2026-05-05 15:33:26
距离上次推荐 面向开发者的 ChatGPT 提示词工程 课程已经快过去了 3 年。如今,大语言模型的能力已经不可同日而语:上下文的容量得到巨大提升,推理能力变强,幻觉率下降,在长时任务的表现也变得更好,而且更多模型开始支持多模态。
最近,吴恩达和 deeplearning.ai 推出了新课 AI Prompting for Everyone,趁着五一假期,我也学习了一下,更新自己的知识。
这个课程分为三大部分:获取信息、使用 AI 作为思维伙伴以及使用 AI 处理多媒体和代码。课程架构清晰,每个部分的知识点衔接自然,深入浅出。即讲了提示词技巧,还介绍了背后的基本原理,并举了大量的例子帮助理解。是一个非常好的 「AI 通识课」以及「入门实践课程」,里面提到的方法不论用哪家 AI 服务都能使用。
课程地址:https://learn.deeplearning.ai/courses/ai-prompting-for-everyone/information
中文翻译视频地址(非官方):https://www.bilibili.com/video/BV1UT9qBDET7
以下是我整理的课程大纲与笔记:《AI Prompting for Everyone-大纲&笔记》


https://wulu.zone/posts/ChatGPT-Prompt-Engineering-for-Developers-in-Chinese
2026-03-01 19:56:03
去年只看完了一本书。
作者:塔拉·韦斯特弗
译者:任爱红
出版社:南海出版公司在看这本书之前,我陆续听说过,但一直没什么兴趣去了解。在我印象中这是一本"励志"书,而我并不喜欢"励志"或"成功学"类的书籍。当时我正在看一些工具书,读得艰难有些疲惫,就想换本有故事性的书来放松一下。
于是,这本书陪我度过了多个通勤和午休前的时间。读完后我发现,虽然作者的故事确实很励志,但这本书想表达的不止于此——它给我带来的更多是关于个体与家庭、个人与信仰关系的思考。
书中最让我印象深刻的,是作者在"回归家庭"和"保持自我"之间的挣扎。也许这两者并非完全对立,但她极端的成长经历把这种冲突逼到了非此即彼的境地。更难的是,"回归"这个选项有着真实的诱惑:回到家庭,回到宗教,仿佛就可以不再烦恼。放弃自己的主体性,不用再为自己负责,上帝会解决一切。那种安稳,并不是没有吸引力的。
这让我想到一个我一直在思考的问题。这种用归属感换取安全感的冲动,在宗教信仰里同样存在——信仰一个至高无上的力量,仿佛生活的问题都能得到解答,仿佛你也能借此拥有某种庇护。这种对外部至高力量的依赖,与作者面临的选择很相似:是选择依赖某个更大的存在来承担自己,还是承担独立思考的重负,以及随之而来的孤独?作者的选择给出了她的答案。
总的来说,我觉得这本书有一种温柔的治愈力量。它没有简单地批判或赞美她的家人,也没有简单地美化自己的选择,而是以真诚的探索和思考,展现了一个人如何在复杂的关系网络中寻找自己的位置。
2026-01-25 20:24:16
本文记录我使用树莓派 5 过程的经验,即是笔记,也是分享。
我在我的树莓派 5 4GB 上跑 Docker,部署了多个服务。当加入 Nextcloud 后,系统开始出现明显卡顿,响应速度大幅下降。输入 top 命令发现,内存几乎用满,swap 更是直接 100% 占用:
MiB Mem : 4049.9 total, 146.7 free, 3369.8 used, 789.0 buff/c
MiB Swap: 200.0 total, 0.0 free, 200.0 used. 680.1 avail这时我才发现树莓派 5 的 Raspberry Pi OS (Bookworm) 默认仅配置了 200MB swap。这个保守的设置可能是为了照顾使用 SD 卡的用户——毕竟频繁的 swap 读写会严重缩短 SD 卡寿命。
但既然树莓派 5 已经配备了 PCIe 接口,官方也推出了专用的 M.2 HAT+ 和 SSD 套件,如果你和我一样使用 SSD 作为系统盘,完全可以将 swap 调大,充分发挥 SSD 的读写性能和耐用性优势。
打开配置文件:
sudo nano /etc/dphys-swapfile修改 CONF_SWAPSIZE,我的树莓派系统是安装在 SSD 上的,所以 swap 调大点没关系。如果你用的是 SD 卡,建议设置小点,不要超过 1GB,因为频繁的 swap 读写会大幅缩短 SD 卡寿命。
CONF_SWAPSIZE=4096 为了设置超过 2GB 的 swap, 还需要修改 CONF_MAXSWAP 调大限制,可以和 CONF_SWAPSIZE 一致,也可以设置的更大一些方便后续调整。
CONF_MAXSWAP=4096重启 swap 服务
sudo /etc/init.d/dphys-swapfile restart验证
free -h在 AI 的建议下,我还开启了 zram。zram 是一个在内存中创建压缩交换空间的技术。简单来说,它会将不常用的内存页压缩后存储在内存里,通常能达到 2-3 倍的压缩比。对于树莓派这种内存有限的设备来说,zram 是个非常实用的优化手段。
安装
sudo apt update
sudo apt install zram-tools验证
cat /proc/swaps可以看到
Filename Type Size Used Priority
/dev/zram0 partition 262128 257344 100
/var/swap file 4194288 697648 -2如果你使用树莓派 5 搭配 树莓派官方 M.2 套件(HAT+),建议不要把树莓派直接叠放在路由器上。
之前有段时间,我发现树莓派经常重启,有时甚至直接卡死无响应。最严重的一次,我部署的 Karakeep 书签服务因为底层数据错误导致数据库损坏,数据瞬间全丢,万幸最后从 Meilisearch 中抢救回来了。
排查过程中我尝试了很多方法(包括修改PCIe节能设置等),最后发现罪魁祸首可能是官方 FPC 排线的抗干扰能力不足(虽然官方说是抗干扰的)。后来我将树莓派与路由器物理分离一段距离后,就再也没出现过类似问题。
如果你不需要使用树莓派的 WiFi 功能,也建议关闭。
https://linuxblog.io/raspberry-pi-performance-add-zram-kernel-parameters/
https://github.com/geerlingguy/raspberry-pi-pcie-devices/issues/559
2025-11-20 21:53:39
默认情况下,Antigravity 使用 Open VSX 作为扩展市场,因此许多在 Visual Studio Code 中可安装的扩展在 Antigravity 里可能搜不到。如果在从 VS Code 迁移过来,可能会很不习惯。
可以通过下面方式,让 Antigravity 能够使用 VS Code 的应用扩展商店:
在 Antigravity 的菜单栏中的 “首选项” 中打开 “Antigravity Setting”。
在设置中的 “Editor” 区域,设置以下参数:
Marketplace Item URL
https://marketplace.visualstudio.com/itemsMarketplace Gallery URL
https://marketplace.visualstudio.com/_apis/public/gallery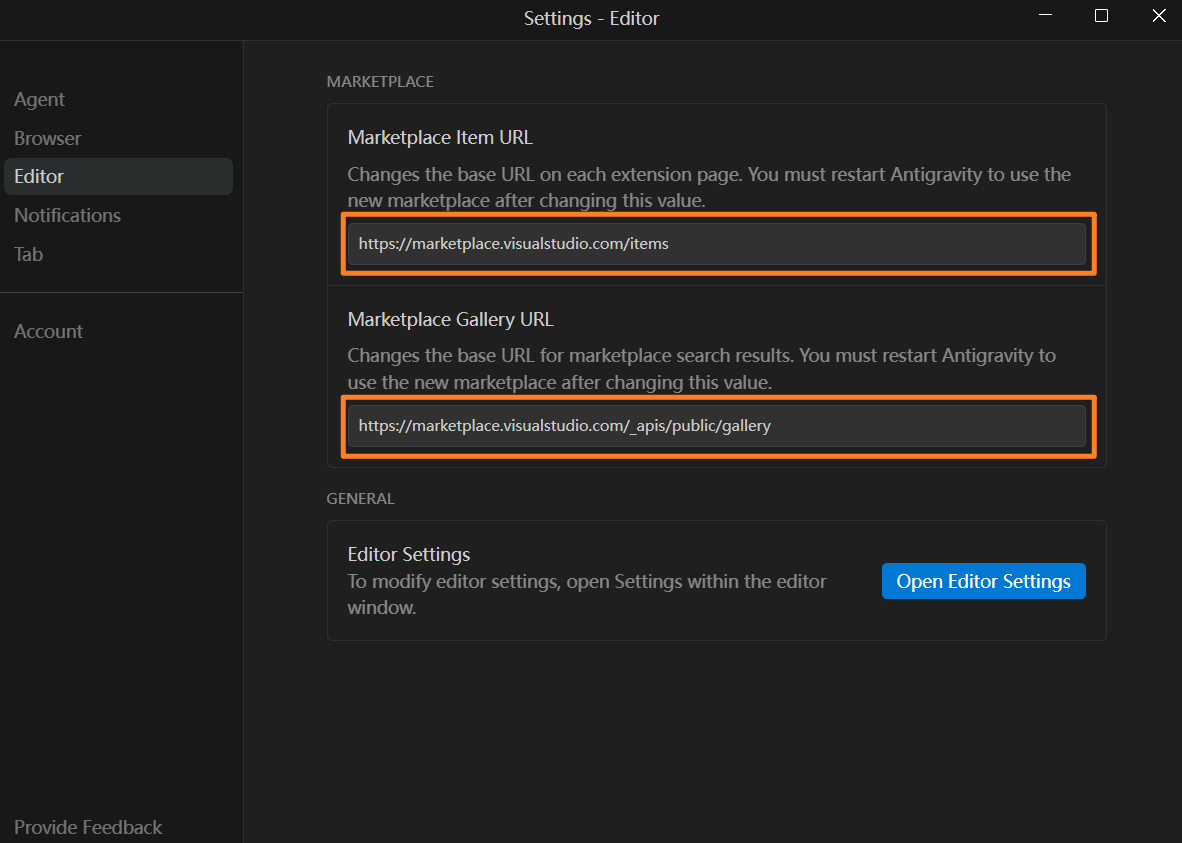
重启 Antigravity 即可。
2025-09-27 12:02:51
时隔多年再次重装 OpenWrt,早已忘记当初的安装方法。许多教程已经过时或缺少关键细节,因此记录本文以便日后查阅,也方便有需要的人参考。如有问题,欢迎在评论区讨论。本文仅作为参考,请谨慎操作,数据风险自负。
本文将演示如何在树莓派4B上安装 ImmortalWrt 并进行扩容。
ImmortalWrt 是 OpenWrt 的一个分支 ,它移植了更多的软件包,支持更广泛的设备,默认优化了配置文件,并为中国大陆用户进行了本地化修改。
前往 ImmortalWrt 固件选择工具 下载对应固件:
搜索设备型号,查找对应固件。

每个设备一般会对应四个固件:

首次安装,选择 FACTORY 版本,树莓派设备推荐使用 EXT4。
下载 FACTORY(EXT4) 的版本。
利用 rufus 工具将上一步得到的 immortalwrt-[版本号]-bcm27xx-bcm2711-rpi-4-ext4-factory.img.gz 直接烧录到内存卡,保持 rufus 默认设置即可。
ImmortalWrt 不再默认创建 Wi-Fi 热点,所以需要通过有线的方式连接到它。
把内存卡插到树莓派中,接通电源。然后用网线连接树莓派和电脑。
在电脑上访问 192.168.1.1。默认账号名为 root,密码为空。
登录后按照提示修改默认密码。
进入 “网络” - “接口”,然后编辑默认 lan 接口。

根据实际需求配置网络。
由于我将其作为旁路网关使用,所以设置了静态 IP 地址,并指定了相应的网关和 DNS。且在“DHCP 服务器”界面,勾选“忽略此接口”。
确认无误后,点击“保存并应用”,并强制执行。
然后,就可以用网线将树莓派连接到路由器了。
完成后上述步骤后,ImmortalWrt 就能正常使用了。但是默认 ImmortalWrt 只用了 300MB 的储存,并没有用完整张储存卡。所以可用空间很少,并且被浪费。
接下来我们来扩容。
安装需要用到的工具
opkg update
opkg install fdisk resize2fs losetup查看当前分区状况
fdisk -l你会看到类似下面的输出(120GB 的内存卡,只用了 64MB + 300MB):

重新分区
进入 fdisk 工具:
fdisk /dev/mmcblk0输入 p 查看分区表,记住第二分区开始的位置:

输入 d 删除第二个分区:

输入 n 重新创建分区:
p ,或直接回车使用默认值。2 ,或直接回车使用默认值。147456(根据实际情况替换,使用原起始扇区)。N。
最后,输入 w 确认并执行变更:

再次查询分区情况,可以看到第二个分区现在已经扩大。
fdisk -l
接下来还需要让系统能够识别这个分区:
先查看当前是否有循环设备:
losetup此时,输出可能为空。或者有一些设备。在下个命令中,不要与已有设备冲突,可以用 loop1 或其他未使用的编号。
创建循环设备:
losetup /dev/loop0 /dev/mmcblk0p2扩展文件系统到分区全部空间:
resize2fs -f /dev/loop0重启系统,网页访问树莓派,可以看到扩容成功,磁盘空间大小已经更新。
reboot
2025-08-10 15:37:37
Motrix 是一款基于 aria2 的下载工具,支持 HTTP、FTP、BT、磁力链等多种资源下载,界面简洁易用。
Motrix 在 v1.8.19 版本中开始支持 arm64 设备,可以在树莓派等设备上运行。树莓派功耗低、运行安静,很适合 24 小时运行下载服务。由于我的树莓派没有安装桌面系统,所以通过 docker-baseimage-gui 项目制作了一个 docker 镜像。docker-baseimage-gui 提供了集成轻量级桌面环境、VNC 服务和 Web 访问功能的基础镜像,专门用于在无头服务器上运行 GUI 应用。
项目是开源的,具体实现可以查看:eMUQI/motrix-arm64-vnc
以下以我的树莓派 5 为例:
Raspberry Pi 5 Model B Rev 1.0
OS: Debian GNU/Linux 12 (bookworm) aarch64
Kernel: 6.12.34+rpt-rpi-2712请确保您的宿主机系统已安装 Docker 及 Docker Compose。
docker-compose.yml
在宿主机上创建项目目录,并在该目录中新建 docker-compose.yml 文件。
mkdir motrix-server
cd motrix-server
touch docker-compose.yml
将以下内容写入 docker-compose.yml 文件:
docker-compose.yml
services:
motrix:
image: emuqi/motrix-arm64-vnc:latest
container_name: motrix-vnc
ports:
# 5800: 用于 noVNC (Web 浏览器) 访问的端口
- "5800:5800"
# 5900: (可选) 用于标准 VNC 客户端直接访问的端口
- "5900:5900"
volumes:
# 将宿主机的 ./data 目录映射到容器的 /config/Downloads 目录
# 用于持久化存储下载的文件
- ./data:/config/Downloads
environment:
# 关键:设置容器内应用的用户与用户组 ID。
# 建议修改为宿主机当前用户的 UID 和 GID,以避免挂载目录的权限冲突。
# 可在宿主机终端执行 `id` 命令获取。
- USER_ID=1000
- GROUP_ID=1000
# 设置 VNC 会话的显示分辨率
- DISPLAY_WIDTH=1280
- DISPLAY_HEIGHT=720
# (可选) 设置 VNC 访问密码。取消注释并替换为强密码。
# - VNC_PASSWORD=your_secret_password
restart: unless-stopped
在 docker-compose.yml 文件所在的目录下,执行以下命令以启动服务:
docker compose up -d
Web 浏览器 (noVNC):
访问 http://<宿主机IP地址>:5800
VNC 客户端:
使用 VNC 客户端 (如 RealVNC Viewer, TigerVNC) 连接至 vnc://<宿主机IP地址>:5900
为确保下载文件能正确保存至宿主机映射目录,首次启动后必须在 Motrix 应用内完成以下配置:
在 Motrix 图形界面中,导航至 偏好设置 -> 基础设置。
定位到 下载路径 选项,点击 “更改”。
将路径手动设置为容器内部的绝对路径:/config/Downloads。

保存并应用设置。
此操作仅需配置一次。完成后,所有下载任务产生的文件,都将被保存在您之前创建的 motrix-server 项目目录内的 data 文件夹中。
noVNC 不支持传统意义上的直接、无缝剪贴板调用。这主要是由于现代网页浏览器的安全限制。
当你通过浏览器访问此项目时,需要通过以下方式将下载链接复制 Motrix:
在你的本地电脑上复制文本。
打开 noVNC 界面侧边的控制条,找到剪贴板工具。

将文本粘贴到 noVNC 的剪贴板文本框中。

此时,文本被发送到远程服务器的剪贴板。你现在可以在远程桌面环境中使用粘贴命令(如 Ctrl+V)来粘贴内容。

| 环境变量 | 描述 | 默认值 |
|---|---|---|
USER_ID |
定义容器内运行 Motrix 进程的用户 ID (UID)。 | 1000 |
GROUP_ID |
定义容器内运行 Motrix 进程的用户组 ID (GID)。 | 1000 |
DISPLAY_WIDTH |
VNC 会话的屏幕显示宽度(单位:像素)。 | 1280 |
DISPLAY_HEIGHT |
VNC 会话的屏幕显示高度(单位:像素)。 | 720 |
VNC_PASSWORD |
为 VNC 服务设置连接密码。若留空或注释,则无需密码即可访问。 | (未设置) |
还有一个 Motrix-Web 项目实现了在网页上运行 Motrix 的功能。该项目的前端用户界面与 aria2 后端是分离的。Motrix-Web 作为前端 UI,直接从浏览器发出请求以控制后端的 aria2。这意味着,当考虑将 Motrix-Web 部署到公网环境时,aria2 也需要相应地部署到公网。
而本项目 motrix-arm64-vnc 将向 aria2 发送的网络请求封装在容器内部。这种架构的好处是,aria2 无需直接暴露在公网上,从而提供了更为安全的运行环境。
值得注意的是,无论选择哪种部署方案,出于安全考虑,都不建议将上述提及的两个项目直接暴露在公网上。在任何面向公网的部署场景中,都应考虑将其置于某种验证机制之后,例如 Cloudflare Access 或其他反向代理与身份验证解决方案。