2025-01-23 08:00:00
Immich 默认识别出来的照片位置都奇奇怪怪的,不仅仅是英文,还有一些不常见的名字,在照片分类搜索的时候非常麻烦。周末仔细研究了下 Immich 到底是怎么实现反向地理编码的,并想办法对其进行了汉化。
如果你到这里,是为了实现地名汉化的话,请直接前往 这个项目
为了能够实现汉化的目标,首先我们得先明白 Immich 是怎么在本地实现反向地理编码的。
以下以 v1.124.2 为例,Immich 的反向地理编码都实现在 reverseGeocode 这个函数中,传入的是一个 GeoPoint 对象,实际上就是经度和纬度。
之后,根据经纬度,进行了如下的 SQL 查询
1
2
3
4
5
6
7
8
9
10
11
SELECT *
FROM geodata_places
WHERE
earth_box(ll_to_earth_public(${point.latitude}, ${point.longitude}), 25000)
@> ll_to_earth_public(latitude, longitude)
ORDER BY
earth_distance(
ll_to_earth_public(${point.latitude}, ${point.longitude}),
ll_to_earth_public(latitude, longitude)
)
LIMIT 1;
这其中
earth_box 创建一个以给定点为中心的球体范围ll_to_earth_public 将地理坐标 (纬度和经度) 转换为三维球体上的点WHERE 子句筛选出 距离输入的目标点 25,000 米(25 公里)范围内 的地理点,ORDER BY 子句根据距离从近到远排序。换句话说,就是找到了 geodata_places 库中,距离输入点最近的地理点。
找到了最近的点之后,取出这个点的 { countryCode, name: city, admin1Name },也就是 国家码、名称、一级行政区名称。整理一下顺序,将国家码转换成国家名,这就对应了我们在 Immich 中看到的照片位置中的 国、省、市 三级。至于这个表是如何构建的,后面我们再单独分析。
这里名称和一级行政区名称都是直接从数据库表中得到的,而国家名是从国家码转换得到的,这里用到了 node-i18n-iso-countries 这个库的 getName 方法。但在 Immich 中,调用时的代码是 getName(countryCode, 'en'),将语言用 'en' 写死了,所以只能是英文,并没有加上任何 i18n 的机制。
而如果上面没有找到的话,就会再进行一次 SQL 查询
1
2
3
4
SELECT *
FROM naturalearth_countries
WHERE coordinates @> point(:longitude, :latitude)
LIMIT 1;
这段 SQL 就是在 naturalearth_countries 表中找到哪些记录的 coordinates 包含输入的坐标,也就是根据自然地球中国家的划分,确定坐标所在的国家。如果走到这一条,则不会再去确定更细粒度的省市两级划分。
简而言之,Immich 就是在数据库里事先准备好了大量地名,然后用照片的坐标去匹配数据库里最近的地名,之后就以该地名作为照片的地名。找不到的话,就退化到只用国家信息,根据国家的区划划分。
接下来的一个大问题就是,数据库里的数据是从哪来的。
Immich 所有的反向地理编码数据都来的 GeoNames,放在了 /build/geodata 文件夹下,每次发版都会从 这里 获取最新的数据。
文件夹中有这么几个文件:
id | name | name ascii | geoname id)id | name | name ascii | geoname id)Immich 导入的入口在 init 函数中,这里会首先查看 system-metadata 中 key 为 reverse-geocoding-state 的值,里面记录了 lastUpdate 的时间,也就是上次导入数据的时间。会将这个时间与 geodata-date.txt 文件中的时间进行比较,如果文件中时间较新则说明有更新的数据则开始导入,否则就跳过避免重复导入。
具体导入的逻辑在 importGeodata 中,其中抛开建立表的逻辑,核心在于 loadCities500 函数。
cities500.txt 中格式类似 csv,以 \t 作为分隔,通过如下规则转换成数据库中的内容
1
2
3
4
5
6
7
8
9
10
11
id: Number.parseInt(lineSplit[0]),
name: lineSplit[1],
alternateNames: lineSplit[3],
latitude: Number.parseFloat(lineSplit[4]),
longitude: Number.parseFloat(lineSplit[5]),
countryCode: lineSplit[8],
admin1Code: lineSplit[10],
admin2Code: lineSplit[11],
modificationDate: lineSplit[18],
admin1Name: admin1Map.get(`${lineSplit[8]}.${lineSplit[10]}`) ?? null,
admin2Name: admin2Map.get(`${lineSplit[8]}.${lineSplit[10]}.${lineSplit[11]}`) ?? null,
这其中 admin1Map 和 admin2Map 就是通过读取 admin1CodesASCII.txt 和 admin2Codes.txt 中 id 到 name 的映射关系得到的。
再结合前面提到的反向编码逻辑,就是根据 latitude 和 longitude 找到最近的点,然后拿到他的 countryCode、admin1Name 和 name,这一信息就作为了照片的地理位置信息。
没错,admin2Name 根本没用上,admin2Codes.txt 也没用
Immich 将照片的地理位置信息分为了 国、省、市 三级。再捋一遍文件的作用,也就是
作用搞清楚了,接下来汉化的思路就好搞了
这一步骤主要依赖 node-i18n-iso-countries 这个库,而 代码 中把转换的目标语言写死为了 en,那么没有办法改目标语言,就只能从这个库的数据入手。
这个库的数据来源也是通过静态文件的形式实现的,具体文件内容可以看 这里。en.json 就是转换成 'en' 时候的数据来源,那我们只需要将其改写成中文即可,而中文的信息就在 zh.json 里,替换掉即可,就像 这样。
最后,将修改后的文件替换掉 Immich 镜像中的原始文件就可以了。
省的名称都在 admin1CodesASCII.txt 文件中,好在 GeoNames 提供了 alternateNamesV2.zip 这一文件,包含了许多地点的不同语言的名称,借助这一信息可以直接进行翻译,替换掉原来的名称即可。代码实现在 这里。
cities500.txt 这个文件主要的目标就是翻译 name 字段,但观察这个文件后可以发现,它的粒度非常细,不仅仅到市一级,还可能是区或者县,还是很古老的名字,非常不适合使用。
为了解决这个问题,可以通过地图提供商的逆向地理编码 API 对这些地方进行重新识别,获得标准的一级、二级行政区划名称,这里分别实现了适用于 国内采用高德的版本 和 国外使用 LocationIQ 的版本。
另外,默认的 cities500.txt 文件由于数据量有限,部分地区数据点较少,就会导致 Immich 在反向地理编码的时候出错。而实际上,GeoNames 还提供了不同国家的完整地理点信息,比如 CN.zip,可以作为补充添加进 cities500.txt 以提升效果,实现在 这里。但考虑到数据量庞大,所以只默认增加了直辖市,有需要的再增加。
以上总结了 Immich 逆向地理编码的原理,以及分享了如何实现汉化的,代码都放在了这个 仓库 中,也有现成的东西可以用。
2024-01-24 08:00:00
在使用 Go 的泛型时,如果泛型类型存在 constraint,而传入的类型在实现这个 constraint 时使用的是 pointer receiver,那么就会遇到 XXX does not satisfy XXX (method XXX has pointer receiver) 的报错,就比如下面这个例子希望用 Create 函数完成所有创建 Person 的操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
type Person interface {
SetID(id int)
}
type Student struct {
ID int
}
func (p *Student) SetID(id int) {
p.ID = id
}
func Create[T Person](id int) *T {
var person T
person.SetID(id)
return &person
}
这里 Student 用 (p *Student) 实现了 Person,然而如果用 Create[Student](id) 这种方式调用时,编译会遇到这个报错
1
Student does not satisfy Person (method SetID has pointer receiver)
问题就在于这段代码中的 (p *Student)
1
2
3
func (p *Student) SetID(id int) {
p.ID = id
}
在 Go 中会认为是 *Student 实现了 SetID 方法,或者说实现了 Person interface,而不是 Student,因此提示 Student 并不满足 Person。
那一个办法是把实现 interface 传入的改成 value receiver
1
2
3
func (p Student) SetID(id int) { // 传入的 p 类型去掉了 *
p.ID = id
}
这样可以通过编译且正常运行,但问题是变成了值传递后,SetID 并不会作用于传入的那个变量,这个函数也形同虚设。
另一个解决方案是可以把调用函数时改成 Create[*Student](1),加上这个 *,报错也会随之消除。但问题就解决了吗?
再仔细看这个函数在传入类型后会变成什么样
1
2
3
4
5
6
7
// T -> *Student
func Create[T Person](id int) *T {
var person T // var person *Student
person.SetID(id)
return &person
}
这里暂且不论原本的返回类型 *T 会变成 **Student 的问题,这个很容易通过调整返回值类型解决。
核心问题在于第二行我们声明了一个 *Student 类型的指针,但实例化在哪?我们创建了一个空指针,所以在运行时会遇到 runtime error: invalid memory address or nil pointer dereference。同时由于语言限制,我们手上的 T* 并不能转成 T 然后让我们完成实例化。
那么能不能传入 T,然后转成指针再调用 interface 的方法呢?
1
2
3
4
5
func Create[T Person](id int) *T {
person := new(T)
person.SetID(id) // 报错
return &person
}
然而编译器又给了一个错误 person.SetID undefined (type *T is pointer to type parameter, not type parameter),这个问题在于 SetID 是定义给 Student 的,不是给 Student* 用的。
很遗憾,由于 Go 语言层面的缺陷,在仅使用 T 这一个参数时并不能完成我们想要的东西,如果有办法,请通过网页最下方的邮件告诉我,不甚感激。
问题在于用 T 编译器不认 constraint,用 T* 又拿不到 T 进行实例化,那么只能去掉 T 的限制,同时再传入带有限制的 T*。思路如此,具体实现来说需要定义这么一个 interface
1
2
3
4
type PersonPtr[T any] interface {
*T
Person
}
这个定义了一个指针 interface,第一行这里暂时先去掉了 constraint,允许传入任意类型 T,然后通过第二行使得这个 interface 允许的类型是且只能是 *T,让我们能从 T 拿到指针,再通过第三行去保证实现了 Person 这个 interface。
那我们就可以进一步修改函数,将传入的类型改为 PersonPtr
1
2
3
4
5
func Create[Ptr PersonPtr[T]](id int) *T {
var ptr Ptr = new(T)
ptr.SetID(id)
return ptr
}
但这仍然不够,编译器会提示 undefined: T,因为我们没有定义 T,所以必须在函数的泛型列表中加上 T,这个函数只能变为
1
2
3
4
5
func Create[T any, Ptr PersonPtr[T]](id int) *T {
var ptr Ptr = new(T)
ptr.SetID(id)
return ptr
}
调用时就变成了
1
stu := Create[Student, *Student](1)
这样调用真的很丑,但好在 Go 这回终于做了个人,通过类型的自动推导可以自动推导出第二个参数,所以调用时可以简化为
1
stu := Create[Student](1)
这样调用看起来就和谐了许多(虽然背后的实现需要用些难懂的 trick,但我们至少终于实现了 Go 中的泛型与 pointer receiver 的共存…
珍爱生命,远离 Go 的泛型!
2023-03-22 08:00:00
N5105 运行虚拟机会随机死机/重启的问题很常见,之前我采取过如下办法
只能说降低了死机概率,一般能撑到一天以上,所以我选择在半夜自动重启,勉强可以正常使用,但日常使用还是不可避免的会断网。
不过现在似乎有了一个终极解决方案,可以彻底解决 N5105 的死机问题,根据这个链接反馈,已经可以超过 10 天稳定运行,我目前也暂时未遇到死机问题。
UPDATE: 我已经几十天都没有死机过了
解决方案就是更新 microcode 至 0x24000024 版本。
1
2
3
4
5
6
# 安装 microcode
apt update
apt install intel-microcode
reboot
# 查看 microcode 版本
dmesg -T | grep microcode
重启完成后,microcode 应该就已经更新到不会死机的版本了,你应该可以看到 0x24000024 字样。
1
2
3
4
5
root@pve:~# dmesg -T | grep microcode
[Wed Mar 22 22:23:26 2023] microcode: microcode updated early to revision 0x24000024, date = 2022-09-02
[Wed Mar 22 22:23:26 2023] SRBDS: Vulnerable: No microcode
[Wed Mar 22 22:23:30 2023] microcode: sig=0x906c0, pf=0x1, revision=0x24000024
[Wed Mar 22 22:23:30 2023] microcode: Microcode Update Driver: v2.2.
或者 grep 'stepping\|model\|microcode' /proc/cpuinfo 查看 microcode 版本。
1
2
3
4
5
root@pve:~# grep 'stepping\|model\|microcode' /proc/cpuinfo
model : 156
model name : Intel(R) Celeron(R) N5105 @ 2.00GHz
stepping : 0
microcode : 0x24000024
但如果源版本比较老的话,更新的版本还是例如 0x24000023 的话,就请继续后续步骤
1
2
3
4
5
6
7
# 接下来继续更新
wget https://github.com/intel/Intel-Linux-Processor-Microcode-Data-Files/archive/main.zip
unzip main.zip -d MCU
cp -r /root/MCU/Intel-Linux-Processor-Microcode-Data-Files-main/intel-ucode/. /lib/firmware/intel-ucode/
update-initramfs -u
reboot
# 重启后应当可以更新至 0x24000024
2023-03-09 08:00:00
PVE 下通过 LXC 安装的 Ubuntu 启动 Docker 镜像时候提示
1
2
3
4
docker: Error response from daemon: AppArmor enabled on system but the docker-default profile could not be loaded:
running `/usr/sbin/apparmor_parser apparmor_parser -Kr /var/lib/docker/tmp/docker-default6944525`
failed with output: apparmor_parser: Unable to replace "docker-default".
Permission denied; attempted to load a profile while confined?
解决方式是在调整启动配置
PVE 设置中 选项-功能 中选中 嵌套
然后在宿主机中找到 /etc/pve/lxc/100.conf(注意把 100 替换成你的 LXC 容器 id),增加如下几句话,之后重启
1
2
3
lxc.apparmor.profile: unconfined
lxc.cgroup.devices.allow: a
lxc.cap.drop:
2021-11-17 08:00:00
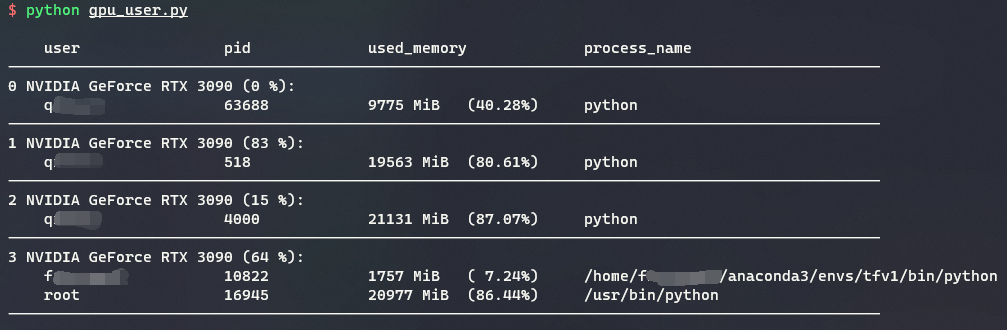
使用方法: python gpu.py
需要的依赖: xmltodict
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
import subprocess
import xmltodict, pwd, json
UID = 1
EUID = 2
def owner(pid):
"""Return username of UID of process pid"""
for ln in open("/proc/{}/status".format(pid)):
if ln.startswith("Uid:"):
uid = int(ln.split()[UID])
return pwd.getpwuid(uid).pw_name
def add_user(process):
tmp = []
for p in process:
p["user"] = owner(p["pid"])
tmp.append(p)
return tmp
def simplify(gpu):
tmp = {}
for k in gpu.keys():
if k in [
"@id",
"product_name",
"fan_speed",
"fb_memory_usage",
"utilization",
"temperature",
"processes",
]:
tmp[k] = gpu[k]
return tmp
def get_gpu_info():
sp = subprocess.Popen(
["nvidia-smi", "-q", "-x"],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
out_str = sp.communicate()
out_str = out_str[0].decode("utf-8")
o = xmltodict.parse(out_str)["nvidia_smi_log"]
o = json.loads(json.dumps(o))
gpu_list = []
if not isinstance(o["gpu"], list):
o["gpu"] = [o["gpu"]]
for gpu in o["gpu"]:
if gpu["processes"] is None:
gpu["processes"] = {}
gpu["processes"]["process_info"] = []
process = gpu["processes"]["process_info"]
if not isinstance(process, list):
process = [process]
process = add_user(process)
gpu["processes"]["process_info"] = process
gpu = simplify(gpu)
gpu_list.append(gpu)
o["gpu"] = gpu_list
return o
gpu = get_gpu_info()
print()
print(
" {: <13}\t{: <8}\t{: <20}\t{}".format(
"user", "pid", "used_memory", "process_name"
)
)
print(
"---------------------------------------------------------"
)
for i, g in enumerate(gpu["gpu"]):
print(
"{} {} ({}):".format(
i,
g["product_name"],
g["utilization"]["gpu_util"],
)
)
total = int(g["fb_memory_usage"]["total"].split(" ")[0])
for p in g["processes"]["process_info"]:
used = int(p["used_memory"].split(" ")[0])
print(
" {: <13}\t{: <8}\t{: <20}\t{}".format(
p["user"],
p["pid"],
"{: <10} ({:5.2f}%)".format(
p["used_memory"], 100 * used / total
),
p["process_name"],
)
)
print(
"---------------------------------------------------------"
)
print()
使用效果: