2026-07-30 18:18:50

Explaining stock market movements is always a little bit of a fool’s errand; no one really understands why stocks boom or crash on a given day or in a given week. Over the long run, the stock market displays lots of “excess volatility” — prices move up and down much more than is warranted by changes in earnings or other measures of fundamental value. There are plenty of theories about why those swings happen, but it’s very hard to know which of those — if any — is in operation at any given time. And so although every big stock market movement is followed by lots of articles claiming to know why, you should take them all — including this one — with several grains of salt.
Anyway, having said all that…
The Korean stock market has been crashing for weeks now. Around March, Korean stocks went on an epic tear; the KOSPI index rose from around 5,000 to over 9,000. Then, just over a month ago, it all went into reverse, with the index falling back to around 5,500:
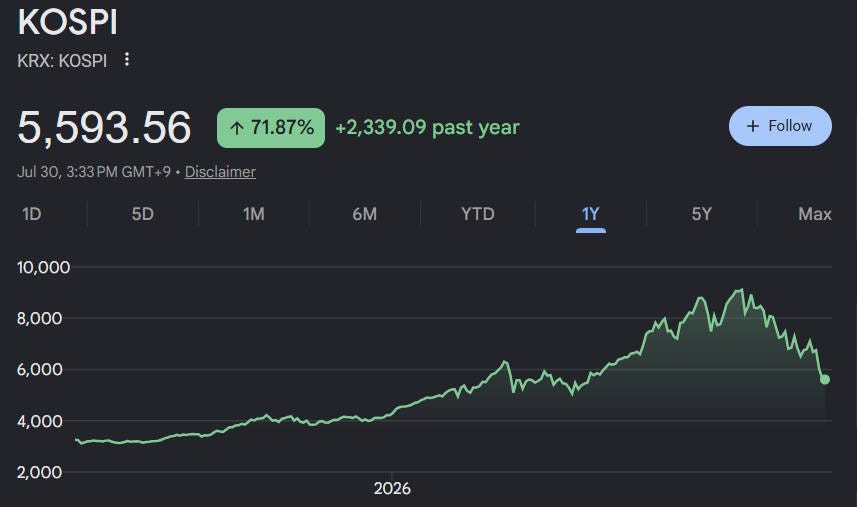
There are probably two stories regarding why this happened — one about fundamentals, and another about finance. In fact, this is typical for bubbles and crashes, not just in stocks but in every asset class. There’s almost always some kind of connection to fundamentals — some story about how we’re in a new economy, followed by doubts about whether that story is really true, and so on. But the big market movements are almost always accelerated by purely financial factors — “noise traders” armed with piles of excess cash, opportunistic speculators looking to ride the wave of sentiment, and so on.1
For Korea, the fundamental story was about memory stocks. Korean companies like SK Hynix and Samsung make a lot of the world’s computer memory. Under normal circumstances, computer memory isn’t a great business to be in — the technology is fairly commoditized, the industry is brutally competitive, it takes a LOT of capital to build the factories, and it’s very risky to make long-term bets on the evolution of memory technology.
But computer memory is really important for AI data centers. And so the AI boom kicked off the mother of all memory booms. Only a few companies had the scale to meet a large amount of this demand explosion, and the two biggest of these were in South Korea. SK Hynix’s operating profit went from under $10 billion in the first quarter of 2025 to over $35 billion in the first quarter of 2026:
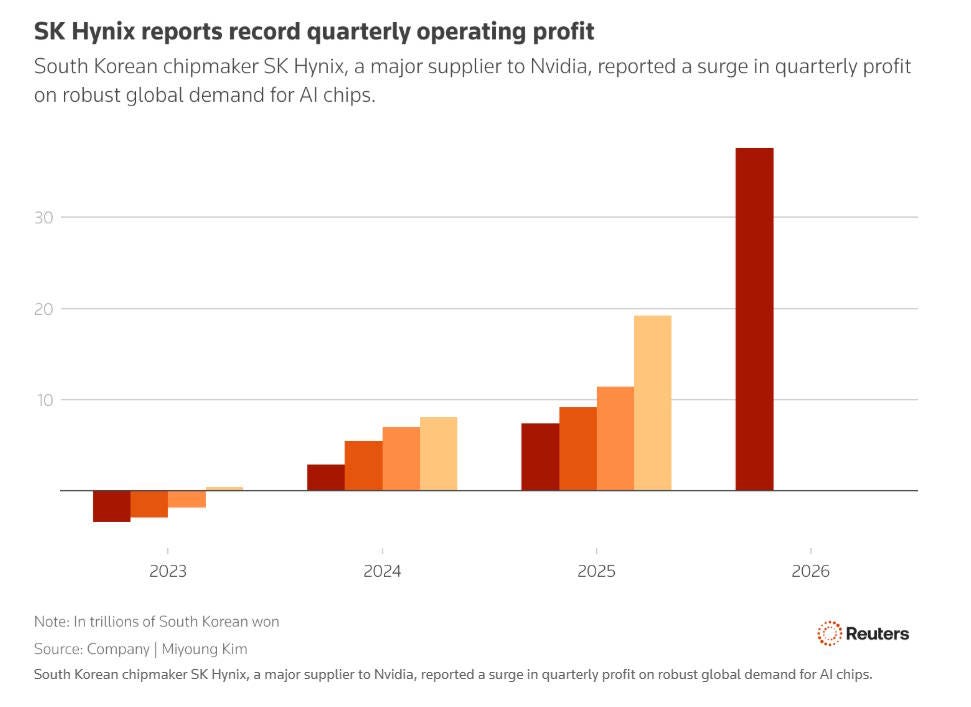
Hynix, which specializes in memory, briefly had a higher market capitalization than Samsung, simply because the memory boom is so huge. Korea’s exports rose over 70% in just one year; in fact, the country’s whole national GDP growth rate increased by a noticeable amount over the past two quarters, just because of this one product:
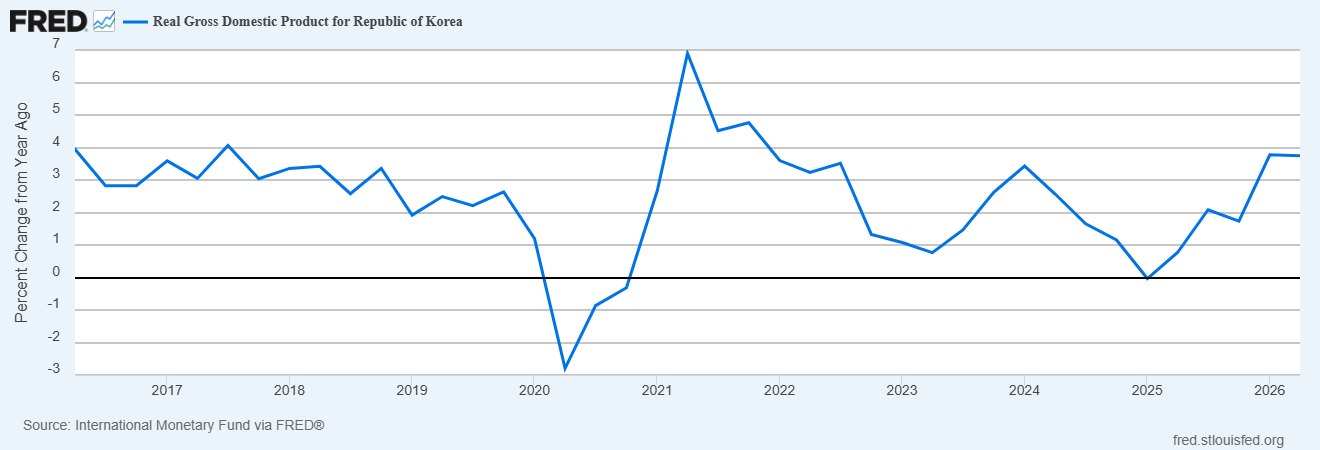
That’s a pretty strong fundamental story about why South Korean stocks should be worth a lot more. So it’s no surprise that the Korean stock market boomed as soon as people realized in early 2026 that AI technology is going to be extremely valuable. Here’s a thread about just how epic the runup in these companies’ stock prices was:
This is where the financial story rears its head, though. A bunch of traders saw this enormous price rise and decided to buy into it. You’d think a lot of these would be foreign, but international investors mostly avoided the boom (except for a few who bet big on Korean memory stocks). The most frenzied buyers were regular Korean people — the proverbial taxi drivers and teenagers.
These investors probably didn’t understand the fundamental story about AI and data centers and so on. Instead, they probably had extrapolative expectations — they see the price go up and up, and they figure stocks are just a “goer upper”. As more and more buy in and the stock goes up more and more, the perception of a structural upward trend is only reinforced, causing yet more people to buy in. This isn’t the only explanation for coordinated “noise trader” buying frenzies, but it’s probably the most likely.
Normal people don’t have a lot of cash sitting around. But earlier this year, regular Korean people got the opportunity to effectively borrow lots of money to invest it in stocks, via the introduction of leveraged single-stock ETFs. When you buy a share in a leveraged single-stock ETF in SK Hynix, it’s like borrowing money to buy SK Hynix stock.
A whole lot of Koreans used leveraged ETFs and other borrowing methods to borrow huge amounts of money and buy lots and lots of Korean stocks — especially the memory company stocks that were driving everything.
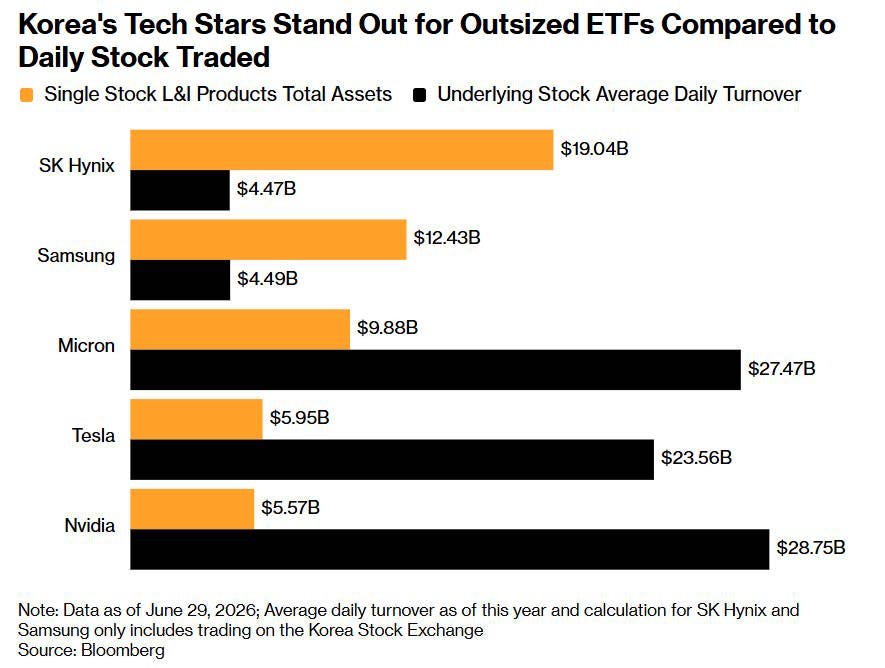
There were some people selling — notably, foreign investors “taking profits” and getting out. But the noise traders overwhelmed all the selling pressure, and sent stock prices soaring.
Then something happened last month — either something fundamental or something financial. Hynix and Samsung are doing fine in terms of earnings growth, but it’s possible that something suddenly gave traders reason to doubt the overall story about the AI boom sending these companies’ profits to the moon. The other possibility is that Korea simply ran out of hotheaded day traders willing to borrow more and more in order to bet on stocks, and the influx of cash naturally came to a halt.
Whichever it was, at that point the price faltered and began to fall. All that borrowed money accelerated the fall on the way down. When prices fall, leveraged ETFs have to sell some of what they hold.2 When a bunch of leveraged ETFs do this at the same time, it pushes prices down, forcing others to sell. In the meantime, people who had borrowed money to buy stock faced margin calls (or bankruptcy), forcing them to sell stock to raise cash. All of this created extra selling pressure, and so increased the rate at which Korean stock prices fell since late June.
Anyway, that’s the financial story. It’s a very old story — financial leverage plus unsophisticated new buyers plus a strong fundamental story often produces a bubble and crash, or exacerbates one that was already in progress. No wonder Korea is now moving — a little belatedly — to restrict leveraged ETFs.
But while financial factors affected the timing and the size of the stock price boom and bust, the fundamental story is more interesting. Fears of an AI bubble are quietly creeping back.
In 2025, as consumer chatbots struggled to find a market big enough to justify the kind of investments being made, there was a lot of talk about an AI bubble. One possibility was that AI revenues wouldn’t grow fast enough to justify the amount being invested in data centers. Another possibility was that AI companies wouldn’t have enough of a “moat” to make them consistently profitable.
In 2026, Claude Code exploded onto the scene, and everyone realized that AI had finally found “product-market fit”. We now know at least one thing that AI is incredibly useful for — writing computer code. Suddenly, an AI bubble seemed much less likely. Spending on AI was skyrocketing, and Anthropic — the new market leader — was successfully capturing much of the profits. Cybersecurity and other zero-sum applications — where having the absolute best model can matter a lot — started to seem like the “moat” that AI had previously lacked. Suddenly, the giant data center construction boom seemed a lot more reasonable.
But slowly, doubts have begun to creep back in. AI is amazing at writing software, but writing software is different from selling it. So far, huge increases in coding productivity are translating into only minor increases in the amount of software being shipped:
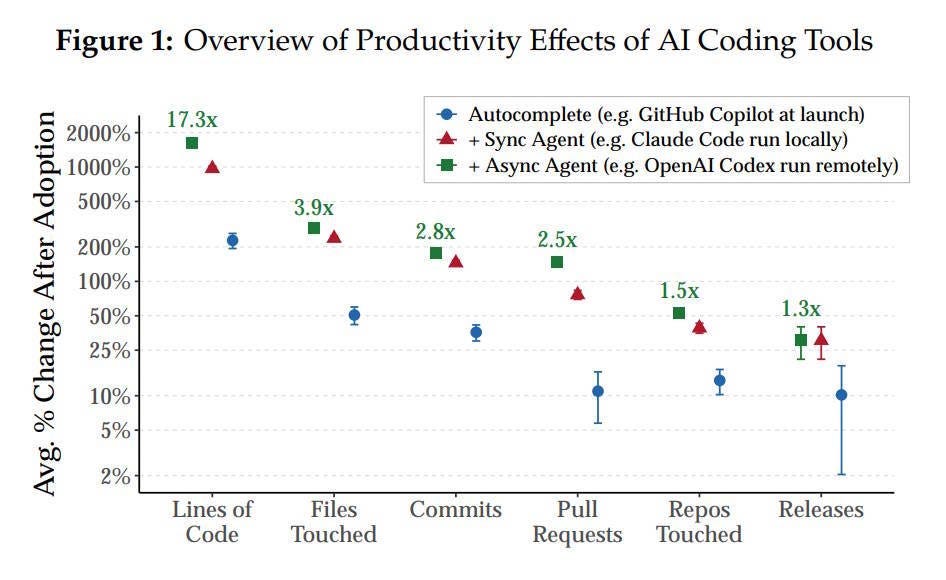
It’s possible that a significant fraction of the explosion in the use of coding agents is just “tokenmaxxing” — companies trying to use as much AI as they can, either to learn to use the tools, or perhaps just to look like they’re doing something. If so, we can expect a retrenchment and a temporary slowdown of AI spending growth.
It’s also possible that even the revenue growth we’ve seen isn’t enough to offset the enormous costs of the data center boom. Here’s a recent report from The Economist:
A back-of-the-envelope calculation finds that covering AI capex through identifiable AI income requires revenue on the order of $2.5trn per year, more than tech’s entire combined revenue today…Anthropic pulls in perhaps $75bn, annualised; OpenAI makes tens of billions; Google, via its AI model Gemini, and Microsoft probably get a bit less. SpaceX may have a few billion dollars’ worth of revenue from enterprise AI this year. Meta also makes a few bucks from AI. Add this up and you land at roughly $150bn a year. [emphasis mine]
AI revenue is growing very fast, but if these calculations are right, it’ll have to grow by 17x from where it is now in order to justify the capital being spent. In other words, even Claude Code isn’t enough; AI revenue has to accelerate even further, and while it’s perfectly plausible that it could do that, it’s a big question mark.
There’s also the possibility that the moat of companies like Anthropic is less invincible than it looked just a couple of months ago. A Chinese company called Moonshot AI has released a model called Kimi K3 that nearly equals the best available American models. American companies are using cheap Chinese AI models more and more for daily tasks. If Anthropic and OpenAI lose the overall b2b market to cheap Chinese competition — which is undoubtedly supported, of course, by China’s usual blizzard of subsidies and government supports — there’s not much chance that they’ll be able to pay for the data center boom.
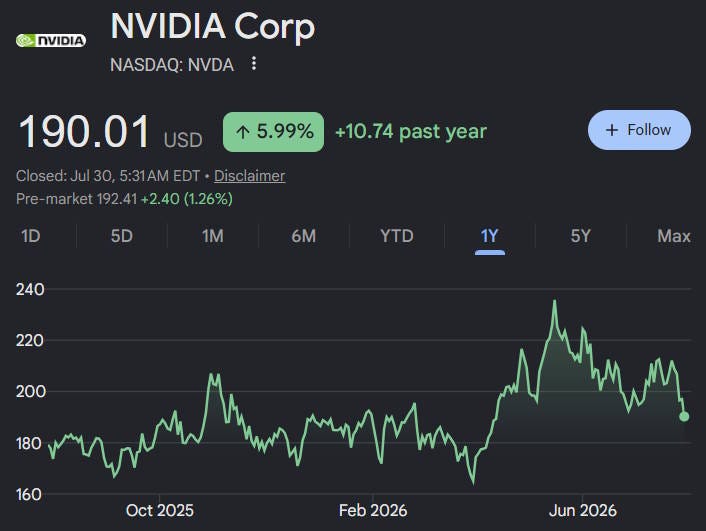
And at that point, there could be a big, big bust — similar to when railroads went under in 1873. Investors are probably already beginning to worry about this. It isn’t just Korean AI-related stocks that have taken a hit recently. Here’s Nvidia, which designs and furnishes the chips that run data centers:
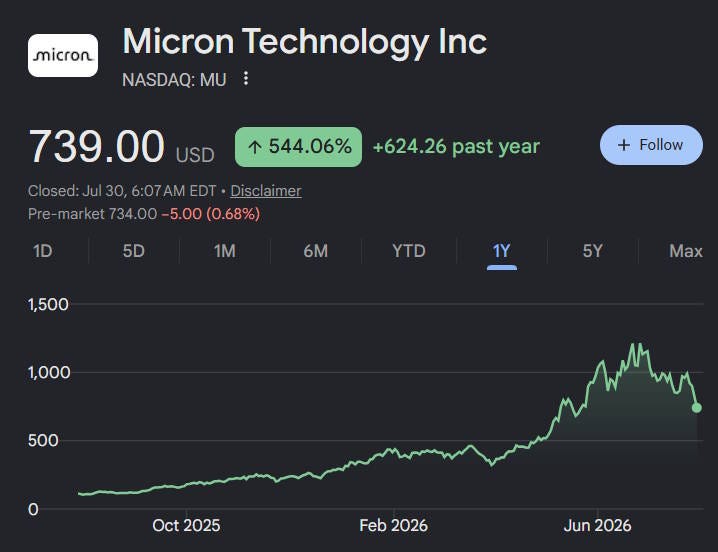
And here’s Micron, America’s top memory chip maker:
And here’s Microsoft, a big part of whose business is installing AI data centers:
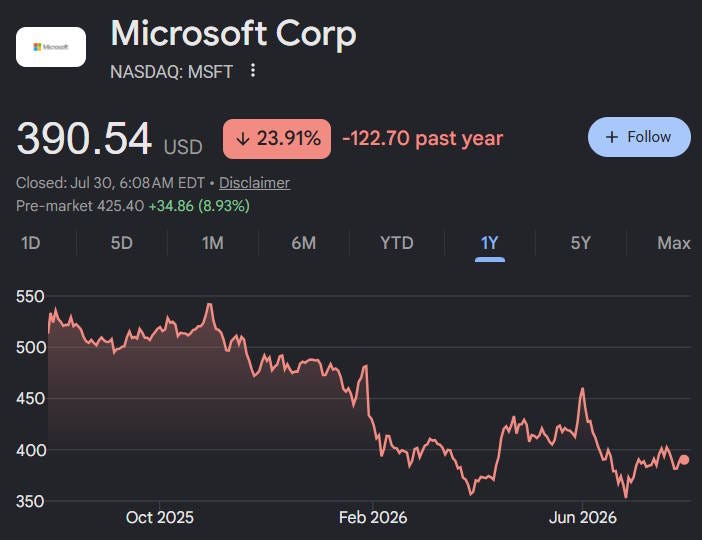
There are similar (if less dramatic) stories at Google and Amazon, who also run a ton of data centers.
Here’s Bloomberg’s story about the decline of the so-called “Magnificent 7” tech stocks:
Wall Street is growing increasingly concerned about the hundreds of billions of dollars Big Tech is spending on artificial intelligence…“The real problem is the amount of spend that’s going on,” said Ken Mahoney, chief executive officer of Mahoney Asset Management. “No one knows what the return on investment is.”…The selloff is coming as investors grow increasingly cautious about the massive sums that Big Tech firms are spending to build out their AI infrastructure. The Mag 7 index is now down 11% from a record reached in late May, erasing $2 trillion in market value.
So although South Korea’s epic stock crash was probably related to Korea-specific financial factors, it could also herald the return of the “AI bubble” story. AI is far and away the most important thing going on in the American economy right now, so any hint of a bubble is worrying.
Update: One possibility I should have mentioned is that the Korean stock crash is the start of a general crash in AI stocks — the long-awaited “AI bubble pop”. So far the carnage hasn’t been too extensive, but it’s notable that some people who bet big on the smooth, uninterrupted exponential growth of AI are now seeing those bets blow up:
Citadel — a big traditional mainstream finance firm — is now stepping in to buy many of the stocks owned by Situational Awareness.
And as Derek Thompson noted a couple of weeks ago, Korean retail investors aren’t the only ones borrowing money to buy stocks:
Derek flags the rise of margin buying and leveraged ETFs in America, but I also noticed that some pretty big companies are leveraging themselves to the teeth here:
For the best simple explanation of how financial markets can go haywire, I recommend the famous paper by DeLong et al. (1990). If you don’t feel like reading through a mathematical model, just ask AI to explain it to you in simple terms.
Usually, futures or options or some other derivatives tied to the value of the underlying stock.
2026-07-28 08:33:43

Hallo, awesome readers! It’s time for a roundup. I actually never think of a theme for these in advance. I just dump everything in my list of “stuff I don’t have time to write a full post about" into the Substack editor, then try to figure out some kind of thread that ties the items together. Today’s list is, roughly speaking, about industrial policy — deliberate policies that governments can take in order to encourage specific sectors or pieces of their economies.
But first, podcasts! I went on Scott Galloway’s Prof G Markets podcast, to talk about the macroeconomic implications of AI:
You can also watch a video if you prefer! Not sure why, but it looks like I haven’t shaved in a long time even though it’s only 12 hours of beard shadow.
I also went on Jayden Clark’s podcast, Members of Technical Staff, with Sam D’Amico (founder of Impulse Labs). We talked about San Francisco’s local politics, while cooking steak on an Impulse stove:1
Anyway, on to this week’s list of interesting stuff!
The Trump administration, generally speaking, has been the worst on science policy in the country’s entire history. As part of its effort to root out wokeness from American institutions, it has slashed science budgets. Thanks to its conviction that immigrants are foreign invaders intent on overthrowing Western civilization, it has blocked or scared away lots of the foreign researchers that American science depends on. And due to its bizarre political alliance with pseudo-leftist conspiracy theorists, it has elevated quasi-mystical antivaxxers to positions of authority over biomedical policy.
But at the same time, there are some people within the Trump administration who are trying to take things in a more positive direction. The Office of Science and Technology Policy recently released a report called “Science: A New Golden Age” that contains a number of interesting and promising ideas. Alec Stapp of the Institute for Progress wrote a quick summary of what he likes about the plan:
The most important proposal is probably the idea to shift funding from organizations to individual scientists:
Refocus on the Individual Scientist: Put the working researcher back at the center of America’s scientific enterprise. Free them from the growing administrative burdens that now weigh them down for nearly half their working hours. Bet on people, not just projects, by expanding portable graduate fellowships like the National Science Foundation (NSF) Graduate Research Fellowship Program (GRFP), backing early-career independence, and scaling long-horizon grants for the best and brightest modeled on National Institutes of Health (NIH) Director’s Pioneer Award. Open alternative pathways beyond standard academia, and ensure that selection rests purely on merit, not the political fashions of the day.
This is probably a very good idea on the merits. And you can also see how the OSTP folks are selling it to a skeptical Trump administration. Bypassing universities and funding researchers directly seems like it would naturally appeal to administration people who think universities are engines of woke ideology.
Another good idea is to diversify federal science funding mechanisms:
Move beyond consensus-driven peer review by adopting a broader menu of selection mechanisms suited to different kinds of science. Examples include “golden tickets” that empower individual reviewers to champion ambitious proposals, fast grants that deliver rapid funding decisions, prize challenges and advanced market commitments that pay for results, and regranting models that delegate funding authority to scientists to draw on distributed expertise…
Many of today’s most important problems are too large for an academic lab, too cross-disciplinary for a single department, and too hard to commercialize for a private corporation. Federal funding should support a wider range of performers. The recently launched X-Labs can assemble agile, time-bound teams of professional scientists and engineers to break specific bottlenecks. Advanced Research Projects Agencies (ARPAs) can empower individual program managers to make bold bets and curate researchers to execute them. Curiosity-driven institutes can give our best minds the stability needed to pursue fundamental questions over long time horizons.
Science is changing fast in the age of AI, and old funding models may not always be the best for every discipline. Also, notice that there’s a bit of industrial policy here — the mention of advanced market commitments suggests that Kratsios and the OSTP understand the intimate relationship between lab results and industrial scale-up in fields like chemistry and materials science.
Finally, OSTP wants to do metascience — they want to evaluate new funding methods as they’re implemented, to see what’s working and what isn’t:
Stand up an empowered metascience unit in federal science agencies, reporting directly to the director, with authority to run controlled experiments on review and funding mechanisms and to drive change across the organization.
I am in favor of all of these proposals. They’re very good, and most are long overdue. The problem is that they’re going to cost a lot of money. OSTP’s report isn’t a piece of legislation, or even a funding request; it’s just a plan, by one little piece of the government, that may or may not ever be implemented. Trump’s budgets still call for huge cuts to science funding, which would basically throw the OSTP plan right in the trashcan or (at best) turn it into a tiny symbolic demonstration program.
But these ideas are good enough that they need to be bipartisan. If Democrats take back the White House in 2028, they need to pick up this plan, slap a little token partisan gloss on it, maybe have Claude rewrite the language a little, and fully fund it.
I’ve been shouting about the national debt for years now (including when Biden was President), so it’s good to see other people who aren’t fiscal perma-hawks shouting about it too. One of these people is Martha Gimbel, who worked for Biden’s Council of Economic Advisors. She writes that America’s national debt is already being reflected in higher long-term interest rates:
What should matter is that the consequences of this debt are not off in the future, but already here. The government’s deficits have saddled many American families with higher costs, largely from rising interest rates. The Budget Lab, the policy research center at Yale where I am the executive director, recently estimated that congressional-spending decisions since 2015 have raised Treasury yields by almost a full percentage point, which affects what American households pay to borrow. For someone taking out a 30-year mortgage at last year’s median home price, this rise in long-term interest rates has increased their borrowing costs by about $2,500 a year, or roughly $76,000 over the life of the loan.
The bloated government budgets and waning federal revenues of the past decade are driving up costs across the board. Compared with a world in which these fiscal-policy changes did not take place, the annual borrowing costs on a typical auto loan are now up by about $120, and by about $770 on a typical small-business loan. Credit-card borrowing rates are also hovering near record highs. [emphasis mine]
Gimbel is no one’s idea of a fiscal perma-hawk. But actual perma-hawks, like the people at the Committee for a Responsible Federal Budget, are naturally freaking out even more. Here is their illustration of how government debt can spiral out of control, when higher interest rates force the government to spend more even as they depress growth and reduce tax revenues, leading to even higher interest rates:
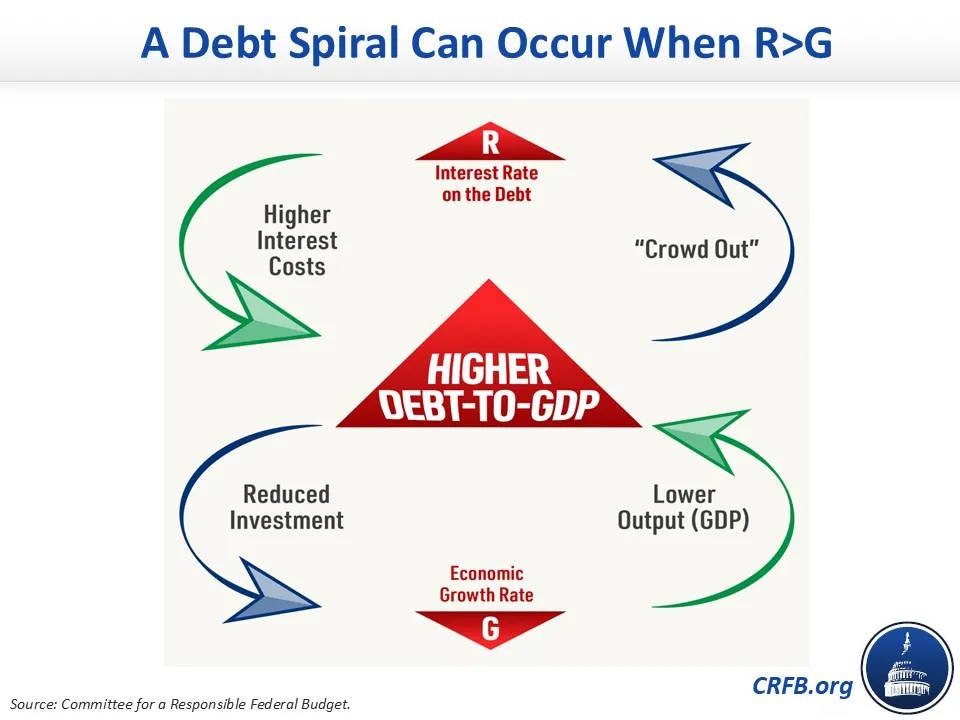
Relentlessly rising federal interest payments show why we’re in danger of this spiral right now.
Once this kind of spiral takes off, the only thing you can really do is print money, which can easily lead to horribly damaging inflation. A few macroprogressives on the left and die-hard supply-siders on the right still discount that possibility, but the experience of 2021-22 shows why Democrats and Republicans need to ignore those folks.
So what do we do? In fact, we have lots of levers to fix the debt. Here’s Gimbel again:
The main remedies for these problems—higher taxes and spending cuts—are generally politically unpopular. Every budget fix will have its critics, but some options are more palatable than others. Better funding for the IRS, for example, could help close the “tax gap”—the amount of taxes legally owed that are not paid in a timely way—which the IRS estimated at about $700 billion a year in 2022. Other levers include raising the retirement age and reducing Social Security benefits for high earners, who also tend to live longer; reforming Medicare Advantage, a program that has been shown to allow private insurers to overcharge the federal government; and removing the tax exemption on employer-provided health insurance, so that these benefits can be taxed as income. The Congressional Budget Office regularly publishes policies that could help close the deficit, and Americans need to decide what we’re willing to pay for and what we’re not.
It’ll take political will, but we managed to muster that political will back in the early 1990s. What we need, most urgently, is to destroy all vestiges of the bipartisan “deficits don’t matter” consensus that emerged in the 2010s and early 2020s. Yes, deficits DO matter.
Over the past decade or two, Europe has become increasingly hostile to the software industry. Although Europe does have a few successful software companies (SAP, Spotify), these are few and becoming fewer. Europe has generally chosen to regulate software rather than build it, enacting the free world’s most onerous software regulation — GDPR — in 2016. That regulation, which is why you have those useless, annoying “Accept cookies” popups on every website you visit, convinced European leaders that they can control the direction of software development by regulation alone — trading access to the European market in exchange for the ability of European leaders to have a say in how global software is made and run.
Why exactly Europe decided to regulate software instead of building it is a topic that deserves a deeper and longer discussion. It’s possible that European leaders just concluded, like Xi Jinping did in 2021, that software is a consumer toy that isn’t “real” technology — that it absorbs resources that are better used for manufacturing, that it doesn’t strengthen the nation or create real value, etc. It’s also possible that, like progressives in America, European leaders got negatively polarized against the “techbro” class — the industrialists who amassed vast personal fortunes figuring out new uses for software — and who used software regulation as a way to deprecate the social status of those industrialists.
But whatever it was, the European bias against software is looking more and more dangerous and self-defeating in the age of AI. AI is definitely not a toy, and not just a consumer good — it will be a crucial input into every manufacturing process on Earth, and a critical tool of national security. Countries that don’t have access to the best models may be at the mercy of those that do. They will be more vulnerable to cyberattacks, less capable of controlling drone armies (which now dominate the battlefield), and far less competitive in any export industry.
In other words, software matters now in a way it didn’t matter as much back when Europe decided it didn’t need the industry.
A group of European think-tankers and researchers have written a document called Europe 2031, illustrating the danger that their region is facing. It’s a bit long and dramatic, but it gets the point across. The report paints a vivid picture of what it would look like for Europe to become a de facto economic satellite state of the U.S. and China.
Avoiding this will require Europe to adopt a different approach toward AI than it did toward the consumer internet. Overregulation needs to be avoided, but that’s not enough. As the authors of Europe 2031 note, simple NIMBYism — similar to the kind that paralyzes the U.S. — will be sufficient to stop Europe from building data centers. European leaders aren’t just going to have to allow the AI industry to develop — they’re going to have to overcome their ambivalence toward software technology enough to fight entrenched NIMBY interests to get data centers built.
Fortunately, the Europeans appear to understand the gravity of the situation. But modern Europe has a long and storied history of issuing rhetoric and proclamations about the need for policy change, but not making anything happen. Basically, Europe needs to re-learn the political art of making things happen, because the era when it could coast on the legacy of post-WW2 industrialization has already come to an end.
The U.S. notoriously has one of the worst rail transit networks in the world. This is partly because building trains is so incredibly expensive in America. The Transit Costs Project did a deep dive into figuring out why, and concluded that there are a bunch of different factors — bad procurement procedures, lack of standardization, and so on. Basically, my interpretation of this report is that American cities and states decided that trains weren’t that important, which prompted them to A) gut their train-related state capacity, B) allow a bunch of essentially parasitic consulting firms, contractors, and unions to dominate what rail budgets did exist, and C) ignore the need to streamline regulations that prevented rail from getting built. If we started caring about trains more, we could start fixing those problems.
But it’s also notable that trains aren’t equally expensive everywhere in America. The Boyd Institute produced a good chart of the Transit Costs Project’s data, showing the dispersion of costs per mile of tunneled train in various countries:
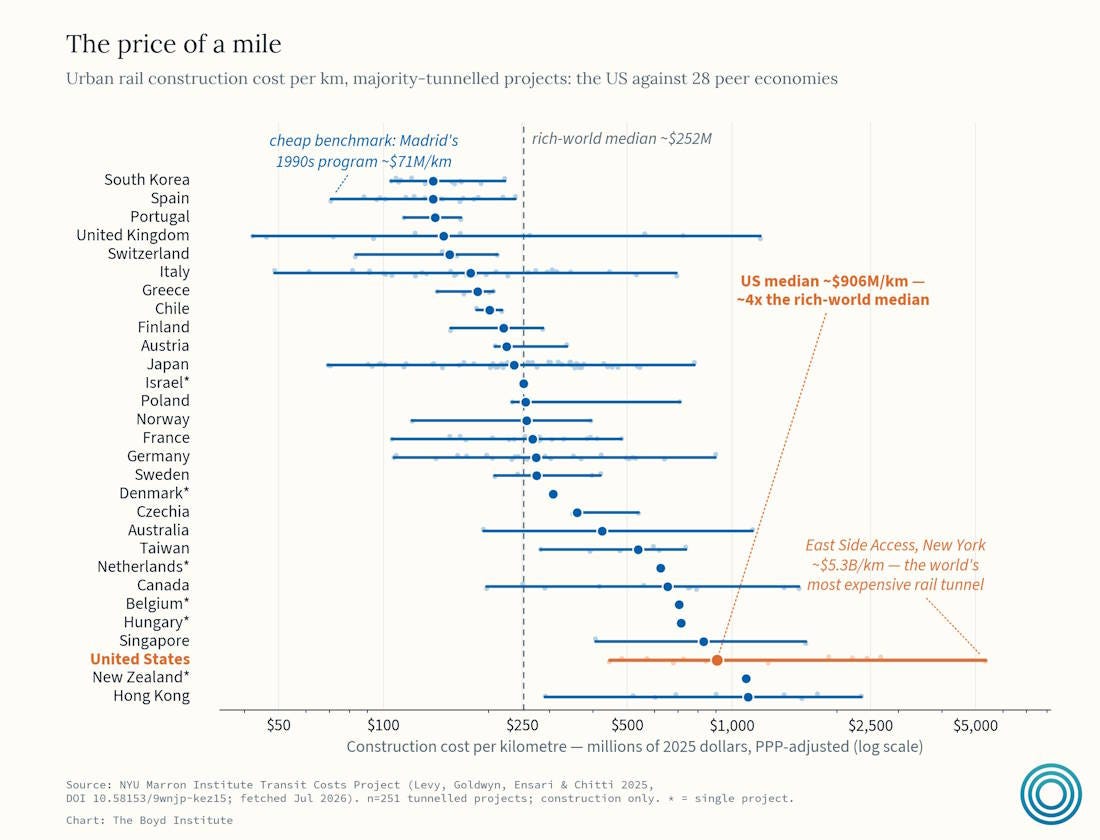
This is a logarithmic chart, so the cost differences are very big. The U.S. cost per mile is 4x that of the median rich country. But note that in median terms, we’re barely more expensive than Singapore, and we’re actually cheaper than Hong Kong — both of which have great rail networks. If we wanted to, we could build great trains too, like Singapore and Hong Kong, despite the costs.
But we don’t. To me, this drives home the fact that our cost problem has a feedback loop with our unwillingness to build. Yes, high costs make us less willing to build trains, but not building trains keeps costs high. If we’re going to get better rail in America, we can’t only focus on pure cost factors like station standardization and procurement processes (though these are important). We’ve got to want to build more trains! That probably means things like denser development patterns and less crime and disorder on trains.
But the chart also shows something else — a few train systems, like NYC’s, cost an absolutely enormous amount. NYC is already train-dependent, so their problem isn’t a lack of trains — it’s the inefficiency, corruption, and incompetence they’ve allowed to become endemic in their system. So in NYC, the problem really is just fixing the system. The Transit Costs Project does have a new report on how to do exactly that, but it’ll require New Yorkers to get very mad at their government and demand change.
“Critical minerals” are metals that are very important for modern technology — traditional industrial metals like aluminum, nickel, and cobalt, rare earths like neodymium and yttrium, and others like gallium and germanium. For years now, American leaders have understood that our country is in grave danger from China cutting off our access to many of these critical minerals.
But a lot of Americans seem to still misunderstand why that danger exists. A lot of people seem to think that it’s all about mining the minerals, and that if we just A) discovered more deposits, and B) loosened regulation enough to allow mines to be constructed, America would have ample supply of these metals. This is wrong and misinformed. The reason China controls our supply of critical minerals is not because we don’t mine these metals, it’s because we don’t refine them.
When you dig metal up out of the ground, it’s not in a form you can use in industrial applications. To turn it from ore into something usable takes a bunch of steps — mostly, dunking it in various baths of chemicals. This is called refining.
Most critical mineral refining is done in China. Every year the IEA comes out with a report on critical minerals. Here’s a chart from this year’s report that shows how dominant China is in refining, even for things like cobalt that China mines very little of:
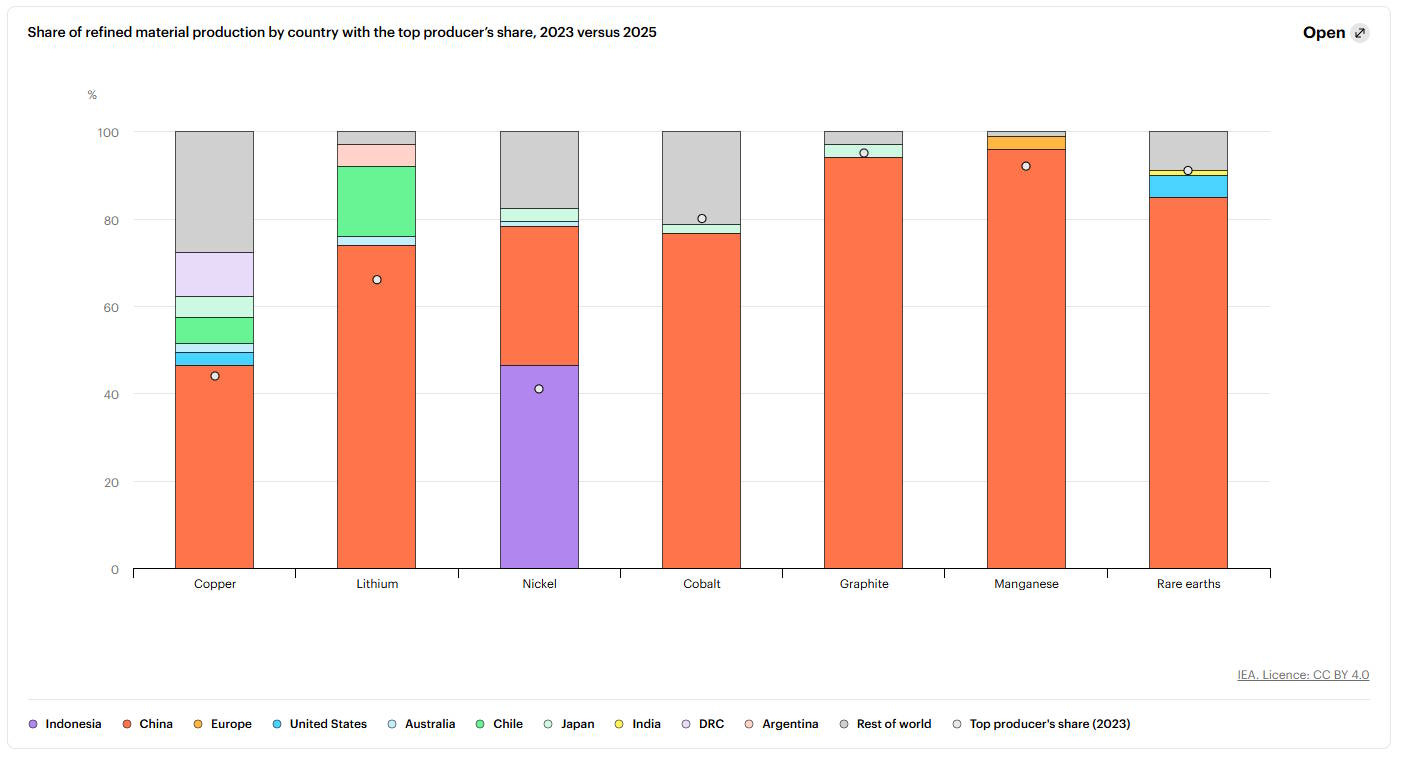
In fact, China is becoming even more dominant in minerals like lithium and manganese. This is despite the fact that other than graphite and gallium, China doesn’t dominate the mining of any of these metals.
Why does China dominate refining of critical minerals? A few reasons:
China dominates the downstream industries in which some of these minerals are used. For example, China makes most of the world’s lithium-ion batteries, so it makes economic sense to locate lithium refining near to the Chinese factories.
China’s financial system gives a huge amount of cheap bank loans to companies that refine critical minerals, making it very cheap to finance these expensive plants.
China has somewhat looser environmental restrictions than Western countries.
China has been investing heavily in metal refining for decades, meaning that they’ve built up a tremendous amount of distributed tacit knowledge in difficult refining processes (such as rare earth refining).
If the U.S. and its allies want to get out from under the Chinese yoke, they will need to address all of these shortcomings at once. They’ll need to promote downstream industries like batteries (which Trump has discouraged and attacked) and electronics. They’ll need to revamp their financial systems to allow big loans for refineries. They’ll need to loosen environmental restrictions in targeted, judicious ways. And they’ll probably need to use AI to quickly reproduce the distributed tacit knowledge that makes Chinese refineries so efficient.
One big barrier to Indian industrialization is that women in India haven’t gone to work en masse. In most countries, industrialization starts when a ton of women move off of farms into cities and work in factories doing “light industry” — clothing, fabrics, toys, electronics assembly, and so on. This creates manufacturing companies with the capital and know-how to move up the value chain into more valuable and capital-intensive parts of manufacturing. Eventually the wealth created by high-value manufacturing creates the demand for high-value services industries.
That’s the typical story, but in India it isn’t working yet. This isn’t because factory automation has made labor-intensive “light industry” irrelevant — witness Bangladesh, which has grown a bit faster than India since 2004, largely on the back of its garment industry. Bangladesh has a relatively low female labor force participation rate, but it has increased its rate steadily over the decades. India has not; women in India are much less likely to work outside the home than women in other developing countries throughout the region:
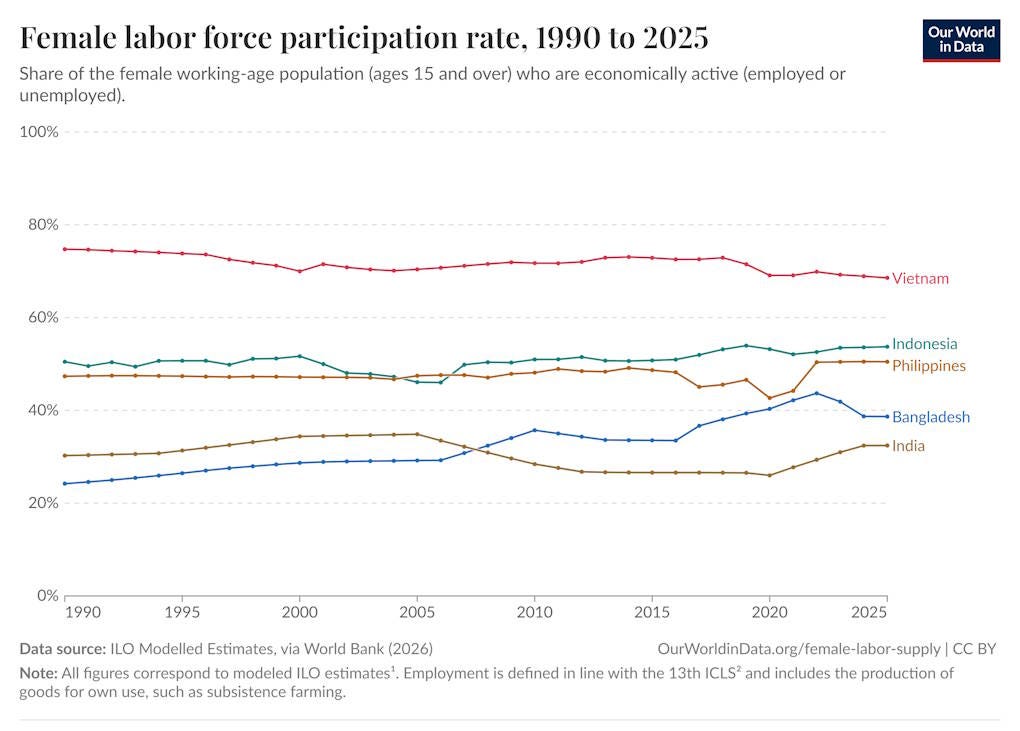
Goldman Sachs analysts believe that getting Indian women out of the house and into the factory represents a huge economic opportunity. But Indian society seems to be resisting this.
A new paper by Alison Andrew and Andrea Smurra helps us shed a little bit of light on what’s going on. Low-income Indian women are increasingly not even leaving their homes:
We use rich time-use data on where, and how, individuals spend their time to quantify and describe women’s seclusion in India. We document extremely high levels of seclusion with the median married woman leaving home for just 0.5 hours/day and 45% not leaving home at all on a given day. Seclusion has increased markedly over the past two decades. While richer and more-educated women were, and still are, the most secluded on average, this gradient has flattened over time….Women are more likely than men to specialize in activities that are more readily done at home but are also more likely to carry out any given activity at home.
Why are Indian women becoming such hikikomori? Why hasn’t the lure of factory jobs been enough to draw them out of the countryside to the bright lights of the big city, as it was in Bangladesh, Vietnam, China, and a bunch of other countries? Andrew and Smurra don’t even hazard a guess. It’s not because they’re busy having lots of kids; Indian fertility rates are low and falling. Part of it might be simple lack of awareness of economic opportunities in factories. But whatever it is, it presents a big economic problem for India.
A lot of people like to have nostalgia for the 1950s. In fact, measuring by the murder rate, America is actually less violent now than it was back in the 50s (after a brief spike in the late 2010s and early 2020s):
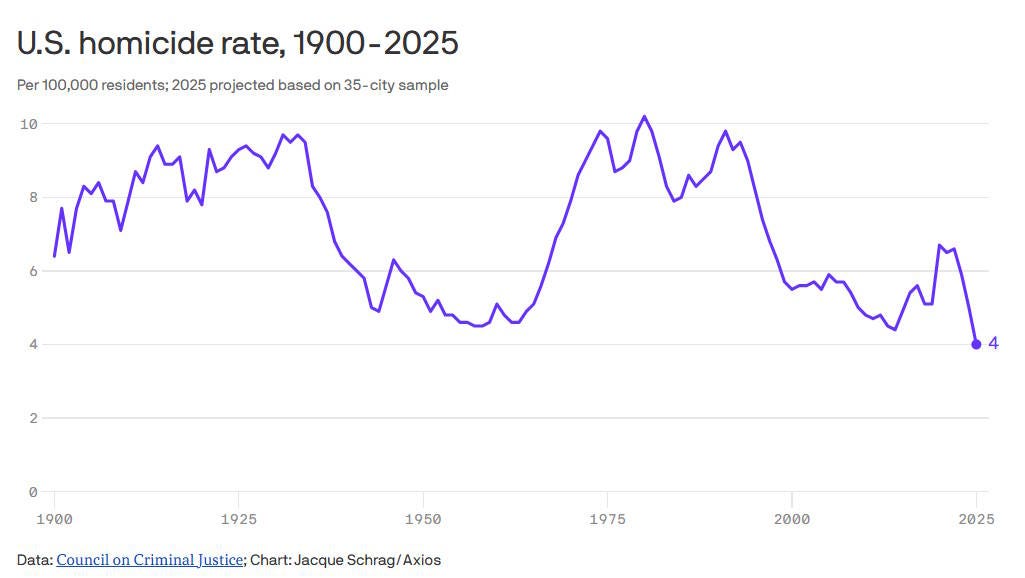
People who think of the 1950s as being very safe tend to instinctively resist this conclusion; they think something must be wrong with the data. And so many latch on to the myth that murder rates have only fallen because of improved trauma care in American hospitals.
But it’s just not true. In a recent blog post, Jeff Asher explained how this myth got started, and how we know the narrative is wrong:
Basically, the myth rests on a 2002 paper by Harris et al., claiming to show that Americans are getting shot more and more often, but are surviving the shootings much more, leading to a decline in death but a rise in violence. Here’s their key chart:
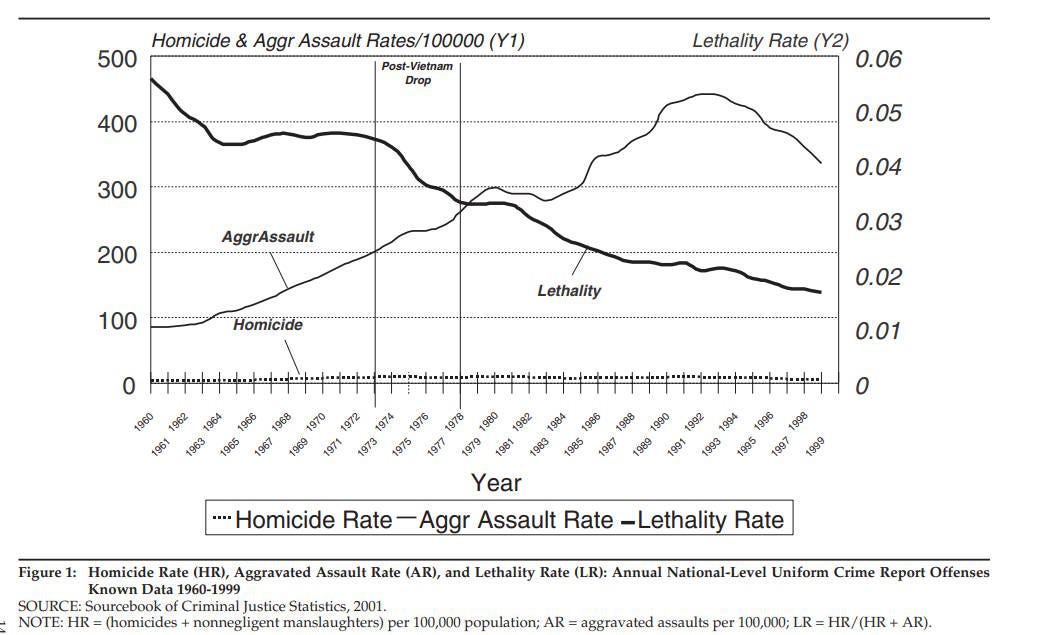
So what’s wrong with this chart? The data on “lethality” isn’t official data — it’s just the authors dividing the aggravated assault rate by the murder rate.2 And the aggravated assault data they use is bad. They use the aggravated assault rate as reported by police. But as Asher explains in his post, American police forces got a lot more professional and thorough throughout the late 20th century. If someone hit you with a bat in 1955, there was a good chance you wouldn’t call the cops, or they wouldn’t record the incident. By 1995, there was a much better chance.
In fact, we can just go and ask people if they’ve been the victims of a shooting or an assault. When we do that, we can easily see that even as police-reported shootings rose in the 70s and 80s, shootings reported by victims didn’t rise:
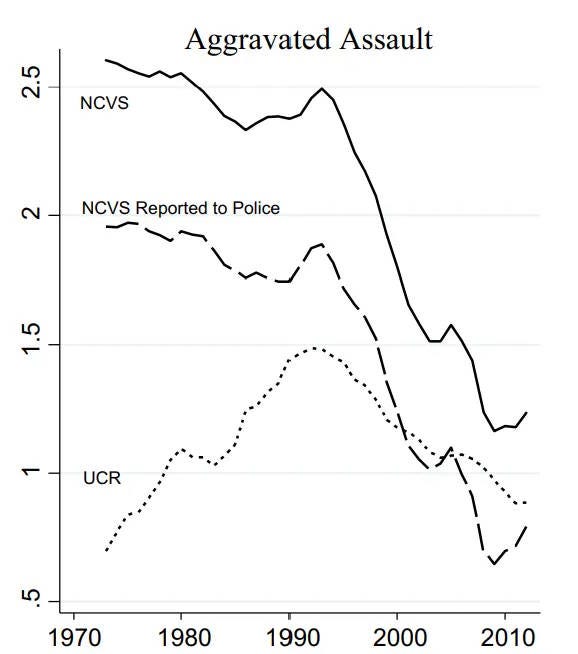
So did aggravated assaults really rise in the 60s, 70s, and 80s? Almost certainly not. So aggravated assaults were probably not becoming less lethal over that time period. Yes, we had better trauma care, but we also had a lot better guns and a lot more dedicated murderers.3
In other words, America today really is about as safe as 1950s America. Sure, violence in the 50s was concentrated in poor and Black neighborhoods, but that’s true today too.4 What really changed in America since the 50s isn’t the lethal sort of violence, it’s urban decay and disorder. That’s what we need to focus on fixing.
Disclosure: I own shares in Impulse Labs.
This rests on the bad assumption that aggravated assaults are just unsuccessful murders. In fact, most aren’t. But anyway, that isn’t the main reason the chart is bad.
My guess is that a lot more murders these days are connected with the drug trade than in the 1950s, meaning that big money is at stake instead of just momentary passion.
Of course as I often point out, one reason America is as safe as it is today is because people moved out of the inner cities. Suburbanization acts as a defense-in-depth against street violence. So some of the 50s nostalgia isn’t misplaced. But nice suburbs in the 50s — the kind you see in all the nostalgic photos and old advertisements and memes — were probably a little more violent than the equivalent suburbs of today.
2026-07-26 15:56:22

“[I]ntelligence, that counterentropic conjoined twin of information, must become the most powerful force in the universe, the energy to which all other physical laws must eventually kneel…Intelligence was destiny, manifest.” — Ian McDonald, “Verthandi’s Ring”
Not a lot of people expected that AI would come for the mathematicians before it came for the truck drivers, but it did. The other day, an AI model disproved the Jacobian Conjecture — an 87-year-old open problem that human mathematicians had struggled to solve. The greatest living human mathematician, Terence Tao, turned to AI to help him understand the solution. Around the same time, AI solved a very important open question in quantum cryptography. Solving Erdos problems has now become almost child’s play for the best AI models. And this is the worst AI will ever be at math. Model capabilities, and the amount of compute available, both continue to increase at rapid rates. (Meanwhile, long-distance trucking employment is slightly higher than it was a decade ago.)
I don’t expect mathematicians to actually lose their jobs en masse, of course.1 But it’s becoming clearer and clearer that humankind has invented machines that are smarter than we are. Intelligence isn’t defined for machines the same way it is for humans — AI’s capabilities are spiky in different ways than ours — but it’s undeniable that the technology is improving rapidly in every domain of cognitive capability. It’s still possible to find some mental tasks that humans are better than machines at, but those final advantages tend to disappear almost as quickly as we can identify them. “AGI”, or “ASI”, or whatever you want to call it, is certainly here.
And yet…the world remains much the same. In lots of sci-fi books, as soon as artificial superintelligence arrives, it bootstraps itself to even more godlike intelligence in an explosive “singularity” that rapidly transforms the entire physical universe. Lots of people, especially “AI safety” and “effective altruist” types, expected things to play out basically the same way in reality. But looking around, not much has changed since we entered the intelligence explosion. There’s a huge data center boom, and most people use AI on a daily basis, but we still live basically the same lives — driving to work or taking the train, sitting in front of a computer, scrolling on our phones, collecting a paycheck. People are staying in their jobs longer, but employment hasn’t been disrupted in a significant way:
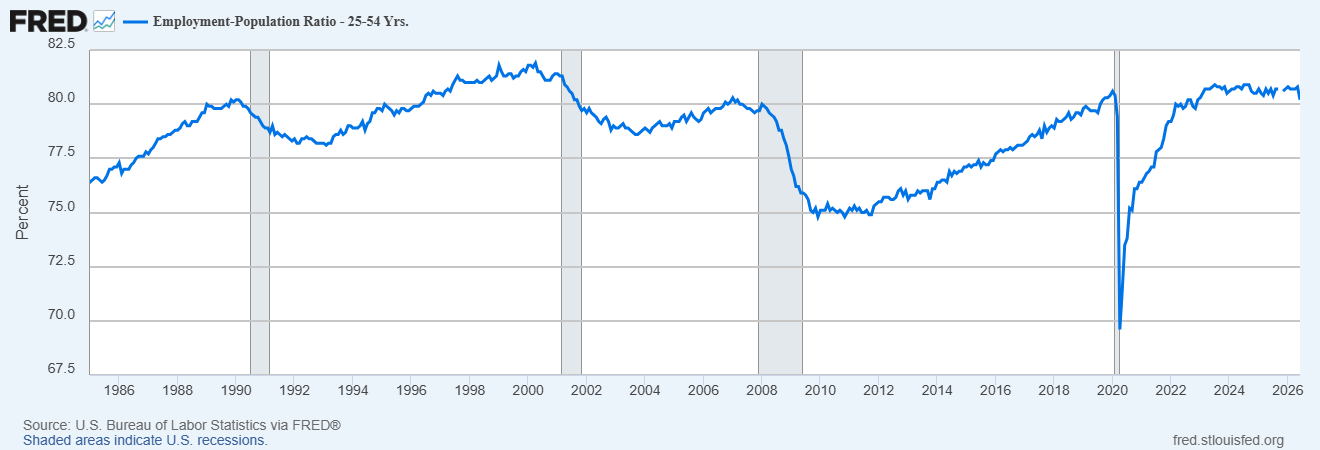
Meanwhile, we’ve had decently robust productivity growth, but nothing really amazing:
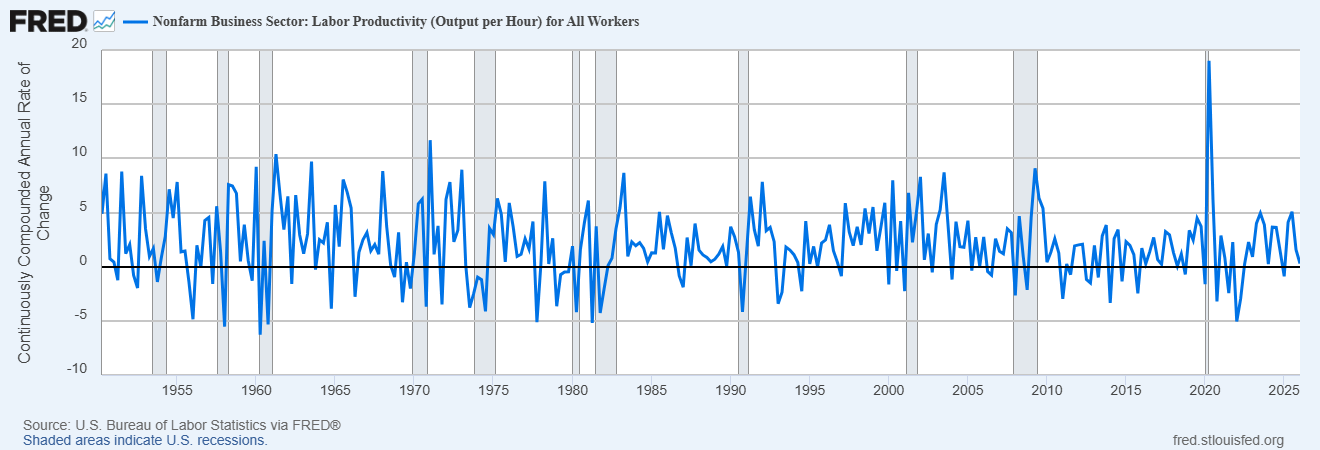
A lot of people I know are surprised by this. Ruxandra Teslo writes:
Walking around the world today one might notice that it is weirdly unchanged…To many, this is surprising. Just the other day I was at a conference where someone remarked that if he could have seen today’s AI capabilities a few years ago, he would have been astonished — and would have assumed the world by now would look far more transformed, with much higher GDP growth.
And Clifford Sosin writes:2
Superintelligence arrived. You probably didn’t notice, because it turned out to be kind of incremental…Don’t believe me? Run the test. Talk to Fable 5 for an hour, then talk to your ten smartest friends. Which one is smarter? Don’t worry, they won’t be offended…We were told to expect something bigger. Once machines crossed some line, the system’s IQ would climb to heights we couldn’t follow, and we’d be sharing the planet with something that designs warp drives and thinks thoughts as far past us as mine are past my dog…What we got is a tool that writes excellent code, beats people at a startling range of tasks, and will clearly reshape the economy. It’s also, somehow, incremental. No takeoff. No explosion. That’s the strange part.
Teslo blames bottlenecks — governance and other “frictions” — for the slow economic impact. But some others are advancing a more radical hypothesis3 — that intelligence itself is subject to diminishing returns.
One of these is Francois Chollet, an AI researcher who specializes in measuring AI’s capabilities. In a highly controversial series of tweets back in March, he conjectured that intelligence might be subject to diminishing returns:
One of the biggest misconceptions people have about intelligence is seeing it as some kind of unbounded scalar stat, like height. "Future AI will have 10,000 IQ", that sort of thing. Intelligence is a conversion ratio, with an optimality bound. Increasing intelligence is not so much like "making the tower taller", it's more like "making the ball rounder". At some point it's already pretty damn spherical and any improvement is marginal.
Now of course smart humans aren't quite at the optimal bound yet on an individual level, and machines will have many advantages besides intelligence -- mostly the removal of biological bottlenecks: greater processing speed, unlimited working memory, unlimited memory with perfect recall... but these are mostly things humans can also access through externalized cognitive tools.
In fact, this is a possibility I myself had raised in a post a year earlier:
It seems possible that humans are simply incredibly specialized in a few types of cognitive tasks — extracting patterns from sparse data, synthesizing various patterns into “intuition” and “judgement”, and communicating those patterns in language — and that we’ve basically approached the theoretical maximum in those narrow areas…That would explain why AI has gotten much better at things like math and coding and forecasting over the last year, but why the basic chatbot interface doesn’t seem much more “intelligent”. It would also explain why when you talk to Terence Tao about math, it’s like talking to a superhuman, but when you talk to him about where to get lunch or which movies are the best, he’ll just sound like a fairly smart normal dude. AI will eventually get better than Tao at math…but it may never get much better than the most thoughtful, eloquent humans at deciding where to get lunch or recommending movies. It may simply not be mathematically possible to get much better than we already are at that sort of thing.
Why would intelligence top out like this? Well, if we think of intelligence as the ability to extract information from data, then even an infinitely advanced model endowed with infinite compute will be limited by the fact that there’s a limited amount of information that can be extracted from the data.
For one thing, data itself is in limited supply. You can’t transform the world unless you can (in some generalized sense) understand it, and you can’t understand the world unless you can measure it, and our ability to measure the world is inherently limited and finite.
This is basically the hypothesis advanced by Arvind Narayanan and Sayash Kapoor:
We think there are relatively few real-world cognitive tasks in which human limitations are so telling that AI is able to blow past human performance (as AI does in chess). In many other areas, including some that are associated with prominent hopes and fears about AI performance, we think there is a high “irreducible error”—unavoidable error due to the inherent stochasticity of the phenomenon—and human performance is essentially near that limit….We predict that AI will not be able to meaningfully outperform trained humans (particularly teams of humans and especially if augmented with simple automated tools) at forecasting geopolitical events (say elections).[emphasis mine]
Sosin says something similar:
We hold a thin scatter of facts about the world, and intelligence or reasoning is whatever fills the space between them…Where the space between the facts behaves well, this is close to godlike…Coding, math and most administrative work are [like this]. What makes them easy is that they have relatively smooth solution spaces and are tractably verifiable…Most of what matters doesn't behave like that. The universe is mostly the emergent behavior of complex systems…The limit is contact with reality. A smarter reasoner fills the gaps between known facts in simple areas faster and better, but it doesn't produce new facts.
Sosin makes an important point here, which is that the limitations of intelligence aren’t necessarily about limited data. Even if we can keep on collecting infinite data, the cost of extracting additional information from that data might explode to infinity. This is the idea of chaos. Even in a deterministic universe where the present states of all particles are enough to perfectly determine the future, our ability to predict the future can be inherently limited; the tiniest infinitesimal error in our measurement of the present explodes into a huge error when we attempt to extrapolate even a small distance into the future.
So although we don’t know yet, it’s possible that humans were already hitting the point of diminishing returns with regards to individual cognitive capacity, and that superintelligent machines will never be as far beyond us as we are beyond dogs. But even if that’s true, I can think of at least three reasons why machine superintelligence could still deliver huge productivity gains.
The most obvious advantage that machine superintelligence confers is replicability. The number of human intelligences is fixed by the fertility rate, and we don’t know how to substantially boost that rate; in fact, it’s falling inexorably, and the human race is set to shrink.
AI isn’t bound by those limitations. By building more data centers with more compute, you can run more agents in parallel — essentially, you get more cognitive work. It’s not free, but nor is it limited. It’s good old physical capital; unlike human capital, you can just build more of it whenever you like, simply by reinvesting some portion of your economic output. Imagine if we suddenly discovered a way to manufacture more land in any city on the planet; this is similar.4
Of course, lots of tasks are physical ones, and for these you need physical machines — basically, robots. This is probably why so many AI people are now working on robotics, world models, physical AI, and so on. The roboticization of the world has a huge tailwind — the battery revolution, which allows energy to be stored and moved around much more easily. Conveniently, we got the physical tools to turn dumb matter into smart matter just as we also got the digital tools.
(It’s also worth noting that like the energy in batteries, the intelligence in robots is divisible. A robot the size of an ant can be remotely controlled by a data center the size of a football field. This is also a capability that human intelligence lacks.)
This doesn’t mean economic output will explode to infinity. But what it does mean is that humans will be able to use physical capital — GPUs and robots — to do more and more tasks at once, including many cognitive tasks that we used to do the hard way. In the long-run steady state, this should increase the capital-to-labor ratio of our society; each human will essentially leverage an army of intelligent machines. It’s basically another industrial revolution, and it has very little to do with whether artificial intelligence is smarter than human intelligence in any sort of head-to-head matchup.
The German company Zeiss makes the best glass on the planet. If one of the mirrors that Zeiss makes for ASML’s EUV chipmaking machines were the size of Germany, the biggest bump on that mirror would be just one millimeter high. Only a few other companies — and maybe no other company on Earth — can match that. Zeiss’ mirrors also have a number of other amazing properties, like not distorting much due to temperature changes.
How does Zeiss make glass this good? No one knows — not even the people at Zeiss. If the technology were capable of being written down on a blueprint, China would have hacked Zeiss and stolen it, the way Huawei hacked Cisco and Nortel. If the technology were capable of being explained by a former Zeiss employee, or even several former Zeiss employees, China would have paid those people many millions of dollars to spill the beans.
Zeiss’ technology basically can’t be stolen, because it’s tacit and distributed. It consists of a vast number of little tricks and techniques that a huge number of individual employees use on a daily basis. These people don’t always even realize all those little things they’re doing that make the glass come out so good. And each employee knows a different set of tricks and techniques. The knowledge exists at the level of the organization itself, and is thus very hard to steal or recreate.
This is true of lots of corporate technology. A big part of the reason China can cut off the supply of rare earths to the rest of the world any time it wants to is that other countries aren’t very good at refining rare earths. Rare earths are difficult to separate from each other in solutions; it takes a ton of little chemistry tricks to do it cheaply at scale. Chinese refiners have spent four decades building up those little tricks and techniques; American or Japanese refiners won’t simply be able to replicate their efficiency overnight, and so it’ll continue to cost much more to produce rare earths outside China.
Except in the age of AI, this might change. Suppose American rare earth refiners give their employees a bunch of equipment to record everything they do — smart glasses, gloves, and so on — in addition to sensors distributed throughout their plants. AI will be able to synthesize all that information and very rapidly suggest small ways to improve the production process. Many of those little experiments will fail; others will succeed and will quickly be adopted, allowing another round of experimentation and improvement to begin very quickly. Crucially, AI’s ability to do this doesn’t depend on its raw intelligence — only on its ability to handle huge amounts of data very quickly.
In other words, in the age of AI, distributed tacit knowledge might not be nearly as big of a barrier to technological diffusion. This could improve economy-wide productivity, as lagging firms catch up to leading firms much more quickly. A more equal distribution of productivity would also make the economy more competitive, creating more surplus for consumers (though possibly reducing the incentive for firms to innovate, by making technology less excludable).
AI’s ability to quickly produce distributed tacit process knowledge might also supercharge productivity growth at the frontier. Imagine if any company could optimize any production process five times faster than today. The whole economy would speed up, as components got cheaper, turnaround times and product cycles got shorter, and scale-up got much faster.
And as with the previous example, improving the production of distributed tacit knowledge wouldn’t depend on AI’s raw intelligence. It would spring from AI’s ability to act like a computer — to interface directly with sensors, to handle lots of data, to perceive tiny details, and to do everything very very quickly.
For decades, researchers in the field of natural language processing tried to figure out the principles behind human linguistic communication. They made frustratingly little progress; the processes by which humans convey information to each other through words just don’t seem to obey simple laws, like the ones that govern electromagnetism or the circulatory system.
Then along came AI, and suddenly linguistic communication seemed like a solved problem. LLMs can reliably sound like a human being, even if we don’t understand how they manage to do it.
What if there are lots of other aspects of the Universe that work the same way — too complex to understand in terms of simple laws, but not so complex that they just dissolve into unknowable chaos? It’s possible that we can reliably control these complex phenomena with AI, even if we never reduce them to the kind of principles that we can teach a grad student in a textbook. In fact, I wrote an essay called “The Third Magic”, where I suggested that this might be equivalent to a whole new scientific revolution:
Another way of saying this is that there may be laws of the universe that humans can’t understand but AI can. I call these “cloud laws” — causal regularities that can be exploited by technology, but which are too diffuse and complex for an individual human being to either intuit or communicate.
Human language seems to obey cloud laws, so why not other phenomena too? Perhaps social sciences like economics, sociology, and political science obey similarly complex regularities, and AI can help us find them. Perhaps there are physical processes — plasma, or topological materials, or aerial turbulence, etc. — that obey cloud laws instead of chaos?
In other words, thanks to AI, we might be on the precipice of a new age of scientific advancement. And this won’t necessarily depend on how smart AI is in comparison to a single human; it’ll depend on its computer-like ability to hold huge amounts of data in its working memory and extract complex patterns from that data.
If this turns out to be true, it means Francois Chollet is wrong. Chollet hypothesizes that groups of humans, using pre-AI computing tools, can approach AI’s level of scientific competence. But human collaboration is bottlenecked — it’s limited by our ability to intuit patterns at an individual level, and to communicate these patterns from one individual to another. AI, being a computer, just doesn’t have this sort of limitation; it can work with vast, diffuse patterns without having to break them into pieces or simplify them in order to compress them into the tiny pipelines of person-to-person explanation.
So even if AI never gets much better than humans at the kind of science that humans have done heretofore, it might open up whole realms of scientific discovery that have previously been totally inaccessible to even the largest groups of the smartest humans. If much of the Universe turns out to be ruled by cloud laws, we could be on the precipice of a scientific renaissance.
The common thread in all three of these examples is that AI may revolutionize productivity not by being much smarter than a single individual human — not by simply solving harder and harder math problems — but by marrying human-style intelligence to the vast, inhuman capabilities of computers. We could simply be thinking about the benefits of intelligence wrong — arrogantly privileging the kind of mental tasks we humans happen to do especially well, while ignoring the value of the tasks we do poorly.
Why? Several reasons. Tenure still exists. Humans who can do math at a high level will still be needed if we care about understanding the results that AI spits out. Human math teachers will still probably be valuable. And most importantly, humans will be needed to tell AI what kind of math we want it to solve, and why.
Or at least, prompts AI to write.
I think there is a widespread, tacit assumption among many intelligent humans that the quality that had made them stand out among their peers was the fundamental stuff of the Universe, the font of all value. I will write more about this at some point, but I think it helps explain why the idea that intelligence is just one production factor among many seems so unthinkable, heretical, and revolutionary to so many people in the tech industry.
Yes, I know we can reclaim land from the ocean. But the opportunities for this are fairly limited, and the cost is often very high.
2026-07-24 15:46:56

The story of the rise and possible impending fall of the American university system is, in many ways, the story of modern America. It ties together the changes in our culture, our economy, and our politics since the mid-20th century. Understanding why universities came to be our most important and most functional institution, and why that model is now under threat, can help us understand how our country might look different going forward.
Let me try to tell a condensed version of that story.
The United States used to have a bunch of institutions that bound us together and forged us into a unified society. Many American communities were centered around churches; these facilitated networking, helped people find spouses, provided community services like day care and mutual aid, and homogenized values and culture at the local level. During the World Wars (and to a lesser extent, the Vietnam War), the military was very large and threw together Americans from various social classes. In the early postwar decades, corporations were also a unifying institution. Mass media provided us with shared cultural context. Even public transit put people of various backgrounds in close social contact on a daily basis.
In the half-century from around 1970 to 2020, those unifying institutions became much weaker. Church attendance slowly declined and then fell off a cliff in the 2010s. The military shrank into a small, professionalized volunteer force. Corporations ended their brief flirtation with lifetime employment, and outsourced many of their roles. Mass media fragmented in the age of the internet. Public transit dwindled in importance as Americans moved to the suburbs and drove.
As the country’s unifying institutions withered, one new institution attempted to step into the void: the American university. Universities were not new in the late 20th century, of course, but mass attendance certainly was. From 1970 to 2020, the share of Americans age 25-29 with a bachelor’s degree went from 16.4% to 39.6%. Around two out of three have completed some college.
College went from something that only the upper crust did, to something that most people were expected to do if they wanted to be economically successful in life. This expansion inadvertently but inevitably thrust a new role on American universities — that of a broad socially unifying institution. College was where people from a variety of backgrounds mingled and mixed — not just in classes, but in dorms, campus activities, and college towns.
College became the new church, the new military, and the neighborhood bowling alley all rolled into one. Instead of preachers homogenizing Americans’ values from the pulpit, university administrators taught college kids to value things like diversity, consent, and so on, and college students hashed out their own differences in millions of late-night dorm room discussions. Instead of meeting their first love in high school, Americans increasingly delayed sex until college; many of these relationships turned into marriages. Young people went into college as children and came out adults.
This was a heavy burden to bear for an institution that hadn’t been designed for it. But American universities were accustomed to taking on big new duties. Our universities began as essentially a copy of the British model — teaching-focused institutions designed to provide broad education and mentorship to the upper class. In the early 20th century they tacked on the German model — a research-focused lab apprenticeship system by which top scientists taught other top scientists and readied them for research jobs while also producing cutting-edge basic research.
This dual system enabled a remarkable form of cross-subsidization. Undergrad tuition payments — and state support for undergrad education, and undergrad alumni gifts — created a flood of money that paid for grad student stipends, lab facilities, professor salaries, and more. The federal government and companies also funded university research, of course, through grants and sponsorships. But undergrad money was a huge tailwind. And the prestige generated by successful and famous researchers helped universities charge undergrads more.
The hybrid of the old British and German models was naturally symbiotic, and it meant that even as America’s other institutions came under pressure, universities thrived and grew — especially once they used their prestige to attract high-paying and highly skilled foreign students from around the globe. Universities became the lynchpin of America’s research effort:
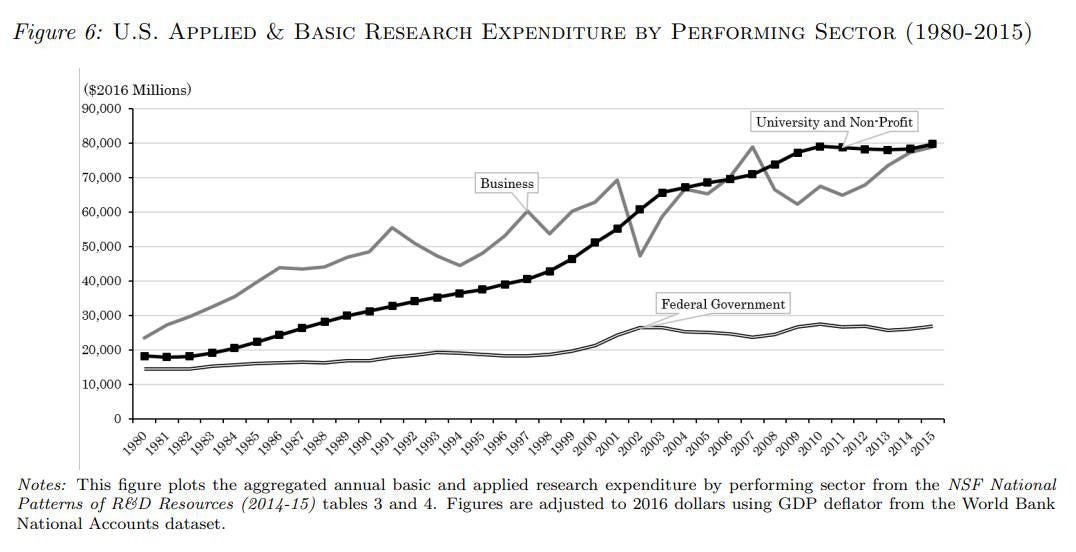
American universities had a lock on both the nation’s research output and on its production of human capital, and those roles were mutually reinforcing.
I suspect that their success at handling education and research at the same time probably gave American universities a lot of confidence about their ability to handle society and culture as well. Colleges spent more and more on dorms and “student services” and hired administrators (many of whom dealt with undergrad life) at an astonishing rate.1
But replacing churches, the military, and the neighborhood bowling alley proved harder than replacing the corporate lab had been. There was just one basic problem with college as America’s primary unifying institution, which is that not everyone can go to college.
First of all, college is difficult. To complete college courses, you need some degree of raw intelligence, but you also need work ethic and a certain degree of independence. As much as we might like to believe otherwise, not everyone in America has those traits, and we don’t yet know how to instill them in everyone. As a result, there’s a limit to how much you can expand college enrollment — and college completion — without loosening standards.
In fact, loosening standards is exactly what American colleges have done. Universities have necessarily become less and less selective over the years, as they have taken in a larger and larger fraction of the young American population. For a while, this led to lower college completion rates, but in the 1990s, more and more students began finishing their bachelors’ degrees. Why? Because colleges implemented grade inflation, making it easier to finish school without learning the material well. Here’s Denning et al. (2021):
We find that most of the increase in graduation rates can be explained by grade inflation, and that other factors such as changing student characteristics and institutional resources play little or no role. This is because GPA strongly predicts graduation and that GPAs have been rising since the 1990s. This finding holds in national survey data and in records from 9 large public universities. We also find that at a public liberal arts college, grades increased holding performance on identical exams fixed.
At some point, though, this process hits a wall. A large fraction of young Americans just isn’t prepared for college, even with grade inflation, and doesn’t end up going. College enrollment by recent high school graduates plateaued in the early 2000s and actually fell back to early 1990s levels during and after the pandemic:
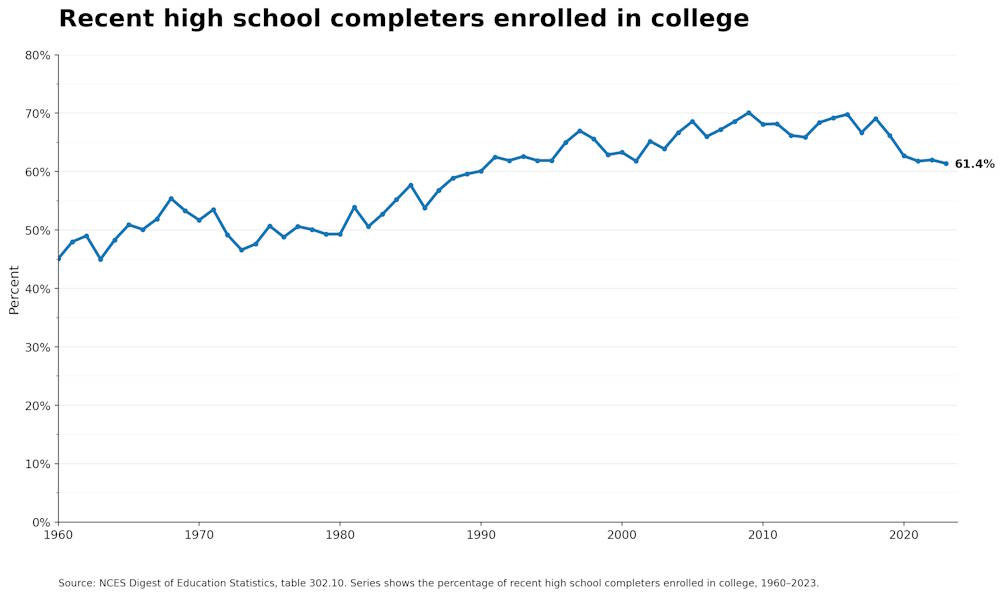
2026-07-22 15:34:05

Let’s take a break from discussing the insanity of American politics, the tragedy of British economic mismanagement, and other weighty topics, and talk about something fun and light. Who was the greatest monster of the 20th century?
Well, ok, that’s not really fun and light. The 20th century featured hundreds of millions of people slaughtered in wars, genocides, political persecutions, and preventable famines. Many of my own extended family members were killed in the Holocaust, and I have plenty of friends whose relatives died in World War 2, the Great Leap Forward, the Cultural Revolution, the Cambodian Genocide, and other such calamities. Those deaths are even more tragic because of all the good things that were happening in that century — the fabulous economic growth and technological progress. Everything could have just been a smooth upward glide to luxury and comfort, and yet people were still being machine-gunned into mass graves.
With time, the emotional power of those events fades — Genghis Khan killed tens of millions in his campaigns of conquest eight hundred years ago, but today he’s more likely to be invoked as a joke, or an object of reverence, than as a monster. It can happen surprisingly fast. By the early 2000s, hipsters in my dorm were already hanging ironic Chairman Mao posters in their rooms. Today, you can see leftist pundits like Hasan Piker praising Mao without a trace of irony:
Plenty of other leftists joined in the Mao lovefest.
Piker is wrong, of course; if you read the authoritative biography of Mao by Jung Chang and Jon Halliday, you’ll see that the dictator repeatedly aggrandized himself at China’s expense, willfully derailing multiple periods of reform and recovery by launching the country into destructive episodes of chaos like the Great Leap Forward and the Cultural Revolution. Nor was he much help against the Japanese invaders in World War 2, preferring to let them fight and weaken his Chinese rivals (again, at the expense of many Chinese lives). It was Deng Xiaoping, not Mao, who made modern China great.
But the people who say that Mao was history’s greatest tyrant, with an unsurpassed body count of 40-50 million people, are also probably overreaching a bit. Yes, about 36-40 million people did die in Mao’s Great Famine, caused by his various foolhardy agricultural policies and the inefficiencies of China’s communist economic system. Nor was this merely an accident; even after Mao learned that his policies were failing, he kept them in place to avoid losing face in front of CCP rivals. But killing tens of millions of his own people was never Mao’s plan.
Intent is an important factor to consider when ranking history’s greatest monsters. The reason has to do with why we should care about the question. The point of ranking evil regimes isn’t to have fun marveling at the scale of human brutality — it’s not like trying to figure out what the biggest dinosaur was, or whether Michael Jordan was better than LeBron. Sometimes real life forces you to choose between monsters.
In World War 2, America had to decide whether allying with Stalin against Hitler was worth it, or whether we should simply sit it out and be neutral as the two villains slugged it out. Our decision probably tipped the course of the war. Later, we formed a quasi-alliance with Mao’s China against the Soviet Union, helping to hasten the latter’s downfall.
Many populations, of course, have an even grimmer choice — they have to choose which ruthless, cruel regime to support in a civil war. If you lived in Syria in 2016, did you support Bashar al-Assad, ISIS, or offshoots of al Qaeda? If you lived in Russia in 1919, did you support the Reds or the Whites? And so on.
So when we ask “Who was worse”, the question is actually pretty relevant. Obviously it’s a matter of opinion, but I think some factors we should consider when assessing the horribleness of a regime are:
Overall death toll during the regime’s time in power
How much of the death toll was intentional
How much of the death toll was willful versus accidental
How harmful the regime was relative to the size of the population it controlled
What other bad things the regime planned to do but was unable to accomplish
What life was like for the people who lived under the regime and didn’t die
So with that in mind, here’s my ranking for last century:
For me, Hitler easily takes the top spot, and it isn’t really a question. The reason isn’t that the Jewish Holocaust — Hitler’s most-discussed atrocity — was uniquely horrible compared to other acts of genocide. It’s that the Jewish Holocaust was only the beginning of Hitler’s wave of destruction.
The slaughter of 5-6 million Jews was deliberate, but it was only one part of Hitler’s plans for genocide in Europe and Asia. Generalplan Ost, the Nazis’ plan for East Europe, involved the deliberate slaughter or enslavement of tens of millions of people in Russia and other countries to Germany’s east. Here’s a chart from Wikipedia:

“Removed” here means “killed”, since the Nazis intended to take all of the land.
Hitler’s invasion of the USSR — Operation Barbarossa — was meant to carry out this unprecedented genocide. The main tool was starvation — Nazi Germany’s “Hunger Plan” called for intentional mass famines to wipe out most of the people living in the USSR and East Europe.
The Nazis actually implemented this plan to a significant degree. Out of the 27 million Soviet citizens killed by the Nazis during World War 2, 19 million were civilians, and most of these probably died from hunger and disease, caused in large part by the Nazis’ deliberate policy of mass starvation during the war. The Nazis also mass-executed or starved millions of Soviet POWs. Had the U.S. not stepped in to help, the death toll in the USSR might have been twice as large, or more. Those that weren’t killed were to be enslaved, but given the experience of the “workers” at Auschwitz — and considering that Nazi ideology stated that superior races lived and inferior ones died off — it’s an open question how long those slave populations would have been allowed to survive.
And why would Hitler have stopped there? Having overcome the Soviets, would the Nazis really have allowed the Chinese, or the Arabs, to live their lives and hold their lands unmolested? Not a chance. Hitler’s regime was purpose-built for conquest and genocide — it could only keep killing or die. In this sense, the Holocaust, as horrifying as it was, was only the tip of the iceberg.
It’s not clear whether there has ever been another regime quite like Hitler’s, even when we look back to the barbarity of premodern times. Genghis Khan, Timur (Tamerlane), and other conquerors killed millions, but only in order to subdue and rule, not to annihilate. Other regimes have attempted annihilation of subject peoples, but have generally done this within their own borders rather than trying to do it to the rest of the world.
Hitler and the Nazis should thus stand as the undisputed all-time champion of evil. With an intentional body count of over 30 million, and plans to do even more, they were less like other historical tyrants and more like some kind of alien armada. In my mind, the decision to ally with Stalin in order to defeat that unique menace was unquestionably the right one.
The Japanese Empire in the 1930s and 1940s was very different than the empire that came before. The military usurped civilian rule, put an end to the democracy that Japanese people had enjoyed in the 1920s, and made their society increasingly totalitarian. Japan had conquered and colonized before — Taiwan and Korea — but in the 1930s and 40s, they became increasingly brutal.
By the time they went after all of China in 1937 and Southeast Asia in 1941, genocide had become their standard tool of conquest. Like the Mongols 700 years earlier, the Japanese conquerors were very aware of China’s greater population, and intentionally used genocide in order to make China easier to rule. They killed 14 million Chinese people in their invasion (some say only 6 million, some say 20 million), mostly by deliberately starving them or slaughtering whole towns — similar to what the Nazis did in the USSR, but without the camps. They used biological weapons to try to kill even more. And of course they famously killed over 10,000 people by experimenting on them. This is in addition to a long list of massacres and atrocities carried out in the rest of Asia.
We tend to leave Japan off of the list of “history’s worst monsters”, because these crimes were committed in a very distributed way. They were not a result of official state ideology, like the Nazis’ ideology of race war. Individual figures like Tojo Hideki sometimes did encourage policies of mass starvation, mass shootings, and biological warfare, but the Imperial Japanese Army was remarkably decentralized, and lots of local commanders did atrocities all on their own. The Emperor probably knew about at least some of the atrocities being committed in his name, but didn’t try to intervene.
Still, collectively, Imperial Japan was the closest thing to the Nazis that existed in the 20th century, and like the Nazis they would have gotten far worse if they hadn’t been forcibly stopped.
Pol Pot and the Khmer Rouge had a total body count that was much lower than the other regimes on this list — 1.5 to 3 million instead of tens of millions — and they didn’t try to conquer the surrounding lands (though they sometimes attacked their neighbors). But the reason they only killed a few million people was that Cambodia only contained a few million people. The Khmer Rouge slaughtered a fifth to a quarter of their populace, higher than anyone else on the list — or maybe in recorded history. And had they had the power to conquer any of their larger neighbors, they probably would have conquered and killed even more. As it was, their reign of terror was only stopped by a Vietnamese invasion.
In terms of the cold, systematic nature of the mass murder, the Khmer Rouge are second only to the Nazis. The Killing Fields are legendary. You can go see the “magic tree” where Pol Pot’s soldiers would dash babies’ brains out, or gaze upon nice neat rows of human skulls. It really doesn’t get more psychotic than these guys.
Stalin is generally held responsible for somewhere between 10 and 20 million deaths, of which maybe 6-10 million starved to death because of communist agricultural policies. Like Mao, Stalin learned of these deaths but turned a blind eye rather than admit a mistake. But there may have been more to it in Stalin’s case — he probably wanted a famine in Ukraine in order to intentionally reduce the Ukrainian population and make the “republic” easier to rule.
Stalin’s deliberate murders were fewer than Hitler’s but that’s a relative statement; he did slaughter maybe 3 million political opponents by murdering them or sending them to gulags to die of neglect. He committed small local genocides, killing over a hundred thousand Poles in WW2, mass-expelling a bunch of minority populations (like the Crimean Tatars) and killing many in the process, and so on.
His armies were also very brutal in Germany during World War 2, mass-raping literally millions of German women, expelling and enslaving large numbers of Germans in East and Central Europe, and so on. On top of all that, Stalin’s USSR was famously nightmarish, with people living in a constant state of fear and encouraged to rat out their neighbors.
What Stalin mostly didn’t do was conquer and expand the USSR’s territory. With a few exceptions, he just sat on his existing empire, dominated surrounding states with proxy arrangements, and focused on internal ideological and economic reorganization and maintaining his personal power. This lack of world-conquering ambition made him palatable as an ally against Hitler. Ultimately, he mostly just sat there and brutalized the people already under his own control.
The vast majority of Mao’s deaths come from the famine. He also killed maybe 2-4 million people deliberately, through political purges, executions and forced labor during the Great Leap Forward, and the insanity of the Cultural Revolution. But the basic story of Mao is that he implemented insane policies in an attempt to gain and hold onto power, and often viewed Chinese deaths as collateral damage in his power struggles.
Mao, like Stalin, was also a villain that other countries learned to live with. He conquered Tibet and invaded South Korea (before being repulsed), but overall he wasn’t much interested in conquest. Like Stalin, he sat on his giant empire and brutally attempted to bend it to his (often insane) will. The society he created was desperately poor, paranoid, and totalitarian, but also often chaotic and even anarchic in places.
In my mind, those five regimes stand head and shoulders above the rest, but there are certainly no shortage of other bad ones. Seven honorable mentions:
The Young Turks: Turkey’s junta carried out the Armenian Genocide during World War I, killing around a million people.
North Korea: One of the world’s most nightmarish totalitarian regimes, North Korea tried to conquer South Korea, and also caused at least one mass famine with its policies of deliberate isolation.
Rwanda’s Hutu government: The Hutu government in the 1990s committed the famous Rwandan genocide, and helped foment and prosecute the Second Congo War that killed millions of people in central Africa. An ideology of ethnic supremacy was a big part of the reason why.
The Derg: Ethiopia’s communist regime in the 1970s and 1980s doesn’t get talked about much, but they killed maybe 500,000 people in political executions and ended up starving hundreds of thousands of Ethiopians to death.
Yahya Khan: Under Yahya Khan in 1971, Pakistan tried to terrorize Bangladesh into remaining under Pakistan’s control. The army killed anywhere between 300,000 and 3 million Bangladeshis, and raped hundreds of thousands more.
Suharto: Although Indonesia saw robust economic growth under Suharto, he killed over half a million people for political and ethnic reasons.
King Leopold II: The Belgian king’s extractive regime in the Congo killed anywhere from 1.2 to 10 million people there. The bulk of the atrocities in the 19th century, however; Leopold’s rule over Congo ended in 1908.
I realize that this list is subject to differences of opinion, depending on A) which estimates you believe, and B) which factors you weight more heavily in the calculation of regime evilness. But I think it’s a pretty defensible list, and it demonstrates at least two important lessons.
First of all, the very worst atrocities come during times of war — especially wars of conquest, where foreign peoples are dehumanized and armies are given carte blanche. The fascist regimes of WW2 come off as the worst because they were engaged in massive wars of conquest. And wars often increase a regime’s appetite for further conquest and destruction. So basically, regimes that invade other countries tend to be worse.
Second, communist regimes tended to starve a lot of their people to death. Insane agricultural policies were a hallmark of communist economics — probably because successful communist revolutions usually began as revolts by agrarian peasantry rather than proletarian workers as Marx had envisioned. In trying to transform agriculture, communists ended up just starving their people to death.
So while communism probably caused more aggregate human misery than fascism in the 20th century, that was only because fascism didn’t have time; it was so incredibly malignant that it was stopped very quickly by external coalitions. Communism was more like a chronic debilitating disease, while fascism war more like ebola.
That leaves us one more interesting question: By these criteria, who have been the worst regimes of the current century, so far? So far, the 21st century has been somewhat less destructive than the 20th — by 1926 we had already seen World War I, the Armenian Genocide, Lenin’s political purges, the Russian Civil War, and so on. The years 2000-2026 have, thankfully, been somewhat less brutal and chaotic so far. But we still have plenty of tyrannical villains. Here would be a tentative top five:
1. The RSF, Omar al-Bashir, and the Janjaweed: There has basically been a rolling series of genocides in Sudan this whole century — the first Darfur genocide, the second Darfur genocide, the Masalit genocide, and so on. Some of this was done at the behest of former president Omar al-Bashir, who encouraged murderous militias known as the Janjaweed, who later morphed into the RSF.
2. ISIS: This is the closest thing we’ve had to the Khmer Rouge in recent decades. ISIS’ extremist ideology led them to create a nightmarish totalitarian state in the areas of Iraq and Syria under their control, genocide the Yazidis, and throw much of the Arabian Peninsula into chaos. Their total death toll wasn’t as high as some of the others, but this was because they were stopped quickly; they were so horrible that everyone immediately united to fight and destroy them.
3. Vladimir Putin: Putin is one of the most aggressive leaders of modern times. He started wars in Georgia and Ukraine, and got heavily involved in the war in Syria. Over half a million people have died in Ukraine so far, and Putin bears some responsibility for the hundreds of thousands more who perished in Syria. It seems clear at this point that he’s not going to stop prosecuting wars of aggression until he dies or is defeated.
4. Bashar al-Assad: In his desperation to hang onto power, Assad laid waste to his country, killing hundreds of thousands and even using chemical weapons on rebels before ultimately fleeing.
5. The Tatmadaw: Myanmar’s military has been locked in a brutal civil war against ethnic minorities for decades, but in 2021 things really kicked into high gear after the army staged a coup against the country’s democratically elected government and put down protests with extreme brutality. The country is now an anarchic wasteland with war crimes galore.
These tyrants and murderers are somewhat less impressive, numbers-wise, than their 20th century counterparts. They also don’t clearly fit into the “fascism vs. communism” dichotomy that dominated much of the previous century; they’re more likely to be motivated either by Islamism, local ethnic chauvinism, or simple personal lust for power. But looking back at the 20th century, we should remember how bad dictators and totalitarian regimes can get, especially when they go to war — and how important it is to stop the worst of them in their tracks, before they can get even worse.
2026-07-20 14:51:10

“Be assured, my young friend, that there is a great deal of ruin in a nation.” — Adam Smith
The U.S. and the UK have one of the longest and most important relationships in all of history. The UK is America’s parent civilization, and even after the two diverged and had a period of rivalry, they came back together to more or less jointly craft the entire modern age. In terms of science, philosophy, government, and every other realm, the Anglo-American alliance was more than an alliance — it was a joint civilizational project.1
That also means that the U.S. and UK are able to learn from each other’s mistakes. This is often a painful and fraught process, because it involves quite a lot of cross-Atlantic shouting and insults. If you bring up the UK’s flaws on social media, you’re going to get an earful about how America elected Trump, Americans have no health care, American kids are constantly dodging bullets, and so on, so Americans have no room to talk. This is unhelpful, but inevitable. It’s a defensive reaction by left-leaning British intellectuals and elites who are occupied with their own internal policy and culture-war battles with other British people. Any criticism from an American is seen as giving free ammunition to the local enemy, so the natural impulse is to screech “Shut up, Yank!!”.
But the Yanks must not shut up. Whether or not the Brits need our advice, we need to have our own internal discussion about what’s going on over in the UK and how we can use it to inform our own choices. And although there are still a few things to admire across the pond, the UK mostly now functions as a cautionary tale for the U.S. — yes, despite Trump, and guns, and high health care costs.
Whether you think the UK has been falling behind America economically for a decade or for two decades depends on which set of prices you use to measure living standards. If you use the two countries’ national price indices, the UK has been growing slower than the U.S. since the financial crisis of 2008; if you use PPP prices, as Paul Krugman prefers, the UK’s relative stagnation has come only since Brexit in 2016:
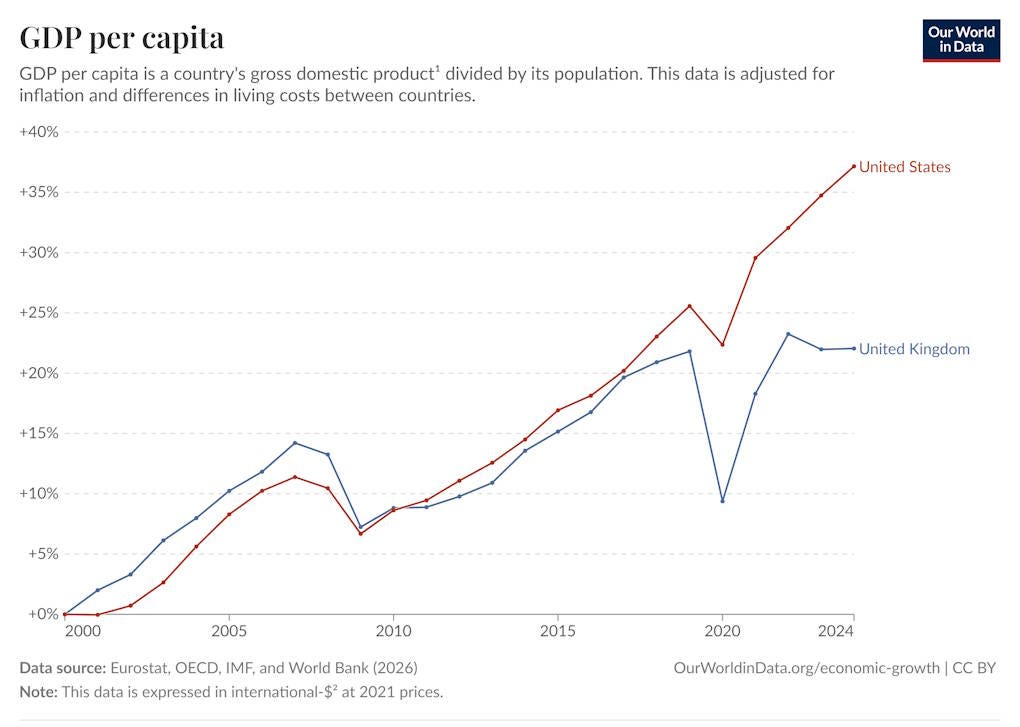
That controversy leaves an important question unanswered — whether 2008 or Brexit was ultimately more damaging to British growth. But it also obscures an even more important fact, which is that by any of these measures, the UK is much poorer than the United States:
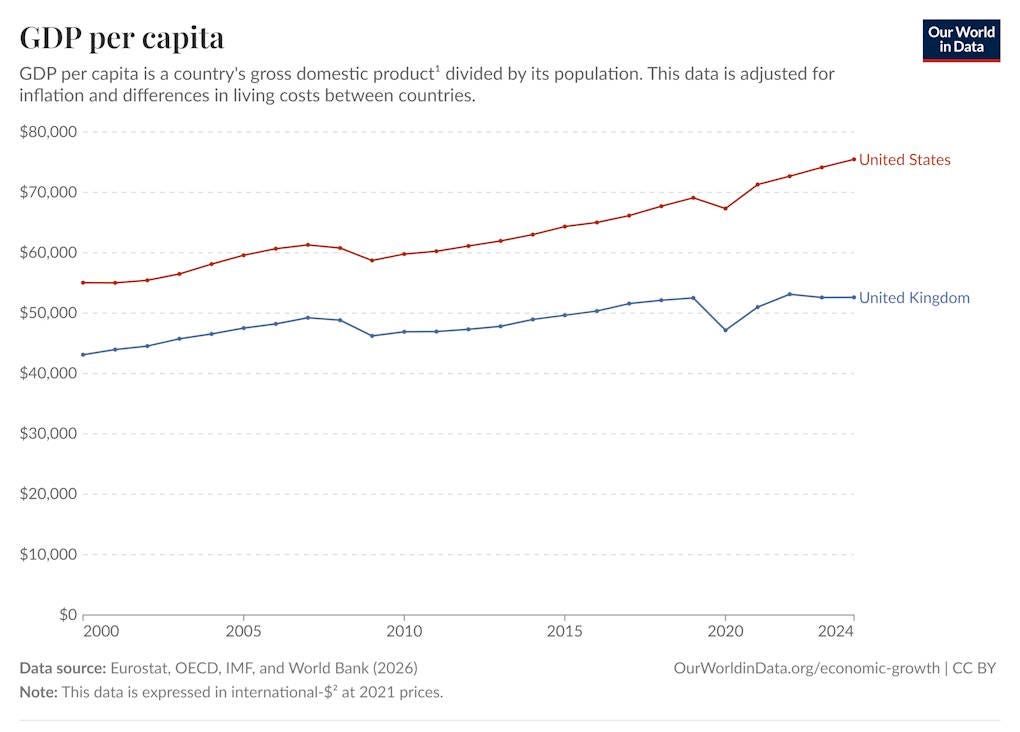
A data point that gets thrown around a lot is that the UK is as poor as Mississippi. In GDP (PPP) terms, that’s true — Mississippi’s income per capita is about $56,000, roughly similar to the UK. That doesn’t mean life is equally as good in the two countries — Mississippi is more violent and less healthy than Britain. But unless you think that Britain had to sacrifice a significant portion of its material wealth in order to be safer and healthier, this is a bit beside the point. France and Germany, which are just as safe and healthy as the UK (if not more so), also have significantly higher incomes. This is from a Resolution Foundation report:
Middle-income Brits are now 20 per cent poorer than their peers in Germany and 9 per cent poorer than those in France. Worse, low-income households in the UK are now around 27 per cent poorer than their French and German counterparts. It’s important to comprehend just how material these gaps are: the living standards of the lowest-income households in the UK are £4,300 lower than their French equivalents.
A very deep principle in economics is that if two countries are roughly equivalent in terms of their basic institutions, they ought to converge to similar income levels. The fact that the UK and the U.S. have diverged rather than converged suggests that the former must have some institutional weaknesses relative to the latter. And that implies that there are cautionary tales here for America.
What are those cautionary tales? There are a number of good breakdowns of the UK’s problems, and you can learn a lot from observing the overlaps and disagreements between them. Ben Southwood, Samuel Hughes, and Sam Bowman have a long piece called “Foundations”, which basically makes a libertarian YIMBY argument; they claim the UK is over-regulated and can’t build housing, infrastructure, or really anything else. Jim Tomlinson has a rebuttal in which he argues that the real barrier to investment is the financialization of the UK economy. Ben Ansell argues that the UK is in a version of the “high-level equilibrium trap” — the UK is still fairly wealthy, so its politics center around how to divide up the pie rather than growing it. The Resolution Foundation’s report has lots of suggestions for how to get Britain growing again. Michelle Kilfoyle also has some recommendations. These are only a few examples.
But my favorite rundown is probably the recent Atlantic article by Idrees Kahloon. The article points out that it isn’t just private industry that’s broken in the UK; it’s also the effectiveness of the government institutions that many British people cherish. This includes the fabled National Health Service. Kahloon writes:
Taxation is at the highest level since World War II, yet public services have deteriorated. The National Health Service, the celebrated pillar of the British cradle-to-grave welfare state, has a backlog of 6 million patients—almost a tenth of the population—waiting for treatment. The health service now has to spend more money settling maternity-malpractice claims than it does on actually providing maternity care. Many Brits can neither obtain an appointment with a publicly funded dentist nor afford a private one; in a 2023 survey, one in 10 reported doing DIY dental work, in extreme cases extracting their own teeth or gluing broken crowns back together…
Incomes can be shockingly low: Junior doctors recently went on strike for the 15th time in three years over their salaries, which start at just £38,800; the median salary for British civil servants is £35,680…
Recent plans to transform the country['s transportation system] have rested in no small part on High Speed 2, a superfast rail line intended to connect London with Birmingham, Leeds, and Manchester. But since HS2 was proposed, in 2009, its costs have tripled, to more than £100 billion. It is the most expensive rail line in the world. (A special structure to protect a rare bat species near the rail line in Buckinghamshire required 8,000 permits and was built at a cost of £216 million.) The most important sections of the proposed route have been lopped off. The rump line—going from Birmingham, Britain’s second-largest city, to not-quite-central London—may be finished by 2040…
Building infrastructure, or much of anything else, has become all but impossible in the United Kingdom. In addition to having the world’s most expensive (not yet built) train line, Britain also hosts the world’s most expensive (not yet built) nuclear-power plant, Hinkley Point C. Its environmental-impact assessment ran 31,401 pages; the plant will feature a £700 million “fish disco,” which will pulse sounds underwater to deter animals from its intake pipes. The government spent 32 years and £179 million planning a tunnel beneath Stonehenge to relieve traffic, only to officially scrap the plan this year. Even basic tasks, such as obtaining power, can be nightmarish…
Britain suffers from a housing crisis significantly worse than America’s. The problem cannot even be blamed on zoning, because Britain does not have a zoning regime to speak of. Rather, every attempt to build is a painful, ad hoc negotiation with local government councils and NIMBY residents. As a result, housing costs per square foot are among the highest in Europe. In the words of one report, “Our housing stock offers the worst value for money of any advanced economy.” France has roughly the same population as the U.K., but almost 50 percent more homes. And yet, since the financial crisis, the U.K.’s rate of housing production has only fallen…In London, the typical house sold in 2024 cost 11 times median earnings.
One of the key lessons here appears to be that NIMBYism kills the economy by a thousand small cuts. But Americans already know this. Kahloon’s description of Britain’s struggle to build high speed rail sounds uncomfortably like California’s story. And the housing story is also very similar to America’s. Most of the other analyses I listed above identify NIMBY-driven housing scarcity as one of the key factors holding back growth in the UK, and recommend various different strategies to address it.
I’m not sure the U.S. has a lot to learn from those various proposals, since they’re highly specific to the UK’s institutional context. But the overall lessons here are worth reiterating: Approval policies full of veto points and cumbersome procedures are a drag on the economy, local control can easily go too far, good infrastructure is often a matter of low-cost efficiency rather than pure willingness to pay, and so on. Americans have a severe NIMBY problem, but they can look over at the UK as a cautionary tale of how bad things will get if the NIMBY problem is allowed to fester.
Another lesson that Americans have already learned is the peril of excessive financialization of the economy. Almost everyone agrees that the UK economy is excessively concentrated in London. John Burn-Murdoch writes:
It will surprise nobody that London accounts for an outsized share of Britain’s output, but the magnitude of the UK’s economic monopolarity is remarkable. Removing London’s output and headcount would shave 14 per cent off British living standards, precisely enough to slip behind the last of the US states. Britain in the aggregate may not be as poor as Mississippi, but absent its outlier capital it would be.
Not only does this mean that the fruits of the UK economy are inequitably distributed — requiring a constant stream of politically difficult transfers to keep other regions afloat — but it also means that NIMBYism bites much harder than it otherwise would, because pricing people out of London means pricing them out of participation in one of the few healthy parts of Britain’s economy, and because pricing people out of highly productive cities hurts productivity.
And part of the reason the UK’s economy clusters in London is finance. As Reuters reports, the UK economy specializes in finance:
The United Kingdom is unusually dependent on finance. Financial services account for about 12% of economic output, opens new tab, compared with around 7% in the United States. Much of that activity emanates from London. The City is the world’s second-largest asset management hub, the leading venue for foreign exchange trading, and the number one location for over-the-counter derivatives.
Finance is an industry with an especially strong clustering effect; almost every country has just one city that’s the “financial capital” — NYC in the U.S., Tokyo in Japan, etc. But in an economy as financialized as Britain’s, the financial capital is the center of the entire economy, probably to an unhealthy degree.
Another obvious downside of financialization is that specialization in a single tentpole industry made the UK economy unusually vulnerable to a crash in that industry. The financial crisis of 2008, and the follow-on Euro Crisis in the years afterward, dealt a heavy blow to the UK finance industry — and, thus, to the UK economy. Whether you think Britain’s GDP stagnation truly began in 2008 or 2016, it’s inarguable that real wages stagnated and fell for years after 2008. Compare average weekly earnings in the UK to those in the U.S., and the difference is crystal clear:2
Whether financialization has other drawbacks — excessive corporate short-termism causing lack of investment and deindustrialization, financialization of housing development causing shortages, etc. — isn’t clear. But just these two negative effects — the UK economy’s hyper-concentration in London, and its vulnerability to single-sector shocks — provide a cautionary tale about letting an economy rely too much on the finance industry.
Again, this is a lesson that Americans already learned, at least partially, after 2008 (though thankfully, the lesson was somewhat less painful for us than for the Brits). But one lesson from 2008 that the U.S. should pay attention to is that fiscal austerity, if done too abruptly and carelessly, can leave long-term scars on an economy. Kahloon writes:
[T]he government’s actions during and after the [2008] crisis compounded the damage. Rather than increase spending to revive depressed demand, as modern Keynesians would counsel, the government…opted to slash budgets as revenue plunged…
Funding for day-to-day NHS operations was maintained, for instance, but only by cannibalizing the capital budget. A 2024 government report found that, as a result of austerity, Britain has “crumbling buildings, mental health patients being accommodated in Victoria-era cells infested with vermin with 17 men sharing two showers, and parts of the NHS operating in decrepit portacabins.”…
After austerity cuts to welfare benefits took effect, the share of children who grew up in long-term poverty, meaning half their childhood or more, shot up from about 14 percent to 23 percent. Nutrition appeared to suffer, and doctors reported increased cases of diseases stemming from vitamin deficiencies, such as rickets and scurvy.
The U.S. needs to hear this lesson. Our debt problem is becoming unsustainable:
We’re going to need to do fiscal austerity, but it’s important that we do it gradually, by restraining the growth of spending (and raising taxes), rather than by abruptly slashing government services and public works.
Kahloon’s example of the NHS actually demonstrates another lesson — the UK’s strategy of providing health care is probably uniquely flawed. In most advanced countries, the government provides universal health insurance; the government pays part of the cost of health care, but it doesn’t actually provide the care directly. The UK government, in contrast, provides health care directly to its people as a state-owned enterprise.
Britain’s NHS helps control costs in the short term; the system is cheaper than those of other rich countries, for roughly similar outcomes. But in the long term, it makes the UK’s health system subject to the whims and vagaries of politics. After the 2008 crisis, the UK disinvested severely from health care because of fiscal austerity policy, while other countries continued to do the necessary capital spending to maintain future services. This is a big part of the reason why the NHS system is now widely seen as falling apart.
The U.S. is vanishingly unlikely to switch to nationalized, state-run health care provision — at the very most, we’ll get a system of national insurance, like most other rich countries have. But watching the degradation of the NHS should remind us of why direct government provision of necessary services is so dangerous. It’s not necessarily that government is inherently inefficient; it’s that it’s inherently political. UK-style austerity is one reason government can starve its own enterprises of capital spending, but it’s not the only one — under Hugo Chavez, Veneuzela’s government starved its own state-owned oil company of capital investment in order to deliver a bonanza of government largesse, with predictably disastrous results. We should remember this when socialists like Zohran Mamdani promise to run essential services through the government.
One key lesson that all the analyses of Britain’s troubles seem to already have internalized, but which the U.S. needs to pay attention to, is that maintaining overseas markets is very important. Whether 2008 caused a long-term economic slowdown or not, 2016 definitely seems to have done so. Brexit is the huge, looming shadow that hangs over everything that has happened to the UK economy over the past decade.
Bloom et al. (2025) study the growth impact of Brexit, looking at both macro data and micro data. For the macro, they assume Brexit was an unanticipated shock, and compare the UK to other countries. For the micro, they look at how various British businesses fare after Brexit, according to how dependent they were on the EU before the big surprise breakup. Both estimates agree that Brexit was a negative shock:
[B]y the end of 2025 Brexit had reduced UK GDP by 6% to 8%, with the impact accumulating steadily over time. We estimate that investment was reduced by 12% to 13%, employment by 3% to 4% and productivity by 3% to 4%. These negative impacts reflect a combination of elevated uncertainty, reduced demand, diverted management time, and increased misallocation of resources from a protracted Brexit process.
The U.S. should look at Britain’s experience and remember that international markets matter. The pre-Brexit UK was a more internationalized economy than the pre-Trump U.S. — exports are over 30% of UK GDP, compared to only 11% in the U.S. But that seemingly small stream of exports revenues supports a lot of more local industries, through the magic of local multiplier effects. If Trump and his successors disrupt those markets by starting pointless trade wars with allies and friendly countries, the results won’t be quite as bad as in the UK, but they won’t be good.
A final lesson that the UK’s failures can teach the U.S. is that energy supply is very important. Most analyses tend to gloss over the chronic energy scarcity that has afflicted the UK in recent years. “Foundations”, however, puts this squarely in the limelight:
High energy costs help make British industry uncompetitive, increasing the country’s reliance on finance. They also directly impoverish the British people, who are forced to make do with much lower energy consumption than people in other rich countries. Here’s electricity generation per capita:
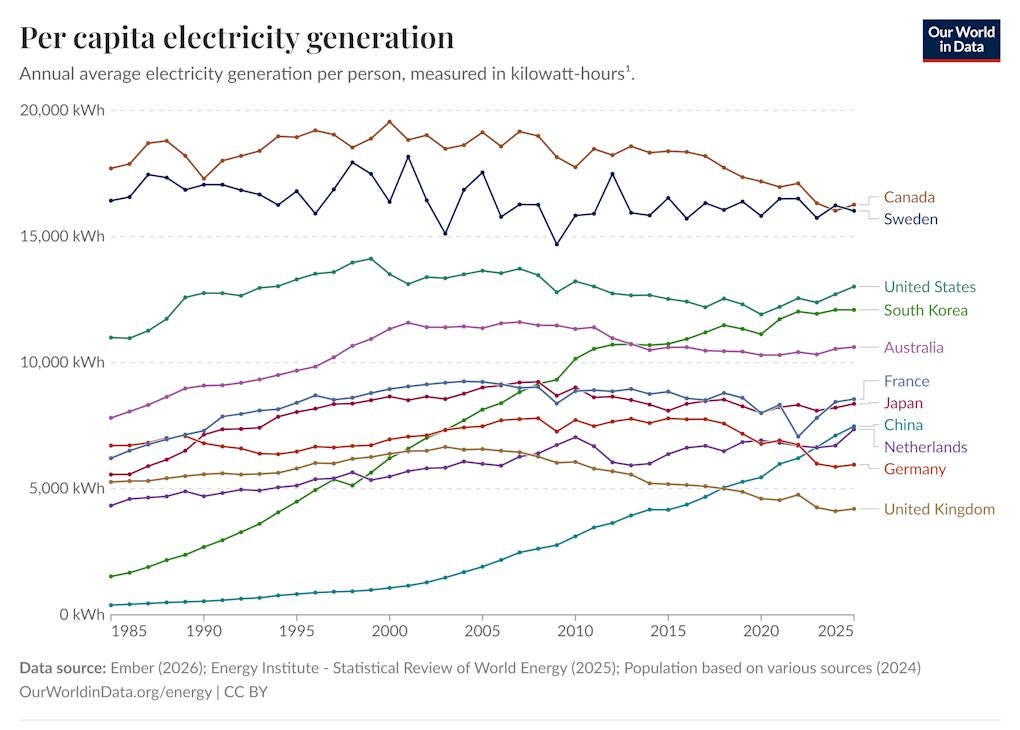
Energy is one very easily identifiable, tangible dimension in which British people are much poorer than Americans.
The Economist ties Britain’s energy scarcity to its overly rapid and haphazard push for decarbonization; having banned coal, and with natural gas now extremely expensive due to the Ukraine war, the UK has been forced to rely on hideously expensive offshore wind power.
The U.S. doesn’t have this exact problem. Because the U.S. has much more land and much more sunlight than the UK, we can use solar power (with batteries), which is much cheaper than offshore wind and are getting cheaper all the time:
But the general lesson remains — there is no such thing as a low-energy rich country. The MAGA movement’s irrational opposition to solar power is even more foolish than Britain’s haphazard push to ban coal.
So to sum up, the UK’s sad experience with economic stagnation offers several important lessons for America:
NIMBYism is very bad
Excessive reliance on the finance industry is dangerous for many reasons
Abrupt, poorly-designed fiscal austerity can do long-term damage to an economy
Direct government provision of essential services is easily politicized
Cutting a country off from its export markets is very bad
Energy abundance is important for both industry and living standards
Overall, the UK should serve as a reminder that economic growth is very important, and countries turn away from growth at their peril. The UK, caught up in endless political turmoil and culture wars, has forgotten the overriding importance of growth for national happiness and well-being. The U.S., facing its own political chaos and culture wars, should try very hard not to make the same mistake.
America’s second most important relationship, and arguably its most important in the post-WW2 period, has been with Japan — our “other special relationship”. But that’s a topic for another post.
Actually this comparison is slightly flawed, because the U.S. data is only for the private sector, but adding in the government won’t change the story because U.S. government workers saw more of a pay increase relative to private-sector workers during this time. Also, note that this comparison doesn’t care about PPP, since each country’s workers are paid — and consume — in their local currency.

{kind=link}
#/media/File:The_University_of_the_Arts_(UArts)_(53590485989).jpg){kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}