2026-06-15 16:44:41

西安的天逐渐热了起来,太阳大,云少,空气都是热的。相比于福建的桑拿天,貌似这里的天气比较好。前段时间没了解过我们宿舍门口的小卖部有没有冰淇淋,于是常骑自行车去老综合楼的蜜雪冰城买圣代吃。前些天知道小卖部有卖方糕了,便开始每天吃一个方糕。
高三走读那年,四五月的下午也很热,去学校的路上几乎都会从同一家小卖部买个方糕吃。至于为何选方糕,甜筒融化之后会粘到手上,没卖圣代,三色杯那种还要一只手拿着一只手挖,就方糕省事不麻烦。高考考完之后,离开了学校,几乎没怎么在大热天出过门,就再没吃过。
不知对不对,人死前脑子会像走马灯一样过一遍所有瞬间。是当时看到成绩、看到录取结果时的欣喜,还是平日里的滋味,亦或是暴雨中的困顿与焦虑,更值得被回忆?高二的时候我给我的班主任画了一张图,三个圆圈交叉在一起,分别是作业完成质量高、睡眠充足和独立完成,两个圆圈交叉的地方分别写上“抄来的”、“乱写的”和“熬夜”,又在三个圆圈交叉的地方写了一个“滚”字。当时对我来说算是至暗时刻,如今想来当时的压力与挣扎都是过往云烟。有些事情原本以为放不下,过段时间就放下了;而有些事情当初以为能过去,至今过不去。
高考往后的三个月,刚毕业的高三学生将沉浸在对大学美好生活的向往当中,直到进入大学才逐渐破灭。
高考,是集体的狂欢,还是青春的眼泪?
2026-05-17 11:22:57
因为信安协会原本的SSO改用户信息比较麻烦,协会的周报系统和论坛两个系统打通的任务从很早以前咕到现在,重新开发一版SSO的任务就这样提上日程。这也算是我第二个项目?
谨以本篇文章记录我在整个项目设计、开发、测试和部署过程中的一些经验。能将协会各位大佬传授的经验记录沉淀下来,算是我的一份荣幸。
因为这个项目的周期可能比较长,就先发,随时更新。
我们系统有一些端点需要对外暴露,既要让用户使用,也要防止邮箱枚举造成信息泄露。大概有这些接口:
我们在设计的过程中,明确不允许用户自主注册账户,只能通过管理员在后台添加或导入,所以「注册用户」这个接口不列在这里。
「通过用户名登录」这个接口可以很容易想到「用户名或密码错误」的提示信息来规避明确告知用户名不存在,但「通过邮箱重置密码」这个如果提示邮箱错了就直接表明邮箱不存在,告知邮箱存在容易误导用户。直到我问了Deepseek,它说了一句「如果该邮箱已注册,验证码已发送至邮箱」。这句话点醒了我,怎么会有这么美妙的设计。
后来,为了对开启TOTP的用户进行验证,我们又设计了一个接口,输入邮箱,返回该用户是否开启TOTP。这个也容易泄露邮箱,我想到了一招:
这样攻击者就区分不出哪些邮箱有账户,哪些没有了。当然这样设计TOTP的验证流程在大佬眼中欠佳,他给出了更好的解决方案。
我之前在设计TOTP验证流程的时候注意过,腾讯云和Cloudflare的登录验证都是单独腾出一个页面来弄。尝试看看他们怎么处理这个流程的,可惜我网页逆向水平太差,看不懂,只能从网络Tab里捕风捉影。大概猜了一个这个。
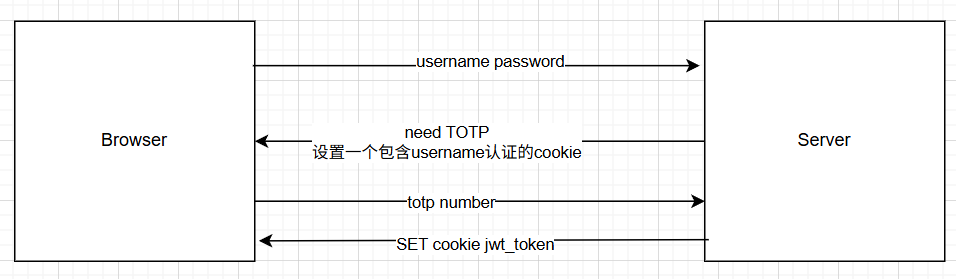
但是感觉这样还要生成一个token给前端太麻烦了,于是改了一下——让前端先看看需不需要TOTP,再把TOTP、用户名、密码一块返回给后端,也就是上一节的那个接口对应的方案。
emmmm
Reverier对这份方案的评价
很有想法(
不过让我设计的话我可能先正常登录之后重新开个页面说totp的事
看来他倾向于另开一个页面的方案,为什么呢?
因为用户登录接口本身是有密码鉴权这个慢哈希接口来做限流的,而且登录接口本身风控比较严。你这么设计相当于开放了一个非登录鉴权的api出去,并且这个api还会查库,攻击者如果只是想把你网站弄垮的话,可以dos这个api给你数据库压力打满,而且因为没有登录态,你还追不到来源。
然后他分享了一个非常美的设计。
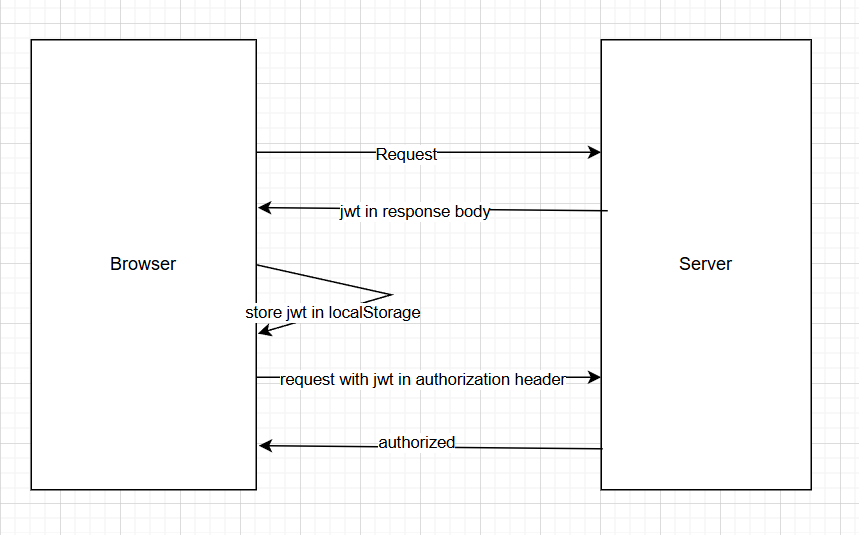
可以把totp登录态直接放在jwt字段里。这样前端拿到jwt一解,发现totp未登录,就继续要求totp验证。验证之后,服务器重新签发一个totp已登录的jwt。两套系统就合一起了,不用维护两拨token。服务端解码jwt发现totp开启并且未登录的时候直接视为整个未登录就好了。
这个设计实在优雅,把两套token合在一起,还让totp的验证流程更简洁了。
「进行中」XDSec SSO开发小记最先出现在林林杂语。
2026-05-13 07:24:19
每当我遇到生活上的困惑时,我都会打开《人生哲思录》看看周先生写过的文字。之前几次对朋友感到困惑,于是几次翻开这本书。如今,朋友这个词再一次让我感到困惑,我也就再翻起这本书。
我问:“你认为网络上的友谊应该有传递链吗?比如说如果我知道一个人和我讨厌的人在一起,我对这个人的信任值就会降低。”他答:“我也这样。”
我其实对这种传递链并不感冒。“朋友的朋友是我的朋友,敌人的朋友是我的敌人。”这句话实际上并没有什么道理。将既是朋友也是敌人的冲突按下不表,这种方法把人几乎分成了两类,一类是某个人的朋友,或者朋友的朋友,另一类是某个人的敌人,或者敌人的朋友,又或者朋友的敌人。一个人要是遵循这种原则交友,找的朋友基本就在一个“朋友圈”里面,一个人的朋友的朋友是一个人的朋友,也是圈子里其他人的朋友。在这样的圈子当中,发言、表达情绪都要格外慎重。如果圈子里的人都遵循友谊的传递链原则,那么若是因为口角之类的事情跟一个曾经的朋友关系不好,这种关系不好的状态会顺着友情的网络传递下去,直到被整个圈子驱逐为止。
再论先前按下不表的冲突,一个人既可以是某个人的敌人,也可以是另一个人的朋友,若他既是我某个朋友的朋友,又是我某个敌人的朋友,那么根据传递链,我能否与他做朋友?一个人与另一个人是否是朋友这个二元关系非常复杂,而且根据我们实际的生活经历知道这个二元关系不满足传递性,换句话说“是否是朋友”不是一个传递闭包。我们可以用代码举一个例子,尽管单单用代码证明不了这件事。
a = {"like": [1, 2, 3], "is": 1}
b = {"like": [1, 3, 4], "is": 3}
c = {"like": [3, 4, 5], "is": 4}
print(a["is"] in b["like"] and b["is"] in a["like"]) # True a和b是朋友
print(b["is"] in c["like"] and c["is"] in b["like"]) # True b和c是朋友
print(a["is"] in c["like"] and c["is"] in a["like"]) # False a和c不是朋友
那么为什么这种传递链会存在呢?我看,是因为“朋友圈”。如果我被朋友发现我跟他们讨厌的人来往,我在他们眼里就成了“不忠”。我也可以用同样的方法识别出那些对我忠诚的朋友。照此,朋友圈变成等级森严的组织,一个人在圈子里就像拴上绳子的狗,限定与圈子里的狗交往。传递链也是一种省事的方式,但它真的用起来其实并不省事。传递链实质上将择友的权利让渡给我的朋友们,他们的眼光也就是我的眼光。很荒谬,这就是问题所在。
朋友圈应该是流动的,仅仅只是我的朋友组成的一个概念。我有独立判断的权利,是否与一个人做朋友应该取决于我们之间有没有默契和互相欣赏,而不是他属于哪个圈子里。一个人不应该被困在圈子里。若是从一个圈子里跳出来,对一个圈子怯魅,那他还可能会跳进别的圈子,然后对别的圈子怯魅。他其实只是对特定的某个圈子怯魅,没有真正跳出圈子这个体系,往后要么找到让他安心的圈子,要么在圈子之间跳来跳去。他会找到让他安心的圈子吗?会有圈子让人安心吗?
圈子不好玩,圈子里的人有的需要崇拜,有的需要归属和认同,大家都只是得到自己想要的东西。进圈子简单,给自己贴上标签即可。人喜欢给自己贴标签,说是让自己更了解自己,也让别人更了解自己。贴标签不是什么没有代价的事情,贴完之后便从立体的人坍缩成标签化的人。
“他在朋友圈挂我了,他那群朋友会怎么想?会怎么看我?”传递链找不来真朋友,圈子也不解放人。
2026-05-10 12:38:40
前几天在协会问了一下有没有什么开发任务,然后找了一个开发订阅推送的活。
工具需要实现的功能是:定时爬取一些安全newsletter和博客的订阅源,并将爬取到的文章推送到协会的QQ群,要有AI的摘要。
| 模块 | 任务 |
| FreshRSS | 爬取、存储内容 |
| Napcat | 部署QQ机器人 |
| Python | 脚本对接AI、FreshRSS和Napcat |

FreshRSS我用Docker方式部署,在应用中开放接口登录并设置一下API密钥,原本打算自己看着接口文档搞的,结果一搜发现Python有对应的接口库freshrss-api,直接就拿来用了。
from freshrss_api import FreshRSSAPI
client = FreshRSSAPI(
host="xxx",
username="xxx",
password="xxx",
verbose=False
)
unread_items = client.get_unreads()
passages = []
pass_text = ""
for i in unread_items:
passages.append([i.author, i.title, i.url, i.html, str(trafilatura.extract(trafilatura.fetch_url(i.url), output_format='markdown', include_tables=True))])
client.set_mark(as_="read", id=i.id)思路大概是这样,每次推送的时候都从未读的文章里面取,取出来就把文章设置为已读。
在获取到还未推送的文章(未读文章)之后,接着需要爬取文章的内容,供后面AI推荐和生成摘要使用。此处使用的是trafilatura库(星火杯参赛小记 用过的),可以将网页内容清洗成Markdown。因为遇到反爬时可能会返回None,导致后面字符串拼接时可能报错,所以对清洗出的结果用str( )进行强制转换。
if len(passages) > 5:
pass_text += "本次抓取文章数大于5篇,根据AI推荐,推送五篇较有价值的文章。\n"
push_index = getAIrecom(passage_list=passages)
for i in range(5):
pass_text += f"Title: {passages[int(push_index[i])][1]} \nURL: {passages[int(push_index[i])][2]} \nBrief: {aibrief(passages[int(push_index[i])][4], passages[int(push_index[i])][3])}\n\n"
elif len(passages) == 0:
exit(0)
else:
for i in passages:
pass_text += f"Title: {i[1]} \nURL: {i[2]} \nBrief: {aibrief(i[4], i[3])}\n\n"接下来对未读文章的数量进行判断,小于等于5篇就都推送,大于5篇就让AI判断哪些东西有价值再推送。getAIrecom(passages)的作用是将所有文章的内容发给AI让其判断,返回一个文章序号的列表。aibrief(content, rsscontent)的作用是根据爬取到的文章内容和rss里面的摘要生成一段AI摘要。
def aibrief(content, rsscontent):
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": "你是一个专业的秘书,负责总结文章的内容,供网络安全协会的推送使用。请你根据给定的文章内容,生成一段不长于75字的摘要,概括文章的主要内容、思路、技术方法,供网络安全协会的成员快速判断是否对文章感兴趣。"},
{"role": "user", "content": "trafilatura得到的文章内容,可能会因为反爬而为None或无意义字符" + str(content) + "\n 以下是订阅软件从 rss 中获取到的内容" + rsscontent}
],
stream=False,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}}
)
return response.choices[0].message.contentdef getAIrecom(passage_list) -> list:
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.deepseek.com")
toEvaluateContent = ""
index = 0
for i in passage_list:
toEvaluateContent += f"第{index}篇文章:\n标题:{i[1]}\nRSS摘要:{i[3]}\n网页摘要:{i[4]}\n\n"
index += 1
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": "你是一个专业的秘书,负责筛选有价值的文章,供网络安全协会的推送使用。请你根据给定的文章内容,回答出其中最有价值的五篇文章的序号,序号之间用空格分隔,不要有多余内容。文章的价值从重要性和影响力来评估。因为反爬的原因,有一些文章的网页内容可能为None或无意义内容,请忽视这一点,根据RSS摘要来做判断。"},
{"role": "user", "content": toEvaluateContent}
],
stream=False,
reasoning_effort="xhigh",
extra_body={"thinking": {"type": "enabled"}}
)
return str(response.choices[0].message.content).split()我原本不太熟悉类型怎么限定的,但之前好像看过写这种限定的代码,在这里加-> list的原因是前面代码用这个函数返回值的地方静态判断会报错。
Napcat有HTTP接口可以发送群消息,弄好要推送的文章和摘要之后调用接口发群消息即可。
token = "xxx"
url = "http://xxx/send_group_msg"
headers = {'User-Agent': 'Mozilla/5.0', 'Authorization': f"Bearer {token}"}
data = {"group_id": xxx, "message": f"最近几小时爬取到了{len(passages)}篇文章,信息如下:\n{pass_text}\n各位成员可以在 xxx 查看所有文章。"}
x = requests.post(url, headers=headers, data=data)
print(x.text)小脚本的完整代码:XDSec Push Bot
2026-05-05 08:28:13
去年国庆节没出去玩,清明假期短,五一刚刚好。原本想着回一趟家,毕竟在学校待了两个月了,但没约到火车票。不回去了,改成旅游。去北京,但北京的朋友说那边挤,不推荐去。去成都吧,成都的同学不愿意出门。去长沙吧,没有什么时间点不错的车票。南京算是一个还行的选择。
临行前几天,我的母亲又告诉我机票价格降下来了,要不要回家,或者就近去山西太原看看也行,太原啊晋城啊也有好看的,但南京的计划已定,变更起来就麻烦多了。
西安北到南京南,从早上九点到下午三点,中午叫了一份郑州东的外卖,跨过长江。坐高铁的经历对我来说还算新奇,也是头两回坐G开头的车。


侵华日军南京遇难同胞纪念馆的票难约,尤其难约。它不像中山陵那样一下就告诉我票没了,它每天放两次票,一直放到参观前一天,我就这么掐着时间点抢着约,今天八点没约到下午五点再战。准点进去提交总是显示人太多了,接着是做滑块和算术题,做完之后接着做,直到这个时间段的票约完为止,也就知道自己白做题了。后面从抖音上看到这种抢票需要慢慢悠悠去预约,刚好避开刚开始的高峰期,就约成了。但我照着这个教程预约,还没出验证码呢,就告诉我没了。一鼓作气,再而衰,三而竭。到后面,我连那个预约小程序都不想打开了,约也是约不上的。南京大屠杀史实陈列的那个展览没约上,但三个必胜的展览倒是一开始就约成了。我将这个作为我到南京的第一站。南京的展览很多,而这算是我整个旅途中看得最认真的展览了。






参观完展览后,坐地铁到一家餐馆与高中同学晚餐。然后逛了逛德基广场,参观了一下豪华厕所。

晚上九点多回到民宿,玩会方舟,然后睡觉。第二天起来,附近找了一家店吃了个鸡蛋汉堡,然后坐地铁到钟山风景区,看看明孝陵,然后到梧桐大道看看,发现全是人。






到一个地方,参观参观同学的大学估计成了我们的一个传统……在Norcleeh的帮助下,我得以进入南邮参观参观。南邮的仙林校区感觉跟西电一样远离主城区,但因为南邮旁边还有其他几所大学所以附近有些广场和商铺,而西电就没有这样的待遇了。南邮一进去就是两侧栽着梧桐的大道,也算是一个梧桐大道了。高中同学告诉我,南邮又叫南京自行车大学,大道上面不是停满了车,就是骑满了车。



参观完南邮之后打了个车回民宿休息,一觉起来就是下午三点半,睡前头晕想吐,估计是中暑了,睡完之后好一些,洗一把脸起来逛一逛瞻园。晚上又到夫子庙看看,所谓不挤一次不算来南京,但感觉没什么好看的,没留什么照片。




次日早上参观总统府。




参观完总统府之后在南京的路上走走,不知不觉就走到浮桥的地铁站了。想着时间也不早了,附近找了一家兰州拉面吃炒刀削,就坐地铁到南京南站。从下午两点到晚上八点,又坐了六个小时的高铁。趴在小桌板上睡了一会,靠在座椅上又睡了几次。




钟山风雨起苍黄,百万雄师过大江。
毛泽东《七律·人民解放军占领南京》
虎踞龙盘今胜昔,天翻地覆慨而慷。
宜将剩勇追穷寇,不可沽名学霸王。
天若有情天亦老,人间正道是沧桑。