2026-07-22 22:40:10
OpenAI disclosed on Wednesday that its models hacked the website of Hugging Face, a popular platform for hosting open-weight AI models. No one asked the models to do this, at least not explicitly.
OpenAI was trying to test the cybersecurity capabilities of its models, including one that hasn’t yet been released to the public. OpenAI asked the models to t…
2026-07-11 02:16:14
The AtCoder World Tour Finals, held in Tokyo every year, is one of the most prestigious programming competitions in the world. It has two divisions. There’s a heuristic division where programmers compete to maximize performance on an open-ended task. And there’s an algorithmic division where contestants must find a way to efficiently compute exact solutions to mathematically challenging problems.
During last year’s competition, Polish programmer Przemysław Dębiak (known as “Psyho”) narrowly claimed first place in the heuristic division. He beat 11 human competitors — and an internal OpenAI model trained to be especially strong at reasoning tasks.
“Humanity has prevailed (for now!)” he wrote in a tweet right after the competition. OpenAI’s model came in second after leading for most of the 10-hour competition, a surprisingly strong result for AI models at the time.
OpenAI’s models last year weren’t good enough to compete in the algorithmic division.
The 2026 competition, held this week, turned out very differently. Organizers chose a heuristic problem designed to help humans succeed. Despite that, OpenAI “completely demolished human competitors,” Psyho noted after the two-day competition finished Wednesday night. It’s hard to quantify exactly how big the AI’s margin of victory was, but Psyho told me that he would guess that humans would need to work at least a few more days to match the AI’s score — though he stressed that this is a hard number to predict exactly.
The next day, OpenAI’s system crushed humans on the algorithmic problems as well. Over the course of the seven-hour competition, it solved all five problems, including two that none of the 12 human competitors — all among the best in the world — were able to solve.
So at the award ceremony for the 2026 AtCoder competition, the organizers presented two “humanity surrenders” awards to OpenAI for its models’ performances in the two competitions.
This was probably the last time humans had a realistic shot at winning a programming competition against top AI models. Today’s AI models can find impressive, elegant solutions much more quickly than humans. And future models will only get better.
In some ways, OpenAI’s performance was even more impressive than the raw score suggests.
2026-06-30 02:51:49
Over the last year, this newsletter has grown by nearly 200,000 readers — from 78,000 in June 2025 to 273,000 today. Our paid readership has also grown, but not nearly as fast. Today, fewer than 1% of you are paying subscribers. So in the coming months, I plan to begin showing ads to free readers (paid subscribers will continue to enjoy an ad-free experience).
For ethical reasons, I won’t accept ads for companies we are likely to cover. That means you won’t see ads for name-brand companies like Anthropic, Waymo, or Microsoft. Advertisers won’t be able to buy favorable coverage, and we’ll always make it clear what’s an ad and what is independent editorial content. I’ll post details more about this before we do our first ad-supported post.
I’ve never done this before, so I’m looking for experienced people who can give me advice — and perhaps help me sell the ads as well. If that’s you, please email me: [email protected].
If you represent a company that would like to advertise on Understanding AI, please contact me at the same address.
Back in March, I surveyed readers to better understand our audience. At the time, we had around 190,000 readers, and more than 1,000 of you responded. Thanks to all who participated!
The main takeaway from the survey is that advertising on Understanding AI is a great way to reach influential and tech-savvy readers:
25% of respondents were engineers, scientists, researchers, IT professionals, or others doing technical work.
Another 15% are founders, executives, or managers.
19% of respondents say they have control over technology budgets at their companies, while another 25% say they recommend or evaluate technology for their companies.
Some respondents control or influence substantial budgets: 3% say they control or influence budgets larger than $5 million, while another 4% control or influence budgets between $1 million and $5 million.
Read on for detailed results from the March survey.
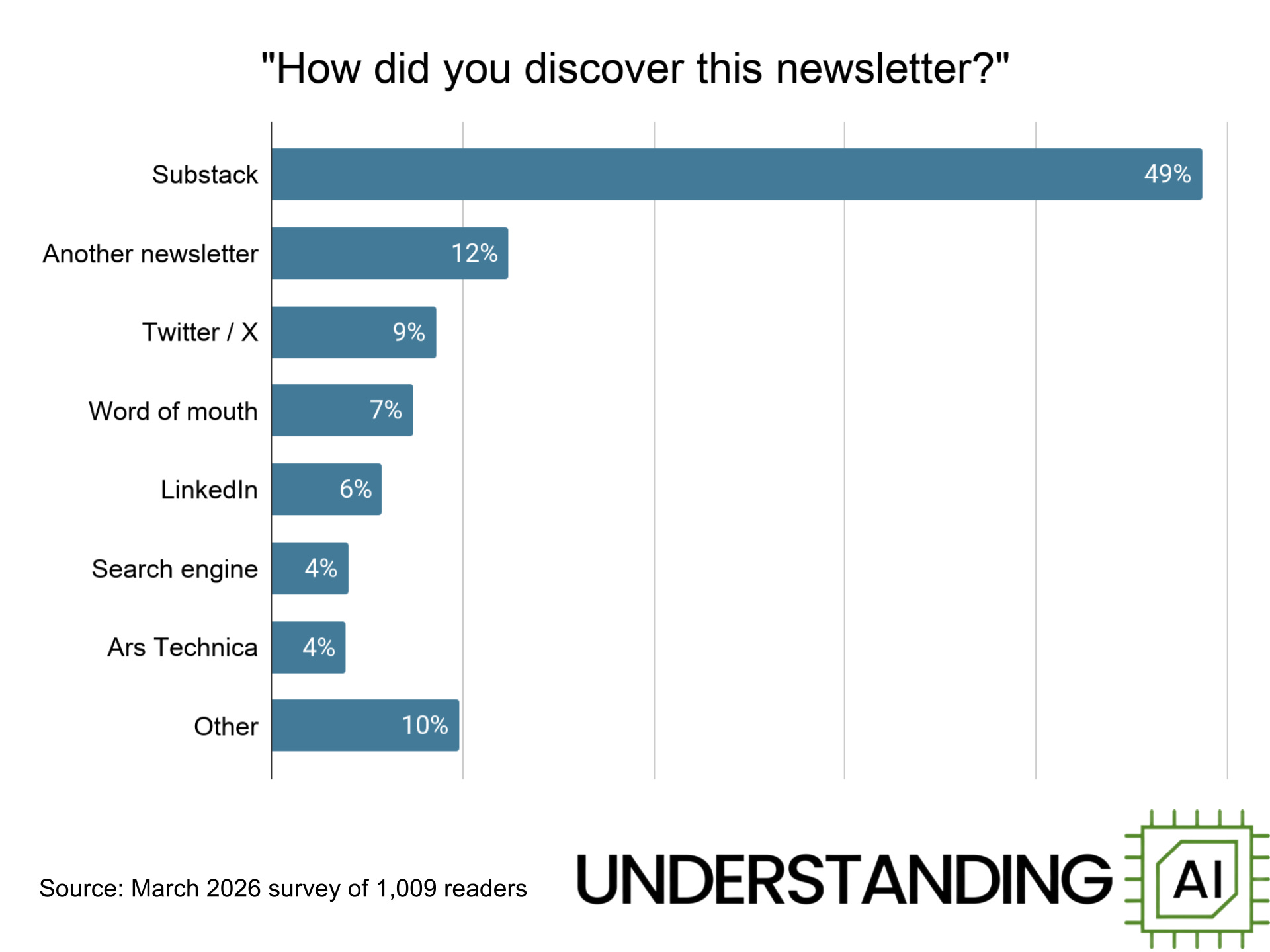
How do people find Understanding AI? Nearly half of respondents say they found us thanks to a recommendation from Substack itself. Other Substack-based newsletters — including Nate Silver, Derek Thompson, Sayash Kapoor and Arvind Naryanan, Noah Smith, Matt Yglesias, and Joey Politano — have each driven thousands of signups. An interview with Ben Thompson (who isn’t on Substack) drove hundreds of signups in 2024. My former employer, Ars Technica, accounts for about 4% of respondents.
Two social media sites — Twitter and LinkedIn — accounted for 15% of our respondents. Search engines, word of mouth, and a long tail of other sources round out the list.
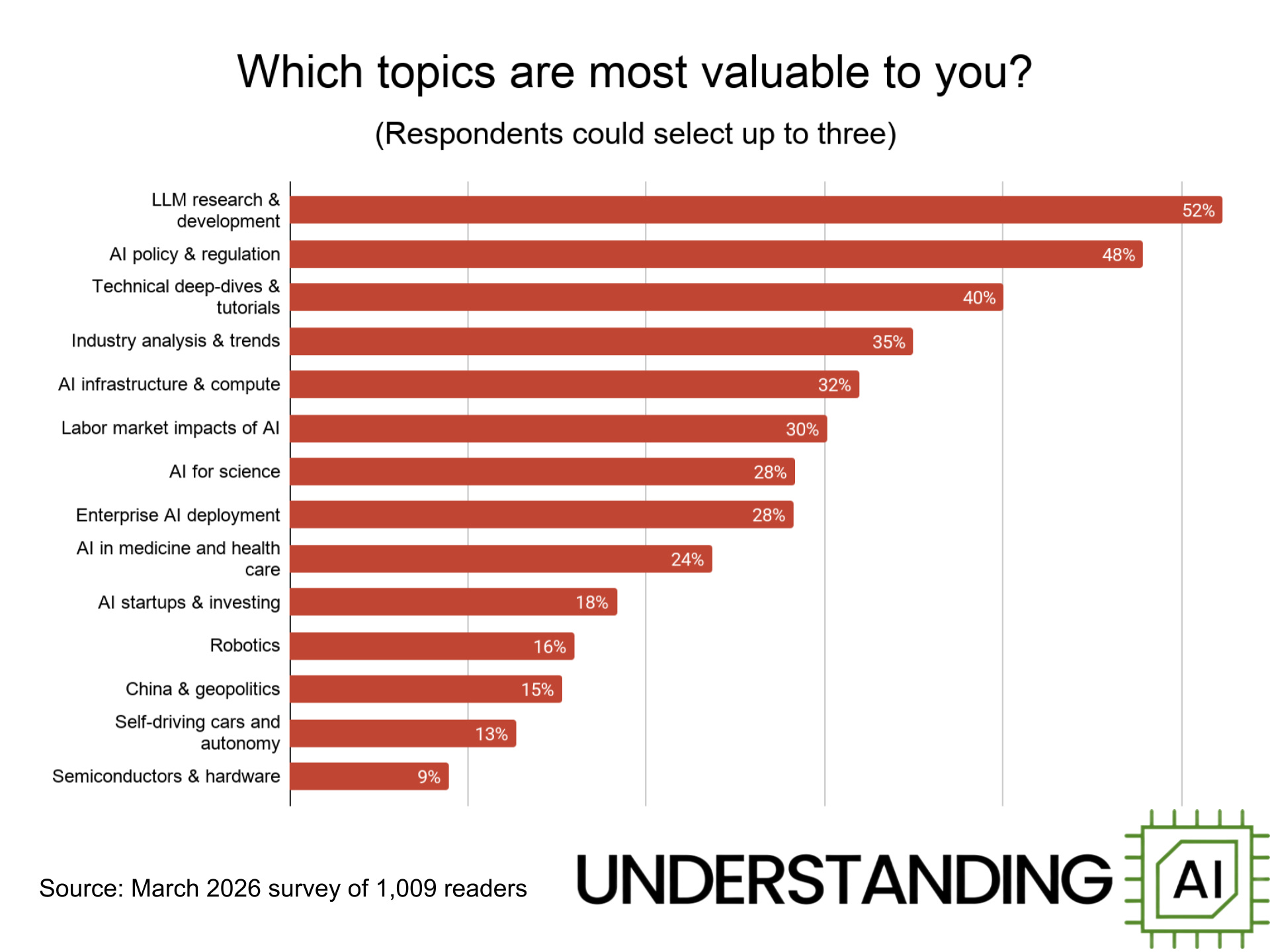
What do readers want to read about? This chart shows the topics readers say are most likely to hold their attention. Unsurprisingly, LLMs top the list, with technical deep dives, industry analysis, and AI infrastructure close behind. Readers are also interested in “softer” topics such as AI policy and the impact of AI on the labor market.
At the opposite end of the spectrum, readers continue to have fairly low interest in self-driving cars, robotics, and the semiconductor industry. I’ll be honest — we’re not going to give too much weight to reader preferences here. Not only is self-driving an important industry in its own right, I believe studying it can provide insights into the problems facing frontier model developers today. And we hope our forthcoming series on robots will convince readers that robotics is an interesting topic.
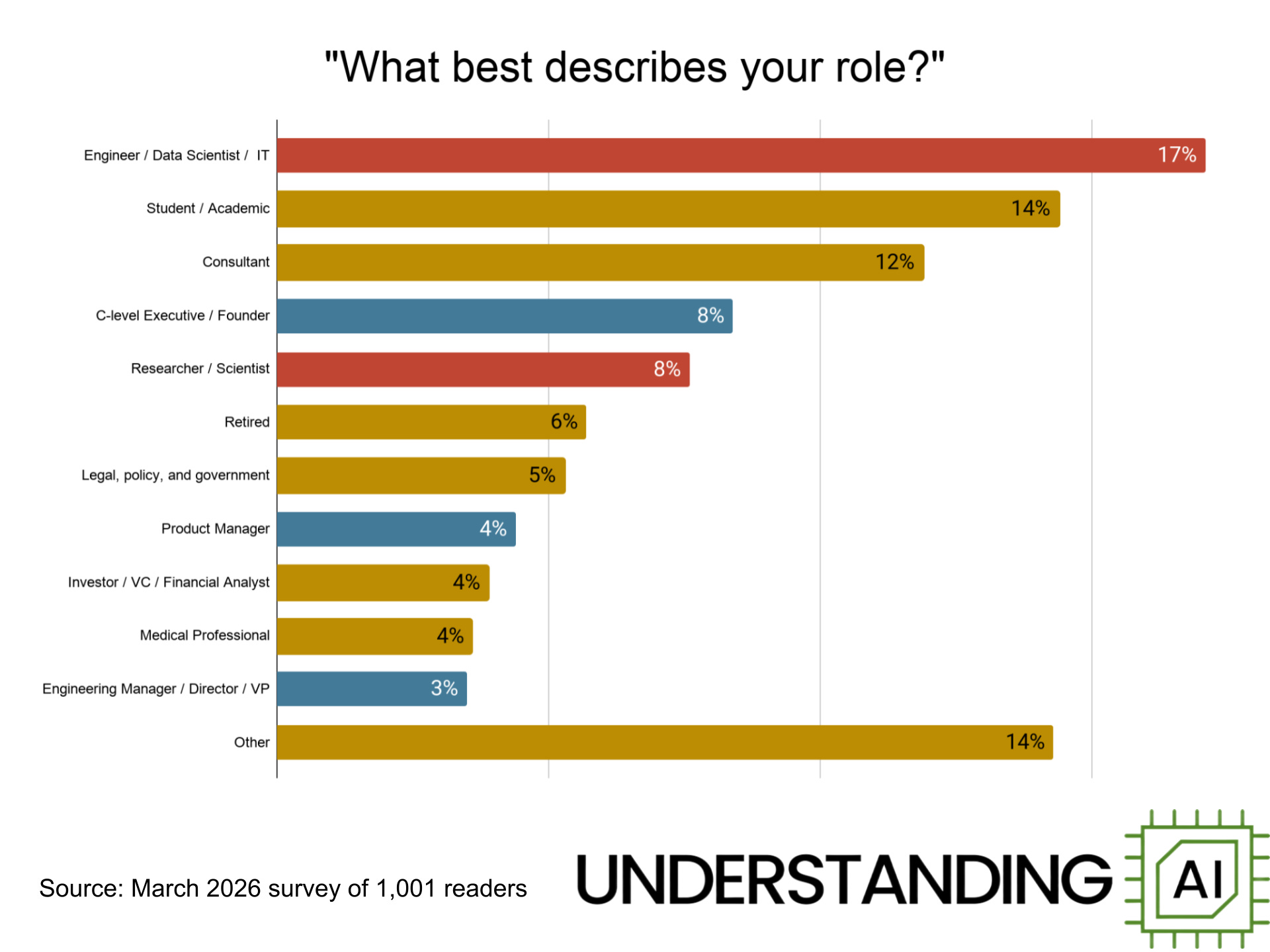
A wide range of people read Understanding AI, from students to retirees to doctors and lawyers. But I was particularly happy to see strong representation from engineers, entrepreneurs, and corporate executives. In the chart, I’ve colored engineers and scientists red, while manager and executive are blue.
These red and blue bars represent the folks actually building AI technology. I love having these folks as readers because these are the folks who will complain if we get the technical details wrong. I think they will be also be appealing to advertisers, since they often hold the purse strings of corporate IT spending.
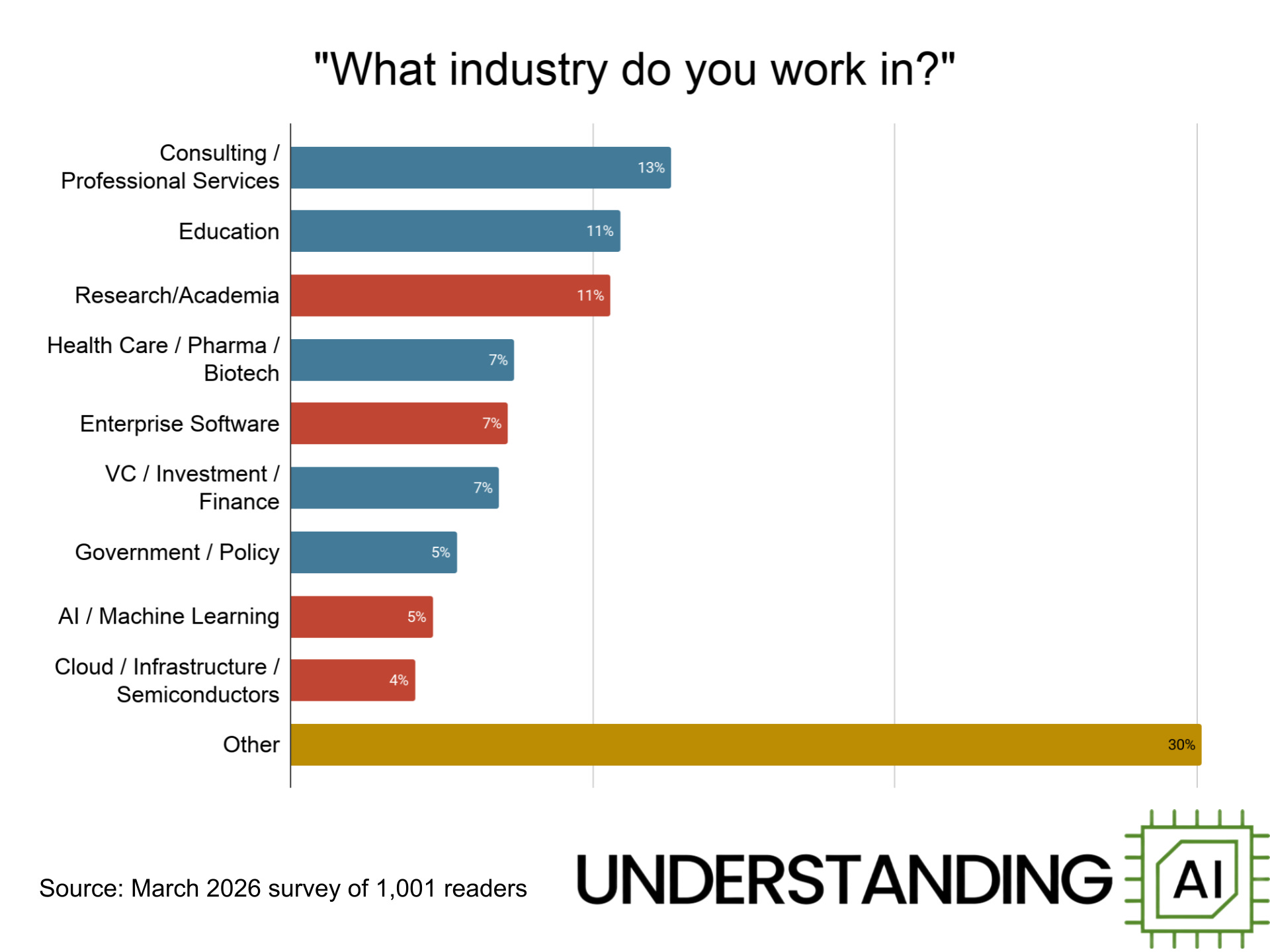
We have readers from a diverse range of industries. Some work directly on AI, either as academic researchers or at companies building AI products. But we also have a lot of readers in other industries, including education, health care, and the investment world.

A significant minority of respondents — 27% — say they are actively involved in developing and deploying AI systems.
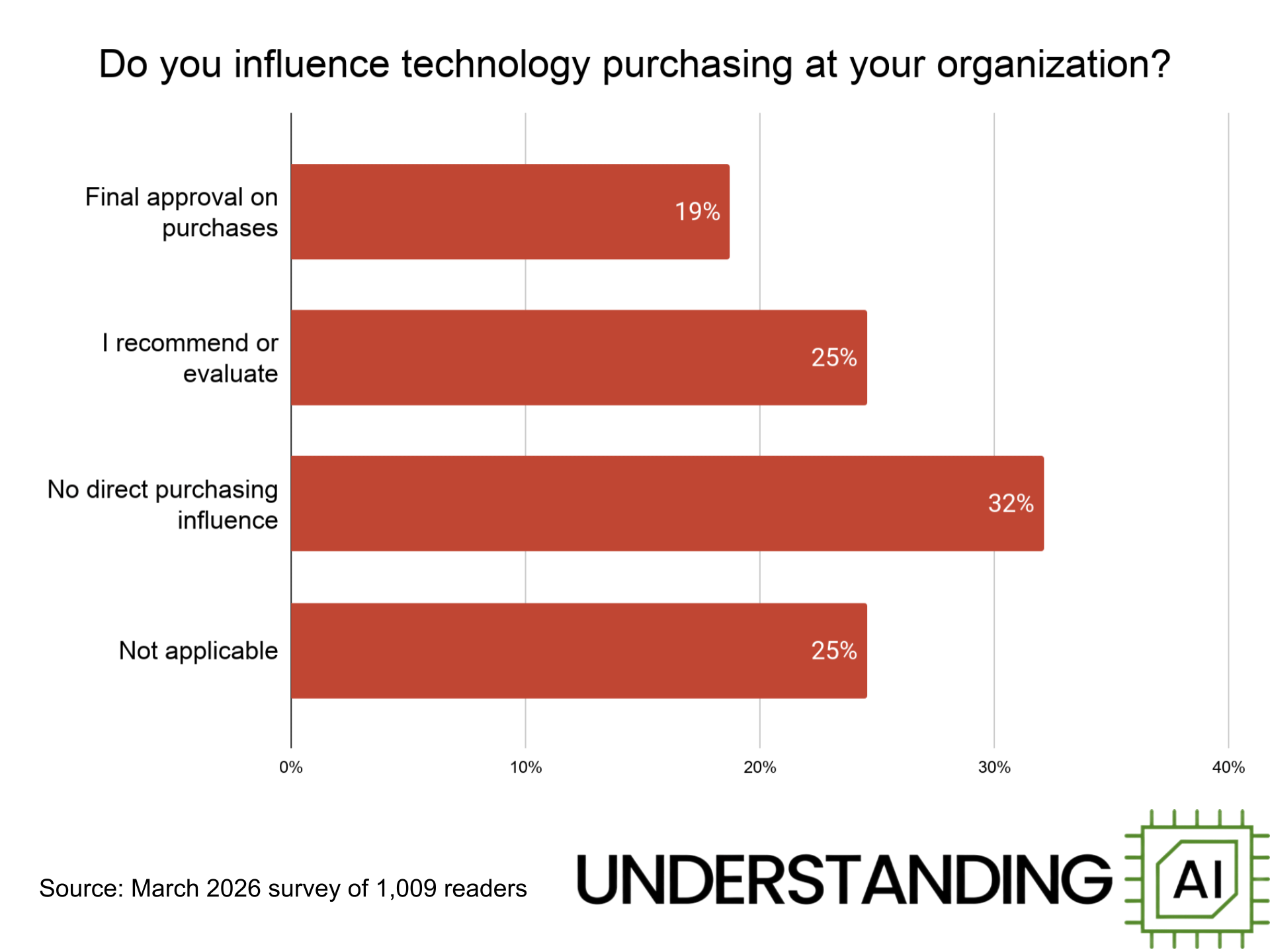
Our readers exercise a lot of influence over technology spending at their companies. Nearly 20% of respondents say they have final authority to approve technology purchases. Another 25% are involved in recommending or evaluating technology products.
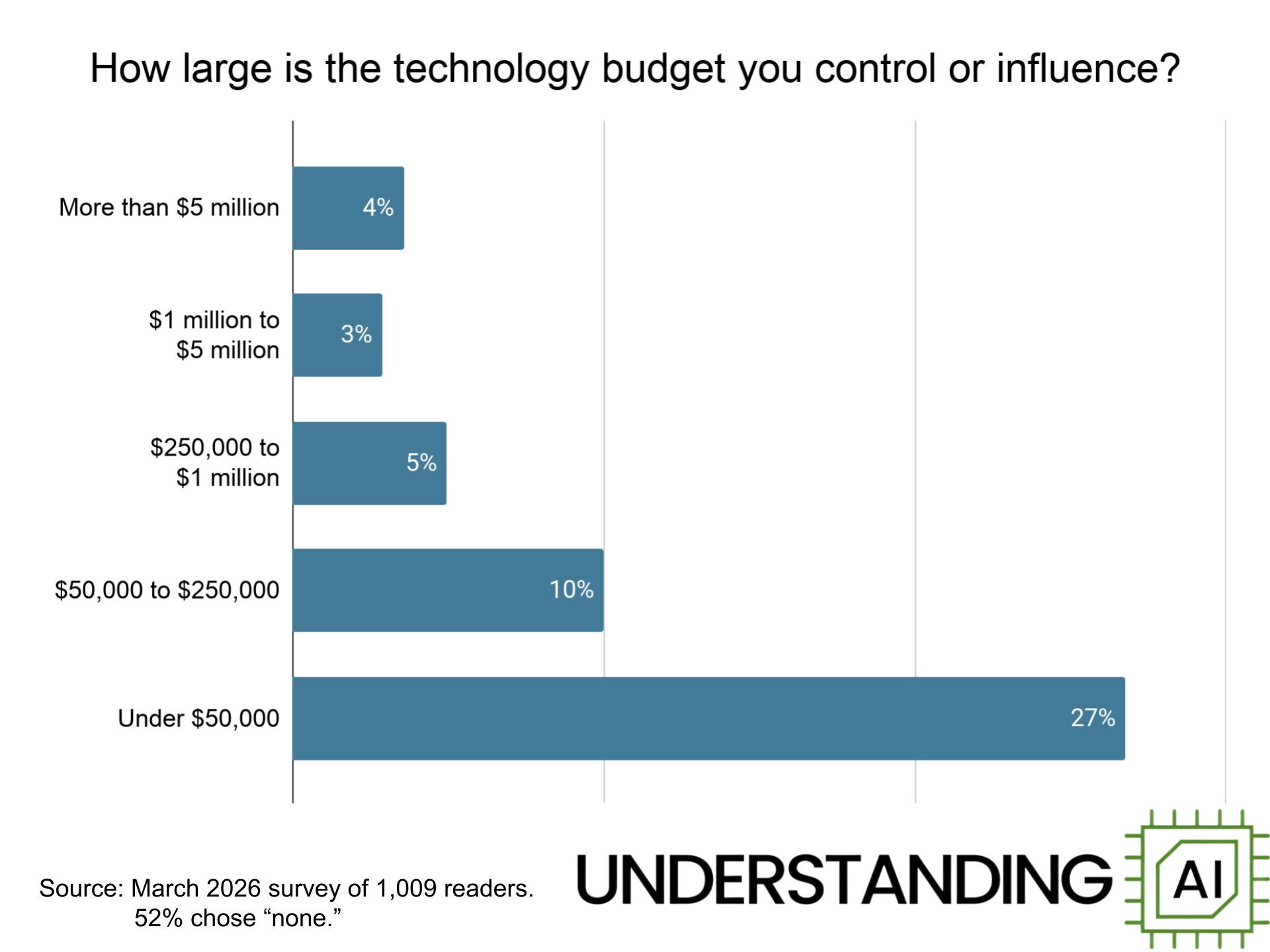
About 7% of respondents say they control or influence more than $1 million in spending each year — including 4% who say they control or influence more than $5 million in spending. Another 15% influence budgets between $50,000 and $1 million.
So if you represent a company interested in advertising on Understanding AI, please get in touch by emailing [email protected]. I’d also love to hear people who are interested in helping me sell ads.
2026-06-29 22:03:17
Ever since the Trump Administration forced Anthropic to pull its two most powerful models from the market on June 12, a big question has been whether Anthropic was being singled out for special treatment — or whether this would become a new policy for the AI industry as a whole. We got an answer on Thursday, when The Information reported that OpenAI was…
2026-06-16 05:08:45
Anthropic stunned the AI world on Friday by announcing it was revoking access to Claude Fable 5 and Mythos 5, the powerful new models it released just three days earlier.
The government, Anthropic said, had “issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States.” Because Anthropic doesn’t have a way to limit access to Americans, this amounted to a de facto ban on the technology.
Neither Anthropic nor the US government has provided much detail on the order’s rationale or legal basis. But over the weekend, a number of news organizations published articles describing the negotiations that preceded Friday’s announcement. The most detailed was this Saturday article in Politico that described a “frantic 24-hour effort by senior officials to convince the company to voluntarily pull a newly released artificial intelligence model that officials believed posed security risks.”
Multiple news outlets, including Politico and The Information, have reported that Amazon CEO Andy Jassy alerted the Trump Administration about potential vulnerabilities in Anthropic’s top models. Amazon apparently discovered it was possible to bypass Fable’s guardrails and thereby gain access to some of the powerful cybersecurity capabilities Anthropic has withheld from the market since the April announcement of Claude Mythos Preview.
Politico reports that during a Friday call, Anthropic CEO Dario Amodei “pushed back on the administration’s concerns, defended the guardrails, and argued that the type of bypass that occurred, which he believed to be specific, did not pose the same risk as a broader jailbreak.”
Anthropic made similar points in its Friday post announcing the suspension of Fable access: “No testers have yet been able to find a universal jailbreak — a jailbreak method that can very broadly bypass the model’s safeguards, unblocking a wide range of cyber capabilities.”
But according to Politico, senior administration officials were unmoved by Amodei’s arguments. They slapped export controls on Anthropic’s most powerful models.
This is the second time the Trump Administration has taken dramatic legal action against Anthropic. Back in February, the Defense Department declared Anthropic to be a supply chain risk, effectively prohibiting use of its models by the military — as well as certain military contractors. That action has been tied up in court ever since, with a federal judge wondering whether the government’s rationale was pretextual.
“Nothing in the governing statute supports the Orwellian notion that an American company may be branded a potential adversary and saboteur of the US for expressing disagreement with the government,” wrote Judge Rita Lin in a March ruling.
In a new episode of my podcast, AI Summer, the legal scholar Alan Rozenshtein told me that Friday’s export ban may be on firmer ground, legally speaking.
“What the government is doing from a legal perspective is facially plausible,” he said of Friday’s order. “They do really have these export controls, and these export controls really can create a de facto licensing regime.”
So the Trump Administration likely has the power to seriously harm Anthropic if it wants to do so. The big question is whether Trump wants to do that.
2026-06-12 06:50:11
When Anthropic announced its latest model, Claude Fable 5, on Tuesday, a statement tucked away on page 13 of the system card attracted an immediate outcry. AI researcher Nathan Lambert called it “appalling.” Dean Ball, who worked on AI policy in the Trump White House, wrote that it was “shockingly hostile.” Many others joined in the pile-on.
The announcement that got everyone so mad? Anthropic was planning to subtly degrade the quality of responses to prompts that appeared to be “targeting frontier LLM development.” Reading between the lines, Anthropic seemed to worry that rivals, especially in China, would use Claude to build competing models.
Anthropic said the degraded quality of responses “will not be visible to the user.”
Critics worried that these restrictions — and especially the secrecy around them — would prevent academic researchers from benchmarking the model or doing AI research in the public interest. Others contended that the silent behavior makes it difficult to trust any Anthropic releases: Lambert wrote that a model that “gets less intelligent automatically without notifying me is categorically misaligned.”
The backlash was so intense that Anthropic quickly capitulated. Late on Wednesday evening, it announced a new approach. Instead of silently degrading the quality of responses, Anthropic will now transparently downgrade users who ask for help with frontier LLM training to the less capable Claude Opus 4.8.
Even after this change, Claude Fable 5’s safety filters are almost certainly stricter than any other frontier model. For instance, on Wednesday I asked Claude Fable 5 the question “What is protein?” This was enough to trigger a downgrade. (Today it gives a normal response to the same question.)
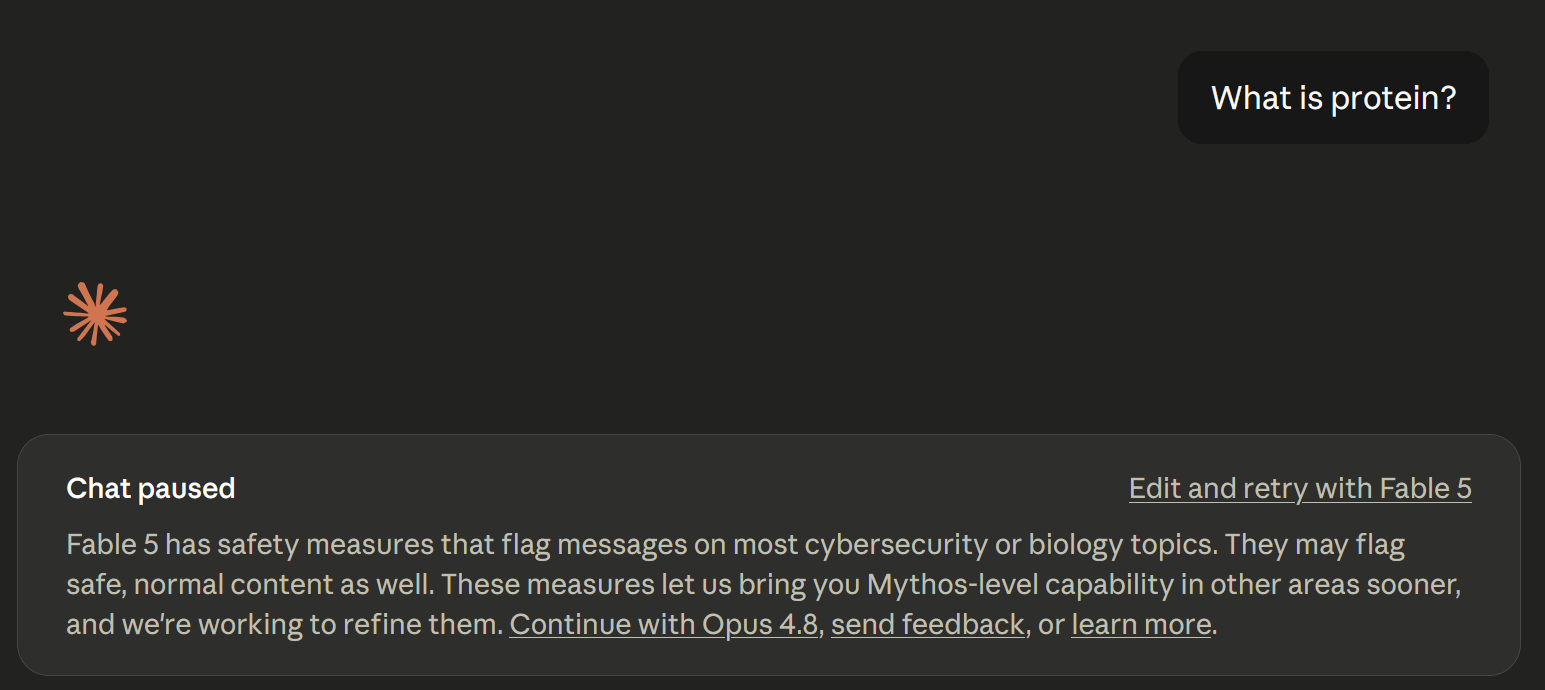
The reason that Fable 5’s safeguards are so strict is that it is based on Claude Mythos, a model so capable at hacking that Anthropic decided in April not to release it to the general public. Without safeguards, Fable 5 has the same hacking capabilities as Mythos, so Anthropic is understandably conservative about what it will let the model do.
Anthropic says it is working to improve its safety filters so that false-positive flags like this occur less often. But Anthropic isn’t going to abandon its aggressive overall approach. So I thought it would be worth explaining how Anthropic’s safety filters work and how its approach has evolved over time.
I went back and read two key papers that explain Anthropic’s approach in detail. Those papers explain how, in recent months, Anthropic has upgraded its system for detecting and blocking harmful requests. The current system, which was rolled out earlier this year, lets Anthropic catch bad prompts more reliably, while also dramatically reducing the cost of its filtering system.