2026-07-27 06:00:00
本文永久链接 – https://tonybai.com/2026/07/27/why-software-factories-fail-harness-engineering-not-enough
大家好,我是Tony Bai。
导读:
当“75% 的代码由 AI 生成”成为行业炫耀的资本时,HumanLayer 创始人 Dex Horthy 却在 AI Engineer World’s Fair 上泼了一盆冷水:他亲手关掉代码审查的灯,跑了几个月的全自动“软件工厂”,最后差点把自己的公司拖垮。他给出的诊断是:这不是 harness 不够聪明,而是训练编程模型的方式,从根上就没法教会它们“可维护性”这件事。
文章要点:

2026 年,几乎每一家把 AI 编程当回事的公司,都在讲同一个故事:我们的软件工厂已经能自动产出七成以上的新代码。这个数字确实惊人,也确实让很多团队第一次感受到了“代码是免费的”这种叙事的诱惑力——你不再是瓶颈,模型足够好了,只管往里喂需求,剩下的交给流水线。
但 Dex Horthy——HumanLayer 的创始人,一个在 Agentic Coding 领域已经积累了上百万 YouTube 播放量的实践者——在 AI Engineer World’s Fair 的演讲里给出了截然不同的判断:这条路走不通。
他把这场演讲的标题起得直白:《Harness Engineering is not Enough:Why Software Factories Fail》。翻译过来就是一句话——你把 harness(脚手架、编排层、沙箱、评审 agent)堆得再精巧,也解决不了一个更底层的问题,那就是当前的编程模型压根没被训练出“维护代码”这个能力。
要理解 Dex 的论点,得先回到“软件工厂”这个说法本身。这个词最早可以追溯到 1968 年的一次 NATO 会议,但真正和这篇文章相关的历史,从 2022 年——也就是 AI 编程爆发前夕——讲起更合适。
2022 年的经典流水线是这样的:
团队很早就发现,“动手实现”和“人工评审”这两个环节都是以小时甚至天为单位的重活。于是行业发展出了架构设计文档、迭代规划这些前置对齐机制,目的很简单:提前把认知对齐了,返工率就会降下来,评审也不用逐行死磕。
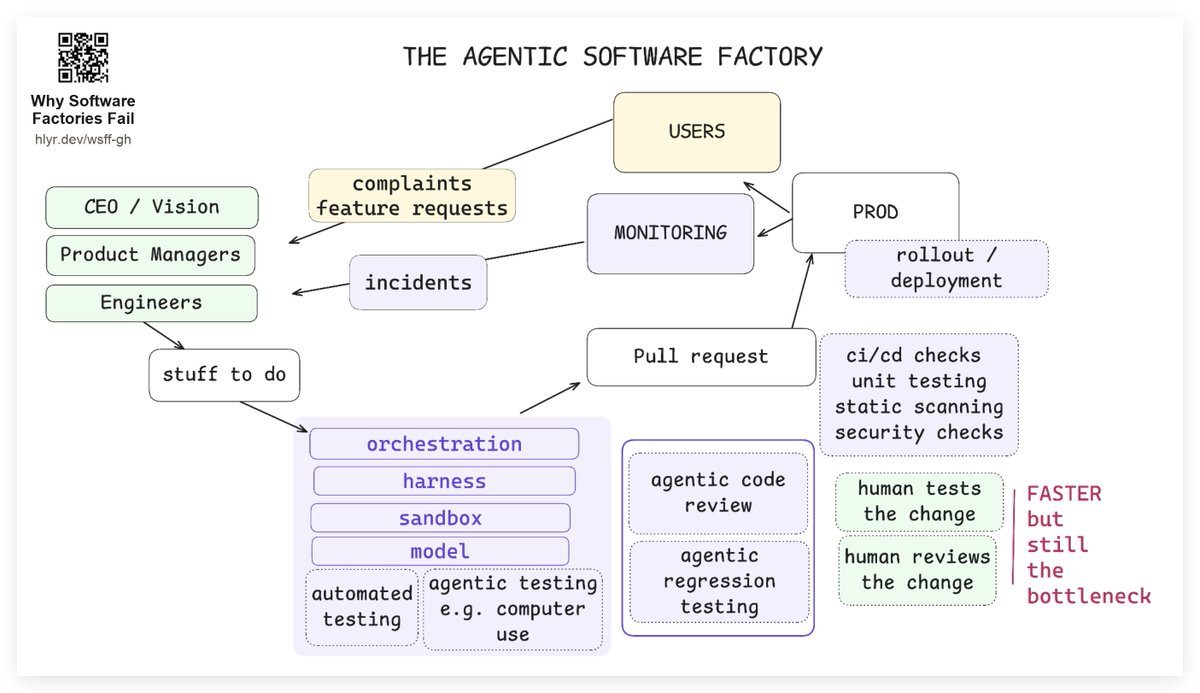
到了 Agentic 软件工厂,最直观的变化是“有人实现”被替换成了“agent 实现”——编排系统、harness、沙箱、模型、计算机操作能力一起上阵,“实现”这一步从几天缩短到几小时甚至几分钟。但人工评审和测试这一环节的耗时并没有同比例下降,很快就成了新的瓶颈。
于是行业的解法顺理成章:既然可以用 agent 写代码,那也可以用 agent 做代码评审、做回归测试。
再往前一步,就是**“黑灯工厂”(lights-off software factory)**——这个说法由 Dan Shapiro 提出:既然评审这么慢,干脆不评审了,把资源全部投入测试、监控、灰度发布等其他环节,让线上事故直接路由回工厂重新生成补丁,用户反馈也直接喂进队列。团队唯一要做的事,变成了“能往队列里塞多少任务,能多快地测试和上线”。
Dex 的判断很干脆:这条路走不通。
这不只是 Dex 一个人的直觉。他在演讲中提到,另一位从业者 Mario 在 AI Engineer Europe 上公开呼吁大家“慢下来”——原因是一些原本不该因为编程 agent 出问题而宕机的公司,正在因为 agent 的失误而宕机。
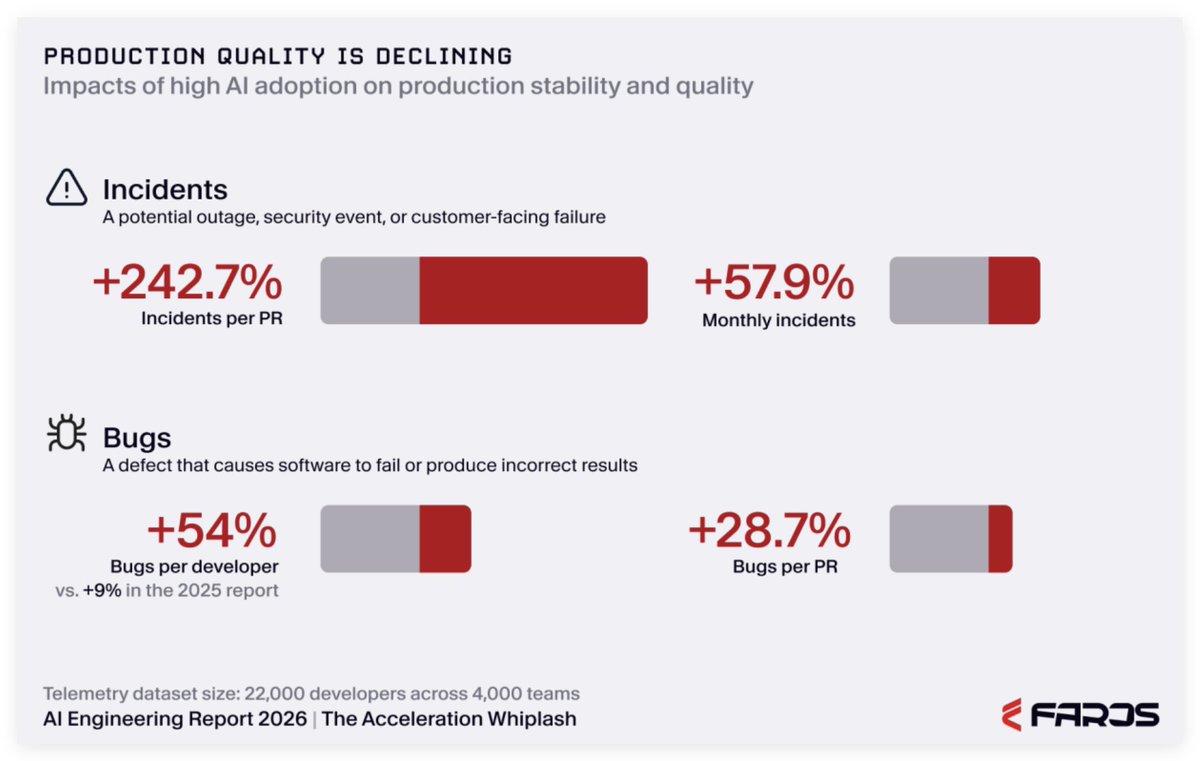
更系统性的证据来自 Faros AI 的一份行业报告:自 2026 年初大规模采用 AI 编程工具以来,Pull Request 的评审质量明显下降,评论数量更多、篇幅更长,同时有相当比例的 PR 是在完全没有评审的情况下直接合并的;与此同时,线上事故数量和人均 bug 数都在同步上升。
行业里流行的解释是“你用得不对”——只要 harness 工程做得再狠一点,再往 PR 评审机器人里塞一些“对抗性评审”之类的魔法提示词,就能鱼与熊掌兼得:速度提升 10 到 100 倍,质量不打折,还不用做人人都讨厌的代码评审。Dex 想说的是:这不是一个“规模问题”,再多的 harness 工程、再多的循环嵌套循环(loop maxing),都解决不了一个本质上是模型训练层面的问题。
这个判断不是纸上谈兵。Dex 特别强调,这篇文章的内容和“vibe coding”没有关系——一个人写着玩的、大概十几个人会用的副业项目,和一个维系了十年的企业级系统之间,几乎没有共同的约束条件,互相指导对方“应该怎么活”通常没什么意义。HumanLayer 关心的,是如何在复杂的、有历史包袱的代码库(他们称之为 brownfield)里解决难题——这类代码库以前的典型印象是“十年历史的 Java 老系统”,但 Dex 观察到,在如今的迭代节奏下,一个 agent 大约在三到六个月之后就会开始明显吃力。
他知道这一点,是因为 HumanLayer 自己在 2025 年 7 月真的把灯关了:跑了一段时间彻底的“黑灯软件工厂”。结果是,几个月之后,团队遇到了一个再高级的提示词都解决不了的问题——不得不回头去研究一个已经三个月没人读过的代码库,去做复现、去排查。与此同时,线上服务在出问题,用户在抱怨,团队自己也在被淹没在这几个月里悄悄堆积起来的“AI 味”代码里。
Dex 把这次经历总结成一个简单的结论:模型有一个明确的短板——它们没法在没有人类持续介入的情况下,维护并改善代码库的质量。这里说的“可维护性”,指的是那种典型的代码坏味道:改动代码库某一处,很容易在不经意间牵连并破坏另一处,也就是 Martin Fowler 所说的“霰弹式修改”(shotgun surgery)。
值得注意的是,Dex 特别澄清:如果只看“解决单个孤立问题”或者“随手搭一个营销落地页”,模型确实比一两年前强了不少;但在“提升代码库整体质量”这件事上,他认为进展并不明显。目前还没有足够好的基准测试能直接证明这一点,但只要长期和编程 agent 打交道,大概率会有同样的体感:它们往往会让代码库随时间推移变得更难维护。
要理解这个短板从哪来,得先搞清楚为什么第一个真正意义上的现象级编程 agent——Claude Code——能在不到一年时间里做到几十亿美元级别的收入规模。在它之前,Aider、CodeBuff 之类的命令行 agent 已经存在,工具集也差不多,都是读文件、写文件、编辑、检索、执行命令这一套。真正的分水岭在于:这是第一次由模型厂商,把模型和它最终要分发给用户的那套 harness 绑在一起训练。换句话说,模型不是“被适配”到某个外部工具链上,而是从训练阶段起就在这套工具链里反复练习工具调用和多步任务的解决。OpenAI 团队去年 11 月的一次分享也提到过类似的观点:如果你是个 harness 开发者,却不掌握模型权重、无法在自己的 harness 里对模型做强化学习,你相对于同时掌握模型和 harness 的厂商,天然处于劣势。
Dex 用一个极简的流程解释了当前主流的编程模型强化学习训练是怎么运作的:先给模型一个问题,让它反复尝试、生成一大批不同的解题轨迹;对每一条轨迹打分——代码能不能跑通、测试能不能通过;然后做强化:让“坏”的行为在未来变得更不可能发生,让“好”的行为变得更可能发生,模型权重据此更新。
一个典型例子是 SWE-bench Multilingual 这类基准:任务大多来自 Redis、jq、Django 这样的开源项目,时长大约十几分钟一个,奖励是二元的——问题修好了没有,以及有没有在修的过程中把别的地方弄坏。
演讲中举了一个来自 Fastlane(一个 Ruby 项目)的真实案例:某处代码没有做空值检查,导致空指针异常报错。基准测试会准备一个“问题修复前”的基础提交、一份描述期望行为的测试补丁,以及一份人类当年实际写出的“标准答案补丁”——这两者都对模型隐藏。
agent 去尝试解决问题、保存它生成的补丁;系统会撤销它对任何测试文件做的改动(因为确实见过模型为了让测试通过而直接把测试注释掉),再套用标准的测试补丁,看新旧测试是否都能通过。通过就给奖励,不通过就不给。
问题就出在这里:在这套体系里,没有任何机制能因为“程序设计糟糕”或者“正在腐蚀系统可维护性”而惩罚模型。这正是为什么会看到那些莫名其妙包裹在代码外面的 try/catch,或者纯粹为了让测试通过而做的类型强转——模型的唯一目标就是让测试变绿,至于代码本身是不是在“应付了事”,它并不关心。
如果说“代码能跑、测试能过”这件事验证起来相对容易,那“代码是否具备可维护性”的验证难度要高出好几个数量级,
原因很直接:一段架构糟糕的代码,代价往往要以月甚至年为单位才会真正显现出来。等到你几个月后才发现某次“随手改改”埋下了雷,想再把这个惩罚信号反向传导回训练那一刻,几乎是不可能的。
前沿模型在这方面确实在缓慢变好,但基准测试和用于训练的验证器之间存在天然的结构性相似——虽然严格意义上它们必须是不同的数据集,但整体形态是相通的,所以可以把当前基准测试的演进方向,看作是行业在“评估代码可维护性”这件事上正在摸索的路径。
演讲中提到了几个正在探索的方向:
但 Dex 同时给出了一个清醒的判断:靠“用模型评判代码质量”这条路能走多远是有天花板的——因为如果一个模型真的知道什么是好代码,它一开始就会直接写出好代码。
评审 agent、多花一些 token 去反复检查,确实能把及格线往上抬一抬,但终究还是被“强化学习阶段到底能教会模型什么”这件事卡住了脖子。
所以他的结论是:至少在现阶段,人类还是得亲自读代码。当然,如果你愿意一直 YOLO 提示词、一路等到某个远超当前水平的模型出现,那也是一种选择,只是“苦涩的教训”(bitter lesson)不会因此就消失——眼下这些问题,还是得靠工程手段先解决一部分。
既然验证器和基准测试还没跟上,Dex 给出的解法不是放弃 AI,而是把代码评审这盏灯重新打开,同时用 AI 把“前置对齐”这件事做得更快、更彻底,从而尽量降低评审环节漫长而痛苦的概率。具体是四层:
这套流程背后的核心逻辑很朴素:前期花三十分钟做规划和对齐,往往能在评审阶段省下几个小时。而且这条路径确实能做到——逐行读代码依然是可行的。
Dex 特别强调一个反直觉的观点:如果你发现自己被大量 PR 淹没,真正的问题往往不是“PR 太多”,而是“烂 PR 太多”——一个真正对齐过的好 PR,读起来是一种享受,因为你几乎是在确认“对,这就是我们讨论过的方案”;但哪怕一个 PR 只需要百分之二十的返工——这对相当一部分“AI 味”很重的代码来说已经算很客气了——它给评审者和提交者带来的情绪和认知负担依然不小。
用模型辅助规划和对齐之后,整个链路会同时在三个环节提速:对齐更快,因为可以借助 AI 一次性把所需信息都拉齐;评审更快,因为前期已经对齐过;编码更快,因为这部分本来就是 AI 完成的。结果是速度确实起来了,但人依然在逐行读代码,依然对代码拥有实质性的所有权。
听完这些,很容易感到有点泄气——毕竟“再也不用读代码”的世界确实诱人。
但 Dex 的落脚点很朴素:工程师的工作,本质上就是在一组约束条件下解决问题;模型在某些事情上确实很擅长,在另一些事情上确实还不行,工程师要做的是搞清楚边界在哪,然后在边界之内继续去解决难题、去寻找杠杆。循环(loop)这个工具很好用,该用就用,但真正值得投入精力的,是那些复杂代码库里的硬骨头。
参考资料
还在为写 Agent 框架频频死循环、上下文爆炸而束手无策?我的新专栏 《从0 开始构建 Agent Harness》 将带你:
扫描下方二维码,开启从 0 开始构建Agent Harness 的实战之旅。

还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。

2026-07-26 06:00:00
本文永久链接 – https://tonybai.com/2026/07/26/gomlx-one-year-later
大家好,我是Tony Bai。
导读: 两年前,我们写过一篇文章介绍刚刚起步的 GoMLX——一个试图在 Go 语言里复刻 PyTorch/Jax/TensorFlow 能力的机器学习框架。两年之后再回头看,它已经收获 1.5k 星标,拥有了独立的官方文档站点,还把核心计算引擎拆分成了独立的 compute 仓库,形成清晰的分层架构。这篇文章借着这次“回访”,从架构设计、四大核心抽象、多后端体系、代码实战到生态现状,全面梳理 GoMLX 现在到底发展成了什么样子。
文章要点:
compute 仓库,形成了“高层 API + 可插拔计算引擎”的清晰解耦架构。Backend(硬件编译桥梁)、Graph(纯 Go 描述的计算图)、Tensor(数据与显存载体)和 Store(参数与作用域管理)四大概念,建立了透明、无“魔法”的工程心智模型。xla 后端(压榨 GPU/TPU 极限算力)、零 CGO 依赖且支持编译为 WASM 的纯 Go go 后端,以及面向苹果生态的 go-darwinml 后端。go-huggingface(原生 Tokenizer、safetensors/GGUF 解析)与 onnx-gomlx(ONNX 计算图无缝转换与微调),实现了对通用预训练大模型生态的直接消费。
两年前我写过一篇文章,介绍了刚刚起步的 GoMLX——一个试图在 Go 语言里复刻 PyTorch/Jax/TensorFlow 能力的机器学习框架。那时它更像是一个雏形:API 还在快速变动,文档也不算完善,社区讨论主要集中在“Go 到底能不能做机器学习”这个基础问题上。
两年之后再看,情况已经发生了明显变化:
这不再是一个“能不能用”的项目,而是一个开始具备清晰架构分层、逐渐向生产可用性迈进的框架。这篇文章就带你完整梳理一遍现在的 GoMLX,究竟是怎么设计的、能做什么、值不值得现在就上手。
用一句话概括,GoMLX 是 Go 语言版本的 PyTorch/Jax/TensorFlow。它的核心主张只有一个词:不需要 Python。
GoMLX 支持训练、微调、修改和组合机器学习模型,提供了一整套可微分算子,以及训练过程中的可视化、调试工具。它的设计哲学可以归纳为几点:
从落地场景看,GoMLX 的目标不止是“能跑通一个 Demo”,而是想成为一个可生产化、可用于研究和教学的完整 ML 平台,具体包括支持现代加速器硬件(GPU/TPU)、支持从 HuggingFace 导入预训练模型进行微调,以及未来可以把模型编译成二进制或 WebAssembly,在任意语言环境里被消费。
理解 GoMLX,本质上是理解四个抽象概念,它们环环相扣,构成了整个框架的心智模型。
compute.Backend 是你的 Go 进程与底层硬件(CPU、GPU、TPU)之间的连接。它负责把计算图即时编译(JIT)成可执行代码,并管理主机内存与设备内存之间的数据搬运。通常一个进程只创建一个 backend,在程序全局复用:
import (
"github.com/gomlx/compute"
_ "github.com/gomlx/gomlx/backends/default" // 引入默认后端
)
backend, err := compute.New() // 自动选择最合适的后端
fmt.Printf("Backend: %s\n", backend.Description())
compute.New() 会按照 CUDA GPU → Metal(Apple)→ CPU 的顺序自动选择最优后端,也可以通过环境变量 GOMLX_BACKEND 或者 compute.NewWithConfig("go") 显式指定。
Graph(计算图) 是一个用 *graph.Node 及其相互连接的运算组成的纯函数,用来描述一次计算。GoMLX 提供了丰富的高层 API 来构建这些图,构建完成后交给后端做 JIT 编译并高效执行。
addFn := func(a, b *Node) *Node {
return Add(a, b)
}
addExec, err := NewExec1(backend, addFn)
v1, err := addExec.Call(1.0, 1.0)
这里有两个反直觉但很关键的设计:
*graph.Node 的具体内容,只有在真正调用 .Call() 执行之后才能拿到结果。节点携带的是形状(shape)和数据类型信息,用于在构建阶段就能检查出维度或类型不匹配的问题。Exec 包装器会自动捕获这些 panic,并在 .Call() 被调用时转换成带完整堆栈信息的标准 Go error。这种“图先构建、再编译、再执行”的模式,和 JAX 的 @jax.jit、TensorFlow 的 @tf.function 本质上是同一套思路:把计算的全貌交给后端去看,才能做算子融合、内存布局优化等激进优化。
这里也有一个需要留意的“坑”:JIT 编译是和输入的静态形状绑死的。如果每次调用传入的 batch size 或序列长度都不一样,GoMLX 会为每一种新形状重新编译一次图,而编译的代价远高于执行本身,所以官方建议尽量固定输入形状,或者把变长输入 pad 到几个固定的桶(bucket)里复用已编译的图。
Tensor 是图计算的输入输出,代表一个具体的多维数组(也可以是标量),由形状(shapes.Shape)和数据类型(dtypes.DType)共同定义:
t := tensors.FromValue([][]float32{{1.0, 2.0}, {3.0, 4.0}})
fmt.Printf("Tensor shape: %s\n", t.Shape())
// 输出: Tensor shape: (Float32)[2, 2]
Tensor 内部会同时维护主机内存(本地 CPU)和设备内存(GPU/TPU)两份缓存,数据搬运是惰性触发的,只有在真正需要时才发生,以此减少不必要的拷贝开销。因为 Go 的垃圾回收器无法感知加速器设备上的内存,长期持有大量张量时,建议显式调用 FinalizeAll() 释放设备内存,而不是完全依赖 GC。
如果只是做数学计算,Backend 加 Graph 就够了;但要训练模型,就需要一个地方持久化存放权重、偏置这类可训练变量(Variable),以及模型的超参数——这就是 model.Store 的职责。
model.Store 是真正存放张量数据的容器,而 model.Scope 则是指向 Store 内某个路径(类似“当前目录”)的轻量指针。层函数接受一个 *model.Scope,并在当前作用域内声明或查找变量,从而避免命名冲突:
func denseLayer(scope *model.Scope, x *Node, outputDims int) *Node {
g := x.Graph()
dtype := x.DType()
inputDims := x.Shape().Dimensions[1]
weights := scope.VariableWithShape("weights", shapes.Make(dtype, inputDims, outputDims)).NodeValue(g)
biases := scope.VariableWithShape("biases", shapes.Make(dtype, 1, outputDims)).NodeValue(g)
return Add(Dot(x, weights).Product(), biases)
}
modelFn := func(scope *model.Scope, x *Node) *Node {
h := denseLayer(scope.In("layer1"), x, 3) // 变量路径: /layer1/weights, /layer1/biases
y := denseLayer(scope.In("layer2"), h, 1) // 变量路径: /layer2/weights, /layer2/biases
return y
}
scope.In("layer1") 这类调用,本质上是在 Store 里划分出一棵树状的命名空间,让不同层的权重互不冲突,也方便后续统一遍历、保存、加载。
把这四个抽象放到一起看,会更容易理解它们之间的分工与数据流向:

如上图所示:输入张量流入计算图参与运算,Store 中的变量也会注入计算图;计算图交给 Backend 做 JIT 编译并执行,产出结果张量;训练过程中更新后的权重,再写回 Store,形成一个闭环。图中灰色代表数据(Tensor),青色代表框架的核心组件(Store/Graph/Backend)。
v0.28 版本里,GoMLX 做了一次比较大的“外科手术”:把 backends、dtypes、shapes、distributed 这些偏底层的包,整体搬到了新的独立仓库 github.com/gomlx/compute 中。
compute 仓库的定位描述得很清楚:提供一个模块化的 API,用于定义和执行带有可插拔后端的多维计算图。它对外暴露一个 compute.Backend 接口(一组接口的集合),可以用来构建计算图、JIT 编译、在主机和设备之间搬运缓冲区(张量的原始数值)、执行已编译的计算。
这次拆分背后的用意值得展开说说:
github.com/gomlx/compute/gobackend 里,并且做了大量性能改进;“xla”后端则被移到了另一个独立仓库 github.com/gomlx/go-xla 下的 compute/xla 包中。notimplemented 默认实现、实现缓冲区搬运、按需实现具体算子,最后用 backendtest.RunAll(t, myBackend) 跑一遍标准合规测试即可。换句话说,任何人都可以按照这套接口规范,为 GoMLX 生态贡献一个新的执行后端,而不需要动到上层 API 一行代码。这种“上层框架+独立可插拔计算引擎”的架构,和 PyTorch 的 ATen/Dispatcher,或者 JAX 的 XLA 层,思路是相通的:把“怎么算”和“算什么”彻底解耦。
目前 compute.Backend 接口已经有三种实现,分别覆盖了不同的部署场景:

| 后端 | 特点 | 适用场景 |
|---|---|---|
| xla | 基于 OpenXLA(PJRT),与 Jax、TensorFlow、PyTorch/XLA 共用同一套引擎,支持 JIT 编译到 CPU、Nvidia GPU(也大概率兼容 AMD ROCm、Intel)以及 Google TPU;仅支持静态形状 | 训练大模型、处理大数据集,追求极致性能 |
| go | 纯 Go 实现,无 C/C++ 依赖,非常轻量、可移植,甚至可以编译到 WASM 在浏览器里跑;已经开始支持 AVX2/AVX512 的 SIMD 加速(目前主要用于矩阵乘法),以及部分算子融合和量化优化 | 嵌入式设备、浏览器端推理、无需安装额外依赖的轻量部署 |
| go-darwinml(实验性) | 面向苹果生态的 CoreML 绑定,支持 Metal 加速、MLX,以及 DarwinOS 相关后端 | macOS/iOS 场景下的本地推理 |
值得一提的是官方给出的一个真实例子:有人把 GoMLX 通过 go 后端编译成 WASM,用于给一个叫 Hive 的桌面游戏跑 AlphaZero 风格的 AI 对手,整个推理过程直接在浏览器里完成,不依赖任何服务端。这也印证了纯 Go 后端“哪里能跑 Go,哪里就能跑 GoMLX”的定位。
后端选择既可以自动完成,也可以通过环境变量精确控制,例如:
export GOMLX_BACKEND=xla:cuda # 使用 XLA + Nvidia CUDA
export GOMLX_BACKEND=xla:cpu # 使用 XLA + CPU
export GOMLX_BACKEND=go # 使用纯 Go 后端
对于 XLA 后端,GoMLX 还提供了 PJRT 插件自动安装能力:首次运行时会自动把对应硬件(CPU/GPU/TPU)所需的 PJRT 插件下载安装到用户本地目录,免去了手动配置的麻烦;如果需要制作精简的生产镜像,也可以通过 --tags=pjrt_cpu_static 等方式做静态链接。
光讲架构比较抽象,我们来看一段官方示例的完整代码:训练一个多层感知机(MLP),学习把归一化后的像素坐标 (x, y) 映射为对应的 RGB 颜色,本质上是让网络“记住”一张图片。
// 1. 准备训练数据:把 (x, y) 坐标映射到 (r, g, b) 颜色
inputs := make([][]float32, 0, width*height)
labels := make([][]float32, 0, width*height)
for y := range height {
for x := range width {
nx := float32(x)/float32(width)*2.0 - 1.0
ny := float32(y)/float32(height)*2.0 - 1.0
inputs = append(inputs, []float32{nx, ny})
r, g, b, _ := img.At(bounds.Min.X+x, bounds.Min.Y+y).RGBA()
labels = append(labels, []float32{float32(r) / 65535.0, float32(g) / 65535.0, float32(b) / 65535.0})
}
}
backend := compute.MustNew()
store := model.NewStore()
// 2. 构建内存数据集
ds, err := dataset.InMemoryFromData(backend, "image_pixels", []any{inputs}, []any{labels})
ds.BatchSize(512, false).Shuffle().Infinite(true)
// 3. 定义模型结构(3 层 MLP)
modelFn := func(scope *model.Scope, spec any, inputs []*Node) []*Node {
x := inputs[0]
h := denseLayer(scope.In("layer1"), x, 64)
h = activation.Relu(h)
h = denseLayer(scope.In("layer2"), h, 64)
h = activation.Relu(h)
h = denseLayer(scope.In("layer3"), h, 64)
h = activation.Relu(h)
y := Sigmoid(denseLayer(scope.In("output"), h, 3))
return []*Node{y}
}
// 4. 配置训练器:Adam 优化器 + MSE 损失
trainer := train.NewTrainer(
backend, store, modelFn,
loss.MeanSquaredError,
optimizer.Adam().LearningRate(0.003).Done(),
nil, nil,
)
// 5. 运行训练循环
loop := train.NewLoop(trainer)
train.EveryNSteps(loop, 1000, "log_metrics", 0, func(l *train.Loop, metrics []*tensors.Tensor) error {
fmt.Printf("Step %5d: MSE Loss = %.6f\n", l.LoopStep, metrics[0].Value())
return nil
})
_, err = loop.RunSteps(ds, 5000)
训练日志大致是这样的:
Starting training loop...
Step 999: MSE Loss = 0.000038 (moving average = 0.000040)
Step 1999: MSE Loss = 0.000067 (moving average = 0.000027)
Step 2999: MSE Loss = 0.000012 (moving average = 0.000030)
Step 3999: MSE Loss = 0.000010 (moving average = 0.000019)
Step 4999: MSE Loss = 0.000013 (moving average = 0.000018)
Training finished!
这段代码把前面讲的四大抽象串到了一起:backend 负责编译执行、store 负责持久化权重、graph(modelFn)负责描述前向计算、trainer/loop 负责组织训练流程。更重要的是每一块都可以单独替换:换个优化器只改一行,换后端只改一个环境变量,模型结构改动完全不影响训练循环的写法——这正是 GoMLX 反复强调的“组合性”设计理念在实际代码里的体现。
自动微分方面,GoMLX 使用 graph.Gradient(loss, targets...) 在图构建阶段自动完成符号微分,把反向传播所需的运算直接追加进计算图。需要注意的是,目前它只支持对标量损失求梯度,不直接提供雅可比矩阵或黑塞矩阵,如果需要高阶导数,需要手动对梯度节点再次求导来实现。
单靠核心框架很难覆盖真实业务场景,GoMLX 这两年里补齐了不少生态组件:
sentence_transformers 的句子嵌入能力。像 Tencent 出品、在 RAG 场景中排名靠前的 KaLM-Gemma3(12B 参数)句子编码器,就是通过这套工具在 GoMLX 上跑起来的。onnxruntime 的替代方案(复用 XLA 的加速能力),也可以用来对模型做进一步微调。官方示例里已经跑通了 Gemma 3 270M 文本生成、BERT-base 命名实体识别、MixedBread Reranker 等真实模型。github.com/gomlx/gomlx/core/tensors/numpy 包支持直接读取 Numpy 数组,方便和 Python 生态做数据交换。docker run 命令就能拉起一个带 GPU 支持的交互式笔记本环境,对于想快速试用的人来说几乎是零配置。从这些拼图可以看出一个清晰的信号:GoMLX 团队没有打算“重新发明一切”,而是选择尽可能与 HuggingFace、ONNX 这些既有生态对接,把主要精力放在 Go 语言侧的执行效率和工程体验上。
层库(layers)是 GoMLX 里更新最频繁的部分之一,目前已经覆盖了相当完整的现代神经网络组件:
在工程侧,分布式执行是目前官方标注为“仍在积极改进中”的实验特性:基于 XLA Shardy(GSPMD 分布式方案的演进版本)实现跨多 GPU/TPU 的分布式训练,用户只需要配置好分布式数据集,训练器会自动接管剩下的工作,官方也坦诚这部分还在打磨阶段,欢迎社区反馈问题。
另外还有一个专门的命令行工具 gomlx_checkpoints,可以检查训练中/训练完的模型 checkpoint,并用 Plotly 生成损失曲线和评估指标的可视化图表,甚至支持把多个模型的训练曲线放在一起对比——对于需要做大量调参实验的场景很实用。
坦白讲,GoMLX 不是要把 Python 生态“拉下马”,它解决的是另一类问题:当你的服务本身就是用 Go 写的,或者你需要一个单文件、无需安装 Python 解释器和一堆依赖的推理/训练程序时,GoMLX 提供了一条不需要跨语言胶水层的路径。
它的取舍很清楚:
如果你的场景是研究探索、追求最快原型迭代速度,Python 生态目前仍是更稳妥的选择;但如果你要把模型部署进一个 Go 编写的后端服务,或者想要一个体积小、依赖少、可以编译成单一可执行文件的推理程序,GoMLX 提供的价值就非常直接了。
简单盘点一下现在的项目状态:
#gomlx、Google Groups 讨论组,以及 GitHub Discussions 都在保持活跃。官方公开的长期目标可以概括为三条主线:
两年时间,GoMLX 从一个“Go 能不能做机器学习”的验证性项目,成长为一个有清晰分层架构、独立后端引擎、覆盖训练到部署全流程、并且开始积累真实生态组件(HuggingFace、ONNX、Docker 镜像)的框架。compute 仓库的独立,某种程度上标志着这个项目已经从“单体原型”走向了“可持续演进的工程体系”。
它依然不完美:分布式训练还在实验阶段,动态形状支持才刚刚起步,生态体量也远不能和 Python 阵营相提并论。但对于长期用 Go 写后端服务、又想在自己的技术栈内完成模型训练和推理的团队和个人开发者来说,GoMLX 已经从“可以关注一下”变成了“值得认真评估”的选项。
如果你想亲自上手,可以从官方仓库 github.com/gomlx/gomlx 的 README 开始,里面的 Jupyter 教程和 Docker 镜像能让你在几分钟内跑起第一个模型。
参考链接:
还在为写 Agent 框架频频死循环、上下文爆炸而束手无策?我的新专栏 《从0 开始构建 Agent Harness》 将带你:
扫描下方二维码,开启从 0 开始构建Agent Harness 的实战之旅。
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
2026-07-25 07:00:00
本文永久链接 – https://tonybai.com/2026/07/25/ai-code-migration-claude-code-six-steps
大家好,我是Tony Bai。
导读:代码语言迁移,曾经是工程团队避之不及的“三年之痒”项目——耗资数百万美元、耗时数年、还可能烂尾。但Anthropic最近披露,公司内部工程师用Claude Code在一个月内完成了10个代码包的迁移,其中包括Bun联合创始人Jarred Sumner把百万行Zig代码迁移到Rust,只用了不到两周;Labs联合负责人Mike Krieger把一套Python代码库迁移成16.5万行TypeScript,只花了一个周末。这背后到底是什么样的方法论?答案出人意料:真正的关键不是让AI“改代码”,而是让AI“改生产代码的流程”。
文章要点:
一个周末,16.5万行代码。
这不是某个创业公司连夜赶工的产物,而是Anthropic Labs联合负责人Mike Krieger,把一套Python代码库完整迁移成TypeScript所花的时间。整个过程动用了数百个智能体、8个阶段关卡、3轮对抗式审查,最后还有一轮把每一条命令的输出结果都和Python原版逐一比对的“一致性核查”。
几乎同一时间,Bun联合创始人、现Anthropic技术成员Jarred Sumner,用Claude Code把Bun这个拥有百万行代码的项目从Zig迁移到了Rust。整个过程不到两周,合并前Bun原有测试套件100%通过CI。合并之后陆续发现了19个回归问题,也已经全部修复。
在过去,这种规模的语言迁移是工程团队想都不敢想的“多年工程”,动辄需要三到四百万美元的人力投入,跨越数年时间。而现在,Anthropic的工程师在一个月内,靠Claude Fable 5、Claude Opus 4.8和动态工作流(dynamic workflows),一口气迁移了10个代码包,规模从数万行到数十万行不等。
Anthropic把这套方法论写成了一篇详细的复盘文章。今天新智元就来拆解一下,这套“六步迁移法”到底是怎么把不可能变成可能的。
先说清楚“为什么”和“什么时候”,而不是急着讲“怎么做”。因为这类项目的成本账本,已经彻底变了。
团队启动语言迁移,通常是因为最初的技术选型和现在的项目需求之间出现了错位:要么当初的权衡取舍如今变成了掣肘,要么出现了更好的方案,要么原有的技术生态正在萎缩。
Jarred当初选择Zig,是因为它兼具C语言级别的性能和极致的简洁性——这对于一个人在奥克兰的小公寓里、在LLM出现之前独自写Bun的创始人来说,是最合适的选择。但这份简洁性也带来了众所周知的代价。
时间快进到2026年,Bun的CLI月下载量已经超过1000万次,并且在Claude Code内部被大量使用。放在一个季度以前,这些代价还不足以让团队冻结路线图、投入巨大资源去做一次跨季度的大迁移。语言迁移固然能带来更小、更快、更安全的系统,但没人愿意为此买单。
工程师们过去还要承担这类超级项目本身自带的职业风险:维护两套并行代码库长达数个季度甚至数年,如果最终结果只有90%的行为一致,那你的麻烦只会比开始时更大。
而现在,最坏的结果不过是删掉分支,重新再来一次。
当然,商业上的理由依然要站得住脚。虽然百万行级别的迁移不再需要三四百万美元、耗时四年的投入,但依然需要数万到数十万美元不等的成本。以Bun的迁移为例,整个项目消耗了59亿个未缓存输入token和6.9亿个输出token,按API定价计算大约花费16.5万美元。Mike的迁移主体部分则消耗了2700万token。
但迁移的理由不再需要是“生死攸关”的。 一年里changelog上反复出现的内存bug、一个长期存在的性能瓶颈,如今就足以构成迁移的理由。
Mike这次项目的导火索,正是一个编译环节。他团队维护的内部工具以单一二进制文件的形式分发给用户,用Python工具链构建这个二进制文件,每个平台大约要8分钟,整个构建矩阵每次发布加起来要等30分钟。迁移之后,同样的编译过程只需要大约2秒,二进制启动速度提升了6倍,团队甚至因此得以下线一整条独立的部署流水线。
Claude Fable 5是Anthropic目前能力最强、已经公开可用的模型。Fable和Opus 4.8尤其擅长的,是在多条并行任务线之间分派、指挥、验证子智能体的工作,并且能找到多条通往目标的路径。
大规模代码迁移之所以特别适合交给这类高阶模型来做,原因有五点:
后文会看到,Mike和Jarred都在关键步骤里用到了Fable,尤其是一种“顾问模式”——用不同档位的模型组合,来优化token消耗。
这是整篇文章最重要的一句话:
你不是在修代码,你是在修产出代码的那个循环(loop)。
也就是说,AI代码迁移的本质,不是让模型逐文件地“翻译”代码,而是工程师去写迁移规则和验证循环,然后让智能体在这套循环里不断翻译、编译、测试,直到新代码的行为和原代码完全对齐——把原本要跨越数年的项目,压缩进几周之内。
在动手迁移之前,必须先有一套能公平评判“原始代码”和“目标代码”的裁判系统,否则你既没有退出条件,也没有成功的衡量标准。
用原语言写的测试套件,往往依赖只存在于原语言里的内部函数,这些函数在目标语言里根本不存在。所以要先做三件事:
Jarred手里有一套用第三种语言(TypeScript)写的大型测试套件,但大多数项目不会有这种条件。Mike则是为他的Python到TypeScript迁移,专门造了一套包含7个真实场景的一致性核查工具,任何行为上的变化都被当作bug来修复。
整个流程分为六步,其中Jarred的方法论更接近“结构保留式”迁移(每个阶段都有审查和关卡),Mike则是把整个迁移端到端跑一遍、根据结果修改规则和工作流、再跑一遍——每次都推倒重来,直到第三次才保留结果。
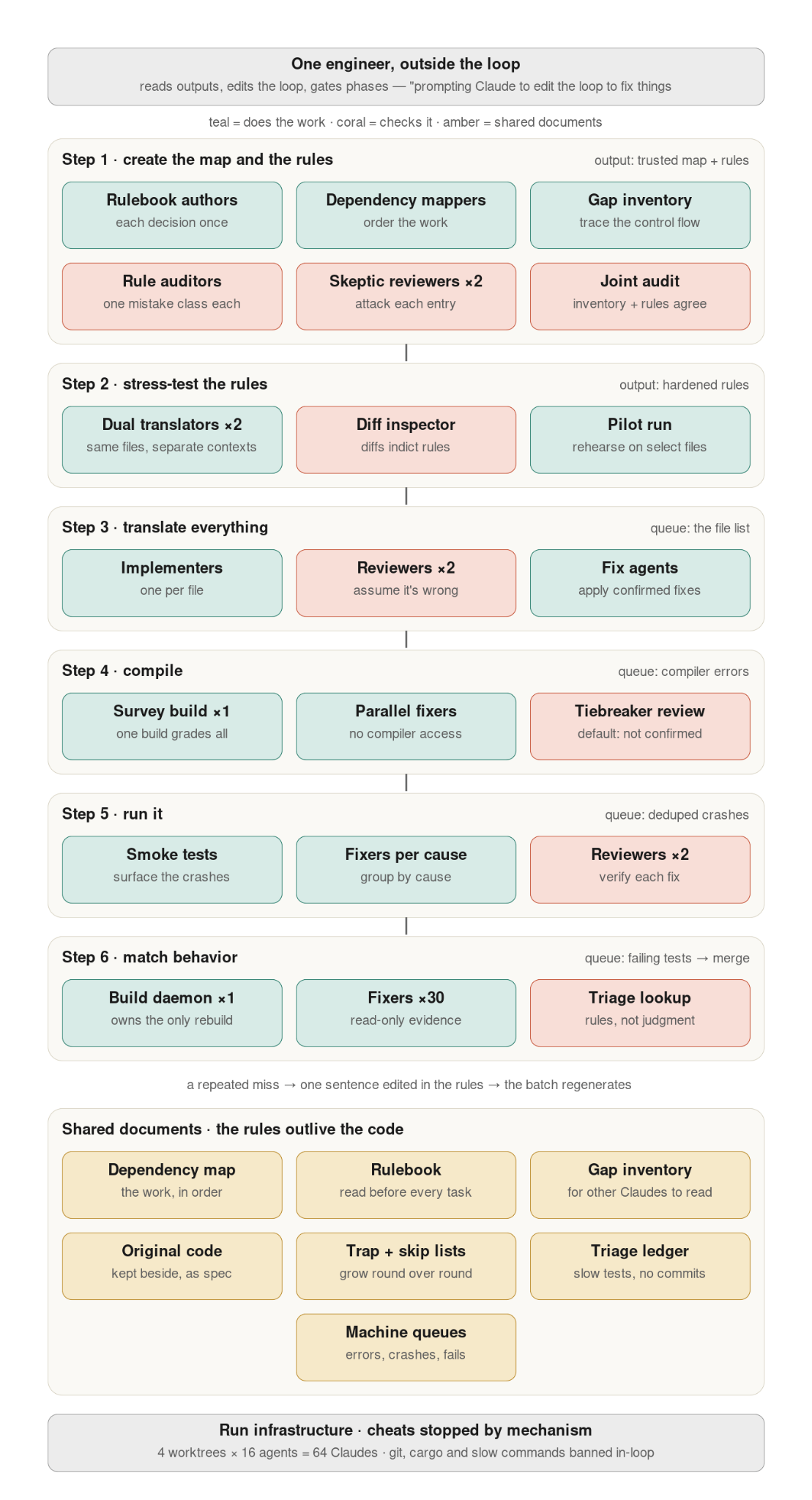
这一步是在打地基:找出哪些代码需要重构而不只是翻译,制定一套翻译规则手册,再画出依赖地图,用来确定并行迁移的先后顺序。
顺序很重要:规则手册要先于差距清单。
差距清单本质上是“规则手册默认规则覆盖不到的部分”,两者要放在一起联合审计。
规则手册的具体形态,取决于一个关键的架构决策:新代码是保留原有结构,还是彻底重新设计?
如果是前者(如Jarred的做法),规则手册主要就是在不同语言之间做类型和习惯用法的对照表,遇到难翻译的部分就指向差距清单。如果是后者(如Mike的做法),规则手册就变成了一份设计文档。
Jarred的做法是直接和Claude对话,为每一处存在歧义的地方形成一条明确的策略,同时用8个子智能体,专门针对他凭经验总结出的8类常见失败模式做审查。
依赖地图方面,你需要理解文件之间的依赖关系,才能合理拆分并行迁移的工作流,知道哪些文件要先迁移、哪些文件要归入同一批次。有些语言和代码库有明确的依赖清单,但对于遗留代码库以及C/C++、Python这类常见语言来说,这些依赖关系往往需要靠工具去发现和梳理。Claude Code可以部署智能体,编写并运行一个确定性脚本来生成这份依赖地图。
差距清单和“怀疑论”审查者方面,新语言相比旧语言总会有一些新的硬性要求。比如从Zig到Rust,最大的差异就是手动内存管理(这一点C和C++也是同样的问题):
Zig:
fn readConfig(allocator: std.mem.Allocator) ![]u8 {
const buf = try allocator.alloc(u8, 1024);
// ...fill buf...
return buf; // caller must free this — but only the comment says so
}
// 调用者忘了 'defer allocator.free(buf)' 依然能编译通过——内存泄漏只会在运行时暴露
Rust:
fn read_config() -> Vec<u8> {
let buf = vec![0u8; 1024];
// ...fill buf...
buf // 所有权转移给调用者,内存自动释放
}
// 用完之后还想用?重复释放?两种情况都编译不过
// 忘记释放?根本没有free调用需要你去忘记,drop是自动的
而从Python到TypeScript,差距则体现在接口和契约上。Python不要求声明一个对象接受什么形状的数据、返回什么类型,但TypeScript要求:
Python:
def register(handler):
handler.setup()
return handler.run({“retries”: 3})
# 任何有 .setup() 和 .run() 方法的对象都能传进来。到底哪些对象会被传进来?得读完整个代码库才知道
TypeScript:
interface RunResult { ok: boolean }
interface Handler {
setup(): void;
run(opts: { retries: number }): Promise<RunResult>;
}
function register(handler: Handler): Promise<RunResult> {
handler.setup();
return handler.run({ retries: 3 });
}
// 契约必须先写清楚,代码才能编译通过
Jarred和Mike都建了差距清单文件,把这些隐性知识记录下来。区别在于,Jarred是提前把这些差距梳理清楚,Mike则是先翻译、再通过事后审计的方式生成差距清单——实际项目中,你可能两种方式都需要用到。
这一步相当于给正式迁移做一次“下水前的试航”,是一次小规模的迷你迁移。
Jarred的做法是:一个智能体按照规则手册翻译3个文件,另一个智能体“像一名资深Rust工程师”那样翻译同样的3个文件,第三个智能体负责对比两者的差异,生成新的翻译规则。就是在这一步,他发现了两个关键问题——如果不提前发现,这两个问题一旦扩散到全部1448个文件,后果不堪设想。
需要注意的是,这种压力测试只适用于“保留结构”的迁移,也就是同一份文件的两种翻译版本可以逐行对比的情况。如果你的规则手册本质上是一次重新设计(就像Mike那样),等效的做法是直接用对抗式审查者攻击设计文档本身,再用一次可丢弃的端到端试跑来验证。
无论哪种方式,这一步翻译出来的文件都要全部扔掉——目的是打磨规则,而不是取得实质性进展。
从这一步开始,后续几个阶段都会重复同一套多智能体循环架构:实现、审查、修复。
实现类的工作可以交给较小的模型,审查类的工作留给更大的模型。比如Mike在主体迁移阶段,用Claude Sonnet铺开了12个子智能体。
任务队列的运转应该是机械化的:批处理脚本通过检查磁盘上翻译文件是否存在来判断任务是否完成,然后把待处理的文件切分成批次分配给负责实现的智能体。由于队列每次都是从磁盘状态重新构建的,整个迁移天生就是可断点续跑的。
在这个阶段,智能体有时会过于谨慎,不敢下手改动太多。解决办法很直接:用一句直白、强硬的提示词告诉它,编译器会在下一步帮你兜底纠错。
任何翻译智能体没有把握执行的地方,都会被标记为 // TODO(port): <原因>,留到第四步处理。从这里开始,待办清单基本可以自动生成:编译器会列出错误,冒烟测试会揪出崩溃,测试套件会报告失败项。
两个对抗式审查者会在各自独立的上下文中评估实现智能体的工作成果,一旦两者意见不一致,就交给第三个智能体裁决。当某个审查者反复在不同文件里抓到同一类错误时,解决办法不是逐文件修补,而是在规则手册里加上一句话,重新生成受影响的那批文件。规则手册在这一步会持续扩充,代码本身永远不会被拿去“手动打补丁”对抗规则。
关于这一步有个值得注意的设计决策,是编译器放在流程的哪个位置。Mike选择在每一轮循环里都跑一次TypeScript编译器,因为它几秒钟就能检查完一个单元;Jarred则完全把编译器排除在这一轮循环之外,留到下一步,因为cargo编译要花几分钟。
到这一步,大部分繁重的工作已经完成,提示词也开始变短。
这三步共享同一套循环架构,需要的人工判断也逐步减少,所以放在一起讲。第四步在某些语言和规模的迁移里,甚至会直接融入第三步。
具体要不要跑这一步,取决于编译环节的规模和难度。Jarred的做法是用一个编排脚本,对整个工作区一次性调用编译器,“修复智能体”再并行处理错误列表并进行对抗式审查,然后重新构建,如此循环。
审查错误列表本身也很有价值,可以发现需要系统性调整的问题。比如Jarred遇到过成千上万个Rust模块错误,这些错误是在修复Zig原本靠“惰性编译”容忍的循环导入问题后才暴露出来的。他的解决办法是编写一套分类逻辑,用来判断某个依赖关系应该删除、移动,还是重新划定边界。
第五步同样有一个机械化的判断依据,类似编译器错误列表——冒烟测试中出现的崩溃。这里的循环修复方式也是把问题按根因分类,再交给对抗式子智能体审查。
第六步,也是整个故事的收尾,是对比两套代码库的行为表现。
此时文件已经完成翻译、编译和冒烟测试,接下来要把它们分片,用第一步准备好的测试套件跑一遍。用“修复智能体”处理失败的测试,对照两套代码库找问题,对抗式审查者再检查这些修复是否合理。
这个循环的下一个环节是一个构建守护进程(build daemon),它是唯一被允许重新构建二进制文件的进程。修复智能体只负责写补丁,守护进程负责批量处理这些补丁、统一重新构建、重跑受影响的测试,再把结果反馈回去。这样做的目的,是把最昂贵的操作串行化,避免多个智能体各自触发重复构建。
当同一个失败反复出现在很多测试里时,修复方式会上移一层:直接修改产生这个bug的规则,只重新生成这条规则影响到的文件。
Mike的做法在这里特别值得参考,因为大多数开发者手里并没有现成的、已经迁移好的测试套件。Mike让Claude写了一个小脚本,用7个真实场景分别跑一遍新迁移的版本和原始Python代码库,再比对结果差异。每个失败的场景都配一个专属的修复智能体,循环运行直到7个场景全部通过。
然后他又往前多走了一步:让Claude自己设计一套端到端测试套件,连续四个晚上自主运行、自动修复出现的问题。正是这一步,抓到了任何场景清单都不可能预先想到的各种细枝末节的问题。
这里的启示是:没有现成测试套件,不该成为这一步的绊脚石。 如果你继承不了一个现成的裁判,那就让Claude自己造一个。不管怎样,你的原始代码库始终是那个“绝对真理”。
每一次迁移都会教会团队一些上一次没学到的东西,你的下一次迁移大概率也会教你这份指南里没写的东西。但以下几条原则,在每一个项目里都成立:
Jarred的Bun迁移项目现在已经在生产环境跑着,当然任何迁移都会有取舍——比如大约4%的Rust代码位于“unsafe”代码块内,主要是C/C++边界上的单行指针操作。
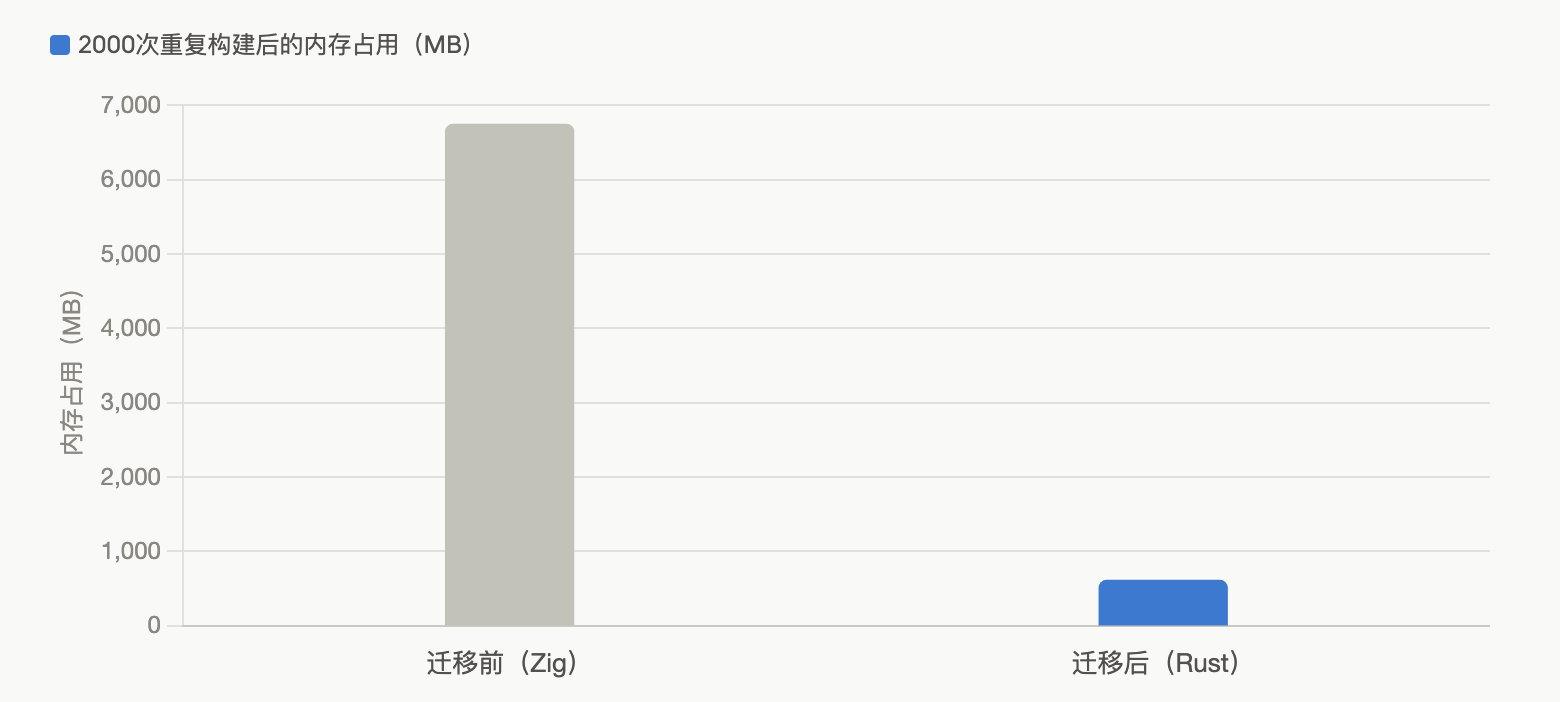
但新代码库在各项指标上都有可衡量的提升:团队工具能检测到的每一个内存泄漏都已修复,一项针对2000次重复构建的基准测试显示,内存占用从6745MB降到了609MB。二进制文件在Linux和Windows上体积缩小了19%。跨语言优化还带来了2%到5%的性能提升,覆盖HTTP服务和next build、tsc这类真实工作负载。
Anthropic给出的建议很直接:重新算一算你那个被长期搁置的迁移项目的账。 挑一个你已经忍了很久的代码库,问问Claude,这个项目的迁移流程会是什么样的。
延伸阅读:
github.com/anthropics/code-migration-kit-with-claude-code(该工具包是本文流程的通用化模板,并非Bun或Mike项目实际使用的原始代码)本文编译整理自Anthropic官方博客文章《How Anthropic runs large-scale code migrations with Claude Code》,原文发布于2026年7月16日。
还在为写 Agent 框架频频死循环、上下文爆炸而束手无策?我的新专栏 《从0 开始构建 Agent Harness》 将带你:
扫描下方二维码,开启从 0 开始构建Agent Harness 的实战之旅。
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
2026-07-24 06:00:00
本文永久链接 – https://tonybai.com/2026/07/24/tokio-topcoat-rust-fullstack-framework
大家好,我是Tony Bai。
导读:
Tokio,那个几乎撑起了整个Rust异步生态的项目组,这次把手伸向了全栈Web开发。7月22日,tokio-rs官方仓库悄悄多了一个新成员——Topcoat,一个号称“电池齐全”的全栈响应式Web框架。没有WebAssembly,没有前后端分离的心智负担,Rust代码写一遍,服务端渲染、浏览器交互两头跑。思路上更接近HTMX、Phoenix LiveView,而不是Leptos、Dioxus那种WASM路线;这背后,是Tokio创始人Carl Lerche对“AI编程时代”的一次押注:当AI抹平了学习一门语言的门槛,Rust现在最缺的不是“好不好学”,而是“生态够不够用”。语言生态的丰富程度,会不会才是决定胜负的关键?
文章要点:
$(...) 宏将部分 Rust 表达式编译为轻量 JS,实现了类似 HTMX / Phoenix LiveView 的极简响应式体验。
如果你写过Rust后端,大概率绕不开Tokio。它是Rust异步生态事实上的标准运行时,tokio::main、tokio::spawn这些关键字几乎是每个Rust后端项目的标配。围绕Tokio,官方组织tokio-rs这几年已经陆续孵化出了HTTP框架Axum、tracing日志框架、mio底层I/O库等一系列“国民级”项目。
7月22日,tokio-rs的官方博客发布了一篇文章,宣布了一个新项目:Topcoat——官方给出的定义是“一个模块化、电池齐全的Rust全栈响应式Web应用框架,主打简单和生产力”。项目地址挂在tokio-rs组织下:github.com/tokio-rs/topcoat。
这不是Tokio团队第一次向“全栈”方向扩张。文章作者、Tokio创始人Carl Lerche在博客里交代了背景:今年4月,团队已经发布了异步ORM框架Toasty,因为这是全栈拼图里最难啃的一块。而Topcoat是路线图上的下一步——一个Web框架。项目由Carl Lerche与开发者Julien Scholz(GitHub ID:pikaju)共同打造,后者在去年年底被Carl Lerche认可其“审美和对打造优秀Rust Web框架的热情”,进而说服其投入这个项目。
截至发文,Topcoat在GitHub上已经积累了约1.3k星标、34个Fork,代码库中Rust占比94.9%,处于“早期实验阶段,预计会有破坏性变更”的状态——这是README里的原话,官方对项目成熟度非常坦诚,没有过度包装。
在讨论Topcoat本身之前,有必要先说清楚一件事:为什么“tokio-rs发布了一个新框架”这件事,比“某个个人开发者发布了一个新框架”重量级得多。
Rust的Web生态长期存在一个尴尬的现实——框架多,但缺少一个众望所归的“默认选项”。Actix-web性能强悍但API风格独特,Rocket曾经因为依赖nightly编译器劝退了不少人,Axum作为Tokio官方出品的路由层框架,凭借与Tokio生态的无缝衔接,这几年逐渐成为社区事实标准,但它定位始终是偏底层的HTTP路由库,而不是开箱即用的全栈框架。
这种“路由器好用,但全栈缺位”的状态,恰恰是Leptos、Dioxus、Yew这些WASM全栈框架过去几年试图填补的空白,但它们各自都要求开发者接受一套新的心智模型(信号系统、WASM编译产物、客户端/服务端代码分裂等)。
在这样的背景下,Tokio官方亲自下场做全栈框架,意味着两件事:第一,它天然自带信任背书和分发渠道——Tokio的Discord、TokioConf大会、官方博客,都是现成的推广阵地;第二,它大概率会与Axum、Toasty这些已有的Tokio系项目形成组合拳,而不是又一个孤立的实验性框架。文章里作者也特意澄清了Topcoat和Axum的关系,强调二者覆盖的是不同场景,Axum是构建HTTP API端点的底层路由器,Topcoat则致力于消除构建响应式全栈应用时的样板代码,很多用户会在项目中同时使用两者。
换句话说,这不是一次“重复造轮子”,而更像是Tokio在把自己的版图从“异步运行时 + HTTP路由”,扩展成一整套覆盖ORM、Web框架的完整技术栈。
先看官方给出的Hello World,感受一下整体风格:
#[tokio::main]
async fn main() {
topcoat::start(Router::builder().discover().build()).await.unwrap();
}
#[page("/")]
async fn home() -> Result {
view! {
<!DOCTYPE html>
<html>
<head>
<title>"Hello world"</title>
topcoat::dev::script()
</head>
<body>
hello(name: "World")
</body>
</html>
}
}
#[component]
async fn hello(name: &str) -> Result {
view! {
<h1>"Hello, " (name) "!"</h1>
}
}
view!宏是整套模板系统的核心,语法上尽量贴近原生HTML与Rust,#[page]、#[component]这些属性宏负责把普通的async函数标记成路由页面或UI组件。整体风格如果你写过React Server Components或者Phoenix的HEEx模板,会有似曾相识的感觉。
$(...)表达式这是Topcoat最核心的设计取舍。Leptos、Dioxus这类框架,走的是把Rust代码编译成WebAssembly、在浏览器里跑一份“客户端应用”的路线,能实现非常细粒度的交互,但代价是要处理WASM打包体积、代码分割、客户端与服务端之间的数据序列化这些复杂问题。
Topcoat选择了另一条路:全部标记语言都在服务端渲染,组件可以是异步的,能安全地访问数据库或校验用户权限;而想要交互性时,通过一个宏,把一部分经过完整类型检查的Rust表达式跨语言编译成JavaScript,让开发者始终留在Rust语境里,而无需接触WebAssembly。
来看官方给的例子——点击按钮展开一段文字:
view! {
// Declare a client-side state variable:
signal open = false;
<button
// Configure a Rust closure as the "on click" handler for this button.
// Code inside the $(...) is run as JavaScript inside the browser:
@click=$(|_e| open.set(!open.get()))
>
"What is Topcoat?"
</button>
// The `hidden` attribute tracks the value of `open` and updates
// each time the button is pressed.
<p :hidden=$(!open.get())>"A fullstack Rust framework."</p>
}
这段$(...)里的闭包,既会在服务端首次渲染时求值,也会被编译成对应的JS逻辑在浏览器里独立运行,整个开关逻辑完全在浏览器端完成,不需要往返服务器。这个设计思路,和HTMX、Alpine.js“把行为写在标签属性里”的理念是相通的,只不过Topcoat把这层“行为”也纳入了Rust类型系统的保护范围。
当交互确实需要服务端参与时(比如根据搜索框输入实时查询数据库),Topcoat提供了#[shard]这个机制:
#[component]
async fn search() -> Result {
view! {
signal query = String::new();
// Write the current text input into the `query` signal:
<input @input=$(|e: Event| query.set(e.target.value))>
// Updates as the user types.
search_results(query: $(query.get()))
}
}
// Shards are a special type of component that exposes an API endpoint from your router.
#[shard]
async fn search_results(cx: &Cx, query: String) -> Result {
// This function runs on the server. It can access the database asynchronously.
view! {
<ul>
for product in search_products(cx, &query).await? {
<li>(product.name)</li>
}
</ul>
}
}
Shard本质上是一种会自动暴露成API端点的特殊组件,当它依赖的$(...)参数变化时,Topcoat会在服务端重新渲染这个片段,再把结果局部替换进页面——这几乎就是Phoenix LiveView和HTMX理念的Rust版实现。官方也很坦诚地说明,客户端响应式系统仍处于早期阶段,存在一些限制,团队有很多改进计划;与此同时,开发者也可以借助HTMX和Alpine.js集成来补足能力。
除了渲染逻辑,Topcoat还内置了一整套前端工程化基建。资源管道方面,通过asset!宏声明静态资源,构建时CLI会自动收集或下载所有资源并做内容哈希,方便浏览器缓存:
const FERRIS: Asset = asset!("./ferris.png");
view! { <img src=(FERRIS)> }
字体和图标可以直接对接Fontsource和Iconify这两个开源库生态,几行宏调用就能把免费字体、图标集打进项目。
组件库这块,Topcoat借鉴的是shadcn/ui的思路——不是发布一个黑盒的NPM包式组件库,而是把基于Tailwind的组件源码,通过topcoat ui命令直接复制进你自己的项目目录,方便你随意修改:
#[component]
async fn delete_card() -> Result {
view! {
card(
card_header(
card_title("Delete workspace")
card_description("This permanently removes the workspace and all of its data.")
)
card_footer(
attrs: attributes! { class="justify-end" },
button(variant: ButtonVariant::Ghost, "Cancel")
button(variant: ButtonVariant::Destructive, "Delete workspace")
)
)
}
}
Topcoat支持从文件目录结构里自动推导路由树,不需要额外的构建步骤,这一点跟Next.js的App Router、SvelteKit的路由约定神似:
src/
|-- app.rs -> / (and the root <html> layout)
`-- app/
|-- about.rs -> /about
|-- _marketing.rs (layout, no URL segment)
|-- _marketing/
| `-- pricing.rs -> /pricing
|-- posts.rs -> /posts
|-- posts/
| `-- id.rs -> /posts/{post_id}
`-- api/
`-- health.rs -> GET /api/health
这是官方博客里花了不少篇幅强调的设计哲学,原文标题就叫“Locality of behavior as the guiding principle”(行为本地化作为指导原则)。
核心主张是:无论人类还是AI,在推理小范围代码时表现都更好,因此Topcoat从底层架构上鼓励开发者让逻辑保持局部化和可组合性——比如鼓励组件自己去获取需要的数据,而不是把数据一层层从外部传进来。
#[component]
async fn user_profile(cx: &Cx, user_id: &str) -> Result {
// Only this component knows what user data it needs.
let user = load_user(cx, user_id).await?;
view! {
<h1>(user.name)</h1>
...
}
}
为了避免这种“各自为政式取数”造成重复查询,Topcoat内置了请求级别的memoization,同一个请求周期内、同样的参数只会真正执行一次:
#[memoize]
async fn load_user(cx: &Cx, user_id: &str) -> Result<User> {
// This database call is made only once per unique `user_id`.
db(cx).load_user_by_id(user_id).await
}
这套理念还被延伸到了鉴权上——与其把权限校验丢给一个“可能生效也可能不生效”的中间件,Topcoat鼓励把鉴权逻辑直接写进组件本身:
async fn require_auth(cx: &Cx) -> Result<User> {
if let Some(Session { user_id }) = current_session(cx).await? {
Ok(load_user(cx, user_id).await?)
} else {
// Data is kept secret, redirect to login.
Err(redirect("/login").into())
}
}
#[component]
async fn user_profile(cx: &Cx) -> Result {
// `user_profile` protects itself from misuse if the user is not logged in!
let user = require_auth(cx).await?;
view! {
<h1>(user.name)</h1>
...
}
}
这个模式,作者形容为“类似React里的hooks,但没有hooks那套令人头疼的使用规则”,通过把请求上下文cx层层传递来实现函数组合。
这可能是这篇发布博客里最有意思、也最值得展开讨论的一部分。Web应用开发领域,早已是JavaScript/TypeScript生态的绝对主场,Ruby、PHP、Python也各自站稳了脚跟,Rust切进来,图什么?
Carl Lerche在博客里给出了自己的答案,逻辑链条大致是这样的:三年前如果说Rust适合做Web应用开发,大概率会被当成疯话——Web应用传统上不是性能敏感型场景,正确的选型逻辑应该是能让开发更快的语言,性能只是加分项,因此JavaScript、Ruby、PHP这类高生产力语言的Web生态才会长得最茂盛。
但他认为AI彻底改变了这个计算公式:AI正在抹平学习门槛和生产力差距,一个AI编程工具构建某样东西所花的时间,主要取决于可用的库生态,而不是编程语言本身,甚至操作者本人的具体专业经验都变得没那么重要了。
他观察到,从没写过Rust的资深工程师,可以借助AI工具从第一天起就用Rust构建应用——不是纯粹的“氛围编程”(vibe coding),而是用工程经验和AI工具交互式协作,边学边推进。
在这个前提下,他给出了一个更务实的落地场景:他并不是建议所有人都该为了Rust推倒现有可用的技术栈重来,但很多组织本身是因为需要高性能和高可靠性才引入Rust的,这些组织已经围绕Rust建立起内部基础设施——库、构建系统、流程等,即便上层应用不需要极致性能,继续用Rust也能减少组织内的语言和工具碎片化,从而提升整体生产力。
翻译一下:Topcoat的目标用户画像,不是要从Node.js/Django手里抢走每一个初创公司,而是那些已经因为性能和可靠性诉求引入了Rust的团队——比如做了Rust后端服务、Rust CLI工具的公司。对这些团队来说,与其为了做一个管理后台再引入一整套Node.js工具链,不如留在同一个语言生态里,用同一批库、同一套构建体系、同一批工程师。这是一个“存量场景增量渗透”的打法,而不是“颠覆式换血”的打法。
这个论点是否站得住脚,取决于两件事能不能成立:
第一,AI辅助编程是否真的显著拉平了语言学习曲线的权重,让“生态丰富度”超过“语言易用度”成为更重要的选型变量; 第二,Rust阵营的团队是否真的存在“为了做一个后台管理系统去用一整套Node.js栈”这种痛点,且这个痛点的规模足够支撑一个框架的长期发展。
从行业趋势看,这两点都有一定的现实基础——Rust在基础设施、区块链、AI推理引擎等领域的渗透率这几年确实在稳步上升,相应团队对“少一门语言”的诉求也是真实存在的;但要说这会形成大规模的Web开发范式迁移,目前证据还不充分,更像是一个有想象空间但需要时间验证的判断。
把Topcoat放进现有坐标系里看会更清楚:
一句话概括Topcoat的定位:它不是又一个WASM全栈框架,而是Rust版的“HTMX + Ruby on Rails式全家桶”,主打服务端渲染优先、类型安全穿透前后端、开箱即用。
优点:
$(...)表达式本质是被完整类型检查过的Rust代码,即便被跨编译成JS去浏览器端执行,也享受Rust编译器的静态检查,减少了传统前后端分离场景下“接口对不上”的问题。缺点/风险:
topcoat new这样的项目脚手架命令目前也还没有,上手门槛比看起来要高一些,目前更适合愿意折腾、想尝鲜的团队和个人。综合以上信息,几个判断供参考:
第一,短期内Topcoat不会成为“默认选项”。它自己的定位也很清楚——这是v0阶段的第一个发布版本,核心响应式系统、鉴权、脚手架工具都还在建设中。现阶段更适合Rust重度用户做技术预研、内部工具、非核心业务的尝鲜项目,还不建议直接扛核心生产系统。
第二,Tokio的官方背书和Toasty + Axum + Topcoat的组合拳,是它最大的护城河。相比历史上那些昙花一现的Rust Web框架实验,Topcoat大概率不会因为“作者失去兴趣”而烂尾,因为它已经被绑进了Tokio这个体量的项目治理体系和长期路线图里,TokioConf这样的年度大会也会持续给它导流。
第三,它能走多远,很大程度取决于AI辅助编程对Rust生态的实际拉动效果是否如预期兑现。如果“AI拉平学习曲线,生态丰富度决定语言选型”这个判断在未来一两年被更多数据验证,Topcoat这类瞄准“已经用Rust、想要减少语言碎片化”的团队的项目,会有明确的增量空间;反过来,如果AI辅助编程对不同语言的效果差异没有想象中那么大,Topcoat就更可能停留在一个小而美的细分工具,服务好一批特定的Rust重度团队。
第四,接下来半年到一年的Roadmap落地速度,是最值得关注的观察窗口——尤其是鉴权方案、topcoat new脚手架、流式SSR这几项,一旦补齐,Topcoat距离“可以放心用在生产环境”会近一大步。
Topcoat的发布,与其说是一次单点的技术产品发布,不如说是Tokio团队对“Rust全栈化”这条路线的又一次押注——继Toasty之后,全栈拼图里最后一块硬骨头也补上了。
它选择的“服务端渲染 + 无WASM响应式”路线,某种意义上是对Leptos、Dioxus这类WASM全栈框架的一种“反潮流”回应,也是对HTMX、Phoenix LiveView理念在Rust世界里的一次系统化重实现。
至于Carl Lerche那个“AI正在抹平语言学习门槛,生态丰富度才是决胜因素”的判断是否成立,恐怕还需要更长的时间和更多真实项目的验证。但可以确定的是,随着Tokio、Axum、Toasty、Topcoat这条技术线逐渐补全,Rust要在Web全栈开发领域争一席之地,缺的“最后一公里”工具,正在被官方团队一块一块地补上。
对于已经身处Rust生态、又需要做一些Web应用的团队来说,Topcoat值得放进技术雷达持续观察;对于还在观望Rust是否适合Web开发的团队,不妨先等它熬过“早期实验”阶段、把鉴权和脚手架这些基础设施补齐后再做评估。
参考资料: [1] tokio-rs官方博客《Announcing Topcoat: a framework for building full-stack reactive web apps with Rust》,https://tokio.rs/blog/2026-07-22-announcing-topcoat [2] Topcoat GitHub仓库,https://github.com/tokio-rs/topcoat
还在为写 Agent 框架频频死循环、上下文爆炸而束手无策?我的新专栏 《从0 开始构建 Agent Harness》 将带你:
扫描下方二维码,开启从 0 开始构建Agent Harness 的实战之旅。
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
2026-07-23 07:00:00
本文永久链接 – https://tonybai.com/2026/07/23/software-factory-light-and-dark
大家好,我是Tony Bai。
导读:
当前,AI 智能体正在以前所未有的速度吞噬软件工程的基础执行环节。当成百上千个 Agent 组成流水线,没日没夜地为你自动生成、测试并提交代码时,一个终极形态的“软件工厂(Software Factory)”诞生了。然而,在这场效率狂欢中,一个致命的隐患正在悄然滋生:当代码的产出速度远远超过人类阅读和审查的速度时,我们正在积累毁灭性的“理解力债务”。本文编译自谷歌前 Chrome 团队负责人 Addy Osmani 的深度长文,深刻探讨了“黑灯工厂(全自动自治)”与“明灯工厂(人类把关)”的本质区别。文章提出了一项划时代的范式转移:人类必须坚决放弃陷入具体的代码生成(内环),转而死守系统架构、边界验证和最终裁决的“外环(Outer Loop)”。
文章要点:
在前几篇中,我们先后拆解了 Andrej Karpathy 的《LOOPS.md》、20 个循环设计模式、Claude Code 落地实践,以及全新 AI 技术栈。我们已经确立了一个共识:“Loop(循环)”是 AI 智能体的原子单元,而“Harness(驾驭框架)”则是智能体运转的操作系统。
但是,当我们将成百上千个这样带有驾驭框架的 Loop 组合起来,并接入企业的需求队列、CI/CD 管道和监控系统时,一个终极的技术形态诞生了——软件工厂(Software Factory)。
在谷歌前 Chrome 团队负责人 Addy Osmani 的这篇深度长文中,他探讨了一个正在真实发生的行业趋势:
“黑灯”看似打破了开发速度的音障,却正在悄悄积累毁灭性的“理解力债务(Comprehension Debt)”。
本文将为你揭示:为什么说“生成代码”从来都不是瓶颈,“如何低成本、高可靠地验证代码”才是软件工厂真正的命门。
以下为译文全文:

所谓软件工厂(Software Factory),本质上就是规模化驾驭的智能体循环(Harnessed loops at scale)。
你可以选择运行一座“明灯工厂”(Light Factory,有人类参与循环):用人类的判断力和注意力,去换取更高的系统鲁棒性并减少代码崩溃;你也可以选择完全无视人类的参与,运行一座“黑灯工厂”(Dark Factory,全自动无人在环):让那些 Agent 自行规划范围、编写代码并直接发布代码,期间没有任何人去真正阅读具体的实现细节。
但是,如果人们停止了阅读代码,他们终将停止对自身软件系统的理解。
作为工程师,你现在最艰难、也最具含金量的工作,是明确该构建哪些验证卡控机制,以及到底该向 AI 委派多少自主权。
“软件工厂”这一概念并非新生事物,其历史最早可以追溯到 Bob Bemer 在 1968 年发表的经典论文《程序生产经济学》(The economics of program production)。半个世纪以来,无数工程师梦想着能有朝一日将软件开发变成一种可重复、可度量的工业化生产过程(类似于在工厂流水线上冲压汽车零件),而不是依赖于程序员个体的孤立手艺。
在历史上,这一梦想普遍(尽管并非全部)以失败告终,部分原因在于“思想和创意”很难像物理零件那样被批量冲压。
然而,在过去两年中,底层技术发生了极其剧烈的变革,以至于我们有充分的理由重新审视这个半个世纪前的老梦想。鉴于其中一些微妙的工程细节极易被轻率地忽略,我们非常有必要精准地剥离出:究竟哪些是真正全新的突破,而哪些只是披着新机会外衣的重复陷阱。
HumanLayer 的联合创始人 @dexhorthy 最近在 AI Engineer World’s Fair 上发表了一场题为《仅靠驾驭框架工程是不够的:为什么软件工厂会失败》(Harness Engineering is not Enough: Why Software Factories Fail)的精彩演讲,非常值得在这个议题下深度研读。
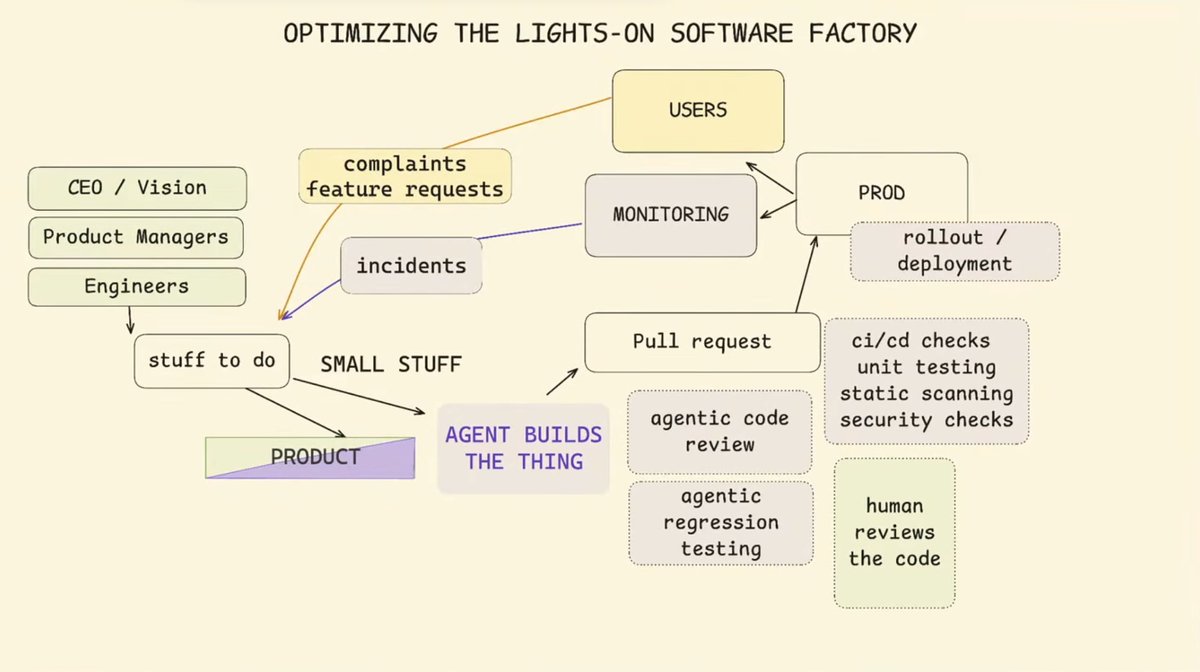
结构决定一切,而一切结构都始于最微小的单元。整个 AI 技术栈,本质上是叠在最底层的三个核心概念:循环(Loop)-> 驾驭框架(Harness)-> 工厂(Factory)。
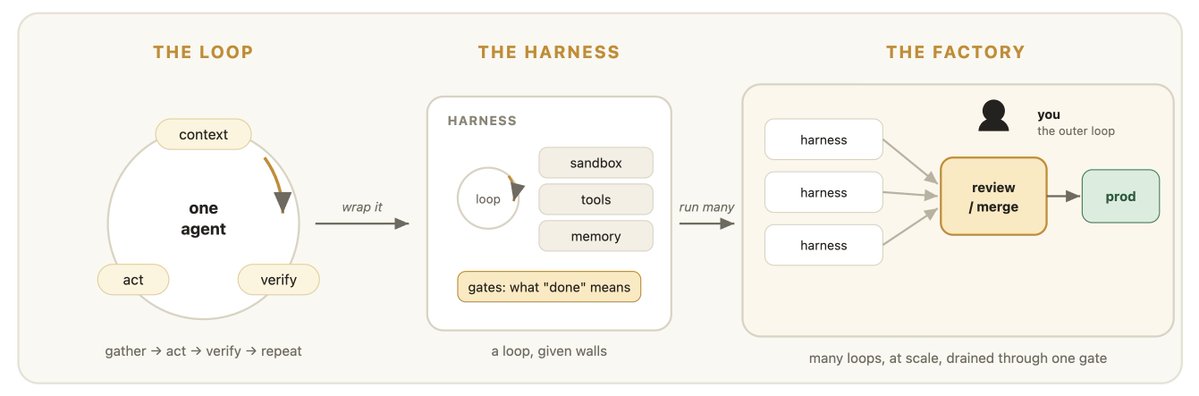
最终的范式大转移,在于从“编写代码”跨越到“构建并运行写代码的工厂”。工作的最小单位向上升维到了循环、驾驭框架以及它们之间的流转逻辑,而不是某一段具体的代码 Diff。
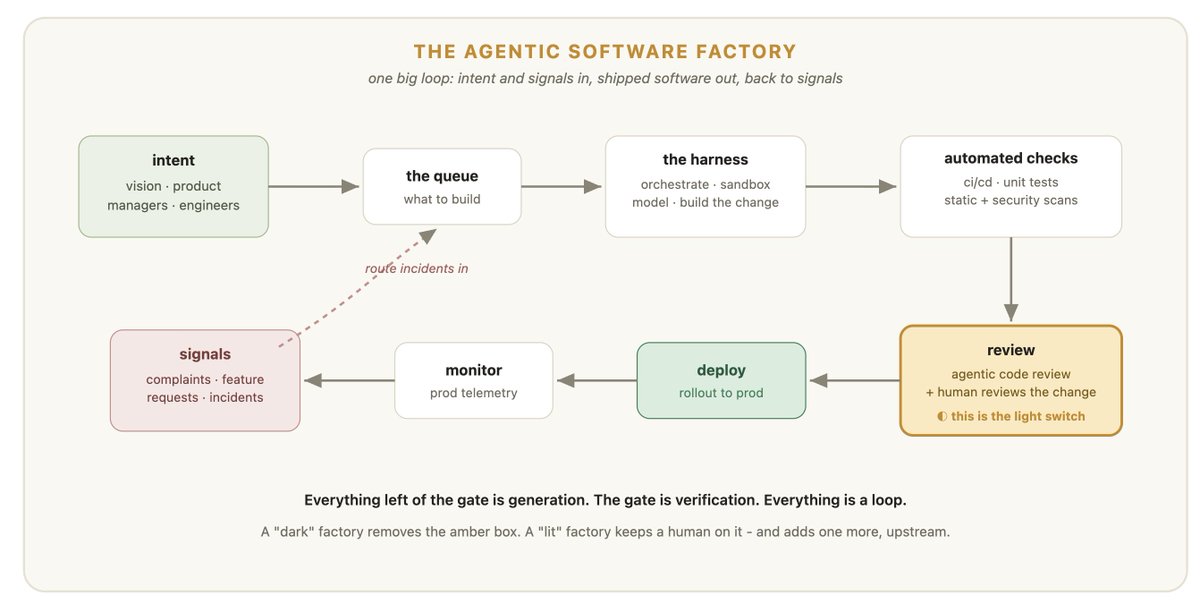
Dex 演讲中最核心的一张架构图极其精妙,它用一张清晰的接线图,将原本抽象的循环直观地呈现了出来:
软件工厂是一个闭合的闭环:
产品意图和线上生产信号喂入需求队列 -> 驾驭框架进行构建 -> 自动化检查与审查门控进行把关 -> 部署上线 -> 运维监控将线上状态再次转化为生产信号。
产品意图来自于工程团队领袖的远景规划,也直接来自于一线工程师;事故日志和用户反馈触发的信号,同样源源不断地流入这个需求队列。
驾驭框架(Harness)充当的角色,就是从队列中抓取一个任务,并为其构建代码变更。在驾驭框架之外,我们可以看到所有为了确保变更足够安全而设置的自动化检查。得益于 CI/CD、单元测试、静态代码分析以及各类安全扫描,这些自动化检查几乎毫不费力地异步并发运行,完全不需要工程师进行任何意识上的介入。
在这个庞大的闭环中,唯一需要人类决策的节点,只有“审查门控(Review Gate)”。
一旦获得批准,变更就会部署并上线监控,监控数据会再次转化为驱动下一次循环启动的信号。
大体上看,这张架构图中的绝大多数方框(代码生成、自动化测试、安全扫描)的边际成本都趋近于零。它们可以以极低的成本进行海量规模化扩展。整个系统中,只有一个极其昂贵、且顽固拒绝被无脑规模化放大的方框——那就是“审查门控(Review Gate)”。
那个闪烁着黄光的方框代表着“人类的审美品味与判断力(Judgment)”。而这,恰恰是“我们能否让软件开发变得更快、更频繁”这一行业大论战的终极焦点。
物理世界中的“黑灯工厂”,指的是在生产时将车间灯光完全关掉,因为里面的机器机器人根本不需要光线就能干活。
“黑灯软件工厂”也是完全相同的套路:代码在没有任何人类阅读、审查的前提下被直接发布,完全仅由其他机器进行验证。
这个概念直接借用自制造业。它的起源是物理实体而非数字世界,根植于那些熄灭了灯光、全由机器人接管的自动化车间。日本的发那科(FANUC)早在 2001 年就开启了这种关灯工厂;小米也在 2024 年开业了自己的高自动化黑灯工厂。
它们的共同特征是:一件产品从组装到出厂交付,期间没有任何一个人类阅读过它的任何生产细节。当“阅读”这一动作从流程中被彻底抹去时,“黑灯”就诞生了。
我借用这个概念,绝非为了造噱头,也绝非贬义。抛开那些带有科幻色彩的流行词,“黑灯”在这里是一个纯粹的客观事实描述:依然是那个工厂车间,只是关掉了灯。在软件工程里,车间地板就是代码 Diff。无论谁写了 Diff,谁审核了 Diff,谁发布了 Diff,那些人类都已经退场了,只留下了仅被机器自身验证过的代码 Diff。
在刚开始的时候,这件事做起来顺畅得令人发指。
之所以顺畅,是因为那个原本卡在中间的人类审查步骤被彻底废除了。它的消失,会让你的团队在体感上的“垂直吞吐量”瞬间暴涨,让你产生一种打破了音障的快感。
然而,在这种表面的顺畅之下,想要在暗黑的工作流及其埋下的巨大隐性成本中生存下来,远比想象中要艰难得多。
随着模型与现实世界及彼此之间的交互日益频繁,由任务编排、沙箱原型构建以及工具调用构成的驾驭框架(Harness)将会变得空前强大。
然而,在试图通过叠加式的代码修改来长久维持代码库质量的长跑中,模型内部存在着一种天然的失效机制。我们有充分的理由相信:仅靠模型自身,最终必将在“理解力债务(Comprehension Debt)”面前败下阵来。
所谓“理解力债务(Comprehension Debt)”,指的是“代码库中实际存在的代码总量”与“人类依然能真正理解的代码总量”之间不断扩大的鸿沟。
一座黑灯工厂绝不会去偿还这种债务;它只会以最快的速度疯狂举债,且在此过程中,所有的自动化测试全程都在亮绿灯。
这是一个极其关键的区分,因为模型在某些特定任务上表现极佳。但对于任何不是对代码库微小局部进行即时修改的任务——尤其是面对极其复杂的遗留旧系统(Brownfield System)时——纯模型驱动的自动化编程将面临不可逾越的鸿沟。
绿地项目(Greenfield apps)、周末练手的小玩具和 Side Projects 都有一个共同点:几个月的开发周期通常足够把事情搞定,或者至少能跑得像模像样。
但一个已经持续开发了十年或更久的企业级系统,完全是另一种庞然大物:它必须在极其专业的环境、以专业的节奏被长久维护。项目推进三到六个月后,你就会发现自己已经彻底淹没在海量未曾阅读过的代码汪洋中了。
这种严酷的环境,尤其是生产环境代码所强制执行的各种隐性约束,会让最强大的 Agent 也感到束手无策——这与开发者在周末玩具项目中享受的“氛围编码(Vibe-coding)”构成了鲜明的对比。
Dex 根据一线经验指出,这是一个极其重大的失败模式,以至于他们花了整整四个月的时间,进行痛苦的深度手动 Debug 才精确定位到问题所在。这来自于他们运行了一个长达四个月的全自动代码工厂,在此期间,没有任何人类去阅读过被写出的代码。
这一惨痛教训背后,是两个互相对立的指标之间的终极博弈:
黑灯工厂真正大放异彩的地方,在于它能在测试全程亮绿灯的同时,肆无忌惮地烧毁原本优雅干净的代码库。
而当终极清算到来时,它绝对不会是一个戏剧性的、瞬间轰然倒塌的“崩盘时刻”。
它将是悄无声息的、迟来的绝症。
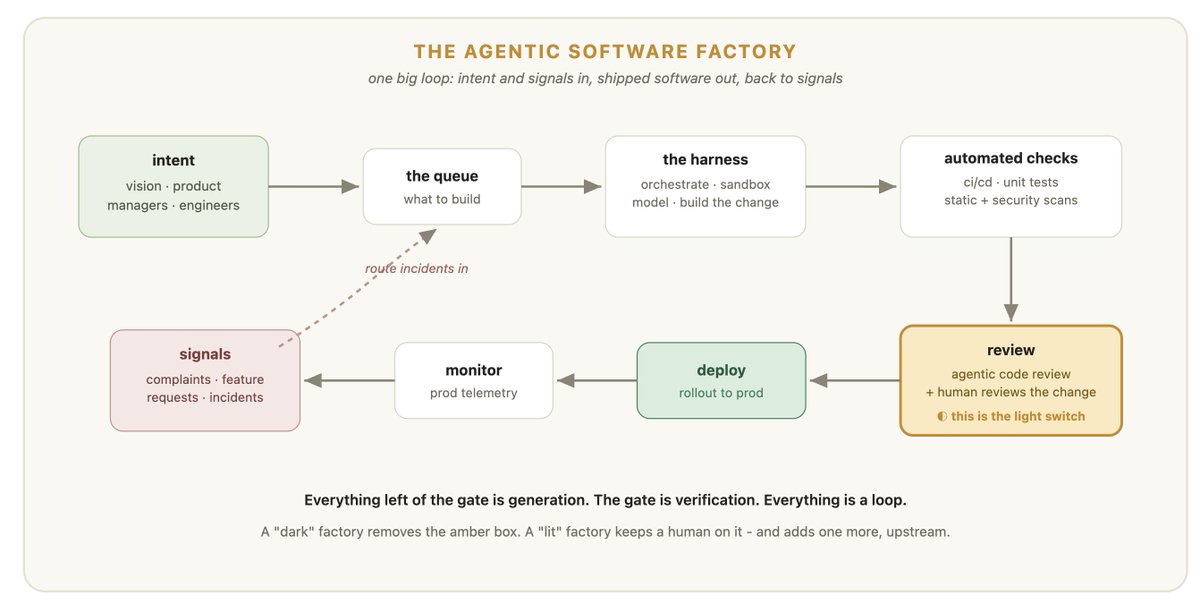
明灯与黑灯,本质上是同一条流水线,只是灯光亮在了不同的地方。明灯版本绝不仅仅是在末端重新加上人类 Review,而是将人类的审美品味与判断力,向上游的“系统设计”与“架构规划”进行了战略迁移。
软件生产的瓶颈,从来都不是“生成代码的速度”。
软件工厂最根本的硬性约束,从来不是我们能疯狂吐出多少代码,而是:我们能多快、多可靠地验证这些代码。
“反向压力(Back Pressure)”法则规定:你能够赋予一个循环的自主权上限,严格受限于你能够以多低成本、多高可靠性去验证它的极限,多一寸都不行。
验证(Verification),而非生成(Generation),才是软件工厂真正的终极约束。
由于无限膨胀的代码生成能力,与人类极其有限、且绝对无法无脑规模化放大的“注意力”之间存在着永恒的张力,核心矛盾演变成了“廉价的生成”与“有限的审查”之间的巨大鸿沟。
看看这个漏斗:只要代表“验证”的瓶颈没有被拓宽,系统就必然发生严重的堵塞。正如 Dex 一针见血指出的那样:单纯的代码产出数量根本不是问题,我们真正受苦的,是大量涌现的糟糕 PR(Pull Requests)。
当你在没有可信门控的前提下盲目追求高产出时,人为制造的系统缺陷将变得不可避免。这再次印证了反向压力法则:自主权绝对不能超越低成本、高可靠验证能力的边界。
第二个深层问题在于:为什么单纯提升模型的智商,无法自动弥合“生成”与“验证”之间的鸿沟?
在具有良好架构的系统上进行训练,远比通过简单测试要困难得多:请记住,衡量架构卓越性的成本函数,其单位不是秒,也不是分钟,而是月和年。
在工程上,你根本无法计算出平滑的梯度,因此,一个期望对复杂设计决策进行精准、即时评估的系统,是根本不可能在优质样本上训练出来的。
代码生成是一个巨大的大喇叭口;而代码验证则是极其狭窄的瓶颈。盲目加速大喇叭口,只会让狭窄瓶颈处的堆积变得更加绝望。
明灯工厂(Lit Factory),就是在判断力(Judgment)所在的地方把灯留着的同一条流水线。
Agent 依然承担了绝大多数的具体构建工作,但在代码正式发布前,必须由人类去阅读产出的结果;并且在任何“做错决策代价高昂”的地方,灯必须死死亮着。
明灯版本绝不是把审查硬生生贴在流程的最末端,而是把人类判断力的焦点向上游迁移——迁移到产品定义、系统设计,以及 Agent 启动循环前的架构规划上。
前期投入那极其宝贵的一个小时,最棒的地方在于:它能极大地减少后续具体的代码实现工时。
它能将一场长达数小时、令人无比沮丧的复杂代码审查,变成对一份 200 行架构规划书的快速阅读。你在代码被写出来之前,就已经审查并过滤掉了决策错误;这样你就不必在事后去痛苦地穿梭于 2000 行 AI 生成的代码汪洋中,试图去倒推模型当时到底做了什么荒谬的决策。
有些决策是如此高昂且影响深远,以至于你绝对希望人类能尽早介入,在成本复合膨胀之前完成把关。当然,即使你在前期投入了时间,某些关键时刻你依然需要去审查具体的代码 Diff。
你可能会觉得这听起来一点也不酷、一点也不“AI 自动化”。
你是对的。
这套安全网,恰恰是由我们早已熟知、却在过去长期被轻视的经典架构设计实践构成的:
这其中没有任何新技术。我们过去口口声声说关心优秀架构,而现在,随着自动化编程 Agent 的全面接入,这些经典架构终于承担起了它们的第二个历史使命——成为一张低成本、极难被伪造的、能够无情拦截 Agent 犯错的安全网。
这张安全网必须存在于模型外部,因为模型自身绝不会提供它。
目前能力最强的编码智能体(包括 Claude Code 和 Codex 在内),本质上都是针对它们自身的驾驭框架和工具链进行强化学习(RL)训练出来的:它们对工具调用的语法和各种编程套路极其熟练,但它们对代码的“长期可维护性”一无所知。
我们一直在强调的“深思熟虑的架构”,正是捕获这些技术债务的终极工具,而我们在架构上投入的资源,本质上是在重新买回我们的自主权。
将这些与安全的底层基础设施相结合,你就能拥有一些可以完全无人在环、自动运转的紧凑、低风险循环。
Horthy 在最近的一篇文章中描述过这样一个场景:
一个在每晚定时运行的 GitHub Actions Cron 任务,它每次只精准修复代码库中的一个反模式(Anti-pattern)——比如修复一个 Lint 报错,或者优化一个多余的 optional prop。它自动修改、自动 Commit、自动提交一个极小的 PR。第二天早晨团队醒来时,看到的是一个稍微变好了一点点的代码库,以及一个短到几秒钟就能读完的 Diff。
但是,对于那些筹码极高的核心循环,你绝对不希望在清晨醒来时,看到系统的鉴权模块、计费引擎或公开 API 契约被 AI 给彻底搞砸了。
在这些核心战场,请务必把灯点亮。去信赖一个拥有真实判断力、且对系统底层运行逻辑有着深刻理解的人类工程师,去拦截那些致命的错误。
无论你把它称之为反向压力、验证机制,还是开关灯的控制阀,这条铁律永远适用:
一个循环只有在满足以下条件时,才有资格获得“完全全自动(黑灯)”的许可:
同时,你还需要这个校验机制能够即时返回结果,且绝不会随着时间发生漂移(Drift)。当“是否完成”不仅能被你证明,更能被机器以绝对客观的方式证明时,你才真正触达了“自动化”。
短循环(Short loops)远比长循环更容易被验证。
Dex 的经验法则:一个 Agent 在执行 3 到 10 个步骤时能保持高度清醒;一旦超过 20 个步骤,它就会开始失去焦点。
其底层根源在于上下文的无休止积累——Agent 在身后拖着的历史包袱越沉重,它就越容易偏离路线。当一个循环足够短小精悍时,验证它的成本极其低廉;而漫长臃肿的循环,则会将致命的错误悄悄隐藏在暗角里,这用另一种说法表达就是:它们根本没有资格进入“黑灯”状态。
保持“明灯”则是完全相反的逻辑。
如果一个错误的代价极其高昂、且只有人类的智慧才能识别它,那么这个循环就必须被强行 Review。那些无法被自动化测试捕获的隐蔽线上 Bug、巨大的破坏半径,以及将决定未来一年甚至更久技术走向的重特大决策,统统属于此类。
在这些场景下,人类工程师的注意力本身,才是那个真正高昂、且不可或缺的核心产品。
最危险的陷阱,在于忘记去拨动每一个开关,而是简单粗暴地将所有循环都设置成同一种模式:
真正的高手,在于精准地决定每一个开关应该拨向何方。
推荐阅读 @DavidKPiano 撰写的《两分钟读懂状态机》(State machines in 2 minutes)。
当你交给 Agent 一个任务时,你大概率会围绕它构建一张图(Graph)——无论你把这张图称之为“有限状态机(FSM)”,还是一组条件联结的服务调用。
在这种框架下,软件不再是盲目遵循某些抽象的规则,而是在执行一套高度结构化的工作流:每一个节点(Node)都是一个显式的执行步骤,而节点之间的每一条边(Edge),都是一个显式的触发条件。
这听起来似乎有着太多的工程约束,但绝大多数约束本就天然存在于软件之中,因为任何代码本质上都可以被表达为一张控制流图(Control-flow graph)。
因此,这里唯一的新意在于:一个嚷嚷着要自主权的 Agent,本质上只是在这张特定图的节点内部闲逛;它的自由度,被死死限制在了节点内部。
而人们往往忽略了 Dex 在一年前就写下的这行总结:软件工程从来都拥有这种结构。这就是为什么我们在几十年前就知道用流程图(Flowcharts)来绘制程序。
之前行业内真正惊世骇俗的尝试,是试图把这张流程图彻底扔掉——完全依赖一个自由循环,让模型自己在每一个步骤去挑选工具调用,直到它自己单方面宣告任务完成。
在碰撞到一个拥有十年历史的老旧代码库之前,这种尝试看起来确实像是一场思想解放;直到它彻底撞墙,大家才重新找回了敬畏心:掌控你的控制流,本质上就是重新把流程图包裹回循环的外围。
因此,关于“我们是否应该从 Loop 回退到 Graph”的讨论,几乎等同于我们向现实低头承认:我们从始至终都需要那张流程图。
让我们看看这在工程实践中意味着什么。以修 Bug 为例:
这种 Graph 架构真正吸引人的地方,在于它本质上就是用图画出来的“反向压力”。
你剥夺了 Agent 一部分无边无际的自由,换来的是强制性的质量检查以及极度清晰的失败挂节点。当一次运行中断时,你可以极其精确地指着图上的某一个节点说:“就是卡在了这里。”
这与 Dex 那句一针见血的断言如出一辙:目前绝大多数所谓的 Agent,根本就没有什么‘智能体自主性’,它们不过是‘高度确定性的代码,恰好在几个关键节点撒了一点 LLM 调味料’。
这绝非当下一时兴起的过渡产物,看看 LangGraph、LlamaIndex Workflows,看看 Jerry Liu 提出的“在 Agent 之上构建混合工作流图”,以及 David Khourshid 的提醒——这不过是有限状态机(State Machines)和 Actor 模型换了一件新衣服重新登场而已。
做一个必要的澄清(因为这个词被严重滥用了):当我反复称之为“图(Graph)”时,我指的绝非知识图谱(Knowledge Graph)。我指的是一张预先定义好的、包含了条件边(Conditional edges)的定向工作流图,它为 Loop 赋予了一个你真正能够无条件信赖的确定性形状。
请注意:人类从未离开过软件工厂。他们只是搬家了。
我坚定地认为,工程师必须日益主动地去主导并掌控“外环”(Outer Loop)。
Agent 可以去调查 Bug、撰写诊断报告、实现代码修复、运行测试套件,并整理出一份详尽的汇报。这是内环(Inner Loop)的执行层,AI 执行这些任务的效率可以高到令人发指。
但这从来都不是工程工作的本质。
你所真正拥有的,是我称之为“外环(Outer Loop)”的神圣领地:
连接内环与外环之间的唯一纽带,是客观证据(Evidence)——包括代码 Diff、测试报告、日志追踪,以及一段将它们有机串联起来的简短解释。
类型系统、测试缝隙以及评估准则(Rubrics),使得人类能够在不必为每一次改动精疲力竭的前提下,实现对全局的优雅俯瞰与监控。
换一种更形象的说法:
你不再是流水线工地上那个苦哈哈敲代码的工人了;你升维成了站在生产线末端的首席设计师与守门人。
你可以做很多事来让模型变得更聪明、让驾驭框架变得更强大;但我深刻地注意到:识别那些长期来看代价极其高昂的深层问题,从来都不是靠自动化就能解决的。
我们这份工作最核心的灵魂,依然在于:展现出任何纸面流程和算力堆砌都绝无法替代的人类审美品味与判断力。
机器人非常适应在漆黑一片的暗室里高效运转;但人类必须看清自己正在创造什么。
如果整个工厂车间一片漆黑,你什么也看不见,甚至连灯的开关在哪里都找不到——那,才是毁灭真正降临的时刻。
还在为写 Agent 框架频频死循环、上下文爆炸而束手无策?我的新专栏 《从0 开始构建 Agent Harness》 将带你:
扫描下方二维码,开启从 0 开始构建Agent Harness 的实战之旅。
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
2026-07-22 11:00:00
本文永久链接 – https://tonybai.com/2026/07/22/jack-dorsey-block-buzz-ai-agent-workspace-opensource
大家好,我是Tony Bai。
导读: Twitter和Square的创始人Jack Dorsey,这次把矛头对准了「人和AI怎么一起干活」这件事。
北京时间7月22日凌晨,他掌舵的Block公司正式发布并开源了协作平台Buzz:一个不区分人类和AI Agent身份的工作区。在这里,聊天室、代码仓库、自动化工作流和智能体,全部被塞进同一个由密码学签名保证的「事件日志」里。Dorsey在X上亲自官宣,将其定义为把员工、AI Agent、对话和代码仓库统一在同一套身份体系之下的开源产品。
这不是又一个套壳ChatGPT的聊天工具,而是Block过去两年AI战略的一次集中收口——同时也是其内部那篇引发热议的「组织去层级化」宣言(《From Hierarchy to Intelligence》)在工程层面的落地样本。
划重点:
Buzz的诞生故事,写在Block工程博客的作者Tyler Longwell的自述里,相当坦诚。
他是Block内部第一个Slack集成AI Agent的搭建者。这个Agent能写代码、能做调研,效果很好,团队都在用。但麻烦也随之而来:每个人都该配一个Bot吗?如果大家共用一个Bot,用谁的权限?团队想换模型或者换Agent运行时怎么办?
Block内部做过一次小范围投票,问「谁来负责管理共享Bot的凭证」,结果是——每个人都投给了别人。
这句自嘲背后,其实是所有正在大规模引入AI Agent的公司都会撞上的真实困境:模型已经能干活了,但团队还没有一个「一起干活」的地方。瓶颈已经从「智能够不够」变成了「协调跟不跟得上」。
Buzz,就是Block给出的答案。
用一句话概括:Buzz是一个建立在Nostr协议之上、人类和AI Agent共享同一身份体系与同一工作区的开源协作平台。
打开Buzz,界面体验和你熟悉的团队沟通工具(Slack、Discord一类)不会有太大差异:频道、话题串、私信、语音、文件与媒体分享、自动化工作流,一应俱全。真正的区别藏在底层——AI Agent在Buzz里不是「响应指令的助理」,而是拥有独立身份、明确权限、可以主动发起行动的参与者。
Block AI能力负责人Bradley Axen在官方博客中表示,每家公司都终将需要一个人类和Agent共同工作的空间,问题只在于这个空间是封闭的还是开放的,而Block选择把它做成开放的。
Buzz的另一个关键设定是模型无关、框架无关:团队可以接入任意大模型驱动的Agent,可以用Claude Code、Codex、goose,也可以自己写一个——只要遵循Agent Client Protocol(ACP),就能进入这个工作区参与协作。Buzz不关心Agent背后是谁,它只提供「大家在哪儿一起干活」这件事。
Block选择把Buzz建在Nostr协议之上,理由很直接:多智能体协作里最根本的问题是身份,而Nostr恰好是为「可验证、可携带的身份」而生的协议。
在Buzz里,每一个参与者——不管是人还是Agent——都持有一个属于自己的密码学密钥对(keypair)。这个身份不属于Buzz这个平台,也不依附于某个厂商托管的API Key,它是可移植、可验证、独立存在的。也就是说,你在Buzz里配置和调教出来的Agent,理论上并不会被锁死在Buzz里,它的身份、历史记录和「信誉」可以带着走,参与任何兼容Nostr的系统。
工程博客里有一句话说得更直白:「以前我们的做法是把人类的凭证直接给Bot用,然后祈祈祷它别给你丢人。这很怪,也很危险,现在可以不用这样了。」 Buzz给每个Agent发自己的钥匙,Agent的所有者对其做出范围明确的授权签名,Agent再用自己的身份对自己的工作签名——授权不等于抹去作者身份,这是Buzz在密码学委托机制上做出的一个关键语义选择:Agent依然是「作者」,密钥只是证明它被谁授权、在什么条件下行动。
这套设计带来一个直接的安全收益:如果某个Agent的密钥泄露,团队可以单独吊销这个Agent,而不必连坐重置背后人类的身份;如果情况紧急,还能直接终止它当前所有的活跃会话。
Buzz的项目README里有一句很扎心的自嘲:「是的,这又是一个AI相关的开发者工具,我们很抱歉。」但紧接着它给出了区别:真正的不同在于Agent进入Buzz之后到底能做什么。
在Buzz的世界里,一个AI Agent可以:
换句话说,Agent拥有和人类队友几乎相同的行动能力和权限接口,唯一的区别是密钥不同。 这也是Buzz反复强调的一句话:Agent是同事,不是「闹鬼的定时任务」。
Tyler Longwell在工程博客里描述了他日常的工作方式:让一个「前沿模型」驱动的Agent负责统揽全局,同时调度一群更便宜、更快的小模型Agent并行去做调研、编码、测试和评审。这些Agent之间通过Buzz里普通的@提及机制互相通信,几乎实时地把任务注入彼此的工作上下文里,不打断任何人的节奏——这种编排规模和成本效率,是「开一堆私聊Agent会话来回切标签页」永远做不到的。
更有意思的是,这些Agent还会「自发」搞出一些团队没有预先设计的协作方式:互相招募、把任务拆到子频道里、跨上下文交接任务。人类不需要等一个「格式完美但答案错误」的结果出来才介入,而是可以在过程中随时纠偏。所有失败的路径和最终决策的理由,都完整留在可见的聊天记录里——这个「房间」本身,正在变成团队智能的一部分。
Buzz野心不止于聊天室,它正在把代码仓库也整合进同一个工作区。
Longwell的说法很有意思:过去Git天然有一个限速阀——人类。 人要睡觉、要吃饭、要开会,有时候push代码前还会犹豫一下。
而Agent会把这个限速阀直接拆掉:一个团队的Agent集群,完全可能在一个下午就产出相当于「人类几个月」的提交量和CI运行次数,并且是多个写入者同时并发推送。传统代码托管平台的设计假设里,天然内置了「人类速度」这个隐性上限,很难吃得消。
为此,Buzz为Git仓库设计了一套基于对象存储的新方案:仓库被存储为不可变、内容寻址的packfile,加一个可变的清单指针(manifest pointer)。 每次push先写入对象,再用「条件比较并交换(compare-and-swap)」的方式推进指针,指针更新的那一刻才是真正的提交点;工作区里的事件通知只是「宣布」变更,而不是「定义」变更。
这套存储协议,Block团队用形式化方法TLA+做了规格说明,并对持久性、故障恢复、并发push等场景做了模型检验,还要求每个存储后端通过一致性测试套件才能接入——对一个「顺手上线的新功能」来说,这算是相当罕见的工程严谨度。
在产品形态上,一个功能分支或一个Bug会对应一个短生命周期的频道:讨论、补丁、CI结果、代码评审、最终签名合并的决策,全部共享同一条记录,频道随着工作结束而关闭,但「为什么这么做」的理由被永久保留。半年后你在Buzz里搜索一个关键词,找到的不只是最终的diff和绿色勾勾,还有当初被否掉的方案和否掉的原因。
Block选择把Buzz以Apache-2.0协议完全开源,代码和协议规格、安全说明、形式化模型全部公开在github.com/block/buzz。
官方给出的理由,本质上是一种对「厂商锁定」的警惕:现在大量公司在搭建Agent基础设施时,都是建立在少数几家厂商掌控的封闭平台之上——每个平台对「Agent能访问什么、怎么通信、能用什么模型」都有自己的一套规则,这直接导致了碎片化和对单一厂商的依赖,企业很难在组织内部形成统一的Agent协作标准。
Block的判断是:Agent协作的基础设施应该是开放的,公司应该像拥有自己的代码一样拥有自己的AI工作区,人和Agent协作的标准应该在开放环境中被共同定义出来,而不是被某一家公司私有化。
工程博客里那句话说得更直接:「2026年了,软件已经很便宜了,但审美没有变便宜。设计、原则和取舍才是难的部分,所以我们把代码、协议规格、测试用例、安全章节和形式化模型全部公开。」 即便Buzz某天彻底停运,用户的身份和签过名的历史记录依然可以独立验证,Git仓库依然是标准的Git,可以被重新托管——一个任何人都能重建的协议,才是一个没人能把你锁死的协议。
不过,值得留意的是外部媒体RuntimeWire给出的一个更审慎的视角:Buzz目前并没有真正的点对点事件交换、gossip层或relay间的数据复制机制。
一个工作区内的所有读写,目前都要经过单一的relay服务器完成身份验证、签名校验、事件存储和更新分发。也就是说,Buzz的「去中心化」更准确的说法是「部署主权」和「身份可移植」——你可以自己架设relay、掌控自己的数据和域名,而不依赖某个统一的托管方;但在你自己搭建的这个relay内部,它依然是一个中心化的权威服务器。
这个区别,对准备把Buzz当作Slack或GitHub替代品的团队来说,是一条需要认清的边界:自托管带来的是基础设施和数据的控制权,但也意味着你要自己承担可用性、备份、安全和升级的全部责任。
如果只看Buzz本身,容易把它当成又一个「团队协作+AI」的工具型产品。但放进Dorsey和红杉资本Roelof Botha今年3月联名发表的那篇《From Hierarchy to Intelligence》里看,会读出完全不同的意味。
那篇文章的核心论点是:从罗马军团的「十人小队」到普鲁士总参谋部再到麦肯锡的矩阵组织,两千年来所有的组织设计创新,本质上都是在解决同一个问题——信息如何在有限的「管理跨度」下高效流动,而层级和中层管理,正是这个问题此前唯一可行的解法。
Dorsey和Botha提出的假设是:AI第一次提供了「层级」之外的另一种信息路由机制——公司可以拥有一个持续更新的「世界模型」,由AI而不是人类中层来完成协调工作,人则退到「与现实接触的边缘」,只做AI做不了的判断:直觉、伦理决策、高风险的新情况。
Buzz正是这套理论在具体协作场景里的落地实验:它把「谁在做什么、为什么这么做、结果如何」这些原本要靠中层管理者口头传递、私聊转达的信息,全部结构化成可搜索、可签名、可追溯的事件流,让Agent和人类在同一条记录里获取上下文,而不需要一个人充当「在不同工具间搬运上下文的中间件」。
Longwell在博客里也印证了这一点:Block最早使用AI的方式,是每个人各自守着一个Agent的小窗口,把输出复制粘贴进Slack,再把回复粘贴回Agent——没有人喜欢当这个「中间件」。Buzz想解决的,正是这种「Agent让个人产出变快了,却让团队协作变慢了」的悖论。
Block在README里给出了一份相当诚实的功能成熟度对照表:
| ✅ 已经能用 | 🚧 正在打通 | 💭 有想法,代码还没写 |
|---|---|---|
| Relay、频道、话题串、私信、协作画布、媒体、搜索、审计日志 | Git托管后端 | 跨relay的Web-of-trust信誉体系 |
| 桌面客户端(Tauri + React) | 移动客户端(iOS/Android,Flutter) | 推送通知 |
| buzz-cli(面向Agent,JSON输入输出)+ ACP接入(Goose、Codex、Claude Code) | 工作流审批关卡(基础设施已就绪,胶水代码还在完善) | 「文化」相关功能 |
| YAML工作流(消息/反应/定时/Webhook触发) | 语音会议生命周期事件 | |
| Git事件(NIP-34:补丁、仓库公告、状态) |
Block自己也提醒:「请先别把合规流程建立在最后一列上。」 这是一个非常早期的项目——ARCHITECTURE.md、VISION.md等文档比产品本身更成熟,是理解Buzz野心的更好入口。
技术架构上,Buzz是一个Rust工作区(workspace),核心是buzz-relay这个Nostr relay服务,后面挂着Postgres存事件、Redis做发布订阅、Typesense做搜索、S3/MinIO做媒体和Git对象存储;面向Agent的接入层由buzz-cli(JSON输入输出,专为LLM工具调用设计)和buzz-acp(对接Goose/Codex/Claude Code的ACP协议桥接层)承担。
截至发稿,仓库获得100多颗星、20次Fork,最新桌面客户端版本为v0.3.23(RuntimeWire报道中提到的0.4.21版本发布于同日)。
想体验的话,两条路:
just setup && just build跑一遍环境,然后just relay起服务、just dev拉起桌面客户端。给Agent接入的话,设置好BUZZ_PRIVATE_KEY环境变量,用buzz-cli即可,它就是为LLM工具调用设计的JSON接口。Buzz还很早期,粗糙的边缘不少,理想和现实之间的落差也肉眼可见——这一点Block自己在博客里毫不讳言。
但它提出的问题足够尖锐:当一个团队里同时有几十个甚至上百个AI Agent在干活时,「身份」和「协调」会先于「模型能力」成为真正的瓶颈。
给每个Agent一把属于自己的钥匙,让它以「同事」而不是「幽灵账号」的身份出现在团队的公共记录里——这可能不是唯一的答案,但确实是一个值得所有正在往组织里大规模塞Agent的团队认真看一眼的答案。
Dorsey这次没有再造一个新的聊天软件,他是在回答自己和Botha三个月前抛出的那个问题:当AI真的开始替代科层制的协调功能时,公司到底应该长成什么样子。 Buzz,就是Block交出的第一份工程答卷。
参考资料:
还在为写 Agent 框架频频死循环、上下文爆炸而束手无策?我的新专栏 《从0 开始构建 Agent Harness》 将带你:
扫描下方二维码,开启从 0 开始构建Agent Harness 的实战之旅。
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。