2026-03-01 07:53:37
I gave a guest lecture in the Neurally Inspired Algorithms and Architectures course at UC Davis; this is my attempt at putting into blog post form.
What are the challenges in visual scene understanding? There’s a long list: occlusion, the presence of many objects, unfamiliar objects, reflections on surfaces, shadows, blur, etc. Due partially to research breakthroughs but mostly to a massive amount of money and resources, we have computer vision systems that can now perform some version of scene understanding for constrained tasks, such as self-driving cars and autonomous warehouse cart robots.
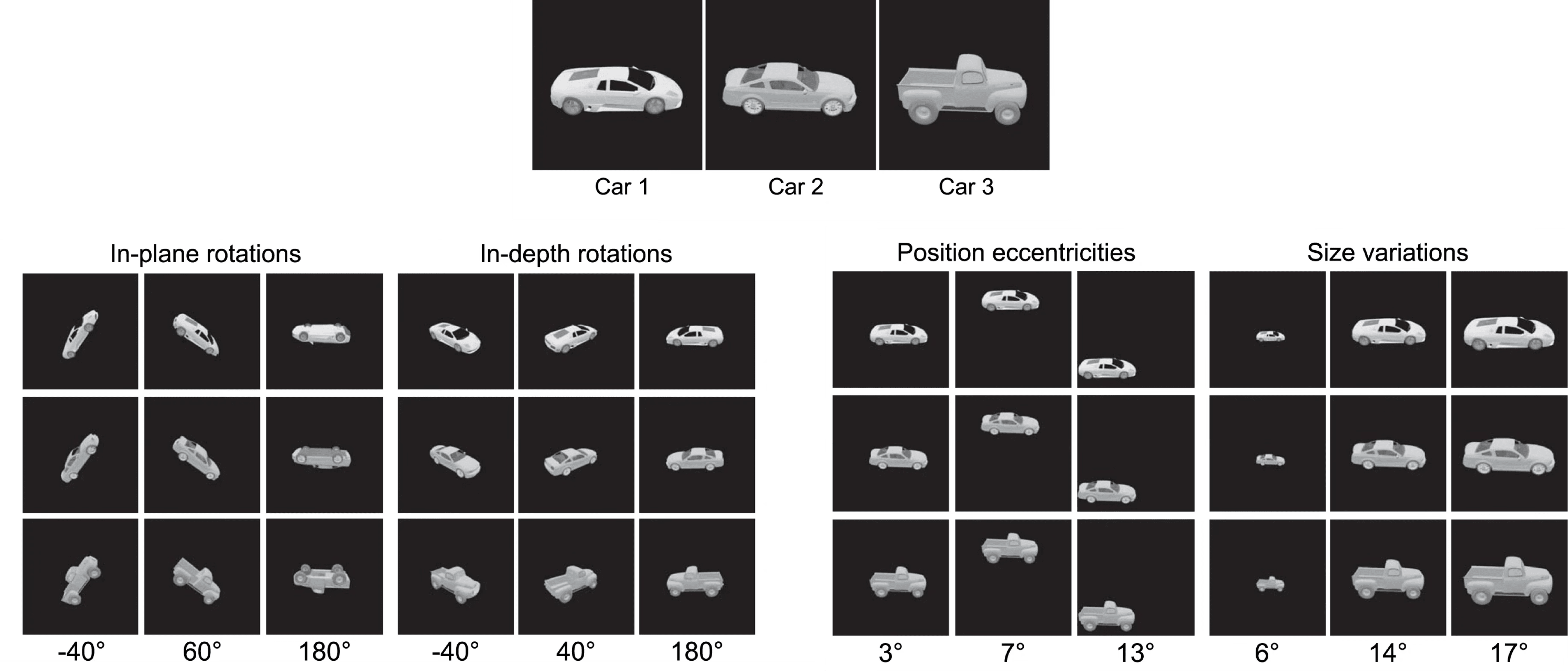
For now, let’s consider an even simpler problem: object recognition. Suppose you perform 3D transformations on three cars. For each resulting image, you ask someone which car is in the image. This feels like an easy task because it happens almost automatically for us. But consider that the pattern of light that hits a sensor is completely different for each image — there are often no pixels in common between two instances of the same object. Systems must both perform complex operations to transform these seemingly unrelated patterns of light into more abstract concepts that eventually map to recognition.
How do current ML/AI systems solve the problem? Deep learning-based computer vision, with mechanisms inspired by early neuroscience research, has had several breakthroughs in the past ~14 years, including convolutional neural networks, residual networks, and vision transformers. We know they work (where the definition of “work” is based on benchmarks and product usage), but it’s hard to claim that we understand how they work, especially as these models have gotten much more complex. And despite successes, there are still strange failures that indicate that something may be missing.
One way to talk about these failures is excessive sensitivity — when small, perceptually irrelevant changes affect model outputs — and excessive invariance — when large changes that should affect the model do not. Here, different frames in the same movie with very little perceptual difference cause a massive drop in the model’s probability of classifying an otter.

Here, despite massive perturbations of the image that render the image unrecognizable, the model still has high confidence of the correct class.

Although these papers are from a few years ago, if you use any current image or video models, I’m sure you’ve seen a lot of other strange failures as well. So what are these models missing? What properties would an ideal vision system (natural or artificial) have? (I posed these as discussion questions to the class; feel free to ponder or respond.)
Wouldn’t it be great if we could borrow concepts from something we know has robust object recognition abilities — the brain? TOO BAD! We don’t know how the brain does it 🤷🏻♀️1. Okay, then let’s think a bit deeper. Suppose we were designing a system for object recognition from scratch: what would be good computational principles to incorporate? There are many answers of course, but in this post I’m going to focus on just a few principles: invariance and equivariance. And more generally, factorization2.
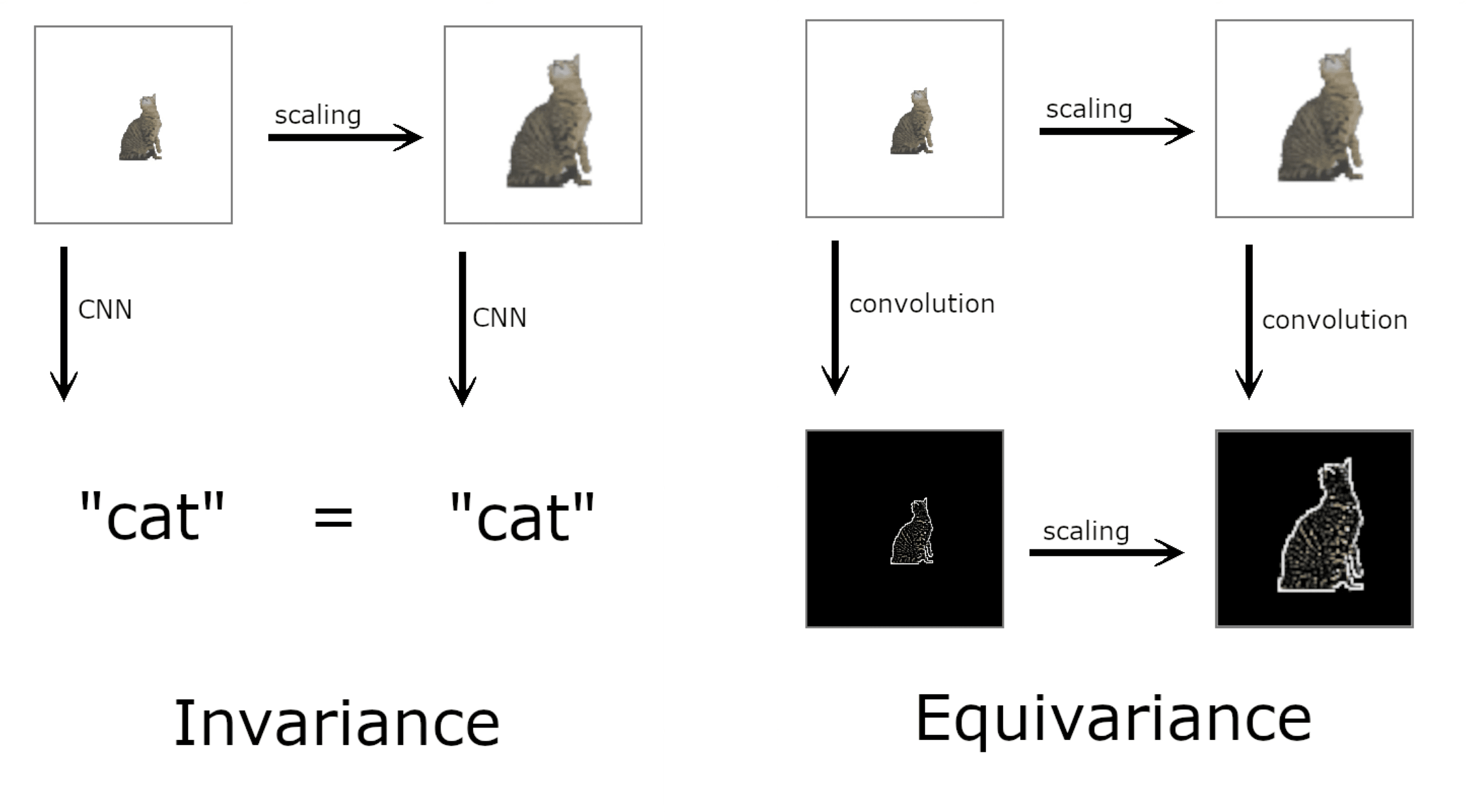
There are formal mathematical definitions for these terms, but for our purposes, I’m going to define them this way: A representation used for recognition should discard transformations irrelevant to object identity (invariant to transformations). For general scene understanding, there should also exist representations equivariant to the transformations, i.e. that change appropriately with the relevant transformation variable3.
On the left, scaling the cat still gets you the cat label, with information about the scaling thrown out. The representation of the cat is invariant to the scaling transform. On the right, scaling gets you a representation that changes along with the scaling of the input; it is equivariant with scaling. Another example of an equivariant representation would be any type of slider in a UI: the position along the bar represents some other relevant variable, e.g. the volume bar on your computer.
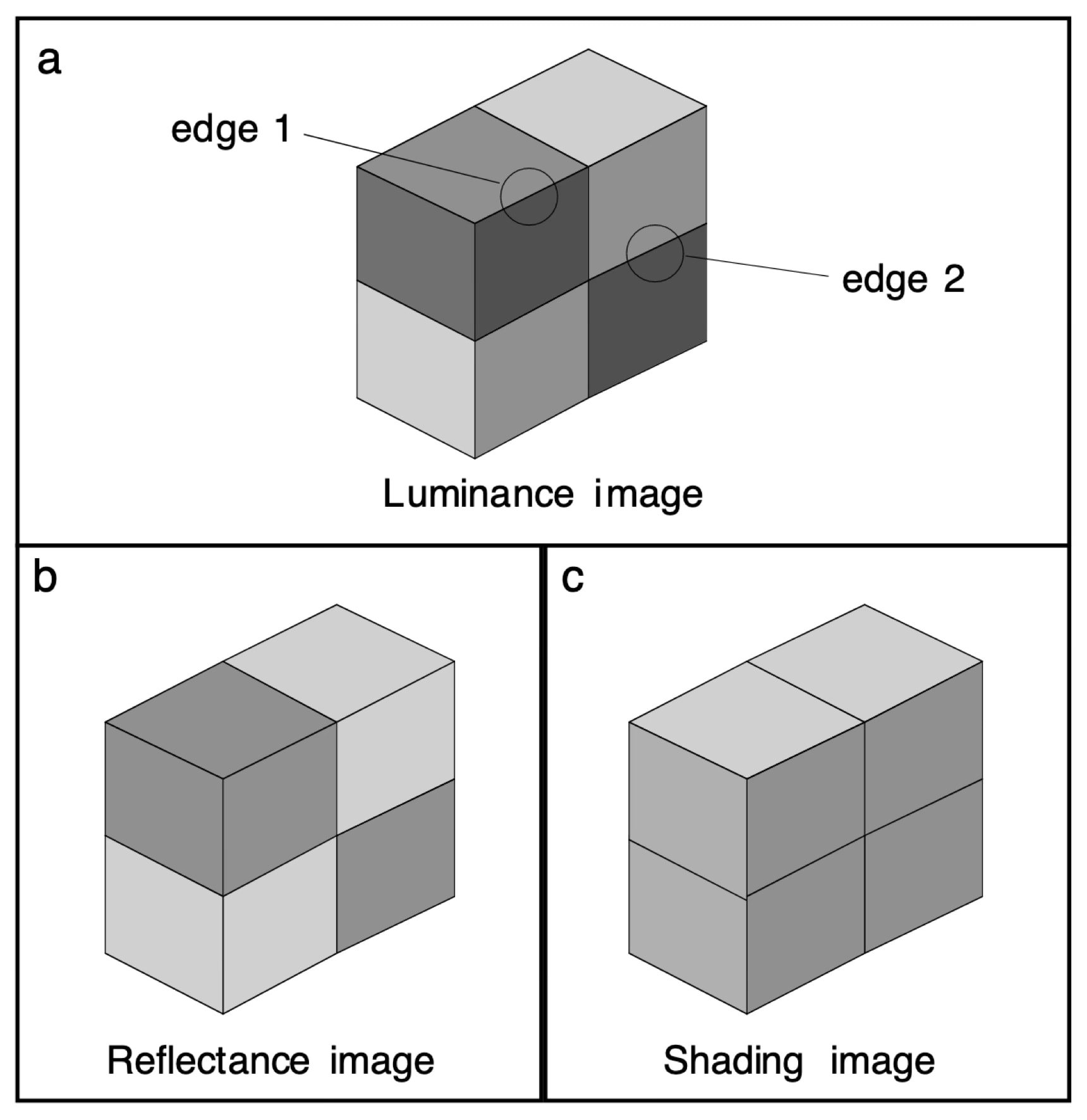
Factorization is the process of disentangling relevant factors into explicit representations. Here, an image can be factorized into reflectance — the properties of the object surface — and shading. If you were performing pattern recognition, it would be useful to have the reflectance image, separate from the shading. But if you wanted to understand a general scene, for example, where the light source is, knowing the shading information is necessary. Even though edge 1 and edge 2 have identical pixel values, we know the causes of these values are due to different factors. The brain is clearly doing some kind of factorization.
This example is simple, but many problems in perception can be framed as factorization, such as identifying someone’s voice in a loud room while understanding what they’re saying, or knowing how an object is oriented in order to grab it4.
Now that I’ve introduced factorization at a high level, I’ll focus in on an example of low-level factorization with invariant and equivariant representations in a model: complex-valued sparse coding. My previous blog post has an intro to regular sparse coding, but here’s a quick summary.
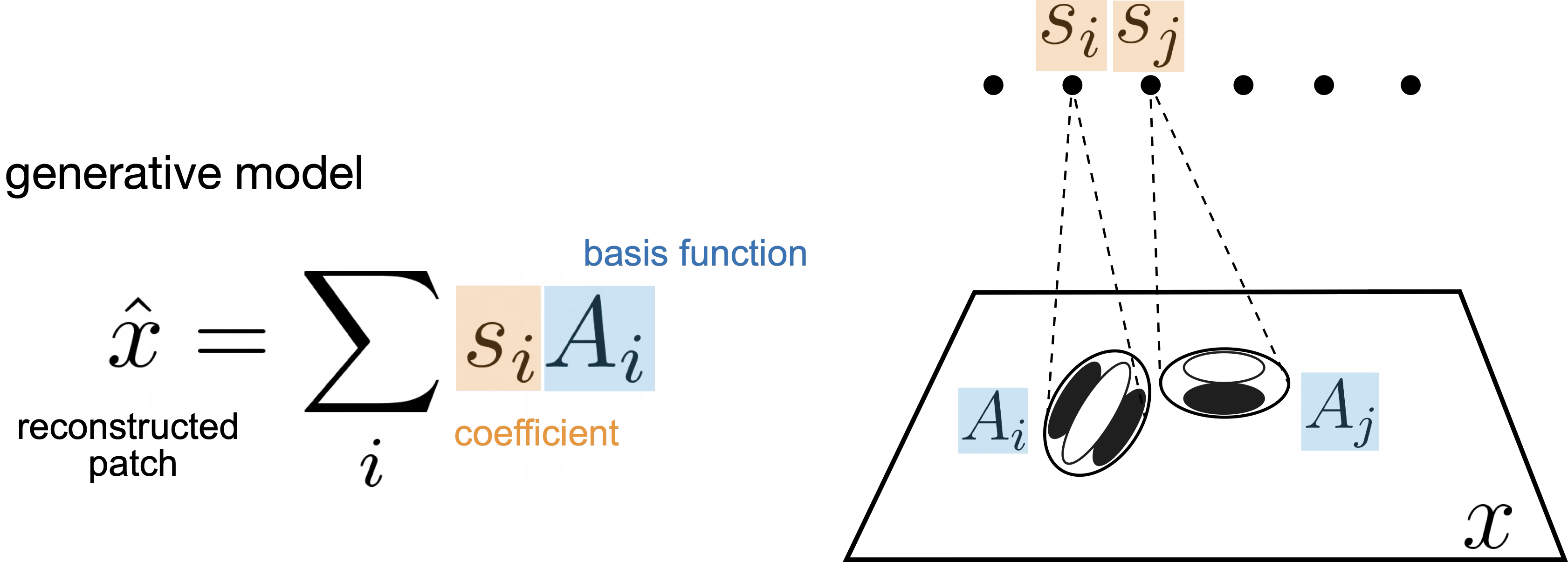

Given a set of images X, the goal of sparse coding is to learn a set of basis functions A (each corresponding to a unit) that can be linearly combined to reconstruct the images. The key is that the coefficients s of the linear combination should be sparse, i.e. mostly zeros. We learn an A for the whole dataset and infer an s for each image by minimizing E with respect to the appropriate variable. s is sparse, and A ends up looking like oriented, bandpass, localized filters (Olshausen & Field 1996).

There’s a slight problem with standard sparse coding, however, which is that patterns are entangled with transformations. Here, I’m showing how the sparse code in orange changes with a shifting input pattern.
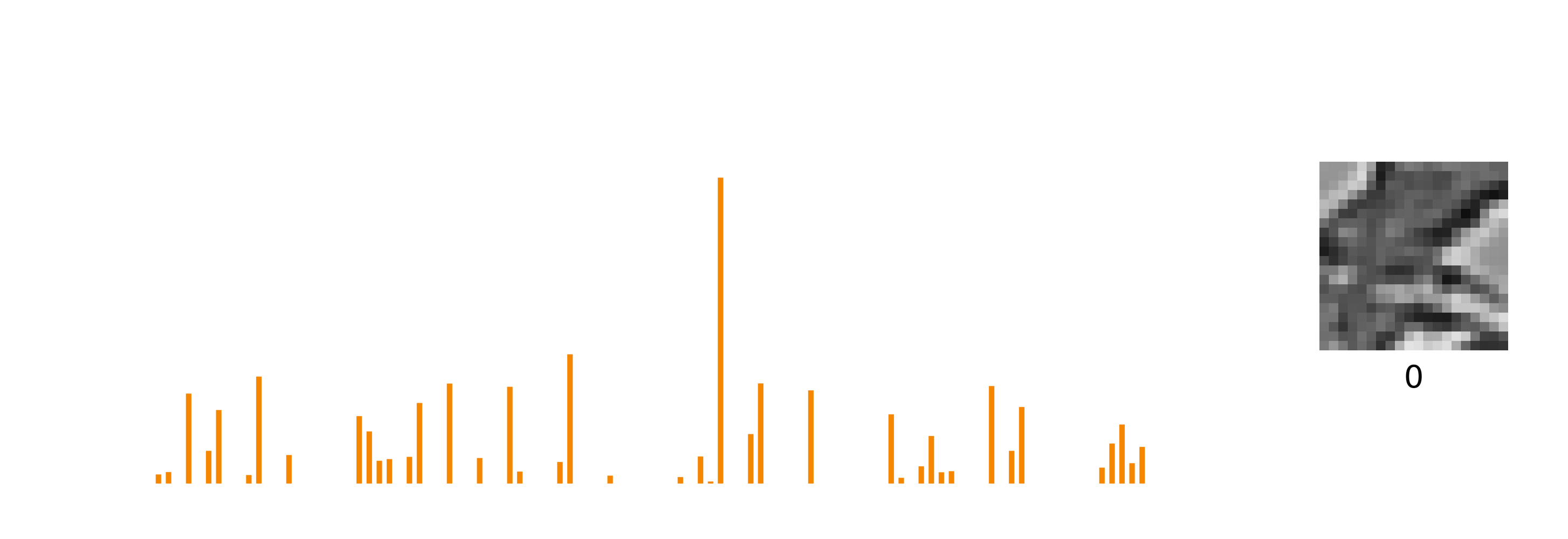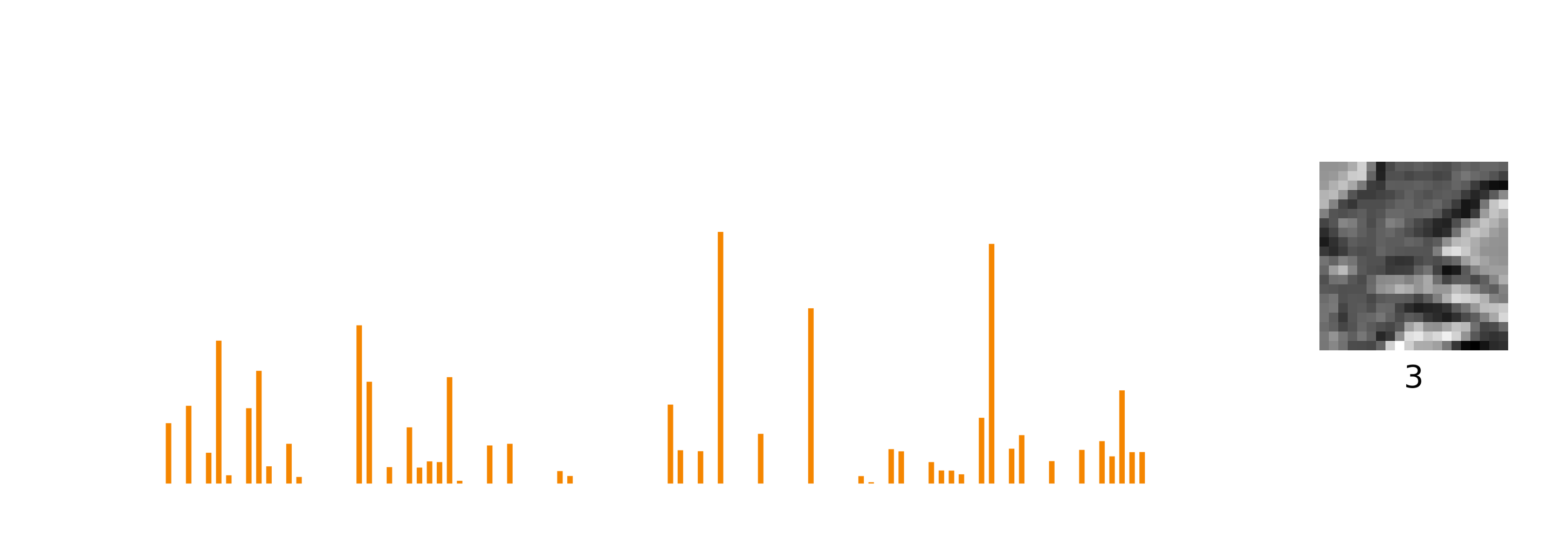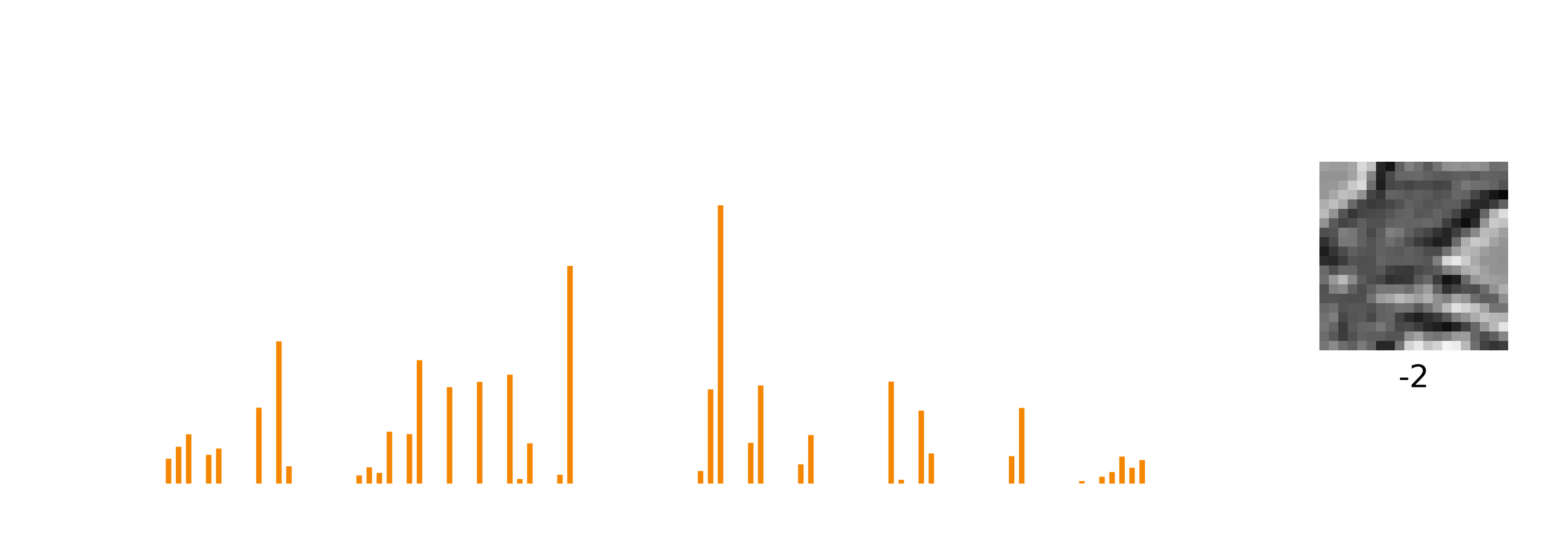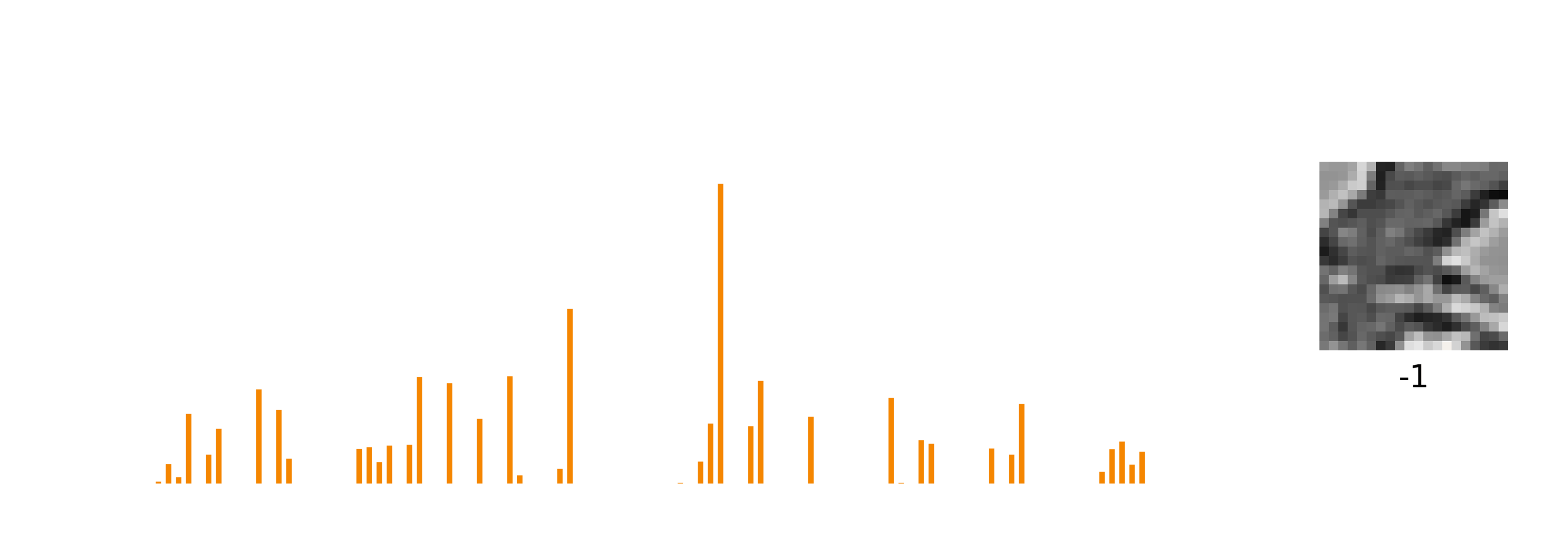
The representation of the image, the sparse code, is changing quite a lot with each frame. You and I can see easily that a static pattern is being shifted vertically. But if all you saw was this sparse code, a set of neurons firing, it would be impossible to tell whether the changes in the sparse code were caused by the pattern itself changing, a transformation to the pattern, or a combination of both. What might be a better representation that makes the pattern and the transform explicit?
Let’s look at complex-valued sparse coding for movies, described in Cadieu & Olshausen 20125, as an example of factorization.
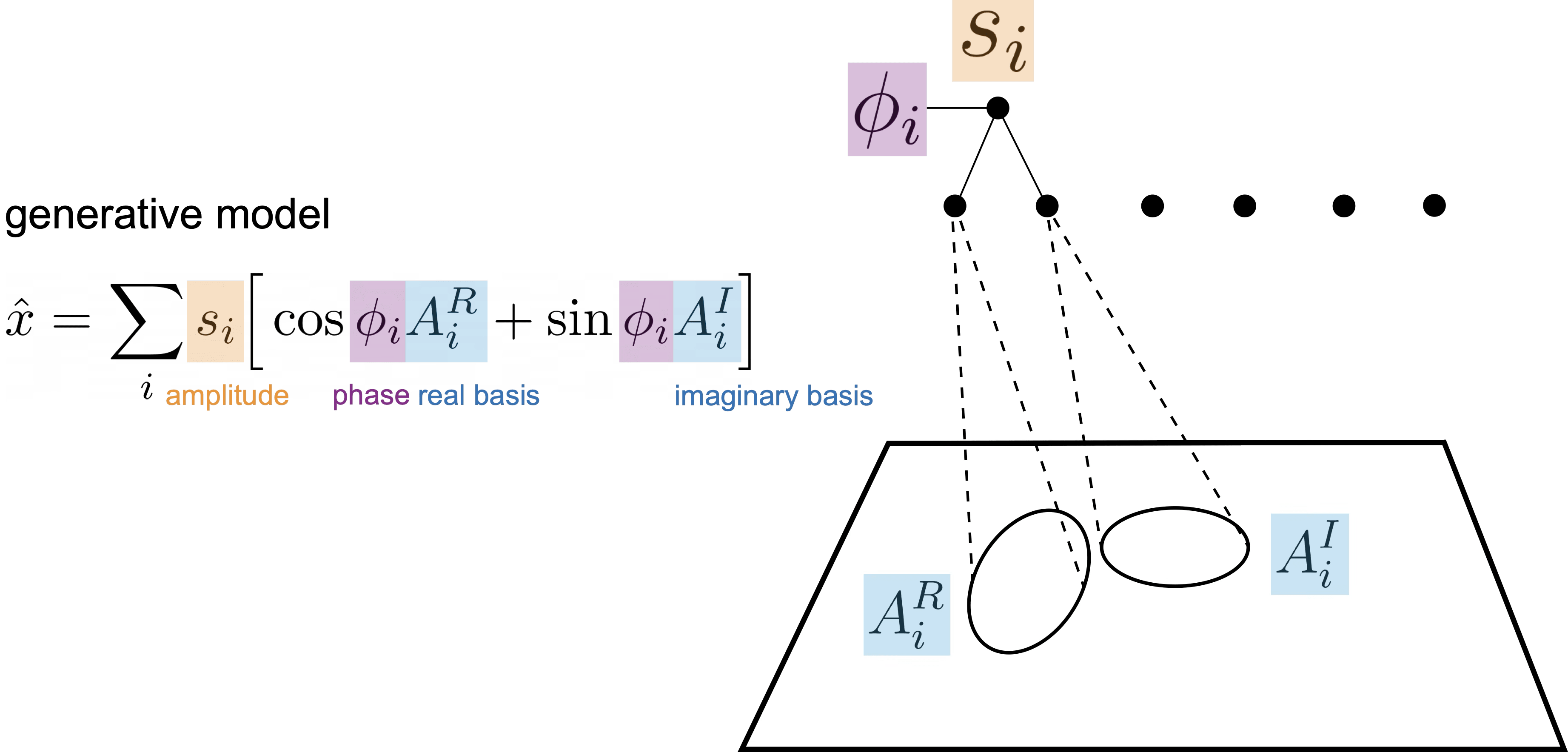
It has the same core algorithm as sparse coding, but the basis functions are now complex-valued. While the s variable is still responsible for the amount of the feature present and is encouraged to be sparse, the phase variable φ is responsible for interpolating between the basis functions, as you can see in the generative model equation above. Put another way, you can steer the exact appearance of the basis function in the reconstruction using φ.
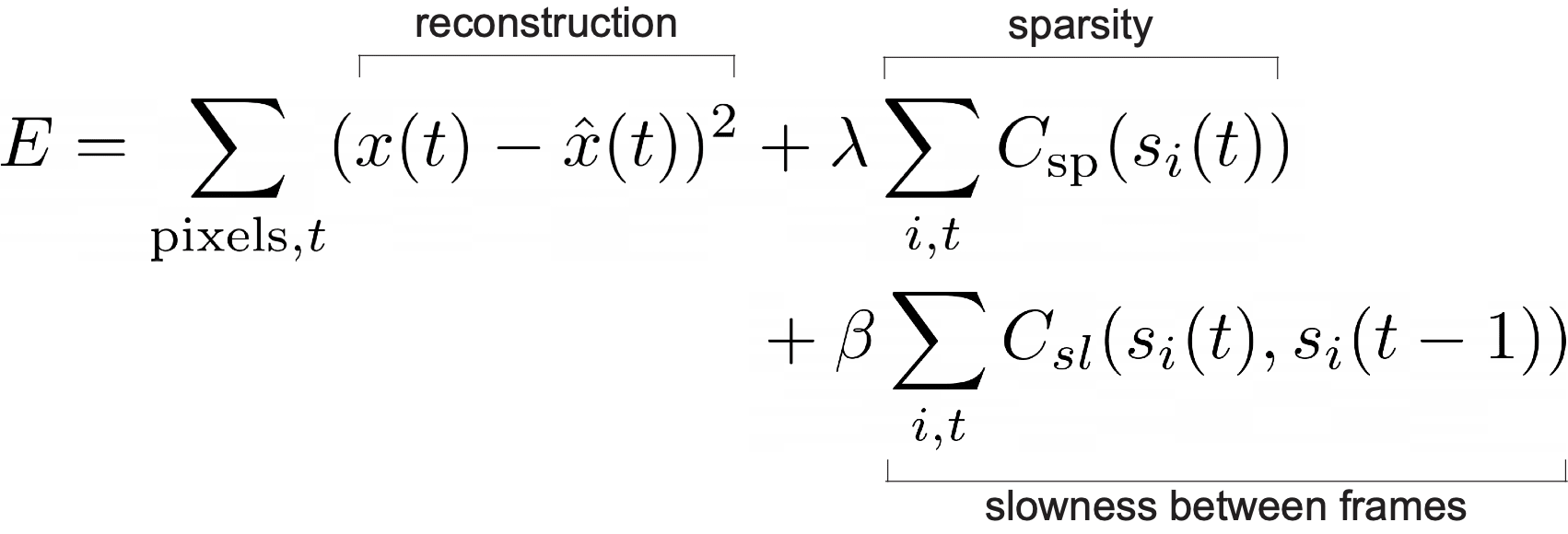
The energy function to be minimized is almost the same as regular sparse coding, with an extra term that encourages s to be similar between frames. This follows the slowness principle6 which says that because of smoothness in the world, i.e. things don’t change suddenly, representations in neighboring frames should be similar to each other. The authors end up with pairs of receptive fields (each pair is the real and imaginary component of one unit) like the ones below, that vary only in phase.

If you animate them, i.e. apply the generative model above for a unit turned on and fixing the amplitude but varying the phase, you get this. This shows the range of possible features that can be expressed by each unit.
So what does this have to do with factorization? How would this representation allow us to disentangle the pattern from the transform in the example earlier? A key insight in this model is that because of the sparsity and slowness penalties on the amplitudes, representations of transformation are conveyed phases, which can spin freely at each frame. Amplitudes stay relatively stable to incur less cost in the objective function. Here, I’m using the same video but showing the complex-valued sparse coding representation. Orange are the amplitudes, purple is the phase structure of the pattern, and green is the change in phase at each step.
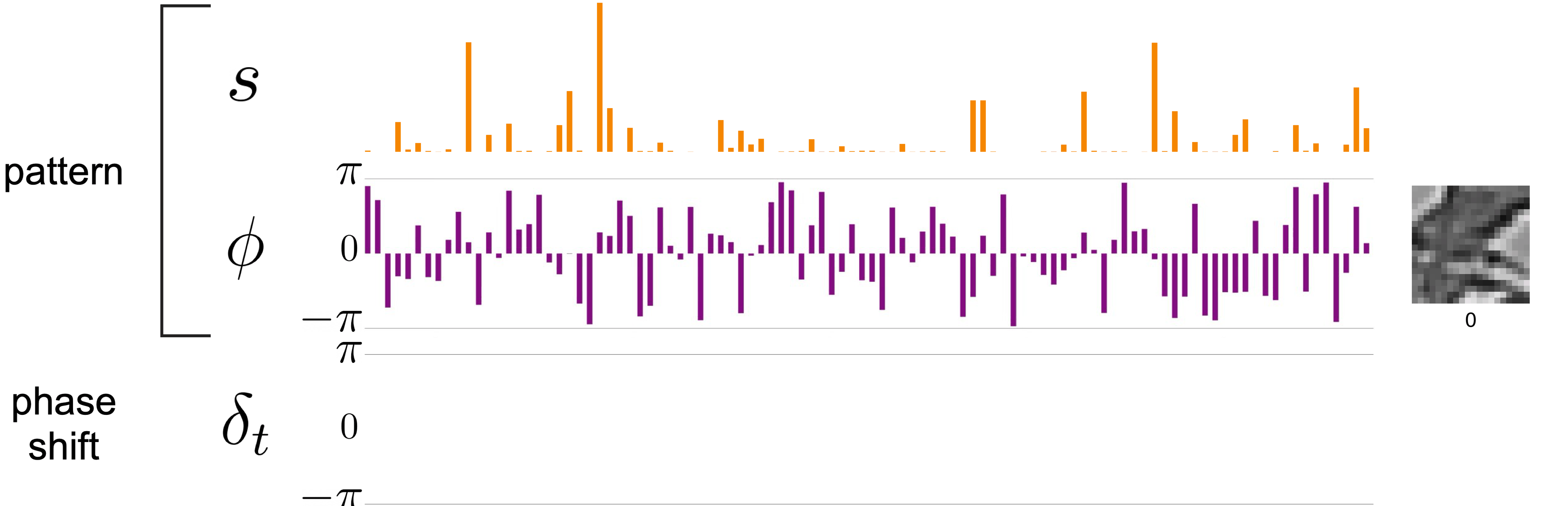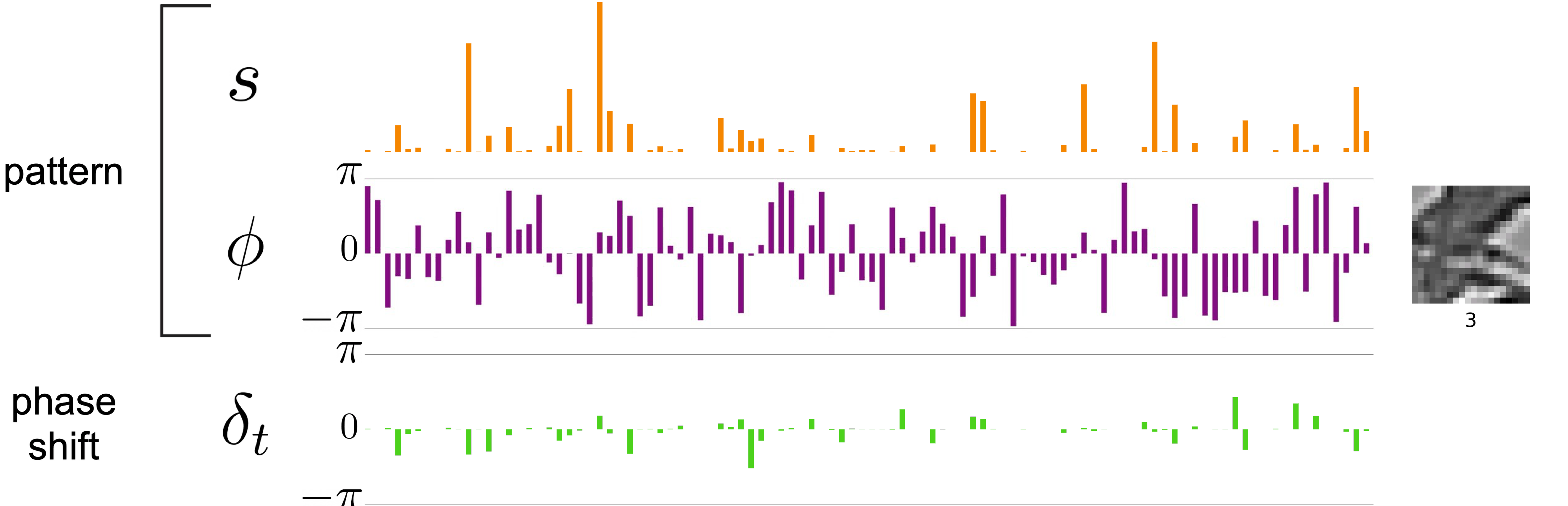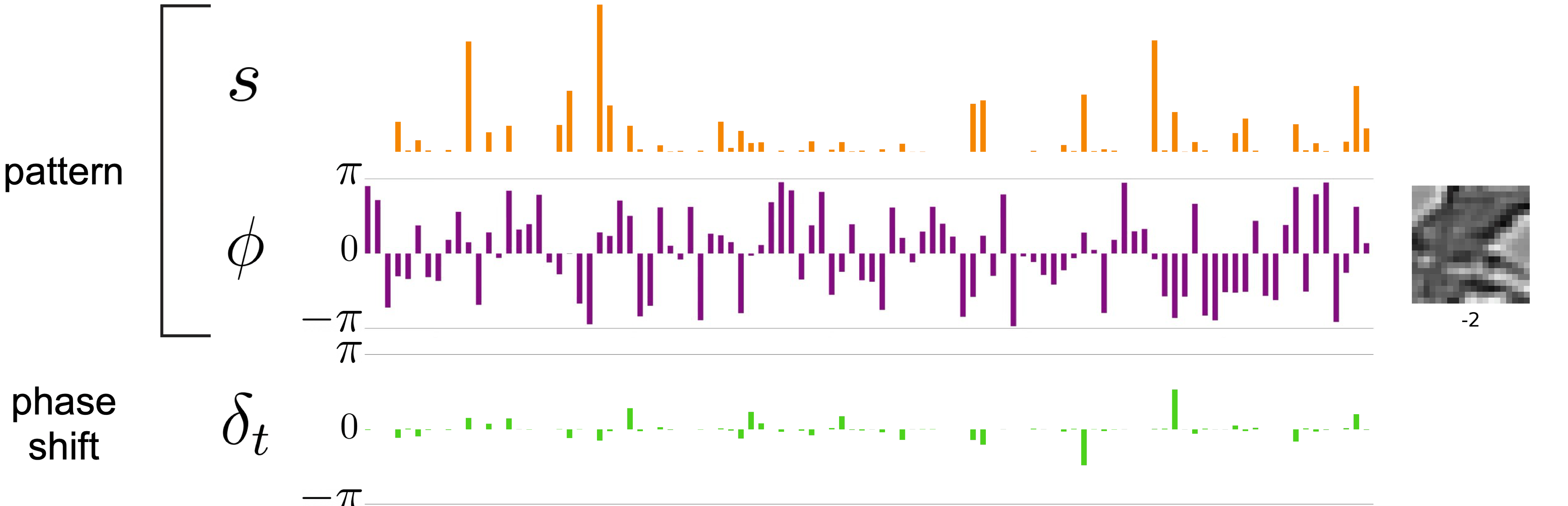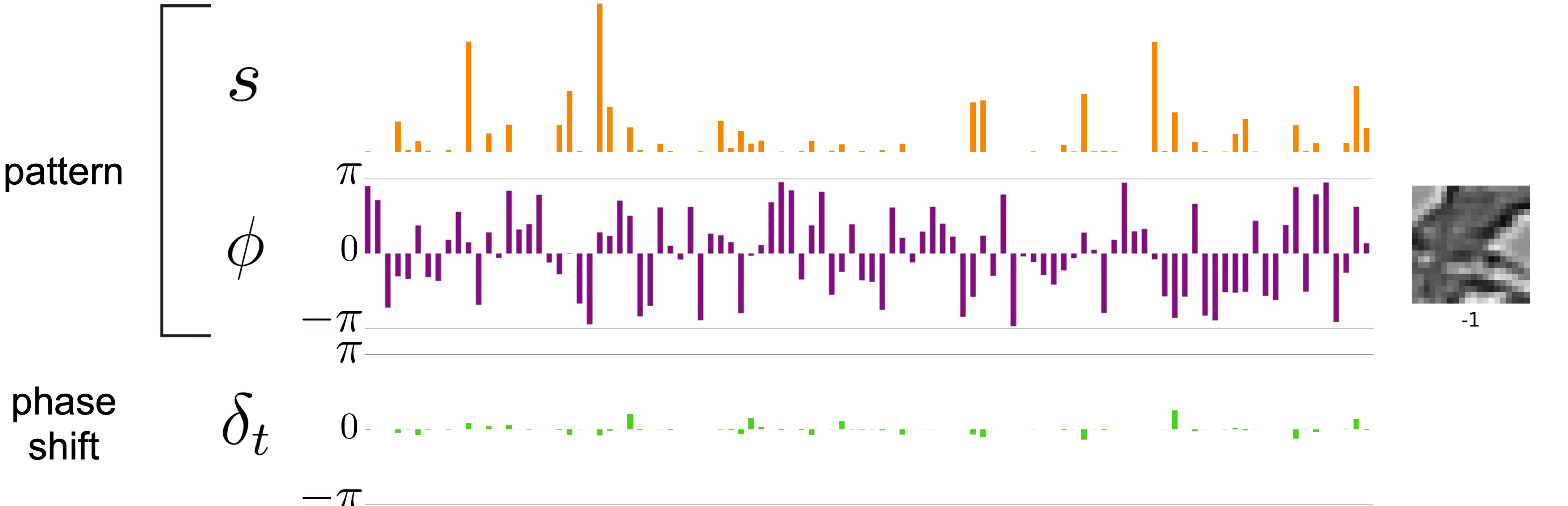

I hope you can see that the information is factorized into two parts: the complex-valued pattern se^{jφ} (orange and purple) whose amplitudes s and phases φ are pretty much constant over time, and the transformation (green) represented by phase shift δ. For this particular transformation, applying local vertical shift does not affect the invariant representation, and the amount of shift is specified by the amount of δ applied — an equivariant representation.
(BTW, I’m not explaining well what about amplitude and phase allows this to work, and I’m actually skipping a portion of the lecture about the importance of phase in images, but this post got too long. I’m planning to write a separate post(s) about phase.)
Furthermore, we can combine patterns and transforms to generalize to novel image sequences. For example, given the complex representation of an unseen pattern, you could apply the appropriate δ to shift it vertically. You can also understand novel sequences: given a known pattern that has been transformed in novel way, you should be able to recover the transform being applied to it, and then apply it to other images. Pretty neat!
Here are example of other transformations, or other δ configurations that can be learned from videos.
The main themes of the lecture were discussing challenges and failures in computer vision, factorization into invariant and equivariant parts as a computational strategy, and complex-valued sparse coding as an example of factorization in a theoretical model of early visual cortex. The subtext of the lecture, however, was that although we live in a society dominated by a very specific type of statistical learning, it is not flawless, and it is not the only way to do things. Although we don’t understand how the brain solves these problems, I think it’s still important to think about fundamental principles of computation for both understanding natural systems and building artificial systems. Maybe we’re wrong: factorization is not how the brain does things, and maybe it’s not the best design for an artificial system. But at least we’ve started to understand the nature of these problems, rather than just throwing data at them7.
We have many, many studies on the neural correlates of vision in many parts of the brain. But what are the necessary and sufficient computational principles and algorithms?
I’m not claiming these properties are sufficient for a robust vision system, but many of the failures of AI indicate that models cannot factorize correctly, e.g. the otter example.
After the lecture, someone said they didn’t understand why equivariance was important. First, while we can recognize objects independent of their transforms, we also simultaneously know their other properties: where they are, how far they are, what color, etc.; we’re not just throwing out all non-invariant information. But the bigger question: Why should we need an explicit representation if we can just decode the equivariant component from the inputs or mid-level representations? I could probably write a whole post about this, but my short argument is: a representation is for something, i.e. some downstream process that should not have to decode, because its job is to perform more complex operations on this explicit representation. All the information you need is indeed the input — invariant and equivariant parts — but it’s entangled. It needs to be transformed into a format that is useful for some task or computation. You may have equivariances earlier in your network, like in this example, or only later, when you need to perform some task, but they must be present somewhere to make sense of the raw data. A reasonable hypothesis is that there are equivariances all throughout the processing stream.
A nice paper with clear examples is Tenenbaum & Freeman 2000, who frame it as separating style and content.
And also, we all had a good time! Right? 😀
2025-05-01 17:00:49
Hello, I’m back after a semester off from blogging! I have a plan for upcoming ✨science✨ posts, but in the meantime, my buddy Luckey invited me to submit to the Unlocked series. I’m using it as an opportunity to write a personal reflection I’ve been putting off for a while.
I wrote my first blog post during my transition from computer science to neuroscience in my PhD. At the time, neuroscience felt religious to me, and I struggled to understand how neuroscientists often have such immutable convictions in the face of so much conflicting yet reputable evidence1.
Even in computational neuroscience, which appeared more concrete to me than experimental neuroscience, no one really agrees on anything. Unlike machine learning models, it is far less clear what it means for a model of the brain to be “useful”2. Should the goal be to fit to recorded neural data? Even if a model predicted spikes with perfectly, would we understood the brain any better? On the other hand, if we had a principled model that did not fit data as well, would that be useful? One could go around in circles forever arguing like this.
Further contributing to my confusion was the fact that I had not yet mapped out the literature and history of the field for myself. I didn’t know what was obvious or accepted, even from my lab’s point of view. I certainly wasn’t ready to form my own beliefs, and as a result, didn’t have a good idea of the research questions I was interested in. I wrote the first blog post with the naive hope that verbalizing my lack of clarity about the field would help me make more sense of everything.
1.5 years later, I am only slightly less naive and only making a little more sense. The biggest change is simply that I have spent much more time reading, talking, writing, and thinking about the brain. Just like practicing an instrument, playing a sport, or learning a language, I feel myself starting to develop proficiency in this new skill of… neuroscience? Let me explain what I mean.
In the past, questions during presentations or even meetings would often send me into a panic. They didn’t have to be particularly hard questions, just ones I hadn’t yet thought too much about. Attempting to answer involved straining through complex logic, or tortuously sifting through figures and equations in my head. I could not understand how people were able to answer hard questions on the fly, or look at a plot and immediately understand what was going on. It was like they were fluent in a language, and all I could do was string together broken phrases. Was I just too stupid to be doing this?3
Through a slow and agonizing process of pushing my research forward and preparing for my qualifying exam, I managed to start orienting myself. I won’t go through the gory details, but I treated it like how I used to practice violin, or prepare for coding interviews in college. I’m sure everyone’s process is different. But as a result, I’ve started to feel the freedom of moving through a new world, truly like developing fluency in a language. I am more comfortable thinking on my feet, as if concepts are flowing around me, and I just need to grab what’s already there. I don’t have to think so hard all the time.
In other words, I have started forming my intuitions about neuroscience, or at least the subfield I’m focusing on now. For example, someone may ask a confusing question about my project, and I can immediately understand their underlying misconception. Or someone brings up an idea, and a simulation I could run with my model will pop into my head. These are things I couldn’t do before, at least not immediately, through reasoning alone.
A lot of this might seem obvious, and I feel a bit silly writing some of this down. But the reason this feels so profound for me is that I have never experienced this in an academic setting. In undergrad and before grad school, I kept hopping around different disciplines and labs to figure out what I wanted to do. I realized that finally, now at the end of my 4th year, this is the longest I’ve ever spent in one field. I am maybe starting to become an expert in something, for the first time?
I can start to see now that after decades of being in a field, a scientist’s intuition might look a lot like what I called religion, from the outside. Their intuition lets them feel that this problem is a good problem, that this approach is the right one. Even if there is evidence that seems to contradict it. Intuition stems from deep understanding, honed from decades of training. Although it may have started there, it goes beyond rational, quantitative scientific thinking.
In Mathematica, David Bessis argues that contrary to popular belief, mathematical ability is not an intrinsic gift certain people are born with. Rather, it is about developing intuitions in your own way, driven by the desire to understand. Although we’re traditionally taught that math is symbols on a page, that’s just one way to communicate intuition. You could also think about math in terms of of something we all have strong intuitions for, such as the physical world. Terence Tao famously rolled on the floor to think about a problem:
Early in his career, he struggled with a problem that involved waves rotating on top of one another. He wanted to come up with a moving coordinate system that would make things easier to see, something like a virtual Steadicam. So he lay down on the floor and rolled back and forth, trying to see it in his mind’s eye. ‘‘My aunt caught me doing this,’’ Tao told me, laughing, ‘‘and I couldn’t explain what I was doing.’’ (NYT)4
There is something very profound about human intuition, and scientists clearly rely on it to guide them. What would science look like without intuition? Unfortunately, understanding intuition itself is a hard problem, certainly harder than next-token prediction (does AI have intuition?). Regardless, it’s part of what makes us human, and more interesting and beautiful than a reasoning machine could ever be.
Let me connect this back to my original point. Similar to religion, intuition is separable from logic and reasoning. Perhaps someone’s intuition is so strong that no evidence they’ve seen so far can convince them otherwise. But ideally, unlike in religion, we learn something when we’re proven wrong. It deepens our understanding, and we modify the intuition accordingly. When someone’s intuition is correct, it may lead to discoveries that would have taken orders of magnitude longer through reasoning.
So for now, I guess I’d revise my opinion from neuroscience as religion to the less extreme neuroscience as intuition5. Through my own attempts to grow as a scientist and seeing others’ processes, I’m realizing how important intuition is in science, and how I might go about developing my own. Maybe these convictions that I see in neuroscientists aren’t as bizarre as they initially seemed. Maybe I will be there too, one day (for better or worse).
This is still just the beginning for me, of course. I still don’t feel comfortable calling myself a neuroscientist (maybe I never will) or a vision scientist (my department, technically), but I’m also definitely not a computer scientist. Whatever I may be, my focus now is not to form beliefs, but to hone my intuition. I guess, until I find a better reframing by the next reflection post.
One concrete example is the fundamental debate between using artificial versus natural stimuli to characterize the visual system. I think we are trending toward natural(istic) stimuli as a field, but there are still well-respected scientists on either side!
I suspect this statement could get me in trouble with ML people 🫣, but that’s another conversation.
I don’t know, jury’s really still out on this one.
More cynically, you could also call it neuroscience as vibes. But everyone’s into vibes these days, so maybe there’s no problem with that.