2026-07-26 17:14:51

The Origin Energy breach down here in Aus is all over the news this week, and as with many breaches, it's multi-faceted. You've got them leading with "don't worry, your credit card is fine", the hacker leading with "they didn't respond when I tried to report it", and now news that the two parties have "come to an agreement". Maybe money was paid, or maybe Origin made some promises to restrain the hounds if commitments about data deletion were made. But both outcomes, of course, provide no guarantee that data has been nuked, so now they get to spend perpetuity waiting for the data that maybe - just maybe - it leaks. And we all should be working on precisely that assumption, just like we did with Optus and Medibank and Latitude and Ticketek and Qantas...




2026-07-21 15:30:24

I reckon this week's video on how Claude is tying together info from UniFi, Home Assistant and the Pi-Hole is an absolute ripper. Or at least the concept is - if ever there was an actual value proposition for AI it's taking lots of noise and converting it into a useful signal. Or, sometimes, it's just helping you see the woods through the trees, and that's exactly what Claude helped me do last night when every Sonos unit in the house refused to connect to any music service. It only took Claude a moment to work out: "you know your Pi-Hole is dead, right?" Uh... I do now! Give it a go, it's pretty awesome (and the Pi-Hole came good with a power cycle on the PoE port).
2026-07-15 08:35:38

"Build a smart home", they said. "It'll make life so much better", they said. Well, life wasn't very bloody good at 23:00 the other night after travelling 33 hours from Paris only to find the IoT doorlock batteries dead and the 9V "jump start" procedure completely failing! Eventually, the locksmith arrived and opened an old-school physical lock on another door in an alarmingly short time. So, lessons:
As I say in the video, we do have other doors that have keys, and if it weren't for the complacency we developed, we would have had one of these accessible. But alas, we didn't. The path forward is to take a deep dive into Ubiquiti's Access ecosystem, which I've flagged in the past, and by pure coincidence, I already had a meeting lined up with them to discuss just this. So, the hardware is on the way, and I'll have something entirely new to play with in the coming weeks. Stay tuned!
2026-07-08 21:54:46

How's this for a location?! I mean, last week was nice with Scott in Mallorca, but Marrakech is, well, wow 😮 Anyway, about those data breaches... This week I'm talking about the futility of attempting to remove piss from a pool, yet here we are, with various companies wanting to place that message alongside the very data breaches they can do nothing about! As I say in the post, I don't question the good intentions behind setting up a service to try to scrub data from legally operating data brokers, but the marketing machines behind those organisations that regularly reach out to me for product placement don't really seem to grasp that reality. At least now they have a nice explainer courtesy of that post 😊
2026-07-03 14:52:41

I can't recall if someone else originally came up with this saying or if I said it in some off-the-cuff comment and it just propagated, but since it's often attributed back to me, I'll relay it here regardless:
Trying to delete yourself from the internet is like trying to take piss out of a swimming pool
Depending on the publication, I'll tailor the saying to be either more broadly palatable or more, uh, "Australian", but the sentiment doesn't change: once data spreads on the internet, you can never put a lid on it. This is important in the context of data breaches because it speaks to the immutability of our exposed personal information. It also speaks to the limited practicality of services that promise to erase your data from the internet, and it's the constant outreach from these organisations looking for marketing opportunities on Have I Been Pwned (HIBP) that's prompted me to write this.
Let's begin with those services, and because there are so many and I don't want to throw any of them under the bus, I won't name names. I also won't name them because whilst they're rather assertive in their marketing outreach, I do believe they're well-intentioned and I don't want to imply otherwise. And they have a role to play; it's just much more limited than is represented. The positioning is often around "data broker removal services", or "protect my data", or "remove my information from the internet". You'll find various companies providing these services by searching for those terms, or you can search for specific organisations... and find others hijacking the search term as they pay to market their brand in front of others. Usual internet marketing shadiness, of course, but IMHO it speaks volumes about the commercialisation of the data removal business.
These services all follow roughly the same marketing handbook:
So let's go through these points one by one, starting with the data broker claim, which is absolutely correct. Your data has value - "data is the new oil" - and there's business in obtaining and selling it. I've dealt with many of them personally over the years, primarily because they've had data breaches. Master Deeds in South Africa was massive. National Public data a couple of years ago was many times larger. Exactis, Adapt, and many others have also been added to HIBP over the years. To the best of my knowledge, they're legally operating services, even if they may exist on the fringe of what most of us would consider "a bit dodgy" as far as respecting our personal information goes.
Which brings us to the second point about nefarious uses. There is a very broad spectrum of legitimacy across data brokers. Let's pick two extremes as far as the legality of the service goes. On the "very legally operating" end of things, we have Experian, and even if you don't like what they do, there's no arguing the fact that they're on the cleaner end of legitimacy and do provide valid services. At the other end, you have the likes of LeakedSource (and pretty much every other service with the word "Leak" in its name) that... well... just Google them. And there are many, many more at each end and everywhere in between. And a lot of it's very grey: different legal jurisdictions, different means of obtaining data, and different tolerances for adhering to opt-out requests.
But it's the data removal piece that's the real problem. If you pay one of the services in question to scrub you from the internet, I have no doubt they'll have some degree of success with the legally operating services. Those services will comply with legal requests and are adequately equipped to receive and process them. But the LeakedSources of the world? Not so much. And that's where the rub begins:
Requests to remove personal information are only effective for services that are willing to honour them.
That should sound profoundly obvious to anyone reading this now, but it doesn't really feature when you read the marketing material on data removal services. But I'm only just warming up...
Imagine trying to remove your data from here:
🚨🇺🇸 ShinyHunters has leaked the data of multiple companies...
— Dark Web Informer (@DarkWebInformer) June 16, 2026
🇺🇸 American Tower Corporation
🇺🇸 JCPenney & subsidiaries under Catalyst Brands & Authentic Brands Group
🇺🇸 Madison Square Garden Sports Corp.
🇺🇸 Ralph Lauren
🇺🇸 https://t.co/08IaUnp1sx pic.twitter.com/TvqanSTO1Y
That's a small snippet of the ShinyHunters website from a couple of weeks ago. At the time of writing, a bunch more data has been dumped, including only about 15 minutes before putting these words down in the draft blog post. These breaches have impacted tens of millions of people, including my wife courtesy of her having previously shopped at Canada Goose. Now, let's see how you go about scrubbing her data from that incident. For all the data broker removal services I'll direct to this post later, how do you do that? Clearly, you can't. The pee is now in the pool, and you're not taking it back out. And it's not just "on the dark web" either, their Tor site links through to a clear web site hosting all the data:
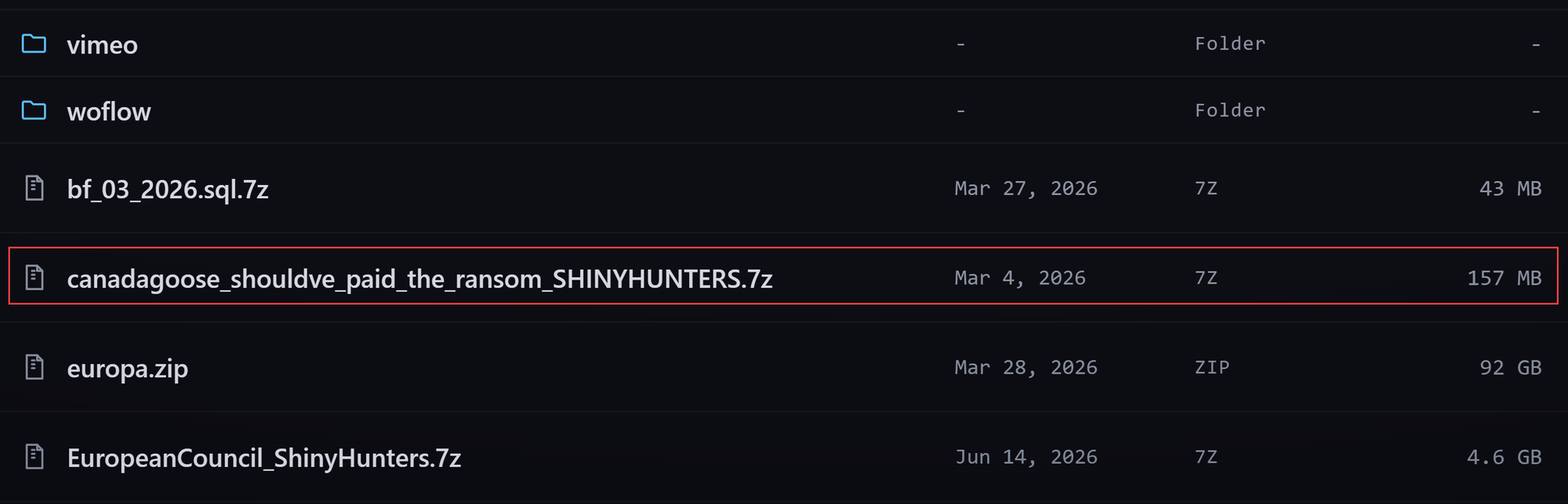
And that's just the beginning. Because we're talking about digitised data posted publicly, it replicates like crazy. There will be tens of thousands of copies of my wife's personal info floating around between personal stashes, Telegram channels and public hacking forums. That genie is never going back in the bottle, not unless we're talking about the narrow scope of a legally operating data broker, which raises another issue:
What legally operating broker is enriching their corpus from data breaches?! That's just not where the legitimate ones source info from. The data comes from surveys, exchanges with other services where you ticked the box to agree to the terms and conditions for exchanging data with "partners", public business directories, and even arrest records. Legal services, legal sources, legal processes. In one of the emails from a company looking for product placement, they described their plan as follows (bold is mine):
a plan which allows you to remove your personal information from any URL (where it's legal) you find your personal information on
So what we're left with is data removal services being effective for legally operating brokers who honour legitimate requests, whilst being completely useless against the worst kinds of sites that replicate and abuse your data. In other words, you may be able to opt out of some marketing material or content that's way too specifically targeted to you, but you can't stop the bad guys trying to steal your identity or extort you because "we caught you watching porn on your PC via the malware we installed". It's a little like the court injunctions being the thoughts and prayers of data breach response I wrote about in October: I can't touch the Qantas data breach because I'm a law-abiding Australian who knows about the injunction, but there's absolutely nothing stopping the genuinely bad actors from abusing that data.
And therein lies the core of why I don't want to entertain partnerships with these organisations: not because I disagree with the service or because it will cause any harm, rather because when someone uses HIBP to search for their email address and finds it in the Canada Gooses of the world, these services can't do anything about it. They're merely skimming the leaves off the top of the pool, and no amount of skimming is going to remove what we all know still lies beneath.
2026-06-30 23:42:54

How's the view?! Back to business, it's now 8 years ago that Scott and I thought it would be a cool idea to build Why no HTTPS? We used the site to shame companies for not implementing their transport later security property, and to make it a bit of fun, we shamed by country as well. This helped people jump on the bandwagon of giving their respective countries a little "encouragement", and we hope they'll do the same now with Why no Passkeys? Following my infamous phishing incident last year, I registered the domain with the intent of building the successor for the TLS version. However, due to a combination of me having no time and Scott getting very good with Claude Code, he's now stood up this project solo and done a wonderful job of it. Go and check it out, and give those big names from your country a little push.