2025-07-02 03:00:00
At the moment, we have no idea what the impact of genAI on software development is going to be. The impact of anything on coding is hard to measure systematically, so we rely on anecdata and the community’s eventual consensus. So, here’s my anecdata. Tl;dr: The AI was not useless.
My current work on Quamina involves dealing with collections of finite-automata states, which, in the Go programming language, are represented as slices of pointers to state instances:
[]*faState
The problem I was facing was deduping them, so that there would be only one instance corresponding to any particular
collection. This is what, in Java, the intern() call does with strings.
The algorithm isn’t rocket science:
Dedupe the states, i.e. turn the collection into a set.
For each set of states, generate a key.
Keep a hash table of sets around, and use the key to see whether you’ve already got such a set, and if so return it. Otherwise, make a new entry in the hash table and return that.
I’m out of touch with the undergrad CS curriculum, but this feels like a second-year assignment or thereabouts? Third?
So I prompted Claude thus:
I need Go code to provide a "intern"-like function for lists of pointers. For example, if I have several different []*int arrays, which may contain duplicates, I want to call intern() on each of them and get back a single canonical pointer which is de-duplicated and thus a set.
Claude did pretty well. It got the algorithm right, the code was idiomatic and usefully commented, and it also provided a
decent unit test (but in a main() stanza rather than a proper Go test file).
I didn’t try actually running it.
The interesting part was the key computation. I, being lazy, had just done a Go fmt.Sprintf("%p")
incantation to get a hex string representing each state’s address, sorted them, joined them, and that was the key.
Claude worked with the pointers more directly.
// Sort by pointer address for consistent ordering
sort.Slice(unique, func(i, j int) bool {
return uintptr(unsafe.Pointer(unique[i])) < uintptr(unsafe.Pointer(unique[j]))
})Then it concatenated the raw bytes of the map addresses and lied to Go by claiming it was a string.
// Create key from pointer addresses
key := make([]byte, 0, len(slice)*8)
for _, ptr := range slice {
addr := uintptr(unsafe.Pointer(ptr))
// Convert address to bytes
for i := 0; i < 8; i++ {
key = append(key, byte(addr>>(i*8)))
}
}
return string(key)This is an improvement in that the keys will be half the size of my string version. I didn’t copy-paste Claude’s code wholesale, just replaced ten or so lines of key construction.
I dunno. I thought the quality of the code was fine, wouldn’t have decomposed the functions in the same way but wouldn’t have objected on review. I was pleased with the algorithm, but then I would be since it was the same one I’d written, and, having said that, quite possibly that’s the only algorithm that anyone has used. It will be super interesting if someone responds to this write-up saying “You and Claude are fools, here’s a much better way.”
Was it worth fifteen minutes of my time to ask Claude and get a slightly better key computation? Only if this ever turns out to be a hot code path and I don’t think anybody’s smart enough to know that in advance.
Would I have saved time by asking Claude first? Tough to tell; Quamina’s data structures are a bit non-obvious and I would have had to go to a lot of prompting work to get it to emit code I could use directly. Also, since Quamina is low-level performance-critical infrastructure code, I’d be nervous about having any volume of code that I didn’t really really understand.
I guess my take-away was that in this case, Claude knew the Go idioms and APIs better than I did; I’d never looked at the unsafe package.
Which reinforces my suspicion that genAI is going to be especially useful at helping generate code to talk to big complicated APIs that are hard to remember all of. Here’s an example: Any moderately competent Android developer could add a feature to an app where it strobes the flash and surges the vibration in sync with how fast you’re shaking the device back and forth, probably in an afternoon. But it would require a couple of dozen calls into the dense forest of Android APIs, and I suspect a genAI might get you there a lot faster by just filling the calls in as prompted.
Reminder: This is just anecdata.
2025-06-23 03:00:00
Back in March I offered Latest Music (feat. Qobuz), describing all the ways I listen to music (Tl;dr: YouTube Music, Plex, Qobuz, record player). I stand by my opinions there but wanted to write more on two subjects: First Qobuz, because it suddenly got a lot better. And a recommendation, for people with fancy A/V setups, that you include a cheap Mac Mini.
That other piece had a list of the reasons to use Qobuz, but times have changed, so let’s revise it:
It pays artists more per stream than any other service, by a wide margin.
It seems to have as much music as anyone else.
It’s album-oriented, and I appreciate artists curating their own music.
Classical music is a first-class citizen.
It’s actively curated; they highlight new music regularly, and pick a “record of the week”. To get a feel, check out Qobuz Magazine; you don’t have to be a subscriber.
It gives evidence of being built by people who love music.
They’re obsessive about sound quality, which is great, but only makes a difference if you’re listening through quality speakers.
A few weeks ago, the mobile app quality switched from adequate to excellent.
I want to side-trip a bit here, starting with a question. How long has it been since an app you use has added a feature that was genuinely excellent and let you do stuff you couldn’t before and didn’t get in your way and created no suspicion that it was strip-mining your life for profit? I’m here to tell you that this can still happen, and it’s a crushing criticism of my profession that it so rarely does.
I’m talking about Qobuz Connect. I believe there are other music apps that can do this sort of stuff, but it feels like magic to me.
It’s like this. I listen to music at home on an audiophile system with big speakers, in our car, and on our boat. The only app I touch is the Qobuz Android app. The only time it’s actually receiving and playing the music itself is in the car, with the help of Android Auto. In the other scenarios it’s talking to Qobuz running on a Mac, which actually fetches the music and routes it to the audio system. Usually it figures out what player I want it to control automatically, although there’ve been a couple times when I drove away in the car and it got confused about where to send the music. Generally, it works great.
The app’s music experience is rich and involving.
It has New Releases and curated playlists and a personalized stream for me and a competent search function for those times I absolutely must listen to Deep Purple or Hania Rani or whoever.
I get a chatty not-too-long email from Qobuz every Friday, plugging a few of the week’s new releases, with sideways and backward looks too. (This week: A Brian Wilson stream.) The app has so much stuff, especially among the themed streams, that I sometimes get lost. But somehow it’s not irritating; what’s on the screen remains musically interesting and you can always hit the app’s Home button.
Qobuz has its own musical tastes that guide its curation. They’re not always compatible with mine — my tolerance for EDM and mainstream Hip-hop remains low. And I wish they were stronger on Americana. But the intersection is broad enough to provide plenty of enjoyable new-artist experiences. Let me share one with you: Kwashibu Area Band, from Ghana.
Oh, one complaint: Qobuz was eating my Pixel’s battery. So I poked around online and it’s a known problem; you have to use the Android preferences to stop it from running in the background. Huh? What was it doing in the background anyhow?! But it seems to work fine even when it’s not doing it.
The music you’re listening to is going to be stored on disk, or incoming from a streaming service. Maybe you want to serve some of the stored music out to listen to it in the car or wherever. There are a variety of audio products in the “Streamer” category that do some of these things in various combinations. A lot of them make fanciful claims about the technology inside and are thus expensive, you can easily spend thousands.
But any reasonably modern computer can do all these things and more, plus it also can drive a big-screen display, plus it will probably run the software behind whatever next year’s New Audio Hotness is.
At this point the harder-core geeks will adopt a superior tone of voice to say “I do all that stuff with FreeBSD and a bunch of open-source packages running on a potato!”
More power to ’em. But I recommend a basic Apple Silicon based Mac Mini, M1 is fine, which you can get for like $300 used on eBay. And if you own a lot of music and video you can plug in a 5T USB drive for a few more peanuts. This will run Plex and Qobuz and almost any other imaginable streaming software. Plus you can plug it into your home-theater screen and it has a modern Web browser so you can also play anything from anywhere on the Web.
I’ve been doing this for a while but I had one big gripe. When I wanted to stream music from the Mac, I needed to use a keyboard and mouse, so I keep one of each, Bluetooth-flavored, nearby. But since I got Qobuz running that’s become a very rare occurrence.
Oh, and yeah, there’s the record player. Playing it requires essentially no software at all, isn’t that great?
2025-06-22 03:00:00
“Wow, Tim, didn’t you do a Long Links just last month? Been spending too much time doomscrolling, have we?” Maybe. There sure are a lot of tabs jostling each other along the top of that browser. Many are hosting works that are both long and good. So here they are; you probably don’t have time for all of ’em but my hope is that one or two might reward your visit.
Let’s start with a really important subject: Population growth oh actually these days it’s population shrinkage. For a short-sharp-shock-flavored introduction I recommend South Korea Is Over which explains the brick wall societies with fertility rates way below the replacement rate of 2.1 children per woman per lifetime are hurtling toward. South Korea, of course, being the canonical example. But also Japan and Taiwan and Italy and Spain and so on.
And, of course, the USA, where the numbers aren’t that much higher: U.S. Fertility Rate (1950-2025). Even so, the population still grows (because of immigration), albeit at less than 1% per annum: U.S. Population Growth Rate. If the MAGAs get their way and eventually stop all non-white immigration, the US will be in South Korea territory within a generation or two.
A reasonable person might ask why. It’s not really complicated, as you can read here: A Bold Idea to Raise the Birthrate: Make Parenting Less Torturous. From which I quote: “To date, no government policies have significantly improved their nation’s birthrates for a sustained period.” The essay argues convincingly that it’s down to two problems: Capitalism and sexism. Neither of which offers an easy fix.
Speaking of the travails of late capitalism, here’s how bad it’s getting: America Is Pushing Its Workers Into Homelessness.
For a refreshingly different take on the business world, here’s Avery Pennarun, CEO of Tailscale: The evasive evitability of enshittification. Not sure I buy what he’s saying, but still worth reading.
Most people who visit these pages are geeks or geek-adjacent. If you’re one of those, and especially if you enjoy the small but vibrant genre of Comical Tech War Stories, I recommend Lock-Free Rust: How to Build a Rollercoaster While It’s on Fire
And here’s write-up on an AWS product which has one of the best explanations I’ve ever read of the different flavors modern databases come in: Introduction to the Fundamentals of Amazon Redshift
Of course, the geek conversation these days is much taken up with the the impact of genAI as in “vibe coding”. To summarize the conversation: A few people, not obviously fools, are saying “This stuff seems to help me” and many others, also apparently sensible, are shouting back “You’re lying to yourself, it can’t be helping!” Here is some of the testimony: Kellan on Vibe coding for teams, thoughts to date, Armin Ronacher on Agentic Coding Recommendations, Harper on Basic Claude Code, and Klabnik on A tale of two Claudes
I lean to believing narratives of personal experience, but on the other hand the skeptics make good points. Another random piece of evidence: Because I’m lazy, I tend to resist adopting technologies that have steep learning curves, which genAI currently does. On many occasions, this has worked out well because those technologies have turned out not to pay off very well. Am I a canary in the coal mine?
Since I introduced myself into the narrative, I’ll note that today is my 70th birthday. I am told that this means that my wisdom has now been maximized, so you’re safe in believing whatever you read in this space. I don’t have anything special to say to commemorate the occasion, so here’s a picture of my neighborhood’s network infrastructure, which outlines the form of a cathedral’s nave. I’m sure there’s a powerful metaphor lurking in there.

Oh, and here’s a photography Long Link: What is HDR, anyway? It’s actually a pitch for a nice-looking mobile camera app, but it offers real value on things that can affect the quality of your pictures.
Regular readers will know that I’m fascinated by the many unsolved issues and open questions in cosmology, which are by definition the largest problems facing human consciousness. The ΛCDM-vs-MOND controversy, i.e. “Is there really dark matter or does gravity get weird starting at the outer edges of galaxies?”, offers great entertainment value. And, there is news!
First of all, here’s a nice overview on the controversy: Modified Newtonian Dynamics: Observational Successes and Failures.
Which points out that the behavior of “wide binary” star systems ought to help resolve the issue, but that people who study it keep coming up with contradictory findings. Here’s the latest, from Korean researchers: Press release New method of measuring gravity with 3D velocities of wide binary stars is developed and confirms modified gravity and peer-reviewed paper: Low-acceleration Gravitational Anomaly from Bayesian 3D Modeling of Wide Binary Orbits: Methodology and Results with Gaia Data Release 3. Spoiler: They think the gravity gets weird. I have a math degree but cosmology math is generally way over my head. Having said that, I think those South Koreans may be a bit out over their skis; I generally distrust heroic statistical methods. We’ll see.
Let’s do politics. It turns out that the barbaric junta which oppresses the people of China does not limit its barbarism to its own geography: Followed, threatened and smeared — attacks by China against its critics in Canada are on the rise.
More politics: The MAGAs are always railing against “elites”. Here are two discussions of what they mean: What the Comfort Class Doesn’t Get and When They Say Elites, They Mean Us.
The world’s biggest political issue should be the onrushing climate crisis. When Trump and his toadies are justly condemned and ridiculed by future historians, it is their malevolent cluelessness on this subject that may burn the hottest. Who knows, maybe they’ll pay attention to this: Insurers Want Businesses to Wake Up to Costs of Extreme Heat.
So I’ll try to end cheerfully.
A graceful essay about an old camera and a dreamy picture: A Bridge Across Time: For Sebastião Salgado
Latin Wikipedia has 140,000 articles; consider the delightful discussion of Equus asinus.

Asinus in opere tesselato Byzantino
Here’s a lovely little song from TORRES and Julien Baker: The Only Marble I’ve Got Left.
Finally, a clear-eyed if lengthy essay on why and how to think: Should You Question Everything?
2025-06-18 03:00:00
Things are happening in the C2PA world; here are a couple of useful steps forward, plus cheers and boos for Adobe. Plus a live working C2PA demo you can try out.
Refresher: The C2PA technology is driven by the Content Authenticity Initiative and usually marketed as “Content Credentials”. I’ve written before about it, an introduction in 2023 and a progress report last October.
Let’s start with a picture.

I was standing with the camera by the ocean at dusk and accidentally left it in the “B” long-exposure setting, so this isn’t really a picture of anything but I thought it was kinda pretty.
As I write this, there are now at least two C2PA-validator Chrome extensions: the ContentLens C2PA Validator from ContentLens and C2PA Content Credentials from Digimarc.
If you install either of them, and then you click on that picture just above in Chrome to get the larger version, then you right-click on the larger picture, the menu will offer Content-Credentials validation.
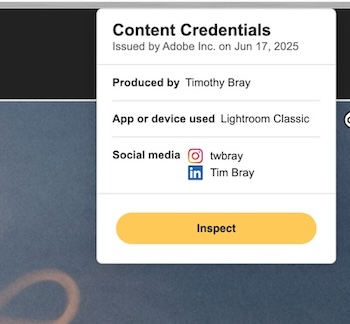
Doing this will produce a little “CR” logo at the top right corner, meaning that the C2PA data has been verified as being present and signed by a trusted certificate issuer, in this case Adobe.
Then there’s a popup; the two extensions’ are on the right. They’re different, in interesting ways. Let’s walk through the second one.
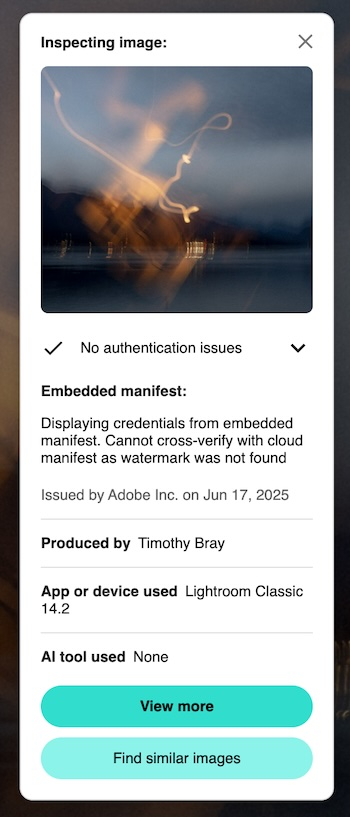
The little thumbnail at the top of the popup is what the image looked like when the C2PA was added. Not provided by the other verifier.
The paragraph beginning “Displaying credentials…” says that the C2PA manifest was embedded in the JPG as opposed to stored out on the cloud; The cloud works fine, and is perhaps a good idea because the C2PA manifest can be quite large. I’m not clear on what the “watermark” is about.
“Issued by Adobe” means that the Chrome extension verified the embedded C2PA against Adobe’s public key and can be confident that yes, this was really signed by them.
“Produced by Timothy Bray” is interesting. How can it know? Well, it turns out that it used LinkedIn’s API to verify that I am timbraysoftwareguy over on LinkedIn. But it goes further; LinkedIn has an integration with Clear, the airport-oriented identity provider. To get a Clear account you have to upload government-issued ID, it’s not trivial.
So this short sentence expands to (take a deep breath) “The validator extension verified that Adobe said that LinkedIn said that Clear said that the government ID of the person who posted this says that he’s named Timothy Bray.”
Note that the first extension’s popup also tells you that Adobe has verified what my LinkedIn and Instagram accounts are. This seems super-useful and I wonder why the other omits it.
“App or device used…” is simple enough, but I’m not actually sure how it works; I guess Adobe has embedded a keypair in my Lightroom installation? If I’d taken the picture with a C2PA-equipped camera this is where that history would be displayed.
“AI tool used None”. Interesting and useful, since Adobe provides plenty of genAI-powered tools. Of course, this relies on Lightroom telling the truth, but still.
The “View More” button doesn’t currently work; it takes you to the interactive contentcredentials.org/verify page, which seems to fail in retrieving the JPG. If you download the picture then upload it into the verify page (go ahead, it’s free) that seems to work fine. In addition to the info on the popup, the verify page will tell you (nontechically i.e. vaguely) what I did to the picture with Lightroom.
Well, it’s here and it works! There’s all this hype about how cool it will be when the C2PA includes info about what model of camera and lens it used and what the shutter speed was and so on, but eh, who cares really? What matters to me (and should matter to the world) is provenance: Who posted this thing?
As I write this, supporters of Israel and Iran are having an AI Slop Fight with fake war photos and videos. In a C2PA-rich world, you could check; If some clip doesn’t have Content Credentials you should probably be suspicious, and if it does, it matters whether it was uploaded by someone at IDF.il versus BBC.co.uk.
Look, I hate to nitpick. I’m overwhelmingly positive on this news, it’s an existence proof that C2PA can be made to work in the wild. My impression is that most of the money and muscle comes from Adobe; good on ’em. But there are things that would make it more useful, and usable by more Web sites. These are not listed in any particular order.
Adobe, it’s nice that you let me establish my identity with LinkedIn, Instagram, and Clear. But what I’d really like is if you could also verify and sign my Fediverse and Bluesky handles. And, Fediverse and ATProto developers, would you please, first of all, stop stripping C2PA manifests from uploaded photo EXIF, and secondly, add your own link to the C2PA chain saying something like “Originally posted by @[email protected].”
Because having verifiable media provenance in the world of social media would be a strong tool against disinformation and slop.
Oh, and another note to Adobe: When I export a photo, the embed-manifest also offers me the opportunity, under the heading “Web3”, to allow the image “be used for NFT creative attribution on supported marketplaces” where the supported marketplaces are Phantom and MetaMask. Seriously, folks, in 2025? Please get this scammy cryptoslime out of my face.
This was done with Chrome extensions. There are people working on extensions for Firefox and Safari, but they’re not here yet. Annoyingly, the extensions also don’t seem to work in mobile Chrome, which is where most people look at most media.
I would love it if this were done directly and automatically by the browser. The major browsers aren’t perfect, but their creators are known to take security seriously, and I’d be much happier trusting one of them, rather than an extension from a company I’d never previously heard of.
The next-best solution would be a nice JS package that just Does The Right Thing. It should work like the way I do fonts: If you look in the source for the page you are now reading, the splodge of JS at the top includes a couple of lines that mention “typekit.com”. Typekit (since acquired by Adobe) offers access to a huge selection of excellent fonts. Those JS invocations result in the text you are now reading being displayed in FF Tisa Web Pro.
Which — this is important — is not free. And to be clear, I am willing to pay to get Content Credentials for the pictures on this blog. It feels exactly like paying a small fee for access to a professionally-managed font library. Operating a Content-Credentials service wouldn’t be free, it’d require running a server and wrangling certs. At scale, though, it should be pretty cheap.
So here’s an offer: If someone launches a service that allows me to straightforwardly include the fact that this picture was sourced from tbray.org in my Content Credentials, my wallet is (modestly) open.
By the way, the core JavaScript code is already under construction; here’s Microsoft and the Content Authority Initiative itself. There’s also a Rust crate for server-side use, and a “c2patool” command-line utility based on it..
You’ll notice that the right-click-for-Content-Credentials doesn’t work on the smaller version of the picture embedded in the text you are now reading; just the larger one. This is because the decades-old Perl-based ongoing publishing software runs the main-page pictures through ImageMagick, which doesn’t do C2PA. I should find a way to route around this.
In fact, it wouldn’t be rocket science for ImageMagick (or open-source packages generally) to write C2PA manifests and insert them in the media files they create. But how should they sign them? As noted, that requires a server that provides cert-based signatures, something that nobody would expect from even well-maintained open-source packages.
I dunno, maybe someone should provide a managed-ImageMagick service that (for a small fee) offers signed-C2PA-manifest embedding?
The work that needs to be done is nontrivial but, frankly, not that taxing. And the rewards would be high. Because it feels like a no-brainer that knowing who posted something is a big deal. Also the inverse: Knowing that you don’t know who posted it.
Where is it an especially big deal? On social media, obviously. It’s really time for those guys to start climbing on board.
2025-06-07 03:00:00
My input stream is full of it: Fear and loathing and cheerleading and prognosticating on what generative AI means and whether it’s Good or Bad and what we should be doing. All the channels: Blogs and peer-reviewed papers and social-media posts and business-news stories. So there’s lots of AI angst out there, but this is mine. I think the following is a bit unique because it focuses on cost, working backward from there. As for the genAI tech itself, I guess I’m a moderate; there is a there there, it’s not all slop. But first…
I promise I’ll talk about genAI applications but let’s start with money. Lots of money, big numbers! For example, venture-cap startup money pouring into AI, which as of now apparently adds up to $306 billion. And that’s just startups; Among the giants, Google alone apparently plans $75B in capital expenditure on AI infrastructure, and they represent maybe a quarter at most of cloud capex. You think those are big numbers? McKinsey offers The cost of compute: A $7 trillion race to scale data centers.
Obviously, lots of people are wondering when and where the revenue will be to pay for it all. There’s one thing we know for sure: The pro-genAI voices are fueled by hundreds of billions of dollars worth of fear and desire; fear that it’ll never pay off and desire for a piece of the money. Can you begin to imagine the pressure for revenue that investors and executives and middle managers are under?
Here’s an example of the kind of debate that ensues.
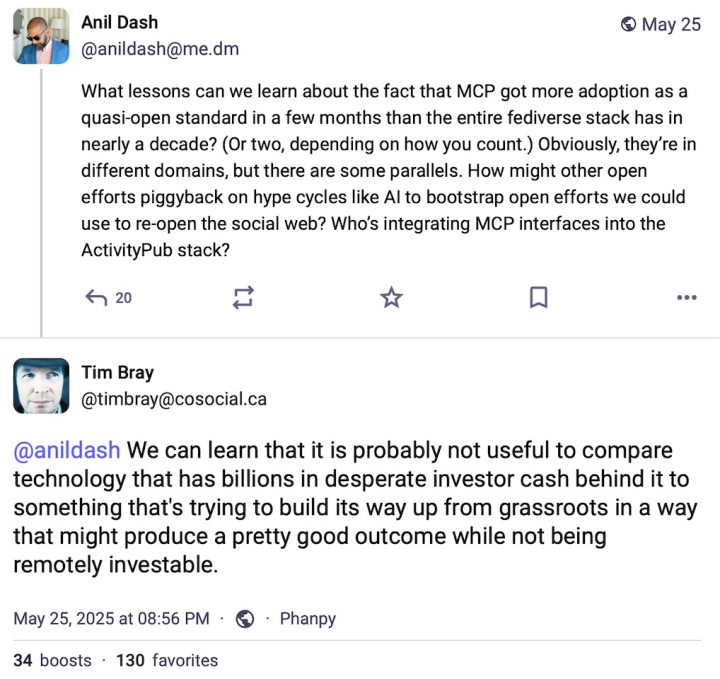
“MCP” is
Model Context Protocol, used for communicating between LLM
software and other systems and services.
I have no opinion as to its quality or utility.
I suggest that when you’re getting a pitch for genAI technology, you should have that greed and fear in the back of your mind. Or maybe at the front.
For some reason, I don’t hear much any more about the environmental cost of genAI, the gigatons of carbon pouring out of the system, imperilling my children’s future. Let’s please not ignore that; let’s read things like Data Center Energy Needs Could Upend Power Grids and Threaten the Climate and let’s make sure every freaking conversation about genAI acknowledges this grievous cost.
Now let’s look at a few sectors where genAI is said to be a big deal: Coding, teaching, and professional communication. To keep things balanced, I’ll start in a space where I have kind things to say.
Wow, is my tribe ever melting down. The pro- and anti-genAI factions are hurling polemical thunderbolts at each other, and I mean extra hot and pointy ones. For example, here are 5600 words entitled I Think I’m Done Thinking About genAI For Now. Well-written words, too.
But, while I have a lot of sympathy for the contras and am sickened by some of the promoters, at the moment I’m mostly in tune with Thomas Ptacek’s My AI Skeptic Friends Are All Nuts. It’s long and (fortunately) well-written and I (mostly) find it hard to disagree with.
it’s as simple as this: I keep hearing talented programmers whose integrity I trust tell me “Yeah, LLMs are helping me get shit done.” The probability that they’re all lying or being fooled seems very low.
Just to be clear, I note an absence of concern for cost and carbon in these conversations. Which is unacceptable. But let’s move on.
It’s worth noting that I learned two useful things from Ptacek’s essay that I hadn’t really understood. First, the “agentic” architecture of programming tools: You ask the agent to create code and it asks the LLM, which will sometimes hallucinate; the agent will observe that it doesn’t compile or makes all the unit tests fail, discards it, and re-prompts. If it takes the agent module 25 prompts to generate code that while imperfect is at least correct, who cares?
Second lesson, and to be fair this is just anecdata: It feels like the Go programming language is especially well-suited to LLM-driven automation. It’s small, has a large standard library, and a culture that has strong shared idioms for doing almost anything. Anyhow, we’ll find out if this early impression stands up to longer and wider industry experience.
Turning our attention back to cost, let’s assume that eventually all or most developers become somewhat LLM-assisted. Are there enough of them, and will they pay enough, to cover all that investment? Especially given that models that are both open-source and excellent are certain to proliferate? Seems dubious.
Suppose that, as Ptacek suggests, LLMs/agents allow us to automate the tedious low-intellectual-effort parts of our job. Should we be concerned about how junior developers learn to get past that “easy stuff” and on the way to senior skills? That seems a very good question, so…
Quite likely you’ve already seen Jason Koebler’s Teachers Are Not OK, a frankly horrifying survey of genAI’s impact on secondary and tertiary education. It is a tale of unrelieved grief and pain and wreckage. Since genAI isn’t going to go away and students aren’t going to stop being lazy, it seems like we’re going to re-invent the way people teach and learn.
The stories of students furiously deploying genAI to avoid the effort of actually, you know, learning, are sad. Even sadder are those of genAI-crazed administrators leaning on faculty to become more efficient and “businesslike” by using it.
I really don’t think there’s a coherent pro-genAI case to be made in the education context.
If you want to use LLMs to automate communication with your family or friends or lovers, there’s nothing I can say that will help you. So let’s restrict this to conversation and reporting around work and private projects and voluntarism and so on.
I’m pretty sure this is where the people who think they’re going to make big money with AI think it’s going to come from. If you’re interested in that thinking, here’s a sample; a slide deck by a Keith Riegert for the book-publishing business which, granted, is a bit stagnant and a whole lot overconcentrated these days. I suspect scrolling through it will produce a strong emotional reaction for quite a few readers here. It’s also useful in that it talks specifically about costs.
That is for corporate-branded output. What about personal or internal professional communication; by which I mean emails and sales reports and committee drafts and project pitches and so on? I’m pretty negative about this. If your email or pitch doc or whatever needs to be summarized, or if it has the colorless affectless error-prone polish of 2025’s LLMs, I would probably discard it unread. I already found the switch to turn off Gmail’s attempts to summarize my emails.
What’s the genAI world’s equivalent of “Tl;dr”? I’m thinking “TA;dr” (A for AI) or “Tg;dr” (g for genAI) or just “LLM:dr”.
And this vision of everyone using genAI to amplify their output and everyone else using it to summarize and filter their input feels simply perverse.
Here’s what I think is an important finding, ably summarized by Jeff Atwood:

Seriously, since LLMs by design emit streams that are optimized for plausibility and for harmony with the model’s training base, in an AI-centric world there’s a powerful incentive to say things that are implausible, that are out of tune, that are, bluntly, weird. So there’s one upside.
And let’s go back to cost. Are the prices in Riegert’s slide deck going to pay for trillions in capex? Another example: My family has a Google workplace account, and the price just went up from $6/user/month to $7. The announcement from Google emphasized that this was related to the added value provided by Gemini. Is $1/user/month gonna make this tech make business sense?
I can sorta buy the premise that there are genAI productivity boosts to be had in the code space and maybe some other specialized domains. I can’t buy for a second that genAI is anything but toxic for anything education-related. On the business-communications side, it’s damn well gonna be tried because billions of dollars and many management careers depend on it paying off. We’ll see but I’m skeptical.
On the money side? I don’t see how the math and the capex work. And all the time, I think about the carbon that’s poisoning the planet my children have to live on.
I think that the best we can hope for is the eventual financial meltdown leaving a few useful islands of things that are actually useful at prices that make sense.
And in a decade or so, I can see business-section stories about all the big data center shells that were never filled in, standing there empty, looking for another use. It’s gonna be tough, what can you do with buildings that have no windows?
2025-06-01 03:00:00
This considers how two modern cameras handle a difficult color challenge, illustrated by photos of a perfect rose and a piano.
We moved into our former place in January 1997 and, that summer, discovered the property included this slender little rose that only had a couple blossoms every year, but they were perfection, beautifully shaped and in a unique shade of red I’d never seen anywhere else (and still haven’t). Having no idea of its species, we’ve always called it “our perfect rose”.
So when we moved last year, we took the rose with us. It seems to like the new joint, has a blossom out and two more on the way and it’s still May.
I was looking at it this morning and it occurred to me that its color might be an interesting challenge to the two fine cameras I use regularly, namely a Google Pixel 7 and a Fujifilm X-T5.
First the pictures.


First of all, let’s agree that this comparison is horribly flawed. To start with, by the time the pixels have made it from the camera to your screen, they’ve been through Lightroom, possibly a social-media-software uploader and renderer, and then your browser (or mobile app) and screen contribute their opinions. Thus the colors are likely to vary a lot depending where you are and what you’re using.
Also, it’s hard to get really comparable shots out of the Pixel and Fuji; their lenses and processors and underlying architectures are really different. I was going to disclose the reported shutter speeds, aperture, and ISO values, but they are so totally non-comparable that I decided that’d be actively harmful. I’ll just say that I tried to let each do its best.
I post-processed both, but limited that to cropping; nothing about the color or exposure was touched.
And having said all that, I think the exercise retains interest.
The Pixel is above, the Fuji below.
The Pixel is wrong. The Fuji is… not bad. The blossom’s actual color, to my eye, has a little more orange than I see in the photo; but only a little. The Pixel subtracts the orange and introduces a suggestion of violet that the blossom, to my eye, entirely lacks.
Also, the Pixel is artificially sharpening up the petals; in reality, the contrast was low and the shading nuanced; just as presented by the X-T5.
Is the Pixel’s rendering a consequence of whatever its sensor is? Or of the copious amount of processing that contributes to Google’s widely-admired (by me too) “computational photography”? I certainly have no idea. And in fact, most of the pictures I share come from my Android because the best camera (this is always true) is the one you have with you. For example…

That same evening we took in a concert put on by the local Chopin Society featuring 89-year-old Mikhail Voskresensky, who plays really fast and loud in an old super-romantic style, just the thing for the music: Very decent Beethoven and Mozart, kind of aimless Grieg, and the highlight, a lovely take on Chopin’s Op. 58 Sonata, then a Nocturne in the encores.
Anyhow, I think the Camera I Had With Me did fine. This is Vancouver’s oldest still-standing building, Christ Church Cathedral, an exquisite space for the eyes and ears.
Maybe I’ll do a bit more conscious color-correction on the Pixel shots in future (although I didn’t on the piano). Doesn’t mean it’s not a great camera.