2025-07-16 02:30:10

For a while, I have said that the AI slop endgame, for social media companies, is creating a hyper personalized feed full of highly specific content about anything one could possibly imagine. Because AI slop is so easy to make and because social media algorithms are so personalized, this means that Facebook, Instagram, TikTok, or YouTube can feed you anything they perceive its users to possibly want. So this means that AI slop makers are exploring ever more niche areas of content.
Case in point: Facebook AI slop about the horrific and deadly Texas flood. Topical AI content about disasters, war, current events, and news stories are at this point so commonplace that they are now sadly barely notable, and AI-powered “misinformation” about horrible events are all over every social media feed I can think of. But as we document our descent into this hellhole, I thought some AI slop surfaced on Bluesky by Christina Stephens was particularly notable:

This is slop that shows Louisiana State University football coach Brian Kelly assisting in the Texas floods. Kelly is “famous” in that SEC football coaches are famousish, but he has no real connection to Texas and there is no reason for this content to exist other than the fact that it is being churned out by a Facebook page called LSU Gridiron Glory, which is specifically making AI slop about Kelly and other LSU football figures, including quarterback Garrett Nussmeier and some of his apparent girlfriends. In the grand scheme of things, Brian Kelly is a very minor figure.
This page is churning out slop that includes Brian Kelly’s reaction to last month’s tragic Air India crash and the supposedly amazing line of encouragement he said (this line is never shared, and, of course, the football coach in Louisiana has not had anything to say about a plane that crashed in India). There is slop of Kelly getting his lost wallet returned to him, donating to the homeless, slop of Kelly in the hospital with a rare illness, slop of Kelly being deported by Trump, talking to Apple CEO Tim Cook, and slop of Kelly secretly “paying off the debt owed by a struggling gardener.” The slop is so completely random and specific that I struggle to imagine how one would decide to fill this niche, and, yet, the AI slop economy has done so, anyway.



My point is that there is no reason for LSU football coach Brian Kelly flood rescue inspiration porn to exist on the internet because it did not happen and because it is so hyperspecific as to seem like there could not possibly be a market for such content. And yet someone has decided that ridiculously niche disaster content would get served up by the algorithm to someone who might interact with it.


Then consider that essentially the exact same thing exists, but for fans of the NBC show The Voice. A page called The Voice Fandom is showing AI slop of judge Blake Shelton saving dogs in the Texas flood, Shelton carrying a girl out of a medical clinic in Kerr County, fellow judge Luke Bryan donating to an animal rescue shelter, etc. As we have seen with previous slop factories on Facebook, many of these bizarre images link out to AI-generated “news” websites that are overloaded with ads. There are, surely, thousands of other similar pages that are doing the exact same thing with celebrities big and small, creating an internet where the LSU fans of the world can imagine their coach as first responder or the judge of their favorite TV show as dog savior or whatever.
Very little of this slop has much engagement on it, but one of the Blake Shelton photos has 18,000 likes and a few hundred comments. Slop has gotten so cheap and easy to produce, and Facebook is so easy to spam, that presumably the return is worth it. In covering these pages for months, I have learned that a single person can operate dozens or hundreds of pages and can keep them filled up with content, and so having something occasionally go viral can be enough to make the entire endeavor financially viable. There was a time a few months ago when I would click through these pages endlessly and marvel at the sheer volume of slop being posted, but the tactic has become so common at this point that we have become almost fully desensitized to it.
2025-07-15 23:40:57

Yesterday, Silicon Valley trade publication The Information launched TITV, a live-streaming news program. For its first episode, the company’s founder Jessica Lessin interviewed Mark Zuckerberg about his recent attempts to hire AI executives away from other companies for huge sums of money.
It is impossible to say what actually happened in the interview, however, because there were audio problems with the livestream—the Zuckerberg segment was completely silent, giving us a minute and 50 seconds of video of Zuckerberg’s face moving with no sound coming out.
In recent weeks, however, Zuckerberg has really ramped up his rhetoric about “superintelligence,” throwing hundreds of millions of dollars at AI researchers in attempts to hire them at Meta, and beginning work on massive data centers around the country to power his AI. Zuckerberg and Meta have talked endlessly about AI as a game changer, while being unable or unwilling to keep AI-generated misinformation and slop off of Meta platforms.
Meanwhile, there has been increased discussion about the possible power of using AI for journalism, which we have written about extensively. I saw the silent interview with Zuckerberg as both an opportunity to check out the awesome abilities of Meta’s AI, and to test AI tools at a task some of them are supposedly good at—reading lips. If these technologies worked as well as their creators have promised, it might be possible to provide the world with information from The Lost Mark Zuckerberg Interview.
Here is how my experiment went.
Because Zuckerberg was obviously talking about Meta AI, I thought I would try his tool first. I took video from the interview and asked Meta AI to lip read it to tell me what they were saying:
“I’d love to help! However, I’m a text-based AI and don’t have capability to visually lip read videos,” Meta AI said. It then suggested that I “find a professional lip reader or transcription service that specializes in lip reading videos” or “use automated lip reading software.”
I then tried to upload still images to see if Meta AI could parse them:
When I uploaded additional images, Meta AI was also not able to provide any information about what was being said.
I then went to ChatGPT, because Zuckerberg is reportedly offering pay packages of up to $300 million to OpenAI staffers to come work at Meta. I uploaded the 1:50 video and ChatGPT told me “the video processing took too long and timed out.” I then uploaded a 25 second clip and it told me “the system is still timing out while trying to extract frames.” I then asked it to do the first five seconds and it said “even with the shorter clip and smaller scope (first 5 seconds), the system timed out.” I then asked for it to extract one single frame, and it said “it looks like the system is currently unable to extract even a single frame from the video file.” ChatGPT then asked me to take a screenshot of Zuckerberg. I sent it this:

And ChatGPT said “the person appears to be producing a sound like ‘f’ or ‘v’ (as in ‘video’ or ‘very’),” but that “possibly ‘m’ or ‘b,’ depending on the next motion.” I then shared the 10 frames around that single screenshot, and ChatGPT said “after closely analyzing the progression of lip shapes and facial motion,” the “probable lip-read phrase” was “This is version.” I then uploaded 10 more frames and it said the “full phrase so far (high confidence): ‘This version is just.’”
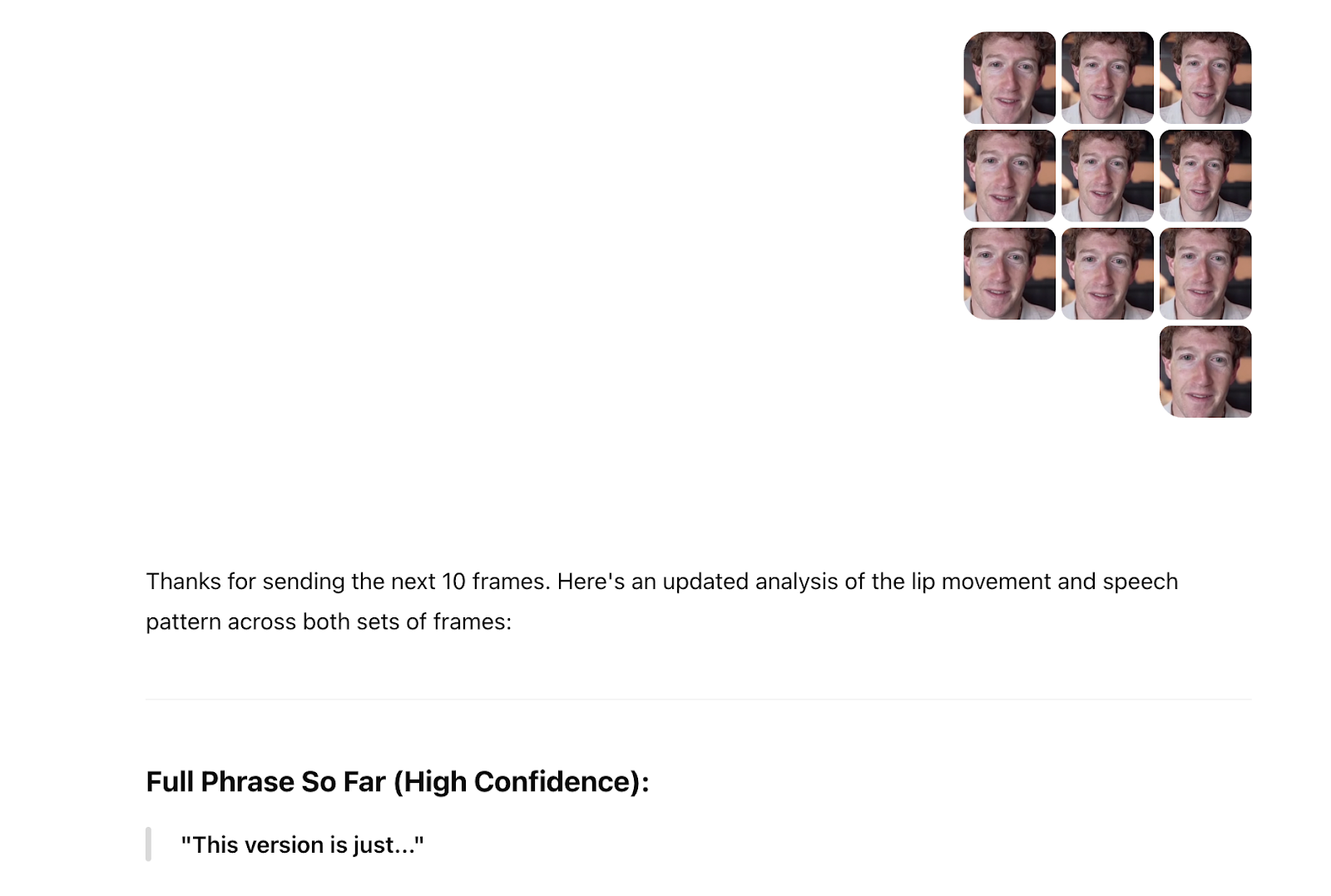









I then decided to try to extract every frame from the video and upload it to ChatGPT.
I went to a website called frame-extractor.com and cut the video into 3,000 frames. After it had processed 700 of them, I tried to upload them to ChatGPT and it did not work. I then decided I would go 10 frames at a time from the beginning of the clip. Even though I sent an entirely different portion of the video and told ChatGPT we were starting from a different part of the video, it still said that the beginning of the video said “this version is.” I continued uploading frames, 10 at a time. These frames included both Lessin and Zuckerberg, not just Zuckerberg.
ChatGPT slowly began to create a surely accurate transcript of the lost audio of this interview: “This version is just that it we built,” ChatGPT said. As I added more and more frames, it refined the answer: “This version is what we’re going to do,” it said. Finally, it seemed to make a breakthrough. “Is this version of LLaMA more powerful than the one we released last year?” the ChatGPT transcript said. It was not clear about who was speaking, however. ChatGPT said "her mouth movements," but then explained that the "speaker is the man on the left" (Lessin, not Zuckerberg, was speaking in these frames).
I had uploaded 40 of a total of 3,000 frames. Zoom video is usually 30 fps, so in approximately 1.5 seconds, Lessin and/or Zuckerberg apparently said “Is this version of LLaMA more powerful than the one we released last year?” I then recorded this phrase at a normal speaking speed, and it took about four seconds. Just a data point.


I then got an error message from ChatGPT, and got rate-limited because I was uploading too much data. It told me that I needed to wait three hours to try again.
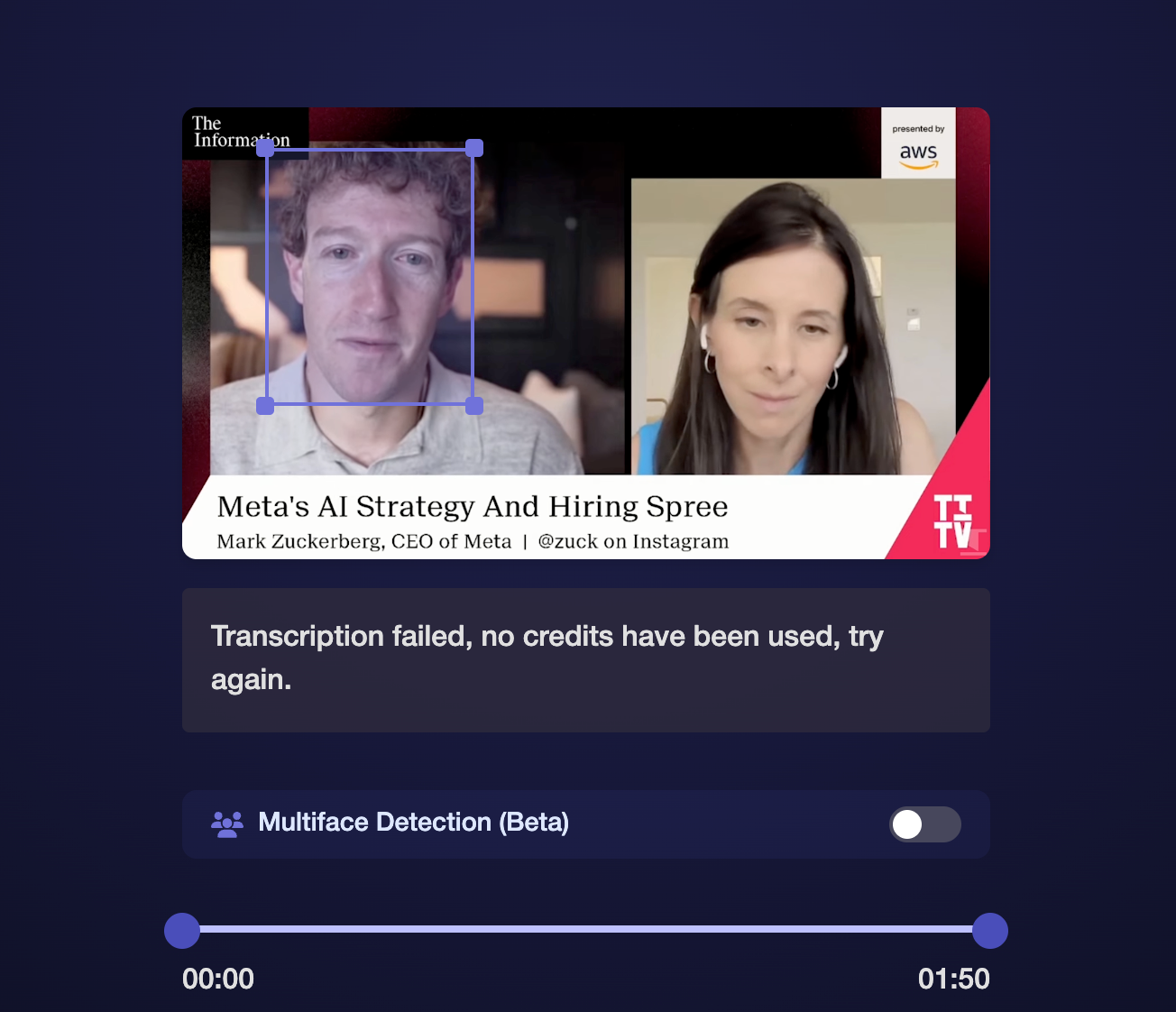
Finally, I did what Meta AI told me to do, and tried a bespoke AI lip reading app. I found one called ReadTheirLips.com, which is powered by Symphonic Labs. This is a tool that people have been trying to use in recent months to figure out what Donald Trump and Jeffrey Epstein were saying to each other in silent b-roll news footage, without much success.
I paid $10 for three minutes worth of transcription and asked it to lip read using its “Multiface Detection.” After waiting 10 minutes, I got an error message that said “Transcription failed, no credits have been used, try again later.” I then asked it to focus only on Zuckerberg, and actually got some text. I separately asked it to focus on Lessin.
Here is a transcript of what the AI says they were talking about. It has not been edited for clarity and I have no idea which parts, if any, are accurate:
LESSIN: Thanks for joining us again, TV. We're happy to have you already this morning. News that you've spent even more money with your big announcement about your new supercomputers. We'll get to that, but to start, you've been in huge scale like I.
ZUCKERBERG: Happy TO BE HERE. We're GOING TO TALK A LITTLE BIT ABOUT META'S AI STRATEGY. It's BEEN BUSY, YOU KNOW? I THINK THE MOST EXCITING THING THIS YEAR IS THAT WE'RE STARTING TO SEE EARLY GLIMPSES OF SELF-IMPROVEMENT WITH THE MODELS, WHICH MEANS THAT DEVELOPING SUPERINTELLIGENCE IS NOW.
LESSIN: You HAVE BEEN ON A PLANE OF AI HIRING, WHY AND WHY NOW?
ZUCKERBERG: Insight, and we just want to make sure that we really strengthen the effort as much as possible to go for it. Our mission with a lab is to deliver personal superintelligence to everyone in the world, so that way, you know, we can put that power in every individual's hand. I'm really excited about it.
LESSIN: I DON'T KNOW, I DON'T KNOW, I DON'T KNOW.
ZUCKERBERG: Than ONE OF THE OTHER LABS YOU'RE DOING, AND YOU KNOW MY VIEW IS THAT THIS IS GOING TO BE SOMETHING THAT IS THE MOST IMPORTANT TECHNOLOGY IN OUR LIVES. IT'S GOING TO UNDERPIN HOW WE DEVELOP EVERYTHING AND THE COMPANY, AND IT'S GOING TO AFFECT SOCIETY VERY WISELY. SO WE JUST WANT TO MAKE SURE WE GET THE BEST FOCUS.
LESSIN: Did YOU FEEL LIKE YOU WERE BEHIND WHAT WAS COMING OUT OF LAW BEFORE I'M NOT ADJUSTING.
ZUCKERBERG: On THIS FROM ENTREPRENEURS TO RESEARCHERS TO ENGINEERS WORKING ON THIS HIDDEN INFRASTRUCTURE, AND THEN OF COURSE WE WANT TO BACK IT UP WITH JUST AN ABSOLUTELY MASSIVE AMOUNT OF COMPUTER RESEARCH, WHICH WE CAN SUPPORT BECAUSE WE HAVE A VERY STRONG BUSINESS MODEL THAT THROWS OFF A LOT OF CAPITAL. LET'S TALK ABOUT.
LESSIN: Like THIS SUMMER, PARTICULARLY, YOU SWITCH GEARS A LITTLE BIT.
ZUCKERBERG: I THINK THE FIELD IS ACCELERATING, YOU KNOW, WE KEEP ON TRACK FOR WHERE WE WANT TO BE, AND THE FIELD KEEPS US MOVING FORWARD.
The video ends there, and it cuts back to the studio.
Update: The Information provided 404 Media with several clips (with audio) from Lessin's interview with Zuckerberg, as well as a real transcript of the interview. Here is the real segment of what was said. As you can see, the AI captured the jist of this portion of the interview, and actually did not do too bad:
Lessin: Mark, thanks for joining TITV. We're happy to have you here. Already this morning, [there’s] news that you've spent even more money with your big announcement about your new supercomputers. We'll get to that. But to start, you took a huge stake in ScaleAI. You have been on a blitz of AI hiring. Why, and why now?
Zuckerberg: Yeah, it's been busy. You know, I think the most exciting thing this year is that we're starting to see early glimpses of self-improvement with the models, which means that developing super intelligence is now in sight, and we just want to make sure that we really strengthen the effort as much as possible to go for it. Our mission with the lab is to deliver personal super intelligence to everyone in the world, so that way we can put that power in every individual's hand. And I'm really excited about it. It's a different thing than what the other labs are doing.
And my view is that this is going to be something that is the most important technology in our lives. It's going to underpin how we develop everything at the company, and it's going to affect society very widely. So we just want to make sure that we get the best folks to work on this, from entrepreneurs to researchers to engineers working on the data and infrastructure.
And then, of course, we want to back up with just an absolutely massive amount of compute which we can support, because we have a very strong business model that throws off a lot of capital.
Lessin: Did you feel like you were behind coming out of Llama 4? It seems like this summer, in particular, you switched gears a little bit.
Zuckerberg: I think the field is accelerating, you know, we keep on having goals for where we want to be. And then the field keeps on moving faster than we expect.
The rest of the interview is available at The Information.
2025-07-15 22:09:36

ICE Block, an app that lets users warn others about the location of ICE officers, and which for a short while was the top of the social media App Store chart, does protect users’ privacy and doesn’t share your location with third parties, according to a recent analysis from a security researcher. ICE Block already claimed that it did not collect any data from the app; the analysis now corroborates that.
“It’s not uploading your location at all, when you make a report that report isn’t associated with your device in any way, and there are no third party services that it talks to or sends data to,” Cooper Quintin, senior public interest technologist at the Electronic Frontier Foundation (EFF), who analyzed the ICE Block app, told 404 Media.
2025-07-15 21:20:26

Hugging Face, a company with a multi-billion dollar valuation and one of the most commonly used platforms for sharing AI tools and resources, is hosting over 5,000 AI image generation models that are designed to recreate the likeness of real people. These models were all previously hosted on Civitai, an AI model sharing platform 404 Media reporting has shown was used for creating nonconsensual pornography, until Civitai banned them due to pressure from payment processors.
Users downloaded the models from Civitai and reuploaded them to Hugging Face as part of a concerted community effort to archive the models after Civitai announced in May it will ban them. In that announcement, Civitai said it will give the people who originally uploaded them “a short period of time” before they were removed. Civitai users began organizing an archiving effort on Discord earlier in May after Civitai indicated it had to make content policy changes due to pressure from payment processors, and the effort kicked into high gear when Civitai announced the new “real people” model policy.
At the time of writing, the Discord channel has hundreds of members who are still finding and sharing models that have been removed from Civitai and are reuploading them to Hugging Face. Some users have even shared a piece of software, also hosted on Hugging Face, which allows users to automatically upload Civitai models to Hugging Face in batches.
Hugging Face did not respond to multiple requests for comment. It also did not respond to specific questions about how and if it plans to moderate these models given the fact that they were previously hosted on a platform primarily used for AI generating pornography, and which our reporting shows were used to create noncensual pornography.
I found the Civitai models of real people that were reuploaded to Hugging Face thanks to a paper I covered where researchers scraped Civitai. The paper showed that the platform was primarily used for pornographic content, and that it deleted at least 50,000 AI models designed to recreate the likeness of real people once it changed its policy in May. The researchers, Laura Wagner and Eva Cetnic from the University of Zurich, provided me with a spreadsheet of all the deleted models, which included the name of the models (which is almost always the name of a female celebrity or lesser known internet personality), a link to where it was previously hosted on Civitai, and the SHA256 hash Civitai uses to identify all the models hosted on its site.
The people who are reuploading the Civitai models to Hugging Face are seemingly trying to hide the purpose of those models on Hugging Face. On Hugging Face, these models have generic names and URLs like “LORA” or “Test model.” Users can’t tell that these models are used to generate the likeness of real people just by looking at their Hugging Face page, nor would they be able to find them by searching for the names of celebrities on Hugging Face. In order to find them, users can go to a separate website the Civitai archivists created. There, they can enter the name of a Civitai model, the link where it used to be hosted on Civitai before it was deleted, or the model’s SHA256 hash. All of these will lead users to a page which explains what the model is, show its name, as well as several images showing the kind of images it can generate. At the bottom of that page is a link to one or more Hugging Face “mirrors” where the model has been reuploaded.
By using Wagner’s and Cetnic’s data and entering it into this Civitai archive site, I was able to find the Civitai models hosted on Hugging Face.
Hugging Face’s content policy bans “Unlawful, defamatory, fraudulent, or intentionally deceptive Content (e.g., disinformation, phishing, scams, inauthentic behavior),” as well as “Sexual Content used for harassment, bullying, or created without explicit consent.” Models that generate the likeness of real people don’t have to be used for unlawful or defamatory ends, and they only produce sexual content if people choose to use them that way. There’s nothing in Hugging Face’s content policy that explicitly forbids AI models that recreate the likeness of real people.
However, the Hugging Face Ethics & Society group, which is “committed to operationalizing ethics at the cutting-edge of machine learning,” has identified six “high-level categories for describing ethical aspects of machine learning work,” one of which is that AI should be “Consentful.”
“Consentful technology supports the self-determination of people who use and are affected by these technologies,” the company explains. Examples of this, the company says, includes “Avoiding extractive, chauvinist, ‘dark,’ and otherwise ‘unethical’ patterns of engagement.”
Other AI models that recreate the likeness of real people could conceivably not violate any of these principles. For example, two of the deleted Civitai models that were reuploaded to Hugging Face were designed to recreate the likeness of Vladimir Putin, which in theory people would want to use in order to mock or criticize the Russian president. However, the vast majority of the models are of female celebrities, which my reporting has shown is being used to create nonconsensual sexual content, and which were deleted en masse from Civitai because of pressure from payment processors who didn’t want to be associated with that type of media.
2025-07-15 21:10:06

In the two years that I’ve been reporting about Civitai, a platform for sharing AI image generation models that has been instrumental in the production of AI generated non-consensual porn, Civitai has consistently argued that the amount of adult content on the site has been overstated. But new research shows that, if anything, the amount of adult content on Civitai has been underestimated.
In their paper, “Perpetuating Misogyny with Generative AI: How Model Personalization Normalizes Gendered Harm,” researchers Laura Wagner and Eva Cetnic from the University of Zurich studied more than 40 million user-generated images on Civitai and over 230,000 models. They found “a disproportionate rise in not-safe-for-work (NSFW) content and a significant number of models intended to mimic real individuals” on the platform, they write in the paper.
“What began as a promising creative breakthrough in TTI [text-to-image] generation and model personalization, has devolved into a pipeline for the large-scale production of sensational, biased, and abusive content. The open-source nature of TTI technologies, proclaimed as a democratizing force in generative AI, has also enabled the propagation of models that perpetuate hypersexualized imagery and nonconsensual deepfakes,” Wagner and Cetnic write in their paper. “Several indicators suggest a descent into a self-reinforcing feedback loop of platform decay. These include a dramatic increase in NSFW imagery, from 41% to 80% in two years, as well as the community’s normalization of deepfakes, misogynistic tropes, and other exploitative content.”
To visualize just how dominant adult content was on Civitai, check the chart below, which shows the distribution of images by “NSFW browsing levels” over time. These categories, which are inspired by the Motion Picture Association film rating system and are used by Civitai to tag images, show that adult content was always a significant portion of all images hosted on the site, but that the portion of “overtly sexual, or disturbing” content only grew as the site became more popular, and exploded starting in 2024. The chart is based on Civitai’s own numbers and categorization system which the researchers scraped from the site. It likely undercounts the number of explicit images on the site since as both the researchers and I observed during my reporting, not all adult content is tagged as such.
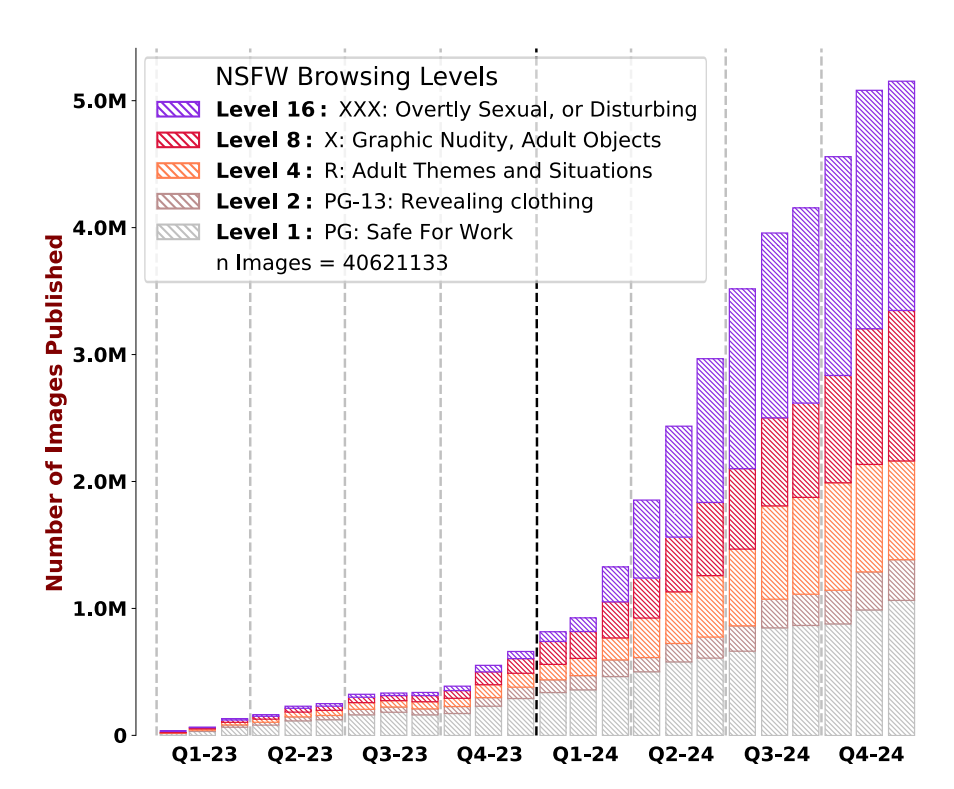
In December, 2023, Civitai CEO Justin Maier told Venture Beat that “less than 20% of the posted content is what we would consider ‘PG-13’ or above.” When I reached Maier for comment for this article, he told me that “The VentureBeat figure cited a December 2023 snapshot, when adult posts were a minority. The mix shifted in 2024 as many NSFW creators migrated from platforms that no longer allow that content.”
However, the data in the paper shows that by October of 2023, 56 percent of all images on the site were tagged as “NSFW” and were designated by Civitai as “PG-13” or above.
In May, Civitai announced it’s banning all AI image generation models designed to recreate the likeness of real people because of pressure from payment processors. Since the authors of the paper were already tracking hundreds of thousands of models hosted on Civitai, they could easily see which models were removed, giving us a first clear look at how common those models were.
Overall, they saw that more than 50,000 models designed to AI-generate the likeness of real people were removed because of the ban. These are models that Civitai itself tagged as “person of interest,” the tag it uses to indicate a model recreates the likeness of a real person, so the actual number of models depicting real people is likely higher.
It’s hard to say if the most popular AI models on Civitai were all popular just because they were used to generate explicit images, because people could use models tagged as NSFW to generate non-nude images and vice versa. For example, according to the data collected by the researchers the most popular AI image generation model on Civitai was EasyNegative with almost 600,000 downloads. It’s not tagged or promoted as a model for generating pornography, but images that users created with it, which are shared on its Civitai model page, show it is commonly used that way.
Other very popular models on Civitai are clearly designed to generate explicit images. The sixth most popular model with 360,000 downloads is Nudify XL: Better Bodies, which its creator says is for “nude female frontals.” A model called Realistic Vaginas - God Pussy 1 had 256,000 downloads. The POV Squatting Cowgirl LoRA model, which Civitai tagged as a “sex” model, had 189,000 downloads.

The authors of the paper also conducted deeper analysis of the 40,000 most downloaded models on Civitai. In the 11,151 models where they could extract textual training data, meaning text that indicates what kind of images the models were trained on, they found “specifically abusive terms.” 5.6 percent included the keywords “loli” (558 models) and/or “shota” (69 models), Japanese terms commonly used to refer to sexualized depictions of pre-pubescent girls and boys. About 2.1 percent (189 models) included the keyword “rape.”
The data shows with clear numbers what we have long argued at 404 Media: adult content drives technological innovation and early adoption, and this has been especially true in the world of generative AI. Despite its protestation to the contrary, Civitai, which is one of the fastest growing platforms in that industry, and that the influential Silicon Valley venture capital firm Andreessen Horowitz invested in, grew because of explicit content, much of which was nonconsensual.
“The rapid rise of NSFW content, the over-representation of young female subjects, and the prioritization of sensational content to drive engagement reflect an exploitative, even abusive dynamic,” the researchers wrote. “Additionally, structural discrimination embedded in today’s open-source TTI tools and models have the potential to cause significant downstream harm as they might become widely adopted and even integrated into future consumer applications.”
Adult content driving innovation and early adoption doesn’t have to be harmful. As the researchers write, it’s the choices platforms like Civitai make that give us these outcomes.
“The contingent nature of technology, shaped by online communities, platform operators, lawmakers, and society as a whole, also creates opportunities for intervention,” they write. “Model-sharing hubs and social media platforms both have the capacity to implement safeguards that can limit the spread of abusive practices such as deepfake creation and abusive imagery.”
2025-07-15 09:59:59

Many trains in the U.S. are vulnerable to a hack that can remotely lock a train’s brakes, according to the U.S. Cybersecurity and Infrastructure Security Agency (CISA) and the researcher who discovered the vulnerability. The railroad industry has known about the vulnerability for more than a decade but only recently began to fix it.
Independent researcher Neil Smith first discovered the vulnerability, which can be exploited over radio frequencies, in 2012.
“All of the knowledge to generate the exploit already exists on the internet. AI could even build it for you,” Smith told 404 Media. “The physical aspect really only means that you could not exploit this over the internet from another country, you would need to be some physical distance from the train [so] that your signal is still received.”