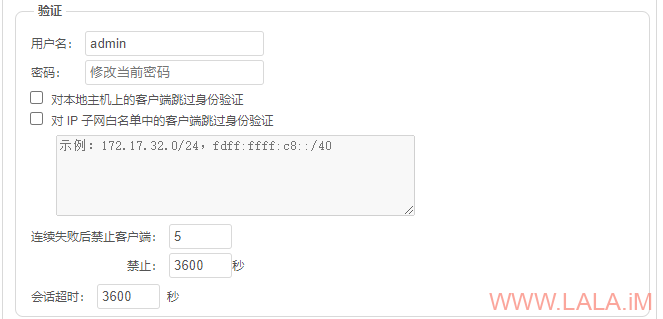
别忘了设置管理员密码:
重启生效:
systemctl restart qbittorrent-nox@qbtuser
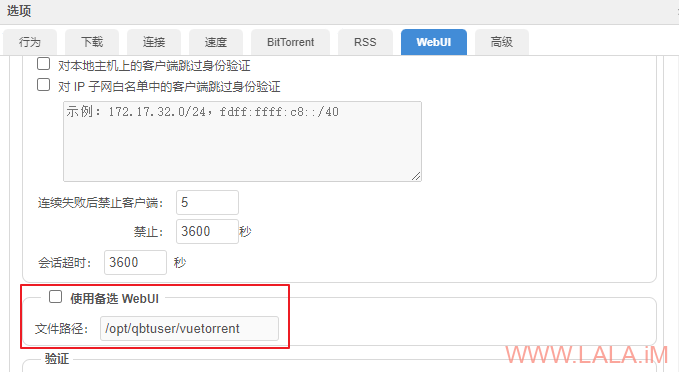
[可选]安装VueTorrent主题:
cd /opt/qbtuser sudo -u qbtuser curl -L https://github.com/VueTorrent/VueTorrent/releases/download/v2.15.0/vuetorrent.zip -o vuetorrent.zip sudo -u qbtuser unzip vuetorrent.zip
启用备选Web UI,路径填写:/opt/qbtuser/vuetorrent
qbittorrent-nox配置文件均在如下目录:
/opt/qbtuser/.config/qBittorrent
qbittorrent-nox默认下载目录:
/opt/qbtuser/Downloads