2024-07-11 18:36:18
本文是我在 VueConf 24 CN 的开场演讲稿,分享我和 Vue.js 的十年的故事。
文中截图来自我的幻灯片。另外我试着挑战了一下 Paper Mario 的主题风格,希望大家喜欢。
- VueConf 24 CN 官网:https://vueconf.cn/
- 在线幻灯片地址:https://jinjiang.dev/slides/my-10-years-with-vuejs/
- 演讲 B 站视频地址:https://www.bilibili.com/video/BV16W421R7ga/

一转眼,Vue.js 已经十周年了,这同时也几乎是我个人参与 Vue.js、参与开源项目的十年。
我和 Vue 缘分的开始应该是自己 2014 年在阿里内部创建的一个项目,名字如果没有记错的话叫 lib-noble。这个库算是一个 data observer 的 JavaScript 实现,后来我们管这种东西叫 reactivity API,再后来叫 signals。在我看来大同小异。写了这个库没多久,我就在 GitHub 上发现了 Vue.js,其中数据处理的相关设计和实现都跟我自己写的东西不谋而合。我当时的第一反应是,这个库比我写的好多了,而且还有很多其他功能,比如组件系统、模板编译等等。于是我就开始关注 Vue.js,并一路参与到了今天。
在这十年里,Vue.js 本身,包括团队,都经历了很多事情。我自己所经历的故事,已经出圈且被大家熟知或调侃的,也许就是自己在 Vue 的第一个 PR (只改了两个空格)、维护中文官网 (今年愚人节我们玩了个“威优易”的彩蛋)、创建了开源项目 Weex 并和 Vue 有一段时间的双向官方合作、以及在 Vue 的纪录片中出镜等等。相关的内容不打算赘述了。这次我主要想分享几则背后发生在 Vue 和我自己身上的小故事。尽可能还原一个更加立体的历经 10 年的开源项目。
时间:2015 年 1 月 5 日

背景是一个工作日的下午,尤雨溪来阿里巴巴西溪园区和团队分享介绍他的新项目 Vue.js,那也是我在团队内部推广 Vue.js 的时间点。分享结束后,我们和另外几个阿里的同事一起去星巴克闲聊。
我们讨论了很多技术相关的话题,另外印象最深刻的是,我通过尤雨溪的介绍认识了很多讨论技术的国际化的社区,这在我之前的工作习惯中是很少接触到的。这也对我后来参与开源项目、通过国际化技术社区了解和交流技术有了很大的帮助。
拥有一个开放的技术视野,对于一个开发者来说是非常重要的。这也是我在与 Vue.js 的十年中的一个不大不小的收获。
时间:2016 + 2017 连续两年

当时我是阿里无线事业部的前端架构负责人,得知天猫前端团队有一个框架选型的窗口,于是试着推荐了一下 Vue.js 给他们。我们第一次谈的时候是 2016 年末,当时天猫前端团队对 Vue.js 的主要质疑是基础功能层面的,比如是否可以支持 IE6 之类的问题。我因此也和小右做了简短的交流,发现其实是有机会的,比如通过 VBScript 做一个数据监听的兼容层。我们还围绕 Vue.js 的一些别的特性做了讨论和交流,但很遗憾的是最终天猫前端团队还是选择了另外一个框架,那个框架的名字叫做 React。这是我们第一次就框架选型进行的交流。
虽然交流结束了,但对于我个人推广 Vue.js 的尝试来说,这只是一个开始。2017 是 Vue.js 快速发展的一年,不但发布了全新的 2.0,同时 Weex 这个项目也宣布开源,和 Vue.js 展开全面的官方合作。2017 年末,听闻天猫前端团队又有一个框架选型的窗口期,我决定跟他们再谈一次。这次的交流更多的是关于 Vue.js 的生态和社区,但仍然是充满了各种质疑,比如天猫方面觉得当时 Vue.js 的生态不够完善,谈话再一次陷入了僵局。我当时觉得完全没有办法改变天猫对 Vue.js 的感官,这次可能又要败兴而归了,临走之前我还是不甘心,甩下了一句接近是发牢骚的话,我说你看去年你们在担心 Vue.js 的特性,我们用了一年时间证明框架的特性完全不再是问题;今天你们再次担心 Vue.js 的生态和社区不够成熟,我虽然没有办法立刻回答这个问题,但我敢打赌,明年我们再见面的时候你们不会再问这个问题了。这段话说完之后自己扬长而去。
后面发生的故事大家可能都知道了,天猫前端团队稍后决定选择 Vue.js + Weex 作为天猫前端的主要框架。
这次“争取客户”的经历让我印象深刻。和我们平时在公司做的项目不同,开源项目的用户不是天生就有的,而且没有专业的市场和运营团队替你做这些事情。唯有自己不断去主动地、反复地争取,才会有转机出现,才会有真正的用户。这是我参与开源前所未有的体验之一。
时间:2016 年末

当时已经是我在 Weex 团队的末期了,和 Vue.js 的官方合作也进行了一段时间。我和自己当时的主管一起在食堂排队打饭。因为队伍很长,我们俩闲来无事,就随便聊天。在谈论到一些工作上的问题时,我在想也许这是一个不错的时机,就把自己心里憋了很久的一段话说了出来。我说自己其实不得不坦承,做开源做到现在,心态已经逐渐发生了微妙的变化,虽然深知自己是阿里的员工,但归属感更加倾向于开源本身,而不是公司,这是一种近乎本能的感受。我的主管听完之后,没有说什么,意味深长地点了点头。
我想说,我们很多人对待开源,都是在自己有工作的基础上利用从业余时间起步的,也许或多或少都经历过这种做事方法和意识形态上的挣扎。当矛盾和冲突出现的时候,是什么让你处于纠结的位置?你会本能地站在哪一边?自己如何分配自己的精力?这些问题,我想,是每一个参与开源项目的人都会遇到的。我把这个称之为开源人的“身份认同”感。
时间:2017 年 8 月

也许人们已经逐渐忘记 2017 年 8 月前端圈发生过什么样的争论,那个时候 Vue.js 逐渐走入了主流的视野,伴随而来的是很多人的挑战和不屑。
我得说,简中互联网一直就不是一个和谐的存在,很多言论都充满了攻击性。在那个时期,每个人的价值观、表达方式、看问题的角度都是不同的,这种差异在互联网上被放大了。我也因为一些言论而被人攻击,也可能不经意间冒犯到了别人。但发生在那段时间对 Vue.js 和小右本人的争论,非常火爆而惨烈,而且看不到收敛的趋势。最后这件事情已经严重影响到了当事人正常的生活,而小右也不得不被老婆没收手机,通过这种“非常规操作”,整件事情才告一段落,大家也才逐渐冷静下来。
当时大家具体的讨论内容,我们今天不必多谈,因为 Vue.js 通过这么多年的发展已经把各种争议逐一摆平。但在那个时刻,作为一个开源项目,当你被更多人看到的那一刻,也就是会被更多人拿起放大镜审视的一刻。这是一个槛儿,一条长征路上的必经之路。
同样地,如果只跟自己公司的客户打交道,你可能永远也不会想到,作为一个开源项目,你无时不刻会遇到各种各样的人,你甚至不知道他们来自哪里,但却需要面对他们的每一个问题和质疑。这是做开源的另一门必修课。
时间:2018 年 11 月 3 日

这是我第一次去日本参会,也是我第一次参加 Vue.js 的一个国际性的大会。我在会场里碰到了很多来自世界各地的开发者,他们对 Vue.js 的热情和专业程度让我印象深刻。
那次会议给我印象最深的其实是我和小右在会后的一次交流。在那次交流中,我们聊了很多关于个人和项目长期发展的话题,比如要有长期的规划,要有壮大团队的准备,要有合理的经营模式等等,包括“被动收入”这个词,就是我第一次从这次交流中听到的。
这让我想到,做开源,不是把源码放到 GitHub 上就完事了,而是需要有一个长期的规划和经营。这个规划和经营,不仅仅是技术上的,还有很多其他方面的,比如社区、商业、生态等等。
时间:2016 年夏

那个时候我还在 Weex 团队,和小右的合作已经进行了一段时间,我们在上海的一个咖啡馆里见面,本身是聊 Vue.js 和 Weex 集成的一些技术细节,但聊完工作之后,大家都还有些时间,就继续闲聊了很多别的技术。印象中同行的还有 Hax,一位非常资深的同行,后来成为了国内为数不多的 TC39 成员。
那是我们接下来无数次讨论打包构建工具的开始,当时 webpack 已经变成毫无争议的主流,但性能和复杂工程的配置问题也逐渐变成了前端工程家家户户难念的经。同年 Rollup.js 也开始崭露头角,我们也讨论了很多关于 Rollup.js 的优势和劣势,以及它和 webpack 的区别。后来大家都知道了 Vite 的诞生,从我的视角来看,Vite 的诞生看似是一次偶然的尝试,但实际上是一个长期的技术积累和思考的结果。直到一个基于上述的创新的想法被证实,才会被大家看到。
有的时候做成一个开源项目,不是因为你知道的东西更多,而是因为你在大家都知道的地方,产生了独创的智慧的想法,做了一些别人没有做到的事情。你需要一双慧眼,哪怕只是改变这个世界一点点。
时间:2023 年 3 月
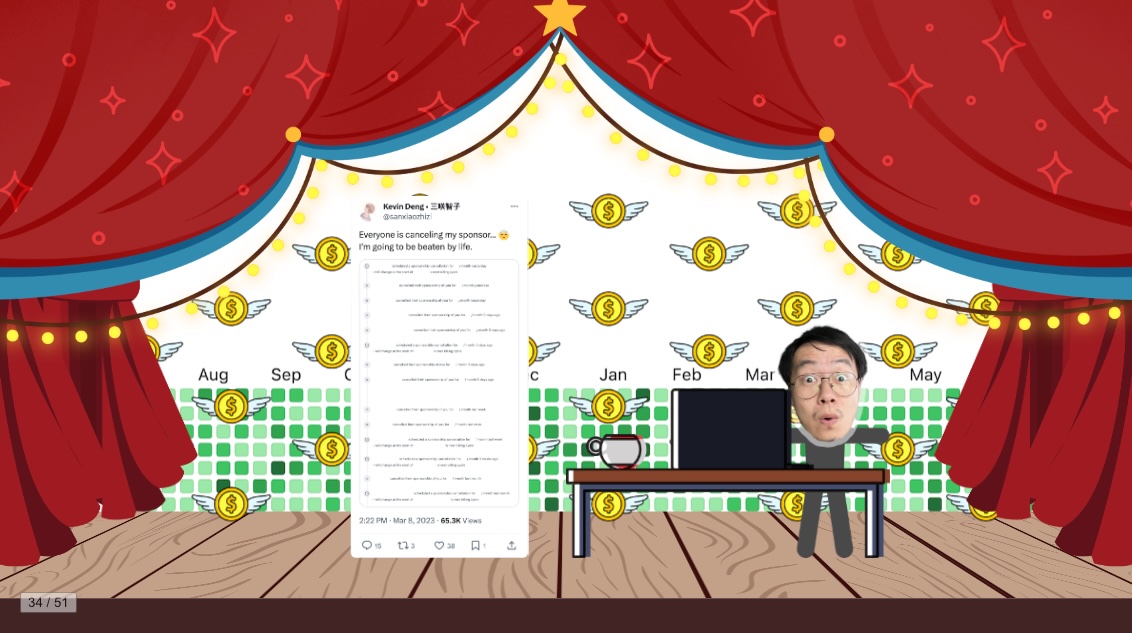
时间来到去年春天,当时 GitHub Sponsor 终止了对 PayPal 的支持,导致我周围很多以接受社区赞助为主要收入来源的开发者都遭遇了一次收入的大幅度下降。很多人都在网上晒自己损失掉的赞助,或表达各种负面的情绪。
我虽然严格意义上不算是靠开源赞助谋生的开发者,但我看到周围的朋友都在失去赞助,心里也特别不是滋味,觉得应该做点什么。于是决定在社交平台上号召更多人加入到赞助的行列。我自己也开始在 GitHub 上赞助自己周围的开源人,虽然不是很多,但我希望能通过自己的实际行动给社区提提气,也希望这是一个好的开始。
通过这次经历,也让我设身处地的感受到,很多开源项目的维护者,尤其是那些靠开源项目谋生的人,他们的生活其实并不容易。即便是那些大名鼎鼎的开源项目,维护者的收入也随时处在不稳定的状态,这种不稳定的状态和不安全感,是我们习惯在大厂上班,有固定的薪水和五险一金,甚至年底还能拿大红包的人所无法体会的。
时间:2021 年至今

我和小右两家人都先后搬来了新加坡,也许你和我一样曾设想过,我们两个每天待在新加坡的某个咖啡馆里讨论技术的场景。但实际上是,我们每次见面绝大部分的话题都是技术以外的琐事,比如如何带小孩,如何管理好自己的时间,当然偶尔也会一起打打游戏看看比赛之类的。
更近距离和小右接触下来,我觉得小右对我来说已经不仅仅是技术上的同行,而更像是生活上的伙伴,一个活生生的人。这种人情味,是我们在 GitHub 上看不到的。但这也让我想到,开源项目的背后,其实都是这样一群人。大家一开始做开源也许只是一个简单纯粹的动作。随着时间的推移,逐渐拥有更多自己的生活、家庭、甚至上有老下有小之后,做开源不再那么简单,而变得复杂。这是难免会遇到的、同时也是需要我们正面面对的问题。

其实除了上述这几则故事,这 10 年间发生在 Vue.js 和我自己身上的珍贵回忆还有非常多,包括项目的 GitHub star 一路飙升,超过别的我们之前仰慕的开源项目的时候;包括每次有大公司宣布选用或赞助 Vue.js 的时候;包括每次新版本 Vue.js 发布的时候;也包括每次参加的团队线下聚会;也包括每次新人加入、旧人离开;这些都是我这 10 年来参与 Vue.js 的一部分。每一段旅程都有值得细品的独一无二的内容。
然而我选择上述这八则故事的原因,是我觉得他们充分体现了五个字:开源之不易。

开源之不易,不仅仅是技术上的高瞻远瞩和灵光乍现,还有很多其他方面的。开源之不易,是因为你需要不断地去争取用户,去解决用户的问题,去回答用户的质疑。开源之不易,是因为你需要不断地去面对各种各样的人,去解决各种各样的问题。开源之不易,是因为你需要不断地去思考未来,去规划未来,去经营未来。开源之不易,是因为你需要不断地去适应变化,去接受挑战,去面对困难。
所以,每次回首 Vue.js 走过的十年,我越来越觉得,这是一段不易的旅程,也越来越庆幸自己能够参与其中,更由衷地感谢所有支持 Vue.js 的人。

在前端技术快速发展迭代的今天,你也许会觉得一个 10 年的框架已经算是“老掉牙的框架”了,但我觉得 Vue.js 并不是,引用我特别喜欢的电视节目《圆桌派》中的一句话:“心中有大志”。如果心中没有伟大的志向,那人才是真的老了。我想说,Vue.js 在 10 年后的今天,依然活力十足,我们有非常多年轻有为的新鲜血液不断加入,也一直在推出新的特性和工具,包括不仅限于这次 VueConf 上介绍的 Vapor mode、新版 DevTools、当然也包括新的 Vite 和 Rolldown 等等。我们有理由期待 Vue.js 的未来。

也希望大家可以跟 Vue.js 一起,再战十年!
2024-03-26 14:30:00
关注我的人可能已经知道我最近作为常驻嘉宾加入了一个叫做《代码之外 Beyond Code》的播客节目。
![]()
这里简单分享一些我参与《代码之外》的故事:
这是一档由 GeekPlux 和 Randy 共同主持的程序员闲聊节目。虽然二位主播都是程序员,但节目基本不谈编程写代码,而是谈一些程序员在工作和生活上比较有共鸣的话题,或是从程序员的视角看待一些社会热点。截至目前我主要参与的部分是听众来信栏目,在节目上公开回答听众们的问题。
我其实和 GeekPlux 和 Randy 之前都相互认识。GeekPlux 是我之前在阿里云的同事,短暂共事过一阵子;而 Randy 是因为之前我做 Weex 这个项目有机会和他认识。后来我从阿里离职,也逐渐跟他们比较少联络了,直到最近我在社交网络上发现他们做了这个节目。我从“第 0 期”就开始听,一方面是因为好奇他们二位最近的工作和生活状态,另一方面也是被节目内容所吸引。
因为我一直觉得技术类的话题在网上包括线下的交流会到处都是,但是技术以外其实还有很多值得探讨的话题,在国内并没有什么平台和机会进行交流和分享。这个观点我之前在关于 D2 前端论坛的一篇博客里曾有提及:
我希望 D2 今后可以有一些关于团队、关于人的主题。我们的技术能搞上去,业绩能搞上去,人,怎么样?
《代码之外》在我心目中恰恰是这样的节目,它让很多值得被关注的非技术议题浮出水面,引发大家的讨论,在我看来是非常非常有意义的,也是我一直想做但一直没有付诸实际行动的事情。所以我每一期都听得津津有味,而且非常有带入感。
大概听了两三期之后,《代码之外》有了自己的 telegram 听友群,我也跟着其他听众一起进了群,跟 GeekPlux 和 Randy 恢复了联络。我跟二位说,节目有我能“插上话”的地方都可以随时找我,非常乐意贡献自己的观点和看法。他们非常爽快地答应了。
后来发生的事情就是我被邀请作为嘉宾录了一期节目:
第 6 集 | 勾股如何看待 Weex 被指 KPI 项目、转管理的经验、向上管理的技巧、如何建立个人品牌、双十一的经历
在这期节目中,我们顺带讨论了一封关于如何建立个人影响力 (reputation) 听众来信。节目播出后效果似乎还不错,再之后我开始作为固定嘉宾参与每一期听众来信的录制。不得不说来信的问题质量都很高,每一个问题都是好问题,我们也是来者不拒,从职场技能聊到个人发展,再聊到开源项目心得等方方面面。
首先是因为之前所提到的我对非技术类话题的价值认同,我觉得这个是核心原因吧。
其次,我非常欣赏 GeekPlux 和 Randy 在节目中展现出的个人气质和魅力,我相信这也是有这么多人收听这个节目的重要原因之一。有机会和他们二位对谈,讨论有价值的议题,碰撞思想,是一件非常珍贵、也是非常酷的事情。

同时从自身的角度,我也希望可以运用好自身多年编码和管理的经验,输出一些自己平时对生活和工作的观察和思考。这段时间对于很多国内的从业者来说,可能是一段特别艰难的时期,我能直接参与和提供的帮助有限。但用现在流行的说法讲,也许我可以通过这个节目提供一些“情绪价值”:)
最后,我也希望自己可以保持一个不断接触新事物的学习的心态。一方面是暗中观察 podcast 前前后后的工作,不只是在节目上传递信息,更包括参与完整的制作和宣发流程,学习相关的专业知识和技巧,结实这个圈子里的有识之士;另一方面也可以被更多年轻的听众认识,近距离观察和学习每个人的经历和看问题的角度。这些长期来看一定会给我自己带来很多收获。
当然也有时间的因素,我现在在新加坡的工作和生活逐渐趋于稳定,有了些闲暇的时间,正好可以支撑我做一些额外的事情。各方面因素综合在一起,让这件事情顺理成章。
截至目前,我和 GeekPlux 和 Randy 二位已经陆陆续续一起做了 7 期节目,包括 1 期我自己的人物访谈和 6 期听众来信:
第一个感受就是每次跟二位聊天都特别开心,一聊就忘记时间停不下来。大家不止一次聊到某个观点的时候发自内心的相互认同,有一种找到知音的感觉。再有就是参与这个节目让我以一种更认真负责细致的态度审视看似平实的东西,每次跟着二位在节目前准备素材、节目中互相碰撞、节目后关注和复盘的过程中,自己都有非常多的收获。
另一个有趣的事情是,我在这个过程中改进了我的声音。尤其是开始参与后期制作的时候,我发现自己有的时候说话有气无力,或者有一些不好的说话习惯,包括那些啧啧啧、嘶嘶嘶的下意识发出的声音,真的是觉得影响听感又非常难克服。我还在持续改进中,并感慨每件事情做到极致都是不容易的。
对于音频/视频的处理,我也算是入了个坑,至少了解了一些常用的软件和专有名词,尤其是音频的剪辑和处理,门道其实还挺多的。由于自己还是菜鸟阶段,没到系统性总结的时候,这里就不展开了。
我通过这个节目还认识了一些优秀的播客们和主持人们,前段时间还有幸跟另外几个播客节目的主播们串了个台,估计节目很快就会上线了,也尽请关注。
当然最开心的莫过于得到了很多来自听众们正面的反馈。我深知做好一档节目有很多地方需要继续努力,这些正面的反馈给了我自己莫大的鼓励和坚持下去的动力。
听勾股聊天还蛮有启发的,建议常驻😆
-- wavever通过读书来学习管理,这挺有趣,因为之前看到一些观点说管理并不能从书本学习到。记录一下《合作的进化》《领导学》
-- piero_cli这期真的学习了很多 Beyond Code and Far more than I learned
-- @user-fv9po5tt3r2个小时,看完了,干货很足,期待后续的节目~
-- @user-ue9kv1tr8o受益良多[打call]
-- 牛头梗0一口气听完,比看场电影都爽
-- 码农有梦想听完最大的感受是,勾股情商好高[吃瓜][打call]
-- 杜府UP很好的节目[支持][支持]目前也在备考雅思 中间嘉宾的发言真是太认同了
1.学习乐器和英语和学习编码的区别之一在于一个相对枯燥,一个相对新奇
2.将最困难最枯燥的事情放在早上精力充沛的时候做
3.对于这种反馈周期长的学习任务,给自己制造一些正反馈
-- 黑丸子丶超级开心啊,之前勾股的访谈那期真的学到了很多,以后变成常驻嘉宾真的太好啦!
-- UsagiCake
有一期节目录完之后,跟 Randy 和 GeekPlux 二位主播 after cut 闲聊,他们都鼓励我做个一对一私人咨询的服务,觉得我的观点和经验会帮助到更多的人,尤其是我们都意识到,现如今听众来信里的很多话题,都逐渐从小众转化为了大众、甚至社会性的话题;同时一对一私人咨询也可以做得比节目更深入,更好的保护当事人或公司的隐私需求,因为节目的时间和机会毕竟有限,且是公开形式的,很难针对性 + 回合式地聊太深。于是我打算抱着试试看的心态做起来,也许近期就会有进展跟大家再分享。
2024-04 更新:我的一对一私人咨询服务已经启动,请移步至:
同时,《代码之外》和听众来信栏目我也会和二位主播一起继续做下去,继续解答大家的问题。
如果大家对于这个一对一咨询服务的形式有什么兴趣、想法或建议,也欢迎通过任何方式让我或《代码之外》节目知道。
以上
2023-08-05 20:31:25
水一篇。这周集中把博客由 Hexo 迁移到了 VitePress,顺便把主题也换了。简单记录一下迁移过程。


根据我的观察 VitePress 目前用的最多的是文档站,比如 Vue 的官方网站、Vite 的官方网站、Rollup 的官方网站等。但是拿它来做博客站的不多,但也完全没有问题,比如 Vue 的官方博客。另外我还找到一个叫 vitepressblog.dev 的站点,它是一个 VitePress 的博客主题。对两者做了简单的比对之后,我觉得 Vue 的官方博客的主题更简单更适合我的需求,所以我就直接把源文件拿来用了。
我之前的博客内容主要分了四部分:
我把这四部分进行了逐步迁移
先把独立页面迁移过来,这个很简单,把每个文件复制到相同的路径就好了
把所有文章都拷贝到新仓库的 blog 目录,但不急于调试文章的展示页面,因为这些文章还暂时没有入口,所以我紧接着先迁移了文章导航
实现文章导航。Vue 的博客站主题有一个明显的局限性,就是它的博客列表不支持分页。我这里运用的是 VitePress 自身的 Dynamic Routes 特性,在工程里同时创建了 page/[page].md 和 page/[page].paths.js 来计算和生产分页信息。如 paths.js 的内容如下:
import { readdirSync } from 'fs'
const PAGE_SIZE = 10
// 计算文章数量
const data = readdirSync('./blog').filter(x => x.match(/\.md$/))
// 计算页面数量
const pageMax = Math.ceil(data.length / PAGE_SIZE)
// 创建分页参数
const pageParams = new Array(pageMax).fill(0)
.map((_, i) => ({ params: { page: i + 1 } }))
export default {
paths() {
return pageParams
}
}这样在相应的渲染组件里就可以:
import { useData } from 'vitepress'
// 这里的 `./posts.data.js` 和 Vue 博客站的实现相同,所以就不赘述了
import { data as posts } from './posts.data.js'
const PAGE_SIZE = 10
const { params } = useData()
const currentPosts = computed(() => {
const { page } = params.value || { page: 1 }
const start = (page - 1) * PAGE_SIZE
const end = start + PAGE_SIZE
return posts.slice(start, end)
})同理,对于归档页面来说,也是对应的实现 archives/page/[page].md 和 archives/page/[page].paths.js,只不过 PAGE_SIZE 我定为了 100。
另外我实现了一个简单的 Pagination.vue,用来实现文章列表页面上的分页器。代码很简单就不贴了。

接下来确保每一篇文章都能够被识别和渲染。因为我之前有些 blog 写得略随意,有些直接用 HTML 写的而不是 Markdown,且标签没有严格闭合和转码,还有些索性往文章里塞了一段内联的 <style> 和 <script> 直接出 demo。这些细节在 VitePress 里多多少少都引发了一些解析错误,我也都逐个修复了。
最后就是静态资源的迁移了。这个比较简单,直接把之前的静态文件拷贝到 public 目录就好了。
经过了这些粗枝大叶的迁移之后,网站差不多可以跑起来了,内容也都正常展示出来了。接下来就是一些细节的完善和优化了。
首先是把模板里不必要的信息注释掉或删掉。Vue Blog 的模板里有一些我这里不需要的信息,比如作者、头像不需要,因为就我一个人写;另外我在写作的时候越来越希望内容本身经得住时间考验,不论是什么时候写的都值得一读,所以发布时间之类的信息我个人觉得干扰阅读,为了极致的阅读场景我把展示这些信息的组件也都拿掉了。同时布局方面我也把侧边栏拿掉了。这完全是我的个人偏好。

还有一个小细节是关于文章列表中每一篇文章的摘要,之前 Hexo 是通过寻找内容中的 <!--more--> 记号并以此为分界来截取摘要的,但 VitePress 中是通过 --- 来识别的,并且在我迁移的那一刻还没有支持自定义分界记号。所以我只能手动 (当然是批量处理的) 把文章内容之前的分界记号全部都改成 ---。不过好消息是我把这个问题提给了 VitePress 并很快得到了支持,最新的版本已经支持自定义分界记号了。大家如果再遇到这个问题就不用手动改了。相关 issue
再接下来是处理文章评论,这里有两部分,第一部分是早期我的博客基于 Typecho 的时候产生的评论,数据在 MySQL 里,当然这部分内容现在看是纯静态的了,不会再有更新了;第二部分是现在我的博客基于 Hexo 的时候产生的评论,数据在 GitHub issues 里,通过一个叫 gitalk 的库进行加载。后者相对容易,我把 gitalk 这个库导入评论组件的 <script setup> 里调用就可以了,并且监听路由改变,如果文章换了就重新初始化并加载对应的评论。
前者就比较麻烦了,因为我不想继续把 Typecho 的数据库挂在服务器上,所以我把数据导出成了 JSON 文件,然后在 transformPageData() 的时候把数据作为 earlyComments 灌入 frontmatter 元数据。这样在 build 的时候,每个页面都可以通过 VitePress 自带的 useData() 访问 useData().frontmatter.value.earlyComments 获取到这个数据,进而在页面上渲染对应的早期评论。

下一步是支持 open graph 之类的元数据。这里绝大多数信息我都是通过 config 中的 transformHead(context) 函数实现的。基本原理就是从 context.pageData 中分析出要展示的元数据,然后生成 <meta> 标签信息返回。但这里有三个特例:
description:首先 pageData 里没有现成的信息,所以我自己写了个很简单粗暴的函数,从文章对应的源文件中读取内容,提取纯文本,然后截断前 200 个字符作为描述信息。不算特别严谨,但反正我平时写作时对格式对运用也比较规矩,所以足够了。大概的实现我提取了一个函数
import fs from 'fs'
import matter from 'gray-matter'
import { markdownToTxt } from 'markdown-to-txt'
export const genDescription = (filepath: string): string | undefined => {
if (fs.existsSync(filepath)) {
const content = fs.readFileSync(filepath, 'utf-8')
const data = matter(content)
const result = markdownToTxt(data.content.replace(/<[^>]+>/g, '')).replace(/\s+/g, ' ')
return result.length > 200 ? result.slice(0, 197) + '...' : result
}
}description 这个元数据 VitePress 本身也会生成,并且在我迁移的那段时间是不支持合并或覆盖的,导致页面生成出来的 HTML 里会有两段 <meta name="description">。这个问题估计你们猜到了,我也提 issue 了,最新版已经修复了。但我在这个 issue 被修复之前采取了另外一个临时的解决办法,就是通过 config 里的 transformHtml(code) 字段,把多余的 <meta name="description"> 标签删掉。
async transformHtml(code) {
// dedupe <meta name="description">
const results = []
const regExp = /<meta name="description"[^>]+>/gi
while (regExp.exec(code)) {
results.push(regExp.lastIndex)
}
if (results.length > 1) {
return code.replace(/<meta name="description"[^>]+>/, '')
}
},og:image / twitter:image 这两个字段目前社区最热门的实现方式是在服务端根据文章信息渲染一张图然后返回 URL (进而让用户觉得反正都已经上 Node 了不然就全站 SSR 吧,或者说至少这个功能跑不掉了那肯定得上 SSR)。说得好像不用这种服务博客都没法写了一样。我冷静的想了想好像也不必,选了个自己能接受的笨办法,就是找个离线工具生成自己想要的缩略图放到静态资源目录,然后在 frontmatter 里手写一个 manual_og_image 字段指向这个文件就好了。所以最终我的博客站用的依然是纯静态服务器。
最终的 transformHead(context) 实现大概是这样 (其中 genMeta 和 getIdFromFilePath 逻辑并不复杂,也不是这里讨论的重点,就不展开了):
async transformHead(context): Promise<HeadConfig[]> {
// add <meta>s
const description = genDescription(context.page)
const title = context.pageData.title
const url = `https://jiongks.name/${getIdFromFilePath(context.page)}`
const published = context.pageData.frontmatter.date
const updated = context.pageData.frontmatter.updated
const ogImage = context.pageData.frontmatter.manual_og_image
const tags = context.pageData.frontmatter.tags || []
const type = context.page.startsWith('blog/') ? 'article' : 'website'
const head: HeadConfig[] = [
// Basic
description ? genMeta('description', description) : undefined,
// Open Graph
description ? genMeta('og:description', description) : undefined,
genMeta('og:title', title),
genMeta('og:url', url),
genMeta('og:type', type),
ogImage ? genMeta('og:image', `https://jiongks.name/${ogImage}`): undefined,
// Twitter
description ? genMeta('twitter:description', description) : undefined,
genMeta('twitter:title', title),
genMeta('twitter:url', url),
ogImage ? genMeta('twitter:image', `https://jiongks.name/${ogImage}`): undefined,
genMeta('twitter:card', ogImage ? 'summary_large_image' : 'summary'),
// Article
published ? genMeta('article:published_time', published) : undefined,
updated ? genMeta('article:modified_time', updated) : undefined,
...tags.map((tag: string) => genMeta('article:tag', tag)),
].filter(Boolean)
return head
},最终生成的代码如下:
<!DOCTYPE html>
<html lang="zh-CN" dir="ltr">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width,initial-scale=1">
<title>中文格式化小工具 zhlint 及其开发心得 | 囧克斯</title>
...
<meta name="description" content="介绍要给小工具给大家:**zhlint** zhlint logo 这个工具可以帮助你快速格式化中文或中英混排的文本。比如常见的中英文之间要不要用空格、标点符号要用全角字符之类的。 看上去这工具似乎和自己的工作和职业关系不大,但其实也是有一定由来的。 项目的由来 自己之前参与过一些 W3C 规范的翻译工作,这其中除了需要一定的词汇量、语法知识和表达技巧之外,最主要的部分应该就是格式了。因为大...">
<meta name="og:description" content="介绍要给小工具给大家:**zhlint** zhlint logo 这个工具可以帮助你快速格式化中文或中英混排的文本。比如常见的中英文之间要不要用空格、标点符号要用全角字符之类的。 看上去这工具似乎和自己的工作和职业关系不大,但其实也是有一定由来的。 项目的由来 自己之前参与过一些 W3C 规范的翻译工作,这其中除了需要一定的词汇量、语法知识和表达技巧之外,最主要的部分应该就是格式了。因为大...">
<meta name="og:title" content="中文格式化小工具 zhlint 及其开发心得">
<meta name="og:url" content="https://jiongks.name/blog/introducing-zhlint">
<meta name="og:type" content="article">
<meta name="og:image" content="https://jiongks.name/og/introducing-zhlint.png">
<meta name="twitter:description" content="介绍要给小工具给大家:**zhlint** zhlint logo 这个工具可以帮助你快速格式化中文或中英混排的文本。比如常见的中英文之间要不要用空格、标点符号要用全角字符之类的。 看上去这工具似乎和自己的工作和职业关系不大,但其实也是有一定由来的。 项目的由来 自己之前参与过一些 W3C 规范的翻译工作,这其中除了需要一定的词汇量、语法知识和表达技巧之外,最主要的部分应该就是格式了。因为大...">
<meta name="twitter:title" content="中文格式化小工具 zhlint 及其开发心得">
<meta name="twitter:url" content="https://jiongks.name/blog/introducing-zhlint">
<meta name="twitter:image" content="https://jiongks.name/og/introducing-zhlint.png">
<meta name="twitter:card" content="summary_large_image">
<meta name="article:published_time" content="2020/04/26 03:53:59">
<meta name="article:modified_time" content="2020/04/27 12:29:56">
<meta name="article:tag" content="Chinese">
<meta name="article:tag" content="lint">
<meta name="article:tag" content="tool">
</head>
<body>
...最后处理了两个 Vue Blog 样式上的小问题:
Dark mode (中文翻译是夜间模式?暗黑模式?深色模式?) 下 <mark> 标签内默认的文字配色有问题,我做了简单的修复。
/* fix color theme in <mark>s */
.dark\:prose-invert mark a,
.dark\:prose-invert mark strong,
.dark\:prose-invert mark code {
color: #111827;
}为了避免过长的 URL 无法折行导致页面布局被破坏,我在必要的地方加了 word-break: keep-all,对应的 Tailwind class 是 break-all (2014-07-15 更新:仅在必要的 URL 前后包裹了一层 <span class="break-all">...</span>,把负面影响降到了最低)。
最后的最后支持了一下统计代码和 RSS 订阅文件 (这个 Vue Blog 就有,我做了些微调,沿用了我的博客站之前的输出格式),大功告成。
简单回顾一下,有几个 config 字段在整个迁移过程中起到了关键的作用,它们基本都在 build hooks 分类里。如果你也有类似的旧版本迁移或想给自己的网站定制一些特殊的功能,可以留意:
transformPageData():预处理页面数据,比如早期的评论transformHead():预处理 <head> 标签内的内容,比如 <meta>
transformHtml():后处理 <body> 标签内的内容,比如 <meta> 去重buildEnd():后处理全站的 HTML 内容,比如 RSS 订阅文件把该迁移的都迁移完毕过后,我又想了想,能不能顺便再给自己的网站加点什么呢?于是我又做了几个小功能:
manual_og_image:这个字段是用来在 <meta> 里指向文章缩略图的,上一节其实已经提到过了,其实算是个新东西,之前没有仔细弄过。不重复介绍了。
View transitions:这是一个相对较新的 W3C 规范,用来定制页面跳转之间的动画。关键代码片段:
<script setup>
import { useRouter } from 'vitepress'
const router = useRouter()
router.onBeforePageLoad = async () => {
if ((document as any).startViewTransition) {
await (document as any).startViewTransition()
}
}
</script>
<template>...</template>
<style>
#app {
view-transition-name: app;
}
@keyframes fade-in {
from { opacity: 0; transform-origin: bottom center; transform: rotate(-5deg); }
}
@keyframes fade-out {
to { opacity: 0; transform-origin: bottom center; transform: rotate(5deg); }
}
::view-transition-old(app) {
animation-name: fade-out;
/* Ease-out Back. Overshoots. */
animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1.275);
}
::view-transition-new(app) {
animation-name: fade-in;
/* Ease-out Back. Overshoots. */
animation-timing-function: cubic-bezier(0.175, 0.885, 0.32, 1.275);
}
</style>动图效果:
![]()
Progress animations:这是一个更新的 W3C 规范,用来定制各种和滚动条进度自动绑定的动画效果。关键代码片段:
<template>
<div class="progress" />
</template>
<style>
/* progress animations */
.progress {
height: 4px;
background: transparent;
position: fixed;
bottom: 0;
left: 0;
width: 100%;
transform-origin: 0 50%;
animation: scaleProgress auto linear, colorChange auto linear;
animation-timeline: scroll(root);
}
@keyframes scaleProgress {
0% {
transform: scaleX(0);
}
100% {
transform: scaleX(1);
}
}
@keyframes colorChange {
0% {
background-color: blue;
}
50% {
background-color: yellow;
}
100% {
background-color: red;
}
}
</style>动图效果:
外链预览图:这是我效仿 WikiPedia 中词条链接的效果,用来在鼠标悬停在外部链接上时显示一个预览图,以方便用户更好地预判要不要将其打开。我用了 floating-vue 这个库,结合一个三方的缩略图生成服务实现的。实际体验够不够好还有待观察。
以上就是我近期对自己的网站做的一些小改动,希望能给你一些启发。如果你也有类似的需求,不妨参考一下我的做法。如果你有更好的想法,欢迎在评论区留言。
相关链接:
2022-11-26 17:46:47
(本文写于 2022 年 11 月)
大约一周之前,我突然接到父母亲的消息,说九十多岁高龄的奶奶身体突然变得非常不好,感觉很难坚持了,虽然立刻飞回去不太现实,但还是希望可以安排个远程视频,见一面。
我非常清楚这意味着什么,这一面就是最后一面了。
隔天早上,我们安排了视频见面。我们上一次见面也是视频见面,当时我们还能相互交谈个几句。这一次,奶奶的身体靠在家人身旁勉强可以坐起来,除了睁大眼睛看着屏幕对面的我,已经动弹不得,也说不出话了。我不确定她还能不能听到我说话,总之我努力说了很多。那一刻,自己心里特别难受——一是不愿看到这一幕,二是悔自己没有办法来得及回去亲自看看或身体力行帮着做点什么。
除了伤感,我决定写一点关于我奶奶的东西,让更多人认识和记住她。
关于我奶奶最早的记忆,应该是自己很小还没有上学的时候,我们是个大家庭,从爷爷奶奶到我父母还有几个亲戚家都住得特别近,很多时候我们也直接住在爷爷奶奶家陪他们。白天我爸妈上班的时候,都是爷爷奶奶在家带我。那是一段其乐融融的日子,当时的街坊邻里也都关系很好,经常有不认识的叔叔阿姨来我们家串门,逗我玩送我小礼物什么的。虽然印象已经很模糊了,但我有一个细节一直到现在都记得,就是奶奶每天很早起床给一家人准备早餐。尤其在冬天的时候,天还没亮,奶奶就先起床了。然后我才会被叫醒吃饭,直到我后来上了学都一直这样。那个时候生活很简单,每天早上能饱饱得吃上一顿早餐,感觉一整天都是开心的。
渐渐的,我自己也慢慢长大,一点一点懂事,有了自己的想法和观点。我能回忆起的事情也具体了起来。我记得自己变得叛逆,不想每天生活在长辈们的教唆和监护之下。比如我吃东西的时候不喜欢别人看着我——现在想起来很荒唐不知道为什么——然而我的小孩现在也这样对我说过相同的话。作为家长,希望确定小孩吃完了吃饱了,然后就可以安排你出门上学或什么别的事情,连我自己现在都觉得理所应当,但是当时自己就是赌气不喜欢。有一次我早上上学前一个人吃早饭,我的奶奶为了迁就我的情绪,就坐得远远的,但是又放心不下,就一边远远坐着一边偷偷看我吃,结果被我发现了,我还因为这个发脾气,把气氛搞得非常不愉快;我自己出门上学,那是大概十分钟左右的路途,我奶奶总是在我出门之后站在阳台上看我,直到我走出从阳台能够看到的视野才罢休,我因为不喜欢这样,总是想办法躲开她的视线,每天贴着墙根走,但中间还是总会有一两段路会被她看到,于是我就每天尝试不同的走法,直到找到了一条路奶奶完全从阳台上看不到,然而晚上放学回家之后才听我爸妈说我奶奶就在阳台上看了一整天,一直放心不下不知道是不是我出了什么事。这大概就是我跟我的奶奶童年时期的典型互动模式,有点像猫捉老鼠,但现在回想起来又觉得自己的做法很幼稚。而这个循环似乎又延续到了我跟我的小孩之间。
再往后,我逐渐考到了一个离家比较远的高中,然后是大学,然后工作,跟家人见面的机会一点一点变少了,偶尔过年过节才回去。虽然见面的机会少了,但是每次回家见爷爷奶奶,有件事仍然格外重要,就是吃饭。奶奶总是在知道我要回去看他们的第一天就开始问我喜欢吃什么,一定要做给我吃,然后就开始每天盼我回去。所以每次我回去,总能吃到我最馋的家乡菜,什么莜面栲栳栳、小炒肉拌面、过油肉,到现在回忆起来,自己还是会流口水,怀念那些风味。我奶奶一直觉得不管是上学还是打工,出门在外就是吃得没有家里好,所以做一顿好饭就是对我最好的欢迎仪式。再有就是每次一顿饭下来,只要桌上的饭菜没吃干净,奶奶就会小声念叨说是不是做得不好吃;只要桌上的饭菜吃完了,奶奶又会小声念叨说今天东西做少了不够我们吃。总之永远有操不完的心。那时的我,虽然自己的味蕾得到了极大程度的满足,但还是有些不解风情,甚至有的时候觉得,自己在北京、杭州、还有其他工作和生活过的地方,其实吃的一点也不差。现在想想,老人家可能就是觉得别的也帮不上什么忙,也不一定懂,但是谈到吃的,老人家最自信了,而且确实拿手。也许在我们之间,这是唯一也是最重要的情感联结的纽带。不论念叨什么,也可能就是想找个话茬聊聊天吧,哪怕是尬聊。倒是自己那么当真,较劲。
渐渐的,奶奶年纪越来越大,家里人也不让奶奶亲自下厨了,我每次回家看爷爷奶奶,大家也就基本聊聊天寒轩个几句。奶奶还是忍不住会问吃得好不好——这真是个永恒的话题。再有就是我们每次家庭聚餐的时候,爷爷奶奶都会找我爸或我姑姑之类的亲戚,拿出相机或手机拍几张照片,录个视频什么的。说实话我到现在都没有完全接受这件事,因为人吃饭的时候难免嘴上手上弄得脏兮兮的,表情也难免怪怪的,就更别说我们这代人好多都是拍完照会 P 个半天直到所有人满意为止的。后来爷爷跟我说,现在他们年纪大了就特别怀旧,平时想见见我们没有什么机会,就喜欢看照片。而每次过年过节正是一大家人团聚的时候,就非常想借这个机会把大家的一举一动都尽可能记录下来,等我们各自回去工作上学了,他们可以拿出来看……
是啊,还有什么比这个更重要的呢。在我们自己每个月用手机拍上百张漂漂亮亮的照片的时候,爷爷奶奶只在乎有没有照片看,有就愿意津津有味得看。
从那以后,我虽然有时家庭聚会吃饭拍照还是有点抗拒,但同时也告诉自己,平时生活在外,要尽量拍些自己日常的生活照发送回去。而且给爷爷奶奶带了个 iPad 回去,这样看最新的照片和视频也方便。
现在回想起我的奶奶,脑海里浮现出来的,永远是她慈祥的笑容和无微不至的关怀。她老人家一生经历了很多我们这一代人无法想象和感同身受的事情,心有永远惦记着的是家庭,还有默默无私的付出。奶奶的想法也很传统,也会跟其他中国式家长一样,在你长大之后问你什么时候找对象,什么时候结婚,什么时候生小孩,要不要再生一个,也会说想让我们生个男的这样的很传统甚至今天大家觉得“政治不正确”的话。我觉得这就是他们这一代人极其朴素、务实而又单纯的一面。奶奶的眼里、心里,一直在盼着这个、盼着那个,照顾这个、照顾那个,我很少见到她谈论她自己,或者说她自己想要个什么东西,想去哪里玩,想过什么样的生活。奶奶自己很舍不得花钱,但是却每年都包大红包给我们晚辈们。她把自己完完全全奉献给了这个大家庭,奉献给了她身边的人,可能也就是除了想多看几张照片,到最后想见大家一面罢了。现在想起来,除了感动,还是感动。
我回忆和记录这些,其实也不只是为了我的奶奶,还包括我的爷爷、已故的姥姥 (外婆)、已故的姥爷 (外公)、爸爸妈妈、丈母娘、老丈人以及其他生活中的长辈们。不论走到哪里,身处何处,他们都是你的家人,都是你生活的一部分。他们有着跟我们不一样的人生经历、不同的想法、甚至跟我们有代沟,但在生活和生命面前,这些都只是插曲,永恒的是那些抹不去的情感记忆和最后对一切的和解。随着时代和科技的进步,我们感受着一些变化,也感受着一些变化。人们的距离被拉进,但也被疏远。每个人在不得不向前走的同时,也值得时不时回头看看吧。奶奶和其他长辈们与我之间这些共同的记忆,会时刻提醒着我,自己来自何方,又该向哪里而去。
如果还有机会,我会由衷的跟奶奶说,我今天吃得特别好,我们全家人都是。
最后,我很喜欢也相信一部动画片《Coco》里的设定:只要一直被人记得,你就在。我会一直记得奶奶,也相信她和我的姥姥、姥爷及其他已故的亲人们一样,一直都还在❤️
这是我在 B 站上找到的那部电影让我最感动的片段,也把电影里的这首歌送给我的奶奶和所有看到这篇文章的人。
Remember me though I have to say goodbye
Remember me, don't let it make you cry
For even if I'm far away, I hold you in my heart
I sing a secret song to you each night we are apartRemember me though I have to travel far
Remember me each time you hear a sad guitar
Know that I'm with you the only way that I can be
Until you're in my arms againRemember me
2020-04-26 11:53:59
介绍要给小工具给大家:zhlint
![]()
这个工具可以帮助你快速格式化中文或中英混排的文本。比如常见的中英文之间要不要用空格、标点符号要用全角字符之类的。
看上去这工具似乎和自己的工作和职业关系不大,但其实也是有一定由来的。
自己之前参与过一些 W3C 规范的翻译工作,这其中除了需要一定的词汇量、语法知识和表达技巧之外,最主要的部分应该就是格式了。因为大家对诸如空格、标点符号等细节的使用其实不太统一,这在团队协作的时候其实会变成问题,大家都花了一些不必要的时间在格式讨论和校对上。感觉这部分工作比较枯燥且机械,但又不得不做。只能花更多时间在上面。
后来因为接触 Vue.js 的关系。这个项目在早期并没有太多人知道它,而且当时社区普遍比较迷信像 Google 这种大厂官方推出的技术方案,对“野生”项目都不是很有兴趣,所以我希望可以把这个项目介绍给更多人认识。结合我之前的翻译经验,我觉得翻译文档是一个比较好的途径,于是就发起了 Vue 中文文档的翻译,结果没想到这件事一发不可收拾,我就不知不觉从 2014/2015 年做到了今天。随着 Vue 的不断发展,关注文档的人也越来越多,中间发生了很多故事,这些故事也让我自己逐步对翻译和中文格式的细节有了更多的认识。
真正触发我做这个项目的事情,是去年的一个翻译讨论:如何翻译 attribute 和 property。这个问题几乎从我接触技术翻译的第一天起就一直是个噩梦。我和周围的小伙伴尝试了各种译法,都不能让所有人满意,无奈之下通过刻意的区分和强化教育,把它们分别译成“特性”和“属性”。这个状态持续了很长一段时间,Vue 的文档也基本都是这么翻译的。直到去年的一段时间,我逐步意识到,也许这两个词不翻译会更好,索性直接保留英文原词,这样不会有歧义,同时随着整个社区的英文程度在提高,像这样的词不翻译大家应该也能顺畅的理解了,中英文混着读也逐渐可以接受了。所以就在 GitHub 开了个 issue,同时也扩散到了 W3C Web 中文兴趣组。没想到这次讨论大家的意见出奇的一致,几乎“全票通过”。看上去困扰我多年的问题终于要解开了……
然而在这之后,我意识到,如何对已经翻译好的大量文档做关键词批量替换并不是一件容易的事情——主要还是格式细节太多了。不能做简单粗暴的文本批量替换。
比如把“特性”换回“attribute”之后,如果“特性”一词的两边也都还是中文,那么“attribute”两边就都需要加一个空格,而如果是标点符号就不需要,而如果是英文,那理论上这个空格已经加过了。所以情况很多很复杂。你读到这里可能觉得那我们稍微加个正则表达式也许可以解决,那我会在告诉你,如果这个词的边上还可能有 HTML 标记或 Markdown 标记,那这个正则该如何写呢?或许也不那么容易了。
因此这个译法改动在去年就已经有定论了,但是实际上到今年上半年我才真正改好。原因是我觉得这次我不打算再靠蛮力去解决问题了,而打算通过工具来解决——这就是我做这个项目的由来和动机——没错我陆陆续续做了一年左右,最近终于做出一个比较文档的版本了,然后才完成了这次译法的替换。
另外一个促使我做这个工具的原因其实是我个人希望尝试一些语法分析之类的技术,因为觉得作为一个前端工程师,未来这个方向的可能性和空间比较大。如之前和很多人都聊到过的,现如今的前端框架全部都开始在编辑器这个环节大做文章。因为它可以帮助你突破一些 JS 语言的限制。所以大家武装到牙齿之后这部分是一定会碰的。我预测接下来这个趋势会从框架往上发展,逐步延申到前端工作的更多环节。做这个工具看上去似乎有那么一点可以积累到的知识和经验,于是就想先做个这个试试看。
接下来回到 zhlint 这个工具,介绍一下我设计的基本用法:
yarn global add zhlint 或 npm install -g zhlint。这样 zhlint 就安装好了。zhlint <filepath>,比如我们创建一个文件叫做 foo.md,其中的文本内容是 中文English。那么运行 zhlint foo.md 会收到一个错误提示,提醒你中英文之间应该有一个空格。zhlint foo.md --fix,顾名思义这个命令会自动修复文件中的格式错误。所以运行之后文件 foo.md 内部的文本内容会变成 中文 English。zhlint src/*.md 可以校验 src 目录下的所有 md 文件。同理也可以加 --fix 做批量自动修复。中文English中文 -> 中文 English 中文
中文 , 中文 -> 中文,中文
1+1=2 -> 1 + 1 = 2
中文, 中文. -> 中文,中文。
Mr. (不转换全角句号)2020/01/02 01:20:30 (在描述时间和日期的时候冒号和斜杠两边没有空格)33.30KB min+gzip (这里的加号两边不会加空格,该 case 没有普遍规律)现在回顾之前的研发过程,首先是做得比较懒散,陆陆续续一点一点做,其次是返工了无数次,发现哪里走不通了就推倒重来,所以经历了太长的时间。
在最初的版本里,我想的比较简单,就只是把中文内容分为几个颗粒度去处理:char、token、full text。所以我当时只做了五件事:
大概的代码结构是这样的:
const checkCharType = char => {...}
const parse = str => {...}
const travel = (tokens, filter, handler) => {...}
const lint = (str, options) => {
// parse options
// travel and process tokens
// join tokens
}然后我逐渐发现 lint 这个函数越写越大,逐渐失控。原因有这么几个:
我们需要 (先做一件事,然后再做一件事,最后再) 做一件事。括号可以断在任意的地方,可以跨越多个句子,可以包含最前边或最后边的标点符号,也可以把它们留在外边,被截断的前后句子单独拿出来也未必是完整的。minute(s))、单引号可以用在英文缩写中 (doesn't) 等等。再比如在描述时间和日期的时候,我们不太习惯在每个数字之间都加空格所以会省略空格 (2020年1月1日 而不是 2020 年 1 月 1 日)。这些都导致设计之初通过简单的线性 token 机制处理很难做好这件事。“Travel and process” 这部分的代码越来越臃肿。逐渐我意识到,这里需要更多的结构化设计。于是我停下来考虑了一段时间。
之后我逐渐想到两个主意:
const rules = [...]; rules.reduce(processRule, str)。这个思路其实我一开始想到过,但觉得把每条规则都抽象并独立出来是很有难度的,所以一直没有下定决心做。经过这次深思熟虑之后我鼓起勇气试了一下,看起来还是可行的,效果也还可以。于是我决定把之前的主分支退役,重新开启一个新的分支,开始以上述思路重构代码。
重构之后的处理流程更像是:
// separated files
const rules = [
(token, index, group, matched, marks) => {...},
(token, index, group, matched, marks) => {...},
(token, index, group, matched, marks) => {...},
// ...
]
// index.js
const checkCharType = char => {...}
const parse = str => {...}
const travel = (tokens, filter, handler) => {...}
const processRule = ({ tokens, marks, ... }, rule) => {...}
const join = (tokens) => {...}
const lint = (str, options) => {...}有了这个结构,我就可以更加专注在格式规则的定义和实现上了。随着工作的深入,我也逐渐加入了一些务实的功能和设计。
截至目前,我们 lint 的假设性目标都是一个字符串——确切的说是单行字符串。但实际上我们需要处理的真实的文本内容是更复杂的。目前绝大多数待处理的文本内容都是 Markdown 格式,可能还夹带了一些 HTML 标记,而且是多行文本。
为了解决真实的问题,我稍微花了一些时间去了解如何解析 Markdown 语法。之前用到 Markdown 的地方基本都是从 Markdown 渲染出最终的 HTML 代码,但这次我们不太需要最终的 HTML 代码,而是 AST,也就是抽象语法树。最终我找到了一个叫做 unified.js 的库,它可以把各种格式的文本内容解析成为相应格式的 AST。其中 remark.js 就是在这个库的基础上用来解析 Markdown 语法的,其 AST 格式为 mdast。大致的用法如下:
const unified = require('unified')
const markdown = require('remark-parse')
const frontmatter = require('remark-frontmatter')
// the content
const content = '...'
const ast = unified().use(markdown).use(frontmatter).parse(content)
// process the Markdown AST接下来就是根据 mdast 庖丁解牛的时刻了。经过研究 mdast 的文档,我发现在 Markdown 语法里,所有的语法节点都可以简单粗暴的区分为两大类:inline 和 block。而 zhlint 要处理的其实就是找出所有不能再拆解的 block,然后把其中的 inline 节点在 zhlint 中标注为我们之前提到过的 mark 类 token。当然其中 inline 节点还要再分为两类:一类是包含文本内容的 (例如加粗、斜体、链接等),需要继续 lint 处理;一类不包含 (例如图片),需要原文保留。对于代码片段,我们从自然语言分析的角度认为它不是文本内容,所以也算后者。更妙的是其实在 Markdown 的 parser 里其实是包含了对 HTML 标记的解析的,所以我们不需要额外引入 HTML parser 就可以完成对 HTML 标记的支持。
源代码中大致的语法节点分类如下:
// 不能再拆解的 block
const blockTypes = [
'paragraph',
'heading',
'table-cell'
]
// 包含文本的 inline
const inlineMarkTypes = [
'emphasis',
'strong',
'delete',
'footnote',
'link',
'linkReference'
]
// 不包含文本的 inline
const rawMarkTypes = [
'inlineCode',
'break',
'image',
'imageReference',
'footnoteReference',
'html'
]这样我们就可以先把所有的文本中不可拆解的 block 找出来,同时对这些 block 内部出现的超文本做好 mark 标记,然后带着这些 mark 逐个 lint,最后再把这些结果填入之前的 block 所在的位置。大致思路如下:
const blocks = parseMarkdown(str).blocks
const blockResults = blocks.map(lintBlock)
const result = replaceBlocks(str, blocksResult.map(
// 意在强调主要处理的信息是处理后的结果和之前所在字符串中的位置
({ value, position }) => ({ value, position })
))当然要想把 Markdown/HTML 语法处理好这还不算完,因为相应的 lint 规则也变得更加复杂了。举个例子,当我们处理空格的时候,希望空格始终出现在 inline mark 的外侧 (中文 [English](a-link-here) 中文 而不是 中文[ English ](a-link-here)中文)。所以对已有规则处理上的复杂度相当于是指数级增长了一倍。而且实际上到最后还需要特别添加一些针对 Markdown/HTML 语法的规则。这里我其实在过程中反复做了各种尝试和搭配组合,才变成了现在的样子。现在的规则已经相对比较稳定了。同时我也在实现类似的规则过程中逐步积累了很多 util functions。所以拜托了一些低级别的重复性问题之后,整个研发过程越往后其实会变得越清晰越简单。
在设计和实现 lint 规则的过程中,自己也积累了一些心得,总体上所有的 lint 规则或选项被分为了四部分,分别对应四种需求:
min+gzip 的时候,之间没有空格。针对这部分规则我们提供了一种注释语法,可以被 zhlint 识别,从而在 join 的时候跳过。
<!-- zhlint ignore: min+gzip -->。[prefix-,]textStart[,textEnd][,-suffix]。这样用户就可以更灵活的使用这一功能。parseMarkdown 机制的基础上加入了 hyper parser chain 的机制,每段文本在真正运行每条 lint 规则之前,都会链式运行所有的 hyper parser。最终包括了 Markdown 解析、Hexo tag plugin 解析、还有被忽略的个别情况的注释解析。这次研发过程中,我比较早,也比较严格的实践了测试驱动开发。基于 Jest 写了很多用例,通过这些用例把工具的行为“卡死”,这样当后期引入更多复杂度的时候 (比如决定重构第二版的时候、或决定支持 Markdown 格式之后),可以通过锁住测试用例进行大胆的重构和尝试,并且在重构的时候一旦发现一些之前没有覆盖到的 edge case,就立刻补充进去,然后重构至这个 case 跑通为止再继续。久而久之整套测试用例也越来越见状。总体下来还是受益匪浅的,帮自己省了很多时间和脑细胞——上一次有这种感觉的项目是 Weex JS runtime 第一版。如一些朋友知道的,当时我们只有 2 个月时间,要从零写一个 JS 框架用在双十一移动主会场,所以除了测试用例我当时谁也没法相信。
完成上述核心功能之后,差不多已经过去一年时间了,最后的一些工作留给了下述这些“外包装”。
值得一提的是自己在打印日志的时候,想实现类似 TSC 或 Vue 3.0 模板编译的错误打印格式,即打印出错误所在的那一行代码,并且在再下一行的出错位置放一个小尖角字符 (^) 以方便用户定位问题,例如这是 Vue 3.0 模板编译里的效果:
2 | <template key=\\"one\\"></template>
3 | <ul>
4 | <li v-for=\\"foobar\\">hi</li>
| ^^^^^^^^^^^^^^
5 | </ul>
6 | <template key=\\"two\\"></template>但问题来到 zhlint 之后遇到了一些比较特别的问题:
为此我采取了一种不太一样的定位展示效果:
chalk,这样就可以为日志上色。所以最终看到的效果,如果把特别的着色去掉的话,看到的效果是:
自动在中文和English之间加入空格
自动在中文和^但实际效果中第二行的“自动在中文和”是看不到的,只会看到一条黑色矩形。运气好的话,如果你的命令行背景也是黑色的,那么就完全看不出差别了。

另外一个测试的时候的小技巧,如果你不希望日志打印把测试报告搞得乱七八糟,可以结合 Jest 的环境变量判断 + 自定义 Console 对象把日志打印到别的流,然后做二次处理或直接抛掉,代码类似:
let stdout = process.stdout
let stderr = process.stderr
let defaultLogger = console
// Jest env
if (global.__DEV__) {
const fs = require('fs')
const { Console } = require('console')
stdout = fs.createWriteStream('./stdout.log', { encoding: 'utf-8' })
stderr = fs.createWriteStream('./stderr.log', { encoding: 'utf-8' })
defaultLogger = new Console({ stdout, stderr })
}
// usage
defaultLogger.log(...)最后推荐几个我用到的 npm 包,如果大家想做类似的事情,可以做个参考 (当然如果你有更好的推荐也可以):
目前 zhlint 已经集成到了 Vue 的中文文档项目中。通过简单的 CI 配置,就可以轻松做到为每个 PR 自动 lint 并返回处理结果。
有了这个工具之后,我们就可以比较没有心智负担地批量替换文本了,替换之后运行一遍类似 zhlint src/*.md --fix 的命令,即可把因批量替换产生的格式问题全部修复。
然后,我就立刻完成了对 attribute 和 property 的替换……
所以“为了批量替换两个单词的译法,我花了差不多一年的时间” (这原本是我设想的这篇文章标题党版本的标题)
之后我们在 Vue 文档中又陆续遇到了讨论 mutation、ref 译法的问题。产生的相应改动也都可以基于 zhlint 很容易的得以实现。
有趣的是,在我在微博和 Twitter 简单分享了这个小工具之后,也有人留言说其实写博客的时候这个工具也非常有用。或许这是 zhlint 可能的更多用途吧😉!
最后,关于心得体会和收获,我觉得有这么几个:
另外 zhlint 其实还没有做完,我已经想到了更多的 feature 和改进点,其实也已知了不少不理想不完美不够好的地方。所以会继续做下去。
以上
