2026-06-23 04:51:12
A few years ago I built a tiny personal tool called Obweb. Its purpose was dead simple: open a browser, type a quick thought, and append it to my Obsidian notes.
Then one day the VPS was shutdown for some reasons, I need to redeploy it on another VPS and it involve some extra boring stuff, such as rebind a sub-domain and configing on VPS. I’m too lazy for this. Obweb slowly became unmaintained since it was developed in JavaScript when I tried to pick some frontend stuff, and I hate JavaScript, luckly, I don’t need to learn it since AI is good at frontend.
I tried going back to the official Obsidian Android app one year ago, but it still felt too heavy for the thing I wanted most: fast capture. It takes too long to open, slow to respond, and I remember Termux is needed for some automatic tasks. I just don’t like it. I am clearly not the only one who feels this way, because I still randomly get emails from people asking about Obweb.
Recently I read an article about self-hosting Bitwarden with Tailscale. That reminded me that Obweb was almost made for this style of deployment. It does not need to live on a VPS. It can just run on my local dev machine, reachable from my own devices, without a public-domain, a nginx or another server to babysit.
So I rewrote it, in the vibe coding way. The new app is called Obr.
Obr is very much a tool shaped around my own workflow. But I think that is also what makes it worth writing about: small personal tools are often where the most honest product decisions happen.
The basic idea is straightforward. Obr puts a lightweight Web interface in front of an Obsidian vault, with search, capture, and editing for the parts I use most often.
Its config points at a few vault-relative paths:
vault_path = "/path/to/obsidian/vault"
daily_dir = "Daily"
entry_dir = "Posts"
image_dir = "Pics"
todo_path = "Posts/todo.md"
annotation_dir = "annotations"
Daily notes go into Daily/YYYY-MM-DD.md, Images live under Pics/. RSS annotations are just Markdown files under annotations/. Obr does not try to invent a new storage model. It stays close to the vault.
The original reason for Obr was capture.
On my phone, I want to open a page, write a few lines, pick a path, optionally attach a link or image, and submit. The backend appends the content to the right Markdown file. A daily note goes into today’s file. A regular entry goes under the configured entry directory. A todo goes into the todo file. By the way, I have found Hermes is also good fit for this kind of thing with proper training.
Image uploading is the one part that needs a little more care. Uploading through Tailscale is not always fast, and mobile networks are not exactly famous for being polite. So Obr has offline drafts and a sync outbox. If a request fails, the note should not disappear. It should sit locally and retry quietly in the background.
That is the kind of feature that sounds boring until the first time it saves a paragraph you wrote on the subway.

I use Chrome’s “Add to Home screen” to put Obr on my phone as an app icon, and I allow it to keep running in the background. That alone makes the whole thing feel much closer to a small mobile app than a web page I occasionally visit.
Under the hood, Obr uses a service worker and a manifest. The shell of the app, along with its CSS and JavaScript, can be cached locally. If the phone is offline, the app can still open, and recently viewed or edited content can often be restored from local cache. Anything that needs to write to the vault goes into the sync outbox when the network is down, then retries after the connection comes back.
The UI also shows the real connection state. Obr pings the backend and updates the online/offline indicator based on actual requests. The tiny dot in the top-right corner is easy to ignore, but it answers the important question: did this reach my vault, or is it still waiting on this device.
Images lazy-load so one article with several large screenshots does not clog the whole connection pool. Reading pages have a progress bar. The RSS detail page hides the top bar while scrolling. None of these are big features by themselves, but together they make the app feel much calmer on a phone.
Obr can render Markdown as HTML, and it can also show the raw file content. But for mobile editing, I wanted something smaller than a full editor.
Most of the time, I do not want to edit an entire article from my phone. I want to fix one sentence, delete one block, or check off one todo item. So Obr supports block-level editing. The backend splits a Markdown file into blocks, and the frontend can save or delete a single block without putting the whole document into a giant textarea.
This matters more than it sounds. Long-form editing on a phone is fragile: the cursor jumps, the keyboard covers half the screen, and suddenly you are questioning your stupid choice on editing something on a phone. Block editing keeps the task small, I am not editing a document, I am editing this paragraph.
Obweb had an RSS reader years ago, and I always missed it. Obr brings it back in a more complete form.
When RSS is enabled, Obr reads feed subscriptions from a file in the vault:
rss_enabled = true
rss_feeds_path = "Zero/feeds.md"
rss_data_dir = "data/rss"
rss_refresh_minutes = 30
rss_fetch_full_content = true
RSS metadata and read state are stored in a local SQLite database. Article bodies are cached under data/rss/content/. If full-content fetching is enabled, Obr uses rs-trafilatura to extract the page body into Markdown. If extraction fails, it falls back to the feed content or summary.

The RSS detail page also supports annotations. When I find a paragraph worth keeping, I can write a note beside it, and Obr saves that note as Markdown under annotations/.
Once RSS was local, adding AI summaries felt like the obvious next step.
Obr can generate Chinese summaries for newly fetched non-Chinese articles. It supports DeepSeek-based summary translation, and it can also translate the full text.
rss_ai_summary_enabled = true
rss_ai_summary_chars = 200
deepseek_api_key = "sk-..."
deepseek_model = "deepseek-v4-flash"

Obr can read and write my Obsidian vault, so security comes first.
At the moment it supports:
Origin and Sec-Fetch-Site checks for cross-site write requests.Obr’s init --tailscale command starts a separate userspace tailscaled, stores its state in $HOME/.local/share/tailscale-obr, and exposes the local 127.0.0.1:8010 service through a stable *.ts.net HTTPS address.
Tailscale can make the app reachable only inside my private network, which feels much better than putting it directly on the public Internet. The downside is that I need the Tailscale client and VPN running on my phone, and that conflicts with the VPN I normally use daily. So I do not always run Obr this way. Tailscale handles the secure device-to-device tunnel; Obr still handles login and authorization. Passkeys are a good fit for that on mobile.
The backend is Rust + Axum. The frontend is plain HTML, CSS, and JavaScript, no 3rd party frontend library, no npm. I hate npm.
Right now the project has about 15 Rust files, around 14,000 lines under src/ including test files, and 7 frontend asset files.
Most of my Mac development still happens with codex/gpt5.5, but a lot of Obr was built with hermes.
The workflow is strange in a good way: I notice something annoying while using the app, send a voice message to Hermes, wait a few minutes, and then double check it after the AI agent restarts the service automatically.
That may be the most interesting part of the project for me. Obr was not designed in a big upfront pass. It was shaped while I was using it, one small irritation at a time.
2026-05-08 08:44:46
五一期间我看到 dhh 发的一个帖子推荐 GitHub TUI: ghui,我安装试了一下,发现还需要安装 bun,另外功能看起来也不太够用。
我也看过 gh-dash,这东西是 gh 的一个 extension,我试了一下同样感觉体验不好,于是手痒开始让 AI 帮我用 Rust 重新写一个。
最近在工作中也写过一个 Rust 的 TUI 工具,感觉 Rust 的生态已经很成熟了,写起来也很顺手。于是就有了 ghr 这个项目。
它的目标一开始很简单:我想少在 GitHub 网页里来回点。作为一个经常看 PR、review 代码、处理 notification 的人,我每天会重复很多小动作:打开 inbox,看谁 @ 了我,扫一眼 assigned PR,点进 diff,读评论,偶尔 checkout 到本地验证一下。
这些动作单独看都不复杂,但它们很碎。浏览器适合处理一次性的探索,不太适合让我连续地做几十个维护动作。于是 ghr 慢慢变成了一个终端里的 GitHub 工作台。如果你喜欢 lazygit,那么应该也会喜欢 ghr,因为 lazygit 主要是针对 Git 相关的操作,而 ghr 主要是围绕 GitHub 上协作的 TUI,比如看 issue、comments、review 代码,merge PR 等等。我甚至想命名为 lazyhub,这样组合起来就是 GitHub 😅。
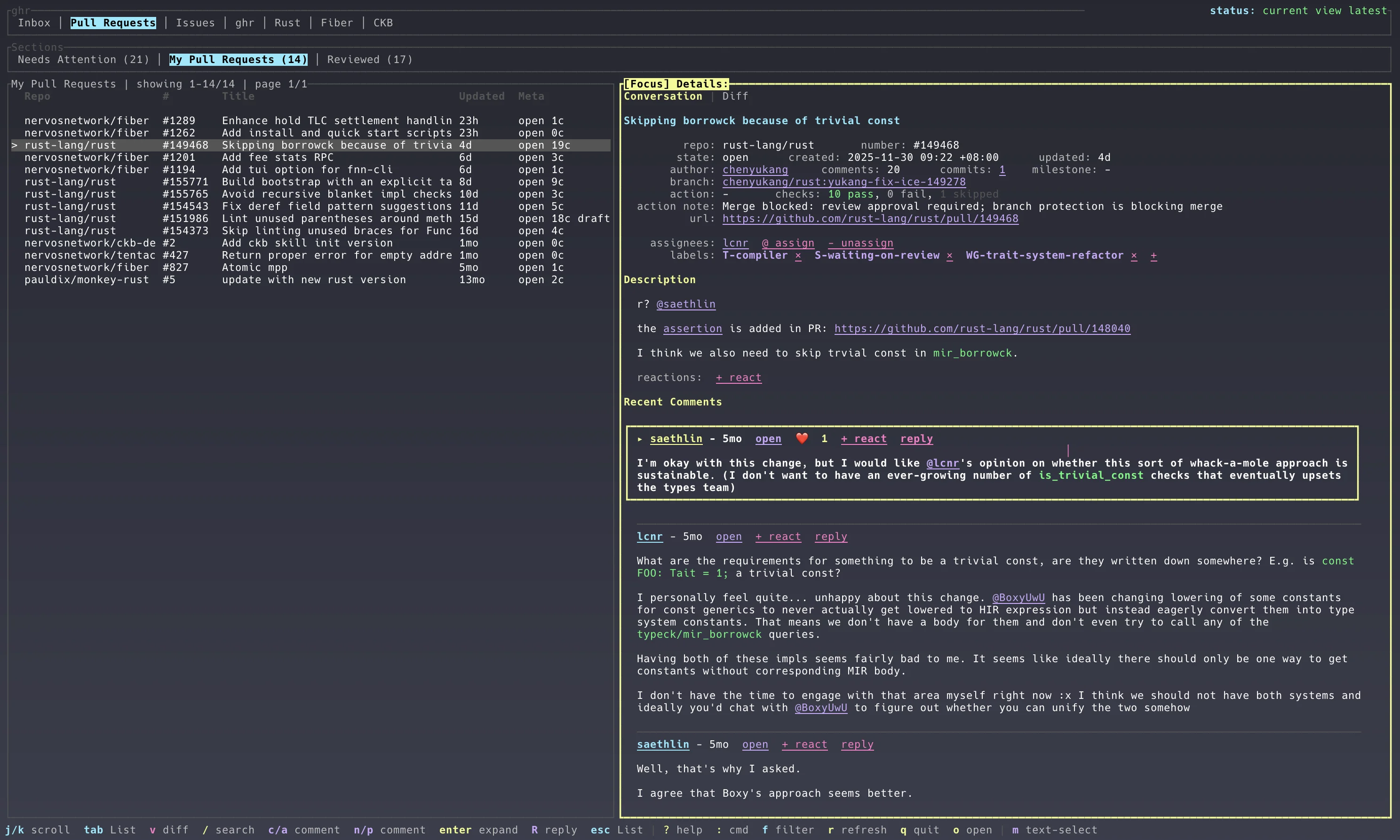
我最早在意的不是功能有多少,而是启动体验。
如果每次打开 TUI 都要等 GitHub API 慢慢返回,那这个工具很快就会被我自己弃用。终端工具有个很残酷的标准:它必须比打开网页更快,否则手会自动去点浏览器。
所以 ghr 现在是 snapshot-first。配置、数据库、日志和 UI 状态都放在 ~/.ghr 下面。启动时先把本地 SQLite 里的 snapshot 展示出来,然后再后台刷新当前列表。这样哪怕网络慢一点,至少我能先看到上次的现场。
这个设计听起来不酷,但它很实用,后来我又回看 ghui,发现他也改成了这个方案。
一开始它像一个 GitHub dashboard:Inbox、Pull Requests、Issues,几块列表摆出来。后面越写越发现,只看列表是不够的。
所以后面加了很多看起来很细的功能:
ghr 会自动把这个 project 加到顶层列表等等各种细节,这些功能单独拿出来都不像“大功能”,但组合起来以后,ghr 才开始有了工作流的味道。
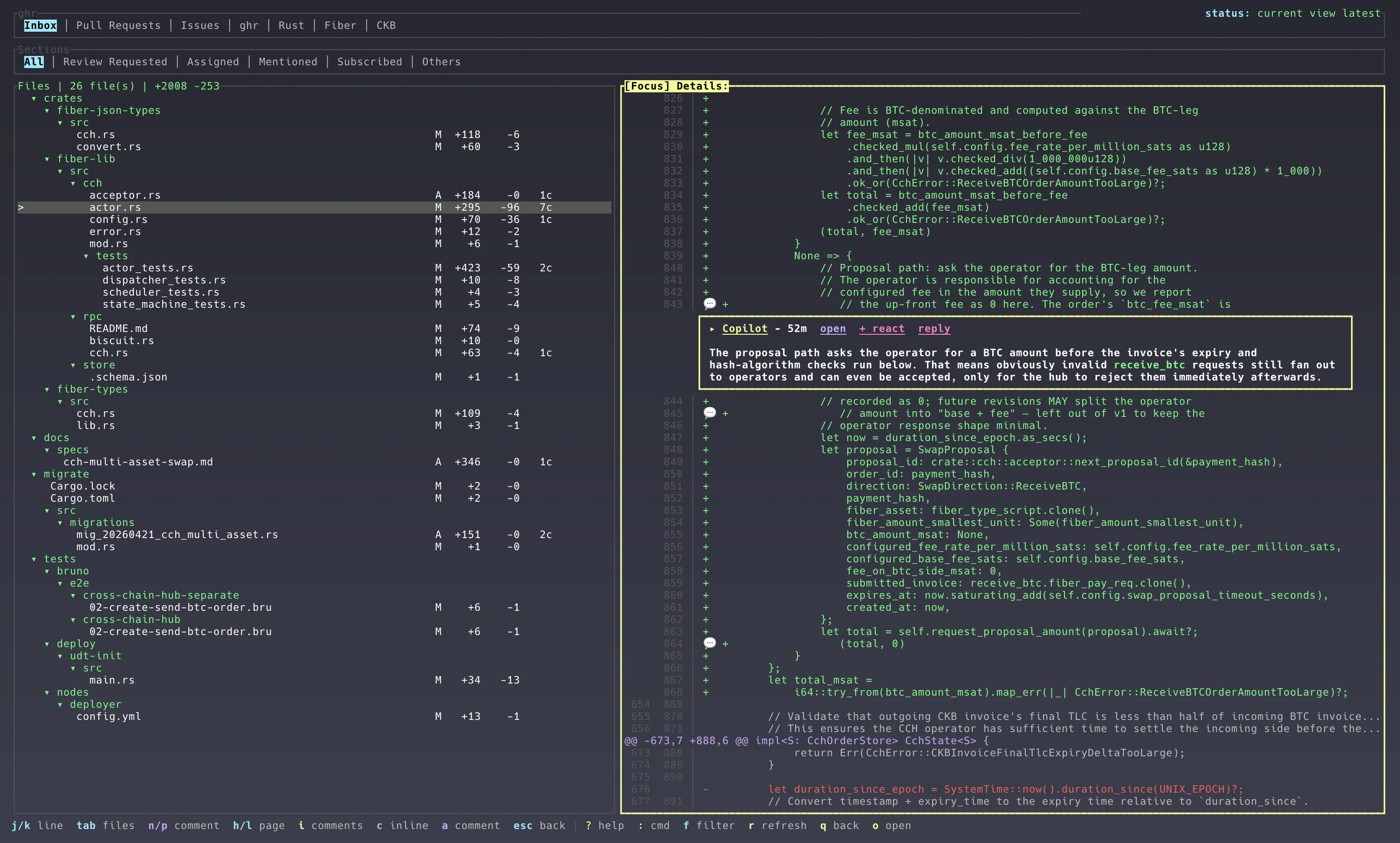
但我也发现 TUI 的局限,比如 diff 这个功能,即使我把细节都打磨好了,但我认为一个 PR 改动比较多的情况下最好的代码 review 体验还是在 VS Code 里,通过 Pull Request 插件直接 checkout 到本地,毕竟代码的 review 还是很依赖于编辑器的功能的(这个插件是我离不开 VS Code 的一个重要原因)。
ghr 这类工具放在以前,我大概率不会写到这个程度。细节太多,投入产出不划算。
TUI 里的鼠标选择、快捷键冲突、评论编辑框、draft 保存、列表分页、缓存失效、各种 GitHub API 的形状,每一个都不难,但都要花时间。AI 让这些小改动的成本降了很多,于是个人工具可以变得更“奢侈”:它不需要证明自己有市场,只要能持续改善我的日常工作流,就值得往前推一点。
欢迎试用,欢迎提 issue,也欢迎 PR:ghr。
2026-05-01 21:08:26
最近写了一个 Chrome 插件,叫 GitHeron。它想解决的问题很简单:
Web highlights and clippings, synced to GitHub as Markdown.
我一直使用 Hypothesis 来同步冲浪记录,然后使用一个 Obsidian 插件来同步到我的知识库。但 hypothesis 的浏览器插件体验不佳,时不时需要登录,选中文字打算做备注时又偶尔无法激活,我就想自己写个插件来解决这个问题。
GitHeron 的思路是直接使用 Github token 访问私有 repo,通过 API 把数据写入仓库。GitHub 当然不是传统意义上的数据库。但对个人工具来说,它已经提供了很多“数据库”才有的能力:同步、历史、权限、备份、API、跨设备访问。更重要的是,这些都完全是由自己控制的。
GitHeron 最核心的功能是网页标注。
在网页上选中一段文字,按下快捷键 (默认 Ctrl+E),就可以打开 note 编辑框。写完之后,这段文字会在页面上变成高亮。下次再打开同一个页面,GitHeron 会自动把之前的高亮恢复出来。
这件事听起来不复杂,但体验上很重要。很多阅读笔记工具只能把内容保存走,却不能在原网页上重新建立上下文。GitHeron 更在意的是“回到现场”:当你再次打开这篇文章时,能立刻看到自己上次为什么停在这里。
写 note 时也可以加 tags,最近使用过的 tags 会出现在输入框附近:

除了高亮,GitHeron 还可以保存当前网页的主要内容。
按下快捷键 (默认 Ctrl + O) 后,它会提取页面正文,转换成 Markdown,然后保存到仓库中的 Clippings 目录。这里保存的是 main content,不是整个网页 HTML,所以导航栏、广告、推荐列表这些内容会尽量被过滤掉。
网页剪藏部分使用 Defuddle 来提取 main content,再转换成 Markdown。它不能保证所有网页都完美,但比直接保存整个 DOM 更接近“我真正想留下来的文章内容”。
这个功能更接近 Obsidian Web Clipper:遇到一篇值得完整保存的文章,不需要复制粘贴,也不需要手工整理格式,直接让它进入自己的 Markdown 仓库。
在 Settings 填入一个 Github repo 地址,私有的或者公开的都行,然后去 Github token 页面生成一个 token 含有写入这个 repo 权限的 token,填入插件的配置里即可。
默认有两个快捷键:
Ctrl+E:给当前选中文字添加 note;Ctrl+O:保存当前网页正文。如果喜欢鼠标操作,也可以开启选中文字后的悬浮按钮;如果不喜欢它打扰阅读,可以在 settings 里关掉,只使用快捷键。
同步 GitHub 时也有两种模式。普通模式会等 GitHub 写入完成再结束;后台同步模式则会先更新页面状态,把任务放到后台慢慢同步。网络失败或 GitHub 返回错误时,可以在 settings 的 tasks 里看到最近任务,并进行 retry。
写 note 应该是一个很轻的动作,不应该因为网络慢而打断阅读节奏。

GitHeron 是一个 Chrome MV3 插件,主要由 content script 和 service worker 组成。
content script 负责页面里的交互:选区、高亮、快捷键、弹框和正文提取。为了避免被网页自身样式影响,弹框和面板都放在 Shadow DOM 里。
service worker 负责设置、后台任务和 GitHub API。写入仓库时使用 GitHub 的 Git Data API 来生成 commit,这样一次保存可以同时更新 Markdown 内容和用于恢复高亮的辅助数据。
这里有一个取舍:Markdown 文件应该尽量保持可读,不应该塞进大段元数据。所以 GitHeron 会把可读内容写进 .md,把用于定位高亮的 selector 信息放到旁边的 JSON 文件里。这样仓库里既有人能直接读的笔记,也有插件重新打开网页时需要的结构化数据。
GitHeron 是一个很个人化的工具,它的目标不是做一个复杂的标注系统,而是让“读到有用内容”到“进入自己的知识库”之间少一点摩擦。
对了,我最近还 Vibe coding 了另一个小插件 auto tabs,也是解决我日常的具体问题的。在 AI 时代,稍微有点编程经验的人都会把自己的工作流优化到极致。
2026-04-24 03:15:24
最近断断续续 Vibe Coding 写了一个小工具,叫 Runnel。因为我之前用的两个机场都跪了 (虽然后来又逐渐恢复了),于是萌生了自己写个工具来翻墙的想法,顺便把一些网络相关的东西重新摸一遍。
Runnel 有“小河流”的意思,我觉得还挺贴切:不是要做一个很宏大的网络基础设施,就是在本机和远端之间挖一条能用、能看、能调试的小通道。
先让 AI 快速撸了一个车 native-http 版本的,然后又加了多路复用的 native-mux 模式。后来又想到一个同事说他一直用自己写的代理工具叫做 daze,所以立马让 AI 用 Rust 重写了一份跑了起来。
于是它现在支持几种模式:native-http、native-mux、几个 daze 风格的模式,以及后来主要投入精力做的 wg 模式。
前面这些更像传统 SOCKS 代理,应用明确连到本地 SOCKS 端口,然后 Runnel 把流量转到远端。WG 模式不一样,它走 TUN 设备和 WireGuard 风格的 UDP 包,更像日常会用的全局 VPN。
真正让我把重心转到 WG 模式的原因也很普通:SOCKS 在浏览器里挺好用,但到系统级流量、命令行工具、各种后台服务时就没那么舒服了。macOS 下总会碰到有些软件不吃系统代理,有些软件自己做 DNS,有些东西干脆只看路由表。最后还是得上 TUN。
WG 模式底层用的是 Cloudflare 的 boringtun,目标很简单:
听起来像配置一遍 WireGuard 而已,但自己写以后就会发现,大部分时间并不在加密和解密上,而是在处理操作系统。
Linux 上需要 /dev/net/tun、ip、sysctl、iptables。macOS 上是 ifconfig、route、networksetup。命令不复杂,但出错方式很多。例如服务端没停干净,再起一次就会卡在:
ip address add 10.8.0.1 peer 10.8.0.2 dev runnel-wg0
因为设备还在,地址也还在。再比如 macOS 上如果之前的 tunnel 没清理干净,WG endpoint 的路由可能会被系统解析到某个 utun 上。这个时候 client 还没真正起来,但发往 server endpoint 的 UDP 包已经准备钻进旧 tunnel,最后当然连不上。
这类问题很烦,但它们也逼着我把启动阶段做得更啰嗦一点。现在 Runnel 会做 preflight,会打印 hook,会在 client 装路由之前先做一次短 handshake probe。key、endpoint 或两端配置有问题时,最好在启动阶段直接报错,而不是把系统路由改完,然后留给用户一个没有响应的黑盒。
我写这类工具最大的感受是:网络工具的“好用”,很多时候不是吞吐量高一点,而是坏的时候知道坏在哪里。
WG 的配置很容易写错,尤其是 private key、peer public key、tunnel IP 这种互相交叉的字段。手写一次就够让人烦了,所以后来加了:
runnel wg-config --server-endpoint SERVER-IP:1443 > runnel.yaml
这个命令会一次生成 client 和 server 两边配置。两台机器用同一个 YAML,只是启动时分别执行:
sudo runnel --config runnel.yaml server
sudo runnel --config runnel.yaml client --tui
它减少了很多“我复制错了吗”的问题,也方便把一些默认值放进去。比如现在生成配置默认带 adblock,默认启用 DNS capture,也会默认带上 noise engine 和 mask obfs:
client:
wg:
engine: noise
obfs: mask
obfs_padding_min: 8
obfs_padding_max: 96
obfs_handshake_padding: 256
obfs_response_padding: 192
这些东西不一定适合所有人,但它们很适合我自己的使用场景:默认配置应该尽量接近日常可用,而不是只给一个裸 tunnel。
我原来只想做 IP 规则,例如:
client:
ip_rules:
direct:
- "10.*"
- "192.168.*"
这个在 WG 模式下比较直观,direct 就是给这些 IP 加本地直连 route,不让它们进 tunnel。后来很快又想要域名规则:
client:
domain_rules:
direct:
- "*.baidu.com"
- "*.cn"
block:
- "*.xxx.com"
问题是 WG 看到的是 IP 包,不知道这个连接原本访问的是 github.com 还是别的什么域名。能抓到域名的地方只有 DNS。
所以现在 WG 的 domain rules 是 DNS 驱动的。client 会把本机 DNS 指到 127.0.0.1:53,Runnel 在本地做一个很小的 DNS forwarder。它看到查询 www.xxx.com,发现命中 direct 规则,就等上游 DNS 返回 IP,然后动态加一条 host route,让这个 IP 走本地网关。
这个方案很实用,但并不完美。第一次访问一个域名时,如果系统还没有拿到解析结果,它可能已经先走了 tunnel。DoH、DoT、浏览器缓存、直接访问 IP,也都绕过这条逻辑。CDN 共享 IP 还会带来另一个问题:你为了某个域名加的直连 route,可能影响另一个解析到同一 IP 的域名。
这些限制没法假装不存在,所以文档里也写清楚了。能解决 80% 的日常问题就很好,剩下 20% 要靠更底层的 packet inspection 或系统扩展,那又是另外一个坑。
后来我把 adblock-rust 集成进来了。原因很简单:既然 WG 模式已经有 DNS capture,那 block 域名就可以顺手做掉。
这里我比较在意优先级。最后定下来是:
domain_rules.block
用户手写规则永远应该赢过订阅规则。否则哪天 EasyPrivacy 把一个你需要的域名拦了,就会很难受。
性能上我一开始也有点担心。毕竟 tunnel 里每个包都可能很密集,如果每个请求、每个 packet 都去跑 adblock,那肯定不行。最后实现是 DNS 级别的:只有新的域名查询会进入规则匹配,订阅会缓存在本地,域名决策也有内存缓存。实际看下来,这个成本可以接受。
有次 TUI 里看到 p.data.cctv.com 被 block,我还专门去查了一下。它不是用户规则拦的,是订阅规则命中的。
Runnel 有一个 TUI,不是为了好看,主要是为了少开几个终端。
WG 模式刚开始出问题时,我经常要同时看:
这些信息散在 log、netstat、route、tcpdump 里会很痛苦。放到一个 TUI 里之后,很多问题一眼能看出方向。
比如看到 HANDSHAKE(REKEY_TIMEOUT) 连续刷,基本就是两边没有成功握手,先别怀疑浏览器。看到 www.qq.com pending,就知道 DNS query 被捕获了,但还没拿到可用于直连的 IP。
我给所有模式都加了一个 mode_perf benchmark。小请求跑 1000 次,大响应跑 8 个 1MiB 下载。非 WG 模式走 SOCKS path,WG 模式会真正拉起 child process,创建 TUN 设备,然后从 tunnel IP 发 HTTP 请求。
本机测试的结果挺有意思:
native-mux 小请求大约 3300 req/s
daze-czar 小请求大约 3400 req/s
wg 小请求大约 2500 req/s
但大响应吞吐 WG 看起来很低,只有几十 MiB/s。刚看到这个数字我也有点怀疑,毕竟实际用起来 WG 并不觉得卡。后来想想也正常:这个 benchmark 是 localhost 上的端到端测试,WG 走真实 TUN 设备,会经过内核路由、用户态加解密、UDP socket、NAT 这些路径;而很多 SOCKS 模式本质上就是本机 TCP 流转发,少了不少系统边界。
日常使用的“流畅”也不完全由大文件吞吐决定。连接建立、DNS、浏览器并发、小请求延迟,这些东西更容易影响体感。WG 在小请求上的数据并不差,而且系统级接管以后,很多应用不用再单独配置代理,反而省心。
所以 benchmark 还是要有,但不能只看一个数。尤其是代理/VPN 这种东西,不同 workload 差别太大。
标准的 WireGuard 长度非常固定,所以基本上会容易检测出来。我在最初使用单纯的 WG 用一段时间开始丢包,于是我开始琢磨如何加噪音来抗审查。
于是给 WG mode 加了 noise engine。默认的 device engine 是让 boringtun 自己管理 WireGuard 设备和 UAPI socket,比较标准。noise engine 则是 Runnel 自己跑 TUN/UDP loop,直接用 boringtun::noise::Tunn 做加解密。
这样做的好处是 transport 变得更可控。比如可以在 WireGuard UDP 包外面包一层 mask,把包头和长度藏一下,再加一些 padding。现在的 obfs: mask 做的就是这个方向。
我不想把它说成什么“抗审查神器”,但从我平稳使用的一周结果看这样的混淆对于个人使用已经足够。现实网络环境要麻烦得多,包长、时序、UDP 行为、重传模式,都可能暴露特征。
我也看了一些类似工具的方向,比如 AmneziaVPN、Nym 把 QUIC 和 WG 组合起来的思路,Runnel 现在还只是很早期的版本,但 noise engine 让后面继续试 QUIC、padding profile、甚至更麻烦的 packet shaping 都方便了一些。
Runnel 还没有到我觉得很完整的阶段,还有些细节可以继续打磨,比如 IPv6 和双栈还需要更好的 schema,macOS 上更细粒度的 app split tunneling 也不是简单路由表能解决的。
但目前这个状态我已经挺满意了,它不是一个周末玩具了,至少已经变成了我自己会认真拿来使用、测试、折腾网络问题的工具。
这大概就是个人项目最舒服的地方:先让自己用得爽一点,遇到问题再修复。我的日常使用场景是 macOS(client) + Linux(server),其他路径目前只是在单元测试中有覆盖,也许其他实际场景会碰到一些配置问题,欢迎 PR。
2026-02-13 00:55:52
今天跑 Rust 编译器测试的时候又发现非常地慢,CPU 资源根本无法利用起来,我记得几年前碰到过这个问题,当时我写了篇文章分享出来,并发现很多人都有同样的困扰。
而我今天碰到的这个问题虽然现象一样,但解决方法又不同了。我不确定是 macOS 系统更新,亦或是我更新了 VS Code 造成的。
复现脚本很简单,循环创建随机命名的 shell 脚本,然后对比首次和再次执行的耗时:
#!/bin/bash
rm -rf /tmp/speed_test
mkdir -p /tmp/speed_test
for i in {1..10}; do
FILENAME=$(openssl rand -hex 10)
echo $'#!/bin/sh\necho Hello' > "/tmp/speed_test/$FILENAME.sh"
chmod a+x "/tmp/speed_test/$FILENAME.sh"
FILE="/tmp/speed_test/$FILENAME.sh"
first=$(TIMEFORMAT="%R"; (time $FILE > /dev/null) 2>&1)
second=$(TIMEFORMAT="%R"; (time $FILE > /dev/null) 2>&1)
echo "第一次: $first 第二次: $second"
done
在 VS Code 终端的输出:
第一次: 0.525 第二次: 0.007
第一次: 0.290 第二次: 0.009
第一次: 0.280 第二次: 0.007
第一次: 0.272 第二次: 0.008
第一次: 0.307 第二次: 0.008
...
差距大概 30-50 倍。换到 Warp 终端跑同一个脚本,两次都在 0.006s 左右。
应该不是我上篇文章提到的 SIP 问题,我确定 System Settings → Privacy & Security → Developer Tools 中已经加入了 VS Code。
看起来也不像是文件系统缓存的原因,因为 0.2-0.5 秒远超磁盘缓存的量级。用 log show 看了下系统日志:
log show --predicate 'subsystem == "com.apple.syspolicy.exec"' --last 2m --style compact
输出大量这样的记录:
GK performScan: PST: (path: 8d0e4c2de41c3e77), (team: (null)), (id: (null)), (bundle_id: (null))
Error Domain=NSOSStatusErrorDomain Code=-67062
GK evaluateScanResult: 2, PST: (path: 8d0e4c2de41c3e77), ... (bundle_id: NOT_A_BUNDLE), 0, 0, 1, 0, 7, 7, 0
从日志上看每次执行新文件 syspolicyd 都会做一次 GK performScan。这就是 macOS 的 Gatekeeper 安全扫描——对首次执行的新可执行文件做代码签名验证和恶意软件检查。扫描结果会被缓存,所以同一个文件第二次执行就快了。
进一步验证:我们把测试脚本里改成 (time /bin/sh $FILE > /dev/null) 2>&1,这样就是直接通过 sh 来执行:
直接执行 ./script.sh → 0.248s (触发 execve → Gatekeeper 扫描)
/bin/sh ./script.sh → 0.006s (只是让 /bin/sh 读取文件,不触发安全扫描)
原因确认了。当用 ./script.sh 执行时,内核的 execve 系统调用会触发 AppleSystemPolicy.kext 中的 MACF hook (mpo_proc_notify_exec_complete),通知 syspolicyd 进行评估。而 /bin/sh script.sh 只是让已受信的 /bin/sh 进程读取文件内容来解释执行,不触发 execve 的安全检查路径。
接着试了 System Settings → Privacy & Security → Full Disk Access,给 VS Code 完全磁盘访问权限。重启 VS Code,再跑脚本:
第一次: 0.005 第二次: 0.005
第一次: 0.005 第二次: 0.005
第一次: 0.006 第二次: 0.006
...
问题消失了。syspolicyd 日志中的 performScan 也不再出现。
Full Disk Access (FDA) 在 macOS 的 TCC (Transparency, Consent, and Control) 框架中对应的是 kTCCServiceSystemPolicyAllFiles 权限。这个权限的含义远超“磁盘访问“——它实际上是 TCC 框架中最高级别的信任授权。
macOS 会追踪每个进程的 responsible process(负责进程)。在 VS Code 终端中敲的命令,它的 responsible process 是 VS Code 本身。当 AppleSystemPolicy.kext 的 MACF hook 拦截到 execve 后,会检查 responsible process 的信任级别。拥有 FDA 授权的进程被识别为高信任来源,syspolicyd 会走快速路径,跳过完整的 Gatekeeper 扫描。
而 Warp 这些原生终端,因为我已经加入系统默认信任的开发工具列表,所以它们派生的子进程一开始就不会触发完整扫描。
需要说明:Apple 没有公开文档化这个具体流程。上面的描述来自实验推断和社区逆向分析,不是官方说法。
发现 FDA 有效之后,我尝试反向验证:把 VS Code 从 FDA 列表中移除,重启 VS Code,再跑脚本。
结果:仍然很快。问题没有复现。
syspolicyd 的扫描评估结果存储在 /var/db/SystemPolicyConfiguration/ExecPolicy 这个 SQLite 数据库中(35MB),同时 AppleSystemPolicy.kext 在内核中维护了一个运行时缓存:
$ sysctl security.mac.asp.stats.cache_entry_count
security.mac.asp.stats.cache_entry_count: 4700
也就是说,当 VS Code 拥有 FDA 时,它被评估为可信 responsible process,这个信任结果被持久化了。移除 FDA 后,历史记录并不会被清除。macOS 的安全评估系统是“学习型“的——它记住过去的信任决策。
要彻底重现原来的问题,可能需要重启 Mac 清除内核缓存,或者更极端地清理 ExecPolicy 数据库。
如果你也遇到类似的问题——新编译的程序、新创建的脚本首次执行莫名其妙地慢,可以检查一下是不是 Gatekeeper 的锅:
# 查看最近的 syspolicyd 扫描记录
log show --predicate 'subsystem == "com.apple.syspolicy.exec"' --last 5m --style compact | grep performScan
解决方案按排序:
2026-01-31 07:00:00
月底升级了 Copilot Pro+,月初额度重置,这几天可以放开用,想到什么就 vibe 一把。
我的博客跑在 Hexo 上很多年了。其实没什么大问题,就是每次看到那几百 MB 的 node_modules,心里总有点膈应——生成几百个静态 HTML,真的需要这么多依赖吗?但迁移到别的博客系统又懒得折腾,所以一直拖着。
这次干脆试试:能不能用 AI 一个下午撸一个 Rust 版的 Hexo?我的目标比较简单:生成跟原来一样的静态文件,兼容我现在用的主题就行。
我用的是 OpenCode + Opus 4.5。陆陆续续聊了一下午,产出了 hexo-rs。能用,但还有些边边角角的问题。
Vibe Coding 的工具和体会以后再写,这篇主要聊 hexo-rs 的实现和踩过的坑。
Hexo 主题基本都用 EJS 模板——就是把 JavaScript 嵌到 HTML 里,跟 PHP 差不多。
用 QuickJS 跑 JS,通过 quick-js crate 调用。好处是不用依赖 Node.js,坏处是 Windows 上编不过(libquickjs-sys 挂了),所以暂时只支持 Linux 和 macOS。
Markdown 用 pulldown-cmark,代码高亮用 syntect,本地服务器用 axum。都是常规选择,没什么特别的。
这个 bug 藏得很深。生成 tag 和 category 页面时,一开始用 HashMap 存文章分组:
let mut tags: HashMap<String, Vec<&Post>> = HashMap::new();
HashMap 迭代顺序不确定,每次生成的 HTML 可能不一样。页面看着没问题,但 diff 一下就发现乱了。改成 BTreeMap 就好了:
let mut tags: BTreeMap<String, Vec<&Post>> = BTreeMap::new();
Hexo 有一堆 helper 函数:url_for、css、js、date 之类的。都得在 Rust 里实现一遍,然后塞进 QuickJS。
最烦的是 date。Hexo 用 Moment.js 的格式(YYYY-MM-DD),Rust 的 chrono 用 strftime(%Y-%m-%d)。得写个转换函数,挺无聊的活。
EJS 的 partial 可以套娃,A 引用 B,B 又引用 C,变量还得一层层传下去。搞了个作用域栈,进 partial 压栈,出来弹栈。不难,但容易写错。
代码 100% 是 AI 写的。我干的事:描述需求、review 代码、把报错贴给它让它改、偶尔拍板选方案。
像 EJS 模板引擎这种东西,自己从头写估计得半天,AI 几分钟就吐出来了。
但 AI 也挺蠢的:
但 AI 又确实非常强,我想到应该使用现在线上的 catcoding.me 来和新生成的内容一一对比,然后它就呼啦啦地一通操作把问题都找出来了,自己修改完。
cargo binstall hexo-rs # 或 cargo install hexo-rs
hexo-rs generate # 生成静态文件
hexo-rs server # 本地预览
hexo-rs clean # 清理
hexo-rs new "标题"
不支持 Hexo 插件,不支持 Stylus 编译(.styl 文件得先用 Node 编译好),Windows 也不行。
简单的博客应该够用。复杂主题可能会有兼容问题。
代码在这:github.com/chenyukang/hexo-rs
用 Hexo 的可以试试。有问题提 issue,我让 AI 来修 :)
这篇文章到底是人写的,还是 AI 写的?
Update 2026-02-13: 鉴于使用 quickjs 对于我来说还是太重了,我后续又做了一些改动,把 ejs template 换成了 tare template,这样就把 vexo 模板直接放在了 Rust 项目里,所以目前 hexo-rs 就是这个博客的 generator 了。