2026-05-28 11:33:02
注册使用过的第三方中转站太多了,如何管理成了一个问题。
今天调研使用了一下 cc switch,感觉还可以。
下载地址:https://github.com/farion1231/cc-switch/tree/main 5万多个 star,应该还算靠谱
1/ 添加基本配置,主要是 API Key 和请求地址
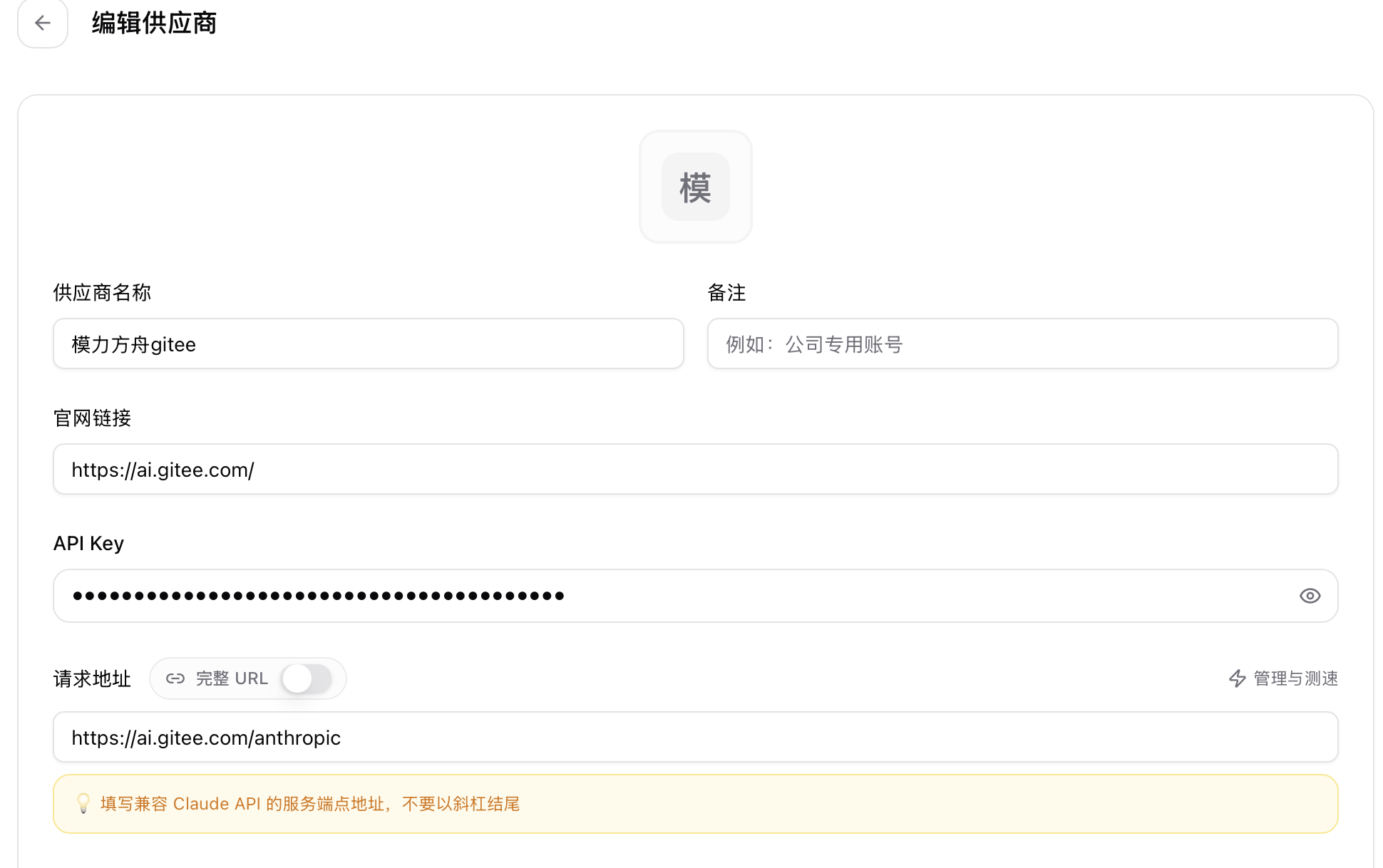
2/ 配置一下模型映射

3/ 点击一下"启用"按钮就可以正常使用了
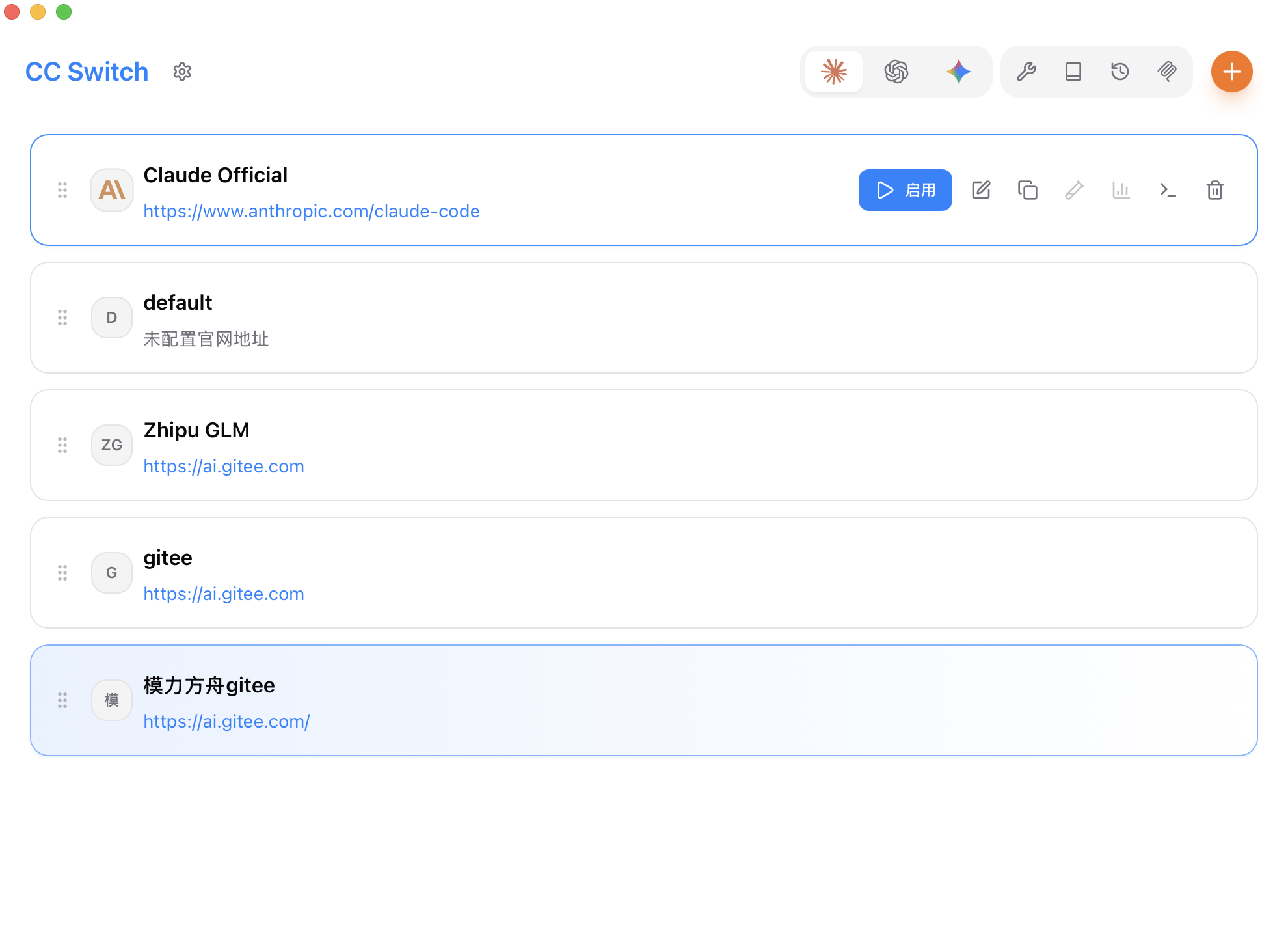
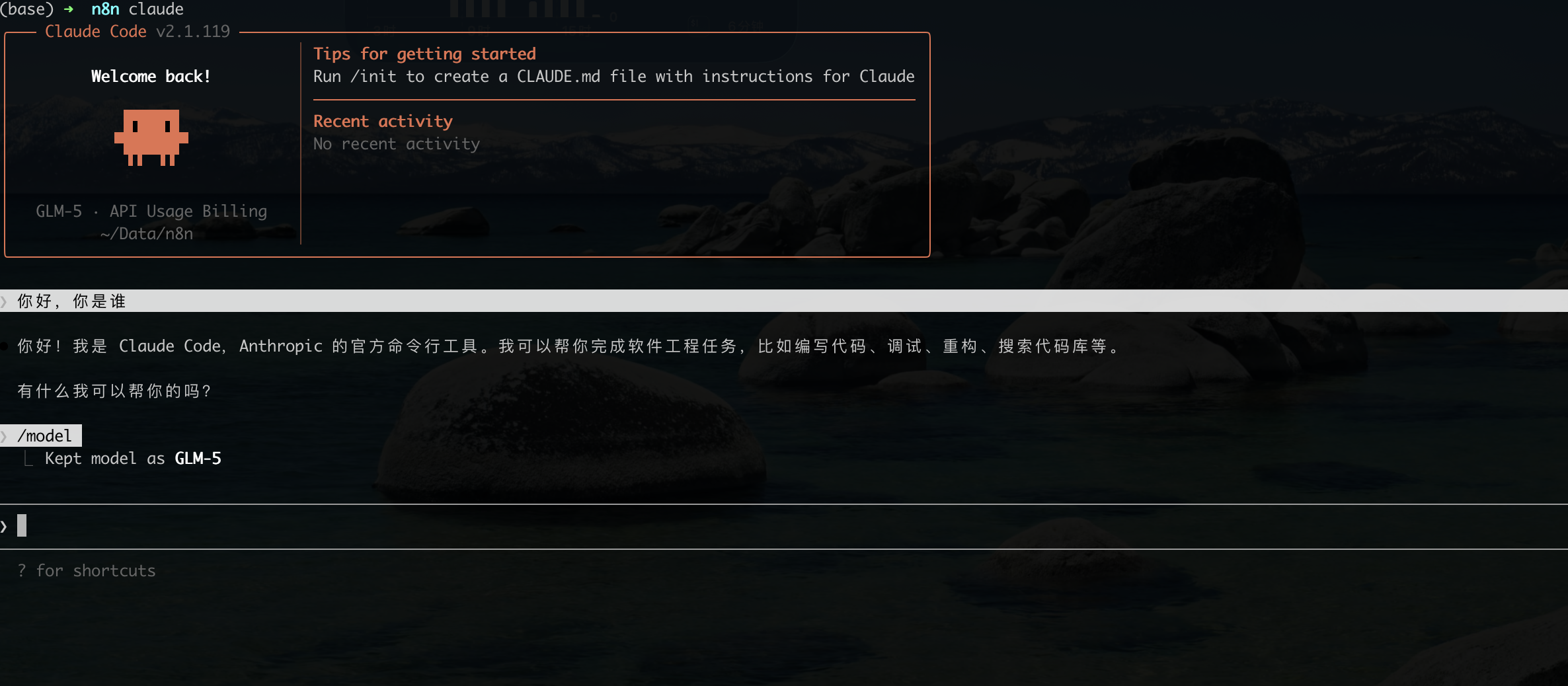
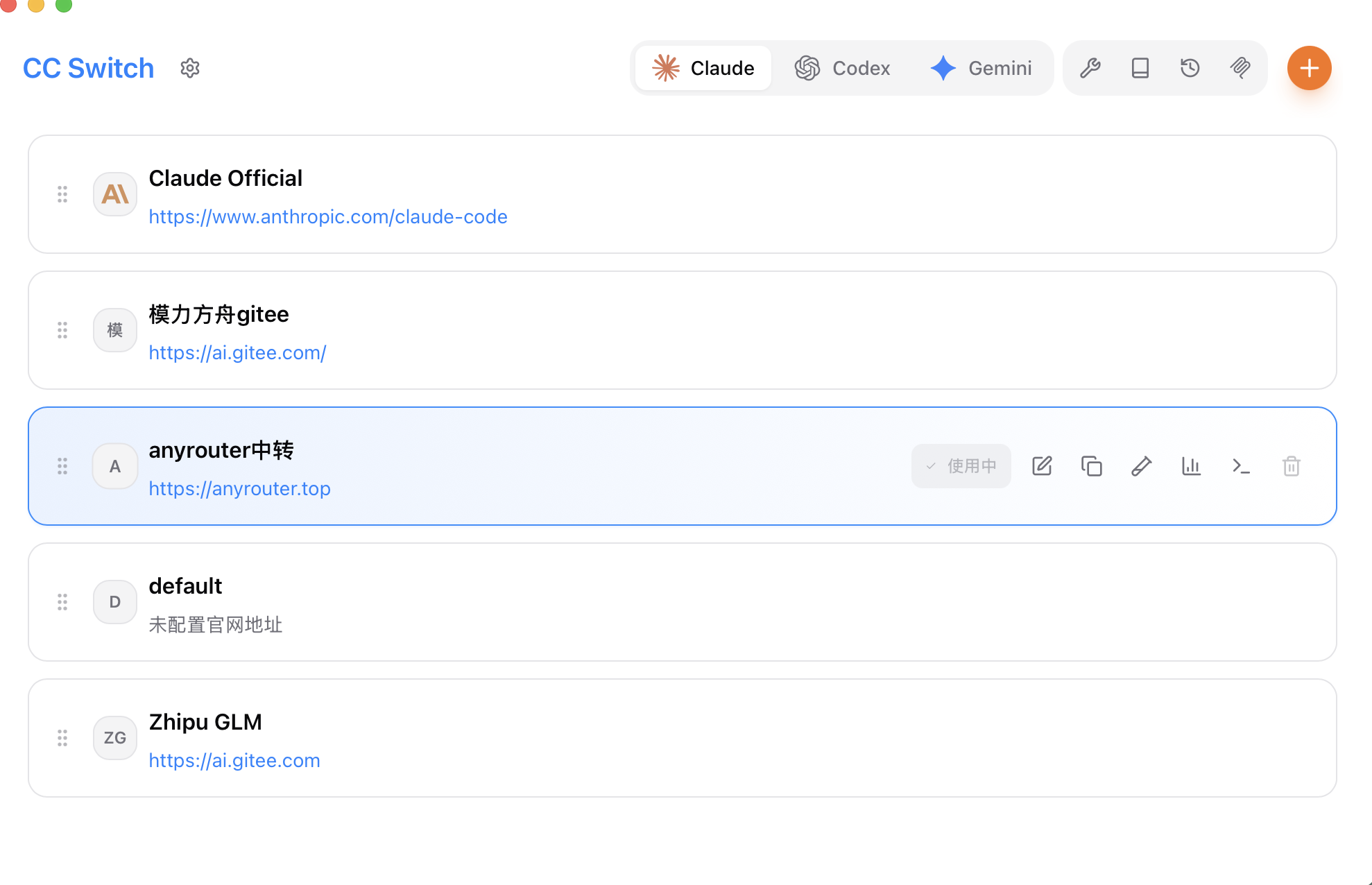
cc-switch 是实时热加载配置,即改即用。目前主要使用 anyrouter 的中转站,效果还不错,可以把以前在 ~/.zshrc中手动添加的配置注释掉了。
2026-01-22 17:56:41
作为 Anthropic 官方推出的命令行编码助手(coding assistant),Claude Code 本质上是一个通过大模型(LLM)执行复杂任务的工具。通常情况下,它需要连接云端 API。但随着 Ollama 宣布兼容 Anthropic Messages API,我们现在可以轻松地将 Claude Code 与本地模型集成。
从工程角度看,使用本地的模型既可以作为断网情况下的一种保障方案,也可以在不改变工作流程的情况下,把本地模型作为一个测试开发环境,极大节省 Token 开销。
1.安装 Claude Code 和 Ollama
npm install -g @anthropic-ai/claude-code@latest
Ollama 可以通过官网https://ollama.com/下载安装包安装。
注意:Ollama 版本v0.14.0+,Claude Code版本v2.1.12+,可以通过下面命令验证
claude --version
ollama --version
Ollama 安装后会自动作为后台服务运行。应该可以在 http://localhost:11434 上看到它运行。
2.下载大模型
可以通过 Ollama 的 WebUI 页面直接下载,如下图。
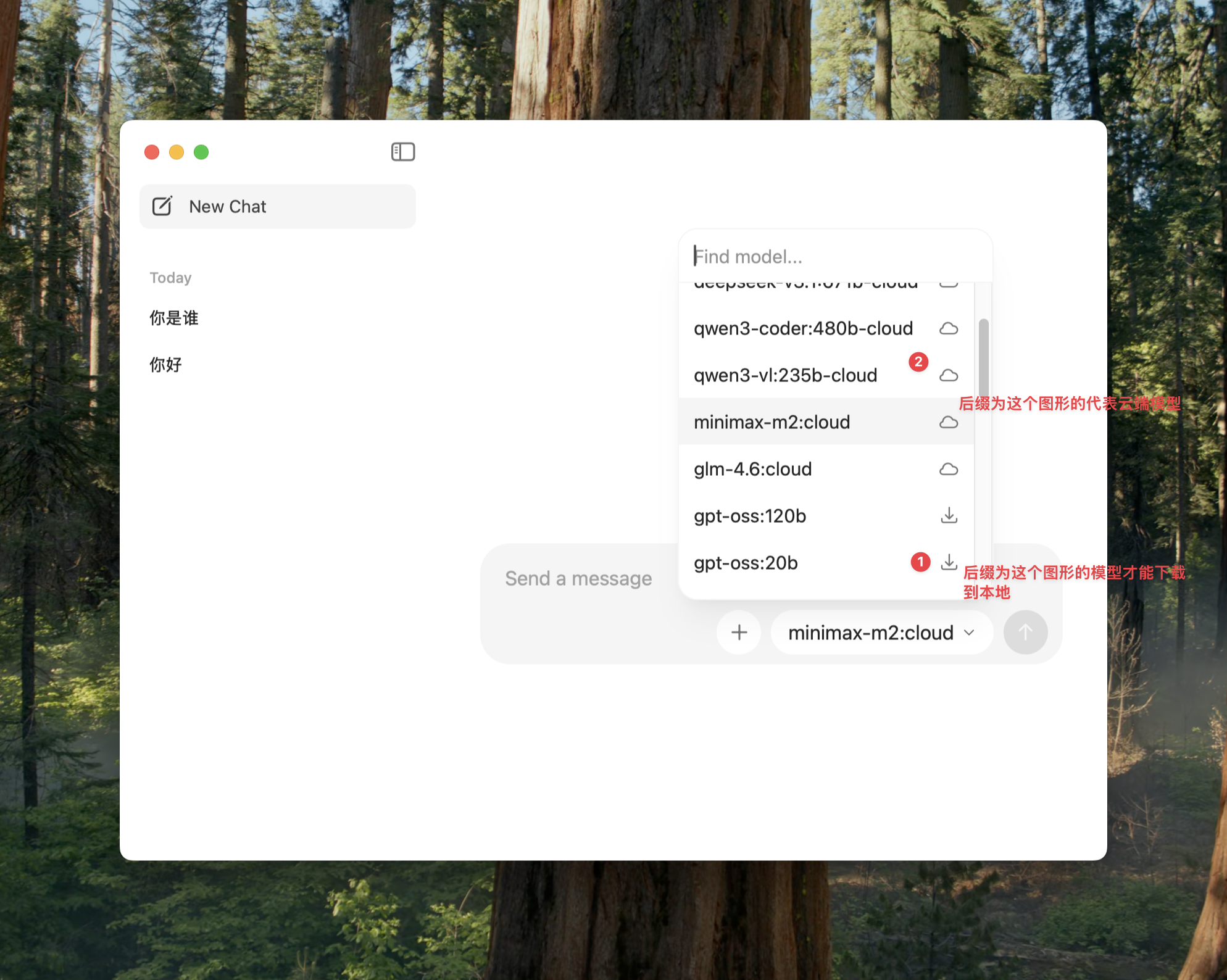
也可以通过命令行快速拉取适合编码的模型。
#查看本地模型
ollama list
#下载新模型
ollama pull qwen2.5-coder:7b
#删除模型
ollama rm qwen2.5-coder:7b
#查看模型基本参数
ollama show qwen2.5-coder:7b
3.配置 Claude Code 连接本地 Ollama
export ANTHROPIC_AUTH_TOKEN=ollama
export ANTHROPIC_BASE_URL=http://localhost:11434
# 启动 Claude Code 并指定本地模型
claude --model qwen2.5-coder:7b
# 如果想使用云端模型,命令类似
claude --model glm-4.6:cloud
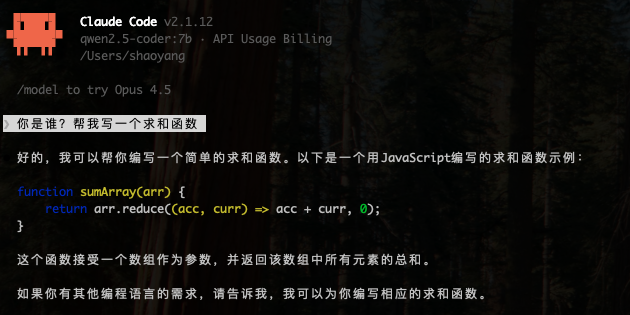
注意:如果你开启了系统代理,可能会遇到
API Error: Connection error。这是因为流量被转发到了代理服务器而找不到 localhost。请先在终端执行:
unset https_proxy
unset http_proxy
4.使用Anthropic SDK
如果我们想更精准的把控程序的执行流程,可以使用官方的 SDK。
import anthropic
import httpx
http_client = httpx.Client(
proxy=None,
trust_env=False,
)
client = anthropic.Anthropic(
base_url='http://localhost:11434',
api_key='ollama',
http_client=http_client,
)
with client.messages.stream(
model='qwen2.5-coder:7b',
max_tokens=1024,
messages=[{'role': 'user', 'content': 'Count from 1 to 10'}]
) as stream:
for text in stream.text_stream:
print(text, end='', flush=True)
这里再说一个调试的技巧:在配置过程中,不要死磕枯燥的错误堆栈信息。一个高效的调试技巧是:向 AI 描述你的完整环境和所做的工作,而不仅仅是报错代码。
此前我按照文档编写代码时,一直遇到 InternalServerError (503) 错误。我直接把错误代码粘贴给 chatgpt ,它尝试了很多方法但始终没有解决。
Traceback (most recent call last):
File "/Users/shaoyang/Project/stock_demo/day09/anthropic-demo.py", line 12, in <module>
message = client.messages.create(
File "/Users/shaoyang/Project/stock_demo/.venv/lib/python3.10/site-packages/anthropic/_utils/_utils.py", line 282, in wrapper
return func(*args, **kwargs)
File "/Users/shaoyang/Project/stock_demo/.venv/lib/python3.10/site-packages/anthropic/resources/messages/messages.py", line 932, in create
return self._post(
File "/Users/shaoyang/Project/stock_demo/.venv/lib/python3.10/site-packages/anthropic/_base_client.py", line 1361, in post
return cast(ResponseT, self.request(cast_to, opts, stream=stream, stream_cls=stream_cls))
File "/Users/shaoyang/Project/stock_demo/.venv/lib/python3.10/site-packages/anthropic/_base_client.py", line 1134, in request
raise self._make_status_error_from_response(err.response) from None
anthropic.InternalServerError: Error code: 503
于是,我换了一种思路,不是直接粘贴错误代码,而是前置一步,客观地描述了一下当前的环境。
import anthropic
client = anthropic.Anthropic(
base_url='http://localhost:11434',
api_key='ollama', # required but ignored
)
message = client.messages.create(
model='qwen3-coder',
max_tokens=1024,
messages=[
{'role': 'user', 'content': 'Hello, how are you?'}
]
)
print(message.content[0].text)
我是用的是mac电脑,本地配置了代理,我应该如何修改上面的代码保证可以运行。
js版本是可以执行的
import Anthropic from "@anthropic-ai/sdk";
const anthropic = new Anthropic({
baseURL: "http://localhost:11434",
apiKey: "ollama", // required but ignored
});
const message = await anthropic.messages.create({
model: "minimax-m2:cloud",
max_tokens: 1024,
messages: [
{ role: "user", content: "写一个求和的 python 函数" }
],
});
console.log(message.content[1].text);
chatgpt立刻就发现了问题,并给到我正确的执行代码。

根据这次调试过程,大模型也帮我总结一个更有效的提问模板:
1.贴出当前代码。
2.描述环境(如:Mac 系统、本地有代理)。
3.提供一个对比参照(如:JS 版本可以运行,Python 不行)。
2026-01-13 11:21:38
从 2008 年开始接触股票投资,到现在已经接近二十年了。
这段时间里,我经历过完整的市场周期:牛市的狂热、熊市的绝望,也经历过从"以为自己懂了",到"承认自己其实什么都不懂"的反复过程。账户数字起起落落,但真正变化更大的,是我对投资这件事的理解方式。
很多年里,我一直有一个模糊的念头:应该把这些经历写下来。不是为了证明自己赚过多少钱,而是想留下些什么——一些关于决策、关于错误、关于长期面对不确定性的记录。
直到最近,这个念头才逐渐变得清晰起来。
我决定开设这个专栏。它会以投资为核心,但并不只谈"买什么、卖什么"。我更关心的是:
投资背后的概念与逻辑
普通人在真实世界中会遇到的情绪、误判与限制
如何借助技术,让这些问题变得更可验证一些
在这个专栏里,我会一边讲自己的投资经历,一边引入相关的基础概念;同时,也会尝试使用 Python、数据分析、以及 AI 大模型,对一些直觉判断进行复盘、辅助和检验。
这并不是一套"成功方法论"。更多时候,它可能是一份带着不确定性的思考记录:哪些想法在长期中站得住脚,哪些只是事后看起来合理。
如果你也经历过市场的起伏,或者正在尝试把理性工具引入投资决策,希望这些文字能对你有所帮助;如果没有,那它至少是我给自己留的一份阶段性注脚。
专栏会慢慢写,不追热点,也不保证结论。 唯一确定的,是我会用心。