2025-03-02 11:23:00
TabPFN 的主要特点:
前置知识:贝叶斯算法、贝叶斯神经网络 BNN
首先,给出后验预测分布(Posterior Predictive Distribution,PPD)的定义: $$\begin{array}{c}{{p(y|x,D)=\displaystyle\int_{\Phi}p(y|x,\phi)p(\phi|D)d\phi}} \\ {{\propto\displaystyle\int_{\Phi}p(y|x,\phi)p(D|\phi)p(\phi)d\phi}}\end{array}$$
公式理解:先遍历所有可能的算法模式,然后根据历史数据 $D$ 分析不同算法模式的后验概率 $p(\phi|D)$,并以此为权重对不同算法模式下的预测分布 $p(y|x,\phi)$ 进行求和,得到最终的后验预测分布(PDD)
先验数据拟合网络 PFNs 的损失函数定义: $$\begin{align*} \ell_{\theta} &= \mathbb{E}_{D \cup x, y \sim p(\mathcal{D})}[-\log q_{\theta}(y | x, D)] \quad &(1) \\ &= -\int_{D, x, y} p(x, y, D) \log q_{\theta}(y | x, D) \quad &(2) \\ &= -\int_{D, x} p(x, D) \int_{y} p(y | x, D) \log q_{\theta}(y | x, D) \quad &(3) \\ &= \int_{D, x} p(x, D) \mathrm{H}\left(p(\cdot | x, D), q_{\theta}(\cdot | x, D)\right) \quad &(4) \\ &= \mathbb{E}_{x, D \sim p(\mathcal{D})}[\mathrm{H}\left(p(\cdot | x, D), q_{\theta}(\cdot | x, D)\right)] \quad &(5) \end{align*}$$
损失函数理解 1:用负对数似然的期望作为 $l_{\theta}$ ,其思路等价于最大似然估计
损失函数理解 2:$\ell_{\theta}$ 实际上是 PDD 与模型输出分布之间的交叉熵,因此 PFNs 模型的训练过程,其本质就是在实现对后验预测概率分布 PDD 的直接近似
损失函数理解 3:$\ell_{\theta}$ 实际上还是 PDD 与模型输出分布之间的 KL 散度(加上一个常数项),推导和证明过程略(具体细节可参阅原论文的附录 A)
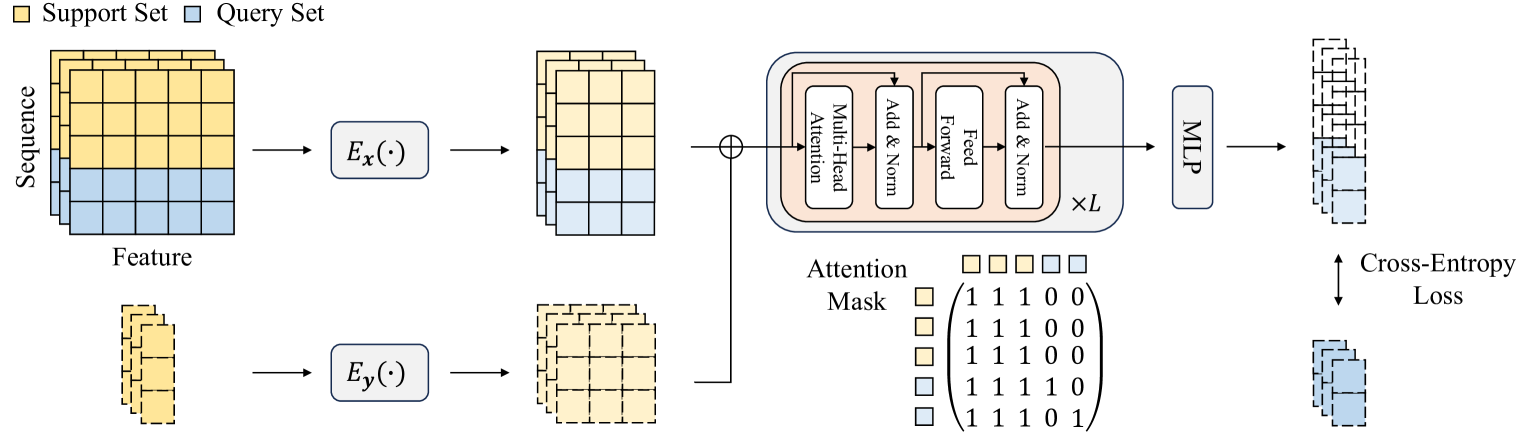
先验数据拟合网络 PFNs 的其他细节补充:
PFNs 通过对 PDD 进行建模和近似,实现了以贝叶斯的方式解决有监督学习问题
PFNs 的优点是保持了 Transformer 强大的上下文学习(in-context learning)能力
前置知识:结构因果模型
PFNs 模型选择基于贝叶斯神经网络(BNN)的先验,而 TabPFN 则在此基础上,扩展了基于结构因果模型(SCMs)的先验,而 PFNs 的一个关键优势,就是能通过贝叶斯的方式组合不同超参数或不同类型下的先验,既处理了超参数的不确定性,也可以融合了不同类型先验的优势
TabPFN 的构建过程保持奥卡姆剃刀的原则,即用尽量少的超参数与因果关系来进行建模
基于 SCM 和 BNN 创建 TabPFN 先验:
TabPFN 的其他细节补充:
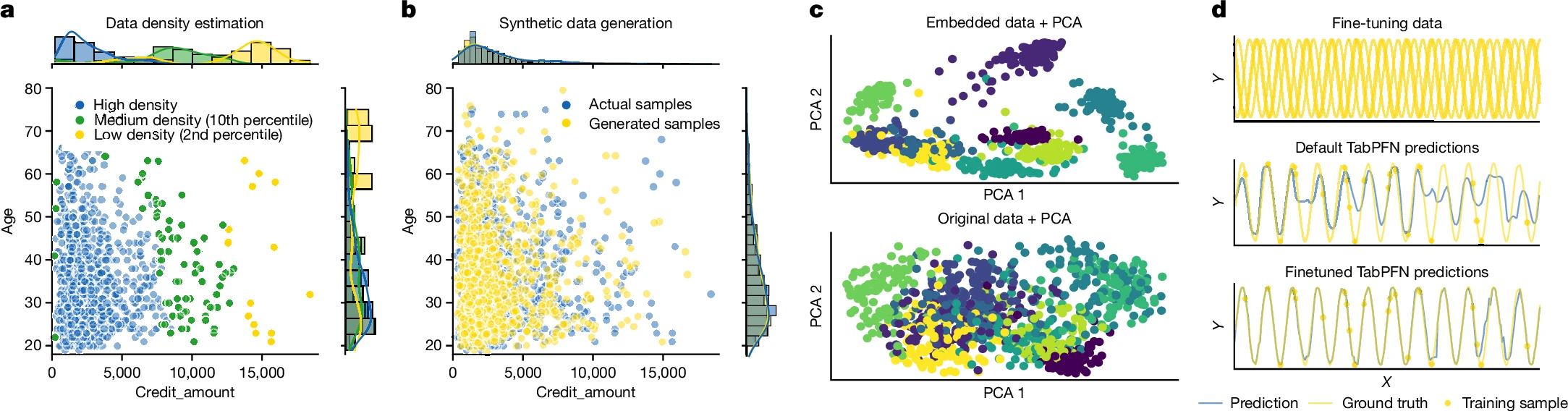
TabPFN 的测试评估
TabPFN 只是整体最优,在部分数据集和任务上依然可能不如传统机器学习的表现
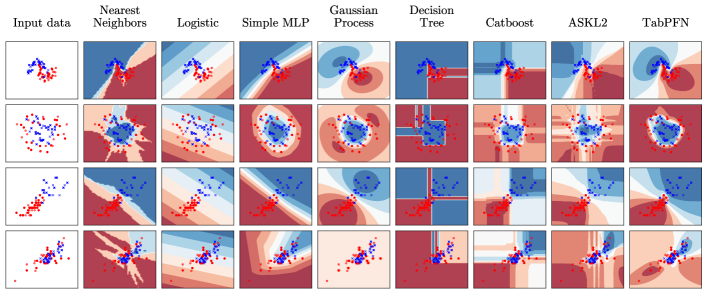
不同算法在 scikit-learn 1_study/Python/Module-sklearn-机器学习/skleran 内置数据集#1 玩具数据集上的决策边界:
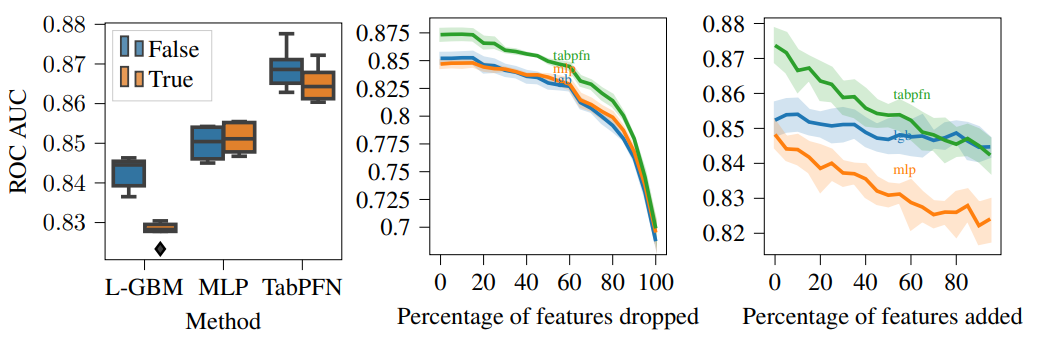
模型的特征鲁棒性分析:
不同先验的消融实验对比:
| BNN | SCM | SCM + BNN | |
|---|---|---|---|
| Mean CE | 0.811±0.009 | 0.771±0.006 | 0.776±0.009 |
| Mean ROC AUC | 0.865±0.007 | 0.881±0.002 | 0.883±0.003 |
TabForest 模型 - TabPFN 在森林数据集上的微调
QuantileTransformer)在转换数据以服从正态分布的同时,增强模型对偏斜和异常值的鲁棒性TabForest 模型的表现(2024 年 5 月 22 日):

主要升级点(2025 年 1 月 8 日发表在《nature》):
TabPFNv2 使用约 1.3 亿合成数据集,在 8 个 RTX2080TI GPU 上训练了 2 周
实验分析与评价 1:TabPFN 的性能表现
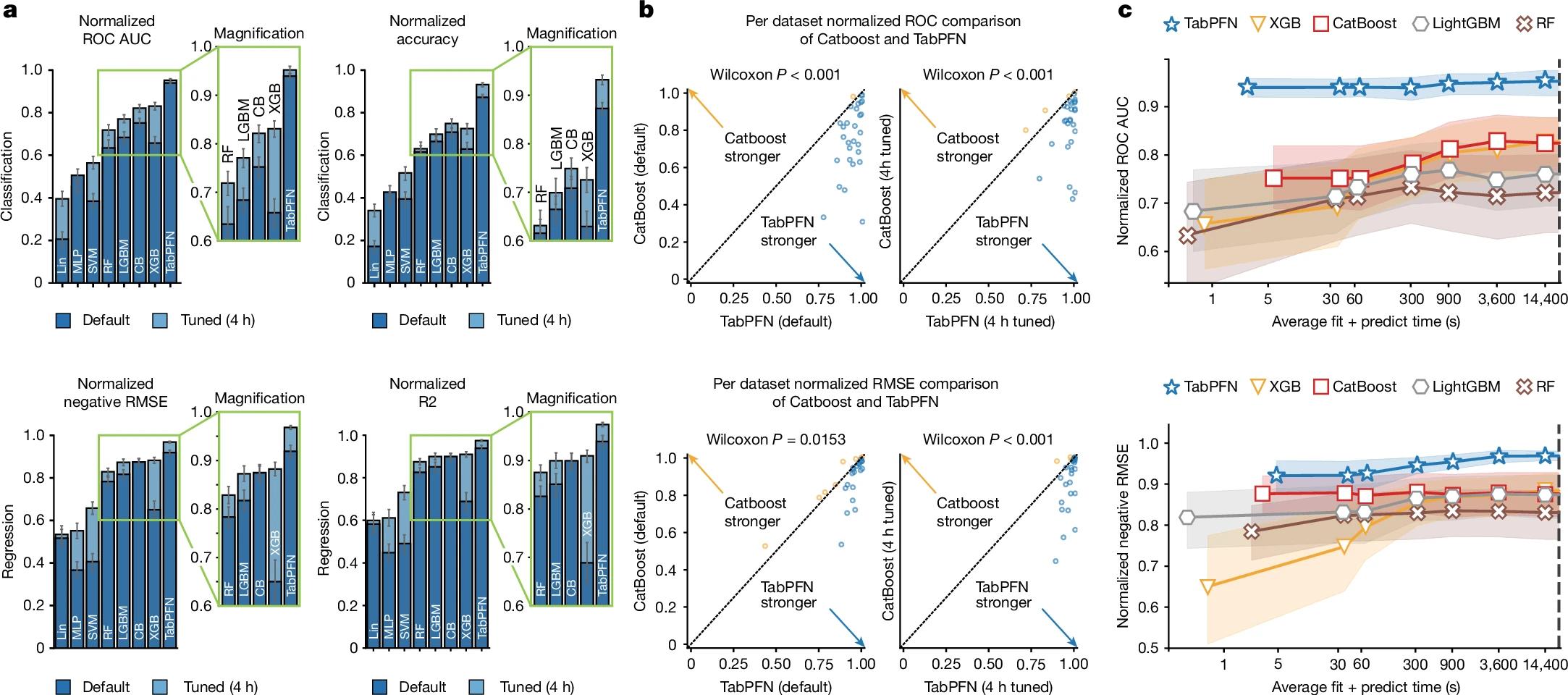
实验分析与评价 2:TabPFN 的可解释性与迁移性
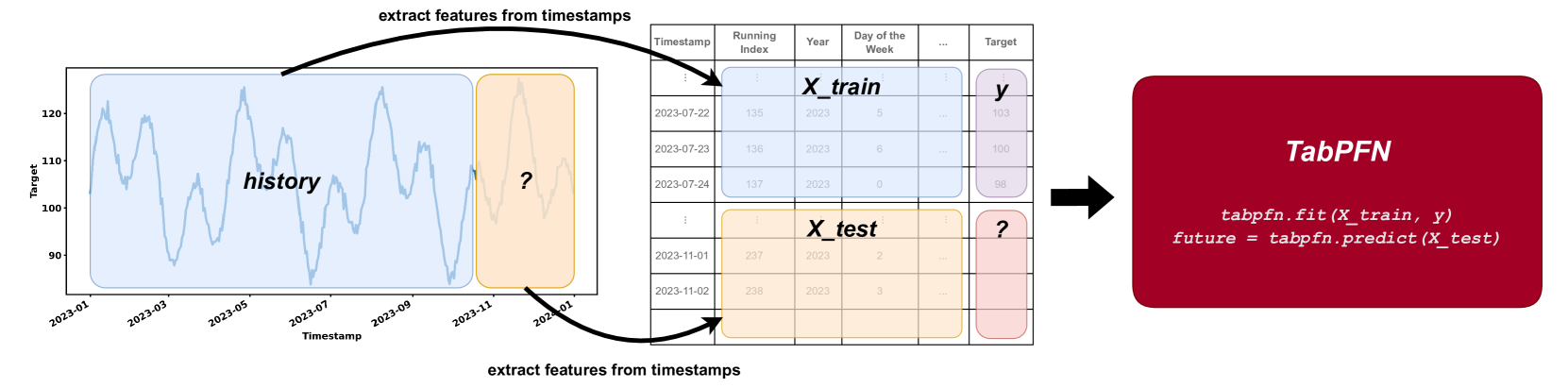
TabPFN-TS(2025 年 1 月 9 日) 是 TabPFN 的变体,可应用于时间序列预测
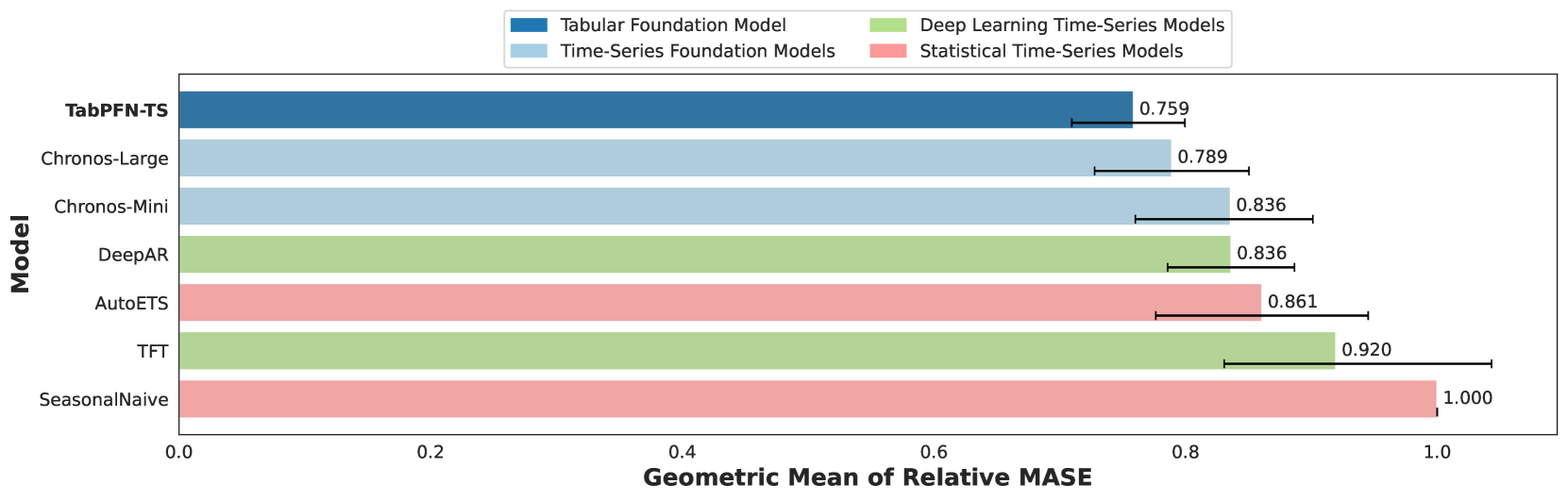
TabPFN-TS 模型中 GIFT-EVAL 时序模型基准测试 Top1(250227)
核心思想:将时间序列预测视为一种表格回归任务
实验结果:TabPFN-TS 的模型表现远高于其他模型
参考文献:
TabPFN: 预训练表格基础模型
PFN: Transformers Can Do Bayesian Inference
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
TabForest: Fine-tuned In-Context Learning Transformers are Excellent Tabular Data Classifiers
TABPFNv2: Accurate predictions on small data with a tabular foundation model
TabPFN-TS: The Tabular Foundation Model TabPFN Outperforms Specialized Time Series Forecasting Models Based on Simple Features
2025-02-28 14:52:00
在分组比较中都占优势的一方,在总评中有时反而是失势的一方
一个辛普森悖论的典型示例:
| 性别 | 法学院录取人数 | 法学院申请人数 | 法学院录取比例 | 商学院录取人数 | 商学院申请人数 | 商学院录取比例 | 合计录取比例 |
|---|---|---|---|---|---|---|---|
| 男生 | 8 | 53 | 15.1% | 201 | 251 | 80.1% | 68.8% |
| 女生 | 51 | 152 | 33.6% | 92 | 101 | 91.1% | 56.5% |
| 合计 | 59 | 205 | 293 | 352 |
辛普森悖论的总结
2025-02-28 10:56:00
ASA 分级标准,指的是美国麻醉医师协会(ASA)于麻醉前根据病人体质状况和对手术危险性进行分类,将病人分成的六级。
E:需要急诊手术的病例(在相应的 ASA 级数之后加“E”字)
具体内容/分级/评价:
Mallampati III 级及 IV 级患者插管发生并发症率高于 I 级及 II 级
具体内容/分级/评价:
纽约心脏病学会(NYHA)心功能四级分类:
Goldman 多因素心脏危险指数(CRI):
| 项目 | 描述 | 分数 |
|---|---|---|
| 年龄 | 年龄>70岁 | 5分 |
| 心肌梗死 | 6个月内发生心肌梗死 | 10分 |
| 心电图异常 | 非窦性心律或有室性期前收缩 | 7分 |
| 心电图异常 | 任何心电图异常 | 5分 |
| 一般状况 | PaO₂<60 mmHg或PaCO₂>50 mmHg等 | 3分 |
| 手术类型 | 高危手术 | 4分 |
| 手术类型 | 胸部、腹部或主动脉手术 | 3分 |
总计 53 分。 1 级:0-5 分,死亡率 0.2%; 2 级:6-12 分,死亡率 2%; 3 级:13-25 分,死亡率 2%; 4 级:>26 分,死亡率 56%。
Lee 改良的心脏危险指数(RCRI)考虑的危险因素如下:
合并 0、1、2 或≥3 项危险因素者严重心脏并发症发生率分别为 0.5%、1.3%、4%。
用途:术前心肺功能评估
具体内容/分级/评价:
用途:慢阻肺生存风险和预后评估。
| 项目 | 描述 | 分数 |
|---|---|---|
| 体重指数(BMI) | >21 kg/m² | 0分 |
| 体重指数(BMI) | ≤21 kg/m² | 1分 |
| 气流阻塞程度(FEV1%预计值) | ≥65% | 0分 |
| 气流阻塞程度(FEV1%预计值) | 50%-64% | 1分 |
| 气流阻塞程度(FEV1%预计值) | 36%-49% | 2分 |
| 气流阻塞程度(FEV1%预计值) | ≤35% | 3分 |
| 呼吸困难程度(mMRC) | 0-1分 | 0分 |
| 呼吸困难程度(mMRC) | 2分 | 1分 |
| 呼吸困难程度(mMRC) | 3分 | 2分 |
| 呼吸困难程度(mMRC) | 4分 | 3分 |
| 运动能力(6 min步行距离) | >350米 | 0分 |
| 运动能力(6 min步行距离) | 250-349米 | 1分 |
| 运动能力(6 min步行距离) | 150-249米 | 2分 |
| 运动能力(6 min步行距离) | <149米 | 3分 |
总分为 0-10 分,分为四级 1 级:0-2 分 2 级:3-4 分 3 级:5-6 分 4 级:7-10 分
级别越高,患者预后越差
| 项目 | 描述 | 分数 |
|---|---|---|
| 肝性脑病 | 无 | 1分 |
| 肝性脑病 | 轻(利用药物可控) | 2分 |
| 肝性脑病 | 中度或(利用药物难控) | 3分 |
| 腹水 | 无 | 1分 |
| 腹水 | 轻(利用利尿剂可控) | 2分 |
| 腹水 | 中度或(利用利尿剂难控) | 3分 |
| 胆红素(mg/dl) | <2 | 1分 |
| 胆红素(mg/dl) | 2-3 | 2分 |
| 胆红素(mg/dl) | >3 | 3分 |
| 白蛋白(g/dl) | >3.5 | 1分 |
| 白蛋白(g/dl) | 2.8-3.5 | 2分 |
| 白蛋白(g/dl) | <2.8 | 3分 |
| 凝血酶原时间/INR | <4 s(INR <1.7) | 1分 |
| 凝血酶原时间/INR | 4-6 s(INR 1.7-2.3) | 2分 |
| 凝血酶原时间/INR | >6 s(INR >2.3) | 3分 |
根据上述五项指标的得分相加,总分将患者分为三级:
| 分数 | 描述 |
|---|---|
| 1分 | 烦躁不安; |
| 2分 | 清醒,安静合作; |
| 3分 | 嗜睡,对指令反应敏捷; |
| 4分 | 浅睡眠状态,可迅速唤醒; |
| 5分 | 入睡,对呼叫反应缓慢; |
| 6分 | 深睡,对呼叫无反应。 |
评估麻醉镇静深度
| 分数 | 描述 |
|---|---|
| 5分 | 完全清醒,对正常音调呼名反应正常; |
| 4分 | 对正常音调呼名反应缓慢; |
| 3分 | 对大声呼名字有反应; |
| 2分 | 对轻度刺激或摇晃有反应; |
| 1分 | 对按压斜方肌有反应; |
| 0分 | 对疼痛性刺激无反应。 |
| 分数 | 描述 |
|---|---|
| +4 | 有攻击性,对工作人员构成直接危险(如拳打脚踢、拔管),极度躁动,需立即干预。 |
| +3 | 非常躁动,试图拔除导管或攻击工作人员;高度躁动,需药物干预。 |
| +2 | 烦躁不安的动作,对抗呼吸机;中度躁动,需关注。 |
| +1 | 焦虑不安,但动作无攻击性或仅有轻微呆滞;轻度躁动,可观察或干预。 |
| 0 | 清醒且平静;理想镇静状态。 |
| -1 | 对声音刺激有短暂觉醒(如呼唤姓名睁眼>10s),轻度镇静。 |
| -2 | 对声音刺激有短暂觉醒(如呼唤姓名睁眼<10s),中度镇静。 |
| -3 | 对声音刺激无反应,但对物理刺激有反应(如轻拍肩膀);深度镇静。 |
| -4 | 对物理刺激无反应,但对疼痛刺激有反应(如按压眉骨或胸骨),过度镇静。 |
| -5 | 无反应,对任何刺激均无反应;昏迷状态。 |
| 项目 | 描述 | 分数 |
|---|---|---|
| 清醒程度 | 完全清醒 | 2分 |
| 清醒程度 | 对刺激有反应 | 1分 |
| 清醒程度 | 对刺激无反应 | 0分 |
| 呼吸道通畅度 | 可轻度咳嗽 | 2分 |
| 呼吸道通畅度 | 可自主维持呼吸道通畅 | 1分 |
| 呼吸道通畅度 | 需呼吸道支持 | 0分 |
| 肢体活动度 | 肢体能作有意识的活动 | 2分 |
| 肢体活动度 | 肢体无意识活动 | 1分 |
| 肢体活动度 | 肢体无活动 | 0分 |
评估术后患者苏醒程度及安全性
| 项目 | 描述 | 分数 |
|---|---|---|
| 活动 | 自主或唤醒活动四肢和头颈:2分 | 2分 |
| 活动 | 自主或唤醒活动局部和/或躯体的某一部分:1分 | 1分 |
| 活动 | 不能活动肢体或颈头:0分 | 0分 |
| 呼吸 | 能深呼吸和有效咳嗽,呼吸频率和幅度正常:2分 | 2分 |
| 呼吸 | 呼吸困难或受限,但有清醒的自主呼吸,可能需氧流量:1分 | 1分 |
| 呼吸 | 呼吸暂停或需药物诱导,需呼吸器治疗或辅助呼吸:0分 | 0分 |
| 血压 | 麻醉前±20%以内:2分 | 2分 |
| 血压 | 麻醉前±20%-49%:1分 | 1分 |
| 血压 | 麻醉前±50%以上:0分 | 0分 |
| 意识 | 完全清醒(准确回答):2分 | 2分 |
| 意识 | 可唤醒,瞌睡:1分 | 1分 |
| 意识 | 无反应:0分 | 0分 |
| 血氧饱和度(SpO₂) | 呼吸空气时SpO₂>92%:2分 | 2分 |
| 血氧饱和度(SpO₂) | 呼吸氧气时SpO₂>92%:1分 | 1分 |
| 血氧饱和度(SpO₂) | 呼吸氧气时SpO₂<92%:0分 | 0分 |
| 项目 | 描述 |
|---|---|
| A部分 | 您在过去24小时里感觉如何?(10个项目,分别计分) |
| 1. 呼吸顺畅 | - |
| 2. 饮食愉快 | - |
| 3. 排尿无痛 | - |
| 4. 睡眠质量佳 | - |
| 5. 独立完成个人卫生和上厕所 | - |
| 6. 能与家人或朋友沟通交流 | - |
| 7. 得到医生和护士的支持 | - |
| 8. 感觉舒适,能够控制情绪 | - |
| 9. 感觉舒适,能够控制情绪 | - |
| 10. 总体上感觉好转 | - |
| B部分 | 你在过去24小时里有以下情况吗?(5个项目,分别计分) |
| 1. 中度疼痛 | - |
| 2. 剧烈疼痛 | - |
| 3. 恶心呕吐 | - |
| 4. 感觉心慌焦虑 | - |
| 5. 感觉悲伤或压抑 | - |
| 项目 | 描述 | 分数 |
|---|---|---|
| 1. 意识变化水平 | 无反应或对刺激刺激有反应:0分 | |
| 1. 意识变化水平 | 对轻度中度刺激有反应:1分 | |
| 1. 意识变化水平 | 正常清醒:0分 | |
| 1. 意识变化水平 | 对正常刺激反应强烈:1分 | |
| 2. 注意力是否集中 | 无法集中注意力或容易分心:1分 | |
| 2. 注意力是否集中 | 注意力正常:0分 | |
| 3. 定向力障碍 | 时间、地点、人物定向障碍:1分 | |
| 3. 定向力障碍 | 定向力正常:0分 | |
| 4. 幻觉-幻听性精神状态 | 有幻觉、错觉或妄想:1分 | |
| 4. 幻觉-幻听性精神状态 | 无幻觉:0分 | |
| 5. 精神运动型激越或迟滞 | 精神运动型激越(如躁动)或阻滞(如动作迟缓):1分 | |
| 5. 精神运动型激越或迟滞 | 正常:0分 | |
| 6. 不恰当的言语和情绪 | 言语和情绪与情境不符:1分 | |
| 6. 不恰当的言语和情绪 | 言语和情绪正常:0分 | |
| 7. 睡眠-觉醒周期紊乱 | 睡眠紊乱(如白天嗜睡,夜间失眠):1分 | |
| 7. 睡眠-觉醒周期紊乱 | 睡眠正常:0分 | |
| 8. 症状波动 | 上述症状在24小时波动:1分 | |
| 8. 症状波动 | 症状稳定:0分 |
2025-02-28 10:31:00
辛普森悖论 提醒我们在分析数据时要仔细考虑分组和混杂因素的影响,而因果推断的作用就是使用适当的方法识别和控制这些因素,从而可以更好地解释数据中的关系,并做出可靠的结论。
相关性与因果性:
因果关系的三个阶段(由易到难):
因果推断的三类任务:
因果推断的两个主流框架
潜在结果框架(Potential Outcome Framework):
下文将以医学实验为例,对潜在结果框架进行说明
符号定义:
潜在结果框架的前提假设:
第 $i$ 个患者的因果效应 individual treatment effect (ITE) $$\tau_{i}\triangleq Y_{i}(1)-Y_{i}(0)$$
干预方案的平均因果效应 average treatment effect (ATE) $$\tau\triangleq\mathbb{E}[Y_{i}(1)-Y_{i}(0)]=\mathbb{E}[Y_{i}(1)]-\mathbb{E}[Y_{i}(0)]$$
ATE 有时也叫做 ACE(average causal effect)
需要注意, $E[Y_{}i(1)]−E[Yi(0)]$ 是一个因果量,而 $E[Y|T=1]−E[Y|T=0]$ 是一个关联量,他们二者是不等价的
ATE 的计算依赖于以上假设,将因果表达式转化成统计表达式: $$\begin{array}{r l}{A T E=\mathbb{E}_{X}[\mathbb{E}[Y\mid T=1,X]-\mathbb{E}[Y\mid T=0,X]]} \\ {={\displaystyle{\frac{1}{n}}}\sum_{i}\left[\mathbb{E}\left[Y\mid T=1,X=x_{i}\right]-\mathbb{E}\left[Y\mid T=0,X=x_{i}\right]\right]}\end{array}$$ 而 $\mathbb{E}\left[Y\mid T=t,X=x_{i}\right]$ 则一般依赖传统机器学习模型来实现预测
结构因果模型(Structural Causal Model,SCM):
概率图 VS 因果图
因果图的假设:
有向无环图(Directed Acyclic Graph,简称 DAG)的因果性

变量间的相关性只会在非阻塞的因果路径中传递
结构方程可用于表示因果关系或因果图(有向无环图 DAG),以吸烟 X 和肺癌 Y 的关系为例,同时考虑年龄 Z 作为混淆变量,则对应因果图为:
该因果图对应的结构方程可以表示为: $$\begin{array}{r}{X=f_{X}(Z,U_{X})} \\ {Y=f_{Y}(X,Z,U_{Y})}\end{array}$$
概念补充 1:d-分割(d-separation)
概念补充 2:do-算子(do-operator)
概念补充 3:后门路径(Backdoor Path)
概念补充 4:后门准则(Backdoor Criterion)
常见的因果关系发现类算法:
利用因果图中节点之间的条件独立性来推断因果关系
通过定义评分函数来寻找因果图,即评分函数最大的有向无环图(DAG)
通过引入更多的假设信息来推断因果关系
现实挑战:
未来趋势:
进阶阅读:
其他参考:
因果推断两大算法框架解析
Causality05-StructuralCausalModel
因果推断综述及基础方法介绍(二)
因果推断(一):因果推断两大框架及因果效应
2025-02-27 10:13:00
贝叶斯神经网络(Bayesian neural networks, BNNs):
注意区分贝叶斯神经网络和贝叶斯网络,贝叶斯网络是一种概率图模型,又称信念网络(belief network)或是有向无环图模型
普通神经网络 VS 贝叶斯神经网络(图源):
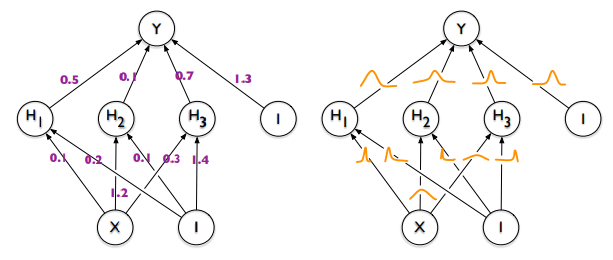
前置知识:
给定一个训练集 $D= {({x}_1, y_1), ({x}_2, y_2),..., ({x}_m, y_m)}$,用于训练一个贝叶斯神经网络,则贝叶斯公式可以写为如下形式: $$ p(w|{x}, y) = \frac{p(y|{x}, w)p(w)}{\int p(y|{x}, w)p(w) dw} $$
BNN 模型的常见训练方法
BBVI 训练时,会使用 ELBO(Evidence Lower Bound)作为目标函数指导超参数 $\lambda$ 的优化,最大化 ELBO 相当于最小化 KL 散度:$KL=logp-ELBO$
优点:
缺点:
参考:
贝叶斯深度学习(bayesian deep learning)
贝叶斯神经网络 BNN (推导+代码实现)
Bayesian Neural Networks:贝叶斯神经网络