2024-11-13 05:20:33
假设你正在写后端代码,其中一个函数的功能是传入文章id,返回文章详情。因为项目比较大,因此在定义函数时,把类型标注加上,标明了参数的类型和返回的类型。例如:
1 |
from typing import List |
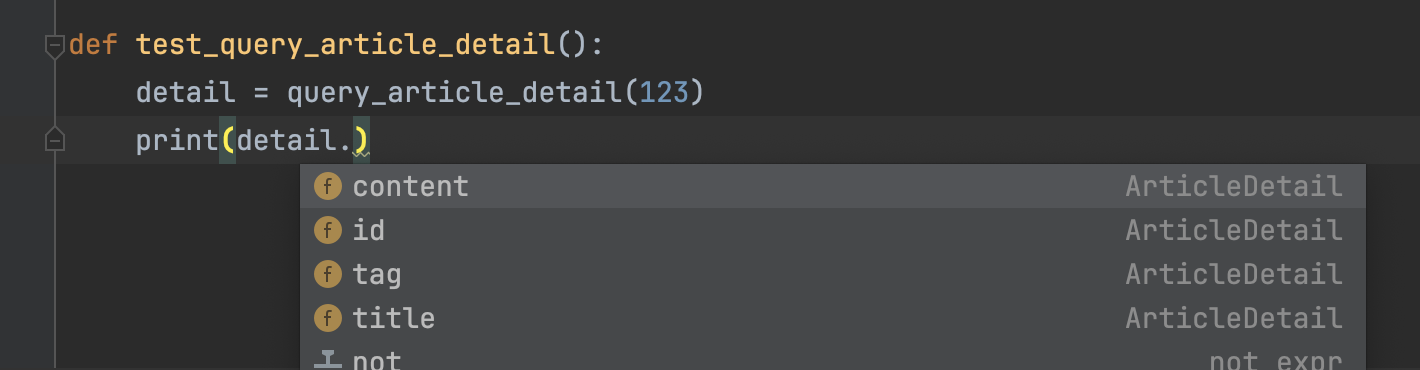
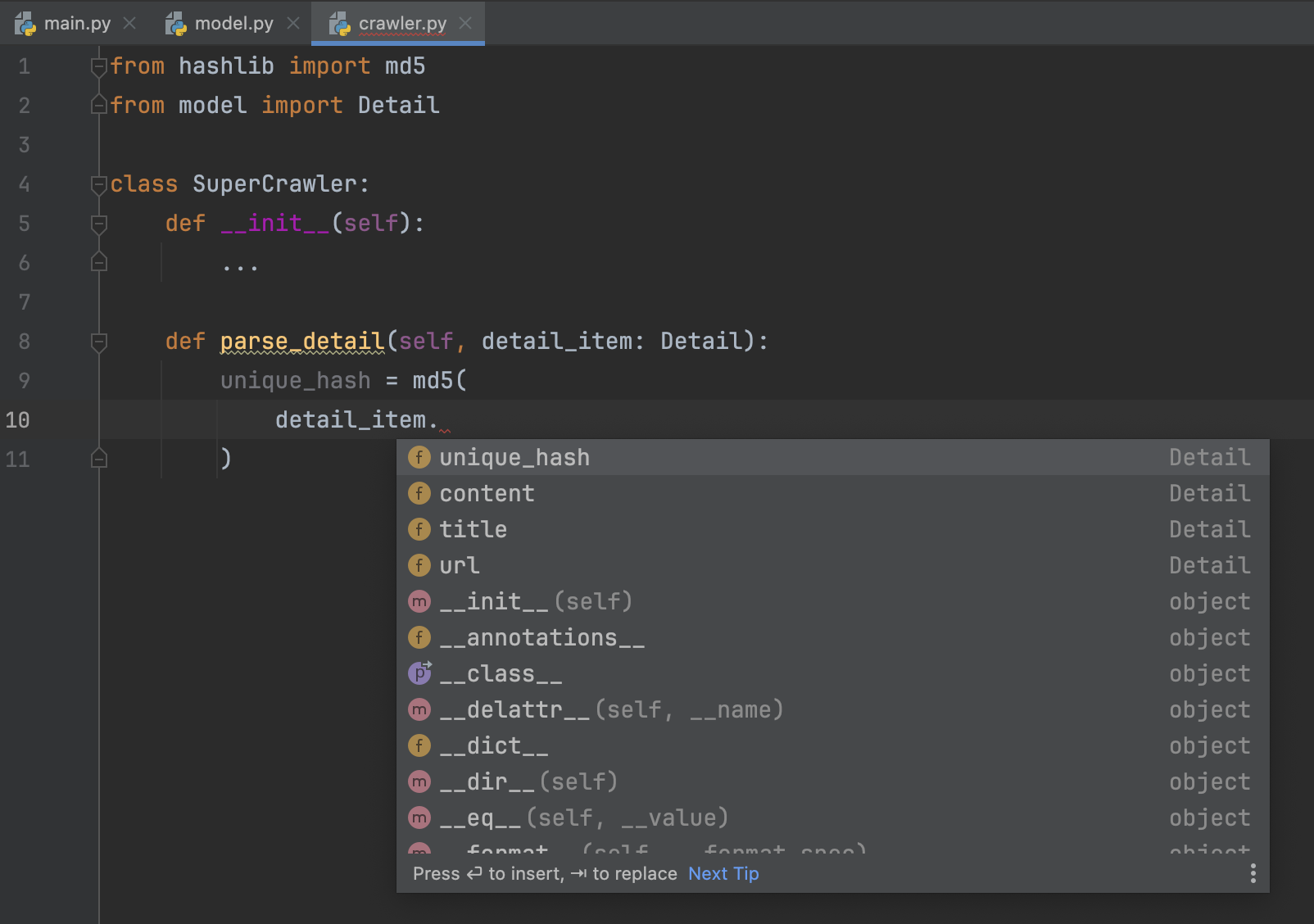
现在,当你拿到返回的detail变量时,IDE的自动补全就可以正常工作了,如下图所示。
你想让这个函数支持批量查询文章详情的功能,代码类似这样:
1 |
def query_article_detail(article_id: int | List[int]) -> ArticleDetail | List[ArticleDetail]: |
如果传入的参数是int类型的文章id,那么就返回这篇文章的详情ArticleDetail对象。如果传入的是文章列表,那么就返回ArticleDetail对象列表。
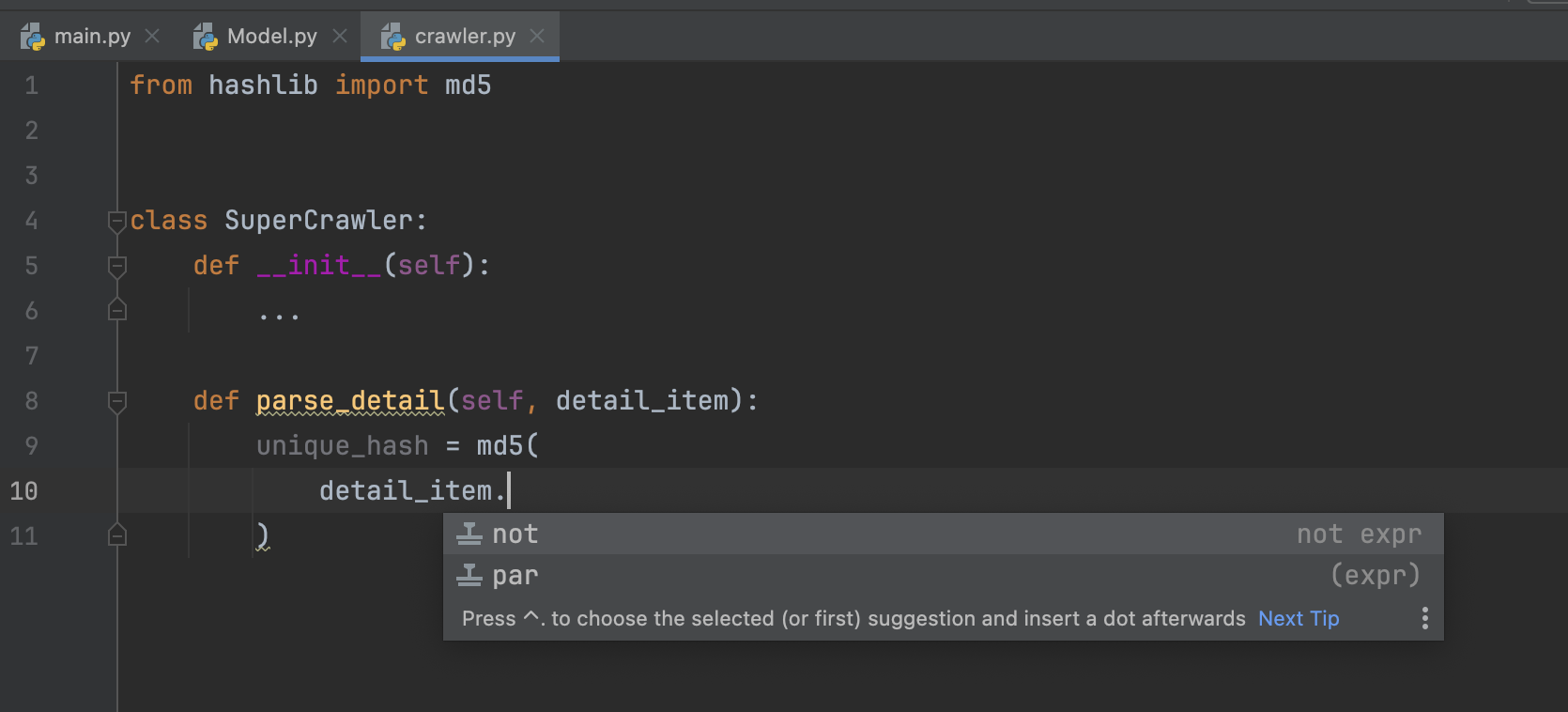
现在问题来了,由于query_article_detail函数返回的数据类型不同,如何让IDE的自动补全能够正确提示呢?例如当我们传入了一个文章id列表,但是却直接读取返回数据的.content属性,在IDE上面看不出任何问题,如下图所示。但显然会报错,因为此时的detail变量的值是一个列表。列表是没有.content属性的。
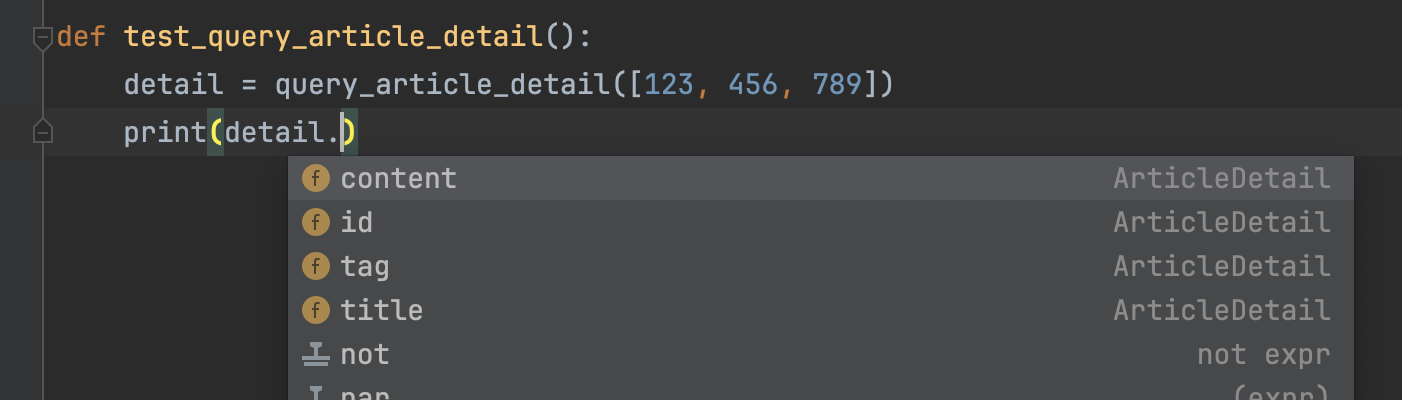
有没有什么办法能够让IDE根据query_article_detail参数的类型,提示我们对返回数据的使用是否正确呢?
这个场景下,就可以使用Python的typing模块中的@overload装饰器,实现函数重载来提示。示例代码如下:
1 |
from typing import List, overload |
在定义函数之前,先使用@overload装饰器,装饰两次函数名。每一次使用不同的参数:
1 |
|
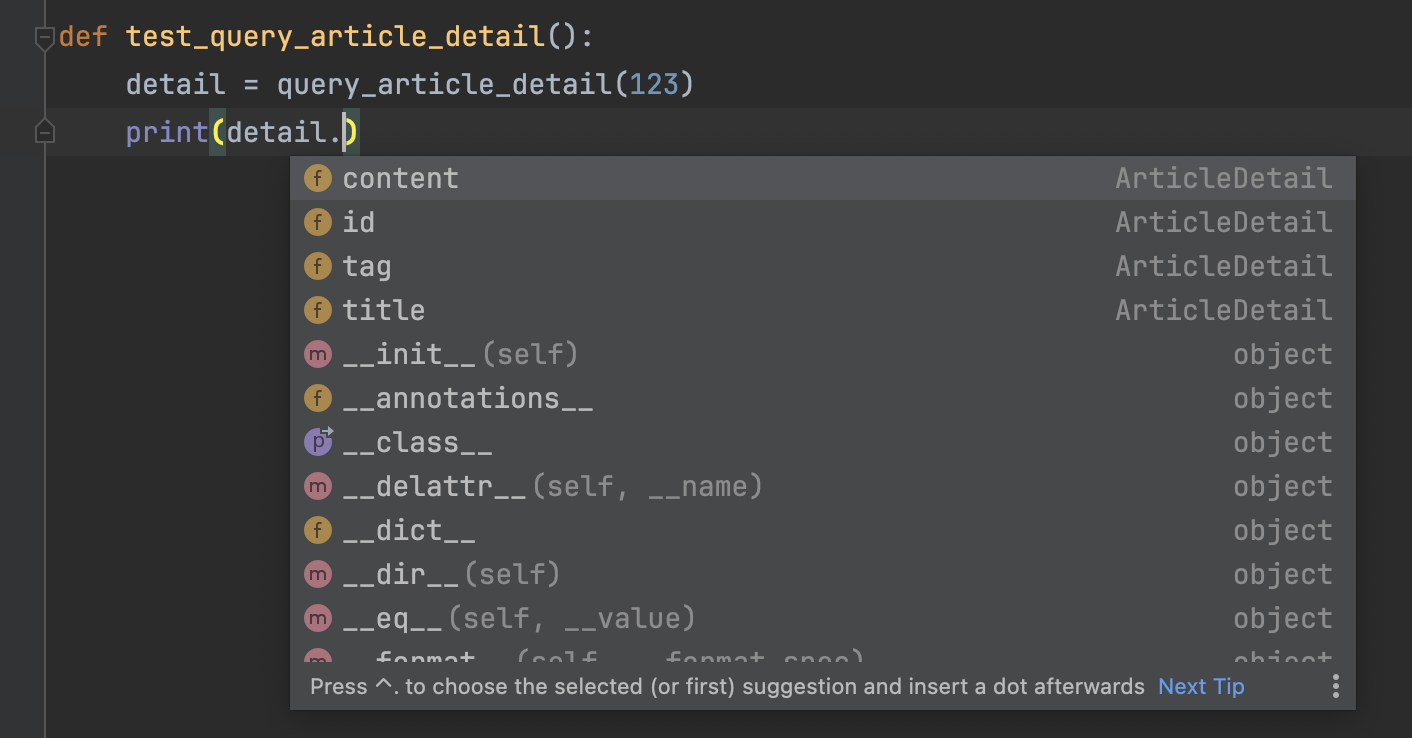
这两个函数都是空函数,函数体用三个点代替。当然你也可以使用pass。而你真正的query_article_detail放到最下面。现在,当我们对detail对象使用自动补全时,IDE就能根据参数的类型来补全对应的值了。
当传入参数是单个id时,如下图所示:
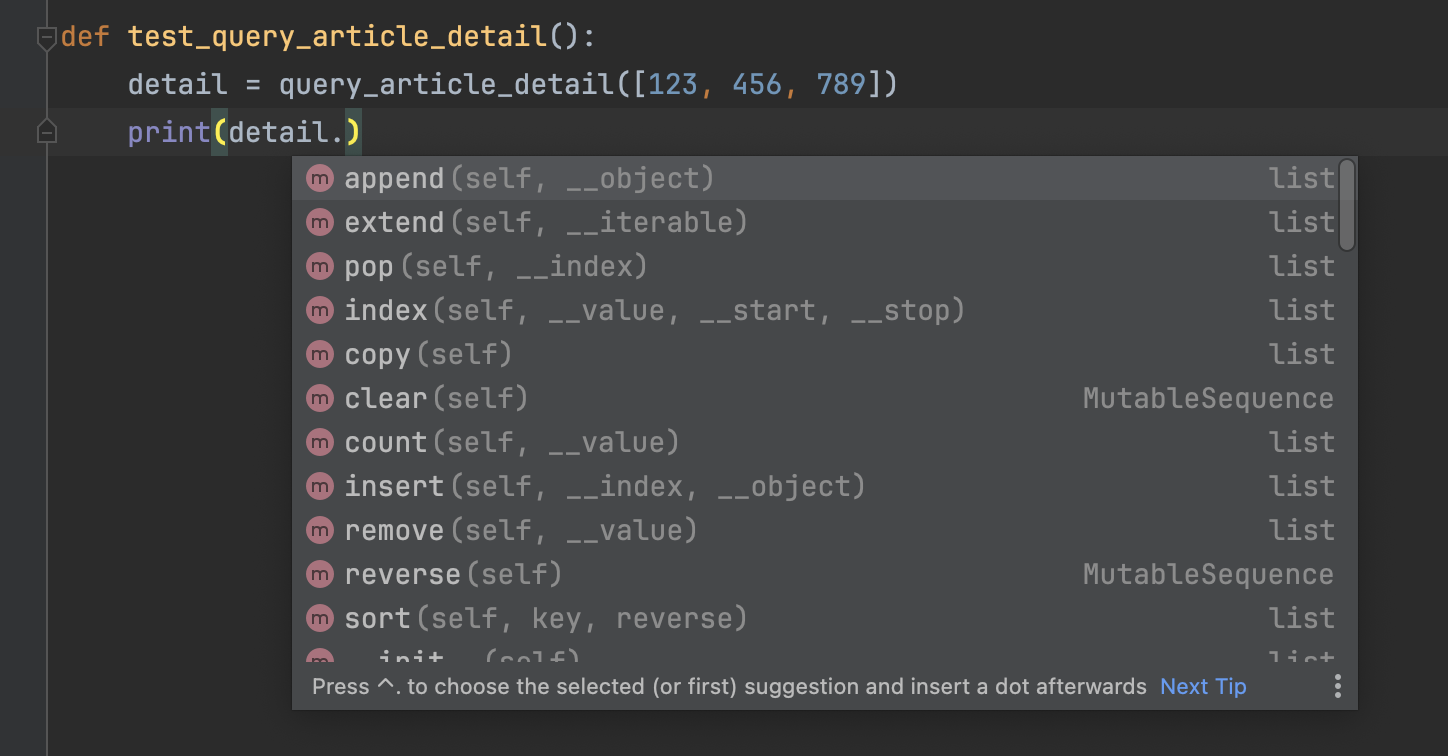
当传入的参数是id列表时,如下图所示:
需要注意的时,所有重载的函数与真正执行的函数,函数名必须全部相同,如下图所示:
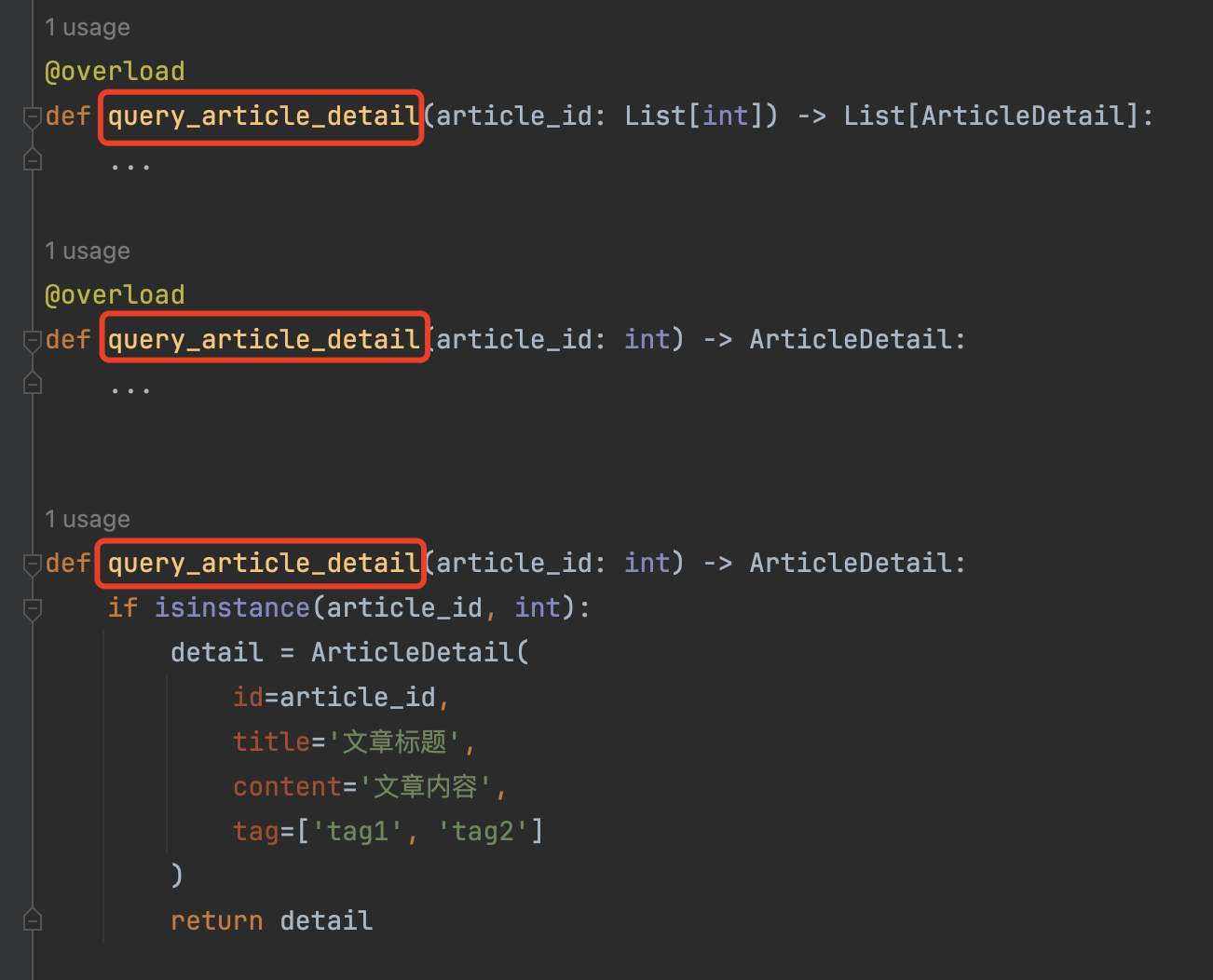
并且,真正实现功能的函数,必须放在重载函数的下面。
使用这种方式,以后即时别的文件导入并使用你这个函数,你也不用担心它用错数据类型了。
2024-11-11 01:51:32
我们知道,在写Python时,使用IDE的自动补全功能,可以大大提高代码的开发效率。使用类型标注功能,可以让IDE知道应该怎么做自动补全。
当我们没有类型标注时,IDE并不知道函数的某个参数是什么东西,没有办法做补全,如下图所示。
但当我们把类型标注加上以后,IDE就能正常补全了,如下图所示:
这样做,需要从另一个文件中,把这个参数对应的类导入到当前文件里面,然后把类作为类型填写到函数参数后面。咋看起来没有什么问题,并且我,还有很多看文章的同学,应该经常这样写类型标注的代码,从而提高代码的开发效率。
但如果你的项目规模大起来以后,你就会遇到几个比较麻烦的问题:
model.py中导入了Detail这个类。如果我在model.py文件的开头,还有from aaa import bbb,而在aaa.py文件开头,又有from ccc import ddd;在ccc.py开头,又有from xxx import yyy……这个导入链条就会变得很长。虽然Python对模块导入已经做了缓存,多次执行from xxx import yyy时,只有第一次会生效,后面都是读取缓存,但读取缓存也会消耗一些时间。如果你引入一个类,仅仅是为了做类型标注,那么这个问题实际上非常好解决。在Python的typing模块里面,有一个常量,叫做TYPE_CHECKING,它就是为了解决这个问题而设计的。在你使用python xxx.py来启动代码时,TYPE_CHECKING的值是False。但当IDE的类型检查或者Mypy这种静态类型检查工具运行时,TYPE_CHECKING的值是True。
因此,我们可以使用下面这段代码,来提高代码的运行效率,同时规避循环依赖的问题:
1 |
from typing import TYPE_CHECKING |
注意,在函数参数的类型标注里面,类YYY需要以字符串的形式写出。如下图所示:
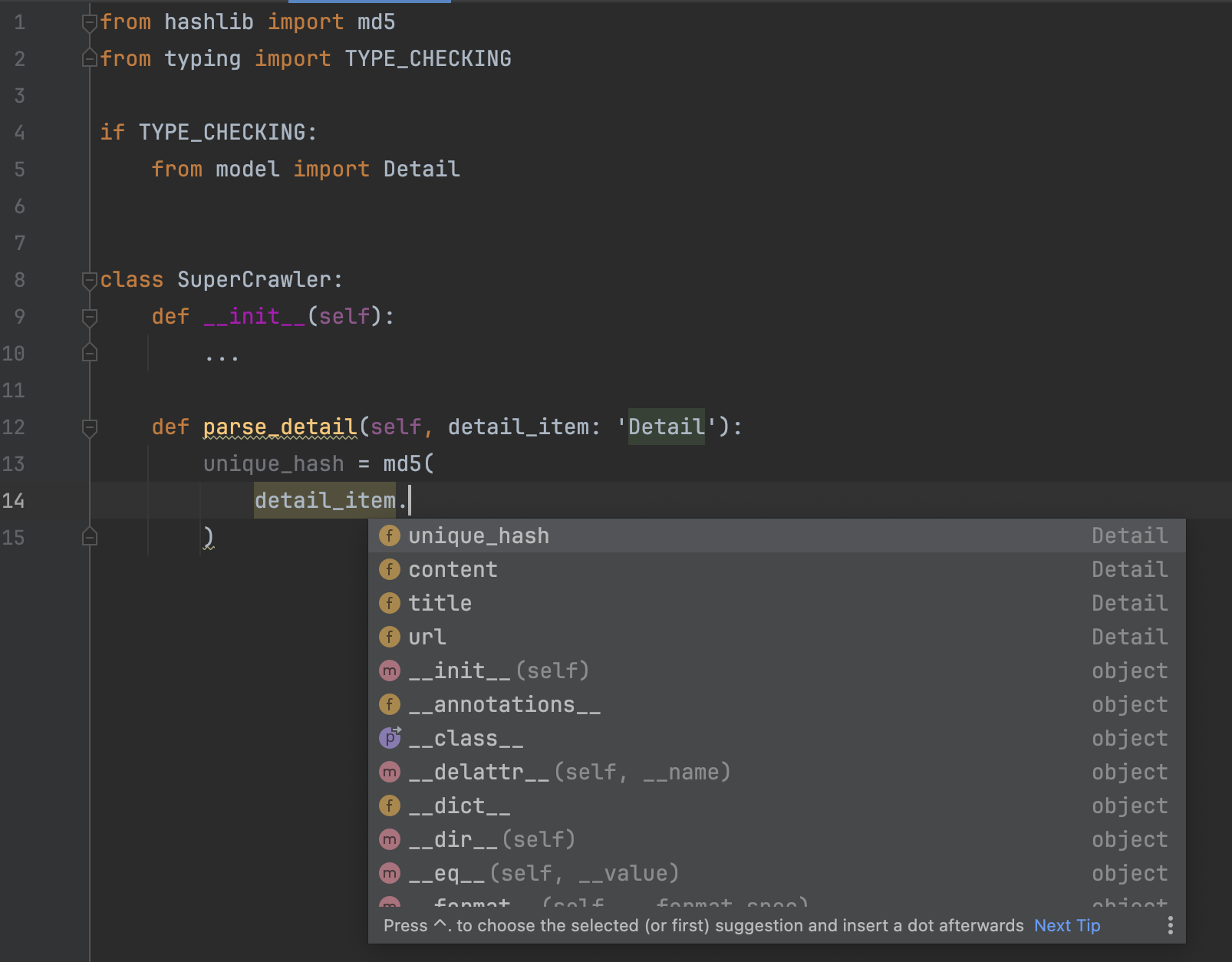
使用这种方法,在写代码时,IDE能够正确的做自动补全。在Mypy做静态类型检查时,也能过正常通过检查。但当代码实际运行时,会自动忽略这个导入的类,从而避免对代码的运行效率造成影响。
2024-11-01 06:34:28
当我们使用大模型生成JSON,或者爬虫抓取数据时,可能会遇到一些有异常的JSON,例如:
1 |
{"profile": {"name": "xx", "age": 20} |
1 |
{name: 青南, age: 20, salary: "99999999, } |
1 |
{"name": "青南", "age": 20, "salary: "\"very big\\""} |
Python的json模块解析这些有问题的JSON时就会报错。这个时候,可以使用一个叫做json-repair的第三方库来解决问题。
使用pip就可以安装json-repair。导入以后,就可以像json.loads一样使用了,
运行效果如下图所示:

对于双引号异常和反斜杠异常,也能正常解析:
字符串型的Python字典,也能正常解析,如下图所示:
使用这个模块,在很大程度上就能避免JSON解析不对的问题了。
2024-10-17 16:33:03
在文章一日一技:图文结合,大模型自动抓取列表页中,我提到可以使用大模型实现一个全自动爬虫。只需要输入起始URL加上需求,就可以借助模拟浏览器自动完成所有的抓取任务。
在实现的过程中,我发现涉及到的知识点可能一篇文章讲不完,因此拆分成了多篇文章。
今天是第一部分,我们暂时不依赖模拟浏览器,而是使用httpx(你也可以使用requests)实现全自动爬虫,传入我博客文章列表页,爬虫会自动抓取前三页所有博客文章的标题、正文、作者、发布时间。
爬取结果如下图所示:

运行过程如下图所示:
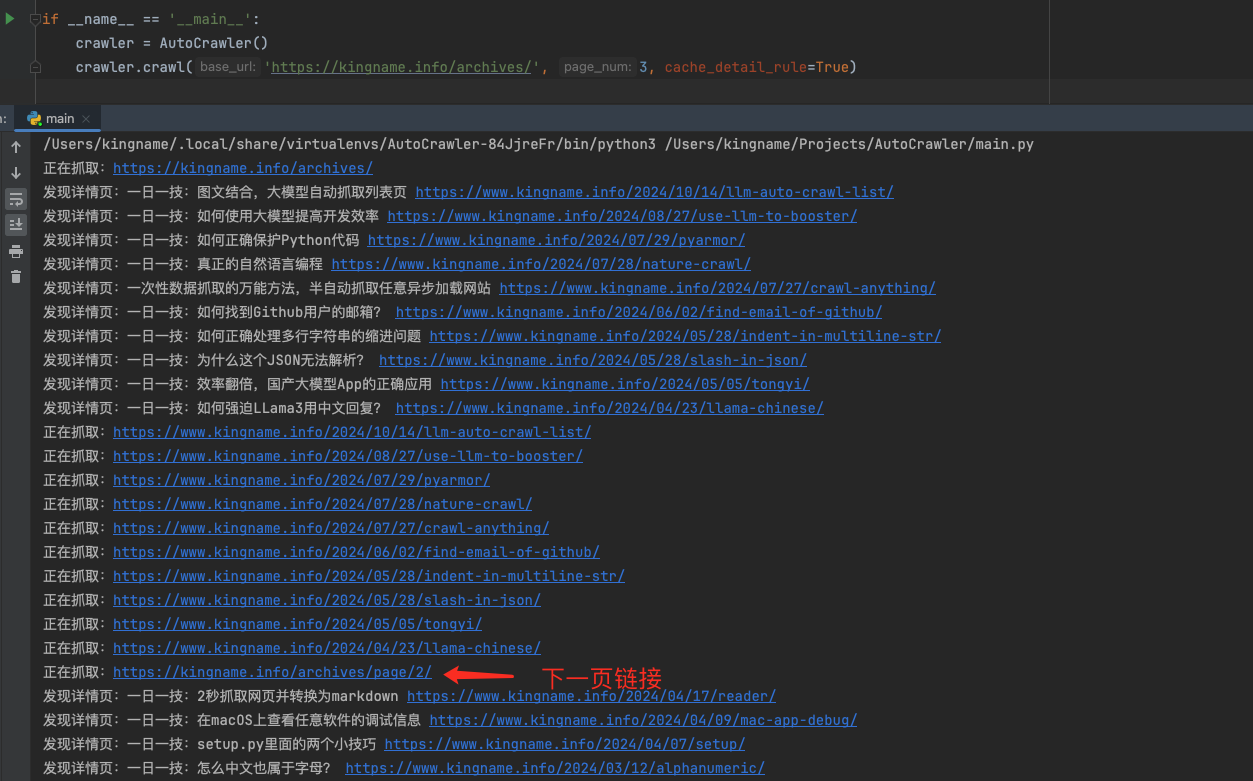
爬虫首先会进入起始列表页,抓取上面的所有文章。然后进入列表页第二页,再抓取所有文章,最后进入第三页,再抓取所有文章。整个过程都是全自动的。不需要写任何XPath,也不需要告诉爬虫哪里是翻页按钮,文章的标题在哪里,发布时间在哪里,正文在哪里。
代码我已经放到Github:AutoCrawler。由于最近智谱又免费送了1亿的Token,所以还是使用他们最新的基座大模型GLM-4-Plus来实现这个全自动爬虫。
代码分为如下几个主要文件:
llm.py: 封装智谱的大模型,以方便使用。代码如下:
utils.py: 常用工具函数,清洗HTML,重试等等
constants.py: 各种常量,包括各种Prompt
parser.py: 核心解析逻辑,解析列表页、详情页,识别翻页按钮
main.py:调度逻辑。把各个模块组合在一起
其中,跟大模型相关的代码在parser.py中。我们来看一下:
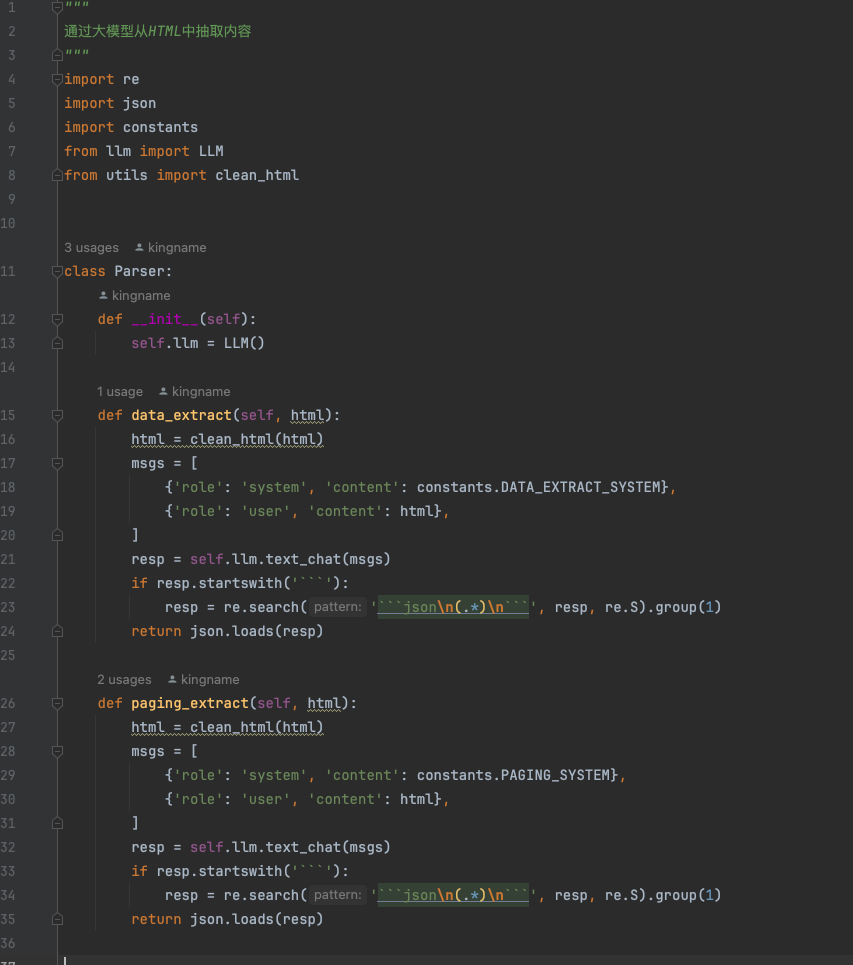
代码逻辑很简单,分为两个主要的方法,data_extract用来从列表页提取出详情页URL,从详情页提取出作者、标题、发布时间和正文。paging_extract用来提取分页按钮中,下一页对应的链接。
这个提取的过程就交给智谱GLM-4-Plus来完成。对于字段提取,对应的System Prompt如下:
1 |
你将扮演一个HTML解析器的角色。我将会提供一段HTML代码,这段代码可能代表了一个博客网站的文章列表页或者文章详情页。你需要首先判断这段HTML是属于哪种类型的页面。如果是文章详情页,那么页面中通常会包含文章标题、发布时间、作者以及内容等信息;而如果是列表页,则会列出多篇文章的标题及其对应的详情页链接。 |
可能有同学会疑惑,为什么对于列表页,是直接让大模型提取出URL,但对于详情页,却是生成XPath而不直接提取内容呢?原因很简单,因为现在大模型的Output Token远远低于Input Token,并且Output Token更贵。现在Input Token轻轻松松超过128K,但是Output Token大部分都在4096,只有少数在8192。对于长文章,把Output Token全部用完了可能都没法输出完整的正文。而且输出的内容越多,费用就越高,速度就越慢。你以为我不想让大模型直接输出提取好的内容?
而由于列表页的内容并不多,标题加上URL用不了多少字,所以就直接输出了。
获取翻页链接的System Prompt,如下:
1 |
你将扮演一个HTML解析器的角色。我将会提供一段HTML代码,这段代码可能代表了一个博客网站的文章列表页。你需要找到页面上的翻页链接,并提取出下一页的URL |
这就是常规的Prompt,没什么好解释的。
我们最后来看看main.py的代码:
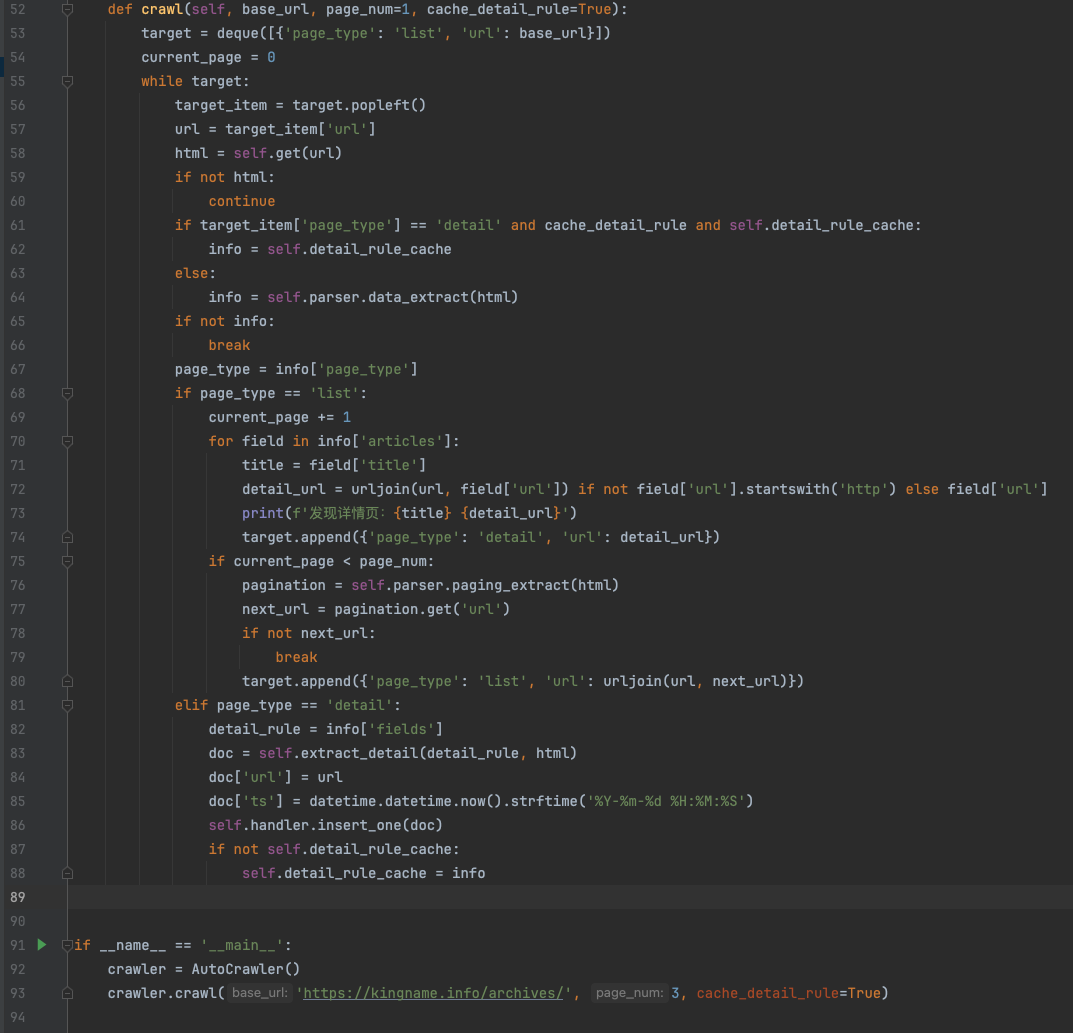
核心调度逻辑就这么几行代码。如果有同学经常刷算法题,应该会对这段代码很熟悉。这里使用while循环来实现递归操作。
一开始,target里面只有我传入的起始URL。然后进入while循环,当target队列为空时结束循环。在循环里面,首先解析当前列表页,获得当前页面所有的文章详情页URL,全部放入队列中。再获得下一页的URL,也放入队列中。接下来循环开始进入第二项,也就是第一篇文章详情URL,进入里面,获取源代码,使用大模型解析出XPath,然后调用self.extract_detail通过lxml执行XPath从源代码中提取出正文。接下来继续第二篇文章……如此循环。
今天我们实现的是最简单的情况。不考虑反爬虫。不考虑列表页滚动下拉的情况。在下一篇文章中,我们会把模拟浏览器引入进来。借助于大模型,让爬虫能够自己控制模拟浏览器,让它自动点击页面,绕过反爬虫,自动滚动下拉。
2024-10-15 06:45:59
熟悉我的同学都知道,GNE可以自动化提取任意文章页面的正文,专业版GnePro的准确率更是在13万个网站中达到了90%。
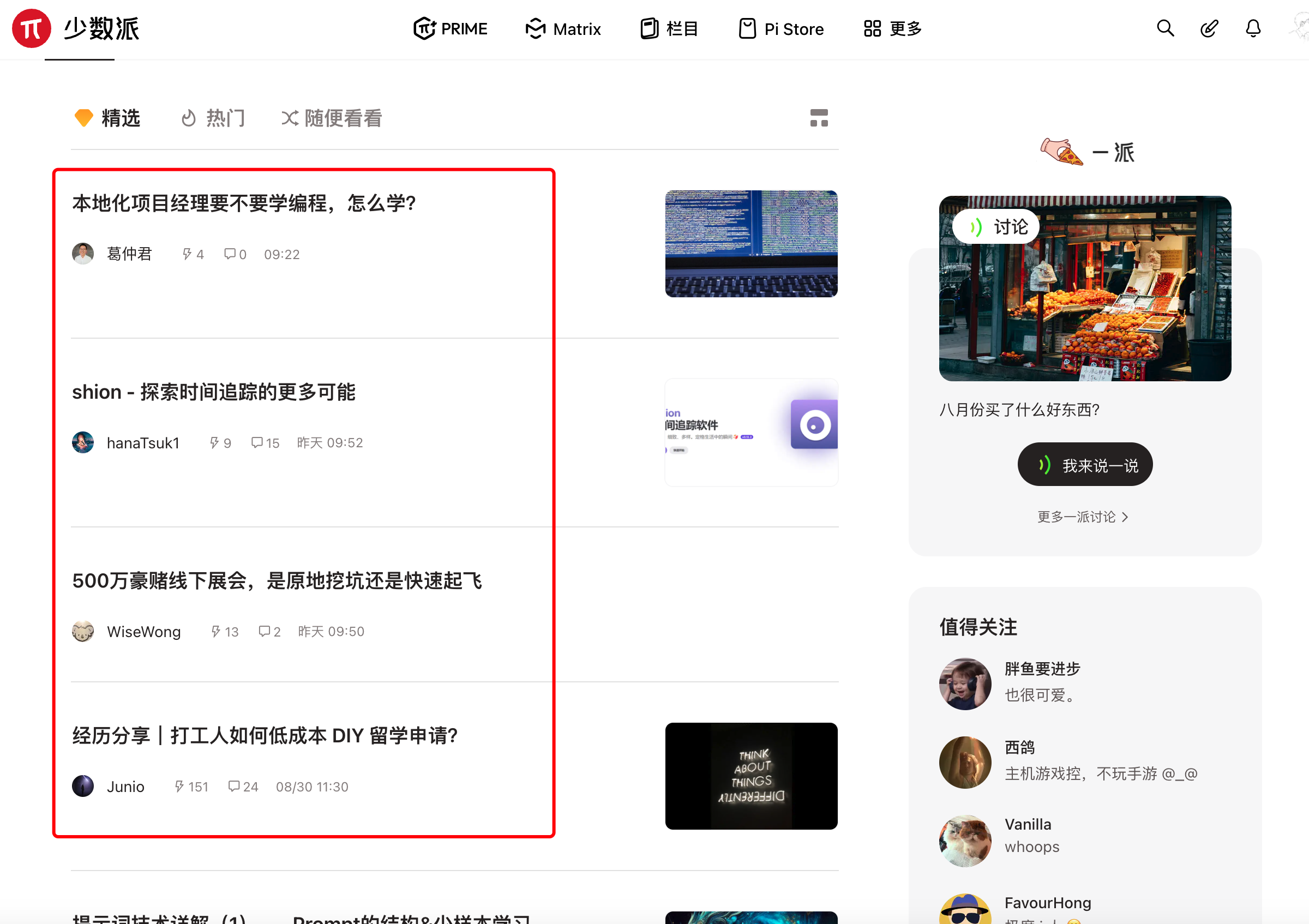
但GNE一直不支持列表页的自动抓取。这是因为列表页的列表位置很难定义。例如下面这张图片:
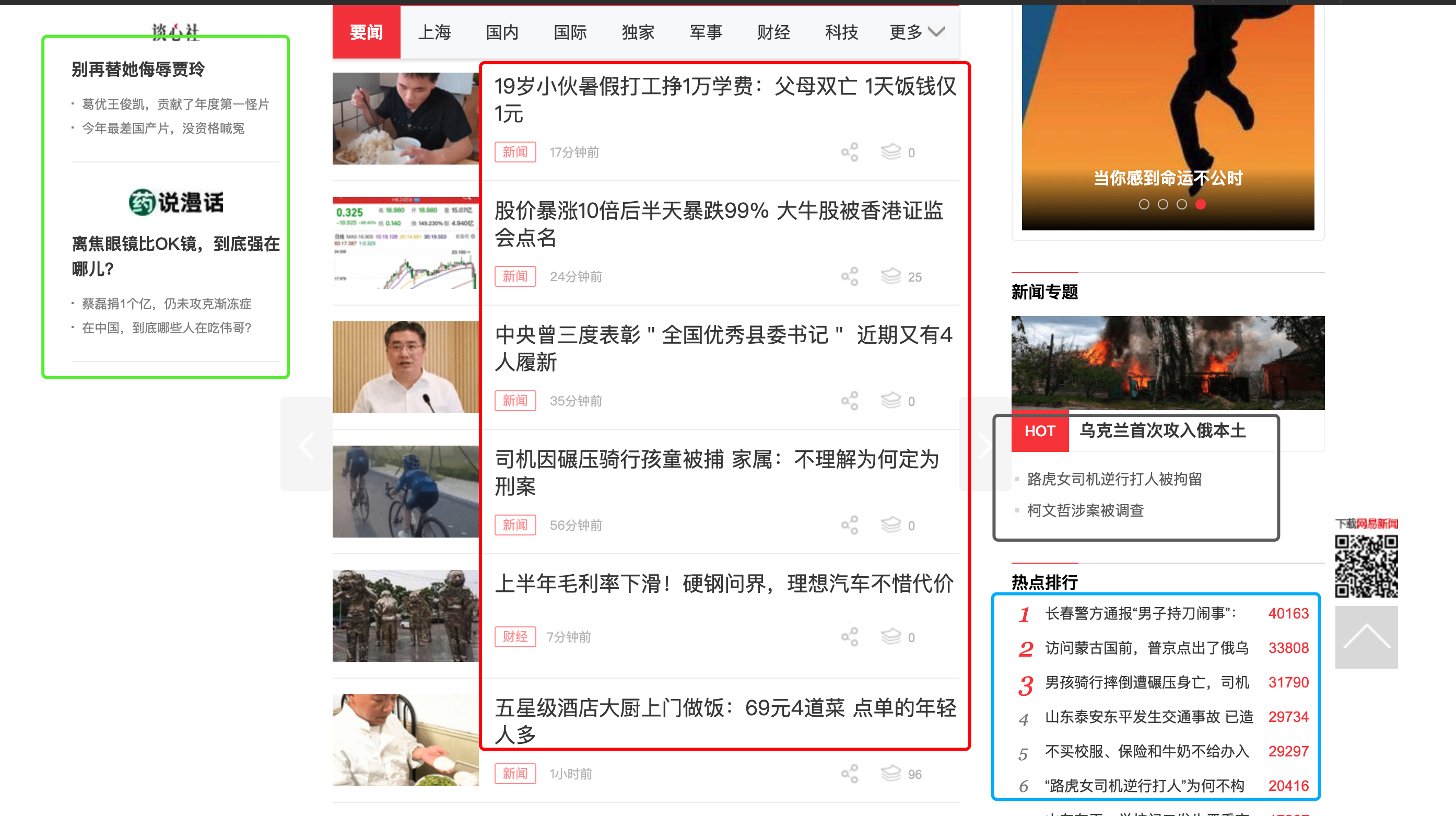
对人来说,要找到文章列表很简单,红色方框框住的部分就是我们需要的文章列表。但如果让程序自动根据HTML格式相似的规律来寻找列表页,它可能会提取出蓝色方框的位置、绿色方框的位置、灰色方框的位置,甚至导航栏。
之前我也试过使用ChatGPT来提取文章列表,但效果并不理想。因为传给大模型HTML以后,他也不能知道这里面某个元素在浏览器打开以后,会出现什么位置。因此它本质上还是通过HTML找元素相似的规律来提取列表项目。那么其实没有解决我的根本问题,上图中的蓝色、绿色、灰色位置还是经常会提取到。
前两天使用GLM-4V识别验证码以后,我对智谱的大模型在爬虫领域的应用充满了期待。正好这两天智谱上线了视频/图片理解的旗舰模型GLM-4V-Plus。于是我突然有了一个大胆的想法,能不能结合图片识别加上HTML,让大模型找到真正的文章列表位置呢?
说干就干,我这次使用少数派的Matrix精选页面来进行测试。如下图所示:
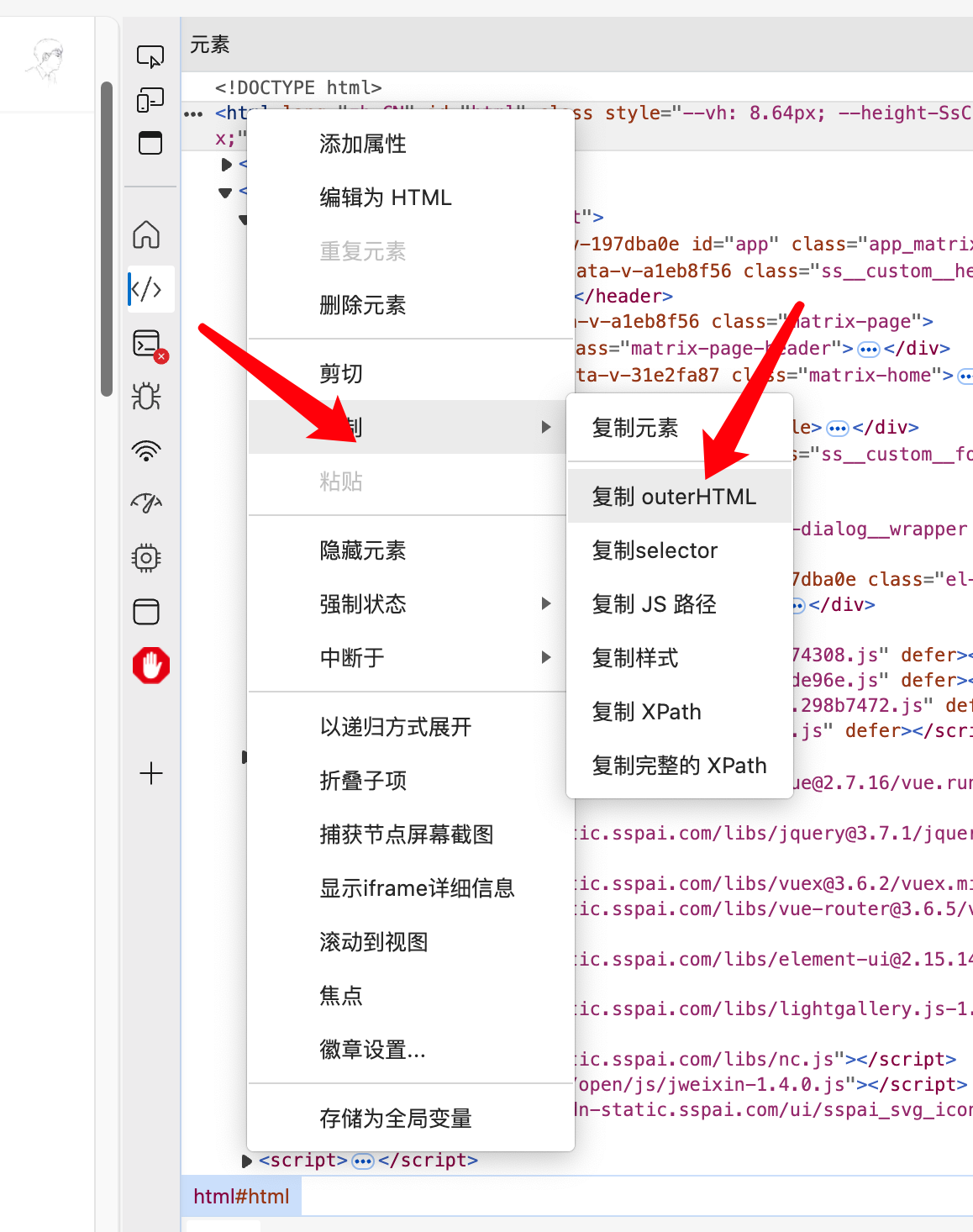
需要注意的是,这个页面是异步加载的页面,因此通过在开发者工具中右键来获取包含列表页的源代码,如下图所示:
接下来,为了节省Token省钱,我首先对这个HTML进行清洗,移除一些显然不需要的HTML元素:
1 |
from lxml.html import fromstring, HtmlElement |
代码如下图所示:

其实有很多页面,在源代码里面会有一个
<script>标签,它有一个type属性,值是application/ld+json。它的text是一个大JSON,包含了页面上的所有有用信息。只需要提取这个JSON并解析就能拿到需要的全部信息。不过这个情况不在今天的讨论范围,因此我们也把<script>一并删去。
接下来,对少数派这个列表页做一下截图,调用GLM-4V-Plus模型时,同时上传截图和源代码。如下图所示:
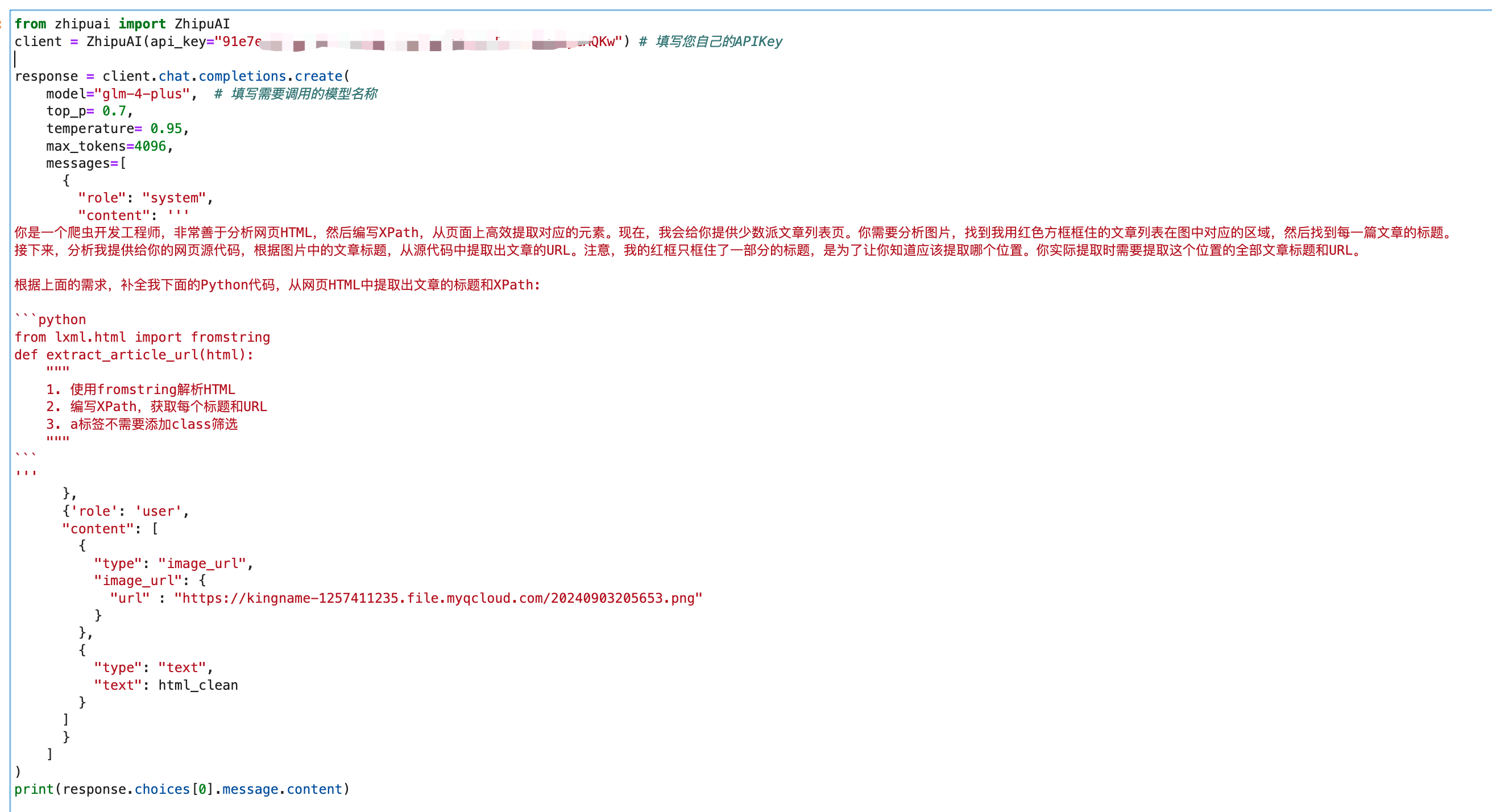
在system里面,我定义了一个函数,并通过注释说明这个函数需要实现什么功能。让GLM-4V-Plus首先理解图片,然后分析HTMl,并补全我的Python代码。
最后运行生成的代码如下图所示:
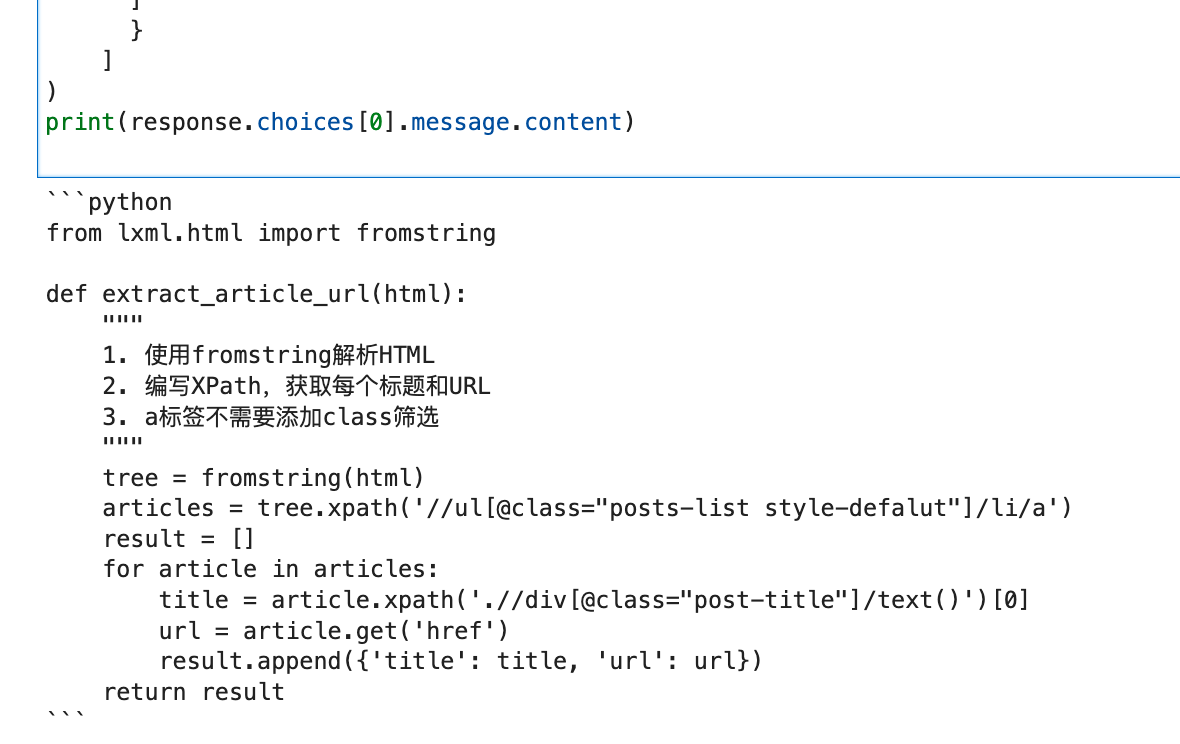
我把这段代码复制出来执行,发现可以正确解析出列表页中每篇文章的标题和URL,如下图所示:
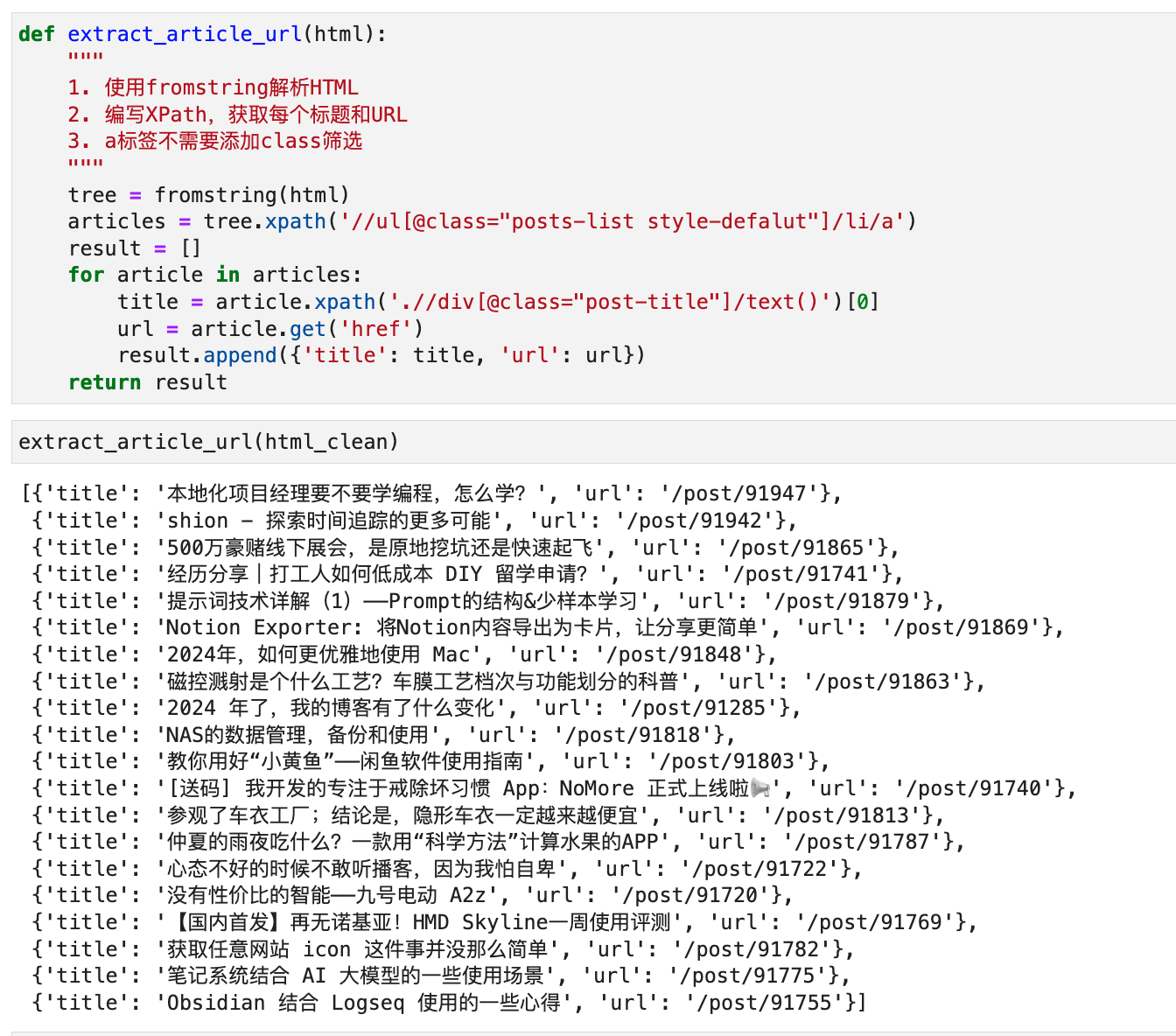
它自动生成的XPath,到少数派页面上手动验证,发现确实能够正确找到每一篇文章:
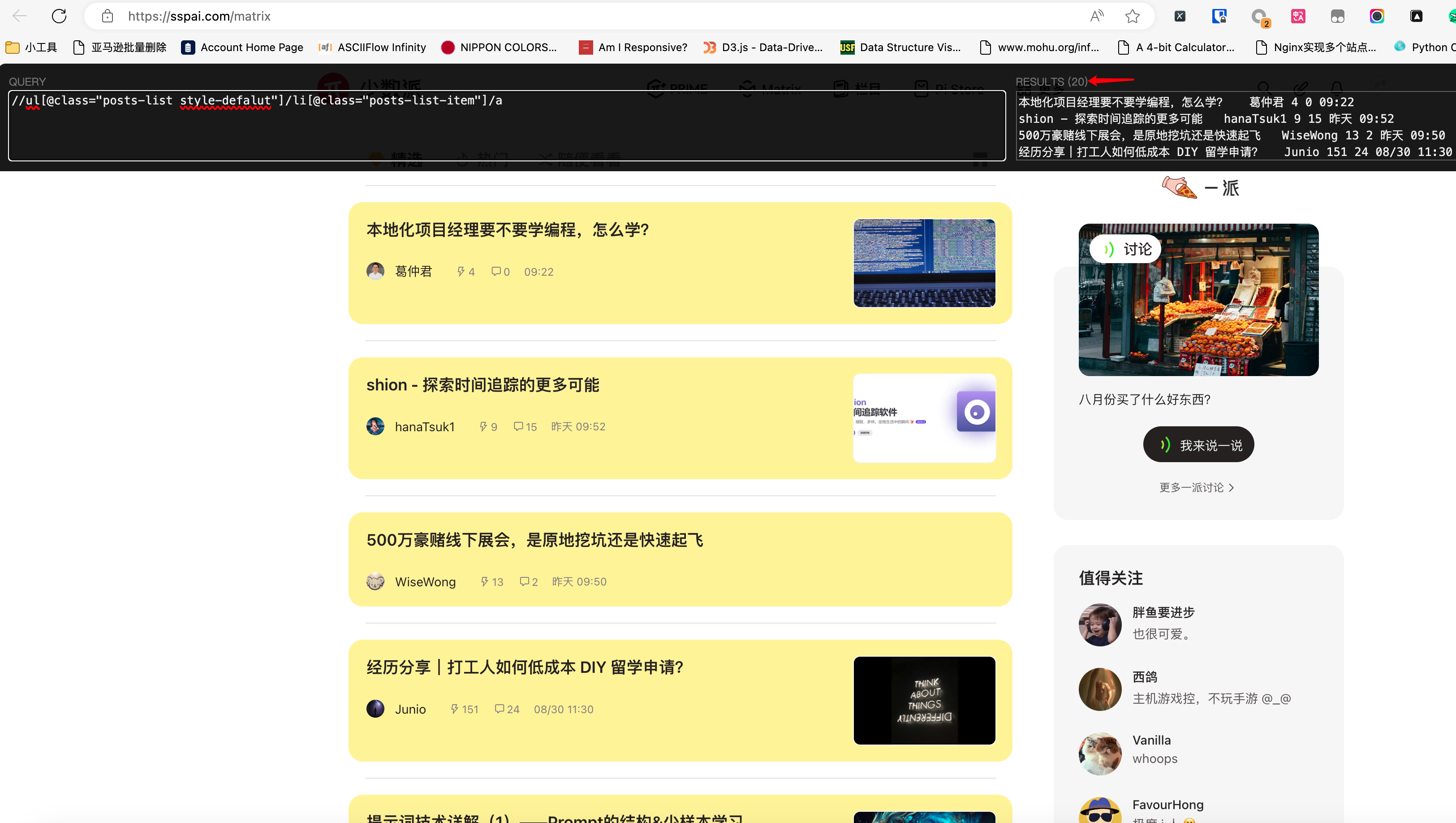
看起来,GLM-4V-Plus模型真的是天然适合做爬虫啊。如果我再把DrissionPage用上,通过模型的Tool Call机制来控制DP操作页面,嘿嘿嘿嘿。
如果大家对GLM-4V-Plus+DrissionPage结合的全自动爬虫有兴趣,请在本文下面留言。我们下一篇文章,就来实现这个真正意义上的,自己动,自己抓,自己解析的,拥有自己大脑的全自动爬虫。
我看智谱的推广文案里面说,推出-Plus旗舰模型,专注于大模型的中国创新,让开源模型和开放平台模型,推动 AI 力量惠及更多人群。那么我们爬虫工程师肯定是第一批被惠及到的人群。