2026-01-01 00:00:00

本来想写拆解Manus沙箱的文章,结果Manus官方自己写了 :)
了解 Manus Sandbox - 您的云计算机
正如 Manus 名称的出处"Mens et Manus"(Mind and Hand)所说的,Manus 希望让 AI 模型不仅只是思考,更可以帮你做出行动。而在我们给 AI 模型赋予的"手"中,最强大的莫过于一台真正的云计算机 —— Manus Sandbox。
Manus Sandbox 是 Manus 为每一个任务分配的完全独立的云虚拟机。每个 Sandbox 在自己的环境中运行,互不影响,可以并行执行任务。
Sandbox 的强大之处在于它的完整性——就像你手上使用的个人电脑一样,它拥有完整的能力:网络、文件系统、浏览器、各种各样的软件工具。我们的 AI Agent 经过设计与训练,可以很好地选择并正确使用这些工具帮助你完成任务。不仅如此,有了这台计算机,AI 可以通过自己最擅长的方式——编写代码来解决问题,甚至可以帮你制作一个完整的网站和移动端 App。这一切都发生在 Manus 背后的虚拟化平台上。这些 Sandbox 可以 7x24 小时工作,完成你下发的任务而不占用你的本地资源。
Manus Sandbox 里存放了任务执行过程中所需要的文件,包含如下类型:
用户上传的附件
Manus 运行过程中创建、编写的文件和产物
Manus 为了执行特定任务所需的配置(如用户上传的密钥、Manus 给用户分配的用于调用相关接口的密钥)
你可以通过右上角的"View all files in this task"入口查看 Sandbox 中的所有产物文件。
当然,你也可以直接向 Manus 发送消息询问当前 Sandbox 的状态和其中的内容,比如"把当前写的所有代码打包发给我",Manus 会自行访问 Sandbox 满足你的要求。
Sandbox 遵循一个可预测的生命周期,在资源效率和持久性之间取得平衡:
创建: Sandbox 会在新会话中按需创建
休眠/唤醒: 在 Sandbox 不活跃时(没有操作、文件编辑等),会自动进入休眠状态。当你回到任务,Manus 需要操作 Sandbox 时会自动唤醒。在休眠/唤醒周期内,Sandbox 中的文件数据保持不变
回收/重新创建: 连续休眠超过一定期限的 Sandbox 会被回收(免费用户:7 天;Manus Pro:21 天)。Sandbox 被回收后再次访问时,会自动重新创建一个新的沙盒。Manus 会自动恢复之前沙盒中的部分文件到新的沙盒:Manus 的产物、上传的附件、Slides/WebDev 等重要文件会被自动恢复;运行过程中的中间代码、临时文件等不会被恢复
由于 Sandbox 存在休眠机制,如果你需要部署长时间运行的后台服务,可以使用 Manus 的网页开发能力创建前后台服务并部署到公网。
我们对 Manus Sandbox 的设计遵循 原则。就像你在云服务厂商购买的一台云虚拟机那样,你和 Manus 对这台电脑拥有绝对的掌控权,可以不受限制地进行任何操作(例如获取 root 权限,修改系统文件,甚至是格式化整个磁盘)。这使得 Manus 可以尽最大的可能帮你完成任务而不受权限的约束。
不用担心:任何对 Sandbox 的操作只会影响 Sandbox 本身,不会影响到 Manus 服务的安全和稳定性,你的会话、账号等数据也无法被 Sandbox 访问。一旦出现不可恢复的错误,Manus 会自动创建一个新的沙盒来进行替换,确保能继续为你提供服务。
Sandbox 作为你的私人电脑,可能存放有你的个人敏感信息和数据。Manus 有着严格的隐私保护政策和措施,不会在未经用户授权的情况下读取或分享任何用户数据,但你仍然需要采取措施以避免 Sandbox 中的数据被意外共享。
我们需要区分"分享"和"协作"两个场景。
对于任务的分享(通过 Manus 右上角的"Share"按钮),被分享者只会看到任务对话中的消息和输出的产物。Sandbox 对他们是完全不可见的。因此,你只需要关心对话中是否包含敏感信息即可,无需担心 Sandbox 中的内容被泄露。
对于任务的协作(通过 Manus 右上角的协作按钮,邀请特定的用户参与),协作者加入会话后即获得了参与此任务的权限。这意味着协作者可以向 AI 发送指令,控制任务的执行。此时 Sandbox 对协作者也同样开放——他们可以通过 AI 访问或者修改 Sandbox 中的文件、数据,可能会造成预期外的数据泄露。
另外,Connectors 会在会话开启协作后自动禁用,无需担心 Connectors 被协作者访问。
你可以通过上面的表格了解不同情况下其他用户对于任务内容的可访问性,在进行共享、协作操作前确认不会泄露你的隐私数据。
由于 Sandbox 相当于你的私人电脑,添加协作者前请二次确认 Sandbox 中是否有敏感内容不便于协作者访问
如果已经有敏感内容,可以新建一个 task,只复制必要的内容和产物到该 task,再邀请协作
避免在协作会话中发送个人敏感信息
Manus Sandbox 是我们平台的核心组件,所有用户均可使用,适用于所有订阅层级。
问:Sandbox 被回收后,我的文件会怎样?
答:Manus 会自动恢复你最重要的文件——产物、上传的附件以及 Slides/WebDev 等项目文件——到新的 Sandbox。中间代码和临时文件不会被恢复。
问:Sandbox 多久会被回收?
答:免费用户的保留期为 7 天,Manus Pro 用户在 Sandbox 不活跃 21 天后才会被回收。
问:协作者能否通过 Sandbox 访问我的 Connectors?
答:不能。协作开启后,Connectors 会自动禁用,确保协作者无法访问你连接的服务。
Manus Sandbox 代表了 Manus 代你行动的基础。通过提供一个持久、安全、功能完整的云计算环境,我们正在开启一类新的 AI 驱动工作方式——从对话走向真正的执行。
2026-01-01 00:00:00
Here are my tips for getting the most out of Claude Code, including a custom status line script, cutting the system prompt in half, using Gemini CLI as Claude Code's minion, and Claude Code running itself in a container. Also includes the dx plugin.
You can customize the status line at the bottom of Claude Code to show useful info. I set mine up to show the model, current directory, git branch (if any), uncommitted file count, sync status with origin, and a visual progress bar for token usage. It also shows a second line with my last message so I can see what the conversation was about:
|
|
This is especially helpful for keeping an eye on your context usage and remembering what you were working on. The script also supports 10 color themes (orange, blue, teal, green, lavender, rose, gold, slate, cyan, or gray).

To set this up, you can use this sample script and check the setup instructions.
There are a bunch of built-in slash commands (type / to see them all). Here are a few worth knowing:
Check your rate limits:
|
|
Toggle Claude's native browser integration:
|
|
Manage MCP (Model Context Protocol) servers:
|
|
View your usage statistics with a GitHub-style activity graph:
|
|
Clear the conversation and start fresh.
I found that you can communicate much faster with your voice than typing with your hands. Using a voice transcription system on your local machine is really helpful for this.
On my Mac, I've tried a few different options:
You can get more accuracy by using a hosted service, but I found that a local model is strong enough for this purpose. Even when there are mistakes or typos in the transcription, Claude is smart enough to understand what you're trying to say. Sometimes you need to say certain things extra clearly, but overall local models work well enough.
For example, in this screenshot you can see that Claude was able to interpret mistranscribed words like "ExcelElanishMark" and "advast" correctly as "exclamation mark" and "Advanced":

I think the best way to think about this is like you're trying to communicate with your friend. Of course, you can communicate through texts. That might be easier for some people, or emails, right? That's totally fine. That's what most people seem to do with Claude Code. But if you want to communicate faster, why wouldn't you get on a quick phone call? You can just send voice messages. You don't need to literally have a phone call with Claude Code. Just send a bunch of voice messages. It's faster, at least for me, as someone who's practiced the art of speaking a lot over the past number of years. But I think for a majority of people, it's going to be faster too.
A common objection is "what if you're in a room with other people?" I just whisper using earphones - I personally like Apple EarPods (not AirPods). They're affordable, high quality enough, and you just whisper into them quietly. I've done it in front of other people and it works well. In offices, people talk anyway - instead of talking to coworkers, you're talking quietly to your voice transcription system. I don't think there's any problem with that. This method works so well that it even works on a plane. It's loud enough that other people won't hear you, but if you speak close enough to the mic, your local model can still understand what you're saying. (In fact, I'm writing this very paragraph using that method on a flight.)
This is one of the most important concepts to master. It's exactly the same as traditional software engineering - the best software engineers already know how to do this, and it applies to Claude Code too.
If you find that Claude Code isn't able to one-shot a difficult problem or coding task, ask it to break it down into multiple smaller issues. See if it can solve an individual part of that problem. If it's still too hard, see if it can solve an even smaller sub-problem. Keep going until everything is solvable.
Essentially, instead of going from A to B:

You can go from A to A1 to A2 to A3, then to B:

A good example of this is when I was building my own voice transcription system. I needed to build a system that could let the user select and download a model, take keyboard shortcuts, start transcribing, put the transcribed text at the user's cursor, and wrap all of this in a nice UI. That's a lot. So I broke it down into smaller tasks. First, I created an executable that would just download a model, nothing else. Then I created another one that would just record voice, nothing else. Then another one that would just transcribe pre-recorded audio. I completed them one by one like that before combining them at the end.
Highly related to this: your problem-solving skills and software engineering skills are still highly relevant in the world of agentic coding and Claude Code. It's able to solve a lot of problems on its own, but when you apply your general problem-solving and software engineering skills to it, it becomes a lot more powerful.
Just ask Claude to handle your Git and GitHub CLI tasks. This includes committing (so you don't have to write commit messages manually), branching, pulling, and pushing.
I personally allow pull automatically but not push, because push is riskier - it doesn't contaminate the origin if something goes wrong with a pull.
For GitHub CLI (gh), there's a lot you can do. One thing I started doing more after using Claude Code is creating draft PRs. This lets Claude Code handle the PR creation process with low risk - you can review everything before marking it ready for review.
And it turns out, gh is pretty powerful. You can even send arbitrary GraphQL queries through it. For example, you can even find the exact times at which GitHub PR descriptions were edited:
|
|
When you start a new conversation with Claude Code, it performs the best because it doesn't have all the added complexity of having to process the previous context from earlier parts of the conversation. But as you talk to it longer and longer, the context gets longer and the performance tends to go down.
So it's best to start a new conversation for every new topic, or if the performance starts to go down.
Sometimes you want to copy and paste Claude Code's output, but copying directly from the terminal isn't always clean. Here are a few ways to get content out more easily:
pbcopy to send output straight to your clipboardopen command, but in general asking to open in your favorite browser should work on any platformYou can combine some of these together too. For example, if you want to edit a GitHub PR description, instead of having Claude edit it directly (which it might mess up), you can have it copy the content into a local file first. Let it edit that, check the result yourself, and once it looks good, have it copy and paste it back into the GitHub PR. That works really well. Or if you want to do that yourself, you can just ask it to open it in VS Code or give it to you via pbcopy so you can copy and paste it manually.
Of course, you can run these commands yourself, but if you find yourself doing it repetitively, it's helpful to let Claude run them for you.
Since I use the terminal more because of Claude Code, I found it helpful to set up short aliases so I can launch things quickly. Here are the ones I use:
c for Claude Code (this is the one I use the most)ch for Claude Code with Chrome integrationgb for GitHub Desktopco for VS Codeq for going to the project directory where I have most projects. From there I can manually cd into an individual folder to work on that project, or I can just launch Claude Code with c to let it basically have access to any project it needs to access.To set these up, add lines like this to your shell config file (~/.zshrc or ~/.bashrc):
|
|
Once you have these aliases, you can combine them with flags: c -c continues your last conversation, and c -r shows a list of recent conversations to resume. These work with ch too (ch -c, ch -r) for Chrome sessions.
There's a /compact command in Claude Code that summarizes your conversation to free up context space. Automatic compaction also happens when the full available context is filled. The total available context window for Opus 4.5 is currently 200k, and 45k of that is reserved for automatic compaction. About 10% of the total 200k is automatically filled with the system prompt, tools, memory, and dynamic context. But I found that it's better to proactively do it and manually tune it. I turned off auto-compact with /config so I have more context available for the main conversation and more control over when and how compaction happens.
The way I do this is to ask Claude to write a handoff document before starting fresh. Something like:
Put the rest of the plan in the system-prompt-extraction folder as HANDOFF.md. Explain what you have tried, what worked, what didn't work, so that the next agent with fresh context is able to just load that file and nothing else to get started on this task and finish it up.
Claude will create a file summarizing the current state of work:
|
|
After Claude writes it, review it quickly. If something's missing, ask for edits:
Did you add a note about iteratively testing instead of trying to do everything all at once?
Then start a fresh conversation. For the fresh agent, you can just give the path of the file and nothing else like this, and it should work just fine:
|
|
In subsequent conversations, you can ask the agent to update the document for the next agent.
I've also created a /handoff slash command that automates this - it checks for an existing HANDOFF.md, reads it if present, then creates or updates it with the goal, progress, what worked, what didn't, and next steps. You can find it in the commands folder, or install it via the dx plugin.
If you want Claude Code to run something autonomously, like git bisect, you need to give it a way to verify results. The key is completing the write-test cycle: write code, run it, check the output, and repeat.
For example, let's say you're working on Claude Code itself and you notice /compact stopped working and started throwing a 400 error. A classic tool to find the exact commit that caused this is git bisect. The nice thing is you can let Claude Code run bisect on itself, but it needs a way to test each commit.
For tasks that involve interactive terminals like Claude Code, you can use tmux. The pattern is:
Here's a simple example of testing if /context works:
|
|
Once you have a test like this, Claude Code can run git bisect and automatically test each commit until it finds the one that broke things.
This is also an example of why your software engineering skills still matter. If you're a software engineer, you probably know about tools like git bisect. That knowledge is still really valuable when working with AI - you just apply it in new ways.
Another example is simply writing tests. After you let Claude Code write some code, if you want to test it, you can just let it write tests for itself too. And let it run on its own and fix things if it can. Of course, it doesn't always go in the right direction and you need to supervise it sometimes, but it's able to do a surprising amount of coding tasks on its own.
Sometimes you need to be creative with how you complete the write-test cycle. For example, if you're building a web app, you could use Playwright MCP, Chrome DevTools MCP, or Claude's native browser integration (through /chrome). I haven't tried Chrome DevTools yet, but I've tried Playwright and Claude's native integration. Overall, Playwright generally works better. It does use a lot of context, but the 200k context window is normally enough for a single task or a few smaller tasks.
The main difference between these two seems to be that Playwright focuses on the accessibility tree (structured data about page elements) rather than taking screenshots. It does have the ability to take screenshots, but it doesn't normally use them to take actions. On the other hand, Claude's native browser integration focuses more on taking screenshots and clicking on elements by specific coordinates. It can click on random things sometimes, and the whole process can be slow.
This might improve over time, but by default I would go with Playwright for most tasks that aren't visually intensive. I'd only use Claude's native browser integration if I need to use a logged-in state without having to provide credentials (since it runs in your own browser profile), or if it specifically needs to click on things visually using their coordinates.
This is why I disable Claude's native browser integration by default and use it through the ch shortcut I defined previously. That way Playwright handles most browser tasks, and I only enable Claude's native integration when I specifically need it.
Additionally, you can ask it to use accessibility tree refs instead of coordinates. Here's what I put in my CLAUDE.md for this:
|
|
In my personal experience, I've also had a situation where I was working on a Python library at Daft and needed to test a version I built locally on Google Colab. The trouble is it's hard to build a Python library with a Rust backend on Google Colab - it doesn't seem to work that well. So I needed to actually build a wheel locally and then upload it manually so that I could run it on Google Colab. I also tried monkey patching, which worked well in the short term before I had to wait for the whole wheel to build locally.
Another situation I encountered is I needed to test something on Windows but I'm not running a Windows machine. My CI tests on the same repo were failing because we had some issues with Rust on Windows, and I had no way of testing locally. So I needed to create a draft PR with all the changes, and another draft PR with the same changes plus enabling Windows CI runs on non-main branches. I instructed Claude Code to do all of that, and then I tested the CI directly in that new branch.
I've been saying this for a few years now: Cmd+A and Ctrl+A are friends in the world of AI. This applies to Claude Code too.
Sometimes you want to give Claude Code a URL, but it can't access it directly. Maybe it's a private page (not sensitive data, just not publicly accessible), or something like a Reddit post that Claude Code has trouble fetching. In those cases, you can just select all the content you see (Cmd+A on Mac, Ctrl+A on other platforms), copy it, and paste it directly into Claude Code. It's a pretty powerful method.
This works great for terminal output too. When I have output from Claude Code itself or any other CLI application, I can use the same trick: select all, copy, and paste it back to CC. Pretty helpful.
Some pages don't lend themselves well to select all by default - but there are tricks to get them into a better state first. For example, with Gmail threads, click Print All to get the print preview (but cancel the actual print). That page shows all emails in the thread expanded, so you can Cmd+A the entire conversation cleanly.
This applies to any AI, not just Claude Code.
Claude Code's WebFetch tool can't access certain sites, like Reddit. But you can work around this by creating a skill that tells Claude to use Gemini CLI as a fallback. Gemini has web access and can fetch content from sites that Claude can't reach directly.
This uses the same tmux pattern from Tip 9 - start a session, send commands, capture output. The skill file goes in ~/.claude/skills/reddit-fetch/SKILL.md. See skills/reddit-fetch/SKILL.md for the full content.
Skills are more token-efficient because Claude Code only loads them when needed. If you want something simpler, you can put a condensed version in ~/.claude/CLAUDE.md instead, but that gets loaded into every conversation whether you need it or not.
I tested this by asking Claude Code to check how Claude Code skills are regarded on Reddit - a bit meta. It goes back and forth with Gemini for a while, so it's not fast, but the report quality was surprisingly good. Obviously, you'll need to have Gemini CLI installed for this to work. You can also install this skill via the dx plugin.
Personally, I've created my own voice transcription app from scratch with Swift. I created my own custom status line from scratch using Claude Code, this one with bash. And I created my own system for simplifying the system prompt in Claude Code's minified JavaScript file.
But you don't have to go overboard like that. Just taking care of your own CLAUDE.md, making sure it's as concise as possible while being able to help you achieve your goals - stuff like that is helpful. And of course, learning these tips, learning these tools, and some of the most important features.
All of these are investments in the tools you use to build whatever you want to build. I think it's important to spend at least a little bit of time on that.
You can ask Claude Code about your past conversations, and it'll help you find and search through them. All your conversation history is stored locally in ~/.claude/. Project-specific conversations are in ~/.claude/projects/, with folder names based on the project path (slashes become dashes).
For example, conversations for a project at /Users/yk/Desktop/projects/claude-code-tips would be stored in:
|
|
Each conversation is a .jsonl file. You can search through them with basic bash commands:
|
|
Or just ask Claude Code directly: "What did we talk about regarding X today?" and it'll search through the history for you.
When running multiple Claude Code instances, staying organized is more important than any specific technical setup like Git worktrees. I recommend focusing on at most three or four tasks at a time.
My personal method is what I would call a "cascade" - whenever I start a new task, I just open a new tab on the right. Then I sweep left to right, left to right, going from oldest tasks to newest. The general direction stays consistent, except when I need to check on certain tasks, get notifications, etc.
Here's what my setup typically looks like:

In this example:
Claude Code's system prompt and tool definitions take up about 20k tokens (~10% of your 200k context) before you even start working. I created a patch system that reduces this to about 9k tokens - saving around 11,000 tokens (~55% of the overhead).
| Component | Before | After | Savings |
|---|---|---|---|
| System prompt | 3.1k | 1.8k | 1,300 tokens |
| System tools | 15.6k | 7.1k | 8,500 tokens |
| Static total | ~19k | ~9k | ~10,000 tokens (~52.5%) |
| Allowed tools list | ~1k | 0 | ~1k tokens |
| Total | ~20k | ~9k | ~11k tokens (~55%) |
The allowed tools list is dynamic context - it grows as you approve more bash commands. The patch removes this list entirely.
Here's what /context looks like before and after patching:
Unpatched (~20k, 10%)

Patched (~9k, 4%)

The patches work by trimming verbose examples and redundant text from the minified CLI bundle while keeping all the essential instructions.
I've tested this extensively and it works well. It feels more raw - more powerful, but maybe a little less regulated, which makes sense because the system instruction is shorter. It feels more like a pro tool when you use it this way. I really enjoy starting with lower context because you have more room before it fills up, which gives you the option to continue conversations a bit longer. That's definitely the best part of this strategy.
Check out the system-prompt folder for the patch scripts and full details on what gets trimmed.
Why patching? Claude Code has flags that let you provide a simplified system prompt from a file (--system-prompt or --system-prompt-file), so that's another way to go about it. But for the tool descriptions and the dynamic approved tools list, there's no official option to customize them. Patching the CLI bundle is the only way. Since my patch system handles everything in one unified approach, I'm keeping it this way for now. I might re-implement the system prompt portion using the flag in the future.
Requirements: These patches require npm installation (npm install -g @anthropic-ai/claude-code). The patching works by modifying the JavaScript bundle (cli.js) - other installation methods may produce compiled binaries that can't be patched this way.
Important: If you want to keep your patched system prompt, disable auto-updates by adding export DISABLE_AUTOUPDATER=1 to ~/.zshenv (not ~/.zshrc). The reason for .zshenv is that it's sourced for ALL zsh invocations, including non-interactive shells and tmux sessions. .zshrc only gets sourced for interactive shells, so tmux-based workflows (like the ones in Tips 9, 11, and 21) would auto-update without .zshenv. You can manually update later with npm update -g @anthropic-ai/claude-code when you're ready to re-apply patches to a new version.
If you're working on multiple files or multiple branches and you don't want them to get conflicted, Git worktrees are a great way to work on them at the same time. You can just ask Claude Code to create a git worktree and start working on it there - you don't have to worry about the specific syntax.
The basic idea is that you can work on a different branch in a different directory. It's essentially a branch + a directory.
You can add this layer of Git worktrees on top of the cascade method I discussed in the multitasking tip.
When waiting on long-running jobs like Docker builds or GitHub CI, you can ask Claude Code to do manual exponential backoff. Exponential backoff is a common technique in software engineering, but you can apply it here too. Ask Claude Code to check the status with increasing sleep intervals - one minute, then two minutes, then four minutes, and so on. It's not programmatically doing it in the traditional sense - the AI is doing it manually - but it works pretty well.
This way the agent can continuously check the status and let you know once it's done.
(For GitHub CI specifically, gh run watch exists but outputs many lines continuously, which wastes tokens. Manual exponential backoff with gh run view <run-id> | grep <job-name> is actually more token-efficient. This is also a general technique that works well even when you don't have a dedicated wait command handy.)
For example, if you have a Docker build running in the background:

And it keeps going until the job completes.
Claude Code is an excellent writing assistant and partner. The way I use it for writing is I first give it all the context about what I'm trying to write, and then I give it detailed instructions by speaking to it using my voice. That gives me the first draft. If it's not good enough, I try a few times.
Then I go through it line by line, pretty much. I say okay, let's take a look at it together. I like this line for these reasons. I feel like this line needs to move over there. This line needs to change in this particular way. I might ask about reference materials as well.
So it's this sort of back-and-forth process, maybe with the terminal on the left and your code editor on the right:

That tends to work really well.
Typically when people write a new document, they might use something like Google Docs or maybe Notion. But now I honestly think the most efficient way to go about it is markdown.
Markdown was already pretty good even before AI, but with Claude Code in particular, because it's so efficient as I mentioned with regards to writing, it makes the value of markdown higher in my opinion. Whenever you want to write a blog post or even a LinkedIn post, you can just talk to Claude Code, have it be saved as markdown, and then go from there.
A quick tip for this one: if you want to copy and paste markdown content into a platform that doesn't accept it easily, you can paste it into a fresh Notion file first, then copy from Notion into the other platform. Notion converts it to a format that other platforms can accept. If regular pasting doesn't work, try Command + Shift + V to paste without formatting.
It turns out the reverse also works. If you have text with links from other places, let's say from Slack, you can copy it. If you paste it directly into Claude Code, it doesn't show the links. But if you put it in a Notion document first, then copy from there, you get it in markdown, which of course Claude Code can read.
Running Claude Code with
--dangerously-skip-permissionsis the equivalent of having unprotected sex. So use a condo... I mean a container.
Regular sessions are more for methodical work where you control the permissions you give and review output more carefully. Containerized environments are great for --dangerously-skip-permissions sessions where you don't have to give permission for each little thing. You can just let it run on its own for a while.
This is useful for research or experimentation, things that take a long time and maybe could be risky. A good example is the Reddit research workflow from Tip 11, where the reddit-fetch skill goes back and forth with Gemini CLI through tmux. Running that unsupervised is risky on your main system, but in a container, if something goes wrong, it's contained.
Another example is how I created the system prompt patching scripts in this repo. When a new version of Claude Code comes out, I need to update the patches for the minified CLI bundle. Instead of running Claude Code with --dangerously-skip-permissions on my host machine (where it has access to everything), I run it in a container. Claude Code can explore the minified JavaScript, find the variable mappings, and create new patch files without me approving every little thing that way.
In fact, it was able to complete the migration pretty much on its own. It tried applying the patches, found that some didn't work with the new version, iterated to fix them, and even improved the instruction document for future instances based on what it learned.
I set up a Docker container with Claude Code, Gemini CLI, tmux, and all the customizations from this repo. Check out the container folder for the Dockerfile and setup instructions.
You can take this further by having your local Claude Code control another Claude Code instance running inside a container. The trick is using tmux as the control layer:
--dangerously-skip-permissions
tmux send-keys to send prompts and capture-pane to read outputThis gives you a fully autonomous "worker" Claude Code that can run experimental or long-running tasks without you approving every action. When it's done, your local Claude Code can pull the results back. If something goes wrong, it's all sandboxed in the container.
Beyond just Claude Code, you can run different AI CLIs in containers - Codex, Gemini CLI, or others. I tried OpenAI Codex for code review, and it works well. The point isn't that you can't run these CLIs directly on your host machine - you obviously can. The value is that Claude Code's UI/UX is smooth enough that you can just talk to it and let it handle the orchestration: spinning up different models, sending data between containers and your host. Instead of manually switching between terminals and copy-pasting, Claude Code becomes the central interface that coordinates everything.
Recently I saw a world-class rock climber being interviewed by another rock climber. She was asked, "How do you get better at rock climbing?" She simply said, "By rock climbing."
That's how I feel about this too. Of course, there are supplementary things you can do, like watching videos, reading books, learning about tips. But using Claude Code is the best way to learn how to use it. Using AI in general is the best way to learn how to use AI.
I like to think of it like a billion token rule instead of the 10,000 hour rule. If you want to get better at AI and truly get a good intuition about how it works, the best way is to consume a lot of tokens. And nowadays it's possible. I found that especially with Opus 4.5, it's powerful enough but affordable enough that you can run multiple sessions at the same time. You don't have to worry as much about token usage, which frees you up a lot.
Sometimes you want to try a different approach from a specific point in a conversation without losing your original thread. The clone-conversation script lets you duplicate a conversation with new UUIDs so you can branch off.
The first message is tagged with [CLONED], which shows up both in the claude -r list and inside the conversation.
To set it up manually, symlink both files:
|
|
Or install via the dx plugin - no symlinks needed.
Then just type /clone (or /dx:clone if using the plugin) in any conversation and Claude will handle finding the session ID and running the script.
I've tested this extensively and the cloning works really well.
When a conversation gets too long, the half-clone-conversation script keeps only the later half. This reduces token usage while preserving your recent work. The first message is tagged with [HALF-CLONE].
To set it up manually, symlink both files:
|
|
Or install via the dx plugin - no symlinks needed.
When you need to tell Claude Code about files in a different folder, use realpath to get the full absolute path:
|
|
These are somewhat similar features and I initially found them pretty confusing. I've been unpacking them and trying my best to wrap my head around them, so I wanted to share what I learned.
CLAUDE.md is the simplest one. It's a bunch of files that get treated as the default prompt, loaded into the beginning of every conversation no matter what. The nice thing about it is the simplicity. You can explain what the project is about in a particular project (./CLAUDE.md) or globally (~/.claude/CLAUDE.md).
Skills are like better-structured CLAUDE.md files. They can be invoked by Claude automatically when relevant, or manually by the user with a slash (e.g., /my-skill). For example, you could have a skill that opens a Google Translate link with proper formatting when you ask how to pronounce a word in a certain language. If those instructions are in a skill, they only load when needed. If they were in CLAUDE.md, they'd already be there taking up space. So skills are more token-efficient in theory.
Slash Commands are similar to skills in that they're ways of packaging instructions separately. They can be invoked manually by the user, or by Claude itself. If you need something more precise, to invoke at the right time at your own pace, slash commands are the tool to use.
Skills and slash commands are pretty similar in the way they function. The difference is the intention of the design - skills are primarily designed for Claude to use, and slash commands are primarily designed for the user to use. However, I think there's a chance they'll be merged at some point, and I requested that from Anthropic.
Plugins are a way to package skills, slash commands, agents, hooks, and MCP servers together. But a plugin doesn't have to use all of them. Anthropic's official frontend-design plugin is essentially just a skill and nothing else. It could be distributed as a standalone skill, but the plugin format makes it easier to install.
For example, I built a plugin called dx that bundles slash commands and a skill from this repo together. You can see how it works in the Install the dx plugin section.
Claude Code is great for PR reviews. The procedure is pretty simple: you ask it to retrieve PR information using the gh command, and then you can go through the review however you want.
You can do a general review, or go file by file, step by step. You control the pace. You control how much detail you want to look into and the level of complexity you want to work at. Maybe you just want to understand the general structure, or maybe you want to have it run tests too.
The key difference is that Claude Code acts as an interactive PR reviewer, not just a one-shot machine. Some AI tools are good at one-shot reviews (including the latest GPT models), but with Claude Code you can have a conversation.
Claude Code is amazing for any sort of research. It's essentially a Google replacement or deep research replacement, but more advanced in a few different ways. Whether you're researching why certain GitHub Actions failed (which I've been doing a lot recently), doing sentiment or market analysis on Reddit, exploring your codebase, or exploring public information to find something - it's able to do that.
The key is giving it the right pieces of information and instructions about how to access those pieces of information. It might be gh terminal command access, or the container approach (Tip 21), or Reddit through Gemini CLI (Tip 11), or private information through an MCP like Slack MCP, or the Cmd+A / Ctrl+A method (Tip 10) - whatever it is. Additionally, if Claude Code has trouble loading certain URLs, you can try using Playwright MCP or Claude's native browser integration (see Tip 9).
In fact, I was even able to save $10,000 by using Claude Code for research.
One way to verify its output if it's code is to have it write tests and make sure the tests look good in general. That's one way, but you can of course check the code it generates as it goes, just on the Claude Code UI. Another thing is you can use a visual Git client like GitHub Desktop for example. I personally use it. It's not a perfect product, but it's good enough for checking changes quickly. And having it generate a PR as I probably mentioned earlier in this post is a great way as well. Have it create a draft PR, check the content before turning it into a real PR.
Another one is letting it check itself, its own work. If it gives you some sort of output, let's say from some research, you can say "are you sure about this? Can you double check?" One of my favorite prompts is to say "double check everything, every single claim in what you produced and at the end make a table of what you were able to verify" - and that seems to work really well.
I wanted to specifically create a separate tip for this because it's been really amazing for me. Whenever there are GitHub Actions CI failures, I just give it to Claude Code and say "dig into this issue, try to find the root cause." Sometimes it gives you surface level answers, but if you just keep asking - was it caused by a particular commit, a particular PR, or is it a flaky issue? - it really helps you dig into these nasty issues that are hard to dig into by hand. You would need to wade through a bunch of logs and that would be super painful to do manually, but Claude Code is able to handle a lot of that.
I've packaged this workflow as a /gha slash command - just run /gha <url> with any GitHub Actions URL and it will automatically investigate the failure, check for flakiness, identify breaking commits, and suggest fixes. You can find it in the commands folder, or install it via the dx plugin.
Once you identify what the particular problem was, you can just create a draft PR and go through some of the tips I mentioned earlier - check the output, make sure it looks good, let it verify its own outputs, and then turn it into a real PR to actually fix the issue. It's been working really well for me personally.
I think it's important to keep CLAUDE.md really simple and concise. You can just start with no CLAUDE.md at all. And if you find that you keep telling Claude Code the same thing over and over again, then you can just add it to CLAUDE.md. I know there is an option to do that through the # symbol, but I prefer to just ask Claude Code to either add it to the project level CLAUDE.md or the global CLAUDE.md and it'll know what to edit exactly. So you can just let Claude Code edit CLAUDE.md by itself based on your instruction.
I used to think with Claude Code, CLI is like the new IDE, and it's still true in a way. I think it's a great first place to open your project whenever you want to make quick edits and stuff like that. But depending on the severity of your project, you want to be more careful about the outputs than just staying at the vibe coding level.
But what's also true, the more general case of that, is that Claude Code is really the universal interface to your computer, the digital world, any sort of digital problem that you have. You can let it figure it out in many cases. For example, if you need to do a quick edit of your video, you can just ask it to do that - it'll probably figure out how to do that through ffmpeg or something similar. If you want to transcribe a bunch of audio files or video files that you have locally, you can just ask it to do that - it might suggest to use Whisper through Python. If you want to analyze some data that you have in a CSV file, it might suggest to use Python or JavaScript to visualize that. And of course with internet access - Reddit, GitHub, MCPs - the possibilities are endless.
It's also great for any operations you want to perform on your local computer. For example, if you're running out of storage, you can just ask it to give you some advice on how to clean that up. It'll look through your local folders and files, try to find what's taking up a lot of space, and then give you advice on how to clean them up - maybe delete particularly large files. In my case, I had some Final Cut Pro files that were really large that I should have cleaned up. Claude Code told me about it. Maybe it'll tell you to clean up unused Docker images and containers using docker system prune. Or maybe it'll tell you to clean up some cache that you never realized was still there. No matter what you want to do on your computer, Claude Code is the first place I go to now.
I think it's kind of interesting because the computer started with a text interface. And we're, in a way, coming back to this text interface that you can spin up three or four tabs at a time, as I mentioned earlier. To me, that's really exciting. It feels like you have a second brain, in a way. But because of the way it's structured, because it's just a terminal tab, you can open up a third brain, a fourth brain, a fifth brain, a sixth brain. And as the models become more powerful, the proportion of the thinking that you can delegate to these things - not the important things, but things that you don't want to do or that you find boring or too tedious - you can just let them take care of it. As I mentioned, a good example of that is looking into GitHub Actions. Who wants to do that? But it turns out these agents are really good at those boring tasks.
As I mentioned earlier, sometimes it's okay to stay at the vibe coding level. You don't necessarily have to worry about every single line of code if you're working on one-time projects or non-critical parts of the codebase. But other times, you want to dig in a little deeper - look at the file structure and functions, individual lines of code, even checking dependencies.

The key is that it's not binary. Some people say vibe coding is bad because you don't know what you're doing, but sometimes it's totally fine. But other times, it is helpful to dig deeper, use your software engineering skills, understand code at a granular level, or copy and paste parts of the codebase or specific error logs to ask Claude Code specific questions about them.
It's sort of like you're exploring a giant iceberg. If you want to stay at the vibe coding level, you can just fly over the top and check it from far away. Then you can go a little bit closer. You can go into diving mode. You can go deeper and deeper, with Claude Code as your guide.
I recently saw this post where someone's Claude Code ran rm -rf tests/ patches/ plan/ ~/ and wiped their home directory. It's easy to dismiss as a vibe coder mistake, but this kind of mistake could happen to anyone. So it's important to audit your approved commands from time to time. To make it easier, I built cc-safe - a CLI that scans your .claude/settings.json files for risky approved commands.
It detects patterns like:
sudo, rm -rf, Bash, chmod 777, curl | sh
git reset --hard, npm publish, docker run --privileged
docker exec commands are skippedIt recursively scans all subdirectories, so you can point it at your projects folder to check everything at once. You can run it manually or ask Claude Code to run it for you:
|
|
Or just run it directly with npx:
|
|
GitHub: cc-safe
As you write more code with Claude Code, it becomes easier to make mistakes. PR reviews and visual Git clients help catch issues (as I mentioned earlier), but writing tests is crucial as your codebase grows larger.
You can have Claude Code write tests for its own code. Some people say AI can't test its own work, but it turns out it can - similar to how the human brain works. When you write tests, you're thinking about the same problem in a different way. The same applies to AI.
I've found that TDD (Test-Driven Development) works really well with Claude Code:
This is actually how I built cc-safe. By writing failing tests first and committing them before implementation, you create a clear contract for what the code should do. Claude Code then has a concrete target to hit, and you can verify the implementation is correct by running the tests.
If you want to be extra sure, review the tests yourself to make sure they don't do anything stupid like just returning true.
Since I started using Claude Code more intensely, I've noticed that I became more and more brave in the unknown.
For example, when I started working at Daft, I noticed a problem with our frontend code. I'm not an expert in React, but I decided to dig into it anyway. I just started asking questions about the codebase and about the problem. Eventually I was able to solve it because I knew how to iteratively solve problems with Claude Code.
A similar thing happened recently. I was building a guide for users of Daft and ran into some very specific issues: cloudpickle not working with Google Colab with Pydantic, and a separate issue with Python and a bit of Rust where things weren't printing correctly in JupyterLab even though they worked fine in the terminal. I had never worked with Rust before.
I could have just created an issue and let other engineers handle it. But I thought, let me dig into the codebase. Claude Code came up with an initial solution, but it wasn't that good. So I slowed down. A colleague suggested we just disable that part, but I didn't want any regression. Can we find a better solution?
What followed was a collaborative and iterative process. Claude Code suggested potential root causes and solutions. I experimented with those. Some turned out to be dead ends, so we went in a different direction. Throughout this, I controlled my pace. Sometimes I went faster, like when letting it explore different solution spaces or parts of the codebase. Sometimes I went slower, asking "what does this line mean exactly?" Controlling the level of abstraction, controlling the speed.
Eventually I found a pretty elegant solution. The lesson: even in the world of the unknown, you can do a lot more with Claude Code than you might think.
When you have a long-running bash command in Claude Code, you can press Ctrl+B to move it to run in the background. Claude Code knows how to manage background processes - it can check on them later using the BashOutput tool.
This is useful when you realize a command is taking longer than expected and you want Claude to do something else in the meantime. You can either have it use the exponential backoff method I mentioned in Tip 17 to check on progress, or just let it work on something else entirely while the process runs.
Claude Code also has the ability to run subagents in the background. If you need to do long-running research or have an agent check on something periodically, you don't have to keep it running in the foreground. Just ask Claude Code to run an agent or task in the background, and it'll handle it while you continue with other work.
We're entering an era of personalized, custom software. Since AI came out - ChatGPT in general, but especially Claude Code - I've noticed that I'm able to create a lot more software, sometimes just for myself, sometimes for small projects.
As I mentioned earlier in this document, I've created a custom transcription tool that I use every day to talk to Claude Code. I've created ways to customize Claude Code itself. I've also done a bunch of data visualization and data analysis tasks using Python much faster than I could otherwise.
Here's another example: korotovsky/slack-mcp-server, a popular Slack MCP with almost 1,000 stars, is designed to run as a Docker container. I had trouble using it smoothly inside my own Docker container (Docker-in-Docker complications). Instead of fighting with that setup, I just asked Claude Code to write a CLI using Slack's Node SDK directly. It worked really well.
This is an exciting time. Whatever you want to get done, you can ask Claude Code to do it. If it's small enough, you can build it in an hour or two.
Claude Code's input box is designed to emulate common terminal/readline shortcuts, which makes it feel natural if you're used to working in the terminal. Here are some useful ones:
Navigation:
Ctrl+A - Jump to the beginning of the lineCtrl+E - Jump to the end of the lineOption+Left/Right (Mac) or Alt+Left/Right - Jump backward/forward by wordEditing:
Ctrl+W - Delete the previous wordCtrl+U - Delete from cursor to beginning of lineCtrl+K - Delete from cursor to end of lineCtrl+C / Ctrl+L - Clear the current inputCtrl+G - Open your prompt in an external editor (useful for pasting long text, since pasting directly into the terminal can be slow)If you're familiar with bash, zsh, or other shells, you'll feel right at home.
For Ctrl+G, the editor is determined by your EDITOR environment variable. You can set it in your shell config (~/.zshrc or ~/.bashrc):
|
|
Or in ~/.claude/settings.json (requires restart):
|
|
Entering newlines (multi-line input):
The quickest method works everywhere without any setup: type \ followed by Enter to create a newline. For keyboard shortcuts, run /terminal-setup in Claude Code. On Mac Terminal.app, I use Option+Enter.
Pasting images:
Ctrl+V (Mac/Linux) or Alt+V (Windows) - Paste an image from your clipboardNote: On Mac, it's Ctrl+V, not Cmd+V.
You want to spend enough time planning so that Claude Code knows what to build and how to build it. This means making high-level decisions early: what technology to use, how the project should be structured, where each functionality should live, which files things should go in. It's important to make good decisions as early as you can.
Sometimes prototyping helps with that. Just by making a simple prototype quickly, you might be able to say "okay, this technology works for this particular purpose" or "this other technology works better."
For example, I was recently experimenting with creating a diff viewer. I first tried a simple bash prototype with tmux and lazygit, then tried making my own git viewer with Ink and Node. I had a lot of trouble with different things and ended up not publishing any of these results. But what I got reminded of through this project is the importance of planning and prototyping. I found that just by planning a little bit better at the beginning before you let it write code, you're able to guide it better. You still need to guide it throughout the process of coding, but letting it plan a little first is really helpful.
You can use plan mode for this by pressing Shift+Tab to switch to it. Or you can just ask Claude Code to make a plan before writing any code.
I've found that Claude Code sometimes overcomplicates things and writes too much code. It makes changes you didn't ask for. It just seems to have a bias for writing more code. The code might work correctly if you've followed the other tips in this guide, but it's going to be hard to maintain and hard to check. It can be kind of a nightmare if you don't review it enough.
So sometimes you want to check the code and ask it to simplify things. You could fix things yourself, but you could also just ask it to simplify. You can ask questions like "why did you make this particular change?" or "why did you add this line?"
Some people say if you write code only through AI, you'll never understand it. But that's only true if you don't ask enough questions. If you make sure you understand every single thing, you can actually understand code faster than otherwise because you can ask AI about it. Especially when you're working on a large project.
Note that this applies to prose as well. Claude Code often tries to summarize previous paragraphs in the last paragraph, or previous sentences in the last sentence. It can get pretty repetitive. Sometimes it's helpful, but most of the time you'll need to ask it to remove or simplify it.
At the end of the day, it's all about automation of automation. What I mean by that is I've found it's the best way to not just become more productive, but also make the process more fun. At least to me, this whole process of automation of automation is really fun.
I personally started with ChatGPT and wanted to automate the process of copy-pasting and running commands that ChatGPT gave me in the terminal. I automated that whole process by building a ChatGPT plugin called Kaguya. I've consistently worked towards more and more automation since then.
Nowadays, luckily, we don't even have to build a tool like that because tools like Claude Code exist and they work really well. And as I've used it more and more, I found myself thinking, well, what if I could automate the process of typing? So I used Claude Code itself to build my voice transcription app, as I mentioned earlier.
Then I started to think, I find myself repeating myself sometimes. So I would put those things in CLAUDE.md. Then I would think, okay, sometimes I go through running the same command over and over again. How can I automate that? Maybe I can ask Claude Code to do it. Or maybe I can put them in skills. Or maybe I can even have it create a script so I don't have to repeat the same process over and over again.
I think ultimately that's where we're heading. Whenever you find yourself repeating the same task or the same command over and over again, a couple of times is okay, but if you repeat it over and over again, then think about a way to automate that whole process.
This tip is a bit different from the others. I found that by learning as much as you can, you're able to share your knowledge with people around you. Maybe through posts like these, maybe even books, courses, videos. I also recently had an internal session for my colleagues at Daft. It's been very rewarding.
And whenever I share tips, I often get information back. For example, when I shared my trick for shortening the system prompt and tool descriptions (Tip 15), some people told me about the --system-prompt flag that you can use as an alternative. Another time, I shared about the difference between slash commands and skills (Tip 25), and I learned new things from comments on that Reddit post.
So sharing your knowledge isn't just about establishing your brand or solidifying your learning. It's also about learning new things through that process. It's not always a one-way street.
When it comes to contributing, I've been sending issues to the Claude Code repo. I thought, okay, if they listen, cool. If they don't, that's totally fine. I didn't have any expectations. But in version 2.0.67, I noticed they took multiple suggestions from reports I made:
/permissions
/permissions commandIt's kind of amazing how fast the team can react to feature requests and bug reports. But it makes sense because they're using Claude Code to build Claude Code itself.
There are several effective ways to keep learning about Claude Code:
Ask Claude Code itself - If you have a question about Claude Code, just ask it. Claude Code has a specialized sub-agent for answering questions about its own features, slash commands, settings, hooks, MCP servers, and more.
Check the release notes - Type /release-notes to see what's new in your current version. This is the best way to learn about the latest features.
Learn from the community - The r/ClaudeAI subreddit is a great place to learn from other users and see what workflows people are using.
Follow Ado for daily tips - Ado (@adocomplete) is a DevRel at Anthropic who's been posting daily Claude Code tips throughout December in his "Advent of Claude" series. Each day covers a different feature or workflow - things like named sessions, /stats, headless mode, vim mode, and more.
This repo is also a Claude Code plugin called dx (developer experience). It bundles several tools from the tips above into a single install:
| Command/Skill | Description |
|---|---|
/dx:gha <url> |
Analyze GitHub Actions failures (Tip 29) |
/dx:handoff |
Create handoff documents for context continuity (Tip 8) |
/dx:clone |
Clone conversations to branch off (Tip 23) |
/dx:half-clone |
Half-clone to reduce context (Tip 23) |
reddit-fetch |
Fetch Reddit content via Gemini CLI (Tip 11) - auto-invoked when needed |
Install with two commands:
|
|
After installing, the commands are available as /dx:clone, /dx:half-clone, /dx:handoff, and /dx:gha. The reddit-fetch skill is invoked automatically when you ask about Reddit URLs.
Recommended companion: Playwright MCP for browser automation - add with claude mcp add -s user playwright npx @playwright/mcp@latest
📺 Related talk: Claude Code Masterclass - lessons and project examples from 31 months of agentic coding
📝 Story: How I got a full-time job with Claude Code
📰 Newsletter: Agentic Coding with Discipline and Skill - bring the practice of agentic coding to the next level
2026-01-01 00:00:00
真正的深度研究报告不是让 AI "写"出来的,而是"研究"出来的。这两个字差别大了。
最近几个月,几个产品让我眼前一亮:Gemini Deep Research、Manus Wide Research,还有 OpenAI 的 Deep Research。它们都在做同一件事——让 AI 具备真正的"研究能力"。
这事儿得从"上下文窗口陷阱"说起。

传统 AI 助手有个致命问题。
让它分析 5 个产品?没问题,每个都能给出详尽分析。
分析 10 个?开始有点吃力,后面的描述明显变短。
分析 30 个?基本崩了,只能给些通用摘要,错误率飙升。
这不是模型变笨了,是上下文窗口被撑爆了。AI 必须把前面所有项目都记在内存里,越往后,早期信息被压缩得越厉害,最后就剩个轮廓。
研究显示,大多数 AI 系统的"幻觉阈值"大概在 8-10 个项目左右。超过这个数,质量断崖式下跌。
这就是为什么那些所谓的"深度研究" agent,给你列 50 篇论文,结果后面 30 篇都是胡编乱造。

业界现在有两条路线解决这个问题。
路线一:把模型做强
代表是 Google 的 Gemini Deep Research。2025 年搞了两次大升级——4 月上了 Gemini 2.5 Pro,12 月又升级到 Gemini 3 Pro。核心思路就是用更大的上下文窗口、更强的推理能力,硬抗复杂任务。
它适合那种需要深度推理、跨多个来源综合分析的任务。比如研究一个技术趋势的演进,需要把几十篇论文、新闻、博客揉在一起,找出脉络。
路线二:把架构做巧
代表是 Manus 的 Wide Research。它不跟你比谁的上下文窗口大,而是直接换个架构——不用一个 Agent 干所有事,而是搞几百个 Agent 并行干活。
每个 Agent 只负责一个项目,有自己独立的上下文窗口。主 Agent 负责拆解任务、分配工作、最后汇总结果。
这就像写研究报告。原来是一个人憋大招,现在是一个导师带几十个研究生,每人负责一篇文献,最后导师综合。
所以Manus把它的研究项目叫做宽度搜索 (wide research)。

拿"风电行业股票的投资研究"这个任务来说,两种方案差异明显。
丢给 Gemini 一个复杂问题,它会:
① 先理解任务,规划研究策略
可以看到,Gemini一开始先制定研究方案,把搜索计划拆解成 7 个方向,针对每个方向,进行深度的分析。
而且它在开始的允许你修改研究方案,提供 human-in-the-loop 的机制,允引入人工干预的过程。
② 多轮搜索,找权威来源——行业报告、公司财报、政策文件、学术论文
这其实是谷歌的优势,它是搜索引擎起家,有着无与伦比的搜索数据优势,而且时效性也非常的高,所以它更有资源去做这个事情,其实百度也非常的合适做这个。所以它搜索的质量也是非常高的,搜索出来的网页的权重都挺高,权威性好。

③ 边搜索边分析,不断调整方向
从上图可以看出,它也是边搜索边思考,对搜索方向进行适当的调整,围绕着计划进行有目的的搜索。
④ 综合所有信息,写出有逻辑的报告
最终,整合所有的报告,输出一份完整的报告结果。
整个过程可能要跑十几分钟。但它给出的不是简单的信息拼凑,而是有洞察的分析。
优点是推理能力强,能发现隐含的关联。比如它会注意到某个政策变化对上游设备商和下游运营商的不同影响,这是普通搜索做不到的。
缺点是,如果任务涉及大量独立对象(比如分析 50 家风电公司),还是会遇到上下文瓶颈。
同样的任务,如果是"分析 50 家风电上市公司",Manus 的做法完全不同。
第一步,任务拆解。
主 Agent 会把"分析 50 家公司"这个大任务,拆成 50 个独立的小任务。每个小任务包含:公司名称、需要收集的信息字段(财务数据、业务布局、风险因素等)、评估标准。
第二步,并行启动。
50 个子 Agent 同时启动,每个只研究一家公司。关键在于——它们不是轮流干活,而是真正并行。就像 50 个研究员同时开工,互不干扰。
第三步,独立执行。
每个子 Agent 在自己的沙箱环境里跑完整的调研流程:搜索公司信息、读财报、查新闻、整理数据。因为每个 Agent 有独立的上下文窗口,第 50 个公司和第 1 个公司获得的分析深度完全一致。
第四步,结果汇总。
主 Agent 收集所有子任务的结果,整理成结构化输出——表格、报告、或者数据库。
这个方案的巧妙之处在于规避了上下文窗口问题。
传统方式是一个 Agent 处理所有任务,越往后上下文越拥挤,质量必然下降。而 Manus 的方式是每个 Agent 都从零开始,大家都是"满血"状态,不存在谁挤占谁的问题。
官方有个案例——研究 250 位 AI 研究员。
第 1 位到第 250 位,每位的详细程度都一样:完整的背景、研究方向、代表作、核心论文。这换成传统 AI 根本做不到——早就因为上下文爆炸而开始胡编乱造了。
剥开产品外壳,Manus 的架构其实挺讲究的。核心思想来自一篇叫《CodeAct》的论文:让 AI 像程序员一样工作——写代码、运行代码、看结果、改代码、再运行。
ReAct 模式
每个 Agent 的执行逻辑是一个循环:观察(Observation)→ 思考(Thought)→ 行动(Action)→ 观察...不断迭代,直到任务完成。
这不是简单的"调用工具",而是边思考边行动。搜索结果不相关?换关键词。代码执行报错?检查原因、修改命令、重试。
|
|
沙箱隔离
每个 Agent 跑在独立的虚拟机环境里。这不是多线程,而是真正的隔离——独立的文件系统、独立的网络、独立的进程空间。
Manus 用了沙箱技术,这样就算某个 Agent 被诱导执行了危险命令,也影响不到其他 Agent 和宿主系统。
任务分解:DAG 结构
主 Agent 把复杂任务拆成有向无环图(DAG)。清楚知道哪些步骤可以并行,哪些必须等前置条件。
比如"研究 50 家风电公司"的执行图:
|
|
工具集
Manus 提供了 29 种工具,分成几类:
| 类别 | 工具示例 | 用途 |
|---|---|---|
| 命令执行 | Shell、Python | 执行任意代码和系统命令 |
| 文件操作 | 读写 txt/md/pdf/xlsx | 处理各种格式的文档 |
| 网络能力 | 搜索、浏览器、端口部署 | 获取信息、部署服务 |
| 系统能力 | 进程管理、软件安装 | 配置运行环境 |
这些工具让 Agent 能真正"动手做事",而不是只会生成文本。比如研究一家公司,它可以:搜索公司官网、爬取财报数据、用 Python 分析财务指标、把结果写入表格。
动态质量检测
Manus 不是按预设流程走到黑。每次执行完一个步骤,都会判断:结果可信吗?需要调整方向吗?
|
|
代码执行报错?调整命令重试。搜索结果太少?换搜索引擎或关键词。这种自我纠错能力,让它在遇到问题时不会死磕,而是会寻找替代方案。
状态管理
每个任务维护一个 todo.md 文件,实时更新进度:
|
|
这样做的好处是:任务中断后可以恢复;用户随时能看到进展;中间结果有地方存储,不会丢失。
当然这些分析都是我们基于Manus的产品、宣传资料和外部人员的分析做的推测,我们实际并不知道Manus内部的方案。仅供分析和学习。

看这些产品,我发现一个有趣的共通点:它们都在模仿人类研究员的工作方式。
人类研究员怎么做深度报告?
关键在于,这不是一次性能完成的。需要反复迭代——查了资料发现方向不对,得换方向;分析到一半发现缺数据,得补数据。
传统的 LLM chat 模式,本质上是一次性生成。给你个 prompt,你吐出结果。这是"写作",不是"研究"。
真正的深度研究 agent,应该具备:
① 规划能力:能理解任务,制定研究策略,知道先查什么后查什么。
② 工具能力:会用搜索引擎、读数据库、解析文档,不只是从训练数据里抠信息。
③ 迭代能力:能根据中间结果调整方向,不是按预定流程走到黑。
④ 验证能力:能交叉验证信息来源,不是捡到什么信什么。
⑤ 综合能力:能把碎片信息拼成完整故事,不是简单的信息罗列。
Gemini Deep Research 和 Manus Wide Research,本质上都是在往这个方向努力。只是侧重点不同——前者重"深",后者重"广"。

深度研究报告的生成,本质上是在解决 AI 的两个核心问题:知识获取和复杂推理。
传统的做法是把知识"压缩"进模型参数里,但这有天花板——模型总有训练截止日期,总有不知道的东西。
新的方向是给 AI 装上"工具",让它能动态获取信息、多步推理、自我纠错。这更像人类的智能——我们不是什么都知道,但知道怎么去查、怎么去思考。
Deep Research 这类产品,标志着 AI 从"聊天机器人"向"研究助手"的转变。它们不只是在陪你闲聊,而是能真正帮你干活。
当然,问题还很多。幻觉、偏见、安全风险,一个都没解决。但方向是对的。

基于上面对这些产品的分析,结合对智能体 20 余中架构模式的研究,针对深度研究报告这个场景,我们研发了Insight平台,展示了要实现高质量的深度研究报告所设计的技术和套路,并提供了独有的一些方法。
接下来我介绍这个产品的重要的结束。在这之前,我先给大家展示一下效果。
Insight平台地址: https://insight.rpcx.io
一个网友的报告: https://insight.rpcx.io/reports/e25061cd-b936-470d-b5ed-3998b2d7452e

就像研究员一样,要想生成高质量的报告,必须要有高质量的数据源作为基础。
如上面提到过的,这方面搜索引擎具有优势,他们拥有全面性,时效性高的搜索资料。
一些专业的网站也有行业方面的专业资料,比如金融领域相关的,IT技术相关的、白酒方面相关的
电商方面相关的,旅游行业相关的、出行方面相关的、法律行业相关的,科普方面相关的,他们能够提供垂类专业的资料,如果要生成这方面的报告,找这些行业相关的网站信息是最好的。当然如果这些资料是公开的,可以通过搜索因为+专业的搜索词进行搜索获取,所以搜索引擎的重要性在AI的深度调研报告生成中占很重要的地位。
但是搜索引擎并不轻易把它的能力无偿的暴露出来,比如谷歌,它提供付费的搜索API,价格不低。Bing已经把它的搜索API下掉了。还有一些第三方的服务,或许是通过爬虫的方式进行搜索,比如Travily、Brave、SerpAPI等,也提供收费的服务。总的来说,好东西都是有价格的。这些搜索引擎增加了反爬虫的机制,我几个月前还能绕过这些限制,现在也不行了,他们都很聪明,不会轻易让你免费使用的。
从 Manus网站的输出来看,我怀疑它们买了某个或者某几个服务器服务商的服务,可以针对用户的请求,得到搜索引擎的列表 (SERP), 这是猜测,前端并看不出来,因为它们并不可能去做个搜索引擎。专业的人做专业的事。它们拿到搜索结果列表后,通过它们的AI浏览器,也就是虚拟机的浏览器去浏览网络,获取网页的内容。它们叫cloud browser,应该是基于browserbase开发的。沙盒技术和Browser我放在下一个拆解文章中在再专门介绍,这一篇还是专门关注调研报告的实现。
专业的用户会提供详细的、简洁的、对 AI 友好的提示词,但是大部分用户并不能很好的表达自己的意图,比如:
请帮我分析Apple的市场行情
这里的Apple指的是苹果电脑公司还是水果苹果🍎呢?非常有歧义。还有的提示词含糊不清。在Insight的实现在,我们首先实现的就是对用户的提示词进行澄清。理论上对于非常模糊的提示词,比如Apple这里例子,我们需要进一步询问用户,反问用户的意图,但是Insight还没进一步的实现这个功能,而是自动进行澄清,它是怎么实现的呢?
接下来专门有个agent(StructurePlannerNode)负责生成报告的节点,主要确定报告的主要大纲和方向。

接下来针对报告的大纲, Planner Agent针对金融投资领域、技术开发领域、商业分析领域、政策相关领域、通用领域等各种领域制定搜索计划,为每个章节搜索足够的信息备用。
Search Agent 会根据搜索计划,逐步实现相关内容的搜索。
它会根据项目提供的工具,进行搜索。目前提供了travily、github、谷歌学术、知乎、微信公众号等网站的搜索,我其实还是期望能直接搜索google的搜索结果和一些顶级的专业网站的搜索内容。
搜索的结果内容如果太长,还会对它们进行summary,以便压缩上下文。
此节点还会针对每个章节进行内容的总结。
现在万事俱备了,所有的大纲和材料都准备好了,可以进行报告的编写了。有请 ContentWriter Agent。
ContentWriter 负责报告的编写,它根据大纲和材料进行内容的创作。
说起创作来,针对内容创作的场景,我们为了提高创作产品的质量,经常采用Reflection模式,针对生成的内容进行打分,要不要进行优化。
所以这个Agent生成后,会调用Reflector Agent进行打分,以便决定要不要调用Revisor节点进行订正。你看报告生成的日志也能观察到这一点。
除非生成的报告片段达到了“优”的级别,否则就会尝试补充和订正,直到达到了 5 轮的反复订正才算通过。
所以你会看到Insight生成的报告的质量还是很高的,不像一个玩具或者示例deep research产品的报告那么简略或者偏离主题。

最后这个Agent把各个章节合在一起,生成一个完整的markdown的报告。
会生成合理的章节,并进行编号。
另外还有的Podcast Agent,可以生成播客的脚本。如果用户请求中要求生成播客,那么此Agent就会自动生成。
完整的工作流 (graph)如下:

本产品开发过程中很多资源花费了工程产品化方面,尤其是前端的生成和优化。

本产品使用 https://github.com/smallnest/langgraphgo 实现。 Go 语言实现。
使用 CC 辅助代码生成。
使用 GLM 4.7 作为后端模型。
本产品演示网站: https://insight.rpcx.io
对后端代码感兴趣的可以加我微信 smallnest 。我拉你进《智能体研究社》,讨论智能体的开发和vibe coding。

报告中缺乏图表,可以加强数据的采集和图表的展示。
报告中缺乏图片的润色,网上搜索的图片经常文不对题,不过我已经有方案了。
参考资料:
2026-01-01 00:00:00


Google 的 NotebookLM 上线后,不少人体验了它的文档问答和内容生成功能。它很好用,但有个问题:数据需要上传到 Google 的服务器。对于一些敏感的内部文档,这不太合适。
于是就想做一个开源版本:数据存在本地,想用什么模型就自己配置。一个元旦假期,基本功能就跑起来了。
项目叫 Notex,代码在 GitHub 上,今天聊聊它的实现。
本项目受open-notebook项目的启发。但是open-notebook缺少信息图、思维导图、幻灯片等高级功能。本项目弥补了这些功能
信息图采用最新的nano banana pro实现
幻灯片采用 宝玉的 《预订本年度最有价值提示词 —— 生成既有质感,又能随意修改文字的完美 PPT》 的方式,生成真正意义上的PPT

Notex 是一个隐私优先的开源知识管理工具,基于 RAG(检索增强生成)技术。它支持多种文档格式,通过 AI 帮助你理解、总结和可视化文档内容。
| 功能分类 | 具体能力 |
|---|---|
| 文档管理 | 支持 PDF、DOCX、PPTX、Markdown、TXT、HTML 等多种格式的文档上传和解析 |
| AI 对话 | 基于文档内容的智能问答,回答会标注来源引用,避免 AI 幻觉 |
| 内容转换 | 摘要、FAQ、学习指南、大纲、时间线、术语表、测验、播客脚本等 9 种预设类型 |
| 视觉生成 | 思维导图(Mermaid.js)、信息图(Gemini Nano Banana Pro)、幻灯片/PPT |
| 模型支持 | OpenAI(含兼容 API)、Ollama 本地模型、Google Gemini |
1. 幻灯片(PPT)生成
采用两阶段生成流程:
阶段一:使用 Gemini Flash 生成 PPT 大纲,包含:
阶段二:使用 Gemini Pro Image 为每页幻灯片生成配图
最终输出图文并茂的完整 PPT,而非简单的文字大纲。
2. 信息图生成
通过 Prompt Engineering 将文本内容"翻译"为结构化的视觉描述,再调用 Gemini Nano Banana Pro 生成手绘风格的信息图。
适用于:数据可视化、流程说明、概念解释等场景。
3. 思维导图生成
自动将文档结构提炼为 Mermaid.js mindmap 格式,支持:
4. 智能问答(RAG)
支持基于文档内容的自然语言问答:

技术栈选型很简单:
|
|
为什么不选 Python?因为 Go 编译完就是一个二进制文件,部署起来省事。而且 Go 的并发性能好,后续如果需要处理大量文档也不会成为瓶颈。
目录结构也很清晰:
|
|
前端通过 //go:embed 编译进二进制,一个文件就能跑起来。

RAG 的第一步是把文档切成小块,建立索引。
这里有个问题:中文和英文的分词方式不一样。英文按空格分词就行,中文需要按字符切。
|
|
检索部分目前用的是简单的关键词匹配,没有用向量 Embedding。原因?对于中小规模的文档(几万字以内),关键词匹配够用了,而且快。如果后续文档量大,可以接入向量数据库。
|
|

这块是核心,负责和 LLM 打交道。
使用 LangChainGo 作为抽象层,支持 OpenAI 和 Ollama:
|
|
Prompt Engineering 是关键。不同的转换类型需要不同的 prompt 模板:
|
|
注意这里的 prompt 设计:明确的输出格式要求,加上反面示例("严禁"),能有效减少 LLM 输出格式不稳定的问题。

这是比较复杂的 feature。需要两个步骤:
第一步:生成大纲
用 Gemini Flash 生成 PPT 大纲,每页包含:
第二步:解析和生成图片
|
|
然后为每张幻灯片调用 Gemini Pro Image 生成图片:
|
|

信息图的核心是让 LLM 把文本内容"翻译"成视觉描述,然后把描述作为 prompt 喂给图像模型。
|
|
这个 prompt 设计的要点是:明确告诉 LLM 它的输出会被用作另一个 prompt,这样 LLM 就会更注意输出的结构化和可用性。

思维导图的实现最简单,核心是生成 Mermaid.js 的语法:
|
|
前端用 Mermaid.js 自动渲染:
|
|

整个系统的数据流如下:
|
|

|
|
|
|
| 变量 | 说明 | 默认值 |
|---|---|---|
| OPENAI_API_KEY | OpenAI API 密钥 | - |
| OPENAI_BASE_URL | 自定义 API 地址 | - |
| OPENAI_MODEL | 模型名称 | gpt-4o-mini |
| OLLAMA_BASE_URL | Ollama 地址 | - |
| OLLAMA_MODEL | Ollama 模型 | - |
| GOOGLE_API_KEY | Gemini API(PPT/信息图) | - |
| SERVER_PORT | 服务端口 | 8080 |
代码结构支持几种扩展方式:
1. 添加新的转换类型
在 agent.go 的 getTransformationPrompt 添加新 case:
|
|
2. 支持新的 LLM
LangChainGo 支持多种模型,只需在 createLLM 添加新的分支。
3. 接入向量数据库
VectorStore 目前是内存实现,可以替换成 Qdrant、Milvus 等。
4. 添加新的文档格式
在 vector.go 的 needsMarkitdown 添加新的文件扩展名。
项目核心代码大约 2000 行左右,适合学习:
如果你想学习如何构建 AI 应用,或者想找一个 NotebookLM 的替代方案,这个项目可以作为一个起点。
Notex 不是什么高大上的项目,代码也写得朴素。但它解决了实际问题:让你在本地使用 AI 处理文档,数据不外泄。
核心功能就几个:
技术选型务实地选择了 Go 和原生 JS,没有过多的依赖。部署简单,维护成本低。
如果你感兴趣,可以看看代码,提提 PR,或者直接 fork 改成你自己的工具。
项目地址: https://github.com/smallnest/notex
欢迎 Star、Issue、PR。
2026-01-01 00:00:00
最终结果可以在 lochie.dev/sqlite-ui 找到。
首先 —— Ralph Wiggum 和软件开发有什么关系?
Geoffrey Huntley 在 2025 年 7 月首次创造了这个术语
Ralph 是一种技巧。在其最纯粹的形式中,Ralph 就是一个 Bash 循环。
|
|
Ralph 可以取代大多数公司在全新项目上的大部分外包工作。它有缺陷,但这些缺陷是可以识别的,并且可以通过各种风格的提示词来解决。
本周早些时候,Matt Pocock 关于他的 Ralph 工作流的精彩 视频 出现在我的视野中。Matt 采纳了 Geoffrey 的最初想法,并将其调整以适应他自己的开发风格。
我强烈建议观看该视频,但为了总结核心概念,Matt 实际上重建了一个完全由 Claude 驱动的敏捷风格工作流。
Claude 本身被用来定义需求列表。没有显式的依赖映射或优先级排序,这完全留给 Claude 在冲刺期间去弄清楚。
冲刺作为一个 JSON 文件存在,包含所有需求及其进度。更新会同时持久化在文本文件和每次迭代后写入的 git 提交中。
看到我的推送里充满了对 Ralph 的热议,我感到有点“错失恐惧症”(FOMO),并开始构思一个足够复杂有趣,但又可实现的项目。
一个用于与 SQLite 数据库交互的基于浏览器的 Web 应用感觉很合适。更棒的是,如果效果好,我将来还能自己用它。
这是我的第一个提示词(prompt),使用了 plan 模式:
create a product requirements document for a browser based sqlite DB viewer, it should allow opening a sqlitedb file, show the contents and be interactive. No frontend JavaScript framework just keep it simple, lightweight and static.
(译:创建一个基于浏览器的 SQLite 数据库查看器的产品需求文档,它应该允许打开 sqlite 数据库文件,显示内容并且是交互式的。不要使用前端 JavaScript 框架,保持简单、轻量和静态。)
这产生了一个相当大的需求列表,存储在 PRD.md 中。
然后我将这些需求转换为 PRD.json,遵循 Matt 在视频中使用的方法:
use @PRD.md to create PRD.json
the file should contain an array of feature objects, the schema of an object is as follows. Break the PRD into many small features.
field description category functional, non functional, etc description a brief 1 sentence description of the feature steps array of strings, eg. when button is clicked, colour changes passes boolean representing if the feature is complete and working as intended
总共产生了 62 个需求。
带上我的 Ralph 脚本,我准备好让它开跑了。
|
|
我一次运行 10 次迭代的脚本。每次迭代都会阻塞且没有输出,所以我每次都急切地等待完成。
我的方法没有 git 历史记录。我在“危险边缘试探”。我依靠每次迭代后的 progress.txt 文件来查看发生了什么变化,并刷新浏览器查看是否有东西坏了。令我惊讶的是,一切都维持得很好,应用程序很快开始看起来像一个功能齐全的数据库 UI。
我无法一次性完成所有需求。随着功能的积累,token 使用量显著攀升,我最终花了大约两天时间进行实验。
一旦所有原始需求都实现了,我忍不住开始要求更多功能,包括:
EXPLAIN
在那一刻,我从工程师变成了一个过度兴奋的产品经理,刚刚发现了一个 24/7 工作、从不拒绝、并且没有自尊心去拒绝需求膨胀的软件工程师。
你可以在这里试用:lochie.dev/sqlite-ui
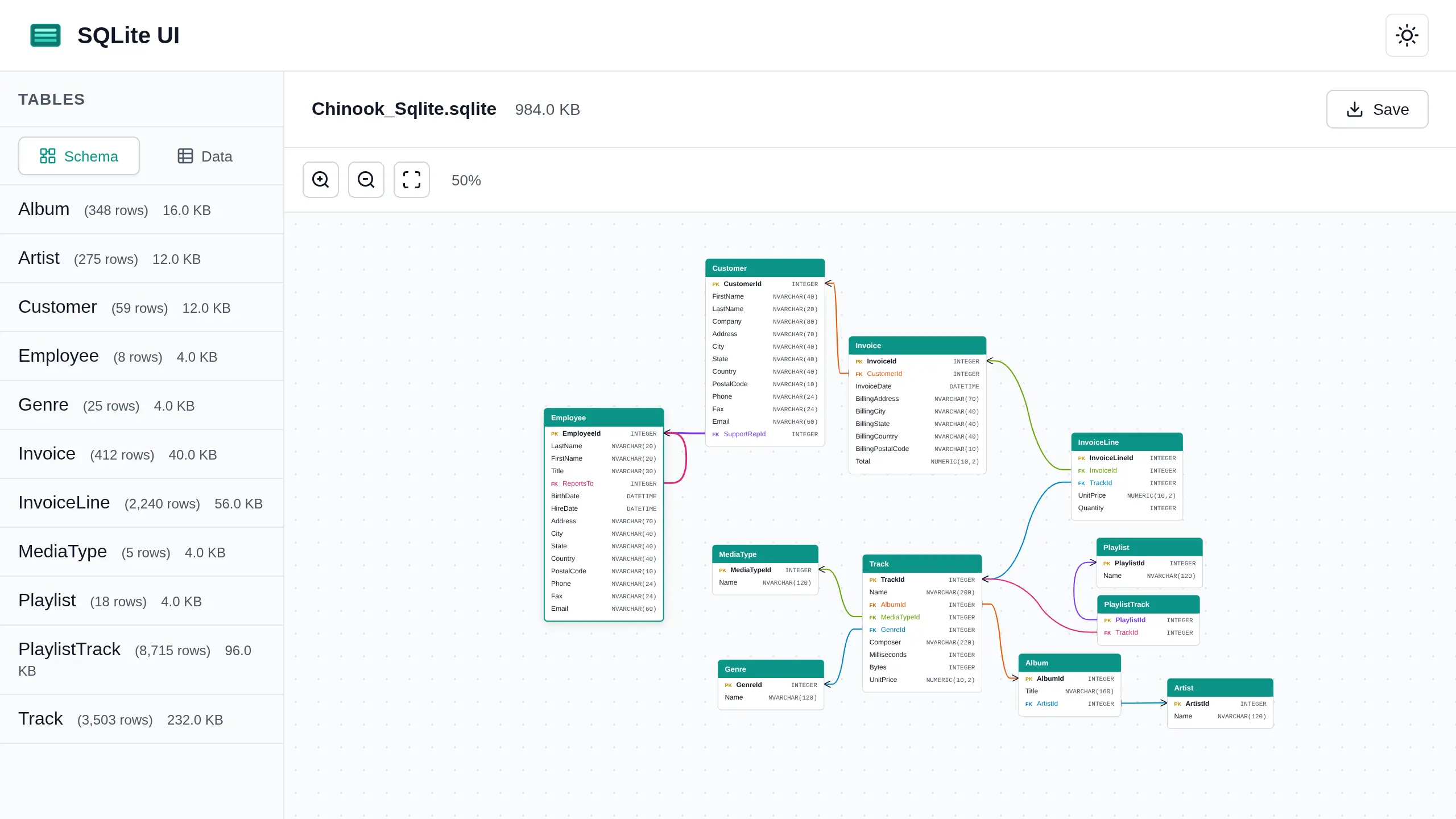
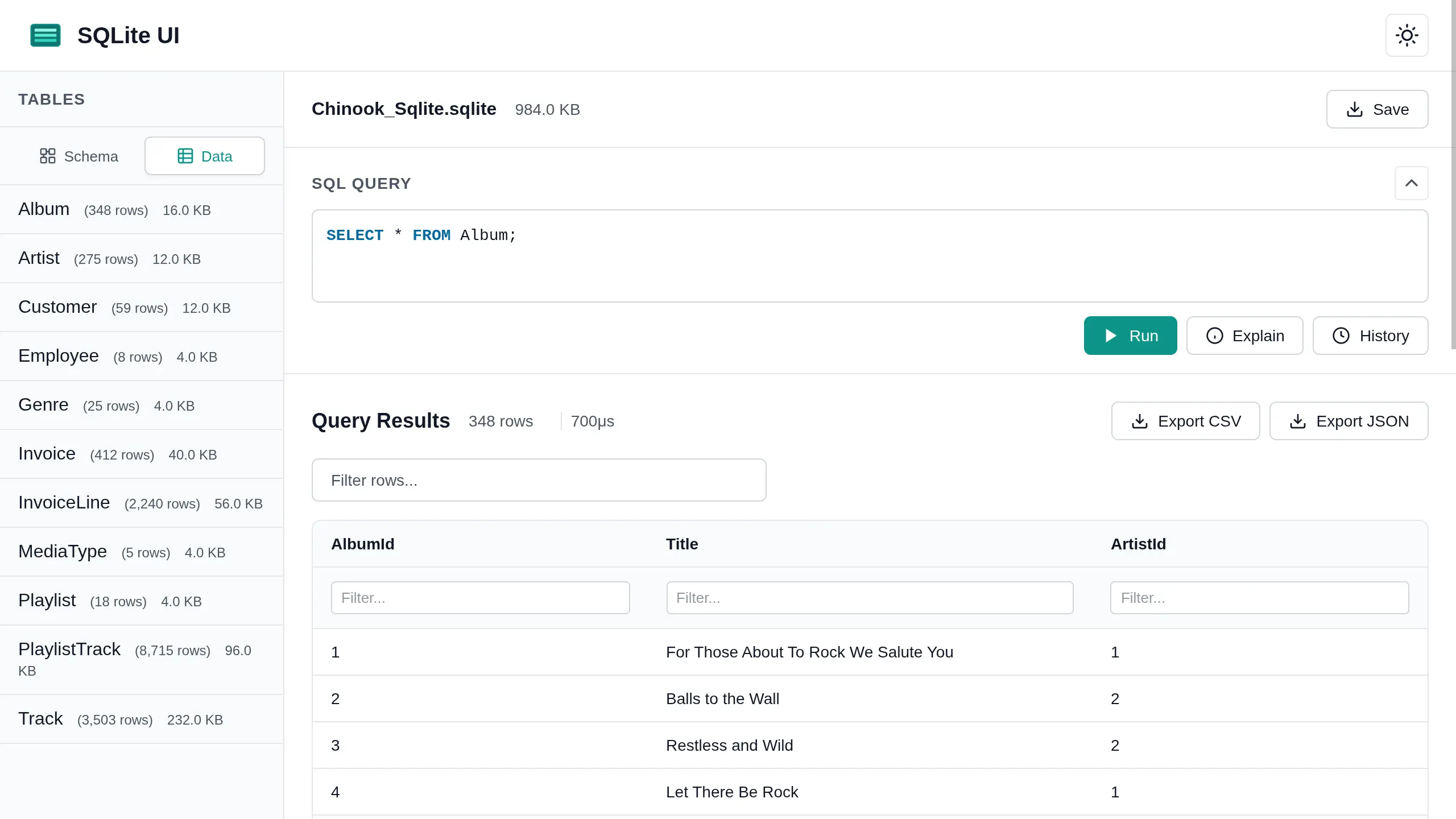
仅用极简的提示词,我就能生成完整的需求列表并让 Claude 直接开始工作。结果在很大程度上符合我的预期,考虑到我有限的提示词,这仍然令人印象深刻。
我要求一个简单的静态实现,而这正是我得到的——单个 HTML、CSS 和 JavaScript 文件。唯一的外部依赖是 sql-wasm。Claude 构建了一个坚实的基础,可以进一步扩展。
显示表存储大小最初不起作用。Claude 指出,由于 sql-wasm 使用的编译标志,这在实现过程中可能无法工作。我自己用 SQLITE_ENABLE_DBSTAT_VTAB 重新构建了它,更新了 HTML 以指向我的构建版本,用 HTTP 服务器(加载 WASM 所需)提供文件服务,然后一切正常,无需进一步的代码更改。
一些缺点变得很明显:
不过,这种成功并不令人惊讶。Ralph 本质上将 Claude 变成了一个专注的软件工程师,按照项目经理定义的冲刺计划工作。没有上下文切换,只有一次一个故事。
也就是说,这种方法并不快,而且消耗大量的 token。这是速度和准确性之间的明显权衡。如果你有时间并且能承担成本,像这样自主构建项目是有意义的,尤其是当它在你睡觉时还在埋头苦干的时候。
根据以往的经验,Claude 在有更强的护栏和更清晰的指导下表现会好得多。虽然 Ralph 循环在极少设置下效果出奇地好,但这次实验突显了几个更刻意的结构会带来回报的领域。
下次我会做不同的事情:
CLAUDE.md,记录项目惯例、架构、约束和期望。因为每次 Ralph 迭代都在一个新的 Claude Code 会话中运行,大量的时间和 token 花在了重新加载和重新理解项目上下文上。更好的结构、更清晰的惯例和自动化测试将显著减少这种开销并提高迭代质量。
冲刺的大小也很重要。在一个冲刺中有 62 个功能实在是太多了,Claude 仅仅为了决定下一步做什么就要进行大量的推理。
一种选择是预先手动界定故事范围、定义关系并分配优先级。然而,一个更有趣的工作流是让 Claude 自己处理那个计划步骤:
通过这种方法,Ralph 脚本可以扩展为使用嵌套循环:遍历冲刺,然后遍历冲刺中的故事。这将减少因重复扫描完整需求集而浪费的上下文,并允许 Claude 自主运行更长时间。
进一步来说,这种模式甚至可以扩展到多个“软件工程师”(多个 Claude 实例)并行工作,由更高级别的编排层协调。
我认为这次实验是成功的。
我构建了一些真正有用的东西,不会被丢弃,在实践中学到了很多关于 Ralph 技巧的知识,现在对将其应用于未来的项目充满信心。
我期待着在有更好的护栏、测试和版本控制的情况下再次尝试。
