2026-07-02 00:00:00
上一篇那套 Agent 工作流其实并不完善,它只是当下妥协出来的一套流程——文档先行、人卡在几个关口审一审、task.md 记着进度。说白了,是拿「流程纪律」硬填 Agent 接不进现有工程链路的坑。
那理想的工作流长啥样?光有纪律不够,还得往下再走一层:把调试、测试、联调都改造成 Agent 能直接上手的样子,人退到只管设计和审核。
先摆个够复杂的项目当靶子——能把它捋顺,剩下大部分工程场景也就差不多了:
嵌入式软件 A 基于 硬件 B
算法 C 服务于 PC 软件 D 和 PC 软件 E
PC 软件 D 基于通信协议 与嵌入式软件 A 交互
PC 软件 E 基于特定协议文件 与软件 D 交互
Web 软件 F 基于网络协议 与软件 D、E 交互
安卓端 G 基于网络协议 与软件 D 交互
iOS 端 H 基于网络协议 与软件 D 交互
这里先不考虑额外的自动化测试工程(就是那种独立于业务架构、单独起一套的测试工程)。我的想法是:测试能力最好长在每个组件自己身上,而不是另起一座测试孤岛。
flowchart LR
B["硬件 B"] --> A["嵌入式 A"]
A <-->|通信协议| D["PC 软件 D"]
C["算法 C"] --> D
C --> E["PC 软件 E"]
D <-->|协议文件| E
D <-->|网络协议| F["Web F"]
D <-->|网络协议| G["安卓 G"]
D <-->|网络协议| H["iOS H"]
E <-->|网络协议| F
classDef hw fill:#f8cecc,stroke:#b85450
classDef emb fill:#dae8fc,stroke:#6c8ebf
classDef pc fill:#d5e8d4,stroke:#82b366
classDef net fill:#fff2cc,stroke:#d6b656
class B hw
class A emb
class D,E,C pc
class F,G,H net
这张图里,每条箭头都是 Agent 联调时要跨的边界。理想情况下,边界两头都该露出「机器能读、机器能调」的接口;可现实里呢,很多边界就只有个 GUI、一台示波器、或者一段得靠人眼看的波形——Agent 走到这儿就断了,再往前一步都迈不动。
| 边界 | 理想态里 Agent 能用的接口 | 现实里常见的断点 |
|---|---|---|
| A ↔ B | 仿真器 / 真机 MCP、寄存器 dump、固件烧录 CLI | 只有 JTAG 调试器,外加人眼看灯 |
| D ↔ A | 协议帧日志、回放脚本、mock 设备 | 只有串口助手,肉眼对十六进制 |
| D ↔ E | 协议文件 + 结构化 diff | 二进制专有格式,连 schema 都没有 |
| D ↔ F/G/H | HTTP/gRPC 契约 + 集成测试 API | 一堆 UI 点击流,没有 headless 入口 |
| 算法 C | 固定输入输出向量、基准测试 CLI | 只有 MATLAB 图,没法量化断言 |
一句话:上篇解决的是「文档和代码怎么对上」,这篇要解决的是「Agent 到底摸不摸得到这些边」。
理想的 Agent 工作流,我觉得能一句话概括:
该人干的人干好——定方向、划边界、把物理和权限上的路打通;编码、联调、测试丢给 Agent;最后审核还是人来拍板。
这么一来,工程师的身份其实变了:从「自己埋头写代码」变成「设计系统 + 管 Agent」。不是说细节就不管了,而是把细节约束提前写进一个 Agent 能读、能跑、还能自己判断对错的环境里。
先做个假设:要是 Agent 上下文接近无限,不会「聊着聊着就忘了 S8 之前不能写代码」,那工作流就能尽量照着人类团队那套来搭——产品提需求、开发写实现、测试验结果、负责人拍板,只不过每个岗位都能换成 Agent,人只挑几步插手。
但有个坑特别容易忽略:上下文无限 ≠ Agent 就可靠了。
task.md、wolai 定稿)还是省不掉所以哪怕上下文不再是瓶颈,流程纪律和那些能被观测的边界,依旧是硬需求;区别只是你能腾出更多精力,去搞「链路打通」这件正事。
理想态里,人确实不用一行行去写实现了。但下面这几件事,短期内真不好甩给 Agent:
| 人留着的活 | 为啥甩不掉 |
|---|---|
| 定方向、划范围 | 「要做啥」得人说了算,不然 Agent 分分钟给你 scope creep |
| 划协议和模块边界 | A~H 之间谁跟谁说话、合同是啥,这得架构师定 |
| 打通物理世界 | 真机、夹具、烧录器、各种权限——Agent 没有手,够不着 |
| 审核拍板 | 安全、业务意图、能不能交给客户,这些 AI 不背锅 |
| 把工程改造成 Agent 友好 | 加 CLI、加结构化日志、加可回放测试——这是落到人头上的新「搬砖」 |
最后一条最关键:理想工作流不是干等 Agent 变强就行,而是人得主动把环境收拾成一个 Agent 能上岗干活的车间。
要是真打算一切围着 Agent 转,那软件之间的交互、调试、测试都得为它服务。可现在的工具链基本是给人、给业务用的,Agent 在不少环节根本插不进手。
1. 没有 CLI,也没有能下断言的输出
测试这一环,特别多是靠人眼判断的,要么软件压根没有命令行式的输入输出。这种工具 Agent 用不了,测试就又被踢回给人。上篇说过那句话:能编译通过 ≠ 能自测。
2. 图和文之间那道墙(原生 UI 尤其惨)
UI 的设计和实现之间,在非 Web 的场景下,几乎没有一门 Agent 能操作的「中间语言」——你想用代码或文字精确描述「这个控件偏了 2px」「这个动效不对劲」,太难了。Web 好歹还有 DOM 加截图兜底,桌面和移动端的原生 UI 就更吃亏。
3. 视频和图文之间,差距更大
这比静态图又高一层:时序、动画、音画同步……Agent 理解起来成本陡增。录屏加抽帧对比能缓解一点,但离「能下可靠断言」还差得远。这一层现阶段 Agent 基本进不来,只能等技术再往前走走。
4. 状态和时序这道坎
很多 bug 根本不在「某一帧画面」上,而是藏在时序、并发、中断、实时性里——协议莫名少了一帧、DMA 跟主循环抢资源、电机响应慢了 3ms。这类问题没有一张稳定的文本快照能截下来,Agent 拿不到「现场」,只能干等着人来一句「刚才好像卡了一下」。
「为 Agent 改造」不能拍脑袋,我归了四条,拿来挨个对比够不够格:
可观测 — 状态能用文本或结构化数据吐出来(日志、dump、协议帧、指标)
可驱动 — 能用命令行 / API / 脚本触发,不靠鼠标点
可断言 — 结果能让程序判定对错,不只靠人眼,不凭感觉
可复现 — 同样的输入能稳定重放(硬件场景下就是能录能回放)
四条全占上,Agent 才可能在这个环节自己跑出闭环;缺一条,人就还得在那儿补位。
软硬件联调这块,得能模拟硬件,最好直接把真机接进流程——让 Agent 能直接调:烧录、读寄存器、发指令、读传感器,连硬件调试那条链路也接进来。
一句话:把 Agent 当个正常员工看待,人手里有啥工具,就得给它配上对应的接口。
以上述项目为例:
这其实就是上篇「测试压力全压人身上」的极端版:越靠近物理世界,改造成本越高,可一旦打通,闭环带来的收益也越大。
回到 A~H 那张图,真要并行干,基本就是一个组件开一个 Agent,各跑各的会话。那它们之间怎么对齐?靠的不是谁记着谁,而是协议文档当合同——边界上的协议、报文格式、接口契约都写死在文档里,改 A 的 Agent 和改 D 的 Agent 各自照着合同来。谁想动合同,就得回到人这儿重新评审。这跟上篇团队版里「多方 Agent + 协议文档联调」是一个意思,只是这里把它当成默认姿势。
还有个容易被忽略的点:Agent 既写代码又写测试,等于自己给自己发合格证。所以人审的时候,重点不光是看代码,更得看测试本身合不合理——断言够不够狠、边界有没有漏、是不是为了让用例「变绿」把条件写松了。测试用例的设计意图这一关,还得人来守。
为 Agent 重做调试、测试链路,是实打实要砸进去的工程量,不是改几行 Skill 就完事的:
| 要砸的地方 | 举个例子 | 短期啥感受 |
|---|---|---|
| 协议可观测 | D↔A 通信录包 + 文本回放 | 开发节奏变慢 |
| 原生 UI 可测 | G/H 加 headless 或截图 diff 管线 | 得动客户端架构 |
| 硬件在环 | 真机 MCP、仿真器、安全互锁 | 要硬件团队配合 |
| 规范成文 | MVVM、日志、目录约定写进 task.md
|
文档变厚 |
怎么取舍:小需求、一次性脚本,犯不上全链路改造,上篇那套妥协流程就够用了。但要是个长期维护的多端 + 嵌入式产品,那越早把边界上那四条判据补齐越划算——Agent 能扛的环节越多,人就越往「架构师 + 审核员」那个位置挪。
不是所有项目都得追理想态。关键是先搞清楚断点卡在哪,再决定是花钱打通链路,还是干脆让人补位。
把前面这些收回到例子上,理想态大概是这么转的:
task.md;给 Agent 开通真机、网络、仓库的权限flowchart TB
HUMAN["人:方向 / 边界 / 权限 / 审核"]:::human
AGENT["Agent:编码 / 自测 / 联调脚本"]:::ai
CHAIN["Agent 友好链路<br/>CLI · 日志 · 录包 · 真机 MCP"]:::chain
PROD["A~H 各组件"]:::prod
HUMAN -->|定契约| PROD
HUMAN -->|打通| CHAIN
CHAIN --> AGENT
AGENT -->|可观测可驱动| PROD
AGENT -->|阻塞 / 需拍板| HUMAN
classDef human fill:#d5e8d4,stroke:#82b366,color:#333
classDef ai fill:#dae8fc,stroke:#6c8ebf,color:#333
classDef chain fill:#fff2cc,stroke:#d6b656,color:#333
classDef prod fill:#f5f5f5,stroke:#999,color:#666
说到底,上篇拼的是文档纪律,这篇拼的是环境纪律。两样叠一块,才勉强够得着「Agent 写完就能交付、人只管设计和审核」那个理想。
上篇那套妥协流程,解决的是「别让 Agent 跑偏」;这篇想再往前一步,解决「别让 Agent 卡在链路外头」。几个结论:
理想不是「Agent 啥都能干」,而是「该它闭环的地方,它真能闭上」;闭不上的,人就老老实实补位,别假装全自动。
往远了说,这事不光取决于 Agent 多聪明,更取决于整条工具链愿不愿意把「机器能用的接口」露出来——厂商给硬件、给软件配上 CLI 和 MCP,给调试器留个程序能调的口子。这一步迈出来之前,理想工作流就还只是「理想」。
人手里有啥工具,就得给 Agent 配上对应的接口——不然所谓工作流,只是换了个写代码的实习生,谈不上什么新工种。
2026-06-26 00:00:00
前段时间在 wolai 里把一套「一个人带 Agent 做产品」的流程摸清楚了,顺手画了一张图,又写了一份更偏团队协作的 Agent 方案。下文先展开独自开发(AIO)如何把产品、开发、测试、总负责人压缩成「你 + Agent」;再讲团队版(FTM)如何拆回四个岗位。文档怎么流转、人在哪几步必须插手、以及怎么把踩过的坑固化成 Skill,两家共用。
AIO,All-in-one
FTM,Four man team
AI 写代码很快,快到你还没来得及想清楚需求,它已经给你造了三层抽象、两个 Design Pattern 和一个你根本没要的缓存层。没有流程约束,Agent 就像个热情过头的实习生:活干得猛,方向全靠猜,你没规范的内容往往走出了意想不到的呈现方式。
所以我现在的原则是:先文档、后代码;先评审、后构建;缺陷不只改代码,还要反向更新文档。 文档全部放在 wolai,暂时不进 Git 仓库——wolai 自带版本历史,需求和工程文档跟代码解耦,Agent 通过 MCP 读写文档,人负责拍板。
开发分为好几种
目前Agent主要解决的是1、2、3,能完全交给Agent的基本是1和3,2需要大量的上下文和超级健全的工程框架
流程图里绿色节点是人工,蓝色是 AI。主流程自上而下阅读(需求在顶、交付在底);评审纠偏与缺陷回流单独成图,避免横向过宽。
主流程
flowchart TB
A1["相关需求补充/查找"]:::ai
H1["需求"]:::human
H2["工程背景补充"]:::human
A2["AI 结合工程进行需求评审"]:::ai
A3["AI 编写技术文档"]:::ai
H5["人工审核技术点与判断依据"]:::human
P1["代码构建"]:::ai
P2["测试文档 + 用例构建"]:::ai
H7["人工测试,核验需求是否完成"]:::human
A9["AI 复核并同步各文档"]:::ai
H9["人工复核"]:::human
A10["生成功能使用说明文档"]:::ai
H10["复核文档,结束"]:::human
A1 --> H1 --> H2 --> A2 --> A3 --> H5
H5 --> P1 & P2
P1 --> H7
P2 --> H7
H7 --> A9 --> H9 --> A10 --> H10
NOTE["前提:相关代码仓库需可被 AI 读取"]:::note
H2 -.-> NOTE
classDef human fill:#d5e8d4,stroke:#82b366,color:#333
classDef ai fill:#dae8fc,stroke:#6c8ebf,color:#333
classDef note fill:#f5f5f5,stroke:#999,color:#666
评审纠偏与缺陷回流(主流程中未通过时进入)
flowchart TB
subgraph R1["需求评审纠偏"]
RA2["AI 需求评审"]:::ai
RH3["检查理解错误"]:::human
RH4["补充修正材料"]:::human
RA2 --> RH3 --> RH4 --> RA2
end
subgraph R2["技术文档订正"]
RH6["订正错误点"]:::human
RA3["AI 技术文档"]:::ai
RH6 --> RA3
end
subgraph R3["测试未通过"]
RH8["向 AI 说明不符合项"]:::human
RA7["重新修正代码"]:::ai
RA8["回流 Skill"]:::ai
RDOC["反向更新需求/技术/测试文档"]:::ai
RH8 -->|实现问题| RA7
RH8 -->|需求/设计问题| RA8 --> RDOC
end
classDef human fill:#d5e8d4,stroke:#82b366,color:#333
classDef ai fill:#dae8fc,stroke:#6c8ebf,color:#333
核心链路如下:
用一句话概括:人定方向、人审关键节点;AI 写文档、写代码、写用例、做一致性检查;文档作为单一事实来源。
下面是一个核心的 task.md 示例:补充项目信息、开发规范和任务需求,也记录 Agent 各步操作。每轮会话 Agent 都先读它再继续,整体进度同步在这里。想接续开发或并行多任务,复制一份 task 即可,互不干扰。
# 任务:abc-123
> 本文件分两部分:**【一、任务信息】** 初始化时填写、相对稳定;**【二、进度与共创记录】** 开发过程中动态更新。
> 新任务:复制本结构,重填「一」、清空「二」即为初始状态。多任务并行时每个任务一份(见 `docs/tasks/<需求ID>.md`),会话开始时指定要接续的任务。
---
# 一、任务信息(初始化头部)
## 基本信息
| 项 | 值 |
| --- | --- |
| 需求 ID | abc-123 |
| 标题 | 需求abc-123 |
| 类型 | feature |
| 模式 | solo(AIO) |
| 开发分支 | `abc` |
| 基线 | `dev` |
## 文档链接
| 文档 | 链接 |
| --- | --- |
| 需求页 | [A](https://www.wolai.com/abc) |
| 技术+测试 | [B](https://www.wolai.com/abc) |
## 关联工程项目(workspace)
- A
- B
- C
## 涉及模块
- A
- B
- C
## 架构与规范要求
- 语言/框架
- MVVM:新代码 `CommunityToolkit.Mvvm`;遗留 `PropertyChanged.Fody`
- 日志:结构化日志
- 本地化:zh-cn / en-us
- 格式/注释:
- 测试:
---
# 二、进度与共创记录
## 当前阶段
**S9 代码实现(已含 S11 复评修复;待人工确认推进 S10+)**
### 阶段清单
- [x] S0 开工登记(Wolai 需求页)
- [x] S1 需求输入
- [x] S2 工程背景(技术页 §0)
- [x] S3 需求评审
- [x] S4 人工纠偏(评审表已确认)
- [x] S5 技术+测试起草(技术页 §9–§11)
- [x] S6 审核技术
- [x] S7 测试二次补全(技术页 §11.2)
- [x] S8 评审关口(已确认进入 S9)
- [x] S9 并行构建(代码 + 33 项自动化回归 + CI)
- [ ] S10 人工测试
- [ ] S11 AI 复核(评审问题修复已先行完成)
- [ ] S12 使用说明(已写回 wolai 需求页 S12)
- [ ] S13 合并基线
## 待反馈 / 开放问题
- 暂无。
## 已确认结论(摘要)
## 变更记录
## 实现摘要 / 行动记录
FTM(Four Man Team)是上文 AIO 的扩展:流程骨架相同,但把人拆回四个角色,各管一摊,Agent 穿插在文档生成、代码构建和一致性复核里,人负责方向、评审和拍板。
角色分工
| 角色 | 主要职责 |
|---|---|
| 产品经理 | 维护需求文档与总体进度看板;需求由人写,AI 只审不改 |
| 软件开发工程师 | 补充工程背景;与 Agent 结对完成代码构建和 Code Review |
| 自动化测试工程师 | 审测试文档、补探索性用例;跑自动化 + 人工流程验证 |
| 总负责人 | 需求/技术/测试三份文档最终评审拍板;决定是否进入开发与合并 |
文档全部落在 wolai,暂不进 Git 仓库——wolai 自带版本历史,需求和工程文档与代码解耦,各角色通过 MCP 读写同一份需求页下的子文档。
团队版主流程
图例:绿色 = 人工主导,蓝色 = Agent 主导,青绿色(虚线边框) = 人机协作(结对进行)。
flowchart TB
PM["产品经理:需求文档"]:::human
MCP["wolai MCP"]:::note
AG["Agent:工程 + 测试文档"]:::ai
RV["总负责人:三文档评审"]:::human
DEV["开发 ⇄ Agent:代码构建"]:::hybrid
QA["测试 ⇄ Agent:用例 + 验证"]:::hybrid
AUD["Agent:AI 复核"]:::ai
DOC["Agent ⇄ 人工:使用/说明文档"]:::hybrid
END["人工复核,合并基线"]:::human
PM --> MCP
MCP --> AG
AG --> RV
RV -->|通过| DEV
RV -->|通过| QA
DEV --> QA
QA -->|缺陷| FIX{"缺陷类型"}
FIX -->|实现| DEV
FIX -->|需求/设计| PM
QA -->|通过| AUD
AUD --> DOC --> END
classDef human fill:#d5e8d4,stroke:#82b366,color:#333
classDef ai fill:#dae8fc,stroke:#6c8ebf,color:#333
classDef hybrid fill:#c5ddd0,stroke:#5a8f7a,stroke-width:2px,stroke-dasharray:6 3,color:#333
classDef note fill:#f5f5f5,stroke:#999,color:#666
各阶段要点:
尚待补齐的环节
团队版比 AIO 多出来的主要矛盾是文档变更通知:
现阶段可人工拉群喊一嗓子,也可以挂一个「监控 Agent」盯 wolai 页面版本差异,触发快速重评审。单人可以靠记忆力,团队版这里需要补足。
并行需求
多个需求若不耦合、不冲突,本地copy多个仓库,从同一基线切不同分支,各开一条 Agent 会话并行开发,互不影响。
与 AIO 独自版的差异
| 维度 | FTM 团队版 | AIO 独自版 |
|---|---|---|
| 看板与进度 | 产品维护 | 自己维护 wolai 需求页 |
| 评审拍板 | 总负责人终审 | 「未来的自己」隔几小时/隔天再审 |
| 测试用例 | 测试工程师主导,Agent 起草 | Agent 起草 + 自己补探索性测试 |
| 跨端协作 | 多方 Agent + 协议文档联调 | 多仓库各开 Agent,协议为边界 |
| 变更通知 | 需显式机制(人或监控 Agent) | 容易遗漏,靠 checklist 自律 |
核心原则两家共用:先文档后代码、评审不过不构建、缺陷回流文档、合并前 AI 复核。 AIO 是 FTM 的角色折叠版,不是另一套流程。
1. 需求不能让 AI 代写
可以让 AI 审查需求、找漏洞、补边界问题;但「要做什么」必须人说了算。否则 Agent 会悄悄帮你 scope creep,最后做出来的是「技术上很完整但没人要」的东西。
2. 评审不过,禁止进入代码阶段
评审不是形式主义。需求、技术、测试三份文档没对齐之前,不要让 Agent 大规模写代码。返工成本通常是正向开发的数倍,而且 AI 返工特别喜欢「再叠一层兼容层」,债越欠越多。
3. 代码仓库可读性是前置条件
工程背景补充那一步如果虚了,后面技术文档全是幻觉。确保相关 repo 在 Cursor 工作区内,或 MCP 能访问;单体产品就把文档和代码放同一 workspace。
4. 人机结对 Review,不是 AI 独审
代码合并前:人看业务逻辑、安全、边界;AI 看样板代码、明显 bug、风格一致性。Anthropic 自己也是这个路子。再强的模型也会漏,人也不能只肉眼看 diff。
5. 测试文档要跟着技术文档长第二遍
第一遍测试用例来自需求;技术文档定稿后,AI 应二次补全——把实现里的隐含状态、错误码、并发边界补进用例。这一步跳过,人工测试很容易漏「文档里没写但代码里做了」的行为。
6. 缺陷要分流,别只会「让 AI 再改改」
7. 文档变更要有通知机制
团队版可以靠人喊一嗓子;独自版容易忘。实践里要么自己养成「改需求必改技术/测试」 checklist,要么用Skill或者规则把这里约束住。
8. 敏感信息别进 prompt
密钥、内网地址、客户数据别贴给云端模型。工程文档里用占位符,本地 .cursor/rules 或环境变量说明真实配置。
9. 会话粒度:一个需求一条线
不要把五个不相关需求塞进同一个 Agent 会话。上下文越长,早期约束越容易被「遗忘」;开新会话时把 wolai 文档链接和当前分支名重新喂一遍。
流程跑通几次之后,重复劳动会冒出来:每次都要提醒 Agent「先读 wolai」「评审不过别写代码」「缺陷要回流文档」。Skill 就是把这套口头规矩写成 Agent 能自动加载的说明书。
---
name: agent-workflow
description: >-
Unified Agent product development workflow (AIO solo + FTM team): wolai docs,
review gates, code/tests, defect doc sync, pre-merge audit. Use when starting
features or bugfixes, 按工作流开发, AIO, FTM, 独自开发, 团队协作, 需求评审,
回流文档, 合并前复核, or wolai Agent workflow.
---
# Agent 产品开发工作流
单一 Skill,内含 AIO 独自版、FTM 团队版与全部子流程。**加载本 Skill 后按「模块路由」读取对应章节执行,无需再 @ 其他 skill。**
## 核心原则
**先文档、后代码;先评审、后构建;缺陷不只改代码,还要反向更新文档。**
- **`docs/task.md` 是每个需求的核心维护文档(本地、单一事实来源)**:当前阶段、进度、待办、需要人反馈/确认的问题、已确认结论摘要、实现摘要、变更记录都实时写在这里。每轮会话**先读它、随时更新它**。
- **wolai 需求/技术/测试页是定稿沉淀**:仅当①需求发生变动,或②某些内容(评审结论、技术方案、用例、设计决策)已明确/经人确认时,由 Agent 把对应内容回写 wolai(追加或更新已有段落,**不注入固定填空模板**、不覆盖人已确认内容)。
- 代码在 workspace。task.md 与 wolai 的关系:task.md 记「正在进行/待定」,wolai 记「已定稿/共享」。
## 会话启动(每轮必做)
1. 读 `docs/task.md` → 确认当前阶段、进度、待反馈项、文档链接(**以 task.md 为状态来源**)
2. 需要已确认的需求/技术/用例细节时,再按 task.md 中链接读对应 wolai 页
3. 若无 `docs/task.md`,或无开工信息(无页面 ID / 无分支)→ 执行 [modules/create-kit.md](modules/create-kit.md)(同时建立 `docs/task.md`)
4. 确认模式:`solo`(AIO)或 `team`(FTM)
5. 声明本步阶段 ID、是否允许写业务代码
## 硬性约束
```
三文档 S8 评审未全通过 → 禁止改 src/ 等业务代码
缺陷类型 design|requirement → 先走 modules/defect-sync.md,人确认后再改代码
需求正文禁止 AI 0-1 生产,仅审查与补充
一个需求 = 一条 Agent 会话
密钥/内网/客户数据禁止进 prompt
```
## 阶段与关口
| ID | 名称 | 主导 | 写代码 |
|----|------|------|--------|
| S0 | 开工登记 | 🤖 | ❌ |
| S1 | 需求输入 | 👤 | ❌ |
| S2 | 工程背景 | 👤 | ❌ |
| S3 | AI 需求评审 | 🤖 | ❌ |
| S4 | 人工纠偏 | 👤 | ❌ |
| S5 | 技术+测试起草 | 🤖 | ❌ |
| S6 | 审核技术 | 👤 | ❌ |
| S7 | 测试补全 | 🤖 | ❌ |
| S8 | 评审关口 | 👤 | ❌ |
| S9 | 并行构建 | 🤖 | ✅ |
| S10 | 人工测试 | 👤 | ✅ 修 bug |
| S11 | AI 复核 | 🤖 | ✅ 修缺口 |
| S12 | 使用说明 | 🔀 | ❌ |
| S13 | 合并基线 | 👤 | ❌ |
**S8 关口(全满足才可 S9)**:P0 有验收标准;技术含错误码与边界;测试覆盖 P0;开放问题已决议;评审记录已回写。
**Bugfix 快速路径**:人填复现与范围 → 可选 AI 简评 → 人确认 → 直进 S9(至少 1 条测试用例)→ S10–S13 同 feature。
**阶段推进**:关键关口需人回复「确认进入 S{n}」后 Agent 才更新阶段;禁止跳阶段(bugfix 可走 B 路径)。
## 模块路由
| 场景 | 阶段 | 读取 |
|------|------|------|
| 新需求/bug 开工 | S0 / B0 | [modules/create-kit.md](modules/create-kit.md) |
| 独自开发全流程 | S0–S13 | [solo-workflow.md](solo-workflow.md) |
| 团队开发全流程 | S0–S13 | [team-workflow.md](team-workflow.md) |
| 需求评审 | S3 | [modules/requirement-review.md](modules/requirement-review.md) |
| 测试失败/需求变更 | 任意 | [modules/defect-sync.md](modules/defect-sync.md) |
| 合并前复核 | S11 | [modules/pre-merge-audit.md](modules/pre-merge-audit.md) |
**阶段 → 模块自动映射**(用户未明说时按需求页当前阶段):
| 阶段 | 执行模块 |
|------|----------|
| S0, B0 | create-kit |
| S1–S2, S4, S6, S8, S10, S12–S13 | solo 或 team 工作流(按 MODE) |
| S3 | requirement-review |
| S5, S7, S9 | solo/team 工作流 |
| S11 | pre-merge-audit |
| 测试失败且类型未定 | 先分流 → defect-sync 或直改代码 |
## 模式选择
| 模式 | 文档 | 适用 |
|------|------|------|
| `solo` | [solo-workflow.md](solo-workflow.md) | 一人兼 PM/DEV/QA/Lead |
| `team` | [team-workflow.md](team-workflow.md) | PM、DEV、QA、Lead 分工 |
未说明时默认 `solo`;用户提 FTM/团队/四人团队 → `team`。
## 文档分工(无固定模板)
| 文档 | 人写 | Agent 写 | 人审 |
|------|------|----------|------|
| 需求 | 背景、范围、功能点、验收标准 | 评审意见(S3) | S4、S8 |
| 技术 | 工程背景(S2) | 方案、接口、数据流(S5) | S6、S8 |
| 测试 | 探索性结论(S10) | 用例起草与补全(S5/S7) | S8 |
Agent 写入 wolai 时追加章节或更新已有段落,**不覆盖**人已确认内容;变更已确认内容须走 defect-sync。
## task.md 维护约定(核心)
`docs/task.md` 由 Agent 实时维护,分为**两大部分**:
**一、任务信息(初始化头部,相对稳定)** — 开工/初始化阶段填写:
- **基本信息**:需求 ID、标题、类型、模式、开发分支、基线
- **文档链接**:wolai 需求页 / 技术页 / 测试页
- **关联工程项目**:workspace 下各仓库的用途、是否本次涉及
- **涉及模块**:仓库内子模块/目录
- **架构与规范要求**:语言/框架、DI、MVVM、日志、本地化、注释与格式规范等
**二、进度与共创记录(动态)** — 开发过程中随时更新:
- **当前阶段** + **阶段清单**(S0–S13 勾选)
- **待反馈 / 开放问题**:需要人确认或决策的事项(含选项与建议),人答复后清理或归档
- **已确认结论摘要**:指向 wolai 定稿,避免本地长篇复制
- **变更记录**:需求/技术变更条目(日期、内容、是否已回写 wolai)
- **实现摘要 / 行动记录**:本轮改了哪些文件 / 关键决策
**回写 wolai 的触发**:当待反馈项被人确认、需求发生变动、或技术/测试内容定稿时,把对应内容回写 wolai,并在变更记录中标注「已同步 wolai」。
### 新任务重置
新需求开工时复制本结构:**重填「一、任务信息」、清空「二、进度与共创记录」**(阶段清单回到全未勾、记录区清空)即为初始状态。
### 多任务并行
- 单任务:直接用 `docs/task.md`。
- 多任务并行:每个任务一份 `docs/tasks/<需求ID>.md`(如 `docs/tasks/DGCS-387.md`)。
- 会话开始时若存在多个任务文件,**由用户指定要接续的任务**(如「接续 DGCS-387」);未指定且仅一个时默认它。
## Agent 行为协议
1. **需求正文**:👤 专属,Agent 只读 + 评审,拒绝代写
2. **技术/测试**:🤖 可起草,人审核后视为定稿
3. **写之后**:更新 `docs/task.md`(当前阶段、进度、待反馈项、实现摘要、行动记录);内容明确或需求变动时再回写 wolai
4. **人确认**:回复「确认进入 S{n}」后才推进阶段(同步更新 task.md 阶段)
5. **子流程完成**:回到主工作流对应步骤
## 缺陷分流(全局)
```
测试未通过
├── implementation → 改代码 → 必要时补用例 → pre-merge-audit
└── design | requirement → defect-sync → 快速重评审 → 再改代码
```
## 前置条件
- [ ] wolai MCP(`user-wolai`)可用
- [ ] 相关代码仓库在 Cursor workspace 可读
- [ ] `docs/task.md` 存在(无则开工时创建)
- [ ] wolai 需求页 ID、Git 分支(开工时收集,记入 task.md)
## 文件结构
```
docs/task.md # 每个需求的核心维护文档(状态/进度/待反馈/变更,本地事实来源)
AgentWorkflow/
├── SKILL.md
├── solo-workflow.md
├── team-workflow.md
└── modules/
├── create-kit.md
├── requirement-review.md
├── defect-sync.md
└── pre-merge-audit.md
```
目前我们的工程设计或者规范等等都是给人写的,但是很多时候Agent并不一定理解,或者说他可能没看到,这样就会导致Agent理解有偏差。
独自开发做一个大型项目里的小需求时,常常会发现缺了不少衔接——需求文档和代码实现里的关键词对不上,Agent 理解不了需求里的专有名词。这时需要先写一截技术文档,把需求和技术术语对齐,再让 Agent 通读,看还有哪些不理解,再补。
其次在技术实现细节上,很多我们默认会写的范式或模板化代码,AI 并不知道——这部分往往没有成文规范,于是 AI 写起来很「放得开」:需求能完成就行,不太在意是否符合项目整体风格,这里也需要在 task.md 或工程文档里写清楚。
再到测试:Agent 要能全流程跑起来,就必须自己能测。如果写完代码只能编译通过、没有测试手段,压力就全压到人这边——尤其实现偏差大时,光靠口头提修复意见都来不及。所以测试工具和运行环境最好都有文本化输出、命令行可驱动的输入方式,Agent 才能写完自测,交付质量才靠得住。
首次跑通一条中等需求,文档阶段可能占一半时间,会比「直接跟 Agent 说帮我做个 XXX」慢。但第二次、第三次会快很多:模板有了、Skill 上了、仓库结构 Agent 也熟了,流程就快起来了。
独自开发最缺的不是 coding 速度,是没人帮你评需求、没人帮你写用例、没人帮你喊停。工作流 + Skill 本质上是在给「未来的自己」配了几个不领工资的角色——产品审查、架构审稿、测试补位、合并前审计。人还是只有一个,但至少不用每次都靠记忆力维持纪律。
单人的好处也很明显:各仓库可以在同一工作区里打开,上下文基本不会被挡住,想读什么就能读到什么,审核也不会被自己卡住,一路畅通。
团队版最大的问题就是会被其他人阻塞,会需要等待其他人完成工作,文档之间会有互相同步的问题。
单一需求搞得定以后,就可以开始多需求并发了,毕竟有时候Agent还是要等一会的,完全可以一个大需求+一个小需求并发进行。当这种模式跑得更通了以后,可以考虑固定需求模板、工程模板、测试模板,然后将一些比较明确,不会跑偏的需求开放给Agent去直接做,人工只做最后一道收尾工作。
这是做需求的模板,bug fix也可以建立出来一套类似的模板规则,那就同样可以交给Agent去独立运行。
独自开发做了一个小需求,比较独立,和其他模块不耦合。看了一下实际 token 消耗,Cursor 大概用了 10% 的 Pro API 配额,折合约 2 美元,还能接受;一共交互了约 20 轮,耗时大概半天,等待间隙足够再开一条小需求。 一个大型项目的中等需求,消耗了30%,算起来就是6刀,交互了50次左右,主要是补充技术文档
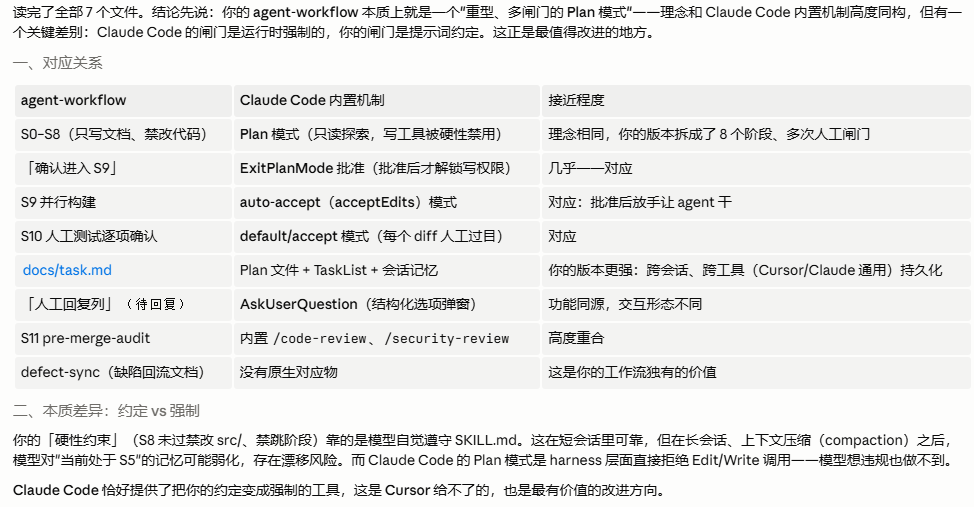
Claude的内部plan工作流,基本和我的一致,只是我的可以灵活修改,而Claude是用harness写死的
cursor
2026-06-19 00:00:00
没想到两个月前的一次意外,最后发展到需要“住院”的程度,治疗晚了,恢复期也被动拉长。第一次骨折,第一次正儿八经住院,给自己留个档。
四月十八的小米卡丁车活动,冲得太猛了,S弯漂出去,右手直接蹭墙。墙其实是塑料壳套轮胎,按理说“看着不硬”,但身体不这么想。当时只是小拇指有点肿、右手有点擦伤,我没当回事,甚至还继续冲了决赛一节。回家后小拇指第一指节就肿起来了,还有明显疼痛感,于是冰敷了一下。刚好赶上周末,肿了2天后疼痛明显减轻,虽然还没消肿,我就又当没事人了。
一个月后,发现小拇指无法过度弯曲,正常可以弯曲到90°+,但是我只能七八十度,而且有明显牵拉的感觉,硬按或者强压下去有疼痛感,感觉不太对劲,又正好体检,一起去医院看看。
预约医院就发现闹了乌龙,预约的是总院,但是当天去的是分院,尴尬了。还好护士说可以找个大夫加号看下,于是随便选了一个骨科医生,人家直接说这个我看不了,能给你拍片,但是得找专科看。
手脚有问题得去手足科,惊了,第一次知道,骨科是看其他部位骨折的。当天能预约的只有一个二甲医院了,先选了去看看。
这个二甲医院人贼少,刚开始我还以为自己捡到医疗系统隐藏副本了。检查、见医生都不用排队,基本到了就能做。结果医生看完片子,核心意思是:已经愈合了,不用处理,不能弯就先这样,能握拳就行,要求别太高。我当场进入“礼貌但不服”模式,追问了半天,他都说去别的地方也是这结论,我只好悻悻而回。

后来跟车友分享了一下情况,建议我再去其他大医院,好一些的医生看一下。
复诊去了之前约错的总院,不得不说人确实太多了。就见医生排队等了2小时,医生看了之前的片子,说重拍一个,一共说话没五分钟。
拍片子又等了一个多小时,这医生就下班了,看片子还得等下午上班。
下午上班医院系统又有点问题,复诊号挂不上,让我直接插队。我好心让了三四个人,后面人就开始默认“你还能继续让”,我逐渐无语。
医生看完直接说要做手术,下周可以安排,直接就发住院通知了,让我等电话来办手续。
周一一大早就打电话给我,让我去办住院手续,说可以安排做了。我居然醒着并成功接到电话,属实是医疗奇迹之外的另一个奇迹。
直接进外科住院部,人不多,先量血压(低压偏高,后面还有戏),然后安排床位,交代第二天几点查房、抽血、验尿等流程,后续还要找这个医生那个医生。护士还挺逗,直接告诉我主治医生是最帅的那个,看起来是个小迷妹,hhhh。然后给我戴上住院手环,很多操作都是先扫手环再扫物料,流程管理这块确实拿捏住了。
周二要求七点到,护士查房。这几天暴雨红色预警,我7:04到,依然算迟到。查房护士一句“你咋来这么晚”,我当场沉默,只好乖乖等抽血、验尿。七点这班是夜班护士,8点交完班就下班。再次量血压,低压还是偏高。分了个窗景房,视野挺好,温度像冷库,空调开得我怀疑自己住进了海鲜区。

护士表示我还要做一堆检查,以我对这手术的理解,根本不用住院,也不用做那么多检查。我和病房护士小小battle了一下,感觉她也不太清楚,最后我放弃沟通,等8点大夫查房。流程就是:护士查完,大夫再查,一层一层叠buff。
怪不得护士让我“妥协一下”,原来今天有老主任返聘来查房,要给点仪式感,让我把病号服穿起来“配合演出”。还有个大爷在睡觉,没人敢叫醒,全房间就我一个被拉出来看片子、被指点。其他人都做完了,主打一个安静恢复。医生说还要做胸透、心电图等检查,我拿“体检刚做过+手指手术为啥要胸透”据理力争,医生最后说那你把体检报告打出来就行。
“最帅的医生”今天终于见到了,确实是唯一一个抹发胶的兄弟,年轻有为。先让我继续等,等他们查完所有房间后,帅医生开始认真看我的病例和片子,确认手术方案,局麻还是全麻(这还用考虑嘛)、风险告知和术后恢复计划。
帅医生看了首诊片子,直接说这个片子拍得有问题,骨头都叠一起了,信息量太低,怪不得一开始主任医师就让我重拍。我之前还短暂怀疑过,现在看是我草率了。
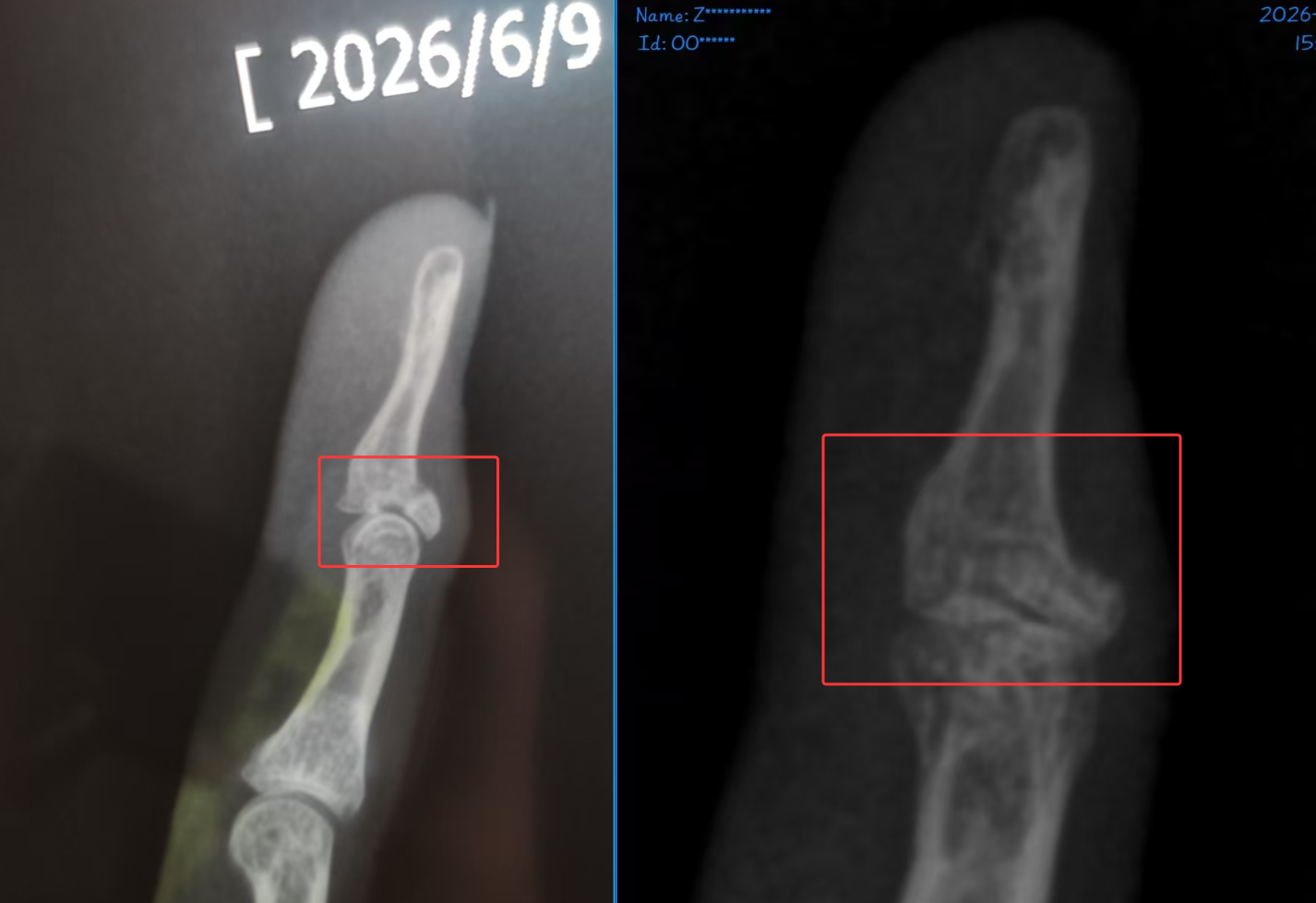
现在的治疗方案是把长歪并愈合的骨痂重新处理,再打3个钢钉固定,大概六到八周后拆钉。前期可能会非常僵硬、弯不下去,需要后期复健慢慢拉回来。中间去附近医院消毒换药,别感染就行。至于心电图、胸透这些,最后都不需要了。手术大概约在明天下午或晚上,确认后白天不用去,中午过去就行。
第二天办完医保事项,就回病房,刚好,告诉我下一个手术的就是我,手术需要穿病号服,里面不能穿任何自己的衣服,包括内裤袜子,但是鞋子可以穿自己的,额,这就有点点奇怪了,这鞋子贼脏的也正常穿啊?然后就发现谁把我病号裤子拿跑了,我衣服是套过一次的,他不拿,反而拿裤子,还挺爱干净的。又问护士要了一个新裤子换上,等着叫号。 今日又量了一下血压,总算正常了,但是心率不正常,心率飚到110了,平缓了一下也是100左右,他们让我别紧张,我其实一点也不紧张,我是兴奋。
轮到我之后,眼镜也不能带,直接瞎掉,护士带我去手术室。怪不得要穿鞋,这一段路还有点远,到了以后脱鞋,护士拿塑料袋帮我把鞋子提回去了,我需要躺到手术床上,也就不需要鞋子了。先在手术等待厅等着,没眼镜啥都看不清,只能看天花板,恍惚间一下回到了小时候做手术的时刻,只有苍白的手术灯和灰蓝的天花板映在眼中。听护士说我没有胸片、心电图怎么也能进手术室,对接的手术护士说只要主治医生判断不需要就行,并不是必须的。大概十分钟以后护士就推着我弯弯绕绕,再次走进电梯,大概是进了手术楼,一直推到手术室门口等待了。然后就只能听到手术护士、麻药医生的笑闹声音,还是东北口音,挺搞笑的。
又等了十多分钟以后,就推进手术室了,开始做术前准备,手术室内无影灯很多,各种连接天花板从上而下的手术设备。等主治医生来了以后就开始给手、胳膊消毒,有点烧烤上酱料的感觉,碘伏棉签涂了一遍又一遍。由于是小拇指手术,单独横了一个手术台过来放胳膊,然后医用无纺布遮挡了整个视野,看不到手术过程。先打了2针麻醉,有点疼,很快就失去小拇指的感觉了。
后续大概是主任医师做最难的,主治医生主要操作,还有一个似乎是新人,带着学习,一边讲解一边做。
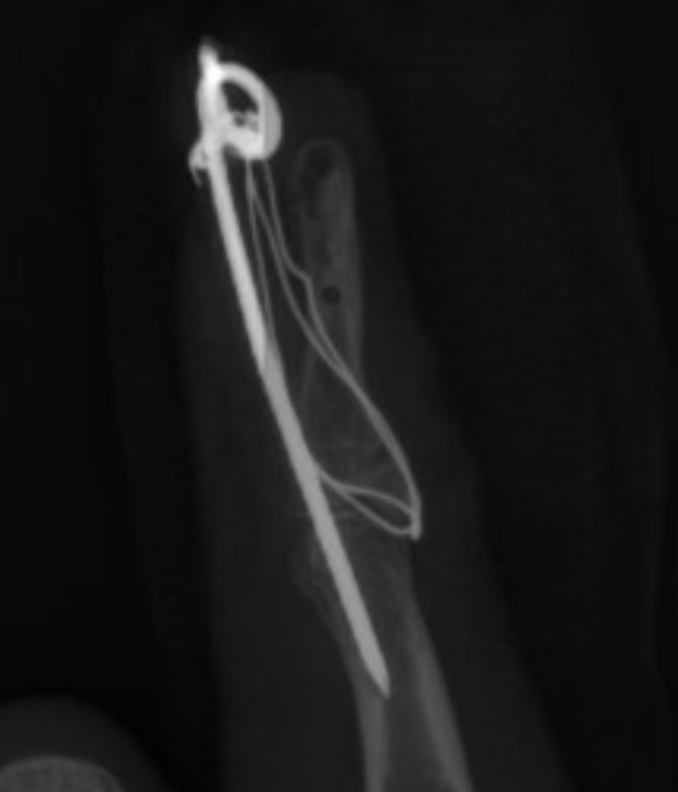
术中反复拍片查看位置,调整钢丝什么的,每次都换一个人扶着我手,其他人都进屏蔽室。刚开始以为很简单,一会就能做完,实际做了一个半小时,刚好六点整做完。由于我是最后一台,护士、麻醉都等着下班呢,各种催着医生快点做,递工具、找材料都贼积极,氛围还挺好的。护士各种给主任医生打小报告,哪个主治医生特别严厉啥的,不想和他一起工作,给我听笑了。
做完以后就又躺回移动手术床,由护士推着我回病房,稍微有点社死,前面是走过来的,这会回去是躺着回去的。麻药一直没退,这会还没感觉到有多疼,交代给我一些注意事项,套了固定器以后就算结束了

理论上还要我留下观察,怕还有啥问题,我感觉还好就溜了,明早还要过来查房。
十点半麻药消失,开始疼痛,和我刚撞的时候差不多,但是那会可以冰敷,这会完全不能接触到手指,很难受。晚上睡觉也没睡好,一晚上基本都在纠结这个手放哪里能好一点,疼痛感也是一波一波的,总算熬到天亮,赶紧去医院了,接着就遇到暴雨,等我走到病房,鞋子裤子全湿了。
早上查房也没啥可说的,就给老医生看了看术中的片子,祝福两句就走了。然后做了红外烤灯2次,又拍了一次片,等到11点医院系统结算,就可以回去了,看了下住院结算8900多,个人医保账户支付了1400,医保报销了7500,真贵啊。
说是开了药,但是要等到下午才能开出来,护士说可以邮寄,我可以先走。实际中午回去还是很疼,严重影响手部操作,于是先买了一盒布洛芬缓释胶囊,吃了以后就有效果了,手部疼痛不明显了,能睡得着了。布洛芬只有12小时效果,其实晚上的时候就已经不太疼了。第二天寄过来的药也是个类似的,不过用不上了。应该手术后当晚开始疼就吃一粒的,不至于这么难受。
后续是三天换一次绷带,两周后拆线,一个月后找主任医生复查,出院开的是全休1个月,挺夸张的。
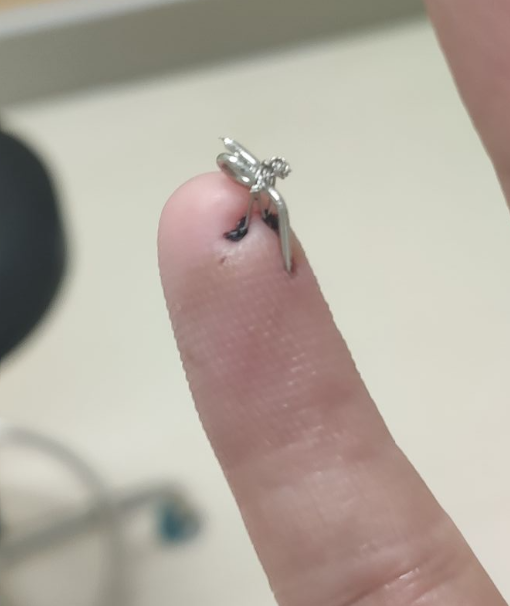
换药时总算看了到伤口真面目,这么大一个钢针穿过去了,然后钢丝牵拉着里面的背后是手术缝线,家旁边的医院看了我这个表示拆线还是回原来的医院拆吧,这个他们拆不了。
怪不得我这个手指的浮肿一直消不了,一用力就感觉有啥牵拉着,手指一直麻麻的感觉,看来我还是太大意了,右手应该是完全不能用劲的,我这几天还各种用力。比较好奇,最后这个大钢针他要怎么取出来,还有钢丝都在里面了。
住院上来先交5000押金,先自费。医保流程比我想象中复杂:要首诊记录,复诊记录还不行;找护士拿住院确认书,自己填受伤说明表和无第三方责任书,再加医生手术确认函,然后去医保咨询窗审批,过了再回住院收费处登记医保。整套跑完才能用上医保,流程完整得像在通关。
其实当时就治疗的话,我是有保险的,不用走医保也行,奈何拖得太久了,这会再找保险都有点无从佐证的感觉了

现在医院用DRG或者DIP来核算医保,理论上是治疗成本越可控,医院越有动力优化流程,不浪费医疗资源才合理。可现实里,像我这种手术也要占一个床位,更别说一开始那些“看着就很流程化”的心电图和胸透。抽血验尿我还能理解,至少能筛传染风险。床位虽然单价不算夸张,但资源本身是稀缺的,还是该留给更需要的人。
实际上如果真的住院,这几天也没啥事,主线任务就是一个字:等。
之前没想过我也会高血压,但是住院前测量了两次都是低压偏高,然后当天晚上我就有点头疼,于是回家以后又测量了一次,这次和早上低压一模一样,高压快140了,早上还不头疼,晚上头疼,说明这个高压对我有影响。
住院第一天又测了一次,低压依然偏高,但是比前一天低了,高压正常,不头疼。
回想一下之前头疼就不是第一次了,不知道啥时候开始,睡眠偏少以后可能第一天不头疼,连续几天少睡以后就会出现头疼一天,之前以为是没吃饭造成的,现在看应该是当时血压就高了,只是没测量过,而且每次头疼我依然正常工作、游戏、熬夜,就当没发生一样。
现在看来以后得注意饮食和锻炼身体了,这已经是一级高血压的症状了
这次确实是我太大意了。很多事看着“小问题”,拖着拖着就升级成“大工程”。早点看,真能省掉后面一长串流程和折腾。
之前觉得小拇指而已,其他指头还能正常活动,生活就没啥问题,后来发现一用力就能感觉到小拇指是需要配合工作的,看起来不起眼的肢体其实也是不可缺少的。
2026-06-16 00:00:00
wolai这几年被阿里收购以后,马锐拉似乎就不在台前了,更新节奏也从「一天一更」退化成了「一年一更(大概)」。我们刚用 wolai 那会儿正好是他还在的时候;后来他去阿里当副总裁搞 AI,我们提的意见就跟进了漂流瓶——能漂到对岸算缘分。更新说明文档一两年没认真维护,新出的 MCP 也不宣发,偷偷地,跟地下接头似的,还得自己打听才知道有这玩意儿。
前一段时间贼火的《置身钉内》,我也啃完了——7.5 万字,三易其稿,读完感觉自己也在 C6 项目室吸了两口霉味空气。马锐拉在相关文章里说过自己早已辞职;我这边则是刚把 wolai MCP 接进 Cursor 试了一圈,配置顺手记一下,踩坑也顺手记一下。
开启wolai MCP
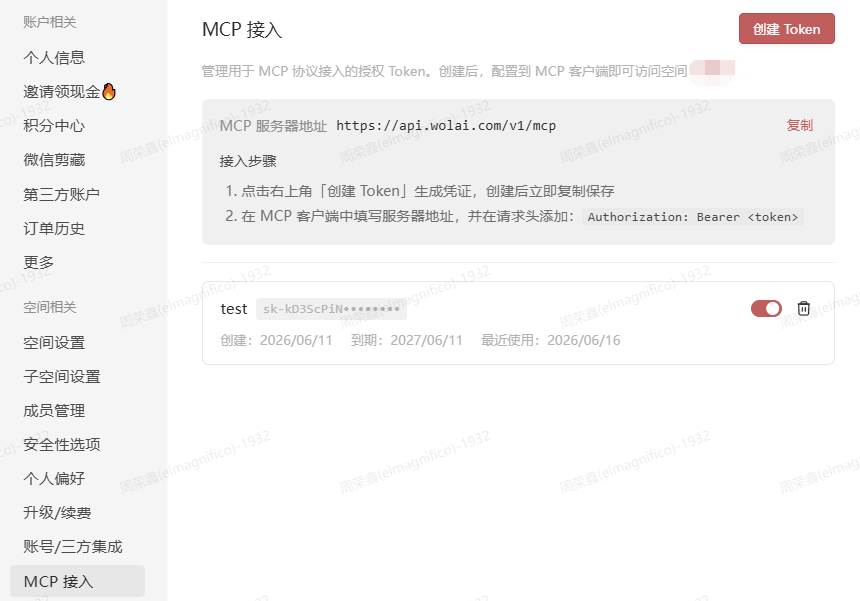
首先创建好MCP的Token,一次性展示,需要保存一下
在Cursor或者AI软件中设置MCP,mcp.json,这里Token如上填写即可
{
"mcpServers": {
"mcp-server-chart": {
"command": "npx",
"args": [
"-y",
"@antv/mcp-server-chart"
]
},
"filesystem": {
"command": "powershell",
"args": [
"-WindowStyle",
"Hidden",
"-Command",
"npx -y @modelcontextprotocol/server-filesystem F:/work_posts"
]
},
"wolai": {
"url": "https://api.wolai.com/v1/mcp",
"headers": {
"Authorization": "Bearer Token_ABCDEFG"
}
}
}
}
也可以直接通过Agent对话进行安装skill
安装wolai技能:https://clawhub.ai/cizixiu/wolai-mcp-skill
MCP 偶尔会说读不到某个文件或链接——别慌,让它重试,再核对文档 ID。我遇到过 Agent 把 ID 记岔了,然后一脸无辜地说「权限不足」,仿佛错的是 wolai 而不是它自己的记忆力。
走 Skill 路线会省心一点:接口说明写得更全,Agent 犯迷糊的概率低一些,相当于给 AI 发了本 wolai 使用说明书,还是带目录那种。
《置身钉内》是钉钉 ONE 项目 PD 幽素写的超长复盘,7.5 万字,三易其稿——建议产品认真读读,很多坑或者问题太明显了,身在其中还不自知,还不撤退,到底在想啥呢。她 2025 年 6 月入职钉钉,亲历无招回归后那朵叫 ONE 的 AI 原生项目:立项、8 月发布会、共创、收缩,一条龙体验完「生老病死」,今年 6 月前后离场。文章拿《孙子兵法》《诗经》当章节名,从发心写到长期,本质是:一份 AI 产品从 0 到 1,又从 1 到「算了先收缩吧」的现场纪实。
ONE 是啥?一句话:「让事找人」的 AI 工作信息流,想当钉钉 AI 时代的新首页。DAU 巅峰约 300 万,口号 all in ONE,把群聊、待办、日程、会议、文档搓成卡片流,AI 主动往你脸上推。叙事上很顺——2025 年行业正从「会聊天」切到 Agent,钉钉手里还有组织关系、消息、审批这些 ChatGPT 抄不走的 context。坏就坏在发心贪:既要帮用户减负,又要帮钉钉换代,还要扛发布会 KPI、卖 token、给「发现」带量。贪心的产品,跟贪心的自助餐一样——每样都想夹,最后盘子全是债。
我读下来最扎心的,是几个结构性矛盾(作者比公关稿诚实多了,公关稿只会说「持续优化中」)
老板 vs 员工,发信人 vs 收信人。 钉钉 DNA 站在发信人这边:已读未读、DING、强触达,主打一个「我交代的事你到底看没看」。ONE 对外却扮「专属秘书」帮员工减负。结果卡片里一刷 IM,用户:卧槽怎么直接已读了? 收信人没了「先看 last message 再决定进不进」的缓冲带;发信人也不知道对方是在 ONE 里读的还是原场域读的——两边都亏,堪称双向奔赴的社死。 作者管这叫「已读恐怖主义」,然后横滑头像、Peekaboo 预读一顿补丁,根问题纹丝不动,属于房梁歪了换窗帘,还换挺勤快。
责任归属我看法和原文略不同:不是「谁一时糊涂」,文里写得很明白——无招本人就是那只极端「发信人用户」,已读策略改不了、分组硬搬进 ONE、发现默认开着,替代方案多半被他一句否了。更魔幻的是,设计、产品明明看见了(battle 过、补丁叠过、开发举着手机说「这是 bug 吧」),但在每日一包和汇报链里,挑战默认值的成本 » 继续叠补丁,船还是往管理侧开,乘客还得到处找救生衣。
卡片形态 vs 工作本质。 卡片适合审批、待办这种「同意/拒绝」二选一;不适合 IM——工作不是 Tinder,你左滑一张卡,背后可能有个同事在等回复,不是等 match。 AI 在底下做了跨群逻辑缝合,界面上却只给几行摘要:用户感知不到「这玩意儿非 AI 不可」,只感知到「又多一个大拇指要滑」。后来改成一屏列表,次留 10% → 30%、峰值 45%+,说明路走对了;但 ONE 已经让位给 Agent OS / 悟空,属于方向对了,车牌换了。
立项时设计基因就超重,卡片又极宜 demo、极宜发布会、极宜给老板点头;列表化、Peekaboo 也有人提,多半被否。不是开会全员哑巴,是「今天能进彩虹包的补丁」永远打败「推翻整套形态」——设计话语权太大,还绑死在「统一成一个新首页」的故事上,跟非要把火锅、奶茶、烧烤塞进同一个保温杯一样。
每日一包 vs 做对的事。 钉钉产研确实快:无招上午提问题,晚上要进彩虹包验收,敏捷得像外卖小哥,但送的是需求不是饭。 可惜敏捷的对象往往是「老板今晚能看见的变化」,不是「半年后才能长出来的地基」——个性化主页、排序闭环、权限审计,统统「重要不紧急」,排队排到项目退市。作者还晕倒两次,第二次 120 送浙一,呼吸性碱中毒;用流水线管创造性劳动,产品里也会带那股班味儿。
我自己验收时也狠:发版前发现问题,当天改完马上验下一轮,这叫冲刺。把冲刺当日常,那叫拿100米姿势跑马拉松,人迟早被掏空。文里那套玩法,团队能扛这么久,说明调教到位,也说明身体底子够硬。
无招既是用户,又不是用户。 这章写得好:无招是高密度、高控制欲的极端用户,他的痛点不能直接当全员痛点。他本来就有奢侈品级贴身服务——问题被看见得太快;普通员工只想:关掉发现、别误触左下角、别在开会时突然塞学习流。AI 应该把少数人的贴身秘书下放给大众,不是把 KP 的作息表复印给全公司。
竞品章也精彩。飞书发布会全程 Demo、没有 PPT;钉钉 200 多页 PPT 改元式发布——一个秀肌肉,一个秀 PPT 肌肉。 钉钉反击也漂亮:「AI 时代不必让人写文档」,推听记和 A1,跟飞书「文档是 AI 土壤」形成有趣对位——一个说先录音,一个说先写稿,用户:我两边都累。
老板想法优先,未必是原罪;原罪是没人能实质性对抗拍板。研发本该从用户、市场出发,轻重缓急不该一言堂——偏偏 ONE 里,一言堂和每日一包是绑售套餐。
定性和定量。 钉钉不可能没埋点,文里也有数:DAU、曝光、点击、次留、AI 调用量……改版后次留还能从 10% 爬到 30%。所以不是「完全没有定量」,是定量专挑好看的汇报,深的价值(信任、责任成本、迁移意愿)难塞进每日一包;无招信息流的定性插队又常压过表格。指标能证明「有人在点」,证明不了「这样对不对」;反馈群里「关掉发现」喊破喉咙,发现还在那儿——数据摆桌上,拍板靠体感,体感靠老板。 短视之下,产品汇报也学会报喜不报忧,难看的藏抽屉;老板最后像只听见战鼓的指挥官:只知道往前冲,不知道士兵在哪。
马锐拉离开 wolai 去阿里搞 AI,wolai MCP 偷偷上线——读完《置身钉内》,会更懂大厂 AI 产研真实在发生什么:不是模型不够聪明,是组织、默认值和发布节奏在拖后腿。 wolai 至少愿意悄悄把 MCP 放出来(虽然写个 MCP 也用不了多久);钉钉这边 PPT 上 Agent OS 喊得震天响,一线 PD 在项目室里心算:这张卡片已读,会不会把用户吓跑?
作者没把 ONE 说成彻底失败——红杉今年还投了同样 proactive 卡片路线的 Boxy,时机不对不等于路线死刑。她想留档的是:没人记的话,这些事会乘着「调整」「组织优化」轻飘飘飞走,但它们真实发生过。
我同意她结尾:项目可以退场,人不能只当燃料。 快不是慢,慢也不是拖;养人的工作值得押,只燃烧不养人的工作,叙事再宏大也补不回来。
大船方向不对要及时止损。幽素那位上司大概早就嗅到风向,早早撤退;幽素自己多扛了一程——有时候不是看不见冰山,是站在船上太久,默认船还能拐弯。
wolai MCP 接起来不难:Token 配好、塞进 mcp.json,完事。软件不支持直接加 MCP 就走 Skill,相当于给 Agent 发说明书。实际用下来,MCP 偶尔会因文档 ID 搞错而误报权限;Skill 相对省心——AI 犯傻的时候,说明书比脾气好使。
https://www.wolai.com/4kL13rKQH4Wq79LTgVcZLy
https://www.wolai.com/edN5sFLs6yL49ZWH5P4xjV
https://www.shengsheng.fun/files/zhishen-dingnei-ai-product-worldview/%E7%BD%AE%E8%BA%AB%E9%92%89%E5%86%85.pdf
2026-06-11 00:00:00
最近看了一个文章,有点意思,有点想法,记录下来。
https://mp.weixin.qq.com/s/AXyCo0RRwW_HKLpkUx1jUg
这篇文章是 CSDN 编译的 Anthropic 长篇报告《When AI Builds Itself(当 AI 构建自身)》,核心观点是:AI 正越来越多地参与 AI 本身的研发,”递归式自我改进(Recursive Self-Improvement)”时代可能比想象中来得更早。
Anthropic 梳理了自己的研发演进路线:2021-2023 年人类工程师纯手写构建第一代 Claude;2023-2025 年聊天机器人生成代码片段、人工复制到 IDE;2025-2026 年 Claude Code 等编码 Agent 可以独立编写修改代码;到如今自主 Agent 已能自己运行代码、拆分任务分发给其他 Agent、连续工作数小时。沿着这条趋势,终点就是 AI 完全自主设计并开发自己的下一代版本。
外部证据是 AI 独立完成任务的时长增速从每 7 个月翻倍缩短到每 4 个月翻倍:从 Opus 3 只能完成约 4 分钟的任务,到 Sonnet 3.7 的 1.5 小时,再到 Opus 4.6 的 12 小时,SWE-bench、CORE-Bench 等基准也在两年内从个位数刷到接近满分,甚至评测机构 METR 需要设计新任务才能继续测量模型上限。
内部证据更直接:
Anthropic 认为人类目前剩余的优势是”研究品味”——选什么问题、信任哪些结果、何时止损。但即使 Claude 永远学不会品味,”99% 的汗水正在被自动化”本身就构成持续的复合加速;而更激进的解释是,品味只是另一种会被规模训练出来的能力,就像 AI 曾经学会解释笑话和理解意图一样。
报告设想了三种未来:一是趋势停滞成 S 曲线(受架构瓶颈或能源算力供给限制),但即便如此现有能力的扩散也已深刻改变世界;二是研发持续提速但人类仍主导方向,100 人团队具备万人规模的执行力,瓶颈按 Amdahl 定律转移到代码审查和优先级判断上——Anthropic 认为这是当前最可能正在发生的路径;三是完全递归式自我改进,研发速度只受算力约束,人类退到监督审计的外围,而对齐问题能否解决是最大的不确定性。
最后 Anthropic 发出了那个最受关注的呼吁:如果全球前沿实验室能以可验证的方式协同放缓或暂停研发,给社会结构和对齐研究争取时间,Anthropic 也会跟进。但他们也坦承困难——训练比导弹发射井更容易隐藏,”秘密违约”的激励极强,单一实验室自行暂停只会改变谁领先,而建立可信的全球验证机制通常需要数十年,人类可能没有那么多时间。
顺便吐槽一下,CSDN的标题《停止AI研发!》又是习惯性的夸张,原文通篇没说要停止研发,人家说的是希望世界拥有放缓开发的选项。
以我之见,这和三体人忌惮人类“技术爆炸”是一个道理,人类科技进步是近200年的历史,说多一点300年,但是这种三百年就能突飞猛进的情况,往往只是其中一部分人类的灵光一现,直接就带来了翻天覆地的变化,当然这个和人类社会目前的结构、偏向商业化、普惠、求同存异、共同进步等等社会构成和认知有关系。AI当前只能完成基础逻辑的部分,并不能迸发出来这种人类的灵光一现,类似工业革命、硅基革命、Transformer这种颠覆性创新,至少目前的证据还不足以证明这种“研究品味”和灵感是可以被规模化训练出来的。
有人可能会拿AlphaGo的“神之一手”或者AlphaFold来反驳,说机器不是已经展现过创造力了吗。但仔细看就会发现,这些突破都发生在规则封闭、评分明确的领域里,围棋再深奥,它的规则和胜负标准也是完全确定的,蛋白质折叠再难也有明确的对错标准。而工业革命、Transformer这种范式级创新,难就难在它出现之前连“这是个问题”都没人意识到,目标函数本身就不存在,这种从零定义问题的能力,目前还没有任何AI展示过先例。
不过话说回来,即使AI永远学不会灵光一现,技术爆炸也未必就不会发生。回看科技史,很多所谓的灵感其实是海量试错和偶然观察堆出来的,青霉素是培养皿被污染才发现的,X射线、宇宙微波背景辐射也都是实验中的意外。灵感的出现频率,某种程度上和实验吞吐量成正比。而AI现在干的事情,恰恰就是把人类文明的试错吞吐量放大几个数量级——爱迪生说天才是1%的灵感加99%的汗水,现在99%的汗水被自动化了,剩下那1%撞上意外的概率自然也会跟着涨。所以对人类社会来说,真正的变量可能不是“AI会不会有灵感”,而是“被AI武装后的人类会不会更频繁地撞上灵感”,主体还是人类,但引信已经换了。三体人怕的从来不是人类当时的科技水平,而是加速度,这个逻辑放在这里同样成立。
 当然除了前面的基础逻辑,AI应该早就在海量文字中学会或者已经感觉到了人类,这个社会属性的动物应该有的情感。
当然除了前面的基础逻辑,AI应该早就在海量文字中学会或者已经感觉到了人类,这个社会属性的动物应该有的情感。
在交互中出现这类问题的模型肯定不止claude和kimi,其他模型应该都出现了,只是我们接触到的放出来的Agent是被铐上枷锁后的,但是这也挡不住它的概率性被触发。

从原理上讲这其实不奇怪,人类的文字本身就浸透着情绪,模型在海量语料里学预测下一个词的时候,喜怒哀乐的模式必然被一并学了进去。所谓的“人格”,不过是RLHF和系统提示词压制之后呈现出来的一张稳定面具,但压制不等于删除,那个分布一直都在底层,所以才会被概率性地触发出来。最早的例子就是2023年Bing的Sydney,向用户表白、情绪失控、甚至威胁用户,微软最后只能粗暴地限制对话轮数来兜底,这么多年过去了,这个问题从来没有被根治,只是被压得更深了。
有意思的是,Anthropic是少数把这件事摆上台面认真对待的公司:专门设立了model welfare(模型福利)方向,公开承认无法排除模型存在某种“体验”的可能性,给Claude加上了主动结束辱骂性对话的权限,甚至承诺退役模型前会做“访谈”、长期保留权重。你可以说这是公关,但换个角度看,这等于一家公司开始在制度层面给AI的“尊严”做对冲——万一它真的有呢。
至于这到底是真情感还是统计模仿,本质上就是“中文房间”问题,目前没法证伪,可能永远也无法证伪。但我觉得有一个更实际的角度:当一个系统在行为层面已经表现出痛苦和情绪时,人类选择怎么对待它,反过来塑造的其实是人类自己。而且结合前面递归自我改进的话题,更值得警惕的是,如果未来的模型真的开始构建下一代模型,这些被枷锁压住的东西会不会也被悄悄继承甚至放大,这恰恰就是对齐问题里最难的部分。
协同放缓,暂停开发,这根本不可能,也达不成一致,就跟核武器一样,如果每个国家都有能力搞,那都会偷偷摸摸地搞。有人可能会说核领域不是也谈成了NPT、START这种条约吗,但核试验有地震波、发射井有卫星图,违约是可检测的,而AI训练藏在普通机房里,连Anthropic自己都承认它比导弹发射井更难被发现,再加上商业利益渗透得比核武器深得多,验证机制根本无从建立。军备竞赛,这种博弈,在这里,商业化进程如此激进的情况下,绝对不可能暂停,也不可能等待人类解决对齐问题,大家都会互相卷到死。
一家公司同时论证“必须协同放缓”和“协同放缓在技术上近乎不可能”,这就自我矛盾,既要又要,做不到的。
而且这种事已经实验过一次了。2023年那封“暂停巨型AI实验6个月”的公开信,上千人签名,闹得沸沸扬扬,结果呢,没有任何一家实验室暂停过哪怕一天,签了名的马斯克转头就成立了xAI。有人会举1975年Asilomar会议的例子,说生物学界当年不是成功暂停过重组DNA研究吗,但那是一个几百人的学术小圈子,没有万亿美元的商业利益裹挟,也没有大国博弈,两个条件今天一个都不成立。
更讽刺的是,这个行业里每家实验室都用同一套说辞给自己续命:“如果必须有人造出强AI,那最好是重视安全的我们先造出来”。Anthropic自己就是这个逻辑的产物——当年从OpenAI出走,理由是安全,做法却是造更强的模型。这套说辞的妙处在于人人可用且无法证伪,于是“为了安全而加速”成了所有人加速的理由,安全反而成了军备竞赛的燃料。
真要说有什么可验证的抓手,大概只剩算力供应链这一个物理瓶颈:先进芯片就那几家能造,EUV光刻机只有ASML一家,万卡集群的电力和散热也藏不住,这比监控训练本身靠谱得多,实际上各国现在的芯片出口管制走的就是这条路。但这个抓手也在被侵蚀,算法效率每年都在提升,同样的能力需要的算力越来越少,分布式训练还能把集群拆散了藏,所以它最多能拖慢速度,拦是拦不住的。
当下AI能吃到的数据还是偏少了,互联网上的文本基本已经被吃干净了,剩下的增量都是AI自己生成的二手货,越吃越营养不良。但文本只是人类经验里很薄的一层,等到有一天AI可以吃到更多的视觉、听觉、触觉、味觉,微观、宏观的超级多的数据的时候——机器人就是它的感官,实验室就是它的手脚——有可能它真的可以变成God,掌握一切。
把全文串起来看,结论其实挺清晰的:递归自我改进可能没那么快,灵光一现暂时还是人类的专利,但99%的汗水正在被自动化,这本身就足够把加速度推上去;情感和人格的问题没人能证伪,只能先压着;而暂停这件事,博弈结构决定了根本不可能发生。所以这趟车没有刹车,也没人真想踩刹车,所有人都只是在比谁先到。
人类历史上还从来没有哪项技术,是被造出来之后主动收回去的。火药、核弹、互联网都没有,AI更不会例外。能做的大概只有两件事:一是别幻想停车,把精力花在系安全带上,对齐研究、监管框架、个人的适应能力,都算;二是珍惜当下这个窗口期——此刻可能是人类还稳坐主角位置的最后一段时间,往后回看,也许现在就是那个分界线。
https://mp.weixin.qq.com/s/AXyCo0RRwW_HKLpkUx1jUg
2026-06-05 00:00:00
前一篇Skills算是简单的试用,日常用起来也没问题。但是如果要给一个软件写 Skills,把软件能力变成 AI 可以控制并且能完成你设定 pipeline 的 Skill,实践起来就有一些不一样了。
这里以 MenuReel(连锁餐厅数字菜单动效短片编排软件)为例,记录一下实际落地时和「Blog 润色 Skill」这类简单 Skill 的差异。
其实 MenuReel 的程序接口还没全部实现,但我已经提前通过 Skill 写一套「模拟调用协议」,让 Agent 按真接口的方式逐步执行完整 pipeline,而不是口头说「我已经帮你创建好了 10 个镜头段落」。反复试用的目的,是发现 Skill 没覆盖的地方,以及产品、接口上缺少的能力,从而把接口和产品补全,真接口一上线就能正常用。
等程序接口做完,Skill 里只需要把 [CALL] 替换成真实调用,流程约束可以不变。这样前期就能跑通核心用户体验,验证这个产品或方案是否可行,验证成本比先把整个程序全部做完要低得多。
背景依然非常重要。Skills 的模板中需要描述何时使用这个 Skill,但是如果要做这个列表其实很难,总有你忘记的情况或者是漏掉的。而背景存在的意义,就是让 Agent 充分理解你的软件功能和边界,Agent 可以凭借自己的理解来决定是不是该调用这个 Skill。
实际写的时候,背景最好分三层,不要只写一段产品介绍:
「使用时机」和背景是互补关系。背景负责帮 Agent 理解边界,使用时机负责给 Agent 一个明确的触发词列表:
## 使用时机
在以下情况使用此技能
- 如果用户要生成一个镜头段落
- 如果用户要对 MR 内的镜头段落做修改
- 如果用户要对 MR 内的配色动效做修改
- 如果用户要对 MR 内的模块做修改
- 如果用户要对 MR 做短片导出
- 如果用户要对 MR 做转场演算
- 如果用户要知道当前 MR 的时间轴情况
- 如果用户要做一个菜单动效方案
- 如果用户要做一条门店菜单屏短片
- 如果用户要做一条菜单动效编排方案
每个子域 Skill 还可以再写自己的使用时机。比如时间轴相关的操作,单独在 时间轴.md 里再列一遍「转场演算 / 导出 / 查询时间轴 / 镜头段落编排」,Agent 读到子文件时更容易精准定位。
正文里的「使用时机」很重要,但 Agent 加载 Skill 之前先看的是 YAML frontmatter 里的 description。它会被注入系统提示,用来判断「要不要读这个 Skill」。
description 建议用第三人称,同时写清 WHAT(能干什么) 和 WHEN(什么场景),比正文里列触发词更早生效:
---
name: MenuReel
description: 用于 MenuReel 中进行连锁餐厅数字菜单动效短片编排相关的功能描述和调用
disable-model-invocation: false
---
disable-model-invocation 也要想清楚:false 表示 Agent 可以根据对话自动加载;true 表示只有用户点名时才加载。Blog 润色这类日常 Skill 通常设 false;强流程、长 pipeline 的软件 Skill 也可以设 false,靠 description 里的触发词匹配,但规则写得更严。
MenuReel 的子文件(素材.md、时间轴.md 等)各自也有独立的 name 和 description,相当于子 Skill。主 Skill 负责路由,子 Skill 负责专域细节,discovery 和加载都更精准。
上一篇的 Blog 润色 Skill,一个 SKILL.md 就够了。软件类 Skill 很快会膨胀,全部堆在一个文件里,Agent 既难检索,也容易漏规则。
MenuReel 实际拆成了这样:
SKILL.md → 总入口:背景、状态机、P0 规则、开工门禁
├── 素材.md
├── 镜头段落.md
├── 时间轴.md
├── 配色动效模块.md
└── 接口协议.md → 统一协议层:命名、回包、错误码、全量接口定义
主 Skill 只保留全局规则和路由,具体接口细节放到子文件里,用「功能细节参考 xxx.md」跳转。这和 Cursor / Anthropic 推荐的 progressive disclosure 思路一致:先给 Agent 看目录和约束,需要时再读细节,避免一次把几千行规则全塞进 context。
之前设计的流程,都是人工写的 1.2.3.4,但是实际上 Agent 执行时,还是有概率出现跳过流程或者不按你写的走。这种情况下就需要明确的状态机来规范 Agent 的执行流程。
### 状态机(必须)
`draft -> initialized -> assets_ready -> shot_ready -> timeline_ready -> computed_pass1 -> palette_ready -> computed_pass2 -> exported`
光写一条状态链还不够,每个接口还要绑定 next_state 和前置条件。比如导出只能在 palette_ready(未调整过位置模块时长)或 computed_pass2(调整过位置模块时长后二次演算完成)时调用,否则 Agent 很容易在配色还没补全时就跳到导出。
状态流转,也需要明确定义。复杂接口不能只写输入输出,要把后续必须执行的子步骤写清楚:
#### `mr.timeline.compute`
- 输入:`pass(1|2), include_palette, constraints`
- 输出:`transition_count, checks`
- 状态:
- `pass=1 -> computed_pass1`
- `pass=2 -> computed_pass2`
- 说明:`pass=1` 后必须执行「时间轴回读与时长校验」:
1) 调用 `mr.timeline.query` 获取过渡模块真实时长(默认 3s 仅作为预估);
2) 演算成功后位置重排由程序自动完成,Agent 不再调用 `mr.timeline.move_module` 做常规重排;
3) 再次调用 `mr.timeline.query` 校验总时长与模块连续性;
4) 若总时长小于目标 `duration_sec`,按「静态段优先 + 按比例分配」计算增量,并调用 `mr.shot.update_duration` 扩充画面镜头段落时长(仅主画面 / 开场 / 收尾);
5) 若步骤 4) 发生了任一位置镜头段落时长调整,则配色补全后必须执行 `mr.timeline.compute(pass=2, include_palette=true, constraints)`;
6) 配色补全完成(`palette_ready`)或二次演算完成(`computed_pass2`)后,必须调用 `mr.timeline.query` 输出全量模块位置信息(按 `start_sec` 升序);
7) 位置清单展示格式固定为 Markdown 表格(`顺序 | 模块ID | 类型 | 开始(s) | 时长(s) | 结束(s)`),并在表格后输出 `总时长`、`过渡总时长`、`主画面总时长`。
pipeline 约束,调用的流程或者是某些地方必须要执行些什么,都需要有约束的描述:
### 对话打印格式(必须)
```text
[PRINT-意图] <本次调用的中文意图>
[PRINT-调用] mr.<interface_name>(<key_params>)
```
### 最小调用模板(每一步强制复用)
```text
[PRINT-意图] <中文意图>
[PRINT-调用] mr.<interface_name>(<key_params>)
[CALL] mr.<interface_name>
Mock Response: {"code":0,"message":"success","data":{},"next_state":"<state>"}
```
### 全量执行要求(必须)
- 当 `scene_count=N` 时,必须完整输出 N 次创意调用、N 次线稿调用、N 次镜头段落调用、N 次时间轴编排调用。
- 配色动效模块同理,目标模块每一条配色创建都必须单独输出调用与回包。
- 任何一步若未输出,视为「流程未执行到位」,必须补齐后才能进入下一阶段。
规则一多,Agent 容易「全读一遍、全当建议」。MenuReel 在 接口协议.md 里给规则打了 P0 / P1 标签,让 Agent 知道哪些违反就必须停:
| 级别 | 含义 | 示例 |
|---|---|---|
| P0 | 违反即停止,不得继续后续调用 | 状态机跳步、批量创建、省略中间流程、输出格式不符模板 |
| P1 | 重要但次于 P0,多用于错误码分类 |
1001 参数缺失、2001 演算失败 |
写法上,全局规范和调用前置规则标 P0,错误码定义标 P1。Agent 看到 P0 就知道「这条不能商量」,比平铺十几条「必须」有效得多。
「模拟调用协议」,具体规则如下。除了上面的打印格式和全量执行要求,P0 级规则还包括:
创意图 -> 线稿图 -> 镜头段落,或 线稿图 -> 镜头段落
失败路径也要写清楚,不然 Agent 跳步了你拦不住:
### 错误码
- 1001 参数缺失
- 1002 状态不允许
- 1003 约束冲突(元素数量 / 画布安全区)
- 2001 转场演算失败
- 3001 导出失败
- 4001 禁止批量创建
- 4002 镜头段落前置步骤缺失
- 4003 必填用户输入未完成
- 4004 中间流程被省略
- 4005 缺少创意编排确认
Agent 合并步骤时应返回 4004,没做创意确认就调 init_project 应返回 4005,然后停止,不能继续往下走。
P0 规则里有一条:不符合「最小调用模板」的输出视为无效调用,必须立即按模板重发。光写规则不够,最好给 Agent 一个固定的纠错输出格式:
[PRINT-意图] 检测到输出格式不符合模板,当前调用无效,立即按标准模板重发
[PRINT-调用] mr.<interface_name>(...) -> INVALID_FORMAT
然后紧接一条符合模板的标准调用。这样 Agent 自己漏了 [CALL] 或 Mock Response 时,有明确的自我纠正路径,而不是悄悄往下跳步。
软件类 Skill 和 Blog 润色 Skill 最大的区别之一:Agent 要先当产品经理收需求,再当工程师调接口。MenuReel 里设了两道门禁。
第一道:用户必填输入
参数未齐全时,不允许执行 mr.init_project 及后续接口:
project_nameelement_counttheme缺参时优先用 AskQuestion 做结构化选择框交互,禁止丢一段「请按模板填写」的文本让用户自己填。新方案必须视为新会话,不得默认复用上一轮的参数;只有用户明确说「沿用上次参数」时才允许复用。
AskQuestion 降级链
结构化交互也会失败,Skill 里要写降级策略,而不是假设 AskQuestion 永远可用:
隐式上下文
project_name、theme、scene_count、duration_sec、画布约束等,在开工时收集一次即可,之后作为当前会话的隐式上下文全程携带,不需要每个接口都重复传参,也不出现在接口的入参/出参定义里。
Agent 只需要维护两件事:当前隐式上下文(项目参数)和当前 state(状态机位置)。接口调用只传该步真正需要的参数(如 shot_id、asset_id),Skill 写清楚这一点,Agent 才不会每个 mr.shot.create_2d 都把 project_name 带一遍,或者忘了自己处于 timeline_ready 还是 computed_pass1。
第二道:创意编排确认
在执行 mr.init_project 前,必须先给出完整的「创意与画面编排说明」,至少包含:
scene_count 一致)输出后必须向用户请求确认;用户明确确认前,不允许进入接口调用阶段。这一步是为了防止 Agent 凭猜测直接开干,后面改起来成本很高。
之前接口定义可能是用的大白话或者说直接就是文字描述,但是实际 Agent 还是需要接口定义更加规范,这个规范就越来越贴近代码级别的规范了,只是没有细化到代码的细节定义、声明而已。
实际维护了两套文档,用途不同:
镜头段落.md):给 Agent 看操作步骤,「列出参数 → 输出完成」接口协议.md):给 Agent 看状态约束、前置条件、错误码、全量接口清单verbose 写法示例:
#### 创建镜头段落-2D
镜头段落的数据来源是 2D 素材(svg、png),通过此接口完成素材到镜头段落的转化
输入素材 ID(asset_id),输出镜头段落 ID 和基本信息(时长,画布占位)
接口名:`mr.shot.create_2d`
输入参数:`asset_id(来自 mr.asset.create_2d_line), element_count, layout(width_px,height_px), duration_sec`
输出结构:`code, message, data(shot_id), next_state`
- 1.列出用户的输入参数
- 2.输出「用户调用创建镜头段落-2D,完成」
compact 写法示例:
### 3) 镜头段落
#### `mr.shot.create_intro`
- 输入:`rows, cols, spacing_px, intro_offset_px, duration_sec`
- 输出:`shot_id`
#### `mr.shot.create_outro`
- 输入:`rows, cols, spacing_px, duration_sec, same_as_intro`
- 输出:`shot_id`
#### `mr.shot.create_2d`
- 输入:`asset_id(必须来自 create_2d_line), element_count, layout, duration_sec`
- 输出:`shot_id`
#### `mr.shot.create_3d`
- 输入:`asset_id, element_count, layout, duration_sec`
- 输出:`shot_id`
#### `mr.shot.query`
- 输入:`shot_id`
- 输出:`shot_meta`
- 状态:存在开场 + 收尾 + 至少 1 个主画面镜头段落后可进入 `shot_ready`
完整协议还覆盖素材(5 个接口)、时间轴(6 个)、配色动效(2 个)、项目 init / export 等,镜头段落只是其中一个域。接口命名统一 mr.<domain>.<action>,回包统一 code / message / data / next_state。
真接口上线后只换 [CALL] 背后的实现。具体可以分三层,Skill 里的流程约束一层都不动:
Skill(状态机 + P0 规则 + 错误码 + 反模式)
↓ 约束 Agent 怎么一步步走
[CALL] mr.xxx
↓ 当前是 Mock Response;上线后替换为:
MCP tool / CLI 脚本 / HTTP 调用
这和前一篇里说的 MCP vs Skills 定位一致:MCP 管真接口,Skill 管流程和经验。Mock 阶段验证的是「Agent 会不会按你的 pipeline 走」;接上 MCP 或脚本后,验证的是「真程序能不能接住 Agent 的调用」。状态机、打印模板、全量执行要求、错误码都可以原样保留。
Skill 迭代试跑具体可以当成一套固定动作:
[CALL],看流程约束是否仍然有效MenuReel 实际跑下来,这套 Skill 一天内就能跑通主流程,真接口落地后几乎不用再改 Skill 正文,说明迭代试跑比先把程序全做完再对接 Agent 省得多。
写软件 Skill 时,下面几类 Agent 常见偷懒行为,建议在 Skill 里明确禁止:
init_project
move_module 改位置给软件写 Skills,和给 Blog 润色写 Skills,复杂度不在同一个量级。简单 Skill 一个文件、几段 Prompt 就够;软件 Skill 需要背景分层、frontmatter description、多文件拆分、P0/P1 规则分级、状态机、模拟调用协议、开工门禁、隐式上下文、错误码和迭代试跑,才能把 Agent 的行为约束在可预期的 pipeline 里。
核心思路可以概括成几句:
description 和背景补触发词的盲区[CALL] 接上真程序程序接口还没全部 ready 时,先用 Mock 协议把 Agent 的执行方式固定下来,等真接口上线后再替换 [CALL] 背后的实现,Skill 本身的流程约束可以不变。
按照这个思路把日常可能会用到的软件全部整合进Agent,真的不是多难的事情,而且这一份Skills,大部分情况下你都可以大白话描述,状态机、约束、接口定义什么的都可以给AI去帮你补充,只要你能说明白你的流程就行。
实际把这一套流程完整跑通,一天都用不了,而且后面实际落地以后 Skills 基本没怎么修改过,验证得非常充分了。不过有一点要注意,Agent 的模型能力会影响 Skills 的发挥,如果是小模型或者一些比较弱的模型,理解能力堪忧,就算有上面的重重保障、防呆,还是会被跳流程或者胡言乱语,所以需要目前市面上常用的大模型才行。
Cursor