2025-07-01 03:00:00
A little while back I heard about the White House launching their version of a Drudge Report style website called White House Wire. According to Axios, a White House official said the site’s purpose was to serve as “a place for supporters of the president’s agenda to get the real news all in one place”.
So a link blog, if you will.
As a self-professed connoisseur of websites and link blogs, this got me thinking: “I wonder what kind of links they’re considering as ‘real news’ and what they’re linking to?”
So I decided to do quick analysis using Quadratic, a programmable spreadsheet where you can write code and return values to a 2d interface of rows and columns.
I wrote some JavaScript to:
whitehouse.gov/wire
In a few minutes I had a quick analysis of what kind of links were on the page:
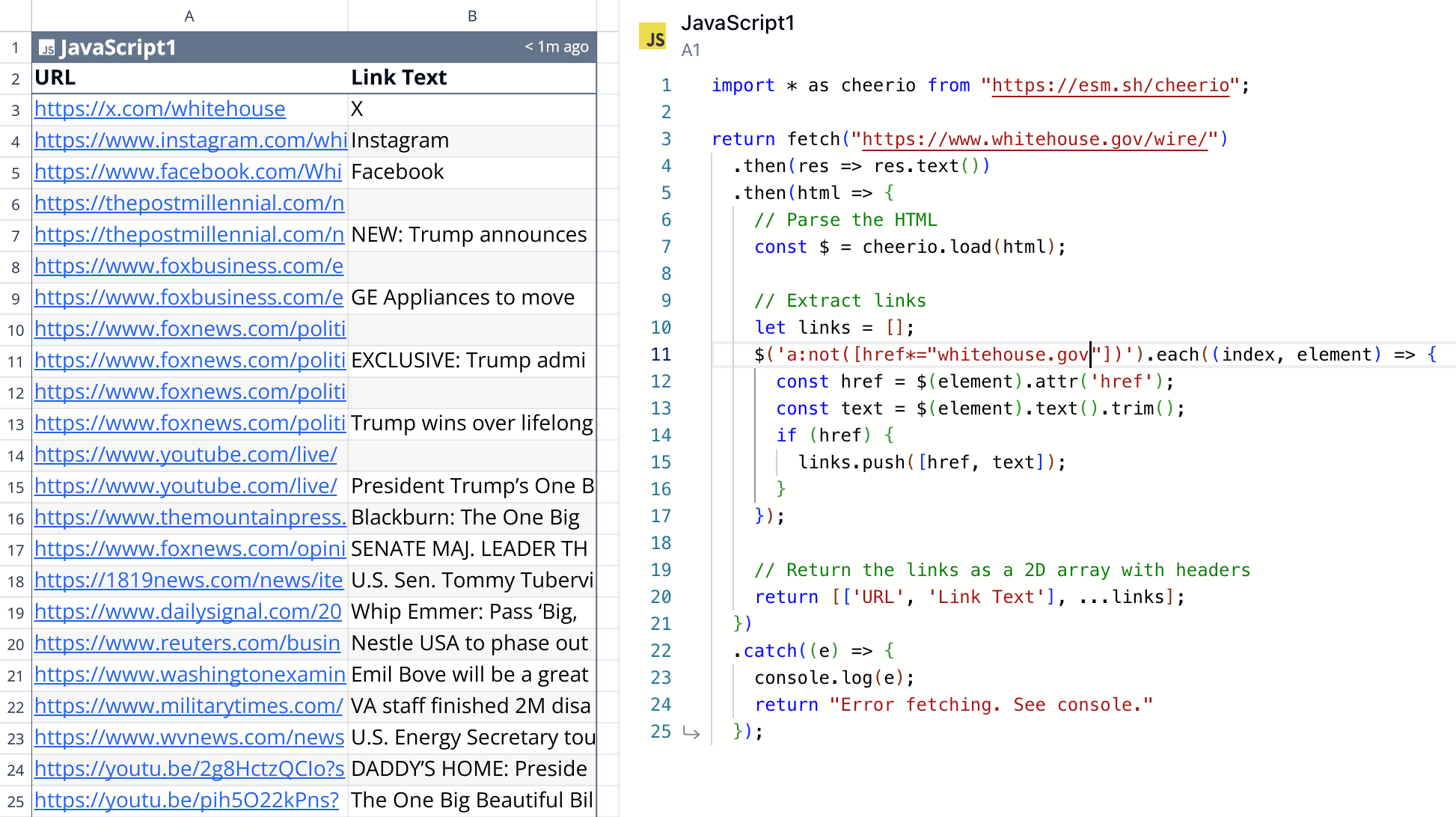
This immediately sparked my curiosity to know more about the meta information around the links, like:
So I got to building.
Quadratic today doesn’t yet have the ability for your spreadsheet to run in the background on a schedule and append data. So I had to look elsewhere for a little extra functionality.
My mind went to val.town which lets you write little scripts that can 1) run on a schedule (cron), 2) store information (blobs), and 3) retrieve stored information via their API.
After a quick read of their docs, I figured out how to write a little script that’ll run once a day, scrape the site, and save the resulting HTML page in their key/value storage.

From there, I was back to Quadratic writing code to talk to val.town’s API and retrieve my HTML, parse it, and turn it into good, structured data. There were some things I had to do, like:
Selfish plug: Quadratic made this all super easy, as I could program in JavaScript and use third-party tools like tldts to do the analysis, all while visualizing my output on a 2d grid in real-time which made for a super fast feedback loop!
Once I got all that done, I just had to sit back and wait for the HTML snapshots to begin accumulating!
It’s been about a month and a half since I started this and I have about fifty days worth of data.
The results?
Here’s the top 10 domains that the White House Wire links to (by occurrence), from May 8 to June 24, 2025:
youtube.com (133)foxnews.com (72)thepostmillennial.com (67)foxbusiness.com (66)breitbart.com (64)x.com (63)reuters.com (51)truthsocial.com (48)nypost.com (47)dailywire.com (36)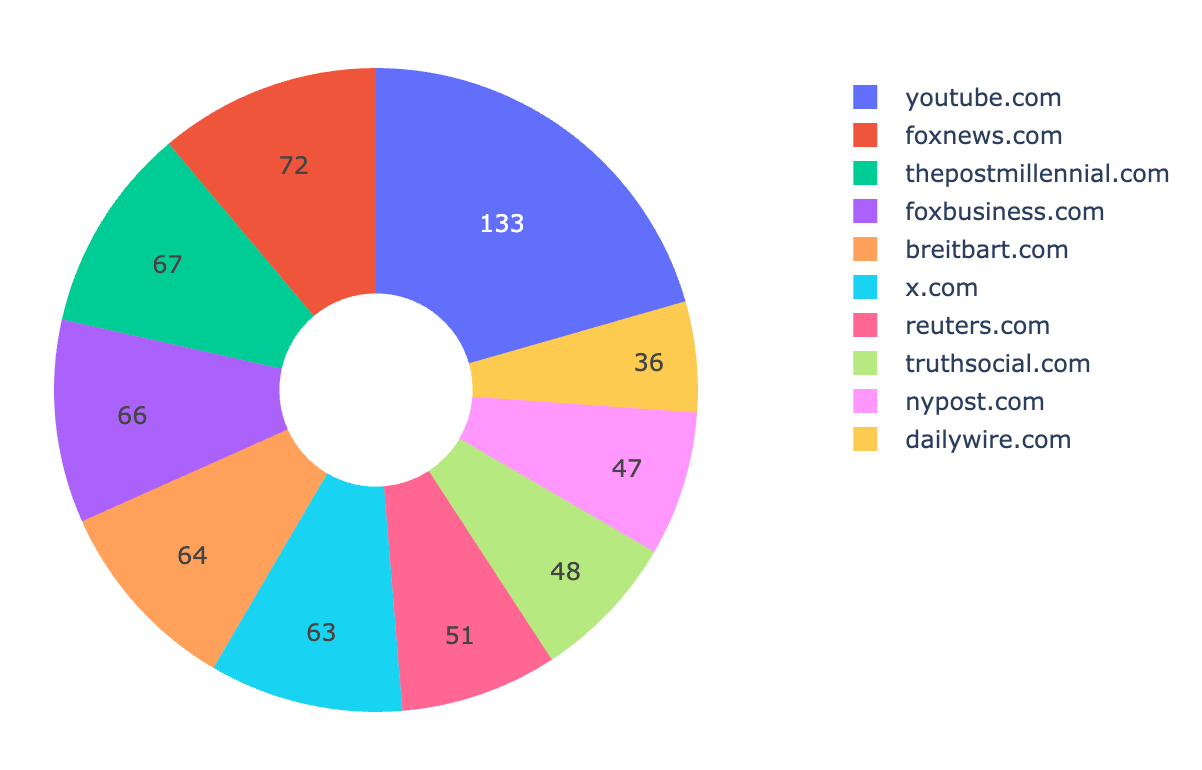
From the links, here’s a word cloud of the most commonly recurring words in the link headlines:
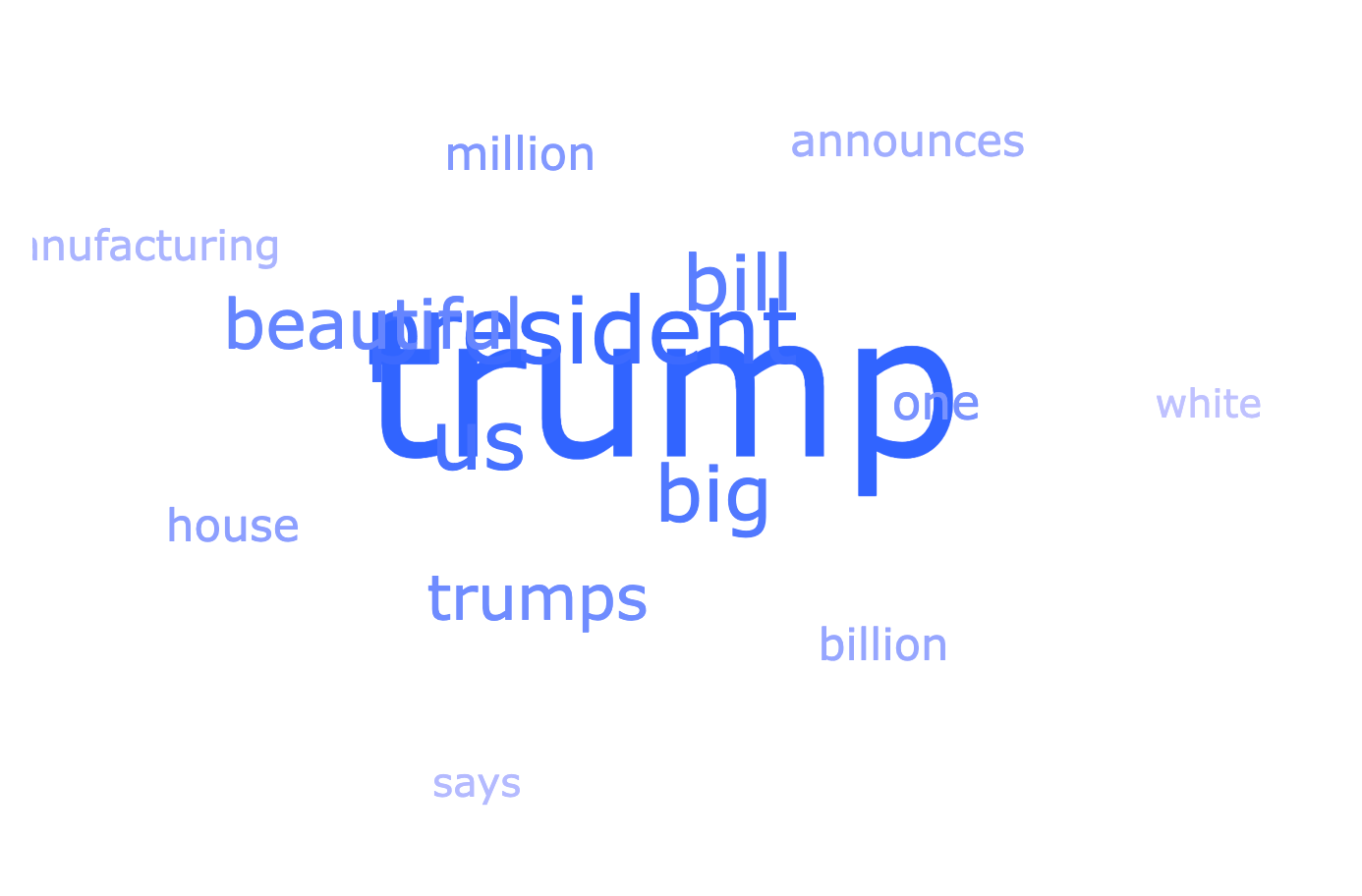
The data and these graphs are all in my spreadsheet, so I can open it up whenever I want to see the latest data and re-run my script to pull the latest from val.town. In response to the new data that comes in, the spreadsheet automatically parses it, turn it into links, and updates the graphs. Cool!
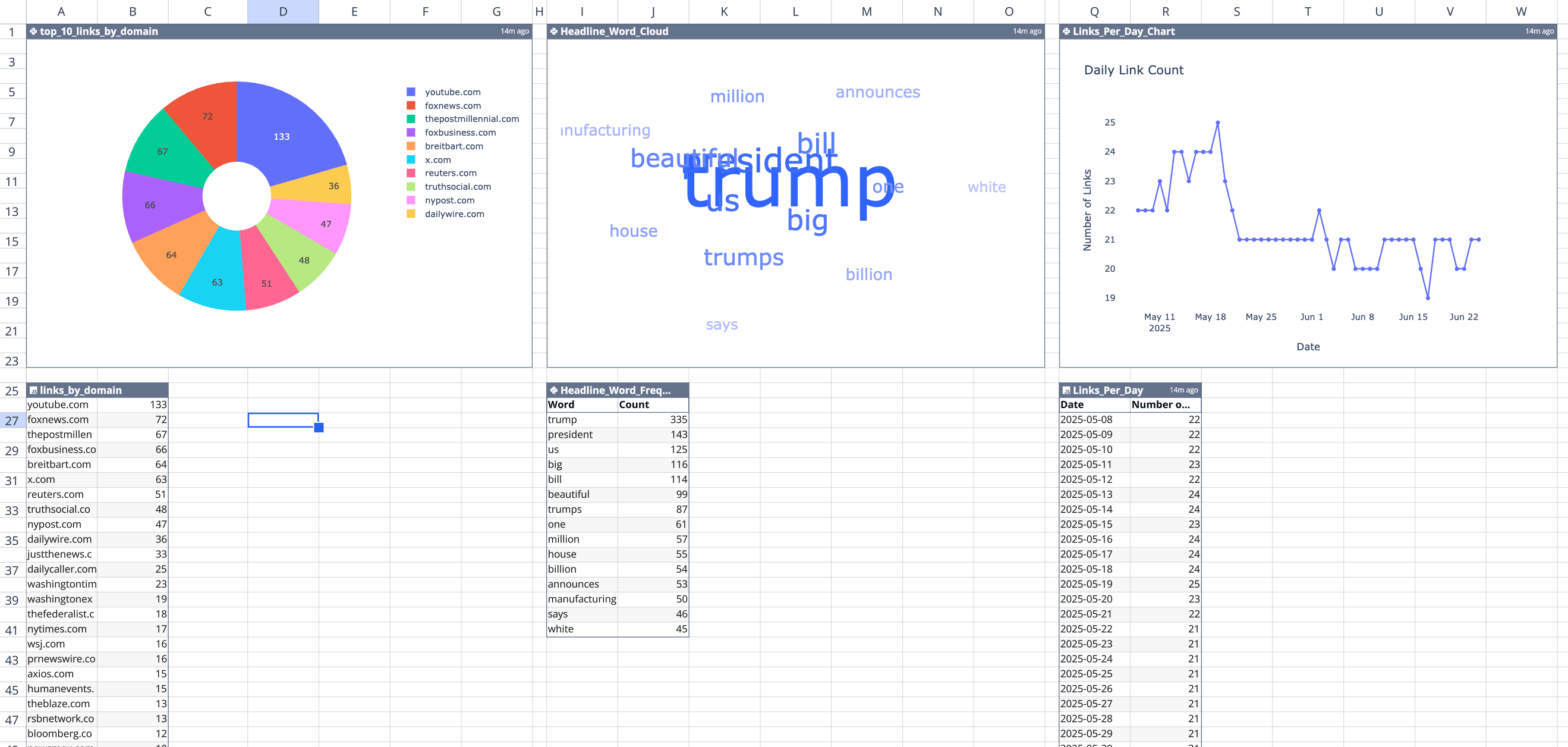
If you want to check out the spreadsheet — sorry! My API key for val.town is in it (“secrets management” is on the roadmap). But I created a duplicate where I inlined the data from the API (rather than the code which dynamically pulls it) which you can check out here at your convenience.
2025-06-26 03:00:00
I’ve long wanted the ability to create custom collections of icons from my icon gallery.
Today I can browse collections of icons that share pre-defined metadata (e.g. “Show me all icons tagged as blue”) but I can’t create your own arbitrary collections of icons.
That is, until now!
I created a page at /lookup that allows you to specify however many id search params you want and it will pull all the matching icons into a single page.
Here’s an example of macOS icons that follow the squircle shape but break out of it ever-so-slightly (something we’ll lose with macOS Tahoe).
It requires a little know how to construct the URL, something I’ll address later, but it works for my own personal purposes at the moment.
So how did I build it?
So the sites are built with a static site generator, but this feature requires an ability to dynamically construct a page based on the icons specified in the URL, e.g.
/lookup?id=foo&id=bar&id=baz
How do I get that to work? I can’t statically pre-generate every possible combination[1] so what are my options?
No. 1: this is fine, but I don’t have a JSON API for clients to query and I don’t want to create one. Plus I have to duplicate template logic, etc. I’m already rendering lists of icons in my static site generator, so can’t I just do that? Which leads me to:
No. 2: this works, but I do have 2000+ icons so the resulting HTML page (I tried it) is almost 2MB if I render everything (whereas that same request for ~4 icons but filtered by the server would be like 11kb). There’s gotta be a way to make that smaller, which leads me to:
No. 3: this is great, but it does require I have a “server” to construct pages at request time.
Enter Netlify’s Edge Functions which allow you to easily transform an existing HTML page before it gets to the client.
To get this working in my case, I:
/lookup/index.html that has all 2000+ icons on it (trivial with my current static site generator).lookup.ts edge function that intercepts the request to /lookup/index.html /lookup?id=a&id=b&id=c turns into ['a','b','c']
<a id='a'>…</a><a id='z'>…</a> might get pruned down to <a id='a'>…</a>
It took me a second to get all the Netlify-specific configurations right (put the function in ./netlify/edge-functions not ./netlify/functions, duh) but once I strictly followed all of Netlify’s rules it was working! (You gotta use their CLI tool to get things working on localhost and test it yourself.)
I don’t particularly love that this ties me to a bespoke feature of Netlify’s platform — even though it works really well!
But that said, if I ever switched hosts this wouldn’t be too difficult to change. If my new host provided control over the server, nothing changes about the URL for this page (/lookup?id=…). And if I had to move it all to the client, I could do that too.
In that sense, I’m tying myself to Netlify from a developer point of view but not from an end-user point of view (everything still works at the URL-level) and I’m good with that trade-off.
/lookup?id=1&id=2? It said the number is 2^2000 which is “astronomically large” and “far more than atoms in the universe”. So statically pre-generating them is out of the question. ⏎
2025-06-25 03:00:00
Here’s a screenshot of my inbox from when I was on the last leg of my flight home from family summer vacation:

That’s pretty representative of the flurry of emails I get when I fly, e.g.:
In addition to email, the airline has my mobile number and I have its app, so a large portion of my email notifications are also sent as 1) push notifications to my devices, as well as 2) messages to my mobile phone number.
So when the plane begins boarding, for example, I’m told about it with an email, a text, and a push notification.
I put up with it because I’ve tried pruning my stream of notifications from the airlines in the past, only to lose out on a vital notification about a change or delay. It feels like my two options are:
All of this serendipitously coincided with me reading a recent piece from Nicholas Carr where he described these kinds of notifications as “little data”:
all those fleeting, discrete bits of information that swarm around us like gnats on a humid summer evening.
That feels apt, as I find myself swiping at lots of little data gnats swarming in my email, message, and notification inboxes.
No wondering they call it “fly”ing 🥁
2025-06-23 03:00:00
I recently got my copy of the Internet Phone Book. Look who’s hiding on the bottom inside spread of page 32:

The book is divided into a number of categories — such as “Small”, “Text”, and “Ecology” — and I am beyond flattered to be listed under the category “HTML”! You can dial my site at number 223.
As the authors note, the sites of the internet represented in this book are not described by adjectives like “attention”, “competition”, and “promotion”. Instead they’re better suited by adjectives like “home”, “love”, and “glow”.
These sites don’t look to impose their will on you, soliciting that you share, like, and subscribe. They look to spark curiosity, mystery, and wonder, letting you decide for yourself how to respond to the feelings of this experience.
But why make a printed book listing sites on the internet? That’s crazy, right? Here’s the book’s co-author Kristoffer Tjalve in the introduction:
With the Internet Phone Book, we bring the web, the medium we love dearly, and call it into a thousand-year old tradition [of print]
I love that! I think the juxtaposition of websites in a printed phone book is exactly the kind of thing that makes you pause and reconsider the medium of the web in a new light. Isn’t that exactly what art is for?
Kristoffer continues:
Elliot and I began working on diagram.website, a map with hundreds of links to the internet beyond platform walls. We envisioned this map like a night sky in a nature reserve—removed from the light pollution of cities—inviting a sense of awe for the vastness of the universe, or in our case, the internet. We wanted people to know that the poetic internet already existed, waiting for them…The result of that conversation is what you now hold in your hands.
The web is a web because of its seemingly infinite number of interconnected sites, not because of it’s half-dozen social platforms. It’s called the web, not the mall.
There’s an entire night sky out there to discover!
2025-06-16 03:00:00
This post is a secret to everyone! Read more about RSS Club.
I’ve been reading Apple in China by Patrick McGee.
There’s this part in there where he’s talking about a guy who worked for Apple and was known for being ruthless, stopping at nothing to negotiate the best deal for Apple. He was so aggressive yet convincing that suppliers often found themselves faced with regret, wondering how they got talked into a deal that in hindsight was not in their best interest.[1]
One particular Apple executive sourced in the book noted how there are companies who don’t employ questionable tactics to gain an edge, but most of them don’t exist anymore. To paraphrase: “I worked with two kinds of suppliers at Apple: 1) complete assholes, and 2) those who are no longer in business.”
Taking advantage of people is normalized in business on account of it being existential, i.e. “If we don’t act like assholes — or have someone on our team who will on our behalf[1] — we will not survive!” In other words: All’s fair in self-defense.
But what’s the point of survival if you become an asshole in the process?
What else is there in life if not what you become in the process?
It’s almost comedically twisted how easy it is for us to become the very thing we abhor if it means our survival.
(Note to self: before you start anything, ask “What will this help me become, and is that who I want to be?”)
2025-06-12 03:00:00
Dan Abramov in “Static as a Server”:
Static is a server that runs ahead of time.
“Static” and “dynamic” don’t have to be binaries that describe an entire application architecture. As Dan describes in his post, “static” or “dynamic” it’s all just computers doing stuff.
Computer A requests something (an HTML document, a PDF, some JSON, who knows) from computer B. That request happens via a URL and the response can be computed “ahead of time” or “at request time”. In this paradigm:
But these definitions aren’t binaries, but rather represent two ends of a spectrum. Ultimately, however you define “static” or “dynamic”, what you’re dealing with is a response generated by a server — i.e. a computer — so the question is really a matter of when you want to respond and with what.
Answering the question of when previously had a really big impact on what kind of architecture you inherited. But I think we’re realizing we need more nimble architectures that can flex and grow in response to changing when a request/response cycle happens and what you respond with.
Perhaps a poor analogy, but imagine you’re preparing holiday cards for your friends and family:
But between these two are infinite possibilities, such as:
Are those examples “static” or “dynamic”? [Cue endless debate].
The beauty is that in proving the space between binaries — between what “static” means and what “dynamic” means — I think we develop a firmer grasp of what we mean by those words as well as what we’re trying to accomplish with our code.
I love tools that help you think of the request/response cycle across your entire application as an endlessly-changing set of computations that happen either “ahead of time”, “just in time”, or somewhere in-between.