2020-06-27 09:36:00
最近因为新冠病毒长期宅在家里,决定开始一个很早就想做的项目:搭一个服务器机架。第一次搭经验不足,买错过几次零件,只能重新下单,前前后后花了不少时间。于是写了这篇博客介绍下用到的设备和配件,给有兴趣自己搭一个的朋友做参考。

我选择的机架是 Raising 的 15U 机架。这个机架优点是够结实,深度可变,价格也比 StarTech 的便宜一点。如果预算足够可以考虑买 StarTech 的机架(12U, 25U)。这里 U 是用来衡量机架中组件高度的单位,1U 约等于 43.66 毫米。机架上每个 U 的高度都会对应的三个孔,如下图所示。

因为我有不少没法直接固定在机架上的设备,得把它们放在隔板上。我一共买了四块隔板:
此外出于美观考虑还可以买挡板,StarTech 的 1U 挡板就挺好。
配线架(Patch Panel)可以让前面板的网线看起来干净清爽。它的背面连接各种设备的背部网线口,正面用短网线连接路由器和其他网线口在正面的设备。网上大多数的配线架都是一面连 CAT 5/6 网线,另一面是打线柱,很少有两面都是网线口的配线架。于是我买了两条 TRENDnet 1U 24 口空白网络配线架,加上 48 个两端都是网线口的 Keystone。这个 Keystone 从用户评论来看,以太网供电(PoE)和网速都不会受到影响。
过长的网线用在前面板也不好看,我先试了 1ft (30cm) 的 Monoprice 网线,装上以后还是觉得网线太长。后来换成了 0.5ft (15cm) 的 网线,看起来干净好多。
设备选择方面,我只是把原有的监控设备和服务器搬了过来,放在了层板上。犹豫过要不要买一个机架式服务器,但是考虑到机架式服务器的耗电量,加上已经有了视频监控机和独立 NAS,最后还是买了个翻新的 HP EliteDesk i7-4785T 用来跑智能家居服务和 Unifi Controller。除了 HP 以外,Dell 和 Lenovo 都有类似的微主机,买一个二手的很适合当智能家居服务器。另外推荐使用 Intel T 系列的 CPU,专门为了省电设计。
机架上的一些其他设备:
具体的智能家居和监控的使用这篇文章就不细谈了,对它们感兴趣的朋友,可以参考我的另外两篇博文:
2019-07-22 11:54:27
家里用的是三星的洗衣机和烘干机,买的时候为了完成时有提醒特地挑了带有「智能监控」功能的机型。然而对应的三星洗衣机的 app 几乎没法用,推送和状态更新都有问题。于是我打算自己实现一个类似的功能。
因为洗衣机和烘干机用电量比较大,通过监控用电量很容易判断出设备当前的运行状态,于是我决定用智能插座来实现这个功能。现在很多智能插座都有电量检测的功能,选择的时候要注意插座支持的最大电量,我用了 TP-Link 的 HS110,支持最多 1500 瓦的设备,对于一般的洗衣机和烘干机来说绰绰有余。和智能插座对接的系统依然是 Home Assistant,它对 HS110 的支持很好,可以方便地读出设备当前用电量。
接下来是 Home Assistant 的配置部分,主要分状态定义和自动化脚本。
为了简化我只用两种状态(空闲和运转)描述洗衣机和烘干机的状态(代码只给出了洗衣机部分,烘干机部分几乎一样):
input_select:
washer_status:
name: Washer Status
options:
- Idle
- Running
initial: Idle
为什么要定义状态而不是直接通过用电量判断呢?因为这些机器运转过程里会有几次几乎不用电的阶段,如果只通过用电量很容易产生错误信号,用电量配合状态持续时间才能做出更精准的判断。
接下来定义虚拟的洗衣机传感器,我们会通过自动化脚本更新这个传感器的值:
sensor:
- platform: template
sensors:
washer_status:
value_template: '{{ states.input_select.washer_status.state}}'
friendly_name: 'Washer Status'
自动化脚本分两块,一块是检测到电量后的更新洗衣机状态为运转。这里我用了 10 瓦作为运转开始的阈值。
automation:
- alias: Set washer active when power detected
trigger:
- platform: numeric_state
entity_id: switch.hs110_washer
value_template: '{{ state.attributes.current_power_w }}'
above: 10
condition:
condition: or
conditions:
- condition: state
entity_id: sensor.washer_status
state: Idle
action:
- service: input_select.select_option
data:
entity_id: input_select.washer_status
option: Running
另一块是设备停止运转的检测,根据不同的设备可能要进行微调。我这里设置了洗衣机用电低于 3 瓦且超过 1 分钟以上后,把状态切换成空置并通过 Twilio 发送短信通知。
automation:
- alias: Set washer inactive
trigger:
- platform: numeric_state
entity_id: switch.hs110_washer
value_template: '{{ state.attributes.current_power_w }}'
below: 3
for:
minutes: 1
condition:
condition: or
conditions:
- condition: state
entity_id: sensor.washer_status
state: Running
action:
- service: input_select.select_option
data:
entity_id: input_select.washer_status
option: Idle
- service: notify.twilio_sms
data:
message: Washer finished at {{ now() }}
target:
- 15555555555
这个脚本用了一个多月没出现误报,虽然一开始折腾一点,最后还是省了我们不少时间。
关于智能家居和 Home Assistant 的更多信息,可以参考我写的其他文章。
2019-03-30 07:03:45
随着无人驾驶的兴起,激光雷达数据的目标检测成为了这几年的研究热点之一。常见的 3D 检测模型可以分成两类,一类是用 3D 小方格代表所有的激光点数据,每个小方格包含了这个方格内的特征,例如 VoxelNet 和 Vote3deep 。另一类则是先把三维信息投射到一个二维平面,通常是鸟瞰图 (BEV, Bird Eye View) 或是正视图 (Range View),生成二维特征图后再用传统的二维目标模型检测图中的物体,例如 MV3D 和 FaF。
无人驾驶场景中的大多数的目标物体都处在同一地面上,非常适合 BEV。相比正视图,BEV 中的目标在不同位置大小固定,我们可以用已知的常见物体大小优化检测效果。对于 BEV 模型来说,主要的问题在于如何选择最终图像的特征,如何生成的图像中做出精确的检测。此文旨在介绍 BEV 检测相关的模型 Pixor 和 HDNet。
Pixor 是 Uber ATG 的 Bin Yang 等人在 CVPR 18 上提出的 BEV 检测模型。在特征生成方面,Pixor 把整个点云切成了 L x W x H 个小方格,每个小方格用 0 或 1 表示这个方格内是否有激光点存在,接着沿高度方向把三维特征压缩到一个二维平面,每个压缩后的二维方格就有了 H 个特征表示这个方格上的不同高度是否有点存在。此外 Pixor 还计算了落在每个方格中激光点的平均强度作为额外的特征,最终拿到了一个分辨率为 L x W、包含 H + 1 个特征通道的图像。
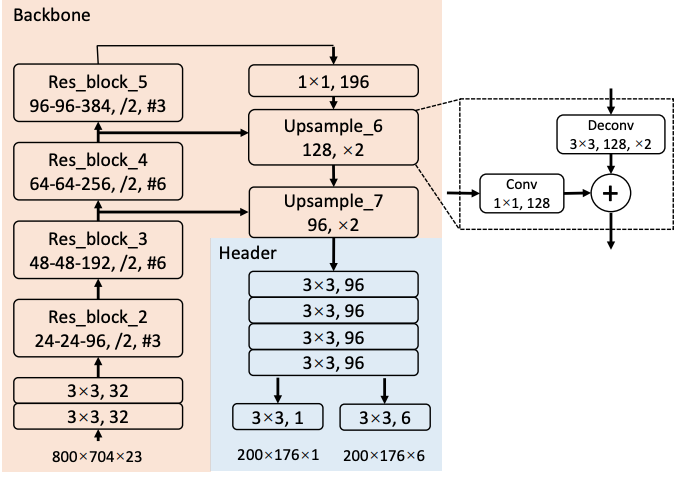
检测方面,Pixor 采用了基于 RetinaNet 的 one-stage 的结构,如上图所示(这里用了海报上的截图,和论文中的有一些细小的差别)。网络里面用了 ResNet 和类似 FPN 的结构。FPN 结构输出的特征图经过一个头部网络后,直接生成对每个像素点的分类和 bounding box 的回归结果。
优化目标方面,分类目标用了 RetinaNet 中的 focal loss,回归目标用了 smoooth L1。论文中回归目标有笔误,按照海报和 FAQ 的说法应该是 \(\{ \cos 2\theta, \sin 2\theta, dx, dy, \log W, \log L \}\)。这里巧妙的用了 \(2 \theta\) 的三角函数作为车头朝向的回归目标,因为车辆是往前还是往后开这个问题会在 tracker 中处理,在检测的时候只要知道车身线的偏离角度就行了,至于这个角度是 5° 还是 185° 影响不大。
整个网络的运行速度非常快,在 Titan XP 上可以在 35 毫秒内完成。除此之外论文还测试了不同 backbone 网络和头部网络特征层共享的不同选择,做了模型简化测试 (ablation study),感兴趣的朋友可以细读。
Pixor 沿高度方向把整个点云切成不同的高度区间,例如 Kitti 数据集上 -2.5 到 1 米之间的点会被分成 35 片,这个区间之外的点会被忽略。当地面坡度较大时,远处的点很容易被排除在外。为了解决这个问题,Bin Yang 等人提出了把高精地图作为额外特征的方案,发表在 CoRL 18 上。

如图所示,HDNet 的核心思路在于引入了高精地图信息,从而可以把地面「摊平」(图 b),并提供道路语义信息帮助检测(图 d)。网络结构和 Pixor 非常相似,采用了 FPN,并把 Pixor 中的反卷积层换成了更高效的双线性插值层。
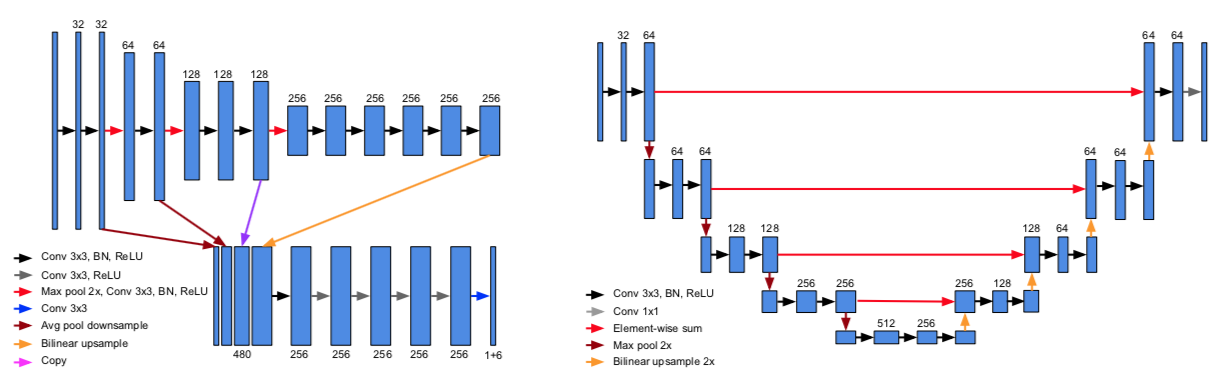
为了提高模型的稳定性,确保在缺失地图信息或者地图不准确的情况下仍然有较好的检测结果,作者会在训练模型时随机去除地图信息,并提出了通过 Lidar 扫描结果在线生成地图的方案。
本文介绍了两篇近期的基于纯激光雷达数据的 BEV 检测论文。基于纯激光雷达的模型非常适合车辆的检测,但对于行人检测的精度并不理想,往往需要借助图像提供额外的信息。在接下来的博客中我会和大家一起分享更多的相关研究,同时也欢迎各位提出不同的意见。
最后做一个小广告,我目前在 Ike 做无人卡车视觉的相关工作。我们公司在旧金山,最近拿到了 5200 万 A 轮融资,正在招人中。如果你对无人卡车感兴趣,欢迎联系我。
2018-10-31 12:35:07
来美国五年后绿卡终于批了,没有太大曲折,不过也干等了好久,中间还找了议员催绿。总结下流程,希望给后来的朋友有帮助。
整个过程中 EB-3 的 I-140 拖了好久,因为律师说加急需要 9089 原件,而我的原件已经在第一份 I-140 申请中提交了,没法再次加急。另外比较后悔的一件事就是绿卡面试前没有再去准备一份体检卡。面试通知上写着体检要求「valid within last year」,我以为只要是前一年办过体检就行,律师也建议面试完了再看要不要补办。等重新做体检提交,第二个月正好排期倒退了。
另外一个经验就是即使绿卡面试完了,也得催律师重新申请 EAD / AP。我的律师觉得绿卡马上拿到了就没急着帮我重新申 AP,导致我在绿卡迟迟没下来加上 Visa 过期的情况下,年底出游计划受限不少,如果有一张 AP 就可以放心安排出国计划了。
催绿方面,我们研究过参议员和众议员两个方案。两者效果应该差不多,都是通过官方问一下进度,以免你的 case 堆积在某个角落没人管。我们只联系了众议员,具体的流程如下:
整个过程没等多久,而且工作人员态度很好,之后发邮件问都是一刻钟内会有回复。
拿到绿卡后似乎还要去更新下 SSN,去掉上面的工作限制。另外就是可以办 Global Entry 啦。
祝愿等绿卡的各位早日顺利拿到绿卡。
2018-08-07 15:56:13
最后一周讲定位 (localization),也就是 SLAM 里面的 L。主要包括粒子滤波和迭代最近点。
里程计定位法直接从设备里读取信息,更新当前的位置状态。例如要跟踪车子的位置状态,可以在车轮上安装计数器记录车轮转动的次数,从而了解车子前进了多少。对于转弯的情况,可以从内外轮子的计数差得到转弯的角度。假设内轮转了 \(e_i\) 圈,外轮转了 \(e_o\) 圈,内轮半径 \(r_i\),外轮半径 \(r_o\),则有 \[ e_i = \theta r_i \\ e_o = \theta r_o \] 这里 \(\theta\) 就是车子转动的角度,上面的方程可以解得 \[ \theta = \frac{e_o - e_i}{r_o - r_i} \] 然后就能根据转动角度更新车辆当前的位置了。
这种方法用车辆本身的坐标系统记录位置,虽然实现起来简单但是测量精度非常局限于测量误差。例如上例中轮子打滑或事漂移都会导致结果不准确。更成熟的方案需要结合地图信息。
可以用下面三张图来来介绍地图定位问题,左图是当前的区域地图,中间是激光测距传感器得到的结果,地图定位的目的就是根据传感器返回的结果判断机器人当前坐标和朝向,右图就是一个理想的结果。
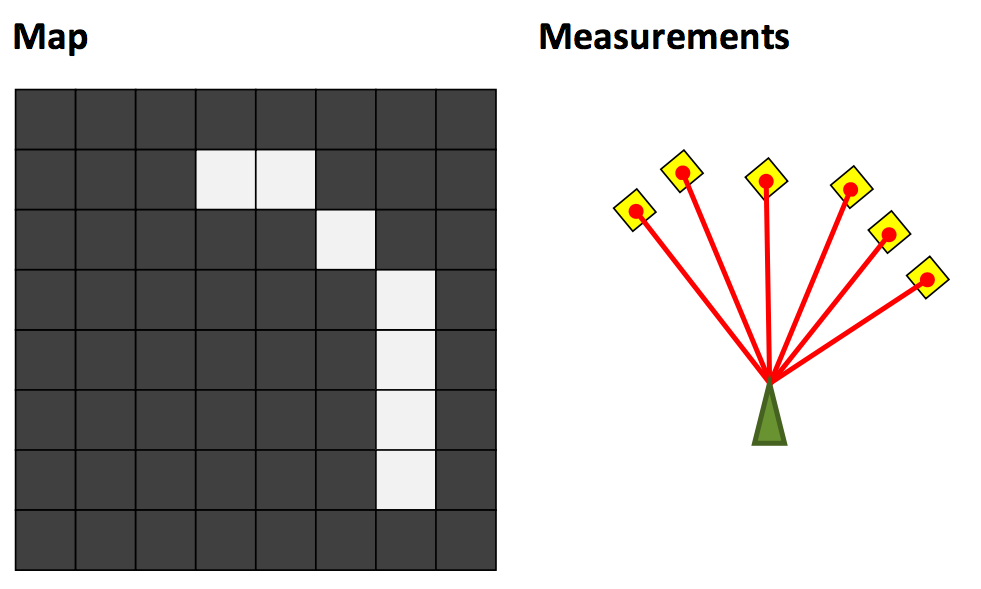
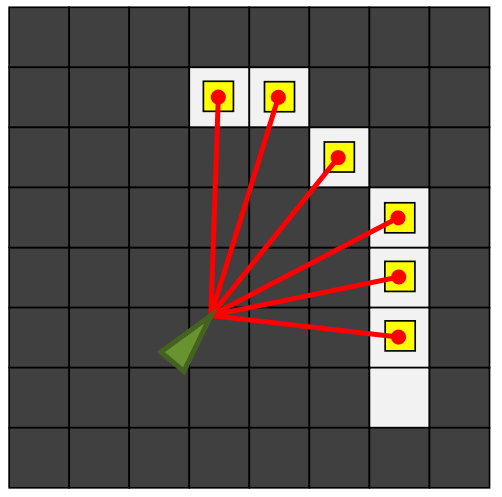
配合第三周讲的占据栅格地图障碍物的概率 \(m(x, y)\),我们可以定义最佳定位结果应该满足 \[ \max_p \sum_r \delta(p_x + r\cos(p_{\theta} + r_{\theta}), p_y + r\sin(p_{\theta} + r_{\theta})) \cdot{m(x,y)} \] 接下来介绍两种解决地图定位的方法。
粒子滤波(有没有觉得这个术语的中文翻译很科幻)又称为序列蒙特卡洛 (Sequential Monte Carlo),是一种非参数 (non-parametric) 模型。它用一系列样本(粒子)表示可能性分布。每一个粒子都是方差接近于 0 的高斯分布,这种分布又被称为狄拉克δ函数 (Dirac Delta),采用这个分布好处之一是可以把连续数学中的工具应用到离散的结果中。
在地图定位问题中,粒子的状态代表位置和朝向,同时每个粒子分别有自己的权重。初始状态的粒子滤波分布由一开始的假设决定,可能是均匀分布,也可能是以某个点为中心的高斯分布。初始化完成后,重复以下步骤更新粒子的分布:
粒子滤波的缺点之一在于高维度中,需要大量的粒子才能保证理想的分布。ICP 算法可以更好的适应高维度的场景。
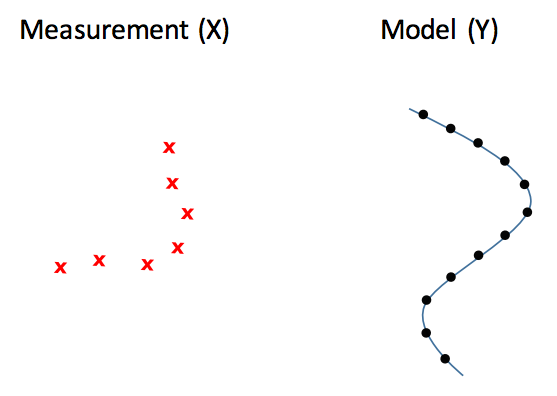
如图所示,ICP 的目的在于已知测量结果和地图,要求出左侧测量结果如何旋转移动后,可以和右侧的地图局部吻合。这里主要有两个问题,一是旋转和移动矩阵,二是测量点和地图点的对应关系。具体的 ICP 算法可以参考这篇论文,它的大致思路和第一周提到的解高斯混合模型的 EM 算法很接近:
这次的作业是实现一个粒子滤波,应该是整个课程最麻烦的一次了。问题本身不算难,尤其简化了动力学模型之后。但是调参比较麻烦,尤其是最后提交的那个地图,容易卡在某个转角跑不出来。
动力学模型方面,我一开始假设机器人位置和朝向的变化量和前一次接近,移动一次粒子之后再添加噪音。这个方法在机器人变向的时候容易位置偏离过多导致粒子失效,后来注意到作业的 Tips 里面建议假设机器人不动,利用高斯噪音移动粒子,这样的话相当于就不需要针对动力学模型做任何操作了。
计算每个例子的得分时,一种做法是用上一周的作业中用到的 bresenham 函数计算发出点到障碍物中间所经历的空白格,然后对每个空白格计算加权,但是这个做法实在太慢了,我最后计算得分时只用了障碍物所在格的状态。
关于粒子的数量,我看到网上有一种做法是设置一个得分的阈值(例如 70% 的障碍物要正好打到墙上),如果所有的粒子都没法超过这个阈值,就重新再跑一次。这么做容易在测量不准时卡死,而且和书中的实现有出入,在现实中会导致粒子滤波每次估计位置时使用的时间不稳定。比较好的做法还是把粒子的数量和高斯分布的参数放在一起调,跑偏了可以看看是因为粒子不够还是分布参数有问题。
作业里其实有两个地图,样例地图比较容易过(可能是参数变化不大)。提交用的地图调参要不少时间,我看了自己的输出以后,发现有几个点的运动变化很大,有可能是这几个点的测量本身也不精确。另外两个地图用来标记墙和空白方格的数值也是不一样的。
至此 Robotics Estimation and Learning 这门课就上完了。课程设置不错,但是讲解不够详细,尤其是第二周和第四周,这小哥讲得太简单了,slides 上还有不少错误。推荐《Probabilistic Robotics》这本书,在上课的时候参考了里面一部分章节,写得很详细,作者 Thrun 也是机器人领域的大神。
2018-08-01 15:07:22
这一周的内容和地图有关,最后的作业就是通过传感器的数据创建一个地图。
常见的题目类型有三种:
在现实中绘制地图有几个难点,一是测量误差会导致坐标不精确,二是设备本身需要不断地移动才能绘制,三是地图本身是对现实世界的反应,会不断的变化。
栅格地图用二维栅格表示整个环境,每个栅格都有一个概率值表示这个栅格是否有物体存在。绘制栅格地图常用的设备之一是测距传感器,通过发出激光并测量接受反射所用的时间,传感器可以了解前方障碍物的大致距离。
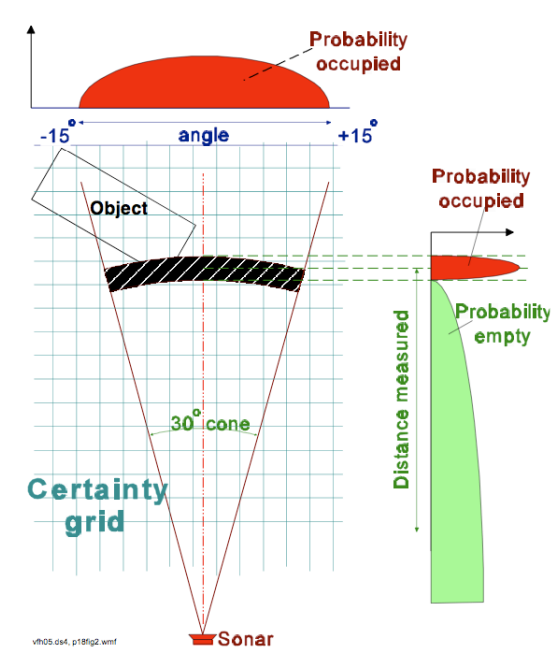
如图所示,传感器本身测量存在误差,我们只能认为在传感器正前方给定距离处有一定几率存在障碍物。对于这种测量有误差的环境,我们再次引入贝叶斯模型描述。记 \(p(m_{x, y})\) 为 (x, y) 格中存在障碍物的概率的先验知识,根据测量的设备模型我们可以得到条件概率 \(p(z | m_{x,y})\)。\(p(z=1|m_{x,y}=1)\) 就代表栅格中有障碍物,且检测成功的概率,而 \(p(z=1|m_{x,y}=0)\) 则代表栅格中不存在障碍物,但是却检测到障碍的概率(假阳性)。
根据贝叶斯公式,我们可以得到测量之后的后验概率 \[ p(m_{x,y}|z) = \frac{p(z | m_{x,y}) p(m_{x,y})}{p(z)} \] 为了简化计算,引入 \(Odd(X) = \frac{p(X)}{p(\neg{X})}\) ,则有 \[ Odd(m_{x,y} = 1 | z) = \frac{p(m_{x,y} = 1 | z)}{p(m_{x,y} = 0 | z)} = \frac{p(z | m_{x,y} = 1) p(m_{x,y} = 1)}{p(z | m_{x,y} = 0) p(m_{x,y} = 0)} \] 其中最后一步可以代入贝叶斯公式得到。对 \(Odd\) 求对数,则有 \[ \begin{align} \log \frac{p(m_{x,y} = 1 | z)}{p(m_{x,y} = 0 | z)} &= \log \frac{p(z | m_{x,y} = 1) p(m_{x,y} = 1)}{p(z | m_{x,y} = 0) p(m_{x,y} = 0)} \\ &= \log \frac{p(z | m_{x,y} = 1)}{p(z | m_{x,y} = 0)} + \log \frac{p(m_{x,y} = 1)}{p(m_{x,y} = 0)} \end{align} \] 令 \(\log{odd\ meas}\) 表示 \(\log \frac{p(z | m_{x,y} = 1)}{p(z | m_{x,y} = 0)}\) ,上式可以简化为 \[ \log odd(m_{x,y} = 1 | z) = \log{odd\ meas} + \log odd(m_{x,y} = 1) \] 如果用 \(\log{odd}\) 表示栅格的状态,这一状态可以简单的通过加减来维护。当检测到障碍物时,该栅格的 \(\log{odd}\) 增加 \(\frac{p(z=1 | m_{x,y} = 1)}{p(z=1 | m_{x,y} = 0)}\),没有检测到障碍物时,该栅格的 \(\log{odd}\) 减少 \(\frac{p(z=0 | m_{x,y} = 0)}{p(z=0 | m_{x,y} = 1)}\)。初始状态为 0,即 \(odd = 1\)。
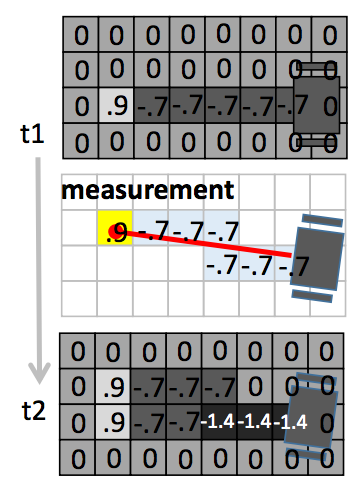
下图为一个具体的例子,第一个栅格地图为 t1 时刻的状态,做了一次探测后,经过的空闲栅格的 \(\log{odd}\) 减少 0.7(这个值由传感器决定),而最后的障碍物所在格的 \(\log{odd}\) 增加了 0.9。第三个栅格地图为 t2 时刻更新后的状态。
常见的三维传感器:
地图的数据格式也有多个方案:
这次的作业是根据一组 Lidar 测量结果绘制一个二维地图。输入包含四个参数(这里 K 为扫描总次数,N 为 Lidar 光线数):
我实现的方法没有用向量并行,用了两层循环依次处理每次测试的各条光线。在 i7 6700K 上大概 25 秒可以跑完最终测试,测试程序里会提到整个过程可能要五分钟,性能差一点的机器这个时间里面应该也能跑完了。
最后跑地图的时候,注意 example_test.m 里传给 occGridMapping 的参数只取了前 1000 次测量结果,所以要制作完整地图要把这个限制去掉。另外文档里面坐标转换时用了 ceil,我在本地测试时只能拿到 27/30 分,换成 round 就能到满分了。
