2025-06-01 04:30:00

原文来自于 Addy Osmani,他是 Google Chrome 的工程主管,在 Google 工作多年。
开发人员越来越依赖 AI 编程助手来加速我们的日常工作流程。这些工具可以自动完成函数、建议修复错误,甚至生成整个模块或 MVP。然而,正如我们许多人所了解的那样,AI 输出的质量很大程度上取决于你提供的提示的质量。换句话说,提示工程已经成为一项必备技能。一个措辞不当的请求可能会产生不相关或笼统的答案,而一个精心设计的提示可以产生周到、准确甚至富有创造性的代码解决方案。本文将实际探讨如何系统地构建适用于常见开发任务的提示。
AI 结对程序员很强大但并非神奇——除了你告诉他们的或包含在上下文中的信息外,对你特定的项目或意图没有先验知识。你提供的信息越多,输出就越好。我们将提炼出开发者反响热烈的提示模式、可重复的框架和难忘的示例。你将看到好与坏提示的并排比较以及实际的 AI 响应,并附有评论以了解为什么一个成功而另一个失败。以下是入门小贴士:
| 技巧 | 提示模板 | 目的 |
|---|---|---|
| 1. 角色提示 | “你是一名资深的{语言名}开发者。请审查这个函数以实现{目标}。” | 模拟专家级的代码审查、调试或重构 |
| 2. 明确上下文设定 | “问题如下:{问题说明}。下面是代码。它本应做到{预期行为},但实际上做了 {实际行为}。为什么?” | 明确框定问题,避免泛泛而谈的回答 |
| 3. 输入/输出示例 | “这个函数在输入{输入内容}时应返回{预期输出}。你能编写或修复这段代码吗?” | 通过示例引导 AI 理解意图 |
| 4. 迭代分步 | “首先生成这个组件的骨架。接下来我们添加状态。然后处理 API 调用。” | 将大任务拆解为步骤,避免模糊或过载的提示 |
| 5. 模拟调试 | “逐行走查这个函数。变量值是什么?哪里可能出错?” | 引导 AI 模拟运行时行为,发现隐藏的 bug |
| 6. 功能蓝图 | “我正在构建{功能特性}。需求如下:{具体说明}。技术栈为:{技术栈说明}。请搭建初始组件并解释你的选择。” | 启动 AI 主导的功能规划与脚手架搭建 |
| 7. 重构指导 | “请重构这段代码以提升{目标},比如(如:可读性、性能、符合语言习惯的风格)。请使用注释解释变更。” | 让 AI 的重构符合你的目标,而不是随意更动 |
| 8. 请求替代方案 | “你能用函数式风格重写这段代码吗?递归版本会是什么样?” | 探索多种实现方式,扩展工具箱 |
| 9. 橡皮鸭调试 | “我觉得这个函数的作用是:{你的解释}。我遗漏了什么吗?有没有 bug?” | 让 AI 质疑你的理解并发现潜在问题 |
| 10. 约束锚定 | “请避免(例如:递归),并遵守(例如:ES6 语法、无外部库)。优化方向为(例如:内存)。这是函数代码:” | 防止 AI 过度发挥或引入不兼容的模式 |
向 AI 编码工具提示与与一个非常有原则、有时会知识渊博的合作者交流有点像。为了获得有用的结果,您需要清楚地设置场景,并指导 AI 您想要什么以及如何实现。
2024-12-30 06:30:00

伴随着 OpenAI、Anthropic 等等公司的努力,大型语言模型(LLM)的性能不断提升,AI 产品的应用场景也越来越广泛。从口袋里的智能助手到驰骋未来的自动驾驶,从辅助医疗诊断的慧眼到洞察市场风云的智脑,AI 正以前所未有的速度改变着世界。但是在这个过程中,我们会注意到一些问题,我们会陷入“技术至上”的误区,过分强调技术的先进性,而忽略了用户的需求和体验。这就导致了很多 AI 产品虽然技术先进,但却无法真正满足用户的需求,最终无法实现商业价值。究其原因,许多 AI 系统在与人类交互时,常常陷入**“鸡同鸭讲”的窘境**——对上下文的理解捉襟见肘,难以领会人类语言中的微妙含义;更令人担忧的是“幻觉”问题,AI 煞有介事地编造着“一本正经的胡说八道”,让用户无所适从;而在用户体验方面,许多 AI 产品更是差强人意,机械式的交互和冰冷的界面让人难以产生亲近感。有些时候我们有些失望:帕累托法则(或者叫做 28 原则),一直在发挥着神秘的力量。
抛开模型开发公司本身而言,面向客户的 AI 产品的设计和开发是一个复杂的过程,需要综合考虑技术、商业和用户体验等多个方面。在这个过程中,如何保证产品的质量和用户体验成为了关键问题。传统的产品设计方法往往是由设计师和工程师等专业人员完成,而用户往往只是产品的使用者。然而,随着 LLM 的发展,新的交互形式不停的出现,比如之前的聊天产品和语音助手交互产品普遍反馈交互感太差并不实用。新的实时多模态模型的出现,让这些可以更好的理解用户的需求,更好的满足用户的需求。
但,无论如何,要充分释放 AI 的潜力,必须将用户需求和体验置于核心地位。这不仅仅是一句口号,更是一种深刻的变革,要求我们将用户的需求、期望和体验置于 AI 产品设计的最核心。这意味着,我们需要像人类学家一样去观察和理解用户的真实诉求,像心理学家一样去揣摩用户的情感和认知模式,并将这些洞察深深地烙印在产品的基因之中。只有这样,才能打造出真正被用户拥抱、信任并从中受益的 AI 产品。
本文就是我在最近两年开发 AI 产品的一些体悟,希望能够给 AI 产品的设计和开发带来一些启发。虽然我是一个工程师视角,但是斗胆今天就来聊一聊 AI 产品的设计和体验问题。
毋庸置疑,现在 AI 在“力大砖飞”的背景之下,已经在许多领域展现出了强大的能力。从自然语言处理到计算机视觉,从智能推荐到智能对话,AI 的应用场景越来越广泛,技术也越来越成熟。在过去的两年中,我们见证了每隔几个月到半年,LLM 就进行了一种大范围的能力提升变革。然而,AI 的能力和局限性也给产品设计带来了许多挑战。这些局限性并非是无法克服的,有些也仅仅局限于当前的技术水平,但是我们必须清楚地认识到这些局限性,才能更好地设计和开发 AI 产品。
这些问题你可能在很多地方看到过,让我再赘述一遍:
这些问题并非无法解决,但是我们必须清楚地认识到这些问题,才能更好地设计和开发 AI 产品。在 AI 产品设计中,我们需要充分考虑这些问题,从而更好地满足用户的需求和体验。而在这个过程中,我认为针对人机回环(Human in the loop, HITL)的设计思想是非常重要的。通过完善这个设计思想,我们可以更好地解决上述问题,提高 AI 产品的质量和用户体验。
以人为本,是产品设计的灵魂所在,对于 AI 产品而言更是如此。对这种方式而言,一般会以下面的方式为循环来进行:
2024-11-14 19:28:00
Genkit 是一个 Google Firebase 团队开发的 AI Agent 开发框架,用于构建现代、高效的 AI 应用。它目前包含一个 Node.js 的实现 和一个 Go 语言的实现。之所以注意到这个框架是因为 Go 团队在他们的十五周年博客中提到了它。Go 团队在博客中提到,他们正在努力使 Go 成为构建生产 AI 系统的优秀语言,并且他们正在为流行的 Go 语言框架提供支持,包括 LangChainGo 和 Genkit。如果你了解过 AI 开发,那么 LangChain 一定并不陌生。LangChainGo 就是 LangChain 的 Go 语言实现。但是对应的,我们还需要一个单独的 AI Agent 开发框架,帮助我们组织 AI Agent 的开发。LangChain 的生态位中,对应的是 LangGraph,在 Go 语言的生态位中,你可以选择 Genkit 或者 LangGraphGo。
但是,值得注意的是,目前 Genkit 仍旧是在 Alpha 的状态,所以,如果你希望将 Genkit 用于生产环境,在 2024 年这个时间点请注意未来可能的 API 变动。 目前 Genkit 官方支持的模型功能仍旧是以 Google 家的产品为主,如果你需要使用其他 AI 模型,你可能需要暂时先使用第三方 plugin(比如 OpenAI)。
2024-06-03 19:15:00
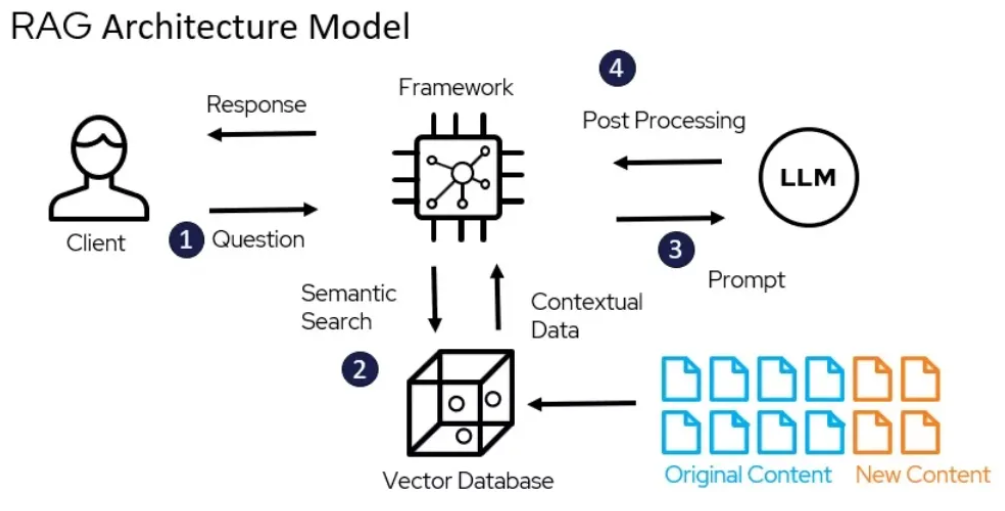
检索增强生成(Retrieval Augmented Generation,简称RAG)技术正逐渐成为提升大型语言模型(LLM)性能的关键。OpenAI 的 John Allard 和 Colin Jarvis 在一场分享中,以实际案例为基础,深入浅出地讲解了如何将 RAG 技术应用于实际工程问题,并分享了他们的最佳实践经验。这些内容对于 RAG 技术的应用者来说,无疑是非常有价值的。事实上,OpenAI 开放了很多的他们的最佳实践内容,包括不限于 Prompt Engineering、Data Augmentation、Fine-tuning、Inference Optimization 等等。有空除了多看一下相关论文,OpenAI 的 Github 和 Youtube 频道都值得看一下。比如说这次分享就是来源于 OpenAI 的 Youtube 频道。
优化 LLM 性能并非易事,哪怕丁点的区别都可能导致结果上出现很大的差异。目前优化性能主要存在以下挑战:
为了解决上述挑战,OpenAI 提出了一个二维优化框架,将优化方向分为__内容优化__和__LLM优化__两个部分。
内容优化指的是优化模型可访问的知识内容。如果模型缺乏必要的知识或信息质量较差,那么即使模型本身的能力很强,也难以给出令人满意的答案。
为了补全这部分的知识内容,可以采用以下方法进行:
通过优化模型本身提升效果。如果模型本身存在缺陷,例如容易产生幻觉或难以理解复杂指令,那么即使有充足的知识,也难以给出合理的答案。
在这个优化方案中,可以采用下面的方式进行:
在这个框架下,OpenAI 建议开发者采用以下流程进行优化:
2024-04-10 17:15:00
在开始看这篇文章之前,推荐你阅读前一篇概念介绍文章。这篇文章之内不会再额外介绍概念上的内容,仅仅从实践角度演示如何是用 HyDE 和 RAG 结合。正如同前文提到的那样,我们会是用 LangChain 构建这个演示 Demo。当然,如果你熟悉 LlamaIndex 或者其他框架,其实主要流程大致差不多,只不过是用的 API 和库有一些区别。这些就不再赘述。
让我们假设你在为麦当劳制作一个问答系统。这个问答系统的目的是帮助用户解决一些常见问题,比如:麦当劳的营业时间,麦当劳的菜单,麦当劳的优惠活动等等。这些问题的答案通常是可以在麦当劳的官方网站上找到的,但是用户可能并不知道这些信息,或者他们可能会用自己的方式提出问题。这时候,我们就需要一个 RAG 模型来帮助我们回答这些问题。但是麦当劳实际上有非常多的商品,那么它的知识库可能会非常大,而且用户提出的问题可能并不在知识库中。这时候 HyDE 就可以帮助我们处理这些问题。
我们会是用一些基本的 Python 相关工具(pdm 等等)、Ollama和chroma。关于 Ollama 的介绍,可以查看我的之前的文章。出于成本考虑,这里使用了开源的本地模型实现,请确保你的 Ollama 是在运行的状态。当然,如果你是用 GPT-4 Turbo(今天凌晨刚刚发布了新版本),效果要远比开源模型好很多。
mkdir hydemo && cd hydemo
pdm init
pdm add langchain chromadb beautifulsoup4
source .venv/bin/activate
请注意,在本文编写时,使用的 LangChain 的版本为 0.1.14,如果你的版本较低或者过高,可能存在部分 API 出入,请根据具体情况调整引用的模块和对应的 API。
from langchain.chains.hyde.base import HypotheticalDocumentEmbedder
from langchain.chains.llm import LLMChain
from langchain.embeddings.ollama import OllamaEmbeddings
from langchain.globals import set_debug
from langchain.llms.ollama import Ollama
from langchain.vectorstores.chroma import Chroma
def main():
set_debug(True) # 设置 langchain 的调试模式,后面我们会看到具体的效果
llm = Ollama(model="qwen:7b") # 使用通义千问 7b 模型
olemb = OllamaEmbeddings(
model="nomic-embed-text"
) # 嵌入模型我们是使用的 nomic-embed-text
embeddings = HypotheticalDocumentEmbedder.from_llm(
llm,
base_embeddings=olemb,
prompt_key="web_search", # 加载预置的 Web Search Prompt
)
print(embeddings.llm_chain.prompt)
if __name__ == "__main__":
main()
让我们先执行一下,看一下 Prompt 会是什么样子的:
2024-04-09 22:15:00
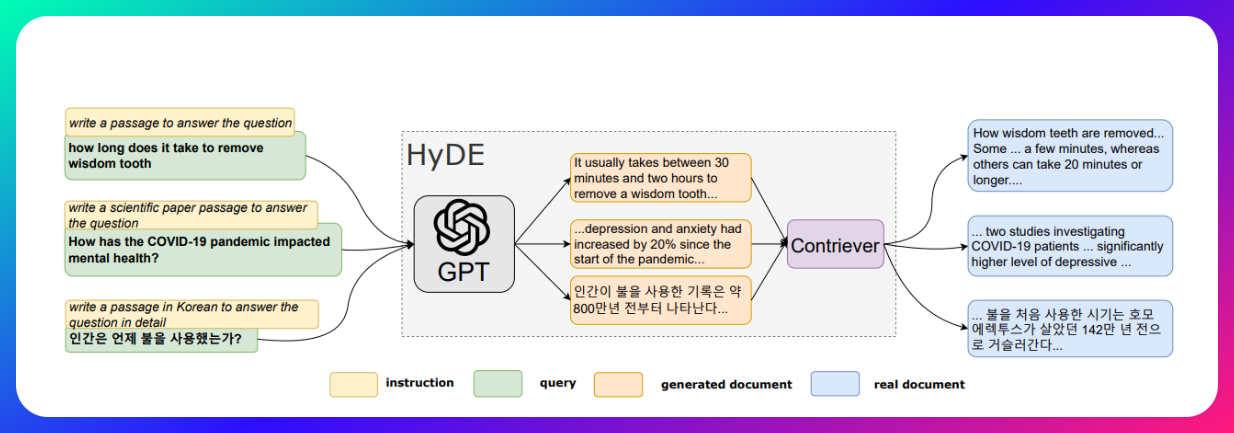
最近看到了一篇新的论文,关于评估 RAG 中的各种技术的评估。这篇《ARAGOG: Advanced RAG Output Grading》提供了一个对比多种 RAG 技术的评估。其中提到 HyDE 和 LLM re-rank 能够很好的提高检索精度。不过似乎 HyDE 其实讨论并不是很多,那么咱就对这块内容添砖加瓦一下,让我们从零开始进行一段 HyDE 的冒险。
大语言模型(LLM)虽然在过去的一段时间中成为大家眼中的香馍馍,但它们也存在一些关键的局限性:
要解决这些问题,那么就需要是用 RAG 来帮助解决。那么,什么是 RAG 呢?
Retrieval-Augmented Generation (RAG) 是一种基于检索的生成式模型,它结合了检索式和生成式的优点,可以在生成式模型(Generative Model)中引入外部知识。RAG 模型由两部分组成:一个是检索器,另一个是生成器。检索器负责从知识库中检索相关信息,生成器则负责生成答案。与传统的大语言模型(LLM)仅依靠自身有限的知识进行文本生成不同,RAG 模型能够动态地从海量的外部知识库中检索相关信息,并将这些信息融入到生成过程中,产生更加准确、连贯的输出内容。
换句话说,当用户提出一个查询或者需要生成某种类型的文本时,RAG 模型首先会利用一个信息检索子模块,从知识库中检索出与查询相关的信息。然后,RAG 的生成子模块会结合这些检索到的相关信息,生成最终的输出文本。这种结合检索和生成的方式,使 RAG 模型能够弥补传统 LLM 的局限性,提高生成内容的准确性和可靠性。
简单点来说,RAG 的基本流程如下:

但是在是用 RAG 的时候,你往往也会遇到一些问题。
让我们设想一个场景:我们有一个知识库,里面存储了大量的文档,我们希望使用 RAG 模型来回答用户的问题。但是,原始的 RAG 只能处理知识库中包含的数据,但是对于知识库中不存在的数据,RAG 无法处理。比较常见的场景包含用户的问答系统,帮助中心,对话系统等。用户通常对你的系统或者专有名词并不了解,他们通常会提出一些根据自己理解或者自己熟悉概念中的名词问题,这些表达方式可能并不在你的知识库中。这时候 RAG 就无法从知识库中检索到相关信息。