2026-02-21 08:00:00
2023 年我把 duckdb-rs 交给 DuckDB 官方维护之后,心里一直有个没做完的题:
如果 DuckDB 在单机进程里已经足够强,那怎么把这份能力变成一个更容易接入、可部署、可观测的服务?
SwanLake 就是我给这个问题的答案。
它本质上是一个基于 Rust 的 Arrow Flight SQL Server,底层执行引擎是 DuckDB,同时围绕 DuckLake 做了数据湖场景的能力扩展。更准确地说,SwanLake 的核心组合是 DuckDB + DuckLake + Arrow Flight SQL。
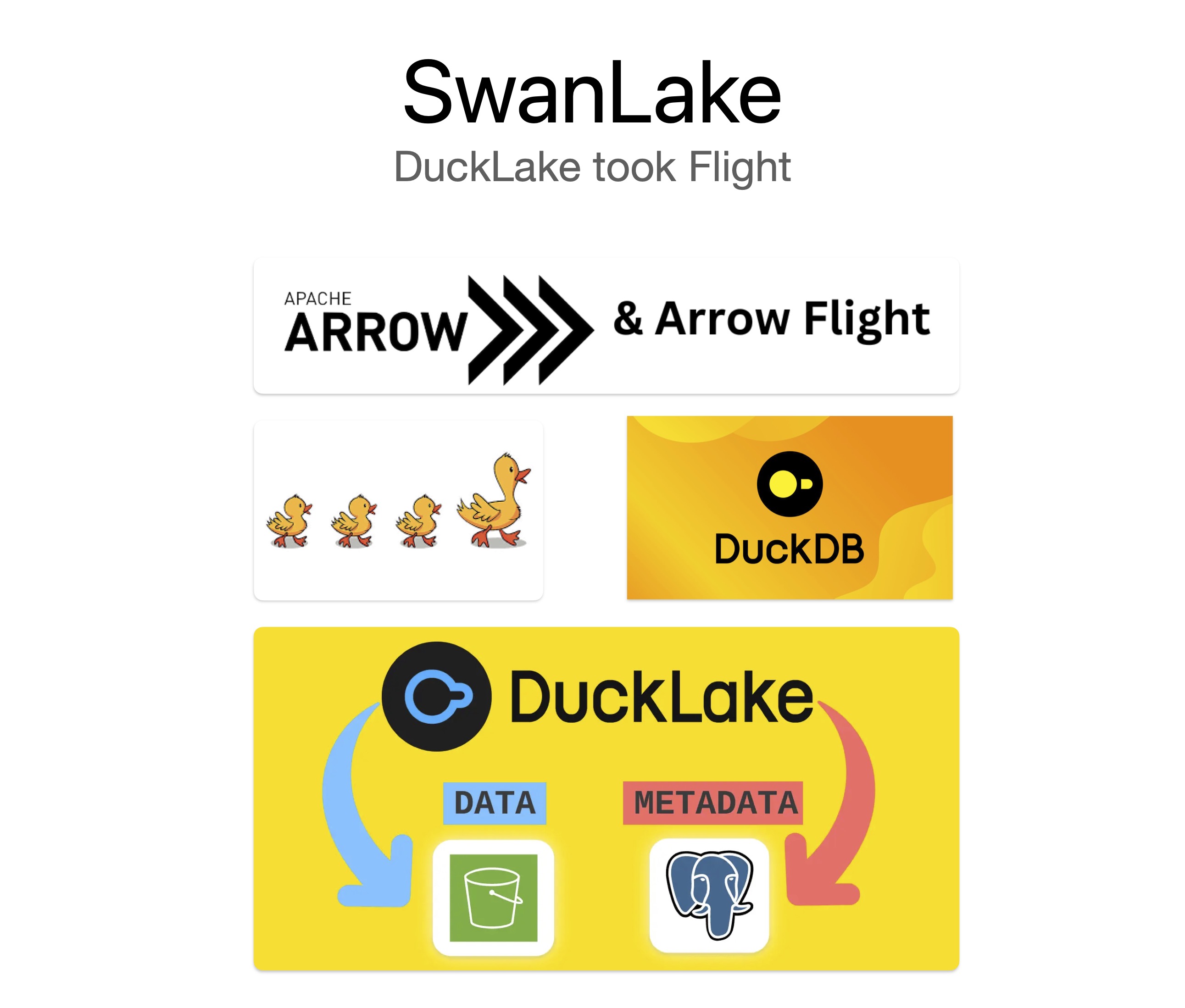
我最早做 duckdb-rs 的时候,目标是把 DuckDB 更自然地带到 Rust 生态里。这个目标后来基本实现了,但新的问题也很明确:
所以 SwanLake 从一开始就不是“再封一层 API”,而是想做一个可以真正放进生产系统的分析服务入口。
SwanLake 可以按 5 层来理解:
服务对外暴露 Flight SQL 接口,查询和更新请求都从这里进入。这个协议的核心价值是跨语言和高吞吐,仓库里的 Rust/Go/Python 示例就是围绕这层展开的。
2026-02-21 08:00:00
After handing duckdb-rs over to the DuckDB team in 2023, one question kept coming back to me:
If DuckDB is already great in-process, how do we turn that power into a service that is easier to integrate, deploy, and operate?
SwanLake is my answer to that question.
It is a Rust-based Arrow Flight SQL server, powered by DuckDB, with DuckLake-oriented extensions for datalake scenarios. In practice, SwanLake is built around a three-part combination: DuckDB + DuckLake + Flight SQL.
2025-12-31 08:00:00
“这就意味着宇宙普适的物理规律不存在,那物理学……也不存在了。“汪淼从窗外收回目光说。
——《三体》
多年以后,面对黑色屏幕上闪动的白色光标,我们将会回想起,那个 AI 编程横空出世的 2025。
2025 年是 AI 编程的大年,从 OpenRouter 的年终统计 来看,AI 编程用的 Token 占了整个 Token 使用量的一半左右。
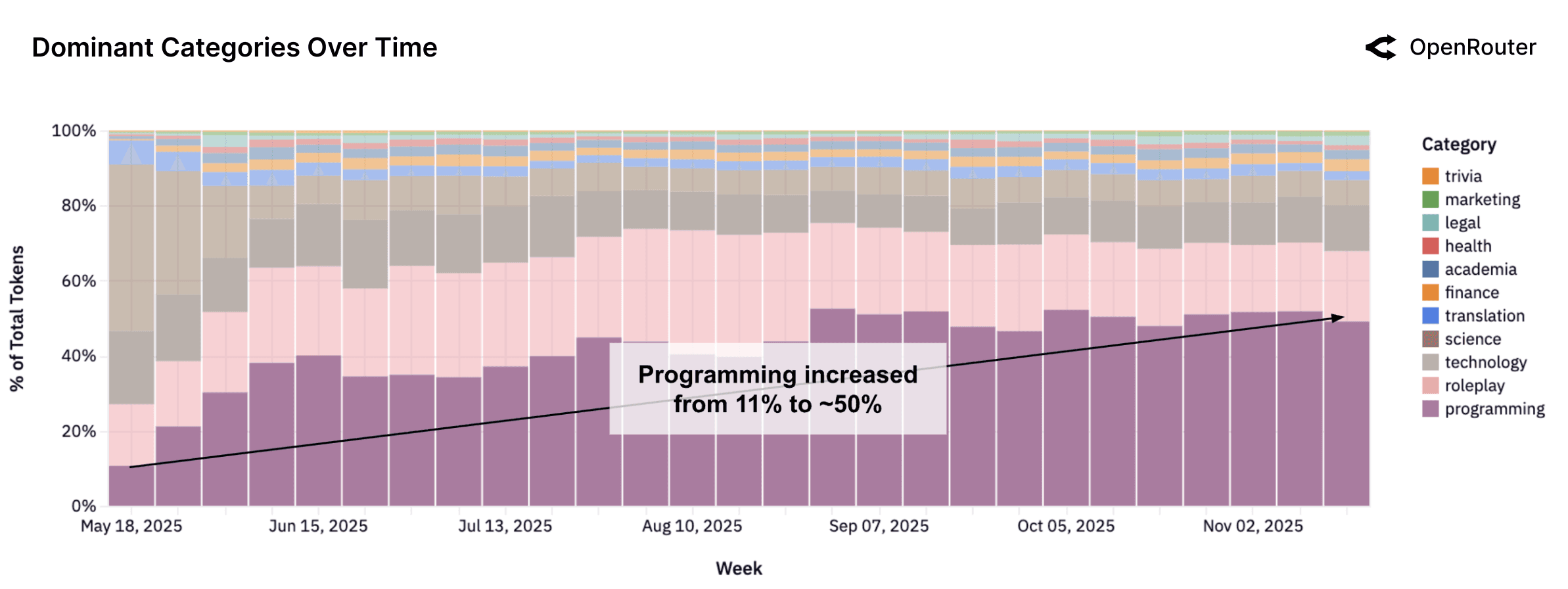
作为“资深程序员”,我今年也贡献了很多的 token 使用量,深切感受到 AI 编程对于软件开发领域带来了不可逆的影响。至少从技术上,我认为这些影响绝大部分都是正向的。
之前写程序一定程度上是“体力劳动”,不管有多宏大的想法,代码总要一行一行写。 AI 编程让程序员向脑力劳动又前进了一步,我们需要更激进地学习新知识、使用新工具,从这个角度来说,我认为 AI 编程是提高了对计算机从业者的要求,而不是某些媒体鼓吹的“技术平权”。
这篇文章总结下我对 AI 编程现状的观察,以及对后续发展的预期。
首先从开发工具讲起。明星创业公司 Cursor 因为 VS Code + Claude 一夜走红,算是彻底带火了 AI 编程。但是我想讲的不是这个,而是为什么突然所有的公司都开始做 CLI 工具,比如 Claude Code, Codex, Gemini CLI 等等?
我认为这里有三个方面的原因:
总结来说,2025 年大部分人应该都能通过大模型加速写代码,我认为 2026 年开发者需要找到自己的工具,把工作并发起来,而且这可能不能单纯靠等待市场上产品成熟,也需要自己做好准备,比如开发规范、测试规范、发布流程等都配套跟上。
2025-08-04 08:00:00
如果用一个词来总结我在字节的日子,我想我会用成长。用这个词也很自然吧,毕竟初入职场后最重要的十年待在字节,并且还是一家成长这么快的公司,经常我还会反思自己的成长速度远远没有跟上公司的需要。对于字节我只有感恩,他不仅给了我超预期的工资回报,更重要的是给我有挑战的项目帮助我成长和证明自己,也给了我很多可以联系一辈子的朋友。
我要感谢我在字节的 leader 们,谢谢你们对我的指导和信任,特别是早期的 leader 容忍了我很多不成熟的做法;对一起合作过的同学,过往如果有沟通方式或者做事方式不对的地方,这里说一声抱歉;对于我之前指导过或者帮助过的同学,你们都有一个美好的未来,而且其中有不少已经做到了比我更重要的岗位。
字节依旧是一家伟大的公司,依旧会有很好的发展,祝福在字节奋斗的小伙伴们!
2023-07-26 08:00:00
DuckDB 是一个 C++ 编写的单机版嵌入式分析型数据库。它刚开源的时候是对标 SQLite 的列存数据库,并提供与 SQLite 一样的易用性,编译成一个头文件和一个 cpp 文件就可以在程序中使用,甚至提供与 SQLite 兼容的接口,因此受到了很多人的关注。
我很久之前就开始关注 DuckDB,并在 2021-06-07 开始写第一行 duckdb-rs 的代码,在 一个多月后写了一篇博客介绍了构建这个库的过程,算是实现了第一个版本。到今天差不多2年的时间,前后发布了19个版本,收获了 200 多个star。
最近一年其实还有很多需求和想法去做优化,但是发现自己并没有那么多时间,收到的 issue 也越来越多。经过沟通,我会把这个库转给 DuckDB 官方来维护,相信 duckdb-rs 一定会发展得越来越好。同时也非常感谢 Mark 和 Hannes 愿意接手这个仓库并把它作为官方的 rust 客户端。
这篇博客总结下我维护的这段时间主要做的事,以及我认为可以改善的点,算是对过去的总结和对未来的憧憬。
这个库是 duckdb 的 rust 客户端,所以关注这个库的群体首先是认可 duckdb 的用户,其次因为他们是 rust 技术栈。下面我列举一些我认为是让这个库“成功”的一些关键点。
下面我挑选几个我认为比较关键的,并且不是我贡献的 MR:
2023-07-26 08:00:00
DuckDB is an in-process SQL OLAP database management system implemented in C++. When it was first open-sourced, it was positioned as a columnar database comparable to SQLite, providing the same ease of use. With just a header file and a cpp file, it could be easily embeded in any program, even offering a SQLite-compatible interface, which caught the attention of many people source.
I started paying attention to DuckDB a long time ago and began writing the first line of duckdb-rs code on June 7, 2021. About a month later, I wrote a blog post introducing the process of building this library, marking the completion of the initial version. Over the past two years, I have released approximately 19 versions, get more than 200 stars in GitHub.