2024-11-17 18:50:44
事情要从上周的一次事故说起,我们用 docker 部署的程序有一点问题,要马上回滚到上一个版本。
这个 docker 是一个比较复杂的和 BPF 有关的程序,启动时候需要设置很多 mount 和 environments,docker run 的命令特别长。所以我用 Ansible 来配置好这些变量,然后启动 docker,一个实例要花费 3~5 分钟才能启动。
同事突然说,某实例他手动启动了,当时我就震惊了,怎么手速这么快?!
请教了一下,原来是用的 runlike 工具,项目地址是:https://github.com/lavie/runlike。
这个工具的原理是,docker inspect <container-name> | runlike --stdin ,就会生成这个容器的 docker run 命令。这个思路简直太棒了。就和 Chrome 的 copy as cURL 功能一样好用!
2024-11-10 17:08:35
我们写程序不需要写 ARP request 和 response 相关的逻辑,因为这部分是操作系统帮我们做的。
Linux 处理 ARP 请求的逻辑是:
如果操作系统收到了一个 ARP reuqest,并且本机中某一个接口配置了 ARP request 中请求的 IP,那就回复这个 ARP request,回复的 ARP response 中,使用收到此 ARP request 的 interface 的 MAC 地址作为答案。
这个逻辑看起来没有问题:从 Linux 的视角,既然我能从一个 interface 收到 ARP 请求,那么对方向这个 interface 发送数据包,我也可以从这个 interface 收到,所以,回复 interface 的 MAC 地址即可。
但是,在下面这种情况就会出问题:
满足这两个条件的话,当有 LAN 中有主机发送 ARP request 广播包,交换机会转发到自己的所有端口,Linux 会从这两个端口都收到此 ARP request 广播包。按照以上处理逻辑,Linux 会回复 2 个 ARP reply,因为收到了两个 request,两个 interface 各回复一次,并且这两个 ARP reply 分别是两个 interface 的 MAC 地址。
实验环境如下图所示:
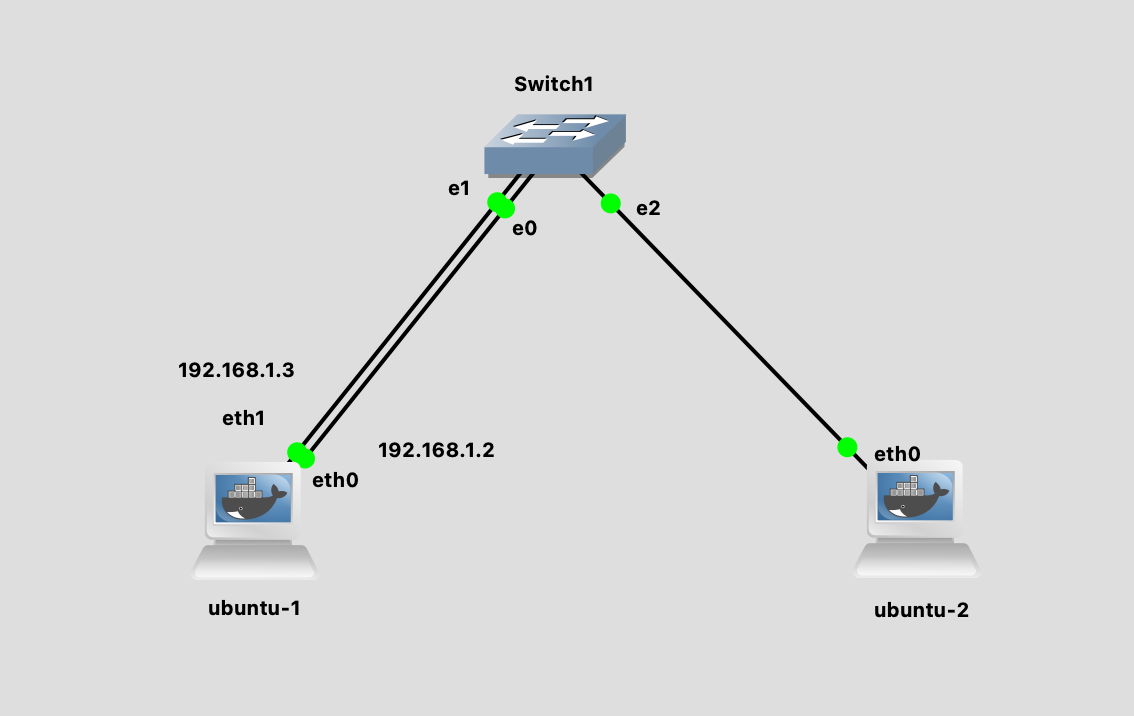
配置好 IP 之后,我们在 ubuntu-2 主机发送 ARP request。
root@ubuntu-2:/$ arping 192.168.1.2 -c 3
ARPING 192.168.1.2
42 bytes from aa:b6:66:3c:98:45 (192.168.1.2): index=0 time=1.017 msec
42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=1 time=1.032 msec
42 bytes from aa:b6:66:3c:98:45 (192.168.1.2): index=2 time=300.636 usec
42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=3 time=557.981 usec
42 bytes from aa:b6:66:3c:98:45 (192.168.1.2): index=4 time=308.836 usec
42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=5 time=546.011 usec
--- 192.168.1.2 statistics ---
3 packets transmitted, 6 packets received, 0% unanswered (3 extra)
rtt min/avg/max/std-dev = 0.301/0.627/1.032/0.299 ms一共发送了 3 个 request,却收到了 6 个 ARP reply。并且有两种 MAC 地址。
这个就是 ARP Flux 问题。
因为 ARP 是在 LAN 内的,如果两个 interface 分别配置在不同的 subnet,就不会有这个问题了。
但是有时候我们的软件守交换机网段的限制,只能配置在一个网段。并且有些场景需要两个线路和两个 IP,比如管理和数据面分开(带外管理),就又会遇到这个问题。
使用 ip link set dev eth0 arp off 可以禁用 interface 的 ARP 恢复,这样,在 LAN 上就相当于把这个 interface 隐藏了,因为没有人可以发现它的 MAC 地址了。在四层负载均衡中,如果使用 DSR 的模式并且不加隧道的话,就需要对 RS 的 VIP 禁用 ARP 回复1。
这里有一个有意思的现象:假设 192.168.1.2 配置在 eth0 上,但是我们把 eth0 的 ARP 禁用了。
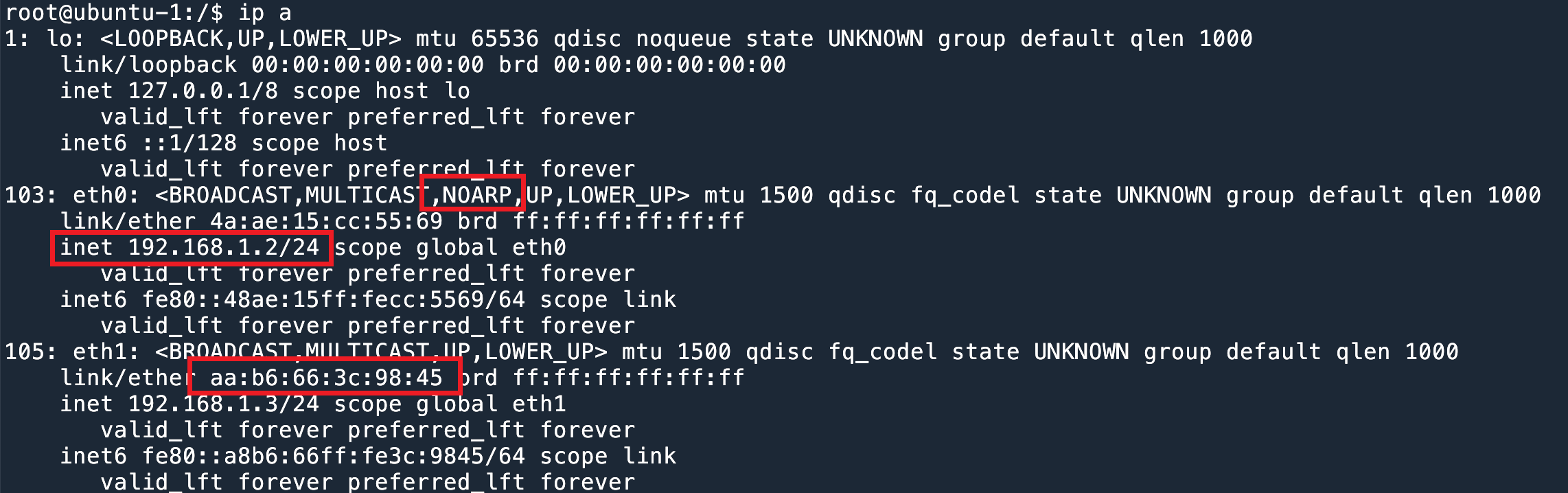
192.168.1.2 所在的 eth0 ARP禁用这时候如果请求 192.168.1.2 的地址,会拿到 eth1 的 MAC 地址。参考上文讨论过的 Linux ARP 工作原理。
root@ubuntu-2:/$ arping 192.168.1.2 -c 3
ARPING 192.168.1.2
42 bytes from aa:b6:66:3c:98:45 (192.168.1.2): index=0 time=313.417 usec
42 bytes from aa:b6:66:3c:98:45 (192.168.1.2): index=1 time=240.823 usec
42 bytes from aa:b6:66:3c:98:45 (192.168.1.2): index=2 time=294.223 usec
--- 192.168.1.2 statistics ---
3 packets transmitted, 3 packets received, 0% unanswered (0 extra)
rtt min/avg/max/std-dev = 0.241/0.283/0.313/0.031 ms这个方法只能通过 interface 级别来设置,如果一个 interface 上有多个 IP 地址,那么只能全部禁用或者开启。
如果要 by IP 来禁用 ARP,可以使用 arptables(8)23.
arp_ignore
直接禁用 ARP 差不多等于把这个 interface 关闭了,大部分情况下不是我们想要的结果。
我们希望的效果是对于 ARP request 只回复一次,并且只有 IP 在自己的 interface 上才回复,不要代替其他 interface 回复。
通过 arp_ignore4 可以改变 Linux 的 ARP 行为:
0 – 默认,只要本地有的 IP 就会回复,无论是哪一个 interface;1 – 只有当 ARP request 询问的 IP 配置在收到 ARP 的接口上时,才会回复;1,并且 sender 的 IP 在本地 IP 的相同 subnet 内,才会回复;3 – scope host 不会回复,只有 scope link 和 scope global 才会回复 (可以通过 ip address 命令查看配置的 IP scope);4–7 – 保留字段;8 – 所有 local address 都不回复;配置方法:通过 sysctl -w 可以修改配置。arp_ignore 是 per interface 的配置。
root@ubuntu-1:/$ sysctl -a | grep arp_ignore
net.ipv4.conf.all.arp_ignore = 0
net.ipv4.conf.default.arp_ignore = 0
net.ipv4.conf.eth0.arp_ignore = 0
net.ipv4.conf.eth1.arp_ignore = 0
net.ipv4.conf.eth2.arp_ignore = 0
net.ipv4.conf.eth3.arp_ignore = 0
net.ipv4.conf.lo.arp_ignore = 0其中 all 是一个全局变量,最终在 interface 上生效的值是 max(all, eth0)。以最大的为准。
default 是模板变量,在新建一个 interface 的时候,会自动使用这个值。
我们可以给所有的 interface 都设置为 1.
root@ubuntu-1:/$ sysctl -w net.ipv4.conf.all.arp_ignore=1
net.ipv4.conf.all.arp_ignore = 1然后再发送 arp 请求,就会发现回复之后一个了,并且是正确的那个。
root@ubuntu-2:/$ arping 192.168.1.2 -c 3
ARPING 192.168.1.2
42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=0 time=602.926 usec
42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=1 time=312.438 usec
42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=2 time=236.994 usec
--- 192.168.1.2 statistics ---
3 packets transmitted, 3 packets received, 0% unanswered (0 extra)
rtt min/avg/max/std-dev = 0.237/0.384/0.603/0.158 msarp_filter
另一个方法是使用 arp_filter 参数,这个参数是一个 bool,默认是 0 ,如果开启为 1,就意味着,如果收到 ARP request,ARP 请求的 IP 为 A,收到 ARP 的 interface 为 X 和 Y,那么 kernel 就测试路由,假设要发出去 source IP 为 A 的包,从 X 发出去还是从 Y 发出去。如果从 X 发出去,那么只有 X 会回复。(source based rotuing).
举例来说,我们现在有两个接口和两个 IP,回复 192.168.1.10 的 ARP 时,可以测试当前的路由情况:
root@ubuntu-1:/$ ip route get 192.168.1.10 from 192.168.1.2
192.168.1.10 from 192.168.1.2 dev eth0 uid 0
cache
root@ubuntu-1:/$ ip route get 192.168.1.10 from 192.168.1.3
192.168.1.10 from 192.168.1.3 dev eth0 uid 0
cache可以看到无论 source IP 是哪一个,都会从 eth0 口出。
这是因为我们的 ip route 配置:
root@ubuntu-1:/$ ip route show table all
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.2
192.168.1.0/24 dev eth1 proto kernel scope link src 192.168.1.3会永远走第一条路由。
所以我们如果发送 ARP request,对 .2 和 .3 两个地址,得到的结果会是一样的,因为都是 eth0 在回复。
root@ubuntu-2:/$ arping 192.168.1.2 -c 3
ARPING 192.168.1.2
42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=0 time=165.606 usec
42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=1 time=161.927 usec
42 bytes from 4a:ae:15:cc:55:69 (192.168.1.2): index=2 time=179.383 usec
--- 192.168.1.2 statistics ---
3 packets transmitted, 3 packets received, 0% unanswered (0 extra)
rtt min/avg/max/std-dev = 0.162/0.169/0.179/0.008 ms
root@ubuntu-2:/$ arping 192.168.1.3 -c 3
ARPING 192.168.1.3
42 bytes from 4a:ae:15:cc:55:69 (192.168.1.3): index=0 time=230.590 usec
42 bytes from 4a:ae:15:cc:55:69 (192.168.1.3): index=1 time=182.955 usec
42 bytes from 4a:ae:15:cc:55:69 (192.168.1.3): index=2 time=149.800 usec
--- 192.168.1.3 statistics ---
3 packets transmitted, 3 packets received, 0% unanswered (0 extra)
rtt min/avg/max/std-dev = 0.150/0.188/0.231/0.033 ms如果我们把第一条路由删了,那么现在就都走 eth1 了,这时候 ARP 结果就都是 eth1 了。
root@ubuntu-1:/$ ip route del 192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.2
root@ubuntu-1:/$ ip route get 192.168.1.10 from 192.168.1.3
192.168.1.10 from 192.168.1.3 dev eth1 uid 0
cache
root@ubuntu-1:/$ ip route get 192.168.1.10 from 192.168.1.2
192.168.1.10 from 192.168.1.2 dev eth1 uid 0
cache答案是是的(虽然听起来很没道理)。这个主要是跟路由有关。
当我们在给 lo 绑定一个地址的时候,kernel 会默认添加 2 条路由,lo 所在网段和 lo 的地址会被标记成 dev lo 的本地路由。
root@ubuntu-1:/$ ip route show table local
local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
broadcast 127.255.255.255 dev lo proto kernel scope link src 127.0.0.1
local 192.168.1.0/24 dev lo proto kernel scope host src 192.168.1.2
local 192.168.1.2 dev lo proto kernel scope host src 192.168.1.2
broadcast 192.168.1.255 dev lo proto kernel scope link src 192.168.1.2其实,当我们给 lo 地址添加 192.168.1.2/24 的时候,由于自动添加的 192.168.1.0/24 的 route (第5行),导致我们其他的接口也不会回复这个网段的 ARP 请求了。这个时候从 ubuntu-2 上 arping 192.168.1.10 和 192.168.1.11 都会 timeout。
这个是默认的行为。但是如果我们改一下,删除这两条路由,添加另一条从 eth0 口出的路由的话,就会发现,arping lo 接口的 IP,也会收到 ARP response 了。
root@ubuntu-1:/$ ip route del local 192.168.1.0/24 dev lo proto kernel scope host src 192.168.1.2
root@ubuntu-1:/$ route del local 192.168.1.2 dev lo table local proto kernel scope host src 192.168.1.2
root@ubuntu-1:/$ ip route add local 192.168.1.2 dev eth0 proto kernel scope host src 192.168.1.2root@ubuntu-1:/$ ip address show dev lo
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet 192.168.1.2/24 scope global lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever在 ubuntu-2 可以 ping 通。
root@ubuntu-2:/$ arping 192.168.1.2 -c 3
ARPING 192.168.1.2
42 bytes from 56:6b:38:20:7e:56 (192.168.1.2): index=0 time=274.702 usec
42 bytes from 56:6b:38:20:7e:56 (192.168.1.2): index=1 time=299.748 usec
42 bytes from 56:6b:38:20:7e:56 (192.168.1.2): index=2 time=296.380 usec
--- 192.168.1.2 statistics ---
3 packets transmitted, 3 packets received, 0% unanswered (0 extra)
rtt min/avg/max/std-dev = 0.275/0.290/0.300/0.011 ms所以说 lo 接口是否回复 ARP request,主要和 ip route 的设置有关。
2024-11-05 13:42:41
在 Ethernet 环境中,所有的数据最终都要以二层 Ethernet Frame 的形式发送,要添加 Src MAC, Dst MAC, 以及其他的 header,比如 CRC 等,Ethernet 就会把数据送达到目的地。
我们在编程的时候经常指定 IP 和 Port,但是几乎从没有指定过 MAC 地址,那么 Frame 是怎么发出去的呢?这是操作系统帮我做了这件事。如果系统不知道一个 IP 对应的 MAC 地址是什么,系统会发送一个广播的 ARP 请求,(由于这个请求也是要通过 Ethernet 发送出去的,所以也要填充 Dst MAC,Dst MAC 就是 ff:ff:ff:ff:ff:ff。)询问谁有目的 IP,如果有,请回复给 MAC-B。广播域中所有的 Host 都会收到这个请求,只有拥有这个 IP 的 Host 才会回复给 MAC-B 自己的 MAC 地址,这样,B 就知道了这个 IP 对应的 MAC 地址。
这就是普通的 ARP request 和 response 的过程。
其中,里面的几个值得注意的 field 如下:
对于 ARP request 来说:
1 (1表示 request, 2 表示 response);对于 ARP Response 来说:
2;ARP 是一个很简单的协议,但是人们基于交换机和主机的工作原理,设计了其他的用法。这些用法其实并不复杂,最重要的就是理解这些设备最基本的工作原理,这样就可以理解这些特殊的 ARP 设计意图了。
在之前的博客中介绍过两次使用 Gratuitous ARP 的例子。Gratuitous ARP 的目的是更新其他设备的 ARP cache,或者交换机 mac-address table。
在 VRRP1 中,目的主要是切换网关,更新的对象是 mac-address table。交换机的 mac-address table 主要是通过收到的包的 Src MAC 来学习 MAC 对应的物理 port 的,所以最重要的是 Src MAC,其他的都不重要。
所以在 VRRP 中的 Gratuitous ARP 是这样的:
1 (request);在 Linux 的 balance-alb bonding 模式2中,ARP 的目的是为了刷新其他主机的 ARP Cache,并且希望不同的主机拿到不一样的 MAC 地址,所以使用的 ARP 是 response,并且是 unicast。
取决于使用场景,Gratuitous ARP 也是 broadcast 的 reply,将 response 信息广播给所有的主机3。
ARP Probe 的作用是,在分配到一个 IP 之后,但是在 IP 使用之前,可以先用 ARP 协议来检查一下当前的 LAN 内有没有人在使用这个 IP。
检查的方式就是用 ARP 询问这个 IP 的 MAC 地址,如果有主机正在使用,那么就会收到 ARP reply。
但是这里有一个问题。一个主机如果收到了 ARP request,询问谁有 IP X?请发送回复给 IP 地址 Y at MAC 地址 Z。即使这个主机没有 IP X,也不会单纯丢弃这个 ARP request,而是会从这个 ARP request 中学习到,IP Y 对应 MAC Z,会将它放到自己的 ARP cache 中。
这里我们只是想检查一个 IP 是否正在被使用,我们还没有真正地开始使用这个 IP。如果用普通的 ARP 请求来询问,假设这个 IP 已经被使用,那么发出去的 ARP request 就会传达错误的信息,其他主机就会根据这个 ARP request 来更新自己的 ARP cache。
为了解决这个问题,ARP Probe 使用的 request 将 Src IP 设置为 0.0.0.0,这样,这个 ARP request 就完全无害了。
ARP 请求如下(加粗部分是和普通的 ARP request 不一样的部分)。
1 (request);0.0.0.0;ARP Announce 用于在 ARP Probe 确定没有问题之后,决定使用这个 IP,但是再一次确定唯一性。
ARP Announce 发送一个普通的 ARP request, 在 LAN 内询问自己将要使用的 IP,正常情况下不会收到任何回复,因为这个 IP 是自己的。异常情况下收到回复,那么说明 LAN 已经有人在使用这个 IP 了,需要终止继续使用这个 IP。
ARP Announce 是普通的 ARP 请求,和 Gratuitous ARP 很像。询问的目标 IP 是自己的 IP。
ARP Announce 又叫做 Unsolictied ARP。
ARP Announce 和 ARP Probe 的唯一区别就是 Src IP 不同,ARP Announce 使用自己的 IP 来发送,所以也会更新 LAN 内其他设备的 ARP cache。
1 (request);参考资料:
2024-10-11 00:44:05
裕廊坊新开了一家杂菜饭,欣很喜欢。
杂菜饭,我又叫它「这个,那个」。因为大部分食客点菜的时候都只会说「这个」,「那个」。有一些杂菜饭店干脆取名字就叫做这个那个,英文名字叫 This and That.
杂菜饭多开在食阁里面,价格实惠,菜品很多。一餐大概在人民币 30 元到 45 元。
杂菜饭的价格一直是一个迷。食客用「这个」、「那个」来交流,点完菜之后,老板会脱口而出一个数字,然后我们按照这个数字付钱。老板说多少,就付多少,反正也便宜。(其中,鱼类一般是杂菜饭刺客,点上3条油炸小黄鱼或者一片水煮鱼之类的,一餐可能要到 50元。)
欣执迷想知道每一个菜品的价格,这就比较难了。
虽然店里面挂着菜单和价格,但是看这些名字和菜也对不上。
欣试图靠记忆对比这一顿和上一顿菜的差别试图解出每一个变量的值,却发现这次得到一个值,下次和我点的一比较又矛盾了。
我说,「别忙活了,我们公司旁边有一家,我和我的同事们吃了 3 年了,还没摸透每一个菜多少钱呢!」
依我看,杂菜饭老板会依照当天天气和自己心情来定价,加入一定的随机变量,避免定价秘密泄漏出去。
2024-09-13 10:04:47
一个数据中心有一万台机器,如何将这些机器连接起来?
最直观的方式是在每一个 Rack (机柜)上放一个交换机 (TOR, Top-of-Rack),然后再用更大的交换机作为核心,把所有的 TOR 连接起来,组成一个集群。Google 在 2004 年使用的就是这种方式。
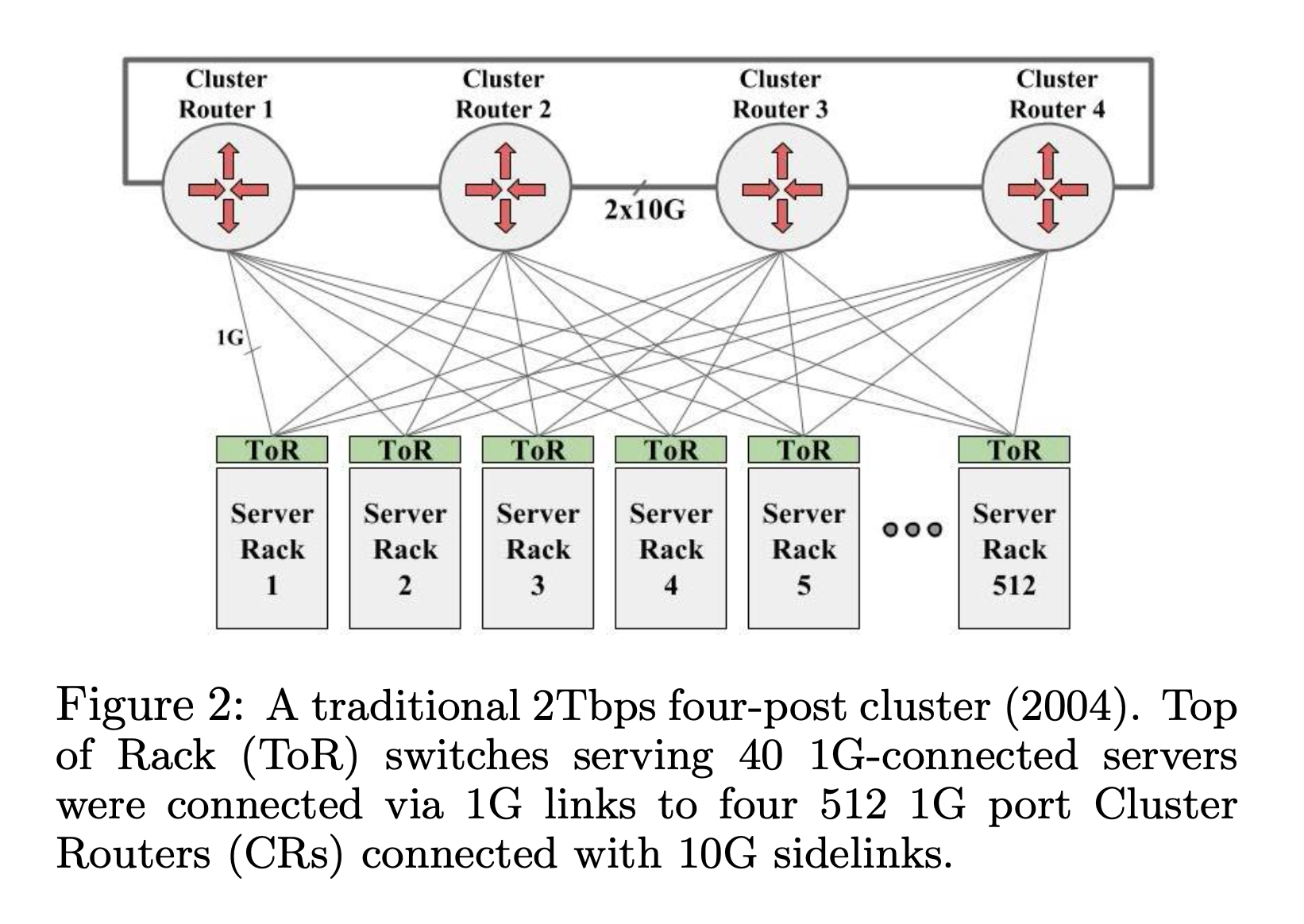
高端的集群交换机 (CR) 有 512 ports,那么每一个 CR 可以连接 512 个 TOR,4 个 CR 可以提供 512 * 4 ports, 每一个 TOR 使用两条线连接 CR,那么一共可以支持 512 * 4 / 2 = 1024 个 TOR。每一个 TOR 支持同 Rack 的 40 个 1RU 机器,一个最大支持 4万台机器 (1024 * 40 = 40960) 的集群就组成了。
虽然支持的机器数量足够了,但是这个集群存在很多问题。
问题1: 严重的 oversubscribe,TOR 下的机器之间有 1G 带宽,但是 TOR 上行只有 2G,跨越 CR 的带宽就更小了。
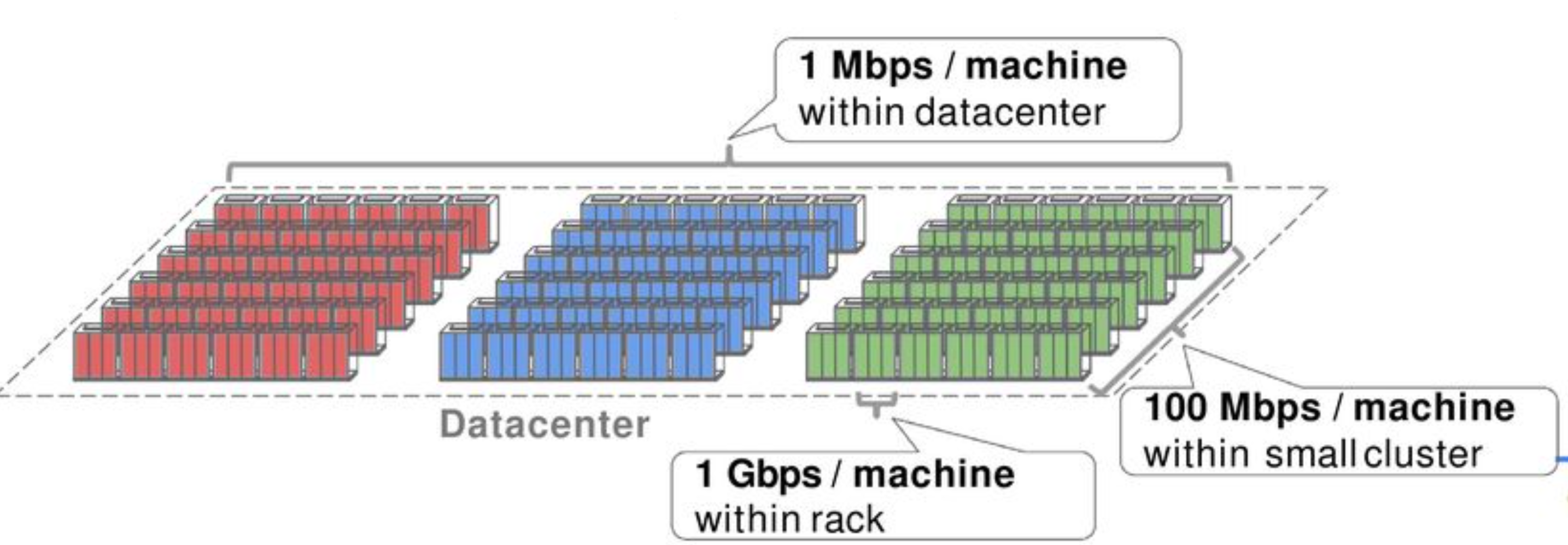
这对应用的扩容影响很大,如果应用之间有带宽需求,就必须使用复杂的调度算法,来让带宽需求高的应用尽可能部署在一起。Google 的业务中,搜索,广告需要大量的索引生成和存储,对东西向(服务器和服务器之间)的带宽要求越来越高,集群之间的带宽成为严重的瓶颈。
假设所有的机器点到点直接的带宽都是 1G,那应用就可以自由地扩容,调度算法就可以很简单,不必考虑 Locality,伸缩能力也更强。
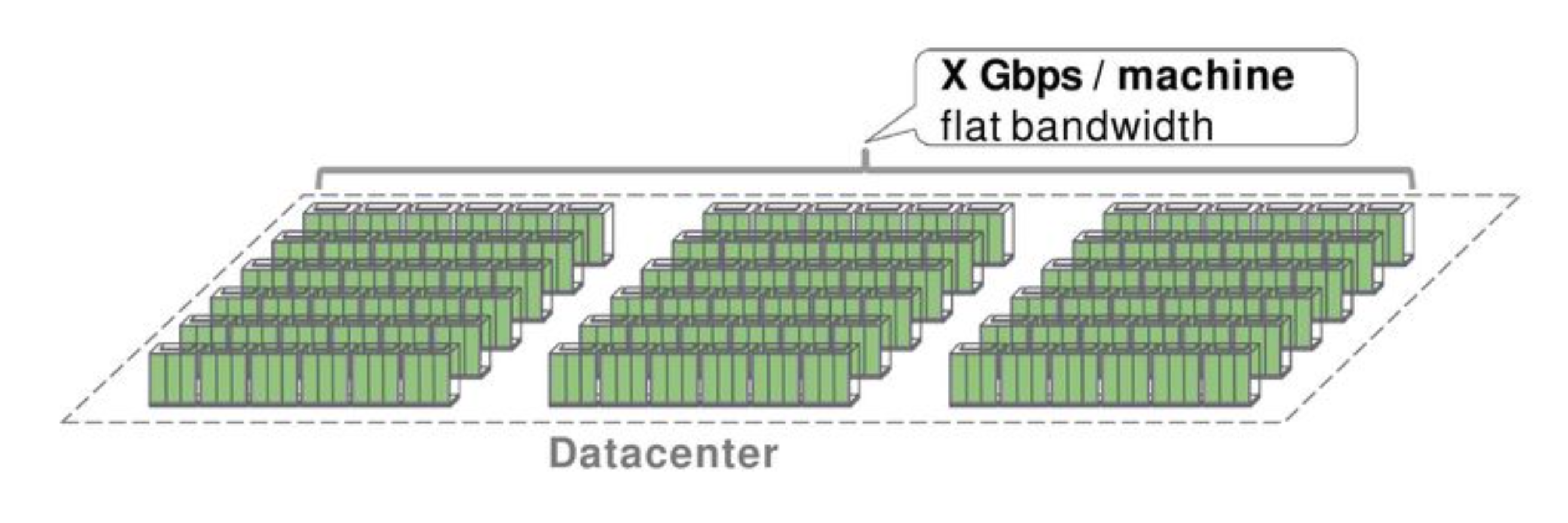
问题2: 部署机构最好能够横夸更大的故障域。数据中心的电力是按照楼层部署的,如果电源失败,那么整层机器都会下线。所以,软件最好部署在集群的多个故障域来提高可用性。但是,这又和上面说的,要尽量把软件部署在一起来利用同集群内更高的带宽违背。这也证明了扁平化大网络的必要性。
问题3: 受集群交换机 CR 的限制。这个结构能够支持多大的规模,完全取决于集群交换机的带宽,端口数。集群交换机能做到多高端,就看思科、华为这种设备制造商的能耐了。
这些高端交换机通常成本高昂,因为这些设备的技术通常是从 ISP 下放的。高端交换机的需求大部分都在 ISP 那边,像 Google 这种数据中心规模的客户很少。以 ISP 为核心客户的交换机还有以下问题:1)交换机都是单个独立配置的,但在数据中心中都是静态的拓扑结构,大量交换机使用独立配置的方法很复杂;2)花高成本实现的 HA 对于数据中心来说不划算。WAN 线路非常昂贵,挂掉一个交换机的损失很大,所以在 ISP 这边花大成本实现 HA 是值得的。但是在数据中心,线路都是多路部署的,很便宜,交换机挂了影响也不大。这些高成本实现的高可用交换机就不划算了;3)ISP 交换机需要支持很多 feature 来满足路由 policy 的需要,也要支持很多路由协议,来满足不同的区域间路由。但是在数据中心,拓扑结构是有一个实体控制和设计的,而且是静态的,一种路由协议就足够了,所以 ISP 级的高端交换机上大部分的 feature,在数据中心是没有用武之地的。
除去这些缺点,还有一个最大的问题,就是 Google 需要的交换机在市场上买不到,无论花多少钱,都没有交换机产品能够支持 Google 的规模。
Google 把数据中心作为一个巨型计算机来使用1,把很多磁盘磁盘当作是一个大型的文件系统来用2,那么为什么不把很多个 Switch 当作一个 Switch 来用呢?
本文算是对 Google 在 2015 年发布的论文 Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network3 的精读,介绍了 Google 的数据中心网络 10 年间使用过的 5 代架构。
Google 的数据中心网络设计有三个核心的原则,这三个原则也是和其他的数据中心很不一样的地方。
Clos 是现在数据中心网络的主流设计,简单来说,它可以将多个芯片组合成一个交换机,交换机组合成更大的交换机,一组交换机相互连接,组合成一张网(fabric),从而支持数据中心级别的网络需求。
它能提供:
具体的 Clos 是什么,以及实现,可以见下文讨论的第一代架构。
上文提到,小批量,大功能集,高可用的高端交换机不适用于数据中心。所以 Google 采用普通的、General purpose 的,技术已经比较成熟,大规模生产的商用芯片。
这样的好处是性价比高,可以用廉价的硬件打造适合数据中心的设备。新的芯片面世,可以直接升级设备,用上最新的芯片来支持最高的带宽(从下面 5 代架构的发展也可以看出来,几乎是新技术一出现,Google 就开始切换了)。能够快速平滑升级设备,Clos 架构也功不可没。
因为 Clos 架构的部署和运行需要大量的设备。如果像传统网络一样,对每一台设备登录,单独配置,就会有大量的维护工作,而且容易出错。
Google 的网络使用自己设计的控制面,所有的交换机设备都存储了整个网络的拓扑图,交换机上报自己和邻居之间的线路状态,给中心控制面,控制面下发这个链路的状态给所有的交换机。然后这些交换机基于自己存储的拓扑图和链路状态计算路由。
这个和传统的网络不同:传统的网络中,链路状态检测,拓扑图的发现(如果是 link-state routing 的话),以及 routing 的计算,都是在本地完成的。
和某一些 SDN 也不同,比如 Open vSwitch4 的 OpenFlow5,拓扑图和路由计算都是放在中心点的。
Google 的网络有点像介于两者之间。
接下来就逐一介绍 Google 设计和使用过的五代网络架构。我们从第一代开始讨论,第一代的篇幅会稍微多一些,后续的就简单了,相同的原理就不需要再次介绍了。
Firehose 1.0 是 Google 的首个自研网络。设计目标是:
那么原材料有什么呢——一个 8 个接口的卡(所谓的商用芯片)。但是使用 Clos 架构,我们可以将上万台服务器用 8 接口的卡连接起来。
ToR Switch 使用的应该不是同样的 8x10G 卡,而是 2x10G up, 24x1Gdown. 每一个 ToR 向下连接同 Rack 的 20 台机器,向上使用两条线连接 Aggregation Block,每一条的带宽是 10G,这样,总下行和总上行是对等的,都是 20G,每一台机器都是 1Gbps 带宽。
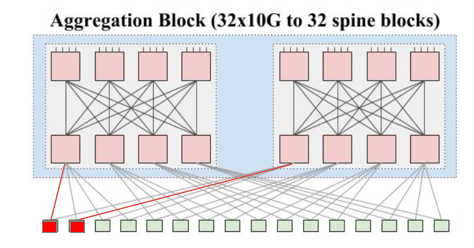
再看 Aggregation Block。8个接口肯定是不够用的。但是我们可以使用 Clos 架构,用 8接口的卡组装起来一台接口更多的交换机。方法是:取4张卡在上,4张卡在下。上4张卡每一张里面使用4个接口,分别连接下四张卡。这样,一共8张卡,每张卡有4个接口内部连接使用,4个接口作为对外连接,相当于8张卡做了一个 4 * 8 * 10G,共 32 接口,每个接口带宽 10G 的「交换机」。这样的组合,在一个 Aggregation Block 里面可以放两组。如下图所示。
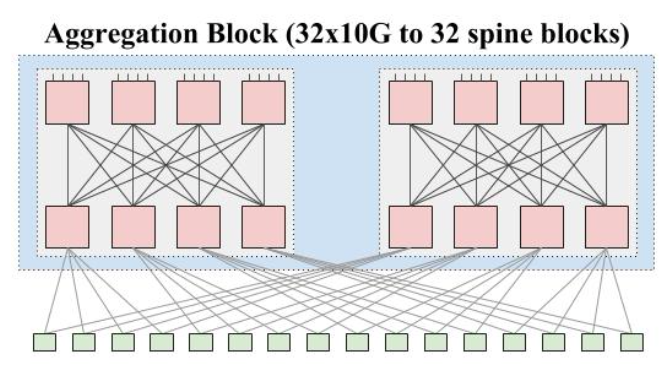
图中每一个粉红色的方块都表示一个 8x10G 网卡,如此连接,总共可以有 8网卡 x 4 x 10G = 32x10G up,同理 32x10G down。总体上,可以看作是一个 64x10G 的交换机了。在本文中,我们将它称作是一个 Aggregation Block。
其中,ToR 有 2x10G up,使用两条 10G 的 link 连接到 同一个 Aggregation Block 的两个模块中。每一个 Aggregation Block 有 32x10G 向下接口,每一个 ToR 用 2 条 link 连接到 Aggregation Block,向下总共可以连接 16 个 ToR。
一个 Aggregation Block 总共可以支持 16 ToR x 20 Server = 320 Servers, 并且所有服务器之间都是 1G 带宽的。
但是 320 台服务器肯定是不够的,我们需要添加多个 Aggregation Block。
我们可以继续使用 Clos 架构交换机的思想来设计一个交换机集群。现在,我们把一个 Aggregation Block 看作是一个整体,假设有 32 个 Aggregation Block,我们可以使用一个 32 口的交换机把这些 Aggregation Block 都连接起来。
怎么制作一个 32 接口的交换机呢?还是使用刚刚的方法。
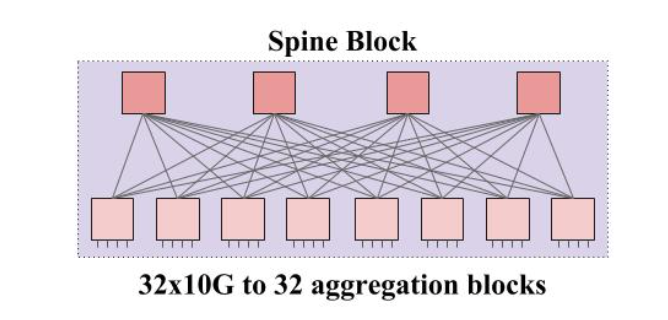
只不过这个交换机没有 Up link 了,都是 Down link。按照这个方法连接,一共可以提供 8×4 个 1G 接口。这样,一个 Spine Block 就可以把所有的 Aggregation Block 连接起来。缺点是跨 Aggregation Block 的带宽只有 1G。但是 Aggregation Block 向上有 32 个接口,所以我们总共可以使用 32 个 Spine Block,每一个 Spine Block 都连接所有的 Aggregation Block。
这样,32 个 Spine Block 提供的带宽就是 32x32x1G, 所有 Aggregation Block 向上的带宽也是 32x32x1G,所有的服务器,无论是同 Aggregation Block 还是跨 Block 都有 1G 带宽了。最多支持 32 个 Aggregation Block,一个集群最多就可以提供 320×32=10240 Servers.
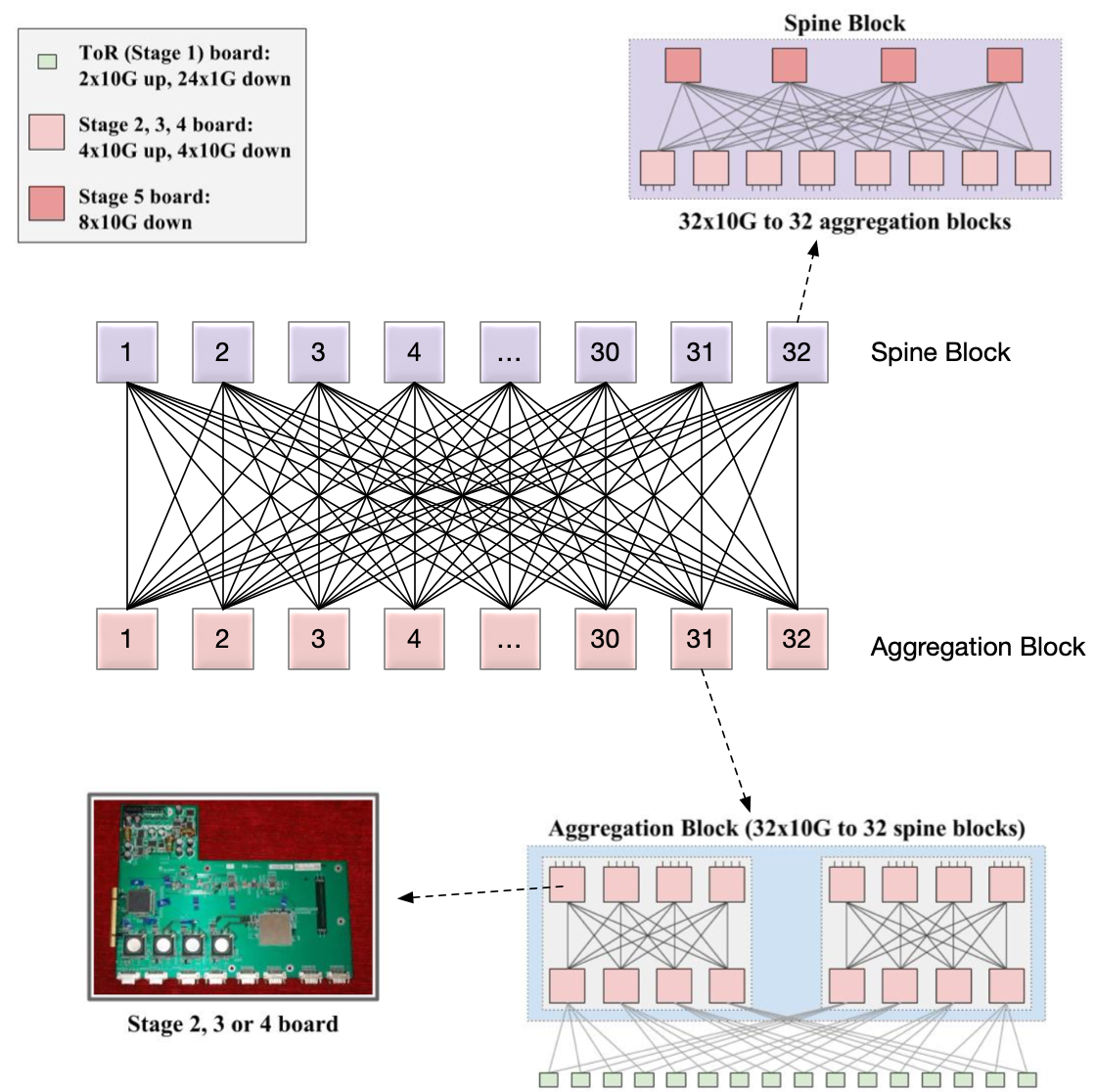
把 32 个 Spine Block 加 32 个 Aggregation Block 看作是一个整体,就相当于是一个有 512 个接口的交换机。这个连接方式就是 Clos 架构,要注意的是,每一个 Spine 都连接了所有的 Aggregation Block,但是 Spine 之间是没有连接的。
这种架构的好处是:
这个架构存在一个问题,就是 ToR 到 Aggregation Block 的线路不够多样。本质上,每一个 ToR 只用两条线连接到逻辑上的两组 Fabric(Fabric 就是指的交换网,在这里,指的是 Aggregation Block 中两个 Fabric 中的一个)。
如果两个红色的 ToR 分别有一个 Link down,那么这两个 ToR 下的服务器彼此之间就无法连通了。但是这两个 ToR 下的机器都可以和其他的机器连通。
此时,作为第一代架构,Google 还没有制造自己的交换机的经验。但是 Google 有丰富的服务器制作和维护经验。
当你手里握着一把锤子,看什么都像钉子。
所以 Google 尝试用服务器来制作交换机:把 8 接口的卡通过 PCI6 接口插到服务器上。这样有很多其他问题,服务器不像交换机一样,可以长时间稳定运行。服务器需要升级和维护的次数更加频繁,并且启动时间更长。作为 ToR 的服务器问题更大,因为 ToR 一旦下线维护,意味着这个 ToR 下的服务器都下线了。
从本文后面对 Google 自研网络协议、控制面等的投入也可以看出,除了网络架构,相关的配置套也非常重要。所以 Firehose 1.0 作为起步阶段,遇到很多问题,比如 Clos 架构类似 Full mesh,需要大量的接线工作,电力稳定性问题,高可用问题,等等。Firehose 1.0 并没有实际投入到生产中,不过作为一个实验性的尝试,已经给 Google 带来了很多宝贵经验。
第二代架构叫做 Firehose 1.1,从名字也可以看出,它是 Firehose 1.0 的升级版,解决了很多问题,真正地投入生产了。
FH1.1 不再使用服务器做交换机的思路,而是直接定制了机箱专门用于路由器,机箱可以支持最多 6 个线卡,使用专门的单板机 (Single-Board Com- puter, SBC) 来通过 PCI 控制线卡。
一个 Aggregation Block 还是由 16 个线卡组成,所以至少需要 3 个机箱,分别放 6、6、4 个线卡。正好可以放在一个 Rack 中。如下图所示。
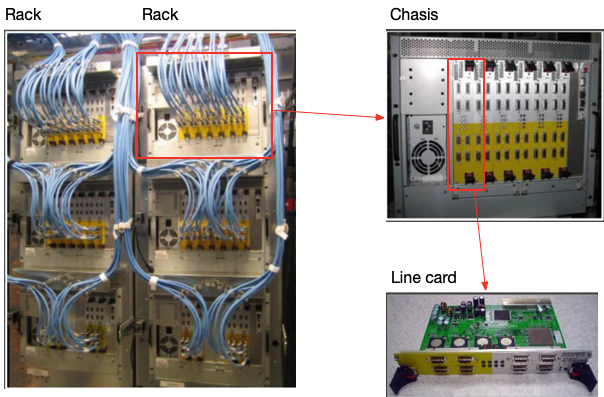
机箱内部没有连接卡的背板,所有的卡还是通过机箱外的线路相互连接的。线卡也采用了和 1.0 不同的硬件。SBC 通过带外管理 (out-of-band) 来和 CPN 网络 (Control Plane Network) 连接, CPN 网络在下文还会详细讨论。
Spine Block 的拓扑结构和 1.0 大致一样。
ToR 的设计和之前不同。现在 ToR 使用的卡是 4x10G+24x1G,其中:
这样,一个 ToR 就可以有 4x10G up, 48x1G down. 在 1.1 的结构中,ToR 是两两一组搭配在一起的,意味着 4x10G up 中,有 2x10G 是连接 Aggregation Block,2x10G 连接的是邻居 ToR。综上,每两个 ToR 可以向下连接 80 台服务器,4x10G 连接到 Aggregation Block。up:down 会有 1:2 的 oversubscrib。到这里可能比较复杂了,读者可以和 Aggregation Block 一起参考下图理解。
Aggregation Block 与 1.0 有些许不同。还是 16 个卡组成一个 Aggregation Block,但是不再像 1.0 一样,8个卡组成一个全连接,每个 Aggregation Block 是两组 Fabric。而是 16 个卡直接组成一个 Fabric。接线就有些复杂了,我这里画了一个彩色的图。可以看的稍加清晰一些。
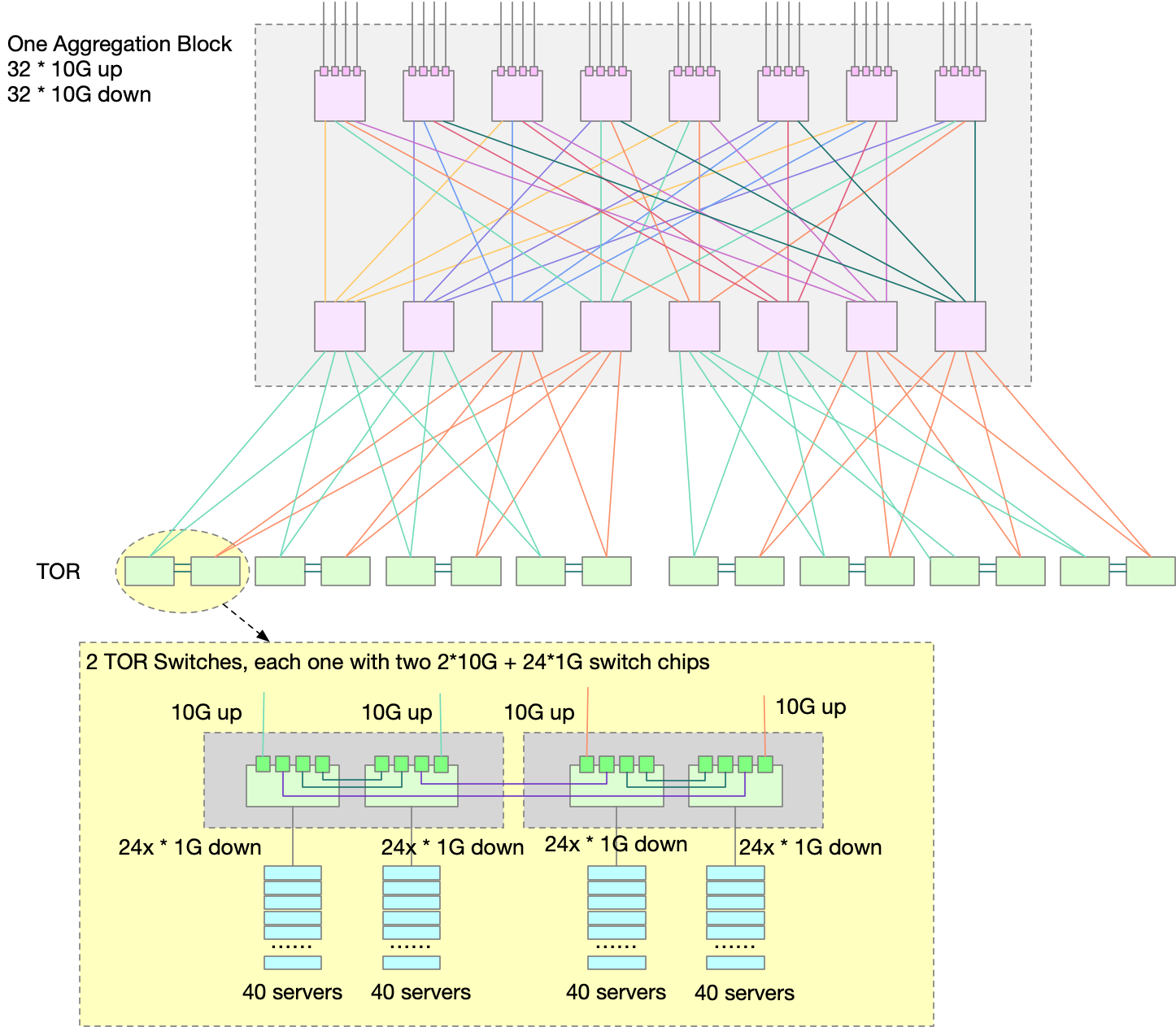
1.0 中提到的同一个 Aggregation 的 2 个 ToR link down 的场景,在 1.1 的架构下,依然有多条可达的路线。可以有任意两条 link 同时 down 掉。
这是第一次从传统 Four-post 架构到自研的 Clos 架构迁移。所以需要有快速回滚机制。
迁移的方式就是每一个 ToR 预留 4 个 1G接口,用于连接 4 个之前的商用交换机。因为之前 Four-post 架构用的就是 1G 的口,所以不会占用新架构的 10G up link。这样如果有问题的话,可以一键迁移回到旧的架构。
Firehose 1.1 架构最主要的问题就是线太多了,从逻辑架构图就可以看出来,Rack 内的线,Spine- Aggregation 的 full mesh 线,都非常多。第三代架构主要解决了这个问题。
第一个优化的地方就是减少 Rack 内的连线。Firehose 1.1 是没有背板去连接线卡的,卡之间都是通过网线在外部连接。Watchtower 添加了背板(backplane),在机箱内部就连接多个交换芯片。这样,网线使用就少了很多。交换芯片也进行了升级,现在使用的是 16x10G 芯片。

每一个 watchtower (左上角)一共有8个线卡组成,每一个线卡有 3 个交换芯片,连接逻辑图是左下角。可以看到,每一个线卡可以暴露 8 up 和 8 down,一共可以提供 64 up 和 64 down,总共高达 128x10G 的带宽。右图是 4 个 watcher tower 机箱,每一个只占用半个 Rack。对比 Firehose 1.1 的架构,占用 1 个 Rack 的 Aggregation Block 提供的带宽是 64x10G。Watchtower 是 Rack 减少一倍,能力强了一倍。
这个逻辑线路连线有个细节:之前的 Aggregation Block 是两层的架构,为什么到这里使用三层呢?中间这一层,即没有增加带宽,也没有增加接口数量,用处是什么呢?
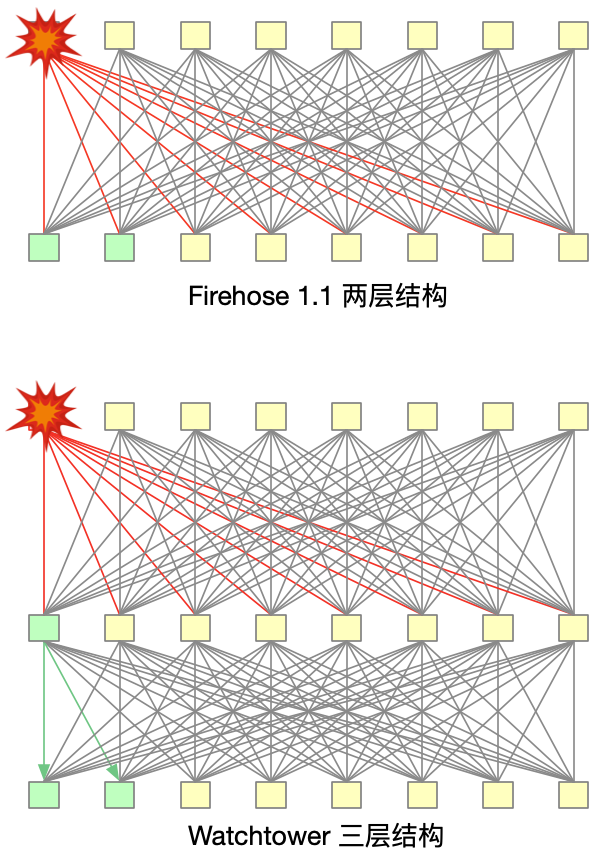
在两层架构,假设有一个交换芯片的流量已经被打满了,那么下面的芯片会有 1/8 的流量被 Blocking 了,是一种 Blocking 的架构。
在三层架构中,如果发生这种情况,下面的芯片依然可以通过中间一层来交换,没有 Blocking 的地方,所以是一种 Nonblocking 架构。
外面无法避免的连线,通过 Fiber bundling 来优化连线。
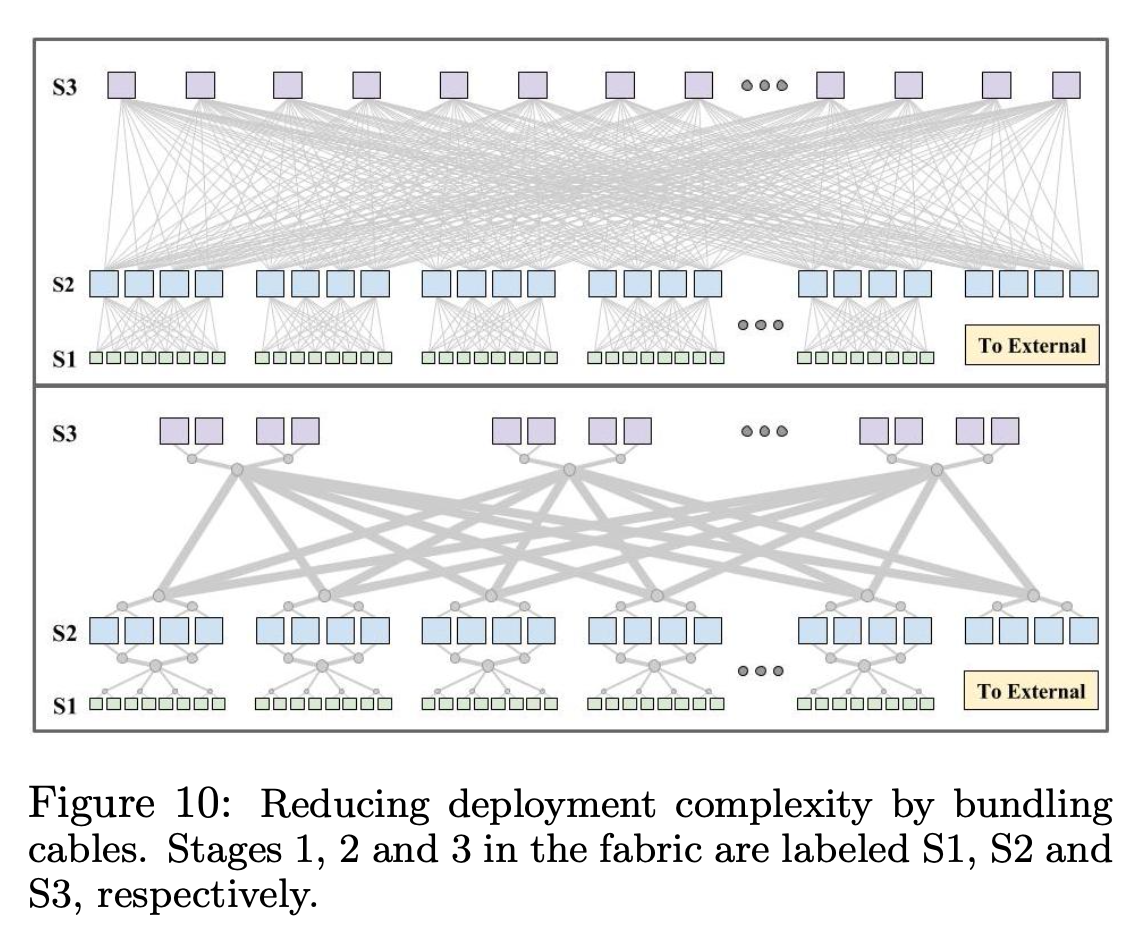
Fiber bundling 有两个好处:
前面提到,Clos 架构的一个好处是可以根据实际带宽需要部署,集群不需要那么高的带宽的时候,可以通过部署更少的成本来节省带宽。
方式主要有两种:A) 节省第二层 Aggregation Block 的交换机数量;B) 节省第三层 Spine Block 的交换机数量。如下图所示。
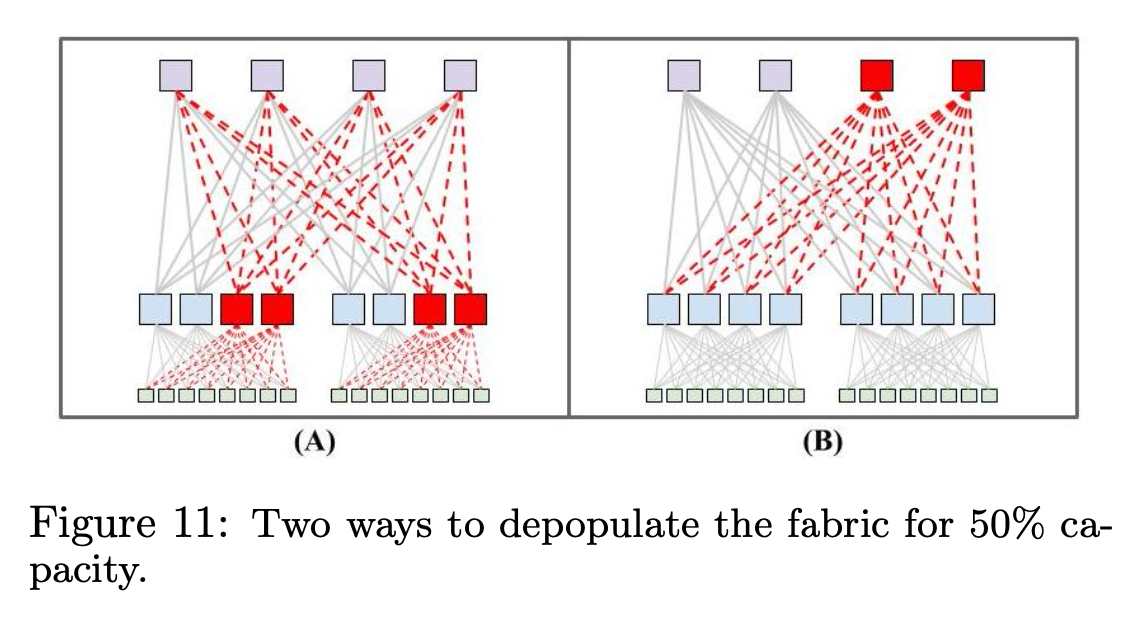
方案 A 和 B 能够提供的总带宽是一样的,都是最大的 50%。
A 方案好处:
B 方案的好处:
在 Watchtower 中,使用的是 A 方案,最大化节省成本。在后续的 Saturn 和 Jupiter 网络中,使用的是 B 方案,因为随着网络规模的扩大,部署 Spine Block 的成本相比 Aggregation Block 更高,更高的 ToR burst 带宽带来的收益也更高。
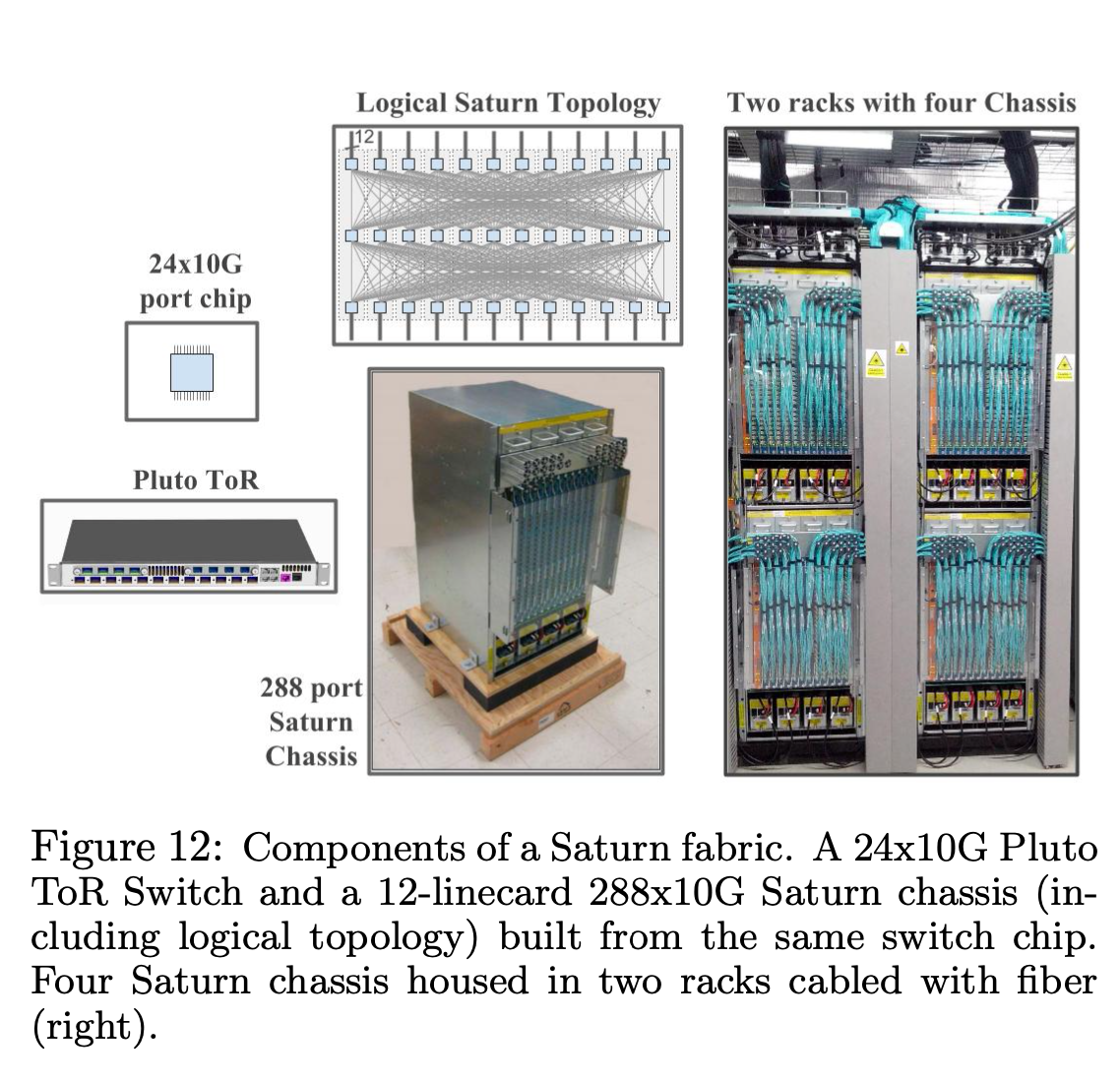
Saturn 主要的变化是,提供的带宽更高,集群的规模可以更大。
Saturn 用的 Merchant silicon 规格是 24x10G,使用的机箱可以支持 12 个线卡,机箱也是 half rack,相比于前一代,总体带宽从 128x10G 上升到了 288x10G,都是 Nonblocking。
ToR 换成了 Pluto single-chip ToR switch,向上可以提供 4x10G 带宽,向下可以连接 2x20G 到服务器。对带宽有更高需求的服务器,支持配置成 8x10G up, 16x10G down. 每台机器最大带宽 5G.
服务器最大 burst 带宽可以到 10G。
Merchant Silicon 的规模已经来到了 40G,下一代网络的设计的目的有两个:使用最新的 Merchant Silicon,设计一个 6 倍于上一代的网络,得到一个前所未有的巨大资源池;应对更加频繁的网络设备维护工作。
在这么大的规模下,网络结构就需要考虑物理建筑的结构了。
之前的设计中的部署单元有两种方式:Firehose 是机箱内部没有连接,都是走外面接线连接线卡;Watchtower 和 Saturn 是通过内部背板连接线卡。
Jupiter 采用了中间的方式,一个部署单元叫做 Centauri 机箱,是一个 4 个 RU (Rack Unit,占用 4 个 Rack 单位)的机箱,可以插 2 个线卡,每一个线卡可以有两个交换芯片,16x40G,总共就是 2 line card x 2 switch chips x 16x40G = 64x40G. 每一个线卡都有单独的 CPU 控制。每一个口都可以配置成 4x10G 模式,或者 40G 模式。机箱内部没有背板连接。
Centauri 因为内部没有连线,所以非常灵活。Jupiter 是通过不同的接线方式组合多个 Centauri 来做 ToR, Spine 和 Aggregation。
下面是 Jupiter 的总体架构图,可以看到,其实 Centauri 出现在了不同的角色中。
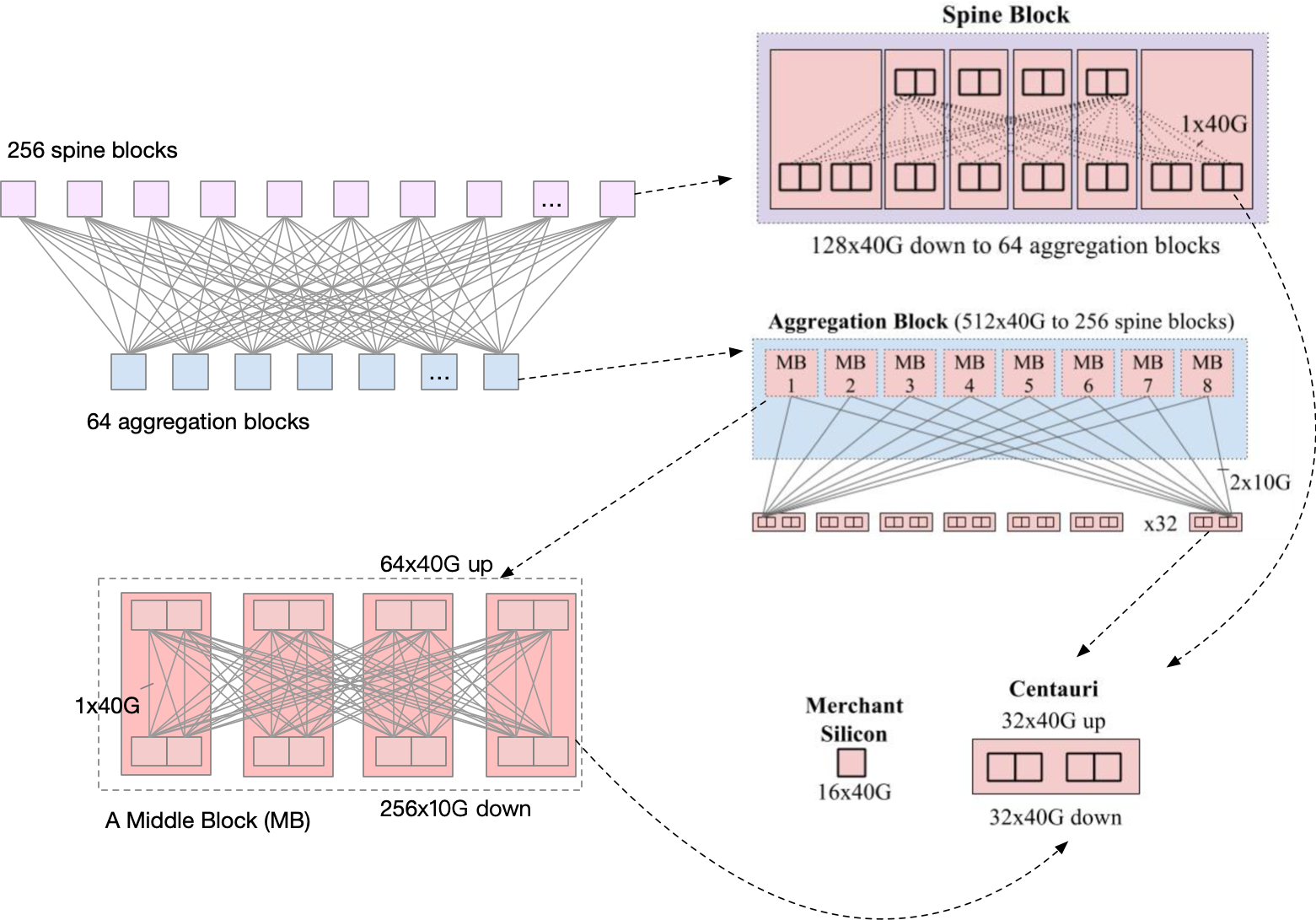
先看 ToR。因为 Centauri 是没有内部连线的,所以作为 ToR 的时候,4 个芯片可以当作 4 个交换机来看待。每一个芯片是 16x10G up, 48x10G down,每一个芯片下的服务器都是一个单独的 subnet。服务器可以 burst 到 40G 带宽。
每一个 ToR 的 16x10G up 去连接 8 个 Middle Block(MB), 和每一个 MB 之间的连接都是双线 10G。
MB 其实就是 4 个 Centauri 的组合,连线方式见图,可以提供 64x40G up, 256x10G down.
Spine Block 也是 Centauri 的组合,使用了 6 台,连线方式见图。可以提供 128x40G down,连接 64 个 Aggregation Block,每一个 Aggregation Block 使用双线 40G 连接 Spine Block 来提供冗余。
可以看到,Aggregation Block 最大是有 512x40G,但是实际只使用了 256x40G,如果有需要,可以通过增加 Spine Block 的数量来提高带宽。
集群的总带宽的计算方法:一个 Spine Block 可以提供 128x40G, 一共有 256 个 Spine Block,总带宽达 64x128x40G= ~1.3Pbps.

图中是两个 Rack,一共 8 个 MB。
以上就是 Google 的 5 代网络了,但是还有其他的问题需要解决。以上介绍的都是一个网络集群是如何连接的,但是一个网络集群是不够的,Google 需要多个网络集群,那么多个集群间如何连接呢?以及集群通向外网的网络如何连接呢?
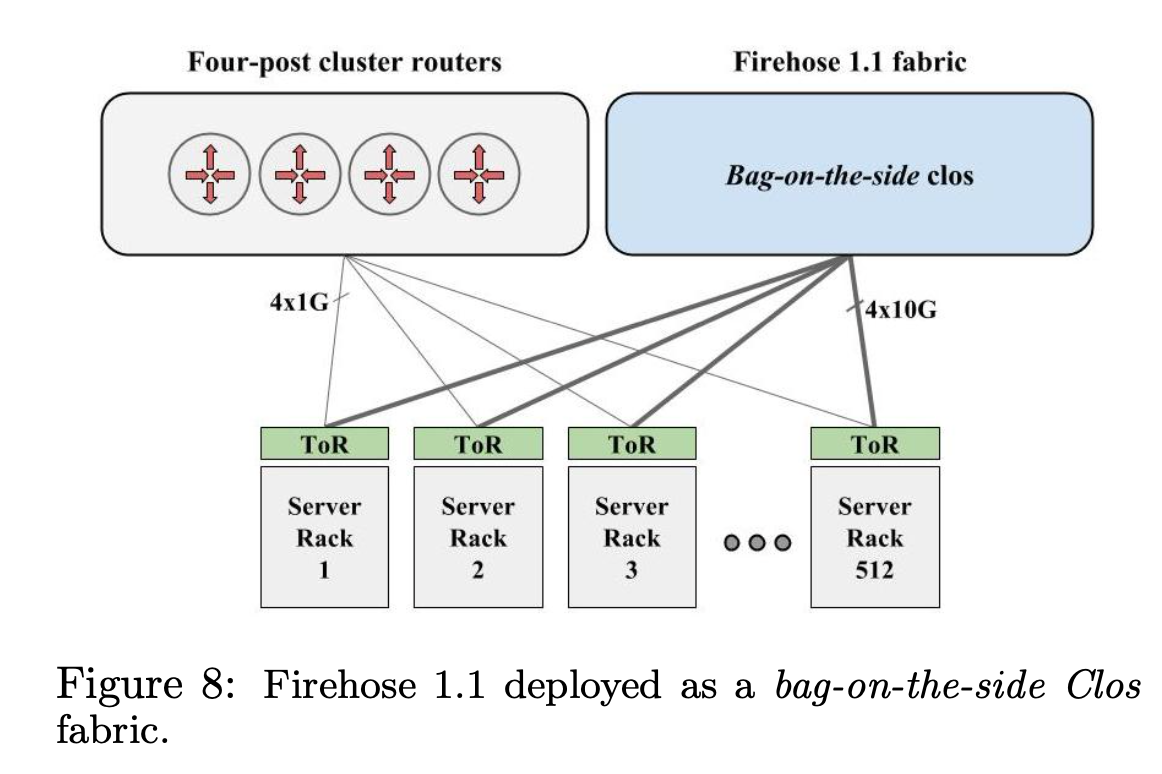
在 Watchtower 刚开始部署的时候,出于安全的考虑,还是 bag-on-the-side 模式部署的。
在这个模式下,Cluster 内部的流量,走 fabric,如果要跨 Cluster,还是要走 Cluster Router。
但是这样部署的复杂度高,成本也高,性能差。尤其是如果在 Cluster 之间拷贝数据或者迁移索引文件,会受到 Cluster Router 的带宽限制。
所以,第一步就是彻底下线掉 Cluster Router。方法就是把跨集群的 Cluster Border Router(CBR) 直接连接到 fabric 上,跨 Cluster 可以直接通过 fabric 去 CBR。
把 CBR 连接到 fabric 的方式有 4 种:
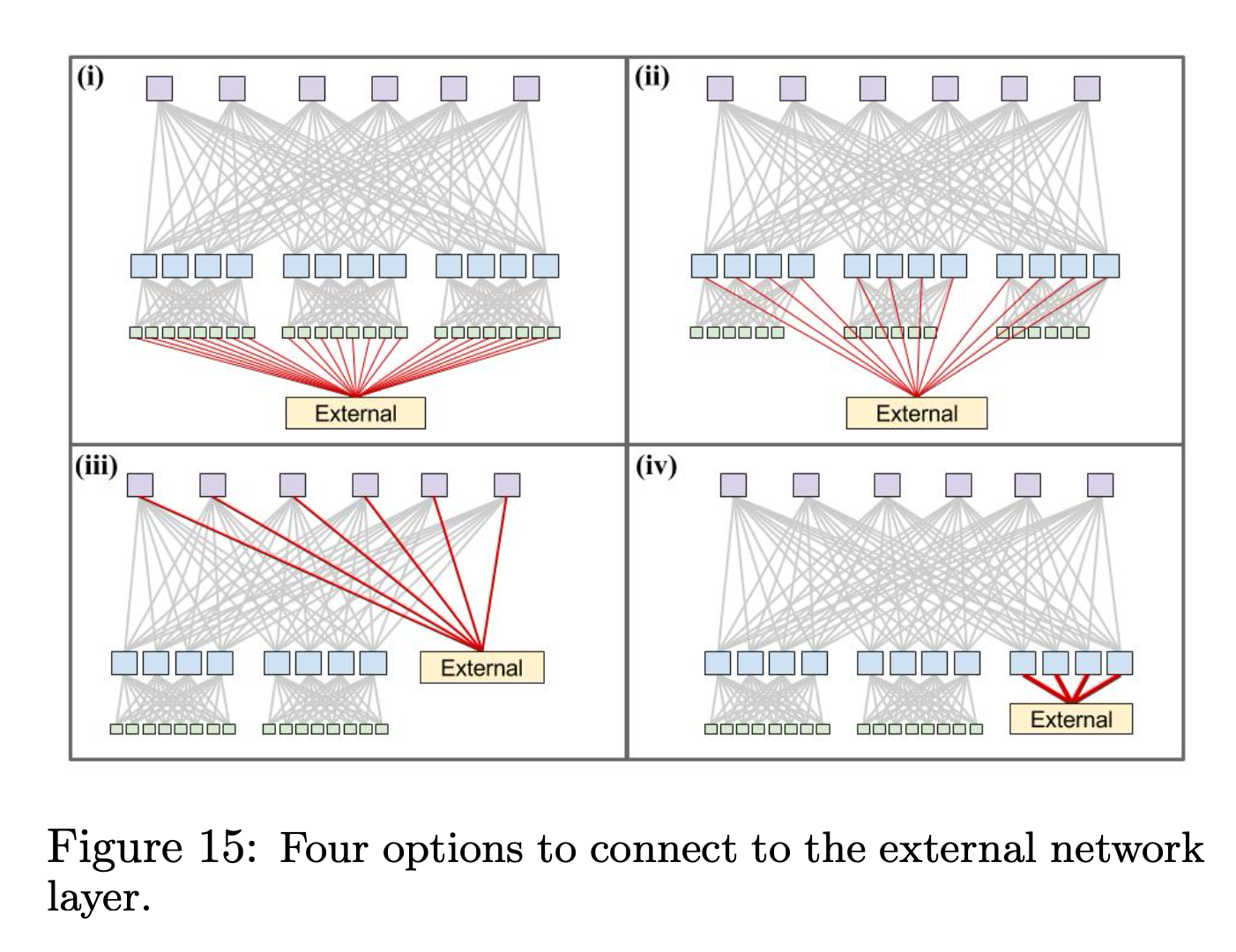
其中,(1) 和 bag-on-the-side 的部署模式是类似的, (1) 和 (2) 都无法提高 burst 带宽。因为流量不走 fabric,server -> ToR -> External, ToR -> External 线路是固定的,server -> ToR -> Aggregation Block -> External, 有一定的 burst 能力,但是最多用上同 Aggregation Block 到 External 的带宽。
(3) 和 (4) 的 burst 带宽最高,可以 burst 到全部到 External 的线路。
Google 最后选的方案是 (4), 因为 (4) 可以限制爆炸半径,连接到 External 的网络聚合在一个 Aggregation Block 下面。可以最大减少集群外配置失误而引起的影响。
实际运行中,到集群外带宽大约是 fabric 带宽的 10% 左右,所以会分配大概 1-3 个 Aggregation Block 用于连接到 External。这些 Aggregation Block 和其他连接 ToR 的 Aggregation Block 并没有什么区别,只不过连接的不是 ToR,而是连接 CBR。
CBR 和集群外交换机的连接用 LAG7 连接,运行标准的 eBGP8 协议,然后将学习到的默认路由重分发9到 Cluster 内,集群内路由协议使用的是 Google 自己研发的 IGP,叫 Firepath,后文还会详细介绍。
在数据中心园区中,有多个机房大楼,每一个大楼有多个 Cluster。得益于上面的退役 CR,CBR 直连 fabric 项目,现在 CBR 可以在跨集群间提供超大的带宽,Watchtower 的 Aggregation Block 可以提供 2.56Tbps 带宽,Saturn 可以提供 5.76Tbps。但是再往外面的网路,用的设备就还是商用设备。所以基础设施的任务调度上,考虑到物理距离以及网络成本,要考虑 campus-level 和 building-level 的 locality。
下一步,就是把这部分网络设备也替换成自研的,用来在集群间提供更大的带宽。
核心的思想还是 Clos 架构的 fabric。
首先用路由器为单位,多个路由器组合成一个 Freedome Blocks (FDB), 每一个 FDB 的南向端口是北向端口的 8 倍;
FDB 中有两个角色:
FDB 每一个 Block 内部使用 iBGP,北向端口和南向端口都是用 eBGP 作路由。
基于 FDB 为部署单位,四个 FDB 组成一个 CFD (Campus Freedome) 南向连接 FDB,北向连接 WAN。是一个园区最核心的网络单元,是进出园区的经过组件。
四个 FDB 组成一个 DFD (Datacenter Freedome) 南向连接 Cluster,北向连接园区网 CFD。
到这里我们就可以把一整个园区的图都画出来了,从 WAN 入 CFD,然后进入 DFD,最后通过 CBR 到 Cluster 内部。如下图所示。
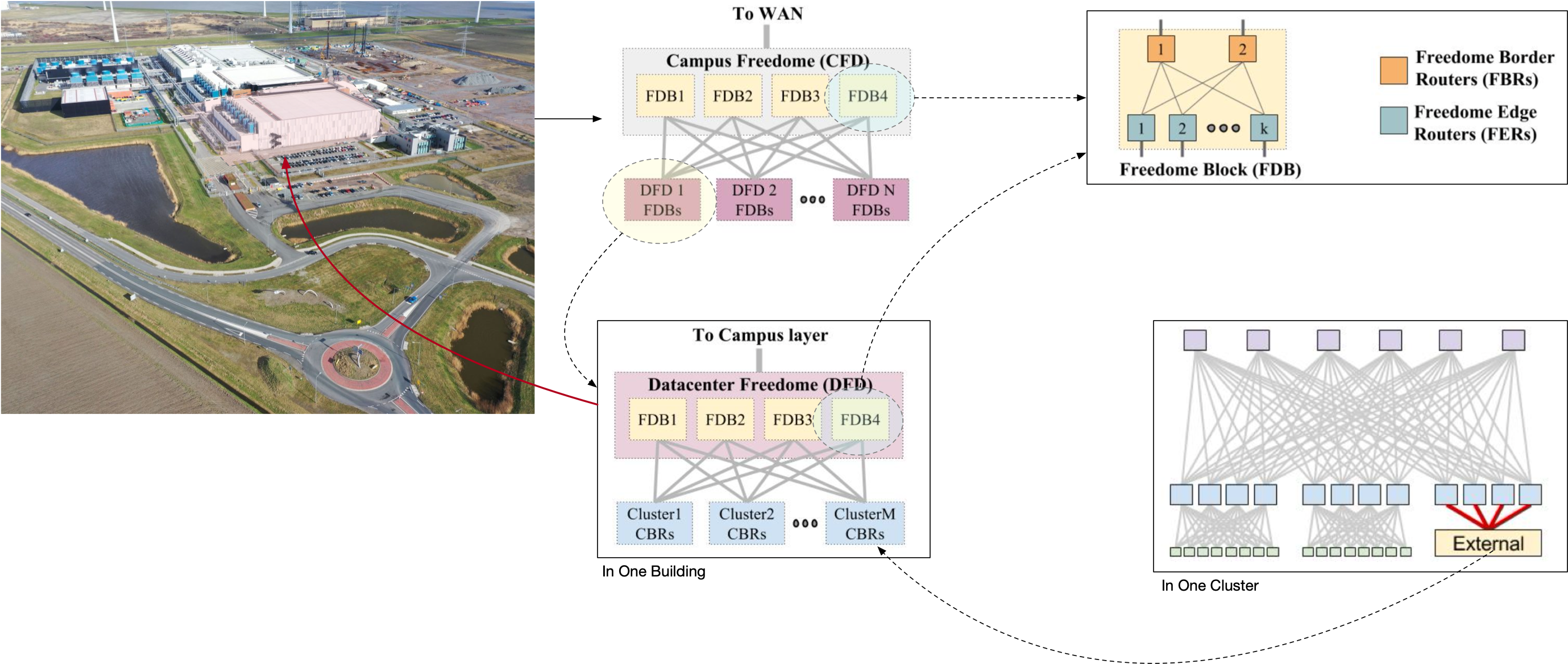
其中,由 4 个 FDB 组成的 CFD 和 DFD,都可以随时损失 25% 的最大带宽进行下线 FDB 维护,非常方便。
有关网络架构方面,我们基本上就讨论完了, 可以看到,Clos 应用在了园区网,集群网,交换机内部,可谓是无处不在。如此庞大的网络,就是由一颗颗交换芯片组成的。
这么大的网络,传统的网络管理方式已经无法工作了,Google 重新设计的自己的控制面和路由协议。
在设计控制面的时候,可以选择使用传统的 OSPF/IS-IS/BGP 这种分布式路由协议,优点是已经经过了几十年的验证,足够「正确」;另一种选择是根据自己的需求从头开始设计一个路由协议和控制面。
Google 选择设计自己的路由协议和控制面。原因如下:
数据中心网络的特点是巨量的多路径(Clos 架构),静态拓扑,每一个交换机角色是根据它的位置来确定的。所以 Google 重新设计了一个 Control Plane network (CPN), 中心化的控制面,通过带外连接 (out-of-band) 控制交换机。
每一个交换机都知道整个网络的拓扑结构。交换机会上报 Link 的状态到控制面,控制面把这个状态变更发送到所有其他的交换机,交换机收到 Link 状态变更之后,加上自己知道的拓扑结构,来重新计算路由。
这个设计本质上是把整个网络当作是一个由上万个接口的交换机。中心化的控制面,也是受之前的分布式存储系统设计的启发。
除了 Jupiter,Google 的 B4 WAN12 也是用了这种控制面的设计方式。
Google 的自研路由协议叫 Firepath,是基于现代 SDN 设计。工作方式如下:
Firepath master 之间通过选举协议来实现多点部署,提高可用性。
在 fabric 的 edge 节点,运行 BGP 和外部交换路由,然后把通过 BGP 学习到的路由重分发到 Firepath。
Clos 网络依赖大量的连线,物理接线在实施的时候很容易出现错误,一开始接线对了,后续维护的时候(比如更换线卡)还可能接错。接线错误可能会造成路由环路13。
如果 Link down 了或者错误率过高,交换机也需要发现,并且上报。
Google 开发了 Neighbor Discovery (ND) 来解决这个问题。有点像开放的 LLDP (Link Layer Discovery Protocol) 协议和 Cisco 专有的 CDP (Cisco Discovery Protocol) 协议。但是 ND 做的事情更多。路由器通过自己存储的拓扑结构和自己的 ID,从拓扑中找到自己的位置,得出自己应该连接的 peer ID,然后通过 ND 去得到真实的 peer ID 进行比较,如果不一样,就是接错线了。这样就会在早起发现机房实施中的错误。
交换机内嵌的 Interface Manager(IFM) 模块可以判断 link 状态,只有 PHY UP 和 ND UP 才算是 UP,才会开始参与路由。线卡上有 LED 会展示 ND 的状态,可以辅助定位问题。ND 的状态通过监控系统上报,在监控面板上也可以看到。ND 通过类似 keepalive 的机制不断检测对端的状态,如果对方宕机或者出现 Link 问题,就会从路由中隔离掉。
线来看一下网络的划分。二层和三层的分界线在 ToR,ToR 以上运行的是三层,跑的内部 IGP 协议,叫做 Firepath。ToR 以下是一个二层的广播域。连接到同一个 ToR 的服务器在同一个广播域中。ToR 分配到的子网是连续的,并且和 Aggregation Block 对齐,这样,网络的转发表可以比较小。
拓扑中所有链路和节点的状态是中心化的,路由计算依赖两个主要的组件:
在初次启动的时候,每一个 client 都会加载预先配置好的拓扑图,包含整个 fabric,叫做 cluster config。每一个客户端然后收集本地端口状态,发送给 master。master 基于此创建 Link State Database (LSD),基于全局 ID 递增的方式标识状态变化,然后通过 UDP/IP 走 CPN 发送给路由器。
初始化结束之后,后续只会推送增量变更的部分。
整个网络的 LSD 可以放到一个 64KB 的 payload 中。
当收到 LSD 更新,每一个客户端会重新计算路由,然后修改本地的(硬件)转发表。master 节点会限制发给 client 的 LSD 更新的频率,避免 overload client。
master 和客户端之间还有 keepalive 机制,master 会定期发送自己的 master ID 和 LSD version number,如果 client 发现与此失去同步,就会重新请求 full LSD,相当于重新开始初始化。
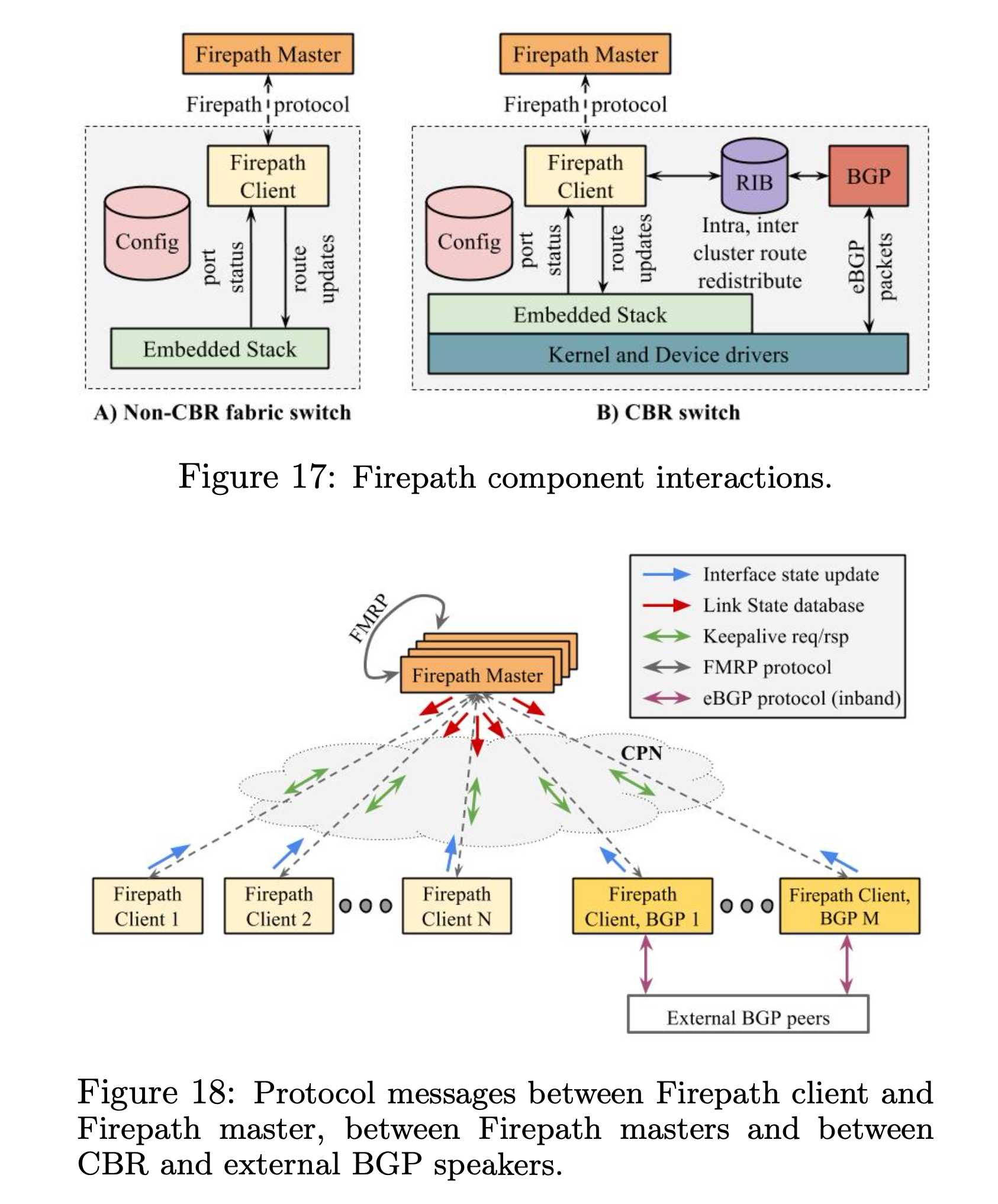
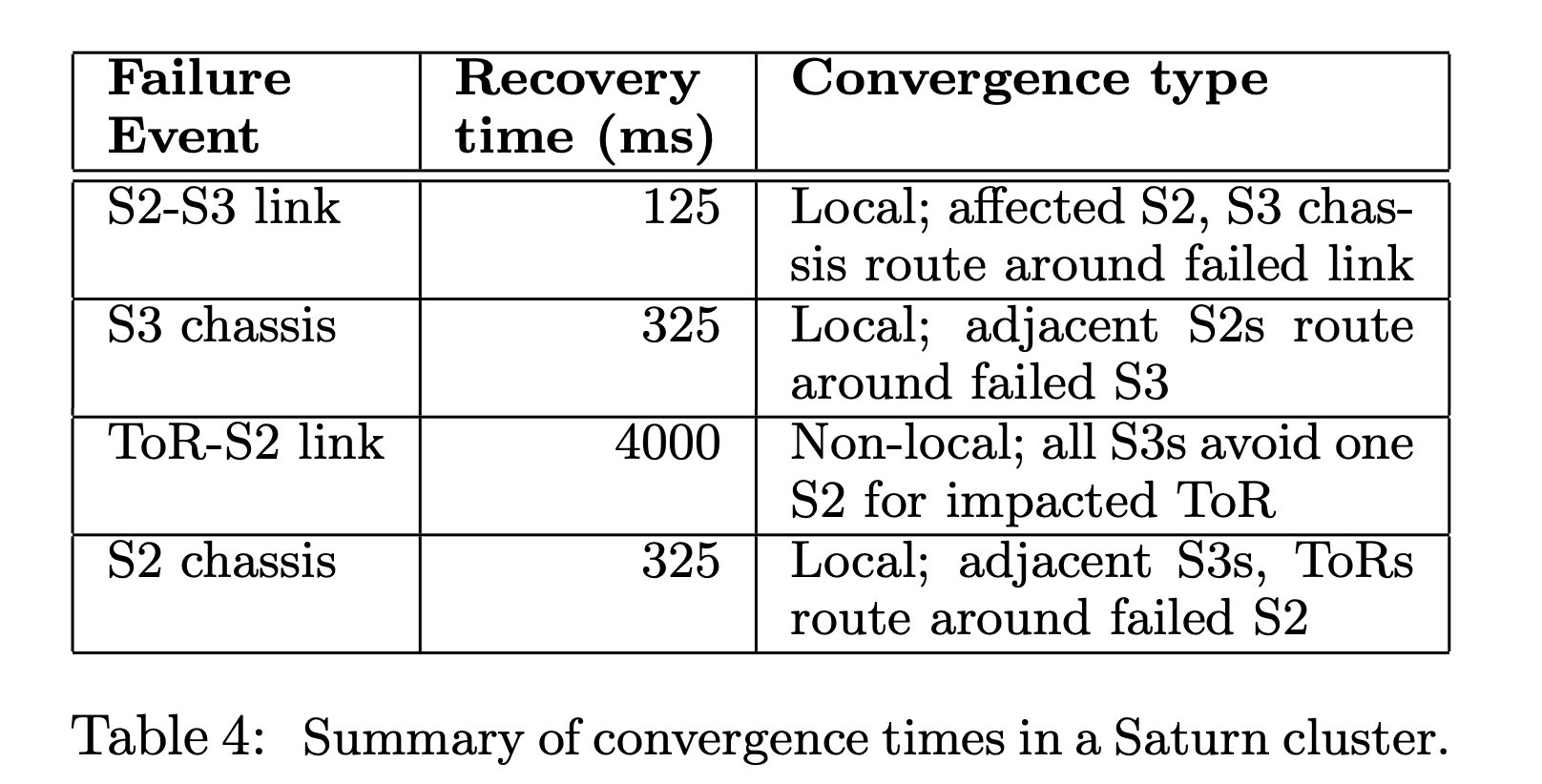
当出现故障的时候,因为大部分的故障点,都是可以本地恢复的,所以恢复速度非常快。本地恢复以为着不需要通知更多的下一级节点来恢复。比如 S3(就是 Spine Block)挂了,那么在 S2(Aggregation Block)的路由中摘除这个 S3 就可以了。一个反例是当 ToR 挂了,首先 S2 要摘除这个 ToR,然后 S3 要摘除路由不通的 S2,核心问题是 ToR 到 S2 的线路不够多。但是相比于传统路由,也都已经很快了。在传统路由,当故障发生的时候,路由要一层一层传下去,整体上恢复速度很慢。而中心化的控制面,交换机告诉 Firepath master,Firepath master 告诉所有其他的交换机,就可以了。
为了实现 Firepath master 节点的高可用,Google 部署多个 Firepath masters 作为一组,master 之间通过 Firepath Master Redundancy Protocol (FMRP) 来做 master 选举和保活,这一组叫做 CPN FMRP multicast group。
当启动的时候,master 进入 Init 状态,发送 LSD,然后等待其他的 master。如果从其他的 master 收到 LSD 更新,就进入 backup 状态,否则,就进入 electing 状态开始选举。选举是广播 election 请求到所有的 master 候选。拥有最高 LSD 版本的节点会胜出。胜出的 master 就进入 master 状态。这个过程其实和之前博客中讨论过的 VRRP (HSRP)14 很像。
FMRP 的 master 选举是 sticky 的,意味着如果所有的节点都健康,那么上一个 master 也会在下一次的选举成为 master,所以即使错误配置的 master 节点加入,也不会引起集群震荡。在极端情况下,可能出现多个 master,这时候需要监控发现,人工介入解决。
CBR 需要用 eBGP 与外部网络连接。这部分工作主要有两方面:需要和外部运行 eBGP 路由协议;需要作为边界网关,在 EGP 和 IGP 之间同步 (redistribute) 路由。
eBGP 路由是运行在 inband 的,即控制面的 eBGP 包和数据包使用相同的网线。这里是通过嵌入式的 IO 引擎分离出来控制面和数据面,控制面的包拿到之后通过 netdev 交给 eBGP 协议处理。
CBR 上运行着一个代理进程,负责将内部 Firepath 路由写到 BGP RIB 中,也把 BGP RIB 的路由发布到 Firepath 中。但是这里不是做的真正的路由学习,而是做了一个非常简单的假设:对于内部集群,直接发布一个 /0 路由,即所有的出集群流量全部发给 CBR,对外,发布 Cluster prefix 到 BGP 中,即假设 CBR 可以连通集群内部的任意角落。得益于 Clos 高可用性,让路由数据变得很少。
整个集群网络自上到下作为一个静态的 fabric 看待,而不是自下到上单独配置每一个设备。整体配置的参数很少,只有一些必要配置,减少了复杂性。
配置的生成是一个 pipeline,输入必要参数:spine 数量,IP 前缀,ToR 和 rack 列表,就可以自动生成多份配置:
同一份配置会下发到所有的交换机,非常简单。缺点是当有配置需要变更的时候,需要变更所有的交换机,但是这么做的频率并不高。
Google 不像其他公司一样,区分网络设备和服务器来分开管理,而是将网络设备也当成服务器来管理。比如系统镜像管理和安装,大规模监控,syslog 收集,alerting 等等。
交换机很多程序需要同时 apply 配置,所以配置变更实现了类似二阶段提交的功能。
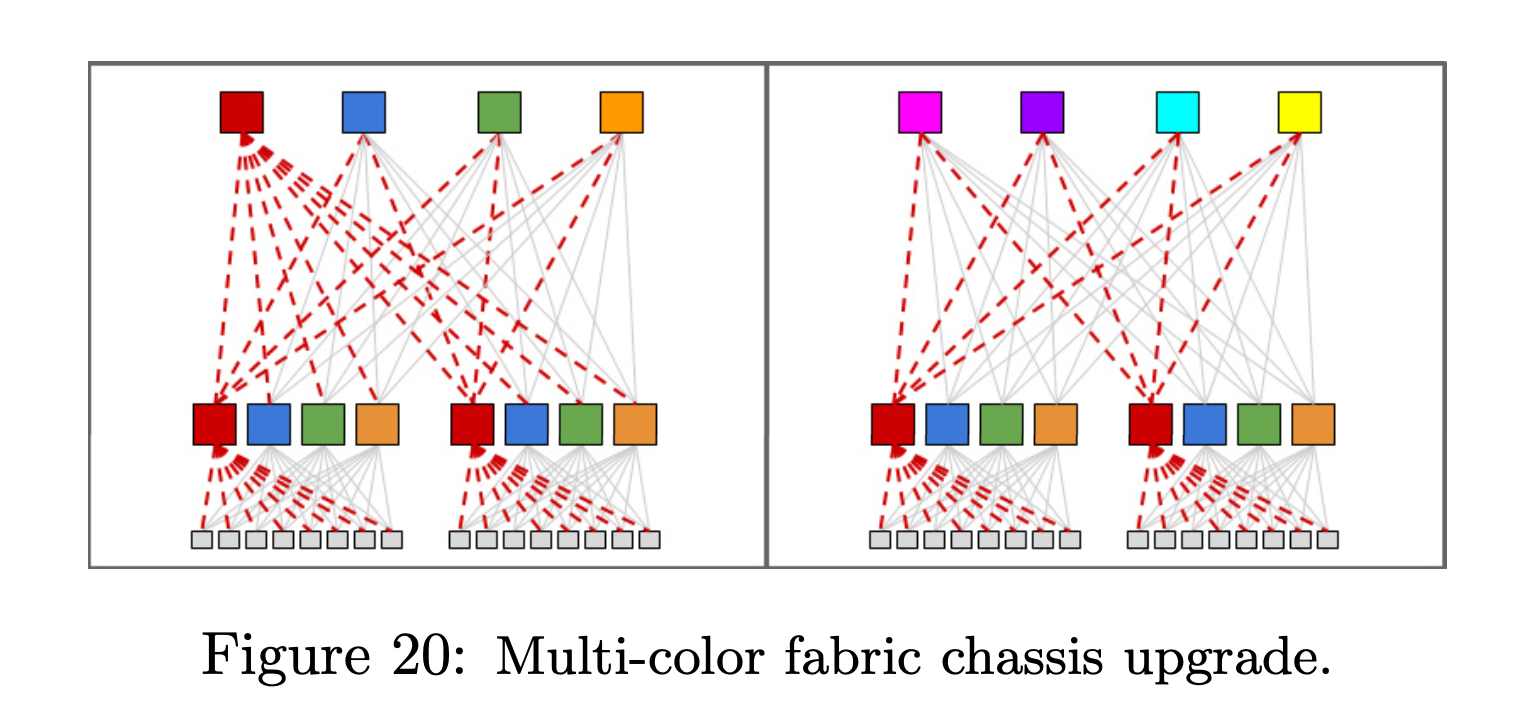
商用高端交换机都支持原地不停机升级,是一个非常牛逼(昂贵)的 Feature。但得益于 Clos 高可用的特点,这些不需要啦。升级完全可以先主要 drain 掉设备,牺牲掉 56.25% (75%*75%) 的带宽(下图左)来直接升级 1/4 的设备。图右的方式损失的带宽更小,但是花的时间更多。
Fabric 使用率大概 25% 的时候会发生丢包。拥塞主要的原因:
优化方法如下:
文章中介绍了3个故障案例。
第一个最有意思,还记得上面提到过 ND 和路由计算之间的关系吗?在一次数据中心发生断电重启之后,整个 fabric 的 ND 都在检查链路状态上报,所有的交换机都在计算路由,交换机的 CPU 并不是很强,因为路由本身的设计就比较小。所以大量的路由计算耗光了 CPU,导致交换机无法响应邻居 ND 的 keepalive,邻居认为自己挂了,于是又上报链路状态,带来了更多的计算量。导致集群处于雪崩状态,永远无法恢复。
优化方法是增加类似场景的 stress test,重新检查所有代码中和时间有关的参数,考虑它们在最坏的情况下有没有问题,最后提高 ND 在 CPU 的优先级。
第二个是 CPN 网络,链路错误率很高甚至挂掉,但是链路健康检查并不是很完善,导致 CPN 网络中还认为链路是健康的。
第三个是配置文件 apply 的时候出现了两个进程同时修改配置的问题。
到这里,这篇论文就结束了。论文很慷慨地介绍了 Google 的物理网络架构,软件管理,路由协议,内容颇多。虽然是 2015 年发布的内容了, 但是放在今天来看,依然非常先进。
PS 这篇文章开始,博客用脚注的方式放链接,而不是文字加超链接,这样可以把链接放到同一个地方去,方便读者逐个查看。不知道读者有何反馈?
 ︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎
︎