2026-06-22 08:00:00
Technology businesses are heavily influenced by waves of technology change, like the rise of the internet or AI. Knowing how to adjust strategy for these changes is one of the most important skills to develop.
As technology has advanced, technology waves have become larger, more frequent, and more sudden. In just the last 30 years (less than a full career, literally less than the time between graduation and your first 401k payout) we’ve seen:
This has happened for thousands of years. I’m sure there was some Bronze Age metalsmith in 3000 BC who had to explain to his pissed-off wife that he lost his job because some asshole figured out you could make a better sword out of iron. Disruption from technology waves has been happening for thousands of years and will continue for the indefinite future.
I’ve been around long enough to watch multiple technology waves swell and break on the shore. There are a few super simple questions below that I ask as early as possible in a technology wave that I’ve found invaluable for orientation. The key is to ask them, in order, every time:
These questions are not hard to answer. They do not require a deep math background or Machiavellian cleverness. If this is a road trip, you’re not trying to find a shortcut through backroads, you’re just trying to figure out if the bridge you’re about to drive over has collapsed. But it is essential that you actually take the time to ask them, which is surprisingly hard because…
Whenever a new technology wave comes along (like the internet, mobile, or AI), a huge number of businesses simply ignore it because change is annoying. Maybe if we ignore these dumb phones they’ll go away. This GPT thing can’t count how many Rs are in the word “strawberry,” it’s useless.
(Worth noting that the tendency to ignore new technology waves seems to have gone down over time. There were many, many more internet skeptics than AI skeptics)
Ignoring new technology waves feels good because most technology waves do sputter out. The few big businesses built on crypto have (so far) been mainly related to speculating or buying drugs. VR games never got mainstream adoption. Only weirdos and tinkerers have 3D printers in their homes. Being lazy pays off pretty often. It also lets you talk down to others, which many people unfortunately enjoy.
Additionally, just assuming that nothing is happening is a somewhat self-correcting problem. You can ignore iPhones for a long time, but eventually literally everyone you’ve ever met has one, and you can just shamefully pretend that you never said they were pointless. As a result, being lazy is often less dangerous than the other trap…
A lot of senior leaders, even “leaders” at tech companies, are fundamentally insecure about technology. They’re either not technical by training or so out of practice that they don’t know how their products work. This is especially true in fields where projecting confidence is a key part of the job: Sales, Marketing, Human Resources, and arguably even Security are all examples.
So in order to instill confidence in their teams, or to win whatever political battle is being fought this week, whenever a tech wave appears on the horizon many execs feel compelled to project wisdom and understanding.
Critically, these execs don’t actually understand what’s going on – they haven’t followed the steps outlined above, and they often also fall into the trap of being lazy. So instead they follow the hype: This is popular on X (or worse, LinkedIn), all our competitors are leaning in, or “Gartner said this is the next big thing.” It’s classic herd behavior. Once the hype is loud enough, these leaders’ next step is to declare that the new technology is the birth of a new machine god, and that they will be its prophet.
Going all-in on something you don’t understand can work out fine if you capture something like the iPhone moment and build a mobile empire. But it’s deeply damaging if it causes you to mortgage your business’ future on some Web3 technology with 0 actual users. Or if you cancel your entire roadmap to put a hat that says “I ♥️ AI” on top of your product, when your customers actually wanted you to add better approval flows.
Blind over-rotation is the default strategic mistake in times of major change. To avoid it, you need to make sure that you and your team aren’t falling into the trap of avoiding embarrassment by leaning in on whatever is hot.
New technology waves can make or break your business, but only some of the bumps in the water actually matter.
Follow the steps of thoughtfully asking whether the technology is impactful, researching how it functions, establishing the facts on what it makes possible, and considering whether it impacts your business. Beyond that, don’t assume it’s just nothing, and don’t let embarrassment drive you to go all-in just because everyone else is.
Most importantly: The greatest sin of technology waves is missing an obvious wave and pretending it wasn’t real because of your ego. If you miss a wave, the single most important step is to swallow your pride and immediately take strides to catch up:
The silver lining of technology waves is that when they matter they’re big, and when they’re big they’re eventually obvious. Missing them, more than anything else, is truly business-killing, but luckily you don’t need to be that clever to detect a wave that matters.
2026-06-16 08:00:00
Building a great organization is all about finding skills that complement each other. People tend to think everyone can do everything—especially at the leadership level. VP and above, the assumption is that for the amount they’re paid, leaders should be great strategically, operationally, technically, and every other way you can imagine.
This is almost never the case.
Almost every leader has at least one major weakness. The great strategist is weak operationally. The great technician is weak strategically. And so on.
The real damage happens when you stack weaknesses - when a leader is weak at something and their direct reports are weak at the same thing. This is a disaster, and it happens far more often than you’d think. Part of the reason for this is that leaders tend to hire people with the same skills they have. They’ll dress it up as hiring for “values” instead of “skills” so it doesn’t look like they’re cloning themselves - but people ultimately search for and evaluate the things they’re good at.
An even more challenging reason leaders do this is that they often don’t even know that they should try to hire for a skill - a true unknown unknown.
When you stack weaknesses, you warp reality. Put two operationally weak leaders in a row and the odds that the organization beneath them is operationally strong are zero. These leaders can’t run operations themselves, and they don’t even know how to hire or manage people who can. It’s like asking two monolingual English speakers to hire a great French translator. What the heck do they know about le chat noir?
Avoiding stacked weakness starts with admitting weakness, which is hard for a lot of leaders. The great ones know out of the gate what they’re good at and what they’re not, and they hire for the gaps. An org with no meaningful stacked weaknesses is robust to the changes and challenges that cause stacked-weakness orgs to collapse.
If you need a quick guide to covering your gaps - most roles have a component of the following skills: technical/domain knowledge, management, process/operational, strategy, presentation/speaking, raw aptitude. Rank yourself on those honestly and fill the gaps with strong hires. And the simplest way to not trick yourself about your abilities is to never say “I could do that if I wanted to” when evaluating that list.
2026-06-04 08:00:00
When baby sea turtles are born on the shore, they immediately rush by the thousand towards the ocean. Every predator in the area swarms to devour as many as they can. Only a few dozen make it to the water. An even smaller number make it to adulthood, and ultimately return to start the next generation.
Startups, like Mother Nature, are a brutal numbers game. This is what it’s like to become one of the few turtles that makes it back to the beach.
You’re standing awkwardly in a one-room office. A guy in a T-shirt hands you a laptop, but tells you to factory reset it first. It belonged to a different engineer yesterday. The startup doesn’t have enough money for excess laptops. It’s 10am and there’s nobody else in the room.
He’s talking about how there’s a form to early-exercise your stock options, and you’ve got 30 days to mail a different form to the IRS, and do you have a check, and this is really important if there’s a “liquidity event” one day… you can already feel your eyes glazing over. You ask where you can grab a notepad and pen to take notes for the rest of onboarding. Laptop Guy stares at you blankly. This conversation is the entire onboarding, and there aren’t any notepads or pens, either. He says that if you need office supplies you can buy them at CVS and he’ll reimburse you.
“So, uh… what do you want your email address to be?”
You go to Thanksgiving and tell your grandma the name of the startup, again. Your mom tries to describe what it does and gets it about 40% right. It doesn’t matter. Everyone’s moved onto discussing their fantasy football teams.
You were a smart teenager. You went to an amazing college, and your family was so proud. How did you wind up here? Your startup’s CI runs on a Mac Mini under your desk. It burns your legs. You have $0 in revenue. You’d think that this was rock bottom, but you’d be wrong. The startup used to have some revenue, but you churned it away, so now you’re back to $0. You’ve had 3 Heads of Sales in as many years – this at least does make sense, since they never seem to sell anything.
You have no idea whether more funding will land, but you can tell that you need it. Your best friend from high school just graduated med school. Pass the gravy.
* * *
The stock market has closed for the day, and the IPO is now inevitable. Aspects of the deal are still being discussed, the Book is being built, but there is nothing left that can disrupt it. You have spent weeks worrying about disasters that could have caused an issue in the markets and canceled the deal. It’s become a paranoid loop running in your head. But the big day has finally arrived and there aren’t enough hours left to fuck it up.
The adrenaline dump after a decade of white-knuckling the steering wheel is intense. You’ve worried about the company’s fortunes constantly, for years, and you can’t really turn it off, even on the eve of the IPO. You check your phone – same email address, same Slack handle that you picked in that office years ago. When the menus arrive for the celebration dinner you barely have the mental energy to order.
You’re looking at memorabilia that you’ve kept stuffed in a folder at home, relics from when the startup was tiny, seed stage. You opened up the printed (!) directory of an event from a decade ago. Techcrunch Disrupt. You remember it well – huge waterfront venue, full soundstage, two days of presentations, hundreds of booths, your team tucked in the back by the water coolers with the other fledgling startups. So much positive energy, so many excited faces, so many teams with such bright futures.
Based on a quick scan, your company is the only one that’s still in business. None of the other turtles made it home.
You arrive at the stock exchange to an extensive corporate buffet. It’s a huge reunion with people flying in from across the world. You haven’t seen some of them in-person in years. You’ve never seen any of them in a suit this early in the morning.
The CEO, founders, and early execs are celebrities. A Director who joined 8 months ago comes up to you – this is their chance to meet in person. “Did you expect this day would come?” Dude. That’s like asking if I expected to get hit by a meteor.
You’re in a sterile, brightly lit holding pen. The exchange has sent in what can only be described as a corporate hype-man to get everyone fired up before the big moment.
The experience of having this high-budget camp counselor run a 5 minute pump-up exercise is utterly bizarre. For you, this is the most important day of your career. Your grandparents fled their home countries under literal gunfire to help you get here, to America, to the center of the capitalist universe. Today is a crowning moment in that saga. For Gary the hype-man, it is Tuesday.
You’re standing on a street level sound stage. You’ve seen this place dozens of times: on the news, in the newspaper, on the glossy websites of the world’s most famous venture capital firms. Surreally, this time you are on the stage looking out. You see the city through soundproofed glass.
Above you on the soundstage are a semi-circle of TVs showing news channels across the globe – Bloomberg, BBC, MSNBC, international versions of CNN that you didn’t know existed. Screens are showing everything from bored looking news anchors to commercials for some Malaysian soap, killing time as the US markets prepare to open. Someone yells final instructions – there will be confetti, remember to smile, clap until we say stop, you’re about to be on TV.
The countdown begins. The emotional tenor of the room reaches a fever pitch. You look down for a moment, and think of the steps that brought you here. Closing that first enterprise contract 9 years ago, the database incident that almost sank the company, the panicked breakfast in the lobby of a Marriott in Seattle after your biggest competitor’s product launch, the conference room you were in when you hit $30M ARR. You can remember everything, and nothing, from the decade-plus journey.
You look up as the TVs change, showing the opening bell ceremony of the stock markets of the United States. You are on every channel.
For a brief moment, all the spotlights in the grand arena of capitalism arc towards a single point, the exact coordinates in the global economy where you’re currently standing. Everyone goes wild – you probably didn’t need Gary hype-man. The guy who handed you the laptop all those years ago triggers the “bell” just a few feet to your left. You clap and cheer for what feels like 5 seconds and 50 minutes at the same time.
The confetti has dropped and it’s time for a brief photo op outside. People are taking selfies. As you walk off stage, the thought crosses your mind that you’ll most likely never be in this room again.
You’re hugging people outside – a small group of elated people in suits and skirts taking selfies on the street, like tourists in business casual. There is a fire in your team’s eyes that you’ve never seen before: Relief and excitement, like you’d expect, but in some of them, there’s also a novel confidence. The ones who endured years of anonymity and struggle to get here will retain that fiery, intense confidence forever.
A disoriented Argentinian family is shuffling their children away from an increasingly insistent person in an Elmo costume. Life in New York City goes on. Nobody gives a shit.
Back at the exchange they’re going through the actual offering itself. People are popping champagne as the numbers tick up, and up, and up. All of the startup’s private venture rounds were run as cloistered secretive events. This time, they’ve literally got some guy with a headset running the deal with the price fluctuating on a live ticker. Bankers and venture capitalists are wandering around everywhere. It isn’t necessarily a bad thing, but you’re starkly reminded that all of your efforts were ultimately distilled into a financial product.
The numbers stop. The “offering” is over. The Company’s shares, trapped in suspended animation in Carta for ⅓ of your life, are now being bought and sold by total strangers. You call up your stock tracking app and see a name that you’ve typed a hundred thousand times staring back at you. You’re like a caveman looking at the touchscreen console of a Tesla; you can’t process it.
As you walk off the floor, you look back at the screens and see the frozen price where the offering concluded. You remember when you made your 83(b) election after that confusing onboarding session years ago. It wasn’t a lot of money to exercise that initial grant, but exercising options in such a tiny startup felt vaguely irresponsible, like you were getting scammed. The shares you purchased are up 50000x.
Your mind starts calculating. Share Count times Current Stock Price – this is a calculation that your brain will become exceedingly good at over the coming years, as your share price rises and falls, as you learn what it feels like to make (or lose) sums of money that you didn’t imagine you’d ever have over the course of a day, or an hour, or 5 minutes of after-hours earnings market gyrations. But this moment, staring at a small white number on a cool blue background on an anonymous trading floor monitor, is the first time you’ve run the calculation for real. So it takes you a few seconds. You never need to work again.
That afternoon, you open up Slack. The fanfare is over, and people in faraway countries are still sending you messages, and you’re going to be reporting numbers quarterly… forever. So you open up your laptop – same email address, same Slack handle. And you start crawling your way back towards the open ocean.
2026-04-15 08:00:00
True startup people are one of the most important advantages that many tech companies have. Startup people are aggressive, entrepreneurial, and often bring a dynamism that allows them to cut through significant roadblocks. When there’s a large platform shift (e.g. the AI wave that is currently occurring), they’re often literally the only people at your organization that can help you transition into the new world. There is a reason that many sharp investors strongly prefer to bet on founder-led companies and their startup-oriented teams, particularly during times of extreme change.
But if you’re going to make the most of startup people you need to know how to work with them. And if you want to work with startup people, you need to know how to manage their tendencies – including one of their most distinctive traits, which I call high amplitude disagreeableness.
Disagreeableness is kind of like a sound wave. Waves have properties of:
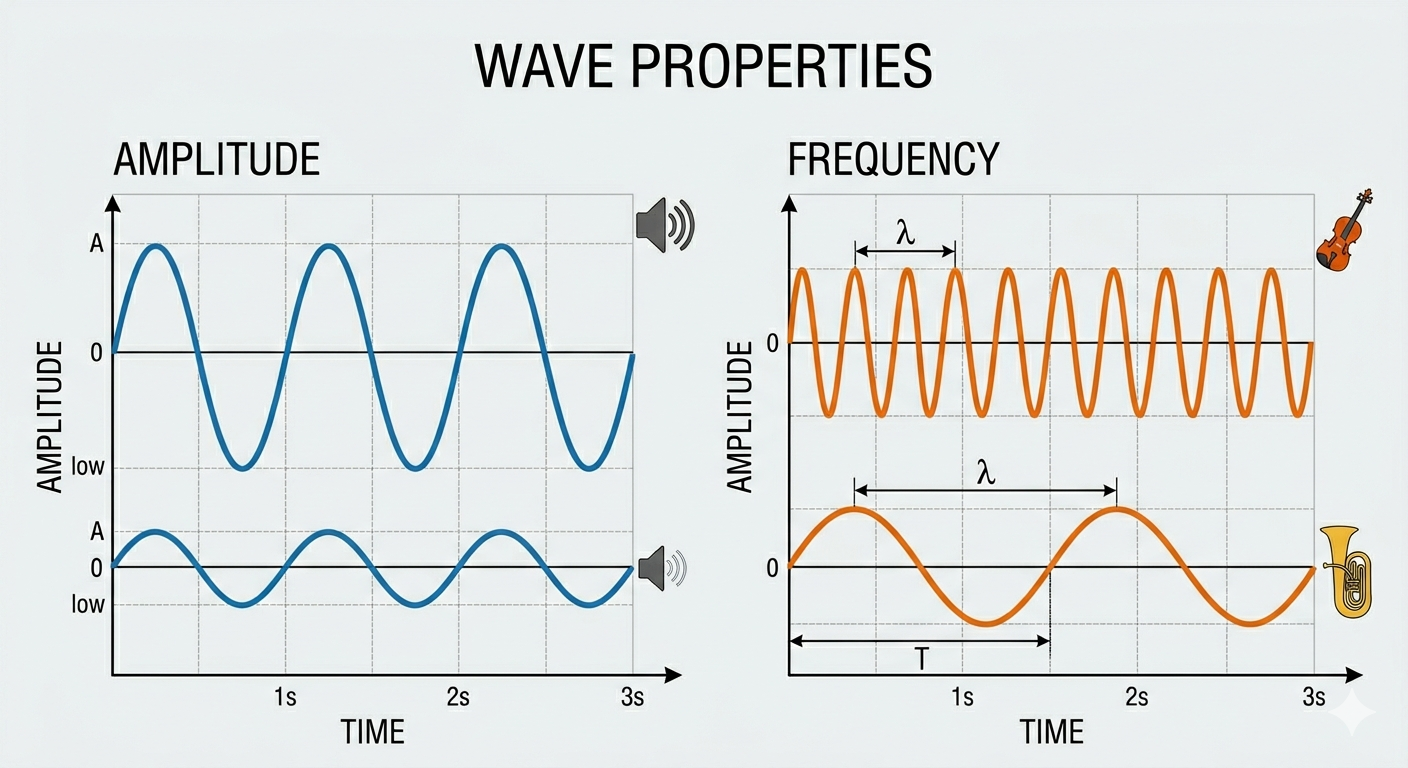 Amplitude vs. Frequency
Amplitude vs. Frequency
Some people are basically argumentative and combative all the time: high frequency. Others are actually very genial and (usually) conflict-avoidant: low frequency. That’s just human nature.
But all startup people share an ability to reach an extremely high amplitude of disagreeableness – if you’re really wrong, they will fucking nuke you from orbit, and they are willing to get in front of the entire company and call you an idiot because it doesn’t bother them one bit if there’s an audience when they push the big red button. One of the defining traits of a startup person is their willingness to disagree publicly, even with senior people, and to remain insistent over a long period of time – for example, fighting to change a bad process or build the right product even if it takes years. When you see a mid-level person politely but firmly disagree with some member of the C-suite in front of a hundred people, you’re seeing the startup spirit at work.
This pattern of high amplitude disagreeableness among startup people is essentially universal in my experience. As a result, if you want to tap the intensity of an entrepreneurial team, you will need to contend with (or harness) this pattern of behavior. There are a few management implications if you want to attract, retain, or deploy entrepreneurial talent.
First off – what creates this trait? Startup people tend to view their jobs in terms of creation instead of the more typical approach of viewing your job as extraction. If you’re just trying to extract value from a company, it’s really important that people don’t dislike you – and disagreeing vehemently is a pretty quick way to be disliked.
What this means is that if you never seriously disagree with people, even when it’s warranted, startup people won’t respect you. Your inability to reach a high amplitude of disagreeableness is actually an indicator that you aren’t a part of the tribe: You’re an extractor not a creator. They are people who are willing to fight for what they believe in with righteous anger; if you aren’t the same, they’ll think that you’re weak at best or lack integrity at worst. Startup people will quit working for these sorts of managers.
Additionally, you can disagree very strongly with startup people, even in public, and they’re surprisingly likely to just brush it off. Big-company corporate types hate getting pushback – it challenges their authority, and the perception of authority is how you climb the corporate ladder. High amplitude disagreement destabilizes existing power structures because it levels the playing field – it lets people step out of their lane to make change as long as they have enough conviction. Startup types don’t exactly like being challenged, but they recognize it as necessary at times, and a sign that someone actually cares. You can often recognize a healthy entrepreneurial culture because it accepts people being highly disagreeable (within reason) without permanently branding them as a troublemaker.
You also need to have a culture where strong disagreement doesn’t lead to punishment or ostracism. This can be surprisingly challenging. If you manage entrepreneurial startup types, you will find yourself explaining, defending, or occasionally apologizing for the fact that they very intensely disagreed with someone else surprisingly often. It’s essential that you create a culture that can accommodate the fact that there are going to be some intense arguments, while also making sure that your workplace stays professional and pleasant.
Finally, startup people really tend to hold grudges if you’re confidently wrong. At the root of high amplitude disagreeableness is a belief that the truth is knowable and that it matters, deeply. Startup people are running software where their conviction meter maxes out at a much higher level. This means that if you’re wrong in big ways, and you don’t correct it, startup people are guaranteed to remember and hold it against you since they believe that the difference between right and wrong really matters. Corporate types might hold their noses and put up with outright incorrectness, but startup people won’t. If you want to lose the startup people on your team, the most reliable way is to be confidently wrong.
2026-03-12 08:00:00
AI tools hit a true inflection point in late 2025. Building things got cheaper. AI tools got expensive. And the gap between good management and bad management got a whole lot wider.
Here’s how to think about management in 2026.
Managers must be builders in 2026 for two reasons.
First, you have to learn AI tools. Without a deep understanding of how people build and execute with AI, you will be completely clueless about what to expect from your team and how to guide them.
This cannot be overstated.
A manager’s job is to do things like help people get better at their job and set expectations. Without hands-on fluency with AI tooling, you will be fundamentally unable to do these things well. It would be like trying to manage a software team in 2015 without knowing how to use the internet.
Second, building is often the most efficient path for the team. In the old world, a manager might spend five hours in meetings defending the team’s time against a drive-by request from another team. In 2026, the manager should just spend an hour and build the damn thing.
Managers must build because not building is now the bigger waste of time.
People have incredibly powerful tools at their disposal and companies are spending real money on them. Managers have to raise expectations of output. This will require willful effort, but that effort must be taken.
If you need a cheat sheet for raising expectations:
AI tooling is also putting immense pressure on underperformers. Engineers who can’t review code effectively. PMs and Designers who are bottlenecks. Leaders who can’t adapt to change. 2026 is going to put everyone below the bar underwater, and you need to be ready to step in.
AI tools are moving to consumption-based pricing, which means managers are going to have to think about how much money to invest in each individual. This is a massive paradigm shift. It’s like if you had to decide every month how good of a laptop each person on your team gets, and sometimes people run out of laptop halfway through the month.
Start thinking through these challenges now:
None of this has established best practice yet. The managers who figure it out first will have a meaningful edge.
With more tooling and raw power than ever, your teams need precise goals. The fuzziness that used to get figured out later during slow build cycles will now kill you in the short run.
When your team can build fast, building the wrong thing is the primary risk.
Make sure your teams and individuals have precise goals, or you’ll spend $10k per person per month on AI tools and find out it all added up to a pile of features that didn’t move the business.
Documents are getting longer. Code is getting more verbose. Toolchains are exploding in complexity. Everyone is heads-down with their personal fleet of agents, cranking out work in parallel.
This is great for raw throughput. It is terrible for coherence.
Collaboration in 2026 requires intense, deliberate focus from managers. Week by week, you will need to pull people out of their individual sprints long enough to make sure they’re all running in the same direction. If you don’t force this, your team will ship fast and end up with a product that feels like it was built by five different companies.
A mis-hire in 2026 is catastrophic. The delta between a great engineer with AI tools and a mediocre one with the same tools is not 2x — it’s 100x. One ships compounding value. The other ships compounding slop.
Raise your hiring bar now or spend the rest of the year cleaning up after it.
Management is not dead. In fact, 2026 is the year where management becomes a key differentiator between teams that win and teams that drown in their own output.
This is the year you need to adapt faster, expect more, and start building again.
2026-03-06 08:00:00
There is enormous variability in the frequency with which teams have emergencies.
Some teams have emergencies regularly. We need a new report; someone has to put together a presentation; we need to change plans to incorporate new feedback. Other teams essentially only have emergencies due to exogenous or hard-to-predict factors: us-east-1 went down; we’re getting sued; our CEO got in a car crash. This variability is universal across industries and company sizes; I’ve even heard of non-profits with a culture of constant emergencies. Madness.
As you would expect, better managers have fewer emergencies, and worse managers have more. And at the extremes, it’s common to find that the best managers basically never have preventable emergencies, and the worst managers have teams which are constantly in a state of emergency, to the point that they’re 100% reactive.
There are a few factors that contribute to a very significantly lower rate of emergencies on well-managed teams, and happily they’re easy to copy:
One of the dumbest form of emergencies is simple underestimation of the amount of effort required to get a team’s projects done. Good management can prevent this in a few ways.
First and most importantly, managers need to be deep experts in what their teams actually do, and put in real effort to stay informed. If they’re an engineering manager, they need to be a solid engineer themselves and also stay up-to-date on the state of the technology that their team owns, their biggest challenges, and their capabilities. Bad managers love to black box their teams in the name of delegation: “I shouldn’t need to inspect what’s going on with my team, they should just handle it.” Good managers trust but verify by staying informed before delegating. They know if that report they’re suddenly asking for is easy or hard to produce.
Next, good managers just ask questions. Contrast two identical situations where an ask came from your CEO:
Simply asking the question resolves a surprising amount of emergencies before they get started. If it’s truly impractical to get the report this afternoon, it’s better to just find out upfront rather than pulling all of the fire alarms immediately.
Finally, good managers set expectations and communicate reasoning. “I need you to get me a report on project X but if it’s going to take more than 30min let me know before you do anything. I want to get a readout to a new sales prospect but it’s not essential.” Especially when seniority gaps are large, a little expectation-setting goes a long way.
A huge amount of artificial emergencies stem from managers who don’t understand what is actually important for their teams.
If you don’t know what matters for your team, the latest thing that just popped into your brain often feels critical. If you didn’t have strong conviction about whatever project was in-flight, any new good idea always seems like it could be worthwhile. Bad managers can’t stay on target, and because they can’t stay on target they never say no to new work, creating constant emergencies for their teams.
A simple technique that works here is to always make sure that you have very strong conviction that what your team is working on matters, and actively force yourself to make sure you always know why their roadmap is important. This is critical to give you the courage to push back on the worst sorts of emergencies: executive requests like “[CEO] needs a full proposal on how we’d tackle this idea today.” If your team is really working on business critical needs, responses like “we can get you that after [critical work] is finished” or “how about we get you 5 bullets and a summary, because we’re finishing [work we all agreed matters]” actually become available arrows in your quiver.
This is a more subtle concept, but one of the most important.
Good managers have a strong mental model for how their team operates and the role it plays within the company, and have a strong understanding of the state of the business and industry. This empowers them to more accurately forecast what will be needed of their teams in the future.
For example, let’s say that I’m running a Product Design team. I know that my team currently outputs pictures of what we’re going to build. But I also know that AI is shaking an already dynamic landscape: for example, there’s more AI prototyping including from non-designers, a rise in vibe coding, and all of this amid rising UX standards for enterprise software.
With this simple mental model, I can make a number of moves that will prevent emergencies down the line:
This concept always reminds me of college-level math. If you take college-level electromagnetism, differential equations, or probability and statistics, you’ll often find that there are two ways to pass your tests:
To really prevent emergencies, you need to be in the second state when it comes to your team.
And finally… good managers simply care more about their teams’ well-being. And if you care about your team, you’re much less likely to throw a hand grenade into the room and walk out the door while your team is still inside.
Despite the many bitter comments that you hear on internet forums and bars at 5pm, in my experience many managers really do care deeply about their teams. I’ve had so many conversations with managers who are working their butts off to prevent emergencies from impacting their teams.
The simple fact is that in many cases emergencies are a choice – specifically, they come from making the choice to satiate some desire by sacrificing your own team’s time. You can prevent this: you just need to care more about your team’s long-term productivity than a short-term boost to your career or mental health.
One of the best parts of following this advice to prevent emergencies is that it really will make your team happier and more productive, and it will do so almost immediately. Nobody wants to live in a world of constant emergencies, but it’s all too common across every industry. Great people want to do great work, and a culture of emergencies is anathema to the focus that great work requires. If you can find a way to keep your team operating from a level-headed playing field, you’ll have unlocked one of the best talent retention mechanisms that exists.