2024-06-11 23:13:00
上班之后的生活千篇一律:起床,上班,去食堂吃午饭,去游戏室睡觉,上班,下班,看视频玩游戏,睡觉。按朋友的话来说,这样的日子会让人“班味很重”。所以当在3月份第一次听说公司组织的Aspire Start Strong+活动的时候,我虽然不是那么一个喜欢旅游的人,但是还是仍然感觉非常激动,很珍惜这个机会,毕竟这个活动由公司出钱、不占用自己的假期、和全世界去年的校招生一起去美国参加,而因为有了这三点,活动具体是干什么的反而都不重要了,在全新的环境里给生活暂时换个节奏,按同事的话说,“洗洗班味”,是最重要的。于是开始火速走流程,给老板科普这个活动是干什么的、去北京办美签、订酒店,终于在上周成行。

这不是我第一次出国出境,但是确实是第一次在到美国,这个完全和国内、甚至东亚主流生活方式完全不一样的地方。
由于活动会场在市区,所以我们住在西雅图的市区(downtown)。这一个区域确实有大城市的感觉,高楼大厦鳞次栉比,由于西雅图并不平,有山,车道也普遍仅有双向四车道,第一次进市区以为回到了重庆的渝中。但是这个区域并不移居,人不多,有经典流浪汉,并且也比较危险,途中左边的麦当劳被称为“死亡麦当劳”,听说我们到达的前一天发生了枪击案,因此,第三天晚上被迫不得不在快天黑的时候出去时,我和舍友不得不加快脚步。并且,市区虽然有很多商场,但是实际上非常萧条,我们去的一个比较大的商场Pacific Place里面仅仅只有几个商店。


而在市区之外的地方,并不是国内郊区常见的农田或者工厂,而仍然是城市,只不过是一望无际的平房大house,大多数的中产生活在这里。这些地方不能叫西雅图的郊区,因为实际上是另一个小城市,各个城市有自己的downtown,甚至Apple Store和一些品牌的专卖店都只有这些小城市的购物中心才有。各个城市之间的交通,也主要以车为主。各个城市之间非常近,例如微软总部所在的Redmond和西雅图市区开车仅需30分钟,相当于同属主城区的闵行和人民广场之间的距离。所以,这次我深刻体验到了什么叫”没车就是没腿”。

由于我对我的驾驶技术并没有太大信心,加上市区开车成本极高,所以没有租车,所以我也只能在市区简单逛逛旅游景点,旅游景点之间的交通也是通过打车。这和国内所有资源都集中在市区的情况可谓大相径庭。
世界的不同同样也体现在社会的各个角落:和陌生人进入电梯也要打招呼,和其他人沟通时经常能看到幅度很大甚至有点夸张的表情和肢体动作,几乎每次打车遇到的司机都想和乘客聊天,甚至餐厅吃饭时,服务员的服务,结账时的流程也完全不同,于是在前一两天,干啥事都要做好出丑的准备。
微软官方对这个活动的主要内容的一个关键词就是Networking,社交。整个活动总共三天,每一天都由几个讲座以及讲座之间的休息时间组成,而在休息时间,也包括讲座期间,主要工作就是和其他人社交。到这里,E人听了狂喜,I人听了害怕。而我作为一个IE各半的人(测试结果仅供参考),虽然并不害怕日常社交,但是仍然感觉有点陌生和有挑战性,完全不知道和这些来自世界各地的人会如何社交。

在活动正式开始的前一天,我所在的组织安排了一次参观交流的活动,邀请了全组织的新人去园区参观,以及和组织内老板的的交流。这种形式的参观交流活动,我也是经历过很多次了,本科时我甚至参与组织过一次组织微软俱乐部的同学去苏州微软参观交流的活动,总体体验还是比较放松的:行程都安排好了,照着做就好了,交流的时候有问题就问,不想公开问就等着私下交流的时候问,没啥好问的就划水,轻松+愉快。但这次的参观交流活动加上了浓浓的社交元素,情况就完全不一样了。从10点多登上去园区的大巴开始,一直到4点整个活动结束,社交过程一刻不停:在大巴车上,主持人就让所有人打乱座位,开始和不认识的同事聊天;下午,先和老板有一次Panel,也就是各位领导坐在前面,参与者坐在下面,领导分享,参与者提问的形式,之后,又是所有所有的参与者在一个空间里自由的交流。只有上下午中间的参观园区的Visitor Center的环节有一点休息的时间。

而接下来的三天也是同样的节奏:讲座的时间,大家坐在一个大圆桌,除了听讲座的内容,就是根据讲座的要求做一些同桌之间的交流;而在讲座时间以外,就是在一个大会场内找吃的喝的,以及社交。甚至第三天的晚上,公司组织了所有的参与者去西雅图的流行音乐博物馆(Museum of Pop Culture, MoPoP),在里面除了常规的参观博物馆展馆,还可以参与蹦迪、剧场小游戏等可能在西方世界常见的娱乐活动,而,当然,还有一个大的空间可以用于社交。每天这样的节奏从早到晚,使得每天晚上几乎都是沾枕头就能睡着。


由于我从小到大都是生活在汉语的环境下,社交遇到的第一个问题就是语言。
虽说工作在外企,但是这只意味着工作相关的文字资料以及占据少比例时间的会议是英文的,而其他时候,尤其是日常的沟通交流,仍然使用汉语。而当处在英语环境下的时候,情况就完全不一样了。读写英文对大多数来说都不是问题,看到不会的可以查,写的时候可以慢慢斟酌用词,也可以让AI帮忙。而开会的时候,由于大多数内容都是工作相关的,工作相关的内容本来从头就是用英文思考的,所以听说没有遇到什么大的障碍,即使遇到可能听不懂的,也可以用Teams的Live Caption实时生成字幕,把听转换为读,难度一下子就降下来了。而日常交流最重要的是听和说的情况就完全不一样了。
关于听,容易出现的一个问题就是在关键的地方卡壳,这会使聊天进入一个不停地pardon/sorry状态,很影响聊天的氛围。第二天中午吃饭的时候和几个来自美国的员工聊关于电动汽车的事情,其中一个美国员工提到美国对中国的电动汽车加征了100%的关税tariff。这个词如果写出来给我看我还是认识的,但是当时完全没有反应过来,于是聊天被迫中断了一下。还好我很快根据语境猜出了这个词是在说关税,聊天才可以继续进行下去。这还是比较容易的情况,而更多的例子是伙伴说了一句话,我甚至没有听出这句话是在问问题,敷衍地笑笑,然后尴尬地发现聊天中断了,甚至还不知道为什么。另外,众所周知,微软、亚马逊等公司招募在大量的来自全世界的员工,本次活动我推测来自美国、英国等英语国家的员工甚至不到一半,而非英语国家的员工的英文也有不同的口音,毫不夸张地说,每听一句话都说一下sorry,让对方重复一下。
而至于说,说出一个句子简单,但要流畅、快速地说出完整的、简单的句子继续对话,这让我耗费了大量精力,以至于时间长了我甚至有点不敢说话了。去园区参观的车程总共20分钟,我在对话刚开始的时候,除了找关键词表达意思之外,还可以注意句子的时态、语法等细节。但是聊到后面,尤其是聊到熟悉或者不熟悉的话题、情绪比较激动的时候,就只能保证表达出关键词,什么is/was、问句结构,通通一边去吧。另外,由于中文和英文的语言表达习惯不一样,而我仍然是用中文思考,加一个汉译英的环节,这会使得说出来的话不那么简洁,甚至感觉有点奇怪。有一次打车的时候,我想问司机最近有没有接到其他同样来自微软的员工。由于我仍然是中文思维,要说出来需要进行一次汉译英,但是定语稍微一长(这里的同样来自微软),我就喜欢用从句,于是我脱口而出:
Have you taken any other people who also come from Microsoft?
说到who的时候,我就感觉有点奇怪,于是后面变得有点不自信,说话声音都变小了。果不其然,司机没有听清,于是我又重新说了一句这段话,这时才感觉到,似乎没有必要这样说,一个简单的Microsoft employees甚至Microsoft people就行。
总的来说,这是我第一次在全英文的环境下的与人日常交流。虽然大家都会很耐心,但是在本来就不是很擅长日常聊天的情况下叠加一个语言debuff,仍然让我精疲力竭。我一直以为我的英语能力还可以,每天都无字幕看YouTube视频,但是真到对应的环境下,还是处处体现出不适应。语言果然还是要一个环境,没有环境的语言就是哑巴语言,如果之后真被relocate到国外,第一个要迈的坎就是语言壁垒。
由于公司在上海的规模不大,而且近几年校招的名额非常少,分配到每个组的新人就更少,而且绝大多数员工来公司都不是来奋斗的(奋斗比滚出微软!),所以公司的氛围比较传统,公司就是工作,到点就回家,甚至公司组织的活动都是面向家庭的。这对于有家庭的人来说当然是天堂,但是对于我这种刚毕业单身狗来说,虽然工作也非常轻松愉快,但是同样容易感觉无聊。再加上公司所在的地理位置又是邻近一个50年代开始开发的郊区卫星城,周边的城建、商业、住房等都是纯纯的老城区模样,居民也是中老年人居多,甚至在附近的羽毛球俱乐部里每次都能遇上头发花白的老大爷老奶奶,毛估所有参与者的平均年龄没有40也得有35。虽然有两个高校,但是高校自成一体,基本和社会面不在一个圈子里。本来我并没有注意到身边环境的特征,而契机是在今年春节回家时,和研究生同学约在家里的附近羽毛球馆,发现球馆里全是年轻人的时候,我突然意识到,我所处的环境似乎有点老了。
这次去了Aspire活动,我体验到了一种年轻人的环境。所有参与者都是2023年4月后加入微软的校招新员工,背景都是类似的,很多人还愿意去互相了解,对职业发展抱有期待,聊天的时候更容易有共同话题,即使都只是工作中,由于同处同一个职业阶段,所以大家思考的、追求的东西基本都是类似的。在去园区参观的路上,我和一位来自印度的女生聊了很久,虽然上文提到,对我来说听说仍然不够流畅,但是仍然交流了很多,为什么选择学计算机,为什么来微软,来美国的感受,组内的情况,想要什么样的生活。我们甚至后面还留了邮箱,互相发了几封极其类似上学时英语课写的小作文(英语课小作业还是有用的:D)。在活动中,也认识了来自印度、美国、日本、以色列等各个地方的新同事。有的同事很符合“刻板印象”,有的甚至完全相反;有的主动过来聊天,完全被带飞,而有的交流寥寥几句后,似乎只能以Nice to meet you结束;有的加了LinkedIn等联系方式,有的甚至出现在面前也不会再认出来。在认识新人之外,同样也见了很多许久没有见面的、同在微软的南大同学,聊的话题除了工作,还包括本科时期经过的一些事情,似乎又回到了2020年前的本科生活。
回想这次活动之前和期间的自己的感受,我发现环境真的很影响人。为什么在学校的时候,和同学交朋友似乎很容易?朝夕相处,同处一个人生阶段,工作和休息的节奏、思考、烦恼、追求的事情都是一致的,自然而然就能有话聊,相互理解,发展关系。而在工作后,有家庭的同事的生活的重心自然而然会放到家庭中去,没有家庭的也会去形成以自己为主的工作生活节奏,不会轻易因为他人而改变,即使参加活动,目的性也都极为明确,也就是说,每个人或多或少都会稳定到一个适合自己的生活方式上。而环境又会影响回每个人。如果实验室的同学都在努力学习发论文,那么自己不去科研就会被认为为“异类”;如果身边的人都到处参加活动,那么自己可能也在某一刻想去试试;如果身边的人的生活都非常稳定,那自己也得主动或者被动地去寻找一个稳定的生活方式。而这个环境的不同,才是上学和上班最大的区别。
由于没有找到固定的搭子抱团,所以我并没有安排活动的后续旅程,活动结束后在市区和几位之前认识的小伙伴简单玩了玩市区景点后就回上海了。
回想起来,我到底得到了什么?在西雅图的全新的环境中,锻炼了一下之前一直处于哑巴状态的英语,体验了美国的生活方式,和来自全世界各地的同龄人高强度社会……这是一次独一无二,甚至很可能不会再有第二次的机会。感谢在西雅图的6天短暂、全新,比现在更有活力的生活,让我更理解环境的意义,让我在解决“我想要什么”这个终极问题的路上更进一步。
2024-01-17 22:58:00
在上一篇文章中,我给博客增加了点击量监测,并将这个服务部署到了Azure,数据库采用了使用SQL Server的Azure的SQL服务。由于SQL Server有免费的订阅,微软的Azure Data Studio也还算好用,于是我觉得可以重用一下刚才学习的这个技能,将其他的服务也使用SQL Server部署。
我之前在用wakatime来记录我的编程的数据(例如每天的编程时间、所使用的编程语言等),但是wakatime免费用户只能保存14天的数据,而且wakatime没有提供官方的可自己部署的后端,所以我也一直在寻找wakatime的替代品。之前尝试使用了一段时间的codetime。这个软件的功能和wakatime类似,但是它当前只支持VSCode客户端,虽然免费保存数据,但是仍然没有提供可自己部署的后端。我在很早之前也尝试找过wakatime的后端替代品,但是当时并没有找到一个能用的。但前不久,同学给我推荐了wakapi项目,这个项目重新实现了wakatime的后端API,这样wakatime的丰富的客户端插件可以直接使用,并且完全可以自己部署,不用担心数据并存放在别人的服务器上。
它就是我一直寻找的wakatime替代品!
很激动地浏览了一下项目,看到wakapi当时并没有原生支持SQL Server,但是在README中提到,wakatime使用了gorm作为数据库访问框架,而gorm本身是支持SQL Server的。
我想,既然库都支持了,SQL Server支持有什么难的?引入gorm.io/sqlserver包,引入创建一个Dialector,用gorm的API编写的绝大多数数据库操作就完成了。
sqlserver.Open(mssqlConnectionString(c))这有什么难的,开跑!结果遇到了一大堆报错。
仔细一看,这些报错主要是来自于数据库migration中的原生SQL语句和片段。
程序启动的时候,会运行数据库migration脚本。随着软件开发更多的新功能,其使用的数据库的结构总会发生变化,而migration是指一些代码,这些代码的作用是修改数据库schema、让schema满足当前版本的要求。当软件功能越来越多,对数据库的变化也就越来越多,所以在一个成熟的软件中,你常常会看到有很多的数据库migration的代码。在程序启动的时候,这些migration将会被一个一个地执行,使得程序正式开始时,数据库的schema也更新到最新。
> tree migrations
migrations
├── 20201103_rename_language_mappings_table.go
├── 20201106_migration_cascade_constraints.go
├── 20210202_fix_cascade_for_alias_user_constraint.go
├── 20210206_drop_badges_column_add_sharing_flags.go
├── 20210213_add_has_data_field.go
├── 20210221_add_created_date_column.go
├── 20210411_add_imprint_content.go
├── 20210411_drop_migrations_table.go
├── 20210806_remove_persisted_project_labels.go
而有的migration(尤其是自动生成的migration)很可能包含了一些原生SQL。同时,由于ORM是对数据库操作的抽象,而再强大的抽象也不如原生的SQL来得强大和方便,所以很多时候,开发者仍然会选择在一些地方使用原生SQL语句的片段或者语句来实现一些功能。虽然SQL本身是有标准的,但是各个数据库厂商实际上自己实现了很多新功能,很多时候我们本以为理所当然的功能,实际上并不在标准中,而是数据库厂商自己实现的,一旦手写SQL而没有意识到有的SQL实际上只在部分数据库中兼容,就可能会在不兼容的数据库中遇到问题。
举个例子,wakapi的某个版本需要在数据库的users表中新增一个has_data列,而对于已经存在的users表中的数据,这个列需要被设置为TRUE。代码中用于执行此次migration的代码使用如下SQL语句实现了这个功能:
UPDATE users SET has_data = TRUE WHERE TRUE;看上去是个很简单的人畜无害的SQL语句,对吧?但是这个SQL语句在mssql中中是非法的,因为mssql中并没有TRUE, FALSE常量!sqlserver中没有boolean类型,所有这些类型都是使用一个字节的tinyint来表示的,而TRUE和FALSE就对应使用1和0来表示。但是,1和0在sql server中并不是一个合法的boolean表达式,所以它们并不能直接用在WHERE中。所以,在MSSQL中,以上SQL语句就必须重新成以下的样子:
UPDATE users SET has_data = 1;另一个情况是SQL语句片段。虽然ORM的一大作用就是将软件代码映射为SQL语句,减少我们手写SQL可能带来的错误,但是为了实现的灵活性,ORM常常同样也允许在自己的API中编写一些SQL的片段,而ORM会尝试将这些SQL片段嵌入进去。但是这些SQL片段可能也会有不兼容的情况!例如,下面的代码
result := db.Table("summaries AS s1").
Where("s1.id IN ?", faultyIds).
Update("num_heartbeats", "3")上述gorm数据库仓库将会被映射为类型以下的SQL语句。注意Table和Where方法的参数与下列SQL语句中对应的语句的对应关系。
update summaries AS s1 set num_heartbeats = 3 where s1.id IN ?是不是感觉很简单?但是MSSQL仍然不支持!MSSQL不支持在update持语句中给表新增一个别名,所以以上SQL语句中的AS s1必须被去掉。
再看一个SQL语句片段:
r.db.Model(&models.User{}).Select("users.id as user, max(time) as time").这段SQL语句一般会被映射为:
select users.id as user, max(time) as time from users;有问题吗?有!user在MSSQL中是关键词,要作为标识符使用必须使用""或者[]将它包裹起来!而user在mysql等数据库引擎中都不是关键词,因此可以随意直接使用。
这个将关键词作为字符串使用的过程实际上编程中很常见,被称为escape,或者更简单的叫quote,加引号。但是更坑的是,不同的SQL引擎所使用的加引号的方法不一样。MSSQL使用的是""或者[],但是mysql使用的是`。如何通过一段代码来为不同的数据库加上正确的引号呢?
其实,这个加引号的过程实在是非常常见,只要ORM需要将程序员所写的名字(表名、列名等)映射到SQL,那么就需要考虑给这些名字叫上引号,防止这些名字和SQL自己的关键词冲突。如果你写一个名字叫select的表,没有这段逻辑,那么这个表就没法通过ORM来映射成SQL了!
因此,根据Don't Repeat Yourself原则,ORM为数据库系统的适配器中肯定会有对应的逻辑。而我们与其自己编写这个处理逻辑,最好的方法当然是调用适配器中已经写好的逻辑了。
gorm使用Dialector接口作为ORM支持不同数据库系统的适配器的接口,所有gorm支持的数据库都有一个对应的实现了Dialector接口的Dialector。所以,第一步就是去看看gorm的Dialector里定义了哪些接口。
// https://github.com/go-gorm/gorm/blob/0123dd45094295fade41e13550cd305eb5e3a848/interfaces.go#L12C1-L21C2
type Dialector interface {
Name() string
Initialize(*DB) error
Migrator(db *DB) Migrator
DataTypeOf(*schema.Field) string
DefaultValueOf(*schema.Field) clause.Expression
BindVarTo(writer clause.Writer, stmt *Statement, v interface{})
QuoteTo(clause.Writer, string)
Explain(sql string, vars ...interface{}) string
}从名字判断,这个QuoteTo方法似乎就是我们要的接口。再随便点开一个dialector实现的代码浏览一下,就能确定,QuoteTo就是加引号的方法。
可是这个方法看上去和我们想象中的不太一样:我们预期这个功能是一个(string) => string的函数,这里怎么是一个(clause.Writer, string) => void的函数,这个clause.Writer是什么玩意?
由于拼接SQL说到底,就是要生成各个SQL的片段,然后将这些片段的字符串拼接起来。在绝大多数编程语言里,string都是不可变的,所以拼接字符串实际上是创建了第三个字符串,然后把两个字符串的内容复制进去。这个过程如果进行太多次,就非常浪费时间和内存。所以编程语言常常会提供一个组装字符串的工具类。这个工具类可以理解成是一个可变的字符串,你可以直接在这个_字符串_的后面增加新的字符串,而不需要每次操作都创建一个全新的字符串对象。而这个Writer接口,就是gorm定义的一个这样的能够组装字符串的工具类所需要实现的接口。这个Writer接口定义如下:
// https://github.com/go-gorm/gorm/blob/0123dd45094295fade41e13550cd305eb5e3a848/clause/clause.go#L13
type Writer interface {
WriteByte(byte) error
WriteString(string) (int, error)
}很简单,很直白:WriteByte:在后面增加一个字符;WriteString,在后面增加一个字符串。
熟悉Go的同学可能会说了:啊,这个接口看上去非常熟悉,原生的strings.Builder就是用来做这个事情的,而且也有这两个方法!是不是可以直接用一个strings.Builder来作为这个clause.Writer?
正确!所以我们可以直接创建一个*strings.Builder来作为clause.Writer(用指针的原因是这个strings.Builder的这两个成员方法是使用的指针接收者而不是值接收者,所以只有对应的指针类型才算实现了这个接口。具体关于指针接收者和值接收者的区别我们就不在这里介绍了,有兴趣的可以学习一下Go语言),并在调用后获取这个builder最终的字符串,这样就直接调用了dialector中实现了加引号逻辑。
func QuoteDbIdentifier(db *gorm.DB, identifier string) string {
builder := &strings.Builder{}
db.Dialector.QuoteTo(builder, identifier)
return builder.String()
}然后,我们将此函数用在所有需要在SQL片段中使用自定义的名字的地方,这样,我们就重用了dialector的逻辑,用同一套代码兼容了所有的数据库。
r.db.Model(&models.User{}).Select(
fmt.Sprintf("users.id as %s, max(time) as time"), utils.QuoteDbIndentifier(r.db, "user")
)而在进一步查找并修改原生SQL的语句中,我找到了一段如下的原生SQL语句,直接让我眼前一黑。
with projects as (
select project, user_id, min(time) as first, max(time) as last, count(*) as cnt
from heartbeats
where user_id = ? and project != ''
and time between ? and ?
and language is not null and language != '' and project != ''
group by project, user_id
order by last desc
limit ? offset ? )
select distinct project, min(first) as first, min(last) as last, min(cnt) as count, first_value(language) over (partition by project order by count(*) desc) as top_language
from heartbeats
inner join projects using (project, user_id)
group by project, language
order by last desc这段SQL语句就这样赤裸裸地写在代码里。经过以上几个例子,是不是以为这个SQL在MSSQL中必定问题巨大,不重新写一份根本跑不起来?
我一开始也是这么想的。而我自己对SQL Server并没有那么熟悉,所以聪明的我,在给一些名字叫上引号后,直接把这段代码扔给了GitHub Copilot,让它帮我改成SQL Server能用的。反直觉的是,这段代码实际上问题没那么大:
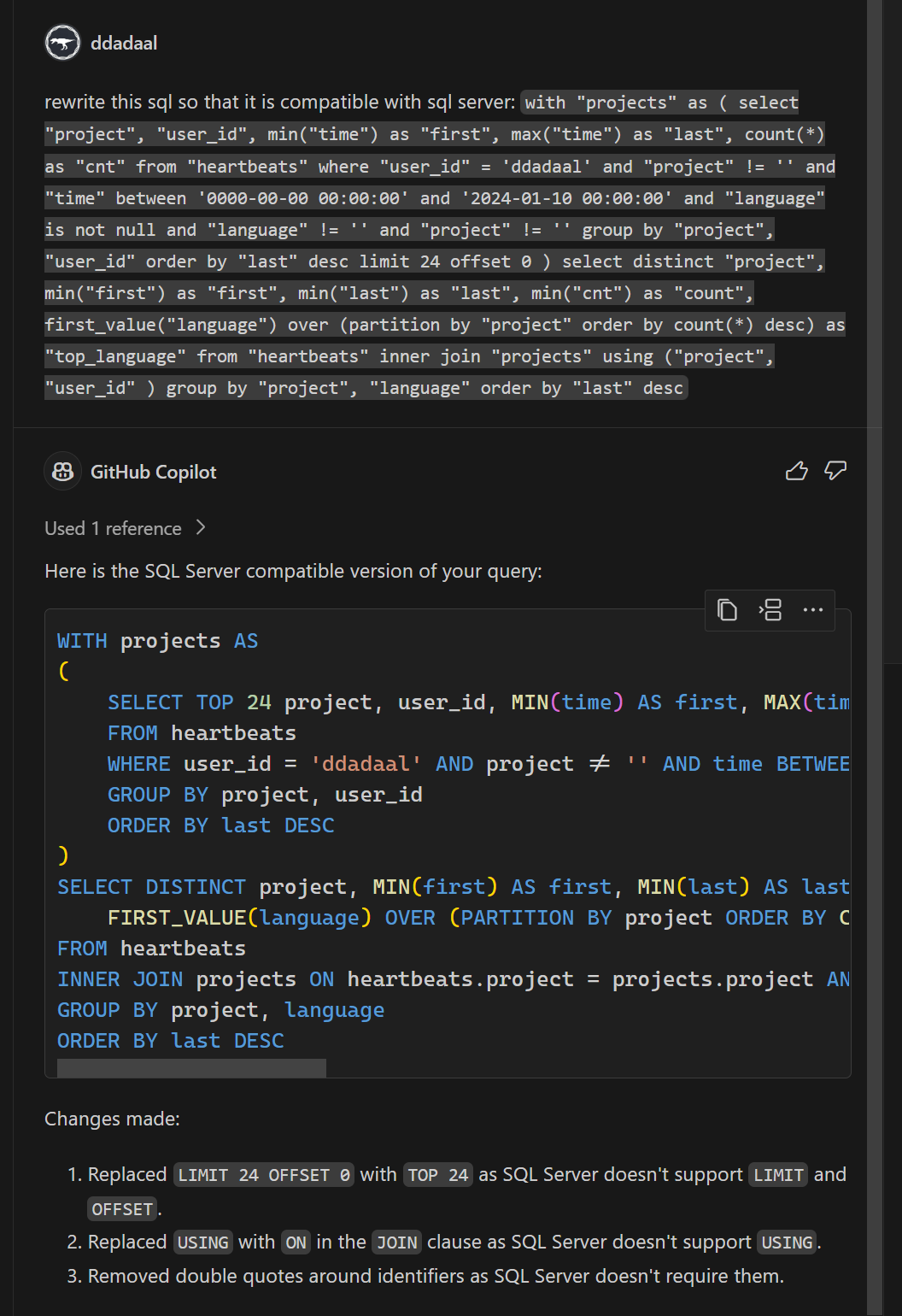
具体来说,除了第三点去掉了不需要的引号后,有两个问题:
join using,需要使用常规的join on代替limit offset。查找了一下,mssql可以使用offset ? ROWS fetch next ? rows only来代替,当然limit和offset的参数顺序是反过来的啊,原来这么简单!由于需要修改的地方并不多,于是我就简单的通过if判断,将其中SQL Server不兼容的部分修改为SQL Server兼容的SQL语句,这段SQL语句也就完成了。
修改了这些SQL语句后,程序仍然运行不起来,仔细一看,报错如下:
mssql: A table can only have one timestamp. Because table 'users' already has one, the column 'last_logged_in_at' cannot be added.
简单翻译,一个表只能有一个类型为timestamp的列,而users中有多个列都是timestamp的类型,所以SQL Server报错了。
去代码中一看,users表对应的Userstruct确实有好几个字段都通过gorm的field tag功能type:timestamp,确定了在数据库中这些列需要映射为timestamp类型。
// https://github.com/muety/wakapi/blob/fc483cc35cb06313da8231424d1d85b291655881/models/user.go#L17
type User struct {
// ...
CreatedAt CustomTime `gorm:"type:timestamp; default:CURRENT_TIMESTAMP" swaggertype:"string" format:"date" example:"2006-01-02 15:04:05.000"`
LastLoggedInAt CustomTime `gorm:"type:timestamp; default:CURRENT_TIMESTAMP" swaggertype:"string" format:"date" example:"2006-01-02 15:04:05.000"`
// ...
SubscribedUntil *CustomTime `json:"-" gorm:"type:timestamp" swaggertype:"string" format:"date" example:"2006-01-02 15:04:05.000"`
SubscriptionRenewal *CustomTime `json:"-" gorm:"type:timestamp" swaggertype:"string" format:"date" example:"2006-01-02 15:04:05.000"`
}timestamp有什么问题呢?MySQL不都是使用timestamp来代表时间类型吗?去查找sql server timestamp,我才发现,SQL Server里的timestamp的含义和别的数据库中的含义不一样。在别的数据库中,timestamp就是一个表示时间戳/时间点的类型,而根据这个stackoverflow回答,sql server中的timestamp主要用于乐观锁的情况(具体不在这里阐述),只是用来标记本行上一次被修改的时间,所以每个表只能存在一个timestamp的列。而在SQL Server中如果要表示一个时间戳,需要使用datetimeoffset。
所以现在问题就变成了:如何将一个类型在不同的数据库中映射为不同的列的类型。
type:timestamp这个tag肯定是不能用了,于是我们就需要查找有没有其他更动态的方法,可以自定义一个go字段映射到数据库中的类型。经过一番查找,我们找到了Customize Data Type功能。gorm允许定义一个自定义的struct,并给这个struct实现GormDBDataTypeInterface接口,来返回这个类型的字段所真正对应的数据库类型。
type GormDBDataTypeInterface interface {
GormDBDataType(*gorm.DB, *schema.Field) string
}这个函数的第一个参数就是gorm.DB对象,指向当前操作的数据库对象,可以获取到当前正在使用什么类型的Dialector,我们就可以根据Dialector类型,来输出对应的数据库列类型。另外,这个CustomTime正好是代码中所定义的一个新的struct,我们可以直接在CustomTime上实现这个接口。
看来比较简单,但是为了以防万一,我们再全局搜索一下type:timestamp,看看有没有什么其他的用法。果然被我找到了!
// https://github.com/muety/wakapi/blob/fc483cc35cb06313da8231424d1d85b291655881/models/heartbeat.go#L27
type Heartbeat struct {
// ...
Time CustomTime `json:"time" gorm:"type:timestamp(3); index:idx_time; index:idx_time_user" swaggertype:"primitive,number"`
// ...
}这里用到了timestamp(3)。根据mysql的文档,timestamp(n)中的n是代表精确到秒后面的第几位浮点位,3代表精确到毫秒,而6代表精确到微秒。而SQL Server的datetimeoffset也支持类似的标记(文档),datetimeoffset(n)中的n也同样表示精确到秒后面的第几位浮点位。由于我们不能直接使用typetag,但是我们还需要一个tag用来表示这个精确的位数(根据sql server的文档,将这个位数称为scale),所以,我们可以定义一个全新的timeScale的tag,其值就是scale的值。而一个字段上具体有哪些tag,正好可以通过GormDBDataType的第二个参数获取。
于是根据这个思路,我们实现了CustomTime的GormDBDataType方法:
// https://github.com/muety/wakapi/blob/1ea64f0397e5ee109777b367e9bd907cfdd59bdb/models/shared.go#L44
func (j CustomTime) GormDBDataType(db *gorm.DB, field *schema.Field) string {
t := "timestamp"
// 如果使用的是SQL Server Dialector,则将其类型设置为datetimeoffset
if db.Config.Dialector.Name() == (sqlserver.Dialector{}).Name() {
t = "datetimeoffset"
}
// 如果一个属性有TIMESCALE的tag,那么给类型后面增加(n)参数
// gorm将所有gorm下的tag的key转换成了全大写
// 参考:https://github.com/go-gorm/gorm/blob/0123dd45094295fade41e13550cd305eb5e3a848/schema/utils.go#L35
if scale, ok := field.TagSettings["TIMESCALE"]; ok {
t += fmt.Sprintf("(%s)", scale)
}
return t
}同时,我们将所有的timestamp都直接去掉,将type:timestamp(n)修改为了timeScale:n:
// https://github.com/muety/wakapi/blob/1ea64f0397e5ee109777b367e9bd907cfdd59bdb/models/user.go#L17
type User struct {
// ...
CreatedAt CustomTime `gorm:"default:CURRENT_TIMESTAMP" swaggertype:"string" format:"date" example:"2006-01-02 15:04:05.000"`
LastLoggedInAt CustomTime `gorm:"default:CURRENT_TIMESTAMP" swaggertype:"string" format:"date" example:"2006-01-02 15:04:05.000"`
// ...
SubscribedUntil *CustomTime `json:"-" swaggertype:"string" format:"date" example:"2006-01-02 15:04:05.000"`
SubscriptionRenewal *CustomTime `json:"-" swaggertype:"string" format:"date" example:"2006-01-02 15:04:05.000"`
}
// https://github.com/muety/wakapi/blob/1ea64f0397e5ee109777b367e9bd907cfdd59bdb/models/heartbeat.go#L12
type Heartbeat struct {
// ...
Time CustomTime `json:"time" gorm:"timeScale:3; index:idx_time; index:idx_time_user" swaggertype:"primitive,number"`
// ...
}这样就解决了这个问题。
没想到的是,到这里仍然无法启动程序。报错如下:
[2.938ms] [rows:0] CREATE TABLE "summary_items" ("id" bigint IDENTITY(1,1),"summary_id" bigint,"type" smallint,"key" nvarchar(255),"total" bigint,PRIMARY KEY ("id"),CONSTRAINT "fk_summaries_editors" FOREIGN KEY ("summary_id") REFERENCES "summaries"("id") ON DELETE CASCADE ON UPDATE CASCADE,CONSTRAINT "fk_summaries_operating_systems" FOREIGN KEY ("summary_id") REFERENCES "summaries"("id") ON DELETE CASCADE ON UPDATE CASCADE,CONSTRAINT "fk_summaries_machines" FOREIGN KEY ("summary_id") REFERENCES "summaries"("id") ON DELETE CASCADE ON UPDATE CASCADE,CONSTRAINT "fk_summaries_projects" FOREIGN KEY ("summary_id") REFERENCES "summaries"("id") ON DELETE CASCADE ON UPDATE CASCADE,CONSTRAINT "fk_summaries_languages" FOREIGN KEY ("summary_id") REFERENCES "summaries"("id") ON DELETE CASCADE ON UPDATE CASCADE)
2024-01-19T19:29:35.607826413+08:00 [ERROR] mssql: Could not create constraint or index. See previous errors.
panic: mssql: Could not create constraint or index. See previous errors.Could not create constraint or index. See previous errors.这个等于什么都没说嘛,只知道创建一个外键约束或者索引的时候失败了,而其他的错误信息被gorm或者gorm的sqlserver dialector忽略了。还
还好我能看到具体执行的SQL语句,所以我们可以把这段SQL语句手动输入到Azure Data Studio中,看看数据库引擎到底报了什么错误。
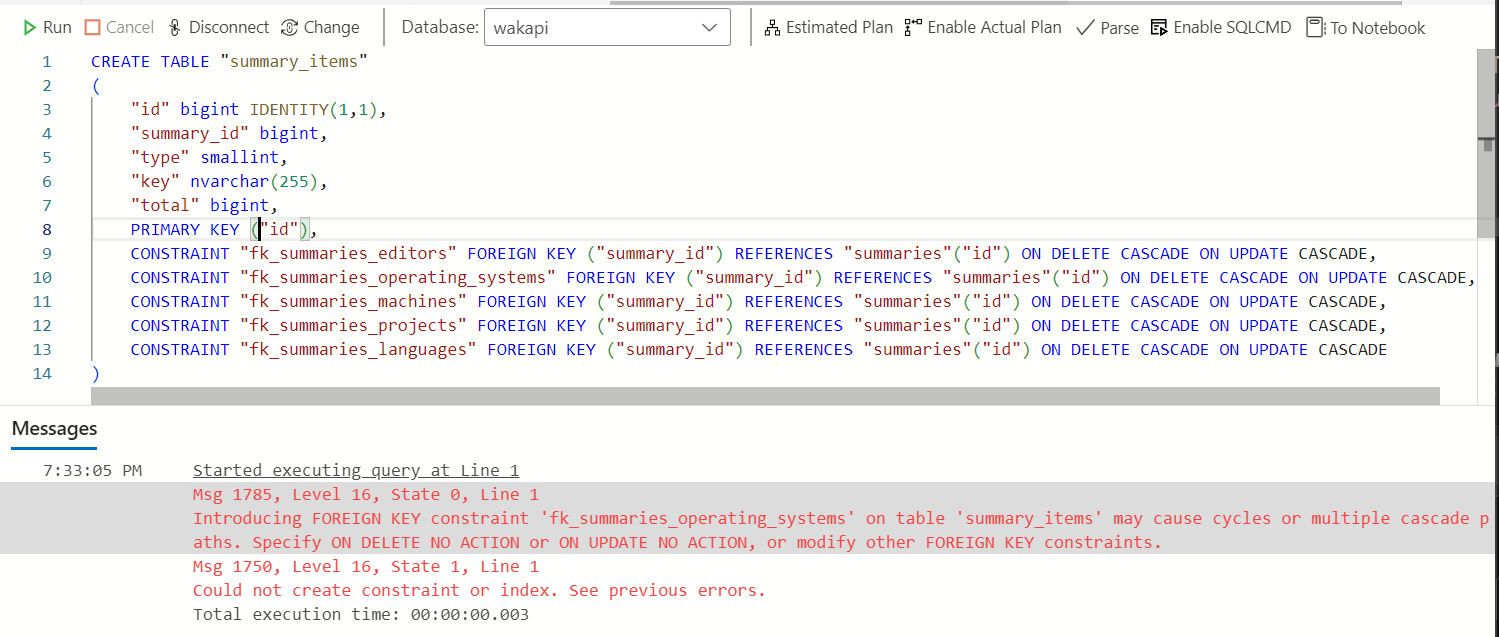
Introducing FOREIGN KEY constraint 'fk_summaries_operating_systems' on table 'summary_items' may cause cycles or multiple cascade paths. Specify ON DELETE NO ACTION or ON UPDATE NO ACTION, or modify other FOREIGN KEY constraints.
看起来,是因为fk_summaries_operating_systems这个级联的外键索引会造成级联递归(cycles)。和外键约束有关,而外键约束是通过gorm定义,所以我们先去看看代码里涉及这个外键约束的两个表的定义。
// https://github.com/muety/wakapi/blob/fc483cc35cb06313da8231424d1d85b291655881/models/summary.go#L29
type Summary struct {
// ...
Projects SummaryItems `json:"projects" gorm:"constraint:OnUpdate:CASCADE,OnDelete:CASCADE"`
Languages SummaryItems `json:"languages" gorm:"constraint:OnUpdate:CASCADE,OnDelete:CASCADE"`
Editors SummaryItems `json:"editors" gorm:"constraint:OnUpdate:CASCADE,OnDelete:CASCADE"`
OperatingSystems SummaryItems `json:"operating_systems" gorm:"constraint:OnUpdate:CASCADE,OnDelete:CASCADE"`
Machines SummaryItems `json:"machines" gorm:"constraint:OnUpdate:CASCADE,OnDelete:CASCADE"`
}
type SummaryItems []*SummaryItem
type SummaryItem struct {
// ...
Summary *Summary `json:"-" gorm:"not null; constraint:OnUpdate:CASCADE,OnDelete:CASCADE"`
SummaryID uint `json:"-" gorm:"size:32"`
}也就是说,Summary和SummaryItem两个表是1:m的关系,这个关系映射到数据库中,也就是SummaryItem表中有到Summary的ID的外键summary_id,而这个外键的约束则是通过Summary表中的tag定义的。
转回头去看生成的SQL,生成的SQL里有5个完全相同的外键(fk_summaries_editors, fk_summaries_operating_systems,fk_summaries_machines,fk_summaries_projects和fk_summaries_languages)。由于这五个外键都是级联删除(ON DELETE CASCADE)和级联更新(ON UPDATE CASCADE),实际上确实是会存在一个级联递归:当一个SummaryItem被删除,会造成其对应的Summary被删除,而Summary被删除可能会造成这个SummaryItem也被删除。
那问题又来了,那为什么之前在MySQL、PostgresSQL等数据库里均正常呢?通过这篇Stack Overflow的回答,我们知道了这种问题在其他数据库中并不是问题:其他数据库会尝试解出一条级联路径出来。而SQL Server不会去尝试解,发现了这种循环,就会直接报错。
那如何解决这个问题呢?根据外键名和Summary中的属性的对应关系,我们可以推测,这五个外键是Summary中五个引用一一对应过来的。由于这五个外键实际上是一模一样的,只需要保留一个就可以了。所以,最终的解决方案是,只保留一个字段的外键tag,其他字段全部给一个-的tag,让gorm不要为这些字段生成外键。
// https://github.com/muety/wakapi/blob/1ea64f0397e5ee109777b367e9bd907cfdd59bdb/models/summary.go#L30
type Summary struct {
Projects SummaryItems `json:"projects" gorm:"constraint:OnUpdate:CASCADE,OnDelete:CASCADE"`
Languages SummaryItems `json:"languages" gorm:"-"`
Editors SummaryItems `json:"editors" gorm:"-"`
OperatingSystems SummaryItems `json:"operating_systems" gorm:"-"`
Machines SummaryItems `json:"machines" gorm:"-"`
}至此,系统终于能启动起来了,并且大多数功能已经可以正常使用了。而在代码审核过程中,作者还发现了一个问题:代码中有一个Heartbeat表,它就是wakatime的客户端插件定期给服务器端发送的数据,其中包含了正在工作的项目、使用的编程语言等信息。而这个表中有一个字段为Hash,这个字段的值根据其他信息算出来,并且有一个unique index,通过这个字段,就避免给Heartbeat表插入多个重复的数据。
// https://github.com/muety/wakapi/blob/1ea64f0397e5ee109777b367e9bd907cfdd59bdb/models/heartbeat.go#L13
type Heartbeat struct {
// ...
Hash string `json:"-" gorm:"type:varchar(17); uniqueIndex"`
// ...
}在插入的时候,作者使用了ON CONFLICT DO NOTHING的语句,这个语句的作用就是,如果当插入一行的时候,发现有些行违反了某个unique index的要求,则忽略这个问题,不插入这一行,也不报错。这刚好非常适合插入有可能有重复的Heartbeat的场景。
// https://github.com/muety/wakapi/blob/1ea64f0397e5ee109777b367e9bd907cfdd59bdb/repositories/heartbeat.go#L52
// 下述代码将会被映射为ON CONFLICT DO NOTHING
if err := r.db.
Clauses(clause.OnConflict{
DoNothing: true,
}).
Create(&heartbeats).Error; err != nil {
return err
}
return nil这种行为被称为插入或者更新,又被称为Upsert(Update/Insert),其行为是一个简单的判断:如果一行已经存在,则更新这一行的内容;如果不存在,则插入这一行。而如何判断一行是否存在呢?则是通过unique index来判断。
可是遗憾的是,SQL Server不支持ON CONFLICT DO NOTHING。要想在SQL Server中模拟upsert的行为,有很多方式,一个比较常见的方法是使用merge into语句。具体如何编写比较复杂,这里就不再具体讲解。
由于这里是使用的gorm的API,并不是使用原生SQL语句,所以理论上来说,gorm是可以知道用户的意图,并根据不同的数据库生成行为相同的、但是兼容对应数据库的SQL语句的。根据这个issue,gorm的SQL Server库确实在很早之前就尝试通过生成一段的SQL Server兼容的SQL语句来支持这个功能,在gorm的文档里也提到了,clause.OnConflict会根据不同的数据库生成不同的语句,而对于SQL Server,其对应生成的正好就是MERGE INTO语句。
但是,既然库都支持了,那为什么还会遇到这个错误呢?再次检查所实际执行的SQL,发现这一次Create实际上生成的SQL语句仍然是最普通的INSERT INTO,并没有不是正确的MERGE INTO,。
024/01/19 20:10:23 /home/ddadaal/Code/wakapi/repositories/heartbeat.go:54 mssql: Cannot insert duplicate key row in object 'dbo.heartbeats' with unique index 'idx_heartbeats_hash'. The duplicate key value is (d926be93ebcc4b6f).
[10.830ms] [rows:0] INSERT INTO "heartbeats" ("user_id","entity","type","category","project","branch","language","is_write","editor","operating_system","machine","user_agent","time","hash","origin","origin_id","created_at") OUTPUT INSERTED."id" VALUES ('ddadaal','/home/user1/dev/project1/main.go','file','','wakapi','','Go',1,'','','','curl/8.5.0','2024-01-16 02:16:18.954','d926be93ebcc4b6f','','','2024-01-19 20:10:23.378');看来,要想弄明白这个问题,就得进到gorm的源码里来查看问题出在哪里了。使用VSCode启动一个调试版本的程序,给上面的代码的位置打上断电,使用curl连续插入两次同样的Heartbeat,根据断点往内查找,当进入到gorm的sqlserver的适配器的时候的代码的时候,我们发现了一些端倪:
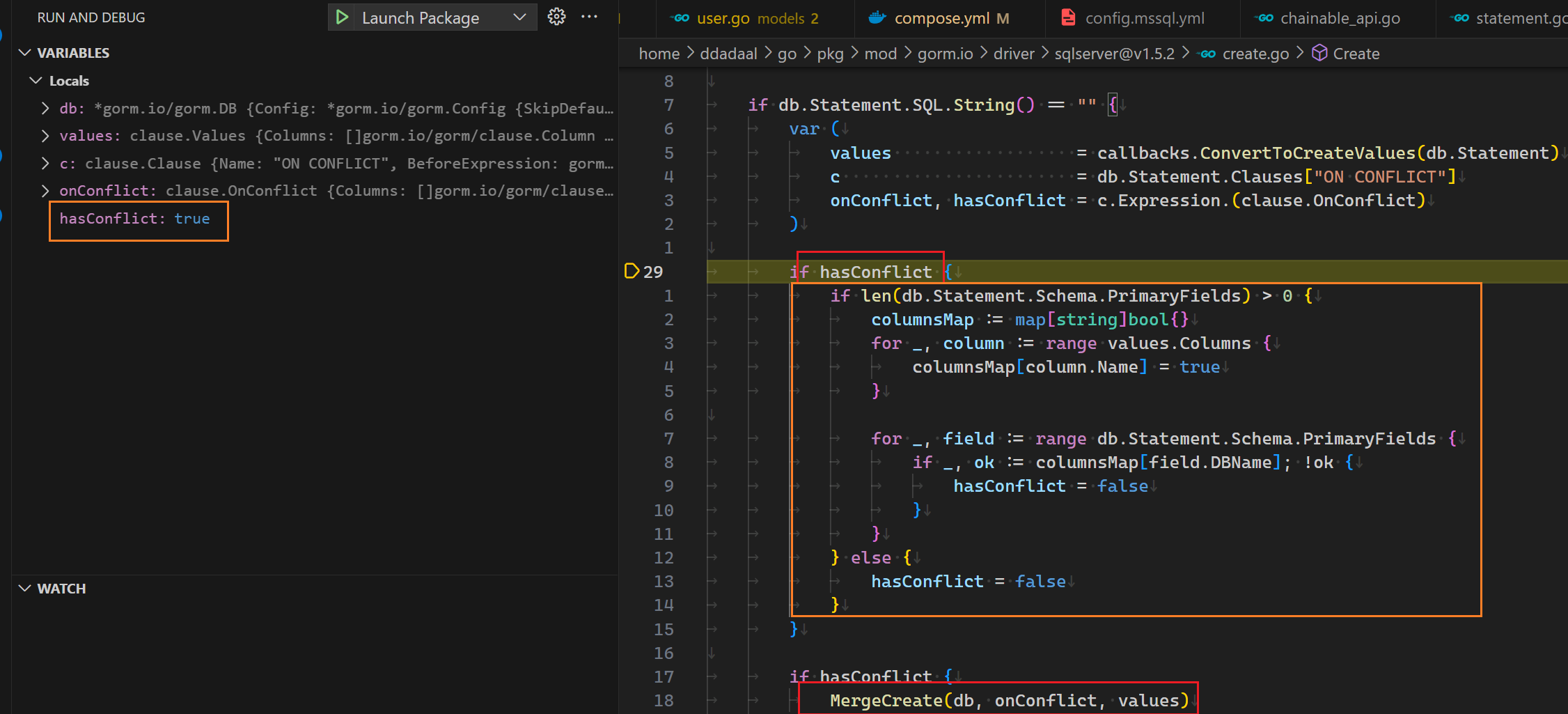
当前,我们正在图中的if hasConflict的位置,且hasConflict当前为true。根据下面的一段代码,如果hasConflict为true的话,将会进入MergeCreate函数,而这个函数即是一个在MySQL实现类似行为的SQL的语句的代码。但是,实际在橙色块结束后,hasConflict被改成了false,所以最终并没有进入MergeCreate,最终的结果就是一个普通的INSERT INTO SQL。那么也就是说,橙色这段代码就是罪魁祸首!
这段代码干了什么事情呢?简单来说,它会检查要插入的行中的各个列中有没有包含主键。如果没有设置主键,则将会把hasConflict改为false;而如何设置了主键,才会进入MERGE INTO流程。回想前面,要想正确生成upsert行为,我们需要判断一行是否存在。而很显然,这里的代码将一行是否存在的判断标准等价为了主键是否存在,而忽略了其他具有的unique index的列。
当然,其他人也发现了这个问题,gorm-sqlserver的仓库中也有已经半年前打开的issue正好就是关于这个问题。而很遗憾,这个问题过了半年依然没有修复。
要想解决这个问题,有多种方法,而我最终选择了最简单粗暴的方法:不管!这个函数的目的是同时插入多个Heartbeatt,那我们就手动一个一个插入,如果一个行插入失败了,我们简单判断一下,如果这个错误是因为hash重复造成了,那我们就不管了!检查了一下代码中调用这个方法的场景,其实大多数情况下都是只插入一行,所以这样写对性能造成的影响是可以接受的。
// https://github.com/muety/wakapi/blob/1ea64f0397e5ee109777b367e9bd907cfdd59bdb/repositories/heartbeat.go#L34
if r.db.Dialector.Name() == (sqlserver.Dialector{}).Name() {
for _, h := range heartbeats {
err := r.db.Create(h).Error
if err != nil {
if strings.Contains(err.Error(), "Cannot insert duplicate key row in object 'dbo.heartbeats' with unique index 'idx_heartbeats_hash'") {
// ignored
} else {
return err
}
}
}
return nil
}终于,经过了一周的时间,本来以为只是一个简单的调库,结果却发现了这么多的问题。经过这个过程,之前连SQL Server用都没用过的我也知道了很多SQL Server的细节;之前没有接触过gorm,现在却连源代码都好好翻了一通。
而关于go,虽然我一直不喜欢go的语法,觉得它太简单,类型系统太弱,很多代码都花在固定的模板代码上(比如if err := nil),但是不得不承认的一点是,go确实非常的explicit。没那么多乱七八糟的反射、运行时黑魔法,控制流非常清晰,想知道什么代码调用了一个方法,直接Shift+F12就完事了,出来的结果不会多不会少;要想某个错误是在哪里处理的,跟着繁琐的错误处理代码总能找到。它确实缺少一些特性,但是它非常地工业化。
解决这些问题后,PR顺利合并进了主分支,成就感满满,这可能也是我第一个没那么简单的开源项目的贡献了。
对我来说,设定一个目标是学习的最好的途径,在这次实践里再次得到了印证。
2024-01-07 23:55:00
作为一个创作者,我还是很希望能够获取我的网站的一些统计和监控信息的,例如各个页面的点击量等。且不说这些数据到底有什么具体的作用,但是单纯地看着网站的访问量上涨,这对我来说还是非常有成就感的,说明我写的东西还是有人看的😂
但是在过去的5年里,我的博客一直没有部署一个稳定的统计系统。之前用过使用Google Analytics、友盟以及百度统计,但是最后均遇到了各种各样的问题没能使用下去。例如,Google Analytics的数据过于复杂,我甚至没搞懂怎么看某一页的访问量?友盟的信息只保存一年等。前几天看到一个Analytix的服务,看界面非常清新简洁,也没有提到要付费的情况,非常对我胃口,结果装进去发现报告数据的API有错误,仍然无法使用。
来到了新的一年,我打算这次一口气解决这个问题。我连简历的样式都是自己用CSS排的,写个统计功能还难住我了?用第三方功能总会有所担心,担心要收费、数据丢失,自己写的功能就没有这些问题了。于是花了一天完成了一个最简单的博客点击量统计功能,并正式上线。
绝大多数统计网站访问者的模式都是相同的:先在平台上注册一个账号并注册自己的网站,平台给予一个<script>HTML标签,这个标签需要被加到被统计的网站上。当标签加上去后,这个标签就会下载一段javascript脚本,这个脚本会将一些访问者的信息发送到平台上,平台收集数据后做数据统计,这样我们就获得了网站访问者的信息了。
这个脚本具体怎么写呢?在研究上文提到的Analytix为啥用不了的时候,我研究了它要求我们插入的脚本:https://analytix.linkspreed.com/js/script.js(点击直接查看)。它所做的事情,主要有两个:
page、来源地址referrer、屏幕分辨率screen_resolution发送到他们的endpointhistory.pushState函数,当这个函数被调用时(即页面URL修改时),再次执行上面这个事件这样,每次用户访问网站时,脚本就会把访问信息上报到API,并且通过history.pushState确保即使是单页应用,也能正确报告所有访问的URL。
要想分析用户的信息,最简单的方式莫过于把用户的IP地址收集上来。有了IP地址,我们就可以分析很多信息了,例如用户来源的分布等。但是,我们再仔细看看Analytix所收集的信息,只有三个:当前页面地址、来源地址以及屏幕分辨率。是不是感觉有点少?没有IP地址,怎么去重,怎么分析哪些来访者是来自于何处?
我认为这很可能和GDPR有关。GDPR(通用数据保护条例)是欧盟的一项关于数据隐私的法律,是对所有欧盟个人关于数据保护和隐私的规范,所有互联网服务只要涉及到和欧盟的人或者公司,都需要遵守这个规定。这个规定非常复杂,我也没有信心完全读懂,但是其中以下几点非常重要:
把这两点连起来看,就是说网站不经过用户同意就能收集的信息实际上就非常有限了。Analytix可能也是考虑到这个因素,所以才默认只收集了URL以及屏幕分辨率信息,最重要的IP地址等均没有被收集。除此之外,脚本中还单独判断了navigator.doNotTrack,如果这个值为真,则不报告信息。根据MDN的信息,navigator.doNotTrack是个非标准的API,当用户浏览器设置了Do Not Track时,这个值为true。这也充分满足了用户的意愿,如果用户不愿意被track,就真的不会被track。这也是为什么现在很多网站在第一次访问时都会有一个很明显的弹出框等方式,里面会明确说明网站会使用cookie、记录访问者的IP地址,以及给用户说明如果不愿意收集可以明确被退出,要求用户显式地同意。这些也都是GDPR、以及其他国家后续类似推出的信息保护条例的要求。
作为一个负责人的网站开发者,我认为个人信息确实是非常重要。目前我也没有必要收集用户的IP地址来做进一步的分析。为了保护用户的隐私,我也选择了和Analytix一样的收集方式,目前只收集了这些和个人信息无关的信息。您可以访问https://services.ddadaal.me/monitor/script.js来获知访问网站时下载的脚本具体执行了什么代码,发送了什么信息。
目前网站的统计逻辑基本上就是照抄Analytix,写一个信息上报地址、写一个脚本,然后在博客中加一个<script>标签。
项目本身我采用了我比较熟悉的Node.js,使用fastify HTTP库编写了代码。之后,我将其打包为Docker镜像,部署到了Azure App Service上,并将services.ddadaal.me解析到部署后的地址。Azure App Service使用的是最便宜的版本,每个月的费用预计为15刀左右。

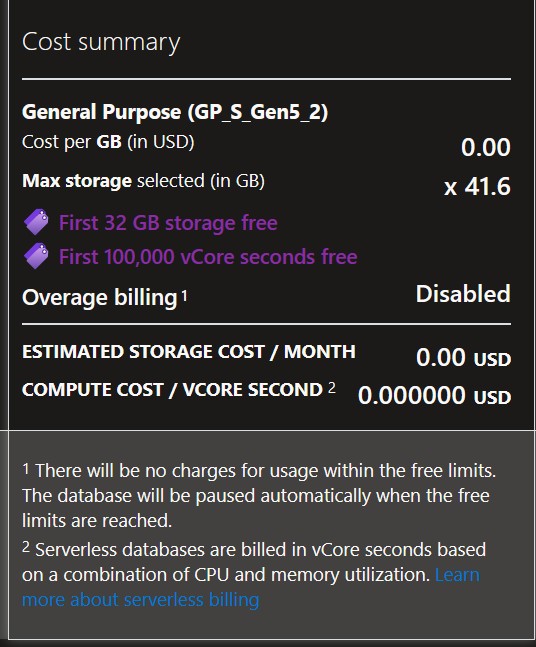
采集到的信息保存在Azure SQL Database上,主要原因是它有一个免费的offer,每个月32G存储和第一个100000核秒的计算是免费的,这些计算能力和存储对我来说绰绰有余了。
它实际上是一个Microsoft SQL Server SQL服务器,Node.js下虽然有能用的mssql库,但是生态支持mssql的还是太少了,为了更方便地访问数据库,我使用了支持mssql的Prisma,正好尝试了一下这个全新的"ORM"框架。目前总体用起来,和传统的mikro-orm等用起来还是有不少的区别的,例如它的客户端是通过codegen生成出来的,编写schema也是通过自己的prisma语法,不是传统的用TypeScript来定义。总的来说,因为这个库是有公司在背后支持的,所以可用性还是不错的。另外,微软的Azure Data Studio甚至Prisma的Prisma Studio都可以访问MSSQL的数据,维护起来问题不大。
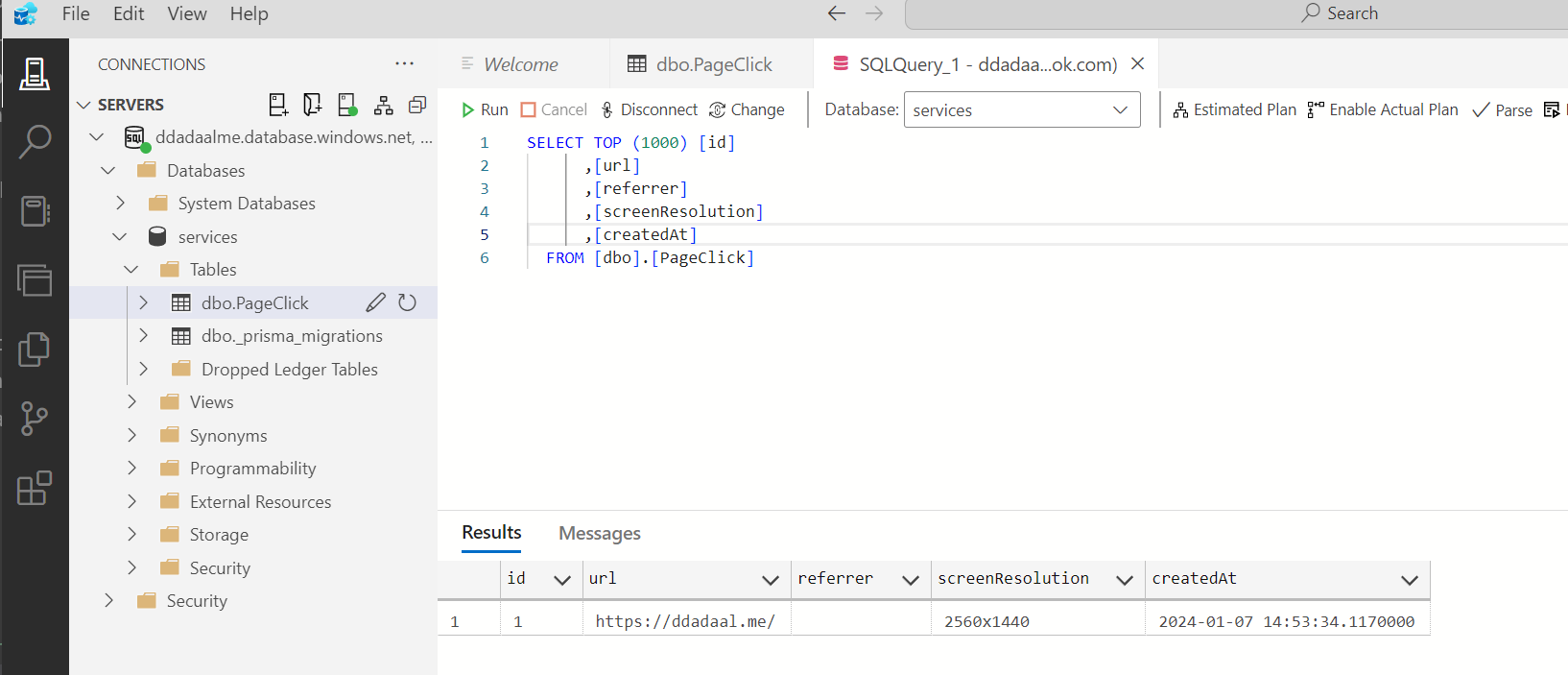
有了统计数据,之后第一件事肯定是数据分析。目前可以通过SQL语句来分析,但是这也太不直观了,后续可能我会开发一个简单的dashboard用来查看统计数据。
另外,这个博客是一个静态博客,所有的动态功能均需要单独部署服务来实现。而services.ddadaal.me会变成博客后端的服务的基础。后续博客的动态功能也会部署到这个域名之下。
2024-01-01 10:20:00
当昨天的2023年总结发出后,朋友圈有人对文章做出了总结,这启发了我,何不自己用AI给文章加个总结功能呢?正好也是第一次在真实场景中实装AI功能,看看目前在真实项目中集成AI需要什么步骤,体验怎么样,能做到什么功能。

确定了要做这事,下一步就开始调研应该用什么AI服务。
第一反应肯定用OpenAI API,去年某段时间注册OpenAI账号不需要手机号,趁着这个机会直接注册了一个,至少最基本的ChatGPT可以用GPT 3.5模型聊天了。而当我想去用OpenAI的API的时候,发现要获得OpenAI的API需要验证手机号,而国内手机号当然验证不了的。除了手机号,支付方式也是一个问题,虽然我有国内银行的VISA卡但是似乎仍然不能使用。
于是接下来我想到了公司的Azure OpenAI服务。虽然Azure的服务都偏贵,但是由于公司每年都给员工送150刀的Azure额度,所以一点简单的应用还是可以开发的。可是真的去注册的时候发现Azure OpenAI Service并没有完全开放给所有客户,要注册必须填个注册表,且必须以公司身份注册。
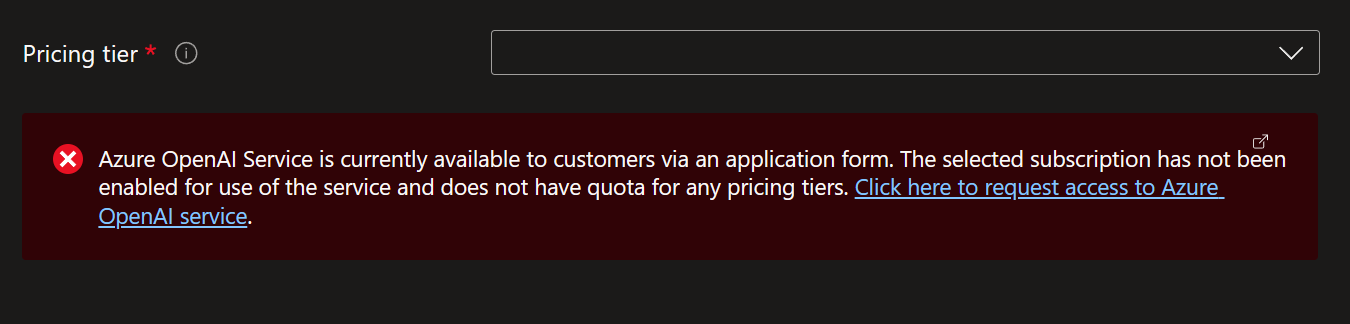
正当我在想“不会要去找国产服务了吧”的时候,我想到两个月前在Ignite上亮相的Azure AI Studio。仔细研究了下,发现这个功能本身只是一个集成平台,它是基于一些已经已经发布的Azure AI服务,而上面想尝试的Azure OpenAI只是这些服务内的一个。在这些服务中,有一个Language服务,正好用于处理自然语言的场景,而其中正好还自带了Summarization功能,其中的Abstractive summarization模式只要输入文本,它就能输出一段总结这段文本的文字。
一切都是正好。微软爸爸真懂我。
根据Quickstart文档,我们首先需要创建了一个Language资源,获取资源对应的endpoint以及key。
文章总结功能的一大好处是这个功能不需要实时交互。也就是说,我可以在后台把总结生成好,像文章内容本身一样作为静态资源放在仓库里。这样,我们根本不需要能够支持大量调用的AI服务,只要运行一次,就完全可以使用了。创建的资源的时候,每个subscription可以创建一个免费的资源,我们本来也就不到50篇文章,免费的资源就完全够用了。
接下来需要在项目中安装SDK来使用这个资源。我们的博客使用的是Node.js,于是我们选择Node.js继续进行下一步。使用npm install --save @azure/[email protected]安装SDK后,根据指示直接在项目使用SDK即可。
由于只要内容不变,总结就没有必要更新,所以最简单最直接的做法,就是直接放在本地写个脚本,读取文章的内容,然后把文章内容的markdown直接一股脑送给服务获得内容的总结,然后把总结的内容生成到文章对应的目录下,读取文章的时候顺便读取生成的总结,然后在UI中渲染就好。
// 总结文本
async function summarize(text: string, languageCode: string): Promise<string[] | Error> {
const lro = await client.beginAnalyzeBatch([
// 使用AbstractiveSummarization模式
{ kind: "AbstractiveSummarization" },
// 根据文章的语言指定所使用的语言,实现中文文章输出中文总结,英文文章输出英文总结
], [text], languageCode);
// 这是个耗时操作,等待耗时操作结束
const results = await lro.pollUntilDone();
for await (const actionResult of results) {
if (actionResult.kind !== "AbstractiveSummarization") {
return new Error(`Expected extractive summarization results but got: ${actionResult.kind}`);
}
if (actionResult.error) {
const { code, message } = actionResult.error;
return new Error(`Unexpected error (${code}): ${message}`);
}
for (const result of actionResult.results) {
if (result.error) {
const { code, message } = result.error;
return new Error(`Unexpected error (${code}): ${message}`);
}
// 返回输出的结果
return result.summaries.map((x) => x.text);
}
}
throw new Error("No result");
}
async function summarizeArticle(articleDir: string) {
// 获取此文章的所有markdown文件
const mdFiles = (await readdir(articleDir)).filter((x) => x.endsWith(".md"));
for (const mdFile of mdFiles) {
const mdFilePath = join(articleDir, mdFile);
// 读取并解析文章内容
const mdContent = await readFile(mdFilePath, "utf-8");
const { data: frontMatter, content } = matter(mdContent);
// 计算并更新文章Hash,如果文章内容hash没有变,之后就不要重新生成总结了
const contentHash = hashContent(content);
const summaryJsonFilePath = join(articleDir, `${frontMatter.lang}.summary.json`);
if (existsSync(summaryJsonFilePath) && (await stat(summaryJsonFilePath)).isFile()) {
const existingSummaryJson: ArticleSummary = JSON.parse(await readFile(summaryJsonFilePath, "utf-8"));
existingSummaryJson.hash = contentHash;
if (contentHash === existingSummaryJson.hash) {
log("log", "Content is not changed after the last summarization. Skip summarization.");
continue;
}
}
// 总结文本
const summary = await summarize(content,
azureLanguageCodeMap[frontMatter.lang as keyof typeof azureLanguageCodeMap]);
if (summary instanceof Error) {
log("error", "Error on summarizing %s of lang %s: %s", frontMatter.id, frontMatter.lang, summary.message);
continue;
}
// 在文章目录下生成一个[语言id].summary.json文件,存放内容hash、总结以及相关操作信息
const summaryJson: ArticleSummary = {
articleId: frontMatter.id,
lang: frontMatter.lang,
lastUpdateStartTime: startTime,
lastUpdateEndTime: new Date().toISOString(),
summaries: summary,
hash: contentHash,
};
log("log", "Write summary of %s of lang %s to %s", frontMatter.id, frontMatter.lang, summaryJsonFilePath);
await writeFile(summaryJsonFilePath, JSON.stringify(summaryJson, null, 2));
}
}
最终效果嘛,你在打开本文章的时候应该就看到了。如果一篇文章能够成功生成总结,那么文章页面的一开头,以及右侧的目录部分就会有AI总结这部分内容。
为什么说“如果可以成功生成总结”呢?在具体操作中,2020年总结这篇文章死活不能生成总结。

而对应成功生成总结的文章,总的来说英文文章的总结效果显著好于中文文章。例如,An Infinite Loop Caused by Updating a Map during Iteration这篇文章的总结包括了问题描述、问题解决过程以及最终的解决方案,语言流畅,逻辑清晰;
The author encountered a problem during the development of the 2.0 version of [simstate], where an infinite loop occurred during the iteration of a set of ' observers' stored in a ES6 Map. The problem was initially confused due to the Map having only one element and remaining unchanged between and inside loops. However, after investigation, the author discovered that the root of the problem was the call to observer, which alters the Map itself during iteration. This led to the infinite loop, even when deleting and re-adding an entry during iteration.
而同样类型的问题探究类文章一次生产环境的文件丢失事故:复盘和教训,得出的总结就过于简单,而且也没有找到问题重点,得出的文本中甚至都是英文标点。
作者通过log、数据库数据等找到了受到影响的用户,通过邮箱、电话和短信提醒他们重新上传文件。
这是我第一次在实际项目中运用AI,在充分的文档帮助下,整个过程花费了6个小时左右,其中集成这个功能可能花了1个小时左右,而最终的效果不能算非常完美,但是也是是差强人意。在2023年的最后一天完成这个过程,在新年的第一天给博客实现这个新的功能,也算是一个新年礼物了吧。在AI的时代,与其害怕AI替代自己,不如主动拥抱AI提高生产效率,而这对于从业者的我们天生就有优势。
2023-12-31 23:59:00
从2019年10月开始,在我对未来的所有计划中,2023年就是最后一年。我知道我会在2023年完成毕业论文并毕业,加入一个公司(在2022年确定是上海微软),再往后会发生什么,就彻底没有意识了。对我来说,2023是19年学生生涯的结束,也是我最熟悉的生活的终结。
由于疫情,2020年的毕业季变为了宅家季,整个研究生期间的生活也受到了不小的影响,更别说在北京,以至于之前连出京看个牙有时候都是一种挑战。随着疫情防控的结束,生活总算可以回归正常。因此,我也在学生生涯的末尾再次体验到了一把久违的正常生活。
作为一个经历了体重困扰22年的“减肥困难户”,我一直以为体育运动和我没有关系。可谁知道竟然能在研究生期间减重成功,结交了愿意一起运动的朋友,甚至还加入了院里的球队。生活正常了后,各种比赛也多了起来,在来自同学、球队的帮助下,我也有机会参加各种比赛。
3月在清华综合体育馆,第二个球就把腰闪了,坚持打完21分后在场馆边成为“球场流浪汉”;4月法学院组织的比赛,当时因为身体不太舒服没有上场,却与王适娴面对面,队友还获取了王适娴在球衣上的亲笔签名;5月和球队参加硕博杯比赛,可是却打出只获得3分、5分的惨烈对局,最后甚至还发现3分那一场的对手在朋友圈里;6月和老搭档的比赛前半局大比分领先,可后面却被逆转。这可能这是这半年最大的遗憾了吧,没能在实力接近的比赛中赢下一局。

今年可能是我出游最多的一年。3月QQ火花1100天+的大学同学考研复试,在北京参观;4月大学同学回国飞深圳,3天时间在深圳闲逛,顺带拜访了港中深的同学;6月和研究生同学去了明孝陵和青岛、淄博和济南;7月大学同学回国飞香港,快十年后又一次出境游,回到国内后窝在民宿里,除了吃饭就是聊天,一个景点都没有去,还顺路在江门和研究生同学打了一场球;8月陪研究生同学游重庆。

我不喜欢一个人旅游,对我来说,旅游的重点不在去哪儿,而在和谁一起去。有这么多愿意玩的同学朋友,我感到很幸运也很感激。
随着负责的实验室项目迈入正轨,项目的事情也逐渐越来越多。从一开始的只要按照自己的写代码,到后面要去投稿、参加会议、和人越来越多的团队合作。虽然马上要毕业了,之后应该也与学术圈不会再有交集,但是在老师的支持下,在这最后半年里,浅浅体验了一下这条我之后不会再有机会经历的道路。

另外,要毕业的时候,赶上了HackPKU Hackathon比赛的末班车。上大学以来总共参加和组织过5次hackathon,每次hackathon都是一次学习效率拉满的体验,这次hackathon更是在完全不同的情况下,在ChatGPT的支持下学习了一些WebGPU相关的能力,虽然真的很累,这种以兴趣驱动、有目标导向的体验真的难得。

虽然三年前我们仍然能够回到学校,在学校度过本科阶段最后的日子,但是没有正式的毕业活动,总感觉没有真正的结束。还好,19年的学生生活有一个完美的结局。毕业典礼最后合唱燕园情的环节,不仅是对燕园、三年研究生生活的告别,也是对学生生活的告别。

新的生活一开始是让人激动的,后面才意识到,它是复杂的。
今年来租房的时候,根据去年经验,我和合租的同学定下了一个以下要求:不要老破小,通勤时间短,周边生活方便。可是,在到上海的前几天,预先看好的房源一个一个被订走,我们只好妥协对户型和地铁站距离的要求,最后租了一套在附近住房里离公司最近的、21年才交付的全新的动迁房,再购买了一辆二手电动车,从出门到公司电动车停车位停车总共8分钟。

入住后一番收拾,在客厅的一角把台式机打造成了工作站,设置好了厨房,后面还邀请了在工作中认识了几位南软的小伙伴,请他们在来家里一起吃我们订的螃蟹和做的饭。

由于是实习转正,所以入职直接进了去年实习的组,一切都是那么熟悉。办公环境没有变,工位和实习工位隔了2m,老板没有变,同事没有多没有少,工作仍然是接手的实习项目,熟悉到入职第一周就完成了一个功能。

总的来看,一切就和当年想的一样进行着。
但是哪儿有完美的事情呢?
工作上,这四个月内我一直在做一个新的业务,具体的功能实现和节奏都由带我的同事和我自己掌握。而与此同时,我的在其他组的同学每天有具体的要求,还有从早到晚的各种会议,工作十分充实,这个对比让我十分不解:我的工作是不是太水了?和老板进行了一次6个小时的一对一聊天,了解到了组里的情况,组里目前还没有业务,分配给我的任务也是探索性质的,所以目前仍然是比较自由的状态。对纯粹混日子来说,这种组无疑是很合适的,但是毕竟公司主要还是以盈利为主,如果一个组一直不出业绩,组里分到的资源以及个人的发展前途肯定会受到影响,而这些事情是目前我一个小兵无法左右的。另外更具体地了解薪资和结构后,简单计算一下得知,即使是在升职顺利且不被裁员的情况下,收入前五年平均下来也只能维持几乎不变,距离在上海买房那还是差远了。
升职加薪没啥指望了,重点就要在生活上找乐子了。理论上来说,在上海应该不缺乐子。可是,如果要进市区的话,地铁出行一小时刚到徐家汇,开车由于经常堵车时间并没有本质区别,再加上没有搭子,即使去市区,等到了地方,也只能简单逛逛就得准备往回走,音乐会等最好多人一起参加的活动至今也还没有参加过。不进市区的话,周边都是工厂和农田,在冬天降温之前为了运动,倒是骑着共享单车把周边都转了一圈。
由于来了全新的城市,原来的朋友都在外地,而工作中的认识的同事以及现在仍然方便联系的朋友全部都已经有对象、有家庭甚至有小孩,都有自己要关心的更重要的事情,不太可能再像之前一样想约就约。公司倒是比较慷慨,组织了几次团建活动,迪士尼、甪直古镇,以及在市区一个酒吧的团建,但是主要也是为了大家单纯的放松和白嫖团建预算而已。

11月的时候办户口,虽然户口可以网上办理,但是为了再和上半年的朋友们再见一次,我还是再次去北京待了3天,在可预期的未来最后一次见了北京的朋友们,三天见了6波人。之前做MBTI做出来结果为E,我自己都感觉不可思议,但是从社交是否能给我带来活力来说,这个结果确实挺准确的。
我从国内顶尖的学校毕业,进入了梦想的行业,在梦想的公司过着压力不大的、通勤10分钟的工作,我原来的目标似乎完全实现了。
自很小的时候在父母的单位上接触了电脑(从一张老照片上确认是2001年)后,我对计算机产生了兴趣。那个年代比尔盖茨的故事家喻户晓,我也认为计算机软件是我将会从事一生的行业。当别的小孩在外面疯玩的时候,我在家里鼓捣电脑,甚至还给小区里的邻居装系统、解决电脑问题。高考填志愿的时候,我果断地填了软件工程专业,在坚定的目标中度过了充实的七年大学和研究生时光。选择工作的时候,我也完全没有考虑目前很火的考公、国企,我喜欢我做的工作,虽然这两年裁员、降薪新闻一个接一个,但是我仍然选择了这个行业。而当大家都去国内大厂的时候,我却只盯着外企,以至于目前三段实习经历都是外企,最后也除了出于好奇往华为投了一份简历(然后面试通过后石沉大海)之外,一个其他企业都没有投,最后也顺利把握住了最近两年最后一批校招的机会,进入了微软。
但是,成年人的世界就是选择并承担后果。选择了Work Life Balance的外企,就要接受工资不高不低以及存疑的稳定性;选择了住在郊区,享受了极快的通勤时间和相对市区低廉的房租,摆脱了干什么都要排队的拥挤,就必须接受出行的不便以及看着像30年前小镇子的环境。
仔细想来,我完全不能抱怨环境。工作条件灵活,假期充足,老板不push,工作内容暂时压力不大,相处的同事能力强好沟通,甚至还能带我去俱乐部打球,可以说我可能很难再找到这样的环境。我也感觉一直非常的幸运,一直到今天,所经历过的事情、认识和结交的人都非常的nice。那我还有什么不满意的呢?归根结底,是我还需要回答这个最重要的问题:我到底想要什么。
但这个问题有那么好回答吗?
工作之前觉得郊区生活成本低,通勤方便,房价低,有希望能留下;而现在却觉得,住在这么偏远,出行动辄1小时,也算在上海吗?同样一份Work Life Balance的工作,之前觉得工作和待遇取得平衡,现在却觉得待遇离能在上海定居差了十万八千里,晋升又慢,还要担心中美关系,混日子工作有什么意义吗?同样是居住,4个月前我唯一的念头就是离公司近,但是现在却萌生了去市区居住和体验的想法。又回想到2019年,从“坚持”本科毕业去工作到保研,这个转变也就发生在一个月内。
前段时间看到有人说,一个人成长的标志是感觉到以前的自己非常幼稚。我很高兴我仍然处于成长当中,但更重要的在成长中找寻新的方向。在过去的十九年中,总有一个“毕业升学”的目标围绕着我。而现在以及以后,永远不会再有这样一个固定的目标了,找寻新的目标成为了以后最重要的问题。明年,我将会更熟悉工作的状态,可能会和更多人合作,承担更多的工作;明年合租的同学离开,我将再有一次换居住环境的机会;可能会通过更多的渠道认识到更多的人。希望我能在不停的变化、体验、接触之中,慢慢地搞清楚我究竟想要什么样的生活。